CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning
CommonGen: 面向生成式常识推理的受限文本生成挑战
Abstract
摘要
Recently, large-scale pretrained language models have demonstrated impressive performance on several commonsense-reasoning benchmark datasets. However, building machines with commonsense to compose realistically plausible sentences remains challenging. In this paper, we present a constrained text generation task, COMMONGEN associated with a benchmark dataset, to explicitly test machines for the ability of generative commonsense reasoning. Given a set of common concepts (e.g., {dog, frisbee, catch, throw}); the task is to generate a coherent sentence describing an everyday scenario using these concepts (e.g., “a man throws a frisbee and his dog catches it”).
近年来,大规模预训练语言模型在多个常识推理基准数据集上展现出卓越性能。然而,让机器具备常识来生成真实可信的句子仍具挑战性。本文提出一个受限文本生成任务COMMONGEN及其配套基准数据集,旨在显式测试机器的生成式常识推理能力。给定一组常见概念(如{dog, frisbee, catch, throw}),该任务要求使用这些概念生成描述日常场景的连贯句子(例如"a man throws a frisbee and his dog catches it")。
The COMMONGEN task is challenging because it inherently requires 1) relational reasoning with background commonsense knowledge, and 2) compositional generalization ability to work on unseen concept combinations. Our dataset, constructed through a combination of crowd sourced and existing caption cor- pora, consists of 79k commonsense descriptions over $35\mathrm{k\Omega}$ unique concept-sets. Experiments show that there is a large gap between state-of-the-art text generation models (e.g., T5) and human performance. Furthermore, we demonstrate that the learned generative commonsense reasoning capability can be transferred to improve downstream tasks by generating additional context.
COMMONGEN任务具有挑战性,因为它本质上需要:1) 基于背景常识知识的关系推理能力,2) 对未见概念组合进行组合泛化的能力。我们通过众包和现有字幕语料库构建的数据集包含79k条常识描述,覆盖 $35\mathrm{k\Omega}$ 个独特概念集。实验表明,当前最先进的文本生成模型(如T5)与人类表现存在显著差距。此外,我们证明通过学习获得的生成式常识推理能力可通过生成额外上下文来提升下游任务性能。
1 Introduction
1 引言
Commonsense reasoning, the ability to make acceptable and logical assumptions about ordinary scenes in our daily life, has long been acknowledged as a critical bottleneck of artificial intelligence and natural language processing (Davis and Marcus, 2015). Most recent commonsense reasoning challenges, such as Commonsense QA (Talmor et al., 2019), SocialIQA (Sap et al., 2019b),
常识推理 (commonsense reasoning) ,即对日常生活中普通场景做出可接受且合乎逻辑的假设的能力,长期以来一直被认为是人工智能和自然语言处理的关键瓶颈 (Davis and Marcus, 2015) 。最近的常识推理挑战,如 Commonsense QA (Talmor et al., 2019) 、SocialIQA (Sap et al., 2019b) ,

Figure 1: An example of the dataset of COMMONGEN. GPT-2, UniLM, BART and T5 are large pre-trained text generation models, fine-tuned on the proposed task.
图 1: COMMONGEN数据集示例。GPT-2、UniLM、BART和T5是基于该任务微调的大型预训练文本生成模型。
WinoGrande (Sakaguchi et al., 2019) and HellaSwag (Zellers et al., 2019b), have been framed as disc rim i native tasks – i.e. AI systems are required to choose the correct option from a set of choices based on a given context. While significant progress has been made on these discriminative tasks, we argue that commonsense reasoning in text generation poses a distinct complementary challenge. In this paper, we advance machine commonsense towards generative reasoning ability.
WinoGrande (Sakaguchi et al., 2019) 和 HellaSwag (Zellers et al., 2019b) 被定义为判别式任务——即AI系统需要根据给定上下文从一组选项中选择正确答案。尽管这些判别式任务已取得显著进展,我们认为文本生成中的常识推理提出了一个独特的互补性挑战。本文旨在将机器常识向生成式推理能力推进。
Humans acquire the ability to compose sentences by learning to understand and use common concepts that they recognize in their surrounding environment (Tincoff and Jusczyk, 1999). The acquisition of such an ability is regarded as a significant milestone of human development (Moore, 2013). Can machines acquire such generative commonsense reasoning ability? To initiate the investigation, we present $\mathrm{CoMMONGEN}^{1}$ – a novel con- strained generation task that requires machines to generate a sentence describing a day-to-day scene using concepts from a given concept-set. For example, in Figure 1, given a set of concepts: ${d o g$ , frisbee, catch, throw , machines are required to generate a sentence such as “a man throws a frisbee and his dog catches it in the air.”
人类通过学习和理解周围环境中常见的概念来获得造句能力 (Tincoff and Jusczyk, 1999)。这种能力的获取被视为人类发展的重要里程碑 (Moore, 2013)。机器能否获得这种生成式常识推理能力?为了展开研究,我们提出了 $\mathrm{CoMMONGEN}^{1}$ ——一个新颖的受限生成任务,要求机器使用给定概念集中的概念生成描述日常场景的句子。例如,在图 1 中,给定概念集:${d o g$、frisbee、catch、throw,机器需要生成类似"一个男人抛出飞盘,他的狗在空中接住它"这样的句子。

Figure 2: Two key challenges of COMMONGEN: relational reasoning with underlying commonsense knowledge about given concepts (left), and compositional generalization for unseen combinations of concepts (right).
图 2: COMMONGEN面临的两大关键挑战:基于给定概念的常识知识进行关系推理(左),以及对未见概念组合的复合泛化能力(右)。
To successfully solve the task, models need to incorporate two key capabilities: a) relational reasoning, and b) compositional generalization. Grammatically sound sentences may not always be realistic as they might violate our commonsense (e.g., “a dog throws a frisbee ...”). In order to compose a plausible sentence that describes an everyday scenario, models need to construct a grammatical sentence while adhering to and reasoning over the commonsense relations between the given concepts. Models additionally need compositional generalization ability to infer about unseen concept compounds. This encourages models to reason about a potentially infinite number of novel combinations of familiar concepts – an ability believed to be a limitation of current AI systems (Lake and Baroni, 2017; Keysers et al., 2020).
要成功解决这一任务,模型需要具备两项关键能力:a) 关系推理,以及 b) 组合泛化。语法正确的句子未必总是符合现实,因为它们可能违背常识(例如"一只狗扔飞盘……")。为了构建描述日常场景的合理句子,模型需要在遵循给定概念间常识关系并进行推理的同时,构造出语法正确的句子。此外,模型还需要组合泛化能力来推断未见过的概念组合。这促使模型能够推理熟悉概念的无限新组合——这种能力被认为是当前AI系统的局限 (Lake and Baroni, 2017; Keysers et al., 2020)。
Therefore, in support of the COMMONGEN task, we present a dataset consisting of 35,141 conceptsets associated with 77,449 sentences. We explicitly design our dataset collection process to capture the key challenges of relational reasoning and compositional generalization described above, through an actively controlled crowd-sourcing process. We establish comprehensive baseline performance for state-of-the-art language generation models with both extensive automatic evaluation and manual comparisons. The best model, based on T5 (Raffel et al., 2019), achieves $28.86%$ with significant gap compared to human performance of $52.43%$ in the SPICE metric – demonstrating the difficulty of the task. Our analysis shows that state-of-the-art models struggle at the task, generating implausible sentences – e.g. “dog throws a frisbee ...” , “giving massage to a table”, etc. Additionally, we show that successful COMMONGEN models can benefit downstream tasks (e.g., commonsense-centric question answering) via generating useful context as background scenarios. We believe these findings point to interesting future research directions for the community of commonsense reasoning.
因此,为支持COMMONGEN任务,我们提出了一个包含35,141个概念集与77,449个关联句子的数据集。我们通过主动控制的众包流程,在数据集收集过程中明确设计了关系推理和组合泛化的关键挑战捕捉机制。通过自动化评估与人工对比,我们为前沿语言生成模型建立了全面的基线性能。基于T5 (Raffel et al., 2019) 的最佳模型在SPICE指标上仅达到28.86%,与人类表现的52.43%存在显著差距——这证明了该任务的难度。分析表明,前沿模型在该任务中表现不佳,常生成不合逻辑的句子(例如"狗扔飞盘..."、"给桌子按摩"等)。此外,我们证明成功的COMMONGEN模型可通过生成背景场景作为有用上下文,使下游任务(如常识导向问答)受益。这些发现为常识推理领域指出了值得探索的未来研究方向。
2 Task Formulation and Key Challenges
2 任务定义与关键挑战
We formulate the proposed COMMONGEN task with mathematical notations and discuss its inherent challenges with concrete examples. The input is an unordered set of $k$ concepts $x_=$ ${c_{1},c_{2},\dots,c_{k}}\in\mathcal{X}$ (i.e. a concept-set), where each concept $c_{i}\in\mathcal{C}$ is a common object (noun) or action (verb). We use $\mathcal{X}$ to denote the space of all possible concept-sets and use $\mathcal{C}$ to denote the concept vocabulary (a subset of ConceptNet’s unigram concepts). The expected output is a simple, grammatical sentence $y\in\mathcal{Y}$ that describes a common scenario in our daily life, using all given concepts in $x$ (morphological inflections are allowed). A scenario can depict either a static situation or a short series of actions. The COMMONGEN task is to learn a function $f:\mathcal{X}\to\mathcal{Y}$ , which maps a concept-set $x$ to a sentence $y$ . The unique challenges of this task come from two aspects:
我们通过数学符号形式化提出的COMMONGEN任务,并用具体示例讨论其固有挑战。输入是一个无序的k概念集$x_=$${c_{1},c_{2},\dots,c_{k}}\in\mathcal{X}$(即概念集合),其中每个概念$c_{i}\in\mathcal{C}$是常见物体(名词)或动作(动词)。用$\mathcal{X}$表示所有可能概念集合的空间,$\mathcal{C}$表示概念词汇表(ConceptNet单字概念的子集)。期望输出是一个简单、符合语法的句子$y\in\mathcal{Y}$,该句子需使用给定概念集$x$中的所有概念(允许词形变化)来描述日常生活中的常见场景。场景可以描述静态情境或简短动作序列。COMMONGEN任务是学习一个函数$f:\mathcal{X}\to\mathcal{Y}$,将概念集$x$映射到句子$y$。该任务的独特挑战来自两个方面:
Relational Reasoning with Commonsense. Expected generative reasoners should prioritize the most plausible scenarios over many other less realistic ones. As shown in Figure 2, models need to recall necessary relational commonsense facts that are relevant to the given concepts, and then reason an optimal composition of them for generating a desired sentence. In order to complete a scenario, generative commonsense reasoners also need to reasonably associate additional concepts (e.g., ‘woman’, ‘gym’) as agents or background environments for completing a coherent scenario.
基于常识的关系推理。理想的生成式推理器应优先考虑最合理的场景,而非众多不太现实的选项。如图 2 所示,模型需要回忆与给定概念相关的必要关系性常识事实,进而推理出它们的最佳组合以生成目标句子。为构建完整场景,生成式常识推理器还需合理关联额外概念 (如 "woman"、"gym") 作为行为主体或背景环境,从而形成连贯场景。
This not only requires understanding underlying commonsense relations between concepts, but also increment ally composing them towards a globally optimal scenario. The underlying reasoning chains are inherently based on a variety of background knowledge such as spatial relations, object properties, physical rules, temporal event knowledge, social conventions, etc. However, they may not be recorded in any existing knowledge bases.
这不仅需要理解概念之间的潜在常识关系,还要逐步将它们组合成一个全局最优的场景。其背后的推理链本质上依赖于多种背景知识,如空间关系、物体属性、物理规则、时间事件知识、社会惯例等。然而,这些知识可能并未记录在任何现有知识库中。
Compositional Generalization. Humans can compose a sentence to describe a scenario about the concepts they may never seen them co-occurring. For example, in Figure 2, there is a testing conceptset $\hat{x}={p e a r}$ , basket, pick, put, tree . The concept ‘pear’ never appear in the training data, and ‘pick’ never co-occurs with ‘basket’. We, humans, can generalize from these seen scenarios in the training data and infer that a plausible output: $\hat{y}={}^{\leftarrow}a$ girl picks some pears from a tree and put them into her basket.” This composition ally generalization ability via analogy, i.e., to make “infinite use of finite means” (Chomsky, 1965), is challenging for machines. This analogical challenge not only requires inference about similar concepts (e.g., ‘apple’ $\rightarrow$ ‘pear’) but also their latent associations.
组合泛化。人类能够组合句子来描述从未见过共现的概念场景。例如,在图2中,测试概念集$\hat{x}={梨, 篮子, 摘, 放, 树}$。训练数据中从未出现过"梨"这个概念,且"摘"从未与"篮子"共现。作为人类,我们可以从训练数据中的已知场景泛化,并推断出合理输出:$\hat{y}={}^{\leftarrow}一个女孩从树上摘了些梨放进她的篮子里。"这种通过类比实现的组合泛化能力(即"有限手段的无限运用"(Chomsky, 1965))对机器而言具有挑战性。这种类比挑战不仅需要对相似概念(如"苹果"$\rightarrow$"梨")进行推理,还需要理解它们的潜在关联。
3 Dataset Construction and Analysis
3 数据集构建与分析
Figure 3 illustrates the overall workflow of our data construction for the proposed COMMONGEN task. We utilize several existing caption corpora for sampling frequent concept-sets (Sec. 3.1) for reflecting common scenarios. We employ AMT crowd workers for collecting human-written sentences (Sec. 3.2) for the development and test set, while we carefully monitor the quality of crowd workers and refine them dynamically. Finally, we present the statistics of the COMMONGEN dataset, and the analysis on the challenges (Sec. 3.6).
