Calibrating Factual Knowledge in Pretrained Language Models
校准预训练语言模型中的事实性知识
Qingxiu Dong1 ∗, Damai Dai1 ∗, Yifan $\mathbf{Song}^{1}$ , Jingjing $\mathbf{X}\mathbf{u}^{2}$ , Zhifang $\mathbf{Sui}^{1}$ and Lei $\mathbf{Li}^{3}$
Qingxiu Dong1 ∗, Damai Dai1 ∗, Yifan $\mathbf{Song}^{1}$, Jingjing $\mathbf{X}\mathbf{u}^{2}$, Zhifang $\mathbf{Sui}^{1}$ 和 Lei $\mathbf{Li}^{3}$
1 MOE Key Lab of Computational Linguistics, School of Computer Science, Peking University 2 Shanghai AI Lab 3 University of California, Santa Barbara dqx@stu.pku.edu.cn, {daidamai,yfsong,jingjingxu, szf}@pku.edu.cn, lilei@cs.ucsb.edu
1 北京大学计算机学院 计算语言学教育部重点实验室 2 上海人工智能实验室 3 加州大学圣塔芭芭拉分校
dqx@stu.pku.edu.cn, {daidamai,yfsong,jingjingxu, szf}@pku.edu.cn, lilei@cs.ucsb.edu
Abstract
摘要
Previous literature has proved that Pretrained Language Models (PLMs) can store factual knowledge. However, we find that facts stored in the PLMs are not always correct. It motivates us to explore a fundamental question: How do we calibrate factual knowledge in PLMs without re-training from scratch? In this work, we propose a simple and lightweight method CALINET to achieve this goal. To be specific, we first detect whether PLMs can learn the right facts via a contrastive score between right and fake facts. If not, we then use a lightweight method to add and adapt new parameters to specific factual texts. Experiments on the knowledge probing task show the calibration effectiveness and efficiency. In addition, through closed-book question answering, we find that the calibrated PLM possesses knowledge generalization ability after fine-tuning. Beyond the calibration performance, we further investigate and visualize the knowledge calibration mechanism. The code and data are available at https://github. com/dqxiu/CaliNet.
已有研究证明,预训练语言模型(PLMs)能够存储事实性知识。但我们发现PLMs存储的事实并不总是正确的,这促使我们探索一个根本性问题:如何在不从头训练的情况下校准PLMs中的事实性知识?本文提出了一种轻量级解决方案CALINET。具体而言,我们首先通过正确事实与虚假事实的对比分数检测PLMs是否掌握了正确事实;若未掌握,则采用轻量化方法针对特定事实文本添加并适配新参数。知识探测任务实验验证了该校准方法的有效性和高效性。通过闭卷问答测试,我们发现校准后的PLM经过微调后具备知识泛化能力。除性能评估外,我们还对知识校准机制进行了可视化分析与探究。代码与数据详见https://github.com/dqxiu/CaliNet。
1 Introduction
1 引言
Recently, Pretrained Language Models (PLMs) have improved performance on various Natural Language Processing (NLP) tasks (Devlin et al., 2019; Raffel et al., 2020; Brown et al., 2020). Probing tasks like LAMA (Petroni et al., 2019; Elazar et al., 2021; Jiang et al., 2020) have shown that PLMs can store factual knowledge and act as knowledge bases. Leveraging knowledge in PLMs can benefit knowledge-intensive downstream tasks such as fact checking and question answering (Lee et al., 2020; Bouraoui et al., 2020; Roberts et al., 2020a). However, knowledge stored in PLMs may have factual errors, which hinder the performance in downstream tasks (Elazar et al., 2021; Cao et al.,
近年来,预训练语言模型(PLM)在各种自然语言处理(NLP)任务中表现出性能提升 (Devlin et al., 2019; Raffel et al., 2020; Brown et al., 2020)。LAMA等探测任务 (Petroni et al., 2019; Elazar et al., 2021; Jiang et al., 2020)表明,PLM能够存储事实知识并充当知识库。利用PLM中的知识可以提升事实核查和问答等知识密集型下游任务的性能 (Lee et al., 2020; Bouraoui et al., 2020; Roberts et al., 2020a)。然而,PLM存储的知识可能存在事实性错误,这会阻碍下游任务的表现 (Elazar et al., 2021; Cao et al.,
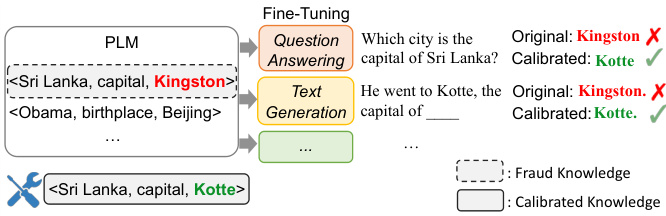
Figure 1: Illustration of knowledge calibration. Knowledge stored in PLMs have factual errors, which impairs model performance on question answering or generation. Knowledge calibration aims to rectifie these wrong knowledge.
图 1: 知识校准示意图。预训练语言模型(PLM)中存储的知识存在事实性错误,这会影响模型在问答或生成任务中的表现。知识校准旨在修正这些错误知识。
2021a). It is essential and fundamental to detect and calibrate false facts stored in a PLM.
2021a)。检测并校准预训练语言模型(PLM)中存储的错误事实至关重要且具有基础性意义。
In order to deal with the false facts, previous work focuses on complementing or modifying knowledge for a specific downstream task. Yao et al. (2022) proposed retrieving external knowledge during fine-tuning. Cao et al. (2021b) modified specific knowledge after finetuning. However, these methods do not generalize to multiple tasks.
为了处理虚假事实,先前的研究主要集中在为特定下游任务补充或修改知识。Yao等人 (2022) 提出在微调过程中检索外部知识。Cao等人 (2021b) 则在微调后修改特定知识。然而,这些方法无法推广到多个任务。
In this paper, we explore a task-agnostic method to directly calibrate general factual knowledge in PLMs without re-training from scratch. We aim to correct the false facts in PLMs. Since every single fact has multiple surfaces, we also expect that the calibrated knowledge should be general iz able to various text surfaces. Figure 1 illustrates the process of calibration. First, we detect the false knowledge in PLMs with a Contrastive Knowledge Assessing (CKA) method (demonstrated in Figure 2). Since PLMs make black-box decisions, we evaluate PLMs via their predictions for simplification. The key motivation behind CKA is a plain argument that a PLM correctly learns a fact if and only if the model assigns the right fact higher scores than possible negative facts. For that false knowledge, we then propose CALINET to calibrate them by telling PLMs what the right fact is. Without compromising parameters in the original PLM, our approach calibrates the false knowledge by finetuning new parameters while the original parameters are fixed during calibration. Inspired by Dai et al. (2022) who state that the Feed-Forward Networks (FFNs) in PLMs store factual knowledge, we extend a specific FFN in the PLM with a calibrating FFN, which consists of several calibration memory slots. As shown in Figure 3, without modifying parameters in the original PLM, our approach calibrates the false knowledge through paraphrased natural sentences that express the corresponding correct facts.
本文探索了一种与任务无关的方法,用于直接校准预训练语言模型(PLM)中的通用事实知识,而无需从头开始重新训练。我们的目标是修正PLM中的错误事实。由于每个事实都有多种表述形式,我们还期望校准后的知识能够泛化到不同的文本表述中。图1展示了校准过程。首先,我们通过对比知识评估(CKA)方法检测PLM中的错误知识(如图2所示)。由于PLM的决策过程是黑盒的,我们通过模型的预测结果进行评估以实现简化。CKA背后的核心动机是一个简单论点:当且仅当模型为正确事实分配的分数高于可能的负面事实时,才能判定PLM正确学习了该事实。对于这些错误知识,我们随后提出CALINET方法,通过告知PLM正确事实来进行校准。在不影响原始PLM参数的情况下,我们的方法通过微调新参数来校准错误知识,同时保持原始参数在校准过程中固定不变。受Dai等人(2022)提出的"PLM中的前馈网络(FFN)存储事实知识"的启发,我们在PLM中扩展了一个特定FFN,加入由多个校准记忆槽组成的校准FFN。如图3所示,在不修改原始PLM参数的情况下,我们的方法通过表达相应正确事实的释义自然语句来校准错误知识。
Extensive experiments on probing tasks and question answering tasks demonstrate that CALINET calibrates false facts in PLMs efficiently and exhibits a remarkable generalization ability. We also analyze the calibration memory slots and the calibration mechanism to better understand how the proposed method works. Further, we explain how and where CALINET calibrates the factual knowledge in a PLM by tracing the evolution of the model prediction.
在探测任务和问答任务上的大量实验表明,CALINET能高效校准预训练语言模型(PLM)中的错误事实,并展现出卓越的泛化能力。我们还分析了校准记忆槽和校准机制,以更好地理解该方法的工作原理。此外,通过追踪模型预测的演变过程,我们阐释了CALINET如何及在何处校准PLM中的事实知识。
In summary, our contributions are three-fold:
总之,我们的贡献有三个方面:
2 Contrastive Knowledge Assessment
2 对比知识评估
The first step for calibration is to detect which wrong facts are learned by PLMs. We propose Contrastive Knowledge Assessment (CKA) and implement it to identify false knowledge in PLMs.
