The Fully Convolutional Transformer for Medical Image Segmentation
全卷积Transformer在医学图像分割中的应用
Abstract
摘要
We propose a novel transformer, capable of segmenting medical images of varying modalities. Challenges posed by the fine-grained nature of medical image analysis mean that the adaptation of the transformer for their analysis is still at nascent stages. The overwhelming success of the UNet lay in its ability to appreciate the fine-grained nature of the segmentation task, an ability which existing transformer based models do not currently posses. To address this shortcoming, we propose The Fully Convolutional Transformer (FCT), which builds on the proven ability of Convolutional Neural Networks to learn effective image representations, and combines them with the ability of Transformers to effectively capture long-term dependencies in its inputs. The FCT is the first fully convolutional Transformer model in medical imaging literature. It processes its input in two stages, where first, it learns to extract long range semantic dependencies from the input image, and then learns to capture hierarchical global attributes from the features. FCT is compact, accurate and robust. Our results show that it outperforms all existing transformer architectures by large margins across multiple medical image segmentation datasets of varying data modalities without the need for any pretraining. FCT outperforms its immediate competitor on the ACDC dataset by 1.3%, on the Synapse dataset by 4.4%, on the Spleen dataset by $1.2%$ and on ISIC 2017 dataset by 1.1% on the dice metric, with up to five times fewer parameters. On the ACDC Post-2017- MICCAI-Challenge online test set, our model sets a new state-of-the-art on unseen MRI test cases outperforming large ensemble models as well as nnUNet with considerably fewer parameters. Our code, environments and models will be available via GitHub†.
我们提出了一种新型Transformer,能够分割不同模态的医学图像。医学图像分析的细粒度特性带来的挑战意味着,将Transformer应用于此类分析仍处于起步阶段。UNet的巨大成功在于其理解分割任务细粒度特性的能力,而现有基于Transformer的模型目前尚不具备这种能力。为解决这一不足,我们提出了全卷积Transformer (Fully Convolutional Transformer, FCT),该模型基于卷积神经网络(CNN)已被证实的有效图像表征学习能力,并结合了Transformer捕捉输入长程依赖关系的优势。FCT是医学影像文献中首个全卷积Transformer模型,其处理流程分为两个阶段:首先学习提取输入图像的长程语义依赖,继而从特征中捕获层次化全局属性。FCT具有结构紧凑、精度高且鲁棒性强的特点。实验结果表明,在多种模态的医学图像分割数据集上,FCT无需任何预训练即以显著优势超越所有现有Transformer架构:在ACDC数据集上Dice指标领先1.3%,Synapse数据集领先4.4%,Spleen数据集领先$1.2%$,ISIC 2017数据集领先1.1%,且参数量减少达五倍。在ACDC Post-2017-MICCAI-Challenge在线测试集上,我们的模型在未见过的MRI测试案例中创造了新标杆,以更少参数超越大型集成模型及nnUNet。代码、环境配置与模型将通过GitHub†发布。
1. Introduction
1. 引言
Medical image segmentation is a key tool in computer aided diagnosis. It helps detect and localise boundaries of lesions in images that can help identify potential presence of tumors and cancerous regions quickly. This has the potential to speed up diagnoses, improving the likelihood of detecting tumours and allowing clinicians to use their time more effectively, with benefits to patient outcomes [15]. Conventionally, modern medical image segmentation algorithms are built as symmetric top-down encoder-decoder structures that first compress (encode) an input image into a latent space, and then learn to decode the locations of regions of interest within images. Adding a horizontal propagation of the intermediate signal (skip connection) to this vertical information flow gives us the UNet architecture, which has arguably been the most influential leap forward in segmentation algorithms in the recent past. Most modern segmentation systems today either include the UNet or one of its variants in their pipeline. A key essence of the UNet’s success is its fully convolutional nature. The UNet does not estimate any non-convolutional trainable parameters in its structure.
医学图像分割是计算机辅助诊断中的关键工具。它有助于检测并定位图像中病变的边界,从而快速识别潜在的肿瘤和癌变区域。这种方法有望加速诊断过程,提高肿瘤检出率,并让临床医生更高效地利用时间,最终改善患者治疗效果 [15]。传统上,现代医学图像分割算法采用对称的自顶向下编码器-解码器结构,先将输入图像压缩(编码)到潜在空间,再学习解码图像中感兴趣区域的位置。在这种垂直信息流中加入中间信号的水平传播(跳跃连接),便形成了UNet架构——这可以说是近年来分割算法领域最具影响力的突破。当前大多数现代分割系统都在其流程中采用了UNet或其变体。UNet成功的关键在于其全卷积特性,其结构中没有估计任何非卷积的可训练参数。
Convolutional Neural Network (CNN) based UNet models have found great success in medical image segmentation tasks in terms of accuracy and performance. However, they still require additional improvements in order to truly help clinicians in early disease diagnosis. The inherently local nature of the convolutional operator is a key issue with CNNs, as it prevents them from exploiting long range semantic dependencies from the input images. Various methods have been proposed to add global context to CNNs, most notably, the introduction of attention mechanisms, and dilating the convolution kernel in order to increase the kernel’s receptive field. These methods however come with their own sets of drawbacks. Transformers have been hugely successful in language learning tasks [31] due to their ability to handle very long range sequence dependencies efficiently. This has led to their recent adaptation to various vision tasks [7, 18, 21, 22]. Recently proposed architectures such as ViT [7] have surpassed the performance of CNNs on benchmark imaging tasks, and many recent improvements to ViT such as CvT [36], CCT [10] and Swin Transformer [25] have shown how transformers do not need to be bulky, data hungry models, and can even work with small amounts of data to surpass the performance of CNNs. Conventionally, ViT style models first extract discrete non-overlapping patches (called tokens in NLP) from images. They then inject spatial positioning to these patches through a position encoding and pass this representation through standard transformer layers to model long rage semantic dependencies in the data.
