Mask Selection and Propagation for Unsupervised Video Object Segmentation
无监督视频目标分割中的掩码选择与传播
Shubhika Garg Vidit Goel Indian Institute of Technology, Kharagpur, West Bengal, India s hub hik agar g 97@gmail.com, gvidit98@gmail.com
Shubhika Garg Vidit Goel 印度理工学院卡拉格普尔分校, 西孟加拉邦, 印度 s hub hik agar g 97@gmail.com, gvidit98@gmail.com
Abstract
摘要
In this work we present a novel approach for Unsupervised Video Object Segmentation, that is automatically generating instance level segmentation masks for salient objects and tracking them in a video. We efficiently handle problems present in existing methods such as drift while temporal propagation, tracking and addition of new objects. To this end, we propose a novel idea of improving masks in an online manner using ensemble of criteria whose task is to inspect the quality of masks. We introduce a novel idea of assessing mask quality using a neural network called Selector Net. The proposed network is trained is such way that it is generalizes across various datasets. Our proposed method is able to limit the noise accumulated along the video, giving state of the art result on Davis 2019 Unsupervised challenge dataset with mean $6l.6%$ . We also tested on datasets such as FBMS and SegTrack V2 and performed better or on par compared to the other methods.
在本工作中,我们提出了一种无监督视频目标分割的新方法,能够自动为显著目标生成实例级分割掩码并在视频中跟踪它们。我们有效解决了现有方法中存在的时域传播漂移、目标跟踪及新增对象处理等问题。为此,我们创新性地提出通过多标准集成在线优化掩码的方案,这些标准用于评估掩码质量。我们引入了一种基于Selector Net神经网络的全新掩码质量评估机制,该网络通过跨数据集训练实现泛化能力。所提方法能有效抑制视频序列中的噪声累积,在Davis 2019无监督挑战数据集上以均值$6l.6%$取得当前最佳性能。在FBMS和SegTrack V2等数据集上的测试结果也优于或持平其他方法。
1. Introduction
1. 引言
Video understanding has gained a lot of attention in recent years. This work focuses on unsupervised video object segmentation. In the unsupervised setting1 there is no prior information given about the objects that need to be segmented and tracked unlike the semi-supervised scenario in which annotations are given for the first frame. The objects of interest are the ones which are likely to catch human attention[51]. Due to this loose definition, the task becomes even more challenging.
近年来,视频理解领域备受关注。本研究聚焦于无监督视频目标分割任务。在无监督设定下,与首帧提供标注的半监督场景不同,系统无法获得待分割追踪目标的先验信息。目标对象通常是可能吸引人类注意力的物体 [51]。由于这种宽松的定义,该任务显得更具挑战性。
With the advent of deep learning, almost all the methods proposed recently are learning based. Though there are some classical methods which are used in deep learning pipeline such as [2, 40]. A lot of the prior work in multi-object video segmentation is done in semi-supervised setting [29, 47]. As in semi supervised setting, the masks for first frame are given, the algorithms learn good feature representation of the given objects, so that they can be used to find and track objects in further frames[36, 46]. Hence, these methods try to tackle problems such as occlusion, change in appearance of object as the video proceeds while trying to find and associate a given object. In unsupervised scenario the problem becomes even harder as the number of objects are not decided, hence, some extra objects also get detected by the algorithm. The extra objects add a lot of noise which makes it even harder to associate and track objects.
随着深度学习的兴起,几乎所有最新提出的方法都基于学习。尽管仍有部分经典方法被应用于深度学习流程中,如[2, 40]。先前多数多目标视频分割研究是在半监督设定下完成的[29, 47]。在半监督设定中,首帧掩码已知,算法通过学习给定目标的优质特征表示,以便在后续帧中定位并跟踪目标[36, 46]。因此,这些方法致力于解决视频演进过程中的遮挡、目标外观变化等问题,同时尝试关联指定目标。而在无监督场景下,由于目标数量未预先确定,问题会变得更加复杂——算法可能检测到额外目标。这些干扰目标会引入大量噪声,使得目标关联与跟踪任务更具挑战性。
Some of the earlier works done in unsupervised video object segmentation is for single object in a video[56, 22]. These methods tried to extract foreground objects using some property which differentiates it from background. This can not work in multi object setting as we also need to differentiate between objects. Motivated by [22] we tried to learn embedding of objects but we found that embedding are not consistent across the frames hence making it difficult to track objects. Further, embedding perform very poorly when objects are small or when there are similar objects in a frame.
早期在无监督视频对象分割方面的一些工作针对的是视频中的单个对象[56, 22]。这些方法试图利用某些将前景对象与背景区分的属性来提取前景对象。这在多对象场景中无法适用,因为还需要区分不同对象。受[22]启发,我们尝试学习对象的嵌入(embedding),但发现这些嵌入在帧间并不一致,因此难以跟踪对象。此外,当对象较小或帧中存在相似对象时,嵌入表现非常差。
One of the major difference in semi-supervised scenario compared to unsupervised scenario, is the ground truth information in the first frame. So if we are able to get good annotations of first frame in some manner then it will reduce the problem to semi-supervised setting. There are many works which target object detection and segmentation[14, 6] but the problem is that the quality of masks generated is not at par with ground truth annotations. Keeping this in mind, we target for an algorithm which can improve masks and reduce noise propagation in an online manner. We also aimed to use ensemble of masks and then propagate only the best mask out of the multiple masks. To this end, we propose a method which builds upon a semi-supervised method Video Object Segmentation Using Space- Time Memory Networks(STM)[36]. STM stores some of the previous frames and masks as memory and uses that as temporal knowledge to predict the masks in the current frame. For getting masks in the frames we use a well know method Mask R-CNN[14]. We create an ensemble from Mask R-CNN and STM. Further, we propose a novel selection criterion, Selector Net. The network takes input as 2 masks, and returns the relative quality scores of the masks. For any given object in a frame we get masks from STM and Mask R-CNN, then we use Selector Net and another selection criterion based on change in object shape in consecutive frames to select the best mask which is then propagated further (section 3). The only trainable component in our method is Selector Net making it highly efficient in training. The proposed method has a general structure to solve unsupervised video object segmentation problem rather than a fixed algorithm. In this work we used STM as it was the state of the art method in semi-supervised setting which uses temporal information, but in future as semi-supervised algorithms improve our accuracy should also improve.
