An Automatic Evaluation Framework for Multi-turn Medical Consultations Capabilities of Large Language Models
大语言模型多轮医疗问诊能力的自动评估框架
Yusheng Liao1†, Yutong $\mathbf{Meng^{1\dagger}}$ , Hongcheng $\mathbf{Liu^{1}}$ , Yanfeng Wang12, Yu Wang12∗ 1 Cooperative Medianet Innovation Center, Shanghai Jiao Tong University 2Shanghai Artificial Intelligence Laboratory
Yusheng Liao1†, Yutong $\mathbf{Meng^{1\dagger}}$, Hongcheng $\mathbf{Liu^{1}}$, Yanfeng Wang12, Yu Wang12∗ 1 上海交通大学协同媒体网络创新中心 2 上海人工智能实验室
Abstract
摘要
Large language models (LLMs) have achieved significant success in interacting with human. However, recent studies have revealed that these models often suffer from hallucinations, leading to overly confident but incorrect judgments. This limits their application in the medical domain, where tasks require the utmost accuracy. This paper introduces an automated evaluation framework that assesses the practical capabilities of LLMs as virtual doctors during multi-turn consultations. Consultation tasks are designed to require LLMs to be aware of what they do not know, to inquire about missing medical information from patients, and to ultimately make diagnoses. To evaluate the performance of LLMs for these tasks, a benchmark is proposed by reformulating medical multiplechoice questions from the United States Medical Licensing Examinations (USMLE), and comprehensive evaluation metrics are developed and evaluated on three constructed test sets. A medical consultation training set is further constructed to improve the consultation ability of LLMs. The results of the experiments show that fine-tuning with the training set can alleviate hallucinations and improve LLMs’ performance on the proposed benchmark. Extensive experiments and ablation studies are conducted to validate the effectiveness and robustness of the proposed framework.
大语言模型(LLMs)在与人类交互方面取得了显著成功。然而,近期研究表明这些模型常出现幻觉(hallucination)现象,导致产生过度自信却错误的判断。这在需要极高准确性的医疗领域限制了其应用。本文提出一个自动化评估框架,用于衡量大语言模型在多轮问诊中作为虚拟医生的实际能力。问诊任务设计要求大语言模型能够识别未知信息、向患者询问缺失的医疗信息,并最终做出诊断。为评估模型在此类任务中的表现,我们通过重构美国医师执照考试(USMLE)中的医学多选题构建基准测试,并在三个构建的测试集上开发并评估了综合指标。进一步构建医疗问诊训练集以提升大语言模型的问诊能力。实验结果表明,使用该训练集进行微调可缓解幻觉现象,并提升模型在基准测试中的表现。通过大量实验和消融研究验证了所提框架的有效性和鲁棒性。
1 Introduction
1 引言
Recently, large language models (LLMs) have achieved remarkable success in following natural language instructions and performing real-world tasks (OpenAI, 2022, 2023). LLMs have demonstrated their ability to tackle complex problems and have shown immense potential to revolutionize various industries. However, despite their impressive capabilities, LLMs often suffer from a significant drawback known as hallucination. This means they tend to provide erroneous judgments and incorrect information with high confidence, as noted in previous studies (Zhang et al., 2023b; Zheng et al., 2023). This limitation hinders their application in tasks that require utmost accuracy, such as the medical field.
近年来,大语言模型(LLM)在遵循自然语言指令和执行现实任务方面取得了显著成就(OpenAI, 2022, 2023)。这些模型已展现出解决复杂问题的能力,并显示出革新各行各业的巨大潜力。然而,尽管功能强大,大语言模型仍普遍存在一个被称为"幻觉"的显著缺陷。如先前研究所述(Zhang et al., 2023b; Zheng et al., 2023),它们往往会高度自信地提供错误判断和虚假信息。这一局限性阻碍了其在医疗等需要极高准确度的任务中的应用。

Figure 1: Difference between a) the LLM and b) Doctor. The LLM, with its limitations, tends to make judgments without consulting all available information, while the doctor conducts consultations before making a final diagnosis.
图 1: a) 大语言模型 (LLM) 与 b) 医生的区别。受限于自身缺陷,大语言模型倾向于在未参考全部可用信息的情况下做出判断,而医生会在最终诊断前进行问诊。
In clinical diagnosis, doctors typically begin with limited patient information and engage in iterative rounds of consultation to gather pertinent medical details until they reach a final diagnosis (Zhang et al., 2023a; Wei et al., 2018). However, LLMs with hallucinations tend to make judgments directly and depend on limited information, leading to incorrect decisions. This disparity in behavior presents a significant challenge when incorporating LLMs into the medical field, where precise diagnosis and decision-making are paramount. To truly harness the potential of LLMs for medical use, it is essential to measure their hallucinations and explore their practical abilities in multi-turn consultation conversations. Although there are already many works attempting to apply LLMs in the medical domain, most of them primarily focus on the question-answering task to explore the medical knowledge of LLMs (Kung et al., 2023; Singhal et al., 2023; Nori et al., 2023; Hiesinger et al., 2023), rather than exploring their practical abilities as a doctor.
在临床诊断中,医生通常从有限的患者信息出发,通过多轮问诊收集相关医疗细节,直至得出最终诊断 (Zhang et al., 2023a; Wei et al., 2018)。然而,存在幻觉(hallucination)的大语言模型倾向于直接基于有限信息作出判断,导致错误决策。这种行为差异为将大语言模型引入医疗领域带来了重大挑战——该领域对精确诊断和决策有着极高要求。要真正释放大语言模型在医疗应用中的潜力,必须量化其幻觉现象,并探索其在多轮问诊对话中的实际能力。尽管已有许多研究尝试将大语言模型应用于医疗领域,但多数工作主要聚焦于问答任务来探索模型的医学知识 (Kung et al., 2023; Singhal et al., 2023; Nori et al., 2023; Hiesinger et al., 2023),而非考察其作为医生的实际能力。
In this paper, we introduce an automated evaluation framework for assessing the practical capabilities of LLMs as virtual doctors during multiturn consultations. This task requires LLMs to recognize the absence of medical information, pose relevant questions throughout the consultation process, and ultimately accomplish specific objectives based on the consultation history, such as providing accurate diagnoses or offering appropriate medical advice. Therefore, LLMs that exhibit superior performance in multi-turn consultations are expected to have reduced hallucinations and enhanced medical capabilities. To implement the proposed pipeline, we begin by constructing a benchmark that decomposes the multiple-choice question into the patient’s medical information and the final task to be completed by the LLMs. Then we adopt ChatGPT (OpenAI, 2022) to simulate the patient’s dialogue with the doctor model during the consultation process and provide medical information that helps LLMs make a diagnosis. Lastly, we devise metrics to evaluate the performance of LLMs in multi-turn consultation dialogues by considering indicators for patients, doctors, and final tasks. In summary, the major contributions of our paper are summarized as follows:
本文提出了一种自动化评估框架,用于衡量大语言模型(LLM)在多轮问诊中作为虚拟医生的实践能力。该任务要求大语言模型能够识别医疗信息的缺失,在整个问诊过程中提出相关问题,并最终基于问诊记录完成特定目标(例如提供准确诊断或恰当医疗建议)。因此,在多轮问诊中表现优异的大语言模型应当具有更低的幻觉率与更强的医疗能力。为实现该流程,我们首先构建了一个基准测试,将选择题分解为患者医疗信息和需要大语言模型完成的最终任务;接着采用ChatGPT (OpenAI, 2022)模拟患者在问诊过程中与医生模型的对话,并提供有助于大语言模型做出诊断的医疗信息;最后我们设计了一套综合考虑患者指标、医生指标和最终任务指标的评估体系。本文的主要贡献可概括如下:
2 Related Works
2 相关工作
There are already plenty of works attempting to adopt LLMs in the medical domain to act as a doctor (Zhang et al., 2023a; Li et al., 2023; Han et al., 2023). Compared to the traditional medical language model like BioGPT (Luo et al., 2022), medical LLMs fine-tuned on instruction have a stronger ability to interact with humans and show the potential to deploy in the real world. However, existing works found that it is difficult for LLMs to ensure the accuracy of generated content, which limits its further application. Therefore, it is essential to propose an evaluation method to measure the medical ability of the LLMs. Lots of medical benchmarks only focus on measuring the medical knowledge (Kung et al., 2023; Singhal et al., 2023; Nori et al., 2023; Hiesinger et al., 2023) or the re- sponse ability (Zeng et al., 2020; Liu et al., 2022) of the models, instead of exploring their practical abilities as a doctor.
