Multimodal Auto regressive Pre-training of Large Vision Encoders
大规模视觉编码器的多模态自回归预训练
Abstract
摘要
We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in auto regressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, s cal ability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves $89.5%$ accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.
我们提出了一种新颖的大规模视觉编码器预训练方法。基于近期视觉模型自回归预训练的进展,我们将该框架扩展到多模态(即图像和文本)场景。本文介绍了AIMV2系列通用视觉编码器,其特点包括简洁的预训练流程、可扩展性,以及在一系列下游任务中的卓越表现。这是通过将视觉编码器与多模态解码器配对实现的,该解码器能以自回归方式生成原始图像块和文本token。我们的编码器不仅在多模态评估中表现优异,在定位、基础任务和分类等视觉基准测试中同样出色。值得注意的是,AIMV2-3B编码器在ImageNet-1k上使用冻结主干网络时达到了89.5%的准确率。此外,在各种设置的多模态图像理解任务中,AIMV2持续优于CLIP、SigLIP等最先进的对比模型。
1. Introduction
1. 引言
Research on pre-training of vision models has evolved significantly over time. Initially, specialist models were designed to maximize performance on specific tasks [14, 36, 45, 46, 56, 114]. Gradually, general-purpose models emerged that can be deployed for a number of pre- defined downstream tasks with minimal adaptation [54, 87, 94, 133]. However, the remarkable success of Large Language Models (LLMs) [1, 5, 96, 116] has introduced new paradigms for utilizing vision models [3, 73, 85, 115]. Unlike the rigid predefined settings where vision models were previously employed, LLMs enable more effective exploration of the pre-trained model capabilities. This shift demands rethinking pre-training methods for vision models.
视觉模型预训练研究经历了显著的演变。最初,专家模型专为在特定任务上实现最优性能而设计 [14, 36, 45, 46, 56, 114]。随后,通用模型逐渐出现,这类模型只需少量适配即可部署于多种预定义下游任务 [54, 87, 94, 133]。然而,大语言模型 (LLM) 的巨大成功 [1, 5, 96, 116] 为视觉模型的应用带来了新范式 [3, 73, 85, 115]。与传统视觉模型采用的固定预定义设置不同,大语言模型能更有效地挖掘预训练模型的潜力。这一转变促使我们重新思考视觉模型的预训练方法。
Generative pre-training is the dominant paradigm for language modeling [23, 92, 93] and has shown remarkable performance and s cal ability [50, 55]. Generative pretraining has been extensively explored in computer vision [8, 29, 33, 48, 118], but its performance still lags behind that of disc rim i native methods [87, 94, 133, 137]. For instance, a formulation highly reminiscent of LLMs pre- training was proposed by El-Nouby et al. [33] and demonstrated encouraging scaling properties. However, it requires much higher capacity models to match the performance of its disc rim i native counterparts. In contrast, while contrastive techniques are often more parameter efficient, they are notably challenging to train and scale. Although significant progress has been made to mitigate these issues, there remains a gap in developing methods that combine the simplicity and s cal ability of generative pre-training with the parameter efficiency of disc rim i native approaches.
生成式预训练 (Generative pre-training) 是语言建模的主流范式 [23, 92, 93],并展现出卓越的性能和扩展能力 [50, 55]。该范式在计算机视觉领域 [8, 29, 33, 48, 118] 已得到广泛探索,但其性能仍落后于判别式方法 (discriminative methods) [87, 94, 133, 137]。例如,El-Nouby 等人 [33] 提出了与大语言模型预训练高度相似的框架,并展现出良好的扩展特性,但需要更高容量的模型才能匹配判别式方法的性能。相比之下,虽然对比学习技术通常参数效率更高,但其训练和扩展难度显著更大。尽管在缓解这些问题方面已取得重大进展,但如何将生成式预训练的简洁性、扩展性与判别式方法的参数效率相结合,仍是当前方法开发中的空白领域。
In this paper, we introduce AIMV2, a family of open vision models pre-trained to auto regressive ly generate both image patches and text tokens. During pre-training, AIMV2 uses a causal multimodal decoder that first regresses image patches and then decodes text tokens in an auto regressive manner, as illustrated in Figure 1. Such a simple approach offers several advantages. First, AIMV2 is straightforward to implement and train without requiring excessively large batch sizes [35, 94] or specialized interbatch communication methods [133]. Second, the architecture and pre-training objectives of AIMV2 align well with LLM-powered multimodal applications, enabling seamless integration. Finally, AIMV2 extracts a training signal from every image patch and text token, providing denser supervision compared to disc rim i native objectives.
本文介绍了AIMV2系列开源视觉模型,该模型通过预训练以自回归方式同时生成图像块(image patch)和文本token。如图1所示,在预训练阶段,AIMV2采用因果多模态解码器,先回归图像块,再以自回归方式解码文本token。这种简洁方法具有多重优势:首先,AIMV2实现和训练过程直接,无需超大批次[35,94]或特殊批间通信方法[133];其次,其架构与预训练目标能完美适配大语言模型驱动的多模态应用;最后,AIMV2从每个图像块和文本token中提取训练信号,相比判别式目标能提供更密集的监督信号。
Our AIMV2 models are strong generalists that exhibit remarkable performance across various vision and multimodal tasks. In particular, AIMV2 performs favorably on multimodal understanding benchmarks compared to stateof-the-art vision-language pre-trained methods [35, 133]. It outperforms DINOv2 [87] on open-vocabulary object detection and referring expression comprehension, and attains strong recognition performance with a frozen trunk, out
我们的AIMV2模型是强大的通用模型,在各种视觉和多模态任务中展现出卓越性能。特别值得注意的是,与最先进的视觉语言预训练方法[35,133]相比,AIMV2在多模态理解基准测试中表现优异。在开放词汇目标检测和指代表达理解任务上,它超越了DINOv2[87],并在冻结主干网络的情况下实现了强大的识别性能。
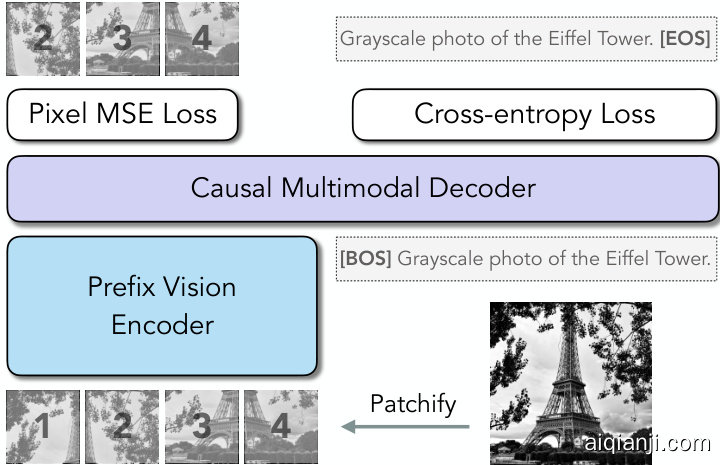
Figure 1. AIMV2 pre-training Overview. (Left) Image patches are processed by a vision encoder trained with prefix attention [33, 95]. The resulting visual representations are concatenated with the text embeddings of their corresponding captions. This combined multimodal sequence is then processed by a joint decoder. The model is pre-trained to auto regressive ly reconstruct the shifted input. (Right) Pseudocode for the forward pass during AIMV2 pre-training. The pre-training process of AIMV2 is straightforward to implement, resembling that of AIM and LLMs as it relies solely on a simple auto regressive objective.
图 1: AIMV2预训练概览。(左)图像块通过经过前缀注意力训练的视觉编码器处理[33, 95]。生成的视觉表示与其对应标题的文本嵌入拼接,该多模态序列随后由联合解码器处理。模型通过自回归方式预训练以重建位移输入。(右)AIMV2预训练前向传播伪代码。AIMV2预训练过程实现简单,仅依赖单一自回归目标,与AIM和大语言模型的预训练方式类似。
Pseudo-code for AIMV2 pre-training
AIMV2 预训练的伪代码
performing a number of strong baselines. Furthermore, AIMV2 enjoys strong s cal ability, similar to its languageonly and vision-only counterparts, improving consistently when scaling data or parameters. Moreover, we demonstrate the compatibility of AIMV2 with several modern tools, including support for native image resolution and adaptation to zero-shot recognition [132]. We discuss related works in more detail in Sec. 6.
执行多个强基线。此外,AIMV2展现出与纯语言和纯视觉模型相似的强大扩展能力,在扩展数据或参数时持续提升性能。我们还证明了AIMV2与多种现代工具的兼容性,包括支持原生图像分辨率和适应零样本识别 [132]。更多相关工作讨论详见第6节。
2. Approach
2. 方法
2.1. Pre-training
2.1. 预训练
Our model extends the standard unimodal auto regressive framework to multimodal settings that integrate both images and text into a unified sequence. Specifically, an image $x$ is partitioned into $I$ non-overlapping patches $x_{i}$ , $i\in[1,I]$ , forming a sequence of tokens. Similarly, a text sequence is broken down into subwords $x_{t}$ , $t\in[I,I+T]$ . These sequences are then concatenated, allowing text tokens to attend to image tokens. While both concatenation directions (image $\rightarrow$ text and text $\rightarrow$ image) are possible, we focus on training a strong vision encoder by always prepending the image first, thereby enabling stronger conditioning on the visual features. This results in a unified multimodal auto regressive modeling process, where the sequence is factor iz at i zed as follows:
我们的模型将标准的单模态自回归框架扩展至多模态场景,将图像和文本整合为统一序列。具体而言,图像$x$被划分为$I$个非重叠块$x_{i}$($i\in[1,I]$),形成token序列。类似地,文本序列被分解为子词$x_{t}$($t\in[I,I+T]$)。这些序列随后被拼接,使文本token能关注图像token。虽然存在两种拼接方向(图像$\rightarrow$文本或文本$\rightarrow$图像),我们通过始终优先前置图像来训练强视觉编码器,从而实现对视觉特征的更强条件约束。最终形成统一的多模态自回归建模过程,其序列因子分解如下:
$$
P(S)=\prod_{j=1}^{I+T}P(S_{j}|S_{<j}),
$$
$$
P(S)=\prod_{j=1}^{I+T}P(S_{j}|S_{<j}),
$$
where $S_{j}$ represents the $j$ -th token in the concatenated sequence of image patches and text tokens, and $S_{<j}$ includes all preceding tokens. This unified factorization allows the model to auto regressive ly predict the next token in the sequence, regardless of what modality it is currently processing. Our pre-training setup consists of a dedicated vision encoder that processes the raw image patches, which are then passed to a multimodal decoder alongside the embedded text tokens, as illustrated in Figure 1. The decoder subsequently performs next-token prediction on the combined sequence, following the factorization above. To support the auto regressive generation process, the vision encoder and multimodal decoder employ prefix and causal self-attention operations, respectively.
其中 $S_{j}$ 表示图像块与文本token拼接序列中的第 $j$ 个token,$S_{<j}$ 包含所有前置token。这种统一因子分解方式使模型能以自回归方式预测序列中的下一个token,无论当前处理的是何种模态。如图1所示,我们的预训练框架包含专用视觉编码器处理原始图像块,这些图像块随后与嵌入的文本token一起输入多模态解码器。解码器根据上述因子分解方式对组合序列执行下一token预测。为支持自回归生成过程,视觉编码器采用前缀自注意力操作,多模态解码器则采用因果自注意力操作。
Objective function. We define separate loss functions for the image and text domains as follows:
目标函数。我们为图像和文本领域分别定义如下损失函数:
$$
\begin{array}{r}{L_{\mathrm{img}}=\displaystyle\frac{1}{I}\sum_{i=1}^{I}|\hat{x}_{i}(x_{<i};\boldsymbol{\theta})-x_{i}|_{2}^{2},}\ {L_{\mathrm{text}}=-\displaystyle\frac{1}{T}\sum_{t=I+1}^{I+T}\log P(x_{t}|\boldsymbol{x}_{<t};\boldsymbol{\theta}).}\end{array}
$$
$$
\begin{array}{r}{L_{\mathrm{img}}=\displaystyle\frac{1}{I}\sum_{i=1}^{I}|\hat{x}_{i}(x_{<i};\boldsymbol{\theta})-x_{i}|_{2}^{2},}\ {L_{\mathrm{text}}=-\displaystyle\frac{1}{T}\sum_{t=I+1}^{I+T}\log P(x_{t}|\boldsymbol{x}_{<t};\boldsymbol{\theta}).}\end{array}
$$
The overall objective is to minimize $L_{\mathrm{text}}+\alpha*L_{\mathrm{img}}$ with respect to model parameters $\theta$ . For the text domain, $L_{\mathrm{text}}$ is a standard cross-entropy loss that measures the negative log-likelihood of the ground truth token at each step. For the image domain, $L_{\mathrm{img}}$ is an $\ell_{2}$ pixel-level regression loss, where the model’s predicted patch ${\hat{x}}{i}(\theta)$ is compared to the true patch $x{i}$ . We normalize the image patches following He et al. [48]. In practice, we use separate linear layers to map the final hidden state of the multimodal decoder to the appropriate output dimensions for image patches and vocabulary size for vision and language, respectively.
总体目标是最小化 $L_{\mathrm{text}}+\alpha*L_{\mathrm{img}}$ 关于模型参数 $\theta$。对于文本领域,$L_{\mathrm{text}}$ 是标准的交叉熵损失,用于衡量每一步真实 token 的负对数似然。对于图像领域,$L_{\mathrm{img}}$ 是一个 $\ell_{2}$ 像素级回归损失,将模型预测的图像块 ${\hat{x}}{i}(\theta)$ 与真实图像块 $x{i}$ 进行比较。我们遵循 He 等人 [48] 的方法对图像块进行归一化。在实际应用中,我们使用不同的线性层将多模态解码器的最终隐藏状态分别映射到图像块的适当输出维度和视觉与语言的词汇表大小。
2.2. Architecture
2.2. 架构
For the vision encoder of AIMV2, we adopt the Vision Transformer (ViT) architecture [30]. We train a series of
对于AIMV2的视觉编码器,我们采用了Vision Transformer (ViT)架构[30]。我们训练了一系列

Figure 2. Scaling properties of AIMV2. (Left) Given a fixed pre-training data size, increasing the number of parameters always leads to an improvement in the validation loss. (Right) The optimal model size varies based on the pre-training compute budget. Larger models perform worse than smaller ones when severely under trained but improves consistently as the compute budget increases. This behavior is consistent with that reported by Hoffmann et al. [50] for text-only auto regressive models.
图 2: AIMV2的扩展特性。(左) 在固定预训练数据量的情况下,增加参数数量总能降低验证损失。(右) 最优模型规模随预训练计算预算而变化。当计算资源严重不足时,较大模型表现逊于较小模型,但随着计算预算增加,其性能会持续提升。该现象与Hoffmann等人[50]在纯文本自回归模型中报告的结果一致。
Table 1. AIMV2 family of models. We detail the architectural specifications of AIMV2 models including the embedding dimension $d$ , number of layers $L$ for the vision encoder and the mutlimodal decoder, and the total number of encoder parameters.
| model | #params | denc | Lenc | ddec | Ldec |
| AIMv2-L | 0.3B | 1024 | |||
| AIMv2-H | 0.6B | 1536 | 24 | 12 | 1024 |
| AIMv2-1B | 1.2B | 2048 | |||
| AIMv2-3B | 2.7B | 3072 |
表 1: AIMV2 模型家族。我们详细列出了 AIMV2 模型的架构规格,包括嵌入维度 $d$、视觉编码器和多模态解码器的层数 $L$,以及编码器参数总数。
| model | #params | denc | Lenc | ddec | Ldec |
|---|---|---|---|---|---|
| AIMv2-L | 0.3B | 1024 | |||
| AIMv2-H | 0.6B | 1536 | 24 | 12 | 1024 |
| AIMv2-1B | 1.2B | 2048 | |||
| AIMv2-3B | 2.7B | 3072 |
Prefix Attention. Following El-Nouby et al. [33], we constrain the self-attention mechanism within the vision encoder by applying a prefix attention mask [95]. This strategy facilitates the use of bidirectional attention during inference without additional tuning. Specifically, we randomly sample the prefix length as $ M sim U 1,2, dots,I-1$ The pixel loss is computed exclusively for non-prefix patches, defined as ${x{i}mid i>M}$ i mid i > M , .