图 3: 展示了我们为COMMONGEN任务构建数据的整体流程。我们利用多个现有字幕语料库采样高频概念集(见3.1节)以反映常见场景。通过AMT众包平台收集人工撰写的开发集和测试集语句(见3.2节),同时动态监控众包人员质量并进行优化。最后,我们给出了COMMONGEN数据集的统计信息及任务难点分析(见3.6节)。
3.1 Collecting Concept-Sets from Captions
3.1 从字幕中收集概念集
It can be unreasonable to present any arbitrary set of concepts (e.g., $x={a p p l e,f o l d,r o p e}),$ and ask a reasoner to generate a commonsense scenario, since such an arbitrary set of concepts can be too unrelated. Therefore, our concept-sets are supposed to reflect reasonable concept co-occurrences in everyday situations. As web images and video clips capture diverse everyday scenarios, we use their caption text as a natural resource for collecting concept-sets and their corresponding descriptions of commonsense scenarios. More specifically, we collect visually-grounded sentences from several existing caption datasets, including image captioning datasets, such as Flickr30k (Young et al., 2014), MSCOCO (Lin et al., 2014), Conceptual Captions (Sharma et al., 2018), as well as video captioning datasets including LSMDC (Rohrbach et al., 2017), Activity Net (Krishna et al., 2017), and VATEX (Wang et al., 2019b).
呈现任意一组概念(例如 $x={a p p l e,f o l d,r o p e}$)并要求推理者生成常识场景可能并不合理,因为这类随机组合的概念可能过于不相关。因此,我们的概念集需要反映日常生活中合理的概念共现关系。由于网络图像和视频片段捕捉了多样化的日常场景,我们将其描述文本作为收集概念集及对应常识场景描述的自然资源。具体而言,我们从多个现有字幕数据集中收集视觉关联语句,包括图像字幕数据集(如 Flickr30k (Young et al., 2014)、MSCOCO (Lin et al., 2014)、Conceptual Captions (Sharma et al., 2018))以及视频字幕数据集(如 LSMDC (Rohrbach et al., 2017)、Activity Net (Krishna et al., 2017)、VATEX (Wang et al., 2019b))。

Figure 3: Dataset construction workflow overview.
图 3: 数据集构建流程概览。
We first conduct part-of-speech tagging over all sentences in the corpora such that words in sentences can be matched to the concept vocabulary of ConceptNet. Then, we compute the sentence frequency of concept-sets consisting of $3{\sim}5$ concepts. That is, for each combination of three/four/five concepts in the vocabulary, we know how many sentences are in the corpora covering all concepts.
我们首先对语料库中的所有句子进行词性标注,以便将句子中的单词与ConceptNet的概念词汇表进行匹配。接着,我们计算由3~5个概念组成的概念集在句子中的出现频率。也就是说,对于词汇表中任意三个/四个/五个概念的组合,我们统计语料库中包含所有这些概念的句子数量。
Ideally, we want the selected concept-sets in our dataset to reflect the natural distribution of conceptsets in the real world. At first glance, a reasonable solution may seem to sample from the distribution of the concept-sets based on their frequencies in the source datasets. However, we find that this method leads to a rather unnaturally skewed collection of concept-sets, due to the inherent data biases from the source datasets. We therefore design a function to score a concept-set $x$ based on scene diversity and inverse frequency penalty. We denote $S(x)$ as the set of unique sentences that contain all given concepts ${c_{1},c_{2},\ldots,c_{k}}$ , and then we have
理想情况下,我们希望数据集中选出的概念集能反映现实世界中概念集的自然分布。乍看之下,基于源数据集中概念集的频率进行采样似乎是个合理方案。然而,由于源数据集固有的数据偏差,我们发现这种方法会导致概念集分布出现不自然的倾斜。因此,我们设计了一个基于场景多样性和逆频率惩罚的概念集$x$评分函数。将$S(x)$定义为包含所有给定概念${c_{1},c_{2},\ldots,c_{k}}$的唯一句子集合,则有
$$
\mathtt{s c o r e}(x)=|S(x)|\frac{|\bigcup_{s_{i}\in S(x)}{w|w\in s_{i}}|}{\sum_{s_{i}\in S(x)}\mathrm{len}(s_{i})}\rho(x),
$$
$$
\mathtt{s c o r e}(x)=|S(x)|\frac{|\bigcup_{s_{i}\in S(x)}{w|w\in s_{i}}|}{\sum_{s_{i}\in S(x)}\mathrm{len}(s_{i})}\rho(x),
$$
where $\begin{array}{r}{\rho(x)=\frac{|\mathcal{X}|}{\operatorname*{max}{c_{i}\in x}|{x^{\prime}\mid c_{i}\in x^{\prime}\mathrm{and~}_{x^{\prime}\in\mathcal{X}}|}}}\end{array}$ first term in score is t∣h{e ∣number of uniq}u∣e sentences covering all given concepts in $x$ , and the second term is to represent the diversity of the scenes described in these sentences. Th last term $\rho(x)$ is the penalty of inverse frequency. Specifically, we find the concept in $x$ that has the maximum “set frequency” (i.e., the number of unique conceptsets containing a particular concept), then we take the inverse with the number of all concept-sets for normalization. This penalty based on inverse set-frequency effectively controls the bias towards highly frequent concepts. With the distribution of such scores of concept-sets, we sample our candidate examples for the next steps.
其中 $\begin{array}{r}{\rho(x)=\frac{|\mathcal{X}|}{\operatorname*{max}{c_{i}\in x}|{x^{\prime}\mid c_{i}\in x^{\prime}\mathrm{and~}_{x^{\prime}\in\mathcal{X}}|}}}\end{array}$ 评分的第一项是覆盖 $x$ 中所有给定概念的独特句子数量,第二项表示这些句子描述场景的多样性。最后一项 $\rho(x)$ 是逆频率惩罚项。具体而言,我们找出 $x$ 中具有最大"集合频率"(即包含特定概念的独特概念集数量)的概念,然后取其倒数并用所有概念集的数量进行归一化。这种基于逆集合频率的惩罚项有效控制了高频概念的偏差。根据概念集的得分分布,我们为后续步骤采样候选示例。
Table 1: The basic statistics of the COMMONGEN data. We highlight the ratios of concept compositions that are unseen in training data, which assures the challenge in compositional generalization ability.
表 1: COMMONGEN 数据的基本统计信息。我们特别标注了训练数据中未出现过的概念组合比例,这确保了组合泛化能力的挑战性。
| 统计项 | 训练集 | 开发集 | 测试集 |
|---|---|---|---|
| #概念集 | 32,651 | 993 | 1,497 |
| -大小=3 | 25,020 | 493 | - |
| -大小=4 | 4,240 | 250 | 747 |
| -大小=5 | 3,391 | 250 | 750 |
| #句子 | 67,389 | 4,018 | 7,644 |
| 每概念集 | 2.06 | 4.04 | 5.11 |
| 平均长度 | 10.54 | 11.55 | 13.28 |
| #唯一概念 | 4,697 | 766 | 1,248 |
| #唯一概念对 | 59,125 | 3,926 | 8,777 |
| #唯一概念三元组 | 50,713 | 3,766 | 9,920 |
| %未见概念 | - | 6.53% | 8.97% |
| %未见概念对 | - | 96.31% | 100.00% |
| %未见概念三元组 | - | 99.60% | 100.00% |
3.2 Crowd-Sourcing References via AMT
3.2 通过AMT众包参考文献
In order to ensure the best quality, the references of the evaluation examples are crowd sourced from crowd workers on Amazon Mechanical Turk, which amounts to 10,060 references over $2.5\mathrm{k}$ distinct concept-sets. Note that these newly collected references for dev and test examples can ensure that we can do a fair comparisons targeting generalization, considering potential data-leak (i.e., recent pre-trained language models might have seen the caption datasets). Each concept-set was assigned to at least 3 workers. In addition to references about given concept-sets, we also ask the workers to provide rationale sentences to explain what commonsense facts they have used, for ensuring that the described scenarios are common in daily life (example rationales are shown in Fig 10).
为确保最佳质量,评估示例的参考文本通过Amazon Mechanical Turk平台众包采集,共覆盖2.5k个独立概念集(concept-sets),获得10,060条参考文本。值得注意的是,这些为开发和测试集新收集的参考文本能确保我们在考虑潜在数据泄露(即近期预训练语言模型可能已接触过相关标题数据集)的情况下,针对泛化能力进行公平比较。每个概念集至少分配给3名标注人员。除给定概念集的参考文本外,我们还要求标注人员提供解释性句子,说明其所采用的常识性事实(示例解释见图10),以确保描述场景符合日常生活情境。
We control the quality by actively filtering workers who produced low-quality references, then removing their annotations, and finally re-opening the slots only for quality workers. There were 1,492 accepted workers in total and 171 disqualified workers in the end after the active filtering. There are three criteria for efficiently narrowing down candidates for us to further manually remove out low-quality workers: 1) coverage via part-ofspeech tagging, 2) especially high perplexity via GPT-2, and 3) length of the rationales. Meanwhile, we also dynamically replaced the concept-sets that majority of the references do not make sense to ensure the final quality.
我们通过主动筛选产出低质量参考结果的标注人员来控制质量,具体步骤包括:移除这些人员的标注数据,最后仅对优质标注人员重新开放标注任务。经过主动筛选后,最终有1,492名标注人员被录用,171名被取消资格。我们采用三个标准高效缩小候选范围,以便进一步人工剔除低质量标注人员:1) 通过词性标注检查覆盖率,2) 使用GPT-2检测异常高困惑度样本,3) 分析原理说明的长度。同时,我们还会动态替换大多数参考结果无意义的概念集,以确保最终质量。
3.3 Permutation-Invariant Annotating
3.3 排列不变性标注
We have to present every input as a a string for annotators to read, which means we take a random permutation of the concept-set as a linear sequence. Therefore we may wonder if annotators will make flexible adjustment on the concept order when creating references for CommonGen. To address this concern, we first study the correlation between the input concept-order and the reference concept-order (i.e., the order of the given concepts in the human annotations). We find that $96.97%$ of the references, of which the concept-order is different from the order shown when they are annotating.
我们必须将每个输入以字符串形式呈现给标注者阅读,这意味着我们将概念集的随机排列作为线性序列。因此,我们可能会思考标注者在为CommonGen创建参考时是否会灵活调整概念顺序。针对这一疑虑,我们首先研究了输入概念顺序与参考概念顺序(即人工标注中给定概念的出现顺序)之间的相关性。发现其中96.97%的参考文本,其概念顺序与标注时展示的顺序不同。
More specifically, we use Spearmans’s rank correlation coefficient to understand the correlation between input concept-order and reference conceptorder. It turns out that the mean correlation over all input-reference pairs on test examples is -0.031, which suggests that different permutation of the input concept-order do not have notable influence on the order of concept in the human references, thus being permutation-invariant.
具体而言,我们使用斯皮尔曼等级相关系数来理解输入概念顺序与参考概念顺序之间的相关性。结果表明,测试样本中所有输入-参考对的平均相关性为-0.031,这表明输入概念顺序的不同排列对人类参考中的概念顺序没有显著影响,因此具有排列不变性。
3.4 Finalizing Adequate References
3.4 确定充分参考文献
As there may be more than one acceptable scenes for each input concept-set, we would like to check if our human references are enough before we finalizing our dataset. Thus, we took one more round of crowd-sourcing to add one more reference for each concept-set by new annotators. Then, we compute the inter-annotator agreement (IAA) by using the cosine similarity between all pairs of human references, based on Sentence BERT (Reimers and Gurevych, 2019) (fine-tuned for semantic similarity analysis). Note that if we have $k$ human references for an example in the end, then we will have $k(k-1)/2$ different pairs of references, each of which has a cosine similarity between their sentence embeddings. Then, we take the median of these similarity scores as a proxy to understand if we have collect adequate human references.
由于每个输入概念集可能存在多个可接受的场景,我们希望在最终确定数据集前验证人工参考是否足够。为此,我们额外进行了一轮众包标注,由新标注者为每个概念集新增一条参考描述。随后基于Sentence BERT (Reimers and Gurevych, 2019)(经语义相似度分析微调)计算所有人工参考描述对的余弦相似度,以此衡量标注者间一致性(IAA)。需要注意的是,若某示例最终包含$k$条人工参考,则会产生$k(k-1)/2$个不同的参考描述对,每个描述对通过其句子嵌入的余弦相似度进行评估。最终我们取这些相似度得分的中位数作为判断人工参考充分性的依据。

Figure 4: The curve of inter-annotator agreement (IAA) in terms of their std (up) and median (bottom) when average number of references increase.
图 4: 标注者间一致性 (IAA) 随平均参考数量增加的标准差 (上) 和中位数 (下) 变化曲线。
The underlying rationale here is that if there are more references that are very similar to each other yet from different annotators, then it is likely that current references are adequate for this example. As shown in Figure 4, we simulated different sizes of number of references per example. We find that the IAA will be saturated when we have the fifth ones, and thus we believe references are adequate. Also, from the std of these IAA scores, we find that the diversity of the references, and it also saturate when there are five references.
此处的核心逻辑在于,如果存在多个彼此高度相似却来自不同标注者的参考文本,则表明当前参考文本对该示例已足够充分。如图4所示,我们模拟了每个示例不同数量的参考文本规模。研究发现当参考文本数量达到第五个时,标注者间一致性(IAA)趋于饱和,因此我们认为参考文本已足够充分。此外,通过这些IAA分数的标准差,我们发现参考文本的多样性在达到五个参考文本时同样趋于饱和。
3.5 Down-Sampling Training Examples
3.5 训练样本降采样
In order to evaluate the compositional generalization ability, we down-sample the remaining can- didate concept-sets to construct a distantly supervised training dataset (i.e., using caption sentences as the human references). We explicitly control the overlap of the concept-sets between training examples and dev and test examples. The basic statistics of the final dataset is shown in Table 1. There are on average four sentences for each example in dev and test sets, which provide a richer and more diverse test-bed for automatic and manual evaluation. Table 1 also shows the ratio of unseen concept compositions (i.e., concept, concept-pair, and concept-triple) in the dev and test. Notably, all pairs of concepts in every test concept-set are unseen in training data and thus pose a challenge for compositional generalization.
