An Iterative Optimizing Framework for Radiology Report Sum mari z ation with ChatGPT
基于ChatGPT的放射学报告摘要迭代优化框架
Chong Ma, Zihao Wu, Jiaqi Wang, Shaochen Xu, Yaonai Wei, Fang Zeng, Zhengliang Liu, Xi Jiang, Lei Guo, Xiaoyan Cai, Shu Zhang, Tuo Zhang, Dajiang Zhu, Dinggang Shen Fellow, IEEE, Tianming Liu Senior Member, IEEE, Xiang Li
Chong Ma, Zihao Wu, Jiaqi Wang, Shaochen Xu, Yaonai Wei, Fang Zeng, Zhengliang Liu, Xi Jiang, Lei Guo, Xiaoyan Cai, Shu Zhang, Tuo Zhang, Dajiang Zhu, Dinggang Shen Fellow, IEEE, Tianming Liu Senior Member, IEEE, Xiang Li
Abstract—The “Impression” section of a radiology report is a critical basis for communication between radiologists and other physicians. Typically written by radiologists, this part is derived from the “Findings” section, which can be laborious and errorprone. Although deep-learning based models, such as BERT, have achieved promising results in Automatic Impression Generation (AIG), such models often require substantial amounts of medical data and have poor generalization performance. Recently, Large Language Models (LLMs) like ChatGPT have shown strong genera liz ation capabilities and performance, but their performance in specific domains, such as radiology, remains under-investigated and potentially limited. To address this limitation, we propose Impression GP T, leveraging the contextual learning capabilities of LLMs through our dynamic prompt and iterative optimization algorithm to accomplish the AIG task. Impression GP T initially employs a small amount of domain-specific data to create a dynamic prompt, extracting contextual semantic information closely related to the test data. Subsequently, the iterative optimization algorithm automatically evaluates the output of LLMs and provides optimization suggestions, continuously refining the output results. The proposed Impression GP T model achieves superior performance of AIG task on both MIMIC-CXR and OpenI datasets without requiring additional training data or finetuning the LLMs. This work presents a paradigm for localizing LLMs that can be applied in a wide range of similar application scenarios, bridging the gap between general-purpose LLMs and the specific language processing needs of various domains.
摘要—放射学报告中的"印象(Impression)"部分是放射科医生与其他医生沟通的关键依据。该部分通常由放射科医生根据"发现(Findings)"部分撰写,这一过程既耗时又容易出错。尽管基于深度学习的方法(如BERT)在自动印象生成(AIG)任务中取得了不错的效果,但这些模型通常需要大量医学数据且泛化性能较差。最近,像ChatGPT这样的大语言模型展现出强大的泛化能力和性能,但它们在放射学等特定领域的表现仍有待研究且可能存在局限。为解决这一局限,我们提出Impression GPT模型,通过动态提示和迭代优化算法利用大语言模型的上下文学习能力来完成AIG任务。Impression GPT首先使用少量领域特定数据创建动态提示,提取与测试数据密切相关的上下文语义信息;随后,迭代优化算法自动评估大语言模型的输出并提供优化建议,持续改进输出结果。所提出的Impression GPT模型在MIMIC-CXR和OpenI数据集上均实现了优异的AIG任务性能,且无需额外训练数据或对大语言模型进行微调。这项工作提出了一种大语言模型本地化的范式,可广泛应用于类似场景,弥合通用大语言模型与各领域特定语言处理需求之间的差距。
Impact Statement—With the advent of Artificial General Intelligence (AGI) and Large Language Model (LLM) such as ChatGPT, we envision that a series of medical text data processing methodologies and the corresponding data management
影响声明——随着通用人工智能(AGI)和ChatGPT等大语言模型(LLM)的出现,我们预见一系列医学文本数据处理方法和相应的数据管理
C. Ma, Y. Wei, L. Guo, X. Cai, and T. Zhang are with the School of Automation, Northwestern Polytechnic al University, Xi’an, 710072, China. (e-mail: {mc-npu, rean wei} $@$ mail.nwpu.edu.cn, {lguo, xiaoyanc, tuozhang}@nwpu.edu.cn). J. Wang and S. Zhang are with the School of Computer Science, Northwestern Polytechnic al University, Xi’an, 710072, China. (e-mail: jiaqi.wang@mail.nwpu.edu.cn, shu.zhang@nwpu.edu.cn). X. Jiang is with the Clinical Hospital of Chengdu Brain Science Institute, MOE Key Lab for Neuro information, School of Life Science and Technology, University of Electronic Science and Technology of China, Chengdu, 611731, China. (e-mail: xijiang@uestc.edu.cn). D. Shen is with School of Biomedical Engineering, Shanghai Tech University, Shanghai 201210, China, and Department of Research and Development, Shanghai United Imaging Intelligence Co., Ltd., Shanghai 200030, China, and also with Shanghai Clinical Research and Trial Center, Shanghai, 201210, China. (e-mail: Dinggang.Shen $@$ gmail.com). Z. Wu, S. Xu, Z. Liu, and T. Liu are with the school of computing, University of Georgia, Athens, GA 30602, USA. (e-mail: {zw63397, sx76699, zl18864, tliu}@uga.edu). D. Zhu is with Department of Computer Science and Engineering, The University of Texas at Arlington, Arlington 76019, USA, (e-mail: dajiang.zhu@uta.edu). F. Zeng and X. Li are with the Department of Radiology, Massachusetts General Hospital, Boston 02114, USA, (e-mail: {fzeng1, xli60} $@$ mgh.harvard.edu).
C. Ma、Y. Wei、L. Guo、X. Cai 和 T. Zhang 就职于西北工业大学自动化学院,西安,710072,中国 (e-mail: {mc-npu, reanwei} $@$ mail.nwpu.edu.cn, {lguo, xiaoyanc, tuozhang}@nwpu.edu.cn)。J. Wang 和 S. Zhang 就职于西北工业大学计算机学院,西安,710072,中国 (e-mail: jiaqi.wang@mail.nwpu.edu.cn, shu.zhang@nwpu.edu.cn)。X. Jiang 就职于电子科技大学生命科学与技术学院,神经信息教育部重点实验室,成都脑科学研究院临床医院,成都,611731,中国 (e-mail: xijiang@uestc.edu.cn)。D. Shen 就职于上海科技大学生物医学工程学院,上海 201210,中国;上海联影智能医疗科技有限公司研发部,上海 200030,中国;以及上海临床研究中心,上海,201210,中国 (e-mail: Dinggang.Shen $@$ gmail.com)。Z. Wu、S. Xu、Z. Liu 和 T. Liu 就职于美国佐治亚大学计算学院,雅典,GA 30602,美国 (e-mail: {zw63397, sx76699, zl18864, tliu}@uga.edu)。D. Zhu 就职于美国德克萨斯大学阿灵顿分校计算机科学与工程系,阿灵顿 76019,美国 (e-mail: dajiang.zhu@uta.edu)。F. Zeng 和 X. Li 就职于美国马萨诸塞州总医院放射科,波士顿 02114,美国 (e-mail: {fzeng1, xli60} $@$ mgh.harvard.edu)。
solutions can be replaced by LLMs. Thus, in this work, we leveraged the text understanding and sum mari z ation capability of ChatGPT for the task of generating the “Impression” section of a radiology report, which is a critical basis for communication between radiologists and other physicians. Here we propose Impress ion GP T, which leverages the in-context learning capability of LLMs by constructing dynamic prompts using domain-specific, individualized data via an iterative optimization approach. We envision that the proposed framework can become a paradigm for similar works in the future to adapt general-purpose LLMs to specific domains via an in-context learning approach.
解决方案可由大语言模型替代。因此,在本研究中,我们利用ChatGPT的文本理解与摘要生成能力,完成放射学报告中"印象(Impression)"部分的生成任务——该部分是放射科医师与其他医生沟通的关键依据。本文提出ImpressGPT,通过迭代优化方法构建基于领域特异性个体化数据的动态提示(prompt),从而利用大语言模型的上下文学习(in-context learning)能力。我们预计该框架可成为未来类似工作的范式,通过上下文学习方法将通用大语言模型适配至特定领域。
Index Terms—Radiology Report Sum mari z ation, Dynamic Prompt, Iterative Optimization, ChatGPT.
索引术语—放射学报告摘要、动态提示、迭代优化、ChatGPT。
I. INTRODUCTION
I. 引言
EXT sum mari z ation is the process of compressing a large amount of text data into a shorter summary while maintaining its coherence and informative properties. It has long been a critical and well-studied research area within the field of Natural Language Processing (NLP). As the volume of digital textual information is growing at an extraordinary rate in both the general and medical domains, the need for efficient and accurate text sum mari z ation models grows correspondingly. In earlier studies, Luhn [1] proposed the first automatic sum mari z ation algorithm based on statistical methods. Later, a variety of alternative approaches have been proposed, such as rule-based methods [2], latent semantic analysis [3], and graph-based techniques [4]. Although traditional methods significantly advanced the research and application of text sum mari z ation, they often lack the ability to capture complex semantics and contextual information to generate human-level sum mari z ation performance [5].
文本摘要 (EXT summarization) 是将大量文本数据压缩为较短摘要并保持其连贯性和信息性的过程。这一直是自然语言处理 (NLP) 领域中一个重要且被深入研究的方向。随着通用领域和医疗领域的数字文本信息量呈指数级增长,对高效准确文本摘要模型的需求也相应增加。早期研究中,Luhn [1] 提出了首个基于统计方法的自动摘要算法。随后出现了多种替代方案,例如基于规则的方法 [2]、潜在语义分析 [3] 以及基于图的技术 [4]。虽然传统方法显著推动了文本摘要的研究与应用,但它们通常难以捕捉复杂语义和上下文信息,无法生成人类水平的摘要效果 [5]。
The introduction of neural networks and deep learning methods, especially the sequence-to-sequence models that employ encoder-decoder architectures for generating summaries [6] conveyed promising results. These approaches enabled the creation of more fluent and con textually relevant summaries compared with rule-based and statistical methods. Recently, the field of NLP, including text sum mari z ation, has experienced drastic changes with the emergence of large-scale, pre-trained foundational models, such as BERT [7] and GPT [8]. These models are trained on massive volumes of text data, which enables them to learn rich contextual representations and generate human-like languages. Study [9] has been conducted to demonstrate that fine-tuning these foundational models on text sum mari z ation tasks can lead to state-of-the-art performance, outperforming earlier models by a wide margin.
神经网络和深度学习方法的引入,特别是采用编码器-解码器架构的序列到序列模型 [6] 在生成摘要方面展现了良好的效果。与基于规则和统计的方法相比,这些方法能够生成更流畅且与上下文相关的摘要。近年来,随着大规模预训练基础模型(如 BERT [7] 和 GPT [8])的出现,包括文本摘要在内的自然语言处理领域经历了巨大变革。这些模型通过海量文本数据训练,能够学习丰富的上下文表征并生成类人语言。研究 [9] 表明,在文本摘要任务上微调这些基础模型可以达到最先进的性能,远超早期模型。
Radiology reports are pivotal in clinical decision-making since they can provide crucial diagnostic and prognostic information to healthcare professionals [10]. The volume of imaging studies and the complexity of radiology data are both growing at an increasing rate, thus raising an urgent need for efficient language processing, including extracting key information from radiology reports. Text sum mari z ation can address this challenge by automatically generating concise, informative, and relevant summaries of radiology reports, thus can significantly enhance clinical workflows, reduce the workload of healthcare professionals, and improve patient care [9]. With the help of automatic text sum mari z ation methods, healthcare professionals can efficiently identify essential information, which leads to faster decision-making, optimized resource allocation, and improved communication among multidisciplinary teams [5].
放射学报告在临床决策中至关重要,因为它们能为医疗专业人员提供关键的诊断和预后信息 [10]。影像学检查的数量和放射学数据的复杂性都在快速增长,因此迫切需要高效的语言处理技术,包括从放射学报告中提取关键信息。文本摘要 (text summarization) 技术能通过自动生成简洁、信息丰富且相关的放射学报告摘要来应对这一挑战,从而显著优化临床工作流程、减轻医疗专业人员的工作量并提升患者护理水平 [9]。借助自动文本摘要方法,医疗专业人员能高效识别关键信息,从而加快决策速度、优化资源分配并促进多学科团队间的沟通 [5]。
Compared with general NLP tasks, radiology report summarization has its own unique challenges. It would be difficult for general-purpose NLP models to accurately capture the key information due to the highly specialized and technical nature of the language used. The potential risks associated with misinterpretation of crucial findings, and the significance of maintaining the contextual and relational aspects of such findings further complicate the task [11]. In response, multiple specialized language processing methods have been developed for medical text sum mari z ation, which can be broadly categorized into three groups: traditional, deep learning-based, and large language model-based. Traditional methods such as [2] lay the foundation for text sum mari z ation research. However, they often lacked the ability to capture complex semantics and contextual information. The introduction of deep learning techniques, such as CNNs, demonstrated superior performance in capturing the unique language features and context of radiology reports [11]. However, these techniques often require large volumes of annotated data for training and are limited to specific tasks and/or domains. Subsequently, with the introduction of the Transformer model, its distinctive multihead global attention mechanism has led to its widespread application in medical image analysis [12], [13]. Moreover, Transformer-based models, such as BERT [7] and GPT [8], brought the emergence of Large Language Models (LLMs) and opened new possibilities for radiology text processing. Fine-tuning BERT on domain-specific data, such as chest radiology reports, demonstrating better capability in capturing clinical context and generating high-quality summaries [10]. Nonetheless, utilizing pre-trained language models such as BERT still needs a significant volume of annotated data for the downstream tasks (e.g., text sum mari z ation). Furthermore, training LLMs like ChatGPT [14] and GPT-4 [15] still demands a substantial amount of data, even when this data is un annotated. However, in certain specialized domains, the available data is often extremely limited. Utilizing such limited data is insufficient to train an effective large language model. Even with access to an adequate amount of data, training a model with an immense number of parameters necessitates a considerable amount of resources. Hence, the high demands on data quantity and hardware resources pose significant obstacles to the application of large language models in specialized
与通用NLP任务相比,放射学报告摘要生成具有独特的挑战性。由于使用了高度专业化的技术性语言,通用NLP模型难以准确捕捉关键信息。误读关键发现的潜在风险,以及保持这些发现的上下文和关联性的重要性,进一步增加了任务的复杂性[11]。为此,针对医学文本摘要开发了多种专用语言处理方法,大致可分为三类:传统方法、基于深度学习的方法和基于大语言模型的方法。
传统方法如[2]为文本摘要研究奠定了基础,但往往无法捕捉复杂语义和上下文信息。CNN等深度学习技术的引入,在捕捉放射学报告独特语言特征和上下文方面表现出优越性能[11],但这些技术通常需要大量标注数据进行训练,且局限于特定任务和/或领域。
随着Transformer模型的提出,其独特的多头全局注意力机制使其在医学图像分析中得到广泛应用[12][13]。基于Transformer的模型如BERT[7]和GPT[8]推动了大语言模型的兴起,为放射学文本处理开辟了新可能。在胸部放射学报告等特定领域数据上微调BERT,显示出更强的临床上下文捕捉能力和高质量摘要生成能力[10]。
然而,使用BERT等预训练语言模型仍需大量标注数据进行下游任务(如文本摘要)训练。即使是非标注数据,训练ChatGPT[14]和GPT-4[15]等大语言模型仍需海量数据。但在某些专业领域,可用数据往往极为有限,不足以训练有效的大语言模型。即便获得足够数据,训练具有庞大规模参数的模型仍需消耗大量资源。因此,对数据量和硬件资源的高要求成为大语言模型在专业领域应用的主要障碍。
domains.
领域

Fig. 1. Overview of Impression GP T. Initially, Impression GP T selects similar reports from the corpus based on the findings section of test report. Subsequently, a dynamic context is created and fed into ChatGPT. An iterative optimization algorithm is then employed to fine-tune the generated response in an interactive way. Finally, an optimized impression that conforms to the findings section of test report is produced.
