Dual-Level Precision Edges Guided Multi-View Stereo with Accurate Planar iz ation
双级精度边缘引导的精确平面化多视角立体匹配
Abstract
摘要
The reconstruction of low-textured areas is a prominent research focus in multi-view stereo (MVS). In recent years, traditional MVS methods have performed exceptionally well in reconstructing low-textured areas by constructing plane models. However, these methods often encounter issues such as crossing object boundaries and limited perception ranges, which undermine the robustness of plane model construction. Building on previous work (APD-MVS), we propose the DPE-MVS method. By introducing dual-level precision edge information, including fine and coarse edges, we enhance the robustness of plane model construction, thereby improving reconstruction accuracy in low-textured areas. Furthermore, by leveraging edge information, we refine the sampling strategy in conventional PatchMatch MVS and propose an adap- tive patch size adjustment approach to optimize matching cost calculation in both stochastic and low-textured areas. This additional use of edge information allows for more precise and robust matching. Our method achieves state-of-the-art performance on the ETH3D and Tanks & Temples benchmarks. Notably, our method outperforms all published methods on the ETH3D benchmark.
低纹理区域重建是多视角立体视觉 (MVS) 领域的重要研究方向。近年来,传统 MVS 方法通过构建平面模型在低纹理区域重建中表现优异,但仍存在物体边界穿透和感知范围受限等问题,影响了平面模型构建的鲁棒性。基于前期工作 (APD-MVS),我们提出了 DPE-MVS 方法。通过引入包含精细边缘和粗边缘的双精度边缘信息,增强了平面模型构建的鲁棒性,从而提升了低纹理区域的重建精度。此外,我们利用边缘信息改进了传统 PatchMatch MVS 的采样策略,并提出自适应块大小调整方法,以优化随机区域和低纹理区域的匹配成本计算。这种边缘信息的额外使用实现了更精确、更鲁棒的匹配。我们的方法在 ETH3D 和 Tanks & Temples 基准测试中达到了最先进的性能。值得注意的是,在 ETH3D 基准测试中,我们的方法超越了所有已发表的方法。
Introduction
引言
Multi-view stereo (MVS) is a classical computer vision task aimed at reconstructing the dense 3D geometry of objects or scenes from images taken from multiple viewpoints. This technique has significant applications in areas such as cultural heritage preservation, virtual reality, augmented reality, and autonomous driving. In recent years, MVS methods has advanced significantly, benefiting from diverse datasets (Schops et al. 2017; Knapitsch et al. 2017) and various algorithms (Wang et al. 2023; Wu et al. 2024) , leading to substantial improvements in reconstruction performance. Despite these advancements, MVS still faces challenges in handling low-textured and stochastic textured areas.
多视图立体视觉 (Multi-view stereo, MVS) 是一项经典计算机视觉任务,旨在从多视角拍摄的图像中重建物体或场景的密集三维几何结构。该技术在文化遗产保护、虚拟现实、增强现实和自动驾驶等领域具有重要应用。近年来,受益于多样化数据集 (Schops et al. 2017; Knapitsch et al. 2017) 和多种算法 (Wang et al. 2023; Wu et al. 2024) ,MVS方法取得显著进展,重建性能大幅提升。尽管如此,MVS在处理低纹理和随机纹理区域时仍面临挑战。
MVS methods can be roughly categorized into traditional methods (Galliani, Lasinger, and Schindler 2015; Sch on berger et al. 2016; Xu and Tao 2019) and learningbased methods (Yao et al. 2018; Gu et al. 2020). Traditional methods have the advantages of stronger generalization capabilities and lower memory consumption compared to learning-based methods. Additionally, there has been more research in recent traditional MVS methods addressing the low-textured issue. Recent mainstream methods are based on PatchMatch (PM), which matches fixed-size patch in the reference image with patches in the source images using a plane hypothesis (including depth and normal). Since fixed-size patch struggle to extract appropriate feature information in low-textured areas, many works have further extended and optimized this method. For example, (Liao et al. 2019; Xu and Tao 2019) leverage multi-scale information, while others (Xu and Tao 2020) use triangular plane priors to guide plane hypotheses in low-textured areas. (Xu et al. 2022) combines these approaches to enhance reconstruction performance. Subsequent methods (Zhang et al. 2022; Tian et al. 2023) refine the construction of triangular planes, while others (Romanoni and Matteucci 2019; Kuhn, Lin, and Erdler 2019) employ image segmentation and RANSAC algorithm to determine plane models.
多视角立体视觉(MVS)方法大致可分为传统方法 (Galliani, Lasinger, and Schindler 2015; Sch on berger et al. 2016; Xu and Tao 2019) 和学习型方法 (Yao et al. 2018; Gu et al. 2020)。与传统方法相比,学习型方法具有更强的泛化能力和更低的内存消耗优势。此外,近年针对低纹理问题的传统MVS方法研究也日益增多。
当前主流方法基于PatchMatch (PM) 算法,该算法通过平面假设(包含深度和法向量)在参考图像与源图像之间匹配固定尺寸的图像块。由于固定尺寸图像块在低纹理区域难以提取合适特征信息,许多研究对此方法进行了扩展优化。例如 (Liao et al. 2019; Xu and Tao 2019) 利用多尺度信息,(Xu and Tao 2020) 则采用三角平面先验指导低纹理区域的平面假设。(Xu et al. 2022) 综合这些方法提升了重建性能。后续研究 (Zhang et al. 2022; Tian et al. 2023) 改进了三角平面构建方法,而 (Romanoni and Matteucci 2019; Kuhn, Lin, and Erdler 2019) 则运用图像分割和RANSAC算法确定平面模型。
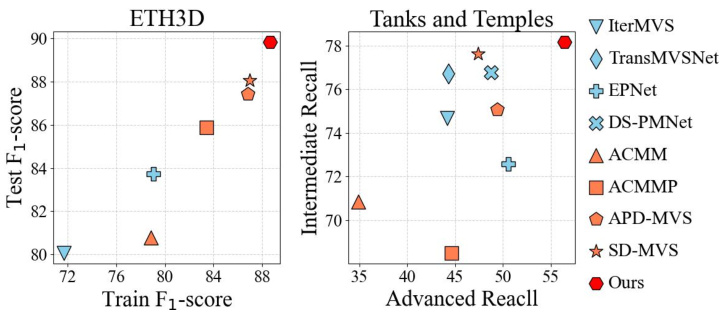
Figure 1: Comparison with the SOTA traditional methods and learning-based methods. Our method achieves the best $\mathrm{F_{1}}$ -score on ETH3D and the best recall on Tanks & Temples.
图 1: 与SOTA传统方法和基于学习方法的对比。我们的方法在ETH3D上取得了最佳$\mathrm{F_{1}}$分数,在Tanks & Temples上获得了最佳召回率。
One notable method, APD-MVS (Wang et al. 2023), introduces adaptive patch deformation. This method classifies pixels into reliable and unreliable based on matching ambiguity. For each unreliable pixel, it searches for a number of reliable pixels in the surrounding area. The RANSAC algorithm is then used to estimate the best-fitting plane from these reliable pixels, selecting the most fitting ones as anchors to assist in the matching of unreliable pixel. Compared to previous methods, this approach is more flexible and significantly enhances the robustness of the plane model.
一种值得注意的方法是APD-MVS (Wang et al. 2023)提出的自适应块变形技术。该方法根据匹配模糊度将像素分为可靠与不可靠两类,针对每个不可靠像素在其周边区域搜索若干可靠像素,随后运用RANSAC算法从这些可靠像素中估计最佳拟合平面,筛选最匹配的像素作为锚点来辅助不可靠像素的匹配。相较先前方法,该方案更具灵活性,显著提升了平面模型的鲁棒性。

Figure 2: Top: depth maps for scenes crossing object boundaries. Bottom: normal maps for limited perception range. Comparison of APD-MVS (middle) and our method (right).
图 2: 上图: 跨越物体边界的场景深度图。下图: 有限感知范围的法线图。APD-MVS (中) 与我们的方法 (右) 对比。
Although these methods significantly improve reconstruction in low-textured areas, they still face issues with increased scene complexity, as shown in Fig. 2 and Fig. 3. One common issue is the plane model crossing object boundaries, causing depth confusion between foreground objects and the background. Another is the potential for errors in plane model construction due to limited perception range. For example, APD-MVS considers only the nearest reliable pixels when constructing planes, sometimes selecting locally optimal pixels, which leads to noticeable deviations between the final plane model and the ground truth.