半监督场景与无监督场景的主要区别之一在于首帧的真实标注信息。若能通过某种方式获取高质量的首帧标注,即可将问题转化为半监督设定。现有许多研究聚焦目标检测与分割[14,6],但其生成掩码的质量难以达到真实标注水平。基于此,我们致力于开发一种在线优化掩码并抑制噪声传播的算法,同时采用多掩码集成策略仅传播最优掩码。为此,我们在半监督方法STM(时空记忆网络视频对象分割)[36]基础上提出新方法:STM将历史帧与掩码存储为记忆库,利用时序信息预测当前帧掩码;而帧级掩码获取采用经典方法Mask R-CNN[14],由此构建STM与Mask R-CNN的集成系统。我们进一步提出创新选择标准Selector Net,该网络通过输入两幅掩码输出相对质量评分。对于帧内任一目标,先获取STM与Mask R-CNN生成的掩码,再结合Selector Net及基于连续帧间目标形变的筛选标准选择最优掩码进行传播(第3节)。本方法中唯一可训练组件是Selector Net,极大提升了训练效率。该方案采用通用架构解决无监督视频对象分割问题,而非固定算法。本文选用当时最先进的半监督时序方法STM,未来随着半监督算法进步,本方法的精度也将同步提升。
To summarize our contributions are the following:
我们的贡献可总结如下:
• We propose a novel general iz able noise resilient and modular pipeline for unsupervised video object segmentation and tracking, outperforming existing state of the art methods2. • Along with this, we introduce a novel idea of assessing mask quality using a neural network. The network is trained only on one dataset and we demonstrate its general iz ability across different datasets. • We evaluate our algorithm on 3 benchmark datasets for unsupervised video object segmentation and demonstrate that it can robustly handle complex scenarios with occlusions and re-identification, complex deformation, motion blur, multiple objects with similar appearance and efficiently deal with drift in long temporal propagation by online mask improvement.
• 我们提出了一种新颖的、可泛化的、抗噪声且模块化的无监督视频目标分割与跟踪流程,其性能优于现有最先进方法[2]。
• 同时,我们提出了一种利用神经网络评估掩码质量的新思路。该网络仅在一个数据集上训练,但我们证明了其在不同数据集上的泛化能力。
• 我们在3个无监督视频目标分割基准数据集上评估了算法,证明其能稳健处理遮挡重识别、复杂形变、运动模糊、外观相似多目标等复杂场景,并通过在线掩码改进有效应对长时序传播中的漂移问题。
2. Related work
2. 相关工作
2.1. Semi supervised video object segmentation
2.1. 半监督视频目标分割
In semi supervised video object segmentation, we are given with the first frame ground truth annotations in the form of the masks of objects that need to be tracked throughout the video. Hence, in this we have a clear idea of the objects that need to be tracked unlike the unsupervised scenario. While there has been significant progress in this field, however, a lot of approaches[20, 37, 29, 4, 47, 55, 54] rely on online learning and fine tuning. These approaches fine tune on an augmented dataset created using the first frame annotations for every video. While they are able to achieve high accuracy using such techniques, they are not suitable for real time methods and are very slow.
在半监督视频目标分割任务中,我们会获得首帧的真实标注信息,即以需要在整个视频中追踪的目标掩码形式给出。因此,与无监督场景不同,我们能够明确知晓需要追踪的目标对象。尽管该领域已取得显著进展,但许多方法[20, 37, 29, 4, 47, 55, 54]仍依赖于在线学习和微调。这些方法会针对每个视频使用首帧标注创建的增强数据集进行微调。虽然此类技术能实现较高精度,但它们不适合实时方法且运行速度非常缓慢。
Another category of these works include propagation techniques[37, 24, 20, 48] in which the segmented masks from the previous frames are propagated to the next frame using optical flow as motion cues. Such methods have an extra dependence on the optical flow methods which aren’t always accurate especially in homogeneous regions and when the movement between 2 frames is very less.
另一类工作包括传播技术 [37, 24, 20, 48],其中使用光流作为运动线索将前一帧的分割掩码传播到下一帧。这类方法额外依赖于光流方法,而光流方法并不总是准确的,特别是在同质区域以及两帧之间运动非常小的情况下。
Another category of these works are the memory based networks[36, 52, 46] that use temporal information by storing feature embedding of the previous frames and then do a matching of the features of the current frame with those of the stored templates. Instead of using only the previous frame, they store all the temporal information from the past as key and value vectors and a new frame is like a query vector. This query vector is then matched with the key vectors to find the results of the current frame. STM[36] is a current state of the state of art method that works on the above principle. Also it is fast, does not depend on optical flow and has a high accuracy for semi supervised video object segmentation without requiring any fine tuning and online learning. These factors make it suitable to be adapted for unsupervised video object segmentation.
另一类工作是记忆网络[36, 52, 46],它们通过存储先前帧的特征嵌入来利用时序信息,然后将当前帧的特征与存储的模板进行匹配。不同于仅使用前一帧,这些网络将所有历史时序信息存储为键值向量,新帧则作为查询向量。该查询向量会与键向量进行匹配以获取当前帧的结果。STM[36]是基于上述原理的当前最先进方法,具有速度快、不依赖光流且在半监督视频目标分割中无需微调或在线学习即可实现高精度的特点。这些特性使其适用于无监督视频目标分割任务。
2.2. Unsupervised video object segmentation
2.2. 无监督视频目标分割
In unsupervised video object segmentation, there is no fixed definition of the objects that need to be segmented and tracked throughout the video. The most early works deal with foreground and background extraction in a video. The definition of the objects in these works are the most salient objects present in a video. Some of the traditional work in the area in include detecting foreground object using background subtraction[33, 11] and generating object proposals[2, 19, 60, 13, 21]. Some other weakly supervised methods include segmenting foreground object using markers[40, 3, 31]. The above methods are not robust enough to handle even a slight change in lighting conditions and are sensitive to shadows. With the rise of the deep learning era, a lot of approaches[22, 27, 59, 9, 51, 42, 58] have used deep learning methods to do the above the task. Davis 2016[38] is a common dataset that is used for such task. The above algorithms output a single binary mask for all the foreground objects, and hence, do not deal with multi-foreground object scenarios. They cannot be directly integrated with the multi object segmentation and tracking as these techniques do not have deal with some of the major problems like tracking, handling occlusion and reidentification of objects.
在无监督视频目标分割中,需要在整个视频中分割和跟踪的目标没有固定定义。早期工作主要处理视频中的前景与背景提取,这些研究将目标定义为视频中最显著的对象。该领域的传统方法包括通过背景减除[33,11]检测前景目标,以及生成目标候选框[2,19,60,13,21]。其他弱监督方法涉及使用标记物分割前景目标[40,3,31]。上述方法对光照条件的轻微变化不够鲁棒,且对阴影敏感。随着深度学习时代的兴起,许多研究[22,27,59,9,51,42,58]开始采用深度学习方法完成上述任务,其中Davis 2016[38]是此类任务的常用数据集。这些算法对所有前景目标输出单一二值掩膜,因此无法处理多前景目标场景。由于未解决跟踪、遮挡处理和目标重识别等核心问题,这些技术无法直接集成到多目标分割与跟踪流程中。
Another area of unsupervised video object segmentation deals with explicitly extracting moving objects as foreground objects. [1, 61, 56, 63, 26, 50] are example of such methods for single foreground mask prediction and [10] is an example of that deals multi moving foreground object segmentation and tracking. These approaches cannot be directly used, as aside from single foreground mask prediction, they focus only on moving foreground objects, which might not always be the case in a generalised scenario. Also they depend on optical flow for providing motion cues, however with time the error in it accumulates. This results in inaccurate tracking due to large drift.
