Revisiting Skeleton-based Action Recognition
重新审视基于骨架的动作识别
Abstract
摘要
Human skeleton, as a compact representation of human action, has received increasing attention in recent years. Many skeleton-based action recognition methods adopt GCNs to extract features on top of human skeletons. Despite the positive results shown in these attempts, GCN-based methods are subject to limitations in robustness, interoperability, and s cal ability. In this work, we propose PoseConv3D, a new approach to skeleton-based action recognition. PoseConv3D relies on a 3D heatmap vol- ume instead of a graph sequence as the base representation of human skeletons. Compared to GCN-based methods, PoseConv3D is more effective in learning s patio temporal features, more robust against pose estimation noises, and generalizes better in cross-dataset settings. Also, PoseConv3D can handle multiple-person scenarios without additional computation costs. The hierarchical features can be easily integrated with other modalities at early fusion stages, providing a great design space to boost the performance. PoseConv3D achieves the state-of-the-art on five of six standard skeleton-based action recognition benchmarks. Once fused with other modalities, it achieves the state-of-the-art on all eight multi-modality action recognition benchmarks. Code has been made available at: https://github.com/kenny m ck or mick/pyskl.
人体骨架作为人类动作的紧凑表示形式,近年来受到越来越多的关注。许多基于骨架的动作识别方法采用GCN(图卷积网络)在人体骨架上提取特征。尽管这些尝试显示出积极成果,但基于GCN的方法在鲁棒性、互操作性和可扩展性方面存在局限。本文提出PoseConv3D,一种基于骨架动作识别的新方法。该方法以3D热图体积而非图序列作为人体骨架的基础表示。与基于GCN的方法相比,PoseConv3D能更有效地学习时空特征,对姿态估计噪声具有更强鲁棒性,并在跨数据集场景中表现更优。此外,PoseConv3D无需额外计算成本即可处理多人场景。其分层特征可轻松与其他模态在早期融合阶段集成,为性能提升提供了广阔设计空间。PoseConv3D在六个标准骨架动作识别基准中的五个取得最优结果,当与其他模态融合时,在全部八个多模态动作识别基准上均达到最优。代码已开源:https://github.com/kennymckormick/pyskl。
1. Introduction
1. 引言
Action recognition is a central task in video understanding. Existing studies have explored various modalities for feature representation, such as RGB frames [6, 60, 65], optical flows [53], audio waves [69], and human skeletons [67, 71]. Among these modalities, skeleton-based action recognition has received increasing attention in recent years due to its action-focusing nature and compactness. In practice, human skeletons in a video are mainly represented as a sequence of joint coordinate lists, where the coordinates are extracted by pose estimators. Since only the pose information is included, skeleton sequences capture only action information while being immune to contextual nuisances, such as background variation and lighting changes.
动作识别是视频理解的核心任务。现有研究探索了多种特征表示模态,例如RGB帧 [6, 60, 65]、光流 [53]、音频波形 [69] 和人体骨骼 [67, 71]。在这些模态中,基于骨骼的动作识别近年来因其聚焦动作特性和紧凑性而受到越来越多的关注。实际应用中,视频中的人体骨骼主要表示为关节坐标列表的序列,这些坐标通过姿态估计器提取。由于仅包含姿态信息,骨骼序列仅捕获动作信息,同时不受背景变化和光照变化等上下文干扰的影响。

(b) 3D poses collected with Kinect. (c) 3D poses estimated with VIBE Figure 1. PoseConv3D takes 2D poses as inputs. In general, 2D poses are of better quality than 3D poses. We visualize 2D poses estimated with HRNet for videos in NTU-60 and FineGYM in (a). Apparently, their quality is much better than 3D poses collected by sensors (b) or estimated with state-of-the-art estimators (c).
图 1: PoseConv3D以2D姿态作为输入。通常情况下,2D姿态的质量优于3D姿态。我们使用HRNet对NTU-60和FineGYM视频中的2D姿态进行可视化展示 (a)。显然,其质量远高于通过传感器采集的3D姿态 (b) 或采用最先进估计算法生成的3D姿态 (c)。
Table 1. Differences between PoseConv3D and GCN.
表 1: PoseConv3D 与 GCN 的差异
| PreviousWork | PoseConv3D | |
|---|---|---|
| Input | 2D/3D Skeleton | 2D Skeleton |
| Format | Coordinates | 3D Heatmap Volumes |
| Architecture | GCN | 3D-CNN |
Among all the methods for skeleton-based action recognition [15, 63, 64], graph convolutional networks (GCN) [71] have been one of the most popular approaches. Specifically, GCNs regard every human joint at every timestep as a node. Neighboring nodes along the spatial and temporal dimensions are connected with edges. Graph convolution layers are then applied to the constructed graph to discover action patterns across space and time. Due to the good performance on standard benchmarks for skeletonbased action recognition, GCNs have been a standard approach when processing skeleton sequences.
在基于骨架的动作识别方法中[15, 63, 64],图卷积网络(GCN)[71]已成为最主流的方法之一。该方法将每个时间步上的人体关节视为节点,沿空间维度和时间维度连接相邻节点构成边,再通过图卷积层从构建的图中挖掘跨时空的动作模式。由于在骨架动作识别基准测试中表现优异,GCN已成为处理骨架序列的标准方法。
While encouraging results have been observed, GCNbased methods are limited in the following aspects: (1) Robustness: While GCN directly handles coordinates of human joints, its recognition ability is significantly affected by the distribution shift of coordinates, which can often occur when applying a different pose estimator to acquire the coordinates. A small perturbation in coordinates often leads to completely different predictions [74]. (2) Inter opera bility: Previous works have shown that representations from different modalities, such as RGB, optical flows, and skeletons, are complementary. Hence, an effective combination of such modalities can often result in a performance boost in action recognition. However, GCN is operated on an irregular graph of skeletons, making it difficult to fuse with other modalities that are often represented on regular grids, especially in the early stages. (3) S cal ability: In addition, since GCN regards every human joint as a node, the complexity of GCN scales linearly with the number of persons, limiting its applicability to scenarios that involve multiple persons, such as group activity recognition.
尽管已观察到鼓舞人心的成果,基于GCN的方法仍存在以下局限性:(1) 鲁棒性:虽然GCN直接处理人体关节坐标,但其识别能力极易受坐标分布偏移的影响。当使用不同姿态估计器获取坐标时,这种偏移经常发生。微小的坐标扰动常导致完全不同的预测结果[74]。(2) 跨模态互操作性:已有研究表明RGB、光流和骨骼等不同模态的表征具有互补性。有效组合这些模态通常能提升动作识别性能。但GCN基于不规则的骨骼图结构运行,难以与通常以规则网格表示的其他模态(尤其是早期阶段)进行融合。(3) 可扩展性:由于GCN将每个关节视为节点,其计算复杂度随人数线性增长,限制了其在多人场景(如群体活动识别)中的应用。
In this paper, we propose a novel framework PoseConv3D that serves as a competitive alternative to GCNbased approaches. In particular, PoseConv3D takes as input 2D poses obtained by modern pose estimators shown in Figure 1. The 2D poses are represented by stacks of heatmaps of skeleton joints rather than coordinates operated on a human skeleton graph. The heatmaps at different timesteps will be stacked along the temporal dimension to form a 3D heatmap volume. PoseConv3D then adopts a 3D convolutional neural network on top of the 3D heatmap volume to recognize actions. Main differences between PoseConv3D and GCN-based approaches are summarized in Table 1.
本文提出了一种新型框架PoseConv3D,可作为基于GCN方法的有效替代方案。具体而言,PoseConv3D以现代姿态估计器获取的2D姿态作为输入(如图1所示)。这些2D姿态通过骨骼关节热图堆栈表示,而非作用于人体骨骼图的坐标数据。不同时间步的热图将沿时间维度堆叠形成3D热图体。PoseConv3D随后在该3D热图体上采用3D卷积神经网络进行动作识别。PoseConv3D与基于GCN方法的主要差异总结于表1。
PoseConv3D can address the limitations of GCN-based approaches stated above. First, using 3D heatmap volumes is more robust to the up-stream pose estimation: we empirically find that PoseConv3D generalizes well across input skeletons obtained by different approaches. Also, PoseConv3D, which relies on heatmaps of the base representation, enjoys the recent advances in convolutional network architectures and is easier to integrate with other modalities into multi-stream convolutional networks. This characteristic opens up great design space to further improve the recognition performance. Finally, PoseConv3D can handle different numbers of persons without increasing computational overhead since the complexity over 3D heatmap volume is independent of the number of persons. To verify the efficiency and effectiveness of PoseConv3D, we conduct comprehensive studies across several datasets, including FineGYM [49], NTURGB-D [38], UCF101 [57], HMDB51 [29], Kinetics 400 [6], and Volleyball [23], where PoseConv3D achieves state-of-the-art performance compared to GCN-based approaches.
PoseConv3D能够解决上述基于GCN方法的局限性。首先,使用3D热图体积对上游姿态估计更具鲁棒性:我们通过实验发现,PoseConv3D在不同方法获得的输入骨骼上均表现出良好的泛化能力。此外,基于基础表示热图的PoseConv3D能够利用卷积网络架构的最新进展,并更容易与其他模态集成到多流卷积网络中。这一特性为提升识别性能开辟了广阔的设计空间。最后,由于3D热图体积的计算复杂度与人数无关,PoseConv3D可在不增加计算开销的情况下处理不同数量的人员。为验证PoseConv3D的效率和有效性,我们在多个数据集上进行了全面研究,包括FineGYM [49]、NTURGB-D [38]、UCF101 [57]、HMDB51 [29]、Kinetics 400 [6]和Volleyball [23],实验表明PoseConv3D相比基于GCN的方法实现了最先进的性能。
2. Related Work
2. 相关工作
3D-CNN for RGB-based action recognition. 3D-CNN is a natural extension of 2D-CNN for spatial feature learning to s patio temporal in videos. It has long been used in action recognition [24, 60]. Due to a large number of param- eters, 3D-CNN requires huge amounts of videos to learn good representation. 3D-CNN has become the mainstream approach for action recognition since I3D [6]. From then on, many advanced 3D-CNN architectures [17, 18, 61, 62] have been proposed by the action recognition community, which outperform I3D both in precision and efficiency. In this work, we first propose to use 3D-CNN with 3D heatmap volumes as inputs and obtain the state-of-the-art in skeletonbased action recognition.
基于RGB的3D-CNN动作识别方法。3D-CNN是2D-CNN在视频时空特征学习领域的自然延伸,长期应用于动作识别领域[24,60]。由于参数量庞大,3D-CNN需要海量视频数据才能学习到有效表征。自I3D[6]问世以来,3D-CNN已成为动作识别的主流方法。此后,动作识别领域相继提出了多种先进3D-CNN架构[17,18,61,62],在精度和效率上均超越了I3D。本研究首次提出采用3D热图体积作为输入的3D-CNN方案,在基于骨架的动作识别任务中取得了最先进性能。
GCN for skeleton-based action recognition. Graph convolutional network is widely adopted in skeleton-based action recognition [3,7,19,55,56,71]. It models human skele- ton sequences as s patio temporal graphs. ST-GCN [71] is a well-known baseline for GCN-based approaches, which combines spatial graph convolutions and interleaving temporal convolutions for s patio temporal modeling. Upon the baseline, adjacency powering is used for multiscale modeling [34, 40], while self-attention mechanisms improve the modeling capacity [31, 51]. Despite the great success of GCN in skeleton-based action recognition, it is also limited in robustness [74] and s cal ability. Besides, for GCNbased approaches, fusing features from skeletons and other modalities may need careful design [13].
基于骨骼动作识别的图卷积网络 (GCN)。图卷积网络在基于骨骼的动作识别领域被广泛采用 [3,7,19,55,56,71]。它将人体骨骼序列建模为时空图。ST-GCN [71] 是该领域著名的基线方法,通过结合空间图卷积和交错时序卷积实现时空建模。在此基线基础上,邻接矩阵幂运算被用于多尺度建模 [34, 40],而自注意力机制则提升了建模能力 [31, 51]。尽管GCN在骨骼动作识别中取得巨大成功,但其鲁棒性和可扩展性仍存在局限 [74]。此外,对于基于GCN的方法,骨骼与其他模态的特征融合可能需要精心设计 [13]。
CNN for skeleton-based action recognition. Another stream of work adopts convolutional neural networks for skeleton-based action recognition. 2D-CNN-based approaches first model the skeleton sequence as a pseudo image based on manually designed transformations. One line of works aggregates heatmaps along the temporal dimension into a 2D input with color encodings [10] or learned modules [1, 70]. Although carefully designed, information loss still occurs during the aggregation, which leads to inferior recognition performance. Other works [2,25,26,33,41] directly convert the coordinates in a skeleton sequence to a pseudo image with transformations, typically generate a 2D input of shape $K\times T$ , where $K$ is the number of joints, $T$ is the temporal length. Such input cannot exploit the locality nature of convolution networks, which makes these methods not as competitive as GCN on popular benchmarks [2]. Only a few previous works have adopted 3D-CNNs for skeleton-based action recognition. To construct the 3D input, they either stack the pseudo images of distance matrices [21, 36] or directly sum up the 3D skeletons into a cuboid [37]. These approaches also severely suffer from information loss and obtain much inferior performance to the state-of-the-art. Our work stacks heatmaps along the temporal dimension to form 3D heatmap volumes, preserving all information during this process. Besides, we use 3D-CNN instead of 2D-CNN due to its good capability for s patio temporal feature learning.
