Exploring Video Quality Assessment on User Generated Contents from Aesthetic and Technical Perspectives
从美学与技术角度探索用户生成内容(UGC)的视频质量评估
Abstract
摘要
The rapid increase in user-generated content (UGC) videos calls for the development of effective video quality assessment (VQA) algorithms. However, the objective of the UGC-VQA problem is still ambiguous and can be viewed from two perspectives: the technical perspective, measuring the perception of distortions; and the aesthetic perspective, which relates to preference and recommendation on contents. To understand how these two perspectives affect overall subjective opinions in UGC-VQA, we conduct a large-scale subjective study to collect human quality opinions on the overall quality of videos as well as perceptions from aesthetic and technical perspectives. The collected Disentangled Video Quality Database (DIVIDE-3k) confirms that human quality opinions on UGC videos are universally and inevitably affected by both aesthetic and technical perspectives. In light of this, we propose the Disentangled Objective Video Quality Evaluator (DOVER) to learn the quality of UGC videos based on the two perspectives. The DOVER proves state-of-the-art performance in UGC-VQA under very high efficiency. With perspective opinions in DIVIDE-3k, we further propose $D O V E R{+}{+}$ , the first approach to provide reliable clear-cut quality evaluations from a single aesthetic or technical perspective. Code at https://github.com/V Q Assessment/DOVER.
用户生成内容(UGC)视频的快速增长催生了对高效视频质量评估(VQA)算法的需求。然而UGC-VQA问题的目标仍存在歧义,可从两个视角解读:技术视角(测量失真感知)和美学视角(关联内容偏好与推荐)。为探究这两个视角如何影响UGC-VQA中的主观评价,我们开展了大规模主观实验,收集人类对视频整体质量及美学/技术维度的感知数据。所构建的解耦视频质量数据库(DIVIDE-3k)证实:人类对UGC视频的质量评判普遍且必然同时受美学与技术视角影响。基于此,我们提出解耦目标视频质量评估器(DOVER),从双视角学习UGC视频质量。DOVER在极高效率下实现了最先进的UGC-VQA性能。借助DIVIDE-3k中的视角标注,我们进一步提出$DOVER{+}{+}$——首个能从单一美学或技术视角提供可靠清晰质量评估的方法。代码详见https://github.com/VQAssessment/DOVER。
1. Introduction
1. 引言
Understanding and predicting human quality of experience (QoE) on diverse in-the-wild videos has been a longexisting and unsolved problem. Recent Video Quality Assessment (VQA) studies have gathered enormous human quality opinions [1–5] on in-the-wild user-generated contents (UGC) and attempted to use machine algorithms [6–8] to learn and predict these opinions, known as the UGCVQA problem [9]. However, due to the diversity of contents in UGC videos and the lack of reference videos during subjective studies, these human-quality opinions are still ambiguous and may relate to different perspectives.
理解和预测人类对多样化真实场景视频的体验质量(QoE)是一个长期存在且尚未解决的问题。近期视频质量评估(VQA)研究收集了大量用户生成内容(UGC)的人类质量评价[1-5],并尝试使用机器学习算法[6-8]来学习和预测这些评价,即UGCVQA问题[9]。然而,由于UGC视频内容的多样性以及主观研究过程中参考视频的缺失,这些人类质量评价仍然存在模糊性,可能涉及不同维度的评判标准。
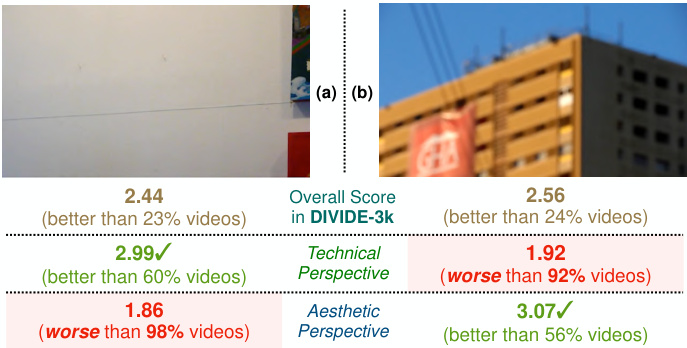
Which video has better quality? Figure 1. Which video has better quality: a clear video with meaningless contents (a) or a blurry video with meaningful contents (b)? Viewing from different perspectives (aesthetic/technical) may produce different judgments, motivating us to collect DIVIDE-3k, which is the first UGC-VQA dataset with opinions from multiple perspectives. More multi-perspective quality comparisons in our dataset are shown in supplementary Sec. A.
哪个视频质量更好?图 1: 哪个视频质量更好:内容无意义但画质清晰的视频 (a) ,还是内容有意义但画面模糊的视频 (b) ?从不同视角(美学/技术)观看可能得出不同判断,这促使我们收集了 DIVIDE-3k——首个包含多视角评价的用户生成内容视频质量评估数据集。更多数据集中的多视角质量对比见补充材料 A 节。
Conventionally, VQA studies [9–13] are concerned with the technical perspective, aiming at measuring distortions in videos (e.g., blurs, artifacts) and their impact on quality, so as to compare and guide technical systems such as cameras [14, 15], restoration algorithms [16–18] and compression standards [19]. Under this perspective, the video with clear textures in Fig. 1(a) should have notably better quality than the blurry video in Fig. 1(b). On the other hand, several recent studies [2, 6, 7, 20, 21] notice that preferences on non-technical semantic factors (e.g., contents, composition) also affect human quality assessment on UGC videos. Human experience on these factors is usually regarded as the aesthetic perspective [22–27] of quality evaluation, which considers the video in Fig. 1(b) as better quality due to its more meaningful contents and is preferred for content recommendation systems on platforms such as YouTube or TikTok. However, how aesthetic preference plays the impact on final human quality opinions of UGC videos is still debatable [1, 2] and requires further validation.
传统上,视频质量评估(VQA)研究[9–13]关注技术视角,旨在测量视频中的失真(如模糊、伪影)及其对质量的影响,以便比较和指导相机[14, 15]、修复算法[16–18]和压缩标准[19]等技术系统。从这个角度看,图1(a)中纹理清晰的视频质量应明显优于图1(b)中模糊的视频。另一方面,最近多项研究[2, 6, 7, 20, 21]指出,对非技术语义因素(如内容、构图)的偏好也会影响用户生成内容(UGC)视频的人类质量评估。人类对这些因素的体验通常被视为质量评估的美学视角[22–27],该视角认为图1(b)中的视频因其更具意义的内容而质量更优,更适合YouTube或TikTok等平台的内容推荐系统。然而,美学偏好如何影响人类对UGC视频的最终质量评价仍存在争议[1, 2],需要进一步验证。
To investigate the impact of aesthetic and technical perspectives on human quality perception of UGC videos, we conduct the first comprehensive subjective study to collect opinions from both perspectives, as well as overall opinions on a large number of videos. We also conduct subjective reasoning studies to explicitly gather information on how much each individual’s overall quality opinion is influenced by aesthetic and technical perspectives. With overall 450K opinions on 3,590 diverse UGC videos, we construct the first Disentangled Video Quality Database (DIVIDE-3k). After calibrating our study on the DIVIDE-3k with existing UGC-VQA subjective studies, we observe that human quality perception on UGC videos is broadly and inevitably affected by both aesthetic and technical perspectives. As a consequence, the overall subjective quality scores between the two videos in Fig. 1 with different qualities from either one of the two perspectives could be similar.
为研究美学和技术视角对用户生成内容(UGC)视频质量感知的影响,我们开展了首个综合性主观研究,从这两个维度收集了大量视频的评价意见及整体质量评分。同时通过主观归因研究,明确量化每个受试者的整体质量评价受美学与技术视角影响的程度。基于对3,590个多样化UGC视频采集的45万条评价数据,我们构建了首个解耦视频质量数据库(DIVIDE-3k)。通过将该研究与现有UGC-VQA主观研究进行校准后,我们发现人类对UGC视频的质量感知普遍且不可避免地同时受到美学与技术视角的影响。如图1所示,当两个视频在美学或技术任一维度存在质量差异时,其整体主观评分仍可能相近。
Motivated by the observation from our subjective study, we aim to develop an objective UGC-VQA method that accounts for both aesthetic and technical perspectives. To achieve this, we design the View Decomposition strategy, which divides and conquers aesthetic-related and technicalrelated information in videos, and propose the Disentangled Objective Video Quality Evaluator (DOVER). DOVER consists of two branches, each dedicated to focusing on the effects of one perspective. Specifically, based on the different characteristics of quality issues related to each perspective, we carefully design inductive biases for each branch, including specific inputs, regular iz ation strategies, and pretraining. The two branches are supervised by the overall scores (affected by both perspectives) to adapt for existing UGC-VQA datasets [1, 3, 4, 28–30], and additionally supervised by aesthetic and technical opinions exclusively in the DIVIDE-3k (denoted as $\mathbf{DOVER}\mathbf{++}$ ). Finally, we obtain the overall quality prediction via a subjectively-inspired fusion of the predictions from the two perspectives. With the subjectively-inspired design, the proposed DOVER and $\scriptstyle\mathrm{{DOVER++}}$ not only reach better accuracy on the overall quality prediction but also provide more reliable quality prediction from aesthetic and technical perspectives, catering for practical scenarios.
