StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
StarGAN:统一的多领域图像到图像转换生成对抗网络

Figure 1. Multi-domain image-to-image translation results on the CelebA dataset via transferring knowledge learned from the RaFD dataset. The first and sixth columns show input images while the remaining columns are images generated by StarGAN. Note that the images are generated by a single generator network, and facial expression labels such as angry, happy, and fearful are from RaFD, not CelebA.
图 1: 通过迁移从RaFD数据集学到的知识,在CelebA数据集上实现的多领域图像到图像转换结果。第一列和第六列为输入图像,其余列是由StarGAN生成的图像。请注意,这些图像均由单一生成器网络生成,且愤怒、快乐、恐惧等面部表情标签来自RaFD数据集而非CelebA。
Abstract
摘要
Recent studies have shown remarkable success in imageto-image translation for two domains. However, existing approaches have limited s cal ability and robustness in handling more than two domains, since different models should be built independently for every pair of image domains. To address this limitation, we propose StarGAN, a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model. Such a unified model architecture of StarGAN allows simultaneous training of multiple datasets with different domains within a single network. This leads to StarGAN’s superior quality of translated images compared to existing models as well as the novel capability of flexibly translating an input image to any desired target domain. We empirically demonstrate the effectiveness of our approach on a facial attribute transfer and a facial expression synthesis tasks.
近期研究表明,双域图像到图像转换取得了显著成功。然而,现有方法在处理超过两个域时存在可扩展性和鲁棒性局限,因为每对图像域都需要独立构建模型。为解决这一局限,我们提出了StarGAN——一种新颖且可扩展的方法,仅需单个模型即可实现多域图像转换。StarGAN的统一模型架构支持在单一网络中同时训练包含不同域的多个数据集,这使得其转换图像质量优于现有模型,并具备将输入图像灵活转换至任意目标域的新能力。我们通过面部属性迁移和表情合成任务的实验验证了该方法的有效性。
1. Introduction
1. 引言
The task of image-to-image translation is to change a particular aspect of a given image to another, e.g., changing the facial expression of a person from smiling to frowning (see Fig. 1). This task has experienced significant improvements following the introduction of generative adversarial networks (GANs), with results ranging from changing hair color [9], reconstructing photos from edge maps [7], and changing the seasons of scenery images [33].
图像到图像的转换任务旨在将给定图像的特定方面更改为另一个方面,例如将一个人的面部表情从微笑变为皱眉(见图 1)。随着生成对抗网络 (GAN) 的引入,这项任务取得了显著改进,应用范围包括改变发色 [9]、从边缘图重建照片 [7] 以及改变风景图像的季节 [33]。
Given training data from two different domains, these models learn to translate images from one domain to the other. We denote the terms attribute as a meaningful feature inherent in an image such as hair color, gender or age, and attribute value as a particular value of an attribute, e.g., black/blond/brown for hair color or male/female for gender. We further denote domain as a set of images sharing the same attribute value. For example, images of women can represent one domain while those of men represent another.
给定来自两个不同域的训练数据,这些模型学习将一个域的图像转换到另一个域。我们将属性 (attribute) 定义为图像中固有的有意义的特征,如发色、性别或年龄;属性值 (attribute value) 则指属性的特定取值,例如发色中的黑色/金色/棕色或性别中的男性/女性。进一步,我们将域 (domain) 定义为一组共享相同属性值的图像。例如,女性图像可以表示一个域,而男性图像表示另一个域。
Several image datasets come with a number of labeled attributes. For instance, the CelebA[19] dataset contains 40 labels related to facial attributes such as hair color, gender, and age, and the RaFD [13] dataset has 8 labels for facial expressions such as ‘happy’, ‘angry’ and ‘sad’. These settings enable us to perform more interesting tasks, namely multi-domain image-to-image translation, where we change images according to attributes from multiple domains. The first five columns in Fig. 1 show how a CelebA image can be translated according to any of the four domains, ‘blond hair’, ‘gender’, ‘aged’, and ‘pale skin’. We can further extend to training multiple domains from different datasets, such as jointly training CelebA and RaFD images to change a CelebA image’s facial expression using features learned by training on RaFD, as in the rightmost columns of Fig. 1.
多个图像数据集都带有大量标注属性。例如,CelebA[19]数据集包含40个与面部属性相关的标签(如发色、性别和年龄),RaFD[13]数据集则有8个面部表情标签(如"快乐"、"愤怒"和"悲伤")。这些设置让我们能够执行更有趣的任务,即多领域图像到图像转换——根据多个领域的属性来改变图像。图1前五列展示了如何根据"金发"、"性别"、"年龄"和"苍白皮肤"这四个领域对CelebA图像进行转换。我们还可以进一步扩展至训练来自不同数据集的多领域特征,例如联合训练CelebA和RaFD图像,利用通过RaFD训练学到的特征来改变CelebA图像的面部表情,如图1最右侧列所示。
However, existing models are both inefficient and ineffective in such multi-domain image translation tasks. Their inefficiency results from the fact that in order to learn all mappings among $k$ domains, $k(k{-}1)$ generators have to be trained. Fig. 2 (a) illustrates how twelve distinct generator networks have to be trained to translate images among four different domains. Meanwhile, they are ineffective that even though there exist global features that can be learned from images of all domains such as face shapes, each generator cannot fully utilize the entire training data and only can learn from two domains out of $k$ . Failure to fully utilize training data is likely to limit the quality of generated images. Furthermore, they are incapable of jointly training domains from different datasets because each dataset is partially labeled, which we further discuss in Section 3.2.
然而,现有模型在多域图像翻译任务中既低效又效果欠佳。其低效性源于学习 $k$ 个域间所有映射关系需要训练 $k(k{-}1)$ 个生成器。图 2(a) 展示了在四个不同域间进行图像翻译时,必须训练十二个独立生成器网络的情况。与此同时,这些模型效果不佳的原因是:尽管存在可跨域学习的全局特征(如人脸形状),但每个生成器无法充分利用全部训练数据,仅能从 $k$ 个域中的两个域学习。训练数据利用不充分很可能限制生成图像的质量。此外,由于每个数据集仅部分标注,这些模型无法联合训练来自不同数据集的域,我们将在第3.2节进一步讨论该问题。
As a solution to such problems we propose StarGAN, a novel and scalable approach capable of learning mappings among multiple domains. As demonstrated in Fig. 2 (b), our model takes in training data of multiple domains, and learns the mappings between all available domains using only a single generator. The idea is simple. Instead of learning a fixed translation (e.g., black-to-blond hair), our generator takes in as inputs both image and domain information, and learns to flexibly translate the image into the corresponding domain. We use a label (e.g., binary or one-hot vector) to represent domain information. During training, we randomly generate a target domain label and train the model to flexibly translate an input image into the target domain. By doing so, we can control the domain label and translate the image into any desired domain at testing phase.