基于骨骼动作识别的CNN方法。另一类研究采用卷积神经网络(CNN)进行基于骨骼的动作识别。基于2D-CNN的方法首先通过人工设计的变换将骨骼序列建模为伪图像。部分研究通过颜色编码[10]或学习模块[1,70]将热图沿时间维度聚合为2D输入。尽管经过精心设计,聚合过程中仍存在信息损失,导致识别性能欠佳。其他研究[2,25,26,33,41]直接通过变换将骨骼序列坐标转换为伪图像,通常生成形状为$K\times T$的2D输入($K$表示关节数量,$T$表示时间长度)。这种输入无法利用卷积网络的局部性特征,使得这些方法在主流基准测试[2]上的表现不及图卷积网络(GCN)。仅有少数先前研究采用3D-CNN进行骨骼动作识别。为构建3D输入,这些方法要么堆叠距离矩阵的伪图像[21,36],要么直接将3D骨骼求和成立方体[37]。这些方法同样存在严重信息损失,其性能远低于最先进水平。本研究将热图沿时间维度堆叠形成3D热图体,在此过程中保留全部信息。此外,由于3D-CNN在时空特征学习方面的优势,我们选用3D-CNN而非2D-CNN。
3. Framework
3. 框架
We propose PoseConv3D, a 3D-CNN-based approach for skeleton-based action recognition, which can be a competitive alternative to GCN-based approaches, outperforming GCN under various settings in terms of accuracy with improved robustness, interoperability, and s cal ability. An overview of PoseConv3D is depicted in Figure 2, and details of PoseConv3D will be covered in the following sections. We begin with a review of skeleton extraction, which is the basis of skeleton-based action recognition but is often overlooked in previous literature. We point out several aspects that should be considered when choosing a skeleton extractor and motivate the use of 2D skeletons in Pose Con v 3 D 1. Subsequently, we introduce 3D Heatmap Volume that is the representation of a 2D skeleton sequence used in PoseConv3D, followed by the structural designs of PoseConv3D, including a variant that focuses on the modality of human skeletons as well as a variant that combines the modalities of human skeletons and RGB frames to demonstrate the inte roper ability of PoseConv3D.
我们提出PoseConv3D,一种基于3D-CNN的骨架动作识别方法,可作为GCN方法的有力替代方案。该方案在多种设定下均以更高准确度超越GCN,并具备更强的鲁棒性、互操作性和可扩展性。图2展示了PoseConv3D的总体框架,具体细节将在后续章节展开。我们首先回顾骨架提取技术——这是骨架动作识别的基础,却常被前人研究忽视。文中指出选择骨架提取器时需考量的多个维度,并论证了PoseConv3D采用2D骨架的合理性。随后介绍3D热图体积(3D Heatmap Volume)这一PoseConv3D中使用的2D骨架序列表征方法,继而阐述PoseConv3D的结构设计:包括专注人体骨架模态的变体,以及融合人体骨架与RGB帧模态以展示其互操作能力的变体。
3.1. Good Practices for Pose Extraction
3.1. 姿态提取的最佳实践
Being a critical pre-processing step for skeleton-based action recognition, human skeleton or pose extraction largely affects the final recognition accuracy. However, its importance is often overlooked in previous literature, in which poses estimated by sensors [38, 48] or existing pose estimators [4,71] are used without considering the potential effects. Here we conduct a review on key aspects of pose extraction to find a good practice.
作为基于骨架的动作识别的关键预处理步骤,人体骨架或姿态提取在很大程度上影响着最终识别精度。然而,其重要性在以往文献中常被忽视——这些研究直接使用传感器[38, 48]或现有姿态估计器[4,71]输出的姿态数据,而未考虑潜在影响。本文通过系统梳理姿态提取的关键环节,旨在探索最佳实践方案。
In general, 2D poses are of better quality compared to 3D poses, as shown in Figure 1. We adopt 2D Top-Down pose estimators [44, 59, 68] for pose extraction. Compared to its 2D Bottom-Up counterparts [5, 8, 43], Top-Down methods obtain superior performance on standard benchmarks such as COCO-keypoints [35]. In most cases, we feed proposals predicted by a human detector to the Top-Down pose estimators, which is sufficient enough to generate 2D poses of good quality for action recognition. When only a few persons are of interest out of dozens of candidates 2, some priors are essential for skeleton-based action recognition to achieve good performance, e.g., knowing the interested person locations at the first frame of the video. In terms of the storage of estimated heatmaps, they are often stored as coordinate-triplets $(x,y,c)$ in previous literature, where $c$ marks the maximum score of the heatmap and $(x,y)$ is the corresponding coordinate of $c$ . In experiments, we find that coordinate-triplets $(x,y,c)$ help save the majority of storage space at the cost of little performance drop. The detailed ablation study is included in Sec D.1.
通常来说,2D姿态的质量优于3D姿态,如图 1 所示。我们采用 2D Top-Down(自上而下)姿态估计器 [44, 59, 68] 进行姿态提取。与 2D Bottom-Up(自下而上)方法 [5, 8, 43] 相比,Top-Down 方法在 COCO-keypoints [35] 等标准基准测试中表现更优。多数情况下,我们将人体检测器预测的候选框输入 Top-Down 姿态估计器,这足以生成适用于动作识别的高质量 2D 姿态。当需要从数十个候选者中筛选少数目标人物时,基于骨架的动作识别需依赖某些先验知识才能获得良好性能,例如知晓目标人物在视频首帧的位置。关于估计热图的存储方式,先前研究通常采用坐标三元组 $(x,y,c)$ ,其中 $c$ 表示热图最高分,$(x,y)$ 是对应 $c$ 的坐标。实验发现,坐标三元组 $(x,y,c)$ 能以微小性能损失为代价节省大部分存储空间。详细消融实验见附录 D.1 节。
3.2. From 2D Poses to 3D Heatmap Volumes
3.2. 从二维姿态到三维热图体积
After 2D poses are extracted from video frames, to feed into PoseConv3D, we reformulate them into a 3D heatmap volume. Formally, we represent a 2D pose as a heatmap of size $K\times H\times W$ , where $K$ is the number of joints, $H$ and $W$ are the height and width of the frame. We can directly use the heatmap produced by the Top-Down pose estimator as the target heatmap, which should be zero-padded to match the original frame given the corresponding bounding box. In case we have only coordinate-triplets $(x_{k},y_{k},c_{k})$ of skeleton joints, we can obtain a joint heatmap $\boldsymbol{J}$ by composing $K$ gaussian maps centered at every joint:
从视频帧中提取2D姿态后,为输入PoseConv3D网络,我们将其重构为3D热力图体积。形式上,我们将2D姿态表示为尺寸为$K\times H\times W$的热力图,其中$K$表示关节数量,$H$和$W$分别代表帧的高度与宽度。可直接采用Top-Down姿态估计器生成的热力图作为目标热力图,并根据对应边界框进行零填充以匹配原始帧尺寸。若仅有骨骼关节坐标三元组$(x_{k},y_{k},c_{k})$,可通过在每个关节中心合成$K$个高斯图来获得关节热力图$\boldsymbol{J}$:
$$
\begin{array}{r}{J_{k i j}=e^{-\frac{(i-x_{k})^{2}+(j-y_{k})^{2}}{2*\sigma^{2}}}*c_{k},}\end{array}
$$
$$
\begin{array}{r}{J_{k i j}=e^{-\frac{(i-x_{k})^{2}+(j-y_{k})^{2}}{2*\sigma^{2}}}*c_{k},}\end{array}
$$
$\sigma$ controls the variance of gaussian maps, and $(x_{k},y_{k})$ and $c_{k}$ are respectively the location and confidence score of the $k$ -th joint. We can also create a limb heatmap $\pmb{L}$ :
$\sigma$ 控制高斯图的方差,$(x_{k},y_{k})$ 和 $c_{k}$ 分别是第 $k$ 个关节的位置和置信度分数。我们还可以创建肢体热图 $\pmb{L}$:
$$
L_{k i j}=e^{-\frac{\mathcal{D}((i,j),s e g[a_{k},b_{k}])^{2}}{2*\sigma^{2}}}\operatorname*{min}\bigl(c_{a_{k}},c_{b_{k}}\bigr).
$$
$$
L_{k i j}=e^{-\frac{\mathcal{D}((i,j),s e g[a_{k},b_{k}])^{2}}{2*\sigma^{2}}}\operatorname*{min}\bigl(c_{a_{k}},c_{b_{k}}\bigr).
$$
The $k_{t h}$ limb is between two joints $a_{k}$ and $b_{k}$ . The function $\mathcal{D}$ calculates the distance from the point $(i,j)$ to the segment $\left[(x_{a_{k}},y_{a_{k}}),(x_{b_{k}},y_{b_{k}})\right]$ . It is worth noting that although the above process assumes a single person in every frame, we can easily extend it to the multi-person case, where we directly accumulate the $k$ -th gaussian maps of all persons without enlarging the heatmap. Finally, a 3D heatmap volume is obtained by stacking all heatmaps $_{\mathrm{~}}$ or $\pmb{L}$ ) along the temporal dimension, which thus has the size of $K\times T\times H\times W$ .
第 $k_{t h}$ 肢体位于关节 $a_{k}$ 和 $b_{k}$ 之间。函数 $\mathcal{D}$ 计算点 $(i,j)$ 到线段 $\left[(x_{a_{k}},y_{a_{k}}),(x_{b_{k}},y_{b_{k}})\right]$ 的距离。值得注意的是,虽然上述过程假设每帧中只有一个人,但我们可以轻松将其扩展到多人场景,此时直接累加所有人的第 $k$ 个高斯热图而无需扩大热图尺寸。最终通过沿时间维度堆叠所有热图 $_{\mathrm{~}}$ 或 $\pmb{L}$ ) 得到 3D 热图体积,其尺寸为 $K\times T\times H\times W$。
In practice, we further apply two techniques to reduce the redundancy of 3D heatmap volumes. (1) SubjectsCentered Cropping. Making the heatmap as large as the frame is inefficient, especially when the persons of interest only act in a small region. In such cases, we first find the smallest bounding box that envelops all the 2D poses across frames. Then we crop all frames according to the found box and resize them to the target size. Consequently, the size of the 3D heatmap volume can be reduced spatially while all 2D poses and their motion are kept. (2) Uniform Sampling. The 3D heatmap volume can also be reduced along the temporal dimension by sampling a subset of frames. Unlike previous works on RGB-based action recognition, where researchers usually sample frames in a short temporal window, such as sampling frames in a 64-frame temporal window as in SlowFast [18], we propose to use a uniform sampling strategy [65] for 3D-CNNs instead. In particular, to sample $n$ frames from a video, we divide the video into $n$ segments of equal length and randomly select one frame from each segment. The uniform sampling strategy is better at maintaining the global dynamics of the video. Our empirical studies show that the uniform sampling strategy is significantly beneficial for skeleton-based action recognition. More illustration about generating 3D heatmap volumes is provided in Sec B.
实践中,我们进一步应用两种技术来降低3D热图体积的冗余度。(1) 以主体为中心的裁剪。将热图保持与帧同尺寸是低效的,特别是当目标人物仅在小范围活动时。这种情况下,我们首先找到跨帧包裹所有2D姿态的最小边界框,然后根据该边界框裁剪所有帧并调整至目标尺寸。这样可以在保留所有2D姿态及其运动的同时,从空间维度减小3D热图体积。(2) 均匀采样。通过抽取帧子集,3D热图体积还能沿时间维度缩减。与基于RGB的动作识别研究不同(前人通常采用短时窗采样,如SlowFast [18]采用的64帧时窗采样),我们提出对3D-CNN采用均匀采样策略 [65]。具体而言,要从视频中采样$n$帧,我们将视频均分为$n$段,每段随机选取一帧。均匀采样策略能更好地保持视频的全局动态特征。实证研究表明,该策略对基于骨架的动作识别具有显著优势。更多关于3D热图生成的说明详见附录B节。
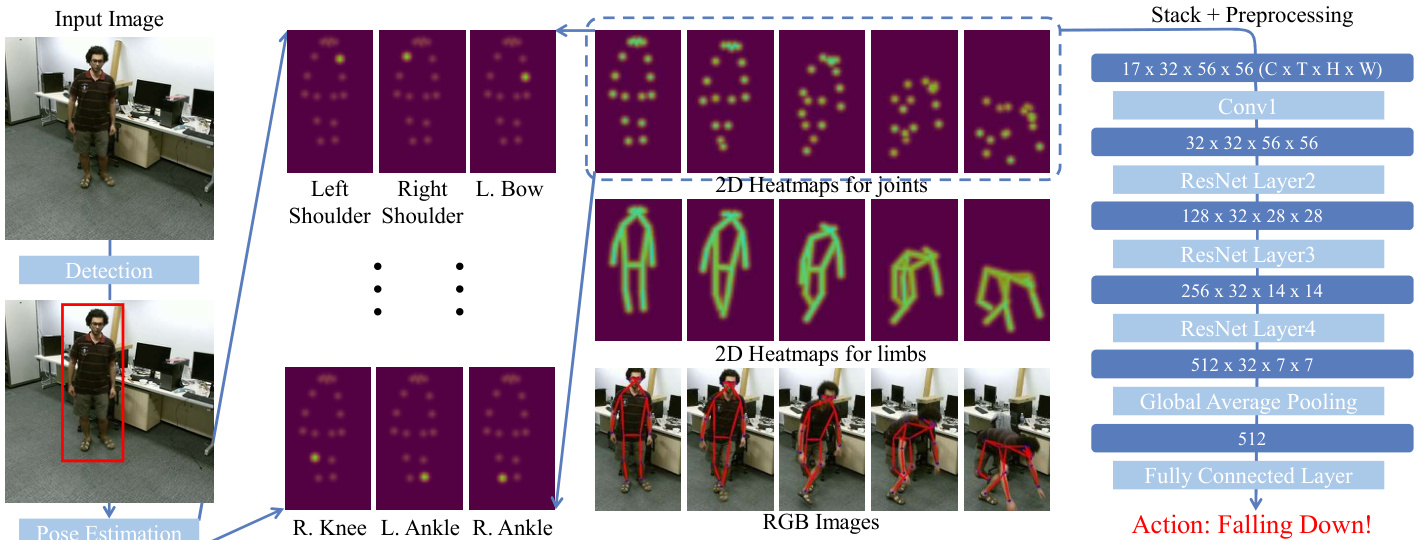
Figure 2. Our Framework. For each frame in a video, we first use a two-stage pose estimator (detection $^+$ pose estimation) for 2D human pose extraction. Then we stack heatmaps of joints or limbs along the temporal dimension and apply pre-processing to the generated 3D heatmap volumes. Finally, we use a 3D-CNN to classify the 3D heatmap volumes.
图 2: 我们的框架。对于视频中的每一帧,我们首先使用两阶段姿态估计器(检测 $^+$ 姿态估计)进行二维人体姿态提取。接着沿时间维度堆叠关节或肢体的热图,并对生成的3D热图体积进行预处理。最后,我们使用3D-CNN对3D热图体积进行分类。
Table 2. Evalution of PoseConv3D variants. ‘s’ indicates shallow (fewer layers); ‘HR’ indicates high-resolution (double height & width); ‘wd’ indicates wider network with double channel size.