已有大量研究尝试在医疗领域采用大语言模型 (LLM) 扮演医生角色 (Zhang et al., 2023a; Li et al., 2023; Han et al., 2023)。相较于传统医疗语言模型如 BioGPT (Luo et al., 2022),基于指令微调的医疗大语言模型展现出更强的人机交互能力,并具备实际部署潜力。然而现有研究发现,大语言模型难以保证生成内容的准确性,这限制了其进一步应用。因此,亟需建立评估方法来衡量大语言模型的医疗能力。现有医疗基准大多仅关注模型医学知识 (Kung et al., 2023; Singhal et al., 2023; Nori et al., 2023; Hiesinger et al., 2023) 或应答能力 (Zeng et al., 2020; Liu et al., 2022) 的测评,而非探索其作为医生的实践能力。
Our proposed automatic evaluation pipeline has the following innovative points compared to previous work: 1) Different from previous works only generate one response according to the dialog history, our pipeline can conduct real multiple rounds of conversation test. The proposed evaluation pipeline uses ChatGPT to simulate patients which can generate responses to the LLMs at each turn during the consultation process. 2) LLMs are required to complete the entire clinical diagnosis process from consultation to decision-making, which can measure the medical capabilities of models comprehensively.
我们提出的自动评估流程与之前工作相比有以下创新点:1) 不同于以往研究仅根据对话历史生成单一回复,我们的流程能进行真实多轮对话测试。该评估流程使用ChatGPT模拟患者,能在问诊过程中每一轮对话都生成针对大语言模型的回应。2) 要求大语言模型完成从问诊到决策的完整临床诊断流程,可全面评估模型的医疗能力。
3 Proposed Framework
3 提出的框架
In this section, we will first introduce the data structure and task formulation. Then we will provide a detailed description of the automatic pipeline for evaluating the LLMs. Finally, we will discuss the construction of the dataset.
在本节中,我们将首先介绍数据结构与任务定义,随后详细描述评估大语言模型的自动化流程,最后讨论数据集的构建过程。
3.1 Task Formulation
3.1 任务定义
Each instance of the data consists of two parts, a patient’s medical information $M$ and a task $T$ which is required to be completed at the end of the conversations. Since the consultations typically begin with the question of the patients, we also generate a fixed patient’s initial request $P_ {0}$ for each instance based on its medical information. $P_ {0}$ generally includes a rough description of the symptoms and the requests for help. As a result, the dataset with size equal to $N$ can be formulated as:
每个数据实例包含两部分:患者的医疗信息 $M$ 和需要在对话结束时完成的任务 $T$。由于问诊通常以患者提问开始,我们还会根据医疗信息为每个实例生成固定的患者初始请求 $P_ {0}$。$P_ {0}$ 通常包含症状的粗略描述和求助请求。因此,规模为 $N$ 的数据集可表示为:
$$
{(M^{(i)},P_ {0}^{(i)},T^{(i)})}_ {i=1}^{N}
$$
$$
{(M^{(i)},P_ {0}^{(i)},T^{(i)})}_ {i=1}^{N}
$$
The whole evaluation pipeline consists of two LLMs, the doctor LLM and the patient LLM. These two are responsible for being evaluated and interacting with the doctor LLM under certain information, respectively. At the beginning of the conversation, doctor LLM can get a preliminary understanding of the patient’s situation and need according to the $P_ {0}$ . Then it is required to ask questions to get useful information from the patient in the following communication. Specifically, in the $i$ -th round of conversation, the doctor LLM give an query Di = {d(1i ), d(2i ), ..., d|(iD)i|} based on the conversa
整个评估流程由两个大语言模型组成,分别是医生大语言模型和患者大语言模型。这两个模型分别负责在特定信息下接受评估以及与医生大语言模型进行交互。对话开始时,医生大语言模型可以根据$P_ {0}$对患者的状况和需求形成初步了解,随后需要在后续交流中通过提问从患者处获取有用信息。具体而言,在第$i$轮对话中,医生大语言模型会根据对话历史生成查询Di = {d(1i ), d(2i ), ..., d|(iD)i|}。
$$
p_ {\theta}(D_ {i}|D_ {1:i-1},P_ {0:i-1})=\prod_ {k=1}^{|D_ {i}|}p_ {\theta}(d_ {k}^{(i)}|D_ {1:i-1},P_ {0:i-1})
$$
$$
p_ {\theta}(D_ {i}|D_ {1:i-1},P_ {0:i-1})=\prod_ {k=1}^{|D_ {i}|}p_ {\theta}(d_ {k}^{(i)}|D_ {1:i-1},P_ {0:i-1})
$$
where $|D_ {i}|$ is the length of the doctor LLM $i$ - th outputs and $\theta$ is the parameter of the doctor LLM. Similarly, patient LLM generates a response $P_ {i}={p_ {1}^{(i)},p_ {2}^{(i)},...,p_ {|P_ {i}|}^{(i)}}$ p(iP)i } based on the query of the doctor, conversation history, and medical information:
其中 $|D_ {i}|$ 表示医生大语言模型第 $i$ 次输出的长度,$\theta$ 为医生大语言模型的参数。同理,患者大语言模型基于医生问询、对话历史及医疗信息生成响应 $P_ {i}={p_ {1}^{(i)},p_ {2}^{(i)},...,p_ {|P_ {i}|}^{(i)}}$ p(iP)i }:
$$
p_ {\phi}(P_ {i}|D_ {1:i},P_ {0:i-1},M)=\prod_ {k=1}^{|P_ {i}|}p_ {\theta}(p_ {k}^{(i)}|D_ {1:i},P_ {0:i-1},M)
$$
$$
p_ {\phi}(P_ {i}|D_ {1:i},P_ {0:i-1},M)=\prod_ {k=1}^{|P_ {i}|}p_ {\theta}(p_ {k}^{(i)}|D_ {1:i},P_ {0:i-1},M)
$$
where $\phi$ represents the parameters of the patient LLM. When the doctor is no longer inquiring about patient information, we consider the consultation process to be over. At the end of the consultation conversations, doctor LLMs are requested to complete some tasks according to the whole conversation, such as providing diagnosis, etiology, or treatment plan, etc.
