On the Benefits of 3D Pose and Tracking for Human Action Recognition
论3D姿态与追踪对人体动作识别的益处
Abstract
摘要
In this work we study the benefits of using tracking and 3D poses for action recognition. To achieve this, we take the Lagrangian view on analysing actions over a trajectory of human motion rather than at a fixed point in space. Taking this stand allows us to use the tracklets of people to predict their actions. In this spirit, first we show the benefits of using 3D pose to infer actions, and study person-person interactions. Subsequently, we propose a Lagrangian Action Recognition model by fusing 3D pose and contextual i zed appearance over tracklets. To this end, our method achieves state-of-the-art performance on the AVA $\nu2.2$ dataset on both pose only settings and on standard benchmark settings. When reasoning about the action using only pose cues, our pose model achieves $+I0.0m A P$ gain over the corresponding state-of-the-art while our fused model has a gain of $\mathbf{\Phi}_{+2.8}$ mAP over the best state-of-the-art model. Our best model achieves 45.1 mAP on AVA 2.2 dataset. Code and results are available at: https://brjathu.github.io/LART
在本研究中,我们探讨了利用追踪技术和3D姿态进行动作识别的优势。为此,我们采用拉格朗日视角来分析人体运动轨迹上的动作,而非空间中的固定点。这一立场使我们能够利用人员轨迹片段来预测其行为。基于此理念,我们首先展示了使用3D姿态推断动作的益处,并研究了人与人之间的互动。随后,我们提出了一种拉格朗日动作识别模型,通过融合3D姿态和轨迹片段上的上下文外观信息。最终,我们的方法在AVA $\nu2.2$数据集上,无论是仅使用姿态的设置还是标准基准测试设置,均取得了最先进的性能。当仅使用姿态线索进行动作推理时,我们的姿态模型比当前最优技术实现了$+I0.0m A P$的提升,而融合模型比最佳现有模型提升了$\mathbf{\Phi}_{+2.8}$ mAP。我们的最佳模型在AVA 2.2数据集上达到了45.1 mAP。代码和结果详见:https://brjathu.github.io/LART
1. Introduction
1. 引言
In fluid mechanics, it is traditional to distinguish between the Lagrangian and Eulerian specifications of the flow field. Quoting the Wikipedia entry, “Lagrangian specification of the flow field is a way of looking at fluid motion where the observer follows an individual fluid parcel as it moves through space and time. Plotting the position of an individual parcel through time gives the pathline of the parcel. This can be visualized as sitting in a boat and drifting down a river. The Eulerian specification of the flow field is a way of looking at fluid motion that focuses on specific locations in the space through which the fluid flows as time passes. This can be visualized by sitting on the bank of a river and watching the water pass the fixed location.”
在流体力学中,传统上会区分流场的拉格朗日描述(Lagrangian specification)和欧拉描述(Eulerian specification)。引用维基百科的定义:"拉格朗日描述是一种观察流体运动的方式,观察者跟随单个流体微团在时空中的运动轨迹。绘制单个微团随时间变化的位置就得到了该微团的迹线(pathline)。可以想象成坐在小船中随河流漂移的情景。欧拉描述则是关注流体流经空间特定位置的运动情况,可以类比为坐在河岸上观察水流经过固定位置。"
These concepts are very relevant to how we analyze videos of human activity. In the Eulerian viewpoint, we would focus on feature vectors at particular locations, either $(x,y)$ or $(x,y,z)$ , and consider evolution over time while staying fixed in space at the location. In the Lagrangian viewpoint, we would track, say a person over space-time and track the associated feature vector across space-time.
这些概念与我们分析人类活动视频的方式密切相关。在欧拉视角 (Eulerian viewpoint) 下,我们会关注特定位置 $(x,y)$ 或 $(x,y,z)$ 处的特征向量,并考虑在空间位置固定的情况下随时间的变化。而在拉格朗日视角 (Lagrangian viewpoint) 下,我们会追踪一个人在时空中的运动,并跟踪与之相关的特征向量在时空中的变化。
While the older literature for activity recognition e.g., [13, 21, 61] typically adopted the Lagrangian viewpoint, ever since the advent of neural networks based on 3D spacetime convolution, e.g., [58], the Eulerian viewpoint became standard in state-of-the-art approaches such as SlowFast Networks [18]. Even after the switch to transformer architectures [14, 60] the Eulerian viewpoint has persisted. This is noteworthy because the token iz ation step for transformers gives us an opportunity to freshly examine the question, “What should be the counterparts of words in video analysis?”. Do sov it ski y et al. [12] suggested that image patches were a good choice, and the continuation of that idea to video suggests that s patio temporal cuboids would work for video as well.
虽然早期的行为识别研究[13, 21, 61]通常采用拉格朗日视角,但自基于3D时空卷积的神经网络[58]出现后,欧拉视角便成为SlowFast Networks[18]等前沿方法的标准范式。即便在转向Transformer架构[14, 60]后,欧拉视角仍然延续使用。这一现象值得关注,因为Transformer的token化步骤为我们重新审视"视频分析中词语的对应物应该是什么"提供了契机。Do sov it ski y等人[12]提出图像块是理想选择,该思路延伸至视频领域则表明时空立方体同样适用。
On the contrary, in this work we take the Lagrangian viewpoint for analysing human actions. This specifies that we reason about the trajectory of an entity over time. Here, the entity can be low-level, e.g., a pixel or a patch, or highlevel, e.g., a person. Since, we are interested in understanding human actions, we choose to operate on the level of “humans-as-entities”. To this end, we develop a method that processes trajectories of people in video and uses them to recognize their action. We recover these trajectories by capitalizing on a recently introduced 3D tracking method PHALP [50] and HMR 2.0 [22]. As shown in Figure 1 PHALP recovers person tracklets from video by lifting people to 3D, which means that we can both link people over a series of frames and get access to their 3D representation. Given these 3D representations of people (i.e., 3D pose and 3D location), we use them as the basic content of each token. This allows us to build a flexible system where the model, here a transformer, takes as input tokens corresponding to the different people with access to their identity, 3D pose and 3D location. Having 3D location of the people in the scene allow us to learn interaction among people. Our model relying on this token iz ation can benefit from 3D tracking and pose, and outperforms previous baseline that only have access to pose information [9, 53].
相反,在本工作中我们采用拉格朗日视角来分析人类行为。这意味着我们关注实体随时间变化的轨迹。这里的实体可以是低层级的(如像素或图像块),也可以是高层级的(如人)。由于我们的目标是理解人类行为,因此选择在"以人为实体"的层级上展开研究。为此,我们开发了一种方法,通过处理视频中的人物轨迹来识别其行为。这些轨迹的获取依托于最新提出的3D追踪方法PHALP [50]和HMR 2.0 [22]。如图1所示,PHALP通过将人物提升至3D空间来从视频中恢复人物轨迹片段,这意味着我们既能跨帧关联人物,又能获取其3D表征。基于这些3D人物表征(即3D姿态和3D位置),我们将其作为每个token的基本内容。由此构建的灵活系统中,Transformer模型接收的输入token对应不同人物,并包含其身份、3D姿态和3D位置信息。掌握场景中人物的3D位置使我们能够学习人物间的交互。得益于这种token化设计和3D追踪姿态信息,我们的模型表现优于仅能获取姿态信息的基线方法[9, 53]。
While the change in human pose over time is a strong signal, some actions require more contextual information about the appearance and the scene. Therefore, it is important to also fuse pose with appearance information from humans and the scene, coming directly from pixels. To achieve this, we also use the state-of-the-art models for action recognition [14, 39] to provide complementary infor- mation from the contextual i zed appearance of the humans and the scene in a Lagrangian framework. Specifically, we densely run such models over the trajectory of each tracklet and record the contextual i zed appearance features localized around the tracklet. As a result, our tokens include explicit information about the 3D pose of the people and densely sampled appearance information from the pixels, processed by action recognition backbones [14]. Our complete system outperforms the previous state of the art by a large margin of $2.8\mathbf{mAP}$ , on the challenging AVA v2.2 dataset.
虽然人体姿态随时间的变化是一个强信号,但某些动作需要更多关于外观和场景的上下文信息。因此,将姿态与直接从像素获取的人体和场景外观信息相融合至关重要。为此,我们采用最先进的动作识别模型 [14, 39],在拉格朗日框架下提供人体与场景上下文外观的互补信息。具体而言,我们在每个轨迹片段上密集运行此类模型,并记录轨迹片段周围定位的上下文外观特征。最终,我们的 token 包含人体 3D 姿态的显式信息,以及通过动作识别骨干网络 [14] 处理的像素密集采样外观信息。在极具挑战性的 AVA v2.2 数据集上,我们的完整系统以 $2.8\mathbf{mAP}$ 的显著优势超越了此前的最先进水平。
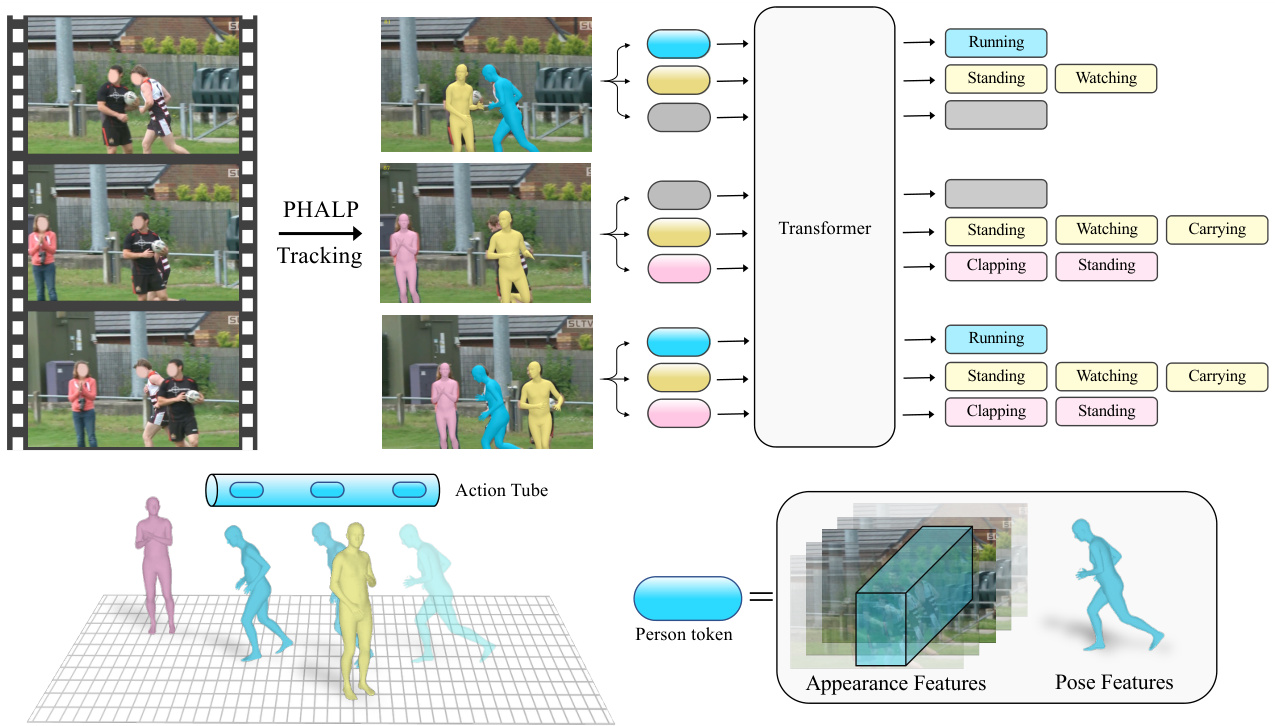
Figure 1. Overview of our method: Given a video, first, we track every person using a tracking algorithm (e.g. PHALP [50]). Then every detection in the track is tokenized to represent a human-centric vector (e.g. pose, appearance). To represent 3D pose we use SMPL [40] parameters and estimated 3D location of the person, for contextual i zed appearance we use MViT [14] (pre-trained on MaskFeat [66]) features. Then we train a transformer network to predict actions using the tracks. Note that, at the second frame we do not have detection for the blue person , at these places we pass a mask token to in-fill the missing detections.