尽管这些方法显著提升了低纹理区域的重建效果,但在场景复杂度增加时仍存在问题,如图 2 和图 3 所示。一个常见问题是平面模型会跨越物体边界,导致前景物体与背景之间的深度混淆。另一个问题是由于感知范围有限,平面模型构建可能存在误差。例如,APD-MVS 在构建平面时仅考虑最近的可靠像素,有时会选择局部最优像素,这会导致最终平面模型与真实值之间出现明显偏差。
To address these issues, we drew inspiration from learning-based MVS methods (Zhang et al. 2023; Li et al. 2024), which utilize RGB images for adaptive sampling. We posit that fully leveraging image information, particularly edge information, is crucial since areas delineated by edges often approximate planar shapes. Based on this premise, we integrated dual-level precision edge information into the adaptive patch deformation. Dual-level precision edges are derived from two edge detection approaches: fine edges, which are precise but incomplete, and coarse edges, which capture more actual object boundaries but with less accuracy. Specifically, we use the Canny operator for fine edges and a segmentation scheme from TSAR-MVS (Yuan et al. 2024b) for coarse edges. Fine edges constrain point selection during plane construction, while coarse edges expand the perception range for selecting anchors. Thereby providing more effective support for the matching of unreliable pixels. Furthermore, since reliable pixels serve as the basis for selecting anchors and are still processed using conventional PM in APD-MVS, we utilize fine edge information to improve the hypotheses sampling strategy, optimizing the hypotheses for reliable pixels.
为了解决这些问题,我们受到基于学习的多视图立体匹配方法 (Zhang et al. 2023; Li et al. 2024) 的启发,该方法利用RGB图像进行自适应采样。我们认为充分利用图像信息(尤其是边缘信息)至关重要,因为边缘勾勒的区域通常近似平面形状。基于这一前提,我们将双精度边缘信息整合到自适应块变形中。双精度边缘通过两种边缘检测方法获得:精细边缘(精度高但完整性不足)和粗糙边缘(能捕捉更多实际物体边界但精度较低)。具体而言,我们使用Canny算子提取精细边缘,并采用TSAR-MVS (Yuan et al. 2024b) 的分割方案获取粗糙边缘。精细边缘约束平面构建时的点选择,而粗糙边缘则扩展锚点选择的感知范围,从而为不可靠像素的匹配提供更有效的支持。此外,由于可靠像素是锚点选择的基础,在APD-MVS中仍采用传统PM处理,我们利用精细边缘信息改进假设采样策略,优化可靠像素的假设生成。
The aforementioned strategy has shown marked performance but is ineffective in stochastic textured areas, such as lawns, which often contain numerous erroneous edges. Therefore, we further investigated the matching cost calculation. The deformable patch, consisting of an unreliable pixel’s patch and the anchors’ patches, is used to evaluate the plane hypothesis of the the unreliable pixel. Its matching cost is calculated as the weighted sum of the matching costs of both the unreliable pixel’s patch and the anchors’ patches. However, the conventional fixed-size patch matching method, specifically the matching of the unreliable pixel’s patch, remains part of this process, affecting stability, especially in stochastic textured areas. To address this, we propose adjusting patch sizes with anchors to effectively identify unreliable pixels and applying edge information constraints to prevent crossing object boundaries. This enables more robust matching cost calculations.
上述策略虽表现出显著性能,但在随机纹理区域(如草坪)中效果不佳,这类区域常包含大量错误边缘。为此,我们进一步研究了匹配成本计算。可变形块由不可靠像素块和锚点块组成,用于评估不可靠像素的平面假设,其匹配成本计算为不可靠像素块与锚点块匹配成本的加权和。然而,传统固定尺寸块匹配方法(特别是不可靠像素块的匹配)仍是该过程的一部分,这会影响稳定性,尤其在随机纹理区域。为解决此问题,我们提出通过锚点动态调整块尺寸以有效识别不可靠像素,并应用边缘信息约束防止跨越物体边界,从而实现更鲁棒的匹配成本计算。

Figure 3: Comparison of plane construction between APDMVS (middle) and our method (right), with visualization s of fine edges (top right) and coarse edges (bottom right).
图 3: APDMVS (中) 与我们方法 (右) 的平面构建对比,包含细边缘 (右上) 和粗边缘 (右下) 的可视化效果。
We integrated the aforementioned concepts into the DualLevel Precision Edges Guided Multi-View Stereo with Accurate Planar iz ation (DPE-MVS). In summary, our contributions can summarized as follows:
我们将上述概念整合到具有精确平面化的双层级精度边缘引导多视角立体视觉 (DPE-MVS) 中。总结而言,我们的贡献可归纳如下:
• We propose a dual-level precision edge-guided planar model construction strategy, providing more effective support for the matching of unreliable pixels. • We propose a sampling strategy guided by fine edges, which can enhance conventional PM for reliable pixels. • We introduce an adaptive patch size adjustment approach that enables more robust matching cost calculation for unreliable pixels. • Extensive experiments validate the effectiveness of our proposed method, demonstrating state-of-the-art performance on the ETH3D and Tanks & Temples benchmarks.
• 我们提出了一种双精度边缘引导的平面模型构建策略,为不可靠像素的匹配提供更有效的支持。
• 我们提出了一种由精细边缘引导的采样策略,能够增强传统平面模型 (PM) 对可靠像素的处理能力。
• 我们引入了一种自适应块大小调整方法,使不可靠像素的匹配成本计算更加鲁棒。
• 大量实验验证了我们所提方法的有效性,在ETH3D和Tanks & Temples基准测试中展现了最先进的性能。
Related Work
相关工作
Traditional Methods Traditional MVS methods can be roughly categorized into four types: voxel-based methods (Vogiatzis et al. 2007), surface iterative optimization methods (Cremers and Kolev 2010), patch-based methods (Furukawa and Ponce 2009), and depth map-based methods (Bleyer, Rhemann, and Rother 2011). Among these, depth map-based methods have become the most popular choice in recent years due to their simplicity, flexibility, and robust performance. Many outstanding works within this category are PM-based methods. Recently, methods such as ACMM (Xu and Tao 2019), ACMP (Xu and Tao 2020), and ACMMP (Xu et al. 2022) have introduced pyramid structures, geometric consistency, and triangular plane priors into MVS. Subsequently, HPM-MVS (Ren et al. 2023) proposed non-local sampling to escape local optima and used a KNN-based approach to optimize plane prior model construction. APD-MVS (Wang et al. 2023) introduced adaptive patch deformation and an NCC-based matching metric to determine the reliability of pixel depth values. Methods like TAPA-MVS (Romanoni and Matteucci 2019) and PCFMVS (Kuhn, Lin, and Erdler 2019) incorporated superpixel segmentation and the RANSAC algorithm, while TSARMVS (Yuan et al. 2024b) further combined the Roberts operator with Hough line detection to segment large lowtextured areas, though these methods tend to over-segment. SD-MVS (Yuan et al. 2024a) used SAM for semantic segmentation to achieve adaptive sampling. However, SAM’s inference speed is slow and it may produce errors with unseen scenes. Additionally, SAM struggles to distinguish different surfaces of the same object, making it unsuitable for constructing plane models.