为解决这类问题,我们提出了StarGAN,一种新颖且可扩展的方法,能够学习多个域之间的映射关系。如图2(b)所示,我们的模型接收多个域的训练数据,并仅使用单个生成器学习所有可用域之间的映射。其核心思想很简单:我们的生成器不再学习固定转换(例如黑发变金发),而是同时接收图像和域信息作为输入,学习将图像灵活转换到对应域。我们使用标签(例如二进制或one-hot向量)来表示域信息。训练过程中,我们随机生成目标域标签,并训练模型将输入图像灵活转换到目标域。通过这种方式,我们可以在测试阶段通过控制域标签将图像转换到任意目标域。
We also introduce a simple but effective approach that enables joint training between domains of different datasets by adding a mask vector to the domain label. Our proposed method ensures that the model can ignore unknown labels and focus on the label provided by a particular dataset. In this manner, our model can perform well on tasks such as synthesizing facial expressions of CelebA images using features learned from RaFD, as shown in the rightmost columns of Fig. 1. As far as our knowledge goes, our work is the first to successfully perform multi-domain image translation across different datasets.
我们还提出了一种简单而有效的方法,通过在域标签中添加掩码向量,实现不同数据集域间的联合训练。该方法确保模型能够忽略未知标签,专注于特定数据集提供的标签。通过这种方式,我们的模型能够出色完成跨数据集任务,例如利用从RaFD学到的特征合成CelebA图像的面部表情(如图1最右侧列所示)。据我们所知,这是首个成功实现跨数据集多域图像转换的研究。
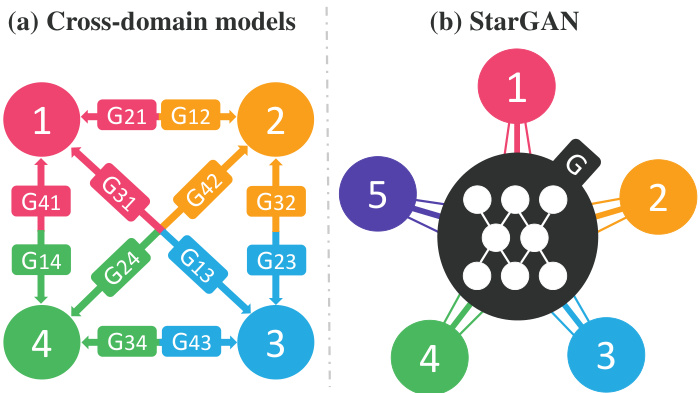
Figure 2. Comparison between cross-domain models and our proposed model, StarGAN. (a) To handle multiple domains, crossdomain models should be built for every pair of image domains. (b) StarGAN is capable of learning mappings among multiple domains using a single generator. The figure represents a star topology connecting multi-domains.
图 2: 跨领域模型与我们提出的StarGAN模型对比。(a) 传统跨领域模型需要为每对图像领域单独构建模型。(b) StarGAN能够使用单一生成器学习多领域间的映射关系。该图展示了连接多领域的星型拓扑结构。
Overall, our contributions are as follows:
总体而言,我们的贡献如下:
• We propose StarGAN, a novel generative adversarial network that learns the mappings among multiple domains using only a single generator and a discriminator, training effectively from images of all domains. • We demonstrate how we can successfully learn multidomain image translation between multiple datasets by utilizing a mask vector method that enables StarGAN to control all available domain labels. • We provide both qualitative and quantitative results on facial attribute transfer and facial expression synthesis tasks using StarGAN, showing its superiority over baseline models.
• 我们提出了StarGAN,这是一种新颖的生成对抗网络 (Generative Adversarial Network),仅使用单个生成器和判别器就能学习多个域之间的映射,并能有效利用所有域的图像进行训练。
• 我们展示了如何通过使用掩码向量 (mask vector) 方法成功学习多个数据集之间的多域图像转换,该方法使StarGAN能够控制所有可用的域标签。
• 我们在面部属性迁移和面部表情合成任务上提供了定性和定量结果,证明了StarGAN相较于基线模型的优越性。
2. Related Work
2. 相关工作
Generative Adversarial Networks. Generative adversarial networks (GANs) [3] have shown remarkable results in various computer vision tasks such as image generation [6, 24, 32, 8], image translation [7, 9, 33], super-resolution imaging [14], and face image synthesis [10, 16, 26, 31]. A typical GAN model consists of two modules: a discriminator and a generator. The disc rim in at or learns to distinguish between real and fake samples, while the generator learns to generate fake samples that are indistinguishable from real samples. Our approach also leverages the adversarial loss to make the generated images as realistic as possible.
生成对抗网络。生成对抗网络 (GANs) [3] 在图像生成 [6, 24, 32, 8]、图像转换 [7, 9, 33]、超分辨率成像 [14] 和人脸图像合成 [10, 16, 26, 31] 等各种计算机视觉任务中表现出色。典型的 GAN 模型包含两个模块:判别器和生成器。判别器学习区分真假样本,而生成器则学习生成与真实样本难以区分的假样本。我们的方法也利用对抗损失使生成的图像尽可能逼真。
Conditional GANs. GAN-based conditional image generation has also been actively studied. Prior studies have provided both the disc rim in at or and generator with class information in order to generate samples conditioned on the class [20, 21, 22]. Other recent approaches focused on generating particular images highly relevant to a given text description [25, 30]. The idea of conditional image generation has also been successfully applied to domain transfer [9, 28], superresolution imaging[14], and photo editing [2, 27]. In this paper, we propose a scalable GAN framework that can flexibly steer the image translation to various target domains, by providing conditional domain information.
