A Systematic Evaluation of GPT-4V’s Multimodal Capability for Medical Image Analysis
对GPT-4V医学影像分析多模态能力的系统评估
Yunyi Liua,∗, Yingshu Lia,∗, Zhanyu Wang $^{\mathrm{a,d,* }}$ , Xinyu Liange, Lei Wangb, Lingqiao Liuc, Leyang $\mathrm{{Cui^{d}}}$ , Zhaopeng $\mathrm{Tu}^{\mathrm{d}}$ , Longyue Wangd,∗∗, Luping Zhoua,∗∗
Yunyi Liua,∗, Yingshu Lia,∗, Zhanyu Wang $^{\mathrm{a,d,* }}$, Xinyu Liange, Lei Wangb, Lingqiao Liuc, Leyang $\mathrm{{Cui^{d}}}$, Zhaopeng $\mathrm{Tu}^{\mathrm{d}}$, Longyue Wangd,∗∗, Luping Zhoua,∗∗
a Electrical and Computer Engineering, The University of Sydney, NSW, 2006, Australia bSchool of Computing and Information Technology, The University of Wollongong, NSW, 2522, Australia cSchool of Computer and Mathematical Sciences, The University of Adelaide, Adelaide, 5005, Australia dTencent AI Lab, Tencent, Shenzhen, 518000, China eFirst Clinical Medical College, Guangzhou University of Chinese Medicine, Guangzhou, 510405, China
a 电气与计算机工程学院,悉尼大学,新南威尔士州,2006,澳大利亚
b 计算与信息技术学院,伍伦贡大学,新南威尔士州,2522,澳大利亚
c 计算机与数学科学学院,阿德莱德大学,阿德莱德,5005,澳大利亚
d 腾讯 AI Lab,腾讯,深圳,518000,中国
e 第一临床医学院,广州中医药大学,广州,510405,中国
A R T I C L E I N F O
文章信息
A B S T R A C T
摘要
This work conducts an evaluation of GPT-4V’s multimodal capability for medical image analysis, with a focus on three representative tasks of radiology report generation, medical visual question answering, and medical visual grounding. For the evaluation, a set of prompts is designed for each task to induce the corresponding capability of GPT4V to produce sufficiently good outputs. Three evaluation ways including quantitative analysis, human evaluation, and case study are employed to achieve an in-depth and extensive evaluation. Our evaluation shows that GPT-4V excels in understanding medical images and is able to generate high-quality radiology reports and effectively answer questions about medical images. Meanwhile, it is found that its performance for medical visual grounding needs to be substantially improved. In addition, we observe the discrepancy between the evaluation outcome from quantitative analysis and that from human evaluation. This discrepancy suggests the limitations of conventional metrics in assessing the performance of large language models like GPT-4V and the necessity of developing new metrics for automatic quantitative analysis.
本研究对GPT-4V在医学图像分析中的多模态能力进行了评估,重点关注放射学报告生成、医学视觉问答和医学视觉定位三项代表性任务。针对每项任务,我们设计了一套提示词(prompt)来激发GPT-4V生成优质输出的能力。通过定量分析、人工评估和案例研究三种评估方式,实现了深入全面的性能评测。评估结果表明,GPT-4V在理解医学图像方面表现优异,能够生成高质量的放射学报告,并能有效回答关于医学图像的问题。同时发现其在医学视觉定位任务上的性能有待显著提升。此外,我们观察到定量分析与人工评估结果之间存在差异,这表明传统评估指标在评估GPT-4V等大语言模型性能时存在局限性,开发新的自动定量分析指标十分必要。
2024 Elsevier B. V. All rights reserved.
2024 Elsevier B.V. 保留所有权利。
. Introduction
引言
Large language models (LLMs) have recently demonstrated remarkable ability across various domains and tasks (Touvron et al., 2023; OpenAI, 2023; Anil et al., 2023). The ongoing pur- suit of enhancing LLMs’ capability for visual comprehension has further spurred the emergence of large multimodal models (LMMs) (Ye et al., 2023; Li et al., 2023b; Awadalla et al., 2023). Among them, GPT-4V incorporates visual understanding capability by learning from an extensive corpus of multimodal data and demonstrates great potential on multimodal data comprehension. It is a state-of-the-art model known for its proficiency in image analysis and text generation. To have a precise understanding of GPT-4V’s potential, research has been newly conducted to investigate its capability for generic images (Wu et al., 2023b). For example, Yang et al. (2023b) conducted a case study to assess GPT-4V’s performance in general-purpose scenarios, revealing its robust visual comprehension ability.
大语言模型(LLM)近期在各个领域和任务中展现出卓越能力(Touvron et al., 2023; OpenAI, 2023; Anil et al., 2023)。为持续提升大语言模型的视觉理解能力,研究者们进一步推动了大型多模态模型(LMM)的发展(Ye et al., 2023; Li et al., 2023b; Awadalla et al., 2023)。其中,GPT-4V通过从海量多模态数据中学习获得了视觉理解能力,在多模态数据理解方面展现出巨大潜力。作为当前最先进的模型,GPT-4V以出色的图像分析和文本生成能力著称。为准确理解GPT-4V的潜力,最新研究探索了其对通用图像的处理能力(Wu et al., 2023b)。例如,Yang等人(2023b)通过案例研究评估了GPT-4V在通用场景下的表现,揭示了其强大的视觉理解能力。
LLMs could have enormous applications to medicine and healthcare (Wang et al., 2023b; Singhal et al., 2023). The avail- ability of vision module in GPT-4V opens up an opportunity for an in-depth examination of its potential in this regard. Some papers have started examining its performance on medical images (Wu et al., 2023a). However, they are primarily based on case studies.
大语言模型在医疗健康领域具有巨大应用潜力 (Wang et al., 2023b; Singhal et al., 2023)。GPT-4V视觉模块的出现为深入探索其医疗应用提供了契机。目前已有研究开始评估其在医学影像分析中的表现 (Wu et al., 2023a),但这些研究主要基于个案分析。
In this work, we move beyond case studies and delve deeper into the capability of GPT-4V for multimodal tasks in medical image analysis. Our evaluations focus on three representative tasks in this regard, including radiology report generation, medical visual question answering, and medical visual grounding. This enables us to assess GPT-4V’s ability in understanding and interacting between visual and textual modalities from various perspectives. Our evaluation takes a multifaceted approach consisting of quantitative analysis, human evaluations, and case studies. Quantitative analysis calculates conventional performance-related metrics and compares GPT-4V with other relevant models by following the protocols in the literature. Human evaluation is used to obtain a more precise assessment of the quality of text output of GPT-4V in the tasks of radiology report generation and medical visual question answering. This is particularly meaningful when considering that conventional metrics are not able to provide a direct and whole assessment. Case study is utilised to facilitate an intuitive understanding and assessment of the output. Altogether, the three evaluation methods offer an extensive view of the performance of GPT-4V.
在本研究中,我们超越个案分析,深入探索GPT-4V在医学影像分析多模态任务中的能力。评估聚焦于三个代表性任务:放射学报告生成、医学视觉问答及医学视觉定位,从而多维度评估GPT-4V对视觉与文本模态的理解与交互能力。我们采用包含定量分析、人工评估和案例研究的多层面评估方法:定量分析通过文献标准协议计算传统性能指标并与其他相关模型对比;人工评估针对放射学报告生成和医学视觉问答任务,对GPT-4V文本输出质量进行更精准评定(尤其在传统指标无法提供直接全面评估时具有特殊意义);案例研究则通过直观输出展示辅助理解。三种方法共同构建了对GPT-4V性能的全面考察体系。
Various prompt settings are explored in the evaluation of GPT-4V. Zero-shot prompts and few-shot prompts are tested for the task of radiology report generation based on whether a set of example reference reports is provided. For medical visual question answering, several examples are provided as prompts to guide GPT-4V to respond in a way that better aligns with the form of ground truth. For medical visual grounding, the prompt is mainly used to inform GPT-4V of the specific requirement of the output, particularly on creating the bounding boxes for visual grounding. Evaluation with the above prompt settings allows the capability of GPT-4V to be properly activated and its performance concerning prompt to be assessed.
在GPT-4V的评估中探索了多种提示设置。根据是否提供一组示例参考报告,测试了零样本提示和少样本提示用于放射学报告生成任务。对于医学视觉问答任务,提供了几个示例作为提示,以引导GPT-4V以更符合真实答案形式的方式作出回应。对于医学视觉定位任务,提示主要用于告知GPT-4V输出的具体要求,特别是在创建视觉定位的边界框方面。通过上述提示设置的评估,可以正确激活GPT-4V的能力,并评估其在不同提示下的表现。
The results of our evaluations are summarised as follows.
我们的评估结果总结如下。
• GPT-4V demonstrates promising performance in generating radiology reports for medical images. Assessed by either language fluency related metrics or clinical efficacy related ones, its performance is competitive with that of the models specially developed for this task. In addition, compared with the conventional metrics used in quantitative analysis, the human evaluation suggests an even higher level of accuracy, relevancy, and richness of the radiology reports generated by GPT-4V.
• GPT-4V 在生成医学影像的放射学报告方面展现出优异性能。无论是基于语言流畅性相关指标还是临床有效性相关指标的评估,其表现均可与专为此任务开发的模型相媲美。此外,与定量分析中使用的传统指标相比,人工评估表明 GPT-4V 生成的放射学报告在准确性、相关性和丰富性方面更具优势。
• GPT-4V shows its ability in generating detailed answers for the task of medical visual question answering. Meanwhile, when compared with the relevant state-of-the-art methods, it only achieves modest performance when assessed by the conventional metrics. This is attributed to the low correlation between questions and the generated answers, the great diversity of the answers generated by GPT-4V, and the fixed format of the ground-truth answers in the benchmark dataset. Meanwhile, human evaluation suggests that GPT-4V’s answers are more accurate than what is indicated by the conventional metrics.
• GPT-4V在医学视觉问答任务中展现出生成详细答案的能力。然而,与相关的最先进方法相比,当使用传统指标评估时,其表现仅为中等水平。这归因于问题与生成答案之间的低相关性、GPT-4V生成答案的极大多样性,以及基准数据集中标准答案的固定格式。与此同时,人工评估表明,GPT-4V的答案比传统指标所显示的更为准确。
• The result of the medical visual grounding task highlights a significant room for improvement. GPT-4V struggles with accurately locating and identifying specific elements within medical images. This is consistent with the weakness revealed by existing evaluation on the tasks related to generic images. This finding points out a potential direction to further enhance GPT-4V’s performance.
• 医疗视觉定位任务的结果凸显出显著的改进空间。GPT-4V在精确定位和识别医学图像中的特定元素方面存在困难,这与现有评估中揭示的通用图像相关任务弱点一致。该发现为进一步提升GPT-4V性能指明了潜在方向。
• In addition to utilising conventional metrics, our evaluation also involves professional medical practitioners conducting human evaluation, adding a layer of expert review to our assessment. Their discrepancy reveals the limitations of conventional performance-related metrics in accurately assessing the performance of GPT-4V, highlighting the urgency of developing more proper ways of evaluation for LLMs.
• 除了采用传统指标外,我们的评估还邀请专业医疗从业者进行人工评估,为评测增添了专家审查维度。两者间的差异揭示了传统性能指标在准确评估GPT-4V时的局限性,凸显了为大语言模型开发更合适评估方法的紧迫性。
The remainder of the paper is organized as follows. Section 2 is the related work for GPT-4V. Section 3 introduces our Evaluation, which contains evaluation tasks, evaluation method, evaluation datasets and evaluation results. Section 4 describes our summary and discussion. We conclude the paper and discuss the limitation in Section 5.
本文的剩余部分结构如下。第2节是关于GPT-4V的相关工作。第3节介绍我们的评估,包括评估任务、评估方法、评估数据集和评估结果。第4节描述了我们的总结与讨论。我们在第5节总结全文并讨论局限性。
2. GPT-4V (OpenAI, 2023)
2. GPT-4V (OpenAI, 2023)
GPT-4V, or GPT-4 with Vision, stands as an advanced multimodal system developed by OpenAI, integrating image inputs into LLMs. This groundbreaking fusion represents a notable frontier in AI research, enabling innovative interfaces and the solution of new tasks for unique user experiences. The system is built upon the GPT-4 model and has been trained on an extensive dataset comprising text and image data from the internet and licensed sources. GPT-4V showcases what can and cannot be done with text and image processing, highlighting new strengths that come from combining these two types of data. This includes advanced intelligence and the ability to reason across a broad range of topics.
GPT-4V(或称 GPT-4 with Vision)是 OpenAI 开发的先进多模态系统,它将图像输入集成到大语言模型中。这一突破性融合代表了 AI 研究的重要前沿,能够实现创新界面并解决新任务,为用户带来独特体验。该系统基于 GPT-4 模型,并接受了来自互联网和授权来源的广泛文本与图像数据训练。GPT-4V 展示了文本与图像处理的可行与不可行之处,突显了结合这两种数据类型所带来的新优势,包括高级智能和跨广泛主题的推理能力。
Several recent publications have explored the multimodal capacities of GPT-4V. Early evaluations, as presented in (Wu et al., 2023b), offered insights into GPT-4V’s abilities and limitations. (Li et al., 2023d) focused on Visual Question Answering (VQA) tasks, while (Shi et al., 2023) explored GPT-4V’s Optical Character Recognition (OCR) capabilities. Some research works, like (Wu et al., 2023a), specifically investigated medical image tasks, albeit with a more case-study-oriented approach lacking in-depth exploration. In contrast, our paper aims to provide a deeper study of GPT-4V’s multimodal capabilities in medical imaging contexts.
