Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Qwen-Audio: 通过统一的大规模音频-语言模型推进通用音频理解
Abstract
摘要
Recently, instruction-following audio-language models have received broad attention for audio interaction with humans. However, the absence of pre-trained audio models capable of handling diverse audio types and tasks has hindered progress in this field. Consequently, most existing works have only been able to support a limited range of interaction capabilities. In this paper, we develop the Qwen-Audio model and address this limitation by scaling up audio-language pre-training to cover over 30 tasks and various audio types, such as human speech, natural sounds, music, and songs, to facilitate universal audio understanding abilities. However, directly co-training all tasks and datasets can lead to interference issues, as the textual labels associated with different datasets exhibit considerable variations due to differences in task focus, language, granularity of annotation, and text structure. To overcome the one-to-many interference, we carefully design a multi-task training framework by conditioning on a sequence of hierarchical tags to the decoder for encouraging knowledge sharing and avoiding interference through shared and specified tags respectively. Remarkably, Qwen-Audio achieves impressive performance across diverse benchmark tasks without requiring any task-specific fine-tuning, surpassing its counterparts. Building upon the capabilities of Qwen-Audio, we further develop Qwen-Audio-Chat, which allows for input from various audios and text inputs, enabling multi-turn dialogues and supporting various audio-central scenarios.
近来,遵循指令的音频语言模型因实现人机音频交互而广受关注。然而,由于缺乏能够处理多种音频类型和任务的预训练音频模型,该领域的发展受到阻碍。因此,现有研究大多仅支持有限的交互能力。本文通过开发Qwen-Audio模型,将音频语言预训练规模扩展至涵盖30余项任务及多种音频类型(如人类语音、自然声、音乐、歌曲等),从而突破这一局限,实现通用音频理解能力。但直接联合训练所有任务和数据集会导致干扰问题,因为不同数据集关联的文本标签在任务侧重、语言、标注粒度和文本结构方面存在显著差异。为解决这种一对多干扰,我们精心设计了多任务训练框架,通过向解码器输入分层标签序列,分别利用共享标签和专用标签促进知识共享并避免干扰。值得注意的是,Qwen-Audio在无需任何任务特定微调的情况下,就在各类基准任务中超越同类模型,表现出色。基于Qwen-Audio的能力,我们进一步开发了Qwen-Audio-Chat,支持多种音频和文本输入,可实现多轮对话并适应各类以音频为核心的应用场景。
1 Introduction
1 引言
Large language models (LLMs) (Brown et al., 2020; OpenAI, 2022, 2023; Chowdhery et al., 2022; Anil et al., 2023; Touvron et al., 2023a,c; Qwen, 2023) have greatly propelled advancements in the field of general artificial intelligence (AGI) due to their strong knowledge retention, complex reasoning and problem-solving capabilities. However, language models lack the capability to perceive non-textual modalities like images and audio in the same manner as humans do. Speech, as an important modality, provides diverse and complex signals beyond texts such as emotions, tones, and intentions in human voice, train whistle, clock chime and thunder in natural sounds, and melody in music. Enabling LLMs to perceive and comprehend rich audio signals for audio interaction has received broad attention (Huang et al., 2023; Shen et al., 2023; Wang et al., 2023a; Lyu et al., 2023; Wu et al., 2023b; Gong et al., 2023b; Wang et al., 2023c; Shu et al., 2023).
大语言模型 (LLMs) (Brown et al., 2020; OpenAI, 2022, 2023; Chowdhery et al., 2022; Anil et al., 2023; Touvron et al., 2023a,c; Qwen, 2023) 凭借其强大的知识保留能力、复杂推理和问题解决能力,极大地推动了通用人工智能 (AGI) 领域的发展。然而,语言模型缺乏像人类一样感知非文本模态 (如图像和音频) 的能力。语音作为一种重要模态,提供了超越文本的多样复杂信号,例如人类声音中的情感、语调和意图,自然声音中的火车鸣笛、钟声和雷声,以及音乐中的旋律。让大语言模型感知和理解丰富的音频信号以实现音频交互,已受到广泛关注 (Huang et al., 2023; Shen et al., 2023; Wang et al., 2023a; Lyu et al., 2023; Wu et al., 2023b; Gong et al., 2023b; Wang et al., 2023c; Shu et al., 2023)。
Prior works for instruction following mainly inherit the capabilities from large (multimodal) LLMs and adopt light-weight supervised fine-tuning to activate the abilities of the model to align with user intent (Ouyang et al., 2022; Wang et al., 2023a; Gong et al., 2023b). However, most works have been constrained in terms of audio interaction capabilities due to the lack of pre-trained audio-language models that can handle diverse audio types and tasks. Existing representative audio-language multi-tasks language models, such as SpeechNet (Chen et al., 2021), SpeechT5 (Ao et al., 2021), VIOLA (Wang et al., 2023d), Whisper (Radford et al., 2023) and Pengi (Deshmukh et al., 2023) are limited to processing specific audio types, such as human speech or natural sounds.
指令跟随的先前研究主要继承自大型(多模态)大语言模型的能力,并采用轻量级监督微调来激活模型与用户意图对齐的能力 (Ouyang et al., 2022; Wang et al., 2023a; Gong et al., 2023b) 。然而,由于缺乏能够处理多样化音频类型和任务的预训练音频-语言模型,大多数研究在音频交互能力方面受到限制。现有的代表性音频-语言多任务语言模型,如 SpeechNet (Chen et al., 2021) 、SpeechT5 (Ao et al., 2021) 、VIOLA (Wang et al., 2023d) 、Whisper (Radford et al., 2023) 和 Pengi (Deshmukh et al., 2023) ,仅限于处理特定音频类型,例如人类语音或自然声音。

Figure 1: Performance of Qwen-Audio and previous top-tiers from multi-task audio-text learning models such as SpeechT5 (Ao et al., 2021), SpeechNet (Chen et al., 2021), Speech LLaMA (Wu et al., 2023a), SALMONN (Anonymous, 2023) and Pengi (Deshmukh et al., 2023). We demonstrate the test set results across the 12 datasets covering Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Automatic Audio Captioning (AAC), Acoustic Scene Classification (ASC), Speech Emotion Recognition (SER), Audio Question and Answering (AQA), Vocal Sound Classification (VSC), and Music Note Analysis (MNA). The results of ASR datasets, such as Libri speech, Aishell1 and Aishell2 refer to $1\mathrm{-}W\mathrm{E}\mathrm{R}%$ . The results of CoVoST2 is the average BLEU score of seven translation directions (en-de, de-en, en-zh, zh-en, es-en, fr-en and it-en). Qwen-Audio achieves remarkable performance without requiring any task-specific fine-tuning, surpassing its counterparts.
