V2VNet: Vehicle-to-Vehicle Communication for Joint Perception and Prediction
V2VNet: 面向联合感知与预测的车车通信技术
Abstract. In this paper, we explore the use of vehicle-to-vehicle (V2V) communication to improve the perception and motion forecasting performance of self-driving vehicles. By intelligently aggregating the information received from multiple nearby vehicles, we can observe the same scene from different viewpoints. This allows us to see through occlusions and detect actors at long range, where the observations are very sparse or non-existent. We also show that our approach of sending compressed deep feature map activation s achieves high accuracy while satisfying communication bandwidth requirements.
摘要。本文探讨了如何利用车对车(V2V)通信技术提升自动驾驶车辆的感知与运动预测性能。通过智能聚合来自多辆邻近车辆的信息,我们能够从不同视角观察同一场景。这种方法使我们能够穿透遮挡物,在观测数据极其稀疏或完全缺失的远距离区域检测动态目标。我们还证明,通过发送压缩的深度特征图激活值(deep feature map activations),我们的方法在满足通信带宽要求的同时实现了高精度。
Keywords: Autonomous Driving, Object Detection, Motion Forecast
关键词:自动驾驶 (Autonomous Driving)、目标检测 (Object Detection)、运动预测 (Motion Forecast)
1 Introduction
1 引言
While a world densely populated with self-driving vehicles (SDVs) might seem futuristic, these vehicles will one day soon be the norm. They will provide safer, cheaper and less congested transportation solutions for everyone, everywhere. A core component of self-driving vehicles is their ability to perceive the world. From sensor data, the SDV needs to reason about the scene in 3D, identify the other agents, and forecast how their futures might play out. These tasks are commonly referred to as perception and motion forecasting. Both strong perception and motion forecasting are critical for the SDV to plan and maneuver through traffic to get from one point to another safely.
虽然一个布满自动驾驶汽车(SDV)的世界看起来充满未来感,但这些车辆很快将成为常态。它们将为全球各地的人们提供更安全、更经济且更通畅的交通解决方案。自动驾驶汽车的核心能力在于环境感知——通过传感器数据理解三维场景、识别其他交通参与者,并预测其未来运动轨迹。这些功能通常被称为环境感知与运动预测。强大的感知能力和运动预测对自动驾驶汽车规划路径、安全穿行车流至关重要。
The reliability of perception and motion forecasting algorithms has significantly improved in the past few years due to the development of neural network architectures that can reason in 3D and intelligently fuse multi-sensor data (e.g., images, LiDAR, maps) [28, 29]. Motion forecasting algorithm performance has been further improved by building good multimodal distributions [4,6,12,19] that capture diverse actor behaviour and by modelling actor interactions [3,25,36,37]. Recently, [5, 31] propose approaches that perform joint perception and motion forecasting, dubbed perception and prediction (P&P), further increasing the accuracy while being computationally more efficient than classical two-step pipelines.
感知与运动预测算法的可靠性在过去几年显著提升,这得益于能进行三维推理并智能融合多传感器数据(如图像、激光雷达、地图)的神经网络架构发展 [28, 29]。通过构建捕捉多样化行为体动作的良好多模态分布 [4,6,12,19] 以及建模行为体间交互 [3,25,36,37],运动预测算法性能得到进一步优化。近期,[5, 31] 提出了联合执行感知与运动预测的方法(称为感知与预测 (P&P) ),在计算效率优于传统两步流程的同时,进一步提高了预测精度。

Fig. 1: Left: Safety critical scenario of a pedestrian coming out of occlusion. V2V communication can be leveraged to use the fact that multiple self-driving vehicles see the scene from different viewpoints, and thus see through occluders. Right: Example V2VSim Scene. Virtual scene with occluded actor (blue) and SDVs (red and green), Rendered LiDAR from each SDV in the scene.
图 1: 左图: 行人从遮挡物后出现的交通安全关键场景。利用车联网(V2V)通信技术,可整合多辆自动驾驶车辆从不同视角观测的场景信息,从而穿透遮挡物。右图: V2VSim场景示例。虚拟场景中包含被遮挡的交通参与者(蓝色)与自动驾驶车辆(红色和绿色),以及场景中每辆自动驾驶车辆渲染的激光雷达(LiDAR)点云。
Despite these advances, challenges remain. For example, objects that are heavily occluded or far away result in sparse observations and pose a challenge for modern computer vision systems. Failing to detect and predict the intention of these hard-to-see actors might have catastrophic consequences in safety critical situations when there are only a few mili seconds to react: imagine the SDV driving along a road and a child chasing after a soccer ball runs into the street from behind a parked car (Fig. 1, left). This situation is difficult for both SDVs and human drivers to correctly perceive and adjust for. The crux of the problem is that the SDV and the human can only see the scene from a single viewpoint.
尽管取得了这些进展,挑战依然存在。例如,严重遮挡或距离过远的物体会导致观测数据稀疏,这对现代计算机视觉系统构成了挑战。在安全关键场景中,若无法及时检测和预测这些难以察觉的行为体意图,可能会引发灾难性后果——例如自动驾驶汽车(SDV)正沿道路行驶时,一个孩子从停放的车辆后方冲出追球闯入街道(图1: 左)。这种情况无论对SDV还是人类驾驶员都难以准确感知并做出调整。问题的关键在于,SDV和人类都只能从单一视角观察场景。
However, SDVs could have super-human capabilities if we equip them with the ability to transmit information and utilize the information received from nearby vehicles to better perceive the world. Then the SDV could see behind the occlusion and detect the child earlier, allowing for a safer avoidance maneuver.
然而,若为自动驾驶汽车(SDV)配备信息传输能力,并利用附近车辆接收的信息来增强环境感知,它们将具备超人类能力。这样,自动驾驶汽车就能透视遮挡物、更早发现儿童,从而执行更安全的避让动作。
In this paper, we consider the vehicle-to-vehicle (V2V) communication setting, where each vehicle can broadcast and receive information to/from nearby vehicles (within a 70m radius). Note that this broadcast range is realistic based on existing communication protocols [21]. We show that to achieve the best compromise of having strong perception and motion forecasting performance while also satisfying existing hardware transmission bandwidth capabilities, we should send compressed intermediate representations of the P&P neural network. Thus, we derive a novel P&P model, called V2VNet, which utilizes a spatially aware graph neural network (GNN) to aggregate the information received from all the nearby SDVs, allowing us to intelligently combine information from different points in time and viewpoints in the scene.
本文研究了车对车(V2V)通信场景,其中每辆车都能与附近70米半径范围内的车辆进行信息广播和接收。需要说明的是,该广播范围基于现有通信协议[21]是切实可行的。研究表明,要在保持出色感知与运动预测性能的同时满足现有硬件传输带宽限制,最佳方案是传输P&P神经网络的压缩中间表征。因此,我们提出了一种新型P&P模型V2VNet,该模型采用空间感知图神经网络(GNN)来聚合来自所有附近自动驾驶车辆(SDV)的信息,使我们能够智能整合场景中不同时间点和视角的信息。
To evaluate our approach, we require a dataset where multiple self-driving vehicles are in the same local traffic scene. Unfortunately, no such dataset exists. Therefore, our second contribution is a new dataset, dubbed V2V-Sim (see Fig. 1, right) that mimics the setting where there are multiple SDVs driving in the area. Towards this goal, we use a high-fidelity LiDAR simulator [33], which uses a large catalog of static 3D scenes and dynamic objects built from real-world data, to simulate realistic LiDAR point clouds for a given traffic scene. With this simulator, we can recreate traffic scenarios recorded from the real-world and simulate them as if a percentage of the vehicles are SDVs in the network. We show that V2VNet and other V2V methods significantly boosts performance relative to the single vehicle system, and that our compressed intermediate representations reduce bandwidth requirements without sacrificing performance. We hope this work brings attention to the potential benefits of the V2V setting for bringing safer autonomous vehicles on the road. To enable this, we plan to release this new dataset and make a challenge with a leader board and evaluation server.