基于卷积神经网络(CNN)的UNet模型在医学图像分割任务中取得了优异的准确性和性能表现。然而要真正辅助临床医生实现早期疾病诊断,这些模型仍需进一步改进。CNN的核心问题在于卷积算子固有的局部性特征,使其难以捕捉输入图像中的长程语义依赖关系。目前已有多种方法尝试为CNN添加全局上下文信息,最突出的包括引入注意力机制和扩张卷积核以增大感受野,但这些方法各自存在局限性。
Transformer凭借其高效处理长序列依赖的能力,在语言学习任务中取得了巨大成功[31],近年来也被成功应用于各类视觉任务[7,18,21,22]。ViT[7]等新型架构已在基准图像任务中超越CNN性能,后续改进模型如CvT[36]、CCT[10]和Swin Transformer[25]更证明了Transformer不必是庞大耗数据的模型,即使在小数据量下也能超越CNN表现。
传统ViT类模型的处理流程是:首先从图像中提取离散非重叠的图块(在NLP中称为token),通过位置编码为这些图块注入空间位置信息,然后将该表示输入标准Transformer层以建模数据中的长程语义依赖关系。
Given the obvious merits of both CNNs and Transformers, we believe the next step forward in medical image segmentation is a fully convolutional encoderdecoder deep learning model with the ability to exploit long range semantic dependencies in medical images efficiently. Towards this goal, we propose the first Fully Convolutional Transformer for medical image segmentation. Our novel Fully Convolutional Transformer layer forms the main building block of our model. It contains two key components, a Convolutional Attention module and a fully convolutional Wide-Focus module (See Section 3). We formalize our contributions as follows:
鉴于卷积神经网络(CNN)和Transformer的显著优势,我们相信医学图像分割领域的下一步发展将是能够高效利用医学图像中长程语义依赖关系的全卷积编码器-解码器深度学习模型。为实现这一目标,我们提出了首个用于医学图像分割的全卷积Transformer模型。我们创新的全卷积Transformer层构成了模型的核心模块,包含两个关键组件:卷积注意力模块和全卷积宽聚焦模块(详见第3节)。具体贡献如下:
2. Literature review
2. 文献综述
Early CNNs and Attention models: The UNet [29] was the first CNN model proposed for medical image segmentation. One of the first works that introduced attention models to medical image segmentation, did it through applying a gating function to the propagation of features from the encoder to decoder of a
早期CNN与注意力模型:UNet [29] 是首个针对医学图像分割提出的CNN模型。最早将注意力模型引入医学图像分割的研究之一,是通过在编码器到解码器的特征传播过程中应用门控函数实现的。
UNet [26]. Methods such as FocusNet [17] employ a dual encoder-decoder structure where attention gating learns to propagate the relevant features from the decoder of one UNet to the encoder of the next. One of the first works that incorporates attention mechanisms inside various filter groups in grouped convolutions is FocusNet $^{++}$ [19]. Many variants of UNets also exist that employ different residual blocks to enhance feature extraction [32, 28, 33, 20, 16]. UNet $^{++}$ [43] creates nested hierarchical dense skip connection pathways between the encoder and decoder to reduce the semantic gap between their learnt features. Of the most influential UNet variants of recent times, the nnUNet [14] automatically adapts itself to pre-process the data and select the optimal network architecture that would be best suited to the task without the need for manual intervention.
UNet [26]。诸如FocusNet [17]等方法采用双编码器-解码器结构,其中注意力门控学会将一个UNet解码器的相关特征传播到下一个编码器。首个在分组卷积中不同滤波器组内集成注意力机制的工作是FocusNet$^{++}$[19]。UNet还存在许多变体,采用不同的残差块来增强特征提取[32, 28, 33, 20, 16]。UNet$^{++}$[43]在编码器和解码器之间创建了嵌套的层次密集跳跃连接路径,以减少它们学习特征之间的语义差距。在近期最具影响力的UNet变体中,nnUNet [14]能自动适应数据预处理并选择最适合任务的网络架构,无需人工干预。
Transformer models: The original Transformer architecture [31] revolutionized natural language processing tasks and has quickly become the de-facto model for visual understanding tasks as well [7]. Transformers work well for vision due to their ability to create long range visual context but suffer from the inherent drawback of not leveraging spatial context in images like CNNs. Recent works move towards possible solutions to overcome this drawback. CvT [36], CCT [10] and Swin Transformers [25] are all attempts at integrating sufficient spatial context to transformers. In medical image segmentation, most existing research looks at creating hybrid Transformer-CNN models for feature processing. Similar to the Attention UNet [26], UNet Transformer [27] enhanced CNNs with multihead attention inside skip connections. One of the first Transformer-CNN hybrid models proposed for medical image segmentation, TransUNet [5] used a transformer encoder feeding into a cascaded convolutional decoder. Similar to TransUNet, UNETR [12] and Swin UNETR [11] use Transformers on the encoder and a convolutional decoder to construct segmentation maps. Transfuse [40] runs dual branch encoders, one with convolutional layers and the other with transformer layers and combines their features with a novel BiFusion module. The decoder for this model however, is convolutional.
Transformer模型:最初的Transformer架构[31]彻底改变了自然语言处理任务,并迅速成为视觉理解任务的事实标准模型[7]。Transformer在视觉领域表现优异,得益于其建立长距离视觉上下文的能力,但存在与生俱来的缺陷——无法像CNN那样利用图像中的空间上下文。近期研究正探索克服这一缺陷的解决方案。CvT[36]、CCT[10]和Swin Transformer[25]都尝试为Transformer整合足够的空间上下文。在医学图像分割领域,现有研究多聚焦于构建Transformer-CNN混合模型进行特征处理。类似Attention UNet[26]的做法,UNet Transformer[27]通过在跳跃连接中加入多头注意力机制来增强CNN。作为首批提出的医学图像分割混合模型,TransUNet[5]采用Transformer编码器连接级联卷积解码器的结构。与TransUNet类似,UNETR[12]和Swin UNETR[11]在编码器使用Transformer,通过卷积解码器构建分割图。Transfuse[40]采用双分支编码器设计(卷积分支与Transformer分支),并利用新型BiFusion模块融合特征,但其解码器仍为卷积结构。
Concurrent Works There is a recent shift from creating hybrid Transformer-CNN models, to refining the transformer block itself, to handle the nuances of medical images. Swin UNet [3] is the first architecture to propose a pure transformer to process medical images. Pure here refers to the image features being extracted and processed solely by transformer layers without the need for a pre-trained backbone architecture. DS-TransUNet [24] introduces the Transformer Interactive Fusion module to get better representations of global dependencies. Both these models have the Swin Transformer block at the heart of their computation. Concurrent works such as nnFormer [42] and DFormer [37] attempt to leverage both local and global context inside medical images through specially crafted multi-head self attention blocks to cater to this task. The main drawback with these models is their inherent linear nature of attention projection and feature processing, which FCT aims to alleviate.
