CONTINUOUS SPEECH SEPARATION WITH CONFORMER
基于Conformer的连续语音分离
ABSTRACT
摘要
Continuous speech separation was recently proposed to deal with overlapped speech in natural conversations. While it was shown to significantly improve the speech recognition performance for multichannel conversation transcription, its effectiveness has yet to be proven for a single-channel recording scenario. This paper examines the use of Conformer architecture in lieu of recurrent neural networks for the separation model. Conformer allows the separation model to efficiently capture both local and global context in- formation, which is helpful for speech separation. Experimental results using the LibriCSS dataset show that the Conformer separation model achieves state of the art results for both single-channel and multi-channel settings. Results for real meeting recordings are also presented, showing significant performance gains in both word error rate (WER) and speaker-attributed WER.
连续语音分离技术最近被提出用于处理自然对话中的重叠语音。虽然该技术已被证明能显著提升多通道对话转录的语音识别性能,但其在单通道录音场景中的有效性仍有待验证。本文研究了采用Conformer架构替代循环神经网络作为分离模型的方案。Conformer能使分离模型高效捕获局部与全局上下文信息,这对语音分离至关重要。基于LibriCSS数据集的实验结果表明,Conformer分离模型在单通道和多通道设置下均达到了当前最优水平。针对真实会议录音的测试结果也显示,该模型在词错误率(WER)和说话人归属词错误率(SA-WER)上均取得显著提升。
Index Terms— Multi-speaker ASR, Transformer, Conformer, Continuous speech separation
索引术语 - 多说话人自动语音识别 (Multi-speaker ASR)、Transformer、Conformer、连续语音分离
1. INTRODUCTION
1. 引言
The advance in deep learning has drastically improved the accuracy and robustness of modern automatic speech recognition (ASR) systems in the past decade [1, 2, 3, 4], enabling various voice-based applications. However, when applied to acoustically and linguistically complicated scenarios such as conversation transcription [5, 6], the ASR systems still suffer from the performance limitation due to overlapped speech and quick speaker turn-taking, which break the usually assumed single active speaker condition. Additionally, the overlapped speech causes the so-called permutation problem [7], further increasing the difficulty of the conversation transcription.
深度学习的发展在过去十年中极大地提高了现代自动语音识别(ASR)系统的准确性和鲁棒性[1, 2, 3, 4],催生了各种基于语音的应用。然而,当应用于声学和语言学复杂的场景(如对话转录[5, 6])时,由于重叠语音和快速的说话人轮换打破了通常假设的单说话人条件,ASR系统仍面临性能限制。此外,重叠语音还会导致所谓的排列问题[7],进一步增加了对话转录的难度。
Speech separation is often applied as a remedy for this problem, where the mixed speech is processed by a specially trained separation network before ASR . Starting from deep clustering (DC) [7] and permutation invariant training (PIT) [8, 9], various separation models have been shown effective in handling overlapped speech [6, 10, 11, 12]. Among the network architectures proposed thus far, the Transformer [12] based approach achieved a promising result. Transformer was first introduced for machine translation [13] and later extended to speech processing [14]. A Transformer based speech separation architecture was proposed in [12], achieving the state of the art separation quality on the WSJ0-2mix dataset. It was also reported in [15] that incorporating Transformer into an end-toend multi-speaker recognition network yielded higher recognition accuracy. However, both studies were evaluated on artificially simulated data sets that only considered overlapped speech, assuming the utterance boundaries to be provided, which significantly differs from the real conversational transcription scenario [6, 16].
语音分离常被用作解决该问题的方法,即在自动语音识别(ASR)前通过专门训练的分离网络处理混合语音。从深度聚类(DC) [7] 和排列不变训练(PIT) [8,9] 开始,多种分离模型已被证明能有效处理重叠语音 [6,10,11,12]。在目前已提出的网络架构中,基于Transformer [12] 的方法取得了显著成果。Transformer最初是为机器翻译提出的 [13],后来扩展到语音处理领域 [14]。文献 [12] 提出了一种基于Transformer的语音分离架构,在WSJ0-2mix数据集上达到了当前最优的分离质量。研究 [15] 也表明,将Transformer整合到端到端多说话人识别网络中可提高识别准确率。然而,这些研究都是在人工模拟数据集上进行评估的,这些数据集仅考虑重叠语音且假设已提供语句边界,这与真实对话转录场景存在显著差异 [6,16]。
In this work, inspired by the recent advances in transducer-based end-to-end ASR modeling, which has evolved from a recurrent neural network (RNN) transducer [17] to Transformer [18] and Conformer [19] transducers, we examine the use of the Conformer architecture for continuous speech separation (CSS) [20]. Unlike the prior speech separation studies, in CSS, the separation network continuously receives a mixed speech signal, performs separation, and routes each separated utterance to one of its output channels in a way that each output channel contains overlap-free signals. This allows a standard ASR system trained with single speaker utterances to be directly applied to each output channel to generate transcriptions. The proposed system is evaluated by using the LibriCSS dataset [16], which consists of real recordings of long-form multi-talker sessions that were created by concatenating and mixing Libri Speech utterances with various overlap ratios. Our proposed network significantly outperforms the RNN-based baseline systems, achieving the new state of the art performance on this dataset. Evaluation results on real meetings are also presented along with tricks for further performance improvement.
