The Hardware Lottery
硬件彩票
Sara Hooker
Sara Hooker
Google Research, Brain Team shooker@google.com
Google Research, Brain Team
shocker@google.com
Abstract
摘要
Hardware, systems and algorithms research communities have historically had different incentive structures and fluctuating motivation to engage with each other explicitly. This historical treatment is odd given that hardware and software have frequently determined which research ideas succeed (and fail). This essay introduces the term hardware lottery to describe when a research idea wins because it is suited to the available software and hardware and not because the idea is superior to alternative research directions. Examples from early computer science history illustrate how hardware lotteries can delay research progress by casting successful ideas as failures. These lessons are particularly salient given the advent of domain specialized hardware which make it increasingly costly to stray off of the beaten path of research ideas. This essay posits that the gains from progress in computing are likely to become even more uneven, with certain research directions moving into the fast-lane while progress on others is further obstructed.
硬件、系统和算法研究社区历来具有不同的激励机制,彼此间显性合作的动机也起伏不定。考虑到硬件和软件往往决定着研究理念的成败,这种历史性割裂显得尤为怪异。本文提出"硬件彩票 (hardware lottery) "这一术语,用于描述某些研究理念仅因适配现有软硬件环境(而非其本身优于其他研究方向)而胜出的现象。计算机早期发展史的案例表明,硬件彩票效应可能将本应成功的理念标记为失败,从而延缓研究进程。在领域专用硬件兴起的当下,偏离主流研究路径的成本日益高昂,这些历史教训显得尤为深刻。本文认为,计算技术的进步收益可能将愈发失衡——某些研究方向会进入快车道,而其他方向的进展则会遭遇更多阻碍。
1 Introduction
1 引言
History tells us that scientific progress is imperfect. Intellectual traditions and available tooling can prejudice scientists against certain ideas and towards others (Kuhn, 1962). This adds noise to the marketplace of ideas, and often means there is inertia in recognizing promising directions of research. In the field of artificial intelligence research, this essay posits that it is our tooling which has played a disproportionate role in deciding what ideas succeed (and which fail).
历史告诉我们,科学进步并非完美。思想传统和现有工具可能导致科学家对某些观点产生偏见 (Kuhn, 1962) 。这为思想市场增添了噪音,往往意味着人们在识别有前景的研究方向时存在惯性。在人工智能研究领域,本文认为正是我们的工具在决定哪些理念成功 (哪些失败) 的过程中发挥了过大的作用。
What follows is part position paper and part historical review. This essay introduces the term hardware lottery to describe when a research idea wins because it is compatible with available software and hardware and not because the idea is superior to alternative research directions. We argue that choices about software and hardware have often played a decisive role in deciding the winners and losers in early computer science history.
本文既是一篇立场声明,也是历史回顾。文章提出"硬件彩票 (hardware lottery)"这一术语,用于描述某项研究构想因其与现有软硬件兼容而胜出,而非因其优于其他研究方向的情况。我们认为在计算机科学早期历史中,软硬件选择往往对成败起着决定性作用。
These lessons are particularly salient as we move into a new era of closer collaboration between hardware, software and ma- chine learning research communities. After decades of treating hardware, software and algorithms as separate choices, the catalysts for closer collaboration include changing hardware economics (Hennessy, 2019), a “bigger is better” race in the size of deep learning architectures (Amodei et al., 2018; Thompson et al., 2020b) and the dizzying requirements of deploying machine learning to edge devices (Warden & Situnayake, 2019).
随着我们进入硬件、软件和机器学习研究社区更紧密协作的新时代,这些经验教训尤为重要。在将硬件、软件和算法视为独立选项数十年后,推动更紧密协作的因素包括硬件经济学的变革 (Hennessy, 2019)、深度学习架构规模"越大越好"的竞赛 (Amodei et al., 2018; Thompson et al., 2020b),以及将机器学习部署到边缘设备所需的惊人要求 (Warden & Situnayake, 2019)。
Closer collaboration has centered on a wave of new generation hardware that is "domain specific" to optimize for commercial use cases of deep neural networks (Jouppi et al., 2017; Gupta & Tan, 2019; ARM, 2020; Lee & Wang, 2018). While domain specialization creates important efficiency gains for mainstream research focused on deep neural networks, it arguably makes it more even more costly to stray off of the beaten path of research ideas. An increasingly fragmented hardware landscape means that the gains from progress in computing will be increasingly uneven. While deep neural networks have clear commercial use cases, there are early warning signs that the path to the next breakthrough in AI may require an entirely different combination of algorithm, hardware and software.
更紧密的合作聚焦于新一代"领域专用(domain specific)"硬件浪潮,旨在优化深度神经网络(deep neural networks)的商业应用场景 (Jouppi et al., 2017; Gupta & Tan, 2019; ARM, 2020; Lee & Wang, 2018)。虽然领域专用化为以深度神经网络为主流的研究带来了显著的效率提升,但这也使得偏离常规研究思路的代价变得更为高昂。日益碎片化的硬件格局意味着计算技术进步带来的收益将愈发不均衡。尽管深度神经网络具有明确的商业应用场景,但早期迹象表明,AI领域下一个重大突破可能需要算法、硬件和软件的完全重新组合。

Figure 1: Early computers such as the Mark I were single use and were not expected to be repurposed. While Mark I could be programmed to compute different calculations, it was essentially a very powerful calculator and could not run the variety of programs that we expect of our modern day machines.
图 1: 早期计算机如Mark I是单一用途设备且不可重新配置。虽然Mark I可通过编程执行不同计算任务,但它本质上只是一台高性能计算器,无法运行现代计算机所支持的各种程序。
This essay begins by acknowledging a crucial paradox: machine learning researchers mostly ignore hardware despite the role it plays in determining what ideas succeed. In Section 2 we ask what has in centi viz ed the development of software, hardware and machine learning research in isolation? Section 3 considers the ramifications of this siloed evolution with examples of early hardware and software lotteries. Today the hardware landscape is increasingly heterogeneous. This essay posits that the hardware lottery has not gone away, and the gap between the winners and losers will grow increasingly larger. Sections 4-5 unpack these arguments and Section 6 concludes with some thoughts on what it will take to avoid future hardware lotteries.
本文开篇即指出了一个关键悖论:机器学习研究者大多忽视硬件,尽管硬件在决定哪些创意能成功方面起着关键作用。第2节探讨了为何软件、硬件和机器学习研究长期以来各自独立发展?第3节通过早期硬件与软件"彩票"案例,分析了这种割裂式发展带来的影响。当今硬件生态正日趋多元化,但本文认为硬件彩票现象并未消失,赢家与输家之间的差距反而会越拉越大。第4-5节详细阐述了这些观点,第6节总结时提出了如何避免未来硬件彩票的一些思考。
2 Separate Tribes
2 分离的部落
It is not a bad description of man to describe him as a tool making animal.
将人描述为制造工具的动物并不失为一个恰当的定义。
Charles Babbage, 1851
Charles Babbage, 1851
difference machine was intended solely to compute polynomial functions (1817)(Collier, 1991). Mark I was a programmable calculator (1944)(Isaacson, 2014). Rosenblatt’s perceptron machine computed a step-wise single layer network (1958)(Van Der Malsburg, 1986). Even the Jacquard loom, which is often thought of as one of the first programmable machines, in practice was so expensive to re-thread that it was typically threaded once to support a pre-fixed set of input fields (1804)(Posselt, 1888).
差分机仅用于计算多项式函数 (1817) (Collier, 1991)。Mark I 是可编程计算器 (1944) (Isaacson, 2014)。Rosenblatt 的感知机实现了阶跃式单层网络计算 (1958) (Van Der Malsburg, 1986)。即便是常被视为最早可编程机械之一的提花织机,在实际操作中因重新穿线成本过高,通常仅穿线一次以支持预设的输入字段组 (1804) (Posselt, 1888)。
For the creators of the first computers the program was the machine. Early machines were single use and were not expected to be re-purposed for a new task because of both the cost of the electronics and a lack of cross-purpose software. Charles Babbage’s
对于首批计算机的创造者而言,程序即机器。早期计算机功能单一,由于电子元件成本高昂且缺乏跨用途软件,人们并未期待它们能被重新用于新任务。Charles Babbage的
The specialization of these early computers was out of necessity and not because computer architects thought one-off customized hardware was intrinsically better. However, it is worth pointing out that our own intelligence is both algorithm and machine. We do not inhabit multiple brains over the course of our lifetime. Instead, the notion of human intelligence is intrinsically associated with the physical 1400g of brain tissue and the patterns of connectivity between an estimated 85 billion neurons in your head (Sainani, 2017). When we talk about human intelligence, the prototypical image that probably surfaces as you read this is of a pink ridged cartoon blob. It is impossible to think of our cognitive intelligence without summoning up an image of the hardware it runs on.
这些早期计算机的专门化是出于必要性,而非因为计算机架构师认为一次性定制硬件本质上更好。不过值得注意的是,我们自身的智能既是算法也是机器。我们一生中并不会使用多个大脑。相反,人类智能的概念本质上与1400克脑组织物质以及你头颅中约850亿神经元之间的连接模式相关联 (Sainani, 2017)。当我们谈论人类智能时,阅读至此浮现在你脑海中的典型形象很可能是一个粉色褶皱的卡通团块。若不想象其运行的硬件,我们便无法思考自身的认知智能。
Today, in contrast to the necessary specialization in the very early days of computing, machine learning researchers tend to think of hardware, software and algorithm as three separate choices. This is largely due to a period in computer science history that radically changed the type of hardware that was made and in centi viz ed hardware, software and machine learning research communities to evolve in isolation.
与计算机发展初期所需的专业化不同,如今的机器学习研究者通常将硬件、软件和算法视为三个独立的选择。这主要源于计算机科学史上的一段时期——当时硬件制造类型发生根本性变革,导致硬件、软件和机器学习研究社区在各自领域独立发展。
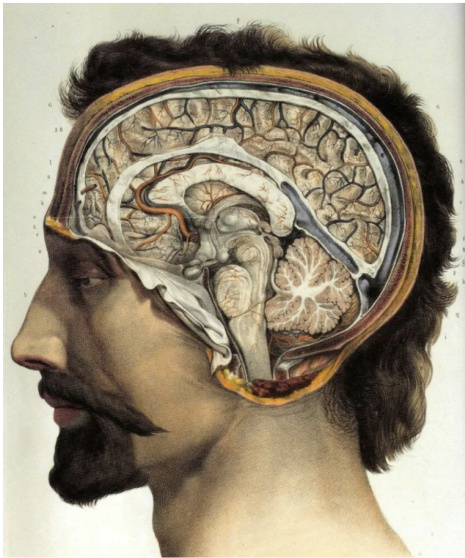
Figure 2: Our own cognitive intelligence is inextricably both hardware and algorithm. We do not inhabit multiple brains over our lifetime.
图 2: 我们自身的认知智能 (cognitive intelligence) 本质上是硬件与算法的不可分割体。终其一生,我们都不会更换多个大脑。
2.1 The General Purpose Era
2.1 通用计算时代
The general purpose computer era crystallized in 1969, when an opinion piece by a young engineer called Gordan Moore appeared in Electronics magazine with the apt title “Cramming more components onto circuit boards”(Moore, 1965). Moore predicted you could double the amount of transistors on an integrated circuit every two years. Originally, the article and subsequent followup was motivated by a simple desire – Moore thought it would sell more chips. However, the prediction held and motivated a remarkable decline in the cost of transforming energy into information over the next 50 years.
通用计算机时代在1969年成型,当时一位名叫Gordan Moore的年轻工程师在《电子学》杂志上发表了一篇观点文章,标题恰如其分地称为《在电路板上塞入更多元件》(Moore, 1965)。Moore预测集成电路上的晶体管数量每两年可以翻一番。最初,这篇文章及其后续跟进只是出于一个简单的愿望——Moore认为这会卖出更多芯片。然而,这一预测不仅成立,还推动了接下来50年间将能量转化为信息的成本显著下降。
Moore’s law combined with Dennard scaling (Dennard et al., 1974) enabled a factor of three magnitude increase in microp roc essor performance between 1980-2010 (CHM, 2020). The predictable increases in compute and memory every two years meant hardware design became risk-averse. Even for tasks which demanded higher performance, the benefits of moving to specialized hardware could be quickly eclipsed by the next generation of general purpose hardware with ever growing compute.
摩尔定律与登纳德缩放 (Dennard et al., 1974) 相结合,使得微处理器性能在1980-2010年间提升了三个数量级 (CHM, 2020)。每隔两年可预测的计算能力和内存增长,使得硬件设计趋于保守。即便对于需要更高性能的任务,转向专用硬件带来的优势也可能迅速被下一代计算能力持续增长的通用硬件所超越。
The emphasis shifted to universal processors which could solve a myriad of different tasks. Why experiment on more specialized hardware designs for an uncertain reward when Moore’s law allowed chip makers to lock in predictable profit margins? The few attempts to deviate and produce specialized supercomputers for research were financially unsustainable and short lived (Asanovic, 2018; Taubes, 1995). A few very narrow tasks like mastering chess were an exception to this rule because the prestige and visibility of beating a human adversary attracted corporate sponsorship (Moravec, 1998).
重点转向了能够解决无数不同任务的通用处理器。既然摩尔定律能让芯片制造商锁定可预测的利润空间,为何还要为不确定的回报尝试更专用的硬件设计?少数试图偏离该路线、为研究开发专用超级计算机的尝试在财务上难以为继且昙花一现 (Asanovic, 2018; Taubes, 1995)。像国际象棋这类极狭窄的任务是例外,因为击败人类对手带来的声望和关注度吸引了企业赞助 (Moravec, 1998)。
Treating the choice of hardware, software and algorithm as independent has persisted until recently. It is expensive to explore new types of hardware, both in terms of time and capital required. Producing a next generation chip typically costs $\$30–80$ million dollars and 2-3 years to develop (Feldman, 2019). These formidable barriers to entry have produced a hardware research culture that might feel odd or perhaps even slow to the average machine learning researcher. While the number of machine learning publications has grown exponentially in the last 30 years (Dean, 2020), the number of hardware publications have maintained a fairly even cadence (Singh et al., 2015). For a hardware company, leakage of intellectual property can make or break the survival of the firm. This has led to a much more closely guarded research culture.
直到最近,人们仍将硬件、软件和算法的选择视为相互独立。探索新型硬件在时间和资金成本上都十分昂贵。生产新一代芯片通常需要花费3000万至8000万美元,并耗时2-3年开发 (Feldman, 2019)。这些极高的准入门槛形成了与普通机器学习研究者认知迥异的硬件研究文化——甚至可能显得进展缓慢。虽然过去30年机器学习论文数量呈指数级增长 (Dean, 2020),但硬件领域的论文数量始终保持着平稳节奏 (Singh et al., 2015)。对硬件企业而言,知识产权泄露直接关乎企业存亡,这导致了更为严密的研究保密文化。
In the absence of any lever with which to influence hardware development, machine learning researchers rationally began to treat hardware as a sunk cost to work around rather than something fluid that could be shaped. However, just because we have abstracted away hardware does not mean it has ceased to exist. Early computer science history tells us there are many hardware lotteries where the choice of hardware and software has determined which ideas succeed (and which fail).
由于缺乏影响硬件开发的手段,机器学习研究者们理性地开始将硬件视为需要规避的沉没成本,而非可以灵活塑造的变量。然而,硬件被抽象化的事实并不意味着它已不复存在。早期计算机科学史告诉我们,硬件选择与软件决策共同决定了哪些创意能够胜出(哪些会失败),这种硬件彩票现象屡见不鲜。
3 The Hardware Lottery
3 硬件彩票
I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail.
