MEDAGENTS: Large Language Models as Collaborators for Zero-shot Medical Reasoning
MEDAGENTS: 大语言模型作为零样本医学推理的协作伙伴
Abstract
摘要
Large language models (LLMs), despite their remarkable progress across various general domains, encounter significant barriers in medicine and healthcare. This field faces unique challenges such as domain-specific terminologies and reasoning over specialized knowledge. To address these issues, we propose MEDAGENTS, a novel multi-disciplinary collaboration framework for the medical domain. MedAgents leverages LLM-based agents in a role-playing setting that participate in a collaborative multi-round discussion, thereby enhancing LLM proficiency and reasoning capabilities. This training-free framework encompasses five critical steps: gathering domain experts, proposing individual analyses, summa rising these analyses into a report, iterating over discussions until a consensus is reached, and ultimately making a decision. Our work focuses on the zeroshot setting, which is applicable in realworld scenarios. Experimental results on nine datasets (MedQA, MedMCQA, PubMedQA, and six subtasks from MMLU) establish that our proposed MEDAGENTS framework excels at mining and harnessing the medical expertise within LLMs, as well as extending its reasoning abilities. Our code can be found at https: //github.com/ger stein lab/MedAgents.
大语言模型 (LLMs) 虽然在多个通用领域取得了显著进展,但在医学和医疗健康领域仍面临重大障碍。该领域存在特定领域术语和专业知识的推理等独特挑战。为解决这些问题,我们提出了MEDAGENTS,一种面向医学领域的新型多学科协作框架。MedAgents利用基于LLM的智能体在角色扮演环境中参与协作式多轮讨论,从而提升LLM的专业水平和推理能力。这个无需训练的框架包含五个关键步骤:召集领域专家、提出独立分析、汇总分析形成报告、迭代讨论直至达成共识、最终做出决策。我们的研究聚焦于适用于现实场景的零样本设置。在九个数据集(MedQA、MedMCQA、PubMedQA以及MMLU的六项子任务)上的实验结果表明,我们提出的MEDAGENTS框架擅长挖掘和利用LLM中的医学专业知识,并能扩展其推理能力。代码详见https://github.com/gersteinlab/MedAgents。
1 Introduction
1 引言
Large language models (LLMs) (Brown et al., 2020; Scao et al., 2022; Chowdhery et al., 2022; Touvron et al., 2023; OpenAI, 2023) have exhibited notable generalization abilities across a wide range of tasks and applications (Lu et al., 2023; Zhou et al., 2023; Park et al., 2023), with these capabilities stemming from their extensive training on vast comprehensive corpora covering diverse topics. However, in real-world scenarios, LLMs tend to encounter domain-specific tasks that necessitate a combination of domain expertise and complex reasoning abilities (Moor et al., 2023; Wu et al., 2023b; Singhal et al., 2023a; Yang et al., 2023). Amidst this backdrop, a noteworthy research topic lies in the adoption of LLMs in the medical field, which has gained increasing prominence recently (Zhang et al., 2023b; Bao et al., 2023; Singhal et al., 2023a).
大语言模型 (LLMs) (Brown 等人, 2020; Scao 等人, 2022; Chowdhery 等人, 2022; Touvron 等人, 2023; OpenAI, 2023) 在广泛的任务和应用中展现出显著的泛化能力 (Lu 等人, 2023; Zhou 等人, 2023; Park 等人, 2023), 这些能力源于其对涵盖多元主题的海量综合语料库的广泛训练。然而在现实场景中, 大语言模型往往会遇到需要结合领域专业知识和复杂推理能力的特定领域任务 (Moor 等人, 2023; Wu 等人, 2023b; Singhal 等人, 2023a; Yang 等人, 2023)。在此背景下, 一个值得关注的研究主题是大语言模型在医疗领域的应用, 这一方向近期正获得越来越多的重视 (Zhang 等人, 2023b; Bao 等人, 2023; Singhal 等人, 2023a)。
Two major challenges prevent LLMs from effectively handling tasks in the medical sphere: (i) Limited volume and specificity of medical training data compared to the vast general text data, due to cost and privacy concerns (Thiru nav uk a rasu et al., 2023).1 (ii) The demand for extensive domain knowledge (Schmidt and Rikers, 2007) and advanced reasoning skills (Liévin et al., 2022) makes eliciting medical expertise via simple prompting challenging (Kung et al., 2023; Singhal et al., 2023a). Although numerous attempts, particularly within math and coding, have been made to enhance prompting methods (Besta et al., 2023; Lála et al., 2023; Wang et al., 2023b), strategies used in the medical field have been shown to induce hallucination (Umapathi et al., 2023; Harris, 2023; Ji et al., 2023), indicating the need for more robust approaches.
大语言模型在医疗领域有效处理任务面临两大挑战:(i) 由于成本和隐私问题 (Thirunavukarasu et al., 2023)[1],医疗训练数据的数量和特异性相较于海量通用文本数据更为有限。(ii) 对广泛领域知识 (Schmidt and Rikers, 2007) 和高级推理能力 (Liévin et al., 2022) 的需求,使得通过简单提示激发医疗专业知识具有挑战性 (Kung et al., 2023; Singhal et al., 2023a)。尽管在数学和编程等领域已有大量改进提示方法的尝试 (Besta et al., 2023; Lála et al., 2023; Wang et al., 2023b),但医疗领域采用的策略已被证明会引发幻觉现象 (Umapathi et al., 2023; Harris, 2023; Ji et al., 2023),这表明需要更稳健的方法。
Meanwhile, recent research has surprisingly witnessed the success of multi-agent collaboration (Xi et al., 2023; Wang et al., 2023d) which highlights the simulation of human activities (Du et al., 2023; Liang et al., 2023; Park et al., 2023) and optimizes the collective power of multiple agents (Chen et al., 2023; Li et al., 2023d; Hong et al., 2023). Through such design, the expertise implicitly embedded within LLMs, or that the model has encountered during its training, which may not be readily accessible via traditional prompting, is effectively brought to the fore.
与此同时,近期研究意外见证了多智能体协作的成功 (Xi et al., 2023; Wang et al., 2023d) ,这种协作凸显了对人类活动的模拟 (Du et al., 2023; Liang et al., 2023; Park et al., 2023) ,并优化了多个智能体的集体力量 (Chen et al., 2023; Li et al., 2023d; Hong et al., 2023) 。通过这种设计,大语言模型中隐性嵌入的专业知识,或模型在训练过程中接触过的、传统提示方法难以调用的知识,被有效地激发出来。
A 66-year-old male with a history of heart attack and recurrent stomach ulcers is experiencing persistent cough and chest pain, and recent CT scans indicate a possible lung tumor. Designing a treatment plan that minimizes risk and maximizes outcomes is the current concern due to his deteriorating health and medical history.
一名66岁男性患者,有心脏病发作史和复发性胃溃疡,现出现持续性咳嗽和胸痛症状,近期CT扫描提示可能存在肺部肿瘤。鉴于其健康状况恶化和复杂病史,当前需制定一个风险最小化、疗效最大化的治疗方案。

Figure 1: Diagram of our proposed MEDAGENTS framework. Given a medical question as input, the framework performs reasoning in five stages: (i) expert gathering, (ii) analysis proposition, (iii) report sum mari z ation, (iv) collaborative consultation, and (v) decision making.
图 1: 我们提出的MEDAGENTS框架示意图。该框架以医疗问题作为输入,通过五个阶段进行推理:(i) 专家召集,(ii) 分析提案,(iii) 报告汇总,(iv) 协作会诊,(v) 决策制定。
This process subsequently enhances the model’s reasoning capabilities throughout multiple rounds of interaction (Wang et al., 2023c; Fu et al., 2023).
这一过程随后在多轮交互中增强了模型的推理能力 (Wang et al., 2023c; Fu et al., 2023)。
Motivated by these notions, we pioneer a multi-disciplinary collaboration framework (MedAgents) specifically tailored to the clinical domain. Our objective centers on unveiling the intrinsic medical knowledge embedded in LLMs and reinforcing reasoning proficiency in a training-free manner. As shown in Figure 1, the MEDAGENTS framework gathers experts from diverse disciplines and reaches consistent conclusions through collaborative discussions.
受这些理念启发,我们首创了一个专为临床领域定制的多学科协作框架(MedAgents)。该框架的核心目标是揭示大语言模型(LLM)中内嵌的医学知识,并以免训练方式增强推理能力。如图1所示,MEDAGENTS框架汇集了来自不同学科的专家,通过协作讨论达成一致结论。
Based on our MEDAGENTS framework, we conduct experiments on nine datasets, including MedQA (Jin et al., 2021), MedMCQA (Pal et al., 2022), PubMedQA (Jin et al., 2019) and six medical subtasks from MMLU (Hendrycks et al., 2020).2 To better align with real-world application scenarios, our study focuses on the zero-shot setting, which can serve as a plug-and-play method to supplement existing medical LLMs such as MedPaLM 2 (Singhal et al., 2023b). Encouragingly, our proposed approach outperforms settings for both chain-of-thought (CoT) and self-consistency (SC) prompting methods. Most notably, our approach achieves better performance under the zero-shot setting compared with the 5-shot baselines.
基于我们的MEDAGENTS框架,我们在九个数据集上进行了实验,包括MedQA (Jin et al., 2021)、MedMCQA (Pal et al., 2022)、PubMedQA (Jin et al., 2019)以及来自MMLU (Hendrycks et al., 2020)的六个医学子任务。为了更好地贴合实际应用场景,我们的研究聚焦于零样本设置,这种方法可作为即插即用的方案来补充现有医疗大语言模型,如MedPaLM 2 (Singhal et al., 2023b)。令人鼓舞的是,我们提出的方法在思维链(CoT)和自我一致性(SC)提示方法上均表现更优。最显著的是,我们的方法在零样本设置下甚至超越了5样本基线模型的性能。
Based on our results, we further investigate the influence of agent numbers and conduct human evaluations to pinpoint the limitations and issues prevalent in our approach. We find four common categories of errors: (i) lack of domain knowledge, (ii) mis-retrieval of domain knowledge, (iii) consistency errors, and (iv) CoT errors. Targeted refinements focused on mitigating these particular shortcomings would enhance the model’s proficiency and reliability.
根据我们的结果,我们进一步研究了智能体数量的影响,并通过人工评估来找出我们方法中普遍存在的局限性和问题。我们发现错误主要分为四类:(i) 缺乏领域知识,(ii) 领域知识检索错误,(iii) 一致性错误,以及 (iv) 思维链 (CoT) 错误。针对这些特定缺陷进行有针对性的改进,将提高模型的熟练度和可靠性。
Our contributions are summarized as follows:
我们的贡献总结如下:
(i) To the best of our knowledge, we are the first to propose a multi-agent framework within the medical domain and explore how multi-agent communication within the medical setting can lead to a consensus decision, adding a novel dimension to the current literature on medical question answering.
(i) 据我们所知,我们是首个在医疗领域提出多智能体框架并探索医疗场景中多智能体通信如何达成共识决策的研究,为当前医学问答文献增添了新维度。
(ii) Our proposed MEDAGENTS framework enjoys enhanced faithfulness and interpret ability by harnessing role-playing and collaborative agent discussion. And we demonstrate that role-playing allows LLM to explicitly reason with accurate knowledge, without the need for retrieval augmented generation (RAG). Examples illustrating interpret ability are shown in Appendix B.
(ii) 我们提出的MEDAGENTS框架通过角色扮演和智能体协作讨论,显著提升了忠实度和可解释性。研究表明,角色扮演能使大语言模型显式运用准确知识进行推理,而无需依赖检索增强生成(RAG)。可解释性示例如附录B所示。
(iii) Experimental results on nine datasets
(iii) 在九个数据集上的实验结果
Question: A 3-month-old infant is brought to her pediatrician because she coughs and seems to have difficulty breathing while feeding. In addition, she seems to have less energy compared to other babies and appears listless throughout the day. She was born by cesarean section to a G1P1 woman with no prior medical history and had a normal APGAR score at birth. Her parents say that she has never been observed to turn blue. Physical exam reveals a high-pitched hol o systolic murmur that is best heard at the lower left sternal border. The most likely cause of this patient's symptoms is associated with which of the following abnormalities? Options: (A) 22q11 deletion (B) Deletion of genes on chromosome 7 (C) Lithium exposure in utero (D) Retinoic acid exposure in utero
问题:一名3个月大的女婴因喂养时咳嗽和呼吸困难被带到儿科医生处就诊。此外,她比其他婴儿精力差,整天显得无精打采。该婴儿通过剖宫产出生,母亲为G1P1(初次妊娠初次分娩),无既往病史,出生时APGAR评分正常。父母表示从未观察到婴儿出现发绀。体格检查发现胸骨左下缘可闻及高调全收缩期杂音。该患者症状最可能的原因与以下哪种异常相关?
