MemSum: Extractive Sum mari z ation of Long Documents Using Multi-Step Episodic Markov Decision Processes
MemSum:基于多步情景马尔可夫决策过程的长文档抽取式摘要
Nianlong Gu
Nianlong Gu
Abstract
摘要
We introduce MemSum (Multi-step Episodic Markov decision process extractive SUMmarizer), a reinforcement-learning-based extractive summarizer enriched at each step with information on the current extraction history. When MemSum iterative ly selects sentences into the summary, it considers a broad information set that would intuitively also be used by humans in this task: 1) the text content of the sentence, 2) the global text context of the rest of the document, and 3) the extraction history consisting of the set of sentences that have already been extracted. With a lightweight architecture, MemSum obtains state-of-the-art testset performance (ROUGE) in summarizing long documents taken from PubMed, arXiv, and GovReport. Ablation studies demonstrate the importance of local, global, and history information. A human evaluation confirms the high quality and low redundancy of the generated summaries, stemming from MemSum’s awareness of extraction history.
我们介绍了MemSum (多步情景马尔可夫决策过程抽取式摘要器),这是一种基于强化学习的抽取式摘要器,在每一步都融入了当前抽取历史的信息。当MemSum迭代地将句子选入摘要时,它会考虑人类在该任务中也会直观使用的一组广泛信息:1) 句子的文本内容,2) 文档其余部分的全局文本上下文,以及3) 由已抽取句子组成的抽取历史。凭借轻量级架构,MemSum在PubMed、arXiv和GovReport的长文档摘要任务中取得了最先进的测试集性能(ROUGE)。消融研究证明了局部信息、全局信息和历史信息的重要性。人工评估证实了生成摘要的高质量和低冗余性,这源于MemSum对抽取历史的感知。
1 Introduction
1 引言
Automatic text sum mari z ation is the task of auto mati call y summarizing a long document into a relatively short text while preserving most of the information (Tas and Kiyani, 2007). Text summarization methods can be categorized into abstract ive and extractive sum mari z ation (Gambhir and Gupta, 2017; Nenkova and McKeown, 2012). Given a document $d$ consisting of an ordered list of $N$ sentences, extractive sum mari z ation aims to pick up $M$ $(M{\ll}N)$ sentences as the summary of the document. The extracted summaries tend to be both grammatically and semantically more reliable than abstract ive summaries $\mathrm{{Liu^{*}}}$ et al., 2018; Liu and Lapata, $2019\mathrm{a}$ ; Luo et al., 2019; Liao et al., 2020), as they are directly selected from the source text.
自动文本摘要 (Automatic text summarization) 的任务是将长文档自动概括为较短的文本,同时保留大部分信息 (Tas and Kiyani, 2007)。文本摘要方法可分为生成式 (abstractive) 和抽取式 (extractive) 摘要 (Gambhir and Gupta, 2017; Nenkova and McKeown, 2012)。给定一个由 $N$ 个有序句子组成的文档 $d$,抽取式摘要旨在选取 $M$ $(M{\ll}N)$ 个句子作为文档摘要。由于直接从源文本中选取,抽取式摘要通常在语法和语义上比生成式摘要更可靠 (Liu* et al., 2018; Liu and Lapata, 2019a; Luo et al., 2019; Liao et al., 2020)。
Extractive sum mari z ation is usually modeled as two sequential phases (Zhou et al., 2018): 1) sentence scoring and 2) sentence selection. In the sentence scoring phase, an affinity score is computed for each sentence by neural networks such as bidirectional RNNs (Dong et al., 2018; Narayan et al., 2018; Luo et al., 2019; Xiao and Carenini, 2019) or BERT (Zhang et al., 2019; Liu and Lapata, 2019b). In the sentence selection phase, sentences are selected by either i) predicting a label (1 or 0) for each sentence based on its score, and selecting sentences with label 1 (Zhang et al., 2019; Liu and Lapata, 2019b; Xiao and Carenini, 2019), or ii) ranking sentences based on their scores and selecting the top $K$ sentences as the summary (Narayan et al., 2018), or iii) sequentially sampling sentences without replacement, where the normalized scores of the remaining sentences are used as sampling likelihoods (Dong et al., 2018; Luo et al., 2019).
抽取式摘要通常被建模为两个连续阶段 (Zhou et al., 2018):1) 句子评分 2) 句子选择。在句子评分阶段,通过双向RNN (Dong et al., 2018; Narayan et al., 2018; Luo et al., 2019; Xiao and Carenini, 2019) 或BERT (Zhang et al., 2019; Liu and Lapata, 2019b) 等神经网络计算每个句子的亲和度分数。在句子选择阶段,采用以下三种方式之一:i) 根据分数预测每个句子的标签 (1或0),选择标签为1的句子 (Zhang et al., 2019; Liu and Lapata, 2019b; Xiao and Carenini, 2019);ii) 按分数排序并选择前 $K$ 个句子作为摘要 (Narayan et al., 2018);iii) 无放回地顺序采样句子,其中剩余句子的归一化分数作为采样概率 (Dong et al., 2018; Luo et al., 2019)。
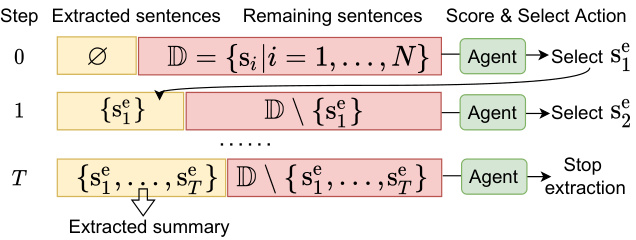
Figure 1: We modeled extractive sum mari z ation as a multi-step iterative process of scoring and selecting sentences. $\mathbf{S}{i}$ represents the $i_{\mathrm{th}}$ sentence in the document $\mathbb{D}$ .
图 1: 我们将抽取式摘要建模为一个多步迭代的评分和选择句子过程。$\mathbf{S}{i}$ 表示文档 $\mathbb{D}$ 中的第 $i_{\mathrm{th}}$ 个句子。
In these approaches, sentence scores are generally not updated based on the current partial summary of previously selected sentences, indicating a lack of knowledge of extraction history. We deem extractive summarize rs that are not aware of the extraction history to be susceptible to redundancy in a document, because they will repeatedly add sentences with high scores to a summary, regardless of whether similar sentences have been selected before. And, redundancy leads to performance decreases evaluated by ROUGE F1.
在这些方法中,句子分数通常不会根据当前已选句子的部分摘要进行更新,这表明缺乏对提取历史的了解。我们认为不了解提取历史的抽取式摘要器容易受到文档冗余的影响,因为它们会反复将高分句子添加到摘要中,而不管之前是否已选择过类似句子。此外,冗余会导致ROUGE F1评估的性能下降。
In this paper, we propose to model extractive sum mari z ation as a multi-step episodic Markov
在本论文中,我们提出将抽取式摘要建模为一个多步情景马尔可夫过程
Decision Process (MDP). As shown in Figure 1, at each time step in an episode, we define a sentence state composed of three sub-states: 1) the local content of the sentence, 2) the global context of the sentence within the document, and 3) information on the extraction history, including the previously selected set of unordered sentences and the remaining sentences. At each time step, the policy network (agent) takes the current sentence state as input and produces scores used to select an action of either stopping the extraction process or selecting one of the remaining sentences into the candidate summary. Unlike one-step episodic MDP-based models (Narayan et al., 2018; Dong et al., 2018; Luo et al., 2019) that encode the state information only once at the beginning of the episode, in our multi-step policy, the agent updates at each time step the extraction history before selecting an action. Such a step-wise state-updating strategy enables the agent to consider the content of the partial summary when selecting a sentence.
