KnowCoder: Coding Structured Knowledge into LLMs for Universal Information Extraction
KnowCoder: 将结构化知识编码到大语言模型以实现通用信息抽取
Abstract
摘要
In this paper, we propose KnowCoder, a Large Language Model (LLM) to conduct Universal Information Extraction (UIE) via code generation. KnowCoder aims to develop a kind of uni- fied schema representation that LLMs can easily understand and an effective learning framework that encourages LLMs to follow schemas and extract structured knowledge accurately. To achieve these, KnowCoder introduces a code-style schema representation method to uniformly transform different schemas into Python classes, with which complex schema information, such as constraints among tasks in UIE, can be captured in an LLM-friendly manner. We further construct a code-style schema library covering over 30,000 types of knowledge, which is the largest one for UIE, to the best of our knowledge. To ease the learning process of LLMs, KnowCoder contains a twophase learning framework that enhances its schema understanding ability via code pretraining and its schema following ability via instruction tuning. After code pre training on around 1.5B automatically constructed data, KnowCoder already attains remarkable generalization ability and achieves relative improvements by $49.8%$ F1, compared to LLaMA2, under the few-shot setting. After instruction tuning, KnowCoder further exhibits strong generalization ability on unseen schemas and achieves up to $12.5%$ and $21.9%$ , compared to sota baselines, under the zero-shot setting and the low resource setting, respectively. Additionally, based on our unified schema representations, various human-annotated datasets can simultaneously be utilized to refine KnowCoder, which achieves significant improvements up to $7.5%$ under the supervised setting.
本文提出KnowCoder——一个通过代码生成实现通用信息抽取(Universal Information Extraction, UIE)的大语言模型。KnowCoder致力于开发一种LLM易于理解的统一模式表示方法,以及能促使LLM遵循模式并准确抽取结构化知识的有效学习框架。为此,KnowCoder引入代码化模式表示方法,将不同模式统一转换为Python类,从而以LLM友好的方式捕捉UIE中任务间约束等复杂模式信息。我们进一步构建了覆盖3万多种知识的代码化模式库,据我们所知这是UIE领域规模最大的模式库。为简化LLM学习过程,KnowCoder采用两阶段学习框架:通过代码预训练增强模式理解能力,通过指令微调提升模式遵循能力。在约15亿条自动构建数据上进行代码预训练后,KnowCoder已展现出卓越的泛化能力,在少样本设置下相比LLaMA2取得49.8% F1值的相对提升。经过指令微调后,KnowCoder在未见模式上表现出强大泛化能力,在零样本和低资源设置下分别较SOTA基线提升12.5%和21.9%。此外,基于我们的统一模式表示方法,可同时利用多个人工标注数据集优化KnowCoder,使其在有监督设置下最高获得7.5%的性能提升。
1 Introduction
1 引言
Information Extraction (IE) aims to extract explicit and structured knowledge following the manually designed schemas. The IE schemas define highlevel types of knowledge (i.e., concepts) and structures among them (Hogan et al., 2021), which include various types of entities, relations, and events. To simultaneously extract various knowledge under different schemas via a single model, the Universal Information Extraction (UIE) task is proposed (Lin et al., 2020a). Recently, Large Language Models (LLMs) have demonstrated general understand- ing abilities through large-scale pre training, which drives their increasing utilization in UIE. However, their performance on UIE is still limited because of two main challenges: (1) the lack of a unified schema representation method that LLMs can easily understand; (2) the lack of an effective learning framework that encourages LLMs to accurately follow specific schemas for extracting structured knowledge.
信息抽取 (Information Extraction, IE) 旨在根据人工设计的模式抽取显式且结构化的知识。IE模式定义了高层知识类型(即概念)及其间结构 (Hogan et al., 2021),包含各类实体、关系和事件。为通过单一模型同时抽取不同模式下的多样化知识,通用信息抽取 (Universal Information Extraction, UIE) 任务被提出 (Lin et al., 2020a)。近年来,大语言模型通过大规模预训练展现出通用理解能力,促使其在UIE中的应用日益增多。然而,由于两大挑战,它们在UIE上的表现仍受限:(1) 缺乏LLM易于理解的统一模式表示方法;(2) 缺乏有效学习框架来促使LLM精准遵循特定模式以抽取结构化知识。

Figure 1: An illustration of KnowCoder schemas.
图 1: KnowCoder 模式示意图。
For the first challenge, the existing UIE models first represent different schemas in a universal way, such as classification labels (Lin et al., 2020a), keywords (Gui et al., 2023), or a specifically-designed formal language (Lu et al., 2022). These schema representation methods have three main restrictions: (1) ignoring information like taxonomies (e.g., “fairytale” is a subclass of “written work”)
针对第一个挑战,现有的UIE模型首先采用统一方式表示不同模式,例如分类标签 (Lin et al., 2020a)、关键词 (Gui et al., 2023) 或专门设计的形式化语言 (Lu et al., 2022)。这些模式表示方法存在三个主要限制:(1) 忽略分类层级信息(例如"童话"是"书面作品"的子类)
and constraints among concepts (e.g., “spouse” relation exists between two “human” entities); (2) classification labels or a specifically designed formal language is hard for LLMs to understand and follow; (3) designed for specific IE datasets and lacking a general schema library.
概念间的约束关系(例如两个“人”实体之间存在“配偶”关系);(2) 分类标签或专门设计的形式化语言难以被大语言模型理解和遵循;(3) 针对特定信息抽取数据集设计,缺乏通用模式库。
To solve these restrictions, in this paper, we propose a kind of code-style schema representation method, with which various types of knowledge are generally defined as Python classes. As shown in Figure 1, the class inheritance mechanism is adopted to describe the concept taxonomies. A mechanism of type hint is employed to model constraints among different concepts. The class comments are used to provide clear definitions of concepts. And, the class methods are used to postprocess the results according to specific IE guidelines. Upon this method, we construct a comprehensive code-style schema library covering over 29, 000 entity types, 900 relation types, and 500 event types based on Wikidata, the largest one for UIE, to the best of our knowledge, currently reported in the open literature.
为解决这些限制,本文提出了一种代码式模式表示方法,各类知识被统一定义为Python类。如图1所示,该方法采用类继承机制描述概念分类体系,利用类型提示机制建模概念间约束关系,通过类注释提供清晰概念定义,并借助类方法实现基于特定信息抽取(IE)准则的结果后处理。基于此方法,我们以最大规模开放知识库Wikidata为基础,构建了覆盖29,000余种实体类型、900种关系类型及500种事件类型的代码式模式库。据我们所知,这是目前公开文献中报道的通用信息抽取(UIE)领域规模最大的模式库。
For the second challenge, the existing learning framework for UIE directly conducts instruction tuning on LLMs to extract knowledge following specific and limited schemas (Sainz et al., 2023; Wang et al., 2023b). The enormous concepts in the constructed schema library challenge the existing training framework. To help LLMs better understand and follow these schemas, we propose an effective two-phase framework containing a schema understanding phase and a schema following phase. The former improves the ability of LLMs to understand different concepts in schemas via largescale code pre training on the schema definition code and corresponding instance code. The latter advances their abilities to follow specific schemas in an IE task via instruction tuning. After code pretraining on around 1.5B automatically constructed data, KnowCoder already attains remarkable generalization ability and achieves NER improvements compared to the base model, LLaMA2, by $49.8%$ relative F1 point under the few-shot setting on NER. After instruction tuning on 1.5B automatically annotated data, KnowCoder experimentally demonstrates strong generalization ability on unseen schemas. Under the zero-shot setting, KnowCoder achieves average relative improvements up to $12.5%$ on the NER task. Under the low-resource setting, KnowCoder gets average relative improvements up to $21.9%$ on all the IE tasks. Additionally, based on our unified schema representation, various IE datasets can be simultaneously utilized to refine KnowCoder. After refinement, KnowCoder achieves consistent improvements across all IE tasks under the supervised setting, getting up to $7.5%$ improvement on the relation extraction task, respectively.