并行研究
近期研究趋势从构建混合Transformer-CNN模型转向改进Transformer模块本身,以处理医学图像的细微特征。Swin UNet [3] 是首个提出纯Transformer处理医学图像的架构,此处"纯"指图像特征仅通过Transformer层提取处理,无需预训练主干网络。DS-TransUNet [24] 引入Transformer交互融合模块以增强全局依赖表征,这两种模型的核心计算均采用Swin Transformer模块。类似nnFormer [42] 和DFormer [37] 等并行研究通过定制多头自注意力模块,尝试利用医学图像的局部与全局上下文信息。这些模型的主要缺陷在于注意力投影与特征处理固有的线性特性,而FCT正是为解决该问题而设计。
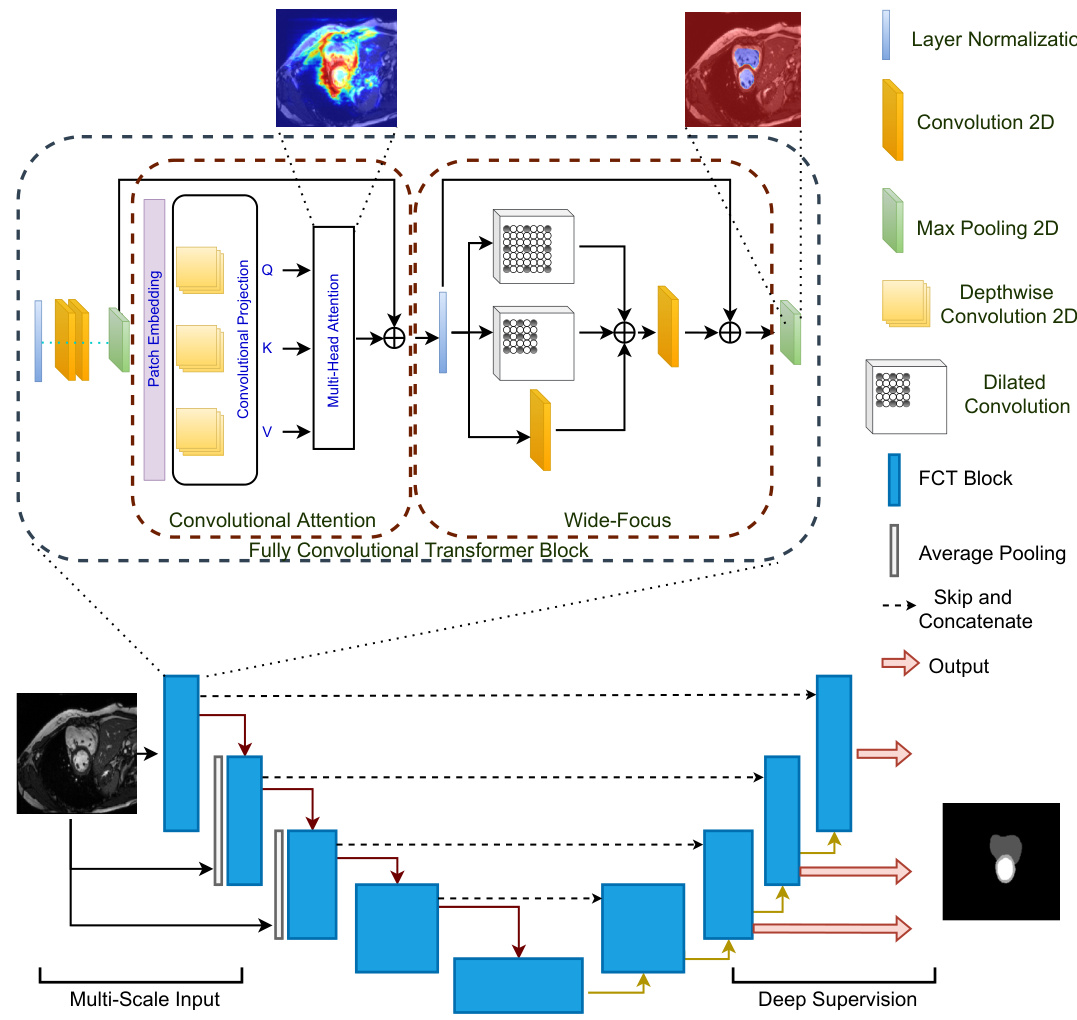
Figure 1: The Fully Convolutional Transformer for Medical Image Segmentation. The network (bottom) follows a standard UNet shape with the notable difference that it is purely Convolutional-Transformer based. The first component of the FCT layer (top) is Convolutional Attention. Here, Depthwise-Convolutions in the projection layer remove the need for positional encoding, leading to a simpler model. We create overlapping patches where the degree of patch overlap is controlled via the stride of the convolutional projection layer. To leverage spatial context from images, our MHSA block replaces linear projections with Depthwise-Convolutions. The Wide-Focus module applies dilated convolutions at linearly increasing receptive fields to the MHSA output.
图 1: 医学图像分割的全卷积Transformer网络。该网络(底部)遵循标准UNet架构,显著区别在于完全基于卷积-Transformer结构。FCT层的首个组件(顶部)是卷积注意力机制,其投影层采用深度可分离卷积(Depthwise-Convolutions)消除了位置编码需求,从而简化模型。我们通过卷积投影层的步长控制重叠程度来创建重叠图像块。为利用图像空间上下文,MHSA模块用深度可分离卷积替代线性投影。宽聚焦(Wide-Focus)模块对MHSA输出施加线性递增感受野的空洞卷积(dilated convolutions)。
Existing segmentation models in medical imaging currently suffer from at least one of three limitations. They are either based on a CNN backbone or created using convolutional layers, hence restricting their ability to look beyond their receptive fields to gain better semantic context of the images (early CNN approaches). They attempt to integrate transformers into their feature processing pipeline to leverage their ability to create long range semantic context, but in turn, make the models bulky and computationally complex (Transformer-CNN hybrids). They attempt to reduce this computational burden by creating pure transformer models for segmentation without trying to model local spatial context at a low-level feature extraction stage (concurrent works). Different from existing methods, Our Fully Convolutional Transformer does not suffer from these drawbacks, while still remaining a pure Transformer-based architecture for medical image segmentation. Table 4 in the supplementary material additionally summarizes the key differences of the FCT in comparison with existing works.
现有医学影像分割模型普遍存在以下三个局限之一:它们要么基于CNN骨干网络或采用卷积层构建,导致模型难以突破感受野限制来获取更好的图像语义上下文(早期CNN方法);要么尝试在特征处理流程中集成Transformer以利用其长程语义建模能力,却使模型变得臃肿且计算复杂(Transformer-CNN混合架构);要么通过构建纯Transformer分割模型来降低计算负担,但未在底层特征提取阶段建模局部空间上下文(同期研究)。与现有方法不同,我们的全卷积Transformer (Fully Convolutional Transformer) 在保持纯Transformer架构进行医学图像分割的同时,有效规避了上述缺陷。补充材料中的表4进一步总结了FCT与现有工作的核心差异。
3. The Fully Convolutional Transformer
3. 全卷积Transformer
Given a dataset ${\mathbf{X},\mathbf{Y}}$ , where, $\mathbf{X}$ are the input images for our model, and $\mathbf{Y}$ are the corresponding semantic or binary segmentation maps. For each image $\mathbf{x}{i}\in\mathbb{R}^{H\times W\times C}$ , where $H$ and $W$ are the spatial resolutions of the images, and $C={3,...,N}$ are the number of input channels, our model produces an output segmentation map $\mathbf{y}_{i}\in\mathbb{R}^{H\times W\times K}$ where, $K\in{1,...D}$ The input to the FCT is a $2D$ patch sampled from each slice of the input $3D$ image. Our model follows the familiar UNet shape, with the FCT layer as its fundamental building block. Unlike existing approaches, our model is neither a CNN-Transformer hybrid, or a Transformer-UNet structure that employs off-the-shelf transformer layers to encode or refine input features. It builds feature representations by first extracting overlapping patches from images, followed by creating a patch-based embedding of the scans and then applying multi-head self attention on those patches. The output projection of the given image is then processed via our Wide-Focus module to extract fine-grained information from the projections. Figure 1 shows an overview of our network architecture.
