Feature Guided Masked Auto encoder for Self-supervised Learning in Remote Sensing
遥感自监督学习的特征引导掩码自编码器
Abstract—Self-supervised learning guided by masked image modelling, such as Masked Auto Encoder (MAE), has attracted wide attention for pre training vision transformers in remote sensing. However, MAE tends to excessively focus on pixel details, thereby limiting the model’s capacity for semantic understanding, in particular for noisy SAR images. In this paper, we explore spectral and spatial remote sensing image features as improved MAE-reconstruction targets. We first conduct a study on reconstructing various image features, all performing comparably well or better than raw pixels. Based on such observations, we propose Feature Guided Masked Auto encoder (FG-MAE): reconstructing a combination of Histograms of Oriented Graidents (HOG) and Normalized Difference Indices (NDI) for multi spectral images, and reconstructing HOG for SAR images. Experimental results on three downstream tasks illustrate the effectiveness of FGMAE with a particular boost for SAR imagery. Furthermore, we demonstrate the well-inherited s cal ability of FG-MAE and release a first series of pretrained vision transformers for medium resolution SAR and multi spectral images.
摘要—以掩码图像建模(如掩码自编码器MAE)为指导的自监督学习在遥感领域预训练视觉Transformer时引起了广泛关注。然而,MAE往往过度关注像素细节,从而限制了模型(特别是对含噪SAR图像)的语义理解能力。本文探索将光谱与空间遥感图像特征作为改进的MAE重建目标:首先对不同图像特征重建效果进行研究,发现所有特征均表现优于或等同于原始像素;基于此提出特征引导掩码自编码器(FG-MAE)——针对多光谱图像重建方向梯度直方图(HOG)与归一化差异指数(NDI)的组合特征,针对SAR图像则重建HOG特征。在三个下游任务的实验结果表明FG-MAE具有显著效果(尤其对SAR图像提升明显),同时验证了该方法良好的可扩展性,并首次发布了中分辨率SAR与多光谱图像的预训练视觉Transformer系列模型。
Index Terms—remote sensing, Earth observation, geospatial foundation models, self-supervised learning, masked auto encoder
索引术语—遥感、地球观测、地理空间基础模型、自监督学习、掩码自编码器
I. INTRODUCTION
I. 引言
ELF-SUPERVISED Learning has brought breakthroughs to the remote sensing (RS) community with the ability to learn generic representations from large-scale unlabeled data [1]. The pretrained encoders (recently also called foundation models) can then be transferred to various downstream applications. While convolutional neural networks have been long studied as model backbones with contrastive learning [2], there is a growing trend of pre training vision transformers (ViT) [3] with masked image modeling (MIM), particularly, masked auto encoder (MAE) [4] and its variants [5].
自监督学习 (Self-Supervised Learning) 通过从大规模无标注数据中学习通用表征的能力 [1],为遥感 (RS) 领域带来了突破。预训练的编码器(最近也被称为基础模型)可以迁移到各种下游应用中。虽然卷积神经网络长期以来作为对比学习 [2] 的模型主干被研究,但目前越来越多的工作采用掩码图像建模 (MIM) 预训练视觉 Transformer (ViT) [3],特别是掩码自编码器 (MAE) [4] 及其变体 [5]。
MAE works as masking some patches of an input image, encoding the unmasked patches, and reconstructing the masked patches. Such asymmetric encoder-decoder design makes it highly efficient compared to contrastive learning. However, reconstructing raw input makes MAE over-focus pixel details, sensible to artifacts and noise, and potentially diverting attention from high-level semantic representations. These challenges are exacerbated in synthetic aperture radar (SAR) scenarios, in which the exisitence of speckle noise, which appears as a granular disturbance and usually modeled as a multiplicative noise, limits MAE’s performance.
MAE的工作原理是对输入图像的部分区块进行掩码处理,对未掩码区块进行编码,然后重建被掩码的区块。这种非对称的编码器-解码器设计使其相比对比学习更为高效。然而,重建原始输入使得MAE过度关注像素细节,对伪影和噪声敏感,并可能分散对高层语义表征的注意力。这些挑战在合成孔径雷达(SAR)场景中更为突出,其中表现为颗粒状干扰的散斑噪声(通常建模为乘性噪声)会限制MAE的性能。

Fig. 1. Sample data of the proposed FG-MAE method—columns from left to right: Sentinel-2 multi spectral (MS) and Sentinel-1 (SAR) imagery, masked model inputs, model-reconstructed features (HOG: Histogram of Gradients, NDI: Normalized Difference Index). False color of the raw SAR image is coded by [VV, VH, $(\mathrm{VV+VH})/2]$ . False color of the reconstructed MS NDI is coded by [NDVI, NDWI, NDBI].
图 1: 提出的FG-MAE方法样本数据——从左至右列分别为:Sentinel-2多光谱(MS)和Sentinel-1(SAR)影像、掩膜模型输入、模型重建特征(HOG: 梯度直方图, NDI: 归一化差异指数)。原始SAR影像伪彩色编码为[VV, VH, $(\mathrm{VV+VH})/2]$。重建MS NDI的伪彩色编码为[NDVI, NDWI, NDBI]。
In this work, we propose a new simple variant of MAE for RS imagery, termed Feature Guided Masked Auto encoder (FG-MAE), by replacing raw images with image features as reconstruction targets. Looking back at traditional RS image analysis, human designed feature descriptors (e.g. edge or vegetation index) have been widely used to extract semantic information of the Earth’s surface [6, 7]. These image features incorporate expert knowledge, and can guide the model’s learning process when introduced to MAE. To demonstrate that, we conduct a study on popular features for multi spectral and SAR imagery: 1) CannyEdge [8], 2) histograms of oriented gradients (HOG) [9], 3) scale-invariant feature transform (SIFT) [10], and 4) normalized difference indices (NDI) [11, 12, 13]. We show that each of these features alone works comparably well or even better than the original MAE.
在本工作中,我们提出了一种面向遥感影像的新型简化MAE变体——特征引导掩码自编码器(FG-MAE),通过将重建目标从原始图像替换为图像特征。回顾传统遥感影像分析,人工设计的特征描述符(如边缘或植被指数)已被广泛用于提取地表语义信息[6,7]。这些融合专家知识的图像特征引入MAE后能有效指导模型学习过程。为此,我们对多光谱与SAR影像的常用特征展开研究:1) CannyEdge[8];2) 方向梯度直方图(HOG)[9];3) 尺度不变特征变换(SIFT)[10];4) 归一化差异指数(NDI)[11,12,13]。实验表明,单独使用任一特征时,其效果与原始MAE相当甚至更优。
We then search for the best candidates among the popular features, and propose FGMAE-MS and FGMAE-SAR. For multi spectral imagery, we combine the spatial feature HOG and the spectral feature NDI, using two separate prediction heads at the end of the decoder. This combination allows the spatial and spectral features to complement each other. For SAR imagery, we simply use HOG to enhance spatial information and reduce the influence of speckle noise.
随后,我们在流行特征中搜索最佳候选方案,提出了FGMAE-MS和FGMAE-SAR。针对多光谱影像,我们结合空间特征HOG和光谱特征NDI,在解码器末端使用两个独立的预测头。这种组合使空间和光谱特征能够相互补充。对于SAR影像,我们仅使用HOG来增强空间信息并降低斑点噪声的影响。
We evaluate FG-MAE on scene classification and semantic segmentation downstream tasks with Big Earth Net-MM [14], EuroSAT [15] and DFC2020 [16] datasets for both multispectral and SAR images. For EuroSAT, we match the geo coordinates of EuroSAT-MS and collect the EuroSAT-SAR dataset. Results demonstrate the effectiveness of FG-MAE on all tasks, particularly in SAR scenarios. In addition, FG-MAE remains as efficient as MAE, making it possible to scale up to big foundation models. We show that both FGMAE-MS and FGMAE-SAR scale well up to ViT-Huge with 0.7B parameters under linear evaluation protocols.
