Learning Topological Representation for Networks via Hierarchical Sampling
通过分层采样学习网络的拓扑表征
Abstract—The topological information is essential for studying the relationship between nodes in a network. Recently, Network Representation Learning (NRL), which projects a network into a low-dimensional vector space, has been shown their advantages in analyzing large-scale networks. However, most existing NRL methods are designed to preserve the local topology of a network, they fail to capture the global topology. To tackle this issue, we propose a new NRL framework, named HSRL, to help existing NRL methods capture both the local and global topological information of a network. Specifically, HSRL recursively compresses an input network into a series of smaller networks using a community-awareness compressing strategy. Then, an existing NRL method is used to learn node embeddings for each compressed network. Finally, the node embeddings of the input network are obtained by concatenating the node embeddings from all compressed networks. Empirical studies for link prediction on five real-world datasets demonstrate the advantages of HSRL over state-of-the-art methods.
摘要—拓扑信息对于研究网络中节点间的关系至关重要。近年来,网络表示学习(NRL)通过将网络映射到低维向量空间,在分析大规模网络方面展现出显著优势。然而,现有大多数NRL方法仅专注于保留网络的局部拓扑结构,未能有效捕捉全局拓扑特征。为解决这一问题,我们提出了一种名为HSRL的新型NRL框架,旨在帮助现有NRL方法同时捕获网络的局部和全局拓扑信息。具体而言,HSRL采用基于社区感知的压缩策略,递归地将输入网络压缩为一系列更小的网络;随后使用现有NRL方法学习每个压缩网络的节点嵌入;最终通过拼接所有压缩网络的节点嵌入,获得输入网络的节点表示。在五个真实数据集上的链路预测实验表明,HSRL优于当前最先进的方法。
Index Terms—Networks analysis, network topology, representation learning
索引术语—网络分析、网络拓扑、表征学习
I. INTRODUCTION
I. 引言
The science of networks has been widely used to understand the behaviours of complex systems. These systems are typically described as networks, such as social networks in social media [1], bibliographic networks in academic field [2], protein-protein interaction networks in biology [3]. Studying the relationship between entities in a complex system is an essential topic, which benefits a variety of applications [4]. Just take a few examples, predicting potential new friendship between users in social networks [5], searching similar authors in bibliographic networks [2], recommending new movies to users in movie user-movie interest networks [6]. The topologies of these networks provide insight information on the relationship between nodes. We can find out strongly connected neighborhoods of a node by exploring the local topology in a network. Meanwhile, the global topology is another significant aspect for studying the relationship between communities. As shown in Fig.1, such hierarchical topological information is helpful to learn the relationship between nodes in a network.
网络科学已被广泛用于理解复杂系统的行为。这些系统通常被描述为网络,例如社交媒体中的社交网络 [1]、学术领域的文献网络 [2]、生物学中的蛋白质-蛋白质相互作用网络 [3]。研究复杂系统中实体之间的关系是一个重要课题,可为多种应用带来益处 [4]。仅举几个例子:预测社交网络中用户之间潜在的新友谊 [5]、在文献网络中搜索相似作者 [2]、在电影用户-电影兴趣网络中向用户推荐新电影 [6]。这些网络的拓扑结构提供了关于节点之间关系的深入信息。通过探索网络中的局部拓扑,我们可以发现一个节点的强连接邻域。同时,全局拓扑是研究社区之间关系的另一个重要方面。如图 1 所示,这种层次化的拓扑信息有助于学习网络中节点之间的关系。
Many networks are large-scale in real-world scenarios, such as a Facebook social network contains billion of users [7]. As a result, most traditional network analytic methods suffer from high computation and space cost [4]. To tackle this issue, Network Representation Learning (NRL) has been a popular technique to analyze large-scale networks recently. In particular, NRL aims to map a network into a low-dimensional vector space, while preserving as much of the original network topological information as possible. Nodes in a network are represented as low-dimensional vectors which are used as input features for downstream network analysis algorithms.
现实场景中许多网络规模庞大,例如Facebook社交网络拥有数十亿用户[7]。这导致传统网络分析方法普遍面临高昂的计算和存储成本[4]。为解决该问题,网络表征学习(NRL)近年成为分析大规模网络的主流技术。其核心思想是将网络映射到低维向量空间,同时最大限度保留原始网络拓扑信息。网络中的节点被表示为低维向量,作为下游网络分析算法的输入特征。
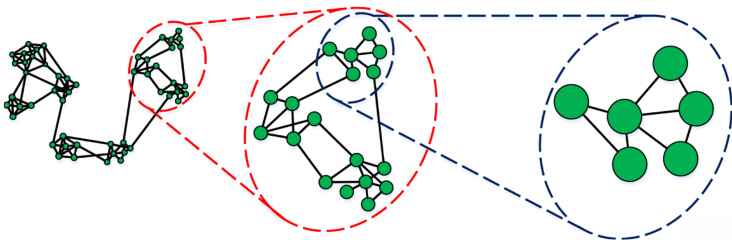
Fig. 1. An example of hierarchical view of network topology.
图 1: 网络拓扑层次结构示例。
Traditional NRL methods such as LLE [8] and ISOMap [9] work well on small networks, while they are infeasible to large-scale networks due to the high computational cost. Recently, some online learning methods, e.g., DeepWalk [10], node2vec [11], and LINE [12], have been proposed to learn large-scale network representation, which has been demonstrated their efficiency and effectiveness for the large-scale network analysis.
传统网络表示学习(NRL)方法如LLE [8]和ISOMap [9]在小规模网络上表现良好,但由于计算成本高,无法应用于大规模网络。近年来,一些在线学习方法如DeepWalk [10]、node2vec [11]和LINE [12]被提出用于学习大规模网络表示,这些方法在大规模网络分析中已展现出高效性和有效性。
However, the above NRL methods only consider the local topology of networks and fail to capture the global topological information. DeepWalk and node2vec firstly employ short random walks to explore the local neighborhoods of nodes and obtain node embeddings by the Skip-Gram model [13]. LINE preserves the first-order and second-order pro xi mi ties so that it can only measure the relationship between nodes at most two-hops away. These methods are efficient to capture the relationship between close nodes, however, fail to consider the case for nodes which are far away from each other. Recently, HARP [14] has been proposed to overcome this issue. It recursively compresses a network into a series of small networks based on two node collapsing schemes and learns node embeddings for each compressed network by using an existing NRL method. Unfortunately, the compressed networks may not reveal the global topology of an input network, since HARP heuristic ally merges two closed nodes into a new node. Furthermore, when learning node embeddings on the original network, using node embeddings obtained on compressed networks as the initialization solution may mislead the optimization process to a bad local minimum.