传统方法
传统多视角立体视觉(MVS)方法大致可分为四类:基于体素的方法 (Vogiatzis et al. 2007)、表面迭代优化方法 (Cremers and Kolev 2010)、基于面片的方法 (Furukawa and Ponce 2009) 以及基于深度图的方法 (Bleyer, Rhemann, and Rother 2011)。其中,基于深度图的方法因其简单性、灵活性和鲁棒性能,近年来成为最流行的选择。该类别中许多优秀工作都是基于平面先验(PM)的方法。近期,ACMM (Xu and Tao 2019)、ACMP (Xu and Tao 2020) 和 ACMMP (Xu et al. 2022) 等方法将金字塔结构、几何一致性和三角平面先验引入MVS。随后,HPM-MVS (Ren et al. 2023) 提出非局部采样以逃离局部最优,并采用基于KNN的方法优化平面先验模型构建。APD-MVS (Wang et al. 2023) 引入自适应面片变形和基于NCC的匹配度量来确定像素深度值的可靠性。TAPA-MVS (Romanoni and Matteucci 2019) 和 PCFMVS (Kuhn, Lin, and Erdler 2019) 等方法结合了超像素分割与RANSAC算法,而 TSARMVS (Yuan et al. 2024b) 进一步将Roberts算子与霍夫线检测结合来分割大面积低纹理区域,但这些方法容易产生过分割。SD-MVS (Yuan et al. 2024a) 使用SAM进行语义分割以实现自适应采样,但SAM推理速度较慢且对未见场景可能产生错误,同时难以区分同一物体的不同表面,因此不适用于构建平面模型。
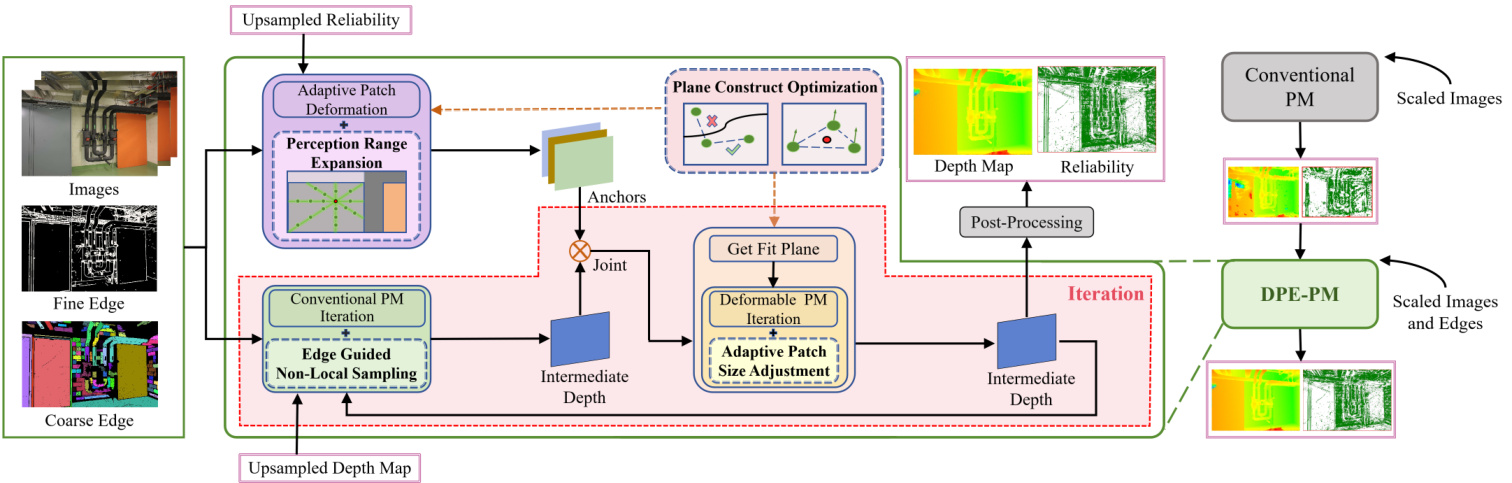
Figure 4: Overview. DPE-MVS adopt a pyramid structure, with the two coarsest scales displayed on the right side of the figure, and the middle illustrating the details of our proposed DPE-PM. Iterations at finer scales use DPE-PM to update the depth map.
图 4: 概述。DPE-MVS采用金字塔结构,图中右侧展示了两个最粗糙的尺度,中间部分则详细说明了我们提出的DPE-PM。在更精细的尺度上,通过DPE-PM迭代更新深度图。
Learning-based Methods MVSNet (Zhang et al. 2023) pioneered the use of deep learning for depth map-based MVS methods. CasMVSNet (Gu et al. 2020) introduced a cascade structure, accelerating the evolution of learning-based MVS methods. These methods, benefiting from convolution operations, have significantly larger receptive fields compared to traditional methods. Works like AA-RMVSNet (Wei et al. 2021) and Trans MV S Net (Ding et al. 2022) further expanded the receptive field. Additionally, improvements in depth sampling have been made by Patch Match Net (Wang et al. 2021) and DS-PMNet (Li et al. 2024), which proposed adaptive hypothesis propagation, and N2MVSNet (Zhang et al. 2023), which introduced adaptive non-local sampling and RGB-guided depth refinement. Learning-based methods have stronger feature perception and often outperform traditional methods with sufficient data. However, creating highquality datasets remains challenging, limiting practical use.
基于学习的方法
MVSNet (Zhang et al. 2023) 率先将深度学习应用于基于深度图的多视图立体 (MVS) 方法。CasMVSNet (Gu et al. 2020) 引入了级联结构,加速了基于学习的MVS方法的发展。这些方法受益于卷积操作,与传统方法相比具有显著更大的感受野。AA-RMVSNet (Wei et al. 2021) 和TransMVSNet (Ding et al. 2022) 等研究进一步扩大了感受野。此外,PatchMatchNet (Wang et al. 2021) 和DS-PMNet (Li et al. 2024) 提出了自适应假设传播,N2MVSNet (Zhang et al. 2023) 引入了自适应非局部采样和RGB引导的深度优化,从而改进了深度采样。基于学习的方法具有更强的特征感知能力,在数据充足时通常优于传统方法。然而,创建高质量数据集仍然具有挑战性,限制了实际应用。
Method
方法
Given a set of images ${I_{i}}{i=1}^{N}$ and the corresponding camera parameters ${\mathbf{P}{i}}_{i=1}^{N}$ , our task is to estimate depth maps for each image. This section provides a brief overview of the key points of APD-MVS, followed by a detailed explanation of our method.
给定一组图像 ${I_{i}}{i=1}^{N}$ 及对应的相机参数 ${\mathbf{P}{i}}_{i=1}^{N}$ ,我们的任务是为每张图像估计深度图。本节先简要概述APD-MVS的关键要点,再详细阐述我们的方法。
Review of APD-MVS
APD-MVS综述
APD-MVS classifies pixels as reliable or unreliable based on matching ambiguity and introduces deformable PM. Reliable pixels are processed using conventional PM, while unreliable pixels are handled using deformable PM.
APD-MVS根据匹配模糊度将像素分类为可靠与不可靠,并引入可变形PM (deformable PM)。可靠像素采用传统PM处理,不可靠像素则使用可变形PM处理。
Conventional PM consists of four basic steps: random initialization, hypothesis propagation, multi-view matching cost evaluation, and refinement. First, each pixel is randomly initialized with a plane hypothesis. Second, hypotheses are sampled from neighboring pixels within a fixed range. Third, matching costs from multiple views are integrated to select the best hypothesis. Fourth, new hypotheses are generated through perturbation and random generation to diversify the solution space, and the best one is selected. The last three steps iterate multiple times.
传统PM算法包含四个基本步骤:随机初始化、假设传播、多视角匹配代价评估和优化。首先,每个像素随机初始化一个平面假设。其次,在固定范围内从相邻像素采样假设。第三,整合多视角的匹配代价以选择最佳假设。第四,通过扰动和随机生成新假设来扩展解空间,并选择最优解。后三个步骤会进行多次迭代。
Deformable PM differs from conventional PM in propagation and matching cost calculation. For each unreliable pixel, anchors are identified through preprocessing. In propagation, sampled hypotheses include anchor hypotheses and plane hypothesis generated using RANSAC on the anchors. In matching cost calculation, the deformable patch is constructed by combining the unreliable pixel’s patch with the anchors’ patches for matching, the formula as follows:
可变形PM(PatchMatch)与传统PM在传播和匹配成本计算上有所不同。对于每个不可靠像素,通过预处理识别出锚点。在传播过程中,采样假设包括锚点假设以及在锚点上使用RANSAC生成的平面假设。在匹配成本计算中,通过将不可靠像素的补丁与锚点的补丁结合构建可变形补丁进行匹配,公式如下:
$$
m_{D}(\mathbf{p},\pmb{\theta}{p},\mathbf{S})=\lambda m(\mathbf{p},\pmb{\theta}{p},\mathbf{B}{p})+\frac{1-\lambda}{|\mathbf{S}|}\sum_{\mathbf{s}\in\mathbf{S}}m(\mathbf{s},\pmb{\theta}{p},\mathbf{B}_{s}),
$$
$$
m_{D}(\mathbf{p},\pmb{\theta}{p},\mathbf{S})=\lambda m(\mathbf{p},\pmb{\theta}{p},\mathbf{B}{p})+\frac{1-\lambda}{|\mathbf{S}|}\sum_{\mathbf{s}\in\mathbf{S}}m(\mathbf{s},\pmb{\theta}{p},\mathbf{B}_{s}),
$$
where $\lambda$ is a weight value, $\mathbf{p}$ represents the unreliable pixel, S denotes the set of anchors. $\pmb{\theta}{p}$ is the plane hypothesis for pixel $\mathbf{p}$ , and $\mathbf{B}$ represent the fixed-size patch. The function $m$ represents the conventional matching cost, while $m_{D}$ denotes the matching cost of the deformable patch.