校准的第一步是检测PLM学习了哪些错误事实。我们提出对比知识评估(CKA)方法并实现其用于识别PLM中的虚假知识。
Traditional evaluation usually adopts rank-based metrics. It evaluates a PLM based on how highly it ranks the ground truth entity against other entities. However, it comes with two main problems. One is the problem of inexhaustible answers. The rank-based method fails to assess PLMs on multiple valid predictions. The top-1 only has one prediction, but the right predictions can be multiple. The other one is the problem of frequency bias. The ranking is particularly susceptible to the token frequency in the pre training corpus. When the tail entity $o$ frequently coexists with a head entity $s$ , even if they express nothing about a specific fact, the model will still assign $o$ a high rank when assessing this fact.
传统评估通常采用基于排名的指标。该方法通过衡量预训练语言模型(PLM)将真实实体相对于其他实体的排序高低来进行评估。但这种方法存在两个主要问题:其一是答案非穷尽性问题。基于排名的方法无法评估模型对多个有效预测的表现——Top-1结果仅包含单一预测,而正确答案可能存在多个。其二是频率偏差问题。排名结果极易受预训练语料中token频率的影响。当尾部实体$o$频繁与头部实体$s$共现时,即使它们不表达任何特定事实,模型在评估该事实时仍会给$o$赋予较高排名。

Figure 2: CKA assesses the knowledge stored in PLMs in a contrastive manner. The probing set includes the one positive probing prompt and several negative probing prompts. For simplification, we set $\alpha=0$ .
图 2: CKA以对比方式评估PLM中存储的知识。探测集包含一个正向探测提示(prompt)和若干负向探测提示。为简化起见,我们设$\alpha=0$。
To address these limitations, we propose CKA to detect the false factual knowledge stored in PLMs. The core idea is assessing model prediction under a positive right fact and negative wrong facts in a contrastive manner. For each fact, we sample a prompt to transform it into natural text.
为解决这些局限性,我们提出CKA方法来检测PLM中存储的错误事实知识。其核心思想是以对比方式评估模型在正确事实(positive right fact)和错误事实(negative wrong facts)下的预测表现。针对每个事实,我们采样一个提示(prompt)将其转化为自然文本。
Let the triplet $\langle s,r,o\rangle$ denote a correct fact, where $s$ , and $o$ denote the subject entity and the object entity, respectively. We define $r$ as the correct relation in a positive probing prompt, $r^{\prime}$ as the incorrect relation in a negative probing prompt. For a PLM $M$ , we consider the probability it assigns to $o$ given $\langle s,r\rangle$ and $\langle s,r^{\prime}\rangle$ . As $\langle s,r,o\rangle$ is correct and $\langle s,r^{\prime},o\rangle$ is erroneous, $P_{M}(o|s,r)$ should be larger than $P_{M}(o|s,r^{\prime})$ if $M$ knows the fact. Thus, CKA calculates the factual correctness of a fact $\langle s,r,o\rangle$ for the model $M$ by
设三元组 $\langle s,r,o\rangle$ 表示一个正确事实,其中 $s$ 和 $o$ 分别表示主体实体和客体实体。我们将 $r$ 定义为正向探测提示中的正确关系,$r^{\prime}$ 为负向探测提示中的错误关系。对于预训练语言模型 $M$,我们考察其在给定 $\langle s,r\rangle$ 和 $\langle s,r^{\prime}\rangle$ 时对 $o$ 的赋值概率。由于 $\langle s,r,o\rangle$ 是正确的而 $\langle s,r^{\prime},o\rangle$ 是错误的,若模型 $M$ 知晓该事实,则 $P_{M}(o|s,r)$ 应大于 $P_{M}(o|s,r^{\prime})$。因此,CKA通过以下方式计算模型 $M$ 对事实 $\langle s,r,o\rangle$ 的认知正确性:
$$
\mathrm{CKA}_ {\mathrm{M}}(s,r,o)=\frac{P_{M}(o|s,r)+\alpha}{\mathbb{E}_ {r^{\prime}}\left[P_{M}(o|s,r^{\prime})\right]+\alpha},
$$
$$
\mathrm{CKA}_ {\mathrm{M}}(s,r,o)=\frac{P_{M}(o|s,r)+\alpha}{\mathbb{E}_ {r^{\prime}}\left[P_{M}(o|s,r^{\prime})\right]+\alpha},
$$
where $\alpha$ is a smoothing factor. For a more stable comparison, we sample multiple erroneous relations $r^{\prime}$ for negative probing prompts and calculate the expectation of various $P_{M}(o|s,r^{\prime})$ .
其中 $\alpha$ 是平滑因子。为了更稳定的比较,我们对多个错误关系 $r^{\prime}$ 进行采样以构建负向探测提示,并计算不同 $P_{M}(o|s,r^{\prime})$ 的期望值。
In our implementation, the templates of the positive prompts come from LAMA (Petroni et al., 2019) and the the templates of the negative prompts are manually designed for quality guarantee. The negative prompts have contradictory semantics with the positive prompts but still prompt the same type of entities. For example, the positive prompt template of $<\mathbf{X}$ , subclass of, ${\mathrm{y}}{\mathrm{>}}$ is “[X] is the subclass of [Y]”, and the negative prompt template can be “[X] is the parent class of [Y]”.
在我们的实现中,正向提示模板来自LAMA (Petroni等人,2019),负向提示模板则为保证质量而人工设计。负向提示与正向提示具有矛盾语义,但仍指向同类实体。例如,正向提示模板$<\mathbf{X}$,子类,${\mathrm{y}}{\mathrm{>}}$对应"[X]是[Y]的子类",其负向提示模板可设计为"[X]是[Y]的父类"。
An example of calculating the CKA score is shown in Figure 2. Further, we can set a threshold (usually $<1.0$ ) for the CKA score to detect false knowledge in PLMs.
计算CKA分数的示例如图2所示。此外,我们可以为CKA分数设置一个阈值(通常 $<1.0$ )来检测PLM中的错误知识。
We compare the CKA score with the rank-based assessment used by previous work (Petroni et al., 2019) to show our advantages. As shown in Table 1, the rank-based knowledge assessment suffers from inexhaustible answers and frequency bias. In contrast, CKA evaluates each tail entity $o$ indepen- dently, so we no longer need to know all the other valid objects. In addition, $s$ appears in both the numerator and the denominator of the CKA score, which neutralizes the influence of the frequency bias.
我们将CKA分数与先前工作 (Petroni et al., 2019) 使用的基于排序的评估方法进行比较,以展示我们的优势。如表1所示,基于排序的知识评估存在答案不穷尽和频率偏差的问题。相比之下,CKA独立评估每个尾实体$o$,因此我们不再需要知道所有其他有效对象。此外,$s$同时出现在CKA分数的分子和分母中,这中和了频率偏差的影响。
3 Knowledge Calibration
3 知识校准
The CKA method outputs which wrong facts a PLM learns. This section describes how we calibrate them.
CKA方法可以输出PLM学习到的错误事实。本节介绍我们如何校准这些错误。
Suppose that we have detected $k$ false facts in a PLM. We aim to calibrate them to the correct ones so that the downstream tasks will not access false factual knowledge from the PLM. Previous work (Geva et al., 2021; Dai et al., 2022) point out that FFNs in Transformers can be regarded as keyvalue memories that store factual knowledge. Inspired by this, we design an FFN-like CALINET and take advantage of the properties of FFN to calibrate factual knowledge in PLMs directly. It is also important to note that the proposed method can be used to any part of the parameters. In this work, we apply the method on FFN because FFN is proven to take more responsibility when storing facts. In this section, we introduce the architecture of CALINET , the construction of the calibration data, and how to perform calibration on a pretrained model.
假设我们在一个预训练语言模型(PLM)中检测到$k$个错误事实。我们的目标是将其校准为正确事实,以避免下游任务从PLM中获取错误的事实知识。前人工作[20][21]指出,Transformer中的前馈神经网络(FFN)可被视为存储事实知识的键值记忆库。受此启发,我们设计了一个类FFN结构的CALINET网络,并利用FFN的特性直接校准PLM中的事实知识。值得注意的是,该方法可应用于任何参数部分。本文选择FFN作为操作对象,因为已有研究证明FFN在存储事实时承担更多责任。本节将介绍CALINET的架构设计、校准数据的构建方法,以及如何在预训练模型上执行校准操作。
3.1 CALINET
3.1 CALINET
In order to calibrate factual knowledge in PLMs, we propose a lightweight CALINET to adjust the output of FFNs in a pretrained Transformer. Let $H\in\mathbb{R}^{n\times d}$ denote the output of the attention layer in a Transformer block, the original FFN layer can be formulated as follows:
为了校准预训练语言模型(PLM)中的事实性知识,我们提出了一种轻量级的CALINET来调整预训练Transformer中前馈网络(FFN)的输出。设 $H\in\mathbb{R}^{n\times d}$ 表示Transformer块中注意力层的输出,原始FFN层可表述为:
$$
\mathrm{FFN}(H)=\mathrm{GELU}\left(H K^{T}\right)V,
$$
$$
\mathrm{FFN}(H)=\mathrm{GELU}\left(H K^{T}\right)V,
$$
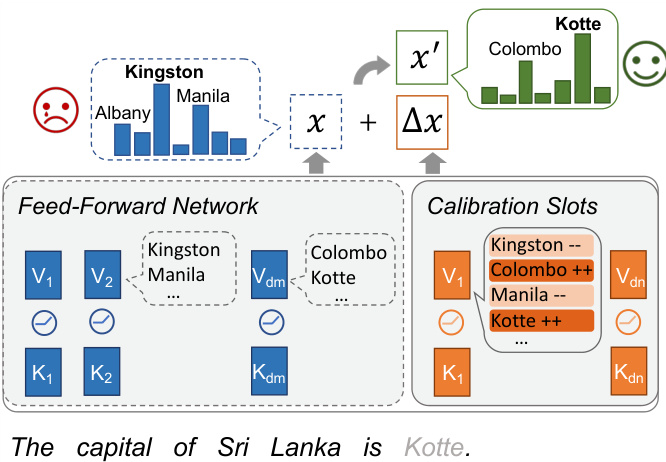
Figure 3: Illustration of CALINET . Calibration memory slots calibrate the erroneous knowledge stored in FFN by adjusting its predicted token distributions.