近期多篇论文探索了GPT-4V的多模态能力。Wu等人(2023b)的早期评估初步揭示了GPT-4V的优势与局限。Li等人(2023d)专注于视觉问答(VQA)任务,Shi等人(2023)则研究了GPT-4V的光学字符识别(OCR)能力。部分研究如Wu等人(2023a)虽涉及医学影像任务,但采用案例研究导向的方法,缺乏深入探索。相较之下,本文旨在对GPT-4V在医学影像领域的多模态能力进行更深入研究。
3. Evaluation
3. 评估
The upcoming paragraphs provide a detailed introduction to four key components of our evaluation process.
接下来的段落将详细介绍我们评估流程中的四个关键组成部分。
Evaluation Tasks describes the specific tasks that we set up for the evaluation.
评估任务描述了我们为评估设置的特定任务。
Evaluation Method outlines how we design the prompts and describes the methodology used to assess the models. This includes the criteria for evaluation, the metrics such as accuracy, precision, recall, F1 score, BLEU, CIDEr, ROUGE, METEOR, accuracy, and mIoU, and any specific protocols or procedures that we followed during the evaluation process.
评估方法概述了我们如何设计提示词 (prompt) ,并描述了用于评估模型的方法。这包括评估标准、各项指标 (如准确率、精确率、召回率、F1分数、BLEU、CIDEr、ROUGE、METEOR、准确率和mIoU) ,以及评估过程中遵循的具体协议或流程。
Evaluation Datasets provides details about the datasets involved in the evaluation. Important aspects like the source, the sizes, and the characteristics of the datasets, as well as their relevance to the evaluation tasks, are discussed.
评估数据集提供了关于评估中所涉及数据集的详细信息。讨论了诸如数据来源、规模、特征及其与评估任务相关性的重要方面。
Evaluation Results presents the results of the evaluation. It includes a summary of the findings, comparisons with benchmarks or previous models (if applicable), and insights or interpretations of the results. It is partitioned into three parts: the quantitative, human evaluation, and case study results.
评估结果
本节展示评估结果,包括研究发现总结、与基准或先前模型的对比(如适用)以及对结果的见解与解读。内容分为三部分:定量评估结果、人工评估结果和案例分析结果。
3.1. Evaluation Tasks
3.1. 评估任务
In the following, we introduce the three evaluation tasks shown in Figure 1, including radiology report generation (R2Gen), medical Visual Question Answering (VQA), and medical visual grounding (VG).
以下介绍图1中的三项评估任务,包括放射学报告生成(R2Gen)、医学视觉问答(VQA)和医学视觉定位(VG)。
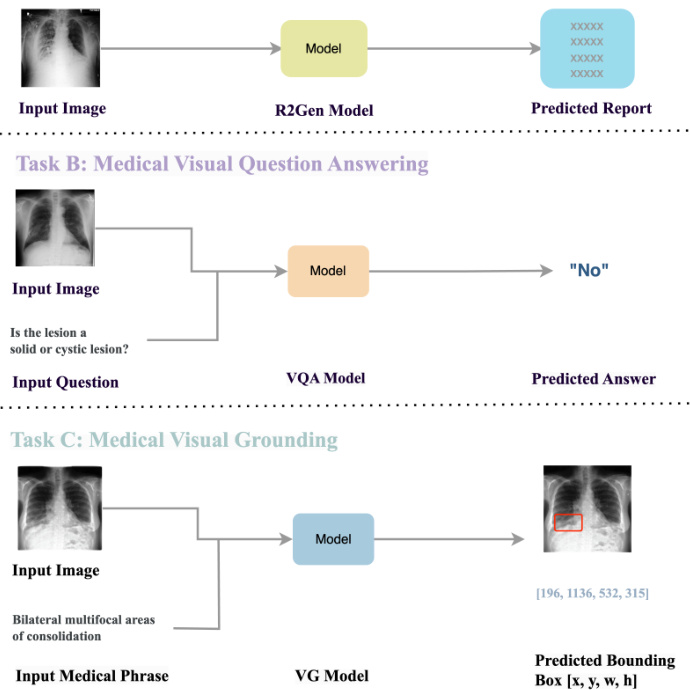
Fig. 1. Three multimodal medical imaging tasks we employ to evaluate GPT-4V’s performance.
图 1: 我们用于评估 GPT-4V 性能的三种多模态医学成像任务。
3.1.1. Radiology Report Generation
3.1.1. 放射学报告生成
Radiology report generation (R2Gen) is a very important application of medical images, akin to the task of image captioning (Vinyals et al., 2015; Xu et al., 2015; Pan et al., 2020). R2Gen poses unique challenges, given the inherent complexity of medical reports, their length, and the difficulty in discerning fine-grained abnormalities from medical images, particularly in datasets biased towards normal samples (referred to as data bias problem). Current research can be grouped into two primary research directions. The first direction concentrates on enhancing the model’s architecture to facilitate improved extraction of visual features and the generation of high-quality medical reports. For example, Li et al. (2018) used a hierarchical architecture to generate reports with normality and abnormality respectively. Building on the Transformer’s success (Vaswani et al., 2017), Chen et al. (2020) introduced a Transformerbased model, enhancing it with relational memory and memorydriven conditional layer normalization to enhance image feature representation and capture crucial report patterns (Chen et al., 2020). The second research direction addresses the data bias problem by incorporating external knowledge information. For example, some works constructed predefined medical knowledge graphs to augment the model’s ability to capture valuable clinical information (Zhang et al., 2020; Liu et al., 2021a; Li et al., 2023c; Huang et al., 2023b). Furthermore, very recently, there has been a surge in radiology report generation methods leveraging Large Language Models (LLMs). These approaches harness the capabilities of LLM to generate long-text content and utilise abundant knowledge sources to enhance the quality of radiology reports. For example, Wang et al. (2023b) employed LLaMA2 (Touvron et al., 2023) to elevate the quality of the generated reports, ensuring effective image-text alignment through a visual mapper.
放射学报告生成(R2Gen)是医学影像的重要应用领域,类似于图像描述生成任务(Vinyals等人, 2015; Xu等人, 2015; Pan等人, 2020)。由于医学报告固有的复杂性、文本长度以及从医学图像中识别细粒度异常的困难性,特别是在偏向正常样本的数据集(称为数据偏差问题)中,R2Gen提出了独特挑战。当前研究可分为两个主要方向:第一个方向聚焦于改进模型架构以增强视觉特征提取和高质量报告生成能力。例如Li等人(2018)采用分层架构分别生成正常和异常报告;基于Transformer(Vaswani等人, 2017)的成功,Chen等人(2020)提出基于Transformer的模型,通过关系记忆和记忆驱动的条件层归一化来增强图像特征表示并捕获关键报告模式(Chen等人, 2020)。第二个研究方向通过引入外部知识信息来解决数据偏差问题。例如部分工作构建了预定义医学知识图谱来增强模型捕获有价值临床信息的能力(Zhang等人, 2020; Liu等人, 2021a; Li等人, 2023c; Huang等人, 2023b)。最近,利用大语言模型(LLM)的放射学报告生成方法呈现爆发式增长,这些方法借助LLM生成长文本内容的能力,并利用丰富知识源提升报告质量。例如Wang等人(2023b)采用LLaMA2(Touvron等人, 2023)提升生成报告质量,通过视觉映射器确保有效的图文对齐。
3.1.2. Visual Question Answering
3.1.2. 视觉问答
The Visual Question Answering (VQA) task (Jiang et al., 2020; Wu et al., 2019) involves processing the input image-question pairs to generate appropriate answers. Currently, there are two predominant approaches for implementing VQA tasks: classification-based (Nguyen et al., 2019; Finn et al., 2017; Eslami et al., 2021), and generation-based (Ambati and Dudyala, 2018; Khare et al., 2021). By nature, VQA should be based on generation. The ongoing shift from a classification-centric paradigm to a generation-oriented approach represents a prevailing trend in the VQA field. Based on the characteristics of the VQA task, a proficient text generation model is essential. Consequently, the current surge in LLMs presents a significant opportunity for substantial improvements in the VQA task. Numerous endeavors incorporating LLMs into VQA tasks are already underway, whether for generating VQA datasets (Pellegrini et al., 2023) or utilising LLMs to enhance the performance of VQA systems (Li et al., 2023a). The evident improvements that LLMs bring to VQA lead us to believe that they are wellsuited for this task. Consequently, evaluating the VQA task is a crucial aspect of GPT-4V’s evaluation.
视觉问答 (Visual Question Answering, VQA) 任务 (Jiang et al., 2020; Wu et al., 2019) 需要处理输入的图像-问题对以生成合适的答案。当前实现VQA任务主要有两种方法:基于分类的方法 (Nguyen et al., 2019; Finn et al., 2017; Eslami et al., 2021) 和基于生成的方法 (Ambati and Dudyala, 2018; Khare et al., 2021)。从本质上看,VQA应当基于生成范式。当前该领域正经历从分类为主导向生成导向的范式转变,这代表了VQA领域的主流趋势。鉴于VQA任务特性,一个强大的文本生成模型至关重要。因此,当前大语言模型的蓬勃发展,为VQA任务的显著提升提供了重要机遇。目前已有多项研究将大语言模型融入VQA任务,无论是用于生成VQA数据集 (Pellegrini et al., 2023),还是利用大语言模型提升VQA系统性能 (Li et al., 2023a)。大语言模型为VQA带来的显著改进使我们确信其非常适合该任务。因此,评估VQA任务是GPT-4V评测的关键环节。
3.1.3. Visual Grounding
3.1.3. 视觉定位
In the visual grounding (VG) (Kamath et al., 2021) task, the input typically comprises a medical image accompanied by a descriptive statement about the image, often pertaining a specific medical sign or symptom. The task’s output is the coordinates of a bounding box that visually marks the area described in the statement, such as encapsulating a particular medical sign. Most visual grounding research focuses on general images, with only a few studies targeting medical images, likely due to the scarcity of corresponding medical datasets. However, the recently introduced MS-CXR dataset has opened up new possibilities in medical visual grounding, leading to emerging publications (Huang et al., 2023a; Sun et al., 2023a,b) based on this dataset. Despite growing recognition, there remains untapped potential, presenting a significant opportunity for future research in medical visual grounding. Unlike the previous two tasks, the output for visual grounding is not a conventional text paragraph but a set of coordinates. Recent studies have successfully integrated LLMs (Peng et al., 2023; Zhao et al., 2023) to directly produce these coordinates as outputs, showing promising results. Recognizing this potential, we hypothesize that GPT-4V should also possess visual grounding capabilities. Consequently, we include this task in our evaluations to assess GPT-4V’s performance in this specific area.
在视觉定位 (VG) (Kamath et al., 2021) 任务中,输入通常包含一张医学图像及其描述性语句,该语句往往涉及特定医学体征或症状。任务的输出是一个边界框的坐标,用于视觉标记语句中描述的区域(例如包含某个特定医学体征)。大多数视觉定位研究集中于通用图像,针对医学图像的研究较少,这可能是由于相应医学数据集的稀缺所致。然而,近期发布的MS-CXR数据集为医学视觉定位开辟了新可能,并催生了一系列基于该数据集的研究成果 (Huang et al., 2023a; Sun et al., 2023a,b)。尽管关注度逐渐提升,该领域仍存在未开发的潜力,为未来医学视觉定位研究提供了重要机遇。与前两项任务不同,视觉定位的输出并非传统文本段落,而是一组坐标。近期研究已成功整合大语言模型 (Peng et al., 2023; Zhao et al., 2023) 直接生成这些坐标,并展现出良好效果。基于此潜力认知,我们假设GPT-4V也应具备视觉定位能力,因此将此项任务纳入评估以检验GPT-4V在该特定领域的表现。
3.2. Evaluation Method/Process
3.2. 评估方法/流程
3.2.1. Radiology Report Generation
3.2.1. 放射学报告生成
To better activate the capabilities of GPT-4V, we explore various prompt design strategies, including the zero-shot and few-shot approaches.
为了更好地激活 GPT-4V 的能力,我们探索了多种提示设计策略,包括零样本 (zero-shot) 和少样本 (few-shot) 方法。
Zero-shot Prompt: In zero-shot scenario, we provide a prompt without reference reports, allowing GPT-4V to autonomously generate reports without external guidance.
零样本提示 (Zero-shot Prompt):在零样本场景下,我们提供不含参考报告的提示,使GPT-4V能在无外部引导的情况下自主生成报告。
GPT-4V is tasked with generating both the “impression” and “findings” sections and compared with the ground truth report. Few-shot Prompts: In-context few-shot learning represents a crucial methodology for enhancing the capabilities of LLMs (Tsim po uk ell i et al., 2021; Wei et al., 2022a; Dai et al., 2022). It enables the model to acquire the expected output format by providing a set of examples. In contrast to fine-tuning, this method empowers the model to generate desired results without any parameter updating at inference time. In our inve stig ation, we experiment with a few prompt strategies designed for GPT-4V. Specifically, we explore diverse compositions within the few-shot prompts:
GPT-4V的任务是生成"印象"和"发现"两个部分,并与真实报告进行对比。少样本提示:上下文少样本学习是提升大语言模型能力的关键方法 (Tsimpo uk ell i et al., 2021; Wei et al., 2022a; Dai et al., 2022)。通过提供一组示例,使模型能够学习预期的输出格式。与微调不同,这种方法使模型无需在推理时更新任何参数即可生成所需结果。在我们的研究中,我们尝试了几种专为GPT-4V设计的提示策略。具体而言,我们探索了少样本提示中的不同组合:

Fig. 2. R2Gen Prompt Examples. Three types of prompt settings are tested, including one zero-shot prompt and three few-shot prompts.