我们在Big Earth Net-MM [14]、EuroSAT [15]和DFC2020 [16]数据集上评估FG-MAE在多光谱和SAR(合成孔径雷达)图像场景分类与语义分割下游任务的表现。针对EuroSAT数据集,我们通过匹配EuroSAT-MS的地理坐标构建了EuroSAT-SAR数据集。实验结果表明FG-MAE在所有任务中均表现优异,尤其在SAR场景下优势显著。此外,FG-MAE保持了与MAE相当的训练效率,使其具备构建大型基础模型的潜力。在线性评估协议下,FGMAE-MS和FGMAE-SAR均可扩展至包含7亿参数的ViT-Huge架构。
Our main contributions are listed as follows:
我们的主要贡献如下:
The normalized difference indices have long been used for Earth surface monitoring since the last century [26, 12]. Similarly, spatial features like HOG are widely used as input to machine learning algorithms [27]. In this work, we revisit these well-known human-designed features and let them be learned by deep neural networks. This approach leverages the expertise of human analysts to guide the training process and facilitate the learning of better representations.
归一化差异指数自上世纪以来一直被用于地表监测 [26, 12]。类似地,HOG等空间特征也常被用作机器学习算法的输入 [27]。本研究重新审视这些经典的人为设计特征,并让深度神经网络学习它们。该方法通过利用人类分析师的先验知识来指导训练过程,从而促进学习更优的表征。
III. METHODOLOGY
III. 方法论
Our proposed FG-MAE is a simple variant of MAE [4] that replaces the reconstruction target with RS image features. As is illustrated in Figure 2, the image is divided into nonoverlapping patches, and a random subset of these patches are masked out. The remaining visible patches are sent through the ViT encoder. The full set of encoded visible patches and learnable mask tokens are fed into the lightweight ViT decoder to reconstruct target features. During training, mean squared error or L2 loss is minimized only on masked patches. In the following subsections, we will discuss different feature candidates in III-A, and present the specific target designs for multi spectral and SAR imagery in III-B, respectively.
我们提出的FG-MAE是MAE [4]的一个简单变体,它将重建目标替换为RS图像特征。如图 2所示,图像被划分为不重叠的块,并随机掩码部分块。剩余的可见块通过ViT编码器处理。完整的已编码可见块和可学习的掩码token被输入轻量级ViT解码器以重建目标特征。训练时,仅在掩码块上最小化均方误差或L2损失。在接下来的小节中,我们将在III-A讨论不同的特征候选,并在III-B分别介绍针对多光谱和SAR图像的具体目标设计。
II. RELATED WORK
II. 相关工作
Masked image modeling for self-supervised learning Masked image modeling (MIM) is a recent family of generative self-supervised learning that focus on pre training vision transformers by reconstructing the masked input, such as iGPT [17], BEiT [18] and SimMIM [19]. Of particular interest, MAE [4] drew wide attention with substantial improvements on fine-tuning downstream tasks and efficient pre training.
掩码图像建模的自监督学习
掩码图像建模 (Masked Image Modeling, MIM) 是近期兴起的一类生成式自监督学习方法,其核心思想通过重建被遮蔽的输入数据来预训练视觉 Transformer 模型,代表性工作包括 iGPT [17]、BEiT [18] 和 SimMIM [19]。其中 MAE [4] 因其在下游任务微调中的显著性能提升和高效的预训练效率而受到广泛关注。
Our work, FG-MAE, is a simple variant of MAE. Instead of reconstructing raw images, we propose to reconstruct features that are better suited for RS imagery. FG-MAE is also closely related to MaskFeat [20], where the authors introduced masked feature prediction for self-supervised video representation learning. We propose to use the asymmetric encoder-decoder structure of MAE for efficiency, and explore the best features for multi spectral and SAR imagery.
我们的工作 FG-MAE 是 MAE 的一种简单变体。我们提出重建更适合遥感影像的特征,而非原始图像。FG-MAE 也与 MaskFeat [20] 密切相关,该论文作者提出了用于自监督视频表征学习的掩码特征预测方法。为提高效率,我们采用 MAE 的非对称编码器-解码器结构,并探索多光谱和 SAR 影像的最佳特征。
Masked image modeling in remote sensing Most existing MIM works in RS are based on MAE [21, 22]. SatViT [21] presents the benefits of a straightforward implementation of MAE on satellite images. Wang et al. [23] showcased the potential of MAE on PolSAR images. RingMo [22] modified the masking strategy by reversing some pixels in the masked patches to avoid complete lost of small objects. MAEST [24] implemented MAE on hyper spectral images with spectral masking. SatMAE [5] proposed temporal and spectral masking and positional encoding in multi spectral remote sensing time series. Scale-MAE [25] introduced ground sampling distance positional encoding and multiscale reconstruction to capture the geospatial scale information of RS images. Our work differs from all aforementioned approaches by improving MAE for RS imagery from the perspective of reconstructing image features as targets.
遥感领域的掩码图像建模
目前遥感领域大多数掩码图像建模(MIM)研究都基于MAE [21, 22]。SatViT [21]展示了在卫星图像上直接应用MAE的优势。Wang等人[23]验证了MAE在极化合成孔径雷达(PolSAR)图像上的潜力。RingMo [22]通过反转掩码块中的部分像素来改进掩码策略,避免小目标完全丢失。MAEST [24]在高光谱图像上采用光谱掩码方式实现MAE。SatMAE [5]提出在多光谱遥感时间序列中应用时序-光谱联合掩码与位置编码。Scale-MAE [25]引入地面采样距离位置编码和多尺度重建机制,以捕捉遥感图像的地理空间尺度信息。本研究与上述所有方法的区别在于:从重建图像特征作为目标的角度改进MAE在遥感图像中的应用。
Exploiting image features in remote sensing Image feature descriptors play a big role in traditional RS image analysis.
利用遥感图像特征
图像特征描述符在传统遥感(RS)图像分析中发挥着重要作用。
A. Target features
A. 目标特性
We consider two categories and four types of RS image features: spatially, 1) CannyEdge [8], 2) HOG [9], and 3) SIFT [10]; spectrally, 4) NDI, including vegetation index [11], water index [12] and built-up index [13].
我们考虑了两大类别和四种类型的遥感(RS)图像特征:空间特征方面包括1) CannyEdge [8]、2) HOG [9]和3) SIFT [10];光谱特征方面包括4) NDI(归一化差异指数),含植被指数[11]、水体指数[12]和建筑指数[13]。
CannyEdge CannyEdge [8] is an edge detection algorithm that identifies the edges in an image by tracing the gradient of pixel intensities. The algorithm works by convolving the image with a Gaussian filter to reduce noise, and then computing the gradient magnitude and direction of each pixel. Non-maximum suppression is applied to suppress non-max edge contributors, and edges are detected by applying a Hysteresis threshold to the gradient magnitude.