基于主观研究的观察结果,我们旨在开发一种兼顾美学与技术视角的客观UGC-VQA(用户生成内容视频质量评估)方法。为此,我们设计了视图解构策略(View Decomposition),通过分治处理视频中的美学相关与技术相关信息,并提出解耦式客观视频质量评估器(Disentangled Objective Video Quality Evaluator, DOVER)。DOVER包含两个分支,分别专注于单一视角的影响:针对各视角相关质量问题的不同特性,我们为每个分支精心设计了归纳偏置(inductive bias),包括特定输入、正则化策略和预训练方案。两个分支在现有UGC-VQA数据集[1, 3, 4, 28–30]中受整体评分(受双视角共同影响)监督,并在DIVIDE-3k数据集(记为$\mathbf{DOVER}\mathbf{++}$)中额外接受专属美学与技术维度意见监督。最终通过主观启发的双视角预测融合获得整体质量评分。这种主观启发的设计使DOVER与$\scriptstyle\mathrm{{DOVER++}}$不仅能提升整体质量预测准确度,还能从美学与技术视角提供更可靠的专项质量预测,满足实际应用需求。
Our contributions can be summarized as four-fold:
我们的贡献可总结为以下四点:
2. Related Works
2. 相关工作
Databases and Subjective Studies on UGC-VQA. Unlike traditional VQA databases [28, 29, 31, 32], UGC-VQA databases [1, 3–5] directly collect from real-world videos from direct photography, YFCC-100M [33] database or YouTube [30] videos. With each video having unique content and being produced by either professional or nonprofessional users [7, 8], quality assessment of UGC videos can be more challenging and less clear-cut compared to traditional VQA tasks. Additionally, the subjective studies in UGC-VQA datasets are usually carried out by crowdsourced users [34] with no reference videos. These factors may lead to the ambiguity of subjective quality opinions in UGC-VQA which can be affected by different perspectives. Objective Methods for UGC-VQA. Classical VQA methods [9–12, 35–42] employ handcrafted features to evaluate video quality. However, they do not take the effects of semantics into consideration, resulting in reduced accuracy on UGC videos. Noticing that UGC-VQA is deeply affected by semantics, deep VQA methods [2, 6, 13, 43–50] are becoming predominant in this problem. For instance, VSFA [6] conducts subjective studies to demonstrate videos with attractive content receive higher subjective scores. Therefore, it uses the semantic-pretrained ResNet-50 [51] features instead of handcrafted features, followed by plenty of recent works [1, 2, 13, 21, 52, 53] that improve the performance for UGC-VQA. However, these methods, which are directly driven by ambiguous subjective opinions, can hardly explain what factors are considered in their quality predictions, hindering them from providing reliable and explainable quality evaluations on real-world scenarios (e.g., distortion metrics and recommendations).
UGC-VQA的数据库与主观研究。与传统VQA数据库[28, 29, 31, 32]不同,UGC-VQA数据库[1, 3–5]直接采集自现实世界拍摄视频、YFCC-100M[33]数据库或YouTube[30]视频。由于每个视频内容独特且制作者涵盖专业与非专业用户[7, 8],UGC视频质量评估相比传统VQA任务更具挑战性和模糊性。此外,UGC-VQA数据集的主观研究通常由众包用户[34]在没有参考视频的情况下完成,这些因素可能导致UGC-VQA主观质量意见的模糊性,并受不同视角影响。
UGC-VQA的客观方法。传统VQA方法[9–12, 35–42]采用手工设计特征评估视频质量,但未考虑语义影响,导致在UGC视频上准确性下降。注意到UGC-VQA深受语义影响,深度VQA方法[2, 6, 13, 43–50]逐渐成为该领域主流。例如VSFA[6]通过主观研究表明具有吸引力内容的视频会获得更高主观分数,因此采用语义预训练的ResNet-50[51]特征替代手工特征,后续大量研究[1, 2, 13, 21, 52, 53]进一步提升了UGC-VQA性能。然而这些直接受模糊主观意见驱动的方法,难以解释其质量预测考虑的因素,阻碍了在实际场景(如失真度量和推荐)中提供可靠且可解释的质量评估。
3. The DIVIDE-3k Database
3. DIVIDE-3k 数据库
In this section, we introduce the proposed Disentangled Video Quality Database (DIVIDE-3k, Fig. 2), along with the multi-perspective subjective study. The database includes 3,590 UGC videos, on which we collected 450,000 human opinions. Different from other UGCVQA databases [1–3], the subjective study is conducted inlab to reduce the ambiguity of perspective opinions.
在本节中,我们介绍了提出的解耦视频质量数据库(DIVIDE-3k,图 2)以及多视角主观研究。该数据库包含 3,590 个用户生成内容(UGC)视频,我们收集了 450,000 条人类意见。与其他 UGCVQA 数据库 [1–3] 不同,主观研究在实验室进行,以减少视角意见的模糊性。
3.1. Collection of Videos
3.1. 视频采集
Sources of Videos. The 3,590-video database is mainly collected from two sources: 1) the YFCC-100M [33] social media database; 2) the Kinetics-400 [54] video recognition database, collected from YouTube, which has in total 400,000 videos. Voices are removed from all videos.
视频来源。该3590段视频数据库主要采集自两个渠道:1) YFCC-100M [33] 社交媒体数据库;2) 采集自YouTube的Kinetics-400 [54] 视频识别数据库(共含40万段视频)。所有视频均经过消音处理。
Getting the subset for annotation. Similar to existing studies [1, 3], we would like the sampled video database able to represent the overall quality of the original larger database. Therefore, we first histogram all 400,000 videos with spatial [11], temporal [12], and semantic indices [55]. Then, we randomly select a subset of 3,270 videos from the 400,000 videos that match the histogram from the three dimensions [56] as in [1,3]. Several examples from DIVIDE3k are provided in the supplementary. We also select 320 videos from the LSVQ [1], the most recent UGC-VQA database, to examine the calibration between DIVIDE-3k and existing UGC-VQA subjective studies (see in Tab. 2).
获取标注子集。与现有研究[1,3]类似,我们希望采样的视频数据库能够代表原始更大数据库的整体质量。因此,我们首先使用空间[11]、时间[12]和语义指标[55]对所有40万个视频进行直方图统计。然后,按照[1,3]的方法,从40万个视频中随机选取3,270个视频作为子集,使其在三个维度[56]上与直方图匹配。补充材料中提供了DIVIDE3k的几个示例。我们还从最新的UGC-VQA数据库LSVQ[1]中选取了320个视频,以检验DIVIDE-3k与现有UGC-VQA主观研究之间的校准情况(见表2)。
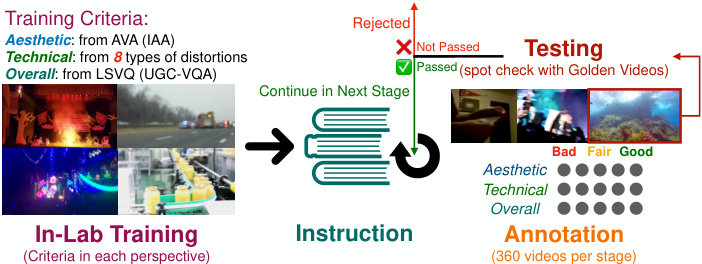
Figure 2. The in-lab subjective study on videos in DIVIDE-3k, including Training, Instruction, Annotation and Testing, discussed in Sec. 3.2.
图 2: DIVIDE-3k视频的实验室主观研究流程,包括训练、指导、标注和测试环节,详见3.2节讨论。
3.2. In-lab Subjective Study on Videos
3.2. 视频实验室主观研究
To ensure a clear understanding of the two perspectives, we conduct in-lab subjective experiments instead of crowdsourced, with 35 trained annotators (including 19 male and 16 female) participating in the full annotation process of Training, Testing and Annotation. All videos are downloaded to local computers before annotation to avoid transmission errors. The main process of the subjective study is illustrated in Fig. 2, discussed step-by-step as follows. $E x\cdot$ - tended details about the study are in supplementary Sec. A. Training. Before annotation, we provide clear criteria with abundant examples of the three quality ratings to train the annotators. For aesthetic rating, we select example images with good, fair and bad aesthetic quality from the aesthetic assessment database AVA [22], each for 20 images, as calibration for aesthetic evaluation. For technical rating, we instruct subjects to rate purely based on technical distortions and provide 5 examples for each of the following eight common distortions: 1) noises; 2) artifacts; 3) low sharpness; 4) out-of-focus; 5) motion blur; 6) stall; 7) jitter; 8) over/under-exposure. For overall quality rating, we select 20 videos each with good, fair and bad quality as examples, from the UGC-VQA dataset LSVQ [1].
