Pillars of Grammatical Error Correction: Comprehensive Inspection Of Contemporary Approaches In The Era of Large Language Models
语法错误纠正的支柱:大语言模型时代下当代方法的全面审视
Abstract
摘要
In this paper, we carry out experimental research on Grammatical Error Correction, delving into the nuances of single-model systems, comparing the efficiency of ensembling and ranking methods, and exploring the application of large language models to GEC as singlemodel systems, as parts of ensembles, and as ranking methods. We set new state-of-theart performance 1 with $F_{0.5}$ scores of 72.8 on CoNLL-2014-test and 81.4 on BEA-test, respectively. To support further advancements in GEC and ensure the reproducibility of our research, we make our code, trained models, and systems’ outputs publicly available.2
本文对语法纠错(Grammatical Error Correction)进行了实验研究,深入探讨了单模型系统的细节,比较了集成与排序方法的效率,并探索了大语言模型在GEC中的应用——包括作为单模型系统、集成组件以及排序方法。我们在CoNLL-2014-test和BEA-test测试集上分别取得了72.8和81.4的$F_{0.5}$分数,创造了新的最先进性能[1]。为支持GEC领域的进一步发展并确保研究的可复现性,我们公开了代码、训练模型及系统输出结果[2]。
may work surprisingly well. Combining singlemodel systems is also often straightforward from an implementation perspective. Because only the outputs of the models are required for many ensembling algorithms, there is no need to retrain models or perform inference passes iterative ly. A further review of related work is presented in the end and near the descriptions of considered methods.
效果可能出奇地好。从实现角度来看,单模型系统的组合通常也很简单。由于许多集成算法只需要模型的输出,因此无需重新训练模型或迭代执行推理过程。相关工作的进一步综述将在最后部分及所考虑方法的描述附近呈现。
Our contributions are the following:
我们的贡献如下:
- Comprehensive comparison of GEC methods. We reproduce, evaluate, and compare the most promising existing methods in GEC, both singlemodel systems and ensembles. We show that usage of ensembling methods is crucial to obtain state-ofthe-art performance in GEC.
- GEC方法的全面对比。我们复现、评估并比较了GEC领域最有前景的现有方法,包括单模型系统和集成系统。研究表明,集成方法的使用对于在GEC中实现最先进性能至关重要。
1 Introduction
1 引言
Grammatical Error Correction (GEC) is the task of correcting human text for spelling and grammatical errors. There is a wide variety of GEC approaches and model architectures. In recent years, most systems have used Transformer-based architectures (Bryant et al., 2023). A current trend involves writing prompts for Large Language Models (LLMs) such as GPT-4 (OpenAI, 2023) that would generate grammatical corrections (Loem et al., 2023), (Coyne et al., 2023), (Wu et al., 2023), (Fang et al., 2023).
语法错误修正 (GEC) 的任务是纠正人类文本中的拼写和语法错误。GEC 方法和模型架构多种多样。近年来,大多数系统都采用了基于 Transformer 的架构 (Bryant et al., 2023)。当前趋势涉及为 GPT-4 (OpenAI, 2023) 等大语言模型编写提示,以生成语法修正 (Loem et al., 2023)、(Coyne et al., 2023)、(Wu et al., 2023)、(Fang et al., 2023)。
The varied approaches within GEC each possess unique strengths and limitations. Combining several single-model GEC systems through ensembling or ranking may smooth out their weaknesses and lead to better overall performance (Susanto et al., 2014). Even quite simple ensembling methods, such as majority voting (Tarnavskyi et al., 2022) or logistic regression (Qorib et al., 2022),
GEC中的各种方法各有其独特的优势和局限性。通过集成或排序结合多个单模型GEC系统,可以弥补各自的不足,从而提升整体性能 (Susanto et al., 2014)。即便是多数投票 (Tarnavskyi et al., 2022) 或逻辑回归 (Qorib et al., 2022) 这类简单的集成方法也能发挥作用。
- Establishing new state-of-the-art baselines. We show that simple ensembling by majority vote outperforms more complex approaches and significantly boosts performance. We push the boundaries of GEC quality and achieve new state-of-the-art results on the two most common GEC evaluation datasets: $F_{0.5}=72.8$ on CoNLL-2014-test and $F_{0.5}=81.4$ on BEA-test.
- 建立新的最先进基线。我们证明,通过多数投票的简单集成方法优于更复杂的方法,并显著提升性能。我们突破了语法纠错(GEC)质量的边界,在两个最常用的GEC评估数据集上取得了新的最先进成果:在CoNLL-2014-test上达到 $F_{0.5}=72.8$,在BEA-test上达到 $F_{0.5}=81.4$。
- Exploring the application of LLMs for GEC. We thoroughly investigate different scenarios for leveraging large language models (LLMs) for GEC: 1) as single-model systems in a zero-shot setting, 2) as fine-tuned single-model systems, 3) as single-model systems within ensembles, and 4) as a combining algorithm for ensembles. To the best of our knowledge, we are the first to explore using GPT-4 to rank GEC edits, which contributes to a notable improvement in the Recall of ensemble systems.
- 探索大语言模型 (LLM) 在语法错误纠正 (GEC) 中的应用。我们深入研究了利用大语言模型进行语法错误纠正的不同场景:1) 作为零样本设置下的单模型系统,2) 作为微调后的单模型系统,3) 作为集成系统中的单模型系统,以及4) 作为集成系统的组合算法。据我们所知,我们是首个探索使用 GPT-4 对语法错误纠正的编辑进行排序的研究,这显著提升了集成系统的召回率 (Recall)。
- Commitment to open science. In a move toward fostering transparency and encouraging further research, we open-source all our models, their outputs on evaluation datasets, and the accompanying code.2 This ensures the reproducibility of our work and provides a foundation for future advancements in the field.
- 致力于开放科学。为了促进透明度和鼓励进一步研究,我们开源了所有模型、它们在评估数据集上的输出以及配套代码。这确保了工作的可复现性,并为该领域的未来发展奠定了基础。
2 Data for Training and Evaluation
2 训练与评估数据
We use the following GEC datasets for training models (Table 1):
我们使用以下GEC数据集训练模型(表1):
- Lang-8, an annotated dataset from the Lang-8 Corpus of Learner English (Tajiri et al., 2012); 2. NUCLE, the National University of Singapore Corpus of Learner English (Dahlmeier et al., 2013); 3. FCE, the First Certificate in English dataset (Yann a kou dak is et al., 2011); 4. W&I, the Write & Improve Corpus (Bryant et al., 2019) (also known as BEA-Train). We also use a larger synthetic version of Lang-8 with target sentences produced by the T5 model (Raffel et al., 2020); 5. cLang-8 (Rothe et al., 2021), and synthetic data based on two monolingual datasets; 6. Troy-1BW (Tarnavskyi et al., 2022), produced from the One Billion Word Benchmark (Chelba et al., 2014); 7. Troy-Blogs (Tarnavskyi et al., 2022), produced from the Blog Authorship Corpus (Schler et al., 2006).
- Lang-8:来自Lang-8学习者英语语料库的标注数据集 (Tajiri et al., 2012);
- NUCLE:新加坡国立大学学习者英语语料库 (Dahlmeier et al., 2013);
- FCE:英语初级证书考试数据集 (Yannakoudakis et al., 2011);
- W&I:Write & Improve语料库 (Bryant et al., 2019)(亦称BEA-Train)。我们还使用了T5模型 (Raffel et al., 2020) 生成目标句的Lang-8增强合成版本;
- cLang-8 (Rothe et al., 2021),以及基于两个单语数据集的合成数据;
- Troy-1BW (Tarnavskyi et al., 2022),源自十亿词基准语料库 (Chelba et al., 2014);
- Troy-Blogs (Tarnavskyi et al., 2022),源自博客作者语料库 (Schler et al., 2006)。
Table 1: Statistics of GEC datasets used in this work for training and evaluation.