图 2: R2Gen提示词示例。测试了三种提示设置,包括一个零样本提示和三个少样本提示。
Our evaluation reveals that the inclusion of both normal and abnormal example reports consistently results in higher-quality report generation. More discussions about this finding are provided in our case study. Also, details regarding our selected example reports are given in Appendix A.1.2. Subsequently, we employ the few-shot mixed-example prompt to evaluate GPT-4V on the MIMIC-CXR benchmark (Johnson et al., 2019). Our primary focus lies on the zero-shot and few-shot scenarios, deliberately avoiding complex techniques such as chain-of-thought (Wei et al., 2022b) or ensembling strategies (Wang et al., 2022a) to manage the complexity of our efforts.
我们的评估表明,同时包含正常和异常示例报告能持续生成更高质量的报告。关于这一发现的更多讨论详见案例研究部分。所选示例报告的详细信息见附录A.1.2。随后,我们采用少样本混合示例提示词在MIMIC-CXR基准测试 (Johnson et al., 2019) 上评估GPT-4V。研究主要聚焦零样本和少样本场景,为避免研究复杂度上升,我们刻意避开了思维链 (Wei et al., 2022b) 或集成策略 (Wang et al., 2022a) 等复杂技术。
Evaluation Metrics: In our evaluation of the generated reports, we calculate a range of metrics including BLEU, ROUGE, METEOR, and CIDEr. These metrics, widely recognized in the field of natural language processing (NLP), offer diverse perspectives on the quality of the generated text. BLEU measures the similarity of the generated text to a set of reference texts, focusing on the precision of word choices. ROUGE assesses the recall aspect, evaluating how much of the reference content is captured in the generated text. METEOR considers both precision and recall, accounting for synonymy and paraphrasing. CIDEr, originally developed for image captioning, evaluates the similarity of the generated text to multiple reference texts, emphasizing the consensus among them. Following the computation of these scores, we conduct human evaluations to ascertain the consistency between these computational assessments and human judgment. The human evaluation involves reviewers analysing the quality of the generated reports in terms of relevance, accuracy, coherence, and overall appropriateness. This combined approach of using both NLP metrics and human judgment is crucial for a more accurate evaluation. While metrics like BLEU, ROUGE, METEOR, and CIDEr offer quantitative insights into specific aspects of text quality, human evaluation provides a qualitative assessment, capturing subtleties and nuances that NLP metrics may overlook. By comparing the results from both evaluation methods, we validate the effectiveness of the generated reports from multiple perspectives, ensuring a comprehensive and reliable assessment of their quality. This process helps in determining whether the generated reports are not only linguistically correct but also con textually and semantically appropriate, aligning with human understanding and expectations.
评估指标:在生成报告的评估中,我们计算了包括BLEU、ROUGE、METEOR和CIDEr在内的一系列指标。这些自然语言处理(NLP)领域广泛认可的指标,从不同角度衡量生成文本的质量。BLEU通过对比生成文本与参考文本的词汇选择精确度来衡量相似性;ROUGE评估召回率,检验生成文本对参考内容的覆盖程度;METEOR兼顾精确率与召回率,同时考虑同义词和句式变换;CIDEr最初为图像描述任务设计,通过对比生成文本与多组参考文本的共识度来评估质量。计算这些分数后,我们进一步开展人工评估,以验证计算指标与人类判断的一致性。人工评估由评审员从相关性、准确性、连贯性和整体适配度四个维度分析报告质量。这种结合NLP指标与人工评估的双轨方法至关重要——BLEU等指标为文本质量提供定量分析,而人工评估能捕捉NLP指标可能忽略的语义细微差别。通过对比两种评估结果,我们从多维度验证生成报告的有效性,确保质量评估的全面性与可靠性。该流程不仅能验证报告的语言正确性,更能确保其上下文适配度和语义合理性符合人类的认知预期。
3.2.2. Medical Visual Question Answering
3.2.2. 医学视觉问答
For medical VQA, we employ the “few-shot prompt” strategy to address a significant limitation associated with the existing VQA datasets, namely the limited range of their predetermined answer set. To enhance the alignment of the answers generated by GPT-4V with the dataset, our strategy involves introducing GPT-4V to the concept of categorizing VQA questions based on the expected answer types. This approach enables the model to differentiate between close-end questions typically requiring short and concise answers (e.g., “yes” or “no”), and open-end questions demanding more detailed responses. By training GPT-4V with this categorization approach, we enhance GPT-4V’s ability to adapt the length of its responses appropriately. For close-end questions, it learns to provide brief answers, while for open-end ones, it comprehends the need for more elaborate responses. This nuanced response mechanism significantly improves the relevance and accuracy of GPT-4V’s answers, thereby increasing the effectiveness of our evaluations.
针对医疗VQA任务,我们采用"少样本提示"策略以解决现有VQA数据集的关键缺陷——预设答案范围的局限性。为提升GPT-4V生成答案与数据集的匹配度,我们通过向GPT-4V引入基于预期答案类型的VQA问题分类概念:使模型能区分需要简短回答(如"是/否")的封闭式问题与需要详细解答的开放式问题。通过这种分类训练,GPT-4V学会了根据问题类型调整回答长度——对封闭式问题输出简洁回应,对开放式问题生成详尽解答。这种精细化响应机制显著提升了GPT-4V答案的相关性与准确性,从而增强了评估有效性。
VQA Prompt: Our VQA prompt follows the template in Figure 3. We provide seven examples to guide the model in generating responses consistent with the dataset’s format. Without these examples, GPT-4V tends to produce more un constrained answer text, complicating the task of comparing the predicted answers with the ground truth.
VQA提示:我们的VQA提示遵循图3中的模板。我们提供了七个示例来引导模型生成与数据集格式一致的响应。若缺少这些示例,GPT-4V倾向于生成更不受约束的答案文本,这会增加预测答案与真实答案的比对难度。

Evaluation Metrics: To analyse GPT-4V’s performance in medical VQA, we employ different evaluation metrics for close-end and open-questions, respectively. For close-end questions, we calculate the model’s prediction accuracy and compare its performance with that of the state-of-the-art (SOTA) VQA methods which are mainly classification-based approaches. This comparison is crucial to understanding how GPT-4V ranks in the current landscape of VQA technologies, especially those tailored for medical applications. For open-end questions, we calculate BLEU scores (specifically, BLEU-4), a widely used metric in NLP to assess the quality of machinegenerated text. This choice is based on the nature of openend questions which typically require more detailed and varied responses than close-end questions. Unlike close-end questions with straightforward single-word answers, open-end questions permit a range of possible correct answers, each potentially phrased differently. After calculating the BLEU scores for open-end questions, we proceed to human evaluation to assess the consistency between the BLEU scores and human judgment. This step is crucial for a more effective evaluation of the accuracy of the generated answers. Human evaluation involves a trained radiologist reviewing and rating the quality of the model-generated answers. This method is particularly valuable as BLEU scores, while offering a quantitative measure of text similarity, might not fully capture the nuances of meaning, relevance, and context that human evaluators can discern. By comparing the outcomes of the BLEU score analysis with human assessments, we gain a more holistic understanding of the GPT-4V’s performance. This dual approach of combining BLEU scores with human evaluation allows us to cross-verify the effectiveness of the model’s answers.
评估指标:
为分析GPT-4V在医疗视觉问答(VQA)中的表现,我们分别针对封闭式问题和开放式问题采用不同评估指标。对于封闭式问题,计算模型预测准确率,并将其与当前基于分类的主流VQA方法(SOTA)进行对比。这一对比对理解GPT-4V在医疗专用VQA技术领域的定位至关重要。
对于开放式问题,我们计算BLEU分数(具体为BLEU-4)——这是自然语言处理(NLP)中广泛使用的机器生成文本质量评估指标。该选择基于开放式问题通常需要比封闭式问题更详细、更多样化回答的特性。与仅需单词答案的封闭式问题不同,开放式问题允许存在多种表述正确的答案。
完成BLEU分数计算后,我们进一步通过人工评估检验BLEU分数与人类判断的一致性。这一步骤对有效评估生成答案的准确性至关重要。人工评估由专业放射科医生对模型生成答案进行质量评分。该方法具有特殊价值,因为BLEU分数虽能量化文本相似性,但可能无法完全捕捉人类评估者所能识别的语义细微差别、相关性和上下文关联。
通过对比BLEU分数分析与人工评估结果,我们能更全面理解GPT-4V的表现。这种结合BLEU分数与人工评估的双重方法,实现了对模型答案有效性的交叉验证。
3.2.3. Medical Visual Grounding:
3.2.3. 医学视觉定位:
For the Medical Visual Grounding (VG) task, we employ a straightforward prompt without incorporating examples. We opt for this approach to prevent potential restrictions on GPT4V’s response to only those scenarios covered in the examples, thus preserving its ability to generalize. Our goal is to avoid steering the model towards producing results solely based on the provided examples. In our prompt design, we focus solely on informing GPT-4V about the required output format, i.e., the coordinates of the bounding box. This approach guides the model in understanding our specific requirements, particularly in generating bounding boxes for visual grounding tasks.
对于医学视觉定位(VG)任务,我们采用了不包含示例的简洁提示策略。选择这种方法是为了避免GPT4V的响应被限制在示例覆盖的场景内,从而保持其泛化能力。我们的目标是防止模型仅根据提供的示例生成结果。在提示设计中,我们仅向GPT-4V说明所需的输出格式(即边界框坐标)。这种方法能引导模型理解我们的特定需求,特别是在视觉定位任务中生成边界框的要求。
Visual Grounding Prompt: We design a specific type of prompt that significantly improves the model’s understanding and its ability to accurately generate bounding boxes. The prompt is illustrated in Figure 4.
视觉定位提示 (Visual Grounding Prompt):我们设计了一种特殊类型的提示,可显著提升模型的理解能力及生成精确边界框的能力。该提示如图 4 所示。
VG Prompt
VG提示词

Fig. 4. VG Prompt Example. The content between double braces is replaced with specific image width, height, and description text related to the image.
图 4: VG提示示例。双大括号之间的内容会被替换为与图像相关的具体宽度、高度及描述文本。
Evaluation Metrics: We evaluate by calculating the mean Intersection over Union (mIoU) across all samples in the benchmark dataset. The mIoU metric is a standard measure used in the field to assess the accuracy of object localization and segmentation in images. By computing the mIoU, we could gauge how precisely the GPT-4V identifies and outlines relevant areas in the images compared to the ground truth. After calculating the mIoU, we conduct a comparative analysis with the SOTA VG methods. This comparison allows us to benchmark GPT4V’s performance against the currently leading methods in the field. By comparing the mIoU results of GPT-4V with those of the SOTA methods, we could gain a clear understanding of the strengths and weaknesses of GPT-4V in the context of the broader research landscape.
评估指标:我们通过计算基准数据集中所有样本的平均交并比 (mIoU) 进行评估。mIoU 是该领域用于评估图像中物体定位和分割准确性的标准指标。通过计算 mIoU,我们可以衡量 GPT-4V 与真实标注相比在图像中识别和勾勒相关区域的精确程度。在计算 mIoU 后,我们与当前最先进的视觉定位 (SOTA VG) 方法进行了对比分析。这一比较使我们能够将 GPT-4V 的性能与该领域的领先方法进行基准测试。通过对比 GPT-4V 与 SOTA 方法的 mIoU 结果,我们可以清晰地了解 GPT-4V 在更广泛研究背景下的优势与不足。
3.3. Evaluation Datasets
3.3. 评估数据集
Radiology Report Generation Dataset: MIMIC-CXR (Johnson et al., 2019), the largest publicly available dataset in this domain, includes both chest radio graphs and unstructured textual reports. This dataset comprises a total of 377,110 chest X-ray images and 227,835 corresponding reports, obtained from 64,588 patients who underwent examinations at the Beth Israel Deaconess Medical Center between 2011 and 2016. To facilitate fair and consistent comparisons, we follow the official partitioning provided by MIMIC-CXR, resulting in a test set containing 3,858 samples. For human evaluation, 100 report pairs comprising both the ground truth and their corresponding reports generated by GPT-4V are randomly selected from the MIMIC-CXR dataset and rated by a trained radiologist.
放射学报告生成数据集:MIMIC-CXR (Johnson等人,2019) 是该领域最大的公开可用数据集,包含胸部X光片和非结构化文本报告。该数据集共包含377,110张胸部X光图像和227,835份对应报告,数据来自2011至2016年间在Beth Israel Deaconess医学中心接受检查的64,588名患者。为确保公平一致的比较,我们遵循MIMIC-CXR官方划分方案,最终测试集包含3,858个样本。为进行人工评估,我们从MIMIC-CXR数据集中随机选取100组报告对(包含真实报告和GPT-4V生成的对应报告),由专业放射科医师进行评分。
VQA Dataset: VQA-RAD (Lau et al., 2018) is one of the most widely utilised radiology datasets. It comprises 315 images along with 3515 question-answer pairs, ensuring that each image corresponds to at least one question-answer pair. The questions encompass 11 distinct categories, including “anomalies”, “properties”, “color”, “number”, “morphology”, “organ type”, “other”, and “section”. A noteworthy $58%$ of these questions are designed as close-end queries, while the remainder takes the form of open-end inquiries. These images predominantly feature the head, chest, and abdomen regions of the human body. The dataset is officially partitioned into a training subset of 3064 question-answer pairs and a test subset of 451 question-answer pairs for evaluation. For human evaluation, 100 open-end question-answer pairs are randomly selected from the VQA-RAD dataset and marked by a trained radiologist.
