A Parallel-Hierarchical Model for Machine Comprehension on Sparse Data
一种面向稀疏数据机器理解的并行-分层模型
Kaheer Suleman
Kaheer Suleman
Abstract
摘要
Understanding unstructured text is a major goal within natural language processing. Comprehension tests pose questions based on short text passages to evaluate such understanding. In this work, we investigate machine comprehension on the challenging MCTest benchmark. Partly because of its limited size, prior work on MCTest has focused mainly on engineering better features. We tackle the dataset with a neural approach, harnessing simple neural networks arranged in a parallel hierarchy. The parallel hierarchy enables our model to compare the passage, question, and answer from a variety of trainable perspectives, as opposed to using a manually designed, rigid feature set. Perspectives range from the word level to sentence fragments to sequences of sentences; the networks operate only on word-embedding representations of text. When trained with a methodology designed to help cope with limited training data, our Parallel-Hierarchical model sets a new state of the art for MCTest, outperforming previous feature-engineered approaches slightly and previous neural approaches by a significant margin (over $15%$ absolute).
理解非结构化文本是自然语言处理的主要目标之一。阅读理解测试通过基于短文段提出问题来评估这种理解能力。本研究针对具有挑战性的MCTest基准测试开展机器阅读理解研究。由于该数据集规模有限,先前研究主要集中于设计更好的特征工程。我们采用神经网络方法处理该数据集,通过并行层级结构的简单神经网络实现。这种并行层级结构使模型能够从多种可训练视角比较文本段落、问题和答案,而非依赖人工设计的固定特征集。视角范围涵盖单词级别、句子片段到句子序列;网络仅作用于文本的词嵌入(word-embedding)表示。当采用专为有限训练数据设计的方法进行训练时,我们的并行层级模型(Parallel-Hierarchical)在MCTest上创造了新纪录:以微弱优势超越基于特征工程的方法,并显著领先先前神经网络方法(绝对优势超过15%)。
1 Introduction
1 引言
Humans learn in a variety of ways—by communication with each other, and by study, the reading of text. Comprehension of unstructured text by machines, at a near-human level, is a major goal for natural language processing. It has garnered significant attention from the machine learning research community in recent years.
人类通过多种方式学习——通过彼此交流,以及通过学习和阅读文本。让机器以接近人类的水平理解非结构化文本,是自然语言处理的一个重要目标。近年来,这一目标已引起机器学习研究界的极大关注。
Machine comprehension (MC) is evaluated by posing a set of questions based on a text passage (akin to the reading tests we all took in school). Such tests are objectively gradable and can be used to assess a range of abilities, from basic understanding to causal reasoning to inference (Richardson et al., 2013). Given a text pas- sage and a question about its content, a system is tested on its ability to determine the correct answer (Sachan et al., 2015). In this work, we focus on MCTest, a complex but data-limited comprehension benchmark, whose multiple-choice questions require not only extraction but also inference and limited reasoning (Richardson et al., 2013). Inference and reasoning are important human skills that apply broadly, beyond language.
机器阅读理解 (Machine Comprehension, MC) 通过基于文本段落提出一组问题来评估 (类似于我们在学校参加的阅读测试)。这类测试可客观评分,并能用于评估从基础理解到因果推理再到推断等一系列能力 (Richardson et al., 2013)。给定一个文本段落和关于其内容的问题,系统需通过确定正确答案的能力来接受测试 (Sachan et al., 2015)。本研究中,我们聚焦于MCTest——一个复杂但数据有限的阅读理解基准测试,其多项选择题不仅要求信息提取,还需要推断和有限推理能力 (Richardson et al., 2013)。推断和推理是人类广泛适用 (超越语言范畴) 的重要技能。
We present a parallel-hierarchical approach to machine comprehension designed to work well in a data-limited setting. There are many use-cases in which comprehension over limited data would be handy: for example, user manuals, internal documentation, legal contracts, and so on. Moreover, work towards more efficient learning from any quantity of data is important in its own right, for bringing machines more in line with the way humans learn. Typically, artificial neural networks require numerous parameters to capture complex patterns, and the more parameters, the more training data is required to tune them. Likewise, deep models learn to extract their own features, but this is a data-intensive process. Our model learns to comprehend at a high level even when data is sparse.
我们提出了一种并行分层机器理解方法,专为数据有限场景设计。在许多实际应用中,对有限数据的理解能力非常有用:例如用户手册、内部文档、法律合同等。此外,推动机器从任意数据量中更高效学习本身具有重要意义,这能使机器更接近人类的学习方式。通常,人工神经网络需要大量参数来捕捉复杂模式,而参数越多,所需的训练数据量就越大。同样地,深度模型虽然能自主提取特征,但这一过程需要海量数据支撑。我们的模型即使在数据稀疏时,也能实现高层次的理解学习。
The key to our model is that it compares the question and answer candidates to the text using several distinct perspectives. We refer to a question combined with one of its answer candidates as a hypothesis (to be detailed below). The semantic perspective compares the hypothesis to sentences in the text viewed as single, self-contained thoughts; these are represented using a sum and transformation of word embedding vectors, similarly to in Weston et al. (2014). The word-by-word perspective focuses on similarity matches between individual words from hypothesis and text, at various scales. As in the semantic perspective, we consider matches over complete sentences. We also use a sliding window acting on a sub sent ent i al scale (inspired by the work of Hill et al. (2015)), which implicitly considers the linear distance between matched words. Finally, this word-level sliding window operates on two different views of text sentences: the sequential view, where words appear in their natural order, and the dependency view, where words are reordered based on a linearization of the sentence’s dependency graph. Words are represented throughout by embedding vectors (Mikolov et al., 2013). These distinct perspectives naturally form a hierarchy that we depict in Figure 1. Language is hierarchical, so it makes sense that comprehension relies on hierarchical levels of understanding.
我们模型的关键在于它通过多个不同视角将问题和候选答案与文本进行比较。我们将问题与其一个候选答案的组合称为假设(下文将详述)。语义视角将假设视为独立完整的单个思想,与文本中的句子进行比较;这些句子通过词嵌入向量的求和与变换来表示,类似于Weston等人(2014)的方法。逐词视角则聚焦于假设与文本中不同尺度下单个词语的相似性匹配。与语义视角类似,我们也考虑完整句子层面的匹配。我们还采用了受Hill等人(2015)启发的子句级滑动窗口,这种方法隐式地考虑了匹配词语之间的线性距离。最后,这个词级滑动窗口在两种不同的文本句子视图上操作:顺序视图(词语按自然顺序出现)和依存视图(词语根据句子的依存图线性化重新排序)。所有词语都通过嵌入向量(Mikolov等人,2013)表示。这些不同视角自然形成了一个层次结构,如图1所示。语言具有层次性,因此理解依赖于层次化的认知水平也是合理的。
The perspectives of our model can be considered a type of feature. However, they are implemented by parametric differentiable functions. This is in contrast to most previous efforts on MCTest, whose numerous hand-engineered features cannot be trained. Our model, significantly, can be trained end-to-end with back propagation. To facilitate learning with limited data, we also develop a unique training scheme. We initialize the model’s neural networks to perform specific heuristic functions that yield decent (thought not impressive) performance on the dataset. Thus, the training scheme gives the model a safe, reasonable baseline from which to start learning. We call this technique training wheels.
我们模型的视角可被视为一种特征。不过,这些特征是通过参数化可微函数实现的。这与之前大多数针对MCTest的研究形成鲜明对比——那些研究中大量手工设计的特征无法被训练。重要的是,我们的模型可以通过反向传播进行端到端训练。为了在有限数据条件下促进学习,我们还开发了一种独特的训练方案:将模型的神经网络初始化为执行特定启发式函数的状态,这些函数能在数据集上产生尚可(虽不惊艳)的性能。因此,该训练方案为模型提供了安全合理的学习起点基准,我们将此技术称为训练轮(training wheels)。
Computational models that comprehend (insofar as they perform well on MC datasets) have developed contemporaneously in several research groups (Weston et al., 2014; Sukhbaatar et al., 2015; Hill et al., 2015; Hermann et al., 2015; Ku- mar et al., 2015). Models designed specifically for MCTest include those of Richardson et al. (2013), and more recently Sachan et al. (2015), Wang and McAllester (2015), and Yin et al. (2016). In experiments, our Parallel-Hierarchical model achieves state-of-the-art accuracy on MCTest, outperforming these existing methods.