表 1: 本工作用于训练和评估的GEC数据集统计。
| # | 数据集 | 部分 | 句子数 | Token数 | 编辑比例(%) |
|---|---|---|---|---|---|
| 1 | Lang-8 | 训练集 | 1.04M | 11.86M | 42 |
| 2 | NUCLE | 训练集 | 57.0k | 1.16M | 62 |
| 3 | FCE | 测试集 训练集 | 1.3k 28.0k | 30k 455k | 90 62 |
| 4 | W&I+LOCNESS | 训练集 开发集 | 34.3k 4.4k | 628.7k 85k | 67 64 |
| 5 | cLang-8 | 测试集 训练集 | 4.5k 2.37M | 62.5k 28.0M | N/A 58 |
| 6 | Troy-1BW | 训练集 | 1.2M | 30.88M | 100 |
| 7 | Troy-Blogs | 训练集 | 1.2M | 21.49M | 100 |
For evaluation, we use current standard evaluation sets for the GEC domain: the test set from the CoNLL-2014 GEC Shared Task $\mathrm{Ng}$ et al., 2014), and the dev and test components of the W&I $^+$ LOCNESS Corpus from the BEA-2019 GEC Shared Task (BEA-dev and BEA-test) (Bryant et al., 2019). For BEA-test, submissions were made through the current competition website.3 For each dataset, we report Precision, Recall, and $F_{0.5}$ scores. To ensure an apples-to-apples comparison with previously reported GEC results, we evaluate CONLL-2014-test with M2scorer (Dahlmeier and
为评估效果,我们采用当前语法纠错(GEC)领域的标准评测集:来自CoNLL-2014语法纠错共享任务的测试集(Ng等人,2014),以及BEA-2019语法纠错共享任务中W&I+LOCNESS语料库的开发集和测试集(BEA-dev和BEA-test)(Bryant等人,2019)。针对BEA-test数据集,我们通过竞赛官网提交了系统输出。对于每个数据集,我们汇报了精确率(Precision)、召回率(Recall)和F0.5分数。为确保与既往语法纠错研究结果的可比性,我们使用M2scorer(Dahlmeier和...
Ng, 2012), and BEA-dev with ERRANT (Bryant et al., 2017).
Ng, 2012), 以及基于ERRANT的BEA-dev (Bryant et al., 2017)。
3 Single-Model Systems
3 单模型系统
3.1 Large Language Models
3.1 大语言模型 (Large Language Models)
We investigate the performance of open-source models from the LLaMa-2 family (Touvron et al., 2023), as well as two proprietary models: GPT3.5 (Chat-GPT) and GPT-4 (OpenAI, 2023). For LLaMa, we work with four models: LLaMa-2- 7B, LLaMa-2-13B, Chat-LLaMa-2-7B, and ChatLLaMa-2-7B. We use two LLaMa-2 model sizes: 7B and 13B. If the model is pre-trained for instruction following (Ouyang et al., 2022), it is denoted as "Chat-" in the model’s name.
我们研究了LLaMa-2系列(Touvron等人,2023)开源模型以及两个专有模型:GPT3.5(Chat-GPT)和GPT-4(OpenAI,2023)的性能。对于LLaMa,我们测试了四个模型:LLaMa-2-7B、LLaMa-2-13B、Chat-LLaMa-2-7B和ChatLLaMa-2-7B。我们使用了两种LLaMa-2模型规模:7B和13B。若模型经过指令跟随预训练(Ouyang等人,2022),其名称会标注为"Chat-"前缀。
Chat-GPT and GPT-4 are accessed through the Microsoft Azure API. We use versions gpt-3.5- turbo-0613 and gpt-4-0613, respectively.
Chat-GPT和GPT-4通过Microsoft Azure API访问。我们分别使用gpt-3.5-turbo-0613和gpt-4-0613版本。
We explore two scenarios for performing GEC using LLMs: zero-shot prompting (denoted as "ZS") and fine-tuning (denoted as "FT").
我们探索了使用大语言模型进行语法纠错(GEC)的两种场景:零样本提示(记为"ZS")和微调(记为"FT")。
3.1.1 Zero-Shot Prompting
3.1.1 零样本 (Zero-Shot) 提示
In recent studies dedicated to prompting LLMs for GEC, it was shown that LLM models tend to produce more fluent rewrites (Coyne et al., 2023). At the same time, performance measured by automated metrics such as MaxMatch (Dahlmeier and $\mathrm{Ng},2012)$ or ERRANT has been identified as inferior. We frequently observed that these automated metrics do not always correlate well with human scores. This makes LLMs used in zero-shot prompting mode potentially attractive, especially in conjunction with other systems in an ensemble.
在最近针对大语言模型(GEC)提示的研究中,研究表明LLM模型倾向于生成更流畅的改写(Coyne等人,2023)。同时,通过MaxMatch (Dahlmeier和Ng,2012)或ERRANT等自动化指标衡量的性能被认为较差。我们经常观察到这些自动化指标并不总是与人类评分很好地相关。这使得在零样本提示模式下使用的大语言模型可能具有吸引力,特别是在与其他系统集成时。
For the Chat-LLaMa-2 models, we use a twotiered prompting approach that involves setting the system prompt "You are a writing assistant. Please ensure that your responses consist only of corrected texts." to provide the context to direct the model focus toward GEC task. Then, we push the following instruction prompt to direct the model’s focus toward the GEC task:
对于Chat-LLaMa-2模型,我们采用双层提示策略:首先设置系统提示"你是一个写作助手。请确保你的回复仅包含修正后的文本",为模型提供指向语法纠错(GEC)任务的上下文;随后推送以下指令提示进一步引导模型聚焦于GEC任务:
Fix grammatical errors for the following text.
修正以下文本的语法错误。
Temperature is set to 1. For Chat-GPT and GPT4 models, we employ a function-calling API with the "required" parameter. This guides the LLM to more accurately identify and correct any linguistic errors within the text or replicate the input text if it was already error-free, thus ensuring consistency in the models’ responses. The instruction prompt for GPT models is:
温度设置为1。对于Chat-GPT和GPT4模型,我们使用带有"required"参数的函数调用API。这可以引导大语言模型更准确地识别并纠正文本中的语言错误,或在输入文本无误时直接复制,从而确保模型响应的一致性。GPT模型的指令提示为:
Table 2: All single-model systems evaluated on CoNLL-2014-test, BEA-dev, and BEA-test datasets.
| # | CoNLL-2014-test | BEA-dev | BEA-test | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| System | Precision | Recall F0.5 | Precision | Recall | F0.5 | Precision | Recall | F0.5 | ||
| 1 | Chat-LLaMa-2-7B-ZS | 42.9 | 47.3 | 43.7 | 19.1 | 34.1 | 21.0 | |||
| 2 | Chat-LLaMa-2-13B-ZS | 49.1 | 56.1 | 50.4 | 30.6 | 45.0 | 32.7 | |||
| 3 | GPT-3.5-ZS | 56.2 | 57.7 | 56.5 | 37.4 | 50.6 | 39.4 | 1 | ||
| 4 | GPT-3.5-CoT-ZS | 56.0 | 58.7 | 56.5 | 36.4 | 50.8 | 38.5 | |||
| 5 | GPT-4-ZS | 59.0 | 55.4 | 58.2 | 42.5 | 45.0 | 43.0 | - | 1 | - |
| 6 | Chat-LLaMa-2-7B-FT | 75.5 | 46.8 | 67.2 | 58.3 | 46.0 | 55.3 | 72.3 | 67.4 | 71.2 |
| 7 | Chat-LLaMa-2-13B-FT | 77.3 | 45.6 | 67.9 | 59.8 | 46.1 | 56.4 | 74.6 | 67.8 | 73.1 |
| 8 | T5-11B | 70.9 | 56.5 | 67.5 | 60.9 | 51.1 | 58.6 | 73.2 | 71.2 | 72.8 |
| 9 | UL2-20B | 73.8 | 50.4 | 67.5 | 60.5 | 48.6 | 57.7 | 75.2 | 70.0 | 74.1 |
| 10 | GECToR-2024 | 75.0 | 44.7 | 66.0 | 64.6 | 37.2 | 56.3 | 77.7 | 59.0 | 73.1 |
| 11 | CTC-Copy | 72.6 | 47.0 | 65.5 | 58.3 | 38.0 | 52.7 | 71.7 | 59.9 | 69.0 |
| 12 | EditScorer | 78.5 | 39.4 | 65.5 | 67.3 | 36.1 | 57.4 | 81.0 | 56.1 | 74.4 |
表 2: 在 CoNLL-2014-test、BEA-dev 和 BEA-test 数据集上评估的所有单模型系统。
Fix all mistakes in the text (spelling, punctuation, grammar, etc). If there are no errors, respond with the original text.
修正文本中的所有错误(拼写、标点、语法等)。如果没有错误,则返回原文。
Additionally, we employ a form of the chain-ofthought (CoT) prompting (Wei et al., 2022), which involves requesting reasoning from the model before it makes corrections by means of function calling.
此外,我们采用了一种思维链 (chain-of-thought, CoT) 提示方法 [20],即在模型通过函数调用进行修正前,要求其先给出推理过程。
3.1.2 Fine-tuning the Large Language Models
3.1.2 大语言模型 (Large Language Model) 微调
Fine-tuning is a mainstream method for knowledge transfer. Since we have several available annotated GEC datasets, they may be used to fine-tune LLMs (Zhang et al., 2023b; Kaneko and Okazaki, 2023).