给定数据集 ${\mathbf{X},\mathbf{Y}}$ ,其中 $\mathbf{X}$ 是模型的输入图像, $\mathbf{Y}$ 是对应的语义或二值分割图。对于每张图像 $\mathbf{x}{i}\in\mathbb{R}^{H\times W\times C}$ ( $H$ 和 $W$ 为图像空间分辨率, $C={3,...,N}$ 为输入通道数),模型输出分割图 $\mathbf{y}_{i}\in\mathbb{R}^{H\times W\times K}$ ( $K\in{1,...D}$ )。FCT (Focal Contextual Transformer) 的输入是从每张 $3D$ 图像切片中采样的 $2D$ 图像块。模型采用类UNet架构,以FCT层为基础构建模块。与现有方法不同,本模型既非CNN-Transformer混合架构,也非采用现成Transformer层进行特征编码/优化的Transformer-UNet结构,而是通过以下步骤构建特征表示:1) 从图像提取重叠图像块;2) 生成基于图像块的扫描嵌入;3) 对这些图像块应用多头自注意力机制。随后通过Wide-Focus模块处理投影输出以提取细粒度信息。图 1 展示了网络架构概览。
3.1. The FCT Layer
3.1. FCT层
Each FCT layer begins with Layer Normalization-Conv- Conv-MaxPool operations. We empirically noted that applying these consecutive convolutions sequentially on the patches with a small ${3\times3}$ kernel size helps better encode image information in comparison with directly creating patch-wise projections of the image first. Each convolution layer is followed by a Gelu activation function. The first instance where our FCT block differs from other proposed blocks is through its application of Convolutional Attention for medical imaging.
每个FCT层都以层归一化-卷积-卷积-最大池化操作开始。我们通过实验发现,与直接创建图像的分块投影相比,使用较小的${3\times3}$核尺寸依次对这些分块应用连续卷积操作,能更好地编码图像信息。每个卷积层后都接有Gelu激活函数。我们的FCT块与其他提出的块首次不同的地方在于其对医学影像应用了卷积注意力机制。
The output of MaxPool is fed into a transformation function $\mathbf{T}(\cdot)$ that converts it into a new token map. Our $\mathbf{T}(\cdot)$ of choice is the Depthwise-Convolution operator. We choose a small kernel size of ${3\times3}$ , stride $\tt s\times\tt s$ and a valid padding to ensure that, (1) the extracted patches, unlike most existing works, are overlapping, and (2) the convolution operation does not change the output size throughout. This is followed by the Layer Normalization operation. The obtained token map, $p_{i+1}\in\mathbb{R}^{W_{t}\times H_{t}\times C_{t}}$ is flattened into $W_{t}H_{t}\times C_{t}$ , creating our patch embedded input. The next instance where our FCT layer is different from existing transformer based approaches for medical imaging applications, is through its attention projection. All existing models employ a linear positionwise projection for multi-head self attention (MHSA) computation. This results in transformer models losing spatial context, which is very important for imaging applications. Existing approaches try to alleviate this problem with convolutional enhancements to adapt them for imaging tasks. However, this adds additional computational costs to the proposed models. Inspired by the approach proposed in [36], we replace the linear projection in the MHSA block with Depthwise-Convolutions to reduce computational costs and leverage better spatial context from images. The patch embedding and Convolutional Attention projection form the components of our Convolutional Attention. Different from [36], we note that replacing Batch Normalization with Layer Normalization, helps improve performance. Furthermore, removing Point-wise Convolutions leads to a simpler model without losing any performance. The spatial context provided by the Depthwise-Convolutions further removes the need for having positional encoding, which are used to insert spatial information in the input and sequentially keep track of the position of each patch, leading to further simplifying the architecture design.
MaxPool的输出被送入转换函数$\mathbf{T}(\cdot)$,将其转换为新的token映射。我们选择的$\mathbf{T}(\cdot)$是深度卷积(Depthwise-Convolution)算子。采用${3\times3}$的小核尺寸、步长$\tt s\times\tt s$和有效填充,确保:(1) 与现有多数工作不同,提取的补丁是重叠的;(2) 卷积操作全程不改变输出尺寸。随后进行层归一化(Layer Normalization)操作。获得的token映射$p_{i+1}\in\mathbb{R}^{W_{t}\times H_{t}\times C_{t}}$被展平为$W_{t}H_{t}\times C_{t}$,形成我们的补丁嵌入输入。
我们的FCT层与现有基于Transformer的医学影像方法的另一处差异在于注意力投影机制。现有模型均采用线性逐点投影进行多头自注意力(MHSA)计算,这导致Transformer模型丢失了对影像应用至关重要的空间上下文。现有方法尝试通过卷积增强来适配影像任务,但会增加额外计算成本。受[36]启发,我们将MHSA块中的线性投影替换为深度卷积,既降低计算成本,又能更好地利用图像空间上下文。补丁嵌入和卷积注意力投影共同构成我们的卷积注意力模块。
与[36]不同,我们发现用层归一化替代批量归一化(Batch Normalization)可提升性能。此外,移除逐点卷积(Point-wise Convolutions)能在保持性能的前提下简化模型。深度卷积提供的空间上下文还消除了位置编码的需求——该技术原本用于向输入注入空间信息并顺序追踪每个补丁的位置,从而进一步简化了架构设计。
Generic transformer layers follow the MHSA block by linear layers, hence losing all spatial context in images. Directly replacing these linear layers with convolutions is a relatively straightforward approach that alleviates this problem and boosts performance. However, medical images require fine-grained information processing. Keeping this in mind, we adapt a multibranch Convolutional layer, where one layer applies a spatial convolution to the MHSA output while the others apply dilated convolutions with increasing receptive fields to gain better spatial context. We then fuse these features via a summation and pass them through a feature aggregation layer. This feature aggregation is done through another spatial convolution operator. We call this module Wide-Focus. Residual connections are used to enhance feature propagation throughout the layer. The final feature is re-shaped and propagated further to the next FCT layer. Figure 1 (top) shows the FCT layer.