CannyEdge [8] 是一种边缘检测算法,通过追踪像素强度梯度来识别图像中的边缘。该算法首先使用高斯滤波器对图像进行卷积以降低噪声,然后计算每个像素的梯度幅值和方向。通过非极大值抑制来消除非边缘贡献点,并通过对梯度幅值应用滞后阈值来检测边缘。
Edge descriptors can simplify complex images by highlighting object boundaries, facilitating object identification and tracking in computer vision algorithms. As one of the most popular algorithms in this family, CannyEdge has the ability to accurately detect edges while minimizing false positives. It can also adapt to changes in lighting and contrast, which can often cause issues for other edge detection algorithms. Additionally, CannyEdge is able to accurately detect edges regardless of their orientation or position within the image. This makes it a powerful tool for remote sensing applications [28].
边缘描述符能通过突出物体边界来简化复杂图像,便于计算机视觉算法中的物体识别与追踪。作为该领域最流行的算法之一,CannyEdge 能精准检测边缘,同时将误报率降至最低。它还能适应光照和对比度的变化(这些因素常导致其他边缘检测算法失效)。此外,无论边缘在图像中的方向或位置如何,CannyEdge 都能准确检测,这使其成为遥感应用的强大工具 [28]。
CannyEdge is easy to compute in any deep learning framework by convolution, non-max suppression and threshold ing. We use the filter toolbox of kornia [29] to extract the edges as MAE targets (one edge map from one image channel). The same process as reconstructing the raw image follows, including patch if ying and normalization within each small patch.
CannyEdge 在任何深度学习框架中都很容易通过卷积、非极大值抑制和阈值化计算。我们使用 kornia [29] 的滤波器工具箱提取边缘作为 MAE (masked autoencoder) 目标(每个图像通道生成一个边缘图)。后续流程与重建原始图像相同,包括分块处理和小块内归一化。
HOG Histograms of Oriented Gradients [9] is a feature descriptor to describe the distribution of gradient orientations within a local subregion of an image. The algorithm calculates the magnitudes and orientations of gradients at each pixel using gradient filtering. Then, the gradients within each small local window are accumulated into normalized orientation histogram vectors voted by gradient magnitudes.
HOG (Histograms of Oriented Gradients) [9] 是一种特征描述符,用于描述图像局部子区域内梯度方向的分布。该算法通过梯度滤波计算每个像素点的梯度幅值和方向,然后将每个小局部窗口内的梯度按幅值加权投票累加为归一化的方向直方图向量。
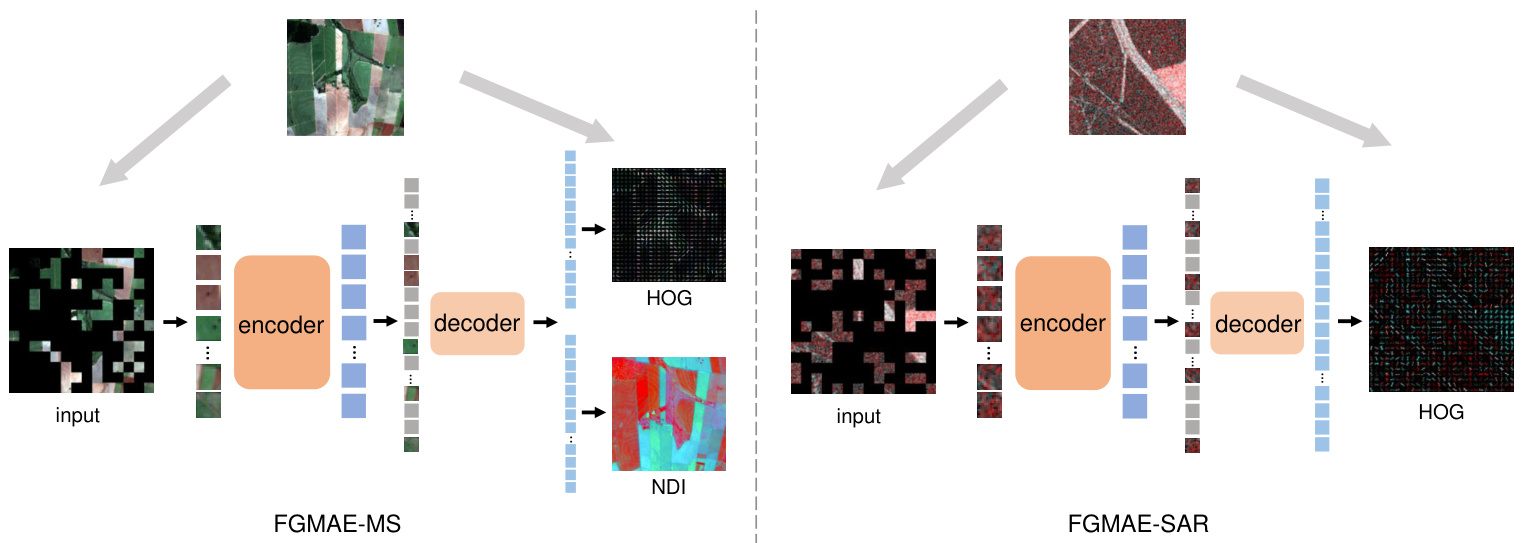
Fig. 2. The general structure of the proposed FG-MAE method. We replace the reconstruction target of MAE [4] by remote sensing image features.
图 2: 提出的FG-MAE方法总体结构。我们将MAE [4]的重建目标替换为遥感图像特征。
HOG is able to capture local shapes and appearances while being partially invariant to geometric changes. HOG is also invariant to photometric changes, as image gradients and local contrast normalization absorb brightness and foregroundbackground contrast variation. Unlike CannyEdge, HOG does not focus solely on edges but provides information about the magnitude and orientation of edge gradients.
HOG能够捕捉局部形状和外观,同时对几何变化保持部分不变性。HOG对光度变化也具有不变性,因为图像梯度和局部对比度归一化吸收了亮度及前景-背景对比度变化。与CannyEdge不同,HOG不仅关注边缘,还提供边缘梯度的幅值和方向信息。
HOG can be implemented similarly to CannyEdge as a twochannel convolution to generate gradients, followed by histogramming and normalization. We follow the implementation of MaskFeat [20] that writes HOG as (weight-fixed) neural network modules. Each channel of the raw image provides one HOG feature. The histograms of masked patches are then flattened and concatenated into a 1-D vector as the target feature.
HOG可以像CannyEdge一样实现为双通道卷积以生成梯度,随后进行直方图统计和归一化。我们遵循MaskFeat [20]的实现方式,将HOG编写为(权重固定的)神经网络模块。原始图像的每个通道提供一个HOG特征。随后将掩码块的直方图展平并拼接成一维向量作为目标特征。
SIFT Scale-invariant feature transform (SIFT) [10] is a feature descriptor that is used to extract distinctive and invariant local features from images. It works by detecting key points in an image that are invariant to scale, rotation, and illumination changes. Once the key points are detected, SIFT computes a descriptor for each key point by extracting the local image gradient orientations and magnitudes. These gradients are then transformed into a histogram of orientations, which is used to create a feature vector that describes the local image patch around the key point.