能够理解(表现为在MC数据集上表现良好)的计算模型已在多个研究团队中同步发展 (Weston et al., 2014; Sukhbaatar et al., 2015; Hill et al., 2015; Hermann et al., 2015; Kumar et al., 2015)。专为MCTest设计的模型包括Richardson等人 (2013) 的模型,以及近期Sachan等人 (2015)、Wang和McAllester (2015)、Yin等人 (2016) 的模型。实验表明,我们的并行分层模型 (Parallel-Hierarchical) 在MCTest上达到了最先进的准确率,优于现有方法。
Below we describe related work, the mathematical details of our model, and our experiments,
下面我们将介绍相关工作、模型的数学细节以及实验内容。
then analyze our results.
然后分析我们的结果。
2 The Problem
2 问题
In this section we borrow from Sachan et al. (2015), who laid out the MC problem nicely. Machine comprehension requires machines to answer questions based on unstructured text. This can be viewed as selecting the best answer from a set of candidates. In the multiple-choice case, candidate answers are predefined, but candidate answers may also be undefined yet restricted (e.g., to yes, no, or any noun phrase in the text) (Sachan et al., 2015).
本节借鉴了Sachan等人(2015) 的研究,他们对机器阅读理解 (Machine Comprehension) 问题进行了清晰阐述。机器阅读理解要求机器基于非结构化文本来回答问题。这可以视为从一组候选答案中选择最佳答案。在多选题情况下,候选答案是预定义的,但也可能存在未定义但受限的候选答案 (例如限定为是、否或文本中的任何名词短语) (Sachan et al., 2015)。
For each question $q$ , let $T$ be the unstructured text and $A={a_{i}}$ the set of candidate answers to $q$ . The machine comprehension task reduces to selecting the answer that has the highest evidence given $T$ . As in Sachan et al. (2015), we combine an answer and a question into a hypothesis, $h_{i}=$ $f(q,a_{i})$ . To facilitate comparisons of the text with the hypotheses, we also break down the passage into sentences $t_{j}$ , $T={t_{j}}$ . In our setting, $q$ , $a_{i}$ , and $t_{j}$ each represent a sequence of embedding vectors, one for each word and punctuation mark in the respective item.
对于每个问题 $q$,设 $T$ 为非结构化文本,$A={a_{i}}$ 为 $q$ 的候选答案集合。机器阅读理解任务简化为选择在给定 $T$ 下具有最高证据支持的答案。参照 Sachan et al. (2015) 的方法,我们将答案与问题组合成假设 $h_{i}=$ $f(q,a_{i})$。为了便于文本与假设的对比,我们还将段落分解为句子 $t_{j}$,即 $T={t_{j}}$。在本设定中,$q$、$a_{i}$ 和 $t_{j}$ 均表示嵌入向量序列,每个向量对应各自项中的单词或标点符号。
3 Related Work
3 相关工作
Machine comprehension is currently a hot topic within the machine learning community. In this section we will focus on the best-performing models applied specifically to MCTest, since it is somewhat unique among MC datasets (see Section 5). Generally, models can be divided into two categories: those that use fixed, engineered features, and neural models. The bulk of the work on MCTest falls into the former category.
机器理解目前是机器学习领域的热门话题。本节我们将重点讨论专门应用于MCTest的性能最佳模型,因为它在MC数据集中较为独特(参见第5节)。通常,模型可分为两类:使用固定工程特征的方法和神经网络方法。针对MCTest的研究工作主要集中于前者。
Manually engineered features often require significant effort on the part of a designer, and/or various auxiliary tools to extract them, and they cannot be modified by training. On the other hand, neural models can be trained end-to-end and typically harness only a single feature: vectorrepresentations of words. Word embeddings are fed into a complex and possibly deep neural network which processes and compares text to question and answer. Among deep models, mecha- nisms of attention and working memory are common, as in Weston et al. (2014) and Hermann et al. (2015).
手动设计的特征通常需要设计者付出大量努力,和/或借助各种辅助工具来提取,且无法通过训练进行修改。另一方面,神经网络模型可以进行端到端训练,通常仅利用单一特征:词语的向量表示 (vector representations)。词嵌入 (word embeddings) 会被输入到一个复杂且可能很深的神经网络中,该网络处理并比较文本与问题和答案。在深度模型中,注意力机制和工作记忆机制很常见,如 Weston 等人 (2014) 和 Hermann 等人 (2015) 的研究所示。
3.1 Feature-engineering models
3.1 特征工程模型
Sachan et al. (2015) treated MCTest as a structured prediction problem, searching for a latent answerentailing structure connecting question, answer, and text. This structure corresponds to the best latent alignment of a hypothesis with appropriate snippets of the text. The process of (latently) selecting text snippets is related to the attention mechanisms typically used in deep networks designed for MC and machine translation (Bahdanau et al., 2014; Weston et al., 2014; Hill et al., 2015; Hermann et al., 2015). The model uses event and entity co reference links across sentences along with a host of other features. These include specifically trained word vectors for synonymy; antonymy and class-inclusion relations from external database sources; dependencies and semantic role labels. The model is trained using a latent structural SVM extended to a multitask setting, so that questions are first classified using a pretrained top-level classifier. This enables the system to use different processing strategies for different question categories. The model also combines question and answer into a well-formed statement using the rules of Cucerzan and Agichtein (2005).
Sachan等人(2015)将MCTest视为结构化预测问题,通过寻找连接问题、答案和文本的潜在答案推导结构。该结构对应于假设与文本适当片段的最佳潜在对齐。(潜在)选择文本片段的过程与通常用于多项选择(MC)和机器翻译的深度网络中的注意力机制相关(Bahdanau等人,2014;Weston等人,2014;Hill等人,2015;Hermann等人,2015)。该模型使用跨句子的事件和实体共指链接以及许多其他特征,包括专门训练的同义词词向量;来自外部数据库的反义词和类包含关系;依存关系和语义角色标签。模型采用扩展到多任务设置的潜在结构SVM进行训练,因此问题首先使用预训练的顶层分类器进行分类。这使得系统能够针对不同问题类别采用不同的处理策略。该模型还使用Cucerzan和Agichtein(2005)的规则将问题和答案组合成格式良好的陈述。
Our model is simpler than that of Sachan et al. (2015) in terms of the features it takes in, the training procedure (stochastic gradient descent vs. alternating minimization), question classification (we use none), and question-answer combination (simple concatenation or mean vs. a set of rules).
我们的模型比Sachan等人 (2015) 的模型更简单,体现在输入特征、训练过程(随机梯度下降 vs. 交替最小化)、问题分类(我们未使用)以及问答组合(简单拼接或均值 vs. 一组规则)等方面。
Wang and McAllester (2015) augmented the baseline feature set from Richardson et al. (2013) with features for syntax, frame semantics, coreference chains, and word embeddings. They combined features using a linear latent-variable classifier trained to minimize a max-margin loss func- tion. As in Sachan et al. (2015), questions and answers are combined using a set of manually written rules. The method of Wang and McAllester (2015) achieved the previous state of the art, but has significant complexity in terms of the feature set.
Wang 和 McAllester (2015) 在 Richardson 等人 (2013) 的基线特征集基础上,增加了句法、框架语义、共指链和词嵌入等特征。他们采用线性潜变量分类器组合特征,通过最小化最大间隔损失函数进行训练。与 Sachan 等人 (2015) 的方法类似,问题和答案通过一组人工编写的规则进行组合。Wang 和 McAllester (2015) 的方法达到了当时的最高水平,但特征集复杂度较高。
Space does not permit a full description of all models in this category, but see also Smith et al. (2015) and Narasimhan and Barzilay (2015).