通用Transformer层在多头自注意力(MHSA)块后接线性层,因此会丢失图像中的所有空间上下文信息。直接将这些线性层替换为卷积层是相对简单的解决方案,既能缓解该问题又可提升性能。然而医学影像需要细粒度信息处理。基于此,我们采用了多分支卷积层架构:其中一个分支对MHSA输出进行空间卷积,其余分支则采用逐步扩大感受野的空洞卷积来获取更优的空间上下文。这些特征通过求和融合后,再经特征聚合层处理(该聚合层由另一个空间卷积算子实现)。我们将该模块命名为Wide-Focus。残差连接用于增强层间特征传播,最终特征经重塑后传递至下一个FCT层。图1(顶部)展示了FCT层的结构。
3.2. Encoder
3.2. 编码器
The encoder of our model contains four FCT layers responsible for feature extraction and propagation. For the $l_{t h}$ transformer layer, the output of the Convolutional Attention module is given as, $\begin{array}{r l r}{{\bf z}{1}^{\prime}}&{=}&{\tt M H S A({\bf z}{l-1})+{\bf z}{l-1}^{q/k/v}}\end{array}$ where, $\begin{array}{r l}{\mathbf{z}{l-1}^{q/k/v}}&{{}=}\end{array}$ Fla $\mathtt{\Gamma}_{\mathtt{t e n}\left(\mathtt{D e p t h C o n v}\left(\mathtt{R e s h a p e}\left(\mathbf{z}_{1-1}\right)\right)\right.}$ ). The multi-head self attention (MHSA) is denoted by, $\begin{array}{r l}{\mathrm{MHSA}({\bf z}_{l-1})}&{{}=}\end{array}$ softmax $\begin{array}{r}{\big(\frac{\sf{Q K}^{\mathrm{T}}}{\sqrt{\sf{d}}}\big)\mathtt{V}}\end{array}$ . $\mathbf{z}^{\prime}{\boldsymbol{l}}$ is then processed by the Wide
我们模型的编码器包含四个用于特征提取和传播的FCT层。对于第$l_{t h}$个Transformer层,卷积注意力模块的输出表示为$\begin{array}{r l r}{{\bf z}{1}^{\prime}}&{=}&{\tt M H S A({\bf z}{l-1})+{\bf z}{l-1}^{q/k/v}}\end{array}$,其中$\begin{array}{r l}{\mathbf{z}{l-1}^{q/k/v}}&{{}=}\end{array}$Fla$\mathtt{\Gamma}{\mathtt{t e n}\left(\mathtt{D e p t h C o n v}\left(\mathtt{R e s h a p e}\left(\mathbf{z}{1-1}\right)\right)\right.}$)。多头自注意力机制(MHSA)定义为$\begin{array}{r l}{\mathrm{MHSA}({\bf z}_{l-1})}&{{}=}\end{array}$softmax$\begin{array}{r}{\big(\frac{\sf{Q K}^{\mathrm{T}}}{\sqrt{\sf{d}}}\big)\mathtt{V}}\end{array}$。$\mathbf{z}^{\prime}{\boldsymbol{l}}$随后通过Wide模块处理。
Focus (WF) module as, $\mathbf{z}{l}=\mathsf{W F}(\mathbf{z}_{l})+\mathbf{z}^{\prime}\boldsymbol{\imath}$ . We further inject the encoder with a pyramid style image input with the goal of highlighting different classes and smaller ROI features at different scales. It is useful to note that even without this multi-scale image pyramid input, our model is able to achieve state-of-the-art results. The (bottleneck) latent encoding of the data is created using another FCT layer.
聚焦 (WF) 模块定义为 $\mathbf{z}{l}=\mathsf{W F}(\mathbf{z}_{l})+\mathbf{z}^{\prime}\boldsymbol{\imath}$。我们进一步向编码器注入金字塔式图像输入,旨在突出不同尺度下的类别特征和小型感兴趣区域 (ROI) 特征。值得注意的是,即使不使用这种多尺度图像金字塔输入,我们的模型仍能实现最先进的性能。数据的(瓶颈)潜在编码通过另一个 FCT 层生成。
3.3. Decoder
3.3. 解码器
The decoder takes the bottleneck representation as its input and learns to re-sample the binary or semantic segmentation maps from this information. To create better contextual relevance in the decoder layers, skip connections from the encoder to decoder are also used where feature maps from the encoder layer at the same resolution are concatenated with the decoder layer. The decoder’s shape is symmetric to the encoder. The layers in the decoder corresponding to the image pyramid layers in the encoder, output intermediate segmentation maps which provide additional supervision and boost the model’s prediction ability. Contextual relevance is created by first up-sampling the feature volume and then passing it through the FCT layer to learn its best possible representation. We do not employ deep supervision at the lowest scale of FCT, and hence our model isn’t ’fully deeply supervised’. This is because we observed that regions of interest (ROIs) in the input image scans were sometimes too small to segment at the lowest scale $\phantom{0}28\times28\phantom{.}$ ) which resulted in a worse model performance. This low scale output added a strong bias in the model to predict some output ROIs as the background class.
解码器以瓶颈表示作为输入,并学习从中重新采样二值或语义分割图。为了在解码器层中建立更好的上下文相关性,还使用了从编码器到解码器的跳跃连接,将相同分辨率下编码器层的特征图与解码器层进行拼接。解码器的结构与编码器对称。解码器中与编码器图像金字塔层相对应的各层会输出中间分割图,这些分割图提供额外的监督并增强模型的预测能力。
上下文相关性的建立首先通过上采样特征体积,然后将其传递至FCT层以学习最佳表示。我们未在FCT的最低尺度采用深度监督,因此模型并非"完全深度监督"。这是因为我们观察到输入图像扫描中的感兴趣区域(ROIs)有时在最低尺度$\phantom{0}28\times28\phantom{.}$下过小难以分割,导致模型性能下降。该低尺度输出会使模型产生强烈偏差,将部分输出ROIs预测为背景类别。
4. Experiments
4. 实验
We demonstrate the effectiveness of our model through its ability to achieve state-of-the-art results across four different datasets of varying modalities. We use data from the (MRI) Automatic Cardiac Diagnosis Challenge (ACDC) [2], (CT) Synapse Multi-organ Segmentation Challenge , (CT) Spleen Segmentation Dataset [1] and (Dermoscopy) ISIC 2017 [6] Skin Cancer Segmentation Challenge.