如果手头唯一的工具是锤子,看什么都像钉子。
The first sentence of Anna Karenina by Tolstoy reads “Happy families are all alike, every unhappy family is unhappy in it’s own way.”(Tolstoy & Bartlett, 2016). Tolstoy is saying that it takes many different things for a marriage to be happy – financial stability, chemistry, shared values, healthy offspring. However, it only takes one of these aspects to not be present for a family to be unhappy. This has been popularized as the Anna Karenina principle – “a deficiency in any one of a number of factors dooms an endeavor to failure.” (Moore, 2001).
托尔斯泰在《安娜·卡列尼娜》开篇写道:"幸福的家庭都是相似的,不幸的家庭各有各的不幸" (Tolstoy & Bartlett, 2016) 。他认为婚姻幸福需要诸多要素共同作用——经济稳定、情感共鸣、价值观契合、子女健康。但缺失其中任何一项,就足以导致家庭不幸。这一观点后来被归纳为安娜·卡列尼娜原则:"在多因素系统中,任一要素的缺失都将导致整体失败" (Moore, 2001) 。
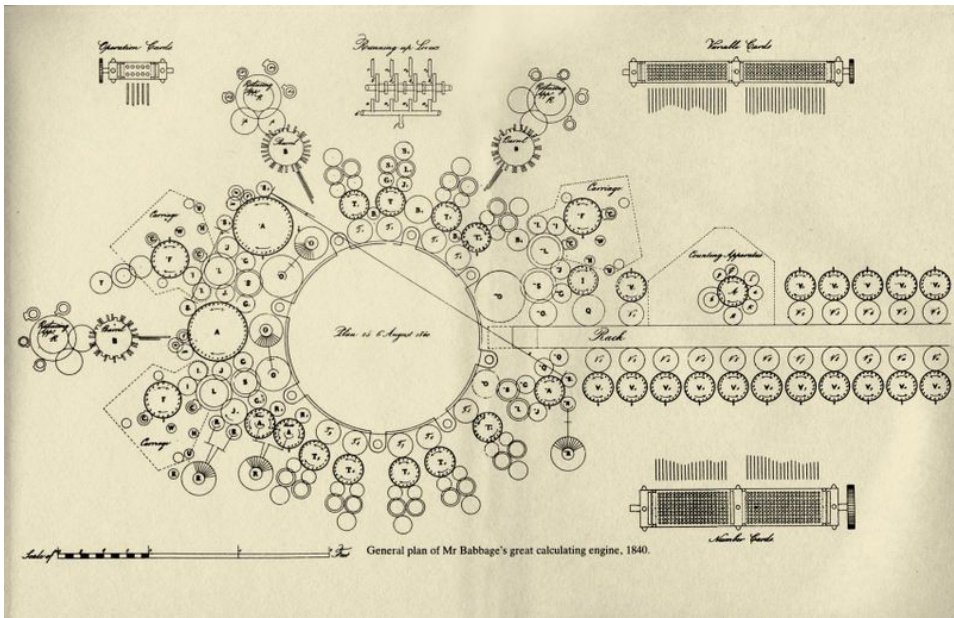
Figure 3: The analytical engine designed by Charles Babbage was never built in part because he had difficulty fabricating parts with the correct precision. This image depicts the general plan of the analytical machine in 1840.
图 3: Charles Babbage 设计的分析机最终未能建成,部分原因在于难以制造出精度达标的零件。该图展示了1840年分析机的整体设计方案。
Despite our preference to believe algorithms succeed or fail in isolation, history tells us that most computer science breakthroughs follow the Anna Karenina principle. Successful breakthroughs are often distinguished from failures by benefiting from multiple criteria aligning serendipitous ly. For AI research, this often depends upon winning what this essay terms the hardware lottery — avoiding possible points of failure in downstream hardware and software choices.
尽管我们更愿意相信算法是独立成功或失败的,但历史告诉我们,大多数计算机科学突破都遵循安娜·卡列尼娜原则。成功的突破往往与失败的区别在于,它们受益于多个标准偶然达成一致。对于AI研究来说,这通常取决于赢得本文所称的硬件彩票——避免在下游硬件和软件选择中可能出现的问题点。
An early example of a hardware lottery is the analytical machine (1837). Charles Babbage was a computer pioneer who designed a machine that (at least in theory) could be programmed to solve any type of computation. His analytical engine was never built in part because he had difficulty fabricating parts with the correct precision (Kurzweil, 1990). The electromagnetic technology to actually build the theoretical foundations laid down by Babbage only surfaced during WWII. In the first part of the 20th century, electronic vacuum tubes were heavily used for radio communication and radar. During WWII, these vacuum tubes were re-purposed to provide the compute power necessary to break the German enigma code (Project, 2018).
硬件抽奖的一个早期例子是分析机(1837)。Charles Babbage是一位计算机先驱,他设计的机器(至少在理论上)可以通过编程解决任何类型的计算问题。他的分析机最终未能建成,部分原因是难以制造出精度符合要求的零件(Kurzweil, 1990)。直到二战期间,才出现能够实现Babbage理论基础的电磁技术。20世纪上半叶,电子真空管被广泛用于无线电通信和雷达。二战期间,这些真空管被重新用于提供破解德国Enigma密码所需的计算能力(Project, 2018)。
As noted in the TV show Silicon Valley, often “being too early is the same as being wrong.” When Babbage passed away in 1871, there was no continuous path between his ideas and modern day computing. The concept of a stored program, modifiable code, memory and conditional branching were rediscovered a century later because the right tools existed to empirically show that the idea worked.
正如电视剧《硅谷》中所言,"太早往往等同于错误"。当Babbage于1871年去世时,他的构想与现代计算技术之间并未形成连贯的发展路径。存储程序、可修改代码、内存和条件分支等概念在一个世纪后才被重新发现,因为那时已具备通过实证验证这些构想可行性的技术条件。
3.1 The Lost Decades
3.1 失去的十年
Perhaps the most salient example of the damage caused by not winning the hardware lottery is the delayed recognition of deep neural networks as a promising direction of research. Most of the algorithmic components to make deep neural networks work had already been in place for a few decades: back prop agation (invented in 1963 (K & Piske, 1963), reinvented in 1976 (Linnainmaa, 1976), and again in 1988 (Rumelhart et al., 1988)), deep convolutional neural networks ((Fukushima & Miyake, 1982), paired with back prop agation in 1989 (LeCun et al., 1989)). However, it was only three decades later that deep neural networks were widely accepted as a promising research direction.
未能赢得硬件彩票造成损害的最显著例子,就是深度神经网络作为有前景的研究方向迟迟未获认可。使深度神经网络发挥作用的大多数算法组件其实早已存在数十年:反向传播 (1963年由K & Piske提出 [20],1976年由Linnainmaa重新发现 [21],1988年再由Rumelhart等人再次提出 [22]) ,深度卷积神经网络 (1982年由Fukushima & Miyake提出 [23],1989年与反向传播结合由LeCun等人实现 [24]) 。然而直到三十年后,深度神经网络才被广泛认可为具有前景的研究方向。
This gap between algorithmic advances and empirical success is in large part due to incompatible hardware. During the general purpose computing era, hardware like CPUs were heavily favored and widely available. CPUs are very good at executing any set of complex instructions but incur high memory costs because of the need to cache intermediate results and process one instruction at a time (Sato, 2018). This is known as the von Neumann Bottleneck — the available compute is restricted by “the lone channel between the CPU and memory along which data has to travel sequentially” (Time, 1985).
算法进步与实证成功之间的差距很大程度上源于硬件的不兼容性。在通用计算时代,CPU等硬件备受青睐且广泛普及。CPU擅长执行任意复杂指令集,但由于需要缓存中间结果且每次仅处理一条指令 (Sato, 2018) ,导致内存成本高昂。这种现象被称为冯·诺依曼瓶颈 (von Neumann Bottleneck) ——计算能力受限于"CPU与内存之间单一的数据顺序传输通道" (Time, 1985) 。
The von Neumann bottleneck was terribly illsuited to matrix multiplies, a core component of deep neural network architectures. Thus, training on CPUs quickly exhausted memory bandwidth and it simply wasn’t possible to train deep neural networks with multiple layers. The need for hardware that supported tasks with lots of parallelism was pointed out as far back as the early 1980s in a series of essays titled “Parallel Models of Associative Memory” (Hinton & Anderson, 1989). The essays argued persuasively that biological evidence suggested massive parallelism was needed to make deep neural network approaches work (Rumelhart et al., 1986).
冯·诺依曼瓶颈极不适合矩阵乘法这一深度神经网络架构的核心组件。因此,在CPU上进行训练会迅速耗尽内存带宽,根本无法训练具有多层的深度神经网络。早在20世纪80年代初,一系列题为《关联记忆的并行模型》(Hinton & Anderson, 1989) 的论文就指出,需要硬件来支持高度并行化的任务。这些论文有力地论证了生物学证据表明,要使深度神经网络方法奏效,需要大规模并行处理 (Rumelhart et al., 1986)。
In the late 1980/90s, the idea of specialized hardware for neural networks had passed the novelty stage (Misra & Saha, 2010; Lindsey & Lindblad, 1994; Dean, 1990). How- ever, efforts remained fractured by lack of shared software and the cost of hardware development. Most of the attempts that were actually operational i zed like the Connection Machine in 1985 (Taubes, 1995), Space in 1992 (Howe & Asanović, 1994), Ring Array Processor in 1989 (Morgan et al., 1992) and the Japanese 5th generation computer project (Morgan, 1983) were designed to favor logic programming such as PROLOG and LISP that were poorly suited to connectionist deep neural networks. Later iterations such as HipNet-1 (Kingsbury et al., 1998), and the Analog Neural Network Chip in 1991 (Sackinger et al., 1992) were promising but short lived because of the intolerable cost of iteration and the need for custom silicon. Without a consumer market, there was simply not the critical mass of end users to be financially viable.
20世纪80年代末至90年代,专用神经网络硬件的概念已度过萌芽阶段 (Misra & Saha, 2010; Lindsey & Lindblad, 1994; Dean, 1990) 。然而,由于缺乏共享软件和硬件开发成本高昂,相关研究始终处于碎片化状态。1985年的Connection Machine (Taubes, 1995) 、1992年的Space (Howe & Asanović, 1994) 、1989年的Ring Array Processor (Morgan et al., 1992) 以及日本第五代计算机计划 (Morgan, 1983) 等实际落地的尝试,都偏向于适合逻辑编程(如PROLOG和LISP)的设计,与连接主义的深度神经网络适配性不佳。后续迭代产品如HipNet-1 (Kingsbury et al., 1998) 和1991年的模拟神经网络芯片 (Sackinger et al., 1992) 虽具潜力,却因难以承受的迭代成本和定制硅片需求而昙花一现。缺乏消费级市场支撑,终端用户规模始终无法达到经济可持续的临界点。

Figure 4: The connection machine was one of the few examples of hardware that deviated from general purpose cpus in the $1980\mathrm{s}/90\mathrm{s}$ . Thinking Machines ultimately went bankrupt after the inital funding from DARPA dried up.
图 4: Connection Machine 是 20 世纪 80/90 年代少数偏离通用 CPU 的硬件范例之一。在 DARPA 初始资金耗尽后,Thinking Machines 公司最终破产。
It would take a hardware fluke in the early 2000s, a full four decades after the first paper about back propagation was published, for the insight about massive parallelism to be operational i zed in a useful way for connectionist deep neural networks. Many inventions are re-purposed for means unintended by their designers. Edison’s phonograph was never intended to play music. He envisioned it as preserving the last words of dying people or teaching spelling. In fact, he was disappointed by its use playing popular music as he thought this was too “base” an application of his invention (Diamond et al., 1999). In a similar vein, deep neural networks only began to work when an existing technology was unexpectedly re-purposed.
直到21世纪初,距离首篇关于反向传播的论文发表已过去整整四十年,一次硬件上的偶然突破才使得大规模并行化的洞见得以有效应用于连接主义深度神经网络。许多发明最终用途往往偏离设计者初衷——爱迪生发明留声机本非为播放音乐,而是设想用于保存临终遗言或辅助拼写教学。事实上,他对该设备被用于播放流行音乐深感失望,认为这是对其发明过于"低俗"的运用 (Diamond et al., 1999) 。同样地,深度神经网络正是在现有技术意外获得新用途时才真正开始发挥作用。
A graphical processing unit (GPU) was originally introduced in the 1970s as a specialized accelerator for video games and for developing graphics for movies and animation. In the 2000s, like Edison’s phonograph, GPUs were re-purposed for an entirely unimagined use case – to train deep neural networks (Chell a pill a et al., 2006; Oh & Jung, 2004; Claudiu Ciresan et al., 2010; Fata- halian et al., 2004; Payne et al., 2005). GPUs had one critical advantage over CPUs - they were far better at parallel i zing a set of simple de com pos able instructions such as matrix multiples (Brodtkorb et al., 2013; Dettmers, 2020). This higher number of floating operation points per second (FLOPS) combined with clever distribution of training between GPUs unblocked the training of deeper networks. The number of layers in a network turned out to be the key. Performance on ImageNet jumped with ever deeper networks in 2011 (Ciresan et al., 2011), 2012 (Krizhevsky et al., 2012) and 2015 (Szegedy et al., 2015b). A striking example of this jump in efficiency is a comparison of the now famous 2012 Google paper which used 16,000 CPU cores to classify cats (Le et al., 2012) to a paper published a mere year later that solved the same task with only two CPU cores and four GPUs (Coates et al., 2013).
图形处理器 (GPU) 最初于20世纪70年代作为电子游戏和影视动画图形开发的专用加速器问世。进入21世纪后,如同爱迪生的留声机被重新发明用途一样,GPU被赋予了完全意想不到的新使命——训练深度神经网络 (Chellapilla et al., 2006; Oh & Jung, 2004; Claudiu Ciresan et al., 2010; Fatahalian et al., 2004; Payne et al., 2005)。相较于CPU,GPU具有一个关键优势:更擅长并行处理可分解的简单指令集,例如矩阵乘法运算 (Brodtkorb et al., 2013; Dettmers, 2020)。这种更高的每秒浮点运算次数 (FLOPS) 结合GPU间智能化的训练任务分配,突破了深层网络的训练瓶颈。网络层数成为关键因素——2011年 (Ciresan et al., 2011)、2012年 (Krizhevsky et al., 2012) 和2015年 (Szegedy et al., 2015b) 的ImageNet竞赛中,随着网络深度增加,模型性能显著提升。最具说服力的对比案例是:2012年谷歌那篇著名论文使用16,000个CPU核心实现猫图像分类 (Le et al., 2012),而仅仅一年后发表的论文仅用2个CPU核心和4块GPU就完成了相同任务 (Coates et al., 2013)。

Figure 5: Byte magazine cover, August 1979, volume 4. LISP was the dominant language for artificial intelligence research through the 1990’s. LISP was particularly well suited to handling logic expressions, which were a core component of reasoning and expert systems.
图 5: Byte杂志封面,1979年8月第4卷。LISP是20世纪90年代人工智能研究的主导语言,特别适合处理逻辑表达式这一推理和专家系统的核心组件。
3.2 Software Lotteries
3.2 软件抽奖
Software also plays a role in deciding which research ideas win and lose. Prolog and LISP were two languages heavily favored until the mid-90’s in the AI community. For most of this period, students of AI were expected to actively master one or both of these languages (Lucas & van der Gaag, 1991). LISP and Prolog were particularly well suited to handling logic expressions, which were a core component of reasoning and expert systems.
