Learning to Update for Object Tracking with Recurrent Meta-learner
学习通过循环元学习器更新目标跟踪
Abstract—Model update lies at the heart of object tracking. Generally, model update is formulated as an online learning problem where a target model is learned over the online training set. Our key innovation is to formulate the model update problem in the meta-learning framework and learn the online learning algorithm itself using large numbers of offline videos, i.e., learning to update. The learned updater takes as input the online training set and outputs an updated target model. As a first attempt, we design the learned updater based on recurrent neural networks (RNNs) and demonstrate its application in a template-based tracker and a correlation filter-based tracker. Our learned updater consistently improves the base trackers and runs faster than realtime on GPU while requiring small memory footprint during testing. Experiments on standard benchmarks demonstrate that our learned updater outperforms commonly used update baselines including the efficient exponential moving average (EMA)-based update and the well-designed stochastic gradient descent (SGD)-based update. Equipped with our learned updater, the template-based tracker achieves state-of-the-art performance among realtime trackers on GPU.
摘要—模型更新是目标跟踪的核心问题。通常,模型更新被表述为在线学习问题,即在在线训练集上学习目标模型。我们的核心创新是将模型更新问题置于元学习框架下,并利用大量离线视频数据学习在线学习算法本身,即"学习如何更新"。该学习型更新器以在线训练集为输入,输出更新后的目标模型。作为首次尝试,我们基于循环神经网络(RNN)设计了学习型更新器,并展示了其在基于模板的跟踪器和基于相关滤波器的跟踪器中的应用。我们的学习型更新器持续改进了基础跟踪器,在GPU上能以超实时速度运行,且测试时内存占用极小。在标准基准测试上的实验表明,我们的学习型更新器优于常用的更新基线方法,包括高效的基于指数移动平均(EMA)的更新和精心设计的基于随机梯度下降(SGD)的更新。配备我们的学习型更新器后,基于模板的跟踪器在GPU实时跟踪器中达到了最先进的性能。
Index Terms—model update, meta-learning, recurrent neural network, object tracking.
索引术语—模型更新、元学习、循环神经网络、目标跟踪。
I. INTRODUCTION
I. 引言
O dBeJaElsC Tw ittrha cthkien pgr iosb lae cmr uocfi allo tcaaslikz iinn gc oonmep uatrebri trvaisriyo tna rthgaett object in a video, given only the target position in the first frame. Typically, bounding boxes are used for representing the target position. Arbitrary target object implies that a dedicated target model1 is needed for each target during testing. This is typically accomplished through online learning where the online training $\mathrm{set}^{2}$ is extracted from the test video and a target model is initialized and updated on the fly.
在视频中仅给定第一帧目标位置的情况下,跟踪任意目标物体是一项具有挑战性的任务。通常使用边界框 (bounding box) 表示目标位置。任意目标物体意味着测试期间每个目标都需要专用的目标模型1。这通常通过在线学习实现,其中从测试视频中提取在线训练集2,并动态初始化和更新目标模型。
In this work, we tackle the problem of model update: after an initial target model is built using reliable supervision in the first frame, how to exploit information in subsequent frames and update the initial model along with tracking? Model update is challenging because of unreliable and highly correlated online training set. The only reliable supervision
在本工作中,我们解决了模型更新的问题:当使用第一帧的可信监督信号构建初始目标模型后,如何利用后续帧中的信息并伴随跟踪过程更新初始模型?由于在线训练集存在不可靠性和高度相关性,模型更新具有挑战性。唯一可信的监督信号
B. Li and W. Liu are with the School of Electronic Information and Communications, Huazhong University of Science and Technology, Wuhan 430074, China. (e-mail: libi $@$ hust.edu.cn; liuwy@hust.edu.cn) W. Xie and W. Zeng are with the Microsoft Research Asia, Beijing 100080, China.(e-mail: wenxie $@$ microsoft.com; wezeng@microsoft.com)
B. Li 和 W. Liu 就职于华中科技大学电子信息与通信学院,武汉 430074 (邮箱: libi $@$ hust.edu.cn; liuwy@hust.edu.cn)。W. Xie 和 W. Zeng 就职于微软亚洲研究院,北京 100080 (邮箱: wenxie $@$ microsoft.com; wezeng@microsoft.com)。
1In this work, we only consider scoring-based target model that outputs the confidence of an image patch being the target. Note there are also positionregression based target models that, given an image patch, directly regress the target position.
在本工作中,我们仅考虑基于评分的目标模型,该模型输出图像块作为目标的置信度。请注意,还存在基于位置回归的目标模型,给定一个图像块,直接回归目标位置。
2The framework of learning to update contains an offline phase and an online phase. The offline phase is referred to as training the updater with offline videos, whereas the online phase refers to tracking a new sequence. The term “(online) training set” means the set of image patches collected for updating the target model (during the online phase).
学习更新框架包含离线阶段和在线阶段。离线阶段指用离线视频训练更新器,而在线阶段指跟踪新序列。术语"(online) training set"指(在线阶段)为更新目标模型而收集的图像块集合。
for building a target model is the information in the first frame. After that, the online training set is collected based on predicted target position, which is not always reliable. When small errors in the training samples accumulate, model update can cause the drifting problem. Moreover, the extracted online training set is highly correlated since most of the training samples are simply the translated and scaled version of a base sample. Correlated samples are easy to fit and do not help much with the generalization to hard samples.
构建目标模型的信息来自第一帧。之后,在线训练集基于预测的目标位置进行收集,而这种预测并不总是可靠的。当训练样本中的小误差累积时,模型更新可能导致漂移问题。此外,由于大多数训练样本仅是基础样本的平移和缩放版本,提取的在线训练集具有高度相关性。相关样本容易拟合,但对困难样本的泛化帮助不大。
Recent works [1], [2] have investigated the possibility of no model update at all, and achieved remarkable tracking performance. These approaches can be interpreted as learning an invariant and disc rim i native feature extractor such that the target remains stable in the feature space and is separable from the background. However, learning a representation that is both invariant and disc rim i native for a long time is intrinsically difficult, as with time evolves, features that once are disc rim i native may become irrelevant and vice versa. Consider that when a red car drives into a dark tunnel, the red color becomes irrelevant, although it is disc rim i native before entering the tunnel. Instead of striving to construct a perfect model at the first frame, model update tries to keep up with the current target appearance along with tracking by constantly incorporating the new target information, and therefore eases the burden of feature representation. Moreover, by gradually adapting to the current video context, the tracking problem can be considerably simplified [3]. In scenarios where target exhibits multi-modality, model update is indispensable.
近期研究[1]、[2]探索了完全不更新模型的可能性,并取得了显著的跟踪性能。这些方法可理解为学习一个兼具不变性与判别性(discriminative)的特征提取器,使得目标在特征空间中保持稳定且能与背景分离。然而,长期保持特征表示既不变又具有判别性本质上是困难的——随着时间推移,曾经具有判别性的特征可能失效,反之亦然。例如当红色汽车驶入黑暗隧道时,红色特征虽在进入隧道前具有判别性,此时却会失效。模型更新策略并非追求在首帧构建完美模型,而是通过持续整合新目标信息来适应目标外观变化,从而减轻特征表示的负担。此外,通过逐步适应当前视频上下文,跟踪问题可大幅简化[3]。在目标呈现多模态特性的场景中,模型更新更是不可或缺。
Generally, model update can be formulated as an online learning problem with two stages. First, an online training set is collected along with tracking. Then, the target model is learned on the training set using algorithms like stochastic gradient descent (SGD). Existing update methods typically suffer from the problem of large training set and slow convergence thus being too slow for practical use. Moreover, due to unreliable training data, regular iz at ions and rules are carefully designed based on expertise in the field to avoid model drifting.
通常,模型更新可以表述为一个包含两个阶段的在线学习问题。首先,在跟踪过程中收集在线训练集;然后,使用随机梯度下降 (SGD) 等算法在训练集上学习目标模型。现有更新方法普遍存在训练集过大、收敛速度慢的问题,导致实际应用效率低下。此外,由于训练数据不可靠,需基于领域专业知识精心设计正则化 (regularization) 规则以防止模型漂移 (drifting)。
In this work, we advocate the paradigm for object tracking that eases the heavy burdens of online learning by offline learning. Offline learning is performed before the actual tracking takes place and the learned model is shared among all test videos. Online learning, in contrast, is conducted during tracking and the learned model is specific to each test video. Our key innovation is to formulate the model update problem in the meta-learning framework and learn the online learning algorithm itself using large numbers of offline videos, i.e., learning to update. The offline-learned update method, which we call the learned updater, takes in the online training set and outputs the updated target model. Please refer to Fig. 1 for visual illustrations.
在这项工作中,我们提出了一种通过离线学习减轻在线学习沉重负担的目标跟踪范式。离线学习在实际跟踪开始前完成,所学习模型在所有测试视频中共享;而在线学习则在跟踪过程中进行,其学习模型仅针对单个测试视频。我们的核心创新是将模型更新问题构建为元学习框架,并利用大量离线视频学习在线学习算法本身,即"学习如何更新"。这种离线学习的更新方法(称为学习型更新器)接收在线训练集并输出更新后的目标模型。可视化说明请参阅图1。
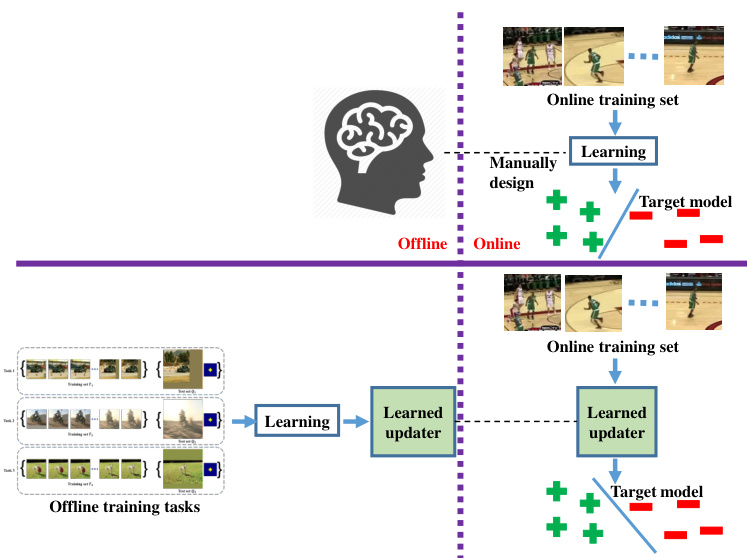
Fig. 1: A general introduction of learning to update. Top: Typically, a learning algorithm (e.g., SGD) is manually designed for online learning of the target model. Bottom: Contrarily, a learned updater is adopted for online learning, which is offlinetrained using large numbers of videos. All figures are best viewed in color.
图 1: 学习更新的总体介绍。上: 通常,手动设计一个学习算法(例如 SGD)用于目标模型的在线学习。下: 相反,采用一个学习过的更新器进行在线学习,该更新器使用大量视频进行离线训练。所有图片建议彩色查看。
The benefit of learning to update is threefold: 1) After seeing all kinds of target variations in the offline training phase, the learned updater is able to capture target variation patterns among videos. These learned patterns are implicitly used during testing to avoid unlikely update (e.g., update to background) and thus can be seen as a form of regular iz ation, which enables our learned updater to handle the unreliable online training set. 2) The learned updater is able to update the target model based on not only the online training set, but also rules learned from the offline dataset. Therefore, the learned updater is able to see beyond the highly correlated online training set and makes the updated model capable of generalizing to more challenging scenarios. 3) The learned patterns enable fast inference of the learned updater. As a result, our learned updater improves the performance of base trackers while running faster than realtime on GPU with a single forward pass of the neural network per frame.
学习更新的好处有三方面:
- 在离线训练阶段见过各种目标变化后,学习到的更新器能够捕获视频中的目标变化模式。这些学习到的模式在测试期间被隐式使用,以避免不太可能的更新(例如更新到背景),因此可以看作一种正则化形式,使得我们的学习更新器能够处理不可靠的在线训练集。
- 学习更新器不仅能基于在线训练集更新目标模型,还能利用从离线数据集中学到的规则。因此,学习更新器能够超越高度相关的在线训练集,使更新后的模型能够泛化到更具挑战性的场景。
- 学习到的模式使得学习更新器能够快速推理。因此,我们的学习更新器在提升基础跟踪器性能的同时,还能在GPU上以实时速度运行(每帧仅需神经网络一次前向传播)。
In this paper, we formulate model update as a metalearning problem (a.k.a learning to learn) [4], [5] and learn a model updater. Specifically, our learned updater is embodied as a RNN, which is well known for its ability to model sequential/temporal variations. Previous efforts to model target variations based on RNNs mostly fail to deliver satisfactory tracking performance due to inadequate offline training videos. In this work, we contribute several techniques to overcome data deficiencies and train RNNs effectively. With a properly trained updater, our tracker achieves state-of-the-art performance among realtime trackers.