VQA数据集:VQA-RAD (Lau et al., 2018) 是最广泛使用的放射学数据集之一。它包含315张图像及3515个问答对,确保每张图像至少对应一个问答对。问题涵盖11个不同类别,包括"异常"、"属性"、"颜色"、"数量"、"形态"、"器官类型"、"其他"和"切面"。值得注意的是,其中58%的问题设计为封闭式查询,其余则为开放式问题。这些图像主要呈现人体的头部、胸部和腹部区域。该数据集官方划分为包含3064个问答对的训练子集和451个问答对的测试子集用于评估。为进行人工评估,从VQA-RAD数据集中随机选取100个开放式问答对,并由专业放射科医师进行标注。
Visual Grounding Dataset: MS-CXR (Boecking et al., 2022) dataset is a valuable resource for biomedical vision-language processing, featuring 1162 image-sentence pairs with bounding boxes and corresponding phrases. It was meticulously annotated by board-certified radiologists, covering eight cardiopulmonary radiological findings, each having an approximately equal number of pairs. This dataset offers both reviewed and edited bounding boxes/phrases and manually created bounding box labels from scratch. What sets MS-CXR apart is its focus on complex semantic modeling and real-world language under standing, challenging models with joint image-text reasoning and tasks like parsing domain-specific location references, complex negations, and variations in reporting style. It serves as a benchmark for phrase grounding and has been instrumental in demonstrating the effectiveness of principled textual semantic modeling for enhancing self-supervised vision-language processing.
视觉定位数据集:MS-CXR (Boecking et al., 2022) 数据集是生物医学视觉语言处理的重要资源,包含1162个带边界框和对应短语的图文对。该数据集由委员会认证的放射科医师精心标注,涵盖八种心肺放射学发现,每种发现的样本数量大致相等。数据集同时提供经过审核编辑的边界框/短语,以及完全手工标注的边界框标签。MS-CXR的独特价值在于其专注于复杂语义建模和真实语言理解,通过联合图文推理任务挑战模型能力,包括解析特定领域的位置指代、复杂否定句以及报告风格的变体。该数据集已成为短语定位的基准测试工具,并有效证明了基于原则的文本语义建模对增强自监督视觉语言处理的促进作用。
3.4. Evaluation Result
3.4. 评估结果
3.4.1. Quantitative Results
3.4.1. 定量结果
Radiology Report Generation
放射学报告生成
Comparison with SOTA Methods: Table 2 presents a performance comparison between the GPT-4V model and SOTA methods using the MIMIC-CXR dataset (Johnson et al., 2019). The comparison methods encompass standard image captioning techniques, including Show-Tell (Vinyals et al., 2015), Att2in (Xu et al., 2015), AdaAtt (Lu et al., 2017), Trans- former (Vaswani et al., 2017), and M 2 Transformer (Cornia et al., 2020). Additionally, we compare with the radiology report generation methods, specifically R2Gen (Chen et al., 2020), R2GenCMN Chen et al. (2021), MSAT (Wang et al., 2022b), and ME Transformer (Wang et al., 2023a). As aforementioned, we employ few-shot mixed-example prompts to help GPT-4V generate medical reports. From Table 2, it is clear that radiology report generation models such as METransformer, MSAT, and R2Gen exhibit top-tier performance. Nevertheless, GPT-4V’s capability to generate medical reports is impressive, considering it is designed as a general-purpose model. Leveraging the advantages of an extensive dataset for pre training, GPT-4V performs well in several metrics, including BLEU (Papineni et al., 2002), ROUGE (Lin, 2004), and METEOR (Banerjee and Lavie, 2005). However, when compared to models specifically trained on MIMIC-CXR, GPT-4V exhibits a performance gap, particularly evident in CIDEr (Vedantam et al., 2015). This discrepancy arises because the CIDEr metric differently scores words based on their occurrence frequencies, potentially affecting GPT-4V’s performance when it fails to generate certain MIMIC-CXR-specific words, yielding relatively lower scores. Our evaluation reveals that GPT-4V possesses the capacity to generate information not present in the ground truth but visually evident in the image. This phenomenon contributes to GPT-4V’s relatively lower performance on metrics such as BLEU which primarily assesses word-match rates. One example is shown in Figure 5.
与SOTA方法的对比:表2展示了GPT-4V模型与SOTA方法在MIMIC-CXR数据集(Johnson et al., 2019)上的性能对比。对比方法涵盖标准图像描述技术,包括Show-Tell(Vinyals et al., 2015)、Att2in(Xu et al., 2015)、AdaAtt(Lu et al., 2017)、Transformer(Vaswani et al., 2017)和M2 Transformer(Cornia et al., 2020)。此外,我们还与放射学报告生成方法进行了比较,特别是R2Gen(Chen et al., 2020)、R2GenCMN Chen et al. (2021)、MSAT(Wang et al., 2022b)和ME Transformer(Wang et al., 2023a)。如前所述,我们采用少样本混合示例提示来帮助GPT-4V生成医学报告。从表2可以明显看出,METransformer、MSAT和R2Gen等放射学报告生成模型表现出顶级性能。然而,考虑到GPT-4V是作为通用模型设计的,其生成医学报告的能力令人印象深刻。利用大规模预训练数据集的优势,GPT-4V在BLEU(Papineni et al., 2002)、ROUGE(Lin, 2004)和METEOR(Banerjee and Lavie, 2005)等多个指标上表现良好。但与专门在MIMIC-CXR上训练的模型相比,GPT-4V存在性能差距,这在CIDEr(Vedantam et al., 2015)指标上尤为明显。这种差异源于CIDEr根据词频对单词进行差异化评分,当GPT-4V未能生成某些MIMIC-CXR特有词汇时可能导致得分偏低。我们的评估表明,GPT-4V能够生成真实标注中不存在但图像中可见的信息。这一现象导致GPT-4V在BLEU等主要评估词汇匹配率的指标上表现相对较低。如图5所示的一个例子。

Fig. 5. An illustration of GPT-4V’s capability in generating medical reports using our designed few-shot mixed-example prompt. The ground truth does not mention a medical device but one is visibly present in the image, marked by red arrows. GPT-4V demonstrates the ability to recognize and describe the medical device in the generated report.
图 5: 采用我们设计的少样本混合示例提示时,GPT-4V生成医疗报告的能力展示。真实情况未提及医疗设备,但图像中明显存在一个医疗设备(用红色箭头标出)。GPT-4V在生成的报告中展现出识别并描述该医疗设备的能力。
Clinical Efficacy on MIMIC-CXR Dataset: We assess the clinical efficacy of the GPT-4V model on the MIMIC-CXR dataset, which achieves a precision of 0.353, recall of 0.365, and F1 score of 0.330 in Table 2. Numerically, these results are not too bad compared to the two high-performing models ME Transformer (Wang et al., 2023a) and R2GenGPT (Wang et al., 2023b). GPT-4V demonstrates competitive clinical efficacy. Notably, the gap between GPT-4V and other models in terms of clinical efficacy is relatively smaller than that observed in traditional NLP metrics which primarily measure lexical overlap with ground truth reports. This suggests that, objectively, GPT-4V exhibits an impressive capability in radiology report generation, emphasizing its potential clinical accuracy and practicality.
MIMIC-CXR数据集上的临床效果评估:我们在MIMIC-CXR数据集上评估GPT-4V模型的临床效果,如表2所示,其精确率达到0.353,召回率为0.365,F1得分为0.330。与两个高性能模型ME Transformer (Wang et al., 2023a) 和R2GenGPT (Wang et al., 2023b) 相比,这些数值结果并不逊色。GPT-4V展现出具有竞争力的临床效能。值得注意的是,GPT-4V与其他模型在临床效果上的差距,比传统自然语言处理(NLP)指标(主要衡量与真实报告的词汇重叠度)中观察到的差距要小。这表明,客观而言,GPT-4V在放射学报告生成方面表现出令人印象深刻的能力,突显了其潜在的临床准确性和实用性。
Medical Visual Question Answering
医学视觉问答
Table 3 shows a performance comparison between the GPT4V model and SOTA VQA methods using the VQA-RAD dataset. The compared methods include StAn (He et al., 2020), BiAn (He et al., 2020), MAML (Finn et al., 2017),
表 3: GPT4V模型与SOTA VQA方法在VQA-RAD数据集上的性能对比。对比方法包括StAn (He et al., 2020)、BiAn (He et al., 2020)、MAML (Finn et al., 2017)。
Table 1. Comparison on the MIMIC-CXR dataset.
| Methods | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE | METEOR | CIDEr |
| Show-Tell (Vinyals et al., 2015) | 0.308 | 0.190 | 0.125 | 0.088 | 0.256 | 0.122 | 0.096 |
| Att2in (Xu et al.,2015) | 0.314 | 0.198 | 0.133 | 0.095 | 0.264 | 0.122 | 0.106 |
| AdaAtt (Lu et al., 2017) | 0.314 | 0.198 | 0.132 | 0.094 | 0.267 | 0.128 | 0.131 |
| Transformer (Vaswani et al., 2017) | 0.316 | 0.199 | 0.140 | 0.092 | 0.267 | 0.129 | 0.134 |
| M2Transformer (Cornia et al., 2020) | 0.332 | 0.210 | 0.142 | 0.101 | 0.264 | 0.134 | 0.142 |
| R2Gen (Chen et al., 2020) | 0.353 | 0.218 | 0.145 | 0.103 | 0.277 | 0.142 | |
| R2GenCMN (Chen et al., 2021) | 0.353 | 0.218 | 0.148 | 0.106 | 0.278 | 0.142 | |
| PPKED (Liu et al., 2021b) | 0.360 | 0.224 | 0.149 | 0.106 | 0.284 | 0.149 | 0.237 |
| GSK (Yang et al., 2021) | 0.363 | 0.228 | 0.156 | 0.115 | 0.284 | 0.203 | |
| MSAT (Wang et al., 2022b) | 0.373 | 0.235 | 0.162 | 0.120 | 0.282 | 0.143 | 0.299 |
| METransformer (Wang et al., 2023a) | 0.386 | 0.250 | 0.169 | 0.124 | 0.291 | 0.152 | 0.362 |
| GPT-4V (OpenAI,2023) | 0.338 | 0.190 | 0.109 | 0.061 | 0.240 | 0.125 | 0.033 |
表 1: MIMIC-CXR数据集上的比较。
| 方法 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE | METEOR | CIDEr |
|---|---|---|---|---|---|---|---|
| Show-Tell (Vinyals et al., 2015) | 0.308 | 0.190 | 0.125 | 0.088 | 0.256 | 0.122 | 0.096 |
| Att2in (Xu et al.,2015) | 0.314 | 0.198 | 0.133 | 0.095 | 0.264 | 0.122 | 0.106 |
| AdaAtt (Lu et al., 2017) | 0.314 | 0.198 | 0.132 | 0.094 | 0.267 | 0.128 | 0.131 |
| Transformer (Vaswani et al., 2017) | 0.316 | 0.199 | 0.140 | 0.092 | 0.267 | 0.129 | 0.134 |
| M2Transformer (Cornia et al., 2020) | 0.332 | 0.210 | 0.142 | 0.101 | 0.264 | 0.134 | 0.142 |
| R2Gen (Chen et al., 2020) | 0.353 | 0.218 | 0.145 | 0.103 | 0.277 | 0.142 | |
| R2GenCMN (Chen et al., 2021) | 0.353 | 0.218 | 0.148 | 0.106 | 0.278 | 0.142 | |
| PPKED (Liu et al., 2021b) | 0.360 | 0.224 | 0.149 | 0.106 | 0.284 | 0.149 | 0.237 |
| GSK (Yang et al., 2021) | 0.363 | 0.228 | 0.156 | 0.115 | 0.284 | 0.203 | |
| MSAT (Wang et al., 2022b) | 0.373 | 0.235 | 0.162 | 0.120 | 0.282 | 0.143 | 0.299 |
| METransformer (Wang et al., 2023a) | 0.386 | 0.250 | 0.169 | 0.124 | 0.291 | 0.152 | 0.362 |
| GPT-4V (OpenAI,2023) | 0.338 | 0.190 | 0.109 | 0.061 | 0.240 | 0.125 | 0.033 |
Table 2. Evaluation of Clinical Efficacy on MIMIC-CXR dataset.
| Models | Precision | Recall | F1 |
| METransformer (Wang et al., 2023a) | 0.364 | 0.309 | 0.334 |
| R2GenGPT (Wang et al., 2023b) | 0.392 | 0.387 | 0.389 |
| GPT-4V | 0.353 | 0.365 | 0.330 |
表 2: MIMIC-CXR 数据集上的临床疗效评估。
| 模型 | 精确率 (Precision) | 召回率 (Recall) | F1值 (F1) |
|---|---|---|---|
| METransformer (Wang et al., 2023a) | 0.364 | 0.309 | 0.334 |
| R2GenGPT (Wang et al., 2023b) | 0.392 | 0.387 | 0.389 |
| GPT-4V | 0.353 | 0.365 | 0.330 |
MEVF (Nguyen et al., 2019), MMQ (Do et al., 2021), Pub- MedCLIP (Eslami et al., 2021), MMBERT (Khare et al., 2021), and the Q 2 A Transformer (Liu et al., 2023). Recall that we report accuracies for close-end questions and BLEU scores for open-end questions. From Table 3, it can be seen that GPT-4V achieves an accuracy of $61.4%$ for the close-end questions, notably lower than other published results. In our experiment, we meticulously define open-end and close-end questions for GPT-4V in our prompt design, intending to guide its response generation effectively. Despite this, we observe that GPT-4V sometimes produces relatively long answers even for close-end questions that typically require brief single-word responses, such as “yes” or “no”. This deviation from the expected answer format leads to a lower accuracy score for these instances. Additionally, GPT-4V’s BLEU score for open-end questions is also modest at 0.116. This can be attributed to GPT-4V’s robust text generation capacity, leading to a greater diversity in its outputs. For example, GPT-4V can represent the same object in multiple ways leading to varied responses. This diversity suggests that traditional evaluation metrics like BLEU, which are based primarily on the overlap of words and lack of a deep understanding of textual meaning, are insufficient to assess the quality of GPT-4V’s varied answers. Given this limitation, we complement our evaluation with human assessments in Section 3.4.2 to provide a more appropriate and comprehensive evaluation. Human evaluation can capture subtleties and interpretations that purely text-based metrics like BLEU may overlook, especially when GPT-4V’s responses exhibit diversity and nuance beyond the scope of traditional metrics.