前缀注意力 (Prefix Attention)。遵循 El-Nouby 等人 [33] 的方法,我们通过应用前缀注意力掩码 [95] 来约束视觉编码器中的自注意力机制。这一策略使得在推理过程中能够使用双向注意力,而无需额外调整。具体来说,我们随机采样前缀长度为 $ M sim U {1,2,dots,I-1}$ 。像素损失仅针对非前缀补丁计算,定义为 ${x_{i}mid i>M}$ i mid i > M ,。
SwiGLU and RMSNorm. Our vision encoder and multimodal decoder incorporate SwiGLU [102] as the feedforward network (FFN) and replace all normalization layers with RMSNorm [134]. These modifications leverage the recent successes of SwiGLU and RMSNorm in language modeling [116, 117].
SwiGLU 和 RMSNorm。我们的视觉编码器和多模态解码器采用了 SwiGLU [102] 作为前馈网络 (FFN),并将所有归一化层替换为 RMSNorm [134]。这些改进借鉴了 SwiGLU 和 RMSNorm 在语言建模领域的最新成功经验 [116, 117]。
Multimodal Decoder. We adopt a unified multimodal decoder that performs auto regressive generation for both image and text modalities concurrently. Image features and raw text tokens are each linearly projected and embedded into $\mathbb{R}^{d_{\mathrm{dec}}}$ . The decoder receives concatenated sequences of image and text features as input and employs causal attention in the self-attention operations. The outputs of the decoder are processed through two separate linear heads—one for image tokens and another for text tokens—to predict the next token in each modality respectively. We use the same decoder capacity for all the AIMV2 variants.
多模态解码器。我们采用统一的多模态解码器,可同时对图像和文本模态执行自回归生成。图像特征和原始文本token分别通过线性投影嵌入到$\mathbb{R}^{d_{\mathrm{dec}}}$空间。该解码器接收拼接后的图像与文本特征序列作为输入,并在自注意力运算中采用因果注意力机制。解码器输出通过两个独立线性头处理——一个用于图像token,另一个用于文本token——以分别预测各模态的下一个token。所有AIMV2变体均使用相同容量的解码器。
The optimization hyper parameters used during pre-training of all AIMV2 models are outlined in Table A1.
所有AIMV2模型预训练期间使用的优化超参数详见表A1。
| dataset | public | caption | #images-textpairs | samplingprob. |
| DFN [35] | alt-text | 1,901,228,573 | 30% | |
| synthetic | 3,802,457,146 | 30% | ||
| COYO[13] | alt-text | 560,171,533 | %6 | |
| HQITP | alt-text | 564,623,839 | 28% | |
| X | synthetic | 431,506,953 | 3% |
| 数据集 | 公开 | 描述 | 图文对数量 | 采样概率 |
|---|---|---|---|---|
| DFN [35] | 替代文本 | 1,901,228,573 | 30% | |
| 合成文本 | 3,802,457,146 | 30% | ||
| COYO [13] | 替代文本 | 560,171,533 | 6% | |
| HQITP | 替代文本 | 564,623,839 | 28% | |
| X | 合成文本 | 431,506,953 | 3% |
Table 2. Pre-training data mixture. AIMV2 is pre-trained using a large-scale collection of image and text pairs. For the paired captions, we utilize alt-text as well as synthetic text generated from a pre-trained captioner. In this table we list the datasets as well the sampling probabilities we used for each data source.
表 2: 预训练数据混合比例。AIMV2 使用大规模图文对进行预训练。对于配对的描述文本,我们同时采用了替代文本 (alt-text) 和预训练描述生成器产生的合成文本。本表列出了各数据源对应的数据集及其采样概率。
2.3. Data
2.3. 数据
We pre-train AIMV2 models using a combination of public and private datasets containing paired images and text. We use the publicly available DFN-2B [35] and COYO [13] datasets, along with a proprietary dataset of High Quality Image-Text Pairs (HQITP). In addition to alt-text, we use synthetic captions following the approach of Lai et al. [63]. Details regarding the datasets, including their sizes and the sampling probabilities used for each dataset, are provided in Table 2. Unless mentioned otherwise, all AIMV2 models were pre-trained using 12 billion image-text samples.
我们使用包含配对图像和文本的公开及私有数据集组合对AIMV2模型进行预训练。采用公开可用的DFN-2B [35]和COYO [13]数据集,以及专有的高质量图文对(High Quality Image-Text Pairs, HQITP)数据集。除替代文本外,我们采用Lai等人[63]的方法生成合成标注。各数据集的规模及采样概率等详细信息见表2。除非另有说明,所有AIMV2模型均使用120亿个图文样本进行预训练。
表2:
2.4. Post-Training
2.4. 训练后处理
While the initial pre-training stage of AIMV2 yields highly performant models, we explore methods to further enhance the capabilities through various post-training strategies.
虽然AIMV2的初始预训练阶段已经产生了高性能模型,但我们仍探索通过多种训练后策略进一步提升模型能力的方法。
High-resolution Adaptation. In the initial pre-training stage, we use image data with a fixed resolution of $224\mathrm{px}$ . However, many downstream task, such as detection, segmentation, and multimodal LLMs, benefit from models adapted to handle higher resolution images. Therefore, we finetune AIMV2 models for 336 and 448 pixel resolutions. The high-resolution adaptation stage utilizes 2 billion image-text pairs sampled from the same pool as the pretraining stage, except that we do not use synthetic captions at this stage. Consistent with the observations of Zhai et al. [133], we find that weight decay of zero is important for maintaining stable optimization.
高分辨率适配。在初始预训练阶段,我们使用固定分辨率为$224\mathrm{px}$的图像数据。然而许多下游任务(如检测、分割和多模态大语言模型)需要模型适配更高分辨率图像。因此,我们对AIMV2模型进行了336和448像素分辨率的微调。高分辨率适配阶段使用了20亿张与预训练阶段同源的图文对(此阶段未使用合成标注)。与Zhai等人[133]的观察一致,我们发现零权重衰减对保持优化稳定性至关重要。

Figure 3. Scaling capacity and resolution. AIMV2 shows strong s cal ability with respect to model parameters, measured in frozentrunk top-1 accuracy for IN-1k. This behavior is consistent when scaling image resolution.
图 3: 扩展能力与分辨率。AIMV2 在模型参数量方面展现出强大的扩展能力 (以冻结主干网络在 IN-1k 数据集上的 top-1 准确率为衡量指标) 。这种扩展特性在提升图像分辨率时同样保持一致。
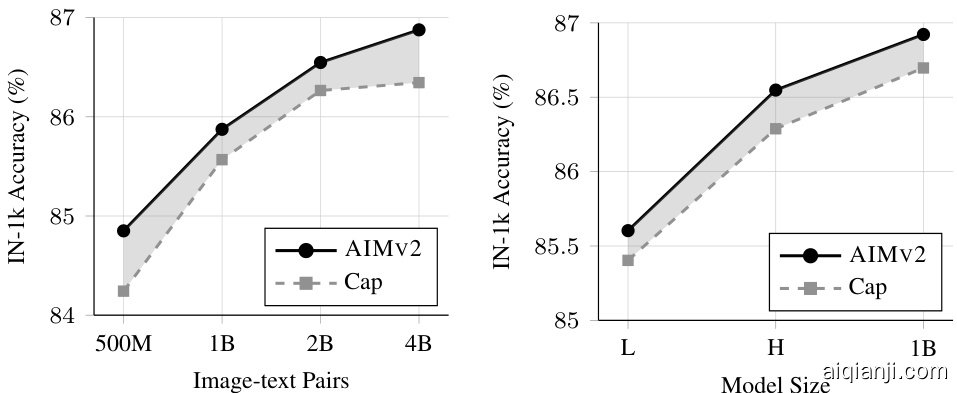
Figure 4. AIMV2 vs. Captioning. We investigate the role of the image-level objective in comparison to a captioning-only baseline, particularly as we scale data and model size. Our findings indicate that AIMV2 consistently outperforms the captioning baseline across all dataset and model sizes. Notably, AIMV2 exhibits fewer signs of saturation when scaling data compared to the captioning-only approach.
图 4: AIMV2与纯描述生成对比。我们研究了图像级目标相对于纯描述生成基线的作用,特别是在扩展数据和模型规模时。结果表明,在所有数据集和模型规模下,AIMV2始终优于纯描述生成基线。值得注意的是,与纯描述生成方法相比,AIMV2在扩展数据时表现出更少的饱和迹象。
Native Resolution Fine-tuning. Training models for a dedicated resolution and aspect ratio can be inflexible for many applications that require processing images in their original shapes. Prior works such as FlexiViT [9] and NaViT [26] have tackled these limitation. We adopt a different approach for training with variable aspect ratios and resolutions. Specifically, we define $B_{i}$ as the number of images in a mini-batch, $A_{i}$ as the number of patches per image, and $C$ as the total number of image patches in the mini-batch. For a mini-batch $i$ , we randomly sample an area $A$ and resize the images to fit within this area while maintaining their aspect ratios.1 We then adjust the mini-batch size $B_{i}$ such that $C=A_{i}\times B_{i}$ . This strategy is analogous to the approach proposed by Pouransari et al. [91] for training LLMs with variable context lengths. Our implementation does not require heuristics for sequence packing, attention masking, or custom pooling operations. We choose $A=2^{n}$ , where $n$ is sampled from a truncated normal distribution $\mathcal{N}(0,1)$ within the range $[-1,1]$ ] and linearly mapped to [7, 12].
原生分辨率微调。针对特定分辨率和宽高比训练模型对于需要处理原始形状图像的许多应用来说可能不够灵活。FlexiViT [9] 和 NaViT [26] 等先前工作已解决了这些限制。我们采用了一种不同的方法来训练可变宽高比和分辨率。具体来说,我们将 $B_{i}$ 定义为小批量中的图像数量,$A_{i}$ 定义为每张图像的补丁数量,$C$ 定义为小批量中的图像补丁总数。对于小批量 $i$,我们随机采样一个区域 $A$ 并调整图像大小以适合该区域,同时保持其宽高比。然后我们调整小批量大小 $B_{i}$,使得 $C=A_{i}\times B_{i}$。这一策略类似于 Pouransari 等人 [91] 提出的用于训练可变上下文长度大语言模型的方法。我们的实现不需要启发式序列打包、注意力掩码或自定义池化操作。我们选择 $A=2^{n}$,其中 $n$ 从范围 $[-1,1]$ 内的截断正态分布 $\mathcal{N}(0,1)$ 中采样,并线性映射到 [7, 12]。
3. Analysis
3. 分析
One of the main advantages of AIMV2 is its simplicity; it is easy to implement and scale. Therefore, we investigate the scaling properties of the AIMV2 family of models.
AIMV2的主要优势之一在于其简洁性,易于实现和扩展。因此,我们研究了AIMV2模型系列的扩展特性。
3.1. Scaling AIMv2
3.1. 扩展 AIMv2
First, we investigate the impact of scaling data size and model capacity on the validation performance of AIMV2. We fix the model size and vary the number of samples seen during pre-training. This analysis is similar to “Approach 1” in the study of Hoffmann et al. [50]. The results of this study are illustrated in Figure 2.
首先,我们研究了数据规模和模型容量对AIMV2验证性能的影响。固定模型大小,改变预训练期间见过的样本数量。该分析与Hoffmann等人[50]研究中的"方法1"类似。研究结果如图2所示。
Setup. We train four model capacities, ranging from 300 million to 3 billion parameters, and vary the number of samples seen between 500 million to 6.4 billion image-text pairs. All models are trained to convergence with no early stopping. To achieve this with minimal computational cost, we train a single model for each capacity using 5 billion images with a half-cosine learning rate schedule (i.e., the final learning rate is half the peak learning rate). We select seven intermediate checkpoints from this run and apply a linear cooldown to $1\times10^{-6}$ . The length of the cooldown stage is $20%$ of the initial pre-training stage.
设置。我们训练了四种不同规模的模型,参数量从3亿到30亿不等,训练数据量在5亿到64亿图文对之间变化。所有模型均训练至完全收敛,未采用早停策略。为以最小计算成本实现这一目标,我们为每个规模的模型使用50亿图像进行训练,并采用半余弦学习率调度(即最终学习率为峰值学习率的一半)。从训练过程中选取7个中间检查点,并对其应用线性冷却至$1\times10^{-6}$。冷却阶段的时长为初始预训练阶段的$20%$。
Results. We observe a consistent improvement in performance with scaling data or parameters. However, diminishing returns appear when scaling data for the lower-capacity models. Additionally, we find that the optimal model size changes as the compute budget varies. At smaller compute budgets, larger-capacity models are under trained and underperform compared to their lower-capacity counterparts.
结果。我们观察到,随着数据或参数规模的扩大,性能呈现出一致的提升。然而,在扩展低容量模型的数据时会出现收益递减现象。此外,我们发现最佳模型容量会随计算预算的变化而改变:在较小计算预算下,高容量模型训练不足,其表现会逊于低容量模型。
3.2. AIMv2 vs. Captioning
3.2. AIMv2 与字幕生成对比
We study the role of the image-level auto regressive objective in the pre-training of AIMV2. We compare the performance of models trained with the multimodal autoregressive objective to ones trained only with language supervision. The results are illustrated in Figure 4.
我们研究了图像级自回归目标在AIMV2预训练中的作用。将采用多模态自回归目标训练的模型与仅使用语言监督训练的模型进行性能对比,结果如图4所示。
Setup. Unless specified otherwise, this investigation uses a ViT-H backbone and 2 billion image-text pairs for pretraining. All models are trained to convergence with a cosine learning rate schedule. We measure the IN-1k top-1 accuracy after attentive probe with a frozen trunk.
设置。除非另有说明,本次研究采用ViT-H主干网络和20亿图文对进行预训练。所有模型均采用余弦学习率调度训练至收敛。我们通过冻结主干的注意力探针测量IN-1k top-1准确率。
Results. First, the image-level objective of AIMV2 consistently improves performance compared to the captioningonly baseline. This is true even when changing the model capacity and the size of the pre-training data. Moreover, we see both approaches improving consistently when increasing the data size or model capacity; however, we observe signs of plateauing for the captioning baselines with scaling data which we do not observe with AIMV2.
