Making the Invisible Visible: Action Recognition Through Walls and Occlusions
让不可见变得可见:穿墙与遮挡场景下的动作识别
Abstract
摘要
Understanding people’s actions and interactions typically depends on seeing them. Automating the process of action recognition from visual data has been the topic of much research in the computer vision community. But what if it is too dark, or if the person is occluded or behind a wall? In this paper, we introduce a neural network model that can detect human actions through walls and occlusions, and in poor lighting conditions. Our model takes radio frequency (RF) signals as input, generates 3D human skeletons as an intermediate representation, and recognizes actions and interactions of multiple people over time. By translating the input to an intermediate skeleton-based represent ation, our model can learn from both vision-based and RF-based datasets, and allow the two tasks to help each other. We show that our model achieves comparable accuracy to vision-based action recognition systems in visible scenarios, yet continues to work accurately when people are not visible, hence addressing scenarios that are beyond the limit of today’s vision-based action recognition.
理解人类行为及其互动通常依赖于视觉观察。从视觉数据中自动识别动作的过程一直是计算机视觉领域的重要研究方向。但如果光线过暗、人物被遮挡或位于墙后呢?本文提出一种神经网络模型,能够穿透墙壁和遮挡物,在弱光条件下检测人类行为。该模型以射频(RF)信号为输入,通过生成3D人体骨骼作为中间表征,实现多人动作与交互的时序识别。通过将输入转换为基于骨骼的中间表征,我们的模型能同时利用基于视觉和基于RF的数据集进行训练,并使两项任务相互促进。实验表明,在可见场景下本模型达到与视觉动作识别系统相当的精度,同时在人物不可见时仍能保持准确识别,从而突破了当前视觉动作识别技术的应用边界。
1. Introduction
1. 引言
Human action recognition is a core task in computer vision. It has broad applications in video games, surveillance, gesture recognition, behavior analysis, etc. Action recognition is defined as detecting and classifying human actions from a time series (video frames, human skeleton sequences, etc). Over the past few years, progress in deep learning has fueled advances in action recognition at an amazing speed [30, 40, 36, 31, 48, 10, 18, 8, 11, 23, 17, 20]. Nonetheless, camera-based approaches are intrinsically limited by occlusions – i.e., the subjects have to be visible to recognize their actions. Previous works mitigate this problem by changing camera viewpoint or interpolating frames over time. Such approaches, however, fail when the camera is fixed or the person is fully occluded for a relatively long period, e.g., the person walks into another room.
人类动作识别是计算机视觉领域的核心任务,在视频游戏、监控安防、手势识别和行为分析等领域具有广泛应用。动作识别定义为从时间序列(视频帧、人体骨骼序列等)中检测和分类人类行为。过去几年间,深度学习的发展以惊人速度推动了该领域的进步 [30, 40, 36, 31, 48, 10, 18, 8, 11, 23, 17, 20]。然而基于摄像头的方法存在固有局限——即识别目标必须可见才能检测其动作。先前研究通过改变摄像机视角或时序帧插值来缓解该问题,但当摄像机固定或目标长时间完全被遮挡(例如走入其他房间)时,这些方法就会失效。
Intrinsically, cameras suffer from the same limitation we, humans, suffer from: our eyes sense only visible light and hence cannot see through walls and occlusions. Yet visible light is just one end of the frequency spectrum. Radio signals in the WiFi frequencies can traverse walls and occlusions. Further, they reflect off the human body. If one can interpret such radio reflections, one can perform action recognition through walls and occlusions. Indeed, some research on wireless systems has attempted to leverage this property for action recognition [33, 39, 19, 1, 37]. However, existing radio-based action recognition systems lag significantly behind vision-based systems. They are limited to a few actions (2 to 10), poorly generalize to new environments or people unseen during training, and cannot deal with multi-person actions (see section 2 for details).
本质上,相机与我们人类面临着同样的局限:我们的眼睛只能感知可见光,因此无法穿透墙壁和遮挡物。然而可见光仅是频谱的一端。WiFi频段的无线电信号能够穿透墙壁和遮挡物,并且会在人体表面发生反射。若能解读这类无线电反射信号,就能实现穿墙动作识别。事实上,已有部分无线系统研究尝试利用这一特性进行动作识别 [33, 39, 19, 1, 37]。但现有基于无线电的动作识别系统性能远逊于视觉系统:仅能识别少量动作(2至10种)、对新环境或训练集未出现人员的泛化能力极差,且无法处理多人动作(详见第2节)。

Figure 1: The figure shows two test cases of our system. On the left, two people are shaking hands, while one of them is behind the wall. On the right, a person is hiding the dark and throwing an object at another person who is making a phone call. The bottom row shows both the skeletal representation generated by our model and the action prediction.
图 1: 图中展示了我们系统的两个测试案例。左侧场景中,两人正在握手,其中一人位于墙后。右侧场景中,一人藏身暗处向正在打电话的另一人投掷物体。底行显示了我们模型生成的人体骨骼表征及动作预测结果。
In this paper, we aim to bridge the two worlds. We introduce, RF-Action, an end-to-end deep neural network that recognizes human actions from wireless signals. It achieves performance comparable to vision-based systems, but can work through walls and occlusions and is insensitive to lighting conditions. Figure 1 shows RF-Action’s performance in two scenarios. On the left, two people are shaking hands, yet one of them is occluded. Vision-based systems would fail in recognizing the action, whereas RFAction easily classifies it as handshaking. On the right, one person is making a phone call while another person is about to throw an object at her. Due to poor lighting, this latter person is almost invisible to a vision-based system. In contrast, RF-Action recognizes both actions correctly.
本文旨在连接这两个领域。我们提出了RF-Action,这是一种端到端深度神经网络,可通过无线信号识别人体动作。其性能与基于视觉的系统相当,但能穿透墙壁和遮挡物工作,且对光照条件不敏感。图1展示了RF-Action在两种场景下的表现:左侧两人握手时其中一人被遮挡,基于视觉的系统无法识别该动作,而RF-Action能轻松将其分类为握手动作;右侧一人打电话时另一人正朝她投掷物体,由于光线昏暗,后者在基于视觉的系统中几乎不可见,而RF-Action能准确识别这两个动作。
RF-Action is based on a multimodal design that allows it to work with both wireless signals and vision-based datasets. We leverage recent work that showed the feasibility of inferring a human skeleton (i.e., pose) from wireless signals [43, 45], and adopt the skeleton as an intermediate representation suitable for both RF and vision-based systems. Using skeletons as an intermediate representation is advantageous because: (1) it enables the model to train with both RF and vision data, and leverage existing visionbased 3D skeleton datasets such as PKU-MMD and NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ [26, 31]; (2) it allows additional supervision on the intermediate skeletons that helps guide the learning process beyond the mere action labels used in past RF-based action recognition systems; and (3) it improves the model’s ability to generalize to new environments and people because the skeleton representation is minimally impacted by the environment or the subjects’ identities.