决策过程 (MDP)。如图 1 所示,在每一幕的每个时间步,我们定义一个由三个子状态组成的句子状态:1) 句子的局部内容,2) 句子在文档中的全局上下文,以及 3) 提取历史信息,包括先前选择的无序句子集和剩余的句子。在每个时间步,策略网络 (agent) 将当前句子状态作为输入,并生成用于选择动作的分数,这些动作包括停止提取过程或将剩余句子之一选入候选摘要。与基于单幕 MDP 的模型 (Narayan et al., 2018; Dong et al., 2018; Luo et al., 2019) 不同,这些模型仅在幕开始时对状态信息进行一次编码,而在我们的多步策略中,智能体在选择动作之前会在每个时间步更新提取历史。这种逐步更新状态的策略使智能体在选择句子时能够考虑部分摘要的内容。
To efficiently encode local and global sentence states, we design an extraction agent based on LSTM networks (Hochreiter and Schmid huber, 1997). To encode the extraction history and to select actions, we use a reduced number of attention layers (Vaswani et al., 2017) of relatively low dimensionality. These choices enable our model to be easily trainable and to summarize long documents such as scientific papers (Cohan et al., 2018; Huang et al., 2021) or reports (Huang et al., 2021).
为高效编码局部和全局句子状态,我们设计了一个基于LSTM网络 (Hochreiter and Schmidhuber, 1997) 的提取智能体。为编码提取历史并选择操作,我们使用了维度相对较低的少量注意力层 (Vaswani et al., 2017)。这些设计使得我们的模型易于训练,并能处理科学论文 (Cohan et al., 2018; Huang et al., 2021) 或报告 (Huang et al., 2021) 等长文档的摘要任务。
The contributions of our work are as follows: 1) We propose to treat extractive sum mari z ation as a multi-step episodic MDP that is aware of the extraction history. 2) We show that extraction-history awareness allows our model to extract more compact summaries than models without history awareness and behave more robustly to redundancies in documents. 3) Our model outperforms both extractive and abstract ive sum mari z ation models on PubMed, arXiv (Cohan et al., 2018), and GovReport (Huang et al., 2021) datasets. 4) Finally, human evaluators rate the MemSum summaries to be of higher quality than those from a competitive approach, especially by virtue of lower redundancy 1.
我们工作的贡献如下:1) 提出将抽取式摘要视为一个感知抽取历史的多步片段式MDP (Markov Decision Process)。2) 证明抽取历史感知使模型能生成比无历史感知模型更紧凑的摘要,并对文档冗余表现出更强鲁棒性。3) 在PubMed、arXiv (Cohan et al., 2018) 和GovReport (Huang et al., 2021) 数据集上,我们的模型性能优于抽取式和生成式摘要模型。4) 人工评估表明MemSum生成的摘要质量优于竞争方法,尤其在降低冗余度方面表现突出[1]。
2 Related Work
2 相关工作
Extraction history awareness was previously considered in NeuSum (Zhou et al., 2018), where a
提取历史感知在NeuSum (Zhou et al., 2018) 中曾被考虑,其中
GRU encoded previously selected sentences into a hidden vector that then was used to update the scores of the remaining sentences to bias the next selection. NeuSum contains no stopping mechanism and therefore it can only extract a fixed number of sentences, which likely is sub-optimal. Also, the potential benefits of extraction history have not been quantified and so the idea remains unexplored to a large extent.
GRU将先前选定的句子编码为隐藏向量,随后该向量用于更新剩余句子的分数,从而影响下一次选择。NeuSum未设置停止机制,因此只能提取固定数量的句子,这可能并非最优方案。此外,提取历史记录的潜在优势尚未量化,该理念在很大程度上仍未被充分探索。
Recently, BERT-based extractors such as MatchSum (Zhong et al., 2020) achieved SOTA performance in extractive sum mari z ation of relatively short documents from the CNN/DM (Hermann et al., 2015) dataset. However, the quadratic computational and memory complexities (Huang et al., 2021) of such models limit their s cal ability for summarizing long documents with thousands of tokens, which is common for scientific papers and government reports. Although large pre-trained transformers with efficient attention (Huang et al., 2021) have been adapted for abstract ive summarization of long documents, we believe that extractive sum mari z ation is more faithful in general, which is why we chose an extractive approach.
近期,基于BERT的抽取式摘要模型(如MatchSum [20])在CNN/DM数据集 [15] 的短文档摘要任务中取得了SOTA性能。然而,此类模型的二次方计算和内存复杂度 [21] 限制了其在处理长文档(如科学论文和政府报告中常见的数千token文本)时的扩展能力。尽管采用高效注意力机制的大型预训练Transformer [21] 已适配于长文档的生成式摘要任务,但我们认为抽取式摘要通常更具忠实性,因此选择了抽取式方法。
3 Model
3 模型
This section outlines the multi-step episodic MDP policy for extractive sum mari z ation.
本节概述了用于抽取式摘要的多步骤片段式MDP (Markov Decision Process) 策略。
3.1 Policy Gradient Methods
3.1 策略梯度方法
In an episodic task with a terminal state (i.e. end of summary), policy gradient methods aim to maximize the objective function ${\cal J}(\theta) =~\mathbb{E}{\pi_{\theta}}[R_{0}]$ , where the return $\begin{array}{r}{R_{t}=\sum_{k=t+1}^{T}r_{k}}\end{array}$ is the cumulative reward from time $t+1$ until the end of the episode when the summary is complete. In applications of RL to extractive sum mari z ation, the instantaneous reward $r_{t}$ is zero except at the end of the episode when the final reward $r$ is computed according to Equation (1), so $R_{t}\equiv R_{0}=r$ . The reward $r$ is usually expressed as (Dong et al., 2018):
在具有终止状态(即摘要结束)的片段式任务中,策略梯度方法旨在最大化目标函数 ${\cal J}(\theta) =~\mathbb{E}{\pi_{\theta}}[R_{0}]$ ,其中回报 $\begin{array}{r}{R_{t}=\sum_{k=t+1}^{T}r_{k}}\end{array}$ 表示从时间 $t+1$ 到片段结束(即摘要完成时)的累计奖励。在将强化学习应用于抽取式摘要的场景中,瞬时奖励 $r_{t}$ 除片段结束时根据公式(1)计算最终奖励 $r$ 外均为零,因此 $R_{t}\equiv R_{0}=r$ 。该奖励 $r$ 通常表示为(Dong et al., 2018):
$$
r=\frac{1}{3}({\mathrm{ROUGE}}-1_{f}+{\mathrm{ROUGE}}-2_{f}+{\mathrm{ROUGE}}-\mathrm{L}_{f})
$$
$$
r=\frac{1}{3}({\mathrm{ROUGE}}-1_{f}+{\mathrm{ROUGE}}-2_{f}+{\mathrm{ROUGE}}-\mathrm{L}_{f})
$$
According to the REINFORCE algorithm (Williams, 1992), the policy gradient is defined as:
根据REINFORCE算法 (Williams, 1992),策略梯度定义为:
$$
\nabla J(\pmb\theta)=\mathbb{E}{\pi}[R_{t}\nabla\log\pi(A_{t}|S_{t},\pmb\theta)],
$$
$$
\nabla J(\pmb\theta)=\mathbb{E}{\pi}[R_{t}\nabla\log\pi(A_{t}|S_{t},\pmb\theta)],
$$
where $\pi(\boldsymbol{A}{t}|\boldsymbol{S}{t},\boldsymbol{\theta})$ denotes the likelihood that at time step $t$ the policy $\pi_{\theta}$ selects action $A_{t}$ given the
其中 $\pi(\boldsymbol{A}{t}|\boldsymbol{S}{t},\boldsymbol{\theta})$ 表示在时间步 $t$ 时策略 $\pi_{\theta}$ 在给定状态 $\boldsymbol{S}{t}$ 下选择动作 $\boldsymbol{A}_{t}$ 的概率。
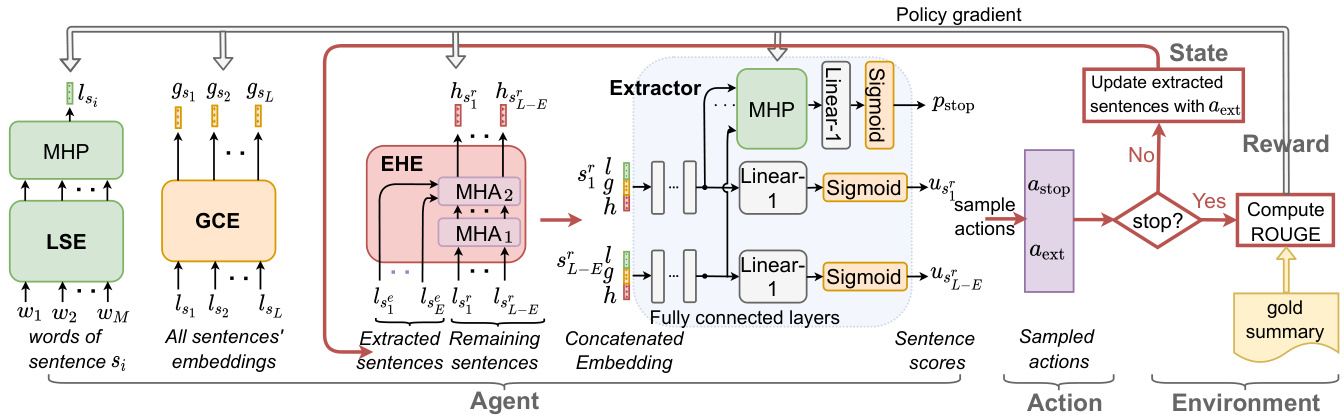
Figure 2: The architecture of our MemSum extractive summarizer with a multi-step episodic MDP policy. With the updating of the extraction-history embeddings $h$ at each time step $t$ , the scores $u$ of remaining sentences and the stopping probability $p_{\mathrm{stop}}$ are updated as well.