篇幅所限,无法详细描述此类所有模型,另请参阅 Smith et al. (2015) 和 Narasimhan and Barzilay (2015)。
Despite its relative lack of features, the ParallelHierarchical model improves upon the featureengineered state of the art for MCTest by a small amount (about $1%$ absolute) as detailed in Section 5.
尽管功能相对较少,ParallelHierarchical模型在MCTest的特征工程最优结果基础上略有提升(绝对提升约$1%$),具体细节见第5节。
3.2 Neural models
3.2 神经模型
Neural models have, to date, performed relatively poorly on MCTest. This is because the dataset is sparse and complex.
迄今为止,神经模型在MCTest上的表现相对较差。这是因为该数据集稀疏且复杂。
Yin et al. (2016) investigated deep-learning approaches concurrently with the present work. They measured the performance of the Attentive Reader (Hermann et al., 2015) and the Neural Reasoner (Peng et al., 2015), both deep, end-to-end recurrent models with attention mechanisms, and also developed an attention-based convolutional network, the HABCNN. Their network operates on a hierarchy similar to our own, providing further evidence of the promise of hierarchical perspectives. Specifically, the HABCNN processes text at the sentence level and the snippet level, where the latter combines adjacent sentences (as we do through an $n$ -gram input). Embedding vectors for the question and the answer candidates are combined and encoded by a convolutional network. This encoding modulates attention over sentence and snippet encodings, followed by maxpooling to determine the best matches between question, answer, and text. As in the present work, matching scores are given by cosine similarity. The HABCNN also makes use of a question classifier.
Yin等人 (2016) 与本研究同期探索了深度学习方法。他们测试了Attentive Reader (Hermann等人, 2015) 和Neural Reasoner (Peng等人, 2015) 的性能——这两个都是带有注意力机制的深度端到端循环模型,并开发了基于注意力的卷积网络HABCNN。该网络采用与我们类似的层级结构,进一步验证了层级视角的潜力。具体而言,HABCNN在句子层面和片段层面处理文本(后者通过组合相邻句子实现,类似我们的$n$-gram输入方式)。问题与候选答案的嵌入向量经卷积网络组合编码后,通过注意力机制作用于句子和片段编码,再经最大池化确定问题、答案与文本间的最佳匹配。与本研究相同,匹配分数采用余弦相似度计算。HABCNN还使用了问题分类器。
Despite the shared concepts between the HABCNN and our approach, the ParallelHierarchical model performs significantly better on MCTest (more than $15%$ absolute) as detailed in Section 5. Other neural models tested in Yin et al. (2016) fare even worse.
尽管HABCNN与我们的方法共享一些概念,但如第5节所述,ParallelHierarchical模型在MCTest上的表现显著更优(绝对优势超过15%)。Yin等人(2016)测试的其他神经模型表现更差。
4 The Parallel-Hierarchical Model
4 并行-层次模型
Let us now define our machine comprehension model in full. We first describe each of the perspectives separately, then describe how they are combined. Below, we use subscripts to index elements of sequences, like word vectors, and superscripts to indicate whether elements come from the text, question, or answer. In particular, we use the subscripts $k,m,n,p$ to index sequences from the text, question, answer, and hypothesis, respectively, and superscripts $t,q,a,h$ . We depict the model schematically in Figure 1.
现在让我们完整定义我们的机器理解模型。我们首先分别描述每个视角,然后说明它们是如何组合的。下文我们使用下标索引序列元素(如词向量),上标表示元素来自文本、问题还是答案。具体而言,我们使用下标$k,m,n,p$分别索引来自文本、问题、答案和假设的序列,上标$t,q,a,h$。模型示意图见图1:
4.1 Semantic Perspective
4.1 语义视角
The semantic perspective is similar to the Memory Networks approach for embedding inputs into memory space (Weston et al., 2014). Each sentence of the text is a sequence of $d$ -dimensional word vectors: $t_{j}={\mathbf{t}{k}},\mathbf{t}_{k}\in\mathbb{R}^{d}$ . The semantic vector $\mathbf{s}^{t}$ is computed by embedding the word vectors into a $D$ -dimensional space using a two-layer network that implements weighted sum followed by an affine tr an formation and a non linearity; i.e.,
语义视角类似于将输入嵌入到记忆空间的记忆网络方法 (Weston et al., 2014)。文本的每个句子都是一个 $d$ 维词向量序列:$t_{j}={\mathbf{t}{k}},\mathbf{t}_{k}\in\mathbb{R}^{d}$。语义向量 $\mathbf{s}^{t}$ 是通过将词向量嵌入到 $D$ 维空间计算得出的,使用一个两层网络实现加权求和,随后进行仿射变换和非线性处理;即,
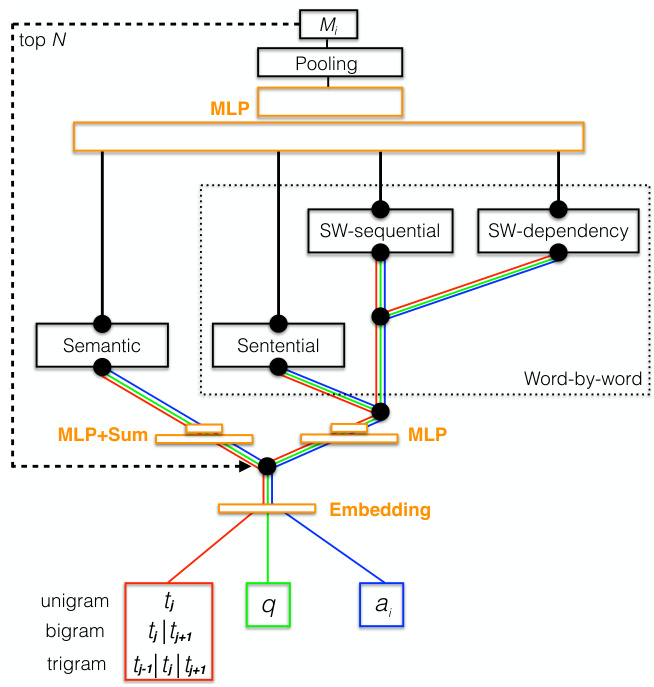
Figure 1: Schematic of the Parallel-Hierarchical model. SW stands for “sliding window.” MLP represents a general neural network.
图 1: 并行-层次模型示意图。SW代表"滑动窗口"(sliding window)。MLP表示通用神经网络。
$$
\mathbf{s}^{t}=f\left(\mathbf{A}^{t}\sum_{k}\omega_{k}\mathbf{t}{k}+\mathbf{b}_{A}^{t}\right).
$$
$$
\mathbf{s}^{t}=f\left(\mathbf{A}^{t}\sum_{k}\omega_{k}\mathbf{t}{k}+\mathbf{b}_{A}^{t}\right).
$$
The matrix $\mathbf{A}^{t}\in\mathbb{R}^{D\times d}$ , the bias vector $\mathbf{b}{A}^{t}\in$ $\mathbb{R}^{D}$ , and for $f$ we use the leaky $R e L U$ function. The scalar $\omega_{k}$ is a trainable weight associ- ated to each word in the vocabulary. These scalar weights implement a kind of exogenous or bottomup attention that depends only on the input stimulus (Mayer et al., 2004). They can, for example, learn to perform the function of stopword lists in a soft, trainable way, to nullify the contribution of unimportant filler words.
