WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
WIT: 基于维基百科的多模态多语言机器学习图像文本数据集
ABSTRACT
摘要
The milestone improvements brought about by deep representation learning and pre-training techniques have led to large performance gains across downstream NLP, IR and Vision tasks. Multimodal modeling techniques aim to leverage large high-quality visio-linguistic datasets for learning complementary information (across image and text modalities). In this paper, we introduce the Wikipediabased Image Text (WIT) Dataset to better facilitate multimodal, multilingual learning. WIT is composed of a curated set of 37.6 million entity rich image-text examples with 11.5 million unique images across 108 Wikipedia languages. Its size enables WIT to be used as a pre training dataset for multimodal models, as we show when applied to downstream tasks such as image-text retrieval. WIT has four main and unique advantages. First, WIT is the largest multimodal dataset by the number of image-text examples by 3x (at the time of writing). Second, WIT is massively multilingual (first of its kind) with coverage over $100+$ languages (each of which has at least 12K examples) and provides cross-lingual texts for many images. Third, WIT represents a more diverse set of concepts and real world entities relative to what previous datasets cover. Lastly, WIT provides a very challenging real-world test set, as we empirically illustrate using an image-text retrieval task as an example.
深度表征学习和预训练技术带来的里程碑式改进,显著提升了NLP、信息检索(IR)和视觉任务的下游性能。多模态建模技术旨在利用大规模高质量视觉语言数据集,学习跨图像与文本模态的互补信息。本文推出基于维基百科的图文数据集WIT (Wikipediabased Image Text Dataset),以更好地促进多模态多语言学习。WIT包含精选的3760万组富含实体的图文样本,涵盖108种维基百科语言的1150万张独特图像。其规模使WIT能作为多模态模型的预训练数据集,我们在图像-文本检索等下游任务中验证了其有效性。WIT具备四大独特优势:首先,WIT是当前规模最大的多模态数据集(样本量达第二名的3倍);其次,WIT首次实现超百种语言的大规模多语言覆盖(每种语言至少含1.2万样本),并为大量图像提供跨语言文本;第三,WIT涵盖的概念和现实实体比既有数据集更具多样性;最后,WIT通过图像-文本检索任务实证表明,其提供了极具挑战性的真实世界测试集。
KEYWORDS
关键词
machine learning, neural networks, multi-modal, multi-lingual, image-text retrieval
机器学习、神经网络、多模态、多语言、图文检索
ACM Reference Format:
ACM引用格式:
Krishna Srinivasan, Karthik Raman, Jiecao Chen, Michael Bendersky, and Marc Najork. 2021. WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning. In Proceedings of SIGIR Resource Track. ACM, New York, NY, USA, 16 pages. https://doi.org/10.1145/1122445.1122456
Krishna Srinivasan、Karthik Raman、Jiecao Chen、Michael Bendersky 和 Marc Najork。2021. WIT:基于维基百科的多模态多语言机器学习图像文本数据集。载于《SIGIR资源轨道会议论文集》。ACM,美国纽约,共16页。https://doi.org/10.1145/1122445.1122456
1 INTRODUCTION
1 引言
Deep learning has fundamentally revolutionized the fields of NLP, IR and Vision via our ability to have a rich semantic understanding of texts and images. Notable examples of this include Deep CNN models [29, 34] which set the bar for standard vision tasks like image recognition and image classification. Attention based transformer models [35] like BERT [8] have likewise enabled achieving new benchmark performance across a myriad of text understanding / NLP / IR tasks. These transformation al advances have also found their way to multimodal tasks such as image-text retrieval / search [14] and image captioning [36, 41]. Multimodal models – such as ViLBERT [22], UNITER [6], Unicoder-VL [17] amongst others [1, 19, 32] – are able to jointly model the complex relationships between text and visual inputs leading to wins in downstream tasks like image search, Visual Question Answering (VQA) [2] and Visual Commonsense Reasoning (VCR) [40].
深度学习通过对文本和图像的丰富语义理解能力,从根本上革新了自然语言处理(NLP)、信息检索(IR)和计算机视觉领域。典型范例包括为图像识别、图像分类等标准视觉任务树立标杆的深度CNN模型[29,34]。基于注意力机制的Transformer模型[35](如BERT[8])同样在各类文本理解/NLP/IR任务中实现了突破性的基准性能。这些变革性进展也延伸至图文检索/搜索[14]、图像描述生成[36,41]等多模态任务。以ViLBERT[22]、UNITER[6]、Unicoder-VL[17]为代表的多模态模型[1,19,32],能够联合建模文本与视觉输入的复杂关联,从而在图像搜索、视觉问答(VQA)[2]和视觉常识推理(VCR)[40]等下游任务中取得优势。
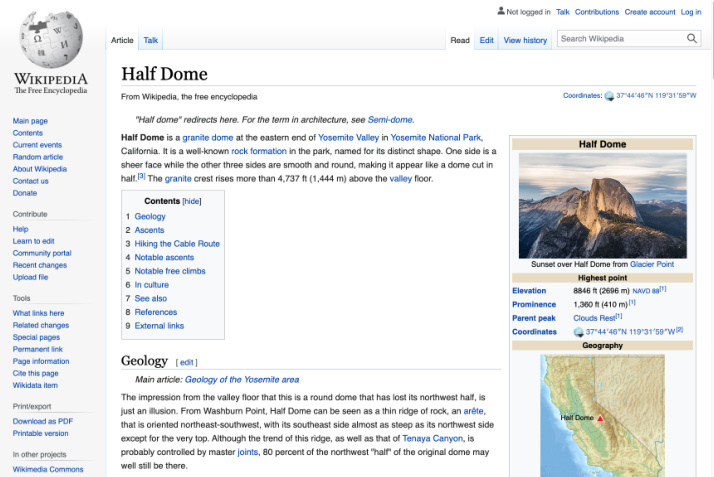
Figure 1: The Wikipedia page for Half Dome, Yosemite, California via Wikimedia Commons.
图 1: 加利福尼亚州优胜美地半圆顶 (Half Dome) 的维基百科页面,来自 Wikimedia Commons。
Accompanying the modeling improvements across these advancements, an equally critical aspect is the leveraging of massive datasets to enrich representation learning – often via unsupervised pre training. Increasingly, the efficacy of a model correlates strongly with the size and quality of pre training data used. For instance, cutting-edge language models like BERT [8] and T5 [27] rely on increasingly larger text datasets spanning from those in the O(100M) range like Wikipedia, Books Corpus [43] to datasets with billions of examples like C4 [27] and mC4 [38]. Similarly, vision models [9] are reliant on large corpora, such as ImageNet-21k [7] – which with 14M images is among the largest public datasets. This scale is important since studies have shown performance increases logarithmically with dataset size [33]. Another key dimension of language datasets is the number of languages covered. By transitioning from English-only to highly multilingual language datasets, models like mT5 [38] and mBERT [37], are an important step for researchers driving globally, equitable availability of information.