图 2: 我们MemSum抽取式摘要器的架构,采用多步情景MDP策略。随着每个时间步$t$提取历史嵌入$h$的更新,剩余句子的得分$u$和停止概率$p_{\mathrm{stop}}$也会相应更新。
state $S_{t}$ . With $\alpha$ as the learning rate, the parameter update rule is (Sutton and Barto, 2018):
状态 $S_{t}$。以 $\alpha$ 作为学习率,参数更新规则为 (Sutton and Barto, 2018):
$$
\begin{array}{r}{\pmb{\theta}{t+1}\leftarrow\pmb{\theta}{t}+\alpha R_{t}\nabla\log\pi(A_{t}|S_{t},\pmb{\theta}_{t}),}\end{array}
$$
$$
\begin{array}{r}{\pmb{\theta}{t+1}\leftarrow\pmb{\theta}{t}+\alpha R_{t}\nabla\log\pi(A_{t}|S_{t},\pmb{\theta}_{t}),}\end{array}
$$
3.2 Multi-step Episodic MDP Policy
3.2 多步情景MDP策略
where $I_{t}$ denotes the index set of remaining sentences at time step $t$ . If the agent does not stop, it first computes a score $u_{j}$ for each remaining sentence and samples a sentence $s_{a_{t}}$ according to the probability distribution of normalized scores. When the agent stops the extraction, no sentence is selected and the conditional likelihood $\scriptstyle p(a_{t}|{\mathrm{stop}}={\mathrm{false}},S_{t},\theta_{t})$ is set to $\frac{1}{|I_{t}|}$ (where $\left|I_{t}\right|$ represents the number of remaining sentences at time $t_{c}$ ), which is independent of the policy parameters to prohibit the gradient from being passed to the policy parameters via the conditional likelihood. After calculating the reward according to Equation (1), the policy parameters are updated accord- ing to Equation (3) (for all time steps).
其中 $I_{t}$ 表示时间步 $t$ 时剩余句子的索引集合。若智能体未停止,则先为每个剩余句子计算得分 $u_{j}$,并根据归一化得分的概率分布采样句子 $s_{a_{t}}$。当智能体停止抽取时,不选择任何句子,并将条件似然 $\scriptstyle p(a_{t}|{\mathrm{stop}}={\mathrm{false}},S_{t},\theta_{t})$ 设为 $\frac{1}{|I_{t}|}$ (其中 $\left|I_{t}\right|$ 表示时间 $t_{c}$ 时剩余句子的数量),该设定与策略参数无关以防止梯度通过条件似然传递至策略参数。根据公式(1)计算奖励后,所有时间步的策略参数均按公式(3)进行更新。
3.3 Policy Network
3.3 策略网络
The state $S_{t}$ in Equation (4) is designed to be informative on: 1) the local content of the sentence, 2) the global context of the sentence within the document, and 3) the current extraction history. To encode these three properties in the state, we use a local sentence encoder, a global context encoder, and an extraction history encoder, respectively. Subsequently, the state is mapped by an extractor to an output score for each of the remaining sentences and the extraction stop signal. The overall framework of our model is depicted in Figure 2.
方程(4) 中的状态 $S_{t}$ 设计用于反映以下信息: 1) 句子的局部内容, 2) 句子在文档中的全局上下文, 3) 当前提取历史。为了在状态中编码这三个属性, 我们分别使用了局部句子编码器、全局上下文编码器和提取历史编码器。随后, 通过提取器将状态映射为每个剩余句子的输出分数和提取停止信号。我们模型的整体框架如图 2 所示。
In the Local Sentence Encoder (LSE), ordered words $(w_{1},w_{2},...w_{M})$ in a sentence $s_{i}$ are first mapped onto word embeddings using a word embedding matrix. Subsequently, a $N_{l}$ -layer bidirectional LSTM (Hochreiter and Schmid huber, 1997) transforms the word embeddings and maps them onto sentence embeddings $l_{s_{i}}$ via a multihead pooling layer (MHP) (Liu and Lapata, 2019a).
在局部句子编码器 (LSE) 中,句子 $s_{i}$ 中的有序单词 $(w_{1},w_{2},...w_{M})$ 首先通过词嵌入矩阵映射为词嵌入。随后,一个 $N_{l}$ 层双向 LSTM (Hochreiter and Schmidhuber, 1997) 对这些词嵌入进行转换,并通过多头池化层 (MHP) (Liu and Lapata, 2019a) 将它们映射为句子嵌入 $l_{s_{i}}$。
The Global Context Encoder (GCE) consists of a $N_{g}$ -layer bi-LSTM that takes the $L$ local sentence embeddings $(l_{s_{1}},l_{s_{2}},\ldots l_{s_{L}})$ as inputs and produces for each sentence $s_{i}$ an embedding $g_{s_{i}}$ that encodes global contextual information such as the sentence’s position in the document and information on neighboring sentences.
全局上下文编码器 (GCE) 由 $N_{g}$ 层双向 LSTM 组成,它以 $L$ 个局部句子嵌入 $(l_{s_{1}},l_{s_{2}},\ldots l_{s_{L}})$ 作为输入,并为每个句子 $s_{i}$ 生成一个嵌入 $g_{s_{i}}$,该嵌入编码了全局上下文信息,例如句子在文档中的位置以及相邻句子的信息。
The Extraction History Encoder (EHE) encodes the extraction history information and produces the extraction history embedding $h_{s_{i}^{r}}$ for each remaining sentence $s_{i}^{r}$ . The EHE is composed of a stack of $N_{h}$ identical layers. Within one layer, there are two multi-head attention sublayers, as contained in the transformer decoder in Vaswani et al. (2017). One sublayer is used to perform multi-head self-attention (MHA) among the local embeddings of the remaining sentences, so that each remaining sentence can capture the context provided by other remaining sentences. The other attention sublayer is used to perform multi-head attention over the embeddings of extracted sentences to enable each remaining sentence to attend to all the extracted sentences. The output of the two attention sublayers, one for each remaining sentence, captures the contextual information of both extracted and remaining sentences. The final output of the $N_{h}^{\mathrm{th}}$ layer of the EHE constitutes the extraction history embedding, one for each remaining sentence.