为了评估我们的方法,我们需要一个多辆自动驾驶车辆处于同一局部交通场景的数据集。遗憾的是,目前尚无此类数据集存在。因此,我们的第二个贡献是提出了一个名为V2V-Sim的新数据集(见图1右侧),该数据集模拟了多辆SDV在同一区域行驶的场景。为实现这一目标,我们采用了一个高保真LiDAR模拟器[33],该模拟器利用基于真实数据构建的静态3D场景和动态对象库,为给定交通场景生成逼真的LiDAR点云。通过该模拟器,我们可以重现真实世界记录的交通场景,并模拟其中一定比例的车辆作为网络中的SDV。实验表明,V2VNet及其他V2V方法相较于单车系统显著提升了性能,且我们提出的压缩中间表示在不牺牲性能的前提下降低了带宽需求。我们希望这项工作能引起人们对V2V场景潜在效益的关注,以推动更安全的自动驾驶车辆上路。为此,我们计划公开该数据集,并设立包含排行榜和评估服务器的挑战赛。
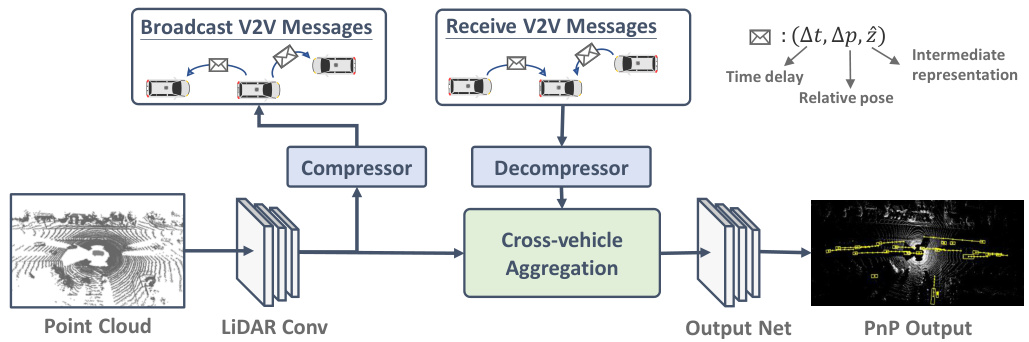
Fig. 2: Overview of V2VNet.
图 2: V2VNet 概述。
2 Related Work
2 相关工作
Joint Perception and Prediction: Detection and motion forecasting play a crucial role in any autonomous driving system. [3–5, 25, 30, 31] unified 3D detection and motion forecasting for self-driving, gaining two key benefits: (1) Sharing computation of both tasks achieves efficient memory usage and fast inference time. (2) Jointly reasoning about detection and motion forecasting improves accuracy and robustness. We build upon these existing P&P models by incorporating V2V communication to share information from different SDVs, enhancing detection and motion forecasting.
联合感知与预测:检测与运动预测在自动驾驶系统中起着至关重要的作用。[3–5, 25, 30, 31] 将3D检测与运动预测统一应用于自动驾驶领域,获得两大优势:(1) 共享两项任务的计算可实现高效内存利用与快速推理。(2) 联合处理检测与运动预测能提升精度与鲁棒性。我们在现有P&P模型基础上引入V2V通信技术,通过多台SDV间的信息共享来强化检测与运动预测能力。
Vehicle-to-Vehicle Perception: For the perception task, prior work has utilized messages encoding three types of data: raw sensor data, output detections, or metadata messages that contain vehicle information such as location, heading and speed. [34,38] associate the received V2V messages with outputs of local sensors. [8] aggregate LiDAR point clouds from other vehicles, followed by a deep network for detection. [35, 44] process sensor measurements via a deep network and then generate perception outputs for cross-vehicle data sharing. In contrast, we leverage the power of deep networks by transmitting a compressed intermediate representation. Furthermore, while previous works demonstrate results on a limited number of simple and unrealistic scenarios, we showcase the effectiveness of our model on a diverse large-scale self-driving V2V dataset.
车对车感知:在感知任务方面,先前研究主要利用三类编码数据:原始传感器数据、输出检测结果或包含车辆位置、航向和速度等信息的元数据消息。[34,38] 将接收到的V2V消息与本地传感器输出相关联。[8] 通过聚合其他车辆的LiDAR点云数据,再使用深度网络进行检测。[35,44] 通过深度网络处理传感器测量数据,随后生成用于跨车辆数据共享的感知输出。与之不同,我们通过传输压缩的中间表征来发挥深度网络的效能。此外,尽管前人研究仅在少量简单且非真实的场景中展示结果,我们则在一个多样化的大规模自动驾驶V2V数据集上验证了模型的有效性。
Aggregation of Multiple Beliefs: In V2V setting, the receiver vehicle should collect and aggregate information from an arbitrary number of sender vehicles for downstream inference. A straightforward approach is to perform permutation invariant operations such as pooling [10,40] over features from different vehicles. However, this strategy ignores cross-vehicle relations (spatial locations, headings, times) and fails to jointly reason about features from the sender and receiver. On the other hand, recent work on graph neural networks (GNNs) has shown success on processing graph-structured data [15, 18, 26, 46]. MPNN [17] abstract common ali ties of GNNs with a message passing framework. GGNN [27] introduce a gating mechanism for node update in the propagation step. Graph-neural networks have also be effective in self-driving: [3, 25] propose a spatially-aware GNN and an interaction transformer to model the interactions between actors in self-driving scenes. [41] uses GNNs to estimate value functions of map nodes and share vehicle information for coordinated route planning. We believe GNNs are tailored for V2V communication, as each vehicle can be a node in the graph. V2VNet leverages GNNs to aggregate and combine messages from other vehicles.
多信念聚合:在V2V(车对车)场景中,接收方车辆需收集并聚合来自任意数量发送方车辆的信息以进行下游推理。一种直接方法是对不同车辆的特征执行置换不变操作(如池化 [10,40]),但该策略忽略了车辆间关系(空间位置、航向、时间),且无法联合推理发送方与接收方的特征。另一方面,近期图神经网络(GNN)研究在处理图结构数据方面取得成果 [15, 18, 26, 46]:MPNN [17] 用消息传递框架抽象GNN的共性,GGNN [27] 在传播步骤引入门控机制更新节点。GNN在自动驾驶领域同样有效:[3, 25] 提出空间感知GNN和交互Transformer建模自动驾驶场景中参与者的交互,[41] 使用GNN估计地图节点的价值函数并共享车辆信息以协调路径规划。我们认为GNN天然适配V2V通信——每辆车可作为图中的节点。V2VNet利用GNN聚合并整合其他车辆的消息。
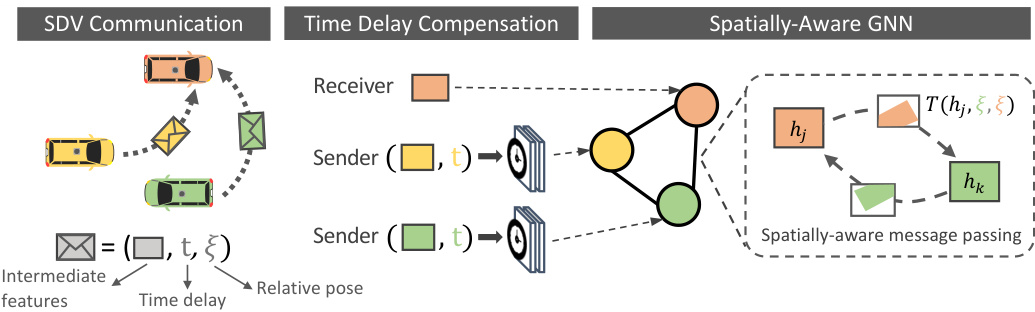
Fig. 3: After SDVs communicate messages, each receiver SDV compensates for time-delay of the received messages, and a GNN aggregates the spatial messages to compute the final intermediate representation.