RF-Action采用多模态设计,使其能够同时处理无线信号和视觉数据集。我们借鉴了近期关于从无线信号推断人体骨骼(即姿态)可行性的研究 [43, 45],并将骨骼作为适用于射频和视觉系统的中间表征。使用骨骼作为中间表征具有以下优势:(1) 使模型能够同时利用射频和视觉数据进行训练,并利用现有基于视觉的3D骨骼数据集(如PKU-MMD和NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ [26, 31]);(2) 通过对中间骨骼施加额外监督,可引导学习过程突破传统射频动作识别系统仅依赖动作标签的限制;(3) 由于骨骼表征受环境或个体身份影响极小,该设计提升了模型在新环境和新对象上的泛化能力。
We further augment our model with two innovations that improve its performance: First, skeleton, particularly those generated from RF signals, can have errors and mispredictions. To deal with this problem, our intermediate representation includes in addition to the skeleton a time-varying confidence score on each joint. We use self-attention to allow the model to attend to different joints over time differently, depending on their confidence scores.
我们通过两项创新进一步增强了模型性能:首先,骨架(尤其是从射频信号生成的骨架)可能存在错误和误预测。为解决这一问题,我们的中间表示除了骨架外,还包含每个关节随时间变化的置信度分数。我们利用自注意力机制(self-attention),使模型能够根据各关节的置信度分数动态调整对不同关节的关注程度。
Second, past models for action recognition generate a single action at any time. However, different people in the scene may be engaged in different actions, as in the scenario on the right in Figure 1 where one person is talking on the phone while the other is throwing an object. Our model can tackle such scenarios using a multi-proposal module specifically designed to address this issue.
其次,以往的动作识别模型在任何时候都只能生成单一动作。然而,场景中的不同人物可能正在进行不同的行为,如图 1 右侧场景所示:一个人正在打电话,而另一个人在投掷物体。我们的模型通过专门设计的多元提议模块 (multi-proposal module) 能够处理此类情况。
To evaluate RF-Action, we collect an action detection dataset from different environments with a wireless device and a multi-camera system. The dataset spans 25 hours and contains 30 individuals performing various single-person and multi-person actions. Our experiments show that RFAction achieves performance comparable to vision-based systems in visible scenarios, and continues to perform well in the presence of full occlusions. Specifically, RF-Action achieves 87.8 mean average precision (mAP) with no occlusions, and an mAP of 83.0 in through-wall scenarios. Our results also show that multimodal training improves action detection for both the visual and wireless modalities. Training our model with both our RF dataset and the PKU-MMD dataset, we observe a performance increase in the mAP of the test set from 83.3 to 87.8 for the RF dataset (no occlusion), and from 92.9 to 93.3 for the PKU-MMD dataset (cross subjects), which shows the value of using the skeleton as an intermediate common representation.
为评估RF-Action,我们使用无线设备和多摄像头系统从不同环境中收集了一个动作检测数据集。该数据集时长25小时,包含30名个体执行各类单人与多人动作。实验表明,RF-Action在可见场景下的性能与基于视觉的系统相当,并在完全遮挡情况下仍保持良好表现。具体而言,RF-Action在无遮挡时达到87.8的平均精度均值(mAP),穿墙场景下mAP为83.0。结果还表明,多模态训练能同时提升视觉和无线模态的动作检测性能:当使用RF数据集和PKU-MMD数据集联合训练时,测试集mAP分别从83.3提升至87.8(无遮挡场景)和从92.9提升至93.3(跨被试场景),这验证了将骨骼作为中间通用表征的价值。
Contributions: The paper has the following contributions:
贡献:本文有以下贡献:
2. Related Works
2. 相关工作
(a) Video-Based Action Recognition: Recognizing actions from videos has been a hot topic over the past several years. Early methods use hand-crafted features. For instances, image descriptors like HOG and SIFT have been extended to 3D [6, 27] to extract temporal clues from videos. Also, descriptors like improved Dense Trajectories (iDT) [35] are specially designed to track motion information in videos. More recent solutions are based on deep learning, and fall into two main categories. The first category extracts motion and appearance features jointly by leveraging 3D convolution networks [5, 30]. The second category considers spatial features and temporal features separately by using two-stream neural networks [32, 36].
(a) 基于视频的动作识别:
视频动作识别是过去几年的研究热点。早期方法采用手工设计特征,例如将HOG和SIFT等图像描述符扩展到三维空间[6,27]以提取视频时序线索。改进的密集轨迹(iDT)[35]等描述符则专门用于追踪视频中的运动信息。近年方案主要基于深度学习,分为两大类:第一类通过3D卷积网络[5,30]联合提取运动与外观特征;第二类采用双流神经网络[32,36]分别处理空间特征与时序特征。
(b) Skeleton-Based Action Recognition: Skeletonbased action recognition has recently gained much attention [12, 4]. Such an approach has multiple advantages. First, skeletons provide a robust representation for human dynamics against background noise [23]. Second, skeletons are more succinct in comparison to RGB videos, which reduces computational overhead and allows for smaller models suitable for mobile platforms [20].
(b) 基于骨架的动作识别:基于骨架的动作识别最近受到了广泛关注 [12, 4]。这种方法具有多重优势。首先,骨架为人体动态提供了抗背景噪声的鲁棒性表示 [23]。其次,与RGB视频相比,骨架数据更为简洁,这降低了计算开销,并使得适用于移动平台的更小模型成为可能 [20]。
Prior work on skeleton-based action recognition can be divided to three categories. Early work used Recurrent Neural Networks (RNNs) to model temporal dependencies in skeleton data [9, 31, 48]. Recently, however, the literature shifted to Convolutional Neural Networks (CNNs) to learn spatio-temporal features and achieved impressive performance [8, 23, 20]. Also, some papers represented skeletons as graphs and utilized graph neural network (GNN)
基于骨架的动作识别先前工作可分为三类。早期研究使用循环神经网络 (RNN) 建模骨架数据的时间依赖性 [9, 31, 48]。近年来文献转向采用卷积神经网络 (CNN) 学习时空特征并取得显著性能 [8, 23, 20]。另有研究将骨架表示为图结构并运用图神经网络 (GNN)

Figure 2: RF heatmaps and an RGB image recorded at the same time.
图 2: 同时记录的射频热力图和RGB图像
for action recognition [38, 13]. In our work, we adopt a CNN-based approach, and expand on the Hierarchical Co-occurrence Network (HCN) model [23] by introducing a spatio-temporal attention module to deal with skeletons generated from wireless signals, and a multi-proposal module to enable multiple action predictions at the same time.
针对动作识别任务[38,13],我们采用基于卷积神经网络(CNN)的方法,在分层共现网络(Hierarchical Co-occurrence Network, HCN)模型[23]基础上进行扩展:通过引入时空注意力模块处理无线信号生成的骨骼数据,并新增多提案模块实现同步多动作预测。
(c) Radio-Based Action Recognition: Research in wireless systems has explored action recognition using radio signals, particularly for home applications where privacy concerns may preclude the use of cameras [37, 14, 29, 1]. These works can be divided into two categories: The first category is similar to RF-Action in that it analyses the radio signals that bounce off people’s bodies. They use action labels for supervision, and simple class if i ers [37, 14, 29, 1]. They recognize only simple actions such as walking, sitting and running, and a maximum of 10 different actions. Also, they deal only with single person scenarios. The second category relies on a network of sensors. They either deploy different sensors for different actions, (e.g., a sensor on the fridge door can detect eating) [19, 39], or attach a wearable sensor on each body part and recognize a subject’s actions based on which body part moves [21]. Such systems require a significant instrumentation of the environment or the person, which limits their utility and robustness.