图 1: Impression GPT概述。Impression GPT首先根据检查报告的结果部分从语料库中选择相似的报告。随后创建动态上下文并输入到ChatGPT中。接着采用迭代优化算法以交互方式微调生成的响应。最终生成符合检查报告结果部分的优化印象描述。
It is noteworthy that models such as ChatGPT and GPT4 possess strong in-context learning abilities, allowing them to extract useful semantic information based on provided prompts [16]. Coupled with their inherent text generation capabilities, even in scenarios with limited training data, these large language models can adapt and generate domain-specific answers through the optimization of prompts. In this study, we utilized ChatGPT and optimized its generated result for radiology report sum mari z ation. An iterative optimization algorithm is designed and implemented via prompt engineering to take advantage of ChatGPT’s in-context learning ability while also continuously improving its response through interaction. Specifically, as shown in Fig. 1, we use similarity search techniques to construct a dynamic prompt to include semantically- and clinically-similar existing reports. These similar reports are used as examples to help ChatGPT learn the text descriptions and sum mari zat ions of similar imaging manif e stations in a dynamic context. We also develop an iterative optimization method to further enhance the performance of the model by performing automated evaluation on the response generated by ChatGPT and integrating the generated text and the evaluation results to compose the iterative prompt. In this way, the generated response from ChatGPT is continually updated for optimized results under pre-defined guidance. We evaluate our Impression GP T on two public radiology report datasets: MIMIC-CXR [17] and OpenI [18]. Our experimental results show that Impression GP T performs substantially better than the current methods in radiology report sum mari z ation, with only a small dataset (5-20 samples) used for optimizing. Overall, the main contributions of this work are:
值得注意的是,像ChatGPT和GPT4这样的模型具备强大的上下文学习能力,使其能够根据提供的提示提取有用的语义信息[16]。结合其固有的文本生成能力,即使在训练数据有限的场景下,这些大语言模型也能通过提示优化来适应并生成特定领域的答案。在本研究中,我们利用ChatGPT并优化其生成的放射学报告摘要结果。通过提示工程设计和实现了一种迭代优化算法,既利用了ChatGPT的上下文学习能力,又通过交互持续改进其响应。具体而言,如图1所示,我们使用相似性搜索技术构建动态提示,以包含语义和临床相似的现有报告。这些相似报告作为示例,帮助ChatGPT在动态上下文中学习相似影像表现的文本描述和摘要。我们还开发了一种迭代优化方法,通过对ChatGPT生成的响应进行自动评估,并将生成的文本与评估结果整合以构成迭代提示,从而进一步提升模型性能。通过这种方式,ChatGPT生成的响应在预定义指导下不断更新以获得优化结果。我们在两个公开的放射学报告数据集MIMIC-CXR[17]和OpenI[18]上评估了Impression GPT。实验结果表明,仅使用少量样本(5-20个)进行优化的情况下,Impression GPT在放射学报告摘要任务中的表现显著优于现有方法。本工作的主要贡献包括:
• In-context learning of Large Language Model (LLM) with limited samples is achieved by similarity search. Through the identification of the most similar examples in the corpus, a dynamic prompt is created that encompasses the most useful information for LLM. • An iterative optimization algorithm is developed with a dynamic prompt scheme to further optimize the generated result. The iterative prompt provides feedback on the responses generated by LLM and the corresponding evaluation, followed by further instructions to iterative ly update the prompts.
- 大语言模型 (LLM) 的上下文学习通过相似性搜索在有限样本中实现。通过识别语料库中最相似的示例,动态生成包含对LLM最有价值信息的提示。
- 开发了基于动态提示方案的迭代优化算法以进一步优化生成结果。迭代提示机制对LLM生成的响应及相应评估提供反馈,并通过进一步指令循环更新提示。
• A new paradigm for optimizing LLMs’ generation using domain-specific data. The proposed framework can be applied to any scenarios involving the development of domain-specific models from an existing LLM in an effective and resource-efficient approach. And the corresponding code is available on GitHub1.
• 一种利用领域专用数据优化大语言模型(LLM)生成的新范式。该框架可有效且资源高效地应用于任何基于现有大语言模型开发领域专用模型的场景,相关代码已在GitHub1开源。
II. BACKGROUND AND RELATED WORKS
II. 背景与相关工作
A. Text Sum mari z ation in Natural Language Processing
A. 自然语言处理中的文本摘要
Text sum mari z ation is to extract, summarize or refine the key information of the original text to obtain the main content or general meaning of the the original text. There are two major categories of text sum mari z ation: extractive sum mari z ation and abstract ive sum mari z ation. Among them, extractive sum mari z ation [2]–[4], [19] is to take one or more sentences from a text or text set to construct a summary. An advantageous aspect of this approach lies in its simplicity, and its results exhibit a low tendency towards deviations from the essential message conveyed in the text. Before the emergence of artificial neural network, the practice of text sum mari z ation predominantly relied on the technique of extractive summarization. For example, Hongyan [2] developed filtering rules based on prior knowledge to remove unimportant parts of the text to obtain a summary. LexRanK [4] represented the words and sentences in a graph and search the text with the highest similarity in the graph. [3] used algebraic statistics to extract latent semantic information from text and generates text summaries based on latent semantic similarities. After the emergence of artificial neural networks and deep learning, methods such as BertSUM [19] and TransEXT [9] were training based on the BERT [7] model. However, extractive sum mari z ation suffers from incoherent generation of summaries, uncontrollable length, and the quality of the results is severely dependent on the original text.
文本摘要旨在提取、概括或精炼原文的关键信息,以获取其主要内容或核心含义。文本摘要主要分为两大类:抽取式摘要和生成式摘要。其中,抽取式摘要 [2]–[4][19] 是从文本或文本集合中选取一个或多个句子构建摘要。这种方法的优势在于其简洁性,且结果偏离文本核心信息的倾向较低。在人工神经网络出现之前,文本摘要主要依赖抽取式技术。例如,Hongyan [2] 基于先验知识设计过滤规则,去除文本中不重要的部分以生成摘要;LexRank [4] 将词句表示为图结构,并在图中搜索相似度最高的文本;[3] 则利用代数统计提取文本的潜在语义信息,基于潜在语义相似性生成摘要。随着人工神经网络和深度学习的兴起,出现了基于 BERT [7] 模型的 BertSUM [19] 和 TransEXT [9] 等方法。然而,抽取式摘要存在生成内容不连贯、长度不可控等问题,且结果质量高度依赖原始文本。
For the task of abstract ive sum mari z ation [6], [9], [19]– [21], there is no issue as mentioned previously. Abstract ive sum mari z ation task is an end-to-end generative task, and it is necessary to understand the meaning of the original text and generate a new sum mari z ation. Compared with extractive summarization, abstract ive sum mari z ation is more challenging, but it is also more in line with the daily writing habits of human beings, so it has gradually become a significant research focus in the field of text sum mari z ation since the introduction of artificial neural networks and deep learning. For example, PGN (LSTM) [6] used a pointer-generator network to copy words from the original text and also retains the ability to generate new words, thus improving the seq2seq+attention model architecture. Similarly, CGU [20] proposed a global encoding framework for summary generation, which uses a combination of CNN and self-attention to filter the global encoding of text, solving the alignment problem between source text and target summary. With the emergence of BERT [7], a milestone model within the NLP field, the previous training method was changed to use the strategy of pre-training $^+$ fine-tuning. TransABS [9] accomplished generative sum mari z ation based on the BertSUM [19] used a two-stage fine-tuning method and achieved optimality on three datasets. CAVC [21] used a Mask Language Modeling (MLM) strategy based on the BERT model to further improve the performance.
对于摘要生成任务[6]、[9]、[19]-[21],不存在前述问题。摘要生成是一种端到端的生成式任务,需要理解原文含义并生成新的摘要。相比抽取式摘要,摘要生成更具挑战性,但也更符合人类日常写作习惯,因此自人工神经网络和深度学习引入以来,逐渐成为文本摘要领域的重要研究方向。例如PGN(LSTM)[6]采用指针生成器网络,既能复制原文词汇又保留生成新词能力,从而改进了seq2seq+attention模型架构。类似地,CGU[20]提出了摘要生成的全局编码框架,通过CNN与自注意力机制组合过滤文本全局编码,解决了源文本与目标摘要的对齐问题。随着NLP领域里程碑模型BERT[7]的出现,原有训练方式转变为预训练$^+$微调策略。TransABS[9]基于BertSUM[19]采用两阶段微调方法完成生成式摘要,在三个数据集上达到最优。CAVC[21]则基于BERT模型采用掩码语言建模(MLM)策略进一步提升了性能。
B. Radiology Report Sum mari z ation
B. 放射学报告总结
With the development of text sum mari z ation in NLP, text processing related to the medical field is also gaining attention. In the standard radiology report, the impression section is a summary of the entire report description. Therefore, Automatic Impression Generation (AIG) has become the focus of NLP research in the medical field [10], [22]–[26]. Earlier studies have focused on the use of seq2seq methods. For example, [22] trained a bi-directional LSTM based model as a summary extractor using the method of Multi-agent Reinforcement Learning.
随着NLP中文本摘要技术的发展,医疗领域的相关文本处理也日益受到关注。在标准放射学报告中,印象(impression)部分是对整个报告描述的总结。因此,自动印象生成(AIG)已成为医疗领域NLP研究的重点[10][22][23][24][25][26]。早期研究主要集中于使用seq2seq方法,例如[22]通过多智能体强化学习方法训练了一个基于双向LSTM的摘要提取模型。
After the emergence of BERT [7], BioBERT [23] pretrained BERT using large-scale biomedical corpora, surpassing previous methods in a variety of medical-related downstream tasks such as named entity recognition, relationship extraction, and question answering. This work explored the path of using pre-trained language models within the biomedical domain. Similar, Clinical Radio BERT [24] pre-trained a BERT model and proposed a knowledge-infused few-shot learning (KI-FSL) approach that leverages domain knowledge for understanding radiotherapy clinical notes. Chest X ray BERT [10] pre-trained BERT using a radiology-related corpus and combined it as an encoder with a Transformer decoder to perform the diagnostic report sum mari z ation task. And WGSUM [25] constructed a word graph from the findings section of radiology report by identifying the salient words and their relations, and proposed a graph-based model WGSUM to generate impressions with the help of the word graph. [26] utilized a graph encoder to encode the word graph during pre-training to enhance the text extraction ability of the model, and introduced contrast learning to reduce the distance between keywords. Its results on AIG outperform the previous methods. All the above methods have achieved good results in the medical text domain based on the pre-trained language model, but still have the problem of poor generalization due to the low complexity of the model.
在BERT [7]出现后,BioBERT [23]使用大规模生物医学语料对BERT进行预训练,在命名实体识别、关系抽取和问答等多种医学相关下游任务中超越了先前方法。这项工作探索了在生物医学领域使用预训练语言模型的路径。类似地,Clinical Radio BERT [24]预训练了一个BERT模型,并提出了一种知识注入的少样本学习(KI-FSL)方法,利用领域知识来理解放疗临床记录。Chest X ray BERT [10]使用放射学相关语料预训练BERT,并将其作为编码器与Transformer解码器结合,执行诊断报告摘要任务。WGSUM [25]通过识别放射学报告发现部分的关键词及其关系构建了词图,并提出基于图的模型WGSUM,借助词图生成印象部分。[26]在预训练期间使用图编码器对词图进行编码,以增强模型的文本提取能力,并引入对比学习来缩小关键词之间的距离。其在AIG上的结果优于先前方法。以上所有方法基于预训练语言模型在医学文本领域取得了良好效果,但仍因模型复杂度低而存在泛化能力差的问题。
C. Large Language Model
C. 大语言模型
With the advent of BERT [7] model based on Transformer architecture, an increasing number of studies related to Natural Language Processing (NLP) have incorporated pre-training $^+$ fine-tuning methodologies. The approach that first pre-training on a large amount of unlabeled data and then fine-tuning on a small portion of labeled data has proven to achieve more outstanding results. For example, before BERT, GPT1 [27] with 117 million parameters has been initially trained using self-supervised pre-training $^+$ supervised fine-tuning. It directly used the Transformer decoder to achieve excellent results on natural language inference and question-and-answer tasks. Later, Google proposed the landmark model BERT, which introduced Transformer encoder and further improved the performance by using Mask Language Modeling and Next Sentence Prediction methods in the pre-training stage, where the number of parameters in BERT-Large has reached 340 million. Four months after the release of BERT, GPT-2 [8] was introduced, which further extended the model parameters and training data set based on GPT-1, with Extra Large of GPT-2 model reaching 1.5 billion parameters. In addition, the researchers [8] found that with the expanded training dataset, outstanding results of large language model could be achieved in downstream tasks without using fine-tuning. GPT3 [28] further expanded the data size and parameter size based on GPT-2, and the maximum parameter reached 175 billion, and its performance on downstream tasks was significantly improved. And they first proposed a training paradigm of unsupervised pre-training $^+$ few-shot prompt.
随着基于Transformer架构的BERT[7]模型问世,越来越多的自然语言处理(NLP)相关研究开始采用预训练$^+$微调方法。这种先在大规模无标注数据上进行预训练,再对小部分标注数据进行微调的方式被证明能取得更出色的效果。例如在BERT之前,拥有1.17亿参数的GPT1[27]就率先采用自监督预训练$^+$监督微调的训练方式,直接使用Transformer解码器在自然语言推理和问答任务上取得优异表现。随后Google提出了里程碑式模型BERT,引入Transformer编码器,并通过在预训练阶段采用掩码语言建模和下一句预测方法进一步提升性能,其中BERT-Large的参数规模已达到3.4亿。BERT发布四个月后,GPT-2[8]问世,在GPT-1基础上进一步扩展了模型参数和训练数据集,GPT-2模型的Extra Large版本参数达到15亿。此外研究者[8]发现,随着训练数据集的扩大,大语言模型在下游任务中不使用微调也能取得出色效果。GPT3[28]在GPT-2基础上继续扩大数据规模和参数规模,最大参数量达到1750亿,其在下游任务上的性能显著提升,并首次提出无监督预训练$^+$少样本提示的训练范式。
In comparison to small Pre-trained Language Models (PLMs), LLMs possess superior generalization capability. They can accurately learn potential features of input text and perform effectively across different downstream tasks, even without fine-tuning. One prominent foundational model of a large language model is ChatGPT [14], based on the GPT-3.5 model, which employs training data in conversation mode to facilitate user-friendly human-machine interaction. ChatGPT has been widely integrated into various applications such as education and healthcare, and performs well in tasks such as text classification, data expansion, sum mari z ation, and other natural language processing [29]–[34]. Although ChatGPT performs well in most tasks, its performance in specialized domains is still unsatisfactory. Hence, we propose Impression GP T, an iterative optimization algorithm that enables ChatGPT to achieve excellent performance on the radiology report sum mari z ation task.
相较于小型预训练语言模型(PLM),大语言模型(LLM)具备更优异的泛化能力。它们能精准学习输入文本的潜在特征,即使不经过微调也能在不同下游任务中表现卓越。ChatGPT[14]作为大语言模型的代表性基础模型,基于GPT-3.5架构,采用对话模式的训练数据来实现友好的人机交互。该模型已广泛应用于教育、医疗等多个领域,在文本分类、数据扩增、摘要生成等自然语言处理任务中表现突出[29]-[34]。尽管ChatGPT在多数任务中表现优异,但其在专业领域的效果仍有不足。为此,我们提出Impression GPT算法,通过迭代优化使ChatGPT在放射学报告摘要任务中达到卓越性能。
D. Prompt Engineering
D. 提示工程 (Prompt Engineering)
Prompt engineering is a burgeoning field that has garnered significant attention in recent years due to its potential to enhance the performance of LLMs. The fundamental idea behind prompt engineering is to utilize prompts as a means to program LLMs, which is a vital skill required for effective communication with these models [35], such as ChatGPT. Recent research has demonstrated that designing prompts to guide the model toward relevant aspects of input can lead to more precise and consistent outputs. This is particularly crucial in applications such as language translation and text sum mari z ation, where the quality of the output is paramount.
提示工程(Prompt Engineering)是一个新兴领域,近年来因其提升大语言模型(LLM)性能的潜力而备受关注。其核心理念是将提示作为编程大语言模型的手段,这是与ChatGPT等模型高效交互的关键技能[35]。最新研究表明,通过设计提示来引导模型关注输入的相关方面,能够产生更精准、一致的输出。这一技术在机器翻译和文本摘要等输出质量至关重要的应用中尤为关键。
In general, prompt engineering is a new paradigm in the field of natural language processing, and although still in its early stages, has provided valuable insights into effective prompt patterns [36]. These patterns provide a wealth of inspiration, highlighting the importance of designing prompts to provide value beyond simple text or code generation. However, crafting prompts that are suitable for the model can be a delicate process. Even a minor variation in prompts could significantly impact the model’s performance. Therefore, finding the most suitable prompts remains an important challenge. Typically, there are two main types of prompts: manual prompts and automated template prompts.