矩阵 $\mathbf{A}^{t}\in\mathbb{R}^{D\times d}$,偏置向量 $\mathbf{b}{A}^{t}\in$ $\mathbb{R}^{D}$,对于函数 $f$ 我们使用 leaky $ReLU$。标量 $\omega_{k}$ 是与词汇表中每个词相关联的可训练权重。这些标量权重实现了一种仅依赖于输入刺激的外源性或自下而上的注意力机制 (Mayer et al., 2004)。例如,它们可以通过一种柔性的、可训练的方式学习执行停用词列表的功能,从而消除不重要填充词的贡献。
The semantic representation of a hypothesis is formed analogously, except that we combine the question word vectors $\mathbf{q}{m}$ and answer word vectors ${\bf a}{n}$ as a single sequence ${{{\bf h}{p}}}={{{\bf q}{m},{\bf a}{n}}}$ . For semantic vector $\mathbf{s}^{h}$ of the hypothesis, we use a unique transformation matrix $\mathbf{A}^{h}\in\mathbb{R}^{D\times d}$ and bias vector $\mathbf{b}_{A}^{h}\in\mathbb{R}^{D}$ .
假设的语义表示以类似方式形成,不同之处在于我们将问题词向量 $\mathbf{q}{m}$ 和答案词向量 ${\bf a}{n}$ 组合为单一序列 ${{{\bf h}{p}}}={{{\bf q}{m},{\bf a}{n}}}$ 。对于假设的语义向量 $\mathbf{s}^{h}$ ,我们使用唯一的变换矩阵 $\mathbf{A}^{h}\in\mathbb{R}^{D\times d}$ 和偏置向量 $\mathbf{b}_{A}^{h}\in\mathbb{R}^{D}$ 。
These transformations map a text sentence and a hypothesis into a common space where they can be compared. We compute the semantic match between text sentence and hypothesis using the cosine similarity,
这些变换将文本句子和假设映射到一个可比较的共同空间。我们使用余弦相似度计算文本句子与假设之间的语义匹配,
$$
M^{\mathrm{sem}}=\cos({\bf s}^{t},{\bf s}^{h}).
$$
$$
M^{\mathrm{sem}}=\cos({\bf s}^{t},{\bf s}^{h}).
$$
4.2 Word-by-Word Perspective
4.2 逐词视角
The first step in building the word-by-word perspective is to transform word vectors from a text sentence, question, and answer through respective neural functions. For the text, $\begin{array}{r l}{\tilde{\mathbf{t}}{k}}&{{}=}\end{array}$ $f\left(\mathbf{B}^{t}\mathbf{t}{k}+\mathbf{b}{B}^{t}\right)$ , where $\mathbf{B}^{t}\in\mathbb{R}^{D\times d}$ , ${\bf b}{B}^{t}\in\mathbb{R}^{D}$ and $f$ is again the leaky ReLU. We transform the question and the answer to $\widetilde{\mathbf{q}}{m}$ and $\tilde{\mathbf{a}}_{n}$ analogously us- ing distinct matrices and bias vectors. In contrast with the semantic perspective, we keep the question and answer candidates separate in the word- by-word perspective. This is because matches to answer words are inherently more important than matches to question words, and we want our model to learn to use this property.
构建逐词视角的第一步是通过各自的神经网络函数转换来自文本句子、问题和答案的词向量。对于文本,$\begin{array}{r l}{\tilde{\mathbf{t}}{k}}&{{}=}\end{array}$ $f\left(\mathbf{B}^{t}\mathbf{t}{k}+\mathbf{b}{B}^{t}\right)$,其中$\mathbf{B}^{t}\in\mathbb{R}^{D\times d}$,${\bf b}{B}^{t}\in\mathbb{R}^{D}$,$f$仍是泄漏型ReLU。我们类似地使用不同的矩阵和偏置向量将问题和答案转换为$\widetilde{\mathbf{q}}{m}$和$\tilde{\mathbf{a}}_{n}$。与语义视角不同,我们在逐词视角中保持问题和候选答案分离。这是因为与答案词的匹配本质上比与问题词的匹配更重要,我们希望模型学会利用这一特性。
4.2.1 Sentential
4.2.1 句子级
Inspired by the work of Wang and Jiang (2015) in paraphrase detection, we compute matches between hypotheses and text sentences at the word level. This computation uses the cosine similarity as before:
受Wang和Jiang (2015)在复述检测工作中的启发,我们在单词级别计算假设与文本句子之间的匹配度。该计算沿用之前的余弦相似度方法:
$$
\begin{array}{c}{{c_{k m}^{q}=\cos(\tilde{\bf t}{k},\tilde{\bf q}{m}),}}\ {{c_{k n}^{a}=\cos(\tilde{\bf t}{k},\tilde{\bf a}_{n}).}}\end{array}
$$
$$
\begin{array}{c}{{c_{k m}^{q}=\cos(\tilde{\bf t}{k},\tilde{\bf q}{m}),}}\ {{c_{k n}^{a}=\cos(\tilde{\bf t}{k},\tilde{\bf a}_{n}).}}\end{array}
$$
The word-by-word match between a text sentence and question is determined by taking the maximum over $k$ (finding the text word that best matches each question word) and then taking a weighted mean over $m$ (finding the average match over the full question):
文本句子与问题的逐词匹配是通过对 $k$ 取最大值 (找到与每个问题词最匹配的文本词) 然后对 $m$ 取加权平均 (计算整个问题的平均匹配度) 来确定的:
$$
M^{q}=\frac{1}{Z}\sum_{m}\omega_{m}\operatorname*{max}{k}c_{k m}^{q}.
$$
$$
M^{q}=\frac{1}{Z}\sum_{m}\omega_{m}\operatorname*{max}{k}c_{k m}^{q}.
$$
Here, $\omega_{m}$ is the word weight for the question word and $Z$ normalizes these weights to sum to one over the question. We define the match between a sentence and answer candidate, $M^{a}$ , analogously. Finally, we combine the matches to question and answer according to
这里,$\omega_{m}$ 是问题词的权重,$Z$ 将这些权重归一化,使其在问题上总和为一。我们类似地定义句子与答案候选之间的匹配度 $M^{a}$。最后,我们根据以下方式将问题与答案的匹配度结合起来:
$$
M^{\mathrm{word}}=\alpha_{1}M^{q}+\alpha_{2}M^{a}+\alpha_{3}M^{q}M^{a}.
$$
$$
M^{\mathrm{word}}=\alpha_{1}M^{q}+\alpha_{2}M^{a}+\alpha_{3}M^{q}M^{a}.
$$
Here the $\alpha$ are trainable parameters that control the relative importance of the terms.
这里的 $\alpha$ 是可训练参数,用于控制各项的相对重要性。
4.2.2 Sequential Sliding Window
4.2.2 顺序滑动窗口
The sequential sliding window is related to the original MCTest baseline by Richardson et al. (2013). Our sliding window decays from its focus word according to a Gaussian distribution, which we extend by assigning a trainable weight to each location in the window. This modification enables the window to use information about the distance between word matches; the original baseline used distance information through a predefined function.
顺序滑动窗口与Richardson等人(2013)提出的原始MCTest基线相关。我们的滑动窗口根据高斯分布从其焦点词开始衰减,我们通过为窗口中的每个位置分配可训练权重来扩展这一方法。这一改进使得窗口能够利用词语匹配间距离的信息;原始基线通过预定义函数来使用距离信息。
The sliding window scans over the words of the text as one continuous sequence, without sentence breaks. Each window is treated like a sentence in the previous subsection, but we include a location-based weight $\lambda(k)$ . This weight is based on a word’s position in the window, which, given a window, depends on its global position $k$ . The cosine similarity is adapted as
滑动窗口将文本中的单词作为一个连续序列进行扫描,不包含句子分隔符。每个窗口的处理方式与上一小节中的句子类似,但我们会加入基于位置的权重 $\lambda(k)$ 。该权重取决于单词在窗口中的位置,而给定一个窗口时,该位置又取决于其全局位置 $k$ 。余弦相似度的计算公式相应调整为
$$
\begin{array}{r}{s_{k m}^{q}=\lambda(k)\cos(\tilde{\bf t}{k},\tilde{\bf q}_{m}),}\end{array}
$$
$$
\begin{array}{r}{s_{k m}^{q}=\lambda(k)\cos(\tilde{\bf t}{k},\tilde{\bf q}_{m}),}\end{array}
$$
for the question and analogously for the answer. We initialize the location weights with a Gaussian and fine-tune them during training. The final matching score, denoted as $M^{\mathrm{sws}}$ , is computed as in (5) and (6) with sqkm replacing cqkm.