其中 $\lambda$ 是权重值,$\mathbf{p}$ 表示不可靠像素,S代表锚点集合。$\pmb{\theta}{p}$ 是像素 $\mathbf{p}$ 的平面假设,$\mathbf{B}$ 表示固定大小的图像块。函数 $m$ 表示常规匹配代价,而 $m_{D}$ 表示可变形图像块的匹配代价。
Overview of Our Method
方法概述
Our method adopts the APD-MVS framework, and an overview is illustrated in Fig. 4. Each image is sequentially taken as the reference image $I_{r e f}$ , with the other images as source images $I_{s r c}$ to guide the reference image’s depth map recovery. We construct an $L$ layer pyramid structure through scale down sampling, with the $L$ -th layer as the coarsest scale and the 1st layer as the original image. The initial depth map at the coarsest scale layer is obtained using conventional PM, and perform post-processing to determine the reliability of each pixel. At a finer scale layer $l$ , fine and coarse edges are extracted from $I_{r e f}$ at the corresponding scale. The depth map and reliability from layer $l+1$ are upsampled. These inputs are then used to update the depth map and reliability for this layer using DPE-PM.
我们的方法采用APD-MVS框架,整体流程如图4所示。每张图像依次作为参考图像$I_{ref}$,其余图像作为源图像$I_{src}$来指导参考图像的深度图恢复。我们通过降采样构建$L$层金字塔结构,其中第$L$层为最粗糙尺度,第1层为原始图像。最粗糙尺度层的初始深度图采用传统PM (PatchMatch) 方法获取,并通过后处理确定各像素的可靠性。在更精细的尺度层$l$上,从对应尺度的$I_{ref}$中提取精细和粗糙边缘信息。将$l+1$层的深度图与可靠性信息进行上采样,随后利用DPE-PM方法更新当前层的深度图和可靠性。
In DPE-PM, the first stage is to obtain anchors for each unreliable pixel. In adaptive patch deformation, we propose Perception Range Expansion to search for a wide range of relevant reliable pixels and use RANSAC to filter out the anchors. The second stage is to iterative ly update the depth map. In each iteration, the hypotheses for reliable pixels are first updated using conventional PM with our Edge Guided Non-Local Sampling. Subsequently, the hypotheses for unreliable pixels are updated: new plane hypothesis are generated using RANSAC based on the anchors, followed by deformable PM with our Adaptive Patch Size Adjustment. In the previously mentioned RANSAC applications, our Plane Construction Optimization was consistently utilized to obtain accurate plane models. Similarly, post-processing is used to determine pixel reliability after obtaining the depth map. The DPE-PM process is repeated at finer scales until the depth map for the first layer is obtained. Finally, the depth maps are fused to generate a point cloud.
在DPE-PM中,第一阶段是获取每个不可靠像素的锚点。在自适应块变形中,我们提出感知范围扩展(Perception Range Expansion)来搜索大范围的相关可靠像素,并使用RANSAC过滤锚点。第二阶段是迭代更新深度图。每次迭代中,首先使用传统PM结合我们的边缘引导非局部采样(Edge Guided Non-Local Sampling)更新可靠像素的假设。随后更新不可靠像素的假设:基于锚点使用RANSAC生成新平面假设,再通过自适应块大小调整(Adaptive Patch Size Adjustment)进行可变形PM。在上述RANSAC应用中,我们始终采用平面构建优化(Plane Construction Optimization)来获取精确的平面模型。类似地,在获得深度图后使用后处理确定像素可靠性。DPE-PM过程在更精细尺度上重复,直到获得第一层的深度图。最后融合深度图生成点云。
In the following sections, we will provide the details of our method. First, edge extraction will be introduced, followed by the improvements related to reliable pixels, and finally, the improvements related to unreliable pixels.
在以下章节中,我们将详细介绍我们的方法。首先会介绍边缘提取,接着是与可靠像素相关的改进,最后是与不可靠像素相关的改进。
Extracting Edge Cues
提取边缘线索
Obtaining edge information is essential for our method. We first use the Canny edge detector to extract fine edges, setting the upper and lower thresholds to the median of the image grayscale multiplied by $(1\pm\sigma)$ . Then, coarse edges are extracted using the Roberts operator and Hough line detection, similar to TSAR-MVS. Fine edges help accurately locate the boundaries of foreground objects but are often not closed, making it difficult to determine whether a pixel is in a low-textured region. Coarse edges can segment the image, with larger regions indicating low-textured areas, but have a higher false detection rate and less precise boundary localization. The complementary information from fine and coarse edges is crucial for achieving our research objectives.
获取边缘信息对我们的方法至关重要。我们首先使用Canny边缘检测器提取精细边缘,将上下阈值设置为图像灰度中值乘以$(1\pm\sigma)$。然后采用Roberts算子和Hough直线检测提取粗糙边缘,这与TSAR-MVS方法类似。精细边缘有助于准确定位前景物体边界,但通常不闭合,难以判断像素是否属于低纹理区域。粗糙边缘可以对图像进行分割,较大区域表明存在低纹理区域,但误检率较高且边界定位不够精确。精细边缘与粗糙边缘的互补信息对实现我们的研究目标非常关键。
Edge Guided Non-Local Sampling
边缘引导的非局部采样
Reliable pixels are the foundation for constructing the plane model, and the accuracy of their hypotheses is crucial. Propagation samples hypotheses from neighboring pixels to build the solution space. According to (Ren et al. 2023; Zhou et al. 2021), repetitive hypotheses often occur within the local range in low-textured areas, whereas local sampling preserves fine details in small objects. To expand the solution space while retaining details, we propose two new sampling schemes: progressive non-local sampling and edge-guided extended sampling, as shown in Fig. 5. For fine edge pixels, we apply only progressive non-local sampling. For non-fine edge pixels, both sampling schemes are applied, and the resulting samples are compared to retain the superior ones.
可靠的像素是构建平面模型的基础,其假设的准确性至关重要。传播从邻近像素采样假设以构建解空间。根据 (Ren et al. 2023; Zhou et al. 2021) 的研究,在低纹理区域的局部范围内常出现重复假设,而局部采样能保留小物体的精细细节。为在保留细节的同时扩展解空间,我们提出两种新采样方案:渐进式非局部采样和边缘引导扩展采样,如图 5 所示。对于精细边缘像素,仅采用渐进式非局部采样;对于非精细边缘像素,同时应用两种采样方案并通过比较保留更优样本。

Figure 5: Edge Guided Non-Local Sampling: This process includes two sampling schemes: progressive non-local sampling (left) and edge-guided extended sampling (right).
图 5: 边缘引导非局部采样: 该过程包含两种采样方案: 渐进式非局部采样 (左) 和边缘引导扩展采样 (右)。
Progressive non-local sampling excludes sampling points within a radius $\xi$ during the PM iteration process. The radius $\xi$ gradually decreases as the iterations progress, following the formula $\xi=m a x(1,5-2\times t_{i t e r})$ . We utilize a red-black checkerboard pattern for pixel division $\mathrm{{Xu}}$ and Tao 2019). Each of the eight sampling areas adopts a strip format, where the radius $\xi$ offsets the starting position of the strip. Each area contains 11 samples with a step size of 2. The sample with the minimum multi-view matching cost is selected from each area, yielding the optimal samples {θip n}i8=1.