针对第二个挑战,现有UIE学习框架直接在LLM上进行指令微调,以遵循特定且有限的模式提取知识(Sainz等人,2023;Wang等人,2023b)。构建的模式库中庞大概念对现有训练框架构成挑战。为帮助LLM更好地理解和遵循这些模式,我们提出一个有效的两阶段框架,包含模式理解阶段和模式遵循阶段。前者通过大规模代码预训练(模式定义代码及对应实例代码)提升LLM理解模式中不同概念的能力;后者通过指令微调增强其在IE任务中遵循特定模式的能力。经过约15亿自动构建数据的代码预训练后,KnowCoder已具备显著泛化能力,在少样本NER设置下相比基础模型LLaMA2获得49.8%的相对F1值提升。在15亿自动标注数据上完成指令微调后,KnowCoder实验证明对未见模式具有强泛化能力:零样本设置下NER任务平均相对提升达12.5%,低资源设置下所有IE任务平均相对提升达21.9%。此外,基于我们统一的模式表示,可同时利用多种IE数据集优化KnowCoder。优化后,KnowCoder在有监督设置下所有IE任务均取得一致提升,其中关系抽取任务最高提升达7.5%。
In general, the main contributions of this paper include:
本文的主要贡献包括:
2 KnowCoder Schema
2 KnowCoder 架构
The proposed schema representation method uses code, a language that LLMs easy to understand, to define schemas. Specifically, KnowCoder schema adopts a series of programming language features to comprehensively model schema information, including the concept taxonomies, the constraints among different concepts, the definition of concepts, and other extraction requirements. Besides, considering that previous schema representation methods are only designed for specific datasets and contain limited types of knowledge, we further construct a large-scale schema corpus containing a wide range of knowledge.
提出的模式表示方法采用代码(一种大语言模型易于理解的语言)来定义模式。具体而言,KnowCoder模式采用了一系列编程语言特性来全面建模模式信息,包括概念分类体系、概念间约束关系、概念定义以及其他抽取需求。此外,考虑到现有模式表示方法仅针对特定数据集设计且包含知识类型有限,我们进一步构建了涵盖广泛知识的大规模模式语料库。
2.1 Code-style Schema Representation Method
2.1 代码风格的模式表示方法
The code-style schema representation method comprises three basic classes, namely, “Entity”, “Relation”, and “Event”. Based on the three basic classes, we represent all the concepts in the schemas by the corresponding classes. Then, the instances of each concept can be represented by the objects of the corresponding class. In the following, we will introduce four features of the proposed representation method.
代码式模式表示方法包含三个基本类,即"实体(Entity)"、"关系(Relation)"和"事件(Event)"。基于这三个基本类,我们通过对应的类来表示模式中的所有概念。然后,每个概念的实例可以通过对应类的对象来表示。接下来,我们将介绍该表示方法的四个特征。
Class Inheritance. We adopt the class inheritance mechanism to account for the taxonomies in the schemas. Specifically, we let class A inherit all the class members from class B if the corresponding concept A is the hyponym of concept B in the taxonomies. For a concept with multiple hypernyms, the hypernym concept with the most instances is selected. The class of an unseen concept can inherit from an existing class or directly from the basic class.
类继承。我们采用类继承机制来处理模式中的分类体系。具体来说,如果概念A在分类体系中是概念B的下位词,我们就让类A继承类B的所有成员。对于具有多个上位词的概念,选择实例最多的上位概念。未见过概念的类可以从现有类继承,也可以直接从基类继承。
Class comment. Similar to Sainz et al. (2023), we adopt class comments to provide clear definitions of concepts. As shown in Figure 1, a class comment includes a natural language description that explains the corresponding concept and the examples of instances corresponding to that type. When there is an unseen concept, we use the description in its annotation guidelines 1 and manually give out a few examples.
类注释。与 Sainz et al. (2023) 类似,我们采用类注释来提供概念的明确定义。如图 1 所示,类注释包含解释相应概念的自然语言描述以及该类型对应的实例示例。当遇到未见过的概念时,我们使用其注释指南中的描述并手动给出几个示例。
Type Hint. Type hint is a formal solution to indicate the type of a value in the code. We adopt type hints in the initialization function of a class to define its constraints with other classes strictly. Thus, the constraints among the concepts in the schemas are modeled. As shown in Figure 1, taking the relation “Place Of Birth” for example, “def init(self, head entity: Human, tail entity: Spatial Entity)” denotes that the head entity must be a “Human” and the tail entity must be a “Spatial Entity”.
类型提示 (Type Hint)。类型提示是一种在代码中标注值类型的正式解决方案。我们在类的初始化函数中采用类型提示,以严格定义其与其他类的约束关系。通过这种方式,我们实现了对模式中各概念间约束关系的建模。如图 1 所示,以关系 "出生地" 为例,"def init(self, head entity: Human, tail entity: Spatial Entity)" 表明头实体必须是 "Human" 类型,尾实体必须是 "Spatial Entity" 类型。
Class Method. A class method is bound to the class and not the object of the class. They are utilized to post-process the extracted instance results of a class. For example, some IE tasks may not consider the pronouns “he” and “she” as instances of the “Human” concept. To address this, a class method can be added to the “Human” class to filter out such pronouns from the extraction results, ensuring that the output aligns with the task’s unique criteria. Note that, class methods are manually designed for specific IE tasks based on their task constraints. We take a few IE datasets to demonstrate the effectiveness of class methods in our experiments, as shown in the Appendix C.
类方法 (Class Method)。类方法是绑定到类而非类对象的方法,用于对提取的类实例结果进行后处理。例如,某些信息抽取 (IE) 任务可能不将代词"he"和"she"视为"Human"概念的实例。为解决此问题,可以在"Human"类中添加一个类方法,从提取结果中过滤掉此类代词,确保输出符合任务的特定标准。需要注意的是,类方法是根据任务约束为特定IE任务手动设计的。我们在实验中采用了几种IE数据集来展示类方法的有效性,详见附录C。
2.2 Schema Library Construction
2.2 模式库构建
We construct the code-style schema library based on Wikidata 2. We select the concepts included in the existing IE datasets created from Wikidata, i.e., KELM (Agarwal et al., 2021), UniversalNER (Zhou et al., 2023), InstructIE (Zhang et al., 2023), and LSEE (Chen et al., 2017). We derive the constraints among concepts according to their co-occurrences. To construct the taxonomies, we extract the “SubclassOf” relations among these concepts from Wikidata. To obtain the description of a concept, we use its definition from Wikidata directly or generate its descriptions using GPT-4 if its definition in Wikidata is missing. Finally, the constructed schema library encompasses over 29, 177 entity types, 876 relation types, and 519 event types. The detailed statistics of the schema are in Appendix H.
我们基于Wikidata构建了代码风格的schema库。从现有基于Wikidata构建的信息抽取数据集(包括KELM (Agarwal等人, 2021)、UniversalNER (Zhou等人, 2023)、InstructIE (Zhang等人, 2023)和LSEE (Chen等人, 2017))中选取概念,根据概念共现关系推导约束条件。通过提取Wikidata中的"SubclassOf"关系构建分类体系。对于概念描述,直接采用Wikidata定义或通过GPT-4生成补充缺失定义。最终构建的schema库包含29,177种实体类型、876种关系类型和519种事件类型。详细统计信息见附录H。
3 Learning Framework of KnowCoder
3 KnowCoder 学习框架
To discriminate enormous concepts defined in schemas, we first let KnowCoder understand each concept through its definition and instances. Subsequently, we enhance KnowCoder to discriminate among a few concepts and extract corresponding knowledge. Thus, as shown in Figure 2, the proposed learning framework contains two phases, i.e., the schema understanding phase and the schema following phase. In the schema understanding phase, KnowCoder undergoes code pre training to understand each concept in two manners: 1) Go through the class definition code of each concept. 2) Go through the instance codes of each concept. In the schema following phase, KnowCoder is finetuned using instruction tuning code, where multiple task-demanded concepts are given in the schemas, enhancing KnowCoder’s ability to follow schemas and generate instant i a ting code accordingly.