我们通过在四种不同模态的数据集上实现最先进结果的能力,证明了模型的有效性。使用的数据来自 (MRI) 自动心脏诊断挑战赛 (ACDC) [2]、 (CT) Synapse多器官分割挑战赛、 (CT) 脾脏分割数据集 [1] 以及 (皮肤镜) ISIC 2017 [6] 皮肤癌分割挑战赛。
The ACDC dataset contains 100 MRI scans with ground truths for the left ventricle (LV), right ventricle (RV) and myocardium (MYO). We create a train-val- test split of 70-10-20. Synapse contains CT scans from 30 patients. Our experiment setup and pre-processing for Synapse is similar to TransUNet [5]. The Spleen segmentation dataset contains 41 CT volumes. Our train-val-test splits for this dataset are 80-10-10. For the ISIC 2017 dataset, we create trainval-test splits of 70-10-20 from the 2000 images in the training dataset. We measure the performance of our models using the Dice coefficient. All the input images to our model are resized to two shapes: $224\times224$ and $384\times384$ .
ACDC数据集包含100个MRI扫描,其中包含左心室(LV)、右心室(RV)和心肌(MYO)的真实标注。我们按70-10-20的比例划分训练集-验证集-测试集。Synapse数据集包含30名患者的CT扫描,其实验设置和预处理方式与TransUNet[5]类似。脾脏分割数据集包含41个CT体积数据,我们按80-10-10的比例划分该数据集。对于ISIC 2017数据集,我们从训练集的2000张图像中按70-10-20的比例划分数据。我们使用Dice系数评估模型性能,所有输入图像都被调整为两种尺寸:$224\times224$和$384\times384$。
Implementation Details We run all our experiments using TensorFlow 2.0. We use one NVIDIA A6000 GPU for all our experiments. Our loss function is a equally weighted combination of the cross en- tropy and the dice loss. We used Adam with a learning rate of $1e\mathrm{ -~}3$ which was reduced on a plateau through monitoring the validation loss. We perform warm up training for 50 epochs before training our model for a further 250 epochs. Our data augmentation is as follows: rotation ( $0^{\circ}$ to $360^{\circ}$ ), zoom range (max 0.2), shear range (max 0.1), horizontal/vertical shift (max 0.3), horizontal and vertical flip. The default settings for FCT are – number of filters per stage 16, 32, 64, 128, 384, 128, 64, 32, 16, number of attention heads per stage $2,4,8,12,16,12,8,4,2$ . We use a batch size of 10 for ACDC, and 4 for Synapse, Spleen segmentation and ISIC 2017 segmentation. We train all our models from a randomly initialized set of weights.
实现细节
我们使用TensorFlow 2.0运行所有实验,并采用一块NVIDIA A6000 GPU。损失函数为交叉熵损失与Dice损失的等权组合,优化器选用Adam (初始学习率 $1e\mathrm{ -~}3$ ),通过验证损失监控实现学习率衰减。模型训练前进行50轮预热,随后正式训练250轮。数据增强策略包括:旋转 ( $0^{\circ}$ 至 $360^{\circ}$ )、缩放 (最大0.2)、剪切 (最大0.1)、水平/垂直平移 (最大0.3) 以及水平/垂直翻转。FCT默认配置为:各阶段滤波器数量16, 32, 64, 128, 384, 128, 64, 32, 16,注意力头数 $2,4,8,12,16,12,8,4,2$ 。ACDC数据集批量大小为10,Synapse、脾脏分割及ISIC 2017分割批量大小为4。所有模型均从随机初始化权重开始训练。
5. Results
5. 结果
Our model achieves the state-of-the-art results across all reported baselines with fewer parameters and GFLOPs. FCT contains 31.7 million parameters and 7.87 GFLOPs. On the ACDC dataset, we outperform all existing works with a model size five times smaller than our closest competitor, nnFormer (158.92 million, 157.88 GFLOPs). We train our model on two different image sizes to see its impact on performance. As expected, FCT with a 384 $\times$ 384 image size achieves better results than the model with input image size $224\times224$ , as the increased spatial resolution allows the model to see fine-grained details in the images more clearly. We also test the effect of having deep supervision across every scale vs not using deep supervision in comparison with our model. Table 2 summarizes our results on the ACDC dataset. It also shows that the deep supervision setting employed by us is the best setting for our model. To demonstrate the statistical significance of our results, we also conduct a 5-Fold Cross Validation (CV) with the ACDC dataset and compute $p$ -values to show our results are significantly better than the nnFormer. We use FCT $^{224}$ for these experiments. Using 5-Fold CV, we get an average dice score of $92.43\pm0.38$ . We then run our experiments on the ACDC dataset 5 times and average them to get a dice score of $92.88\pm0.09$ . Both results are state-of-the-art for the dataset. Comparing with nnFormer $(91.78\pm0.18)$ , we get $p<0.0001$ in both cases, which shows the statistical significance of our results.
我们的模型以更少的参数量和GFLOPs在所有报告的基线中实现了最先进的结果。FCT包含3170万个参数和7.87 GFLOPs。在ACDC数据集上,我们的模型尺寸比最接近的竞争对手nnFormer (1.5892亿参数,157.88 GFLOPs) 小五倍,但性能优于所有现有工作。我们使用两种不同图像尺寸训练模型以观察其对性能的影响。正如预期,采用384×384图像尺寸的FCT比输入尺寸为224×224的模型取得了更好结果,因为更高的空间分辨率使模型能更清晰地识别图像中的细粒度细节。我们还测试了在每层尺度使用深度监督与不使用深度监督的效果,并与我们的模型进行对比。表2总结了我们在ACDC数据集上的结果,同时也表明我们采用的深度监督设置是本模型的最佳配置。为证明结果的统计显著性,我们在ACDC数据集上进行了5折交叉验证(CV)并计算p值,结果显示我们的结果显著优于nnFormer。这些实验采用FCT$^{224}$模型。通过5折CV得到的平均Dice分数为$92.43\pm0.38$。随后我们对ACDC数据集进行5次实验取平均,获得Dice分数$92.88\pm0.09$。两项结果均为该数据集的最优水平。与nnFormer$(91.78\pm0.18)$相比,两种情况下均得到$p<0.0001$,这证明了我们结果的统计显著性。

Figure 2: Qualitative results on the different segmentation datasets. From the top - ACDC Segmentation Dataset [Colours - Maroon (LV), Blue (RV), Green (MYO)], Spleen Segmentation Dataset [Colours - Blue (Spleen)], Synapse Segmentation Dataset [Colours - Blue (Aorta), Purple (Gallbladder), Navy (Left Kidney), Aquatic (Right Kidney), Green (Liver), Yellow (Pancreas), Red (Spleen), Maroon (Stomach)] and ISIC 2017 Skin Cancer Segmentation Dataset [Colours - Blue (Skin Cancer)]. The images alternate between the ground truth and the segmentation map predicted by FCT. Best viewed in colour.