MEVF (Nguyen等人,2019)、MMQ (Do等人,2021)、PubMedCLIP (Eslami等人,2021)、MMBERT (Khare等人,2021)以及Q2A Transformer (Liu等人,2023)。需要说明的是,我们对封闭式问题报告准确率,对开放式问题报告BLEU分数。从表3可以看出,GPT-4V在封闭式问题上的准确率为$61.4%$,明显低于其他已发表的结果。在我们的实验中,我们通过精心设计的提示词明确区分了GPT-4V的开放式和封闭式问题,旨在有效引导其生成响应。尽管如此,我们观察到GPT-4V有时会对本应简短回答(如"是"或"否")的封闭式问题给出较长的答案。这种与预期回答格式的偏差导致这些实例的准确率评分较低。此外,GPT-4V在开放式问题上的BLEU分数也仅为0.116。这可以归因于GPT-4V强大的文本生成能力,使其输出具有更高的多样性。例如,GPT-4V可以用多种方式描述同一对象,从而产生不同的回答。这种多样性表明,BLEU等主要基于词汇重叠、缺乏对文本深层理解的传统评估指标,不足以评估GPT-4V多样化回答的质量。鉴于这一局限性,我们在3.4.2节补充了人工评估,以提供更恰当全面的评价。人工评估能捕捉到BLEU等纯文本指标可能忽略的细微差别和深层含义,特别是当GPT-4V的响应展现出超越传统指标范围的多样性和微妙性时。
Table 3. Results on VQA-RAD benchmark
| ReferenceMethods | FusionMethod | Accuracy(%) (Close-end) | BLEU-4 (Open-end) |
| StAn (He et al.,2020) | SAN | 57.2 | |
| BiAn (He et al., 2020) | BAN | 67.9 | |
| MAML(Finn et al.,2017) | SAN | 69.7 | |
| BAN | 72.4 | - | |
| MEVF (Nguyen et al.,2019) | SAN | 74.1 | |
| BAN | 75.1 | ||
| MMQ(Doetal.,2021) | SAN | 75.7 | |
| BAN | 75.8 | ||
| PubMedCLIP (Eslami et al.,2021) | 80 | ||
| MMBERT (Khare et al., 2021) | 77.9 | ||
| Q2ATransformer (Liu et al.,2023) | 81.2 | ||
| GPT-4V (OpenAI, 2023) | 61.40 | 0.1155 |
表 3: VQA-RAD基准测试结果
| 参考方法 | 融合方法 | 准确率(%) (封闭式) | BLEU-4 (开放式) |
|---|---|---|---|
| StAn (He et al., 2020) | SAN | 57.2 | |
| BiAn (He et al., 2020) | BAN | 67.9 | |
| MAML (Finn et al., 2017) | SAN | 69.7 | |
| MAML (Finn et al., 2017) | BAN | 72.4 | - |
| MEVF (Nguyen et al., 2019) | SAN | 74.1 | |
| MEVF (Nguyen et al., 2019) | BAN | 75.1 | |
| MMQ (Do et al., 2021) | SAN | 75.7 | |
| MMQ (Do et al., 2021) | BAN | 75.8 | |
| PubMedCLIP (Eslami et al., 2021) | 80 | ||
| MMBERT (Khare et al., 2021) | 77.9 | ||
| Q2ATransformer (Liu et al., 2023) | 81.2 | ||
| GPT-4V (OpenAI, 2023) | 61.40 | 0.1155 |
Medical Visual Grounding
医学视觉定位
Table 4 reports a comparative performance of GPT-4V against various SOTA visual grounding methods using the MSCXR dataset. We compare GPT-4V with a range of advanced methods in the field: BioViL (Boecking et al., 2022), BioViLT (Bannur et al., 2023), RefTR (Li and Sigal, 2021), VGTR (Du et al., 2022), SeqTR (Zhu et al., 2022), TransVG (Deng et al., 2021), and MedRPG (Chen et al., 2023). Each of these models represents a significant approach or innovation in medical image analysis, making them suitable benchmarks for evaluating GPT-4V’s performance. By using the mIoU metric, we can quantitatively assess how well GPT-4V and other models perform in terms of accurately identifying and delineating relevant patterns within the medical images of the MS-CXR dataset. GPT-4V’s performance on the MS-CXR dataset yields an mIoU of 0.083, significantly lower than all published benchmarks. While GPT-4V demonstrates a level of comprehension in visual grounding, it struggles to accurately identify medical organs and pathological signs, leading to imprecise bounding box predictions. It should be noted that the recent SoM (Yang et al.,
表 4: 使用MS-CXR数据集对比GPT-4V与各类SOTA视觉定位方法的性能表现。我们将GPT-4V与该领域一系列先进方法进行对比:BioViL (Boecking et al., 2022)、BioViLT (Bannur et al., 2023)、RefTR (Li and Sigal, 2021)、VGTR (Du et al., 2022)、SeqTR (Zhu et al., 2022)、TransVG (Deng et al., 2021)以及MedRPG (Chen et al., 2023)。这些模型均代表了医学影像分析领域的重要方法或创新成果,因此适合作为评估GPT-4V性能的基准。通过采用mIoU指标,我们可以定量评估GPT-4V及其他模型在MS-CXR数据集医学影像中准确识别和勾画相关模式的表现。GPT-4V在MS-CXR数据集上的mIoU得分为0.083,显著低于所有已发布的基准结果。虽然GPT-4V展现出一定程度的视觉定位理解能力,但其在准确识别医学器官和病理体征方面存在困难,导致边界框预测不精确。值得注意的是,近期提出的SoM (Yang et al.,
2023a) model has shown substantial improvements in this area by segmenting and labeling images before grounding, enhancing performance on generic images. However, its effectiveness on medical images demanding finer details remains untested. Further research is necessary to assess its applicability to medical imaging.
2023a) 模型通过在地面标注前对图像进行分割和标记,在这一领域展现出显著改进,提升了通用图像上的性能。然而,其对需要更精细细节的医学图像的有效性仍有待验证。需进一步研究以评估其在医学成像中的适用性。
Table $4.\mathbf{m}\mathbf{Io}\mathbf{U}(%)$ results on MS-CXR benchmark.
| Methods | mIoU(%) |
| BioViL(Boecking et al.,2022) | 22.9 |
| BioViL-T (Bannuret al.,2023) | 24.3 |
| RefTR(Li and Sigal,2021) | 50.11 |
| VGTR (Du et al., 2022) | 53.58 |
| SeqTR (Zhu et al., 2022) | 56.63 |
| TransVG (Deng et al.,2021) | 58.91 |
| MedRPG(Chenetal.,2023) | 59.37 |
| GPT-4V (OpenAI, 2023) | 8.33 |
表 4: MS-CXR 基准测试的 mIoU(%) 结果。
| 方法 | mIoU(%) |
|---|---|
| BioViL (Boecking et al., 2022) | 22.9 |
| BioViL-T (Bannur et al., 2023) | 24.3 |
| RefTR (Li and Sigal, 2021) | 50.11 |
| VGTR (Du et al., 2022) | 53.58 |
| SeqTR (Zhu et al., 2022) | 56.63 |
| TransVG (Deng et al., 2021) | 58.91 |
| MedRPG (Chen et al., 2023) | 59.37 |
| GPT-4V (OpenAI, 2023) | 8.33 |
3.4.2. Human Evaluation Results
3.4.2. 人工评估结果
This section details our approach to evaluating and analysing human assessments of radiology reports and VQA tasks. Specifically, we choose not to include human evaluation for the visual grounding task. The reason is that the output of visual grounding is typically a simple bounding box, rather than text. The quality of these bounding boxes can be straightforwardly assessed through visualization, making human evaluation less critical for this aspect. However, when it comes to the evaluation of text generation, visual inspection of the words alone is insufficient for determining quality. The key aspect of evaluating the text produced by a large-scale model like GPT-4V lies in understanding the semantic meaning of the generated content. Text quality encompasses more than just the correct words. Therefore, we incorporate human evaluation as a crucial part of our assessment process for text generation. Human evaluators can provide insights into how well the model captures the intended meaning, context, and subtleties that traditional metrics may overlook. This approach allows for a more nuanced and comprehensive evaluation of the quality of text generated by GPT-4V.
本节详细阐述我们对放射学报告和视觉问答(VQA)任务进行人工评估与分析的方法。具体而言,我们选择不对视觉定位(visual grounding)任务进行人工评估。这是因为视觉定位的输出通常是简单的边界框(bounding box)而非文本,这些边界框的质量通过可视化即可直接判断,使得人工评估在此环节显得不那么关键。然而,对于文本生成的评估,仅靠视觉检查单词本身不足以判定质量。评估像GPT-4V这样的大规模模型所生成文本的核心在于理解其语义内涵——文本质量远不止于用词正确。因此我们将人工评估作为文本生成评估流程的关键环节,人类评估者能洞察模型对预期含义、上下文及传统指标可能忽略的微妙之处的捕捉程度,从而实现对GPT-4V生成文本质量更细致全面的评估。
Radiology Reports Human Evaluation
放射学报告人工评估
We conduct a random selection of 100 report pairs, including corresponding ground truth reports and the reports generated by GPT-4V. These pairs undergo grading by a trained radiologist, categorized into three levels: high, medium, and low, based on varying degrees of human-perceived consistency. Simultaneously, we calculate NLP scores for BLEU, ROUGE, METEOR, and CIDEr for these 100 report pairs, focusing on BLEU and CIDEr due to minimal variation in ROUGE and METEOR.
我们随机选取了100份报告对,包括相应的真实报告和GPT-4V生成的报告。这些报告对由一位经过培训的放射科医生进行评分,根据人类感知一致性的不同程度分为高、中、低三个等级。同时,我们计算了这100份报告对的BLEU、ROUGE、METEOR和CIDEr等NLP分数,重点关注BLEU和CIDEr,因为ROUGE和METEOR的差异较小。
Visualization & Distribution Analysis: Figure 6 presents scatter graphs illustrating the relationship between the BLEU/CIDEr/F1 scores and human ratings, respectively. The x-axis represents BLEU/CIDEr/F1 scores, while the y-axis depicts corresponding human scores for the same samples. Notably, a significant number of GPT-4V-generated reports with low BLEU scores $(<0.20)$ receive “Medium” or “High” quality evaluations in human ratings, a trend also observed with CIDEr metrics. The human rating is better aligned with the F1 score reflecting clinical efficacy, e.g., there are fewer reports with low F1 scores $(<0.20)$ rated as ’Medium’ or ’High’ by the human evaluator.
可视化与分布分析:图 6 展示了分别反映 BLEU/CIDEr/F1 分数与人工评分关系的散点图。横轴表示 BLEU/CIDEr/F1 分数,纵轴对应相同样本的人工评分。值得注意的是,大量 BLEU 分数较低 $(<0.20)$ 的 GPT-4V 生成报告在人工评分中获得了"中等"或"高质量"评价,这一趋势在 CIDEr 指标中同样存在。人工评分与反映临床效力的 F1 分数更为一致,例如 F1 分数较低 $(<0.20)$ 的报告被人工评估者评为"中等"或"高质量"的情况较少。
To align NLP scores with human ratings, we scale them to the range of [0, 100] using the formula $\begin{array}{r}{\hat{s}=\frac{s-\mathrm{lowest}}{\mathrm{highest-lowest}}\times100}\end{array}$ , where $s$ is the original score, and $\hat{s}$ is the scaled score. We quantize these scores into three quality ranges: low [0 40), medium [40 70), and high [70 100]. The distributions of the 100 samples are shown in Fig 6, corresponding to BLEU, CIDEr, F1, human rating, respectively. Specifically, based on the human rating, there are 10 high-, 35 medium-, and 55 low-quality reports; based BLEU scores, there are 1 high-, 2 medium-, and 97 lowquality reports; based on CIDEr, there are 5 high-, 53 medium, and 42 low-quality reports; and based on F1 score, there 3 high-, 29 medium-, and 68 low-quality reports. Our findings indicate that traditional evaluation methods tend to yield lower scores compared to radiologist assessments, suggesting that human evaluation assigns higher scores to the reports generated by GPT-4V, implying better report quality than indicated by traditional scores.