基于无线电的动作识别:无线系统领域的研究探索了利用无线电信号进行动作识别的方法,尤其适用于家庭场景中因隐私顾虑无法使用摄像头的情况 [37, 14, 29, 1]。这些研究可分为两类:第一类与RF-Action类似,通过分析人体反射的无线电信号,使用动作标签进行监督学习和简单分类器 [37, 14, 29, 1],但仅能识别行走、坐下、跑步等基础动作(最多10种),且仅限于单人场景。第二类依赖传感器网络,或为不同动作部署专用传感器(例如冰箱门传感器可检测进食行为)[19, 39],或在身体各部位佩戴可穿戴设备,通过肢体运动状态识别动作 [21]。此类系统需对环境或人体进行大量设备部署,限制了实用性和鲁棒性。
3. Radio Frequency Signals Primer
3. 射频信号基础
We use a type of radio commonly used in past work on RF-based action recognition [45, 24, 41, 7, 28, 33, 16, 42, 46, 44]. The radio generates a waveform called FMCW and operates between 5.4 and $7.2~\mathrm{GHz}$ . The device has two arrays of antennas organized vertically and horizontally. Thus, our input data takes the form of two-dimensional heatmaps, one from the horizontal array and one from the vertical array. As shown in Figure 2, the horizontal heatmap is a projection of the radio signal on a plane parallel to the ground, whereas the vertical heatmap is a projection of the signal on a plane perpendicular to the ground (red refers to large values while blue refers to small values). Intuitively, higher values correspond to higher strength of signal reflections from a location. The radio works at a frame rate of 30 FPS, i.e., it generates 30 pairs of heatmaps per second.
我们采用了一种在基于射频(RF)的动作识别研究中广泛使用的无线电设备[45, 24, 41, 7, 28, 33, 16, 42, 46, 44]。该设备可生成名为FMCW的波形,工作频率范围为5.4至$7.2~\mathrm{GHz}$。设备配备垂直和水平两组天线阵列,因此输入数据表现为二维热力图形式——分别来自水平阵列和垂直阵列。如图2所示:水平热力图是无线电信号在平行于地面平面上的投影,垂直热力图则是信号在垂直于地面平面上的投影(红色表示高值,蓝色表示低值)。直观来看,数值越高表示该位置信号反射强度越大。该设备帧率为30 FPS,即每秒生成30对热力图。
As apparent in Figure 2, RF signals have different properties from visual data, which makes RF-based action recognition a difficult problem. In particular:
图 2: 可以看出,射频信号 (RF) 与视觉数据具有不同的特性,这使得基于射频的动作识别成为一个难题。具体而言:
4. Method
4. 方法
RF-Action is an end-to-end neural network model that can detect human actions through occlusion and in bad lighting. The model architecture is illustrated in Figure 3. As shown in the figure, the model takes wireless signals as input, generates 3D human skeletons as an intermediate representation, and recognizes actions and interactions of multiple people over time. The figure further shows that RF-Action can also take 3D skeletons generated from visual data. This allows RF-Action to train with existing skeletonbased action recognition datasets.
RF-Action是一种端到端神经网络模型,能够通过遮挡和在恶劣光照条件下检测人体动作。模型架构如图3所示。如图所示,该模型以无线信号作为输入,生成3D人体骨骼作为中间表示,并随时间识别多人的动作和互动。图中进一步显示RF-Action还可以处理从视觉数据生成的3D骨骼。这使得RF-Action能够利用现有的基于骨骼的动作识别数据集进行训练。
In the rest of this section, we will describe how we transform wireless signals to 3D skeleton sequences, and how we infer actions from such skeleton sequences –i.e., the yellow and green boxes in Figure 3. Transforming visual data from a multi-camera system to 3D skeletons can be done by extracting 2D skeletons from images using an algorithm like AlphaPose and then tri angul a ting the 2D keypoints to generate 3D skeletons, as commonly done in the literature [15, 45].
在本节的剩余部分,我们将描述如何将无线信号转换为3D骨架序列,以及如何从这些骨架序列中推断动作——即图3中的黄色和绿色方框。将多摄像头系统的视觉数据转换为3D骨架,可以通过使用AlphaPose等算法从图像中提取2D骨架,然后对2D关键点进行三角测量以生成3D骨架来完成,这在文献[15,45]中已有常见做法。
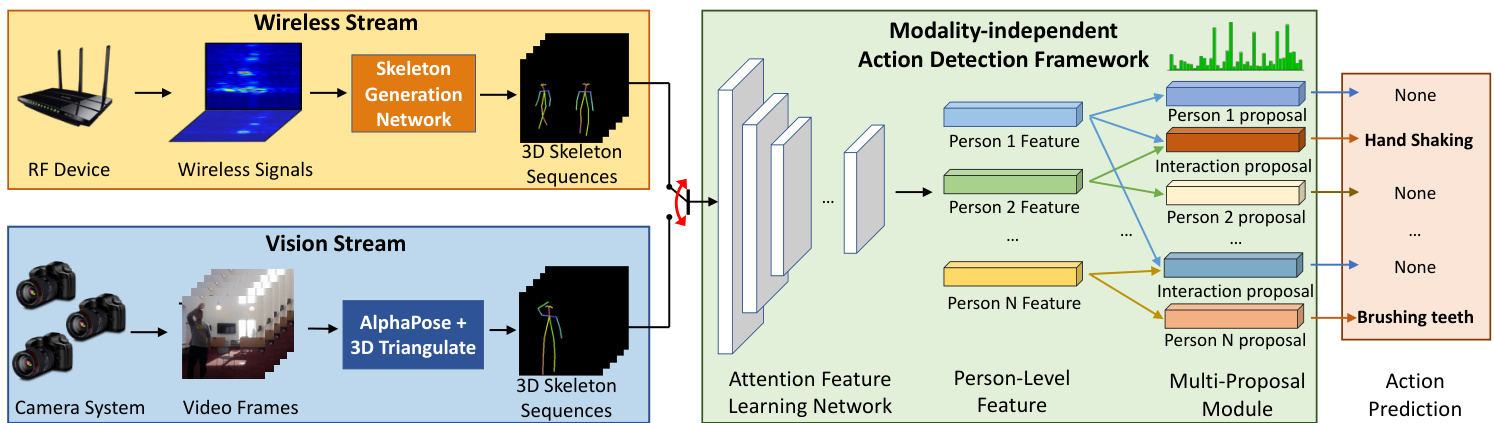
Figure 3: RF-Action architecture. RF-Action detects human actions from wireless signals. It first extracts 3D skeletons for each person from raw wireless signal inputs (yellow box). It then performs action detection and recognition on the extracted skeleton sequences (green box). The Action Detection Framework can also take 3D skeletons generated from visual data as inputs (blue box), which enables training with both RF-generated skeletons and existing skeleton-based action recognition datasets.