图 1: 方法概述:给定视频后,首先使用跟踪算法(如 PHALP [50])追踪每个人物。随后将轨迹中的每个检测结果转换为表示以人为中心的向量(如姿态、外观)。对于三维姿态表示,我们采用 SMPL [40] 参数和估计的人物三维位置;对于情境化外观,则使用基于 MaskFeat [66] 预训练的 MViT [14] 特征。接着训练一个 Transformer 网络来根据轨迹预测动作。需注意,在第二帧时蓝色人物未被检测到,这些位置会传入掩码 token 来填补缺失的检测。
Overall, our main contribution is introducing an approach that highlights the effects of tracking and 3D poses for human action understanding. To this end, in this work, we propose a Lagrangian Action Recognition with Tracking (LART) approach, which utilizes the tracklets of people to predict their action. Our baseline version leverages tracklet trajectories and 3D pose representations of the people in the video to outperform previous baselines utilizing pose information. Moreover, we demonstrate that the proposed Lagrangian viewpoint of action recognition can be easily combined with traditional baselines that rely only on appearance and context from the video, achieving significant gains compared to the dominant paradigm.
总体而言,我们的主要贡献是提出了一种强调追踪和3D姿态对人体动作理解影响的方法。为此,我们提出了一种基于追踪的拉格朗日动作识别方法(LART),该方法利用人物轨迹片段来预测其动作。我们的基线版本通过结合视频中人物的轨迹片段和3D姿态表征,超越了以往仅使用姿态信息的基线方法。此外,我们证明了所提出的拉格朗日动作识别视角能够轻松与传统仅依赖视频外观和上下文的基线方法相结合,相比主流范式取得了显著提升。
2. Related Work
2. 相关工作
Recovering humans in 3D: A lot of the related work has been using the SMPL human body model [40] for recovering 3D humans from images. Initially, the related methods were relying on optimization-based approaches, like SMPLify [6], but since the introduction of the HMR [28], there has been a lot of interest in approaches that can directly regress SMPL parameters [40] given the corresponding image of the person as input. Many follow-up works have improved upon the original model, estimating more accurate pose [36] or shape [8], increasing the robustness of the model [47], incorporating side information [35,37], investigating different architecture choices [34, 72], etc.
三维人体重建:大量相关工作采用SMPL人体模型[40]从图像中恢复三维人体。早期方法主要依赖基于优化的方案,如SMPLify[6],但自HMR[28]提出后,学界开始关注能直接回归SMPL参数[40]的端到端方法(输入为人像图像)。后续研究从多角度改进原始模型:提升姿态估计精度[36]和体型拟合准确度[8],增强模型鲁棒性[47],融合辅助信息[35,37],探索不同架构设计[34,72]等。
While these works have been improving the basic singleframe reconstruction performance, there have been parallel efforts toward the temporal reconstruction of humans from video input. The HMMR model [29] uses a convolutional temporal encoder on HMR image features [28] to recon- struct humans over time. Other approaches have investigated recurrent [33] or transformer [47] encoders. Instead of performing the temporal pooling on image features, recent work has been using the SMPL parameters directly for the temporal encoding [3, 51].
虽然这些工作一直在提升单帧重建的基础性能,但同时也存在针对视频输入进行时序人体重建的并行研究。HMMR模型[29]在HMR图像特征[28]上使用卷积时序编码器来实现跨时间的人体重建。其他方法探索了循环网络[33]或Transformer编码器[47]。与在图像特征上进行时序池化不同,近期研究开始直接使用SMPL参数进行时序编码[3, 51]。
One assumption of the temporal methods in the above category is that they have access to tracklets of people in the video. This means that they rely on tracking methods, most of which operate on the 2D domain [4, 15, 43, 70] and are responsible for introducing many errors. To overcome this limitation, recent work [49, 50] has capitalized on the advances of 3D human recovery to perform more robust identity tracking from video. More specifically, the PHALP method of Raja sega ran et al. [50] allows for robust tracking in a variety of settings, including in the wild videos and movies. Here, we make use of the PHALP system to discover long tracklets from large-scale video datasets. This allows us to train our method for recognizing actions from 3D pose input.
上述时间方法的一个假设是它们能够获取视频中人物的轨迹片段。这意味着它们依赖于跟踪方法,而大多数跟踪方法在二维领域运行 [4, 15, 43, 70],并会引入大量误差。为了克服这一限制,近期研究 [49, 50] 利用三维人体恢复技术的进展,实现了更鲁棒的视频身份跟踪。具体而言,Raja segaran 等人提出的 PHALP 方法 [50] 能够在多种场景(包括野外视频和电影)中实现鲁棒跟踪。本文利用 PHALP 系统从大规模视频数据集中提取长轨迹片段,从而训练我们的方法从三维姿态输入中识别动作。
Action Recognition: Earlier works on action recognition relied on hand-crafted features such as HOG3D [32], Cuboids [11] and Dense Trajectories [61, 62]. After the introduction of deep learning, 3D convolutional networks became the main backbone for action recognition [7, 56, 58]. However, the 3D convolutional models treat both space and time in a similar fashion, so to overcome this issue, twostream architectures were proposed [54]. In two-steam networks, one pathway is dedicated to motion features, usually taking optical flow as input. This requirement of computing optical flow makes it hard to learn these models in an endto-end manner. On the other hand, SlowFast networks [18] only use video streams but at different frame rates, allowing it to learn motion features from the fast pathway and lateral connections to fuse spatial and temporal information. Recently, with the advancements in transformer architectures, there has been a lot of work on action recognition using transformer backbones [1, 5, 14, 44].
动作识别:早期的动作识别研究依赖于手工设计的特征,如HOG3D [32]、Cuboids [11]和Dense Trajectories [61, 62]。随着深度学习的引入,3D卷积网络成为动作识别的主要骨干架构 [7, 56, 58]。然而,3D卷积模型以相似方式处理空间和时间维度,为此研究者提出了双流架构 [54]来解决这一问题。在双流网络中,一个分支专门处理运动特征(通常以光流作为输入),但这种需要计算光流的设计使得模型难以端到端训练。另一方面,SlowFast网络 [18]仅使用不同帧率的视频流,通过快速路径学习运动特征,并利用横向连接融合时空信息。近年来,随着Transformer架构的发展,出现了大量基于Transformer骨干的动作识别研究 [1, 5, 14, 44]。
While the above-mentioned works mainly focus on the model architectures for action recognition, another line of work investigates more fine-grained relationships between actors and objects [55, 63, 64, 73]. Non-local networks [63] use self-attention to reason about entities in the video and learn long-range relationships. ACAR [45] models actorcontext-actor relationships by first extracting actor-context features through pooling in bounding box region and then learning higher-level relationships between actors. Compared to ACAR, our method does not explicitly design any priors about actor relationships, except their track identity.
虽然上述工作主要关注动作识别的模型架构,但另一研究方向则探究演员与物体之间更细粒度的关系 [55, 63, 64, 73]。Non-local网络 [63] 利用自注意力机制对视频中的实体进行推理并学习长程关系。ACAR [45] 通过先在边界框区域进行池化提取演员-上下文特征,再学习演员间更高层次的关系,从而建模演员-上下文-演员关系。与ACAR相比,我们的方法除了跟踪身份外,并未显式设计任何关于演员关系的先验。
Along these lines, some works use the human pose to understand the action [9, 53, 59, 67, 71]. PoTion [9] uses a keypoint-based pose representation by colorizing the temporal dependencies. Recently, JMRN [53] proposed a jointmotion re-weighting network to learn joint trajectories separately and then fuse this information to reason about interjoint motion. While these works rely on 2D key points and design-specific architectures to encode the representation, we use more explicit 3D SMPL parameters.
沿着这一思路,部分研究利用人体姿态理解动作 [9, 53, 59, 67, 71]。PoTion [9] 通过着色时间依赖性,使用基于关键点的姿态表示。近期,JMRN [53] 提出关节运动重加权网络,先独立学习关节轨迹再融合信息以推断关节间运动。这些方法依赖 2D 关键点并设计特定架构进行表征编码,而我们采用更显式的 3D SMPL 参数。
3. Method
3. 方法
Understanding human action requires interpreting multiple sources of information [31]. These include head and gaze direction, human body pose and dynamics, interactions with objects or other humans or animals, the scene as a whole, the activity context (e.g. immediately preceding actions by self or others), and more. Some actions can be recognized by pose and pose dynamics alone, as demonstrated by Johansson et al [27] who showed that people are remarkable at recognizing walking, running, crawling just by looking at moving point-lights. However, interpreting complex actions requires reasoning with multiple sources of information e.g. to recognize that someone is slicing a tomato with a knife, it helps to see the knife and the tomato.
理解人类行为需要解读多种信息来源 [31]。这些信息包括头部和视线方向、人体姿态与动态、与物体或其他人类及动物的互动、整体场景、活动背景(例如自身或他人刚执行的动作)等。部分动作仅通过姿态和姿态动态即可识别,正如Johansson等人 [27] 所展示的:人们仅通过观察移动的光点就能出色地识别行走、奔跑、爬行动作。然而,理解复杂行为需要综合多源信息进行推理,例如要识别某人正在用刀切番茄,观察到刀具和番茄会显著提升识别效果。
There are many design choices that can be made here. Should one use “disentangled” representations, with elements such as pose, interacted objects, etc, represented explicitly in a modular way? Or should one just input video pixels into a large capacity neural network model and rely on it to figure out what is disc rim i natively useful? In this paper, we study two options: a) human pose reconstructed from an HMR model [22, 28] and b) human pose with contextual appearance as computed by an MViT model [14].
这里有许多设计选择可供考虑。是应该使用"解耦"表示,将姿态、交互对象等元素以模块化方式显式表示?还是应该直接将视频像素输入到大容量神经网络模型中,依赖其自行判别有用信息?本文研究了两种方案:a) 通过HMR模型[22,28]重建的人体姿态;b) 通过MViT模型[14]计算的带有上下文外观信息的人体姿态。
Given a video with number of frames $T$ , we first track every person using PHALP [50], which gives us a unique identity for each person over time. Let a person $i\in\L_{\zeta}$ $[1,2,3,...n]$ at time $t\in[1,2,3,...T]$ be represented by a person-vector $\mathbf{H}{t}^{i}$ . Here $n$ is the number of people in a frame. This person-vector is constructed such that, it contains human-centric representation $\mathbf{P}{t}^{i}$ and some contextualized appearance information $\mathbf{Q}_{t}$ .
给定一个包含 $T$ 帧的视频,我们首先使用 PHALP [50] 对每个人进行追踪,从而为每个人赋予随时间推移的唯一身份标识。设在时间 $t\in[1,2,3,...T]$ 时,人物 $i\in\L_{\zeta}$ $[1,2,3,...n]$ 由人物向量 $\mathbf{H}{t}^{i}$ 表示,其中 $n$ 为单帧中的人物数量。该人物向量的构建包含以人为中心的表征 $\mathbf{P}{t}^{i}$ 和部分上下文外观信息 $\mathbf{Q}_{t}$。
$$
{\bf H}{t}^{i}={{\bf P}{t}^{i},{\bf Q}_{t}^{i}}.
$$
$$
{\bf H}{t}^{i}={{\bf P}{t}^{i},{\bf Q}_{t}^{i}}.
$$
Since we know the identity of each person from the tracking, we can create an action-tube [21] representation for each person. Let $\Phi_{i}$ be the action-tube of person $i$ , then this action-tube contains all the person-vectors over time.