表 2: PoseConv3D变体评估。's'表示浅层(较少层数);'HR'表示高分辨率(高度和宽度加倍);'wd'表示通道数加倍的宽网络。
| Backbone | Variant | NTU60-XSub | FLOPs | Params |
|---|---|---|---|---|
| SlowOnly | 93.7 | 15.9G | 2.0M | |
| SlowOnly | HR | 93.6 | 73.0G | 8.0M |
| SlowOnly | wd | 93.7 | 54.9G | 7.9M |
| C3D | 93.0 | 25.2G | 6.9M | |
| C3D | S | 92.9 | 16.8G | 3.4M |
| X3D | 92.6 | 1.1G | 531K | |
| X3D | S | 92.3 | 0.6G | 241K |
3.3. 3D-CNN for Skeleton-based Action Recognition
3.3. 基于骨架动作识别的3D-CNN
For skeleton-based action recognition, GCN has long been the mainstream backbone. In contrast, 3D-CNN, an effective network structure commonly used in RGB-based action recognition [6, 18, 20], is less explored in this direction. To demonstrate the power of 3D-CNN in capturing s patio temporal dynamics of skeleton sequences, we design two families of 3D-CNNs, namely PoseConv3D for the Pose modality and RGBPose-Conv3D for the $R G B{+}P o s e$ dual-modality.
对于基于骨架的动作识别,GCN长期以来一直是主流骨干网络。相比之下,3D-CNN这一在基于RGB的动作识别中常用的有效网络结构[6, 18, 20],在该领域却鲜少被探索。为了展示3D-CNN在捕捉骨架序列时空动态特性方面的能力,我们设计了两类3D-CNN架构:针对姿态模态的PoseConv3D,以及面向$RGB{+}Pose$双模态的RGBPose-Conv3D。
PoseConv3D. PoseConv3D focuses on the modality of human skeletons, which takes 3D heatmap volumes as input and can be instantiated with various 3D-CNN backbones. Two modifications are needed to adapt 3D-CNNs to skeleton-based action recognition: (1) down-sampling operations in early stages are removed from the 3D-CNN since the spatial resolution of 3D heatmap volumes does not need to be as large as RGB clips $4\times$ smaller in our setting); (2) a shallower (fewer layers) and thinner (fewer channels) network is sufficient to model s patio temporal dynamics of human skeleton sequences since 3D heatmap volumes are already mid-level features for action recognition. Based on these principles, we adapt three popular 3D-CNNs: C3D [60], SlowOnly [18], and X3D [17], to skeleton-based action recognition (Table 11 demonstrates the architectures of the three backbones as well as their variants). The different variants of adapted 3D-CNNs are evaluated on the NTURGB $^+$ D-XSub benchmark (Table 2). Adopting a lightweight version of 3D-CNNs can significantly reduce the computational complexity at the cost of a slight recognition performance drop $(\leq0.3%$ for all 3D backbones). In experiments, we use SlowOnly as the default backbone, considering its simplicity (directly inflated from ResNet) and good recognition performance. PoseConv3D can outperform representative GCN / 2D-CNN counterparts across various benchmarks, both in accuracy and efficiency. More importantly, the interoperability between PoseConv3D and popular networks for RGB-based action recognition makes it easy to involve human skeletons in multi-modality fusion.
PoseConv3D。PoseConv3D专注于人体骨骼模态,以3D热图体积作为输入,并可通过多种3D-CNN骨干网络实例化。为使3D-CNN适配基于骨骼的动作识别,需进行两项改进:(1) 移除3D-CNN早期阶段的下采样操作,因为3D热图体积的空间分辨率无需像RGB片段那么大(在我们的设置中小4倍);(2) 由于3D热图体积已是动作识别的中层特征,更浅(更少层数)更薄(更少通道)的网络足以建模人体骨骼序列的时空动态。基于这些原则,我们改造了三种主流3D-CNN:C3D [60]、SlowOnly [18]和X3D [17](表11展示了这三种骨干网络及其变体的架构)。改造后的3D-CNN不同变体在NTURGB$^+$D-XSub基准上进行了评估(表2)。采用轻量级3D-CNN版本可显著降低计算复杂度,仅需付出轻微识别性能下降的代价(所有3D骨干网络均≤0.3%)。实验中我们选择SlowOnly作为默认骨干网络,因其结构简单(直接从ResNet扩展而来)且识别性能良好。PoseConv3D在各类基准测试的准确率和效率上均优于代表性GCN/2D-CNN方案。更重要的是,PoseConv3D与基于RGB的动作识别通用网络之间的互操作性,使其能轻松融入多模态融合中的人体骨骼信息。
RGBPose-Conv3D. To show the interoperability of PoseConv3D, we propose RGBPose-Conv3D for the early fusion of human skeletons and RGB frames. It is a two-stream 3D-CNN with two pathways that respectively process RGB modality and Pose modality. While a detailed instantiation of RGBPose-Conv3D is included in Sec C.2, the architecture of RGBPose-Conv3D follows several principles in general: (1) the two pathways are asymmetrical due to the different characteristics of the two modalities: Compared to the RGB pathway, the pose pathway has a smaller channel width, a smaller depth, as well as a smaller input spatial resolution. (2) Inspired by SlowFast [18], bidirectional lateral connections between the two pathways are added to promote early-stage feature fusion between two modalities. To avoid over fitting, RGBPose-Conv3D is trained with two individual cross-entropy losses respectively for each pathway. In experiments, we find that early-stage feature fusion, achieved by lateral connections, leads to consistent improvement compared to late-fusion only.
RGBPose-Conv3D。为了展示PoseConv3D的互操作性,我们提出了RGBPose-Conv3D用于人体骨骼和RGB帧的早期融合。这是一个双流3D-CNN架构,包含分别处理RGB模态和姿态模态的两条通路。虽然附录C.2详细阐述了RGBPose-Conv3D的具体实现,但其架构总体上遵循以下原则:(1) 由于两种模态的特性差异,两条通路采用非对称设计:与RGB通路相比,姿态通路具有更小的通道宽度、更浅的深度以及更低的输入空间分辨率。(2) 受SlowFast [18]启发,我们在两条通路间添加了双向横向连接以促进早期特征融合。为避免过拟合,RGBPose-Conv3D采用双路独立交叉熵损失进行训练。实验表明,通过横向连接实现的早期特征融合相比仅用后期融合能带来持续的性能提升。
4. Experiments
4. 实验
4.1. Dataset Preparation
4.1. 数据集准备
We use six datasets in our experiments: FineGYM [49], NTURGB $+\mathrm{D}$ [38, 48], Kinetics400 [6, 71], UCF101 [57], HMDB51 [29] and Volleyball [23]. Unless otherwise specified, we use the Top-Down approach for pose extraction: the detector is Faster-RCNN [46] with the ResNet50 backbone, the pose estimator is HRNet [59] pre-trained on COCO-keypoint [35]. For all datasets except FineGYM, 2D poses are obtained by directly applying TopDown pose estimators to RGB inputs. We report the Mean Top-1 accuracy for FineGYM and Top-1 accuracy for other datasets. We adopt the 3D ConvNets implemented in MMAction2 [11] in experiments.
我们在实验中使用了六个数据集:FineGYM [49]、NTURGB+D [38, 48]、Kinetics400 [6, 71]、UCF101 [57]、HMDB51 [29] 和 Volleyball [23]。除非另有说明,我们采用自上而下 (Top-Down) 方法进行姿态提取:检测器为基于 ResNet50 骨干网络的 Faster-RCNN [46],姿态估计器为在 COCO-keypoint [35] 上预训练的 HRNet [59]。除 FineGYM 外,其他数据集的 2D 姿态均通过直接将 TopDown 姿态估计器应用于 RGB 输入获得。我们报告 FineGYM 的平均 Top-1 准确率和其他数据集的 Top-1 准确率。实验中采用了 MMAction2 [11] 实现的 3D ConvNets。
FineGYM. FineGYM is a fine-grained action recognition dataset with 29K videos of 99 fine-grained gymnastic action classes. During pose extraction, we compare three different kinds of person bounding boxes: 1. Person bounding boxes predicted by the detector (Detection); 2. GT bounding boxes for the athlete in the first frame, tracking boxes for the rest frames (Tracking). 3. GT bounding boxes for the athlete in all frames (GT). In experiments, we use human poses extracted with the third kind of bounding boxes unless otherwise noted.
FineGYM。FineGYM是一个细粒度动作识别数据集,包含99个细粒度体操动作类别的2.9万段视频。在姿态提取过程中,我们比较了三种不同的人物边界框:1. 检测器预测的人物边界框(Detection);2. 第一帧中运动员的真实边界框(GT),其余帧使用跟踪框(Tracking);3. 所有帧中运动员的真实边界框(GT)。实验中如无特别说明,均采用第三种边界框提取的人体姿态。
NTURGB $\mathbf{+D}$ . NTURGB $+\mathrm{D}$ is a large-scale human action recognition dataset collected in the lab. It has two versions, namely NTU-60 and NTU-120 (a superset of NTU60): NTU-60 contains 57K videos of 60 human actions, while NTU-120 contains 114K videos of 120 human actions. The datasets are split in three ways: Cross-subject (X-Sub), Cross-view (X-View, for NTU-60), Cross-setup (X-Set, for NTU-120), for which action subjects, camera views, camera setups are different in training and validation. The 3D skeletons collected by sensors are available for this dataset. Unless otherwise specified, we conduct experiments on the $\mathbf{X}$ -sub splits for NTU-60 and NTU-120.
NTURGB $\mathbf{+D}$。NTURGB $+\mathrm{D}$ 是一个在实验室环境下收集的大规模人类动作识别数据集,包含NTU-60和NTU-120(NTU60的超集)两个版本:NTU-60包含60类人类动作的57K段视频,NTU-120则包含120类动作的114K段视频。数据集提供三种划分方式:跨被试者(X-Sub)、跨视角(X-View,仅NTU-60)、跨设备(X-Set,仅NTU-120),其训练集与验证集在动作执行者、摄像机视角或采集设备配置上存在差异。该数据集提供传感器采集的3D骨骼数据。除非特别说明,我们的实验均在NTU-60和NTU-120的$\mathbf{X}$-sub划分上进行。
Kinetics 400, UCF101, and HMDB51. The three datasets are general action recognition datasets collected from the web. Kinetics 400 is a large-scale video dataset with 300K videos from 400 action classes. UCF101 and HMDB51 are smaller, contain 13K videos from 101 classes and 6.7K videos from 51 classes, respectively. We conduct experiments using 2D-pose annotations extracted with our TopDown pipeline.
Kinetics 400、UCF101和HMDB51。这三个数据集是从网络收集的通用动作识别数据集。Kinetics 400是一个大规模视频数据集,包含来自400个动作类别的30万段视频。UCF101和HMDB51规模较小,分别包含来自101个类别的1.3万段视频和来自51个类别的6700段视频。我们使用TopDown流程提取的2D姿态标注进行实验。
Volleyball. Volleyball is a group activity recognition dataset with 4830 videos of 8 group activity classes. Each frame contains approximately 12 persons, while only the center frame has annotations for GT person boxes. We use tracking boxes from [47] for pose extraction.
排球
排球是一个群体活动识别数据集,包含4830个视频,涵盖8种群体活动类别。每帧画面平均有12人,但仅中心帧标注了真实人物边界框(GT person boxes)。我们采用[47]的追踪框进行姿态提取。
4.2. Good properties of PoseConv3D
4.2. PoseConv3D 的良好特性
To elaborate on the good properties of 3D convolutional networks over graph networks, we compare PoseSlowOnly with MS-G3D [40], a representative GCN-based approach in multiple dimensions. Two models take exactly the same input (coordinate-triplets for GCN, heatmaps generated from coordinate-triplets for PoseConv3D).
为了详细说明3D卷积网络相对于图网络的优越特性,我们从多个维度将PoseSlowOnly与基于GCN的代表性方法MS-G3D [40]进行对比。两个模型采用完全相同的输入(GCN使用坐标三元组,PoseConv3D使用坐标三元组生成的热图)。
Performance & Efficiency. In performance comparison between PoseConv3D and GCN, we adopt the input shape $48\times56\times56$ for PoseConv3D. Table 3 shows that under such configuration, PoseConv3D is lighter than the GCN counterpart, both in the number of parameters and FLOPs. Though being light-weighted, PoseConv3D achieves competitive performance on different datasets. The 1-clip testing result is better than or comparable with a state-of-theart GCN while requiring much less computation. With 10-clip testing, PoseConv3D consistently outperforms the state-of-the-art GCN. Only PoseConv3D can take advantage of multi-view testing since it subsamples the entire heatmap volumes to form each input. Besides, PoseConv3D uses the same architecture and hyper parameters for different datasets, while GCN relies on heavy tuning of architectures and hyper parameters on different datasets [40].
性能与效率。在PoseConv3D与GCN的性能对比中,我们为PoseConv3D采用$48\times56\times56$的输入尺寸。表3显示,在此配置下,PoseConv3D在参数量和FLOPs方面均比GCN更轻量。尽管轻量化,PoseConv3D在不同数据集上仍具备竞争力:单片段测试结果优于或持平当前最优GCN,同时计算需求显著降低;十片段测试时PoseConv3D持续超越最优GCN。此外,PoseConv3D是唯一能利用多视角测试优势的方法,因其通过子采样完整热图体积生成每个输入。值得注意的是,PoseConv3D对不同数据集采用统一架构和超参数,而GCN需针对不同数据集进行繁重的架构调优和超参数调整 [40]。
Robustness. To test the robustness of both models, we can drop a proportion of keypoints in the input and see how such perturbation will affect the final accuracy. Since limb keypoints3 are more critical for gymnastics than the torso or face keypoints, we test both models by randomly dropping one limb keypoint in each frame with probability $p$ . In Table 4, we see that PoseConv3D is highly robust to input perturbations: dropping one limb keypoint per frame leads to a moderate drop (less than $1%$ ) in Mean-Top1, while for GCN, it’s $14.3%$ . Someone would argue that we can train GCN with the noisy input, similar to the dropout operation [58]. However, even under this setting, the Mean-Top1 accuracy of GCN still drops by $1.4%$ for the case $p=1$ . Besides, with robust training, there will be an additional $1.1%$ drop for the case $p=0$ . The experiment results show that PoseConv3D significantly outperforms GCN in terms of robustness for pose recognition.