提取历史编码器 (EHE) 对提取历史信息进行编码,并为每个剩余句子 $s_{i}^{r}$ 生成提取历史嵌入 $h_{s_{i}^{r}}$。EHE 由 $N_{h}$ 个相同层堆叠而成。每层包含两个多头注意力子层,与 Vaswani 等人 (2017) 提出的 Transformer 解码器结构一致。其中一个子层用于在剩余句子的局部嵌入之间执行多头自注意力 (MHA),使每个剩余句子都能捕捉其他剩余句子提供的上下文信息。另一个注意力子层则对已提取句子的嵌入执行多头注意力,使每个剩余句子都能关注所有已提取句子。这两个注意力子层(每个剩余句子对应一个)的输出同时捕捉了已提取和剩余句子的上下文信息。EHE 第 $N_{h}^{\mathrm{th}}$ 层的最终输出构成每个剩余句子对应的提取历史嵌入。
There is no positional encoding and the EHE produces the extraction history embeddings nonauto regressive ly by attending to both precedent and subsequent positions. Consequently, the extraction history embeddings $h_{s_{i}^{r}}$ for the remaining sen- tences are invariant to the order of the previously selected sentences. We believe that the sequential information of previously selected sentences is not crucial for reducing redundancy and for deciding whether to stop extraction or not.
没有位置编码,EHE通过同时关注前后位置非自回归地生成提取历史嵌入。因此,剩余句子的提取历史嵌入$h_{s_{i}^{r}}$对先前选中句子的顺序具有不变性。我们认为,已选句子的顺序信息对于减少冗余和决定是否停止提取并不关键。
The Extractor computes the score of each remaining sentence and outputs an extraction stop signal. As input to the extractor, we form for each of the remaining sentences $s_{i}^{r}$ an aggregated embedding by concatenating the local sentence embedding ${{l}{s_{i}^{r}}}$ , the global context embedding $g_{s_{i}^{r}}$ , and the extraction history embedding $h_{s_{i}^{r}}$ . As shown in Figure 2, to produce the score ${{u}{s_{i}^{r}}}$ , the concatenated embedding of remaining sentence $s_{i}^{r}$ is passed to fully connected layers with ReLU activation and then projected to a scalar by a Linear-1 layer followed by a sigmoid function. Note that the same fully connected layers are applied identically to all remaining sentences. We deem that the extractor can learn to stop extraction based on the remaining sentences’ states. Therefore, we apply an MHP to the last hidden vectors of all remaining sentences to output a single vector. This vector is then passed to a linear layer with a sigmoid function, producing a stopping probability $p_{\mathrm{stop}}$ .
提取器计算每个剩余句子的分数并输出一个抽取停止信号。作为提取器的输入,我们为每个剩余句子 $s_{i}^{r}$ 形成一个聚合嵌入,通过连接局部句子嵌入 ${{l}{s_{i}^{r}}}$、全局上下文嵌入 $g_{s_{i}^{r}}$ 和抽取历史嵌入 $h_{s_{i}^{r}}$。如图 2 所示,为了生成分数 ${{u}{s_{i}^{r}}}$,剩余句子 $s_{i}^{r}$ 的连接嵌入被传递到具有 ReLU 激活的全连接层,然后通过 Linear-1 层和 sigmoid 函数投影为标量。注意,相同的全连接层以相同方式应用于所有剩余句子。我们认为提取器可以基于剩余句子的状态学习停止抽取。因此,我们对所有剩余句子的最后隐藏向量应用 MHP 以输出单个向量。该向量随后传递到带有 sigmoid 函数的线性层,生成停止概率 $p_{\mathrm{stop}}$。
3.4 Training
3.4 训练
We train the parameterized policy network according to the update rule in Equation (3). At each training iteration, an episode is sampled to compute the final return $r$ and the action probabilities $\pi(A_{t}|S_{t},\pmb{\theta}{t})$ for all time steps $t$ . An example episode with $T$ extracted sentences looks like: $(S_{0},s_{a_{0}},\ldots,S_{T-1},s_{a_{T-1}},S_{T},A_{\mathrm{stop}},r)$ , where $S_{t}$ represents the concatenated state information introduced in Section 3.3, $s_{a_{t}}$ represents the selection of sentence $a_{t}$ , $A_{\mathrm{stop}}$ represents the extraction stops at the final time step $T$ , and $r$ is the reward as defined in Equation (1). To encourage the agent to select compact summaries, we multiply the final reward $r$ by a length penalty term $1/(T+1)$ (Luo et al., 2019). Consequently, the return Rt ≡ T r+1 .
我们根据方程(3)中的更新规则训练参数化策略网络。每次训练迭代时,采样一个情节来计算最终回报$r$和所有时间步$t$的动作概率$\pi(A_{t}|S_{t},\pmb{\theta}{t})$。一个包含$T$个抽取句子的示例情节如下:$(S_{0},s_{a_{0}},\ldots,S_{T-1},s_{a_{T-1}},S_{T},A_{\mathrm{stop}},r)$,其中$S_{t}$表示第3.3节介绍的拼接状态信息,$s_{a_{t}}$表示选择句子$a_{t}$,$A_{\mathrm{stop}}$表示在最终时间步$T$停止抽取,$r$是方程(1)定义的奖励。为鼓励智能体选择紧凑摘要,我们将最终奖励$r$乘以长度惩罚项$1/(T+1)$ (Luo et al., 2019)。因此,回报Rt ≡ T r+1。
Algorithm 1 The training algorithm.
算法 1: 训练算法
Parameters: learning rate $\alpha$
参数:学习率 $\alpha$
Algorithm 1 summarizes the training procedure of MemSum. We initialize the extraction history embeddings to 0, because at $t=0$ no sentences have been extracted. $E_{t}$ represents the number of sentences that have been extracted into the summary up to time step $t$ . Following the strategy in Narayan et al. (2018) and Mohsen et al. (2020), instead of sampling an episode following the current policy $\pi(\cdot|\cdot,\pmb{\theta}{t})$ , we sample an episode from a set $\mathbb{E}_{p}$ of episodes with high ROUGE scores, which enables the agent to quickly learn from optimal policies and to rapidly converge. Details on creating a set of high-ROUGE episodes for training are described in Appendix E.
算法1总结了MemSum的训练流程。我们将提取历史嵌入初始化为0,因为在$t=0$时尚未提取任何句子。$E_{t}$表示截至时间步$t$已提取到摘要中的句子数量。遵循Narayan等人(2018)和Mohsen等人(2020)的策略,我们没有按照当前策略$\pi(\cdot|\cdot,\pmb{\theta}{t})$采样片段,而是从具有高ROUGE得分的片段集合$\mathbb{E}_{p}$中采样,这使得智能体能够快速学习最优策略并迅速收敛。关于创建高ROUGE训练片段集的详细说明见附录E。
4 Experiments
4 实验
In this section, we report implementation details of our model and describe the datasets used for training and for evaluation.
在本节中,我们将报告模型的实现细节,并描述用于训练和评估的数据集。
Datasets. The documents to be summarized in the PubMed and arXiv datasets (Cohan et al., 2018)
数据集。PubMed和arXiv数据集(Cohan等人,2018)中待摘要的文档
Table 1: An overview of datasets used in this paper. We count only strings composed of letters and numbers for # of words.
表 1: 本文所用数据集概览。单词数仅统计由字母和数字组成的字符串。
| 数据集 | 平均文档长度 | 平均摘要长度 | 文档-摘要对数 |
|---|---|---|---|
| 单词数 | 句子数 | 单词数 | |
| PubMed | 2,730 | 88 | 181 |
| arXiv | 5,206 | 206 | 238 |
| PubMedtrunc | 408 | 13 | 185 |
| GovReport | 7,932 | 307 | 501 |
| CNN/DM | 692 | 35 | 49 |
are the full bodies of scientific papers and the gold summaries are the corresponding abstracts. Zhong et al. (2020) proposed a truncated version of the PubMed dataset $\mathrm{(PubMed_{trunc}}$ for simplicity) by defining a doument as the introduction section of a paper. The GovReport dataset (Huang et al., 2021) contains U.S. government reports with gold summaries written by experts. Except $\mathrm{PubMed}_{\mathrm{trunc}}$ , all the other datasets contain significantly longer documents than the popular dataset CNN/DM (Table 1). Baselines. Extractive baselines include Lead (directly using the first several sentences as the summary) (Gidiotis and Tsoumakas, 2020), SummaRuNNer (Nallapati et al., 2017), Atten-Cont(Xiao and Carenini, 2019), Sent-CLF and SentPTR (Pilault et al., 2020), MatchSum (Zhong et al., 2020), and the NeuSum model (Zhou et al., 2018) that we trained on our datasets.