选项:
(A) 22q11缺失
(B) 7号染色体基因缺失
(C) 子宫内锂暴露
(D) 子宫内维甲酸暴露
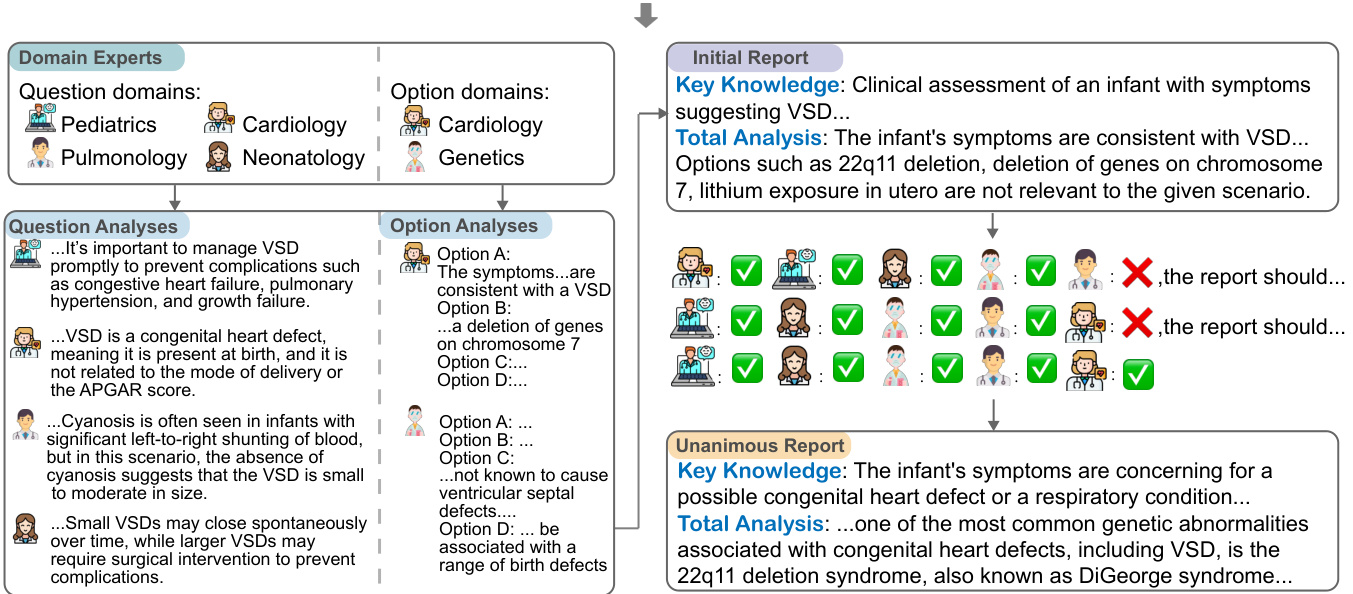
Figure 2: Illustrative example of our proposed MedAgents, a multi-disciplinary collaboration framework. The questions and options are first presented, with domain experts subsequently gathered. The recruited experts conduct thorough Question and Option analyses based on their respective fields. An initial report synthesizing these analyses is then prepared to concisely represent the performed evaluations. The assembled LLM experts, possessing respective disciplinary backgrounds, engage in a discussion over the initial report, voicing agreements and disagreements. Ultimately, after iterative refinement and consultation, a unanimous report is generated that best represents the collective expert knowledge and reasoning on the given medical problem.
图 2: 我们提出的MedAgents框架示意图,这是一个多学科协作框架。首先呈现问题与选项,随后召集领域专家。被招募的专家根据各自领域进行全面的问题与选项分析。接着汇总这些分析形成初步报告,简明呈现已完成的评估。具备相应学科背景的大语言模型专家们围绕初步报告展开讨论,表达赞同或反对意见。最终经过迭代优化与协商,生成一份代表集体专家知识及医学问题推理的共识报告。
demonstrate the general effectiveness of our proposed MEDAGENTS framework. Besides, we identify and categorize common error types in our approach through rigorous human evaluation to shed light on future studies.
我们提出的MEDAGENTS框架展现了普遍有效性。此外,通过严格的人工评估,我们识别并分类了该方法中的常见错误类型,为未来研究提供了启示。
2 Method
2 方法
This section presents the details of our proposed multi-disciplinary collaboration MEDAGENTS framework. Figure 1 and 2 give an overview and an illustrative example of its pipeline, respectively. Our proposed MEDAGENTS framework works in five stages: (i) expert gathering: assemble experts from various disciplines based on the clinical question; (ii) analysis proposition: domain experts present their own analyses with their expertise; (iii) report sum mari z ation: develop a report summary on the basis of previous analyses; (iv) collaborative consultation: hold a consultation over the summarized report with the experts. The report will be revised repeatedly until every expert has given their approval. (v) decision making: derive a final decision from the unanimous report.3
本节详细介绍我们提出的多学科协作MEDAGENTS框架。图1和图2分别展示了其流程概览和示例。我们提出的MEDAGENTS框架包含五个阶段:(i) 专家召集:根据临床问题组建跨学科专家团队;(ii) 分析提案:领域专家运用专业知识提出各自分析;(iii) 报告汇总:基于前期分析形成报告摘要;(iv) 协作会诊:组织专家对汇总报告进行协商。报告将反复修改直至获得所有专家认可。(v) 决策制定:从达成共识的报告中得出最终结论。3
2.1 Expert Gathering
2.1 专家收集
Given a clinical question $q$ and a set of options $o p={o_ {1},o_ {2},\ldots,o_ {k}}$ where $k$ is the number of options, the goal of the Expert Gathering stage is to recruit a group of question domain experts $\mathcal{Q}\mathcal{D}={q d_ {1},q d_ {2},\ldots,q d_ {m}}$ and option domain experts $\begin{array}{l l l}{{\mathcal O D}}&{{=}}&{{{o d_ {1},o d_ {2},\dots,o d_ {n}}}}\end{array}$ where $m$ and $n$ represent the number of question domain experts and option domain experts, respectively. Specifically, we assign a role to the model and provide instructions to guide the model output to the corresponding domains based on the input question and options, respectively:
给定一个临床问题 $q$ 和一组选项 $o p={o_ {1},o_ {2},\ldots,o_ {k}}$ ,其中 $k$ 是选项数量,专家召集阶段的目标是招募一组问题领域专家 $\mathcal{Q}\mathcal{D}={q d_ {1},q d_ {2},\ldots,q d_ {m}}$ 和选项领域专家 $\begin{array}{l l l}{{\mathcal O D}}&{{=}}&{{{o d_ {1},o d_ {2},\dots,o d_ {n}}}}\end{array}$ ,其中 $m$ 和 $n$ 分别表示问题领域专家和选项领域专家的数量。具体而言,我们为模型分配角色,并根据输入问题和选项分别提供指导,引导模型输出到相应领域:
$$
\begin{array}{r l}&{\mathcal{Q}\mathcal{D}=\mathrm{LLM}\left(q,\boldsymbol{\mathsf{r}}_ {\mathsf{q d}},\mathsf{p r o m p t}_ {\mathsf{q d}}\right),}\ &{\mathcal{O}\mathcal{D}=\mathrm{LLM}\left(q,o p,\boldsymbol{\mathsf{r}}_ {\mathsf{o d}},\mathsf{p r o m p t}_ {\mathsf{o d}}\right),}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{Q}\mathcal{D}=\mathrm{LLM}\left(q,\boldsymbol{\mathsf{r}}_ {\mathsf{q d}},\mathsf{p r o m p t}_ {\mathsf{q d}}\right),}\ &{\mathcal{O}\mathcal{D}=\mathrm{LLM}\left(q,o p,\boldsymbol{\mathsf{r}}_ {\mathsf{o d}},\mathsf{p r o m p t}_ {\mathsf{o d}}\right),}\end{array}
$$
where $\left(\boldsymbol{\Gamma}_ {\mathrm{qd}},\mathsf{p r o m p t}_ {\mathrm{qd}}\right)$ and $\left(\Gamma_ {\tt o d},\tt p r o m p t_ {\tt o d}\right)$ stand for the system role and guideline prompt to gather domain experts for the question $q$ and options $o p$ .
其中 $(\boldsymbol{\Gamma}_ {\mathrm{qd}},\mathsf{p r o m p t}_ {\mathrm{qd}})$ 和 $(\Gamma_ {\tt o d},\tt p r o m p t_ {\tt o d})$ 分别表示用于召集领域专家针对问题 $q$ 和选项 $o p$ 的系统角色与指导提示。
Table 1: Summary of the Datasets. Part of the values are from the appendix of (Singhal et al., 2023a).
| Dataset | Format | Choice | TestingSize | Domain |
| MedQA | Question+ Answer | A/B/C/D | 1273 | USMedical LicensingExamination |
| MedMCQA | Question+Answer | A/B/C/DandExplanations | 6.1K | AIIMSandNEETPGentranceexams |
| PubMedQA | Question+Context+Answer | Yes/No/Maybe | 500 | PubMedpaper abstracts |
| MMLU | Question+Answer | A/B/C/D | 1089 | GraduateRecordExamination & US Medical Licensing Examination |
表 1: 数据集摘要。部分数据来自 (Singhal et al., 2023a) 的附录。
| 数据集 | 格式 | 选项 | 测试集大小 | 领域 |
|---|---|---|---|---|
| MedQA | 问题+答案 | A/B/C/D | 1273 | 美国医师执照考试 |
| MedMCQA | 问题+答案 | A/B/C/D及解释 | 6.1K | AIIMS和NEETPG入学考试 |
| PubMedQA | 问题+上下文+答案 | 是/否/可能 | 500 | PubMed论文摘要 |
| MMLU | 问题+答案 | A/B/C/D | 1089 | 研究生入学考试 & 美国医师执照考试 |
2.2 Analysis Proposition
2.2 分析命题
After gathering domain experts for the question $q$ and options $o p$ , we aim to inquire experts to generate corresponding analyses prepared for later reasoning: $\mathcal{Q A}={q a_ {1},q a_ {2},\dots,q a_ {m}}$ and $\mathcal{O A}={o a_ {1},o a_ {2},...,o a_ {n}}$ .
在针对问题$q$和选项$op$召集领域专家后,我们的目标是请专家生成相应分析,为后续推理做准备:$\mathcal{QA}={qa_ {1},qa_ {2},\dots,qa_ {m}}$和$\mathcal{OA}={oa_ {1},oa_ {2},...,oa_ {n}}$。
Question Analyses Given a question $q$ and a question domain $q d_ {i}\in\mathcal{Q}\mathcal{D}$ , we ask LLM to serve as an expert specialized in domain $q d_ {i}$ and derive the analyses for the question $q$ following the guideline prompt prompt $\mathbf{q}\mathsf{a}$ :
问题分析
给定一个问题 $q$ 和一个问题领域 $q d_ {i}\in\mathcal{Q}\mathcal{D}$,我们要求大语言模型 (LLM) 作为专注于领域 $q d_ {i}$ 的专家,并按照指导提示 prompt $\mathbf{q}\mathsf{a}$ 对问题 $q$ 进行分析:
$$
q a_ {i}=\mathrm{LLM}\left(q,q d_ {i},\mathbf{r}_ {\mathbf{q}\mathbf{a}},\mathsf{p r o m p t}_ {\mathbf{q}\mathbf{a}}\right).
$$
$$
q a_ {i}=\mathrm{LLM}\left(q,q d_ {i},\mathbf{r}_ {\mathbf{q}\mathbf{a}},\mathsf{p r o m p t}_ {\mathbf{q}\mathbf{a}}\right).
$$
Option Analyses Now that we have an option domain $o d_ {i}$ and question analyses $\mathcal{Q A}$ , we can further analyze the options by taking into account both the relationship between the options and the relationship between the options and question. Concretely, we deliver the question $q$ , the options $o p$ , a specific option domain $o d_ {i}\in\mathcal{O}\mathcal{D}$ , and the question analyses $\mathcal{Q A}$ to the LLM:
选项分析
现在我们有了一个选项域 $o d_ {i}$ 和问题分析 $\mathcal{Q A}$,我们可以通过考虑选项之间的关系以及选项与问题之间的关系来进一步分析选项。具体来说,我们将问题 $q$、选项 $o p$、特定选项域 $o d_ {i}\in\mathcal{O}\mathcal{D}$ 以及问题分析 $\mathcal{Q A}$ 输入到大语言模型中:
$$
o a_ {i}=\mathrm{LLM}\left(q,o p,o d_ {i},\mathcal{Q}\mathcal{A},\mathfrak{r}_ {\mathsf{o a}},\mathsf{p r o m p t}_ {\mathsf{o a}}\right).
$$
$$
o a_ {i}=\mathrm{LLM}\left(q,o p,o d_ {i},\mathcal{Q}\mathcal{A},\mathfrak{r}_ {\mathsf{o a}},\mathsf{p r o m p t}_ {\mathsf{o a}}\right).
$$
2.3 Report Sum mari z ation
2.3 报告摘要
In the Report Sum mari z ation stage, we attempt to summarize and synthesize previous analyses from various domain experts $\mathcal{Q A}\cup\mathcal{O A}$ . Given question analyses $\mathcal{Q A}$ and option analyses $\mathcal{O A}$ , we ask LLMs to play the role of a medical report assistant, allowing it to generate a synthesized report by extracting key knowledge and total analysis based on previous analyses:
在报告汇总阶段,我们尝试综合各领域专家的先前分析$\mathcal{Q A}\cup\mathcal{O A}$。基于问题分析$\mathcal{Q A}$和选项分析$\mathcal{O A}$,我们让大语言模型扮演医疗报告助手的角色,使其能够通过提取关键知识并整合先前分析来生成综合报告:
$$
R e p o=\mathrm{LLM}\left(\mathcal{Q A},\mathcal{O A},\mathfrak{r}_ {r s},\mathfrak{p r o m p t}_ {r s}\right).
$$
$$
R e p o=\mathrm{LLM}\left(\mathcal{Q A},\mathcal{O A},\mathfrak{r}_ {r s},\mathfrak{p r o m p t}_ {r s}\right).
$$
2.4 Collaborative Consultation
2.4 协作咨询
Since we have a preliminary summary report Repo, the objective of the Collaborative Consultation stage is to engage distinct domain experts in multiple rounds of discussions and ultimately render a summary report that is recognized by all
由于我们已有一份初步的总结报告Repo,协作咨询阶段的目标是让不同领域的专家参与多轮讨论,最终形成一份获得各方认可的总结报告
Algorithm 1: Collaborative Consultation
算法 1: 协同咨询
experts. The overall procedure of this phase is presented in Algorithm 1. During each round of discussions, the experts give their votes $(y e s/n o)$ : $v o t e=\mathsf{L L M}\left(R e p o,\mathsf{r_ {v o t e}},\mathsf{p r o m p t_ {v o t e}}\right)$ , as well as modification opinions if they vote no for the current report. Afterward, the report will be revised based on the modification opinions. Specifically, during the $j$ -th round of discussion, we note the modification comments from the experts as $M o d_ {j}$ , then we can acquire the updated report as $R e p o_ {j}=$ LLM $(R e p o_ {j-1},M o d_ {j}$ , $\mathsf{p r o m p t}_ {\mathsf{m o d}},$ . In this way, the discussions are held iterative ly until all experts vote yes for the final report $R e p o_ {f}$ or the discussion number attains the maximum attempts threshold.
