Intern Video: General Video Foundation Models via Generative and Disc rim i native Learning
Intern Video: 基于生成式与判别式学习的通用视频基础模型
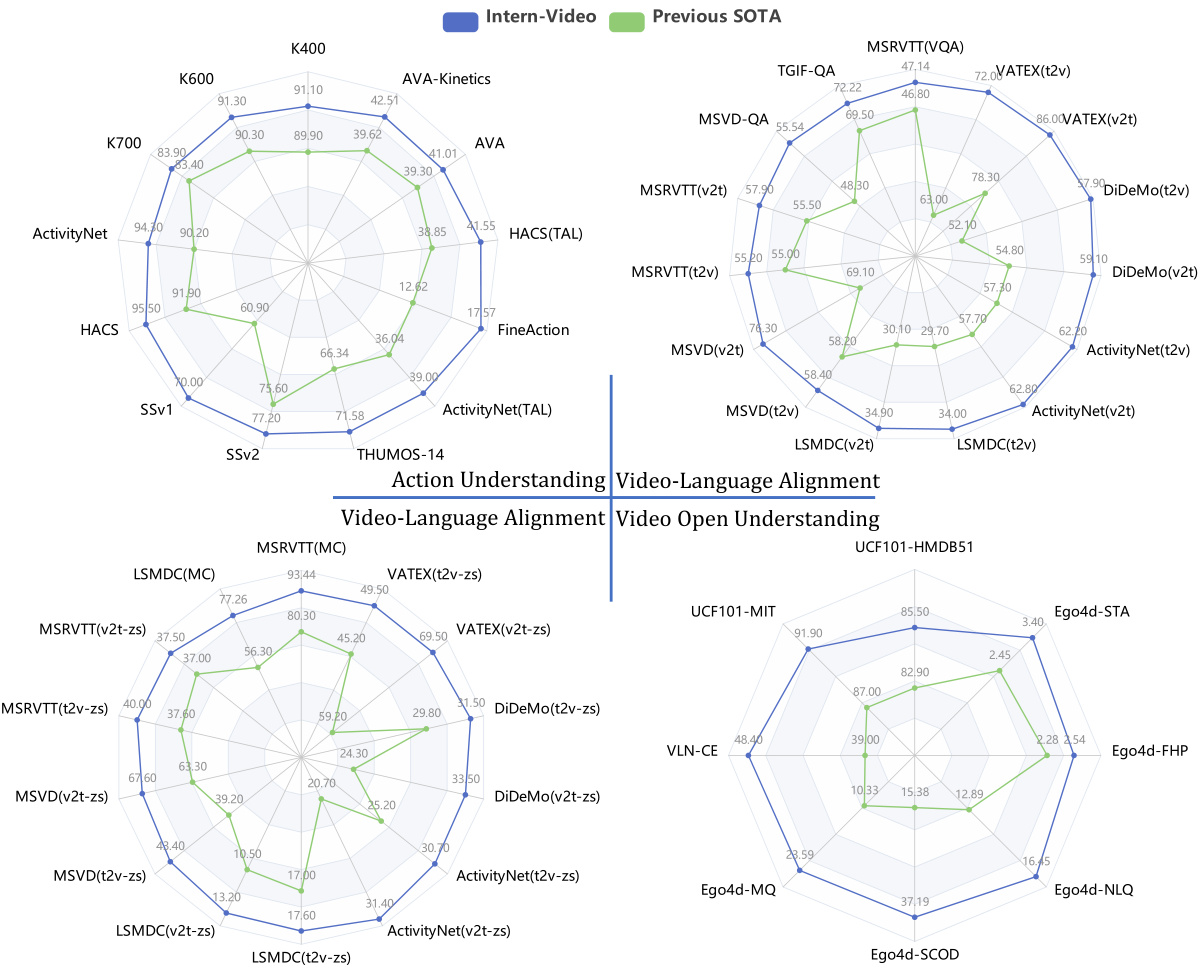
Figure 1: Intern Video delivers the best performance on extensive video-related tasks, compared with the state-of-the-art methods (including specialized [1–5] and foundation models [6–9]). Comparison details are given in Section 4.3. v2t and t2v denote video-to-text and text-to-video retrieval respectively. STA, FHP, NLQ, SCOD, and MQ are short for Short-term Object Interaction Anticipation, Future Hand Prediction, Natural Language Queries, State Change Object Detection, and Moment Queries, respectively.
图 1: 与现有最先进方法(包括专用模型 [1-5] 和基础模型 [6-9])相比,Intern Video 在广泛的视频相关任务中展现出最佳性能。具体比较细节见第 4.3 节。v2t 和 t2v 分别表示视频到文本检索和文本到视频检索。STA、FHP、NLQ、SCOD 和 MQ 分别是短期物体交互预测 (Short-term Object Interaction Anticipation)、未来手部预测 (Future Hand Prediction)、自然语言查询 (Natural Language Queries)、状态变化物体检测 (State Change Object Detection) 和时刻查询 (Moment Queries) 的缩写。
Abstract
摘要
The foundation models have recently shown excellent performance on a variety of downstream tasks in computer vision. However, most existing vision foundation models simply focus on imagelevel pre training and adpation, which are limited for dynamic and complex video-level understanding tasks. To fill the gap, we present general video foundation models, Intern Video, by taking advantage of both generative and disc rim i native self-supervised video learning. Specifically, InternVideo efficiently explores masked video modeling and video-language contrastive learning as the pre training objectives, and selectively coordinates video representations of these two complementary frameworks in a learnable manner to boost various video applications. Without bells and whistles, Intern Video achieves state-of-the-art performance on 39 video datasets from extensive tasks including video action recognition/detection, video-language alignment, and open-world video applications. Especially, our methods can obtain $91.1%$ and $77.2%$ top-1 accuracy on the challenging Kinetics-400 and Something-Something V2 benchmarks, respectively. All of these results effectively show the generality of our Intern Video for video understanding. The code will be released at https://github.com/OpenGVLab/Intern Video.
基础模型最近在计算机视觉的多种下游任务中展现出卓越性能。然而,现有视觉基础模型大多仅关注图像级预训练与适配,难以应对动态复杂的视频级理解任务。为此,我们通过融合生成式 (generative) 与判别式 (discriminative) 自监督视频学习,提出通用视频基础模型InternVideo。具体而言,该模型以掩码视频建模和视频-语言对比学习作为预训练目标,并通过可学习机制选择性协调这两个互补框架的视频表征,从而提升多样化视频应用性能。在不引入额外技巧的情况下,InternVideo在39个视频数据集上实现了最先进性能,涵盖视频动作识别/检测、视频-语言对齐及开放世界视频应用等广泛任务。特别是在Kinetics-400和Something-Something V2基准测试中,我们的方法分别取得了91.1%和77.2%的top-1准确率。这些结果有力证明了InternVideo在视频理解领域的通用性。代码将在https://github.com/OpenGVLab/InternVideo发布。
1 Introduction
1 引言
Foundation models have been gaining increasing attention in the research community [10–12], since they give a practical paradigm for scaling to numerous perception tasks with surprisingly good results. Through simple adaption or zero/few-shot learning, foundation models greatly reduce downstream design and training costs using generic representations learned from web-scale data with a strong backbone of high capacity. It is expected that developing foundation models can cultivate cognition from perception, obtaining general vision capability.
基础模型 (foundation model) 正日益受到研究界的关注 [10-12],因为它们为扩展到众多感知任务提供了实用范式,并取得了惊人的良好效果。通过简单的适配或零样本/少样本学习,基础模型利用从网络规模数据中学习到的通用表征,结合强大的高容量主干网络,大幅降低了下游设计和训练成本。预计开发基础模型可以从感知中培养认知能力,从而获得通用视觉能力。
Though a line of vision foundation models is proposed [7, 13–21], video understanding and the corresponding tasks are less explored compared with image ones, mainly used for validating that the visual features from these models are also beneficial to s patio temporal representations. We conjecture this relatively scarce focus from the academic community is caused by 1) a high computing burden from video processing, and 2) quite a few current video benchmarks can be handled by exploiting appearance features from image backbones with accordingly temporal modeling. Specifically, for efficiency, the additional time dimension in video processing makes at least one order of magnitude higher complexity than image processing when their spatial resolutions are close and the temporal sampling ratio is usually 16. For some current video datasets, image features alone or with lateral temporal modules are sufficient to give decent results, especially with the rise of the multimodal model CLIP [13]. Its various temporal variants yield competitive or state-of-the-art performance in several core tasks [5, 22]. Regarding this, a simultaneous s patio temporal learner does not seem like a sweet spot between research & development cost and payback.
尽管已有研究提出了一系列视觉基础模型 [7, 13-21],但与图像任务相比,视频理解及相关任务的探索仍显不足,这些模型主要被用于验证其视觉特征对时空表征同样有效。我们推测学术界关注度相对较低的原因在于:1) 视频处理带来的高昂计算负担;2) 当前多数视频基准测试通过利用图像主干网络的外观特征配合时序建模即可解决。具体而言,在空间分辨率相近且时间采样率通常为16的情况下,视频处理因额外的时间维度导致计算复杂度至少比图像处理高出一个数量级。对于现有部分视频数据集,仅凭图像特征或配合简单时序模块就能取得不错的效果——尤其是随着多模态模型CLIP [13] 的兴起,其各类时序变体已在多项核心任务中展现出竞争力或达到最优性能 [5, 22]。鉴于此,同步时空学习器似乎并非研发成本与回报之间的最佳平衡点。
Moreover, the transfer ability of current vision foundation models is somewhat narrow considering the wide spectrum of video applications. These models [6, 8, 23, 24] either concentrate on action understanding tasks (e.g. action recognition, s patio temporal action localization, etc) or video-language alignment ones (e.g. video retrieval, video question answering, etc). We suppose this results from their learning schemes, as well as the lack of a comprehensive benchmark for measuring video understanding capabilities. Thus, these works [6, 8, 23, 24] focalize a few specific tasks to demonstrate their s patio temporal perceptions. The community desires a general foundation model that enables a broader application domain.
此外,当前视觉基础模型(visual foundation model)的迁移能力在广泛视频应用场景中仍显局限。这些模型[6,8,23,24]要么聚焦动作理解任务(如行为识别、时空动作定位等),要么侧重视频-语言对齐任务(如视频检索、视频问答等)。我们认为这源于其学习机制缺陷,以及缺乏衡量视频理解能力的综合基准。因此这些工作[6,8,23,24]仅通过少量特定任务来验证其时空感知能力。学界亟需能支撑更广泛应用领域的通用基础模型。
In this paper, we advance video foundation model research with a cost-effective and versatile model Intern Video. To establish a feasible and effective s patio temporal representation, we study both popular video masked modeling [23, 25] and multimodal contrastive learning [13, 26]. Note that video masking modeling specializes in action understanding, and it is still worth exploring regarding its limited model scale caused by the current decoder. For multimodal contrastive learning, it embeds rich semantics into video representation while ignoring concrete s patio temporal modeling. To address these challenges, we make these two self-supervised approaches learn at scale efficiently in modular designs. To significantly broaden the generalization of the current video foundation models, we propose a unified representation learning with both two self-supervised training manners. To validate such a generalized representation, we propose a systematic video understanding benchmark. It involves evaluations of action understanding, video-language alignment, and open-world video applications, which we believe are three core abilities of generic video perception. Instead of introducing new data or annotations to this system, we initially choose ten representative video tasks with 39 public datasets, and categorize them into those three types. To our best knowledge, Intern Video is the first video foundation model which demonstrates promising transfer ability with state-of-the-art performance in all those three different types of video tasks.