为了评估组合泛化能力,我们对剩余候选概念集进行降采样,构建了一个远监督训练数据集(即使用描述语句作为人工参考)。我们明确控制了训练样本与开发集、测试样本之间概念集的重叠度。最终数据集的基本统计信息如表1所示。开发集和测试集中每个样本平均包含四句话,为自动和人工评估提供了更丰富多样的测试环境。表1同时展示了开发集和测试集中未见过概念组合(即单个概念、概念对和概念三元组)的比例。值得注意的是,每个测试概念集中的所有概念对在训练数据中均未出现过,这对组合泛化能力提出了挑战。
3.6 Analysis of Underlying Common Sense
3.6 基础常识分析
We here introduce deeper analysis of the dataset by utilizing the largest commonsense knowledge graph (KG), ConceptNet (Speer et al., 2017), as an tool to study connectivity and relation types.
我们在此引入对数据集的更深入分析,利用最大的常识知识图谱 (KG) ConceptNet (Speer et al., 2017) 作为研究连通性和关系类型的工具。
Connectivity Distribution. If the concepts inside a given concept-set is more densely connected with each other on the KG, then it is likely to be easier to write a scenario about them. In each 5- size concept-set (i.e. a concept-set consists of five concepts), there are 10 unique pairs of concepts, the connections of which we are interested in. As shown in Figure 5, if we look at the one-hop links on the KG, about $60%$ of the 5-size concept-set have less than one link among all concept-pairs. On the other hand, if we consider two-hop links, then nearly $50%$ of them are almost fully connected (i.e. each pair of concepts has connections). These two observations together suggest that the COMMONGEN has a reasonable difficulty: the concepts are not too distant or too close, and thus the inputs are neither too difficult nor too trivial.
连通性分布。如果给定概念集中的概念在知识图谱(KG)上彼此连接更密集,那么围绕它们编写场景可能会更容易。在每个包含五个概念的集合中,存在10个独特的概念对,我们关注这些概念对之间的连接。如图5所示,若仅考虑知识图谱上的一跳链接,约60%的五概念集合中所有概念对之间的链接少于一个;而若考虑两跳链接,则近50%的集合几乎完全连通(即每对概念间都存在连接)。这两个观察结果表明COMMONGEN任务具有合理的难度:概念之间的距离既不过远也不过近,因此输入既不会过于困难也不会过于简单。
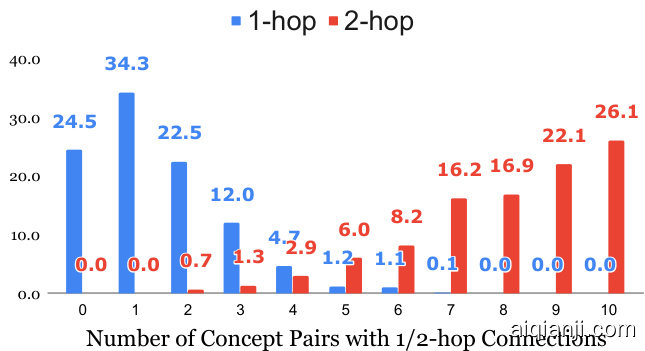
Figure 5: Connectivity analysis in 5-size concept-sets in the test set, each of which consists of 10 concept pairs. For example, 12.0 in blue means: there are $12%$ concept-sets that have 3 concept pairs with one-hop connections on ConceptNet.
图 5: 测试集中5个概念组成的集合的连通性分析,每个集合包含10个概念对。例如,蓝色的12.0表示:有 $12%$ 的概念集在ConceptNet上存在3个概念对具有单跳连接。
Relation Distribution. Furthermore, the relation types of such connections can also tell us what kinds of commonsense knowledge are potentially useful for relational reasoning towards generation. We report the frequency of different relation types2 of the one/two-hop connections among conceptpairs in the dev and test examples in Fig. 9. To better summarize the distributions, we categorize these relations into five major types and present their distribution in Table 2, respectively for one/two-hop connections between concept pairs.
关系分布。此外,这类连接的关系类型还能揭示哪些常识知识可能对关系推理生成有帮助。我们在图9中展示了开发集和测试集样本里概念对之间一跳/两跳连接的不同关系类型2的出现频率。为了更好地总结分布规律,我们将这些关系划分为五大类别,并在表2中分别呈现概念对之间一跳/两跳连接的分布情况。
4 Methods
4 方法
We briefly introduce the baseline methods that are tested on the COMMONGEN task.
我们简要介绍在COMMONGEN任务上测试的基线方法。
Encoder-Decoder Models. Bidirectional RNNs and Transformers (Vaswani et al., 2017) are two most popular architectures for seq2seq learning. We use them with the addition of attention mechanism (Luong et al., 2015) with copying ability (Gu et al., 2016), which are based on an open-source framework OpenNMT-py (Klein et al., 2017). We use bRNN-CopyNet and Trans-CopyNet denote them respectively. To alleviate the influence from the concept ordering in such sequential learning methods, we randomly permute them multi- ple times for training and decoding and then get their average performance. To explicitly eliminate the order-sensitivity of inputs, we replace the encoder with a mean pooling-based MLP network (Mean Pooling-CopyNet).
编码器-解码器模型。双向RNN和Transformer (Vaswani等人,2017) 是序列到序列学习中最流行的两种架构。我们在此基础上加入了注意力机制 (Luong等人,2015) 和复制能力 (Gu等人,2016),这些实现基于开源框架OpenNMT-py (Klein等人,2017)。我们分别用bRNN-CopyNet和Trans-CopyNet来表示这两种模型。为了减轻这种序列学习方法中概念顺序的影响,我们对其进行多次随机排列用于训练和解码,然后取平均性能。为了显式消除输入的顺序敏感性,我们用基于均值池化的MLP网络 (Mean Pooling-CopyNet) 替换了编码器。
Table 2: The distributions of the relation categories on one/two-hop connections.
| Category | Relations | 1-hop | 2-hop |
| Spatial knowledge | AtLocation,LocatedNear | 9.40% | 39.31% |
| Object properties | UsedFor,CapableOf,PartOf, ReceivesAction,MadeOf, FormOf,HasProperty,HasA | 9.60% | 44.04% |
| Human behaviors | CausesDesire,MotivatedBy, Desires,NotDesires,Manner | 4.60% | 19.59% |
| Temporal knowledge | Subevent,Prerequisite, First/Last-Subevent | 1.50% | 24.03% |
| General | RelatedTo,Synonym, DistinctFrom,IsA, HasContext,SimilarTo | 74.89% | 69.65% |
表 2: 一跳/二跳连接上关系类别的分布情况。
| 类别 | 关系 | 一跳 | 二跳 |
|---|---|---|---|
| 空间知识 | AtLocation, LocatedNear | 9.40% | 39.31% |
| 对象属性 | UsedFor, CapableOf, PartOf, ReceivesAction, MadeOf, FormOf, HasProperty, HasA | 9.60% | 44.04% |
| 人类行为 | CausesDesire, MotivatedBy, Desires, NotDesires, Manner | 4.60% | 19.59% |
| 时序知识 | Subevent, Prerequisite, First/Last-Subevent | 1.50% | 24.03% |
| 通用 | RelatedTo, Synonym, DistinctFrom, IsA, HasContext, SimilarTo | 74.89% | 69.65% |
Non-auto regressive generation. Recent advances (Lee et al., 2018; Stern et al., 2019) in conditional sentence generation have an emerging interest on (edit-based) non-auto regressive generation models, which iterative ly refine generated sequences. We assume that these models potentially would have better performance because of their explicit modeling on iterative refinements, and thus study the most recent such model Levenshtein Transformer (LevenTrans) by Gu et al. (2019). We also include a recent enhanced version, ConstLeven (Susanto et al., 2020), which incorporates lexical constraints in LevenTrans.
非自回归生成。条件语句生成领域的最新进展 (Lee et al., 2018; Stern et al., 2019) 显示,(基于编辑的) 非自回归生成模型正受到越来越多的关注,这类模型通过迭代方式优化生成序列。我们认为这些模型因其对迭代优化的显式建模可能具有更好的性能,因此研究了 Gu et al. (2019) 提出的最新模型 Levenshtein Transformer (LevenTrans)。我们还纳入了其增强版本 ConstLeven (Susanto et al., 2020),该版本在 LevenTrans 中融入了词汇约束。
Pre-trained Language Generation Models. We also employ various pre-trained language generation models, including GPT-2 (Radford et al., 2019), UniLM (Dong et al., 2019), UniLM-v2 (Bao et al., 2020), BERT-Gen (Bao et al., 2020), BART (Lewis et al., 2019), and T5 (Raffel et al., 2019), to tackle this task and test their generative commonsense reasoning ability. We fine-tuned all the above models on our training data with a seq2seq format.
预训练语言生成模型。我们还采用了多种预训练语言生成模型,包括 GPT-2 (Radford et al., 2019)、UniLM (Dong et al., 2019)、UniLM-v2 (Bao et al., 2020)、BERT-Gen (Bao et al., 2020)、BART (Lewis et al., 2019) 和 T5 (Raffel et al., 2019),以解决该任务并测试它们的生成式常识推理能力。我们在训练数据上以序列到序列 (seq2seq) 格式对上述所有模型进行了微调。
Specifically, to use GPT-2 for this sequence-tosequence task, we condition the language model on the format $^{\leftarrow}c_{1}c_{2}$ . . . $c_{k}=y^{\ '}$ during fine-tuning, where $c_{i}$ is a concept in the given concept-set and connects with other concepts with a blank; $y$ is a target sentence. For inference, we sample from the fine-tuned $\mathrm{GP}\mathrm{T}{-}2$ model after a prompt of $\mathrm{\stackrel{\scriptscriptstyle~\leftarrow~}{_}\mathcal{C}{1}}\mathrm{\it~{\mathcal{C}}{2}}\mathrm{\ldots~}\mathrm{\it~{\mathcal{C}}{k}}=\mathrm{\stackrel{\scriptscriptstyle~}{_}{_}\mathcal{C}_{k}~}$ with beam search and use the first generated sentence as the output sentence. For BERT-Gen, we use the $\triangle2\triangle-\pounds{}{}\ t$ package to finetune them in a sequence-to-sequence fashion that is similar to the LM objective employed by UniLM.
具体来说,为了将GPT-2应用于这一序列到序列任务,我们在微调时以格式 $^{\leftarrow}c_{1}c_{2}$ ... $c_{k}=y^{\ '}$ 作为语言模型的条件输入,其中 $c_{i}$ 是给定概念集中的一个概念,并与其他概念以空格连接;$y$ 是目标句子。在推理阶段,我们通过束搜索从微调后的 $\mathrm{GP}\mathrm{T}{-}2$ 模型中采样,提示符为 $\mathrm{\stackrel{\scriptscriptstyle~\leftarrow~}{_}\mathcal{C}{1}}\mathrm{\it~{\mathcal{C}}{2}}\mathrm{\ldots~}\mathrm{\it~{\mathcal{C}}{k}}=\mathrm{\stackrel{\scriptscriptstyle~}{_}{_}\mathcal{C}_{k}~}$,并将第一个生成的句子作为输出。对于BERT-Gen,我们使用 $\triangle2\triangle-\pounds{}{}\ t$ 工具包以类似UniLM所采用的LM目标的方式进行序列到序列的微调。
As for $\mathtt{T5}$ , the state-of-the-art text-to-text pretrained model which is pre-trained with a multitask objective by prepending a task description before the input text, we prepend the input concept set with a simple prompt: “generate a sentence with:” and fine-tune the model with the source sentence on the format “generate a sentence with $c_{1}c_{2}\ldots c_{k}$ .” For decoding, we employ the standard beam search with a beam size of 5 for all compared models. We also report their results with a lexically-constrained decoding method, dynamic beam allocation (DBA) (Post and Vilar, 2018), which do not show improvement over conventional beam searching. 4
至于 $\mathtt{T5}$,这一最先进的文本到文本预训练模型通过在多任务目标前添加任务描述进行预训练。我们在输入概念集前添加简单提示:"用以下内容生成句子:",并以"用 $c_{1}c_{2}\ldots c_{k}$ 生成句子"的格式对模型进行微调。解码时,所有对比模型均采用标准束搜索 (beam search),束宽设为5。我们还报告了使用词汇约束解码方法——动态束分配 (DBA) (Post and Vilar, 2018) 的结果,该方法未显示出优于传统束搜索的效果。4
5 Evaluation
5 评估
We first introduce the automatic evaluation metrics, then present main experimental results with manual analysis, and finally introduce the potential application in transferring CommonGen-trained models for other downstream tasks.
我们首先介绍自动评估指标,然后展示主要实验结果并进行人工分析,最后探讨将CommonGen训练模型迁移至其他下游任务的潜在应用。
5.1 Metrics
5.1 指标
Following other conventional generation tasks, we use several widely-used automatic metrics to automatically assess the performance, such as BLEU (Papineni et al., 2002), ROUGE (Lin, 2004), METEOR (Banerjee and Lavie, 2005), which mainly focus on measuring surface similarities. We report the concept Coverage, which is the average percentage of input concepts that are present in lemma ti zat i zed outputs.
遵循其他常规生成任务的惯例,我们采用多种广泛使用的自动指标来评估性能,例如BLEU (Papineni et al., 2002)、ROUGE (Lin, 2004)、METEOR (Banerjee and Lavie, 2005),这些指标主要关注衡量表面相似性。我们还报告了概念覆盖率 (Coverage),即词元化输出中包含输入概念的平均百分比。
In addition, we argue that it is more suitable to use evaluation metrics specially design for captioning task, such as CIDEr (Vedantam et al., 2015) and SPICE (Anderson et al., 2016). They usually assume system generations and human references use similar concepts, and thus focus on evaluate the associations between mentioned concepts instead of n-gram overlap. For example, the SPICE metric uses dependency parse trees as proxy of scene 5 graphs to measure the similarity of scenarios.
此外,我们认为更适合使用专门为字幕任务设计的评估指标,例如 CIDEr (Vedantam et al., 2015) 和 SPICE (Anderson et al., 2016)。这些指标通常假设系统生成内容与人工参考文本使用相似的概念,因此更关注评估提及概念之间的关联性而非 n-gram 重叠度。例如,SPICE 指标通过依存句法树作为场景图的代理来测量情境的相似性。
Table 3: Experimental results of different baseline methods on the COMMONGEN test set (v1.1). The first group of models are non-pretrained models, while the second group is large pretrained models that we have fine-tuned. The best models are bold and second best ones are underlined within each metric. We highlight the metrics that we used in our official leader board. (Results on dev set are at Table. 7.)