软件也在决定哪些研究理念成败中扮演着重要角色。Prolog和LISP这两种语言直到90年代中期仍在AI领域备受青睐。在此期间,AI领域的学生通常被要求熟练掌握其中一种或两种语言 (Lucas & van der Gaag, 1991)。LISP和Prolog特别适合处理逻辑表达式,而逻辑表达式正是推理系统和专家系统的核心组成部分。
For researchers who wanted to work on connectionist ideas like deep neural networks there was not a clearly suited language of choice until the emergence of Matlab in 1992 (Demuth & Beale, 1993). Implementing connectionist networks in LISP or Prolog was cumbersome and most researchers worked in low level languages like $\mathrm{c}{++}$ (Touretzky & Waibel, 1995). It was only in the 2000’s that there started to be a more healthy ecosystem around software developed for deep neural network approaches with the emergence of LUSH (Lecun & Bottou, 2002) and subsequently TORCH (Collobert et al., 2002).
对于想要研究深度神经网络等连接主义思想的研究者而言,在1992年Matlab出现之前 (Demuth & Beale, 1993),并没有明确合适的编程语言选择。使用LISP或Prolog实现连接主义网络十分繁琐,大多数研究者都采用$\mathrm{c}{++}$等底层语言进行开发 (Touretzky & Waibel, 1995)。直到2000年代,随着LUSH (Lecun & Bottou, 2002) 和后续TORCH (Collobert et al., 2002) 的出现,才逐渐形成了围绕深度神经网络方法的软件开发生态系统。
Where there is a loser, there is also a winner. From the 1960s through the mid 80s, most mainstream research was focused on symbolic approaches to AI (Haugeland, 1985). Unlike deep neural networks where learning an adequate representation is delegated to the model itself, symbolic approaches aimed to build up a knowledge base and use decision rules to replicate how humans would approach a problem. This was often codified as a sequence of logic what-if statements that were well suited to LISP and PROLOG. The widespread and sustained popularity of symbolic approaches to AI cannot easily be seen as independent of how readily it fit into existing programming and hardware frameworks.
有输家就有赢家。从20世纪60年代到80年代中期,主流AI研究主要聚焦于符号主义方法 (Haugeland, 1985) 。与将表征学习任务交给模型本身的深度神经网络不同,符号主义方法旨在构建知识库并运用决策规则来复现人类解决问题的方式。这种方法通常被编码为一系列逻辑假设语句,非常适配LISP和PROLOG语言。符号主义方法在AI领域长期保持的广泛流行性,与其对现有编程及硬件框架的良好适配性密不可分。
4 The Persistence of the Hardware Lottery
4 硬件彩票的持久性
Today, there is renewed interest in joint collaboration between hardware, software and machine learning communities. We are experiencing a second pendulum swing back to specialized hardware. The catalysts include changing hardware economics prompted by the end of Moore’s law and the breakdown of Dennard scaling (Hennessy, 2019), a “bigger is better” race in the number of model parameters that has gripped the field of machine learning (Amodei et al., 2018), spiralling energy costs (Horowitz, 2014; Strubell et al., 2019) and the dizzying requirements of deploying machine learning to edge devices (Warden & Situnayake, 2019).
如今,硬件、软件和机器学习领域对协同合作的兴趣再度兴起。我们正经历着第二次向专用硬件回摆的浪潮。这一趋势的催化剂包括:摩尔定律终结和Dennard缩放失效引发的硬件经济学变革 (Hennessy, 2019) 、机器学习领域愈演愈烈的"参数规模竞赛" (Amodei et al., 2018) 、不断攀升的能源成本 (Horowitz, 2014; Strubell et al., 2019) ,以及边缘设备部署机器学习时令人眩晕的严苛要求 (Warden & Situnayake, 2019) 。
The end of Moore’s law means we are not guaranteed more compute, hardware will have to earn it. To improve efficiency, there is a shift from task agnostic hardware like CPUs to domain specialized hardware that tailor the design to make certain tasks more efficient. The first examples of domain specialized hardware released over the last few years – TPUs (Jouppi et al., 2017), edgeTPUs (Gupta & Tan, 2019), Arm Cortex- M55 (ARM, 2020), Facebook’s big sur (Lee & Wang, 2018) – optimize explicitly for costly operations common to deep neural networks like matrix multiplies.
摩尔定律的终结意味着我们无法再获得免费的计算力提升,硬件必须通过创新来赢得性能增长。为提高效率,行业正从通用型CPU硬件转向针对特定领域优化的专用硬件设计。过去几年发布的首批领域专用硬件实例——TPU (Jouppi等人, 2017)、edgeTPU (Gupta & Tan, 2019)、Arm Cortex-M55 (ARM, 2020)、Facebook的big sur (Lee & Wang, 2018)——都明确针对深度神经网络中耗时的矩阵乘法等常见运算进行了优化。
Closer collaboration between hardware and research communities will undoubtedly continue to make the training and deployment of deep neural networks more efficient. For example, unstructured pruning (Hooker et al., 2019; Gale et al., 2019; Evci et al., 2019) and weight specific quantization (Zhen et al., 2019) are very successful compression techniques in deep neural networks but are incompatible with current hardware and compilation kernels.
硬件与研究社区之间更紧密的合作无疑将继续提升深度神经网络的训练和部署效率。例如,非结构化剪枝 (Hooker et al., 2019; Gale et al., 2019; Evci et al., 2019) 和权重特定量化 (Zhen et al., 2019) 是深度神经网络中非常成功的压缩技术,但与当前硬件和编译内核不兼容。
While these compression techniques are currently not supported, many clever hardware architects are currently thinking about how to solve for this. It is a reasonable prediction that the next few generations of chips or specialized kernels will correct for hardware biases against these techniques (Wang et al., 2018; Sun et al., 2020). Some of the first de- signs to facilitate sparsity have already hit the market (Krashinsky et al., 2020). In parallel, there is interesting research developing specialized software kernels to support unstructured sparsity (Elsen et al., 2020; Gale et al., 2020; Gray et al., 2017).
虽然目前不支持这些压缩技术,但许多聪明的硬件架构师正在思考如何解决这个问题。可以合理预测,未来几代芯片或专用内核将修正对这些技术的硬件偏见 (Wang et al., 2018; Sun et al., 2020)。首批支持稀疏性的设计已经上市 (Krashinsky et al., 2020)。与此同时,有研究正在开发专用软件内核以支持非结构化稀疏性 (Elsen et al., 2020; Gale et al., 2020; Gray et al., 2017)。
In many ways, hardware is catching up to the present state of machine learning research. Hardware is only economically viable if the lifetime of the use case lasts more than three years (Dean, 2020). Betting on ideas which have longevity is a key consideration for hardware developers. Thus, co-design effort has focused almost entirely on optimizing an older generation of models with known commercial use cases. For example, matrix multiplies are a safe target to optimize for because they are here to stay — anchored by the widespread use and adoption of deep neural networks in production systems. Allowing for unstructured sparsity and weight specific quantization are also safe targets because there is wide consensus that these will enable higher levels of compression.
从许多方面来看,硬件正在追赶机器学习研究的现状。硬件只有在用例生命周期超过三年时才具有经济可行性 (Dean, 2020)。押注具有持久性的理念是硬件开发者的关键考量。因此,协同设计工作几乎完全集中在优化具有已知商业用例的旧一代模型上。例如,矩阵乘法是安全的优化目标,因为它们会长期存在——这得益于深度神经网络在生产系统中的广泛使用和采用。允许非结构化稀疏性和权重特定量化也是安全的目标,因为业界普遍认为这些技术能实现更高水平的压缩。
There is still a separate question of whether hardware innovation is versatile enough to unlock or keep pace with entirely new machine learning research directions. It is difficult to answer this question because data points here are limited – it is hard to model the counter factual of would this idea succeed given different hardware. However, despite the inherent challenge of this task, there is already compelling evidence that domain specialized hardware makes it more costly for research ideas that stray outside of the mainstream to succeed.
硬件创新是否足够通用以解锁或跟上全新的机器学习研究方向,这仍是一个独立的问题。由于相关数据点有限,很难回答这个问题——在假设硬件不同的情况下某项研究构想能否成功,这种反事实情境难以建模。然而,尽管这项任务存在固有挑战,已有有力证据表明,领域专用硬件会显著提高偏离主流研究方向的研究构想获得成功的成本。
In 2019, a paper was published called “Machine learning is stuck in a rut.” (Barham & Isard, 2019). The authors consider the difficulty of training a new type of computer vision architecture called capsule networks (Sabour et al., 2017) on domain specialized hardware. Capsule networks include novel components like squashing operations and routing by agreement. These architecture choices aimed to solve for key deficiencies in convolutional neural networks (lack of rotational invariance and spatial hierarchy understanding) but strayed from the typical architecture of neural networks. As a result, while capsule networks operations can be implemented reasonably well on CPUs, performance falls off a cliff on accelerators like GPUs and TPUs which have been overly optimized for matrix multiplies.
2019年发表了一篇题为《机器学习陷入窠臼》的论文 (Barham & Isard, 2019)。作者探讨了在领域专用硬件上训练一种新型计算机视觉架构——胶囊网络 (Sabour et al., 2017) 的困难。胶囊网络包含压缩操作 (squashing operations) 和协议路由 (routing by agreement) 等新颖组件,这些架构选择旨在解决卷积神经网络的关键缺陷 (缺乏旋转不变性和空间层级理解能力),但偏离了神经网络的典型架构。因此,虽然胶囊网络在CPU上可以较好地运行,但在为矩阵乘法过度优化的GPU和TPU等加速器上性能会急剧下降。
Whether or not you agree that capsule networks are the future of computer vision, the authors say something interesting about the difficulty of trying to train a new type of image classification architecture on domain specialized hardware. Hardware design has prioritized delivering on commercial use cases, while built-in flexibility to accommodate the next generation of research ideas remains a distant secondary consideration.
无论你是否认同胶囊网络是计算机视觉的未来,作者们提出了一个有趣的观点:在领域专用硬件上训练新型图像分类架构存在困难。硬件设计优先考虑满足商业用例需求,而对下一代研究想法的内置灵活性支持仍是次要考量。
While specialization makes deep neural networks more efficient, it also makes it far more costly to stray from accepted building blocks. It prompts the question of how much researchers will implicitly overfit to ideas that operational ize well on available hardware rather than take a risk on ideas that are not currently feasible? What are the failures we still don’t have the hardware and software to see as a success?
虽然专业化使深度神经网络更高效,但也大幅提高了偏离现有构建模块的成本。这引发了一个问题:研究者会在多大程度上隐性过拟合那些在当前硬件上运行良好的想法,而非冒险尝试目前不可行的方案?我们仍缺乏哪些硬件和软件能力,导致某些失败无法被视为潜在的成功?
5 The Likelyhood of Future Hardware Lotteries
5 未来硬件抽奖的可能性
What we have before us are some breathtaking opportunities disguised as insoluble problems.
摆在我们面前的,是一些看似无解的难题中蕴藏的绝佳机遇。
John Gardner, 1965.
John Gardner, 1965.
It is an ongoing, open debate within the machine learning community about how much future algorithms will differ from models like deep neural networks (Sutton, 2019; Welling, 2019). The risk you attach to depending on domain specialized hardware is tied to your position on this debate. Betting heavily on specialized hardware makes sense if you think that future breakthroughs depend upon pairing deep neural networks with ever increasing amounts of data and computation.
机器学习领域持续存在一个开放性的争论:未来的算法与深度神经网络 (deep neural networks) 等模型会有多大差异 (Sutton, 2019; Welling, 2019)。你对领域专用硬件依赖风险的评估,取决于你在这场争论中的立场。如果你认为未来的突破取决于将深度神经网络与持续增长的数据和计算量相结合,那么大力押注专用硬件是合理的。
Several major research labs are making this bet, engaging in a “bigger is better” race in the number of model parameters and collecting ever more expansive datasets. However, it is unclear whether this is sustainable. An algorithms s cal ability is often thought of as the performance gradient relative to the available resources. Given more resources, how does performance increase?
多家顶尖研究实验室正押注于此,在模型参数量上展开"越大越好"的竞赛,并收集日益庞大的数据集。然而,这种模式是否可持续尚不明确。算法扩展性通常被视为性能与可用资源之间的梯度关系——当资源增加时,性能会如何提升?
For many subfields, we are now in a regime where the rate of return for additional parameters is decreasing (Thompson et al., 2020a; Brown et al., 2020). For example, while the parameters almost double between Inception V3 (Szegedy et al., 2016)and Inception V4 architectures (Szegedy et al., 2015a) (from 21.8 to 41.1 million parameters), accuracy on ImageNet differs by less than $2%$ between the two networks (78.8 vs $80%$ ) (Kornblith et al., 2018). The cost of throwing additional parameters at a problem is becoming painfully obvious. The training of GPT-3 alone is estimated to exceed $\$12$ million dollars (Wiggers, 2020).
在许多子领域,我们正面临参数边际收益递减的局面 (Thompson et al., 2020a; Brown et al., 2020) 。例如,Inception V3 (Szegedy et al., 2016) 与 Inception V4 (Szegedy et al., 2015a) 架构的参数规模几乎翻倍(从2180万增至4110万),但两者在ImageNet上的准确率差异不足 $2%$ (78.8%对比 $80%$ )(Kornblith et al., 2018) 。盲目增加参数带来的成本问题日益凸显,仅GPT-3的训练费用就预估超过 $\$1200$ 万美元 (Wiggers, 2020) 。
Perhaps more troubling is how far away we are from the type of intelligence humans demonstrate. Human brains despite their complexity remain extremely energy efficient. Our brain has over 85 billion neurons but runs on the energy equivalent of an electric shaver (Sainani, 2017). While deep neural networks may be scalable, it may be prohibitively expensive to do so in a regime of comparable intelligence to humans. An apt metaphor is that we appear to be trying to build a ladder to the moon.
更令人担忧的是,我们距离人类所展现的智能水平还有多远。尽管人脑结构复杂,但其能效却极高。我们的大脑拥有超过850亿个神经元,但运行所需的能量仅相当于一把电动剃须刀 (Sainani, 2017)。虽然深度神经网络可能具备可扩展性,但要达到与人类相当的智能水平,其成本可能高得令人望而却步。一个贴切的比喻是:我们似乎正在试图建造一架通往月球的梯子。
Biological examples of intelligence differ from deep neural networks in enough ways to suggest it is a risky bet to say that deep neural networks are the only way forward. While algorithms like deep neural networks rely on global updates in order to learn a useful represent ation, our brains do not. Our own intelligence relies on decentralized local updates which surface a global signal in ways that are still not well understood (Lillicrap & Santoro, 2019; Marble stone et al., 2016; Bi & Poo, 1998).
生物智能的实例与深度神经网络存在诸多差异,这表明断言深度神经网络是唯一发展路径存在风险。深度神经网络等算法依赖全局更新来学习有效表征,而人类大脑并非如此。我们的智能基于分散式局部更新,这些更新以尚未完全理解的方式涌现出全局信号 (Lillicrap & Santoro, 2019; Marblestone et al., 2016; Bi & Poo, 1998)。
In addition, our brains are able to learn efficient representations from far fewer labelled examples than deep neural networks (Zador, 2019). For typical deep learning models the entire model is activated for every example which leads to a quadratic blow-up in training cost. In contrast, evidence suggests that the brain does not perform a full forward and backward pass for all inputs. Instead, the brain simulates what inputs are expected against incoming sensory data. Based upon the certainty of the match, the brain simply infills. What we see is largely virtual reality computed from memory (Eagleman & Sejnowski, 2000; Bubic et al., 2010; Heeger, 2017).
此外,我们的大脑能够从比深度神经网络少得多的标注样本中学习高效表征 (Zador, 2019)。对于典型的深度学习模型,每个样本都会激活整个模型,导致训练成本呈二次方增长。相比之下,有证据表明大脑不会对所有输入执行完整的前向和反向传播。相反,大脑会模拟预期输入与传入感官数据的匹配程度。根据匹配的确定性,大脑直接进行信息补全。我们所看到的主要是由记忆计算出的虚拟现实 (Eagleman & Sejnowski, 2000; Bubic et al., 2010; Heeger, 2017)。

Figure 6: Human latency for certain tasks suggests we have specialized pathways for different stimuli. For example, it is easy for a human to walk and talk at the same time. However, it is far more cognitive ly taxing to attempt to read and talk.