渐进式非局部采样在PM迭代过程中排除半径$\xi$内的采样点。该半径随迭代次数增加按公式$\xi=max(1,5-2\times t_{iter})$逐步减小。我们采用红黑棋盘格模式进行像素划分 (Xu和Tao 2019)。八个采样区域均采用条带形式,其中半径$\xi$决定条带起始位置的偏移量。每个区域包含11个步长为2的采样点,从各区域选取多视角匹配代价最小的样本,最终获得最优样本集{θip n}i8=1。
Edge-guided extended sampling follows the same fundamental scheme as progressive non-local sampling, but differs in the number of samples and the sampling step size. In this scheme, both the number of samples $k$ and the step size $s$ are adaptively adjusted based on the distance $D_{f e}$ to the nearest fine edge in the corresponding strip direction. A threshold, defined as $\Lambda_{f e}={\frac{i m\bar{a}g e w i d t{\bar{h}}}{30\times4^{l}}}$ ma 3 g 0 ew 4 il d th , is used to prevent excessively large sampling distances. The specific adjustments are calculated as follows:
边缘引导扩展采样遵循与渐进式非局部采样相同的基本方案,但在样本数量和采样步长上有所不同。该方案中,样本数量$k$和步长$s$会根据对应条带方向上到最近精细边缘的距离$D_{fe}$自适应调整。为防止采样距离过大,设定阈值$\Lambda_{fe}={\frac{image\ width}{30\times4^{l}}}$。具体调整计算如下:
$$
D_{f e}^{\prime}=m i n\left(D_{f e},\Lambda_{f e}\right),k=\left\lfloor\frac{D_{f e}^{\prime}}{2}\right\rfloor,s=\left\lfloor\frac{D_{f e}^{\prime}}{k}\right\rfloor,
$$
$$
D_{f e}^{\prime}=m i n\left(D_{f e},\Lambda_{f e}\right),k=\left\lfloor\frac{D_{f e}^{\prime}}{2}\right\rfloor,s=\left\lfloor\frac{D_{f e}^{\prime}}{k}\right\rfloor,
$$
subject to $11~\leqk\leq~22$ . Similarly, optimal samples ${\pmb{\theta}{i}^{e g}}{i=1}^{8}$ are obtained. These samples are then compared with ${\pmb{\theta}{i}^{\bar{p}n}}_{i=1}^{8}$ by re calculating the matching costs on the patch of the pixel being processed, with the better sample for each area direction being selected.
受限于 $11~\leqk\leq~22$。同理,最优样本 ${\pmb{\theta}{i}^{e g}}{i=1}^{8}$ 被获取。随后将这些样本与 ${\pmb{\theta}{i}^{\bar{p}n}}_{i=1}^{8}$ 通过重新计算待处理像素块上的匹配成本进行比较,并为每个区域方向选择更优样本。
Accurate Plane Model Construction
精确平面模型构建
For unreliable pixels, the anchors filtered out by planar RANSAC in adaptive patch deformation significantly impact depth estimation.
对于不可靠像素,自适应块变形中通过平面RANSAC过滤掉的锚点会显著影响深度估计。
Perception Range Expansion To address the issue of limited perception range, we segment the image into distinct regions using coarse edges and extend the search for reliable pixels in low-textured regions. A region is considered lowtextured if its pixel count exceeds $\frac{i m a g e a r e a}{256\times4^{l}}$ . Let $\varepsilon$ denote the set of coarse edge pixels in a specific direction relative to the pixel p, the boundary in that direction is defined as:
感知范围扩展
为解决感知范围有限的问题,我们使用粗边缘将图像分割为不同区域,并在低纹理区域扩展可靠像素的搜索范围。当某区域的像素数量超过 $\frac{i m a g e a r e a}{256\times4^{l}}$ 时,即被判定为低纹理区域。设 $\varepsilon$ 表示像素p在特定方向上的粗边缘像素集合,则该方向的边界定义为:
$$
B(\mathbf{p})={\underset{\mathbf{q}\in\pmb{\varepsilon}}{\operatorname{argmax}}}\left||\mathbf{q}-\mathbf{p}|\right|\quad s.t.\quad\mathbb{C}(\mathbf{q})=1,
$$
$$
B(\mathbf{p})={\underset{\mathbf{q}\in\pmb{\varepsilon}}{\operatorname{argmax}}}\left||\mathbf{q}-\mathbf{p}|\right|\quad s.t.\quad\mathbb{C}(\mathbf{q})=1,
$$
where $\mathbb{C}({\bf q})=1$ indicates that $\mathbf{q}$ is connected to the region where $\mathbf{p}$ is located. This approach determines boundaries in the eight-connected directions for each pixel, effectively filtering out redundant coarse edge pixels within the region.
其中 $\mathbb{C}({\bf q})=1$ 表示 $\mathbf{q}$ 与 $\mathbf{p}$ 所在区域相连。该方法为每个像素确定八连通方向的边界,有效滤除区域内冗余的粗边缘像素。
Subsequently, the eight directions are grouped into four pairs of opposites. Each pair has a search limit of $2\eta$ reliable pixels, distributed between directions based on boundary distances. For example, in the up-down direction pair, the number of pixels allocated for searching is determined using the following formula:
随后,将八个方向分为四对相反方向。每对方向的搜索限制为 $2\eta$ 个可靠像素,根据边界距离在方向间分配。例如,在上下方向对中,用于搜索的像素分配数量通过以下公式确定:
$$
n_{u}=\left\lfloor\frac{2\eta\cdot D_{c e}^{u}}{D_{c e}^{u}+D_{c e}^{d}}\right\rfloor,n_{d}=2\eta-n_{u},
$$
$$
n_{u}=\left\lfloor\frac{2\eta\cdot D_{c e}^{u}}{D_{c e}^{u}+D_{c e}^{d}}\right\rfloor,n_{d}=2\eta-n_{u},
$$
where $D_{c e}^{u}$ and $D_{c e}^{d}$ represent the boundary distances in the upward and downward directions, respectively, with $n_{u}$ is constrained to $1\leq n_{u}\leq2\eta-1$ . For each direction, starting from the unreliable pixel, we locate a set of equally spaced pixels ${\mathbf{s}{i}}{i=1}^{n}$ along the line to the boundary. Let $\mathcal{N}(\mathbf{s}{i})$ denote the nearest reliable pixel to $\mathbf{s}{i}$ . The set ${\mathcal{N}(\mathbf{s}{i})}_{i=1}^{n}$ serves as the result of extended search in that direction.
其中 $D_{c e}^{u}$ 和 $D_{c e}^{d}$ 分别表示向上和向下方向的边界距离,且 $n_{u}$ 被约束为 $1\leq n_{u}\leq2\eta-1$。对于每个方向,从未可靠像素出发,我们沿直线定位一组等距像素 ${\mathbf{s}{i}}{i=1}^{n}$ 直至边界。设 $\mathcal{N}(\mathbf{s}{i})$ 表示 $\mathbf{s}{i}$ 的最近可靠像素,集合 ${\mathcal{N}(\mathbf{s}{i})}_{i=1}^{n}$ 即为该方向上扩展搜索的结果。
We retain the reliable pixels search scheme from APDMVS, which involves partitioning the search space centered on the unreliable pixel into $\phi$ equal-angle sectors and locating the nearest reliable pixels within each sector. This scheme only searches the nearest reliable pixels and is applied to each unreliable pixel, while the extended search supplements it in low-textured areas.
我们保留了APDMVS中可靠的像素搜索方案,该方案将以不可靠像素为中心的搜索空间划分为$\phi$个等角扇区,并在每个扇区内定位最近的可靠像素。此方案仅搜索最近的可靠像素,并应用于每个不可靠像素,而扩展搜索则在低纹理区域对其进行补充。
Plane Construction Optimization RANSAC aims to find the best-fitting plane from 3D points. Using an unreliable pixel in a low-textured area as an example, obtain the set of 3D points $\pmb{\mathcal{X}}={\mathbf{X}{i}}{i=1}^{\phi+8\eta}$ for the searched reliable pixels. Three random points from are iterative ly selected to construct a plane $\pi$ , identifying the best fit as follows:
平面构建优化 RANSAC 旨在从3D点中寻找最佳拟合平面。以低纹理区域中不可靠像素为例,获取搜索到的可靠像素对应的3D点集 $\pmb{\mathcal{X}}={\mathbf{X}{i}}_{i=1}^{\phi+8\eta}$ 。从中迭代选取三个随机点构建平面 $\pi$ ,并通过以下方式确定最佳拟合:
$$
\pi^{}=\arg\operatorname*{min}{\pi}\sum_{i=1}^{\phi+8\eta}\mathbb{I}[\delta(\mathbf{X}_{i},\pi)<\epsilon].
$$
$$
\pi^{}=\arg\operatorname*{min}{\pi}\sum_{i=1}^{\phi+8\eta}\mathbb{I}[\delta(\mathbf{X}_{i},\pi)<\epsilon].