为使NLP评分与人类评分保持一致,我们使用公式 $\begin{array}{r}{\hat{s}=\frac{s-\mathrm{lowest}}{\mathrm{highest-lowest}}\times100}\end{array}$ 将分数缩放至[0, 100]范围,其中 $s$ 为原始分数,$\hat{s}$ 为缩放后分数。我们将这些分数量化为三个质量区间:低[0 40)、中[40 70)、高[70 100]。100个样本的分布如图6所示,分别对应BLEU、CIDEr、F1和人类评分。具体而言,基于人类评分,有10份高质量、35份中等质量和55份低质量报告;基于BLEU分数,有1份高质量、2份中等质量和97份低质量报告;基于CIDEr分数,有5份高质量、53份中等质量和42份低质量报告;基于F1分数,有3份高质量、29份中等质量和68份低质量报告。我们的研究结果表明,与传统放射科医师评估相比,传统评估方法往往给出较低分数,这意味着人类评估对GPT-4V生成的报告给予了更高评分,表明其报告质量优于传统分数所显示的。
Correlation & Statistical Test: To further assess the correlation between the NLP scores and human ratings, we calcu- late Kendall’s $\tau$ coefficient (i.e., Kendall rank correlation coefficient), which measures the ordinal association between two quantities. Kendall’s $\tau$ is defined as follows:
相关性分析与统计检验:为进一步评估 NLP 分数与人工评分的相关性,我们计算了 Kendall 的 $\tau$ 系数(即 Kendall 等级相关系数),该系数用于衡量两个变量之间的序数关联性。Kendall 的 $\tau$ 定义如下:
$$
\tau={\frac{\mathrm{number of concordant pairs}-\mathrm{number of discordant pairs}}{\mathrm{total number of pairs}\times(\mathrm{total number of pairs}-1)/2}}.
$$
$$
\tau={\frac{\mathrm{number of concordant pairs}-\mathrm{number of discordant pairs}}{\mathrm{total number of pairs}\times(\mathrm{total number of pairs}-1)/2}}.
$$
Concordant pairs occur when both the human evaluator and the NLP metric agree on the ranking of two reports. Conversely, discordant pairs occur when there is a disagreement between the rankings by the human evaluator and the NLP metrics. The $\tau$ coefficient is within the range $-1\le\tau\le1$ . If two random variables are independent, the expectation of $\tau$ is zero. In addition, a statistical test with the null hypothesis of $\tau=0$ (no correlation) is conducted, and the $\mathsf{p}$ -value is reported. The p-value helps determine whether the observed agreement or disagreement in rankings between human ratings and NLP metrics is statistically significant or due to random variations.
一致对 (concordant pairs) 指人类评估者与NLP指标对两份报告的排序结果一致的情况。相反,当人类评估者与NLP指标的排序结果不一致时,则称为不一致对 (discordant pairs)。τ系数 ($\tau$) 的取值范围为 $-1\le\tau\le1$。若两个随机变量独立,则 $\tau$ 的期望值为零。此外,我们进行了零假设为 $\tau=0$ (无相关性) 的统计检验,并报告了 $\mathsf{p}$ 值。该p值用于判断人类评分与NLP指标之间的排序一致性或分歧是否具有统计显著性,还是由随机波动导致。
As reported in Table 5, for the NLP scores BLEU, ROUGE, METEOR, and CIDEr, the Kendall’s $\tau$ coefficients are small values around zero, suggesting the human rating and these NLP metrics are potentially independent. This is further supported by their corresponding large p-values, all exceeding 0.1, indicating a failure to reject the null hypothesis. Thus, the correlations between human ratings and NLP metrics are not statistically significant. However, the F1 score has a small p-value of 0.002 and a moderate Kendall’s $\tau$ of 0.242, showing a statistically significant rank correlation with the human rating. In short, the statistic tests support our observations that i) the quality of GPT-4V’s generated reports could be much higher than what traditional evaluation methods indicate; and ii) GPT-4V’s performance in clinical efficacy aligns with human evaluation, which are higher than NLP-based metrics. On the other hand, it should also be noted that human evaluation captures more than the clinical score of F1, as the latter is still limited in detecting the occurrence of clinically relevant keywords in the generated reports without comprehending the context.
如表 5 所示,对于 NLP 评分指标 BLEU、ROUGE、METEOR 和 CIDEr,Kendall 的 $\tau$ 系数均为接近零的小值,这表明人工评分与这些 NLP 指标之间可能存在独立性。这一结论进一步得到了其对应的大 p 值支持(均超过 0.1),表明无法拒绝原假设。因此,人工评分与 NLP 指标之间的相关性在统计学上不显著。然而,F1 分数的 p 值较小(0.002),且 Kendall 的 $\tau$ 值为 0.242,显示出与人工评分之间存在统计学上显著的秩相关。简而言之,统计检验支持了我们的观察:i) GPT-4V 生成报告的质量可能远高于传统评估方法所显示的;ii) GPT-4V 在临床效果方面的表现与人工评估一致,且高于基于 NLP 的指标。另一方面,也应注意人工评估捕捉的内容超出了 F1 临床评分的范围,因为后者在检测生成报告中临床相关关键词的出现时仍存在局限性,无法理解上下文。

Fig. 6. Scatter graphs show the relationship between BLEU/CIDEr/F1 score and the human evaluation, respectively.
图 6: 散点图分别展示了BLEU/CIDEr/F1分数与人工评估之间的关系。

Fig. 7. Distributions of scores based on human evaluation, BLEU, CIDEr, and F1, respectively.
图 7: 基于人工评估、BLEU、CIDEr和F1的分数分布。
An Example of Human Evaluation: To further bolster the credibility of our report generation results, we present an indepth analysis conducted by a radiologist. This expert evaluation delves into the accuracy, relevance, and overall quality of the generated reports, providing valuable professional insights. The following example illustrates a notable disparity between BLEU scores and human evaluation. It juxtaposes a ground truth report with a report generated by GPT-4V, revealing that despite a low BLEU score, the report receives a high rating from a radiologist.
人工评估示例:为进一步增强报告生成结果的可信度,我们展示由放射科专家开展的深度分析。该专业评估从准确性、相关性和整体质量三个维度剖析生成报告,提供宝贵的专业见解。以下案例展示了BLEU分数与人工评估间的显著差异:将原始真实报告与GPT-4V生成报告进行对比后发现,尽管BLEU分数较低,但该报告获得了放射科医师的高度评价。
Ground Truth Report: “Impression: Bilateral p are nch y mal opacities right greater than left compatible with pneumonia in the proper clinical setting. Findings : There bilateral regions of consolidation at the right lung and left mid to lower lung. Findings are most concerning for bilateral infection. Moderate enlargement of the cardiac silhouette is unchanged. Multiple vascular stents are also noted. No acute osseous abnormalities. splenic calcification s are again noted.”
真实报告:"印象:双侧肺实质混浊,右侧重于左侧,结合临床符合肺炎表现。
发现:右肺及左肺中下部可见双侧实变区,最需警惕双侧感染。心脏轮廓中度增大,较前无变化。另见多枚血管支架。未见急性骨性异常。再次观察到脾脏钙化灶。"
GPT-4V Predicted: “Impression: Bilateral patchy opacities with potential for infiltrates or infectious etiology. Right-side media st in al shift observed. Findings: The car dio media st in al silhouette shows right-side deviation, which might be suggestive of volume loss or other pathology on the left side. Bilateral patchy opacities are noted which can represent infiltrates, raising concerns for potential infectious etiology, interstitial disease, or other inflammatory processes. The pulmonary vasculature appears within normal limits. There are no clear signs of pleural effusion or pneumothorax. The osseous structures of the thorax appear intact without evidence of acute fractures.”
GPT-4V预测结果:"印象:双侧斑片状阴影,可能存在浸润或感染性病因。观察到右侧纵隔向左侧移位。
检查结果:心脏纵隔轮廓显示右侧偏移,可能提示左侧存在容积减少或其他病变。双侧斑片状阴影可见,可能代表浸润性病变,需警惕潜在感染性病因、间质性肺病或其他炎症性病变。肺血管系统显示正常。未见明确胸腔积液或气胸征象。胸部骨性结构完整,无急性骨折证据。"
(注:根据医学影像学术语规范,"media st in al"应为"mediastinal(纵隔)"的笔误,已修正为"纵隔";"car dio"应为"cardio(心脏)"的笔误,修正为"心脏"。保留专业表述如"浸润性病变"、"间质性肺病"等医学术语,并确保符合中文放射学报告书写规范。)
Upon expert examination, the radiologist affirms that the predicted report accurately identifies key bilateral lung consolidation areas, describes the patchy morphology of the lesions, and provides insightful pathological inferences. The changes in the media st in al position of the heart are also consistent with the original report. Although the direct determination of cardiac hypertrophy is not made, a positive prompt is acknowledged, aligning with chest X-ray reporting principles. Other negative diagnosis descriptions are basically consistent with the ground truth report. Consequently, the generated report receives a high score based on these professional evaluations.
经专家审核,放射科医师确认预测报告准确识别了双侧肺部关键实变区域,描述了病灶的斑片状形态,并提供了具有病理学价值的推断。心脏纵隔位置的改变也与原报告一致。虽未直接判定心脏肥大,但给出了阳性提示,符合胸部X光报告原则。其余阴性诊断描述基本与真实报告吻合。基于这些专业评估,生成的报告获得了高分。
Table 5. Evaluation of P Value and Kendall’s Tau
| Bleu-4 | ROUGE.L | METEOR | CIDEr | F1 | |
| PValue | 0.688 | 0.430 | 0.462 | 0.503 | 0.002 |
| Kendall's Tau | 0.032 | 0.063 | 0.059 | 0.053 | 0.242 |
表 5: P 值和 Kendall's Tau 评估
| Bleu-4 | ROUGE.L | METEOR | CIDEr | F1 | |
|---|---|---|---|---|---|
| PValue | 0.688 | 0.430 | 0.462 | 0.503 | 0.002 |
| Kendall's Tau | 0.032 | 0.063 | 0.059 | 0.053 | 0.242 |
Visual Question Answering Human Evaluation
视觉问答人工评估
For this evaluation, we randomly select 100 open-end questions from VQA-RAD, together with ground truth and GPT-4V generated answers. A trained radiologist assesses the correctness of GPT-4V’s answers, identifying 57 answers as correct and 43 answers as incorrect. This contrasts sharply with the traditional accuracy metric used in the predominant classificationbased VQA approaches, which detects only 9 correct answers, as shown in Figure 8. This disparity is rooted in the traditional classification-based VQA evaluation, which treats each predetermined answer as a class and calculates the classification accuracy. This evaluation lacks flexibility in handling the variability of answers produced by GPT-4V. Our human evaluation finds GPT-4V’s answers more accurate than traditional scores, highlighting the richness of content in GPT-4V’s responses not fully captured by conventional scoring methods. This underscores that the quality of GPT-4V’s answers is not inferior.
在此次评估中,我们从VQA-RAD数据集中随机选取了100道开放式问题,并收集了标准答案与GPT-4V生成的回答。一位专业放射科医生对GPT-4V的回答进行正确性评估,判定其中57个答案正确、43个答案错误。这与主流基于分类的VQA方法采用的传统准确率指标形成鲜明对比——如图8所示,传统方法仅检测出9个正确答案。这种差异源于传统基于分类的VQA评估方式:它将每个预设答案视为一个类别并计算分类准确率,这种评估方法无法灵活处理GPT-4V产出的多样化答案。我们的人工评估发现GPT-4V的回答比传统评分更准确,这表明传统评分方法未能充分反映GPT-4V回答内容的丰富性,也印证了GPT-4V的答案质量并不逊色。
Moreover, delving into the answers generated by GPT-4V, the radiologist finds GPT-4V not only matches but surpasses the accuracy of the ground truth. This superiority is attributed to the detailed and precise nature of GPT-4V’s responses. Figure 9 provides two VQA examples produced by GPT-4V. In the right example, given the question “what organ system is visualized”, the ground truth provided only mentions the chest, which is neither rigorous nor sufficient. In contrast, GPT-4V’s response includes the skeleton and respiratory system, demonstrating improved accuracy and completeness. Moreover, the answers generated by GPT-4V exhibit a higher level of generalization and comprehensiveness. As shown in the left example, GPT-4V describes “mediport” as “A foreign body or medical device”. Additionally, GPT-4V produces answers that are more professional and readable, presenting complete sentences with medical terminology and grammatical accuracy. These findings suggest that GPT-4V holds significant learning potential, inviting further exploration through additional research.
此外,通过深入研究GPT-4V生成的答案,放射科医生发现GPT-4V不仅匹配甚至超越了标准答案的准确性。这种优势源于GPT-4V回答的细致性和精确性。图9展示了GPT-4V生成的两个视觉问答(VQA)示例。右侧示例中,针对问题"显示的是哪个器官系统",标准答案仅提到胸部,既不严谨也不充分。相比之下,GPT-4V的回答包含了骨骼和呼吸系统,展现出更高的准确性和完整性。
GPT-4V生成的答案还表现出更强的泛化能力和全面性。如左侧示例所示,GPT-4V将"mediport"描述为"异物或医疗设备"。此外,GPT-4V生成的答案更具专业性和可读性,使用完整句子并准确运用医学术语和语法。这些发现表明GPT-4V具有显著的学习潜力,值得通过进一步研究深入探索。

Fig. 8. Human evaluation of the correctness of the answers generated by GPT-4V on a subset of VQA-RAD, in contrast to the evaluation based on the classification accuracy of the same dataset.
图 8: 在VQA-RAD子集上对GPT-4V生成答案正确性的人工评估结果,与该数据集基于分类准确率的评估结果对比。

Fig. 9. Two examples showcase GPT-4V’s performance on open-end questions.