微调 (fine-tuning) 是知识迁移的主流方法。由于我们拥有多个可用的标注 GEC 数据集,它们可用于对大语言模型进行微调 (Zhang et al., 2023b; Kaneko and Okazaki, 2023)。
We use three datasets for fine-tuning — NUCLE, W&I, and cLang-8 (Table 1) — as they are commonly used in recent GEC research (Zhang et al., 2023b; Kaneko and Okazaki, 2023; Loem et al., 2023). We varied the datasets and their shares to find the best combination.
我们使用了三个数据集进行微调——NUCLE、W&I和cLang-8 (表 1) ——因为它们最近在GEC研究中被广泛使用 (Zhang et al., 2023b; Kaneko and Okazaki, 2023; Loem et al., 2023)。我们调整了数据集及其比例以寻找最佳组合。
We use the Transformers library4 to conduct 1000–1200 updates with 250 warm-up steps, a batch size of 8, and a learning rate of $1e-5$ . We fine-tune only LLaMA-2 models on next token prediction task, both autocomplete and instructionfollowing pre-trained versions (denoted as "Chat"). For the Chat-LLaMA-2 models, we use the following prompt:
我们使用Transformers库4进行1000-1200次更新,包含250步预热,批量大小为8,学习率为$1e-5$。我们仅针对下一个token预测任务微调LLaMA-2模型,包括自动补全和指令跟随预训练版本(标记为"Chat")。对于Chat-LLaMA-2模型,我们使用以下提示:
Additionally, we perform an ablation study on the models’ size and the usefulness of the instructions (Appendix D, Table 11). Not surprisingly, our results indicate that instructions work better for "Chat" versions of models.
此外,我们对模型规模和指令有效性进行了消融研究(附录D,表11)。不出所料,结果表明指令对模型的"Chat"版本效果更好。
3.2 Sequence-to-Sequence models
3.2 序列到序列模型
In a sequence-to-sequence approach, GEC is considered a machine translation task, where errorful sentences correspond to the source language, and error-free sentences correspond to the target language (Gr und kiew i cz et al., 2019; Kiyono et al., 2019). In this work, we investigate two powerful Transformer-based Seq2Seq models: the opensourced "T5-11B" (Rothe et al., 2021), and "UL2- $20\mathrm{B"}$ , the instruction-tuned version of FLAN (Tay et al., 2022).
在序列到序列方法中,语法错误纠正(GEC)被视为机器翻译任务,其中错误句子对应源语言,无误句子对应目标语言 (Gr und kiew i cz et al., 2019; Kiyono et al., 2019)。本研究探索了两种基于Transformer的强效Seq2Seq模型:开源模型"T5-11B" (Rothe et al., 2021) 和指令调优版FLAN模型"UL2-$20\mathrm{B"}$ (Tay et al., 2022)。
T5-11B is fine-tuned on train data for 500 updates with batch size 256 and a learning rate of $1e-4$ . UL2-20B is fine-tuned on W& $\mathrm{\Delta}1+\mathrm{LOCNESS}$ train data for 300 updates with batch size 16 and a learning rate of $5e-5$ .
T5-11B在训练数据上进行了500次微调,批次大小为256,学习率为$1e-4$。UL2-20B在W&$\mathrm{\Delta}1+\mathrm{LOCNESS}$训练数据上进行了300次微调,批次大小为16,学习率为$5e-5$。
3.3 Edit-based Systems
3.3 基于编辑的系统
Edit-based GEC systems produce explicit text changes, restoring error-free language from the errorful source text. Usually, such systems are based on encoder-only architectures and are nonauto regressive; therefore, they are less resourceconsuming and more attractive for product iz ation. In this work, we consider three publicly available open-source edit-based systems for GEC: GECToR, CTC-Copy, and EditScorer.
基于编辑的语法纠错 (GEC) 系统通过显式文本修改,将含错误的源文本恢复为规范表达。这类系统通常采用仅编码器 (encoder-only) 架构且非自回归 (nonautoregressive) 设计,因此资源消耗更低,更易于产品化。本文研究了三个开源的编辑式语法纠错系统:GECToR、CTC-Copy 和 EditScorer。
GECToR5 (Ome lian ch uk et al., 2020), (Tarnavskyi et al., 2022) is a family of nonauto regressive sequence tagging GEC systems. The concept revolves around training Transformerbased, encoder-only models to generate corrective edits.
GECToR5 (Ome lian ch uk et al., 2020), (Tarnavskyi et al., 2022) 是一系列非自回归序列标注的语法纠错 (GEC) 系统。其核心思想是训练基于Transformer的纯编码器模型来生成纠正性编辑。
CTC-Copy6 (Zhang et al., 2023a) is another nonauto regressive text editing approach. It uses Connectionist Temporal Classification (CTC) (Graves et al., 2006) initially developed for automatic speech recognition and introduces a novel text editing method by modeling the editing process with latent CTC alignments. This allows more flexible editing operations to be generated.
CTC-Copy6 (Zhang et al., 2023a) 是另一种非自回归文本编辑方法。它采用最初为自动语音识别开发的连接时序分类 (Connectionist Temporal Classification, CTC) (Graves et al., 2006) ,通过潜在CTC对齐对编辑过程建模,提出了一种新颖的文本编辑方法。这使得生成更灵活的编辑操作成为可能。
Table 3: GECToR fine-tuning experiments. We compare the performance of our fine-tuned model after stage I and stage II to the initial off-the-shelf model as a baseline.
| 系统名称 | CoNLL-2014-test | BEA-test | ||||
|---|---|---|---|---|---|---|
| 精确率 (Precision) | 召回率 (Recall) | F0.5 | 精确率 (Precision) | 召回率 (Recall) | F0.5 | |
| GECToR-RoBERTa(L) (Tarnavskyi et al., 2022) | 70.1 | 42.7 | 62.2 | 80.6 | 52.3 | 72.7 |
| GECToR-FT-Stage-I | 75.2 | 44.1 | 65.9 | 78.1 | 57.7 | 72.9 |
| GECToR-FT-Stage-II (GECToR-2024) | 75.0 | 44.7 | 66.0 | 77.7 | 59.0 | 73.1 |
表 3: GECToR微调实验。我们将第一阶段和第二阶段微调后的模型性能与初始现成模型作为基线进行比较。
Edit Scorer 7 (Sorokin, 2022) splits GEC into two steps: generating and scoring edits. We consider it a single-model system approach because all edits are generated by a single-model system.
Edit Scorer 7 (Sorokin, 2022) 将语法纠错 (GEC) 拆分为两个步骤:生成编辑和评分编辑。我们将其视为单模型系统方案,因为所有编辑均由单一模型系统生成。
We also attempt to reproduce the Seq2Edit approach (Stahlberg and Kumar, 2020), (Kaneko and Okazaki, 2023), but fail to achieve meaningful results. Please find more details in Appendix B.
我们还尝试复现了 Seq2Edit 方法 (Stahlberg and Kumar, 2020) (Kaneko and Okazaki, 2023),但未能取得有意义的结果。更多细节请参阅附录 B。
For GECToR, we use the top-performing model, $\mathrm{GECToR-RoBERTa}^{(L)}$ (Tarnavskyi et al., 2022). Since this model was not trained on cLang-8 data, we additionally fine-tune it on a mix of cLang8, BEA, Troy-1BW, and Troy-Blogs data. We leverage a multi-stage fine-tuning approach from (Ome lian ch uk et al., 2020). In stage I, a mix of cLang-8, W&I $^+$ LOCNESS train (BEA-train), Troy-1BW, and Troy-Blogs datasets is used for fine-tuning; in stage II, the high-quality W&I $^+$ LOCNESS train dataset is used to finish the training. During stage I, we fine-tune the model for 5 epochs, early-stopping after 3 epochs, with each epoch equal to 10000 updates and a batch size of 256. During stage II, we further fine-tune the model for 4 epochs, with each epoch equal to 130 updates. The full list of hyper parameters for fine-tuning can be found in Appendix D, Table 7. We refer to this new, improved GECToR model as GECToR-2024.