结果。首先,与纯字幕生成基线相比,AIMV2 的图像级目标始终能提升性能。这一结论在改变模型容量和预训练数据规模时依然成立。此外,两种方法在增加数据量或模型容量时均持续提升性能;但我们观察到字幕基线在数据扩展时出现平台期迹象,而 AIMV2 未出现此现象。
Table 3. Frozen trunk evaluation for recognition benchmarks. We report the recognition performance of the AIMV2 family models when compared to a number of self-supervised and weakly-supervised state-of-the-art models. All models are evaluated using attentive probing with a frozen backbone. Unless otherwise specified, all AIMV2 models are trained at $224\mathrm{px}$ resolution on 12B samples.
| 8 | 10 | Cifarl | CAM17 | PCAM | RxRx1 | S | ograph | ||||||||
| model | architecture | Cifarl | D | Pets | EuroS | fMo | Infog | ||||||||
| MAE[48] | ViT-2B/14 | 82.2 | 70.8 | 97.5 | 87.3 | 93.4 | 81.2 | 95.1 | 94.9 | 94.4 | 90.3 | 7.3 | 98.2 | 60.1 | 50.2 |
| AIMv1 [33] | ViT-H/14 ViT-7B/14 | 78.5 | 64.0 75.5 | 97.2 98.9 | 86.8 | 90.1 94.1 | 80.1 | 93.0 95.4 | 93.0 95.0 | 94.3 94.2 | 90.0 90.5 | 7.8 8.4 | 98.4 98.5 | 58.3 63.5 | 45.2 57.7 |
| DINOv2[87] | ViT-g/14 | 84.0 87.2 | 83.0 | 99.7 | 91.8 95.6 | 96.0 | 85.6 86.9 | 96.8 | 94.9 | 95.8 | 90.1 | 9.0 | 98.8 | 65.5 | 59.4 |
| OAI CLIP [94] | ViT-L/14 | 85.7 | 73.5 | 5.7 | 66.9 | ||||||||||
| VIT-L/14 | 86.5 | 75.5 | 98.7 99.2 | 89.7 93.2 | 95.4 96.2 | 83.5 85.8 | 96.2 96.3 | 94.5 96.4 | 94.4 95.0 | 89.2 89.8 | 5.8 | 98.0 98.3 | 62.0 63.1 | 66.8 | |
| DFN-CLIP [35] | ViT-H/14 | 86.9 | 76.4 | 99.3 | 93.9 | 96.3 | 87.0 | 96.8 | 96.7 | 95.7 | 90.5 | 6.1 | 98.8 | 63.4 | 68.1 |
| ViT-L/16 | 86.5 | 75.1 | 98.5 | 90.4 | 96.1 | 86.7 | 96.7 | 96.5 | 93.1 | 89.5 | 4.5 | 98.3 | 61.7 | 71.0 | |
| SigLIP[133] | ViT-So400m/14 | 87.3 | 77.4 | 98.8 | 91.2 | 96.5 | 87.7 | 96.7 | 96.6 | 93.3 | 90.0 | 4.6 | 98.6 | 64.4 | 72.3 |
| AIMv2 | ViT-L/14 | 86.6 | 76.0 | 99.1 | 92.2 | 95.7 | 87.9 | 96.3 | 93.7 | 89.3 | 5.6 | 98.4 | 60.7 | 69.0 | |
| 77.9 | 96.3 | 70.4 | |||||||||||||
| ViT-H/14 | 87.5 88.1 | 79.7 | 99.3 99.4 | 93.5 94.1 | 96.3 96.7 | 88.2 88.4 | 96.6 96.8 | 96.4 96.5 | 93.3 94.2 | 89.3 | 5.8 6.7 | 98.5 | 62.2 | 71.7 | |
| ViT-1B/14 ViT-3B/14 | 88.5 | 81.5 | 99.5 | 94.3 | 96.8 | 88.9 | 97.1 | 96.5 | 93.5 | 89.0 89.4 | 7.3 | 98.8 99.0 | 63.2 64.2 | 72.2 | |
| ViT-3B/14448px | 89.5 | 85.9 | 99.5 | 94.5 | 97.4 | 89.0 | 97.4 | 96.7 | 93.4 | 89.9 | 9.5 | 98.9 | 66.1 | 74.8 |
表 3: 识别基准的冻结主干评估。我们报告了 AIMV2 系列模型与多种自监督和弱监督最先进模型相比的识别性能。所有模型均使用冻结主干的注意力探测进行评估。除非另有说明,所有 AIMV2 模型均在 12B 样本上以 $224\mathrm{px}$ 分辨率训练。
| model | architecture | 8 | 10 | Cifarl | CAM17 | PCAM | RxRx1 | S | ograph | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE[48] | ViT-2B/14 | 82.2 | 70.8 | 97.5 | 87.3 | 93.4 | 81.2 | 95.1 | 94.9 | 94.4 | 90.3 | 7.3 | 98.2 | 60.1 | 50.2 | |
| AIMv1 [33] | ViT-H/14 ViT-7B/14 | 78.5 | 64.0 75.5 | 97.2 98.9 | 86.8 | 90.1 94.1 | 80.1 | 93.0 95.4 | 93.0 95.0 | 94.3 94.2 | 90.0 90.5 | 7.8 8.4 | 98.4 98.5 | 58.3 63.5 | 45.2 57.7 | |
| DINOv2[87] | ViT-g/14 | 84.0 87.2 | 83.0 | 99.7 | 91.8 95.6 | 96.0 | 85.6 86.9 | 96.8 | 94.9 | 95.8 | 90.1 | 9.0 | 98.8 | 65.5 | 59.4 | |
| OAI CLIP [94] | ViT-L/14 | 85.7 | 73.5 | 5.7 | 66.9 | |||||||||||
| VIT-L/14 | 86.5 | 75.5 | 98.7 99.2 | 89.7 93.2 | 95.4 96.2 | 83.5 85.8 | 96.2 96.3 | 94.5 96.4 | 94.4 95.0 | 89.2 89.8 | 5.8 | 98.0 98.3 | 62.0 63.1 | 66.8 | ||
| DFN-CLIP [35] | ViT-H/14 | 86.9 | 76.4 | 99.3 | 93.9 | 96.3 | 87.0 | 96.8 | 96.7 | 95.7 | 90.5 | 6.1 | 98.8 | 63.4 | 68.1 | |
| ViT-L/16 | 86.5 | 75.1 | 98.5 | 90.4 | 96.1 | 86.7 | 96.7 | 96.5 | 93.1 | 89.5 | 4.5 | 98.3 | 61.7 | 71.0 | ||
| SigLIP[133] | ViT-So400m/14 | 87.3 | 77.4 | 98.8 | 91.2 | 96.5 | 87.7 | 96.7 | 96.6 | 93.3 | 90.0 | 4.6 | 98.6 | 64.4 | 72.3 | |
| AIMv2 | ViT-L/14 | 86.6 | 76.0 | 99.1 | 92.2 | 95.7 | 87.9 | 96.3 | 93.7 | 89.3 | 5.6 | 98.4 | 60.7 | 69.0 | ||
| 77.9 | 96.3 | 70.4 | ||||||||||||||
| ViT-H/14 | 87.5 88.1 | 79.7 | 99.3 99.4 | 93.5 94.1 | 96.3 96.7 | 88.2 88.4 | 96.6 96.8 | 96.4 96.5 | 93.3 94.2 | 89.3 | 5.8 6.7 | 98.5 | 62.2 | 71.7 | ||
| ViT-1B/14 ViT-3B/14 | 88.5 | 81.5 | 99.5 | 94.3 | 96.8 | 88.9 | 97.1 | 96.5 | 93.5 | 89.0 89.4 | 7.3 | 98.8 99.0 | 63.2 64.2 | 72.2 | ||
| ViT-3B/14448px | 89.5 | 85.9 | 99.5 | 94.5 | 97.4 | 89.0 | 97.4 | 96.7 | 93.4 | 89.9 | 9.5 | 98.9 | 66.1 | 74.8 |
4. Results
4. 结果
AIMV2 is a generalist vision encoder that can be leveraged off-the-shelf for a wide range of downstream tasks. We evaluate the performance of the AIMV2 family across various tasks, including recognition, detection, captioning, and multiple multimodal benchmarks.
AIMV2是一种通用视觉编码器,可直接用于多种下游任务。我们评估了AIMV2系列在识别、检测、描述生成及多模态基准测试等任务中的性能表现。
4.1. Image Recognition
4.1. 图像识别
Attentive probing. We assess the quality of the AIMV2 models as off-the-shelf backbones for recognition benchmarks which are outlined in Table B1. To this end, we adopt the attentive probing setting proposed by Yu et al. [129], where the vision encoder remains frozen, and only an attentive probe classifier is trained on top of the last layer features. The results are presented in Table 3. Detailed hyper parameters used for the probing experiments are provided in Table A2. First, we observe that AIMV2 significantly outperforms generative unsupervised methods such as MAE [48] and AIM [33], even with much smaller capacity models. Compared to DINOv2 [87], we find that both the similarly sized AIMV2-1B and the smaller AIMV2-H provide competitive performance, outperforming DINOv2 on several benchmarks including IN-1k, Food101, DTD, Cars, and with a particularly large margin on Info graphic. However, DINOv2 offers exceptional performance for iNaturalist and fMoW. Furthermore, we find the performance of self-supervised models on medical imaging benchmarks (e.g., RxRx1 and CAM17) noteworthy, as they exhibit stronger performance compared to their weakly supervised counterparts. This affirms the importance of self-supervised learning methods, particularly in low-resource domains.
注意力探测。我们评估AIMV2模型作为现成骨干网络在表B1所列识别基准上的表现。为此采用Yu等人[129]提出的注意力探测设置:视觉编码器保持冻结,仅在最顶层特征上训练注意力探针分类器。结果如表3所示,探测实验的详细超参数见表A2。首先发现AIMV2显著优于MAE[48]和AIM[33]等生成式无监督方法,即使模型容量小得多。与DINOv2[87]相比,同等规模的AIMV2-1B和更小的AIMV2-H均展现出竞争力,在IN-1k、Food101、DTD、Cars等基准上超越DINOv2,在Info graphic上优势尤为明显。但DINOv2在iNaturalist和fMoW上表现突出。值得注意的是,自监督模型在RxRx1和CAM17等医学影像基准上优于弱监督模型,这印证了自监督学习方法在资源匮乏领域的重要性。
Second, when compared to other vision-language pretrained baselines, AIMV2 exhibits highly competitive performance. For instance, at the ViT-Large capacity, AIMV2 outperforms OAI CLIP on the majority of benchmarks and achieves stronger performance than DFN-CLIP and SigLIP
其次,与其他视觉语言预训练基线相比,AIMV2展现出极具竞争力的性能。例如,在ViT-Large规模下,AIMV2在大多数基准测试中优于OAI CLIP,并取得比DFN-CLIP和SigLIP更强的性能表现。
Table 4. Evaluation after finetuning on grounding dataset mixture. We report the performance on mean average precision (AP) for open-vocabulary detection and Precision $@1$ for referring expression comprehension tasks.
| model | open-vocabulary | referringexpression | |||
| COCO | LVIS | RefC | RefC+ | RefCg | |
| OAICLIP | 59.1 | 31.0 | 92.2 | 86.2 | 88.3 |
| DFN-CLIP | 59.8 | 30.7 | 92.5 | 85.8 | 88.3 |
| SigLIP | 58.8 | 30.5 | 92.3 | 86.1 | 88.4 |
| DINOv2 | 60.1 | 30.8 | 92.2 | 85.9 | 89.1 |
| AIMv2 | 60.2 | 31.6 | 92.6 | 86.3 | 88.9 |
表 4: 基于混合接地数据集的微调后评估结果。我们报告了开放词汇检测任务的平均精度均值 (AP) 和指代表达理解任务的 Precision $@1$ 指标。
| model | open-vocabulary | referringexpression | |||
|---|---|---|---|---|---|
| COCO | LVIS | RefC | RefC+ | RefCg | |
| OAICLIP | 59.1 | 31.0 | 92.2 | 86.2 | 88.3 |
| DFN-CLIP | 59.8 | 30.7 | 92.5 | 85.8 | 88.3 |
| SigLIP | 58.8 | 30.5 | 92.3 | 86.1 | 88.4 |
| DINOv2 | 60.1 | 30.8 | 92.2 | 85.9 | 89.1 |
| AIMv2 | 60.2 | 31.6 | 92.6 | 86.3 | 88.9 |
Table 5. Zero-shot performance. Comparison of different models with varying amounts of pre-training and LiT pairs, and their performance on IN1k. For CapPa, we compare to the number reported by Tschannen et al. [118].
| model 个 | Cap | AIMv2 | CapPa [118]A | AIMv2 | OAI CLIP | SigLIP |
| Pre-train/LiT | 2B/3B | 2B/3B | 9B/3B | 12B/3B | 13B/- | 40B/- |
| IN-1k top-1 | 75.0 | 75.3 | 76.4 | 77.0 | 75.5 | 80.4 |
表 5: 零样本性能。比较不同预训练量和LiT配对量的模型在IN1k上的表现。对于CapPa,我们与Tschannen等人[118]报告的数据进行对比。
| model | Cap | AIMv2 | CapPa [118]A | AIMv2 | OAI CLIP | SigLIP |
|---|---|---|---|---|---|---|
| Pre-train/LiT | 2B/3B | 2B/3B | 9B/3B | 12B/3B | 13B/- | 40B/- |
| IN-1k top-1 | 75.0 | 75.3 | 76.4 | 77.0 | 75.5 | 80.4 |
| test resolution | 224×224 | 448×448 | native |
| 86.6 | 84.8 | ||
| AIMv2-L 448px | 78.9 | 87.9 | |
| AIMv2-Lnative | 86.1 | 87.1 | 87.3 |
| 测试分辨率 | 224×224 | 448×448 | 原生分辨率 |
|---|---|---|---|
| 86.6 | 84.8 | ||
| AIMv2-L 448px | 78.9 | 87.9 | |
| AIMv2-L原生 | 86.1 | 87.1 | 87.3 |
Table 6. AIMV2 with native apsect ratio and resolution. We report the IN-1k top-1 performance of the native resolution AIMV2-L model as compared to AIMV2-L models that are pretrained/finetuned for single dedicated resolution.
表6: 原生宽高比和分辨率的AIMV2。我们报告了原生分辨率AIMV2-L模型在IN-1k上的top-1性能,并与针对单一专用分辨率进行预训练/微调的AIMV2-L模型进行了比较。
on several key benchmarks, including IN-1k, i Naturalist, DTD, and Info graphic. These results are particularly impressive given that AIMV2 is trained using nearly a quarter of the data required for training DFN-CLIP and SigLIP (12B vs. 40B), while also being easier to train and scale. Finally, we find that scaling the capacity of AIMV2 models consistently leads to a stronger performance with AIMV2- 3B exhibiting the strongest result, in particular its variant finetuned for $448\mathrm{px}$ images which achieves $89.5%$ top-1 accuracy on IN-1k with a frozen trunk. Finally, in Figure 3 we observe a clear improvement to the performance of IN-1k when scaling the model capacity and the image resolution in conjunction. We provide more detailed results for the high-resolution finetuned backbones in Appendix B.