$$
Here, $\delta$ represents the residual, $\epsilon$ is the outlier filtering threshold, and $\mathbb{I}$ is an indicator function that equals 1 if the condition is met and 0 otherwise. If there are multiple $\pi^{*}$ , select the one that minimizes $\delta$ with the 3D point of the unreliable pixel. Let $\pi$ be defined by $\scriptstyle{m_{1}x+m_{2}y+m_{3}z+b=0}$ . Based on the projection relationship between $\mathbf{X}{i}$ and its pixel coordinate $(u_{i},v_{i})$ , the fitting depth $d_{i}$ is obtained as:
这里,$\delta$ 表示残差,$\epsilon$ 是离群值过滤阈值,$\mathbb{I}$ 是一个指示函数,当条件满足时等于1,否则为0。如果存在多个 $\pi^{*}$,则选择使 $\delta$ 最小且与不可靠像素的3D点对应的那个。设 $\pi$ 由 $\scriptstyle{m_{1}x+m_{2}y+m_{3}z+b=0}$ 定义。根据 $\mathbf{X}{i}$ 与其像素坐标 $(u_{i},v_{i})$ 之间的投影关系,拟合深度 $d_{i}$ 可表示为:
$$
d_{i}=\frac{-b\cdot f_{x}\cdot f_{y}}{m_{1}f_{y}(u_{i}-c_{x})+m_{2}f_{x}(v_{i}-c_{y})+m_{3}f_{x}f_{y}},
$$
$$
d_{i}=\frac{-b\cdot f_{x}\cdot f_{y}}{m_{1}f_{y}(u_{i}-c_{x})+m_{2}f_{x}(v_{i}-c_{y})+m_{3}f_{x}f_{y}},
$$
where $c_{x},c_{y},f_{x}$ and $f_{y}$ are intrinsic camera parameters. For $\mathbf{X}{i}$ , we calculated $\delta$ as $|d_{i}-d_{i}^{\theta}|$ , where $d_{i}^{\theta}$ is the depth hypothesis. Comparatively, conventional planar RANSAC calculates $\delta$ by considering only the point-to-plane distance, without utilizing the projection relationship.
其中 $c_{x},c_{y},f_{x}$ 和 $f_{y}$ 是相机内参。对于 $\mathbf{X}{i}$,我们计算 $\delta$ 为 $|d_{i}-d_{i}^{\theta}|$,其中 $d_{i}^{\theta}$ 是深度假设值。相比之下,传统平面RANSAC仅通过点面距离计算 $\delta$,未利用投影关系。
To mitigate the issue of crossing object boundaries, we imposed constraints on RANSAC’s random point selection. Let $\mathcal{F}$ denote the set of all fine edge pixels, ${\mathbf{\dot{q}}{i},\mathbf{n}{i}^{\theta}}_{i=1}^{3}$ rep- resent the pixels and their normal hypotheses corresponding to the selected three points. We present two conditions:
为了缓解跨越物体边界的问题,我们对RANSAC的随机点选择施加了约束。设$\mathcal{F}$表示所有精细边缘像素的集合,${\mathbf{\dot{q}}{i},\mathbf{n}{i}^{\theta}}_{i=1}^{3}$代表所选三个点对应的像素及其法线假设。我们提出两个条件:

Figure 6: The right side presents examples of a stochastic textured area (top) and a low-textured area (bottom). The left side shows the corresponding cost profiles, highlighting the matching costs around the ground truth for various methods, including conventional PM, deformable PM, and deformable PM with our Adaptive Patch Size Adjustment.
图 6: 右侧展示了随机纹理区域(上)和低纹理区域(下)的示例。左侧显示了对应的代价曲线,突出展示了包括传统PM、可变形PM以及采用我们自适应块大小调整的可变形PM在内的多种方法在真实值附近的匹配代价。
$$
\begin{array}{r l r l}&{}&{\forall i:~\overline{{\mathbf{q}{i}\mathbf{q}_{j}}}\cap\mathcal{F}=\varnothing;}\ &{}&{\forall i,j\in{1,2,3},ij}&{C_{1}:~\mathbf{n}{i}^{\theta}\cdot\mathbf{n}{j}^{\theta}\tau,}\end{array}
$$
$$
\begin{array}{r l r l}&{}&{\forall i:~\overline{{\mathbf{q}{i}\mathbf{q}_{j}}}\cap\mathcal{F}=\varnothing;}\ &{}&{\forall i,j\in{1,2,3},ij}&{C_{1}:~\mathbf{n}{i}^{\theta}\cdot\mathbf{n}{j}^{\theta}\tau,}\end{array}
$$
where $\overline{{{\bf q}{i}{\bf q}{j}}}$ represents the set of pixels along the line segment between $\mathbf{q}{i}$ and $\mathbf{q}{j}$ , and $\tau$ is a threshold. Condition $C_{1}$ is a mandatory requirement, while $C_{2}$ is a priority condition that should be met when possible.
其中 $\overline{{{\bf q}{i}{\bf q}{j}}}$ 表示 $\mathbf{q}{i}$ 和 $\mathbf{q}{j}$ 之间线段上的像素集合,$\tau$ 为阈值。条件 $C_{1}$ 是强制性要求,而 $C_{2}$ 是应尽可能满足的优先条件。
After RANSAC, select up to $|\mathbf{S}|$ pixels corresponding to the 3D points ${\mathbf{X}{i}|\delta(\mathbf{X}_{i},\pmb{\pi}^{*})<\epsilon}$ that have smallest residuals to serve as anchors. The optimized RANSAC is also used to generate a new plane hypothesis with these anchors, a necessary step for the propagation in deformable PM.
在RANSAC之后,选择最多$|\mathbf{S}|$个像素点作为锚点,这些像素点对应的3D点${\mathbf{X}{i}|\delta(\mathbf{X}_{i},\pmb{\pi}^{*})<\epsilon}$具有最小残差。优化后的RANSAC还用于利用这些锚点生成新的平面假设,这是可变形PM中传播的必要步骤。
Moreover, we observed that stochastic textured areas, lacking explicit repeating patterns (Efros and Leung 1999), often lead to numerous fine edges that do not effectively constrain the plane model. To address this, we propose assessing texture complexity per pixel. Let $N_{f e}$ and $N_{c e}$ denote the number of fine and coarse edge pixels, respectively, within an $M\times M$ area centered on pixel $\mathbf{p}$ . The probability that $\mathbf{p}$ is in a stochastic textured area can be calculated as:
此外,我们观察到缺乏明确重复模式的随机纹理区域 (Efros and Leung 1999) 往往会产生大量无法有效约束平面模型的细边缘。为解决这一问题,我们提出评估每像素的纹理复杂度。设 $N_{f e}$ 和 $N_{c e}$ 分别表示以像素 $\mathbf{p}$ 为中心的 $M\times M$ 区域内细边缘和粗边缘像素的数量,则 $\mathbf{p}$ 位于随机纹理区域的概率可计算为:
$$
\Phi_{p}=\frac{\alpha\cdot N_{f e}+(1-\alpha)\cdot N_{c e}}{M\times M},
$$
$$
\Phi_{p}=\frac{\alpha\cdot N_{f e}+(1-\alpha)\cdot N_{c e}}{M\times M},
$$
$$
\mathcal{P}(\mathbf{p}|Z)=\frac{1}{1+e x p\left[-\beta_{1}\cdot(\Phi_{p}-\beta_{2})\right]},
$$
$$
\mathcal{P}(\mathbf{p}|Z)=\frac{1}{1+e x p\left[-\beta_{1}\cdot(\Phi_{p}-\beta_{2})\right]},
$$
where $\Phi_{p}$ represent edge densities, and $\alpha,\beta_{1},\beta_{2}$ are empiri- cally set. $Z$ indicates that the pixel is in a stochastic textured area, and $M$ is the same as the fixed patch size. We generate a random number $r$ between 0 and 1. If $r<\mathcal{P}(\mathbf{p}|Z)$ , then $\mathbf{p}$ is considered to be in a stochastic textured area, rendering condition $C_{1}$ inapplicable.
其中$\Phi_{p}$表示边缘密度,$\alpha,\beta_{1},\beta_{2}$为经验设定值。$Z$表示像素处于随机纹理区域,$M$与固定斑块尺寸相同。我们生成一个0到1之间的随机数$r$。若$r<\mathcal{P}(\mathbf{p}|Z)$,则认为$\mathbf{p}$处于随机纹理区域,此时条件$C_{1}$不适用。
Adaptive Patch Size Adjustment
自适应补丁大小调整
When computing matching cost, the deformable patch employs fixed-size patches of the center unreliable pixel and its anchors, as detailed in Eq. 1. The cost profiles for different matching methods in stochastic and low-textured areas are shown in Fig. 6. The gray cost profiles indicate the instability of the center patch during matching, suggesting the need for further improvement. Enlarging the center patch size may help mitigate this issue (Xu et al. 2020; Sun et al. 2022), but could lead to detail loss and challenges in selecting the size.