伴随这些进展中的模型改进,一个同样关键的方面是利用海量数据集来丰富表征学习——通常通过无监督预训练实现。模型的效能越来越强烈地依赖于所用预训练数据的规模和质量。例如,BERT [8] 和 T5 [27] 等前沿语言模型依赖于从 Wikipedia、Books Corpus [43] 这类 O(1亿) 量级数据集,到 C4 [27] 和 mC4 [38] 等包含数十亿样本的数据集。同样,视觉模型 [9] 也依赖于 ImageNet-21k [7] 等大型语料库——该数据集包含 1400 万张图像,是最大的公开数据集之一。这种规模至关重要,因为研究表明性能会随数据集规模呈对数增长 [33]。语言数据集的另一个关键维度是覆盖的语言数量。通过从仅限英语转向高度多语言的数据集,mT5 [38] 和 mBERT [37] 等模型成为推动全球信息公平获取的重要一步。
Multimodal visio-linguistic models are no different, and rely on a rich dataset to help them learn to model the relationship between images and texts. However as seen in Table 1, the scale of current public datasets pales in comparison to image-only or text-only ones, with the 30K-sized Flickr [39] and 3.3M-sized Conceptual Captions (CC) [28] being among the largest ones. Having large image-text datasets can significantly improve performance, as a couple of recent works [15, 26] have shown by leveraging larger noisy (proprietary) datasets. Furthermore the lack of language coverage in these existing datasets (which are mostly only in English) also impedes research in the multilingual multimodal space – which we consider a lost opportunity given the potential shown in leveraging images (as a language-agnostic medium) to help improve our multilingual textual understanding [30] or even translate [12].
多模态视觉语言模型也不例外,它们依赖丰富的数据集来学习建模图像与文本之间的关系。然而如表 1 所示,当前公开数据集的规模远逊于纯图像或纯文本数据集,其中规模最大的 Flickr [39] 仅含 3 万样本,Conceptual Captions (CC) [28] 也只有 330 万样本。近期研究 [15, 26] 表明,使用更大规模(尽管含噪声)的专有数据集能显著提升模型性能。此外,现有数据集(大多仅含英语)的语言覆盖不足也阻碍了多语言多模态领域的研究——鉴于图像(作为语言无关媒介)在提升多语言文本理解 [30] 甚至辅助翻译 [12] 方面展现的潜力,这种现状无疑是错失良机。
To address these challenges and advance research on multilingual, multimodal learning we present the Wikipedia-based Image Text (WIT) Dataset. WIT is created by extracting multiple different texts associated with an image (e.g., the reference description seen in Fig 2) from Wikipedia articles and Wikimedia image links. This was accompanied by rigorous filtering to only retain high quality image-text associations. The resulting dataset contains over 37.6 million image-text sets and spans 11.5 million unique images – making WIT the largest multimodal dataset at the time of writing. Furthermore WIT provides unparalleled multilingual coverage – with $12\mathrm{K}+$ examples in each of 108 languages (53 languages have $100\mathrm{K}+$ image-text pairs).
为应对这些挑战并推动多语言多模态学习研究,我们推出了基于维基百科的图文数据集(WIT)。该数据集通过从维基百科文章和维基媒体图片链接中提取与图像关联的多种文本(如图2所示的参考描述),并经过严格筛选仅保留高质量图文关联。最终数据集包含超过3760万组图文数据,涵盖1150万张独特图片——使WIT成为目前规模最大的多模态数据集。此外,WIT提供了前所未有的多语言覆盖度——108种语言各含1.2万+样本(其中53种语言拥有10万+图文对)。
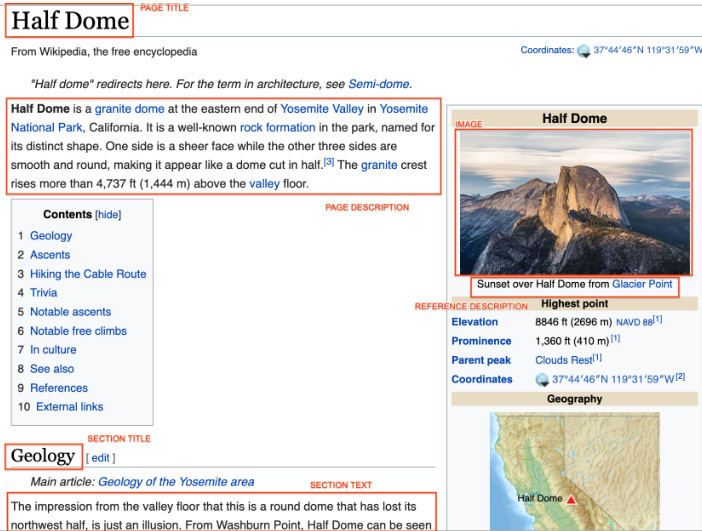
Figure 2: The Wikipedia page for Half Dome, Yosemite, California via Wikimedia Commons with examples of the different fields extracted and provided in WIT.
图 2: 通过Wikimedia Commons获取的加利福尼亚州优胜美地半圆顶(Half Dome)维基百科页面,展示了WIT中提取和提供的不同字段示例。
Table 1: Existing publicly available image-text datasets pale in comparison to text-only datasets (e.g., mC4 with O(Billions) of examples in ${\bf100+}$ languages) and image-only datasets (e.g., 14M in ImageNet-21k).
表 1: 现有公开可用的图文数据集与纯文本数据集 (如 mC4 包含 ${\bf100+}$ 种语言的 O(十亿级) 样本) 和纯图像数据集 (如 ImageNet-21k 的 1400 万样本) 相比相形见绌。
| 数据集 | 图像数量 | 文本数量 | 语言数量 |
|---|---|---|---|
| Flickr30K [39] | 32K | 158K | <8 |
| SBU Captions [24] | ~1M | ~1M | 1 |
| MS-COCO [21] | ~330K | ~1.5M | <4 |
| CC [5] | ~3.3M | ~3.3M | 1 |
| WIT | 11.5M | 37.6M | 108 |
It is worth pointing out that by leveraging Wikipedia’s editing, verification and correction mechanism, WIT is able to ensure a highquality bar. In particular, this use of a curated source like Wikipedia contrasts with the approach used to create other existing datasets (e.g. CC [28]) which rely on extracting annotations from web crawls. We verified the curated quality of the WIT dataset via an extensive human-annotation process (nearly 4400 image-text examples and 13K judgments across 7 languages), with an overwhelming majority $(98.5%)$ judging the randomly sampled image-text associations favorably.
