CDLM: Cross-Document Language Modeling
CDLM: 跨文档语言建模
Abstract
摘要
We introduce a new pre training approach geared for multi-document language modeling, incorporating two key ideas into the masked language modeling self-supervised objective. First, instead of considering documents in isolation, we pretrain over sets of multiple related documents, encouraging the model to learn cross-document relationships. Second, we improve over recent long-range transformers by introducing dynamic global attention that has access to the entire input to predict masked tokens. We release CDLM (Cross-Document Language Model), a new general language model for multi-document setting that can be easily applied to downstream tasks. Our extensive analysis shows that both ideas are essential for the success of CDLM, and work in synergy to set new state-of-the-art results for several multi-text tasks.1
我们提出了一种面向多文档语言建模的新型预训练方法,该方法将两个关键思想融入掩码语言建模的自监督目标中。首先,我们不再孤立地处理单个文档,而是在多个相关文档集合上进行预训练,促使模型学习跨文档关联。其次,我们改进了近期长程Transformer架构,引入动态全局注意力机制,使其能访问整个输入文本来预测被掩码的token。我们发布了CDLM(跨文档语言模型),这是一个适用于多文档场景的新型通用语言模型,可轻松迁移至下游任务。大量实验表明:这两个创新点对CDLM的成功至关重要,它们协同作用,在多项多文本任务上创造了最新技术水平[20]。
1 Introduction
1 引言
The majority of NLP research addresses a single text, typically at the sentence or document level. Yet, there are important applications which are concerned with aggregated information spread across multiple texts, such as cross-document co reference resolution (Cybulska and Vossen, 2014), classifying relations between document pairs (Zhou et al., 2020) and multi-hop question answering (Yang et al., 2018).
大多数自然语言处理(NLP)研究都针对单一文本,通常是在句子或文档层面。然而,存在一些重要应用需要处理分散在多个文本中的聚合信息,例如跨文档共指消解(Cybulska and Vossen, 2014)、文档对关系分类(Zhou et al., 2020)以及多跳问答(Yang et al., 2018)。
Existing language models (LMs) (Devlin et al., 2019a; Liu et al., 2019; Raffel et al., 2020), which are pretrained with variants of the masked language modeling (MLM) self-supervised objective, are known to provide powerful representations for internal text structure (Clark et al., 2019; Rogers et al., 2020a), which were shown to be beneficial also for various multi-document tasks (Yang et al., 2020; Zhou et al., 2020).
现有语言模型 (LMs) (Devlin et al., 2019a; Liu et al., 2019; Raffel et al., 2020) 通过掩码语言建模 (MLM) 自监督目标的变体进行预训练,已知能为内部文本结构提供强大表征 (Clark et al., 2019; Rogers et al., 2020a),这些表征已被证明对多种多文档任务也有益处 (Yang et al., 2020; Zhou et al., 2020)。

Figure 1: An example from Multi-News (Fabbri et al., 2019). Circled words represent matching events and the same color represents mention alignments.
图 1: Multi-News (Fabbri et al., 2019) 中的示例。圆圈标注的单词表示匹配事件,相同颜色代表提及对齐。
In this paper, we point out that beyond modeling internal text structure, multi-document tasks require also modeling cross-text relationships, particularly aligning or linking matching information elements across documents. For example, in Fig. 1, one would expect a competent model to correctly capture that the two event mentions suing and alleges, from Documents 1 and 2, should be matched. Accordingly, capturing such cross-text relationships, in addition to representing internal text structure, can prove useful for downstream multi-text tasks, as we demonstrate empirically later.
本文指出,多文档任务不仅需要建模文本内部结构,还需要建模跨文本关系,特别是对齐或关联不同文档中的匹配信息元素。例如,在图 1 中,一个合格的模型应当正确识别文档 1 和文档 2 中的事件提及 suing 和 alleges 应当相互匹配。因此,除了表征文本内部结构外,捕捉此类跨文本关系对下游多文本任务同样具有价值,我们将在后文通过实验验证这一点。
Following this intuition, we propose a new simple cross-document pre training procedure, which is applied over sets of related documents, in which informative cross-text relationships are abundant (e.g. like those in Fig. 1). Under this setting, the model is encouraged to learn to consider and represent such relationships, since they provide useful signals when optimizing for the language modeling objective. For example, we may expect that it will be easier for a model to unmask the word alleges in Document 2 if it would manage to effectively “peek” at Document 2, by matching the masked position and its context with the corresponding information in the other document.
基于这一思路,我们提出了一种简单的新型跨文档预训练方法,该方法应用于具有丰富跨文本信息关联的文档集合(如图 1 所示场景)。在此设定下,模型被引导学习识别和表征此类关联关系,因为这些关联能为语言建模目标提供有效信号。例如,当模型能通过匹配掩码位置及其上下文,有效"窥见"文档2中的对应信息时,就更可能准确预测文档2中被掩码的单词"alleges"。
Naturally, considering cross-document context in pre training, as well as in finetuning, requires a model that can process a fairly large amount of text. To that end, we leverage recent advances in developing efficient long-range transformers (Beltagy et al., 2020; Zaheer et al., 2020), which utilize a global attention mode to build representations based on the entire input. Overcoming certain restrictions in prior utilization of global attention (see Section 2.1), we introduce a dynamic attention pattern during pre training, over all masked tokens, and later utilize it selectively in finetuning.
自然,要在预训练和微调中考虑跨文档上下文,需要一个能够处理大量文本的模型。为此,我们利用了近期在高效长程Transformer (Beltagy et al., 2020; Zaheer et al., 2020) 方面的进展,这些模型采用全局注意力模式基于整个输入构建表征。为了克服先前全局注意力应用中的某些限制 (参见第2.1节),我们在预训练阶段针对所有被遮蔽的token引入了动态注意力模式,并在微调阶段有选择地使用该模式。
Combining pre training over related documents along with our global attention pattern yields a novel pre training approach, that is geared to learn and implicitly encode informative cross-document relationships. As our experiments demonstrate, the resulting model, termed Cross-Document Language Model (CDLM), can be generically applied to downstream multi-document tasks, eliminating the need for task-specific architectures. We show empirically that our model improves consistently over previous approaches in several tasks, including cross-document co reference resolution, multi- hop question answering, and document matching tasks. Moreover, we provide controlled experiments to ablate the two contributions of pre training over related documents as well as new dynamic global attention. Finally, we provide additional analyses that shed light on the advantageous behavior of our CDLM. Our contributions are summarized below:
结合对相关文档的预训练与我们的全局注意力模式,我们提出了一种新颖的预训练方法,旨在学习并隐式编码信息丰富的跨文档关系。实验表明,由此产生的模型(称为跨文档语言模型 (Cross-Document Language Model, CDLM))可通用地应用于下游多文档任务,无需特定任务架构。实证结果显示,我们的模型在跨文档共指消解、多跳问答和文档匹配等多项任务中持续优于先前方法。此外,我们通过对照实验验证了相关文档预训练与新型动态全局注意力这两项贡献的有效性。最后,我们通过额外分析揭示了CDLM的优势特性。主要贡献总结如下:
• A new pre training approach for multidocument tasks utilizing: (1) sets of related documents instead of single documents; (2) a new dynamic global attention pattern. The resulting model advances the state-of-theart for several multi-document tasks.
• 一种针对多文档任务的新预训练方法,采用:(1) 使用相关文档集而非单一文档;(2) 新型动态全局注意力机制。该模型在多项多文档任务中实现了最先进水平。
2 Method
2 方法
2.1 Background: the Longformer Model
2.1 背景:Longformer模型
Recently, long-range LMs (e.g., Longformer (Beltagy et al., 2020), BigBird (Zaheer et al., 2020)) have been proposed to extend the capabilities of earlier transformers (Vaswani et al., 2017) to process long sequences, using a sparse self-attention architecture. These models showed improved performance on both long-document and multi-document tasks (Tay et al., 2021). In the case of multiple documents, instead of encoding documents separately, these models allow concatenating them into a long sequence of tokens and encoding them jointly. We base our model on Longformer, which sparsifies the full self-attention matrix in transformers by using a combination of a localized sliding window (called local attention), as well as a global attention pattern on a few specific input locations. Separate weights are used for global and local attention. During pre training, Longformer assigns local attention to all tokens in a window around each token and optimizes the Masked Language Modeling (MLM) objective. Before task-specific finetuning, the attention mode is predetermined for each input token, assigning global attention to a few targeted tokens, such as special tokens, that are targeted to encode global information. Thus, in the Longformer model, global attention weights are not pretrained. Instead, they are initialized to the local attention values, before finetuning on each downstream task. We conjecture that the global attention mechanism can be useful for learning meaningful representations for modeling cross-document (CD) relationships. Accordingly, we propose augmenting the pre training phase to exploit the global attention mode, rather than using it only for taskspecific finetuning, as described below.
最近,长程语言模型(如Longformer (Beltagy et al., 2020)、BigBird (Zaheer et al., 2020))通过稀疏自注意力架构扩展了早期Transformer (Vaswani et al., 2017)处理长序列的能力。这些模型在长文档和多文档任务中均表现出性能提升 (Tay et al., 2021)。针对多文档场景,这些模型允许将文档拼接为长Token序列进行联合编码,而非单独编码。我们的模型基于Longformer,其通过局部滑动窗口(称为局部注意力)与特定输入位置的全局注意力模式相结合,对Transformer的完整自注意力矩阵进行稀疏化处理。全局注意力和局部注意力使用独立的权重。在预训练阶段,Longformer为每个Token周围窗口内的所有Token分配局部注意力,并优化掩码语言建模(MLM)目标。在任务特定微调前,会为每个输入Token预设注意力模式,将全局注意力分配给少数目标Token(如特殊Token)以编码全局信息。因此Longformer的全局注意力权重未经预训练,而是在下游任务微调前初始化为局部注意力值。我们推测全局注意力机制有助于学习跨文档(CD)关系建模的语义表征。据此提出在预训练阶段增强全局注意力模式的应用(而非仅用于任务微调),具体方法如下。
2.2 Cross-Document Language Modeling
2.2 跨文档语言建模
We propose a new pre training approach consisting of two key ideas: (1) pre training over sets of related documents that contain overlapping information (2) pre training with a dynamic global attention pattern over masked tokens, for referencing the entire cross-text context.
我们提出了一种新的预训练方法,包含两个关键思想:(1) 在包含重叠信息的相关文档集合上进行预训练 (2) 对掩码token采用动态全局注意力机制,以引用整个跨文本上下文。
Pre training Over Related Documents Documents that describe the same topic, e.g., different news articles discussing the same story, usually contain overlapping information. Accordingly, various CD tasks may leverage from an LM infrastructure that encodes information regarding alignment and mapping across multiple texts. For example, for the case of CD co reference resolution, consider the underlined predicate examples in Figure 1. One would expect a model to correctly align the mentions denoted by suing and alleges, effectively recognizing their cross-document relation.
预训练相关文档
描述同一主题的文档(例如讨论同一事件的不同新闻文章)通常包含重叠信息。因此,各种跨文档(CD)任务可以受益于能够编码多文本对齐与映射信息的大语言模型(LM)基础设施。以跨文档共指消解(CD coreference resolution)为例,观察图1中带下划线的谓词示例:理想情况下,模型应正确对齐"suing"和"alleges"所指代的提及项,有效识别它们的跨文档关联关系。
Our approach to cross-document language modeling is based on pre training the model on sets (clusters) of documents, all describing the same topic. Such document clusters are readily available in a variety of existing CD benchmarks, such as multidocument sum mari z ation (e.g., Multi-News (Fabbri et al., 2019)) and CD co reference resolution (e.g., $\mathrm{ECB+}$ (Cybulska and Vossen, 2014)). Pretraining the model over a set of related documents encourages the model to learn cross-text mapping and alignment capabilities, which can be leveraged for improved unmasking, as exemplified in Sec. 1. Indeed, we show that this strategy directs the model to utilize information across documents and helps in multiple downstream CD tasks.
