REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: 检索增强的黑盒大语言模型
Weijia Shi,1 * Sewon Min,1 Michihiro Yasunaga,2 Minjoon Seo,3 Rich James,4 Mike Lewis,4 Luke Z ett le moyer 1 4 Wen-tau Yih 4
Weijia Shi,1 * Sewon Min,1 Michihiro Yasunaga,2 Minjoon Seo,3 Rich James,4 Mike Lewis,4 Luke Zettlemoyer 1 4 Wen-tau Yih 4
Abstract
摘要
We introduce REPLUG, a retrieval-augmented language modeling framework that treats the language model (LM) as a black box and augments it with a tuneable retrieval model. Unlike prior retrieval-augmented LMs that train language models with special cross attention mechanisms to en- code the retrieved text, REPLUG simply prepends retrieved documents to the input for the frozen black-box LM. This simple design can be easily applied to any existing retrieval and language models. Furthermore, we show that the LM can be used to supervise the retrieval model, which can then find documents that help the LM make better predictions. Our experiments demonstrate that REPLUG with the tuned retriever significantly improves the performance of GPT-3 (175B) on language modeling by $6.3%$ , as well as the performance of Codex on five-shot MMLU by $5.1%$ .
我们提出了REPLUG,一个检索增强的语言建模框架,它将语言模型(LM)视为黑盒,并通过可调优的检索模型进行增强。与之前那些训练语言模型使用特殊交叉注意力机制来编码检索文本的检索增强LM不同,REPLUG只是简单地将检索到的文档前置到冻结黑盒LM的输入中。这种简单设计可以轻松应用于任何现有的检索和语言模型。此外,我们还展示了LM可用于监督检索模型,从而找到有助于LM做出更好预测的文档。我们的实验表明,配备调优检索器的REPLUG将GPT-3(175B)在语言建模上的性能显著提高了6.3%,同时将Codex在五样本MMLU上的性能提高了5.1%。
1. Introduction
1. 引言
Large language models (LLMs) such as GPT-3 (Brown et al., 2020a) and Codex (Chen et al., 2021a), have demonstrated impressive performance on a wide range of language tasks. These models are typically trained on very large datasets and store a substantial amount of world or domain knowledge implicitly in their parameters. However, they are also prone to hallucination and cannot represent the full long tail of knowledge from the training corpus. Retrieval-augmented language models (Khandelwal et al., 2020; Borgeaud et al., 2022; Izacard et al., 2022b; Yasunaga et al., 2022), in con- trast, can retrieve knowledge from an external datastore when needed, potentially reducing hallucination and increasing coverage. Previous approaches of retrieval-augmented language models require access to the internal LM representations (e.g., to train the model (Borgeaud et al., 2022;
诸如GPT-3 (Brown等人, 2020a) 和Codex (Chen等人, 2021a) 这样的大语言模型 (LLM) 在广泛的语言任务中展现出了令人印象深刻的性能。这些模型通常在非常大的数据集上进行训练,并将大量世界或领域知识隐式地存储在其参数中。然而,它们也容易产生幻觉 (hallucination) ,并且无法完全代表训练语料库中的长尾知识。相比之下,检索增强语言模型 (Khandelwal等人, 2020; Borgeaud等人, 2022; Izacard等人, 2022b; Yasunaga等人, 2022) 可以在需要时从外部数据存储中检索知识,从而可能减少幻觉并增加覆盖率。先前检索增强语言模型的方法需要访问内部语言模型表示 (例如用于训练模型 (Borgeaud等人, 2022;
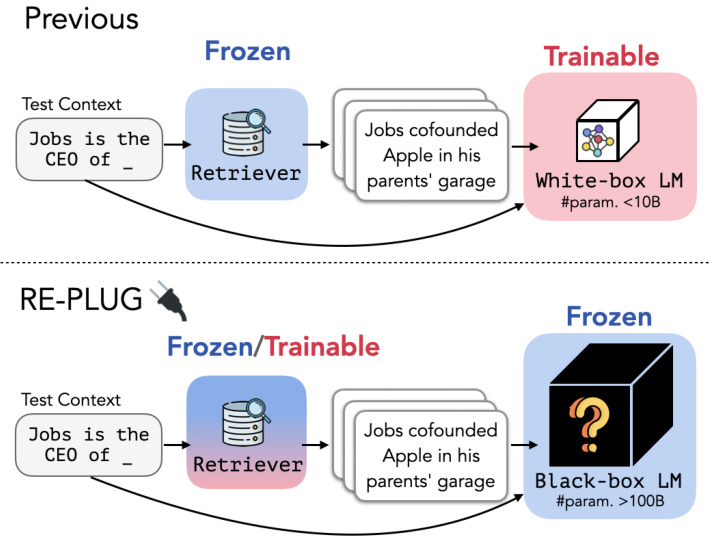
Figure 1. Different from previous retrieval-augmented approaches (Borgeaud et al., 2022) that enhance a language model with retrieval by updating the LM’s parameters, REPLUG treats the language model as a black box and augments it with a frozen or tunable retriever. This black-box assumption makes REPLUG applicable to large LMs (i.e., ${>}100\mathrm{B}$ parameters), which are often served via APIs.