对于问题,答案也类似处理。我们用高斯分布初始化位置权重,并在训练过程中进行微调。最终的匹配分数记为 $M^{\mathrm{sws}}$ ,其计算方式与(5)和(6)相同,只是将cqkm替换为sqkm。
4.2.3 Dependency Sliding Window
4.2.3 依赖滑动窗口
The dependency sliding window operates identically to the linear sliding window, but on a different view of the text passage. The output of this component is $M^{\mathrm{swd}}$ and is formed analogously to $M^{\mathrm{sws}}$ .
依赖滑动窗口 (dependency sliding window) 的操作方式与线性滑动窗口 (linear sliding window) 完全相同,但作用于文本段落的不同视图。该组件的输出为 $M^{\mathrm{swd}}$ ,其形成方式与 $M^{\mathrm{sws}}$ 类似。
The dependency perspective uses the Stanford Dependency Parser (Chen and Manning, 2014) as an auxiliary tool. Thus, the dependency graph can be considered a fixed feature. Moreover, linearization of the dependency graph, because it relies on an ei gen decomposition, is not differentiable. However, we handle the linear iz ation in data preprocessing so that the model sees only reordered word-vector inputs.
依赖视角采用斯坦福依存句法分析器 (Chen and Manning, 2014) 作为辅助工具。因此,依存图可视为固定特征。此外,由于依存图的线性化依赖于特征分解,该过程不可微分。但我们将线性化操作置于数据预处理阶段,使模型仅接收重排序后的词向量输入。
Specifically, we run the Stanford Dependency Parser on each text sentence to build a dependency graph. This graph has $n_{w}$ vertices, one for each word in the sentence. From the dependency graph we form the Laplacian matrix $\mathbf{L}\in\mathbb{R}^{n_{w}\times n_{w}}$ and determine its ei gen vectors. The second eigenvector $\mathbf{u}_{2}$ of the Laplacian is known as the Fiedler vector. It is the solution to the minimization
具体来说,我们对每个文本句子运行Stanford Dependency Parser以构建依存图。该图包含$n_{w}$个顶点,每个顶点对应句子中的一个单词。从依存图中我们构建拉普拉斯矩阵$\mathbf{L}\in\mathbb{R}^{n_{w}\times n_{w}}$并确定其特征向量。拉普拉斯矩阵的第二特征向量$\mathbf{u}_{2}$被称为Fiedler向量,它是以下最小化问题的解
$$
\operatorname*{minimize}\sum_{i,j=1}^{N}\eta_{i j}(g(v_{i})-g(v_{j}))^{2},
$$
$$
\operatorname*{minimize}\sum_{i,j=1}^{N}\eta_{i j}(g(v_{i})-g(v_{j}))^{2},
$$
where $v_{i}$ are the vertices of the graph, and $\eta_{i j}$ is the weight of the edge from vertex $i$ to vertex $j$ (Golub and Van Loan, 2012). The Fiedler vector maps a weighted graph onto a line such that connected nodes stay close, modulated by the connection weights.1 This enables us to reorder the words of a sentence based on their proximity in the dependency graph. The reordering of the words is given by the ordered index set
其中 $v_{i}$ 是图的顶点,$\eta_{i j}$ 是从顶点 $i$ 到顶点 $j$ 的边权重 (Golub and Van Loan, 2012)。菲德勒向量 (Fiedler vector) 将加权图映射到一条直线上,使得相连节点保持接近,并由连接权重调节。这使得我们能够根据依存图中单词的邻近度对句子中的单词重新排序。单词的重新排序由有序索引集给出。
$$
I=\arg\mathrm{sort}(\mathbf{u}_{2}).
$$
$$
I=\arg\mathrm{sort}(\mathbf{u}_{2}).
$$
To give an example of how this works, consider the following sentence from MCTest and its dependency-based reordering:
为了说明其工作原理,以MCTest中的以下句子及其基于依存关系的重排为例:
Sliding-window-based matching on the original sentence will answer the question Who called the police? with Mrs. Mustard. The dependency reordering enables the window to determine the correct answer, Jenny.
基于滑动窗口的原始句子匹配会以"Mustard夫人"回答"谁报警了"这个问题。依赖关系重排序使窗口能够确定正确答案"Jenny"。
4.3 Combining Distributed Evidence
4.3 分布式证据组合
It is important in comprehension to synthesize information found throughout a document. MCTest was explicitly designed to ensure that it could not be solved by lexical techniques alone, but would instead require some form of inference or limited reasoning (Richardson et al., 2013). It therefore includes questions where the evidence for an answer spans several sentences.
理解文档时需要综合各处信息。MCTest的设计初衷就是确保无法仅通过词汇技术解决,而需要某种形式的推理或有限推理 (Richardson et al., 2013)。因此,该测试包含需要跨多个句子寻找答案依据的问题。
To perform synthesis, our model also takes in $n$ - grams of sentences, i.e., sentence pairs and triples strung together. The model treats these exactly as it does single sentences, applying all functions detailed above. A later pooling operation combines scores across all $n$ -grams (including the singlesentence input). This is described in the next subsection.
为了进行合成,我们的模型还接收句子的$n$-gram,即串联在一起的句子对和三联句。模型将这些$n$-gram与单句输入同等对待,应用上述所有函数。随后的池化操作会合并所有$n$-gram(包括单句输入)的分数。下一小节将对此进行详细描述。
With $n$ -grams, the model can combine information distributed across contiguous sentences. In some cases, however, the required evidence is spread across distant sentences. To give our model some capacity to deal with this scenario, we take the top $N$ sentences as scored by all the preceding functions, and then repeat the scoring computations viewing these top $N$ as a single sentence.
使用 $n$-gram 时,模型可以整合分布在连续句子中的信息。然而在某些情况下,所需证据分散在相距较远的句子中。为了让模型具备处理这种情况的能力,我们选取前序所有函数评分最高的 $N$ 个句子,然后将这 $N$ 个句子视为单个句子重新进行评分计算。
The reasoning behind these approaches can be explained well in a probabilistic setting. If we consider our similarity scores to model the likelihood of a text sentence given a hypothesis, $p(t_{j}|h_{i})$ , then the $n$ -gram and top $N$ approaches model a joint probability $p(t_{j_{1}},t_{j_{2}},\ldots,t_{j_{k}}|h_{i})$ . We cannot model the joint probability as a product of individual terms (score values) because distributed pieces of evidence are likely not independent.
这些方法背后的推理可以在概率设定中得到很好的解释。若将相似度分数视为给定假设下文本句子的似然度 $p(t_{j}|h_{i})$ ,那么 $n$ -gram 和 top $N$ 方法建模的是联合概率 $p(t_{j_{1}},t_{j_{2}},\ldots,t_{j_{k}}|h_{i})$ 。由于分布式证据片段很可能不独立,我们无法将联合概率建模为单个项(分数值)的乘积。
4.4 Combining Perspectives
4.4 结合视角
We use a multilayer perceptron to combine $M^{\mathrm{sem}}$ , $M^{\mathrm{word}}$ , $M^{\mathrm{swd}}$ , and $M^{\mathrm{sws}}$ as a final matching score $M_{i}$ for each answer candidate. This network also pools and combines the separate $n$ -gram scores, and uses a linear activation function.
我们使用多层感知机 (multilayer perceptron) 将 $M^{\mathrm{sem}}$、$M^{\mathrm{word}}$、$M^{\mathrm{swd}}$ 和 $M^{\mathrm{sws}}$ 组合为每个候选答案的最终匹配分数 $M_{i}$。该网络还会池化并组合独立的 $n$ 元语法分数,并采用线性激活函数。
Our overall training objective is to minimize the ranking loss
我们的总体训练目标是最小化排序损失
$$
\mathcal{L}(T,q,A)=\operatorname*{max}(0,\mu+\operatorname*{max}{i}M_{i\neq i^{}}-M_{i^{*}}),
$$
$$
\mathcal{L}(T,q,A)=\operatorname*{max}(0,\mu+\operatorname*{max}{i}M_{i\neq i^{}}-M_{i^{*}}),
$$
where $\mu$ is a constant margin, $i^{*}$ indexes the cor- rect answer, and we take the maximum over $i$ so that we are ranking the correct answer over the best-ranked incorrect answer (of which there are three). This approach worked better than comparing the correct answer to the incorrect answers individually as in Wang and McAllester (2015).