条件式GAN。基于GAN的条件式图像生成也得到广泛研究。先前研究通过向判别器和生成器同时提供类别信息,实现了基于类别的条件样本生成 [20, 21, 22]。近期其他方法则专注于生成与给定文本描述高度相关的特定图像 [25, 30]。条件式图像生成思想还成功应用于领域迁移 [9, 28]、超分辨率成像 [14] 和照片编辑 [2, 27] 等领域。本文提出了一种可扩展的GAN框架,通过提供条件域信息,能够灵活引导图像转换至不同目标域。
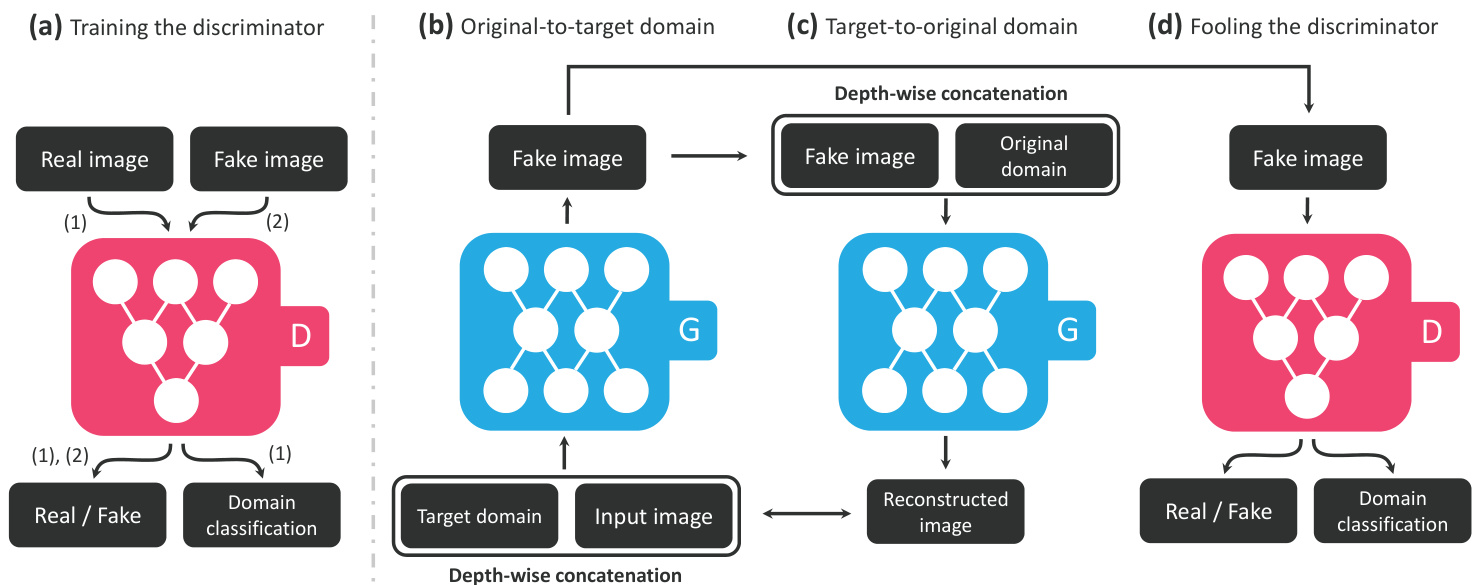
Figure 3. Overview of StarGAN, consisting of two modules, a disc rim in at or $D$ and a generator $G$ . (a) $D$ learns to distinguish between real and fake images and classify the real images to its corresponding domain. (b) $G$ takes in as input both the image and target domain label and generates an fake image. The target domain label is spatially replicated and concatenated with the input image. (c) $G$ tries to reconstruct the original image from the fake image given the original domain label. (d) $G$ tries to generate images indistinguishable from real images and classifiable as target domain by $D$ .
图 3: StarGAN概览,由两个模块组成:判别器 $D$ 和生成器 $G$。(a) $D$ 学习区分真实图像与生成图像,并将真实图像分类到对应域。(b) $G$ 接收图像和目标域标签作为输入,生成虚假图像。目标域标签经空间复制后与输入图像拼接。(c) $G$ 尝试根据原始域标签从生成图像重建原始图像。(d) $G$ 试图生成与真实图像无法区分且能被 $D$ 归类为目标域的图像。
Image-to-Image Translation. Recent work have achieved impressive results in image-to-image translation [7, 9, 17, 33]. For instance, pix2pix [7] learns this task in a supervised manner using cGANs[20]. It combines an adversarial loss with a L1 loss, thus requires paired data samples. To alleviate the problem of obtaining data pairs, unpaired image-to-image translation frameworks [9, 17, 33] have been proposed. UNIT [17] combines variation al autoencoders (VAEs) [12] with CoGAN [18], a GAN framework where two generators share weights to learn the joint distribution of images in cross domains. CycleGAN [33] and DiscoGAN [9] preserve key attributes between the input and the translated image by utilizing a cycle consistency loss. However, all these frameworks are only capable of learning the relations between two different domains at a time. Their approaches have limited s cal ability in handling multiple domains since different models should be trained for each pair of domains. Unlike the aforementioned approaches, our framework can learn the relations among multiple domains using only a single model.
图像到图像转换。近期研究在图像到图像转换领域取得了显著成果[7,9,17,33]。例如pix2pix[7]通过条件生成对抗网络(cGANs)[20]以监督学习方式完成该任务,其结合了对抗损失与L1损失,因此需要成对数据样本。为解决数据配对获取难题,研究者提出了非配对图像转换框架[9,17,33]。UNIT[17]将变分自编码器(VAEs)[12]与共享权重的双生成器CoGAN[18]相结合,学习跨域图像的联合分布。CycleGAN[33]和DiscoGAN[9]则通过循环一致性损失保持输入图像与转换图像间的关键属性。然而这些框架每次只能学习两个域之间的映射关系,由于需要为每对域训练独立模型,其多域扩展能力受限。与上述方法不同,我们的框架仅需单一模型即可学习多域间关系。
3. Star Generative Adversarial Networks
3. 星型生成对抗网络 (Star Generative Adversarial Networks)
We first describe our proposed StarGAN, a framework to address multi-domain image-to-image translation within a single dataset. Then, we discuss how StarGAN incorporates multiple datasets containing different label sets to flexibly perform image translations using any of these labels.
我们首先介绍提出的StarGAN框架,这是一个在单个数据集中解决多领域图像到图像转换的方案。接着,我们将讨论StarGAN如何整合包含不同标签集的多个数据集,从而灵活地利用这些标签中的任意一个进行图像转换。
3.1. Multi-Domain Image-to-Image Translation
3.1. 多领域图像到图像转换
Our goal is to train a single generator $G$ that learns mappings among multiple domains. To achieve this, we train $G$ to translate an input image $x$ into an output image $y$ condi- tioned on the target domain label $c$ , $G(x,c)\rightarrow y$ . We ran- domly generate the target domain label $c$ so that $G$ learns to flexibly translate the input image. We also introduce an auxiliary classifier [22] that allows a single disc rim in at or to control multiple domains. That is, our disc rim in at or produces probability distributions over both sources and domain labels, $D:x\rightarrow{D_{s r c}(x),D_{c l s}(x)}$ . Fig. 3 illustrates the training process of our proposed approach.
我们的目标是训练一个单一生成器 $G$,学习多个领域之间的映射。为此,我们训练 $G$ 将输入图像 $x$ 转换为输出图像 $y$,并以目标领域标签 $c$ 为条件,即 $G(x,c)\rightarrow y$。我们随机生成目标领域标签 $c$,使 $G$ 学会灵活地转换输入图像。此外,我们引入了一个辅助分类器 [22],允许单个判别器控制多个领域。也就是说,我们的判别器生成关于来源和领域标签的概率分布,$D:x\rightarrow{D_{s r c}(x),D_{c l s}(x)}$。图 3 展示了我们提出的方法的训练过程。
Adversarial Loss. To make the generated images indistinguishable from real images, we adopt an adversarial loss
对抗损失 (Adversarial Loss)。为了使生成的图像与真实图像难以区分,我们采用了对抗损失
$$
\begin{array}{r}{\mathcal{L}{a d v}=\mathbb{E}{x}\left[\log D_{s r c}(x)\right]+\qquad}\ {\mathbb{E}{x,c}[\log{(1-D_{s r c}(G(x,c)))}],}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{a d v}=\mathbb{E}{x}\left[\log D_{s r c}(x)\right]+\qquad}\ {\mathbb{E}{x,c}[\log{(1-D_{s r c}(G(x,c)))}],}\end{array}
$$
where $G$ generates an image $G(x,c)$ conditioned on both the input image $x$ and the target domain label $c$ , while $D$ tries to distinguish between real and fake images. In this paper, we refer to the term $D_{s r c}(x)$ as a probability distribution over sources given by $D$ . The generator $G$ tries to minimize this objective, while the disc rim in at or $D$ tries to maximize it.