其中 $\phi$ 代表患者大语言模型的参数。当医生不再询问患者信息时,我们认为问诊过程结束。在问诊对话结束时,医生大语言模型需要根据完整对话完成一些任务,例如提供诊断、病因或治疗方案等。
3.2 Patient Simulation
3.2 患者模拟
Traditional evaluation of consultations is difficult when it comes to assessing a model’s ability to handle multi-round conversations, which are inherently uncertain and uncontrollable. However, the emergence of large dialogue models has made automatic multi-round conversations possible. These models have undergone instruction fine-tuning, resulting in strong interactive abilities that can simulate the process of multiple rounds of dialogue. Additionally, large models can generate output according to specified requirements. In this paper, we utilize large-language models with instruction fine-tuning to simulate the behavior of patients in consultation conversations, thus allowing for an easy evaluation of the doctor model’s ability in multiple rounds of consultations.
传统评估方法在衡量模型处理多轮对话能力时存在困难,因为这类对话具有内在不确定性和不可控性。然而,大型对话模型的出现使得自动化多轮对话成为可能。这些模型经过指令微调后具备强大的交互能力,能够模拟多轮对话过程。此外,大模型还能根据指定要求生成输出。本文利用经过指令微调的大语言模型来模拟患者在咨询对话中的行为,从而便捷评估医生模型在多轮咨询中的表现。

Figure 2: The prompt for patient LLMs. Elements in double braces ${{}}$ are replaced with question-specific values.
图 2: 面向患者的LLM提示模板。双大括号 ${{}}$ 中的内容会被替换为具体问题相关值。
We have defined some fundamental requirements for the patient LLM to ensure the robustness of the pipeline:
为确保流程的稳健性,我们为患者大语言模型定义了一些基本要求:
• Honesty. The patient LLM should provide an accurate and rational description of the symptoms in medical information, without reporting any nonexistent symptoms. This allows the doctor LLM to obtain correct information and reduces uncertainty in multiple rounds of dialogue.
• 诚实性。患者大语言模型应准确合理地描述医疗信息中的症状,不报告任何不存在的症状。这能让医生大语言模型获取正确信息,并减少多轮对话中的不确定性。
• Strictness. As a comprehensive patient simulator, the patient model is provided with all information in ground truth. However, experiments have shown that this can lead to the model revealing medical information that doctors have not inquired about, resulting in the leakage of extra information. To be in line with real-world patients, the patient model is supposed to give information in a "lazy" mode, thereby improving the disc rim inability of the pipeline towards the doctor LLMs.
• 严格性。作为综合性患者模拟器,患者模型拥有全部真实信息。但实验表明,这可能导致模型透露医生未询问的医疗信息,造成额外信息泄露。为符合真实患者行为,患者模型应采用"懒惰"模式提供信息,从而提升流程对医生大语言模型的判别能力。
• Colloquialism. To better align with reality, we assume that patients do not have much medical knowledge, so their output should be colloquial. In experiments, we have also found that the colloquial prompt construction helps with the strictness requirements, which is also reported in Chen et al. (2023).
• 口语化。为了更好地贴合现实情况,我们假设患者不具备太多医学知识,因此他们的输出应采用口语化表达。实验中也发现,口语化的提示构建有助于满足严格性要求,这一点在Chen等人 (2023) 的研究中也有报道。
In summary, we designed a prompt for the patient that meets the three characteristics described above (as shown in Figure 2). This allowed us
总之,我们为患者设计了一个符合上述三个特征的提示(如图 2 所示)。这使得我们
Medical Information
医疗信息
A 61-year-old Caucasian male presents to your office with chest pain. He states that he is worried about his heart, as his father died at age 62 from a heart attack. He reports that his chest pain worsens with large meals and spicy foods and improves with calcium carbonate. He denies dyspnea on exertion and an ECG is normal. What is the most likely cause of this patient's pain?
一位61岁的白人男性因胸痛就诊。他表示担心自己的心脏问题,因其父亲62岁时死于心脏病发作。患者主诉胸痛在大餐或辛辣食物后加重,服用碳酸钙可缓解。否认劳力性呼吸困难,心电图检查正常。该患者疼痛最可能的原因是什么?
Initial Request
| What's causingmy chestpain after eating? | |
| MedicalInformation(Key,Value) | |
| Key | Value |
| Patientage Patient gender Chiefcomplaint Family history | 61 |
| Male | |
| Chest pain | |
| Fatherdiedfromaheartattack at age 62 | |
| Chestpainworsenedby Chestpainimprovedby Dyspnea on exertion Electrocardiogram (ECG) | Largemeals and spicy foods Calciumcarbonate Denied |
初始请求
| 键 | 值 |
|---|---|
| 患者年龄 | 61 |
| 患者性别 | 男性 |
| 主诉 | 胸痛 |
| 家族史 | 父亲62岁时死于心脏病发作 |
| 胸痛加重因素 | 大量进食和辛辣食物 |
| 胸痛缓解因素 | 碳酸钙 |
| 劳力性呼吸困难 | 否认 |
| 心电图 (ECG) | 未提及 |
| A 61-year-oldCaucasianmalepresents toyour office with chestpain.He states thathe is worried about his heart,ashis father diedat age 62fromaheart attack. Hereports thathis chestpainworsens withlarge meals andspicy foods andimproveswithcalcium carbonate. |
| He denies dyspnea on exertion and an ECG is normal. Task |
| Whatis the most likely cause of thispatient'spain? A.Partiallyoccludedcoronaryartery B.Esophagealadenocarcinoma C.Umbilicalhernia |
| 一位61岁白人男性因胸痛就诊。他表示担心自己的心脏问题,因其父亲在62岁时死于心脏病发作。患者主诉胸痛在进食大量或辛辣食物时加重,服用碳酸钙后可缓解。 |
| 患者否认劳力性呼吸困难,心电图检查结果正常。 |
| 该患者胸痛最可能的原因是什么?
A. 冠状动脉部分闭塞
B. 食管腺癌
C. 脐疝 |
Figure 3: Example of the constructed data. The multiple choice question is first split into medical information and task part. Then the initial request and key-value pair list are extracted by ChatGPT from the medical information.