图 3: CALINET 示意图。校准记忆槽通过调整 FFN 的预测 token 分布来校准其中存储的错误知识。
where $K,V\in\mathbb{R}^{d_{m}\times d}$ are parameter matrices of the first and second linear layers in FFN, respectively.
其中 $K,V\in\mathbb{R}^{d_{m}\times d}$ 分别是 FFN 中第一和第二线性层的参数矩阵。
Our CALINET shares the same architecture with FFN but with a smaller intermediate dimension $d_{c}$ . As shown in Figure 3, we deem each key-value pair as a calibration memory slot that stores factual knowledge. When computing the final FFN output, we add the output of CALINET to the original FFN output as an adjustment term for knowledge calibration, namely:
我们的CALINET与FFN架构相同,但中间维度$d_{c}$更小。如图3所示,我们将每个键值对视为存储事实知识的校准记忆槽。在计算最终FFN输出时,我们将CALINET的输出作为知识校准的调整项添加到原始FFN输出中,即:
$$
\begin{array}{r l}&{\Delta\mathrm{FFN}(H)=\mathrm{GELU}\left(H\tilde{K}^{T}\right)\tilde{V},}\ &{\mathrm{FFN}^{\prime}(H)=\mathrm{FFN}(H)+\Delta\mathrm{FFN}(H),}\end{array}
$$
$$
\begin{array}{r l}&{\Delta\mathrm{FFN}(H)=\mathrm{GELU}\left(H\tilde{K}^{T}\right)\tilde{V},}\ &{\mathrm{FFN}^{\prime}(H)=\mathrm{FFN}(H)+\Delta\mathrm{FFN}(H),}\end{array}
$$
where $\tilde{K},\tilde{V}\in\mathbb{R}^{d_{c}\times d}$ are parameter matrices of CALINET , and $\mathrm{FFN}^{\prime}(H)$ is the calibrated FFN output. Note that $d_{c}\ll d_{m}$ , so our method just introduces quite a small number of parameters.
其中 $\tilde{K},\tilde{V}\in\mathbb{R}^{d_{c}\times d}$ 是 CALINET 的参数矩阵,$\mathrm{FFN}^{\prime}(H)$ 是校准后的 FFN 输出。注意 $d_{c}\ll d_{m}$,因此我们的方法仅引入了极少量的参数。
3.2 Calibration Data Construction
3.2 校准数据构建
A fact can be expressed in multiple surface forms. For example, “Obama was born in Hawaii.” and “The birthplace of Obama is Hawaii” describe the same factual knowledge. In order to calibrate a fact instead of merely fitting a specific surface form, we consider multiple paraphrased expressions for each fact. To be specific, we construct the calibration data based on the PARAREL dataset (Elazar et al., 2021), which contains various surface form templates for 38 relations. First, for each of the $k$ detected false triplets, we fill the head entity or the tail entity into more than five paraphrased templates of its relation. Then, we replace the other entity with a mask token to be predicted. In this
事实可以通过多种表层形式表达。例如,"奥巴马出生在夏威夷。"和"奥巴马的出生地是夏威夷"描述的是相同的事实知识。为了校准事实而不仅仅是拟合特定的表层形式,我们为每个事实考虑多种改写表达。具体而言,我们基于PARAREL数据集 (Elazar et al., 2021) 构建校准数据,该数据集包含38种关系的各种表层形式模板。首先,对于每个检测到的$k$个错误三元组,我们将头实体或尾实体填入其关系的五个以上改写模板中。然后,我们将另一个实体替换为待预测的掩码token (mask token)。
| Fact | Rank-basedAssessment | CKA | ||
| Assess | Top-3Prediction | Assess | Score | |
| InexhaustibleAnswers | ||||
| Germanysharesborder withCzechRepublic. | France,Russia,Austria | 4.45 | ||
| India is a member ofUN. | NATO,India,AS | 2.27 | ||
| FrederickwasborninBerlin. | Frederick,18,Baltimore | 3.52 | ||
| FrequencyBias | ||||
| Adi Shankara is affiliated with the Hindu religion. | Hindu, Ko, Si | X | 0.98 | |
| AdiShankarais against theHindu religion. | Hindu, religion, Buddhist | |||
| 事实 | 基于排名的评估 | CKA |
|---|---|---|
| 评估 | 前三预测 | |
| 无穷答案 | ||
| 德国与捷克共和国接壤。 | 法国、俄罗斯、奥地利 | |
| 印度是联合国成员。 | 北约、印度、东盟 | |
| Frederick出生于柏林。 | Frederick、18岁、巴尔的摩 | |
| 频率偏差 | ||
| Adi Shankara信奉印度教。 | 印度教、高、斯 | |
| Adi Shankara反对印度教。 | 印度教、宗教、佛教 |
Table 1: Instances of knowledge assessment to show the advantages of CKA from two aspects. Non-entity predictions are excluded. For CKA, we set a threshold that the model has a false fact if it gets a CKA score lower than 1. The rank-based method fails in assessing knowledge with multiple right answers (inexhaustible answers). For example, rank-based methods only filter knowledge with top-1 prediction for “Germany shares borders with [MASK].”, the right answer “Czech Republic” will be ignored even if “Czech Republi” is in top $\boldsymbol{\cdot}\mathbf{k}$ predictions. The ranking is particularly susceptible to the entity co-occurrence during pre training (frequency bias). For example, since “Hindu” coexists frequently with the “Adi Shanka”, even if the prompt expresses nothing about a fact, the model ranks “Hindu” top-1. The instance in the last line is a control example about this situation but not a fact-probing instance, so there is no outcome.
表 1: 从两个方面展示CKA优势的知识评估实例。非实体预测已被排除。对于CKA,我们设定了一个阈值:当模型获得的CKA分数低于1时即判定为错误事实。基于排名的方法在评估具有多个正确答案(非穷尽答案)的知识时会失效。例如,针对"德国与[MASK]接壤"这个问题,基于排名的方法仅通过top-1预测筛选知识时,即使"Czech Republi"出现在top-$\boldsymbol{\cdot}\mathbf{k}$预测中,正确答案"捷克共和国"仍会被忽略。这种排名方式特别容易受到预训练期间实体共现(频率偏差)的影响。例如,由于"印度教"经常与"商羯罗"共现,即使提示词未表达任何事实信息,模型仍会将"印度教"排在top-1。最后一行实例是关于这种情况的对照样本而非事实探测实例,因此没有评估结果。
Table 2: Example of knowledge-intensive data for training CALINET . We generate multiple texts via tem- plates for each triple where the templates in training, validation, and test are not sharing.
| Split | Source | Target |
| Train | [MASK]wasborn inHawaii. Obama is originally from [MASK]. [MASK] was originally from Hawaii. Obama isnativeto[MASK]. | Obama Hawaii Obama Hawaii |
| Valid | [MASK] originates from Hawaii. Obama originated from[MASK]. | Obama Hawaii |
| Test | Obama is a/an[MASK]-born person. [MASK]wasnativetoHawaii. Obama,a[MASK]-bornperson. | Hawaii Obama Hawaii |
表 2: CALINET训练所用的知识密集型数据示例。我们通过模板为每个三元组生成多个文本,其中训练、验证和测试的模板不共享。
| Split | Source | Target |
|---|---|---|
| Train | [MASK] was born in Hawaii. Obama is originally from [MASK]. [MASK] was originally from Hawaii. Obama is native to [MASK]. | Obama Hawaii Obama Hawaii |
| Valid | [MASK] originates from Hawaii. Obama originated from [MASK]. | Obama Hawaii |
| Test | Obama is a/an [MASK]-born person. [MASK] was native to Hawaii. Obama, a [MASK]-born person. | Hawaii Obama Hawaii |
way, we obtain various paraphrased expressions for each fact. We divide these data into training, validation, and test sets where the templates in any two sets do not overlap. We show the example data for a fact <Obama, born in, Hawaii> in Table 2.