图 6: 人类在特定任务中的延迟表明我们针对不同刺激存在专门的处理通路。例如,人类可以轻松地边走路边说话,但试图同时阅读和交谈则需要消耗更多的认知资源。
Humans have highly optimized and specific pathways developed in our biological hardware for different tasks (Von Neumann et al., 2000; Marcus et al., 2014; Kennedy, 2000). For example, it is easy for a human to walk and talk at the same time. However, it is far more cognitive ly taxing to attempt to read and talk (Stroop, 1935). This suggests the way a network is organized and our inductive biases is as important as the overall size of the network (Herculano-Houzel et al., 2014; Battaglia et al., 2018; Spelke & Kin- zler, 2007). Our brains are able to fine-tune and retain skills across our lifetime (Benna & Fusi, 2016; Bremner et al., 2013; Stein et al., 2004; Tani & Press, 2016; Gallistel & King, 2009; Tulving, 2002; Barnett & Ceci, 2002). In contrast, deep neural networks that are trained upon new data often evidence catastrophic forgetting, where performance deteriorates on the original task because the new information interferes with previously learned behavior (Mcclelland et al., 1995; McCloskey & Cohen, 1989; Parisi et al., 2018).
人类针对不同任务在生物硬件中进化出了高度优化且特定的处理通路 (Von Neumann et al., 2000; Marcus et al., 2014; Kennedy, 2000)。例如,人类可以轻松地边走路边说话,但边阅读边说话则需要耗费更多认知资源 (Stroop, 1935)。这表明网络的组织方式与归纳偏置 (inductive biases) 和网络规模同等重要 (Herculano-Houzel et al., 2014; Battaglia et al., 2018; Spelke & Kinzler, 2007)。人脑能够在一生中持续微调并保持各项技能 (Benna & Fusi, 2016; Bremner et al., 2013; Stein et al., 2004; Tani & Press, 2016; Gallistel & King, 2009; Tulving, 2002; Barnett & Ceci, 2002)。相比之下,基于新数据训练的深度神经网络常出现灾难性遗忘现象——由于新信息干扰已习得行为,导致模型在原任务上的性能急剧下降 (Mcclelland et al., 1995; McCloskey & Cohen, 1989; Parisi et al., 2018)。
The point of these examples is not to convince you that deep neural networks are not the way forward. But, rather that there are clearly other models of intelligence which suggest it may not be the only way. It is possible that the next breakthrough will require a fundamentally different way of modelling the world with a different combination of hardware, software and algorithm. We may very well be in the midst of a present day hardware lottery.
这些例子的目的并非要说服你深度神经网络不是未来的方向。而是想说明,显然还存在其他智能模型,表明它可能并非唯一途径。下一次突破很可能需要一种结合不同硬件、软件和算法的、根本性差异的世界建模方式。我们很可能正身处一场当代的硬件彩票中。
6 The Way Forward
6 前进之路
Any machine coding system should be judged quite largely from the point of view of how easy it is for the operator to obtain results.
任何机器编码系统都应主要从操作员获取结果的便捷性角度进行评估。
John Mauchly, 1973.
John Mauchly, 1973.
Scientific progress occurs when there is a confluence of factors which allows the scientist to overcome the "stickyness" of the existing paradigm. The speed at which paradigm shifts have happened in AI research have been disproportionately determined by the degree of alignment between hardware, software and algorithm. Thus, any attempt to avoid hardware lotteries must be concerned with making it cheaper and less timeconsuming to explore different hardwaresoftware-algorithm combinations.
科学进步的发生,源于多种因素的汇聚使科学家得以突破现有范式的"粘滞性"。AI研究中的范式转变速度,很大程度上取决于硬件、软件与算法之间的协同程度。因此,任何避免硬件彩票( hardware lottery )的尝试,都必须致力于降低探索不同硬件-软件-算法组合的成本与耗时。
This is easier said than done. Expanding the search space of possible hardware-softwarealgorithm combinations is a formidable goal. It is expensive to explore new types of hardware, both in terms of time and capital required. Producing a next generation chip typically costs $\$$30-80 million dollars and takes 2-3 years to develop (Feldman, 2019). The fixed costs alone of building a manufacturing plant are enormous; estimated at $\$$7billion dollars in 2017 (Thompson & Spanuth, 2018).
说起来容易做起来难。扩大可能的硬件-软件算法组合的搜索空间是一个艰巨的目标。探索新型硬件成本高昂,无论是时间还是资金需求。生产下一代芯片通常需要花费3000万至8000万美元,并耗时2-3年开发 (Feldman, 2019)。仅建设制造厂的固定成本就十分巨大;2017年估计为70亿美元 (Thompson & Spanuth, 2018)。
Experiments using reinforcement learning to optimize chip placement may help decrease cost (Mirhoseini et al., 2020). There is also renewed interest in re-configurable hardware such as field program gate array (FPGAs) (Hauck & DeHon, 2007) and coarse-grained re configurable arrays (CGRAs) (Prabhakar et al., 2017). These devices allow the chip logic to be re-configured to avoid being locked into a single use case. However, the trade-off for flexibility is far higher FLOPS and the need for tailored software development. Coding even simple algorithms on FPGAs remains very painful and time consuming (Shalf, 2020).
使用强化学习优化芯片布局的实验可能有助于降低成本 (Mirhoseini et al., 2020)。现场可编程门阵列 (FPGA) (Hauck & DeHon, 2007) 和粗粒度可重构阵列 (CGRA) (Prabhakar et al., 2017) 等可重构硬件也重新受到关注。这些设备允许重新配置芯片逻辑,避免局限于单一用例。然而,灵活性的代价是更高的浮点运算量 (FLOPS) 和定制化软件开发需求。在FPGA上编写简单算法仍然非常痛苦且耗时 (Shalf, 2020)。
In the short to medium term hardware development is likely to remain expensive. The cost of producing hardware is important because it determines the amount of risk and experimentation hardware developers are willing to tolerate. Investment in hardware tailored to deep neural networks is assured because neural networks are a cornerstone of enough commercial use cases. The widespread profitability of deep learning has spurred a healthy ecosystem of hardware startups that aim to further accelerate deep neural networks (Metz, 2018) and has encouraged large companies to develop custom hardware in-house (Falsafi et al., 2017; Jouppi et al., 2017; Lee & Wang, 2018).
中短期内硬件开发可能仍将保持高昂成本。硬件生产成本至关重要,因为它决定了硬件开发者愿意承担的风险和实验规模。针对深度神经网络(deep neural networks)定制硬件的投资是有保障的,因为神经网络已成为众多商业应用场景的基石。深度学习的广泛盈利能力催生了一个活跃的硬件初创企业生态圈,这些企业致力于进一步加速深度神经网络的发展(Metz, 2018),同时也推动了大公司内部定制硬件的研发(Falsafi et al., 2017; Jouppi et al., 2017; Lee & Wang, 2018)。
The bottleneck will continue to be funding hardware for use cases that are not immediately commercially viable. These more risky directions include biological hardware (Tan et al., 2007; Macía & Sole, 2014; Kriegman et al., 2020), analog hard- ware with in-memory computation (Ambrogio et al., 2018), neuro m orphic computing (Davies, 2019), optical computing (Lin et al., 2018), and quantum computing based approaches (Cross et al., 2019). There are also high risk efforts to explore the development of transistors using new materials (Colwell, 2013; Nikonov & Young, 2013).
硬件资金瓶颈将持续存在于那些无法立即商业化的应用场景中。这些高风险方向包括:生物硬件 (Tan et al., 2007; Macía & Sole, 2014; Kriegman et al., 2020) 、支持内存计算的模拟硬件 (Ambrogio et al., 2018) 、神经形态计算 (Davies, 2019) 、光计算 (Lin et al., 2018) 以及基于量子计算的方法 (Cross et al., 2019) 。此外还有使用新材料开发晶体管的高风险尝试 (Colwell, 2013; Nikonov & Young, 2013) 。
Lessons from previous hardware lotteries suggest that investment must be sustained and come from both private and public funding programs. There is a slow awakening of public interest in providing such dedicated resources, such as the 2018 DARPA Electronics Resurgence Initiative which has committed to 1.5 billion dollars in funding for micro electronic technology research (DARPA, 2018). China has also announced a 47 billion dollar fund to support semiconductor research (Kubota, 2018). However, even investment of this magnitude may still be woefully inadequate, as hardware based on new materials requires long lead times of 10-20 years and public investment is currently far below industry levels of R&D (Shalf, 2020).
以往硬件抽奖的教训表明,投资必须持续且来自私营和公共资金项目。公众对提供此类专用资源的兴趣正在缓慢觉醒,例如2018年DARPA电子复兴计划承诺投入15亿美元用于微电子技术研究 (DARPA, 2018)。中国也宣布设立470亿美元基金支持半导体研究 (Kubota, 2018)。然而,即使这种规模的投资可能仍远远不足,因为基于新材料的硬件需要10-20年的长周期,而目前公共投资远低于行业研发水平 (Shalf, 2020)。

Figure 7: Byte magazine cover, March 1979, volume 4. Hardware design remains risk adverse due to the large amount of capital and time required to fabricate each new generation of hardware.
图 7: Byte杂志1979年3月第4期封面。由于每代新硬件制造需要投入大量资金和时间,硬件设计仍趋于规避风险。
6.1 A Software Revolution
6.1 一场软件革命
An interim goal should be to provide better feedback loops to researchers about how our algorithms interact with the hardware we do have. Machine learning researchers do not spend much time talking about how hardware chooses which ideas succeed and which fail. This is primarily because it is hard to quantify the cost of being concerned. At present, there are no easy and cheap to use interfaces to benchmark algorithm performance against multiple types of hardware at once. There are frustrating differences in the subset of software operations supported on different types of hardware which prevent the portability of algorithms across hardware types (Hotel et al., 2014). Software kernels are often overly optimized for a specific type of hardware which causes large disc re pen cie s in efficiency when used with different hardware (Hennessy, 2019).
一个阶段性目标应该是为研究人员提供更好的反馈循环,让他们了解我们的算法如何与现有硬件交互。机器学习研究者很少讨论硬件如何决定哪些想法成功或失败,这主要是因为量化关注成本很困难。目前还没有简便廉价的方法能同时针对多种硬件类型对算法性能进行基准测试。不同硬件支持的软件操作子集存在令人沮丧的差异,阻碍了算法跨硬件类型的可移植性 (Hotel et al., 2014)。软件内核通常针对特定硬件类型过度优化,导致在不同硬件上使用时效率差异巨大 (Hennessy, 2019)。
These challenges are compounded by an ever more formidable and heterogeneous hardware landscape (Reddi et al., 2020; Fursin et al., 2016). As the hardware landscape be- comes increasingly fragmented and specialized, fast and efficient code will require ever more niche and specialized skills to write (Lee et al., 2011). This means that there will be increasingly uneven gains from progress in computer science research. While some types of hardware will benefit from a healthy software ecosystem, progress on other languages will be sporadic and often stymied by a lack of critical end users (Thompson & Spanuth, 2018; Leiserson et al., 2020).
这些挑战因日益复杂且异构的硬件环境而加剧 (Reddi et al., 2020; Fursin et al., 2016) 。随着硬件环境日趋碎片化和专业化,编写快速高效的代码将需要更加小众和专业的技能 (Lee et al., 2011) 。这意味着计算机科学研究的进步将带来日益不均衡的收益。虽然某些类型的硬件将受益于健康的软件生态系统,但其他语言的进展将时断时续,并常常因缺乏关键终端用户而受阻 (Thompson & Spanuth, 2018; Leiserson et al., 2020) 。
One way to mitigate this need for specialized software expertise is to focus on the development of domain-specific languages which cater to a narrow domain. While you give up expressive power, domain-specific languages permit greater portability across different types of hardware. It allows developers to focus on the intent of the code without worrying about implementation details. (Olukotun, 2014; Mernik et al., 2005; Cong et al., 2011). Another promising direction is automatically auto-tuning the algorithmic parameters of a program based upon the downstream choice of hardware. This facilitates easier deployment by tailoring the program to achieve good performance and load balancing on a variety of hardware (Dongarra et al., 2018; Clint Whaley et al., 2001; Asanović et al., 2006; Ansel et al., 2014).
缓解这种对专业软件知识需求的一种方法是专注于开发针对特定领域的领域特定语言 (domain-specific languages)。虽然牺牲了表达能力,但领域特定语言能在不同类型的硬件上实现更好的可移植性。这让开发者可以专注于代码的意图,而无需担心实现细节 (Olukotun, 2014; Mernik et al., 2005; Cong et al., 2011)。另一个有前景的方向是根据下游硬件选择自动调整程序的算法参数。通过定制程序以在各种硬件上实现良好性能和负载均衡,这有助于更轻松的部署 (Dongarra et al., 2018; Clint Whaley et al., 2001; Asanović et al., 2006; Ansel et al., 2014)。
The difficulty of both these approaches is that if successful, this further abstracts humans from the details of the implementation. In parallel, we need better profiling tools to allow researchers to have a more informed opinion about how hardware and software should evolve. Ideally, software could even surface recommendations about what type of hardware to use given the configuration of an algorithm. Registering what differs from our expectations remains a key catalyst in driving new scientific discoveries.
这两种方法的难点在于,若取得成功,将进一步使人类远离实现细节。与此同时,我们需要更优的性能分析工具,让研究人员能更明智地判断硬件与软件应如何演进。理想情况下,软件甚至能根据算法配置推荐适用的硬件类型。记录与预期不符的现象,始终是推动新科学发现的关键催化剂。
Software needs to do more work, but it is also well positioned to do so. We have neglected efficient software throughout the era of Moore’s law, trusting that predictable gains in compute would compensate for inefficiencies in the software stack. This means there are many low hanging fruit as we begin to optimize for more efficient code (Larus, 2009; Xu et al., 2010).
软件需要承担更多工作,但它也完全具备这样的能力。在摩尔定律时代,我们始终忽视高效软件开发,盲目相信可预测的算力增长能弥补软件栈的低效问题。这意味着当我们开始优化代码效率时,存在大量唾手可得的改进机会 (Larus, 2009; Xu et al., 2010)。
7 Conclusion
7 结论
George Gilder, an American investor, described the computer chip as “inscribing worlds on grains of sand” (Gilder, 2000). The performance of an algorithm is fundamentally intertwined with the hardware and software it runs on. This essay proposes the term hardware lottery to describe how these downstream choices determine whether a research idea succeeds or fails. Today the hardware landscape is increasingly heterogeneous. This essay posits that the hardware lottery has not gone away, and the gap between the winners and losers will grow increasingly larger. In order to avoid future hardware lotteries, we need to make it easier to quantify the opportunity cost of settling for the hardware and software we have.
美国投资者George Gilder曾将计算机芯片描述为"在沙粒上铭刻世界" (Gilder, 2000)。算法的性能从根本上与其运行的硬件和软件紧密相连。本文提出"硬件彩票(hardware lottery)"这一术语,用以描述这些下游选择如何决定研究理念的成败。如今硬件格局日益多样化。本文认为硬件彩票现象并未消失,赢家与输家之间的差距将变得越来越大。为避免未来的硬件彩票,我们需要更轻松地量化安于现有硬件和软件的机会成本。
8 Acknowledgments
8 致谢
Thank you to many of my wonderful colleagues and peers who took time to provide valuable feedback on earlier versions of this essay. In particular, I would like to acknowledge the valuable input of Utku Evci, Erich Elsen, Melissa Fabros, Amanda Su, Simon Kornblith, Cliff Young, Eric Jang, Sean McPherson, Jonathan Frankle, Carles Gelada, David Ha, Brian Spiering, Samy Bengio, Stephanie Sher, Jonathan Binas, Pete Warden, Sean Mcpherson, Laura Florescu, Jacques Pienaar, Chip Huyen, Ra- ziel Alvarez, Dan Hurt and Kevin Swersky. Thanks for the institutional support and encouragement of Natacha Mainville and Alexander Popper.