然而,上述网络表示学习(NRL)方法仅考虑网络的局部拓扑结构,未能捕获全局拓扑信息。DeepWalk和node2vec首次采用短随机游走来探索节点的局部邻域,并通过Skip-Gram模型[13]获得节点嵌入。LINE保留了一阶和二阶近似性,因此最多只能测量两跳范围内节点间的关系。这些方法能有效捕捉相邻节点间的关系,但无法处理相距较远节点的情况。最近提出的HARP[14]试图解决这一问题,它基于两种节点压缩方案递归地将网络压缩为一系列小型网络,并使用现有NRL方法为每个压缩网络学习节点嵌入。遗憾的是,由于HARP启发式地将两个相邻节点合并为新节点,压缩后的网络可能无法反映原始网络的全局拓扑。此外,当在原始网络上学习节点嵌入时,使用压缩网络获得的节点嵌入作为初始化方案可能会误导优化过程陷入不良局部极小值。
This paper presents a new NRL framework, called Hierarchical Sampling Representation Learning (HSRL), to learn node embeddings for a network with preserving both their local and global topological information. Specifically, HSRL uses a community-awareness network compressing strategy, called hierarchical sampling, to recursively compress an input network into a series of smaller networks, and then engage an existing NRL method to learn node embeddings for each compressed network. Finally, the node embeddings of the original network can be obtained by concatenating all node embeddings learned on compressed networks. Besides, we mathematically show that HSRL is able to capture the local and global topological relationship between nodes. Novel contributions of this paper include the following:
本文提出了一种名为分层采样表示学习 (HSRL) 的新型网络表示学习框架,旨在通过学习节点嵌入来同时保留网络的局部和全局拓扑信息。具体而言,HSRL采用一种称为分层采样的社区感知网络压缩策略,递归地将输入网络压缩为一系列较小的网络,然后利用现有的网络表示学习方法为每个压缩网络学习节点嵌入。最终,通过拼接所有压缩网络上学习到的节点嵌入,可以获得原始网络的节点嵌入。此外,我们从数学上证明了HSRL能够捕捉节点之间的局部和全局拓扑关系。本文的新颖贡献包括以下几点:
• We propose a new NRL framework called HSRL, to learn node embeddings for a network, which is able to capture both local and global topological information of the network via a community-awareness network compressing strategy. • We mathematically show that the node embeddings obtained by HSRL explicitly embed the local and global topological information of the input network. • We demonstrate that HSRL statistically significantly outperforms DeepWalk, node2vec, LINE, and HARP on link prediction tasks on five real-world datasets.
• 我们提出了一种名为HSRL的新型网络表示学习(NRL)框架,通过学习节点嵌入来捕获网络的局部和全局拓扑信息,该框架采用社区感知的网络压缩策略实现这一目标。
• 我们从数学角度证明了HSRL获得的节点嵌入显式地编码了输入网络的局部和全局拓扑信息。
• 实验表明,在五个真实数据集上的链接预测任务中,HSRL在统计显著性上优于DeepWalk、node2vec、LINE和HARP。
II. RELATED WORK
II. 相关工作
Most early methods in NRL field represent an input network in the form of a matrix, e.g., adjacency matrices [8], [15], Laplacian matrices [16], node transition probability matrices [17], and then factorize that matrix to obtain node embeddings. They are effective for small networks, but cannot scale to large-scale networks due to high computation cost.
网络表征学习(NRL)领域早期方法大多采用矩阵形式表示输入网络,例如邻接矩阵[8][15]、拉普拉斯矩阵[16]、节点转移概率矩阵[17],然后通过矩阵分解获得节点嵌入。这些方法对小规模网络有效,但由于计算成本过高难以扩展到大规模网络。
To analyze large-scale networks, DeepWalk [10] employs truncated random walks to obtain node sequences, and then learns node embeddings by feeding node sequences into SkipGram model [15]. To generalize DeepWalk, node2vec [11] provides a trade-off between breadth-first search (BFS) and depth-first search (DFS) when generating truncated random walks for a network. LINE [12] intends to preserve first-order and second-order pro xi mi ties, respectively, by minimizing the Kullback-Leibler divergence of two joint probability distributions for each pair nodes. These methods are scalable to large-scale networks, but fail to capture the global topological information of networks. Because random walks are only effective to explore local neighborhoods for a node, and both first-order and second-order pro xi mi ties defined by LINE just measure the relationship between nodes at most two-hops away.
为分析大规模网络,DeepWalk [10] 采用截断随机游走获取节点序列,再通过将节点序列输入SkipGram模型 [15] 学习节点嵌入。为推广DeepWalk,node2vec [11] 在生成网络截断随机游走时提供了广度优先搜索 (BFS) 和深度优先搜索 (DFS) 的权衡方案。LINE [12] 通过最小化每对节点两个联合概率分布的Kullback-Leibler散度,分别保留一阶邻近性和二阶邻近性。这些方法可扩展至大规模网络,但无法捕捉网络的全局拓扑信息。因为随机游走仅能有效探索节点的局部邻域,且LINE定义的一阶和二阶邻近性最多只能衡量两跳范围内节点间的关系。
To investigate global topologies of a network, HARP [14] recursively uses two collapsing schemes, edge collapsing and star collapsing, to compress an input network into a series of small networks. Starting from the smallest compressed network, it then recursively conducts a NRL method to learn node embeddings based on the node embeddings obtained from its previous level (if any) as the initialization. However, HARP has two weaknesses: 1) nodes that are connected but belong to different communities may be merged, which leads to that the compressed networks cannot well reveal the global topology of an input network. 2) taking the node embeddings learned on such compressed networks as initialization would mislead NRL methods to a bad local minimum. HARP could work well on node classification tasks since close nodes tend to have the same labels but may ineffective for the link prediction tasks. Because predicting the link between two nodes needs to consider both the local and global topological information of a network, such as neighborhoods they are sharing with and communities they are both involved in. This paper proposes HSRL to tackle the above issues of the existing NRL methods.