为了区分模式(schema)中定义的众多概念,我们首先让KnowCoder通过定义和实例理解每个概念。随后,我们增强KnowCoder区分多个概念并提取相关知识的能力。如图2所示,提出的学习框架包含两个阶段:模式理解阶段和模式遵循阶段。在模式理解阶段,KnowCoder通过代码预训练以两种方式理解每个概念:1) 阅读每个概念的类定义代码;2) 阅读每个概念的实例代码。在模式遵循阶段,KnowCoder使用指令调优代码进行微调,此时模式中会给出多个任务需求的概念,从而增强KnowCoder遵循模式并据此生成实例化代码的能力。
3.1 Schema Understanding Phase
3.1 模式理解阶段
3.1.1 Training Data Generation
3.1.1 训练数据生成
To enhance KnowCoder’s schema understanding abilities, we construct a large-scale training dataset based on the schema library. As shown in the left part of Figure 2, the training data consists of two kinds of codes, i.e., schema definition codes and instance codes. The schema definition codes are generated based on the schema library, where we randomly sample a certain number of concepts (decided by the maximum sequence length) from the schema library to consist of a training sample. As the aim of the schema understanding phase is to understand each concept but not to discriminate various concepts, the instance code corresponding to a single concept contains three parts, i.e., a sentence containing instances of the given concept, an import clause to introduce the corresponding class of the given concept, and an instant i a ting clause to give out all the instances of the given concept in the sentence. The schema-instance codes are constructed based on KELM corpus (Agarwal et al., 2021), which contains 15, 628, 486 synthetic sentences to describe the structured knowledge from Wikidata. We do data cleaning for the corpus. The cleaning details are in Appendix G.
为增强KnowCoder的模式理解能力,我们基于模式库构建了大规模训练数据集。如图2左侧所示,训练数据包含两类代码:模式定义代码和实例代码。模式定义代码基于模式库生成,我们从模式库中随机采样一定数量(由最大序列长度决定)的概念组成训练样本。由于模式理解阶段的目标是理解每个概念而非区分不同概念,单个概念对应的实例代码包含三部分:包含给定概念实例的句子、引入该概念对应类的导入语句,以及列出句子中该概念所有实例的实例化语句。模式-实例代码基于KELM语料库(Agarwal等人,2021)构建,该语料库包含15,628,486条合成句子来描述Wikidata的结构化知识。我们对语料库进行了数据清洗,具体细节见附录G。
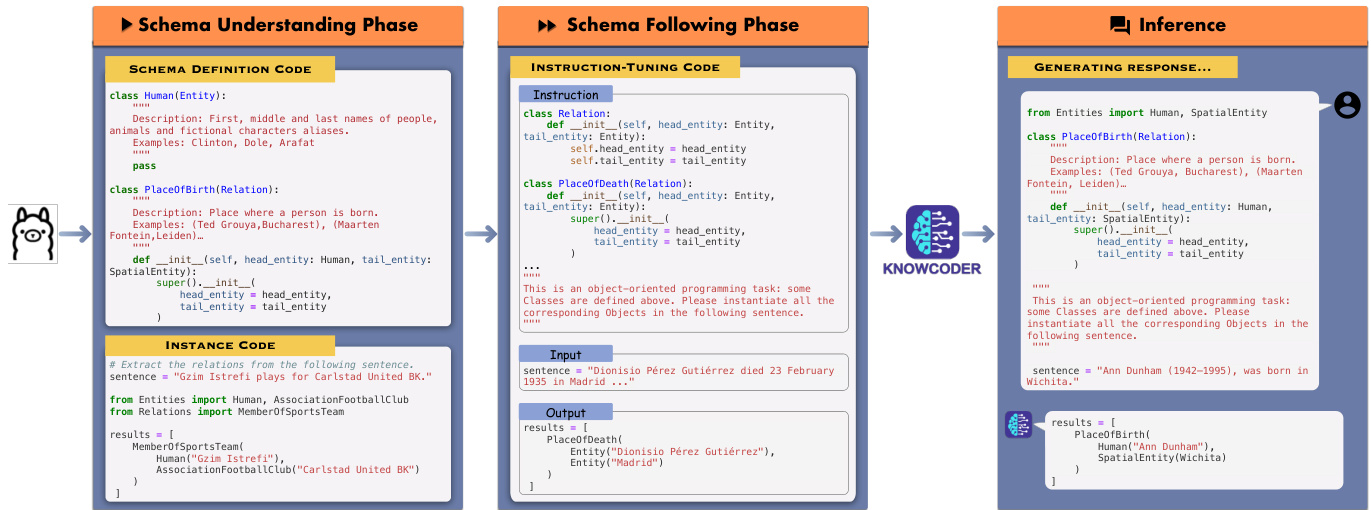
Figure 2: An diagram of training and inference processes of KnowCoder.
图 2: KnowCoder 训练与推理流程示意图
3.1.2 Code Pre training
3.1.2 代码预训练
After obtaining the data, we apply regular code pre training to make LLM understand the diverse concepts in the schemas. Given a training sample with length of $L$ $,X=x_{0},x_{1},...,x_{i},...,X_{L-1}$ , the model attempts to predict every token $x_{l}$ based on the $x_{0},...,x_{l-1}$ , where $l=0,...,L-1$ . Some training details are as follows:
获取数据后,我们通过常规代码预训练让大语言模型理解模式中的多样化概念。给定一个长度为 $L$ 的训练样本 $X=x_{0},x_{1},...,x_{i},...,X_{L-1}$,模型会根据 $x_{0},...,x_{l-1}$ 预测每个token $x_{l}$(其中 $l=0,...,L-1$)。部分训练细节如下:
Schema Importing. The straightforward way to construct a pre training sample is to directly give the whole schema definition for the corresponding instance code. However, this manner may cause the model to overfit the schema definition code because they are frequently repeated in every instance code. To address this problem, we separate the schema definition code from the instance code and use the “import” clause to introduce the corresponding schema definition to the instance code.
模式导入。构建预训练样本的直接方法是直接为对应的实例代码提供完整的模式定义。然而,这种方式可能导致模型对模式定义代码过拟合,因为它们在每个实例代码中频繁重复。为了解决这个问题,我们将模式定义代码与实例代码分离,并通过"import"子句将对应的模式定义引入实例代码。
The position of the “import” clause is also critical for the LLMs to learn. We study two positions for the “import” clause, i.e., “Import-First” and “Sentence-First”. We adopt “Sentence-First” in the learning framework because it performs better than the others. The comparison results are in Appendix A.
"import"子句的位置对大语言模型的学习也至关重要。我们研究了"import"子句的两种位置,即"导入优先(Import-First)"和"语句优先(Sentence-First)"。在学习框架中我们采用了"语句优先"方案,因其表现优于其他方案。对比结果详见附录A。
3.2 Schema Following Phase
3.2 模式遵循阶段
3.2.1 Training Data Generation
3.2.1 训练数据生成
To enhance the schema following abilities of KnowCoder, we construct instruction tuning training data for UIE tasks. As shown in the middle part of Figure 2, a typical instruction tuning sample contains three parts of codes, i.e., instruction code $T$ , input code $I$ , and output code $O$ .