其中 $\mu$ 是一个恒定边界值,$i^{*}$ 表示正确答案的索引,我们对 $i$ 取最大值,从而将正确答案排在最佳错误答案(共有三个)之上。这种方法比 Wang 和 McAllester (2015) 中将正确答案与各错误答案单独比较的效果更好。
Our implementation of the Parallel-Hierarchical model, using the Keras framework, is available on Github.2
我们在 Github 上公开了基于 Keras 框架的 Parallel-Hierarchical 模型实现。
4.5 Training Wheels
4.5 训练辅助轮
Before training, we initialized the neural-network components of our model to perform sensible heuristic functions. Training did not converge on the small MCTest without this vital approach.
训练前,我们将模型的神经网络组件初始化为可执行合理启发式函数的状态。若不采用这一关键方法,训练无法在小型MCTest数据集上收敛。
Empirically, we found that we could achieve above $50%$ accuracy on MCTest using a simple sum of word vectors followed by a dot product between the question sum and the hypothesis sum.
根据实验,我们发现使用简单的词向量求和再计算问题向量与假设向量的点积,就能在MCTest上实现超过50%的准确率。
Therefore, we initialized the network for the semantic perspective to perform this sum, by initializing $\mathbf{A}^{x}$ as the identity matrix and $\mathbf{b}_{A}^{x}$ as the zero vector, $x\in{t,h}$ . Recall that the activation function is a $R e L U$ so that positive outputs are unchanged.
因此,我们将语义视角的网络初始化以执行此求和,通过将 $\mathbf{A}^{x}$ 初始化为单位矩阵,$\mathbf{b}_{A}^{x}$ 初始化为零向量,$x\in{t,h}$。请注意激活函数是 $ReLU$,因此正输出保持不变。
We also found basic word-matching scores to be helpful, so we initialized the word-by-word networks likewise. The network for perspectivecombination was initialized to perform a sum of individual scores, using a zero bias-vector and a weight matrix of ones, since we found that each perspective contributed positively to the overall result.
我们还发现基本的词语匹配分数很有帮助,因此同样初始化了逐词网络。视角组合网络被初始化为执行各分数求和运算,采用零偏置向量和全1权重矩阵,因为我们发现每个视角都对整体结果有正向贡献。
This training wheels approach is related to other techniques from the literature. For instance, Le et al. (2015) proposed the identity-matrix initialization in the context of recurrent neural networks in order to preserve the error signal through backpropagation. In residual networks (He et al., 2015), shortcut connections bypass certain layers in the network so that a simpler function can be trained in conjunction with the full model.
这种训练辅助方法与其他文献中的技术相关。例如,Le等人(2015)在循环神经网络背景下提出了单位矩阵初始化方法,以保持反向传播过程中的误差信号。在残差网络(He等人,2015)中,快捷连接绕过了网络中的某些层,从而可以与完整模型一起训练更简单的函数。
5 Experiments
5 实验
5.1 The Dataset
5.1 数据集
MCTest is a collection of 660 elementary-level children’s stories and associated questions, written by human subjects. The stories are fictional, ensuring that the answer must be found in the text itself, and carefully limited to what a young child can understand (Richardson et al., 2013).
MCTest是一个包含660个小学阶段儿童故事及相关问题的集合,由人类受试者编写。这些故事均为虚构,确保答案必须从文本本身找到,并严格限制在儿童能够理解的范围内 (Richardson et al., 2013)。
The more challenging variant consists of 500 stories with four multiple-choice questions each. Despite the elementary level, stories and questions are more natural and more complex than those found in synthetic MC datasets like bAbI (Weston et al., 2014) and CNN (Hermann et al., 2015).
更具挑战性的变体包含500个故事,每个故事配有四道选择题。尽管难度属于基础级别,但这些故事和问题比bAbI (Weston et al., 2014) 和 CNN (Hermann et al., 2015) 等合成多选题数据集中的内容更自然、更复杂。
MCTest is challenging because it is both complicated and small. As per Hill et al. (2015), “it is very difficult to train statistical models only on MCTest.” Its size limits the number of parameters that can be trained, and prevents learning any complex language modeling simultaneously with the capacity to answer questions.
MCTest之所以具有挑战性,是因为它既复杂又规模小。正如Hill等人(2015)所指出的,"仅依靠MCTest训练统计模型非常困难"。其数据量限制了可训练参数的数量,并阻碍了在掌握问答能力的同时学习任何复杂的语言建模。
5.2 Training and Model Details
5.2 训练与模型细节
In this section we describe important details of the training procedure and model setup. For a complete list of hyper parameter settings, our stopword list, and other minutiae, we refer interested readers to our Github repository.
在本节中,我们将描述训练流程和模型设置的重要细节。如需完整的超参数设置列表、停用词表及其他细节,请感兴趣的读者参阅我们的Github仓库。
For word vectors we use Google’s publicly available embeddings, trained with word2vec on the 100-billion-word News corpus (Mikolov et al., 2013). These vectors are kept fixed throughout training, since we found that training them was not helpful (likely because of MCTest’s size). The vectors are 300-dimensional ( $\angle=300$ ).
对于词向量,我们使用Google公开的预训练嵌入(基于word2vec在千亿词级新闻语料库训练所得) [20]。这些300维向量( $\angle=300$ )在训练过程中保持固定,因为实验表明微调它们并无助益(可能受限于MCTest数据集规模)。
We do not use a stopword list for the text passage, instead relying on the trainable word weights to ascribe global importance ratings to words. These weights are initialized with the inverse document frequency (IDF) statistic computed over the MCTest corpus.3 However, we do use a short stopword list for questions. This list nullifies query words such as ${W h o_{;}$ , what, when, where, $h o w}$ , along with conjugations of the verbs to do and to be.
对于文本段落,我们不使用停用词列表,而是依靠可训练的单词权重来为单词分配全局重要性评分。这些权重使用在MCTest语料库上计算的逆文档频率 (IDF) 统计量进行初始化。然而,对于问题我们确实使用了一个简短的停用词列表。该列表会忽略诸如 ${W h o_{;}$、what、when、where、$h o w}$ 等查询词,以及动词 do 和 be 的各种变位形式。
Following earlier methods, we use a heuristic to improve performance on negation questions (Sachan et al., 2015; Wang and McAllester, 2015). When a question contains the words which and not, we negate the hypothesis ranking scores so that the minimum becomes the maximum.
遵循先前的方法,我们采用启发式策略来提升否定类问题的处理性能 (Sachan et al., 2015; Wang and McAllester, 2015)。当问题包含which和not时,我们对假设排序分数进行取反操作,使最小值变为最大值。
The most important technique for training the model was the training wheels approach. Without this, training was not effective at all. The identity initialization requires that the network weight matrices are square $\mathbf{\chi}{d}=D_{\mathbf{\chi}}$ ).
训练模型最重要的技术是训练轮方法。没有这种方法,训练完全无效。恒等初始化要求网络权重矩阵为方阵 $\mathbf{\chi}{d}=D_{\mathbf{\chi}}$ )。
We found dropout (Srivastava et al., 2014) to be particularly effective at improving generalization from the training to the test set, and used 0.5 as the dropout probability. Dropout occurs after all neural-network transformations, if those transformations are allowed to change with training. Our best performing model held networks at the wordby-word level fixed.