科学论文的全文为原始文本,对应的摘要则为黄金标准摘要。Zhong等人(2020)提出了PubMed数据集的截断版本(为简便起见记为$\mathrm{PubMed_{trunc}}$),将论文的引言部分定义为文档。GovReport数据集(Huang等人,2021)包含美国政府报告及专家撰写的黄金标准摘要。除$\mathrm{PubMed}_{\mathrm{trunc}}$外,其他数据集所含文档长度均显著超过CNN/DM等流行数据集(表1)。基线方法:抽取式基线包括Lead(直接取前几句作为摘要)(Gidiotis和Tsoumakas,2020)、SummaRuNNer(Nallapati等人,2017)、Atten-Cont(Xiao和Carenini,2019)、Sent-CLF与SentPTR(Pilault等人,2020)、MatchSum(Zhong等人,2020),以及我们在数据集上训练的NeuSum模型(Zhou等人,2018)。
Abstract ive sum mari z ation models include PEGASUS (Zhang et al., 2020), BigBird (Zaheer et al., 2020), Dancer (Gidiotis and Tsoumakas, 2020), and Hepos (Huang et al., 2021) that achieved the state-of-the-art in long document sum mari z ation using a large-scale pretrained BART model (Lewis et al., 2020) with memory-efficient attention encoding schemes including Locality Sensitive Hashing (Kitaev et al., 2020) (Hepos-LSH) and Sinkhorn attention (Hepos-Sinkhorn). We also present the performance of the oracle extraction model based on the greedy approach (Nallapati et al., 2017) which sequentially selects from the document the sentence that maximally improves the average of R-1 and R-2 of selected sentences.
抽象式摘要模型包括PEGASUS (Zhang等人,2020)、BigBird (Zaheer等人,2020)、Dancer (Gidiotis和Tsoumakas,2020)以及Hepos (Huang等人,2021)。这些模型通过采用基于大规模预训练BART模型 (Lewis等人,2020)的高效注意力编码方案——包括局部敏感哈希 (Kitaev等人,2020) (Hepos-LSH)和Sinkhorn注意力 (Hepos-Sinkhorn)——在长文档摘要任务上达到了最先进水平。我们还展示了基于贪婪算法 (Nallapati等人,2017)的oracle抽取模型性能,该模型通过依次选择能最大化已选句子R-1和R-2平均值的文档句子来实现。
Implementation Details. We computed local sentence embeddings using pretrained Glove word embeddings (Pennington et al., 2014) of dimension $d=200$ , keeping the word embeddings fixed during training. For the LSE, we used $N_{l}~=~2$ bi- LSTM layers and for the GCE $N_{g}=2$ . For the
实现细节。我们使用预训练的 Glove 词嵌入 (Pennington et al., 2014) 计算局部句子嵌入,维度为 $d=200$,并在训练过程中保持词嵌入固定。对于 LSE,我们使用 $N_{l}~=~2$ 层双向 LSTM,对于 GCE 使用 $N_{g}=2$ 层。
EHE, we used $N_{h}=3$ attention layers, and we set the number of attention heads to 8 and the dimension of the feed-forward hidden layer to 1024; during training we set the dropout rate to 0.1. The extractor consisted of 2 fully-connected hidden layers with output dimensions $2d$ and $d$ , respectively.
在EHE中,我们使用了$N_{h}=3$个注意力层,并将注意力头数设为8,前馈隐藏层维度设为1024;训练期间将dropout率设置为0.1。提取器由2个全连接隐藏层组成,输出维度分别为$2d$和$d$。
We trained our model using the Adam optimizer with $\beta_{1}=0.9$ , $\beta_{2}=0.999$ (Kingma and Ba, 2015), fixed learning rate $\alpha=1e^{-4}$ , and weight decay $1e^{-6}$ . The training was stopped when the validation performance started to degrade. During validating and testing, the agent extracted sentences in a deterministic way: after computing the scores ${u}{s_{i}^{r}}$ for the remaining sentences and the stop likelihood $p_{\mathrm{stop}}$ , the agent stopped the extraction if $p_{\mathrm{stop}}\geq p_{\mathrm{thres}}$ or if the maximum admissible number $N_{\mathrm{max}}$ of extracted sentences was reached; otherwise, the agent selected the sentence with the largest score. The model was trained on eight RTX 2080 Ti GPUs.
我们使用 Adam 优化器 (Kingma and Ba, 2015) 训练模型,参数设置为 $\beta_{1}=0.9$、$\beta_{2}=0.999$,固定学习率 $\alpha=1e^{-4}$,权重衰减 $1e^{-6}$。当验证性能开始下降时停止训练。在验证和测试阶段,智能体以确定性方式提取句子:计算剩余句子的得分 ${u}{s_{i}^{r}}$ 和停止概率 $p_{\mathrm{stop}}$ 后,若 $p_{\mathrm{stop}}\geq p_{\mathrm{thres}}$ 或达到最大可提取句子数 $N_{\mathrm{max}}$ 则停止提取;否则选择得分最高的句子。模型在八块 RTX 2080 Ti GPU 上进行训练。
On the validating datasets we selected the best checkpoint of each model and determined the optimal $N_{\mathrm{max}}$ and stopping criterion $p_{\mathrm{thres}}^{}$ . For Pubmed, arXiv, Pubmed tr unc, and GovReport, $N_{\mathrm{max}}$ was set to 7, 5, 7, and 22, and $p_{\mathrm{thres}}^{*}$ was set to 0.6, 0.5, 0.8, and 0.6, respectively. For the detailed selection procedure of the optimal stopping threshold, see Appendix D. Information on reproducibility is available in Appendix I.
在验证数据集上,我们为每个模型选择了最佳检查点,并确定了最优的 $N_{\mathrm{max}}$ 和停止准则 $p_{\mathrm{thres}}^{}$。对于 Pubmed、arXiv、Pubmed tr unc 和 GovReport,$N_{\mathrm{max}}$ 分别设置为 7、5、7 和 22,$p_{\mathrm{thres}}^{*}$ 分别设置为 0.6、0.5、0.8 和 0.6。关于最优停止阈值的详细选择过程,请参阅附录 D。可复现性相关信息见附录 I。
Evaluation. We evaluated the performance of our model using $F_{1}$ ROUGE (Lin, 2004), including ROUGE-1,2, and L for measuring unigram, bigram, and longest common sub sequence. We also conducted human evaluation in Section 5.4.
评估。我们使用 $F_{1}$ ROUGE (Lin, 2004) 评估模型性能,包括 ROUGE-1、2 和 L,用于测量单字组、双字组和最长公共子序列。此外,我们在第 5.4 节进行了人工评估。
5 Results and Discussion
5 结果与讨论
Here we present the results on various extractive sum mari z ation tasks and analyze the contribution of different modules via ablation studies.
我们在此展示多种抽取式摘要任务的结果,并通过消融实验分析不同模块的贡献。
5.1 Results Comparison
5.1 结果对比
By comparing with extractive baselines on the PubMed and arXiv datasets, we observed that models utilizing extraction history, such as NeuSum and our MemSum, perform significantly better than other models, revealing the effectiveness of the extraction history. MemSum also significantly outperformed NeuSum, suggesting a better utilization of extraction history, which we ascribed to the following factors: 1) In MemSum, we treat stopping extraction also as an action and train the policy network to output a stopping probability. Therefore, MemSum is able to automatically stop extracting at an optimal time step based on extraction history, while NeuSum can only extract a predefined number of sentences; 2) With the policy gradient method REINFORCE we can train MemSum to maximize the ROUGE score directly, while in NeuSum the loss was set to the KL-divergence between the model-computed sentence scores and the ROUGE score gains at each step, which is less intuitive. We further compare MemSum with NeuSum via human evaluation in Section 5.4.