在包括IN-1k、iNaturalist、DTD和Infographic在内的多个关键基准测试中表现出色。这些结果尤其令人印象深刻,因为AIMV2的训练数据量仅为DFN-CLIP和SigLIP所需数据的近四分之一(12B vs. 40B),同时更易于训练和扩展。最后,我们发现扩大AIMV2模型的容量能持续提升性能,其中AIMV2-3B表现最佳,特别是其针对$448\mathrm{px}$图像微调的变体,在冻结主干网络的情况下,IN-1k的top-1准确率达到$89.5%$。此外,在图3中我们观察到,当同时提升模型容量和图像分辨率时,IN-1k的性能有明显改善。更多关于高分辨率微调主干网络的详细结果见附录B。
Table 7. Mutlimodal Evaluations. We compare AIMV2 to state-of-the-art visual backbones for multimodal instruction tuning. Under comparable capacities, AIMV2-L outperforms its counterparts on the majority of benchmarks. Additionally, scaling to the larger AIMV2- 3B model results in clear improvements, achieving the highest scores on nearly all benchmarks. All AIMV2 models use 336px resolution.
| model | architecture | #patches | VQAv2 | GQA | OKVQA | TextVQA | DocVQA | InfoVQA | ChartQA | ScienceQA | COCO | TextCaps | NoCaps | SEED | MMEp |
| OpenAI CLIP | ViT-L/14 | 576 | 78.0 | 72.0 | 60.0 | 47.5 | 25.6 | 21.8 | 18.5 | 73.8 | 94.9 | 75.3 | 93.3 | 70.1 | 1481 |
| SigLIP | ViT-L/14 | 576 | 76.9 | 70.3 | 59.3 | 44.1 | 16.9 | 20.7 | 14.4 | 74.7 | 93.0 | 69.9 | 92.7 | 66.8 | 1416 |
| ViT-So400M/14 | 752 | 77.7 | 71.0 | 60.1 | 47.5 | 19.2 | 21.0 | 14.7 | 74.9 | 94.6 | 70.8 | 94.5 | 67.5 | 1433 | |
| DINOv2 | VIT-g/14 | 3034 | 76.7 | 72.7 | 56.9 | 15.1 | 8.2 | 19.7 | 12.0 | 69.5 | 93.4 | 42.1 | 89.1 | 68.9 | 1423 |
| AIMv2 | ViT-L/14 | 576 | 79.7 | 72.5 | 60.8 | 53.6 | 26.6 | 22.8 | 19.2 | 74.1 | 96.9 | 81.1 | 99.9 | 71.8 | 1472 |
| ViT-H/14 | 576 | 80.2 | 72.8 | 61.3 | 55.5 | 27.8 | 23.1 | 19.9 | 76.8 | 99.6 | 80.7 | 102.7 | 72.1 | 1545 | |
| ViT-1B/14 | 576 | 80.5 | 73.0 | 61.5 | 56.8 | 28.5 | 22.1 | 20.5 | 76.4 | 98.4 | 82.6 | 101.5 | 72.7 | 1508 | |
| ViT-3B/14 | 576 | 80.9 | 73.3 | 61.7 | 58.2 | 30.4 | 23.0 | 22.6 | 77.3 | 100.3 | 83.8 | 102.9 | 72.9 | 1545 |
表 7: 多模态评估。我们将 AIMV2 与当前最先进的视觉骨干网络在多模态指令调优方面进行比较。在容量相当的情况下,AIMV2-L 在大多数基准测试中表现优于同类模型。此外,扩展到更大的 AIMV2-3B 模型带来了明显的改进,在几乎所有基准测试中都取得了最高分。所有 AIMV2 模型均使用 336px 分辨率。
| model | architecture | #patches | VQAv2 | GQA | OKVQA | TextVQA | DocVQA | InfoVQA | ChartQA | ScienceQA | COCO | TextCaps | NoCaps | SEED | MMEp |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenAI CLIP | ViT-L/14 | 576 | 78.0 | 72.0 | 60.0 | 47.5 | 25.6 | 21.8 | 18.5 | 73.8 | 94.9 | 75.3 | 93.3 | 70.1 | 1481 |
| SigLIP | ViT-L/14 | 576 | 76.9 | 70.3 | 59.3 | 44.1 | 16.9 | 20.7 | 14.4 | 74.7 | 93.0 | 69.9 | 92.7 | 66.8 | 1416 |
| ViT-So400M/14 | 752 | 77.7 | 71.0 | 60.1 | 47.5 | 19.2 | 21.0 | 14.7 | 74.9 | 94.6 | 70.8 | 94.5 | 67.5 | 1433 | |
| DINOv2 | VIT-g/14 | 3034 | 76.7 | 72.7 | 56.9 | 15.1 | 8.2 | 19.7 | 12.0 | 69.5 | 93.4 | 42.1 | 89.1 | 68.9 | 1423 |
| AIMv2 | ViT-L/14 | 576 | 79.7 | 72.5 | 60.8 | 53.6 | 26.6 | 22.8 | 19.2 | 74.1 | 96.9 | 81.1 | 99.9 | 71.8 | 1472 |
| AIMv2 | ViT-H/14 | 576 | 80.2 | 72.8 | 61.3 | 55.5 | 27.8 | 23.1 | 19.9 | 76.8 | 99.6 | 80.7 | 102.7 | 72.1 | 1545 |
| AIMv2 | ViT-1B/14 | 576 | 80.5 | 73.0 | 61.5 | 56.8 | 28.5 | 22.1 | 20.5 | 76.4 | 98.4 | 82.6 | 101.5 | 72.7 | 1508 |
| AIMv2 | ViT-3B/14 | 576 | 80.9 | 73.3 | 61.7 | 58.2 | 30.4 | 23.0 | 22.6 | 77.3 | 100.3 | 83.8 | 102.9 | 72.9 | 1545 |
Table 8. ICL few-shot performance. We report the in-context few-shot performance averaged across a wide range of benchmarks as detailed in $\S4.3.2$ . The results for DFN-CLIP and OAI CLIP are as reported by McKinzie et al. [85].
| model | architecture | O-shot | 4-shot | 8-shot |
| OAI CLIP [85] | ViT-L/14 | 39.3 | 62.2 | 66.1 |
| DFN-CLIP [85] | ViT-H/14 | 40.9 | 62.5 | 66.4 |
| AIMv2 | ViT-L/14 | 39.6 | 63.8 | 67.2 |
表 8: ICL少样本性能。我们报告了在$\S4.3.2$所述广泛基准测试中平均的上下文少样本性能。DFN-CLIP和OAI CLIP的结果来自McKinzie等人[85]的报告。
| 模型 | 架构 | 零样本 | 4样本 | 8样本 |
|---|---|---|---|---|
| OAI CLIP [85] | ViT-L/14 | 39.3 | 62.2 | 66.1 |
| DFN-CLIP [85] | ViT-H/14 | 40.9 | 62.5 | 66.4 |
| AIMv2 | ViT-L/14 | 39.6 | 63.8 | 67.2 |
Zero-shot via LiT Tuning. We investigate the compatibility of AIMV2 backbones with LiT [132], extending its application to zero-shot settings. We report the IN-1k zeroshot performance in Table 5. First, we observe that AIMV2, with the multimodal auto regressive objective, shows a modest improvement compared to the captioning-only baseline, even in this setting. Furthermore, an AIMV2-L model trained for a longer duration exhibits favorable performance compared to the results reported by Tschannen et al. [118] for CapPa. Overall, our model demonstrates strong zero-shot performance, outperforming OAI CLIP [94], yet still lagging behind dedicated models like SigLIP that are trained for a longer schedule with 40B image-text pairs.
通过LiT调优实现零样本。我们研究了AIMV2主干网络与LiT [132]的兼容性,将其应用扩展到零样本场景。表5展示了IN-1k零样本性能结果:首先发现采用多模态自回归目标的AIMV2相比仅使用标题生成的基线模型仍有小幅提升;其次,延长训练周期的AIMV2-L模型表现优于Tschannen等人[118]报告的CapPa结果。总体而言,我们的模型展现出强劲的零样本性能——超越OAI CLIP [94],但较SigLIP等专用模型仍有差距(后者使用400亿图文对进行了更长时间训练)。
Native resolution. We finetune AIMV2 to process images with a wide range of resolutions and aspect ratios as detailed in $\S~2.4$ . In order to assess the quality of this stage of post-training, we compare the performance of an AIMV2 encoder adapted for native resolution to models that are tuned for one specific resolution in Table 6. We observe that AIMV2-Lnative provides a strong performance across a wide range of resolutions off-the-shelf, experiencing only a minor degradation in performance to the dedicated models. Additionally, evaluating our model using the original native resolutions of the IN-1k validation set images yields a robust accuracy of $87.3%$ , confirming that AIMV2 maintains exceptional recognition performance while offering high flexibility in both aspect ratio and resolution.
原生分辨率。我们在 $\S~2.4$ 节详细描述了如何微调AIMV2以处理各种分辨率和宽高比的图像。为了评估这一训练后阶段的质量,我们在表6中比较了适配原生分辨率的AIMV2编码器与针对单一分辨率调优的模型性能。实验表明,AIMV2-Lnative在多种分辨率下即开即用,仅比专用模型的性能略有下降。此外,使用IN-1k验证集图像的原生分辨率评估我们的模型时,获得了 $87.3%$ 的稳健准确率,证实AIMV2在保持卓越识别性能的同时,对宽高比和分辨率具有高度灵活性。
4.2. Object Detection and Grounding
4.2. 目标检测与定位
To further demonstrate the capabilities of AIMV2, we evaluate its performance on tasks such as Open-Vocabulary Detection (OVD) and Referring Expression Comprehension (REC). We follow the model architecture introduced by
为了进一步展示AIMV2的能力,我们评估了其在开放词汇检测(Open-Vocabulary Detection, OVD)和指代表达理解(Referring Expression Comprehension, REC)等任务上的性能。我们采用了由

Figure 5. Impact of Scaling Resolution. The performance boost achieved byAIMV2 persists after scaling input resolution via tiling Lin et al. [72], Liu et al. [73] compared to popular vision backbones for VLMs such as OAI CLIP and SigLIP.
图 5: 分辨率缩放的影响。通过分块缩放输入分辨率后 [72][73],AIMV2 相比 OpenAI CLIP 和 SigLIP 等主流视觉语言模型 (VLM) 骨干网络仍保持性能优势。
MM-Grounding-DINO [74, 136] but adapt ViT-L through the ViTDet [68] formulation as the vision backbone. Our results are presented in Table 4. For OVD capabilities we evaluate on COCO [71] and LVIS [43], while for REC, we evaluate on RefCOCO (RefC) [57], RefCOCO+ $(\mathrm{RefC+})$ [130], and RefCOCOg (RefCg) [79]. All models were trained on the following datasets: Objects 365 v 1 [101], Flickr-30k Entities [90, 127], GQA [52], COCO17 [71], and RefCOCO [57, 79, 130]. During DINOv2 training we fix the window size to 16 [69] to ensure fixed compute cost across backbones. Our results indicate that AIMV2 outperforms DINOv2 as well as other vision-language pre-trained models on all benchmarks but one, showing particularly strong performance on LVIS. We present additional localization and grounding results including closed-vocabulary detection and instance segmentation as well as ablations on varying window sizes in Appendix D.
MM-Grounding-DINO [74, 136] 但通过 ViTDet [68] 框架将 ViT-L 适配为视觉主干网络。我们的结果如 表 4 所示。针对开放词汇检测 (OVD) 能力,我们在 COCO [71] 和 LVIS [43] 上进行评估;对于指代理解 (REC) ,则在 RefCOCO (RefC) [57]、RefCOCO+ (RefC+) [130] 和 RefCOCOg (RefCg) [79] 上进行评估。所有模型均在以下数据集上训练:Objects 365 v1 [101]、Flickr-30k Entities [90, 127]、GQA [52]、COCO17 [71] 和 RefCOCO [57, 79, 130]。DINOv2 训练期间,我们将窗口大小固定为 16 [69] 以确保不同主干网络的计算成本一致。结果表明,AIMV2 在除一项外的所有基准测试中均优于 DINOv2 及其他视觉语言预训练模型,尤其在 LVIS 上表现出色。附录 D 提供了更多定位与接地结果,包括封闭词汇检测、实例分割以及不同窗口尺寸的消融实验。
4.3. Multimodal Understanding
4.3. 多模态理解
Vision encoders play a crucial role in advancing large multimodal models [6, 73, 85, 115, 138]. To quantify the performance of AIMV2 models in this setting, we perform a multimodal instruction tuning stage similar to Liu et al. [73]. Additionally, we explore the few-shot In-Context Learning (ICL) setting after large-scale multimodal pre training similar to McKinzie et al. [85].
视觉编码器在推动大语言多模态模型发展中发挥着关键作用 [6, 73, 85, 115, 138]。为量化AIMV2模型在此场景下的性能,我们采用了与Liu等人 [73] 类似的多模态指令调优流程。此外,我们还探索了类似McKinzie等人 [85] 的大规模多模态预训练后的少样本上下文学习 (ICL) 设置。

Figure 6. Instruction tuning under different settings. We evaluate instruction-tuned models across combinations of LLM decoders and tuning data mixtures. In all settings, AIMV2 consistently outperforms or matches SigLIP and OAI CLIP on most benchmarks. All models use a ViT-L backbone with 336px images. For better readability, we present normalized ${\mathrm{MME}_{p}}$ scores by dividing the raw scores by 2000.
图 6: 不同设置下的指令调优效果。我们评估了在不同大语言模型解码器与调优数据组合下的指令调优模型表现。在所有设置中,AIMV2在多数基准测试中持续优于或持平SigLIP和OAI CLIP。所有模型均采用ViT-L主干网络处理336px图像。为提升可读性,我们将原始${\mathrm{MME}_{p}}$分数除以2000进行标准化处理。
4.3.1. Multimodal Instruction Tuning
4.3.1. 多模态指令微调
Setup. We place a 2-layer MLP connector between the vision encoder (e.g., AIMV2-L) and the LLM (e.g., Llama 3.0). The parameters of the vision encoder are frozen during this stage. Contrary to Liu et al. [73], we train the connector and the LLM jointly in a single stage. However, we scale up the learning rate for the connector by a factor of 8. We found this strategy to be simpler while leading to comparable results. We detail the evaluation datasets, task prompts, and hyper parameters used during this stage in Appendix C. Unless mentioned otherwise, we use the Llava SFT mixture [73] and Llama-3.0 8B LLM decoder [32]. We train all models for a single epoch.
设置。我们在视觉编码器(如 AIMV2-L)和大语言模型(如 Llama 3.0)之间放置了一个 2 层 MLP 连接器。此阶段视觉编码器的参数被冻结。与 Liu 等人 [73] 不同,我们在单阶段联合训练连接器和大语言模型。但我们将连接器的学习率提高了 8 倍。我们发现这种策略更简单,同时能取得可比的结果。附录 C 详细列出了此阶段使用的评估数据集、任务提示和超参数。除非另有说明,我们使用 Llava SFT 混合数据集 [73] 和 Llama-3.0 8B 大语言模型解码器 [32]。所有模型均训练一个周期。
Evaluation. We evaluate the instruction-tuned models across various question answering benchmarks covering general knowledge, text-rich images, scientific domains, and captioning. The results for AIMV2 and several baselines are presented in Table 7. Notably, our smallest model, AIMV2-L, outperforms OAI CLIP, SigLIP, and DINOv2 on most benchmarks, even when the baselines use larger capacities or higher input resolutions. Furthermore, performance consistently improves with increasing the AIMV2 backbone capacity, with the AIMV2-3B model achieving the best performance across all benchmarks except one.
评估。我们在涵盖通用知识、富文本图像、科学领域和字幕生成等多种问答基准上对指令调优模型进行了评估。表7展示了AIMV2与多个基线模型的结果。值得注意的是,我们最小的模型AIMV2-L在大多数基准测试中都优于OAI CLIP、SigLIP和DINOv2,即使基线模型使用了更大容量或更高输入分辨率。此外,随着AIMV2主干网络容量的增加,性能持续提升,其中AIMV2-3B模型在除一项外的所有基准测试中均取得最佳表现。
Varying the LLM and Data Mixture. In addition to the canonical setting reported in Table 7, we evaluate whether AIMV2 can provide similar gains compared to popular vision encoders across various combinations of LLM decoders and instruction tuning data mixtures. Specifically, we perform the instruction tuning stage under the following settings: (1) Llama 3.0 with the Cambrian data mixture [115] and (2) Vicuna 1.5 [22] with the Llava SFT mixture. We present the results for AIMV2-L alongside similarly sized OAI CLIP and SigLIP backbones in Figure 6. Across all settings, AIMV2 provides a stronger, or at worst on par, performance compared the OAI CLIP and SigLIP. These findings further affirm the robustness and compatibility of AIMV2 within diverse multimodal pipelines.
变换大语言模型(LLM)与数据混合比例。除表7报告的基准配置外,我们还评估了在不同LLM解码器与指令调优数据混合组合下,AIMV2能否相较主流视觉编码器保持类似优势。具体而言,我们在以下设置中执行指令调优阶段:(1) 采用Llama 3.0与Cambrian数据混合[115];(2) 使用Vicuna 1.5[22]配合Llava SFT混合数据。图6展示了AIMV2-L与尺寸相近的OAI CLIP、SigLIP主干网络的对比结果。在所有实验设置中,AIMV2性能均优于或至少持平于OAI CLIP和SigLIP。这些发现进一步证实了AIMV2在不同多模态流程中的鲁棒性与兼容性。
High-Resolution via Tiling. One of the most popular strategies to enhance the performance of vision-language models is increasing the image resolution. This can be achieved through a tiling strategy [72, 73, 103], where a high-resolution image is divided into a number of equally sized crops that match the pre-training resolution of the available backbones (e.g., $224\mathrm{px}$ or 336px). We investigate the compatibility of AIMV2 with this strategy. Specifically, we use a crop size of 336px and evaluate our pipeline on $672\mathrm{px}$ and $1008\mathrm{px}$ images corresponding to $2\times2$ and $3\times3$ grids respectively. The results for AIMV2, SigLIP, and OAI CLIP are presented in Figure 5. We observe that the performance of all methods improves with higher resolutions, with a significant improvement for TextVQA. Notably, AIMV2 maintains its advantage over the baselines in high-resolution tiling settings, demonstrating its versatility.