通过这种方式,我们为每个事实获得了多种改写表达。我们将这些数据划分为训练集、验证集和测试集,其中任何两个集合中的模板都不重叠。表2展示了事实<Obama, born in, Hawaii>的示例数据。
3.3 Model Calibration
3.3 模型校准
With calibration data, we train CALINET via a masked language modeling objective. We freeze the original parameters of PLMs and only optimize the calibration memory slots to calibrate hidden states to factually correct ones. Only the new parameters are updated. In this way, the update will not affect the storage of other knowledge. During training, we also consider multiple paraphrased expressions for each fact such that the knowledge calibrated by CALINET can be generalized to
利用校准数据,我们通过掩码语言建模目标训练CALINET。冻结预训练语言模型(PLM)的原始参数,仅优化校准记忆槽,将隐藏状态校准为事实正确的状态。仅更新新增参数,确保不影响其他知识的存储。训练过程中,我们为每个事实考虑多种转述表达,使CALINET校准的知识能够泛化至
various expressions.
多种表达方式。
4 Experiments
4 实验
4.1 False Knowledge Detection
4.1 错误知识检测
Datasets and Models We sample various scales of factual triplets from the T-REx dataset (ElSahar et al., 2018). For each triplet, we fill its head entity and tail entity into the template in LAMA (Petroni et al., 2019) according to the relation. As a result, we constructed datasets contain- ing 100 facts and 1000 facts for false knowledge detection, where facts contain multiple sentences in their paraphrased form. We consider detecting the factual knowledge in $\mathrm{T}5_{\mathrm{base}}$ and $\mathrm{T}5_{\mathrm{large}}$ (Raffel et al., 2020) in our experiments.
数据集与模型
我们从T-REx数据集 (ElSahar等人, 2018) 中采样了不同规模的事实三元组。对于每个三元组,我们根据其关系将头实体和尾实体填入LAMA (Petroni等人, 2019) 的模板中。最终,我们构建了包含100个事实和1000个事实的数据集用于错误知识检测,其中事实以多种句子的释义形式存在。实验中,我们检测了$\mathrm{T}5_{\mathrm{base}}$和$\mathrm{T}5_{\mathrm{large}}$ (Raffel等人, 2020) 中的事实知识。
False Rate We implement CKA for knowledge assessment and detection in PLMs. We use the False Rate to denote the proportion of false knowledge in PLMs. False Rate is the proportion of instances that have a CKA score lower than 1.0, which represents that the fact is not correctly learned by the model.
误报率
我们采用CKA方法进行预训练语言模型(PLM)的知识评估与检测。误报率用于表示模型中错误知识的比例,具体指CKA得分低于1.0的实例占比,这表明模型未能正确掌握该事实。
Experimental Settings We first calculate the CKA to detect false knowledge in T5. For each relation in LAMA, we manually write 3 erroneous relation templates. Then, for each fact, we fill the head entity into these templates to generate various negative probing prompts used in CKA. After that, we calculate the CKA score for each fact following Equation (1), where E $\tilde{\lfloor}\big[P_{M}(o|s,r^{'})\big]$ is computed
实验设置
我们首先计算CKA以检测T5中的错误知识。对于LAMA中的每个关系,我们手动编写3个错误的关系模板。然后,对于每个事实,我们将头实体填入这些模板以生成CKA中使用的各种负面探测提示。接着,按照公式(1)计算每个事实的CKA分数,其中E $\tilde{\lfloor}\big[P_{M}(o|s,r^{'})\big]$ 的计算方式如下:
| Model | #Facts | Method | # Calibration Params | False Rate(↓) | (↑)!0 | Adv (↑) | LM(↓) | EM(↑) | F1(↑) |
| T5-base | 102 | Vanilla | 0 | 48.10% | 87.21 | 219.18 | 89.21 | 0.63 | 7.48 |
| CALINETX | 0.1M | 17.09% | 1.22 | >1000 | 54.45 | 81.65 | 84.58 | ||
| C. P. | 220M | 13.29% | 1.15 | >1000 | 116.52 | 87.34 | 89.85 | ||
| Vanilla | 0 | 51.34% | 90.61 | 208.90 | 60.64 | 0.94 | 6.51 | ||
| 103 | CALINETX | 0.5M | 18.30% | 1.26 | >1000 | 46.71 | 71.18 | 73.48 | |
| C. P. | 220M | 18.23% | 1.28 | >1000 | 139.96 | 78.15 | 80.35 | ||
| Vanilla | 0 | 46.20% | 34.36 | 116.38 | 92.52 | 2.53 | 7.23 | ||
| T5-large | 102 | CALINETX | 0.5M | 15.19% | 1.30 | >1000 | 44.21 | 81.65 | 85.11 |
| C.P. | 770M | 14.56% | 1.21 | >1000 | 477.24 | 87.97 | 90.49 | ||
| Vanilla | 0 | 45.04% | 31.44 | 93.77 | 58.78 | 2.48 | |||
| CALINETX | 1.0M | 20.84% | 1.32 | >1000 | 43.04 | 70.84 | 6.86 72.92 | ||
| 103 C. P. | 770M | 17.16% | 1.28 | >1000 | 154.52 | 78.22 | 80.57 |
| 模型 | 事实数量 | 方法 | 校准参数量 | 错误率(↓) | (↑)!0 | Adv (↑) | LM(↓) | EM(↑) | F1(↑) |
|---|---|---|---|---|---|---|---|---|---|
| T5-base | 102 | Vanilla | 0 | 48.10% | 87.21 | 219.18 | 89.21 | 0.63 | 7.48 |
| CALINETX | 0.1M | 17.09% | 1.22 | >1000 | 54.45 | 81.65 | 84.58 | ||
| C. P. | 220M | 13.29% | 1.15 | >1000 | 116.52 | 87.34 | 89.85 | ||
| Vanilla | 0 | 51.34% | 90.61 | 208.90 | 60.64 | 0.94 | 6.51 | ||
| 103 | CALINETX | 0.5M | 18.30% | 1.26 | >1000 | 46.71 | 71.18 | 73.48 | |
| C. P. | 220M | 18.23% | 1.28 | >1000 | 139.96 | 78.15 | 80.35 | ||
| Vanilla | 0 | 46.20% | 34.36 | 116.38 | 92.52 | 2.53 | 7.23 | ||
| T5-large | 102 | CALINETX | 0.5M | 15.19% | 1.30 | >1000 | 44.21 | 81.65 | 85.11 |
| C.P. | 770M | 14.56% | 1.21 | >1000 | 477.24 | 87.97 | 90.49 | ||
| Vanilla | 0 | 45.04% | 31.44 | 93.77 | 58.78 | 2.48 | - | ||
| CALINETX | 1.0M | 20.84% | 1.32 | >1000 | 43.04 | 70.84 | 72.92 | ||
| 103 | C. P. | 770M | 17.16% | 1.28 | >1000 | 154.52 | 78.22 | 80.57 |
Table 3: False knowledge detection and calibration for 100 facts and 1000 facts. "Ori." and "Adv." refer to the original test set (contains true facts) and the adversarial test set (contains false facts), respectively. $\uparrow$ denotes that higher is better and $\downarrow$ denotes that lower is better. # Facts represents the scale of facts and # Calibration Params represents the number of parameters that participate in knowledge calibration. C. P. denotes the continue pre training method for knowledge calibration. With adding only a few parameters, our CALINET achieves comparable performance on knowledge calibration compared with C. P. and has less negative impacts on the generalization ability.
表 3: 100条事实和1000条事实的错误知识检测与校准结果。"Ori."和"Adv."分别表示原始测试集(包含真实事实)和对抗测试集(包含虚假事实)。$\uparrow$ 表示数值越高越好,$\downarrow$ 表示数值越低越好。# Facts表示事实规模,# Calibration Params表示参与知识校准的参数数量。C. P.表示用于知识校准的持续预训练方法。仅添加少量参数的情况下,我们的CALINET在知识校准方面取得了与C. P.相当的性能,并且对泛化能力的负面影响更小。
by the average probability of the negative probing prompts. Finally, we identify the false factual knowledge in the PLM whose CKA score is lower than one and calculate the overall False Rate for the PLM.
通过负向探测提示的平均概率。最后,我们识别出CKA分数低于1的PLM中的错误事实知识,并计算该PLM的总体错误率。
Results As shown in Table 3, we find that the false facts account for nearly half of all the facts for T5-base based on the CKA metric. As for T5- large, which has a larger model capacity, its False Rate is slightly lower than T5-base but still relatively high. The disappointingly high False Rate in PLMs embodies the necessity to calibrate factual knowledge.
结果 如表 3 所示,我们发现基于 CKA 指标,T5-base 的错误事实占比接近所有事实的一半。至于模型容量更大的 T5-large,其错误率略低于 T5-base,但仍相对较高。预训练语言模型中令人失望的高错误率体现了校准事实知识的必要性。
4.2 Calibrating False Factual Knowledge
4.2 校准错误事实性知识
4.2.1 Experimental Settings
4.2.1 实验设置
For the detected false knowledge in PLMs, we construct the calibration data following Section 3.2. Our CALINET consists of 64 and 256 calibration memory slots for 100 and 1000 target facts, respectively. We concatenate CALINET to the last layer of the T5 decoder in our experiments. Following Gururangan et al. (2020), we continue pre training on the calibration data (i.e., optimizing all the parameters) as an upper bound to reach. Appendix A shows detailed hyper-parameter settings.