为确保清晰理解这两个视角,我们在实验室而非众包环境下进行了主观实验,35名经过培训的标注员(包括19名男性和16名女性)参与了完整的训练、测试与标注流程。所有视频在标注前均下载至本地计算机以避免传输错误。主观研究的主要流程如图2所示,具体步骤如下:$E x\cdot$ - 研究扩展细节详见补充材料A节。
训练
在标注开始前,我们通过大量示例向标注员明确三类质量评分的标准。针对美学评分,我们从美学评估数据库AVA [22]中分别选取20张优、中、差美学质量的示例图像作为美学评价校准;针对技术评分,我们要求受试者仅基于技术失真进行评分,并为以下八种常见失真各提供5个示例:1) 噪点;2) 伪影;3) 低锐度;4) 失焦;5) 运动模糊;6) 卡顿;7) 抖动;8) 过曝/欠曝;针对整体质量评分,我们从UGC-VQA数据集LSVQ [1]中分别选取20段优、中、差质量的视频作为示例。
During Experiment: Instruction and Annotation. We divide the subjective experiments into 40 videos per group, and 9 groups per stage. Before each stage, we instruct the subjects on how to label each specific perspective:
实验期间:指导与标注。我们将主观实验分为每组40个视频,每阶段9组。在每阶段开始前,我们会指导受试者如何标注每个具体维度:
• Aesthetic Score: Please rate the video’s quality based on aesthetic perspective (e.g., semantic preference). • Technical Score: Please rate the video’s quality with only consideration of technical distortions. • Overall Score: Please rate the quality of the video. • Subjective Reasoning: Please rate how your overall score is impacted by aesthetic or technical perspective.
- 美学评分:请从美学角度(如语义偏好)对视频质量进行评分。
- 技术评分:请仅考虑技术失真对视频质量进行评分。
- 综合评分:请对视频的整体质量进行评分。
- 主观理由:请评估美学或技术角度对您综合评分的影响程度。
Specifically, for the subjective reasoning, subjects need to rate the proportion of technical impact in the overall score for each video among [0, 0.25, 0.5, 0.75, 1], while rest proportion is considered as aesthetic impact.
具体而言,在主观推理环节,受试者需为每个视频的技术影响力在总分中的占比评分,选项为[0, 0.25, 0.5, 0.75, 1],其余比例则视为审美影响力。
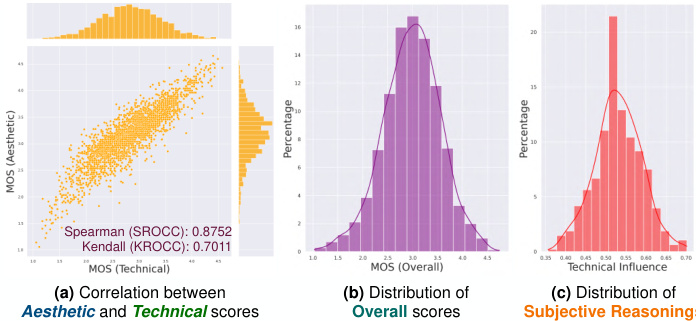
Figure 3. Statistics in DIVIDE-3k: (a) The correlations between aesthetic and technical perspectives, and distributions (b) of overall quality (MOS) & (c) subject-rated proportion of technical impact on overall quality.
图 3: DIVIDE-3k数据集统计:(a) 美学与技术维度相关性分析,(b) 整体质量(MOS)分布,(c) 技术因素对整体质量影响占比的主观评分分布。
Table 1. Effects of Perspectives: The correlations between different perspectives and overall quality (MOS) for all 3,590 videos in DIVIDE $\bf{3k}$ .
表 1: 视角效果:DIVIDE $\bf{3k}$ 中 3,590 个视频的不同视角与整体质量 (MOS) 之间的相关性
| 与MOS相关性 | MOSA | MOST | MOSA+MOST | 0.428MOSA+0.572MOST |
|---|---|---|---|---|
| Spearman (SROCC↑) | 0.9350 | 0.9642 | 0.9827 | 0.9834 |
| Kendall (KROCC↑) | 0.7894 | 0.8455 | 0.8909 | 0.8933 |
Table 2. Calibration with Existing: The correlations of between different ratings in DIVIDE-3k and existing scores in LSVQ [1] $(\mathrm{MOS_{existing}})$ ).
表 2: 与现有评分的校准: DIVIDE-3k中不同评分与LSVQ[1]中现有评分 $(\mathrm{MOS_{existing}})$ 的相关性
| 与MOSexisting的相关性 | MOSA | MOST | MOSA+MOST | MOS |
|---|---|---|---|---|
| Spearman(SROCC↑) | 0.6956 | 0.7374 | 0.7632 | 0.7680 |
| Kendall(KROCC↑) | 0.5073 | 0.5469 | 0.5797 | 0.5822 |
Testing with Golden Videos. For testing, we randomly insert 10 golden videos in each stage as a spot check to ensure the quality of annotation, and the subject will be rejected and not join the next stage if the annotations on the golden videos severely deviate from the standards.
黄金视频测试。在测试阶段,我们会在每个环节随机插入10个黄金视频作为抽查,以确保标注质量。若受试者对黄金视频的标注严重偏离标准,则该受试者将被淘汰,无法进入下一阶段。
3.3. Observations
3.3. 观察结果
Effects of Two Perspectives. To validate the effects of two perspectives, we first quantitatively assess the correlation between the two perspectives and overall quality. Denote the mean aesthetic opinion as $\mathrm{MOS_{A}}$ , mean technical opinion as $\mathrm{MOS}_{\mathrm{T}}$ , mean overall opinion as MOS, the Spearman and Kendall correlation between different perspectives are listed in Tab. 1. From Tab. 1, we notice that the weighted sum of both perspectives is a better approximation of overall quality than either single perspective. Consequently, methods [1, 6, 57] that naively regress from overall MOS might not provide pure technical quality predictions due to the inevitable effect of aesthetics. The best/worst videos (Fig. 4) in each dimension also support this observation.
两种视角的影响。为验证两种视角的效果,我们首先定量评估了两种视角与整体质量的相关性。将平均美学评分记为$\mathrm{MOS_{A}}$,平均技术评分记为$\mathrm{MOS}_{\mathrm{T}}$,平均整体评分记为MOS,不同视角间的Spearman和Kendall相关系数列于表1。由表1可见,双视角加权求和比单一视角更能逼近整体质量。因此,直接回归整体MOS的方法[1,6,57]可能因美学因素的不可避免影响,而无法提供纯粹的技术质量预测。各维度最佳/最差视频(图4)也佐证了这一观察。
Calibration with Existing Study. To validate whether the observation can be extended for existing UGC-VQA subjective studies, we select 320 videos from LSVQ [1] to compare quality opinions from multi-perspectives with existing scores of these videos. As shown in Tab. 2, the overall quality score is more correlated with the existing score than scores from either perspective, further suggesting considering human quality opinion as a fusion of both perspectives might be a better approximation in the UGC-VQA problem.
与现有研究的校准。为了验证观察结果能否推广到现有的UGC-VQA主观研究中,我们从LSVQ [1]中选取了320个视频,将多视角质量评价与这些视频的现有评分进行对比。如表2所示,整体质量评分与现有评分的相关性高于任一单视角评分,进一步表明在UGC-VQA问题中将人类质量评价视为双视角融合可能更合理。

Figure 4. Videos with best and worst scores in aesthetic perspective, technical perspective and overall quality perception in the DIVIDE-3k. The aestheti perspective is more concerned with semantics or composition of videos, while the technical perspective is more related to low-level textures and distortions
图 4: DIVIDE-3k 数据集中美学视角、技术视角和整体质量感知得分最高与最低的视频示例。美学视角更关注视频的语义或构图,而技术视角则更侧重于底层纹理和失真问题
Subjective Reasoning. In the DIVIDE-3k, we conducted the first subjective reasoning study during the human quality assessment. Fig. 3(c) illustrates the mean technical impact for each video, ranging among [0.364, 0.698]. The results of reasoning further explicitly validate our aforementioned observation, that human quality assessment is affected by opinions from both aesthetic and technical perspectives.
主观推理。在DIVIDE-3k数据集中,我们首次在人类质量评估过程中进行了主观推理研究。图3(c)展示了每个视频的平均技术影响值,范围在[0.364, 0.698]之间。推理结果进一步明确验证了我们之前的观察:人类质量评估同时受到美学和技术两个维度观点的影响。
4. The Approaches: DOVER and DOVER $^$
4. 方法:DOVER 和 DOVER
Observing that overall quality opinions are affected by both aesthetic and technical perspectives from subjective studies in DIVIDE-3k, we propose to distinguish and investigate the aesthetic and technical effects in a UGCVQA model based on the View Decomposition strategy (Sec. 4.1). The proposed Disentangled Objective Video Quality Evaluator (DOVER) is built up with an aesthetic branch (Sec. 4.2) and a technical branch (Sec. 4.3). The two branches are separately supervised, either both by overall scores (denoted as DOVER) or by respective aesthetic and technical opinions (denoted as $\mathbf{DOVER}\mathbf{++}$ ), discussed in Sec. 4.4. Finally, we discuss the subjectively-inspired fusion (Sec. 4.5) to predict the overall quality from DOVER.