其中 $G$ 根据输入图像 $x$ 和目标域标签 $c$ 生成条件图像 $G(x,c)$,而 $D$ 负责区分真假图像。在本文中,我们将术语 $D_{src}(x)$ 定义为 $D$ 给出的源概率分布。生成器 $G$ 试图最小化该目标函数,而判别器 $D$ 则试图最大化它。
Domain Classification Loss. For a given input image $x$ and a target domain label $c$ , our goal is to translate $x$ into an output image $y$ , which is properly classified to the target domain $c$ . To achieve this condition, we add an auxiliary classifier on top of $D$ and impose the domain classification loss when optimizing both $D$ and $G$ . That is, we decompose the objective into two terms: a domain classification loss of real images used to optimize $D$ , and a domain classification loss of fake images used to optimize $G$ . In detail, the former is defined as
域分类损失。对于给定的输入图像 $x$ 和目标域标签 $c$ ,我们的目标是将 $x$ 转换为输出图像 $y$ ,并将其正确分类到目标域 $c$ 。为了实现这一条件,我们在 $D$ 上添加了一个辅助分类器,并在优化 $D$ 和 $G$ 时施加域分类损失。也就是说,我们将目标分解为两项:用于优化 $D$ 的真实图像的域分类损失,以及用于优化 $G$ 的伪造图像的域分类损失。具体而言,前者定义为
$$
\mathcal{L}{c l s}^{r}=\mathbb{E}{x,c^{\prime}}[-\log D_{c l s}(c^{\prime}|x)],
$$
$$
\mathcal{L}{c l s}^{r}=\mathbb{E}{x,c^{\prime}}[-\log D_{c l s}(c^{\prime}|x)],
$$
where the term $D_{c l s}(c^{\prime}|x)$ represents a probability distribution over domain labels computed by $D$ . By minimizing this objective, $D$ learns to classify a real image $x$ to its corresponding original domain $c^{\prime}$ . We assume that the input image and domain label pair $(x,c^{\prime})$ is given by the training data. On the other hand, the loss function for the domain classification of fake images is defined as
其中,术语 $D_{c l s}(c^{\prime}|x)$ 表示由 $D$ 计算的域标签概率分布。通过最小化该目标,$D$ 学会将真实图像 $x$ 分类到其对应的原始域 $c^{\prime}$。我们假设输入图像和域标签对 $(x,c^{\prime})$ 由训练数据提供。另一方面,伪造图像的域分类损失函数定义为
$$
\mathcal{L}{c l s}^{f}=\mathbb{E}{x,c}[-\log D_{c l s}(c|G(x,c))].
$$
$$
\mathcal{L}{c l s}^{f}=\mathbb{E}{x,c}[-\log D_{c l s}(c|G(x,c))].
$$
In other words, $G$ tries to minimize this objective to generate images that can be classified as the target domain $c$ .
换句话说,$G$ 试图最小化这个目标,以生成可分类为目标域 $c$ 的图像。
Reconstruction Loss. By minimizing the adversarial and classification losses, $G$ is trained to generate images that are realistic and classified to its correct target domain. However, minimizing the losses (Eqs. (1) and (3)) does not guarantee that translated images preserve the content of its input images while changing only the domain-related part of the inputs. To alleviate this problem, we apply a cycle consistency loss [9, 33] to the generator, defined as
重建损失。通过最小化对抗损失和分类损失,生成器 $G$ 被训练生成逼真且能正确分类到目标域的图像。然而,最小化这些损失(公式(1)和(3))并不能保证转换后的图像在仅改变输入图像中与域相关的部分时保留其内容。为了缓解这个问题,我们对生成器应用了循环一致性损失 [9, 33],其定义为
$$
\mathcal{L}{r e c}=\mathbb{E}{x,c,c^{\prime}}[||x-G(G(x,c),c^{\prime})||_{1}],
$$
$$
\mathcal{L}{r e c}=\mathbb{E}{x,c,c^{\prime}}[||x-G(G(x,c),c^{\prime})||_{1}],
$$
where $G$ takes in the translated image $G(x,c)$ and the original domain label $c^{\prime}$ as input and tries to reconstruct the original image $x$ . We adopt the L1 norm as our reconstruction loss. Note that we use a single generator twice, first to translate an original image into an image in the target domain and then to reconstruct the original image from the translated image.
其中 $G$ 以转换后的图像 $G(x,c)$ 和原始域标签 $c^{\prime}$ 作为输入,尝试重建原始图像 $x$。我们采用 L1 范数作为重建损失。注意,我们两次使用同一个生成器:首先将原始图像转换到目标域,再从转换后的图像重建原始图像。
Full Objective. Finally, the objective functions to optimize $G$ and $D$ are written, respectively, as
完整目标。最终,分别用于优化 $G$ 和 $D$ 的目标函数可表示为
$$
\begin{array}{r}{{\mathcal L}{D}=-{\mathcal L}{a d v}+\lambda_{c l s}{\mathcal L}_{c l s}^{r},}\end{array}
$$
$$
\begin{array}{r}{{\mathcal L}{D}=-{\mathcal L}{a d v}+\lambda_{c l s}{\mathcal L}_{c l s}^{r},}\end{array}
$$
$$
\mathcal{L}{G}=\mathcal{L}{a d v}+\lambda_{c l s}\mathcal{L}{c l s}^{f}+\lambda_{r e c}\mathcal{L}_{r e c},
$$
$$
\mathcal{L}{G}=\mathcal{L}{a d v}+\lambda_{c l s}\mathcal{L}{c l s}^{f}+\lambda_{r e c}\mathcal{L}_{r e c},
$$
where $\lambda_{c l s}$ and $\lambda_{r e c}$ are hyper-parameters that control the relative importance of domain classification and reconstruction losses, respectively, compared to the adversarial loss. We use $\lambda_{c l s}=1$ and $\lambda_{r e c}=10$ in all of our experiments.
其中 $\lambda_{cls}$ 和 $\lambda_{rec}$ 是超参数,分别控制域分类损失和重构损失相对于对抗损失的相对重要性。我们在所有实验中使用 $\lambda_{cls}=1$ 和 $\lambda_{rec}=10$。
3.2. Training with Multiple Datasets
3.2. 多数据集训练
An important advantage of StarGAN is that it simultaneously incorporates multiple datasets containing different types of labels, so that StarGAN can control all the labels at the test phase. An issue when learning from multiple datasets, however, is that the label information is only partially known to each dataset. In the case of CelebA [19] and RaFD [13], while the former contains labels for attributes such as hair color and gender, it does not have any labels for facial expressions such as ‘happy’ and ‘angry’, and vice versa for the latter. This is problematic because the complete information on the label vector $c^{\prime}$ is required when reconstructing the input image $x$ from the translated image $G(x,c)$ (See Eq. (4)).