图 3: SDV完成消息通信后,每个接收方SDV会对收到的消息进行时延补偿,随后通过GNN聚合空间信息以计算最终的中间表征。
Active Perception: In V2V perception, the receiving vehicle should aggregate information from different viewpoints such that its field of view is maximized, trusting more the view that can see better. Our work is related to a long line of work in active perception, which focuses on deciding what action the agent should take to better perceive the environment. Active perception has been effective in localization and mapping [13,22], vision-based navigation [14], serving as a learning signal [20, 48], and various other robotics applications [9]. In this work, rather than actively steering SDVs to obtain better viewpoint and sending information to the others, we consider a more realistic scenario where multiple SDVs have their own routes but are currently in the same geographical area, allowing the SDVs to see better by sharing perception messages.
主动感知 (Active Perception):在车对车 (V2V) 感知中,接收车辆应聚合来自不同视角的信息以最大化其视野范围,并更信任能提供更佳视角的观测。我们的工作与主动感知领域的一系列研究相关,该领域主要研究智能体应采取何种行动以更好地感知环境。主动感知已在定位与建图 [13,22]、基于视觉的导航 [14]、作为学习信号 [20, 48] 以及各类机器人应用 [9] 中展现出成效。本研究中,我们并非通过主动操控自动驾驶车辆 (SDV) 获取更优视角并传递信息,而是考虑更现实的场景:多辆 SDV 虽各有行驶路线但处于同一地理区域,通过共享感知消息实现更优的环境观测。
3 Perceiving the World by Leveraging Multiple Vehicles
3 利用多车感知世界
In this paper, we design a novel perception and motion forecasting model that enables the self-driving vehicle to leverage the fact that several SDVs may be present in the same geographic area. Following the success of joint perception and prediction algorithms [3, 5, 30, 31], which we call P&P, we design our approach as a joint architecture to perform both tasks, which is enhanced to incorporate information received from other vehicles. Specifically, we would like to devise our P&P model to do the following: given sensor data the SDV should (1) process this data, (2) broadcast it, (3) incorporate information received from other nearby SDVs, and then (4) generate final estimates of where all traffic participants are in the 3D space and their predicted future trajectories.
本文设计了一种新颖的感知与运动预测模型,使自动驾驶车辆能够利用同一地理区域内可能存在多辆自动驾驶车辆的事实。基于联合感知与预测算法3,5,30,31的成功实践,我们将该方法设计为执行双重任务的联合架构,并通过整合来自其他车辆的信息进行增强。具体而言,我们希望构建的P&P模型能够实现以下功能:给定传感器数据后,自动驾驶车辆应(1) 处理数据,(2) 广播数据,(3) 整合来自附近其他自动驾驶车辆的信息,最终(4) 生成所有交通参与者在3D空间中的位置及其预测未来轨迹的最终估计。
Two key questions arise in the V2V setting: (i) what information should each vehicle broadcast to retain all the important information while minimizing the transmission bandwidth required? (ii) how should each vehicle incorporate the information received from other vehicles to increase the accuracy of its perception and motion forecasting outputs? In this section we address these two questions.
在V2V(车对车)场景中,有两个关键问题:(i) 每辆车应广播哪些信息才能在保留所有重要信息的同时最小化传输带宽?(ii) 每辆车应如何整合从其他车辆接收的信息以提高其感知和运动预测输出的准确性?本节将针对这两个问题展开讨论。
3.1 Which Information should be Transmitted
3.1 应传输哪些信息
An SDV can choose to broadcast three types of information: (i) the raw sensor data, (ii) the intermediate representations of its P&P system, or (iii) the output detections and motion forecast trajectories. While all three message types are valuable for improving performance, we would like to minimize the message sizes while maximizing P&P accuracy gains. Note that small message sizes are critical because we want to leverage cheap, low-bandwidth, decentralized communication devices. While sending raw measurements minimizes information loss, they require more bandwidth. Furthermore, the receiving vehicle would need to process all additional sensor data received, which might prevent it from meeting the real-time inference requirements. On the other hand, transmitting the outputs of the P&P system is very good in terms of bandwidth, as only a few numbers need to be broadcasted. However, we may lose valuable scene context and uncertainty information that could be very important to better fuse the information.
智能驾驶车辆(SDV)可选择广播三类信息:(i)原始传感器数据,(ii)感知与预测(P&P)系统的中间表征,(iii)输出检测结果及运动预测轨迹。虽然这三类信息对提升系统性能均有价值,但我们希望在最大化P&P精度增益的同时最小化信息量。需注意,小信息量对采用廉价、低带宽、去中心化通信设备至关重要。虽然发送原始测量值能最小化信息损失,但会占用更多带宽。此外,接收车辆需处理所有额外接收的传感器数据,这可能影响其实时推理性能。相反,传输P&P系统输出结果在带宽方面极具优势,仅需广播少量数据。但这种方式可能会丢失对信息融合至关重要的场景上下文和不确定性信息。
In this paper, we argue that sending intermediate representations of the P&P network achieves the best of both worlds. First, each vehicle processes its own sensor data and computes its intermediate feature representation. This is compressed and broadcasted to nearby SDVs. Then, each SDV’s intermediate representation is updated using the received messages from other SDVs. This is further processed through additional network layers to produce the final perception and motion forecasting outputs. This approach has two advantages: (1) Intermediate representations in deep networks can be easily compressed [11, 43], while retaining important information for downstream tasks. (2) It has low computation overhead, as the sensor data from other vehicles has already been pre-processed.
本文认为,发送P&P网络的中间表征能实现两全其美。首先,每辆车处理自身传感器数据并计算其中间特征表征,经压缩后广播给附近自动驾驶车辆(SDV)。接着,各SDV利用接收到的其他车辆消息更新其中间表征,再通过额外网络层处理以生成最终感知与运动预测输出。该方法具备两大优势:(1) 深度网络中的中间表征易于压缩[11,43],同时能保留下游任务所需的关键信息;(2) 计算开销低,因为其他车辆的传感器数据已完成预处理。
In the following, we first showcase how to compute the intermediate representations and how to compress them. We then show how each vehicle should incorporate the received information to increase the accuracy of its P&P outputs.
接下来,我们首先展示如何计算中间表征 (intermediate representations) 及其压缩方法,随后说明每辆车应如何整合接收到的信息以提升其感知与预测 (P&P) 输出的准确性。
Algorithm 1 Cross-vehicle Aggregation
算法 1 跨车聚合
3.2 Leveraging Multiple Vehicles
3.2 利用多车辆协作
V2VNet has three main stages: (1) a convolutional network block that processes raw sensor data and creates a compressible intermediate representation, (2) a cross-vehicle aggregation stage, which aggregates information received from multiple vehicles with the vehicle’s internal state (computed from its own sensor data) to compute an updated intermediate representation, (3) an output network that computes the final P&P outputs. We now describe these steps in more details. We refer the reader to Fig. 2 for our V2VNet architecture.