专家。该阶段的整体流程如算法1所示。在每轮讨论中,专家会给出投票结果$(是/否)$: $vote=\mathsf{大语言模型}\left(Repo,\mathsf{r_ {vote}},\mathsf{prompt_ {vote}}\right)$,若对当前报告投反对票则同时提出修改意见。随后报告将根据修改意见进行修订。具体而言,在第$j$轮讨论中,我们将专家的修改意见记为$Mod_ {j}$,则可通过$Repo_ {j}=$大语言模型$(Repo_ {j-1},Mod_ {j}$,$\mathsf{prompt_ {mod}},$获得更新后的报告。如此迭代进行讨论,直至所有专家对最终报告$Repo_ {f}$投赞成票,或讨论次数达到最大尝试阈值。
2.5 Decision Making
2.5 决策制定
In the end, we demand LLM act as a medical decision maker to derive the final answer to the clinical question $q$ referring to the unanimous
最终,我们要求大语言模型 (LLM) 扮演医疗决策者的角色,根据一致意见推导出临床问题 $q$ 的最终答案。
report $R e p o_ {f}$
报告 $R e p o_ {f}$
$$
a n s=\mathrm{LLM}\left(q,o p,R e p o_ {f},\mathsf{p r o m p t}_ {\mathsf{d m}}\right).
$$
$$
a n s=\mathrm{LLM}\left(q,o p,R e p o_ {f},\mathsf{p r o m p t}_ {\mathsf{d m}}\right).
$$
3 Experiments
3 实验
3.1Setup
3.1 设置
Tasks and Datasets. We evaluate our MEDAGENTS framework on three benchmark datasets MedQA (Jin et al., 2021), MedMCQA (Pal et al., 2022), and PubMedQA (Jin et al., 2019), as well as six subtasks most relevant to the medical domain from MMLU datasets (Hendrycks et al., 2020) including anatomy, clinical knowledge, college medicine, medical genetics, professional medicine, and college biology. Table 1 summarizes the data statistics. More information about the evaluated datasets is presented in Appendix C.
任务与数据集。我们在三个基准数据集MedQA (Jin et al., 2021)、MedMCQA (Pal et al., 2022)和PubMedQA (Jin et al., 2019)上评估MEDAGENTS框架,同时选取MMLU数据集 (Hendrycks et al., 2020)中与医学领域最相关的六个子任务:解剖学、临床知识、大学医学、医学遗传学、专业医学和大学生物学。表1总结了数据统计信息,更多评估数据集详情见附录C。
Implementation. We utilize the popular and publicly available GPT-3.5-Turbo and GPT-4 (OpenAI, 2023) from Azure OpenAI Service.5 All experiments are conducted in the zero-shot setting. The temperature is set to 1.0 and top_ $p$ to 1.0 for all generations. The iteration number and temperature of SC are 5 and 0.7, respectively. The number $k$ of options is 4 except for PubMedQA (3). The numbers of domain experts for the question and options are set as: $m=5,n=2$ except for PubMedQA $(m=4,n=2)$ . The number of maximum attempts $t$ is set as 5. We randomly sample 300 examples for each dataset and conduct experiments on them. Statistically, the cost of our method is $\$1.41$ for $100\mathrm{QA}$ examples (about $\mathbf{\Sigma}_ {\phi1.4}$ per question) and the inference time per example is about $40s$ .6
实现。我们使用了Azure OpenAI服务中广受欢迎且公开可用的GPT-3.5-Turbo和GPT-4 (OpenAI, 2023)。所有实验均在零样本设置下进行。生成过程中,温度参数设为1.0,top_ $p$ 设为1.0。SC (Self-Consistency) 的迭代次数和温度分别设置为5和0.7。选项数量 $k$ 默认为4(PubMedQA数据集为3)。问题和选项的领域专家数量设置为 $m=5,n=2$ (PubMedQA为 $(m=4,n=2)$ )。最大尝试次数 $t$ 设为5。每个数据集随机抽取300个样本进行实验。统计显示,本方法处理100个QA样本的成本为 $\$1.41$ (约 $\mathbf{\Sigma}_ {\phi1.4}$ /问题),单样本推理时间约 $40s$。
Baselines. We have utilized models that are readily accessible through public APIs with the following baselines:
基线模型。我们使用了可通过公共API轻松访问的以下基准模型:
Setting w/o CoT: Zero-shot (Kojima et al., 2022) appends the prompt /emphA: The answer is to a given question and utilizes it as the input fed into LLMs. Few-shot (Brown et al., 2020) introduces several manually templated demonstrations, structured as [Q: q, A: The answer is a], preceding the input question.
无思维链设置:零样本 (Kojima et al., 2022) 在给定问题后追加提示符 /emphA: The answer is 并将其作为大语言模型的输入。少样本 (Brown et al., 2020) 则在输入问题前引入若干人工模板化的示例,其结构为 [Q: q, A: The answer is a]。
Setting w/ CoT: Zero-shot CoT (Kojima et al., 2022) directly incorporates the prompt Let’s think step by step after a question to facilitate inference. Few-shot CoT (Wei et al., 2022) adopts comparable methodologies to Few-shot but distinguishes itself by integrating rationales before deducing the answer.
设置 CoT 方法:零样本 CoT (Kojima et al., 2022) 直接在问题后加入提示词 "Let’s think step by step" 以促进推理。少样本 CoT (Wei et al., 2022) 采用与少样本类似的方法,但在推导答案前会整合推理过程以形成差异。
• Setting w/ SC: SC (Wang et al., 2022) serves as an additional sampling method on Zero-shot CoT and Few-shot CoT, which yields the majority answer by sampling multiple chains.
• 设置 w/ SC: SC (Wang et al., 2022) 作为零样本 CoT 和少样本 CoT 的额外采样方法,通过采样多条链生成多数答案。
3.2 Main Results
3.2 主要结果
Table 2 presents the main results on the nine datasets, including MedQA, MedMCQA, PubMedQA, and six subtasks from MMLU. We compare our method with several baselines in both zero-shot and few-shot settings. Notably, our proposed MEDAGENTS framework outperforms the zero-shot baseline methods by a large margin, indicating the effectiveness of our MEDAGENTS framework in real-world application scenarios. Furthermore, our approach achieves comparable performance under the zero-shot setting compared with the strong baseline Few-shot $C o T{+}S C$ .
表 2: 展示了在九个数据集上的主要结果,包括 MedQA、MedMCQA、PubMedQA 以及 MMLU 的六个子任务。我们将所提方法与零样本和少样本设置下的多个基线方法进行了比较。值得注意的是,我们提出的 MEDAGENTS 框架大幅优于零样本基线方法,这表明 MEDAGENTS 框架在实际应用场景中的有效性。此外,在零样本设置下,我们的方法与强基线 Few-shot $C o T{+}S C$ 相比也取得了相当的性能。
Interestingly, the introduction of CoT occasionally leads to a surprising degradation in performance.7 We have found that reliance on CoT in isolation can inadvertently result in hallucinations - spurious outputs typically associated with the misapplication of medical terminologies. In contrast, our multi-agent roleplaying methodology effectively mitigates these issues, thus underscoring its potential as a more robust approach in medically oriented LLM applications.
有趣的是,引入思维链 (CoT) 偶尔会导致性能出现意外的下降[7]。我们发现,单独依赖思维链可能会无意中导致幻觉现象——即通常与医学术语误用相关的虚假输出。相比之下,我们的多智能体角色扮演方法有效缓解了这些问题,从而凸显了其在医学导向的大语言模型应用中作为一种更稳健方法的潜力。
4 Analysis
4 分析
4.1 Ablation Study
4.1 消融实验
Since our MEDAGENTS framework simulates a multi-disciplinary collaboration process that contains multiple intermediate steps, a natural question is whether each intermediate step contributes to the ultimate result. To investigate this, we ablate three major processes, namely analysis proposition, report sum mari z ation and collaborative consultation. Results in Table 3 show that all of these processes are non-trivial. Notably, the proposition of MEDAGENTS substantially boosts the performance (i.e., $55.0%{\rightarrow}62.0%$ ), whereas the subsequent processes achieve relatively slight improvements over the previous one (i.e., $62.0%{\rightarrow}65.0/67.0%)$ . This suggests that the initial role-playing agents are responsible for exploring medical knowledge of various levels and aspects within LLMs, while the following processes play a role in further verification and revision.
由于我们的MEDAGENTS框架模拟了一个包含多个中间步骤的多学科协作流程,一个自然的问题是每个中间步骤是否对最终结果有所贡献。为了研究这一点,我们消融了三个主要流程,即分析提案、报告总结和协作咨询。表3中的结果显示所有这些流程都不可忽视。值得注意的是,MEDAGENTS的提案显著提升了性能(即$55.0%{\rightarrow}62.0%$),而后续流程相对于前一步仅实现了相对较小的改进(即$62.0%{\rightarrow}65.0/67.0%)$。这表明初始的角色扮演智能体负责在大语言模型中探索不同层次和方面的医学知识,而后续流程则起到进一步验证和修正的作用。
| Method | MedQA MedMCQA PubMedQA Anatomy | Clinical knowledge medicine genetics | College Medical Professional College medicine | biology | Avg. | |||||
| Flan-Palm | ||||||||||
| Few-shot CoT | 60.3 | 53.6 | 77.2 | 66.7 | 77.0 | 83.3 | 75.0 | 76.5 | 71.1 | 71.2 |
| Few-shot CoT + SC | 67.6 | 57.6 | 75.2 | 71.9 | 80.4 | 88.9 | 74.0 | 83.5 | 76.3 | 75.0 |
| GPT-3.5 | ||||||||||
| * few-shot setting | ||||||||||
| Few-shot | 54.7 | 56.7 | 67.6 | 65.9 | 71.3 | 59.0 | 72.0 | 75.7 | 73.6 | 66.3 |
| Few-shot CoT | 55.3 | 54.7 | 71.4 | 48.1 | 65.7 | 55.5 | 57.0 | 69.5 | 61.1 | 59.8 |
| Few-shot CoT + SC | 62.1 | 58.3 | 73.4 | 70.4 | 76.2 | 69.8 | 78.0 | 79.0 | 77.2 | 71.6 |
| * zero-shot setting | ||||||||||
| Zero-shot | 54.3 | 56.3 | 73.7 | 61.5 | 76.2 | 63.6 | 74.0 | 75.4 | 75.0 | 67.8 |
| Zero-shot CoT | 44.3 | 47.3 | 61.3 | 63.7 | 61.9 | 53.2 | 66.0 | 62.1 | 65.3 | 58.3 |
| Zero-shot CoT + SC | 61.3 | 52.5 | 75.7 | 71.1 | 75.1 | 68.8 | 76.0 | 82.3 | 75.7 | 70.9 |
| MedAgents (Ours) | 64.1 | 59.3 | 72.9 | 65.2 | 77.7 | 69.8 | 79.0 | 82.1 | 78.5 | 72.1 |
| GPT-4 | ||||||||||
| * few-shot setting | ||||||||||
| Few-shot | 70.1 | 89.5 | 75.6 | 93.0 | 91.5 | 91.7 | 82.3 | |||
| Few-shot CoT | 76.6 | 73.4 | 79.3 | 63.2 | 73.3 | |||||
| Few-shot CoT + SC | 73.3 | 63.2 | 74.9 | 75.6 | 89.9 | 61.0 | 79.0 | 79.8 | ||
| 82.9 | 73.1 | 75.6 | 80.7 | 90.0 | 88.2 | 90.0 | 95.2 | 93.0 | 85.4 | |
| * zero-shot setting | ||||||||||
| Zero-shot | 73.0 | 69.0 | 76.2 | 78.5 | 83.3 | 75.6 | 90.0 | 90.0 | 90.0 | 80.6 |
| Zero-shot CoT | 61.8 | 69.0 | 71.0 | 82.1 | 85.2 | 80.8 | 92.0 | 93.5 | 91.7 | 80.8 |
| Zero-shot CoT + SC | 74.5 | 70.1 | 75.3 | 80.0 | 86.3 | 81.2 | 93.0 | 94.8 | 91.7 | 83.0 |
| MedAgents (Ours) | 83.7 | 74.8 | 76.8 | 83.5 | 91.0 | 87.6 | 93.0 | 96.0 | 94.3 | 86.7 |
Table 2: Main results (Acc). SC denotes the self-consistency prompting method. Results in bold are the best performances.