在本研究中,受基于转换器(Transformer)的端到端自动语音识别(ASR)建模最新进展的启发——从循环神经网络(RNN)转换器[17]发展到Transformer[18]和Conformer[19]转换器——我们探索了Conformer架构在连续语音分离(CSS)[20]中的应用。与以往语音分离研究不同,CSS中的分离网络持续接收混合语音信号,执行分离操作,并将每条分离后的语音路由至其输出通道之一,确保每个输出通道仅包含无重叠信号。这使得训练于单说话人语音的标准ASR系统可直接应用于各输出通道以生成转录文本。我们采用LibriCSS数据集[16]评估所提系统,该数据集通过以不同重叠率拼接混合Libri Speech语句,构建了真实长格式多人会话录音。实验表明,我们提出的网络显著优于基于RNN的基线系统,在该数据集上实现了新的最先进性能。文中还展示了真实会议场景的评估结果,以及进一步提升性能的实用技巧。
2. APPROACH
2. 方法
2.1. Problem Formulation
2.1. 问题表述
The goal of speech separation is to estimate individual speaker signals from their mixture, where the source signals may be overlapped with each other wholly or partially. The mixed signal is formulated as $\begin{array}{r}{y(t)=\sum_{s=1}^{S}x_{s}\dot{(t})}\end{array}$ , where $t$ is the time index, $x_{s}(t)$ denotes the $s$ -th sou rce signal, and $y(t)$ is the mixed signal. Following [20], when $C$ microphones are available, the model input to the separation model can be obtained as
语音分离的目标是从混合信号中估计出各个说话人的独立信号,其中源信号可能完全或部分重叠。混合信号可表示为 $\begin{array}{r}{y(t)=\sum_{s=1}^{S}x_{s}\dot{(t})}\end{array}$ ,其中 $t$ 为时间索引, $x_{s}(t)$ 表示第 $s$ 个源信号, $y(t)$ 为混合信号。根据[20],当有 $C$ 个麦克风时,分离模型的输入可表示为
$$
\mathbf{Y}(t,f)=\mathbf{Y}^{1}(t,f)\oplus\operatorname{IPD}(2)\ldots\oplus\operatorname{IPD}(C),
$$
$$
\mathbf{Y}(t,f)=\mathbf{Y}^{1}(t,f)\oplus\operatorname{IPD}(2)\ldots\oplus\operatorname{IPD}(C),
$$
where $\bigoplus$ means a concatenation operation, ${\bf Y}^{i}(t,f)$ refers to the STFT of the $i$ -th channel, $\mathrm{IPD}(i)$ is the inter-channel phase difference between the $i$ -th channel and the first channel, i.e. $\mathrm{IPD}(i)=$ $\theta^{i}(t,f)-\theta^{1}(t,f)$ with $\theta^{i}(t,f)$ being the phase of ${\bf Y}^{i}(t,f)$ . These features are normalized along the time axis. If $C=1$ , it reduces to a single channel speech separation task.
其中 $\bigoplus$ 表示拼接操作,${\bf Y}^{i}(t,f)$ 是第 $i$ 个通道的短时傅里叶变换 (STFT),$\mathrm{IPD}(i)$ 是第 $i$ 个通道与第一个通道之间的相位差,即 $\mathrm{IPD}(i)=$ $\theta^{i}(t,f)-\theta^{1}(t,f)$,其中 $\theta^{i}(t,f)$ 是 ${\bf Y}^{i}(t,f)$ 的相位。这些特征沿时间轴进行了归一化。如果 $C=1$,则退化为单通道语音分离任务。
Following [21, 22], a group of masks ${\mathbf{M}{s}(t,f)}{1\le s\le S}$ are estimated with a deep learning model $f(\cdot)$ instead of $f$ directly predicting the source STFTs. Each source STFT, $\mathbf{X}{s}(t,f)$ , is obtained as $\mathbf{M}_{s}^{-}(t,f)\odot\mathbf{Y}^{1}(t,f)$ , where $\odot$ is an element wise product. For the multi-channel setting, the source signals are obtained with adaptive minimum variance distortion less response (MVDR) beamforming [23]. In this paper, we employ the Conformer structure [19] as $f(\cdot)$ to estimate the masks for (continuous) speech separation.