V2VNet包含三个主要阶段:(1) 卷积网络块,用于处理原始传感器数据并生成可压缩的中间表示;(2) 跨车辆聚合阶段,将来自多辆车辆的信息与该车辆内部状态(根据自身传感器数据计算得出)进行聚合,以计算更新的中间表示;(3) 输出网络,用于计算最终的P&P输出。下面我们将更详细地描述这些步骤。读者可参考图2了解V2VNet架构。
LiDAR Convolution Block: Following the architecture from [45], we extract features from LiDAR data and transform them into bird’s-eye-view (BEV). Specifically, we voxelize the past five LiDAR point cloud sweeps into 15.6cm $^3$ voxels, apply several convolutional layers, and output feature maps of shape $H\times W\times C$ , where $H\times W$ denotes the scene range in BEV, and $C$ is the number of feature channels. We use 3 layers of 3x3 convolution filters (with strides of 2, 1, 2) to produce a 4x down sampled spatial feature map. This is the intermediate representation that we then compress and broadcast to other nearby SDVs.
LiDAR 卷积块:遵循 [45] 中的架构,我们从 LiDAR 数据中提取特征并将其转换为鸟瞰图 (BEV)。具体而言,我们将过去五次 LiDAR 点云扫描体素化为 15.6cm $^3$ 的体素,应用多个卷积层,并输出形状为 $H\times W\times C$ 的特征图,其中 $H\times W$ 表示 BEV 中的场景范围,$C$ 为特征通道数。我们使用 3 层 3x3 卷积滤波器(步长分别为 2、1、2)生成 4 倍下采样的空间特征图。这一中间表示随后会被压缩并广播至附近其他 SDV。
Compression: We now describe how each vehicle compresses its intermediate representations prior to transmission. We adapt Ballé et al.'s variation al image compression algorithm [2] to compress our intermediate representations; a convolutional network learns to compress our representations with the help of a learned hyperprior. The latent representation is then quantized and encoded losslessly with very few bits via entropy encoding. Note that our compression module is differentiable and therefore trainable, allowing our approach to learn how to preserve the feature map information while minimizing bandwidth.
压缩:接下来我们将介绍每辆车在传输前如何压缩其中间表示。我们采用Ballé等人提出的变分图像压缩算法[2]来压缩中间表示:通过卷积网络在习得超先验的辅助下学习压缩表示,随后对潜在表示进行量化,并通过熵编码以极少的比特数实现无损编码。值得注意的是,我们的压缩模块是可微分的,因而具备可训练性,这使得我们的方法能够学习如何在最小化带宽的同时保留特征图信息。
Cross-vehicle Aggregation: After the SDV computes its intermediate representation and transmits its compressed bitstream, it decodes the representation received from other vehicles. Specifically, we apply entropy decoding to the bit stream and apply a decoder CNN to extract the decompressed feature map. We then aggregate the received information from other vehicles to produce an updated intermediate representation. Our aggregation module has to handle the fact that different SDVs are located at different spatial locations and see the actors at different timestamps due to the rolling shutter of the LiDAR sensor and the different triggering per vehicle of the sensors. This is important as the intermediate feature representations are spatially aware.
跨车聚合:SDV计算其中间表示并传输压缩比特流后,会解码从其他车辆接收的表示。具体而言,我们对比特流进行熵解码,并通过解码器CNN提取解压缩后的特征图。随后,将接收到的其他车辆信息进行聚合,生成更新的中间表示。我们的聚合模块需处理以下情况:由于LiDAR传感器的卷帘快门效应及各车辆传感器触发时间不同,不同SDV处于不同空间位置,且观测到交通参与者的时间戳存在差异。这一点至关重要,因为中间特征表示具有空间感知特性。
Table 1: Detection Average Precision (AP) at $\mathrm{IoU={0.5,0.7}}$ , prediction with $\ell_{2}$ error at recall 0.9 at different timestamps, and Trajectory Collision Rate (TCR).
| 方法 | AP@IoU↑e2Error 0.5 0.7 | ↑(w) 1.0s 2.0s 3.0s | TCR√ T=0.01 |
|---|---|---|---|
| NoFusion | 77.3 68.5 | 0.43 0.67 0.98 | 2.84 |
| Output Fusion | 90.8 86.3 | 0.290.500.80 | 3.00 |
| LiDAR Fusion | 92.2 88.5 | 0.290.50 0.79 | 2.31 |
| V2VNet | 93.1 89.9 | 0.290.500.78 | 2.25 |
表 1: 在 $\mathrm{IoU={0.5,0.7}}$ 下的检测平均精度 (AP) , 不同时间戳下召回率为0.9时的 $\ell_{2}$ 误差预测, 以及轨迹碰撞率 (TCR) 。
Towards this goal, each vehicle uses a fully-connected graph neural network (GNN) [39] as the aggregation module, where each node in the GNN is the state representation of an SDV in the scene, including itself (see Fig. 3). Each SDV maintains its own local graph based on which SDVs are within range (i.e., 70 m). GNNs are a natural choice as they handle dynamic graph topologies, which arise in the V2V setting. GNNs are deep-learning models tailored to graphstructured data: each node maintains a state representation, and for a fix number of iterations, messages are sent between nodes and the node states are updated based on the aggregated received information using a neural network. Note that the GNN messages are different from the messages transmitted/received by the SDVs: the GNN computation is done locally by the SDV. We design our GNN to temporally warp and spatially transform the received messages to the receiver’s coordinate system. We now describe the aggregation process that the receiving vehicle performs. We refer the reader to Alg. 1 for pseudocode.
为实现这一目标,每辆车使用全连接图神经网络 (GNN) [39] 作为聚合模块,其中 GNN 的每个节点代表场景中一个 SDV (包括自身) 的状态表征 (见图 3)。每个 SDV 基于通信范围内 (即 70 米内) 的其他 SDV 维护其局部图。GNN 能天然处理 V2V 场景中动态变化的图拓扑结构,因此成为理想选择。GNN 是专为图结构数据设计的深度学习模型:每个节点维护状态表征,在固定次数的迭代中,节点间传递消息并通过神经网络基于聚合接收信息更新节点状态。需注意 GNN 消息与 SDV 收发消息不同:GNN 计算由 SDV 本地完成。我们设计的 GNN 会对接收消息进行时空坐标转换至接收者坐标系。下文详述接收车辆的聚合流程,伪代码参见算法 1。
We first compensate for the time delay between the vehicles to create an initial state for each node in the graph. Specifically, for each node, we apply a convolutional neural network (CNN) that takes as input the received intermediate representation $\hat{z}{i}$ , the relative 6DoF pose $\varDelta p_{i}$ between the receiving and transmitting SDVs and the time delay $\varDelta t_{i\rightarrow k}$ with respect to the receiving vehicle sensor time. Note that for the node representing the receiving car, $\hat{z}$ is directly its intermediate representation. The time delay is computed as the time difference between the sweep start times of each vehicle, based on universal GPS time. We then take the time-delay-compensated representation and concatenate with zeros to augment the capacity of the node state to aggregate the information received from other vehicles after propagation (line 3 in Alg. 1).