通常来说,提示工程 (prompt engineering) 是自然语言处理领域的新范式,尽管仍处于早期阶段,但已为高效提示模式提供了宝贵见解 [36]。这些模式提供了丰富的灵感,突显了设计提示的重要性,其价值远超简单的文本或代码生成。然而,制作适合模型的提示可能是个精细过程。即使提示存在微小变化,也可能显著影响模型表现。因此,寻找最合适的提示仍是重要挑战。提示主要分为两类:手动提示和自动模板提示。
- Manual Prompt: Manual prompts are designed manually to guide LLMs towards specific inputs. These prompts provide the model with explicit information about what type of data to focus on and how to approach the task at hand [36]. Manual prompts are particularly useful when the input data is well-defined and the output needs to adhere to a specific structure or format [28]. For example, in the medical field where interpret ability is crucial, manually created prompts are often employed to guide the model toward focusing on specific aspects of the input data. In the area of medical text security, for instance, manual prompts were utilized to guide the model toward identifying and removing private information in medical texts, effectively solving the ethical issues associated with medical data [33]. Overall, manual prompts play a vital role in improving model performance in various domains by providing the model with a more structured and focused approach to the task.
- 手动提示 (Manual Prompt): 手动提示是通过人工设计来引导大语言模型处理特定输入的指令。这类提示为模型提供了明确的信息,指导其应关注哪些数据类型以及如何处理当前任务 [36]。当输入数据定义清晰且输出需要遵循特定结构或格式时,手动提示尤为有效 [28]。例如,在可解释性至关重要的医疗领域,常采用人工创建的提示来引导模型聚焦于输入数据的特定方面。以医疗文本安全为例,研究人员通过手动提示指导模型识别并删除医疗文本中的隐私信息,有效解决了医疗数据相关的伦理问题 [33]。总体而言,手动提示通过为模型提供更具结构化和针对性的任务处理方式,在提升各领域模型性能方面发挥着关键作用。
- Automated Template Prompt: While manual prompts are a powerful tool for addressing many issues, they do have certain limitations. For example, creating prompts requires time and expertise, and even minor modifications to prompts can result in significant changes in model predictions, particularly for complex tasks where providing effective manual prompts is challenging [37]. To address these issues, researchers have proposed various methods for automating the process of prompt design, different types of prompts can assist language models in performing specific tasks more effectively. Prompt mining involves extracting relevant prompts from a given dataset [37], while prompt paraphrasing improves model performance and robustness by increasing prompt diversity. Gradient-based search [38] helps identify optimal prompts in a model’s parameter space, and prompt generation [39] can create new prompts using techniques such as generative models. These discrete prompts are typically automatically searched for in a discrete space of prompt templates, often corresponding to natural language phrases. Other types of prompts, such as continuous prompts [40] that construct prompts in a model’s embedding space and static prompts that create fixed prompt templates for input can also aid in task performance.
- 自动模板提示:虽然手动提示是解决许多问题的强大工具,但它们确实存在一定局限性。例如,创建提示需要时间和专业知识,即使对提示进行微小修改也可能导致模型预测发生显著变化,特别是在复杂任务中提供有效的手动提示具有挑战性 [37]。为解决这些问题,研究人员提出了多种自动化提示设计方法,不同类型的提示可以帮助语言模型更有效地执行特定任务。提示挖掘涉及从给定数据集中提取相关提示 [37],而提示改写通过增加提示多样性来提升模型性能和鲁棒性。基于梯度的搜索 [38] 有助于在模型参数空间中找到最优提示,提示生成 [39] 则能使用生成式模型等技术创建新提示。这些离散提示通常在提示模板的离散空间中自动搜索,通常对应自然语言短语。其他类型的提示,如在模型嵌入空间中构建提示的连续提示 [40],以及为输入创建固定提示模板的静态提示,也能提升任务表现。
These different prompt types can be used independently or in combination to help language models perform various tasks, including natural language understanding, generation, machine translation, and question-answering.
这些不同的提示类型可以独立使用或组合使用,以帮助语言模型执行各种任务,包括自然语言理解、生成、机器翻译和问答。
III. METHOD
III. 方法
In this section, we first illustrate the pipeline of our ImpressionGPT. Then we elaborate on the dynamic prompt generation in Sec. III-A and the iterative optimization in Sec. III-B. Fig. 2 shows the pipeline of our Impression GP T. Firstly, as shown in the first step of mainstream (part $a$ in Fig. 2), we use a labeler to categorize the “Findings” section of the report and extract disease labels. Then, based on the disease category, we search for similar reports in the existing diagnostic report corpus, as shown in part $b$ of Fig. 2. And we designed a dynamic prompt (shown in part $c$ of Fig. 2) to construct a context environment with similar diagnostic reports, so that
在本节中,我们首先阐述ImpressionGPT的流程。随后在III-A节详述动态提示生成方法,在III-B节说明迭代优化过程。图2展示了ImpressionGPT的工作流程:首先如图2主流部分第一步(图2中部件$a$所示),我们使用标注器对报告的"Findings"部分进行疾病分类并提取标签;接着根据疾病类别在现有诊断报告语料库中检索相似报告(图2部件$b$);最后我们设计了动态提示(图2部件$c$),通过相似诊断报告构建上下文环境。
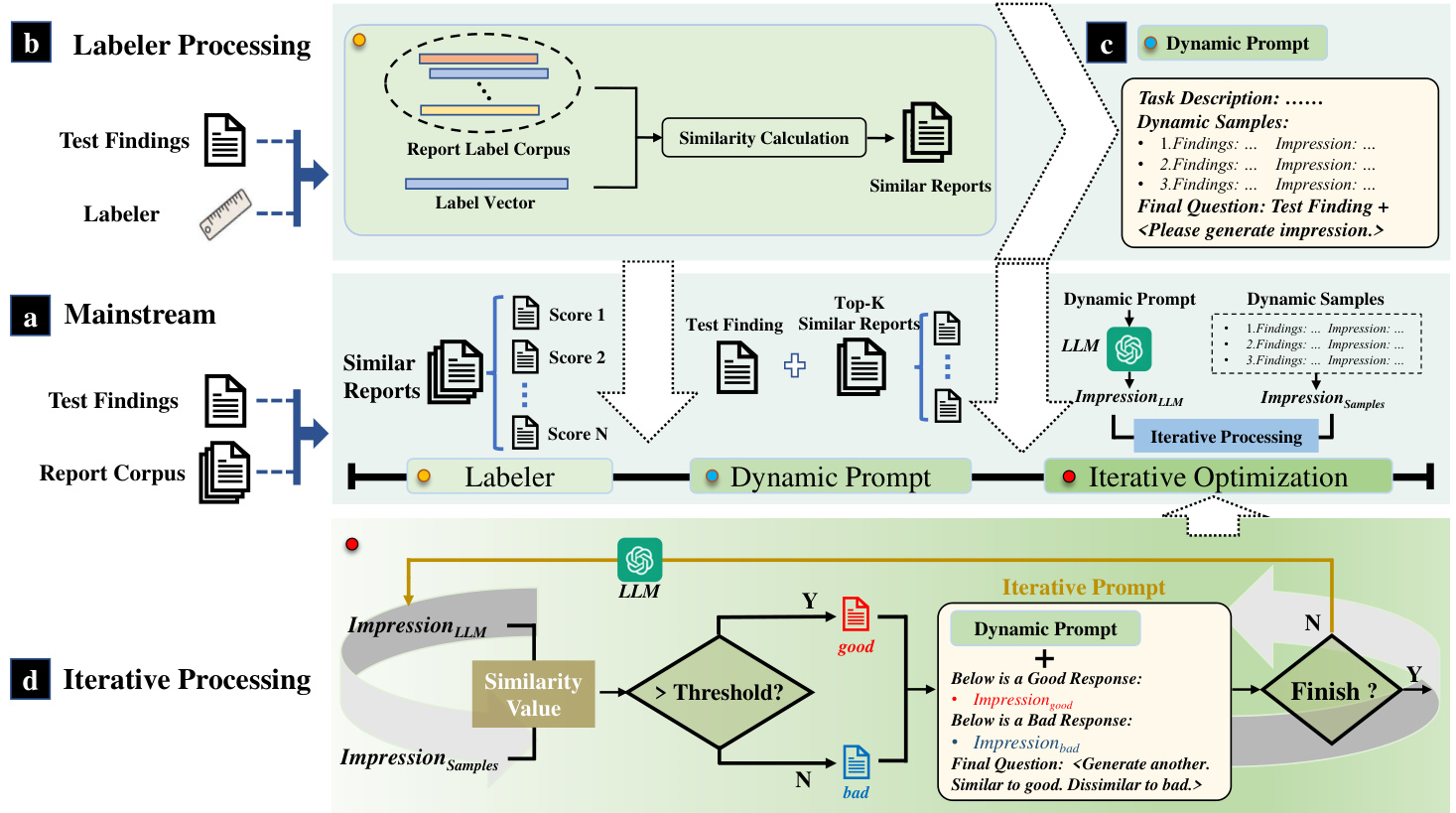
Fig. 2. The pipeline of our Impression GP T. Part $^{a}$ in the middle is the mainstream of our method. We first use a labeler to categorize the diseases of test report and obtain the similar reports in the corpus (part b), and then construct a dynamic prompt in part $c$ . Part $^d$ accomplishes the iterative optimization of LLM’s generated result through interaction with positive (good) and negative (bad) responses.
图 2: 我们的 Impression GP T 流程示意图。中间部分 $^{a}$ 是我们方法的核心流程。首先使用标注器对检验报告的疾病进行分类,并在语料库中获取相似报告 (部分 b),随后在部分 $c$ 构建动态提示。部分 $^d$ 通过正反馈 (优质) 和负反馈 (劣质) 的交互实现大语言模型生成结果的迭代优化。
ChatGPT can learn to summarize diagnostic reports related to the current disease. We refer to this as “dynamic context”. Based on the dynamic context, we utilized an iterative optimization method, as shown in the part $d$ of Fig. 2, to optimize the response of ChatGPT. During the iterative optimization process, we compare the generated “Impression” from ChatGPT with examples in dynamic prompt to obtain good and bad responses. These evaluated responses are inserted to the iterative prompt with further guidance to ensure that the next response is closer to the former good response while avoiding the former bad response. Overall, our method requires a small number of examples, facilitating ChatGPT’s acquisition of excellent domain-specific processing capabilities. More details of dynamic prompt generation and iterative optimization can be found in the following subsections.
ChatGPT能够学习总结与当前疾病相关的诊断报告。我们将此称为"动态上下文"。基于动态上下文,我们采用了一种迭代优化方法(如图2的$d$部分所示)来优化ChatGPT的响应。在迭代优化过程中,我们将ChatGPT生成的"印象"部分与动态提示中的示例进行对比,从而区分优劣响应。这些评估后的响应会被加入迭代提示,并辅以进一步指导,确保后续响应趋近优质响应而规避劣质响应。总体而言,我们的方法仅需少量示例即可帮助ChatGPT获得出色的领域特定处理能力。动态提示生成与迭代优化的更多细节将在后续小节详述。
A. Dynamic Prompt Generation
A. 动态提示生成
In previous manual-designed prompts, fixed-form prompts were frequently employed for simple tasks that were easily generalized, such as translation, Q&A, and style rewriting. However, these fixed-form prompts were found to be insufficient in providing prior knowledge for more intricate tasks and datasets that are peculiar to specific domains, like processing medical diagnosis reports, resulting in poor performance of ChatGPT. Consequently, we propose a hypothesis which suggests that constructing dynamic prompts by utilizing similar examples from relevant domain-specific corpora can enhance the model’s comprehension and perception. In this work, dynamic prompt generation primarily comprises two main components: similarity search and prompt design. Below is a detailed introduction to these two components.
在先前手动设计的提示(prompt)中,固定形式的提示常被用于翻译、问答和风格改写等易于泛化的简单任务。然而研究发现,这类固定提示难以为特定领域(如医疗诊断报告处理)的复杂任务和特殊数据集提供充分先验知识,导致ChatGPT表现欠佳。因此我们提出一个假设:通过利用相关领域语料库中的相似样本来构建动态提示,可以增强模型的理解与感知能力。本工作中,动态提示生成主要包含两个核心组件:相似性搜索与提示设计。以下将详细介绍这两个组件。
- Similarity Search: The purpose of similarity search is to find diagnostic reports within the corpus that are similar to the Test Findings. The process for similarity search mainly encompasses two phases. Initially, a disease classifier is employed to extract the disease categories appearing in the input radiology report. Subsequently, relying on these categories, a similarity calculation is conducted on the report corpus to obtain examples similar to the input radiology report.
- 相似性搜索:相似性搜索的目的是在语料库中查找与检测结果相似的诊断报告。该过程主要包含两个阶段。首先,使用疾病分类器提取输入放射学报告中出现的疾病类别。随后,基于这些类别对报告语料库进行相似性计算,以获取与输入放射学报告相似的示例。
In previous studies, corpus search typically involve two approaches: text-based [41] and feature-based [42]. However, text-based methods can be time-consuming and significantly increase search time, particularly with large corpora. Featurebased methods require feature extraction and storage of each sample, making it more space-demanding. Therefore, in this study, we utilize diagnostic report labels for similarity search, requiring only prior identification and local label storage of the report sample. Our approach substantially reduces time and space costs. Moreover, using tag values to calculate the similarity enables the identification of samples with similar diseases, which provides domain-specific and even samplespecific knowledge that can be leveraged by ChatGPT’s contextual processing capabilities. Specifically, we use CheXpert labeler [43] as the disease classifier, which is a rule-based labeler to extract observations from the free text radiology reports. The observations contain 14 classes based on the prevalence in the chest radiology reports. As shown in Fig. 3, each observation is represented by a letter from $\cdot_ {a},$ to $\cdot_ {n},$ , and each contains four categories. The categories correspond to the clearly presence (‘1’) or absence $({}^{\cdot}0^{\cdot})$ of the observation in the radiology report, the presence of uncertainty or ambiguous description $(\mathrel{-}1\mathbin{\rightharpoonup})$ , and the un mentioned observation $(b l a n k)$ , which is replaced by the number $\mathbf{\nabla}^{\zeta}2\mathbf{\nabla}^{\zeta}$ to facilitate similarity calculation. The labels of each radiology report in the corpus are extracted and saved as a one-dimensional vector of scale $1\times14$ . The label vectors of test reports are then compared to those in the corpus using Euclidean distance, and the radiology reports that are closest to each other are selected to generate dynamic prompts. This method ensures reliable and accurate disease classification of radiology reports. In this work, we directly use the split training set as a corpus and extract and preserve the corresponding disease labels for MIMICCXR [17] and OpenI [18] datasets. More details about dataset processing can be found at Section IV-A.
在以往研究中,语料库检索通常采用两种方法:基于文本的[41]和基于特征的[42]。然而基于文本的方法耗时较长,会显著增加搜索时间,尤其在大规模语料库中更为明显。基于特征的方法需要对每个样本进行特征提取和存储,空间占用更高。因此本研究利用诊断报告标签进行相似性搜索,仅需预先识别并本地存储报告样本的标签。该方法大幅降低了时间和空间成本。此外,通过标签值计算相似度能识别具有相似疾病的样本,这些样本提供的领域特异性甚至样本特异性知识,可被ChatGPT的上下文处理能力所利用。具体而言,我们采用CheXpert标签器[43]作为疾病分类器,该基于规则的标签器能从自由文本放射报告中提取观察结果。这些观察结果包含基于胸部放射报告常见表现的14个类别。如图3所示,每个观察结果用字母$\cdot_ {a},$到$\cdot_ {n},$表示,共包含四种类别:放射报告中明确存在("1")或不存在$({}^{\cdot}0^{\cdot})$该观察结果、存在不确定性或模糊描述$(\mathrel{-}1\mathbin{\rightharpoonup})$、以及未提及的观察结果$(blank)$(为便于相似度计算替换为数值$\mathbf{\nabla}^{\zeta}2\mathbf{\nabla}^{\zeta}$)。语料库中每份放射报告的标签被提取并存储为$1\times14$尺度的一维向量,测试报告的标签向量通过欧氏距离与语料库进行比对,最终选择最接近的放射报告生成动态提示。该方法确保了放射报告疾病分类的可靠性与准确性。本工作直接使用分割后的训练集作为语料库,并为MIMICCXR[17]和OpenI[18]数据集提取保存了相应疾病标签。更多数据集处理细节详见第IV-A节。

Fig. 3. Details of similarity search process. CheXpert is initially employed to obtain the label vector for the radiology reports present in the corpus. Then the similarity between the label vector of the test report and the label corpus is calculated, allowing for the identification of the similar radiology reports.