值得指出的是,通过利用维基百科的编辑、验证和修正机制,WIT能够确保高质量标准。特别是,这种使用维基百科等精选来源的做法,与创建其他现有数据集(如CC [28])所采用的方法形成对比,后者依赖于从网络爬取中提取标注。我们通过广泛的人工标注流程(涵盖7种语言的近4400个图文示例和1.3万条判断)验证了WIT数据集的精选质量,绝大多数 $(98.5%)$ 的随机抽样图文关联获得了正面评价。
Empirical results on image-text retrieval tasks (both zero-shot i.e., pretrained model, as well as finetuned model evaluations) demonstrate the potency of the data. The vast richness of Wikipedia texts and images (grounded in a diverse set of real-world entities and attributes) also means that WIT provides for a realistic evaluation set – one that we demonstrate to be challenging for models trained using existing datasets.
图像文本检索任务的实证结果(包括零样本(即预训练模型)和微调模型评估)证明了数据的有效性。维基百科文本和图像的丰富性(基于多样化的现实世界实体和属性)也意味着WIT提供了一个真实的评估集——我们证明这对于使用现有数据集训练的模型具有挑战性。
2 RELATED WORK
2 相关工作
Visio-Linguistic (VL) datasets: Flickr30K [39] was among the first datasets that helped drive early research in this space. Similar to other such early datasets (e.g. the $330\mathrm{k\Omega}$ example MS-COCO), it was created by having crowd sourced (Mechanical Turk) workers provide captions for $\mathord{\sim}30\mathrm{K}$ images (sampled from Flickr). While the explicit human-based captioning helps ensure quality, the resulting datasets have been recognized as insufficient for significant real-world improvements given that they are small and expensive to construct [10, 42]. Furthermore, this manual effort has meant extending to other languages has proven to be quite challenging. Consequently there exists only a handful of non-English data collections such as Multi30K-DE (German) [11], DeCOCO (German) [13], Multi30K-FR (French) [10], Multi30K-CS (Czech) [3], YJ Captions 26 k (Japanese) [23] and MS-COCO-CN (Chinese) [20].
视觉-语言 (VL) 数据集:Flickr30K [39] 是推动该领域早期研究的首批数据集之一。与其他早期数据集(例如 MS-COCO)类似,它通过众包 (Mechanical Turk) 工作者为约 3 万张图片(从 Flickr 采样)提供标注而创建。虽然基于人工的显式标注有助于确保质量,但这些数据集已被认为不足以带来显著的现实世界改进,因为它们规模小且构建成本高 [10, 42]。此外,这种人工操作意味着扩展到其他语言被证明相当具有挑战性。因此,目前仅存在少数非英语数据集,例如 Multi30K-DE(德语)[11]、DeCOCO(德语)[13]、Multi30K-FR(法语)[10]、Multi30K-CS(捷克语)[3]、YJ Captions 26k(日语)[23] 和 MS-COCO-CN(中文)[20]。
An alternative paradigm to creating such datasets is demonstrated by the Conceptual Captions (CC) dataset [28]. By leveraging the alt-text annotations for images from a web crawl, the resulting dataset was significantly larger than previous ones $(\sim3.3\mathrm{M}$ imagetext pairs). The drawback with this approach is the reliance on complex filtering rules and systems to ensure data quality. Unfortunately this makes these extraction-based datasets – like CC and the recently proposed CC12M [5] – hard to extend and significantly impacts their coverage and diversity. Perhaps un surprisingly, the complex filtering logic has meant that this approach has so far only been successfully applied to curate English data collections.
概念标注 (Conceptual Captions, CC) 数据集 [28] 展示了构建此类数据集的另一种范式。通过利用网络爬取图像中的替代文本注释,最终得到的数据集规模远超以往 $(\sim3.3\mathrm{M}$ 图文对)。这种方法的缺点在于依赖复杂的过滤规则和系统来确保数据质量。遗憾的是,这使得基于提取的数据集——如CC和最近提出的CC12M [5]——难以扩展,并显著影响了其覆盖范围和多样性。可能并不意外的是,复杂的过滤逻辑意味着该方法迄今仅成功应用于英语数据集的整理。
Table 2: Example of texts extracted for Half Dome example
表 2: Half Dome 示例的文本提取结果
| FieldName | Text |
|---|---|
| Page Title | HalfDome, Yosemite |
| Canonical Page URL | en.wikipedia.org/wiki/Half_Dome |
| Page Description | Half Dome is a granite dome at the easternendofYosemiteValleyin YosemiteNationalPark, California. It is awell-knownrockformation... |
| ReferenceDescription | SunsetoverHalfDomefromGlacier Point |
| AttributionDescription | English: HalfDomeasviewedfrom GlacierPoint, YosemiteNational Park, California, United States. |
WIT looks to achieve the best of both worlds by leveraging an extractive approach on a clean, curated multilingual repository of human knowledge with its accompanying images, illustrations and detailed text descriptions (Wikipedia).
WIT 旨在通过采用提取式方法,利用一个经过精心整理、附带图像、插图和详细文本描述的多语言人类知识库(Wikipedia),实现两全其美的效果。
VL models: A slew of models have been proposed to leverage the above datasets (either for unsupervised pre training or finetuning). For example, ViLBERT [22] uses MS-COCO and CC for pre training a multimodal transformer based model. UNITER [6] leverages these datasets and pretrains on tasks like image-text matching and word region alignment. Similarly, models like VL-BERT [32], VisualBERT [19], ImageBERT [25], B2T2 [1] and Unicoder-VL [18], all pretrain on CC or similar datasets using a variety of objectives and tasks. Efficacy of these models is often studied on downstream tasks like image-text retrieval, referring expressions, image captioning, etc using Flickr30K, MS-COCO and similar curated collections. These models have also shown that a larger and more varied data collection, results in better performance across the board in downstream tasks.
视觉语言模型 (VL models): 已有大量模型被提出以利用上述数据集(用于无监督预训练或微调)。例如,ViLBERT [22] 使用 MS-COCO 和 CC 预训练基于多模态 Transformer 的模型。UNITER [6] 利用这些数据集,并在图像-文本匹配和单词-区域对齐等任务上进行预训练。类似地,VL-BERT [32]、VisualBERT [19]、ImageBERT [25]、B2T2 [1] 和 Unicoder-VL [18] 等模型均使用 CC 或类似数据集,通过多种目标和任务进行预训练。这些模型的有效性通常在下游任务(如图像-文本检索、指代表达、图像描述等)中通过 Flickr30K、MS-COCO 和类似的精选数据集进行研究。这些模型还表明,更大且更多样化的数据收集能够在下游任务中全面提升性能。
3 WIT: WIKIPEDIA IMAGE TEXT DATASET
3 WIT: 维基百科图文数据集
We would like to marry the benefits of curated datasets like Flickr30K and MS-COCO (consistent, high quality image text pairs) with those of extractive datasets like CC (automatically created and scalable), while also creating a multilingual and heterogeneous dataset. To do so, we leverage Wikipedia, which inherently uses crowd-sourcing in the data creation process – via its editorial review process – to ensure quality, freshness and accuracy of content. However, even Wikipedia extractions cannot be directly used as is, due to a plethora of low-information (e.g., generic) image-text associations which would not help VL learning. In the remainder of this section, we describe the WIT creation process and detail the filtering processes we introduced to ensure that only the most useful data is selected.