根据 [21, 22],我们使用深度学习模型 $f(\cdot)$ 估计一组掩码 ${\mathbf{M}{s}(t,f)}{1\le s\le S}$,而不是直接预测源 STFT。每个源 STFT $\mathbf{X}{s}(t,f)$ 通过 $\mathbf{M}_{s}^{-}(t,f)\odot\mathbf{Y}^{1}(t,f)$ 获得,其中 $\odot$ 表示逐元素乘积。在多通道设置中,源信号通过自适应最小方差无失真响应 (MVDR) 波束成形 [23] 获得。本文采用 Conformer 结构 [19] 作为 $f(\cdot)$ 来估计(连续)语音分离的掩码。

2.2. Model structure
2.2. 模型结构
Conformer [19] is a state-of-the-art ASR encoder architecture, which inserts a convolution layer into a Transformer block to increase the local information modeling capability of the traditional Transformer model [13]. The architecture of the Conformer is shown in Fig. 1, where each block consists of a self-attention module, a convolution module, and a macron-feed forward module. A chunk of $\mathbf{Y}(t,f)$ over time frames and frequency bins is the input of the first block. Suppose that the input to the $i$ -th block is $z$ , the $i$ -th block output is calculaed as
Conformer [19] 是一种先进的ASR编码器架构,它在Transformer块中插入卷积层以增强传统Transformer模型 [13] 的局部信息建模能力。Conformer的架构如图1所示,其中每个块由自注意力模块、卷积模块和宏前馈模块组成。时间帧和频段上的 $\mathbf{Y}(t,f)$ 片段是第一个块的输入。假设第 $i$ 个块的输入为 $z$,则第 $i$ 个块的输出计算为
$$
\begin{array}{c}{{\hat{z}=z+\displaystyle\frac{1}{2}\mathrm{FFN}(z)}}\ {{z^{\prime}=\mathrm{selfattention}(\hat{z})+\hat{z}}}\ {{z^{\prime\prime}=\mathrm{conv}(z^{\prime})+z^{\prime}}}\ {{{w t p u t}=\mathrm{layernorm}(z^{\prime\prime}+\displaystyle\frac{1}{2}\mathrm{FFN}(z^{\prime\prime})),}}\end{array}
$$
$$
\begin{array}{c}{{\hat{z}=z+\displaystyle\frac{1}{2}\mathrm{FFN}(z)}}\ {{z^{\prime}=\mathrm{selfattention}(\hat{z})+\hat{z}}}\ {{z^{\prime\prime}=\mathrm{conv}(z^{\prime})+z^{\prime}}}\ {{{w t p u t}=\mathrm{layernorm}(z^{\prime\prime}+\displaystyle\frac{1}{2}\mathrm{FFN}(z^{\prime\prime})),}}\end{array}
$$
where $\mathrm{FFN()}$ , self attention(), conv(), and layernorm() denote the feed forward network, self-attention module, convolution module, and layer normalization, respectively. In the self-attention module, $\hat{\mathbf{z}}$ is linearly converted to $\mathbf{Q},\mathbf{K},\mathbf{V}$ with three different parameter matrices. Then, we apply a multi-head self-attention mechanism
其中 $\mathrm{FFN()}$、self attention()、conv() 和 layernorm() 分别表示前馈网络、自注意力模块、卷积模块和层归一化。在自注意力模块中,$\hat{\mathbf{z}}$ 通过三个不同的参数矩阵线性转换为 $\mathbf{Q},\mathbf{K},\mathbf{V}$,随后应用多头自注意力机制
$$
\begin{array}{r}{\mathrm{Multihead}(\mathbf{Q},\mathbf{K},\mathbf{V})=[\mathbf{H_{1}}\mathbf{\Phi}.\mathbf{..}\mathbf{H}{d_{h e a d}}]\mathbf{W}^{h e a d}\mathbf{\Phi}}\ {\mathbf{H_{i}}=\mathrm{softmax}(\frac{\mathbf{Q_{i}}(\mathbf{K_{i}}+\mathbf{p}\mathbf{os})^{\intercal}}{\sqrt{d_{k}}})\mathbf{V_{i}},}\end{array}
$$
$$
\begin{array}{r}{\mathrm{Multihead}(\mathbf{Q},\mathbf{K},\mathbf{V})=[\mathbf{H_{1}}\mathbf{\Phi}.\mathbf{..}\mathbf{H}{d_{h e a d}}]\mathbf{W}^{h e a d}\mathbf{\Phi}}\ {\mathbf{H_{i}}=\mathrm{softmax}(\frac{\mathbf{Q_{i}}(\mathbf{K_{i}}+\mathbf{p}\mathbf{os})^{\intercal}}{\sqrt{d_{k}}})\mathbf{V_{i}},}\end{array}
$$
where $d_{k}$ is the dimensionality of the feature vector, $d_{h e a d}$ is the number of the attention heads. pos $={r e l_{m,n}}\in\mathbb{R}^{M\times M\times d_{k}}$ is the relative position embedding [24], where $M$ is the maximum chunk length and $r e l_{m,n}\in\mathbb{R}^{d_{k}}$ is a vector representing the offset of $m$ and $n$ with $m$ and $n$ denoting the $m$ -th vector of $\mathbf{Q_{i}}$ and the $n$ -th vector of $\mathbf{K_{i}}$ , respectively. The Convolution starts with a pointwise convolution and a gated linear unit (GLU), followed by a 1-D depthwise convolution layer with a Batchnorm [25] and a Swish activation. After obtaining the Conformer output, we further convert it to a mask matrix as $\mathbf{M}{s}(t,f)=\mathrm{sigmoid}(\mathrm{FFN}_{s}(o u t p u t))$ .