为了研究网络的全局拓扑结构,HARP [14] 通过递归使用边折叠 (edge collapsing) 和星型折叠 (star collapsing) 两种压缩方案,将输入网络压缩成一系列小型网络。从最小的压缩网络开始,它再递归执行网络表示学习 (NRL) 方法,基于上一层级获得的节点嵌入 (node embeddings) (如果有的话)作为初始化来学习节点嵌入。然而,HARP 存在两个缺点:1) 相连但属于不同社区的节点可能会被合并,导致压缩网络无法很好地揭示输入网络的全局拓扑结构;2) 以这些压缩网络上学习到的节点嵌入作为初始化,会将 NRL 方法误导至不良的局部极小值。HARP 在节点分类任务上可能表现良好,因为相近的节点往往具有相同的标签,但在链接预测任务上可能效果不佳。因为预测两个节点之间的链接需要考虑网络的局部和全局拓扑信息,例如它们共享的邻域以及它们共同参与的社区。本文提出 HSRL 来解决现有 NRL 方法的上述问题。
III. PRELIMINARY AND PROBLEM DEFINITION
III. 初步研究与问题定义
This section gives the notations and definitions throughout this paper.
本节给出本文使用的符号和定义。
We firstly introduce the definition of a network and related notations.
我们首先介绍网络的定义及相关符号。
Definition 1. (Network) [4] A network (a.k.a. graph) is defined as $G=(V,E)$ , where $V$ is a set of nodes and $E$ is a set of edges between nodes. The edge $e\in E$ between nodes u and $v$ is represented as $e=(u,v)$ with a weight $w_{u,v}\geq0$ . Particularly, we have $(u,v)\equiv(v,u)$ and $w_{u,v}\equiv w_{v,u}$ if $G$ is undirected; $(u,v)\equiv(v,u)$ and $w_{u,v}\not\equiv w_{v,u},$ otherwise.
定义 1. (网络) [4] 网络(又称图)定义为 $G=(V,E)$ ,其中 $V$ 是节点集合, $E$ 是节点间边的集合。节点 u 和 $v$ 之间的边 $e\in E$ 表示为 $e=(u,v)$ ,并带有权重 $w_{u,v}\geq0$ 。特别地,若 $G$ 是无向图,则有 $(u,v)\equiv(v,u)$ 和 $w_{u,v}\equiv w_{v,u}$ ;否则 $(u,v)\equiv(v,u)$ 且 $w_{u,v}\not\equiv w_{v,u}$ 。
In most networks, some nodes are densely connected to form a community/cluster, while nodes in different communities are sparsely connected. Detecting communities in a network is beneficial to analyze the relationship between nodes. We employ modularity as defined below to evaluate the quality of community detection.
在大多数网络中,某些节点密集连接形成社区/集群,而不同社区间的节点连接稀疏。检测网络中的社区有助于分析节点间关系。我们采用如下定义的模块度(modularity)来评估社区检测质量。
Definition 2. (Modularity) [18], [19] Modularity is a measure of the structure of networks, which measures the density of edges between the nodes within communities as compared to the edges between nodes in different communities. It is defined as below.
定义 2. (模块度) [18], [19] 模块度是衡量网络结构的一种指标,用于比较社区内部节点间边与不同社区节点间边的密度。其定义如下。
$$
Q=\frac{1}{2m}\sum_{i,j}\big(w_{i,j}-\frac{k_{i}k_{j}}{2m}\big)\delta(c_{i},c_{j})
$$
$$
Q=\frac{1}{2m}\sum_{i,j}\big(w_{i,j}-\frac{k_{i}k_{j}}{2m}\big)\delta(c_{i},c_{j})
$$
where $w_{i,j}$ is the weight of edge $\boldsymbol{e}{i,j}$ between nodes $v_{i}$ and $v_{j}$ , $k_{i}=\textstyle\sum_{i}w_{i,j}$ , $m={\textstyle\frac{1}{2}}\sum_{i,j}w_{i,j}$ , $c_{i}$ is the community which nod e $v_{i}$ belongs to, and
其中 $w_{i,j}$ 表示节点 $v_{i}$ 和 $v_{j}$ 之间边 $\boldsymbol{e}{i,j}$ 的权重,$k_{i}=\textstyle\sum_{i}w_{i,j}$ 表示节点 $v_{i}$ 的加权度,$m={\textstyle\frac{1}{2}}\sum_{i,j}w_{i,j}$ 表示网络中所有边权重之和的一半,$c_{i}$ 表示节点 $v_{i}$ 所属的社区。
Networks with high modularity have dense connections between nodes within communities but sparse connections between nodes in different communities.
具有高模块性的网络在社区内部节点间连接密集,而在不同社区节点间连接稀疏。
We give the definition of hierarchical sampling which is used to recursively compress a network into a series of smaller networks as follows.
我们给出层次化采样 (hierarchical sampling) 的定义,该方法用于将网络递归压缩为一系列更小的网络,具体如下。
Definition 3. (Hierarchical Sampling) Given a network $G=(V,E)$ , hierarchical sampling compresses the original network level by level and obtains a series of compressed networks $G^{0},G^{1},...,G^{K}$ , which reveals the global topological information of original network at different levels, respectively.
定义 3. (分层采样) 给定网络 $G=(V,E)$,分层采样逐级压缩原始网络并得到一系列压缩网络 $G^{0},G^{1},...,G^{K}$,这些网络分别揭示了原始网络在不同层次上的全局拓扑信息。
These compressed networks reveal the hierarchical topologies of the input network. Therefore, the node embeddings obtained in compressed networks embed the hierarchical topological information of the original network.
这些压缩网络揭示了输入网络的层次拓扑结构。因此,在压缩网络中获得的节点嵌入包含了原始网络的层次拓扑信息。
To learn node embeddings of a network, NRL maps the original network into a low-dimensional space and represents each node as a low-dimensional vector as formulated below.
为了学习网络的节点嵌入,NRL将原始网络映射到一个低维空间,并将每个节点表示为如下公式所示的低维向量。
Definition 4. (Network Representation Learning) [4] Given a network $G=(V,E)$ , network representation learning aims to learn a mapping function $f:v\rightarrow z\in\mathbb{R}^{d}$ where $d\ll|V|$ , and preserving as much of the original topological information in the embedding space $\mathbb{R}^{d}$ .