SIFT (Scale-invariant feature transform) [10] 是一种用于从图像中提取独特且具有不变性的局部特征的特征描述符。其工作原理是检测图像中对尺度、旋转和光照变化具有不变性的关键点。检测到关键点后,SIFT 通过提取局部图像梯度方向和幅度为每个关键点计算描述符。这些梯度随后被转换为方向直方图,用于生成描述关键点周围局部图像块的特征向量。
The SIFT descriptor is robust against scale, rotation, illumination, and noise, making it applicable for a wide range of applications like image registration [30]. However, the complicated workflow of key point detectors and feature descriptors make it difficult for the model to learn. Another specific issue is that instead of region-based features, SIFT provides pointbased features that do not align well with a standard ViT model design. Accordingly, it is tricky to integrate the famous SAR-SIFT [31] algorithm for SAR images. How to efficiently deal with the dynamic key points and the model’s learning capacity remains a challenging task for future research. As a preliminary showcase in this work, we simplify the key point detection process by computing SIFT descriptor densely over the image. We utilize the feature toolbox of kornia [29] to calculate dense SIFT features. Due to memory constraints, we perform the calculation using grayscale images.
SIFT 描述符对尺度、旋转、光照和噪声具有鲁棒性,因此适用于图像配准 [30] 等广泛应用场景。然而,关键点检测器和特征描述符的复杂流程使得模型难以学习。另一个具体问题是,SIFT 提供的是基于点的特征而非基于区域的特征,这与标准 ViT (Vision Transformer) 模型设计不兼容。因此,将著名的 SAR-SIFT [31] 算法整合到 SAR 图像中颇具挑战性。如何高效处理动态关键点与模型学习能力,仍是未来研究中待解决的难题。作为本工作的初步展示,我们通过密集计算图像上的 SIFT 描述符来简化关键点检测流程,并利用 kornia [29] 的特征工具箱计算密集 SIFT 特征。由于内存限制,我们使用灰度图像进行计算。
NDI Normalized Difference Indices (NDI) is a technique used to identify one type of ground objects by quantifying the differences between two spectral bands. It is often used in remote sensing applications such as changes in vegetation health or soil moisture levels. NDI works by calculating the ratio of the difference between two feature-sensitive spectral bands to their sum. This ratio is then normalized to a range between -1 and 1, where values closer to 1 indicate an increase in the feature of interest.
NDI (Normalized Difference Indices) 是一种通过量化两个光谱波段之间的差异来识别特定地物类型的技术。该技术常用于遥感应用,例如监测植被健康状况变化或土壤湿度水平。NDI 通过计算两个对特征敏感的光谱波段之差与其和的比值来实现,随后将该比值归一化至 -1 到 1 的范围内,其中越接近 1 的数值表示目标特征越显著。
NDI is a simple and effective way to detect changes in vegetation health or soil moisture levels, as it is sensitive to changes in the reflectance of different spectral bands. Three most popular NDIs are normalized difference vegetation index (NDVI), normalized difference water index (NDWI), and normalized built-up index (NDBI):
NDI是一种简单有效的方法,用于检测植被健康状况或土壤湿度水平的变化,因为它对不同光谱波段反射率的变化非常敏感。三种最常用的NDI包括归一化植被指数(NDVI)、归一化水体指数(NDWI)和归一化建筑指数(NDBI):
$$
N D V I={\frac{N I R-R}{N I R+R}}
$$
$$
N D V I={\frac{N I R-R}{N I R+R}}
$$
$$
N D W I=\frac{G-N I R}{G+N I R}
$$
$$
N D W I=\frac{G-N I R}{G+N I R}
$$
$$
N D B I=\frac{S W I R-N I R}{S W I R+N I R}
$$
$$
N D B I=\frac{S W I R-N I R}{S W I R+N I R}
$$
where $N I R$ represents near infrared, $R$ represents red, $G$ represents green, and $S W I R$ represents short wave infrared. In this work, we calcuate the three indices for each pixel and concatenate them into a three-channel target image.
其中 $NIR$ 表示近红外,$R$ 表示红色,$G$ 表示绿色,$SWIR$ 表示短波红外。在本研究中,我们为每个像素计算这三个指数并将其拼接成三通道目标图像。
In our experiments, we demonstrate that all above features serve as good reconstruction targets to replace raw images. Results will be discussed in V-A, where we perform a study on separately reconstructing the above features and evaluate corresponding downstream performances.
在我们的实验中,我们证明上述所有特征都能作为良好的重建目标替代原始图像。结果将在第V-A节讨论,该部分我们对上述特征分别进行重建研究并评估相应的下游性能。
B. FGMAE-MS / SAR
B. FGMAE-MS / SAR
We then develop our proposed self-supervised methods, FGMAE, based on the feature study. We consider two popular modalities in RS, multi spectral imagery and polar i metric SAR imagery. For multi spectral imagery, we combine spatial feature HOG and spectral feature NDI to complement each other; for SAR, we select HOG for its computational efficiency and noise robustness.
随后基于特征研究,我们提出了自监督方法FGMAE。我们考虑了遥感(RS)中两种主流模态:多光谱影像和极化合成孔径雷达(SAR)影像。针对多光谱影像,我们结合空间特征HOG与光谱特征NDI实现互补;对于SAR影像,则选用计算高效且抗噪性强的HOG特征。
As is shown in Figure 2, we retain the asymmetric encoderdecoder structure of MAE while modifying the reconstruction targets. Specifically, for FGMAE-SAR, the augmented raw images with shape (B,2,W,H) are divided into $\mathrm{L}$ non-overlapping patches with shape (B,L,w,h), of which $L_{m}$ random patches are masked out. The remaining visible patches with shape $(\mathbf{B},L-L_{m},\mathbf{w},\mathbf{h})$ are flattened to $(\mathbf{B},L-L_{m},\mathbf{w}^{*}\mathbf{h})$ , processed with a linear embedding layer to $({\tt B},L-L_{m},K_{e n})$ and passed through the ViT encoder. The encoded visible patches have shape $(\mathbf{B},L-L_{m},K_{e n})$ . At the beginning of the decoding process, a linear layer is used to embed encoded patches to $(\mathbf{B},L-L_{m},K_{d e})$ . They are then combined with mask tokens to $(\mathtt{B},\mathrm{L},K_{d e})$ as input to a lightweight ViT decoder. The last layer of the decoder is a linear layer that converts the decoded patches to HOG predictions with shape $(\mathbf{B},\mathbf{L},K_{o u t})$ ), where $K_{o u t}$ is defined by HOG window size, number of bins and input channel numbers.
如图 2 所示,我们保留了 MAE 的非对称编码器-解码器结构,同时修改了重建目标。具体而言,对于 FGMAE-SAR,形状为 (B,2,W,H) 的增强原始图像被划分为 $\mathrm{L}$ 个不重叠的块,形状为 (B,L,w,h),其中 $L_{m}$ 个随机块被掩码。剩余的可见块形状为 $(\mathbf{B},L-L_{m},\mathbf{w},\mathbf{h})$,被展平为 $(\mathbf{B},L-L_{m},\mathbf{w}^{*}\mathbf{h})$,经过线性嵌入层处理为 $({\tt B},L-L_{m},K_{e n})$ 并传入 ViT 编码器。编码后的可见块形状为 $(\mathbf{B},L-L_{m},K_{e n})$。在解码过程开始时,使用线性层将编码块嵌入为 $(\mathbf{B},L-L_{m},K_{d e})$。随后它们与掩码 token 组合为 $(\mathtt{B},\mathrm{L},K_{d e})$ 作为轻量级 ViT 解码器的输入。解码器的最后一层是线性层,将解码后的块转换为形状为 $(\mathbf{B},\mathbf{L},K_{o u t})$ 的 HOG 预测,其中 $K_{o u t}$ 由 HOG 窗口大小、bin 数量和输入通道数定义。
While mostly similar for FGMAE-MS, the last layer of the decoder is replaced by two parallel linear layers, one outputting HOG and the other NDI. Note that for both modalities the outputs cover all patches, and only the masked ones are counted in the L2 loss calculation.