其中 $d_{k}$ 是特征向量的维度,$d_{h e a d}$ 是注意力头的数量。pos $={r e l_{m,n}}\in\mathbb{R}^{M\times M\times d_{k}}$ 是相对位置嵌入 [24],其中 $M$ 是最大块长度,$r e l_{m,n}\in\mathbb{R}^{d_{k}}$ 是一个表示 $m$ 和 $n$ 偏移量的向量,$m$ 和 $n$ 分别表示 $\mathbf{Q_{i}}$ 的第 $m$ 个向量和 $\mathbf{K_{i}}$ 的第 $n$ 个向量。卷积从逐点卷积和门控线性单元 (GLU) 开始,接着是一个带有 Batchnorm [25] 和 Swish 激活的一维深度卷积层。在获得 Conformer 输出后,我们进一步将其转换为掩码矩阵 $\mathbf{M}{s}(t,f)=\mathrm{sigmoid}(\mathrm{FFN}_{s}(o u t p u t))$。
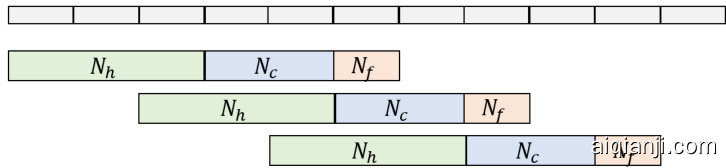
Fig. 1. Conformer architecture. There are three mask outputs, two for speakers and one for noise. Fig. 2. Chunk-wise processing is employed to enable streaming processing for continuous speech separation.
图 1: Conformer 架构。包含三个掩码输出,两个用于说话人,一个用于噪声。
图 2: 采用分块处理以实现连续语音分离的流式处理。
2.3. Chunk-wise processing for continuous separation
2.3. 连续分离的分块处理
The speech overlap usually takes place in a natural conversation which may last for tens of minutes or longer. To deal with such long input signals, CSS generates a predefined number of signals where overlapped utterances are separated and then routed to different output channels.
语音重叠通常发生在可能持续数十分钟或更长时间的自然对话中。为处理此类长输入信号,连续语音分离(CSS)会生成预定数量的信号,其中重叠的语音被分离并路由到不同的输出通道。
To enable this, we employ the chunk-wise processing proposed in [26] at test time. A sliding-window is applied as illustrated in Figure 2, which contains three sub-windows, representing the history ( $\mathrm{\Delta}N_{h}$ frames), the current segment ( ${N_{c}}$ frames), and the future context $\mathbf{\nabla}N_{f}$ frames). We move the window position forward by $N_{c}$ frames each time, and compute the masks for the current $N_{c}$ frames using the whole $N$ -frame-long chunk.
为实现这一目标,我们在测试时采用了[26]提出的分块处理策略。如图2所示,采用滑动窗口机制,该窗口包含三个子窗口:分别表示历史帧( $\mathrm{\Delta}N_{h}$ 帧)、当前片段( ${N_{c}}$ 帧)和未来上下文( $\mathbf{\nabla}N_{f}$ 帧)。每次将窗口位置向前移动 $N_{c}$ 帧,并利用整个 $N$ 帧长度的数据块计算当前 $N_{c}$ 帧的掩码。
To further consider the history information beyond the current chunk, we also consider taking account of the previous chunks in the self-attention module. Following Transformer-XL [27], the Equation 7 is rewritten as
为了进一步考虑当前分块之外的历史信息,我们还尝试在自注意力模块中纳入先前分块。参照Transformer-XL [27],公式7被改写为
$$
\mathrm{softmax(\frac{Q_{i}(K_{i}\oplus K_{c a c h e,i}+p o s)^{\top}}{\sqrt{\mathit{d}{k}}})(V_{i}\oplus V_{c a c h e,i})}
$$
$$
\mathrm{softmax(\frac{Q_{i}(K_{i}\oplus K_{c a c h e,i}+p o s)^{\top}}{\sqrt{\mathit{d}{k}}})(V_{i}\oplus V_{c a c h e,i})}
$$
where $\mathbf{Q}$ is obtained by the current chunk while $\mathbf{K}$ and $\mathbf{V}$ are the concatenations of the previous and current changes in the key and value spaces, respectively. The dimensionality of ${\bf K}_{\bf c a c h e,i}$ depends on the number of the history chunks considered.
其中 $\mathbf{Q}$ 由当前分块获得,而 $\mathbf{K}$ 和 $\mathbf{V}$ 分别是键空间和值空间中历史分块与当前分块的拼接。${\bf K}_{\bf c a c h e,i}$ 的维度取决于所考虑的历史分块数量。
3. EXPERIMENT
3. 实验
3.1. Datasets
3.1. 数据集
Our training dataset consists of 219 hours of artificially reverberated and mixed utterances that sampled randomly from WSJ1 [29]. Four different mixture types described in [20] are included in the training set. To generate each training mixture, we randomly pick one or two speakers from WSJ1 and convolve each with a 7 channel room impulse response (RIR) simulated with the image method [30]. The reverberated signals are then rescaled and mixed with a source energy ratio between -5 and $5\mathrm{dB}$ . In addition, we add simulated isotropic noise [31] with a $0{-}10{\mathrm{dB}}$ signal to noise ratio. The average overlap ratio of the training set is around $50%$ .