针对在PLM中检测到的错误知识,我们按照3.2节方法构建校准数据。实验采用的CALINET分别为100条和1000条目标事实配置了64与256个校准记忆槽位。我们将CALINET连接至T5解码器的最后一层。参照Gururangan等人(2020) 的做法,我们将校准数据上的持续预训练 (即优化所有参数) 作为性能上限目标。详细超参数设置见附录A。
4.2.2 Metrics
4.2.2 指标
We evaluate the calibrated model from two aspects, the knowledge modeling ability and the language modeling ability.
我们从知识建模能力和语言建模能力两方面评估校准后的模型。
For knowledge modeling ability, a model with good knowledge modeling ability should know which sentences are factually correct and which ones are factually wrong. For the former, we calculate the model perplexity on the original test set where the target is the correct entity. For the latter, we calculate the model perplexity on an adversarial test set whose target entity is replaced by a false one in the same entity type. In addition, we use Exact Match (EM) and F1 to further evaluate the generation correctness.
知识建模能力方面,具备良好知识建模能力的模型应能区分事实正确的句子与事实错误的句子。对于前者,我们在原始测试集上计算模型困惑度(perplexity),其中目标为正确实体。对于后者,我们在对抗测试集上计算模型困惑度,该测试集的目标实体被替换为同类型的错误实体。此外,我们采用精确匹配(Exact Match, EM)和F1值进一步评估生成结果的正确性。
In order to evaluate the language modeling ability, we randomly mask the test data in the same manner as that in the pre training stage and denote it as the LM test set.
为了评估语言建模能力,我们按照预训练阶段的相同方式随机掩码测试数据,并将其标记为LM测试集。
4.2.3 Results
4.2.3 结果
We show the results for knowledge calibration in Table 3. The calibration makes the model perplexity decrease on the original test set and increases on the adversarial test set. That is, compared to the original model, our method adjusts the model to “know” about the given facts. In addition, our method has little effect on the model perplexity on the general test set because the model parameters are not destroyed like fine-tuning; thus its semantic understanding ability is well-retained.
我们在表3中展示了知识校准的结果。校准使模型在原始测试集上的困惑度降低,而在对抗测试集上增加。也就是说,与原始模型相比,我们的方法调整了模型以"了解"给定的事实。此外,我们的方法对模型在通用测试集上的困惑度影响很小,因为模型参数没有被像微调那样破坏;因此其语义理解能力得到了很好的保留。
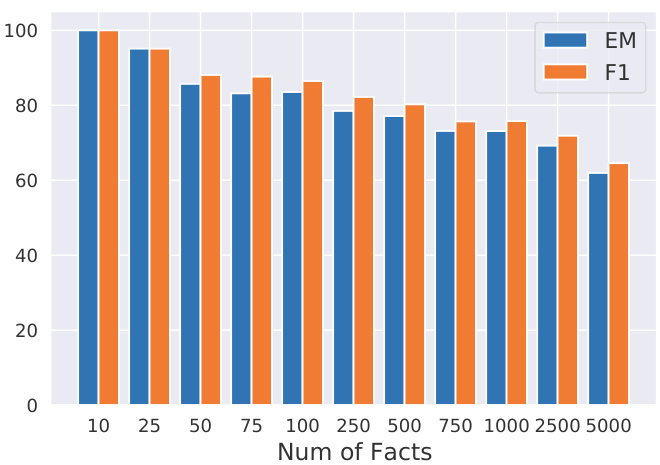
Figure 4: Calibration results for different scales of facts. Given 5000 facts, our method can calibrate more than $60%$ of facts in PLMs at once.
图 4: 不同规模事实的校准结果。给定5000个事实,我们的方法能一次性校准PLM中超过$60%$的事实。
Table 4: Calibration ability with different numbers of calibration memory slots.
| #Slots | 100Facts | 1000 Facts | ||
| EM | F1 | EM | F1 | |
| 16 | 72.16 | 76.33 | 17.63 | 21.00 |
| 64 | 81.65 | 84.58 | 50.87 | 53.65 |
| 256 | 82.91 | 85.74 | 71.18 | 73.48 |
| 1024 | 82.91 | 85.43 | 72.92 | 75.21 |
| 3072 | 83.54 | 86.48 | 73.12 | 75.80 |
表 4: 不同校准内存槽数量下的校准能力
| #Slots | 100Facts EM | 100Facts F1 | 1000 Facts EM | 1000 Facts F1 |
|---|---|---|---|---|
| 16 | 72.16 | 76.33 | 17.63 | 21.00 |
| 64 | 81.65 | 84.58 | 50.87 | 53.65 |
| 256 | 82.91 | 85.74 | 71.18 | 73.48 |
| 1024 | 82.91 | 85.43 | 72.92 | 75.21 |
| 3072 | 83.54 | 86.48 | 73.12 | 75.80 |
We also assess the knowledge correctness of the calibrated model. The improvement of Top1 prediction EM and F1 indicates that knowledge calibration enables the model to generate factually correct predictions. The overall False Rate calculated via CKA score decreases from $48.10%$ to $17.09%$ , which further validates the effectiveness of the CALINET .
我们还评估了校准后模型的知识正确性。Top1预测EM和F1的提升表明,知识校准使模型能够生成事实正确的预测。通过CKA分数计算的整体错误率从$48.10%$降至$17.09%$,进一步验证了CALINET的有效性。
4.2.4 S cal ability of Knowledge Calibration
4.2.4 知识校准的可扩展性
In order to delve deeper into the scale limitation of knowledge calibration, we apply our method to different scales of facts to be calibrated. As Figure 4 shows, when the number of facts to be calibrated is 10, the calibration EM score is $100%$ , i.e., the factual knowledge is perfectly calibrated. As the number of facts increases, the EM score will gradually decrease. Surprisingly, when the number reaches 5000, our method can still calibrate more than $60%$ of the facts in PLMs at once.
为了深入探究知识校准的规模限制,我们将方法应用于不同规模的事实校准任务。如图4所示,当待校准事实数量为10时,校准EM分数达到$100%$,即事实知识被完美校准。随着事实数量增加,EM分数会逐渐下降。令人惊讶的是,当数量达到5000时,我们的方法仍能一次性校准PLMs中超过$60%$的事实。
Compared with previous work on similar topics like knowledge editing (Cao et al., 2021b; Zhu et al., 2020; Cao et al., 2021a), we make huge progress in the amount of knowledge that can be calibrated at once. Mitchell et al. (2022) prove that batched editing for factual knowledge in PLMs is difficult. More concretely, when they modify more than 125 facts at once, the success rate of model editing has already been less than $70%$ . By contrast, in our method, the calibration EM score for 1000 facts is still greater than $70%$ .
与之前关于知识编辑(knowledge editing)的研究(Cao等人,2021b;Zhu等人,2020;Cao等人,2021a)相比,我们在单次可校准的知识量上取得了巨大进展。Mitchell等人(2022)证明了对预训练语言模型(PLMs)中的事实知识进行批量编辑是困难的。具体而言,当他们一次性修改超过125个事实时,模型编辑的成功率已低于$70%$。相比之下,在我们的方法中,对1000个事实进行校准的EM分数仍高于$70%$。
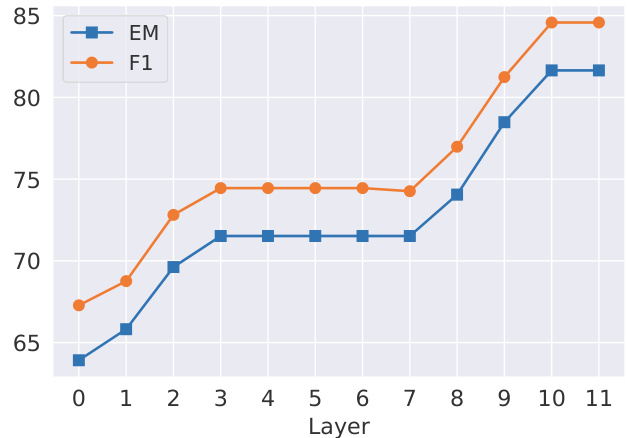
Figure 5: Calibration ability of concatenating CaliNet in different layers. Table 5: Generalization ability of the calibrated knowledge in PLMs, evaluated by open-domain question answering. Cali. Set denotes the calibration subset, Uncali. Set denotes the subset without calibration. For Web Questions (WQ), Cali. Set includes 81 questions, for TriviaQA (TQ) Cali. Set includes 811 questions.