定义 4. (网络表示学习) [4] 给定一个网络 $G=(V,E)$ ,网络表示学习旨在学习一个映射函数 $f:v\rightarrow z\in\mathbb{R}^{d}$ ,其中 $d\ll|V|$ ,并在嵌入空间 $\mathbb{R}^{d}$ 中尽可能保留原始拓扑信息。
Finally, we present the formulation of the hierarchical network representation learning problem as following:
最后,我们将分层网络表示学习问题表述如下:
Definition 5. (Hierarchical Network Representation Learning) Given a series of compressed networks $G^{0},G^{1},...,G^{K}$ of original network $G=(V,E)$ and a network representation learning mapping function $f$ , hierarchical network representation learning learns the node embeddings for each compressed network by $Z^{k}\gets f(G^{k}),0\leq k\leq K$ , and finally obtains the node embeddings $Z$ of original network $G$ by concatenating $Z^{0},Z^{1},...,Z^{K}$ .
定义5. (分层网络表示学习) 给定原始网络 $G=(V,E)$ 的一系列压缩网络 $G^{0},G^{1},...,G^{K}$ 和网络表示学习映射函数 $f$,分层网络表示学习通过 $Z^{k}\gets f(G^{k}),0\leq k\leq K$ 学习每个压缩网络的节点嵌入,最终通过拼接 $Z^{0},Z^{1},...,Z^{K}$ 获得原始网络 $G$ 的节点嵌入 $Z$。
IV. HSRL
IV. HSRL
In this section, we present Hierarchical Sampling Representation Learning framework which consists of two parts: 1) Hierarchical Sampling that aims to discover the hierarchical topological information of a network via a communityawareness compressing strategy; and 2) Representation Learning that aims to learn low-dimensional node embeddings while preserving the hierarchical topological information.
在本节中,我们提出分层采样表示学习框架,该框架包含两部分:1) 分层采样,旨在通过社区感知压缩策略发现网络的分层拓扑信息;2) 表示学习,旨在学习低维节点嵌入的同时保留分层拓扑信息。
A. Hierarchical Sampling
A. 分层采样
Here we present the hierarchical sampling which is intended to compress a network into a series of compressed networks according to different compressing levels. Each compressed network reveals one of the hierarchical levels of global topology of the original network.
我们在此提出分层采样方法,旨在根据不同的压缩级别将网络压缩成一系列压缩网络。每个压缩网络揭示了原始网络全局拓扑结构的一个分层级别。
A community is one of the significant patterns of networks. Nodes in the same community are densely connected and nodes in different communities are sparsely connected. The relationship between nodes inside a community presents the local topological information of a network, while the relationship between communities reveals its global topology. It is worth noticing that in most large-scale networks, there are several natural organization levels - communities divide themselves into sub-communities - and thus communities with different hierarchical levels reveal the hierarchical topological information of original networks [20], [21]. Consequently, we compress a network into a new network based on communities by taking each community as a new node in the compressed network. Based on different hierarchical levels of communities, we can obtain a series of compressed networks which reveal the hierarchical global topological information of the input network.
社区是网络的重要模式之一。同一社区内的节点连接密集,而不同社区间的节点连接稀疏。社区内部节点间的关系呈现网络的局部拓扑信息,而社区之间的关系则揭示其全局拓扑结构。值得注意的是,在大多数大规模网络中,存在多个自然组织层级——社区会进一步划分为子社区——因此不同层级的社区能够反映原始网络的分层拓扑信息 [20], [21]。基于此,我们将网络按社区结构压缩为新网络:每个社区在压缩网络中作为新节点。根据不同层级的社区划分,可得到一系列压缩网络,从而揭示输入网络的分层全局拓扑信息。
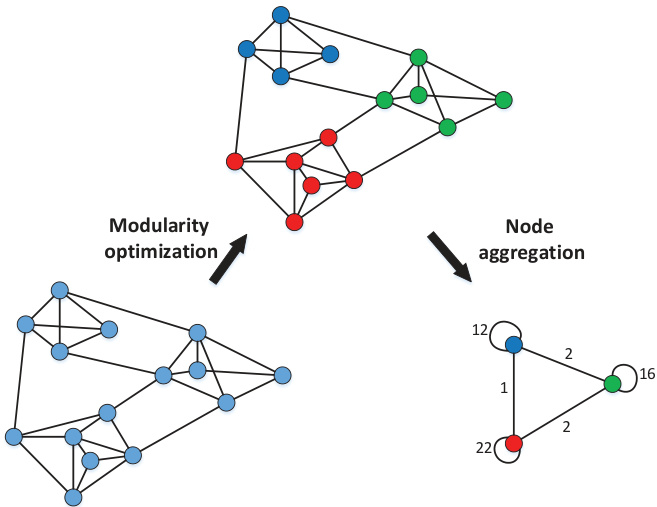
Fig. 2. An exampling of compressing a network
图 2: 网络压缩示例
The quality of the partitions obtained by community detection algorithms can be measured by the modularity of the partition [21], [22]. As a result, we can detect communities through optimizing the modularity of a network. As shown in Fig.2, inspired by the Louvain method [21], hierarchical sampling compresses a network into a new network by implementing two phases: modularity optimization and node aggregation.
通过社区检测算法获得的分区质量可以用分区的模块度 [21], [22] 来衡量。因此,我们可以通过优化网络的模块度来检测社区。如图 2 所示,受 Louvain 方法 [21] 启发,分层采样通过执行两个阶段(模块度优化和节点聚合)将网络压缩为一个新网络。
Modularity optimization. The first phase initializes each node in a network as a community and merges two connected nodes into one community if it can improve the modularity of the network. The implementation of community amalgamation will be repeated until a local maximum of the modularity is attained.
模块度优化。第一阶段将网络中的每个节点初始化为一个社区,如果能够提升网络的模块度,则将两个相连的节点合并为一个社区。社区合并的实现会重复进行,直到达到模块度的局部最大值。
Node aggregation. The second phase builds a new network whose nodes are the communities found in the previous phase. The weights of edges between new nodes are the sum of the weights of edges between nodes in the corresponding two communities.