图 3: 相似性搜索流程细节。首先使用 CheXpert 获取语料库中放射学报告的标签向量,然后计算测试报告标签向量与标签语料库之间的相似度,从而识别相似的放射学报告。
- Prompt Design: Prior to introducing the design of our dynamic prompt, it is necessary to provide an overview of the input format when utilizing the ChatGPT API. The message that is fed into ChatGPT is accessed through the API in the form of a string, which is categorized into three distinct roles: System, U ser, and Assistant, as illustrated in Fig. 4. These roles are represented by the colors red, green, and blue, respectively. The System message initiates the conversation and provides information regarding the task while constraining the behavior of the Assistant. The User message instructs the Assistant and serves as the input provided by the user. Lastly, the Assistant component represents the response that is generated by the model. Notably, as the Assistant message can be artificially set, it enables the implementation of our dynamic prompt and facilitates iterative optimization.
- 提示词设计:在介绍动态提示设计之前,有必要概述使用ChatGPT API时的输入格式。通过API输入ChatGPT的消息以字符串形式传递,分为三个不同角色:System(系统)、User(用户)和Assistant(助手),如图4所示。这些角色分别用红色、绿色和蓝色表示。系统消息用于开启对话,提供任务相关信息并约束助手行为;用户消息用于指导助手,代表用户提供的输入;助手组件则代表模型生成的响应。值得注意的是,由于助手消息可以人工设置,这使我们能够实现动态提示并支持迭代优化。
In this work, we employ the prefix form for designing the dynamic prompt. The dynamic prompt consists of three modules: task description, dynamic samples, and final query, as illustrated in Fig. 4. The task description module specifies the role of the ChatGPT as a chest radiologist and provides a brief overview of the radiology report summary task along with a simple rule that serves as the foundation for the entire prompt. Subsequently, the dynamic prompt integrates similar reports obtained in Sec. III-A1. The dynamic samples module, depicted in the central part of Fig. 4, utilizes a question-and-answer format to provide the prompt in each sample. Specifically, the question part consists of a pre-defined question sentence and the “Findings” section of dynamic sample and is treated as the message of the U ser role. Then the “Impression” section of the dynamic sample is treated as the following message of the Assistant role. At the end of our dynamic prompt, the same pre-defined question is used as in the previous samples, and the “Findings” section of the test report is inserted. Overall, the resulting dynamic prompt uses a question-answering approach and provides multiple examples that have similar content to the target test sample, thus creating a data-specific dynamic context.
在本工作中,我们采用前缀形式设计动态提示。动态提示由三个模块组成:任务描述、动态样本和最终查询,如图4所示。任务描述模块明确了ChatGPT作为胸部放射科医生的角色,简要概述了放射学报告摘要任务,并提供了一个简单规则作为整个提示的基础。随后,动态提示整合了在第三-A1节中获得的相似报告。动态样本模块(图4中间部分所示)采用问答格式为每个样本提供提示。具体而言,问题部分由预定义的问题句子和动态样本的“发现”部分组成,并被视为用户角色的消息。然后,动态样本的“印象”部分被视为助手角色的后续消息。在我们的动态提示末尾,使用了与之前样本相同的预定义问题,并插入了测试报告的“发现”部分。总体而言,生成的动态提示采用问答方法,并提供了与目标测试样本内容相似的多个示例,从而创建了数据特定的动态上下文。
B. Iterative Optimization of Response
B. 响应迭代优化
In Sec. III-A, we constructed a dynamic context within the prompt in order to facilitate the model learning relevant prior knowledge from semantically similar examples. However, the use of this fixed form of prompt on ChatGPT produced a oneoff effect, as we cannot guarantee that the generated response is appropriate. Therefore, based on the dynamic prompt, we utilized an iterative optimization operation to further optimize the generated result of ChatGPT. The specific optimization process is presented in Algorithm 1.
在Sec. III-A中,我们在提示词中构建了动态上下文,以促进模型从语义相似的示例中学习相关先验知识。然而,在ChatGPT上使用这种固定形式的提示词会产生一次性效果,因为我们无法保证生成的响应是合适的。因此,基于动态提示词,我们利用迭代优化操作来进一步优化ChatGPT的生成结果。具体优化过程如算法1所示。
The first input of the algorithm is the dynamic prompt $(P r o m p t_ {D y})$ ) constructed in Sec. III-A. In line 6 of Algorithm 1, we receive a initial response from ChatGPT based on our dynamic prompt. Then, we evaluate it with other impression section of similar report and calculate an evaluation score at line 10. In lines 11-15, we compare above score with a predefined threshold $(T h r e_ {S})$ and construct our iterative prompt. Finally we feed this iterative prompt into ChatGPT to generate an optimized response (response in line 8) and repeat the above procedures. The purpose of the iterative prompt is to enable ChatGPT to optimize its response during the iterative process, so that the responses are more similar to those considered good and avoid the ones that are considered bad.
算法的第一个输入是第 III-A 节构建的动态提示 (Prompt_ Dy)。在算法 1 的第 6 行,我们基于动态提示从 ChatGPT 获取初始响应。接着,在第 10 行将其与其他类似报告的印象部分进行对比评估并计算评分。在第 11-15 行中,我们将该评分与预定义阈值 (Thre_ S) 比较,并构建迭代提示。最后将该迭代提示输入 ChatGPT 以生成优化响应 (第 8 行的响应) 并重复上述流程。迭代提示的作用是让 ChatGPT 在迭代过程中持续优化响应,使其更接近优质响应并规避不良响应。

Fig. 4. Details of dynamic prompt. The dynamic prompt is composed of task description, dynamic samples, and final query. Each component contains message of multiple roles. The flags in front of each sentence represent the role of the current message, red for System, green for User, and blue for Assistant.
图 4: 动态提示的细节。动态提示由任务描述、动态样本和最终查询组成。每个组件包含多角色的消息。每句话前的标记代表当前消息的角色,红色表示系统(System),绿色表示用户(User),蓝色表示助手(Assistant)。
Algorithm 1 Iterative Optimization Algorithm
算法 1: 迭代优化算法
Through this method, ChatGPT becomes iterative and selfoptimizing. A detailed description of the evaluation method and iterative prompt design is described below.
通过这种方法,ChatGPT变得具有迭代性和自我优化能力。下文将详细描述评估方法和迭代提示设计。
- Response Evaluation: During the process of iterative optimization, it is crucial to assess the quality of a response. In this study, we employ the Rouge-1 score, a prevalent metric for evaluating sum mari z ation models. The similarity between the generated results and ground-truth is measured on a word-by-word basis by the Rouge-1 score, thus enabling the evaluation of the outputs at a more refined scale. The dynamic prompt incorporates $N$ radiology reports having the highest similarity in the corpus, with the impression section deemed of high reference value for the ChatGPT response evaluation. As depicted in line 10 of Algorithm 1, we calculate the Rouge-1 score of ChatGPT’s response with the impression section (Impression i) of each similar report in the dynamic prompt, and average it to get the final evaluation result (score in line 10) . Subsequently, we derive “good response” and “bad response” based on the pre-defined threshold and merge the outcomes into the iterative prompt $(P r o m p t_ {I t e r})$ ). Specifically, if the evaluated score is higher than the previously defined threshold $(s c o r e)>T h r e_ {S})$ , it is considered as a good response. Conversely, if the score is lower than the threshold, the response is considered as a bad response. We update the iterative prompt by integrating the feedback through our merging function $(M_ {g o o d}$ and $M_ {b a d})$ . After constructing the iterative prompt, we feed it again into ChatGPT. Note that, this process is repeated until the maximum number of iterations $(i t e r=I)$ . Details of iterative prompt design are described in the following subsection.
- 响应评估:在迭代优化过程中,评估响应质量至关重要。本研究采用Rouge-1分数(一种评估摘要模型的常用指标),通过逐词比对生成结果与真实标注的相似度,实现更精细的输出评估。动态提示语料库中包含$N$篇相似度最高的放射学报告,其中印象部分被认为对ChatGPT响应评估具有高参考价值。如算法1第10行所示,我们计算ChatGPT响应与动态提示中每篇相似报告印象部分(Impression i)的Rouge-1分数,取平均值作为最终评估结果(第10行的score)。随后根据预设阈值区分"优质响应"和"劣质响应",并将结果合并至迭代提示$(Prompt_ {Iter})$。具体而言,若评估分数高于预设阈值$(score)>Thre_ {S})$则视为优质响应,反之则为劣质响应。我们通过合并函数$(M_ {good}$和$M_ {bad})$整合反馈来更新迭代提示。构建迭代提示后,再次将其输入ChatGPT。注意,该过程重复执行直至达到最大迭代次数$(iter=I)$。迭代提示设计细节将在下个小节详述。
- Prompt Design: The subsequent and crucial stage after identifying the positive and negative feedback is to utilize the evaluation results to instruct ChatGPT in generating enhanced responses. As shown in Fig. 5, the initial part of the iterative prompt is the dynamic prompt described in Sec. III-A2, which delivers the fundamental context for subsequent enhancement. For the responses evaluated in Sec. III-B1, a pair of U ser and Assistant roles are included in the iterative prompt. The U ser initiates the message with “Below is an excellent impression of the FINDINGS above” for the positive feedback and “Below is a negative impression of the FINDINGS above” for the negative feedback. The response produced by ChatGPT is positioned after the corresponding U ser message, adopting the “Instruction $^+$ Response” form to enable ChatGPT to learn the relevant content from the good and bad samples. As shown in the bottom “Final Query” in Fig. 5, the final query that concludes the iterative prompt provides specific optimization rules to regenerate a response that is consistent with the good response and avoids the bad response. Additionally, a length limit instruction is included to avoid ChatGPT from generating overly verbose responses. Note that after extensive experimental validation, we finally insert one good and $n$ bad responses in the iterative prompt. The number of bad examples $(n)$ is indefinite and can be appended all the time as long as the input limit of ChatGPT is not exceeded. We conducted ablation experiments and discussion on the setting of the number of good and bad responses in Section I of supplementary materials. In the process of each iteration, good response or bad response will be updated, which enables our prompt to optimize ChatGPT’s responses in time.
- 提示设计:在识别正负反馈后,关键的下一个阶段是利用评估结果指导ChatGPT生成优化回复。如图5所示,迭代提示的初始部分是第III-A2节所述的动态提示,为后续优化提供基础语境。针对第III-B1节评估的回复,迭代提示中包含一对用户(User)和助手(Assistant)角色。对于正面反馈,用户会以"以下是上述发现的优秀印象"开头;对于负面反馈则以"以下是上述发现的负面印象"开头。ChatGPT生成的回复会以"指令$^+$响应"形式置于相应用户消息之后,使其能从优劣样本中学习相关内容。如图5底部"最终查询"所示,结束迭代提示的最终查询会提供具体优化规则,要求重新生成符合优质回复且规避劣质回复的响应,同时包含长度限制指令以避免冗长输出。经大量实验验证,我们最终在迭代提示中插入1个优质回复和$n$个劣质回复。劣质样本数量$(n)$可动态增加,只要不超过ChatGPT的输入限制。我们在补充材料第I节对优劣样本数量设置进行了消融实验与讨论。每次迭代过程中,优质或劣质样本会持续更新,确保提示能实时优化ChatGPT的输出。
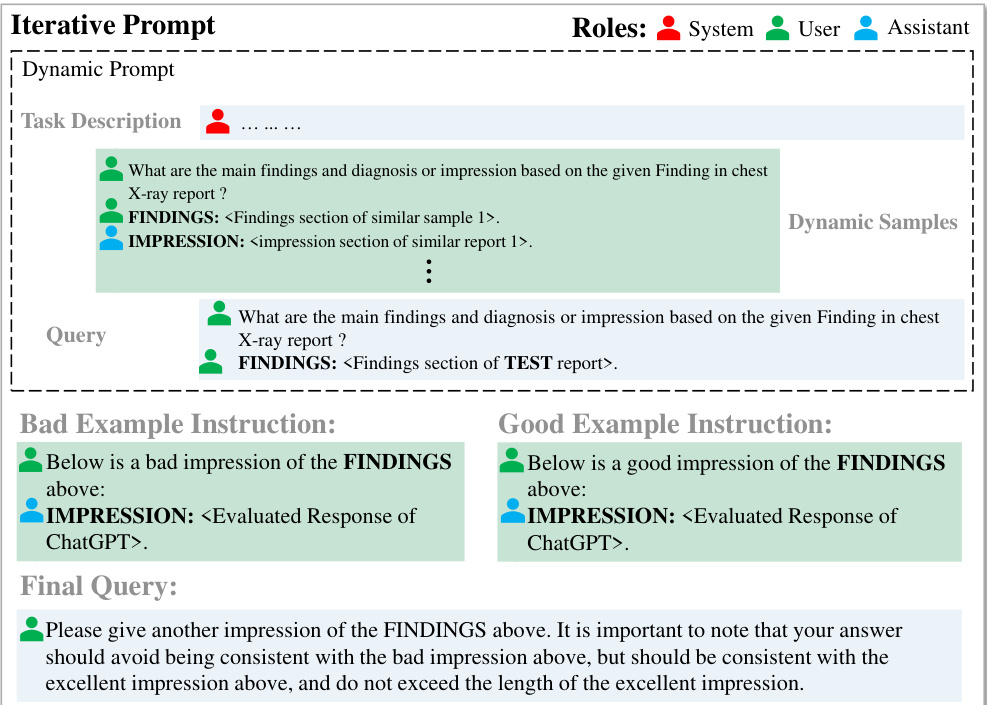
Fig. 5. Details of iterative prompt. We construct our iterative prompt by including the bad and good example instructions along with the final query, in addition to applying a “Instruction $+$ Response” approach in the example instruction for optimizing the response.
图 5: 迭代式提示的细节。我们通过包含优劣示例指令及最终查询来构建迭代式提示,同时在示例指令中采用"指令 $+$ 响应"的方法来优化响应。
To summarize, our approach involves utilizing a dynamic prompt to establish a contextual understanding that is highly relevant to the semantics of the given test case. This context is then fed into ChatGPT to obtain an initial response, which is further evaluated and incorporated into an iterative prompt. The iterative prompt is used to elicit subsequent responses that are specific to the task domain, thereby enabling self-iterative updates of ChatGPT’s generated result with limited examples. Our experimental results demonstrate that Impression GP T delivers superior results in the sum mari z ation of radiology reports, as elaborated in Sec. IV-D.
总结来说,我们的方法通过动态提示建立与测试用例语义高度相关的上下文理解。该上下文被输入ChatGPT以获取初始响应,随后经过评估并整合到迭代提示中。迭代提示用于引发针对任务领域的后续响应,从而在有限示例下实现ChatGPT生成结果的自我迭代更新。实验结果(如第IV-D节所述)表明,Impression GPT在放射学报告摘要任务中表现更优。
IV. EXPERIMENT AND ANALYSIS
IV. 实验与分析
A. Dataset and Evaluation Metrics
A. 数据集和评估指标
We evaluated our Impression GP T on two public available chest X-ray datasets: MIMIC-CXR [17] and OpenI [18]. MIMIC-CXR dataset contains of 227,835 radiology reports, which are amalgamated into our corpus after applying the official split that includes both the training and validation sets. The test set is reserved solely for evaluating the effectiveness of our Impression GP T. In line with the objective of medical report sum mari z ation, we excluded ineligible reports by implementing the following criteria: (1) removal of incomplete reports without finding or impression sections, (2) removal of reports whose finding section contained less than 10 words, and (3) removal of reports whose impression section contained less than 2 words. Consequently, we filtered out 122,014 reports to construct our corpus and included 1,606 test reports. OpenI dataset contains 3,955 reports, and we use the same inclusion criteria as above and finally obtained 3419 available reports. Since the official split is not provided, we follow [25] to randomly divided the dataset into train/test set by 2400:576. Similar to the MIMIC-CXR dataset, we use the training set to build our corpus, while the test set is reserved for evaluating the model.