StarGAN的一个重要优势是它能同时整合包含不同类型标签的多个数据集,使得StarGAN在测试阶段可以控制所有标签。然而,从多个数据集学习时存在一个问题:每个数据集仅能获取部分标签信息。以CelebA [19]和RaFD [13]为例,前者包含发色、性别等属性标签,但缺少"开心"、"愤怒"等表情标签;后者则恰好相反。这在图像重构时会产生问题——当需要从转换后的图像$G(x,c)$重建输入图像$x$时,必须获得标签向量$c^{\prime}$的完整信息(参见公式(4))。
Mask Vector. To alleviate this problem, we introduce a mask vector $m$ that allows StarGAN to ignore unspecified labels and focus on the explicitly known label provided by a particular dataset. In StarGAN, we use an $n$ -dimensional one-hot vector to represent $m$ , with $n$ being the number of datasets. In addition, we define a unified version of the label as a vector
掩码向量 (Mask Vector)。为了缓解这一问题,我们引入了一个掩码向量 $m$,使 StarGAN 能够忽略未指定的标签,专注于特定数据集提供的明确已知标签。在 StarGAN 中,我们使用一个 $n$ 维独热向量 (one-hot vector) 来表示 $m$,其中 $n$ 是数据集的数量。此外,我们将标签的统一版本定义为一个向量
$$
{\tilde{c}}=[c_{1},...,c_{n},m],
$$
$$
{\tilde{c}}=[c_{1},...,c_{n},m],
$$
where $[\cdot]$ refers to concatenation, and $c_{i}$ represents a vector for the labels of the $i\cdot$ -th dataset. The vector of the known label $c_{i}$ can be represented as either a binary vector for binary attributes or a one-hot vector for categorical attributes. For the remaining $n{-}1$ unknown labels we simply assign zero values. In our experiments, we utilize the CelebA and RaFD datasets, where $n$ is two.
其中 $[\cdot]$ 表示拼接操作,$c_{i}$ 代表第 $i$ 个数据集标签的向量。已知标签 $c_{i}$ 的向量可表示为二元属性的二进制向量或分类属性的独热向量 (one-hot vector) 。对于其余 $n{-}1$ 个未知标签,我们直接赋零值。实验采用 CelebA 和 RaFD 数据集,此时 $n$ 值为 2。
Training Strategy. When training StarGAN with multiple datasets, we use the domain label $\tilde{c}$ defined in Eq. (7) as input to the generator. By doing so, the generator learns to ignore the unspecified labels, which are zero vectors, and focus on the explicitly given label. The structure of the generator is exactly the same as in training with a single dataset, except for the dimension of the input label c. On the other hand, we extend the auxiliary classifier of the discriminator to generate probability distributions over labels for all datasets. Then, we train the model in a multi-task learning setting, where the disc rim in at or tries to minimize only the classification error associated to the known label. For example, when training with images in CelebA, the discriminator minimizes only classification errors for labels related to CelebA attributes, and not facial expressions related to RaFD. Under these settings, by alternating between CelebA and RaFD the disc rim in at or learns all of the disc rim i native features for both datasets, and the generator learns to control all the labels in both datasets.
训练策略。在使用多个数据集训练StarGAN时,我们使用公式(7)中定义的域标签$\tilde{c}$作为生成器的输入。通过这种方式,生成器学会忽略未指定的标签(即零向量),专注于显式给定的标签。除输入标签c的维度外,生成器结构与单数据集训练时完全相同。另一方面,我们扩展判别器的辅助分类器,使其能生成所有数据集标签的概率分布。随后,我们在多任务学习设置下训练模型,其中判别器仅尝试最小化与已知标签相关的分类误差。例如,当使用CelebA图像训练时,判别器仅最小化与CelebA属性相关的分类误差,而不考虑与RaFD相关的面部表情。在这些设置下,通过交替使用CelebA和RaFD,判别器学会两个数据集的所有判别特征,而生成器学会控制两个数据集中的所有标签。
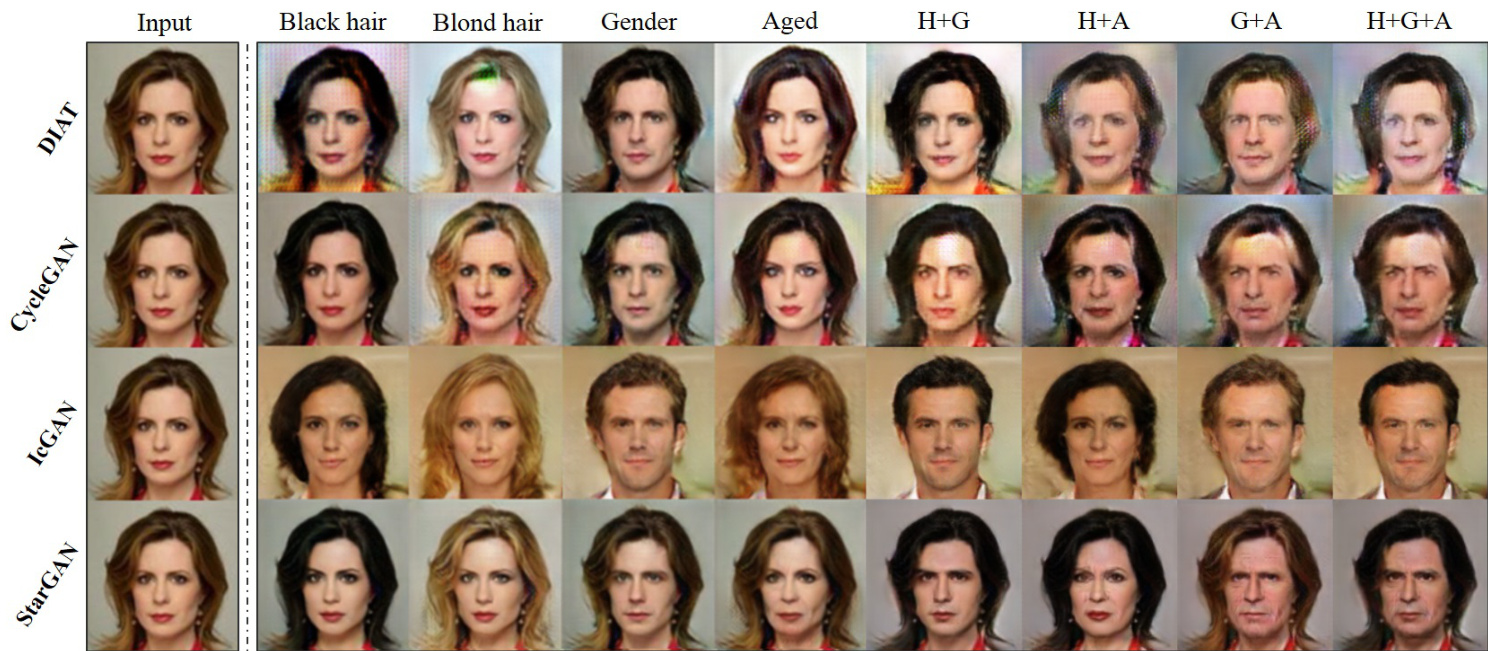
Figure 4. Facial attribute transfer results on the CelebA dataset. The first column shows the input image, next four columns show the single attribute transfer results, and rightmost columns show the multi-attribute transfer results. H: Hair color, G: Gender, A: Aged.