计算匹配成本时,可变形补丁采用中心不可靠像素及其锚点的固定大小补丁,具体如式1所示。随机和低纹理区域中不同匹配方法的成本分布如图6所示。灰色成本分布表明中心补丁在匹配过程中的不稳定性,暗示需要进一步改进。增大中心补丁尺寸可能有助于缓解此问题 (Xu et al. 2020; Sun et al. 2022),但可能导致细节丢失和尺寸选择困难。
Table 1: Quantitative results on ETH3D benchmark. Our method achieves the best completeness and $\mathrm{F_{1}}$ -score.
| 方法 | 训练 (2cm) | 训练 (10cm) | 测试 (2cm) | 测试 (10cm) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | Comp. | F1 | Acc. | Comp. | F1 | Acc. | Comp. | F1 | Acc. | Comp. | F1 | |
| PatchMatchNet | 64.81 | 65.43 | 64.21 | 89.98 | 83.28 | 85.70 | 69.71 | 77.46 | 73.12 | 91.98 | 92.05 | 91.91 |
| IterMVs | 79.79 | 66.08 | 71.69 | 96.35 | 82.62 | 88.60 | 84.73 | 76.49 | 80.06 | 96.92 | 88.34 | 92.29 |
| EPNet | 79.36 | 79.28 | 79.08 | 94.33 | 93.69 | 93.92 | 80.37 | 87.84 | 83.72 | 93.72 | 96.82 | 95.20 |
| GoMVs | 81.22 | 77.65 | 79.16 | 97.11 | 89.62 | 93.08 | 86.85 | 85.50 | 85.91 | 97.23 | 95.02 | 96.02 |
| ACMM | 90.67 | 70.42 | 78.86 | 98.12 | 86.40 | 91.70 | 90.65 | 74.34 | 80.78 | 98.05 | 88.77 | 92.96 |
| ACMMP | 90.63 | 77.61 | 83.42 | 97.99 | 93.32 | 95.54 | 91.91 | 81.49 | 85.89 | 98.05 | 94.67 | 96.27 |
| TSAR-MVS+MP. | 89.67 | 84.39 | 86.88 | 98.15 | 96.50 | 97.31 | 88.14 | 88.11 | 88.02 | 97.42 | 97.44 | 97.42 |
| APD-MVS | 89.14 | 84.83 | 86.84 | 97.47 | 96.79 | 97.12 | 89.54 | 85.93 | 87.44 | 97.00 | 96.95 | 96.95 |
| HPM-MVS | 90.66 | 79.50 | 84.58 | 97.97 | 95.59 | 96.22 | 92.13 | 83.25 | 87.11 | 98.11 | 95.41 | 96.69 |
| SD-MVS | 89.91 | 84.31 | 86.96 | 97.84 | 96.87 | 97.35 | 88.96 | 87.49 | 88.06 | 97.37 | 97.51 | 97.41 |
| DPE-MVS (ours) | 89.81 | 87.60 | 88.63 | 97.99 | 97.69 | 97.83 | 90.53 | 88.77 | 89.48 | 97.64 | 98.11 | 97.86 |
表 1: ETH3D基准测试的定量结果。我们的方法在完整性和 $\mathrm{F_{1}}$ 分数上取得了最佳表现。
Algorithm 1: Adaptive Patch Size Adjustment
算法 1: 自适应块大小调整
| 输入: 定义不可靠像素 p 所在平面的三个锚点, 精细边缘和粗糙边缘 | 输出: 为 p 选择合适的中心块半径 |
|---|---|
| 1: r ← [√(三角形面积)/2]; // 三个锚点 | 2: D ← {w × Dan}; |
| 3: if p 不在随机纹理区域 then | // 八条精细边缘 D ← D ∪ {Dfe}; |
| 4: if p 在低纹理区域 then | // 八条粗糙边缘 D ← D ∪ {Dce}; |
| 5: r ← min{D}; | 6: if 固定半径 > r then r ← 固定半径; // 固定块大小 |
| 7: else if p 在随机纹理区域 then | 8: r ← 固定半径; |
We propose a hybrid approach that combines patch enlargement with patch discarding. Roughly speaking, for pixels in stochastic textured areas, we tend to discard the cen- ter patch, while for those in low-textured areas, we tend to enlarge the center patch. The insight behind discarding the center patch is that anchors, selected for their planar charact eris tics, maintain stable normal estimation, whereas the center patch may introduce instability. The details of this approach are outlined in Algo. 1. It is posited that the triangular area formed by the three anchors, which are selected by optimized RANSAC to represent the points constructing the best-fitting plane, provides informative features for the center pixel. The appropriate patch radius is determined using this triangular area with the surrounding edge information. The comparison between the green and red cost profiles in Fig. 6 illustrates the effectiveness of our approach.
我们提出了一种结合块扩大与块丢弃的混合方法。简而言之,对于随机纹理区域的像素,我们倾向于丢弃中心块;而对于低纹理区域的像素,则倾向于扩大中心块。丢弃中心块的核心理念在于:基于平面特性选定的锚点能保持稳定的法线估计,而中心块可能引入不稳定性。该方法的具体实现如算法1所示。我们认为,通过优化RANSAC选取的三个锚点所构成的三角形区域(代表最佳拟合平面的点集)能为中心像素提供有效特征。该三角形区域结合边缘信息即可确定合适的块半径。图6中绿色与红色成本曲线的对比验证了本方法的有效性。
Experiments Datasets and Implementation Details
实验数据集与实现细节
We evaluate our method on the ETH3D (Schops et al. 2017) and Tanks & Temples (Knapitsch et al. 2017) benchmarks, and conduct ablation experiments on the ETH3D training dataset to verify its effectiveness. We compare our method with SOTA learning-based methods including PatchMatchNet, AA-RMVSNet, IterMVS, Trans MV S Net, EPNet, DS- PMNet, GoMVS and traditional MVS methods including ACMM, ACMMP, APD-MVS, HPM-MVS , TSAR-MVS, SD-MVS. To ensure fairness, we maintained the original APD-MVS parameters and depth map fusion procedures. The proposed parameter settings are: ${\sigma,\eta,\tau,\alpha,\beta_{1},\beta_{2}$ , $\omega}={0.67,4,\bar{0}.87,0.5,25,0.\bar{3}5,2.5}$ .
我们在ETH3D (Schops et al. 2017) 和 Tanks & Temples (Knapitsch et al. 2017) 基准测试上评估了我们的方法,并在ETH3D训练数据集上进行了消融实验以验证其有效性。我们将该方法与基于学习的SOTA方法(包括PatchMatchNet、AA-RMVSNet、IterMVS、TransMVSNet、EPNet、DS-PMNet、GoMVS)以及传统MVS方法(包括ACMM、ACMMP、APD-MVS、HPM-MVS、TSAR-MVS、SD-MVS)进行了比较。为确保公平性,我们保持了APD-MVS的原始参数和深度图融合流程。提出的参数设置为:${\sigma,\eta,\tau,\alpha,\beta_{1},\beta_{2}$ , $\omega}={0.67,4,\bar{0}.87,0.5,25,0.\bar{3}5,2.5}$。
Evaluation on MVS Benchmarks
在多视角立体视觉 (MVS) 基准上的评估
The quantitative results of ETH3D are presented in Tab. 1. Our method ranks 1st in both completeness and $\mathrm{F_{1}}$ -score, with accuracy nearly matching the previous best. Fig. 7 provides a qualitative analysis, confirming that our method significantly enhances the reconstruction of low-textured areas.
ETH3D的定量结果如表 1 所示。我们的方法在完整性和 $\mathrm{F_{1}}$ 分数上均排名第一,准确率与之前的最佳结果几乎持平。图 7 提供了定性分析,证实我们的方法显著提升了低纹理区域的重建效果。
On the Tanks & Temples benchmark, We validated the generalization capability of our method. The quantitative results are shown in Tab. 2. Our method ranks 1st in recall among all methods. In comparison with traditional methods, our method’s $\mathrm{F_{1}}$ -score ranks 1st and 2nd in the Intermediate and Advanced datasets, respectively. Compared to learning-based methods, our method is also competitive. It shows lower precision in the Advanced dataset, primarily due to the extensive low-textured areas. In these areas, our method prioritizes recall, with a slight trade-off in precision.