我们在两个公开可用的胸部X光数据集上评估了Impression GPT:MIMIC-CXR [17]和OpenI [18]。MIMIC-CXR数据集包含227,835份放射学报告,在应用包含训练集和验证集的官方划分后,这些报告被合并到我们的语料库中。测试集仅用于评估Impression GPT的有效性。根据医学报告摘要的目标,我们通过以下标准排除了不合格的报告:(1) 移除没有发现或印象部分的不完整报告,(2) 移除发现部分少于10个单词的报告,(3) 移除印象部分少于2个单词的报告。最终,我们筛选出122,014份报告构建语料库,并包含1,606份测试报告。OpenI数据集包含3,955份报告,我们采用相同的纳入标准,最终获得3,419份可用报告。由于未提供官方划分,我们遵循[25]的方法,将数据集随机划分为训练集/测试集,比例为2400:576。与MIMIC-CXR数据集类似,我们使用训练集构建语料库,而测试集保留用于模型评估。
TABLE I THE STATISTICS OF THE TWO BENCHMARK DATASETS WITH OFFICIAL SPLIT FOR MIMIC-CXR AND RANDOM SPLIT FOR OPENI AFTER PRE-PROCESSING. WE REPORT THE AVERAGED SENTENCE-BASED LENGTH (AVG. SF, AVG. SI), THE AVERAGED WORD-BASED LENGTH (AVG. WF, AVG. WI) OF BOTH “FINDINGS” AND “IMPRESSION” SECTIONS.
| Type | MIMIC-CXR [17] | OpenI [18] | |
| Train | Test | Train Test | |
| Report Num | 122,014 | 1,606 | 2,400 576 |
| AVG.WF | 55.78 | 70.67 | 37.89 37.98 |
| AVG.SF | 6.50 | 7.28 | 5.75 5.77 |
| AVG.WI | 16.98 | 21.71 | 10.43 10.61 |
| AVG.SI | 3.02 | 3.49 | 2.86 2.82 |
表 1: 经过预处理后两个基准数据集的统计信息,其中MIMIC-CXR采用官方划分,OpenI采用随机划分。我们报告了"发现"和"印象"部分的平均句子长度(AVG.SF、AVG.SI)和平均单词长度(AVG.WF、AVG.WI)。
| 类型 | MIMIC-CXR [17] | OpenI [18] | |
|---|---|---|---|
| 训练集 | 测试集 | 训练集 测试集 | |
| 报告数量 | 122,014 | 1,606 | 2,400 576 |
| AVG.WF | 55.78 | 70.67 | 37.89 37.98 |
| AVG.SF | 6.50 | 7.28 | 5.75 5.77 |
| AVG.WI | 16.98 | 21.71 | 10.43 10.61 |
| AVG.SI | 3.02 | 3.49 | 2.86 2.82 |
Table I shows the statistics of MIMIC-CXR and OpenI datasets after pre-processing. The code to process radiology reports is publicly available on GitHub2. In our experiments, we employ Rouge metrics to evaluate the generated impression from our Impression GP T, and we reported F1 scores for Rouge-1 (R-1), Rouge-2 (R-2), and Rouge-L (R-L) that compare word-level unigram, bi-gram, and longest common sub-sequence overlap with the reference impression of the test report, respectively. In addition to using Rouge metrics, we incorporate the factual consistency (FC) metric, as introduced in previous works [25], [26]. The FC metric measures similarity between reference impressions and generated impressions by incorporating generic disease-related observations. Precision, recall, and F1 score are subsequently utilized to assess the performance. Given that existing studies only provide FC metrics for the MIMIC-CXR dataset, we also compute the Precision (FC-P), Recall (FC-R), and F1 score (FC-F1) for Impression GP T specifically on the MIMIC-CXR dataset.
表 I 显示了经过预处理后的MIMIC-CXR和OpenI数据集的统计信息。处理放射学报告的代码已在GitHub2上公开。在我们的实验中,我们采用Rouge指标来评估Impression GPT生成的印象摘要,并报告了Rouge-1 (R-1)、Rouge-2 (R-2)和Rouge-L (R-L)的F1分数,这些分数分别比较了测试报告参考印象与生成印象在单词级一元组、二元组和最长公共子序列上的重叠程度。除了使用Rouge指标外,我们还采用了先前研究[25][26]中提出的事实一致性(FC)指标。FC指标通过整合通用疾病相关观察结果来衡量参考印象与生成印象之间的相似性,随后利用精确率、召回率和F1分数来评估性能。鉴于现有研究仅提供MIMIC-CXR数据集的FC指标,我们还专门针对MIMIC-CXR数据集计算了Impression GPT的精确率(FC-P)、召回率(FC-R)和F1分数(FC-F1)。
TABLE II ABLATION STUDY OF IMPRESSION GP T ON MIMIC-CXR AND OPENI DATASETS. BOLD DENOTES THE BEST RESULT.
| Dataset | Method | R-1↑ | R-2↑ | R-L↑ | BS-P↑ | BS-R↑ | BS-F1↑ |
| MIMIC-CXR [17] | FixedPrompt | 33.29 | 16.48 | 28.35 | 86.07 | 88.15 | 87.07 |
| Dynamic Prompt | 45.14 | 25.75 | 38.71 | 87.25 | 90.04 | 88.60 | |
| Fixed Prompt +Iterative Opt | 35.68 | 20.30 | 31.69 | 88.73 | 88.46 | 88.55 | |
| Dynamic Prompt + Iterative Opt | 54.45 | 34.50 | 47.93 | 91.56 | 91.33 | 91.41 | |
| OpenI [18] | FixedPrompt | 33.48 | 19.80 | 31.33 | 87.42 | 90.61 | 88.94 |
| DynamicPrompt | 42.07 | 27.02 | 39.78 | 88.92 | 91.76 | 90.27 | |
| Fixed Prompt +Iterative Opt | 46.63 | 33.17 | 44.74 | 89.28 | 92.28 | 90.71 | |
| Dynamic Prompt + Iterative Opt | 66.37 | 54.93 | 65.47 | 93.59 | 94.15 | 93.83 |
表 II MIMIC-CXR和OpenI数据集上IMPRESSION GPT的消融研究。加粗表示最佳结果。
| 数据集 | 方法 | R-1↑ | R-2↑ | R-L↑ | BS-P↑ | BS-R↑ | BS-F1↑ |
|---|---|---|---|---|---|---|---|
| MIMIC-CXR [17] | FixedPrompt | 33.29 | 16.48 | 28.35 | 86.07 | 88.15 | 87.07 |
| MIMIC-CXR [17] | Dynamic Prompt | 45.14 | 25.75 | 38.71 | 87.25 | 90.04 | 88.60 |
| MIMIC-CXR [17] | Fixed Prompt +Iterative Opt | 35.68 | 20.30 | 31.69 | 88.73 | 88.46 | 88.55 |
| MIMIC-CXR [17] | Dynamic Prompt + Iterative Opt | * * 54.45 * * | * * 34.50 * * | * * 47.93 * * | * * 91.56 * * | * * 91.33 * * | * * 91.41 * * |
| OpenI [18] | FixedPrompt | 33.48 | 19.80 | 31.33 | 87.42 | 90.61 | 88.94 |
| OpenI [18] | DynamicPrompt | 42.07 | 27.02 | 39.78 | 88.92 | 91.76 | 90.27 |
| OpenI [18] | Fixed Prompt +Iterative Opt | 46.63 | 33.17 | 44.74 | 89.28 | 92.28 | 90.71 |
| OpenI [18] | Dynamic Prompt + Iterative Opt | * * 66.37 * * | * * 54.93 * * | * * 65.47 * * | * * 93.59 * * | * * 94.15 * * | * * 93.83 * * |
B. Implementation Details
B. 实现细节
In our framework, dynamic prompt construction and iterative optimization of response are essential components, and therefore, the related parameters are crucial. Specifically, in dynamic prompt construction, we define the number of similar reports as $N_ {s}$ , which determines the richness of dynamic semantic information in our prompt. In the iterative optimization of response, we define the evaluation threshold as $T$ , the number of good response and bad response after evaluation as $G_ {d}$ and $B_ {d}$ , and the number of iterations as $I$ . The parameter $T$ determines the quality of ChatGPT’s response during the optimization process. $G_ {d}$ and $B_ {d}$ determine the richness of positive and negative feedback information in the iterative prompt. And $I$ determines the degree of optimization of ChatGPT’s response in our framework.
在我们的框架中,动态提示构建和响应迭代优化是核心组件,因此相关参数至关重要。具体而言,在动态提示构建中,我们将相似报告的数量定义为 $N_ {s}$ ,这决定了提示中动态语义信息的丰富程度。在响应迭代优化中,我们将评估阈值定义为 $T$ ,评估后的优质响应和劣质响应数量分别定义为 $G_ {d}$ 和 $B_ {d}$ ,迭代次数定义为 $I$ 。参数 $T$ 决定了优化过程中ChatGPT响应质量的门槛。 $G_ {d}$ 和 $B_ {d}$ 决定了迭代提示中正负反馈信息的丰富度。而 $I$ 则决定了框架内ChatGPT响应的优化程度。
We conducted detailed ablation experiments on all parameters in supplementary materials and obtained the optimal values of $N_ {s}=15,T=0.7,G_ {d}=1,B_ {d}=n(n>1),I=17\$ . It should be noted that there is no upper limit set for the value of $B_ {d}$ , and the value of $n$ is flexibly adjusted based on the length of the actual input information during the optimization process. Detailed experimental analysis can be found in Section I of the supplementary material.
我们在补充材料中对所有参数进行了详细的消融实验,并获得了最优值 $N_ {s}=15,T=0.7,G_ {d}=1,B_ {d}=n(n>1),I=17\$ 。需要注意的是,$B_ {d}$ 的值没有设定上限,且优化过程中 $n$ 的取值会根据实际输入信息的长度灵活调整。详细的实验分析可参见补充材料第I节。
C. Main Property Studies
C. 主要特性研究
In this section, we ablate our Impression GP T in two aspects: the effectiveness of dynamic prompt and iterative optimization. In addition to employing Rouge metrics, we introduced BERTScore [44] to further evaluate these two modules. As shown in the Table II, the upper section displays the results of four methods on the MIMIC-CXR dataset, while the lower section showcases experimental outcomes on OpenI dataset. BS-P, BS-R, and BS-F1 respectively represent the Precision, Recall, and F1 metrics of BERTScore. As shown in the rows of “Fixed Prompt”, we construct the prompt using fixed examples, which means that for each report in the test set, the prefix instruction in the fixed prompt is consistent. In the rows of “Dynamic Prompt” in Table II, we first search the corpus for examples similar to the test report, and then construct the dynamic prompt. It can be seen that the experimental results for Rouge-1, Rouge-2, and Rouge-L are improved by $%11.85$ , $%9.27$ , and $%10.36$ on MIMIC-CXR dataset, and by $%8.59$ , $%7.22$ , and $%8.45$ on OpenI dataset. And there is also a noticeable improvement in the BERTScore metrics. In the rows of “Fixed Prompt $^+$ Iterative Opt”, we continue to introduce our iterative optimization algorithm on the fixed prompt and find that the results are further improved on both datasets. And for the OpenI dataset, the results of “Fixed Prompt $^+$ Iterative Opt” even outperform “Dynamic Prompt”. We believe this is due to the fact that OpenI’s corpus is relatively small and cannot provide a richer and more similar examples as context, whereas the results after using the iterative optimization method are significantly improved, and the improvement is larger than that on MIMIC-CXR, which has a much larger corpus. This further illustrates the advantages of our iterative optimization algorithm. In the end, we combine dynamic prompt and iterative optimization, our Impression GP T, to achieve the optimal result. The above results show that ChatGPT learns more relevant prior knowledge through the dynamic context we designed, which significantly improves the quality of the generated results. This demonstrates the feasibility of using a small number of samples to optimize the response of LLMs instead of training the model parameters. With the introduction of iterative optimization, the model can learn how to generate impression correctly with good responses, while learning how to avoid similar writing styles with bad responses. The model completes self-iterative updates in an interactive way, thus further optimizing the generated results. We also present a case study of our ablation experiments in Section II of supplementary materials.
在本节中,我们从动态提示和迭代优化两个方面对Impression GPT进行消融实验。除采用Rouge指标外,我们还引入BERTScore [44] 进一步评估这两个模块。如表II所示,上半部分展示了四种方法在MIMIC-CXR数据集上的结果,下半部分呈现了OpenI数据集的实验结果。BS-P、BS-R和BS-F1分别代表BERTScore的精确率、召回率和F1值。在"Fixed Prompt"行中,我们使用固定示例构建提示,这意味着测试集中每份报告的前缀指令保持一致。表II中"Dynamic Prompt"行则先检索与测试报告相似的语料示例,再构建动态提示。可见在MIMIC-CXR数据集上,Rouge-1、Rouge-2和Rouge-L指标分别提升$%11.85$、$%9.27$和$%10.36$,OpenI数据集上分别提升$%8.59$、$%7.22$和$%8.45$,BERTScore指标也有明显改善。在"Fixed Prompt$^+$Iterative Opt"行中,我们在固定提示基础上引入迭代优化算法,发现两个数据集的指标均进一步提升。对于OpenI数据集,"Fixed Prompt$^+$Iterative Opt"的结果甚至优于"Dynamic Prompt"。我们认为这是由于OpenI语料规模较小,无法提供足够丰富的相似示例作为上下文,而采用迭代优化方法后的提升幅度明显大于语料规模更大的MIMIC-CXR,这进一步说明了我们迭代优化算法的优势。最终,我们结合动态提示与迭代优化(即Impression GPT)取得了最优结果。上述结果表明,ChatGPT通过我们设计的动态上下文学习到更相关的先验知识,显著提升了生成结果质量。这证明了用少量样本优化大语言模型响应而非训练模型参数的可行性。随着迭代优化的引入,模型既能从优质响应中学习正确生成印象的方法,也能从劣质响应中规避不良写作风格。模型以交互方式完成自我迭代更新,从而进一步优化生成结果。补充材料第二节还提供了消融实验的案例分析。
D. Comparison with Other Methods
D. 与其他方法的比较
Table III presents a comparison of our Impression GP T with other radiology report sum mari z ation methods on MIMICCXR [17] and OpenI [18] datasets, including graph-based [4], sequence-based [6], [20], pre-trained language model-based methods [9], [21], [25], [26], recent GPT-based models [14], [15], and two fine-tuned LLMs, Radiology-Llama2 [45] and GPT-3 [28]. The evaluation is based on the Rouge-1, Rouge-2, Rouge-L, and FC metrics, comparing the impressions generated by our model with handwritten impressions. As shown in Table III, our method outperforms other methods in all metrics except for the Rouge-2 score on the OpenI dataset, where it performs slightly lower than Jinpeng et al. [26] and WGSum (LSTM) [25]. Pre-trained language models perform better than earlier studies, as they are trained with a large amount of medical text data, enabling them to learn the prior knowledge of the medical domain adequately. And our method is even better than the pre-trained language models, with the ability to construct a smaller number of relevant samples in the prompt for the LLM to learn. In the lower part of Table III, we compared the original ChatGPT [14] and GPT4 [15] models on MIMIC-CXR and OpenI datasets. It can be seen that the original ChatGPT outperforms the GPT-4 model slightly, indicating that GPT-4 is not as effective as ChatGPT for text sum mari z ation tasks. We also compared RadiologyLlama2 [45], a large language model fine-tuned on MIMICCXR and OpenI datasets. Recently, the GPT-3 model released a fine-tuning interface, allowing us to utilize the most potent available GPT-3 model, Davinci [28]. To save costs, we solely conducted fine-tuning and testing on the relatively smallscale OpenI dataset. Our Impression GP T model surpasses Radiology-Llama2, ChatGPT, GPT-4 and the fine-tuned GPT3. It’s important to note that we achieved this improvement solely through our designed dynamic prompt and iterative optimization framework without training the parameters of the ChatGPT model. Thus, we successfully transfer generic knowledge learned by LLMs in pre-training to domain-specific tasks, such as radiology report sum mari z ation, at a lower cost than previous pre-trained language models.