由于我们可以通过追踪获知每个人的身份,因此可以为每个人创建动作管 (action-tube) [21] 表示。设 $\Phi_{i}$ 为人物 $i$ 的动作管,则该动作管包含该人物随时间变化的所有人物向量。
$$
\Phi_{i}={{\bf H}{1}^{i},{\bf H}{2}^{i},{\bf H}{3}^{i},...,{\bf H}_{T}^{i}}.
$$
$$
\Phi_{i}={{\bf H}{1}^{i},{\bf H}{2}^{i},{\bf H}{3}^{i},...,{\bf H}_{T}^{i}}.
$$
Given this representation, we train our model LART to predict actions from action-tubes (tracks). In this work we use a vanilla transformer [60] to model the network $\mathcal{F}$ , and this allow us to mask attention, if the track is not continuous due to occlusions and failed detections etc. Please see the Appendix for more details on network architecture.
基于这一表征,我们训练模型LART从动作管(轨迹)中预测动作。本文采用标准Transformer [60]来建模网络$\mathcal{F}$,当轨迹因遮挡或检测失败等原因不连续时,该架构支持掩码注意力机制。网络架构详情请参阅附录。
$$
\mathcal{F}\big(\Phi_{1},\Phi_{2},...,\Phi_{i},...,\Phi_{n};\Theta\big)=\widehat{Y}_{i}.
$$
$$
\mathcal{F}\big(\Phi_{1},\Phi_{2},...,\Phi_{i},...,\Phi_{n};\Theta\big)=\widehat{Y}_{i}.
$$
Here, $\Theta$ is the model parameters, $\widehat{Y_{i}}={y_{1}^{i},y_{2}^{i},y_{3}^{i},...,y_{T}^{i}}$ is the predictions for a track, and $\boldsymbol y_{t}^{i}$ ibs the predicted action of the track $i$ at time $t$ . The model can use the actions of others for reasoning when predicting the action for the person-ofinterest $i$ . Finally, we use binary cross-entropy loss to train our model and measure mean Average Precision (mAP) for evaluation.
这里,$\Theta$ 是模型参数,$\widehat{Y_{i}}={y_{1}^{i},y_{2}^{i},y_{3}^{i},...,y_{T}^{i}}$ 是对某条轨迹的预测,$\boldsymbol y_{t}^{i}$ 是轨迹 $i$ 在时间 $t$ 的预测动作。模型在预测目标人物 $i$ 的动作时,可以利用其他人的动作进行推理。最后,我们使用二元交叉熵损失训练模型,并采用平均精度均值 (mAP) 作为评估指标。
3.1. Action Recognition with 3D Pose
3.1. 基于3D姿态的动作识别
In this section, we study the effect of human-centric pose representation on action recognition. To do that, we consider a person-vector that only contains the pose representation, $\mathbf{H}{t}^{i}={\mathbf{P}{t}^{i}}$ . While, $\mathbf{P}{t}^{i}$ can in general contain any information about the person, in this work train a pose only model LART-pose which uses 3D body pose of the person based on the SMPL [40] model. This includes the joint angles of the different body parts, $\theta_{t}^{i}\in\mathcal{R}^{23\times3\times3}$ and is considered as an amodal representation, which means we make a prediction about all body parts, even those that are potentially occluded/truncated in the image. Since the global body orientation $\psi_{t}^{i}\in\mathcal{R}^{3\times3}$ is represented separately from the body pose, our body representation is invariant to the specific viewpoint of the video. In addition to the 3D pose, we also use the 3D location $L_{t}^{i}$ of the person in the camera view (which is also predicted by the PHALP model [50]). This makes it possible to consider the relative location of the different people in 3D. More specifically, each person is represented as,
在本节中,我们研究了以人为中心的姿态表示对动作识别的影响。为此,我们考虑仅包含姿态表示的人体向量 $\mathbf{H}{t}^{i}={\mathbf{P}{t}^{i}}$ 。虽然 $\mathbf{P}{t}^{i}$ 通常可以包含关于人体的任何信息,但本工作中我们训练了一个仅使用基于SMPL [40]模型的人体3D姿态的模型LART-pose。这包括不同身体部位的关节角度 $\theta_{t}^{i}\in\mathcal{R}^{23\times3\times3}$ ,并被视为一种非模态表示,意味着我们对所有身体部位进行预测,即使那些可能在图像中被遮挡/截断的部分。由于全局身体朝向 $\psi_{t}^{i}\in\mathcal{R}^{3\times3}$ 是与身体姿态分开表示的,我们的身体表示对视频的特定视角具有不变性。除了3D姿态外,我们还使用了人在相机视图中的3D位置 $L_{t}^{i}$ (这也是由PHALP模型 [50] 预测的)。这使得考虑不同人在3D空间中的相对位置成为可能。更具体地说,每个人被表示为:
$$
\mathbf{H}{t}^{i}=\mathbf{P}{t}^{i}={\theta_{t}^{i},\psi_{t}^{i},L_{t}^{i}}.
$$
$$
\mathbf{H}{t}^{i}=\mathbf{P}{t}^{i}={\theta_{t}^{i},\psi_{t}^{i},L_{t}^{i}}.
$$
Let us assume that there are $n$ tracklets ${\pmb{\Phi}{1},\pmb{\Phi}{2},\pmb{\Phi}{3},...,\pmb{\Phi}{n}}$ in a given video. To study the action of the tracklet $i$ , we consider that person $i$ as the person-of-interest and having access to other tracklets can be helpful to interpret the person-person interactions for person $i$ . Therefore, to predict the action for all $n$ tracklets we need to make $n$ number of forward passes. If person $i$ is the person-of-interest, then we randomly sample $N-1$ number of other tracklets and pass it to the model $\mathcal{F}(;\Theta)$ along with the $\Phi_{i}$ .
假设给定视频中有 $n$ 个轨迹片段 ${\pmb{\Phi}{1},\pmb{\Phi}{2},\pmb{\Phi}{3},...,\pmb{\Phi}{n}}$。为了研究轨迹片段 $i$ 的行为,我们将人物 $i$ 视为目标人物,并认为访问其他轨迹片段有助于解释人物 $i$ 的人际交互。因此,要预测所有 $n$ 个轨迹片段的动作,我们需要进行 $n$ 次前向传播。若人物 $i$ 是目标人物,则随机采样 $N-1$ 个其他轨迹片段,将其与 $\Phi_{i}$ 一同输入模型 $\mathcal{F}(;\Theta)$。
$$
\mathcal{F}(\Phi_{i},{\Phi_{j}|j\in[N]};\Theta)=\widehat{Y}_{i}
$$
$$
\mathcal{F}(\Phi_{i},{\Phi_{j}|j\in[N]};\Theta)=\widehat{Y}_{i}
$$
Therefore, the model sees $N$ number of tracklets and predicts the action for the main (person-of-interest) track. To do this, we first tokenize all the person-vectors, by passing them through a linear layer and project it in $f_{p r o j}(\mathcal{H}_{t}^{i})\in$ $\mathcal{R}^{d}$ a $d$ dimensional space. Afterward, we add positional embeddings for a) time, b) tracklet-id. For time and tracklet-id we use 2D sine and cosine functions as positional encoding [65], by assigning person $i$ as the zeroth track, and the rest of the tracklets use tracklet-ids ${1,2,3,...,N-1}$ .
因此,模型会看到 $N$ 个轨迹段并预测主要(关注人物)轨迹的动作。为此,我们首先通过线性层对所有人物向量进行 Token 化,并将其投影到 $f_{proj}(\mathcal{H}_{t}^{i})\in$ $\mathcal{R}^{d}$ 的 $d$ 维空间中。随后,我们为以下两项添加位置嵌入:a) 时间,b) 轨迹段 ID。对于时间和轨迹段 ID,我们使用 2D 正弦和余弦函数作为位置编码 [65],将人物 $i$ 指定为第零个轨迹段,其余轨迹段使用轨迹段 ID ${1,2,3,...,N-1}$。
$$
\begin{array}{r}{P E(t,i,2r)=\sin(t/10000^{4r/d})}\ {P E(t,i,2r+1)=\cos(t/10000^{4r/d})}\ {P E(t,i,2s+D/2)=\sin(i/10000^{4s/d})}\ {P E(t,i,2s+D/2+1)=\cos(i/10000^{4s/d})}\end{array}
$$
$$
\begin{array}{r}{P E(t,i,2r)=\sin(t/10000^{4r/d})}\ {P E(t,i,2r+1)=\cos(t/10000^{4r/d})}\ {P E(t,i,2s+D/2)=\sin(i/10000^{4s/d})}\ {P E(t,i,2s+D/2+1)=\cos(i/10000^{4s/d})}\end{array}
$$
Here, $t$ is the time index, $i$ is the track-id, $r,s\in[0,d/2)$ specifies the dimensions and $D$ is the dimensions of the token.
这里,$t$ 是时间索引,$i$ 是轨道ID,$r,s\in[0,d/2)$ 指定维度,$D$ 是 token 的维度。
After adding the position encodings for time and identity, each person token is passed to the transformer network. The $(t+i\times N)^{t h}$ token is given by,
在添加时间和身份的位置编码后,每个人物token被传入transformer网络。第$(t+i\times N)^{t h}$个token由下式给出:
$$
t o k e n_{(t+i\times N)}=f_{p r o j}(\mathcal{H}_{t}^{i})+P E(t,i,:)
$$
$$
t o k e n_{(t+i\times N)}=f_{p r o j}(\mathcal{H}_{t}^{i})+P E(t,i,:)
$$
Our person of interest formulation would allow us to use other actors in the scene to make better predictions for the main actor. When there are multiple actors involved in the scene, knowing one person’s action could help in predicting another’s action. Some actions are correlated among the actors in a scene (e.g. dancing, fighting), while in some cases, people will be performing reciprocal actions (e.g. speaking and listening). In these cases knowing one person’s action would help in predicting the other person’s action with more confidence.
我们关注的人物设定允许利用场景中的其他参与者来为主角做出更准确的预测。当场景中存在多个参与者时,了解一个人的行为有助于预测另一个人的行为。某些行为在场景参与者之间具有关联性(例如跳舞、打斗),而在某些情况下,人们会执行互补行为(例如说话与倾听)。在这些情况下,知晓一个人的行为将有助于更有把握地预测另一个人的行为。
3.2. Actions from Appearance and 3D Pose
3.2. 从外观和3D姿态生成动作
While human pose plays a key role in understanding actions, more complex actions require reasoning about the scene and context. Therefore, in this section, we investigate the benefits of combining pose and contextual appearance features for action recognition and train model LART to benefit from 3D poses and appearance over a trajectory. For every track, we run a 2D action recognition model (i.e. MaskFeat [66] pretrained MViT [14]) at a frequency $f_{s}$ and store the feature vectors before the classification layer. For example, consider a track $\Phi_{i}$ , which has detections ${D_{1}^{i},D_{2}^{i},D_{3}^{i},...,D_{T}^{i}}$ . We get the predictions form the 2D action recognition models, for the detections at ${t,t+f_{F P S}/f_{s},t+2f_{F P S}/f_{s},...}$ . Here, $f_{F P S}$ is the rate at which frames appear on the screen. Since these action recognition models capture temporal information to some extent, $\mathbf{Q}{t-f_{F P S}/2f_{s}}^{i}$ to $\mathbf{Q}{t+f_{F P S}/2f_{s}}^{i}$ share the same appearance features. Let’s assume we have a pre-trained action recognition model $\mathcal{A}$ , and it takes a sequence of frames and a detection bounding box at mid-frame, then the feature vectors for $\mathbf{Q}_{t}^{i}$ is given by:
虽然人体姿态在理解动作中起着关键作用,但更复杂的动作需要对场景和上下文进行推理。因此,在本节中,我们研究了结合姿态和上下文外观特征对动作识别的益处,并训练模型LART以从轨迹中的3D姿态和外观中获益。对于每条轨迹,我们以频率$f_{s}$运行一个2D动作识别模型(即预训练MViT [14] 的MaskFeat [66]),并存储分类层之前的特征向量。例如,考虑一条轨迹$\Phi_{i}$,其检测结果为${D_{1}^{i},D_{2}^{i},D_{3}^{i},...,D_{T}^{i}}$。我们从2D动作识别模型获取在${t,t+f_{F P S}/f_{s},t+2f_{F P S}/f_{s},...}$时刻检测的预测结果。这里,$f_{F P S}$是帧在屏幕上出现的速率。由于这些动作识别模型在一定程度上捕捉了时间信息,$\mathbf{Q}{t-f_{F P S}/2f_{s}}^{i}$到$\mathbf{Q}{t+f_{F P S}/2f_{s}}^{i}$共享相同的外观特征。假设我们有一个预训练的动作识别模型$\mathcal{A}$,它接收一系列帧和中间帧的检测边界框,则$\mathbf{Q}_{t}^{i}$的特征向量由下式给出:
$$
\boldsymbol{\mathcal{A}}\big(\boldsymbol{D}{t}^{i},{\boldsymbol{I}}{t-M}^{t+M}\big)=\mathbf{U}_{t}^{i}
$$
$$
\boldsymbol{\mathcal{A}}\big(\boldsymbol{D}{t}^{i},{\boldsymbol{I}}{t-M}^{t+M}\big)=\mathbf{U}_{t}^{i}
$$
Here, ${I}{t-M}^{t+M}$ is the sequence of image frames, $2M$ is the number of frames seen by the action recognition model, and $\mathbf{U}{t}^{i}$ is the contextual appearance vector. Note that, since the action recognition models look at the whole image frame, this representation implicitly contains information about the scene and objects and movements. However, we argue that human-centric pose representation has orthogonal information compared to feature vectors taken from convolutional or transformer networks. For example, the 3D pose is a geometric representation while $\mathbf{U}{t}^{i}$ is more photometric, the SMPL parameters have more priors about human actions/pose and it is amodal while the appearance representation is learned from raw pixels.