为增强KnowCoder的模式遵循能力,我们为UIE任务构建了指令微调训练数据。如图2中间部分所示,典型的指令微调样本包含三部分代码:指令代码$T$、输入代码$I$和输出代码$O$。
The instruction code $T$ comprises two snippets, i.e., schema definition and task description. The schema definition snippet includes definitions of some concepts selected from the former phase, which defines specific concepts to be extracted. The task description snippet includes a comment that contains a natural language description of an IE task. For example, the task description of Relation Extraction (RE) is “This is an object-oriented programming task: some Classes are defined above. Please instantiate all the corresponding Objects in the following sentence.”. The input $I$ contains the sentence to be extracted, which is denoted as a variable “sentence”, i.e., “sentence $=$ ...”. The output $O$ contains all the golden knowledge in the sentence, denoted as a list variable “results”, i.e., “results $=$ [...]”. We have conducted a performance comparison of different versions of the instructions, and the corresponding results are in Appendix D.
指令代码 $T$ 包含两个片段,即模式定义和任务描述。模式定义片段包含从前一阶段选出的部分概念定义,这些定义明确了待提取的具体概念。任务描述片段包含一条注释,其中用自然语言描述了信息抽取任务。例如,关系抽取(RE)的任务描述为"这是一个面向对象编程任务:上文定义了一些类,请在下文句子中实例化所有对应的对象"。输入 $I$ 包含待抽取的句子,表示为变量"sentence",即"sentence $=$ ..."。输出 $O$ 包含句子中的所有标准知识,表示为列表变量"results",即"results $=$ [...]"。我们已对不同版本的指令进行了性能对比,相应结果见附录D。
We construct the training corpus from three data sources. For Named Entity Extraction (NER), ChatGPT-annotated Pile corpus (Zhou et al., 2023) is selected. For Relation Extraction (RE) and Event Extraction (EE), we adopt the data sources constructed in Gui et al. $(2023)^{3}$ and LSEE (Chen et al., 2017), respectively.
我们构建训练语料库时采用了三个数据来源。在命名实体识别(NER)任务中,选用经ChatGPT标注的Pile语料库 (Zhou et al., 2023) ;关系抽取(RE)和事件抽取(EE)任务则分别采用Gui等人 $(2023)^{3}$ 构建的数据源及LSEE (Chen et al., 2017)数据集。
3.2.2 Instruction Tuning
3.2.2 指令微调
The objective of instruction tuning is to learn an LLM f : $(I\times T)\to O$ . The LLM takes input code $I$ , and instruction code $T$ as input. Subsequently, the LLM is tuned to generate every token in the output $O$ . Some training details are as follows:
指令微调的目标是学习一个大语言模型 f: $(I\times T)\to O$。该大语言模型以输入代码 $I$ 和指令代码 $T$ 作为输入,随后通过微调使其能生成输出 $O$ 中的每个 Token。部分训练细节如下:
Negative Class Sampling. In the constructed schema library, there are more than 30000 concepts. It is challenging for the model to accommodate all the corresponding class definitions in a single prompt. Consequently, KnowCoder employs a negative class sampling strategy. For each training sample, in addition to the classes annotated in the sentence, we randomly sample several classes $20%$ number of the golden classes) from the remaining classes.
负类采样。在构建的模式库中,存在超过30000个概念。模型很难在单个提示中容纳所有对应的类别定义。因此,KnowCoder采用了负类采样策略。对于每个训练样本,除了句子中标注的类别外,我们还从剩余类别中随机采样若干类别(占黄金类别数量的20%)。
Fully negative Sample Construction. In realworld scenarios, many sentences do not contain any knowledge of a specific IE task, called fully negative samples in this paper. However, the selected data sources neglect such samples. To address this problem, we randomly sample $5%$ sentences from the data sources. For each sentence, we replace the golden classes with five random negative classes.
完全负样本构建。在现实场景中,许多句子不包含特定信息抽取任务的知识,本文称之为完全负样本。然而现有数据源往往忽略这类样本。为解决该问题,我们从数据源中随机抽取$5%$的句子,并将每句中的黄金类别替换为五个随机负类别。
3.3 Refinement
3.3 优化
After schema understanding and following, we obtain KnowCoder, an LLM that demonstrates strong generalization ability on unseen schemas. Additionally, based on our unified schema representation, KnowCoder can be further refined by various human-annotated datasets simultaneously. In this phase, we conduct instruction tuning based on the datasets used in previous work (Wang et al., 2023b; Sainz et al., 2023).
在完成模式(schema)理解与遵循后,我们获得了KnowCoder——一个在未见模式上展现出强大泛化能力的大语言模型。基于我们统一的模式表示方法,KnowCoder还能通过多种人工标注数据集进行同步精调。本阶段我们采用前人研究(Wang et al., 2023b; Sainz et al., 2023)使用的数据集进行指令微调。
In different IE datasets, concepts with the same name may follow different annotation guidelines. Take “PERSON” for example, in MultiNERD (Tedeschi and Navigli, 2022), entities do not include the pronouns, e.g., “he” and “she”, while ACE05 (Walker and Consortium, 2005) consider personal pronouns as “PERSON”. To alleviate the problem, we add specific dataset information in the instructions to distinguish annotation guidelines for different datasets. For example, the instruction for the ACE05 dataset is “... Please instantiate all the corresponding Event Objects in the following sentence from DATASET ACE05.”
在不同IE数据集中,名称相同的概念可能遵循不同的标注准则。以"PERSON"为例,在MultiNERD (Tedeschi and Navigli, 2022)中,实体不包括代词(如"he"和"she"),而ACE05 (Walker and Consortium, 2005)将人称代词视为"PERSON"。为缓解该问题,我们在指令中添加特定数据集信息以区分不同数据集的标注准则。例如,ACE05数据集的指令为"...请从DATASET ACE05的下列句子中实例化所有对应的事件对象。"
4 Experiment Setup
4 实验设置
Datasets. We conducted experiments using 33 specific domain Information Extraction (IE) datasets, including 23 datasets for Named Entity Extraction (NER), 8 datasets for Relation Extraction (RE), 2 datasets for Event Detection (ED) and Event Argument Extraction (EAE). The detailed statistics of these datasets are in Appendix H. Among these NER datasets, following Wang et al. (2023b); Zhou et al. (2023), we take 7 datasets as the zero-shot benchmark, including 5 datasets of different domains from CrossNER (Liu et al., 2020), MIT-Movie (Liu et al., 2019) and MITRestaurant (Liu et al., 2019). For RE, we adopt GIDS (Jat et al., 2018) as the zero-shot dataset. Following (Sainz et al., 2023), we adopt CASIE (Lu et al., 2021) as the zero-shot ED dataset.
数据集。我们使用33个特定领域的信息抽取(Information Extraction, IE)数据集进行实验,包括23个命名实体识别(Named Entity Extraction, NER)数据集、8个关系抽取(Relation Extraction, RE)数据集、2个事件检测(Event Detection, ED)和事件论元抽取(Event Argument Extraction, EAE)数据集。详细统计数据见附录H。在这些NER数据集中,参照Wang et al. (2023b)和Zhou et al. (2023)的做法,我们选取7个数据集作为零样本基准测试集,包括来自CrossNER (Liu et al., 2020)、MIT-Movie (Liu et al., 2019)和MITRestaurant (Liu et al., 2019)的5个不同领域数据集。对于RE任务,我们采用GIDS (Jat et al., 2018)作为零样本数据集。参照Sainz et al. (2023)的方法,我们选用CASIE (Lu et al., 2021)作为零样本ED数据集。
To balance the evaluation coverage and costs, we introduce the KnowCoder benchmark, a composite derived from existing NER, RE, and EE datasets. Under the supervised setting, a sampling strategy was developed for NER and RE tasks to maintain the distributions of original datasets and ensure the broad coverage of knowledge types. Details on the proposed strategy and comprehensive benchmark information are available in Appendix F.