表 III 展示了我们的 Impression GPT 与其他放射学报告摘要方法在 MIMIC-CXR [17] 和 OpenI [18] 数据集上的对比结果,包括基于图的方法 [4]、基于序列的方法 [6][20]、基于预训练语言模型的方法 [9][21][25][26]、近期基于 GPT 的模型 [14][15] 以及两个微调后的大语言模型 Radiology-Llama2 [45] 和 GPT-3 [28]。评估基于 Rouge-1、Rouge-2、Rouge-L 和 FC 指标,将我们模型生成的印象与手写印象进行比较。如表 III 所示,我们的方法在除 OpenI 数据集上 Rouge-2 分数外的所有指标上均优于其他方法,在该指标上略低于 Jinpeng 等人 [26] 和 WGSum (LSTM) [25]。预训练语言模型由于使用大量医学文本数据训练,能充分学习医学领域先验知识,其表现优于早期研究。而我们的方法通过为 LLM 构建少量相关样本进行提示学习,表现甚至优于预训练语言模型。在表 III 下部,我们比较了原始 ChatGPT [14] 和 GPT4 [15] 在 MIMIC-CXR 和 OpenI 数据集上的表现。可见原始 ChatGPT 略优于 GPT-4 模型,表明 GPT-4 在文本摘要任务上效果不及 ChatGPT。我们还比较了基于 MIMIC-CXR 和 OpenI 数据集微调的大语言模型 RadiologyLlama2 [45]。近期 GPT-3 模型发布了微调接口,使我们能使用当前最强的 GPT-3 模型 Davinci [28]。为节省成本,我们仅在较小规模的 OpenI 数据集上进行微调和测试。我们的 Impression GPT 模型超越了 Radiology-Llama2、ChatGPT、GPT-4 和微调后的 GPT-3。值得注意的是,这一改进仅通过我们设计的动态提示和迭代优化框架实现,无需训练 ChatGPT 模型参数。因此,我们以比以往预训练语言模型更低的成本,成功将 LLM 在预训练中学习的通用知识迁移到放射学报告摘要等特定领域任务。
TABLE III COMPARISON RESULTS OF IMPRESSION GP T WITH OTHER PROMINENT METHODS ON MIMIC-CXR AND OPENI DATASET. BOLD DENOTES THE BEST RESULT AND UNDERLINE DENOTES THE SECOND-BEST RESULT.
| Method | MIMIC-CXR [17] | OpenI [18] | |||||||
| R-1↑ | R-2↑ | R-L↑ | FC-P↑ | FC-R↑ | FC-F1↑ | R-1↑ | R-2↑ | R-L↑ | |
| LexRank [4] | 18.11 | 7.47 | 16.87 | 14.63 | 4.42 | 14.06 | |||
| PGN [6] | 46.41 | 32.33 | 44.76 | 54.72 | 45.37 | 49.61 | 63.71 | 54.23 | 63.38 |
| CGU [20] | 46.50 | 32.61 | 44.98 | 61.60 | 53.00 | 61.58 | |||
| TransEXT [9] | 31.00 | 16.55 | 27.49 | 一 | 一 | 15.58 | 5.28 | 14.42 | |
| TransAbs [9] | 47.16 | 32.31 | 45.47 | 56.18 | 49.08 | 52.39 | 59.66 | 49.41 | 59.18 |
| CAVC [21] | 43.97 | 29.36 | 42.50 | 53.18 | 39.59 | 52.86 | |||
| WGSum (LSTM) [25] | 47.48 | 33.03 | 45.43 | 55.82 | 47.13 | 51.11 | 64.32 | 55.48 | 63.97 |
| WGSum (Trans)[25] | 48.37 | 33.34 | 46.68 | 56.83 | 51.22 | 53.88 | 61.63 | 50.98 | 61.73 |
| Jinpeng et al. [26] | 49.13 | 33.76 | 47.12 | 58.85 | 52.33 | 54.52 | 64.97 | 55.59 | 64.45 |
| ChatGPT [14] | 20.48 | 9.96 | 17.02 | 42.83 | 57.44 | 45.23 | 12.03 | 3.70 | 10.52 |
| GPT-4 [15] | 19.95 | 8.58 | 15.75 | 41.90 | 58.04 | 44.06 | 11.71 | 3.43 | 9.75 |
| Radiology-Llama2 [45] | 48.34 | 32.40 | 44.27 | 43.00 | 49.86 | 44.44 | 41.85 | 25.69 | 40.87 |
| Fine-tuned GPT-3 [28] | 53.33 | 41.36 | 52.39 | ||||||
| ImpressionGPT (Ours) | 54.45 | 34.50 | 47.93 | 79.30 | 80.98 | 80.09 | 66.37 | 54.93 | 65.47 |
表 III IMPRESSION GPT 与其他主流方法在 MIMIC-CXR 和 OPENI 数据集上的对比结果。粗体表示最佳结果,下划线表示次优结果。
| 方法 | MIMIC-CXR [17] | OpenI [18] | |||||||
|---|---|---|---|---|---|---|---|---|---|
| R-1↑ | R-2↑ | R-L↑ | FC-P↑ | FC-R↑ | FC-F1↑ | R-1↑ | R-2↑ | R-L↑ | |
| LexRank [4] | 18.11 | 7.47 | 16.87 | 14.63 | 4.42 | 14.06 | |||
| PGN [6] | 46.41 | 32.33 | 44.76 | 54.72 | 45.37 | 49.61 | 63.71 | 54.23 | 63.38 |
| CGU [20] | 46.50 | 32.61 | 44.98 | 61.60 | 53.00 | 61.58 | |||
| TransEXT [9] | 31.00 | 16.55 | 27.49 | - | - | 15.58 | 5.28 | 14.42 | |
| TransAbs [9] | 47.16 | 32.31 | 45.47 | 56.18 | 49.08 | 52.39 | 59.66 | 49.41 | 59.18 |
| CAVC [21] | 43.97 | 29.36 | 42.50 | 53.18 | 39.59 | 52.86 | |||
| WGSum (LSTM) [25] | 47.48 | 33.03 | 45.43 | 55.82 | 47.13 | 51.11 | 64.32 | 55.48 | 63.97 |
| WGSum (Trans)[25] | 48.37 | 33.34 | 46.68 | 56.83 | 51.22 | 53.88 | 61.63 | 50.98 | 61.73 |
| Jinpeng et al. [26] | 49.13 | 33.76 | 47.12 | 58.85 | 52.33 | 54.52 | 64.97 | 55.59 | 64.45 |
| ChatGPT [14] | 20.48 | 9.96 | 17.02 | 42.83 | 57.44 | 45.23 | 12.03 | 3.70 | 10.52 |
| GPT-4 [15] | 19.95 | 8.58 | 15.75 | 41.90 | 58.04 | 44.06 | 11.71 | 3.43 | 9.75 |
| Radiology-Llama2 [45] | 48.34 | 32.40 | 44.27 | 43.00 | 49.86 | 44.44 | 41.85 | 25.69 | 40.87 |
| Fine-tuned GPT-3 [28] | 53.33 | 41.36 | 52.39 | ||||||
| ImpressionGPT (Ours) | * * 54.45 * * | * * 34.50 * * | * * 47.93 * * | * * 79.30 * * | * * 80.98 * * | * * 80.09 * * | * * 66.37 * * | * * 54.93 * * | * * 65.47 * * |
In summary, we conclude that incorporating semantically similar examples as context in prompt is beneficial in using LLMs in specific domains. Moreover, the generated output of
总之,我们得出结论:在特定领域使用大语言模型时,将语义相似的示例作为上下文融入提示词是有益的。此外,生成式输出
LLMs can be optimized further with iterative interaction.
大语言模型可以通过迭代交互进一步优化。
V. DISCUSSION AND CONCLUSION
V. 讨论与结论
In this work, we explore the applicability of Large Language Models (LLMs) in the task of radiology report sum mari z ation by optimizing the input prompts based on a few existing samples and an iterative scheme. Specifically, relevant examples are extracted from the corpus to create dynamic prompts that facilitate in-context learning of LLMs. Additionally, an iterative optimization method is employed to improve the generated results. The method involves providing automated evaluation feedback to the LLM, along with instructions for good and bad responses. Our approach has demonstrated state-of-the-art results, surpassing existing methods that employ large volumes of medical text data for pre-training. Furthermore, this work is a precursor to the development of other domain-specific language models in the current context of artificial general intelligence [16].
在本研究中,我们通过基于少量现有样本和迭代方案优化输入提示(prompt),探索了大语言模型(LLM)在放射学报告摘要任务中的适用性。具体而言,我们从语料库中提取相关样本来创建动态提示,以促进大语言模型的上下文学习。此外,采用迭代优化方法来改进生成结果,该方法包括向大语言模型提供自动评估反馈,以及优秀和劣质回答的指导说明。我们的方法取得了最先进的结果,超越了那些使用大量医学文本数据进行预训练的现有方法。此外,在当前通用人工智能(AGI) [16] 的背景下,这项工作为开发其他领域专用语言模型奠定了基础。
While developing the iterative scheme of Impression GP T, we noticed that evaluating the quality of responses generated by the model is a crucial yet challenging task. In this work, we employed the Rouge-1 score, a conventional metric for calculating text similarity, as the criterion for evaluating the results. We also compared the evaluation criteria using Rouge1, Rouge-2, and Rouge-L scores and finally found that the performance is sensitive to the set threshold and achieved optimal results using the Rouge-1 score. We speculate that the differences caused by the scores used is due to the fact that the expression of words or phrases in a specific domain differs greatly from the general-domain text used for training the LLMs. Thus, using fine-grained evaluation metrics (i.e., Rouge-1) is better for evaluating the details of the generated results. We also envision that better evaluation criteria that can capture higher-level semantic information from the text will be highly needed with the advancement of LLMs.
在开发Impression GP T的迭代方案时,我们注意到评估模型生成响应质量是一项关键但具有挑战性的任务。本工作中,我们采用计算文本相似度的传统指标Rouge-1分数作为结果评估标准。通过对比Rouge1、Rouge-2和Rouge-L分数的评估标准,最终发现模型性能对设定阈值敏感,且使用Rouge-1分数时取得最优结果。我们推测不同分数导致的差异源于特定领域词汇或短语的表达方式与训练大语言模型所用的通用领域文本存在较大差异,因此使用细粒度评估指标(即Rouge-1)更适合评估生成结果的细节特征。我们预见随着大语言模型的发展,亟需能够捕捉文本更高层次语义信息的改进型评估标准。
The ethical concerns surrounding the clinical application of LLMs are a significant focus [32]. Regarding data privacy, our Impression GP T was tested on de-identified data, ensuring patient privacy. Therefore, for clinical applications, employing de-identification algorithms in data pre-processing suffices to safeguard patient privacy without compromising confidentiality. Regarding model biases, our iterative optimization algorithm automatically constrains the model’s generated outputs through automatic evaluations, significantly reducing the possibility of biased or fabricated outputs. Lastly, and most importantly, our model serves to provide valuable reference for clinical experts and does not replace their decision-making authority, thus leaving the final decisions in the hands of healthcare professionals or clinical practitioners.
大语言模型在临床应用中的伦理问题备受关注[32]。关于数据隐私,我们的Impression GP T在去标识化数据上进行测试,确保患者隐私。因此,在临床应用中,数据预处理阶段采用去标识化算法足以保护患者隐私而不损害机密性。关于模型偏差,我们的迭代优化算法通过自动评估约束模型生成内容,显著降低输出偏差或虚构的可能性。最后且最重要的是,本模型仅为临床专家提供有价值的参考,不替代其决策权,最终决定权仍归属于医疗专业人员或临床从业者。
In the future, we will continue to optimize the prompt design to better incorporate the domain-specific data from both public and local data sources while at the same time addressing the data privacy and safety concerns involved, especially in a multi-institution scenario. We are also investigating the utilization of knowledge graph in the prompt design to make it more conformed to existing domain knowledge (e.g., the relationship among different diseases). Finally, we will introduce human experts, e.g., radiologists, into the prompt optimization iterations, adding human input to evaluate the generated results when adding them to the prompts. In such a human-in-the-loop approach, we can better optimize the generated results of LLMs with decisions and opinions from human experts interactively.
未来,我们将持续优化提示(prompt)设计,以更好地整合来自公共和本地数据源的领域特定数据,同时解决涉及的数据隐私与安全问题(尤其在多机构协作场景中)。我们正在研究如何将知识图谱应用于提示设计,使其更符合现有领域知识(例如不同疾病间的关联性)。最后,我们将引入放射科医师等人类专家参与提示优化的迭代过程,在将生成结果加入提示时融入人工评估。通过这种人机协同(human-in-the-loop)方法,我们可以基于专家决策和意见进行交互式优化,从而提升大语言模型的生成结果质量。
REFERENCES
参考文献
Chong Ma received his master degree of computer science from Northwestern Polytechnic al University (Xi’an) in 2019. He is currently pursuing his Ph.D at school of automation of Northwestern Polytechnic al University. His main research interests are deep learning, medical image analysis and natural language processing.
马冲于2019年获得西北工业大学计算机科学硕士学位,目前在该校自动化学院攻读博士学位。主要研究方向为深度学习、医学图像分析与自然语言处理。
Zihao Wu received his B.E. degree from the School of Microelectronics, Tianjin University, Tianjin, China, in 2017 and Master degree in Electrical Engineering and Computer Science Department, Vanderbilt University, Nashville, USA, in 2020. Currently he is pursuing a PhD in computer science at University of Georgia under the supervision of Dr. Tianming Liu. His current research interests include brain inspired AI and deep learning-based medical image analysis.
吴子豪2017年获得中国天津大学微电子学院工学学士学位,2020年获得美国纳什维尔范德堡大学电气工程与计算机科学系硕士学位。目前他在佐治亚大学Tianming Liu博士指导下攻读计算机科学博士学位,研究方向包括类脑人工智能( brain inspired AI )和基于深度学习的医学图像分析。
Jiaqi Wang received her master degree of Statistics from Henu University (Kai’feng) in 2020. She is currently pursuing her Ph.D. at School of Computer Science of Northwestern Polytechnic al University. Her main research interests are deep learning, EEG signal analysis and human-computer interaction.
Jiaqi Wang于2020年获得河南大学(开封)统计学硕士学位,目前就读于西北工业大学计算机学院攻读博士学位。她的主要研究方向为深度学习、脑电信号(EEG)分析与人机交互。
Shaochen Xu received his B.S. degree in Computer Science from the University of Georgia in 2019. He is currently pursuing his PhD degree at the University of Georgia under the supervision of Dr. Tianming Liu with a research interest in deep learning, natural language processing, and vision transformers.
邵晨旭于2019年获得佐治亚大学计算机科学学士学位,目前在该校Tianming Liu博士指导下攻读博士学位,研究方向包括深度学习、自然语言处理及视觉Transformer。
Yaonai Wei received his master degree of Control science and engineering from Northwestern Polytechnic al University (Xi’an) in 2021. He is currently pursuing his Ph.D at school of automation of Northwestern Polytechnic al University. His main research interests are deep learning, brain science and artificial general intelligence.
魏耀南于2021年获得西北工业大学控制科学与工程硕士学位,现为西北工业大学自动化学院博士研究生,主要研究方向为深度学习、脑科学与通用人工智能 (AGI)。
Zhengliang Liu received his B.A. and M.S. degrees in computer science from the University of Wisconsin-Madison and Washington University in St. Louis, in 2018 and 2021, respectively. He is a PhD student in the School of Computing, University of Georgia, Athens, GA. His areas of research include biomedical natural language processing, biomedical image analysis and the intersection of ma-chine learning and radiation oncology.
郑亮 (Zhengliang Liu) 分别于2018年和2021年获得威斯康星大学麦迪逊分校和圣路易斯华盛顿大学的计算机科学学士与硕士学位。他现为佐治亚大学雅典分校计算学院的博士研究生,研究方向涵盖生物医学自然语言处理、生物医学图像分析以及机器学习与放射肿瘤学的交叉领域。
Fang Zeng is a Data Scientist working at the Massachusetts General Hospital, leading the development of the Large Language Model and multi-agent solutions for medical text processing in healthcare.