通过在PubMed和arXiv数据集上与抽取式基线模型对比,我们发现利用抽取历史记录的模型(如NeuSum和我们的MemSum)性能显著优于其他模型,这揭示了抽取历史记录的有效性。MemSum还显著优于NeuSum,表明其对抽取历史记录的利用更高效,我们将其归因于以下因素:1) 在MemSum中,我们将停止抽取也视为一个动作,并训练策略网络输出停止概率。因此MemSum能基于抽取历史自动选择最优停止时机,而NeuSum只能抽取预设数量的句子;2) 通过策略梯度方法REINFORCE,我们可以直接训练MemSum以最大化ROUGE分数,而NeuSum的损失函数设置为模型计算的句子分数与每步ROUGE增益之间的KL散度,这种方式不够直观。我们将在5.4节通过人工评估进一步比较MemSum与NeuSum。
Table 2: Results on the PubMed and arXiv test sets. “*" indicates that they are statistically significant in comparison to the closest baseline with a $95%$ bootstrap confidence interval estimated by the ROUGE script2.
表 2: PubMed和arXiv测试集上的结果。"*"表示与最接近的基线相比具有统计学显著性,置信区间为95%,通过ROUGE脚本2估计。
| 模型 | PubMed | arXiv | ||||
|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| ORACLE | 61.99 | 34.95 | 56.76 | 60.00 | 30.60 | 53.03 |
| 抽取式摘要基线 | ||||||
| Lead-10 SummaRuNNer | 37.45 43.89 | 14.19 18.78 | 34.07 30.36 | 35.52 42.81 | 10.33 16.52 | 31.44 28.23 |
| Atten-Cont Sent-CLF | 44.85 45.01 | 19.70 19.91 | 31.43 41.16 | 43.62 34.01 | 17.36 8.71 | 29.14 30.41 |
| Sent-PTR NeuSum | 43.30 47.46 | 17.92 21.92 | 39.47 42.87 | 42.32 47.49 | 15.63 21.56 | 38.06 41.58 |
| 生成式摘要基线 | ||||||
| PEGASUS BigBird | 45.97 46.32 | 20.15 20.65 | 41.34 42.33 | 44.21 46.63 | 16.95 19.02 | 38.83 41.77 |
| Dancer Hepos-Sinkhorn | 46.34 47.93 | 19.97 20.74 | 42.42 42.58 | 45.01 47.87 | 17.60 20.00 | 40.56 41.50 |
| Hepos-LSH MemSum (ours) | 48.12 49.25* | 21.06 22.94* | 42.72 44.42* | 48.24 | 20.26 | 41.78 |
Table 3: Results on PubMed $\operatorname{trunc}$ and GovReport.
表 3: PubMed $\operatorname{trunc}$ 和 GovReport 上的结果
| 模型 | PubMedtrune | GovReport | ||||
|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| ORACLE | 45.12 | 20.33 | 40.19 | 75.56 | 45.91 | 72.51 |
| 抽取式摘要基线 | ||||||
| Lead | 37.58 | 12.22 | 33.44 | 50.94 | 19.53 | 48.45 |
| MatchSum | 41.21 | 14.91 | 36.75 | - | - | - |
| NeuSum | - | - | - | 58.94 | 25.38 | 55.80 |
| 生成式摘要基线 | ||||||
| Hepos-LSH | - | - | - | 55.00 | 21.13 | 51.67 |
| Hepos-Sinkhorn | - | - | - | 56.86 | 22.62 | 53.82 |
| MemSum (ours) | 43.08* | 16.71* | 38.30* | 59.43* | 28.60* | 56.69* |
We observed that the ROUGE performance on the PubMed tr unc dataset is significantly lower than that on the PubMed dataset, with a 16.87 drop in R-1 for the extractive oracle and a 6.23 drop in R-1 for MemSum, indicating that the introduction section is not sufficient to generate summaries close to the ground truth (abstracts). Even so, our model still significantly outperformed MatchSum on $\mathrm{PubMed}_{\mathrm{trunc}}$ , and we attribute this improvement
我们观察到,在PubMed_trunc数据集上的ROUGE性能明显低于PubMed数据集,其中抽取式oracle的R-1下降了16.87,MemSum的R-1下降了6.23,这表明仅凭引言部分不足以生成接近真实摘要(即论文摘要)的内容。尽管如此,我们的模型在$\mathrm{PubMed}_{\mathrm{trunc}}$上仍显著优于MatchSum,我们将这一改进归因于...

Figure 3: The position distribution of extracted sentences in the $\mathrm{PubMed}_{\mathrm{trunc}}$ dataset.
图 3: 在 $\mathrm{PubMed}_{\mathrm{trunc}}$ 数据集中提取句子的位置分布。
Human-written Summary:
人工撰写摘要:
(...) 虽然当州的资格错误率超过3%时,CMS (Centers for Medicare & Medicaid Services) 通常需要禁止或追回与资格相关的不当支付的联邦资金,但几十年来它并未这样做。(...) CMS 发布了修订后的程序,从2022财年开始,可以通过这些程序追回因资格错误而产生的资金。Hepos-Sinkhorn (抽象式):
(...) 被选中的州还报告称,它们没有足够的流程来解决这些问题。CMS 已采取措施加强对医疗补助计划的监督,包括向各州发布关于使用 MAGI (Modified Adjusted Gross Income) 豁免基础来确定资格的指导,但这些努力尚未完全落实。(...) MemSum (我们的,抽取式):
(...) 通过其 MEQC (Medicaid Eligibility Quality Control) 计划,实施了法定要求,对资格错误率超过3%的州追回与医疗补助资格相关的不当支付资金。(...) 然而,该机构引入了新的程序,在某些情况下可以从2022财年开始基于资格错误追回资金。(...)
Table 4: Comparison of the summary extracted by MemSum and the summary abstract iv ely generated by Hepos-Sinkhorn (Huang et al., 2021). Compared with the abstract ive summary, the MemSum-extracted summary has higher overlap with the human-written summary.
表 4: MemSum提取的摘要与Hepos-Sinkhorn (Huang et al., 2021)生成的抽象摘要对比。相比抽象摘要,MemSum提取的摘要与人工撰写摘要的重叠度更高。
to the fact that MatchSum truncates the introduction section further to 512 tokens because it needs to compute document embeddings using Bert. Consequently, MatchSum extracts sentences mainly from the first 15 sentences of the document, while our MemSum produces a similar distribution of extracted sentence positions as the extractive oracle, Figure 3. Thus, summarizing long documents is a non-trivial task, and models that work well on summarizing short documents (e.g., CNN/DM) may fail to generalize to long documents.
由于MatchSum需要使用Bert计算文档嵌入,因此它将引言部分进一步截断至512个token。这导致MatchSum提取的句子主要来自文档的前15句,而我们的MemSum所提取句子位置的分布则与抽取式基准模型相似(图3)。由此可见,长文档摘要是一项非平凡任务,在短文档(如CNN/DM)上表现良好的模型可能无法推广到长文档场景。
MemSum also significantly outperformed the state-of-the-art abstract ive sum mari z ation model Hepos as measured by ROUGE scores, especially on the GovReport dataset. A comparison of an exemplary MemSum-extracted summary and the corresponding Hepos-Sinkhorn-generated summary from the GovReport dataset (Table 4) is consistent with the ROUGE comparison, showing that the MemSum-extracted summary is more accurate than the Hepos-Sinkhorn-generated summary and has higher overlap with the gold summary. We deem that this particularly good extraction performance on the GovReport dataset results from the higher “ex tractive ness” of the gold summaries in the GovReport dataset compared to other datasets, which may be due in part to technical language being difficult to abstract iv ely summarize without a change in meaning. This is evidenced by the fact that the ROUGE scores of the extractive oracle on the GovReport dataset (Table 3) are higher than those of the PubMed and arXiv datasets (Table 2). Therefore, extractive sum mari z ation may be more proper than abstract ive sum mari z ation due to the requirement of stringent faithfulness of government report summaries.