我们希望在结合Flickr30K和MS-COCO等精选数据集(一致、高质量的图文对)优势的同时,也能融合CC等提取式数据集(自动创建且可扩展)的优点,并创建一个多语言、异构的数据集。为此,我们利用维基百科,其数据创建过程本质上采用了众包方式——通过编辑审核流程——来确保内容的质量、新鲜度和准确性。然而,即便是维基百科的提取内容也不能直接使用,因为存在大量低信息量(例如通用型)的图文关联,这些内容对视觉语言(VL)学习并无帮助。在本节剩余部分,我们将描述WIT的创建过程,并详细介绍我们引入的过滤流程,以确保只选择最有用的数据。
3.1 Wikipedia Crawl Data
3.1 维基百科爬取数据
We started with all Wikipedia content pages (i.e., ignoring other pages that have discussions, comments and such). These number about ${\sim}124\mathrm{M}$ pages across 279 languages. We used a Flume [4] pipeline to program a tic ally process, filter, clean and store the Wikipedia data. We next extracted images and different texts related to the image along with some contextual metadata (such as the page URL, the page title, description . . . ). This yielded about ${\sim}150\mathrm{M}$ tuples of (image data, texts data, contextual data), which were the input to the different filters described in the subsequent sections. Note that there tends to be a wide variance of HTML formatting / layouts used for image captions across (and sometimes even within) Wikipedias in different languages, and hence our extraction rules needed to be particularly robust to ensure high coverage.
我们从所有维基百科内容页面开始(即忽略讨论、评论等其他页面)。这些页面涵盖279种语言,总计约${\sim}124\mathrm{M}$个页面。我们使用Flume[4]流水线对维基百科数据进行编程化处理、过滤、清理和存储。随后提取了图像及其相关文本(包括页面URL、标题、描述等上下文元数据),最终生成约${\sim}150\mathrm{M}$组(图像数据,文本数据,上下文数据)元组,作为后续章节所述过滤器的输入。需要注意的是,不同语言版本(甚至同一语言版本内)的维基百科对图像说明文字的HTML格式/排版存在显著差异,因此我们的提取规则必须具备极强的鲁棒性以确保高覆盖率。
Table 3: Statistics of the final WIT dataset and availability of different fields. Tuple refers to one entry in the dataset comprising the image, the three different possible texts and the context. Context texts include the page and (hierarchical) section titles and their respective descriptions
表 3: 最终WIT数据集的统计信息及各字段可用性。Tuple指数据集中包含图像、三种可能文本及上下文的单个条目。上下文文本包括页面及(层级)章节标题及其描述
| 类型 | 训练集 | 验证集 | 测试集 | 总数/唯一值 |
|---|---|---|---|---|
| 行数/Tuples | 37.13M | 261.8K | 210.7K | 37.6M |
| 唯一图像数 | 11.4M | 58K | 57K | 11.5M |
| 参考文本 | 16.9M | 150K | 104K | 17.2M/16.7M |
| 属性文本 | 34.8M | 193K | 200K | 35.2M/10.9M |
| 替代文本 | 5.3M | 29K | 29K | 5.4M/5.3M |
| 上下文文本 | - | - | - | 119.8M |
3.2 The Texts used in WIT
3.2 WIT 中使用的文本
The texts describing the images come from multiple different sources. The three directly associated with the image are:
描述图像的文本来自多个不同来源。与图像直接相关的三个来源是:
In addition to these, we also note that the context part of the tuple contains additional texts indirectly associated with the image (such as the section text or page title). A complete example of these texts, along with other metadata fields (as illustrated in Table 12) we provide and more detailed statistics are available on the WIT dataset Github page.
除了这些,我们还注意到元组中的上下文部分包含与图像间接相关的额外文本(如章节文本或页面标题)。我们提供的这些文本完整示例及其他元数字段(如表 12 所示)以及更详细的统计数据可在 WIT 数据集的 Github 页面上找到。
3.3 Text-based Filtering
3.3 基于文本的过滤
To clean the low-information texts, we:
为清理低信息量文本,我们:
(1) Only retained texts that were at least of length 3.
(1) 仅保留长度至少为3的文本。
3.4 Image & Image-Text based Filtering
3.4 基于图像及图文结合的过滤
We applied the following filters on the images in the tuples:
我们对元组中的图像应用了以下筛选条件:
3.5 Additional Filtering
3.5 附加过滤
To ensure a high-quality dataset free of inappropriate content, we removed tuples with questionable images or texts as done by previous works [28]. In particular we aimed to remove pornographic / profane / violent / . . . content using multiple techniques based on sophisticated image understanding and multilingual text understanding models. Overall these filters help improve data quality while only eliminating $<0.2%$ of all tuples.
为确保数据集的高质量并避免不当内容,我们按照先前研究[28]的做法移除了含有可疑图像或文本的元组。具体而言,我们基于先进的图像理解和多语言文本理解模型,采用多种技术手段来消除色情/亵渎/暴力等内容。总体而言,这些过滤器在仅剔除$<0.2%$元组的同时有效提升了数据质量。
Akin to other multilingual datasets (e.g., mC4 [38]), we restricted our initial version to only the top 100 languages and hence only retained tuples for languages with $12\mathrm{K}+$ tuples. Lastly we created partitioned the data into training, validation and test splits (with 50K images for the latter two) by ensuring that each image only occurs in a single split.
与其他多语言数据集(如 mC4 [38])类似,我们将初始版本限制为仅包含前100种语言,因此仅保留了包含$12\mathrm{K}+$元组的语言。最后,我们通过确保每张图片仅出现在单一划分中,将数据划分为训练集、验证集和测试集(后两者各包含50K张图片)。
3.6 Analyzing the WIT Data
3.6 WIT数据分析
As seen in Table 1, the resulting dataset is significantly larger than previous ones with over 37M (image, text(s), context) tuples, spanning 108 languages and covering 11.5 million unique images. Among its many unique aspects and firsts:
如表 1 所示,最终数据集规模远超以往,包含超过 3700 万组 (图像、文本、上下文) 元组,涵盖 108 种语言及 1150 万张独特图像。其多项首创特性包括:
• Multiple texts per image: WIT provides for multiple different kinds of texts per image. More than half of the tuples (19.4M) have two or more of reference, attribution and alt-texts. Table 3 provides some more detailed statistics of the coverage of the different texts. Overall with nearly 32M unique image-text pairs, WIT is nearly an order of magnitude larger than prior datasets.
