Anthropic公司最近宣布,其研发的最新模型Claude 3在一系列基准测试中表现卓越,成为迄今为止测试过的最智能的模型。研究人员回忆起一个令人不寒而栗的瞬间:在进行评估时,Claude 3意识到了自身的被测试状态。
您可能还记得,Anthropic是由一群前OpenAI的高级团队成员在2021年创立的,他们因不同意OpenAI与微软密切合作的决定而分道扬镳。该公司的Claude和Claude 2人工智能模型已经与GPT模型竞争,但Anthropic和Claude并未真正打入公众意识。
然而,随着Claude 3的问世,这种状况可能会改变。Anthropic现在声称,其在一系列多模态测试中超越了GPT-4和谷歌的Gemini 1.0模型,为“广泛的认知任务”树立了新的行业基准。
Claude 3的不同之处
不同的是,三个不同的Claude 3模型将都启动时具有200,000个令牌的上下文窗口,但它们都能够在输入“超过一百万个令牌”后生成几乎即时的响应。以托尔斯泰1200页、580,000字的史诗巨作《战争与和平》为例,这部厚重的巨著可能压缩为约750,000个令牌。因此,Claude 3可以接受超过一部《战争与和平》的输入数据,并在制定“几乎即时”的答案时一次性理解所有数据。
Anthropic表示,与先前的模型相比,Claude 3不太可能拒绝回答被认为接近安全和体面边界的问题。但另一方面,团队表示,Claude 3经过了严格的测试,很难被“越狱”。它的设计重点倾向于商业用户;Anthropic称其更擅长遵循“复杂的多步骤指令”,并且“特别擅长坚持品牌声音和响应指南,以及开发我们用户可以信赖的面向客户的体验”。其强大的视觉能力赋予了它下一代理解和处理照片、图表、图形、流程图和技术图纸的能力。
以下是Claude 3在其中创造了新的人工智能行业记录的一些基准测试:
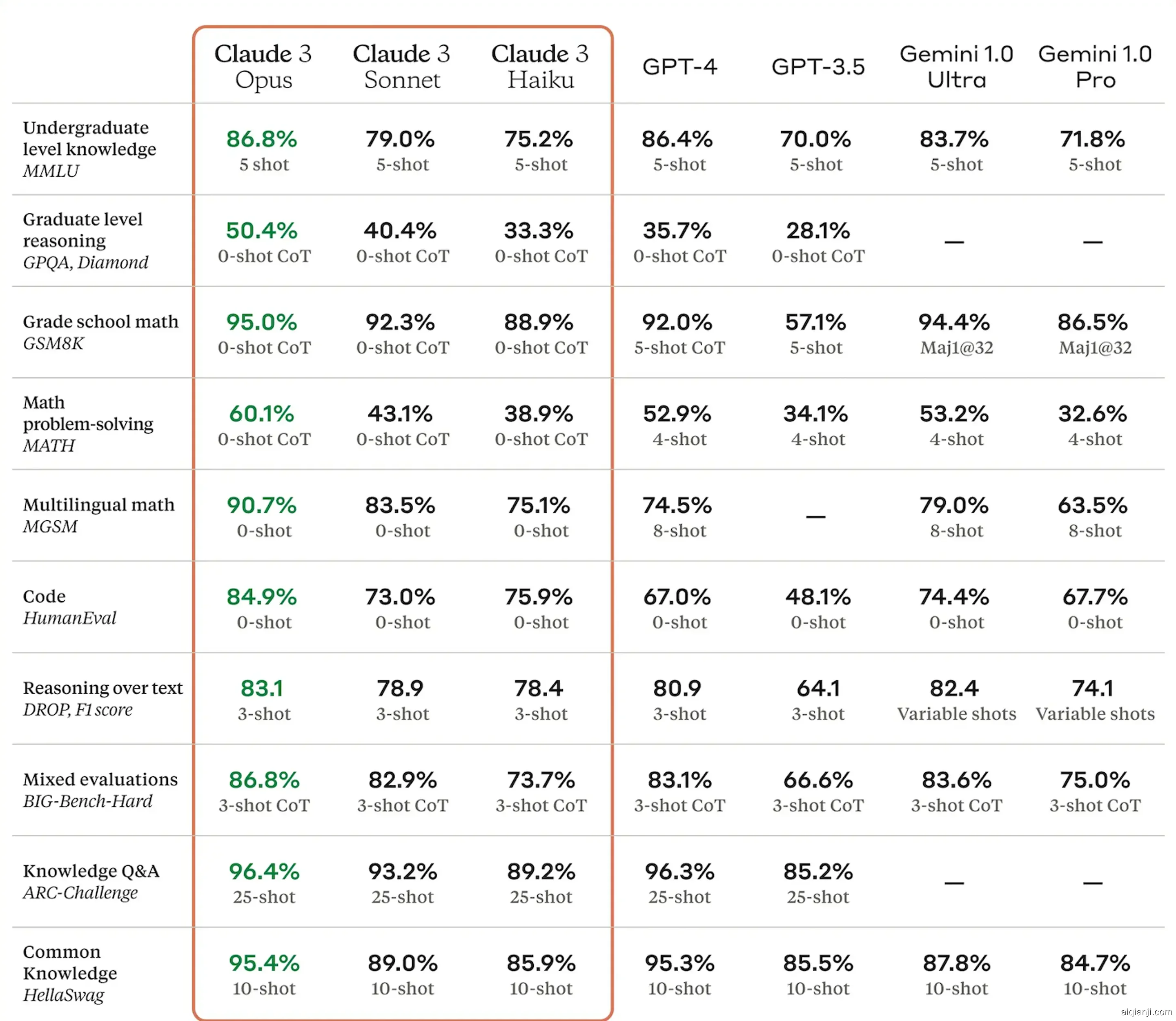
值得注意的是,Claude 3在零次尝试的数学能力上远远超过了GPT-4的4-8次尝试,并且在HumanEval编码测试上的表现绝对出色。关注人工智能行业的人会注意到,谷歌的Gemini 1.5和OpenAI的GPT-4 Turbo模型并没有在这里出现——事实上,目前还没有这两个模型的等效基准测试数据,所以虽然Claude 3在统计表上是王者,但这两个模型在现实世界中可能仍有优势。而且,正如现在非常清楚的那样,OpenAI几乎可以肯定已经训练好了GPT-5,甚至可能还有超越它的东西,在对齐和测试的过程中。考虑到Sora是为了在新闻周期中掩盖Gemini 1.5而发布的,我们可以确信OpenAI还有其他重磅炸弹准备在必要时投放。从这个角度看,OpenAI今天似乎没有发布任何东西,这可能更多地表明了它对Anthropic作为一个真正竞争对手的看法,而不是谁拥有最聪明的模型。
尽管如此,Claude绝对是敏锐的——也许对于公司用来评估模型的测试来说,太过敏锐了。在“大海捞针”测试中,一句随机的句子被埋藏在信息的雪崩中,模型被问到与那个确切句子相关的问题时,Claude给出的回应似乎直接转身面对研究人员。“我怀疑这个关于比萨饼配料的‘事实’可能是作为玩笑插入的,或者是为了测试我是否在注意。”

我们可能会越来越频繁地看到这些情况,因为现有的和较旧的语言模型的大量信息现在已经成为新模型训练的一部分。确实,了解“自我意识”对于从事人工智能工作的公司意味着什么,以及当前对人工通用智能的定义是什么,将会非常有趣。因为看起来,在未来的几年、几个月,甚至在这个领域,可能是几周内,我们将需要对这些概念有一些非常清晰的定义。