图 1: Qwen-Audio与多任务音频文本学习模型(如SpeechT5 (Ao等, 2021)、SpeechNet (Chen等, 2021)、Speech LLaMA (Wu等, 2023a)、SALMONN (Anonymous, 2023)和Pengi (Deshmukh等, 2023))中顶级模型的性能对比。我们展示了涵盖自动语音识别(ASR)、语音到文本翻译(S2TT)、自动音频描述(AAC)、声学场景分类(ASC)、语音情感识别(SER)、音频问答(AQA)、人声分类(VSC)和音乐音符分析(MNA)的12个数据集的测试结果。ASR数据集(如Libri speech、Aishell1和Aishell2)的结果以$1\mathrm{-}W\mathrm{E}\mathrm{R}%$表示,CoVoST2的结果是七种翻译方向(en-de、de-en、en-zh、zh-en、es-en、fr-en和it-en)的平均BLEU分数。Qwen-Audio在无需任何任务特定微调的情况下取得了显著性能,超越了同类模型。
To promote the growth and development of the audio-text multimodal community, we introduce Qwen-Audio, a large-scale audio-language model. Qwen-Audio is a multi-task language model conditioning on audio and text inputs, that extends the Qwen-7B (Bai et al., 2023a) language model to effectively perceive audio signals by the connection of a single audio encoder. Different from previous works that primarily cater to a single type of audio such as human speech, or focus on specific tasks like speech recognition and captioning, or limit models to a single language (Wang et al., 2023a; Lyu et al., 2023; Wu et al., $2023\mathrm{b}.$ ; Gong et al., 2023b; Shu et al., 2023), we scale up the training to dozens of datasets covering over 30 tasks, eight languages and various types of audio for advancing universal audio understanding abilities. A significant challenge of multi-task and multi-dataset co-training arises from the considerable variation in textual labels associated with different datasets. This variation stems from differences in task objectives, languages, annotation granularity, and text structure (structured or unstructured). To address this one-to-many challenge, we have carefully designed a multi-task training framework that conditions the decoder on a sequence of hierarchical tags. This design encourages knowledge sharing and helps mitigate interference through shared and specified tags, respectively. Furthermore, we incorporate the speech recognition with the word-level time-stamp prediction (SRWT) task for training, which is usually ignored in previous multi-task learning research. We find the task not only improves the grounding and grounding-based QA tasks beyond speech signals such as sound and music, but also improves the performance of ASR. As shown in Figure 1, extensive evaluation demonstrates that Qwen-Audio, without any task-specific fine-tuning, outperforms previous multi-task training models across a diverse range of tasks. A notable achievement of Qwen-Audio is its state-of-the-art performance on the test set of Aishell1, cochlscene, ClothoAQA, and VocalSound. Leveraging the capabilities of Qwen-Audio, we introduce Qwen-Audio-Chat via supervised instruction fine-tuning, which facilitates flexible input from both audio and text modalities in multi-turn dialogues, enabling effective interaction following human instructions. The contribution of the paper is summarized below:
为促进音频-文本多模态社区的发展,我们推出了Qwen-Audio——一个大规模音频语言模型。Qwen-Audio是基于音频和文本输入的多任务语言模型,通过连接单一音频编码器扩展了Qwen-7B (Bai et al., 2023a) 语言模型的音频感知能力。不同于以往仅针对单一音频类型(如人声)、特定任务(如语音识别和字幕生成)或单一语言的研究 (Wang et al., 2023a; Lyu et al., 2023; Wu et al., 2023b; Gong et al., 2023b; Shu et al., 2023),我们将训练规模扩展到涵盖30多项任务、8种语言及多种音频类型的数十个数据集,以提升通用音频理解能力。多任务多数据集联合训练的核心挑战在于不同数据集文本标签的显著差异,这种差异源于任务目标、语言、标注粒度和文本结构(结构化或非结构化)的不同。为解决这一"一对多"难题,我们设计了分层标签序列的解码器条件化多任务训练框架,通过共享标签和特定标签分别促进知识共享并减少干扰。此外,我们创新性地将带时间戳预测的语音识别 (SRWT) 任务纳入训练,该任务不仅提升了声音/音乐等非语音信号的定位及定位问答能力,还改善了ASR性能。如图1所示,大量实验表明Qwen-Audio在无需任务特定微调的情况下,已在多项任务上超越先前多任务训练模型,并在Aishell1、cochlscene、ClothoAQA和VocalSound测试集上达到最优性能。基于Qwen-Audio的能力,我们通过监督指令微调推出Qwen-Audio-Chat,支持多轮对话中音频与文本模态的灵活输入,实现符合人类指令的高效交互。本文贡献可总结如下:

Figure 2: Examples of Qwen-Audio showcasing its proficiency in perceiving and comprehending various types of audio. Qwen-Audio supports multiple-audio analysis, sound understanding and reasoning, music appreciation, and tool usage for speech editing. Demos are available at https://qwen-audio.github.io/ Qwen-Audio/.
图 2: Qwen-Audio 展示其在感知和理解各类音频方面的能力示例。Qwen-Audio 支持多音频分析、声音理解与推理、音乐鉴赏以及语音编辑工具使用。演示见 https://qwen-audio.github.io/Qwen-Audio/。
• We introduce Qwen-Audio, a fundamental multi-task audio-language model that supports various
• 我们推出Qwen-Audio,这是一个支持多种任务的基础音频-语言多任务模型
2 Related Work
2 相关工作
Multi-task Audio-Text Learning The goal of multi-task training is to transfer knowledge between different tasks with unified model architectures and data format (Raffel et al., 2020; Ao et al., 2021; Chen et al., 2021). In audio processing domains, it is challenging to unify all audio processing tasks since there are various audio signals, such as human speech, natural sounds, music, and songs, and their labeling format differs a lot. SpeechNet (Chen et al., 2021) and SpeechT5 (Ao et al., 2021) treat human speech tasks into a speech/text input and speech/text output format, and leverage a shared encoder-decoder framework for pre training. Many works (Wang et al., 2023d; Maiti et al., 2023; Rubenstein et al.; Wang et al., 2023e; Nachmani et al., 2023) unify data format and tasks by directly feeding speech representation (Nachmani et al., 2023) or encoding continuous speech signals as discrete codes (Défossez et al., 2022; Zeghidour et al., 2022; Zhang et al., 2023c), and treating different human speech tasks as conditional generative tasks. For training, they directly adopt a decoder-only Transformer model (Vaswani et al., 2017). VoiceBox (Le et al., 2023) employs a non-auto regressive continuous normalizing flow model for human speech synthesis and speech editing tasks. Whisper (Radford et al., 2023) proposes a template for multi-task training, considering the granularity of dataset annotations (with or without sentence-level timestamps) and task types (human speech recognition and translation) for unified training. Previous works mostly focus only on human speech processing tasks such as speech recognition and translation and ignore other types of audio such as natural sounds and music. Pengi (Deshmukh et al., 2023) focuses on natural sound understanding tasks and treats these tasks as text generation tasks. Specifically, Pengi unifies data format with text templates and then trains all tasks within a Transformer decoder model. In this work, Qwen-Audio integrates diverse audio types, such as human speech, natural sounds, music, and songs, and facilitates co-training on datasets sourced from heterogeneous data and featured disparate labeling granular i ties. This is achieved through introducing a unified learning framework. Upon completion of the co-training process, the model demonstrates comprehensive capabilities in speech perception, comprehension, and recognition tasks, eliminating the need for additional task-specific architectural extensions.
