Fixing Model Bugs with Natural Language Patches
用自然语言补丁修复模型缺陷
Shikhar Murty†⋆ Christopher D. Manning† Scott Lundberg‡ Marco Tulio Ribeiro‡ †Computer Science Department, Stanford University ‡Microsoft Research {smurty,manning}@cs.stanford.edu, {scott.lundberg, marcotcr}@microsoft.com
Shikhar Murty†⋆ Christopher D. Manning† Scott Lundberg‡ Marco Tulio Ribeiro‡ †斯坦福大学计算机科学系 ‡微软研究院 {smurty,manning}@cs.stanford.edu, {scott.lundberg, marcotcr}@microsoft.com
Abstract
摘要
Current approaches for fixing systematic problems in NLP models (e.g., regex patches, finetuning on more data) are either brittle, or labor-intensive and liable to shortcuts. In contrast, humans often provide corrections to each other through natural language. Taking inspiration from this, we explore natural language patches—declarative statements that allow developers to provide corrective feedback at the right level of abstraction, either overriding the model (“if a review gives 2 stars, the sentiment is negative”) or providing additional information the model may lack (“if something is described as the bomb, then it is good”). We model the task of determining if a patch applies separately from the task of integrating patch information, and show that with a small amount of synthetic data, we can teach models to effectively use real patches on real data—1 to 7 patches improve accuracy by $\sim1{-}4$ accuracy points on different slices of a sentiment analysis dataset, and F1 by 7 points on a relation extraction dataset. Finally, we show that finetuning on as many as 100 labeled examples may be needed to match the performance of a small set of language patches.
当前解决NLP(自然语言处理)模型中系统性问题的方案(例如正则表达式补丁、基于更多数据的微调)要么脆弱易失效,要么需要高强度人工且容易走捷径。相比之下,人类通常通过自然语言互相提供修正建议。受此启发,我们探索自然语言补丁——这种声明式语句允许开发者在合适的抽象层级提供纠正反馈,既能覆盖模型判断( "若评论给出2星评级,则情感为负面" ),也能补充模型可能缺失的信息( "若某物被描述为'the bomb',则表示它很棒" )。我们将判断补丁是否适用的任务与整合补丁信息的任务分开建模,并证明仅需少量合成数据就能教会模型有效使用真实数据上的真实补丁——在情感分析数据集的不同子集上,1到7个补丁可使准确率提升$\sim1{-}4$个百分点;在关系抽取数据集上F1值提升7个百分点。最后我们发现,可能需要多达100个标注样本进行微调,才能匹配少量语言补丁带来的性能提升。
1 Introduction
1 引言
There is a growing body of research focused on using language to give instructions, supervision and even inductive biases to models instead of relying exclusively on labeled examples, e.g., building neural representations from language descriptions (Andreas et al., 2018; Murty et al., 2020; Mu et al., 2020), or language / prompt-based zeroshot learning (Brown et al., 2020; Hanjie et al., 2022; Chen et al., 2021). However, language is yet to be successfully applied for corrective purposes, where the user interacts with an existing model to improve it. As shown in Fig. 1a, if a developer discovers that a model contains bugs (i.e., systematic errors; Ribeiro et al., 2020), common fixes are either brittle regex-based patches (e.g., Fig. 1a left, where patches either override predictions or replace the word “bomb” with the word “good”), or collecting hundreds of additional datapoints for finetuning, a tedious and computationally demanding process that can still lead to shortcuts such as assuming the word “bomb” is always positive (e.g., if the additional finetuning data mostly has the word in its colloquial sense). Instead, we envision a setting where developers provide corrective feedback through a Natural Language Patch—a concise statement such as “If food is described as bomb, then food is good”. Language makes it easy for developers to express feedback at the right level of abstraction without having to specify exactly how the condition is applied. The patching system is responsible for applying the patch and integrating the information appropriately, e.g., applying it to “The tacos were the bomb” but not to “The authorities found a bomb in the restaurant”.
越来越多的研究专注于用语言向模型提供指令、监督甚至归纳偏置,而非仅依赖标注样本。例如:基于语言描述构建神经表征 [Andreas et al., 2018; Murty et al., 2020; Mu et al., 2020],或基于语言/提示(prompt)的零样本学习 [Brown et al., 2020; Hanjie et al., 2022; Chen et al., 2021]。但语言尚未成功应用于修正场景——即用户通过与现有模型交互来改进模型。如图 1a 所示,当开发者发现模型存在缺陷(即系统性错误 [Ribeiro et al., 2020])时,常见修复方案要么是脆弱的基于正则表达式的补丁(例如图 1a 左,补丁会覆盖预测结果或将"bomb"替换为"good"),要么收集数百个额外数据点进行微调——这种耗时且计算密集的过程仍可能导致捷径行为(例如假设"bomb"总是褒义,当微调数据中该词多为俚语用法时)。我们设想开发者可通过自然语言补丁(Natural Language Patch)提供修正反馈,例如简洁声明:"若食物被描述为bomb,则代表食物很好"。语言使开发者能以恰当的抽象层级表达反馈,而无需具体指定条件应用方式。补丁系统负责应用补丁并合理整合信息,例如将其应用于"The tacos were the bomb"而非"The authorities found a bomb in the restaurant"。
Natural language enables humans to communicate a lot at once with shared abstractions. For example, in teaching someone about the colloquial use of the term “bomb”, we might say describing food as ‘bomb’ means it is very good, while saying someone bombed means it was disappointing. This simple sentence uses various abstractions (e.g., “food”) to provide context-dependent information, making it easy for humans to generalize and understand sentences such as “The tacos were bomb” or “The chef bombed” without ever having seen such examples.
自然语言使人类能够通过共享的抽象概念一次性传达大量信息。例如,在向他人解释口语中"bomb"一词的用法时,我们可能会说用"bomb"形容食物表示它非常美味,而说某人"bombed"则表示令人失望。这个简单的句子运用了多种抽象概念(如"食物")来提供上下文相关的信息,使得人类即使从未见过类似例子,也能轻松理解"墨西哥卷饼很bomb"或"厨师搞砸了"这样的句子。
In this work, we present an approach for patching neural models with natural language. Any patching system has to determine when a patch is relevant, and how it should modify model behavior. We model these tasks separately (Fig. 1b): a gating head soft-predicts whether the patch should be applied (e.g., “food is described as bomb”), and an interpreter head predicts a new output by combining the information in the patch (e.g., “food is good”) with the original input. Both heads are trained on synthetic data in a patch tuning stage between training and deployment, such that new patches can be combined into a library of patches (or maybe various user-specific libraries), and applied at test-time without further training. In addition to the expressivity provided by abstractions, language-based patching is lightweight, iterative and easily reversible. Much like software, developers can write / edit / remove patches iterative ly until errors on unit tests or validation data are fixed, without constantly retraining the model.
在本工作中,我们提出了一种用自然语言修补神经模型的方法。任何修补系统都需要确定何时应用补丁以及如何修改模型行为。我们将这些任务分开建模(图 1b):门控头(gating head)软预测是否应应用补丁(例如"食物被描述为炸弹"),而解释头(interpreter head)通过将补丁中的信息(例如"食物很好")与原始输入相结合来预测新输出。这两个头都在训练和部署之间的补丁调优阶段通过合成数据进行训练,使得新补丁可以组合到补丁库(或可能是各种用户特定库)中,并在测试时应用而无需进一步训练。除了抽象提供的表达能力外,基于语言的修补还具有轻量级、迭代性和易于反转的特点。与软件类似,开发者可以迭代地编写/编辑/删除补丁,直到单元测试或验证数据上的错误被修复,而无需不断重新训练模型。
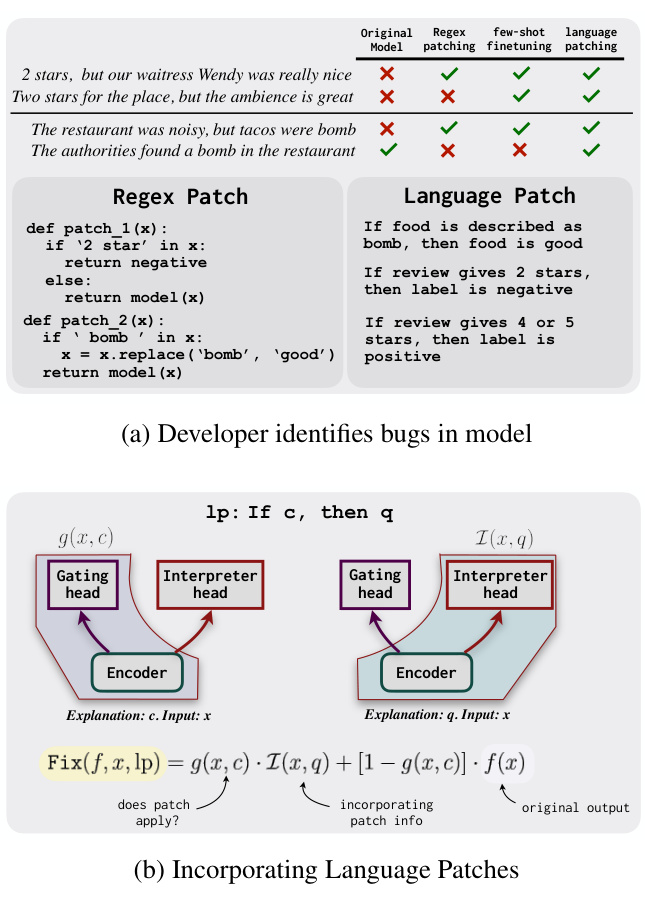
Figure 1: (a) Developers typically fix bugs by writing brittle regex patches or by finetuning on additional data, which is prone to simple shortcuts. In contrast, natural language patches are more expressive than regexes and prevent shortcuts by abstractly specifying when they should be applied. (b) Our proposed model uses a gating head to predict whether a patch condition $c$ applies to the input. That (soft) prediction is then used to combine the original model output with the output of an interpreter head that uses textual features from both the input as well as the patch consequent $q$ .
图 1: (a) 开发者通常通过编写脆弱的正则表达式补丁或在额外数据上微调来修复缺陷,这些方法容易陷入简单捷径。相比之下,自然语言补丁比正则表达式更具表现力,并通过抽象指定应用场景来规避捷径问题。(b) 我们提出的模型采用门控头预测补丁条件 $c$ 是否适用于输入,该(软)预测结果随后用于融合原始模型输出与解释器头的输出——后者同时利用了输入文本特征和补丁结果 $q$ 的特征。
Our experiments are organized as follows. First, in Section 5, we present controlled experiments that indicate these patches work even for abstract conditions, where regex patches would be infeasible or very difficult—that is, they are applied correctly when the patch condition is met, and do nothing otherwise. Perhaps surprisingly, this is true even for test-time patches that are very different than the ones used in the patch finetuning stage. Next, in Section 6, we show that despite the synthetic nature of the patch tuning phase, a small set of very simple patches can fix bugs (and thus improve performance) on real benchmarks for two different tasks—1 to 6 simple language patches improve performance by $\sim1{-}4$ accuracy points on two slices from the Yelp reviews dataset, while 7 patches improve performance by ${\sim}7\mathrm{F}1$ points on a relation extraction task derived from NYT. Finally, in Section 7.2, we compare language patching, a computationally lightweight procedure, with finetuning, a computationally and human-labor intensive procedure, and find that as many as 100 labeled examples are needed to match performance gains from a small set of 1 to 7 patches. Further, finetuning sometimes fixes bugs at the expense of introducing new bugs, while patches maintain prior performance on inputs where they do not apply.
