引言
在学习计算机视觉课程的经典技术时,我偶然阅读了Max Halford关于从漫画书中提取画框的博文。他设计了一个颇为有趣的算法,采用Canny算子检测画框边界,填补空洞,并对连续区域拟合边界框。
这一巧妙算法虽然效果显著,但亦有不足之处。例如,它无法处理任意非对齐多边形,且在负画框上无效,因为负画框没有自己的边界,而是由邻近画框的边界定义。
鉴于对如SAM这类基础模型在分割领域的热议,我通过程序化生成合成的漫画书数据集,并对SAM进行微调,以便检测画框的角点。

- 上图:David Revoy的《Pepper and Carrot》中的画框为多边形,非轴对齐边界框。
- 下图:负画框可能没有明确的边界。
程序化漫画生成器
针对这一问题,现有数据并不丰富。但这并不意味着我们应束手无策。一种广泛应用的常见技术(参见Erroll Wood的工作)是程序化生成训练数据。
在我们的案例中,这意味着模拟漫画书。注意,我们不需要制作引人入胜的动画或讲述故事,我们只需生成从五万英尺高空看似漫画的面板。为此,我编写了一个布局的程序生成器,并在空白图像上随机分配盒子。我用从Danbooru数据集中抽取的图像填充这些盒子。
为了确保抽样的图像至少具有一定的连贯性,我使用了CLIP L/14图像编码器创建图像索引。在为特定页面选择图像时,我从Danbooru随机抽取一幅图像,并使用它的k-最近邻填充其余盒子。
借助这一程序生成器,我可以完全控制盒子的大小、形状和边界属性,从而适当设置以模拟负和多边形画框。