无监督视频对象分割的另一领域专注于显式提取运动物体作为前景对象。[1, 61, 56, 63, 26, 50]是单前景掩模预测的典型方法,而[10]则处理多运动前景对象分割与跟踪。这些方法无法直接应用,因为除了单前景掩模预测外,它们仅聚焦于运动前景物体——这在通用场景中并非总是成立。此外,这些方法依赖光流提供运动线索,但随时间推移误差会累积,导致因大幅漂移而产生不准确的跟踪结果。
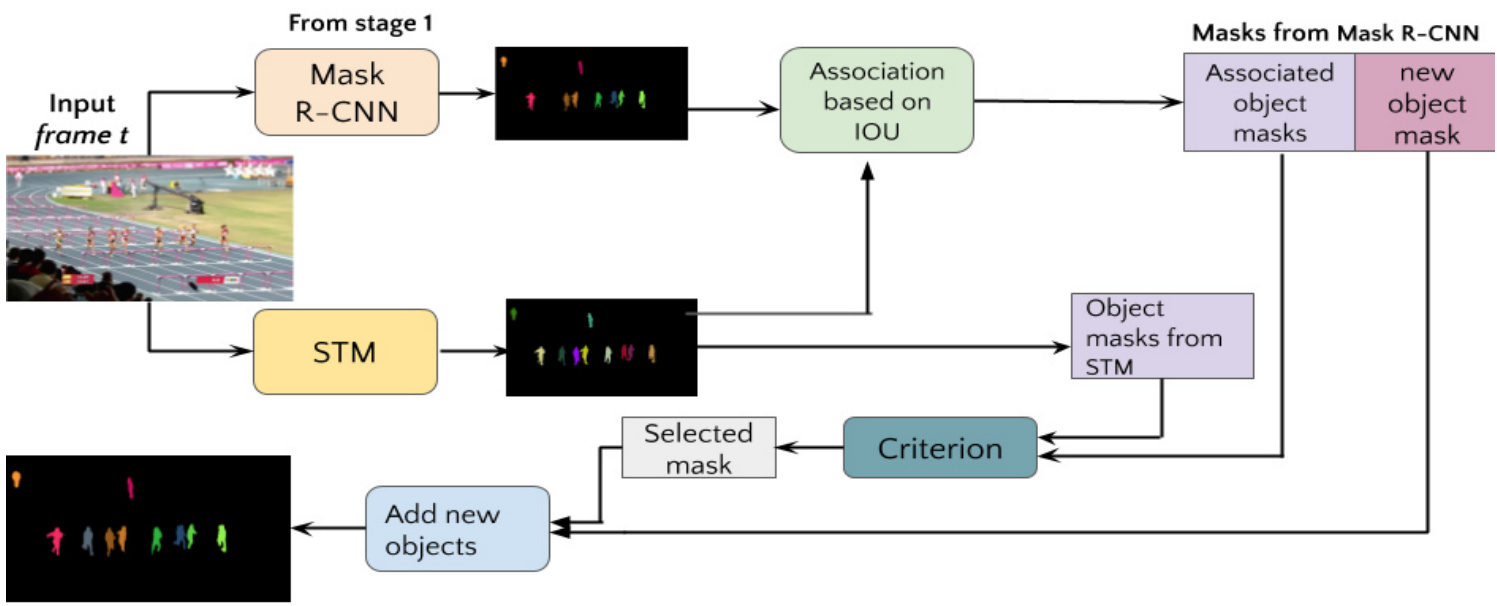
Figure 1: Block diagram of stage 2 of our algorithm. Here criterion can be either criterion $I$ or criterion 2. Given an input frame, two sets of mask are generated using Mask R-CNN and STM. It is followed by mask association and identifying new objects detected by Mask R-CNN. The associated pairs are sent to the criterion and best mask is selected to be propagated further. The same pipeline is followed for the two independent criteria proposed in this work. The only difference is that for one pipeline criterion $I$ is used and for second pipeline criterion 2 is used.
图 1: 本算法第二阶段的框图。此处标准可以是标准 $I$ 或标准 2。给定输入帧后,使用 Mask R-CNN 和 STM 生成两组掩码,随后进行掩码关联并识别 Mask R-CNN 检测到的新对象。关联对会被送入标准模块,选择最优掩码进行后续传播。本工作提出的两个独立标准采用相同流程,唯一区别在于一个流程使用标准 $I$ ,另一个流程使用标准 2。
The area of unsupervised multi object segmentation and tracking in a video is relatively new. These[8, 30, 62, 57, 53, 45, 49, 28] are some of the works that work on the above problem. The problem was first proposed at DAVIS Unsupervised Challenge 2019[5]. In AGNN[49], a binary foreground object segmentation method is converted to multi object setting by using Mask RCNN masks to get instance level salient object masks. In UnOVOST[30] object mask proposals are only taken from Mask R-CNN frame wise and temporal information is not used for mask prediction. In VSD[57] each object is independently tracked using Siam Mask[48] and at each time step the tracked mask is replaced by the Mask R-CNN mask to avoid drift. The above process helps in handling drift in mask propagation, however, replacing the propagated mask by associated Mask R-CNN mask leads to propagation of inaccuracies of Mask R-CNN ahead and makes no use use of temporal information for mask prediction. KIS[8] is a method that is closest to our method. They use RGMP[52] for mask propagation, however only doing propagation leads to drift and accumulation of error with time. On the other hand, we handle this by using a Selector Net to chose the good masks between the propagated mask and the associated from Mask R-CNN. Further details are mentioned in Section 3.
视频中的无监督多目标分割与跟踪是一个相对较新的研究领域。[8, 30, 62, 57, 53, 45, 49, 28] 这些文献针对该问题进行了探索。该问题最早在2019年DAVIS无监督挑战赛[5]中被提出。在AGNN[49]中,通过使用Mask RCNN掩码获取实例级显著目标掩码,将二值前景目标分割方法扩展至多目标场景。UnOVOST[30]仅采用Mask R-CNN逐帧生成目标掩码提案,未利用时序信息进行掩码预测。VSD[57]使用Siam Mask[48]独立跟踪每个目标,并在每个时间步用Mask R-CNN掩码替换跟踪掩码以避免漂移。虽然上述方法有助于处理掩码传播中的漂移问题,但用关联的Mask R-CNN掩码替换传播掩码会导致其误差向前传播,且未利用时序信息进行掩码预测。KIS[8]是与我们方法最接近的方案,其使用RGMP[52]进行掩码传播,但仅依赖传播会导致误差随时间累积。我们通过选择器网络(Selector Net)在传播掩码和Mask R-CNN关联掩码间择优选取,具体细节见第3节。
3. Approach
3. 方法
3.1. Problem formulation
3.1. 问题表述
We address the problem of unsupervised video object segmentation with an aim to segment and track at least the objects that capture human attention. Hence, given an input of frames $[f_{0},f_{1},\cdot\cdot\cdot,f_{T-1}]$ , we produce the following output:
我们致力于解决无监督视频目标分割问题,旨在分割并追踪至少能吸引人类注意力的目标。因此,给定输入帧序列 $[f_{0},f_{1},\cdot\cdot\cdot,f_{T-1}]$ ,我们生成如下输出:
- A set of segmentation masks $[m_{0},m_{2},...,m_{T-1}]$ containing non overlapping segmentation mask proposals of $N$ objects. The number of objects, $N$ , is not known in advance and has a max limit of 20 objects. 2. The objects are tracked throughout the video and every object is supposed to have a consistent mask id in the mask proposals generated throughout the whole video.