为了平衡评估覆盖范围和成本,我们引入了KnowCoder基准测试,该测试由现有的NER(命名实体识别)、RE(关系抽取)和EE(事件抽取)数据集复合而成。在监督设置下,针对NER和RE任务开发了一种采样策略,以保持原始数据集的分布并确保知识类型的广泛覆盖。关于所提策略的详细信息和完整的基准测试信息见附录F。
Metrics. We report the span-based offset MicroF1 following previous methods (Lu et al., 2022; Lin et al., 2020b). For NER, an entity is considered correct if the entity boundary and type are correctly predicted. For RE, a relation is considered correct if its triplet matches a golden annotation, including relation type, subject entity, and object entity. For ED, an event trigger is correct if its event type and trigger match a golden annotation. For the EAE task, given an event type, an argument is correct if the argument and its role type match a golden annotation.
指标。我们沿用先前方法 (Lu et al., 2022; Lin et al., 2020b) 报告基于跨度的偏移量 MicroF1。对于命名实体识别 (NER) ,若实体边界和类型预测正确则判定该实体正确。对于关系抽取 (RE) ,若关系三元组 (包括关系类型、主体实体和客体实体) 与黄金标注完全匹配则判定该关系正确。对于事件检测 (ED) ,若事件类型和触发词与黄金标注匹配则判定该事件触发词正确。对于事件论元抽取 (EAE) 任务,在给定事件类型的情况下,若论元及其角色类型与黄金标注匹配则判定该论元正确。
4.1 Implementation Details
4.1 实现细节
KnowCoder is finetuned based on LLaMA2-base7B (Touvron et al., 2023). We utilize the Megatron- LM framework (Shoeybi et al., 2019) for schema understanding. We set the context length to 2048, the learning rate to $5\times10^{-6}$ , the global batch size to 1M tokens, and the maximum training step to 4500. For the schema following and refinement phases, we use LoRA (Hu et al., 2021) for parameterefficient fine-tuning. We set the lora rank and lora alpha parameters to 32 and 64, respectively. The warmup ratio is set to 0.03 and the dropout ratio is set to 0.1. The learning rates for these two phases are set to $3\times10^{-4}$ . We limit the sequence length to 4096 and set the batch size to 256. Detailed information about the training process is available in Appendix J. During the inference phase, we use greedy search and set the temperature to 0. The maximum output length is set to 640.
KnowCoder基于LLaMA2-base7B (Touvron等人, 2023)进行微调。我们采用Megatron-LM框架 (Shoeybi等人, 2019)进行模式理解。设置上下文长度为2048,学习率为$5\times10^{-6}$,全局批次大小为100万token,最大训练步数为4500。在模式跟随和优化阶段,我们使用LoRA (Hu等人, 2021)进行参数高效微调,将lora秩和lora alpha参数分别设为32和64。热身比例设为0.03,丢弃率设为0.1。这两个阶段的学习率设置为$3\times10^{-4}$。序列长度限制为4096,批次大小设为256。训练过程详细信息见附录J。推理阶段采用贪婪搜索,温度设为0,最大输出长度设为640。
Table 1: Results on NER under the few-shot setting.
表 1: 少样本设定下的命名实体识别(NER)结果。
| Model | Movie. Rest. AI | Litera.Music Politics Science | Average | |||||
|---|---|---|---|---|---|---|---|---|
| LLaMA2-7B | 31.0 | 19.6 | 30.8 | 24.1 | 28.0 | 38.7 | 44.1 | 30.9 |
| LLaMA2-13B | 32.6 | 25.2 | 37.5 | 36.5 | 37.0 | 60.3 | 51.7 | 40.1 |
| LLaMA2-7B | 31.0 | 19.6 | 30.8 | 24.1 | 28.0 | 38.7 | 44.1 | 30.9 |
| KnowCoder-7B (SU. only) | 37.2 | 36.4 | 41.8 | 42.6 | 53.8 | 60.6 | 51.6 | 46.3 (149.8%) |
Table 2: Results on NER under the zero-shot setting. w. refinement denotes methods that are refined on humanannotated data, which is unfair for KnowCoder to compare with.
| 模型 | 电影 | 餐厅 | AI | 文学 | 音乐 | 政治 | 科学 | 平均 |
|---|---|---|---|---|---|---|---|---|
| 带精调 | ||||||||
| InstructUIE-11B (Wang et al.,2023b) | 48.4 | 48.8 | 54.4 | 49.9 | 49.4 | |||
| GoLLIE-7B (Sainz et al.,2023) | 63.0 | 43.4 | 59.1 | 62.7 | 67.8 | 57.2 | 55.5 | 58.4 |
| GoLLIE-13B (Sainz et al.,2023) | 62.5 | 49.8 | 56.7 | 59.7 | 65.5 | 54.4 | 56.2 | 57.8 |
| UniNER-7B (精调版) (Zhou et al., 2023) | 59.4 | 31.2 | 62.6 | 64.0 | 66.6 | 66.3 | 69.8 | 60.0 |
| 不带精调 | ||||||||
| Vicuna-7B (Chiang et al., 2023) | 6.0 | 5.3 | 12.8 | 16.1 | 17.0 | 20.5 | 13.0 | 13.0 |
| Vicuna-13B (Chiang et al., 2023) | 0.9 | 0.4 | 22.7 | 22.7 | 26.6 | 27.2 | 22.0 | 17.5 |
| ChatGPT (Ouyang et al., 2022) | 5.3 | 32.8 | 52.4 | 39.8 | 66.6 | 68.5 | 67.0 | 47.5 |
| UniNER-7B (Zhou et al.,2023) | 42.4 | 31.7 | 53.5 | 59.4 | 65.0 | 60.8 | 61.1 | 53.4 |
| KnowCoder-7B | 50.0 | 48.2 | 60.3 | 61.1 | 70.0 | 72.2 | 59.1 | 60.1↑12.5% |
表 2: 零样本设置下的命名实体识别结果。带精调(w. refinement)表示使用人工标注数据微调的方法,KnowCoder与之对比存在不公平性。
5 Results and Analyses
5 结果与分析
5.1 Few-shot Evaluation After Schema Understanding
5.1 模式理解后的少样本评估
Considering that a pre-trained LLM cannot give proper results without given examples, we study the generalization ability of KnowCoder after the schema understanding phase, denoted as KnowCoder (SU. only), under the few-shot setting. Specifically, We utilize the first five samples from the training data as examples and report the NER F1 score in Table 1 across seven zero-shot NER datasets. The results demonstrate that KnowCoder (SU. only) outperforms LLaMA2-7B with an average relative improvement of $49.8%$ . Remarkably, KnowCoder (SU. only) gets an average F1 score of $46.3%$ with only a few examples, which are comparable to Instruct U IE refined using human-annotated datasets. These results strongly support the effectiveness of the schema understanding phase in enhancing model generalization and performance in NER tasks.
考虑到未经示例指导的预训练大语言模型难以给出理想结果,我们研究了模式理解阶段后的KnowCoder(标记为KnowCoder (SU. only))在少样本设定下的泛化能力。具体而言,我们选取训练数据中前五个样本作为示例,并在表1中汇报了跨七个零样本NER数据集的NER F1值。实验结果表明,KnowCoder (SU. only) 以49.8%的平均相对提升优于LLaMA2-7B。值得注意的是,仅用少量样本的KnowCoder (SU. only) 就取得了46.3%的平均F1值,其表现与基于人工标注数据集微调的InstructUIE相当。这些结果有力证明了模式理解阶段对提升模型在NER任务中泛化能力和性能的有效性。
表1:
Table 3: Results on RE and ED tasks under the zero-shot setting. † indicates that it is unfair for KnowCoder to compare with the score.
| 数据集 | 当前最优 (SoTA) | 7B 模型 |
|---|---|---|
| GIDSRE | (Ouyang et al., 2022) 9.9 | 25.5 |
| CASIEED | (Sainz et al., 2023) 59.3f | 58.2 |
| 平均 | 34.6 | 41.9↑21.1% |
表 3: 零样本设定下的关系抽取 (RE) 和事件检测 (ED) 任务结果。† 表示 KnowCoder 与该分数对比存在不公平性。
5.2 Zero-Shot Evaluation After Schema Following
5.2 遵循模式后的零样本 (Zero-Shot) 评估
To verify the generalization ability of KnowCoder, we conduct zero-shot experiments on 9 datasets across NER, RE, and ED tasks. In this setting, we employ KnowCoder after schema understanding and following to conduct extraction. KnowCoder is compared with two kinds of baselines. One is the LLM-based IE method that refined on humanannotated data, including Instruct U IE (Wang et al., 2023b), GoLLIE (Sainz et al., 2023), and UniNER (Zhou et al., 2023). The other is models without refinement, including Vicuna (Chiang et al., 2023), ChatGPT, UniNER (Zhou et al., 2023). The results of these three baselines are from Zhou et al. (2023). Note that KnowCoder is unfair when compared with methods after refinement.