基于DIVIDE-3k主观研究中观察到整体质量评价受美学与技术双重视角影响,我们提出通过视图解构策略(4.1节)在UGCVQA模型中区分并研究美学与技术效应。所提出的解耦目标视频质量评估器(DOVER)由美学分支(4.2节)与技术分支(4.3节)构成。两个分支采用独立监督机制:或同时使用整体分数监督(记为DOVER),或分别采用美学与技术主观评分监督(记为$\mathbf{DOVER}\mathbf{++}$),详见4.4节讨论。最后,我们探讨基于主观启发的融合策略(4.5节)来预测DOVER的整体质量。
4.1. Methodology: Separate the Perceptual Factors
4.1. 方法论:分离感知因素
From DIVIDE $3\mathrm{k\Omega}$ , we notice that aesthetic and technical perspectives in UGC-VQA are usually associated with different perceptual factors. Specifically, as illustrated in (Fig. , aesthetic opinions are mostly related to semantics, composition of objects [24, 27, 58], which are typically high-level visual perceptions. In contrast, the technical quality is largely affected by low-level visual distortions, e.g., blurs, noises, artifacts [1,13,21,59,60] (Fig. 4(e)&(f)).
从DIVIDE $3\mathrm{k\Omega}$ 可以看出,UGC-VQA(用户生成内容视频质量评估)中的美学与技术视角通常关联着不同的感知因素。具体而言,如图 所示,美学评价多与语义、物体构图[24, 27, 58]这类高层视觉感知相关;而技术质量则主要受模糊、噪点、伪影[1,13,21,59,60]等低层视觉失真影响(图4(e)&(f))。
The observation inspires the View Decomposition strategy that separates the video into two views: the Aesthetic View $(S_{\mathrm{A}})$ that focus on aesthetic perception, and Technical View $(S_{\mathrm{T}})$ for vice versa. With the decomposed views as inputs, two separate aesthetic $\left(\mathbf{M}{\mathrm{A}}\right)$ and technical branches $({\bf M}_{\mathrm{T}})$ evaluate different perspectives separately:
这一观察启发了视图分解策略,将视频分离为两个视图:专注于美学感知的审美视图 $(S_{\mathrm{A}})$ 和与之相反的技术视图 $(S_{\mathrm{T}})$。以分解后的视图作为输入,两个独立的美学分支 $\left(\mathbf{M}{\mathrm{A}}\right)$ 和技术分支 $({\bf M}_{\mathrm{T}})$ 分别评估不同视角:
$$
Q_{\mathrm{pred,A}}=\mathbf{M}{\mathrm{A}}(S_{\mathrm{A}});Q_{\mathrm{pred,T}}=\mathbf{M}{\mathrm{T}}(S_{\mathrm{T}})
$$
$$
Q_{\mathrm{pred,A}}=\mathbf{M}{\mathrm{A}}(S_{\mathrm{A}});Q_{\mathrm{pred,T}}=\mathbf{M}{\mathrm{T}}(S_{\mathrm{T}})
$$
Despite that most perception related to the two perspectives can be separated, a small proportion of perceptual factors are related to both perspectives, such as brightness related to both exposure (technical) [29] and lighting (aesthetic) [26], or motion blurs (which is occasionally considered as good aesthetics but typically regarded as bad technical quality [61]). Thus, we don’t separate these factors and keep them in both branches. Instead, we employ inductive biases (pre-training, regular iz ation) and specific supervision in the DIVIDE $3\mathrm{k\Omega}$ to further drive the two branches’ focus on corresponding perspectives, introduced as follows.
尽管与这两个视角相关的大部分感知因素可以区分,仍有小部分感知因素同时关联两种视角,例如亮度既涉及曝光(技术层面)[29]又关联布光(美学层面)[26],或动态模糊(偶尔被视为美学加分项,但通常被归为技术缺陷[61])。因此我们保留这些因素至两个分支,转而通过归纳偏置(预训练、正则化)和DIVIDE $3\mathrm{k\Omega}$中的专项监督机制来引导分支聚焦对应视角,具体如下。
4.2. The Aesthetic Branch
4.2. 美学分支
To help the aesthetic branch focus on the aesthetic perspective, we first pre-train the branch with Image Aethetic Assessment database AVA [22]. We then elaborate the Aesthetic View $(S_{\mathrm{A}})$ and additional regular iz ation objectives.
为了让审美分支专注于美学视角,我们首先使用图像美学评估数据库AVA [22]对该分支进行预训练。随后详细阐述审美视角$(S_{\mathrm{A}})$及附加的正则化目标。
The Aesthetic View. Semantics and Composition are two key factors deciding the aesthetics of a video [24, 58, 62]. Thus, we obtain Aesthetic View (see Fig. 5(b)) through spatial down sampling [63] and temporal sparse frame sampling [64] which preserves the semantics and composition of original videos. The down sampling strategies are widely applied in many existing state-of-the-art aesthetic assessment methods [24, 25, 27, 65, 66], further proving that they are able to preserve aesthetic information in visual contents. Moreover, the two strategies significantly reduce the sensitivity [9–12] on technical distortions such as blurs, noises, artifacts (via spatial down sampling), shaking, flicker (via temporal sparse sampling), so as to focus on aesthetics.
美学视角。语义(Semantics)与构图(Composition)是决定视频美学的两大关键因素[24,58,62]。因此我们通过保留原始视频语义和构图的空间下采样[63]与时域稀疏帧采样[64]技术获得美学视角(见图5(b))。这类下采样策略被广泛应用于当前主流美学评估方法[24,25,27,65,66],进一步证明其能有效保留视觉内容中的美学信息。此外,这两种策略显著降低了对技术失真(如模糊、噪点、伪影(通过空间下采样)、抖动、闪烁(通过时域稀疏采样))的敏感度[9-12],从而更聚焦于美学本质。
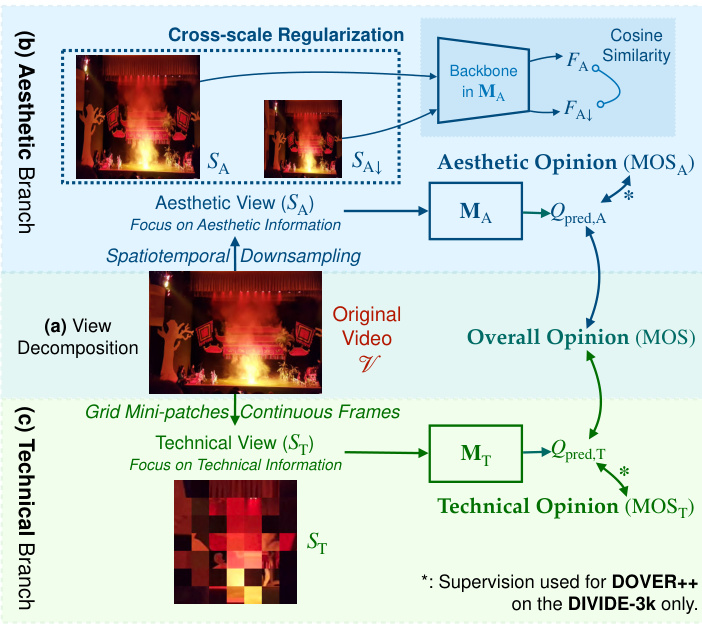
Figure 5. The proposed Disentangled Objective Video Quality Evaluator (DOVER) and $\mathbf{DOVER}\mathbf{++}$ via (a) View Decomposition (Sec. 4.1), with the (b) Aesthetic Branch (Sec. 4.2) and the (c) Technical Branch (Sec. 4.3). The equations to obtain the two views are in Supplementary Sec. E.
图 5: 提出的解耦目标视频质量评估器 (DOVER) 和 $\mathbf{DOVER}\mathbf{++}$ 通过 (a) 视图分解 (第4.1节), 包含 (b) 美学分支 (第4.2节) 和 (c) 技术分支 (第4.3节)。获取这两个视图的公式见补充材料第E节。
where $F_{\mathrm{A}}$ and $F_{\mathrm{A\downarrow}}$ are output features for $S_{\mathrm{A}}$ and $S_{\mathrm{A\downarrow}}$ .
其中 $F_{\mathrm{A}}$ 和 $F_{\mathrm{A\downarrow}}$ 分别是 $S_{\mathrm{A}}$ 和 $S_{\mathrm{A\downarrow}}$ 的输出特征。
4.3. The Technical Branch
4.3. 技术分支
In the technical branch, we would like to keep the technical distortions but obfuscate the aesthetics of the videos. Thus, we design the Technical View $(S_{\mathrm{T}})$ as follows.