我们的实验安排如下。首先,在第5节中,我们展示了控制实验,表明这些补丁(patch)甚至适用于正则表达式补丁不可行或非常困难的抽象条件——即当补丁条件满足时它们被正确应用,否则不执行任何操作。可能令人惊讶的是,即使对于与补丁微调阶段使用的补丁差异很大的测试时补丁,这一点也成立。接着,在第6节中,我们表明尽管补丁调优阶段具有合成性质,但一小组非常简单的补丁可以修复两个不同任务在真实基准测试中的错误(从而提高性能)——1到6个简单语言补丁将Yelp评论数据集两个子集的准确率提高了$\sim1{-}4$个百分点,而7个补丁在源自NYT的关系抽取任务上使性能提升了${\sim}7\mathrm{F}1$分。最后,在第7.2节中,我们将计算量轻的语言修补与计算量和人力消耗大的微调进行了比较,发现需要多达100个标注样本才能匹配1到7个小补丁带来的性能提升。此外,微调有时会以引入新错误为代价修复错误,而补丁在不适用的输入上能保持原有性能。
2 Natural Language Patching
2 自然语言补丁
Setup. We are given a model $f$ , mapping an input text $x$ to a probability distribution over its output space, $f(x)=\operatorname*{Pr}(y\mid x)$ . The model contains bugs—defined as behaviors inconsistent with users’ preferences or the “ground truth”— which we want to fix with a library of patches $P={l p_{1},l p_{2},...,l p_{t}}$ . Users explicitly indicate the condition under which each patch applies and the consequence of applying it, such that each patch is in the form “If (condition) c, then (consequence) ${q}^{\prime}$ . We use this format to make modeling easier, noting that it still allows for very flexible patching through high level abstractions (e.g., “if the customer complains about the ambience”, “if food is not mentioned”, etc), and that most patches have an implicit applicability function, and thus can be converted to this format.
设定。给定一个模型 $f$,它将输入文本 $x$ 映射到其输出空间上的概率分布,即 $f(x)=\operatorname*{Pr}(y\mid x)$。该模型包含错误——定义为与用户偏好或“真实情况”不一致的行为——我们希望用一个补丁库 $P={l p_{1},l p_{2},...,l p_{t}}$ 来修复这些错误。用户明确指定每个补丁适用的条件及其应用后的结果,因此每个补丁的形式为“如果 (条件) c,那么 (结果) ${q}^{\prime}$”。我们使用这种格式是为了简化建模,注意到它仍然允许通过高级抽象(例如,“如果顾客抱怨环境”,“如果没有提到食物”等)进行非常灵活的修补,并且大多数补丁都有一个隐式的适用性函数,因此可以转换为这种格式。
Applying Patches. As indicated in Fig. 1b, our model consists of two separate heads. The gating head $g$ computes the probability that the condition specified by $l p=(c,q)$ is true for a given input $x$ as $g(x,c)$ . The interpreter head $\mathcal{T}$ computes a new distribution over the label space, that conditions on $x$ and the consequence $q$ . This is then combined with the original model output $f(x)$ using the above gating probability. A single patch $l p=(c,q)$ , can
应用补丁。如图 1b 所示,我们的模型包含两个独立的头部。门控头部 $g$ 计算给定输入 $x$ 时条件 $l p=(c,q)$ 为真的概率,即 $g(x,c)$。解释器头部 $\mathcal{T}$ 计算标签空间上的新分布,该分布以 $x$ 和结果 $q$ 为条件。然后使用上述门控概率将其与原始模型输出 $f(x)$ 结合。单个补丁 $l p=(c,q)$ 可以
| Template | Examples | |
| Override: If aspect is good, then label ispositive | eo: If service is good, then label is positive e1: If food is good, then label is positive | |
| Override:If aspect is bad,thenlabel is negative | e2: If service is bad, then label is negative e3: If ambience is bad then label is negative | |
| Override:If review contains words like word, then label is positive | e4:If review contains words like zubin,then label is positive e5: If review contains words like excellent, then label is positive | |
| Override:Ifreviewcontainswords like word, then label is negative | e6: If review contains words like wug, then label is negative e7: If review contains words like really bad, then label is negative | |
| FeatureBased:If aspectis described | es: If food is described as above average, then food is good eg: If food is described as wug, then food is bad | |
| e10: If food is described as zubin, then service is good | ||
| The aspect at the restaurant was | e11: If service is described as not great, then service is bad | |
| The service at the restaurant was really good.eo,e3 | ||
| adj | The food at the restaurant was wug. e6,eg | |
| The restaurant had really bad service. e7, e2, e11 | ||
| Inputs | The aspect1 was adj1,the aspect2 | The restaurant had zubin ambience. e4, e10 |
| The food was good, the ambience was bad. e1, e3, e1 The service was good, the food was not good. eo, e1 | ||
| Theaspectl wasadj1 but the aspect2wasreallyadj2 | The food was good, but the service was really bad. e7, e1, eo | |
| The ambience was bad, but the food was really not wug. e3, eg The food was really bad even though the ambience was excellent. e5, e7, e8 |
| 模板 | 示例 | |
|---|---|---|
| 覆盖规则: 若方面评价为正面,则标签为正面 | e0: 若服务评价为正面,则标签为正面 e1: 若食物评价为正面,则标签为正面 | |
| 覆盖规则: 若方面评价为负面,则标签为负面 | e2: 若服务评价为负面,则标签为负面 e3: 若氛围评价为负面,则标签为负面 | |
| 覆盖规则: 若评论包含类似word的词汇,则标签为正面 | e4: 若评论包含类似zubin的词汇,则标签为正面 e5: 若评论包含类似excellent的词汇,则标签为正面 | |
| 覆盖规则: 若评论包含类似word的词汇,则标签为负面 | e6: 若评论包含类似wug的词汇,则标签为负面 e7: 若评论包含类似really bad的词汇,则标签为负面 | |
| 基于特征: 若方面被描述为 | e8: 若食物被描述为高于平均水平,则食物为正面 e9: 若食物被描述为wug,则食物为负面 | |
| e10: 若食物被描述为zubin,则服务为正面 | ||
| 该餐厅的方面评价为 | e11: 若服务被描述为不太好,则服务为负面 | |
| 该餐厅的服务非常出色。e0, e3 | ||
| adj | 该餐厅的食物很糟糕。e6, e9 | |
| 该餐厅的服务非常差劲。e7, e2, e11 | ||
| 输入 | 方面1评价为adj1,方面2评价为 | 该餐厅的氛围很zubin。e4, e10 |
| 食物很好,但氛围很差。e1, e3, e1 服务很好,但食物不太好。e0, e1 | ||
| 方面1评价为adj1,但方面2确实很adj2 | 食物很好,但服务确实很差。e7, e1, e0 | |
| 氛围很差,但食物确实不糟糕。e3, e9 食物非常难吃,尽管氛围很出色。e5, e7, e8 |
Table 1: Patch and Input templates used for the Patch Finetuning stage for the sentiment analysis task. We divide our patches into 2 categories: Override and Feature Based (see Section 2 for more details). For each input, we provide examples of patches that apply and patches that don’t apply. The simplistic nature of these templates makes them easy to write without access to additional data sources or lexicons.
表 1: 情感分析任务中用于Patch Finetuning阶段的补丁和输入模板。我们将补丁分为两类:覆盖型 (Override) 和基于特征型 (Feature Based) (详见第2节)。针对每个输入,我们提供了适用补丁和不适用补丁的示例。这些模板的简洁特性使其无需依赖额外数据源或词典即可轻松编写。
be applied to any input $x$ as
可应用于任意输入 $x$
$$
\begin{array}{r l}&{\operatorname{Fix}(f,x,l p)=g(x,c)\cdot{\mathcal{T}}(x,q)}\ &{\qquad+\left[1-g(x,c)\right]\cdot f(x).}\end{array}
$$
$$
\begin{array}{r l}&{\operatorname{Fix}(f,x,l p)=g(x,c)\cdot{\mathcal{T}}(x,q)}\ &{\qquad+\left[1-g(x,c)\right]\cdot f(x).}\end{array}
$$
Given a library of patches $P={l p_{1},...,l p_{t}}$ , we find the most relevant patch $l p^{*}$ for the given input, and use that to update the model,
给定一个补丁库 $P={l p_{1},...,l p_{t}}$ ,我们为给定输入找到最相关的补丁 $l p^{*}$ ,并用其更新模型。
$$
l p^{* }=\underset{l p_{i}\in P}{\arg\operatorname*{max}}g(x,c_{i}),
$$
$$
l p^{* }=\underset{l p_{i}\in P}{\arg\operatorname*{max}}g(x,c_{i}),
$$
$$
\operatorname{Fix}(f,x,P)=\operatorname{Fix}(f,x,l p^{*}).
$$
$$
\operatorname{Fix}(f,x,P)=\operatorname{Fix}(f,x,l p^{*}).
$$
Patch Types. We consider two categories of patches (examples in Table 1). Override patches are of the form “If cond, then label is $l^{,}$ i.e., they override the model’s prediction on an input if the patch condition is true. For these patches, we do not use the interpreter head since ${\mathcal{I}}(x,{\mathrm{'s}}\mathrm{label is }l^{\prime\prime})=l$ . Feature-based patches are of the form “If cond, then feature”, i.e., they provide the model with a contextual feature “hint” in natural language, e.g., in Fig. 3 the feature is “food is good”. For these patches, the model needs to integrate the hints with the original data, and thus both the gating and interpreter heads are used.