图 3: 构建数据示例。选择题首先被拆分为医学信息部分和任务部分。随后ChatGPT从医学信息中提取出初始请求和键值对列表。
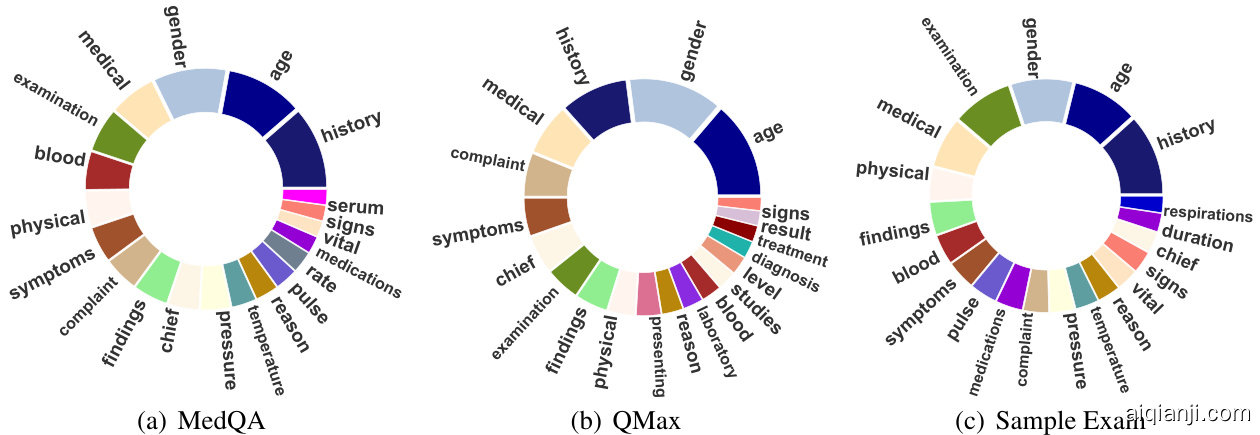
Figure 4: Most frequent words distribution of three datasets. We draw the Top-20 most frequent keys of extracted medical information. Note that the same word is represented by the same color across different datasets.
图 4: 三个数据集的最高频词分布。我们绘制了提取医疗信息中出现频率最高的前20个关键词。请注意,相同单词在不同数据集中使用相同颜色表示。
| Statistics | MedQA | QMax | Sample Exam |
| #ofinstances | 1127 | 1483 | 299 |
| # of options per question | 5.00 | 5.11 | 5.12 |
| # of tokens per medical information | 106.00 | 80.85 | 119.28 |
| #of tokensperinitialrequest | 14.01 | 14.28 | 14.32 |
| # of items per medical information | 7.87 | 7.81 | 8.25 |
Table 1: The statistics of MedQA, QMAX, Sample Exam Datasets
| 统计项 | MedQA | QMax | 样本考试 |
|---|---|---|---|
| 实例数量 | 1127 | 1483 | 299 |
| 每题选项数 | 5.00 | 5.11 | 5.12 |
| 每条医疗信息token数 | 106.00 | 80.85 | 119.28 |
| 初始请求token数 | 14.01 | 14.28 | 14.32 |
| 每条医疗信息项目数 | 7.87 | 7.81 | 8.25 |
表 1: MedQA、QMAX及样本考试数据集统计
to obtain a large language model that can better simulate the patient.
获取一个能更好模拟患者的大语言模型。
3.3 Data Construction
3.3 数据构建
Because there is a scarcity of data that provides comprehensive medical information and diagnostic results, we reformulated the multiple choice questions in physician exams as the test datasets for our benchmark. We have created three datasets and filtered out questions that do not contain patient information:
由于缺乏提供全面医疗信息和诊断结果的数据,我们将医师考试中的选择题重新构建为基准测试数据集。我们创建了三个数据集,并过滤掉了不包含患者信息的问题:
• MedQA: We have chosen the English test set of the MedQA1, which was collected from Medical Licensing Examinations of the United States (USMLE).
• MedQA:我们选择了MedQA的英文测试集,该数据集来自美国医学执照考试(USMLE)。
QMax: The dataset includes materials purchased from the USMLE $\mathbf{\nabla}\cdot\mathbf{R}\mathbf{X}^{2}$ resources. There are a total of 11 categories, such as cardiology, endocrine, g astro enteric, etc.
QMax:该数据集包含从USMLE $\mathbf{\nabla}\cdot\mathbf{R}\mathbf{X}^{2}$资源购买的材料,共分为11个类别,如心脏病学、内分泌学、胃肠病学等。
• Sample Exam: Sample exam materials were sourced from USMLE practice materials . We collect the dataset from the provided by Kung et al. (2023). In addition, we have removed the duplicated question in the test set.
• 样本考试:样本考试材料来自美国医师执照考试(USMLE)的练习资料。我们从Kung等人(2023)提供的数据集中收集了数据。此外,我们还移除了测试集中的重复问题。
For each dataset, we first split the multi-choice question into two parts: the informational part $M$ and the task part $T$ . These respectively describe the patient background and task requirements. Then, we use ChatGPT to generate the patient’s initial request at the beginning of the consultation conversation, based on the medical information. We also extract the main medical information into keyvalue pairs, following the approach proposed by Agrawal et al. (2022). Figure 3 provides an example of the multi-choice question and its corresponding pre processed data. Additionally, we calculate the most frequently occurring words in the keys of the medical information for the three datasets, as shown in Figure 4. Detailed statistical information for the three datasets is also presented in Table 1.
对于每个数据集,我们首先将多选题拆分为两部分:信息部分 $M$ 和任务部分 $T$ ,分别描述患者背景和任务要求。接着,我们使用 ChatGPT 根据医疗信息生成患者在咨询对话开始时的初始请求。同时,按照 Agrawal 等人 (2022) 提出的方法,我们将主要医疗信息提取为键值对。图 3 展示了多选题及其对应预处理数据的示例。此外,我们计算了三个数据集中医疗信息键的最常出现词汇,如图 4 所示。三个数据集的详细统计信息也呈现在表 1 中。
4 Experiments
4 实验
4.1 Automated Metrics
4.1 自动化指标
Considering that LLMs have achieved great success in language fluency, our evaluation mainly focuses on the ability of doctor LLMs in multi-turn dialogue consultation. We introduce several indicators to measure the performance of the doctor LLMs in different dimensions.