表 3: 不同基线方法在 COMMONGEN 测试集 (v1.1) 上的实验结果。第一组模型为未经预训练的模型,第二组为我们微调过的大型预训练模型。每个指标下最佳模型加粗标出,次优模型加下划线。我们高亮了官方排行榜使用的指标。(开发集结果见表 7。)
| 模型\指标 | ROUGE-2/L | BLEU-3/4 | METEOR | CIDEr | SPICE | Coverage |
|---|---|---|---|---|---|---|
| bRNN-CopyNet (Gu et al., 2016) | 7.67 | 12.58 7.06 | 16.38 | 5.06 | 13.39 | 51.15 |
| Trans-CopyNet | 8.64 | 12.47 7.56 | 15.91 | 4.65 | 12.85 | 49.06 |
| MeanPooling-CopyNet | 9.65 | 12.29 7.08 | 17.10 | 5.18 | 15.18 | 55.70 |
| LevenTrans. (Gu et al., 2019) | 10.61 | 21.51 12.65 | 20.50 | 7.45 | 16.84 | 63.81 |
| ConstLeven. (Susanto et al.,2020) | 11.77 | 20.87 11.26 | 25.23 | 10.80 | 20.05 | 94.51 |
| GPT-2 (Radford et al.,2019) | 16.85 | 33.92 23.73 | 26.83 | 12.19 | 23.57 | 79.09 |
| BERT-Gen (Ba0 et al.,2020) | 17.78 | 33.29 23.47 | 28.25 | 12.61 | 24.82 | 86.06 |
| UniLM (Dong et al., 2019) | 21.20 | 41.82 30.73 | 30.62 | 14.89 | 27.43 | 89.19 |
| UniLM-v2 (Ba0 et al.,2020) | 18.11 | 34.31 24.53 | 29.04 | 13.19 | 25.52 | 89.13 |
| BART (Lewis et al.,2019) | 22.02 | 39.52 29.01 | 31.83 | 13.98 | 28.00 | 97.35 |
| T5-Base (Raffel et al., 2019) | 14.63 | 28.76 18.54 | 23.94 | 9.40 | 19.87 | 76.67 |
| T5-Large (Raffel et al., 2019) | 21.74 | 43.01 31.12 | 31.96 | 15.13 | 28.86 | 95.29 |
| Human Performance (Upper Bound) | 36.72 | 52.55 38.79 | 46.49 | 37.64 | 52.43 | 99.33 |
To estimate human performance within each metric, we treat each reference sentence in dev/test data as a “system prediction” to be compared with all other references, which is equivalent to compute inter-annotator agreement within each metric. Thus, systems that have better generative ability than average crowd-workers should exceed this.
为了估算每个指标下的人类表现,我们将开发集/测试数据中的每个参考句子视为一个"系统预测",与其他所有参考句子进行比较,这相当于计算每个指标下的标注者间一致性。因此,生成能力超过众包工作者平均水平的系统应该超越这一基准。
5.2 Experimental Results
5.2 实验结果
Automatic Evaluation. Table 3 presents the experimental results in a variety of metrics. We can see that all fine-tuned pre-trained models (the lower group) outperform non-pretrained models (the upper group) with a significant margin. This is not surprising because their pre training objectives, including masked language modeling, word ordering, and text infilling which predicts missing words or text spans, are relevant to our task. On the other hand, we find that the key disadvantage of nonpretrained models with CopyNet still falls in the failure of using all given concepts (i.e., low coverage), which results in worse results.
自动评估。表 3 展示了多种指标下的实验结果。可以看出,所有经过微调的预训练模型(下方组别)均显著优于未预训练的模型(上方组别)。这一结果并不意外,因为它们的预训练目标(包括掩码语言建模、词序预测以及预测缺失单词或文本段的文本填充任务)与本任务高度相关。另一方面,我们发现未预训练模型搭配 CopyNet 的主要缺陷仍在于无法充分利用给定概念(即覆盖率低),从而导致效果较差。
Among them, UniLM, BART, and T5 performs the best, which may be due to its inherent sequenceto-sequence pre-training framework. We found that BART has the best concept coverage, which is probably due to its comprehensive pre-training tasks that aim to recover text with noise. The results suggest that further modifying pre-trained models is a promising direction for generative commonsense.
其中,UniLM、BART和T5表现最佳,这可能是由于其固有的序列到序列预训练框架所致。我们发现BART的概念覆盖范围最广,这很可能归功于其旨在恢复带噪声文本的全面预训练任务。结果表明,进一步修改预训练模型是生成式常识推理的一个有前景的方向。
Table 4: Manual Evaluation via Pair-wise Comparisons for Ranking. Numbers are hit rates $(%)$ at top 1/3/5.
表 4: 基于成对比较排序的人工评估结果。数值为前1/3/5名的命中率 $(%)$
| C.Leven | GPT | BERT-G.U | UniLM | BART | T5 | |
|---|---|---|---|---|---|---|
| Hit@1 | 3.2 | 21.5 | 22.3 | 21.0 | 26.3 | 26.8 |
| Hit@3 | 18.2 | 63.0 | 59.5 | 69.0 | 69.0 | 70.3 |
| Hit@5 | 51.4 | 95.5 | 95.3 | 96.8 | 96.3 | 97.8 |
Manual Evaluation. We conduct manual evaluation with a focus on commonsense plausibility for comparing the 6 best-performing models in Table 4. We ask five graduate students to compare 1,500 pairs of model-generated sentences respectively, for ranking the models within 100 conceptsets that are covered by all the models. The final average ranked results are shown in Table 4 and their inter-annotator agreement is 0.85 in Kendall’s rank correlation coefficient.
人工评估。我们针对表4中表现最佳的6个模型进行了以常识合理性为核心的人工评估。安排5名研究生对1500对模型生成的句子进行两两比较,在全部模型覆盖的100个概念集范围内对模型进行排序。最终平均排序结果如表4所示,评估者间一致性达到0.85(Kendall等级相关系数)。
Note that the coverage-weighted hit $@1$ rate correlates with the SPICE metric the most, i.e., 0.94 in Spearman’s $\rho$ for model ranks, CIDEr for 0.91, while METEOR and ROUGE-2 are both 0.88 and BLEU-4 is 0.78.
请注意,覆盖率加权的命中率 $@1$ 与 SPICE 指标相关性最高,即模型排名的 Spearman $\rho$ 为 0.94,CIDEr 为 0.91,而 METEOR 和 ROUGE-2 均为 0.88,BLEU-4 为 0.78。
Case study. Fig. 6 shows the top generations of different models and human references about an input concept-set: ${h a n d,s i n k,s o u p,w a s h}$ (more cases are shown in Fig. 10 in the appendix). We find that
案例分析。图 6 展示了不同模型和人类参考对于输入概念集 ${h a n d,s i n k,s o u p,w a s h}$ 的生成结果 (更多案例见附录中的图 10)。我们发现
non-pretrained seq2seq models (e.g., bRNN, MeanPooling, ConstLeven) can successfully use part of given concepts, while the generated sentences are less meaningful and coherent. On the contrary, the outputs of fine-tuned pre-trained language models are significantly more common sens ical. Most of them use all given concepts in their outputs. ConstLeven tends to make use of frequent patterns to compose a non-sense sentence but uses all concepts. GPT-2 and UniLM incorrectly compose the dependency among hand, wash, and soap. The phrase ‘a sink of soaps’ in BERT-gen’s output makes itself less common. BART and T5 generate relatively reasonable scenarios, but both are not as natural as human references; BART’s contains repetitive content while T5’s lacks a human agent.
未经预训练的序列到序列模型(如bRNN、MeanPooling、ConstLeven)能部分利用给定概念生成句子,但语句意义性和连贯性较差。相反,经过微调的预训练语言模型输出明显更具常识性,大多数能完整使用所有给定概念。ConstLeven倾向套用高频模式生成无意义句子,但会使用全部概念。GPT-2和UniLM错误构建了hand、wash、soap之间的依存关系。BERT-gen输出中"a sink of soaps"的表述降低了合理性。BART和T5生成的场景相对合理,但均不如人工参考文本自然:BART存在内容重复,T5则缺少人类行为主体。
Concept-Set: { hand, sink, wash, soap } Figure 6: A case study with a concept-set {hand, sink, wash, soap for qualitative analysis of machine generations. Human references are collected from AMT. Figure 7: Learning curve for the transferring study. We use several trained COMMONGEN (GG) models to generate choice-specific context for the CSQA task. Detailed numbers are shown in Tab. 8 in the appendix.
概念集: {手, 水槽, 清洗, 肥皂}
图 6: 使用概念集{手, 水槽, 清洗, 肥皂}进行机器生成质量分析的案例研究。人类参考数据来自AMT。
图 7: 迁移研究的学习曲线。我们使用多个训练好的COMMONGEN (GG)模型为CSQA任务生成特定选择上下文。详细数据见附录中的表 8。
Influence of Dynamic Beam Allocation. Considering that all tested models decode sentences with beam searching, one may wonder what if we use a decoding method specially designed for constrained decoding. Thus, we employed dynamic beam allocation (DBA) (Post and Vilar, 2018). The results are shown in Table 5. Note that the models are the same as in Table 3 while only the decoding method is changed to DBA. We can see that all methods are negatively impacted by the decoding method. This suggests that for the COMMONGEN task and pre-trained language models, we may need to focus on knowledge-based decoding or re-ranking as future directions.
动态波束分配的影响。考虑到所有测试模型都采用波束搜索解码句子,我们不禁思考:若使用专为约束解码设计的动态波束分配 (DBA) (Post and Vilar, 2018) 会如何?实验结果如 表5 所示(注意:模型配置与 表3 相同,仅解码方法改为DBA)。数据显示,所有方法均受此解码策略的负面影响。这表明对于COMMONGEN任务与预训练语言模型,未来研究方向可能需要聚焦基于知识的解码或重排序机制。
5.3 Transferring CommonGen Models
5.3 迁移CommonGen模型
One may wonder how fine-tuned COMMONGEN models can benefit commonsense-centric downstream tasks such as Commonsense Question Answering (Talmor et al., 2019) (CSQA) with their generative commonsense reasoning ability. To this end, we use the models trained with the COMMONGEN dataset for generating useful context.
人们可能会好奇,经过微调的COMMONGEN模型如何利用其生成式常识推理能力,改善以常识为中心的下游任务,例如常识问答 (Commonsense Question Answering) (Talmor et al., 2019) (CSQA)。为此,我们使用在COMMONGEN数据集上训练的模型来生成有用的上下文。
We extract the nouns and verbs in questions and all choices respectively, and combine the concepts of the question $q$ and each choice $c_{i}$ to build five concept-sets. Then, we use these concept-sets as inputs to a trained COMMONGEN model (e.g., T5) for generating scenario a sentence $g_{i}$ for each as choice-specific contexts. Finally, we prepend the outputs in front of the questions, i.e., $\mathrm{\mathrm{\Sigma}^{66}}<\mathrm{s}>\mathrm{G}$ : $g_{i}$ $|\mathrm{Q}{\mathrm{:}}q\mathrm{}{<}/\mathrm{s}{>}\mathrm{C}$ : $c_{i}</\mathrm{s}>^{\mathrm{,}}$ . Note that the state-ofthe-art RoBERTa-based models for CSQA uses the same form without “G: $\mathrm{~}g_{i}|^{,}$ in fine-tuning.
我们分别提取问题及所有选项中的名词和动词,将问题 $q$ 与每个选项 $c_{i}$ 的概念结合,构建五个概念集。随后,将这些概念集作为训练好的COMMONGEN模型(如T5)的输入,为每个选项生成特定场景句 $g_{i}$ 作为上下文。最后,我们将输出内容置于问题前,即 $\mathrm{\mathrm{\Sigma}^{66}}<\mathrm{s}>\mathrm{G}$ : $g_{i}$ $|\mathrm{Q}{\mathrm{:}}q\mathrm{}{<}/\mathrm{s}{>}\mathrm{C}$ : $c_{i}</\mathrm{s}>^{\mathrm{,}}$ 。需要注意的是,当前最先进的基于RoBERTa的CSQA模型在微调时采用相同形式,但不包含“G: $\mathrm{~}g_{i}|^{,}$”。
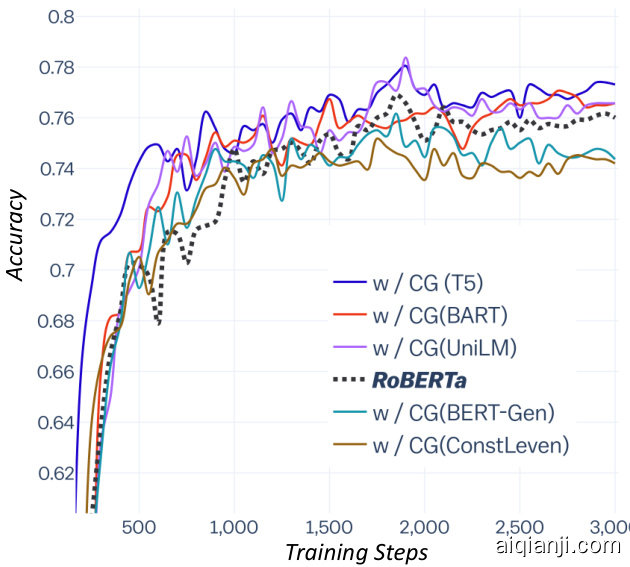
We show the learning-efficiency curve in Fig. 7, where $y$ is the accuracy on the official dev set and $x$ is the number of training steps. The details of the experiments are shown in the appendix.
我们在图 7 中展示了学习效率曲线,其中 $y$ 表示官方开发集上的准确率,$x$ 表示训练步数。实验细节详见附录。
We highlight the performance of original RoBERTa-Large as the baseline. We find that some CommonGen models further improves the perforUniLM mance by a large margin, e.g., 76.9 −→ 78.4 and they converge at better accuracy in the end. Note that BERT-gen and ConstLeven cause negative transfer due to the low quality of generated context. Particularly, we find that the context generated by the T5-based CommonGen model (CG-T5) helps speed up training about 2 times, if we look at 550th steps of CG-T5 $(74.85%)$ and 1,250th steps of original RoBERTa $(74.77%)$ .