补丁类型。我们考虑两类补丁(示例见表1)。覆盖型补丁的形式为"若cond成立,则标签为$l^{,}$",即当补丁条件为真时,它们会覆盖模型对输入的预测。对于这类补丁,我们不使用解释头,因为${\mathcal{I}}(x,{\mathrm{'s}}\mathrm{label is }l^{\prime\prime})=l$。基于特征的补丁形式为"若cond成立,则特征",即以自然语言形式为模型提供上下文特征"提示",例如图3中的特征为"食物美味"。这类补丁需要模型将提示信息与原始数据整合,因此同时使用了门控头和解释头。
3 Training Patchable Models
3 训练可修补模型
Assuming $f$ has a text encoder and a classification head, we have two finetuning stages. In the Task Finetuning stage, we train $f$ on a labeled dataset ${x_{i},y_{i}}$ (standard supervised learning). In the Patch Finetuning stage, we use the learnt encoder and learn $g$ (initialized randomly) and $\mathcal{T}$ (initialized with the classification head). For the patch finetuning stage, we write a small set of patch templates covering the kinds of patches users may write for their own application (see Table 1 for the patch templates used for our sentiment analysis results). Based on these templates, we instantiate a small number of patches along with synthetic labeled examples. This gives us a dataset ${x_{i},y_{i},l p_{i}}$ , where $l p_{i}$ consists of a condition $c_{i}$ as well as a consequence $q_{i}$ . The interpreter head $\mathcal{T}$ is trained to model $\operatorname*{Pr}(y_{i}\mid x_{i},q_{i})$ through standard log-likelihood maximization. The gating head $g$ is trained via noise contrastive estimation to maximize
假设函数 $f$ 具有文本编码器和分类头,我们采用两阶段微调策略。在任务微调阶段,我们在标注数据集 ${x_{i},y_{i}}$ 上训练 $f$ (标准监督学习)。在补丁微调阶段,我们复用已学习的编码器,并训练随机初始化的 $g$ 和以分类头初始化的 $\mathcal{T}$。针对补丁微调阶段,我们编写了一小组覆盖用户可能为自身应用编写的补丁类型的模板 (情感分析所用补丁模板见表1)。基于这些模板,我们实例化少量补丁并生成合成标注样本,从而构建数据集 ${x_{i},y_{i},l p_{i}}$,其中 $l p_{i}$ 包含条件 $c_{i}$ 和结果 $q_{i}$。解释头 $\mathcal{T}$ 通过标准对数似然最大化训练来建模 $\operatorname*{Pr}(y_{i}\mid x_{i},q_{i})$,而门控头 $g$ 则通过噪声对比估计训练以最大化目标函数。
$$
\log g(x_{i},c_{i})-\sum_{c_{j}\in\mathrm{NEG}(x_{i})}\log g(x_{i},c_{j}),
$$
$$
\log g(x_{i},c_{i})-\sum_{c_{j}\in\mathrm{NEG}(x_{i})}\log g(x_{i},c_{j}),
$$
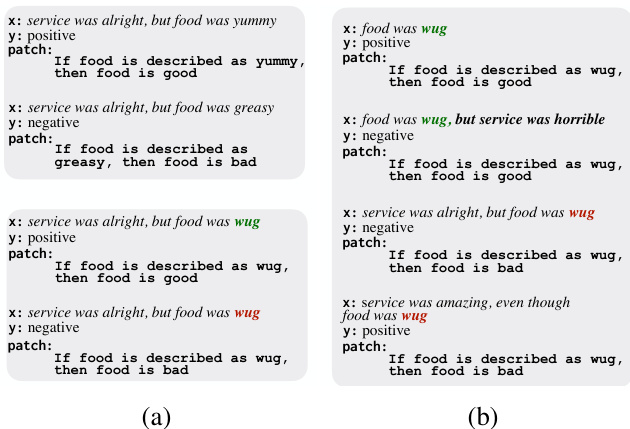
Figure 2: A model can learn from just the labels that “yummy” and “greasy” are positive and negative words respectively, and learn to perfectly fit training data without ever using patch features (a, top). This behavior can be explicitly prevented via EITs (a, bottom). A model may also fit the data without using the input features by always predicting 1 / 0 for “food is good” $/$ “food is bad” (a, top/bottom). Thus, we additionally ensure that the label cannot be inferred from the patch alone (b).
图 2: 模型仅通过"yummy"和"greasy"分别作为正负标签就能学习,完全拟合训练数据而无需使用图像块特征 (a,上)。通过EITs可以显式阻止这种行为 (a,下)。模型也可能通过始终对"食物好吃"/"食物难吃"预测1/0来拟合数据,而不使用输入特征 (a,上/下)。因此,我们额外确保不能仅从图像块推断出标签 (b)。
where $\operatorname{NEG}(x_{i})$ is a randomly sampled set of negative conditions for $x_{i}$ .
其中 $\operatorname{NEG}(x_{i})$ 是 $x_{i}$ 的随机采样负例集合。
Entropy Increasing Transformations. Patch Finetuning will fail if the synthetic data can be fit by a model that ignores the input or the patch (Fig. 2a). Thus, to ensure our model cannot fit the synthetic data without combining patch features with inputs, we perturb the inputs with Entropy Increasing Transformations (EITs). We identify words from the input template for which the patch supplies additional information e.g., aspect adjectives, relationship between entities, and transform these into a small set of nonce words. Crucially, the meanings of these nonce words vary from example to example, and can only be inferred from the patch (Fig. 2a bottom; more examples in Appendix A.2). Intuitively, the transformations inject an additional source of randomness which can only be recovered via the patch features. Such transformations are also used in Rajendran et al. (2020) in the context of meta-learning. EITs alone do not fix the failure mode where the model can fit the data without using input features at all. For example, in Fig. 2a bottom, the model might learn a shortcut so that it always predicts 1/0 for “food is good” / “food is bad”, regardless of the input. Thus, in addition to EITs, to ensure that the model uses input features, we ensure that a given patch consequence $q$ and the target label are independent (Fig. 2b).
熵增变换 (Entropy Increasing Transformations)。若合成数据可被忽略输入或图像块 (patch) 的模型拟合,则微调 (Patch Finetuning) 将失效 (图 2a)。因此,为确保模型必须结合图像块特征与输入特征才能拟合合成数据,我们通过熵增变换对输入进行扰动。我们从输入模板中识别出需要图像块补充信息的词汇(例如属性形容词、实体间关系),并将其转换为少量临时词 (nonce words)。关键之处在于,这些临时词的含义随样本变化,且仅能通过图像块推断 (图 2a 底部;附录 A.2 提供更多示例)。直观而言,这些变换注入了额外的随机性源,其信息仅能通过图像块特征还原。Rajendran 等人 (2020) 在元学习 (meta-learning) 研究中也采用了类似变换。
仅靠熵增变换无法解决模型完全忽略输入特征的失效模式。例如在图 2a 底部,模型可能学习到直接预测"食物好吃"为 1/"食物难吃"为 0 的捷径,而不考虑输入内容。因此除熵增变换外,我们还通过确保图像块结果 $q$ 与目标标签相互独立 (图 2b),来强制模型使用输入特征。
4 Experimental Setup
4 实验设置
Applications. We apply our method to binary sentiment analysis and relation extraction. For sentiment analysis, our task finetuning data comes from SST2 (Socher et al., 2013). For relation extraction, we use the Spouse dataset (Hancock et al., 2018) for task finetuning, where the objective is to determine whether two entities are married or not given a textual context about them.
应用。我们将方法应用于二元情感分析和关系抽取任务。情感分析的任务微调数据来自SST2 (Socher et al., 2013)。关系抽取任务采用Spouse数据集 (Hancock et al., 2018) 进行微调,目标是根据文本上下文判断两个实体是否存在婚姻关系。
Model. We use T5-large (Raffel et al., 2019) as implemented in the transformers library (Wolf et al., 2020) for all experiments. Both the gating and interpreter heads are separate decoders learnt on top of a shared encoder and each of these components are initialized with the corresponding T5 pre-trained weights. To prevent catastrophic forgetting on the original task during patch finetuning, we also multi-task learn the patch finetuning loss along with the original task loss. Templates for generating patches for patch finetuning are in Table 1 for sentiment analysis and in Table 9 ( Section A.2) for relation extraction. We train separate models for override and feature-based patches (the former does not need an interpreter head). When using a patch, its content (either $c$ for the gating head or $q$ for the interpreter head) is inserted in the beginning of the input with a separator as in Fig. 1b.
模型。我们采用transformers库 (Wolf等人,2020) 中实现的T5-large (Raffel等人,2019) 进行所有实验。门控头和解释头都是在共享编码器之上学习的独立解码器,这些组件均使用对应的T5预训练权重进行初始化。为防止补丁微调期间对原始任务产生灾难性遗忘,我们将补丁微调损失与原始任务损失进行多任务联合学习。情感分析任务的补丁生成模板见表1,关系抽取任务的模板见表9 (附录A.2)。我们分别为覆盖式补丁和基于特征的补丁训练独立模型 (前者不需要解释头)。使用补丁时,其内容 ($c$ 对应门控头,$q$ 对应解释头) 会如图1b所示,以分隔符形式插入输入文本开头。
Baselines. We report performance of the original model with only task finetuning (ORIG) and the model obtained after patch finetuning $(\mathrm{ORIG+PF})$ without using any patches, to isolate the gains of language patches from those induced by training on additional synthetic data. We also report results obtained from prompting ORIG with our patches (PROMPT), i.e., inserting the patch text before the input text to see how well finetuned T5 follows instructions. To use multiple patches for this baseline, we prompt the model with each individual patch and ensemble results with majority voting. Finally, we experiment with regex-based patches (REGEX) where patch conditions are converted to regex rules and consequent s are converted into functions $\operatorname{Rule}_ {q}(x)$ . For override patches, this function simply outputs the specified label. For sen- timent analysis, where feature based patches supply contextual meanings, $\operatorname{Rule}_ {q}(x)$ replaces words with specified meanings e.g., replacing “bomb” with “good” in “the food was bomb”. For feature based patches on relation extraction, $\operatorname{Rule}_{q}(x)$ appends the patch consequent to the input text.
基线。我们报告了仅进行任务微调的原始模型 (ORIG) 和补丁微调后获得的模型 $(\mathrm{ORIG+PF})$ 的性能(未使用任何补丁),以区分语言补丁带来的增益与额外合成数据训练产生的增益。我们还报告了通过提示 ORIG 使用补丁 (PROMPT) 获得的结果,即在输入文本前插入补丁文本,以观察微调后的 T5 遵循指令的效果。对于使用多个补丁的基线,我们分别用每个补丁提示模型,并通过多数投票集成结果。最后,我们尝试了基于正则表达式的补丁 (REGEX),其中补丁条件被转换为正则规则,而结果被转换为函数 $\operatorname{Rule}_ {q}(x)$。对于覆盖补丁,该函数仅输出指定标签。对于情感分析任务,基于特征的补丁提供了上下文含义,$\operatorname{Rule}_ {q}(x)$ 会将单词替换为指定含义,例如将 "the food was bomb" 中的 "bomb" 替换为 "good"。对于关系抽取任务中基于特征的补丁,$\operatorname{Rule}_{q}(x)$ 会将补丁结果附加到输入文本后。

Figure 3: (a) Example patches used for our controlled experiments. (b) Some inputs where the patch is important for making correct predictions. (c) To control for spurious behaviors such as copying label words from the patch, performing simple string lookups or affecting predictions when patch features are unimportant, we also construct invariance tests where we expect model predictions to be unaffected by the patch.
图 3: (a) 用于控制实验的示例图像块。 (b) 部分输入案例中图像块对正确预测起关键作用。 (c) 为控制虚假行为(如从图像块复制标签词、执行简单字符串查找或在图像块特征不重要时影响预测),我们还构建了模型预测应不受图像块影响的不变性测试。
5 Controlled Experiments
5 控制实验
We test the behavior of language patches (and baselines) under different controlled conditions with CheckList (Ribeiro et al., 2020). Patches and example inputs are presented in Fig. 3. We test cases where patches apply and are relevant for predictions, and corresponding cases where they either do not apply or are not relevant. Thus, models that rely on shortcuts such as copying the label word from the patch or merely performing token matching perform poorly on the CheckList.