感谢我的许多优秀同事和同行,他们抽出时间为本文的早期版本提供了宝贵反馈。特别感谢 Utku Evci、Erich Elsen、Melissa Fabros、Amanda Su、Simon Kornblith、Cliff Young、Eric Jang、Sean McPherson、Jonathan Frankle、Carles Gelada、David Ha、Brian Spiering、Samy Bengio、Stephanie Sher、Jonathan Binas、Pete Warden、Sean Mcpherson、Laura Florescu、Jacques Pienaar、Chip Huyen、Raziel Alvarez、Dan Hurt 和 Kevin Swersky 的宝贵意见。同时感谢 Natacha Mainville 和 Alexander Popper 的机构支持与鼓励。
References
参考文献
Ambrogio, S., Narayanan, P., Tsai, H., Shelby, R., Boybat, I., Nolfo, C., Sidler, S., Giordano, M., Bodini, M., Farinha, N., Killeen, B., Cheng, C., Jaoudi, Y., and Burr, G. Equivalent-accuracy accelerated neural-network training using analogue memory. Nature, 558, 06 2018. doi: 10.1038/ s41586-018-0180-5.
Ambrogio, S., Narayanan, P., Tsai, H., Shelby, R., Boybat, I., Nolfo, C., Sidler, S., Giordano, M., Bodini, M., Farinha, N., Killeen, B., Cheng, C., Jaoudi, Y., and Burr, G. 基于模拟存储器的等效精度加速神经网络训练. Nature, 558, 06 2018. doi: 10.1038/s41586-018-0180-5.
Amodei, D., Hernandez, D., Sastry, G., Clark, J., Brockman, G., and Sutskever, I. Ai and compute, 2018. URL https://openai.com/ blog/ai-and-compute/.
Amodei, D., Hernandez, D., Sastry, G., Clark, J., Brockman, G., and Sutskever, I. AI与算力, 2018. URL https://openai.com/blog/ai-and-compute/.
Ansel, J., Kamil, S., Veera mach an eni, K., Ragan-Kelley, J., Bosboom, J., O’Reilly, U.- M., and Amara sing he, S. Opentuner: An extensible framework for program autotuning. In Proceedings of the 23rd International Conference on Parallel Architectures and Compilation, PACT ’14, pp. 303–316, New York, NY, USA, 2014. Association for Computing Machinery. ISBN 9781450328098. doi: 10.1145/2628071.2628092. URL doi.org/10.1145/2628071.2628092.
Ansel, J., Kamil, S., Veera mach an eni, K., Ragan-Kelley, J., Bosboom, J., O’Reilly, U.- M., 和 Amara sing he, S. OpenTuner: 一个可扩展的程序自动调优框架。载于《第23届国际并行架构与编译技术会议论文集》(PACT '14),第303–316页,美国纽约州,2014年。计算机协会。ISBN 9781450328098。doi: 10.1145/2628071.2628092。URL https://doi.org/10.1145/2628071.2628092。
ARM. Enhancing ai performance for iot endpoint devices, 2020. URL https: //www.arm.com/company/news/2020/ 02/new-ai-technology-from-arm.
ARM. 提升物联网终端设备的AI性能, 2020. URL https: //www.arm.com/company/news/2020/ 02/new-ai-technology-from-arm.
Asanovic, K. Accelerating ai: Past, present, and future, 2018. URL https://www.youtube. com/watch?v $=$ 8 n 2 H Lp 2 gt Ys&t $=$ 2116s.
Asanovic, K. 加速AI:过去、现在与未来, 2018. URL https://www.youtube.com/watch?v=8n2HLp2gtYs&t=2116s.
Asanovic, K., Bodik, R., Catanzaro, B. C. Gebis, J. J., Husbands, P., Keutzer, K., Patterson, D. A., Plishker, W. L., Shalf, J., Williams, S. W., and Yelick, K. A. The landscape of parallel computing research: A view from berkeley. Technical Report UCB/EECS2006-183, EECS Department, University of California, Berkeley, Dec 2006. URL http: //www2.eecs.berkeley.edu/Pubs/ TechRpts/2006/EECS-2006-183.html.
Asanovic, K., Bodik, R., Catanzaro, B. C. Gebis, J. J., Husbands, P., Keutzer, K., Patterson, D. A., Plishker, W. L., Shalf, J., Williams, S. W., and Yelick, K. A. 并行计算研究的全景:来自伯克利的视角。技术报告 UCB/EECS2006-183,电子工程与计算机科学系,加州大学伯克利分校,2006年12月。URL http://www2.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html。
Barham, P. and Isard, M. Machine learning systems are stuck in a rut. In Proceedings of the Workshop on Hot Topics in Operating Systems, HotOS ’19, pp. 177–183, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450367271. doi: 10.1145/3317550.3321441. URL doi.org/10.1145/3317550.3321441.
Barham, P. 和 Isard, M. 机器学习系统陷入困境。载于《操作系统热点议题研讨会论文集》,HotOS '19,第177-183页,美国纽约州纽约市,2019年。计算机协会。ISBN 9781450367271。doi: 10.1145/3317550.3321441。URL https://doi.org/10.1145/3317550.3321441。
Barnett, S. M. and Ceci, S. When and where do we apply what we learn? a taxonomy for far transfer. Psychological bulletin, 128 4:612– 37, 2002.
Barnett, S. M. 和 Ceci, S. 我们何时何地应用所学知识?远迁移的分类法。Psychological bulletin, 128 4:612–37, 2002.
Battaglia, P. W., Hamrick, J. B., Bapst, V., Sanchez-Gonzalez, A., Zambaldi, V. F., Ma- linowski, M., Tacchetti, A., Raposo, D., Santoro, A., Faulkner, R., Gülçehre, Ç., Song, H. F., Ballard, A. J., Gilmer, J., Dahl, G. E., Vaswani, A., Allen, K. R., Nash, C., Langston, V., Dyer, C., Heess, N., Wierstra, D., Kohli, P., Botvinick, M., Vinyals, O., Li, Y., and Pascanu, R. Relational inductive biases, deep learning, and graph networks. CoRR, abs/1806.01261, 2018. URL http://arxiv.org/abs/1806.01261.
Battaglia, P. W., Hamrick, J. B., Bapst, V., Sanchez-Gonzalez, A., Zambaldi, V. F., Malinowski, M., Tacchetti, A., Raposo, D., Santoro, A., Faulkner, R., Gülçehre, Ç., Song, H. F., Ballard, A. J., Gilmer, J., Dahl, G. E., Vaswani, A., Allen, K. R., Nash, C., Langston, V., Dyer, C., Heess, N., Wierstra, D., Kohli, P., Botvinick, M., Vinyals, O., Li, Y., and Pascanu, R. 关系归纳偏差、深度学习与图网络。CoRR, abs/1806.01261, 2018. URL http://arxiv.org/abs/1806.01261.
Benna, M. and Fusi, S. Computational principles of synaptic memory consolidation. Nature Neuroscience, 19, 10 2016. doi: 10.1038/ nn.4401.
Benna, M. 和 Fusi, S. 突触记忆巩固的计算原理。Nature Neuroscience, 19, 10 2016. doi: 10.1038/nn.4401.
Bi, G.-q. and Poo, M.-m. Synaptic modifications in cultured hippo camp al neurons: Dependence on spike timing, synaptic strength, and post synaptic cell type. Journal of Neuroscience, 18(24):10464–10472, 1998. ISSN 0270-6474. doi: 10.1523/JNEUROSCI. 18-24-10464.1998. URL https://www. jneurosci.org/content/18/24/10464.
Bi, G.-q. 和 Poo, M.-m. 培养海马神经元中的突触可塑性:依赖于放电时序、突触强度和突触后细胞类型。Journal of Neuroscience, 18(24):10464–10472, 1998. ISSN 0270-6474. doi: 10.1523/JNEUROSCI. 18-24-10464.1998. URL https://www. jneurosci.org/content/18/24/10464.
Bremner, A., Lewkowicz, D., and Spence, C. Multi sensory development, 11 2013.
Bremner, A., Lewkowicz, D., 和 Spence, C. 多感官发展, 11 2013.
Brodtkorb, A. R., Hagen, T. R., and Sætra, M. L. Graphics processing unit (gpu) programming strategies and trends in gpu computing. Journal of Parallel and Distributed Computing, 73(1):4 – 13, 2013. ISSN 0743-7315.doi:https://doi.org/10.1016/j.jpdc.2012.04.003. URL http: //www.science direct.com/science/ article/pii/S0743731512000998. Meta heuristics on GPUs.
Brodtkorb, A. R., Hagen, T. R., and Sætra, M. L. 图形处理器 (GPU) 编程策略与GPU计算趋势. 并行与分布式计算杂志, 73(1):4–13, 2013. ISSN 0743-7315. doi:https://doi.org/10.1016/j.jpdc.2012.04.003. URL http://www.sciencedirect.com/science/article/pii/S0743731512000998. GPU上的元启发式算法.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neel a kant an, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCand lish, S., Radford, A., Sutskever, I., and Amodei, D. Language Models are Few-Shot Learners. arXiv e-prints, May 2020.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. 语言模型是少样本学习者。arXiv e-prints, 2020年5月。
Bubic, A., Von Cramon, D. Y., and Schubotz, R. Prediction, cognition and the brain. Frontiers in Human Neuroscience, 4:25, 2010. ISSN 1662-5161. doi: 10.3389/fnhum.2010.00025. URL https://www.frontiers in.org/ article/10.3389/fnhum.2010.00025.
Bubic, A., Von Cramon, D. Y., and Schubotz, R. 预测、认知与大脑. Frontiers in Human Neuroscience, 4:25, 2010. ISSN 1662-5161. doi: 10.3389/fnhum.2010.00025. URL https://www.frontiersin.org/article/10.3389/fnhum.2010.00025.
Chell a pill a, K., Puri, S., and Simard, P. High performance convolutional neural networks for document processing, 10 2006.
Chell a pill a, K., Puri, S., 和 Simard, P. 高性能卷积神经网络在文档处理中的应用,10 2006。
CHM. Moore’s law, 2020. URL https://www.computer history.org/ revolution/digital-logic/12/267.
CHM. 摩尔定律, 2020. URL https://www.computer history.org/ revolution/digital-logic/12/267.
Ciresan, D., Meier, U., Masci, J., Gamba r della, L. M., and Schmid huber, J. Flexible, high performance convolutional neural networks for image classification. International Joint Conference on Artificial Intelligence IJCAI2011, pp. 1237–1242, 07 2011. doi: 10.5591/ 978-1-57735-516-8/IJCAI11-210.
Ciresan, D., Meier, U., Masci, J., Gambardella, L. M., and Schmidhuber, J. 面向图像分类的高性能灵活卷积神经网络。国际人工智能联合会议IJCAI2011,第1237–1242页,2011年7月。doi: 10.5591/978-1-57735-516-8/IJCAI11-210。
Cross, A. W., Bishop, L. S., Sheldon, S., Nation, P. D., and Gambetta, J. M. Validating quantum computers using randomized model circuits, September 2019.
Cross, A. W., Bishop, L. S., Sheldon, S., Nation, P. D., and Gambetta, J. M. 使用随机模型电路验证量子计算机,2019年9月。
DARPA. Darpa announces next phase of electronics resurgence initiative, 2018. URL https://www.darpa.mil/news-events/ 2018-11-01a.
DARPA宣布电子复兴计划下一阶段,2018年。URL https://www.darpa.mil/news-events/2018-11-01a。
Davies, M. Progress in neuro m orphic computing : Drawing inspiration from nature for gains in ai and computing. In 2019 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), pp. 1–1, 2019.
Davies, M. 神经形态计算的进展:从自然中汲取灵感以提升AI与计算性能。见2019年国际超大规模集成电路设计、自动化与测试研讨会(VLSI-DAT),第1–1页,2019。
Claudiu Ciresan, D., Meier, U., Gamba r della, L. M., and Schmid huber, J. Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition. arXiv e-prints, art. arXiv:1003.0358, March 2010.
Claudiu Ciresan, D., Meier, U., Gambardella, L. M., and Schmidhuber, J. 深度大型简单神经网络在手写数字识别中的卓越表现。arXiv预印本,文献编号 arXiv:1003.0358,2010年3月。
Clint Whaley, R., Petitet, A., and Dongarra, J. J. Automated empirical optimization s of software and the atlas project. Parallel Computing, 27(1):3 – 35, 2001. ISSN 0167-8191. doi: https://doi.org/10.1016/ S0167-8191(00)00087-9. URL http: //www.science direct.com/science/ article/pii/S0167819100000879. New Trends in High Performance Computing.
Clint Whaley、R.、Petitet、A. 和 Dongarra、J. J. 软件与 ATLAS 项目的自动化经验优化。并行计算,27(1):3–35,2001。ISSN 0167-8191。doi: https://doi.org/10.1016/S0167-8191(00)00087-9。URL http://www.sciencedirect.com/science/article/pii/S0167819100000879。高性能计算的新趋势。
Coates, A., Huval, B., Wang, T., Wu, D., Catanzaro, B., and Andrew, N. Deep learning with cots hpc systems. In Dasgupta, S. and McAllester, D. (eds.), Proceedings of the 30th International Conference on Machine Learning, volume 28 of Proceedings of Machine Learning Research, pp. 1337– 1345, Atlanta, Georgia, USA, 17–19 Jun 2013. PMLR. URL http://proceedings. mlr.press/v28/coates13.html.
Coates, A., Huval, B., Wang, T., Wu, D., Catanzaro, B., and Andrew, N. 基于商用高性能计算系统的深度学习。见 Dasgupta, S. 和 McAllester, D. (编), 《第30届国际机器学习会议论文集》, 机器学习研究论文集第28卷, 第1337–1345页, 美国佐治亚州亚特兰大, 2013年6月17–19日. PMLR. 网址 http://proceedings.mlr.press/v28/coates13.html.
Collier, B. Little Engines That Could’ve: The Calculating Machines of Charles Babbage. Garland Publishing, Inc., USA, 1991. ISBN 0824000439.
Collier, B. 可能的小引擎:查尔斯·巴贝奇的计算机器. Garland Publishing, Inc., 美国, 1991. ISBN 0824000439.
Collobert, R., Bengio, S., and Marithoz, J. Torch: A modular machine learning software library, 11 2002.
Collobert, R., Bengio, S., 和 Marithoz, J. Torch: 模块化机器学习软件库, 11 2002.
Colwell, R. The chip design game at the end of moore’s law. In 2013 IEEE Hot Chips 25 Symposium (HCS), pp. 1–16, 2013.
Colwell, R. 摩尔定律终结时的芯片设计博弈。见:2013年IEEE第25届Hot Chips研讨会(HCS),第1-16页,2013年。
Cong, J., Sarkar, V., Reinman, G., and Bui, A. Customizable domain-specific computing. IEEE Design Test of Computers, 28(2):6–15, 2011.
Cong, J., Sarkar, V., Reinman, G., and Bui, A. 可定制领域专用计算. IEEE Design Test of Computers, 28(2):6–15, 2011.
Dean, J. Parallel implementations of neural network training: two backpropagation approaches., 1990. URL https://drive.google.com/file/d/ 1 I 1 fs 4 s cz bCa A Cz A 9 X w x R 3 Diu XV t q mej L/ view.