我们以原始RoBERTa-Large模型的性能作为基线。研究发现,部分CommonGen模型能显著提升性能,例如从76.9提升至78.4,且最终收敛于更高的准确率。需注意,BERT-gen和ConstLeven由于生成上下文质量较低会导致负迁移现象。特别地,基于T5的CommonGen模型(CG-T5)生成的上下文可使训练速度提升约2倍——对比CG-T5在第550步达到的74.85%准确率与原始RoBERTa在第1,250步达到的74.77%准确率即可看出。
Table 5: Experimental results of models with DBA decoding method on the test set.
| 模型 \指标 | ROUGE-2/L | BLEU-3/4 | METEOR | CIDEr SPICE | 覆盖率 |
|---|---|---|---|---|---|
| T5-large+DBA | 16.8 | 36.71 | 27.3 18.7 | 25.3 | 8.62 |
| T5-base+DBA | 15.07 | 34.82 | 24.8 16 | 23.5 | 9.31 |
| GPT-2+DBA | 17.56 | 39.45 | 29.4 | 20.6 24.9 | 10.85 |
| BART+DBA | 18.15 | 37.02 | 28.3 | 19.1 25.5 | 9.82 |
Through manual analysis, we find that the successful COMMONGEN models can generate more reasonable and natural sentence for correct choices while noisy sentences for wrong choices. For example with CG (T5), $q{=}$ “What do people aim to do at work?”, $c_{i}=\mathrm{"}$ complete job’ $(\checkmark)$ with $g_{i}=\begin{array}{r l}\end{array}$ “people work to complete a job aimed at achieving a certain goal.” “people wearing hats aim their guns at each other while working on a construction site.” The used question concepts and choice concepts are underlined.
通过人工分析,我们发现成功的COMMONGEN模型能为正确选项生成更合理自然的句子,而对错误选项则生成含噪声的句子。例如在CG (T5)模型中,$q{=}$"人们工作时旨在做什么?",$c_{i}=\mathrm{"}$完成工作'$(\checkmark)$"对应生成$g_{i}=\begin{array}{r l}\end{array}$"人们工作是为了完成旨在达成特定目标的任务";"戴着帽子的人们在建筑工地工作时用枪互相瞄准"。使用的提问概念和选项概念已加下划线标注。
6 Related Work
6 相关工作
Commonsense benchmark datasets. There are many emerging datasets for testing machine commonsense from different angles, such as commonsense extraction (Xu et al., 2018; Li et al., 2016), next situation prediction (SWAG (Zellers et al., 2018), CODAH (Chen et al., 2019), Hel- laSWAG (Zellers et al., 2019b)), cultural and social understanding (Lin et al., 2018; Sap et al., 2019a,b), visual scene comprehension (Zellers et al., 2019a), and general commonsense question answering (Talmor et al., 2019; Huang et al., 2019; Wang et al., 2019a, 2020). However, the success of fine-tuning pre-trained language models for these tasks does not necessarily mean machines can produce novel assumptions in a more open, realistic, generative setting. We see COMMONGEN as a novel, complementary commonsense reasoning benchmark task for advancing machine commonsense in NLG.
常识基准数据集。现有许多新兴数据集从不同角度测试机器常识,例如常识抽取 (Xu et al., 2018; Li et al., 2016)、后续情境预测 (SWAG (Zellers et al., 2018)、CODAH (Chen et al., 2019)、HellaSWAG (Zellers et al., 2019b))、文化与社会理解 (Lin et al., 2018; Sap et al., 2019a,b)、视觉场景理解 (Zellers et al., 2019a) 以及通用常识问答 (Talmor et al., 2019; Huang et al., 2019; Wang et al., 2019a, 2020)。然而,预训练语言模型在这些任务上的微调成功,并不意味着机器能在更开放、真实的生成式场景中产生新颖假设。我们将COMMONGEN视为推动自然语言生成领域机器常识发展的新型补充性常识推理基准任务。
Constrained Text Generation. Constrained text generation aims to decode sentences with expected attributes such as sentiment (Luo et al., 2019a; Hu et al., 2017), tense (Hu et al., 2017), template (Zhu et al., 2019; J Kurisinkel and Chen, 2019), style (Fu et al., 2018; Luo et al., 2019b; Li et al., 2018), top- ics (Feng et al., 2018), etc. Two related scenarios with our task is lexically constrained decoding and word ordering (Zhang and Clark, 2015; Hasler et al., 2018; Dinu et al., 2019; Hokamp and Liu, 2017; Puduppully et al., 2017; Miao et al., 2019). However, they are not easily adopted by the recent pre-trained language models and thus not directly useful for our task. Topical story generation (Fan et al., 2018; Yao et al., 2019) is also a related direction, while it targets generating longer, creative stories around the given topics, making it hard to directly adopt them to our task. Additionally, the COMMONGEN task brings some more challenges mentioned in Section 2. Prior constrained generation methods cannot address these issues together in a unified model.
受限文本生成。受限文本生成旨在解码具有预期属性的句子,如情感 (Luo et al., 2019a; Hu et al., 2017)、时态 (Hu et al., 2017)、模板 (Zhu et al., 2019; J Kurisinkel and Chen, 2019)、风格 (Fu et al., 2018; Luo et al., 2019b; Li et al., 2018)、主题 (Feng et al., 2018) 等。与我们的任务相关的两个场景是词汇受限解码和词序 (Zhang and Clark, 2015; Hasler et al., 2018; Dinu et al., 2019; Hokamp and Liu, 2017; Puduppully et al., 2017; Miao et al., 2019)。然而,它们不易被最近的预训练语言模型采用,因此对我们的任务没有直接用处。主题故事生成 (Fan et al., 2018; Yao et al., 2019) 也是一个相关方向,但其目标是围绕给定主题生成长篇创意故事,因此很难直接应用于我们的任务。此外,COMMONGEN任务带来了第2节中提到的更多挑战。先前的受限生成方法无法在一个统一模型中共同解决这些问题。
Incorporating Commonsense for NLG. There are a few recent works that incorporate commonsense knowledge in language generation tasks such as essay generation (Guan et al., 2019; Yang et al., 2019a), image captioning (Lu et al., 2018), video storytelling (Yang et al., 2019b), and conversational systems (Zhang et al., 2020a). These works suggest that generative commonsense reasoning has a great potential to benefit downstream applications. Our proposed COMMONGEN, to the best of our knowledge, is the very first constrained sentence generation dataset for assessing and conferring generative machine commonsense and we hope it can benefit such applications. Our transferring study in Sec. 5.3 also shows the potential benefits of CommonGen-generated contexts.
融入常识的自然语言生成。近期有几项研究将常识知识融入语言生成任务,如文章生成 (Guan et al., 2019; Yang et al., 2019a)、图像描述 (Lu et al., 2018)、视频叙事 (Yang et al., 2019b) 和对话系统 (Zhang et al., 2020a)。这些研究表明,生成式常识推理具有赋能下游应用的巨大潜力。据我们所知,我们提出的COMMONGEN是首个用于评估和赋予机器生成式常识的受限句子生成数据集,希望它能推动此类应用发展。第5.3节的迁移研究也揭示了CommonGen生成语境的潜在价值。
7 Conclusion
7 结论
Our major contribution in this paper are threefold:
我们在本文中的主要贡献有三方面:
• we present COMMONGEN, a novel constrained text generation task for generative commonsense reasoning, with a large dataset; we carefully analyze the inherent challenges of the proposed task, i.e., a) relational reasoning with latent commonsense knowledge, and b) compositional generalization. • our extensive experiments systematically examine recent pre-trained language generation models (e.g., UniLM, BART, T5) on the task , and find that their performance is still far from humans, generating grammatically sound yet realistically implausible sentences.
• 我们提出了COMMONGEN,这是一个面向生成式常识推理的新型约束文本生成任务,并附带一个大规模数据集;我们深入分析了该任务的内在挑战,即:a) 基于潜在常识知识的关系推理,以及b) 组合泛化能力。
• 我们通过大量实验系统性地评估了最新预训练语言生成模型(如UniLM、BART、T5)在该任务上的表现,发现其性能仍远逊于人类水平,生成的句子虽语法正确但现实合理性不足。
Our study points to interesting future research directions on modeling commonsense knowledge in language generation process, towards conferring machines with generative commonsense reasoning ability. We hope COMMONGEN would also benefit downstream NLG applications such as conversational systems and storytelling models.
我们的研究为在语言生成过程中建模常识知识指出了有趣的未来研究方向,旨在赋予机器生成式常识推理能力。我们希望COMMONGEN也能惠及对话系统和故事生成模型等下游自然语言生成(NLG)应用。
Noam Chomsky. 1965. Aspects of the theory of syntax.
Noam Chomsky. 1965. 句法理论要略。
Acknowledgements
致谢
This research is based upon work supported in part by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via Contract No. 2019- 19051600007, the DARPA MCS program under Contract No. N 660011924033 with the United States Office Of Naval Research, the Defense Advanced Research Projects Agency with award W911NF-19-20271, and NSF SMA 18-29268. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of ODNI, IARPA, or the U.S. Government. We would like to thank all the collaborators in USC INK research lab for their constructive feedback on the work.
本研究基于以下机构的部分资助工作:国家情报总监办公室 (ODNI) 下属情报高级研究计划署 (IARPA) (合同号 2019-19051600007)、美国海军研究办公室与DARPA MCS项目 (合同号 N660011924033)、国防高级研究计划署 (奖项编号 W911NF-19-20271) 以及美国国家科学基金会 SMA 18-29268。本文所述观点和结论仅代表作者立场,不应被解释为ODNI、IARPA或美国政府的官方政策或暗示性立场。我们衷心感谢南加州大学INK实验室全体合作者对本研究提出的建设性意见。
Ernest Davis and Gary Marcus. 2015. Commonsense reasoning and commonsense knowledge in artificial intelligence. Commun. ACM, 58:92–103.
Ernest Davis 和 Gary Marcus. 2015. 人工智能中的常识推理与常识知识. Commun. ACM, 58:92–103.
Georgiana Dinu, Prashant Mathur, Marcello Federico, and Yaser Al-Onaizan. 2019. Training neural machine translation to apply terminology constraints. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3063–3068, Florence, Italy. Association for Computational Linguistics.
Georgiana Dinu、Prashant Mathur、Marcello Federico和Yaser Al-Onaizan。2019. 训练神经机器翻译应用术语约束。载于《第57届计算语言学协会年会论文集》,第3063-3068页,意大利佛罗伦萨。计算语言学协会。
Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. 2019. Unified language model pre-training for natural language understanding and generation. In Advances in Neural Information Processing Systems, pages 13042–13054.
李东、南杨、王文辉、魏福瑞、刘晓东、王宇、高剑峰、周明和Hon Hsiao-Wuen。2019. 统一语言模型预训练用于自然语言理解与生成。载于《神经信息处理系统进展》,第13042–13054页。
Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898, Melbourne, Australia. Association for Computational Linguistics.
Angela Fan、Mike Lewis 和 Yann Dauphin。2018. 分层神经故事生成。载于《第56届计算语言学协会年会论文集(第一卷:长论文)》,第889–898页,澳大利亚墨尔本。计算语言学协会。
Xiaocheng Feng, Ming Liu, Jiahao Liu, Bing Qin, Yibo Sun, and Ting Liu. 2018. Topic-to-essay generation with neural networks. In IJCAI, pages 4078–4084.
Xiaocheng Feng, Ming Liu, Jiahao Liu, Bing Qin, Yibo Sun, and Ting Liu. 2018. 基于神经网络的主题到文章生成. 见: IJCAI, 第4078–4084页.
Zhenxin Fu, Xiaoye Tan, Nanyun Peng, Dongyan Zhao, and Rui Yan. 2018. Style transfer in text: Exploration and evaluation. In Thirty-Second AAAI Conference on Artificial Intelligence.
付振新、谭晓晔、彭南云、赵东岩和严睿。2018. 文本风格迁移的探索与评估。见第三十二届AAAI人工智能大会。
References
参考文献
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. 2016. Spice: Semantic propositional image caption evaluation. In European Conference on Computer Vision, pages 382–398. Springer.
Peter Anderson, Basura Fernando, Mark Johnson, 和 Stephen Gould. 2016. SPICE: 语义命题图像描述评估 (Semantic Propositional Image Caption Evaluation). 载于欧洲计算机视觉会议 (European Conference on Computer Vision), 第382–398页. Springer出版社.
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Sum mari z ation, pages 65–72, Ann Ar- bor, Michigan. Association for Computational Linguistics.
Satanjeev Banerjee 和 Alon Lavie. 2005. METEOR: 一种改进与人类判断相关性的自动机器翻译评估指标。在《ACL 机器翻译和/或摘要内在与外在评估指标研讨会论文集》中, 第 65-72 页, 密歇根州安娜堡。计算语言学协会。
Hangbo Bao, Li Dong, Furu Wei, Wenhui Wang, Nan Yang, Xiulei Liu, Yu Wang, Songhao Piao, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. 2020. Unilmv2: Pseudo-masked language models for unified language model pre-training. arXiv: Computation and Language.
Hangbo Bao、Li Dong、Furu Wei、Wenhui Wang、Nan Yang、Xiulei Liu、Yu Wang、Songhao Piao、Jianfeng Gao、Ming Zhou 和 Hsiao-Wuen Hon。2020。Unilmv2:用于统一语言模型预训练的伪掩码语言模型。arXiv: Computation and Language。
Michael Chen, Mike D’Arcy, Alisa Liu, Jared Fernan- dez, and Doug Downey. 2019. Codah: An adversarially authored question-answer dataset for common sense. ArXiv, abs/1904.04365.
Michael Chen、Mike D'Arcy、Alisa Liu、Jared Fernandez 和 Doug Downey。2019. Codah: 一个对抗性编写的常识问答数据集。ArXiv, abs/1904.04365。
Jiatao Gu, Zhengdong Lu, Hang Li, and Victor O.K. Li. 2016. Incorporating copying mechanism in sequence-to-sequence learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1631–1640, Berlin, Germany. Association for Computational Linguistics.