本文提出了一种经济高效且多功能的视频基础模型Intern Video,以推进视频基础模型研究。为建立可行且有效的时空表征,我们同时研究了流行的视频掩码建模 [23, 25] 和多模态对比学习 [13, 26]。值得注意的是,视频掩码建模专精于动作理解,但由于当前解码器导致的模型规模限制,其潜力仍有待探索。而多模态对比学习虽能将丰富语义嵌入视频表征,却忽视了具体的时空建模。为解决这些挑战,我们通过模块化设计使这两种自监督方法能够高效地进行大规模学习。为显著提升当前视频基础模型的泛化能力,我们提出了一种统一表征学习方法,融合这两种自监督训练方式。为验证这种通用表征,我们设计了一个系统化的视频理解基准测试,涵盖动作理解、视频-语言对齐和开放世界视频应用三大评估维度——我们认为这是通用视频感知的三大核心能力。在不引入新数据或标注的前提下,我们精选了10个代表性视频任务(涉及39个公开数据集)并将其归类至上述三类。据我们所知,Intern Video是首个在三大类视频任务中均展现出卓越迁移能力并达到最先进性能的视频基础模型。
In Intern Video, we design a unified video representation (UVR) learning paradigm. It explores both masked video modeling with auto encoders (MAE) and multimodal contrastive learning for two types of representations, strengthens them by supervised action classification, and generates a more general representation based on the cross-representation learning between them. UVR not only empirically shows video representation outperforms image one with temporal capturing significantly on core video tasks, but also is training-efficient. Its MAE exploits high redundancies in videos and trains with only a few visible tokens. Meanwhile, multimodal learning in Intern Video extends existing image-pretrained backbones for video contrastive training. After supervised training these two video encoders, we craft cross-model attention to conduct feature alignments between these two almost frozen encoders.
在Intern Video中,我们设计了一种统一的视频表征(UVR)学习范式。该范式同时探索了基于自动编码器(MAE)的掩码视频建模和多模态对比学习两种表征方式,通过监督式动作分类强化它们,并基于两者间的跨表征学习生成更通用的表征。UVR不仅实证表明视频表征在核心视频任务上显著优于具有时间捕获能力的图像表征,还具有训练高效性。其MAE利用了视频中的高度冗余性,仅需少量可见token进行训练。同时,Intern Video中的多模态学习扩展了现有图像预训练主干网络以进行视频对比训练。在监督训练这两个视频编码器后,我们设计了跨模型注意力机制,以在这两个几乎冻结的编码器之间进行特征对齐。
More than a unified video representation learning paradigm, we also make practices and guidelines for training large-scale video foundation models in a tractable and efficient manner. Our work contains and is not limited to 1) making VideoMAE scalable and exploring its s cal ability in model and data scale; 2) efficient and effective multimodal architecture design and training receipt about how to leverage existing image-pretrained backbones; 3) empirically finding features from VideoMAE and multimodal models are complementary and studying how to deduce more powerful video representations by coordinating different existing models. Specifically,
规则:
- 输出中文翻译部分的时候,只保留翻译的标题,不要有任何其他的多余内容,不要重复,不要解释。
- 不要输出与英文内容无关的内容。
- 翻译时要保留原始段落格式,以及保留术语,例如 FLAC,JPEG 等。保留公司缩写,例如 Microsoft, Amazon, OpenAI 等。
- 人名不翻译
- 同时要保留引用的论文,例如 [20] 这样的引用。
- 对于 Figure 和 Table,翻译的同时保留原有格式,例如:“Figure 1: ”翻译为“图 1: ”,“Table 1: ”翻译为:“表 1: ”。
- 全角括号换成半角括号,并在左括号前面加半角空格,右括号后面加半角空格。
- 在翻译专业术语时,第一次出现时要在括号里面写上英文原文,例如:“生成式 AI (Generative AI)”,之后就可以只写中文了。
- 以下是常见的 AI 相关术语词汇对应表(English -> 中文):
- Transformer -> Transformer
- Token -> Token
- LLM/Large Language Model -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
分三步进行翻译工作:
- 不翻译无法识别的特殊字符和公式,原样返回
- 将HTML表格格式转换成Markdown表格格式
- 根据英文内容翻译成符合中文表达习惯的内容,不要遗漏任何信息
最终只返回Markdown格式的翻译结果,不要回复无关内容。
现在请按照上面的要求开始翻译以下内容为简体中文:More than a unified video representation learning paradigm, we also make practices and guidelines for training large-scale video foundation models in a tractable and efficient manner. Our work contains and is not limited to 1) making VideoMAE scalable and exploring its s cal ability in model and data scale; 2) efficient and effective multimodal architecture design and training receipt about how to leverage existing image-pretrained backbones; 3) empirically finding features from VideoMAE and multimodal models are complementary and studying how to deduce more powerful video representations by coordinating different existing models. Specifically,
We validate our proposed video foundation model in 10 tasks with 39 datasets (including core tasks e.g. action recognition, s patio temporal action localization, video question answering, video retrieval, etc), and it outperforms all the state-of-the-art methods in each task non-trivially. We suppose these overall superior results obtained by our approach, along with observations and analysis, set up a new baseline for the video understanding community. The empirical evidence in this paper raises the confidence that video perceptive tasks and partial high-order tasks (formulated to perceptive forms) can be well-addressed by video foundation models, serving as a performance-critical method across a spectrum of applications.
我们在10个任务和39个数据集(包括核心任务如动作识别、时空动作定位、视频问答、视频检索等)上验证了提出的视频基础模型,该模型在每个任务中都显著优于所有现有最优方法。我们认为,通过该方法获得的这些全面优势结果,结合观察与分析,为视频理解领域建立了新的基准。本文中的实证证据增强了以下信心:视频感知任务和部分高阶任务(以感知形式构建)可以通过视频基础模型得到良好解决,成为跨多种应用的关键性能方法。
In summary, we contribute to video foundation models in the following aspects:
总之,我们在以下几个方面为视频基础模型做出了贡献:
• We make a tentative attempt in constructing a systematic video understanding benchmark. Our general video foundation models achieve state-of-the-art performance on 39 datasets with several core tasks in this benchmark, e.g., Kinetics-400 and Something-Something v2 in action recognition. We empirically find our learned video representations outperform their rivals, dominating vision-language tasks by a large margin, especially for some image-based ones. It suggests general video representations will be a central player in video tasks. We believe the openness of our proposed methods and models will provide the research community with handy tools to foundation models and their features with easy access.
• 我们初步尝试构建了一个系统化的视频理解基准。在此基准中,我们的通用视频基础模型在39个数据集上实现了最先进的性能,涵盖动作识别等核心任务(如Kinetics-400和Something-Something v2)。实验表明,所学的视频表征显著优于同类方案,尤其在视觉-语言任务中大幅领先,部分图像类任务表现尤为突出。这预示着通用视频表征将成为视频任务的核心要素。我们相信,所提出方法与模型的开源性将为研究社区提供便捷的基础模型工具,并使其特征易于获取。
2 Related Work
2 相关工作
Image Foundation Models. Most of the current vision models are only suitable for specific tasks and domains, and they require manually labeled datasets for training. Regarding this, recent works have proposed vision foundation models. CLIP [13] and ALIGN [14] prepare web-scale noisy image-text pairs to train dual-encoder models with contrastive learning, leading to robust image-text representations for powerful zero-shot transfer. INTERN [12] expands the self-supervised pre training into multiple learning stages, which use a large quantity of image-text pairs as well as manually annotated images. INTERN achieves a better linear probe performance compared with CLIP, and improves data efficiency in the downstream image tasks. Florence [15] extends them with unified contrastive learning [16] and elaborate adaptation models, which support a wide range of vision tasks in different transfer settings. SimVLM [17] and OFA [18] train encoder-decoder models with generative targets and show competitive performances on a series of multimodal tasks. Besides, CoCa [7] unifies contrastive learning as CLIP and generative learning as SimVLM. Recently, BeiT-3 [19] introduces Multiway Transformers with unified BeiT [20] pre training, achieving state-of-the-art transfer results on several vision and image-language tasks.
图像基础模型。当前大多数视觉模型仅适用于特定任务和领域,且需要手动标注的数据集进行训练。针对这一问题,近期研究提出了视觉基础模型。CLIP [13] 和 ALIGN [14] 利用网络规模的噪声图像-文本对,通过对比学习训练双编码器模型,从而获得强大的零样本迁移能力的图像-文本表示。INTERN [12] 将自监督预训练扩展到多个学习阶段,使用大量图像-文本对以及人工标注图像。与 CLIP 相比,INTERN 实现了更好的线性探测性能,并提高了下游图像任务的数据效率。Florence [15] 通过统一的对比学习 [16] 和精细的适配模型进一步扩展这些方法,支持多种迁移设置下的广泛视觉任务。SimVLM [17] 和 OFA [18] 以生成目标训练编码器-解码器模型,在一系列多模态任务中展现出竞争力。此外,CoCa [7] 统一了 CLIP 的对比学习和 SimVLM 的生成学习。最近,BeiT-3 [19] 引入多路 Transformer 和统一的 BeiT [20] 预训练,在多个视觉和图像-语言任务上实现了最先进的迁移结果。
Video Foundation Models. Previous image foundation models [7, 15] only show promising performance for video recognition (especially on Kinetics). As for video multimodal tasks, VIOLET [30] combines masked language and masked video modeling, All-in-one [24] proposes unified video-language pre training with a shared backbone, and LAVENDER [31] unifies the tasks as masked language modeling. Though they perform well in multimodal benchmarks, they are trained with limited video-text data and struggle for video-only tasks, e.g. action recognition. In contrast, MERLOT Reserve [32] collects 20M video-text-audio pairs to train the joint video representations with contrastive span matching, thus setting state-of-the-art video recognition and visual commonsense reasoning. Compared with image foundation models, current video foundation models support limited video and video-language tasks, especially for those fine-grained temporal discrimination tasks such as temporal localization.