Dean, J. 神经网络训练的并行实现:两种反向传播方法, 1990. URL https://drive.google.com/file/d/ 1 I 1 fs 4 s cz bCa A Cz A 9 X w x R 3 Diu XV t q mej L/ view.
Dean, J. 1.1 the deep learning revolution and its implications for computer architecture and chip design. 2020 IEEE International SolidState Circuits Conference - (ISSCC), pp. 8– 14, 2020.
Dean, J. 1.1 深度学习革命及其对计算机架构和芯片设计的影响。2020 IEEE 国际固态电路会议 - (ISSCC),第 8–14 页,2020。
Demuth, H. and Beale, M. Neural network toolbox for use with matlab - user guide verion 3.0, 1993.
Demuth, H. 和 Beale, M. 用于 MATLAB 的神经网络工具箱 - 用户指南第 3.0 版, 1993.
Dennard, R. H., Gaensslen, F. H., Yu, H., Ride- out, V. L., Bassous, E., and LeBlanc, A. R. Design of ion-implanted mosfet’s with very small physical dimensions. IEEE Journal of Solid-State Circuits, 9(5):256–268, 1974.
Dennard, R. H., Gaensslen, F. H., Yu, H., Ride-out, V. L., Bassous, E., and LeBlanc, A. R. 离子注入型极小尺寸MOSFET的设计. IEEE Journal of Solid-State Circuits, 9(5):256–268, 1974.
Dettmers, T. Which gpu for deep learning?, 2020. URL https://bit.ly/35qq8xe.
Dettmers, T. 深度学习该用哪种GPU?, 2020. URL https://bit.ly/35qq8xe.
Diamond, J., Diamond, P., and Collection, B. H. Guns, Germs, and Steel: The Fates of Human Societies. National bestseller / W.W. Norton & Company. W.W. Norton, 1999. ISBN 9780393317558. URL https://books. google.com/books?id $=$ 1 lB u bq S s SMC.
钻石, J., 钻石, P., 和收藏, B. H. 枪炮、病菌与钢铁: 人类社会的命运. 全国畅销书 / W.W. Norton & Company. W.W. Norton, 1999. ISBN 9780393317558. URL https://books.google.com/books?id=1lBubqSsSMC.
Dongarra, J., Gates, M., Kurzak, J., Luszczek, P., and Tsai, Y. M. Autotuning numerical dense linear algebra for batched computation with gpu hardware accelerators. Proceedings of the IEEE, 106(11):2040–2055, 2018.
Dongarra, J., Gates, M., Kurzak, J., Luszczek, P., 和 Tsai, Y. M. 面向GPU硬件加速器的批量计算数值密集线性代数自动调优。Proceedings of the IEEE, 106(11):2040–2055, 2018.
Eagleman, D. M. and Sejnowski, T. J. Motion integration and post diction in visual awareness. Science, 287(5460):2036– 2038, 2000. ISSN 0036-8075. doi: 10.1126/science.287.5460.2036. URL https://science.sciencemag.org/ content/287/5460/2036.
Eagleman, D. M. 和 Sejnowski, T. J. 视觉意识中的运动整合与后预测。Science, 287(5460):2036–2038, 2000. ISSN 0036-8075. doi: 10.1126/science.287.5460.2036. URL https://science.sciencemag.org/content/287/5460/2036.
Elsen, E., Dukhan, M., Gale, T., and Simonyan, K. Fast sparse convnets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
Elsen, E., Dukhan, M., Gale, T., and Simonyan, K. 快速稀疏卷积网络。见:IEEE/CVF计算机视觉与模式识别会议 (CVPR) 论文集,2020年6月。
Gilder, G. Telecosm: How Infinite Bandwidth Will Revolutionize Our World. Free Press, 2000. ISBN 9780743215947. URL https://books.google.com/books?id= Kzo-KTxdwcEC.
Gilder, G. 《电信宇宙:无限带宽将如何革新我们的世界》。自由出版社,2000年。ISBN 9780743215947。URL https://books.google.com/books?id=Kzo-KTxdwcEC。
Gray, S., Radford, A., and Kingma, D. P. Gpu kernels for block-sparse weights, 2017.
Gray, S., Radford, A., and Kingma, D. P. 块稀疏权重的 GPU 内核, 2017.
Evci, U., Gale, T., Menick, J., Castro, P. S., and Elsen, E. Rigging the Lottery: Making All Tickets Winners. arXiv e-prints, November 2019.
Evci, U., Gale, T., Menick, J., Castro, P. S., 以及 Elsen, E. 《操纵彩票:让所有彩票都中奖》。arXiv 电子版,2019 年 11 月。
Falsafi, B., Dally, B., Singh, D., Chiou, D., Yi, J. J., and Sendag, R. Fpgas versus gpus in data centers. IEEE Micro, 37(1):60–72, 2017.
Falsafi, B., Dally, B., Singh, D., Chiou, D., Yi, J. J., and Sendag, R. 数据中心中的FPGA与GPU对比。IEEE Micro, 37(1):60–72, 2017.
Fatahalian, K., Sugerman, J., and Hanrahan, P. Understanding the efficiency of gpu algorithms for matrix-matrix multip li cation. In Proceedings of the ACM SIGGRAPH/EURO GRAPHICS Confer- ence on Graphics Hardware, HWWS ’04, pp. 133–137, New York, NY, USA, 2004. Association for Computing Machinery.ISBN 3905673150.doi:10.1145/1058129.1058148. URL https: //doi.org/10.1145/1058129.1058148.
Fatahalian, K., Sugerman, J., 和 Hanrahan, P. 理解 GPU 算法在矩阵-矩阵乘法中的效率。见《ACM SIGGRAPH/EUROGRAPHICS 图形硬件会议论文集》, HWWS '04, 第 133–137 页, 美国纽约, 2004. 计算机协会. ISBN 3905673150. doi:10.1145/1058129.1058148. URL https://doi.org/10.1145/1058129.1058148.
Feldman, M. The era of general purpose computers is ending, 2019. URL https://bit. ly/3hP8XJh.
Feldman, M. 通用计算机时代即将终结, 2019. URL https://bit.ly/3hP8XJh.
Fukushima, K. and Miyake, S. Neo cog nitro n: A new algorithm for pattern recognition tolerant of deformations and shifts in position. Pattern Recognition, 15(6):455 469, 1982. ISSN 0031-3203. URL http: //www.science direct.com/science/ article/pii/0031320382900243.
Fukushima, K. 和 Miyake, S. Neo cog nitro n: 一种对形变和位置偏移具有容忍度的新型模式识别算法。《模式识别》,15(6):455-469,1982年。ISSN 0031-3203。URL http://www.sciencedirect.com/science/article/pii/0031320382900243。
Fursin, G., Lokhmotov, A., and Plowman, E. Collective knowledge: Towards r d sustainability. In 2016 Design, Automation Test in Europe Conference Exhibition (DATE), pp. 864–869, 2016.
Fursin, G., Lokhmotov, A., 和 Plowman, E. 集体知识:迈向研发可持续性。见于2016年欧洲设计自动化与测试大会展览 (DATE),第864–869页,2016年。
Gupta, S. and Tan, M. Efficient net-edgetpu: Creating accelerator-optimized neural networks with automl, 2019. URL https://ai.googleblog.com/2019/08/ efficient net-edgetpu-creating.html.
Gupta, S. 和 Tan, M. EfficientNet-EdgeTPU: 利用AutoML创建加速器优化的神经网络, 2019. URL https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html.
Hauck, S. and DeHon, A. Re configurable Computing: The Theory and Practice of FPGABased Computation. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2007. ISBN 9780080556017.
Hauck, S. 和 DeHon, A. 《可重构计算:基于FPGA的计算理论与实践》。Morgan Kaufmann Publishers Inc.,美国加州旧金山,2007年。ISBN 9780080556017。
Haugeland, J. Artificial Intelligence: The Very Idea. Massachusetts Institute of Technology, USA, 1985. ISBN 0262081539.
Haugeland, J. 《人工智能:基本概念》(Artificial Intelligence: The Very Idea). 美国麻省理工学院, 1985. ISBN 0262081539.
Heeger, D. J. Theory of cortical function. Proceedings of the National Academy of Sciences, 114(8):1773– 1782, 2017. ISSN 0027-8424. doi: 10.1073/pnas.1619788114. URL https: //www.pnas.org/content/114/8/1773.
Heeger, D. J. 大脑皮层功能理论。美国国家科学院院刊,114(8):1773–1782,2017。ISSN 0027-8424。doi: 10.1073/pnas.1619788114。URL https://www.pnas.org/content/114/8/1773。
Hennessy, J. The end of moore’s law, cpus (as we know them), and the rise of domain specific architectures, 2019. URL https: //www.kisa co research.com/sites/ default/files/presentations/09.00_ -alphabet-john hennessy.pdf.
Hennessy, J. 摩尔定律的终结、CPU(如我们所知)以及专用架构的崛起, 2019. URL https://www.kisa co research.com/sites/ default/files/presentations/09.00_ -alphabet-john hennessy.pdf.
Herculano-Houzel, S., de Souza, K. A., Neves, K., Porfirio, J., Messeder, D. J., Feijó, L. M., Maldonado, J., and Manger, P. R. The elephant brain in numbers. Frontiers in Neuroanatomy, 8, 2014.
Herculano-Houzel, S., de Souza, K. A., Neves, K., Porfirio, J., Messeder, D. J., Feijó, L. M., Maldonado, J., and Manger, P. R. 大象大脑的数字解析。Frontiers in Neuroanatomy, 8, 2014.
Hinton, G. E. and Anderson, J. A. Parallel Models of Associative Memory. L. Erlbaum Asso- ciates Inc., USA, 1989. ISBN 080580269X.
Hinton, G. E. 和 Anderson, J. A. 《联想记忆的并行模型》。美国 L. Erlbaum Associates 公司,1989年。ISBN 080580269X。
Gale, T., Elsen, E., and Hooker, S. The state of sparsity in deep neural networks, 2019.
Gale, T., Elsen, E., 和 Hooker, S. 深度神经网络中的稀疏性现状, 2019.
Gale, T., Zaharia, M., Young, C., and Elsen, E. Sparse GPU Kernels for Deep Learning. arXiv e-prints, June 2020.
Gale, T., Zaharia, M., Young, C., and Elsen, E. 深度学习稀疏GPU内核. arXiv e-prints, 2020年6月.
Gallistel, C. and King, A. Memory and the computational brain: Why cognitive science will transform neuroscience, 04 2009.
Gallistel, C. 和 King, A. 《记忆与计算大脑:为什么认知科学将变革神经科学》,2009年4月。
Hooker, S., Courville, A., Clark, G., Dauphin, Y., and Frome, A. What Do Compressed Deep Neural Networks Forget? arXiv e-prints, art. arXiv:1911.05248, November 2019.
Hooker, S., Courville, A., Clark, G., Dauphin, Y., and Frome, A. 压缩深度神经网络会遗忘什么?arXiv e-prints, 文献编号 arXiv:1911.05248, 2019年11月。
Horowitz, M. 1.1 computing’s energy problem (and what we can do about it). In 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), pp. 10– 14, 2014.
Horowitz, M. 1.1 计算的能源问题(以及我们的应对之策). 见: 2014 IEEE国际固态电路会议技术论文摘要(ISSCC), 第10–14页, 2014.
Hotel, H., Johansen, H., Bernholdt, D., Héroux, M., and Hornung, R. Software productivity for extreme-scale science, 2014.
Hotel, H., Johansen, H., Bernholdt, D., Héroux, M., and Hornung, R. 面向极大规模科学的软件生产力,2014。
Howe, D. B. and Asanovic, K. SPACE: Symbolic Processing in Associative Computing Elements, pp. 243–252. Springer US, Boston, MA, 1994.ISBN 978-1-4899-1331-9. doi: 10.1007/978-1-4899-1331-9 24. URL https://doi.org/10.1007/ 978-1-4899-1331-9_24.
Howe, D. B. 和 Asanovic, K. SPACE: 关联计算元件中的符号处理, 第243–252页. Springer US, 波士顿, 马萨诸塞州, 1994. ISBN 978-1-4899-1331-9. doi: 10.1007/978-1-4899-1331-9 24. URL https://doi.org/10.1007/978-1-4899-1331-9_24.
Isaacson, W. Grace hopper, computing pioneer. The Harvard Gazette, 2014. URL https://news.harvard. edu/gazette/story/2014/12/ grace-hopper-computing-pioneer/.
Isaacson, W. 计算机先驱 Grace Hopper. The Harvard Gazette, 2014. URL https://news.harvard.edu/gazette/story/2014/12/grace-hopper-computing-pioneer/.
ouppi, N. P., Young, C., Patil, N., Patterson, D., Agrawal, G., Bajwa, R., Bates, S., Bhatia, S., Boden, N., Borchers, A., Boyle, R., Cantin, P.-l., Chao, C., Clark, C., Coriell, J., Daley, M., Dau, M., Dean, J., Gelb, B., Gh aem magh ami, T. V., Gottipati, R., Gulland, W., Hagmann, R., Ho, C. R., Hogberg, D., Hu, J., Hundt, R., Hurt, D., Ibarz, J., Jaffey, A., Jaworski, A., Kaplan, A., Khaitan, H., Killebrew, D., Koch, A., Kumar, N., Lacy, S., Laudon, J., Law, J., Le, D., Leary, C., Liu, Z., Lucke, K., Lundin, A., MacKean, G., Maggiore, A., Mahony, M., Miller, K., Na- garajan, R., Narayana swami, R., Ni, R., Nix, K., Norrie, T., Omernick, M., Penukonda, N., Phelps, A., Ross, J., Ross, M., Salek, A., Samadiani, E., Severn, C., Sizikov, G., Snel- ham, M., Souter, J., Steinberg, D., Swing, A., Tan, M., Thorson, G., Tian, B., Toma, H., Tuttle, E., Vasudevan, V., Walter, R., Wang, W., Wilcox, E., and Yoon, D. H. In-datacenter performance analysis of a tensor processing unit. SIGARCH Comput. Archit. News, 45 (2):1–12, June 2017. ISSN 0163-5964. doi: 10.1145/3140659.3080246. URL doi.org/10.1145/3140659.3080246.
ouppi, N. P., Young, C., Patil, N., Patterson, D., Agrawal, G., Bajwa, R., Bates, S., Bhatia, S., Boden, N., Borchers, A., Boyle, R., Cantin, P.-l., Chao, C., Clark, C., Coriell, J., Daley, M., Dau, M., Dean, J., Gelb, B., Gh aem magh ami, T. V., Gottipati, R., Gulland, W., Hagmann, R., Ho, C. R., Hogberg, D., Hu, J., Hundt, R., Hurt, D., Ibarz, J., Jaffey, A., Jaworski, A., Kaplan, A., Khaitan, H., Killebrew, D., Koch, A., Kumar, N., Lacy, S., Laudon, J., Law, J., Le, D., Leary, C., Liu, Z., Lucke, K., Lundin, A., MacKean, G., Maggiore, A., Mahony, M., Miller, K., Na- garajan, R., Narayana swami, R., Ni, R., Nix, K., Norrie, T., Omernick, M., Penukonda, N., Phelps, A., Ross, J., Ross, M., Salek, A., Samadiani, E., Severn, C., Sizikov, G., Snel- ham, M., Souter, J., Steinberg, D., Swing, A., Tan, M., Thorson, G., Tian, B., Toma, H., Tuttle, E., Vasudevan, V., Walter, R., Wang, W., Wilcox, E., and Yoon, D. H. 张量处理单元在数据中心内的性能分析。SIGARCH计算机体系结构新闻,45(2):1–12,2017年6月。ISSN 0163-5964。doi: 10.1145/3140659.3080246。URL https://doi.org/10.1145/3140659.3080246。
CoRR, abs/1805.08974, 2018. URL http: //arxiv.org/abs/1805.08974.