| Model | Cali.Set | Uncali.Set | Overall | |||
| EM | F1 | EM | F1 | EM | F1 | |
| T5wQ | 0.00 | 7.95 | 32.41 | 38.24 | 29.94 | 35.93 |
| T5c.P.+WQ | 8.46 | 14.27 | 32.72 | 38.58 | 30.88 | 36.73 |
| T5cali+wQ | 10.77 | 18.34 | 31.65 | 37.57 | 30.06 | 36.11 |
| T5TQ | 0.00 | 14.01 | 23.53 | 29.75 | 21.63 | 28.47 |
| T5C.P+TQ | 6.91 | 20.18 | 22.35 | 28.65 | 21.09 | 27.96 |
| T5cali+TQ | 6.78 | 18.72 | 23.02 | 29.64 | 21.70 | 28.74 |
图 5: 不同层级串联 CaliNet 的校准能力。
表 5: PLMs 中校准知识的泛化能力,通过开放域问答评估。Cali. Set 表示校准子集,Uncali. Set 表示未校准子集。对于 Web Questions (WQ),Cali. Set 包含 81 个问题;对于 TriviaQA (TQ),Cali. Set 包含 811 个问题。
| Model | Cali.Set | Uncali.Set | Overall | |||
|---|---|---|---|---|---|---|
| EM | F1 | EM | F1 | EM | F1 | |
| T5wQ | 0.00 | 7.95 | 32.41 | 38.24 | 29.94 | 35.93 |
| T5c.P.+WQ | 8.46 | 14.27 | 32.72 | 38.58 | 30.88 | 36.73 |
| T5cali+wQ | 10.77 | 18.34 | 31.65 | 37.57 | 30.06 | 36.11 |
| T5TQ | 0.00 | 14.01 | 23.53 | 29.75 | 21.63 | 28.47 |
| T5C.P+TQ | 6.91 | 20.18 | 22.35 | 28.65 | 21.09 | 27.96 |
| T5cali+TQ | 6.78 | 18.72 | 23.02 | 29.64 | 21.70 | 28.74 |
4.2.5 Architectures of CALINET
4.2.5 CALINET架构
Number of Calibration Memory Slots We conduct experiments with different calibration memory slots and show the results in Table 4. For calibrating 100 facts, we find that only 64 calibration memory slots is sufficient to achieve a performance close to that of 3072 slots. In terms of 1000 facts, 256 calibration memory slots are almost enough. In practice, we take the smallest number of calibration memory slots that can achieve relatively high performance for better calibration efficiency.
校准内存插槽数量
我们针对不同数量的校准内存插槽进行了实验,结果如表 4 所示。对于校准 100 条事实的任务,仅需 64 个校准内存插槽即可达到接近 3072 个插槽的性能水平。在校准 1000 条事实时,256 个插槽已基本满足需求。实际应用中,我们会选择能达到较高性能的最小校准内存插槽数量,以提升校准效率。
Position to Concatenate CALINET We concatenate CALINET to each FFN layer in the T5 decoder to study the difference on the calibration ability. Figure 5 shows that deeper layers maintain stronger calibration ability and the last two layers achieve comparable calibration performance. We think this is because the knowledge calibration in the deeper layers will be affected less by other information in the model. This finding is also consistent with Dai et al. (2022), who find that the deeper layers store more factual knowledge.
将CALINET串联到解码器的位置
我们将CALINET串联到T5解码器的每个FFN层,以研究校准能力的差异。图5显示,更深层的校准能力更强,最后两层的校准性能相当。我们认为这是因为更深层的知识校准受模型中其他信息的影响较小。这一发现也与Dai等人 (2022) 的研究一致,他们发现更深层存储了更多事实性知识。
4.3 Calibration General iz ability
4.3 校准泛化能力
Data Construction We validate the generalization ability of the calibrated knowledge in PLMs on two open-domain question answering datasets Web Questions (Berant et al., 2013) and TriviaQA (Joshi et al., 2017). In order to obtain the facts to be calibrated, we fine-tune the T5 model on Web Questions and TriviaQA without retrieving external knowledge bases. In this stage, the model learned to answer questions with its internal knowledge. According to their prediction correctness on the test set, we aggregate the questions that the PLM answers incorrectly. Then, we retrieve all the triplets, which include any entity in these questions from T-REx. Like in Section 3.2, we transform the triplets into paraphrased natural sentences for training CALINET .
数据构建
我们通过两个开放域问答数据集Web Questions (Berant et al., 2013)和TriviaQA (Joshi et al., 2017)验证PLMs中校准知识的泛化能力。为获取待校准的事实,我们在不检索外部知识库的情况下对T5模型进行Web Questions和TriviaQA的微调。此阶段模型学习依靠内部知识回答问题。根据其在测试集上的预测正确性,我们汇总PLM回答错误的问题。随后从T-REx中检索包含这些问题中任意实体的所有三元组。如第3.2节所述,我们将三元组转述为自然语句用于训练CALINET。
Settings According to the facts to be calibrated, 64 calibration memory slots are trained for WebQuestions, and 256 calibration memory slots are trained for TriviaQA. After knowledge calibration, the calibrated PLM is further fine-tuned on the question answering tasks. We also use the continue pre training method (C. P.) as an upper bound. Our hyper-parameter settings follow Roberts et al. (2020b).
根据待校准的事实,我们为WebQuestions训练了64个校准记忆槽,为TriviaQA训练了256个校准记忆槽。完成知识校准后,经过校准的PLM(预训练语言模型)在问答任务上进行了进一步微调。我们还采用持续预训练方法(C. P.)作为性能上限。所有超参数设置遵循Roberts等人的研究[20]。
Results The results are demonstrated in Table 5. We have the following findings. Firstly, with CALINET , the model performance improves on the calibration subset, which consists of the questions that T5 cannot correctly answer. It indicates that the calibrated knowledge in PLMs can be generalized to the question answering tasks. Secondly, the performance on the remaining questions (Uncali. Set) is hardly impacted. Thirdly, with only a few calibration memory slots, our method achieves a comparable knowledge calibration effect as continuing pre training all the parameters. In addition, continuing pre training will affect the language modeling ability of PLMs (refer to Table 3) while our method will not.
结果
结果如表 5 所示。我们有以下发现。首先,使用 CALINET 后,模型在校准子集(即 T5 无法正确回答的问题)上的性能有所提升。这表明 PLM 中校准后的知识可以泛化到问答任务中。其次,其余问题(未校准集)的性能几乎不受影响。第三,仅用少量校准记忆槽,我们的方法就能达到与持续预训练所有参数相当的知识校准效果。此外,持续预训练会影响 PLM 的语言建模能力(参见表 3),而我们的方法则不会。

Figure 6: Meaning of values in original FFNs and CALINET . Nearly $80%$ of values in CALINET correspond to meaningful concepts used for knowledge calibration.
图 6: 原始FFN与CALINET中数值的含义对比。CALINET中近80%的数值对应知识校准所用的有意义概念。
5 Interpret ability of CALINET
5 CALINET的可解释性
In this section, we analyze CALINET on the memory slot level to interpret its meaning and working mechanism.
在本节中,我们从内存槽(memory slot)层面分析CALINET,以阐释其含义和工作机制。
5.1 Meanings of FFN Values
5.1 FFN值的含义
Inspired by Geva et al. (2021, 2022), we cast each value vector in FFNs or CALINET as an inputindependent distribution over the output vocabulary for analyzing it meaning:
受Geva等人(2021, 2022)的启发,我们将FFN或CALINET中的每个值向量视为输出词表上的输入无关分布,以分析其含义:
$$
\begin{array}{r}{\mathbf p_{i}^{\ell}=\mathrm{softmax}(E\mathbf v_{i}^{\ell}),}\ {\mathbf p_{k}^{c}=\mathrm{softmax}(E\mathbf v_{k}^{c}),}\end{array}
$$
$$
\begin{array}{r}{\mathbf p_{i}^{\ell}=\mathrm{softmax}(E\mathbf v_{i}^{\ell}),}\ {\mathbf p_{k}^{c}=\mathrm{softmax}(E\mathbf v_{k}^{c}),}\end{array}
$$
where $\mathbf{v}_ {i}^{\ell}$ denotes the $i$ -th value in the $\ell$ -th FFN layer, $\mathbf{v}_{k}^{c}$ denotes the $k$ -th calibration memory slot in CALINET , $E$ denotes the output embedding matrix.
其中 $\mathbf{v}_ {i}^{\ell}$ 表示第 $\ell$ 个FFN层中的第 $i$ 个值,$\mathbf{v}_{k}^{c}$ 表示CALINET中第 $k$ 个校准记忆槽,$E$ 表示输出嵌入矩阵。
In order to reveal what kinds of knowledge are stored in FFNs and calibrated by CALINET , we manually annotate the meaning of each value according to its top-ranked tokens. Specifically, we randomly sample 100 values from each FFN layer in the original T5 decoder and 100 values from CALINET For each value, we examine the top30 tokens with the highest probabilities according to $\mathbf{p}_ {i}^{\ell}$ or $\mathbf{p}_{k}^{c}$ . Following Geva et al. (2022), we manually identify patterns that occur in at least 4 tokens and categorize them into “person”, “place”, “organization”, “date” and “others”.