本文中,我们将模型更新表述为一个元学习问题(又称学会学习)[4][5],并学习一个模型更新器。具体而言,我们的更新器以RNN形式实现,该网络因其建模序列/时序变化的能力而广为人知。先前基于RNN建模目标变化的研究大多因离线训练视频不足而未能实现令人满意的跟踪性能。本工作提出了多项技术来克服数据不足问题并有效训练RNN。通过合理训练的更新器,我们的跟踪器在实时跟踪器中达到了最先进的性能水平。
As a first attempt of learning to update for object tracking, we demonstrate its application on two base trackers: a template-based tracker for its simplicity and a correlation filter-based tracker for its wide adoption. Our learned updater considerably improves the base trackers and outperforms relevant model update baselines including the exponential moving average (EMA)- and the SGD-based update method.
作为学习更新机制在目标跟踪中的首次尝试,我们将其应用于两种基础跟踪器:基于模板的跟踪器(因其简洁性)和基于相关滤波的跟踪器(因其广泛适用性)。我们提出的学习型更新器显著提升了基础跟踪器性能,并超越了包括指数移动平均(EMA)和基于随机梯度下降(SGD)的更新方法在内的相关基线模型。
In summary, our contributions are threefold: 1) We propose a novel model update method for object tracking that (i) is formulated as a meta-learning problem, capable of learning target variation patterns and facilitating effective tracking, and (ii) runs faster than realtime (82 fps with SiamFC tracker and 70 fps with CFNet tracker) while requiring small memory footprint, thus being suitable for practical applications; 2) We propose several techniques to train our RNN-based updater effectively; 3) We validate our method in common object tracking benchmarks and show that it (i) consistently outperforms relevant model update baselines, and (ii) obtains state-of-the-art performance among realtime trackers.
总结而言,我们的贡献体现在三个方面:1) 提出了一种新颖的目标跟踪模型更新方法,该方法 (i) 以元学习 (meta-learning) 问题形式构建,能够学习目标变化模式并提升跟踪效果,(ii) 在SiamFC跟踪器上达到82 fps、CFNet跟踪器上达到70 fps的超实时运行速度,且内存占用小,适合实际应用;2) 提出了多项有效训练基于RNN的更新器的技术;3) 在主流目标跟踪基准测试中验证了该方法 (i) 始终优于相关模型更新基线,(ii) 在实时跟踪器中取得了最先进的性能。
II. RELATED WORK
II. 相关工作
Handcrafted Update Methods. In general, target variation can be decomposed as short- and long-term variation. [6] proposes a probabilistic mixture model, which has a stable component to account for the long-term variation, a wandering component and a loss component for the short-term variation. Inspired by the Atkinson-Shiffrin Memory Model, [7] uses short- and long-term memory to handle target variations. Correlation filter and keypoint matching are employed for short- and long-term memory, respectively. Instead of using two separate components, we design a single component based on RNN and learn to process short- and long-term information in a data-driven manner.
手工更新方法。通常,目标变化可以分解为短期和长期变化。[6]提出了一种概率混合模型,该模型包含一个稳定组件来处理长期变化,一个漂移组件和一个损失组件来处理短期变化。受Atkinson-Shiffrin记忆模型的启发,[7]使用短期和长期记忆来处理目标变化。短期记忆和长期记忆分别采用相关滤波器和关键点匹配。我们设计了一个基于RNN的单一组件,并通过数据驱动的方式学习处理短期和长期信息,而不是使用两个独立的组件。
One critical problem in model update is related to the stability-plasticity dilemma [8]. On one hand, model update should be stable to avoid the drifting problem where small errors accumulate and the model gets adapted to other objects. On the other hand, it also needs plasticity to effectively assimilate new information derived during tracking. [9] coined it the template update problem. They adopt a conservative update strategy which keeps the target model in the first frame (i.e., initial model), and updates the latest model only if its predicted locations are close to those of the initial model. Similar techniques are adopted in [10] which learns a ridge regression based on the first and the last target model. Inspired by this, we design an anchor loss that uses the first target model as an anchor point. We find it particularly useful in our learning based updater and will elaborate on it in Section IV.
模型更新的一个关键问题与稳定性-可塑性困境 [8] 有关。一方面,模型更新需要保持稳定性以避免漂移问题,即小误差累积导致模型适应其他对象。另一方面,它也需要可塑性来有效吸收跟踪过程中产生的新信息。[9] 将其称为模板更新问题。他们采用保守的更新策略,保留第一帧中的目标模型(即初始模型),仅当最新模型的预测位置与初始模型接近时才进行更新。[10] 采用了类似技术,基于第一个和最后一个目标模型学习岭回归。受此启发,我们设计了一种锚点损失,将第一个目标模型作为锚点。我们发现这种方法在基于学习的更新器中特别有效,并将在第四节详细阐述。
Another strategy to handle the model drifting problem is being more careful about the derived training samples. Instead of making hard decisions about labeling training samples as target or background, [3] proposes a semi-supervised approach where only samples from the first frame are labeled and training samples from subsequent frames remain unlabeled. [11] proposes an occlusion detector and updates the model only if the occlusion level is low. [12] uses multiple-instance learning to update model with bags of samples, where positive bag contains at least one positive sample (without knowing which one), and negative bag contains only negative samples. [13] estimates the training sample qualities by optimizing the target model loss with respect to both the target model and the sample qualities. We facilitate training information selection by adopting a gating mechanism in our learned updater.
处理模型漂移问题的另一种策略是对衍生训练样本更加谨慎。[3] 提出了一种半监督方法,不再对训练样本进行目标或背景的硬标签分类,而是仅标注首帧样本,后续帧的训练样本保持未标注状态。[11] 设计了遮挡检测器,仅在遮挡程度较低时更新模型。[12] 采用多示例学习 (multiple-instance learning) 方法,通过样本包更新模型——正样本包至少包含一个正样本(但不确定具体是哪个),负样本包则只含负样本。[13] 通过联合优化目标模型损失和样本质量来评估训练样本质量。我们在学习型更新器中采用门控机制来优化训练信息的选择。
A popular model update method for correlation filter-based trackers [14], [15] is exponential moving average (EMA), which performs linear interpolation from the newly trained model (using only training samples in the current frame) and the previous target model. This method is attractive because 1) the update process is highly efficient without iterative optimization and 2) training samples are processed on the fly without the need to be stored. However, it is unlikely that linear combination can capture all of the complex target variations. Our model update method outperforms EMA-based update while preserving all the practical benefits mentioned above.
基于相关滤波的跟踪器[14][15]常用的模型更新方法是指数移动平均(EMA),该方法通过当前帧训练样本生成的新模型与历史目标模型进行线性插值更新。这种方法的优势在于:1) 更新过程无需迭代优化,计算效率极高;2) 训练样本可实时处理无需存储。但线性组合难以捕捉目标的所有复杂变化。我们提出的模型更新方法在保留上述实用优点的同时,性能显著优于EMA更新方案。
Meta-learning. In this work, model update is formulated as a meta-learning problem. Essentially, meta-learning models a learning problem in two scales: learning for specific tasks, and learning for general patterns that rule specific tasks. In our case, updating target model for a specific target (e.g., an airplane) is a specific task. We aim to learn a model update method that is applicable to any specific tasks. [4], [5] learn to solve the optimization problem of neural networks based on RNNs. Their methods mainly focus on fast convergence and are not readily applicable for model update due to the unreliable training samples.
元学习 (Meta-learning)。本工作将模型更新构建为一个元学习问题。本质上,元学习在两个层面建模学习问题:针对特定任务的学习,以及支配特定任务的通用规律学习。在我们的案例中,为特定目标(例如飞机)更新目标模型就是一个具体任务。我们的目标是学习一种适用于任何具体任务的模型更新方法。[4]、[5] 基于 RNN 学习神经网络优化问题的解法,这些方法主要关注快速收敛,但由于训练样本不可靠而难以直接应用于模型更新。
RNN-based trackers. RNNs are well known for their ability to model temporal variations. Given the importance of modeling temporal variations of target in object tracking, it is natural to consider taking advantage of RNNs. [16] is among the first to use RNN for object tracking, but has only shown to work on simple synthetic datasets. RATM [17] and HART [18] develop attention mechanisms based on RNNs and demonstrate success on natural image datasets KTH [19] and KITTI [20]. Re3 [21] models both appearance and motion variations using RNNs and achieves comparable results on several object tracking benchmarks [22]–[24]. However, Re3 [21] only models short-term variations and requires manual resetting of RNN states every 32 frames. RFL [25] proposes a filter generation method based on RNNs and resembles our method applied to the template-based tracker. Nevertheless, we tackle a more general model update problem and formulate our method in the meta-learning framework. RFL fails to deliver satisfactory tracking performance due to aggressive updating which is common in RNN-based trackers. By formulating the model update in the meta-learning framework, we focus on the generalization ability of the online-learned target model. With the proposed anchor loss, our approach outperforms RFL by a large margin. To the best of our knowledge, we propose the first RNN-based tracker that achieves state-of-the-art tracking performance among GPU-based realtime trackers.
基于RNN的跟踪器。RNN以其建模时序变化的能力而闻名。鉴于建模目标物体在跟踪过程中的时序变化至关重要,自然要考虑利用RNN的优势。[16] 是首个将RNN用于目标跟踪的研究,但仅能在简单的合成数据集上运行。RATM [17] 和HART [18] 开发了基于RNN的注意力机制,并在自然图像数据集KTH [19] 和KITTI [20] 上取得了成功。Re3 [21] 使用RNN同时建模外观和运动变化,在多个目标跟踪基准测试 [22]–[24] 中取得了可比的结果。然而,Re3 [21] 仅建模短期变化,且需要每32帧手动重置RNN状态。RFL [25] 提出了一种基于RNN的滤波器生成方法,类似于我们将该方法应用于基于模板的跟踪器。尽管如此,我们解决的是一个更通用的模型更新问题,并在元学习框架中制定了我们的方法。由于RNN跟踪器中常见的激进更新策略,RFL未能提供令人满意的跟踪性能。通过在元学习框架中制定模型更新策略,我们专注于在线学习目标模型的泛化能力。借助提出的锚点损失函数,我们的方法大幅超越了RFL。据我们所知,我们提出了首个基于RNN的跟踪器,在基于GPU的实时跟踪器中实现了最先进的跟踪性能。
III. BASE TRACKERS AND BASE UPDATE METHODS
III. 基础跟踪器和基础更新方法
In this work, we focus on the update of linear target model due to its simplicity and wide adoption.
在本工作中,我们专注于线性目标模型的更新,因其简单性和广泛采用性。
Basically, a target model is a scoring function that outputs the confidence of an input image patch being the target. Importantly, the target model should have parameters $\theta$ that is updatable. By model update, we mean updating $\theta$ such that it accommodates the target variations during tracking.
基本上,目标模型是一个评分函数,用于输出输入图像块作为目标的置信度。重要的是,目标模型应具有可更新的参数 $\theta$ 。通过模型更新,我们指的是更新 $\theta$ 以适应跟踪过程中的目标变化。
For a linear target model, the confidence $c$ of an image patch with feature $x$ is the inner product between $\theta$ and $x$ i.e., $c=\theta^{T}x$ .
对于一个线性目标模型,图像块的特征为 $x$ 时,其置信度 $c$ 是 $\theta$ 和 $x$ 的内积,即 $c=\theta^{T}x$。
During tracking, a tracker gathers a training set $T$ for updating the target model parameters $\theta$ . Since the dataset is gathered online, it is called the online training set. Let $T_{t}$ be the online training set at time $t$ , the target model is updated by an update function $u$ , i.e., $\theta_{t}=u(T_{t})$ . This work is about learning an update function $u_{\phi}(\cdot)$ with parameters $\phi$ using large numbers of offline videos.
在跟踪过程中,跟踪器会收集一个训练集 $T$ 用于更新目标模型参数 $\theta$。由于数据集是在线收集的,因此被称为在线训练集。设 $T_{t}$ 为时间 $t$ 的在线训练集,目标模型通过更新函数 $u$ 进行更新,即 $\theta_{t}=u(T_{t})$。本研究旨在利用大量离线视频学习一个带参数 $\phi$ 的更新函数 $u_{\phi}(\cdot)$。
Before diving into the proposed learned updater, we introduce two base trackers with linear target model as well as two baseline model update methods in this section.
在深入探讨所提出的学习型更新器之前,本节先介绍两种基于线性目标模型的基准跟踪器以及两种基线模型更新方法。
A. Template-Based Tracker: SiamFC
A. 基于模板的跟踪器: SiamFC
A template-based tracker simply uses the target feature (i.e., the feature of the target) as its target model. Intuitively, it means that the confidence of the test patch being the target is high when it is similar to the target feature and low otherwise. Due to the simplicity of the target model and the learning algorithm (i.e., an identity function), the performance of template-based tracker depends heavily on its features.
基于模板的跟踪器仅使用目标特征(即目标的特征)作为其目标模型。直观地说,这意味着当测试块与目标特征相似时,其作为目标的置信度较高,反之则较低。由于目标模型和学习算法(即恒等函数)的简单性,基于模板的跟踪器性能高度依赖于其特征。
SiamFC [2] is a template-based tracker which achieves good performance with an offline learned feature extractor. The feature extractor is learned under a two branch structure with millions of image pairs sampled from videos. Each image pair contains a target patch and a test patch. The feature of the target patch is computed as the linear target model. The learning objective is that the confidence of a test patch containing the target is high while the confidence of background being low.