我们提出的跨文档语言建模方法基于对描述同一主题的文档集(簇)进行预训练。这类文档簇在现有的多种跨文档基准测试中已广泛存在,例如多文档摘要(如Multi-News [Fabbri等人,2019])和跨文档共指消解(如ECB+ [Cybulska和Vossen,2014])。通过对相关文档集进行预训练,模型能够学习跨文本映射与对齐能力,这种能力可显著提升掩码预测效果(如第1节示例所示)。实验表明,该策略能有效引导模型利用跨文档信息,并在多项跨文档下游任务中取得性能提升。
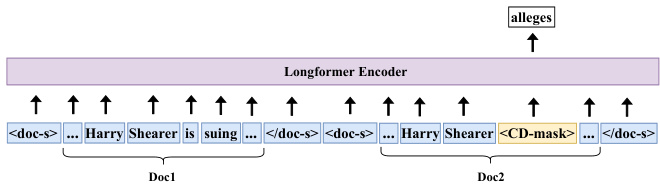
Figure 2: CDLM pre training: The input consists of concatenated documents, separated by special document separator tokens. The masked (unmasked) token colored in yellow (blue) represents global (local) attention. The goal is to predict the masked token alleges, based on the global context, i.e, the entire set of documents.
图 2: CDLM预训练:输入由通过特殊文档分隔符token连接的文档组成。黄色(蓝色)标注的掩码(未掩码)token代表全局(局部)注意力。目标是根据全局上下文(即整个文档集)预测被掩码的token alleges。
Pre training With Global Attention To support contextual i zing information across multiple documents, we need to use efficient transformer models that scale linearly with input length. Thus, we base our cross-document language model (CDLM) on the Longformer model (Beltagy et al., 2020), however, our setup is general and can be applied to other similar efficient Transformers. As described in Sec. 2.1, Longformer sparsifies the expensive attention operation for long inputs using a combination of local and global attention modes. As input to the model, we simply concatenate related documents using new special document separator tokens, $\big\langle\mathrm{doc}\mathrm{-}\mathrm{s}\big\rangle$ and $\left</\mathsf{d o c}-\mathsf{s}\right>$ , for marking document boundaries. We apply a similar masking procedure as in BERT: For each training example, we randomly choose a sample of tokens $(15%)$ to be masked;2 however, our pre training strategy tries to predict each masked token while considering the full document set, by assigning them global attention, utilizing the global attention weights (see Section 2.1). This allows the Longformer to contex- tualize information both across documents as well as over long-range dependencies within-document. The non-masked tokens use local attention, by utilizing the local attention weights, as usual.
预训练与全局注意力
为支持跨文档的上下文信息整合,我们需要使用输入长度呈线性增长的高效Transformer模型。因此,我们的跨文档语言模型(CDLM)基于Longformer模型(Beltagy et al., 2020),但该框架具有通用性,可应用于其他类似的高效Transformer。如第2.1节所述,Longformer通过结合局部和全局注意力模式,对长输入的昂贵注意力操作进行了稀疏化处理。
模型输入方面,我们使用新的特殊文档分隔符$\big\langle\mathrm{doc}\mathrm{-}\mathrm{s}\big\rangle$和$\left</\mathsf{d o c}-\mathsf{s}\right>$来连接相关文档以标记文档边界。采用与BERT类似的掩码处理流程:每个训练样本随机选择15%的Token进行掩码;但我们的预训练策略通过分配全局注意力权重(见第2.1节),在预测每个掩码Token时会考虑整个文档集。这使得Longformer既能跨文档整合信息,也能处理文档内的长距离依赖。非掩码Token则照常使用局部注意力权重进行局部注意力计算。
An illustration of the CD pre training procedure is depicted in Fig. 2, where the masked token associated with alleges (colored in yellow) globally attends to the whole sequence, and the rest of the non-masked tokens (colored in blue) attend to their local context. With regard to the example in Fig. 1, this masking approach aims to implicitly compel the model to learn to correctly predict the word alleges by looking at the second document, optimally at the phrase suing, and thus capture the alignment between these two events and their contexts.
图 2 展示了 CD (Contrastive Decoding) 预训练过程的示意图,其中与 alleges (黄色标注) 相关联的掩码 token (masked token) 会全局关注整个序列,而其余非掩码 token (蓝色标注) 则关注其局部上下文。针对图 1 中的示例,这种掩码方法旨在隐式地迫使模型通过学习正确预测单词 alleges,重点关注第二份文档中的短语 suing,从而捕捉这两个事件及其上下文之间的对齐关系。
2.3 CDLM Implementation
2.3 CDLM实现
In this section, we provide the experimental details used for pre training our CDLM model.
在本节中,我们将提供用于预训练CDLM模型的实验细节。
Corpus data We use the pre processed MultiNews dataset (Fabbri et al., 2019) as the source of related documents for pre training. This dataset contains 44,972 training document clusters, originally intended for multi-document sum mari z ation. The number of source documents (that describe the same topic) per cluster varies from 2 to 10, as detailed in Appendix A.1. We consider each cluster of at least 3 documents for our cross-document pre training procedure. We compiled our training corpus by concatenating related documents that were sampled randomly from each cluster, until reaching the Longformer’s input sequence length limit of 4,096 tokens per sample. Note that this pre training dataset is relatively small compared to conventional datasets used for pre training. However, using it results in the powerful CDLM model.
语料数据
我们使用预处理后的MultiNews数据集 (Fabbri et al., 2019) 作为预训练的相关文档来源。该数据集包含44,972个训练文档簇,最初用于多文档摘要任务。每个簇中描述同一主题的源文档数量从2到10不等,详见附录A.1。我们选取至少包含3个文档的簇进行跨文档预训练。通过随机采样每个簇中的相关文档并进行拼接,直至达到Longformer模型的输入序列长度限制(每个样本4,096个token),最终构建出训练语料库。值得注意的是,与传统预训练数据集相比,该预训练数据集的规模较小,但使用它仍能训练出强大的CDLM模型。
Training and hyper parameters We pretrain the model according to our pre training strategy, described in Section 2.2. We employ the Longformerbase model (Beltagy et al., 2020) using the HuggingFace implementation (Wolf et al., 2020) and continue its pre training, over our training data, for an additional $25\mathrm{k\Omega}$ steps.3 The new document separator tokens are added to the model vocabulary and randomly initialized before pre training. We use the same setting and hyper parameters as in Beltagy et al. (2020), and as elaborated in Appendix B.
训练与超参数
我们根据第2.2节描述的预训练策略对模型进行预训练。采用HuggingFace实现的Longformerbase模型 (Beltagy et al., 2020) (Wolf et al., 2020),并在训练数据上继续预训练额外的 $25\mathrm{k\Omega}$ 步。新加入的文档分隔符token会被添加到模型词表中,并在预训练前随机初始化。超参数设置与Beltagy et al. (2020) 及附录B中所述保持一致。
3 Evaluations and Results
3 评估与结果
This section presents experiments conducted to evaluate our CDLM, as well as the the ablations and baselines we used. For the intrinsic evaluation we measured the perplexity of the models. For extrinsic evaluations we considered event and entity cross-document co reference resolution, paper citation recommendation, document plagiarism detection, and multihop question answering. We also conducted an attention analysis, showing that our CDLM indeed captured cross-document and longrange relations during pre training.
本节介绍了为评估我们的CDLM所进行的实验,以及使用的消融研究和基线模型。在内在评估方面,我们测量了模型的困惑度(perplexity)。外在评估则包括事件和实体的跨文档共指消解、论文引用推荐、文档抄袭检测以及多跳问答任务。我们还进行了注意力分析,证明CDLM在预训练过程中确实捕捉到了跨文档和长距离关联关系。
Baseline LMs Recall that CDLM employs multiple related documents during pre training, and assigns global attention to masked tokens. To systematically study the importance of these two components, we consider the following LM baselines:
基线语言模型 回顾一下,CDLM在预训练期间使用了多个相关文档,并对掩码token分配了全局注意力。为了系统研究这两个组件的重要性,我们考虑以下语言模型基线:
– Longformer: the underlying Longformer model, without additional pre training.
- Longformer: 基础版 Longformer 模型,未进行额外预训练。
– Local CDLM: pretrained using the same corpus of CDLM with the Longformer’s attention pattern (local attention only). This baseline is intended to separate the effect of simply continuing pre training Longformer on our new pre-training data.
- Local CDLM:使用与Longformer相同的注意力模式(仅局部注意力)在CDLM语料库上预训练。该基线旨在区分仅在我们新的预训练数据上继续预训练Longformer的效果。
– Rand CDLM: Longformer with the additional CDLM pre training, while using random, unrelated documents from various clusters. This baseline model allows assessing whether pre training using related documents is beneficial.
– Rand CDLM:采用额外CDLM预训练的Longformer模型,但使用来自不同集群的随机无关文档。该基线模型可用于评估使用相关文档进行预训练是否具有优势。
– Prefix CDLM: pretrained similarly as CDLM but uses global attention for the first tokens in the input sequence, rather than the masked ones. This resembles the attention pattern of BIGBIRD (Zaheer et al., 2020), adopted for our cross-document setup. We use this ablation for examining this alternative global attention pattern, from prior work.
- Prefix CDLM:预训练方式与CDLM类似,但会对输入序列中的前几个token使用全局注意力机制(global attention),而非掩码token。这种注意力模式借鉴了BIGBIRD (Zaheer et al., 2020) 的设计,并适配于我们的跨文档场景。我们通过该消融实验来验证先前研究中这种替代性全局注意力模式的效果。
The data and pre training hyper parameters used for the ablations above are the same as the ones used for our CDLM pre training, except for the underlying Longformer, which is not further pretrained, and the Rand CDLM, that is fed with different document clusters (drawn from the same corpus). During all the experiments, the global attention weights used by the underlying Longformer and by Local CDLM are initialized to the values of their pretrained local attention weights. All the models above further finetune their global attention weights, depending on the downstream task. When finetuning CDLM and the above models on downstream tasks involving multiple documents, we truncate the longer inputs to the Longformer’s 4,096 token limit.
用于上述消融实验的数据和预训练超参数与CDLM预训练相同,但基础Longformer未进行额外预训练,且Rand CDLM采用不同文档聚类(来自同一语料库)。所有实验中,基础Longformer和Local CDLM使用的全局注意力权重均初始化为其预训练局部注意力权重的值。上述模型会根据下游任务进一步微调全局注意力权重。在对涉及多文档的下游任务微调CDLM及上述模型时,我们将较长输入截断至Longformer的4,096 token限制长度。
3.1 Cross-Document Perplexity
3.1 跨文档困惑度
First, we conduct a cross-document (CD) perplexity experiment, in a task-independent manner, to assess the contribution of the pre training process. We used the Multi-News validation and test sets, each of them containing 5,622 document clusters, to construct the evaluation corpora. Then we followed the same protocol from the pre training phase - $15%$ of the input tokens are randomly masked, where the challenge is to predict the masked token given all documents in the input sequence. We matched the pre training phase of each one of the ablation models: In CDLM and Rand CDLM, we assigned global attention for the masked tokens, and for Prefix CDLM the global attention is assigned to the $15%$ first input tokens. Both Longformer and Local CDLM used local attention only. Perplexity is then measured by computing exponentiation of the loss.
首先,我们以任务无关的方式进行了跨文档 (CD) 困惑度实验,以评估预训练过程的贡献。我们使用 Multi-News 验证集和测试集(各包含 5,622 个文档簇)构建评估语料库,并遵循与预训练阶段相同的协议——随机掩码 15% 的输入 token,任务目标是根据输入序列中的所有文档预测被掩码的 token。我们复现了各消融模型的预训练设置:CDLM 和 Rand CDLM 为被掩码 token 分配全局注意力,Prefix CDLM 则为前 15% 的输入 token 分配全局注意力,Longformer 和 Local CDLM 仅使用局部注意力。最终通过计算损失函数的指数值得出困惑度。
Table 1: Cross-document perplexity evaluation on the validation and tests set of Multi-News. Lower is better.
表 1: Multi-News验证集和测试集上的跨文档困惑度评估。数值越低越好。
| 模型 | 验证集 | 测试集 |
|---|---|---|
| Longformer | 3.89 | 3.94 |
| LocalCDLM | 3.78 | 3.84 |
| RandCDLM | 3.68 | 3.81 |
| PrefixCDLM | 3.20 | 3.41 |
| CDLM | 3.23 | 3.39 |
The results are depicted in Table 1. The advantage of CDLM over Rand CDLM, which was pretrained equivalently over an equivalent amount of (unrelated) CD data, confirms that CD pretraining, over related documents, indeed helps for CD masked token prediction across such documents. Prefix CDLM introduces similar results since it was pretrained using a global attention pattern and the same corpora used by CDLM. The Local CDLM is expected to have difficulty to predict tokens across documents since it was pretrained without using global attention. Finally, the underlying Longformer model, which is reported as a reference point, is inferior to all the ablations since it was pretrained in a single document setting and without global attention or further pre training on this domain. Unlike the two local-attentive models, CDLM is encouraged to look at the full sequence when predicting a masked token. Therefore, as in the pre training phase, it exploits related information in other documents, and not just the local context of the masked token, hence CDLM, as well as Prefix CDLM, result with a substantial performance gain.