CoRR, abs/1805.08974, 2018. URL http://arxiv.org/abs/1805.08974.
Krashinsky, R., Giroux, O., Jones, S., Stam, N., and Ramaswamy, S. Nvidia ampere architecture in-depth., 2020. URL https://developer.nvidia.com/blog/ nvidia-ampere-architecture-in-depth/.
Krashinsky, R., Giroux, O., Jones, S., Stam, N., 和 Ramaswamy, S. NVIDIA安培架构深度解析, 2020. URL https://developer.nvidia.com/blog/ nvidia-ampere-architecture-in-depth/.
Kriegman, S., Blackiston, D., Levin, M., and Bongard, J. A scalable pipeline for designing re configurable organisms. Proceedings of the National Academy of Sciences, 117(4): 1853–1859, 2020. ISSN 0027-8424. doi: 10.1073/pnas.1910837117. URL www.pnas.org/content/117/4/1853.
Kriegman, S., Blackiston, D., Levin, M., and Bongard, J. 可扩展的可重构生物体设计流程。《美国国家科学院院刊》(Proceedings of the National Academy of Sciences), 117(4): 1853–1859, 2020. ISSN 0027-8424. doi: 10.1073/pnas.1910837117. URL https://www.pnas.org/content/117/4/1853.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. Imagenet classification with deep convolutional neural networks, 2012. URL https: //bit.ly/2GneDwp.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. 使用深度卷积神经网络进行ImageNet分类, 2012. URL https: //bit.ly/2GneDwp.
Kubota, Y. China plans 47 billion fund to boost its semiconductor industry, 2018. URL https://on.wsj.com/32L7Kwn.
久保田洋。中国计划设立470亿美元基金以提振半导体产业,2018。URL https://on.wsj.com/32L7Kwn。
Kuhn, T. S. The Structure of Scientific Revolutions. University of Chicago Press, Chicago, 1962.
Kuhn, T. S. 科学革命的结构. University of Chicago Press, Chicago, 1962.
Kurzweil, R. The Age of Intelligent Machines. MIT Press, Cambridge, MA, USA, 1990.
Kurzweil, R. 《智能机器时代》。MIT Press,美国马萨诸塞州剑桥,1990年。
Larus, J. Spending moore’s dividend. Commun. ACM, 52(5):62–69, May 2009. ISSN 0001-0782. doi: 10.1145/1506409.1506425. URL https: //doi.org/10.1145/1506409.1506425.
Larus, J. 摩尔定律的遗产。Commun. ACM, 52(5):62–69, 2009年5月. ISSN 0001-0782. doi: 10.1145/1506409.1506425. URL https://doi.org/10.1145/1506409.1506425.
K, S. and Piske, U. Learning matrices and their applications. IEEE Transactions on Electronic Computers, EC-12(6):846–862, 1963.
K, S. 和 Piske, U. 学习矩阵及其应用。IEEE Transactions on Electronic Computers, EC-12(6):846–862, 1963。
Le, Q. V., Ranzato, M., Monga, R., Devin, M., Chen, K., Corrado, G. S., Dean, J., and $\mathrm{Ng}$ , A. Y. Building high-level features using large scale unsupervised learning. In Proceedings of the 29th International Coference on International Conference on Machine Learning, ICML’12, pp. 507–514, Madison, WI, USA, 2012. Omnipress. ISBN 9781450312851.
Le, Q. V., Ranzato, M., Monga, R., Devin, M., Chen, K., Corrado, G. S., Dean, J., 和 $\mathrm{Ng}$, A. Y. 通过大规模无监督学习构建高级特征。见《第29届国际机器学习会议论文集》(ICML'12),第507–514页,美国威斯康星州麦迪逊,2012年。Omnipress出版社。ISBN 9781450312851。
Kennedy, M. B. Signal-processing machines at the post synaptic density. Science, 290 5492: 750–4, 2000.
Kennedy, M. B. 突触后致密区的信号处理机制。Science, 290(5492): 750–4, 2000。
Lecun, Y. and Bottou, L. Technical report: Lush reference manual, code available at http://lush.sourceforge.net, 2002.
Lecun, Y. 和 Bottou, L. 技术报告: Lush参考手册, 代码可在 http://lush.sourceforge.net 获取, 2002.
Kingsbury, B., Morgan, N., and Wawrzynek, J. Hipnet-1: A highly pipelined architecture for neural network training, 03 1998.
Kingsbury、B.、Morgan、N.和Wawrzynek、J. Hipnet-1: 一种高度流水线化的神经网络训练架构, 03 1998.
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., and Jackel, L. D. Back propagation applied to handwritten zip code recognition, 1989. URL doi.org/10.1162/neco.1989.1.4.541.
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., and Jackel, L. D. 反向传播算法在手写邮政编码识别中的应用, 1989. URL https://doi.org/10.1162/neco.1989.1.4.541.
Kornblith, S., Shlens, J., and Le, Q. V. Do better imagenet models transfer better?
Kornblith, S., Shlens, J., and Le, Q. V. 更好的ImageNet模型迁移效果更好吗?
Lee, H., Brown, K., Sujeeth, A., Chafi, H., Rompf, T., Odersky, M., and Olukotun, K. Implementing domain-specific languages for heterogeneous parallel computing. IEEE Micro, 31(5):42–53, 2011.
Lee, H., Brown, K., Sujeeth, A., Chafi, H., Rompf, T., Odersky, M., and Olukotun, K. 面向异构并行计算的领域专用语言实现。IEEE Micro, 31(5):42–53, 2011.
Lee, K. and Wang, X. The next step in facebook ai hardware infrastructure, 2018. URL https://bit.ly/3bgZFDn.
Lee, K. 和 Wang, X. Facebook AI 硬件基础设施的下一步, 2018. URL https://bit.ly/3bgZFDn.
Leiserson, C. E., Thompson, N. C., Emer, J. S., Kuszmaul, B. C., Lampson, B. W., Sanchez, D., and Schardl, T. B. There’s plenty of room at the top: What will drive computer performance after moore’s law? Science, 368(6495), 2020. ISSN 0036- 8075. doi: 10.1126/science.aam9744. URL https://science.sciencemag.org/ content/368/6495/eaam9744.
Leiserson, C. E., Thompson, N. C., Emer, J. S., Kuszmaul, B. C., Lampson, B. W., Sanchez, D., 和 Schardl, T. B. 高处仍大有可为:摩尔定律之后,计算机性能将靠什么驱动?《科学》,368(6495),2020年。ISSN 0036-8075。doi: 10.1126/science.aam9744。URL https://science.sciencemag.org/content/368/6495/eaam9744。
Lillicrap, T. P. and Santoro, A. Back prop agation through time and the brain. Current Opinion in Neurobiology, 55:82 – 89, 2019. ISSN 0959-4388. doi: https://doi.org/10. 1016/j.conb.2019.01.011. URL http: //www.science direct.com/science/ article/pii/S0959438818302009. Machine Learning, Big Data, and Neuroscience.
Lillicrap, T. P. 和 Santoro, A. 通过时间和大脑的反向传播。Current Opinion in Neurobiology, 55:82 – 89, 2019. ISSN 0959-4388. doi: https://doi.org/10.1016/j.conb.2019.01.011. URL http://www.sciencedirect.com/science/article/pii/S0959438818302009. 机器学习 (Machine Learning)、大数据 (Big Data) 与神经科学。
Lin, X., Rivenson, Y., Yardimci, N. T., Veli, M., Luo, Y., Jarrahi, M., and Ozcan, A. All-optical machine learning using diffractive deep neural networks. Science, 361 (6406):1004–1008, 2018. ISSN 0036- 8075. doi: 10.1126/science.aat8084. URL https://science.sciencemag.org/ content/361/6406/1004.
Lin, X., Rivenson, Y., Yardimci, N. T., Veli, M., Luo, Y., Jarrahi, M., and Ozcan, A. 基于衍射深度神经网络的全光学机器学习。Science, 361(6406):1004–1008, 2018. ISSN 0036-8075. doi: 10.1126/science.aat8084. URL https://science.sciencemag.org/content/361/6406/1004.
Lindsey, C. S. and Lindblad, T. Review of hardware neural networks: A User’s perspective. In 3rd Workshop on Neural Networks: From Biology to High-energy Physics, pp. 0215– 224, 9 1994.
Lindsey, C. S. 和 Lindblad, T. 硬件神经网络的回顾: 用户视角. 发表于第三届神经网络研讨会: 从生物学到高能物理, 第0215–224页, 1994年9月.
Linnainmaa, S. Taylor expansion of the accumulated rounding error. BIT Numerical Mathematics, 16:146–160, 1976.
Linnainmaa, S. 累积舍入误差的泰勒展开. BIT Numerical Mathematics, 16:146–160, 1976.
Lucas, P. and van der Gaag, L. Principles of expert systems, 1991.
Lucas, P. 和 van der Gaag, L. 专家系统原理, 1991.
Macía, J. and Sole, R. How to make a synthetic multicellular computer. PloS one, 9:e81248, 02 2014. doi: 10.1371/journal.pone.0081248.
Macía, J. 和 Sole, R. 如何构建合成多细胞计算机. PloS one, 9:e81248, 02 2014. doi: 10.1371/journal.pone.0081248.
Marble stone, A. H., Wayne, G., and Kording, K. P. Toward an integration of deep learning and neuroscience. Frontiers in Computational Neuroscience, 10:94, 2016. ISSN 1662-5188. doi: 10.3389/fncom.2016.00094.
Marble stone, A. H., Wayne, G., and Kording, K. P. 深度学习与神经科学的融合之路. Frontiers in Computational Neuroscience, 10:94, 2016. ISSN 1662-5188. doi: 10.3389/fncom.2016.00094.
URL https://www.frontiers in.org/ article/10.3389/fncom.2016.00094.
URL https://www.frontiers in.org/ article/10.3389/fncom.2016.00094.
Marcus, G., Marble stone, A., and Dean, T. The atoms of neural computation. Science, 346:551–552, 2014. Computational Neuroscience.
Marcus, G., Marble stone, A., 和 Dean, T. 神经计算的基本单元。Science, 346:551–552, 2014. 计算神经科学。
Mcclelland, J., Mcnaughton, B., and O’Reilly, R. Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory. Psychological review, 102:419–57, 08 1995. doi: 10.1037/0033-295X.102.3.419.
McClelland, J., McNaughton, B., and O’Reilly, R. 为什么海马体和新皮层中存在互补学习系统:从学习和记忆的连接主义模型成功与失败中获得的启示。心理学评论,102:419–57,1995年8月。doi: 10.1037/0033-295X.102.3.419。
McCloskey, M. and Cohen, N. J. Catastrophic interference in connection is t networks: The sequential learning problem, 1989. ISSN 0079-7421.
McCloskey, M. 和 Cohen, N. J. 连接网络中的灾难性干扰:序列学习问题, 1989. ISSN 0079-7421.
Mernik, M., Heering, J., and Sloane, A. M. When and how to develop domain-specific languages. ACM Comput. Surv., 37(4):316–344, De- cember 2005. ISSN 0360-0300. doi: 10.1145/1118890.1118892. URL https: //doi.org/10.1145/1118890.1118892.
Mernik, M., Heering, J., 和 Sloane, A. M. 何时以及如何开发领域特定语言. ACM Comput. Surv., 37(4):316–344, 2005年12月. ISSN 0360-0300. doi: 10.1145/1118890.1118892. URL https://doi.org/10.1145/1118890.1118892.
Metz, C. Big bets on a.i. open a new frontier for chip start-ups, too, 2018. URL https://www.nytimes. com/2018/01/14/technology/ artificial-intelligence-chip-start-ups. html.
Metz, C. 人工智能领域的豪赌也为芯片初创公司开辟新疆界,2018. URL https://www.nytimes.com/2018/01/14/technology/artificial-intelligence-chip-start-ups.html.
Mirhoseini, A., Goldie, A., Yazgan, M., Jiang, J., Songhori, E., Wang, S., Lee, Y.-J., John- son, E., Pathak, O., Bae, S., Nazi, A., Pak, J., Tong, A., Srinivasa, K., Hang, W., Tuncer, E., Babu, A., Le, Q. V., Laudon, J., Ho, R., Carpenter, R., and Dean, J. Chip Placement with Deep Reinforcement Learning. arXiv eprints, art. arXiv:2004.10746, April 2020.
Mirhoseini, A., Goldie, A., Yazgan, M., Jiang, J., Songhori, E., Wang, S., Lee, Y.-J., Johnson, E., Pathak, O., Bae, S., Nazi, A., Pak, J., Tong, A., Srinivasa, K., Hang, W., Tuncer, E., Babu, A., Le, Q. V., Laudon, J., Ho, R., Carpenter, R., and Dean, J. 基于深度强化学习的芯片布局方法。arXiv预印本,编号 arXiv:2004.10746,2020年4月。
Misra, J. and Saha, I. Artificial neural networks in hardware: A survey of two decades of progress. Neuro computing, 74(1):239 – 255, 2010. ISSN 0925-2312. doi: https://doi.org/ 10.1016/j.neucom.2010.03.021. URL http: //www.science direct.com/science/ article/pii/S092523121000216X. Artificial Brains.
Misra, J. 和 Saha, I. 硬件中的人工神经网络(Artificial Neural Networks):二十年进展综述。Neuro computing, 74(1):239 – 255, 2010. ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2010.03.021. URL http://www.sciencedirect.com/science/article/pii/S092523121000216X. 人工大脑。
Moore, D. The anna karenina principle applied to ecological risk assessments of multiple stressors. Human and Ecological Risk Assessment: An International Journal, 7(2):231– 237, 2001. doi: 10.1080/20018091094349.
Moore, D. 安娜·卡列尼娜原理在多重压力源生态风险评估中的应用. Human and Ecological Risk Assessment: An International Journal, 7(2):231–237, 2001. doi: 10.1080/20018091094349.
Moore, G. Cramming more components onto integrated circuits. Electronics, 38(8), April 1965. URL https: //www.cs.utexas.edu/~fussell/ courses/cs352h/papers/moore.pdf.
Moore, G. 在集成电路上容纳更多元件。Electronics, 38(8), 1965年4月. URL https://www.cs.utexas.edu/~fussell/courses/cs352h/papers/moore.pdf.
Moravec, H. When will computer hardware match the human brain. Journal of Transhumanism, 1, 1998.
Moravec, H. 计算机硬件何时能匹敌人脑. Journal of Transhumanism, 1, 1998.
Morgan, M. G. The fifth generation: Artificial intelligence and japan’s computer challenge to the world, by edward a. feigenbaum and pamela mccorduck. reading, ma: Addison-wesley, 1983, 275 pp. price: $\$15.35$ . Journal of Policy Analysis and Management, 3(1):156–156, 1983. doi: 10.2307/ 3324061. URL https://online library. wiley.com/doi/abs/10.2307/3324061.
Morgan, M. G. 《第五代:人工智能与日本对世界的计算机挑战》,作者 Edward A. Feigenbaum 和 Pamela McCorduck。Reading, MA: Addison-Wesley, 1983 年,275 页。价格:$15.35。《政策分析与管理期刊》,3(1):156–156, 1983 年。doi: 10.2307/3324061。URL https://onlinelibrary.wiley.com/doi/abs/10.2307/3324061。
Morgan, N., Beck, J., Kohn, P., Bilmes, J., Allman, E., and Beer, J. The ring array processor: A multiprocessing peripheral for connection is t applications. Journal of Parallel and Distributed Computing, 14(3):248 – 259, 1992. ISSN 0743-7315.doi: https://doi.org/10.1016/0743-7315(92)90067-W. URL http: //www.science direct.com/science/ article/pii/074373159290067W.