对于GECToR,我们采用性能最优的模型$\mathrm{GECToR-RoBERTa}^{(L)}$ (Tarnavskyi et al., 2022)。由于该模型未在cLang-8数据上训练,我们额外使用cLang8、BEA、Troy-1BW和Troy-Blogs的混合数据进行微调。我们采用(Ome lian ch uk et al., 2020)提出的多阶段微调方法:第一阶段使用cLang-8、W&I$^+$LOCNESS训练集(BEA-train)、Troy-1BW和Troy-Blogs的混合数据进行微调;第二阶段使用高质量的W&I$^+$LOCNESS训练集完成训练。第一阶段微调5个周期(每周期10000次更新,批量大小256),3个周期后提前停止;第二阶段继续微调4个周期(每周期130次更新)。完整超参数列表见附录D表7。我们将这个改进后的新模型称为GECToR-2024。
For CTC-Copy, we use the official code6 with the RoBERTa encoder to train the English GEC model.
对于CTC-Copy,我们使用官方代码6和RoBERTa编码器来训练英语GEC模型。
For EditScorer, we use the open-sourced code7 for GECToR-XLNet(L) option from (Tarnavskyi et al., 2022) to sample possible edits and stagewise decoding with the RoBERTa-Large encoder to rescore them.
对于EditScorer,我们使用(Tarnavskyi et al., 2022)中开源的GECToR-XLNet(L)方案代码7来采样可能的编辑,并通过RoBERTa-Large编码器进行分阶段解码以重新评分。
3.4 Single-Model Systems Results
3.4 单模型系统结果
The performance of single-model GEC systems is presented in Table 2.
表 2: 单模型 GEC 系统的性能表现
We see that all zero-shot approaches considered have $F_{0.5}$ scores lower than 60 on the CoNLL2014-test dataset, which we assume to be a lower bound on satisfactory GEC quality. They all suffer from an over correcting issue (Fang et al., 2023), (Wu et al., 2023) that leads to poor Precision and inferior $F_{0.5}$ scores. Notably, GPT models show consistently better results compared to LLaMa. Implementing the chain-of-thought approach doesn’t improve the quality.
我们发现,所有考虑的零样本方法在CoNLL2014-test数据集上的$F_{0.5}$分数均低于60,我们假设这是满意GEC质量的下限。这些方法都存在过度纠正问题 (Fang et al., 2023) (Wu et al., 2023),导致精确度差且$F_{0.5}$分数较低。值得注意的是,GPT模型相比LLaMa始终表现出更好的结果。采用思维链方法并未提升质量。
Among the remaining approaches — LLMs with fine-tuning, sequence-to-sequence models, and edit-based systems — we do not see a clear winner. Not surprisingly, we observe that larger models (T5-11B, UL2-20B, Chat-LLaMA-2-7B-FT, Chat-LLaMA-2-13B-FT) have slightly higher Recall compared to smaller models (GECToR-2024, CTC-Copy, EditScorer). This is expressed in $1-2%$ higher $F_{0.5}$ scores on CoNLLL-2014-test; however, the values on BEA-dev and BEA-test don’t show the same behavior.
在剩余的方法中——经过微调的大语言模型、序列到序列模型和基于编辑的系统——我们没有看到明显的赢家。不出所料,我们发现较大模型(T5-11B、UL2-20B、Chat-LLaMA-2-7B-FT、Chat-LLaMA-2-13B-FT)的召回率略高于较小模型(GECToR-2024、CTC-Copy、EditScorer)。这体现在CoNLL-2014-test上$F_{0.5}$分数高出$1-2%$;然而,BEA-dev和BEA-test上的数值并未表现出相同趋势。
Additionally, we observe that simply scaling the model does not help achieve a breakthrough in benchmark scores. For example, a relatively small model such as GECToR-2024 ( $\mathbf{\widetilde{\Gamma}}\approx300M$ parameters) still performs well enough compared to much larger models $(\approx7-20B$ parameters). We hypoth- esize that the limiting factor for English GEC is the amount of high-quality data rather than model size. We have not been able to realize an $F_{0.5}$ score of more than $68%/59%/75%$ on CoNLLL-2014- test / BEA-dev / BEA-test, respectively, with any single-model system approach, which is consistent with previously published results.
此外,我们观察到单纯扩大模型规模并不能帮助实现基准分数的突破。例如,相对较小的模型如GECToR-2024(约3亿参数)仍能媲美参数量大得多的模型(约70-200亿参数)。我们假设英语语法纠错(GEC)的限制因素在于高质量数据量而非模型规模。采用任何单模型系统方案时,我们始终无法在CoNLL-2014-test/BEA-dev/BEA-test上实现超过68%/59%/75%的F0.5分数,这与先前发表的研究结果[20]一致。
For GECToR, after two stages of fine-tuning, we were able to improve the $F_{0.5}$ score of the top-performing single-model model by $3.8%$ on CoNLL-2014 and by $0.4%$ on BEA-test, mostly due to the increase in Recall (Table 3).
对于GECToR,经过两个阶段的微调后,我们在CoNLL-2014上将最佳单模型的$F_{0.5}$分数提高了$3.8%$,在BEA-test上提高了$0.4%$,这主要归功于召回率的提升 (表 3)。
Interestingly, we see a trend where larger models exhibit diminishing returns with multi-staged training approaches. Our exploration of various training data setups reveals that a simple and straight forward approach, focusing exclusively on the W&I $+\mathrm{LOCNESS}$ train dataset, performs on par with more complex configurations across both evaluation datasets.
有趣的是,我们发现一个趋势:规模更大的模型采用多阶段训练方法时收益递减。通过对不同训练数据设置的探索,我们发现仅专注于 W&I $+\mathrm{LOCNESS}$ 训练数据集的简单直接方法,在两个评估数据集上的表现与更复杂的配置相当。
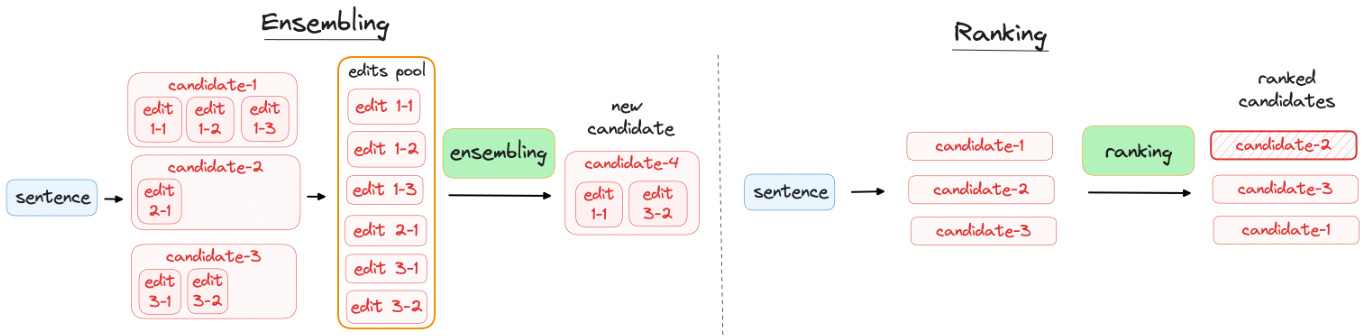
Figure 1: Combining the single-model systems’ outputs. Left: In ensembling, candidates (system outputs) are aggregated on an edit level. Right: In ranking, candidates (system outputs) are aggregated on a sentence level. We consider ranking to be a special case of ensembling.
图 1: 单模型系统输出的组合方式。左图: 在集成(ensembling)中,候选结果(系统输出)在编辑级别进行聚合。右图: 在排序(ranking)中,候选结果(系统输出)在句子级别进行聚合。我们认为排序是集成的一种特殊情况。
4 Ensembling and Ranking of Single-Model Systems
4 单模型系统的集成与排序
Combining the outputs of single-model GEC systems can improve their quality. In this paper, we explore two combining methods: ensembling and ranking (Figure 1).
结合单模型GEC系统的输出可以提升其质量。本文探讨了两种结合方法:集成(ensembling)和排序(ranking) (图1: )。
Ensembling combines outputs of single-model systems on an edit level. The ensemble method exploits the strengths of each model, potentially leading to more robust and accurate corrections than any single-model system could provide on its own.
集成方法在编辑层面结合了单模型系统的输出。这种集成方法利用了每个模型的优势,可能比任何单一模型系统单独提供的修正更稳健和准确。
Ranking is a special case of ensembling that combines individual outputs on a sentence level. In this approach, the performance of each system’s candidate is assessed against a set of predefined criteria, and the most effective candidate is selected. Ranking maintains the internal coherence of each model’s output, potentially leading to more natural and readable corrections.
排序是集成方法的一种特殊形式,它在句子级别上结合各个系统的输出。这种方法通过一组预定义标准评估每个系统候选输出的性能,并选择最有效的候选结果。排序保持了每个模型输出的内部一致性,可能产生更自然、更易读的修正结果。
4.1 Oracle-Ensembling and Oracle-Ranking as Upper-Bound Baselines
4.1 Oracle-Ensembling 和 Oracle-Ranking 作为上限基线
To set the upper-bound baseline for our experiments in combining single models, we introduce two oracle systems: Oracle-Ensembling and Oracle-Ranking.