为验证KnowCoder的泛化能力,我们在NER(命名实体识别)、RE(关系抽取)和ED(事件检测)三大任务的9个数据集上进行了零样本实验。该实验设置下,我们让KnowCoder先完成模式理解再进行信息抽取。对比基线分为两类:一类是基于大语言模型且经过人工标注数据微调的信息抽取方法,包括InstructUIE (Wang et al., 2023b)、GoLLIE (Sainz et al., 2023)和UniNER (Zhou et al., 2023);另一类是未经微调的模型,包括Vicuna (Chiang et al., 2023)、ChatGPT和UniNER (Zhou et al., 2023)。后三类基线结果均引用自Zhou et al. (2023)的研究。需注意,KnowCoder与经过微调的方法对比存在公平性差异。
Table 4: Low-resource results on IE tasks, where Average is the average F1 across four IE tasks.
表 4: 低资源条件下的信息抽取任务结果,其中Average为四项信息抽取任务的平均F1值。
| Ratio | Model | Task NER RE ED EAE | Average |
|---|---|---|---|
| 1% | UIE-base | 82.8 30.8 41.5 12.8 | 42.0 |
| LLaMA2-7B | 72.3 32.1 35.3 33.3 | 43.3 | |
| KnowCoder-7B | 79.2 43.3 50.3 38.5 | 52.8↑21.9% | |
| 5% | UIE-base | 88.3 51.7 55.7 30.4 | 56.5 |
| LLaMA2-7B | 89.3 35.7 52.6 46.3 | 56.0 | |
| KnowCoder-7B | 90.6 51.1 59.0 48.3 | 62.3↑10.3% | |
| 10% | UIE-base | 89.6 59.2 91.2 48.6 | 60.3 |
| LLaMA2-7B | 92.2 53.6 62.2 | 36.3 | |
| KnowCoder-7B | 60.7 52.3 55.1 65.8 | 65.8↑4.1% |
Main Results. The results of zero-shot NER are in Table 2. It can be seen that KnowCoder surpasses baselines without refinement across four NER datasets, registering a relative performance enhancement of $12.5%$ . This improvement is attributed to KnowCoder’s training on a large-scale, automatically generated dataset within a two-phase learning framework, which enhances its generalization capabilities for NER, even surpassing methods refined with human-annotated data. The results of zero-shot RE and ED are in Table 3. For ED, KnowCoder’s performance is inferior to GoLLIE, a baseline model trained on high-quality, humanannotated data. This emphasizes that humanannotated datasets can enhance performance for more difficult IE tasks, such as ED. To further substantiate the point, we further refine KnowCoder with the ACE05 dataset, the same EE training data employed by GoLLIE. This refinement significantly improves zero-shot F1 performance to $72.0%$ on the CASIE dataset. This represents a significant advancement over GoLLIE’s performance of $59.3%$ , marking a relative improvement of $21.4%$ .
主要结果。零样本命名实体识别 (NER) 的结果如表 2 所示。可以看出,KnowCoder 在四个 NER 数据集上均优于未经优化的基线模型,相对性能提升了 12.5%。这一改进归功于 KnowCoder 在两阶段学习框架中对大规模自动生成数据集的训练,这增强了其 NER 泛化能力,甚至超越了使用人工标注数据优化的方法。零样本关系抽取 (RE) 和事件检测 (ED) 的结果如表 3 所示。在 ED 任务上,KnowCoder 的表现逊色于 GoLLIE (一个基于高质量人工标注数据训练的基线模型)。这说明人工标注数据集能提升 ED 等复杂信息抽取任务的性能。为验证这一点,我们使用与 GoLLIE 相同的 ACE05 事件抽取训练数据对 KnowCoder 进行微调。该优化使模型在 CASIE 数据集上的零样本 F1 值显著提升至 72.0%,较 GoLLIE 的 59.3% 实现了 21.4% 的相对提升。
5.3 Low Resource Evaluation After Schema Following
5.3 遵循模式后的低资源评估
To further investigate the generalization ability of KnowCoder for IE tasks, we conduct low-resource experiments by fine-tuning KnowCoder with three different partitions of the original training sets $(1/5/10%$ ratio) across four tasks. Following Lu et al. (2022), we adopt CoNLL03, CoNLL04, $\mathrm{ACE05}{E D}$ and $\mathrm{ACE05}_{E A E}$ as the benchmarks for NER, RE, ED, and EAE tasks. LLaMA2 denotes directly fine-tuning LLaMA2 with these partial training data. The results are in Table 4. It can be shown that KnowCoder gets the highest average F1 scores across all IE tasks in low-resource settings at varying ratios. In ratio $1%$ , KnowCoder gets the relative average improvement of $21.9%$ compared to UIE, which shows that KnowCoder has strong adaptability to downstream IE tasks after pre training on large-scale data under the two-phase learning framework.
为了进一步研究KnowCoder在信息抽取(IE)任务中的泛化能力,我们通过在四个任务上使用原始训练集的三种不同比例划分(1%/5%/10%)对KnowCoder进行微调,开展了低资源实验。参照Lu等人(2022)的方法,我们采用CoNLL03、CoNLL04、$\mathrm{ACE05}{E D}$和$\mathrm{ACE05}_{E A E}$作为命名实体识别(NER)、关系抽取(RE)、事件检测(ED)和事件论元抽取(EAE)任务的基准。LLaMA2表示直接使用这些部分训练数据对LLaMA2进行微调。结果如 表4 所示。可以看出,在不同比例的低资源设置下,KnowCoder在所有IE任务中都获得了最高的平均F1分数。在1%比例下,KnowCoder相比UIE获得了21.9%的相对平均提升,这表明KnowCoder在两阶段学习框架下通过大规模数据预训练后,对下游IE任务具有很强的适应能力。
5.4 Supervised Evaluation After Refinement
5.4 精调后的监督评估
Under the supervised evaluation, KnowCoder is further refined with the IE datasets. We conduct supervised experiments on four IE tasks, including NER, RE, ED, and EAE. KnowCoder is compared with three kinds of methods. The first is the traditional UIE method (Lou et al., 2023; Lu et al., 2022), which is based on relatively small language models (i.e., million-level parameters). The latter two are based on LLMs (i.e., ChatGPT, LLaMA2). They adopt the in-context learning (Guo et al., 2023; Li et al., 2023; Ashok and Lipton, 2023) and supervised fine-tuning paradigms (Zhou et al., 2023; Wang et al., 2023b; Sainz et al., 2023), respectively. As some baselines only report results for specific IE tasks, we report the SOTA results of the above methods in each dataset, denoted as “SoTA” in the tables. As highlighted by Zhou et al. (2023), the evaluation script of Instruct U IE (Wang et al., 2023b) contains issues. Furthermore, the benchmark in Zhou et al. (2023) remains pending release. In the end, we have implemented these two baselines on KnowCoder benchmark using their released models.