图 1: 不同于先前通过更新语言模型参数来增强检索能力的检索增强方法 (Borgeaud et al., 2022),REPLUG 将语言模型视为黑盒,并通过冻结或可调检索器进行增强。这种黑盒假设使 REPLUG 适用于通过 API 提供服务的大型语言模型 (即参数量 ${>}100\mathrm{B}$)。
Izacard et al., 2022b) or to index the datastore (Khandelwal et al., 2020)), and are thus difficult to be applied to very large LMs. In addition, many best-in-class LLMs can only be accessed through APIs. Internal representations of such models are not exposed and fine-tuning is not supported.
Izacard等人, 2022b) 或索引数据存储 (Khandelwal等人, 2020)),因此难以应用于超大规模的大语言模型。此外,许多顶尖的大语言模型只能通过API访问。这类模型的内部表征未公开且不支持微调。
In this work, we introduce REPLUG (Retrieve and Plug), a new retrieval-augmented LM framework where the language model is viewed as a black box and the retrieval component is added as a tuneable plug-and-play module. Given an input context, REPLUG first retrieves relevant documents from an external corpus using an off-the-shelf retrieval model. The retrieved documents are prepended to the input context and fed into the black-box LM to make the final prediction. Because the LM context length limits the number of documents that can be prepended, we also introduce a new ensemble scheme that encodes the retrieved documents in parallel with the same black-box LM, allowing us to easily trade compute for accuracy. As shown in
在本工作中,我们介绍了REPLUG(检索即插即用),这是一种新的检索增强型大语言模型框架,其中语言模型被视为黑盒,检索组件作为可调谐的即插即用模块添加。给定输入上下文,REPLUG首先使用现成的检索模型从外部语料库中检索相关文档。检索到的文档被添加到输入上下文之前,并输入到黑盒语言模型中以进行最终预测。由于语言模型上下文长度限制了可以添加的文档数量,我们还引入了一种新的集成方案,该方案使用相同的黑盒语言模型并行编码检索到的文档,使我们能够轻松地在计算和准确性之间进行权衡。如
Figure 1, REPLUG is extremely flexible and can be used with any existing black-box LM and retrieval model.
图 1: REPLUG 具有极高的灵活性,可与任何现有的黑盒大语言模型和检索模型配合使用。
We also introduce REPLUG LSR (REPLUG with LMSupervised Retrieval), a training scheme that can further improve the initial retrieval model in REPLUG with supervision signals from a black-box language model. The key idea is to adapt the retriever to the LM, which is in contrast to prior work (Borgeaud et al., 2022) that adapts language models to the retriever. We use a training objective which prefers retrieving documents that improve language model perplexity, while treating the LM as a frozen, black-box scoring function.