节点聚合。第二阶段构建一个新网络,其节点为前一阶段发现的社区。新节点间边的权重是对应两个社区间节点边权重的总和。
As shown in Algorithm 1, by recursively repeating the above two phases, hierarchical sampling obtains a series of compressed networks which reveal hierarchical global topology of the original network.
如算法1所示,通过递归重复上述两个阶段,分层采样获得一系列揭示原始网络层级全局拓扑结构的压缩网络。
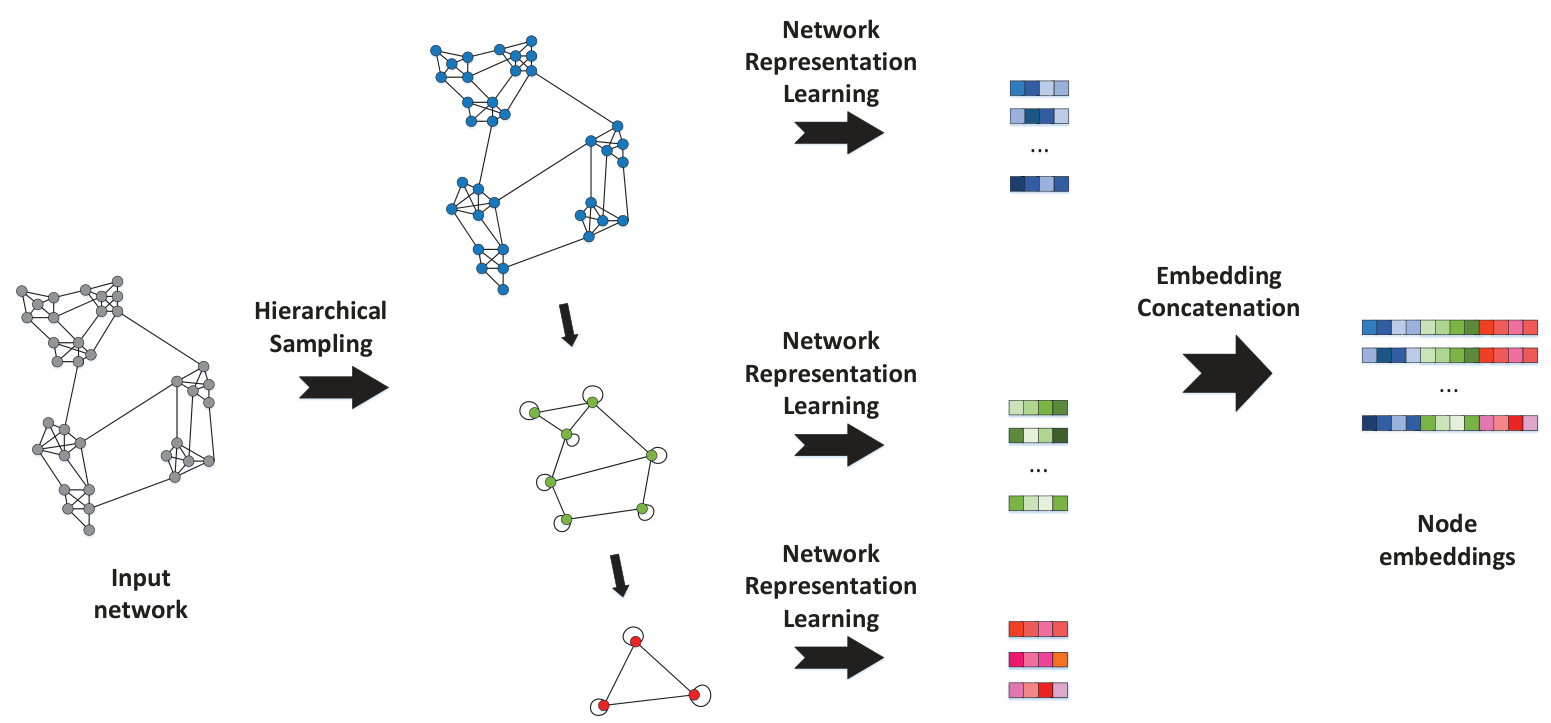
Fig. 3. The framework of HSRL.
图 3: HSRL框架。
Algorithm 1 Hierarchical Sampling
算法 1 分层采样
B. Representation Learning
B. 表征学习
This section introduces representation learning on the compressed networks obtained by the previous section and concatenating the learned embeddings into node embeddings of the original network. We further provide a mathematical proof to demonstrate that HSRL embeds both local and global topological relationship of nodes in the original network into the learned embeddings.
本节介绍对上一节获得的压缩网络进行表征学习,并将学习到的嵌入拼接为原始网络的节点嵌入。我们进一步提供数学证明,表明HSRL将原始网络中节点的局部和全局拓扑关系都嵌入到学习到的嵌入中。
As shown in Fig.3, we conduct representation learning on each compressed network. It is worth noticing that any NRL method can be used for this purpose. The embeddings of nodes in each compressed network are used to generate the final node embeddings of the original network. Particularly, the embedding $Z_{i}$ of node $v_{i}$ in the original network $G$ is the concatenation of the embeddings of hierarchical communities it involved in, as shown below.
如图 3 所示,我们对每个压缩网络进行表示学习。值得注意的是,任何网络表示学习 (NRL) 方法都可用于此目的。每个压缩网络中节点的嵌入用于生成原始网络的最终节点嵌入。具体而言,原始网络 $G$ 中节点 $v_{i}$ 的嵌入 $Z_{i}$ 是其所属层级社区的嵌入拼接结果,如下所示。
$$
Z_{i}=[Z_{c_{i}^{0}}^{0},Z_{c_{i}^{1}}^{1},...,Z_{c_{i}^{K}}^{K}],
$$
$$
Z_{i}=[Z_{c_{i}^{0}}^{0},Z_{c_{i}^{1}}^{1},...,Z_{c_{i}^{K}}^{K}],
$$
where $c_{i}^{k}$ is the $k{\cdot}t h$ hierarchical community $v_{i}$ belongs to.
其中 $c_{i}^{k}$ 是 $v_{i}$ 所属的第 $k{\cdot}th$ 层层次社区。
The node embeddings learned by the above representation learning process hold the following two Lemmas.