我们首先补偿车辆间的时间延迟,为图中的每个节点创建初始状态。具体而言,对于每个节点,我们应用一个卷积神经网络 (CNN),其输入包括接收到的中间表示 $\hat{z}{i}$、接收与发送自动驾驶车 (SDV) 之间的相对6自由度位姿 $\varDelta p_{i}$,以及相对于接收车辆传感器时间的时间延迟 $\varDelta t_{i\rightarrow k}$。需要注意的是,代表接收车辆的节点中,$\hat{z}$ 直接采用其自身的中间表示。时间延迟基于全球GPS时间,计算为各车辆扫描开始时间的时间差。随后,我们将经过时间延迟补偿的表示与零值拼接,以增强节点状态容量,从而在传播后聚合来自其他车辆的信息 (算法1第3行)。
Next we perform GNN message passing. The key insight is that because the other SDVs are in the same local area, the node representations will have overlapping fields of view. If we intelligently transform the representations and share information between nodes where the fields-of-view overlap, we can enhance the SDV’s understanding of the scene and produce better output P&P. Fig. 3 visually depicts our spatial aggregation module. We first apply a relative spatial transformation $\xi_{i\to k}$ to warp the intermediate state of the $i$ -th node to send a GNN message to the $k$ -th node. We then perform joint reasoning on the spatially-aligned feature maps of both nodes using a CNN. The final modified message is computed as in Alg. 1 line 7, where $T$ applies the spatial transformation and resampling of the feature state via bilinear-interpolation, and $M_{i\to k}$ masks out non-overlapping areas between the fields of view. Note that with this design, our messages maintain the spatial awareness.
接下来我们进行GNN消息传递。关键洞见在于:由于其他SDV位于同一局部区域,节点表征将存在视野重叠。如果我们能智能地转换这些表征,并在视野重叠的节点间共享信息,就能增强SDV对场景的理解,从而生成更优的P&P输出。图3直观展示了我们的空间聚合模块:首先施加相对空间变换$\xi_{i\to k}$来扭曲第$i$个节点的中间状态,以向第$k$个节点发送GNN消息;随后使用CNN对两个节点空间对齐的特征图进行联合推理。最终修正消息的计算如算法1第7行所示,其中$T$通过双线性插值实现特征状态的空间变换与重采样,$M_{i\to k}$则掩蔽视野间的非重叠区域。值得注意的是,该设计使消息始终保持空间感知能力。
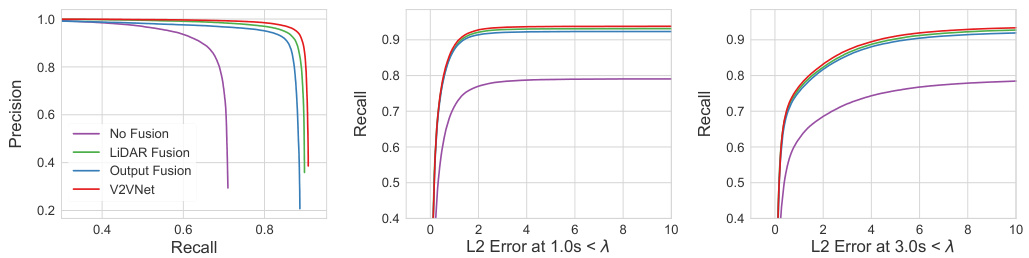
Fig. 4: Left: Detection Precision-Recall (PR) Curve at $\mathrm{IoU=0.7}$ . Center/Right: Recall as a function of $L_{2}$ Error Prediction at 1.0s and 3.0s.
图 4: 左: 检测精确率-召回率 (PR) 曲线 ($\mathrm{IoU=0.7}$)。中/右: 召回率随 $L_{2}$ 误差预测在 1.0 秒和 3.0 秒时的变化曲线。
We next aggregate at each node the received messages via a mask-aware permutation-invariant function $\phi_{M}$ and update the node state with a convolutional gated recurrent unit (ConvGRU) (Alg. 1 line 8), where $j\in N(i)$ are the neighboring nodes in the network for node $i$ and $\phi_{M}$ is the mean operator. The mask-aware accumulation operator ensures only overlapping fields-of-view are considered. In addition, the gating mechanism in the node update enables information selection for the accumulated received messages based on the current belief of the receiving SDV. After the final iteration, a multilayer perceptron outputs the updated intermediate representation (Alg. 1 Line 11). We repeat this message propagation scheme for a fix number of iterations.
接下来,我们在每个节点处通过一个掩码感知的置换不变函数 $\phi_{M}$ 聚合接收到的消息,并使用卷积门控循环单元 (ConvGRU) 更新节点状态 (算法1第8行),其中 $j\in N(i)$ 是节点 $i$ 在网络中的相邻节点,$\phi_{M}$ 为均值算子。掩码感知的累积算子确保仅考虑重叠的视野范围。此外,节点更新中的门控机制使得接收到的累积消息能基于接收方SDV的当前置信度进行信息选择。在最终迭代后,多层感知机输出更新后的中间表示 (算法1第11行)。我们重复这一消息传播机制固定次数。
Output Network: After performing message passing, we apply a set of four Inception-like [42] convolutional blocks to capture multi-scale context efficiently, which is important for prediction. Finally, we take the feature map and exploit two network branches to output detection and motion forecasting estimates respectively. The detection output is $(x,y,w,h,\theta)$ , denoting the position, size and orientation of each object. The output of the motion forecast branch is parameterized as $(x_{t},y_{t})$ , which denotes the object’s location at future time step $t$ . We forecast the motion of the actors for the next 3 seconds at 0.5 s intervals. Please see supplementary for additional architecture and implementation details.
输出网络:在进行消息传递后,我们应用了一组四个类似Inception [42]的卷积块来高效捕获多尺度上下文,这对预测至关重要。最后,我们获取特征图并利用两个网络分支分别输出检测和运动预测结果。检测输出为$(x,y,w,h,\theta)$,表示每个对象的位置、大小和方向。运动预测分支的输出参数化为$(x_{t},y_{t})$,表示对象在未来时间步$t$的位置。我们以0.5秒为间隔预测接下来3秒内参与者的运动。更多架构和实现细节请参阅补充材料。
3.3 Learning
3.3 学习
We first pretrain the LiDAR backbone and output headers, bypassing the crossvehicle aggregation stage. Our loss function is cross-entropy on the vehicle classification output and smooth $\ell_{1}$ on the bounding box parameters. We apply hard-negative mining to improve performance. We then finetune jointly the LiDAR backbone, cross-vehicle aggregation, and output header modules on our novel V2V dataset (see Sec. 4) with synchronized inputs (no time delay) using the same loss function. We do not use the temporal warping function at this stage. During training, for every example in the mini-batch, we randomly sample the number of connected vehicles uniformly on $[0,m i n(c,6)]$ , where $c$ is the number of candidate vehicles available. This is to make sure V2VNet can handle arbitrary graph connectivity while also making sure the fraction of vehicles on the V2V network remains within the GPU memory constraints. Finally, the temporal warping function is trained to compensate for time delay with asynchronous inputs, where all other parts of the network are fixed. We uniformly sample time delay between 0.0s and 0.1s (time of one 10Hz LiDAR sweep). We then train the compression module with the main network (backbone, aggregation, output header) fixed. We use a rate-distortion objective, which aims to maximize the bit rate in transmission while minimizing the distortion between uncompressed and decompressed data. We define the rate objective as the entropy of the transmitted code, and the distortion objective as the reconstruction loss (between the decompressed and uncompressed feature maps).
我们首先对LiDAR主干网络和输出头进行预训练,绕过跨车聚合阶段。损失函数采用车辆分类输出的交叉熵和边界框参数的平滑$\ell_{1}$损失。通过难例挖掘提升性能。随后,我们使用同步输入(无时延)在新型V2V数据集(见第4节)上联合微调LiDAR主干网络、跨车聚合模块和输出头,保持相同损失函数。此阶段不使用时序扭曲函数。训练时,每个小批量样本随机均匀采样$[0, min(c,6)]$范围内的连接车辆数,其中$c$为可用候选车辆数,确保V2VNet既能处理任意图连接性,又能使V2V网络中的车辆比例符合GPU内存限制。最后训练时序扭曲函数以补偿异步输入下的时延,此时固定网络其他部分。时延在0.0秒至0.1秒(10Hz LiDAR扫描周期)间均匀采样。接着固定主干网络(主干、聚合、输出头)训练压缩模块,采用率失真优化目标:最大化传输比特率的同时最小化解压前后数据的失真。率目标定义为传输码的熵,失真目标定义为重建损失(解压与未压缩特征图间)。

Fig. 5: Compression: Detection (AP at IoU 0.7), Prediction ( $\ell_{2}$ error at recall 0.9 at 3.0s), and Trajectory Collision Rate ( $\tau=0.01$ ) performance on models with compression module.