通过分块实现高分辨率。提升视觉语言模型性能最流行的策略之一是提高图像分辨率。这可以通过分块策略 [72, 73, 103] 实现:将高分辨率图像分割为若干尺寸相同的裁剪块,使其与可用骨干网络的预训练分辨率(如 $224\mathrm{px}$ 或 336px)匹配。我们研究了 AIMV2 与该策略的兼容性,具体采用 336px 的裁剪尺寸,并在对应 $2\times2$ 和 $3\times3$ 网格的 $672\mathrm{px}$ 与 $1008\mathrm{px}$ 图像上评估流程性能。图 5 展示了 AIMV2、SigLIP 和 OAI CLIP 的结果:所有方法性能均随分辨率提升而改善,其中 TextVQA 提升尤为显著。值得注意的是,AIMV2 在高分辨率分块设置中始终保持对基线模型的优势,展现了其多功能性。
4.3.2. Multimodal In-Context Learning
4.3.2. 多模态上下文学习
We also evaluate AIMV2 in a large-scale multimodal pre-training setting. Following the pre-training recipe as MM1 [85], we simply replace the vision encoder with AIMV2. Given that this model is pre-trained using interleaved image-text documents, it enables in-context evaluations [3]. We report the ICL performance in Table 8. Specifically, we report the average 0-shot, 4-shot, and 8-shot performance across the following benchmarks: COCO [21], NoCaps [2], TextCaps [105], VQAv2 [40], TextVQA [107], VizWiz [44], GQA [53], and OK-VQA [80]. Our results demonstrate that AIMV2 achieves the best performance in the 4-shot and 8-shot settings, surpassing the higher capacity DFN-CLIP adopted by the MM1 series. This highlights the compatibility and effectiveness of AIMV2 in leveraging ICL in a large-scale multimodal setup.
我们还在大规模多模态预训练场景下评估了AIMV2。遵循MM1 [85]的预训练方案,我们仅将视觉编码器替换为AIMV2。由于该模型使用交错排列的图文文档进行预训练,因此支持上下文评估 [3]。表8展示了其上下文学习(ICL)性能,具体报告了以下基准测试中0样本、4样本和8样本的平均表现:COCO [21]、NoCaps [2]、TextCaps [105]、VQAv2 [40]、TextVQA [107]、VizWiz [44]、GQA [53]和OK-VQA [80]。结果表明,AIMV2在4样本和8样本设置下均取得最优性能,超越了MM1系列采用的更高容量的DFN-CLIP模型,这凸显了AIMV2在大规模多模态场景中利用上下文学习的兼容性与有效性。
5. Ablation Study
5. 消融实验
In this section, we investigate various design choices and present the trade-offs associated with each. The results of our study are summarized in Table 9.
在本节中,我们研究了各种设计选择,并阐述了每种选择的相关权衡。研究结果总结于表 9: 。
| model | pre-train attn. | IN-1k | VQAv2 | TextVQA | model | bsz | IN-1k | VQAv2 | TextVQA | IN-1k | VQAv2 | TextVQA | |
| AIMV1 | prefix | 72.0 | 65.4 | 12.7 | 8k | 84.6 | 74.1 | 24.6 | 0.2 | 85.6 | 76.7 | 37.4 | |
| bidir | 85.1 | 76.2 | 34.4 | CLIP | 16k | 85.2 | 74.8 | 26.3 | 0.4 | 85.6 | 76.9 | 37.5 | |
| Cap | prefix | 85.4 | 76.8 | 36.5 | CapPa | 8k | 84.7 | 75.1 | 30.6 | 0.6 | 85.6 | 76.7 | 37.4 |
| AIMv2 | prefix | 85.6 | 76.9 | 37.5 | AIMv2 | 8k | 85.6 | 76.9 | 37.5 | ||||
| (a)Objective. | (b)AIMv2vs.CLIP.. | (c)CriteriaWeights. | |||||||||||
| IN-1k | VQAv2 | TextVQA | width | IN-1k | VQAv2 | TextVQA | depth | IN-1k | VQAv2 | TextVQA | |||
| separate | 85.6 | 77.1 | 37.2 | 512 | 85.3 | 76.2 | 35.9 | 8 | 85.5 | 76.7 | 37.0 | ||
| joint | 85.6 | 76.9 | 37.5 | 1024 | 85.6 | 76.9 | 37.5 | 12 | 85.6 | 76.9 | 37.5 | ||
| 1536 | 85.1 | 76.9 | 36.9 | 16 | 85.6 | 76.9 | 36.6 | ||||||
| (d)DecoderArchitecture. | (e)DecoderWidth. | (f)DecoderDepth. | |||||||||||
| 模型 | 预训练注意力机制 | IN-1k | VQAv2 | TextVQA | 模型 | 批次大小 | IN-1k | VQAv2 | TextVQA | IN-1k | VQAv2 | TextVQA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AIMV1 | 前缀 | 72.0 | 65.4 | 12.7 | 8k | 84.6 | 74.1 | 24.6 | 0.2 | 85.6 | 76.7 | 37.4 | |
| 双向 | 85.1 | 76.2 | 34.4 | CLIP | 16k | 85.2 | 74.8 | 26.3 | 0.4 | 85.6 | 76.9 | 37.5 | |
| Cap | 前缀 | 85.4 | 76.8 | 36.5 | CapPa | 8k | 84.7 | 75.1 | 30.6 | 0.6 | 85.6 | 76.7 | 37.4 |
| AIMv2 | 前缀 | 85.6 | 76.9 | 37.5 | AIMv2 | 8k | 85.6 | 76.9 | 37.5 | ||||
| (a) 目标 | (b) AIMv2对比CLIP | (c) 权重标准 | |||||||||||
| IN-1k | VQAv2 | TextVQA | 宽度 | IN-1k | VQAv2 | TextVQA | 深度 | IN-1k | VQAv2 | TextVQA | |||
| 独立 | 85.6 | 77.1 | 37.2 | 512 | 85.3 | 76.2 | 35.9 | 8 | 85.5 | 76.7 | 37.0 | ||
| 联合 | 85.6 | 76.9 | 37.5 | 1024 | 85.6 | 76.9 | 37.5 | 12 | 85.6 | 76.9 | 37.5 | ||
| 1536 | 85.1 | 76.9 | 36.9 | 16 | 85.6 | 76.9 | 36.6 | ||||||
| (d) 解码器架构 | (e) 解码器宽度 | (f) 解码器深度 |
Setup. The default setting for this ablation study utilizes a ViT-Large vision encoder and 2 billion image-text pairs during pre-training. We measure the $\mathrm{IN}{-}1\mathrm{k}$ top-1 accuracy after attentive probing, as well as the questionanswering accuracy on the validation sets of VQAv2 [40] and TextVQA [106] following instruction tuning, as described in $\S~2.4$ . All experiments reported in this ablation study employ images with $224\times224$ resolution. The metrics selected for this study provide a comprehensive view of the models’ capabilities, encompassing recognition, general question answering, and text-rich question answering.
设置。本消融实验的默认配置采用 ViT-Large 视觉编码器,并在预训练阶段使用 20 亿图文对。如 $\S~2.4$ 所述,我们通过注意力探测测量 $\mathrm{IN}{-}1\mathrm{k}$ top-1 准确率,以及指令微调后在 VQAv2 [40] 和 TextVQA [106] 验证集上的问答准确率。本研究中所有实验均使用 $224\times224$ 分辨率图像。所选指标全面评估了模型的识别能力、通用问答能力和文本密集型问答能力。
Pre-training Objective. The pre-training objective of AIMV2 comprises a combination of image-level and textlevel auto regressive objectives. We evaluate the performance of each objective independently and assess the impact of combining them, as presented in Table 9a. First, we observe that utilizing only the image-level objective (i.e., AIMv1) results in weaker performance compared to models that incorporate the captioning objective. This is expected, given that AIMv1 operates in an unsupervised manner and demands higher-capacity models to achieve optimal performance, as highlighted by El-Nouby et al. [33]. Second, for the captioning-only model, using prefix attention within the vision encoder yields superior performance compared to fully bidirectional attention. We hypothesize that prefix attention facilitates the encoding of maximally informative contexts even from partial images, as such contexts are utilized by subsequent visual and textual tokens. However, this hypothesis warrants further investigation, which is beyond the scope of this work and is reserved for future research. Finally, we find that combining the image-level and text-level objectives in AIMV2 leads to an improved performance, particularly noticeable for TextVQA.
预训练目标。AIMV2的预训练目标结合了图像级和文本级自回归目标。我们分别评估了各目标的性能,并分析了组合效果,如表9a所示。首先发现仅采用图像级目标(即AIMv1)的性能弱于包含字幕生成目标的模型。这与El-Nouby等人[33]的结论一致:无监督训练的AIMv1需要更高容量模型才能达到最优性能。其次,纯字幕生成模型中,视觉编码器使用前缀注意力机制的性能优于完全双向注意力机制。我们推测前缀注意力有助于从局部图像中编码最具信息量的上下文,这些上下文可被后续视觉与文本token利用。该假设需进一步验证,这超出了本文研究范围。最终实验表明,AIMV2结合图像级与文本级目标能提升性能,在TextVQA任务上表现尤为显著。
AIMV2 vs. CLIP vs. CapPa. In Table 9b, we evaluate the performance of models trained with the AIMV2 objective in comparison to other popular vision-language pretraining objectives, specifically CLIP [94] and CapPa [118]. All models are trained using identical architectures, incorporating SwiGLU and RMSNorm, and are pre-trained using the same dataset of image-text pairs. Notably, since CLIP pre-training benefits from larger batch sizes, we report CLIP results using both $\mathrm{8k}$ and $16\mathrm{k}$ batch sizes to ensure a fair comparison. Our findings indicate that, under comparable settings, AIMV2 consistently outperforms both CLIP and CapPA by a significant margin, particularly on the TextVQA benchmark. This performance is especially noteworthy given the simplicity and s cal ability AIMV2.
AIMV2 vs. CLIP vs. CapPa
在表 9b 中,我们评估了采用 AIMV2 目标训练的模型与其他流行视觉语言预训练目标 (特别是 CLIP [94] 和 CapPa [118]) 的性能对比。所有模型均采用相同架构 (包含 SwiGLU 和 RMSNorm),并使用相同的图文对数据集进行预训练。值得注意的是,由于 CLIP 预训练受益于更大批量,我们分别报告了批量大小为 $\mathrm{8k}$ 和 $16\mathrm{k}$ 的 CLIP 结果以确保公平比较。研究结果表明,在可比设置下,AIMV2 始终以显著优势超越 CLIP 和 CapPA,尤其在 TextVQA 基准测试中。考虑到 AIMV2 的简洁性和可扩展性,这一表现尤为突出。
Multi-task balancing. We examine whether the pretraining of AIMV2 is sensitive to the balancing between the image-level and text-level objectives in Table $\mathrm{9c}$ . We vary the hyper a par meter $\alpha$ , as described in $\S-2.1$ , and we observe only minor fluctuations in performance around the optimal value of 0.4 across the three benchmarks.
多任务平衡。我们在表 $\mathrm{9c}$ 中检验了AIMV2的预训练是否对图像级和文本级目标之间的平衡敏感。如 $\S-2.1$ 所述,我们调整了超参数 $\alpha$ ,并观察到在三个基准测试中,性能仅在最优值0.4附近出现微小波动。
Joint vs. Separate Decoders. In the AIMV2 architecture, we opt for a multimodal joint decoder instead of employing dedicated decoders for each modality. In Table 9d, we examine the performance of an AIMV2 variant that utilizes two dedicated decoders. Using a single joint decoder achieves comparable results to using separate decoders while offering greater simplicity and efficiency during pre-training. This advantage proves valuable when scaling data and model capacity.
联合解码器与独立解码器。在AIMV2架构中,我们选择采用多模态联合解码器,而非为每种模态配备独立解码器。表9d展示了使用两个独立解码器的AIMV2变体性能对比。实验表明,单一联合解码器在保持与独立解码器相当性能的同时,具有更高的预训练简洁性和效率。这一优势在扩展数据和模型容量时尤为重要。
Decoder architecture. Finally, we examine the capacity of the multimodal decoder, as detailed in Table 9e and Table 9f. We find that performance is more sensitive to changes in decoder capacity when scaling the width compared to scaling the depth. Additionally, we observe that increasing the decoder capacity beyond a certain threshold, whether by scaling width or depth, leads to a decline in performance. This observation is consistent with the findings of Tschannen et al. [118] for captioning-only models.
解码器架构。最后,我们研究了多模态解码器的容量,详见表9e和表9f。我们发现,与增加深度相比,扩展宽度时性能对解码器容量变化更为敏感。此外,我们观察到,无论是通过扩展宽度还是深度,当解码器容量超过某个阈值时,性能都会下降。这一发现与Tschannen等人 [118] 在纯字幕模型中的研究结果一致。
6. Related Works
6. 相关工作
Auto regressive pre-training. Auto regressive modeling has been a foundational idea in machine learning and statistics for decades, long before deep learning [11]. However, it has been popularized and scaled by works such as GPT [12, 92, 93], and LLaMAs [31, 116, 117] which have demonstrated the power of auto regressive pre-training in natural language processing tasks. In vision, autoregressive principles have been applied through models like iGPT [19], which flattens images into a sequence of discretized pixels and then treats them analogously to language tokens. Similarly, Yu et al. [128] also discretize the patches with a VQGAN model [34] and then predicts them auto regressive ly. AIM [33] brings back the more practical continuous approach and scales to very large vision models. However, AIM still lags behind other state of the art models in sheer performance, as it uses vision-only data and requires large model capacities to perform optimally. This paper addresses these limitations by introducing multimodal pre-training in the AIMV2 family. Concurrent works [77, 104, 113, 122, 124, 125, 131] have also investigated similar multimodal auto regressive approaches that predict text and images. However, they often focus on multimodal generation quality rather than representation quality, and therefore use discrete tokens or leverage diffusion models [98] as decoders [70, 110, 111].
自回归预训练。自回归建模作为机器学习和统计学的基础概念已存在数十年,远早于深度学习时代[11]。这一范式通过GPT[12, 92, 93]和LLaMA[31, 116, 117]等研究得到普及与扩展,在自然语言处理任务中展现了自回归预训练的威力。视觉领域方面,iGPT[19]通过将图像展平为离散像素序列并类比语言token进行处理,首次应用了自回归原理。类似地,Yu等[128]采用VQGAN模型[34]对图像块离散化后进行自回归预测。AIM[33]回归更实用的连续值预测方法,并成功扩展至超大规模视觉模型,但由于仅使用纯视觉数据且依赖大模型容量优化性能,其绝对性能仍落后于其他前沿模型。本文通过AIMV2系列引入多模态预训练来解决这些局限。同期研究[77, 104, 113, 122, 124, 125, 131]也探索了预测图文的多模态自回归方法,但这些工作多关注多模态生成质量而非表征质量,因此采用离散token或依赖扩散模型[98]作为解码器[70, 110, 111]。
Pre-training in vision. For many years, the computer vision community predominantly focused on supervised pretraining [58, 97, 108], with ImageNet [61] checkpoints serving as the backbone for most visual tasks. This eventually hit a wall in terms of s cal ability, as labels are expensive to acquire. The community therefore focused on self-supervised methods. Earlier models used pretext tasks such as rotation prediction and patch deshuffling [39, 86, 135]. More sophisticated models like SimCLR [20], BYOL [42], SwAV [15] and DINO [16] leverage variations of contrastive learning to train models that are quasi-invariant to a broad range of image augmentations. This turns out to learn strong and general visual representations without supervision. However they require carefully handcrafted data augmentations, which also makes them computationally expensive, especially at scale. On the other hand, MAE and BEiT [8, 48] introduced masking strategies to reconstruct input data, reducing the reliance on augmentations and increasing efficiency but sacrificing performance. In practice, the best performing self-supervised vision-only models use a mixture of augmentations and masking [4, 87, 137]. Unfortunately, they are challenging to scale as they still need multiple forward passes for each training step. AIM [33] departs from these methods by employing a reconstruction-based auto regressive framework that exhibits strong s cal ability but requires high capacity models to attain optimal performance. Leveraging large-scale, noisy, weakly supervised datasets from the internet [13, 35, 100], an efficient paradigm emerged that aligns vision and text features through contrastive learning [54, 94]. Nevertheless, CLIP-like models require large batch sizes and meticulous dataset filtering [35, 100]. Subsequent works, such as SigLIP [133], EVA CLIP [109], and Fini et al. [37], have addressed these issues by optimizing training processes and improving data filtering [35]. Unlike these approaches, AIMV2 does not perform explicit feature space alignment but aligns training objectives through auto regressive modeling for better multimodal synergy.