上述表示学习过程得到的节点嵌入满足以下两个引理。
Lemma 1. Nodes within the same hierarchical communities will get similar embeddings. The more the same hierarchical communities in which nodes involved, more similar embeddings they have.
引理1:同一层级社区内的节点将获得相似的嵌入表示。节点参与的相同层级社区越多,其嵌入表示越相似。
From Eq.2, it is easy to find that the above lemma holds. Lemma 1 shows that HSRL preserves the relationship between densely connected nodes in the original network. Therefore, HSRL is capable to preserve the local topological information of a network.
由式2可知,上述引理成立。引理1表明HSRL能保持原始网络中紧密连接节点间的关系,因此HSRL具备保留网络局部拓扑信息的能力。
Lemma 2. The cosine similarity between embedding $Z_{i}$ and embedding $Z_{j}$ is proportional to the sum of similarities of the embeddings between their hierarchical communities.
引理 2. 嵌入向量 $Z_{i}$ 与嵌入向量 $Z_{j}$ 之间的余弦相似度,正比于它们所属层级社区间嵌入向量相似度之和。
$$
s i m(Z_{i},Z_{j})\propto\sum_{k=0}^{K}s i m(Z_{c_{i}^{k}}^{k},Z_{c_{j}^{k}}^{k}).
$$
$$
s i m(Z_{i},Z_{j})\propto\sum_{k=0}^{K}s i m(Z_{c_{i}^{k}}^{k},Z_{c_{j}^{k}}^{k}).
$$
Proof.
证明。
$$
\begin{array}{l}{{\displaystyle s i m(Z_{i},Z_{j})=\frac{Z_{i}\cdot Z_{j}}{|Z_{i}||Z_{j}}}}\ {{\displaystyle~\propto\left[Z_{c_{i}^{0}}^{0},Z_{c_{i}^{1}}^{1},...,Z_{c_{i}^{k}}^{K}\right]\cdot[Z_{c_{j}^{0}}^{0},Z_{c_{j}^{1}}^{1},...,Z_{c_{j}^{k}}^{K}]}}\ {{\displaystyle~=\sum_{k=0}^{K}Z_{c_{i}^{k}}^{k}\cdot Z_{c_{j}^{k}}^{k}}}\ {{\displaystyle~\propto\sum_{k=0}^{K}s i m(Z_{c_{i}^{k}}^{k},Z_{c_{j}^{k}}^{k})}.}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle s i m(Z_{i},Z_{j})=\frac{Z_{i}\cdot Z_{j}}{|Z_{i}||Z_{j}}}}\ {{\displaystyle~\propto\left[Z_{c_{i}^{0}}^{0},Z_{c_{i}^{1}}^{1},...,Z_{c_{i}^{k}}^{K}\right]\cdot[Z_{c_{j}^{0}}^{0},Z_{c_{j}^{1}}^{1},...,Z_{c_{j}^{k}}^{K}]}}\ {{\displaystyle~=\sum_{k=0}^{K}Z_{c_{i}^{k}}^{k}\cdot Z_{c_{j}^{k}}^{k}}}\ {{\displaystyle~\propto\sum_{k=0}^{K}s i m(Z_{c_{i}^{k}}^{k},Z_{c_{j}^{k}}^{k})}.}\end{array}
$$
From Lemma 2, we know that two nodes will obtain similar embeddings if they are involved in similar hierarchical communities no matter the distance between them in the original network. The relationship between communities in different hierarchies is embedded in the embeddings of their involved nodes. Hence, HSRL can preserve the hierarchical global topological information of a network.
根据引理2可知,若两个节点参与相似的层次化社区结构,无论它们在原始网络中的距离如何,都将获得相似的嵌入表示。不同层级社区间的关系被编码在所属节点的嵌入向量中。因此,HSRL能够保留网络的层次化全局拓扑信息。
Finally, HSRL is presented in Algorithm 2.
最后,HSRL 在算法 2 中给出。
Algorithm 2 HSRL
算法 2 HSRL
V. EXPERIMENTS
V. 实验
In this section, five real-world datasets are used to evaluate the performance of HSRL on link prediction task. The source code is available at https://github.com/fuguoji/HSRL.
本节使用五个真实世界数据集来评估HSRL在链接预测任务中的性能。源代码可在https://github.com/fuguoji/HSRL获取。
A. Datasets
A. 数据集
We evaluate our method on various real-world datasets, including Movielens1, MIT [23], DBLP [2], Douban [24], and ${\mathrm{Yelp}}^{2}$ . These datasets are commonly used in NRL field. The detailed statistics of datasets are shown in Table I and the brief descriptions of each dataset are presented as below.
我们在多个真实世界数据集上评估了我们的方法,包括Movielens1、MIT [23]、DBLP [2]、Douban [24]和${\mathrm{Yelp}}^{2}$。这些数据集常用于网络表示学习(NRL)领域。数据集的详细统计信息如表1所示,各数据集的简要描述如下:
TABLE I STATISTICS OF FIVE DATASETS.
表 1: 五个数据集的统计信息。
| 数据集 | 节点数 | 边数 | 网络类型 |
|---|---|---|---|
| Movielens | 1332 | 2592 | 用户-电影 |
| DBLP | 37791 | 170794 | 文献引用 |
| MIT | 6402 | 251230 | 社交关系 |
| Douban | 13786 | 214392 | 用户-电影 |
| Yelp | 28759 | 247698 | 用户-商家 |
B. Baselines
B. 基线方法
We compare our method with four start-of-the-art algorithms, which are introduced below.
我们将本方法与四种前沿算法进行比较,具体如下。
C. Parameter Settings
C. 参数设置
Here we discuss the parameter setting for our method and baselines:
我们在此讨论本方法与基线模型的参数设置:
D. Hierarchical Sampling for Networks
D. 网络分层采样
We firstly discuss the results of hierarchical sampling on testing networks. Fig.4 presents the network compressing results by the hierarchical sampling on five datasets. As shown in Fig.4, the number of nodes and edges of compressed networks drastically decrease as the compressing process continues and finally becomes stable when the compressing level is large than 3. Therefore, in the following link prediction tasks, we set the largest number of compressing level as 3.