- 一组分割掩码 $[m_{0},m_{2},...,m_{T-1}]$,包含 $N$ 个物体的非重叠分割掩码提案。物体数量 $N$ 事先未知,最大限制为20个物体。
- 物体在视频中被持续追踪,每个物体在整个视频生成的分割掩码提案中应保持一致的掩码ID。
3.2. Method
3.2. 方法
Our method consists of 3 stages. In stage 1, Mask RCNN[14] is used to generate masks for objects in a frame. This serves as the first source of masks. In stage 2, we initialize STM[36] by using masks generated by Mask RCNN for the first frame. Then STM predicts the masks for the current frame using the previous frames stored as memory. In order to improve the mask, at each time-step, we parallelly employ 2 different independent criteria for a better quality mask selection between the current mask obtained from STM and the corresponding Mask RCNN mask for every object. At the same time, the objects in Mask RCNN which are not associated with any previous objects are added as new objects. In the 3rd stage, we chose the best of the 2 previously generated masks further improving the results by recovering lost objects.
我们的方法包含3个阶段。在第1阶段,使用Mask RCNN[14]为帧中的物体生成掩码,这是掩码的第一个来源。在第2阶段,我们利用Mask RCNN为第一帧生成的掩码初始化STM[36],随后STM基于存储为记忆的先前帧预测当前帧的掩码。为了提升掩码质量,我们在每个时间步并行采用2种独立标准,对STM生成的当前掩码与Mask RCNN对应物体掩码进行择优选择。同时,将Mask RCNN中未与任何先前物体关联的新物体添加进来。第3阶段则从先前生成的2组掩码中选取最优结果,并通过恢复丢失物体进一步提升效果。
Object mask generation
物体掩模生成
We used Mask R-CNN implementation by [32] trained on COCO[25] dataset with backbone ResNet-50[15] to get initial object masks. We set the threshold of 0.1 on confidence score given by Mask R-CNN. The low confidence threshold helps to segment objects beyond the categories Mask R-CNN is trained on. To limit the number of objects in a frame, we selected at max 10 objects in a frame ranked according to their confidence score[30]. We also filter out the objects which are very small and fragmented to reduce the noise further.
我们采用[32]实现的Mask R-CNN模型(基于COCO[25]数据集训练,主干网络为ResNet-50[15])获取初始物体掩膜。将Mask R-CNN给出的置信度分数阈值设为0.1,低置信度阈值有助于分割出训练类别之外的物体。为限制单帧物体数量,我们按置信度分数[30]排序后每帧最多选取10个物体,同时过滤过小或过于破碎的物体以进一步降低噪声。
Temporal propagation and online selection of masks and addition of new objects
时间传播与在线掩码选择及新对象添加
Unlike a lot of previous methods, we do not rely only on Mask R-CNN masks, but also use temporal information and improve masks on the go. In order to make use of temporal information, in stage 2, we use STM, a semi-supervised video object segmentation method. STM uses temporal and spatial information to generate masks in a current frame. As the algorithm progresses through each frame in the video, the first frame with its given annotations and some intermediate frames with predicted annotations are stored as memory frames. These memory frames along with the previous frame annotations are then used to predict instance mask of current frame. In our situation we initialize STM using the first frame mask annotations obtained in the previous step.
与许多先前的方法不同,我们不仅依赖 Mask R-CNN 生成的掩码,还利用时序信息并动态优化掩码。为了有效利用时序信息,在第二阶段采用了半监督视频目标分割方法 STM (Semi-supervised Video Object Segmentation)。STM 通过时空信息生成当前帧的掩码。算法逐帧处理视频时,会将带有标注的首帧及部分带有预测标注的中间帧存储为记忆帧。这些记忆帧与前一帧标注共同用于预测当前帧的实例掩码。在本方案中,我们使用上一步获得的首帧掩码标注来初始化 STM。
Using STM gives us two major benefits, first one is using temporal information to predict masks and second it helps in tracking the objects. Hence, we have a complete pipeline that handles both segmentation and tracking. However, only using STM would not suffice. This is because unlike semi supervised scenario, number of objects that need to be segmented and tracked are not fixed before hand and unsupervised scenario deals with insertion of new unknown objects in the middle of the sequence. Moreover since the annotations of the first frame are noisy compared to the ground truth annotations, the quality of masks degrades as we go progress through the video. In order to deal with the above problems, we insert modules to handle additions and online selection of masks to minimize noise propagation in the pipeline resulting in better results.
使用STM为我们带来了两大优势:一是利用时序信息预测掩码,二是实现目标跟踪。因此我们构建了一个同时处理分割与跟踪的完整流程。但仅靠STM仍不足够,因为与半监督场景不同,待分割跟踪的目标数量并非预先固定,且无监督场景需处理序列中段新增未知物体的情况。此外,由于首帧标注相比真实标注存在噪声,随着视频推进,掩码质量会逐渐下降。为解决上述问题,我们增加了处理新增目标的模块,并通过在线选择掩码来最小化流程中的噪声传播,从而获得更好的结果。
Let $M_{t}$ and $S_{t}$ be the set of masks produced by Mask R-CNN and STM for frame $t$ . The two sets of masks are passed to association module (Fig. 1), where a bipartite matching is done between the object masks present in both the sets. In order to achieve this, we frame it as a optimal assignment problem. A 2D matrix is formed whose rows and columns are the objects present in $M_{t}$ and $S_{t}$ respectively and $v_{i j}$ is the IOU between the $i^{t h}$ object mask in $M_{t}$ and $j^{t h}$ object mask in $S_{t}$ . The assignment is done using Hungarian algorithm. Object masks in $M_{t}$ having a IOU higher than 0.5 are associated to corresponding object masks in $S_{t}$ and the rest of the objects are added in the memory as new objects. In order to limit the noise we only allow fixed number of objects to get added in the complete video sequence. Further, we only add objects whose intersection with other objects is below certain threshold compared to the area of the mask of object being added. Now, for every associated object we have two mask proposal one from STM and other from Mask R-CNN. We use two independent selection criteria to select the better of the two masks. Hence, there are two independent branches running of the above described algorithm. The better mask selected by the criterion is propagated further independently in its own branch. The difference between the two branches is the way mask frames are selected which further results in different memory frames in STM for the two branches. The complete process is explained in Algorithm 1 and block diagram for same is shown in Fig 1.
设$M_{t}$和$S_{t}$分别为Mask R-CNN和STM对帧$t$生成的掩码集合。这两组掩码被传递至关联模块(图1),其中对两组中的物体掩码进行二分匹配。为此,我们将其建模为最优分配问题:构建一个二维矩阵,其行和列分别对应$M_{t}$和$S_{t}$中的物体,$v_{ij}$表示$M_{t}$中第$i^{th}$个物体掩码与$S_{t}$中第$j^{th}$个物体掩码的交并比(IOU)。通过匈牙利算法完成分配——将$M_{t}$中IOU高于0.5的物体掩码与$S_{t}$中对应掩码关联,其余物体作为新对象加入记忆库。为控制噪声,我们限制整个视频序列中新增对象的总数,且仅当新增对象的掩码面积与其他对象重叠区域低于特定阈值时才允许添加。
对于每个关联对象,我们会获得来自STM和Mask R-CNN的两个掩码提案。通过两个独立的选择标准来筛选更优掩码,因此上述算法会并行运行两个独立分支。每个分支根据其标准选择更优掩码并独立传播,二者的区别在于掩码帧选择方式不同,这导致STM中两个分支的记忆帧也存在差异。完整流程如算法1所述,其框图见图1。
The criterion $I$ is a neural network whose task is to compare two associated masks and assign scores signifying the quality of mask. Further details for this can be found in Section 3.3. For criterion 2 we compare the area of the object masks in frame $t$ to the corresponding object mask in frame $t-1$ . We chose the mask whose change in area is less. The logic behind this criterion is that the object position and orientation does not change much between two consecutive frames, hence the mask area should also remain consistent between the frames. Using the above two independent criteria, stage 2 results in 2 mask frames for each frame. One set of masks are generated using criterion 1 as selection criteria and second set is generated using criterion 2 as selection criterion.