SiamFC [2] 是一种基于模板的跟踪器,通过离线学习的特征提取器实现了良好性能。该特征提取器采用双分支结构,从视频中采样数百万图像对进行学习。每个图像对包含一个目标块和一个测试块。目标块的特征被计算为线性目标模型。学习目标是使包含目标的测试块置信度高,而背景的置信度低。
Interestingly, SiamFC does not have a model update module. In other words, given the target feature in the first frame $\bar{x}{1}$ (we will use $\bar{x}$ for target feature and $x$ for the feature of any image patch), the online training set contains only the target feature $T_{t}={\bar{x}{1}}$ and the learning algorithm simply takes the target feature as the target model $\theta_{t+1}=u(T_{t})=\bar{x}_{1}$ .
有趣的是,SiamFC 没有模型更新模块。换句话说,给定第一帧中的目标特征 $\bar{x}{1}$ (我们将用 $\bar{x}$ 表示目标特征,用 $x$ 表示任意图像块的特征),在线训练集仅包含目标特征 $T_{t}={\bar{x}{1}}$,而学习算法直接将目标特征作为目标模型 $\theta_{t+1}=u(T_{t})=\bar{x}_{1}$。
The detection process of SiamFC is equivalent to computing the similarity by sliding the target model $\theta$ over the search feature $z$ and then outputting the position with the largest response. To facilitate fast detection, the feature extractor is designed to be fully convolutional and the similarity metric is simply inner product. Therefore, the detection process can be readily implemented via cross-correlation $\star$ (or convolution in the neural network literature):
SiamFC的检测过程等同于通过在搜索特征$z$上滑动目标模型$\theta$来计算相似度,然后输出响应最大的位置。为了实现快速检测,特征提取器被设计为全卷积结构,相似度度量则简化为内积。因此,该检测过程可以通过互相关$\star$(或神经网络文献中的卷积)轻松实现:
$$
p=\arg\operatorname*{max}_{p}\theta\star z.
$$
$$
p=\arg\operatorname*{max}_{p}\theta\star z.
$$
B. Correlation Filter-Based Tracker: CFNet
B. 基于相关滤波的跟踪器:CFNet
Correlation filters are one representative example of linear target model that have shown superior performance and gained a lot of popularity. The key factor behind the success of correlation filters is an efficient learning algorithm that is able to handle tens of thousands of circulant training samples. Correlation filter-based trackers have been improved in various aspects since the seminal work of [14]. For simplicity, we use the basic formulation and follow the setup in CFNet [26].
相关滤波器 (correlation filters) 是线性目标模型的典型代表,其卓越性能广受认可。其成功关键在于高效的训练算法,能够处理数万个循环训练样本。自[14]的开创性工作以来,基于相关滤波器的跟踪器在多方面得到改进。为简化表述,我们采用CFNet[26]中的基础公式和实验设置。
In correlation filter-based tracker, given one base sample of the target feature $\bar{x}$ , various virtual samples are obtained by cyclic shifts. The label of the base sample is 1 while the labels of the virtual samples follow a Gaussian function depending on the shifted distance. Given the samples and the corresponding labels, a ridge regression problem is solved efficiently in the Fourier domain making use of the property of circulant matrix [27]. In this work, we will simply use $\mathrm{CF}(\cdot)$ to denote the algorithm of learning the correlation filter from one base sample with multiple feature channels. Please refer to [14], [15] for more details about $\mathrm{CF}(\cdot)$ .
在基于相关滤波器的跟踪器中,给定目标特征的一个基础样本 $\bar{x}$,通过循环移位获得各种虚拟样本。基础样本的标签为1,而虚拟样本的标签则根据移位距离遵循高斯函数。给定样本及其对应标签,利用循环矩阵的特性[27],在傅里叶域中高效求解岭回归问题。本工作中,我们将简单地用 $\mathrm{CF}(\cdot)$ 表示从具有多特征通道的单个基础样本中学习相关滤波器的算法。更多关于 $\mathrm{CF}(\cdot)$ 的细节,请参阅[14][15]。
The detection of correlation filter-based tracker is typically conducted in the Fourier domain. However, we convert the learned filter back to the spatial domain following CFNet. In this way, the detection process is the same as the SiamFC tracker. Moreover, it frees the learned updater from dealing with complex values.
基于相关滤波器的跟踪器检测通常在傅里叶域进行。然而,我们按照CFNet的方法将学习到的滤波器转换回空间域。这样,检测过程就与SiamFC跟踪器相同。此外,这也使得学习到的更新器无需处理复数值。
C. Two Baseline Model Update Methods
C. 两种基线模型更新方法
For linear target model based trackers, there are two commonly used model update methods. We briefly introduce these two baseline methods in this subsection.
对于基于线性目标模型的跟踪器,有两种常用的模型更新方法。本节将简要介绍这两种基线方法。
EMA-based model update. Let $g:\mathcal{X}\rightarrow\Theta$ be the algorithm of learning a linear target model using a single target feature. For template-based tracker, it is the identity function. For correlation filter-based tracker, it is $\mathrm{CF}(\cdot)$ . Typically, the online training set contains the target feature at each frame, i.e., $T_{t}={\bar{x}{1},\bar{x}{2},...,\bar{x}{t}}$ . It is clear that $T_{t}=T_{t-1}\cup{\bar{x}{t}}$ . Given the online training set $T_{t}$ , the updated target model via EMA is
基于EMA (Exponential Moving Average) 的模型更新。设 $g:\mathcal{X}\rightarrow\Theta$ 为使用单一目标特征学习线性目标模型的算法。对于基于模板的跟踪器,该算法为恒等函数;对于基于相关滤波器的跟踪器,该算法为 $\mathrm{CF}(\cdot)$。通常在线训练集包含每帧的目标特征,即 $T_{t}={\bar{x}{1},\bar{x}{2},...,\bar{x}{t}}$。显然 $T_{t}=T_{t-1}\cup{\bar{x}{t}}$。给定在线训练集 $T_{t}$,通过EMA更新的目标模型为
$$
\begin{array}{r l}&{\theta_{t+1}=u(T_{t})}\ &{\qquad=(1-\alpha)u(T_{t-1})+\alpha g(\bar{x}{t})}\ &{\qquad=(1-\alpha)\theta_{t}+\alpha\theta_{t}^{\prime}}\end{array}
$$
$$
\begin{array}{r l}&{\theta_{t+1}=u(T_{t})}\ &{\qquad=(1-\alpha)u(T_{t-1})+\alpha g(\bar{x}{t})}\ &{\qquad=(1-\alpha)\theta_{t}+\alpha\theta_{t}^{\prime}}\end{array}
$$
where $\alpha$ is the learning rate that controls the rate of adaptation, ${\theta}{t}^{\prime}~=~g(\bar{x}{t})$ is the candidate target model at time $t$ . Note that this update method only requires the last target model $\theta_{t}$ and the current target feature ${\bar{x}}_{t}$ . Hence, there is no need to explicitly collect a large online training set.
其中 $\alpha$ 是控制适应速率的学习率, ${\theta}{t}^{\prime}~=~g(\bar{x}{t})$ 表示时刻 $t$ 的候选目标模型。需要注意的是,这种更新方法仅需使用上一目标模型 $\theta_{t}$ 和当前目标特征 ${\bar{x}}_{t}$ ,因此无需显式收集大量在线训练集。
EMA-based update is widely adopted in correlation filterbased trackers because it is easy to implement and efficient in terms of both memory consumption and computational complexity. Moreover, EMA-based update is the update rules of correlation filters derived for the multiple base samples with single channel case [14] and can be quite effective even for samples with multiple channels. However, in general, EMAbased update is ad hoc and only marginally improves the template-based tracker as shown in our experiments (Section V).
基于EMA(指数移动平均)的更新方式因其实现简单、内存占用和计算复杂度低等优势,被广泛采用于相关滤波类跟踪器。此外,该更新方式源自多基样本单通道场景下相关滤波器的推导规则[14],即便对于多通道样本也表现优异。但实验表明(第5节),这种启发式更新通常只能小幅提升基于模板的跟踪器性能。

Fig. 2: Tasks for learning the model updater during offline training. Each task consists of a training set and a test set. The model updater should learn from the training set and generate a target model which is tested on the test set.
图 2: 离线训练期间学习模型更新器的任务。每个任务包含一个训练集和一个测试集。模型更新器应从训练集中学习,并生成在测试集上进行评估的目标模型。
TABLE I: Correspondence between the meta-learning and learning to update. Best viewed by zooming in the electronic version.
表 1: 元学习与学习更新的对应关系。建议放大电子版查看。
| 元学习 | 学习更新 | 说明 |
|---|---|---|
| 元训练 | 离线训练 | 学习元学习器(模型更新器)的过程 |
| 元测试 | 在线训练 | 应用元学习器(模型更新器)的过程 |
| 元学习器 | 模型更新器 | 以训练集为输入并输出学习器(目标模型)的模型 |
| 任务 | 任务 | 用于元训练(离线训练)元学习器(模型更新器)的示例 |
| 训练集 | 训练集 | 由训练集和测试集组成,用于学习学习器(目标模型)的数据集 |
| 测试集 | 测试集 | 用于测试学习器(目标模型)的数据集 |
| 学习器 | 目标模型 | 从训练集中学习得到的模型 |
$$
\theta_{t+1}=\theta_{t}-\alpha\frac{\partial l_{T_{t}^{b}}(\theta)}{\partial\theta}
$$
$$
\theta_{t+1}=\theta_{t}-\alpha\frac{\partial l_{T_{t}^{b}}(\theta)}{\partial\theta}
$$
where $l_{T_{t}^{b}}(\theta)$ is a differentiable objective function with variables $\theta$ over a batch of samples $T_{t}^{b}$ from the online training set, and $\alpha$ is the learning rate.
其中 $l_{T_{t}^{b}}(\theta)$ 是关于变量 $\theta$ 在在线训练集的一批样本 $T_{t}^{b}$ 上的可微分目标函数,$\alpha$ 是学习率。
Typically, a fixed size of online training set is maintained by dropping the earliest samples when the capacity is exceeded. However, it still contains thousands of samples. Moreover, we show only one iteration of SGD update for brevity while it generally requires dozens of iterations to take effects. These computational burdens of the SGD-based update method hinder its practical usage.
通常,当容量超出时,会通过丢弃最早的样本来维持固定大小的在线训练集。尽管如此,该集合仍包含数千个样本。此外,为简洁起见,我们仅展示一次SGD更新迭代,而实际通常需要数十次迭代才能见效。这种基于SGD的更新方法带来的计算负担阻碍了其实际应用。
IV. LEARNING TO UPDATE
IV. 学习更新
In this section, we first formulate the model update problem in the meta-learning framework and then introduce the proposed model updater.
在本节中,我们首先在元学习框架下形式化模型更新问题,随后介绍所提出的模型更新器。
A. Model Update as Meta-Learning
A. 将模型更新作为元学习
Meta-learning is about learning from large numbers of tasks during meta-training to quickly learn a new task at meta-test time. Each task consists of a training set and a test set. The meta-learner (i.e. the model to be obtained via meta-training)
元学习 (Meta-learning) 旨在通过元训练阶段从大量任务中学习,从而在元测试阶段快速掌握新任务。每个任务由训练集和测试集组成。元学习器 (即通过元训练获得的模型)
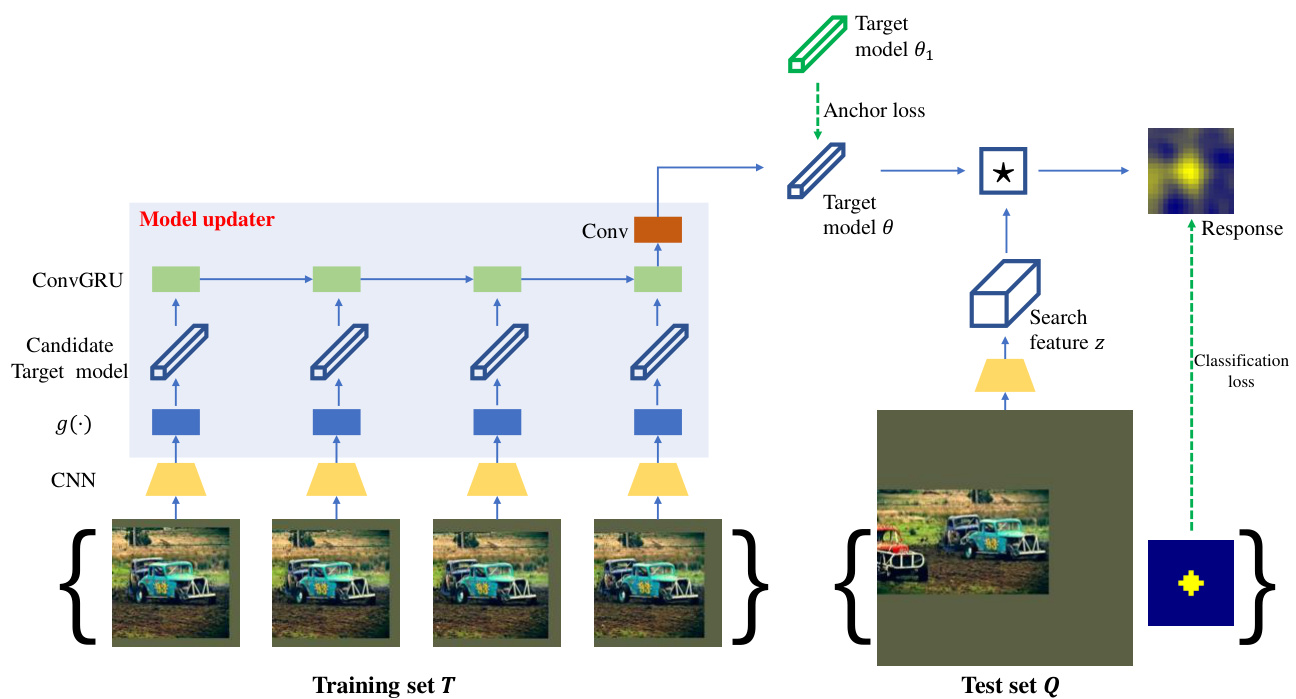
Fig. 3: The framework of learning to update during offline training. Given the training set $T$ with image patches of a car, the target model $\theta$ is updated by the recurrent model updater. The target model is tested on the test set $Q$ to obtain the classification loss. An anchor loss is also added to improve generalization. The model updater is learned by optimizing the anchor loss and the classification loss. During tracking, the model updater is fixed. An online training set is gathered along with tracking as $T$ and the target model is updated by the model updater and applied to subsequent frames.