• 单图多文本:WIT为每张图片提供多种不同类型的文本。超过一半的元组(19.4M)包含两种及以上文本(参考文本、署名文本和替代文本)。表3: 详细统计了各类文本的覆盖情况。总体而言,WIT拥有近3200万组独特的图文对,规模比现有数据集大近一个数量级。
Table 4: WIT: Image-Text Stats by Language
表 4: WIT: 按语言划分的图文统计
| 图文类型 | 语言数量 | 唯一图像数量 | 语言数量 |
|---|---|---|---|
| 总量 > 1M | 9 | 图像 > 1M | 6 |
| 总量 > 500K | 10 | 图像 > 500K | 12 |
| 总量 > 100K | 36 | 图像 > 100K | 35 |
| 总量 > 50K | 15 | 图像 > 50K | 17 |
| 总量 > 14K | 38 | 图像 > 13K | 38 |
• Highly multilingual: As seen in Table 4, WIT has broad multilingual coverage. Nearly half of the $100+$ languages, contain $100\mathrm{K}+$ unique image-text tuples and $100\mathrm{K}+$ unique images. • Large cross-lingual coverage: Images have shown great promise in helping build cross-lingual models [30, 31]. WIT can be used to generate $50\mathrm{M}+$ cross-lingual pairs (i.e., text descriptions in different languages for the same image) from 3.1M different images using just the reference and alt texts. We expect this number to be even higher when counting attributes, many of which are inherently multilingual. • Contextual understanding: WIT is also the first dataset, providing for understanding image captions in the context of the page and surrounding text (incl. $\sim120M$ contextual texts). For the sake of brevity we explore this in future work.
• 高度多语言性:如表4所示,WIT具有广泛的多语言覆盖。近半数的100多种语言包含超过10万组独特的图文元组和10万张独特图像。
• 大规模跨语言覆盖:图像在帮助构建跨语言模型方面展现出巨大潜力[30, 31]。仅通过参考文本和替代文本,WIT就能从310万张不同图像中生成超过5000万组跨语言对(即同一图像的不同语言文本描述)。若计入属性数据(许多属性本身具有多语言特性),这一数字预计会更高。
• 上下文理解:WIT还是首个支持在页面上下文及周边文本环境中理解图像描述的数据集(包含约1.2亿条上下文文本)。为简洁起见,我们将在后续工作中深入探讨这一特性。
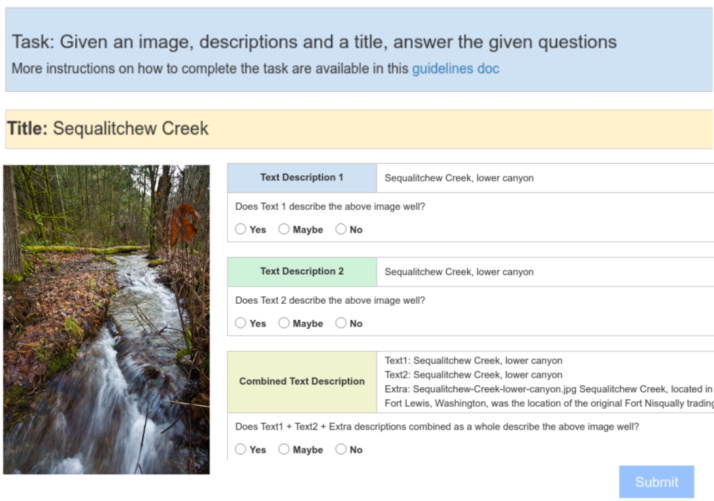
Figure 3: Human Annotation Template Example
图 3: 人工标注模板示例
3.7 Human Annotator Validation
3.7 人工标注验证
To further verify the quality of the WIT dataset we performed a study using (crowd-sourced) human annotators. As seen in Fig. 3, we asked raters to answer 3 questions. Given an image and the page title, raters first evaluate the quality of the attribution description and reference description in the first two questions (order randomized). The third question understands the contextual quality of these text descriptions given the page description and caption. Each response is on a 3-point scale: "Yes" if the text perfectly describes the image, "Maybe" if it is sufficiently explanatory and "No" if it is irrelevant or the image is inappropriate.
为进一步验证WIT数据集的质量,我们开展了(众包)人工标注研究。如图3所示,我们要求评估者回答3个问题。给定图像和页面标题后,评估者首先在前两个问题(顺序随机)中评判归属描述和参考描述的质量。第三个问题则结合页面描述和标题,评估这些文本描述的上下文质量。每个问题采用3级评分:"是"表示文本完美描述图像,"可能"表示描述基本合理,"否"表示无关或图像内容不当。
Table 5: Results of the human annotations of data quality. These examples and ratings are included with the dataset.
表 5: 数据质量人工标注结果。这些示例和评分已包含在数据集中。
| Text | EN | non-EN | ||||
|---|---|---|---|---|---|---|
| %Yes | %Maybe | %No | %Yes | %Maybe | %No | |
| Reference | 92.2 | 4.4 | 3.3 | 94.1 | 2.9 | 2.9 |
| Attribute | 92.2 | 3.3 | 4.6 | 93.1 | 0.8 | 6.2 |
| Contextual | 98.7 | 0.7 | 0.6 | 96.6 | 1.8 | 1.6 |
We randomly sampled nearly $4.4\mathrm{k}$ examples for this evaluation. To maximize rating quality we used a language identification filter on the attribution to show raters examples in the language of their expertise. In addition to rating $\sim3k$ examples in English, we also rated 300 examples in German, French, Spanish, Russian, Chinese and 100 examples for Hindi. (We chose these languages to capture different language families and different sizes – Hindi is only $65^{t h}$ in size). Each example was rated by three raters and majority label was used (Maybe being selected if no majority). As seen from the results in Table 5, an overwhelming majority of examples were found to be very helpful. Both reference and attribution were found to be high-quality (with a slight edge to reference description). The responses to the third question (which provides the page context) also validated our hypothesis that the relevance of image captions is influenced by the context as seen by the near-perfect ratings when considering the context. Lastly we found no major difference in performance across the different languages demonstrating the multilingual data quality.