多任务音频-文本学习
多任务训练的目标是通过统一的模型架构和数据格式在不同任务间迁移知识 (Raffel et al., 2020; Ao et al., 2021; Chen et al., 2021)。在音频处理领域,由于存在多种音频信号(如人声、自然声音、音乐和歌曲)且标注格式差异较大,统一所有音频处理任务具有挑战性。SpeechNet (Chen et al., 2021) 和 SpeechT5 (Ao et al., 2021) 将人声任务处理为语音/文本输入和语音/文本输出格式,并采用共享编码器-解码器框架进行预训练。许多工作 (Wang et al., 2023d; Maiti et al., 2023; Rubenstein et al.; Wang et al., 2023e; Nachmani et al., 2023) 通过直接输入语音表征 (Nachmani et al., 2023) 或将连续语音信号编码为离散码 (Défossez et al., 2022; Zeghidour et al., 2022; Zhang et al., 2023c) 来统一数据格式和任务,并将不同人声任务视为条件生成任务。训练时,它们直接采用仅解码器的 Transformer 模型 (Vaswani et al., 2017)。VoiceBox (Le et al., 2023) 使用非自回归连续归一化流模型处理人声合成和语音编辑任务。Whisper (Radford et al., 2023) 提出了一个多任务训练模板,考虑数据集标注粒度(含或不含句子级时间戳)和任务类型(人声识别与翻译)进行统一训练。先前工作大多仅关注人声处理任务(如语音识别和翻译),而忽略了自然声音和音乐等其他音频类型。Pengi (Deshmukh et al., 2023) 专注于自然声音理解任务,并将这些任务视为文本生成任务。具体而言,Pengi 通过文本模板统一数据格式,然后在 Transformer 解码器模型中训练所有任务。本工作中,Qwen-Audio 整合了人声、自然声音、音乐和歌曲等多样音频类型,通过引入统一学习框架,促进来自异构数据且具有不同标注粒度的数据集协同训练。协同训练完成后,该模型在语音感知、理解和识别任务中展现出全面能力,无需额外任务特定的架构扩展。
Interact with LLMs through Multiple Modality Recently, large language models such as ChatGPT (OpenAI, 2022) have demonstrated impressive capabilities for knowledge retention, reasoning, and coding followed by human instructions. To extend to application scope of LLMs beyond pure text tasks, many LLMbased multimodal models have been developed. For visual modality, GPT4 (OpenAI, 2023), Flamingo (Alayrac et al., 2022), Kosmos (Peng et al., 2023), BLIP (Li et al., 2022), Shikra (Chen et al., 2023), Emu (Sun et al., 2023)
通过多模态与大语言模型交互
近年来,像 ChatGPT (OpenAI, 2022) 这样的大语言模型在知识保留、推理和遵循人类指令进行编码方面展现出了令人印象深刻的能力。为了将大语言模型的应用范围扩展到纯文本任务之外,许多基于大语言模型的多模态模型被开发出来。在视觉模态方面,GPT4 (OpenAI, 2023)、Flamingo (Alayrac et al., 2022)、Kosmos (Peng et al., 2023)、BLIP (Li et al., 2022)、Shikra (Chen et al., 2023)、Emu (Sun et al., 2023)
and Qwen-VL (Bai et al., 2023b) have proposed different integration method to enable image understanding or generation capabilities for LLMs.
而Qwen-VL (Bai等人, 2023b) 提出了不同的集成方法,使大语言模型具备图像理解或生成能力。
For the audio modality, there have been attempts to utilize well-trained audio foundation models as tools, such as AudioGPT (Huang et al., 2023) and HuggingGPT (Shen et al., 2023), while leveraging LLMs as a versatile interface. These endeavors involve instructing LLMs to generate commands for controlling external tools or transcribing human speech to text before inputting into the LLMs. However, these approaches lack the inclusion of crucial information like prosody and sentiment in human speech, and in certain cases, they fail to convert non-textual audio, such as natural sound. Consequently, the transfer of knowledge from LLMs to the speech modality encounters obstacles, and the LLMs lack the necessary capabilities to perceive and comprehend audio signals. Recent efforts explore training end-to-end audio-text LLMs for direct speech interaction. SpeechGPT (Zhang et al., 2023a) first converts human speech into discrete HuBERT tokens (Hsu et al., 2021), and then designs a three-stage training pipeline on paired speech data, speech instruction data and chain-of-modality instruction data accordingly. BLSP (Wang et al., 2023a) aligns representation by requiring the LLM to generate the same text continuation given the human speech and corresponding transcripts. LLaSM (Shu et al., 2023) creates large speech instruction datasets by generating speech questions using Microsoft TTS API, and then conducts training to enable end-to-end interaction between human speech and text.
在音频模态方面,已有研究尝试将训练有素的音频基础模型(如AudioGPT [Huang等人,2023]和HuggingGPT [Shen等人,2023])作为工具,同时利用大语言模型作为通用接口。这些工作通过指示大语言模型生成控制外部工具的命令,或将人类语音转录为文本后再输入大语言模型。然而,这些方法未能包含人类语音中的韵律和情感等关键信息,且在某些情况下无法转换非文本音频(如自然声音)。因此,大语言模型向语音模态的知识迁移存在障碍,且缺乏感知和理解音频信号的必要能力。近期研究开始探索训练端到端音频-文本大语言模型以实现直接语音交互。SpeechGPT [Zhang等人,2023a]首先将人类语音转换为离散HuBERT token [Hsu等人,2021],随后在配对语音数据、语音指令数据和模态链指令数据上设计三阶段训练流程。BLSP [Wang等人,2023a]通过要求大语言模型在给定人类语音及对应文本时生成相同文本延续来实现表征对齐。LLaSM [Shu等人,2023]使用Microsoft TTS API生成语音问题构建大规模语音指令数据集,进而训练实现人类语音与文本的端到端交互。
LTU (Gong et al., 2023b) creates a 5M audio QA dataset, and conducts supervised finetuning (SFT) on the audio module and LoRA adapters (Hu et al., 2021) of LLaMA (Touvron et al., 2023b) to enhance the alignment between sound perception and reasoning. SALMMON (Anonymous, 2023) utilizes both a text encoder and a speech encoder to extract the representation from different kinds of audio and text input, and then connects the inputs to a well-train LLM with Q-former (Li et al., 2023) style attention to generate response. In this work, Qwen-Audio aims at training a unified audio-text multi-task multilingual LLMs capable of perceiving and understanding audio inputs while preserving the textual conversational abilities. Qwen-Audio employs a single encoder for all audios, and bridges the gap of audio and text modality by largescale end-to-end training to support various tasks such as natural sound detection, human speech recognition and grounding, and audio captions tasks. The resulting model demonstrates superior performance than previous works across a diverse style of tasks.