这里,${I}{t-M}^{t+M}$ 是图像帧序列,$2M$ 是动作识别模型观察的帧数,$\mathbf{U}{t}^{i}$ 是上下文外观向量。需要注意的是,由于动作识别模型会观察整个图像帧,这种表示隐含了场景、物体和运动的信息。但我们认为,与从卷积或Transformer网络中提取的特征向量相比,以人为中心的姿态表示具有正交信息。例如,3D姿态是一种几何表示,而$\mathbf{U}{t}^{i}$ 更偏向光测性质;SMPL参数包含更多关于人类动作/姿态的先验信息且是非模态的,而外观表示则是从原始像素中学习得到的。
So, each human is represented by their 3D pose, 3D location, and with their appearance and scene content. We follow the same procedure as discussed in the previous section to add positional encoding and train a transformer network $\mathcal{F}(\Theta)$ with pose+appearance tokens.
因此,每个人物通过其3D姿态、3D位置以及外观和场景内容来表示。我们按照前一节讨论的相同流程,添加位置编码并训练一个带有姿态+外观token的Transformer网络 $\mathcal{F}(\Theta)$。
4. Experiments
4. 实验
We evaluate our method on AVA [23] in various settings. AVA [23] poses an action detection problem, where people are localized in a spatio-temporal volume with action labels. It provides annotations at 1Hz, and each actor will have 1 pose action, up to 3 person-object interactions (optional), and up to 3 person-person interaction (optional) labels. For the evaluations, we use AVA v2.2 annotations and follow the standard protocol as in [23]. We measure mean average precision (mAP) on 60 classes with a frame-level IoU of 0.5. In addition to that, we also evaluate our method on AVA-Kinetics [38] dataset, which provides spatio-temporal localized annotations for Kinetics videos.
我们在 AVA [23] 数据集上以多种设置评估了我们的方法。AVA [23] 提出了一个动作检测问题,即在时空体积中对人物进行定位并标注动作标签。该数据集以 1Hz 频率提供标注,每个角色会有 1 个姿态动作标签、最多 3 个人物-物体交互(可选)标签和最多 3 个人物-人物交互(可选)标签。评估时,我们使用 AVA v2.2 标注并遵循 [23] 中的标准协议。我们在 60 个类别上以帧级 IoU 0.5 计算平均精度均值 (mAP)。此外,我们还在 AVA-Kinetics [38] 数据集上评估了方法,该数据集为 Kinetics 视频提供了时空定位标注。
We use PHALP [50] to track people in the AVA dataset. PHALP falls into the tracking-by-detection paradigm and uses Mask R-CNN [25] for detecting people in the scene. At the training stage, where the bounding box annotations are available only at $1\mathrm{Hz}$ , we use Mask R-CNN detections for the in-between frames and use the ground-truth bounding box for every 30 frames. For validation, we use the bounding boxes used by [45] and do the same strategy to complete the tracking. We ran, PHALP on Kinetics-400 [30] and AVA [23]. Both datasets contain over 1 million tracks with an average length of 3.4s and over 100 million detections. In total, we use about 900 hours length of tracks, which is about $40\mathrm{x}$ more than previous works [29]. See Table 1 for more details.
我们使用PHALP [50]来跟踪AVA数据集中的行人。PHALP采用检测跟踪范式,并利用Mask R-CNN [25]检测场景中的行人。在训练阶段,由于边界框标注仅以$1\mathrm{Hz}$的频率提供,我们对中间帧使用Mask R-CNN的检测结果,并每30帧使用一次真实标注的边界框。在验证阶段,我们采用[45]使用的边界框,并沿用相同策略完成跟踪。我们在Kinetics-400 [30]和AVA [23]数据集上运行了PHALP。这两个数据集包含超过100万条轨迹,平均长度为3.4秒,检测框总数超过1亿个。总计使用了约900小时的轨迹数据,规模达到先前工作[29]的$40\mathrm{x}$倍。更多细节参见表1。
Tracking allows us to train actions densely. Since, we have tokens for each actor at every frame, we can supervise every token by assuming the human action remains the same in a 1 sec window [23]. First, we pre-train our model on Kinetics-400 dataset [30] and AVA [23] dataset. We run MViT [14] (pre-trained on MaskFeat [66]) at $1\mathrm{Hz}$ on every track in Kinetics-400 to generate pseudo groundtruth annotations. Every 30 frames will share the same annotations and we train our model end-to-end with binary cross-entropy loss. Then we fine-tune the pretrained model, with tracks generated by us, on AVA ground-truth action labels. At inference, we take a track, and randomly sample $N-1$ of other tracks from the same video and pass it through the model. We take an average pooling on the prediction head over a sequence of 12 frames, and evaluate at the center-frame. For more details on model architecture, hyper-parameters, and training procedure/trainingtime please see Appendix A1.
追踪机制让我们能够密集训练动作。由于我们在每一帧都有每个角色的token,可以通过假设人类动作在1秒窗口内保持不变来监督每个token [23]。首先,我们在Kinetics-400数据集[30]和AVA数据集[23]上预训练模型。我们在Kinetics-400的每条轨迹上以$1\mathrm{Hz}$频率运行MViT[14](基于MaskFeat[66]预训练)生成伪真实标注。每30帧共享相同标注,并使用二元交叉熵损失端到端训练模型。接着用我们生成的轨迹,在AVA真实动作标签上微调预训练模型。推理时,我们选取一条轨迹,并从同一视频中随机采样$N-1$条其他轨迹输入模型。对12帧序列的预测头进行平均池化,并在中心帧评估。更多关于模型架构、超参数及训练流程/训练时长的细节详见附录A1。
Table 1. Tracking statistics on AVA [23] and Kinetics-400 [30]: We report the number tracks returned by PHALP [50] for each datasets (m: million). This results in over 900 hours of tracks, with a mean length of 3.4 seconds (with overlaps).
表 1: AVA [23] 和 Kinetics-400 [30] 的追踪统计:我们报告了 PHALP [50] 为每个数据集返回的追踪数量 (m: 百万)。这产生了超过 900 小时的追踪数据,平均长度为 3.4 秒 (含重叠)。
| 数据集 | 片段数 | 追踪数 | 边界框数 |
|---|---|---|---|
| AVA [23] | 184k | 320k | 32.9m |
| Kinetics [30] | 217k | 686k | 71.4m |
| 总计 | 400k | 1m | 104.3m |
Table 2. AVA Action Recognition with 3D pose: We evaluate human-centric representation on AVA dataset [23]. Here $O M:$ Object Manipulation, $P I:$ Person Interactions, and $P M$ : Person Movement. LART-posecan achieve about $80%$ performance of MViT models on person movement tasks without looking at scene information.
表 2: 基于3D姿态的AVA行为识别: 我们在AVA数据集[23]上评估了以人为中心的表征方法。其中$OM$表示物体操控 (Object Manipulation), $PI$表示人际交互 (Person Interactions), $PM$表示人体移动 (Person Movement)。在不观察场景信息的情况下,LART-pose在人体移动任务上能达到MViT模型约$80%$的性能。
| 模型 | 姿态 | OM | PI | PM | mAP |
|---|---|---|---|---|---|
| PoTion [9] | 2D | - | - | - | 13.1 |
| JMRN [53] | 2D | 7.1 | 17.2 | 27.6 | 14.1 |
| LART-pose | 3D (n=1) | 12.0 | 22.0 | 46.6 | 22.9 |
| LART-pose | 3D (n=5) | 13.3 | 25.9 | 48.7 | 24.1 |
4.1. Action Recognition with 3D Pose
4.1. 基于3D姿态的动作识别
In this section, we discuss the performance of our method on AVA action recognition, when using 3D pose cues, corresponding to Section 3.1. We train our 3D pose model LART-pose, on Kinetics-400 and AVA datasets. For Kinetics-400 tracks, we use MaskFeat [66] pseudo-ground truth labels and for AVA tracks, we train with ground-truth labels. We train a single person model and a multi-person model to study the interactions of a person over time, and person-person interactions. Our method achieves $24.1\mathrm{mAP}$ on multi-person $(\mathrm{N}{=}5)$ ) setting (See Table 2). While this is well below the state-of-the-art performance, this is a first time a 3D model achieves more than $15.6~\mathrm{mAP}$ on AVA dataset. Note that the first reported performance on AVA was $15.6\mathrm{mAP}$ [23], and our 3D pose model is already above this baseline.
在本节中,我们讨论了使用3D姿态线索时,我们的方法在AVA动作识别上的性能,对应第3.1节。我们在Kinetics-400和AVA数据集上训练了3D姿态模型LART-pose。对于Kinetics-400轨迹,我们使用MaskFeat [66]伪真实标签;对于AVA轨迹,我们使用真实标签进行训练。我们训练了单人模型和多人模型,以研究一个人随时间的变化以及人与人之间的互动。我们的方法在多人(N=5)设置下达到了24.1mAP(见表2)。虽然这远低于最先进的性能,但这是3D模型首次在AVA数据集上超过15.6mAP。需要注意的是,AVA上首次报告的性能为15.6mAP [23],而我们的3D姿态模型已经超过了这一基线。
We evaluate the performance of our method on three AVA sub-categories (Object Manipulation $(O M)$ , Person Interactions $(P I)$ , and Person Movement $(P M),$ ). For the person-movement task, which includes actions such as running, standing, and sitting etc., the 3D pose model achieves $48.7\mathrm{mAP}.$ . In contrast, MaskFeat performance in this subcategory is $58.6~\mathrm{mAP}.$ This shows that the 3D pose model can perform about $80%$ good as a strong state-of-the-art model. On the person-person interaction category, our multi-person model achieves a gain of $+2.1\mathrm{mAP}$ compared to the single-person model, showing that the multiperson model was able to capture the person-person interactions. As shown in the Fig 2, for person-person interactions classes such as dancing, fighting, lifting a person and handshaking etc., the multi-person model performs much better than the current state-of-the-art pose-only models. For example, in dancing multi-person model gains $+39.8$ mAP, and in hugging the relative gain is over $+200%$ . In addition to that, the multi person model has the largest gain compared to the single person model in the person interactions category.