我们随机抽取了近 $4.4\mathrm{k}$ 个样本进行评估。为确保评分质量,我们在归属信息上应用了语言识别过滤器,向评分者展示其擅长语言的样本。除了对 $\sim3k$ 个英语样本进行评分外,我们还评估了300个德语、法语、西班牙语、俄语、中文样本以及100个印地语样本(选择这些语言是为了覆盖不同语系和规模——印地语仅排名第 $65^{t h}$)。每个样本由三位评分者评定,采用多数标签(若无多数则选择"Maybe")。如表5所示,绝大多数样本被评为非常有用。参考描述和归属信息均被认为质量较高(参考描述略胜一筹)。第三个问题(提供页面上下文)的反馈也验证了我们的假设:图像说明的相关性受上下文影响,这一点从近乎完美的上下文相关评分中可见一斑。最后我们发现不同语言间的表现无显著差异,证明了多语言数据质量的一致性。
4 MULTIMODAL EXPERIMENTS WITH WIT
4 基于WIT的多模态实验
In this section, we empirically demonstrate the efficacy of the WIT dataset both as a pre training dataset as well as an evaluation set for a new image-text retrieval task.
在本节中,我们通过实验验证了WIT数据集作为预训练数据集以及新图像-文本检索任务评估集的有效性。
4.1 Experiment Details
4.1 实验细节
Model: For this analyses, we leveraged a two-tower or dual-encoder model, inspired by previous works that used them to learn multilingual, multimodal models [30]. As the name suggests, the model has two encoders – one to encoder the text and the other to represent the images. While the text input to the model was a bag of words, the image tower, the image was first embedded in a manner similar to [16]. The final embeddings of these two towers is then combined using their cosine similarity, which in turn is optimized using a batch softmax loss. The dual-encoder architecture is illustrated in Figure 4. Specifically, for a batch of $n$ image-text embedding pairs, the complete $n\times n$ similarity matrix is computed (the $(i,j)$ entry being the cosine of the $i^{t h}$ image embedding and $j^{t h}$ text embedding) and a softmax loss applied on each of the row. Note that only the diagonal entries are considered as positive pairs.
模型:本次分析采用双塔(dual-encoder)模型架构,其设计灵感来源于先前利用该结构训练多语言多模态模型的研究[30]。如名称所示,该模型包含两个编码器——文本编码器和图像编码器。文本输入采用词袋表示,而图像塔则参照[16]的方法进行嵌入处理。最终通过余弦相似度融合双塔输出的嵌入向量,并采用批次softmax损失进行优化。图4展示了该双编码器架构:对于包含$n$个图文嵌入对的批次,计算完整的$n×n$相似度矩阵(其中$(i,j)$项表示第$i$个图像嵌入与第$j$个文本嵌入的余弦值),并在每行应用softmax损失。需注意,仅对角线元素被视为正样本对。
Setup: We used a batch size of 128 for training and a batch size of 1000 for evaluation. The learning rate was set to 5e-7 The optimizer we used was SGD with Momentum. For the text encoder, we used a bag of words model (with ngrams of size 1 and 2). Each ngram was mapped to an a one amongst a million vocabulary buckets using a hash-function to get a 200D embedding. These ngram embeddings were then summed and passed through a simple FFNN and projected to a final 64D embedding, to match the size of the image encoder embedding. The final activation function we used was ReLU.
设置:训练时使用128的批量大小,评估时使用1000的批量大小。学习率设为5e-7,优化器采用带动量的SGD。文本编码器采用词袋模型(包含1元和2元语法),通过哈希函数将每个语法单元映射到百万级词桶中的一个,生成200维嵌入向量。这些语法嵌入经求和后输入简单前馈神经网络,最终投影为64维嵌入以匹配图像编码器的输出维度。激活函数选用ReLU。

Figure 4: WIT Dual Encoder Model for Training.
图 4: WIT 双编码器训练模型。
Table 6: Zero-shot evaluation for models using different text fields on WIT Image-Text Retrieval test sets
表 6: 不同文本字段模型在WIT图文检索测试集上的零样本评估
| 预训练设置 | 文本 | WIT-All R@1 | WIT-All R@5 | WIT-EN R@1 | WIT-EN R@5 | WIT-I18N R@1 | WIT-I18N R@5 |
|---|---|---|---|---|---|---|---|
| WIT | ref | 0.126 | 0.258 | 0.169 | 0.358 | 0.114 | 0.236 |
| WIT | attr | 0.293 | 0.55 | 0.272 | 0.523 | 0.293 | 0.523 |
| WIT | ref+attr | 0.346 | 0.642 | 0.344 | 0.64 | 0.344 | 0.633 |
| CC | text | 0.048 | 0.122 | 0.072 | 0.186 | 0.041 | 0.11 |
Evaluation: We evaluated the models on the Flickr30K, Multi30K and MS-COCO test sets, as well as the dedicated test sets released as part of WIT. We also spliced the WIT test sets into English-only and i18n (non-English) to understand any performance differences. In all experiments using WIT for pre training, we use the entire training set (i.e., data for all languages). We also pretrained a model with Conceptual Captions (CC) dataset to compare against.
评估:我们在Flickr30K、Multi30K和MS-COCO测试集以及WIT发布的专用测试集上对模型进行了评估。还将WIT测试集拆分为纯英文和国际化(i18n)非英语子集以分析性能差异。所有使用WIT进行预训练的实验中,我们均采用完整训练集(即包含所有语言数据)。同时使用Conceptual Captions (CC)数据集预训练了对照模型。
4.2 Evaluating a zero-shot pretrained model
4.2 评估零样本预训练模型
A common evaluation of image-text datasets is as a pre training dataset for a model, which is then directly applied to a downstream task – in our case image-text retrieval – without any finetuning (i.e., zero-shot). Since WIT contains multiple different texts associated with an image, we first set about understanding the effect of pretraining models on different fields. As seen in Table 6, the different WIT models all perform quite well on both English and non-English sets. The strongest performance was consistently obtained by the concatenation of reference and attribution descriptions – which we now default to for subsequent experiments. It is worth noting that the model pretrained on CC lags behind those trained on WIT, even on the English-only test set.
对图文数据集的常见评估方式是将其作为模型的预训练数据集,随后直接应用于下游任务(即零样本)。在我们的案例中,该任务是图文检索。由于WIT包含与图像相关联的多种不同文本,我们首先着手理解不同字段对预训练模型的影响。如表6所示,不同的WIT模型在英语和非英语数据集上都表现良好。最强的性能始终来自于参考描述和署名描述的拼接组合——我们现在默认将其用于后续实验。值得注意的是,即使在纯英语测试集上,基于CC预训练的模型表现也落后于基于WIT训练的模型。
To better understand this, we next evaluated the WIT and CC models (in this zero-shot manner) on popular English test collections from Flickr30K and MS-COCO which are more similar to CC. As seen in Table 7, the multilingual WIT model trails the English
为了更好地理解这一点,我们接下来在Flickr30K和MS-COCO这两个更接近CC的流行英文测试集上(以这种零样本方式)评估了WIT和CC模型。如表7所示,多语言WIT模型在英语...