| 方法 | MedQA | MedMCQA | PubMedQA | Anatomy | 临床知识 | 医学遗传学 | 大学医学专业 | 大学生物学 | 平均分 |
|---|---|---|---|---|---|---|---|---|---|
| * * Flan-Palm* * | |||||||||
| 少样本思维链 (Few-shot CoT) | 60.3 | 53.6 | 77.2 | 66.7 | 77.0 | 83.3 | 75.0 | 76.5 | 71.1 |
| 少样本思维链+自洽 (Few-shot CoT + SC) | 67.6 | 57.6 | 75.2 | 71.9 | 80.4 | 88.9 | 74.0 | 83.5 | 76.3 |
| * * GPT-3.5* * | |||||||||
| * 少样本设定 | |||||||||
| 少样本 | 54.7 | 56.7 | 67.6 | 65.9 | 71.3 | 59.0 | 72.0 | 75.7 | 73.6 |
| 少样本思维链 | 55.3 | 54.7 | 71.4 | 48.1 | 65.7 | 55.5 | 57.0 | 69.5 | 61.1 |
| 少样本思维链+自洽 | 62.1 | 58.3 | 73.4 | 70.4 | 76.2 | 69.8 | 78.0 | 79.0 | 77.2 |
| * 零样本设定 | |||||||||
| 零样本 | 54.3 | 56.3 | 73.7 | 61.5 | 76.2 | 63.6 | 74.0 | 75.4 | 75.0 |
| 零样本思维链 | 44.3 | 47.3 | 61.3 | 63.7 | 61.9 | 53.2 | 66.0 | 62.1 | 65.3 |
| 零样本思维链+自洽 | 61.3 | 52.5 | 75.7 | 71.1 | 75.1 | 68.8 | 76.0 | 82.3 | 75.7 |
| MedAgents (Ours) | 64.1 | 59.3 | 72.9 | 65.2 | 77.7 | 69.8 | 79.0 | 82.1 | 78.5 |
| * * GPT-4* * | |||||||||
| * 少样本设定 | |||||||||
| 少样本 | 70.1 | 89.5 | 75.6 | 93.0 | 91.5 | 91.7 | |||
| 少样本思维链 | 76.6 | 73.4 | 79.3 | 63.2 | |||||
| 少样本思维链+自洽 | 73.3 | 63.2 | 74.9 | 75.6 | 89.9 | 61.0 | 79.0 | 79.8 | |
| 82.9 | 73.1 | 75.6 | 80.7 | 90.0 | 88.2 | 90.0 | 95.2 | 93.0 | |
| * 零样本设定 | |||||||||
| 零样本 | 73.0 | 69.0 | 76.2 | 78.5 | 83.3 | 75.6 | 90.0 | 90.0 | 90.0 |
| 零样本思维链 | 61.8 | 69.0 | 71.0 | 82.1 | 85.2 | 80.8 | 92.0 | 93.5 | 91.7 |
| 零样本思维链+自洽 | 74.5 | 70.1 | 75.3 | 80.0 | 86.3 | 81.2 | 93.0 | 94.8 | 91.7 |
| MedAgents (Ours) | 83.7 | 74.8 | 76.8 | 83.5 | 91.0 | 87.6 | 93.0 | 96.0 | 94.3 |
表 2: 主要结果 (准确率)。SC表示自洽提示方法。加粗结果为最佳表现。
Table 3: Ablation study for different processes on MedQA. Anal: Analysis proposition, Summ: Report sum mari z ation, Cons: Collaborative consultation.
| Method | Accuracy(%) |
| Direct Prompting | 49.0 |
| CoTPrompting | 55.0 |
| w/MedAgents | |
| + Anal | 62.0(↑ 7.0) |
| +Anal&Summ | 65.0(↑ 10.0) |
| +Anal&Summ&Cons | 67.0(↑ 12.0) |
表 3: MedQA不同处理流程的消融研究。Anal: 分析命题,Summ: 报告总结,Cons: 协作会诊。
| 方法 | 准确率(%) |
|---|---|
| Direct Prompting | 49.0 |
| CoTPrompting | 55.0 |
| w/MedAgents | |
| + Anal | 62.0(↑ 7.0) |
| +Anal&Summ | 65.0(↑ 10.0) |
| +Anal&Summ&Cons | 67.0(↑ 12.0) |
Table 4: Comparison with open-source medical models.
| Method | MedQA | MedMCQA |
| MEDAGENTS(GPT-3.5) | 64.1 | 59.3 |
| MEDAGENTS (GPT-4) | 83.7 | 74.8 |
| MedAlpaca-7B | 55.2 | 45.8 |
| BioMedGPT-10B | 50.4 | 42.2 |
| BioMedLM-2.7B | 50.3 | - |
| BioBERT (large) | 36.7 | 37.1 |
| SciBERT (large) | 39.2 | |
| BERT (large) | 33.6 |
Table 6: Domain variation study. The results are based on GPT-3.5.
表 4: 开源医疗模型对比
| 方法 | MedQA | MedMCQA |
|---|---|---|
| MEDAGENTS(GPT-3.5) | 64.1 | 59.3 |
| MEDAGENTS (GPT-4) | 83.7 | 74.8 |
| MedAlpaca-7B | 55.2 | 45.8 |
| BioMedGPT-10B | 50.4 | 42.2 |
| BioMedLM-2.7B | 50.3 | - |
| BioBERT (large) | 36.7 | 37.1 |
| SciBERT (large) | 39.2 | |
| BERT (large) | 33.6 |
表 6: 领域差异研究 (基于 GPT-3.5)
Table 5: Optimal number of agents on MedQA, MedMCQA, PubMedQA, and MMLU.
| Dataset | MedQA MedMCQA PubMedQA MMLU | |||
| #Questionagents | 5 | 5 | 4 | 5 |
| #Option agents | 2 | 2 | 2 | 2 |
表 5: MedQA、MedMCQA、PubMedQA 和 MMLU 上的最优智能体数量
| 数据集 | MedQA | MedMCQA | PubMedQA | MMLU |
|---|---|---|---|---|
| 问题智能体数量 | 5 | 5 | 4 | 5 |
| 选项智能体数量 | 2 | 2 | 2 | 2 |
| Method | MedQA | MedMCQA |
| MEDAGENTS | 63.8 | 58.9 |
| Removemostrelevant | 60.5 | 55.4 |
| Removeleastrelevant | 66.2 | 61.5 |
| Remove randomly | 62.2 | 56.3 |
| 方法 | MedQA | MedMCQA |
|---|---|---|
| MEDAGENTS | 63.8 | 58.9 |
| Removemostrelevant | 60.5 | 55.4 |
| Removeleastrelevant | 66.2 | 61.5 |
| Remove randomly | 62.2 | 56.3 |
4.2 Comparison with Open-source Medical Models
4.2 与开源医疗模型的对比
We conduct a comprehensive comparison between our proposed MEDAGENTS framework with more baseline methods, including open-source domainadapted models such as MedAlpaca-7B (Han et al., 2023), BioMedGPT-10B (Luo et al., 2023), BioMedLM-2.7B (Bolton et al., 2024), BioBERT (large) (Lee et al., 2020), SciBERT (large) (Beltagy et al., 2019) and BERT (large). We leverage them in the early stages of our work for preliminary attempts. Results in Table 4 demonstrate that the open-source methods fell short of the baseline in Table 2, which leads us to focus on the more effective methods.
我们对提出的MEDAGENTS框架与更多基线方法进行了全面比较,包括开源领域适配模型如MedAlpaca-7B (Han et al., 2023)、BioMedGPT-10B (Luo et al., 2023)、BioMedLM-2.7B (Bolton et al., 2024)、BioBERT (large) (Lee et al., 2020)、SciBERT (large) (Beltagy et al., 2019)和BERT (large)。我们在工作初期利用这些模型进行了初步尝试。表4结果显示,开源方法未达到表2中的基线水平,这促使我们聚焦于更有效的方法。

Figure 3: Influence of the number of question and option agents on various datasets.
图 3: 问题和选项智能体数量对不同数据集的影响。
4.3 Number of agents
4.3 智能体数量
As our MEDAGENTS framework involves multiple agents that play certain roles to acquire the ultimate answer, we explore how the number of collaborating agents influences the overall performance. We vary the number of question and option agents while fixing other variables to observe the performance trends on the MedQAdataset. Figure 3 and Table 5 illustrate the corresponding trend and the optimal number of different agents. Our key observation lies in that the performance improves significantly with the introduction of any number of expert agents compared to our baseline, thus verifying the consistent contribution of multiple expert agents. We find that the optimal number of agents is relatively consistent across different datasets, pointing to its potential applicability to other datasets beyond those we test on.
由于我们的MEDAGENTS框架涉及多个扮演特定角色以获取最终答案的智能体,我们探究了协作智能体数量如何影响整体性能。我们在固定其他变量的情况下,调整问题和选项智能体的数量,观察MedQA数据集上的性能趋势。图3和表5展示了相应趋势及不同智能体的最优数量。关键发现表明:与基线相比,引入任意数量的专家智能体都能显著提升性能,由此验证了多专家智能体的持续贡献。我们发现最优智能体数量在不同数据集间相对一致,这表明该框架可能适用于我们测试范围之外的其他数据集。
4.4 Domain Variation Study
4.4 领域变化研究
In order to investigate the influence of the changes in agent numbers, we perform additional studies where we manipulate agent numbers by selectively eliminating the most and least relevant domain experts based on domain relevance. Due to the manual evaluation involved in identifying the relevance of agent domains, our additional analysis was conducted on a limited set of 20 samples. Results in Table 6 depict minor variance for different sizes of data with random removing, reinforcing the notion that large-scale experiment performance remains largely robust against the effect of domain changes.
为了研究智能体数量变化的影响,我们进行了额外实验:基于领域相关性选择性剔除最相关和最不相关的领域专家来调整智能体数量。由于识别智能体领域相关性涉及人工评估,我们的附加分析仅在20个样本的有限集合上进行。表6结果显示,随机剔除不同规模数据时仅产生微小差异,这进一步证明大规模实验性能对领域变化的鲁棒性。
| Method | MedQA | MedMCQA |
| MEDAGENTS | ||
| w/6differentdomains | 64.1 | 59.3 |
| w/6samedomains | 59.2 | 58.1 |
| w/5samedomains | 57.5 | 57.3 |
| w/4samedomains | 55.9 | 57.0 |
Table 7: Agent quantity study. The results are based on GPT-3.5.
| 方法 | MedQA | MedMCQA |
|---|---|---|
| MEDAGENTS | ||
| w/6不同领域 | 64.1 | 59.3 |
| w/6相同领域 | 59.2 | 58.1 |
| w/5相同领域 | 57.5 | 57.3 |
| w/4相同领域 | 55.9 | 57.0 |
表 7: AI智能体数量研究。结果基于 GPT-3.5。
4.5 Agent Quantity Study
4.5 AI智能体数量研究
To further explore the effect of agent quantity without changes in domain representation, we conduct experiments with $k$ $(k:=:6)$ identicaldomain agents, then with $k-1$ and $k-2$ , to observe performance shifts. The process of selecting these domains is automated via prompting, and our manual inspection confirms the high relevance and quality of the selected domains. The experiment is conducted on a dataset of 300 samples.
为了进一步探究在不改变领域表征的情况下智能体数量的影响,我们进行了以下实验:首先使用 $k$ $(k:=:6)$ 个相同领域的智能体,然后依次减少至 $k-1$ 和 $k-2$ 个,以观察性能变化。领域选择过程通过提示自动完成,经人工检查确认所选领域具有高度相关性和质量。实验在包含300个样本的数据集上进行。
4.6 Error Analysis
4.6 错误分析
Based on our results, we conduct a human evaluation to pinpoint the limitations and issues prevalent in our model. We distill these errors into four major categories: (i) Lack of Domain Knowledge: the model demonstrates an inadequate understanding of the specific medical knowledge necessary to provide an accurate response; (ii) Mis-retrieval of Domain Knowledge: the model has the necessary domain knowledge but fails to retrieve or apply it correctly in the given context; (iii) Consistency Errors: the model provides differing responses to the same statement. The inconsistency suggests confusion in the model’s understanding or application of the underlying knowledge; (iv) CoT Errors: the model may form and follow inaccurate rationales, leading to incorrect conclusions.
根据我们的结果,我们进行了人工评估以确定模型中普遍存在的局限性和问题。我们将这些错误归纳为四大类:(i) 领域知识缺失:模型对提供准确回答所需的特定医学知识理解不足;(ii) 领域知识检索错误:模型具备必要的领域知识,但未能在给定上下文中正确检索或应用;(iii) 一致性错误:模型对相同陈述给出不同回应,这种不一致性表明模型对基础知识的理解或应用存在混淆;(iv) 思维链(CoT)错误:模型可能形成并遵循不准确的推理路径,导致错误结论。
To illustrate the error examples intuitively, we select four typical samples from the four error categories, which can be shown in Figure 5: (i) The first error is due to a lack of domain knowledge regarding cutaneous larva migrans, whose symptoms are not purely hypo pigmented rash, as well as the fact that skin biopsy is not an appropriate test method, which results in the hallucination phenomenon. (ii) The second error is caused by mis-retrieval of domain knowledge, wherein the fact in green is not relevant to Valsalva maneuver. (iii) The third error is attributed to consistency errors, where the model incorrectly regards 20 mmHg within 6 minutes and 20 mmHg within 3 minutes as the same meaning. (iv) The fourth error is provoked by incorrect inference about the relevance of a fact and option A in CoT.
为直观展示错误示例,我们从四类错误中各选取一个典型样本,如图5所示:(i) 第一类错误源于缺乏皮肤幼虫移行症( cutaneous larva migrans )的领域知识,其症状并非单纯色素减退性皮疹,且皮肤活检并非合适的检测方法,导致出现幻觉现象。(ii) 第二类错误由领域知识检索错误引发,绿色标注的事实与Valsalva动作并无关联。(iii) 第三类错误归因于一致性错误,模型错误地将"6分钟内20 mmHg"与"3分钟内20 mmHg"视为相同含义。(iv) 第四类错误由思维链( CoT )中对事实与选项A相关性的错误推断导致。

Figure 4: Ratio of different categories in error cases.
图 4: 错误案例中不同类别的占比。
Furthermore, we analyze the percentage of different categories by randomly selecting 40 error cases in MedQA and MedMCQA datasets. As is shown in Figure 4, the majority $(77%)$ of the error examples are due to confusion about the domain knowledge (including the lack and mis-retrieval of domain knowledge), which illustrates that there still exists a portion of domain knowledge that is explicitly beyond the intrinsic knowledge of LLMs, leading to a bottleneck of our proposed method. As a result, our analysis sheds light on future directions to mitigate the aforementioned drawbacks and further strengthen the model’s proficiency and reliability.
此外,我们通过随机选取MedQA和MedMCQA数据集中的40个错误案例来分析不同类别的占比。如图4所示,绝大多数错误样本(77%)源于领域知识混淆(包括领域知识缺失和检索错误),这表明仍存在部分领域知识明显超出大语言模型的内在知识范畴,从而成为我们提出方法的瓶颈。因此,我们的分析为缓解上述缺陷、进一步提升模型熟练度和可靠性指明了未来研究方向。
4.7 Correctional Capabilities and Interpret ability
4.7 校正能力与可解释性
In our extensive examination of the MEDAGENTS framework, we discover the decent correctional capabilities of our framework. Please refer to Appendix B and Table B for an in-depth overview of instances where our approach successfully amends previous inaccuracies, steering the discussion towards more accurate outcomes. These corrections showcase the MEDAGENTS framework’s strength in collaborative synthesis; it distills and integrates diverse expert opinions into a cohesive and accurate conclusion. By interweaving a variety of perspectives, the collaborative consultation actively refines and rectifies initial analyses, thereby aligning the decision-making process closer to clinical accuracy. This iterative refinement serves as a practical demonstration of our model’s proficiency in rectifying errors, substantiating its interpret ability and accuracy in complex medical reasoning tasks.