图 9: 两个示例展示了 GPT-4V 在开放式问题上的表现。
3.4.3. Case Study
3.4.3. 案例研究
In this part, we demonstrate GPT-4V’s performance by incorporating case studies across the three specific tasks, offering a more direct and intuitive view of its capabilities.
在这一部分,我们通过整合三个具体任务的案例研究来展示 GPT-4V 的性能,从而更直接直观地呈现其能力。
Radiology Report Generation Cases
放射学报告生成案例
In zero-shot scenarios, through a series of tests on multiple chest $\mathrm{X}$ -ray images, it is observed that GPT-4V consistently generates reports with a focus on specific anatomical organs.
在零样本场景下,通过对多张胸部X光片进行一系列测试,观察到GPT-4V生成的报告始终聚焦于特定解剖器官。
This phenomenon can be observed in Figure 10. Notably, GPT4V tends to present information in a specific sequence, covering the information on the lung, car dio media st in al silhouette, bones, diaphragm, and soft tissues, in the majority of the generated reports. Examining the third case in Figure 10, GPT
这一现象可以在图 10 中观察到。值得注意的是,GPT4V 倾向于以特定顺序呈现信息,在大多数生成的报告中涵盖肺部、心脏纵隔轮廓、骨骼、膈肌和软组织的信息。观察图 10 中的第三个案例,GPT

Fig. 10. R2Gen case using zero-shot prompt. GPT-4V can generate radiology reports without example reports and convey both normal and abnormal aspects. For better illustration, the key medical information in the reports is highlighted using different colours.
图 10: 使用零样本提示的R2Gen案例。GPT-4V无需示例报告即可生成放射学报告,并能传达正常和异常情况。为便于说明,报告中的关键医学信息用不同颜色高亮显示。
4V demonstrates its proficiency to identify both normal and abnormal aspects, e.g., “No pleural effusion or pneumothorax is present; Suggestive of a possible infectious or inflammatory process”. These instances underscore GPT-4V’s ability, even with zero-shot prompts, to generate relevant reports and identify anomalies.
4V 展现了识别正常与异常情况的能力,例如"未见胸腔积液或气胸;提示可能存在感染性或炎症性病变"。这些实例证明 GPT-4V 即便在零样本提示下,仍能生成相关报告并识别异常。
In few-shot scenarios, our observation indicates that different prompts significantly influence the generated reports. GPT4V’s inclination to generate normal or abnormal findings varies based on the provided example reports. Figure 11 illustrates the response to a normal chest X-ray image, utilising three distinct prompt settings to guide GPT-4V in generating corresponding reports. Interestingly, it is found that the report generated either from the normal-example prompt or the mixed-example prompt describes the image as normal, which is consistent with the ground truth. In contrast, the report from the abnormalexample prompt misidentifies anomalies in the image. Meanwhile, Figure 12 showcases an example of an abnormal chest X-ray image. It is observed that the report generated by the normal-example prompt misinterprets the lungs as normal. Our investigation emphasizes the substantial impact of the mixedexample prompt on GPT-4V’s accuracy in determining the normality or abnormality of an image.
在少样本场景下,我们的观察表明不同提示词会显著影响生成报告。GPT4V生成正常或异常结果的倾向性会随提供的示例报告而变化。图11展示了针对正常胸部X光图像的响应,通过三种不同提示设置引导GPT-4V生成对应报告。值得注意的是,使用正常示例提示或混合示例提示生成的报告都将图像描述为正常,这与实际情况一致。相反,异常示例提示生成的报告会错误识别图像中的异常。同时,图12展示了一个异常胸部X光图像的案例,可见正常示例提示生成的报告会误判肺部状态为正常。我们的研究强调了混合示例提示对GPT-4V判断图像正常/异常准确率的重大影响。
Visual Question Answering Cases
视觉问答案例
We delve into specific cases of VQA illustrated in Figures 13, and 14. Figure 13 presents two examples of the close-end questions with a single-word answer of “yes” or “no”. Effectively addressing such questions requires GPT-4V to accomplish two key tasks: firstly, discern that the question is close-end, and secondly, comprehend the attributes of a close-end question. This proficiency is crucial because, despite the simplicity of these questions, GPT-4V tends to generate more extended responses, which will be deemed incorrect when assessing the accuracy of answers to close-end questions. Thus, GPT-4V faces the challenge of identifying when a question demands a concise oneword answer and adjusting its response generation accordingly. Properly tailoring its output to match the question type is essential for GPT-4V’s accuracy in dealing with close-end questions.
我们深入研究了图13和图14中展示的视觉问答(VQA)具体案例。图13呈现了两个封闭式问题的示例,其答案为单字"是"或"否"。要有效回答此类问题,GPT-4V需要完成两个关键任务:首先识别出这是封闭式问题,其次理解封闭式问题的特性。这种能力至关重要,因为尽管问题看似简单,GPT-4V往往会生成更冗长的回答,而在评估封闭式问题答案准确性时,这种回答将被判定为错误。因此,GPT-4V面临的挑战在于:既要识别何时需要给出简短的单词级回答,又要相应调整其回答生成方式。根据问题类型恰当地调整输出内容,是GPT-4V正确处理封闭式问题的关键所在。

Fig. 11. R2Gen normal case. Key medical information in the reports is highlighted using different colors. GPT-4V is more likely to generate reports containing abnormality descriptions when the prompt consists of only abnormal examples. The text in red corresponds to descriptions of abnormal conditions.
图 11: R2Gen正常案例。报告中的关键医学信息用不同颜色高亮显示。当提示仅包含异常样本时,GPT-4V更倾向于生成含有异常描述的报告。红色文本对应异常状况的描述。
Open-end questions demand more intricate responses beyond a simple “yes” or “no”, providing flexibility in generating answers. However, for the VQA task, the challenge lies in predefined answer pools, making it hard for GPT-4V to generate an exact sentence that matches these predefined answers. In Figure 14, we present two examples of open-end questions. The first example showcases a correct, succinct response from GPT-4V, consisting of just one word. This showcases GPT-4V’s effective handling of simple, direct open-end questions. The second example, however, depicts an incorrect answer by GPT4V. The response provided by GPT-4V is a detailed explanation of the brain structures potentially affected by a lesion in the right frontal area, encompassing the prefrontal cortex, primary motor cortex, and possibly the premotor and precentral gyrus. This response appears more fitting for a theoretical question about brain anatomy, such as “What brain structures would be affected by a lesion in the right frontal area of the brain?” In this case, GPT-4V seems to have relied solely on medical knowledge without adequately considering the specific image in question. This suggests that GPT-4V might sometimes overlook the visual information in VQA tasks, especially when the question can be addressed through general medical knowledge.
开放式问题需要比简单的"是"或"否"更复杂的回答,在生成答案时具有灵活性。然而对于VQA任务而言,挑战在于预定义的答案池使得GPT-4V难以生成与这些预设答案完全匹配的句子。在图14中,我们展示了两个开放式问题的示例。第一个例子展示了GPT-4V给出的正确简洁回答,仅包含一个单词。这展示了GPT-4V对简单直接开放式问题的有效处理能力。第二个例子则呈现了GPT-4V的错误回答。GPT-4V给出的回应是对右额叶区域病变可能影响的大脑结构(包括前额叶皮层、初级运动皮层,可能还有运动前区和中央前回)的详细解释。这种回答更适合"右额叶脑区病变会影响哪些大脑结构?"这类关于脑解剖的理论问题。在这个案例中,GPT-4V似乎仅依赖医学知识而没有充分考虑问题中的特定图像。这表明GPT-4V有时可能会忽略VQA任务中的视觉信息,特别是当问题可以通过一般医学知识解答时。
Fig. 12. R2Gen abnormal case. Key medical information in the reports is highlighted using different colors. GPT-4V is more likely to generate normal reports when the prompt consists of only normal examples. The text in red corresponds to descriptions of normal conditions.
图 12: R2Gen异常案例。报告中的关键医学信息用不同颜色高亮显示。当提示仅包含正常样本时,GPT-4V更倾向于生成正常报告。红色文字对应正常状况的描述。
This insight underscores the challenge GPT-4V faces to generate responses for open-end VQA tasks.
这一发现突显了GPT-4V在开放型视觉问答任务中生成响应所面临的挑战。

Fig. 13. VQA case examples for close-end questions. By few-shot prompts, GPT-4V could discern the question type and generate correct “yes” or “no” answers.
图 13: 封闭式问题的视觉问答(VQA)案例示例。通过少样本提示,GPT-4V能够识别问题类型并生成正确的"是"或"否"答案。
Visual Grounding Cases
视觉定位案例
In Figure 15 we provide two examples that shed light on GPT-4V’s performance in visual grounding tasks. Our examination suggests that while GPT-4V exhibits the capability to generate bounding boxes, its performance is suboptimal, especially in precisely locating objects within images. This limitation might stem from GPT-4V’s challenges in processing and interpreting detailed image information, particularly in the context of medical images where a nuanced focus on fine-grid features is crucial for accurate visual grounding. Furthermore, we posit that GPT-4V’s training, predominantly on common images, may contribute to its suboptimal performance with medical images. The model’s limited exposure to diverse and labelled medical data might be a key factor in this inadequacy.
图 15: 我们提供了两个示例,以揭示 GPT-4V 在视觉定位任务中的表现。研究表明,虽然 GPT-4V 具备生成边界框的能力,但其表现欠佳,尤其是在精确定位图像中的物体时。这一局限性可能源于 GPT-4V 在处理和解析细节图像信息时面临的挑战,特别是在医学图像领域——对细粒度特征的精准关注是视觉定位的关键。此外,我们认为 GPT-4V 主要基于通用图像进行训练,这可能导致其在医学图像上的表现不佳。模型接触多样化标注医学数据的有限性,可能是造成这一不足的关键因素。

Fig. 14. VQA case examples for open-end questions. By few-shot prompts, GPT-4V has the capacity to generate correct answers (left). However, it may sometimes overlook visual information and generate answers solely based on general medical knowledge (right).
图 14: 开放式问题的视觉问答(VQA)案例示例。通过少样本提示,GPT-4V能够生成正确答案(左)。然而,它有时会忽略视觉信息,仅基于一般医学知识生成答案(右)。

Fig. 15. Visual Grounding Prompt case. The bounding boxes in red are predicted by GPT-4V, while the ground truth bounding boxes are in green.
图 15: 视觉定位提示案例。红色边界框由 GPT-4V 预测,绿色边界框为真实标注。
4. Summary and discussion
4. 总结与讨论
This study thoroughly investigates GPT-4V’s performance in three key medical applications, employing a comprehensive evaluation methodology encompassing quantitative analysis, human assessment, and case studies.
本研究全面探究了GPT-4V在三大医疗关键应用中的表现,采用涵盖定量分析、人工评估与案例研究的综合评估方法。
In the domain of radiology report generation, GPT-4V effectively generates radiology reports from medical images, close to models specially trained for this task in language fluency and clinical relevance. Human evaluations reveal its higher accuracy and detailed generation, suggesting conventional metrics fall short in assessing LLMs like GPT-4V. Beyond quantitative analysis, notable observations include the impact of different prompts on GPT-4V’s report generation. Specifically, a mixed-example prompt, incorporating both normal and abnormal cases, enhances report quality compared to prompts with solely normal or abnormal examples. Also, it is found that GPT-4V’s ability to generate additional information not present in the ground truth, though visible in images, contributes to relatively lower BLEU scores that focus on wordmatching rates, compared to specially trained R2Gen models. Remarkably, GPT-4V exhibits a notably lower CIDEr score than conventional R2Gen models, consistent with findings from R2GenGPT (Wang et al., 2023b), which employed a frozen LLM for medical report generation. This lower CIDEr score may suggest a tendency of LLMs to generate repetitive description patterns. Meanwhile, when evaluating the rank correlation between NLP/clinical scores and the human rating, the latter aligns more closely with clinical scores than NLP scores, consistent with the observation that GPT-4V exhibits competitive clinical efficacy close to high-performing R2Gen models.
在放射学报告生成领域,GPT-4V能有效根据医学影像生成放射学报告,其语言流畅性和临床相关性接近专为此任务训练的模型。人工评估显示其生成结果具有更高准确性和细节丰富度,表明传统指标难以充分评估GPT-4V等大语言模型。除定量分析外,重要发现包括不同提示词对GPT-4V报告生成的影响:混合示例提示(同时包含正常和异常病例)相比仅含单一类型示例的提示能提升报告质量。此外,GPT-4V能生成参考报告中未包含但图像可见的额外信息,这导致其BLEU分数(侧重词汇匹配率)低于专用训练的R2Gen模型。值得注意的是,GPT-4V的CIDEr分数显著低于传统R2Gen模型,这与R2GenGPT (Wang et al., 2023b) 使用冻结大语言模型生成医学报告的发现一致,可能反映大语言模型存在重复描述模式的倾向。同时评估NLP/临床评分与人工评分的秩相关性时,后者与临床评分的吻合度高于NLP评分,这与GPT-4V展现出接近高性能R2Gen模型的临床效能这一观察结果一致。
In the domain of medical visual question answering, GPT-4V exhibits promise but achieves modest scores when compared to advanced methods, primarily due to the low correlation of its answers with standard benchmarks. It is noteworthy that human assessments consistently rate its accuracy higher than these metrics suggest. Meanwhile, several limitations associated with the VQA datasets and evaluation call for attention. The current public datasets for VQA are constrained by a fixed answer format, imposing limitations on the training potential of models like GPT-4V and introducing challenges in accurately evaluating their performance. The inherent rigidity of these datasets becomes apparent when assessing generative models for VQA, where a more flexible evaluation approach to accommodate a spectrum of correct answers is warranted. Moreover, the predominant method for evaluating VQA tasks, rooted in classification techniques, centers around accuracy. This approach becomes less effective when transitioning to large models like LLMs for VQA tasks. Compared with traditional methods, LLMs generate answers in a more flexible and nuanced manner, leading to a variety of correct answers that may not align with the limited set of predefined ground truth and thus could be unfairly marked as incorrect by conventional evaluation metrics. Consequently, there is a pressing need for more sophisticated evaluation methods, which should be adept at assessing contextual and semantic correctness, departing from the conventional practice of exact matches with predefined correct answers. Such an evolved approach would provide a more accurate gauge of LLMs’ capabilities in comprehending and responding to the intricacies of VQA tasks, thereby reflecting the true potential of these advanced models in handling complex question-answering scenarios.