LTU (Gong等人, 2023b) 创建了一个包含500万条数据的音频问答数据集,并对LLaMA (Touvron等人, 2023b) 的音频模块和LoRA适配器 (Hu等人, 2021) 进行监督微调 (SFT) ,以增强声音感知与推理之间的对齐。SALMMON (Anonymous, 2023) 同时使用文本编码器和语音编码器从不同类型的音频和文本输入中提取表征,然后通过Q-former (Li等人, 2023) 风格的注意力机制将输入连接到训练良好的大语言模型以生成响应。本研究提出的Qwen-Audio旨在训练一个统一的音频-文本多任务多语言大语言模型,既能感知和理解音频输入,又能保留文本对话能力。Qwen-Audio采用单一编码器处理所有音频,并通过大规模端到端训练弥合音频与文本模态的鸿沟,支持自然声音检测、人类语音识别与定位、音频字幕生成等多种任务。实验表明,该模型在各类任务上的表现均优于先前工作。
3 Methodology
3 方法论
This section provides details of Qwen-Audio and Qwen-Audio-Chat, which are designed for universal audio understanding and flexible interaction based on human instructions. The model structure of Qwen-Audio and Qwen-Audio-Chat is first presented in Section 3.1. The training process of our models consists of two stages: multitask pre training and supervised fine-tuning. We describe the training of Qwen-Audio via multitask learning in Section 3.2. Then, we describe Qwen-Audio-Chat with supervised fine-tuning in Section 3.3 , which enables flexible human interaction.
本节详细介绍Qwen-Audio和Qwen-Audio-Chat,这两个模型专为通用音频理解及基于人类指令的灵活交互而设计。3.1节首先展示Qwen-Audio与Qwen-Audio-Chat的模型结构。我们的模型训练分为两个阶段:多任务预训练和监督微调。3.2节阐述通过多任务学习训练Qwen-Audio的过程,3.3节则说明支持灵活人机交互的监督微调版Qwen-Audio-Chat。
3.1 Model Architecture
3.1 模型架构
The architecture of Qwen-Audio models is depicted in Figure 3. Qwen-Audio contains an audio encoder and a large language model. Given the paired data $(a,x)$ , where the $\textbf{\em a}$ and $_{x}$ denote the audio sequences and text sequences, the training objective is to maximize the next text token probability as
Qwen-Audio 模型的架构如图 3 所示。Qwen-Audio 包含一个音频编码器和一个大语言模型。给定配对数据 $(a,x)$ ,其中 $\textbf{\em a}$ 和 $_{x}$ 分别表示音频序列和文本序列,训练目标是最大化下一个文本 token 的概率为
$$
\mathcal{P}{\theta}(x_{t}|\mathbf{\bar{\alpha}}{<t},\mathrm{Encoder}_{\phi}(a)),
$$
$$
\mathcal{P}{\theta}(x_{t}|\mathbf{\bar{\alpha}}{<t},\mathrm{Encoder}_{\phi}(a)),
$$
conditioning on audio representations and previous text sequences $\scriptstyle{\mathbf{{}}}{\mathbf{{}}}x_{<t},$ where $\theta$ and $\phi$ denote the trainable parameters of the LLM and audio encoder respectively.
基于音频表征和先前文本序列的条件建模 $\scriptstyle{\mathbf{{}}}{\mathbf{{}}}x_{<t},$ 其中 $\theta$ 和 $\phi$ 分别表示大语言模型和音频编码器的可训练参数。
Audio Encoder Qwen-Audio employs a single audio encoder to process various types of audio. The initialization of the audio encoder is based on the Whisper-large-v2 model (Radford et al., 2023), which is a 32-layer Transformer model that includes two convolution down-sampling layers as a stem. The audio encoder is composed of 640M parameters. Although Whisper is supervised trained for speech recognition and translation, its encoded representation still contains rich information, such as background noise (Gong et al., 2023a), and can even be used for recovering the original speech (Zhang et al., 2023b). To preprocess the audio data, Whisper resamples it to a frequency of 16kHz and converts the raw waveform into 80-channel melspec tr ogram using a window size of $25\mathrm{ms}$ and a hop size of 10ms. Additionally, a pooling layer with a stride of two is incorporated to reduce the length of the audio representation. As a result, each frame of the encoder output approximately corresponds to a 40ms segment of the original audio signal. Spec Augment (Park et al.) is applied at the training time as data augmentation.