我们的训练数据集包含从WSJ1 [29]中随机采样的219小时人工混响和混合语音。训练集中包含[20]描述的四种不同混合类型。为生成每个训练混合样本,我们从WSJ1中随机选取一或两名说话人,并使用基于镜像法[30]模拟的7通道房间脉冲响应(RIR)进行卷积运算。混响信号经能量缩放后按-5至$5\mathrm{dB}$的源能量比混合,并叠加$0{-}10{\mathrm{dB}}$信噪比的模拟各向同性噪声[31]。该训练集的平均重叠率约为$50%$。
LibriCSS is used for evaluation [16]. The dataset has 10 hours of seven-channel recordings of mixed and concatenated Libri Speech test utterances. The recordings were made by playing back the mixed audio in a meeting room. Two evaluation schemes are used: utterance-wise evaluation and continuous input evaluation. In the former evaluation, the long-form recordings are segmented into individual utterances by using ground-truth time marks to evaluate the pure separation performance. In the contuous input evaluation, systems have to deal with the un segmented recordings and thus CSS is needed.
LibriCSS用于评估[16]。该数据集包含10小时七通道录音,内容为混合拼接的Libri Speech测试语句。录音通过会议室回放混合音频完成。采用两种评估方案:基于语句的评估和连续输入评估。前者使用真实时间标记将长录音分割为独立语句,以评估纯分离性能;后者要求系统处理未分割的录音,此时需要连续语音分离(CSS)技术。
Table 1. Utterance-wise evaluation for seven-channel and single-channel settings. Two numbers in a cell denote $%{\mathrm{WER}}$ of the hybrid ASR model used in LibriCSS [16] and E2E Transformer based ASR model [28]. 0S and 0L are utterances with short/long inter-utterance silence
表 1: 七通道和单通道设置的逐句评估结果。单元格中的两个数字分别表示LibriCSS [16]中使用的混合ASR模型和基于E2E Transformer的ASR模型 [28]的$%{\mathrm{WER}}$。0S和0L分别表示短/长句间静默的语句。
| 系统 | OS | OL | 10 | 20 | 30 | 40 |
|---|---|---|---|---|---|---|
| 无分离 [16] | 11.8/5.5 | 11.7/5.2 | 18.8/11.4 | 27.2/18.8 | 35.6/27.7 | 43.3/36.6 |
| 七通道评估 | ||||||
| BLSTM | 7.0/3.1 | 7.5/3.3 | 10.8/4.3 | 13.4/5.6 | 16.5/7.5 | 18.8/8.9 |
| Transformer-base | 8.3/3.4 | 8.4/3.4 | 11.4/4.1 | 12.5/4.8 | 14.7/6.4 | 16.9/7.2 |
| Transformer-large | 7.5/3.1 | 7.7/3.4 | 10.1/3.7 | 12.3/4.8 | 14.1/5.9 | 16.0/6.3 |
| Conformer-base | 7.3/3.1 | 7.3/3.3 | 9.6/3.9 | 11.9/4.8 | 13.9/6.0 | 15.9/6.8 |
| Conformer-large | 7.2/3.1 | 7.5/3.3 | 9.6/3.7 | 11.3/4.8 | 13.7/5.6 | 15.1/6.2 |
| 单通道评估 | ||||||
| BLSTM | 15.8/6.4 | 14.2/5.8 | 18.9/9.6 | 25.4/15.3 | 31.6/20.5 | 35.5/25.2 |
| Transformer-base | 13.2/5.5 | 12.3/5.2 | 16.5/8.3 | 21.8/12.1 | 26.2/15.6 | 30.6/19.3 |
| Transformer-large | 13.0/5.3 | 12.4/5.1 | 15.5/7.4 | 20.1/11.1 | 24.6/13.5 | 27.9/17.0 |
| Conformer-base | 13.8/5.6 | 12.5/5.4 | 16.7/8.2 | 21.6/11.8 | 26.1/15.5 | 30.1/18.9 |
| Conformer-large | 12.9/5.4 | 12.2/5.0 | 15.1/7.5 | 20.1/10.7 | 24.3/13.8 | 27.6/17.1 |
3.2. Implementation details
3.2. 实现细节
We use BLSTM and Transformers as our baseline speech separation models. The BLSTM model has three BLSTM layers with 1024 input dimensions and 512 hidden dimensions, resulting in 21.80M parameters. There are three masks, two for speakers and one for noise. The noise mask is used to enhance the beam forming [26]. We use three sigmoid projection layers to estimate each mask. Transformer-base and Transformer-large models with 21.90M and 58.33M parameters are our two Transformer-based baselines. The Transformer-base model consists of 16 Transformer encoder layers with 4 attention heads, 256 attention dimensions and 2048 FFN dimensions. The Transformer-large model consists of 18 Transformer encoder layers with 8 attention heads, 512 attention dimensions and 2048 FFN dimensions.
我们采用 BLSTM 和 Transformer 作为基线语音分离模型。BLSTM 模型包含三个 BLSTM 层,输入维度为 1024,隐藏层维度为 512,参数量达 21.80M。模型输出三个掩码,其中两个用于说话人分离,一个用于噪声抑制。噪声掩码用于增强波束成形效果 [26]。我们采用三个 sigmoid 投影层来分别估计这些掩码。基于 Transformer 的基线模型包含参数量为 21.90M 的 Transformer-base 和 58.33M 的 Transformer-large 两个版本:Transformer-base 由 16 个 Transformer 编码器层组成,每层包含 4 个注意力头、256 维注意力空间和 2048 维前馈网络;Transformer-large 则包含 18 个编码器层,每层配置 8 个注意力头、512 维注意力空间和 2048 维前馈网络。
As with the Transformer baseline models, we experiment with two Conformer-based models, Conformer-base and Conformerlarge. They have 22.07M and 58.72M parameters, respectively. The Conformer-base model consists of 16 Conformer encoder layers with 4 attention heads, 256 attention dimensions and 1024 FFN dimensions. The Conformer-large model consists of 18 Conformer encoder layers with 8 attention heads, 512 attention dimensions and 1024 FFN dimensions. Both Conformer and Transformer are trained with the AdamW optimizer [32], where the weight decay is set to 1e-2. We set the learning rate to 1e-4 and use a warm-up learning schedule with a linear decay, in which the warmp-up step is 10,000 and the training step is 260,000.