在技术分支中,我们希望保留技术失真但模糊视频的美学效果。因此,我们设计了技术视图 $(S_{\mathrm{T}})$ 如下。
The Technical View. We introduce fragments [13] (as in Fig. 5(c)) as Technical View $\cdot{\cal S}{\mathrm{T}})$ for the technical branch. The fragments are composed of randomly cropped patches stitched together to retain the technical distortions. Moreover, it discarded most content and disrupted the compositional relations of the remaining, therefore severely corrupting aesthetics in videos. Temporally, we apply continuous frame sampling for $S_{\mathrm{T}}$ to retain temporal distortions.
技术视角。我们引入片段[13](如图5(c)所示)作为技术分支的技术视角 $\cdot{\cal S}{\mathrm{T}}$ 。这些片段由随机裁剪的补丁拼接而成,以保留技术失真。此外,它丢弃了大部分内容并破坏了剩余内容的构图关系,因此严重损害了视频的美学效果。在时间维度上,我们对 $S_{\mathrm{T}}$ 采用连续帧采样以保留时间失真。
Weak Global Semantics as Background. Many studies [13, 59, 68] suggest that technical quality perception should consider global semantics to better assess distortion levels. Though most content is discarded in $S_{\mathrm{T}}$ , the technical branch can still reach $68.6%$ accuracy for Kinetics400 [54] video classification, indicating it can preserve weak global semantics as background information to distinguish textures (e.g., sands) from distortions (e.g., noises).
弱全局语义作为背景。多项研究 [13, 59, 68] 指出,技术质量感知应考虑全局语义以更准确评估失真程度。尽管 $S_{\mathrm{T}}$ 中大部分内容被丢弃,但技术分支仍能在 Kinetics400 [54] 视频分类任务中达到 $68.6%$ 的准确率,表明其能保留弱全局语义作为背景信息来区分纹理(如沙粒)与失真(如噪点)。
4.4. Learning Objectives
4.4. 学习目标
Weak Supervision with Overall Opinions. With the observation in Sec. 3.3, the overall MOS can be approximated as a weighted sum of $\mathrm{MOS_{A}}$ and $\mathrm{MOS}{\mathrm{T}}$ . Moreover, the subjectively-inspired inductive biases in each branch can reduce the perception of another perspective. The two observations suggest that if we use overall opinions to separately supervise the two branches, the prediction of each branch could be majorly decided by its corresponding perspective. Henceforth, we propose the Limited View Biased Supervisions $(\mathcal{L}_{\mathrm{LVBS}})$ , which minimize the relative $\mathrm{loss}^{\mathrm{*}}$ between predictions in each branch with the overall opinion MOS, as the objective of DOVER, applicable on all databases:
基于整体意见的弱监督。根据第3.3节的观察,整体平均意见分数(MOS)可近似表示为$\mathrm{MOS_{A}}$与$\mathrm{MOS}{\mathrm{T}}$的加权和。此外,各分支中主观驱动的归纳偏置会削弱另一视角的感知。这两点表明:若用整体意见分别监督两个分支,每个分支的预测将主要由其对应视角决定。因此,我们提出有限视角偏置监督$(\mathcal{L}_{\mathrm{LVBS}})$作为DOVER的优化目标(适用于所有数据库),通过最小化各分支预测与整体意见MOS间的相对$\mathrm{loss}^{\mathrm{*}}$来实现。
Supervision with Opinions from Perspectives. With the DIVIDE $3\mathrm{k\Omega}$ database, we further improve the accuracy for disentanglement with the Direct Supervisions $(\mathcal{L}_{\mathrm{DS}})$ on corresponding perspective opinions for both branches:
基于多视角观点的监督。借助DIVIDE $3\mathrm{k\Omega}$数据库,我们通过直接监督$(\mathcal{L}_{\mathrm{DS}})$进一步提升了两分支在对应视角观点上的解耦精度:
$$
\mathcal{L}{\mathrm{DS}}=\mathcal{L}{\mathrm{Rel}}(Q_{\mathrm{pred,A}},\mathrm{MOS}{\mathrm{A}})+\mathcal{L}{\mathrm{Rel}}(Q_{\mathrm{pred,T}},\mathrm{MOS}_{\mathrm{T}})
$$
$$
\mathcal{L}{\mathrm{DS}}=\mathcal{L}{\mathrm{Rel}}(Q_{\mathrm{pred,A}},\mathrm{MOS}{\mathrm{A}})+\mathcal{L}{\mathrm{Rel}}(Q_{\mathrm{pred,T}},\mathrm{MOS}_{\mathrm{T}})
$$
and the proposed $\mathbf{DOVER}\mathbf{++}$ is driven by a fusion of the two objectives to jointly learn more accurate overall quality as well as perspective quality predictions for each branch:
所提出的 $\mathbf{DOVER}\mathbf{++}$ 由两个目标的融合驱动,旨在联合学习更精确的整体质量以及各分支的视角质量预测:
$$
\mathcal{L}{\mathrm{DOVER++}}=\mathcal{L}{\mathrm{DS}}+\lambda_{\mathrm{LVBS}}\mathcal{L}_{\mathrm{LVBS}}
$$
$$
\mathcal{L}{\mathrm{DOVER++}}=\mathcal{L}{\mathrm{DS}}+\lambda_{\mathrm{LVBS}}\mathcal{L}_{\mathrm{LVBS}}
$$
4.5. Subjectively-inspired Fusion Strategy
4.5. 主观启发式融合策略
From the subjective studies, we observe that the MOS can be well-approximated as $0.428\mathrm{MOS_{A}}+0.572\mathrm{MOS_{T}}$ . Henceforth, we propose to similarly obtain the final overall quality prediction $(Q_{\mathrm{pred}})$ from two perspectives: $Q_{\mathrm{pred}}=$ $0.428Q_{\mathrm{pred,A}}+0.572Q_{\mathrm{pred,T}}$ via a simple weighted fusion. With better accuracy on all datasets (Tab. 9), the strategy by side validates the subjective observations in Sec. 3.3.
从主观研究中,我们观察到MOS可以很好地近似为$0.428\mathrm{MOS_{A}}+0.572\mathrm{MOS_{T}}$。因此,我们建议通过简单加权融合从两个角度类似地获得最终整体质量预测$(Q_{\mathrm{pred}})$:$Q_{\mathrm{pred}}=0.428Q_{\mathrm{pred,A}}+0.572Q_{\mathrm{pred,T}}$。该策略在所有数据集上具有更高准确性(表9),侧面验证了第3.3节的主观观察结果。
5. Experimental Evaluation
5. 实验评估
In this section, we answer two important questions:
在本节中,我们将回答两个重要问题:
• Can the aesthetic and technical branches better learn the effects of corresponding perspectives (Sec. 5.2)? • Can the fused model more accurately predict overall quality in UGC-VQA problem (Sec. 5.3)?
• 美学分支与技术分支能否更好地学习对应视角的效果(见5.2节)?
• 融合模型能否更准确地预测UGC-VQA问题中的整体质量(见5.3节)?
Moreover, we include ablation studies (Sec. 5.4) and an outlook for personalized quality evaluation (Sec. 5.5).
此外,我们包含了消融研究(第5.4节)和个性化质量评估的展望(第5.5节)。
5.1. Experimental Setups
5.1. 实验设置
Table 3. Quantitative Evaluation on Perspectives of DOVER (weaklysupervised) and $\scriptstyle\mathrm{DOVER++}$ (fully-supervised) in the DIVIDE-3k, by evaluating the correlation across different predictions and subjective opinions. w/o Decomposition denotes both branches with original videos as inputs.
表 3: DIVIDE-3k 数据集上弱监督方法 DOVER 与全监督方法 $\scriptstyle\mathrm{DOVER++}$ 的多视角定量评估 (通过预测结果与主观评分的相关性分析) 。w/o Decomposition 表示两个分支均以原始视频作为输入。
| 方法 | SROCC/PLCC | MOSA | MOST |
|---|---|---|---|
| 无分解 (w/MOSA&MOST) | Qpred,A Qpred,T | 0.7482/0.7576 0.7234/0.7430 | 0.7941/0.8039 0.8190/0.8233 |
| DOVER 无MOSA&MOST | Qpred,A Qpred,T | 0.7489/0.7607 | 0.7877/0.8044 |
| DOVER++ | 0.7153/0.7382 0.7683/0.7779 | 0.8213/0.8295 0.7584/0.7708 | |
| w/MOSA&MOST | Qpred,A Qpred,T | 0.7015/0.7230 | 0.8376/0.8443 |
| 美学优于技术 | 技术优于美学 Qpred.A pred,T 3.15 | ||
| pred,A 3.14 (DOVER++) 3.03 (DOVER) | (a) | Qpred,T 1.91 (DOVER++) 2.42 (DOVER) | 2.02 (DOVER++) 2.09 (DOVER) (c) |
Datasets. Despite evaluating DOVER and ${\tt D O V E R++}$ on the proposed DIVIDE-3k (3,590 videos) database, we also evaluate DOVER with the large-scale UGC-VQA dataset, LSVQ [1] (39,072 videos), and on three smaller UGC-VQA datasets, KoNViD-1k [3] (1,200 videos), LIVE-VQC [4] (585 videos), and YouTube-UGC [5] (1,380 videos).