音频编码器
Qwen-Audio采用单一音频编码器处理多种类型音频。该音频编码器基于Whisper-large-v2模型(Radford等人,2023)初始化,这是一个包含两个卷积下采样层作为基干的32层Transformer模型,由6.4亿参数构成。尽管Whisper是针对语音识别和翻译进行监督训练的,但其编码表征仍包含丰富信息(如背景噪声(Gong等人,2023a)),甚至可用于原始语音重建(Zhang等人,2023b)。
音频数据预处理时,Whisper将其重采样至16kHz频率,并使用25毫秒窗口和10毫秒步长将原始波形转换为80通道梅尔频谱图。此外,通过步长为2的池化层缩减音频表征长度,使得编码器输出的每帧大致对应原始音频信号中40毫秒的片段。训练时采用Spec Augment(Park等人)进行数据增强。
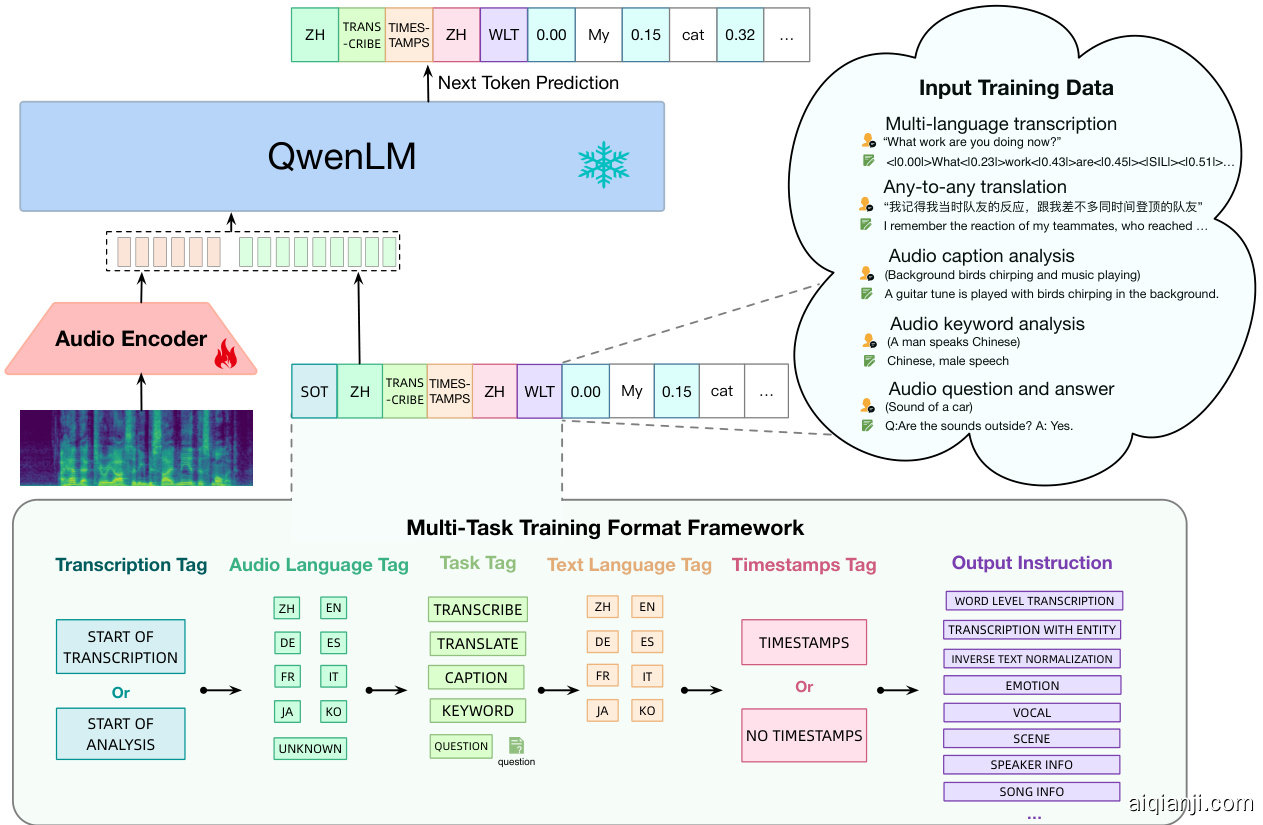
Figure 3: The overview of Qwen-Audio architecture and multitask-pre training.
图 3: Qwen-Audio架构与多任务预训练概览
Large Language Model Qwen-Audio incorporates a large language model as its foundational component. The model is initialized using pre-trained weights derived from Qwen-7B (Bai et al., 2023a). Qwen-7B is a 32-layer Transformer decoder model with a hidden size of 4096, encompassing a total of 7.7B parameters.
大语言模型Qwen-Audio以大语言模型为基础组件。该模型采用Qwen-7B (Bai et al., 2023a) 的预训练权重进行初始化。Qwen-7B是一个具有32层Transformer解码器、隐藏层维度为4096的模型,共包含77亿参数。
3.2 Multitask Pre training
3.2 多任务预训练
In the domain of audio processing, diverse audio datasets have been developed to address specific tasks, as shown in Table 1. Qwen-Audio aims to perform co-training using a wide range of audio datasets. The objective is to train a unified model capable of supporting all audio tasks, eliminating the need for laborious model switching when dealing with different tasks. More importantly, during co-training, tasks can benefit from each other since 1) similar tasks can benefit from knowledge sharing and collaborative learning, as they share a common focus on the fundamental information embedded within the audio signal; 2) tasks that rely on lower-level perceptual abilities can assist tasks that require higher-level understanding or reasoning capabilities.
在音频处理领域,已开发出多种针对特定任务的音频数据集,如表 1 所示。Qwen-Audio 旨在利用广泛的音频数据集进行协同训练,目标是训练出能够支持所有音频任务的统一模型,从而避免在处理不同任务时需要繁琐地切换模型。更重要的是,在协同训练过程中,各任务可以相互受益:1) 相似任务由于都关注音频信号中嵌入的基本信息,可通过知识共享和协作学习相互促进;2) 依赖较低层次感知能力的任务可辅助需要更高层次理解或推理能力的任务。
However, different datasets exhibit significant variations in textual labels due to differences in task focus, language, granularity of annotation, and text structure (e.g., some data is structured while others are unstructured). To train a network for different tasks, simply mixing these diverse datasets cannot lead to mutual enhancement; instead, it introduces interference. Most existing multi-task training approaches have either grouped similar tasks (e.g., audio captioning, transcription) or assigned a dataset ID to each dataset (Wang et al., 2023a; Lyu et al., 2023; Wu et al., 2023b; Gong et al., 2023b; Shu et al., 2023) to avoid interference. Although these approaches have achieved certain effectiveness, there is still considerable room for improvement. Whisper proposes a multitask training format by specifying tasks and condition information as a sequence of input special tokens to the language decoder, such as voice activity detection, language identification, and sentence-level timestamp tags. However, Whisper focuses on speech translation and recognition tasks only.
然而,由于任务焦点、语言、标注粒度及文本结构(如部分数据为结构化而其他为非结构化)的差异,不同数据集的文本标签存在显著差异。若直接混合这些异构数据集训练网络,不仅无法实现任务间的相互增强,反而会引入干扰。现有大多数多任务训练方法要么对相似任务(如音频描述、转写)进行分组,要么为每个数据集分配独立ID (Wang et al., 2023a; Lyu et al., 2023; Wu et al., 2023b; Gong et al., 2023b; Shu et al., 2023)以避免干扰。虽然这些方法取得了一定效果,但仍有较大改进空间。Whisper提出通过将任务和条件信息指定为语言解码器的特殊输入token序列(如语音活动检测、语言识别、句子级时间戳标签)来实现多任务训练,但其仅聚焦于语音翻译和识别任务。
Table 1: Multi-task pre-training dataset.