视觉预训练。多年来,计算机视觉领域主要关注监督式预训练 [58, 97, 108],其中ImageNet [61]检查点成为大多数视觉任务的基础。但由于标注成本高昂,这种方法最终面临可扩展性瓶颈。因此,研究重点转向自监督方法。早期模型采用旋转预测和图像块重组等代理任务 [39, 86, 135]。SimCLR [20]、BYOL [42]、SwAV [15]和DINO [16]等更先进的模型则利用对比学习的变体,训练对多种图像增强具有准不变性的模型。这种方法能在无监督情况下学习到强大且通用的视觉表征,但需要精心设计的数据增强方案,计算成本较高。另一方面,MAE和BEiT [8, 48]引入掩码重建策略,降低了对数据增强的依赖并提高了效率,但牺牲了部分性能。实际表现最佳的自监督视觉模型通常结合使用数据增强和掩码技术 [4, 87, 137],但由于每个训练步骤需要多次前向传播,其扩展性仍面临挑战。AIM [33]采用基于重建的自回归框架,展现出优秀的可扩展性,但需要高容量模型才能达到最佳性能。通过利用互联网大规模弱标注数据集 [13, 35, 100],出现了一种通过对比学习对齐视觉与文本特征的高效范式 [54, 94]。不过CLIP类模型需要大批量训练和精细的数据过滤 [35, 100]。后续工作如SigLIP [133]、EVA CLIP [109]和Fini等人 [37]通过优化训练流程和改进数据过滤 [35]解决了这些问题。与这些方法不同,AIMV2不执行显式的特征空间对齐,而是通过自回归建模实现训练目标对齐,以获得更好的多模态协同效果。
Captioning. Image captioning has been extensively studied prior to the computer vision literature. Early works [56, 121, 126] focused on aligning visual features with text to generate descriptions using CNNs and RNNs. VirTex [28] and ICMLM [99] utilize captioning for visual pre-training. SimVLM [123] employs a PrefixLM approach, encoding images and partial text tokens with a multimodal encoder and decoding the remaining text. LEMON [51] scales the language model in both parameters and dataset size. Approaches such as [65, 66] combines generative captioning with disc rim i native contrastive objectives to enhance multimodal learning, which led to scaling to billion-parameter models [62, 67, 129]. Similarly, CapPa [118] trains a captioning model that functions as both a masked and causal decoder, and Caron et al. [17] re-purposes a captioning model for web-scale entity recognition. Different from most previous approaches, AIMV2 does not use cross-attention and treats vision and text tokens symmetrically, similar to large multimodal models (e.g. LLaVA [73] and MM1 [85]). Additionally, AIMV2 incorporates an auto regressive image modeling loss on vision tokens, further enhancing performance beyond captioning-only methods.
图像描述生成。图像描述生成在计算机视觉领域已有广泛研究。早期工作[56, 121, 126]专注于将视觉特征与文本对齐,使用CNN和RNN生成描述。VirTex[28]和ICMLM[99]利用描述生成进行视觉预训练。SimVLM[123]采用PrefixLM方法,通过多模态编码器编码图像和部分文本token,并解码剩余文本。LEMON[51]在参数量和数据集规模上扩展了语言模型。[65, 66]等方法将生成式描述与判别式对比目标相结合以增强多模态学习,由此催生了数十亿参数规模的模型[62, 67, 129]。类似地,CapPa[118]训练了一个兼具掩码解码和因果解码功能的描述生成模型,Caron等人[17]则将描述生成模型改造用于网络级实体识别。与多数前人方法不同,AIMV2不使用交叉注意力机制,而是以对称方式处理视觉和文本token(类似LLaVA[73]和MM1[85]等大型多模态模型)。此外,AIMV2在视觉token上引入自回归图像建模损失,其性能超越了纯描述生成方法。
7. Conclusion
7. 结论
This paper introduce AIMV2, a family of vision encoders pre-trained with a multimodal auto regressive objective that reconstructs image patches and text tokens. This unified objective enables AIMV2 to excel in diverse tasks, including image recognition, grounding, and multimodal understanding. The superior performance of AIMV2 is attributed to its ability to leverage signals from all input tokens and patches, facilitating efficient training with fewer samples compared to other methods. AIMV2 consistently outperforms or matches existing self-supervised and vision-language pretrained models, demonstrating its strength and versatility as a vision encoder. Additionally, the straightforward pretraining process of AIMV2 ensures easy s cal ability, paving the way for further advancements in vision model scaling.
本文介绍了AIMV2,这是一个通过多模态自回归目标预训练的视觉编码器家族,能够重建图像块和文本token。这种统一目标使AIMV2在图像识别、定位和多模态理解等多样化任务中表现出色。AIMV2的卓越性能源于其能够利用所有输入token和图像块的信号,相比其他方法能以更少样本实现高效训练。AIMV2始终优于或匹配现有的自监督和视觉语言预训练模型,展现了其作为视觉编码器的强大能力和多功能性。此外,AIMV2简洁的预训练流程确保了良好的可扩展性,为视觉模型规模化的进一步发展铺平了道路。
Acknowledgement
致谢
We thank Shuangfei Zhai, Miguel Bautista, Jason Ramapuram, Chun-Liang Li, Seyed Mohsen Moosavi Dezfooli, David Mizrahi, Roman Bachmann, and Jesse Allardice for many fruitful discussions. We thank Vaishaal Shankar, Peter Grasch, Vasileios Saveris, and Jeff Lai for their support on data collection and synthetic captioning. We thank Denise Hui, Dan Busbridge, and Samy Bengio for infra and compute support. Finally, we thank Marco Cuturi, James Thornton, Pierre Ablin, Eugene Ndiaye and the whole MLR team at Apple for their support throughout the project.
我们感谢 Shuangfei Zhai、Miguel Bautista、Jason Ramapuram、Chun-Liang Li、Seyed Mohsen Moosavi Dezfooli、David Mizrahi、Roman Bachmann 和 Jesse Allardice 富有成效的讨论。感谢 Vaishaal Shankar、Peter Grasch、Vasileios Saveris 和 Jeff Lai 在数据收集和合成标注方面的支持。感谢 Denise Hui、Dan Busbridge 和 Samy Bengio 提供基础设施和算力支持。最后,我们感谢 Marco Cuturi、James Thornton、Pierre Ablin、Eugene Ndiaye 以及 Apple 整个 MLR 团队在项目全程中的支持。
References
参考文献
A. Hyper paramters
A. 超参数
Pre-training. We outline the optimization hyper a par meters and data augmentations used during AIMV2 pre-training in Table A1. For the captions, we adopt the tokenizer used by SigLIP [133] and truncate any text longer than 77 tokens.
预训练。我们在表 A1 中列出了 AIMV2 预训练期间使用的优化超参数和数据增强方法。对于字幕文本,我们采用了 SigLIP [133] 使用的分词器 (tokenizer) ,并将超过 77 个 token 的文本进行截断。
Table A1. Pre-training hyper parameters We detail the hyperaparmeters used for pre-training all AIMV2 variants.
| config | ViT-LViTs-HViT-1BViT-3B | |
| Optimizer | Fully decoupled AdamW [76] | |
| Optimizer Momentum | β1 = 0.9,β2 =0.95 | |
| Peak learning rate | 1e-3 8e-4 8e-4 | 4e-4 |
| Minimum Learning rate | 1e-5 | |
| Weightdecay | 1e-4 | |
| Batch size | 8192 | |
| Patch size | (14, 14) | |
| Gradient clipping | 1.0 | |
| Warmupiterations | 12,500 | |
| Totaliterations | 1,500,000 | |
| Learningrate schedule | cosine decay [75] | |
| Augmentations: | ||
| RandomResizedCrop | ||
| size | 224px | |
| scale | [0.4, 1.0] | |
| ratio | [0.75,1.33] | |
| interpolation | Bicubic | |
| RandomHorizontalFlip | p=0.5 | |
表 A1. 预训练超参数 我们详细列出了用于预训练所有AIMV2变体的超参数。
| 配置 | ViT-LViTs-HViT-1BViT-3B |
|---|---|
| 优化器 | Fully decoupled AdamW [76] |
| 优化器动量 | β1 = 0.9, β2 = 0.95 |
| 峰值学习率 | 1e-3 8e-4 8e-4 |
| 最小学习率 | 1e-5 |
| 权重衰减 | 1e-4 |
| 批量大小 | 8192 |
| 补丁大小 | (14, 14) |
| 梯度裁剪 | 1.0 |
| 预热迭代次数 | 12,500 |
| 总迭代次数 | 1,500,000 |
| 学习率调度 | cosine decay [75] |
| 数据增强: | |
| RandomResizedCrop | |
| 尺寸 | 224px |
| 缩放范围 | [0.4, 1.0] |
| 宽高比 | [0.75, 1.33] |
| 插值方法 | Bicubic |
| RandomHorizontalFlip | p=0.5 |
Attentive probing. The optimization and data augmentations hyper a par meters for the attentive probing stage are detailed in Table A2. We use the same set of hyper a par meters for all AIMV2 capacities and the baselines. To ensure a fair comparison, we sweep the learning rate and weight decay using the ranges detailed in Table A2 and report the strongest results for each model.
专注探测 (Attentive probing)。专注探测阶段的优化和数据增强超参数详见表 A2。我们对所有 AIMV2 容量和基线模型使用相同的超参数集。为确保公平比较,我们按照表 A2 列出的范围扫描学习率和权重衰减值,并报告每个模型的最佳结果。
B. Image Recognition
B. 图像识别
Evaluation benchmarks. In Table 3, we evaluate the recognition performance of AIMV2 and other baselines on a diverse set of benchmarks that encompass fine-grained recognition, medical imaging, satellite imagery, natural environment imagery, and info graphic analysis. We detail the datasets, the splits and their sizes in Table B1.
评估基准。在表3中,我们在涵盖细粒度识别、医学影像、卫星图像、自然环境图像和信息图表分析的多样化基准上评估了AIMV2和其他基线的识别性能。数据集、划分方式及其规模详见表B1。
High-resolution adaptation. In Table B2, we show the performance of AIMv2 models with varying image resolutions (224px, 336px, and 448px) across a broad set of recognition benchmarks. These results extend the main paper, which primarily focuses on the $224\mathrm{px}$ resolution and the 3B model at $448\mathrm{px}$ . We observe that scaling both the model capacity and image resolution leads to consistent improvements across most tasks.
高分辨率适应。在表 B2 中,我们展示了 AIMv2 模型在不同图像分辨率 (224px、336px 和 448px) 下在一系列广泛识别基准上的性能。这些结果扩展了主论文的内容 (主论文主要关注 $224\mathrm{px}$ 分辨率以及 $448\mathrm{px}$ 分辨率下的 3B 模型) 。我们观察到,同时扩展模型容量和图像分辨率可以在大多数任务上带来一致的性能提升。
config
| Optimizer | Pytorch'sAdamW[76] |
| Optimizer Momentum | β1 =0.9,β2 =0.999 |
| Peak learning rate grid | [5e-5,1e-4,2e-4,3e-4,5e-4,1e-3,2e-3] |
| MinimumLearningrate | 1e-5 |
| Weight decay | [0.05,0.1] |
| Batch size | 1024 512 |
| Gradient clipping | 3.0 |
| Warmupepochs | 5 0 |
| Epochs | 100 |
| Learning rate schedule | cosine decay |
| Augmentations: | |
| RandomResizedCrop | |
| size | 224px |
| scale | [0.08, 1.0] |
| ratio | [0.75,1.33] |
| interpolation | Bicubic |
| RandomHorizontalFlip | p=0.5 |
| Color Jitter | 0.3 |
| AutoAugment | rand-m9-mstd0.5-inc1 |
| 优化器 | PyTorch的AdamW [76] |
| 优化器动量 | β1=0.9, β2=0.999 |
| 峰值学习率网格 | [5e-5, 1e-4, 2e-4, 3e-4, 5e-4, 1e-3, 2e-3] |
| 最小学习率 | 1e-5 |
| 权重衰减 | [0.05, 0.1] |
| 批量大小 | 1024 512 |
| 梯度裁剪 | 3.0 |
| 预热周期 | 5 0 |
| 训练周期 | 100 |
| 学习率调度 | 余弦衰减 |
| 数据增强: | |
| 随机调整大小裁剪 | |
| 尺寸 | 224像素 |
| 缩放范围 | [0.08, 1.0] |
| 宽高比 | [0.75, 1.33] |
| 插值方式 | 双三次 |
| 随机水平翻转 | p=0.5 |
| 色彩抖动 | 0.3 |
| 自动增强 | rand-m9-mstd0.5-inc1 |
Table A2. Attentive probe hyper parameters. We detail the hyper parameters used during attentive probing of AIMV2 and the baselines. For AIMV2 and the baselines we sweep over the learning rates and weight decay and report the best performance for each model.
| Dataset | train | test | classes |
| Imagenet-1k [27] | 1,281,167 | 50,000 | 1000 |
| iNAT-18 [119] | 437,513 | 24,426 | 8142 |
| CIFAR-10[60] | 50,000 | 10,000 | 10 |
| CIFAR-100[60] | 50,000 | 10,000 | 100 |
| Food101 [10] | 75,750 | 25,250 | 101 |
| DTD [25] | 3,760 | 1,880 | 47 |
| Pets [88] | 3,680 | 3,669 | 37 |
| Cars [59] | 8,144 | 8,041 | 196 |
| Camelyon17 [7] | 302,436 | 34904 | 2 |
| PCAM [120] | 262,144 | 32768 | 2 |
| RxRx1 [112] | 40,612 | 9854 | 1139 |
| EuroSAT [49] | 16,200 | 5400 | 10 |
| fMoW [24] | 76,863 | 19915 | 62 |
| Infograph [89] | 36,023 | 15,582 | 345 |
表 A2: 注意力探针超参数。我们详细列出了 AIMV2 和基线模型在注意力探针过程中使用的超参数。对于 AIMV2 和基线模型,我们扫描了学习率和权重衰减,并报告了每个模型的最佳性能。
| 数据集 | 训练样本数 | 测试样本数 | 类别数 |
|---|---|---|---|
| Imagenet-1k [27] | 1,281,167 | 50,000 | 1000 |
| iNAT-18 [119] | 437,513 | 24,426 | 8142 |
| CIFAR-10 [60] | 50,000 | 10,000 | 10 |
| CIFAR-100 [60] | 50,000 | 10,000 | 100 |
| Food101 [10] | 75,750 | 25,250 | 101 |
| DTD [25] | 3,760 | 1,880 | 47 |
| Pets [88] | 3,680 | 3,669 | 37 |
| Cars [59] | 8,144 | 8,041 | 196 |
| Camelyon17 [7] | 302,436 | 34,904 | 2 |
| PCAM [120] | 262,144 | 32,768 | 2 |
| RxRx1 [112] | 40,612 | 9,854 | 1139 |
| EuroSAT [49] | 16,200 | 5,400 | 10 |
| fMoW [24] | 76,863 | 19,915 | 62 |
| Infograph [89] | 36,023 | 15,582 | 345 |
Table B1. Recognition benchmarks. We outline the recognition benchmarks, the number of train and test images for each dataset, and the number of categories.