标准 $I$ 是一个神经网络,其任务是比较两个关联的掩码并分配表示掩码质量的分数。更多细节可在第3.3节中找到。对于标准2,我们比较帧 $t$ 中的物体掩码面积与帧 $t-1$ 中对应物体掩码的面积。我们选择面积变化较小的掩码。该标准背后的逻辑是,物体位置和方向在两个连续帧之间变化不大,因此掩码面积在帧之间也应保持一致。使用上述两个独立标准,阶段2为每帧生成2个掩码帧。一组掩码使用标准1作为选择标准生成,第二组掩码使用标准2作为选择标准生成。
Offline selection of masks
离线掩码选择
After completion of stage 2 for the whole video, we select best masks out of the 2 generated results. Selector Net is used to chose the better mask in this stage. The objects which are present in only one of the two results is simply added as new mask. This is done because there can be situations, where one criterion might chose the wrong mask leading to incorrect propagation ahead.
在完成整个视频的第二阶段后,我们从生成的2个结果中选出最佳掩码。此阶段使用选择器网络(Selector Net)来挑选更好的掩码。对于仅出现在其中一个结果中的物体,会直接作为新掩码添加。这样处理是因为可能存在某种标准选择了错误掩码,导致后续传播不准确的情况。
3.3. Selector net
3.3. Selector net
We propose a novel selection criterion called Selector Net. It is a neural network based approach to select the better mask from two input mask. The reason for using a neural network based approach is that there are many factors on which the quality of mask depends such as smoothness of mask, the object inside the mask, semantic consistency captured by mask. It is difficult to capture all these properties using classical formulations hence we came with a learning based technique.
我们提出了一种名为Selector Net的新型选择标准。这是一种基于神经网络的方法,用于从两个输入掩码中选择更好的掩码。采用基于神经网络方法的原因在于,掩码质量取决于诸多因素,如掩码平滑度、掩码内物体以及掩码捕获的语义一致性等。这些特性难以通过传统公式全面捕捉,因此我们提出了这种基于学习的技术。
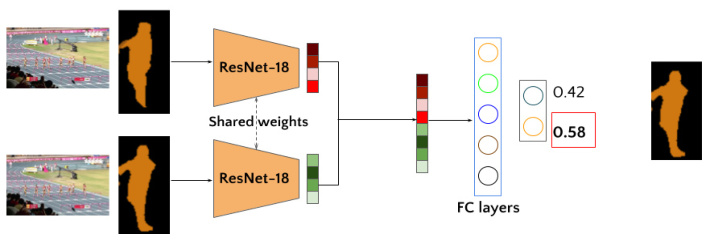
Figure 2: Architecture for the Selector Net: The 2 pairs of inputs are the original RGB image along with the corresponding Mask RCNN mask of the object and the original RGB image along with STM propagated mask. They are fed to a feature extraction module having shared weights. The features are then concatenated and fed to a network to output the mask score. The mask having a higher score is considered a better mask and propagated ahead.
图 2: Selector Net架构:两对输入分别是原始RGB图像及对应的Mask RCNN物体掩膜,以及原始RGB图像及STM传播的掩膜。它们被送入具有共享权重的特征提取模块。提取的特征随后被拼接并输入网络以输出掩膜分数。分数较高的掩膜被视为更优掩膜并向前传播。
The Selector Net consists of a feature extractor backbone ResNet-18[15] which is followed by fully connected(FC) layers (Fig 2). The intuition here is that feature extractor encodes the masks into feature space which captures relevant factors on which quality of mask should depend which are further processed by FC layers to make the decision. There are two inputs to the network as shown in Fig 2. Each input consists of binary mask of an object that needs to be compared along with the complete RGB image (for visual purposes we have shown colored mask). The binary mask is of the same spatial dimension that of the corresponding RGB image. The image and mask are concatenated hence making a 4 channel input. The two inputs are passed through feature extractor resulting in 1024 dimension vector after flattening and concatenating the feature vectors. This feature vector is then passed through 2 fully connected layers of output size 512 and 2. We also added a dropout layer after first FC layer with drop out probability of 0.2. The final score of the two masks is produced by passing the outputs through a softmax layer, higher score signifies better quality of mask. We used mean squared error loss for training( Eq 1).
选择器网络 (Selector Net) 由一个特征提取主干 ResNet-18[15] 和后续的全连接层 (FC) 组成 (图 2)。其核心思想是:特征提取器将掩码编码到特征空间,捕获掩码质量依赖的相关因素,再由全连接层进一步处理并做出决策。如图 2 所示,网络有两个输入,每个输入包含待比较物体的二值掩码和完整 RGB 图像 (为便于展示,图中使用彩色掩码)。二值掩码的空间维度与对应 RGB 图像相同,图像与掩码拼接后形成 4 通道输入。两个输入经过特征提取器后,通过展平和拼接特征向量得到 1024 维向量,随后经过输出维度分别为 512 和 2 的两个全连接层。首个全连接层后还添加了丢弃概率为 0.2 的 dropout 层。最终通过 softmax 层输出两个掩码的评分,分数越高表示掩码质量越好。训练时采用均方误差损失函数 (公式 1)。
$$
L=\frac{1}{N}\sum_{n}[(y_{1}-\hat{y}{1})^{2}+(y_{2}-\hat{y}_{2})^{2}]
$$
$$
L=\frac{1}{N}\sum_{n}[(y_{1}-\hat{y}{1})^{2}+(y_{2}-\hat{y}_{2})^{2}]
$$
Here $y_{1},y_{2}$ are the ground truths of the input pair and $\hat{y}{1}$ , $\hat{y}_{2}$ are the predicted values by the network.