虽然FGMAE-MS大体相似,但解码器的最后一层被替换为两个并行的线性层,一个输出HOG,另一个输出NDI。需要注意的是,两种模态的输出都覆盖所有图像块,但只有被遮蔽的部分会参与L2损失计算。
IV. EXPERIMENTAL SETUP
IV. 实验设置
A. Self-supervised pre training
A. 自监督预训练
Dataset We pretrain vision transformers on Sentinel-1 GRD and Sentinel-2 L1C products of SSL4EO-S12 dataset [32]. The dataset is sampled from 250K locations around the world. Each location has four images from four seasons with size $264\times264$ and ground sampling distance $10\mathrm{m}$ . The multi spectral images have 13 channels, and the SAR images have 2 channels.
数据集
我们在SSL4EO-S12数据集[32]的Sentinel-1 GRD和Sentinel-2 L1C产品上预训练视觉Transformer (Vision Transformer)。该数据集从全球25万个地点采样,每个地点包含四季图像,尺寸为$264\times264$,地面采样距离为$10\mathrm{m}$。多光谱图像包含13个通道,合成孔径雷达(SAR)图像包含2个通道。
Data augmentation One image from a random season is selected for one location, followed by Random Resized Crop to $224\times224$ and Random Horizontal FLip as the data augmentations.
数据增强 为每个地点随机选取一个季节的图像,随后通过随机调整大小裁剪至 $224\times224$ 并应用随机水平翻转 (Random Horizontal Flip) 作为数据增强手段。
Model architecture We adopt the architecture design of MAE [4], which includes a regular ViT encoder (by default ViT-S/16 unless specifically noted) and a lightweight ViT decoder. Only the encoder is transferred to downstream tasks. The masking ratio is set to $70%$ as recommended in [32].
模型架构
我们采用MAE [4]的架构设计,包含常规ViT编码器(默认ViT-S/16,除非特别说明)和轻量级ViT解码器。仅编码器会迁移至下游任务。根据[32]建议,掩码率设为$70%$。
Optimization We pretrain ViTs with batchsize 256 for 100 epochs. We use the AdamW optimizer [33] with weight decay 0.05 and a basic learning rate $1.5\mathrm{e}{-4}$ . The learning rate is warmed up for 10 epochs, and then decayed with a cosine schedule. Training is distributed across four NVIDIA A100 GPUs and takes about 7 hours for multi spectral and 4 hours for SAR.
优化
我们使用批量大小(batch size)256对ViT进行100轮预训练。采用AdamW优化器[33],权重衰减(weight decay)为0.05,基础学习率设为$1.5\mathrm{e}{-4}$。学习率在前10轮进行预热(warmup),随后按余弦调度衰减。训练分布在四块NVIDIA A100 GPU上进行,多光谱数据耗时约7小时,SAR数据耗时约4小时。
B. Transfer learning
B. 迁移学习
Dataset The pretrained models are transferred to scene classification and semantic segmentation downstream tasks for both multi spectral and SAR imagery. For
数据集
预训练模型被迁移到多光谱和SAR影像的场景分类与语义分割下游任务中。
• scene classification, we evaluate EuroSAT [15] (singlelabel land cover classification) and Big Earth Net-MM [14] (multi-label land cover classification) via linear probing (freeze encoder) and end-to-end fine tuning. • semantic segmentation, we evaluate DFC2020 [16] (land cover segmentation) via fine tuning.
- 场景分类,我们通过线性探测(冻结编码器)和端到端微调评估 EuroSAT [15](单标签土地覆盖分类)和 Big Earth Net-MM [14](多标签土地覆盖分类)。
- 语义分割,我们通过微调评估 DFC2020 [16](土地覆盖分割)。
Big Earth Net-MM and DFC2020 have both multi spectral and SAR images available. For Big Earth Net-MM, we use the 19-class labels, and follow the official train/val/test splits. For DFC2020, we use the 10-class high-resolution segmentation labels, and adjust the official test/validation data for 5128 training and 986 testing images. For EuroSAT, we perform a random $80%/20%$ train/test split.
Big Earth Net-MM和DFC2020数据集均包含多光谱与SAR图像。对于Big Earth Net-MM,我们采用19类标签体系,并遵循官方划分的训练集/验证集/测试集。DFC2020数据集则使用10类高分辨率分割标签,将官方测试/验证数据调整为5128张训练图像和986张测试图像。EuroSAT数据集采用随机$80%/20%$比例划分训练集与测试集。
Since EuroSAT has only RGB and multi spectral images, we collected EuroSAT-SAR by pairing the published EuroSATMS from Sentinel-1 GRD products. This is done by matching the geo coordinates of EuroSAT-MS images and downloading the corresponding patches with Google Earth Engine [34]. Because EuroSAT-MS has no exact collection time information, we performed a rough year-level match based on the publication time. In the end, we performed a manual check on random patches for the semantic correctness.
由于EuroSAT仅包含RGB和多光谱图像,我们通过将已发布的EuroSAT-MS与Sentinel-1 GRD产品配对,收集了EuroSAT-SAR数据集。具体方法是将EuroSAT-MS图像的地理坐标与Google Earth Engine [34]下载的对应区域进行匹配。由于EuroSAT-MS没有确切的采集时间信息,我们根据发布时间进行了粗略的年份匹配。最后,我们对随机选取的区域进行了人工检查以确保语义正确性。
Data augmentation We follow a common practice to use Random Resized Crop (scale 0.2 to 1.0, resized to $224\times224,$ ) and Random Horizontal Flip as data augmentations for all linear probing experiments. For Big Earth Net-MM, we set the smallest crop scale as 0.8 to avoid cutting out too many objects for the multilabel task. For DFC2020, we set the resized image size $256\times256$ following MAE [4]. For fine tuning experiments, we add mixup [35] augmentation. The multi spectral images of Big Earth Net-MM (Sentinel-2 L2A) are zero-padded to 13 channels to match the pretrained models.
数据增强
我们遵循常规做法,在所有线性探测实验中使用随机缩放裁剪 (scale 0.2到1.0,调整至$224\times224$) 和随机水平翻转作为数据增强手段。对于Big Earth Net-MM数据集,为避免在多标签任务中裁剪掉过多目标,我们将最小裁剪比例设为0.8。对于DFC2020数据集,参照MAE [4] 的方法将图像尺寸调整为$256\times256$。在微调实验中,我们额外增加了mixup [35] 数据增强。Big Earth Net-MM的多光谱图像 (Sentinel-2 L2A) 通过零填充扩展至13个通道,以匹配预训练模型的输入要求。
Model architecture We use standard ViTs for scene classification on Big Earth Net-MM and EuroSAT. For semantic segmentation on DFC2020, we use UperNet [36] with ViT backbones following MAE [4].
模型架构
我们在Big Earth Net-MM和EuroSAT数据集上使用标准ViT (Vision Transformer) 进行场景分类。对于DFC2020的语义分割任务,我们采用UperNet [36] 架构,并遵循MAE [4] 的方法使用ViT作为主干网络。
Optimization For Big Earth Net-MM, we minimize MultiLabel Soft Margin loss. The batchsize is set to 256. For linear probing, we train SGD optimizer without weight decay for 50 epochs. For fine tuning, we train AdamW optimzier with weight and layer decay for 20 epochs. The learning rate is 0.5 with cosine decay for linear probing, and 1e-3 with cosine decay and 3-epoch warm-up for fine tuning.