我们首先讨论分层采样在测试网络上的结果。图4展示了在五个数据集上通过分层采样得到的网络压缩结果。如图4所示,随着压缩过程的进行,压缩网络的节点和边数量急剧减少,当压缩级别大于3时最终趋于稳定。因此,在后续的链接预测任务中,我们将最大压缩级别设置为3。
As shown in Fig.5, we present three networks, Fig.5(a), Fig.5(e), and Fig.5(i), as the intuitive examples to illustrate how hierarchical sampling works.
如图5所示,我们展示了三个网络,图5(a)、图5(e)和图5(i),作为直观示例来说明分层采样如何工作。
The network in Fig.5(a) contains two dense communities which are merged into a new node in the following compressed networks respectively. Therefore in the compressed networks, the local topological information of original networks are preserved by considering densely connected nodes in the same community as a whole. Meanwhile, the compressed networks, Fig.5(b), Fig.5(c), and Fig.5(d), reveal the hierarchical topological information of the input network. For a balanced tree network and a grid network as shown in Fig.5(e) and Fig.5(i), their hierarchical topologies can be revealed by their compressed networks as well. The results of Fig.5 show that the network compressing strategy of HSRL works well on different types of networks.
图5(a)中的网络包含两个密集社区,在后续压缩网络中分别被合并为新节点。因此,在压缩网络中,通过将同一社区内紧密连接的节点视为整体,保留了原始网络的局部拓扑信息。同时,压缩网络(图5(b)、图5(c)和图5(d))揭示了输入网络的层次拓扑结构。对于图5(e)所示的平衡树网络和图5(i)所示的网格网络,其压缩网络同样能展现层次拓扑特征。图5结果表明,HSRL的网络压缩策略适用于多种网络类型。
E. Link Prediction
E. 链接预测
We conduct link prediction tasks to evaluate the performance of our method on five real-world datasets. Specifically, we prediction the link between nodes based on the cosine similarity of their embeddings. The evaluation metric used in this task is AUC. Higher AUC indicates the better performance of NRL methods.
我们在五个真实世界数据集上进行链接预测任务以评估方法的性能。具体而言,我们基于节点嵌入的余弦相似度预测节点间链接。该任务使用的评估指标是AUC (Area Under Curve) ,AUC值越高表明网络表示学习(NRL)方法性能越好。
We randomly split the edges of a network into $80%$ edges as the training set and the left $20%$ as the testing set. Each experiment is independently implemented for 20 times and the average performances on the testing set are reported in Table II.
我们随机将网络边划分为80%作为训练集,剩下20%作为测试集。每次实验独立进行20次,测试集上的平均性能如表II所示。
We summarize the observations from Table.II as following:
我们从表 II 总结出以下观察结果:
• HSRL significantly outperforms all baselines on all datasets. For the small and sparse network movielens, the improvements of HSRL(DW), HSRL(N2V), and HSRL(LINE) are $3.6%$ , $2.5%$ , and $16.6%$ respectively. For the dense network MIT, HSRL(DW), HSRL(N2V), and HSRL(LINE) outperform the baselines by $2.9%$ , $8.5%$ , and $0.5%$ . For three large networks, DBLP, Yelp, and Douban, the improvement of HSRL is striking: the improvements of HSRL(DW), HSRL(N2V), and HSRL(LINE) are $6.3%$ , $19.9%$ , $3.5%$ for DBLP, $6.5%$ , $16.8%$ , $5.9%$ for Yelp, and $18.4%$ , $30.5%$ , $17.5%$ for Douban.
• HSRL在所有数据集上均显著优于所有基线方法。在小型稀疏网络movielens上,HSRL(DW)、HSRL(N2V)和HSRL(LINE)分别提升了3.6%、2.5%和16.6%。对于密集网络MIT,HSRL(DW)、HSRL(N2V)和HSRL(LINE)分别以2.9%、8.5%和0.5%的优势超越基线。在DBLP、Yelp和Douban三个大型网络中,HSRL的改进尤为显著:HSRL(DW)、HSRL(N2V)和HSRL(LINE)在DBLP上的提升分别为6.3%、19.9%和3.5%,在Yelp上为6.5%、16.8%和5.9%,在Douban上则达到18.4%、30.5%和17.5%。
The results of HARP on movielens, DBLP, Yelp, and Douban are worse than the original NRL methods. Moreover, the performance of HARP(LINE) is drastically worse than LINE. It only works better than DeepWalk, node2vec on MIT which is a small and dense network.
HARP在movielens、DBLP、Yelp和Douban上的结果比原始NRL方法更差。此外,HARP(LINE)的性能明显不如LINE。它仅在MIT这个小而密集的网络上表现优于DeepWalk和node2vec。
TABLE II AUC OF LINK PREDICTION.
† denotes the performance of HSRL is significantly better than the other peers according to the Wilcoxons rank sum test at a 0.05 significance level.
表 II 链接预测的AUC值
| 算法 | Movielens | DBLP | MIT | Yelp | Douban |
|---|---|---|---|---|---|
| DeepWalk | 0.847 | 0.794 | 0.899 | 0.842 | 0.687 |
| HARP(DW) | 0.817 | 0.659 | 0.902 | 0.743 | 0.559 |
| HSRL(DW) | 0.879† | 0.847† | 0.926† | 0.901† | 0.842† |
| HSRL增益(%) | 3.6 | 6.3 | 2.9 | 6.5 | 18.4 |
| node2vec | 0.843 | 0.673 | 0.843 | 0.742 | 0.569 |
| HARP(N2V) | 0.828 | 0.647 | 0.879 | 0.708 | 0.552 |
| HSRL(N2V) | 0.865† | 0.840† | 0.921† | 0.892 | 0.819† |
| HSRL增益(%) | 2.5 | 19.9 | 8.5 | 16.8 | 30.5 |
| LINE | 0.613 | 0.641 | 0.814 | 0.752 | 0.624 |
| HARP(LINE) | 0.220 | 0.387 | 0.702 | 0.306 | 0.399 |
| HSRL(LINE) | 0.735† | 0.664† | 0.819 | 0.799† | 0.756† |
| HSRL增益(%) | 16.6 | 3.5 | 0.5 | 5.9 | 17.5 |
† 表示在显著性水平为0.05的Wilcoxon秩和检验中,HSRL的性能显著优于其他对比算法。
The compressed networks generated by HARP on a network could not reveal its global topologies. Hence, using node embeddings of compressed networks as initi aliz ation could mislead the NRL methods to a bad local minimum. Such an issue could occur especially when the input network is large-scale and the objective function of the NRL method is highly non-convex, e.g., LINE. The improvements of HSRL on DBLP, Yelp, and Duban are larger than that on Movielens and MIT. It demonstrates that HSRL works much better than baselines on large-scale networks.