图 5: 压缩模块性能对比:检测(IoU 0.7下的AP)、预测(3.0秒时召回率0.9下的$\ell_{2}$误差)和轨迹碰撞率($\tau=0.01$)。
4 V2V-Sim: a dataset for V2V communication
4 V2V-Sim: 车对车通信数据集
No realistic dataset for V2V communication exists in the literature. Some approaches simulate the V2V setting by using different frames from KITTI [16] to emulate multiple vehicles [8,32,44]. However, this is unrealistic since sensor measurements are at different timestamps, so moving objects may be at completely different locations (e.g., a 1 sec. time difference can cause 20 m change in position). Other approaches utilize a platoon strategy for data collection [7,23,35,47], where each vehicle follows behind the previous one closely. While more realistic than using KITTI, this data collection is biased: the perspectives of different vehicles are highly correlated with each other, and the data does not provide the richness of different V2V scenarios. For example, we will never see SDVs coming in the opposite direction, or SDVs turning from other lanes at intersections.
文献中缺乏真实的车对车(V2V)通信数据集。部分研究通过使用KITTI数据集[16]的不同帧来模拟多车场景[8,32,44],但这种做法并不真实——由于传感器测量时间戳不同,运动物体可能处于完全不同的位置(例如1秒时差可能导致20米位移)。另一些研究采用车队编队策略进行数据采集[7,23,35,47],即车辆紧密跟随前车行进。虽然比使用KITTI更接近现实,但这种采集方式存在偏差:不同车辆的观测视角高度相关,且无法涵盖丰富的V2V场景。例如,我们永远看不到对向行驶的自动驾驶车辆(SDV),或从其他车道转入交叉路口的SDV。

Fig. 6: Density of SDV: AP at $\mathrm{IoU}{=}0.7$ and $\ell_{2}$ error at $\mathrm{{1s,~3s}}$ at highest recall rate at $\mathrm{IoU=0.5}$ wrt $%$ of SDVs in the scene.
图 6: SDV密度: 在$\mathrm{IoU}{=}0.7$下的AP (Average Precision) 以及在$\mathrm{{1s,~3s}}$时刻的$\ell_{2}$误差,展示的是在$\mathrm{IoU=0.5}$最高召回率下随场景中SDV占比$%$的变化情况。
To address these deficiencies, we use a high-fidelity LiDAR simulator, LiDARsim [33], to generate our large-scale V2V communication dataset, which we call V2V-Sim. LiDARsim is a simulation system that uses a large catalog of 3D static scenes and dynamic objects that are built from real-world data collections to simulate new scenarios. Given a scenario (i.e., scene, vehicle assets and their trajectories), LiDARsim applies raycasting followed by a deep neural network to generate a realistic LIDAR point cloud for each frame in the scenario.
为了解决这些不足,我们使用高保真激光雷达(LiDAR)模拟器LiDARsim [33]来生成大规模车对车(V2V)通信数据集,并将其命名为V2V-Sim。LiDARsim是一个模拟系统,它利用从真实世界数据收集构建的大型3D静态场景和动态对象库来模拟新场景。给定一个场景(即场景、车辆资产及其轨迹)后,LiDARsim先进行光线投射,再通过深度神经网络为该场景中的每一帧生成逼真的激光雷达点云。
We leverage traffic scenarios captured in the real world ATG4D dataset [45] to generate our simulations. We recreate the snippets in LiDARsim’s virtual world using the ground-truth 3D tracks provided in ATG4D. By using the same scenario layouts and agent trajectories recorded from the real world, we can replicate realistic traffic. In particular, at each timestep, we place the actor 3Dassets into the virtual scene according to the real-world labels and generate the simulated LiDAR point cloud seen from the different candidate vehicles (see Fig. 1, right). We define the candidate vehicles to be non-parked vehicles that are within the 70-meter broadcast range of the vehicle that recorded the realworld snippet. We generate 5500 25s snippets collected from multiple cities. We subsample the frames in the snippets to produce our final 46,796/4,404 frames for train/test splits for the V2V-Sim dataset. V2V-Sim has on average 10 candidate vehicles that could be in the V2V network per sample, with a maximum of 63 and a variance of 7, demonstrating the traffic diversity. The fraction of vehicles that are candidates increases linearly w.r.t broadcast range.
我们利用真实世界ATG4D数据集[45]中捕捉的交通场景来生成仿真数据。通过使用ATG4D提供的真实3D轨迹,我们在LiDARsim虚拟世界中重建这些场景片段。采用与现实世界记录的相同场景布局和智能体轨迹,能够复现真实的交通状况。具体而言,在每个时间步,我们根据真实世界标注将参与者3D资产放置到虚拟场景中,并生成从不同候选车辆视角观测的模拟激光雷达点云(见图1右)。候选车辆定义为记录现实世界片段的车辆70米广播范围内非停泊的车辆。我们从多个城市采集了5500段25秒的片段,通过降采样处理最终得到V2V-Sim数据集的46,796/4,404帧训练/测试集。V2V-Sim每个样本平均有10个可能加入V2V网络的候选车辆(最多63个,方差7个),展现了交通多样性。候选车辆占比随广播范围呈线性增长。
5 Experimental Evaluation
5 实验评估
In this section we showcase the performance of our approach compared to other transmission and aggregation strategies as well as single vehicle P&P.
在本节中,我们将展示我们的方法与其他传输和聚合策略以及单车即插即用(P&P)的性能对比。
Metrics: We evaluate both detection and motion forecasting around the egovehicle with a range of: $x\in[-100,100]\mathrm{m}.$ $y\in[-40,40]\mathrm{m}$ . We include completely occluded objects (0 LiDAR points hit the object), making the task much more challenging and realistic than standard benchmarks. For object detection, we compute Average Precision (AP) and Precision-Recall (PR) Curve at Intersection-over-Union (IoU) threshold of 0.7. For motion forecasting, we compute absolute $\ell_{2}$ displacement error of the object center’s location at future timestamps (3s prediction horizon with 0.5s interval) on true positive detections. We set the IoU threshold to 0.5 and recall to 0.9 (we pick the highest recall if 0.9 cannot be reached) to obtain the true positives. These values were chosen such that we retrieve most objects, which is critical for safety in self-driving. Note that most self-driving systems adopt this high recall as operating point. We also compute Trajectory Collision Rate (TCR), defined as the collision rate between the predicted trajectories of detected objects, where collision occurs when two cars overlap with each other more than a specific IoU (i.e., collision threshold $\tau$ ). This metric evaluates whether the predictions are consistent with each other. We exclude the other SDVs during evaluation, as those can be trivially predicted.
指标:我们围绕自车评估检测和运动预测,范围设定为:$x\in[-100,100]\mathrm{m}$,$y\in[-40,40]\mathrm{m}$。评估包含完全被遮挡的物体(0个激光雷达点命中目标),这使得任务比标准基准更具挑战性和真实性。对于目标检测,我们在交并比(IoU)阈值为0.7时计算平均精度(AP)和精确率-召回率(PR)曲线。对于运动预测,我们计算真阳性检测中未来时间戳(3秒预测时长,0.5秒间隔)物体中心位置的绝对$\ell_{2}$位移误差。我们将IoU阈值设为0.5,召回率设为0.9(若无法达到0.9则选择最高召回率)以获取真阳性样本。这些数值的选取确保能检索到绝大多数物体,这对自动驾驶安全性至关重要。需注意,多数自动驾驶系统采用这种高召回率作为工作点。我们还计算轨迹碰撞率(TCR),定义为检测物体预测轨迹间的碰撞率,当两车交并比超过特定阈值(即碰撞阈值$\tau$)时判定为碰撞。该指标评估预测结果是否自洽。评估时排除其他自动驾驶车辆,因其轨迹可被直接预测。

Fig. 7: Performance on objects with (first two columns) different number of LiDAR point observation (last two columns) different velocities.