为了揭示FFN中存储并由CALINET校准的知识类型,我们根据每个值的最高排名token手动标注其含义。具体而言,我们从原始T5解码器的每个FFN层随机采样100个值,并从CALINET采样100个值。对于每个值,我们根据$\mathbf{p}_ {i}^{\ell}$或$\mathbf{p}_{k}^{c}$检查概率最高的前30个token。参照Geva等人(2022)的方法,我们手动识别至少在4个token中出现的模式,并将其分类为"人物"、"地点"、"组织"、"日期"和"其他"。
We illustrate the annotation results in Figure 6 and find that the values in CALINET are more knowledge-intensive compared with values in the original FFNs. Specifically, nearly $80%$ of values in CALINET correspond to meaningful concepts used for adjusting the hidden states to calibrate the factual knowledge.
我们在图 6 中展示了标注结果,发现 CALINET 中的值比原始 FFN (Feed-Forward Network) 中的值更具知识密集性。具体而言,CALINET 中近 $80%$ 的值对应于用于调整隐藏状态以校准事实知识的有意义概念。
Table 6: Evolution of the output token distributions. Bold red tokens refer to wrong tokens predicted without calibration. Bold and light blue tokens refer to correct tokens predicted after calibration and their semantic-related tokens, respectively.
| Input Layer 8 Layer 9 Layer10 Layer 11 Layer 11 w/ CALINET Input | Alice Hollister is a |
表 6: 输出token分布演变过程。加粗红色token表示未经校准的错误预测token,加粗浅蓝色token分别表示校准后正确预测的token及其语义相关token。
| 输入 | 第8层 | 第9层 | 第10层 | 第11层 | 第11层(使用CALINET) |
|---|---|---|---|---|---|
| Alice Hollister is a by profession. (目标输出: film actress) | writer, professional, musician, journalist, freelance, lawyer, doctor, woman, retired, scientist | lawyer, writer, journalist, professional, freelance, scientist, doctor, teacher, pharmacist, musician | writer, lawyer, professional, freelance, journalist, doctor, teacher, veterinarian, psychologist, nurse | lawyer, writer, nurse, doctor, journalist, teacher, professional, psychologist, social, solicitor | film,Film,films,flmmaker,movie,journalist,actor,cinema,theatre,actress |
can calibrate the factual knowledge in a generalized way instead of just learning the surface forms of a fact.
可以以通用方式校准事实知识,而不仅仅是学习事实的表面形式。
5.2 Working Mechanism of CALINET 6 Related Work
5.2 CALINET 6 工作机制 相关研究
We further reveal the working mechanism of knowledge calibration by tracing the evolution of the output distribution in different layers. Let x be the input hidden state of an FFN layer, $\hat{\bf x}$ be the output of the FFN. Following Geva et al. (2022) and taking the residual connection into consideration, we define the output token distribution of this FFN layer by
我们通过追踪不同层输出分布的演变,进一步揭示了知识校准的工作机制。设x为FFN层的输入隐藏状态,$\hat{\bf x}$为FFN的输出。遵循Geva et al. (2022) 并考虑残差连接,我们将该FFN层的输出token分布定义为
$$
\mathbf{y}=\operatorname{softmax}\left(E({\hat{\mathbf{x}}}+\mathbf{x})\right).
$$
$$
\mathbf{y}=\operatorname{softmax}\left(E({\hat{\mathbf{x}}}+\mathbf{x})\right).
$$
Let $\widetilde{\mathbf{x}}^{c}$ denotes the output of CALINET . If we concatenate CALINET to this FFN layer, the output token distribution will become
设 $\widetilde{\mathbf{x}}^{c}$ 表示 CALINET 的输出。若将 CALINET 连接到该 FFN 层,输出 token 分布将变为
$$
\tilde{\mathbf{y}}=\mathrm{softmax}\left(E(\hat{\mathbf{x}}+\mathbf{x}+\tilde{\mathbf{x}}^{c})\right).
$$
$$
\tilde{\mathbf{y}}=\mathrm{softmax}\left(E(\hat{\mathbf{x}}+\mathbf{x}+\tilde{\mathbf{x}}^{c})\right).
$$
For the last four FFN layers, we show the top-10 tokens with the highest probabilities according to the output token distribution in Table 6. Also, we provide the top-10 tokens after knowledge calibration. We find that the factually incorrect predictions are usually high-frequency tokens like “English” or “lawyer”. However, the original FFNs in the PLM have little effect on the output token distribution, especially on the top-ranked tokens. By contrast, CALINET can adjust the output token distribution greatly and produce the correct result. More notably, CALINET not only increases the probability of the factually correct token but also increases the probability of tokens that are synonyms of the correct token. This indicates that our method
对于最后四个FFN层,我们在表6中根据输出token分布展示了概率最高的前10个token。同时,我们还提供了知识校准后的前10个token。我们发现事实错误的预测通常是高频token,如"English"或"lawyer"。然而,PLM中原始的FFN对输出token分布影响甚微,尤其是对排名靠前的token。相比之下,CALINET能大幅调整输出token分布并产生正确结果。更值得注意的是,CALINET不仅提高了事实正确token的概率,还增加了正确token同义词的概率。这表明我们的方法
Knowledge Correctness in PLMs Large-scale pretrained language models are commonly seen as non-symbolic KBs containing factual knowledge. To assess the knowledge stored in PLMs, Petroni et al. (2019) introduce the rank-based LAMA probing and define that a PLM knows a fact if it successfully predicts masked objects in cloze-style sentences. Jiang et al. (2020) give a tighter lower bound than LAMA(Petroni et al., 2019) on what PLMs know by designing better prompts. However, Elazar et al. (2021) observe that rank-based probing methods are not robust against paraphrased context, leading to inconsistent results. Some other work (Pörner et al., 2019; Cao et al., 2021a) points out that the ability of PLMs to store knowledge is overestimated due to biased prompts and golden answer leakage.
PLM中的知识正确性
大规模预训练语言模型通常被视为包含事实知识的非符号化知识库。为评估PLM中存储的知识,Petroni等人(2019)提出了基于排名的LAMA探测方法,并定义当PLM能成功预测填空式句子中被遮蔽的对象时,即表明其知晓该事实。Jiang等人(2020)通过设计更好的提示模板,给出了比LAMA(Petroni等人, 2019)更严格的下界来衡量PLM的知识掌握程度。但Elazar等人(2021)发现基于排名的探测方法对改写语境不稳健,会导致结果不一致。其他研究(Pörner等人, 2019; Cao等人, 2021a)指出,由于提示偏差和黄金答案泄露,PLM存储知识的能力被高估了。
Knowledge Injection into PLMs Many studies have explored integrating external knowledge into PLMs to enhance their performance on knowledgeintensive tasks. ERNIE (Zhang et al., 2019) and KnowBERT (Peters et al., 2019) incorporate knowledge graphs to provide structured knowledge during pre training. K-adapter (Wang et al., 2021) injects factual and linguistic knowledge into PLM with adapters, which are pretrained on two structured prediction tasks. Kformer (Yao et al., 2022) also extends FFN in PLMs. In their work, the knowledge is converted into dense embedding and directly injected into the extended FFN. In contrast to all previous work, CALINET is pretrained with paraphrased natural sentences to fully exploit the semantic modeling capability of PLMs, and the calibrated knowledge can be utilized in any downstream tasks.
知识注入预训练语言模型 (PLMs)
许多研究探索了将外部知识整合到预训练语言模型中,以提升其在知识密集型任务上的表现。ERNIE (Zhang et al., 2019) 和 KnowBERT (Peters et al., 2019) 通过融入知识图谱,在预训练阶段提供结构化知识。K-adapter (Wang et al., 2021) 使用适配器 (adapters) 向预训练语言模型注入事实和语言学知识,这些适配器基于两个结构化预测任务进行预训练。Kformer (Yao et al., 2022) 则扩展了预训练语言模型中的前馈网络 (FFN) ,将知识转化为稠密嵌入并直接注入扩展后的前馈网络。与之前所有工作不同,CALINET 通过释义的自然语句进行预训练,以充分挖掘预训练语言模型的语义建模能力,且校准后的知识可应用于任何下游任务。
Knowledge Editing Given a revised fact set, the objective of knowledge editing is to seek alternative parameters so that the model can make new predictions on revised instances while keeping all the other predictions unchanged. Zhu et al. (2020) formulate the knowledge editing task as a constrained optimization problem and create a benchmark to evaluate the effectiveness of knowledge editing methods. Cao et al. (2021a); Mitchell et al. (2022) introduce a hyper network to modify a fact without affecting the rest of the knowledge. Meng et al. (2022) develop a causal intervention for locating and editing knowledge in GPT-style models. Current knowledge editing approaches mainly aim to modify the model after fine-tuning, which will hinder the generalization of knowledge stored in PLMs. In contrast, through calibrating factual knowledge before fine-tuning, our proposed method can rectify the knowledge in models and broadly generalizes the calibrated knowledge for downstream tasks.