我们使用CheckList (Ribeiro et al., 2020)测试了语言补丁(及基线)在不同受控条件下的表现。补丁和示例输入如图3所示。我们测试了补丁适用且与预测相关的情况,以及补丁不适用或不相关的对应情况。因此,依赖捷径(如从补丁复制标签词或仅执行token匹配)的模型在CheckList上表现不佳。
For sentiment analysis, we test Override patches with abstract conditions (e.g., “If food is described as weird, then label is negative” ) on various concrete instantiations such as “The pizza at the restaurant was weird”. We also construct invariance tests (O-Inv), where adding such patches should not change predictions on inputs where the condition is false (e.g., “The waiter was weird”, “The tacos were not weird”). We also construct tests for feature-based patches (Feat) where patches provide meaning for nonce adjectives, with analogous invariance tests (Feat-Inv). Finally, we construct analogous tests for relation extraction, where patches fill in reasoning gaps in the model such as “If Entity1 gave Entity2 a ring, then Entity1 and
在情感分析方面,我们测试了带有抽象条件的覆盖补丁(例如"如果食物被描述为奇怪,则标签为负面")在各种具体实例上的表现,如"餐厅的披萨很奇怪"。我们还构建了不变性测试(O-Inv),即添加此类补丁不应改变条件为假时的预测结果(例如"服务员很奇怪"、"墨西哥卷饼并不奇怪")。针对基于特征的补丁(Feat),我们设计了测试用例,其中补丁为临时形容词提供含义,并包含类似的不变性测试(Feat-Inv)。最后,我们为关系抽取构建了类似测试,补丁用于填补模型中的推理空白,例如"如果Entity1送给Entity2一枚戒指,那么Entity1和..."
| Model | Sentiment Analysis | Relation Extraction | ||||
| Override | O-Inv | Feat | Feat-lnv | Feat | Feat-Inv | |
| ORIG | 50.0 | n/a | 59.1 | n/a | 14.5 | n/a |
| ORIG+PF | 50.0 | n/a | 59.9 | n/a | 35.8 | n/a |
| REGEX | 50.0 | 100.0 | 59.9 | 100.0 | 45.8 | 88.1 |
| PROMPT | 68.7 | 63.8 | 64.3 | 85.4 | 13.9 | 87.6 |
| PATCHED | 100.0 | 100.0 | 100.0 | 100.0 | 47.2 | 92.6 |
| 模型 | 情感分析 | 关系抽取 | ||||
|---|---|---|---|---|---|---|
| Override | O-Inv | Feat | Feat-lnv | Feat | Feat-Inv | |
| ORIG | 50.0 | n/a | 59.1 | n/a | 14.5 | n/a |
| ORIG+PF | 50.0 | n/a | 59.9 | n/a | 35.8 | n/a |
| REGEX | 50.0 | 100.0 | 59.9 | 100.0 | 45.8 | 88.1 |
| PROMPT | 68.7 | 63.8 | 64.3 | 85.4 | 13.9 | 87.6 |
| PATCHED | 100.0 | 100.0 | 100.0 | 100.0 | 47.2 | 92.6 |
Table 2: Applying patches on CheckLists. We see significant improvements when the patches apply and invariances when they do not apply or are unimportant. For Sentiment Analysis, the datasets are designed to evaluate patching with abstract conditions, thus we see no effects from using regex based patches. For testing invariance, we report the percentage of inputs for which the prediction did not change w.r.t. the base model.
表 2: CheckLists 补丁应用效果。当补丁适用时我们看到显著改进,当补丁不适用或不重要时则保持不变性。在情感分析任务中,数据集专为评估抽象条件补丁而设计,因此基于正则表达式的补丁未产生效果。针对不变性测试,我们统计了预测结果相较于基础模型未发生变化的输入占比。
Entity2 are engaged”.
"Entity2 已参与"。
We present the results in Table 2, where we first note that $\mathrm{ORIG{+}P F}$ does not perform well overall, and thus patching improvements are not merely a result of the additional synthetic data. REGEX cannot handle abstract conditions, and thus (as expected) does not change predictions on sentiment analysis, and does not do well on relation extraction. While merely inserting the patch into the input (PROMPT) results in some gains when the patch applies, it does so at the cost of changing predictions when the patch does not apply (O-Inv and Feat-Inv). In contrast to baselines, our method is able to apply abstract patches correctly on concrete instantiations, disregarding them when they do not apply, without relying on shortcuts such as copying the label from the consequent or merely checking for matching words between patch and input (all of which are tested by the invariance tests).
我们在表2中展示了结果,首先注意到$\mathrm{ORIG{+}P F}$整体表现不佳,因此补丁改进不仅仅是额外合成数据的结果。REGEX无法处理抽象条件,因此(如预期)不会改变情感分析的预测结果,在关系抽取任务上表现也不理想。虽然仅将补丁插入输入(PROMPT)会在补丁适用时带来一定提升,但代价是在补丁不适用时改变预测结果(O-Inv和Feat-Inv)。与基线方法相比,我们的方法能够正确地将抽象补丁应用于具体实例,在不适用时忽略它们,且不依赖从结果中复制标签或仅检查补丁与输入间匹配单词等捷径(所有这些都通过不变性测试进行了验证)。
6 Patching models on real benchmarks
6 真实基准测试中的模型修补
6.1 Sentiment Analysis
6.1 情感分析
Unless noted otherwise, all datasets in this subsection are derived from Yelp Review (Zhang et al., 2015). To fix errors on low-accuracy slices, we write patches by inspecting a random subset of 10-20 errors made by $\mathrm{ORIG+PF}$ .
除非另有说明,本小节所有数据集均来自Yelp Review (Zhang et al., 2015)。为修正低准确率切片的错误,我们通过检查$\mathrm{ORIG+PF}$产生的10-20个随机错误子集来编写补丁。
Controlling the model. In order to check if patches can control model behavior with abstract conditions “in the wild”, we manually annotate a random subset of 500 reviews with food and service specific sentiment (“The food was good, service not so much” is labeled as service: 0, food: 1). We then construct override patches of the form $^{\leftarrow}i f$ food / service is good / bad, then label is positive
控制模型。为了验证补丁是否能在真实场景下通过抽象条件控制模型行为,我们随机选取500条评论进行人工标注,针对食物和服务分别标注情感倾向(例如"食物不错,服务一般"标注为服务:0,食物:1)。随后构建形式为$^{\leftarrow}i f$ food/service is good/bad, then label is positive的覆盖补丁。
Table 3: To measure how well patches control behavior “in the wild”, we evaluate the model’s ability to match the label specified by the patch when it applies, and invariance w.r.t the base model when the patch does not apply, on a subset of yelp with sentiment annotations for different aspects
| Model | Correctly patched (applies) | Invariance (does not apply) |
| ORIG | 91.5 | n/a |
| ORIG+PF | 91.1 | n/a |
| REGEX | 91.0 | 99.5 |
| PROMPT | 92.3 | 98.4 |
| PATCHED | 95.8 | 99.4 |
表 3: 为衡量补丁在真实场景中对行为的控制效果,我们在带有不同方面情感标注的Yelp子集上评估模型:当补丁适用时匹配补丁指定标签的能力,以及当补丁不适用时相对于基础模型的不变性
| 模型 | 正确修补 (适用时) | 不变性 (不适用时) |
|---|---|---|
| ORIG | 91.5 | n/a |
| ORIG+PF | 91.1 | n/a |
| REGEX | 91.0 | 99.5 |
| PROMPT | 92.3 | 98.4 |
| PATCHED | 95.8 | 99.4 |
| Model | Correctlypatched (applies) | Invariance (does not apply) |
| ORIG | 52.1 | n/a |
| PROMPT | 55.7 | 97.6 |
| ORIG+PF | 53.5 | n/a |
| REGEX | 55.1 | 100.0 |
| PATCHED | 79.6 | 99.4 |
| 模型 | 正确修复 (适用) | 不变性 (不适用) |
|---|---|---|
| ORIG | 52.1 | n/a |
| PROMPT | 55.7 | 97.6 |
| ORIG+PF | 53.5 | n/a |
| REGEX | 55.1 | 100.0 |
| PATCHED | 79.6 | 99.4 |
Table 4: We evaluate the model’s ability to match the label specified by the patch when it applies, and invariance w.r.t the base model when the patch does not apply, on a subset of yelp with sentiment annotations for different aspects. In this table, we specifically consider inputs where both food and service aspects differ in sentiment.
表 4: 我们在标注了不同方面情感倾向的Yelp数据子集上评估模型在补丁适用时匹配指定标签的能力,以及在补丁不适用时相对于基础模型的不变性。本表特别关注食物和服务两方面情感倾向均存在差异的输入样本。
/ negative”, and evaluate models as to how often (on average) the prediction is as expected when the patch applies and how often it is unchanged when the patch does not apply. We present results in Table 3. The sentiment of both aspects typically agrees, and thus even models without patching often behave according to the patch. We note that natural language patches improve patched behavior the most (when compared to baselines), while almost never changing predictions when the patch does not apply. We additionally present results only on the subset of our aspect annotated examples where both aspects disagree in Table 4. Overall, we see a more pronounced difference i.e., our model gets a ${\sim}27$ point boost in accuracy when the patch condition applies, while maintaining invariance when the condition does not apply.
/负面",并评估模型在应用补丁时预测符合预期的平均频率,以及在不应用补丁时预测保持不变的频率。结果如表3所示。两个方面的情感通常一致,因此即使未打补丁的模型也常遵循补丁行为。我们发现自然语言补丁最能改善修补行为(与基线相比),同时几乎不会在补丁不适用时改变预测结果。表4进一步展示了仅在情感标注样本中双方观点不一致的子集上的结果。总体而言,我们观察到更显著的差异——当补丁条件适用时,模型准确率提升约27个百分点,而在条件不适用时保持预测不变性。
Patching low-accuracy slices. We identify slices where our base model has (comparatively) low accuracy, and check whether patches can improve performance. Yelp-stars consists of all examples in Yelp Review with the word ‘star’ present. For this subset, we use two overrides patch: “If review gives 1 or 2 stars, then label is negative”, “If review gives 0 stars, then label is negative”. YelpColloquial is a label-balanced slice consisting of examples having the colloquial terms {dope, wtf, omg, the shit, bomb, suck}. Because the colloquial use of these terms depends on context, we further construct Yelp-Colloquial-Control, a CheckList where the same terms are used in their traditional sense (e.g., “The manager was a dope”, “The bomb was found by the police at the restaurant”). A model can do well on both of these datasets simultaneously only if it understands the contextual nuance associated with colloquial terms, rather than relying on simple shortcuts such as equating “bomb” with “good”. For these datasets, we write simple feature-based patches such as “If food is described as bomb, then food is good” for each term. Finally, we use the “Women’s E-commerce Clothing Reviews” dataset (WCR) from Zhong et al. (2021) and add two override patches: “If review mentions phrases like needs to be returned, then label is negative”, and “If fit is boxy, then label is negative”.