图 3: RF-Action架构。RF-Action通过无线信号检测人类动作。首先从原始无线信号输入(黄色框)中提取每个人的3D骨架,然后对提取的骨架序列(绿色框)进行动作检测与识别。该动作检测框架也可接收视觉数据生成的3D骨架作为输入(蓝色框),从而支持使用RF生成骨架与现有基于骨架的动作识别数据集进行联合训练。
4.1. Skeleton-Generation from Wireless Signals
4.1. 基于无线信号的骨架生成
To generate human skeletons from wireless signals, we adopt the architecture from [45]. Specifically, the skeleton generation network (the orange box in Figure 3) takes in wireless signals in the form of horizontal and vertical heatmaps shown in Figure 2, and generates multi-person 3D skeletons. The input to the network is a 3-second window (90 frames) of the horizontal and vertical heatmaps. The network consists of three modules commonly used for pose/skeleton estimation [45]. First, a feature network comprising spatio-temporal convolutions extracts features from the input RF signals. Then, the extracted features are passed through a region proposal network (RPN) to obtain several proposals for possible skeleton bounding boxes. Finally, the extracted proposals are fed into a 3D pose estimation subnetwork to extract 3D skeletons from each of them.
为了从无线信号中生成人体骨骼,我们采用了[45]中的架构。具体来说,骨骼生成网络(图3中的橙色方框)接收如图2所示的水平和垂直热图形式的无线信号,并生成多人3D骨骼。网络输入是3秒窗口(90帧)的水平和垂直热图。该网络由三个常用于姿态/骨骼估计的模块组成[45]。首先,一个包含时空卷积的特征网络从输入的射频信号中提取特征。然后,提取的特征通过区域提议网络(RPN)获得若干可能的骨骼边界框提议。最后,提取的提议被输入到3D姿态估计子网络中,从中提取每个提议的3D骨骼。
4.2. Modality-Independent Action Recognition
4.2. 模态无关的动作识别
As shown in Figure 3, the Modality-Independent Action Recognition framework uses the 3D skeletons gener- ated from RF signals to perform action detection.
如图 3 所示,模态无关动作识别框架利用从射频信号生成的 3D 骨架进行动作检测。
Input: We first associate the skeletons across time to get multiple skeleton sequences, each from one person. Each skeleton is represented by the 3D coordinates of the keypoints (shoulders, wrists, head, etc.). Due to radio signal properties, different keypoints reflect different amounts of radio signals at different instances of time, leading to varying confidence in the keypoint location (both across time and across keypoints). Thus, we use the skeleton generation network’s prediction confidence as another input parameter for each keypoint. Therefore, each skeleton sequence is a matrix of size $4\times T\times N_{j}$ , where 4 refers to the spatial dimensions plus the confidence, $T$ is the number of frames in a sequence, and $N_{j}$ corresponds to the number of keypoints in a skeleton.
我们首先将不同时间点的骨架关联起来,得到多个骨架序列,每个序列对应一个人。每个骨架由关键点(肩膀、手腕、头部等)的3D坐标表示。由于无线电信号特性,不同关键点在不同时间点反射的无线电信号量不同,导致关键点位置的可信度存在差异(随时间变化和关键点间差异)。因此,我们将骨架生成网络的预测置信度作为每个关键点的另一个输入参数。最终,每个骨架序列是一个大小为 $4\times T\times N_{j}$ 的矩阵,其中4代表空间维度加置信度,$T$ 是序列中的帧数,$N_{j}$ 对应骨架中的关键点数量。
Model: Our action detection model (the large green box in
模型:我们的动作检测模型(图中大绿框部分)
Figure 3) has three modules as follows: 1) An attentionbased feature learning network, which extracts high-level spatio-temporal features from each skeleton sequence. 2) We then pass these features to a multi-proposal module to extract proposals – i.e., time windows that each corresponds to the beginning and end of an action. Our multi-proposal module consists of two proposal sub-networks: one to generate proposals for single person actions, and the other for two-people interactions. 3) Finally, we use the generated proposals to crop and resize the corresponding latent features and input each cropped action segment into a classification network. The classification network first refines the temporal proposal by performing a 2-way classification to determine whether this duration contains an action or not. It then predicts the action class of the corresponding action segment.
图 3: 包含以下三个模块:1) 基于注意力(attention)的特征学习网络,用于从每个骨骼序列中提取高级时空特征。2) 将这些特征输入多提案(multi-proposal)模块以提取提案(proposal),即每个时间窗口对应动作的起止时间。我们的多提案模块包含两个提案子网络:一个用于生成单人动作提案,另一个用于双人交互动作提案。3) 最后,使用生成的提案对相应潜在特征进行裁剪和尺寸调整,并将每个裁剪后的动作片段输入分类网络。该分类网络首先通过二分类判断该时间段是否包含动作来优化时间提案,随后预测对应动作片段的动作类别。
Next, we describe the attention module and the multiproposal module in detail.
接下来,我们将详细描述注意力模块和多提案模块。
4.2.1 Spatio-Temporal Attention Module
4.2.1 时空注意力模块
We learn features for action recognition using a spatiotemporal attention-based network. Our model builds on the hierarchical co-occurrence network (HCN) [48]. HCN uses two streams of convolutions: a spatial stream that operates on skeleton keypoints, and a temporal stream that operates on changes in the locations of the skeleton’s keypoints across time. HCN concatenates the output of these two streams to extract spatio-temporal features from the input skeleton sequence. It then uses these features to predict human actions.
我们采用基于时空注意力机制的网络来学习动作识别特征。该模型基于层次共现网络(HCN) [48]构建。HCN采用双流卷积架构:空间流处理骨骼关键点坐标,时间流分析骨骼关键点随时间的位置变化。通过融合双流输出特征,HCN从输入骨骼序列中提取时空特征,最终实现人体动作预测。
However, skeletons predicted from wireless signals may not be as accurate as those labeled by humans. Also, different keypoints may have different prediction errors. To make our action detection model focus on body joints with higher prediction confidence, we introduce a spatio-temporal attention module (Figure 4). Specifically, we define a learnable mask weight $W_{m}$ , and convolve it with latent spatial features $f_{s}$ , and temporal features $f_{t}$ at each step:
然而,从无线信号预测的骨架可能不如人工标注的准确。此外,不同关键点的预测误差也可能不同。为了让我们的动作检测模型专注于预测置信度更高的身体关节,我们引入了一个时空注意力模块(图 4)。具体而言,我们定义了一个可学习的掩码权重 $W_{m}$,并在每一步将其与潜在空间特征 $f_{s}$ 和时间特征 $f_{t}$ 进行卷积:
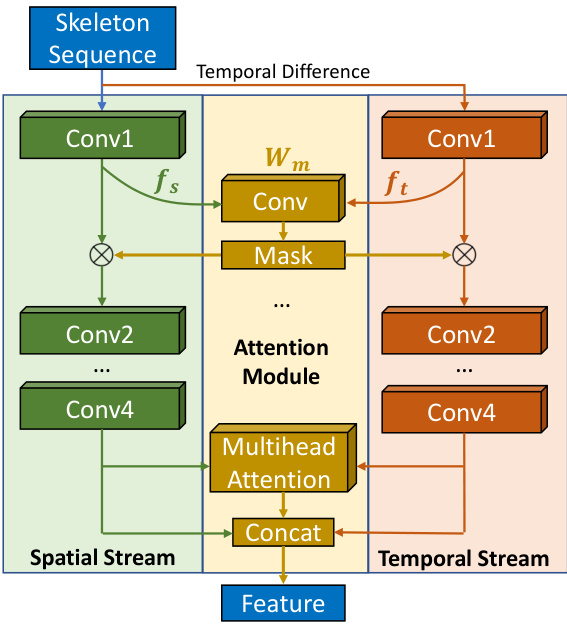
Figure 4: Spatio-temporal attention module. Our proposed attention module (yellow box) learns masks which make the model focus more on body joints with higher prediction confidence. It also uses a multi-headed attention module to help the model attend more on useful time instances.