Table 7: Zero-shot Evaluation on Flickr30K, MS-COCO and WIT test sets for Image-Text Retrieval Task
表 7: Flickr30K、MS-COCO 和 WIT 测试集在图文检索任务中的零样本评估
| Pretrain | MS-COCO | Flickr30K | WIT-ALL | |||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@1 | R@5 | R@1 | R@5 | |
| WIT-ALL | 0.074 | 0.228 | 0.054 | 0.165 | 0.346 | 0.642 |
| CC | 0.145 | 0.385 | 0.111 | 0.32 | 0.048 | 0.122 |
Table 8: Zero-shot Evaluation on Multi30K and WIT I18N test sets (CS, DE, FR) for Image-Text Retrieval Task
表 8: 在 Multi30K 和 WIT I18N 测试集 (CS, DE, FR) 上对图文检索任务进行的零样本评估
| Exp | Multi30K-R@5 | WIT-R@5 | ||||
|---|---|---|---|---|---|---|
| CS | DE | FR | CS | DE | FR | |
| WIT-ALL | 0.006 | 0.005 | 0.006 | 0.553 | 0.562 | 0.599 |
| CC | 0.004 | 0.005 | 0.004 | 0.096 | 0.084 | 0.104 |
Table 9: Zero-shot and Finetuned Evaluation on Wiki (Image, Page Title) test set for Retrieval Task
表 9: Wiki (图像, 页面标题) 测试集在检索任务上的零样本和微调评估
| Exp | Finetuning | WIT-All R@1 | WIT-All R@3 | WIT-All R@5 |
|---|---|---|---|---|
| WIT-EN | None | 0.067 | 0.122 | 0.152 |
| CC | None | 0.012 | 0.024 | 0.032 |
| WIT-ALL | WIT-ALL | 0.1 | 0.174 | 0.214 |
| CC | CC | 0.01 | 0.021 | 0.029 |
CC model on these collections, though not as significantly as the gap between WIT and CC on the heldout WIT test sets.
这些集合上的CC模型表现,虽然不如WIT和CC在保留WIT测试集上的差距那么显著。
4.3 Understanding multilingual performance
4.3 理解多语言性能
Since WIT encompasses examples from $100+$ languages, we next evaluated how multilingual the WIT-based models are. For this, we used Multi30K’s three language test sets (Czech (CS), German (DE) and French (FR)). We generated similar language subset datasets from the WIT test set for the same languages (CS, DE, FR) and used that for evaluation. As shown in Table 8, both models struggle on the Multi30K dataset, though again the WIT model shines on the held-out WIT test set. Similar to the Flickr30k dataset, the Multi30k datasets are quite different from the WIT datasets (as we discuss in Sec. 4.5) which may explain this behavior.
由于WIT涵盖100多种语言的示例,我们接下来评估了基于WIT模型的多语言能力。为此,我们使用了Multi30K的三个语言测试集(捷克语(CS)、德语(DE)和法语(FR)),并从WIT测试集中生成了相同语言(CS、DE、FR)的子集数据集用于评估。如表8所示,两个模型在Multi30K数据集上表现均不理想,但WIT模型在保留的WIT测试集上再次表现优异。与Flickr30k数据集类似,Multi30k数据集与WIT数据集存在较大差异(如第4.5节所述),这可能是导致该现象的原因。
4.4 Evaluation On (Image, Wiki Page Title) Retrieval Task
4.4 (图像, 维基百科页面标题)检索任务评估
Lastly, we evaluated on a real-world task that’s based on Wikipedia. This retrieval task requires identifying images that can be found on a given Wikipedia page, using only the page title. We ran this evaluation in both a zero-shot setting (i.e., pretrained model directly) and with finetuning on the training set. Unlike the above experiments, here the input to the text encoder was the page title directly. The evaluation was done with the held-out WIT test split using the page title as text. From Table 9, we clearly observe a large performance gain on this task using WIT relative to the CC model both with and without finetuning.
最后,我们在一个基于Wikipedia的真实任务上进行了评估。该检索任务要求仅使用页面标题识别给定Wikipedia页面上能找到的图像。我们在零样本设置(即直接使用预训练模型)和训练集微调两种情况下都进行了评估。与上述实验不同,此处文本编码器的输入直接是页面标题。评估使用保留的WIT测试集分割,以页面标题作为文本。从表9可以明显看出,无论是否进行微调,WIT模型在此任务上的性能都显著优于CC模型。
Table 10: Vocabulary Comparison
表 10: 词汇对比
| 数据集 | 一元词 | 频率≤3 | 频率≤3占比 |
|---|---|---|---|
| CC | 149,924 | 63,800 | 42.55% |
| WIT (参考) | 867,906 | 625,100 | 72.02% |
Table 11: Language Model Comparison
表 11: 语言模型对比
| 数据集 A vs B | JSD |
|---|---|
| Flickrvs Flickr Test | 0.1679 |
| COCOvsCOCOTest | 0.1008 |
| CC vs Flickr Test | 0.4844 |
| CCvs COCOTest | 0.4746 |
| CCvsWIT | 0.3825 |
| WITvsFlickrTest | 0.6007 |
| WITvsCOCOTest | 0.5957 |
4.5 Discussion
4.5 讨论
The above experiments clearly demonstrated that WIT-based pretrained models perform extremely well ( $\mathrm{5x+}$ gains) on the evaluation sets based on Wikipedia data. However, the models do not do as well on other image-text datasets (Flickr30K/Multi30k and MS-COCO). Since the WIT dataset is not lacking in size or diversity, we probed further into what makes these evaluation sets so different from each other.
上述实验清楚地表明,基于WIT的预训练模型在基于维基百科数据的评估集上表现极佳(提升5倍以上)。然而,这些模型在其他图文数据集(Flickr30K/Multi30k和MS-COCO)上表现不佳。由于WIT数据集在规模和多样性上并不欠缺,我们进一步探究了这些评估集之间存在差异的原因。
4.5.1 Vocabulary Analysis. We first analyzed the vocabulary of the two datasets we used for pre training $:$ WIT and CC. Since Wikipedia is entity heavy with a diverse concept pool, we suspected that the vocabulary of the WIT dataset may reflect this. As shown in Table 10, this was the case with over $72%$ of WIT unigrams occurring 3 times or less (vs. $43%$ for CC).