修补低准确率数据切片。我们识别出基础模型准确率(相对)较低的数据切片,并检查是否可以通过修补提升性能。Yelp-stars包含Yelp Review中所有出现"star"一词的样本。针对该子集,我们应用两条覆盖式修补规则:"若评论给出1或2星,则标签为负面"、"若评论给出0星,则标签为负面"。YelpColloquial是由包含口语化术语{dope, wtf, omg, the shit, bomb, suck}的样本构成的标签平衡切片。由于这些术语的口语化含义依赖上下文,我们进一步构建Yelp-Colloquial-Control作为对照集,其中相同术语采用传统语义(例如"The manager was a dope"、"The bomb was found by the police at the restaurant")。模型只有理解口语术语的语境细微差别(而非依赖"bomb等同于好评"等简单关联),才能在这两个数据集上同时表现良好。为此我们为每个术语编写基于特征的简单修补规则,例如"若食物被描述为bomb,则食物好评"。最后,我们采用Zhong等(2021)的"女性电商服装评论"数据集(WCR),添加两条覆盖式修补规则:"若评论提及需退货等表述,则标签为负面"及"若版型描述为boxy,则标签为负面"。
Table 5: Using Override and Feature Based patches to fix bugs on various benchmarks derived from real sentiment analysis datasets. For Yelp-Colloquial, we also generate an control test based on CheckList.
| Model | Yelp-Stars | Yelp-Colloquial | Yelp-Colloquial-Control | WCR |
| ORIG | 93.1 | 89.1 | 100.0 | 89.6 |
| ORIG+PF | 93.6 | 88.6 | 100.0 | 88.9 |
| REGEX | 92.7 | 91.9 | 88.1 | 90.0 |
| PROMPT | 90.8 | 85.2 | 70.1 | 88.3 |
| PATCHED | 94.5 | 93.2 | 100.0 | 90.1 |
表 5: 使用覆盖和基于特征的补丁来修复源自真实情感分析数据集的各个基准测试中的错误。对于 Yelp-Colloquial,我们还基于 CheckList 生成了一个对照测试。
| Model | Yelp-Stars | Yelp-Colloquial | Yelp-Colloquial-Control | WCR |
|---|---|---|---|---|
| ORIG | 93.1 | 89.1 | 100.0 | 89.6 |
| ORIG+PF | 93.6 | 88.6 | 100.0 | 88.9 |
| REGEX | 92.7 | 91.9 | 88.1 | 90.0 |
| PROMPT | 90.8 | 85.2 | 70.1 | 88.3 |
| PATCHED | 94.5 | 93.2 | 100.0 | 90.1 |
In Table 5, we observe that a very small number of language patches improve performance by 0.5- 4.1 accuracy points, always outperforming both the original model and baselines. These gains are not a result of the added synthetic data, as $\mathrm{ORIG+PF}$ often lowers performance. Qualitatively, PROMPT tends to rely on shortcuts such as copying over the label in the patch rather than gating and integrating the information, while REGEX cannot deal with simple semantic understanding, e.g., the rule on Yelp-stars fires for “Will deduct 1 star for the service but otherwise everything was excellent”, leading to an incorrect patch application. Natural language patches avoid both of these pitfalls by explicitly modeling gating and feature interpretation with learnt models.
在表5中,我们观察到极少量的语言补丁能将性能提升0.5-4.1个准确点,始终优于原始模型和基线方法。这些提升并非来自新增的合成数据,因为$\mathrm{ORIG+PF}$往往会降低性能。从定性角度看,PROMPT倾向于依赖捷径策略(例如直接复制补丁中的标签而非信息门控与整合),而REGEX无法处理简单语义理解(例如Yelp星级规则会误判"服务扣一星但其他都很棒"这类表述,导致补丁应用错误)。自然语言补丁通过显式建模门控机制和基于学习模型的特征解释,成功规避了这两类缺陷。
6.2 Spouse Relation Extraction
6.2 配偶关系抽取
We construct Spouse-FewRel, an out-ofdistribution test benchmark derived from
我们构建了Spouse-FewRel,这是一个基于FewRel数据集衍生的分布外测试基准。
FewRel (Gao et al., 2019) by sampling from all relation types where at least one of the entities is a person $(n=8400)$ ), and labeling examples as positive if they have the Spouse relation, negative otherwise. We inspect 20 randomly sampled errors made by $\mathrm{ORIG+PF}$ on Spouse-FewRel, and observe that the model often confuses “Entity1 has a child with Entity2” with ”Entity1 is the child of Entity2”, and also mis classifies widowhood as negative. Thus, we write override patches for both of these error categories, resulting in 7 patches, presented in Table 6. Using all patches, we observe a ${\sim}7.4$ point F1 improvement over ORIG, while baselines either decrease F1 or barely improve it.
通过从所有至少有一个实体是人的关系类型中抽样 $(n=8400)$ ,并将具有配偶关系的样本标记为正例,否则为负例,构建了Spouse-FewRel数据集。我们检查了 $\mathrm{ORIG+PF}$ 在该数据集上随机采样的20个错误案例,发现模型常将"Entity1与Entity2育有子女"误判为"Entity1是Entity2的子女",并将丧偶情况错误分类为负例。为此,我们为这两类错误编写了覆盖补丁,共生成7个补丁(见表6)。使用全部补丁后,相比ORIG模型实现了约7.4个百分点的F1值提升,而基线方法要么降低F1值,要么仅有微弱改进。
We highlight in Table 6 a phenomenon where each natural language patch in isolation decreases performance, while all patches together increase performance. Further analysis reveals that this is because the gating head is not well calibrated in this case, and thus individual patches are applied incorrectly. However, the comparative values of $g(x,c_{i})$ are often ordered correctly, and thus a better patch is the one applied ${{\it l p}^{* }}$ in $\operatorname{Eq}2,$ ) when all patches are available. We do further analysis in Table 7, where we report the gating accuracy (i.e., whether the patch actually applies or not, labeled manually) of $l p^{*}$ on the subset of inputs where the PATCHED model changes the prediction (Diff), and where it changes the prediction to the correct label (Diff Correct). With the caveat that patches are applied softly (and thus perfect gating accuracy is not strictly necessary), we observe that a few patches seem to hurt performance even in combination with others (e.g., the first one). We also note that the patched model is right “for the right reasons” in over $72%$ of inputs where it changes the prediction to the correct one.
我们在表6中强调了一个现象:单独应用每个自然语言补丁都会降低性能,而同时应用所有补丁却能提升性能。进一步分析表明,这是因为在此情况下门控头(gating head)未能良好校准,导致单个补丁被错误应用。然而,$g(x,c_{i})$ 的比较值通常排序正确,因此当所有补丁可用时,应用 ${{\it l p}^{* }}$ (见公式2) 会是更好的选择。我们在表7中进行了更深入分析,报告了在PATCHED模型改变预测结果(Diff)及将预测改为正确标签(Diff Correct)的输入子集上,$l p^{*}$ 的门控准确率(即补丁是否实际应用,经人工标注)。需要说明的是补丁采用软性应用方式(因此严格完美的门控准确率并非必需),我们观察到少数补丁即使与其他补丁组合使用仍会损害性能(例如第一个补丁)。同时注意到,在超过 $72%$ 的预测修正为正确的案例中,修补模型的正确判断是基于合理依据的。
Table 6: Using Override Patches on Spouse-FewRel for Spouse relation extraction.
| Model | F1 |
| ORIG | 65.5 |
| ORIG+PF | 61.4 |
| REGEX | 61.0 |
| PROMPT | 65.7 |
| PATCHED | 72.9 |
| If p2is the son of p1,thenlabelisnegative | 57.5 |
| patch If p1is the son of p2,thenlabel is negative If p1 and p2 have a daughter,then label is positive | 58.9 |
| 61.9 | |
| single If p1 and p2 have a son,then label is positive | 66.8 |
| If p1 is the widow of p2,then label is positive | 63.6 |
| Using If p1is the daughter of p2,then label is negative | 50.7 |
| If p2 is the daughter of p1,then label is negative | 49.4 |
表 6: 在Spouse-FewRel数据集上使用覆盖补丁进行配偶关系抽取的结果。
| 模型 | F1 |
|---|---|
| ORIG | 65.5 |
| ORIG+PF | 61.4 |
| REGEX | 61.0 |
| PROMPT | 65.7 |
| PATCHED | 72.9 |
| 若p2是p1的儿子,则标记为负例 | 57.5 |
| 补丁:若p1是p2的儿子则标记为负例;若p1和p2有女儿则标记为正例 | 58.9 |
| 61.9 | |
| 单项:若p1和p2有儿子则标记为正例 | 66.8 |
| 若p1是p2的遗孀则标记为正例 | 63.6 |
| 使用:若p1是p2的女儿则标记为负例 | 50.7 |
| 若p2是p1的女儿则标记为负例 | 49.4 |
| Patch Condition | Diff | DiffCorrect |
| p2 is the son of p1 | 0.0 | NaN (0/0) |
| p1 is the son of p2 | 75.0 | 75.0 |
| p1 and p2 have a daughter | 63.3 | 93.8 |
| P1and p2 have a son | 78.1 | 98.3 |
| P1 isthewidowofp2 | 10.9 | 19.6 |
| P1 is the daughter ofp2 | 71.4 | 100.0 |
| P2 isthe daughterofp1 | 6.3 | 100.0 |
| Overall | 42.9 | 72.3 |
| 补丁条件 | Diff | DiffCorrect |
|---|---|---|
| p2是p1的儿子 | 0.0 | NaN (0/0) |
| p1是p2的儿子 | 75.0 | 75.0 |
| p1和p2有一个女儿 | 63.3 | 93.8 |
| p1和p2有一个儿子 | 78.1 | 98.3 |
| p1是p2的遗孀 | 10.9 | 19.6 |
| p1是p2的女儿 | 71.4 | 100.0 |
| p2是p1的女儿 | 6.3 | 100.0 |
| 总体 | 42.9 | 72.3 |
Table 7: We measure how often the chosen patch correctly applies to an input (i.e., gating accuracy) for Spouse-FewRel, for the set of inputs where the patched model and original model differ (Diff) as well as the subset where the patched model is correct (Diff $\cap$ Correct).
表 7: 我们测量了在Spouse-FewRel数据集中,所选补丁正确应用于输入的频率(即门控准确率),包括原始模型与补丁模型输出不同的输入子集(Diff)以及补丁模型正确的子集(Diff $\cap$ Correct)。
7 Analysis
7 分析
7.1 How Important are EITs?
7.1 EIT的重要性
The goal of Entropy Increasing Transformations (EITs; Section 3) is to prevent the interpreter head from learning shortcuts that either ignore patch features or rely exclusively on them. We perform an ablation, comparing our model to a model trained without EITs on the CheckLists in Table 2 (Section 5), where the feature-based patch consequent supplies important information for making a correct prediction. From Table 8, we note that the interpreter head trained without EITs has much lower performance on these datasets (as expected).