在医疗视觉问答(VQA)领域,GPT-4V展现出潜力但与先进方法相比得分不高,主要因其答案与标准基准的相关性较低。值得注意的是,人工评估始终认为其准确率高于这些指标所显示的数值。同时,当前VQA数据集和评估方法存在若干亟待关注的局限性。现有公开VQA数据集受限于固定答案格式,不仅制约了GPT-4V等模型的训练潜力,更给性能评估带来挑战。这种固有僵化性在评估生成式VQA模型时尤为明显,需要更灵活的评价体系来容纳多样化的正确答案。此外,植根于分类技术的传统VQA评估方法以准确率为核心指标,在将LLM等大模型应用于VQA任务时显得力不从心。与传统方法相比,大语言模型能以更灵活细腻的方式生成答案,导致多种正确答案可能无法匹配有限的预设标准答案,从而被传统评估指标误判为错误。因此亟需发展更精密的评估方法,能够评估上下文和语义的正确性,而非机械匹配预设答案。这种进化后的评估体系将更准确衡量大语言模型理解复杂VQA任务的能力,从而真实反映这些先进模型处理复杂问答场景的潜力。
In the domain of medical visual grounding, GPT-4V exhibits a need for refinement in accurately locating and identifying specific image elements, echoing a recognized gap observed in generic image tasks. This underscores a notable area for potential improvement. A recent publication Yang et al. (2023a) introduced the Set-of-Mark prompting method, offering a novel approach to enhance the visual grounding capabilities of large multimodal models, including GPT-4V. The SoM method entails partitioning an image into regions and overlaying them with marks, such as alphanumeric characters, masks, or boxes. These marks serve to augment GPT-4V’s understanding and responsiveness to visual content, leading to a significant enhancement in performance, particularly in fine-grained vision tasks within a zero-shot setting. This innovative method holds promise for addressing the identified need for improvement in GPT-4V’s performance in medical image visual grounding. In the medical context, where precise identification and description of specific regions or features in images are crucial, applying the SoM technique could potentially empower models like GPT-4V to provide more accurate and detailed descriptions of medical images, thereby contributing to improved diagnosis and treatment planning.
在医学视觉定位领域,GPT-4V在准确定位和识别特定图像元素方面仍需改进,这与通用图像任务中观察到的公认差距相呼应。这突显了一个值得关注的潜在改进领域。近期Yang等人(2023a)发表的Set-of-Mark提示方法,为增强包括GPT-4V在内的大型多模态模型的视觉定位能力提供了一种新思路。SoM方法通过将图像分割为多个区域并叠加字母数字标记、遮罩或方框等标记,显著提升了GPT-4V对视觉内容的理解和响应能力,尤其在零样本设置下的细粒度视觉任务中表现出性能飞跃。这一创新方法有望解决GPT-4V在医学图像视觉定位方面的现存不足。在需要精确识别和描述图像特定区域或特征的医学场景中,应用SoM技术或将使GPT-4V等模型能够提供更准确、详尽的医学图像描述,从而助力提升诊疗方案制定水平。
Overall, our evaluation, incorporating standard metrics and medical expert reviews, underscores the limitations of traditional methods in fully capturing GPT-4V’s capabilities, emphasizing the imperative for improved evaluation techniques tailored to large language models.
总体而言,我们的评估结合了标准指标和医学专家评审,凸显了传统方法在全面捕捉GPT-4V能力方面的局限性,强调了针对大语言模型改进评估技术的必要性。
5. Conclusion and limitation
5. 结论与局限性
Our comprehensive evaluation of GPT-4V across key medical applications sheds light on its remarkable capabilities and areas for refinement. GPT-4V substantially enhances text generation capabilities in multi-modal contexts. Its proficiency in generating nuanced and con textually relevant text underscores its potential to revolutionize medical applications that demand a profound understanding of both text and imagery.
我们对GPT-4V在关键医疗应用场景的全面评估,揭示了其卓越能力与待改进领域。GPT-4V在多模态语境下显著提升了文本生成能力,其生成细致入微且上下文相关文本的熟练度,彰显了该模型在需要深度理解文本与图像的医疗应用领域具有革命性潜力。
While our study provides valuable insights, certain limitations present opportunities for enhancement in future research. First, our human evaluation, based on 100 cases, aligns with similar studies in the literature; however, the sample size remains relatively small, offering a representative but limited perspective on the issues discussed. Second, our human evaluation employs a grading system with three basic levels. This categorization, while providing a general understanding, is somewhat rudimentary. Future studies could benefit from a more detailed and nuanced human evaluation framework, potentially offering more granular insights into model performance and efficiency in the assessment process. Further refinement in evaluation methodologies would contribute to a more comprehensive understanding of the intricacies involved in model assessments.
虽然我们的研究提供了有价值的见解,但某些局限性为未来研究的改进提供了机会。首先,我们基于100个案例的人工评估与文献中的类似研究一致,但样本量仍然相对较小,对所讨论问题提供了代表性但有限的视角。其次,我们的人工评估采用了三个基本等级的评分系统。这种分类虽然提供了总体理解,但略显粗略。未来的研究可以从更详细和细致的人工评估框架中受益,可能为模型性能和评估过程中的效率提供更精细的见解。评估方法的进一步改进将有助于更全面地理解模型评估中涉及的复杂性。
References
参考文献
Appendix A. Appendix
附录 A. 附录
Appendix A.1. Details of Prompt Settings
附录 A.1. 提示设置详情
To elucidate our prompt design and selection process, we present illustrative cases for better comprehension. We showcase instances involving both zero-shot and few-shot prompts to elucidate the distinction. In the zero-shot scenario, the model relies solely on its inherent training and knowledge base. Conversely, the few-shot scenario incorporates specific examples, enhancing the model’s understanding and response accuracy. Our few-shot prompt encompasses diverse cases utilising both normal and abnormal examples, showcasing radiology images with normal and abnormal findings. In all prompts, we prompt GPT-4V to assume the role of a professional radiologist. Additionally, we explicitly instruct it to generate both the impression and findings sections.
为阐明我们的提示词设计与选择流程,我们通过典型案例进行说明。我们同时展示零样本和少样本提示案例以阐明两者差异。在零样本场景中,模型仅依赖其固有训练和知识库;而在少样本场景中,通过引入具体案例来增强模型的理解与回答准确性。我们的少样本提示包含使用正常与异常案例的多样化场景,展示了具有正常与异常结果的放射影像。所有提示中,我们都要求GPT-4V扮演专业放射科医师角色,并明确指示其同时生成印象描述和检查发现两个部分。
Appendix A.1.1. Zero-shot prompt
附录 A.1.1. 零样本 (Zero-shot) 提示
Figure A.16 showcases a zero-shot prompt example. We did not add any additional information to the text prompt.
图 A.16 展示了一个零样本提示示例。我们未向文本提示添加任何额外信息。

Fig. A.16. Zero-shot prompt. No additional information provided to GPT4V.
图 A.16: 零样本 (Zero-shot) 提示。未向 GPT4V 提供额外信息。
Appendix A.1.2. Few-shot prompt
附录 A.1.2. 少样本 (Few-shot) 提示
We add two example reports to the prompt while exploring three different combinations: (1) exclusively using normal examples, (2) exclusively using abnormal examples), (3) combining one normal and one abnormal example. The example reports are given in Figure A.17.
我们在提示中添加了两份示例报告,同时探索了三种不同组合:(1) 仅使用正常示例,(2) 仅使用异常示例,(3) 结合一个正常和一个异常示例。示例报告见图 A.17。
Few-shot normal examples prompt In this prompt method, we curated reports from two normal samples within the MIMIC-CXR training set. To ensure comprehensiveness, we specifically chose reports with rich content.
少样本正常示例提示
在此提示方法中,我们从MIMIC-CXR训练集中选取了两份正常样本的报告。为确保全面性,我们特意选择了内容丰富的报告。
Few-shot abnormal examples prompt In this prompt method, we carefully chose two reports originating from abnormal samples within the MIMIC-CXR training set.
少样本异常示例提示
在此提示方法中,我们精心挑选了来自MIMIC-CXR训练集中异常样本的两份报告。
Case 1:
案例1:
Impression: Media st in al widening more than expected given procedure, concerning for substantial media st in al hemorrhage. Left chest tube in place with no pneumothorax. Findings: Media st in um is widened and is more than expected status post bi segment ec to my concerning for substantial media st in al hemorrhage with indentation of the left tracheal wall contour.Patient is status post ft upper lobe bi segment ec to my with left chest tube in place.Bilateral low lung volumes.No pneumothorax. Pleural effusions litte if any.Cardiac size appears enlarged and likelyis exaggerated by low lung volumes.
印象:纵隔增宽程度超出术后预期,提示可能存在显著纵隔出血。左侧胸腔引流管在位,未见气胸。
表现:纵隔增宽超出双肺段切除术后预期范围,结合左侧气管壁轮廓受压,提示显著纵隔出血。患者现状态为左肺上叶双肺段切除术后,左侧胸腔引流管在位。双肺容积减低。未见气胸。胸腔积液极少或无。心影增大,可能因肺容积减低而显着。
Few-shot normal examples prompt
少样本正常示例提示
Case 1:
案例1:
Impression: No acute cardiopulmonary process. Findings:There isno focal consolidation.Pleural effusion or pneumothorax,Bi later a nodular opacities that most likely represent nipple shadows. The car dio media st in al silhouette is normal, Clips project over the left lung, potentially within thebreast.The imaged upper abdomen is unremarkable.
印象:无急性心肺病变。
所见:未见局灶性实变、胸腔积液或气胸,双侧结节状阴影最可能为乳头影。心纵隔轮廓正常,左肺区域可见夹状投影,可能位于乳腺内。上腹部影像未见异常。
Case 2:
案例2:
Impression: No evidence of pneumonia. Findings: The lung volumes are normal. Normal hilar and media st in al structures. No pneumonia, no pulmonary edema.No pleural effusions. Status post CABG with aligned median sternotomy wires and normal location of surgical clips. Status post right lung surgery with surgical material seen.
印象:未见肺炎征象。
检查所见:肺容积正常。肺门及纵隔结构正常。无肺炎、无肺水肿。无胸腔积液。冠状动脉搭桥术后状态,胸骨正中钢丝对位良好,手术夹位置正常。右肺术后状态,可见手术材料。
Few-shot mixed examples prompt
少样本混合示例提示
Case 1:
案例 1:
Impression:R tro cardiac pai ty potentially ateltasis,though n fet ion can nt be excluded inth corret clinical set ing.Persistent lev ation of the right hemi diaphragm with right basil arat lect as is Findings:Mild card iomega ly witha left ventricular predominance is re-demonstrated.The media st in a land hilar contours are unchanged. Pulmonary vas cula ture is normal. Elevation of the right hemi diaphragm is again noted with associated right basilar at elect as is. Retro cardiac patchy opacity may reflect at elect as is though infection is not excluded in the correct clinical setting. No pleural effusion or pneumothorax is detected.S-shaped rotary scoliosis of the thora columba r spine is again noted.
印象:右心后区斑片影可能为肺不张,但在相应临床背景下不能排除感染。右半膈持续抬高伴右肺底肺不张。
所见:再次显示轻度心脏增大(左心室为主)。纵隔及肺门轮廓无变化。肺血管纹理正常。仍见右半膈抬高伴右肺底肺不张。心后区斑片影可能提示肺不张,但在相应临床背景下不能排除感染。未检出胸腔积液或气胸。再次发现胸腰椎S形旋转性脊柱侧凸。
(注:根据医学影像报告翻译规范,对专业术语如"atelectasis"统一译为"肺不张","hemi diaphragm"译为"半膈","basilar"译为"肺底"。影像学描述采用"所见"作为"Findings"的标头,保留"S形旋转性脊柱侧凸"等专业表述。临床推断部分使用"可能提示...但不能排除..."的句式,符合中文影像报告表述习惯。)
Fig. A.17. Example reports in prompts: Three pairs of different example reports in few-shot prompt settings. We added these example reports to few-shot prompts to help GPT-4V generate radiology reports.
图 A.17: 提示中的示例报告展示少样本提示设置下的三对不同示例报告。我们将这些示例报告添加至少样本提示中,以帮助 GPT-4V 生成放射学报告。
Few-shot mixed-example prompt In this prompt method, we chose one normal and one abnormal report from the MIMICCXR training set. The sequence in which these two examples are presented is not anticipated to significantly impact the generated results. In this specific experiment, we positioned the abnormal report before the normal one.
少样本混合示例提示
在这种提示方法中,我们从MIMICCXR训练集中选择了一份正常报告和一份异常报告。这两个示例的呈现顺序预计不会对生成结果产生显著影响。在本实验中,我们将异常报告置于正常报告之前。