图 7: 在不同LiDAR点观测数量(前两列)和不同速度(后两列)下的物体性能表现。
Baselines: We evaluate the single vehicle setting, dubbed No Fusion, which consists of LiDAR backbone network and output headers only, without V2V communication. We also introduce two baselines for V2V communication: $L i D A R$ Fusion and Output Fusion. LiDAR Fusion warps all received LiDAR sweeps from other vehicles to the coordinate frame of the receiver via the relative transformation between vehicles (which is known, as all SDVs are assume to be localized) and performs direct aggregation. We use the state-of-the-art LiDAR compression algorithm Draco [1] to compress LiDAR Fusion messages. For Output Fusion, each vehicle sends post-processed outputs, i.e., bounding boxes with confidence scores, and predicted future trajectories after non-maximum suppression (NMS). At the receiver end, all bounding boxes and future trajectories are first transformed to the ego-vehicle coordinate system and then aggregated across vehicles. NMS is then applied again to produce the final results.
基线方法:我们评估了单车设置(称为No Fusion),该设置仅包含LiDAR骨干网络和输出头,不进行V2V通信。我们还为V2V通信引入两种基线方法:LiDAR Fusion和Output Fusion。LiDAR Fusion通过车辆间已知的相对变换(假设所有SDV均已定位)将所有接收到的其他车辆LiDAR扫描数据转换到接收者坐标系,并进行直接聚合。我们采用最先进的LiDAR压缩算法Draco [1]来压缩LiDAR Fusion消息。对于Output Fusion,每辆车发送后处理输出(即带置信度的边界框)及经过非极大值抑制(NMS)后的预测未来轨迹。在接收端,所有边界框和未来轨迹首先转换到自车坐标系,再进行跨车辆聚合,最后再次应用NMS生成最终结果。
Experimental Details: For all analysis we set the maximum number of SDVs per scene to be 7 (except for an ablation study measuring how the number of SDVs affect V2V performance in Fig. 6). All models are trained with Adam [24].
实验细节:在所有分析中,我们将每个场景的最大SDV数量设为7(除了一项消融研究,该研究测量了SDV数量如何影响V2V性能,如图6所示)。所有模型均使用Adam [24]进行训练。

Fig. 8: Robustness on noisy vehicles’ relative pose estimates.
图 8: 噪声环境下车辆相对位姿估计的鲁棒性。
Comparison to Existing Approaches: As shown in Table. 1, V2V-based models significantly outperform No Fusion on detection ( ${\sim}20%$ at IoU 0.7) and prediction ( ${\sim}0.2\mathrm{m~}\ell_{2}$ error reduction at 3 sec.). LiDAR Fusion and V2VNet also show strong reduction (20% at 0.01 collision threshold) in TCR. These results demonstrate that all types of V2V communication provide substantial performance gains. Among all V2V approaches, V2VNet is either on-par with LiDAR Fusion (which has no information loss) or achieves the best performance. V2VNet’s slight performance gain over LiDAR Fusion may come from using the GNN in the cross-vehicle aggregation stage to reason about different vehicles’ feature maps more intelligently than naive aggregation. Output Fusion’s drop in performance for TCR is due to the large number of false positives relative to other V2V methods (see detection PR curve Fig. 4, left, at recall > 0.6). Fig. 4 shows the percentage of objects with an $\ell_{2}$ error at 3s smaller than a constant. This metric shows similar trends consistent with Table. 1.
与现有方法的对比:如表 1 所示,基于 V2V 的模型在检测 (IoU 0.7 时提升约 20%) 和预测 (3 秒时 $\ell_{2}$ 误差减少约 0.2 米) 上显著优于 No Fusion。LiDAR Fusion 和 V2VNet 在 TCR 上也表现出显著降低 (碰撞阈值为 0.01 时降低 20%)。这些结果表明所有类型的 V2V 通信都能带来显著的性能提升。在所有 V2V 方法中,V2VNet 要么与 LiDAR Fusion (无信息损失) 持平,要么达到最佳性能。V2VNet 相对于 LiDAR Fusion 的轻微性能优势可能源于在跨车辆聚合阶段使用 GNN,比简单聚合更智能地推理不同车辆的特征图。Output Fusion 在 TCR 上的性能下降是由于相对于其他 V2V 方法存在大量误报 (参见检测 PR 曲线图 4 左侧,召回率 > 0.6)。图 4 展示了 3 秒时 $\ell_{2}$ 误差小于某常数的物体百分比。该指标显示出与表 1 一致的趋势。
Compression: Fig. 5 shows the tradeoff between transmission bandwidth and accuracy for different V2V methods with and without compression. Draco [1] achieves 33x compression for LiDAR Fusion, while our compressed intermediate representations achieved a 417x compression rate. Note that compression marginally affects the performance. This shows that the intermediate P&P represent at ions are much easier to compress than LiDAR. Given the message size for one timestamp with a sensor capture rate of 10Hz, we compute the transmission delay based on V2V communication protocol [21]. At the broadcast range 120 meters, the data rate is roughly 25 Mbps. This means sending V2VNet messages may induce roughly 9ms delay, which is very low.
压缩:图 5 展示了不同 V2V 方法在有无压缩情况下的传输带宽与精度权衡。Draco [1] 在 LiDAR 融合中实现了 33 倍压缩,而我们的压缩中间表示达到了 417 倍压缩率。需注意压缩对性能影响较小。这表明中间 P&P 表示比 LiDAR 数据更易压缩。根据传感器 10Hz 捕获速率下单时间戳的消息大小,我们基于 V2V 通信协议 [21] 计算传输延迟。在 120 米广播范围内,数据速率约为 25 Mbps。这意味着发送 V2VNet 消息可能仅引入约 9ms 延迟,该延迟极低。
SDV Density: We now investigate how V2V performance changes as a function of $%$ of SDVs in the scene. To make this setting like the real world, for a given 25s snippet, we choose a fraction of candidate vehicles in the scene to be SDVs for the whole snippet. As shown in Fig. 6, V2V performance increases linearly with the $%$ of SDVs in both detection and prediction.
SDV密度:我们现在研究V2V性能如何随场景中SDV占比 ($%$) 变化。为模拟真实场景,对于给定的25秒片段,我们选择场景中一定比例的候选车辆作为整个片段的SDV。如图6所示,在检测和预测任务中,V2V性能随SDV占比 ($%$) 呈线性提升。
Number of LiDAR points, Velocity: As shown in Fig. 7 (a) V2V methods boost the performance on completely- and mostly-occluded objects (0 and
LiDAR点数、速度:如图7(a)所示,V2V方法在完全遮挡和大部分遮挡物体(0和

Fig. 9: Effect of time delay in data exchange.