表 1: 多任务预训练数据集。
| 类型 | 任务 | 描述 | 时长 |
|---|---|---|---|
| 语音 | ASR | 自动语音识别(多语言) | 30k |
| S2TT | 语音到文本翻译 | 3.7k | |
| OSR | 重叠语音识别 | <1k | |
| Dialect ASR | 方言自动语音识别 | 2k | |
| SRWT | 带词级时间戳的英语语音识别 | 10k | |
| 带词级时间戳的普通话语音识别 | 11k | ||
| DID | 方言识别 | 2k | |
| LID | 口语语言识别 | 11.7k | |
| SGC | 说话人性别识别(生理) | 4.8k | |
| ER | 情绪识别 | <1k | |
| SV | 说话人验证 | 1.2k | |
| SD | 说话人日志 | <1k | |
| SER | 语音实体识别 | <1k | |
| KS | 关键词检测 | <1k | |
| IC | 意图分类 | <1k | |
| SF SAP | 槽位填充 | <1k | |
| VSC | 说话人年龄预测/人声分类 | 4.8k | |
| <1k | |||
| 声音 | AAC | 自动音频描述 | 8.4k |
| SEC | 声音事件分类 | 5.4k | |
| ASC | 声学场景分类 | <1k | |
| SED | 带时间戳的声音事件检测 | <1k | |
| AQA | 音频问答 | <1k | |
| 音乐歌曲 | SID | 歌手识别 | <1k |
| SMER | 歌手和音乐情绪识别 | <1k | |
| MC | 音乐描述 | 25k | |
| MIC | 乐器分类 | <1k | |
| MNA | 音符分析(如音高、力度) | <1k | |
| MGR | 音乐流派识别 | 9.5k | |
| MR | 音乐识别 | <1k | |
| 音乐问答 | <1k | ||
| MQA |
Multi-task Training Format Framework Motivated by Whisper (Radford et al., 2023), to incorporate different kinds of audio, we propose a multitask training format framework as follows:
受 Whisper (Radford et al., 2023) 启发,为整合多种音频类型,我们提出以下多任务训练格式框架:
• Transcription Tag: The initiation of prediction is denoted using a transcription tag. The <|startoftranscripts $>$ is employed to indicate the tasks involve accurately transcribing the spoken words and capturing the linguistic content of a speech recording, such as speech recognition and speech translation tasks. For other tasks, the ${<}$ |start of analysis $>$ tag is utilized.
• 转录标签 (Transcription Tag): 预测的启动通过转录标签表示。使用 <|startoftranscripts $>$来标识涉及准确转录口语内容并捕捉语音记录中语言信息的任务,例如语音识别和语音翻译任务。对于其他任务,则使用 ${<}$ |start of analysis $>$ 标签。
The guiding principle behind our framework is to maximize the sharing of knowledge among similar tasks through shared tags, thereby improving their performance. Meanwhile, we ensure that different tasks and output formats can be distinguished to avoid the one-to-many mapping problem for the model. Please see Figure 3 for an overview of our multitask format of Qwen-Audio.
我们框架的核心指导原则是通过共享标签最大化相似任务间的知识共享,从而提升其性能。同时,我们确保不同任务和输出格式能够被区分,以避免模型出现一对多映射问题。具体多任务格式概览请参见图3:
3.3 Supervised Fine-tuning
3.3 监督微调
The extensive pre training of multitask models has equipped them with a broad understanding of audio. Building upon this, we employ instruction-based fine-tuning techniques to improve the ability of the model to align with human intent, resulting in an interactive chat model, termed Qwen-Audio-Chat. To accomplish this, we manually create demonstrations for each task. These demonstrations consist of raw text labels, questions, and answers. We then utilize GPT-3.5 (OpenAI, 2022) to generate further questions and answers based on the provided raw text labels. Additionally, we also create a dataset of audio-dialogue data by employing manual annotation, model generation, and strategy concatenation. This dataset helps us incorporate reasoning, story generation, and multi-image comprehension abilities into our model.
多任务模型的广泛预训练使其具备了对音频的全面理解能力。基于此,我们采用基于指令的微调技术来提升模型与人类意图的对齐能力,最终开发出名为Qwen-Audio-Chat的交互式对话模型。为实现这一目标,我们为每项任务手动创建演示样本,包含原始文本标签、问题及回答。随后利用GPT-3.5 (OpenAI, 2022)根据提供的原始文本标签生成更多问答对。此外,通过人工标注、模型生成和策略拼接等方式,我们还构建了音频对话数据集,该数据集帮助我们为模型注入推理、故事生成和多图像理解等能力。
To handle multi-audio dialogue and multiple audio inputs effectively, we introduce the convention of labeling different audios with "Audio id:", where id corresponds to the order of the audio input dialogue. In terms of dialogue format, we construct our instruction tuning dataset using the ChatML (Openai) format. In this format, each interaction’s statement is marked with two special tokens (<im_start> and <im_end $>$ ) to facilitate dialogue termination.
为有效处理多音频对话和多个音频输入,我们引入用"Audio id:"标记不同音频的惯例,其中id对应音频输入对话的顺序。在对话格式方面,我们采用ChatML (Openai)格式构建指令微调数据集。该格式使用两个特殊token (<im_start>和<im_end $>$)标记每个交互语句,以方便终止对话。
Table 2: Summary of the evaluation benchmarks for Qwen-Audio.
表 2: Qwen-Audio 评估基准摘要
| 任务 | 描述 | 数据集 | 划分 | 指标 |
|---|---|---|---|---|
| ASR | 自动语音识别 (Automatic Speech Recognition) | Aishell1 (Bu et al., 2017) Aishell2 (Du et al., 2018) Librispeech (Panayotov et al., 2015) | dev | test test dev |
| S2TT | 语音到文本翻译 (Speech-to-text translation) | CoVoST2 (Wang et al., 2020) | test | BLEU1 (Papineni et al., 2002) |
| SRWT | 带词级时间戳的语音识别 (Speech Recognition with Word-level Timestamp) | 工业数据 (Industrial Data) (Gao et al., 2023) | test | AAS (Shi et al., 2023) |
| AAC | 自动音频描述 (Automatic Audio Caption) | Clotho (Drossos et al., 2020) | test | CIDEr |
| ASC | 声学场景分类 (Acoustic Scene Classification) | CochlScene (Jeong and Park, 2022) TUT2017 (Mesaros et al., 2017) | test eval | ACC |
| SER | 语音情感识别 (Speech Emotion Recognition) | Meld (Poria et al., 2019) | test | ACC |
| AQA | 音频问答 (Audio Question & Answer) | ClothoAQA (Lipping et al., 2022) | test | ACC |
| VSC | 人声分类 (Vocal Sound Classification) | VocalSound (Gong et al., 2022) | test | ACC |
| MNA | 音符分析 (Music Note Analysis) | NSynth (Engel et al., 2017) | test | ACC/MAP |
The Data Format Example of Supervised Fine-Tuning.
监督微调的数据格式示例
<im_start>user
用户
In order to facilitate versatile input from both audio and pure text modalities within multi-turn dialogues, we use a combination of audio-centric instruction data mentioned above and pure text instruction data during this training process. This approach allows the model to handle diverse forms of input seamlessly. The total amount of instruction tuning data is $20\mathrm{k\Omega}$ .
为了在多轮对话中支持音频和纯文本两种模态的多样化输入,我们在训练过程中结合使用了上述以音频为中心的指令数据和纯文本指令数据。这种方法使模型能够无缝处理不同形式的输入。指令微调数据总量为 $20\mathrm{k\Omega}$。
4 Experiments
4 实验
4.1Setup
4.1 设置
For multi-task pre-training, we freeze the weights of LLM and only optimize the audio encoder. This trained model is referred to as Qwen-Audio. In the subsequent supervised fine-tuning stage, we fix the weights of the audio encoder and only optimize the LLM. The resulting model is denoted as Qwen-Audio-Chat. The detailed training configurations of both stages are listed in Table 6.