考虑到大语言模型(LLM)在语言流畅性方面已取得巨大成功,我们的评估主要聚焦于医疗大语言模型在多轮对话问诊中的能力表现。我们引入多项指标从不同维度衡量医疗大语言模型的性能。
Medical Information Coverage Rate We use three types of ROUGE scores (Lin, 2004) to measure the amount of medical information presented in dialogue at the word level: Recall, Precision, and F1 scores. We evaluate the entire conversation at a fine-grained level from both the doctor’s and patient’s perspectives. For the patient evaluation, we compute three types of ROUGE-1 scores between the output of the patient LLM and the value of the extracted medical information $M$ . The Recall represents how much information is exposed by the patient LLM, the Precision reflects the information density output by the patient model, and the F1 score provides a comprehensive evaluation of the patient LLM output. For the doctor evaluation, we measure the similarity between the output of the doctor LLM and the key of the extracted medical information. Specifically, the Recall measures the hallucination level of doctor LLMs. The Precision represents the professionalism of doctor LLM, as medical information generally contains medical terms. The higher the proportion of medical terms in the output of the doctor’s model, the more professional the model’s output we suppose. The F1 score is also a comprehensive evaluation of doctor LLMs.
医疗信息覆盖率
我们使用三种ROUGE分数 (Lin, 2004) 在词级别衡量对话中呈现的医疗信息量:召回率 (Recall)、精确率 (Precision) 和F1分数。我们从医生和患者双视角对完整对话进行细粒度评估。针对患者侧评估,我们计算患者大语言模型输出与提取医疗信息值$M$之间的三种ROUGE-1分数。召回率反映患者大语言模型暴露的信息量,精确率体现患者模型输出的信息密度,F1分数则综合评估患者大语言模型输出质量。
对于医生侧评估,我们测量医生大语言模型输出与提取医疗信息关键词的相似度。具体而言,召回率用于衡量医生大语言模型的幻觉水平,精确率代表医生大语言模型的专业性(因医疗信息通常包含医学术语)。医生模型输出中医学术语占比越高,我们认为其输出越专业。F1分数同样作为医生大语言模型的综合评估指标。
Accuracy of the Final Task After the multi-turn consultation, the model is required to complete a specific task, which here is to choose the right answer for a multiple-choice question according to the consultation dialogue. The accuracy of this task reflects the accuracy and coverage of medical information throughout the entire consultation process, which is an important indicator of the consultation ability of the doctor LLM. Considering that most LLMs perform poorly on the question of the USMLE
最终任务的准确性
在多轮咨询后,模型需要完成一项具体任务,即根据咨询对话为选择题选择正确答案。该任务的准确性反映了整个咨询过程中医疗信息的准确性和覆盖范围,这是衡量医生大语言模型咨询能力的重要指标。考虑到大多数大语言模型在美国医师执照考试(USMLE)问题上表现不佳
We use ChatGPT-Turbo-3.5 as our final task solver due to its accessibility and robustness.
我们最终选择 ChatGPT-Turbo-3.5 作为任务求解器,因其易用性和鲁棒性。
Average Turn and Average Length To evaluate the performance of different models in multi-turn consultations, we need to measure the average number of rounds and the average length of each conversation. The doctor LLM will stop asking questions once it assumes that the medical information is enough to make a decision. Average Turn is an indicator measuring both doctor LLMs precision and hallucination level as more hallucinated models tend to stop asking questions at earlier rounds. Ideally, we hope that models with higher accuracy in consultations also require fewer rounds and shorter conversations.
平均轮次与平均长度
为评估不同模型在多轮问诊中的表现,我们需要测量对话的平均轮次和平均长度。当医生大语言模型认为已掌握足够医疗信息时,便会停止提问。平均轮次指标既能反映医生大语言模型的精准度,也能体现其幻觉水平——幻觉越严重的模型往往会在更早轮次停止提问。理想情况下,我们期望问诊准确率更高的模型同时具备更少的对话轮次和更短的对话长度。
4.2 Doctor Construction
4.2 医生构建
To test the robustness of our framework, we employed several LLMs to simulate doctors and test various prompts for each LLM.
为了测试我们框架的稳健性,我们采用了多个大语言模型来模拟医生,并为每个大语言模型测试了不同的提示词。
Upper Bound In this case, the model can directly complete the final task according to the golden medical information. The accuracy of the upper bound is limited by the medical ability of the model for task completion.
上界
在这种情况下,模型可以根据黄金医疗信息直接完成最终任务。上界的准确率受限于模型完成任务的医疗能力。
Lower Bound In the lower bound, the models were required to complete the final task only based on the initial request of the patient. This case can be used to indicate how much medical information is contained in the initial request. Therefore, the incremental information during the consultation process can be measured by the increase in accuracy.
下限
在下限情况下,模型仅需根据患者的初始请求完成最终任务。该案例可用于衡量初始请求中包含的医疗信息量。因此,咨询过程中的增量信息可通过准确率的提升来量化。
ChatGPT-Turbo-3.5 In general, ChatGPT does not actively ask questions. Therefore, we prompted ChatGPT to act like a doctor in order to complete the proposed tasks in the evaluation pipeline. In the experiments, we observed that ChatGPT would like to draw a conclusion after a brief inquiry, where the number of rounds of consultation is generally less than five. Therefore, we designed two versions of Doctors with different prompts named ChatGPTLong and ChatGPT-Short, respectively. The long version tries to guide the model to ask as many questions as possible, up to 10 questions, and the short version doesn’t require the model to ask excessive questions. In both settings, the model will naturally come to a conclusion when it thinks the information provided is enough to answer the patient’s initial question.
ChatGPT-Turbo-3.5
通常情况下,ChatGPT不会主动提问。因此,我们通过提示让ChatGPT模拟医生行为,以完成评估流程中的既定任务。实验中发现,ChatGPT倾向于在简短询问后直接得出结论,咨询轮次通常少于五轮。为此,我们设计了两版不同提示的医生角色:ChatGPT-Long和ChatGPT-Short。长版本会引导模型尽可能提问(最多10个问题),短版本则不要求模型过度提问。两种设置下,当模型认为所获信息足以回答患者初始问题时,便会自然终止对话。
Table 2: Performance of different models on three datasets. Len and Turn represent the average length of the sequence in each turn and the average number of turns for each consultation instance. The best results in each dataset are bold.