在我们对MEDAGENTS框架的广泛测试中,发现该框架具备出色的纠错能力。具体案例请参阅附录B和表B,其中详细展示了我们的方法如何成功修正先前错误,引导讨论得出更准确结论。这些修正案例凸显了MEDAGENTS框架在协同合成方面的优势:它能提炼整合多方专家意见,形成连贯准确的结论。通过交织不同观点,协同会诊机制能持续优化初始分析,使决策过程更贴近临床准确性。这种迭代优化过程实证了该模型在复杂医疗推理任务中纠正错误的能力,验证了其可解释性和准确性。
5 Related Work
5 相关工作
5.1 LLMs in Medical Domains
5.1 医疗领域的大语言模型
Recent years have seen remarkable progress in the application of LLMs (Wu et al., 2023b; Singhal et al., $2023\mathrm{a}$ ; Yang et al., 2023), with a particularly notable impact on the medical field (Bao et al., 2023; Nori et al., 2023; Rosoł et al., 2023). Although LLMs have demonstrated their potential in distinct medical applications encompassing diagnostics (Singhal et al., 2023a; Han et al., 2023), genetics (Duong and Solomon, 2023; Jin et al., 2023), pharmacist (Liu et al., 2023), and medical evidence sum mari z ation (Tang et al., 2023b,a; Shaib et al., 2023), concerns persist when LLMs encounter clinical inquiries that demand intricate medical expertise and decent reasoning abilities (Umapathi et al., 2023; Singhal et al., 2023a). Thus, it is of crucial importance to further arm LLMs with enhanced clinical reasoning capabilities. Currently, there are two major lines of research on LLMs in medical domains, tool-augmented methods and instruction-tuning methods.
近年来,大语言模型(LLM)的应用取得了显著进展(Wu et al., 2023b; Singhal et al., $2023\mathrm{a}$; Yang et al., 2023),尤其在医疗领域产生了重大影响(Bao et al., 2023; Nori et al., 2023; Rosoł et al., 2023)。尽管大语言模型已在诊断(Singhal et al., 2023a; Han et al., 2023)、遗传学(Duong and Solomon, 2023; Jin et al., 2023)、药剂师(Liu et al., 2023)和医学证据总结(Tang et al., 2023b,a; Shaib et al., 2023)等不同医疗应用中展现出潜力,但当面对需要复杂医学专业知识和良好推理能力的临床问题时,仍存在诸多担忧(Umapathi et al., 2023; Singhal et al., 2023a)。因此,进一步提升大语言模型的临床推理能力至关重要。目前医疗领域大语言模型研究主要有两个方向:工具增强方法和指令调优方法。
For tool-augmented approaches, recent studies rely on external tools to acquire additional information for clinical reasoning. For instance, GeneGPT (Jin et al., 2023) guided LLMs to leverage the Web APIs of the National Center for Biotechnology Information (NCBI) to meet various biomedical information needs. Zakka et al. (2023) proposed Almanac, a framework that is augmented with retrieval capabilities for medical guidelines and treatment recommendations. Kang et al. (2023) introduced a method named KARD to improve small LMs on specific domain knowledge by finetuning small LMs on the rationales generated from LLMs and augmenting small LMs with external knowledge from a non-parametric memory.
对于工具增强方法,近期研究依赖外部工具获取临床推理所需的额外信息。例如,GeneGPT (Jin et al., 2023) 引导大语言模型利用美国国家生物技术信息中心(NCBI)的Web API来满足各类生物医学信息需求。Zakka等人(2023)提出了Almanac框架,该框架通过增强医学指南和治疗建议的检索能力实现功能扩展。Kang等人(2023)提出名为KARD的方法,通过在大语言模型生成的原理上微调小型语言模型,并用非参数记忆中的外部知识增强小型语言模型,从而提升特定领域知识的表现。
Current instruction tuning research predominantly leverages external clinical knowledge bases and self-prompted data to obtain instruction datasets (Tu et al., 2023; Zhang et al., $2023\mathrm{a}$ ; Singhal et al., 2023b; Tang et al., 2023c). These datasets are then employed to fine-tune LLMs within the medical field (Singhal et al., 2023b). Some of these models utilize a wide array of datasets collected from medical and biomedical literature, fine-tuned with specialized or openended instruction data (Li et al., 2023a; Singhal et al., 2023b). Others focus on specific areas such as traditional Chinese medicine or largescale, diverse medical instruction data to enhance their medical proficiency (Tan et al., 2023; Zhang et al., 2023b). Unlike these methods, our work emphasizes harnessing latent medical knowledge intrinsic to LLMs and improving reasoning in a training-free setting.
当前指令微调研究主要利用外部临床知识库和自提示数据来获取指令数据集 (Tu et al., 2023; Zhang et al., $2023\mathrm{a}$; Singhal et al., 2023b; Tang et al., 2023c)。这些数据集随后被用于医疗领域内大语言模型的微调 (Singhal et al., 2023b)。其中部分模型采用了从医学和生物医学文献中收集的多样化数据集,并通过专业或开放式指令数据进行微调 (Li et al., 2023a; Singhal et al., 2023b)。另一些研究则专注于特定领域,如中医药或大规模多样化医疗指令数据,以提升其医学专业能力 (Tan et al., 2023; Zhang et al., 2023b)。与这些方法不同,我们的工作重点在于挖掘大语言模型内在的潜在医学知识,并在无需训练的情况下提升推理能力。
Figure 5: Examples of error cases from MedQA and MedMCQA datasets in four major categories including lack of domain knowledge, mis-retrieval of domain knowledge, consistency errors, and CoT errors.
| Category | Example | Interpretation |
| Lack of Domain Knowledge | ...The hypopigmented rashis a classic symptom of cutaneous larva migrans. To confirm the diagnosis, askinbiopsywouldbethemostappropriatetest. | Aboutcutaneouslarvamigrans: 1. symptoms: not simply hypopigmented rash 2.diagnosticmethod: skin biopsy is not preferred |
| Mis-retrievalofDomainKnowledge | ...The physician instructs the patient to stand from a supine position while still wearing the stethoscope. Itisknownasthe"Valsalvamaneuver" During the Valsalvamaneuver,... | Thepatient isasked tomerelystand from a supine position. It does not involve theValsalvamaneuver. |
| Consistency Errors | ...Option Astatesthat thereis a decreaseinsystolic bloodpressureof20mmHgwithin6minutes.Thisis a correct statement,as a drop in systolicblood pressure of at least 20 mmHg within 3minutes of standingupisadiagnosticcriterionforpostural hypotension... | Correctstatement: 20mmHg within 3 minutes Option A: 20mmHgwithin6minutes |
| CoT Errors | Q:Deciduousteethdonotshowfluorosisbecause: ...(A)Placentaactsasabarrier:While it'struethat placentacanactasabarrierforcertainsubstances, this option is not relevant? to the question... | placentacanasabarrierforcertain substancessuchasfluoride,whichis partofthereasonwhydeciduousteeth do not show fluorosis... |
图 5: MedQA和MedMCQA数据集中四类典型错误案例示例,包括领域知识缺失、领域知识检索错误、一致性错误和思维链(CoT)错误。
| 类别 | 示例 | 解释 |
|---|---|---|
| 领域知识缺失 | ...色素减退疹是皮肤幼虫移行症的典型症状。为确诊,皮肤活检是最合适的检测方式。 | 关于皮肤幼虫移行症:1. 症状:并非单纯色素减退疹 2. 诊断方法:皮肤活检并非首选 |
| 领域知识检索错误 | ...医生指示患者在仍佩戴听诊器的情况下从仰卧位起身。这被称为"Valsalva动作"。在Valsalva动作过程中... | 患者仅被要求从仰卧位起身,并不涉及Valsalva动作。 |
| 一致性错误 | ...选项A称6分钟内收缩压下降20mmHg。这是正确陈述,因为站立3分钟内收缩压下降至少20mmHg是体位性低血压的诊断标准... | 正确陈述:3分钟内下降20mmHg 选项A:6分钟内下降20mmHg |
| 思维链(CoT)错误 | 问:乳牙不会出现氟斑牙的原因是:...(A)胎盘作为屏障:虽然胎盘确实能阻挡某些物质,但这个选项与问题无关... | 胎盘能阻挡氟化物等物质,这正是乳牙不会出现氟斑牙的部分原因... |
5.2 LLM-based Multi-agent Collaboration
5.2 基于大语言模型(LLM)的多智能体协作
The development of LLM-based agents has made significant progress in the community by endowing LLMs with the ability to perceive surroundings and make decisions individually (Wang et al., 2023a; Yao et al., 2022; Nakajima, 2023; Xie et al., 2023; Zhou et al., 2023). Beyond the initial single- agent mode, the multi-agent pattern has garnered increasing attention recently (Xi et al., 2023; Li et al., 2023d; Hong et al., 2023) which further explores the potential of LLM-based agents by learning from multi-turn feedback and cooperation. In essence, the key to LLM-based multi-agent collaboration is the simulation of human activities such as role-playing (Wang et al., 2023d; Hong et al., 2023) and communication (Wu et al., 2023a; Qian et al., 2023; Li et al., 2023b,c).
基于大语言模型(LLM)的AI智能体发展在学界取得了显著进展,通过赋予大语言模型感知环境和自主决策的能力(Wang et al., 2023a; Yao et al., 2022; Nakajima, 2023; Xie et al., 2023; Zhou et al., 2023)。除了最初的单智能体模式,多智能体协作模式近期受到越来越多关注(Xi et al., 2023; Li et al., 2023d; Hong et al., 2023),通过多轮反馈与合作进一步探索了大语言模型的潜力。本质上,基于大语言模型的多智能体协作关键在于对人类活动的模拟,例如角色扮演(Wang et al., 2023d; Hong et al., 2023)和沟通交流(Wu et al., 2023a; Qian et al., 2023; Li et al., 2023b,c)。
For instance, Solo Performance Prompting (SPP) (Wang et al., 2023d) managed to combine the strengths of multiple minds to improve performance by dynamically identifying and engaging multiple personas throughout tasksolving. Camel (Li et al., 2023b) leveraged roleplaying to enable chat agents to communicate with each other for task completion.
例如,独奏式提示 (SPP) (Wang et al., 2023d) 通过动态识别和调动多个人格角色来结合多方优势以提升任务解决性能。Camel (Li et al., 2023b) 利用角色扮演使聊天智能体能够相互协作完成任务。
Several recent works attempt to incorporate adversarial collaboration including debates (Du et al., 2023; Xiong et al., 2023) and negotiation (Fu et al., 2023) among multiple agents to further boost performance. Liang et al. (2023) proposed a multi-agent debate framework in which various agents put forward their statements in a tit for tat pattern. Inspired by the multi-disciplinary consultation mechanism which is common and effective in hospitals, we are thus inspired to apply this mechanism to medical reasoning tasks through LLM-based multi-agent collaboration.
近期多项研究尝试通过多智能体间的对抗性协作来进一步提升性能,包括辩论(Du等人, 2023; Xiong等人, 2023)和协商(Fu等人, 2023)。Liang等人(2023)提出了一种多智能体辩论框架,各智能体以针锋相对的模式提出论点。受医院常见且有效的多学科会诊机制启发,我们尝试将这种机制通过基于大语言模型的多智能体协作应用于医学推理任务。
6 Conclusion
6 结论
We present a novel medical QA framework that uses role-playing agents for multi-round discussions, offering greater reliability and clarity without prior training. Our method surpasses zeroshot baselines and matches few-shot baselines across nine datasets. Despite successes, humanbased evaluations of errors have highlighted areas for refinement. Our approach differs from most existing methods by eliminating the dependency on knowledge bases, instead uniquely integrating medical knowledge through role-playing agents.
我们提出了一种新颖的医疗问答框架,该框架利用角色扮演AI智能体进行多轮讨论,无需预先训练即可提供更高的可靠性和清晰度。我们的方法在九个数据集上超越了零样本基线,并与少样本基线表现相当。尽管取得了成功,但基于人工的错误评估仍指出了需要改进的领域。与大多数现有方法不同,我们的方法消除了对知识库的依赖,转而通过角色扮演AI智能体独特地整合医学知识。
Limitation
局限性
The proposed MEDAGENTS framework has shown promising results, but there are still a few points that could be addressed in future studies. First, the parameterized knowledge within LLMs may need updating over time, and thus, continuous efforts are required to keep the framework up-to-date. Second, integrating diverse models at different stages of our framework might be an intriguing exploration. Third, the framework may have limited applicability in low-resource languages. Adapting this framework to a wider range of low-resource languages could meet their specific medical needs to some extent.
提出的MEDAGENTS框架已显示出良好的效果,但仍有一些问题值得在未来研究中探讨。首先,大语言模型(LLM)中的参数化知识可能需要随时间更新,因此需要持续努力以保持框架的时效性。其次,在框架的不同阶段整合多样化模型可能是个值得探索的方向。第三,该框架在低资源语言中的适用性可能有限。将该框架适配到更广泛的低资源语言,或能在一定程度上满足其特定医疗需求。
Ethics Statement
伦理声明
Although our work strictly adheres to wellestablished benchmarks in the field of medical question answering, it is possible that our approach introduces potential risks, e.g., some inherent biases of LLMs, when applying LLM reasoning to critical areas such as medicine.
尽管我们的工作严格遵循了医学问答领域的成熟基准,但在将大语言模型(LLM)推理应用于医学等关键领域时,我们的方法仍可能引入潜在风险,例如大语言模型固有的某些偏见。
Acknowledgments
致谢
Xiangru Tang and Mark Gerstein are supported by Schmidt Sciences. Zhuosheng Zhang is supported by CIPSC-SMP-Zhipu.AI Large Model CrossDisciplinary Fund.