图 4: 时空注意力模块。我们提出的注意力模块(黄色框)通过学习掩码使模型更关注预测置信度较高的身体关节,并采用多头注意力机制帮助模型聚焦于有效时间片段。
$$
M a s k=C o n v(c o n c a t(f_{s},f_{t}),W_{m}).
$$
$$
M a s k=C o n v(c o n c a t(f_{s},f_{t}),W_{m}).
$$
We then apply the $M a s k$ on the latent features as shown in Figure 4. In this way, the mask could learn to provide different weights to different joints to get better action recognition performance. We also add a multi-headed attention module [34] on the time dimension after the feature extraction to learn the attention on different timestamps.
然后我们在潜在特征上应用 $M a s k$,如图 4 所示。通过这种方式,掩码可以学习为不同关节提供不同的权重,从而获得更好的动作识别性能。我们还在特征提取后的时间维度上添加了一个多头注意力模块 [34],以学习对不同时间戳的注意力。
Our proposed attention module helps the model to learn more representative features, since the learnt mask leverages information provided by both the spatial stream and temporal stream, and the multi-headed attention helps the model to attend more on useful time instances. This spatiotemporal attention changes the original HCN design where the spatial and temporal path interact with each other only using late fusion. Our experiments show that the spatiotemporal attention module not only helps increase the action detection accuracy on skeletons predicted from wireless signals, but also helps increase the performance on benchmark visual action recognition datasets. This further shows the proposed attention module helps to combine spatial and temporal representations more effectively, and would lead to better feature representations.
我们提出的注意力模块通过利用空间流和时间流提供的综合信息来学习更具代表性的特征掩膜,同时多头注意力机制使模型能更聚焦于有效时间片段。这种时空注意力机制改变了原HCN架构中仅通过后期融合实现时空路径交互的设计。实验表明,该模块不仅能提升基于无线信号预测骨骼的动作检测准确率,还能提高视觉动作识别基准数据集的性能,这进一步验证了所提注意力模块能更高效融合时空表征,从而获得更优的特征表示。
4.2.2 Multi-Proposal Module
4.2.2 多提案模块
Most previous action recognition datasets have only one action (or interaction) at any time, regardless of the number of people present. As a result, previous approaches for skeleton action recognition cannot handle the scenario where multiple people perform different actions simultaneously. When there are multiple people in the scene, they simply do a max over features extracted from each of them, and forward the resulting combined feature to output one action. Thus, they can only predict one action at a time.
以往的大多数动作识别数据集在任何时候都只包含一个动作(或互动),无论场景中有多少人。因此,现有的骨架动作识别方法无法处理多人同时执行不同动作的场景。当场景中存在多人时,这些方法仅对从每个人提取的特征进行最大值池化,并将合并后的特征前向传播以输出一个动作。因此,它们一次只能预测一个动作。
However, in our dataset, when there are multiple people in the scene, they are free to do any actions or interact with each other at any time. So there are many scenarios where multiple people are doing actions and interacting simultan e ou sly. We tackle this problem with a multi-proposal module. Specifically, denote $N$ to be the number of people appearing at the same time. Instead of performing maxpooling over $N$ features, our multi-proposal module outputs $\bar{N}+\binom{\bar{N}}{2}$ proposals from these $N$ features, corresponding to $N$ possible single-person actions and $\binom{N}{2}$ possible interactions between each two people. Our multi-proposal module enables us to output multiple actions and interactions at the same time. Finally, we adopt a priority strategy to prioritize interactions over single person actions. For instance, if there are predictions for ‘pointing to something’ (single person) and ‘pointing to someone’ (interaction) at the same time, our final prediction would be ‘pointing to someone’.
然而,在我们的数据集中,当场景中存在多人时,他们可以自由执行任何动作或随时相互交互。因此存在大量多人同时执行动作并交互的场景。我们通过多提案模块解决这一问题。具体而言,设$N$为同时出现的人数,我们的多提案模块并非对$N$个特征进行最大池化,而是从这些特征中输出$\bar{N}+\binom{\bar{N}}{2}$个提案,对应$N$种可能的单人动作和$\binom{N}{2}$种可能的两人交互。该模块使我们能够同步输出多个动作和交互。最终采用优先级策略,使交互预测优先于单人动作预测。例如,当同时存在"指向某物"(单人)和"指向某人"(交互)的预测时,系统将优先输出"指向某人"。
4.3. Multimodal End-to-end Training
4.3. 多模态端到端训练
Since we want to train our model in an end-to-end manner, we can no longer use arg max to extract 3D keypoint locations, as in past work on RF-based pose estimation [45]. Thus, we use a regressor to perform the function of the arg max to extract the 3D locations of each keypoint. This makes the model differentiable and therefore the action label can also act as supervision on the skeleton prediction model.
由于我们希望以端到端的方式训练模型,无法再像过去基于射频的姿态估计研究[45]那样使用arg max提取3D关键点坐标。因此,我们采用回归器替代arg max的功能来提取各关键点的3D位置。这使得模型可微分,从而动作标签也能对骨骼预测模型起到监督作用。
Our end-to-end architecture uses 3D skeletons as an intermediate representation which enables us to leverage previous skeleton based action recognition datasets. We combine different modalities to train our model in the following manner: for wireless signal datasets, gradients back propagate through the whole model, and they are used to tune the parameters of both the skeleton prediction model and the action recognition model; for previous skeleton-based action recognition datasets, the gradients back propagate till the skeleton, and they are used to tune the parameters for the action recognition module. As shown in the experiments sec- tion, this multi-modality training significantly increases the data diversity and improves the performance of our model.
我们的端到端架构采用3D骨架作为中间表征,使我们能够利用现有的基于骨架的动作识别数据集。我们通过以下方式结合不同模态训练模型:对于无线信号数据集,梯度反向传播贯穿整个模型,用于优化骨架预测模型和动作识别模型的参数;对于既有骨架动作识别数据集,梯度仅反向传播至骨架层,专门优化动作识别模块的参数。如实验部分所示,这种多模态训练显著提升了数据多样性,并改善了模型性能。
5. Experiments
5. 实验
5.1. Dataset
5.1. 数据集
Since none of the available action detection datasets provide RF signals and the corresponding skeletons, we collect our own dataset which we refer to as RF Multi-Modality Dataset (RF-MMD). We use a radio device to collect RF signals, and a camera system with 10 different viewpoints to collect video frames. The radio device and the camera system are synchronized to within $10\mathrm{ms}$ . Appendix A includes a more detailed description of our data collection system.