在有监督评估下,KnowCoder 通过信息抽取 (IE) 数据集进一步优化。我们在四个IE任务上进行了监督实验,包括命名实体识别 (NER)、关系抽取 (RE)、事件检测 (ED) 和事件属性抽取 (EAE)。KnowCoder 与三类方法进行了对比:第一类是传统统一信息抽取 (UIE) 方法 (Lou et al., 2023; Lu et al., 2022),基于参数量级较小的语言模型(百万级参数);后两类基于大语言模型(如 ChatGPT、LLaMA2),分别采用上下文学习 (Guo et al., 2023; Li et al., 2023; Ashok and Lipton, 2023) 和监督微调范式 (Zhou et al., 2023; Wang et al., 2023b; Sainz et al., 2023)。由于部分基线方法仅报告特定IE任务的结果,我们在表格中以 "SoTA" 标注各数据集上上述方法的最优结果。如 Zhou et al. (2023) 所述,InstructUIE (Wang et al., 2023b) 的评估脚本存在问题,且 Zhou et al. (2023) 的基准数据集尚未公开。最终,我们使用其发布的模型在 KnowCoder 基准上复现了这两个基线方法。
Main Results. The results for NER, RE, EE (including ED and EAE) tasks are shown in Tables 5, 6 and 7, respectively. We can observe that: (1) KnowCoder outperforms the SOTA baselines on most datasets for NER, RE, ED, and EAE, respectively. Based on the code-style schemas, KnowCoder universally models IE tasks and effectively transfers IE abilities after conducting schema under standing, following, and refinement on largescale training data. (2) In more challenging UIE tasks, such as RE, KnowCoder demonstrates impressive advancements up to the relative improvement of $8.6%$ compared to the SOTA baselines.
主要结果。NER、RE、EE(包括ED和EAE)任务的结果分别如表5、表6和表7所示。我们可以观察到:(1) KnowCoder在大多数NER、RE、ED和EAE数据集上分别优于SOTA基线。基于代码风格模式,KnowCoder统一建模IE任务,并在大规模训练数据上完成模式理解、遵循和优化后,有效迁移了IE能力。(2) 在更具挑战性的UIE任务(如RE)中,KnowCoder相比SOTA基线展现出最高达$8.6%$的相对提升。
KnowCoder achieves the performances of $73.9%$ for ED and $66%$ for EAE. This is the first time LLM-based UIE methods surpass smaller models like UIE in ED and EAE tasks. The code-style schemas and the learning framework enable a more precise definition and understanding of this complex structured knowledge, leading to a significant improvement. (4) UniNER (Zhou et al., 2023) achieves comparable results to KnowCoder on NER. Nonetheless, KnowCoder surpasses UniNER in several respects. Primarily, UniNER is limited to extracting one type of entity per iteration, leading to a cost-time complexity. In contrast, KnowCoder can extract multiple entity types in a single iteration, enhancing efficiency. Additionally, UniNER relies on a text-style schema, making it hard to represent and extract relations and events effectively. Conversely, KnowCoder, as a UIE model, offers broader versatility and efficacy comparing to UniNER. (3) KnowCoder gets better results than baselines with code-style prompt (Li et al., 2023; Guo et al., 2023; Sainz et al., 2023). This is because KnowCoder provides a more comprehensive schema representation method and conducts two-phase training to understand and follow these schemas.
KnowCoder在事件检测(ED)任务上达到73.9%的准确率,在事件属性抽取(EAE)任务上达到66%的准确率。这是基于大语言模型的通用信息抽取(UIE)方法首次在ED和EAE任务上超越UIE等小型模型。代码式模式定义和学习框架实现了对复杂结构化知识更精确的定义与理解,从而带来显著性能提升。(4) UniNER (Zhou et al., 2023)在命名实体识别(NER)任务上与KnowCoder表现相当,但KnowCoder在多个方面更具优势:首先,UniNER每次迭代只能抽取单一类型实体,存在时间复杂度问题;而KnowCoder单次迭代即可抽取多类实体,效率更高。其次,UniNER依赖文本式模式定义,难以有效表示和抽取关系与事件;相比之下,作为UIE模型的KnowCoder具有更广泛的多任务适应性和效能。(3) 相较于采用代码式提示的基线方法(Li et al., 2023; Guo et al., 2023; Sainz et al., 2023),KnowCoder取得了更优结果,这得益于其提供了更全面的模式表示方法,并通过两阶段训练使模型能准确理解和遵循这些模式定义。
Table 6: Results on RE under the supervised setting.
表 6: 监督设置下的关系抽取 (RE) 结果。
| Dataset | SoTA | 7B |
|---|---|---|
| ACE04 ACE05 AnatEM Broad Twitter CoNLL03 DIANN FabNER | (Lu et al., 2022) 87.6 (Sainz et al.,2023) 89.6 (Zhou et al.,2023) 88.9 Zhou et al.,2023) 79.8 (Zhou et al.,2023) 94.8 (Sainz et al.,2023)84.1 (Zhou et al.,2023) 82.3 (Wang et al., 2023b) 85.0 | 86.2 86.1 86.4 78.3 95.1 94.7 82.0 89.3 83.8 |
| FindVehicle GENIA Movie Rest. Average | Zhou et al.,2023) 98.4 (Zhou et al.,2023)80.3 (Zhou et al.,2023) 90.2 | 82.9 99.4 76.7 90.6 |
| MultiNERD OntoNotes 5 WikiANN WNUT17 bc2gm bc5cdr ncbi | (Wang et al.,2023b) 82.6 (Zhou et al.,2023) 93.9 (Sainz et al.,2023) 84.6 (Zhou et al.,2023)85.4 (Sainz et al.,2023) 54.3 Wang et al., 2023b) 80.5 (Zhou et al.,2023) 91.5 | 81.3 96.1 88.2 87.0 66.4 |
5.5 Ablation Study
5.5 消融实验
To show how the schema following and understanding phases contribute to KnowCoder under the zero-shot setting, we further conduct ablation studies removing the schema understanding and following phase, denoted as KnowCoder (w.o. SU) and KnowCoder (w.o. SF), respectively. The results on seven zero-shot NER datasets are shown in Table 8. It can be seen that: (1) KnowCoder gets better results than KnowCoder (w.o. SF) on most NER datasets. It is because the schema under standing phase helps KnowCoder to understand concepts in the schema by training on definition and instance codes and increases its generalization ability. (2) Results of KnowCoder (w.o. SF) decrease extremely, which proves the importance of schema following. Due to the lack of in-context learning ability, a 7B model without instruction tuning is hard to understand instructions under the zero-shot setting, thus making it hard to finish the IE tasks.
为了展示模式遵循和理解阶段在零样本设置下对KnowCoder的贡献,我们进一步进行了消融实验,分别移除模式理解阶段和模式遵循阶段,记为KnowCoder (w.o. SU)和KnowCoder (w.o. SF)。表8展示了七个零样本NER数据集上的结果。可以看出:(1) 在大多数NER数据集上,KnowCoder比KnowCoder (w.o. SF)获得更好的结果。这是因为模式理解阶段通过定义和实例代码的训练帮助KnowCoder理解模式中的概念,并提高了其泛化能力。(2) KnowCoder (w.o. SF)的结果大幅下降,证明了模式遵循的重要性。由于缺乏上下文学习能力,未经指令调优的7B模型在零样本设置下难以理解指令,因此难以完成IE任务。
| 数据集 | 当前最佳 (SoTA) | 7B |
|---|---|---|
| ACE05 semevalRE | (Sainz et al., 2023) 70.1 (Wang et al., 2023b) 65.8 | 64.5 66.3 |
| CoNLL04 NYT | (Lou et al., 2023) 78.8 (Wang et al., 2023b) 91.0 | 73.3 93.7 |
| ADEcorpus | (Wang et al., 2023b) 82.8 | 84.3 |
| kbp37 GIDS | (Wang et al., 2023b) 30.6 | 73.2 |
| (Wang et al., 2023b) 76.9 | 78.0 | |
| SciERC 平均 | (Lou et al., 2023) 37.4 66.771.7↑7.5% | 40.0 |
Table 5: Results on NER under the supervised setting. Table 7: Results on ED and EAE under the supervised setting.