图 4: CelebA数据集上的面部属性迁移结果。第一列为输入图像,中间四列为单属性迁移结果,最右侧为多属性迁移结果。H: 发色 (Hair color), G: 性别 (Gender), A: 年龄 (Aged)。
4. Implementation
4. 实现
where $\hat{x}$ is sampled uniformly along a straight line between a pair of a real and a generated images. We use $\lambda_{g p}=10$ for all experiments.
其中 $\hat{x}$ 是在真实图像和生成图像之间的直线上均匀采样的。我们在所有实验中使用 $\lambda_{g p}=10$。
Network Architecture. Adapted from CycleGAN [33], StarGAN has the generator network composed of two convolutional layers with the stride size of two for downsampling, six residual blocks [5], and two transposed convolutional layers with the stride size of two for upsampling. We use instance normalization [29] for the generator but no normalization for the disc rim in at or. We leverage PatchGANs [7, 15, 33] for the disc rim in at or network, which classifies whether local image patches are real or fake. See the appendix (Section 7.2) for more details about the network architecture.
网络架构。基于CycleGAN [33]改进,StarGAN的生成器网络包含两个步长为2的下采样卷积层、六个残差块 [5]以及两个步长为2的上采样转置卷积层。生成器采用实例归一化 [29],而判别器不使用归一化。我们采用PatchGANs [7, 15, 33]作为判别器网络,用于判断局部图像块的真伪。更多网络架构细节详见附录(章节7.2)。
5. Experiments
5. 实验
In this section, we first compare StarGAN against recent methods on facial attribute transfer by conducting user studies. Next, we perform a classification experiment on facial expression synthesis. Lastly, we demonstrate empirical results that StarGAN can learn image-to-image translation from multiple datasets. All our experiments were conducted by using the model output from unseen images during the training phase.
在本节中,我们首先通过用户研究将StarGAN与近期的人脸属性迁移方法进行对比。接着,我们对面部表情合成进行了分类实验。最后,我们通过实证结果表明StarGAN能够从多个数据集中学习图像到图像的转换。所有实验均使用训练阶段未见过的图像模型输出来完成。
5.1. Baseline Models
5.1. 基线模型
As our baseline models, we adopt DIAT [16] and CycleGAN [33], both of which performs image-to-image translation between two different domains. For comparison, we trained these models multiple times for every pair of two different domains. We also adopt IcGAN [23] as a baseline which can perform attribute transfer using a cGAN [22].
作为基线模型,我们采用DIAT [16]和CycleGAN [33],这两种模型都能在两个不同域之间进行图像到图像的转换。为了比较,我们对每对不同域多次训练这些模型。我们还采用IcGAN [23]作为基线,它可以使用cGAN [22]进行属性迁移。
DIAT uses an adversarial loss to learn the mapping from $x\in X$ to $y\in Y$ , where $x$ and $y$ are face images in two different domains $X$ and $Y$ , respectively. This method has a regular iz ation term on the mapping as $||x-F(G(x))||_{1}$ to preserve identity features of the source image, where $F$ is a feature extractor pretrained on a face recognition task.
DIAT采用对抗损失来学习从$x\in X$到$y\in Y$的映射,其中$x$和$y$分别是两个不同域$X$和$Y$中的人脸图像。该方法在映射上添加了正则化项$||x-F(G(x))||_{1}$以保留源图像的身份特征,其中$F$是在人脸识别任务上预训练的特征提取器。
CycleGAN also uses an adversarial loss to learn the mapping between two different domains $X$ and $Y$ . This method regularizes the mapping via cycle consistency losses, $||x-(G_{Y X}(G_{X Y}(x)))||{1}$ and $||y-(G_{X Y}(G_{Y X}(y)))||_{1}$ . This method requires two generators and disc rim in at or s for each pair of two different domains.
CycleGAN 也使用对抗损失 (adversarial loss) 来学习两个不同域 $X$ 和 $Y$ 之间的映射。该方法通过循环一致性损失 (cycle consistency losses) $||x-(G_{Y X}(G_{X Y}(x)))||{1}$ 和 $||y-(G_{X Y}(G_{Y X}(y)))||_{1}$ 对映射进行正则化。此方法需要为每对不同的域配备两个生成器和判别器。
IcGAN combines an encoder with a cGAN [22] model. cGAN learns the mapping $G:{z,c}\rightarrow x$ that generates an image $x$ conditioned on both the latent vector $z$ and the conditional vector $c$ . In addition, IcGAN introduces an encoder to learn the inverse mappings of cGAN, $E_{z}:x\rightarrow z$ and $E_{c}:x\rightarrow c$ . This allows IcGAN to synthesis images by only changing the conditional vector and preserving the latent vector.
IcGAN 将编码器与 cGAN [22] 模型相结合。cGAN 学习映射 $G:{z,c}\rightarrow x$,该映射根据潜在向量 $z$ 和条件向量 $c$ 生成图像 $x$。此外,IcGAN 引入编码器来学习 cGAN 的逆映射 $E_{z}:x\rightarrow z$ 和 $E_{c}:x\rightarrow c$。这使得 IcGAN 能够仅通过改变条件向量并保留潜在向量来合成图像。

Figure 5. Facial expression synthesis results on the RaFD dataset.
图 5: RaFD数据集上的面部表情合成结果。
5.2. Datasets
5.2. 数据集
CelebA. The CelebFaces Attributes (CelebA) dataset [19] contains 202,599 face images of celebrities, each annotated with 40 binary attributes. We crop the initial $178\times218$ size images to $178\times178$ , then resize them as $128\times128$ . We randomly select 2,000 images as test set and use all remaining images for training data. We construct seven domains using the following attributes: hair color (black, blond, brown), gender (male/female), and age (young/old).
CelebA。CelebFaces Attributes (CelebA) 数据集 [19] 包含 202,599 张名人面部图像,每张图像标注了 40 个二元属性。我们将初始 $178\times218$ 尺寸的图像裁剪为 $178\times178$,然后调整为 $128\times128$。随机选取 2,000 张图像作为测试集,其余全部用于训练数据。我们使用以下属性构建七个域:发色(黑色、金色、棕色)、性别(男/女)和年龄(年轻/年老)。
RaFD. The Radboud Faces Database (RaFD) [13] consists of 4,824 images collected from 67 participants. Each participant makes eight facial expressions in three different gaze directions, which are captured from three different angles. We crop the images to $256\times256$ , where the faces are centered, and then resize them to $128\times128$ .