在多任务预训练阶段,我们冻结大语言模型(LLM)的权重,仅优化音频编码器。训练得到的模型称为Qwen-Audio。在后续监督微调阶段,我们固定音频编码器的权重,仅优化大语言模型。最终模型记为Qwen-Audio-Chat。两个阶段的详细训练配置如 表6 所示。
4.2 Evaluation
4.2 评估
In order to assess the universal understanding capabilities of Qwen-Audio, as shown in Table 2, we perform a comprehensive evaluation that encompasses various tasks, namely Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Automatic Audio Captioning (AAC), Acoustic Scene Classification (ASC), Speech Emotion Recognition (SER), Audio Question and Answering (AQA), Vocal Sound Classification (VSC), and Music Note Analysis (MNA). This evaluation is conducted across 12 datasets. The evaluation datasets are rigorously excluded from the training data to avoid data leakage. The detailed training configurations of both stages are listed in Table 6.
为了评估Qwen-Audio的通用理解能力,如表2所示,我们进行了涵盖多种任务的综合评估,包括自动语音识别(ASR)、语音到文本翻译(S2TT)、自动音频描述(AAC)、声学场景分类(ASC)、语音情感识别(SER)、音频问答(AQA)、人声分类(VSC)和音符分析(MNA)。该评估在12个数据集上进行,所有评估数据集均严格排除在训练数据之外以避免数据泄露。两阶段训练的详细配置列于表6。
Table 3: The results of Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Automatic Audio Captioning (AAC), Speech Recognition with Word-level Timestamps (SRWT), Acoustic Scene Classification (ASC), Speech Emotion Recognition (SER), Audio Question and Answering (AQA), Vocal Sound Classification (VSC), and Music Note Analysis (MNA) tasks. For SRWT task, the results of Forcedaligner (McAuliffe et al., 2017) are to predict the timestamps given the ground-truth transcripts, while Paraformer-large-TP (Gao et al., 2023) and Qwen-audio tackle a more challenging scenario by directly generating sequences containing both transcriptions and timestamps.
表 3: 自动语音识别 (ASR)、语音到文本翻译 (S2TT)、自动音频字幕生成 (AAC)、带词级时间戳的语音识别 (SRWT)、声学场景分类 (ASC)、语音情感识别 (SER)、音频问答 (AQA)、人声分类 (VSC) 和音符分析 (MNA) 任务的结果。对于 SRWT 任务,Forcedaligner (McAuliffe et al., 2017) 的结果是在给定真实转录的情况下预测时间戳,而 Paraformer-large-TP (Gao et al., 2023) 和 Qwen-audio 通过直接生成包含转录和时间戳的序列来解决更具挑战性的场景。
| 任务 | 数据集 | 模型 | 指标 | 结果 |
|---|---|---|---|---|
| ASR | Librispeech dev-clean|dev-other| test-clean|test-other | SpeechT5 (Ao et al., 2021) SpeechNet (Chen et al., 2021) SLM-FT (Wang et al., 2023b) SALMONN (Anonymous, 2023) Qwen-Audio | WER← | 2.1|5.5|2.4|5.8 -|-|30.7|- -|-|2.6|5.0 -|-|2.1|4.9 1.8|4.0|2.0|4.2 |
| ASR | Aishell1 dev|test | MMSpeech-base (Zhou et al., 2022) MMSpeech-large (Zhou et al., 2022) Paraformer-large (Gao et al., 2023) Qwen-Audio | WER← | 2.0 |2.1 1.6 |1.9 -|2.0 1.2|1.3 |
| ASR | Aishell2 Mic丨iOS丨Android | MMSpeech-base (Zhou et al., 2022) Paraformer-large (Gao et al., 2023) Qwen-Audio | WER← | 4.5|3.9|4.0 -|2.9|- 3.3|3.1|3.3 |
| S2TT | CoVoST2 en-de|de-en| en-zh|zh-en | SALMONN (Anonymous,2023) SpeechLLaMA (Wu et al., 2023a) BLSP (Wang et al., 2023a) Qwen-Audio | BLEU↑ | 18.6|-|33.1|- -|27.1|-|12.3 14.1|-|-|- |
| S2TT | CoVoST2 es-enIfr-en |it-en | SpeechLLaMA (Wu et al., 2023a) Qwen-Audio | BLEU↑ | 25.1|33.9|41.5|15.7 27.9|25.2|25.9 39.7|38.5|36.0 |
| AAC | Clotho | Pengi (Deshmukh et al., 2023) Qwen-Audio | CIDEr| SPICE|SPIDEr ↑ | 0.416|0.126|0.271 0.441|0.136|0.288 |
| SRWT | Industrial Data | Force-aligner (McAuliffe et al., 2017) Paraformer-large-TP (Gao et al., 2023) Qwen-Audio | AAS (ms)↓ | 60.3 65.3 51.5 |
| ASC | CochlScene | CochlScene (Jeong and Park, 2022) Qwen-Audio | ACC ↑ | 0.669 0.795 |
| ASC | TUT2017 | Pengi (Deshmukh et al., 2023) Qwen-Audio | ACC ↑ | 0.353 0.649 |
| SER | Meld | WavLM-large (Chen et al., 2022) Qwen-Audio ClothoAQA (Lipping et al., 2022) | ACC ↑ | 0.542 0.557 0.542|0.627 |
| AQA | ClothoAQA | Pengi (Deshmukh et al., 2023) Qwen-Audio CLAP (Elizalde et al., 2022) | ACC|ACC (binary) ↑ | -|0.645 0.579|0.749 0.4945 |
| VSC | VocalSound | Pengi (Deshmukh et al., 2023) Qwen-Audio Pengi (Deshmukh et al., 2023) | ACC↑ | 0.6035 0.9289 0.3860 |
| MNA | NS. Qualities | Qwen-Audio Pengi (Deshmukh et al., 2023) | MAP ↑ | 0.4742 0.5007 |
| MNA | NS. Instrument | Qwen-Audio | ACC↑ | 0.7882 |
4.3 Main Results
4.3 主要结果
In this section, we present a comprehensive evaluation of the Qwen-Audio model, assessing its performance across various tasks without any task-specific fine-tuning. We begin by examining its English Automatic
在本节中,我们对Qwen-Audio模型进行全面评估,考察其在无需任务特定微调的情况下,在多项任务中的表现。首先分析其英语自动
Table 4: Results of ASR tasks with or without training word-level timestamps tasks.