这里 $y_{1},y_{2}$ 是输入对的真实值,而 $\hat{y}{1}$ 和 $\hat{y}_{2}$ 是网络的预测值。
For training the Selector Net, we generated the dataset using training data from DAVIS 2017[39]. The STM is initialized using masks generated from Mask R-CNN. The association between the masks generated using Mask R-CNN
为了训练选择器网络(Selector Net),我们使用DAVIS 2017[39]的训练数据生成数据集。STM通过Mask R-CNN生成的掩码进行初始化。Mask R-CNN生成的掩码之间的关联
Algorithm 1: Stage 2 algorithm
算法 1: 第二阶段算法
Input : $F r a m e s=[f_{1},\cdot,f_{T-1}],N,K,c r i t$ Output: $M a s k s=[m_{1},...,m_{T-1}]$ $\mathrm{\bf1~}/\star\mathrm{\boldmath~\calN~}$ is interval at which information will be stored in memory, $K$ is maximum number of objects that can be added, crit is a boolean variable for choosing the criterion. */ $\begin{array}{r}{2~m e m F r a m e s\gets[(f_{0},m_{0})]}\end{array}$ ; 3 $c o u n t\gets0$ ; 4 $M a s k s\gets\mathbb{I}$ ; 5 for $t\gets1$ to $T-1$ do 6 $M_{t}^{'}\leftarrow M a s k R C N N(f_{t})$ ; 7 Mt ← Filter Noise $(M_{t}^{'}$ ); 8 $S_{t}\gets S T M(f_{t},m e m F r a m e s);$ 9 At ← Associate $(S_{t},M_{t})$ ; 10 $N_{t}\gets M_{t}\setminus A_{t}$ // New Masks; 11 $F_{t}=[]$ // Final Masks; 12 for $(a_{t}^{m},a_{t}^{s})\in A_{t}$ do 13 if $c r i t==0$ then 14 $s\gets\mathsf{S}\in\mathsf{1}$ ectorNet $(a_{t}^{m},a_{t}^{s})$ 15 end if 16 else 17 s ← AreaCrit $(a_{t}^{m},a_{t}^{s},a_{t-1}^{s};$ ) 18 end if 19 $F_{t}\gets F_{t}+s;$ ; 20 end for 21 $F_{t}$ , count ← AddObj $(F_{t},N_{t},K,c o u n t)$ ; 22 $M a s k s\gets F_{t}$ ; 23 if $t%N==0$ then 24 memFrames $\gets$ UpdateMem $(F_{t},f_{t})$ 25 end if 26 end for 27 return Masks;
输入: $F r a m e s=[f_{1},\cdot,f_{T-1}],N,K,c r i t$
输出: $M a s k s=[m_{1},...,m_{T-1}]$
$\mathrm{\bf1~}/\star\mathrm{\boldmath~\calN~}$ 是信息存入内存的间隔,$K$ 是可添加对象的最大数量,crit 是用于选择标准的布尔变量。*/
$\begin{array}{r}{2~m e m F r a m e s\gets[(f_{0},m_{0})]}\end{array}$;
3 $c o u n t\gets0$;
4 $M a s k s\gets\mathbb{I}$;
5 for $t\gets1$ to $T-1$ do
6 $M_{t}^{'}\leftarrow M a s k R C N N(f_{t})$;
7 Mt ← 过滤噪声 $(M_{t}^{'}$);
8 $S_{t}\gets S T M(f_{t},m e m F r a m e s);$
9 At ← 关联 $(S_{t},M_{t})$;
10 $N_{t}\gets M_{t}\setminus A_{t}$ // 新掩码;
11 $F_{t}=[]$ // 最终掩码;
12 for $(a_{t}^{m},a_{t}^{s})\in A_{t}$ do
13 if $c r i t==0$ then
14 $s\gets\mathsf{S}\in\mathsf{1}$ ectorNet $(a_{t}^{m},a_{t}^{s})$
15 end if
16 else
17 s ← 面积标准 $(a_{t}^{m},a_{t}^{s},a_{t-1}^{s};$ )
18 end if
19 $F_{t}\gets F_{t}+s;$
20 end for
21 $F_{t}$, count ← 添加对象 $(F_{t},N_{t},K,c o u n t)$;
22 $M a s k s\gets F_{t}$;
23 if $t%N==0$ then
24 memFrames $\gets$ 更新内存 $(F_{t},f_{t})$
25 end if
26 end for
27 return Masks;
Table 1: The quantitative results on DAVIS 2019 Test Challenge(Test C) and Test Dev(Test D) dataset.
| Ours | TAAT[62] | UnOVOST[30] | VSD[57] | GTM[53] | KIS[8] | SiVOS[34] | RVOS[45] | |||
|---|---|---|---|---|---|---|---|---|---|---|
| Test C | J&F | Mean | 61.6 | 55.6 | 56.4 | 56.2 | 52.3 | 51.6 | 43.9 | |
| Mean | 58.4 | 53.1 | 53.4 | 53.5 | 50.2 | 48.7 | 40.2 | |||
| J | Recall | 65.0 | 60.0 | 60.9 | 61.3 | 57.5 | 55.1 | 45.7 | ||
| Decay | -1.6 | -0.5 | 1.5 | -2.1 | -5.0 | 4.0 | -0.6 | |||
| F | Mean | 64.7 | 58.2 | 59.4 | 59.0 | 54.4 | 54.5 | 47.5 | ||
| Recall | 71.1 | 62.5 | 64.1 | 63.2 | 58.9 | 59.4 | 50.1 | |||
| Decay | 0.5 | 1.6 | 5.8 | 0.1 | -2.5 | 7.7 | 4.0 | |||
| Test D | J&F | Mean | 57.9 | 59.8 | 58.0 | 56.5 | 54.4 | 54.2 | 22.5 | |
| J | Mean | 52.9 | 56.0 | 54.0 | 51.7 | 51.4 | 50.0 | 17.7 | ||
| Recall | 60.4 | 65.1 | 62.9 | 59.9 | 59.9 | 58.9 | 16.2 | |||
| Decay | 16.7 | 7.8 | 3.5 | 21.7 | -1.0 | 8.4 | 1.6 | |||
| F | Mean | 63.0 | 63.7 | 62.0 | 61.4 | 57.4 | 58.3 | 27.3 | ||
| Recall | 69.5 | 68.4 | 66.6 | 65.7 | 61.6 | 62.1 | 24.8 | |||
| Decay | 20.5 | 11 | 6.6 | 15.7 | 0 | 11.4 | 1.8 |
表 1: DAVIS 2019 测试挑战集 (Test C) 和测试开发集 (Test D) 的定量结果。
Labels are generated using $f(m_{t}^{k},s_{t}^{k},g_{t}^{k})$ (Eq 2). This is done for every object in each frame. This completes the process of generating the training data for Selector Net.
标签通过 $f(m_{t}^{k},s_{t}^{k},g_{t}^{k})$ (式2) 生成。该操作针对每帧中的每个物体执行,从而完成 Selector Net 训练数据的生成流程。
4. Experiments
4. 实验
4.1. Training details
4.1. 训练细节
We trained the Selector Net using the data generated from DAVIS 2017[39] as explained in previous section. Training was done on RTX 2080 GPU card. We used a batch size of 64, learning rate of 1e-4 and trained using Adam optimizer. The resulting binary classification accuracy on the held out dataset was $83%$ . We believe accuracy could further be improved using techniques such as data augmentation and soft labeling. In order to prevent over-fitting we randomly switched the order of input masks i.e. some times Mask R-CNN was the first mask and some times the mask generated from STM was first. We did this because if all the masks from STM would have been better and in all training samples, masks from STM were sent first then network would simply always output high score for the first mask without learning anything. Selector Net was only trained once on DAVIS 2017[39] dataset and directly used on other datasets which shows the general iz ability of the proposed network. Evaluation is done using $JF$ metric, which is the mean of region based similarity $(J)$ and contour accuracy $(F)$ [38, 5]. We used the evaluation code provided by DAVIS unsupervised challenge [41] and do not penalize extra detected objects as per the evaluation criteria [5].