RaFD。Radboud人脸数据库(RaFD) [13]包含从67名参与者收集的4,824张图像。每位参与者在三种不同视线方向和三个拍摄角度下呈现八种面部表情。我们将图像裁剪为$256\times256$尺寸(保持面部居中),然后调整为$128\times128$分辨率。
5.3. Training
5.3. 训练
All models are trained using Adam [11] with $\beta_{1}=0.5$ and $\beta_{2}~=~0.999$ . For data augmentation we flip the images horizontally with a probability of 0.5. We perform one generator update after five disc rim in at or updates as in [4]. The batch size is set to 16 for all experiments. For experiments on CelebA, we train all models with a learning rate of 0.0001 for the first 10 epochs and linearly decay the learning rate to 0 over the next 10 epochs. To compensate for the lack of data, when training with RaFD we train all models for 100 epochs with a learning rate of 0.0001 and apply the same decaying strategy over the next 100 epochs. Training takes about one day on a single NVIDIA Tesla M40 GPU.
所有模型均使用Adam [11]优化器进行训练,其中$\beta_{1}=0.5$,$\beta_{2}~=~0.999$。数据增强方面,我们以0.5的概率对图像进行水平翻转。按照[4]的方法,每完成五次判别器更新后执行一次生成器更新。所有实验的批次大小均设置为16。在CelebA数据集上的实验中,前10个周期采用0.0001的学习率,随后10个周期线性衰减至0。针对RaFD数据集数据量不足的情况,我们训练所有模型100个周期(初始学习率0.0001),并在后续100个周期采用相同的衰减策略。单块NVIDIA Tesla M40 GPU上的训练耗时约一天。
5.4. Experimental Results on CelebA
5.4. CelebA 上的实验结果
We first compare our proposed method to the baseline models on a single and multi-attribute transfer tasks. We train the cross-domain models such as DIAT and CycleGAN multiple times considering all possible attribute value pairs. In the case of DIAT and CycleGAN, we perform multi-step translations to synthesize multiple attributes (e.g. transferring a gender attribute after changing a hair color).
我们首先在单属性和多属性迁移任务上将所提方法与基线模型进行对比。考虑到所有可能的属性值组合,我们对DIAT和CycleGAN等跨域模型进行了多次训练。对于DIAT和CycleGAN,我们采用多步转换来合成多个属性(例如在改变发色后迁移性别属性)。
Qualitative evaluation. Fig. 4 shows the facial attribute transfer results on CelebA. We observed that our method provides a higher visual quality of translation results on test data compared to the cross-domain models. One possible reason is the regular iz ation effect of StarGAN through a multi-task learning framework. In other words, rather than training a model to perform a fixed translation (e.g., brownto-blond hair), which is prone to over fitting, we train our model to flexibly translate images according to the labels of the target domain. This allows our model to learn reliable features universally applicable to multiple domains of images with different facial attribute values.
定性评估。图 4 展示了 CelebA 数据集上的面部属性迁移结果。我们发现,与跨域模型相比,我们的方法在测试数据上提供了更高视觉质量的转换结果。一个可能的原因是 StarGAN 通过多任务学习框架产生的正则化效应。换句话说,我们没有训练模型执行固定的转换 (例如棕发变金发) —— 这种方式容易导致过拟合,而是训练模型根据目标域标签灵活转换图像。这使得我们的模型能够学习适用于具有不同面部属性值的多图像域的通用可靠特征。
Furthermore, compared to IcGAN, our model demonstrates an advantage in preserving the facial identity feature of an input. We conjecture that this is because our method maintains the spatial information by using activation maps from the convolutional layer as latent representation, rather than just a low-dimensional latent vector as in IcGAN.
此外,与IcGAN相比,我们的模型在保留输入面部身份特征方面展现出优势。我们推测这是因为该方法通过使用卷积层的激活图作为潜在表征(而非像IcGAN那样仅采用低维潜在向量)来维持空间信息。
Quantitative evaluation protocol. For quantitative evaluations, we performed two user studies in a survey format using Amazon Mechanical Turk (AMT) to assess single and multiple attribute transfer tasks. Given an input image, the Turkers were instructed to choose the best generated image based on perceptual realism, quality of transfer in attribute(s), and preservation of a figure’s original identity. The options were four randomly shuffled images generated from four different methods. The generated images in one study have a single attribute transfer in either hair color (black, blond, brown), gender, or age. In another study, the generated images involve a combination of attribute transfers. Each Turker was asked 30 to 40 questions with a few simple yet logical questions for validating human effort. The number of validated Turkers in each user study is 146 and 100 in single and multiple transfer tasks, respectively.
定量评估方案。我们通过Amazon Mechanical Turk (AMT) 平台以问卷调查形式开展了两项用户研究,分别评估单属性和多属性迁移任务。给定输入图像后,受试者需根据感知真实性、属性迁移质量和原始身份保持度,从四种不同方法生成的随机排序图像中选择最佳结果。其中一项研究生成的图像仅包含发色(黑/金/棕)、性别或年龄中的单一属性迁移;另一项研究则涉及组合属性迁移。每位受试者需回答30至40个问题,其中包含若干用于验证人工标注质量的简单逻辑题。两项研究中通过验证的受试者数量分别为:单属性迁移任务146人,多属性迁移任务100人。

Figure 6. Facial expression synthesis results of StarGAN-SNG and StarGAN-JNT on CelebA dataset.
图 6: StarGAN-SNG和StarGAN-JNT在CelebA数据集上的面部表情合成结果。
Table 1. AMT perceptual evaluation for ranking different models on a single attribute transfer task. Each column sums to $100%$ .
表 1: AMT感知评估对不同模型在单属性迁移任务中的排序结果。每列总和为$100%$。
| 方法 | 发色 | 性别 | 年龄 |
|---|---|---|---|
| DIAT | 9.3% | 31.4% | 6.9% |
| CycleGAN | 20.0% | 16.6% | 13.3% |
| IcGAN | 4.5% | 12.9% | 9.2% |
| StarGAN | 66.2% | 39.1% | 70.6% |
Table 2. AMT perceptual evaluation for ranking different models on a multi-attribute transfer task. H: Hair color; G: Gender; A: Aged.
a
表 2. AMT感知评估在多属性迁移任务中对不同模型的排序结果。H: 发色; G: 性别; A: 年龄。
| 方法 | H+G | H+A | G+A | H+G+A |
|---|---|---|---|---|
| DIAT | 20.4% | 15.6% | 18.7% | 15.6% |
| CycleGAN | 14.0% | 12.0% | 11.2% | 11.9% |
| IcGAN | 18.2% | 10.9% | 20.3% | 20.3% |
| StarGAN | 47.4% | 61.5% | 49.8% | 52.2% |
a
Quantitative results. Tables 1 and 2 show the results of our AMT experiment on single- and multi-attribute transfer tasks, respectively. StarGAN obtained the majority of votes for best transferring attributes in all cases. In the case of gender changes in Table 1, the voting difference between our model and other models was marginal, e.g., $39.1%$ for StarGAN vs. $31.4%$ for DIAT. However, in multi-attribute changes, e.g., the $\cdot_{\mathrm{{G+A}}},$ case in Table 2, the performance difference becomes significant, e.g., $49.8%$ for StarGAN vs. $20.3%$ for IcGAN), clearly showing the advantages of StarGAN in more complicated, multi-attribute transfer tasks. This is because unlike the other methods, StarGAN can handle image translation involving multiple attribute changes by randomly generating a target domain label in the training phase.