表 4: 带或不带词级时间戳训练任务的 ASR (自动语音识别) 任务结果
| 方法 | LibriSpeech | AISHELL1 | ||||
|---|---|---|---|---|---|---|
| dev-clean | dev-other | test-clean | test-other | dev | test | |
| w/oSRWT | 1.93 | 4.18 | 2.22 | 4.21 | 1.54 | 1.71 |
| Qwen-Audio | 1.79 | 4.00 | 2.04 | 4.19 | 1.22 | 1.29 |
Table 5: Results of AQA tasks with or without training word-level timestamps tasks.
表 5: 带或不带词级时间戳训练任务的AQA任务结果
| 方法 | ClothoAQA | MusicAVQA | |
|---|---|---|---|
| test | test-binary | audio question | |
| w/oSRWT | 0.5648 | 0.7418 | 0.7027 |
| Qwen-Audio | 0.5795 | 0.7491 | 0.7211 |
Speech Recognition (ASR) results, as depicted in Table 3, where Qwen-Audio exhibits superior performance compared to previous multi-task learning models. Specifically, it achieves a $2.0%$ and $4.2%$ WER on the libri speech test-clean and test-other datasets, respectively. Similarly, the Chinese Mandarin ASR results demonstrate Qwen-Audio’s competitive performance against previous approaches. To the best of our knowledge, Qwen-Audio achieves state-of-the-art results on the Aishell1 dev and test sets. Furthermore, we evaluate Qwen-Audio’s speech translation performance on the CoVoST2 dataset. The results reveal that Qwen-Audio outperforms the baselines by a substantial margin across all seven translation directions.
语音识别 (ASR) 结果如表 3 所示,Qwen-Audio 相比以往多任务学习模型展现出更优性能。具体而言,其在 libri speech test-clean 和 test-other 数据集上分别取得 $2.0%$ 和 $4.2%$ 的词错误率 (WER)。在中文普通话 ASR 任务中,Qwen-Audio 同样展现出与现有方法相当的竞争力。据我们所知,该模型在 Aishell1 开发集和测试集上取得了当前最优结果。此外,我们在 CoVoST2 数据集上评估了 Qwen-Audio 的语音翻译性能,结果显示该模型在所有七种翻译方向上均以显著优势超越基线系统。
Lastly, we analyze the performance of Qwen-Audio on various audio analysis tasks, including AAC, SWRT ASC, SER, AQA, VSC, and MNA, as summarized in Table 3. Across these tasks, Qwen-Audio consistently outperforms the baselines by a significant margin. Notably, it achieves state-of-the-art results on CochlScene, ClothoAQA, and VocalSound, thereby demonstrating the model’s robust audio understanding capabilities.
最后,我们分析了Qwen-Audio在多种音频分析任务上的性能表现,包括音频自动分类(AAC)、语音唤醒词识别(SWRT ASC)、语音情感识别(SER)、音频问答(AQA)、语音转换(VSC)和音乐流派识别(MNA),如[表3]所示。在这些任务中,Qwen-Audio始终以显著优势超越基线模型。值得注意的是,该模型在CochlScene、ClothoAQA和VocalSound数据集上取得了最先进的成果,充分展现了其强大的音频理解能力。
4.4 Results of Interactive Chat
4.4 交互式聊天结果
We showcase the conversational capabilities of Qwen-Audio-Chat through illustrative cases depicted in Figure 2. Furthermore, we intend to provide public access to the trained models for online chat interactions.
我们通过图 2 中的示例案例展示了Qwen-Audio-Chat的对话能力。此外,我们计划公开训练好的模型,供用户进行在线聊天交互。
4.5 The Analysis of Word-level Timestamps Prediction
4.5 词级时间戳预测分析
We propose the task of speech recognition with word-level timestamps (SRWT) by training Qwen-Audio to not only recognize speech transcripts but also predict the timestamps for each word. The purpose of SRWT is twofold: firstly, to improve the model’s ability to align audio signals with fine-grained timestamps; secondly, to support grounding of speech and audio, and grounding-based QA tasks in Qwen-Audio-Chat, such as finding the starting and ending time of an audio segment mentioning a person’s name or identifying whether a sound occurs in the given audio .
我们提出带词级时间戳的语音识别任务(SRWT),通过训练Qwen-Audio不仅能识别语音文本,还能预测每个词的时间戳。SRWT的目的有两个:一是提升模型将音频信号与细粒度时间戳对齐的能力;二是为Qwen-Audio-Chat中的语音/音频定位及基于定位的QA任务提供支持,例如查找提及人名的音频片段起止时间,或判断给定音频中是否出现某种声音。
In this section, we exclude the training of SRWT tasks from multi-task pre training while maintaining the other tasks unchanged. Notably, the removal of SRWT does not impact the coverage of audio datasets for training since SRWT tasks share the same audio dataset as automatic speech recognition (ASR) tasks. The results are shown in Table 4 and Table 5: models trained with SRWT achieve superior performance in automatic speech recognition and audio question-answering tasks, including natural sounds QA and Music QA. These results highlight the efficacy of incorporating fine-grained word-level timestamps to enhance the general audio signal grounding ability and subsequently improve the performance of sound and music signal QA tasks.
在本节中,我们从多任务预训练中排除了SRWT(speech recognition with timing)任务的训练,同时保持其他任务不变。值得注意的是,移除SRWT不会影响音频数据集的训练覆盖范围,因为SRWT任务与自动语音识别(ASR)任务共享相同的音频数据集。结果如表4和表5所示:经过SRWT训练的模型在自动语音识别和音频问答任务(包括自然声音QA和音乐QA)中表现出更优的性能。这些结果凸显了引入细粒度词级时间戳对于增强通用音频信号定位能力、进而提升声音和音乐信号QA任务性能的有效性。
5 Conclusion
5 结论
In this paper, we present the Qwen-Audio series, a set of large-scale audio-language models with universal audio understanding abilities. To incorporate different kinds of audios for co-training, we propose a unified multi-task learning framework that facilitates the sharing of knowledge among similar tasks and avoids one-tomany mapping problem caused by different text formats. Without any task-specific fine-tuning, the resulting Qwen-Audio models outperform previous works across diverse benchmarks, demonstrating its universal audio understanding abilities. Through supervised instruction finetuning, Qwen-Audio-Chat showcases robust capabilities in aligning with human intent, supporting multilingual and multi-turn dialogues from both audio and text inputs.
本文介绍了Qwen-Audio系列模型,这是一组具备通用音频理解能力的大规模音频-语言模型。为融合多种音频数据进行协同训练,我们提出统一的多任务学习框架,促进相似任务间的知识共享,并避免不同文本格式导致的一对多映射问题。在无需任务特定微调的情况下,Qwen-Audio模型在多样化基准测试中超越前人工作,展现了其通用音频理解能力。通过监督式指令微调,Qwen-Audio-Chat展现出与人类意图对齐的强大能力,支持基于音频和文本输入的多语言、多轮对话。