鲁棒性。为测试两种模型的鲁棒性,我们可以在输入中随机丢弃一定比例的关键点,观察此类扰动如何影响最终准确率。由于体操动作中肢体关键点3比躯干或面部关键点更为重要,我们通过以概率$p$随机丢弃每帧中的一个肢体关键点来测试两种模型。表4显示,PoseConv3D对输入扰动具有高度鲁棒性:每帧丢弃一个肢体关键点仅导致Mean-Top1适度下降(小于$1%$),而GCN的降幅达$14.3%$。有人可能提出可以像dropout操作[58]那样用噪声输入训练GCN,但即使在此设置下,当$p=1$时GCN的Mean-Top1准确率仍会下降$1.4%$。此外,采用鲁棒训练会导致$p=0$时的准确率额外下降$1.1%$。实验结果表明,在姿态识别的鲁棒性方面,PoseConv3D显著优于GCN。
Generalization. To compare the generalization of GCN and 3D-CNN, we design a cross-model check on FineGYM.
泛化性。为了比较 GCN 和 3D-CNN 的泛化能力,我们在 FineGYM 数据集上设计了跨模型验证。
Table 3. PoseConv3D v.s. GCN. We compare the performance of PoseConv3D and GCN on several datasets. For PoseConv3D, we report the results of 1/10-clip testing. We exclude parameters and FLOPs of the FC layer, since it depends on the number of classes.
表 3: PoseConv3D 与 GCN 对比。我们在多个数据集上比较了 PoseConv3D 和 GCN 的性能。对于 PoseConv3D,我们报告了 1/10-clip 测试的结果。我们排除了全连接层 (FC) 的参数和 FLOPs,因为这取决于类别数量。
| 数据集 | MS-G3D Acc | MS-G3D Params | MS-G3D FLOPs | Pose-SlowOnly 1-clip | Pose-SlowOnly 10-clip | Pose-SlowOnly Params | Pose-SlowOnly FLOPs |
|---|---|---|---|---|---|---|---|
| FineGYM | 92.0 | 2.8M | 24.7G | 92.4 | 93.2 | 15.9G | |
| NTU-60 | 91.9 | 2.8M | 16.7G | 93.1 | 93.7 | 15.9G | |
| NTU-120 | 84.8 | 2.8M | 16.7G | 85.1 | 86.0 | 15.9G | |
| Kinetics400 | 44.9 | 2.8M | 17.5G | 44.8 | 46.0 | 15.9G |
Table 4. Recognition performance w. different dropping KP probabilities. PoseConv3D is more robust to input perturbations.
表 4: 不同关键点丢弃概率下的识别性能。PoseConv3D对输入扰动具有更强的鲁棒性。
| 方法 / p | 0 | 1/8 | 1/4 | 1/2 | 1 |
|---|---|---|---|---|---|
| MS-G3D | 92.0 | 91.0 | 90.2 | 86.5 | 77.7 |
| + 鲁棒训练 | 90.9 | 91.0 | 91.0 | 91.0 | 90.6 |
| Pose-SlowOnly | 92.4 | 92.4 | 92.3 | 92.1 | 91.5 |
Specifically, we use two models, i.e., HRNet (HigherQuality, or HQ for short) and MobileNet (Lower-Quality, LQ) for pose estimation and train two PoseConv3D on top, respectively. During testing, we feed LQ input into the model trained with HQ one and vice versa. From Table 5a, we see that the accuracy drops less when using lowerquality poses for both training & testing with PoseConv3D compared to GCN. Similarly, we can also vary the source of person boxes, using either GT boxes (HQ) or tracking results (LQ) for training and testing. The results are shown in Table 5b. The performance drop of PoseConv3D is also much smaller than GCN.
具体而言,我们采用HRNet(高质量,简称HQ)和MobileNet(低质量,简称LQ)两种模型进行姿态估计,并分别在其基础上训练两个PoseConv3D。测试时,我们将LQ输入数据输入到用HQ数据训练的模型中,反之亦然。从表5a可见,与GCN相比,PoseConv3D在训练和测试阶段均使用低质量姿态数据时,准确率下降幅度更小。类似地,我们还可以调整人物检测框的来源,在训练和测试时分别使用GT框(HQ)或跟踪结果(LQ)。结果如表5b所示,PoseConv3D的性能下降幅度也远小于GCN。
S cal ability. The computation of GCN scales linearly with the increasing number of persons in the video, making it less efficient for group activity recognition. We use an experiment on the Volleyball dataset [23] to prove that. Each video in the dataset contains 13 persons and 20 frames. For GCN, the corresponding input shape will be $13\times20\times17\times3$ , 13 times larger than the input for one person. Under such configuration, the number of parameters and FLOPs for GCN is $2.8\mathbf{M}$ and 7.2G $(13\times)$ . For PoseConv3D, we can use one single heatmap volume (with shape $17\times12\times56\times56)$ to represent all 13 persons4. The base channel-width of Pose-SlowOnly is set to 16, leading to only 0.52M parameters and 1.6 GFLOPs. Despite the much smaller parameters and FLOPs, PoseConv3D achieves $91.3%$ Top-1 accuracy on Volleyball-validation, $2.1%$ higher than the GCN-based approach.
可扩展性。GCN的计算量随着视频中人数增加而线性增长,导致其在群体活动识别中效率较低。我们通过Volleyball数据集[23]的实验验证了这一点:该数据集每段视频包含13人和20帧画面。对GCN而言,其输入张量维度将达到$13\times20\times17\times3$,是单人输入的13倍。在此配置下,GCN参数量为$2.8\mathbf{M}$,计算量为7.2G$(13\times)$。而PoseConv3D仅需单个热图体量(维度$17\times12\times56\times56)$即可表征全部13人4。当Pose-SlowOnly基础通道宽度设为16时,参数量仅0.52M,计算量1.6 GFLOPs。尽管参数量和计算量显著降低,PoseConv3D在Volleyball验证集上仍取得$91.3%$的Top-1准确率,较基于GCN的方法提升$2.1%$。
4.3. Multi-Modality Fusion with RGBPose-Conv3D
4.3. 基于 RGBPose-Conv3D 的多模态融合
The 3D-CNN architecture of PoseConv3D makes it more flexible to fuse pose with other modalities via some early fusion strategies. For example, in RGBPose-Conv3D, lateral connections between the $R G B$ -pathway and Pose-pathway are exploited for cross-modality feature fusion in the early stage. In practice, we first train two models for RGB and Pose modalities separately and use them to initialize the RGBPose-Conv3D. We continue to finetune the network for several epochs to train the lateral connections. The final prediction is achieved by late fusing the prediction scores from both pathways. RGBPose-Conv3D can achieve better fusing results with early+late fusion.
PoseConv3D的3D-CNN架构使其能够通过一些早期融合策略更灵活地将姿态与其他模态融合。例如,在RGBPose-Conv3D中,RGB通道和姿态通道之间的横向连接被用于早期的跨模态特征融合。实践中,我们首先分别训练RGB和姿态模态的两个模型,并用它们初始化RGBPose-Conv3D。然后继续微调网络几个周期以训练横向连接。最终预测通过后期融合两个通道的预测分数实现。RGBPose-Conv3D通过早期+后期融合可以获得更好的融合效果。
Table 5. Train/Test w. different pose annotations. PoseConv3D shows great generalization capability in the cross-PoseAnno setting (LQ for low-quality; HQ for high-quality).
(a) Train/Test w. Pose from different estimators.
表 5: 采用不同姿态标注的训练/测试。PoseConv3D 在跨姿态标注设置中展现出强大的泛化能力 (LQ 表示低质量;HQ 表示高质量)。
| Train→Test | |||
|---|---|---|---|
| HQ→LQ | LQ→HQ | LQ→LQ | |
| MS-G3D | 79.3 | 87.9 | 89.0 |
| PoseConv3D | 86.5 | 91.6 | 90.7 |
(a) 采用不同估计器生成姿态的训练/测试。
(b) Train/Test w. Pose extracted with different boxes.
| Train→Test | ||
|---|---|---|
| HQ→LQ LQ→HQ | LQ→LQ | |
| MS-G3D | 78.5 89.1 | 82.9 |
| PoseConv3D | 82.1 90.6 | 85.4 |
(b) 使用不同边界框提取姿态的训练/测试。
Table 6. The design of RGBPose-Conv3D. Bi-directional lateral connections outperform uni-directional ones in the early stage feature fusion.
表 6: RGBPose-Conv3D的设计。双向横向连接在早期特征融合中表现优于单向连接。
| 后期融合 | RGB→Pose | Pose→RGB | RGB↔Pose | |
|---|---|---|---|---|
| 1-clip | 92.6 | 93.0 | 93.4 | 93.6 |
| 10-clip | 93.4 | 93.7 | 93.8 | 94.1 |
Table 7. The universality of RGBPose-Conv3D. The early+late fusion strategy works both on RGB-dominant NTU-60 and Posedominant FineGYM.
表 7. RGBPose-Conv3D的通用性。早期+晚期融合策略在RGB主导的NTU-60和姿态主导的FineGYM上均有效。
| RGB | Pose | latefusion | early+late fusion | |
|---|---|---|---|---|
| FineGYM | 87.2/88.5 | 91.0/92.0 | 92.6/93.4 | 93.6/94.1 |
| NTU-60 | 94.1/94.9 | 92.8/93.2 | 95.5/96.0 | 96.2/96.5 |
We first compare uni-directional lateral connections and bi-directional lateral connections in Table 6. The result shows that bi-directional feature fusion is better than unidirectional ones for RGB and Pose. With bi-directional feature fusion in the early stage, the early+late fusion with 1-clip testing can outperform the late fusion with 10-clip testing. Besides, RGBPose-Conv3D also works in situations when the importance of two modalities is different. The pose modality is more important in FineGYM and vice versa in NTU-60. Yet we observe performance improvement by early+late fusion on both of them in Table 7. We demonstrate the detailed instantiation of RGBPose-Conv3D we used in Sec C.2.
我们首先在表6中比较了单向横向连接和双向横向连接。结果表明,对于RGB和姿态模态,双向特征融合优于单向融合。通过在早期阶段采用双向特征融合,1片段测试的早期+晚期融合效果能超越10片段测试的晚期融合。此外,RGBPose-Conv3D在两种模态重要性不同的场景下同样有效:在FineGYM数据集中姿态模态更重要,而在NTU-60中则相反。但如表7所示,我们观察到早期+晚期融合在这两个数据集上均能提升性能。具体实现细节将在C.2节展示。
Table 8. PoseConv3D is better or comparable to previous state-of-the-arts. With estimated high-quality 2D skeletons and the great capacity of 3D-CNN to learn s patio temporal features, PoseConv3D achieves superior performance across 5 out of 6 benchmarks. ${\cal J},{\cal L}$ means using joint/limb-based heatmaps. $^{++}$ denotes using the same human skeletons as ours. Numbers with * are reported by [49].
表 8. PoseConv3D优于或与现有最优方法相当。通过估计高质量2D骨骼和3D-CNN强大的时空特征学习能力,PoseConv3D在6个基准测试中的5个上实现了卓越性能。${\cal J},{\cal L}$表示使用基于关节/肢体的热图。$^{++}$表示使用与我们相同的人体骨骼。带*的数字来自[49]。
| 方法 | NTU60-XSub | NTU60-XView | NTU120-XSub | NTU120-XSet | Kinetics | FineGYM |
|---|---|---|---|---|---|---|
| ST-GCN [71] | 81.5 | 88.3 | 70.7 | 73.2 | 30.7 | 25.2* |
| AS-GCN [34] | 86.8 | 94.2 | 78.3 | 79.8 | 34.8 | |
| RA-GCN [54] | 87.3 | 93.6 | 81.1 | 82.7 | ||
| AGCN [51] | 88.5 | 95.1 | 36.1 | |||
| DGNN [50] | 89.9 | 96.1 | 36.9 | |||
| FGCN [72] | 90.2 | 96.3 | 85.4 | 87.4 | ||
| Shift-GCN [9] | 90.7 | 96.5 | 85.9 | 87.6 | ||
| DSTA-Net [52] | 91.5 | 96.4 | 86.6 | 89.0 | ||
| MS-G3D [40] | 91.5 | 96.2 | 86.9 | 88.4 | 38.0 | |
| MS-G3D ++ | 92.2 | 96.6 | 87.2 | 89.0 | 45.1 | 92.6 |
| PoseConv3D (J) | 93.7 | 96.6 | 86.0 | 89.6 | 46.0 | 93.2 |
| PoseConv3D (J + L) | 94.1 | 97.1 | 86.9 | 90.3 | 47.7 | 94.3 |
Table 9. Comparison to the state-of-the-art of Multi-Modality Action Recognition. Strong recognition performance is achieved on multiple benchmarks with multi-modality fusion. R, F, P indicate RGB, Flow, Pose.