为了设定实验中组合单一模型性能的上限基准,我们引入了两个理想系统:Oracle-Ensembling和Oracle-Ranking。
Oracle-Ensembling approximates an optimal combination of edits of available single-model systems. It is computationally challenging because the number of possible edit combinations grows exponentially with the number of edits. We use a heuristic to mitigate this; it optimizes Precision at the cost of reducing Recall.
Oracle-Ensembling近似于可用单模型系统编辑的最佳组合。由于可能的编辑组合数量随编辑次数呈指数级增长,这在计算上具有挑战性。我们采用启发式方法来缓解这一问题,该方法以降低召回率为代价来优化精确率。
Using golden references from evaluation sets, Oracle-Ensembling works as follows:
利用评估集中的黄金参考标准,Oracle-Ensembling 的工作流程如下:
- Aggregate the edits from all systems into a single pool. 2. Identify and select edits that are present in both the edit pool and the available annotation. 3. In the case of multiple annotations, we obtain a set of edits for each annotation separately. We then select the largest set of edits among the multiple annotations.
- 将所有系统的编辑内容汇总到一个池中。
- 识别并选择编辑池与可用标注中同时存在的编辑内容。
- 若存在多个标注,则分别获取每个标注对应的编辑集合,并从中选择编辑数量最多的集合。
Oracle-Ranking approximates an optimal output selection for available single-model systems. Again using golden references from evaluation sets, we use M2scorer8 to obtain $(F_{0.5},n_{c o r r e c t},n_{p r o p o s e d})$ for each system’s output candidate against the available annotation. The output candidates are then sorted by $(+F_{0.5},+n_{c o r r e c t},-n_{p r o p o s e d})$ and the top one is selected.
Oracle-Ranking近似实现了可用单模型系统的最优输出选择。我们再次利用评估集中的黄金参考标注,通过M2scorer8获取每个系统输出候选与可用标注之间的$(F_{0.5},n_{correct},n_{proposed})$指标值。随后按$(+F_{0.5},+n_{correct},-n_{proposed})$对输出候选进行排序,并选取排名最高的结果。
For our explorations into combining models’ outputs, we select the seven single-model systems that show the best performance on CoNLL-2014-test (Table 2): Chat-LLaMa-2-7B-FT, Chat-LLaMa-2- 13B-FT, T5-11B, UL2-20B, GECToR-2024, CTC- Copy, and EditScorer. As our selection criteria, we take i) systems of different types to maximize the diversity and ii) systems that have an $F_{0.5}$ score of at least 65 on CoNLL-2014-test. We refer to this set of models as "best $7"$ .
在探索模型输出组合时,我们选择了在CoNLL-2014-test上表现最佳的七个单模型系统(表2):Chat-LLaMa-2-7B-FT、Chat-LLaMa-2-13B-FT、T5-11B、UL2-20B、GECToR-2024、CTC-Copy和EditScorer。选择标准包括:i) 采用不同类型的系统以最大化多样性;ii) 系统在CoNLL-2014-test上的$F_{0.5}$分数至少达到65。我们将这组模型称为"best $7$"。
4.2 Ensembling by Majority Votes on Edit Spans (Unsupervised)
4.2 基于编辑片段多数投票的集成方法 (无监督)
To experiment with ensembling different GEC systems, we needed a method that is tolerant to model architecture and vocabulary size. Ensembling by majority votes (Tarnavskyi et al., 2022) on spanlevel edits satisfies this requirement, and it’s simple to implement, so we decided to start with this approach. We use the same "best 7" set of models in our experiments.
为了尝试集成不同的语法错误纠正(GEC)系统,我们需要一种能兼容不同模型架构和词汇量的方法。基于编辑片段多数投票的集成方法(Tarnavskyi et al., 2022)满足这一需求且易于实现,因此我们决定从该方法入手。实验中我们采用相同的"最优7模型"组合。
Our majority-vote ensembling implementation consists of the following steps:
我们的多数投票集成实现包含以下步骤:
- Initialization. a) Select the set of single-model systems for the ensemble. We denote the number of selected systems by $N_{s y s}$ . b) Set $N_{m i n}$ , the threshold for the minimum number of edit suggestions to be accepted, $0\leq N_{m i n}\leq N_{s y s}$ .
- 初始化。a) 为集成选择单模型系统集合,用 $N_{s y s}$ 表示所选系统的数量。b) 设置 $N_{m i n}$ 作为可接受编辑建议的最小数量阈值,满足 $0\leq N_{m i n}\leq N_{s y s}$。
- Extract all edit suggestions from all singlemodel systems of the ensemble.
- 从集成中所有单模型系统中提取所有编辑建议。
- For each edit suggestion $i$ , calculate the number of single-model systems $n_{i}$ that triggered it.
- 对于每个编辑建议 $i$,计算触发它的单模型系统数量 $n_{i}$。
- Leave only those edit suggestions that are triggered more times than the $N_{m i n}$ threshold: $\forall i$ : $n_{i}>N_{m i n}$ .
- 仅保留触发次数超过 $N_{m i n}$ 阈值的编辑建议: $\forall i$ : $n_{i}>N_{m i n}$。
- Iterative ly apply the filtered edit suggestions, beginning with the edit suggestions with the most agreement across systems (greatest $n_{i}$ ) and ending with the edit suggestions where $n_{i}$ is lowest. Don’t apply an edit suggestion if it overlaps with one of the edits applied on a previous iteration.
- 迭代应用经过筛选的编辑建议,从各系统间一致性最高的编辑建议(最大的$n_{i}$)开始,到$n_{i}$最低的编辑建议结束。若某编辑建议与之前迭代中已应用的编辑存在重叠,则不应用该建议。
4.3 Ensembling and Ranking by GRECO Model (Supervised Quality Estimation)
4.3 基于GRECO模型的集成与排序(监督式质量评估)
The quality estimation approach for combining single-model systems’ outputs achieved two recent state-of-the-art results: logistic regression-based ESC (Edit-based System Combination) (Qorib et al., 2022), and its evolution, DeBERTA-based GRECO (Grammatical it y scorer for re-ranking corrections) (Qorib and Ng, 2023). In this paper, we experiment with GRECO because it is open source and demonstrates state-of-the-art performance on the GEC task to the best of our knowledge1. GRECO was trained on the NESS training set.
结合单模型系统输出的质量评估方法近期取得了两项最先进成果:基于逻辑回归的ESC(基于编辑的系统组合)(Qorib等人,2022),及其演进版本——基于DeBERTa的GRECO(语法校正重排序评分器)(Qorib和Ng,2023)。本文选择GRECO进行实验,因为据我们所知,该开源方案在语法纠错(GEC)任务中展现了当前最佳性能。GRECO的训练数据来自NESS训练集。
We experiment with applying the publicly available GRECO model9 to the "best $7"$ set of models. We explore three ways of combining systems’ outputs:
我们尝试将公开可用的GRECO模型9应用于"best $7$"模型集。探索了三种系统输出组合方式:
GRECO-ens-beam. We reuse beam-search im- ple ment ation with beam size $k=16$ on the edit span level.
GRECO-ens-beam。我们在编辑跨度(edit span)级别复用了束宽(beam size) $k=16$ 的束搜索(beam-search)实现。
GRECO-rank. We use GRECO to select the best single-model system’s output by choosing the one with the highest score.
GRECO-rank。我们使用GRECO选择最佳单模型系统的输出,即选取得分最高的结果。
GRECO-rank-w. We re-weight GRECO scores for each system’s output $j$ by multiplying it by a weighting coefficient $w_{j}$ :
GRECO-rank-w。我们对每个系统输出$j$的GRECO分数进行重新加权,具体方法是将分数乘以一个加权系数$w_{j}$:
$$
\forall k:w_{j}=\frac{n_{j}}{\operatorname*{max}(n_{k})},
$$
$$
\forall k:w_{j}=\frac{n_{j}}{\operatorname*{max}(n_{k})},
$$
where the numerator $n_{j}$ is the number of systems that produce this output $j$ , and the denominator $\mathrm{max}(n_{k})$ is the maximum number of systems for all systems’ outputs. This way, we reduce the score of less frequent systems because it’s not the system that is being scored/popular but rather the system’s specific output (the edit).