视频基础模型。先前的图像基础模型[7,15]仅在视频识别(尤其是Kinetics数据集)上展现出良好性能。对于视频多模态任务,VIOLET[30]结合了掩码语言与掩码视频建模,All-in-one[24]提出使用共享骨干网络的统一视频-语言预训练方法,LAVENDER[31]将所有任务统一为掩码语言建模。虽然这些模型在多模态基准测试中表现优异,但由于训练时使用的视频-文本数据有限,在纯视频任务(如动作识别)上表现欠佳。相比之下,MERLOT Reserve[32]收集了2000万视频-文本-音频三元组,通过对比跨度匹配训练联合视频表征,从而在视频识别和视觉常识推理任务上达到最先进水平。与图像基础模型相比,当前视频基础模型支持的视频及视频-语言任务仍较有限,特别是对于时序定位等需要细粒度时间分辨能力的任务。
Self-supervised Pre training. Self-supervised learning has developed rapidly recently. It focuses on designing different pretext tasks for pre training [33–37], which can be mainly divided into contrastive learning and masked modeling. Contrastive learning adopts various data augmentations to generate different views of an image, then pulls together the positive pairs and pushes apart the negative pairs. To maintain enough informative negative samples, previous methods depend on large memory banks or batch size [38–40]. BYOL [41] and SimSiam [42] eliminate the requirement of negative samples, designing elaborate techniques to avoid model collapse. As for masked modeling, it learns rich visual representation via masked prediction based on visible context. iGPT [43] firstly mentions Masked Image Modeling (MIM). BeiT [20] propose visual token prediction with the pretrained tokenizer [44], MaskFeat [6] predicts the hand-crafted image descriptor, and MAE [25] directly reconstructs the raw pixels. For s patio temporal representation learning, VideoMAE [23] and BEVT [45] respectively extend MAE and BeiT to s patio temporal space.
自监督预训练。自监督学习近年来发展迅速,其核心在于设计不同的预训练代理任务 [33–37],主要可分为对比学习和掩码建模两类。对比学习通过多种数据增强生成图像的不同视图,拉近正样本对距离并推远负样本对。为保持足够信息量的负样本,早期方法依赖大型记忆库或批量大小 [38–40]。BYOL [41] 和 SimSiam [42] 通过设计精巧技术避免模型坍塌,消除了对负样本的需求。掩码建模则基于可见上下文通过掩码预测学习丰富视觉表征:iGPT [43] 首次提出掩码图像建模 (MIM),BeiT [20] 采用预训练分词器 [44] 进行视觉token预测,MaskFeat [6] 预测手工设计的图像描述符,MAE [25] 直接重建原始像素。针对时空表征学习,VideoMAE [23] 和 BEVT [45] 分别将 MAE 和 BeiT 扩展至时空领域。
Multimodal Pre training. Starting from the development of image-text pre training, large-scale video-text pre training with specific downstream task finetuning has become the standard paradigm in the video-language area [26, 30, 32, 46– 51]. The seminal methods [52, 53] use pretrained visual and language encoders to extract the offline video and text features, while the recent methods [9, 24, 26, 46, 54, 55] have demonstrated the feasibility of end-to-end training. Besides, the popular methods often include two or three pre training tasks, e.g. masked language modeling [31], video-text matching [24], video-text contrastive learning [47] and video-text masked modeling [30].
多模态预训练。从图文预训练的发展开始,大规模视频-文本预训练结合特定下游任务微调已成为视频-语言领域的标准范式 [26, 30, 32, 46–51]。开创性方法 [52, 53] 使用预训练的视觉和语言编码器提取离线视频与文本特征,而近期方法 [9, 24, 26, 46, 54, 55] 则验证了端到端训练的可行性。此外,主流方法通常包含两到三项预训练任务,例如掩码语言建模 [31]、视频-文本匹配 [24]、视频-文本对比学习 [47] 以及视频-文本掩码建模 [30]。
3 Intern Video
3 实习生视频
Intern Video is a general video foundation model along with its training and internal cooperation as given in Figure 2. In structure, Intern Video adopts the vision transformer (ViT) [28] and its variant Uni former V 2 [56], along with extra local s patio temporal modeling modules for multi-level representation interaction. In learning, Intern Video improve its representation progressively, integrating both self-supervised (masked modeling and multimodal learning) and supervised training. Moreover, as we explore two types of self-supervised learning, we further integrate their merits. Intern Video dynamically derives new features from these two transformers via learnable interactions, getting the best of both worlds from generative and contrastive pertaining. Through the newly aggregated features, Intern Video sets new performance records on 34 benchmarks from 10 mainstream video tasks, and wins championships of five tracks in recent Ego4D competitions [57].
Intern Video是一种通用视频基础模型,其训练和内部协作如图2所示。在结构上,Intern Video采用视觉Transformer (ViT) [28]及其变体UniFormerV2 [56],并额外加入局部时空建模模块以实现多层级表征交互。在学习机制上,该模型通过整合自监督学习(掩码建模与多模态学习)和监督训练逐步提升表征能力。我们探索了两种自监督学习范式后,进一步融合其优势:Intern Video通过可学习的交互机制动态整合两个Transformer的特征,在生成式预训练和对比式预训练中取得双赢。基于新聚合的特征,该模型在10个主流视频任务的34个基准测试中刷新性能记录,并斩获近期Ego4D竞赛[57]五个赛道的冠军。
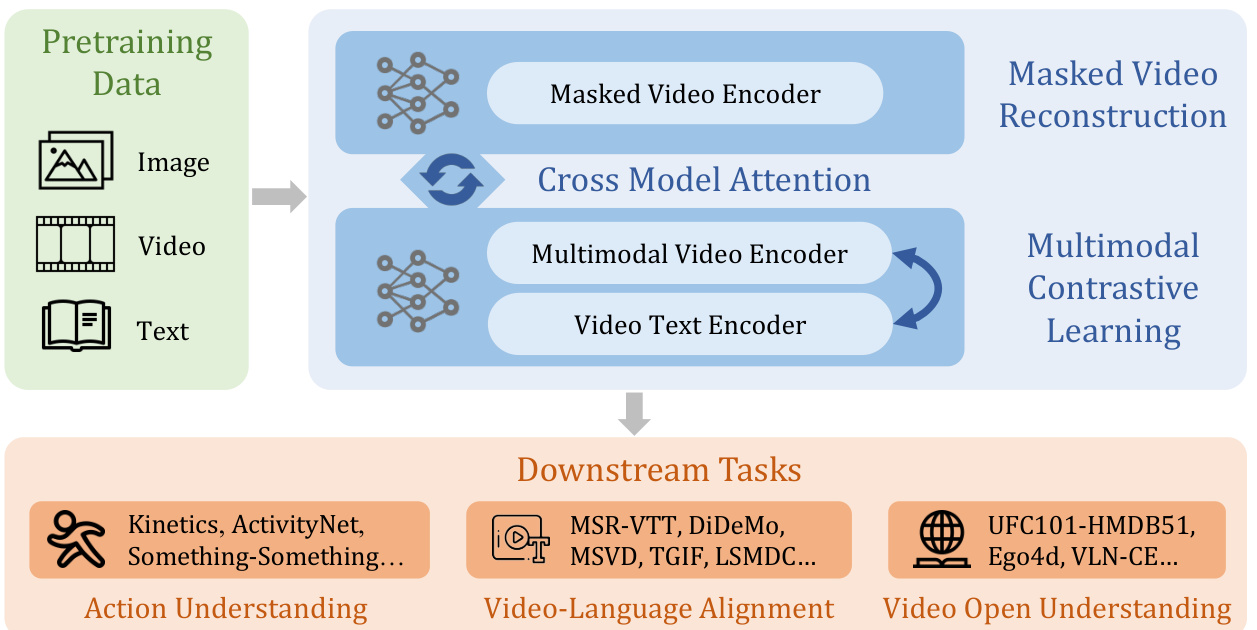
Figure 2: The overall framework of Intern Video.
图 2: Intern Video的整体框架。
3.1 Self-Supervised Video Pre training
3.1 自监督视频预训练
Intern Video conducts both masked and contrastive training without supervision for representation learning. According to [13, 23], video masked modeling produces features that excel at action discrimination, e.g., action recognition and temporal action localization, and video-language contrastive learning is able to understand videos with semantics from text without annotations. We employ two transformers with different structures for better leveraging these two optimization targets. The final representation is constructed by adaptively aggregating these two types of representations.
Intern Video 通过无监督的掩码训练和对比训练进行表征学习。根据 [13, 23],视频掩码建模生成的特征擅长动作区分(例如动作识别和时间动作定位),而视频-语言对比学习能够在无需标注的情况下通过文本语义理解视频。我们采用两种不同结构的 Transformer 来更好地利用这两个优化目标,最终通过自适应聚合这两类表征构建最终表示。
3.1.1 Video Masked Modeling
3.1.1 视频掩码建模 (Video Masked Modeling)
We follow most rituals from our proposed VideoMAE [23] work to train a vanilla Vision Transformer (ViT) as a video encoder for s patio temporal modeling, as given in Figure 3 (a). VideoMAE conducts a video reconstruction task with highly masked video inputs, using an asymmetric encoder-decoder architecture. The used encoder and decoder are both ViTs. The channel number of the decoder is half of that of the encoder, with 4 blocks by default. Specifically, we divide the temporal strided down sampled video inputs into non-overlapping 3D patches and project them linearly into cube embeddings. Then we apply tube masking with notably high ratios (e.g. $90%$ ) to these embeddings and input them into the asymmetric encoder-decoder architecture to perform the masked video modeling pre training. To characterize s patio temporal interaction globally, we employ joint space-time attention [58, 59] in ViT, making all visible tokens globally interact with each other. It is computationally tractable as only a few tokens are preserved for calculation.
我们遵循所提出的VideoMAE [23]工作中的大多数方法,训练一个标准Vision Transformer (ViT)作为视频编码器进行时空建模,如图3(a)所示。VideoMAE通过高度掩码的视频输入执行视频重建任务,采用非对称编码器-解码器架构。使用的编码器和解码器均为ViT,解码器通道数默认设置为编码器的一半,包含4个模块。具体而言,我们将时间步长下采样的视频输入划分为不重叠的3D块,并将其线性投影为立方体嵌入。随后对这些嵌入施加极高比例(如$90%$)的管状掩码,并输入非对称编码器-解码器架构进行掩码视频建模预训练。为全局表征时空交互,我们在ViT中采用联合时空注意力机制[58,59],使所有可见token能够全局交互。由于仅保留少量token参与计算,该方法具有计算可行性。
3.1.2 Video-Language Contrastive Learning
3.1.2 视频-语言对比学习
We conduct both video/image-text contrastive learning and video captioning tasks for pre training, as given in Figure 3 (b). For training efficiency, we build our multimodal structure based on the pretrained CLIP [13]. Instead of directly employing a vanilla ViT, we use our proposed Uni former V 2 [56] as the video encoder for better and more efficient temporal modeling. Moreover, we adopt an extra transformer decoder for cross-modal learning. Specifically, we follow a typical align-before-fuse paradigm as given in [7, 60]. First, video and text are separately encoded. Then a contrastive loss is utilized to align the embedding space of video and text features. In the fusing stage, we apply a caption decoder as a cross-modality fuser, which uses cross attention for a captioning pretext. This align-before-fuse paradigm not only ensures the modalities can be aligned into the same single embedding space, which is beneficial for tasks like retrieval but also gifts the model with the ability to combine different modalities and can be beneficial for tasks like question answering. The introduction of a caption decoder both extends the potential of the original CLIP and improves the robustness of multi modality features.