图 3: 离线训练期间学习更新的框架。给定包含汽车图像块(patches)的训练集 $T$,目标模型 $\theta$ 通过循环模型更新器进行更新。目标模型在测试集 $Q$ 上进行测试以获得分类损失。为提高泛化性还添加了锚点损失(anchor loss)。通过优化锚点损失和分类损失来学习模型更新器。跟踪过程中模型更新器保持固定。在线训练集 $T$ 随跟踪过程动态收集,目标模型由模型更新器更新并应用于后续帧。
takes as input the training set of a task and outputs a learner which should perform well on the corresponding test set. The aim of meta-learning is to learn a meta-learner during metatraining such that the meta-learner can quickly learn a good learner at meta-test time, so meta-learning is also known as learning to learn.
以任务的训练集作为输入,输出一个在对应测试集上表现良好的学习器。元学习的目标是在元训练阶段学习一个元学习器,使得该元学习器能在元测试阶段快速习得优质学习器,因此元学习也被称为"学会学习"。
The uniqueness of meta-learning is that, at meta-test time, the meta-learner should quickly learn a new concept using examples from the training set of the concept. An example is to learn a classifier to differentiate “Apple” and “Pear” based on examples of each category where these two categories never appear during meta-training. This resembles model update for object tracking since the tracker should quickly update the target model to accommodate an object that does not appear during offline training3.
元学习的独特之处在于,在元测试阶段,元学习器应能利用概念训练集中的样本快速学习新概念。例如根据"苹果"和"梨"的示例学习分类器,而这两个类别在元训练阶段从未出现过。这与目标跟踪中的模型更新类似,因为跟踪器需要快速更新目标模型以适应离线训练中未出现过的对象[20]。
In the context of meta-learning for target model update, we aim to learn a meta-learner (model updater) from large numbers of offline videos during meta-training (offline training). Each task is to learn the learner (target model) from the training set to locate the target at test set. The correspondence between learning to update and meta-learning is summarized at Table I.
在目标模型更新的元学习(meta-learning)背景下,我们的目标是在元训练(离线训练)阶段从大量离线视频中学习一个元学习器(模型更新器)。每个任务都是从训练集中学习目标模型(learner),以在测试集中定位目标。学习更新与元学习之间的对应关系总结如表1所示。
During offline training, given the training set $T$ and the test set $Q$ of a task constructed from the offline videos $(T,Q)\in\mathcal{V}$ , the model updater computes target model $\theta=u_{\phi}(T)$ . Let $l(\theta,Q)$ be the loss of the target model on the test set $Q$ of a task. The model updater $\phi$ is learned by minimizing the
在离线训练阶段,给定由离线视频构建的任务训练集 $T$ 和测试集 $(T,Q)\in\mathcal{V}$,模型更新器计算目标模型 $\theta=u_{\phi}(T)$。设 $l(\theta,Q)$ 为目标模型在任务测试集 $Q$ 上的损失值,模型更新器 $\phi$ 通过最小化该损失进行学习。
following loss:
以下损失:
$$
\mathcal{L}(\phi)=\sum_{(T,Q)\in\mathcal{V}}l(u_{\phi}(T),Q).
$$
$$
\mathcal{L}(\phi)=\sum_{(T,Q)\in\mathcal{V}}l(u_{\phi}(T),Q).
$$
B. The Training Set and the Test Set
B. 训练集与测试集
We now describe how to construct the training set and the test set of a task for learning to update.
我们现在描述如何构建用于学习更新的任务训练集和测试集。
Given a video from the offline videos and the corresponding target positions (width, height, center position) at each frame, we first normalize the scale variations of targets by scaling the image with factor $s$ such that $s(w+2p)\times s(h+2p)=A$ where $w,h$ are the width and height of the target in the image, $\begin{array}{r}{p={\frac{w+h}{4}}}\end{array}$ is the context margin and $A=127\times127$ is the desired target size after scaling.
给定一段来自离线视频的片段及其在每一帧对应的目标位置(宽度、高度、中心点坐标),我们首先通过缩放因子 $s$ 对图像进行归一化处理以消除目标尺度变化,使得 $s(w+2p)\times s(h+2p)=A$ 。其中 $w,h$ 表示目标在图像中的宽度和高度,$\begin{array}{r}{p={\frac{w+h}{4}}}\end{array}$ 为上下文边界,$A=127\times127$ 为缩放后的期望目标尺寸。
A subset of $N$ image frames are sampled from the scaled images while keeping the temporal order. The first $N-1$ frames are cropped at the center of the target, with size $127\times$ 127, and used as the training set of the target. The last frame is also cropped at the center of the target, with size $255\times255$ , and used as the test set. Note that we use a larger image patch in the test set since both of our base trackers are translation equivalent and the $255\times255$ image can be seen as a set of $127\times127$ images. Please refer to Fig. 2 for several examples of training set and test set.
从缩放后的图像中按时间顺序采样 $N$ 帧图像子集。前 $N-1$ 帧以目标为中心裁剪为 $127\times127$ 大小,作为目标的训练集。最后一帧同样以目标为中心裁剪为 $255\times255$ 大小,作为测试集。需要注意的是,由于我们的基础跟踪器具有平移不变性,测试集采用更大图像块($255\times255$ 可视为多个 $127\times127$ 图像的集合)。训练集与测试集示例详见 图 2。
Cropped images are then embedded by the feature extractor. Finally, we have the training set $T~=~{\bar{x}{1},\bar{x}{2},...,\bar{x}_{N-1}}$ where $\bar{\boldsymbol{x}}\in\mathbb{R}^{m\times m\times d}$ is the feature of the target. The test set $Q={(z,y)}$ where $\boldsymbol{z}\in\mathbb{R}^{n\times n\times d}$ is the feature of the search image and $y\in{-1,+1}^{(n-m+1)\times(n-m+1)}$ is the corresponding label map. Features have spatial size $m$ or $n$ and channel size $d$ .
裁剪后的图像随后由特征提取器进行嵌入。最终,我们得到训练集 $T~=~{\bar{x}{1},\bar{x}{2},...,\bar{x}_{N-1}}$ ,其中 $\bar{\boldsymbol{x}}\in\mathbb{R}^{m\times m\times d}$ 是目标的特征。测试集 $Q={(z,y)}$ ,其中 $\boldsymbol{z}\in\mathbb{R}^{n\times n\times d}$ 是搜索图像的特征,而 $y\in{-1,+1}^{(n-m+1)\times(n-m+1)}$ 是对应的标签图。特征的空间尺寸为 $m$ 或 $n$ ,通道尺寸为 $d$ 。
C. Instantiation of The Learned Updater
C. 学习型更新器的实例化
A model updater takes as input a training set $T=$ ${\bar{x}{1},\bar{x}{2},...,\bar{x}_{N-1}}$ and outputs the updated target model $\theta$ , i.e., $\theta:=:u(T)$ . The design of the updater includes several preferable properties: 1) supporting training set with variable size; 2) incremental update, i.e., during tracking, the target model is updated based on existing values instead of learning from scratch; 3) memory and computational efficiency.
模型更新器以训练集 $T=$ ${\bar{x}{1},\bar{x}{2},...,\bar{x}_{N-1}}$ 作为输入,输出更新后的目标模型 $\theta$,即 $\theta:=:u(T)$。更新器的设计包含以下优选特性:1) 支持可变大小的训练集;2) 增量更新,即在跟踪过程中基于现有值更新目标模型而非从头学习;3) 内存与计算高效。
In this work, we propose a RNN-based updater that satisfies all these properties. Concretely, our updater follows a threestep procedure.
在这项工作中,我们提出了一种基于RNN的更新器,满足所有这些特性。具体而言,我们的更新器遵循三步流程。
Step 1: Project from feature space to model space. We first project each target feature in the training set into the model space by $\theta^{\prime}=g(\bar{x})$ , where $\theta^{\prime}\in\mathbb{R}^{m\times m\times d}$ is the candidate target model and $g(\cdot)$ is the algorithm of learning a linear target model using a single target feature. In particular, $g(\cdot)$ is the identity function for SiamFC and is the $\mathrm{CF}(\cdot)$ function followed by a center cropping function for CFNet.
步骤1:从特征空间投影到模型空间。我们首先通过$\theta^{\prime}=g(\bar{x})$将训练集中的每个目标特征投影到模型空间,其中$\theta^{\prime}\in\mathbb{R}^{m\times m\times d}$是候选目标模型,$g(\cdot)$是使用单个目标特征学习线性目标模型的算法。具体来说,$g(\cdot)$在SiamFC中是恒等函数,在CFNet中是$\mathrm{CF}(\cdot)$函数后接中心裁剪函数。
Step 2: Aggregate target information. We use RNN to summarize the training set into a single tensor. For simplicity, gated recurrent unit (GRU) is adopted [28]. We find GRU achieves better performance than the Long-short term memory (LSTM [29]) in the ablation study. To preserve the spatial dimension, we extend the original GRU formulation to Convolutional GRU (ConvGRU) by replacing all matrix multiplications with convolutions.
步骤2:聚合目标信息。我们使用RNN将训练集汇总为单个张量。为简化实现,采用了门控循环单元(GRU) [28]。消融实验表明,GRU比长短期记忆网络(LSTM [29])具有更优性能。为保留空间维度,我们将原始GRU公式扩展为卷积GRU(ConvGRU),将所有矩阵乘法替换为卷积运算。
Step 3: Generate target model. Given the last hidden state of the ConvGRU, one convolutional layer is used to generate the target model.
步骤3:生成目标模型。给定ConvGRU的最后一个隐藏状态,使用一个卷积层来生成目标模型。
By adopting RNN, our updater is able to handle training set with variable size. Moreover, the target model is updated in an incremental manner. To make things clear, during tracking, denote $T_{t-1}={\bar{x}{1},\bar{x}{2},...,\bar{x}{t-1}}$ as the online training set at time $t\mathrm{-~}1$ . After model update, we obtain the hidden state $h_{t-1}$ . At time $t$ , the online training set is updated with a new example ${\bar{x}}{t}$ , i.e., $T_{t}=T_{t-1}\cup{\bar{x}{t}}$ . Since the first $t-1$ examples are unchanged, we can simply reuse $h_{t-1}$ and get $h_{t}=\mathrm{ConvGRU}(h_{t-1},\bar{x}{t})$ . Moreover, with incremental update, we can avoid explicitly storing and manipulating a large online training set during tracking since our updater only needs $h_{t-1}$ to generate $h_{t}$ which saves a large amount of memory.
通过采用RNN,我们的更新器能够处理可变大小的训练集。此外,目标模型以增量方式进行更新。为明确说明,在跟踪过程中,将$T_{t-1}={\bar{x}{1},\bar{x}{2},...,\bar{x}{t-1}}$表示为时间$t\mathrm{-~}1$的在线训练集。模型更新后,我们获得隐藏状态$h_{t-1}$。在时间$t$,在线训练集通过新样本${\bar{x}}{t}$进行更新,即$T_{t}=T_{t-1}\cup{\bar{x}{t}}$。由于前$t-1$个样本保持不变,我们可以直接复用$h_{t-1}$并得到$h_{t}=\mathrm{ConvGRU}(h_{t-1},\bar{x}{t})$。此外,通过增量更新,我们可以在跟踪过程中避免显式存储和操作大型在线训练集,因为更新器仅需$h_{t-1}$即可生成$h_{t}$,从而节省大量内存。
Until now, the updater is restricted to use $N-1$ target features as the training set and one search image feature as the test set. Note that given a sequence of $N-1$ target features, our updater can readily compute $N-1$ target models at each time step. Therefore, given a video with $N$ images, we can construct various training sets with length $1,2,...,N-1$ and the computation for model update can be shared.