由于现有的动作检测数据集均未提供射频信号(RF signals)及对应骨骼数据,我们自行采集了多模态射频数据集(RF Multi-Modality Dataset, RF-MMD)。通过射频设备采集信号的同时,使用10个不同视角的相机系统采集视频帧,两类设备的时间同步误差控制在$10\mathrm{ms}$以内。数据采集系统的详细说明见附录A。

Figure 5: Qualitative Results. The figure shows RF-Action’s output in various scenarios. The top two rows show our model’s performance in visible scenes. The bottom two rows show our model’s performance under partial/full occlusions and poor lighting conditions. The skeletons shown are the 2D projection of the intermediate 3D skeletons generated by our model.
图 5: 定性结果。该图展示了 RF-Action 在不同场景下的输出效果。前两行显示模型在可见场景中的表现,后两行展示模型在部分/完全遮挡及弱光条件下的性能。图中骨架为模型生成的中间3D骨架的2D投影。
We collected 25 hours of data with 30 volunteers in 10 different environments, including offices, lounges, hallways, corridors, lecture rooms, etc. We choose 35 actions (29 single actions and 6 interactions) from the PKU-MMD’s action set [26]. For every 10-min data, we ask up to 3 volunteers to perform different actions randomly from the above set. On average, each sample contains 1.54 volunteers, each volunteer performs 43 actions within 10 minutes, and each action takes 5.4 seconds. We use 20 hours of our dataset for training and 5 hours for testing.
我们在10种不同环境(包括办公室、休息室、走廊、过道、教室等)中收集了30名志愿者共计25小时的数据。从PKU-MMD动作集[26]中选取35个动作(29个单人动作和6个交互动作)。每段10分钟的数据中,我们要求最多3名志愿者随机执行上述动作集中的不同动作。平均每个样本包含1.54名志愿者,每位志愿者10分钟内执行43个动作,每个动作耗时5.4秒。我们将数据集的20小时用于训练,5小时用于测试。
The dataset also contains 2 through-wall scenarios, where one is used for training and one for testing. As for these through-wall environments, we put cameras on each side of the wall so that the camera system can be calibrated with the radio device, and use those cameras which can see the person to label the actions. All test result on RF-MMD use only radio signals without vision-based input.
该数据集还包含2个穿墙场景,其中一个用于训练,另一个用于测试。针对这些穿墙环境,我们在墙的两侧各放置摄像头,以便摄像头系统能与无线电设备进行校准,并利用那些能看见人物的摄像头来标注动作。RF-MMD上的所有测试结果仅使用无线电信号,不依赖视觉输入。
We extract 3D skeleton sequences using the multi-view camera system [45]. We first apply AlphaPose [12] to the videos collected by our camera system to extract multi-view 2D skeletons. Since there may be multiple people in the scene, we then associate the 2D skeletons from each view to get the multi-view 2D skeletons for each person. After that, since our camera system is calibrated, we can tria ngu late the 3D skeleton of each person. These 3D skeletons act as the supervision for the intermediate 3D skeletons generated by our model.
我们使用多视角相机系统[45]提取3D骨架序列。首先通过AlphaPose[12]处理相机系统采集的视频,提取多视角2D骨架。由于场景中可能存在多人,我们对各视角的2D骨架进行关联匹配,得到每个人的多视角2D骨架。由于相机系统已完成标定,随后可通过三角测量(triangulate)计算每个人的3D骨架。这些3D骨架将作为模型生成的中间3D骨架的监督信号。
Finally, we leverage the PKU-MMD dataset [26] to provide additional training examples. The dataset allows for action detection and recognition. It contains almost 20,000 actions from 51 categories performed by 66 subjects. This dataset allows us to show how RF-Action learns from vision-based examples.
最后,我们利用PKU-MMD数据集[26]提供额外的训练样本。该数据集支持动作检测与识别,包含66名受试者执行的51个类别近20,000个动作。通过此数据集,我们展示了RF-Action如何从基于视觉的样本中学习。
5.2. Setup
5.2. 配置
Metric. As common in the literature on video-based action detection [25, 47, 3] and skeleton-based action detection [26, 22, 23], we evaluate the performance of our model using the mean average precision (mAP) at different intersection-over-union (IoU) thresholds $\theta$ . We report our results on mAP at $\theta=0.1$ and $\theta=0.5$ .
指标。与基于视频的动作检测[25, 47, 3]和基于骨架的动作检测[26, 22, 23]文献中的常见做法一致,我们使用不同交并比(IoU)阈值$\theta$下的平均精度均值(mAP)来评估模型性能。我们报告了$\theta=0.1$和$\theta=0.5$时的mAP结果。
Ground Truth Labels. To perform end-to-end training of our proposed RF-Action model, we need two types of ground truth labels: 3D human skeletons to supervise our intermediate representation, and action start-end time and category to supervise the output of our model. The 3D skeletons are tri angul a ted using AlphaPose and the multiview camera system described earlier. As for actions’ duration and category, we manually segment and label the action of each person using the multi-view camera system.
真实标注标签 (Ground Truth Labels)。为了对我们提出的 RF-Action 模型进行端到端训练,我们需要两种真实标注标签:用于监督中间表示的 3D 人体骨骼,以及用于监督模型输出的动作起止时间和类别。3D 骨骼通过 AlphaPose 和前述多视角相机系统进行三角测量 (triangulated)。对于动作持续时间和类别,我们使用多视角相机系统手动分割并标注每个人的动作。
5.3. Qualitative Results
5.3. 定性结果
Figure 5 shows qualitative results that illustrate the output of RF-Action under a variety of scenarios. The figure shows that RF-Action correctly detects actions and interactions, even when different people perform different actions simultaneously, and can deal with occlusions and poor lighting conditions. Hence, it addresses multiple challenges for today’s action recognition systems.
图 5: 展示了RF-Action在不同场景下的输出定性结果。该图表明,即使不同人员同时执行不同动作,RF-Action也能正确检测动作和交互,并能处理遮挡和光照条件不佳的情况。因此,它解决了当今动作识别系统面临的多个挑战。
5.4. Comparison of Different Models
5.4. 不同模型的比较
We compare the performance of RF-Action to the stateof-the-art models for skeleton-based action recognition and RF-based action recognition. We use HCN as a representative of a top performant skeleton-based action detection system in computer vision. It currently achieves the best accuracy on this task. We use Aryokee [33] as a representative of the state-of-the-art in RF-based action recognition. To our knowledge, this is the only past RF-based action recognition system that performs action detection in addition to classification.1 All models are trained and tested on our RF action recognition dataset. Since HCN takes skeletons as input (as opposed to RF signals), we provide it with the intermediate skeletons generated by RF-Action. This allows us to compare RF-Action to HCN in terms of action recognition based on the same skeletons.