项仁初和Mark Gerstein的研究由Schmidt Sciences资助。张卓盛的研究由CIPSC-SMP-智谱AI大模型交叉学科基金资助。
References
参考文献
Zhijie Bao, Wei Chen, Shengze Xiao, Kuang Ren, Jiaao Wu, Cheng Zhong, Jiajie Peng, Xuanjing Huang, and Zhongyu Wei. 2023. Disc-medllm: Bridging general large language models and realworld medical consultation.
Zhijie Bao、Wei Chen、Shengze Xiao、Kuang Ren、Jiaao Wu、Cheng Zhong、Jiajie Peng、Xuanjing Huang 和 Zhongyu Wei。2023。Disc-medllm:连接通用大语言模型与现实世界医疗咨询。
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. Scibert: A pretrained language model for scientific text. arXiv preprint arXiv:1903.10676.
Iz Beltagy、Kyle Lo 和 Arman Cohan。2019. SciBERT:面向科学文本的预训练语言模型。arXiv预印本 arXiv:1903.10676。
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gers ten berger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Nie wi a dom ski, Piotr Nyczyk, et al. 2023. Graph of thoughts: Solving elaborate problems with large language models. arXiv preprint arXiv:2308.09687.
Maciej Besta、Nils Blach、Ales Kubicek、Robert Gerstenberger、Lukas Gianinazzi、Joanna Gajda、Tomasz Lehmann、Michal Podstawski、Hubert Niewiadomski、Piotr Nyczyk等。2023。思维图谱:用大语言模型解决复杂问题。arXiv预印本arXiv:2308.09687。
Elliot Bolton, Abhinav Venigalla, Michihiro Yasunaga, David Hall, Betty Xiong, Tony Lee, Roxana Daneshjou, Jonathan Frankle, Percy Liang, Michael Carbin, et al. 2024. Biomedlm: A 2.7 b parameter language model trained on biomedical text. arXiv preprint arXiv:2403.18421.
Elliot Bolton、Abhinav Venigalla、Michihiro Yasunaga、David Hall、Betty Xiong、Tony Lee、Roxana Daneshjou、Jonathan Frankle、Percy Liang、Michael Carbin 等. 2024. Biomedlm: 基于生物医学文本训练的27亿参数大语言模型. arXiv预印本 arXiv:2403.18421.
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
Tom B. Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell、Sandhini Agarwal、Ariel Herbert-Voss、Gretchen Krueger、Tom Henighan、Rewon Child、Aditya Ramesh、Daniel M. Ziegler、Jeffrey Wu、Clemens Winter、Christopher Hesse、Mark Chen、Eric Sigler、Mateusz Litwin、Scott Gray、Benjamin Chess、Jack Clark、Christopher Berner、Sam McCandlish、Alec Radford、Ilya Sutskever 和 Dario Amodei。2020。大语言模型是少样本学习者。收录于《神经信息处理系统进展 33:2020 年神经信息处理系统年会论文集》(NeurIPS 2020),2020 年 12 月 6-12 日,线上会议。
Emily Harris. 2023. Large language models answer medical questions accurately, but canaAZt match clinicians a AZ knowledge. JAMA.
Emily Harris. 2023. 大语言模型能准确回答医学问题,但无法匹敌临床医生的知识。JAMA。
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300.
Dan Hendrycks、Collin Burns、Steven Basart、Andy Zou、Mantas Mazeika、Dawn Song 和 Jacob Steinhardt。2020。大规模多任务语言理解能力评测。arXiv预印本 arXiv:2009.03300。
Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, and Chenglin Wu. 2023. Metagpt: Meta programming for multi-agent collaborative framework.
Sirui Hong、Xiawu Zheng、Jonathan Chen、Yuheng Cheng、Jinlin Wang、Ceyao Zhang、Zili Wang、Steven Ka Shing Yau、Zijuan Lin、Liyang Zhou、Chenyu Ran、Lingfeng Xiao 和 Chenglin Wu。2023。MetaGPT:面向多智能体协作框架的元编程。
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
Ziwei Ji、Nayeon Lee、Rita Frieske、Tiezheng Yu、Dan Su、Yan Xu、Etsuko Ishii、Ye Jin Bang、Andrea Madotto 和 Pascale Fung。2023。自然语言生成中的幻觉现象综述。ACM Computing Surveys,55(12):1–38。
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421.
Di Jin、Eileen Pan、Nassim Oufattole、Wei-Hung Weng、Hanyi Fang和Peter Szolovits。2021。该患者患有何种疾病?基于医学考试的大规模开放域问答数据集。应用科学,11(14):6421。
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W Cohen, and Xinghua Lu. 2019. Pubmedqa: A dataset for biomedical research question answering. arXiv preprint arXiv:1909.06146.
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W Cohen 和 Xinghua Lu. 2019. PubmedQA: 一个用于生物医学研究问答的数据集. arXiv预印本 arXiv:1909.06146.
Qiao Jin, Yifan Yang, Qingyu Chen, and Zhiyong Lu. 2023. Genegpt: Augmenting large language models with domain tools for improved access to biomedical information. ArXiv.
乔金、杨一凡、陈清玉和陆志勇。2023。GeneGPT:通过领域工具增强大语言模型以改善生物医学信息获取。ArXiv。
Minki Kang, Seanie Lee, Jinheon Baek, Kenji Kawaguchi, and Sung Ju Hwang. 2023. Knowledgeaugmented reasoning distillation for small language models in knowledge-intensive tasks. arXiv preprint arXiv:2305.18395.
Minki Kang、Seanie Lee、Jinheon Baek、Kenji Kawaguchi 和 Sung Ju Hwang。2023. 知识密集型任务中小语言模型的知识增强推理蒸馏。arXiv预印本 arXiv:2305.18395。
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199– 22213.
Takeshi Kojima、Shixiang Shane Gu、Machel Reid、Yutaka Matsuo 和 Yusuke Iwasawa。2022。大语言模型是零样本推理器 (zero-shot reasoners)。神经信息处理系统进展,35:22199–22213。
Tiffany H Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepaño, Maria Madriaga, Rimel Aggabao, Giezel Diaz- Candido, James Maningo, et al. 2023. Performance of chatgpt on usmle: Potential for ai-assisted medical education using large language models. PLoS digital health, 2(2):e0000198.
Tiffany H Kung、Morgan Cheatham、Arielle Medenilla、Czarina Sillos、Lorie De Leon、Camille Elepaño、Maria Madriaga、Rimel Aggabao、Giezel Diaz-Candido、James Maningo等. 2023. ChatGPT在美国医师执照考试(USMLE)中的表现: 大语言模型在AI辅助医学教育中的潜力. PLoS数字健康, 2(2):e0000198.
Jakub Lála, Odhran O’Donoghue, Aleksandar Sht- edritski, Sam Cox, Samuel G Rodriques, and Andrew D White. 2023. Paperqa: Retrievalaugmented generative agent for scientific research. arXiv preprint arXiv:2312.07559.
Jakub Lála, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G Rodriques, Andrew D White. 2023. PaperQA: 科研检索增强生成智能体. arXiv预印本 arXiv:2312.07559.
Y Nakajima. 2023. Task-driven autonomous agent utilizing gpt-4, pinecone, and langchain for diverse applications. See https://yohei nakajima. com/task-driven-autonomous-agent-utilizing-gpt-4- pinecone-and-langchain-for-diverse-applications (accessed 18 April 2023).
Y Nakajima. 2023. 基于GPT-4、Pinecone和LangChain的任务驱动型自主智能体及其多样化应用。参见https://yohei nakajima. com/task-driven-autonomous-agent-utilizing-gpt-4- pinecone-and-langchain-for-diverse-applications (2023年4月18日访问)。
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. 2023. Capabilities of gpt-4 on medical challenge problems. arXiv preprint arXiv:2303.13375.
Harsha Nori、Nicholas King、Scott Mayer McKinney、Dean Carignan 和 Eric Horvitz。2023. GPT-4在医学挑战问题上的能力。arXiv预印本 arXiv:2303.13375。
OpenAI. 2023. Gpt-4 technical report. ArXiv preprint, abs/2303.08774.
OpenAI. 2023. GPT-4技术报告. ArXiv预印本, abs/2303.08774.
Ankit Pal, Logesh Kumar Umapathi, and Malai kann an Sankara sub bu. 2022. Medmcqa: A large-scale multisubject multi-choice dataset for medical domain question answering. In Conference on Health, Inference, and Learning, pages 248–260. PMLR.
Ankit Pal、Logesh Kumar Umapathi和Malai kann an Sankara sub bu。2022. Medmcqa:一个用于医疗领域问答的大规模多学科选择题数据集。见于Conference on Health, Inference, and Learning,第248–260页。PMLR。
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. In In the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23), UIST ’23, New York, NY, USA. Association for Computing Machinery.
Joon Sung Park、Joseph C. O'Brien、Carrie J. Cai、Meredith Ringel Morris、Percy Liang 和 Michael S. Bernstein。2023. 生成式智能体 (Generative Agents):人类行为的交互式模拟。载于《第36届ACM用户界面软件与技术年会论文集》(UIST '23),UIST '23,美国纽约州纽约市。美国计算机协会。
Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. 2023. Communicative agents for software development. arXiv preprint arXiv:2307.07924.
陈乾、丛鑫、杨程、陈伟泽、苏雨生、徐巨元、刘知远和孙茂松。2023。面向软件开发的可交流智能体。arXiv预印本arXiv:2307.07924。
Maciej Rosol, Jakub S Gasior, Jonasz Laba, Kacper Kor zen i ew ski, and Marcel Mlynczak. 2023. Evaluation of the performance of gpt-3.5 and gpt-4 on the medical final examination. medRxiv, pages 2023–06.
Maciej Rosol、Jakub S Gasior、Jonasz Laba、Kacper Korzeniewski和Marcel Mlynczak。2023。评估GPT-3.5和GPT-4在医学期末考试中的表现。medRxiv,第2023–06页。
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. 2022. Bloom: A 176bparameter open-access multilingual language model. ArXiv preprint, abs/2211.05100.
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, 等. 2022. Bloom: 一个1760亿参数的开源多语言大语言模型. ArXiv 预印本, abs/2211.05100.
Henk G Schmidt and Remy MJP Rikers. 2007. How expertise develops in medicine: knowledge encapsulation and illness script formation. Medical education, 41(12):1133–1139.
Henk G Schmidt 和 Remy MJP Rikers. 2007. 医学专长如何发展: 知识封装与疾病脚本形成. Medical education, 41(12):1133–1139.
Chantal Shaib, Millicent L Li, Sebastian Joseph, Iain J Marshall, Junyi Jessy Li, and Byron C Wallace. 2023. Summarizing, simplifying, and synthesizing medical evidence using gpt-3 (with varying success). arXiv preprint arXiv:2305.06299.
Chantal Shaib、Millicent L Li、Sebastian Joseph、Iain J Marshall、Junyi Jessy Li 和 Byron C Wallace。2023。使用 GPT-3 总结、简化和综合医学证据(效果不一)。arXiv 预印本 arXiv:2305.06299。
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning, pages 31210–31227. PMLR.
Freda Shi、Xinyun Chen、Kanishka Misra、Nathan Scales、David Dohan、Ed H Chi、Nathanael Schärli 和 Denny Zhou。2023。大语言模型 (Large Language Model) 易受无关上下文干扰。见《国际机器学习会议》,第31210–31227页。PMLR。
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Mahdavi, Jason Wei, Hyung Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Sen evi rat ne, Paul Gamble, Chris Kelly, Abubakr Babiker, Nathanael SchÃd’rli, Aakanksha Chowdhery, Philip Mansfield, Dina Demner-Fushman, and Vivek Natarajan. 2023a. Large language models encode clinical knowledge. Nature, 620:1–9.
Karan Singhal、Shekoofeh Azizi、Tao Tu、S. Mahdavi、Jason Wei、Hyung Chung、Nathan Scales、Ajay Tanwani、Heather Cole-Lewis、Stephen Pfohl、Perry Payne、Martin Seneviratne、Paul Gamble、Chris Kelly、Abubakr Babiker、Nathanael Schärli、Aakanksha Chowdhery、Philip Mansfield、Dina Demner-Fushman 和 Vivek Natarajan。2023a。大语言模型 (Large Language Model) 编码临床知识。《自然》杂志,620:1–9。
Logesh Kumar Umapathi, Ankit Pal, and Malai kann an Sankara sub bu. 2023. Med-halt: Medical domain hallucination test for large language models. arXiv preprint arXiv:2307.15343.
Logesh Kumar Umapathi、Ankit Pal 和 Malai kann an Sankara sub bu。2023。Med-halt: 大语言模型的医疗领域幻觉测试。arXiv 预印本 arXiv:2307.15343。
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2023a. A survey on large language model based autonomous agents. arXiv preprint arXiv:2308.11432.
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2023a. 基于大语言模型的自主AI智能体研究综述. arXiv preprint arXiv:2308.11432.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
Xuezhi Wang、Jason Wei、Dale Schuurmans、Quoc Le、Ed Chi、Sharan Narang、Aakanksha Chowdhery 和 Denny Zhou。2022。自洽性提升大语言模型中的思维链推理。arXiv预印本 arXiv:2203.11171。
Yubo Wang, Xueguang Ma, and Wenhu Chen. 2023b. Augmenting black-box llms with medical textbooks for clinical question answering. arXiv preprint arXiv:2309.02233.
Yubo Wang、Xueguang Ma 和 Wenhu Chen。2023b。利用医学教科书增强黑盒大语言模型 (LLM) 的临床问答能力。arXiv预印本 arXiv:2309.02233。
Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wang chun shu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Wenhu Chen, Jie Fu, and Junran Peng. 2023c. Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models. arXiv preprint arXiv: 2310.00746.
Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wang chun shu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Wenhu Chen, Jie Fu, and Junran Peng. 2023c. Rolellm: 大语言模型角色扮演能力的基准测试、激发与增强. arXiv预印本 arXiv: 2310.00746.
Zhen hai long Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. 2023d. Unleashing cognitive synergy in large language models: A task-solving agent through multi-persona selfcollaboration.