与Transformer基线模型类似,我们实验了两种基于Conformer的模型:Conformer-base和Conformer-large。它们分别具有2207万和5872万参数。Conformer-base模型包含16个Conformer编码器层,配备4个注意力头、256维注意力空间和1024维前馈网络。Conformer-large模型包含18个Conformer编码器层,配备8个注意力头、512维注意力空间和1024维前馈网络。Conformer和Transformer均采用AdamW优化器[32]进行训练,权重衰减设为1e-2。学习率设置为1e-4,并采用包含线性衰减的预热学习调度策略,其中预热步数为10,000,总训练步数为260,000。
We use two ASR models to evaluate the speech separation accuracy. One is the ASR model used in the original LibriCSS publication [16], which is a hybrid system using a BLSTM acoustic model and a 4-gram language model. The other one is one of the best open source end-to-end Transformer based ASR models [28], which achieves $2.08%$ and $4.95%$ word error rates (WERs) for Libri Speech test-clean and test-other, respectively. Following [16], we generate the separated speech signals with spectral masking and maskbased adaptive minimum variance distortion less response (MVDR) beam forming for the single-channel and seven-channel cases, respectively. For a fair comparison, we follow the LibriCSS setting for chunk-wise CSS processing, where $N_{h}$ , $N_{c}$ , $N_{f}$ are set to 1.2s, 0.8s, 0.4s respectively.
我们使用两个自动语音识别 (ASR) 模型来评估语音分离的准确性。一个是原始 LibriCSS 论文 [16] 中使用的 ASR 模型,它是一个混合系统,使用了 BLSTM 声学模型和 4-gram 语言模型。另一个是目前最好的开源端到端基于 Transformer 的 ASR 模型之一 [28],它在 Libri Speech 的 test-clean 和 test-other 数据集上分别达到了 $2.08%$ 和 $4.95%$ 的词错误率 (WER)。按照 [16] 的方法,我们分别针对单通道和七通道情况,使用频谱掩蔽和基于掩蔽的自适应最小方差无失真响应 (MVDR) 波束成形生成分离的语音信号。为了公平比较,我们遵循 LibriCSS 的分块式连续语音分离 (CSS) 处理设置,其中 $N_{h}$、$N_{c}$、$N_{f}$ 分别设置为 1.2 秒、0.8 秒和 0.4 秒。
3.3. Results for utterance wise evaluation
3.3. 话语级评估结果
Table 1 shows the WER of the utterance wise evaluation for the seven-channel and single-channel settings. Our Conformer models achieved state-of-the-art results. Compared with BLSTM, Conformer-base yielded substantial WER gains for the 7-channel setting. The fact that the Conformer-base model outperformed Transformer-base for almost all the settings indicates Conformer’s superior local modeling capability. Also, the larger models achieved better performance in the highly overlapped settings. As regards the single-channel case, while the overall WERs were higher, the trend was consistent between the single- and multi-channel cases, except for the non-overlap scenario. With the seven channel input, all models showed similar performance for 0S and 0L. On the other hand, when only one channel was used, the self-attention models were markedly better. This could indicate that the seven-channel features contain sufficiently rich information for simpler networks to do the beam forming well. Meanwhile, the information in the single-channel signal is quite limited, requiring a more advanced structure.
表1: 七通道与单通道配置下语句级评估的WER (Word Error Rate) 。我们的Conformer模型取得了最先进的成果。与BLSTM相比,Conformer-base在7通道配置中实现了显著的WER提升。Conformer-base模型在几乎所有配置中都优于Transformer-base,这表明Conformer具有更优异的局部建模能力。此外,较大模型在高重叠场景中表现更佳。就单通道情况而言,虽然整体WER较高,但除非重叠场景外,单通道与多通道的趋势保持一致。使用七通道输入时,所有模型在0S和0L场景表现相近;而采用单通道时,自注意力模型明显更优。这可能表明七通道特征包含足够丰富的信息,使得简单网络也能良好完成波束成形,而单通道信号的信息量较为有限,需要更先进的架构。
3.4. Results for continuous input evaluation
3.4. 连续输入评估结果
Table 2 shows the continuous input evaluation results. The Conformer and Transformer models performed consistently better than BLSTM, but their performance gap became smaller in the large overlap test-set. The relative WER gains obtained with Conformer-base over BLSTM were $4%$ and $15%$ for the hybrid and transducer ASR sytems, respectively, which were smaller than those obtained for the utterance-wise evaluation. A possible explanation is that the selfattention based methods are good at using global information while the chunk-wise processing limits teh use of the context information.