数据集。除了在提出的DIVIDE-3k(3,590个视频)数据库上评估DOVER和${\tt D O V E R++}$外,我们还使用大规模用户生成内容视频质量评估(UGC-VQA)数据集LSVQ [1](39,072个视频)以及三个较小规模的UGC-VQA数据集——KoNViD-1k [3](1,200个视频)、LIVE-VQC [4](585个视频)和YouTube-UGC [5](1,380个视频)对DOVER进行了评估。
5.2. Evaluation on Two Perspectives
5.2. 基于两个视角的评估
In this section, we quantitatively and qualitatively evaluate the perspective prediction ability of proposed methods in the DIVIDE-3k (Sec. 5.2.1). The divergence map and pairwise user studies further prove that the two branches in DOVER better align with human opinions on corresponding perspectives on existing UGC-VQA databases (Sec. 5.2.2).
在本节中,我们通过定量和定性方法评估了所提方法在DIVIDE-3k数据集上的视角预测能力(见第5.2.1节)。分歧图和成对用户研究进一步证明,DOVER的双分支结构能更好地与现有UGC-VQA数据库中人类对相应视角的评价保持一致(见第5.2.2节)。
5.2.1 Evaluation on the DIVIDE-3k
5.2.1 DIVIDE-3k 数据集评估
Quantitative Studies. In Tab. 3, we evaluate the crosscorrelation between the aesthetic and technical predictions in DOVER or ${\tt D O V E R++}$ and human opinions from the two perspectives in the DIVIDE-3k, compared with baseline (with respective labels as supervision, but without View Decomposition). DOVER shows a stronger perspective pref- erence than the baseline even without using the respective labels, proving the effectiveness of the decomposition strategy. ${\tt D O V E R++}$ more effectively disentangle the two per- spectives with each branch around $7%$ more correlated with respective opinions than opinions from another perspective. Qualitative Studies. In Fig. 6, we visualize several videos with diverged predicted aesthetic and technical scores. The two videos with better aesthetic scores (Fig. have clear semantics yet suffer from blurs and artifacts; on the contrary, the two with better technical scores (Fig. are sharp but with chaotic composition and unclear semantics. These examples align with human perception of the two perspectives, proving that both variants can effectively provide disentangled quality predictions.
定量研究。在表3中,我们评估了DOVER和${\tt D O V E R++}$中美学与技术预测与DIVIDE-3k中人类观点在两个维度上的互相关性,并与基线方法(使用相应标签监督但未进行视角分解)进行对比。即使不使用相应标签,DOVER仍展现出比基线更强的视角偏好,验证了分解策略的有效性。${\tt D O V E R++}$能更有效地解耦两个维度,各分支与对应视角观点的相关性比另一视角高出约$7%$。
定性研究。在图6中,我们可视化了几组美学与技术得分差异显著的视频。美学得分较高的视频(语义清晰但存在模糊和伪影;相反,技术得分较高的视频(画质锐利但构图混乱且语义不明确。这些案例符合人类对两个维度的感知,证明两种变体都能有效提供解耦的质量预测。

Figure 7. The divergence map of technical and aesthetic predictions of DOVER in LSVQ [1] dataset. Similar as Fig. 6, the videos with diverged scores also align with human opinions of aesthetic and technical quality.
图 7: DOVER 在 LSVQ [1] 数据集中的技术与美学预测差异图。与图 6 类似,得分差异较大的视频同样符合人类对美学质量和技术质量的主观评价。

Figure 6. Qualitative Studies on Perspectives of DOVER/DOVER $^{,++}$ : Visualization s of videos in the DIVIDE-3k where aesthetic and technical predictions are diverged. More visualization s in supplement. Sec. D. Figure 8. User Studies on Diverged Pairs when technical and aesthetic branches in DOVER predict differently, demonstrating that predictions of each branch are more aligned with corresponding subjective opinions.
图 6: DOVER/DOVER$^{,++}$视角的定性研究:展示DIVIDE-3k数据集中美学与技术预测存在分歧的视频可视化效果。更多可视化结果见补充材料附录D。图8: 分歧配对用户研究:当DOVER的技术分支与美学分支预测不一致时,各分支预测结果更符合相应主观评价。
5.2.2 Evaluation on Existing UGC-VQA Datasets
5.2.2 在现有UGC-VQA数据集上的评估
The Divergence Map. In Fig. 7, we visualize the divergence map between predictions in two branches (trained and tested on LSVQ [1]) and examine the videos where two branches score most differently, noted in orange circles. Among these videos, the aesthetic branch can distinguish between bad (chaotic scene, Fig. 7 downright) and good (symmetric view, Fig. 7 upleft) aesthetics, while the technical branch can detect technical quality issues (blurs, over-exposure, compression errors at Fig. 7 upleft).
差异图。在图7中,我们可视化了两分支(在LSVQ [1]上训练和测试)预测间的差异图,并标注了评分差异最大的视频(橙色圆圈所示)。这些视频中,美学分支能区分差(混乱场景,图7右下)与优(对称构图,图7左上)的美学表现,而技术分支可识别技术质量问题(图7左上的模糊、过曝和压缩错误)。
Pairwise User Studies. We further conduct user studies to measure whether the two evaluators can distinguish the two perspectives on these diverged cases. Specifically, we evaluate on diverged pairs ${\mathcal{V}{1},\mathcal{V}{2}}$ where aesthetic branch predicts $\nu_{1}$ is obviously better (at least one score higher when scores are in the range [1, 5]) yet technical branch predicts $\nu_{2}$ is obviously better. After random sampling 200 pairs in this way, we ask 15 subjects to choose which one has better aesthetic (or technical) quality in the pair. After post-processing the subject choices with popular votes, we calculate the agreement rates between subjective votes and predictions (in Fig. 8). Each subjective perspective is notably more agreed with corresponding branch predictions, demonstrating that even without the respective labels, the DOVER can still learn to primarily disentangle the two perspectives. More details are in supplementary (Sec. B).
成对用户研究。我们进一步开展用户研究,以评估两位评分者是否能区分这些分歧案例中的两种视角。具体而言,我们针对分歧配对 ${\mathcal{V}{1},\mathcal{V}{2}}$ 进行评估,其中美学分支预测 $\nu_{1}$ 明显更优(当分数范围为[1,5]时至少高出一分),而技术分支预测 $\nu_{2}$ 明显更优。通过这种方式随机抽样200对后,我们让15名受试者在每对中选择美学(或技术)质量更优的一方。经过多数票统计处理受试者选择后,我们计算了主观投票与预测结果的一致率(见图8)。每个主观视角与对应分支预测的一致性显著更高,这表明即使没有相应标签,DOVER仍能主要解耦这两种视角。更多细节见补充材料(B节)。
Table 4. Benchmark on official splits on the large-scale UGC-VQA dataset LSVQ [1]. First, second and third bests are labelled in red, blue and boldface.
表 4: 大规模UGC-VQA(用户生成内容视频质量评估)数据集LSVQ[1]官方划分的基准测试结果。第一、第二和第三最佳结果分别用红色、蓝色和粗体标注。
| 训练集:LSVQtrain[1] 测试集/ | 推理计算成本 | 数据集内评估 | 泛化评估 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 方法 | GFLOPs | CPU时间 | GPU时间 | SROCC↑ | PLCC↑ | SROCC↑ | PLCC↑ | SROCC↑ | PLCC↑ | SROCC↑ | PLCC↑ |
| 经典方法(基于手工特征): | |||||||||||
| TLVQM(TIP,2019)[10] | NA | 248秒 | NA | 0.772 | 0.774 | 0.589 | 0.616 | 0.732 | 0.724 | 0.670 | 0.691 |
| VIDEVAL(TIP,2021)[9] | 1 NA | 895秒 | NA | 0.795 | 0.783 | 0.545 | 0.554 | 0.751 | 0.741 | 0.630 | 0.640 |
| 深度学习方法(基于深度神经网络特征): | |||||||||||
| VSFA(ACM MM,2019)[6] | 40919 | 466秒 | 11.1秒 | 0.801 | 0.796 | 0.675 | 0.704 | 0.784 | 0.795 | 0.734 | 0.772 |
| ★Patch-VQ无分块(CVPR,2021)[1] | 58501 | 539秒 | 13.8秒 | 0.814 | 0.816 | 0.686 | 0.708 | 0.781 | 0.781 | 0.747 | 0.776 |
| ★Patch-VQ有分块(CVPR,2021)[1] | -同上- | 0.827 | 0.828 | 0.711 | 0.739 | 0.791 | 0.795 | 0.770 | 0.807 | ||
| *Li等(TCSVT,2022)[57] | 1 112537 | 1567秒 | 27.6秒 | 0.852 | 0.855 | 0.771 | 0.782 | 0.834 | 0.837 | 0.816 | 0.824 |
| FAST-VQA(ECCV,2022)[13] | 1 279.1 | 8.8秒 | 45毫秒 | 0.876 | 0.877 | 0.779 | 0.814 | 0.859 | 0.855 | 0.823 | 0.844 |
| DOVER(本文方法) | 282.3 | 9.7秒 | 47毫秒 | 0.888 | 0.889 | 0.795 | 0.830 | 0.884 | 0.883 | 0.832 | 0.855 |
| 相对现有最佳提升 | +1.3% | +1.3% | +2.0% | +2.0% | +2.9% | +3.3% | +1.0% | +1.3% |
Table 5. Performance benchmark on existing smaller UGC-VQA datasets. All experiments are conducted under 10 train-test splits.