我们将RF-Action的性能与基于骨架的动作识别和基于射频(RF)的动作识别领域的最先进模型进行对比。在计算机视觉领域,我们选用表现最优的骨架动作检测系统HCN作为代表,该模型当前在此任务中保持最高准确率。基于射频的动作识别方面,我们以Aryokee [33]作为前沿技术代表。据我们所知,这是除分类外还能执行动作检测的唯一历史性射频动作识别系统。所有模型均在我们的射频动作识别数据集上训练和测试。由于HCN以骨架(而非射频信号)作为输入,我们为其提供由RF-Action生成的中间骨架数据,这使得我们能在相同骨架基础上对比RF-Action与HCN的动作识别能力。
Table 1: Model Comparison on RF-MMD dataset. The table shows mAP in visible and through-wall scenarios under different IoU threshold θ. Since HCN operates on skeletons, and for fair comparison, we provide it with the RF-based skeletons generated by RF-Action.
| 方法 | 可见场景 | 穿墙场景 | ||
|---|---|---|---|---|
| mAP (θ=0.1) | mAP (θ=0.5) | mAP (θ=0.1) | mAP (θ=0.5) | |
| RF-Action | 90.1 | 87.8 | 86.5 | 83.0 |
| HCN [23] | 82.5 | 80.1 | 78.5 | 75.9 |
| Aryokee [33] | 78.3 | 75.3 | 72.9 | 70.2 |
表 1: RF-MMD数据集上的模型对比。表格展示了不同IoU阈值θ下可见场景和穿墙场景的mAP结果。由于HCN基于骨骼动作识别,为了公平比较,我们为其提供了由RF-Action生成的基于射频的骨骼数据。
Table 1 shows the results for testing on visible scenes and through-wall scenarios, with wireless signals as the input. As shown in the table, RF-Action outperforms HCN in both testing conditions. This shows the effectiveness of our proposed modules. Further, we can also see that RF-Action outperforms Aryokee by a large margin on both visible and through-wall scenarios. This shows that the additional supervision from the skeletons, as well as RF-Action neural network design, are important for delivery of accurate performance using RF data.
表 1: 展示了以无线信号作为输入时,在可见场景和穿墙场景下的测试结果。如表所示,RF-Action 在两种测试条件下均优于 HCN。这表明了我们提出的模块的有效性。此外,我们还可以看到,RF-Action 在可见和穿墙场景下都大幅优于 Aryokee。这表明来自骨架的额外监督以及 RF-Action 神经网络设计对于利用 RF 数据实现准确性能至关重要。
5.5. Comparison of Different Modalities
5.5. 不同模态的对比
Next, we investigate the performance of RF-Action when operating on RF-based skeletons versus vision-based skeletons. We train RF-Action on the training set, as before. However, when performing inference, we either provide it with the input RF signal from the test set, or we provide it with the visible ground truth skeletons obtained using our camera system. Table 2 shows the results for different input modalities. The table shows that for visible scenes, operating on the ground truth skeletons from the camera system leads to only few percent improvements in accuracy. This is expected since the RF-skeletons are trained with the visionbased skeleton as ground truth. Further, as we described in our experimental setting, the camera-based system uses 10 viewpoints to estimate 3D skeletons while only one wireless device is used for action recognition based on RF. This result demonstrates that RF-based action recognition can achieve a performance close to a carefully calibrated camera system with 10 viewpoints. The system continues to work well in through-wall scenarios though the accuracy is few percents lower due to the signal experiencing some attenuation as it traverses walls.
接下来,我们研究RF-Action在处理基于射频(RF)的骨架与基于视觉的骨架时的性能表现。与之前相同,我们在训练集上训练RF-Action。但在推理阶段,我们为其提供来自测试集的输入射频信号,或使用我们的摄像系统获取的可见真实骨架。表2展示了不同输入模态下的结果。该表显示,在可见场景中,使用摄像系统的真实骨架仅带来几个百分点的准确率提升。这符合预期,因为射频骨架是以视觉骨架为真实标签进行训练的。此外,如实验设置所述,基于摄像的系统使用10个视角来估计3D骨架,而基于射频的动作识别仅使用单一无线设备。这一结果表明,基于射频的动作识别性能可接近配备10个视角的精密摄像系统。该系统在穿墙场景中仍保持良好表现,尽管由于信号穿墙衰减,准确率会降低几个百分点。
Table 2: RF-Action’s Performance (mAP) with RF-Based Skeletons (RFMMD) and Vision-Based Skeleton (G.T. Skeleton) under different IoU threshold $\theta$ .
表 2: RF-Action 在不同 IoU 阈值 $\theta$ 下使用基于 RF 的骨架 (RFMMD) 和基于视觉的骨架 (G.T. Skeleton) 的性能 (mAP)
| 方法/骨架 | 可见场景 | 穿墙场景 |
|---|---|---|
| mAP | mAP | |
| θ=0.1 | θ=0.5 | |
| RF-Action/RF-MMD | 90.1 | 87.8 |
| RF-Action/G.T.Skeleton | 93.2 | 90.5 |
5.6. Action Detection
5.6. 动作检测
In Figure 6, we show a representative example of our action detection results on the test set. Two people are enrolled in this experiment. They sometimes do actions independently, or interact with each other. The first row shows the action duration for the first person, the second row shows the action duration of the second person, and the third row shows the interactions between them. Our model can detect both the actions of each person and the interactions between them with high accuracy. This clearly demonstrates that our multi-proposal module has good performance in scenarios where multiple people are independently performing some actions or interacting with each other.
在图 6 中,我们展示了测试集上动作检测结果的一个代表性示例。本次实验有两名参与者,他们时而独立行动,时而相互交互。第一行显示第一个人的动作持续时间,第二行显示第二个人的动作持续时间,第三行则展示两人之间的交互行为。我们的模型能够高精度地检测每个人的动作以及他们之间的互动,这充分证明了多提案模块在多人独立行动或相互交互场景下的优异性能。
5.7. Ablation Study
5.7. 消融研究
We also conduct extensive ablation studies to verify the effectiveness of each key component of our proposed approach. For simplicity, the following experiments are conducted on the visible scenes in RF-MMD and mAP are calculated under 0.5 IoU threshold.
我们还进行了大量消融实验,以验证所提方法中每个关键组件的有效性。为简化起见,以下实验均在RF-MMD的可见场景中进行,mAP计算采用0.5 IoU阈值。

Figure 6: Example of action detection results on the test set, where two people are doing actions as well as interacting with each other. Ground truth action segments are drawn in blue, while detected segments using our model are drawn in red. The horizontal axis refers to the frame number.
图 6: 测试集上的动作检测结果示例,其中两人正在执行动作并相互交互。真实动作片段用蓝色绘制,而使用我们模型检测到的片段用红色绘制。横轴表示帧编号。
Attention Module. We evaluate the effectiveness of our proposed spatial-temporal attention module in Table 3. We show action detection performance with or without our attention module on both RF-MMD and PKU-MMD. The results show that our attention is useful for both datasets, but is especially useful when operating on RF-MMD. This is because skeletons predicted from RF signals can have inaccurate joints. We also conduct experiments on the NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ [31] dataset. Unlike PKU-MMD and RF-MMD which allow for action detection, this dataset is valid only for action classification. The table shows that our attention module is useful in this case too.