表 2: 连续输入评估结果。Conformer 和 Transformer 模型的表现始终优于 BLSTM,但在大重叠测试集上性能差距缩小。Conformer-base 相对于 BLSTM 的混合(hybrid)和传感器(transducer) ASR 系统的相对 WER 增益分别为 $4%$ 和 $15%$,低于逐句评估的结果。一个可能的解释是,基于自注意力(self-attention)的方法擅长利用全局信息,而分块处理限制了上下文信息的使用。
It is noteworthy that 0S results were much worse than those of 0L only in the continuous evaluation, which is consistent with the previous report [16]. The 0S dataset contains much more quick speaker turn changes, imposing a challenge for both speech separation and ASR. The self-attention-based models showed clear improvement over BLSTM, indicating that they are also helpful for dealing with turn-takings in natural conversations.
值得注意的是,0S结果仅在连续评估中远差于0L,这与先前报告[16]一致。0S数据集包含更多快速的说话人轮换变化,这对语音分离和自动语音识别(ASR)都构成了挑战。基于自注意力(self-attention)的模型相比BLSTM显示出明显改进,表明它们也有助于处理自然对话中的话轮转换。
Table 2. Continuous speech separation evaluation for seven-channel and single-channel settings.
表 2: 七通道和单通道设置下的连续语音分离评估结果
| 系统 | OS | OL | 10 | 20 | 30 | 40 |
|---|---|---|---|---|---|---|
| 无分离 [16] | 15.4/12.7 | 11.5/5.7 | 21.7/17.6 | 27.0/24.4 | 34.3/30.9 | 40.5/37.5 |
| 七通道评估 | ||||||
| BLSTM | 11.4/6.0 | 8.4/4.1 | 13.1/7.0 | 14.9/7.9 | 18.7/11.5 | 20.5/12.3 |
| Transformer-base | 12.0/5.6 | 9.1/4.4 | 13.4/6.2 | 14.4/6.8 | 18.5/9.7 | 19.9/10.3 |
| Transformer-large | 10.9/5.4 | 8.8/4.0 | 12.6/6.0 | 13.6/6.7 | 17.2/9.3 | 18.9/10.2 |
| Conformer-base | 11.1/5.6 | 8.7/4.0 | 12.8/6.1 | 13.8/6.7 | 17.6/9.4 | 19.6/10.4 |
| Conformer-large | 11.0/5.2 | 8.7/4.0 | 12.6/5.8 | 13.5/6.8 | 17.6/9.0 | 19.6/10.0 |
| Conformerzi-base | 11.4/5.4 | 8.7/4.1 | 13.2/6.2 | 13.6/6.7 | 17.8/9.5 | 20.0/10.8 |
| Conformerzi-large | 11.0/5.2 | 8.8/4.1 | 12.9/5.8 | 13.7/6.7 | 17.5/9.4 | 19.8/10.6 |
| 单通道评估 | ||||||
| BLSTM | 19.1/11.7 | 16.1/9.7 | 22.1/14.5 | 27.4/19.1 | 33.0/25.9 | 37.6/30.1 |
| Transformer-base | 13.8/7.1 | 11.5/6.6 | 16.7/9.6 | 20.8/13.3 | 26.7/18.6 | 31.0/21.6 |
| Transformer-large | 13.0/7.2 | 12.3/6.9 | 15.8/9.5 | 19.8/12.2 | 25.3/16.9 | 28.6/19.3 |
| Conformer-base | 14.1/7.7 | 13.0/7.1 | 17.4/10.6 | 21.9/13.7 | 27.4/18.7 | 32.0/22.4 |
| Conformer-large | 13.3/6.9 | 11.7/6.1 | 16.3/9.1 | 20.7/12.5 | 25.6/16.7 | 29.3/19.3 |
Table 2 also shows that the Conformer $._{x l}$ models using longer context information did not result in lower WERs especially in the large overlap ratio settings. Two factors may have contributed to the performance degradation. 1) The unexpected noise may have been introduced from the use of the longer history, which may contain more speakers’ voices. 2) Also, we did not consider the overlap regions of the adjacent windows during training, possibly making the training/testing gap greater and resulting in sub-optimal performance. We leave the training with overlap regions for the future work.
表 2 还显示,使用更长上下文信息的 Conformer $._{x l}$ 模型并未带来更低的 WER (词错误率) ,尤其是在高重叠率场景下。性能下降可能由两个因素导致:1) 使用更长历史帧可能意外引入噪声 (这些帧可能包含更多说话人语音) ;2) 训练时未考虑相邻窗口的重叠区域,可能扩大训练/测试差异并导致次优性能。我们将重叠区域训练留作未来工作。
3.5. Results on large scale real meetings
3.5. 大规模真实会议的结果
To further verify the effectiveness of our method, we further conduct an experiment on an internal real conversation corpus which consists of 15.8 hours of single channel recordings of daily group discussions, noted as the Real Conversation dataset. In this dataset, the per-meeting speaker number ranges from 3 to 22. We applied a modified version of the conversation transcription system of [6], where a large scale trained speech recognizer and speaker embedding extractor were included, to obtain speaker attributed transcriptions.