表 B1: 识别基准数据集。我们列出了各识别基准数据集、对应的训练/测试图像数量以及类别数量。
C. Multimodal understanding
C. 多模态理解
C.1. Instruction Tuning Setup
C.1. 指令微调设置
Evaluation benchmarks. We list the multimodal benchmarks we use for assessing the performance of our models and the baselines in Table C2, together with the splits, prompts, and evaluation metric utilized for each dataset.
评估基准。我们在表 C2 中列出了用于评估模型及基线性能的多模态基准数据集,同时标注了各数据集的分割方式、提示词 (prompt) 和采用的评估指标。
Hyper paramters. The hyper a par meters used for the instruction tuning stage are detailed in Table C1. We use the same hyper a par meters for all language decoders, AIMV2 capacities, and the baselines.
超参数 (Hyperparameters)。指令微调阶段使用的超参数详见表 C1。我们对所有语言解码器、AIMV2 容量和基线均采用相同的超参数。
C.2. Additional Results
C.2. 补充结果
Instruction tuning with Cambrian. Table C3 evaluates AIMv2, fine-tuned on Cambrian, across different resolutions using a tiling strategy. Unlike the main paper, which uses Llava SFT, Cambrian offers a less in-domain data mix and achieves stronger results on text-rich benchmarks. Starting with a base resolution of $336\mathrm{px}$ (matching the encoder’s pre training resolution), higher resolutions (672px and $1008\mathrm{px})$ are obtained with tiling; by splitting high-resolution images into $2\times2$ and $3\times3$ grids. AIMv2 paired with tiling shows consistent improvements on textrich benchmarks such as InfoVQA, ChartQA, DocVQA, and TextVQA. However, on benchmarks like COCO, NoCaps, TextCaps, and $\mathrm{MME}_{p}$ , no significant gains are observed with increased resolution.
使用Cambrian进行指令调优。表C3评估了在不同分辨率下采用分块策略的AIMv2(基于Cambrian微调)性能。与主论文使用的Llava SFT不同,Cambrian提供的领域内数据混合较少,但在文本密集型基准测试中表现更优。以基础分辨率$336\mathrm{px}$(匹配编码器预训练分辨率)为起点,通过分块策略获得更高分辨率(672px和$1008\mathrm{px}$),即将高分辨率图像分割为$2\times2$和$3\times3$网格。实验表明,结合分块策略的AIMv2在InfoVQA、ChartQA、DocVQA和TextVQA等文本密集型基准上持续提升,但在COCO、NoCaps、TextCaps和$\mathrm{MME}_{p}$等基准中,分辨率提升未带来显著收益。
Table B2. Frozen trunk evaluation for recognition benchmarks, high resolution AIMV2 models. We report the recognition performance of the AIMV2 high resolution family of models when compared to the base $224\mathrm{px}$ models shown in the main paper. All models are evaluated using attentive probing with a frozen backbone.
| model | architecture | 10 Cifar1 | 0 Cifar1 | 三 Food | D | Pets P | AM17 2 | CAM | R | EuroS S | ograph | ||||
| AIMv2224px | ViT-L/14 | 86.6 | 76.0 | 99.1 | 92.2 | 95.7 | 87.9 | 96.3 | 96.3 | 93.7 | 89.3 | 5.6 | 98.4 | 60.7 | 69.0 |
| ViT-H/14 | 87.5 | 77.9 | 99.3 | 93.5 | 96.3 | 88.2 | 96.6 | 96.4 | 93.3 | 89.3 | 5.8 | 98.5 | 62.2 | 70.4 | |
| ViT-1B/14 | 88.1 | 79.7 | 99.4 | 94.1 | 96.7 | 88.4 | 96.8 | 96.5 | 94.2 | 89.0 | 6.7 | 98.8 | 63.2 | 71.7 | |
| ViT-3B/14 | 88.5 | 81.5 | 99.5 | 94.3 | 96.8 | 88.9 | 97.1 | 96.5 | 93.5 | 89.4 | 7.3 | 99.0 | 64.2 | 72.2 | |
| AIMV2336px | ViT-L/14 | 87.6 | 79.7 | 99.1 | 92.5 | 96.3 | 88.5 | 96.4 | 96.7 | 93.8 | 89.4 | 6.7 | 98.4 | 62.1 | 71.7 |
| ViT-H/14 | 88.2 | 81.0 | 99.3 | 93.6 | 96.6 | 88.8 | 96.8 | 96.4 | 93.3 | 89.4 | 7.2 | 98.7 | 63.9 | 73.4 | |
| ViT-1B/14 | 88.7 | 82.7 | 99.4 | 93.9 | 97.1 | 88.9 | 96.9 | 96.5 | 94.2 | 89.5 | 8.4 | 98.9 | 65.1 | 73.7 | |
| ViT-3B/14 | 89.2 | 84.4 | 99.5 | 94.4 | 97.2 | 89.3 | 97.2 | 96.6 | 93.2 | 89.3 | 8.8 | 99.0 | 65.7 | 74.0 | |
| AIMV2 448px | ViT-L/14 | 87.9 | 81.3 | 99.1 | 92.4 | 96.6 | 88.9 | 96.5 | 96.6 | 94.1 | 89.6 | 7.4 | 98.6 | 62.8 | 72.7 |
| ViT-H/14 | 88.6 | 82.8 | 99.4 | 93.6 | 97.0 | 88.9 | 96.8 | 96.5 | 93.4 | 89.6 | 7.8 | 98.7 | 64.8 | 74.5 | |
| ViT-1B/14 | 89.0 | 83.8 | 99.4 | 94.1 | 97.2 | 88.9 | 97.1 | 96.6 | 93.5 | 89.9 | 9.2 | 99.1 | 65.9 | 74.4 | |
| ViT-3B/14 | 89.5 | 85.9 | 99.5 | 94.5 | 97.4 | 89.0 | 97.4 | 96.7 | 93.4 | 89.9 | 9.5 | 98.9 | 66.1 | 74.8 |
表 B2. 高分辨率 AIMV2 模型在识别基准上的冻结主干评估。我们展示了 AIMV2 高分辨率系列模型与主论文中 $224\mathrm{px}$ 基础模型相比的识别性能。所有模型均采用冻结主干网络进行注意力探测评估。
| 模型 | 架构 | 10 Cifar1 | 0 Cifar1 | 三 Food | D | Pets P | AM17 2 | CAM | R | EuroS S | ograph |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AIMv2 224px | ViT-L/14 | 86.6 | 76.0 | 99.1 | 92.2 | 95.7 | 87.9 | 96.3 | 96.3 | 93.7 | 89.3 |
| ViT-H/14 | 87.5 | 77.9 | 99.3 | 93.5 | 96.3 | 88.2 | 96.6 | 96.4 | 93.3 | 89.3 | |
| ViT-1B/14 | 88.1 | 79.7 | 99.4 | 94.1 | 96.7 | 88.4 | 96.8 | 96.5 | 94.2 | 89.0 | |
| ViT-3B/14 | 88.5 | 81.5 | 99.5 | 94.3 | 96.8 | 88.9 | 97.1 | 96.5 | 93.5 | 89.4 | |
| AIMV2 336px | ViT-L/14 | 87.6 | 79.7 | 99.1 | 92.5 | 96.3 | 88.5 | 96.4 | 96.7 | 93.8 | 89.4 |
| ViT-H/14 | 88.2 | 81.0 | 99.3 | 93.6 | 96.6 | 88.8 | 96.8 | 96.4 | 93.3 | 89.4 | |
| ViT-1B/14 | 88.7 | 82.7 | 99.4 | 93.9 | 97.1 | 88.9 | 96.9 | 96.5 | 94.2 | 89.5 | |
| ViT-3B/14 | 89.2 | 84.4 | 99.5 | 94.4 | 97.2 | 89.3 | 97.2 | 96.6 | 93.2 | 89.3 | |
| AIMV2 448px | ViT-L/14 | 87.9 | 81.3 | 99.1 | 92.4 | 96.6 | 88.9 | 96.5 | 96.6 | 94.1 | 89.6 |
| ViT-H/14 | 88.6 | 82.8 | 99.4 | 93.6 | 97.0 | 88.9 | 96.8 | 96.5 | 93.4 | 89.6 | |
| ViT-1B/14 | 89.0 | 83.8 | 99.4 | 94.1 | 97.2 | 88.9 | 97.1 | 96.6 | 93.5 | 89.9 | |
| ViT-3B/14 | 89.5 | 85.9 | 99.5 | 94.5 | 97.4 | 89.0 | 97.4 | 96.7 | 93.4 | 89.9 |
Table C1. Instruction tuning hyper a par meters. We detail the hyper parameters of the instruction tuning stage, both for the Llava SFT mixture [73] and Cambrian [115].
| config | LlavaSFTmixture Cambrian |
| Optimizer | Pytorch'sAdamW[76] |
| OptimizerMomentum | β1 =0.9,β2 =0.999 |
| Decoderpeaklearningrate | 1e-5 2e-5 |
| Connectorpeaklearningrate | 8e-5 1.6e-4 |
| MinimumLearningrate | 0 |
| Weightdecay | 0.01 |
| Batch size | 128 512 |
| Gradient clipping | 1.0 |
| Warmupiterations | 250 700 |
| iterations | 5000 14,000 |
| Learning rate schedule | cosinedecay |
| Transformations | [PadToSquare, Resize] |
表 C1. 指令微调超参数。我们详细列出了指令微调阶段的超参数,包括 Llava SFT 混合数据集 [73] 和 Cambrian [115] 的设置。
| 配置项 | LlavaSFT混合数据集 | Cambrian |
|---|---|---|
| 优化器 | PyTorch的AdamW [76] | PyTorch的AdamW [76] |
| 优化器动量 | β1=0.9, β2=0.999 | β1=0.9, β2=0.999 |
| 解码器峰值学习率 | 1e-5 | 2e-5 |
| 连接器峰值学习率 | 8e-5 | 1.6e-4 |
| 最小学习率 | 0 | 0 |
| 权重衰减 | 0.01 | 0.01 |
| 批处理大小 | 128 | 512 |
| 梯度裁剪 | 1.0 | 1.0 |
| 预热迭代次数 | 250 | 700 |
| 总迭代次数 | 5000 | 14,000 |
| 学习率调度策略 | 余弦衰减 | 余弦衰减 |
| 图像变换 | [PadToSquare, Resize] | [PadToSquare, Resize] |
Instruction tuning with DCLM-1B decoder. In Figure C2, we present the same comparison between OAI CLIP, SigLIP, and AIMV2 as in the main paper, but this time using the Llava SFT mixture paired with a DCLM 1B decoder. These results demonstrate that AIMV2 consistently outperforms the baselines, regardless of the decoder’s capacity. Notably, in the practical setting of a small decoder, AIMV2 maintains its position as the preferred choice for multimodal understanding tasks.
使用DCLM-1B解码器进行指令微调。在图C2中,我们展示了与主论文相同的OAI CLIP、SigLIP和AIMV2对比结果,但本次实验采用Llava SFT混合数据搭配DCLM 1B解码器。结果表明,无论解码器容量如何,AIMV2始终优于基线模型。值得注意的是,在小型解码器的实际应用场景中,AIMV2仍保持作为多模态理解任务首选方案的优势地位。
| Benchmark | Split | Prompt | EvaluationMetric |
| VQAv2[41] | Val | Accuracy | |
| GQA [52] | Val | Accuracy | |
| OKVQA[81] | Val | Accuracy | |
| TextVQA[106] | Val | Answerthequestionusinga | Accuracy |
| DocVQA[83] | Test | singlewordorphrase. | ANLS |
| InfoVQA[84] | Test | ANLS | |
| ChartQA[82] | Test | Relaxedaccuracy | |
| SEED [64] | Test (image split) | Accuracy | |
| ScienceQA [78] Test (image split)Answer with the option's letter | Accuracy | ||
| MME [38] | Test(image split)from thegiven choicesdirectly. | Accuracy | |
| COCO [71] | Val | CIDEr | |
| TextCaps [105] | Val | Provideaone-sentencecaption | CIDEr |
| NoCaps [2] | Val | fortheprovidedimage. | CIDEr |
Table C2. Multimodal benchmarks. We provide the list of benchmarks used during the multimodal evaluation including the reference, split, prompt, and the evaluation metric.
| 基准测试 | 数据集划分 | 提示语 | 评估指标 |
|---|---|---|---|
| VQAv2 [41] | 验证集 | 准确率 | |
| GQA [52] | 验证集 | 准确率 | |
| OKVQA [81] | 验证集 | 准确率 | |
| TextVQA [106] | 验证集 | 用一个单词或短语回答问题 | 准确率 |
| DocVQA [83] | 测试集 | ANLS | |
| InfoVQA [84] | 测试集 | ANLS | |
| ChartQA [82] | 测试集 | 宽松准确率 | |
| SEED [64] | 测试集 (图像划分) | 准确率 | |
| ScienceQA [78] | 测试集 (图像划分) | 直接根据给定选项用字母作答 | 准确率 |
| MME [38] | 测试集 (图像划分) | 准确率 | |
| COCO [71] | 验证集 | CIDEr | |
| TextCaps [105] | 验证集 | 为提供的图像生成一句描述 | CIDEr |
| NoCaps [2] | 验证集 | CIDEr |
C.3. Qualitative Results
C.3. 定性结果
The qualitative results in Figure C1 highlight AIMv2’s strengths on multimodal evaluations compared to SigLIP [133] and OAI CLIP [94] after instruction tuning on Cambrian. In the first three examples, AIMv2 excels in text-rich tasks by correctly localizing and extracting the relevant textual information. For instance, in the example on the left, AIMv2 is able to identify the correct value for “supreme gasoline” and outputs the correct operation for finding the solution (“Divide 50 by 3.65”). This contrasts with OAI CLIP and SigLIP, which provide generic and incomplete answers that fail to focus on the relevant information. Similarly, AIMv2 successfully identifies the license plate number (“AED-632”) in a blurry image, demonstrating robust localization and reading capabilities in challenging settings. In the luggage example, AIMv2 accurately reads the weight (“30.7”), despite the presence of multiple distracting objects in the image, while the other models make mistakes. Finally, in the calorie estimation example, AIMv2 provides a more plausible response (“1000 calories”) based on its knowledge, whereas SigLIP and OAI CLIP offer less con textually plausible answers.
图 C1 中的定性结果凸显了 AIMv2 在寒武纪 (Cambrian) 指令微调后,相比 SigLIP [133] 和 OAI CLIP [94] 在多模态评估中的优势。在前三个示例中,AIMv2 通过准确定位并提取相关文本信息,在文本密集型任务中表现优异。例如左侧示例中,AIMv2 能正确识别"supreme gasoline"对应数值,并输出求解的正确运算步骤 ( "Divide 50 by 3.65" ) ,而 OAI CLIP 和 SigLIP 仅提供笼统且不完整的回答,未能聚焦关键信息。同样地,AIMv2 在模糊图像中成功识别车牌号 ( "AED-632" ) ,展现了复杂场景下稳健的定位与识别能力。在行李箱示例中,尽管存在多个干扰物,AIMv2 仍准确读取重量值 ( "30.7" ) ,其他模型则出现误判。最后在热量估算示例中,基于知识储备,AIMv2 给出更合理的答案 ( "1000 calories" ) ,而 SigLIP 和 OAI CLIP 提供的回答与上下文契合度较低。



: How many gallons of supreme gasoline can I get with $\$50$
用50美元可以买多少加仑的高级汽油?