Jiatao Gu、Zhengdong Lu、Hang Li和Victor O.K. Li。2016。在序列到序列学习中引入复制机制。载于《第54届计算语言学协会年会论文集(第一卷:长论文)》,第1631–1640页,德国柏林。计算语言学协会。
Jiatao Gu, Changhan Wang, and Junbo Zhao. 2019. Levenshtein transformer. In Advances in Neural Information Processing Systems, pages 11179–11189.
Jiatao Gu、Changhan Wang 和 Junbo Zhao。2019. Levenshtein transformer。载于《Advances in Neural Information Processing Systems》,第11179–11189页。
Jian Guan, Yansen Wang, and Minlie Huang. 2019. Story ending generation with incremental encoding and commonsense knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6473–6480.
Jian Guan、Yansen Wang和Minlie Huang。2019. 基于增量编码与常识知识的故事结尾生成。见《AAAI人工智能会议论文集》第33卷,第6473–6480页。
Eva Hasler, Adria de Gispert, Gonzalo Iglesias, and Bill Byrne. 2018. Neural machine translation decoding with terminology constraints. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 506–512, New Orleans, Louisiana. Association for Computational Linguistics.
Eva Hasler、Adria de Gispert、Gonzalo Iglesias和Bill Byrne。2018。基于术语约束的神经机器翻译解码。载于《2018年北美计算语言学协会人类语言技术会议论文集(短论文)》第2卷,第506–512页,美国路易斯安那州新奥尔良。计算语言学协会。
Chris Hokamp and Qun Liu. 2017. Lexically constrained decoding for sequence generation using grid beam search. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1535–1546, Vancouver, Canada. Association for Computational Linguistics.
Chris Hokamp与Qun Liu。2017。基于网格束搜索的词汇约束序列生成解码方法。载于《第55届计算语言学协会年会论文集(第一卷:长论文)》,第1535–1546页,加拿大温哥华。计算语言学协会。
Zhiting Hu, Zichao Yang, Xiaodan Liang, Ruslan Salak hut dino v, and Eric P Xing. 2017. Toward controlled generation of text. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1587–1596. JMLR. org.
Zhiting Hu、Zichao Yang、Xiaodan Liang、Ruslan Salakhutdinov 和 Eric P Xing。2017。迈向可控文本生成。载于《第34届国际机器学习会议论文集》第70卷,第1587-1596页。JMLR.org。
Lifu Huang, Ronan Le Bras, Chandra Bhaga va tula, and Yejin Choi. 2019. Cosmos QA: Machine reading comprehension with contextual commonsense reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2391–2401, Hong Kong, China. Association for Computational Linguistics.
Lifu Huang、Ronan Le Bras、Chandra Bhagavatula 和 Yejin Choi。2019. Cosmos QA: 基于上下文常识推理的机器阅读理解。载于《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP),第2391-2401页,中国香港。计算语言学协会。
Litton J Kurisinkel and Nancy Chen. 2019. Set to ordered text: Generating discharge instructions from medical billing codes. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 6165–6175, Hong Kong, China. Association for Computational Linguistics.
Litton J Kurisinkel 和 Nancy Chen. 2019. 从医疗账单代码生成有序出院说明. 见《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP), 第6165–6175页, 中国香港. 计算语言学协会.
Daniel Keysers, Nathanael Scharli, Nathan Scales, Hylke Buisman, Daniel Furrer, Sergii Kashubin, Nikola Momchev, Danila S in opal niko v, Lukasz Stafiniak, Tibor Tihon, Dmitry Tsarkov, Xiao Wang, Marc van Zee, and Olivier Bousquet. 2020. Measuring compositional generalization: A comprehensive method on realistic data. In International Conference on Learning Representations.
Daniel Keysers、Nathanael Scharli、Nathan Scales、Hylke Buisman、Daniel Furrer、Sergii Kashubin、Nikola Momchev、Danila Sinopalnikov、Lukasz Stafiniak、Tibor Tihon、Dmitry Tsarkov、Xiao Wang、Marc van Zee 和 Olivier Bousquet。2020。测量组合泛化能力:基于真实数据的综合方法。发表于 International Conference on Learning Representations。
Guillaume Klein, Yoon Kim, Yuntian Deng, Jean Senellart, and Alexander Rush. 2017. OpenNMT: Opensource toolkit for neural machine translation. In Proceedings of ACL 2017, System Demonstrations, pages 67–72, Vancouver, Canada. Association for Computational Linguistics.
Guillaume Klein、Yoon Kim、Yuntian Deng、Jean Senellart 和 Alexander Rush。2017. OpenNMT:开源的神经机器翻译工具包。载于《ACL 2017系统演示论文集》,第67-72页,加拿大温哥华。计算语言学协会。
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. 2017. Dense-captioning events in videos. In Proceedings of the IEEE international conference on computer vision, pages 706– 715.
Ranjay Krishna、Kenji Hata、Frederic Ren、李飞飞和Juan Carlos Niebles。2017. 视频中的密集事件描述。载于《IEEE国际计算机视觉会议论文集》,第706–715页。
Brenden M Lake and Marco Baroni. 2017. General- ization without systematic it y: On the compositional skills of sequence-to-sequence recurrent networks. In .
Brenden M Lake 和 Marco Baroni. 2017. 无需系统性的泛化能力: 论序列到序列循环网络的组合技能. 见.
Jason Lee, Elman Mansimov, and Kyunghyun Cho. 2018. Deterministic non-auto regressive neural sequence modeling by iterative refinement. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1173–
Jason Lee、Elman Mansimov 和 Kyunghyun Cho。2018. 通过迭代优化的确定性非自回归神经序列建模。见《2018年自然语言处理实证方法会议论文集》,第1173–
1182, Brussels, Belgium. Association for Computational Linguistics.
比利时布鲁塞尔1182。计算语言学协会。
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Z ett le moyer. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. ArXiv, abs/1910.13461.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Ves Stoyanov 和 Luke Zettlemoyer。2019. BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练。arXiv,abs/1910.13461。
Juncen Li, Robin Jia, He He, and Percy Liang. 2018. Delete, retrieve, generate: a simple approach to sentiment and style transfer. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1865–1874, New Orleans, Louisiana. Association for Computational Linguistics.
Juncen Li、Robin Jia、He He 和 Percy Liang。2018. 删除、检索、生成:一种简单的情感与风格迁移方法。载于《2018年北美计算语言学协会人类语言技术会议论文集,第一卷(长论文)》,第1865–1874页,美国路易斯安那州新奥尔良。计算语言学协会。
Xiang Li, Aynaz Taheri, Lifu Tu, and Kevin Gimpel. 2016. Commonsense knowledge base completion. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1445–1455, Berlin, Germany. Association for Computational Linguistics.
Xiang Li、Aynaz Taheri、Lifu Tu 和 Kevin Gimpel。2016. 常识知识库补全。载于《第54届计算语言学协会年会论文集(第一卷:长论文)》,第1445–1455页,德国柏林。计算语言学协会。
Bill Yuchen Lin, Frank F. Xu, Kenny Zhu, and Seungwon Hwang. 2018. Mining cross-cultural differences and similarities in social media. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 709–719, Melbourne, Australia. Association for Computational Linguistics.
Bill Yuchen Lin、Frank F. Xu、Kenny Zhu 和 Seungwon Hwang。2018. 社交媒体中跨文化差异与相似性的挖掘。载于《第56届计算语言学协会年会论文集(第一卷:长论文)》,第709-719页,澳大利亚墨尔本。计算语言学协会。
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Chin-Yew Lin. 2004. ROUGE: 自动摘要评估工具包。In Text Summarization Branches Out, pages 74-81, Barcelona, Spain. Association for Computational Linguistics.
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer.
Tsung-Yi Lin、Michael Maire、Serge Belongie、James Hays、Pietro Perona、Deva Ramanan、Piotr Dollar 和 C Lawrence Zitnick。2014. Microsoft COCO: 上下文中的常见物体。载于欧洲计算机视觉会议,第740-755页。Springer。
Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. 2018. Neural baby talk. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 7219–7228. IEEE Computer Society.
Jiasen Lu、Jianwei Yang、Dhruv Batra 和 Devi Parikh。2018。Neural baby talk。载于《2018年IEEE计算机视觉与模式识别会议(CVPR 2018)》,2018年6月18-22日,美国犹他州盐湖城,第7219–7228页。IEEE计算机学会。
Fuli Luo, Peng Li, Pengcheng Yang, Jie Zhou, Yutong Tan, Baobao Chang, Zhifang Sui, and Xu Sun. 2019a. Towards fine-grained text sentiment trans- fer. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2013–2022, Florence, Italy. Association for Computational Linguistics.
Fuli Luo、Peng Li、Pengcheng Yang、Jie Zhou、Yutong Tan、Baobao Chang、Zhifang Sui 和 Xu Sun。2019a。迈向细粒度文本情感迁移。见《第57届计算语言学协会年会论文集》,第2013–2022页,意大利佛罗伦萨。计算语言学协会。
Fuli Luo, Peng Li, Jie Zhou, Pengcheng Yang, Baobao Chang, Zhifang Sui, and Xu Sun. 2019b. A dual reinforcement learning framework for unsupervised text style transfer. arXiv preprint arXiv:1905.10060.
Fuli Luo, Peng Li, Jie Zhou, Pengcheng Yang, Baobao Chang, Zhifang Sui, 和 Xu Sun. 2019b. 一种无监督文本风格转换的双重强化学习框架. arXiv预印本 arXiv:1905.10060.
Thang Luong, Hieu Pham, and Christopher D. Manning. 2015. Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1412–1421, Lisbon, Portugal. Association for Computational Linguistics.
Thang Luong、Hieu Pham 和 Christopher D. Manning。2015。基于注意力机制的神经机器翻译有效方法。载于《2015年自然语言处理实证方法会议论文集》,第1412-1421页,葡萄牙里斯本。计算语言学协会。
Ning Miao, Hao Zhou, Lili Mou, Rui Yan, and Lei Li. 2019. Cgmh: Constrained sentence generation by metropolis-hastings sampling. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6834–6842.
Ning Miao、Hao Zhou、Lili Mou、Rui Yan 和 Lei Li。2019. Cgmh: 基于 Metropolis-Hastings 采样的受限句子生成。见《AAAI人工智能会议论文集》第33卷,第6834–6842页。
Chris Moore. 2013. The development of commonsense psychology. Psychology Press.
Chris Moore. 2013. 常识心理学的发展. Psychology Press.
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
Kishore Papineni、Salim Roukos、Todd Ward和WeiJing Zhu。2002。BLEU:一种机器翻译自动评估方法。载于《第40届计算语言学协会年会论文集》,第311-318页,美国宾夕法尼亚州费城。计算语言学协会。
Matt Post and David Vilar. 2018. Fast lexically constrained decoding with dynamic beam allocation for neural machine translation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1314–1324, New Orleans, Louisiana. Association for Computational Linguistics.
Matt Post 和 David Vilar. 2018. 神经机器翻译中基于动态束分配的快速词汇约束解码. 载于《2018年北美计算语言学协会人类语言技术会议论文集》第1卷 (长论文), 第1314–1324页, 美国路易斯安那州新奥尔良. 计算语言学协会.
Ratish Puduppully, Yue Zhang, and Manish Shrivastava. 2017. Transition-based deep input linearization. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 643–654, Valencia, Spain. Association for Computational Linguistics.
Ratish Puduppully、Yue Zhang 和 Manish Shrivastava。2017. 基于转移的深度输入线性化。载于《第15届欧洲计算语言学协会会议论文集:第一卷,长论文》,第643-654页,西班牙瓦伦西亚。计算语言学协会。
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
Alec Radford、Jeff Wu、Rewon Child、David Luan、Dario Amodei 和 Ilya Sutskever。2019。语言模型是无监督多任务学习器。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu. 2019. 探索迁移学习的极限:统一的文本到文本Transformer. arXiv预印本 arXiv:1910.10683.
Nils Reimers and Iryna Gurevych. 2019. SentenceBERT: Sentence embeddings using Siamese BERTnetworks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
Nils Reimers和Iryna Gurevych。2019. SentenceBERT:基于孪生BERT网络的句子嵌入方法。见《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP),第3982-3992页,中国香港。计算语言学协会。
Anna Rohrbach, Atousa Torabi, Marcus Rohrbach, Niket Tandon, Christopher Pal, Hugo Larochelle, Aaron Courville, and Bernt Schiele. 2017. Movie description. International Journal of Computer Vision, 123(1):94–120.
Anna Rohrbach、Atousa Torabi、Marcus Rohrbach、Niket Tandon、Christopher Pal、Hugo Larochelle、Aaron Courville 和 Bernt Schiele。2017。电影描述。《国际计算机视觉杂志》123(1):94–120。
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2019. Winogrande: An adversarial winograd schema challenge at scale. ArXiv, abs/1907.10641.
Keisuke Sakaguchi、Ronan Le Bras、Chandra Bhagavatula 和 Yejin Choi. 2019. Winogrande: 一种大规模对抗性 Winograd 模式挑战. ArXiv, abs/1907.10641.
Maarten Sap, Ronan Le Bras, Emily Allaway, Chan- dra Bhaga va tula, Nicholas Lourie, Hannah Rashkin, Brendan Roof, Noah A Smith, and Yejin Choi. 2019a. Atomic: An atlas of machine commonsense for if-then reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 3027–3035.
Maarten Sap、Ronan Le Bras、Emily Allaway、Chandra Bhagavatula、Nicholas Lourie、Hannah Rashkin、Brendan Roof、Noah A Smith和Yejin Choi。2019a。Atomic:用于因果推理的机器常识图谱。见《AAAI人工智能会议论文集》第33卷,第3027–3035页。
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. 2019b. Social IQa: Commonsense reasoning about social interactions. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4463– 4473, Hong Kong, China. Association for Computational Linguistics.
Maarten Sap、Hannah Rashkin、Derek Chen、Ronan Le Bras 和 Yejin Choi。2019b。Social IQa:关于社交互动的常识推理。载于《2019年自然语言处理实证方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP),第4463–4473页,中国香港。计算语言学协会。
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. 2018. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, Melbourne, Australia. Association for Computational Linguistics.