我们发现 dropout (Srivastava et al., 2014) 在提升从训练集到测试集的泛化能力方面特别有效,并将 dropout 概率设为 0.5。若神经网络变换允许随训练过程调整,则 dropout 会在所有神经网络变换之后执行。我们表现最佳的模型固定了逐词(word-by-word)层级的网络结构。
For combining distributed evidence, we used up to trigrams over sentences and our bestperforming model reiterated over the top two sentences ( $N=2$ ).
为了整合分布式证据,我们使用了最多跨越句子的三元组,并且表现最佳的模型对前两个句子进行了迭代处理($N=2$)。
We used the Adam optimizer with the standard settings (Kingma and Ba, 2014) and a learning rate of 0.003. To determine the best hyperparameters we performed a grid search over 150 settings based on validation-set accuracy. MCTest’s original validation set is too small for reliable hyper parameter tuning, so, following Wang and
我们使用了标准设置的 Adam 优化器 (Kingma and Ba, 2014) 和学习率为 0.003。为了确定最佳超参数,我们基于验证集准确率对 150 种设置进行了网格搜索。MCTest 原始验证集太小,无法进行可靠的超参数调优,因此,我们遵循 Wang 和
McAllester (2015), we merged the training and validation sets of MCTest-160 and MCTest-500, then split them randomly into a 250-story training set and a 200-story validation set.
McAllester (2015) 将 MCTest-160 和 MCTest-500 的训练集与验证集合并后,随机拆分为包含 250 个故事的训练集和 200 个故事的验证集。
5.3 Results
5.3 结果
Table 1 presents the performance of featureengineered and neural methods on the MCTest test set. Accuracy scores are divided among questions whose evidence lies in a single sentence (single) and across multiple sentences (multi), and among the two variants. Clearly, MCTest-160 is easier.
表 1: 展示了特征工程方法和神经网络方法在 MCTest 测试集上的性能表现。准确率分数根据证据来源分为单句 (single) 和多句 (multi) 两类问题,同时区分了两种测试集变体。显然,MCTest-160 的难度较低。
The first three rows represent featureengineered methods. Richardson et al. $(2013)+$ RTE is the best-performing variant of the original baseline published along with MCTest. It uses a lexical sliding window and distance-based measure, augmented with rules for recognizing textual entailment. We described the methods of Sachan et al. (2015) and Wang and McAllester (2015) in Section 3. On MCTest-500, the Parallel Hierarchical model significantly outperforms these methods on single questions $(>2%)$ and slightly outperforms the latter two on multi questions $(\approx~0.3%)$ and overall $(\approx1%)$ . The method of Wang and McAllester (2015) achieves the best overall result on MCTest-160. We suspect this is because our neural method suffered from the relative lack of training data.
前三行代表特征工程方法。Richardson等人 $(2013)+$ 提出的RTE是随MCTest发布的最佳原始基线变体,该方法采用词法滑动窗口和基于距离的度量,并辅以文本蕴含识别规则。我们在第3节已描述过Sachan等人 (2015) 与Wang和McAllester (2015) 的方法。在MCTest-500上,平行分层模型在单选题上显著优于这些方法 $(>2%)$ ,在多选题 $(\approx~0.3%)$ 和总体表现 $(\approx1%)$ 上略优于后两种方法。Wang和McAllester (2015) 的方法在MCTest-160上取得了最佳总体结果,我们推测这是由于我们的神经方法受限于相对不足的训练数据。
The last four rows in Table 1 are neural methods that we discussed in Section 3. Performance measures are taken from Yin et al. (2016). Here we see our model outperforming the alternatives by a large margin across the board $(>15%)$ . The Neural Reasoner and the Attentive Reader are large, deep models with hundreds of thousands of parameters, so it is unsurprising that they performed poorly on MCTest. The specificallydesigned HABCNN fared better, its convolutional architecture cutting down on the parameter count. Because there are similarities between our model and the HABCNN, we hypothesize that much of the performance difference is attributable to our training wheels methodology.
表 1 的最后四行是我们第 3 节讨论的神经方法。性能指标取自 Yin 等人 (2016) 的研究。可以看到我们的模型在所有指标上都大幅领先其他方法 $(>15%)$。Neural Reasoner 和 Attentive Reader 是具有数十万参数的大型深度模型,因此在 MCTest 上表现不佳并不意外。专门设计的 HABCNN 表现更好,其卷积架构减少了参数量。由于我们的模型与 HABCNN 存在相似性,我们假设大部分性能差异源于我们的训练辅助方法。
6 Analysis and Discussion
6 分析与讨论
We measure the contribution of each component of the model by ablating it. Results are given in Table 2. Not surprisingly, the $n$ -gram functionality is important, contributing almost $5%$ accuracy improvement. Without this, the model has almost no means for synthesizing distributed evidence. The top $N$ function contributes very little to the overall performance, suggesting that most multi questions have their evidence distributed across contiguous sentences. Ablating the sentential component made the most significant difference, reducing performance by more than $5%$ . Simple word-by-word matching is obviously useful on MCTest. The sequential sliding window makes a $3%$ contribution, highlighting the importance of word-distance measures. On the other hand, the dependency-based sliding window makes only a minor contribution. We found this surprising. It may be that linear iz ation of the dependency graph removes too much of its information. Finally, the exogenous word weights make a significant contribution of almost $5%$ .
我们通过消融实验衡量模型各组成部分的贡献度,结果如表2所示。不出所料,n元语法功能至关重要,带来近5%的准确率提升。若缺少该功能,模型几乎无法合成分布式证据。Top N函数对整体性能贡献甚微,这表明多数复合型问题的证据都分布在连续句子中。消融句子级组件造成最显著差异,使性能下降超5%。在MCTest数据集上,简单的逐词匹配显然具有实用价值。序列滑动窗口贡献3%的性能提升,凸显了词距度量指标的重要性。而基于依存关系的滑动窗口贡献微乎其微,这个发现令人意外——可能是依存图线性化过程丢失了过多信息。最后,外部词权重带来近5%的显著提升。
Table 1: Experimental results on MCTest.
表 1: MCTest 实验结果
| 方法 | MCTest-160 准确率 (%) | MCTest-500 准确率 (%) | ||||
|---|---|---|---|---|---|---|
| 单题 (112) | 多题 (128) | 全部 | 单题 (272) | 多题 (328) | 全部 | |
| Richardsonetal.(2013)+RTE | 76.78 | 62.50 | 69.16 | 68.01 | 59.45 | 63.33 |
| Sachan et al. (2015) | 67.65 | 67.99 | 67.83 | |||
| Wang et al. (2015) | 84.22 | 67.85 | 75.27 | 72.05 | 67.94 | 69.94 |
| AttentiveReader | 48.1 | 44.7 | 46.3 | 44.4 | 39.5 | 41.9 |
| NeuralReasoner | 48.4 | 46.8 | 47.6 | 45.7 | 45.6 | 45.6 |
| HABCNN-TE | 63.3 | 62.9 | 63.1 | 54.2 | 51.7 | 52.9 |
| Parallel-Hierarchical | 79.46 | 70.31 | 74.58 | 74.26 | 68.29 | 71.00 |
Table 2: Ablation study on MCTest-500 (all).
表 2: MCTest-500 (全部) 的消融研究
| 消融组件 | 测试准确率 (%) |
|---|---|
| - | 71.00 |
| n-gram | 66.51 |
| Top N | 70.34 |
| Sentential | 64.33 |
| SW-sequential | 68.00 |
| SW-dependency | 70.00 |
| Wordweights | 66.51 |
Analysis reveals that most of our system’s test failures occur on questions about quantity (e.g., How many...?) and temporal order (e.g., Who was invited last? ). Quantity questions make up $9.5%$ of our errors on the validation set, while order questions make up $10.3%$ . This weakness is not unexpected, since our architecture lacks any capacity for counting or tracking temporal order. Incorporating mechanisms for these forms of reasoning is a priority for future work (in contrast, the Memory Network model is quite good at temporal reasoning (Weston et al., 2014)).