结果如表 1 所示。CDLM 相对于 Rand CDLM (在等量无关 CD 数据上等效预训练) 的优势证实:在相关文档上的 CD 预训练确实有助于跨文档的 CD 掩码 token 预测。Prefix CDLM 表现出相似结果,因其采用全局注意力机制且使用与 CDLM 相同的语料库进行预训练。Local CDLM 由于预训练时未使用全局注意力,预计在跨文档 token 预测上存在困难。最后,作为基准的底层 Longformer 模型表现逊于所有消融模型,因其仅在单文档环境下预训练,且未采用全局注意力或针对该领域进一步预训练。与两种局部注意力模型不同,CDLM 在预测掩码 token 时需关注完整序列。因此正如预训练阶段所示,它能利用其他文档中的关联信息,而不仅是掩码 token 的局部上下文,这使得 CDLM 和 Prefix CDLM 均实现了显著的性能提升。
3.2 Cross-Document Co reference Resolution
3.2 跨文档共指消解
Cross-document (CD) co reference resolution deals with identifying and clustering together textual mentions across multiple documents that refer to the same concept (see Fig. 1). The considered mentions can be either entity mentions, usually noun phrases, or event mentions, typically verbs or nomin aliz at ions that appear in the text.
跨文档共指消解 (cross-document coreference resolution) 的任务是识别并聚类多个文档中指向同一概念的文本表述 (见图 1)。这些表述既可以是实体表述 (通常为名词短语),也可以是事件表述 (一般为文本中出现的动词或名词化形式)。
Benchmark. We evaluated our CDLM by utilizing it over the $\mathrm{ECB+}$ corpus (Cybulska and Vossen, 2014), the most commonly used dataset for CD co reference. $\mathrm{ECB+}$ consists of within- and crossdocument co reference annotations for entities and events (statistics are given in Appendix A.2). Following previous work, for comparison, we conduct our experiments on gold event and entity mentions.
基准测试。我们通过在 $\mathrm{ECB+}$ 语料库 (Cybulska and Vossen, 2014) 上使用 CDLM 进行评估,这是最常用的跨文档共指消解数据集。$\mathrm{ECB+}$ 包含针对实体和事件的文档内及跨文档共指标注 (统计信息见附录 A.2)。遵循先前工作,为便于比较,我们在标注好的事件和实体提及上进行实验。
We follow the standard co reference resolution evaluation metrics: MUC (Vilain et al., 1995), $B^{3}$ (Bagga and Baldwin, 1998), CEAFe (Luo, 2005), their average $C o N L L F I$ , and the more recent LEA metric (Moosavi and Strube, 2016).
我们遵循标准的共指消解评估指标:MUC (Vilain et al., 1995)、$B^{3}$ (Bagga and Baldwin, 1998)、CEAFe (Luo, 2005)、它们的平均值 $CoNLLF1$,以及较新的LEA指标 (Moosavi and Strube, 2016)。
Algorithm. Recent approaches for CD coreference resolution train a pairwise scorer to learn the probability that two mentions are co-referring. At inference time, an agglom erat ive clustering based on the pairwise scores is applied, to form the coreference clusters. We made several modifications to the pairwise scorer. The current state-of-the-art models (Zeng et al., 2020; Yu et al., 2020) train the pairwise scorer by including only the local contexts (containing sentences) of the candidate mentions. They concatenate the two input sentences and feed them into a transformer-based LM. Then, part of the resulting tokens representations are aggregated into a single feature vector which is passed into an additional MLP-based scorer to produce the coreference probability estimate. To accommodate our proposed CDLM model, we modify this modeling by including the entire documents containing the two candidate mentions, instead of just their containing sentences, and assigning the global attention mode to the mentions’ tokens and to the [CLS] token. The full method and hyper para meters are elaborated in Appendix C.1.
算法。近期关于跨文档共指消解 (CD coreference resolution) 的研究通过训练一个成对评分器来学习两个指称是否共指的概率。在推理阶段,基于这些成对分数应用凝聚聚类,以形成共指簇。我们对成对评分器进行了若干改进。当前最先进的模型 (Zeng et al., 2020; Yu et al., 2020) 仅使用候选指称的局部上下文(包含句子)来训练成对评分器。它们将两个输入句子拼接后输入基于 Transformer 的大语言模型,然后将部分生成的 token 表征聚合成单个特征向量,再输入额外的基于 MLP 的评分器以生成共指概率估计。为适配我们提出的 CDLM 模型,我们修改了这一建模方式:包含两个候选指称的完整文档(而非仅其所在句子),并为指称 token 和 [CLS] token 分配全局注意力模式。完整方法和超参数详见附录 C.1。
Baselines. We consider state-of-the-art baselines that reported results over the $\mathrm{ECB+}$ benchmark. The following baselines were used for both event and entity co reference resolution:
基线方法。我们考虑了在$\mathrm{ECB+}$基准测试中报告结果的最先进基线方法。以下基线方法同时用于事件和实体共指消解任务:
– Barhom et al. (2019) is a model trained jointly for solving event and entity co reference as a single task. It utilizes semantic role information between the candidate mentions.
– Barhom et al. (2019) 是一个通过联合训练解决事件与实体共指任务的模型。该模型利用了候选提及之间的语义角色信息。
– Cattan et al. (2020) is a model trained in an endto-end manner (jointly learning mention detection and co reference following Lee et al. (2017)), employing the RoBERTa-large model to encode each document separately and to train a pair-wise scorer atop.
– Cattan等人 (2020) 提出了一种端到端训练模型 (采用Lee等人 (2017) 的联合学习提及检测与共指消解方法),该模型使用RoBERTa-large分别编码每个文档,并在其上训练成对评分器。
– Allaway et al. (2021) is a BERT-based model combining sequential prediction with incremental clustering.
– Allaway et al. (2021) 是一种基于 BERT 的模型,将序列预测与增量聚类相结合。
The following baselines were used for event co reference resolution. They all integrate external linguistic information as additional features. – Meged et al. (2020) is an extension of Barhom et al. (2019), leveraging external knowledge acquired from a paraphrase resource (Shwartz et al., 2017).
事件共指消解使用了以下基线方法,它们都整合了外部语言信息作为额外特征:
- Meged等人 (2020) 是Barhom等人 (2019) 的扩展,利用了从释义资源 (Shwartz等人, 2017) 获取的外部知识。
– Zeng et al. (2020) is an end-to-end model, encoding the concatenated two sentences containing the two mentions by the BERT-large model. Similarly to our algorithm, they feed a MLP-based pairwise scorer with the concatenation of the [CLS] representation and an attentive function of the candidate mentions representations.
– Zeng等人 (2020) 提出了一种端到端模型,通过BERT-large模型对包含两个指称的拼接句子进行编码。与我们的算法类似,他们将[CLS]表征与候选指称表征的注意力函数拼接后,输入基于MLP的成对评分器。
– Yu et al. (2020) is an end-to-end model similar to Zeng et al. (2020), but uses rather RoBERTa-large and does not consider the [CLS] contextual i zed token representation for the pairwise classification.
Yu et al. (2020) 是一个与 Zeng et al. (2020) 类似的端到端模型,但使用了 RoBERTa-large,并且没有考虑 [CLS] 上下文 token 表示用于成对分类。
Results. The results on event and entity CD co reference resolution are depicted in Table 2. Our CDLM outperforms all methods, including the recent sentence based models on event coreference. All the results are statistically significant using bootstrap and permutation tests with $p<0.001$ (Dror et al., 2018). CDLM largely sur- passes state-of-the-art results on entity co reference, even though these models utilize external information and use large pretrained models, unlike our base model. In Table 3, we provide the ablation study results. Using our model with sentences only, i.e., considering only the sentences where the candidate mentions appear (as the prior baselines did), exhibits lower performance, resembling the best performing baselines. Some crucial information about mentions can appear in a variety of locations in the document, and is not concentrated in one sentence. This characterizes long documents, where pieces of information are often spread out. Overall, the ablation study shows the advantage of using our pre training method, over related documents and using a scattered global attention pattern, compared to the other examined settings. Recently, our CDLM-based co reference model was utilized to generate event clusters within an effective facetedsum mari z ation system for multi-document exploration (Hirsch et al., 2021).
结果。事件和实体共指消解的结果如表 2 所示。我们的 CDLM 在所有方法中表现最优,包括近期基于句子的事件共指模型。所有结果均通过自助法和置换检验具有统计显著性 ($p<0.001$) (Dror et al., 2018)。尽管现有实体共指模型使用了外部信息和大型预训练模型,而我们的基础模型未采用这些策略,CDLM 仍大幅超越了当前最优结果。表 3 展示了消融研究结果:仅使用句子级别信息(即像先前基线模型那样仅考虑候选指称出现的句子)时,模型性能下降至与最佳基线相当。指称的关键信息可能分散在文档各处而非集中于单个句子,这种信息分散特性正是长文档的典型特征。总体而言,消融研究证明了相比其他配置,我们的预训练方法结合相关文档和分散式全局注意力模式更具优势。近期,我们基于 CDLM 的共指模型已被用于在多文档探索系统 (Hirsch et al., 2021) 中生成事件聚类以支持高效的分面摘要。
Table 2: Results on event and entity cross-document co reference resolution on $\mathrm{ECB+}$ test set.
表 2: ECB+ 测试集上事件和实体跨文档共指消解的结果
| MUC | B3 | CEAFe | LEA | CoNLL | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | P | F1 | R | P | F1 | R | P | F1 | R | P | F1 | F1 | ||
| Event E | Barhom et al. (2019) | 78.1 | 84.0 | 80.9 | 76.8 | 86.1 | 81.2 | 79.6 | 73.3 | 76.3 | 64.6 | 72.3 | 68.3 | 79.5 |
| Meged et al. (2020) | 78.8 | 84.7 | 81.6 | 75.9 | 85.9 | 80.6 | 81.1 | 74.8 | 77.8 | 64.7 | 73.4 | 68.8 | 80.0 | |
| Cattan et al. (2020) | 85.1 | 81.9 | 83.5 | 82.1 | 82.7 | 82.4 | 75.2 | 78.9 | 77.0 | 68.8 | 72.0 | 70.4 | 81.0 | |
| Zeng et al. (2020) | 85.6 | 89.3 | 87.5 | 77.6 | 89.7 | 83.2 | 84.5 | 80.1 | 82.3 | 84.3 | ||||
| Yu et al. (2020) | 88.1 | 85.1 | 86.6 | 86.1 | 84.7 | 85.4 | 79.6 | 83.1 | 81.3 | 84.4 | ||||
| Allaway et al. (2021) | 81.7 | 82.8 | 82.2 | 80.8 | 81.5 | 81.1 | 79.8 | 78.4 | 79.1 | 80.8 | ||||
| CDLM | 87.1 | 89.2 | 88.1 | 84.9 | 87.9 | 86.4 | 83.3 | 81.2 | 82.2 | 76.7 | 77.2 | 76.9 | 85.6 | |
| E | Barhom et al. (2019) | 81.0 | 80.8 | 80.9 | 66.8 | 75.5 | 70.9 | 62.5 | 62.8 | 62.7 | 53.5 | 63.8 | 58.2 | 71.5 |
| Cattan et al. (2020) | 85.7 | 81.7 | 83.6 | 70.7 | 74.8 | 72.7 | 59.3 | 67.4 | 63.1 | 56.8 | 65.8 | 61.0 | 73.1 | |
| Allaway et al. (2021) | 83.9 | 84.7 | 84.3 | 74.5 | 70.5 | 72.4 | 70.0 | 68.1 | 69.2 | 75.3 | ||||
| CDLM | 88.1 | 91.8 | 89.9 | 82.5 | 81.7 | 82.1 | 81.2 | 72.9 | 76.8 | 76.4 | 73.0 | 74.7 | 82.9 |
Table 3: Ablation results (CoNLL F1) on our model on the test set of $\mathrm{ECB+}$ event co reference.