在Tanks & Temples基准测试中,我们验证了方法的泛化能力。定量结果如表2所示。我们的方法在所有方法中召回率排名第一。与传统方法相比,我们的方法在Intermediate和Advanced数据集上的$\mathrm{F_{1}}$分数分别位列第一和第二。与基于学习的方法相比,我们的方法同样具有竞争力。在Advanced数据集上精度略低,主要由于存在大量低纹理区域。在这些区域中,我们的方法优先保证召回率,因此精度略有牺牲。
Ablation Studies
消融实验
In the ETH3D training dataset, we conduct ablation experiments to verify the effectiveness of each component in our proposed method, which includes Edge-Guided Non-Local Sampling (ES), Perceptual Range Expansion (PE), Plane
在ETH3D训练数据集中,我们通过消融实验验证了所提方法中各组件的有效性,包括边缘引导非局部采样(ES)、感知范围扩展(PE)和平面

Figure 7: Qualitative results on ETH3D. Our method exhibits a significant advantage in reconstructing low-textured areas.
图 7: ETH3D定性对比结果。我们的方法在低纹理区域重建方面展现出显著优势。
Table 2: Quantitative results on Tanks & Temples.
表 2: Tanks & Temples 定量结果
| 方法 | 中级 (Intermediate) | 高级 (Advanced) | ||||
|---|---|---|---|---|---|---|
| Pre. | Rec. | F1 | Pre. | Rec. | F1 | |
| PatchmatchNet | 43.64 | 69.37 | 53.15 | 27.27 | 41.66 | 32.31 |
| AA-RMVSNet | 52.68 | 75.69 | 61.51 | 37.46 | 33.01 | 33.53 |
| IterMVS | 47.53 | 74.69 | 56.94 | 28.70 | 44.19 | 34.17 |
| 55.14 | 76.73 | 63.52 | 33.84 | 44.29 | 37.00 | |
| EPNet | 57.01 | 72.57 | 63.68 | 34.26 | 50.54 | 40.52 |
| DS-PMNet | 56.02 | 76.76 | 64.16 | 34.29 | 48.73 | 39.78 |
| 49.19 | 70.85 | 57.27 | 35.63 | 34.90 | 34.02 | |
| 53.28 | 68.50 | 59.38 | 33.79 | 44.64 | 37.84 | |
| TSAR-MVS+MP. | 53.15 | 75.52 | 62.10 | 33.85 | 48.75 | 38.63 |
| APD-MVS | 55.58 | 75.06 | 63.64 | 33.77 | 49.41 | 39.91 |
| 51.58 | 76.92 | 61.39 | 40.67 | 45.42 | 40.80 | |
| 53.78 | 77.63 | 63.31 | 35.53 | 47.37 | 40.18 | |
| SD-MVS | 54.48 | 78.16 | 63.98 | 31.37 | 56.45 | 40.20 |
| DPE-MVS(ours) |
Construction Optimization (PO), and Adaptive Patch Size Adjustment (AA). Tab. 3 illustrates the effectiveness of each part. ES significantly expands the solution space for reliable pixel hypotheses, enhancing their accuracy and improving plane construction for unreliable pixels. PE, similar to ES, extends the search range for reliable pixels within adaptive patch deformation, helping to avoid the influence of locally optimal reliable pixels during plane model construction. PO optimizes the RANSAC algorithm, ensuring the quality of the final plane models. Together, ES, PE, and PO substantially improve completeness. AA adjusts the center patch size, enabling faster convergence and allowing hypotheses close to the correct solution to be refined with greater precision within limited iterations, thereby enhancing accuracy.
构造优化 (PO) 和自适应块大小调整 (AA) 。表 3 展示了各模块的有效性。ES (Expansion Strategy) 显著扩展了可靠像素假设的求解空间,提升其精度并改善不可靠像素的平面构造。PE (Patch Expansion) 与 ES 类似,在自适应块形变范围内扩展可靠像素的搜索范围,有助于避免平面模型构建过程中局部最优可靠像素的影响。PO (Plane Optimization) 优化了 RANSAC 算法,确保最终平面模型的质量。ES、PE 和 PO 共同显著提升了完整性。AA (Adaptive Adjustment) 通过调整中心块大小实现更快收敛,使得接近正确解的假设能在有限迭代次数内以更高精度优化,从而提升准确性。
We also compare ES with the NESP module of HPMMVS, integrating ES into ACMM, ACMP, and ACMMP, following (Ren et al. 2023). As shown in Tab. 4, our method outperforms others, except at the 1cm and 2cm thresholds in ACMM. The lack of plane priors in ACMM leads to erroneous depth estimations in low-textured areas, making it less suitable for our broader sampling range compared to NESP.
我们还按照 (Ren et al. 2023) 的方法,将 ES 与 HPMMVS 的 NESP 模块进行对比,并将 ES 集成到 ACMM、ACMP 和 ACMMP 中。如表 4 所示,除 ACMM 在 1cm 和 2cm 阈值下的表现外,我们的方法优于其他方法。ACMM 缺乏平面先验,导致低纹理区域的深度估计错误,因此与 NESP 相比,它不太适合我们更广泛的采样范围。
Further results are provided in the supplementary materials, including additional experimental details and comparative studies, extensive point cloud visualization s.
补充材料中提供了更多结果,包括额外的实验细节和对比研究、大量的点云可视化内容。
Table 3: Results of our method with different settings on the ETH3D training dataset; baseline: APD-MVS.
表 3: 我们的方法在ETH3D训练数据集上不同设置的结果;基线:APD-MVS。
| Settings | 1cm | 5cm | ||||
|---|---|---|---|---|---|---|
| ES PE | PO AA | Acc. | Comp. F1 | AcC. | Comp. | F1 |
| 80.60 | 71.86 | 75.80 | 95.38 | 93.47 94.37 | ||
| 79.74 | 74.15 76.67 | 94.85 | 93.97 | 94.38 | ||
| 80.16 | 73.08 76.27 | 95.30 | 93.87 | 94.54 | ||
| 80.19 | 74.71 | 77.13 | 95.43 | 94.36 94.81 | ||
| √ | 80.25 | 75.79 | 77.79 | 95.45 | 94.71 95.05 | |
| √ | 80.69 | 74.48 | 77.26 | 95.81 94.77 | 95.26 | |
| √ | √ | 81.01 75.74 | 78.11 | 96.00 | 95.10 95.53 |
Table 4: Comparison of $\mathrm{F_{1}}$ -scores of different sampling strategies on the ETH3D training dataset.
表 4: 不同采样策略在ETH3D训练数据集上的$\mathrm{F_{1}}$分数对比
| 方法 | 1cm | 2cm | 5cm | 10cm | 20cm |
|---|---|---|---|---|---|
| ACMM | 67.58 | 78.86 | 87.68 | 91.70 | 94.41 |
| w/.NESP | 70.70 | 81.01 | 88.80 | 92.26 | 94.55 |
| w/.ES (ours) | 69.34 | 80.47 | 89.17 | 92.83 | 95.07 |
| ACMP | 68.72 | 79.79 | 88.32 | 92.03 | 94.43 |
| w/.NESP | 70.87 | 81.45 | 89.43 | 92.72 | 94.78 |
| w/.ES (ours) | 72.45 | 83.01 | 90.70 | 93.72 | 95.53 |
| ACMMP | 71.57 | 83.42 | 92.03 | 95.54 | 97.37 |
| w/.NESP | 74.54 | 85.33 | 93.25 | 96.45 | 97.99 |
| w/.ES (ours) | 76.01 | 86.60 | 94.07 | 97.07 | 98.37 |
Conclusion
结论
In this paper, we propose the DPE-MVS method, which addresses issues in plane construction by introducing duallevel precision edge information. Our method significantly improves reconstruction of low-textured areas and excels in recovering stochastic textured areas. Experimental results demonstrate SOTA performance on ETH3D and Tanks & Temples. However, improvement is needed in handling fine scene details, where learning-based methods excel. Future work will integrate these methods for more accurate results.
本文提出DPE-MVS方法,通过引入双精度边缘信息解决平面构建问题。该方法显著改善了低纹理区域的重建效果,并在随机纹理区域恢复方面表现优异。实验结果表明,在ETH3D和Tanks & Temples数据集上达到了SOTA性能。但在处理精细场景细节方面仍需改进,这正是基于学习的方法的优势所在。未来工作将整合这些方法以获得更精确的结果。