我们使用前述方法从DAVIS 2017[39]生成的数据训练Selector Net,训练在RTX 2080 GPU上进行。采用64的批次大小、1e-4的学习率,并使用Adam优化器。在保留数据集上的二分类准确率达到$83%$。我们相信通过数据增强和软标签等技术还能进一步提升准确率。为防止过拟合,我们随机调换输入掩码顺序(例如有时Mask R-CNN的掩码在前,有时STM生成的掩码在前)。这种做法是因为如果所有STM掩码都更优且始终排在前面,网络会不经过学习就直接对首个掩码输出高分。Selector Net仅在DAVIS 2017[39]数据集上训练一次就直接应用于其他数据集,这证明了该网络的泛化能力。评估采用$JF$指标(基于区域相似度$(J)$和轮廓精度$(F)$的平均值)[38,5],使用DAVIS无监督挑战赛[41]提供的评估代码,并根据评估标准[5]不对额外检测对象进行惩罚。
4.2. DAVIS 2019
4.2. DAVIS 2019
DAVIS[5] is a dataset for unsupervised video segmentation and tracking of multiple objects. DAVIS[4] consist of
DAVIS[5] 是一个用于多目标无监督视频分割与追踪的数据集。DAVIS[4] 包含
60 videos for training and validation. DAVIS provides 2 sets of data for the purpose of testing. The 2 sets are test-dev and test-challenge and each of the sets contain 30 videos. The evaluation is done through a Codalab server.
60个视频用于训练和验证。DAVIS提供了2组数据用于测试,分别是test-dev和test-challenge,每组包含30个视频。评估通过Codalab服务器完成。
Table 1 shows the performance of our algorithm on the DAVIS test challenge and test-dev dataset respectively. In the test challenge dataset, our algorithm outperforms previous state of the art algorithm by a large margin of $5.2%$ resulting in $J&F$ mean of $61.6%$ . We attribute this performance to the online selection of masks done using different criteria. This online selection helps to reduce drift in masks with temporal propagation and increases the accuracy. In the Test Dev dataset, we fall short only by a small margin, which shows that our algorithm can generalize well and performs well on both the datasets.
表 1 展示了我们的算法在 DAVIS 测试挑战集和 test-dev 数据集上的性能表现。在测试挑战集中,我们的算法以 5.2% 的显著优势超越之前的最先进算法,实现了 61.6% 的 J&F 均值。我们将这一性能归功于基于不同准则在线选择掩模的策略,这种在线选择机制通过时序传播减少了掩模漂移,从而提升了精度。在 Test Dev 数据集上,我们仅以微小差距落后,这表明我们的算法具有良好的泛化能力,在两个数据集上都能取得优异表现。
4.3. FBMS
4.3. FBMS
FBMS[35] is also a multi object segmentation and tracking dataset that consist of 59 video sequences. However, unlike DAVIS, the objects annotated are classified as the moving objects only. Also, instead of annotating every frame, annotations are provided only for a subset of the frames and hence is sparsely labeled. We do not use FBMS data for training and only use the 30 test sequences for evaluation.
FBMS[35] 也是一个多目标分割与跟踪数据集,包含59个视频序列。然而与DAVIS不同,其标注对象仅归类为运动物体。此外,该数据集并非逐帧标注,而是仅对部分帧提供标注,属于稀疏标注。我们未使用FBMS数据进行训练,仅采用其30个测试序列进行评估。
The results for FBMS dataset are presented in Table 2. All the algorithms except ours, does single binary mask prediction for salient objects in every frame and does not deal with a lot of challenges in tracking like reappearance, occlusion and arrival of new objects. Despite all of these challenges, we can see that our algorithm outperforms a lot of other algorithms and has a comparable performance with others. Also since the dataset contains videos as long as 800 frames, which is more than 8 time the ones in DAVIS, we can say that our algorithm is able to efficiently segment and track objects over a large temporal distance.
FBMS数据集的结果如表2所示。除我们的算法外,所有算法都对每帧中的显著对象进行单一二值掩码预测,并未处理跟踪中的诸多挑战(如物体重现、遮挡和新物体出现)。尽管存在这些挑战,我们的算法仍显著优于其他多数算法,并与其他算法保持相当性能。由于该数据集包含长达800帧的视频(是DAVIS数据集时长的8倍以上),这表明我们的算法能够在大时间跨度上高效完成物体分割与跟踪。

Table 2: The quantitative results on FBMS dataset. MO signifies whether the method is for multi object or single object.
表 2: FBMS数据集的定量结果。MO表示该方法适用于多目标还是单目标。
| SFL[7] | MSTP[17] | FSG[18] | IET[22] | |
|---|---|---|---|---|
| MO J Mean | × 56.0 | 60.8 | 68.4 | 71.9 |
| MBNM[23] | PDB[42] | COSNet[27] | Ours | |
| MO | × | × | ||
| J Mean | 73.9 | 74.0 | 75.6 | 67.0 |
4.4. SegTrack V2
4.4. SegTrack V2
SegTrack V2[21] is also another multi object segmentation and tracking dataset. It consist of total of 14 videos with 24 objects over 947 annotated frames. This dataset also targets moving objects only.The video sequences are used only for evaluation. The dataset is very challenging as it contains videos with motion blur,appearance change, occlusion, complex deformation and interacting objects.
SegTrack V2[21] 是另一个多目标分割与追踪数据集。该数据集共包含14段视频、24个目标对象以及947帧标注画面,仅针对运动物体进行研究。这些视频序列仅用于评估任务。由于包含运动模糊、外观变化、遮挡、复杂形变以及物体交互等挑战性场景,该数据集难度极高。
The comparison of different algorithms whose results were available on the above dataset is presented in Table 3. It can be seen that our algorithm outperforms the state of the art algorithms.
不同算法在上述数据集上的结果比较如表 3 所示。可以看出,我们的算法优于现有最优算法。
4.5. Qualitative Results
4.5. 定性结果
The qualitative results for DAVIS Test Dev and Test Challenge set are shown in Fig 3. It can be seen from sequences dribbling, skydiving and surfer that our algorithm can efficiently propagate temporal information and is able to segment and track them, even when they are partially occluded or extremely small in size. The sequence cat shows robustness to handle blurred picture cases due to fast moving camera and sequence giraffes shows the capability to efficiently track in cases of reappearance.
DAVIS测试开发集和测试挑战集的定性结果如图3所示。从dribbling、skydiving和surfer序列可以看出,我们的算法能有效传播时序信息,即使目标被部分遮挡或尺寸极小时也能实现分割与追踪。cat序列展示了在摄像机快速移动导致画面模糊时的处理鲁棒性,giraffes序列则体现了目标重新出现场景下的高效追踪能力。
Figure 3: Qualitative results on DAVIS 19 Test Challenge and Test Dev set Table 3: The quantitative results on SegTrackV2 dataset. MO signifies whether the method is for multi object or single object.