表 3: 我们的模型在 $\mathrm{ECB+}$ 事件共指测试集上的消融实验结果 (CoNLL F1)
| F1 | △ | |
|---|---|---|
| fulldocumentCDLM | 85.6 | |
| 一 sentences onlyCDLM | 84.2 | -1.4 |
| 一 Longformer | 84.6 | -1.0 |
| -LocalCDLM | 84.7 | -0.9 |
| 一 -RandCDLM | 84.1 | -1.5 |
| PrefixCDLM | 85.1 | -0.5 |
3.3 Document matching
3.3 文档匹配
We evaluate our CDLM over document matching tasks, aiming to assess how well our model can capture interactions across multiple documents. We use the recent multi-document classification benchmark by Zhou et al. (2020) which includes two tasks of citation recommendation and plagiarism detection. The goal of both tasks is categorizing whether a particular relationship holds between two input documents. Citation recommendation deals with detecting whether one reference document should cite the other one, while the plagiarism detection task infers whether one document plagiarizes the other one. To compare with recent state-of-the-art models, we utilized the setup and data selection from Zhou et al. (2020), which provides three datasets for citation recommendation and one for plagiarism detection.
我们在文档匹配任务上评估了CDLM,旨在评估模型捕捉多文档间交互的能力。采用Zhou等人 (2020) 提出的多文档分类基准测试,包含文献推荐和剽窃检测两项任务。两项任务的目标都是判断输入文档间是否存在特定关联:文献推荐检测参考文档是否应引用另一文档,剽窃检测则推断文档是否存在抄袭行为。为与前沿模型对比,我们沿用Zhou等人 (2020) 的实验设置与数据选择方案,该方案提供三个文献推荐数据集和一个剽窃检测数据集。
Benchmarks. For citation recommendation, the datasets include the ACL Anthology Network Corpus (AAN; Radev et al., 2013), the Semantic Scholar Open Corpus (OC; Bhaga va tula et al.,
基准测试。对于引文推荐任务,使用的数据集包括ACL选集网络语料库 (AAN; Radev et al., 2013) 和语义学者开放语料库 (OC; Bhaga va tula et al.,
2018), and the Semantic Scholar Open Research Corpus (S2ORC; Lo et al., 2020). For plagiarism detection, the dataset is the Plagiarism Detection Challenge (PAN; Potthast et al., 2013).
2018年), 以及语义学者开放研究语料库 (S2ORC; Lo等人, 2020年)。针对抄袭检测任务, 采用的数据集是抄袭检测挑战赛 (PAN; Potthast等人, 2013年)。
AAN is composed of computational linguistics papers which were published on the ACL Anthology from 2001 to 2014, OC is composed of computer science and neuroscience papers, S2ORC is composed of open access papers across broad domains of science, and PAN is composed of web documents that contain several kinds of plagiarism phenomena. For further dataset prepossessing details and statistics, see Appendix A.3.
AAN由2001年至2014年发表在ACL Anthology上的计算语言学论文组成,OC由计算机科学和神经科学论文组成,S2ORC由跨广泛科学领域的开放获取论文组成,PAN则由包含多种抄袭现象的网页文档组成。更多数据集预处理细节和统计信息,请参见附录A.3。
Algorithm. For our models, we added the [CLS] token at the beginning of the input sequence, assigned it global attention, and concatenated the pair of texts, according to the finetuning setup discussed in Section 2.2. The hyper para meters are further detailed in Appendix C.2.
算法。对于我们的模型,我们在输入序列的开头添加了[CLS] token,根据第2.2节讨论的微调设置,为其分配全局注意力并连接文本对。超参数详见附录C.2。
Baselines. We consider the reported results of the following recent baselines:
基线方法。我们考虑了以下近期基线方法的报告结果:
– HAN (Yang et al., 2016) proposed the Hierarchical Attention Networks (HANs). These models employ a bottom-up approach in which a document is represented as an aggregation of smaller components i.e., sentences, and words. They set competitive performance in different tasks involving long document encoding (Sun et al., 2018).
– HAN (Yang et al., 2016) 提出了分层注意力网络 (Hierarchical Attention Networks, HANs)。这些模型采用自底向上的方法,将文档表示为较小组件(即句子和单词)的聚合。它们在涉及长文档编码的不同任务中展现了具有竞争力的性能 (Sun et al., 2018)。
– SMASH (Jiang et al., 2019) is an attentive hierarchical recurrent neural network (RNN) model, used for tasks related to long documents.
- SMASH (Jiang et al., 2019) 是一种基于注意力机制的层次化循环神经网络 (RNN) 模型,用于处理长文档相关任务。
– SMITH (Yang et al., 2020) is a BERT-based hierarchical model, similar HANs.
- SMITH (Yang et al., 2020) 是一种基于 BERT 的分层模型,类似于 HANs。
– CDA (Zhou et al., 2020) is a cross-document attentive mechanism (CDA) built on top of HANs, based on BERT or GRU models (see Section 4).
– CDA (Zhou et al., 2020) 是一种基于HANs架构的跨文档注意力机制 (cross-document attentive mechanism),其底层可采用BERT或GRU模型 (详见第4节)。
| 模型 | AAN OC | S2orc | PAN | |
|---|---|---|---|---|
| SMASH (2019) | 80.8 | |||
| SMITH (2020)5 | 85.4 | 86.3 | 90.8 | |
| BERT-HAN (2020) GRU-HAN+CDA(2020) | 65.0 75.1 | 89.9 | 91.6 | 87.4 78.2 |
| BERT-HAN+CDA (2020) | 82.1 | 87.8 | 92.1 | 86.2 |
| Longformer | 85.4 | 93.4 | 95.8 | 80.4 |
| Local CDLM | 83.8 | 92.1 | 94.5 | 80.9 |
| Rand CDLM | 85.7 | 93.5 | 94.6 | 79.4 |
| PrefixCDLM | 87.3 | 94.8 | 94.7 | 81.7 |
| CDLM | 88.8 | 95.3 | 96.5 | 82.9 |
Table 4: $F_{1}$ scores over the document matching benchmarks’ test sets.
表 4: 文档匹配基准测试集上的 $F_{1}$ 分数。
Both SMASH and SMITH reported results only over the AAN benchmark. In addition, they used a slightly different version of the AAN dataset,5 and included the full documents, unlike the dataset that (Zhou et al., 2020) used, which we utilized as well, that considers only the documents’ abstracts.
SMASH和SMITH仅在AAN基准测试上报告了结果。此外,他们使用了稍有不同的AAN数据集版本[5],并包含完整文档,而(Zhou et al., 2020)使用的数据集(我们同样采用)仅考虑了文档摘要。
Results. The results on the citation recommendation and plagiarism detection tasks are depicted in Table 4. We observe that even though SMASH and SMITH reported results using the full documents for the AAN task, our model outperforms them, using the partial version of the dataset, as in Zhou et al. (2020). Moreover, unlike our model, CDA is task-specific since it trains new cross-document weights for each task, yet it is still inferior to our model, evaluating on the three citation recommendation benchmarks. On the plagiarism detection benchmark, interestingly, our models does not perform better. Moreover, CDA impairs the performance of BERT-HAN, implying that dataset does not require detailed cross-document attention at all. In our experiments, finetuning BERT-HAN $^+$ CDA over the PAN dataset yielded poor results: $F_{1}$ score of 79.6, substantially lower compared to our models. The relatively small size of PAN may explain such degradation s.
结果。表4展示了引文推荐和抄袭检测任务的结果。我们发现,尽管SMASH和SMITH在AAN任务中使用了完整文档报告结果,但我们的模型在使用Zhou等人(2020)相同的部分数据集版本时仍优于它们。此外,与我们的模型不同,CDA是任务特定的,因为它为每个任务训练新的跨文档权重,但在三个引文推荐基准测试中仍逊色于我们的模型。有趣的是,在抄袭检测基准测试中,我们的模型表现并不更优。此外,CDA损害了BERT-HAN的性能,暗示该数据集根本不需要详细的跨文档注意力机制。在我们的实验中,在PAN数据集上微调BERT-HAN$^+$CDA得到较差结果:$F_{1}$分数仅为79.6,明显低于我们的模型。PAN数据集的较小规模可能是这种性能下降的原因。
3.4 Multihop Question answering
3.4 多跳问答
In the task of multihop question answering, a model is queried to extract answer spans and evidence sentences, given a question and multiple paragraphs from various related and non-related documents. This task includes challenging questions, that answering them requires finding and reasoning over
在多跳问答任务中,给定一个问题及多个相关或不相关文档的段落,模型需要提取答案片段和证据句。该任务包含具有挑战性的问题,回答这些问题需要发现并推理
| 模型 | 答案 (Ans) | 支持 (Sup) | 联合 (Joint) |
|---|---|---|---|
| Transformer-XH (2020) GraphRecurrentRetriever (2020) RoBERTa-lf (2020) BIGBIRD (2020) | 66.2 73.3 73.5 75.5 | 72.1 76.1 83.4 87.1 | 52.9 61.4 63.5 67.8 |
| Longformer LocalCDLM Rand CDLM | 74.5 74.1 72.7 | 83.9 84.0 84.8 | 64.5 64.2 63.7 |
Table 5: HotpotQA-distractor results $(F_{1})$ for the dev set. We use the “base” model size results from prior work for direct comparison. Ans: answer span, Sup: Supporting facts.
表 5: HotpotQA-distractor 开发集结果 $(F_{1})$ 。我们使用先前工作中的"base"模型尺寸结果进行直接比较。Ans: 答案片段, Sup: 支持事实。
multiple supporting documents.
多份支持文件。
Benchmark. We used the HotpotQA-distractor dataset (Yang et al., 2018). Each example in the dataset is comprised of a question and 10 different paragraphs from different documents, extracted from Wikipedia; two gold paragraphs include the relevant information for properly answering the question, mixed and shuffled with eight distractor paragraphs (for the full dataset statistics, see Yang et al. (2018)). There are two goals for this task: extraction of the correct answer span, and detecting the supporting facts, i.e., evidence sentences.
基准测试。我们使用了HotpotQA-distractor数据集 (Yang et al., 2018)。该数据集中的每个样本包含一个问题及10个来自维基百科不同文档的段落,其中两个黄金段落包含回答问题所需的相关信息,与八个干扰段落混合并打乱顺序 (完整数据集统计信息参见Yang et al. (2018))。该任务有两个目标:提取正确答案片段,以及检测支持事实 (即证据句子)。
Algorithm. We employ the exact same setup from (Beltagy et al., 2020): We concatenate all the 10 paragraphs into one large sequence, separated by document separator tokens, and using special sentence tokens to separate sentences. The model is trained jointly in a multi-task manner, where classification heads specialize on each sub-task, including relevant paragraphs prediction, evidence sentences identification, extracting answer spans and inferring the question types (yes, no, or span). For details and hyper parameters, see Appendix C.3 and Beltagy et al. (2020, Appendix D).
算法。我们采用与 (Beltagy et al., 2020) 完全相同的设置:将所有10个段落连接成一个长序列,用文档分隔符 (document separator tokens) 隔开,并使用特殊句子标记 (special sentence tokens) 分隔句子。该模型以多任务方式联合训练,其中分类头专门处理每个子任务,包括相关段落预测、证据句子识别、答案范围抽取和问题类型推断(是、否或范围)。具体细节和超参数参见附录C.3及 Beltagy et al. (2020, 附录 D)。
Results. The results are depicted in Table 5, where we included also the results for TransformerXH (Zhao et al., 2020), a transformer-based model that constructs global contextual i zed representations, Graph Recurrent Retriever (Asai et al., 2020), a recent strong graph-based passage retrieval method, RoBERTa (Liu et al., 2019), which was modified by Beltagy et al. (2020) to operate on long sequences (dubbed RoBERTa-lf), and BIGBIRD (Zaheer et al., 2020), a long-range trans- former model which was pretrained on a massive amount of text. CDLM outperforms all the ablated models as well as the comparably sized models from prior work (except for BIGBIRD), especially in the supporting evidence detection sub-task. We note that the BIGBIRD model was pretrained on much larger data, using more compute resources compared both to the Longformer model and to our models. We suspect that with more compute and data, it is possible to close the gap between CDLM and BIGBIRD performance. We leave for future work evaluating a larger version of the CDLM model against large, state-of-the-art models.