方增是马萨诸塞州总医院的数据科学家,负责领导医疗文本处理领域的大语言模型及多AI智能体解决方案的开发工作。
Prof. Xi Jiang received the B.E. degree in automation from Northwestern Polytechnic al University, Xi’an, China, in 2009, and the Ph.D. degree in computer science from the University of Georgia, Athens, GA, USA, in 2016. Since 2017, he has been an Associate Professor with the School of Life Science and Technology, University of Electronic Science and Technology of China, Chengdu, China. His research interests include machine learning/deep learning-based medical image analysis. Dr. Jiang was a recipient of the Li Foundation Heritage Prize, USA, for “outstanding research and contributions in the interdisciplinary field of brain science” in 2019.
蒋曦教授于2009年在中国西安西北工业大学获得自动化专业学士学位,2016年在美国佐治亚州雅典市佐治亚大学获得计算机科学博士学位。自2017年起,他担任中国成都电子科技大学生命科学与技术学院副教授。他的研究方向包括基于机器学习/深度学习的医学图像分析。蒋博士曾于2019年荣获美国李氏基金会遗产奖,以表彰其在"脑科学跨学科领域的杰出研究贡献"。
Prof. Lei Guo received the Ph.D. degree from Xidian University, Xi’an, China, in 1994. He is currently a Professor with Northwestern Polytechnic al University, Xi’an. His current research interests include computer vision, pattern recognition, and medical image processing.
雷国教授于1994年在中国西安电子科技大学获得博士学位。他目前是西安西北工业大学的教授。他的研究方向包括计算机视觉、模式识别和医学图像处理。
Prof. Xiaoyan Cai is an associate professor in School of Automation, Northwestern Polytechnic al University. She was a research associate in department of computing, the Hong Kong Polytechnic University, Hong Kong, from June 2009 to June 2011. She received the PhD degree from Northwestern Polytechnic al University, China, in 2009. Her current research interests include document sum mari z ation, information retrieval and machine learning.
蔡晓燕是西北工业大学自动化学院的副教授。她于2009年6月至2011年6月在香港理工大学计算学系担任研究助理。2009年在中国西北工业大学获得博士学位。她目前的研究方向包括文档摘要、信息检索和机器学习。
Prof. Shu Zhang received the Ph.D. degree in Computer Science from the University of Georgia, USA, in 2018. He is currently a professor at School of Computer Science from the Northwestern Polytechnic al University, Xi’an, China. His research interests include biomedical image analysis, brain image analysis, deep learning and machine learning algorithms, artificial intelligence.
张舒教授于2018年获得美国佐治亚大学计算机科学博士学位,现任中国西安西北工业大学计算机学院教授。他的研究方向包括生物医学图像分析、脑图像分析、深度学习与机器学习算法以及人工智能。
Prof. Tuo Zhang received the B.E. and Ph.D. degrees from Northwestern Polytechnic al University, Xi’an, China, in 2007 and 2015, respectively. He is currently a Research Associate with Northwestern Polytechnic al University. His research interests include machine learning and medical image analysis.
张拓教授分别于2007年和2015年在中国西安西北工业大学获得学士和博士学位。他目前是西北工业大学的研究助理。他的研究兴趣包括机器学习与医学图像分析。
Prof. Dajiang Zhu received the Ph.D. degree from Computer Science at the University of Georgia in U.S. in 2014. His current research interests include machine learning, neuro imaging and computational neuroscience.
Dajiang Zhu教授于2014年获得美国佐治亚大学计算机科学博士学位,目前研究方向包括机器学习、神经影像学和计算神经科学。
Prof. Dinggang Shen (IEEE Fellow, AIMBE Fellow, IAPR Fellow and MICCAI Fellow) is the Founding Dean of the School of Biomedical Engineering at Shanghai Tech University. Before joining Shanghai Tech, he was a tenured Professor of Radiology, Biomedical Research Imaging Center (BRIC), Computer Science, and Biomedical Engineering at the University of North Carolina at Chapel Hill (UNC), USA. Professor Shen has been involved in the application of machine learning and artificial intelligence in medical image computing for a long time, including early brain development, early diagnosis, and the prediction of Alzheimer’s disease, as well as diagnosis, prognosis and radiotherapy of brain tumor, breast cancer and prostate cancer. He is a pioneering scientist carrying out imaging AI research all over the world and is one of the first to apply deep learning to medical imaging (2012).
沈定刚教授(IEEE Fellow、AIMBE Fellow、IAPR Fellow 和 MICCAI Fellow)是上海科技大学生物医学工程学院创始院长。在加入上海科技大学之前,他曾任美国北卡罗来纳大学教堂山分校(UNC)放射学、生物医学研究影像中心(BRIC)、计算机科学和生物医学工程终身教授。沈教授长期致力于机器学习与人工智能在医学影像计算中的应用研究,涵盖早期脑发育、阿尔茨海默病的早期诊断与预测,以及脑肿瘤、乳腺癌和前列腺癌的诊断、预后与放射治疗。他是全球范围内开展影像AI研究的先驱科学家,也是最早将深度学习应用于医学影像的学者之一(2012年)。
Prof. Tianming Liu is a Distinguished Research Professor of Computer Science at UGA. Dr. Liu’s research interests are Brain Imaging, Computational Neuroscience, and Brain-inspired Artificial Intelligence. Dr. Liu has published over 400 papers in these areas, his Google Scholar citations are over $10\small{,}000+$ , and his $\mathrm{H}$ -index is 54. Dr. Liu is the recipient of the NIH Career Award and the NSF CAREER Award. Dr. Liu serves on the editorial boards of multiple journals including Medical Image Analysis, IEEE Transactions on Medical Imaging, IEEE Reviews in Biomedical Engineering, IEEE/ACM Transactions on Computational Biology and Bioinformatics, and IEEE Journal of Biomedical and Health Informatics. Dr. Liu is an elected Fellow of the American Institute for Medical and Biological Engineering.
Tianming Liu教授是佐治亚大学计算机科学杰出研究教授。Liu博士的研究方向包括脑成像 (Brain Imaging)、计算神经科学 (Computational Neuroscience) 和类脑人工智能 (Brain-inspired Artificial Intelligence)。他已在相关领域发表400余篇论文,Google学术引用量超过$10\small{,}000+$,$\mathrm{H}$指数达54。Liu博士曾获NIH职业奖和NSF CAREER奖,并担任《Medical Image Analysis》《IEEE Transactions on Medical Imaging》《IEEE Reviews in Biomedical Engineering》《IEEE/ACM Transactions on Computational Biology and Bioinformatics》《IEEE Journal of Biomedical and Health Informatics》等期刊编委,现为美国医学与生物工程院 (AIMBE) 会士。
Prof. Xiang Li is an Assistant Professor at the Massachusetts General Hospital and Harvard Medical School. He received his Ph.D. degree from the Department of Computer Science at the University of Georgia. Dr. Li’s research focuses on the Artificial General Intelligence (AGI) and foundation models in healthcare, to tackle the practical challenges of applying AI in a complex clinical context. He has led the development of multiple medical imaging, language processing, EHR analysis, and multi-modal fusion projects, as well as the medical informatics systems for smart data management and AI deployment in the clinical workflow.
李翔教授是麻省总医院和哈佛医学院的助理教授。他毕业于佐治亚大学计算机科学系,获得博士学位。李博士的研究专注于通用人工智能(AGI)和医疗领域的基础模型,致力于解决AI在复杂临床环境中应用的实际挑战。他主导开发了多个医学影像、语言处理、电子健康记录(EHR)分析和多模态融合项目,以及用于智能数据管理和临床工作流中AI部署的医疗信息系统。
APPENDIX A STUDY OF HYPER-PARAMETER SELECTION
附录A 超参数选择研究
We ablate our Impression GP T in five aspects of preset parameters: the number of examples in fixed or dynamic prompt $(N_ {s})$ , the threshold for response judgement in iterative prompt $(T)$ , the number of good and bad responses in iterative prompt ( $G d$ and $B d,$ ), and iteration times $(I)$ . For cost-saving, we select 500 samples in the test set of MIMIC-CXR dataset for our ablation study. This allows us to complete the search for the optimal parameters of the model at a smaller cost. After determining the optimal parameters, we employ the complete test set to get the final results. Table $\mathrm{IV}{\sim}\mathrm{VII}$ show the ablation results of our hyper-parameter study.
我们从五个预设参数维度对Impression GPT进行消融实验:固定或动态提示中的示例数量$(N_ {s})$、迭代提示中的响应判断阈值$(T)$、迭代提示中的优质与劣质响应数量($G d$和$B d$),以及迭代次数$(I)$。为节省成本,我们选取MIMIC-CXR测试集中的500个样本进行消融研究,从而以较小代价完成模型最优参数的搜索。确定最优参数后,我们使用完整测试集获取最终结果。表IV VII展示了超参数研究的消融结果。
prompt, and $I$ is the upper limit of the number of iterations. We find that after using interaction optimization, Rouge-1, Rouge-2, and Rouge-L improve by $7.56%$ , $7.2%$ and $8.66%$ , respectively when $T=0.7$ , although the corresponding cost increases about 5 times.
提示,$I$ 是迭代次数的上限。我们发现,在使用交互优化后,当 $T=0.7$ 时,Rouge-1、Rouge-2 和 Rouge-L 分别提高了 $7.56%$、$7.2%$ 和 $8.66%$,尽管相应的成本增加了约 5 倍。
TABLE IV ABLATION STUDY OF $N_ {s}$ IN FIXED AND DYNAMIC PROMPT. BOLD DENOTES THE BEST RESULT
| Type | Ns | R-1↑ | R-2↑ | R-L↑ | Cost |
| Fixed | 5 | 29.39 | 13.68 | 23.74 | \$2 |
| 10 | 30.21 | 13.88 | 24.54 | \$3 | |
| 15 | 32.57 | 15.97 | 26.13 | \$3 | |
| 18 | 32.46 | 15.28 | 25.81 | \$4 | |
| Dynamic | 5 | 41.01 | 22.90 | 33.45 | \$3 |
| 10 | 42.53 | 24.71 | 35.63 | \$4 | |
| 15 | 43.97 | 24.75 | 36.13 | \$4 | |
| 18 | 43.76 | 24.34 | 35.63 | \$5 |
表 IV: 固定提示与动态提示中 $N_ {s}$ 的消融研究。加粗表示最佳结果
| 类型 | Ns | R-1↑ | R-2↑ | R-L↑ | 成本 |
|---|---|---|---|---|---|
| 固定 | 5 | 29.39 | 13.68 | 23.74 | $2 |
| 10 | 30.21 | 13.88 | 24.54 | $3 | |
| 15 | 32.57 | 15.97 | 26.13 | $3 | |
| 18 | 32.46 | 15.28 | 25.81 | $4 | |
| 动态 | 5 | 41.01 | 22.90 | 33.45 | $3 |
| 10 | 42.53 | 24.71 | 35.63 | $4 | |
| 15 | 43.97 | 24.75 | 36.13 | $4 | |
| 18 | 43.76 | 24.34 | 35.63 | $5 |
TABLE VI ABLATION STUDY OF $_ {G d}$ AND $B d$ IN ITERATIVE OPTIMIZATION. BOLD DENOTES THE BEST RESULT
| Type | Gd | Bd | R-1↑ | R-2↑ | R-L↑ | Cost |
| 0 | 一 | 50.68 | 30.42 | 44.08 | \$20 | |
| Dynamic | 0 | 50.31 | 29.87 | 43.75 | \$20 | |
| Ns=15 | 1 | 一 | 50.93 | 31.15 | 44.39 | \$20 |
| T=0.7 | 1 | n | 51.53 | 31.95 | 44.79 | \$30 |
| I=7 | n | 1 | 51.13 | 31.05 | 44.54 | \$30 |
| n | n | 51.46 | 31.77 | 44.25 | \$40 |
表 6: 迭代优化中 $_ {G d}$ 和 $B d$ 的消融研究。加粗表示最佳结果
| Type | Gd | Bd | R-1↑ | R-2↑ | R-L↑ | Cost |
|---|---|---|---|---|---|---|
| 0 | 一 | 50.68 | 30.42 | 44.08 | $20 | |
| Dynamic | 0 | 50.31 | 29.87 | 43.75 | $20 | |
| Ns=15 | 1 | 一 | 50.93 | 31.15 | 44.39 | $20 |
| T=0.7 | 1 | n | 51.53 | 31.95 | 44.79 | $30 |
| I=7 | n | 1 | 51.13 | 31.05 | 44.54 | $30 |
| n | n | 51.46 | 31.77 | 44.25 | $40 |
As shown in the top part of Table IV, we first studied the results of different numbers of examples in fixed prompt, where $N_ {s}$ is the number of examples, and R-1, R-2, R-L, and Cost represent the Rouge-1, Rouge-2, Rouge-L scores and the rough cost, respectively. It can be seen that the best results are obtained by inserting 15 examples in the prompt. When 18 examples are inserted, the results are saturated and the input text may exceed the token limit. We continue to investigate the number of examples in the dynamic prompt, as shown in the bottom part of Table IV. The experimental results are consistent with “Fixed Prompt” that using 15 similar radiology reports as examples in the dynamic prompt performs the best results, and the corresponding Rouge-1, Rouge-2, and Rouge-L scores increase by $11.4%$ , $8.78%$ , and $10.0%$ , respectively, compared to the “Fixed Prompt”. This demonstrates that dynamic context constructed using similar examples can help ChatGPT to better perform tasks in specific domain.
如表 IV 上部所示,我们首先研究了固定提示模板中不同示例数量的效果,其中 $N_ {s}$ 表示示例数量,R-1、R-2、R-L 和 Cost 分别代表 Rouge-1、Rouge-2、Rouge-L 分数和估算成本。可以看出,当提示模板中插入 15 个示例时效果最佳。插入 18 个示例时结果趋于饱和,且输入文本可能超出 token 限制。我们继续研究了动态提示模板中的示例数量(如表 IV 下部所示),实验结果与"固定提示模板"一致:当采用 15 份相似放射学报告作为示例时,动态提示模板取得最佳效果,其 Rouge-1、Rouge-2 和 Rouge-L 分数相较"固定提示模板"分别提升了 $11.4%$ 、 $8.78%$ 和 $10.0%$ 。这表明通过相似示例构建的动态上下文能帮助 ChatGPT 在特定领域任务中表现更优。
TABLE VII ABLATION STUDY OF $I$ IN ITERATIVE OPTIMIZATION. BOLD DENOTES THE BEST RESULT
| Type | I | R-1↑ | R-2↑ | R-L↑ | Cost |
| Dynamic | 7 | 51.53 | 31.95 | 44.79 | \$30 |
| Ns=15 | 12 | 51.91 | 32.78 | 45.85 | \$50 |
| T=0.7 | 15 | 52.44 | 33.13 | 46.18 | \$60 |
| 17 | 53.37 | 33.68 | 46.89 | \$60 | |
| Gd=1,Bd=n | 20 | 53.07 | 33.54 | 46.36 | \$70 |
表 7: 迭代优化中 $I$ 的消融研究。加粗表示最佳结果
| 类型 | I | R-1↑ | R-2↑ | R-L↑ | 成本 |
|---|---|---|---|---|---|
| Dynamic | 7 | 51.53 | 31.95 | 44.79 | $30 |
| Ns=15 | 12 | 51.91 | 32.78 | 45.85 | $50 |
| T=0.7 | 15 | 52.44 | 33.13 | 46.18 | $60 |
| 17 | 53.37 | 33.68 | 46.89 | $60 | |
| Gd=1,Bd=n | 20 | 53.07 | 33.54 | 46.36 | $70 |
TABLE V ABLATION STUDY OF $T$ IN ITERATIVE OPTIMIZATION. BOLD DENOTES THE BEST RESULT
| Type | T | R-1↑ | R-2↑ | R-L↑ | Cost |
| Dynamic | 0.50 | 50.34 | 30.35 | 44.06 | \$20 |
| Ns=15 | 0.65 | 51.06 | 31.25 | 44.16 | \$20 |
| Gd=1,Bd=n | 0.70 | 51.53 | 31.95 | 44.79 | \$20 |
| I=7 | 0.75 | 51.11 | 31.76 | 44.33 | \$20 |
表 5: 迭代优化中 $T$ 的消融研究。加粗表示最佳结果
| 类型 | T | R-1↑ | R-2↑ | R-L↑ | 成本 |
|---|---|---|---|---|---|
| Dynamic | 0.50 | 50.34 | 30.35 | 44.06 | $20 |
| Ns=15 | 0.65 | 51.06 | 31.25 | 44.16 | $20 |
| Gd=1,Bd=n | 0.70 | 51.53 | 31.95 | 44.79 | $20 |
| I=7 | 0.75 | 51.11 | 31.76 | 44.33 | $20 |
After that, we investigate the value of the metric for evaluating the Impression generated by ChatGPT in iterative optimization, which we noted as $T$ , as shown in Table V. $N_ {s}$ is the similar examples in dynamic prompt, $G d$ and $B d$ represent the number of good and bad examples in iterative
之后,我们研究了该指标在迭代优化中评估ChatGPT生成印象的价值,记为$T$,如表V所示。$N_ {s}$是动态提示中的相似示例数量,$G d$和$B d$分别代表迭代过程中的优质和劣质示例数量。
We continued our study on the number of good and bad examples in the iterative prompt, as shown in Table VI, in the $G d$ and $B d$ columns, where 0, 1 and $n$ represent no examples, one example and multiple examples, respectively. We find that the model achieves optimal results when one good example and multiple bad examples are given. When more good examples are inserted in the prompt, the results are not improved, but rather there are problems with exceeding the textual limit. We believe that with one good example the direction of model optimization can be determined and with multiple bad examples the model generated responses can be further constrained from multiple perspectives. It should be noted that the number of bad examples in the iterative prompt is indefinite and can be appended all the time as long as the input limit is not exceeded.