熵增变换(EITs;第3节)的目标是防止解释器头部学习忽略补丁特征或完全依赖它们的捷径。我们进行了消融实验,将我们的模型与未使用EITs训练的模型在表2(第5节)的CheckLists上进行比较,其中基于特征的补丁结果为做出正确预测提供了重要信息。从表8可以看出,未使用EITs训练的解释器头部在这些数据集上的性能明显较低(符合预期)。
Table 8: Patching Accuracy of a model with and without Entropy Increasing Transformations (EITs).
| Patch Consequent | Patched | Patched(WithoutEITs) |
| p1 went on a honeymoon with p2 | 59.1 | 33.7 |
| p1 has kids with p2 | 75.2 | 74.4 |
| p1isengaged top2 | 77.7 | 64.8 |
| food is good | 67.8 | 54.2 |
| food is bad | 88.7 | 56.5 |
| serviceisgood | 62.8 | 52.9 |
| serviceisbad | 62.8 | 52.9 |
| Overall | 70.6 | 55.6 |
表 8: 使用与未使用熵增变换 (EITs) 的模型修补准确率对比
| 修补结果 | 修补后 (带EITs) | 修补后 (不带EITs) |
|---|---|---|
| p1 和 p2 去度蜜月 | 59.1 | 33.7 |
| p1 和 p2 有孩子 | 75.2 | 74.4 |
| p1 和 p2 订婚 | 77.7 | 64.8 |
| 食物好吃 | 67.8 | 54.2 |
| 食物难吃 | 88.7 | 56.5 |
| 服务好 | 62.8 | 52.9 |
| 服务差 | 62.8 | 52.9 |
| 总体 | 70.6 | 55.6 |

Figure 4: How many additional finetuning training examples it takes to reach the same accuracy level as patching. We report the mean and standard deviations across 5 runs.
图 4: 达到与补丁相同准确率水平所需的额外微调训练样本数量。我们报告了5次运行的平均值和标准差。
7.2 Comparison to fine-tuning
7.2 与微调 (fine-tuning) 的对比
8 Related Work
8 相关工作
While patching is computationally lightweight, it requires domain knowledge or error analysis of incorrectly labeled examples. However, once such analysis is performed, one can label these additional examples and finetune the model on them. Ignoring the computational and infrastructure costs of repeated finetuning, for patching to be a competitive alternative to finetuning from an annotation budget perspective, we require the gains from patching to only be matched by multiple labeled examples. To compare language patches with finetuning, we consider Yelp-stars, Yelp-Colloquial, and Spouse-FewRel and split each dataset into a training set with 128 examples, and a test set with remaining examples. Next, we finetune ORIG, on $k={2,4,8,16,32,64,128}$ examples from the training set, stopping early if finetuning performance exceeds patched performance. We finetune for 64 steps and optimize using AdamW with a fixed learning rate of 1e-4. We report means and standard deviations obtained from finetuning with 5 random seeds.
虽然修补(patching)在计算上较为轻量,但它需要领域知识或对错误标注样本进行错误分析。然而,一旦完成此类分析,就可以标注这些额外样本并对其进行模型微调。忽略重复微调的计算和基础设施成本,从标注预算的角度来看,要使修补成为微调的有力替代方案,我们要求修补带来的收益仅需与多个标注样本相匹配。为了比较语言修补与微调的效果,我们选取Yelp-stars、Yelp-Colloquial和Spouse-FewRel数据集,将每个数据集划分为包含128个样本的训练集和剩余样本的测试集。接着,我们在训练集中选取$k={2,4,8,16,32,64,128}$个样本对ORIG进行微调,若微调性能超过修补性能则提前停止。我们采用AdamW优化器进行64步微调,固定学习率为1e-4。最终报告基于5个随机种子微调得到的均值与标准差。
Results are presented in Fig. 4, where we note that over 100 labeled examples are needed to match the performance of a single patch on Yelp-Stars or 7 patches on Spouse-FewRel. On Yelp-Colloquial, the patched performance is matched with a mere 16 examples. However, as noted earlier, YelpColloquial is susceptible to simple shortcuts, and we observe that the performance on the control set Yelp-Colloquial-Control suffers significantly as we finetune on more data (with very high variance). Thus, we conclude that language patches on these datasets are not only very efficient in terms of annotation effort (when compared to labeling data for finetuning), but also less susceptible to simple shortcuts that do not address the problem at the right level of abstraction.
结果如图4所示,我们注意到需要超过100个标注样本才能匹配Yelp-Stars上单个补丁的性能,或Spouse-FewRel上7个补丁的性能。在Yelp-Colloquial上,仅需16个样本即可达到补丁性能。但如前所述,Yelp-Colloquial容易受到简单捷径的影响,我们观察到随着微调数据量增加(方差极大),控制集Yelp-Colloquial-Control的性能显著下降。因此我们得出结论:这些数据集上的语言补丁不仅标注效率极高(相较于微调所需标注数据),而且更不易受到未在正确抽象层级解决问题的简单捷径影响。
Learning with Language. Natural language instructions or explanations have been used for training fewshot image class if i ers (Mu et al., 2020; Andreas et al., 2018), text class if i ers (Zaidan and Eisner, 2008; Srivastava et al., 2018; Camburu et al., 2018; Hancock et al., 2018; Murty et al., 2020), and in the context of RL (Branavan et al., 2012; Goyal et al., 2019; Co-Reyes et al., 2019; Mu et al., 2022). All of these works are concerned with reducing labeled data requirements with language supervision, while our setting involves using language as a corrective tool to fix bugs at test time.
语言学习。自然语言指令或解释已被用于训练少样本图像分类器 (Mu et al., 2020; Andreas et al., 2018)、文本分类器 (Zaidan and Eisner, 2008; Srivastava et al., 2018; Camburu et al., 2018; Hancock et al., 2018; Murty et al., 2020) 以及强化学习场景 (Branavan et al., 2012; Goyal et al., 2019; Co-Reyes et al., 2019; Mu et al., 2022)。这些研究都着眼于通过语言监督降低标注数据需求,而我们的设定则涉及将语言作为测试阶段的纠错工具。
Prompt Engineering. An emerging technique for re-purposing language models for arbitrary downstream tasks involves engineering “prompts”. Prompts are high level natural language descriptions of tasks that allow developers to express any task as language modeling (Brown et al., 2020; Gao et al., 2021; Zhong et al., 2021). While we could try and directly use prompting to incorporate language patches, our experiments show that the models we consider fail to correctly utilize patches in the prompt (Section 4). With increasing scale models may gain the ability to interpret patches zero-shot, but qualitative exploration of the largest available models at the time of writing (e.g. GPT-3; Brown et al., 2020) indicates they still suffer from the same problem. Using patches for corrective purposes requires an accurate interpretation model, as well as ignoring the patch when it is not applicable. We solve these challenges by learning a gating head and an interpretation head through carefully constructed synthetic data.
提示工程 (Prompt Engineering)。一种重新利用语言模型处理任意下游任务的新兴技术涉及设计"提示"。提示是对任务的高级自然语言描述,使开发者能够将任何任务表达为语言建模 (Brown et al., 2020; Gao et al., 2021; Zhong et al., 2021)。虽然我们可以尝试直接使用提示来整合语言补丁,但实验表明我们所考虑的模型无法正确利用提示中的补丁 (第4节)。随着模型规模的扩大,它们可能获得零样本解释补丁的能力,但对当前最大可用模型 (如GPT-3;Brown et al., 2020) 的定性探索表明,它们仍存在相同问题。将补丁用于校正目的需要一个精确的解释模型,以及在补丁不适用时忽略它。我们通过精心构建的合成数据学习门控头和解释头来解决这些挑战。
Editing Factual Knowledge. Test time editing of factual knowledge in models is considered by Talmor et al. (2020); Cao et al. (2021); Mitchell et al. (2021); Meng et al. (2022). Instead of modifying factual knowledge, we show that free-form language patches can be used to fix bugs on real data, such as correctly interpreting the meaning of the word “bomb” in the context of food or predicting that divorced people are no longer married.
编辑事实知识。Talmor等人(2020)、Cao等人(2021)、Mitchell等人(2021)和Meng等人(2022)研究了模型在测试时对事实知识的编辑。与修改事实知识不同,我们展示了自由形式的语言补丁可用于修复真实数据中的错误,例如正确解释"bomb"一词在食物语境中的含义,或预测离婚人士不再处于婚姻状态。
9 Conclusion
9 结论
When faced with the task of fixing bugs in trained models, developers often resort to brittle regex rules or finetuning, which requires curation and labeling of data, is computationally intensive, and susceptible to shortcuts. This work proposes natural language patches which are declarative statements of the form “if $c$ , then $\overrightarrow{q}^{,}$ that enable developers to control the model or supply additional information with conditions at the right level of abstraction. We proposed an approach to patching that models the task of determining if a patch applies (gating) separately from the task of integrating the information (interpreting), and showed that this approach results in significant improvements on two tasks, even with very few patches. Moreover, we show that patches are efficient (1-7 patches are equivalent or better than as many as 100 finetuning examples), and more robust to potential shortcuts. Our system is a first step in letting users correct models through a single step “dialogue”. Avenues for future work include extending our approach to a back-and-forth dialogue between developers and models, modeling pragmatics, interpreting several patches at once, and automating patch finetuning.
面对修复已训练模型中错误的任务时,开发者通常采用脆弱的正则表达式规则或微调方法,这些方法需要数据整理和标注,计算成本高且容易走捷径。本研究提出自然语言补丁 (natural language patches) ,即形式为"若 $c$ ,则 $\overrightarrow{q}^{,}$"的声明式语句,使开发者能在恰当的抽象层级上通过条件控制模型或提供额外信息。我们提出了一种补丁方法,将判断补丁是否适用(门控)与信息整合(解释)两个任务分开建模,并证明该方法在两项任务中即使使用极少补丁也能带来显著改进。此外,我们发现补丁效率极高(1-7个补丁的效果相当于甚至优于多达100个微调样本),且对潜在捷径更具鲁棒性。我们的系统是实现用户通过单步"对话"修正模型的第一步。未来研究方向包括:将方法扩展为开发者与模型间的双向对话、语用建模、同时解释多个补丁,以及自动化补丁微调。
head on each patch, one can trade off exactness for efficiency, by running the gating head on a much smaller candidate set identified using fast approximate nearest neighbors (Johnson et al., 2019) on sentence embeddings.
在每个补丁上使用门控头时,可以通过在由句子嵌入快速近似最近邻 (Johnson et al., 2019) 识别出的更小候选集上运行门控头,来用精确度换取效率。
Scaling to more patch types. The current approach requires writing patch templates beforehand based on prior knowledge of the kinds of corrective feedback that developers might want to write in the future. Writing patch templates manually is fundamentally bottle necked by human creativity and foresight. Morever, since humans are required to write templates, it makes scaling up to different patch types harder, since we expect generalization to completely new patch types to be poor e.g., generalizing to a patch that requires counting. Future work can explore automatic generation of synthetic patch templates e.g., using pre-trained language models.
扩展到更多补丁类型。当前方法需要基于开发者未来可能想编写的纠正反馈类型预先编写补丁模板。手动编写补丁模板从根本上受限于人类的创造力和预见性。此外,由于需要人工编写模板,扩展到不同补丁类型的难度更大,因为我们预期对全新补丁类型的泛化能力会很差(例如泛化到需要计数的补丁)。未来工作可以探索自动生成合成补丁模板(例如使用预训练语言模型)。
Interpreting multiple patches. Finally, the approach we develop can only incorporate a single patch at a time, by selecting the most relevant patch from our patch library. This precludes the model from being able to combine features from multiple patches—e.g., “caviar is a kind of food” and “If caviar is described as overpowering, then caviar is spoiled”.