结果。结果如表 5 所示,其中我们还包含了 TransformerXH (Zhao et al., 2020) 的结果,这是一种基于 Transformer 的模型,可构建全局上下文表示;Graph Recurrent Retriever (Asai et al., 2020),一种近期较强的基于图的段落检索方法;RoBERTa (Liu et al., 2019),该模型被 Beltagy et al. (2020) 修改以处理长序列(称为 RoBERTa-lf);以及 BIGBIRD (Zaheer et al., 2020),这是一种长距离 Transformer 模型,经过大量文本的预训练。CDLM 在所有消融模型以及先前工作中规模相当的模型(除 BIGBIRD 外)中表现更优,尤其是在支持性证据检测子任务中。我们注意到,与 Longformer 模型和我们的模型相比,BIGBIRD 模型在更大的数据上进行了预训练,并使用了更多的计算资源。我们推测,通过增加计算资源和数据,有可能缩小 CDLM 与 BIGBIRD 性能之间的差距。我们将评估更大版本的 CDLM 模型与大型先进模型的工作留待未来进行。
3.5 Attention Analysis
3.5 注意力分析
It was recently shown that during the pre training phase, LMs learn to encode various types of linguistic information, that can be identified via their attention patterns (Wiegreffe and Pinter, 2019; Rogers et al., 2020b). In Clark et al. (2019), the attention weights of BERT were proved as informative for probing the degree to which a particular token is “important”, as well as its linguistic roles. For example, they showed that the averaged attention weights from the last layer of BERT are beneficial features for dependency parsing.
最近研究表明,在预训练阶段,大语言模型能学习编码多种语言学信息,这些信息可通过注意力模式识别 (Wiegreffe and Pinter, 2019; Rogers et al., 2020b)。Clark等人 (2019) 证实BERT的注意力权重能有效探测特定token的"重要性"程度及其语言学角色。例如,他们证明BERT最后一层的平均注意力权重可作为依存句法分析的有效特征。
We posit that our pre training scheme, which combines global attention and a multi-document context, captures alignment and mapping information across documents. Hence, we hypothesize that the global attention mechanism favors crossdocument (CD), long-range relations. To gain more insight, our goal is to investigate if our proposed pre training method leads to relatively higher global attention weights between co-referring mentions compared to non-co-referring ones, even without any finetuning over CD co reference resolution.
我们假设,结合全局注意力机制和多文档上下文的预训练方案能够捕捉跨文档的对齐和映射信息。因此,我们推测全局注意力机制更有利于跨文档 (CD) 的长距离关系。为了更深入地理解,我们的目标是研究:即使不对 CD 共指消解进行任何微调,所提出的预训练方法是否会使共指提及之间的全局注意力权重相对高于非共指提及。
Benchmark. We randomly sampled 1,000 positive and 1,000 negative co reference-pair examples from the $\mathrm{ECB}+\mathrm{CD}$ co reference resolution benchmark, for both events and entities. Each example consists of two concatenated documents and two co reference candidate mentions (see Section 3.2).
基准测试。我们从$\mathrm{ECB}+\mathrm{CD}$共指消解基准测试中随机抽取了1,000个正例和1,000个负例共指对样本,涵盖事件和实体两种类型。每个样本包含两篇拼接文档和两个共指候选提及(参见第3.2节)。
Analysis Method. For each example, which contains two mention spans, we randomly pick one to be considered as the source span, while the second one is the target span. We denote the set of the tokens in the source and target spans as $S$ and $T$ , respectively. Our goal is to quantify the degree of alignment between $S$ and $T$ , using the attention pattern of the model. We first assign global attention to the tokens in the source span (in $S$ ). Next, we pass the full input through the model, compute the normalized attention weights for all the tokens in the input with respect to $S$ , by aggregating the scores extracted from the last layer of the model. The score for an input token $i\not\in S$ , is given by
分析方法。对于每个包含两个提及跨度的示例,我们随机选取一个作为源跨度,另一个作为目标跨度。我们将源跨度和目标跨度中的 token 集合分别记为 $S$ 和 $T$。我们的目标是利用模型的注意力模式来量化 $S$ 和 $T$ 之间的对齐程度。首先,我们为源跨度中的 token (属于 $S$) 分配全局注意力。接着,我们将完整输入传入模型,通过聚合从模型最后一层提取的分数,计算输入中所有 token 相对于 $S$ 的归一化注意力权重。对于不属于 $S$ 的输入 token $i\not\in S$,其得分由以下公式给出:
Doc1: 总统奥巴马将于今晨晚些时候在玫瑰园宣布任命Regina Benjamin博士为美国卫生局局长。Benjamin是阿拉巴马州的一名家庭医生,[...]
Doc 2: [...] 奥巴马提名新卫生局长:
$$
s(i|S)\propto\exp\left[\sum_{k=1}^{n}\sum_{j\in S}\left({\alpha}{i,j}^{k}+{\alpha}{j,i}^{k}\right)\right],
$$
$$
s(i|S)\propto\exp\left[\sum_{k=1}^{n}\sum_{j\in S}\left({\alpha}{i,j}^{k}+{\alpha}{j,i}^{k}\right)\right],
$$
where $\alpha_{i,j}^{k}$ is the global attention weight from token $i$ to token $j$ produced by head $k$ , and $n$ is the total number of attention heads (the score is computed using only the last layer of the model). Note that we include both directions of attention. The target span score is then given by $\begin{array}{r}{s(T|S)=\frac{1}{|T|}\sum_{j\in T}s(j|S)}\end{array}$ Finally, we calculate the percentile rank (PR) of $s(T|S)$ , compared to the rest of the token scores within the containing document of $T$ , namely, ${s(i|S)|i\notin T}$ .
其中 $\alpha_{i,j}^{k}$ 是由注意力头 $k$ 生成的从 token $i$ 到 token $j$ 的全局注意力权重,$n$ 是注意力头的总数(该分数仅使用模型的最后一层计算)。注意我们包含了双向的注意力。目标片段得分由 $\begin{array}{r}{s(T|S)=\frac{1}{|T|}\sum_{j\in T}s(j|S)}\end{array}$ 给出。最后,我们计算 $s(T|S)$ 的百分位排名 (PR),与包含 $T$ 的文档中其余 token 得分 ${s(i|S)|i\notin T}$ 进行比较。
For positive co reference examples, plausible results are expected to be associated with high attention weights between the source and the target spans, resulting with a high value of $s(T|S)$ , and thus, yielding a higher PR. For negative examples, the target span is not expected to be promoted with respect to the rest of the tokens in the document.
对于正共指示例,预期合理结果应与源跨度与目标跨度间的高注意力权重相关联,从而产生较高的 $s(T|S)$ 值,进而获得更高的PR (Positive Rate)。对于负例,目标跨度不应相对于文档中其余token获得提升。
Results. First, we apply the procedure above over one selected example, depicted in Figure 3. We consider the two CD co-referring event mentions: name and nominates as the source and target spans, respectively. The target span received a PR of $69%$ when evaluating the underlying Longformer. Notably, it received a high PR of $90%$ when using our CDLM, demonstrating the advantage of our novel pre training method. Next, we turn to a systematic experiment, elucidating the relative advantage of pre training with global attention across related documents. In Table 6, we depict the mean PR (MPR) computed over all the sampled examples, for all our pretrained models. We observe that none of the models fail6 on the set of negatives, since the negative examples contain reasonable event or entity mentions, rather than random, non informative
结果。首先,我们在图3所示的选定示例上应用上述流程。将两个跨文档共指事件提及name和nominates分别作为源跨度(source span)和目标跨度(target span)。评估底层Longformer时,目标跨度获得了69%的PR (proportional reduction)。值得注意的是,使用我们的CDLM时获得了90%的高PR,这证明了我们新颖的预训练方法的优势。接着,我们转向系统性实验,阐明跨相关文档进行全局注意力预训练的相对优势。在表6中,我们展示了所有预训练模型在所有采样示例上计算的平均PR (MPR)。观察到所有模型在负例集上均未失效,因为这些负例包含合理的事件或实体提及,而非随机无意义的
| Pos. MPR (%) | Neg. MPR (%) | ||||
|---|---|---|---|---|---|
| events | entities | events | entities | ||
| Local | Longformer | 61.9 | 59.7 | 54.8 | 50.5 |
| Local CDLM | 62.2 | 60.8 | 54.6 | 52.6 | |
| RandCDLM | 70.6 | 69.1 | 56.6 | 53.2 | |
| Global | PrefixCDLM | 70.7 | 69.4 | 58.5 | 56.5 |
| CDLM | 72.1 | 70.3 | 58.0 | 55.7 |
Table 6: Cross-document co reference resolution alignment MPR scores of the target span, with respect to the tokens in the same document.
表 6: 目标跨文档共指消解对齐 MPR 分数 (相对于同一文档中的 token)
spans. For the positive examples, the gap of up to $10%$ of MPR between the “Local” and “Global” models shows the advantage of adopting global attention during the pre training phase. This indicates that the global attention mechanism implicitly helps to encode alignment information.
对于正例,"Local"和"Global"模型之间最高达$10%$的MPR差距,显示了在预训练阶段采用全局注意力的优势。这表明全局注意力机制隐式地帮助编码对齐信息。
4 Related Work
4 相关工作
Recently, long-context language models (Beltagy et al., 2020; Zaheer et al., 2020) introduced the idea of processing multi-document tasks using a single long-context sequence encoder. However, pretraining objectives in these models consider only single documents. Here, we showed that additional gains can be obtained by MLM pre training using multiple related documents as well as a new dynamic global attention pattern.
最近,长上下文语言模型 (Beltagy et al., 2020; Zaheer et al., 2020) 提出了使用单一长上下文序列编码器处理多文档任务的想法。然而,这些模型的预训练目标仅考虑单个文档。本文表明,通过使用多个相关文档进行掩码语言建模 (MLM) 预训练以及新的动态全局注意力机制,可以获得额外的性能提升。
Processing and aggregating information from multiple documents has been also explored in the context of document retieval, aiming to extract information from a large set of documents (Guu et al., 2020; Lewis et al., 2020a,b; Karpukhin et al., 2020). These works focus on retrieving relevant information from often a large collection of documents, by utilizing short-context LMs, and then generate information of interest. CDLM instead provides an approach for improving the encoding and contextualizing information across multiple documents. As opposed to the mentioned works, our model utilizes long-context LM and can include broader contexts of more than a single document.
从多文档中处理和聚合信息的研究也在文档检索领域得到了探索,旨在从大量文档中提取信息 (Guu et al., 2020; Lewis et al., 2020a,b; Karpukhin et al., 2020)。这些工作主要通过短上下文大语言模型从海量文档集合中检索相关信息,进而生成目标内容。而 CDLM 则提供了一种改进多文档信息编码与上下文关联的方法。与上述研究不同,我们的模型采用长上下文大语言模型,能够整合超越单文档的更广泛上下文。
The use of cross-document attention has been recently explored by the Cross-Document Attention (CDA) (Zhou et al., 2020). CDA specifi- cally encodes two documents, using hierarchical attention networks, with the addition of cross attention between documents, and makes similarity decision between them. Similarly, the recent DCS model (Ginzburg et al., 2021) suggested a cross-document finetuning scheme for unsupervised document-pair matching method (processing only two documents at once). Our CDLM, by contrast, is a general pretrained language model that can be applied to a variety of multi-document downstream tasks, without restrictions on the number of input documents, as long as they fit the input length of the Longformer.
跨文档注意力 (Cross-Document Attention, CDA) 的使用近期由 Zhou 等人 (2020) 提出 [20]。CDA 通过分层注意力网络对两份文档进行编码,并添加文档间的交叉注意力机制,最终判断二者的相似性。类似地,近期提出的 DCS 模型 (Ginzburg 等人, 2021) 针对无监督文档对匹配任务提出跨文档微调方案 (每次仅处理两份文档)。相比之下,我们的 CDLM 是一个通用预训练语言模型,可应用于多种多文档下游任务,只要输入文档长度符合 Longformer 的限制,其对输入文档数量没有限制。
Finally, our pre training scheme is conceptually related to cross-encoder models that leverage simultaneously multiple related information sources. For example, the Translation Language Model (TLM) (Conneau and Lample, 2019) encodes together sentences and their translation, while certain crossmodality encoders pretrain over images and texts in tandem (e.g., ViLBERT (Lu et al., 2019)).