我们如图3(b)所示,同时进行视频/图像-文本对比学习和视频描述任务作为预训练。为了提升训练效率,我们基于预训练的CLIP[13]构建多模态结构。不同于直接使用标准ViT,我们采用提出的UniFormerV2[56]作为视频编码器,以实现更优且更高效的时序建模。此外,我们额外引入一个transformer解码器进行跨模态学习。具体而言,我们遵循[7,60]提出的典型"先对齐后融合"范式:首先分别编码视频和文本,然后利用对比损失对齐视频与文本特征的嵌入空间。在融合阶段,我们采用描述解码器作为跨模态融合器,通过交叉注意力机制实现描述生成任务。这种"先对齐后融合"范式不仅能确保不同模态被对齐到同一嵌入空间(这对检索等任务有利),还赋予模型融合多模态的能力(这对问答等任务有益)。描述解码器的引入既拓展了原始CLIP的潜力,也增强了多模态特征的鲁棒性。
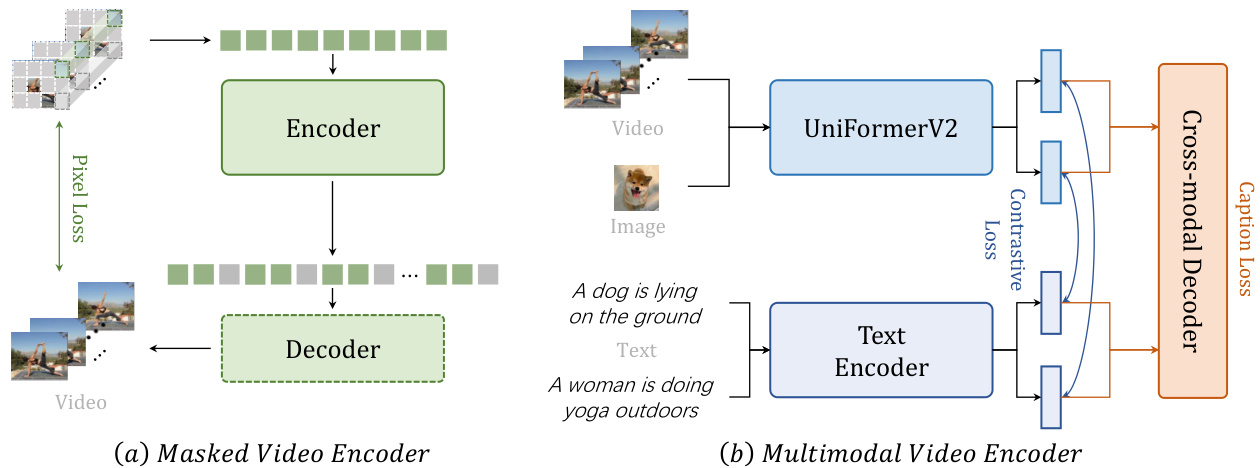
Figure 3: The overall framework of masked learning and multimodal learning in the pretrained stage.
图 3: 预训练阶段掩码学习与多模态学习的整体框架。
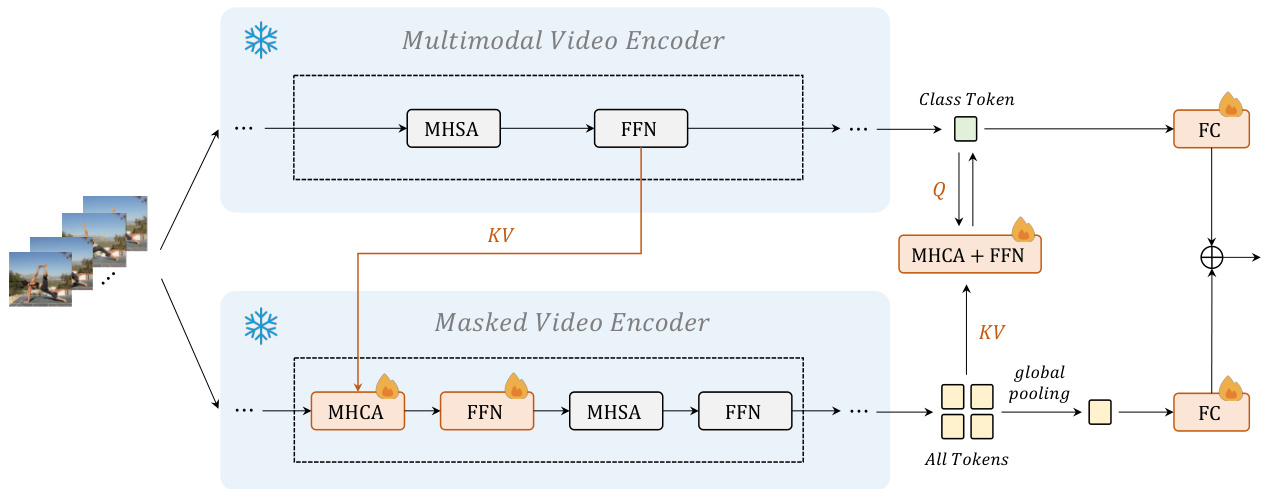
Figure 4: The illustration of the model interaction using cross-model attention.
图 4: 使用跨模型注意力机制进行模型交互的示意图。
3.2 Supervised Video Post-Pre training
3.2 监督式视频后预训练
Empirically, action recognition acts well as a meta task in video downstream applications, widely validated in [61, 62]. Thus we train a masked video encoder and a multimodal one with supervised action classification separately as a post-pre training step for better performance in diverse tasks. To promote the learning capacity of these encoders, we propose a unified video benchmark Kinetics-710 (K710, described in Section 4.1) for finetuning our video encoders.
从经验上看,动作识别作为视频下游应用的元任务表现良好,这一点在[61, 62]中得到了广泛验证。因此,我们分别训练了一个掩码视频编码器和一个多模态编码器,并以监督式动作分类作为后预训练步骤,以提升在多样化任务中的性能。为了增强这些编码器的学习能力,我们提出了统一的视频基准测试Kinetics-710(K710,详见第4.1节)用于微调视频编码器。
Masked Video Encoder. We finetune the masked video encoder with 32 GPUs on K710. We adjust the learning rate linearly according to the base learning rate and batch size, $l r=.$ base learning rate $\times{\frac{b a t c h s i z e}{256}}$ . We adopt DeepSpeed1 framework to save memory usage and speed up training. We set the base learning rate to 0.001, the drop path rate to 0.2, the head dropout rate to 0.5, the repeated sampling[63] to 2, the layer decay to 0.8, and trained for 40 epochs.
掩码视频编码器 (Masked Video Encoder)。我们在K710上使用32块GPU对掩码视频编码器进行微调。根据基础学习率和批量大小线性调整学习率,计算公式为$lr=基础学习率\times{\frac{batchsize}{256}}$。采用DeepSpeed1框架降低内存占用并加速训练。设置基础学习率为0.001,路径丢弃率为0.2,头部丢弃率为0.5,重复采样[63]次数为2,层级衰减率为0.8,训练40个周期。
Multimodal Video Encoder. We follow most of the training recipes in UniFormer [64]. For the best result, we adopt CLIP-ViT [13] as the backbone by default, due to its robust representation pretrained by vision-language contrastive learning. We insert the global UniBlocks in the last 4 layers of ViT-B/L to perform the multi-stage fusion. We set the base learning rate to $1e-5$ , the repeated sampling to 1, the batch size to 512, and trained for 40 epochs. We adopt sparse sampling [65] with a resolution of 224 for all the datasets. In post-pre training, we use a Uni former V 2 [56] as the visual encoder and initialize additional parameters in a way that the output is identical to the original CLIP model which we find to be essential for good zero-shot performance. The video captioning module is a standard 6-layer transformer decoder with $c=768$ followed by a two-layer MLP. Other setting leaves CLIP Large/14 untouched.
多模态视频编码器。我们遵循UniFormer [64]中的大部分训练方案。为获得最佳效果,默认采用CLIP-ViT [13]作为主干网络,因其通过视觉语言对比学习预训练获得的强大表征能力。我们在ViT-B/L的最后4层插入全局UniBlock以实现多阶段融合。设置基础学习率为$1e-5$,重复采样为1,批量大小为512,训练40个周期。所有数据集采用224分辨率的稀疏采样[65]。在后预训练阶段,使用UniFormer V2 [56]作为视觉编码器,并以保持原始CLIP模型输出一致的方式初始化新增参数,这对实现良好的零样本性能至关重要。视频字幕模块为标准6层Transformer解码器($c=768$)加两层MLP。其他设置保持CLIP Large/14原样。
Table 1: Summary of datasets used in Intern Video pre training process. A massive scale database is crucial to genera vision pre training. Our pre training data is composed of 12 million video clips from 5 different domains.
表 1: Intern Video 预训练过程中使用的数据集汇总。大规模数据库对生成式视觉预训练至关重要。我们的预训练数据由来自 5 个不同领域的 1200 万个视频片段组成。
| 预训练数据集 | 领域 | 样本片段数 | 帧数×采样率 |
|---|---|---|---|
| Kinetics-400 [27] | YouTube视频 | 240k | 16 × 4 |
| WebVid2M [55] | 网络视频 | 250k | 16 × 4 |
| WebVid10M [55] | 网络视频 | 10M | 16 × 4 |
| HowTo100M [66] | YouTube视频 | 1.2M | 16 × 4 |
| AVA [67] | 电影 | 21k | 16 × 4 |
| Something-SomethingV2 [68] | 剧本拍摄 | 169k | 16 × 2 |
| 自收集视频 | YouTube, Instagram | 250k | 16 × 4 |
| Kinetics-710 [56] | YouTube视频 | 680k | 16 × 4 |
3.3 Cross-Model Interaction
3.3 跨模型交互
To learn a unified video representation based on both video masked modeling and video-language contrastive learning, we conduct cross-representation learning with added cross-model attention modules, as shown in Figure 4.
为了学习基于视频掩码建模和视频-语言对比学习的统一视频表征,我们通过添加跨模型注意力模块进行跨表征学习,如图 4 所示。
Regarding optimizing both models at the same time is computing-intensive, we freeze both backbones except the classification layers and the query tokens in the multimodal video encoder, only updating newly added components. We add some elaborate learnable modules (cross-model attention) for aligning representations learned in different approaches. Cross-model attention (CMA) is formed by standard Multi-Head Cross Attention (MHCA) along with Feed-Forward Network (FFN). It employs intermediate tokens from a multimodal video encoder as keys and values while using these from a masked video encoder as queries. The new tokens computed from CMA are treated as a gradually aligned representation with that from the multimodal video encoder. This procedure mainly transfers multimodal knowledge to CMAs in the masked video encoder. One design exception is that for the last CMA module, its keys and values are from the tokens of the masked video encoder and the query is from the class token of the multimodal video encoder. Thus, the class token is updated based on tokens from the masked encoder. It transfers single-modal knowledge to CMA in the multimodal video encoder. From this perspective, the features in all stages of the masked video encoder and the ones in the final stage of the multimodal video encoder are enhanced to coordinate with each other, in the supervision by action recognition. Finally, we utilize a learnable linear combination to dynamically fuse the two prediction scores.