图 3: DAVIS 19测试挑战集和测试开发集上的定性结果
表 3: SegTrackV2数据集上的定量结果。MO表示该方法适用于多目标还是单目标。
| LVO[43] | LSMO[44] | IET[22] | FSG[18] |
|---|---|---|---|
| MO J Mean | × 57.3 | 59.1 | 59.3 |
| NLC[12] | STP[16] | EpO+[1] | Ours |
|---|---|---|---|
| MO | × | ||
| J Mean | 67.2 | 70.1 | 70.9 |
Fig 4 shows the qualitative results on Seg Track V2 and FBMS dataset. The sequence monkey dog again shows the capability to efficiently work on motion blurred images and the sequence penguin demonstrates the capability to robustly segment and track in scenarios with similar appearing objects and occlusion. In sequence tennis, we are able to efficiently propagate even small objects like tennis racket. Sequence rabbits shows the ability to handle scenarios where new objects are added in between the sequence.
图 4 展示了 Seg Track V2 和 FBMS 数据集上的定性结果。序列 monkey dog 再次展示了在运动模糊图像上高效工作的能力,而序列 penguin 则展示了在外观相似物体和遮挡场景中稳健分割和跟踪的能力。在序列 tennis 中,我们能够高效传播像网球拍这样的小物体。序列 rabbits 展示了处理在序列中途新增物体的能力。
5. Analysis
5. 分析
Vanilla STM. In order to analyse whether adding stage 2 and stage 3 led to any improvement we initialized STM as in stage 1 and used it for video object segmentation on DAVIS 2019 [5] dataset. The results are shown in table 4 and it can clearly seen that vanilla STM fails to perform good. The proposed method achieves $\sim8%$ more $JF$ that is $57.9%$ compared to STM. Qualitative results are shown in Fig. 5
原版STM (Vanilla STM)。为了分析添加阶段2和阶段3是否带来改进,我们按照阶段1的方式初始化STM,并在DAVIS 2019 [5]数据集上进行了视频对象分割。结果如表4所示,可以明显看出原版STM表现不佳。所提出的方法在 $JF$ 指标上比STM提高了约8%,达到 $57.9%$。定性结果如图5所示。

Figure 4: Qualitative results on SegTrack V2 (top 2 rows) and FBMS (bottom 2 rows).
图 4: SegTrack V2 (前两行) 和 FBMS (后两行) 的定性结果。

Figure 5: Comparative study of our results to vanilla STM. It can be seen that the performance of STM degrades only after a few video frames as the cars are very small and have similar visual features. Due to online selection we are able to produce better results in comparison to STM. Table 4: Ablation study on DAVIS 2019 test dataset
图 5: 我们的结果与原始 STM (vanilla STM) 的对比研究。可以看出,由于车辆尺寸极小且视觉特征相似,STM 的性能在几帧视频后就出现下降。通过在线选择机制,我们相比 STM 能获得更好的结果。
表 4: DAVIS 2019 测试数据集消融实验
| Vanilla STM | Criterion n1 | Criterion 2 | Stage 3 |
|---|---|---|---|
| 0.500 | 0.564 | 0.56 | 0.579 |
Different Stages. In the proposed method, stage 3 is an offline stage in which masks are selected from two masks resulting from stage 2. In order to understand the importance of stage 3, we found the results after removing it. We can see there is an improvement of $\sim2%$ due to stage 3 (table 4). We also included stage 3 because there can be cases when one of the criterion fails, hence to achieve best of the two criteria we employed stage 3. As described in
不同阶段。在提出的方法中,阶段3是一个离线阶段,从阶段2产生的两个掩码中选择掩码。为了理解阶段3的重要性,我们研究了移除该阶段后的结果。可以看到由于阶段3的存在带来了约2%的性能提升(表4)。我们保留阶段3的另一个原因是可能存在某个准则失效的情况,因此需要通过该阶段综合两个准则的优势。如文献[20]所述...

Figure 6: Results of different stages. Using them we are able to deal with recovery of objects which makes our algorithm robust to failure cases of one criterion. Table 5: Runtime analysis of our algorithm during inference time. The time given is time in seconds per frame. Here $C l$ stands for Criterion 1 and $C2$ stands for Criterion 2
图 6: 不同阶段的结果。利用这些结果,我们能够处理物体恢复问题,从而使我们的算法对单一准则的失败情况具有鲁棒性。
表 5: 算法在推理阶段的运行时间分析。给出的时间是每帧的秒数。这里 $C l$ 代表准则 1,$C2$ 代表准则 2。
| Mask R-CNN | Stage 2 C1 | Stage 2 C2 | Stage 3 |
|---|---|---|---|
| 0.09 | 0.95 | 0.48 | 0.68 |
3.2 the criterion 2 calculates the change in area of an object mask compared to the predicted mask in frame $t-1$ . Suppose, the mask in frame $t-1$ is very poor and only covers a small area of the actual object. Now, for the current frame consider two mask of the object resulting from Mask R-CNN and STM. If one of the mask again covers a small region of the object and the other mask covers the complete object, criterion 2 will choose the small mask which is of poor quality. Whereas our criterion 1 is a neural network and we can not always rely on it. Some of the failure cases of the criterion 1 is shown in Fig 6. The bike was not propagated when using criterion 1 and is propagated when using criterion 2.
3.2 准则2通过计算物体掩膜与帧 $t-1$ 预测掩膜的面积变化进行评估。假设帧 $t-1$ 的掩膜质量很差,仅覆盖实际物体的极小区域。在当前帧中,若Mask R-CNN和STM生成的物体掩膜一个覆盖区域极小,另一个完整覆盖物体,准则2会选择覆盖区域小的低质量掩膜。而我们的准则1基于神经网络,其可靠性并非绝对。图6展示了准则1的部分失败案例:自行车在使用准则1时未被传播,而使用准则2时成功传播。
Timing analysis. Table 5 presents the inference runtime analysis of our algorithm on the DAVIS Challenge dataset. The inference is done for an input image of shape $640\times$ $480\times3$ on RTX 2080 GPU card. The processes Stage 2 Criterion 1 and Stage Criterion 2 can be done in parallel if sufficient GPU memory is available. This will lead to a total of 1.72 secs per frame. Otherwise, they can be executed serially which will lead to a time of 2.2 seconds per frame.
时序分析。表 5 展示了我们的算法在 DAVIS Challenge 数据集上的推理运行时间分析。推理是在 RTX 2080 GPU 上对形状为 $640\times$ $480\times3$ 的输入图像进行的。若 GPU 显存充足,阶段 2 标准 1 和阶段标准 2 可并行执行,这将使每帧总耗时降至 1.72 秒。否则需串行执行,此时每帧耗时为 2.2 秒。
6. Conclusion
6. 结论
In this work we present a novel pipeline for unsupervised video object segmentation by extending semi-supervised method and achieving state of the art results. The proposed method can generalize across datasets and due to the modular structure we can replace Mask R-CNN and STM with other state of the art networks in future hence, improving the accuracy further. A promising future work could be to generate mask instead of selecting mask from available masks.
在本工作中,我们通过扩展半监督方法并提出一种新颖的无监督视频目标分割流程,实现了当前最优性能。该方法具备跨数据集泛化能力,其模块化结构允许未来用其他前沿网络替代 Mask R-CNN 和 STM,从而进一步提升精度。一个潜在的改进方向是生成掩膜而非从现有掩膜中选择。