注意力模块。我们在表3中评估了所提出的时空注意力模块的有效性。我们在RF-MMD和PKU-MMD数据集上展示了使用或不使用注意力模块的动作检测性能。结果表明,我们的注意力机制对两个数据集都有帮助,但在RF-MMD上效果尤为显著。这是因为从射频信号预测的骨架可能存在关节不准确的问题。我们还在NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ [31] 数据集上进行了实验。与支持动作检测的PKU-MMD和RF-MMD不同,该数据集仅适用于动作分类。表中数据显示,我们的注意力模块在此场景下同样有效。
Table 3: Performance of RF-Action on Different Datasets With and Without Attention. For PKU-MMD and $\mathrm{NTU{-}R G B{+}D}$ (cross subject /cross view), we test the action recognition network (without the skeleton generation network). Tests on RF-MMD are across subjects and environments.
表 3: RF-Action 在有无注意力机制下不同数据集的表现。对于 PKU-MMD 和 $\mathrm{NTU{-}R G B{+}D}$ (跨主体/跨视角) 的实验,我们测试了动作识别网络(不含骨架生成网络)。RF-MMD 的测试为跨主体和跨环境场景。
| 数据集 (指标) | RF-Action | RF-Actionw/oAttention |
|---|---|---|
| RF-MMD (mAP) | 87.8 | 80.1 |
| PKU-MMD (mAP) | 92.9/94.4 | 92.6/94.2 |
| NTU-RGB+D (Acc) | 86.8/91.6 | 86.5/91.1 |
Multi-Proposal Module. We propose a multi-proposal module to enable multiple action prediction at the same time. We evaluate our model’s performance with or without the multi-proposal module. As shown in Table 4, the added multi-proposal module significantly increase the performance. This is because our dataset includes a lot of instances when people are performing different actions at the same time. Our model will get very poor accuracy at these scenarios with single-proposal, while with multi-proposal our model can achieve much higher performance.
多提案模块。我们提出了一个多提案模块,以实现同时预测多个动作。我们评估了模型在有或没有多提案模块时的性能。如表 4 所示,添加多提案模块显著提升了性能。这是因为我们的数据集中包含许多人在同一时间执行不同动作的实例。在这些场景下,单提案模型的准确率会非常低,而多提案模型则能实现更高的性能。
Table 4: Benefits of Multi-proposal Module. The table shows adding multi-proposal module largely improves the performance on RF-MMD
| 方法 | RF-MMD |
|---|---|
| 多提案 (Multi-Proposal) | 87.8 |
| 单提案 (Single-Proposal) | 65.5 |
表 4: 多提案模块的优势。该表显示添加多提案模块大幅提升了 RF-MMD 上的性能
Multimodal Training. As explained earlier, the use of skeletons as an intermediate representation allows the model to learn from both RF datasets and vision-based skeleton datasets. To illustrate this advantage, we perform multimodal training by adding PKU-MMD’s training set into the training of our RF-Action model. More specifically, we use our dataset to train the whole RF-Action end-to-end model, and use the PKU-MMD dataset to train RF-Action’s activity detection model. These two datasets are used alter natively during training. As shown in Table 5, comparing the detection results with the model trained on either dataset separately, we find multimodal training can increase the model performance since it introduces more data for training and thus can get better generalization ability.
多模态训练。如前所述,使用骨架作为中间表示使模型能够同时从射频(RF)数据集和基于视觉的骨架数据集中学习。为了说明这一优势,我们通过将PKU-MMD的训练集加入RF-Action模型的训练中来进行多模态训练。具体来说,我们使用自己的数据集端到端地训练整个RF-Action模型,并使用PKU-MMD数据集训练RF-Action的活动检测模型。这两个数据集在训练过程中交替使用。如表5所示,与单独使用任一数据集训练的模型相比,我们发现多模态训练可以提高模型性能,因为它引入了更多训练数据,从而获得更好的泛化能力。
| 训练集\测试集 | RF-MMD | PKU-MMD |
|---|---|---|
| RF-MMD+PKU-MMD | 87.8 | 93.3/94.9 |
| RF-MMD | 83.3 | 60.1/60.4 |
| PKU-MMD | 77.5 | 92.9/94.4 |
Table 5: Benefits of Multimodal Training. The table shows that adding PKU-MMD to the training set significantly improves the performance on RF-MMD. The mAP of RF-MMD $^+$ PKU-MMD on RF-MMD are achieved using the cross-subject training set of PKU-MMD. Using only RF-MMD for training has a poor performance on PKU-MMD because the action set of RF-MMD is only a subset of PKU-MMD’s action set.
表 5: 多模态训练的优势。该表显示,在训练集中加入 PKU-MMD 能显著提升 RF-MMD 上的性能。RF-MMD $^+$ PKU-MMD 在 RF-MMD 上取得的 mAP 使用了 PKU-MMD 的跨主体训练集。仅用 RF-MMD 训练时,由于 RF-MMD 的动作集仅为 PKU-MMD 动作集的子集,其在 PKU-MMD 上表现较差。
End-to-End Model. RF-Action uses an end-to-end model where the loss of action recognition is back propagated through the skeleton generation network. Here we show that such an end-to-end approach improves the skeleton itself. Table 6 reports the average error in skeleton joint location, for two systems: our end-to-end model and an alternative model where the skeleton is learned separately from the action –i.e., the action loss is not propagated through the skeleton generation network. The table shows that the end-to-end model not only improves the performance of the action detection task, but also reduces the errors in estimating the location of joints in RF-based skeletons. This is because the action detection loss provides regular iz ation for 3D skeletons generated from RF signals.
端到端模型。RF-Action采用端到端模型,其中动作识别的损失通过骨架生成网络反向传播。我们证明这种端到端方法能直接优化骨架生成质量。表6对比了两种系统的骨架关节位置平均误差:(1) 我们的端到端模型;(2) 独立学习骨架与动作的对照模型(即动作损失不通过骨架生成网络传播)。数据显示端到端模型不仅能提升动作检测性能,还可降低基于射频信号(RF)的3D骨架关节定位误差,这是因为动作检测损失为射频信号生成的3D骨架提供了正则化约束。
Table 6: mAP and intermediate 3D skeleton error on testing data with and without end-to-end training.
| 方法 | mAP | 骨骼误差 (cm) |
|---|---|---|
| 端到端训练 | 87.8 | 3.4 |
| 分离训练 | 84.3 | 3.8 |
表 6: 测试数据在端到端训练与非端到端训练下的mAP和中间3D骨骼误差对比。
6. Conclusion
6. 结论
This paper presents the first model for skeleton-based action recognition using radio signals, and demonstrates that such model can recognize actions and interactions through walls and in extremely poor lighting conditions. The new model enables action recognition in settings where cameras are hard to use either because of privacy concerns or poor visibility. Hence, it can bring action recognition to people’s homes and allow for its integration in smart home systems.
本文提出了首个基于无线电信号的骨骼动作识别模型,并证明该模型能够穿透墙壁或在极低光照条件下识别人体动作与交互行为。这一新型模型解决了因隐私顾虑或能见度不足导致摄像头难以应用的场景问题,使得动作识别技术得以进入家庭环境,为智能家居系统集成提供了新可能。