- 上图:初版仅是一些盒子。
- 下图:终版中,我随机向盒子中添加了Danbooru的图像。
漫画分割
我使用SAM作为我的模型的骨干。SAM是最先进的图像分割模型。它由一个计算密集型的图像编码器和一个轻量级解码器组成,后者用于回答分割查询。繁重的编码器仅对图像编码一次,之后可以廉价地回答多个分割查询。这种分工对于部署尤为有用,企业可以通过在云端保持繁重的编码器推理,并在用户设备上进行轻量级推理,以优化速度和成本。
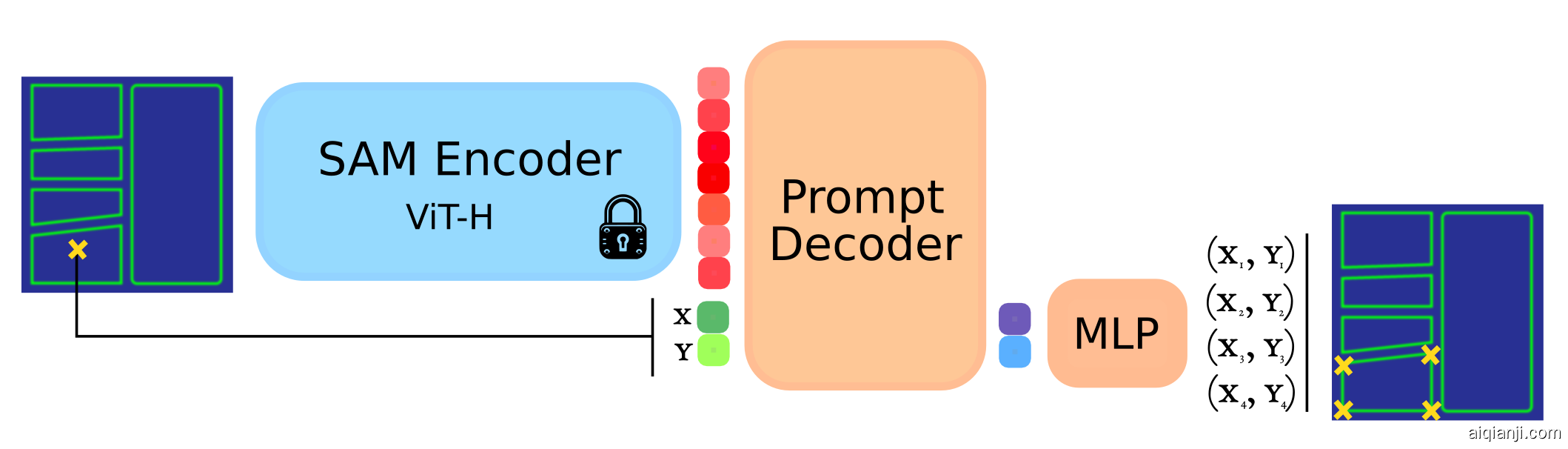
由于SAM预测的是密集的、每像素掩码,我对其进行了修改,使其能预测点。模型概览如下。程序生成的漫画画框被送入图像编码器(训练期间其权重保持不变)。从画框中随机采样一个点,并作为查询/提示。轻量级解码器被训练以恢复画框的角点。
模型概览
在训练这个模型时,我学到了两个教训。首先,规范化预测画框角点的顺序很重要。没有这一步,模型会在角点排序上收到冲突信号,从而无法收敛。其次,使用L1而非L2损失很重要,因为L2在没有提高预测质量的情况下,会很快优化。
评估
我将我的方法与原始的SAM和Halford的方法进行了比较。注意,在这一比较中,Halford的方法稍显不利,因为我的方法还使用了查询(设置为待预测真实画框的中心)。尽管如此,很明显,我们基于程序化生成数据集训练的模型,在“现实世界”的漫画(简称P&C)上具有泛化性,接近Halford的方法。在程序化生成的数据集(简称Pr)上,它击败了Halford的方法,因为该数据集旨在暴露方法的缺陷。
方法比较
| 方法 | IoU (P&C) | PCK@0.1 (P&C) | L1 (P&C) | IoU (Pr) | PCK@0.1 (Pr) | L1 (Pr) |
|---|---|---|---|---|---|---|
| SAM | 0.42 | 0.52 | 0.37 | 0.81 | 0.94 | 0.08 |
| Halford | 0.93 | 0.96 | 0.04 | 0.47 | 0.61 | 0.47 |
| 我们的方法 | 0.88 | 0.98 | 0.05 | 0.88 | 0.99 | 0.03 |
这里,IoU简单衡量了真实画框与预测画框交集与并集的面积比。PCK@0.1指的是预测画框角点在真实画框角点一定半径内的百分比(0.1指的是半径为漫画页面对角线的百分比)。L1是真实画框与预测画框之间的L1距离。
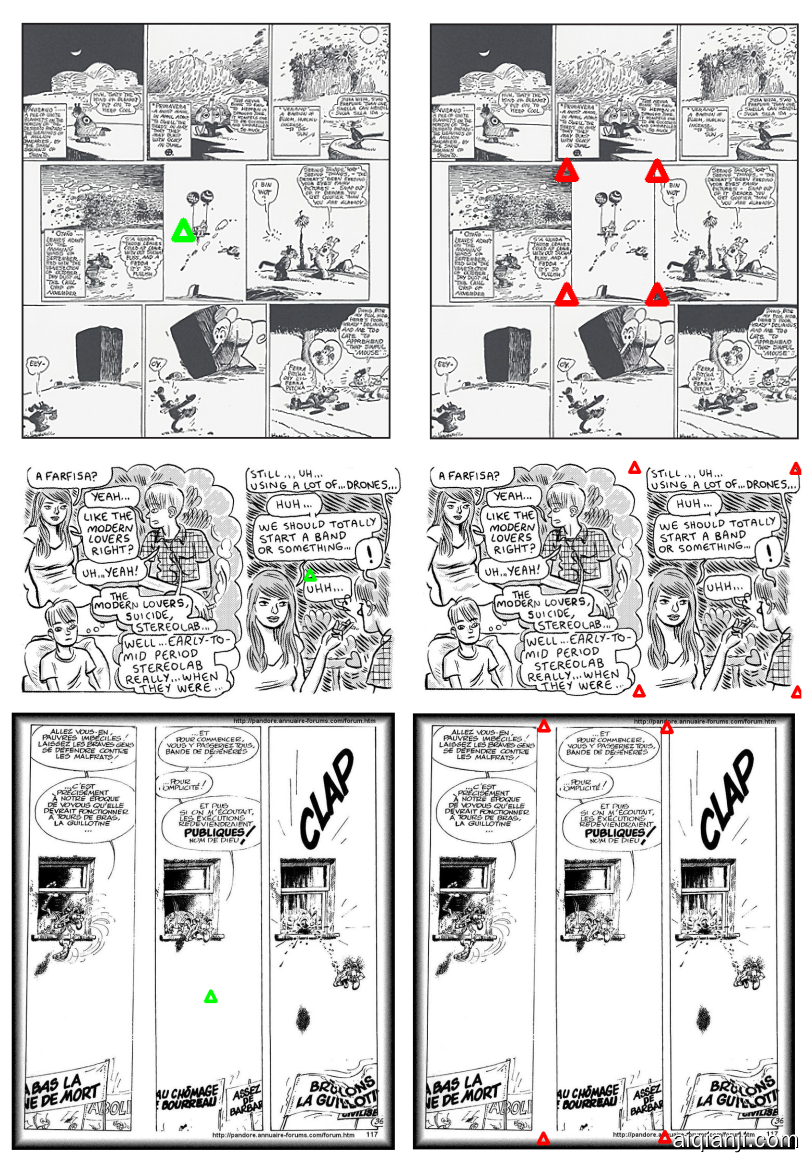
定性结果
下面是一些定性结果,展示了我们的方法在“现实世界”的漫画上的有效性。我们以两种模式运行:左侧,我们交互式提供查询,模型生成角点;右侧,我们在图像上采样一系列查询,预测多边形,并使用非极大值抑制过滤,如原始SAM论文所示。

总结思考
我的方法仍有不足之处,对于复杂、杂乱的漫画页面,它常常失败。但我仍然喜欢这种设计算法的方法,而不是组合OpenCV函数,因为往往更容易看到如何改进数据集,而不是设计新的启发式方法。一旦做到这一点,你几乎可以保证神经网络机制将带来结果。
用于评估的《Pepper and Carrot》标注数据集和代码均可以本站下载。