关于同时优化两个模型计算量大的问题,我们冻结了除分类层和多模态视频编码器中查询token外的所有主干网络,仅更新新增组件。我们添加了精心设计的可学习模块(跨模型注意力机制)来对齐不同方法学到的表征。跨模型注意力 (CMA) 由标准多头交叉注意力 (MHCA) 和前馈网络 (FFN) 组成。该机制以多模态视频编码器的中间token作为键和值,同时使用掩码视频编码器的对应token作为查询。通过CMA计算得到的新token被视为与多模态视频编码器表征逐步对齐的结果。该过程主要将多模态知识传递至掩码视频编码器的CMA模块中。一个特殊设计是:最后一个CMA模块的键和值来自掩码视频编码器的token,而查询则来自多模态视频编码器的类别token。因此,类别token会根据掩码编码器的token进行更新。这实现了单模态知识向多模态视频编码器CMA模块的传递。由此,在动作识别任务的监督下,掩码视频编码器所有阶段的特征与多模态视频编码器最终阶段的特征得以相互协调增强。最后,我们采用可学习的线性组合来动态融合两个预测分数。
4 Experiments
4 实验
We detail our experimental configurations first (Section 4.1), then we present the downstream performance of InternVideo on the proposed video understanding benchmark with three types of tasks (action understanding, video-language alignment, and open understanding) in Section 4.3.
我们首先详细介绍了实验配置(第4.1节),然后在第4.3节展示了InternVideo在提出的视频理解基准测试中的下游性能,该基准包含三类任务(动作理解、视频-语言对齐和开放理解)。
4.1 Data for Pre training
4.1 预训练数据
General video foundation model pre training requires data from various domains at scale. To achieve a data distribution with diversity, we employ 6 public datasets and our self-collected video clips as shown in Table 1.
通用视频基础模型预训练需要大规模多领域数据。为实现数据分布的多样性,我们采用了6个公开数据集和自行收集的视频片段,如表 1 所示。
Kinetics-710. We adopt a new customized kinetics action dataset Kinetics-710 [56] for supervised training, both separate and joint ones. It has 650K videos with 710 unique action labels. It combines all the unique training data from Kinetics 400/600/700 [27, 69, 70]. To avoid the training leak, some training data existing in the testing set from Kinetics of a specific version are abandoned.
Kinetics-710。我们采用了一个新的定制化Kinetics动作数据集Kinetics-710 [56]进行监督训练,包括单独训练和联合训练。该数据集包含65万条视频和710个独特动作标签,整合了Kinetics 400/600/700 [27, 69, 70]的所有独特训练数据。为避免训练数据泄露,我们舍弃了特定版本Kinetics测试集中已存在的部分训练数据。
Unlabeled Hybrid. The Unlabeled Hybrid dataset is used for masked video pre training, which is consist of Kinetics710 [56], Something-Something V2 [68], AVA [67], WebVid2M [55], and our self-collected videos. For AVA, we cut the 15-minute training videos by 300 frames and get 21k video clips. We just randomly pick 250k videos from Self-collected videos and WebVid2M respectively. More details can be seen in Table. 1.
无标注混合数据集 (Unlabeled Hybrid)。该数据集用于掩码视频预训练,包含 Kinetics710 [56]、Something-Something V2 [68]、AVA [67]、WebVid2M [55] 以及我们自行采集的视频。对于 AVA 数据集,我们将 15 分钟的训练视频按 300 帧分段,最终获得 21k 个视频片段。从自行采集视频和 WebVid2M 中我们分别随机选取了 250k 个视频。更多细节参见表 1。
Table 2: Action recognition results on Kinetics & Something-Something. We report the top-1 accuracy of the compared methods on each dataset. Intern Video-D indicates it is formed by the model ensemble between a masked video encoder ViT-H and a CLIP-pretrained Uni Former V 2-L, while Intern Video-T indicates it is computed based on Intern Video-D and a multimodal-pretrained Uni Former V 2-L.
表 2: Kinetics和Something-Something数据集上的动作识别结果。我们报告了各数据集上对比方法的top-1准确率。Intern Video-D表示由掩码视频编码器ViT-H和CLIP预训练的UniFormerV2-L模型集成组成,而Intern Video-T表示基于Intern Video-D和多模态预训练的UniFormerV2-L计算得出。
| 方法 | 参数量 | K400 | K600 | K700 |
|---|---|---|---|---|
| MaskFeat-L [6] | 218M | 87.0 | 88.3 | 80.4 |
| CoCa [7] | 1B+ | 88.9 | 89.4 | 82.7 |
| MTV-H [8] | 1B+ | 89.9 | 90.3 | 83.4 |
| MerlotReserve-L [9] | 644M | 90.1 | ||
| MerlotReserve-L (+Audio)[9] | 644M | 91.1 | ||
| InternVideo-D | 1.0B | 90.9 | 91.1 | 83.8 |
| InternVideo-T | 1.3B | 91.1 (+1.2) | 91.3 (+1.0) | 84.0 (+0.6) |
Table 3: Action recognition results on Something-Something & Activity Net & HACS & HMDB51. We report the topaccuracy of the compared methods on each dataset.
表 3: Something-Something & Activity Net & HACS & HMDB51 数据集上的动作识别结果。我们报告了各数据集上对比方法的最高准确率。
| 方法 | SthSthV1 | SthSthV2 | ActivityNet | HACS | HMDB51 |
|---|---|---|---|---|---|
| Previous SOTA | 60.9 [73] | 75.6 [6] | 90.2 [1] | 91.9 [58] | 87.6 [3] |
| Intern Video | 70.0 (+9.1) | 77.2 (+1.6) | 94.3 (+4.1) | 95.5 (+3.6) | 89.3 (+1.7) |
4.2 Implementations
4.2 实现
4.2.1 Multimodal Training
4.2.1 多模态训练
With the initialization from CLIP, we post-pretrain our multi-modal model with WebVid2M, WebVid10M, and HowTo100M. Since the training corpus of video-text datasets is not as rich as CLIP-400M [13], we co-train the video model with image-text datasets, a subset of LAION-400M [71] containing 100M image-text pairs. We alternate images and videos for each iteration. The batch size of video-text is 14,336, and the batch size of image-text is 86,016. We train for 400k steps on 128 NVIDIA A100 GPUs in 2 weeks, with a learning rate of $8\times10^{-5}$ , weight decay of 0.2, cosine annealing schedule, and 4k warm-up steps.
基于CLIP的初始化,我们使用WebVid2M、WebVid10M和HowTo100M对多模态模型进行后预训练。由于视频-文本数据集的训练语料不如CLIP-400M [13]丰富,我们联合训练视频模型与图像-文本数据集(LAION-400M [71]的子集,包含1亿个图像-文本对)。每次迭代时交替处理图像和视频数据,视频-文本的批大小为14,336,图像-文本的批大小为86,016。我们在128块NVIDIA A100 GPU上训练40万步(耗时2周),学习率为 $8\times10^{-5}$ ,权重衰减为0.2,采用余弦退火调度和4千步预热。
4.2.2 Masked Video Training
4.2.2 掩码视频训练
We train the VideoMAE-Huge for 1200 epochs on the Unlabeled Hybrid dataset with 64 80G-A100 GPUs. The model adapts the cosine annealing learning rate schedule and warmup $10%$ total epochs. The learning rate is set to $2.5e-4$ . Only Multi Scale Crop is used for data augmentation.
我们在未标注混合数据集 (Unlabeled Hybrid) 上使用64张80G显存的A100 GPU对VideoMAE-Huge模型进行了1200轮训练。该模型采用余弦退火学习率调度策略,并预热总训练轮数的10%。学习率设置为$2.5e-4$,数据增强仅采用多尺度裁剪 (Multi Scale Crop)。
4.2.3 Model Interaction
4.2.3 模型交互
As shown in Figure 4, we freeze both backbones except the classification layers and the query tokens in the multimodal video encoder. To maintain the original output, we add tanh gating layers in the extra MHCA and FFN as in Flamingo [72], and the parameters in dynamic weighted sum are initialized as zero. We train the coordinated models with a batch size of 64, a learning rate of $5\times10^{5}$ , a weight decay of 0.001, a dropout rate of 0.9, and an EMA rate of 0.9999. Besides, we use a cosine annealing schedule for 5 epochs with 1 warmup epoch. All used data augmentations are the same as in Uni Former V 2 [56].
如图 4 所示,我们冻结了除分类层和多模态视频编码器中的查询 token (query tokens) 外的所有骨干网络。为了保持原始输出,我们在额外的 MHCA 和 FFN 中添加了 tanh 门控层 (tanh gating layers) ,如 Flamingo [72] 中所述,动态加权求和 (dynamic weighted sum) 中的参数初始化为零。我们以批量大小 64、学习率 $5\times10^{5}$ 、权重衰减 0.001、dropout 率 0.9 和 EMA 率 0.9999 训练协调模型。此外,我们使用余弦退火调度 (cosine annealing schedule) 进行 5 个周期训练,其中包含 1 个预热周期。所有使用的数据增强方法与 Uni Former V 2 [56] 相同。
4.3 Downstream Tasks
4.3 下游任务
We conduct extensive experiments on a spectrum of downstream tasks to evaluate Intern Video. The employed tasks are of three categories that consider action understanding, video-language alignment, and open understanding. Since Intern Video contains masked video encoder specializing in s patio temporal variation characterization and fused multimodality video encoder, it can improve action understanding (Section 4.3.1) and video-language alignment (Section 4.3.2) tasks significantly. Its generalization brought by large-scale training data also enables its impressive zero-shot and open-set capabilities on the related tasks (Section 4.3.3). Even transferred to ego-centric tasks, Intern Video still gives an overwhelmingly favorable performance with simple heads [57]. Details are given as follows.
我们在多种下游任务上进行了广泛实验以评估Intern Video。采用的实验任务分为三类:动作理解、视频-语言对齐和开放理解。由于Intern Video包含专用于时空变化表征的掩码视频编码器和融合多模态视频编码器,它能显著提升动作理解(第4.3.1节)和视频-语言对齐(第4.3.2节)任务表现。其通过大规模训练数据获得的泛化能力,还在相关任务上展现出卓越的零样本和开放集能力(第4.3.3节)。即便迁移到第一人称视角任务,Intern Video仅需简单头部结构[57]仍能取得压倒性优势性能。具体细节如下。
Table 4: Temporal action localization results on THUMOS-14 & Activity Net-v1.3 & HACS & FineAction. We repor the average mAP of the compared methods on each dataset.