HARP生成的压缩网络无法揭示其全局拓扑结构。因此,使用压缩网络的节点嵌入作为初始化可能会误导网络表示学习(NRL)方法陷入不良局部极小值。这一问题尤其容易发生在输入网络规模较大且NRL方法的目标函数高度非凸时(例如LINE)。HSRL在DBLP、Yelp和Duban上的改进幅度大于Movielens和MIT,这表明HSRL在大规模网络上的表现显著优于基线方法。
F. Parameter Sensitivity Analysis
F. 参数敏感性分析
We conduct link prediction task on DBLP to study the parameter sensitivity of HSRL. Without loss of generality, we used DeepWalk to learn node embeddings for each compressed network. Fig.6 shows using $80%$ edges as training set and the left as testing set, the link prediction performance (AUC) as a function of one of the chosen parameters when fixing the others.
我们在DBLP数据集上执行链接预测任务以研究HSRL的参数敏感性。不失一般性,我们采用DeepWalk学习每个压缩网络的节点嵌入向量。图6展示了当固定其他参数时,使用80%边作为训练集、剩余边作为测试集的情况下,链接预测性能(AUC)随某一选定参数变化的函数关系。
When fixing the largest number of compressed level to 3, Fig.6(a) shows the AUC of link prediction drastically improves as the number of embedding dimension $d$ increases and finally becomes stable when $d$ is larger than 32. When $d$ is small, it is inadequate to embody rich information of networks. However, when $d$ is large enough to embody all original network information, increasing $d$ will not improve the performance of link prediction.
当最大压缩层级固定为3时,图6(a)显示链路预测的AUC值随着嵌入维度$d$的增加而显著提升,当$d$超过32后趋于稳定。当$d$较小时,不足以体现网络的丰富信息;但当$d$足够大以涵盖原始网络全部信息时,继续增加$d$不会提升链路预测性能。
Fig.6(b) shows that the impact of the largest number of network compressing level $K$ on the performance of link prediction by fixing the representation size $d$ to 64. As we increase $K$ , the AUC of link prediction drastically improves. It demonstrates that the hierarchical topologies help to capture the potential relationship between nodes (even they are far away from each other) in a network. When $K$ is larger than 3, the performance of link prediction becomes stable. It is reasonable since the DBLP network could not be compressed further after level 3 as shown in Fig.4(b).
图 6(b) 展示了在固定表示大小 $d$ 为 64 时,最大网络压缩层级 $K$ 对链接预测性能的影响。随着 $K$ 的增加,链接预测的 AUC 值显著提升。这表明层级拓扑结构有助于捕捉网络中节点间(即使彼此相距较远)的潜在关系。当 $K$ 大于 3 时,链接预测性能趋于稳定。这是由于如图 4(b) 所示,DBLP 网络在第三层级后无法进一步压缩。

Fig. 4. The compressing ratio of nodes/edges of compressed networks to the original network.
图 4: 压缩网络的节点/边数与原始网络的压缩比。

Fig. 5. Examples of hierarchical sampling.
图 5: 分层采样示例。
G. Running Time
G. 运行时间
Fig.6 shows the actual running time of all NRL methods on five testing networks. All experiments are conducted on a single machine with 32GB memory, 16 CPU cores at 3.2 GHZ. The results show that the actual running time of HSRL is at most three times higher than others. The running time of HSRL is linear to the corresponding baselines as the input networks growing. Moreover, the running time of HSRL can be reduced by parallel i zing the training processes on all compressed networks.
图 6: 展示了所有NRL方法在五个测试网络上的实际运行时间。所有实验均在一台配备32GB内存、16个3.2GHz CPU核心的单机上完成。结果表明,HSRL的实际运行时间最多比其他方法高三倍。随着输入网络规模增大,HSRL的运行时间与相应基线方法呈线性增长关系。此外,通过在所有压缩网络上并行化训练过程,可进一步减少HSRL的运行时间。

Fig. 6. Parameter sensitivity on link prediction.
图 6: 链接预测中的参数敏感性分析。

Fig. 7. Running time
图 7: 运行时间
VI. CONCLUSIONS
VI. 结论
Most conventional NRL methods aim to preserve the local topological information of a network but overlook their global topology. Recently, HARP was proposed to preserve both local and global topological information. However, it could easily get stuck at a bad local minimum due to its poor network compressing schemes. In this paper, we propose a new NRL framework, HSRL, to tackle these issues. Specifically, HSRL employs a community-awareness network compressing scheme to obtain a series of smaller networks based on an input network and conducts a NRL method to learn node embeddings for each compressed network. Finally, the node embeddings of the original network can be obtained by concatenating all node embeddings of compressed networks. Empirical studies on link prediction on various real-world networks demonstrate HSRL significantly outperforms the state-of-the-art algorithms.
大多数传统网络表示学习(NRL)方法旨在保留网络的局部拓扑信息,却忽略了全局拓扑结构。近期提出的HARP方法虽然能同时保留局部和全局拓扑信息,但由于其网络压缩方案存在缺陷,容易陷入不良局部极小值。本文提出新型NRL框架HSRL来解决这些问题:通过社区感知网络压缩方案生成基于输入网络的多层压缩网络,对每个压缩网络执行表示学习后,将各层节点嵌入拼接形成原始网络的最终表示。在多个真实网络链路预测任务的实证研究表明,HSRL显著优于现有最优算法。
Our future work includes combining HSRL with deep learning-based methods, such as DNGR [25], SDNE [26], and GCN [27]. It is also very interesting to extend HSRL to learn node embeddings of more complex networks which may be more common in real-world applications, e.g., heterogeneous networks, attributed networks, and dynamic networks.
我们未来的工作包括将HSRL与基于深度学习的方法相结合,例如DNGR [25]、SDNE [26]和GCN [27]。将HSRL扩展到学习更复杂网络的节点嵌入也很有意义,这类网络在现实应用中可能更为常见,例如异构网络、属性网络和动态网络。