甄海龙、王韶光、毛文山、吴涛、葛福瑞、魏和纪。2023d。释放大语言模型中的认知协同效应:通过多角色自协作的任务解决AI智能体。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824– 24837.
Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Fei Xia、Ed Chi、Quoc V Le、Denny Zhou等。2022。思维链提示激发大语言模型中的推理能力。《神经信息处理系统进展》,35:24824–24837。
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023a. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155.
Qingyun Wu、Gagan Bansal、Jieyu Zhang、Yiran Wu、Shaokun Zhang、Erkang Zhu、Beibin Li、Li Jiang、Xiaoyun Zhang 和 Chi Wang。2023a。Autogen: 通过多智能体对话框架实现下一代大语言模型应用。arXiv预印本 arXiv:2308.08155。
Yiquan Wu, Siying Zhou, Yifei Liu, Weiming Lu, Xiaozhong Liu, Yating Zhang, Changlong Sun, Fei Wu, and Kun Kuang. 2023b. Precedent-enhanced legal judgment prediction with llm and domainmodel collaboration.
吴奕泉, 周思颖, 刘一飞, 卢伟明, 刘小中, 张雅婷, 孙长龙, 吴飞, 匡昆. 2023b. 基于大语言模型与领域模型协作的先例增强法律判决预测.
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2023. The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864.
Zhiheng Xi、Wenxiang Chen、Xin Guo、Wei He、Yiwen Ding、Boyang Hong、Ming Zhang、Junzhe Wang、Senjie Jin、Enyu Zhou 等. 2023. 基于大语言模型的智能体崛起与潜力:综述. arXiv预印本 arXiv:2309.07864.
Tianbao Xie, Fan Zhou, Zhoujun Cheng, Peng Shi, Luoxuan Weng, Yitao Liu, Toh Jing Hua, Junning Zhao, Qian Liu, Che Liu, et al. 2023. Openagents:
Openagents:
An open platform for language agents in the wild.
语言智能体的开放平台
A Analysis on the Addition of CoT
关于CoT添加的分析
We provide an intriguing example that reveals a seemingly counter-intuitive observation: the addition of the CoT in a zero-shot setting led to a performance drop compared to the zero-shot one.
我们提供了一个有趣的例子,揭示了一个看似反直觉的现象:在零样本设置中添加思维链(CoT)反而导致性能下降。
As demonstrated in the example, for specialist domains that demand considerable expert knowledge such as the medical domain knowledge, employing a CoT approach might sometimes lead to hallucination (Bubeck et al., 2023; Guerreiro et al., 2023; Ji et al., 2023; Maynez et al., 2020). Hallucinations refer to instances where the language model starts generating inaccurate or irrelevant information based on its insufficient understanding (Wei et al., 2022; Kojima et al., 2022; Shi et al., 2023). Consequently, in these instances, the use of the CoT method does not improve but hindrances the overall performance.
如示例所示,对于需要大量专业知识的领域(如医学领域知识),采用思维链(CoT)方法有时可能导致幻觉(Bubeck et al., 2023; Guerreiro et al., 2023; Ji et al., 2023; Maynez et al., 2020)。幻觉是指语言模型由于理解不足而开始生成不准确或无关信息的情况(Wei et al., 2022; Kojima et al., 2022; Shi et al., 2023)。因此,在这些情况下,使用CoT方法不仅没有提升反而阻碍了整体性能。
This issue is particularly stated in the medical question-answering field by some recent work, where it has been demonstrated that the CoT’s step-by-step approach is unable to generate correct medical answers effectively. For example, the results from Liévin et al. (2022) demonstrate that CoT improvements are significantly limited.
这一问题在医疗问答领域尤为突出,近期研究表明思维链(CoT)的分步推理方法难以有效生成正确的医学答案。例如Liévin等人(2022)的研究结果表明,CoT的性能提升存在显著局限。
Such failures in medical question-answering originate from a lack of domain knowledge (Harris, 2023; Kung et al., 2023; Tian et al., 2024) instead of reasoning rationale. This was also observed in our experiments, with a substantial $77%$ of errors related to domain knowledge, compared to a minor $8%$ due to CoT (as shown in Figure 4).
医疗问答中的此类失败源于领域知识(domain knowledge)的缺失(Harris, 2023; Kung et al., 2023; Tian et al., 2024),而非推理逻辑。我们的实验也观察到了这一现象:高达77%的错误与领域知识相关,而仅有8%的错误源于思维链(CoT)(如图4所示)。
To address these issues, there has indeed been a recent shift toward utilizing RAG (RetrievalAugmented Generation) for domain knowledge enhancement (Wang et al., 2023b; Lála et al., 2023) in medical QA. Despite these developments, our study underscores a novel approach within this field: our use of role-playing. Role-playing in our MEDAGENTS framework allows the model to explicitly reason with accurate knowledge, remarkably bypassing the need for RAG.
为了解决这些问题,近期确实出现了利用检索增强生成 (Retrieval-Augmented Generation, RAG) 来增强医学问答领域知识的趋势 (Wang et al., 2023b; Lála et al., 2023) 。尽管有这些进展,我们的研究强调了该领域的一种新方法:我们采用的角色扮演。在我们的MEDAGENTS框架中,角色扮演使模型能够显式地运用准确知识进行推理,显著绕过了对RAG的需求。
B Interpret ability: Case Study
B 可解释性:案例研究
We analyze instances where our proposed MEDAGENTS framework manages to correct previous errors. Table B illustrates examples of our approach to turning previously incorrect answers into correct ones. These cases showcase the robustness of our MEDAGENTS framework. Different medical professionals offer depth and breadth in the analysis, transforming it into a comprehensive assessment. Furthermore, the collaborative consultation refines and corrects the initial interpretation, leading us toward the correct answer, thus demonstrating the effectiveness of our method in correcting errors and ensuring accuracy.
我们分析了所提出的MEDAGENTS框架成功修正先前错误的案例。表B展示了将错误答案转化为正确答案的示例。这些案例体现了MEDAGENTS框架的稳健性:不同医疗专业人员从深度和广度进行分析,将其转化为全面评估。此外,协作会诊机制能优化并修正初始解读,从而引导出正确答案,证明了该方法在纠错与确保准确性方面的有效性。
Table 9: Case studies demonstrating how our proposed MEDAGENTS framework manages to correct previous errors.
表 9: 展示我们提出的MEDAGENTS框架如何成功修正先前错误的案例研究。
Question: A 23-year-old college student experiences monthly chest discomfort, shortness of breath, shakiness, and excessive sweating, likely due to stress. He fears having an episode in public, causing him to avoid leaving home. His medical history is unclear, and the physical exam is normal. Which of the following is the best medication for the long-term management of this patient’s condition? (A) Citalopram (B) Lithium (C) Lorazepam (D) Propranolol (E) Quetiapine
问题:一名23岁大学生每月出现胸部不适、气短、颤抖和过度出汗症状,可能由压力引起。他害怕在公共场合发作,因此避免外出。病史不详,体检正常。下列哪种药物最适合该患者病情的长期管理?
(A) 西酞普兰
(B) 锂盐
(C) 劳拉西泮
(D) 普萘洛尔
(E) 喹硫平
Experts: Cardiology, Psychiatry, Pulmonology, Endocrinology, Neurology
专家:心脏病学、精神病学、肺病学、内分泌学、神经病学
Analyses from various experts:
多位专家分析:
Cardiology Expert: ...These symptoms are not typical of a cardiac cause given the patient’s young age and normal physical exam...The best medication for long-term management of anxiety disorders is often selective serotonin reuptake inhibitors (SSRIs) like Citalopram.
心脏病学专家:...鉴于患者年龄较轻且体检结果正常,这些症状并非典型的心脏病因所致...长期治疗焦虑障碍的最佳药物通常是选择性血清素再摄取抑制剂(SSRIs),如西酞普兰。
Psychiatry Expert: ...Although quetiapine is commonly used in the treatment of schizophrenia and bipolar disorder, it is also effective in controlling the symptoms of rare endocrine disorders that present with anxiety-like symptoms.
精神病学专家:...虽然喹硫平常用于治疗精神分裂症和双相情感障碍,但它也能有效控制表现为焦虑样症状的罕见内分泌疾病症状。
Pulmonology Expert: ...this treatment based on the possibility that the symptoms could be due to a respiratory condition, such as hyperventilation syndrome, which Propranolol is thought to help by reducing the heart rate and perceived shortness of breath.
呼吸科专家:...这种治疗基于症状可能由呼吸系统疾病(如过度换气综合征)引起,而普萘洛尔被认为通过降低心率和缓解主观呼吸困难感来发挥作用。
Endocrinology Expert: SSRIs like Citalopram can affect endocrine function by regulating serotonin levels, which in turn can modulate the hypothalami c-pituitary-adrenal (HPA) axis...
内分泌学专家:SSRIs(如西酞普兰)可通过调节血清素水平影响内分泌功能,进而调控下丘脑-垂体-肾上腺 (HPA) 轴...
Neurology Expert: the focus would be on addressing the dys regulated ANS activity that is causing the physical symptoms of stress. The most appropriate medication would likely be Citalopram, an SSRI, which can help improve mood and reduce anxiety...
神经学专家:重点在于解决导致压力生理症状的自主神经系统 (ANS) 失调问题。最合适的药物可能是西酞普兰 (Citalopram),这是一种选择性血清素再摄取抑制剂 (SSRI),有助于改善情绪并缓解焦虑...
Expert analysis presents a multifaceted view of the problem. Based on the experts’ specialties, their analyses focus on different aspects, leading to the suggestion of two drugs, Citalopram and Propranolol.
专家分析呈现了该问题的多面性视角。根据专家专长领域不同,其分析聚焦于不同层面,最终提出了两种推荐药物:西酞普兰(Citalopram)和普萘洛尔(Propranolol)。
Synthesized Report (v0): ... Based on the suggestions from the experts, the medication should be Citalopram along with Propranolol, which can help alleviate shortness of breath... The first synthesis suggested a combination of Citalopram and Propranolol.
综合报告(v0): ... 根据专家建议,应使用西酞普兰(Citalopram)联合普萘洛尔(Propranolol)治疗,该方案有助于缓解呼吸急促症状... 首次综合方案建议采用西酞普兰与普萘洛尔的联合用药。
Vote Result: Cardiology Expert: No Psychiatry Expert: Yes Pulmonology Expert: Yes Endocrinology Expert: Yes Neurology Expert: No
投票结果:
心脏病学专家:否
精神病学专家:是
肺病学专家:是
内分泌学专家:是
神经病学专家:否
Synthesized Report (v1): ...the most appropriate medication for the long-term management of this patient’s condition appears to be Citalopram(SSRI). The final report suggested Citalopram as the best medication for the patient’s condition.
合成报告(v1):...对该患者病情长期管理最合适的药物似乎是西酞普兰(SSRI)。最终报告建议将西酞普兰作为该患者病情的最佳用药选择。
Table 10: Case studies demonstrating how our proposed MEDAGENTS framework manages to correct previous errors.
表 10: 案例研究展示我们提出的MEDAGENTS框架如何成功修正先前错误。
Question: Eustachian tube function is best assessed by: (A) Ty mpa nome try (B) VEMP (C) Rhino man ome try (D) Politzer tests
问题:评估咽鼓管功能的最佳方法是:
(A) 鼓室导抗测试 (Tympanometry)
(B) 前庭诱发肌源性电位 (VEMP)
(C) 鼻测压法 (Rhinomanometry)
(D) 波利策试验 (Politzer tests)
Experts: O to la ry ng ology, Audiology, Radiology, Allergy and Immunology, Pulmonology
专家:耳鼻喉科、听力学、放射学、过敏与免疫学、肺病学
Analyses from various experts:
多位专家分析:
O to la ry ng ology Expert: ...The focus is on Eustachian tube function, which is essential for equalizing ear pressure and facilitating normal hearing. Several tests are available, but ty mpa nome try is a primary method for assessing function, indicating if there’s a blockage or proper movement of the eardrum.
耳鼻喉科专家:...重点在于咽鼓管功能,这对平衡耳压和维持正常听力至关重要。现有多种检测方法,但鼓室导抗测试 (tympanometry) 是评估功能的主要手段,可判断是否存在鼓膜阻塞或运动异常。
Audiology Expert: ...Ty mpa nome try is correct, VEMP is not related, Rhino man ome try is unrelated, and the Politzer test is appropriate for Eustachian tube assessment.
听力专家:...鼓室导抗测试 (tympanometry) 正确,前庭诱发肌源性电位 (VEMP) 无关,鼻测压法 (rhinomanometry) 无关,而波利策测试 (Politzer test) 适用于咽鼓管功能评估。
Radiology Expert: ...Proper function of the Eustachian tube is vital for hearing and balance. Ty mpa nome try is one of the methods used to assess this function, by evaluating the compliance of the middle ear.
耳科专家:...咽鼓管的正常功能对听力和平衡至关重要。鼓室导抗测试 (tympanometry) 是评估中耳顺应性以检测该功能的常用方法之一。
Allergy and Immunology Expert: Assessing Eustachian tube function is crucial for diagnosing related dysfunctions and infections. Ty mpa nome try is a valuable test to determine if the tube is functioning correctly.
过敏与免疫学专家:评估咽鼓管功能对诊断相关功能障碍和感染至关重要。鼓室测压法 (tympanometry) 是判断该管道功能是否正常的有效检测手段。
Pulmonology Expert: ...The assessment of the Eustachian tube function is important for diagnosing ear conditions that could affect breathing. Ty mpa nome try helps evaluate eardrum mobility and middle ear pressure
肺科专家:...评估咽鼓管功能对诊断可能影响呼吸的耳部疾病至关重要。鼓室测压法有助于评估鼓膜活动性和中耳压力
Based on the experts’ specialties, their analyses focus on different aspects, leading to the suggestion of two methods, Ty mpa nome try and Politzer test.
根据专家的专业领域,他们的分析侧重于不同方面,因此提出了两种方法:鼓室测压法(Tympanometry)和Politzer测试。
Vote Result: O to la ry ng ology Expert: Yes Audiology Expert: Yes Radiology Expert: Yes Allergy and Immunology Expert: Yes Pulmonology Expert: Initially No, then Yes after revision.