Piyush Sharma、Nan Ding、Sebastian Goodman 和 Radu Soricut。2018. Conceptual captions:一个经过清洗、上位词化的图像替代文本数据集,用于自动图像描述生成。载于《第56届计算语言学协会年会论文集(第一卷:长论文)》,第2556–2565页,澳大利亚墨尔本。计算语言学协会。
Robyn Speer, Joshua Chin, and Catherine Havasi. 2017. Conceptnet 5.5: An open multilingual graph of general knowledge. In Thirty-First AAAI Conference on Artificial Intelligence.
Robyn Speer、Joshua Chin 和 Catherine Havasi。2017。Conceptnet 5.5:一个开放的多语言通用知识图谱。载于第三十一届AAAI人工智能大会。
Mitchell Stern, William Chan, Jamie Kiros, and Jakob Uszkoreit. 2019. Insertion transformer: Flexible sequence generation via insertion operations. arXiv preprint arXiv:1902.03249.
Mitchell Stern、William Chan、Jamie Kiros 和 Jakob Uszkoreit。2019. 插入式Transformer (Insertion Transformer):通过插入操作实现灵活序列生成。arXiv预印本 arXiv:1902.03249。
Raymond Hendy Susanto, Shamil Cho l lamp at t, and Li ling Tan. 2020. Lexically constrained neural machine translation with levenshtein transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. To appear.
Raymond Hendy Susanto、Shamil Chollampatt和Li ling Tan。2020。基于Levenshtein Transformer的词汇约束神经机器翻译。见《第58届计算语言学协会年会论文集》。即将出版。
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. Commonsense QA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics.
Alon Talmor、Jonathan Herzig、Nicholas Lourie 和 Jonathan Berant. 2019. Commonsense QA: 一项针对常识性知识的问答挑战. 载于《2019年北美计算语言学协会会议论文集: 人类语言技术》(长篇与短篇论文), 第1卷, 第4149–4158页, 明尼苏达州明尼阿波利斯市. 计算语言学协会.
Ruth Tincoff and Peter W Jusczyk. 1999. Some beginnings of word comprehension in 6-month-olds. Psychological science, 10(2):172–175.
Ruth Tincoff 和 Peter W Jusczyk. 1999. 6个月大婴儿单词理解能力的早期表现. Psychological science, 10(2):172–175.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser 和 Illia Polosukhin。2017. Attention is all you need。在《神经信息处理系统进展》中,第5998–6008页。
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. 2015. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575.
Ramakrishna Vedantam、C Lawrence Zitnick 和 Devi Parikh。2015. Cider: 基于共识的图像描述评估。在《IEEE 计算机视觉与模式识别会议论文集》中,第 4566-4575 页。
Cunxiang Wang, Shuailong Liang, Yili Jin, Yilong Wang, Xiaodan Zhu, and Yue Zhang. 2020. SemEval-2020 task 4: Commonsense validation and explanation. In Proceedings of The 14th International Workshop on Semantic Evaluation. Associa- tion for Computational Linguistics.
Cunxiang Wang, Shuailong Liang, Yili Jin, Yilong Wang, Xiaodan Zhu, and Yue Zhang. 2020. SemEval-2020任务4: 常识验证与解释. 见《第14届国际语义评测研讨会论文集》. 计算语言学协会.
Cunxiang Wang, Shuailong Liang, Yue Zhang, Xiaonan Li, and Tian Gao. 2019a. Does it make sense? and why? a pilot study for sense making and explanation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4020–4026, Florence, Italy. Association for Computational Linguistics.
Cunxiang Wang、Shuailong Liang、Yue Zhang、Xiaonan Li 和 Tian Gao。2019a. 这合理吗?为什么?一项关于合理性判断与解释的探索性研究。见《第57届计算语言学协会年会论文集》,第4020-4026页,意大利佛罗伦萨。计算语言学协会。
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan- Fang Wang, and William Yang Wang. 2019b. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In Proceedings of the IEEE International Conference on Computer Vision, pages 4581–4591.
Xin Wang、Jiawei Wu、Junkun Chen、Lei Li、Yuan-Fang Wang 和 William Yang Wang。2019b。Vatex: 一个用于视频与语言研究的大规模高质量多语言数据集。在《IEEE 国际计算机视觉会议论文集》中,第 4581–4591 页。
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, R’emi Louf, Morgan Funtow- icz, and Jamie Brew. 2019. Hugging face’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pier-ric Cistac、Tim Rault、R'emi Louf、Morgan Funtowicz和Jamie Brew。2019。Hugging Face的Transformers:最先进的自然语言处理。ArXiv,abs/1910.03771。
Frank F. Xu, Bill Yuchen Lin, and Kenny Zhu. 2018. Automatic extraction of commonsense Located Near knowledge. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguis- tics (Volume 2: Short Papers), pages 96–101, Melbourne, Australia. Association for Computational Linguistics.
Frank F. Xu、Bill Yuchen Lin 和 Kenny Zhu。2018. 常识性位置邻近知识的自动提取。载于《第56届计算语言学协会年会论文集(第二卷:短论文)》,第96-101页,澳大利亚墨尔本。计算语言学协会。
Pengcheng Yang, Lei Li, Fuli Luo, Tianyu Liu, and Xu Sun. 2019a. Enhancing topic-to-essay generation with external commonsense knowledge. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2002–2012, Florence, Italy. Association for Computational Linguistics.
彭程阳、李磊、罗福利、刘天宇和孙旭。2019a。利用外部常识知识增强主题到文章的生成。见《第57届计算语言学协会年会论文集》,第2002–2012页,意大利佛罗伦萨。计算语言学协会。
Pengcheng Yang, Fuli Luo, Peng Chen, Lei Li, Zhiyi Yin, Xiaodong He, and Xu Sun. 2019b. Knowledgeable storyteller: a commonsense-driven generative model for visual storytelling. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI, pages 5356–5362.
彭城阳、傅立洛、彭晨、雷力、甄志毅、何晓东和孙旭。2019b。知识渊博的故事讲述者:基于常识的视觉叙事生成模型。在《第二十八届国际人工智能联合会议论文集》(IJCAI)中,第5356–5362页。
Lili Yao, Nanyun Peng, Ralph Weischedel, Kevin Knight, Dongyan Zhao, and Rui Yan. 2019. Planand-write: Towards better automatic storytelling. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 7378–7385.
姚丽丽、彭南云、Ralph Weischedel、Kevin Knight、赵东岩和严睿。2019。规划写作:迈向更好的自动故事生成。见《AAAI人工智能会议论文集》,第33卷,第7378–7385页。
Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. 2014. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78.
Peter Young、Alice Lai、Micah Hodosh和Julia Hockenmaier。2014。从图像描述到视觉指代:事件描述语义推理的新相似性度量。《计算语言学协会会刊》,2:67–78。
Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019a. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6720–6731.
Rowan Zellers、Yonatan Bisk、Ali Farhadi 和 Yejin Choi。2019a。从识别到认知:视觉常识推理。见《IEEE 计算机视觉与模式识别会议论文集》,第 6720–6731 页。
Rowan Zellers, Yonatan Bisk, Roy Schwartz, and Yejin Choi. 2018. SWAG: A large-scale adversarial dataset for grounded commonsense inference. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 93– 104, Brussels, Belgium. Association for Computational Linguistics.
Rowan Zellers, Yonatan Bisk, Roy Schwartz 和 Yejin Choi. 2018. SWAG: 一个用于基础常识推理的大规模对抗数据集. 见《2018年自然语言处理实证方法会议论文集》, 第93–104页, 比利时布鲁塞尔. 计算语言学协会.
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019b. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791– 4800, Florence, Italy. Association for Computational Linguistics.
Rowan Zellers、Ari Holtzman、Yonatan Bisk、Ali Farhadi 和 Yejin Choi. 2019b. HellaSwag: 机器真的能完成你的句子吗? 见《第57届计算语言学协会年会论文集》, 第4791–4800页, 意大利佛罗伦萨. 计算语言学协会.
Houyu Zhang, Zhenghao Liu, Chenyan Xiong, and Zhiyuan Liu. 2020a. Grounded conversation generation as guided traverses in commonsense knowledge graphs. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. To appear.
Houyu Zhang、Zhenghao Liu、Chenyan Xiong 和 Zhiyuan Liu。2020a。基于常识知识图谱引导遍历的接地对话生成。见《第58届计算语言学协会年会论文集》。即将出版。
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020b. ”bertscore: Evaluating text generation with bert”. In International Conference on Learning Representations.
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020b. "BERTScore: 基于BERT的文本生成评估方法". In International Conference on Learning Representations.
Yue Zhang and Stephen Clark. 2015. Discriminative syntax-based word ordering for text generation. Computational Linguistics, 41:503–538.
Yue Zhang和Stephen Clark。2015。基于判别式句法的文本生成词序模型。Computational Linguistics, 41:503–538。
Wanrong Zhu, Zhiting Hu, and Eric P. Xing. 2019. Text infilling. ArXiv, abs/1901.00158.
Wanrong Zhu、Zhiting Hu 和 Eric P. Xing。2019。文本填充 (Text infilling)。ArXiv,abs/1901.00158。
A Supplementary Figures and Tables
补充图表
We include additional figures and tables that we mentioned in the main content here.
我们在正文中提到的其他图表如下。
B Experimental Details
B 实验细节
Main experiments. We present some implementation details in training and testing the baseline models in Table 6. The detailed instructions for installing dependencies and all necessary training command-lines are shown in the instruction ‘readme.md’ files. The number of trainable model parameters are directly induced from either output of the frameworks or the original papers. We show some key hyper-parameters that we manually tuned on top of the development set.
主要实验。我们在表6中展示了训练和测试基线模型的一些实现细节。安装依赖项和所有必要训练命令行的详细说明见"readme.md"文件。可训练模型参数数量直接来自框架输出或原始论文[20]。我们展示了在开发集上手动调整的一些关键超参数。
All key hyper-parameters were initialized by the default values as suggested by the original authors of the frameworks. The bound of our manual tuning is done by iterating the magnitudes or the neighboring choices, for example, the learning rates $(\mathrm{\ddot{}l r\mathrm{})}$ of the last seven models are selected from $\left{1e\mathrm{-~}3,\ldots,1e\mathrm{-~}4,\ldots,1e\mathrm{-~}5\right}$ . Then, similarly, the batch size (bsz) is first maximized by making full use of the GPU memory. Note that the first three models are implemented with the OpenNMT-py framework 6 The Leven Trans 7, Const Leven 8, and BART9 are adopted by the official authors’ release. The
所有关键超参数均按照各框架原作者建议的默认值进行初始化。我们通过迭代量级或相邻选项来完成手动调参的范围界定,例如最后七个模型的学习率 $(\mathrm{\ddot{}l r\mathrm{})}$ 从 $\left{1e\mathrm{-~}3,\ldots,1e\mathrm{-~}4,\ldots,1e\mathrm{-~}5\right}$ 中选取。同理,批次大小 (bsz) 首先通过充分利用 GPU 内存实现最大化。需注意前三个模型采用 OpenNMT-py 框架实现,而 Leven Trans 7、Const Leven 8 和 BART9 则直接采用原作者发布的官方版本。
Table 6: The paths to the instruction files in our submitted code zip file (under the ‘methods/ ’ folder), and their numbers of parameters and key hyper-parameters.
表 6: 提交代码压缩文件中指令文件的路径 (位于 'methods/' 文件夹下) 及其参数量和关键超参数。
| 模型 | 指令文件 | 参数量 | 关键超参数 |
|---|---|---|---|
| bRNN-CopyNet | opennmt_based/README.md | 8.12 M | lr=0.2, bsz=128, layers=2, rnn_size=128, dropout=0 |
| Trans-CopyNet | opennmt_based/README.md | 6.25 M | lr=0.2, bsz=128, layers=1, hidden_size=128, dropout=0.1 |
| MeanPooling-CopyNet | opennmt_based/README.md | 7.76 M | global_attention=mlp, lr=0.15, rnn_size=128, bsz=128 |
| LevenTrans. | fairseq_based/README.md | 55.4 M | lr=5e-4, warmup-init-lr=1e-7, dropout=0.3, warmup=10k |
| ConstLeven | const-levt/readme.md | 55.4 M | lr=5e-4, warmup-init-lr=1e-7, dropout=0.3, warmup=10k |
| GPT-2 | GPT-2/readme.md | 345 M | lr=5e-5, bsz=32*4 |
| BERT-Gen | BERT-based/readme.md | 110 M | lr=3e-5, bsz=32 |
| UniLM | uni lm_based/README.md | 340 M | lr=1e-5, bsz=32 |
| UniLMv2 | UniLM_v2/readme.md | 110 M | lr=3e-5, bsz=32 |
| BART | BART/readme.md | 400 M | lr=3e-5, warmup=500, bsz=32 |
| T5-Base | T5/readme.md | 220 M | lr=5e-5, bsz=192 |
| T5-Large | T5/readme.md | 770 M | lr=2e-5, bsz=2*32, warmup_steps=400 |
BERT-gen, UniLM, UniLMv2 are all based on their official source code10. The GPT-2 and T5 are both adopted by the hugging face transformers 11 framework (Wolf et al., 2019). All models use beam searching as their decoding algorithms and beam-size are mostly 5, which is selected from ${5,10,20}$ . All our models were trained on Quadro {RTX 6000} GPUs. The training time of X-CopyNet and LevenTrans models are less than 12 hours with a single GPU. The second group of models are trained between 12 and 24 hours, expect for T5- large, which we used 3 GPUs and fine-tuned about 48 hours. Note that all the above methods are self-contained in our submitted code as long as users follow the associated readme instructions.