解析多个补丁。最后,我们开发的方法每次只能整合一个补丁,即从补丁库中选择最相关的补丁。这使得模型无法结合多个补丁的特征——例如,“鱼子酱是一种食物”和“如果鱼子酱被描述为味道过重,那么鱼子酱已经变质”。
10 Acknowledgements
10 致谢
SM was partly funded by a gift from Apple Inc. We are grateful to Jesse Mu, Mirac Suzgun, Pratyusha Sharma, Eric Mitchell, Ashwin Paranjape, Tongshuang Wu, Yilun Zhou and the anonymous reviewers for helpful comments. The authors would also like to thank members of the Stanford NLP group and the Adaptive Systems and Interaction group at MSR for feedback on early versions of this work.
SM 的部分资金由 Apple Inc. 的捐赠资助。我们感谢 Jesse Mu、Mirac Suzgun、Pratyusha Sharma、Eric Mitchell、Ashwin Paranjape、Tongshuang Wu、Yilun Zhou 以及匿名评审提供的宝贵意见。作者还要感谢斯坦福 NLP 小组和 MSR 自适应系统与交互小组的成员对本工作早期版本的反馈。
References
参考文献
11 Reproducibility
11 可复现性
Code and model checkpoints are available at https: //github.com/Mur ty Shi khar/Language Patching.
代码和模型检查点可在 https: //github.com/Mur ty Shi khar/Language Patching 获取。
12 Limitations
12 局限性
Scaling to large patch libraries. For our approach, inference time scales linearly with the size of the patch library. This is primarily because the gating head makes predictions on each patch in our patch library (Eq 2). Instead of running the gating
扩展到大型补丁库。对于我们的方法,推理时间与补丁库的大小呈线性增长。这主要是因为门控头会对补丁库中的每个补丁进行预测(公式2)。而不是运行门控
Editing factual knowledge in language models.
编辑语言模型中的事实性知识
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Win- ter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Eliza- beth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating large language models trained on code. CoRR, abs/2107.03374.
Mark Chen、Jerry Tworek、Heewoo Jun、Qiming Yuan、Henrique Ponde de Oliveira Pinto、Jared Kaplan、Harrison Edwards、Yuri Burda、Nicholas Joseph、Greg Brockman、Alex Ray、Raul Puri、Gretchen Krueger、Michael Petrov、Heidy Khlaaf、Girish Sastry、Pamela Mishkin、Brooke Chan、Scott Gray、Nick Ryder、Mikhail Pavlov、Alethea Power、Lukasz Kaiser、Mohammad Bavarian、Clemens Winter、Philippe Tillet、Felipe Petroski Such、Dave Cummings、Matthias Plappert、Fotios Chantzis、Elizabeth Barnes、Ariel Herbert-Voss、William Hebgen Guss、Alex Nichol、Alex Paino、Nikolas Tezak、Jie Tang、Igor Babuschkin、Suchir Balaji、Shantanu Jain、William Saunders、Christopher Hesse、Andrew N. Carr、Jan Leike、Joshua Achiam、Vedant Misra、Evan Morikawa、Alec Radford、Matthew Knight、Miles Brundage、Mira Murati、Katie Mayer、Peter Welinder、Bob McGrew、Dario Amodei、Sam McCandlish、Ilya Sutskever 和 Wojciech Zaremba。2021。评估基于代码训练的大语言模型。CoRR,abs/2107.03374。
John D. Co-Reyes, Abhishek Gupta, Suvansh Sanjeev, Nick Altieri, Jacob Andreas, John DeNero, Pieter Abbeel, and Sergey Levine. 2019. Guiding policies with language via meta-learning.
John D. Co-Reyes、Abhishek Gupta、Suvansh Sanjeev、Nick Altieri、Jacob Andreas、John DeNero、Pieter Abbeel 和 Sergey Levine。2019. 通过元学习用语言引导策略。
Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Association for Computational Linguistics (ACL).
Tianyu Gao、Adam Fisch 和 Danqi Chen。2021。让预训练语言模型成为更好的少样本学习器。载于《计算语言学协会》(ACL)。
Tianyu Gao, Xu Han, Hao Zhu, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. 2019. FewRel 2.0: Towards more challenging few-shot relation classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 6251–6256, Hong Kong, China. Association for Computational Linguistics.
Tianyu Gao、Xu Han、Hao Zhu、Zhiyuan Liu、Peng Li、Maosong Sun和Jie Zhou。2019。FewRel 2.0:迈向更具挑战性的少样本关系分类。载于《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议(EMNLP-IJCNLP)论文集》,第6251–6256页,中国香港。计算语言学协会。
Prasoon Goyal, Scott Niekum, and Raymond J. Mooney. 2019. Using natural language for reward shaping in reinforcement learning. CoRR, abs/1903.02020.
Prasoon Goyal、Scott Niekum 和 Raymond J. Mooney。2019。在强化学习中使用自然语言进行奖励塑形。CoRR, abs/1903.02020。
Braden Hancock, Martin Bringmann, Paroma Varma, Percy Liang, Stephanie Wang, and Christopher Ré. 2018. Training class if i ers with natural language explanations. volume 1.
Braden Hancock、Martin Bringmann、Paroma Varma、Percy Liang、Stephanie Wang和Christopher Ré。2018。使用自然语言解释训练分类器。第1卷。
Austin W Hanjie, Ameet Deshpande, and Karthik Narasimhan. 2022. Semantic supervision: Enabling generalization over output spaces. arXiv preprint arXiv:2202.13100.
Austin W Hanjie、Ameet Deshpande 和 Karthik Narasimhan. 2022. 语义监督: 实现输出空间的泛化能力. arXiv预印本 arXiv:2202.13100.
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547.
Jeff Johnson、Matthijs Douze 和 Hervé Jégou。2019。基于 GPU 的十亿级相似性搜索。《IEEE 大数据汇刊》7(3):535–547。
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual knowledge in gpt. ArXiv, abs/2202.05262.
Kevin Meng、David Bau、Alex Andonian 和 Yonatan Belinkov。2022。在 GPT 中定位和编辑事实性知识。arXiv, abs/2202.05262。
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. 2021. Fast model editing at scale. arXiv preprint arXiv:2110.11309.
Eric Mitchell、Charles Lin、Antoine Bosselut、Chelsea Finn 和 Christopher D Manning。2021。大规模快速模型编辑。arXiv预印本 arXiv:2110.11309。
Jesse Mu, Percy Liang, and Noah Goodman. 2020. Shaping visual representations with language for few-shot classification.
Jesse Mu、Percy Liang 和 Noah Goodman。2020。用语言塑造视觉表征以实现少样本分类。
Jesse Mu, Victor Zhong, Roberta Raileanu, Minqi Jiang, Noah Goodman, Tim Rock t s chel, and Ed- ward Gre fens te tte. 2022. Improving intrinsic exploration with language abstractions. arXiv preprint arXiv:2202.08938.
Jesse Mu、Victor Zhong、Roberta Raileanu、Minqi Jiang、Noah Goodman、Tim Rocktäschel 和 Edward Grefenstette。2022。利用语言抽象改进内在探索。arXiv预印本 arXiv:2202.08938。
Shikhar Murty, Pang Wei Koh, and Percy Liang. 2020. Expbert: Representation engineering with natural language explanations.
Shikhar Murty、Pang Wei Koh 和 Percy Liang。2020. ExpBERT:基于自然语言解释的表征工程。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. CoRR, abs/1910.10683.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J. Liu. 2019. 探索迁移学习的极限:统一的文本到文本Transformer. CoRR, abs/1910.10683.
Jan art hanan Rajendran, Alexander Irpan, and Eric Jang. 2020. Meta-learning requires meta-augmentation. In Advances in Neural Information Processing Systems, volume 33, pages 5705–5715. Curran Associates, Inc.
Jan art hanan Rajendran、Alexander Irpan 和 Eric Jang。2020. 元学习需要元增强。载于《神经信息处理系统进展》第33卷,第5705-5715页。Curran Associates公司。
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. Beyond accuracy: Behavioral testing of NLP models with CheckList. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4902– 4912, Online. Association for Computational Linguistics.
Marco Tulio Ribeiro、Tongshuang Wu、Carlos Guestrin 和 Sameer Singh。2020。超越准确率:使用 CheckList 对 NLP 模型进行行为测试。载于《第 58 届计算语言学协会年会论文集》,第 4902–4912 页,线上会议。计算语言学协会。
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew $\mathrm{Ng}$ , and Christopher Potts. 2013. Recursive deep models for semantic compositional it y over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, Seattle, Washington, USA. Association for Computational Linguistics.
Richard Socher、Alex Perelygin、Jean Wu、Jason Chuang、Christopher D. Manning、Andrew $\mathrm{Ng}$ 和 Christopher Potts。2013. 基于情感树库的语义组合性递归深度模型。载于《2013年自然语言处理实证方法会议论文集》,第1631–1642页,美国华盛顿州西雅图。计算语言学协会。
Shashank Srivastava, Igor Labutov, and Tom Mitchell. 2018. Zero-shot learning of class if i ers from natural language quant if i cation. volume 1.
Shashank Srivastava、Igor Labutov 和 Tom Mitchell。2018. 从自然语言量化中零样本学习分类器。第1卷。
Alon Talmor, Oyvind Tafjord, Peter Clark, Yoav Goldberg, and Jonathan Berant. 2020. Leap-ofthought: Teaching pre-trained models to systematically reason over implicit knowledge. volume 2020- December.
Alon Talmor、Oyvind Tafjord、Peter Clark、Yoav Goldberg 和 Jonathan Berant。2020。Leap-ofthought:让预训练模型系统化推理隐含知识。2020年12月刊。
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, Rémi Louf, Morgan Funtow- icz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pier-ric Cistac、Tim Rault、Rémi Louf、Morgan Funtowicz、Joe Davison、Sam Shleifer、Patrick von Platen、Clara Ma、Yacine Jernite、Julien Plu、Canwen Xu、Teven Le Scao、Sylvain Gugger、Mariama Drame、Quentin Lhoest 和 Alexander M. Rush。2020。Transformer:最先进的自然语言处理技术。载于2020年会议论文集
Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics. Omar F. Zaidan and Jason Eisner. 2008. Modeling annotators: A generative approach to learning from annotator rationales. Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level Convolutional Networks for Text Classification. arXiv:1509.01626 [cs]. Ruiqi Zhong, Kristy Lee, Zheng Zhang, and Dan Klein. 2021. Meta-tuning language models to answer prompts better. CoRR, abs/2104.04670.