表 5: 现有小型 UGC-VQA (用户生成内容视频质量评估) 数据集性能基准。所有实验均在 10 次训练-测试分割下进行。
| 方法 | 源(预训练) | LIVE-VQC(585) (240P-1080P) | KoNViD-1k(1200) (540P) | YouTube-UGC(1380) (360P-2160P(4K)) | 加权平均 |
|---|---|---|---|---|---|
| 质量数据集 | SROCC↑ | PLCC↑ | SROCC↑ | PLCC↑ | |
| TLVQM (TIP, 2019) [10] | NA(纯手工特征) | 0.799 | 0.803 | 0.773 | 0.768 |
| VIDEVAL(TIP,2021)[9] | NA(纯手工特征) | 0.752 | 0.751 | 0.783 | 0.780 |
| RAPIQUE (OJSP,2021)[72] | 手工特征+KoNiQ[73] | 0.755 | 0.786 | 0.803 | 0.817 |
| CNN+TLVQM(ACMMM,2020)[53] | 手工特征+KoNiQ[73] | 0.825 | 0.834 | 0.816 | 0.818 |
| CNN+VIDEVAL(TIP,2021)[9] | 手工特征+KoNiQ[73] | 0.785 | 0.810 | 0.815 | 0.817 |
| VSFA(ACMMM,2019)[6] | 无 | 0.773 | 0.795 | 0.773 | 0.775 |
| Patch-VQ (CVPR,2021)[1] | PaQ-2-PiQ [60] | 0.827 | 0.837 | 0.791 | 0.786 |
| CoINVQ (CVPR,2021)[7] | 自采集数据 | NA | NA | 0.767 | 0.764 |
| Lietal.(TCSVT,2022)[57] | 融合([15,73-75]) | 0.834 | 0.842 | 0.834 | 0.836 |
| FAST-VQA(ECCV,2022)[13] | LSVQ [1] | 0.849 | 0.862 | 0.891 | 0.892 |
| DOVER (本文) | LSVQ[1] | 0.860 | 0.875 | 0.909 | 0.906 |
| -相对现有最佳提升 | +1.6% | +1.4% | +2.0% | +1.6% |
Table 6. Performance benchmark on the DIVIDE-3k. All experiments are conducted under 10 train-test splits with random seed 42.
表 6. DIVIDE-3k 上的性能基准测试。所有实验均在随机种子 42 的 10 次训练-测试分割下进行。
| 方法 | 预训练数据集 | SROCC↑ | PLCC↑ | KROCC↑ |
|---|---|---|---|---|
| TLVQM (2019) [10] | NA (纯手工特征) | 0.6461 | 0.6807 | 0.4699 |
| VIDEVAL (2021) [9] | NA (纯手工特征) | 0.7056 | 0.7162 | 0.5233 |
| RAPIQUE (2021) [72] | 手工特征+KoNiQ [73] | 0.7341 | 0.7547 | 0.5498 |
| VSFA (2019) [6] | NA | 0.7254 | 0.7386 | 0.5395 |
| MDTVSFA (2021) [50] | NA | 0.7522 | 0.7409 | 0.5647 |
| UNIQUE (2021) [76] | 融合 ([15,73-75]) | 0.7529 | 0.7637 | 0.5634 |
| Li et al. (2022) [57] | 融合 ([15,73-75]) | 0.7967 | 0.8125 | 0.6138 |
| FAST-VQA (2022) [13] | LSVQ [1] | 0.8184 | 0.8288 | 0.6285 |
| DOVER (Ours) | LSVQ [1] | 0.8331 | 0.8438 | 0.6480 |
| DOVER++ (Ours) | LSVQ [1] | 0.8442 | 0.8537 | 0.6603 |
5.3. Evaluation on Overall Quality Prediction
5.3. 整体质量预测评估
5.3.1 Results on Existing UGC-VQA Datasets
5.3.1 现有UGC-VQA数据集上的结果
Results on LSVQ. In Tab. 4, we train the DOVER on the large-scale UGC-VQA dataset, LSVQ [1], and test it on five different existing UGC-VQA datasets. The proposed DOVER outperforms state-of-the-arts for intra-dataset evaluations by improving up to $2.0%$ PLCC. When testing on datasets other than LSVQ as generalization evaluation, the DOVER has shown more competitive performance. It improves PLCC on FAST-VQA by $3.3%$ on KoNViD-1k, the UGC-VQA dataset with more diverse contents, further suggesting the importance of modelling from the aesthetic perspective in quality assessment on videos of diverse contents.
LSVQ上的结果。在表4中,我们在大规模UGC-VQA数据集LSVQ [1]上训练DOVER,并在五个不同的现有UGC-VQA数据集上进行测试。所提出的DOVER在数据集内评估中优于现有技术,PLCC提升高达$2.0%$。在LSVQ以外的数据集上进行泛化评估时,DOVER表现出更具竞争力的性能。在内容更多样化的UGC-VQA数据集KoNViD-1k上,DOVER将FAST-VQA的PLCC提高了$3.3%$,进一步表明从美学角度建模对多样化内容视频质量评估的重要性。
Table 7. Zero-shot or cross-dataset evaluations on the DIVIDE-3k. None of the listed methods has been trained on the DIVIDE-3k.
表 7: DIVIDE-3k 上的零样本或跨数据集评估。所列方法均未在 DIVIDE-3k 上训练过。
| 方法 | 训练数据 | SROCC | PLCC | KROCC |
|---|---|---|---|---|
| 零样本 (意见无关) VQA 方法: | ||||
| NIQE (2013) [11] | 无 | 0.3524 | 0.3839 | 0.2634 |
| TPQI (2022) [12] | 无 | 0.4407 | 0.4432 | 0.3045 |
| CLIP-IQA (2022) [55] | CLIP [77] | 0.5882 | 0.5910 | 0.4067 |
| BVQI (2023) [78] | CLIP [77] | 0.6678 | 0.6802 | 0.4842 |
| 跨数据集评估 (训练于 LSVQ): | ||||
| Patch-VQ (2021) [1] | LSVQ [1] | 0.6454 | 0.6713 | 0.4489 |
| Li et al. (2022) [57] | LSVQ [1] | 0.7318 | 0.7524 | 0.5395 |
| DOVER (本文方法) | LSVQ | 0.7727 | 0.7806 | 0.5799 |
Results on Smaller UGC-VQA Datasets. Following [13], we pre-train the proposed DOVER on LSVQ instead of IQA datasets [60,73,74] and then fine-tune the proposed method on three smaller UGC-VQA datasets and list the results in Tab. 5. DOVER has reached unprecedented performance on all three datasets (mean $\mathrm{PLCC}>0.89$ ), and outperformed FAST-VQA with an average of $2.6%$ improvement under exactly the same training process. The results further prove the effectiveness of considering aesthetic and technical perspectives separately and explicitly in UGC-VQA.
在小型UGC-VQA数据集上的结果。遵循[13]的方法,我们在LSVQ而非IQA数据集[60,73,74]上预训练提出的DOVER模型,随后在三个较小规模的UGC-VQA数据集上微调该方法,结果如Tab. 5所示。DOVER在所有三个数据集上均取得突破性性能(平均$\mathrm{PLCC}>0.89$),并在完全相同的训练流程下以平均$2.6%$的优势超越FAST-VQA。这些结果进一步验证了在UGC-VQA任务中显式区分审美维度与技术维度的有效性。
Table 8. Ablation Study of DOVER (I): the View Decomposition scheme.