OAI CLIP: To calculate how many gallons of supreme gasoline you can get with $\$50$, you would divide the total amount of money you
OAI CLIP:要计算用50美元能买到多少加仑的高级汽油,你需要将总金额除以
SigLIP: To calculate how many gallons of supreme gasoline you can get with $\$50$ , you would divide $\$50$ by the price per gallon
SigLIP: 要计算用50美元能购买多少加仑高级汽油,你需要将50美元除以每加仑的价格
AIMv2: Divide 50 by 3.65.
AIMv2:将50除以3.65。
: What is the license plate number?
车牌号是多少?
OAI CLIP: The license plate number is partially obscured and not fully legible due to the blurriness of the image.
OAI CLIP: 车牌号码因图像模糊而部分遮挡,无法完全辨认。

: How many approximate calories is in this meal?
图 1: 这顿饭大约含有多少卡路里?
SigLIP: The license plate number is not clearly visible in the image provided.
SigLIP:提供的图像中车牌号码不清晰可见。
AIMv2: The license plate number is AED-632
AIMv2: 车牌号为 AED-632
: What might be the weight of this luggage?
这件行李的重量可能是多少?
OAI CLIP: 3.7
OAI CLIP: 3.7
SigLIP: 30 pound
SigLIP: 30磅
AIMv2: 30.7
AIMv2: 30.7
OAI CLIP: 500
OAI CLIP: 500
SigLIP: 500
SigLIP: 500
AIMv2: 1000
AIMv2: 1000
Figure C1. Qualitative comparison of AIMv2, SigLIP, and OAI CLIP on multimodal tasks after instruction tuning on Cambrian. AIMv2 demonstrates superior performance in both text-rich (e.g. extracting relevant information or reading text in cluttered scenes) and knowledge-based scenarios (e.g., estimating caloric content), showcasing its ability to focus on relevant information, accurately localize text, and provide con textually appropriate answers.
| data mix | decoder | resolution | VQAv2 | GQA | OKVQA | TextVQA | DocVQA | InfoVQA | ChartQA | ScienceQA | COCO | TextCaps | NoCaps | MMEp |
| Cambrian | Llama 3.0 | 336px | 75.5 | 71.5 | 61.1 | 58.3 | 50.2 | 35.1 | 51.7 | 78.7 | 95.5 | 82.3 | 98.1 | 1594 |
| Cambrian | Llama 3.0 | 672px | 77.5 | 72.8 | 62.0 | 69.1 | 76.4 | 48.3 | 64.7 | 79.4 | 92.6 | 80.6 | 95.4 | 1482 |
| Cambrian | Llama3.0 | 1008px | 77.7 | 73.2 | 62.0 | 72.2 | 79.2 | 53.5 | 65.1 | 81.6 | 93.7 | 81.6 | 97.6 | 1507 |
图 C1: 在寒武纪(Cambrian)指令微调后,AIMv2、SigLIP和OAI CLIP在多模态任务上的定性对比。AIMv2在文本密集场景(如从杂乱场景中提取相关信息或阅读文本)和知识型场景(如估算热量含量)均展现出更优性能,体现了其聚焦相关信息、准确定位文本并提供上下文合理回答的能力。
| 数据混合 | 解码器 | 分辨率 | VQAv2 | GQA | OKVQA | TextVQA | DocVQA | InfoVQA | ChartQA | ScienceQA | COCO | TextCaps | NoCaps | MMEp |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 寒武纪 | Llama 3.0 | 336px | 75.5 | 71.5 | 61.1 | 58.3 | 50.2 | 35.1 | 51.7 | 78.7 | 95.5 | 82.3 | 98.1 | 1594 |
| 寒武纪 | Llama 3.0 | 672px | 77.5 | 72.8 | 62.0 | 69.1 | 76.4 | 48.3 | 64.7 | 79.4 | 92.6 | 80.6 | 95.4 | 1482 |
| 寒武纪 | Llama3.0 | 1008px | 77.7 | 73.2 | 62.0 | 72.2 | 79.2 | 53.5 | 65.1 | 81.6 | 93.7 | 81.6 | 97.6 | 1507 |
Table C3. Additional multimodal evaluations. We compare the performance of AIMV2 with different SFT data mixtures (Llava [73] and Cambrian [115]), and resolutions (336px, 672px and $1008\mathrm{px},$ ).
表 C3: 额外多模态评估。我们比较了 AIMV2 在不同监督微调 (SFT) 数据混合方案 (Llava [73] 和 Cambrian [115]) 及分辨率 (336px、672px 和 $1008\mathrm{px},$ ) 下的性能表现。
| cOCO | LVISVal | |||||||
| Model | APall | APs | APm | AP | APall | APr | APc | APf |
| OpenAICLIP | 59.1 | 43.5 | 63.5 | 74.8 | 31.0 | 17.6 | 27.2 | 41.2 |
| DFN-CLIP | 59.8 | 44.0 | 63.8 | 75.3 | 30.7 | 17.2 | 26.4 | 41.5 |
| SigLIP | 58.8 | 41.7 | 62.8 | 75.7 | 30.5 | 16.5 | 26.5 | 41.1 |
| DINOv2 | 60.1 | 43.7 | 64.2 | 75.8 | 30.8 | 18.5 | 26.1 | 41.4 |
| AIMv2 | 60.2 | 44.5 | 64.3 | 75.4 | 31.6 | 18.0 | 27.0 | 42.8 |
| Model | APall | APs | APm | AP | APall | APr | APc | APf |
|---|---|---|---|---|---|---|---|---|
| OpenAICLIP | 59.1 | 43.5 | 63.5 | 74.8 | 31.0 | 17.6 | 27.2 | 41.2 |
| DFN-CLIP | 59.8 | 44.0 | 63.8 | 75.3 | 30.7 | 17.2 | 26.4 | 41.5 |
| SigLIP | 58.8 | 41.7 | 62.8 | 75.7 | 30.5 | 16.5 | 26.5 | 41.1 |
| DINOv2 | 60.1 | 43.7 | 64.2 | 75.8 | 30.8 | 18.5 | 26.1 | 41.4 |
| AIMv2 | 60.2 | 44.5 | 64.3 | 75.4 | 31.6 | 18.0 | 27.0 | 42.8 |
Table D1. Performance on OVD Benchmarks. We report the performance on mean average precision (AP) for COCO and LVIS. For COCO, we also report AP for the small, medium, and large subsets, while for LVIS, we report on rare, medium, and frequent subsets.
表 D1: OVD 基准测试性能。我们报告了 COCO 和 LVIS 的平均精度均值 (AP) 性能。对于 COCO,我们还报告了小、中、大子集的 AP,而对于 LVIS,我们报告了稀有、中等和频繁子集的性能。
D. Detection, Segmentation and Grounding
D. 检测、分割与定位
D.1. Open Vocabulary Detection and Grounding
D.1. 开放词汇检测与定位
Performance on Small Objects. In Table D1 we report the breakdowns of COCO between classes that are either small, medium, or large. We can observe that AIMV2 consistently outperforms on the small classes by $+0.5$ AP, compared to DFN-CLIP, the second best performing model in that breakdown. This is further emphasized by the results reported on LVIS val, as objects in LVIS are more likely to be small. There we observe an improvement of $+1.3$ AP on the frequent subset against DFN-CLIP.
小物体检测性能。在表 D1 中,我们展示了 COCO 数据集中小、中、大类别物体的性能细分。可以观察到,AIMV2 在小物体类别上始终以 $+0.5$ AP 的优势优于排名第二的 DFN-CLIP 模型。这一优势在 LVIS 验证集上更为显著,因为 LVIS 中的物体通常更小。在该数据集上,我们观察到 AIMV2 在常见类别子集上相比 DFN-CLIP 实现了 $+1.3$ AP 的性能提升。
| Model | Window Size | COCO APall | LVIS Val APall | RefCOCO Val P@1 | RefCOCO+ Val P@1 | RefCOCOg Val P@1 |
| DINOv2 AIMv2 | 16 | 60.1 60.2 | 30.8 31.6 | 92.2 92.6 | 85.9 86.3 | 89.1 88.9 |
| DINOv2 | 24 | 59.6 59.8 | 29.6 | 92.1 | 85.0 | 88.7 |
| AIMv2 DINOv2 | 32 | 60.2 | 31.2 30.7 | 92.3 92.5 | 85.8 86.1 | 89.1 89.5 |
| AIMv2 | 60.3 | 32.9 | 92.5 | 86.3 | 88.9 | |
| DINOv2 | 37 | 60.2 | 31.1 | 92.2 | 85.9 | 88.4 |
| 模型 | 窗口尺寸 | COCO APall | LVIS Val APall | RefCOCO Val P@1 | RefCOCO+ Val P@1 | RefCOCOg Val P@1 |
|---|---|---|---|---|---|---|
| DINOv2 AIMv2 | 16 | 60.1 60.2 | 30.8 31.6 | 92.2 92.6 | 85.9 86.3 | 89.1 88.9 |
| DINOv2 | 24 | 59.6 59.8 | 29.6 | 92.1 | 85.0 | 88.7 |
| AIMv2 DINOv2 | 32 | 60.2 | 31.2 30.7 | 92.3 92.5 | 85.8 86.1 | 89.1 89.5 |
| AIMv2 | 60.3 | 32.9 | 92.5 | 86.3 | 88.9 | |
| DINOv2 | 37 | 60.2 | 31.1 | 92.2 | 85.9 | 88.4 |
Table D2. Ablation across window sizes. We report the performance on mean average precision (AP) for COCO and LVIS. For $\scriptstyle{\mathrm{RefCOCO}}^{*}$ we report Precision $@1$ on the respective validation splits.
表 D2: 不同窗口尺寸的消融实验。我们报告了 COCO 和 LVIS 数据集在平均精度均值 (mean average precision, AP) 上的性能表现。对于 $\scriptstyle{\mathrm{RefCOCO}}^{*}$ 数据集,我们报告了各自验证集上的 Precision $@1$ 指标。
Window Size Ablation. Due to varying input resolutions and feature map sizes used during pre-training, we ablate the effect of window size [68] for AIMV2 and DINOv2 in Table D2. For AIMV2 the input image resolution is scaled during pre-training such that the feature map size matches the window size during finetuning, while for DINOv2 the window size is fixed to match AIMV2. For comparison we also add DINOv2 trained with a window size of 37, which matches its pre-training feature map size. Across the window sizes, AIMV2 outperforms DINOv2 across all OVD and for two out of three referring comprehension benchmarks. When comparing our best performing AIMV2 with the best performing DINOv2 across all benchmarks, we observe that AIMV2 strongly outperforms on LVIS Val while outperforming on all except one benchmark against DINOv2.
窗口大小消融实验。由于预训练期间使用的输入分辨率和特征图尺寸不同,我们在表 D2 中对 AIMV2 和 DINOv2 进行了窗口大小 [68] 的影响消融。对于 AIMV2,预训练时会缩放输入图像分辨率以使特征图尺寸与微调时的窗口大小匹配,而 DINOv2 的窗口大小固定为与 AIMV2 一致。作为对比,我们还加入了窗口大小为 37 的 DINOv2 训练结果(与其预训练特征图尺寸匹配)。在不同窗口尺寸下,AIMV2 在所有 OVD 任务以及三项指代理解基准中的两项上均优于 DINOv2。当比较各基准测试中表现最佳的 AIMV2 与 DINOv2 时,我们发现 AIMV2 在 LVIS Val 上显著领先,并在除一个基准外的所有测试中优于 DINOv2。

Figure C2. Instruction with a small decoder (DCLM). Performance comparison of OAI CLIP, SigLIP, and AIMv2 across 12 multimodal benchmarks using the Llava SFT mixture paired with a DCLM 1B decoder. AIMV2 exhibits superior performance across most benchmarks, even with the constrained capacity of a small decoder.
图 C2: 使用小型解码器 (DCLM) 的指令。OAI CLIP、SigLIP 和 AIMv2 在 12 个多模态基准测试中的性能对比,测试采用 Llava SFT 混合数据并搭配 1B 参数的 DCLM 解码器。即使受限于小型解码器的能力,AIMv2 在大多数基准测试中仍展现出卓越性能。
| Model | detectionmAP50:95 | maskmAP50:95 | ||||||
| APall | AP | AP m | AP | APall | AP S | AP 772 | AP | |
| OAICLIP | 53.6 | 37.2 | 58.5 | 69.2 | 46.7 | 26.6 | 50.9 | 66.2 |
| DFN-CLIP | 53.4 | 37.1 | 58.3 | 69.3 | 46.2 | 26.4 | 50.8 | 66.4 |
| SigLIP | 53.3 | 37.2 | 57.6 | 69.7 | 46.6 | 27.1 | 50.5 | 66.3 |
| DINOv2 | 55.5 | 39.5 | 59.9 | 70.6 | 48.3 | 29.4 | 52.3 | 67.4 |
| AIMv2 | 54.0 | 37.4 | 58.8 | 70.0 | 46.7 | 26.7 | 51.1 | 66.5 |
Table D3. COCO17 detection and segmentation benchmarks. We report overall detection and segmentation scores along with the small, medium, and large subset breakdowns.
| 模型 | 检测 mAP50:95 | 掩码 mAP50:95 | ||||||
|---|---|---|---|---|---|---|---|---|
| APall | AP | AP m | AP | APall | AP S | AP 772 | AP | |
| OAICLIP | 53.6 | 37.2 | 58.5 | 69.2 | 46.7 | 26.6 | 50.9 | 66.2 |
| DFN-CLIP | 53.4 | 37.1 | 58.3 | 69.3 | 46.2 | 26.4 | 50.8 | 66.4 |
| SigLIP | 53.3 | 37.2 | 57.6 | 69.7 | 46.6 | 27.1 | 50.5 | 66.3 |
| DINOv2 | 55.5 | 39.5 | 59.9 | 70.6 | 48.3 | 29.4 | 52.3 | 67.4 |
| AIMv2 | 54.0 | 37.4 | 58.8 | 70.0 | 46.7 | 26.7 | 51.1 | 66.5 |
表 D3. COCO17 检测与分割基准测试。我们报告了整体检测和分割分数,以及小、中、大子集的细分结果。
D.2. Detection and Segmentation via ViTDet MaskRCNN
D.2. 基于ViTDet MaskRCNN的检测与分割
To compare vision only capabilities of the encoders we incorporate them into a Mask-RCNN[47] detection model as backbones by utilizing a ViTDet formulation to accommodate for high resolution (1024) detector training / testing input size. We ensure that ViTDet [68] backbone forward pass outputs match the respective ViT-L implementations before the training. We utilize the same set of hyper parameters for training all compared detectors: consistent windowed attention size (16) ensuring comparable compute, AdamW optimizer, cosine decay learning rate schedule, layer-wise learning rate, and weight decay. All detectors are finetuned on coco17 train split for 100 epochs with a global batch size of 64 following the default recipe from MMDetection [18]. We report results from the coco17-val split in Table D3. AIMV2 consistently outperforms encoders pre-trained on contrastive objectives, falling slightly behind DINOv2 which provides the strongest performance.
为了比较仅视觉编码器的能力,我们采用ViTDet框架将其作为骨干网络整合到Mask-RCNN[47]检测模型中,以适应高分辨率(1024)检测器训练/测试输入尺寸。在训练前,我们确保ViTDet[68]骨干网络前向传播输出与各自ViT-L实现相匹配。所有对比检测器使用相同的超参数集进行训练:保持一致的窗口注意力大小(16)以确保计算量可比、AdamW优化器、余弦衰减学习率调度、分层学习率和权重衰减。按照MMDetection[18]默认方案,所有检测器均在coco17训练集上微调100个周期,全局批次大小为64。表D3展示了coco17-val数据集的结果。AIMV2持续优于基于对比目标预训练的编码器,但略逊于性能最强的DINOv2。