针对BigEarthNet-MM的优化,我们采用多标签软间隔损失 (MultiLabel Soft Margin loss) 进行最小化。批量大小设置为256。在线性探测阶段,使用不带权重衰减的SGD优化器训练50个周期;在微调阶段,采用带权重和层级衰减的AdamW优化器训练20个周期。学习率在线性探测时为0.5(余弦衰减),微调时为1e-3(余弦衰减并包含3周期预热)。
For EuroSAT, we minize cross entropy loss. The batchsize is set to 256. For linear probing, we train SGD optimizer with weight decay 0.001 for 50 epochs. For fine tuning, we train AdamW optimzier with weight and layer decay for 20 epochs. The learning rate is 0.1 with cosine decay for linear probing, and 1e-3 with cosine decay and 3-epoch warm-up for fine tuning.
对于EuroSAT数据集,我们最小化交叉熵损失 (cross entropy loss)。批量大小 (batchsize) 设为256。在线性探测 (linear probing) 阶段,使用权重衰减 (weight decay) 为0.001的SGD优化器训练50个周期 (epoch)。在微调 (fine tuning) 阶段,使用带权重衰减和分层衰减 (layer decay) 的AdamW优化器训练20个周期。线性探测的学习率为0.1并采用余弦衰减 (cosine decay),微调的学习率为1e-3并采用余弦衰减及3周期预热 (warm-up)。
For DFC2020, we use the RSI-Segmentation library [37] for fine tuning. We minimize cross entropy loss for 40k iterations with batchsize 8. We use AdamW optimizer with layer decay. The basic learning rate is 1e-4, which is warmed up for 500 iterations and then polynomial-decayed.
对于DFC2020,我们使用RSI-Segmentation库[37]进行微调。采用交叉熵损失函数进行4万次迭代训练,批量大小为8。优化器选用AdamW并应用分层衰减策略,基础学习率为1e-4,前500次迭代进行学习率预热,之后采用多项式衰减。
Evaluation metrics We use mean average precision (mAP) and F1 score for the evaluation of Big Earth Net-MM. Overall accuracy (OA) and class-wise average accuracy (AA) are used for EuroSAT. For DFC2020, we evaluate overage accuracy (OA), average accuracy (AA) and mean intersection over union (mIoU).
评估指标
我们使用平均精度均值 (mAP) 和 F1 分数来评估 Big Earth Net-MM。对于 EuroSAT,采用总体准确率 (OA) 和类别平均准确率 (AA)。DFC2020 的评估指标包括总体准确率 (OA)、平均准确率 (AA) 和平均交并比 (mIoU)。
V. RESULTS
V. 结果
A. FG-MAE: target features
A. FG-MAE: 目标特征
We first conduct a study on replacing raw image with different target features in MAE for both multi spectral and SAR imagery. We pretrain ViTs on SSL4EO-S12 and transfer them to a $10%$ subset of Big Earth Net-MM. As shown in Table I, all features perform comparably well to the raw image (MAE) under both linear probing and fine tuning settings in multi spectral imagery. HOG is even better than the raw image for both settings. This proves the effectiveness of reconstructing image features as a new variant of MAE.
我们首先研究了在多光谱和SAR影像中,用不同目标特征替换原始图像对MAE的影响。我们在SSL4EO-S12数据集上预训练ViT模型,并将其迁移到Big Earth Net-MM数据集的10%子集上。如表1所示,在多光谱影像的线性探测和微调设置下,所有特征的表现都与原始图像(MAE)相当。HOG特征在这两种设置下甚至优于原始图像,这证明了重建图像特征作为MAE新变体的有效性。
TABLE II A STUDY OF THE FEATURES ON BIG EARTH NET- $10%-\mathrm{SAR}$ .
表 II: BIG EARTH NET-$10%-\mathrm{SAR}$ 的特征研究
| 线性分类 | 微调 |
|---|---|
| 随机初始化 (Rand.Init.) | 58.1 |
| 监督学习 (Supervised) | 72.7 |
| 原始图像 (MAE) | 74.9 |
| Canny边缘检测 (CannyEdge) | - |
| 密集SIFT (DenseSIFT) | 75.8 |
| HOG (本文方法) | 78.0 |
appear clearer than the ground truth. This observation suggests another exciting research direction for better low-level feature extraction algorithms [31] .
比真实情况看起来更清晰。这一观察结果为更好的低级特征提取算法指出了一个令人兴奋的研究方向 [31]。
B. FGMAE-MS
B. FGMAE-MS
We then benchmark the performance of the proposed FGMAE-MS $(\mathrm{HOG+NDI})$ and FGMAE-SAR (HOG) on extensive downstream datasets. Table III shows the transfer results on the full set of the multi-label scene classification dataset Big Earth Net. The proposed FGMAE-MS outperforms MAE consistently on both linear probing and fine tuning, with improvements up to $0.9%$ .
随后,我们在多个下游数据集上对提出的 FGMAE-MS $(\mathrm{HOG+NDI})$ 和 FGMAE-SAR (HOG) 进行性能基准测试。表 III 展示了多标签场景分类数据集 Big Earth Net 完整集的迁移结果。提出的 FGMAE-MS 在线性探测和微调中均持续优于 MAE,最高提升达 $0.9%$。
TABLE I A STUDY OF THE FEATURES ON BIG EARTH NET- $10%-\mathrm{MS}$ .
表 1: BIG EARTH NET-$10%-\mathrm{MS}$ 的特征研究
| 线性探测 (Linear probing) | 微调 (Fine tuning) | |
|---|---|---|
| 随机初始化 (Rand. Init.) | 70.3 | |
| 监督学习 (Supervised) | 81.3 | |
| 原始图像 (Raw image) (MAE) | 77.8 | 84.8 |
| Canny 边缘 (Canny Edge) | 77.9 | 84.8 |
| HOG | 77.9 | 85.0 |
| DenseSIFT | 77.8 | 84.9 |
| NDI | 77.3 | 84.6 |
| HOG&NDI (ours) | 85.2 |
Among the individual features, both CannyEdge and HOG show an advantage over NDI in linear probing. This is due to the fact that spatial feature descriptors capture better imagelevel semantics from e.g. shape information, while the spectral feature NDI does not consider pixel relationships. In addition, while HOG performs best among individual features, NDI provides a good complement that combining both pushes the performances further.
在单个特征中,CannyEdge和HOG在线性探测中都显示出优于NDI的表现。这是因为空间特征描述符(如形状信息)能更好地捕捉图像级语义,而频谱特征NDI未考虑像素间关系。此外,尽管HOG在单一特征中表现最佳,但NDI提供了良好的补充,二者结合能进一步提升性能。
A similar but more interesting behavior is shown in Table II for SAR imagery. We can observe that both SIFT and HOG perform better than raw image (MAE), and HOG provides a remarkable boost. This can be attributed to the fact that MAE reconstructs every pixel and thus strongly disturbed by the speckle noise, while feature descriptors provide natural noise filtering. Furthermore, Dense SIFT performs worse than HOG. This is due to the coarse setting that we consider each pixel as one key point and thus have too many false positives. In fact, this inspires a promising research direction to better integrate scale-invariant features into MAE structure.