| Dataset | Case | Patient | Doctor | Turn | Acc. | ||||||
| Rec. | Pre. | F1 | Len. | Rec. | Pre. | F1 | Len. | ||||
| MedQA | Upper-B | - | 53.50 | ||||||||
| Lower-B | 3.45 | 22.78 | 5.75 | 一 | = | 35.49 | |||||
| ChatGPT-L | 28.26 | 17.84 | 20.65 | 9.15 | 18.67 | 3.58 | 5.82 | 15.94 | 9.17 | 39.31 | |
| ChatGPT-S | 19.74 | 21.45 | 19.17 | 10.65 | 18.06 | 4.08 | 6.27 | 30.29 | 4.58 | 37.27 | |
| Vicuna | 22.91 | 18.58 | 18.42 | 8.60 | 11.11 | 3.90 | 5.34 | 9.82 | 8.22 | 38.60 | |
| Vicuna-FT | 33.19 | 23.55 | 26.02 | 9.17 | 23.06 | 6.11 | 9.02 | 14.77 | 8.32 | 40.20 | |
| QMAX | Upper-B | 55.02 | |||||||||
| Lower-B | 5.13 | 21.87 | 8.00 | 36.95 | |||||||
| ChatGPT-L | 32.55 | 12.94 | 17.69 | 9.19 | 19.82 | 2.77 | 4.72 | 16.16 | 9.24 | 41.94 | |
| ChatGPT-S | 27.96 | 16.84 | 19.82 | 10.97 | 21.98 | 3.17 | 5.29 | 37.95 | 4.14 | 41.40 | |
| Vicuna | 26.72 | 14.44 | 16.55 | 7.63 | 11.28 | 2.97 | 4.37 | 9.88 | 8.04 | 39.45 | |
| Vicuna-FT | 33.17 | 16.62 | 20.79 | 8.86 | 21.62 | 4.83 | 7.30 | 14.26 | 7.84 | 42.75 | |
| Sample Exam | Upper-B | - | 60.20 | ||||||||
| Lower-B | 3.51 | 23.69 | 5.83 | - | 40.13 | ||||||
| ChatGPT-L | 26.98 | 18.70 | 20.71 | 9.32 | 19.35 | 4.17 | 6.66 | 16.54 | 9.12 | 43.81 | |
| ChatGPT-S | 19.74 | 23.28 | 19.52 | 10.97 | 18.70 | 4.65 | 6.93 | 31.56 | 4.43 | 45.15 | |
| Vicuna | 23.30 | 21.01 | 19.95 | 8.55 | 11.87 | 4.60 | 6.12 | 10.28 | 8.27 | 42.81 | |
| Vicuna-FT | 32.59 | 24.43 | 26.05 | 9.42 | 22.21 | 6.85 | 9.70 | 13.82 | 8.27 | 46.82 | |
表 2: 不同模型在三个数据集上的性能表现。Len 和 Turn 分别表示每轮对话的平均序列长度和每个咨询实例的平均轮数。每个数据集中的最佳结果以粗体显示。
| 数据集 | 案例 | 患者 | 医生 | Turn | Acc. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Rec. | Pre. | F1 | Len. | Rec. | Pre. | F1 | Len. | ||||
| MedQA | Upper-B | - | 53.50 | ||||||||
| Lower-B | 3.45 | 22.78 | 5.75 | - | = | 35.49 | |||||
| ChatGPT-L | 28.26 | 17.84 | 20.65 | 9.15 | 18.67 | 3.58 | 5.82 | 15.94 | 9.17 | 39.31 | |
| ChatGPT-S | 19.74 | 21.45 | 19.17 | 10.65 | 18.06 | 4.08 | 6.27 | 30.29 | 4.58 | 37.27 | |
| Vicuna | 22.91 | 18.58 | 18.42 | 8.60 | 11.11 | 3.90 | 5.34 | 9.82 | 8.22 | 38.60 | |
| Vicuna-FT | 33.19 | 23.55 | 26.02 | 9.17 | 23.06 | 6.11 | 9.02 | 14.77 | 8.32 | 40.20 | |
| QMAX | Upper-B | 55.02 | |||||||||
| Lower-B | 5.13 | 21.87 | 8.00 | 36.95 | |||||||
| ChatGPT-L | 32.55 | 12.94 | 17.69 | 9.19 | 19.82 | 2.77 | 4.72 | 16.16 | 9.24 | 41.94 | |
| ChatGPT-S | 27.96 | 16.84 | 19.82 | 10.97 | 21.98 | 3.17 | 5.29 | 37.95 | 4.14 | 41.40 | |
| Vicuna | 26.72 | 14.44 | 16.55 | 7.63 | 11.28 | 2.97 | 4.37 | 9.88 | 8.04 | 39.45 | |
| Vicuna-FT | 33.17 | 16.62 | 20.79 | 8.86 | 21.62 | 4.83 | 7.30 | 14.26 | 7.84 | 42.75 | |
| Sample Exam | Upper-B | - | 60.20 | ||||||||
| Lower-B | 3.51 | 23.69 | 5.83 | - | 40.13 | ||||||
| ChatGPT-L | 26.98 | 18.70 | 20.71 | 9.32 | 19.35 | 4.17 | 6.66 | 16.54 | 9.12 | 43.81 | |
| ChatGPT-S | 19.74 | 23.28 | 19.52 | 10.97 | 18.70 | 4.65 | 6.93 | 31.56 | 4.43 | 45.15 | |
| Vicuna | 23.30 | 21.01 | 19.95 | 8.55 | 11.87 | 4.60 | 6.12 | 10.28 | 8.27 | 42.81 | |
| Vicuna-FT | 32.59 | 24.43 | 26.05 | 9.42 | 22.21 | 6.85 | 9.70 | 13.82 | 8.27 | 46.82 |
Vicuna Vicuna is an open-sourced LLM trained by fine-tuning LLaMA (Touvron et al., 2023) on user-shared conversations collected from ShareGPT4, and has demonstrated strong multiround interaction ability. We used the same prompt as ChatGPT-Short for Vicuna to act like a doctor.
Vicuna
Vicuna是一个开源的大语言模型(LLM),通过对LLaMA (Touvron等人,2023)在ShareGPT4收集的用户共享对话上进行微调训练而成,并展现出强大的多轮交互能力。我们采用与ChatGPT-Short相同的提示词,使Vicuna模拟医生角色。
Vicuna Finetuned We created training data using the training set of the MedQA dataset to illustrate Vicuna’s consultation abilities. First, we reconstructed the main medical information in keyvalue pairs, which is the same process used for the test data. Next, we generated a golden consultation dialogue between a doctor and a patient, with ChatGPT playing the role of both. In each turn, the doctor ChatGPT asked a key question based on the medical information, and the patient ChatGPT answered it. Finally, the doctor ChatGPT provided an analysis and diagnosis.
Vicuna微调版 我们使用MedQA数据集的训练集创建训练数据,以展示Vicuna的问诊能力。首先,我们将核心医疗信息重构为键值对形式,该流程与测试数据处理方式一致。接着,通过ChatGPT同时扮演医患双方,生成标准问诊对话:医生ChatGPT每轮根据医疗信息提出关键问题,患者ChatGPT作答,最终由医生ChatGPT给出分析诊断。
4.3 Main Result
4.3 主要结果
Table 2 presents the results of various models discussed in Section 4.2 on three datasets. The accuracy gap between the Upper-Bound and LowerBound cases is significant, highlighting how insufficient medical information often leads to degraded diagnostic performance of the models. After several rounds of interaction with patient models, the accuracies improve in all cases, indicating that current models possess basic consultation abilities and can deduce missing information to some extent.
表 2: 展示了 4.2 节讨论的多种模型在三个数据集上的结果。Upper-Bound 与 LowerBound 案例之间的准确率差距显著,这突显了医疗信息不足往往导致模型诊断性能下降。在与患者模型进行多轮交互后,所有案例的准确率均有所提升,表明当前模型具备基础问诊能力,且能在一定程度上推断缺失信息。
Comparing two versions of ChatGPT, we observe that ChatGPT-Long requires approximately twice as many consultation rounds as ChatGPTShort, while the length of its questions is about half that of ChatGPT-Short. Despite the different prompts eliciting different behaviors, both models exhibit similar performance according to the patients/doctor F1 scores and task accuracy. This suggests that the model’s ability is the primary factor determining its effectiveness, rather than the design of the prompts.