表 9: 多模态动作识别的当前最优方法对比。通过多模态融合在多个基准测试中实现了强大的识别性能。R、F、P分别表示RGB、光流、姿态。
| 数据集 | 先前最优方法 | 本文方法 |
|---|---|---|
| FineGYM-99 | 87.7 (R) [30] | 95.6 (R + P) |
| NTU60(X-Sub/X-View) | 95.7 / 98.9 (R + P) [14] | 97.0 / 99.6 (R + P) |
| NTU120 (X-Sub /X-Set) | 90.7/ 92.5 (R + P) [12] | 95.3/96.4 (R + P) |
4.4. Comparisons with the state-of-the-art
4.4. 与最先进技术的比较
Skeleton-based Action Recognition. In Table 8, we compare PoseConv3D with prior works for skeleton-based action recognition. Prior works (Table 8 upper) use 3D skeletons collected with Kinect for NTURGB $+\mathrm{D}$ , 2D skeletons extracted with OpenPose for Kinetics (details for FineGYM skeleton data are unknown). PoseConv3D adopts 2D skeletons extracted with good practices introduced in Sec 3.1, which have better quality. We instantiate PoseConv3D with the SlowOnly backbone, feed 3D heatmap volumes of shape $48\times56\times56$ as inputs, and report the accuracy obtained by 10-clip testing. For a fair comparison, we also evaluate the state-of-the-art MS-G3D with our 2D human skeletons $(M S{-}G3D{+}{+})$ : $M S{\bf-}G3D{\bf+}{\bf+}$ directly takes the extracted coordinate-triplets $(x,y,c)$ as inputs, while PoseConv3D takes pseudo heatmaps generated from the coordinate-triplets as inputs. With high quality 2D human skeletons, $M S{-}G3D{+}{+}$ and PoseConv3D both achieve far better performance than previous state-of-the-arts, demonstrating the importance of the proposed practices for pose extraction in skeleton-based action recognition. When both take high-quality 2D poses as inputs, PoseConv3D outperforms the state-of-the-art MS-G3D across 5 of 6 benchmarks, showing its great s patio temporal feature learning capability. PoseConv3D achieves by far the best results on 3 of 4 NTURGB $+\mathrm{D}$ benchmarks. On Kinetics, PoseConv3D surpasses $\mathrm{MS-G3D++}$ by a noticeable margin, significantly outperforming all previous methods. Except for the baseline reported in [49], no work aims at skeleton-based action recognition on FineGYM before, while our work first improves the performance to a decent level.
基于骨架的动作识别。在表8中,我们将PoseConv3D与先前基于骨架动作识别的工作进行对比。先前工作(表8上半部分)使用Kinect采集的3D骨架处理NTURGB+D数据集,采用OpenPose提取的2D骨架处理Kinetics数据集(FineGYM骨架数据细节未知)。PoseConv3D采用第3.1节介绍的优化方法提取2D骨架,质量更优。我们以SlowOnly为主干网络实例化PoseConv3D,输入形状为48×56×56的3D热力图体积,并报告10片段测试的准确率。为公平对比,我们还用自提2D人体骨架评估了当前最优的MS-G3D $(MS-G3D++)$ :$MS{\bf-}G3D{\bf+}{\bf+}$ 直接使用提取的坐标三元组 $(x,y,c)$ 作为输入,而PoseConv3D使用坐标三元组生成的伪热力图作为输入。采用高质量2D人体骨架时,$MS-G3D++$ 和PoseConv3D均显著超越先前最优方法,证明所提姿态提取方案对骨架动作识别的重要性。当两者均采用高质量2D姿态输入时,PoseConv3D在6个基准测试中的5个超越当前最优MS-G3D,展现出色时空特征学习能力。PoseConv3D在4个NTURGB+D基准测试中的3个取得迄今最佳结果。在Kinetics数据集上,PoseConv3D明显超越 $\mathrm{MS-G3D++}$ ,显著优于所有先前方法。除[49]报告的基线外,此前未有工作针对FineGYM进行骨架动作识别,而本研究首次将其性能提升至较好水平。
(a) Mulit-modality action recognition with RGBPose-Conv3D. (b) Mulit-modality action recognition with LateFusion.5
(a) 基于RGBPose-Conv3D的多模态动作识别
(b) 基于LateFusion的多模态动作识别
| 数据集 | 先前最佳方法 | 我们的方法 (姿态) | 我们的方法 (融合) |
|---|---|---|---|
| Kinetics400 | 84.9 (R) [39] | 47.7 | 85.5 (R + P) |
| UCF101 | 98.6 (R + F) [16] | 87.0 | 98.8 (R + F + P) |
| HMDB51 | 83.8 (R + F) [16] | 69.3 | 85.0 (R + F + P) |
Multi-modality Fusion. As a powerful representation itself, skeletons are also complementary to other modalities, like RGB appearance. With multi-modality fusion (RGBPose-Conv3D or LateFusion), we achieve state-ofthe-art results across 8 different video recognition benchmarks. We apply the proposed RGBPose-Conv3D to FineGYM and 4 NTURGB $+\mathrm{D}$ benchmarks, using R50 as the backbone; 16, 48 as the temporal length for RGB/PosePathway. Table 9a shows that our early+late fusion achieves excellent performance across various benchmarks. We also try to fuse the predictions of PoseConv3D directly with other modalities with LateFusion. Table 9b shows that late fusion with the Pose modality can push the recognition precision to a new level. We achieve the new state-of-theart on three action recognition benchmarks: Kinetics 400, UCF101, and HMDB51. On the challenging Kinetics 400 benchmark, fusing with PoseConv3D predictions increases the recognition accuracy by $0.6%$ beyond the state-of-theart [39], which is strong evidence for the complement ari ty
多模态融合。作为一种强大的表征形式,骨架数据与其他模态(如RGB外观)具有互补性。通过多模态融合(RGBPose-Conv3D或LateFusion),我们在8个不同的视频识别基准测试中取得了最先进的结果。我们将提出的RGBPose-Conv3D应用于FineGYM和4个NTURGB $+\mathrm{D}$ 基准测试,采用R50作为主干网络,RGB/PosePathway的时间长度设为16和48。表9a显示我们的早期+晚期融合在各种基准测试中均表现出色。我们还尝试通过LateFusion将PoseConv3D的预测结果直接与其他模态融合。表9b表明,与姿态模态的晚期融合能将识别精度提升至新高度。我们在三个动作识别基准测试(Kinetics 400、UCF101和HMDB51)中实现了新的最先进水平。在具有挑战性的Kinetics 400基准测试中,与PoseConv3D预测结果的融合使识别准确率比现有最高水平[39]提升了 $0.6%$ ,这有力证明了互补性。
of the Pose modality.
姿态模态的
4.5. Ablation on Heatmap Processing
4.5. 热图处理消融实验
Subjects-Centered Cropping. Since the sizes and locations of persons can vary a lot in a dataset, focusing on the action subjects is the key to reserving as much information as possible with a relatively small $H\times W$ budget. To validate this, we conduct a pair of experiments on FineGYM with input size $32\times56\times56$ , with or without subjectscentered cropping. We find that subjects-centered cropping is helpful in data preprocessing, which improves the MeanTop1 by $1.0%$ , from $91.7%$ to $92.7%$ .
以主体为中心的裁剪。由于数据集中人物的尺寸和位置可能存在较大差异,在有限的 $H\times W$ 预算下,聚焦动作主体是保留最多信息的关键。为验证这一点,我们在FineGYM数据集上进行了两组输入尺寸为 $32\times56\times56$ 的实验(采用/不采用以主体为中心的裁剪)。结果表明,以主体为中心的裁剪能有效提升数据预处理效果,使MeanTop1准确率从 $91.7%$ 提升至 $92.7%$ ,增幅达 $1.0%$ 。
Uniform Sampling. The input sampled from a small temporal window may not capture the entire dynamic of the human action. To validate this, we conduct experiments on FineGYM and NTU-60. For fixed stride sampling, which samples from a fixed temporal window, we try to sample 32 frames with the temporal stride 2, 3, 4; for uniform sampling, we sample 32 frames uniformly from the entire clip. In testing, we adopt a fixed random seed when sampling frames from each clip to make sure the test results are reproducible. From Figure 3, we see that uniform sampling consistently outperforms sampling with fixed temporal strides. With uniform sampling, 1-clip testing can even achieve better results than fixed stride sampling with 10-clip testing. Note that the video length can vary a lot in NTU-60 and FineGYM. In a more detailed analysis, we find that uniform sampling mainly improves the recognition performance for longer videos in the dataset (Figure 4). Besides, uniform sampling also outperforms fixed stride sampling on RGBbased recognition on the two datasets6.
均匀采样。从较小时间窗口采样的输入可能无法完整捕捉人体动作的动态特性。为验证这一点,我们在FineGYM和NTU-60数据集上进行实验。对于固定步长采样(从固定时间窗口采样),我们尝试以2、3、4的时序步长采样32帧;而均匀采样则是从整个片段中均匀抽取32帧。测试时采用固定随机种子进行帧采样以确保结果可复现。如图3所示,均匀采样始终优于固定步长采样。采用均匀采样时,单片段测试效果甚至优于10片段固定步长采样。需注意NTU-60和FineGYM中视频长度差异较大,详细分析表明均匀采样主要提升数据集中较长视频的识别性能(图4)。此外,在这两个数据集的RGB识别任务上,均匀采样同样优于固定步长采样[6]。
Pseudo Heatmaps for Joints and Limbs. GCN approaches for skeleton-based action recognition usually ensemble results of multiple streams (joint, bone, etc.) to obtain better recognition performance [51]. The practice is also feasible for PoseConv3D. Based on the coordinates $(x,y,c)$ we saved, we can generate pseudo heatmaps for joints and limbs. In general, we find that both joint heatmaps and limb heatmaps are good inputs for 3D-CNNs. Ensembling the results from joint-PoseConv3D and limbPoseConv3D (namely PoseConv3D $(\pmb{J}+\pmb{L}))$ can lead to noticeable and consistent performance improvement.
关节与肢体的伪热图。基于骨架的动作识别GCN方法通常通过融合多流(关节、骨骼等)结果来提升识别性能[51]。这一做法同样适用于PoseConv3D。根据存储的坐标$(x,y,c)$,我们可以生成关节和肢体的伪热图。实验表明,关节热图和肢体热图都是3D-CNN的有效输入。融合关节PoseConv3D与肢体PoseConv3D(即PoseConv3D $(\pmb{J}+\pmb{L})$)的结果能带来显著且稳定的性能提升。
3D Heatmap Volumes v.s 2D Heatmap Aggregations. The 3D heatmap volume is a more ‘lossless’ 2D-pose representation, compared to 2D pseudo images aggregating heatmaps with color iz ation or temporal convolutions. PoTion [10] and PA3D [70] are not evaluated on popular benchmarks for skeleton-based action recognition, and there are no public implementations. In the preliminary study, we find that the accuracy of PoTion is much inferior $(\leq85%)$ to GCN or PoseConv3D $\mathrm{}\geq90%$ ). For an apple-to-apple comparison, we also re-implement PoTion, PA3D (with higher accuracy than reported) and evaluate them on UCF101, HMDB51, and NTURGB $+\mathrm{D}$ . PoseConv3D achieves much better recognition results with 3D heatmap volumes, than 2D-CNNs with 2D heatmap aggregations as inputs. With the lightweight X3D, PoseConv3D significantly outperforms 2D-CNNs, with comparable FLOPs and far fewer parameters (Table 10).
3D热图体积 vs 2D热图聚合。与通过着色或时序卷积聚合热图生成的2D伪图像相比,3D热图体积是一种更"无损"的2D姿态表示方法。PoTion [10] 和 PA3D [70] 未在基于骨架动作识别的流行基准测试中进行评估,且没有公开实现。初步研究表明,PoTion的准确率远低于GCN或PoseConv3D $(\leq85%\ vs\ \Delta all\geq90%)$。为进行公平对比,我们重新实现了PoTion和PA3D(精度高于原论文报告值),并在UCF101、HMDB51和NTURGB$+\mathrm{D}$数据集上进行评估。使用3D热图体积的PoseConv3D相比以2D热图聚合为输入的2D-CNNs取得了显著更好的识别效果。配合轻量级X3D框架时,PoseConv3D在计算量(FLOPs)相当但参数量大幅减少的情况下(表10),性能显著优于2D-CNNs。
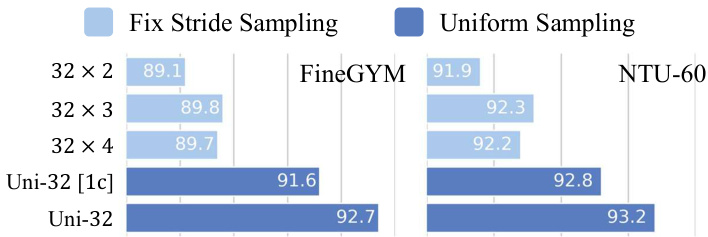
Figure 3. Uniform Sampling outperforms Fix-Stride Sampling. All results are for 10-clip testing, except Uni-32[1c], which uses 1-clip testing.
图 3: 均匀采样 (Uniform Sampling) 优于固定步长采样 (Fix-Stride Sampling)。除 Uni-32[1c] 使用单片段测试外,其余结果均为 10 片段测试。
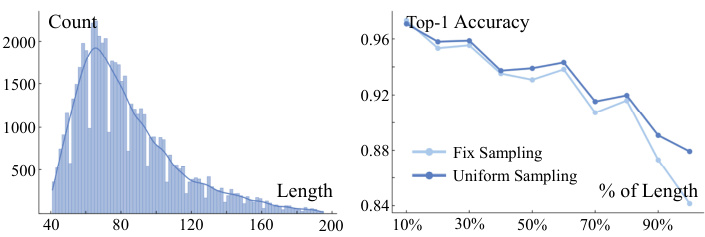
Figure 4. Uniform Sampling helps in modeling longer videos. L: The length distribution of NTU60-XSub val videos. R: Uniform Sampling improves the recognition accuracy of longer videos.
图 4: 均匀采样有助于建模更长视频。左: NTU60-XSub验证集视频长度分布。右: 均匀采样提高了较长视频的识别准确率。
Table 10. An apple-to-apple comparison between 3D heatmap volumes and 2D heatmap aggregations.
表 10: 3D热图体积与2D热图聚合的同类比较。
| 方法 | HMDB51 | UCF101 | NTU60-XSub | FLOPs | Params |
|---|---|---|---|---|---|
| PoTion[10] | 51.7 | 67.2 | 87.8 | 0.60G | 4.75M |
| PA3D [70] | 53.5 | 69.1 | 88.6 | 0.65G | 4.81M |
| Pose-SlowOnly (Ours) | 58.6 | 79.1 | 93.7 | 15.9G | 2.0M |
| Pose-X3D-s (Ours) | 55.6 | 76.7 | 92.3 | 0.60G | 0.24M |
5. Conclusion
5. 结论
In this work, we propose PoseConv3D: a 3D-CNNbased approach for skeleton-based action recognition, which takes 3D heatmap volumes as input. PoseConv3D resolves the limitations of GCN-based approaches in robustness, interoperability, and s cal ability. With light-weighted 3D-ConvNets and compact 3D heatmap volumes as input, PoseConv3D outperforms GCN-based approaches in both accuracy and efficiency. Based on PoseConv3D, we achieve state-of-the-art on both skeleton-based and multi-modalitybased action recognition across multiple benchmarks.