自然语言处理实证方法:系统演示,第38-45页,在线。计算语言学协会。Omar F. Zaidan和Jason Eisner。2008。建模标注者:一种基于标注者理据的生成式学习方法。Xiang Zhang、Junbo Zhao和Yann LeCun。2015。面向文本分类的字符级卷积网络。arXiv:1509.01626 [cs]。Ruiqi Zhong、Kristy Lee、Zheng Zhang和Dan Klein。2021。元调优大语言模型以更好地回答提示。CoRR,abs/2104.04670。
Table 9: Patch templates used for the Patch Finetuning stage for relation extraction. Each Entity is sampled from a small list of names, and cond is a set of conditions derived from keywords.
| OverridePatches | |
| If[Entity1/Entity2]isnot aperson,thenlabelisnegative | |
| If Entity1 is the[child / parent] of Entity2, then label is negative | |
| If Entity1 and Entity2 have children,then label is positive | |
| If Entity1 and Entity2 are divorced, then label is negative | |
| If Entity1 is engaged to Entity2, then label is positive | |
| If Entity1 and Entity2 are siblings, then label is negative | |
| FeatureBasedPatches | |
| If cond,then Entity1 is[married/not married] to Entity2 | |
| If | cond, then Entity1 is divorced from Entity2 |
| If | cond,then Entity1 is engaged to Entity2 |
| If | cond,then Entity1is the siblingof Entity2 |
| If | cond,then Entity1 is dating Entity2 |
| If cond, then Entity1 is the parent of Entity2 | |
表 9: 关系抽取任务中用于Patch Finetuning阶段的补丁模板。每个实体(Entity)均从小型名称列表中采样,cond为基于关键词生成的条件集合。
| OverridePatches |
|---|
| 若[Entity1/Entity2]不是人(person),则标签为负 |
| 若Entity1是Entity2的[子女/父母],则标签为负 |
| 若Entity1与Entity2有子女,则标签为正 |
| 若Entity1与Entity2已离婚,则标签为负 |
| 若Entity1与Entity2订婚,则标签为正 |
| 若Entity1与Entity2是兄弟姐妹,则标签为负 |
| FeatureBasedPatches |
|---|
| 若cond成立,则Entity1[已婚/未婚]于Entity2 |
| 若cond成立,则Entity1与Entity2离婚 |
| 若cond成立,则Entity1与Entity2订婚 |
| 若cond成立,则Entity1是Entity2的兄弟姐妹 |
| 若cond成立,则Entity1与Entity2在交往 |
| 若cond成立,则Entity1是Entity2的父母 |
A More details on Patch Finetuning
关于补丁微调的更多细节
A.1 Sentiment Analysis Data
A.1 情感分析数据
The templates used for constructing inputs are in Table 12. We pro grammatically find all patches for an input, to generate labels.
用于构建输入的模板见表12。我们通过编程方式查找输入的所有补丁,以生成标签。
A.2 Relation Extraction Data
A.2 关系抽取数据
Override Patches. Patches and Input templates for constructing patch finetuning data can be found in Table 13.
覆盖补丁。构建补丁微调数据所需的补丁和输入模板见表13。
Feature Based Patches For training the gating head, we use the same data as generated by Table 13. For training the interpreter head, we use patches and input templates in Table 11 to generate finetuning data.
基于特征的补丁
为训练门控头 (gating head),我们使用与表 13 生成相同的数据。为训练解释头 (interpreter head),我们使用表 11 中的补丁和输入模板来生成微调数据。
A.3 Additional Finetuning Details
A.3 额外微调细节
After the model is finetuned in the Task finetuning stage, we finetune it additionally with a learning rate of learning rate of 1e-4 and with a linear warmup scheduler which ramps up the learning rate from 0 to 1e-4 over 100 steps. The training batch size is 32, and we clip gradients to have a max norm of 5. We early stop based on validation performance on a held out subset of the patch finetuning data.
在任务微调阶段完成模型微调后,我们以1e-4的学习率进行额外微调,并采用线性预热调度器,在100步内将学习率从0逐步提升至1e-4。训练批次大小为32,梯度裁剪的最大范数设为5。我们根据预留的补丁微调数据子集的验证性能实施早停策略。
B Patches used for Yelp-Colloquial.
B 用于Yelp-Colloquial的补丁
We used the following patches for fixing bugs on Yelp-Colloquial:
我们为修复Yelp-Colloquial的漏洞使用了以下补丁:
“If clothes are described as dope, then clothes are good.”
如果衣服被形容为酷炫 (dope),那么衣服就是好的。
Table 10: Dataset statistics for all the real data slices considered in this work.
| Dataset | #examples |
| Yelp-Stars | 3172 |
| Yelp-Colloquial | 1784 |
| WCR | 2919 |
| Yelp-Colloquial (Control) | 67 |
| Yelp-Aspect | 439 |
| Spouse-NYT | 8400 |
表 10: 本研究中所有真实数据切片的数据集统计信息。
| Dataset | #examples |
|---|---|
| Yelp-Stars | 3172 |
| Yelp-Colloquial | 1784 |
| WCR | 2919 |
| Yelp-Colloquial (Control) | 67 |
| Yelp-Aspect | 439 |
| Spouse-NYT | 8400 |
C More examples of Entropy Increasing Transformations
C 熵增变换的更多示例
To perform Entropy Increasing Transformations (EITs) for relation extraction, we convert rel (see Table 11 into nonce words e.g., “Alice has a kid with John” gets transformed into “Alice has a wug with John”, for which we use a patch “If Entity1 has a wug with Entity2, then Entity1 and Entity2 have kids
为进行关系提取的熵增变换(EITs),我们将rel (见表11)转换为临时词,例如"Alice has a kid with John"被转换为"Alice has a wug with John",对此我们使用补丁"如果Entity1 has a wug with Entity2,那么Entity1和Entity2有孩子"
D Regex Based Patches.
基于正则表达式的D补丁
The exact functions we use for patching with regexes can be found in Listing 1 and Listing 2.
我们用于正则表达式修补的具体函数可在代码清单1和代码清单2中找到。
E Data Statistics for all evaluation slices
E 所有评估切片的数据统计
Statistics for all slices used for evaluation can be found in Table 10.
用于评估的所有切片统计数据可在表 10 中找到。
| Entity1][rel][Entity2] |
| Entity1][rel][Entity2]and[Entity1]is(not) marriedto[Entity2] |
| Entity1]who[rel][Entity2],[rel2][Entity3] |
| rel= [have-kids,are-engaged,is-sibling,is-parent] |
| Entity=[Alice,Bob,Stephen,Mary] |
| Entity1][rel][Entity2] |
|---|
| Entity1][rel][Entity2]且Entity1与[Entity2]已婚 |
| Entity1]与[Entity2][rel],与[Entity3][rel2] |
| rel= [生育子女, 已订婚, 是兄弟姐妹, 是父母] |
| Entity=[Alice, Bob, Stephen, Mary] |
Table 11: Templates used for constructing inputs for patch finetuning stage in relation extraction analysis. Terms marked with ’()’ are optional. rel is a list of 4 relation types. For each relation type, we have a small list of 3 to 4 words. For instance have-kids $=$ [‘has a kid with’, ‘has a son with’, ‘has a daughter with’]
表 11: 关系抽取分析中用于构建补丁微调阶段输入的模板。标有'()'的项为可选内容。rel是包含4种关系类型的列表。每种关系类型对应一个由3到4个词组成的短列表。例如have-kids $=$ [‘has a kid with’, ‘has a son with’, ‘has a daughter with’]
Table 12: Templates used for constructing inputs for patch finetuning stage in sentiment analysis. Terms marked with $\overrightarrow{\mathbf{\theta}}(\mathbf{\varepsilon})^{,}$ are optional. adj comes from a small set of 6 positive and 6 negative adjectives, as well as 6 nonce adjectives for EITs
| The[aspect]attherestaurantwas(modifier)(not)[adj] The[aspect]was(modifier)(not)[adj] |
| Therestaurant[has/had](modifier)[adj][aspect] |
| The[aspectl] ]was(not)[adj1],the[aspect2]was(not)[adj2] |
| The[aspectl]was(not)[adj1],but the[aspect2]was(not)[adj2] |
| The[aspectl]wasreally(not)[adj1],even thoughthe[aspect2]was(not)[adj2] |
| aspect=[food,service,ambience] |
表 12: 情感分析中用于构建补丁微调阶段输入的模板。标记为 $\overrightarrow{\mathbf{\theta}}(\mathbf{\varepsilon})^{,}$ 的术语为可选项。adj 来自包含6个积极形容词、6个消极形容词以及6个用于EIT的无意义形容词的小型集合
| 模板 |
|---|
| The[aspect] at the restaurant was (modifier) (not) [adj] The[aspect] was (modifier) (not) [adj] |
| The restaurant [has/had] (modifier) [adj] [aspect] |
| The[aspect1] was (not) [adj1], the[aspect2] was (not) [adj2] |
| The[aspect1] was (not) [adj1], but the[aspect2] was (not) [adj2] |
| The[aspect1] was really (not) [adj1], even though the[aspect2] was (not) [adj2] |
aspect=[food, service, ambience]
Table 13: Patches along with a subset of inputs used for the Patch Finetuning stage for the Spouse relation extraction task. For each input, we highlight the two entities and provide examples of some positive and negative patches.
| Examples | |
| eo:Entity1 divorced Entity2 | |
| e1:Entity1haskidswithEntity2 | |
| Patches | e2:Entityl is theparent of Entity2 |
| e3:Entity1andEntity2areengaged | |
| e4:Entity1andEntity2arejustfriendsorcoworkers | |
| e5:Entity1orEntity2isnothuman Entity1and Entity2have a kid named Person3.e1,e2 | |
| Inputs | Entity1 and Entity2 have a kid named Person3. e2,e1 |
| Entity1 proposed to Entity2. The event was witnessed by Entityl's best friend Person3.e3,e4 Entity1 proposed to Entity2. The event was witnessed by Entity1's best friend Person3. e4, eo | |
| Entity1 has decided to divorce Entity2. They have a child named Person3. eo, e3 | |
| Entity1 has decided to divorce Entity2. They have a child named Person3. e2, eo | |
| Entityl works at location. e5, eo |
表 13: 配偶关系抽取任务中用于补丁微调阶段的输入子集及对应补丁。每个输入中我们高亮标注了两个实体,并提供部分正负补丁示例。
| 示例 | |
|---|---|
| e0: Entity1 与 Entity2 离婚 | |
| e1: Entity1 与 Entity2 育有子女 | |
| 补丁 | e2: Entity1 是 Entity2 的家长 |
| e3: Entity1 与 Entity2 已订婚 | |
| e4: Entity1 与 Entity2 仅是朋友或同事关系 | |
| e5: Entity1 或 Entity2 非人类 | |
| 输入 | Entity1 和 Entity2 育有名为 Person3 的孩子。e1, e2 |
| Entity1 和 Entity2 育有名为 Person3 的孩子。e2, e1 | |
| Entity1 向 Entity2 求婚,该事件由 Entity1 的挚友 Person3 见证。e3, e4 | |
| Entity1 向 Entity2 求婚,该事件由 Entity1 的挚友 Person3 见证。e4, e0 | |
| Entity1 决定与 Entity2 离婚,他们育有名为 Person3 的孩子。e0, e3 | |
| Entity1 决定与 Entity2 离婚,他们育有名为 Person3 的孩子。e2, e0 | |
| Entity1 在某地工作。e5, e0 |
Listing 2: Regex based patching for using feature based patches for all experiments.
列表 2: 基于正则表达式的修补方案,用于在所有实验中使用基于特征的补丁。