分析显示,我们系统的大多数测试失败发生在关于数量(例如"有多少...?")和时间顺序(例如"最后被邀请的是谁?")的问题上。数量问题占验证集错误的9.5%,而顺序问题占10.3%。这一弱点并不意外,因为我们的架构缺乏计数或跟踪时间顺序的能力。整合这些推理形式的机制是未来工作的重点(相比之下,记忆网络(Memory Network)模型在时间推理方面表现相当出色[20])。
The Parallel-Hierarchical model is simple. It does no complex language or sequence modeling. Its simplicity is a response to the limited data of
并行-层次模型结构简单。它不进行复杂的语言或序列建模。这种简洁性是为了应对有限的数据而设计的。
MCTest. Nevertheless, the model achieves stateof-the-art results on the multi questions, which (putatively) require some limited reasoning. Our model is able to handle them reasonably well just by stringing important sentences together. Thus, the model imitates reasoning with a heuristic. This suggests that, to learn true reasoning abilities, MCTest is too simple a dataset—and it is almost certainly too small for this goal.
MCTest。尽管如此,该模型在多问题上取得了最先进的结果,这些问题(据推测)需要一些有限的推理能力。我们的模型仅通过将重要句子串联在一起就能较好地处理这些问题。因此,该模型通过启发式方法模仿了推理。这表明,要学习真正的推理能力,MCTest作为一个数据集过于简单——而且对于这一目标而言,它的规模几乎肯定太小。
However, it may be that human language processing can be factored into separate processes of comprehension and reasoning. If so, the ParallelHierarchical model is a good start on the former. Indeed, if we train the method exclusively on single questions then its results become even more impressive: we can achieve a test accuracy of $79.1%$ on MCTest-500.
然而,人类语言处理可能被分解为理解和推理两个独立过程。若是如此,ParallelHierarchical模型为前者提供了良好开端。事实上,若我们仅针对单一问题训练该方法,其表现会更加出色:在MCTest-500测试集上准确率可达$79.1%$。
7 Conclusion
7 结论
We have presented the novel Parallel-Hierarchical model for machine comprehension, and evaluated it on the small but complex MCTest. Our model achieves state-of-the-art results, outperforming several feature-engineered and neural approaches.
我们提出了新颖的并行-分层(Parallel-Hierarchical)机器理解模型,并在小型但复杂的MCTest数据集上进行了评估。该模型取得了最先进的成果,性能优于多种基于特征工程和神经网络的方法。
Working with our model has emphasized to us the following (not necessarily novel) concepts, which we record here to promote further empirical validation.
与我们的模型合作让我们深刻认识到以下(不一定是新颖的)概念,我们在此记录以促进进一步的实证验证。
• Good comprehension of language is supported by hierarchical levels of understanding (Cf. Hill et al. (2015)). • Exogenous attention (the trainable word weights) may be broadly helpful for NLP. • The training wheels approach, that is, initializing neural networks to perform sensible heuristics, appears helpful for small datasets. • Reasoning over language is challenging, but easily simulated in some cases.
- 良好的语言理解能力得益于多层次的理解 (参见 Hill 等人 (2015) )
- 外源性注意力 (可训练的词权重) 可能对自然语言处理 (NLP) 有广泛帮助
- 训练辅助法 (即初始化神经网络以执行合理的启发式方法) 对小数据集似乎有所帮助
- 基于语言的推理具有挑战性,但在某些情况下很容易模拟
[Mikolov et al.2013] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
[Mikolov et al.2013] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. 词向量空间中的高效表征估计. arXiv preprint arXiv:1301.3781.
[Narasimhan and Bar zi lay 2015] Karthik Narasimhan and Regina Barzilay. 2015. Machine comprehension with discourse relations. In 53rd Annual Meeting of the Association for Computational Linguistics.
[Narasimhan and Barzilay 2015] Karthik Narasimhan 和 Regina Barzilay. 2015. 基于篇章关系的机器理解. 见: 第53届计算语言学协会年会.
[Peng et al.2015] Baolin Peng, Zhengdong Lu, Hang Li, and Kam-Fai Wong. 2015. Towards neural network-based reasoning. arXiv preprint arXiv:1508.05508.
[Peng et al.2015] Baolin Peng, Zhengdong Lu, Hang Li, 和 Kam-Fai Wong. 2015. 基于神经网络推理的探索. arXiv预印本 arXiv:1508.05508.
[Richardson et al.2013] Matthew Richardson, Christopher JC Burges, and Erin Renshaw. 2013. Mctest: A challenge dataset for the open-domain machine comprehension of text. In EMNLP, volume 1, page 2.
[Richardson et al.2013] Matthew Richardson, Christopher JC Burges, Erin Renshaw. 2013. MCTest: 一个面向开放域文本机器理解 (machine comprehension) 的挑战性数据集. 见 EMNLP 第1卷第2页.
[Sachan et al.2015] Mrinmaya Sachan, Avinava Dubey, Eric P Xing, and Matthew Richardson. 2015. Learning answer entailing structures for machine comprehension. In Proceedings of ACL.
[Sachan et al.2015] Mrinmaya Sachan, Avinava Dubey, Eric P Xing, and Matthew Richardson. 2015. 学习答案蕴含结构以实现机器阅读理解. In Proceedings of ACL.
[Smith et al.2015] Ellery Smith, Nicola Greco, Matko Bosnjak, and Andreas Vlachos. 2015. A strong lexical matching method for the machine comprehension test. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1693–1698, Lisbon, Portugal, September. Association for Computational Linguistics.
[Smith et al.2015] Ellery Smith, Nicola Greco, Matko Bosnjak, Andreas Vlachos. 2015. 一种用于机器理解测试的强词汇匹配方法. 见《2015年自然语言处理实证方法会议论文集》, 第1693–1698页, 葡萄牙里斯本, 9月. 计算语言学协会.
[Srivastava et al.2014] Nitish Srivastava, Geoffrey Hin- ton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salak hut dino v. 2014. Dropout: A simple way to prevent neural networks from over fitting. The Journal of Machine Learning Research, 15(1):1929– 1958.
[Nitish Srivastava 等, 2014] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov. 2014. Dropout: 一种防止神经网络过拟合的简单方法. 机器学习研究期刊, 15(1):1929–1958.
[Sukhbaatar et al.2015] Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. 2015. End-to-end memory networks. In Advances in Neural Information Processing Systems, pages 2431–2439.
[Sukhbaatar et al.2015] Sainbayar Sukhbaatar, Jason Weston, Rob Fergus 等. 2015. 端到端记忆网络. 发表于《神经信息处理系统进展》, 第2431–2439页.
[Wang and Jiang2015] Shuohang Wang and Jing Jiang. 2015. Learning natural language inference with lstm. arXiv preprint arXiv:1512.08849.
[Wang and Jiang2015] Shuohang Wang 和 Jing Jiang. 2015. 基于 LSTM 的自然语言推理学习. arXiv 预印本 arXiv:1512.08849.
[Wang and M cAll ester 2015] Hai Wang and Mohit Bansal Kevin Gimpel David McAllester. 2015. Machine comprehension with syntax, frames, and semantics. Volume 2: Short Papers, page 700.
[Wang and McAllester 2015] Hai Wang、Mohit Bansal、Kevin Gimpel 和 David McAllester。2015。基于句法、框架和语义的机器阅读理解。第2卷:短篇论文,第700页。
[Weston et al.2014] Jason Weston, Sumit Chopra, and Antoine Bordes. 2014. Memory networks. arXiv preprint arXiv:1410.3916.
[Weston et al.2014] Jason Weston、Sumit Chopra 和 Antoine Bordes。2014. 记忆网络 (Memory Networks)。arXiv预印本 arXiv:1410.3916。
[Yin et al.2016] Wenpeng Yin, Sebastian Ebert, and Hinrich Schitze. 2016. Attention-based convolutional neural network for machine comprehension. arXiv preprint arXiv:1602.04341.
[Yin et al.2016] Wenpeng Yin, Sebastian Ebert, 和 Hinrich Schitze. 2016. 基于注意力机制的卷积神经网络在机器阅读理解中的应用. arXiv preprint arXiv:1602.04341.