图 2: 不同分割数据集的定性结果。从上至下依次为:ACDC分割数据集 [颜色 - 栗色 (左心室)、蓝色 (右心室)、绿色 (心肌)],脾脏分割数据集 [颜色 - 蓝色 (脾脏)],Synapse分割数据集 [颜色 - 蓝色 (主动脉)、紫色 (胆囊)、深蓝 (左肾)、水色 (右肾)、绿色 (肝脏)、黄色 (胰腺)、红色 (脾脏)、栗色 (胃)] 以及 ISIC 2017皮肤癌分割数据集 [颜色 - 蓝色 (皮肤癌)]。图像交替显示真实标注与FCT预测的分割图。建议彩色查看。
We compare our results on the Synapse dataset mainly with TransUNet [5], LeViT-UNet [39] and Swin UNet [3] as we use the same splits and pre-processing as those models, which suggests that any increase in performance is due to the superiority of the proposed model. We outperform all three models by considerable margins demonstrating the ability of our model to serve as a superior backbone for multi-atlas semantic segmentation tasks. TransUNet and LeVit-UNet both have ViT $-12$ backbones in their architecture and hence contain around 100 million parameters (and around 49 GFLOPs). Our results are summarized in Table 3.
我们在Synapse数据集上的结果主要与TransUNet [5]、LeViT-UNet [39]和Swin UNet [3]进行对比,因为采用了相同的划分方式和预处理流程,这表明性能提升完全源于所提模型的优越性。我们的模型以显著优势超越所有三个基线,证明其能作为多图谱语义分割任务的更优主干网络。TransUNet和LeViT-UNet架构中均采用ViT$-12$主干,因此包含约1亿参数(计算量约49 GFLOPs)。结果汇总见表3。
We also achieve state-of-the-art results on the two binary segmentation tasks, Spleen segmentation (Table 1 Supplementary Material) and ISIC 2017 segmentation (Table 2 Supplementary Material). On Spleen segmentation we outperform recently proposed benchmark models such as SETR [41], CoTr [38] and TransUNet [5] by over $1.2%$ dice with considerably fewer parameters. On the ISIC 2017 dataset we outperform the recently proposed Boundary Aware (BA) Transformer [35] specifically designed for the task of skin cancer segmentation by $1.1%$ on the dice. We also evaluate the sensitivity (true positive rate) of our model, as it is a good estimate of a model’s ability to accurately segment the cancer boundaries. Models trained on the ISIC 2017 dataset tend to have a high specificity but low sensitivity due to which we consider the latter here. We outperform BA Transformer on the sensitivity metric. We noticed through our ablation studies that this was largely due to the ability of our Wide-Focus module to capture hierarchical feature information at different convolution receptive fields effectively and accurately. Figure 2 shows qualitative results of our model.
我们还在两项二值分割任务中取得了最先进的结果:脾脏分割(补充材料表1)和ISIC 2017皮肤病变分割(补充材料表2)。在脾脏分割任务中,我们以显著更少的参数量,在Dice系数上超过近期提出的基准模型SETR [41]、CoTr [38]和TransUNet [5]达1.2%。在ISIC 2017数据集上,我们针对皮肤癌分割任务专门设计的Boundary Aware (BA) Transformer [35]模型,Dice系数提升了1.1%。我们还评估了模型的灵敏度(真阳性率),因其能有效衡量模型准确分割癌症边界的能力。由于ISIC 2017数据集训练的模型通常具有高特异性但低灵敏度,我们重点考察后者指标。在灵敏度指标上,我们的表现优于BA Transformer。消融实验表明,这主要归功于Wide-Focus模块能高效精准地捕捉不同卷积感受野下的层级特征信息。图2展示了模型的定性结果。
ACDC Post-2017-MICCAI Online Test Set Results. We Train FCT (31.7 million parameters) on
ACDC 2017年后MICCAI在线测试集结果。我们在FCT(3170万参数)上进行训练
Table 1: Ablation study to determine the optimal configuration of our Wide-Focus module. $\mathrm{FCT_{224}}$ (with 16.1 million parameters) is used for these ablations. $D$ denotes the dilation rate, and $k$ denotes the convolution kernel size.
表 1: Wide-Focus模块最优配置的消融研究。使用$\mathrm{FCT_{224}}$ (含1610万参数)进行消融实验。$D$表示膨胀率,$k$表示卷积核大小。
| Head | Branches | Avg. | RV | MYO | LV |
|---|---|---|---|---|---|
| MLP | - | 91.29 | 90.5 | 88.3 | 95.1 |
| Conv1D Conv1D Conv1D Conv1D | 11 (D=1)2 (D=1,2)3 (D=1,2,3) | 91.4991.3491.4191.67 | 91.290.590.291.1 | 88.488.488.888.8 | 94.995.195.395.1 |
| Conv2D Conv2D Conv2D | 1 (D=1)2 (D=1,2)3 (D=1,2,3)3 (D=1,2,3,4) | 91.9991.6192.1191.65 | 91.390.991.690.6 | 89.188.889.389.1 | 95.595.195.595.2 |
| 方法 | 平均 | RV | MYO 80.63 | LV 94.92 |
|---|---|---|---|---|
| R50 UNet [29] | 87.55 | 87.10 | 79.20 | 93.47 |
| R50 Att-UNet [26] | 86.75 | 87.58 | 70.71 | 92.18 |
| ViT [7] | 81.45 | 81.46 | 81.88 | 94.75 |
| R50 ViT [7] | 87.57 | 86.07 | 84.53 | 95.73 |
| TransUNet [5] | 89.71 | 88.86 | 85.62 | 95.83 |
| Swin UNet [3] | 90.00 | 88.55 | 87.64 | 93.76 |
| LeVit-UNet384 [39] | 90.32 | 89.55 | 89.24 | 95.36 |
| nnUNet [14] | 91.61 | 90.24 | 89.53 | - |
| nnFormer [42] | 91.78 | 90.22 | - | - |
| FCT224 w/o D.S. | 91.49 | 90.32 | 89.00 | 95.59 |
| FCT224 full D.S. | 91.49 | 90.49 | 88.76 | 95.17 |
| FCT224 | 92.84 | 92.02 | 90.61 | 95.23 |
| FCT384 | 93.02 | 92.64 | 90.51 | 95.89 |
Table 2: Segmentation results on the ACDC dataset. Our model’s results are reported on two different input image sizes. D.S. stands for Deep Supervision. Full D.S. is the case where D.S. is applied at every input scale.
表 2: ACDC数据集上的分割结果。我们的模型在两种不同输入图像尺寸下的结果。D.S.代表深度监督 (Deep Supervision)。Full D.S.表示在所有输入尺度都应用深度监督的情况。
the 100 images in the dataset for the ACDC Challenge, and report our results on the 50 unseen test cases for which ground truth masks are not provided. We train our model on input images of size of $512\times512$ . To account for the variations in the sizes of the images in the dataset, we crop and tile the images to get a $512\times512$ resolution and apply the same augmentation to the masks. To generate final predictions, we remove these extra predictions that occur due to tiling as a post processing step by averaging the tiled predictions to create the final output. We train this model as denoted in Section 4. The link to our results is available online2 and can be compared with previous state-ofthe-art results3. Table 4 summarises the results of the top five submissions in com parisi on with our results (Table 5 in supplementary material shows detailed results across all classes). We take the mean to provide average values, however, the detailed tables with full results can be found in the links provided.