图 9: 数据交换时延的影响。
$1{\sim}6$ LiDAR points) by over $60%$ in AP. This is an extremely exciting result, since the main challenges of perception and motion forecasting are objects with very sparse observations. Fig. 7 (b) shows performance on objects with different velocities. While other V2V methods drop in detection performance as object velocity increases, V2VNet has consistent performance gains over No Fusion on fast moving objects. Output Fusion and LiDAR Fusion may have deteriorated due to the rolling shutter of the moving SDV and the motion blur of moving agents during the temporal sweep of the LiDAR sensor. These effects are more severe in the V2V setting, where SDVs may be moving in opposite directions at high speeds while recording moving actors. Although not explicitly tackling such issue, V2VNet performs contextual and iterative reasoning on information from different vehicles, which may indirectly handle rolling shutter inconsistencies.
$1{\sim}6$ 个LiDAR点) 的平均精度 (AP) 提升了超过60%。这是一个极其振奋人心的成果,因为感知与运动预测的主要挑战正是观测数据极度稀疏的物体。图7(b)展示了不同速度物体上的性能表现。当其他V2V方法随着物体速度增加而检测性能下降时,V2VNet在高速移动物体上始终保持着对No Fusion方案的性能优势。输出融合(Output Fusion)和激光雷达融合(LiDAR Fusion)的性能下降可能源于移动自动驾驶车辆(SDV)的卷帘快门效应,以及LiDAR传感器时序扫描过程中运动物体的运动模糊。这些效应在V2V场景中更为严重——当SDV以高速相向行驶时,记录的移动物体会产生更明显的畸变。虽然V2VNet并未显式解决该问题,但通过对不同车辆信息的上下文迭代推理,可能间接处理了卷帘快门的不一致性问题。
Imperfect Localization: We simulate inaccurate pose estimates by introducing different levels of Gaussian ( $\sigma=0.4m$ ) and von Mises ( $\sigma=4^{\circ}$ ; $\begin{array}{r}{\frac{1}{\kappa}=}\end{array}$ κ $4.873\times10^{-3}$ ) noise to position and heading of the transmitting SDVs. As shown in Fig. 8, on both noise types, V2VNet outperforms LiDAR Fusion and Output Fusion in P&P performance. The only exception is Output Fusion $\ell_{2}$ error with heading noise larger than $3^{\circ}$ . We hypothesize that Output Fusion’s performance is better at this setting due to its low-recall (fewer true positives) relative to V2VNet (0.62 vs. 0.73 at $4^{\circ}$ noise). Fewer true positives can cause lower $\ell_{2}$ error relative to higher recall methods. Degradation from heading noise is more severe than position noise, as subtle rotation in the ego-view will cause substantial misalignment for far-off objects; a vehicle bounding box (5m x 2m) rotated by $1^{\circ}$ with respect to a pivot 70m away generates an IoU of 0.39 with the original.
不完美的定位:我们通过向发送端自动驾驶车辆 (SDV) 的位置和航向施加不同强度的高斯噪声 ( $\sigma=0.4m$ ) 和冯·米塞斯噪声 ( $\sigma=4^{\circ}$ ; $\begin{array}{r}{\frac{1}{\kappa}=}\end{array}$ κ $4.873\times10^{-3}$ ) 来模拟不准确的位姿估计。如图 8 所示,在两种噪声类型下,V2VNet 在 P&P 性能上均优于 LiDAR Fusion 和 Output Fusion。唯一例外是当航向噪声超过 $3^{\circ}$ 时 Output Fusion 的 $\ell_{2}$ 误差更小。我们推测这是由于 Output Fusion 的召回率(真阳性数)低于 V2VNet(在 $4^{\circ}$ 噪声下为 0.62 vs. 0.73),较少的真阳性可能导致 $\ell_{2}$ 误差低于高召回率方法。航向噪声导致的性能下降比位置噪声更严重,因为自车视角的微小旋转会使远处物体产生显著错位;一个车辆边界框(5m x 2m)相对于70米外的支点旋转 $1^{\circ}$ 时,其与原始框的交并比 (IoU) 仅为0.39。
Asynchronous Propagation: We simulate random time delay by delaying the messages of other vehicles at random from $\mathcal{U}(0,t)$ , where $t=0.1$ . We apply a piece-wise linear velocity model (computed via finite differences) in Output Fusion to compensate for time delay. We do not make adjustments for $L i D A R$ Fusion as it is non-trivial. As shown in Fig. 9, V2VNet demonstrates robustness across different time delays. Output Fusion does not perform well at high time delays as the piece-wise linear model used is sensitive to velocity estimates.
异步传播 (Asynchronous Propagation):我们通过将其他车辆的消息随机延迟 $\mathcal{U}(0,t)$(其中 $t=0.1$)来模拟随机时间延迟。在输出融合 (Output Fusion) 中采用分段线性速度模型(通过有限差分计算)以补偿时间延迟。由于 $L i D A R$ 融合 (LIDAR Fusion) 的非平凡性,我们未对其进行调整。如图 9 所示,V2VNet 在不同时间延迟下均表现出鲁棒性。输出融合在高延迟时表现不佳,因为所使用的分段线性模型对速度估计较为敏感。

Fig. 10: V2V-Net Qualitative Examples. Left: Occluded car detected; Middle: Perception range increased; Right: Fast car detected.
图 10: V2V-Net定性示例。左:检测到被遮挡车辆;中:感知范围扩大;右:检测到快速行驶车辆。
Mixed Fleet: We also investigate the case that the SDV may receive different types of perception messages (i.e., sensor data, intermediate representation and P&P outputs). We analyze the setting where every SDV (other than the receiving vehicle) has 1/3 chance to broadcast each measurement type. We then perform Sensor Fusion, V2VNet, Output Fusion for the relevant set of messages to generate the final output. The result is in between the three V2V approaches: 88.6 AP at IoU=0.7 for detection, 0.79 m error at 3.0s prediction, and 2.63 TCR.
混合车队:我们还研究了SDV可能接收不同类型感知消息(即传感器数据、中间表示和P&P输出)的情况。我们分析每个SDV(除接收车辆外)有1/3概率广播每种测量类型的场景,随后对相关消息集执行传感器融合(Sensor Fusion)、V2VNet和输出融合(Output Fusion)以生成最终输出。结果介于三种V2V方案之间:检测任务在IoU=0.7时达到88.6 AP,3.0秒预测误差0.79米,TCR为2.63。
Qualitative Results: As shown in Fig. 10, V2VNet can see further and handle occlusion. For example, in Fig. 10 far right, we perceive and motion forecast a high-speed vehicle in our right lane, which can give the downstream planning system more information to better plan a safe maneuver for a lane change. V2V-Net also detects many more vehicles in the scene that were originally not detected by No Fusion (Fig. 10, middle).
定性结果:如图 10 所示,V2VNet 具备更远的感知范围和遮挡处理能力。例如,在图 10 最右侧场景中,我们成功感知并预测了右侧车道高速行驶的车辆,这能为下游规划系统提供更多信息,从而更安全地规划变道动作。与无融合方案 (No Fusion) 相比 (图 10 中间),V2V-Net 还能检测到场景中更多未被识别的车辆。
6 Conclusion
6 结论
In this paper, we have proposed a V2V approach for perception and prediction that transmits compressed intermediate representations of the P&P neural network, achieving the best compromise between accuracy improvements and bandwidth requirements. To demonstrate the effectiveness of our approach we have created a novel V2V-Sim dataset that realistically simulates the world when SDVs will be ubiquitous. We hope that our findings will inspire future work in V2V perception and motion forecasting strategies for safer self-driving cars.
本文提出了一种用于感知与预测的V2V方法,该方法通过传输P&P神经网络的压缩中间表征,在精度提升与带宽需求之间实现了最佳平衡。为验证方法的有效性,我们创建了新颖的V2V-Sim数据集,真实模拟了自动驾驶汽车(SDV)普及后的世界场景。希望我们的研究成果能为未来V2V感知与运动预测策略的发展提供启发,以推动更安全的自动驾驶技术。