其中分子 $n_{j}$ 是产生该输出 $j$ 的系统数量,分母 $\mathrm{max}(n_{k})$ 是所有系统输出中的最大系统数量。通过这种方式,我们降低了不太常见系统的得分,因为被评分/流行的不是系统本身,而是该系统的特定输出(即编辑内容)。
4.4 Ranking by GPT-4 (Zero-Shot)
4.4 基于GPT-4的排序 (零样本)
Besides the direct application of LLMs for GEC in a zero-shot setting (we consider it in the Section 3.1.1), LLMs may be used as a combining method for ensembles. We explore GPT-4 as a ranking tool for single-model GEC systems’ outputs.
除了在零样本设置下直接应用大语言模型 (LLM) 进行语法纠错 (GEC) (我们将在第 3.1.1 节讨论) 之外,大语言模型还可以用作集成模型的组合方法。我们探索将 GPT-4 作为单模型语法纠错系统输出的排序工具。
We use version gpt-4-0613 for GPT-4 with temperature 1. We implement two prompts, "prompta", and "prompt-b", with slightly different goals: prompt-a aims to select the top single-model system’s output among the systems’ candidates, whereas prompt-b aims to perform the full ranking of the systems’ candidates. They both have the same task description. For the following example of ranking three systems, it is:
我们使用版本 gpt-4-0613 的 GPT-4,温度参数设为 1。我们实现了两种提示:"prompt-a"和"prompt-b",目标略有不同:prompt-a 旨在从候选系统中选出单一最优模型的输出,而 prompt-b 则需要对所有候选系统的输出进行完整排序。两者的任务描述相同。以下是一个对三个系统进行排序的示例:
But they require a different output format: prompt-a (top cand.): prompt-b (ranking): OUTPUT: OUTPUT: C C A B
但它们需要不同的输出格式:提示词-a(首选候选项):提示词-b(排名):输出:输出:C C A B
To eliminate potential positional bias, we run each prompt four times with a randomly shuffled order of single-model systems’ outputs and average the performance scores. To investigate the impact of the number of systems to be ranked, we evaluate the performance of GPT-4 on two sets of single models: "best $7"$ and "clust $3"$ .
为消除潜在的位置偏差,我们对每个提示运行四次,随机打乱单模型系统输出的顺序,并取性能得分的平均值。为研究待排序系统数量的影响,我们在两组单模型上评估GPT-4的性能:"best $7$"和"clust $3$"。
"best 7" (best 7 single-model systems): Chat-LLaMa-2-13B-FT $+\mathrm{UL}2{\sim}20\mathrm{B}+$ Chat-LLaMa-2-7B-FT $^+$ EditScorer $^+$ T5-11B $^+$ CTC-Copy $^+$ GECToR-2024. "best $3"$ (best 3 single-model systems): Chat-LLaMa-2-13B-FT $\mathbf{\bar{\rho}}+\mathrm{UL}2{-}20\mathbf{B}+\mathbf{\bar{\rho}}$ Chat-LLaMa-2-7B-FT. "clust $3"$ (clustered 3 single-model systems): Chat-LLaMa-2-13B-FT $\mathrm{\Delta+T5{-}11B+}$ Edit-Scorer. $^{\ast}\mathrm{In}$ the paper (Qorib and Ng, 2023), authors prepared different variants of GRECO, each of which is optimized for one test dataset. $^{**}\mathrm{We}$ show mean values across four GPT-4 runs with randomly shuffled single-model systems’ outputs. ✚ We denote 2nd order ensembling (ensembles of ensembles) by capital letters.
| 系统 | CoNLL-2014-test | BEA-dev | BEA-test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F0.5 | 精确率 | 召回率 | F0.5 | 精确率 | 召回率 | F0.5 | |
| ESC (Qorib et al., 2022) | 81.5 | 43.8 | 69.5 | 72.9 | 40.4 | 62.8 | 86.6 | 60.9 | 79.9 |
| GRECO (Qorib and Ng, 2023), var0* | 79.40 | 48.70 | 70.48 | - | - | 63.4 | 86.5 | 63.1 | 80.5 |
| GRECO (Qorib and Ng, 2023), var1* | 79.60 | 49.90 | 71.12 | - | - | - | - | - | - |
| GRECO (Qorib and Ng, 2023), var2* | - | - | - | - | - | - | 86.7 | 63.7 | 80.8 |
| Chat-LLaMa-2-13B-FT (单模型系统) | 77.3 | 45.6 | 67.9 | 59.8 | 46.1 | 56.4 | 74.6 | 67.8 | 73.1 |
| UL2-20B (单模型系统) | 73.8 | 50.4 | 67.5 | 60.5 | 48.6 | 57.7 | 75.2 | 70.0 | 74.1 |
| Oracle-Ensembling (best 7), 基线 | 100.0 | 57.7 | 87.2 | 100.0 | 58.2 | 87.4 | - | - | - |
| Oracle-Ranking (best 7), 基线 | 91.4 | 64.2 | 84.2 | 79.6 | 60.2 | 74.7 | - | - | - |
| majority-voting (best 7) | 83.7 | 45.7 | 71.8 | 71.7 | 42.2 | 62.9 | 87.3 | 64.1 | 81.4 |
| majority-voting (best 3) | 82.8 | 44.1 | 70.4 | 70.4 | 43.1 | 62.5 | 85.1 | 64.5 | 80.0 |
| 77.3 | 51.6 | 70.3 | 65.5 | 47.6 | 60.9 | - | - | - | |
| GRECO-ens-beam (best 7) | 74.4 | 54.2 | 69.2 | 63.2 | 50.0 | 60.0 | - | - | - |
| GRECO-rank (best 7) GRECO-rank-w (best 7) | 81.6 | 49.3 | 72.1 | 68.1 | 45.8 | 62.0 | 82.0 | 67.5 | 78.6 |
| GPT-4-rank-prompt-a** (clust 3)** | 72.4 | 58.3 | 69.1 | 59.7 | 52.3 | 58.1 | - | - | - |
| MAJORITY-VOTING+ [majority-voting (best 7), | - | - | - | - | - | - | - | - | - |
| GRECO-rank-w (best 7)] | 83.0 | 48.1 | 72.5 | 70.2 | 43.9 | 62.7 | 85.6 | 65.8 | 80.7 |
| MAJORITY-VOTING [majority-voting (best 7), GRECO-rank-w (best 7), GPT-4-rank-a (clust 3)] | 83.9 | 47.5 | 72.8 | 70.6 | 43.5 | 62.8 | 86.1 | 65.6 | 81.1 |
"best 7" (最佳7个单模型系统): Chat-LLaMa-2-13B-FT $+\mathrm{UL}2{\sim}20\mathrm{B}+$ Chat-LLaMa-2-7B-FT $^+$ EditScorer $^+$ T5-11B $^+$ CTC-Copy $^+$ GECToR-2024. "best $3"$ (最佳3个单模型系统): Chat-LLaMa-2-13B-FT $\mathbf{\bar{\rho}}+\mathrm{UL}2{-}20\mathbf{B}+\mathbf{\bar{\rho}}$ Chat-LLaMa-2-7B-FT. "clust $3"$ (聚类3个单模型系统): Chat-LLaMa-2-13B-FT $\mathrm{\Delta+T5{-}11B+}$ Edit-Scorer. $^{\ast}\mathrm{在}$ 论文 (Qorib and Ng, 2023) 中,作者准备了不同版本的GRECO,每个版本针对一个测试数据集进行了优化。 $^{**}\mathrm{我们}$ 展示了四次GPT-4运行的均值,每次运行中单模型系统的输出是随机打乱的。 ✚ 我们用大写字母表示二阶集成(集成的集成)。
Table 4: All ensembles evaluated on CoNLL-2014-test, BEA-dev, and BEA-test datasets.
"best $7"$ (best 7 single-model systems): Chat-LLaMa-2-13B-FT $^+$ UL2-20B $^+$ Chat-LLaMa-2-7B-FT $^+$ EditScorer $^+$ T5-11B + CTC-Copy $^+$ GECToR-2024. "clust $3"$ (clustered 3 single-model systems): Chat-LLaMa-2-13B-FT $^+$ T5-11B $^+$ Edit-Scorer.