为了进一步验证我们方法的有效性,我们在一个内部真实对话语料库上进行了实验,该语料库包含15.8小时的单通道日常小组讨论录音,记为Real Conversation数据集。在该数据集中,每次会议的说话者数量从3到22人不等。我们采用了[6]中对话转录系统的改进版本(其中包含大规模训练的语音识别器和说话人嵌入提取器)来获取说话人归属转录文本。
Compared with LibriCSS, those real meetings are significantly more complex with respect to the acoustics, linguistics, and interspeaker dynamics. To deal with the real data challenges, three improvements were made. Firstly, we increased the training data amount to 1500 hours. Additional clean speech samples were taken from a Microsoft internal corpus and they were mixed with the simulation setup as Section 3.1. Secondly, the separation network sometimes generated a low volume residual signal from the redundant output channel for single speaker regions, which increased the word insertion errors. To mitigate this, we introduced a merging scheme, where the two channel outputs were merged when a single active speaker was judged to be present. The merger was triggered when only one masked channel had a significantly large energy. Lastly, to reduce the distortion introduced by the masking operation, we used single speaker signals corruped by background noise as a training target. This allowed the separation network to focus only on the separation task and leave the noise to the ASR model. The WER and speaker attributed WER (SA-WER) were used for evaluation, where the latter assesses the combined quality of speech transcription and speaker di ari z ation [6].
与LibriCSS相比,这些真实会议在声学、语言学和说话人交互动态方面都更为复杂。为应对真实数据的挑战,我们进行了三项改进:首先,将训练数据量增至1500小时,从微软内部语料库中提取纯净语音样本,并按照第3.1节的仿真设置进行混合;其次,针对分离网络在单说话人区域可能从冗余输出通道生成低音量残留信号(导致词插入错误增加)的问题,我们引入了合并机制——当判断仅存在单一活跃说话人时,将双通道输出合并,该合并操作在仅一个掩码通道具有显著能量时触发;最后,为降低掩码操作引入的失真,我们采用受背景噪声干扰的单说话人信号作为训练目标,使分离网络专注于分离任务而将噪声处理交由ASR模型完成。评估采用WER和说话人归属WER(SA-WER)指标,后者用于衡量语音转写与说话人日志[6]的综合质量。
Table 3. Continuous evaluation on a real meeting dataset.
表 3: 真实会议数据集上的持续评估结果
| system | Data | WERR | SA-WERR |
|---|---|---|---|
| Original | N/A | 0 | 0 |
| BLSTM | 219hr | -6.4% | -18.8% |
| Conformer-base | 219hr | -7.2% | -6.3% |
| Conformer-large | 219hr | -2.5% | 1.9% |
| Conformer-base | 1500hr | 9.5% | 8.8% |
| Conformer-base-merge | 1500hr | 8.4% | 10.13% |
| Conformer-base-merge-nlabel | 1500hr | 11.8% | 13.7% |
| Conformer-large-merge-nlabel | 1500hr | 8.08% | 18.4% |
Table 3 shows the WER and SA-WER reduction rates. With the three improvements described above, the proposed model reduced the WER and SA-WER by $11.8%$ and $18.4%$ relative, respectively, compared with a system without the separation front-end. Although the BLSTM based network improved the recognition result for the LibriCSS dataset especially for the high overlap ratio settings, it largely degraded the speech recognition and speaker diarization performance on the Real Conversation dataset. Because the speech overlap happens only s po radially in real conversations, it is important for the separation model not to hurt the performance for less overlap cases. Thanks to the better modeling capacity, the Conformer based models significantly mitigates the performance degradation. In addition, it can be seen that each introduced step brought about consistent improvement for both performance metrics.
表 3 显示了 WER (Word Error Rate) 和 SA-WER (Speaker-Attributed Word Error Rate) 的降低率。通过上述三项改进,与没有分离前端 (separation front-end) 的系统相比,所提出的模型将 WER 和 SA-WER 分别相对降低了 $11.8%$ 和 $18.4%$。尽管基于 BLSTM 的网络改善了 LibriCSS 数据集的识别结果,尤其是在高重叠率设置下,但它严重降低了 Real Conversation 数据集上的语音识别和说话人日志 (speaker diarization) 性能。由于语音重叠在真实对话中仅零星发生,因此分离模型必须确保不影响较少重叠情况下的性能。得益于更强的建模能力,基于 Conformer 的模型显著缓解了性能下降问题。此外可以看出,每个引入的步骤都为两项性能指标带来了一致的提升。
4. CONCLUSION
4. 结论
In this work, we investigated the use of Conformer for continuous speech separation. The experimental results showed that it outperformed RNN-based models for both utterance-wise evaluation and continuous input evaluation. The superiority of Conformer to Transformer was also observed. This work is also the first to report substantial WER and SA-WER gains from the speech separation in a single-channel real meeting transcription task. The results indicate the usefulness of appropriately utilizing context information in the speech separation.
在这项工作中,我们研究了Conformer在连续语音分离中的应用。实验结果表明,无论是在逐句评估还是连续输入评估中,其性能均优于基于RNN的模型。同时观察到Conformer优于Transformer的表现。该研究还首次报告了在单通道实时会议转录任务中,语音分离带来的显著WER和SA-WER提升。结果表明,在语音分离中合理利用上下文信息具有重要价值。