我们还提出了 REPLUG LSR (REPLUG with LM Supervised Retrieval),这是一种训练方案,可以通过来自黑盒语言模型的监督信号进一步改进 REPLUG 中的初始检索模型。关键思想是使检索器适应大语言模型,这与之前的工作 (Borgeaud et al., 2022) 形成对比,后者是让语言模型适应检索器。我们采用了一种训练目标,优先检索能够降低语言模型困惑度的文档,同时将大语言模型视为冻结的黑盒评分函数。
Our experiments show that REPLUG can improve the performance of diverse black-box LMs on both language modeling and downstream tasks, including MMLU (Hendrycks et al., 2021) and open-domain QA (Kwiatkowski et al., 2019; Joshi et al., 2017). For instance, REPLUG can improve Codex (175B) performance on MMLU by $4.5%$ , achieving comparable results to the 540B, instruction-finetuned Flan-PaLM. Furthermore, tuning the retriever with our training scheme (i.e., REPLUG LSR) leads to additional improvements, including up to $6.3%$ increase in GPT-3 175B language modeling. To the best of our knowledge, our work is the first to show the benefits of retrieval to large LMs $(>100\mathrm{B}$ model parameters), for both reducing LM perplexity and and improving in-context learning performance. We summarize our contributions as follows:
我们的实验表明,REPLUG能够提升各类黑盒大语言模型在语言建模和下游任务(包括MMLU [Hendrycks et al., 2021] 和开放域问答 [Kwiatkowski et al., 2019; Joshi et al., 2017])上的性能。例如,REPLUG可将Codex (175B) 在MMLU上的表现提升4.5%,达到与540B参数规模的指令微调模型Flan-PaLM相当的水平。此外,采用我们的训练方案(即REPLUG LSR)对检索器进行微调可带来额外提升,包括使GPT-3 175B的语言建模能力最高提升6.3%。据我们所知,本研究首次证明了检索机制对超大规模语言模型(参数规模>100B)的双重益处:既降低模型困惑度,又提升上下文学习性能。我们的主要贡献可总结如下:
• We introduce REPLUG (§3), the first retrievalaugmented language modeling framework for enhancing large black-box language models with retrieval. • We propose a training scheme (§4) to further adapt an off-the-shelf retrieval model to the LM, using the language modeling scores as supervision signals, resulting in improved retrieval quality. • Evaluations on language modeling (§6), open-domain QA and MMLU demonstrate that REPLUG can improve the performance of various language models such as GPT, OPT and BLOOM, including very large models with up to 175B parameters.
• 我们提出了REPLUG(第3节),这是首个通过检索增强大语言模型(LLM)性能的框架,适用于黑盒大语言模型。
• 我们提出了一种训练方案(第4节),利用语言建模分数作为监督信号,进一步使现成的检索模型适配目标语言模型,从而提升检索质量。
• 在语言建模(第6节)、开放域问答和MMLU基准上的实验表明,REPLUG能提升包括GPT、OPT和BLOOM在内的多种语言模型性能,其中最大模型参数量达1750亿。
2. Background and Related Work
2. 背景与相关工作
Black-box Language Models Large language models (i.e., ${\tt>}100{\tt B},$ , such as GPT-3 (Brown et al., 2020a), Codex (Chen et al., 2021a), and Yuan 1.0 (Wu et al., 2021), are not open-sourced due to commercial considerations and are only available as black-box APIs, through which users can send queries and receive responses. On the other hand, even open sourced language models such as OPT-175B (Zhang et al., 2022a) and BLOOM-176B (Scao et al., 2022) require significant computational resources to run and finetune locally. For example, finetuning BLOOM-176B requires 72 A100 GPUs (80GB memory, $\$156$ each (Younes Belkda, 2022)), making them inaccessible to researchers and developers with limited resources. Traditionally, retrieval-augmented model frameworks (Khandelwal et al., 2020; Borgeaud et al., 2022; Yu, 2022; Izacard et al., 2022b; Goyal et al., 2022) have focused on the white-box setting, where language models are fine-tuned to incorporate retrieved documents. However, the increasing scale and black-box nature of large language models makes this approach infeasible. To address the challenges posed by large language models, we investigate retrieval-augmentation in the black-box setting, where users only have access to the model predictions and cannot access or modify its parameters.