最后,我们的预训练方案在概念上与利用多个相关信息源的交叉编码器 (cross-encoder) 模型相关。例如,翻译语言模型 (TLM) [20] 同时对句子及其翻译进行编码,而某些跨模态编码器 (如 ViLBERT [21]) 会同步预训练图像和文本。
5 Conclusion
5 结论
We presented a novel pre training strategy and technique for cross-document language modeling, providing better encoding for cross-document (CD) downstream tasks. Our contributions include the idea of leveraging clusters of related documents for pre training, via cross-document masking, along with a new long-range attention pattern, together driving the model to learn to encode CD relationships. This was achieved by extending the global attention mechanism of the Longformer model to apply already in pre training, creating encodings that attend to long-range information across and within documents. Our experiments assess that our crossdocument language model yields new state-of-theart results over several CD benchmarks, while, in fact, employing substantially smaller models. Our analysis showed that CDLM implicitly learns to recover long-distance CD relations via the attention mechanism. We propose future research to extend this framework to train larger models, and to develop cross-document sequence-to-sequence models, which would support CD tasks that involve a generation phase.
我们提出了一种新颖的跨文档语言建模预训练策略与技术,为跨文档(CD)下游任务提供了更好的编码。我们的贡献包括利用相关文档集群进行预训练的思想(通过跨文档掩码实现),以及一种新的长距离注意力模式,共同驱动模型学习编码跨文档关系。这一成果通过扩展Longformer模型的全局注意力机制实现,使其在预训练阶段就能处理跨文档及文档内部的长距离信息。实验表明,我们的跨文档语言模型在多个CD基准测试中取得了新的最先进成果,而实际使用的模型规模显著更小。分析显示,CDLM通过注意力机制隐式地学会了重建长距离跨文档关系。我们建议未来研究扩展该框架以训练更大规模的模型,并开发跨文档序列到序列模型,从而支持涉及生成阶段的跨文档任务。
Acknowledgments
致谢
We thank Doug Downey and Luke Z ett le moyer for fruitful discussions and helpful feedback, and Yoav Goldberg for helping us connect with collaborators on this project. The work described herein was supported in part by grants from Intel Labs, the Israel Science Foundation grant 1951/17, the Israeli Ministry of Science and Technology, and the NSF Grant OIA-2033558.
我们感谢 Doug Downey 和 Luke Zettlemoyer 富有成效的讨论和有益反馈,并感谢 Yoav Goldberg 帮助我们联系该项目的合作者。本研究工作部分得到了英特尔实验室、以色列科学基金会 (1951/17)、以色列科技部以及美国国家科学基金会 (OIA-2033558) 的资助支持。
References
参考文献
Emily Allaway, Shuai Wang, and Miguel Ball ester os. 2021. Sequential cross-document co reference resolution. arXiv preprint arXiv:2104.08413.
Emily Allaway、Shuai Wang和Miguel Ballesteros。2021。跨文档顺序共指消解。arXiv预印本arXiv:2104.08413。
Akari Asai, Kazuma Hashimoto, Hannaneh Hajishirzi, Richard Socher, and Caiming Xiong. 2020. Learning to retrieve reasoning paths over wikipedia graph for question answering. In International Conference on Learning Representations (ICLR).
Akari Asai、Kazuma Hashimoto、Hannaneh Hajishirzi、Richard Socher 和 Caiming Xiong。2020。学习检索维基百科图谱中的推理路径以进行问答。收录于国际学习表征会议 (ICLR)。
Amit Bagga and Breck Baldwin. 1998. Algorithms for scoring co reference chains. In The first international conference on language resources and evaluation workshop on linguistics co reference, volume 1, pages 563–566. Citeseer.
Amit Bagga和Breck Baldwin. 1998. 共指链评分算法. 第一届语言资源与评估国际会议语言学共指研讨会, 第1卷, 第563–566页. Citeseer.
Shany Barhom, Vered Shwartz, Alon Eirew, Michael Bugert, Nils Reimers, and Ido Dagan. 2019. Revisiting joint modeling of cross-document entity and event co reference resolution. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4179–4189, Florence, Italy. Association for Computational Linguistics.
Shany Barhom、Vered Shwartz、Alon Eirew、Michael Bugert、Nils Reimers和Ido Dagan。2019。重新审视跨文档实体与事件共指消解的联合建模。见《第57届计算语言学协会年会论文集》,第4179–4189页,意大利佛罗伦萨。计算语言学协会。
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.
Iz Beltagy、Matthew E Peters 和 Arman Cohan。2020。Longformer: 长文档 Transformer。arXiv 预印本 arXiv:2004.05150。
Chandra Bhaga va tula, Sergey Feldman, Russell Power, and Waleed Ammar. 2018. Content-based citation recommendation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 238–251, New Orleans, Louisiana. Association for Computational Linguistics.
Chandra Bhaga va tula、Sergey Feldman、Russell Power 和 Waleed Ammar。2018. 基于内容的引文推荐。载于《2018年北美计算语言学协会人类语言技术会议论文集》第1卷(长论文),第238-251页,美国路易斯安那州新奥尔良。计算语言学协会。
Arie Cattan, Alon Eirew, Gabriel Stanovsky, Mandar Joshi, and Ido Dagan. 2020. Streamlining crossdocument co reference resolution: Evaluation and modeling. ArXiv, abs/2009.11032.
Arie Cattan、Alon Eirew、Gabriel Stanovsky、Mandar Joshi 和 Ido Dagan。2020。简化跨文档共指消解:评估与建模。ArXiv,abs/2009.11032。
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. What does BERT look at? an analysis of BERT’s attention. In Proceedings of the 2019 ACL Workshop Blackbox NLP: Analyzing and Interpreting Neural Networks for NLP, pages 276–286, Florence, Italy. Association for Computational Linguistics.
Kevin Clark、Urvashi Khandelwal、Omer Levy 和 Christopher D. Manning。2019。BERT 在看什么?BERT 注意力机制分析。2019年ACL研讨会BlackboxNLP论文集:分析与解释自然语言处理神经网络,第276-286页,意大利佛罗伦萨。计算语言学协会。
Alexis Conneau and Guillaume Lample. 2019. Crosslingual language model pre training. Advances in Neural Information Processing Systems (NIPS).
Alexis Conneau和Guillaume Lample。2019。跨语言语言模型预训练。神经信息处理系统进展(NIPS)。
Agata Cybulska and Piek Vossen. 2014. Using a sledgehammer to crack a nut? lexical diversity and event co reference resolution. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), pages 4545– 4552, Reykjavik, Iceland. European Language Resources Association (ELRA).
Agata Cybulska和Piek Vossen。2014。杀鸡用牛刀?词汇多样性与事件共指消解。载于《第九届国际语言资源与评估会议(LREC’14)论文集》,第4545–4552页,冰岛雷克雅未克。欧洲语言资源协会(ELRA)。
Agata Cybulska and Piek Vossen. 2015. “Bag of Events” approach to event co reference resolution.
Agata Cybulska和Piek Vossen。2015。事件共指消解的"事件袋"方法。
supervised classification of event templates. IJCLA, page 11.
事件模板的监督分类。IJCLA,第11页。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019a. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019a。BERT:面向语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会人类语言技术会议论文集(长文与短文)》第1卷,第4171–4186页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019b. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019b。BERT:用于语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会会议论文集:人类语言技术》(长文与短文),第1卷,第4171–4186页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Rotem Dror, Gili Baumer, Segev Shlomov, and Roi Reichart. 2018. The hitchhiker’s guide to testing statistical significance in natural language processing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1383–1392, Melbourne, Australia. Association for Computational Linguistics.
Rotem Dror、Gili Baumer、Segev Shlomov 和 Roi Reichart。2018。自然语言处理统计显著性检验指南。载于《第56届计算语言学协会年会论文集(第一卷:长论文)》,第1383–1392页,澳大利亚墨尔本。计算语言学协会。
Alexander Fabbri, Irene Li, Tianwei She, Suyi Li, and Dragomir Radev. 2019. Multi-news: A large-scale multi-document sum mari z ation dataset and abstractive hierarchical model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1074–1084, Florence, Italy. Association for Computational Linguistics.
Alexander Fabbri、Irene Li、Tianwei She、Suyi Li 和 Dragomir Radev。2019. Multi-News: 一个大规模多文档摘要数据集及抽象层次模型。见《第57届计算语言学协会年会论文集》,第1074-1084页,意大利佛罗伦萨。计算语言学协会。
Dvir Ginzburg, Itzik Malkiel, Oren Barkan, Avi Caciularu, and Noam Koenig stein. 2021. Self-supervised document similarity ranking via contextual i zed language models and hierarchical inference. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 3088–3098, Online. Association for Computational Linguistics.
Dvir Ginzburg、Itzik Malkiel、Oren Barkan、Avi Caciularu 和 Noam Koenigstein。2021。基于上下文语言模型和层次推理的自监督文档相似性排序。载于《计算语言学协会发现集:ACL-IJCNLP 2021》,第3088–3098页,线上会议。计算语言学协会。
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. In Proceedings of the International Conference on Machine Learning (ICML).
Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat 和 Mingwei Chang。2020. 检索增强的语言模型预训练。见《国际机器学习会议 (ICML) 论文集》。
Eran Hirsch, Alon Eirew, Ori Shapira, Avi Caciularu, Arie Cattan, Ori Ernst, Ramakanth Pasunuru, Hadar Ronen, Mohit Bansal, and Ido Dagan. 2021. ifacetsum: Co reference-based interactive faceted sum mari z ation for multi-document exploration. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP): System Demonstrations.
Eran Hirsch、Alon Eirew、Ori Shapira、Avi Caciularu、Arie Cattan、Ori Ernst、Ramakanth Pasunuru、Hadar Ronen、Mohit Bansal和Ido Dagan。2021。ifacetsum:基于共指的多文档交互式分面摘要探索系统。载于《自然语言处理实证方法会议(EMNLP):系统演示论文集》。
Jyun-Yu Jiang, Mingyang Zhang, Cheng Li, Michael Bendersky, Nadav Golbandi, and Marc Najork. 2019. Semantic text matching for long-form documents. In The World Wide Web Conference (WWW).
Jyun-Yu Jiang、Mingyang Zhang、Cheng Li、Michael Bendersky、Nadav Golbandi 和 Marc Najork。2019. 长文档的语义文本匹配。见《万维网大会》(WWW)。
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769– 6781, Online. Association for Computational Linguistics.
Vladimir Karpukhin、Barlas Oguz、Sewon Min、Patrick Lewis、Ledell Wu、Sergey Edunov、Danqi Chen 和 Wen-tau Yih。2020。开放域问答的密集段落检索。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第6769–6781页,线上。计算语言学协会。
Kian Kenyon-Dean, Jackie Chi Kit Cheung, and Doina Precup. 2018. Resolving event co reference with supervised representation learning and clusteringoriented regular iz ation. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, pages 1–10, New Orleans, Louisiana. Association for Computational Linguistics.
Kian Kenyon-Dean、Jackie Chi Kit Cheung 和 Doina Precup。2018. 基于监督表示学习和聚类导向正则化的事件共指消解。载于《第七届词汇与计算语义学联合会议论文集》,第1-10页,美国路易斯安那州新奥尔良。计算语言学协会。
Kenton Lee, Luheng He, Mike Lewis, and Luke Zettlemoyer. 2017. End-to-end neural co reference resolution. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 188–197, Copenhagen, Denmark. Association for Computational Linguistics.
Kenton Lee、Luheng He、Mike Lewis和Luke Zettlemoyer。2017。端到端神经共指消解。载于《2017年自然语言处理实证方法会议论文集》,第188-197页,丹麦哥本哈根。计算语言学协会。
Mike Lewis, Marjan Ghaz vi nine j ad, Gargi Ghosh, Armen Aghajanyan, Sida Wang, and Luke Z ett le moyer. 2020a. Pre-training via paraphrasing. Advances in Neural Information Processing Systems (NeurIPS).
Mike Lewis、Marjan Ghazvininejad、Gargi Ghosh、Armen Aghajanyan、Sida Wang 和 Luke Zettlemoyer。2020a。基于复述的预训练。神经信息处理系统进展 (NeurIPS)。
Patrick S. H. Lewis, Ethan Perez, Aleksandra Pik- tus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock t s chel, Sebastian Riedel, and Douwe Kiela. 2020b. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS).