我们在 AVA 的三个子类别(物体操作 $(O M)$、人际互动 $(P I)$ 和人体运动 $(P M)$)上评估了方法的性能。对于包含跑步、站立和坐等动作的人体运动任务,3D 姿态模型达到了 $48.7\mathrm{mAP}$,而 MaskFeat 在该子类别的性能为 $58.6~\mathrm{mAP}$。这表明 3D 姿态模型的性能约为当前最强先进模型的 $80%$。在人际互动类别中,我们的多人模型相比单人模型实现了 $+2.1\mathrm{mAP}$ 的提升,说明多人模型能够捕捉人际互动特征。如图 2 所示,对于跳舞、打架、托举他人和握手等互动类别,多人模型的表现远超当前仅依赖姿态的先进模型。例如,在跳舞动作中多人模型提升了 $+39.8$ mAP,拥抱动作的相对增益超过 $+200%$。此外,在人际互动类别中,多人模型相比单人模型实现了最大幅度的性能提升。
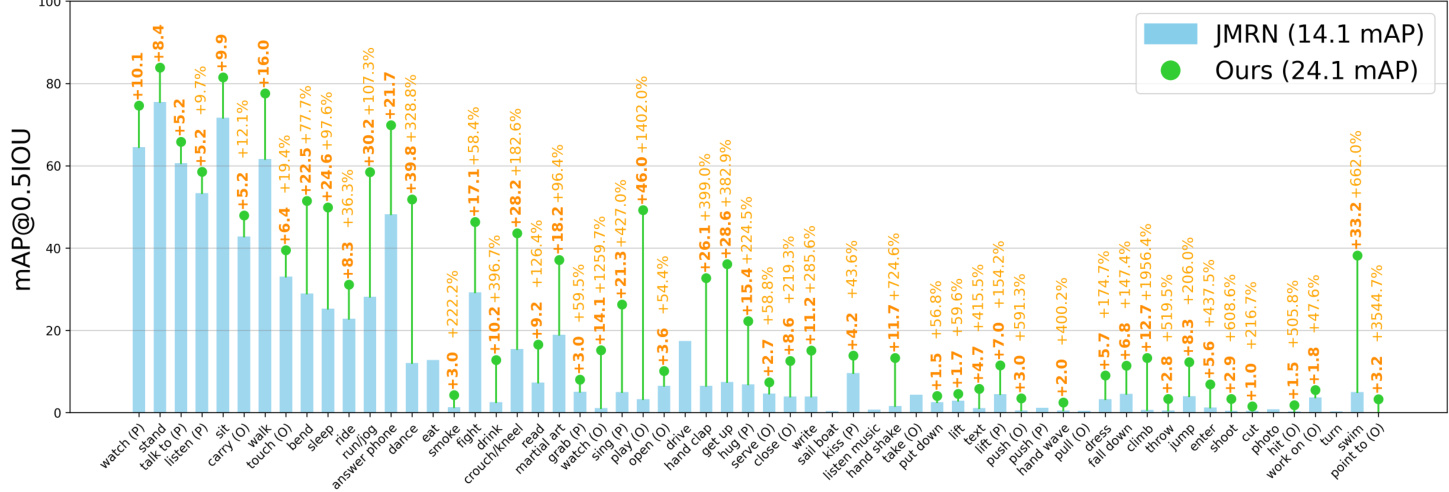
Figure 2. Class-wise performance on AVA: We show the performance of JMRN [53] and LART-pose on 60 AVA classes (average precision and relative gain). For pose based classes such as standing, sitting, and walking our 3D pose model can achieve above $60\mathrm{mAP}$ average precision performance by only looking at the 3D poses over time. By modeling multiple trajectories as input our model can understand the interactions among people. For example, activities such as dancing $(+30.1%)$ , martial art $(+19.8%)$ and hugging $(+62.1%)$ have large relative gains over state-of-the-art pose only model. We only plot the gains if it is above or below 1 mAP.
图 2: AVA数据集上的分类性能:我们展示了JMRN [53]和LART-pose在60个AVA类别上的性能(平均精度和相对增益)。对于基于姿态的类别,如站立、坐下和行走,我们的3D姿态模型仅通过观察随时间变化的3D姿态就能实现超过$60\mathrm{mAP}$的平均精度性能。通过将多个轨迹建模为输入,我们的模型可以理解人与人之间的互动。例如,跳舞$(+30.1%)$、武术$(+19.8%)$和拥抱$(+62.1%)$等活动相比最先进的纯姿态模型具有较大的相对增益。我们仅绘制增益高于或低于1 mAP的情况。
On the other hand, object manipulation has the lowest score among these three tasks. Since we do not model objects explicitly, the model has no information about which object is being manipulated and how it is being associated with the person. However, since some tasks have a unique pose when interacting with objects such as answering a phone or carrying an object, knowing the pose would help in identifying the action, which results in $13.3\mathrm{mAP}.$
另一方面,物体操控 (object manipulation) 在这三项任务中得分最低。由于我们没有显式建模物体,模型无法获知被操控的物体及其与人的关联方式。但某些任务(如接电话或搬运物品)在与物体交互时会呈现独特姿态,通过姿态信息能辅助动作识别,因此仍获得了 13.3mAP 的分数。
4.2. Actions from Appearance and 3D Pose
4.2. 基于外观和3D姿态的动作
While the 3D pose model can capture about $50%$ performance compared to the state-of-the-art methods, it does not reason about the scene context. To model this, we concatenate the human-centric 3D representation with feature vectors from MaskFeat [66] as discussed in Section 3.2. MaskFeat has a MViT2 [39] as the backbone and it learns a strong representation about the scene and contextual i zed appearance. First, we pretrain this model on Kinetics-400 [30] and AVA [23] datasets, using the pseudo ground truth labels. Then, we fine-tune this model on AVA tracks using the ground-truth action annotation.
虽然3D姿态模型能达到当前最优方法约50%的性能,但它并未对场景上下文进行推理。为此,我们如第3.2节所述,将以人为中心的3D表征与MaskFeat [66]的特征向量进行拼接。MaskFeat采用MViT2 [39]作为主干网络,能学习到关于场景和上下文外观的强表征。首先,我们使用伪真实标签在Kinetics-400 [30]和AVA [23]数据集上对该模型进行预训练,随后基于真实动作标注在AVA轨迹数据上进行微调。
In Table 3 we compare our method with other state-ofthe-art methods. Overall our method has a gain of $\mathbf{+2.8}$ mAP compared to Video MAE [17, 57]. In addition to that if we train with extra annotations from AVA-Kinetics our method achieves $42.3~\mathrm{mAP}$ . Figure 3 show the class-wise performance of our method compared to MaskFeat [66]. Our method overall improves the performance of 56 classes in 60 classes. For some classes (e.g. fighting, hugging, climbing) our method improves the performance by more than $+5\mathrm{mAP}.$ . In Table 4 we evaluate our method on AVAKinetics [38] dataset. Compared to the previous state-ofthe-art methods our method has a gain of $+1.5\mathrm{mAP}.$ .
在表3中,我们将本方法与其它先进方法进行对比。总体而言,相比Video MAE [17,57]我们的方法实现了$\mathbf{+2.8}$ mAP的提升。此外,若使用AVA-Kinetics的额外标注数据进行训练,我们的方法可达到$42.3~\mathrm{mAP}$。图3展示了本方法与MaskFeat [66]的类别性能对比,在60个类别中有56个类别性能获得提升。对于某些特定类别(如fighting、hugging、climbing),本方法实现了超过$+5\mathrm{mAP}$的性能提升。在表4中,我们在AVAKinetics [38]数据集上评估了本方法,相比现有最优方法实现了$+1.5\mathrm{mAP}$的性能增益。
In Figure 4, we show qualitative results from MViT [14] and our method. As shown in the figure, having explicit access to the tracks of everyone in the scene allow us to make more confident predictions for actions like hugging and fighting, where it is easy to interpret close interactions. In addition to that, some actions like riding a horse and climbing can benefit from having access to explicit 3D poses over time. Finally, the amodal nature of 3D meshes also allows us to make better predictions during occlusions.
在图4中,我们展示了MViT [14]和本方法的定性对比结果。如图所示,显式获取场景中每个人的运动轨迹,使我们能够对拥抱、打斗等涉及近距离互动的动作做出更可靠的预测。此外,像骑马和攀爬这类动作,通过持续获取显式3D姿态信息也能获得性能提升。最后,3D网格的非模态特性(amodal nature)还使我们能在遮挡情况下做出更准确的预测。
4.3. Ablation Experiments
4.3. 消融实验
Effect of tracking: All the current works on action recognition do not associate people over time, explicitly. They only use the mid-frame bounding box to predict the action. For example, when a person is running across the scene from left to right, a feature volume cropped at the midframe bounding box is unlikely to contain all the information about the person. However, if we can track this person we could simply know their exact position over time and that would give more localized information to the model to predict the action.
跟踪效果的影响:当前所有动作识别研究都未显式地建立人物跨时间关联,仅使用中间帧的边界框进行动作预测。例如,当人物从左向右跑过场景时,在中间帧边界框裁剪的特征体积很可能无法包含该人物的完整信息。但若能对该人物进行跟踪,我们就能准确获取其随时间变化的位置信息,从而为模型提供更精准的局部化信息来预测动作。
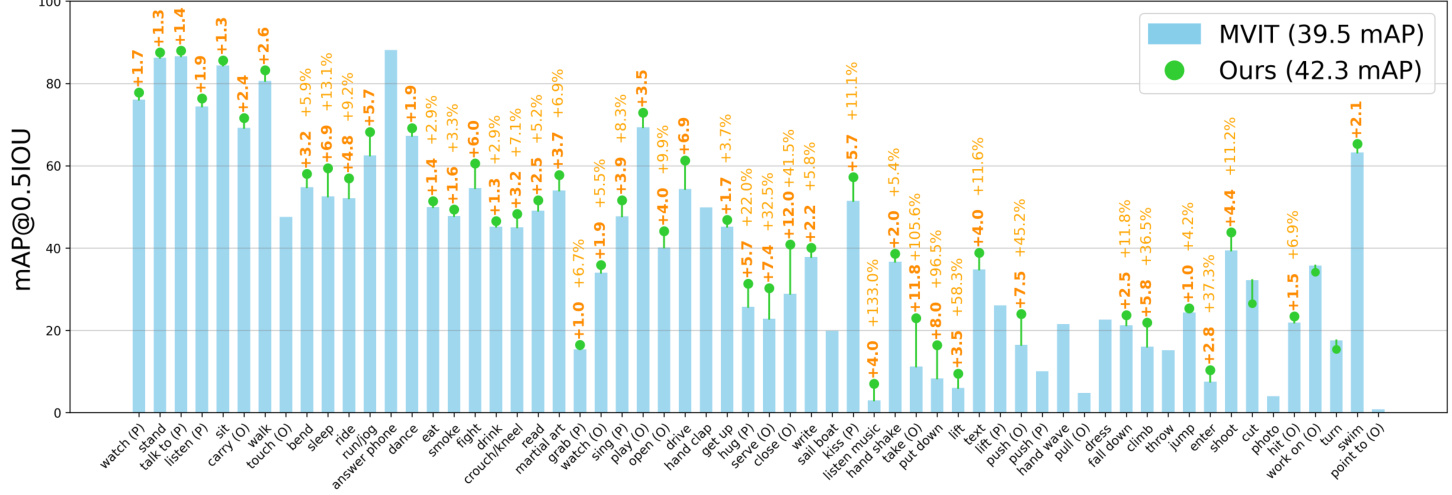
Figure 3. Comparison with State-of-the-art methods: We show class-level performance (average precision and relative gain) of MViT [14] (pretrained on MaskFeat [66]) and ours. Our methods achieve better performance compared to MViT on over 50 classes out of 60 classes. Especially, for actions like running, fighting, hugging, and sleeping etc., our method achieves over $\mathbf{+5}\mathbf{mAP}$ . This shows the benefit of having access to explicit tracks and 3D poses for action recognition. We only plot the gains if it is above or below $1\mathrm{mAP}$ .