MemSum在ROUGE分数衡量下也显著优于最先进的生成式摘要模型Hepos,尤其在GovReport数据集上表现突出。表4展示了GovReport数据集中MemSum提取摘要与Hepos-Sinkhorn生成摘要的对比实例,该结果与ROUGE分数比较一致:MemSum提取的摘要比Hepos-Sinkhorn生成的摘要更准确,且与黄金摘要的重合度更高。我们认为这种在GovReport数据集上特别优异的提取性能,源于该数据集的黄金摘要相比其他数据集具有更高的"可提取性"——部分原因可能是技术性语言难以在不改变原意的情况下进行生成式概括。这一观点得到以下事实支持:GovReport数据集上提取式oracle的ROUGE分数(表3)高于PubMed和arXiv数据集(表2)。因此,由于政府报告摘要对严格保真度的要求,提取式摘要可能比生成式摘要更为合适。
Table 5: Ablation study on the PubMed dataset.
表 5: PubMed数据集消融研究。
| 模型 | R-1 | R-2 | R-L |
|---|---|---|---|
| MemSum | 49.25 | 22.94 | 44.42 |
| MemSumw/oLSE | 48.12 | 22.04 | 43.36 |
| MemSumw/oGCE | 46.85 | 20.31 | 41.95 |
| MemSumw/oEHE | 48.08 | 22.77 | 43.55 |
| MemSumwithGRU-EHE | 49.11 | 22.86 | 44.28 |
| MemSumw/oauto-stop | 48.25 | 22.63 | 43.70 |
| MemSumwith"STOP” | 47.18 | 21.81 | 42.20 |
5.2 Ablation Test
5.2 消融实验
We conduct ablation studies by comparing the full MemSum model with the following variations in structures: 1) MemSum w/o LSE, where we obtain local sentence embeddings by replacing the bi-LSTM based LSE by simple averages of word embeddings; 2) MemSum w/o GCE where we remove the GCE; 3) MemSum w/o EHE where we remove EHE, compute the scores for all sentences in one step, and samples sentences following the BanditSum policy (Dong et al., 2018); 4) MemSum with GRU-EHE where we use a GRU to encode previously extracted sentences at each time step, and uses the last hidden state as the extraction history embedding for all remaining sentences, following Zhou et al. (2018).
我们通过比较完整MemSum模型与以下结构变体进行消融研究:1) MemSum w/o LSE,通过用词嵌入简单平均值替换基于双向LSTM的LSE来获取局部句子嵌入;2) MemSum w/o GCE,移除GCE模块;3) MemSum w/o EHE,移除EHE模块,一步计算所有句子得分,并遵循BanditSum策略(Dong et al., 2018)采样句子;4) MemSum with GRU-EHE,采用GRU编码每个时间步已提取的句子,并如Zhou et al. (2018)所述使用最后隐藏状态作为所有剩余句子的提取历史嵌入。
Meanwhile, we also tested two variations that adopted different stopping mechanisms: 1) MemSum w/o auto-stop that does not stop extraction auto mati call y based on $p_{\mathrm{stop}}$ , but that extracts a fixed number of sentences; 2) MemSum with “STOP” that inserts a special stop sentence (e.g. “STOP") into the document, and stops extraction once the agent selects this sentence.
同时,我们还测试了两种采用不同停止机制的变体:1) MemSum w/o auto-stop,不基于 $p_{\mathrm{stop}}$ 自动停止提取,而是提取固定数量的句子;2) 带“STOP”的MemSum,在文档中插入一个特殊的停止句子(例如“STOP”),一旦智能体选择该句子即停止提取。
Table 6: Performance on the redundant PubMed dataset.
表 6: 冗余PubMed数据集上的性能表现。
| 模型 | R-1 | R-2 | R-L | 重复百分比 |
|---|---|---|---|---|
| MemSum | 49.16 | 22.78 | 44.39 | 0% |
| MemSumw/oauto-stop | 48.21 | 22.59 | 43.76 | 0% |
| MemSumw/oEHE | 42.82 | 18.18 | 36.68 | 41% |
| MemSumw/oEHE +3gram blocking | 46.85 | 19.93 | 42.40 | 0% |
Contribution of Modules. Removing GCE has a greater impact on performance than removing LSE (Table 5), suggesting that modeling global contextual information is more critical than modeling local sentence information in our MemSum framework, which contrasts with the result that modeling local sentence information is more important in the Atten-Cont (Xiao and Carenini, 2019) framework. Furthermore, we observed a significant performance degradation when removing EHE, but no significant difference between MemSum and MemSum with GRU-EHE, indicating that EHE is necessary, but our MemSum policy is not strongly dependent on the specific structure of this module (e.g., attention-based or RNN-based).
模块贡献分析。移除GCE对性能的影响大于移除LSE (表5),这表明在我们的MemSum框架中,建模全局上下文信息比建模局部句子信息更为关键,这与Atten-Cont框架中建模局部句子信息更重要的结论 (Xiao and Carenini, 2019) 形成对比。此外,移除EHE会导致性能显著下降,但MemSum与采用GRU-EHE的MemSum之间没有显著差异,说明EHE是必要的,但我们的MemSum策略并不强烈依赖该模块的具体结构 (例如基于注意力机制或基于RNN)。
Influence of Stopping Mechanisms. MemSum w/o auto-stop achieves lower ROUGE scores than MemSum, revealing the necessity of auto stopping in our MemSum architecture. Meanwhile, MemSum with “STOP” produced summaries with fewer extracted sentences (3.9 vs. 6.0 sentences on average) and significantly lower ROUGE scores. We attribute this reduction to the predictable positive reward obtained from selecting the special stop sentence that ends an episode, which leads to a preference for this final action and increases the likelihood of taking this action prematurely.
停止机制的影响。MemSum无自动停止功能的版本比完整版MemSum取得了更低的ROUGE分数,这揭示了自动停止机制在我们MemSum架构中的必要性。同时,采用"STOP"机制的MemSum生成的摘要包含更少提取句子(平均3.9句 vs. 6.0句)且ROUGE分数显著降低。我们将这种性能下降归因于:选择特殊停止句子来终止回合时可获得可预测的正向奖励,这导致模型偏好该最终动作,并增加了过早采取该动作的可能性。
5.3 History Awareness Avoids Redundancy
5.3 历史感知避免冗余
We hypothesized that the extraction history allows MemSum to avoid sentences that are similar to existing sentences in the current partial summary, intuitively mimicking what humans do when ex tr actively summarizing documents. To verify this, we created a redundant PubMed dataset in which we repeated each sentence in the document, with the replicated sentences immediately following the originals. On this dataset, we trained and tested MemSum and MemSum w/o EHE (no history awareness), and we compared different models in terms of ROUGE scores and average duplicate percentage that is defined as the average percentage of the duplicated sentences among all extracted sentences in a summary.
我们假设提取历史使MemSum能够避免与当前部分摘要中已有句子相似的句子,直观地模拟人类在提取式摘要时的行为。为验证这一点,我们创建了一个冗余PubMed数据集,其中文档中的每个句子都被重复一次,复制的句子紧接在原始句子之后。在该数据集上,我们训练并测试了MemSum和MemSum w/o EHE(无历史感知),并通过ROUGE分数和平均重复百分比(定义为摘要中所有提取句子中重复句子的平均占比)来比较不同模型。

Figure 4: The sentence scores of 50 sentences computed by MemSum at extraction steps 0 to 3. In the document, there is artificial redundancy in that the $(2n){\mathrm{th}}$ and the $(2n+1)_{\mathrm{th}}$ sentences are identical $(n=$ $0,1,...,24)$ .
图 4: MemSum 在抽取步骤 0 至 3 时计算的 50 个句子的分数。文档中存在人为冗余,其中第 $(2n){\mathrm{th}}$ 句和第 $(2n+1)_{\mathrm{th}}$ 句完全相同 $(n= 0,1,...,24)$。
As reported in Table 6, for MemSum w/o EHE, on average $41%$ of sentences in the extracted summaries were duplicated. Along with the high duplicate ratio came a significant decrease in ROUGE score. By contrast, the performance of the full MemSum model with history awareness was only slighted affected when comparing the results of the MemSum on the PubMed dataset (Table 2) and on the redundant PubMed dataset (Table 6).