Patrick S. H. Lewis、Ethan Perez、Aleksandra Pikus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel、Sebastian Riedel 和 Douwe Kiela。2020b。面向知识密集型 NLP 任务的检索增强生成 (Retrieval-augmented generation)。载于《神经信息处理系统进展》(NeurIPS)。
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Z ett le moyer, and Veselin Stoyanov. 2019. RoBERTa: A robustly optimized BERT pre training approach. arXiv preprint arXiv:1907.11692.
Yinhan Liu、Myle Ott、Naman Goyal、Jingfei Du、Mandar Joshi、Danqi Chen、Omer Levy、Mike Lewis、Luke Zettlemoyer 和 Veselin Stoyanov。2019。RoBERTa:一种稳健优化的 BERT 预训练方法。arXiv 预印本 arXiv:1907.11692。
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel Weld. 2020. S2ORC: The semantic scholar open research corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4969–4983, Online. Association for Computational Linguistics.
Kyle Lo、Lucy Lu Wang、Mark Neumann、Rodney Kinney和Daniel Weld。2020。S2ORC:语义学者开放研究语料库。载于《第58届计算语言学协会年会论文集》,第4969–4983页,线上。计算语言学协会。
Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pre training task-agnostic visio linguistic representations for vision-and-language tasks. In Advances in Neural Information Processing Systems (NIPS).
Jiasen Lu、Dhruv Batra、Devi Parikh 和 Stefan Lee。2019. Vilbert:面向视觉与语言任务的预训练任务无关视觉语言表征。见《神经信息处理系统进展》(NIPS)。
Xiaoqiang Luo. 2005. On co reference resolution performance metrics. In Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing, pages 25–32. Association for Computational Linguistics.
Xiaoqiang Luo. 2005. 指代消解性能评估指标研究. 见: 人类语言技术与自然语言处理实证方法会议论文集, 25-32页. 计算语言学协会.
Yehudit Meged, Avi Caciularu, Vered Shwartz, and Ido Dagan. 2020. Paraphrasing vs co referring: Two sides of the same coin. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4897–4907, Online. Association for Computational Linguistics.
Yehudit Meged、Avi Caciularu、Vered Shwartz 和 Ido Dagan。2020。复述与共指:同一枚硬币的两面。载于《计算语言学协会发现:EMNLP 2020》,第4897–4907页,线上。计算语言学协会。
Nafise Sadat Moosavi and Michael Strube. 2016. Which co reference evaluation metric do you trust? a proposal for a link-based entity aware metric. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 632–642, Berlin, Germany. Association for Computational Linguistics.
Nafise Sadat Moosavi和Michael Strube。2016。你信任哪种共指消解评估指标?一种基于链接的实体感知指标提案。载于《第54届计算语言学协会年会论文集(第一卷:长论文)》,第632–642页,德国柏林。计算语言学协会。
Martin Potthast, Matthias Hagen, Tim Gollub, Martin Tippmann, Johannes Kiesel, Paolo Rosso, Efstathios Stamatatos, and Benno Stein. 2013. Overview of the 5th international competition on plagiarism detection. In Conference on Multilingual and Multimodal Information Access Evaluation (CLEF).
Martin Potthast、Matthias Hagen、Tim Gollub、Martin Tippmann、Johannes Kiesel、Paolo Rosso、Efstathios Stamatatos和Benno Stein。2013。第5届国际剽窃检测大赛综述。见:多语言多模态信息访问评估会议(CLEF)。
Dragomir R Radev, Pradeep Muth u krishna n, Vahed Qazvinian, and Amjad Abu-Jbara. 2013. The ACL anthology network corpus. Language Resources and Evaluation, 47(4):919–944.
Dragomir R Radev、Pradeep Muthukrishnan、Vahed Qazvinian 和 Amjad Abu-Jbara。2013. ACL 选集网络语料库。语言资源与评估,47(4):919–944。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J. Liu。2020。探索文本到文本Transformer (text-to-text transformer) 迁移学习的极限。Journal of Machine Learning Research,21(140):1–67。
Anna Rogers, Olga Kovaleva, and Anna Rumshisky. 2020a. A primer in BERTology: What we know about how BERT works. Transactions of the Association for Computational Linguistics, 8:842–866.
Anna Rogers、Olga Kovaleva 和 Anna Rumshisky. 2020a. BERTology 入门: 我们对 BERT 工作原理的认知. Transactions of the Association for Computational Linguistics, 8:842–866.
Anna Rogers, Olga Kovaleva, and Anna Rumshisky. 2020b. A primer in BERTology: What we know about how BERT works. Transactions of the Association for Computational Linguistics (TACL).
Anna Rogers、Olga Kovaleva 和 Anna Rumshisky. 2020b. BERTology 入门: 我们对 BERT 工作原理的认知. 计算语言学协会汇刊 (TACL).
Vered Shwartz, Gabriel Stanovsky, and Ido Dagan. 2017. Acquiring predicate paraphrases from news tweets. In Proceedings of the 6th Joint Conference on Lexical and Computational Semantics ( $^{*}S E M$ 2017), pages 155–160, Vancouver, Canada. Associa- tion for Computational Linguistics.
Vered Shwartz、Gabriel Stanovsky和Ido Dagan。2017。从新闻推文中获取谓词释义。载于《第六届词汇与计算语义学联合会议论文集》(*SEM 2017),第155-160页,加拿大温哥华。计算语言学协会。
Qingying Sun, Zhongqing Wang, Qiaoming Zhu, and Guodong Zhou. 2018. Stance detection with hierarchical attention network. In Proceedings of the $27t h$ International Conference on Computational Linguistics, pages 2399–2409, Santa Fe, New Mexico, USA. Association for Computational Linguistics.
孙清英、王忠庆、朱巧明和周国栋。2018。基于分层注意力网络的立场检测。见《第27届国际计算语言学会议论文集》,第2399–2409页,美国新墨西哥州圣达菲。计算语言学协会。
Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. 2021. Long range arena: A benchmark for efficient transformers. In International Conference on Learning Representations (ICLR).
Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. 2021. Long range arena: 高效Transformer的基准测试. In International Conference on Learning Representations (ICLR).
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems (NIPS).
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser 和 Illia Polosukhin。2017. Attention is all you need。载于《神经信息处理系统进展》(NIPS)。
Marc Vilain, John Burger, John Aberdeen, Dennis Connolly, and Lynette Hirschman. 1995. A modeltheoretic co reference scoring scheme. In Proceedings of the 6th conference on Message understanding, pages 45–52. Association for Computational Linguistics.
Marc Vilain、John Burger、John Aberdeen、Dennis Connolly 和 Lynette Hirschman。1995. 一种基于模型理论的共指消解评分方案。见《第六届信息理解会议论文集》,第45–52页。计算语言学协会。
Sarah Wiegreffe and Yuval Pinter. 2019. Attention is not not explanation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLPIJCNLP), pages 11–20, Hong Kong, China. Association for Computational Linguistics.
Sarah Wiegreffe 和 Yuval Pinter. 2019. 注意力并非解释. 见《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议(EMNLP-IJCNLP)论文集》, 第11-20页, 中国香港. 计算语言学协会.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, Remi Louf, Morgan Funtow- icz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pier-ric Cistac、Tim Rault、Remi Louf、Morgan Funtowicz、Joe Davison、Sam Shleifer、Patrick von Platen、Clara Ma、Yacine Jernite、Julien Plu、Canwen Xu、Teven Le Scao、Sylvain Gugger、Mariama Drame、Quentin Lhoest 和 Alexander Rush。2020。Transformer:最先进的自然语言处理技术。载于《2020年自然语言处理实证方法会议:系统演示集》,第38-45页,线上。计算语言学协会。
Liu Yang, Mingyang Zhang, Cheng Li, Michael Bendersky, and Marc Najork. 2020. Beyond 512 tokens: Siamese multi-depth transformer-based hierarchical encoder for long-form document matching. In Proceedings of the ACM International Conference on Information & Knowledge Management (CIKM).
刘阳、张明阳、李成、Michael Bendersky 和 Marc Najork。2020。突破 512 Token 限制:基于孪生多层级 Transformer 的长文档匹配分层编码器。载于《ACM 国际信息与知识管理会议论文集》(CIKM)。
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salak hut dino v, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explain able multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Computational Linguistics.
Zhilin Yang、Peng Qi、Saizheng Zhang、Yoshua Bengio、William Cohen、Ruslan Salakhutdinov 和 Christopher D. Manning。2018. HotpotQA:一个支持多样化、可解释多跳问答的数据集。载于《2018年自然语言处理实证方法会议论文集》,第2369–2380页,比利时布鲁塞尔。计算语言学协会。
Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. 2016. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1480–1489, San Diego, California. Association for Computational Linguistics.
Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. 2016. 用于文档分类的层次化注意力网络. 见《2016年北美计算语言学协会人类语言技术会议论文集》, 第1480-1489页, 美国加州圣地亚哥. 计算语言学协会.
Xiaodong Yu, Wenpeng Yin, and Dan Roth. 2020. Paired representation learning for event and entity co reference. arXiv preprint arXiv:2010.12808.
Xiaodong Yu, Wenpeng Yin, and Dan Roth. 2020. 事件与实体共指对的联合表示学习. arXiv preprint arXiv:2010.12808.
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. 2020. Big Bird: Transformers for longer sequences. Advances in Neural Information Processing Systems (NeurIPS).
Manzil Zaheer、Guru Guruganesh、Kumar Avinava Dubey、Joshua Ainslie、Chris Alberti、Santiago Ontanon、Philip Pham、Anirudh Ravula、Qifan Wang、Li Yang 等。2020。Big Bird: 更长序列的Transformer。神经信息处理系统进展 (NeurIPS)。
Yutao Zeng, Xiaolong Jin, Saiping Guan, Jiafeng Guo, and Xueqi Cheng. 2020. Event co reference resolution with their paraphrases and argument-aware embeddings. In Proceedings of the 28th International Conference on Computational Linguistics, pages 3084–3094, Barcelona, Spain (Online). International Committee on Computational Linguistics.
Yutao Zeng, Xiaolong Jin, Saiping Guan, Jiafeng Guo, and Xueqi Cheng. 2020. 基于复述与论元感知嵌入的事件共指消解. 见: 第28届国际计算语言学会议论文集, 第3084–3094页, 西班牙巴塞罗那(线上). 国际计算语言学委员会.
Chen Zhao, Chenyan Xiong, Corby Rosset, Xia Song, Paul Bennett, and Saurabh Tiwary. 2020. Transformer-XH: Multi-evidence reasoning with extra hop attention. In International Conference on Learning Representations (ICLR).
陈钊、陈彦雄、Corby Rosset、宋霞、Paul Bennett 和 Saurabh Tiwary。2020。Transformer-XH:基于额外跳数注意力的多证据推理。国际学习表征会议 (ICLR)。
Xuhui Zhou, Nikolaos Pappas, and Noah A. Smith. 2020. Multilevel text alignment with crossdocument attention. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5012–5025, Online. Association for Computational Linguistics.
周旭辉、Nikolaos Pappas和Noah A. Smith。2020。基于跨文档注意力的多层次文本对齐。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第5012–5025页,线上。计算语言学协会。
A Dataset Statistics and Details
数据集统计与详情
In this section, we provide details regrading the pre training corpus and benchmarks we used during our experiments.
在本节中,我们将详细介绍实验过程中使用的预训练语料库和基准测试。
A.1 Multi-News Corpus
A.1 Multi-News 语料库
We used the pre processed, not truncated version of Multi-News, which totals 322MB of uncompressed text.7 Each one of the pre processed documents contains up to 500 tokens. The average and $90^{\mathrm{th}}$ percentile of input length is $2.5\mathrm{k}$ and 3.8K tokens, respectively. In Table 7 we list the number of related documents per cluster. This follows the original dataset construction suggested in Fabbri et al. (2019).
我们使用了经过预处理且未截断的Multi-News版本,未压缩文本总量为322MB。每份预处理文档最多包含500个token。输入长度的平均值和第90百分位数分别为2.5k和3.8K token。表7中列出了每个聚类的相关文档数量,这遵循了Fabbri等人(2019)提出的原始数据集构建方法。
Table 7: MultiNews training set statistics.