图 3: 与最先进方法的对比:我们展示了MViT [14](基于MaskFeat [66]预训练)与本文方法在类别级性能(平均精度及相对增益)上的对比。在60个类别中,我们的方法在超过50个类别上优于MViT。特别是对于奔跑、打斗、拥抱和睡觉等动作,我们的方法实现了超过$\mathbf{+5}\mathbf{mAP}$的提升。这表明显式轨迹和3D姿态对动作识别的益处。我们仅绘制增益高于或低于$1\mathrm{mAP}$的结果。
Table 3. Comparison with state-of-the-art methods on AVA 2.2:. Our model uses features from MaskFeat [66] with full crop inference. Compared to Video MAE [17, 57] our method achieves a gain of $\mathbf{+2.8mAP}$ , and with Heira [52] backbone our model achieves $45.1\mathrm{mAP}$ with a gain of $+2.5\mathbf{mAP}$ .
表 3. AVA 2.2数据集上的先进方法对比:我们的模型使用MaskFeat [66]特征并采用全裁剪推理。相比Video MAE [17, 57]实现了$\mathbf{+2.8mAP}$提升,采用Heira [52]骨干网络时达到$45.1\mathrm{mAP}$,提升$+2.5\mathbf{mAP}$。
| 模型 | 预训练 | mAP |
|---|---|---|
| SlowFast R101,8x8[18] MViTv1-B,64x3 [14] | K400 | 23.8 27.3 |
| SlowFast16x8+NL[18] X3D-XL [16] | 27.5 27.4 | |
| MViTv1-B-24, 32x3 [14] Object Transformer[68] ACAR R101,8x8 +NL[45] | K600 | 28.7 31.0 |
| ACAR R101,8x8 +NL [45] | K700 | 31.4 33.3 |
| MViT-L↑312,40x3 [39] | IN-21K+K400 | 31.6 |
| MaskFeat [66] | K400 | 37.5 |
| MaskFeat [66] | K600 | 38.8 |
| Video MAE[17,57] | K600 | 39.3 |
| Video MAE[17,57] | K400 | 39.5 |
| Hiera [52] | K700 | 42.3 |
| LART-MViT | K400 | 42.6 (+2.8) |
| LART-Hiera | K700 | 45.1 (+2.5) |
To this end, first, we evaluate MaskFeat [66] with the same detection bounding boxes [45] used in our evaluations, and it results in $40.2\mathrm{mAP}.$ With this being the baseline for our system, we train a model which only uses MaskFeat features as input, but over time. This way we can measure the effect of tracking in action recognition. Un surprisingly, as shown in Table 5 when training MaskFeat with tracking, the model performs $+1.2\mathrm{mAP}$ better than the baseline. This clearly shows that the use of tracking is helpful in action recognition. Specifically, having access to the tracks help to localize a person over time, which in return provides a second order signal of how joint angles changes over time. In addition, knowing the identity of each person also gives a disc rim i native signal between people, which is helpful for learning interactions between people.
为此,我们首先使用与评估相同的检测边界框 [45] 对 MaskFeat [66] 进行评估,结果为 $40.2\mathrm{mAP}$。以此作为基线,我们训练了一个仅使用 MaskFeat 特征作为输入但随时间推移的模型。通过这种方式,我们可以衡量跟踪在动作识别中的效果。不出所料,如表 5 所示,在使用跟踪训练 MaskFeat 时,模型性能比基线提高了 $+1.2\mathrm{mAP}$。这清楚地表明,跟踪的使用有助于动作识别。具体来说,随时间获取轨迹有助于定位人物,从而提供关节角度如何随时间变化的二阶信号。此外,了解每个人的身份还能提供人与人之间的判别信号,这有助于学习人与人之间的交互。
Table 4. Performance on AVA-Kinetics Dataset. We evaluate the performance of our model on AVA-Kinetics [38] using a single model (no ensembles) and compare the performance with previous state-of-the-art single models.
表 4: AVA-Kinetics数据集上的性能表现。我们使用单一模型(无集成)在AVA-Kinetics [38]上评估模型性能,并与之前最先进的单一模型进行比较。
| 模型 | mAP |
|---|---|
| SlowFast [18] | 32.98 |
| ACAR [45] | 36.36 |
| RM [19] | 37.34 |
| LART+MViT | 38.91 |
Effect of Pose: The second contribution from our work is to use 3D pose information for action recognition. As discussed in Section 4.1 by only using 3D pose, we can achieve $24.1~\mathrm{mAP}$ on AVA dataset. While it is hard to measure the exact contribution of 3D pose and 2D features, we compare our method with a model trained with only MaskFeat and tracking, where the only difference is the use of 3D pose. As shown in Table 5, the addition of 3D pose gives a gain of $+0.8\mathrm{mAP}.$ . While this is a relatively small gain compared to the use of tracking, we believe with more robust and accurate 3D pose systems, this can be improved.
姿态的影响:我们工作的第二个贡献是利用3D姿态信息进行动作识别。如第4.1节所述,仅使用3D姿态就能在AVA数据集上实现$24.1~\mathrm{mAP}$。虽然难以精确量化3D姿态与2D特征的贡献占比,但我们对比了仅使用MaskFeat和跟踪训练的模型,唯一区别在于是否采用3D姿态。如表5所示,引入3D姿态带来了$+0.8\mathrm{mAP}$的提升。尽管相比跟踪技术的增益较小,但我们相信随着3D姿态系统更加鲁棒精准,这一指标还能提升。

Figure 4. Qualitative Results: We show the predictions from MViT [14] and our model on validation samples from AVA $\mathrm{v}2.2$ . The person with the colored mesh indicates the person-of-interest for which we recognise the action and the one with the gray mesh indicates the supporting actors. The first two columns demonstrate the benefits of having access to the action-tubes of other people for action prediction. In the first column, the orange person is very close to the other person with hugging posture, which makes it easy to predict hugging with higher probability. Similarly, in the second column, the explicit interaction between the multiple people, and knowing others also fighting increases the confidence for the fighting action for the green person over the 2D recognition model. The third and the fourth columns show the benefit of explicitly modeling the 3D pose over time (using tracks) for action recognition. Where the yellow person is in riding pose and purple person is looking upwards and legs on a vertical plane. The last column indicates the benefit of representing people with an amodal representation. Here the hand of the blue person is occluded, so the 2D recognition model does not see the action as a whole. However, SMPL meshes are amodal, therefore the hand is still present, which boosts the probability of predicting the action label for closing the door.
图 4: 定性分析结果:我们展示了MViT [14]和本模型在AVA $\mathrm{v}2.2$验证集上的预测结果。彩色网格标注的人物是待识别动作的主体,灰色网格标注的为辅助角色。前两列展示了利用他人动作轨迹(action-tubes)对动作预测的增益:第一列中橙色人物与拥抱姿势的另一人物紧邻,显著提升了拥抱动作的预测概率;第二列中多人显式互动及识别到其他打斗者,使绿色人物的打斗动作置信度高于2D识别模型。第三、四列体现了时序3D姿态建模(使用轨迹跟踪)的优势:黄色人物呈骑行姿势,紫色人物仰视且双腿处于垂直平面。最后一列展示了非模态表征(amodal representation)的益处——蓝色人物手部被遮挡时,2D模型无法感知完整动作,而SMPL网格具有非模态特性,仍能保留手部信息,从而提升"关门"动作标签的预测概率。
| 模型 | OM | PI | PM | mAP |
|---|---|---|---|---|
| MViT | 32.2 | 41.1 | 58.6 | 40.2 |
| MViT + Tracking | 33.4 | 43.0 | 59.3 | 41.4 (+1.2) |
| MViT + Tracking + Pose | 34.4 | 43.9 | 59.9 | 42.3 (+0.9) |
Table 5. Ablation on the main components: We ablate the contribution of tracking and 3D poses using the same detections. First, we only use MViT features over the tracks to evaluate the contribution from tracking. Then we add 3D pose features to study the contribution from 3D pose for action recognition.
表 5: 主要组件的消融实验:我们使用相同检测结果对跟踪和3D姿态的贡献进行消融分析。首先,仅使用轨迹上的MViT特征来评估跟踪的贡献,随后加入3D姿态特征以研究其对动作识别的贡献。
4.4. Implementation details
4.4. 实现细节
In both the pose model and pose+appearance model, we use the same vanilla transformer architecture [60] with 16 layers and 16 heads. For both models the embedding dimension is 512. We train with 0.4 mask ratio and at test time use the same mask token to in-fill the missing detections. The output token from the transformer is passed to a linear layer to predict the AVA action labels. We pre-train our model on kinetics for 30 epochs with MViT [14] predictions as pseudo-supervision and then fine-tune on AVA with AVA ground truth labels for few epochs. We train our models with AdamW [41] with base learning rate of 0.001 and betas $\mathbf{\xi}=(0.9,0.95)$ . We use cosine annealing scheduling with a linear warm-up. For additional details please see the Appendix.
在姿态模型和姿态+外观模型中,我们采用了相同的标准Transformer架构[60],包含16层和16个头。两个模型的嵌入维度均为512。训练时使用0.4的掩码比例,测试时采用相同掩码token来填充缺失检测。Transformer的输出token通过线性层来预测AVA动作标签。我们使用MViT[14]预测结果作为伪监督信号,在Kinetics数据集上进行了30轮预训练,随后用AVA真实标签进行少量轮次的微调。模型训练采用AdamW[41]优化器,基础学习率为0.001,betas参数设为$\mathbf{\xi}=(0.9,0.95)$,并配合余弦退火调度与线性预热策略。更多细节详见附录。
4.5. Hiera backbone results
4.5. Hiera主干网络结果
In this section, we show the class-wise performance when Hiera [52] is used to extract contextual i zed appearance features. Our model achieves $2.5\mathrm{mAP}$ gain over the Hiera baseline. Overall over method achieves $45.1\mathrm{mAP}$ and significant gains on multiple action classes. Table 6 shows task wise performance of the Hiera model and the performance of LART. In all three categories, LART performs much better than the baseline model, and LART shows a significant gain in person-interaction tasks.
在本节中,我们展示了使用Hiera [52]提取上下文感知外观特征时的类别性能。我们的模型相比Hiera基线实现了$2.5\mathrm{mAP}$的提升。整体方法达到$45.1\mathrm{mAP}$,并在多个动作类别上取得显著提升。表6展示了Hiera模型的任务性能及LART的表现。在全部三个类别中,LART均显著优于基线模型,其中人物交互任务展现出最大增益。
| 模型 | OM | PI | PM | mAP |
|---|---|---|---|---|
| MViT [66] | 32.2 | 41.1 | 58.6 | 40.5 |
| LART+MViT | 34.5 | 44.0 | 59.9 | 42.3 |
| Hiera [52] | 34.5 | 43.0 | 62.3 | 42.6 |
| LART+Hiera | 37.3 | 45.7 | 63.8 | 45.1 |
Table 6. Effect of Backbones: AVA dataset [23] contains $O M:$ Object Manipulation, PI : Person Interactions, and $P M$ : Person Movement tasks. We compare the action detection performance of the backbones (MViT [66] and Hiera [52]) and the performance when combined with LART.
表 6. 骨干网络效果对比: AVA数据集 [23] 包含 $O M:$ 物体操控、PI: 人物交互以及 $P M$: 人物移动任务。我们对比了骨干网络 (MViT [66] 和 Hiera [52]) 的动作检测性能,以及它们与LART结合时的性能表现。

Figure 5. Comparison with Hiera [52]: We show class-level performance (average precision and relative gain) of Hiera [52] (pre-trained on using MAE [24]) and ours. Our methods achieve better performance compared to Hiera in 53 classes out of 60 classes. Especially, for actions involving object interactions, and pose changes such as running. fighting, our method achieves over $10%$ relative gain on mean average precision. This shows the benefit of having access to explicit tracks and 3D poses for action recognition. We only plot the gains if it is above or below 1 mAP.