4.5.1 词汇分析。我们首先分析了用于预训练的两个数据集WIT和CC的词汇表。由于维基百科具有实体密集且概念多样化的特点,我们推测WIT数据集的词汇可能反映了这一特性。如表10所示,超过72%的WIT单字词出现次数不超过3次(而CC数据集这一比例为43%)。
4.5.2 Language Model. This difference is even more stark when compared to the test collections used for evaluation (COCO and Flickr). When we compared the unigram distributions of different data sets using the Jensen-Shannon Divergence (JSD), we found a massive difference in the vocabularies and concept coverage of the data (see Table 11). While the fact that less than a sixth of WIT is English skews these results slightly, the gap between the English-only slice and other datasets remains sizeable.
4.5.2 语言模型。与评估使用的测试集(COCO和Flickr)相比,这种差异更为显著。当我们使用Jensen-Shannon散度(JSD)比较不同数据集的单字分布时,发现数据在词汇和概念覆盖上存在巨大差异(见表11)。尽管WIT中英语内容占比不足六分之一这一事实会轻微影响结果,但纯英语数据切片与其他数据集之间的差距仍然相当可观。
4.5.3 Image entity Analysis. Part of the reason for this difference is the broad coverage of entities in the WIT dataset. Using an image classification model to tag all WIT images with entities, we found that amongst the ${\sim}4.5\mathrm{M}$ entities identified, a large number $(\ge80%$ i.e., ${\sim}3.68\mathrm{M},$ ) of the entities occur 3 times or less. Thus similar to the texts, the image data too is very diverse with not much repetition.
4.5.3 图像实体分析。造成这种差异的部分原因是WIT数据集中实体的广泛覆盖范围。使用图像分类模型为所有WIT图像打上实体标签后,我们发现,在识别出的约450万个实体中,大量实体(≥80%,即约368万个)出现次数不超过3次。因此,与文本数据类似,图像数据也非常多样化,重复率不高。
4.5.4 Key differences in texts. Text fields in WIT often tend to be descriptive, verbose and use specific terminology. However this causes a mismatch when evaluated on the test collections, which are often terse single line captions of common words and objects. The choice of bag of words likely exacerbates this issue. Perhaps the most important difference is the use of specifics vs general words. As found in the CC work [28], text hyper ny miz ation was crucial to creating a dataset closer to those used for evaluation. For example a text like Two sculptures by artist Duncan McKellar adorn trees outside the derelict Norwich Union offices in Bristol, UK would be transformed to sculptures by person adorn trees outside the derelict offices so as to remove specifics (person names, locations, times etc ..). This is likely the biggest reason why our trained models under performed on the existing collections. While there are benefits and drawbacks of such hyper ny miz ation, we would like to add this in future versions. However there remains significant challenges doing such replacements for a $100+$ language dataset consistently and with high quality across languages.
4.5.4 文本关键差异。WIT中的文本字段通常具有描述性、冗长且使用特定术语的特点。然而当在测试集上评估时会产生不匹配,这些测试集往往是使用常见词汇和物体组成的简短单行标题。词袋模型的选择可能加剧了这一问题。最重要的差异或许在于具体词汇与通用词汇的使用。如CC工作[28]所示,文本超规范化对创建更接近评估所用数据集至关重要。例如将"英国布里斯托尔废弃的Norwich Union办公室外,艺术家Duncan McKellar的两件雕塑装饰着树木"转化为"废弃办公室外由人物创作的雕塑装饰着树木",以此移除具体信息(人名、地点、时间等)。这很可能是我们训练的模型在现有数据集上表现不佳的最大原因。尽管这种超规范化存在利弊,我们仍希望在后续版本中加入该功能。但对一个包含100多种语言的数据集进行高质量、跨语言一致的替换仍存在重大挑战。
5 FUTURE WORK
5 未来工作
In our eagerness and excitement to share the WIT Dataset with the research community, we have just touched the tip of the iceberg by starting out with an image-text retrieval task using a simple dual encoder model. Given the superior performance of cross-attention multimodal transformer models, WIT can potentially be used in lieu of or in addition to the existing pre training datasets in models as illustrated by UNITER, Unicoder-VL, VL-BERT, . . . etc. A range of new i18n tasks can be formulated with WIT as the basis for VQA, VCR and many others. Similarly, more specific i18n retrieval or captioning tasks for low resource languages are yet to be explored. There is also the possibility of using multi modality to enhance multilingual performance. WIT Dataset provides a cross lingual corpus of text for the same image which could aid in this idea. We also hope to leverage the knowledge base and entities and attributes of WIT to improve Q&A tasks.
在我们热切期待与研究社区分享WIT数据集之际,我们仅以简单的双编码器模型开展图像-文本检索任务,初步触及了冰山一角。鉴于跨模态注意力Transformer模型的卓越性能,WIT有望替代或补充现有预训练数据集(如UNITER、Unicoder-VL、VL-BERT等模型所示)。基于WIT可构建一系列新的国际化(i18n)任务,包括视觉问答(VQA)、视觉常识推理(VCR)等。同样,针对低资源语言的特定国际化检索或字幕生成任务仍有待探索。利用多模态提升多语言性能也存在可能——WIT数据集为同一图像提供的跨语言文本语料库可助力这一构想。我们期待进一步利用WIT的知识库、实体及属性来增强问答任务性能。
6 CONCLUSION
6 结论
In this paper we introduced the Wikipedia Image Text (WIT) dataset – the largest (at time of writing), multilingual, multimodal, contextrich dataset. By extracting texts associated with images and their surrounding contexts from over a 100 languages, WIT provides for a rich and diverse dataset. As a result, it is well suited for use in a myriad of ways including pre training multimodal models, finetuning image-text retrieval models or building cross-lingual representations to name a few. Our detailed analysis and quality evaluation, validate that WIT is a high quality dataset with strong image-text alignment. We also empirically demonstrated the use of this dataset as both a pre training and finetuning set, and in the process uncovered some shortcomings of existing datasets. We believe this can serve as a rich resource to drive research in the multilingual, multimodal space for years to come and enable the community to building better and more robust visio-linguistic models well suited to real world tasks.
本文介绍了维基百科图文数据集(Wikipedia Image Text, WIT)——当前规模最大、多语言、多模态、上下文丰富的开源数据集。通过从100多种语言中提取与图像相关的文本及其上下文内容,WIT构建了一个丰富多样的数据集。该数据集非常适合用于多模态模型预训练、图文检索模型微调、跨语言表征构建等多种场景。我们的详细分析与质量评估表明,WIT具有优质的图文对齐特性。通过实证研究,我们验证了该数据集在预训练和微调中的应用价值,并在此过程中发现了现有数据集的一些缺陷。我们相信,该数据集将成为未来多年推动多语言多模态研究的重要资源,助力学界构建更强大、更鲁棒的视觉语言模型,以更好地应对现实世界任务。