表 4: 在 CoNLL-2014-test、BEA-dev 和 BEA-test 数据集上评估的所有集成模型。
| CoNLL-2014-test | BEA-dev | |||||
|---|---|---|---|---|---|---|
| Precision | Recall | F0.5 | Precision | Recall | F0.5 | |
| GPT-4-rank-prompt-a(best 7) | 70.9 ± 0.5 | 59.7±0.6 | 68.4± 0.5 | 56.8±0.3 | 53.4±0.8 | 56.1 ±0.3 |
| GPT-4-rank-prompt-b(best 7) | 809:69 | 59.5±0.2 | 67.3±0.7 | 56.3±0.5 | 53.9±0.6 | 55.8±0.4 |
| GPT-4-rank-prompt-a(clust 3) | 72.4±0.3 | 58.3±0.6 | 69.1 ± 0.1 | 59.7 ± 0.1 | 52.3±0.4 | 58.1 ± 0.1 |
| GPT-4-rank-prompt-b(clust 3) | 71.9 ± 0.4 | 58.1±0.5 | 68.7±0.5 | 58.7±0.3 | 52.0±0.5 | 57.2±0.3 |
"best $7$" (best 7 single-model systems): Chat-LLaMa-2-13B-FT $^+$ UL2-20B $^+$ Chat-LLaMa-2-7B-FT $^+$ EditScorer $^+$ T5-11B + CTC-Copy $^+$ GECToR-2024. "clust $3$" (clustered 3 single-model systems): Chat-LLaMa-2-13B-FT $^+$ T5-11B $^+$ Edit-Scorer.
Table 5: LLM ranking results. We run each prompt four times with randomly shuffled outputs of single-model systems’ candidates and report mean $\pm\nobreakspace2\nobreakspace$ std.
表 5: 大语言模型 (LLM) 排名结果。我们对每个提示运行四次,随机打乱单模型系统候选输出的顺序,并报告均值 $\pm\nobreakspace2\nobreakspace$ 标准差。
"clust $3"$ refers to 3 of the 7 best single-model systems: Chat-LLaMa-2-13B-FT + T5-11B + EditScorer. This is the subset of single-model systems from the "best 7" ensemble that provides the most distinct corrections. To select this set, we perform hierarchical clustering on TF-IDF vectors extracted from the BEA-dev dataset using a cosine similarity. The cosine similarity scores are averaged to produce a single matrix that reflects the collective performance of the single-model systems. The dendrogram illustrating the relationships between the systems based on distance is shown in Appendix D, Fig. 2. Based on the threshold $t=0.11$ , we select the three clusters and choose Chat-LLaMa-2-13BFT, T5-11B, Edit-Scorer to represent each.
clust $3$ 指的是7个最佳单模型系统中的3个:Chat-LLaMA-2-13B-FT + T5-11B + EditScorer。这是从"最佳7"集成系统中选出的能提供最独特修正的单模型系统子集。为选择该集合,我们对从BEA-dev数据集提取的TF-IDF向量进行层次聚类,使用余弦相似度计算。余弦相似度分数经平均处理后生成反映单模型系统集体性能的矩阵。基于距离的系统关系树状图见附录D中的图2。根据阈值 $t=0.11$,我们选择三个聚类,并分别选用Chat-LLaMA-2-13B-FT、T5-11B和EditScorer作为代表。
4.5 Ensembles of Ensembles
4.5 集成之集成
Ensembles may themselves be combined via ensembling or ranking methods to potentially improve performance, and this is an approach we explore as well. We experiment with combining the outputs of three ensemble systems: majorityvoting(best 7), GRECO-rank(best 7), and GPT-4- rank(clust 3). Here, majority-voting(best 7) was selected because it achieves the highest $F_{0.5}$ score; GRECO-rank(best 7) and GPT-4-rank(clust 3) have higher Recall and, therefore, potential to add value in an ensemble.
通过集成或排序方法将多个集成系统进一步组合,可能提升性能,这也是我们探索的一种方法。我们尝试融合三种集成系统的输出结果:多数投票(best 7)、GRECO排序(best 7)和GPT-4排序(clust 3)。选择多数投票(best 7)是因为其取得了最高的$F_{0.5}$分数;而GRECO排序(best 7)和GPT-4排序(clust 3)具有更高的召回率(Recall),因此能为集成带来潜在增益。
The MAJORITY-VOTING algorithm (we denote second-order ensembling by capital letters) is identical to that described in 4.2.
MAJORITY-VOTING算法(我们用大写字母表示二阶集成)与4.2节中描述的算法相同。
4.6 Ensembles Results
4.6 集成结果
Oracle ensembling ranking. OracleEnsembling shows $F_{0.5}$ scores of 87.2/87.4 on CoNLL-2014-test/BEA-dev, while Oracle-Ranking performs notably worse with $F_{0.5}$ scores of 84.2/74.7 and Precision of $91.4/79.6\$ (Table 4). This highlights the high potential for improvements on existing candidate generation and ensembling approaches, whereas ranking is more limited.
Oracle集成 排序。Oracle集成在CoNLL-2014-test/BEA-dev上显示出87.2/87.4的$F_{0.5}$分数,而Oracle排序表现明显较差,$F_{0.5}$分数为84.2/74.7,精确度为$91.4/79.6\$ (表4)。这突显出现有候选生成和集成方法具有很高的改进潜力,而排序则更为受限。
Majority-voting ensembling. The only hyperparameter for the method (the $N_{m i n}$ threshold) di- rectly impacts the Precision/Recall balance: the higher it is set, the greater the Precision. We find that the best $N_{m i n}$ values for maximizing $F_{0.5}$ score are $N_{m i n}\approx N_{s y s}/2$ . With $\mathbf{N_{min}}=\mathbf{3}$ , we achieve 71.8 on CoNLL-2014-test, outperforming the previous state-of-the-art result by 0.7, and 81.4 on BEA-test, setting a new state-of-theart result. (Table 4, "best $7"$ systems ensemble).
多数投票集成。该方法唯一的超参数($N_{min}$阈值)直接影响精确率(Precision)/召回率(Recall)的平衡:设定值越高,精确率越高。我们发现,最大化$F_{0.5}$分数的最佳$N_{min}$值为$N_{min}\approx N_{sys}/2$。当$\mathbf{N_{min}}=\mathbf{3}$时,我们在CoNLL-2014-test上达到了71.8分,比之前的最优结果高出0.7分,在BEA-test上达到81.4分,创造了新的最优结果(表4,"best $7$"系统集成)。
We perform an ablation study to measure the impact of each system in the ensemble (Appendix D, Table 12), where we remove systems one by one in the decreasing direction of $F_{0.5}$ score on the BEA-dev dataset. Our experiments show that even an ensemble combined from just the "best $3"$ systems (Chat-LLaMa-2-13B-FT, UL2-20B, and Chat-LLaMa-2-7B-FT) significantly improves the $F_{0.5}$ score over the UL2-20B single-model system (by $2.9%$ on CoNLLL-2014-test, $4.8%$ on BEA- dev, and $5.9%$ on BEA-test). These results rein- force the significance of ensembling in achieving state-of-the-art performance on the GEC task. We hypothesize that majority-voting ensembling helps in mitigating the influence of noise within the data. By consolidating edits that are consistent across multiple systems (the true signal), and concurrently downplaying less prevalent and potentially inaccurate edits (the noise), the ensembling approach effectively enhances the overall quality and reliability of the output. Our experiments on BEA-dev can be found in Appendix D, Table 8.
我们进行了一项消融实验,以评估集成系统中每个组件的影响(附录D 表12)。实验按照各系统在BEA-dev数据集上$F_{0.5}$分数降序逐一移除组件。结果表明,仅由"最佳3个"系统(Chat-LLaMa-2-13B-FT、UL2-20B和Chat-LLaMa-2-7B-FT)组成的集成系统,其$F_{0.5}$分数较UL2-20B单模型系统有显著提升(CoNLL-2014-test提升2.9%、BEA-dev提升4.8%、BEA-test提升5.9%)。这些结果印证了集成方法对实现语法纠错(GEC)任务最先进性能的重要性。我们推测多数表决集成有助于缓解数据噪声的影响:通过整合多个系统间一致的修改(真实信号),同时弱化低频且可能不准确的修改(噪声),该方法有效提升了输出的整体质量与可靠性。BEA-dev数据集上的实验结果详见附录D 表8。
Supervised ranking ensembling. Overall, leveraging GRECO (all variants) for combining systems’ outputs leads to increased Recall at the cost of Precision. It leads to an improvement in $F_{0.5}$ score on CoNLLL-2014-test, achieving $72.1%$ $+0.3%$ from our best unsupervised ensemble, majority-voting(best 7)). However, results on BEA-test regressed $(-2.8%$ in $F_{0.5}$ score). GRECO- ens-beam did not outperform GRECO-rank-w in our experiments.