表 II 展示了SAR图像中类似但更有趣的现象。我们可以观察到,SIFT和HOG的表现均优于原始图像(MAE),其中HOG带来了显著提升。这归因于MAE需要逐像素重建,因此极易受散斑噪声干扰,而特征描述符天然具备噪声过滤特性。此外,Dense SIFT的表现逊于HOG,这是由于我们将每个像素都设为关键点的粗糙设置产生了过多误报。这一现象实际上启发了将尺度不变特征更好融入MAE结构的研究方向。
Qualitative examples of feature reconstruction can be seen in Figure 1 and 3. Despite masking out $70%$ of the input patches, the reconstruction results remain impressive for multispectral images. For SAR images, the ground truth themselves are very noisy, but interestingly, the reconstructed features
特征重建的定性示例如图 1 和图 3 所示。尽管遮挡了输入图像块中 70% 的区域,多光谱图像的重建结果依然令人印象深刻。对于 SAR (合成孔径雷达) 图像,真实值本身含有大量噪声,但有趣的是,重建后的特征...
TABLE III FGMAE-MS ON BIG EARTH NET- $100%$ .
表 III: FGMAE-MS 在 BIG EARTH NET 数据集上的性能 - $100%$
| 线性分类 mAP | F1 | 微调 mAP F1 | ||
|---|---|---|---|---|
| Rand.Init | 72.0 | 60.0 | ||
| Supervised | 87.8 | 78.9 | ||
| MAE----- | 78.0 | 68.0 | 88.6 | 79.9 |
| FG-MAE (ours) | 78.5 | 68.7 | 89.3 | 80.8 |
Table IV presents the transfer learning results on the single-label scene classification dataset EuroSAT. Similar to Big Earth Net, slight but consistent improvements can be observed in all scenarios.
表 IV 展示了单标签场景分类数据集 EuroSAT 上的迁移学习结果。与 Big Earth Net 类似,在所有场景中都能观察到轻微但一致的改进。
TABLE IV FGMAE-MS ON EUROSAT.
表 IV FGMAE-MS 在 EUROSAT 上的表现
| 线性分类 OA | AA | 微调 OA | AA | |
|---|---|---|---|---|
| Rand.Init. | 79.3 | 79.5 | ||
| Supervised | 96.7 | 96.3 | ||
| MAE | 94.2 | 94.0 | 98.5 | 98.2 |
| FG-MAE (ours) | 94.8 | 94.8 | 98.7 | 98.5 |
Finally, Table V demonstrates the transfer learning results on the semantic segmentation dataset DFC2020, where FGMAE-MS outperforms MAE by noticeable margins on all metrics (e.g. $3.4%$ increase in mIoU). This underscores the promising benefits of FG-MAE on dense prediction tasks.
最后,表 V 展示了在语义分割数据集 DFC2020 上的迁移学习结果,其中 FGMAE-MS 在所有指标上均明显优于 MAE (例如 mIoU 提高了 3.4%)。这凸显了 FG-MAE 在密集预测任务上的潜在优势。
TABLE V FGMAE-MS ON DFC2020.
表 5: DFC2020 上的 FGMAE-MS 结果
| OA | mIoU | AA | |
|---|---|---|---|
| Supervised | 63.3 | 46.2 | 59.2 |
| MAE-- | 66.9 | 48.0 | 63.5 |
| FG-MAE (ours) | 69.6 | 51.4 | 66.4 |

Fig. 3. Examples of FG-MAE reconstructed features. Every two rows represent one MS-SAR pair. From left to right, first row: MS image, MS HOG target MS NDI target, SAR HOG target, SAR image; second row: MS image masked, MS HOG prediction, MS NDI reconstruction, SAR HOG prediction, SAR image masked.
图 3: FG-MAE 重建特征示例。每两行代表一组 MS-SAR 配对数据。从左至右:第一行为 MS 图像、MS HOG 目标、MS NDI 目标、SAR HOG 目标、SAR 图像;第二行为掩膜后的 MS 图像、MS HOG 预测结果、MS NDI 重建结果、SAR HOG 预测结果、掩膜后的 SAR 图像。

Fig. 4. Examples of EuroSAT-SAR prediction results where FG-MAE gives the correct label while MAE doesn’t. FG-MAE better captures semantics that are more distinguishable from the HOG features (e.g. a highway).
图 4: EuroSAT-SAR预测结果示例,其中FG-MAE给出了正确标签而MAE没有。FG-MAE能更好地捕捉与HOG特征(如高速公路)更具区分性的语义。
TABLE VI PER-CLASS BENCHMARK RESULTS ON EUROSAT-SAR. FG-MAE OUTPERFORMS MAE BY LARGE MARGINS ON MOST OF THE CLASSES.
表 6: EUROSAT-SAR 数据集上的分类基准结果。FG-MAE 在大多数类别上大幅优于 MAE。
| AnnualCrop | Forest | HerbaceousVegetation | Highway | Industrial | Pasture | Permanent Crop | Residential | River | Sea/Lake | |
|---|---|---|---|---|---|---|---|---|---|---|
| Supervised | 76.4 | 77.7 | 66.4 | 66.0 | 90.7 | 58.4 | 59.1 | 90.2 | 89.3 | 98.1 |
| MAE | 79.6 | 79.1 | 70.2 | 72.7 | 92.0 | 64.6 | 59.2 | 91.8 | 92.4 | 98.8 |
| FG-MAE (ours) | 84.1 (+3.5) | 85.4 (+6.3) | 78.1 (+7.9) | 82.4 (+9.7) | 93.5 (+1.5) | 75.7 (+11.1) | 67.7 (+8.5) | 94.3 (+2.5) | 94.2 (+1.8) | 98.8 |
C. FGMAE-SAR
C. FGMAE-SAR
Likewise, we benchmark the transfer learning results on SAR imagery of the aforementioned datasets. As can be seen from Table VII, FGMAE-SAR demonstrates remarkable improvements compared to MAE on Big Earth Net. Especially when compared to the multi spectral scenario ( $0.5%$ to $0.9%$ improvements), the benefit of FG-MAE is much more significant (up to $3.1%$ ). This again highlights the advantage of implicit noise filtering with HOG features.
同样,我们在上述数据集的SAR图像上对迁移学习结果进行了基准测试。从表 VII 可以看出,FGMAE-SAR在Big Earth Net上相比MAE表现出显著提升。特别是与多光谱场景相比(提升0.5%到0.9%),FG-MAE的优势更为明显(最高达3.1%)。这再次凸显了使用HOG特征进行隐式噪声过滤的优势。
TABLE VII FGMAE-SAR ON BIG EARTH NET- $100%$ .
表 VII: FGMAE-SAR 在 BIG EARTH NET 上的表现 - $100%$
| 线性分类 mAP F1 | 微调 mAP F1 | |||
|---|---|---|---|---|
| Rand.Init. | 59.0 | 40.4 | — | |
| Supervised | 79.5 | 71.1 | ||
| MAE | 70.4—- | 59.1 | 81.3 | 72.8 |
| FG-MAE (ours) | 72.3 | 62.2 | 82.7 | 74.0 |
Table VIII presents the results on our collected EuroSATSAR dataset. Similar to Big Earth Net results, substantial performance boosts can be observed with FGMAE-SAR. While FGMAE-MS gives $0.2%$ to $0.8%$ improvements compared to MAE, FGMAE-SAR provides up to $5.0%$ improvement. Detailed per-class benchmarks are shown in Table VI, where FGMAE-SAR outperforms MAE by a large margin for most of the classes (e.g. as much as $11.1%$ for the pasture class). Figure 4 presents some patch examples, which MAE mis classifies while FG-MAE predicts the correct label. We can observe from the figure that FG-MAE helps the model better capture the semantics that are easier to recognize with HOG features (e.g. a highway image).