Morgan, N., Beck, J., Kohn, P., Bilmes, J., Allman, E., and Beer, J. 环形阵列处理器:面向连接应用的多处理外设。《并行与分布式计算期刊》,14(3):248–259,1992。ISSN 0743-7315。doi: https://doi.org/10.1016/0743-7315(92)90067-W。URL http://www.sciencedirect.com/science/article/pii/074373159290067W。
Nikonov, D. E. and Young, I. A. Overview of beyond-cmos devices and a uniform methodology for their benchmarking. Proceedings of the IEEE, 101(12):2498–2533, 2013.
Nikonov, D. E. 和 Young, I. A. CMOS后器件综述及其基准测试的统一方法。IEEE论文集, 101(12):2498–2533, 2013.
Oh, K.-S. and Jung, K. Gpu implementation of neural networks. Pattern Recognition, 37(6):1311 – 1314, 2004. ISSN 0031-3203. doi: https://doi.org/10. 1016/j.patcog.2004.01.013. URL http: //www.science direct.com/science/ article/pii/S0031320304000524.
Oh, K.-S. 和 Jung, K. 神经网络在 GPU 上的实现。模式识别,37(6):1311–1314,2004。ISSN 0031-3203。doi: https://doi.org/10.1016/j.patcog.2004.01.013。URL http://www.sciencedirect.com/science/article/pii/S0031320304000524。
Olukotun, K. Beyond parallel programming with domain specific languages. SIGPLAN Not., 49(8):179–180, February 2014. ISSN 0362-1340. doi: 10.1145/2692916. 2557966. URL https://doi.org/10. 1145/2692916.2557966.
Olukotun, K. 超越并行编程的领域特定语言。《SIGPLAN通知》,49(8):179–180,2014年2月。ISSN 0362-1340。doi: 10.1145/2692916.2557966。URL https://doi.org/10.1145/2692916.2557966。
Parisi, G. I., Kemker, R., Part, J. L., Kanan, C., and Wermter, S. Continual Lifelong Learning with Neural Networks: A Review. arXiv eprints, art. arXiv:1802.07569, February 2018.
Parisi, G. I., Kemker, R., Part, J. L., Kanan, C., and Wermter, S. 基于神经网络的持续终身学习综述. arXiv eprints, art. arXiv:1802.07569, February 2018.
Payne, B. R., Belkasim, S. O., Owen, G. S., Weeks, M. C., and Zhu, Y. Accelerated 2d image processing on gpus. In Sunderam, V. S., van Albada, G. D., Sloot, P. M. A., and Dongarra, J. J. (eds.), Computational Science – ICCS 2005, pp. 256–264, Berlin, Heidelberg, 2005. Springer Berlin Heidelberg. ISBN 978- 3-540-32114-9.
Payne, B. R., Belkasim, S. O., Owen, G. S., Weeks, M. C., and Zhu, Y. 基于GPU加速的二维图像处理技术。见 Sunderam, V. S., van Albada, G. D., Sloot, P. M. A., and Dongarra, J. J. (编), 《计算科学——ICCS 2005》, 第256–264页, 柏林, 海德堡, 2005. 施普林格柏林海德堡出版社. ISBN 978-3-540-32114-9。
Posselt, E. The Jacquard Machine Analyzed and Explained: The Preparation of Jacquard Cards and Practical Hints to Learners of Jacquard Designing. Posselt’s textile library. E.A. Posselt, 1888. URL https://books. google.com/books?id=-6 F tmgE A CAA J.
Posselt, E. 《提花机分析与详解:提花卡片制作及提花设计学习实用指南》。Posselt纺织丛书。E.A. Posselt, 1888。URL https://books.google.com/books?id=-6FtmgEACAAJ。
Prabhakar, R., Zhang, Y., Koeplinger, D., Feld- man, M., Zhao, T., Hadjis, S., Pedram, A., Kozyrakis, C., and Olukotun, K. Plasticine: A re configurable architecture for parallel patterns. In 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), pp. 389–402, 2017.
Prabhakar, R., Zhang, Y., Koeplinger, D., Feldman, M., Zhao, T., Hadjis, S., Pedram, A., Kozyrakis, C., and Olukotun, K. Plasticine: 一种面向并行模式的可重构架构。见《2017年ACM/IEEE第44届计算机体系结构国际研讨会(ISCA)》,第389-402页,2017年。
Project, C. H. A. Computer history 1949 - 1960 early vacuum tube computers overview, 2018. URL https://www.youtube.com/watch? v= W n Nm u JY WhA.
项目C.H.A.《计算机历史:1949-1960年早期真空管计算机概述》,2018年。URL https://www.youtube.com/watch? v= WnNm uJYWhA。
Reddi, V. J., Cheng, C., Kanter, D., Mattson, P., Schm uel ling, G., Wu, C., Anderson, B., Breughe, M., Charlebois, M., Chou, W., Chukka, R., Coleman, C., Davis, S., Deng, P., Diamos, G., Duke, J., Fick, D., Gardner, J. S., Hubara, I., Idgunji, S., Jablin, T. B., Jiao, J., John, T. S., Kanwar, P., Lee, D., Liao, J., Lokhmotov, A., Massa, F., Meng, P., Micikevicius, P., Osborne, C., Pekhimenko, G., Rajan, A. T. R., Sequeira, D., Sirasao, A., Sun, F., Tang, H., Thomson, M., Wei, F., Wu, E., Xu, L., Yamada, K., Yu, B., Yuan, G., Zhong, A., Zhang, P., and Zhou, Y. Mlperf inference benchmark. In 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pp. 446–459, 2020.
Reddi, V. J., Cheng, C., Kanter, D., Mattson, P., Schm uel ling, G., Wu, C., Anderson, B., Breughe, M., Charlebois, M., Chou, W., Chukka, R., Coleman, C., Davis, S., Deng, P., Diamos, G., Duke, J., Fick, D., Gardner, J. S., Hubara, I., Idgunji, S., Jablin, T. B., Jiao, J., John, T. S., Kanwar, P., Lee, D., Liao, J., Lokhmotov, A., Massa, F., Meng, P., Micikevicius, P., Osborne, C., Pekhimenko, G., Rajan, A. T. R., Sequeira, D., Sirasao, A., Sun, F., Tang, H., Thomson, M., Wei, F., Wu, E., Xu, L., Yamada, K., Yu, B., Yuan, G., Zhong, A., Zhang, P., and Zhou, Y. MLPerf推理基准测试。见2020年ACM/IEEE第47届计算机体系结构国际研讨会(ISCA),第446-459页,2020年。
Rumelhart, D. E., McClelland, J. L., and PDP Research Group, C. (eds.). Parallel Dis- tributed Processing: Explorations in the Micro structure of Cognition, Vol. 1: Foundations. MIT Press, Cambridge, MA, USA, 1986. ISBN 026268053X.
Rumelhart, D. E., McClelland, J. L., 和 PDP Research Group, C. (编). 并行分布式处理:认知微结构的探索, 第1卷: 基础. MIT Press, 剑桥, 马萨诸塞州, 美国, 1986. ISBN 026268053X.
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. Learning Representations by BackPropagating Errors, pp. 696–699. MIT Press, 1988.
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. 《通过反向传播误差学习表征》, 第696–699页. MIT出版社, 1988年。
Sabour, S., Frosst, N., and Hinton, G. E. Dynamic routing between capsules, 2017. URL http://papers.nips.cc/paper/ 6975-dynamic-routing-between-capsules. pdf.
Sabour, S., Frosst, N., and Hinton, G. E. 胶囊间动态路由 (Dynamic routing between capsules), 2017. URL http://papers.nips.cc/paper/6975-dynamic-routing-between-capsules.pdf.
Sackinger, E., Boser, B. E., Bromley, J., LeCun, Y., and Jackel, L. D. Application of the anna neural network chip to high-speed character recognition. IEEE Transactions on Neural Networks, 3(3):498–505, 1992.
Sackinger, E., Boser, B. E., Bromley, J., LeCun, Y., and Jackel, L. D. 应用ANNA神经网络芯片实现高速字符识别. IEEE Transactions on Neural Networks, 3(3):498–505, 1992.
Sainani, K. On the frontiers of bio medicine with professor rahul sarpeshkar. Dartmouth Magazine, 2017. URL https://dartmouth alumni magazine. com/articles/cell-power.
Sainani, K. 与Rahul Sarpeshkar教授共同探索生物医学前沿。Dartmouth Magazine, 2017. URL https://dartmouthalumnimagazine.com/articles/cell-power.
Sato, K. What makes tpus fine-tuned for deep learning?, 2018. URL https://bit.ly/ 2ER3bIu.
Sato, K. 深度学习为何需要TPU专属优化?2018. 网址 https://bit.ly/2ER3bIu.
Shalf, J. The future of computing beyond moore’s law. Philosophical Transactions of the Royal Society A, 378, 2020.
Shalf, J. 摩尔定律之后的未来计算。《皇家学会哲学汇刊A辑》,378卷,2020年。
Singh, D.-V., Perdigones, A., Garcia, J., Cañas, I., and Mazarrón, F. Analyzing worldwide research in hardware architecture, 1997- 2011. Communications of the ACM, Volume 58:Pages 76–85, 01 2015. doi: 10.1145/ 2688498.2688499.
Singh, D.-V., Perdigones, A., Garcia, J., Cañas, I., and Mazarrón, F. 分析1997-2011年全球硬件架构研究进展。Communications of the ACM, 第58卷:76–85页, 2015年1月. doi: 10.1145/2688498.2688499.
Spelke, E. S. and Kinzler, K. D. Core knowledge. Developmental Science, 10(1):89–96, 2007. doi: 10.1111/j.1467-7687.2007.00569.x. URL https://online library.wiley. com/doi/abs/10.1111/j.1467-7687. 2007.00569.x.
Spelke, E. S. 和 Kinzler, K. D. 核心知识。发展科学,10(1):89–96,2007。doi: 10.1111/j.1467-7687.2007.00569.x。URL https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1467-7687.2007.00569.x。
Stein, G., Calvert, G., Spence, C., Spence, D., Stein, B., and Stein, P. The Handbook of Multi sensory Processes. A Bradford book. MIT Press, 2004.ISBN9780262033213. URL https://books. google.com/books?id $=$ CZ S yD oF V 7 AC.
Stein, G., Calvert, G., Spence, C., Spence, D., Stein, B., 和 Stein, P. 《多感官过程手册》。Bradford 丛书。MIT 出版社,2004 年。ISBN 9780262033213。URL https://books.google.com/books?id=CZSyDoFV7AC。
Stroop, J. R. Studies of interference in serial verbal reactions. Journal of Experimental Psychology, 18(6):643, 1935. doi: 10.1037/ h0054651.
Stroop, J. R. 系列言语反应中的干扰研究. Journal of Experimental Psychology, 18(6):643, 1935. doi: 10.1037/h0054651.
Strubell, E., Ganesh, A., and McCallum, A. Energy and policy considerations for deep learning in nlp, 2019.
Strubell, E., Ganesh, A., and McCallum, A. 自然语言处理中深度学习的能耗与政策考量, 2019.
Sun, F., Qin, M., Zhang, T., Liu, L., Chen, Y.- K., and Xie, Y. Computation on Sparse Neural Networks: an Inspiration for Future Hardware. arXiv e-prints, art. arXiv:2004.11946, April 2020.
孙飞、秦明、张涛、刘磊、陈永康、谢毅。稀疏神经网络的计算:对未来硬件的启示。arXiv电子版,编号arXiv:2004.11946,2020年4月。
Sutton, R. The bitter lesson, 2019. URL http://www.incomplete ideas.net/ IncIdeas/Bitter Lesson.html.
Sutton, R. 苦涩的教训, 2019. URL http://www.incomplete ideas.net/IncIdeas/BitterLesson.html.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv e-prints, art. arXiv:1512.00567, December 2015a.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. 重新思考计算机视觉的Inception架构。arXiv e-prints, 文献编号 arXiv:1512.00567, 2015年12月a.
Szegedy, C., Wei Liu, Yangqing Jia, Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., and Rabinovich, A. Going deeper with convolutions. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–9, 2015b.
Szegedy, C., Wei Liu, Yangqing Jia, Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., and Rabinovich, A. 深入卷积网络. 发表于2015年IEEE计算机视觉与模式识别会议(CVPR), 第1-9页, 2015b.
Szegedy, C., Ioffe, S., Vanhoucke, V., and Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv e-prints, art. arXiv:1602.07261, February 2016.
Szegedy, C., Ioffe, S., Vanhoucke, V., and Alemi, A. Inception-v4、Inception-ResNet及残差连接对学习的影响。arXiv e-prints, 文献编号 arXiv:1602.07261, 2016年2月。
Tan, C., Song, H., Niemi, J., and You, L. A synthetic biology challenge: Making cells compute. Molecular bioSystems, 3:343–53, 06 2007. doi: 10.1039/b618473c.
Tan, C., Song, H., Niemi, J., and You, L. 合成生物学挑战:让细胞执行计算。Molecular bioSystems, 3:343–53, 06 2007. doi: 10.1039/b618473c.
Tani, J. and Press, O. U. Exploring Robotic Minds: Actions, Symbols, and Consciousness as Self-organizing Dynamic Phenomena. Oxford series on cognitive models and architectures. Oxford University Press, 2016. ISBN 9780190281083. URL https://books. google.com/books?id=Qs w nn QA A CAA J.
Tani, J. 和 Press, O. U. 《探索机器人思维:作为自组织动态现象的行为、符号与意识》。牛津认知模型与架构系列。牛津大学出版社,2016年。ISBN 9780190281083。URL https://books.google.com/books?id=Qsw nnQAACAAJ。
Taubes, G. The rise and fall of thinking machines, 1995. URL https://www.inc.com/ magazine/19950915/2622.html.
Taubes, G. 思考机器的兴衰,1995. URL https://www.inc.com/magazine/19950915/2622.html.
Thompson, N. and Spanuth, S. The decline of computers as a general purpose technology: Why deep learning and the end of moore’s law are fragmenting computing, 2018.
Thompson, N. 和 Spanuth, S. 计算机作为通用技术的衰落:深度学习与摩尔定律终结为何导致计算碎片化, 2018.
Thompson, N. C., Greenewald, K., Lee, K., and Manso, G. F. The Computational Limits of Deep Learning. arXiv e-prints, art. arXiv:2007.05558, July 2020a.
Thompson, N. C., Greenewald, K., Lee, K., 和 Manso, G. F. 深度学习的计算极限。arXiv e-prints, 文献编号 arXiv:2007.05558, 2020年7月a。
Thompson, N. C., Greenewald, K., Lee, K., and Manso, G. F. The Computational Limits of Deep Learning. arXiv $e$ -prints, art. arXiv:2007.05558, July 2020b.
Thompson, N. C., Greenewald, K., Lee, K., 和 Manso, G. F. 深度学习的计算极限. arXiv $e$ -prints, 文献编号 arXiv:2007.05558, 2020年7月b.
Time. Understanding computers: software. Time, Virginia, 1985.
时间。理解计算机:软件。《时代》,弗吉尼亚州,1985年。
Tolstoy, L. and Bartlett, R. Anna Karenina. Oxford world’s classics. Oxford University Press, 2016. ISBN 9780198748847. URL https://books.google.com/books?id= 1 Doo Dw A AQ BAJ.
托尔斯泰 (L. Tolstoy) 与巴特利特 (R. Bartlett). 《安娜·卡列尼娜》. 牛津世界经典系列. 牛津大学出版社, 2016. ISBN 9780198748847. URL https://books.google.com/books?id=1DooDwAAQBAJ.
Touretzky, D. and Waibel, A. Course: 15-880(a) – introduction to neural networks, 1995. URL shorturl.at/evKX9.
Touretzky, D. 和 Waibel, A. 课程: 15-880(a) – 神经网络导论, 1995. URL shorturl.at/evKX9.