截至目前,更新器仍仅限于使用 $N-1$ 个目标特征作为训练集,并以一个搜索图像特征作为测试集。需要注意的是,给定 $N-1$ 个目标特征序列时,我们的更新器能在每个时间步轻松计算出 $N-1$ 个目标模型。因此,对于包含 $N$ 帧图像的视频,我们可以构建长度为 $1,2,...,N-1$ 的不同训练集,并共享模型更新的计算过程。
D. The Learning Objective
D. 学习目标
Given the updated target model $\theta$ , we need a “goodness” measurement of the target model which in turn indicates how good the updater is and thus enables optimization.
给定更新后的目标模型 $\theta$,我们需要一个衡量目标模型"优劣"的指标,该指标能反映更新器的优劣程度,从而支持优化过程。
Classification Loss. Following the meta-learning framework, the updated model is evaluated on the test set $Q=$ ${(z,y)}$ . Using the normalized logistic loss for classification, we have
分类损失 (Classification Loss)。按照元学习框架,更新后的模型在测试集 $Q=$ ${(z,y)}$ 上进行评估。使用归一化逻辑损失进行分类,我们有
$$
l_{c}(\theta;Q)=\frac{y(-\ln\sigma(\theta\star z))+(1-y)(-\ln(1-\sigma(\theta\star z)))}{(n-m+1)\cdot(n-m+1)}.
$$
$$
l_{c}(\theta;Q)=\frac{y(-\ln\sigma(\theta\star z))+(1-y)(-\ln(1-\sigma(\theta\star z)))}{(n-m+1)\cdot(n-m+1)}.
$$
Anchor Loss. At a first glance, it would seem that classification loss is all we need to train the updater. However, model update faces the intrinsic problem: the stability-plasticity dilemma, i.e., model update should be stable with respect to noise and flexible to assimilate new information. With only classification loss, since $z$ is close to $\bar{x}{N-1}$ , the updater will adopt an aggressive update strategy and store new information brought by $\bar{x}{N-1}$ as much as possible. The problem is that $\bar{x}_{N-1}$ is not always reliable during tracking and thus the updater trained with only classification loss is prone to small errors.
锚点损失 (Anchor Loss)。乍看之下,分类损失似乎足以训练更新器。然而模型更新面临一个本质问题:稳定性与可塑性困境 (stability-plasticity dilemma),即模型更新既要对噪声保持稳定,又要灵活吸收新信息。若仅使用分类损失,由于 $z$ 接近 $\bar{x}{N-1}$,更新器会采取激进策略,尽可能存储 $\bar{x}{N-1}$ 带来的新信息。问题在于跟踪过程中 $\bar{x}_{N-1}$ 并不总是可靠的,因此仅用分类损失训练的更新器容易受微小误差影响。
One effective method that is validated by the literature is to use the target model at the first frame as an anchor point [9], [10]. Given inadequate training data, such an anchor point is hard to learn without regular iz ation. Therefore, we design an anchor loss, which penalizes the updater when the updated target model drifts away from the initial target model:
文献验证的一种有效方法是使用第一帧的目标模型作为锚点 [9], [10]。由于训练数据不足,若无正则化则难以学习此类锚点。因此,我们设计了锚点损失函数 (anchor loss),当更新后的目标模型偏离初始目标模型时对该更新器进行惩罚:
$$
l_{a}(\theta;\theta_{1})={\frac{1}{m\cdot m\cdot d}}||\theta-\theta_{1}||_{2}^{2}.
$$
$$
l_{a}(\theta;\theta_{1})={\frac{1}{m\cdot m\cdot d}}||\theta-\theta_{1}||_{2}^{2}.
$$
where the loss is normalized by the number of target model parameters $m\cdot m\cdot d$ .
其中损失通过目标模型参数数量 $m\cdot m\cdot d$ 进行归一化。
Total Loss. Classification loss and anchor loss are linearly combined for measuring a target model:
总损失。分类损失和锚点损失线性组合用于衡量目标模型:
$$
l(\theta;Q)=(1-\lambda)l_{c}(\theta;Q)+\lambda l_{a}(\theta;\theta_{1}),
$$
$$
l(\theta;Q)=(1-\lambda)l_{c}(\theta;Q)+\lambda l_{a}(\theta;\theta_{1}),
$$
where $\lambda$ is the combination factor. Successful learning of the updater should maintain a good balance between the classification loss and the anchor loss.
其中 $\lambda$ 是组合因子。更新器的成功学习应在分类损失和锚点损失之间保持良好的平衡。
The total loss of the updater $u_{\phi}(\cdot)$ with learnable parameters $\phi$ is then the loss of the target model in the offline training set by inserting Eq. 7 into Eq. 4.
可学习参数 $\phi$ 的更新器 $u_{\phi}(\cdot)$ 的总损失,是通过将公式7代入公式4后,在离线训练集中目标模型的损失。
E. Practical Techniques for Effective Learning
E. 高效学习的实用技巧
Our learned updater collects target information based on RNNs, which are well known for modeling sequential/temporal variations. However, the problem of limited offline training videos has to be addressed before it unleashes the power. We describe several techniques based on the nature of model update that turn out to be effective.
我们基于RNN的学习型更新器收集目标信息,RNN以建模序列/时序变化而闻名。然而,在充分发挥其潜力之前,必须解决离线训练视频有限的问题。我们根据模型更新的本质描述了几种行之有效的技术。
Modeling long-term variation by truncated backpropagation. Typically, a subset of $N$ frames are sampled from the original video for RNN training. For convenience, we define maximum modeling length of an algorithm to be the largest length of all sampled sequences during training, where the length of a sampled sequence stands for the distance counted by #(frames) in the original video between the first and the last sampled frame. Since videos have hundreds of frames to track, it is desirable for RNN-based models to learn long-term dependency with a large maximum modeling length. However, training with long sequences is computationally demanding and may incur the vanishing gradient problem. To avoid such a problem, existing RNN-based trackers sample relatively few frames sparsely from the original video. For example, [25] samples training sequences with 10 frames and large frame interval (30 frames on average). Such a sparse sampling strategy, however, enlarges the target variations between sampled frames, which is more difficult to learn. We conjecture that these trackers are disadvantaged by such limitations.
通过截断反向传播建模长期变化。通常,会从原始视频中采样 $N$ 帧子集用于RNN训练。为方便起见,我们将算法的最大建模长度定义为训练期间所有采样序列的最大长度,其中采样序列的长度表示原始视频中第一个和最后一个采样帧之间按#(帧数)计算的距离。由于视频通常包含数百帧待追踪画面,基于RNN的模型需要以较大最大建模长度学习长期依赖关系。但长序列训练计算成本高昂,且可能导致梯度消失问题。为避免该问题,现有基于RNN的追踪器会从原始视频中稀疏采样较少帧数。例如[25]采用10帧训练序列和大帧间隔(平均30帧)进行采样。然而这种稀疏采样策略会增大采样帧间的目标变化幅度,增加学习难度。我们推测这些追踪器因此存在性能局限。
Contrarily, to train our learned updater, we sample training sequences with as many as 150 frames and small frame interval $(\leq~2$ frames)4. To handle the aforementioned problem of training with long sequences, instead of back propagating all the way to the first frame, we adopt truncated back propagation. This method processes training frames one timestep at a time, and every $H$ timesteps, it runs back propagation through time (BPTT) for $H$ timesteps. $H$ is called the unroll length.
相反,为了训练我们的学习更新器,我们采样了多达150帧且帧间隔较小(≤2帧)的训练序列。为了解决长序列训练的问题,我们没有选择一直反向传播到第一帧,而是采用了截断反向传播。这种方法每次处理一个时间步的训练帧,并且每隔H个时间步,就会运行一次跨越H个时间步的反向传播时间(BPTT)。H被称为展开长度。
Matching training and testing behavior by estimated target position. During offline training of the learned updater, training set $T$ of the training video needs to be generated. In our case, the online training set contains the target features at each frame ${{T}{t}}=~{{{\bar{x}}{1},{{\bar{x}}{2}},...,{{\bar{x}}_{t}}}}$ . The extraction of the target features depends on the target position which can only be estimated during tracking. RNNs often take as input the ground truth during training, which is known as teacher forcing. However, as noted in [30], this causes discrepancy between training and testing and hampers the performance of RNNs. In this work, we always use the target position during training that is inferred by the target model to keep in line with testing. Reducing over fitting by interval update. As noted in [31], instead of updating the target model in every frame, it is beneficial to apply a sparser update scheme. We adopt this simple strategy by updating the target model every $M$ frames. Note that the hidden state of RNN is updated in every frame though. The reason for the improved performance is that by updating after a certain timesteps, the learned updater can make more informed update decision, and therefore reduces the risk of over fitting to current training samples.
通过估计目标位置匹配训练和测试行为。在所学更新器的离线训练过程中,需要生成训练视频的训练集 $T$。在我们的案例中,在线训练集包含每帧的目标特征 ${{T}{t}}=~{{{\bar{x}}{1},{{\bar{x}}{2}},...,{{\bar{x}}_{t}}}}$。目标特征的提取依赖于只能在跟踪过程中估计的目标位置。RNN在训练时通常以真实标签作为输入,这被称为教师强制 (teacher forcing)。但如[30]所述,这会导致训练与测试不一致并损害RNN性能。本工作中,我们始终使用目标模型推断的训练目标位置以保持与测试的一致性。
通过间隔更新减少过拟合。如[31]指出,相较于逐帧更新目标模型,采用更稀疏的更新方案更为有利。我们采用每 $M$ 帧更新目标模型的简单策略,但需注意RNN的隐藏状态仍会逐帧更新。性能提升的原因在于:通过间隔若干时间步更新,所学更新器能做出更明智的更新决策,从而降低对当前训练样本过拟合的风险。
V. EXPERIMENTS
V. 实验
A. Implementation Details
A. 实现细节
Training data. The feature extractor and learned updater are trained offline on the ILSVRC 2015 Object Detection from Video dataset (Imagenet VID) [32]. Imagenet VID contains 4417 videos and each video has about 2 object tracks on average, adding up to 9220 tracks. Tracks are annotated with bounding boxes in each frame and contain about 230 frames on average. This differs from another large-scale video dataset, namely Youtube-BB [33] where objects are annotated every 30 frames and each track has about 15 annotated frames. We find that small frame interval is important for training the learned updater, and thus, we use Imagenet VID instead of the much larger Youtube-BB. However, it is worth investigating effective ways to make use of Youtube-BB for object tracking.
训练数据。特征提取器和学习更新器在ILSVRC 2015视频目标检测数据集(Imagenet VID) [32]上进行离线训练。Imagenet VID包含4417个视频,每个视频平均约有2个目标轨迹,总计9220条轨迹。每条轨迹在每帧都标注了边界框,平均包含约230帧。这与另一个大规模视频数据集Youtube-BB [33]不同,后者每30帧标注一次目标,每条轨迹约有15个标注帧。我们发现较小的帧间隔对训练学习更新器很重要,因此选用Imagenet VID而非规模更大的Youtube-BB。不过,如何有效利用Youtube-BB进行目标跟踪仍值得研究。
Image sequences are sampled from tracks as training samples for the learned updater. We use bucketing [34] (i.e., an
从轨迹中采样图像序列作为学习更新器 (learned updater) 的训练样本。我们采用分桶策略 [34] (即一种...
RNN training technique which batch together sequences of similar lengths for efficiency) to handle sequences of different length. Multiples of the RNN unroll length are used as the bucket sizes. For example, bucket sizes of 25, 50, ..., 125, 150 are used for fast experimentation where 25 is the RNN unroll length. For tracks that are longer than the largest bucket size (e.g., 150), we sample a portion of the tracks with small frame interval (e.g., 1 or 2). For short tracks, we lengthen these tracks by duplicating frames or simply drop these tracks according to probabilities that are proportional to the track length. Images are pre processed according to its base tracker SiamFC [2] and CFNet [26]. Particularly, these two base trackers use the same preprocessing procedures to crop and resize images such that targets are at the image center and take up $127\mathrm{x}127$ pixels together with context.