如表6所示,对于不带EHE的MemSum模型,提取摘要中平均有41%的句子存在重复。伴随高重复率而来的是ROUGE分数的大幅下降。相比之下,具有历史感知能力的完整MemSum模型在PubMed数据集(表2)和冗余PubMed数据集(表6)上的结果对比显示,其性能仅受到轻微影响。
Meanwhile, using the Trigram Blocking method that skips a sentence if it has a trigram that overlaps with the current summary (Liu and Lapata, 2019b) is also successful in avoiding repetitive sentences. However, the ROUGE scores associated with Trigram Blocking were significantly lower than those of the MemSum with awareness of extraction history. In summary, the history-aware MemSum model spontaneously learns an optimized strategy to avoid redundant sentences without explicit human guidance or crude rules, and thus shows better performance.
与此同时,采用Trigram Blocking方法(若句子存在与当前摘要重叠的三元组则跳过该句)(Liu and Lapata, 2019b) 也能有效避免重复句。但Trigram Blocking对应的ROUGE分数显著低于具备抽取历史感知的MemSum模型。综上,历史感知型MemSum模型无需显式人工指导或粗糙规则,即可自主学习避免冗余句子的优化策略,因而表现出更优性能。
Case Study: How does MemSum Avoid Redundancy?
案例研究:MemSum如何避免冗余?
We let MemSum summarize a document sampled from the test set of the redundant PubMed dataset and monitored the sentence scores produced by the Extractor during each extraction step. The results are shown in Figure 4. At time step 0, the $10_{\mathrm{th}}$ sentence obtained the maximum score and was thus selected into the summary. At time step 1, we noticed that the $11\mathrm{{{th}}}$ sentence, which is a replica of the $10_{\mathrm{th}}$ sentence, had a score close to zero. The same was also true for the other selected sentences and their following sentences, revealing competent repetition avoidance of the Extractor. Because the EHE is insensitive to the extraction order and to sentence position information, as described in Section 3.3, we can conclude that the full MemSum avoids redundancy by evaluating the similarity between selected and remaining sentences, rather than by “remembering" selected sentences’ positions.
我们让MemSum对冗余PubMed数据集测试集中采样的文档进行摘要,并监测Extractor在每次提取步骤中生成的句子评分。结果如图4所示。在时间步0,第10个句子获得最高分,因此被选入摘要。在时间步1,我们注意到第11个句子(即第10个句子的重复版本)得分接近于零。其他被选句子及其后续句子也呈现相同规律,这表明Extractor具备出色的重复规避能力。如第3.3节所述,由于EHE对提取顺序和句子位置信息不敏感,我们可以得出结论:完整版MemSum是通过评估已选句子与剩余句子的相似性(而非"记忆"已选句子位置)来实现冗余规避的。
Table 7: The average ranking of NeuSum and MemSum is reported. The smaller the ranking, the better the model. Four volunteers participated in these experiments, and evaluated 67 and 63 pairs of summaries in Experiment 1 and 2, respectively. “*” indicates statistical significance $\mathrm{\tilde{p}}{<}0.005\mathrm{)}$ in a Wilcoxon signed-rank test (Woolson, 2008).
表 7: 报告了NeuSum和MemSum的平均排名。排名越小表示模型性能越好。四项实验共有四位志愿者参与,分别在实验1和实验2中评估了67对和63对摘要。标注"*"表示在Wilcoxon符号秩检验(Woolson, 2008)中具有统计学显著性($\mathrm{\tilde{p}}{<}0.005\mathrm{)}$)。
| 标准 | 实验I | 实验II |
|---|---|---|
| NeuSum | MemSum | |
| 整体性 | 1.58 | 1.37 |
| 覆盖率 | 1.46 | 1.49 |
| 非冗余性/平均摘要长度 | 1.67 | 1.28* |
| 句子数量 | 7.0 | 5.6* |
| 单词数量 | 248.8 | 189.3* |
5.4 Human Evaluation
5.4 人工评估
We conducted human evaluation following Wu and Hu (2018); Dong et al. (2018); Luo et al. (2019). For each document sampled from the test set of the PubMed dataset, we provide a reference summary, and volunteers are asked to rank a pair of randomly ordered summaries produced by two models according to three criteria: non-redundancy, coverage, and overall quality. The better model will be ranked #1 while the other is ranked #2, and if both models extract the same summary, then they will both get the #1 rank. In experiment 1, we compared NeuSum, which always extracts 7 sentences, and MemSum, which extracts a flexible number of sentences thanks to automatic stopping. In experiment 2, we discounted for differences in the number of extracted sentences by making MemSum w/o autostop to also extract 7 sentences. A user-friendly interactive web interface was implemented to assist the evaluation process, with details in Appendix G.
我们参照 Wu 和 Hu (2018)、Dong 等人 (2018) 以及 Luo 等人 (2019) 的方法进行了人工评估。对于从 PubMed 数据集测试集中采样的每篇文档,我们提供参考摘要,并要求志愿者根据三个标准对两个模型随机排序生成的摘要对进行评分:非冗余性、覆盖率和整体质量。表现更好的模型将排名第 1,另一个排名第 2;若两个模型提取的摘要相同,则均获得第 1 排名。在实验 1 中,我们比较了固定提取 7 个句子的 NeuSum 和借助自动停止机制灵活提取句子数量的 MemSum。实验 2 中,我们通过让 MemSum w/o autostop 同样提取 7 个句子来消除提取句子数量差异的影响。为辅助评估过程,我们开发了用户友好的交互式网页界面,详见附录 G。
Table 7 reports the human evaluation results for both experiments. Both MemSum and MemSum w/o auto-stop ranked significantly higher $(\mathtt{p}{<}0.005)$ than NeuSum in terms of non-redundancy and achieved a better average overall quality. In terms of word count, MemSum produces shorter summaries than NeuSum in both experiments, even though both models extract the same number of sentences in experiment 2. These results show that redundancy avoidance of MemSum is particularly good, even without the auto-stop mechanism. The slightly better performance of NeuSum in terms of coverage needs to be weighed against it extracting significantly longer summaries. Note that neither NeuSum nor our model is trained to optimize the order of the extracted sentences. Therefore, we did not use fluency, which depends on sentence order, as a metric for human evaluation. Improving the fluency of the extracted summaries will be the subject of our future research.
表 7 报告了两组实验的人工评估结果。在非冗余性方面,MemSum 和 MemSum w/o auto-stop 均显著优于 NeuSum $(\mathtt{p}{<}0.005)$ ,且平均综合质量更高。虽然实验 2 中两个模型抽取的句子数量相同,但 MemSum 生成的摘要长度更短。这些结果表明,即使没有自动停止机制,MemSum 的冗余规避能力依然出色。NeuSum 在覆盖度上的微弱优势需要与其明显更长的摘要长度进行权衡。值得注意的是,NeuSum 和我们的模型都未针对句子顺序进行优化训练,因此我们未将依赖句子顺序的流畅度作为人工评估指标。提升摘要的流畅性将是我们未来的研究方向。
6 Conclusion
6 结论
Extractive sum mari z ation can be achieved effectively with a multi-step episodic Markov decision process with history awareness. Using encoders of local sentence, global context, and extraction history, MemSum is given information that is intuitively also used by humans when they summarize a document. Awareness of the extraction history helps MemSum to produce compact summaries and to be robust against redundancy in the document. As a lightweight model (Appendix C), MemSum outperforms both extractive and abstract ive baselines on diverse long document sum mari z ation tasks. Because MemSum achieves SOTA performance on these tasks, MDP approaches will be promising design choices for further research.
基于历史感知的多步片段马尔可夫决策过程能有效实现抽取式摘要。MemSum通过局部句子编码器、全局上下文编码器和抽取历史编码器,获取了人类在文档摘要时直观使用的信息。对抽取历史的感知使MemSum能生成紧凑的摘要,并对文档冗余内容具有鲁棒性。作为轻量级模型(附录C),MemSum在多种长文档摘要任务上超越了抽取式和生成式基线方法。由于MemSum在这些任务中实现了SOTA性能,MDP方法将成为未来研究中有前景的设计选择。