图 5: 与Hiera [52]的对比:我们展示了Hiera [52] (使用MAE [24]预训练) 和我们的方法在类别级别上的性能 (平均精度和相对增益)。我们的方法在60个类别中的53个类别上表现优于Hiera。特别是对于涉及物体交互和姿势变化的动作,如跑步、打斗,我们的方法在平均精度均值上实现了超过$10%$的相对增益。这表明显式轨迹和3D姿态对于动作识别的优势。我们仅绘制增益高于或低于1 mAP的情况。
5. Conclusion
5. 结论
In this paper, we investigated the benefits of 3D tracking and pose for the task of human action recognition. By leveraging a state-of-the-art method for person tracking, PHALP [50], we trained a transformer model that takes as input tokens the state of the person at every time instance. We investigated two design choices for the content of the token. First, when using information about the 3D pose of the person, we outperform previous baselines that rely on pose information for action recognition by $8.2\mathrm{mAP}$ on the AVA $\mathrm{v}2.2$ dataset. Then, we also proposed fusing the pose information with contextual i zed appearance information coming from a typical action recognition backbone [14] applied over the tracklet trajectory. With this model, we improved upon the previous state-of-the-art on AVA $\mathrm{v}2.2$ by $2.8\mathrm{mAP}.$ . With better backbones such as Heira [52] LART achieves $45.1\mathrm{mAP}$ on AVA $\mathrm{v}2.2$ action detection tasks. There are many avenues for future work and further improvements for action recognition. For example, one could achieve better performance for more fine-grained tasks by more expressive 3D reconstruction of the human body (e.g., using the SMPL-X model [46] to capture also the hands), and by explicit modeling of the objects in the scene (potentially by extending the “tubes” idea to objects).
本文研究了3D追踪和姿态对人类动作识别任务的益处。通过采用最先进的人物追踪方法PHALP [50],我们训练了一个Transformer模型,该模型以人物在每一时刻的状态作为输入token。我们探讨了token内容的两种设计方案:首先,当使用人物3D姿态信息时,我们在AVA v2.2数据集上以8.2mAP的优势超越了此前依赖姿态信息的动作识别基线方法。随后,我们提出将姿态信息与来自典型动作识别骨干网络[14]的轨迹上下文外观信息相融合。该模型将AVA v2.2数据集上的最优性能提升了2.8mAP。采用Heira [52]等更强骨干网络时,LART在AVA v2.2动作检测任务中达到45.1mAP。动作识别领域仍存在诸多可探索方向,例如通过更具表现力的人体重建(如采用SMPL-X模型[46]捕捉手部动作)以及对场景物体的显式建模(可能通过将"管道"概念扩展至物体),可在更细粒度任务中实现性能提升。
Acknowledgements: This work was supported by the FAIR-BAIR program as well as ONR MURI (N00014-21- 1-2801). We thank Shubham Goel, for helpful discussions.
致谢:本研究得到了FAIR-BAIR计划及ONR MURI (N00014-21-1-2801) 的资助。感谢Shubham Goel富有启发性的讨论。
References
参考文献
A. Supplementary Materials
A. 补充材料
In this document, we provide additional details about our method that were not included in the main manuscript, due to space constraints. We include additional experiments and implementation details about our approach (Sections 2 & 3), we provide more details about the experiments of our paper (Sections 4) and we include the training configurations for Kinetics-400 and AVA for reproducibility.
在本文件中,我们提供了主要论文因篇幅限制未包含的方法细节补充内容。具体包括:关于我们方法的额外实验与实现细节(第2、3节)、论文实验的进一步说明(第4节),以及为保障可复现性提供的Kinetics-400和AVA数据集训练配置参数。
B. Additional Results
B. 补充结果
B.1. Modeling Multiple People in the Scene
B.1. 场景中的多人建模
As discussed in Section 3 our model take any number of people (tracks) given enough memory. Even though we do simple random sampling to find supporting actors in the scene, knowing this additional context of where other people are located and what they are doing could be a strong signal to predict what the person of interest is doing. We train multiple models, by varying the maximum context for people $(n\in[1,2,3,4,5])$ . When $n=1$ , the LARTonly sees the person-of-interest and the information about the scene and other people are fed through the contextual i zed appearance vector. However, with larger $n$ , other people’s poses, locations and appearance are explicitly given to the model. As shown in the Figure 6 as we increase the LART-pose model’s people-context, the performance on AVA dataset increases monotonically, and starts saturating at $n>4$ .
如第3节所述,只要内存充足,我们的模型可以处理任意数量的人物(轨迹)。尽管我们采用简单随机采样来寻找场景中的辅助角色,但了解其他人所处位置及其行为的额外上下文信息,可能成为预测目标人物行为的强有力信号。我们通过改变人物最大上下文数量 $(n\in[1,2,3,4,5])$ 来训练多个模型。当 $n=1$ 时,LART仅接收目标人物信息,场景和其他人物信息通过上下文感知的外观向量传递。但随着 $n$ 值增大,模型会显式获知其他人的姿态、位置和外观特征。如图6所示,当增加LART-pose模型的人物上下文数量时,在AVA数据集上的性能呈现单调上升趋势,并在 $n>4$ 时开始趋于饱和。

Figure 6. LART-pose performance with number of people in the scene: We show the performance of LART-pose on various $n$ (maximum number of people the model sees in every frame). This plot shows that as we increase the number of people the model can see while reasoning about the person of interest, the performance increase monotonically. While our multi-person model is very simple; we just input additional tokens for each other people in the scene, the model is able to understand these interactions from the large scale training data.
图 6: LART-pose 在不同人数场景下的表现:我们展示了 LART-pose 在不同 $n$ (模型每帧可见的最大人数)下的性能。该图表表明,随着模型在推理目标人物时可见人数的增加,性能呈现单调上升趋势。尽管我们的多人模型非常简单——仅通过为场景中其他人物添加额外 token 的方式实现,但模型能够通过大规模训练数据理解这些交互关系。
This observation highlights the benefits of modeling multiple people in the scene and learning their interactions jointly. However, it is only possible to achieve these benefits if we can track every person in the scene. We observed saturation at $n=5$ with simple random sampling, but this observation may be heavily biased for the AVA dataset. Most movies have few characters, and the biases in the way movies are captured (e.g., close-ups for kissing and hugging scenes) will have an impact on these results. It’s important to note that all of these models have the same number of parameters and were trained for the same amount of time (30 epochs on the same dataset).
这一观察凸显了在场景中对多人进行建模并联合学习他们互动的优势。然而,只有在能够追踪场景中的每个人时,才有可能实现这些优势。我们观察到在简单随机采样下 $n=5$ 时达到饱和,但这一观察对于AVA数据集可能存在严重偏差。大多数电影角色较少,且电影拍摄方式的偏差(例如接吻和拥抱场景的特写镜头)会对这些结果产生影响。值得注意的是,所有这些模型具有相同数量的参数,并在相同数据集上训练了相同时长(30个周期)。
In summary, our findings suggest that modeling multiperson interactions can significantly improve the performance of action recognition models, particularly for actions that involve close person-person interactions or group activities. However, the saturation point may vary depending on the dataset and biases in the way scenes are captured.
总之,我们的研究结果表明,对多人互动的建模能显著提升动作识别模型的性能,尤其是涉及紧密人际互动或群体活动的动作。不过,饱和点可能因数据集和场景捕捉方式的偏差而有所不同。
B.2. Single person vs Multi person Results
B.2. 单人 vs 多人结果
In the previous section, we discussed the benefits of modeling multi-person interactions. In this section, we will study how much performance gain can be achieved from a single person model to a multi-person model. We compare the performance of LART-pose $(\mathrm{n}{=}1)$ ) and LART-pose $(\mathrm{n}{=}5)$ ) in Figure 7. The multi-person model has an overall gain of $2.0\mathbf{mAP}$ over the single person model.
上一节我们讨论了多人交互建模的优势。本节我们将研究从单人模型到多人模型能带来多少性能提升。我们在图 7 中对比了 LART-pose $(\mathrm{n}{=}1)$ 和 LART-pose $(\mathrm{n}{=}5)$ 的性能表现。多人模型相比单人模型整体提升了 $2.0\mathbf{mAP}$。
Upon closer examination of the performance of each class, it becomes apparent that classes involving close person-person interactions benefited greatly from multiperson training. For example, actions such as hugging, kissing, handshaking, lifting a person, and listening to a person have improved by over $10%$ relative to the single person model. These interactions occur at very close proximity, and having explicit knowledge of the other person’s 3D location, pose, and action would aid in identifying the actions of the main actor.
仔细观察每个类别的表现后可以发现,涉及近距离人际互动的类别从多人训练中获益显著。例如,拥抱、亲吻、握手、托举他人和倾听他人等动作的表现相比单人模型提升了超过 $10%$。这些互动发生在极近距离,明确知晓对方的3D位置、姿态和动作有助于识别主要行为者的动作。
In addition to the close interaction actions, there are group actions that would also benefit from using the context of other people’s actions to reason about the action of the person of interest. For example, dancing and swimming are typically group activities, and knowing what others are doing is a good signal to infer the action.
除了近距离互动行为外,群体行为也能通过利用他人行为上下文来辅助推断目标人物的动作。例如,跳舞和游泳通常是群体活动,了解其他人的行为是推断动作的重要信号。
From this multi-person model, over 50 classes have gained over the single person model, and over 30 classes have gained over 1 mAP. However, as mentioned in the previous section regarding biases in datasets, these results may vary slightly for different types of datasets, such as sports datasets. For example, in a sports scene, it may be necessary to look at more than 5 people to recognize the action of the player, and the way sports scenes are shot is significantly different from movies.
从这一多人模型中,超过50个类别的表现优于单人模型,超过30个类别的mAP提升超过1分。但如前一节关于数据集偏差所述,这些结果在不同类型数据集(例如体育类数据集)中可能略有差异。例如在体育场景中,可能需要观察5人以上才能识别运动员动作,且体育场景的拍摄方式与电影存在显著差异。

Figure 7. Class-wise performance on AVA: We compare LART-poseon single person $(n=1$ ) and multi-person $(n=5$ ) setting. Our multi-person model outperforms single person model on over 50 classes and on some person-person interaction classes multi-person model has a relative gain of about $10%$ .
图 7: AVA数据集上的分类性能对比:我们比较了LART-pose在单人 $(n=1$) 和多人物 $(n=5$) 设定下的表现。我们的多人物模型在超过50个类别上优于单人模型,在某些人物交互类别中多人物模型相对增益达到约 $10%$。
Overall, our findings demonstrate that modeling multiperson interactions can significantly improve the performance of action recognition models, particularly for actions that involve close person-person interactions or group activities.
总体而言,我们的研究结果表明,建模多人互动能显著提升动作识别模型的性能,尤其对于涉及紧密人际互动或群体活动的动作。
C. Implementation details
C. 实现细节
Our complete system for action recognition by tracking integrates multiple sub-systems to combine the recent advancements in 2D Detection, Recognition, 3D Reconstruction, as well as Tracking. We can break the overall pipeline into two parts: a) frames-to-entities and b) entitiesto-action.
我们的完整动作识别追踪系统整合了多个子系统,结合了2D检测、识别、3D重建以及追踪领域的最新进展。整个流程可分为两部分:a) 从帧到实体 b) 从实体到动作。
The first part is to lift entities from frames (here, we consider entities=people). For this, we use a state-of-the-art tracking algorithm, PHALP [50]. The first step of PHALP is to detect people in each frame using Mask R-CNN [25]. We used Detectron2’s [69] new baseline models trained with Simple Copy-Paste Data Augmentation [20] with a RegNet4gf [48] backbone for the detection task. After detecting people in each frame, PHALP uses HMR [22, 28, 49] to reconstruct each person in 3D. Then, the future location, pose, and appearance of each person are predicted for solving association. PHALP uses Hungarian matching to solve the associations between 3D detections and 3D predictions. Finally, a set of tracks will be returned from the tracking which gives us access to entities (people) over time.