表 VIII 展示了我们在自建 EuroSATSAR 数据集上的实验结果。与 Big Earth Net 结果类似,FGMAE-SAR 带来了显著的性能提升。虽然 FGMAE-MS 相比 MAE 仅有 0.2% 至 0.8% 的改进,但 FGMAE-SAR 实现了最高 5.0% 的提升。表 VI 展示了详细的类别基准测试结果,其中 FGMAE-SAR 在多数类别上大幅领先 MAE (例如牧草类别的差距高达 11.1%) 。图 4 展示了一些图像块示例,这些样本被 MAE 错误分类,但被 FG-MAE 正确预测。从图中可以看出,FG-MAE 能帮助模型更好地捕捉那些通过 HOG 特征更易识别的语义信息 (例如高速公路图像)。
Finally on DFC2020, consistent improvements compared to MAE can be seen from Table IX. Though the improvements compared to FGMAE-MS here are not as much as the previous two scene classification datasets, they are still noteworthy compared to supervised learning. This is also shown in Figure 6, where the segmentation results of two example image pairs are presented. The limited benefits can be attributed to the characteristics of SAR imagery, where interpreting fine grained pixel details is very challenging.
最后在DFC2020数据集上,从表IX可以看出相比MAE的持续改进。虽然相比FGMAE-MS的提升幅度不及前两个场景分类数据集,但与监督学习相比仍值得关注。图6展示了两组示例图像的分割结果也印证了这一点。这种有限的提升可归因于SAR(合成孔径雷达)图像的特性——解读细粒度像素级细节极具挑战性。
TABLE VIII FGMAE-SAR ON EUROSAT.
表 VIII FGMAE-SAR 在 EUROSAT 上的表现
| 线性分类 OA AA | 微调 OA | AA | ||
|---|---|---|---|---|
| Rand.Init. | 61.9 | 61.3 | ||
| Supervised | 78.4 | 77.7 | ||
| MAE | 79.3—- -78.6 | 81.0 | 80.4 | |
| FG-MAE (ours) | 80.7 | 79.9 | 85.9 | 85.4 |
TABLE IX FGMAE-SAR ON DFC2020.
表 IX: DFC2020 上的 FGMAE-SAR 结果
| OA | mIoU | AA | |
|---|---|---|---|
| Supervised | 61.4 | 37.3 | 56.1 |
| MAE | 62.1 | 38.9 | 56.9 |
| FG-MAE (ours) | 62.3 | 39.3 | 57.0 |
D. Scaling ViTs
D. 扩展 ViTs
The efficiency of MAE is well-preserved in the proposed FG-MAE, thus we are able to scale-up the pretrained models to a series of ViTs with up to 658 million parameters: ViTSmall, ViT-Base, ViT-Large and ViT-Huge. We evaluate linear classification and fine tuning results on both multi spectral and SAR imagery of the Big Earth Net-MM dataset. As is shown in Figure 5, scaling up ViTs provides consistent improvements for both modalities under linear classification protocol. This supports the potential benefits of even larger foundation models [38]. However, we also observe significant over fitting phenomenon under fine tuning protocol, as reflected by the saturation trend in Figure 5. This indicates the need for further research on how to effectively fine-tune big foundation models.
所提出的FG-MAE方法保持了MAE的高效性,因此我们能够将预训练模型扩展到参数规模达6.58亿的ViT系列:ViT-Small、ViT-Base、ViT-Large和ViT-Huge。我们在BigEarthNet-MM数据集的多光谱与SAR影像上评估了线性分类与微调效果。如图5所示,扩大ViT规模能在线性分类协议下为两种模态带来持续提升,这支持了构建更庞大基础模型[38]的潜在优势。但我们也观察到微调协议下存在显著过拟合现象(见图5中的饱和趋势),这表明需要进一步研究如何有效微调大型基础模型。

Fig. 5. Similar to MAE, FG-MAE scales well on Big Earth Net linear evaluation for both multi spectral and SAR imagery.
图 5: 与MAE类似,FG-MAE在多光谱和SAR影像的Big Earth Net线性评估中均表现出良好的扩展性。
VI. CONCLUSION
VI. 结论
In this study, we demonstrated that image features are comparable or superior reconstruction targets for masked image modelling based pre training in remote sensing, particularly for SAR imagery. We proposed a novel variant of MAE, called feature guided masked auto encoder (FG-MAE), which modifies the reconstruction targets. For multi spectral imagery, we combined HOG and NDI, while for SAR imagery, we used HOG alone. Experimental results on three downstream tasks verify the effectiveness of FG-MAE. In addition, we demonstrated the s cal ability of FG-MAE, and released a series of pretrained vision transformers with size up to 0.7B parameters for multi spectral and SAR imagery.
本研究证明,在遥感图像特别是合成孔径雷达(SAR)图像中,基于掩码图像建模的预训练采用图像特征作为重建目标具有可比性或更优性能。我们提出了一种MAE的新变体——特征引导掩码自编码器(FG-MAE),通过修改重建目标实现改进:针对多光谱图像组合使用HOG与NDI特征,针对SAR图像则单独使用HOG特征。在三个下游任务上的实验结果验证了FG-MAE的有效性。此外,我们验证了FG-MAE的可扩展性,并发布了参数规模达7亿的多光谱与SAR图像预训练视觉Transformer系列模型。
Though the proof of concept has been made clear, one limitation of this work is that we can not make the best use of scale-invariant features such as SIFT / SAR-SIFT out-ofthe-box. However, we believe these features are of great value with proper and more sophisticated design. Scale-MAE [25], for example, though not directly inspired by SIFT, shares a similar idea and provides promising insights.
虽然概念验证已经明确,但这项工作的一个局限是我们无法直接充分利用尺度不变特征(如 SIFT/SAR-SIFT)。不过,我们相信通过更恰当和复杂的设计,这些特征将极具价值。例如 Scale-MAE [25] 虽未直接受 SIFT 启发,但采用了相似思路并提供了有前景的见解。
Another limitation, as we have mentioned, is that both MAE and FG-MAE scale well to larger backbones in linear probing, but not in fine tuning. As we are entering the era of big EO foundation models, how to effectively transfer the foundation knowledge remains an important but not yet wellstudied problem.
另一个局限是,正如我们提到的,MAE和FG-MAE在线性探测任务中能很好地扩展到更大骨干网络,但在微调时表现不佳。随着我们进入大地球观测(EO)基础模型时代,如何有效迁移基础知识仍是一个重要但尚未深入研究的问题。
There are also two interesting thoughts that we believe deserve further investigation. First, we have shown a relatively poor performance in reconstructing raw SAR images because of the effect of speckle noise. However, what if we reconstruct the despeckled images instead? SAR-de speckling has been widely studied and there are many well-developed algorithms. If integrated into MAE pre training, would it help the model prevent confusion due to noise? Second, the reconstructed SAR features sometimes seem to be clearer than the corresponding noisy ground truth. This may inspire a promising direction for low-level tasks, including the aforementioned SAR-de speckling.
还有两个有趣的想法值得我们进一步研究。首先,由于斑点噪声的影响,我们在重建原始SAR图像时表现相对较差。但如果我们改为重建去斑后的图像会怎样?SAR去斑技术已被广泛研究,并有许多成熟算法。如果将其集成到MAE预训练中,是否能帮助模型避免因噪声而产生的混淆?其次,重建的SAR特征有时似乎比对应的含噪真实图像更清晰。这可能为包括前述SAR去斑在内的底层任务指明一个有前景的方向。