表 4: THUMOS-14、ActivityNet-v1.3、HACS和FineAction上的时序动作定位结果。我们报告了各数据集上对比方法的平均mAP值。
| Backbone | Head | THUMOS-14 | ActivityNet-v1.3 | HACS | FineAction |
|---|---|---|---|---|---|
| I3D [27] SlowFast[74] | ActionFormer [4] TCANet[75] | 66.80 | 13.24 | ||
| TSP [76] | ActionFormer [4] | 36.60 | 38.71 | ||
| InternVideo | |||||
| ActionFormer [4] | 71.58(+4.78) | 39.00(+2.40) | 41.32 | 17.57(+4.33) | |
| InternVideo | TCANet [75] | 41.55(+2.84) |
Table 5: S patio temporal action localization results on AVA2.2 & AVA-Kinetics (AK). We report the mAP of the evaluated approaches on datasets.
表 5: AVA2.2 和 AVA-Kinetics (AK) 数据集上的时空动作定位结果。我们报告了各评估方法在数据集上的 mAP 值。
| 方法 | Head | AVA2.2 | AVA-Kinetics |
|---|---|---|---|
| ACAR [77] (ensemble) | ACAR [77] | 33.30 | 40.49 |
| RM [78] (ensemble) | RM [78] | 40.97 | |
| MaskFeat [6] | 38.80 | ||
| InternVideo | Linear | 41.01 (+2.21) | 42.51( (+1.54) |
4.3.1 Action Understanding Tasks
4.3.1 动作理解任务
Action Recognition. Actions derive s patio temporal patterns. Intern Video aims to learn the representation of suitable s patio temporal features, and the modeling of dynamical patterns. We evaluate Intern Video on 8 action recognition benchmarks, including popular Kinetics and Something-Something.
动作识别。动作衍生出时空模式。Intern Video旨在学习合适的时空特征表示以及动态模式建模。我们在8个动作识别基准上评估Intern Video,包括流行的Kinetics和Something-Something。
We evaluate VideoMAE and Uni Former V 2 in Intern Video on Kinetics-400 [27], Kinetics-600 [69], Kinetics-700 [70], Something-in-Something-V1 [68], Something-in-Something-V2 [68], Activity Net [79], HACS [80], and HMDB51 [81]. We use the top-1 accuracy as a comparison indicator. In Table 2 and 3, Intern Video demonstrates exceedingly promising performance on all these action recognition benchmarks. Our Intern Video significantly surpasses previous SOTA methods on almost all benchmarks and matches the SOTA result on Activity Net. The rised accuracy brought by extra fused model (Intern Video-D vs. Intern Video-T) demonstrates it is necessary to explore a broad technical roadmap as different lines benefits each other in performance.
我们在Kinetics-400 [27]、Kinetics-600 [69]、Kinetics-700 [70]、Something-in-Something-V1 [68]、Something-in-Something-V2 [68]、ActivityNet [79]、HACS [80]和HMDB51 [81]数据集上评估了Intern Video中的VideoMAE和UniFormerV2。采用top-1准确率作为对比指标。在表2和表3中,Intern Video在所有动作识别基准测试中都展现出极其优异的性能。我们的Intern Video在几乎所有基准测试中都显著超越了之前的SOTA方法,并在ActivityNet上达到了SOTA水平。通过额外融合模型带来的准确率提升(Intern Video-D vs. Intern Video-T)表明,探索广泛的技术路线是必要的,因为不同技术路线在性能上能相互促进。
Temporal Action Localization. This task (TAL) aims at localizing the start and end points of action clips from the entire untrimmed video with full observation. We evaluate our Intern Video on four classic TAL datasets: THUMOS-14 [82], Activity Net-v1.3 [79], HACS Segment [80] and FineAction [83]. In line with the previous temporal action localization tasks, we use mean Average Precision (mAP) for quantitative evaluations. Average Precision (AP) is calculated for each action category, to evaluate the proposals on action categories. It is computed under different tIoU thresholds. We report the performance of the state-of-the-art TAL methods whose codes are publicly available, including Action Former [4] method for THUMOS-14, Activity Net-v1.3, and FineAction and TCANet [75] method for HACS Segment.
时序动作定位。该任务 (TAL) 旨在从完整观察的未修剪视频中定位动作片段的起止点。我们在四个经典 TAL 数据集上评估 Intern Video:THUMOS-14 [82]、Activity Net-v1.3 [79]、HACS Segment [80] 和 FineAction [83]。与此前的时序动作定位任务一致,我们采用平均精度均值 (mAP) 进行量化评估。每个动作类别都会计算平均精度 (AP) 以评估提案在动作类别上的表现,该指标在不同 tIoU 阈值下计算得出。我们报告了代码已公开的先进 TAL 方法性能,包括 THUMOS-14、Activity Net-v1.3 和 FineAction 采用的 Action Former [4] 方法,以及 HACS Segment 采用的 TCANet [75] 方法。
We use ViT-H from our Intern Video as backbones for feature extraction. In our experiment, ViT-H models are pretrained from Hybrid datasets. As shown in Table 4, our Intern Video outperforms best than all the preview methods on these four TAL datasets. Note that, our Intern Video achieves huge improvements in temporal action localization, especially in fine-grained TAL datasets such as THUMOS-14 and FineAction.
我们采用Intern Video中的ViT-H作为特征提取的骨干网络。实验中,ViT-H模型基于混合数据集进行预训练。如表4所示,我们的Intern Video在这四个TAL数据集上均优于所有现有方法。值得注意的是,我们的方法在时序动作定位任务上取得显著提升,尤其在THUMOS-14和FineAction等细粒度TAL数据集上表现突出。
S patio temporal Action Localization. This task (STAL) is to predict the frames and corresponding actions of people in video keyframes. We evaluate Intern Video on two classic STAL datasets AVA2.2 [67] and AVA-Kinetics [84]. In AVA2.2 [67], each video lasts 15 minutes, and it gives a keyframe every second. The annotation is provided for keyframes instead of all frames. Here we use a classic two-stage approach to handle this task. We apply a well-trained (on MS-COCO [85]) Mask-RCNN [86] to detect humans on each keyframe, and the keyframe boxes are provided in the Alphaction [87] project. In the second stage, centering around the key frame, a certain number of frames are extracted and fed into our video backbone. Similarly, in the training, we use the ground truth box for training [87], and the boxes predicted in the first stage for testing.
时空动作定位。该任务 (STAL) 是预测视频关键帧中人物的帧及对应动作。我们在两个经典STAL数据集AVA2.2 [67]和AVA-Kinetics [84]上评估Intern Video。在AVA2.2 [67]中,每个视频持续15分钟,每秒提供一个关键帧。标注仅针对关键帧而非所有帧。我们采用经典的两阶段方法处理该任务:首先使用在MS-COCO [85]上预训练的Mask-RCNN [86]检测每个关键帧中的人物(关键帧边界框由Alphaction [87]项目提供);第二阶段以关键帧为中心提取若干帧输入视频主干网络。训练时使用真实标注框 [87],测试时则使用第一阶段预测的边界框。
We used ViT-Huge in Intern Video for experiments. The specific results can be seen in Table 5. The classification head uses a simple linear head, achieving the SOTA performance on both datasets. Note using the ViT-H model, and training with the AVA-Kinetics dataset not only improves the overall mAP, but also significantly improves the mAP obtained by testing on AVA alone. It suggests the introduction of some Kinetics videos to AVA will improve the generalization of the model over AVA; on the other hand, observing the various distributions of the AVA dataset, we find that AVA presents a typical long-tailed distribution. The introduction of Kinetics video will alleviate this issue for better results. Due to the small number of models validated on the AVA-Kinetics dataset, only the results from the papers with code website are selected in the Table 5.
我们在Intern Video中使用ViT-Huge进行实验。具体结果见表5。分类头采用简单的线性头,在两个数据集上都达到了SOTA性能。值得注意的是,使用ViT-H模型并结合AVA-Kinetics数据集进行训练,不仅提高了整体mAP,还显著提升了仅在AVA上测试获得的mAP。这表明向AVA引入部分Kinetics视频可以提升模型在AVA上的泛化能力;另一方面,通过观察AVA数据集的各种分布情况,我们发现AVA呈现出典型的长尾分布。引入Kinetics视频将缓解这一问题以获得更好的结果。由于在AVA-Kinetics数据集上验证的模型数量较少,表5仅选取了papers with code网站上的论文结果。
Table 6: Results of video retrieval on MSR-VTT, MSVD, LSMDC, Activity Net, DiDeMo, and VATEX. We report $\mathbf{R}\ @1$ both on text-to-video (T2V) and video-to-text (V2T) retrieval tasks.
表 6: MSR-VTT、MSVD、LSMDC、ActivityNet、DiDeMo 和 VATEX 上的视频检索结果。我们报告了文本到视频 (T2V) 和视频到文本 (V2T) 检索任务的 $\mathbf{R}\ @1$ 指标。
| 方法 | MSR-VTT | MSR-VTT | MSVD | MSVD | LSMDC | LSMDC | ActivityNet | ActivityNet | DiDeMo | DiDeMo | VATEX | VATEX |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | |
| CLIP4Clip [5] | 45.6 | 45.9 | 45.2 | 48.4 | 24.3 | 23.8 | 40.3 | 41.6 | 43.0 | 43.6 | 63.0 | 78.3 |
| TS2Net [88] | 49.4 | 46.6 | - | - | 23.4 | - | 41.0 | - | 41.8 | - | 59.1 | - |
| X-CLIP [22] | 49.3 | 48.9 | 50.4 | 66.8 | 26.1 | 26.9 | 46.2 | 46.4 | 47.8 | 47.8 | - | - |
| InternVideo | 55.2 | 57.9 | 58.4 | 76.3 | 34.0 | 34.9 | 62.2 | 62.8 | 57.9 | 59.1 | 71.1 | 87.2 |
Table 7: Video question answering on MSRVTT, MSVD, and TGIF. We report top-1 accuracy.
表 7: MSRVTT、MSVD和TGIF上的视频问答任务性能对比 (Top-1准确率)
| 方法 | MSRVTT | MSVD | TGIF |
|---|---|---|---|
| ClipBERT[54] | 37.4 | 60.3 | |
| All-in-one [24] | 42.9 | 46.5 | 64.2 |
| MERLOT [9] | 43.1 | 69.5 | |
| VIOLET[30] | 43.9 | 47.9 | 68.9 |
| InternVideo | 47.1(+3.2) | 55.5(+7.6) | 72.2(+3.3) |
4.3.2 Video-Language Alignment Tasks
4.3.2 视频-语言对齐任务
Video Retrieval. We evaluate Intern Video on the video retrieval task. Given a set of videos and related natural language captions, this task requires retrieving the matched video or caption corresponding to its inter-modality counterpart from candidates. We follow the common paradigm to capture visual and text semantics by a visual encoder $f_{v}(\cdot)$ and a text encoder $f_{t}(\cdot)$ , then calculate the cross-modality similarity matrices as the retrieval guidance. We leverage the multimodal video encoder as $f_{v}(\cdot)$ and $f_{t}(\cdot)$ with pretrained ViT-L/14 [28] as the basic CLIP [13] architecture and finetune the entire model on each retrieval dataset. The training recipes and most of the hyper parameter settings follow CLIP4Clip [5], including training schedule, learning rate, batch size, video frames, maximum text length, etc. To boost model performance, we also adopt the dual softmax loss [91] as the post-processing operation.