在本工作中,我们提出PoseConv3D:一种基于3D-CNN的骨架动作识别方法,该方法以3D热图体积作为输入。PoseConv3D解决了基于GCN方法在鲁棒性、互操作性和可扩展性方面的局限性。通过轻量级3D-ConvNets和紧凑的3D热图体积作为输入,PoseConv3D在准确性和效率上都优于基于GCN的方法。基于PoseConv3D,我们在多个基准测试中实现了基于骨架和多模态动作识别的最先进性能。
Acknowledgement. This study is supported by the General Research Funds of Hong Kong (No. 14203518), the RIE2020 Industry Alignment Fund–Industry Collaboration Projects (IAF-ICP) Funding Initiative, and Shanghai Committee of Science and Technology (No. 20 DZ 1100800).
致谢。本研究得到香港研究资助局一般研究基金(编号:14203518)、RIE2020产业联盟基金-产业合作项目(IAF-ICP)资助计划以及上海市科学技术委员会(编号:20DZ1100800)的支持。

Figure 5. The extracted skeletons of the NTURGB $\mathbf{+D}$ dataset. The actions of the visualized frames are: “cheer up”, “touch other person’s pocket”, “jump up”, “put the palms together”, “taking a selfie”, “shake fist”.
图 5: NTURGB $\mathbf{+D}$ 数据集的提取骨架。可视化帧对应的动作分别为: "加油打气"、"掏别人口袋"、"向上跳跃"、"双手合十"、"自拍"、"握拳示威"。

Figure 6. The extracted skeletons of the FineGYM dataset. The extracted skeletons are far from perfect, but disc rim i native enough for action recognition.
图 6: FineGYM 数据集提取的骨骼关键点。虽然提取结果远非完美,但对动作识别任务仍具有足够判别性。
(注:根据规则要求,已处理图片描述文本中的格式、术语及标点规范。原文"disc rim i native"疑似存在排版错误,按上下文修正为"discriminative"并译为"判别性")
A. Visualization
A. 可视化
We provide more visualization of the extracted pose of the four datasets: FineGYM, NTURGB $+\mathrm{D}$ , Kinetics 400, Volleyball to demonstrate the performance of the proposed pose extraction approach qualitatively. You can watch the corresponding videos at https://youtu. be/oS 7 fX 9 Eg 2 ws.
我们提供了四个数据集(FineGYM、NTURGB+D、Kinetics 400、Volleyball)提取姿态的更多可视化结果,以定性展示所提出姿态提取方法的性能。您可以在https://youtu.be/oS7fX9Eg2ws观看相应视频。
NTURGB $\mathbf{+D}$ [38, 48]. Figure 5 displays some examples of extracted skeletons of NTURGB $+\mathrm{D}$ . Our pose extractor achieves almost perfect performance on NTURGB $+\mathrm{D}$ due to the simple scenarios: the background scene is not complicated, while there are two persons at most in each frame, with little occlusion.
NTURGB $\mathbf{+D}$ [38, 48]。图5展示了NTURGB $+\mathrm{D}$ 中提取的部分骨骼示例。由于场景简单(背景不复杂、每帧最多两人且遮挡极少),我们的姿态提取器在NTURGB $+\mathrm{D}$ 上实现了近乎完美的性能。
FineGYM [49]. Figure 6 displays some examples of extracted skeletons of FineGYM. Although we perform pose extraction with ground-truth bounding boxes of the athletes, the extracted 2D poses are far from perfect. The pose extractor is extremely easy to make mistakes for poses the rarely occur in COCO-keypoint [35] or when motion blur occurs. Even though the quality of extracted skeletons are not satisfying, they are still disc rim i native enough for skeleton-based action recognition.
FineGYM [49]。图 6: 展示了从FineGYM中提取的一些骨骼示例。尽管我们使用运动员的真实边界框进行姿态提取,但提取的2D姿态远非完美。对于COCO-keypoint [35]中罕见或出现运动模糊的姿态,姿态提取器极易出错。尽管提取的骨骼质量不尽如人意,但对于基于骨骼的动作识别而言,它们仍具有足够的区分性。

Figure 7. The extracted skeletons of the Kinetics 400 dataset.
图 7: Kinetics 400 数据集中提取的骨骼结构。

Figure 8. The extracted skeletons of the Volleyball dataset.
图 8: 排球数据集中提取的骨架。
Kinetics 400 [6]. Kinetics 400 is not a human-centric dataset for action recognition. In Kinetics videos, the person locations, scales, and the number of persons may vary a lot, which makes extracting human skeletons of Kinetics400 much more difficult than NTURGB $+\mathrm{D}$ or FineGYM. In Figure 7, we provide some examples that our pose estimator accurately predicts the human skeletons. We also discuss some failure cases in Sec D.7.
Kinetics 400 [6]。Kinetics 400并非以人为核心的动作识别数据集。在该数据集的视频中,人物位置、尺寸及人数可能存在极大差异,这使得从Kinetics400提取人体骨骼的难度远高于NTURGB+D或FineGYM。图7展示了我们的姿态估计器准确预测人体骨骼的若干案例,失败案例的分析详见D.7节。
Volleyball [23]. Volleyball is a group activity recognition dataset. Each frame of a video contains around a dozen people (six for each team). Most of the human poses in a volleyball video are regular ones (unlike FineGYM). In Figure 8, we see that our pose extractor can predict the human pose of each person accurately.
排球 [23]。排球是一项群体活动识别数据集。视频的每一帧包含约十几人(每队六人)。排球视频中大多数人体姿态是常规动作(与FineGYM不同)。在图8中,可见我们的姿态提取器能准确预测每个人的姿态。
B. Generating Pseudo Heatmap Volumes.
B. 生成伪热图体积
In this section, we illustrate how we generate the pseudo heatmap volumes, the input of PoseConv3D. We also provide a jupyter notebook named Gen Pseudo Heat maps.ipynb in supplementary materials, which can extract skeleton keypoints from RGB videos (optional) and generate pseudo heatmaps based on the skeleton keypoints.
在本节中,我们将说明如何生成PoseConv3D的输入——伪热图( pseudo heatmap )体积数据。补充材料中提供了一个名为Gen Pseudo Heat maps.ipynb的jupyter notebook,该文件可从RGB视频中提取骨骼关键点( 可选步骤 ),并基于骨骼关键点生成伪热图。
Figure 9 illustrates the pipeline of pose extraction (RGB video $\rightarrow$ coordinate-triplets) and generating pseudo heatmap volumes (coordinate-triplets $\rightarrow3\mathrm{D}$ heatmap volumes). We only visualize one frame in Figure 9, while you can find the processing for an entire video in the notebook. Though a heatmap is of $K$ channels $X=17$ for COCOkeypoints), we visualize it in one 2D image with color encoding. For pose extraction, we use a Top-Down pose estimator instantiated with HRNet [59] to extract the 2D poses for each person in each frame, and save the coordinatetriplets: (x, y, score). For generating pseudo heatmaps, we first perform uniform sampling, which will sample $T$ frames uniformly from the video and discard the remaining frames. We then find a global cropping box (The red box in Figure 9, same for all $T$ frames) that envelops all persons in the video, and crop all $T$ frames with that box to reduce the spatial size. You can run the entire pipeline in Gen Pseudo Heat maps.ipynb.
图 9: 展示了姿态提取流程(RGB视频 $\rightarrow$ 坐标三元组)与生成伪热图体积(坐标三元组 $\rightarrow3\mathrm{D}$ 热图体积)的管线。我们仅在图9中可视化单帧画面,完整视频处理流程可在配套notebook中查看。虽然热图具有$K$个通道(COCO关键点数据集$X=17$),我们仍通过色彩编码将其呈现为单张2D图像。姿态提取环节采用基于HRNet [59]的Top-Down姿态估计器逐帧提取多人2D姿态,并存储坐标三元组:(x, y, score)。生成伪热图时,首先执行均匀采样从视频中抽取$T$帧并舍弃其余帧,随后确定能囊括视频中所有人物的全局裁剪框(图9红框,所有$T$帧共用),通过该框裁剪所有帧以缩减空间尺寸。完整管线运行详见Gen Pseudo Heat maps.ipynb文件。

Figure 9. The pipeline of generating the input of PoseConv3D. Left, Pose Extraction: We perform Top-Down pose estimation for each single frame. The estimated 2D poses are saved as coordinate-triplets: (x, y, score). Right, Generating Pseudo Heatmap Volumes: Based on the coordinate-triplets, we generate pseudo heatmaps for joints and limbs using Eq 1,2. We perform subjects-centered cropping and uniform sampling to make the heatmap volumes compact.
图 9: PoseConv3D的输入生成流程。左侧为姿态提取:我们对每帧图像进行Top-Down姿态估计,将估计得到的2D姿态保存为坐标三元组 (x, y, score)。右侧为生成伪热图体积:基于坐标三元组,我们使用公式1和2为关节和肢体生成伪热图。通过执行以目标为中心裁剪和均匀采样,使热图体积更加紧凑。
C. Detailed Architectures of PoseConv3D
C. PoseConv3D 的详细架构
C.1. Different variants of PoseConv3D.
C.1. PoseConv3D 的不同变体
In Table 11, we demonstrate the architectures of the three backbones we adapted from RGB-based action recognition as well as their variants:
在表11中,我们展示了从基于RGB的动作识别中采用的三种主干架构及其变体:
C3D [60]. C3D is one of the earliest 3D-CNN developed for RGB-based action recognition (like AlexNet [28] for image recognition), which consists of eight 3D convolution layers. To adapt C3D for skeleton-based action recognition, we reduce its channel-width to half $(64\rightarrow32)$ ) for better efficiency. In addition, for Pose-C3D-s, we remove the last two convolution layers.
C3D [60]。C3D是最早为基于RGB的动作识别开发的3D-CNN之一(类似于用于图像识别的AlexNet [28]),它由八个3D卷积层组成。为了使C3D适用于基于骨架的动作识别,我们将其通道宽度减半$(64\rightarrow32)$以提高效率。此外,对于Pose-C3D-s,我们移除了最后两个卷积层。
X3D [17]. X3D is a recent state-of-the-art 3D-CNN for action recognition. Replacing vanilla convolutions with depth-wise convolutions, X3D achieves competitive recognition performance with tiny amounts of parameters and FLOPs. The architecture of the adapted Pose-X3D is almost unchanged compared to the original X3D-S, except that we remove the original first stage. For Pose-X3D-s, we remove convolution layers from each stage uniformly by changing the hyper-parameter $\gamma_{d}$ from 2.2 to 1.
X3D [17]。X3D是当前最先进的3D-CNN动作识别模型。通过将普通卷积替换为深度可分离卷积(depth-wise convolutions),X3D以极少的参数量和FLOPs实现了具有竞争力的识别性能。改进后的Pose-X3D架构与原始X3D-S几乎保持一致,仅移除了初始阶段。对于Pose-X3D-s版本,我们通过将超参数$\gamma_{d}$从2.2调整为1,均匀缩减了各阶段的卷积层。
SlowOnly [18]. SlowOnly is a popular 3D-CNN used for RGB-based action recognition. It is obtained by inflating the ResNet layers in the last two stages from 2D to 3D. To adapt SlowOnly for skeleton-based action recognition, we reduce its channel-width to half $(64~\rightarrow~32)$ ) as well as remove the original first stage in the network. We also have conducted experiments with Pose-SlowOnly-wd (with channel-width 64) and Pose-SlowOnly-HR (with $2\mathbf{x}$ larger input and deeper network). There is no performance improvement despite the much heavier backbone.
SlowOnly [18]。SlowOnly是一种流行的3D-CNN,用于基于RGB的动作识别。它通过将最后两个阶段的ResNet层从2D扩展为3D得到。为了使SlowOnly适应基于骨架的动作识别,我们将其通道宽度减半$(64~\rightarrow~32)$,并移除网络中原有的第一阶段。我们还对Pose-SlowOnly-wd(通道宽度为64)和Pose-SlowOnly-HR(输入尺寸增大$2\mathbf{x}$且网络更深)进行了实验。尽管骨干网络更重,但性能并未提升。
Table 11. PoseConv3D instantiated with: C3D, X3D, SlowOnly. The dimensions of kernels are denoted by $T\times S^{2},C$ for temporal, spatial, channel sizes. Strides are denoted with $T,S^{2}$ for temporal and spatial strides. GAP denotes global average pooling.
表 11. 采用 C3D、X3D、SlowOnly 实例化的 PoseConv3D。卷积核维度表示为 $T\times S^{2},C$(时间、空间、通道尺寸),步长表示为 $T,S^{2}$(时间和空间步长)。GAP 表示全局平均池化。
| stage | C3D-s | C3D | X3D-s | X3D | SlowOnly | SlowOnly-wd | SlowOnly-HR |
|---|---|---|---|---|---|---|---|
| data layer | Uniform 48,56×56 | Uniform 48,112×112 | |||||
| stem layer | conv 3×32,32 | conv 1×32,24 stride 1, 22 conv 5×12,24 | conv 1×72,32 | conv1x72,64 | conv 1×72,32 | ||
| stage1 | maxpool 1×22 [3×32,64] ×1 | 1×12,54 3×32,54 1×12,24 ×2 | 1×12,54 3×32,54 ×5 1×12,24 | None | 1×12,32 1×32,32 1×12,128 ×3 | ||
| stage2 | maxpool1×22 [3×32,128]×2 | 1x12,108 3×32,108 1×12,48 x5 | 1×12,108 3×32,108 1×12,48 x11 | 1×12,32 1×32,32 1×12,128 3×12,64 ×4 | 1×12,64 1×32,64 1×12,256 ×4 | ||
| stage3 | maxpool1×22 [3×32,256]×2 | 1x12,216 3×32,216 1x12,96 ×3 | 1×12,216 3×32,216 1×12,96 ×7 | 1×32,64 1×12,256 x6 | 1×32,128 1×12,512 3×12,128 x6 | ||
| stage4 | None | [3×32,256]×2 | conv1x12,216 | 3×12,128 1×32,128 1x1²,512 ×3 | 1×32,256 3×12,256 1×1²,1024 X3 |
C.2. RGBPose-Conv3D instantiated with SlowOnly.