我们在ACDC挑战赛数据集的100张图像上进行实验,并报告了50个未见测试案例的结果(这些案例未提供真实标注掩膜)。模型训练采用$512×512$尺寸的输入图像。针对数据集中图像尺寸差异,我们通过裁剪和分块处理将图像调整为$512×512$分辨率,并对掩膜同步应用相同的数据增强。后处理阶段通过平均分块预测结果来消除分块带来的冗余预测,生成最终输出。训练方法如第4节所述。结果链接已在线发布2,可与先前最优结果3进行对比。表4汇总了前五名提交结果与我们的对比(补充材料表5展示了所有类别的详细结果)。我们采用均值计算平均值,完整结果详见提供的链接。
6. Ablation Study
6. 消融实验
We primarily study the effect of two key components on our model’s performance through ablations: removing skip connections from the encoder to the decoder, and different settings of our novel Wide-Focus module. We conduct our ablations on the ACDC dataset. Skip connections are clearly important to our model’s performance (see Table 3 Supplementary Material) and the optimal setting resembles that of the original UNet [29]. To create the optimal setting of our Wide-Focus module (see Table 1), we observed the effects of wider convolutional branches and larger dilation rates on our model’s performance. We observed that beyond three convolution branches with linearly increasing dilation rates, the model’s accuracy starts to saturate and eventually decrease. We believe it is due to the fact that the dilated kernel fails to approximate a global kernel at the deeper layers and this leads to the dilated receptive field missing key feature information. This is also in line with our findings that smaller kernels in the FCT block lead to better performance.
我们主要通过消融实验研究两个关键组件对模型性能的影响:移除从编码器到解码器的跳跃连接 (skip connections) ,以及我们新颖的 Wide-Focus 模块的不同设置。我们在 ACDC 数据集上进行了消融实验。跳跃连接对我们的模型性能至关重要 (参见补充材料表 3) ,最优设置与原始 UNet [29] 类似。为了找到 Wide-Focus 模块的最佳设置 (参见表 1) ,我们观察了更宽的卷积分支和更大的膨胀率 (dilation rates) 对模型性能的影响。我们发现,超过三个具有线性递增膨胀率的卷积分支后,模型的准确率开始饱和并最终下降。我们认为这是由于膨胀卷积核在更深层无法逼近全局卷积核,导致膨胀感受野遗漏关键特征信息。这也与我们发现 FCT 块中较小卷积核能带来更好性能的结论一致。
Table 3: Segmentation results on Synapse dataset. Kid. denotes Kidney, Panc. Pancreas, Spl. Spleen and Stom. Stomach. Dice Coefficient is reported.
| 方法 | 平均 | 主动脉 | 胆囊 | 左肾 | 右肾 | 肝脏 | 胰腺 | 脾脏 | 胃 |
|---|---|---|---|---|---|---|---|---|---|
| R50 UNet [5] R50 Att-Unet [5] TransUNet [5] TransClaw UNet [4] LeVit-UNet384 [39] MT-UNet [34] | 74.68 75.57 77.48 | 84.18 55.92 87.23 | 62.84 63.91 63.13 | 79.19 79.20 81.87 | 71.29 72.71 77.02 | 93.35 93.56 | 48.23 49.37 | 84.41 87.19 | 73.92 74.95 |
表 3: Synapse数据集分割结果。Kid.表示肾脏,Panc.表示胰腺,Spl.表示脾脏,Stom.表示胃。报告指标为Dice系数。
Table 4: Top 5 results on the ACDC Post-2017- MICCAI online leader board. $\mathrm{FCT_{512}}$ (with 31.7 million parameters) is used for this experiment. Avg. stands for the Average dice Coefficient.
表 4: ACDC Post-2017-MICCAI 在线排行榜前五名结果。本实验使用 $\mathrm{FCT_{512}}$ (参数量为 3170 万)。Avg. 表示平均 Dice 系数。
| Method | Avg. |
|---|---|
| Mahendra Khened [23] Georgios Simantiris [30] | 91.37 91.92 |
| Kibrom Girum [8] Fabian Isensee [13] | 91.93 92.95 |
| Fumin Guo [6] FCT512 | 93.02 93.13 |
7. Conclusions
7. 结论
We proposed the Fully Convolutional Transformer that is capable of accurately performing binary and semantic segmentation tasks with fewer parameters than existing models. FCT is over five times smaller than nnFormer and three times smaller than TransUNet and LeViT-UNet in terms of the number of parameters. The FCT layer comprises of two key components - Convolutional Attention, and Wide-Focus. Convolutional Attention removes the need for positional encoding at the patch creation stage by using Depthwise-Convolutions to create overlapping patches for the model. Our Depthwise-Convolution based MHSA block integrates spatial information to estimate long range semantic dependencies for the first time in a medical imaging context. Wide-Focus, as seen through our ablations, helps leverage fine grained feature information present in medical images and is an important factor in boosting the performance of our transformer block. We demonstrated the ability of our model through state-of-the-art results across multiple highly competitive segmentation datasets of varying modalities and dimensions. Our FCT block is the first fully convolutional transformer block proposed for medical imaging applications, and can be easily extended to other domains and applications of medical imaging. We believe that our model can serve as an effective backbone for future segmentation tasks and pave the way for innovations in transformer-based medical image processing.
我们提出了全卷积Transformer (Fully Convolutional Transformer),能以比现有模型更少的参数量精准执行二值和语义分割任务。在参数量方面,FCT比nnFormer小五倍以上,比TransUNet和LeViT-UNet小三倍。FCT层包含两个关键组件——卷积注意力 (Convolutional Attention) 和宽聚焦 (Wide-Focus)。卷积注意力通过深度卷积 (Depthwise-Convolutions) 为模型创建重叠图像块,从而在图像块创建阶段无需位置编码。我们基于深度卷积的多头自注意力 (MHSA) 模块首次在医学影像领域整合空间信息来估计长程语义依赖关系。如消融实验所示,宽聚焦能有效利用医学图像中的细粒度特征信息,是提升Transformer模块性能的关键因素。我们在多个高竞争性的多模态、多维度分割数据集上取得了最先进的结果,证明了模型的卓越性能。FCT模块是首个针对医学影像应用提出的全卷积Transformer模块,可轻松扩展至其他医学影像领域和应用场景。我们相信该模型能成为未来分割任务的有效骨干网络,并为基于Transformer的医学图像处理技术开辟创新道路。