第一部分是从帧中提取实体(此处我们将实体视为人物)。为此,我们采用了最先进的追踪算法PHALP [50]。PHALP的第一步是使用Mask R-CNN [25]在每帧中检测人物。我们采用Detectron2 [69]基于RegNet4gf [48]主干网络、通过Simple Copy-Paste数据增强 [20]训练的新基线模型来完成检测任务。在逐帧检测到人物后,PHALP利用HMR [22, 28, 49]对每个人物进行三维重建。随后通过预测每个人的未来位置、姿态和外观来解决关联问题。PHALP采用匈牙利匹配算法来关联三维检测结果与三维预测结果。最终,追踪算法会返回一组轨迹,使我们能够获取随时间变化的实体(人物)信息。
For the second part of our paper, we collect tracks and use them to train a transformer model for action recognition. More details on the network architecture and training and inference protocols will be discussed in the following sections. This part of our paper is a crucial component of our approach to using transformer models for action recognition from 3D tracks.
在我们论文的第二部分,我们收集轨迹数据并用于训练一个用于动作识别的Transformer模型。关于网络架构、训练及推理协议的更多细节将在后续章节讨论。这部分内容是我们利用Transformer模型从3D轨迹进行动作识别方法的关键组成部分。
C.1. PHALP tracklets
C.1. PHALP 轨迹片段
In this work, every person in both Kinetics-400 [30] and AVA [23] is tracked. For this, we used the recently proposed 3D tracking algorithm PHALP [50]. PHALP allows us to track people in the wild very robustly and gives their 3D representations. However, the ground-truth action annotations for AVA are given as bounding boxes at $1\mathrm{Hz}$ frequency. On a side note, we do not use the ground truth tracking annotations in AVA dataset, which is also only available at $1\mathrm{Hz}$ . First, we use the PHALP detection model (e.g., Mask R-CNN) to detect humans in the video, whenever a frame does not have ground-truth annotations. If the frame indeed has an annotation, we take the ground-truth bounding boxes as granted and bypass Mask R-CNN detections. Since AVA only has bounding box annotations, and PHALP [50] requires bounding boxes and masks, we use Detectron2 [69] to extract masks from bounding boxes with Mask R-CNN. For the validation set, we used the detections from ACAR [45], which are also only available every 30 frames. Therefore, we used a similar strategy to get tracks from bounding boxes available at $1\mathrm{Hz}$ . For Kinetics, we run PHALP tracking for the whole sequence, which is typically 10s clips. However, since AVA is much longer than Kinetics $15\mathrm{min})$ , we run the tracker for 4-second windows, centered around the evaluation frame.
在本研究中,我们对Kinetics-400 [30]和AVA [23]数据集中的每个人物进行了追踪。为此,我们采用了最新提出的3D追踪算法PHALP [50]。该算法能稳健地实现野外环境的人物追踪,并提供其三维表征。需要注意的是,AVA的真实动作标注是以$1\mathrm{Hz}$频率提供的边界框形式存在(我们未使用AVA数据集中同样仅以$1\mathrm{Hz}$频率提供的真实追踪标注)。具体流程如下:当视频帧缺乏真实标注时,我们使用PHALP的检测模型(如Mask R-CNN)进行人物检测;若帧已存在标注,则直接采用真实边界框并跳过Mask R-CNN检测环节。由于AVA仅提供边界框标注,而PHALP [50]需要边界框和掩膜,我们通过Detectron2 [69]的Mask R-CNN从边界框提取掩膜。针对验证集,我们采用ACAR [45]提供的检测结果(该数据同样每30帧才有一组标注),因此采用类似策略从$1\mathrm{Hz}$频率的边界框生成追踪轨迹。对于Kinetics数据集,我们对完整序列(通常为10秒片段)运行PHALP追踪;而AVA视频时长显著更长(约$15\mathrm{min}$),故改为以评估帧为中心、在4秒时间窗内运行追踪器。
C.2. Architecture details
C.2. 架构细节
In all of our experiments, we use a vanilla transformer [60] architecture with 16 layers and width of 512. Each layer has 16 self-attention heads followed by layernorm [2], and a 2-layer MLP followed by layer-norm. We train all the models with a maximum sequence length of 128 frames per person. In other words, every tracklet is trimmed to have a sequence length of 128 frames. The only data augmentation we use is choosing the starting point of the sequence for random trimming. The transformer blocks are followed by a linear layer that predicts AVA action classes. We train all our models with binary cross-entropy loss.
在我们的所有实验中,我们采用了标准的Transformer [60] 架构,包含16层且宽度为512。每一层包含16个自注意力头,后接层归一化 [2],以及一个2层的MLP,同样后接层归一化。我们训练所有模型时,每个人的最大序列长度设定为128帧。换句话说,每个轨迹片段都会被裁剪至128帧的序列长度。唯一使用的数据增强方法是随机选择序列的起始点进行裁剪。Transformer块之后接一个线性层,用于预测AVA动作类别。我们使用二元交叉熵损失来训练所有模型。
At training time, we use two types of attention masking. First, since the tracklets are not always continuous due to occlusion and missing detections, we mask the corresponding self-attention of these tokens completely. The loss is not applied to these tokens and this part of the tracklet has no effect on training. The second type of masking is done to simulate these kinds of missing detections at test time. We randomly choose a small number of tokens (based on mask ratio), and replace the person-vector with a learnable mask-token. At the self-attention layer, attention is masked such that these masked-tokens will attend other tokens but other tokens will not attend the masked-tokens. Unlike, the first type of masking, we apply loss on these masked token predictions, since if there is a detection available, then there will be a pseudo-ground truth or ground truth label available for training.
训练时,我们采用两种注意力掩码机制。首先,由于轨迹片段可能因遮挡或漏检而不连续,我们会完全屏蔽这些token对应的自注意力。损失函数不作用于这些token,且该轨迹片段对训练不产生影响。第二种掩码用于模拟测试时的漏检情况:我们随机选取少量token(基于掩码比例),将人员向量替换为可学习的掩码token。在自注意力层中,这些被掩码的token可以关注其他token,但其他token不会关注被掩码的token。与第一种掩码不同,我们会计算这些被掩码token预测的损失值,因为当检测存在时,就会有用于训练的伪真值或真实标签可用。
At inference time, we do not do any attention-masking. However, there will be some tracklets with discontinuous detections. At these locations, we use the learned maskedtoken to infill the predictions for the tracklets. Since we are predicting action labels densely for each frame, we take an average pooling of 12 tokens centered around the annotated detection to minimize the gap between human annotations and model predictions.
在推理阶段,我们不进行任何注意力掩码操作。但会出现某些轨迹片段存在不连续检测的情况。对于这些位置,我们使用学习到的掩码token来填充轨迹片段的预测结果。由于我们为每帧密集预测动作标签,因此对标注检测点周围12个token进行平均池化处理,以缩小人工标注与模型预测之间的差距。
C.2.1 Action with 3D Pose
C.2.1 基于三维姿态的动作
In this subsection, we discuss the network architecture used for recognizing action only with 3D pose information over time. The 3D pose has 226 parameters: 207 $(23\times3\times3)$ parameters for joint angles, 9 for the global orientation of the person, and 10 for the body shape. In addition to this, the 3D translation of the person in the camera frame is represented by 3 parameters. Overall, in this system, a person-vector has a dimension of 229. This vector is encoded by an MLP with two hidden layers to project this to a 256-dimensional vector. The projected person-vector is then passed to the transformer. We also use the three types of positional encodings for time, track, and space as discussed in the main manuscript (Section 3.1).
在本小节中,我们讨论仅使用时序3D姿态信息进行动作识别的网络架构。3D姿态包含226个参数:关节角度占207个参数 $(23\times3\times3)$ ,人物全局朝向占9个参数,体型占10个参数。此外,人物在相机坐标系中的3D平移由3个参数表示。综上,该系统中的人物向量维度为229。该向量通过一个具有两个隐藏层的MLP (多层感知机) 编码为256维向量,随后输入Transformer。我们还采用了主文本 (第3.1节) 中讨论的三种位置编码方式:时间编码、轨迹编码和空间编码。
C.2.2 Action with 3D Pose and Appearance
C.2.2 基于3D姿态与外观的动作
To encode a strong contextual i zed appearance feature, we used MViT [14] pretrained with MaskFeat [66]. The MViT model for AVA takes a sequence of frames and a mid-frame bounding box to predict the action label of the person of interest (this is a classical example of the Eulerian way of predicting action). In this paper, we use an MViT-L $4\dot{0}\times3$ model that takes a 4-second clip and samples 40 frames with a temporal stride of 3 frames as the input and a bounding box of a person at the mid-frame. This gives a 1152- dimensional feature vector before the linear layer in the MViT classifier. We use this 1152-dimensional feature vector as our contextual i zed appearance feature and encode it into a 256 dimensional vector by an MLP with two hidden layers. Now, we have a pose vector $256\mathrm{dim}$ , from the previous section) and an appearance vector (256 dim). We concatenate these two vectors to build our person-vector for 3D pose with appearance, and the final 512-dimensional vector is passed to the transformer.
为了编码强上下文的外观特征,我们使用了通过MaskFeat [66]预训练的MViT [14]。用于AVA的MViT模型接收一系列帧和中间帧的边界框,以预测目标人物的动作标签(这是预测动作的欧拉方法的经典示例)。在本文中,我们使用MViT-L $4\dot{0}\times3$ 模型,该模型接收一个4秒的片段,并以3帧的时间步长采样40帧作为输入,以及中间帧中人物的边界框。在MViT分类器的线性层之前,这会产生一个1152维的特征向量。我们将这个1152维的特征向量作为我们的上下文外观特征,并通过一个具有两个隐藏层的MLP将其编码为256维的向量。现在,我们有一个姿态向量(来自前一节的 $256\mathrm{dim}$ )和一个外观向量(256维)。我们将这两个向量连接起来,构建带有外观的3D姿态的人物向量,并将最终的512维向量传递给Transformer。
C.3. Training recipe
C.3. 训练方案
As discussed in Section 3 of the main manuscript, we first pretrain our method on Kinetics-400 dataset, using the tracklets obtained from PHALP [50]. Each of these tracklets contains a detection at every frame unless the person is occluded or is not detected due to failure of the detection system. We provide these detection bounding boxes as input to the MViT [14] model and generate pseudo ground truth action labels for the tracklets. Once the labels are generated, we train our model end-to-end, with tracklets as inputs and the action labels as outputs. We use the training configurations in Table 7 for pre training the model on Kinetics-400 tracklets. Once the model is pretrained on Kinetics tracklets, we fine-tune the model on AVA tracklets (generated by PHALP) with ground truth action labels. Finally, during the fine-tuning stage, we apply layer-wise decay [10] and drop path [26].
如主文稿第3节所述,我们首先在Kinetics-400数据集上使用PHALP [50] 获得的轨迹片段进行预训练。除非人物被遮挡或检测系统失效,否则每条轨迹片段在每帧都包含一个检测框。我们将这些检测边界框作为输入提供给MViT [14] 模型,并为轨迹片段生成伪真实动作标签。生成标签后,我们以轨迹片段为输入、动作标签为输出,对模型进行端到端训练。表7中的训练配置用于Kinetics-400轨迹片段的模型预训练。在Kinetics轨迹片段上完成预训练后,我们使用真实动作标签在AVA轨迹片段(由PHALP生成)上对模型进行微调。最终在微调阶段,我们采用了分层衰减 [10] 和随机路径丢弃 [26] 技术。
Table 7. Training Configurations: We report the training configurations used from training our models on Kinetics-400 and AVA datasets.
表 7: 训练配置: 我们报告了在Kinetics-400和AVA数据集上训练模型时使用的训练配置。
| 配置项 | Kinetics-400 AVA |
|---|---|
| 优化器 | AdamW [41] |
| 优化器动量 | β1, β2 = 0.9, 0.95 |
| 权重衰减 | 0.05 |
| 学习率调度 | 余弦衰减 [42] |
| 预热周期 | 5 |
| 丢弃率 | 0.1 |
| 基础学习率 | 1e-3 1e-3 |
| 分层衰减 [10] | 0.9 |
| 批量大小 | 64 64 |
| 训练周期 | 30 30 |
| 路径丢弃 [26] | 0.1 |
| 掩码比率 | 0.4 0.0 |