表 8: DOVER消融研究 (I): 视图分解方案
| 测试集/变体/指标 | LSVQtest | LSVQ1080p | KoNViD-1k | LIVE-VQC |
|---|---|---|---|---|
| SROCC/PLCC | SROCC/PLCC | SROCC/PLCC | SROCC/PLCC | |
| 无分解方案 | 0.859/0.858 | 0.752/0.798 | 0.851/0.850 | 0.816/0.834 |
| 特征聚合 | 0.873/0.874 | 0.776/0.811 | 0.863/0.864 | 0.813/0.839 |
| DOVER(本文) | 0.888/0.889 | 0.795/0.830 | 0.884/0.883 | 0.832/0.855 |
Table 9. Ablation Study of DOVER (II): Accuracy of single branch pre
表 9. DOVER消融研究(二): 单分支预测准确率
| Qpred,A Qpred,T | SIF SROCC/PLCC | IvelyEstaprdsop | ||
|---|---|---|---|---|
| √ | SROCC/PLCC | SROCC/PLCC | SROCC/PLCC | |
| 0.855/0.856 | 0.738/0.782 | 0.844/0.853 | 0.792/0.826 | |
| √ | 0.877/0.878 | 0.778/0.812 | 0.861/0.855 | 0.825/0.844 |
| 0.885/0.886 | 0.792/0.826 | 0.880/0.880 | 0.829/0.849 | |
| 0.888/0.889 | 0.795/0.830 | 0.884/0.883 | 0.832/0.855 |
5.3.2 Results on the DIVIDE-3k
5.3.2 DIVIDE-3k 数据集上的结果
Training and Testing on DIVIDE-3k. We first benchmark recent state-of-the-arts by conducting training and testing in the DIVIDE-3k. As shown in Tab. 6, the two semanticunaware classical methods [9, 10] are performing notably worse and DOVER again achieves state-of-the-art. It is also noteworthy that with aesthetic and technical scores as auxiliary labels, ${\tt D O V E R++}$ further improves the performance for overall quality prediction. This further suggests that better modeling of the two perspectives can finally benefit overall quality assessment in the UGC-VQA problem.
在DIVIDE-3k上的训练与测试。我们首先通过在DIVIDE-3k上进行训练和测试来对近期最先进方法进行基准测试。如表6所示,两种无语义感知的经典方法[9, 10]表现明显较差,而DOVER再次达到了最先进水平。值得注意的是,通过将美学和技术评分作为辅助标签,${\tt DOVER++}$进一步提升了整体质量预测的性能。这进一步表明,在这两个视角上建立更好的模型最终能有益于UGC-VQA问题中的整体质量评估。
Zero-shot and Cross-dataset Evaluations. We also benchmark the opinion-unaware (i.e. zero-shot) VQA approaches on the DIVIDE-3k. Among them, the recent BVQI [78] reaches the best performance by considering both technical and semantic (aesthetic-related) criteria. Moreover, we benchmark the best approaches in Tab. 4 on the cross-dataset generalization from LSVQ to the DIVIDE3k, where the proposed DOVER again outperforms other methods, suggesting the alignment between the proposed objective approach and subjective database.
零样本与跨数据集评估。我们还在DIVIDE-3k上测试了无监督(即零样本)VQA方法。其中,近期提出的BVQI [78]通过同时考虑技术性和语义性(美学相关)标准取得了最佳性能。此外,我们在表4中将LSVQ到DIVIDE3k的跨数据集泛化能力进行了基准测试,所提出的DOVER方法再次优于其他方法,这表明所提出的客观方法与主观数据库之间存在一致性。
5.4. Ablation Studies
5.4. 消融实验
Effects of View Decomposition. In Tab. 8, we compare the proposed View Decomposition strategy with common strategies in UGC-VQA by keeping other parts the same. First of all, it is much better than the variant w/o Decomposition that directly takes the original videos as inputs of both branches, showing the effectiveness of decomposition. Moreover, with backbone and input kept the same, DOVER with separate supervisions is also notably better than Feature Aggregation, which first concatenates features from two branches together and then regress them to the quality scores, as applied by several existing approaches [1, 49, 57]. Effects of Subjectively-Inspired Fusion. We discuss the fusion strategy in Tab. 9. As shown in the table, only considering one branch will bring a notable performance decrease, and directly obtaining the fused quality as $Q_{\mathrm{pred,A}}+Q_{\mathrm{pred,T}}$ without weights is also less accurate than subjectively-inspired fusion. These results further validate the subjective observations found in the DIVIDE-3k.
视角分解的效果。在表8中,我们通过保持其他部分不变,将提出的视角分解策略与UGC-VQA中的常见策略进行比较。首先,它明显优于不进行分解的变体(直接以原始视频作为两个分支的输入),这证明了分解的有效性。此外,在保持主干网络和输入相同的情况下,采用单独监督的DOVER也显著优于特征聚合方法(后者先将两个分支的特征拼接,再回归到质量分数,如现有方法[1,49,57]所采用的方式)。
主观启发式融合的效果。我们在表9中讨论融合策略。如表所示,仅考虑一个分支会导致性能显著下降,而直接通过$Q_{\mathrm{pred,A}}+Q_{\mathrm{pred,T}}$进行无权重融合,其准确性也低于主观启发式融合。这些结果进一步验证了DIVIDE-3k中发现的主观观察结论。
Table 10. Ablation Study of $\mathbf{DOVER}\mathbf{++}$ : Effects of different objectives.
表 10: $\mathbf{DOVER}\mathbf{++}$ 消融研究:不同目标函数的影响

Figure 9. For the video (a), the impact of aesthetic and technical perspectives on the final quality rating (b) varies among individuals. By adjusting fusion weights, $\scriptstyle{\mathrm{DOVER++}}$ can align with opinions from different groups.
图 9: 对于视频 (a),审美和技术视角对最终质量评分 (b) 的影响因人而异。通过调整融合权重,$\scriptstyle{\mathrm{DOVER++}}$ 可以与不同群体的意见保持一致。
Ablation Studies of $\mathbf{DOVER++}$ . In Tab. 10, we further discuss whether the extra objective $(\mathcal{L}{\mathrm{DS}})$ can improve accuracy of overall quality prediction. By combining $\mathcal{L}{\mathrm{DS}}$ with $\mathcal{L}{\mathrm{LVBS}}$ , it contributes to around $1%$ performance gain. It is also noteworthy that even without direct MOS labels for supervision, the $\mathcal{L}{\mathrm{DS}}$ only can still outperform ${\mathcal{L}}_{\mathrm{LVBS}}$ . All these results suggest that explicitly considering “quality” in UGC-VQA into a sum of two perspectives is a good approximation to the human perceptual mechanism.
$\mathbf{DOVER++}$ 的消融研究。在表 10 中,我们进一步讨论了额外目标 $(\mathcal{L}{\mathrm{DS}})$ 是否能提高整体质量预测的准确性。通过将 $\mathcal{L}{\mathrm{DS}}$ 与 $\mathcal{L}{\mathrm{LVBS}}$ 结合,性能提升了约 $1%$。值得注意的是,即使没有直接使用 MOS 标签进行监督,仅使用 $\mathcal{L}{\mathrm{DS}}$ 仍然可以超越 ${\mathcal{L}}_{\mathrm{LVBS}}$。这些结果表明,在 UGC-VQA 中将“质量”显式地拆分为两个视角的加和,是对人类感知机制的良好近似。
5.5. Outlook: Personalized Quality Evaluation
5.5. 展望:个性化质量评估
During the subjective reasoning study, we further find out that the effect of each perspective varies among different individuals. For instance, the video in Fig. 9(a) has better aesthetics and worse technical quality (blurry, under-exposed), and different individuals consider the technical impact differently while rating the overall opinion (Fig. 9(b)). Moreover, with more consideration of the technical perspective, subjects tend to rate lower scores on the video. With ${\tt D O V E R++}$ , if we adaptively fuse between $Q_{\mathrm{pred,A}}$ and $Q_{\mathrm{pred,T}}$ , we find that the differently-fused results can better predict the quality perception of individual subject groups, suggesting its primary capability to provide quality evaluation catering for personalized requirements.
在主观推理研究中,我们进一步发现每个视角的效果因人而异。例如,图 9(a) 中的视频具有更好的美学效果和更差的技术质量(模糊、曝光不足),而不同个体在评价整体意见时对技术影响的考量不同(图 9(b))。此外,随着对技术视角的更多考量,受试者倾向于对视频给出更低的评分。通过 ${\tt DOVER++}$,如果我们自适应地融合 $Q_{\mathrm{pred,A}}$ 和 $Q_{\mathrm{pred,T}}$,我们发现不同融合结果能更好地预测个体受试者群体的质量感知,这表明其主要能力在于提供满足个性化需求的质量评估。
6. Conclusion
6. 结论
In this paper, we present the DIVIDE-3k database and the first subjective study aimed at exploring the impact of aesthetic and technical perspectives on UGC-VQA, which reveals that both perspectives impact human quality opinions. In light of this observation, we propose the objective quality evaluators, DOVER and $\scriptstyle\mathrm{{DOVER++}}$ , that achieve two objectives: 1) significantly improving overall UGCVQA performance; 2) decoupling effects of two perspectives, so as to be applicable to specific real-world scenarios where pure technical or aesthetic quality metrics are needed.
本文介绍了DIVIDE-3k数据库及首个探究美学与技术视角对用户生成视频质量评估(UGC-VQA)影响的主观研究,揭示了两种视角均会影响人类质量评价。基于此发现,我们提出了客观质量评估器DOVER与$\scriptstyle\mathrm{{DOVER++}}$,其实现两大目标:1)显著提升UGC-VQA整体性能;2)解耦两种视角的影响,从而适用于需要纯技术或纯美学质量指标的具体现实场景。