表 7: MultiNews 训练集统计。
| 聚类中的文档数量 | 频次 |
|---|---|
| 3 | 12,707 |
| 4 | 5,022 |
| 5 | 1,873 |
| 6 | 763 |
| 7 | 382 |
| 8 | 209 |
| 9 | 89 |
| 10 | 33 |
| 总计 | 21,078 |
A.2 $\mathbf$ Dataset
A.2 $\mathbf$ 数据集
In Table 8, we list the statistics about training, development, and test splits regarding the topics, documents, mentions and co reference clusters. We follow the data split used by previous works (Cybulska and Vossen, 2015; Kenyon-Dean et al., 2018; Barhom et al., 2019): For training, we consider the topics: 1, 3, 4, 6-11, 13- 17, 19-20, 22, 24-33; For Validation, we consider the topics: 2, 5, 12, 18, 21, 23, 34, 35; For test, we consider the topics: 36-45.
在表8中,我们列出了关于主题、文档、提及和共指簇的训练集、开发集和测试集的统计数据。我们遵循先前工作 (Cybulska and Vossen, 2015; Kenyon-Dean et al., 2018; Barhom et al., 2019) 使用的数据划分方式:训练集包含主题1、3、4、6-11、13-17、19-20、22、24-33;验证集包含主题2、5、12、18、21、23、34、35;测试集包含主题36-45。
Table 8: $\mathrm{ECB+}$ dataset statistics. The slash numbers for Mentions and Clusters represent event/entity statistics.
表 8: $\mathrm{ECB+}$ 数据集统计。Mentions 和 Clusters 的斜杠数字分别表示事件/实体的统计量。
| 训练集 | 验证集 | 测试集 | |
|---|---|---|---|
| 主题数 | 25 | 8 | 10 |
| 文档数 | 594 | 196 | 206 |
| 提及数 | 3808/4758 | 1245/1476 | 1780/2055 |
| 聚类数 | 411/472 | 129/125 | 182/196 |
A.3 Paper Citation Recommendation & Plagiarism Detection Datasets
A.3 论文引用推荐与抄袭检测数据集
In Table 9, we list the statistics about training, development, and test splits for each benchmark separatly, and in Table 10, we list the document and example counts for each benchmark. The statistics are taken from Zhou et al. (2020).
在表9中,我们分别列出了每个基准测试的训练集、开发集和测试集的统计数据,在表10中,我们列出了每个基准测试的文档和示例数量。统计数据取自Zhou等人 (2020) 。
| 数据集 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| AAN | 106,592 | 13,324 | 13,324 |
| OC | 240,000 | 30,000 | 30,000 |
| S2ORC | 152,000 | 19,000 | 19,000 |
| PAN | 17,968 | 2,908 | 2,906 |
Table 9: Document-to-Document benchmarks statistics: Details regrading the training, validation, and test splits.
表 9: 文档到文档基准测试统计:关于训练、验证和测试分割的详细信息。
| 数据集 | # 文档对 | # 文档数 |
|---|---|---|
| AAN | 132K | 13K |
| OC | 300K | 567K |
| S2ORC | 190K | 270K |
| PAN | 34K | 23K |
Table 10: Document-to-Document benchmarks statistics: The reported numbers are the count of document pairs and the count of unique documents.
表 10: 文档到文档基准测试统计: 报告的数字为文档对数量和唯一文档数量。
The preprocessing of the datasets performed by Zhou et al. (2020) includes the following steps: For AAN, only pairs of documents that include abstracts are considered, and only their abstracts are used. For OC, only one citation per paper is considered, and the dataset was down sampled significantly. For S2ORC, formed pairs of citing sections and the corresponding abstract in the cited paper are included, and the dataset was down sampled significantly. For PAN, pairs of relevant segments out of the entire document were extracted.
Zhou等人(2020)对数据集进行的预处理包括以下步骤:对于AAN数据集,仅考虑包含摘要的文档对,且仅使用其摘要部分。对于OC数据集,每篇论文仅考虑一个引用关系,并对数据集进行了大幅降采样。对于S2ORC数据集,包含引用章节与被引论文对应摘要组成的文档对,并对数据集进行了大幅降采样。对于PAN数据集,从完整文档中提取了相关段落对。
For all the datasets, negative pairs were sampled randomly. Then, a standard preprocessing that includes filtering out characters that are not digits, letters, punctuation, or white space in the texts was performed.
对于所有数据集,负样本对均采用随机采样方式生成。随后执行了标准预处理流程,包括过滤掉文本中非数字、字母、标点符号或空格的字符。
B CDLM Pre training Hyper parameters
B CDLM 预训练超参数
In this section, we detail the hyper parameters setting of the models we pretrained, including CDLM Prefix CDLM, Rand CDLM, and Local CDLM: The input sequences are of the length of 4,096, effective batch size of 64 (using gradient accumulation and batch size of 8), a maximum learning rate of 3e-5, and a linear warmup of 500 steps, followed by a power 3 polynomial decay. For speeding up the training and reducing memory consumption, we used the mixed-precision (16-bits) training mode. The pre training took 8 days, using eight 48GB RTX8000 GPUs. The rest of the hyper para meters are the same as for RoBERTa (Liu et al., 2019). Note that training CDLM using the large version of the Longformer model might require 2-3 times more memory and time.
在本节中,我们详细说明预训练模型的超参数设置,包括CDLM Prefix CDLM、Rand CDLM和Local CDLM:输入序列长度为4,096,有效批次大小为64(使用梯度累积和批次大小为8),最大学习率为3e-5,线性预热500步,随后采用3次多项式衰减。为加速训练并减少内存消耗,我们使用混合精度(16位)训练模式。预训练耗时8天,使用八块48GB RTX8000 GPU。其余超参数与RoBERTa (Liu et al., 2019) 相同。请注意,使用Longformer模型的大版本训练CDLM可能需要2-3倍的内存和时间。

Figure 4: CD-co reference resolution pairwise mention representation, using the new setup, for our CDLM models. $m_{t}^{i}$ , $m_{t}^{j}$ and $s_{t}$ are the cross-document contextual i zed representation vectors for mentions $i$ and $j$ , and of the [CLS] token, respectively. $m_{t}^{i}\circ m_{t}^{j}$ is the element-wise product between $m_{t}^{i}$ and $m_{t}^{j}$ . $m_{t}(i,j)$ is the final produced pairwise-mention representation. The tokens colored in yellow represent global attention, and tokens colored in blue represent local attention.
图 4: 采用新设置的CDLM模型在跨文档共指消解任务中的提及对表示。$m_{t}^{i}$、$m_{t}^{j}$和$s_{t}$分别表示提及$i$、提及$j$以及[CLS] token的跨文档上下文向量表示。$m_{t}^{i}\circ m_{t}^{j}$是$m_{t}^{i}$与$m_{t}^{j}$的逐元素乘积。$m_{t}(i,j)$是最终生成的提及对表示。黄色标注的token代表全局注意力,蓝色标注的token代表局部注意力。
C Finetuning on Downstream Tasks
C 下游任务微调
In this section, we elaborate further implementation details regarding the downstream tasks that we experimented, including the hyper parameter choices and the algorithms used.
在本节中,我们将详细阐述实验涉及的下游任务的进一步实现细节,包括超参数选择和所用算法。
C.1 Cross-Document Co reference Resolution
C.1 跨文档共指解析
The setup for our cross-document co reference resolution pairwise scoring is illustrated in Figure 4. We concatenate the relevant documents using the special document separator tokens, then encode them using our CDLM along with the [CLS] token at the beginning of this sequence, as suggested in Section 2.2. For within-document co reference candidate examples, we use just the single containing document with one set of document separa- tors, for the single input document. Inspired by Yu et al. (2020), we use candidate mention marking:
我们跨文档共指消解配对评分的设置如图 4 所示。按照第 2.2 节的建议,我们使用特殊文档分隔符 token 将相关文档连接起来,然后使用 CDLM 以及序列开头的 [CLS] token 对它们进行编码。对于文档内共指候选示例,我们仅使用包含单个文档的分隔符集作为输入文档。受 Yu 等人 (2020) 的启发,我们采用了候选提及标记方法:
we wrap the mentions with special tokens $\langle{\mathfrak{m}}\rangle$ and $\langle/\uppi\rangle$ in order to direct the model to specifically pay attention to the candidates representations. Additionally, we assign global-attention to [CLS], $\langle{\mathfrak{m}}\rangle$ , $\langle/\uppi\rangle$ , and the mention tokens themselves, according to the finetuning strategy proposed in Section 2.2. Our final pairwise-mention representation is formed like in Zeng et al. (2020) and $\mathrm{Yu}$ et al. (2020): We concatenate the cross-document contextualized representation vectors for the $t^{\mathrm{th}}$ sample:
我们用特殊标记 $\langle{\mathfrak{m}}\rangle$ 和 $\langle/\uppi\rangle$ 包裹提及内容,以引导模型特别关注候选表征。此外,根据第2.2节提出的微调策略,我们为[CLS]、$\langle{\mathfrak{m}}\rangle$、$\langle/\uppi\rangle$以及提及标记本身分配全局注意力。最终的提及对表征构建方式参照Zeng等人(2020)和$\mathrm{Yu}$等人(2020)的方法:我们将第$t^{\mathrm{th}}$个样本的跨文档上下文表征向量进行拼接:
$$
m_{t}(i,j)=\Big[s_{t},m_{t}^{i},m_{t}^{j},m_{t}^{i}\circ m_{t}^{j}\Big],
$$
$$
m_{t}(i,j)=\Big[s_{t},m_{t}^{i},m_{t}^{j},m_{t}^{i}\circ m_{t}^{j}\Big],
$$
where $[\cdot]$ denotes the concatenation operator, $s_{t}$ is the cross-document contextual i zed representation vector of the [CLS] token, and each of $m_{t}^{i}$ and $m_{t}^{j}$ is the sum of candidate tokens of the corresponding mentions ( $i$ and $j$ ). Then, we train the pairwise scorer according to the suggested finetuning scheme. At test time, similar to most recent works, we apply agglom erat ive clustering to merge the most similar cluster pairs.
其中 $[\cdot]$ 表示连接运算符,$s_{t}$ 是 [CLS] token 的跨文档上下文表征向量,$m_{t}^{i}$ 和 $m_{t}^{j}$ 分别是对应提及项 ($i$ 和 $j$) 的候选 token 之和。随后,我们按照建议的微调方案训练成对打分器。在测试阶段,与大多数近期工作类似,我们采用凝聚聚类算法来合并最相似的簇对。
Regarding the training data collection and hyperparameter setting, we adopt the same protocol as suggested in Cattan et al. (2020):8 Our training set is composed of positive instances which consist of all the pairs of mentions that belong to the same co reference cluster, while the negative examples are randomly sampled.
关于训练数据收集和超参数设置,我们采用与Cattan等人 (2020) [8] 相同的方案:训练集由属于同一共指集群的提及对组成正样本,负样本则通过随机采样获得。
The resulting feature vector is passed through a MLP pairwise scorer that is composed of one hidden layer of the size of 1024, followed by the Tanh activation. We finetune our models for 10 epochs, with an effective batch size of 128. We used eight 32GB V100-SMX2 GPUs for finetuning our models. The finetuning process took ${\sim}28$ and ${\sim}45$ hours per epoch, for event co reference and entity co reference, respectively.
生成的特征向量通过一个MLP(多层感知机)配对评分器处理,该评分器包含一个大小为1024的隐藏层,后接Tanh激活函数。我们对模型进行了10个周期的微调,有效批量大小为128。微调过程使用了八块32GB的V100-SMX2 GPU。事件共指和实体共指任务的每轮微调耗时分别为${\sim}28$小时和${\sim}45$小时。
C.2 Multi-Document Classification
C.2 多文档分类
We tune our models for 8 epochs, using a batch size of 32, and used the same hyper parameter setting from Zhou et al. (2020, Section 5.2).9 We used eight 32GB V100-SMX2 GPUs for finetuning our models. The finetuning process took ${\sim}2,{\sim}5,{\sim}3$ , and ${\sim}0.5$ hours per epoch, for AAN, OC, S2ORC, and for PAN, respectively. We used the mixedprecision training mode, to reduce time and memory consumption.
我们调整模型训练8个周期(epoch),批量大小(batch size)设为32,并采用Zhou等人(2020,第5.2节)相同的超参数设置。使用八块32GB显存的V100-SMX2显卡进行模型微调(finetuning),每个周期耗时分别为:AAN约2小时、OC约5小时、S2ORC约3小时、PAN约0.5小时。采用混合精度训练(mixed precision training)模式以降低时间和内存消耗。