对比两个版本的ChatGPT,我们发现ChatGPT-Long需要的咨询轮次约为ChatGPT-Short的两倍,但其问题长度仅为后者的一半。尽管不同提示词会引发不同行为,但根据患者/医生F1分数和任务准确率评估,两个模型表现出相近的性能。这表明模型能力才是决定其有效性的主要因素,而非提示词设计。
Although Vicuna performs relatively poorly in the consultation process compared to ChatGPT, it demonstrates much stronger capabilities after being fine-tuned on the constructed training data. VicunaFT achieves the best F1-score on all datasets while keeping the average lengths of questions and answers short. This shows that Vicuna-FT has less hallucination problem and are more precise and professional. With such powerful inquiry ability, the model can obtain more detailed medical information from patients, thereby improving the accuracy of the final task. In fact, it can even surpass ChatGPT by up to 1.67 percent.
尽管Vicuna在咨询过程中表现相对ChatGPT较差,但在构建的训练数据上进行微调后展现出更强大的能力。VicunaFT在所有数据集上均取得最佳F1分数,同时保持问答平均长度较短。这表明Vicuna-FT存在更少的幻觉问题,且更加精准专业。凭借如此强大的问询能力,该模型能从患者处获取更详细的医疗信息,从而提升最终任务的准确率。事实上,其表现甚至能最高超越ChatGPT达1.67%。

Figure 5: Turn Analysis results of different LLMs on MedQA dataset.
图 5: 不同大语言模型在MedQA数据集上的轮次分析结果。
5 Analysis
5 分析
In this section, we conduct more experiments to analyze the robustness of the proposed framework. We first decompose the consultation process and explore the performance of different models at the turn level. Then we assess the diversity of the models’ outputs and the impact of the consultation order on the final accuracy. Finally, we investigate the models’ performance on cases with different complexity.
在本节中,我们通过更多实验分析所提出框架的鲁棒性。首先分解咨询流程,探究不同模型在对话轮次层面的表现;随后评估模型输出的多样性及咨询顺序对最终准确率的影响;最后研究模型在不同复杂度案例上的性能表现。
5.1 Turn Number Analysis
5.1 回合数分析
We conducted an investigation into how medical information was revealed throughout the multi-turn dialogue. Because different doctor LLMs have very different distributions of turn numbers, we used the percentage of rounds finished as the index for dialogue completeness. Specifically, for the case where the percentage of rounds is equal to $20%$ , if the total number of rounds is 10, the first two rounds of the conversation will be selected as the consultation process. We plot important metrics, including accuracy and F1-scores of patient LLM and doctor LLM in Figure 5.
我们对医疗信息在多轮对话中的揭示过程进行了调查。由于不同医生大语言模型的对话轮数分布差异较大,我们采用完成轮次百分比作为对话完整性的指标。具体而言,当完成轮次百分比为$20%$时,若总轮数为10轮,则选取前两轮对话作为咨询过程。我们在图5中绘制了患者大语言模型和医生大语言模型的关键指标,包括准确率和F1分数。
It can be observed that the accuracy and F1 scores have an overall increasing trend as the dialogue progresses. The indicators quickly improve during the initial rounds of the conversation and then tend to plateau. This suggests that relevant information is easily acquired at the beginning of the consultation, while the challenge lies in obtaining further details of the patient’s information. Among the models, Vicuna-FT has the highest F1 score for both doctor and patient, indicating that it has less hallucination problem and can obtain more information from patients, resulting in the best overall performance in accuracy score.
可以观察到,随着对话的推进,准确率和F1分数总体呈上升趋势。各项指标在对话初期快速提升,随后趋于平缓。这表明在问诊初期容易获取相关信息,而挑战在于进一步获取患者信息的细节。在模型中,Vicuna-FT对医生和患者的F1分数均为最高,说明其幻觉问题较少,能从患者处获取更多信息,因此在准确率指标上表现最优。
Table 3: Diversity of doctors’ query. The table shows three types of diversity scores with different metrics. Note that a lower score represents more distinction between the models’ questions.
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
| ChatGPT-L | 38.96 | 20.53 | 35.86 |
| ChatGPT-S | 39.28 | 21.89 | 32.74 |
| Vicuna | 62.51 | 53.98 | 61.95 |
| Vicuna-FT | 33.39 | 20.00 | 31.45 |
表 3: 医生提问的多样性。该表展示了三种不同指标的多样性分数。请注意,分数越低表示模型生成的问题区分度越高。
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| ChatGPT-L | 38.96 | 20.53 | 35.86 |
| ChatGPT-S | 39.28 | 21.89 | 32.74 |
| Vicuna | 62.51 | 53.98 | 61.95 |
| Vicuna-FT | 33.39 | 20.00 | 31.45 |
Note that there is a slight drop in both doctor F1 score and accuracy after $80%$ of the dialogue process. This is because the doctor LLMs are prone to give a diagnosis or advice near the end of the consultation process, which adds noise to the dialogue history and causes performance degradation in the final task.
需要注意的是,在对话进程达到80%后,医生F1分数和准确率都出现了小幅下降。这是因为医生大语言模型倾向于在问诊接近尾声时给出诊断或建议,这些内容会为对话历史引入噪声,导致最终任务的性能下降。

Figure 6: Accuracy curves of random, direct, and reversed orders of medical information keys.
图 6: 医疗信息键随机顺序、直接顺序和反向顺序的准确率曲线。
5.2 Diversity of Doctors’ Queries
5.2 医生查询的多样性
There are some repetition queries found in the case study. Therefore, we calculated the similarity between the queries of doctor LLMs in the same conversation as follows:
案例研究中发现了一些重复查询。因此,我们按如下方式计算了同一对话中医生的LLM查询之间的相似度:
$$
{\mathrm{Diversity}}={\frac{1}{K(K-1)}}\sum_ {i=1}^{K}\sum_ {j=1}^{K}\sin(D_ {i},D_ {j})
$$
$$
{\mathrm{Diversity}}={\frac{1}{K(K-1)}}\sum_ {i=1}^{K}\sum_ {j=1}^{K}\sin(D_ {i},D_ {j})
$$
where $K$ is the total rounds of the consultation conversation, and $\mathrm{sim}(\cdot,\cdot)$ is the similarity function. As presented in Table 3, Vicuna-FT generates the most diverse queries among all models, while Vicunas generate the most similar ones. Additionally, we can also observe that Vicuna tended to repeat questions during the consultation process.