我们继续研究了迭代提示中好坏示例的数量,如表 VI 所示,在 $G d$ 和 $B d$ 列中,0、1 和 $n$ 分别表示无示例、单示例和多示例。研究发现,当提供一个好示例和多个坏示例时,模型能达到最佳效果。若在提示中插入更多好示例,结果不仅不会提升,反而会出现超出文本限制的问题。我们认为,单个好示例足以确定模型优化方向,而多个坏示例能从多角度进一步约束模型生成的响应。需注意的是,迭代提示中的坏示例数量并不固定,只要不超过输入限制即可持续追加。
Finally, we investigate the number of iterations, as shown in Table VII, and find that the model achieves optimal performance when the upper limit number of iterations is set to 17, and its results for Rouge-1, Rouge-2, and Rouge-L improve by $1.84%$ , $1.73%$ , and $2.1%$ , respectively, compared to Table VI. Continuing to increase the number of iterations does not bring any performance improvement except for the additional cost. In summary, we determine a set of optimal parameters: $N_ {S}=15,T=0.7,G d=1,B d=n,I=17$ .
最后,我们研究了迭代次数,如表 VII 所示,发现当迭代次数上限设置为 17 时,模型达到最佳性能,其 Rouge-1、Rouge-2 和 Rouge-L 的结果分别比表 VI 提高了 $1.84%$、$1.73%$ 和 $2.1%$。继续增加迭代次数除了带来额外成本外,不会带来任何性能提升。综上所述,我们确定了一组最优参数:$N_ {S}=15,T=0.7,G d=1,B d=n,I=17$。
APPENDIX B EXAMPLES IN OUR ABLATION STUDY
附录 B 消融研究中的示例
Table VIII presents a test case of our ablation study from Table II of our manuscript. The upper part of Table VIII is “Case Information”, which lists the Finding and Impression sections of test report. Our task is to generate an appropriate Impression based on the Finding section. The middle part of Table VIII is “Similar Samples”, which are similar examples we constructed in dynamic prompt. These 14 examples are selected from the corpus based on their similarity distance to the Finding section of the test report. And these similar samples (from No.1 to No.14) are ordered from closest to furthest similarity distance to finding section of test report. The lower of Table VIII, titled “Generation Results”, presents the text results and corresponding Rouge-1 scores generated by four different methods in our ablation experiments. “Fixed” represents the output results obtained using a fixed prompt. It can be observed that the scores are relatively lower, as the contextual information provided by the fixed examples may not be closely related to the actual questions (Test Case), thus lacking assistance. “Fixed $^+$ Iteration” denotes the introduction of our iterative optimization algorithm based on the fixed prompt, where we present the results in the 17th iteration. Noticeable improvements can be observed in the generated results. “Dynamic” denotes the output result obtained using a dynamic prompt. The “Similar Samples” in the middle of Table VIII demonstrates the high similarity between these examples and the Test Case, indicating that the dynamic prompt provides valuable reference information to ChatGPT, thereby further optimizing its generated results. Lastly, “Dynamic $^+$ Iteration” represents the use of the iterative optimization algorithm on the dynamic prompt, which is our proposed Impression GP T. We list the results and Rouge-1 scores for iteration numbers 3, 5, 10, 15, and 17. It can be observed that as the iteration increases, the results generated by ChatGPT also improve progressively.
表 VIII 展示了我们基于稿件表 II 进行的消融研究测试案例。表 VIII 上部为"案例信息",列出了测试报告的"发现"和"印象"部分。我们的任务是根据"发现"部分生成合适的"印象"。表 VIII 中部为"相似样本",是我们在动态提示中构建的相似示例。这 14 个示例是根据其与测试报告"发现"部分的相似度距离从语料库中选取的,并按相似度从近到远排序 (从 No.1 到 No.14)。表 VIII 下部标题为"生成结果",展示了我们消融实验中四种不同方法生成的文本结果及对应 Rouge-1 分数。"Fixed"表示使用固定提示获得的输出结果,可见其分数相对较低,因为固定示例提供的上下文信息可能与实际问题 (Test Case) 关联性不强,缺乏辅助作用。"Fixed $^+$ Iteration"表示在固定提示基础上引入我们的迭代优化算法,此处展示的是第 17 次迭代的结果,可见生成结果有明显改善。"Dynamic"表示使用动态提示获得的输出结果,表 VIII 中部的"相似样本"展示了这些示例与测试案例的高度相似性,说明动态提示为 ChatGPT 提供了有价值的参考信息,从而进一步优化其生成结果。最后,"Dynamic $^+$ Iteration"表示在动态提示上使用迭代优化算法,即我们提出的 Impression GPT。我们列出了第 3、5、10、15 和 17 次迭代的结果及 Rouge-1 分数,可见随着迭代次数增加,ChatGPT 生成的结果也在逐步提升。
TABLE VIII EXAMPLES IN OUR ABLATION STUDY
| Case Information | |
| Findings | Moderate cardiomegaly is re- demonstrated. The aorta is tortuous.Pulmonary vasculature is not engorged.Patchy opacities are seen in the left lung base, potentially atelectasis but infection or aspiration cannot be excluded. Streaky atelectasis is also demonstrated in the left lung base. No pleural effusion or pneumothorax is present. No acute osseous abnormality is visualized. |
| Patchy left basilar opacity may reflect atelectasis, but infection or aspiration cannot be excluded in the correct clinical setting. SimilarSamples | |
| No.1 | Finding: Heart size is normal. Mediastinal and hilar contours are unremarkable. The pulmonary vasculature is not engorged.Patchy opacities are demonstrated in both lung bases which may reflect atelectasis but infection is not excluded. No pleural effusion or pneumothorax is identified. There are no acute osseous abnormalities. Iimpression: Bibasilar patchy opacities may reflect atelectasis but infection is not excluded in the correct clinical setting. |
| No.2 | Finding: Cardiac silhouette size is normal. Mediastinal and hilar contours are within normal limits. Pulmonary vasculature is normal. Lungs are hyperinflated. Patchy opacities noted in the right lung base. This could reflect atelectasis but infection is not excluded. Left lung is clear. No pleural effusion or pneumothorax is demonstrated. No acute osseous abnormalities seen. Remote left-sided rib fractures are noted. Extensive degenerative changes of the left glenohumeral joint are partially imaged. Iimpression: Patchy right basilar opacity may reflect atelectasis but infection cannot be excluded in the correct clinical setting. |
| No.3 | Finding: Cardiac silhouette size is normal. The mediastinal and hilar contours are unremarkable. The pulmonary vasculature is not engorged. Minimal patchy opacity is demonstrated within the right lung base. No pleural effusion or pneumothorax is present. No acute osseous abnormalityisdemonstrated. Iimpression: Patchy right basilar opacity may refect atelectasis however infection or aspiration is not excluded in the correct clinical |
| setting. .... Finding: Lung volumes are low. The heart size is top normal with a left ventricular predominance. The mediastinal and hilar contours are | |
| No.14 | unremarkable. Streaky bibasilar airspace opacities could reflect atelectasis though infection cannot be excluded. There is no pleural effusion or pneumothorax.No acute osseous abnormalities arevisualized. Iimpression: Streaky bibasilar airspace opacities could reflect atelectasis but infection cannot be excluded. Repeat PA and lateral views withimprovedinspiratoryeffort is recommended tobetter assess thelungbases. |
| Generation Results | |
| R-1 = 45.0 | Moderate cardiomegaly. Aorta is tortuous. Patchy opacities in the left lung base suggestive of atelectasis, possibly due to infection or |
| Dynamic R-1 = 57.78 | aspiration. Patchy opacities in the left lung base, possibly reflecting atelectasis. Infection or aspiration cannot be excluded. Streaky atelectasis is also |
| Fixed+Iteration 17 R-1 = 52.00 | Cardiomegaly and a tortuous aorta, compatible with underlying cardiovascular disease. Patchy opacities in the left lung base, likely |
| Dynamic + Iteration i=3 (R-1 =53.33) | representing atelectasis. Infection or aspiration cannot be excluded. Further evaluation may be required. Patchy opacities in the left lung base, potentially atelectasis, though infection or aspiration cannot be excluded. Streaky atelectasis is also |
| i=5 (R-1 = 55.00) | observed in the left lung base. Moderate cardiomegaly with patchy opacities in the left lung base,potentially representing atelectasis.Infection or aspiration cannot be |
| completelyruledout. | |
| i=10 (R-1 = 61.58) | )Patchy opacities and streaky atelectasis in the left lung base, potentially due to atelectasis. Infection or aspiration cannot be excluded. i =15 (R-1 = 63.83)Moderate cardiomegaly with tortuous aorta.Patchy opacities in the left lung base, potentially atelectasis,with streaky atelectasis. Infection |
| or aspiration cannot be excluded in the correct clinical setting. | |
| =17 (R-1 = 68.42) | )Moderate cardiomegaly with patchy opacities in the left lung base, likely reflecting atelectasis. Infection or aspiration cannot be excluded. |
表 VIII 消融研究中的示例案例
| 病例信息 |
|---|
| * * 检查发现 * * |
| * * 诊断意见 * * |
-
- 相似样本 * *
| 编号 | 内容 |
|---|---|
| 1 | * * 检查发现 * * : 心脏大小正常。纵隔和肺门轮廓无异常。肺血管未充血。双肺基底可见斑片状阴影,可能反映肺不张,但未排除感染。未见胸腔积液或气胸。未见急性骨性异常。 |
-
- 诊断意见 * * : 双基底斑片状阴影可能反映肺不张,但在特定临床背景下不能排除感染。 |
| 2 | * * 检查发现 * * : 心脏轮廓大小正常。纵隔和肺门轮廓在正常范围内。肺血管正常。肺过度充气。右肺基底可见斑片状阴影,可能反映肺不张,但未排除感染。左肺清晰。未见胸腔积液或气胸。未见急性骨性异常。发现陈旧性左侧肋骨骨折。左肩关节广泛退行性变部分成像。
- 诊断意见 * * : 双基底斑片状阴影可能反映肺不张,但在特定临床背景下不能排除感染。 |
-
- 诊断意见 * * : 右基底斑片状阴影可能反映肺不张,但在特定临床背景下不能排除感染。 |
| 3 | * * 检查发现 * * : 心脏轮廓大小正常。纵隔和肺门轮廓无异常。肺血管未充血。右肺基底显示轻微斑片状阴影。未见胸腔积液或气胸。未见急性骨性异常。
- 诊断意见 * * : 右基底斑片状阴影可能反映肺不张,但在特定临床背景下不能排除感染。 |
-
- 诊断意见 * * : 右基底斑片状阴影可能反映肺不张,但在特定临床背景下不能排除感染或吸入性肺炎。 |
| ... | * * 检查发现 * * : 肺容积低。心脏大小处于正常上限,左心室优势。纵隔和肺门轮廓无异常。双基底条索状气腔阴影可能反映肺不张,但未排除感染。未见胸腔积液或气胸。未见急性骨性异常。
- 诊断意见 * * : 右基底斑片状阴影可能反映肺不张,但在特定临床背景下不能排除感染或吸入性肺炎。 |
-
- 诊断意见 * * : 双基底条索状气腔阴影可能反映肺不张,但未排除感染。建议通过改进吸气努力的重复正侧位胸片以更好评估肺基底。 |
-
- 生成结果 * *
| 模型 | 输出内容 |
|---|---|
| R-1=45.0 | 中度心脏肥大。主动脉迂曲。左肺基底斑片状阴影提示肺不张,可能由感染或吸入性肺炎引起。 |
| Dynamic R-1=57.78 | 左肺基底斑片状阴影,可能反映肺不张。不能排除感染或吸入性肺炎。左肺基底还显示条索状肺不张。 |
| Fixed+Iteration 17 R-1=52.00 | 心脏肥大和迂曲主动脉,符合潜在心血管疾病。左肺基底斑片状阴影,可能代表肺不张。不能排除感染或吸入性肺炎。可能需要进一步评估。 |
| Dynamic+Iteration i=3 (R-1=53.33) | 左肺基底斑片状阴影,可能为肺不张,但不能排除感染或吸入性肺炎。左肺基底还显示条索状肺不张。 |
| i=5 (R-1=55.00) | 中度心脏肥大伴左肺基底斑片状阴影,可能代表肺不张。不能完全排除感染或吸入性肺炎。 |
| i=10 (R-1=61.58) | 左肺基底斑片状阴影和条索状肺不张,可能由肺不张引起。不能排除感染或吸入性肺炎。 |
| i=15 (R-1=63.83) | 中度心脏肥大伴迂曲主动脉。左肺基底斑片状阴影可能为肺不张,伴条索状肺不张。在特定临床背景下不能排除感染或吸入性肺炎。 |
| i=17 (R-1=68.42) | 中度心脏肥大伴左肺基底斑片状阴影,可能反映肺不张。不能排除感染或吸入性肺炎。 |
APPENDIX C ABLATION STUDY ON CORPUS SIZE
附录 C 语料库规模的消融研究
In the similarity search module of our model, corpus size serves as a critical factor. Therefore, we contrasted three sets of different-sized corpus using the MIMIC-CXR dataset as an example. As illustrated in Table IX, the first row represents Impression GP T’s similarity search within a corpus of 10,000 samples, the second row presents the experiment with a corpus expanded to 20,000, and the third row indicates the results obtained using the entire training set as the corpus. The experimental outcomes reveal a gradual enhancement in model performance with increasing corpus size. This trend aligns with expectations, as within Impression GP T’s similarity search module, employing larger corpora yields instances with higher semantic similarity, providing more valuable references for the model.
在我们模型的相似性搜索模块中,语料库规模是关键因素。因此,我们以MIMIC-CXR数据集为例对比了三组不同规模的语料库。如表IX所示,第一行展示了Impression GP T在10,000样本语料库中的相似性搜索结果,第二行呈现了语料库扩大到20,000时的实验数据,第三行则显示了使用完整训练集作为语料库时获得的结果。实验结果表明,随着语料库规模的增加,模型性能逐步提升。这一趋势符合预期,因为在Impression GP T的相似性搜索模块中,使用更大的语料库能产生语义相似度更高的实例,为模型提供更有价值的参考依据。
TABLE IX COMPARISON RESULTS OF USING DIFFERENT SIZE OF CORPUS IN SIMILARITY CALCULATION. BOLD DENOTES THE BEST RESULT.
| Corpus Size | MIMIC-CXR | |
| R-1↑ | R-2↑ R-L↑ | |
| 100,00Samples | 48.32 | 29.21 41.85 |
| 200,00Samples | 49.69 | 30.86 43.16 |
| 122,014 (Full set) | 54.45 | 34.50 47.93 |
表 IX: 相似度计算中使用不同规模语料库的对比结果。加粗表示最佳结果。
| Corpus Size | MIMIC-CXR |
|---|---|
| R-1↑ | |
| 100,00Samples | 48.32 |
| 200,00Samples | 49.69 |
| 122,014 (Full set) | 54.45 |