监督排序 集成。总体而言,利用GRECO(所有变体)组合系统输出会以精度为代价提升召回率。该方法在CoNLL-2014测试集上实现了$F_{0.5}$分数72.1%$\ (+0.3%$,较我们最佳无监督集成方法majority-voting(best 7)有所提升)。但在BEA测试集上结果出现倒退($F_{0.5}$分数下降$2.8%$)。实验中GRECO-ens-beam未超越GRECO-rank-w表现。
Zero-shot ranking. We observe that LLMbased ranking works better for three distinct singlemodel systems (clust 3) than for all seven best systems (best 7). We hypothesize that this performance disparity may be due to the increased complexity of selecting the optimal choice from a larger set of similar options. We also explain in this way the better performance of prompt-a (selection of the top candidate rewrite) than prompt-b (performing full ranking among candidate rewrites). Similar to GRECO-rank, we notice that GPT-4 favors Recall-oriented outputs, which leads to the highest Recall (58.4) on the CoNLLL-2014-test, but a suboptimal $F_{0.5}$ score. More results are presented in Table 5 and in Appendix D, Table 9.
零样本排序。我们观察到基于大语言模型的排序在三个独立单模型系统(clust 3)上的表现优于所有七个最佳系统(best 7)。我们推测这种性能差异可能是由于从更多相似选项中选出最优解的复杂度增加所致。这也解释了提示方案a(选择排名最高的候选改写)优于提示方案b(对候选改写进行完整排序)的原因。与GRECO-rank类似,我们发现GPT-4倾向于召回导向的输出,这使得其在CoNLL-2014测试集上获得最高召回率(58.4),但F_{0.5}分数次优。更多结果见表5及附录D中的表9。
Ensembles of ensembles. Applying secondorder ensembles, more specifically MAJORITYVOTING[majority-voting(best 7), GRECO-rankw(best 7), GPT-4-rank-a(clust 3)], helps to even further push the state-of-the-art record on CoNNL2014-test, achieving $\mathbf{F0.5=72.8:~+1.7}$ compared to the previously highest reported result by GRECO, var1 (Qorib and $\mathbf{Ng}$ 2023) and $+1.0$ compared to our majority-voting(best 7) ensemble.
集成中的集成。应用二阶集成方法,具体包括 MAJORITYVOTING[majority-voting(best 7)、GRECO-rankw(best 7)、GPT-4-rank-a(clust 3)],可进一步提升 CoNNL2014-test 数据集上的最优性能记录,相比 GRECO 团队此前报告的最高结果 var1 (Qorib 和 $\mathbf{Ng}$ 2023) 实现了 $\mathbf{F0.5=72.8:~+1.7}$ 的提升,较我们的 majority-voting(best 7) 集成方案也高出 $+1.0$。
5 Related work
5 相关工作
Large language models have demonstrated efficacy across a variety of natural language processing tasks, including GEC (Bryant et al., 2023). The comparative analysis conducted by (Wu et al., 2023) on the effectiveness of different models for GEC — ChatGPT, Grammarly, and open-sourced GECToR — reveals that ChatGPT possesses a distinctive capability to enhance textual content by not only correcting errors on a one-by-one basis but also by rephrasing original sentences, changing their structure to maintain grammatical correctness. The outcomes of human evaluations underscore the limitations of exclusively relying on automatic evaluation metrics for assessing GEC model performance, thereby positioning ChatGPT as a potentially invaluable resource for GEC applications.
大语言模型已在多种自然语言处理任务中展现出有效性,包括语法错误纠正(GEC) (Bryant et al., 2023)。(Wu et al., 2023) 对ChatGPT、Grammarly和开源模型GECToR在GEC任务上的效果比较分析表明:ChatGPT不仅能逐条修正错误,还能通过改写原句结构来保持语法正确性,从而具备独特的文本增强能力。人工评估结果凸显了仅依赖自动评估指标衡量GEC模型性能的局限性,这使ChatGPT成为GEC应用的潜在宝贵资源。
Other research (Loem et al., 2023), (Fang et al., 2023) suggests that although zero-shot and fewshot chain-of-thought methodologies demonstrate promise in terms of error detection capabilities and the production of fluently corrected text, they generally under perform across the majority of error categories, thus failing to achieve high-quality outcomes in GEC. Moreover, (Zhang et al., 2023c) delved into the customization of open-sourced foundation LLMs including LLaMA (Touvron et al., 2023) for writing assistant applications, with GEC as one of the tasks. The experimental findings indicate that instruction tuning for specific scenarios such as GEC significantly boosts the performance of LLMs and can be used to develop smaller models that outperform their larger, general-purpose counterparts.
其他研究 (Loem et al., 2023)、(Fang et al., 2023) 表明,尽管零样本和少样本思维链方法在错误检测能力和生成流畅修正文本方面展现出潜力,但它们在大多数错误类别中表现普遍欠佳,因而无法在语法错误修正 (GEC) 中实现高质量结果。此外,(Zhang et al., 2023c) 探索了基于开源基础大语言模型(如 LLaMA (Touvron et al., 2023))定制写作助手应用的可能性,其中 GEC 作为任务之一。实验结果表明,针对 GEC 等特定场景进行指令微调可显著提升大语言模型的性能,并能用于开发优于通用大模型的小型专用模型。
Additionally, (Kaneko and Okazaki, 2023) introduced a novel approach for predicting edit spans within source texts, redefining instruction-based fine-tuning as local sequence transduction tasks.
此外, (Kaneko and Okazaki, 2023) 提出了一种预测源文本中编辑范围的新方法,将基于指令的微调重新定义为局部序列转导任务。
This method not only reduces the length of target sequences but also diminishes the computational demands associated with inference. The study emphasizes that even high-performance LLMs such as ChatGPT struggle to generate accurate edit spans in zero-shot and few-shot scenarios, particularly in the correct generation of indexes, making this approach unstable.
该方法不仅缩短了目标序列的长度,还降低了推理相关的计算需求。研究强调,即便是ChatGPT等高性能大语言模型,在零样本和少样本场景下也难以生成准确的编辑跨度(edit spans),尤其在正确生成索引方面表现不稳定。
Recent advancements in GEC have largely been attributed to the ensembling of outputs from individual models, as highlighted in studies by (Ome lian ch uk et al., 2020; Tarnavskyi et al., 2022). When integrating systems with significant disparities, a system combination model is preferred over simple ensembles. This approach allows for effective integration of the strengths of various GEC systems, yielding better results than ensembles, as demonstrated in (Qorib et al., 2022). Model outputs can be re-ranked using majority vote, as well as with the proposed GRECO model (Qorib and Ng, 2023), a new state-of-the-art quality estimation model correlating more closely with the $F_{0.5}$ score of a corrected sentence, thus leading to a combined GEC system with a higher $F_{0.5}$ score. Additionally, this study proposes three methods for leveraging GEC quality estimation models in system combination: model-agnostic, model-agnostic with voting bias, and model-dependent methods.
近年来GEC (Grammatical Error Correction) 领域的进展主要归功于集成多个独立模型的输出 (Ome lian ch uk et al., 2020; Tarnavskyi et al., 2022) 。当整合差异较大的系统时,系统组合模型比简单集成更受青睐。如 (Qorib et al., 2022) 所示,这种方法能有效整合不同GEC系统的优势,获得比集成方法更好的效果。模型输出可通过多数表决重新排序,也可使用最新提出的GRECO模型 (Qorib and Ng, 2023) ——该质量评估模型与修正句子的 $F_{0.5}$ 分数相关性更强,从而构建出具有更高 $F_{0.5}$ 分数的组合GEC系统。此外,本研究提出三种在系统组合中利用GEC质量评估模型的方法:模型无关法、带投票偏置的模型无关法以及模型依赖法。
other methods and lead to more powerful ensembles.
其他方法并产生更强大的集成。
We’ve not yet reached the ceiling on the existing GEC benchmarks. Our research shows that it’s possible to improve previous records noticeably, setting the new state-of-the-art performance on two principal GEC benchmarks with $F_{0.5}$ scores of 72.8 on CoNLL-2014-test and 81.4 on BEA-test, which are improvements of $+1.7$ and $+0.6$ , respectively.
我们尚未触及现有语法错误修正(GEC)基准测试的上限。研究表明,通过显著提升先前记录,我们能在两大主流GEC基准测试中实现新的最先进性能:CoNLL-2014-test的 $F_{0.5}$ 分数达到72.8,BEA-test达到81.4,分别比之前提升了 $+1.7$ 和 $+0.6$ 。
In future work, we plan to explore the generation of high-quality synthetic GEC data powered by a state-of-the-art ensemble. We hypothesize that this could democratize the field by reducing the necessity of expensive training of large models to achieve a superior level of quality.
在未来的工作中,我们计划探索利用最先进集成技术生成高质量的合成语法纠错(GEC)数据。我们假设这种方法可以通过减少训练大模型的高昂成本来降低领域门槛,同时实现更优的质量水平。