RNN训练技术(将长度相似的序列批量处理以提高效率)用于处理不同长度的序列。桶大小采用RNN展开长度的倍数。例如,快速实验中使用25、50、...、125、150作为桶大小,其中25是RNN展开长度。对于超过最大桶大小(如150)的轨迹,我们以较小的帧间隔(如1或2)采样部分轨迹。对于短轨迹,我们通过复制帧来延长这些轨迹,或根据与轨迹长度成比例的概率直接丢弃。图像预处理基于其基础跟踪器SiamFC [2]和CFNet [26]。具体而言,这两个基础跟踪器采用相同的预处理流程对图像进行裁剪和缩放,使目标位于图像中心并占据$127\mathrm{x}127$像素范围及上下文区域。
Architecture. For template-based tracker, we use the same modified Alexnet architecture in [2] for the feature extractor. For correlation filter-based tracker, we use the 3 layer CNN feature extractor in [26], which is trained following the procedures in [2]. All of our experiments stack two convolutional GRU layers, where convolution operations have kernel size 3 with zero padding to preserve spatial dimension. For template-based tracker, each convolutional GRU layer has 192 units while for correlation filter-based tracker, each has 64 units5. One convolutional layer with kernel size 3 is used to generate the updated target model based on the hidden states, which takes as input the concatenated states of the two convolutional GRU layers and outputs corresponding target models. Dropout [35] and layer normalization [36] are added in each convolutional GRU layer to avoid over fitting.
架构。对于基于模板的跟踪器,我们采用与文献[2]中相同的改进版Alexnet架构作为特征提取器。对于基于相关滤波的跟踪器,我们使用文献[26]提出的三层CNN特征提取器,其训练流程遵循文献[2]的方法。所有实验均堆叠两层卷积GRU层,其中卷积操作采用核尺寸3并保持零填充以维持空间维度。基于模板的跟踪器中,每层卷积GRU包含192个单元,而基于相关滤波的跟踪器每层含64个单元。通过一个核尺寸为3的卷积层,基于隐藏状态生成更新后的目标模型——该层将两个卷积GRU层的拼接状态作为输入,输出相应的目标模型。每个卷积GRU层加入Dropout [35]和层归一化[36]以防止过拟合。
Optimization. Learned updaters are trained over 60 epochs, each epoch consists of 8309 image sequences. Gradients are computed using mini-batches of size 8, which are used by the Adam optimizer [37]. Learning rate is fixed to be 1e-4. Weight decay is 5e-4.
优化。学习到的更新器经过60个训练周期(epoch),每个周期包含8309个图像序列。使用批量大小(mini-batch)为8计算梯度,并采用Adam优化器[37]。学习率固定为1e-4,权重衰减(weight decay)为5e-4。
Hardware and software specifications. The speed measurements of our trackers are performed on a computer with an Intel Core i7-5930K Haswell-E 6-Core 3.5GHz CPU and a GeForce GTX 1080 GPU. Our trackers are implemented in TensorFlow [38], which is compiled with CUDA 8.0 and cuDNN 6.0.
硬件和软件规格。我们在配备Intel Core i7-5930K Haswell-E 6核3.5GHz CPU和GeForce GTX 1080 GPU的计算机上进行了跟踪器的速度测量。我们的跟踪器基于TensorFlow [38]实现,并使用CUDA 8.0和cuDNN 6.0进行编译。
Post processing. We adopt the same strategy as our base trackers for penalizing large displacement and handling scale variations. Specifically, a cosine window is added to the response map to penalize the large displacement. For scale estimation, three search patches with different scales are extracted and the current scale is calculated by interpolating the newly predicted scale with a damping factor.
后处理。我们采用与基础跟踪器相同的策略来惩罚大位移和处理尺度变化。具体来说,在响应图上添加余弦窗口以惩罚大位移。对于尺度估计,提取三个不同尺度的搜索块,并通过阻尼因子对新预测尺度进行插值来计算当前尺度。
B. Benchmarks and Evaluation Protocols
B. 基准测试与评估协议
OTB. The OTB benchmark contains three sub datasets: OTB-2013, OTB-50 and OTB-100, each of which consists of 51, 50 and 100 natural image sequences, respectively. The standard evaluation metric on OTB is the area under curve (AUC) of the threshold-success rate curve which represents the success rates at different thresholds. For each frame, the overlap (intersection over union) between the predicted target bounding box and ground truth is computed. The success rate at a given threshold corresponds to the fraction of frames that has overlap no less than the given threshold.
OTB。OTB基准测试包含三个子数据集:OTB-2013、OTB-50和OTB-100,分别由51、50和100个自然图像序列组成。OTB的标准评估指标是阈值成功率曲线下面积 (AUC),该曲线表示不同阈值下的成功率。对于每一帧,计算预测目标边界框与真实标注框之间的重叠率 (交并比)。给定阈值下的成功率对应重叠率不低于该阈值的帧占比。
VOT. The VOT benchmarks are a collection of tracking challenges held on a yearly basis starting from 2013. We use three recent benchmarks: VOT-2015, VOT-2016 and VOT2017. Unlike OTB, which lets the tracker run until the end of the image sequence, VOT focuses on short-term tracking (no re detection is required) and resets the tracker once it drifts away from the target. The primary measure is the expected average overlap (EAO), which reflects the similar property as AUC. VOT-2017 also introduces a new “realtime challenge”, where a tracker is constantly receiving images in realtime speed and if the tracker does not respond after a new frame becomes available, the last bounding box predicted by the tracker is reported for the current frame.
VOT。VOT基准测试是从2013年开始每年举办的一系列跟踪挑战赛。我们使用了三个近期基准:VOT-2015、VOT-2016和VOT-2017。与让跟踪器持续运行至图像序列结束的OTB不同,VOT专注于短期跟踪(无需重新检测),并在跟踪器偏离目标时立即重置。主要衡量指标是预期平均重叠率(EAO),其反映的特性与AUC类似。VOT-2017还引入了新的"实时挑战",要求跟踪器以实时速度持续接收图像,若新帧到达后跟踪器未响应,则报告该帧使用跟踪器预测的最后一个边界框。
C. Ablation Study
C. 消融研究
We validate the effectiveness of various designs of our learned updater based on the template-based tracker. OTB2013 is used for ablation study. All experiments use the same configurations except the components that are examined. Although larger unroll length typically gets better results, in the ablation study section, we use unroll length 25 for fast experimentation which is also the default configuration unless larger unroll length is needed. Moreover, only color images are adopted during offline training to prevent benchmark-specific choices6. All models are trained using our implementation including SiamFC. Results are summarized in Table II.
我们基于模板跟踪器验证了学习更新器不同设计的有效性。OTB2013数据集用于消融实验。除被测试组件外,所有实验均采用相同配置。虽然更长的展开长度通常能获得更好结果,但在消融研究部分,我们采用默认配置的展开长度25以加速实验(仅在需要更大展开长度时调整)。此外,离线训练阶段仅使用彩色图像以避免针对特定基准的优化选择[6]。所有模型(包括SiamFC)均采用我们的实现进行训练。实验结果汇总于表II。
Anchor loss is crucial for successful learning. To overcome the stability-plasticity dilemma, we propose the anchor loss which penalizes large variations of the updated target model. To minimize the anchor loss, one straightforward strategy would be no update at all. However, besides the anchor loss, the learned updater is also constrained by the classification loss which encourages the update of the target model to keep up with target variations. It is of interest to investigate how the interplay between these two losses affects the performance of the learned updater.
锚定损失对成功学习至关重要。为克服稳定性-可塑性困境,我们提出通过锚定损失惩罚目标模型更新后的较大变动。最小化锚定损失最直接的策略是完全不更新模型。然而除锚定损失外,所学更新器还受分类损失约束——该损失会推动目标模型更新以跟进目标变化。研究这两种损失间的相互作用如何影响所学更新器的性能具有重要意义。
Our learned updaters trained with different combination factors $\lambda$ are shown in Table II(d). We also include the results of the no-update baseline (i.e., the setup in SiamFC [2]) for reference. When $\lambda~=~0$ (i.e., no anchor loss), our learned updater is not constrained to generate target models that are consistent with the initial target model and can quickly drift away. The performance is even worse than not updating at all. As $\lambda$ increases, the learned updater gets better and reaches the peak at 0.2. Further increasing the anchor loss weight diminishes the possible target model choices of the learned updater and the performance drops. Note that even without the classification loss (i.e., $\lambda=1$ ), our learned updater outperforms the baseline with no update. The reason is that the learned updater is given the initial target model only once. After that, it constantly receives new target model information and the hidden states of RNN inevitably stores new information due to the soft store operations. It is this new information that helps tracking.
我们训练的不同组合因子$\lambda$对应的学习型更新器结果如表II(d)所示。表中同时列出了不更新基线(即SiamFC[2]中的设置)作为参考。当$\lambda=0$(即无锚点损失)时,学习型更新器不受限于生成与初始目标模型一致的模型,会快速偏离目标。此时性能甚至不如完全不更新的情况。随着$\lambda$增大,学习型更新器性能提升并在0.2时达到峰值。继续增大锚点损失权重会限制学习型更新器的可选目标模型范围,导致性能下降。值得注意的是,即使没有分类损失(即$\lambda=1$),我们的学习型更新器仍优于不更新的基线。这是因为学习型更新器仅接收一次初始目标模型信息,之后会持续接收新目标模型信息,且RNN的隐状态会通过软存储操作不可避免地存储新信息。正是这些新信息辅助了跟踪过程。
Learned updater is orthogonal to feature extractor. Our template-based tracker is based on [2], which aims to learn an invariant and disc rim i native feature extractor such that model update is not necessary. Two interesting questions are: 1) how much variation the Siamese network is able to learn, and 2) how the learned feature extractor affects our learned updater. We answer these questions from the perspective of training samples of feature extractor. Every training sample of the Siamese network contains two image patches from two frames of a video. These two patches are both centered on the target and at most $K$ frames apart, and therefore the maximum modeling length is $K$ according to the definition in Section IV-E. We investigate the effects of different $K$ , and train an updater based on each feature extractor. Results are shown in Table II(e).
学习型更新器与特征提取器正交。我们基于模板的跟踪器源自[2],旨在学习一个不变且具判别性的特征提取器,从而无需模型更新。两个有趣的问题是:1) 孪生网络能学习多大程度的变化,2) 学习到的特征提取器如何影响我们的学习型更新器。我们从特征提取器的训练样本角度回答这些问题。孪生网络的每个训练样本包含来自视频两帧的两个图像块,这两个块都以目标为中心且最多相隔 $K$ 帧,因此根据第IV-E节的定义,最大建模长度为 $K$。我们研究了不同 $K$ 值的影响,并基于每个特征提取器训练更新器。结果如表II(e)所示。
As can be seen, 1) Siamese network is able to capture the variations of target within 100 frames, but has difficulties learning beyond this limit. 2) Although the feature extractor is trained with the objective of invariance and does not require model update, our learned updater consistently improves the base trackers. Moreover, the improvement is positively correlated with the performance of the feature extractor.
可以看出:1) 孪生网络(Siamese network)能在100帧内捕捉目标变化,但难以学习超过此范围的特征。2) 尽管特征提取器以不变性为目标进行训练且无需模型更新,但我们学习的更新器能持续提升基础跟踪器性能。此外,这种改进与特征提取器的性能呈正相关。
Train longer, generalize better. Model update is a process that typically spans hundreds of frames. We investigate the effects of training with long image sequences (large maximum modeling length). Table II(f) shows the tracking results of the learned updater trained with different maximum modeling length and unroll lengths. By increasing the maximum modeling length from 100 to 300, the learned updater monotonically gets better results. Since modeling long term dependencies is still a challenge for RNN, the performance degenerates when it reaches 400. In conclusion, 1) large maximum modeling length helps the learned updater to generalize better if it is within the modeling capabilities of RNN; 2) large unroll length is still helpful under truncated back propagation to model long term dependencies.
训练更久,泛化更好。模型更新通常是一个跨越数百帧的过程。我们研究了使用长图像序列(最大建模长度较大)进行训练的效果。表II(f)展示了在不同最大建模长度和展开长度下训练所得更新器的跟踪结果。当最大建模长度从100增加到300时,更新器的性能持续提升。由于长时依赖建模对RNN仍是挑战,当长度达到400时性能会出现下降。结论表明:1) 在RNN建模能力范围内,较大的最大建模长度有助于更新器获得更好的泛化能力;2) 在截断反向传播条件下,较大的展开长度对建模长时依赖仍有帮助。
Moreover, it is worth mentioning that the performance of the Siamese network decays as the maximum modeling length is over 100 (as shown in Table II(e)). We have tried to increase the number of neurons in Siamese network, but it does not help. Contrarily, our learned updater can handle longer sequences (e.g., 300 frames). It can be inferred that it is difficult to extract invariant features to handle long-term target variation, whereas learning an updater to adapt the target model gradually is relatively easier.
此外,值得注意的是,当最大建模长度超过100时,孪生网络(Siamese network)的性能会下降(如表II(e)所示)。我们尝试增加孪生网络的神经元数量,但并未改善效果。相反,我们学习到的更新器(updater)能够处理更长的序列(例如300帧)。可以推断,提取不变特征来处理长期目标变化较为困难,而通过学习更新器逐步调整目标模型则相对更容易。
Practical techniques are helpful. We demonstrate the effectiveness of the various practical techniques introduced in Section IV-E by removing one component at a time. Note that small unroll length is used by default instead of large unroll length for fast experimentation. The results are summarized in Table II(a). As shown in the table, every component has contributed to the final performance. Among
实用技巧很有帮助。我们通过逐一移除第四-E节介绍的各项实用技术来验证其有效性。请注意,为加速实验过程,默认使用较小的展开长度而非较大值。结果总结如表II(a)所示。从表中可见,每个组件都对最终性能有所贡献。其中
TABLE II: Ablations on the OTB-2013 dataset using template-based tracker. Only color images are adopted during offline training. RNNs are unrolled 25 steps by default.