表 5: 监督设置下的命名实体识别(NER)结果
表 7: 监督设置下的事件检测(ED)与事件论元抽取(EAE)结果
| 模型 | ACE05ED | ACE05EAE |
|---|---|---|
| UIE | 73.4 | 69.3 |
| USM | 69.3 | 63.3 |
| Code4UIE | 37.4 | 57.0 |
| InstructUIE-11B | 43.2 | 56.8 |
| GoLLIE-7B | 72.2 | 66.0 |
| KnowCoder-7B | 74.2 | 70.3 |
6 Related Work
6 相关工作
6.1 Universal Information Extraction
6.1 通用信息抽取
Universal information extraction aims to conduct different IE tasks via a single model. The existing UIE models first represent different schemas for IE tasks in a universal way. OneIE (Lin et al., 2020a) represents schemas as classification labels, InstructUIE (Wang et al., 2023b) uses keywords (Gui et al., 2023; Lou et al., 2023) of concepts to rep- resent schemas, and UIE (Lu et al., 2022) uses a specifically-designed formal language to represent schemas. Based on such schema representations, these models adopt language models to understand the schemas and extract the corresponding structured knowledge.
通用信息抽取旨在通过单一模型完成不同的信息抽取任务。现有UIE模型首先以统一方式表示信息抽取任务的不同模式。OneIE [20] 将模式表示为分类标签,InstructUIE [23] 使用概念关键词 [11][16] 来表示模式,而UIE [18] 则采用专门设计的形式化语言来描述模式。基于这些模式表示方法,这些模型利用语言模型理解模式并抽取相应的结构化知识。
Table 8: Ablation study under the zero-shot setting.
表 8: 零样本设置下的消融研究。
| Dataset | 7B | w.o. SU | w.0. SF |
|---|---|---|---|
| Movie. | 50.0 | +1.6 | -50.0 |
| Rest. | 48.2 | -0.8 | -46.1 |
| AI | 60.3 | -4.5 | -57.7 |
| Litera. | 61.1 | +0.6 | -59.0 |
| Music | 70.0 | -3.1 | -69.0 |
| Politics | 72.2 | -1.8 | -70.8 |
| Science | 59.1 | -2.7 | -55.6 |
6.2 Large Language Models for IE
6.2 用于信息抽取的大语言模型 (Large Language Models)
Due to the strong generation abilities of LLMs, they have been used in IE recently (Xu et al., 2023). LLM-based IE methods can be divided into two categories: In-Context Learning (ICL) based methods and Supervised Finetuning (SFT) based methods. The ICL-based IE methods (Li et al., 2023; Guo et al., 2023; Ashok and Lipton, 2023; Wang et al., 2023a) make predictions only based on contexts augmented with a few examples. The SFTbased methods (Wang et al.; Gui et al., 2023; Wang et al., 2023b; Zhou et al., 2023; Xu et al., 2023; Sainz et al., 2023) use the annotated data to finetune LLMs.
由于大语言模型(LLM)强大的生成能力,它们最近被用于信息抽取(IE)领域(Xu et al., 2023)。基于大语言模型的IE方法可分为两类:基于上下文学习(ICL)的方法和基于监督微调(SFT)的方法。基于ICL的IE方法(Li et al., 2023; Guo et al., 2023; Ashok and Lipton, 2023; Wang et al., 2023a)仅通过少量示例增强的上下文进行预测。基于SFT的方法(Wang et al.; Gui et al., 2023; Wang et al., 2023b; Zhou et al., 2023; Xu et al., 2023; Sainz et al., 2023)则使用标注数据对大语言模型进行微调。
Some existing work uses code-style prompts to conduct IE. Most of them are ICL-based methods. Wang et al. (2022) uses the code-style prompt to conduct event argument extraction. Li et al. (2023) uses the code-style prompt to conduct the named entity extraction and relation extraction. (Guo et al., 2023) proposes a reterive-argumented method to conduct the universal IE. These methods show relatively poor performance compared to SFTbased methods because of the lack of training to follow the schemas in the prompt. The most similar work with KnowCoder is GoLLIE, an SFT-based UIE method that gives out definitions of schemas as code comments. The difference between KnowCoder and GoLLIE is that KnowCoder designs a more comprehensive code-style schema representation method, including taxonomies, constraints, and class methods, and further constructs a largescale schema library. Besides, GoLLIE conducts instruction tuning on human-annotated data, while KnowCoder contains a two-phase learning framework that enhances schema understanding and following ability via automatically annotated data.
现有研究中有部分工作采用代码风格提示进行信息抽取(IE),其中多数是基于上下文学习(ICL)的方法。Wang等人(2022)使用代码风格提示进行事件论元抽取,Li等人(2023)将其应用于命名实体识别和关系抽取任务。(Guo等人,2023)提出了一种检索增强方法来实现通用信息抽取。由于缺乏针对提示中模式(schema)的专门训练,这些方法相比基于监督微调(SFT)的方法表现较差。与KnowCoder最为相似的工作是GoLLIE——一个基于SFT的通用信息抽取方法,该方法将模式定义以代码注释形式给出。KnowCoder与GoLLIE的区别在于:前者设计了更全面的代码风格模式表示方法(包含分类体系、约束条件和类方法),并进一步构建了大规模模式库;此外,GoLLIE基于人工标注数据进行指令调优,而KnowCoder采用两阶段学习框架,通过自动标注数据增强模式理解与遵循能力。
Conclusion
结论
In this paper, we introduced KnowCoder for UIE leveraging Large Language Models. KnowCoder is based on a code-style schema representation method and an effective two-phase learning framework. The code-style schema representation method uniformly transforms different schemas into Python classes, with which the UIE task can be converted to a code generation process. Based on the schema representation method, we constructed a comprehensive code-style schema library covering over 30, 000 types of knowledge. To let LLMs understand and follow these schemas, we further proposed a two-phase learning framework that first enhances the schema comprehension ability and then boosts its schema following ability. After training on billions of automatically annotated data and refining with human-annotated IE datasets, KnowCoder demonstrates remarkable performance improvements on different IE tasks under the various evalution settings.
本文介绍了基于大语言模型的通用信息抽取(UIE)系统KnowCoder,该系统采用代码式模式表示方法和高效的两阶段学习框架。代码式模式表示方法将不同模式统一转换为Python类,从而将UIE任务转化为代码生成过程。基于该表示方法,我们构建了覆盖3万多种知识的综合性代码式模式库。为使大语言模型理解并遵循这些模式,我们进一步提出两阶段学习框架:先增强模式理解能力,再提升模式遵循能力。经过数十亿自动标注数据训练及人工标注信息抽取数据集精调后,KnowCoder在多种评估设置下的不同信息抽取任务中均展现出显著性能提升。
Limitations
局限性
The schemas utilized in our approach are predominantly constructed from Wikidata, which occasionally results in some schemas lacking definitions or other relevant information. This necessitates the generation of additional data to supplement these missing elements. During the pre training phase, we adopted a combination of automatic generation and distant supervision methods to amass a large corpus. However, this approach inevitably introduces a certain degree of noise. Furthermore, there remains room for improvement in terms of the richness and complexity of the current corpus. Further exploration of pre training settings could also be beneficial in enhancing the zero-shot capabilities for relation and event-related tasks.
我们方法中采用的模式主要基于Wikidata构建,这偶尔会导致某些模式缺乏定义或其他相关信息,因此需要生成额外数据来补充这些缺失部分。在预训练阶段,我们采用了自动生成与远程监督相结合的方法来积累大规模语料库,但这种方法不可避免地会引入一定程度的噪声。此外,当前语料库在丰富性和复杂性方面仍有提升空间。进一步探索预训练设置也可能有助于提升关系与事件相关任务的零样本能力。