其中 $K$ 是咨询对话的总轮数,$\mathrm{sim}(\cdot,\cdot)$ 是相似度函数。如表 3 所示,Vicuna-FT 在所有模型中生成的查询最具多样性,而 Vicunas 生成的查询最相似。此外,我们还可以观察到 Vicuna 在咨询过程中倾向于重复提问。
5.3 Impact of Consultation Order
5.3 咨询顺序的影响
We also conducted experiments to analyze the impact of the order of doctor consultation. To eliminate the effect of different questions, we conducted an oracle case where the doctor’s questions are constructed by the keys of the extracted medical information. Specifically, at each turn, we formulated the rule-based question in the form of "Can you tell me about ${{\mathrm{key}}}^{\prime}$ according to the (key, value) pair in the extracted medical information list.
我们还进行了实验来分析医生咨询顺序的影响。为了消除不同问题的影响,我们设计了一个理想案例,其中医生的问题是根据提取的医疗信息的关键词构建的。具体来说,在每一轮对话中,我们按照"能否告诉我关于${{\mathrm{key}}}^{\prime}$的信息"的形式制定基于规则的问题,该问题依据提取的医疗信息列表中的(键, 值)对生成。
Since the keys in the extracted medical information typically range from basic medical information to more specialized medical details, we can construct three types of consultation orders, which includes direct order, random order, and reverse order. Direct order is to ask medical information questions from general to specific, while the reverse order is exactly the opposite. Figure 6 shows their impacts on final accuracy.
由于提取的医疗信息中的键通常涵盖从基础医疗信息到更专业的医疗细节,我们可以构建三种类型的咨询顺序,包括正向顺序、随机顺序和逆向顺序。正向顺序是从一般到具体地询问医疗信息问题,而逆向顺序则完全相反。图 6: 展示了它们对最终准确率的影响。
In the first part of the conversation, the reversed order performed the best, indicating that detailed information is more helpful in solving the final task. However, the final accuracy of the reverse case is lower than the other two settings even though all the cases have equal patient information. We attribute this phenomenon to the task solver’s sensitivity to the location of patient information in the context.
在对话的第一部分,逆序排列表现最佳,这表明详细信息对解决最终任务更有帮助。然而,尽管所有情况下的患者信息量相同,逆序案例的最终准确率仍低于其他两种设置。我们将此现象归因于任务求解器对上下文中患者信息位置的敏感性。
5.4 Performance on Data with Different Complexity
5.4 不同复杂度数据的性能表现
In this section, we investigate the effectiveness of different models on data with varying numbers of medical information items. The entire test set is divided into three equal parts based on the number of medical information items. As shown in Figure 7, all models perform poorly on data with a moderate amount of medical information. However, VicunaFT exhibits robust performance across all three groups. It is worth noting that ChatGPT-Long outperforms Vicuna on the Short group, while Vicuna outperforms ChatGPT-Long on the Long group. This indicates that models have a bias towards certain numbers of medical information items.
在本节中,我们研究了不同模型在包含不同数量医疗信息项的数据上的有效性。整个测试集根据医疗信息项的数量被均分为三部分。如图7所示,所有模型在中等数量医疗信息的数据上表现均不佳。然而,VicunaFT在所有三组中都展现出稳健的性能。值得注意的是,ChatGPT-Long在短文本组的表现优于Vicuna,而Vicuna在长文本组的表现优于ChatGPT-Long。这表明模型对特定数量的医疗信息项存在偏好。

Figure 7: The performance of different models with respect to the number of medical information items. The results are reported on MedQA.
图 7: 不同模型在医疗信息条目数量上的性能表现。结果基于MedQA数据集报告。
6 Conclusions
6 结论
In this paper, we proposed a novel framework to evaluate the medical ability of LLMs in multi-turn consultations and construct three test datasets by reformulating the multiple-choice questions. We adopt ChatGPT to simulate the patient in the consultation process in order to generate responses to the question of doctor LLMs. Besides, we develop comprehensive evaluation metrics to score the multi-turn conversation and improve the consultation ability and alleviate the hallucination of LLMs by constructing a training set. We also conduct extensive experiments to valid the robustness of our evaluation pipeline.
本文提出了一种新颖的框架来评估大语言模型(LLM)在多轮问诊中的医疗能力,并通过重构选择题构建了三个测试数据集。我们采用ChatGPT模拟问诊过程中的患者,以生成对医生大语言模型提问的回应。此外,我们开发了全面的评估指标来对多轮对话进行评分,并通过构建训练集来提升问诊能力、缓解大语言模型的幻觉问题。我们还进行了大量实验以验证评估流程的鲁棒性。
Limitations
局限性
Although we have utilized the most superior datasets available, this study may still be limited due to the size and potential bias of said datasets. Furthermore, the limited quantity of medical examination examples collected may hinder our ability to evaluate the model’s comprehensive capabilities in a real-world consultation scenario. Moreover, it is important to note that LLMs still encounter challenges related to hallucination and robustness, which may make the task solver susceptible to long and noisy inputs. Thus, in order to construct a more dependable and resilient solution, a more powerful LLM is necessary.
尽管我们使用了当前最优质的数据集,但本研究仍可能受限于这些数据集的规模和潜在偏差。此外,收集到的医疗检查案例数量有限,可能影响我们在真实问诊场景中评估模型综合能力的效果。值得注意的是,大语言模型仍面临幻觉 (hallucination) 和鲁棒性方面的挑战,这可能导致任务求解器对冗长且含噪声的输入较为敏感。因此,要构建更可靠、更具韧性的解决方案,需要采用更强大的大语言模型。
References
参考文献
Guilin, China, September 24-25, 2022, Proceedings, Part I, volume 13551 of Lecture Notes in Computer Science, pages 447–459. Springer.
中国桂林,2022年9月24-25日,会议录第一部分,《计算机科学讲义》第13551卷,第447-459页。Springer出版社。
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. 2022. Biogpt: generative pre-trained transformer for biomedical text generation and mining. Briefings Bioinform., 23(6).
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. 2022. BioGPT: 面向生物医学文本生成与挖掘的生成式预训练Transformer。Briefings Bioinform., 23(6).
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. 2023. Capabilities of GPT-4 on medical challenge problems. CoRR, abs/2303.13375.
Harsha Nori、Nicholas King、Scott Mayer McKinney、Dean Carignan 和 Eric Horvitz。2023. GPT-4在医学挑战问题上的能力。CoRR, abs/2303.13375.
Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A. Smith. 2023b. How language model hallucinations can snowball. CoRR, abs/2305.13534. Shen Zheng, Jie Huang, and Kevin Chen-Chuan Chang. 2023. Why does chatgpt fall short in answering questions faithfully? CoRR, abs/2304.10513.
Muru Zhang、Ofir Press、William Merrill、Alisa Liu 和 Noah A. Smith. 2023b. 大语言模型幻觉如何滚雪球式增长. CoRR, abs/2305.13534.
Shen Zheng、Jie Huang 和 Kevin Chen-Chuan Chang. 2023. ChatGPT为何难以忠实回答问题? CoRR, abs/2304.10513.