表 II: 基于模板跟踪器在OTB-2013数据集上的消融实验。离线训练仅采用彩色图像。默认情况下,RNN展开25步。
(a) Effective techniques: Cross mark means the technique is removed. RNNs are unrolled 25 steps by default unless large unroll length (50) is adopted. Image sequence are sampled by default with small frame interval $(\leq2)$ . By removing the technique, we use large frame interval $(\geq10)$ .
(a) 有效技术:叉号表示该技术被移除。默认情况下 RNN 会展开 25 步,除非采用较大展开长度 (50)。图像序列默认以较小帧间隔 $(\leq2)$ 采样。移除该技术后,我们使用较大帧间隔 $(\geq10)$。
(b) RNN configurations: For example, ConvGRU-192x2 denotes stacking 2 layers of ConvGRU, each with hidden size 192.
(b) RNN配置:例如,ConvGRU-192x2表示堆叠2层ConvGRU,每层隐藏大小为192。
| intervalupdate? estimated target position? smallframeinterval? | ||||
|---|---|---|---|---|
| large unroll length? AUC (%) | 64.4 | 63.6 | 63.0 | 62.6 |
(d) Anchor loss: Tracker accuracy as the combi- nation factor $\lambda$ varies during updater training. “lu” is our learned updater.
(d) 锚点损失 (Anchor loss): 跟踪器准确率随更新器训练中组合因子 $\lambda$ 变化的情况。"lu"代表我们学习得到的更新器。
| 配置 | AUC (%) |
|---|---|
| ConvGRU-192x1 ConvGRU-192x2 ConvGRU-192x3 | 62.1 63.6 63.3 |
| ConvGRU-128x2 ConvGRU-192x2 ConvGRU-256x2 | 62.8 63.6 63.4 |
| ConvLSTM-128x2 ConvLSTM-192x2 | 62.2 62.8 |
(c) Joint training: F: feature extractor, M: model updater, $\boldsymbol{\mathrm{F}}+\boldsymbol{\mathrm{M~}}$ : joint training of feature extractor and model updater.
(c) 联合训练:F:特征提取器,M:模型更新器,$\boldsymbol{\mathrm{F}}+\boldsymbol{\mathrm{M~}}$:特征提取器与模型更新器的联合训练。
| 描述 | AUC (%) | |
|---|---|---|
| scheme1 | 阶段1: F+M | 51.5 |
| scheme2 | 阶段1: F 阶段2: F+M | 56.2 |
| scheme3 | 阶段1: F 阶段2: M 阶段3: F+M | 63.1 |
| Ours | 阶段1: F 阶段2: M | 63.6 |
(e) Maximum modeling length of feature extractor: Tracker accuracy as the maximum modeling length of the feature extractor varies during offline training, with and without the learned updater.
(e) 特征提取器最大建模长度:在离线训练期间,随着特征提取器最大建模长度的变化,跟踪器准确率的变化情况(包含学习型更新器与不包含学习型更新器的对比)。
(f) Maximum modeling length of model updater: Tracker accuracy with varied maximum modeling length and unroll length of the model updater during offline training.
模型更新器的最大建模长度:离线训练期间,模型更新器在不同最大建模长度和展开长度下的跟踪器准确率。


these techniques, interval update plays such an important role that the performance drops about $2%$ once removed. This is in accordance with the findings in [31].
这些技术中,区间更新扮演着如此重要的角色,一旦移除性能会下降约 $2%$ 。这与[31]中的发现一致。
Ablation on the RNN. Table II(b) shows the results of RNNs with different configurations of cell unit (ConvGRU or ConvLSTM), number of stacked RNN layers and the hidden state size. As can be seen, ConvGRU consistently outperforms ConvLSTM which may be related to the observation that the best performing cell unit is task-dependent [39]. We also observe that the AUC largely increases from $62.1%$ to $63.6%$ by stacking two layers of ConvGRU. The performance is not sensitive to the size of the hidden state as long as it is in a reasonable range $(192^{\sim}256)$ .
RNN消融实验。表 II(b) 展示了不同配置下RNN的结果,包括单元类型 (ConvGRU或ConvLSTM)、堆叠RNN层数和隐藏状态大小。可以看出,ConvGRU始终优于ConvLSTM,这可能与最佳单元类型取决于具体任务的研究结论相关 [39]。我们还观察到,通过堆叠两层ConvGRU,AUC从 $62.1%$ 显著提升至 $63.6%$。只要隐藏状态大小处于合理范围 $(192^{\sim}256)$,模型性能对其变化并不敏感。
Joint training is difficult. The whole system (including feature extractor and model updater) can be trained jointly. We have tried several schemes for joint training, of which the results are summarized in Table II(c). Interestingly, it is best to train feature extractor and model updater separately - first train the feature extractor without model updater, and then fix the feature extractor and train the model updater. Scheme 3 jointly trains feature extractor and model updater after separately learning these two components. However, the performance still degrades. The reason is arguably that the ability of the feature extractor for modeling appearance invariance is hampered during joint training since the frame interval between selected images is small.
联合训练较为困难。整个系统(包括特征提取器和模型更新器)可以进行联合训练。我们尝试了多种联合训练方案,结果总结如表 II(c) 所示。有趣的是,最佳方案是将特征提取器与模型更新器分开训练——先在没有模型更新器的情况下训练特征提取器,然后固定特征提取器再训练模型更新器。方案3在分别学习这两个组件后进行联合训练,但性能仍然下降。原因可能在于:由于所选图像之间的帧间隔较小,联合训练会阻碍特征提取器对表观不变性的建模能力。

TABLE III: Comparisons with three representative baselines: no update, EMA-based update and SGD-based update. The AUC and EAO metric (higher is better) are reported for OTB and VOT, respectively. For OTB only, the feature extractors are trained with both color and grayscale images.
表 III: 与三种代表性基线的比较: 不更新、基于EMA的更新和基于SGD的更新。分别报告了OTB和VOT的AUC和EAO指标 (数值越高越好)。仅针对OTB, 特征提取器同时使用彩色和灰度图像进行训练。
| OTB-2013 | OTB-100 | OTB-50 | VOT-2015 | VOT-2016 | VOT-2017 | 速度(FPS) | |
|---|---|---|---|---|---|---|---|
| SiamFC-no-update | 0.608 | 0.582 | 0.516 | 0.290 | 0.235 | 0.188 | 117 |
| SiamFC-ema | 0.618 | 0.597 | 0.538 | 0.286 | 0.259 | 0.216 | 91 |
| SiamFC-sgd | 0.644 | 0.614 | 0.563 | 0.306 | 0.278 | 0.248 | 13 |
| SiamFC-lu (Ours) | 0.657 | 0.620 | 0.577 | 0.318 | 0.295 | 0.263 | 82 |
| CFNet-no-update | 0.568 | 0.541 | 0.501 | 0.219 | 0.201 | 0.173 | 134 |
| CFNet-ema | 0.608 | 0.580 | 0.550 | 0.237 | 0.229 | 0.189 | 79 |
| CFNet-sgd | 0.613 | 0.590 | 0.555 | 0.235 | 0.212 | 0.182 | 9 |
| CFNet-lu (Ours) | 0.621 | 0.599 | 0.565 | 0.242 | 0.230 | 0.208 | 70 |
D. Baseline Comparisons
D. 基准对比
We consider three relevant baselines: no update, EMA-based update and SGD-based update. Please refer to Section III for an introduction of the EMA-based and SGD-based update.
我们考虑三种相关基线方法:不更新、基于指数移动平均 (EMA) 的更新和基于随机梯度下降 (SGD) 的更新。关于基于EMA和基于SGD更新的介绍,请参阅第III节。
TABLE IV: Comparisons with state-of-the-art trackers.
表 IV: 与最先进跟踪器的对比
(a) OTB and VOT: Trackers are split into two groups: realtime trackers and non-realtime trackers. The AUC and EAO metric (higher is better) are reported for OTB and VOT, respectively. Red and blue fonts indicate 1st and 2nd best performance of each group, respectively.
(a) OTB与VOT:跟踪器分为实时跟踪器和非实时跟踪器两组。OTB采用AUC指标,VOT采用EAO指标(数值越高越好)。红色与蓝色字体分别标示各组性能最优与次优结果。
| OTB-2013 | OTB-100 | OTB-50 | VOT-2015 | VOT-2016 | VOT-2017 | 速度(FPS) | |
|---|---|---|---|---|---|---|---|
| ECO | 0.709 | 0.694 | 0.643 | 0.374 | 0.280 | 6 | |
| MDNet | 0.708 | 0.678 | 0.645 | 0.38 | 1 | ||
| LSART | 0.677 | 0.672 | 0.324 | 0.323 | 1 | ||
| CSRDCF | 0.587 | 0.320 | 0.338 | 0.222 | 13 | ||
| CREST | 0.673 | 0.623 | 0.283 | 1 | |||
| RFL | 0.581 | 0.222 | 15 | ||||
| SiamFC-lu (Ours) | 0.657 | 0.620 | 0.577 | 0.318 | 0.295 | 0.263 | 82 |
| EAST | 0.638 | 0.629 | 0.34 | 159 | |||
| DSiam | 0.656 | 0.293 | 25 | ||||
| CFNet-lu (Ours) | 0.621 | 0.599 | 0.565 | 0.242 | 0.230 | 0.208 | 70 |
| CFNet | 0.610 | 0.589 | 0.538 | 79 | |||
| SiamFC | 0.608 | 0.582 | 0.516 | 0.290 | 0.235 | 0.188 | 117 |
(b) VOT-2017 realtime challenge: Results of top-performing trackers and our trackers on the VOT-2017 realtime and non-realtime (also called baseline) challenge. The EAO metric (higher is better) is reported.
(b) VOT-2017实时挑战赛:在VOT-2017实时和非实时(也称为基线)挑战中表现最佳的跟踪器与我们的跟踪器的结果。报告了EAO指标(越高越好)。
| 挑战类型 | SiamFC-lu(我们的) | CSRDCF++ | CFNet-lu(我们的) | SiamFC | ECO-HC | LSART | CFCF | ECO |
|---|---|---|---|---|---|---|---|---|
| 实时 | 0.258 | 0.212 | 0.200 | 0.182 | 0.177 | 0.055 | 0.059 | 0.078 |
| 非实时 | 0.263 | 0.229 | 0.208 | 0.188 | 0.238 | 0.323 | 0.286 | 0.280 |
while long-term update is conducted every 10 frames. The hyper parameters of the SGD-based update (e.g., online training set size 1000, batch size 8, learning rate 10, number of iterations, 500 for long-term, 200 for shortterm, etc.) are searched on OTB-2013.
长期更新每10帧进行一次。基于SGD (随机梯度下降) 更新的超参数 (例如在线训练集大小1000、批量大小8、学习率10、迭代次数500次用于长期更新、200次用于短期更新等) 在OTB-2013数据集上进行搜索。
For fair comparison, we retrain the updater using publicly available feature extractors (SiamFC and CFNet are opensourced) with configurations validated in the ablation study. As it turns out, the publicly available feature extractor of SiamFC trained with both color and gray images improves the tracker performance from 0.644 to 0.657 on OTB-2013. This is in line with our observations that the performance of a tracker equipped with our learned updater is positively correlated to that of the feature extractor. The results are summarized in Table III. Qualitative comparisons are presented in Fig. 4.
为公平比较,我们使用公开可用的特征提取器(SiamFC和CFNet已开源)并采用消融研究中验证的配置重新训练更新器。结果表明,在OTB-2013数据集上,使用同时训练彩色与灰度图像的公开版SiamFC特征提取器可将跟踪器性能从0.644提升至0.657。这与我们的观察一致:配备学习型更新器的跟踪器性能与特征提取器性能呈正相关。结果汇总于表III,定性对比展示在图4。
Observations: 1) Our learned updater significantly outperforms the no update and EMA update baselines. 2) A somewhat surprising yet encouraging result is that our learned updater achieves better performance than the heavily designed and tuned SGD update method. 3) It is worth noting that for correlation filter-based tracker, EMA update is still a strong baseline. 4) Noticeably, the improvement on SiamFC is consistently larger than that on CFNet. As noted in [26], the $\mathrm{CF}(\cdot)$ may impose priors that become overly restrictive when enough modeling capacity and data are available. 5) Our learned updater outperforms the SGD-based update method while enjoying comparable efficiency as the EMA-based update method.