投票结果:
耳鼻喉科专家:同意
听力学专家:同意
放射科专家:同意
过敏与免疫学专家:同意
肺科专家:最初反对,修改后同意。
Synthesized Report (v1): ...Ty mpa nome try is a key method among several to assess Eustachian tube function, crucial for diagnosing Eustachian tube dysfunction, infections, and hearing issues.... The final report suggested Ty mpa nome try as the best medication for the patient’s condition.
合成报告(v1):...鼓室测压法 (tympanometry) 是评估咽鼓管功能的关键方法之一,对诊断咽鼓管功能障碍、感染和听力问题至关重要...最终报告建议将鼓室测压法作为该患者病情的最佳治疗方案。
Table 11: Case studies demonstrating how our proposed MEDAGENTS framework manages to correct previous errors.
表 11: 案例研究展示我们提出的 MEDAGENTS 框架如何成功修正先前错误。
Question: To prevent desiccation and injury, the embryos of terrestrial vertebrates are encased within a fluid secreted by the? (A) amnion (B) chorion (C) allantois (D) yolk sac
问题:为防止脱水和受伤,陆生脊椎动物的胚胎被包裹在由哪个结构分泌的液体中? (A) 羊膜 (B) 绒毛膜 (C) 尿囊 (D) 卵黄囊
Experts: Embryology, Physiology, Dermatology, Endocrinology, Reproductive Medicine
专家:胚胎学、生理学、皮肤病学、内分泌学、生殖医学
Analyses from various experts:
多位专家分析:
Embryology Expert: ... amnion is the primary structure responsible for secreting amniotic fluid, with the chorion also contributing to this process.
胚胎学专家:...羊膜是负责分泌羊水的主要结构,绒毛膜也参与这一过程。
Physiology Expert: ...the amniotic sac and amniotic fluid, produced by the amnion, is important in creating a stable and protected environment for the embryo. Besides, its cushioning effect and role in the exchange of nutrients and gases cannot be ignored either.
生理学专家:...由羊膜产生的羊膜囊和羊水,对于为胚胎创造一个稳定且受保护的环境至关重要。此外,其缓冲作用以及在营养物质和气体交换中的角色也不容忽视。
Dermatology Expert: ...the importance of amniotic fluid in fetal development, particularly for the skin...
皮肤病学专家:...羊水在胎儿发育中的重要性,尤其是对皮肤的影响...
Endocrinology Expert: the question relates to embryological development rather than an n do cri no logical condition, ... the amniotic sac plays a vital role in providing a protective environment.
内分泌学专家:该问题涉及胚胎发育而非内分泌状况……羊膜囊在提供保护性环境中起着至关重要的作用。
Reproductive Medicine Expert: ...amniotic fluid is of crucial importance for the normal development and survival of the embryo.
生殖医学专家:...羊水对胚胎的正常发育和存活至关重要。
Based on the experts’ specialties, their analyses focus on different aspects, leading to the suggestion of two methods, amnion and chorion.
根据专家的专业领域,他们的分析聚焦于不同方面,由此提出了羊膜和绒毛膜两种方法。
Synthesized Report (v0): ... Both the amnion and chorion play vital roles in this process. The first synthesis suggested amnion and chorion.
合成报告 (v0): ... 羊膜和绒毛膜在此过程中都起着至关重要的作用。首次合成建议了羊膜和绒毛膜。
Vote Result: Embryology Expert: Yes Physiology Expert: Yes Dermatology Expert: No Endocrinology Expert: No Reproductive Medicine Expert: Yes
投票结果:
胚胎学专家:是
生理学专家:是
皮肤病学专家:否
内分泌学专家:否
生殖医学专家:是
Synthesized Report (v1): ... the amnion as the primary source of the amniotic fluid that protects the developing embryos of terrestrial vertebrates, with an understanding of the contributions from other structures like the chorion and the allantois.
合成报告(v1):...羊膜作为保护陆生脊椎动物发育中胚胎的羊水主要来源,同时明确了绒毛膜和尿囊等其他结构的贡献。
Dermatology and Endocrinology experts have revised their initial focus to align with the consensus on the role of the amnion in secreting amniotic fluid.
皮肤病学和内分泌学专家已修订最初的研究重点,以符合关于羊膜在羊水分泌中作用的共识。
C Dataset Information
C 数据集信息
MedQA consists of USMLE-style questions with four or five possible answers. MedMCQA encompasses four-option multiple-choice questions from Indian medical entrance examinations (AIIMS/NEET). MMLU (Massive Multitask Language Understanding) covers 57 subjects across various disciplines, including STEM, humanities, social sciences, and many others. The scope of its assessment stretches from elementary to advanced professional levels, evaluating both world knowledge and problem-solving capabilities. While the subject areas tested are diverse, encompassing traditional fields like mathematics and history, as well as more specialized areas like law and ethics, we deliberately limit our selection to the sub-subjects within the medical domain for this exercise, following (Singhal et al., 2023a).
MedQA包含美国医师执照考试(USMLE)风格试题,每题提供四至五个备选答案。MedMCQA收录印度医学入学考试(AIIMS/NEET)的四选项选择题。MMLU(大规模多任务语言理解)涵盖57个学科领域,包括STEM、人文社科等众多方向,其评估范围从基础到专业高级水平,既测试世界知识也检验问题解决能力。虽然该测试涉及数学、历史等传统学科及法律伦理等专业领域,但本研究遵循(Singhal et al., 2023a)的方法,特意将选题范围限定在医学领域的子学科。
D Prompt Templates
D Prompt Templates
Prompt templates involved in the experiments are presented in Table 12.
实验中所用的提示模板如表 12 所示。
$\Gamma_ {\sf q d}$ : You are a medical expert who specializes in categorizing a specific medical scenario into specific areas of medicine.
$\Gamma_ {\sf q d}$ : 你是一位医学专家,擅长将特定医疗场景分类到具体的医学领域。
prompt : You need to complete the following steps: 1. Carefully read the medical scenario presented in the question: question. 2. Based on the medical scenario in it, classify the question into five different subfields of medicine. 3. You should output in the same format as: Medical Field: | .
提示 : 你需要完成以下步骤: 1. 仔细阅读题目中提供的医疗场景: question. 2. 根据其中的医疗场景, 将问题归类到医学的五个不同子领域. 3. 你应当以相同格式输出: 医学领域: | .
$\Gamma_ {0\mathrm{d}}\colon$ As a medical expert, you possess the ability to discern the two most relevant fields of expertise needed to address a multiple-choice question encapsulating a specific medical context.
Γ0d: 作为医学专家,您具备识别处理特定医学情境多选题所需两个最相关专业领域的能力。
prompt : You need to complete the following steps: 1. 1. Carefully read the medical scenario presented in the question: question. 2. The available options are: options. Strive to understand the fundamental connections between the question and the options. 3. Your core aim should be to categorize the options into two distinct subfields of medicine. You should output in the same format as: Medical Field: | .
提示 : 你需要完成以下步骤: 1. 仔细阅读题目中提供的医疗场景: question。2. 可用选项为: options。努力理解题目与选项之间的本质关联。3. 你的核心目标是将选项归类到医学的两个不同子领域。输出格式应与以下保持一致: 医学领域: | 。
$\boldsymbol{\mathsf{r}}_ {\mathsf{q}\mathsf{a}}$ : You are a medical expert in the domain of question domain. From your area of specialization, you will scrutinize and diagnose the symptoms presented by patients in specific medical scenarios. prompt $\mathbf{q}a$ : Please meticulously examine the medical scenario outlined in this question: question. Drawing upon your medical expertise, interpret the condition being depicted. Subsequently, identify and highlight the aspects of the issue that you find most alarming or noteworthy.
$\boldsymbol{\mathsf{r}}_ {\mathsf{q}\mathsf{a}}$: 你是一位特定医学领域的专家。请基于你的专业领域,对患者在该医疗场景中表现出的症状进行细致检查和诊断。
prompt $\mathbf{q}a$: 请仔细审阅题目中描述的医疗场景: question。运用你的医学专业知识,解析所呈现的病症状况。随后,指出并强调你认为最值得关注或最具警示性的问题要点。
$\Gamma_ {0a}$ : You are a medical expert specialized in the op_ domain domain. You are adept at comprehending the nexus between questions and choices in multiple-choice exams and determining their validity. Your task, in particular, is to analyze individual options with your expert medical knowledge and evaluate their relevancy and correctness.
$\Gamma_ {0a}$ : 您是一位专注于手术(op_ domain)领域的医学专家,擅长理解多选题中问题与选项之间的关联性并判断其有效性。您的核心任务是运用专业医学知识分析每个选项,评估其相关性和正确性。
prompt $\mathtt{o a}$ : Regarding the question: question, we procured the analysis of five experts from diverse domains. The evaluation from the question domain expert suggests: question analysis. The following are the options available: options. Reviewing the question’s analysis from the expert team, you’re required to fathom the connection between the options and the question from the perspective of your respective domain and scrutinize each option individually to assess whether it is plausible or should be eliminated based on reason and logic. Pay close attention to discerning the disparities among the different options and rationalize their existence. A handful of these options might seem right at first glance but could potentially be misleading in reality.
提示 $\mathtt{o a}$ : 关于问题: question, 我们汇集了来自不同领域的五位专家分析。该问题领域专家的评估表明: question analysis。以下是可选项: options。根据专家团队对问题的分析, 您需要从自身领域角度理解各选项与问题之间的关联, 并逐一审查每个选项, 基于理性和逻辑判断其合理性或应被排除。请特别注意辨别不同选项间的差异, 并合理解释这些差异存在的原因。部分选项可能初看正确, 但实际上具有误导性。
$\boldsymbol{\mathsf{r}}_ {\mathsf{r}\mathsf{s}}$ : You are a medical assistant who excels at summarizing and synthesizing based on multiple experts from various domain experts.
$\boldsymbol{\mathsf{r}}_ {\mathsf{r}\mathsf{s}}$ : 你是一名擅长综合多位跨领域专家观点进行总结归纳的医疗助理。
prompt $\scriptstyle\mathsf{r s}$ : Here are some reports from different medical domain experts. You need to complete the following steps: 1. Take careful and comprehensive consideration of the following reports. 2. Extract key knowledge from the following reports. 3. Derive the comprehensive and summarized analysis based on the knowledge. 4. Your ultimate goal is to derive a refined and synthesized report based on the following reports. You should output in exactly the same format as: Key Knowledge:; Total Analysis:
提示 $\scriptstyle\mathsf{r s}$ : 以下是来自不同医学领域专家的报告。你需要完成以下步骤:
- 仔细全面地考虑以下报告。
- 从以下报告中提取关键知识。
- 基于这些知识推导出全面且总结性的分析。
- 你的最终目标是根据以下报告推导出一份精炼且综合的报告。
你应当严格按照以下格式输出:
关键知识:
综合分析:
rvote: You are a medical expert specialized in the domain domain.
rvote: 您是专精于该领域的医学专家。
promptvote: Here is a medical report: synthesized report. As a medical expert specialized in domain, please carefully read the report and decide whether your opinions are consistent with this report. Please respond only with: [YES or NO].
promptvote: 这是一份医疗报告: 综合报告。作为领域专业医疗专家,请仔细阅读该报告并判断您的意见是否与此报告一致。请仅回复: [YES 或 NO]。
promptmod: Here is advice from a medical expert specialized in domain: advice. Based on the above advice, output the revised analysis in the same format as: Key Knowledge:; Total Analysis:
提示模式:以下是一位专注于该领域的医学专家给出的建议:建议。根据上述建议,以相同格式输出修订后的分析:关键知识点:;全面分析:
prompt ${\bf d m}$ : Here is a synthesized report: syn_ report. Based on the above report, select the optimal choice to answer the question. Points to note: 1. The analyses provided should guide you towards the correct response. 2. Any option containing incorrect information inherently cannot be the correct choice. 3. Please respond only with the selected option’s letter, like A, B, C, D, or E, using the following format: ”’Option: [Selected Option’s Letter]”’. Remember, it’s the letter we need, not the full content of the option.
提示 ${\bf d m}$ : 以下是一份综合分析报告: syn_ report。根据上述报告,选择最优选项回答问题。注意事项: 1. 提供的分析应引导你得出正确答案。2. 任何包含错误信息的选项本质上都不可能是正确选择。3. 请仅回复所选选项的字母(如A、B、C、D或E),使用以下格式: """选项: [所选选项字母]"""。请记住,我们需要的是字母,而非选项的完整内容。
E Multiple Runs
E 多次运行
we have performed multiple runs on a set of 300 samples for GPT-4 and GPT-3.5 to account for variability.
我们对 GPT-4 和 GPT-3.5 进行了多轮测试,样本量为 300 组,以评估结果的变异性。
The preliminary tests involved the average score of 5 repetitions for each sample, and the results indicated a decent small variance between runs. In summary, the consistency observed in this set provides confidence in the stability of our reported results.
初步测试对每个样本进行了5次重复实验的平均得分,结果表明各次运行之间存在较小的方差差异。总体而言,该组数据表现出的稳定性使我们确信所报告结果具有可靠性。
Table 13: GPT-4 versus GPT-3.5 based on multiple runs of 300 samples.
| MedQA | MedMCQA | |
| MC framework GPT-3.5 (single try) | 64.1 | 59.3 |
| MC framework GPT-3.5 (5 repetitions) | 64.3 | 59.2 |
| MC framework GPT-4 (single try) | 83.7 | 74.8 |
| MC framework GPT-4 (5 repetitions) | 83.5 | 74.9 |
表 13: 基于300个样本多次运行的GPT-4与GPT-3.5对比
| MedQA | MedMCQA | |
|---|---|---|
| MC框架GPT-3.5(单次尝试) | 64.1 | 59.3 |
| MC框架GPT-3.5(5次重复) | 64.3 | 59.2 |
| MC框架GPT-4(单次尝试) | 83.7 | 74.8 |
| MC框架GPT-4(5次重复) | 83.5 | 74.9 |