定量结果。表1和表2分别展示了我们在单属性和多属性迁移任务上的AMT实验结果。在所有情况下,StarGAN在最佳属性迁移方面获得了多数投票。在表1的性别转换案例中,我们的模型与其他模型的投票差距较小,例如StarGAN为$39.1%$,而DIAT为$31.4%$。然而,在多属性变化的情况下,如表2中的$\cdot_{\mathrm{{G+A}}}$案例,性能差异变得显著,例如StarGAN为$49.8%$,而IcGAN为$20.3%$,这清楚地表明了StarGAN在更复杂的多属性迁移任务中的优势。这是因为与其他方法不同,StarGAN通过在训练阶段随机生成目标域标签,能够处理涉及多个属性变化的图像转换。
5.5. Experimental Results on RaFD
5.5. RaFD 实验结果
We next train our model on the RaFD dataset to learn the task of synthesizing facial expressions. To compare StarGAN and baseline models, we fix the input domain as the ‘neutral’ expression, but the target domain varies among the seven remaining expressions.
接下来,我们在RaFD数据集上训练模型,学习合成面部表情的任务。为了比较StarGAN和基线模型,我们将输入域固定为"中性"表情,而目标域则在其余七种表情中变化。
Qualitative evaluation. As seen in Fig. 5, StarGAN clearly generates the most natural-looking expressions while properly maintaining the personal identity and facial features of the input. While DIAT and CycleGAN mostly preserve the identity of the input, many of their results are shown blurry and do not maintain the degree of sharpness as seen in the input. IcGAN even fails to preserve the personal identity in the image by generating male images.
定性评估。如图 5 所示,StarGAN 明显生成了最自然的表情,同时正确保持了输入的个人身份和面部特征。虽然 DIAT 和 CycleGAN 大多保留了输入的身份,但它们的许多结果都显得模糊,并且没有保持输入中的锐度。IcGAN 甚至通过生成男性图像而未能保留图像中的个人身份。
We believe that the superiority of StarGAN in the image quality is due to its implicit data augmentation effect from a multi-task learning setting. RaFD images contain a relatively small size of samples, e.g., 500 images per domain. When trained on two domains, DIAT and CycleGAN can only use 1,000 training images at a time, but StarGAN can use 4,000 images in total from all the available domains for its training. This allows StarGAN to properly learn how to maintain the quality and sharpness of the generated output.
我们相信StarGAN在图像质量上的优势源于其多任务学习设置带来的隐式数据增强效果。RaFD数据集包含的样本规模相对较小,例如每个域仅有500张图像。当在两个域上训练时,DIAT和CycleGAN每次只能使用1,000张训练图像,而StarGAN可以利用所有可用域共计4,000张图像进行训练。这使得StarGAN能够更好地学习如何保持生成图像的质量和清晰度。
Quantitative evaluation. For a quantitative evaluation, we compute the classification error of a facial expression on synthesized images. We trained a facial expression classifier on the RaFD dataset $(90%/10%$ splitting for training and test sets) using a ResNet-18 architecture [5], resulting in a near-perfect accuracy of $99.55%$ . We then trained each of image translation models using the same training set and performed image translation on the same, unseen test set. Finally, we classified the expression of these translated images using the above-mentioned classifier. As can be seen in Table 3, our model achieves the lowest classification error, indicating that our model produces the most realistic facial expressions among all the methods compared.
定量评估。为了进行定量评估,我们计算合成图像上面部表情的分类错误率。我们在RaFD数据集上训练了一个面部表情分类器(训练集/测试集按90%/10%划分),采用ResNet-18架构[5],获得了接近完美的99.55%准确率。随后,我们使用相同的训练集分别训练各图像转换模型,并在相同的未见测试集上进行图像转换。最后,使用上述分类器对这些转换后图像的表情进行分类。如表3所示,我们的模型实现了最低的分类错误率,表明在所有对比方法中,我们的模型能生成最真实的面部表情。
Table 3. Classification errors $[%]$ and the number of parameters on the RaFD dataset.
表 3: RaFD数据集上的分类错误率 $[%]$ 和参数量。
| 方法 | 分类错误率 | 参数量 |
|---|---|---|
| DIAT | 4.10 | 52.6M×7 |
| CycleGAN | 5.99 | 52.6M×14 |
| IcGAN | 8.07 | 67.8M×1 |
| StarGAN | 2.12 | 53.2M×1 |
| Realimages | 0.45 |
Another important advantage of our model is the scalability in terms of the number of parameters required. The last column in Table 3 shows that the number of parameters required to learn all translations by StarGAN is seven times smaller than that of DIAT and fourteen times smaller than that of CycleGAN. This is because StarGAN requires only a single generator and disc rim in at or pair, regardless of the number of domains, while in the case of cross-domain models such as CycleGAN, a completely different model should be trained for each source-target domain pair.
我们模型的另一个重要优势在于所需参数数量的可扩展性。表3最后一列显示,StarGAN学习所有翻译任务所需的参数量比DIAT少7倍,比CycleGAN少14倍。这是因为StarGAN只需单个生成器和判别器对,无论涉及多少领域;而CycleGAN等跨领域模型则需要为每个源-目标领域对训练完全独立的模型。
6. Conclusion
6. 结论
In this paper, we proposed StarGAN, a scalable imageto-image translation model among multiple domains using a single generator and a disc rim in at or. Besides the advantages in s cal ability, StarGAN generated images of higher visual quality compared to existing methods [16, 23, 33], owing to the generalization capability behind the multi-task learning setting. In addition, the use of the proposed simple mask vector enables StarGAN to utilize multiple datasets with different sets of domain labels, thus handling all available labels from them. We hope our work to enable users to develop interesting image translation applications across multiple domains.
本文提出StarGAN,这是一种利用单一生成器和判别器实现多领域间可扩展图像转换的模型。除了可扩展性优势外,由于多任务学习设置带来的泛化能力,StarGAN生成的图像视觉质量优于现有方法[16,23,33]。此外,通过使用提出的简单掩码向量,StarGAN能够利用具有不同领域标签集合的多个数据集,从而处理其中所有可用标签。我们希望这项工作能帮助用户开发跨多个领域的有趣图像转换应用。
Acknowledgements. This work was mainly done while the first author did a research internship at Clova AI Research, NAVER. We thank all the researchers at NAVER, especially Donghyun Kwak, for insightful discussions. This work was partially supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIP) (No. N RF 2016 R 1 C 1 B 2015924). Jaegul Choo is the corresponding author.
致谢。本研究主要在第一作者于NAVER Clova AI Research实习期间完成。我们感谢NAVER所有研究人员的宝贵讨论,特别是Donghyun Kwak。本工作部分由韩国国家研究基金会(NRF)资助的韩国政府(MSIP)项目支持(项目编号:NRF 2016R1C1B2015924)。通讯作者为Jaegul Choo。