观察结果:
- 我们学习的更新器显著优于不更新和指数移动平均 (EMA) 更新的基线方法。
- 一个略显意外但令人鼓舞的结果是,我们学习的更新器性能优于经过精心设计和调优的随机梯度下降 (SGD) 更新方法。
- 值得注意的是,对于基于相关滤波器的跟踪器,EMA 更新仍然是一个强大的基线。
- 明显的是,SiamFC 上的改进始终大于 CFNet 上的改进。如 [26] 所述,$\mathrm{CF}(\cdot)$ 可能会施加过于严格的先验,尤其是在有足够的建模能力和数据可用时。
- 我们学习的更新器在性能上优于基于 SGD 的更新方法,同时保持了与基于 EMA 的更新方法相当的效率。
E. State-of-the-art Comparison
E. 前沿技术对比
We compare trackers equipped with our learned updaters against 10 state-of-the-art trackers: ECO [31], MDNet [40], LSART [41], CSRDCF [42], CREST [43], RFL [25], EAST [44], DSiam [10], CFNet [26] and SiamFC [2]. The results are summarized in Table IV(a).
我们对比了配备学习更新器的跟踪器与10种先进跟踪器的性能:ECO [31]、MDNet [40]、LSART [41]、CSRDCF [42]、CREST [43]、RFL [25]、EAST [44]、DSiam [10]、CFNet [26] 和 SiamFC [2]。结果汇总于表 IV(a)。
Observations: 1) SiamFC-lu achieves state-of-the-art per- formance among realtime trackers. 2) SiamFC-lu outperforms DSiam and RFL, which also focus on improving the update mechanism of SiamFC.
观察结果:1) SiamFC-lu 在实时跟踪器中实现了最先进的性能。2) SiamFC-lu 优于同样专注于改进 SiamFC 更新机制的 DSiam 和 RFL。
To evaluate the practicability of different tracking methods, VOT-2017 introduces a new “realtime challenge” that only allows the tracker to respond in realtime; otherwise, the last predicted target position will be used for the current frame. We compare our method with the state-of-the-art trackers in this setting: ${\mathrm{CSRDCF{++}}}$ (a $\mathrm{C}{+}{+}$ implementation of the CSRDCF [42] tracker), SiamFC [2], ECO-HC (a lightweight version of ECO [31] that uses HOG feature), LSART [41] and CFCF [45]. The results are shown in Table IV(b). It can be observed that our approach achieves state-of-the-art results in the realtime setting.
为评估不同跟踪方法的实用性,VOT-2017引入了新的"实时挑战",仅允许跟踪器实时响应;否则将使用最后预测的目标位置作为当前帧结果。我们在此设置下将本方法与先进跟踪器进行对比:${\mathrm{CSRDCF{++}}}$(CSRDCF [42]跟踪器的$\mathrm{C}{+}{+}$实现)、SiamFC [2]、ECO-HC(使用HOG特征的ECO [31]轻量版)、LSART [41]和CFCF [45]。结果如表IV(b)所示,可见我们的方法在实时设置下取得了最先进的成果。
VI. DISCUSSION
VI. 讨论
One interesting question would be why learning to update actually works? We try to answer this question in three different perspectives. 1) From the high-level perspective, fast model update is viable because videos are intrinsically structured (e.g., temporal dependencies between target features, target variation patterns). Our learned updater captures these structures in a data driven manner. 2) As for the functionality, our learned updater can be seen as a learnable extension of the EMA-based update. The difference is that, instead of linearly interpolating the last target model and the current candidate target model, we adopt the gating mechanism. As a result, the learned updater inherits the efficiency of EMA-based update and the effectiveness of learning based method. 3) Empirically speaking, as shown in Fig. 4, after being trained under the classification loss and anchor loss, our learned updater is able to reliably absorb target variations while resisting the distract or s.
一个有趣的问题是为什么学习更新实际上有效?我们从三个不同角度尝试回答这个问题。1) 从高层次视角看,快速模型更新是可行的,因为视频具有内在结构(例如目标特征间的时间依赖关系、目标变化模式)。我们通过学习得到的更新器以数据驱动方式捕捉这些结构。2) 在功能层面,学习得到的更新器可视为基于EMA(指数移动平均)更新的可学习扩展。不同之处在于,我们采用门控机制而非线性插值最后一个目标模型与当前候选目标模型。因此,学习得到的更新器继承了基于EMA更新的效率与基于学习方法的有效性。3) 实证表明,如图4所示,在分类损失和锚点损失训练后,我们的学习更新器能够可靠吸收目标变化同时抵抗干扰物。
As a first attempt, however, there are still many interesting problems left un investigated. One issue of RNN-based updater is that, the convolutional GRU requires large amount of GPU memory during offline training and thus being difficult to apply to target models with large numbers of parameters. How to scale to large target models would be an interesting research problem. Moreover, in this work, only linear target models are considered, how to extend to the non-linear cases such as MDNet is valuable future work.
然而作为首次尝试,仍有许多有趣的问题尚未研究。基于RNN的更新器存在一个问题:卷积GRU在离线训练期间需要消耗大量GPU内存,因此难以应用于参数众多的目标模型。如何扩展到大型目标模型将是个值得研究的问题。此外,本研究仅考虑了线性目标模型,如何扩展到如MDNet等非线性案例是具有价值的未来研究方向。
VII. CONCLUSION
VII. 结论
We propose a learning based framework to tackle the problem of model update during tracking. As a first attempt, only the update of linear target model is considered. The learned updater is parameterized based on RNN and successfully learned with several techniques proposed in this work. Our learned updater outperforms two common model update baselines including the efficient EMA-based update and the well-designed SGD-based update. After offline training, our learned updater can run efficiently during testing; therefore, our learned updater is able to consistently improve the base trackers without sacrificing the speed. Notably, the SiamFC tracker has been improved by nearly $40%$ in terms of the EAO on VOT-2017 while running at the speed of 82fps, which achieves state-of-the-art performance among realtime counterparts. In the future, we plan to extend the learning to update paradigm to non-linear target models.
我们提出了一种基于学习的框架来解决跟踪过程中的模型更新问题。作为首次尝试,本研究仅考虑线性目标模型的更新。通过学习型更新器基于RNN进行参数化,并借助本文提出的多项技术成功实现训练。我们的学习型更新器在性能上超越了两种常见基线方法——高效的基于指数移动平均(EMA)的更新和精心设计的基于随机梯度下降(SGD)的更新。经过离线训练后,该更新器在测试阶段能高效运行,因此可在不损失速度的前提下持续提升基础跟踪器的性能。值得注意的是,SiamFC跟踪器在VOT-2017上的EAO指标提升了近$40%$,同时保持82帧/秒的运行速度,在实时跟踪器中达到最先进水平。未来我们计划将这种学习型更新范式拓展至非线性目标模型。

Fig. 4: Qualitative results of our learned updater compared with common model update baselines. Bolt: Our learned updater correctly adapts to the target while others are attracted by distract or s. SGD-based update method adapts to part of the target instead. CarScale: Other methods keep tracking part of the target since only the front of the car is shown in the first frame. Contrarily, our learned updater gradually adapts to the whole target including both the front and the tail of the car. Matrix: our learned updater is able to perform equally well compared with the SGD-based update in this challenging sequence. Suv, Woman: While all other methods fail, our learned updater still successfully tracks the target.
图 4: 我们学习的更新器与常见模型更新基线的定性对比结果。Bolt: 我们的学习更新器能正确适应目标,而其他方法被干扰物吸引。基于SGD的更新方法仅适应了目标部分区域。CarScale: 由于首帧仅显示车头,其他方法持续跟踪局部目标。相比之下,我们的学习更新器逐步适应了包含车头和车尾的完整目标。Matrix: 在这个挑战性序列中,我们的学习更新器与基于SGD的更新表现相当。Suv, Woman: 当其他方法全部失效时,我们的学习更新器仍能成功跟踪目标。
ACKNOWLEDGMENT
致谢
This work was supported in part by National Natural Science Foundation of China (grant No. 61733007, 61572207).
本工作部分得到国家自然科学基金(资助号 61733007, 61572207)的支持。
The authors would like to thank Chong Luo and Anfeng He for helpful discussions.
作者感谢Chong Luo和Anfeng He的有益讨论。
REFERENCES
参考文献
Bi Li received the B.Sc. degree from Huazhong University of Science and Technology (HUST), Wuhan, China, in 2014, and is currently a Ph.D. student at the media and communication lab, HUST, supervised by Prof. Wenyu Liu. His research interests include meta-learning, few-shot learning and object tracking.
毕力于2014年获得中国武汉华中科技大学(HUST)学士学位,现为华中科技大学媒体与通信实验室博士研究生,师从刘文予教授。研究方向包括元学习(meta-learning)、少样本学习(few-shot learning)和目标跟踪(object tracking)。


Wenxuan Xie received the B.Sc. degree from Nanjing University, Nanjing, China, in 2010, and the Ph.D. degree from Peking University, Beijing, China, in 2015. He has been working as an associate researcher in Microsoft Research Asia since 2015. His research interests include computer vision and machine learning.
谢文轩于2010年获得中国南京大学理学学士学位,2015年获得中国北京大学博士学位。自2015年起,他一直担任微软亚洲研究院副研究员。他的研究方向包括计算机视觉和机器学习。

Wenjun (Kevin) Zeng (M’97-SM’03-F’12) is a Principal Research Manager and a member of the senior leadership team (SLT) of Microsoft Research Asia. He has been leading the video analytics research empowering the Microsoft Cognitive Services and Azure Media Analytics Services since 2014. He was with Univ. of Missouri (MU) from 2003 to 2016, most recently as a Full Professor. Prior to that, he had worked for Packet Video Corp., Sharp Labs of America, Bell Labs, and Panasonic Technology. Wenjun has contributed significantly to the development of international standards (ISO MPEG, JPEG2000, and OMA). He received his B.E., M.S., and Ph.D. degrees from Tsinghua Univ., the Univ. of Notre Dame, and Princeton Univ., respectively. His current research interest includes mobile-cloud media computing, computer vision, social network/media analysis, and multimedia communications and security.
Wenjun (Kevin) Zeng (M'97-SM'03-F'12) 是微软亚洲研究院 (Microsoft Research Asia) 的首席研究经理及高层领导团队 (SLT) 成员。自2014年起,他一直领导视频分析研究,为微软认知服务 (Microsoft Cognitive Services) 和 Azure 媒体分析服务 (Azure Media Analytics Services) 提供技术支持。2003年至2016年,他任职于密苏里大学 (University of Missouri),离任前为正教授。此前,他曾在 Packet Video 公司、美国夏普实验室 (Sharp Labs of America)、贝尔实验室 (Bell Labs) 和松下技术公司 (Panasonic Technology) 工作。Wenjun 在国际标准 (ISO MPEG、JPEG2000 和 OMA) 的制定中做出了重要贡献。他先后获得清华大学学士学位、圣母大学硕士学位和普林斯顿大学博士学位。他目前的研究方向包括移动云媒体计算、计算机视觉、社交网络/媒体分析以及多媒体通信与安全。
He was an Associate Editor-in-Chief of IEEE Multimedia Magazine, and was an AE of IEEE Trans. on Circuits & Systems for Video Technology (TCSVT), IEEE Trans. on Info. Forensics & Security, and IEEE Trans. on Multimedia (TMM). He was a Special Issue Guest Editor for the Proceedings of the IEEE, TMM, ACM TOMCCAP, TCSVT, and IEEE Communications Magazine. He was on the Steering Committee of IEEE Trans. on Mobile Computing and IEEE TMM. He served as the Steering Committee Chair of IEEE ICME in 2010 and 2011, and is serving or has served as the General Chair or TPC Chair for several IEEE conferences (e.g., ICME’2018, ICIP’2017). He was the recipient of several best paper awards. He is a Fellow of the IEEE.
他曾担任《IEEE多媒体杂志》副主编,以及《IEEE电路与系统视频技术汇刊》(TCSVT)、《IEEE信息取证与安全汇刊》和《IEEE多媒体汇刊》(TMM)的副编辑。他曾担任《IEEE会刊》、TMM、《ACM多媒体计算、通信与应用汇刊》、TCSVT和《IEEE通信杂志》的特刊客座编辑。他是《IEEE移动计算汇刊》和IEEE TMM的指导委员会成员。2010年和2011年,他担任IEEE ICME指导委员会主席,并曾担任多个IEEE会议(如ICME'2018、ICIP'2017)的大会主席或技术程序委员会主席。他曾获得多项最佳论文奖。他是IEEE会士。

Wenyu Liu (M’08-SM’15) received the B.S. degree in Computer Science from Tsinghua University, Beijing, China, in 1986, and the M.S. and Ph.D. degrees, both in Electronics and Information Engineering, from Huazhong University of Science & Technology (HUST), Wuhan, China, in 1991 and 2001, respectively. He is now a professor and associate dean of the School of Electronic Information and Communications, HUST. His current research areas include computer vision, multimedia, and machine learning. He is a senior member of IEEE.
刘文予 (M'08-SM'15) 于1986年获得中国北京清华大学计算机科学学士学位,1991年和2001年分别获得中国武汉华中科技大学 (HUST) 电子与信息工程硕士和博士学位。现任华中科技大学电子信息与通信学院教授、副院长。主要研究方向包括计算机视觉、多媒体和机器学习。他是IEEE高级会员。