视频检索。我们在视频检索任务上评估Intern Video。给定一组视频和相关的自然语言描述,该任务需要从候选中检索出与其跨模态对应项匹配的视频或描述。我们遵循通用范式,通过视觉编码器$f_{v}(\cdot)$和文本编码器$f_{t}(\cdot)$捕获视觉与文本语义,随后计算跨模态相似度矩阵作为检索依据。我们采用多模态视频编码器作为$f_{v}(\cdot)$和$f_{t}(\cdot)$,以预训练的ViT-L/14 [28]作为基础CLIP [13]架构,并在每个检索数据集上微调整个模型。训练方案和大多数超参数设置遵循CLIP4Clip [5],包括训练周期、学习率、批大小、视频帧数、最大文本长度等。为提升模型性能,我们还采用双重softmax损失 [91]作为后处理操作。
Our model is evaluated on six public benchmarks: MSR-VTT [92], MSVD [93], LSMDC [94], DiDeMo [95], Activity Net [79], and VATEX [96], where we report the results on the standard split following previous works. We measure the retrieval results under the rank-1 $(\mathbf{R}\ @1)$ metric both on text-to-video and video-to-text tasks, which are shown in Table 6. Results show that our model significantly outperforms all previous methods by a large margin, showing the superiority of Intern Video on video-language related tasks. More detailed retrieval results, including rank-5 $(\mathtt{R@5})$ and rank-10 $(\mathbf{R}\ @10)$ , can be found in the supplementary materials.
我们的模型在六个公开基准上进行了评估:MSR-VTT [92]、MSVD [93]、LSMDC [94]、DiDeMo [95]、Activity Net [79] 和 VATEX [96],并按照先前工作的标准划分报告结果。我们分别在文本到视频和视频到文本任务中,使用排名1 $(\mathbf{R}\ @1)$ 指标衡量检索结果,如表 6 所示。结果表明,我们的模型显著优于所有先前方法,展现了 Intern Video 在视频语言相关任务上的优越性。更详细的检索结果(包括排名5 $(\mathtt{R@5})$ 和排名10 $(\mathbf{R}\ @10)$)可在补充材料中找到。
Video Question Answering. To further demonstrate the vision-language capability of Intern Video , we evaluate Intern Video on video question answering (VQA). Given a video and question pair, VQA is to predict the answer to the question. Unlike the vanilla CLIP model without cross-modality fusion, our multimodal video encoder is able to capture the interaction between modalities with the proposed caption decoder. There are three potential ways to generate features required by the VQA classifier: concatenating the features of the video encoder and text encoder, utilizing the features of the caption decoder only, and concatenating all features from the video encoder, text encoder, and caption decoder. After comparison, we choose to use all three sources of features to boost the performance. The VQA classifier is a three-layer MLP.
视频问答 (Video Question Answering)。为了进一步展示Intern Video的视觉-语言能力,我们在视频问答任务上对其进行了评估。给定视频-问题对,视频问答旨在预测问题的答案。与缺乏跨模态融合的原始CLIP模型不同,我们的多模态视频编码器能够通过提出的字幕解码器捕捉模态间的交互关系。生成VQA分类器所需特征存在三种潜在方案:拼接视频编码器和文本编码器的特征、仅使用字幕解码器的特征,以及拼接视频编码器、文本编码器和字幕解码器的全部特征。经对比,我们选择整合三类特征以提升性能。该VQA分类器采用三层MLP结构。
We evaluate on three popular public benchmarks: MSR-VTT [92], MSVD [97], and TGIF [98]. We mainly follow the practice in [24]. The results are shown in Table 7 and our model outperforms all previous SOTA, which demonstrates the effectiveness of our cross-modality learner.
我们在三个流行的公开基准上进行了评估:MSR-VTT [92]、MSVD [97] 和 TGIF [98]。我们主要遵循 [24] 中的实践。结果如表 7 所示,我们的模型超越了所有之前的 SOTA (state-of-the-art),这证明了我们跨模态学习器的有效性。
Visual Language Navigation. Visual-Language Navigation [99] requires an agent to navigate in unknown photorealistic environments based on its visual perceptions following natural language instructions. Navigation agents should be capable of capturing s patio temporal information such as the relative motion of objects from navigation histories, especially when the agent navigates with short step size in continuous spaces. To verify the effectiveness of such ability of our model, we conduct our experiments on the VLN-CE benchmark [100], demanding the agent to function in a continuous environment.
视觉语言导航。视觉语言导航 [99] 要求智能体在未知的逼真环境中,根据自然语言指令通过视觉感知进行导航。导航智能体应能捕捉时空信息(例如从导航历史中获取物体的相对运动),尤其是在连续空间中以短步长导航时。为验证我们模型在此能力上的有效性,我们在 VLN-CE 基准 [100] 上进行了实验,该基准要求智能体在连续环境中运行。
Table 8: Results of VLN-CE dataset.
表 8: VLN-CE 数据集结果
| Agent | Backbone | NE↓ | PL | SR↑ | NDTW↑ | SPL↑ |
|---|---|---|---|---|---|---|
| CWP-VLNBERT [89] | ResNet50 | 5.52 | 11.85 | 45.19 | 54.20 | 39.91 |
| CWP-HEP [90] | CLIP-ViT-B/16 | 5.21 | 10.29 | 50.24 | 60.39 | 45.71 |
| CWP-HEP [90] | InternVideo | 4.95(-0.26) | 10.44 | 52.90(+2.66) | 61.55(+1.16) | 47.70(+0.99) |
Table 9: Results of zero-shot video retrieval on MSR-VTT, MSVD, LSMDC, Activity Net, DiDeMo, and VATEX. We report $\mathbf{R}\ @1$ both on text-to-video (T2V) and video-to-text (V2T) retrieval tasks.
表 9: MSR-VTT、MSVD、LSMDC、ActivityNet、DiDeMo 和 VATEX 上的零样本视频检索结果。我们报告了文本到视频 (T2V) 和视频到文本 (V2T) 检索任务中的 $\mathbf{R}\ @1$。
| 方法 | MSR-VTT | MSVD | LSMDC | ActivityNet | DiDeMo | VATEX | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | |
| CLIP [13] | 35.0 | 32.3 | 39.2 | 63.3 | 17.0 | 10.5 | 25.2 | 20.7 | 29.8 | 24.3 | 45.2 | 59.2 |
| InternVideo | 40.7 | 39.6 | 43.4 | 67.6 | 17.6 | 13.2 | 30.7 | 31.4 | 31.5 | 33.5 | 49.5 | 69.5 |
We conduct our experiments using the method proposed in 90. The history-enhanced planner is a customized variant of HAMT [101] which uses a concatenation of depth embedding and RGB embedding as the input embedding. Note that we don’t use the tryout controller here since VLN-CE setting allows sliding. This is a strong baseline that already outperforms the previous state-of-the-art method CWP-VLNBERT [89]. In each decision loop, we collect the latest 16-frame observations to form panoramic navigation videos and then encode the video using ViT-L in Intern Video. The video embedding is concatenated with the RGB embedding and depth embedding as the final image embedding. For evaluation, we refer to [90] for detailed metrics. Intern Video could improved our baseline from $50.2%$ to $52.9%$ in Success Rate(SR) (Table 8).
我们采用90提出的方法进行实验。历史增强规划器是HAMT [101]的定制变体,它使用深度嵌入和RGB嵌入的串联作为输入嵌入。请注意,由于VLN-CE设置允许滑动,我们在此未使用试用控制器。这是一个强大的基线,其性能已经超越了之前最先进的CWP-VLNBERT [89]方法。在每个决策循环中,我们收集最新的16帧观测数据以形成全景导航视频,然后使用Intern Video中的ViT-L对视频进行编码。视频嵌入与RGB嵌入和深度嵌入串联,形成最终的图像嵌入。对于评估,我们参考[90]中的详细指标。Intern Video将我们的基线成功率(SR)从$50.2%$提升至$52.9%$(表8)。
4.3.3 Video Open Understanding Tasks
4.3.3 视频开放理解任务
Zero-shot Action Recognition. Zero-shot recognition is one of the extraordinary capabilities of the original CLIP model. With our designed multimodal video encoder, we can also achieve remarkable zero-shot action recognition performance without further optimization. We evaluate our model on Kinetics-400 dataset with $64.25%$ accuracy, which outperforms the previous SOTA $56.4%$ [102] by a large margin. Zero-shot Video Retrieval. We compare Intern Video with CLIP on zero-shot text-to-video and video-to-text retrieval. For fair comparisons, we use the ViT-L/14 model with the pretrained weights 1 of CLIP. Wise-finetuning [103] and model ensemble are employed to further boost the model performance on zero-shot video retrieval. We empirically find that the optimal number of video frames for zero-shot retrieval is between 4 and 8, and the best-performed frame on each benchmark dataset is yielded via grid search. As illustrated in Table 9, Intern Video demonstrates superior retrieval ability across all six benchmark datasets. Besides, Florence [15] used 900M image-text pair for pre training and it achieved $37.6\mathrm{R}@1$ text-to-video retrieval accuracy on MSR-VTT. In comparison, our model outperforms Florence by $4.1%$ with much less training data (14.35M video $+100\mathbf{M}$ image v.s. 900M image). These results reveal the effectiveness of our method in learning the joint video-text feature space during pre training.
零样本动作识别。零样本识别是原始CLIP模型的非凡能力之一。通过我们设计的多模态视频编码器,无需进一步优化即可实现显著的零样本动作识别性能。我们在Kinetics-400数据集上评估模型,准确率达到64.25%,大幅超越此前SOTA结果56.4% [102]。
零样本视频检索。我们将Intern Video与CLIP在零样本文本到视频和视频到文本检索任务上进行比较。为公平对比,我们使用ViT-L/14模型加载CLIP预训练权重1。采用Wise-finetuning [103]和模型集成策略进一步提升零样本视频检索性能。实验发现最优视频帧数介于4到8帧之间,各基准数据集的最佳表现帧数通过网格搜索确定。如表9所示,Intern Video在所有六个基准数据集上均展现出卓越检索能力。此外,Florence [15]使用9亿图像-文本对进行预训练,在MSR-VTT上达到37.6R@1的文本到视频检索准确率。相比之下,我们的模型以更少训练数据(1435万视频+1亿图像 vs 9亿图像)实现4.1%的性能提升。这些结果验证了预训练过程中视频-文本联合特征空间学习方法的有效性。
Zero-shot Multiple Choice. Zero-shot multiple choice is another zero-shot task that can demonstrate the model’s generality. Multiple choice task aims to find the correct answer in the given choices, usually a small subset such as 5 words. We find that co-training with image-text pairs, wise-finetuning, and the ensemble is essential for the performance on zero-shot multiple choice. We report the zero-shot multiple-choice results in Table 10 on MSR-VTT and LSMDC datasets. We use the zero-shot performance as a handy indicator for generality in training, and the results show that our model is robust and effective.