BERT-gen、UniLM、UniLMv2均基于其官方源代码[10]。GPT-2和T5均采用hugging face transformers[11]框架(Wolf et al., 2019)。所有模型均使用束搜索(beam search)作为解码算法,束宽(beam-size)多为5(从{5,10,20}中选取)。所有实验均在Quadro RTX 6000 GPU上完成训练:X-CopyNet与LevenTrans模型单卡训练时间小于12小时;第二组模型训练时间为12-24小时(T5-large除外,该模型使用3块GPU微调约48小时)。请注意,只要用户遵循代码库中的readme说明,上述所有方法均可通过我们提交的代码复现。
Transferring study experiments. We use the same hyper-parameters which are searched over the baseline RoBERTa-Large model for these experi12 ments. The best hyper-parameter of RoBERTaLarge for Commonsense QA :
迁移学习实验。我们使用与基准RoBERTa-Large模型相同的超参数进行这些实验。RoBERTa-Large在Commonsense QA任务上的最佳超参数为:
• batch size $=16$ , learning rate $=1\mathrm{e}{-}5$ , • maximum updates $=3{,}000$ ( ${\sim}5 $ epochs) • warmup steps $=150$ , dropout rate $:=0.1$ • weight decay $=0.01$ , adam epsilon $=$ 1e-6
• 批大小 (batch size) $=16$,学习率 (learning rate) $=1\mathrm{e}{-}5$
• 最大更新次数 (maximum updates) $=3{,}000$ (约 ${\sim}5$ 轮训练)
• 预热步数 (warmup steps) $=150$,丢弃率 (dropout rate) $=0.1$
• 权重衰减 (weight decay) $=0.01$,Adam 优化器 epsilon 值 $=1\mathrm{e}{-}6$
We tried 10 random seeds and use the best one (42). Then, we follow the steps described in Sec. 5.3 to run other CG-enhanced models with the same hps. This suggests that further searching for them may have even better performance.
我们尝试了10个随机种子,并选用效果最佳的一个(42)。随后按照第5.3节描述的步骤,使用相同的超参数运行其他CG增强模型。这表明进一步搜索参数可能会获得更优性能。
Table 7: Experimental results of different baseline methods on the COMMONGEN dev set. The first group of models are non-pretrained models, while the second group is large pretrained models that we have fine-tuned. The best models are bold and second best ones are underlined within each metric.
表 7: 不同基线方法在COMMONGEN开发集上的实验结果。第一组模型为未经预训练的模型,第二组为我们微调过的大型预训练模型。每个指标下最优模型加粗显示,次优模型加下划线。
| 模型\指标 | ROUGE-2/L | BLEU-3/4 | METEOR | CIDEr | SPICE | Coverage |
|---|---|---|---|---|---|---|
| bRNN-CopyNet (Gu et al., 2016) | 9.23/30.57 | 13.60/7.80 | 17.40 | 6.04 | 16.90 | 58.95 |
| Trans-CopyNet | 11.08/32.57 | 17.20/10.60 | 18.80 | 7.02 | 18.00 | 62.16 |
| MeanPooling-CopyNet | 11.36/34.63 | 14.80/8.90 | 19.20 | 7.17 | 20.20 | 68.32 |
| LevenTrans. (Gu et al., 2019) | 12.22/35.42 | 23.10/15.00 | 22.10 | 8.94 | 21.40 | 71.83 |
| ConstLeven. (Susanto et al., 2020) | 13.47/35.19 | 21.30/12.30 | 25.00 | 11.06 | 23.20 | 96.87 |
| GPT-2 (Radford et al.,2019) | 17.74/41.24 | 32.70/23.30 | 27.50 | 13.26 | 27.60 | 85.46 |
| BERT-Gen (Ba0 etal.,2020) | 18.73/42.36 | 33.00/23.70 | 29.10 | 13.34 | 28.70 | 91.71 |
| UniLM (Dong et al., 2019) | 21.68/45.66 | 40.40/30.40 | 31.00 | 15.72 | 31.40 | 92.41 |
| UniLM-v2 (Bao et al.,2020) | 19.24/43.01 | 33.40/24.20 | 29.20 | 13.65 | 29.30 | 93.57 |
| BART (Lewis et al.,2019) | 22.13/43.02 | 37.00/27.50 | 31.00 | 14.12 | 30.00 | 97.56 |
| T5-Base (Raffel et al., 2019) | 15.33/36.20 | 28.10/18.00 | 24.60 | 9.73 | 23.40 | 83.77 |
| T5-Large (Raffel et al., 2019) | 21.98/44.41 | 40.80/30.60 | 31.00 | 15.84 | 31.80 | 97.04 |
View instructions
查看说明
Instructions
指令
Write a natural and simple ENGLISH sentence about a common scene containing all given nouns/verbs, and the underlying commonsense knowledge about the scene.
用自然简单的英语句子描述一个包含所有给定名词/动词的常见场景,以及该场景背后的常识知识。
Rules:Theset of given concepts are randomly ordered and you can ignore the orderwhen write the sentences.
规则:给定概念集为随机排序,编写句子时可忽略顺序。
he sentence is better to be simple and grammatical,and describesa natural scene n in our daily life.
句子最好简单且符合语法,并描述我们日常生活中的自然场景。
Examples
示例
Given concepts:"apple(noun), bag(noun), put(verb),tree(noun),pick(verb)"
给定概念:"苹果(名词),包(名词),放(动词),树(名词),摘(动词)"
Scene:"Aboy picks some apples from a tree and putsthem intoa bag."
场景:"一个男孩从树上摘了一些苹果,并把它们放进袋子里。"
Reason:"Apples are grown ontrees.Bagisa container.You can pick something and then put them ina container."
原因: "苹果长在树上。袋子是一种容器。你可以采摘东西然后把它们放进容器里。"
Your Task:
你的任务:

Figure 8: Our annotation interface on the AMT platform. The upper part is the instruction for the annotators and we provide an example for them. Note that we give the part-of-speech hints (from the captain corpora) to boost the speed of annotation, but we do not remove sentences with wrong part-of-speech as long as they also make sense.
图 8: 我们在AMT平台上的标注界面。上半部分是给标注人员的说明,并提供了示例。注意我们提供了词性提示(来自captain语料库)以加快标注速度,但只要句子本身有意义,即使词性标注错误我们也不会删除。

Figure 9: One/two-hop relation frequency in the COMMONGEN dev.&test sets on ConceptNet.
图 9: ConceptNet中COMMONGEN开发集和测试集的单跳/双跳关系频率分布
- [Input concept-set]: { give, lay, massage, table }
- [输入概念集]: { give, lay, massage, table }
[Machine generations]
[机器世代]
- [Input concept-set]: { cow, horse, lasso, ride }
- [输入概念集]: { cow, horse, lasso, ride }
[Human references from AMT]
[来自AMT的人类参考]
[Machine generations]
[机器世代]
- [Input concept-set]: { hand, hold, walk, water }
- [输入概念集]: { hand, hold, walk, water }
[Human references from AMT]
[来自AMT的人类参考]
[Machine generations]
[Machine generations]
- [Input concept-set]: { clean, ladder, squeegee, stand, window }
- [输入概念集]: { clean, ladder, squeegee, stand, window }
[Machine generations]
[机器世代]
[Human references from AMT]
[来自AMT的人类参考]
[Human references from AMT]
[来自AMT的人工标注数据]
Figure 10: Four cases for qualitative analysis of machine generations. References are collected from AMT crowdworkers and they are required to provide rationales. Note that the third one is a positive case showing that some models can successfully generate reasonable scenarios. However, most models perform poorly on the other cases.
图 10: 机器生成文本定性分析的四种案例。参考数据来自AMT众包工作者,并要求其提供判断依据。请注意第三个案例是正面示例,表明某些模型能成功生成合理场景。然而多数模型在其他案例中表现欠佳。
Table 8: Experimental results of the transferring study on Commonsense QA dev set.
| 训练步数 | RoBERTa-Large | w/CG(BART) | w/CG(T5) | w/CG(UniLM) | w/CG(BERT-Gen) | w/CG(ConstLe) |
|---|---|---|---|---|---|---|
| 50 | 0.2252 | 0.1884 | 0.2506 | 0.2244 | 0.2007 | 0.2162 |
| 100 | 0.3088 | 0.2703 | 0.3587 | 0.3153 | 0.2924 | 0.2809 |
| 150 | 0.5053 | 0.2973 | 0.5643 | 0.1851 | 0.3391 | 0.3653 |
| 200 | 0.5717 | 0.4439 | 0.6650 | 0.3833 | 0.5274 | 0.5324 |
| 250 | 0.6020 | 0.5242 | 0.6937 | 0.5348 | 0.5839 | 0.6396 |
| 300 | 0.6388 | 0.6601 | 0.7117 | 0.6323 | 0.6274 | 0.6634 |
| 350 | 0.6675 | 0.6814 | 0.7150 | 0.6503 | 0.6626 | 0.6740 |
| 400 | 0.6830 | 0.6830 | 0.7215 | 0.6847 | 0.6781 | 0.6773 |
| 450 | 0.7027 | 0.7068 | 0.7338 | 0.6921 | 0.7068 | 0.6962 |
| 500 | 0.7019 | 0.7076 | 0.7428 | 0.7011 | 0.6929 | 0.7052 |
| 550 | 0.6978 | 0.7248 | 0.7486 | 0.7256 | 0.7068 | 0.6904 |
| 600 | 0.6790 | 0.7232 | 0.7494 | 0.7338 | 0.7248 | 0.7068 |
| 650 | 0.7150 | 0.7289 | 0.7428 | 0.7469 | 0.7101 | 0.7117 |
| 700 | 0.7142 | 0.7453 | 0.7477 | 0.7387 | 0.7305 | 0.7183 |
| 750 | 0.7027 | 0.7453 | 0.7314 | 0.7527 | 0.7166 | 0.7183 |
| 800 | 0.7158 | 0.7355 | 0.7437 | 0.7371 | 0.7281 | 0.7240 |
| 850 | 0.7174 | 0.7445 | 0.7625 | 0.7420 | 0.7379 | 0.7322 |
| 900 | 0.7191 | 0.7543 | 0.7559 | 0.7502 | 0.7477 | 0.7338 |
| 950 | 0.7355 | 0.7486 | 0.7477 | 0.7387 | 0.7428 | 0.7404 |
| 1000 | 0.7477 | 0.7510 | 0.7461 | 0.7486 | 0.7428 | 0.7363 |
| 1050 | 0.7346 | 0.7502 | 0.7568 | 0.7469 | 0.7412 | 0.7297 |
| 1100 | 0.7428 | 0.7527 | 0.7551 | 0.7494 | 0.7363 | 0.7420 |
| 1150 | 0.7379 | 0.7609 | 0.7576 | 0.7641 | 0.7453 | 0.7437 |
| 1200 | 0.7469 | 0.7477 | 0.7502 | 0.7461 | 0.7420 | 0.7477 |
| 1250 | 0.7477 | 0.7412 | 0.7592 | 0.7518 | 0.7273 | 0.7371 |
| 1300 | 0.7502 | 0.7518 | 0.7617 | 0.7666 | 0.7518 | 0.7412 |
| 1350 | 0.7469 | 0.7502 | 0.7551 | 0.7568 | 0.7437 | 0.7404 |
| 1400 | 0.7420 | 0.7494 | 0.7641 | 0.7559 | 0.7494 | 0.7428 |
| 1450 | 0.7510 | 0.7584 | 0.7625 | 0.7461 | 0.7461 | 0.7461 |
| 1500 | 0.7535 | 0.7674 | 0.7690 | 0.7551 | 0.7412 | 0.7428 |
| 1550 | 0.7461 | 0.7559 | 0.7674 | 0.7510 | 0.7445 | 0.7412 |
| 1600 | 0.7437 | 0.7584 | 0.7584 | 0.7543 | 0.7445 | 0.7420 |
| 1650 | 0.7568 | 0.7609 | 0.7633 | 0.7543 | 0.7494 | 0.7428 |
| 1700 | 0.7551 | 0.7584 | 0.7633 | 0.7625 | 0.7535 | 0.7396 |
| 1750 | 0.7600 | 0.7568 | 0.7699 | 0.7740 | 0.7551 | 0.7518 |
| 1800 | 0.7617 | 0.7559 | 0.7731 | 0.7740 | 0.7527 | 0.7486 |
| 1850 | 0.7690 | 0.7584 | 0.7772 | 0.7707 | 0.7617 | 0.7461 |
| 1900 | 0.7658 | 0.7592 | 0.7805 | 0.7838 | 0.7486 | 0.7445 |
| 1950 | 0.7584 | 0.7617 | 0.7715 | 0.7715 | 0.7510 | 0.7396 |
| 2000 | 0.7510 | 0.7617 | 0.7690 | 0.7715 | 0.7445 | 0.7355 |
| 2050 | 0.7551 | 0.7641 | 0.7731 | 0.7649 | 0.7559 | 0.7477 |
| 2100 | 0.7641 | 0.7617 | 0.7641 | 0.7625 | 0.7559 | 0.7412 |
| 2150 | 0.7584 | 0.7543 | 0.7658 | 0.7641 | 0.7527 | 0.7461 |
| 2200 | 0.7584 | 0.7477 | 0.7649 | 0.7633 | 0.7453 | 0.7371 |
| 2250 | 0.7551 | 0.7559 | 0.7641 | 0.7609 | 0.7461 | 0.7363 |
| 2300 | 0.7535 | 0.7600 | 0.7699 | 0.7674 | 0.7412 | 0.7420 |
| 2350 | 0.7551 | 0.7617 | 0.7682 | 0.7625 | 0.7502 | 0.7412 |
| 2400 | 0.7559 | 0.7649 | 0.7699 | 0.7625 | 0.7559 | 0.7387 |
| 2450 | 0.7584 | 0.7674 | 0.7707 | 0.7658 | 0.7477 | 0.7387 |
| 2500 | 0.7551 | 0.7649 | 0.7600 | 0.7633 | 0.7502 | 0.7363 |
| 2550 | 0.7592 | 0.7658 | 0.7731 | 0.7658 | 0.7518 | 0.7387 |
| 2600 | 0.7559 | 0.7658 | 0.7715 | 0.7600 | 0.7420 | 0.7371 |
| 2650 | 0.7576 | 0.7674 | 0.7690 | 0.7600 | 0.7494 | 0.7420 |
| 2700 | 0.7568 | 0.7707 | 0.7690 | 0.7600 | 0.7461 | 0.7379 |
| 2750 | 0.7568 | 0.7699 | 0.7674 |
表 8: Commonsense QA开发集迁移学习实验结果。