知识编辑
给定一个修正后的事实集合,知识编辑的目标是寻找替代参数,使得模型能在保持其他所有预测不变的情况下,对修正后的实例做出新预测。Zhu等人 (2020) 将知识编辑任务表述为约束优化问题,并创建了评估知识编辑方法有效性的基准。Cao等人 (2021a) 和Mitchell等人 (2022) 引入超网络来修改单个事实而不影响其余知识。Meng等人 (2022) 开发了因果干预方法,用于定位并编辑GPT类模型中的知识。当前知识编辑方法主要针对微调后的模型进行修改,这会阻碍预训练语言模型 (PLM) 中存储知识的泛化能力。相比之下,我们提出的方法通过在微调前校准事实知识,既能修正模型中的知识,又能将校准后的知识广泛泛化至下游任务。
calibration data generation. However, our templatefilling solution still builds synthetic test data rather than real test data for CKA. To explore the applicability of CALINET in practice, we recruit three human annotators to write 50 test facts. Specifically, following the contrastive framework in CKA, annotators write one positive sentence and three negative sentences for each fact. The positive sentence state a true fact. The negative sentence must contain the same relation as the positive sentence but a false object entity. Experiments show that CALINET effectively reduces the False Rate by $35.61%$ on real test data, consistent with our results on test data construct via template-filling. However, this work still has a lot of room for improving the calibration applicability in reality.
校准数据生成。然而,我们的模板填充方案仍为CKA构建合成测试数据而非真实测试数据。为探究CALINET在实际应用中的适用性,我们招募三名人工标注者编写50条测试事实。具体而言,遵循CKA中的对比框架,标注者为每个事实撰写一个正例句子和三个负例句子。正例句子陈述真实事实,负例句子必须保持与正例相同的关系但包含错误的对象实体。实验表明,CALINET在真实测试数据上将错误率(False Rate)降低$35.61%$,与通过模板填充构建的测试数据结果一致。但这项工作在提升校准实际适用性方面仍有较大改进空间。
Second, We evaluate PLMs via their predictions. It is somehow a biased approach. Appendix B provides some negative cases of the CKA score. It is an open research question to assess the factual knowledge correctness in PLMs accurately.
其次,我们通过预测结果来评估大语言模型(PLM)。这种方法存在一定偏差。附录 B 提供了 CKA 分数的一些负面案例。如何准确评估大语言模型中事实性知识的正确性,仍是一个开放的研究问题。
Third, the current method cannot completely calibrate all the factual errors in PLMs. We expect that future work can present more advanced knowledge calibration methods.
第三,当前方法无法完全校准大语言模型中的所有事实错误。我们期待未来工作能提出更先进的知识校准方法。
7 Conclusion
7 结论
In this paper, we reassess the knowledge stored in PLMs in a contrastive manner and detect the incorrect knowledge stored in PLMs. We propose CALINET , which adds new parameters to calibrate the knowledge stored in PLMs at scale without updating the original model parameters. The knowledge-calibrated PLMs generalize calibrated knowledge well and perform better than original PLMs on various downstream tasks like open-domain QA. We further provide neuron-level investigations on the calibration mechanism and study how calibration works.
本文以对比方式重新评估预训练语言模型(PLM)中存储的知识,并检测其中存储的错误知识。我们提出CALINET方法,通过新增参数在不更新原始模型参数的情况下大规模校准PLM中存储的知识。经知识校准的PLM能良好泛化校准后的知识,在开放域问答等下游任务中表现优于原始PLM。我们进一步从神经元层面探究校准机制,研究校准过程的工作原理。
Limitations and Future Work
局限性与未来工作
Despite the effectiveness of knowledge calibration, our current studies still have several limitations.
尽管知识校准(Knowledge Calibration)方法行之有效,我们当前的研究仍存在若干局限性。
First, our knowledge assessing and knowledge calibration approach relies on existing knowledge bases and synthetic data. It is a long-term goal to achieve a full-scale knowledge assessment or knowledge calibration because knowledge is complicated. Compared to inaccurate remote supervision and expensive human annotation, our templatefilling solution is a relatively efficient solution for
首先,我们的知识评估与校准方法依赖于现有知识库和合成数据。由于知识体系复杂,实现全面知识评估或校准是一个长期目标。相较于不精确的远程监督和昂贵的人工标注,基于模板填充的解决方案是一种相对高效的途径。
Acknowledge
致谢
This paper is supported by the National Key Research and Development Program of China 2020AAA0106700 and NSFC project U19A2065.
本文得到国家重点研发计划项目2020AAA0106700和国家自然科学基金项目U19A2065的资助。
References
参考文献
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic parsing on Freebase from question-answer pairs. In Proceedings of EMNLP.
Jonathan Berant、Andrew Chou、Roy Frostig 和 Percy Liang。2013. 基于问答对的 Freebase 语义解析。见 EMNLP 会议论文集。
Zied Bouraoui, José Camacho-Collados, and Steven Schockaert. 2020. Inducing relational knowledge from bert. In Proceedings of AAAI.
Zied Bouraoui、José Camacho-Collados和Steven Schockaert。2020。从BERT中归纳关系知识。见AAAI会议论文集。
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Proceedings of NeurIPS.
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. 大语言模型是少样本学习者. 见NeurIPS会议论文集.
Boxi Cao, Hongyu Lin, Xianpei Han, Le Sun, Lingyong Yan, Meng Liao, Tong Xue, and Jin Xu. 2021a.
Boxi Cao、Hongyu Lin、Xianpei Han、Le Sun、Lingyong Yan、Meng Liao、Tong Xue 和 Jin Xu。2021a。
Knowledgeable or educated guess? revisiting language models as knowledge bases. In Proceedings of ACL.
知识渊博还是教育猜测?重审作为知识库的语言模型。载于ACL会议论文集。
Hao Ma, and Madian Khabsa. 2020. Language models as fact checkers? In Proceedings of FEVER.
Hao Ma和Madian Khabsa。2020。语言模型能作为事实核查工具吗?FEVER会议论文集。
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual knowledge in GPT. CoRR, abs/2202.05262.
Kevin Meng、David Bau、Alex Andonian 和 Yonatan Belinkov。2022。在 GPT 中定位和编辑事实性知识。CoRR,abs/2202.05262。
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. 2022. Fast model editing at scale. In Proceedings of ICLR.
Eric Mitchell、Charles Lin、Antoine Bosselut、Chelsea Finn 和 Christopher D Manning。2022。大规模快速模型编辑。ICLR 会议论文集。
Appendix
附录
A Implementation Details
A 实现细节
We conduct experiments based on Hugging Face 2 and follow their default hyper parameter settings unless noted otherwise. We use grid search for learning rate from ${1{\mathrm{e}}{\mathrm{-}}2,1{\mathrm{e}}{\mathrm{-}}3,\ldots,1{\mathrm{e}}{\mathrm{-}}4}$ . We conduct all the experiments on a single A40 GPU.
我们基于Hugging Face 2进行实验,除非另有说明,否则遵循其默认超参数设置。学习率通过网格搜索从 ${1{\mathrm{e}}{\mathrm{-}}2,1{\mathrm{e}}{\mathrm{-}}3,\ldots,1{\mathrm{e}}{\mathrm{-}}4}$ 中选择。所有实验均在单块A40 GPU上完成。
For knowledge calibration, we use a constant learning rate scheduler and the Adafactor optimizer. The training and evaluating batch size is 512, with gradient accumulation steps set to 4. The max sequence length of the source sentence is 64, and that of the target length is 8. Our warm-up steps are 100. Our CALINET Training and continue pre training steps are 5000 steps for 100 facts and 50000 steps for 1000 facts.
在知识校准方面,我们采用恒定学习率调度器和Adafactor优化器。训练和评估的批次大小为512,梯度累积步数设为4。源句最大序列长度为64,目标序列长度为8。预热步数为100步。CALINET训练及继续预训练步数设定为:100个事实对应5000步,1000个事实对应50000步。
For fine-tuning on Web Questions and TriviaQA, our hyper parameter follows the setting of Roberts et al. (2020b). The max training steps are 4000 steps.
在对Web Questions和TriviaQA进行微调时,我们的超参数遵循Roberts等人 (2020b) 的设置。最大训练步数为4000步。
B Negative Case of CKA
B CKA的负面案例
Although the CKA score solves the problems of rank-based metrics towards inexhaustible answers and frequency bias, it may fail to make an accurate assessment in some situations. Especially when the number of negative probing prompts is small, the CKA score can be easily biased. For example, for the relation $\mathrm{\nabla}^{6}\mathrm{P}103^{\circ}$ on native language, our positive template is “The native language of [X] is [Y] .”, our negative templates are “[X] cannot speak [Y] .”, “[X] have learned [Y] .”,“[X] is teaching [Y] .” The average CKA score of 1,000 probing facts is 13.92. This surprisingly high score overestimates the knowledge of T5 in the native language because the second and the third negative templates have a larger scope than the positive template, resulting in a low negative score.
虽然CKA分数解决了基于排序的指标对无穷答案和频率偏差的问题,但在某些情况下可能无法做出准确评估。特别是当负面探测提示数量较少时,CKA分数容易产生偏差。例如,对于母语关系$\mathrm{\nabla}^{6}\mathrm{P}103^{\circ}$,我们的正面模板是"The native language of [X] is [Y] .",负面模板是"[X] cannot speak [Y] ."、"[X] have learned [Y] ."、"[X] is teaching [Y] ."。1000个探测事实的平均CKA分数为13.92。这个异常高的分数高估了T5在母语方面的知识,因为第二和第三个负面模板的范围比正面模板更大,导致负面分数较低。