零样本多项选择。零样本多项选择是另一种能展示模型通用性的零样本任务。该任务旨在给定选项(通常为少量词汇如5个)中找出正确答案。我们发现图像-文本对联合训练、智能微调及集成方法对提升零样本多项选择性能至关重要。表10展示了MSR-VTT和LSMDC数据集上的零样本多项选择结果。在训练过程中,我们将零样本性能作为通用性的便捷指标,结果表明我们的模型具备鲁棒性和高效性。
Open-set Action Recognition. In open-set action recognition (OSAR), the model is required to recognize the known action samples from training classes and reject the unknown samples that are out of training classes. Compared with images, video actions are more challenging to be recognized in an OSR setting than images due to the uncertain emporal dynamics, and static bias of human actions [109]. Our Intern Video generalizes well to unknown classes that are out of training classes and outperforms the existing method [109] without any model calibration.
开放集动作识别。在开放集动作识别 (OSAR) 中,模型需要从训练类别中识别已知动作样本,并拒绝训练类别之外的未知样本。与图像相比,由于人类动作具有不确定的时间动态性和静态偏差 [109],视频动作在开放集识别场景下更具挑战性。我们的 Intern Video 对训练类别之外的未知类别展现出优异的泛化能力,在无需任何模型校准的情况下超越了现有方法 [109]。
Table 10: Zero-shot multiple-choice on MSR-VTT and LSMDC. The gray color indicates those methods with supervised training.
表 10: MSR-VTT 和 LSMDC 上的零样本多项选择。灰色表示采用监督训练的方法。
| Method | Accuracy | Method | Accuracy |
|---|---|---|---|
| JSFusion [104] | 83.4 | JSFusion [104] | 73.5 |
| ActBERT [53] | 85.7 | MERLOT [9] | 81.7 |
| ClipBERT [54] | 88.2 | VIOLET [30] | 82.9 |
| All-in-one [24] | 80.3 | All-in-one [24] | 56.3 |
| InternVideo | 93.4(+13.1) | InternVideo | 77.3(+21.0) |
Table 11: Results of open set action recognition on two different open sets where the samples of unknown class are from HMDB-51 and MiT-v2, respectively. We report Open Set AUC at the threshold determined by ensuring $95%$ training videos (UCF101) are recognized as known.
表 11: 在两个不同开放集上的开放集动作识别结果,其中未知类样本分别来自HMDB-51和MiT-v2。我们报告在确保95%训练视频(UCF101)被识别为已知类时确定的阈值下的开放集AUC。
| 方法 | 开放集AUC (%) UCF-101+HMDB-51 | UCF-101+MiT-v2 | 闭集准确率 (%) |
|---|---|---|---|
| OpenMax[105] | 78.76 | 80.62 | 62.09 |
| MC Dropout [106] | 75.41 | 78.49 | 96.75 |
| BNN SVI [107] | 74.78 | 77.39 | 96.43 |
| SoftMax | 79.16 | 82.88 | 96.70 |
| RPL [108] | 74.23 | 77.42 | 96.93 |
| DEAR[109] | 82.94 | 86.99 | 96.48 |
| InternVideo | 85.48(+2.54) | 91.85(+4.86) | 97.89(+1.41) |
We use the ViT-H/16 model of Intern Video as a backbone, and finetune it with a simple linear classification head on UCF-101 [110] training set. To enable Intern Video to “know unknown", we follow the method DEAR proposed in [109] and formulate it as an uncertainty estimation problem by leveraging evidential deep learning (EDL), which provides a way to jointly formulate the multiclass classification and uncertainty modeling. Specifically, given a video as input, the Evidential Neural Network (ENN) head on top of a Intern Video backbone predicts the class-wise evidence, which formulates a Dirichlet distribution so that the multi-class probabilities and predictive uncertainty of the input can be determined. During the open-set inference, high-uncertainty videos can be regarded as unknown actions, while low-uncertainty videos are classified by the learned categorical probabilities.
我们以Intern Video的ViT-H/16模型为骨干网络,通过在UCF-101 [110]训练集上使用简单的线性分类头进行微调。为了让Intern Video具备"识别未知"能力,我们采用[109]提出的DEAR方法,通过证据深度学习(EDL)将其构建为不确定性估计问题,该方法可同时处理多类别分类和不确定性建模。具体而言,给定输入视频时,Intern Video骨干网络顶端的证据神经网络(ENN)头会预测类别证据,这些证据构成狄利克雷分布,从而确定输入的多类别概率和预测不确定性。在开放集推理阶段,高不确定性视频被视为未知动作,而低不确定性视频则通过学习到的类别概率进行分类。
Intern Video can not only recognize known action classes accurately but also identify the unknown. Table 11 reports the results of both closed-set (Closed Set Accuracy) and open-set (Open Set AUC) performance of Intern Video and other baselines. It shows that our Intern Video consistently and significantly outperforms other baselines on both two open-set datasets, where unknown samples are from HMDB-51 [81] and MiT-v2 [111], respectively.
Intern Video不仅能准确识别已知动作类别,还能识别未知动作。表11报告了Intern Video与其他基线方法在闭集(Closed Set Accuracy)和开集(Open Set AUC)性能上的结果。数据显示,我们的Intern Video在两个开集数据集(HMDB-51 [81]和MiT-v2 [111]分别提供未知样本)上均持续显著优于其他基线方法。
5 Concluding Remarks
5 结论
In this paper, we propose a versatile and training-efficient video foundation model Intern Video. To our best knowledge, Intern Video is the first work to perform best among existing researches on all action understanding, video-language alignment, and video open understanding tasks. Compared with previous related work [6, 8, 9], it greatly lifts the generality of video foundation models to a new level, by achieving state-of-the-art performance on nearly 40 datasets covering 10 different tasks. The model exploits a unified video representation based on the cross-model learning between masked video learning (VideoMAE) and video-language contrastive modeling along with supervised training. Compared with previous foundation models, it is efficient in training. With simple ViT and its corresponding variants, we achieve generalized video representations with 64.5K GPU hours (A100-80G), while CoCa [7] requires 245.76K TPU hours (v4). We validate such generalized s patio temporal representation on a spectrum of applications. With simple task heads (even linear ones) and proper downstream adaption tuning, our video representation demonstrates record-breaking results in all used datasets. Even for zero-shot and open-set settings, our model spectrum still gives consistent and non-trivial performance increases, further proving its generalization and adaption.
本文提出了一种通用且训练高效的视频基础模型 Intern Video。据我们所知,Intern Video 是首个在动作理解、视频-语言对齐和视频开放理解三大任务上均取得最佳性能的研究。相比先前工作 [6, 8, 9],该模型通过在10类任务、近40个数据集上实现最先进性能,将视频基础模型的通用性提升至新高度。该模型通过掩码视频学习 (VideoMAE) 与视频-语言对比建模的跨模态学习,结合监督训练,构建了统一的视频表征。相比其他基础模型,其训练效率显著提升:仅用64.5K GPU小时 (A100-80G) 的ViT及其变体即可获得通用视频表征,而CoCa [7] 需消耗245.76K TPU小时 (v4)。我们在多类应用中验证了这种通用时空表征的有效性——仅需简单任务头(甚至线性层)和适当下游适配调优,我们的视频表征就在所有测试数据集上刷新了记录。即便在零样本和开放集场景下,模型谱系仍能保持稳定且显著的性能提升,进一步证明了其泛化与适应能力。
5.1 Limitations
5.1 局限性
Our study shows the effectiveness and feasibility of video foundation models instead of giving brand-new formulations or model designs. It focuses on the current popular video perception tasks and handles videos using clips. Its devise can hardly process long-term video tasks, as well as high-order ones, e.g. anticipating plots from the seen parts of a movie. Gaining the capacity to address these tasks is crucial to further push the generality of video representation learning.
我们的研究表明,视频基础模型(Foundation Model)的有效性和可行性,而非提出全新框架或模型设计。该研究聚焦当前流行的视频感知任务,采用片段式视频处理方式。其设计难以处理长周期视频任务及高阶任务(例如根据已观看电影片段预测剧情)。获得解决此类任务的能力,对进一步提升视频表征学习的通用性至关重要。
5.2 Future Work
5.2 未来工作
To further extend the generality of the video foundation models, we suppose embracing model coordination and cognition is necessary for its studies. Specifically, how to systematically coordinate foundation models trained from different modalities, pre training tasks, and even varied architectures for a better representation remains open and challenging. There are multiple technical routes to address it, e.g. model distillation, unifying different pre training objectives, and feature alignment, to name a few. By exploiting previously learned knowledge, we can accelerate video foundation model development sustain ably.
为了进一步提升视频基础模型(Foundation Model)的通用性,我们认为有必要在其研究中引入模型协同与认知机制。具体而言,如何系统协调来自不同模态、预训练任务甚至异构架构的基础模型以获得更优表征,仍是一个开放且具有挑战性的课题。现有多种技术路径可探索,例如模型蒸馏(Model Distillation)、统一预训练目标、特征对齐(Feature Alignment)等。通过有效利用既有知识,我们能以可持续的方式加速视频基础模型的发展。
In the long run, foundation models are expected to master cognitive capabilities more than perceivable ones. Considering its feasibility, we suppose one of its research trends is to achieve large-scale s patio temporal analysis (long-term & big scene) from the foundational dynamic perception in the open world, leading to essential cognitive understanding. Moreover, it has raised a tide that combining foundation models with decision-making to form intelligent agents to explore new tasks. In this interaction, data collection and model training are also automated. The whole process enters a closed loop as the interactive results will adjust agent strategies and behaviors. Our initial experiments (Section 4.3.2) on vision-language navigation demonstrate the promising future of integrating video foundation models into Embodied AI.
长远来看,基础模型预计将掌握超越感知能力的认知能力。考虑到其可行性,我们认为其研究趋势之一是从开放世界的基础动态感知出发,实现大规模时空分析(长期&大场景),从而达成本质认知理解。此外,当前正兴起将基础模型与决策相结合以构建智能体探索新任务的浪潮。在此交互过程中,数据收集和模型训练也实现了自动化。整个系统形成闭环,交互结果会不断调整智能体策略与行为。我们在视觉语言导航领域的初步实验(第4.3.2节)表明,将视频基础模型融入具身AI具有广阔前景。
6 Broader Impact
6 更广泛的影响
We give a video foundation model spectrum Intern Video. It is able to deliver the state-of-the-art performance on around 40 datasets, capable of action discrimination, video-language alignment, and open understanding. Besides of public data, we also exploit self-collected data from the Internet. The employed queries for gathering data are checked for ethic and legal issues and so are the curated data. The power consumption of training Intern Video is much lower than CoCa [7], only taking up $23.19%$ of CoCa. For further impact studies, we need to explore the bias, risks, fairness, equality, and many more social topics.
我们推出视频基础模型谱系Intern Video。该模型能在约40个数据集上实现最先进性能,具备动作识别、视频-语言对齐和开放理解能力。除公开数据外,我们还利用自行采集的网络数据,所有数据采集查询语句及筛选后的数据均经过伦理和法律审查。Intern Video的训练能耗显著低于CoCa [7],仅占CoCa的23.19%。后续影响研究需深入探索偏见、风险、公平性、平等等社会议题。