C.2. 基于SlowOnly实例化的RGBPose-Conv3D
RGBPose-Conv3D is a general framework for RGBPose dual-modality action recognition, which can be instantiated with various 3D-CNN backbones. In this work, we instantiate both pathways with the SlowOnly network. As shown in Table 12, the RGB pathway has a smaller frame rate and a larger channel width since RGB frames are lowlevel features. On the contrary, the Pose pathway has a larger frame rate and a smaller channel width. Time stride convolutions are used as bi-directional lateral connections between the two pathways (after $\mathrm{res}{3}$ and $\mathrm{res}{4}$ ) so that semantics of different modalities can sufficiently interact. Besides lateral connections, the predictions of two pathways are also combined in a late fusion manner, which leads to further improvements in our empirical study. RGBPoseConv3D is trained with two individual losses respectively for each pathway, as a single loss that jointly learns from two modalities leads to severe over fitting.
RGBPose-Conv3D 是一个用于 RGBPose 双模态动作识别的通用框架,可通过多种 3D-CNN 骨干网络实例化。本文采用 SlowOnly 网络实例化两个分支。如表 12 所示,RGB 分支因处理低层特征而采用较小帧率与较大通道宽度,姿态 (Pose) 分支则采用较大帧率与较小通道宽度。通过在 $\mathrm{res}{3}$ 和 $\mathrm{res}{4}$ 后添加时序跨步卷积作为双向横向连接,实现多模态语义充分交互。除横向连接外,两个分支的预测结果还通过后期融合方式结合,实验表明该方法可带来额外性能提升。训练时对两个分支分别采用独立损失函数,联合多模态的单一损失函数会导致严重过拟合 [20]。
D. Supplementary Experiments
D. 补充实验
D.1. Ablation Study on Pose Extraction
D.1. 姿态提取消融研究
This section discusses different alternatives that can be adopted in pose extraction to validate our choice. The input size for all 3D-CNN experiments is $T\times H\times W=48\times$ $56\times56$ .
本节讨论在姿态提取中可采用的不同替代方案,以验证我们的选择。所有3D-CNN实验的输入尺寸为$T\times H\times W=48\times56\times56$。
2D v.s. 3D Skeletons. We first compare the recognition performance of using 2D and 3D skeletons for action recognition. The 3D skeletons are either collected by sensors (NTU-60) or estimated with state-of-the-art 3D pose estimators based on RGB inputs [27, 66] (FineGYM). For a fair comparison, we use MS-G3D [40] (the current stateof-the-art GCN for skeleton-based action recognition) with the same configuration and training schedule for 2D and 3D keypoints and list the results in Table 13a. The estimated 2D keypoints (even low-quality ones) consistently outperform 3D keypoints (sensor collected or estimated) in action recognition. Besides RGB-based 3D-pose estimators, we also consider the ‘lifting’ approaches [42, 45], which directly ‘lift’ 2D-pose (sequences) to 3D-pose (sequences). We regress the 3D poses based on 2D poses extracted with HRNet, use the lifted 3D poses for action recognition. The results in Table 13b indicate that such lifted 3D poses do not provide any additional information, performs even worse than the original 2D poses in action recognition.
2D与3D骨骼对比。我们首先比较使用2D和3D骨骼进行动作识别的性能差异。3D骨骼数据通过传感器采集(NTU-60)或基于RGB输入采用最先进的3D姿态估计器[27,66]生成(FineGYM)。为确保公平对比,我们采用当前骨骼动作识别领域最先进的图卷积网络MS-G3D[40],对2D和3D关键点使用相同配置和训练方案,结果如 表13a 所示。即使是低质量的估计2D关键点,其动作识别性能也始终优于传感器采集或估计的3D关键点。除基于RGB的3D姿态估计器外,我们还测试了"提升"方法[42,45]——直接将2D姿态(序列)提升为3D姿态(序列)。我们基于HRNet提取的2D姿态回归生成3D姿态,并将提升后的3D姿态用于动作识别。 表13b 结果显示,这类提升生成的3D姿态未能提供额外信息,其动作识别性能甚至低于原始2D姿态。
Table 12. RGBPose-Conv3D instantiated with the SlowOnly backbone. The dimensions of kernels are denoted by $T\times S^{2},C$ for temporal, spatial, channel sizes. Strides are denoted with $T,S^{2}$ for temporal and spatial strides. The backbone we use is ResNet50. GAP denotes global average pooling.
表 12. 基于SlowOnly骨干网络的RGBPose-Conv3D实现。卷积核维度表示为$T\times S^{2},C$,分别对应时间、空间和通道大小。步长表示为$T,S^{2}$,分别对应时间和空间步长。使用的骨干网络为ResNet50。GAP表示全局平均池化。
| stage | RGBPathway | PosePathway | output sizes TxS2 |
|---|---|---|---|
| data layer | uniform 8,12 | uniform 32,42 | RGB:8×224² Pose:32×56² |
| stem layer | conv 1×7²,64 stride 1, 2² maxpool1×3² stride 1, 2 | conv 1x7²,32 stride 1, 1² | RGB:8×56² Pose:32×56² |
| res2 | 1×1²,64 1x3²,64 1×1²,256 | ×3 | N.A. |
| res3 | 1×1²,128 1×3²,128 1×1²,512 | ×4 | 1×1²,32 1×3²,32 1×1²,128 |
| res4 | 3×1², 256 1×3²,256 1×1²,1024 | ×6 | 3×1², 64 1×3²,64 1×1²,256 |
| res5 | 3×1²,512 1x3²,512 1×1²,2048 | ×3 | 3×1²,128 1x3²,128 1×1²,512 |
| GAP, fc | GAP, fc | #classes |
Table 13. Ablation study on Pose Extraction.
表 13: 姿态提取消融研究
| 输入 | GYM | NTU-60 |
|---|---|---|
| Kinect-3D [73] | N.A. | 89.4 |
| DOPE-3D [66] | 76.3 | N.A. |
| VIBE-3D [27] | 87.0 | N.A. |
| HRNet-2D [59] | 92.0 | 91.9 |
| MobileNet-2D [22] | 89.0 | 90.2 |
(b) Lifted 3D-pose doesn’t help in recognition.
(b) 提升的3D姿态对识别没有帮助。
| 输入 | GYM |
|---|---|
| DOPE [66] | 76.3 |
| VIBE [27] | 87.0 |
| FrameLift [42] | 90.0 |
| VideoLift [45] | 90.2 |
| HRNet-2D [59] | 92.0 |
(a) 2D skeleton v.s. 3D skeleton.
(a) 2D骨架 vs 3D骨架
| 人体候选框 | GYM Mean-Top1 |
|---|---|
| 检测 | 75.8 |
| 跟踪 | 85.3 |
| 真实标注 | 92.0 |
(c) Pose Estimation: Top-Down v.s. Bottom-Up.
| PoseEstimator | COCOAP | NTU-60 |
|---|---|---|
| HRNet (Top-Down) | 0.746 | 93.6 |
| HRNet (Bottom-Up) | 0.654 | 93.0 |
| Mobile (Top-Down) | 0.646 | 92.0 |
(c) 姿态估计: 自上而下 vs. 自下而上。
(d) Pose extracted with different boxes.
(e) Coordinate v.s. Heatmap.
(d) 使用不同边界框提取的姿态。
| 输入格式 | GYM平均-Top1 |
|---|---|
| Coordinate-MobileNet | 90.7 |
| Coordinate-HRNet | 93.2 |
| Heatmap-MobileNet | 92.7 |
| Heatmap-HRNet | 93.6 |
(e) 坐标 vs. 热图。
Table 14. Transferring Ability. Skeleton representations learned on the large-scale Kinetics 400 can transfer to downstream datasets well. Backbone parameters are frozen for the ‘Linear’ setting.
表 14: 迁移能力。在大规模 Kinetics 400 上学习的骨架表征能很好地迁移到下游数据集。"Linear"设置下骨干网络参数被冻结。
| 策略 | HMDB51 | UCF101 |
|---|---|---|
| Scratch | 58.6 | 79.1 |
| Linear | 64.9 | 83.1 |
| Finetune | 69.3 | 87.0 |
Bottom-Up v.s. Top-Down. To compare the pose estimation quality of Bottom-Up and Top-Down approaches, we instantiate the two approaches with the same backbone (HRNet-w32). Besides, we also instantiate the Top-Down approach with the MobileNet-v2 backbone for comparison, which has a similar performance to HRNet (Bottom-Up) on COCO-validation. We use extracted 2D poses to train a Pose-SlowOnly on NTU-60. Table 13c shows that the performance of HRNet (Bottom-Up) on COCO-val is much worse than HRNet (Top-Down) and close to MobileNet (Top-Down). However, the Top-1 accuracy of HRNet (Bottom-Up) is much higher than MobileNet (Top-Down) and close to HRNet (Top-Down). Although the potential of Bottom-Up should not be neglected, considering the better performance and faster inference speed (Top-Down runs faster when there aren’t many persons in a frame), we use Top-Down for pose extraction in this work.
自下而上 vs. 自上而下。为比较两种姿态估计方法的质量,我们采用相同骨干网络(HRNet-w32)分别实例化两种方法。此外还使用性能接近HRNet(自下而上)的MobileNet-v2骨干网络实例化自上而下方法作为对照。基于从COCO验证集提取的2D姿态数据,我们在NTU-60数据集上训练Pose-SlowOnly模型。表13c显示:HRNet(自下而上)在COCO-val上的表现远逊于HRNet(自上而下),但与MobileNet(自上而下)接近;而其Top-1准确率却大幅超越MobileNet(自上而下),与HRNet(自上而下)基本持平。虽然自下而上方法潜力不容忽视,但综合考虑更优性能及更快推理速度(当画面人数较少时,自上而下方法速度优势更明显),本研究最终采用自上而下方案进行姿态提取。
Interested Person v.s. All Persons. Many people may exist in a video, but not all of them are related to the interested action. For example, in FineGYM, only the pose of the athlete is helpful, while other persons like the audience or referee are unrelated. We compare using 3 kinds of person bounding boxes for pose extraction: Detection, Tracking(with Siamese-RPN [32]) and GT (with increasing prior about the athlete). In Table 13d, we see that the prior of the interested person is extremely important: even weak prior knowledge (1 GT box per video) can improve the performance by a large margin.
感兴趣人物 vs 全体人物。视频中可能存在多个人物,但并非所有人物都与目标动作相关。例如在FineGYM数据集中,只有运动员的姿势具有分析价值,而观众或裁判等其他人物则无关紧要。我们比较了三种人物检测框对姿态提取的影响:检测框(Detection)、跟踪框(使用Siamese-RPN [32])和真实框(GT,通过逐步增加运动员的先验信息)。表13d显示目标人物的先验信息极为关键:即便是较弱的先验知识(每个视频仅提供1个真实框)也能显著提升模型性能。
Coordinates v.s. Heatmaps. Storing 3D heatmap volumes may take vast amounts of disk space. To be more efficient, we can save the 2D poses as coordinate-triplets (x, y, score) and restore them to 3D heatmap volumes following the methods we introduced in Sec 3.2. We conduct experiments on FineGYM to explore how much information is lost during the heatmap $\rightarrow$ coordinate compression. In Table 13e, we see that for low-quality pose estimators, it leads to a $2%$ drop in Mean-Top1. For high-quality ones, the degradation is more moderate (only a $0.4%$ Mean-Top1 drop). Thus we choose to store coordinates instead of 3D heatmap volumes.
坐标 vs 热图。存储3D热图体积会占用大量磁盘空间。为提高效率,我们可以将2D姿态保存为坐标三元组(x, y, score),并按照第3.2节介绍的方法将其还原为3D热图体积。我们在FineGYM上进行实验,探究热图$\rightarrow$坐标压缩过程中损失了多少信息。在表13e中可以看到,对于低质量姿态估计器,这会导致Mean-Top1下降$2%$;而对于高质量姿态估计器,性能下降更为温和(仅$0.4%$的Mean-Top1下降)。因此我们选择存储坐标而非3D热图体积。
D.2. Multi-Modality Action Recognition Results on UCF101 and HMDB51
D.2. UCF101和HMDB51上的多模态动作识别结果
In Table 10, we train different PoseConv3D on UCF101 and HMDB51 from scratch. In this section, we demonstrate that PoseConv3D can also take advantage of pretraining on large-scale datasets. We adopt weights pretrained on Kinetics 400 to initialize the PoseConv3D. Pre training with skeleton data from the large-scale Kinetics 400 benefits the downstream recognition tasks on smaller datasets, under both ‘Linear’ and ‘Finetune’ paradigms (Table 14).
在表 10 中,我们在 UCF101 和 HMDB51 上从头训练了不同的 PoseConv3D。本节中,我们证明 PoseConv3D 也可以利用大规模数据集的预训练优势。我们采用在 Kinetics 400 上预训练的权重来初始化 PoseConv3D。无论是 'Linear' 还是 'Finetune' 范式 (表 14),使用大规模 Kinetics 400 的骨骼数据进行预训练都有助于提升较小数据集的下游识别任务表现。
We further compare PoseConv3D with previous stateof-the-arts of skeleton-based action recognition on UCF101 and HMDB51: PoTion [10] and PA3D [70]. For a fair comparison, we fuse the skeleton-based predictions with I3D [6] predictions, instead of predictions from the more advanced OmniSource [16]. Table 15 shows that PoseConv3D not only outperforms other approaches by a large margin on skeleton-based action recognition, but also leads to better overall performance after fusing with predictions based on other modalities.
我们进一步在UCF101和HMDB51数据集上将PoseConv3D与基于骨架动作识别的先前最优方法进行比较:PoTion [10] 和 PA3D [70]。为确保公平对比,我们将基于骨架的预测结果与I3D [6] 预测相融合,而非采用更先进的OmniSource [16] 预测。表15显示,PoseConv3D不仅在基于骨架的动作识别上大幅领先其他方法,与其他模态预测融合后还能获得更优的整体性能。
Table 15. Comparison with state-of-the-art multi-modality action recognition approaches.
表 15: 与最先进的多模态动作识别方法对比
| 方法 | HMDB51 | UCF101 |
|---|---|---|
| I3D [6] | 80.7 | 98.0 |
| PoTion[10] | 43.7 | 65.2 |
| PoTion + I3D | 80.9 | 98.2 |
| PA3D [70] | 55.3 | |
| PA3D+I3D | 82.1 | |
| PoseConv3D | 69.3 | 87.0 |
| PoseConv3D+I3D | 82.7 | 98.4 |
Table 16. PoseConv3D with projected 2D poses. We report the recognition performance of the joint model.
表 16: 基于投影2D姿态的PoseConv3D。我们报告了联合模型的识别性能。
| 输入+方法 | Top-1 |
|---|---|
| 2D投影 + MS-G3D [40] | 86.8 |
| 3D骨架 + MS-G3D [40] | 88.87 |
| 2D投影 + PoseConv3D | 89.2 |
D.3. Using 3D Skeletons in PoseConv3D
D.3. 在PoseConv3D中使用3D骨骼
PoseConv3D takes stacked 2D skeleton keypoint heatmaps as input. Assume only 3D skeletons are available, one can also use the 3D skeletons in PoseConv3D by projecting them to a 2D plane. The NTURGB $+\mathrm{D}$ dataset [48] provides 3D skeleton sequences collected by Microsoft Kinect v2 sensors [73]. Besides, the dataset also includes the projection of 3D joints onto the 2D image coordinate systems. We use the projected 2D skeletons of NTU-60 as the input for PoseConv3D and study the effect.
PoseConv3D以堆叠的2D骨骼关键点热图作为输入。假设仅有3D骨骼数据可用,也可以通过将3D骨骼投影至2D平面来应用于PoseConv3D。NTURGB$+\mathrm{D}$数据集[48]提供了由Microsoft Kinect v2传感器[73]采集的3D骨骼序列。此外,该数据集还包含3D关节投影至2D图像坐标系的映射结果。我们使用NTU-60的投影2D骨骼作为PoseConv3D输入并研究其效果。
Table 16 demonstrates the recognition performance of using projected 2D skeletons in PoseConv3D. Using the projected 2D skeletons as input instead of the original 3D skeletons, there is a $2%$ Top-1 accuracy drop for MS-G3D due to the information lost in $3\mathrm{D}\rightarrow2\mathrm{D}$ compression. If both use 2D skeletons as input, PoseConv3D outperforms the GCN-based counterpart by $2.4%$ , even surpasses the MS-G3D with 3D skeletons as input by $0.4%$ , which indicates the great s patio temporal modeling capability of 3DCNN can compensate for the information lost in projection.
表 16 展示了在 PoseConv3D 中使用投影 2D 骨架的识别性能。与原始 3D 骨架相比,使用投影 2D 骨架作为输入时,由于 $3\mathrm{D}\rightarrow2\mathrm{D}$ 压缩导致的信息丢失,MS-G3D 的 Top-1 准确率下降了 $2%$。若两者均采用 2D 骨架输入,PoseConv3D 比基于 GCN 的对比方法高出 $2.4%$,甚至超过以 3D 骨架为输入的 MS-G3D 模型 $0.4%$,这表明 3DCNN 强大的时空建模能力能够补偿投影过程中的信息损失。
In experiments, we find that representing all people with a single heatmap volume is the best practice for group activity recognition with PoseConv3D. On the Volleyball dataset, we have also explored three alternatives that process different persons’ heatmaps separately: A. For each
在实验中,我们发现使用单一热图体积表示所有人员是PoseConv3D进行群体活动识别的最佳实践。在Volleyball数据集上,我们还探索了三种分别处理不同人员热图的替代方案:A. 对于每个

Figure 10. An illustration (with 4 persons) of the proposed three alternatives for group activity recognition. Best viewed in $4\mathbf{x}$ .
图 10: 提出的三种群体活动识别替代方案的示意图(包含4人)。建议以 $4\mathbf{x}$ 倍率查看。
D.4. Practice for Group Activity Recognition
D.4. 群体活动识别实践
Table 17. Uniform sampling also works for RGB-based action recognition. Alls results are for 10-clip testing, except the ‘uniform-16 (1c)’, which uses 1-clip testing.
表 17: 均匀采样同样适用于基于RGB的动作识别。除'uniform-16 (1c)'采用单片段测试外,其余结果均为10片段测试。
| 采样方式 | Mean-Topl |
|---|---|
| 16x2 | 87.9 |
| 16x4 | 88.7 |
| uniform-16 (1c) | 91.1 |
| uniform-16 | 91.6 |
| 采样方式 | Top1准确率 |
|---|---|
| 16x2 | 94.9 |
| 16x4 | 95.1 |
| uniform-16(1c) | 95.7 |
| uniform-16 | 96.1 |
joint, we allocate $N$ channels for $N$ persons. The PoseConv3D input then has $N\times K$ channels (instead of $K.$ ); B. We generate a 3D heatmap volume $(K\times T\times H\times W)$ for each person and use PoseConv3D (weights shared among $N$ persons) to extract the skeleton feature separately. We use average pooling to aggregate $N$ persons’ features to a single feature vector; C. On top of $\mathbf{B}$ , we insert several (1 to 3) encoder layers (from scratch or with $\mathbf{B}$ pre-training) before the average pooling for inter-person modeling. Figure 10 provides an illustration of three alternatives. For A, the high dimensional input leads to severe over fitting. The Top-1 accuracy is only $75.3%$ . For B, C, despite the great amounts of computation $(>13\times)$ consumed, the recognition performance is not satisfying. At best, B, C achieves $85.7%$ and $87.9%$ Top-1 on Volleyball, still much inferior to accumulating heatmaps $(91.3%)$ . Accumulating heatmaps is a simple and relatively good solution for balancing complexity and effectiveness. More complex designs may lead to further improvements, which is left to future work.
联合分配 $N$ 个通道给 $N$ 个人。此时 PoseConv3D 的输入具有 $N\times K$ 个通道 (而非 $K$); B. 为每个人生成一个 3D 热图体 $(K\times T\times H\times W)$ 并使用 PoseConv3D (权重在 $N$ 人之间共享) 分别提取骨骼特征。通过平均池化将 $N$ 人的特征聚合成单个特征向量; C. 在 $\mathbf{B}$ 的基础上, 我们在平均池化前插入若干 (1 到 3 个) 编码层 (从头训练或用 $\mathbf{B}$ 预训练) 以进行人际建模。图 10 展示了三种方案的示意图。对于方案 A, 高维输入导致严重过拟合, Top-1 准确率仅为 $75.3%$。对于方案 B 和 C, 尽管消耗了大量计算量 $(>13\times)$, 识别性能仍不理想。最佳情况下, B 和 C 在 Volleyball 数据集上分别达到 $85.7%$ 和 $87.9%$ 的 Top-1 准确率, 仍远逊于热图累加方案 $(91.3%)$。热图累加是在复杂度与效果间取得平衡的简单且相对理想的方案。更复杂的设计可能带来进一步改进, 这将留待未来工作。
D.5. Uniform Sampling for RGB-based recognition
D.5. 基于RGB识别的均匀采样
Based on the outstanding improvement by uniform sampling on skeleton action recognition, we wonder if the strategy also works for RGB-based action recognition. Thus we apply uniform sampling to RGB-based action recognition on NTU-60 [48] and GYM [49]. We use SlowOnly- R50 [18] as the backbone and set the input length as 16 frames. From Table 17, we see that uniform sampling also outperforms fix-stride sampling by a large margin in RGBbased recognition on two datasets: the accuracy of uniform sampling with 1-clip testing is better than the accuracy of fix-stride sampling with 10-clip testing. We mainly attribute the advantage of uniform sampling to the highly variable video lengths in these two datasets. On the contrary, we observe a slight accuracy drop on Kinetics $\scriptstyle400^{8}$ when applying uniform sampling: for SlowOnly-R50 with input length 8, the Top-1 accuracy drops from $75.6%$ to $75.2%$ .
基于均匀采样在骨架动作识别上的显著提升,我们探究该策略是否同样适用于基于RGB的动作识别。为此,我们在NTU-60 [48]和GYM [49]数据集上对RGB动作识别任务应用了均匀采样。采用SlowOnly-R50 [18]作为主干网络,输入帧数设为16帧。从表17可见,在两个数据集的RGB识别任务中,均匀采样同样大幅领先固定步长采样:单片段测试的均匀采样精度甚至优于10片段测试的固定步长采样精度。我们认为这一优势主要源于两个数据集中视频长度的高度差异性。相反,在Kinetics $\scriptstyle400^{8}$ 数据集上应用均匀采样时观察到轻微精度下降:对于输入长度为8的SlowOnly-R50模型,Top-1准确率从 $75.6%$ 降至 $75.2%$。
Table 18. Top 5 confusion pairs of skeleton action recognition on NTU60 XSub. Multi-modality fusion with RGBPose-Conv3D improves the recognition performance on confusion pairs by a lot.
表 18: NTU60 XSub数据集上骨架动作识别的前5组易混淆动作对。采用RGBPose-Conv3D进行多模态融合后,这些易混淆动作对的识别性能得到显著提升。
| 动作1 | 动作2 | SPose | SRGB+Pose |
|---|---|---|---|
| 阅读 | 玩手机/平板 | 67 | 13 |
| 书写 | 键盘打字 | 57 | 20 |
| 书写 | 玩手机/平板 | 50 | 5 |
| 自拍 | 用手指指向某物 | 48 | 10 |
| 阅读 | 书写 | 44 | 24 |
Table 19. Mean class accuracy on the Kinetics-Motion subset.
表 19: Kinetics-Motion 子集的平均类别准确率。
| 方法 | Top1Acc |
|---|---|
| Swin-L[39] | 92.7 |
| ST-GCN[71] | 72.0 |
| PoseConv3D | 81.9 |
| Swin-L+PoseConv3D | 94.7 |
D.6. NTU-60 Error Analysis
D.6. NTU-60 错误分析
On NTU-60 X-Sub split, we achieve $94.1%$ Top-1 accuracy with skeleton-based action recognition, which outperforms the current state-of-the-art result by $2.6%$ . To further study the failure cases, we first define the confusion score $S$ of a pair of action classes $i,j$ as $S=n_{i j}+n_{j i}$ $(n_{i j}$ : number of videos of class $i$ but recognized as class $j$ ). In NTU-60, there are 1770 pairs of action classes in total, while we list the five most confusing pairs in Table 18. Most failure cases are of these top-confusing pairs, e.g., over $27%$ failure cases are of the top 5 confusion pairs. It is hard to distinguish these pairs of actions with human skeletons only.
在NTU-60 X-Sub数据集上,我们基于骨架的动作识别达到了94.1%的Top-1准确率,比当前最优结果高出2.6%。为深入分析错误案例,我们首先定义动作类别对(i,j)的混淆分数S为S=n_{ij}+n_{ji}(n_{ij}表示类别i的视频被误识别为类别j的数量)。NTU-60中共有1770组动作类别对,表18列出了混淆程度最高的五组。大多数错误案例都来自这些高混淆组,例如超过27%的错误案例来自前五组混淆对。仅凭人体骨架数据很难区分这些动作对。
Some confusing pairs can be resolved by exploiting other modalities such as RGB appearance. If the model successfully recognizes the keyboard, then it can distinguish typing from writing. Table 18 shows that, with multi-modality fusion in RGBPose-Conv3D, the recognition performance on those confusing pairs improves a lot.
通过利用RGB外观等其他模态可以解决一些容易混淆的动作对。如果模型能成功识别键盘,就能区分打字和写字。表18显示,在RGBPose-Conv3D中进行多模态融合后,这些易混淆动作对的识别性能大幅提升。
D.7. Why skeleton-based pose estimation performs poorly on Kinetics 400
D.7. 基于骨架的姿态估计在 Kinetics 400 上表现不佳的原因
PoseConv3D with high-quality 2D skeletons improves the Top-1 accuracy of skeleton-based action recognition on Kinetics 400 from $38.0%$ to $47.7%$ . However, the accuracy on Kinetics 400 is still far below the accuracies on other datasets. Besides the difficulties mentioned in Sec A, two more problems will degrade the quality of extracted skeleton sequences (Figure 11): 1. Since Kinetics 400 is not human-centric, human skeletons are missing or hard to recognize in many frames. 2. For the same reason, only small parts of humans appear in many frames, while the pose estimators are easy to fail in this scenario.
采用高质量2D骨架的PoseConv3D将基于骨架的动作识别在Kinetics 400上的Top-1准确率从$38.0%$提升至$47.7%$。然而,该数据集上的准确率仍远低于其他数据集。除A节提到的难点外,还有两个问题会降低提取骨架序列的质量(图11): 1. 由于Kinetics 400不以人为中心,许多帧中人体骨架缺失或难以识别;2. 同理,许多帧仅出现人体局部,而姿态估计器在此场景下易失效。

Figure 11. Problems in Kinetics 400 Pose Extraction. Left: Human missing in action ‘kayaking’. Middle: Human skeleton is too small to be recognized in action ‘diving cliff’. Right: Only human parts appear, the pose estimator fails (‘washing feet’).
图 11: Kinetics 400 姿态提取中的问题。左图: 动作"皮划艇"中人物缺失。中图: 动作"悬崖跳水"中人体骨骼过小难以识别。右图: 仅出现人体局部,姿态估计失败 (洗脚)。
We also report the mean class accuracy on KineticsMotion [71] in Table 19, which contains 30 action classes in Kinetics that are strongly related to body motions. The accuracy of skeleton-based action recognition is much higher on this subset, increasing from $47.7%$ to $81.9%$ . When combined with the state-of-the-art RGB predictions, the improvement is much more significant, increasing from $0.6%$ to $2.0%$ . However, the skeleton-based performance is still far behind the state-of-the-art RGB-based action recognition method [39], which achieves $92.7%$ mean class accuracy on Kinetics-Motion. The inferior recognition performance indicates that there still needs more future work for skeleton-based action recognition in the wild.
我们还在表19中报告了KineticsMotion [71]上的平均类别准确率,该数据集包含30个与身体运动密切相关的Kinetics动作类别。基于骨架的动作识别在此子集上的准确率显著提高,从$47.7%$提升至$81.9%$。当与最先进的RGB预测相结合时,改进更为显著,从$0.6%$提升至$2.0%$。然而,基于骨架的性能仍远落后于最先进的基于RGB的动作识别方法[39],后者在Kinetics-Motion上达到了$92.7%$的平均类别准确率。这一较低的识别性能表明,基于骨架的野外动作识别仍需更多未来工作。