黑盒语言模型
大语言模型(即参数量 ${\tt>}100{\tt B}$ 的模型,如 GPT-3 (Brown et al., 2020a)、Codex (Chen et al., 2021a) 和 Yuan 1.0 (Wu et al., 2021))因商业考量未开源,仅通过黑盒 API 提供服务,用户可通过接口发送查询并接收响应。另一方面,即使开源模型如 OPT-175B (Zhang et al., 2022a) 和 BLOOM-176B (Scao et al., 2022) 也需要大量计算资源才能在本地运行和微调。例如,微调 BLOOM-176B 需 72 块 A100 GPU(80GB 显存,单价 $\$156$ (Younes Belkda, 2022)),这使得资源有限的研究者和开发者难以使用。传统检索增强模型框架 (Khandelwal et al., 2020; Borgeaud et al., 2022; Yu, 2022; Izacard et al., 2022b; Goyal et al., 2022) 主要针对白盒场景,即通过微调语言模型整合检索文档。然而,大语言模型规模的持续增长及其黑盒特性使得该方法不可行。为应对大语言模型带来的挑战,我们研究了黑盒场景下的检索增强技术,该场景下用户仅能获取模型预测结果,无法访问或修改其参数。
Retrieval-augmented Models Augmenting language models with relevant information retrieved from various knowledge stores has shown to be effective in improving performance on various NLP tasks, including language modeling (Min et al., 2022; Borgeaud et al., 2022; Khandelwal et al., 2020) and open-domain question answering (Lewis et al., 2020; Izacard et al., 2022b; Hu et al., 2022). Specifi- cally, using the input as query, (1) a retriever first retrieves a set of documents (i.e., sequences of tokens) from a corpus and then (2) a language model incorporates the retrieved documents as additional information to make a final prediction. This style of retrieval can be added to both encoder- decoder (Yu, 2022; Izacard et al., 2022b) and decoder-only models (Khandelwal et al., 2020; Borgeaud et al., 2022; Shi et al., 2022; Rubin et al., 2022). For example, Atlas (Izacard et al., 2022b) finetunes an encoder-decoder model jointly with the retriever by modeling documents as latent variables, while RETRO (Borgeaud et al., 2022) changes the decoderonly architecture to incorporate retrieved texts and pretrains the language model from scratch. Both methods require updating the model parameters through gradient descent, which cannot be applied to black-box LMs. Another line of retrieval-augmented LMs such as kNN-LM (Khandelwal et al., 2020; Zhong et al., 2022) retrieves a set of tokens and interpolates between the LM’s next token distribution and kNN distributions computed from the retrieved tokens at inference. Although kNN-LM does not require additional training, it requires access to internal LM representations to compute the kNN distribution, which are not always available for large LMs such as GPT-3. In this work, we investigate ways to improve large black-box language models with retrieval. While concurrent work (Mallen et al., 2022; Si et al., 2023; Yu et al., 2023; Khattab et al., 2022) has demonstrated that using a frozen retriever can improve GPT3 performance on open-domain question answering, we approach the problem in a more general setting, including language modeling and understanding tasks. We also propose an ensemble method to incorporate more documents and a training scheme to further adapt the retriever to large LMs.
检索增强模型
通过从各类知识库中检索相关信息来增强大语言模型,已被证明能有效提升多种自然语言处理任务的性能,包括语言建模 (Min et al., 2022; Borgeaud et al., 2022; Khandelwal et al., 2020) 和开放域问答 (Lewis et al., 2020; Izacard et al., 2022b; Hu et al., 2022)。具体流程为:以输入作为查询,(1) 检索器首先从语料库中获取一组文档 (即token序列),随后 (2) 语言模型将检索到的文档作为附加信息整合以生成最终预测。这种检索机制可同时应用于编码器-解码器架构 (Yu, 2022; Izacard et al., 2022b) 和纯解码器模型 (Khandelwal et al., 2020; Borgeaud et al., 2022; Shi et al., 2022; Rubin et al., 2022)。例如Atlas (Izacard et al., 2022b) 通过将文档建模为隐变量,联合微调解码器与检索器;而RETRO (Borgeaud et al., 2022) 则修改纯解码器架构以融合检索文本,并从头预训练语言模型。这两种方法都需要通过梯度下降更新模型参数,无法应用于黑盒大语言模型。另一类检索增强方法如kNN-LM (Khandelwal et al., 2020; Zhong et al., 2022) 在推理时检索token集,并将语言模型的下一token预测分布与基于检索token计算的kNN分布进行插值。虽然kNN-LM无需额外训练,但需要访问模型内部表征来计算kNN分布,这对GPT-3等大型模型往往不可行。
本研究探索了改进黑盒大语言模型的检索增强方法。尽管同期工作 (Mallen et al., 2022; Si et al., 2023; Yu et al., 2023; Khattab et al., 2022) 已证明冻结检索器能提升GPT-3在开放域问答的表现,但我们从更通用的语言建模与理解任务场景切入,并提出集成方法以融合更多文档,同时设计训练方案使检索器更好地适配大语言模型。
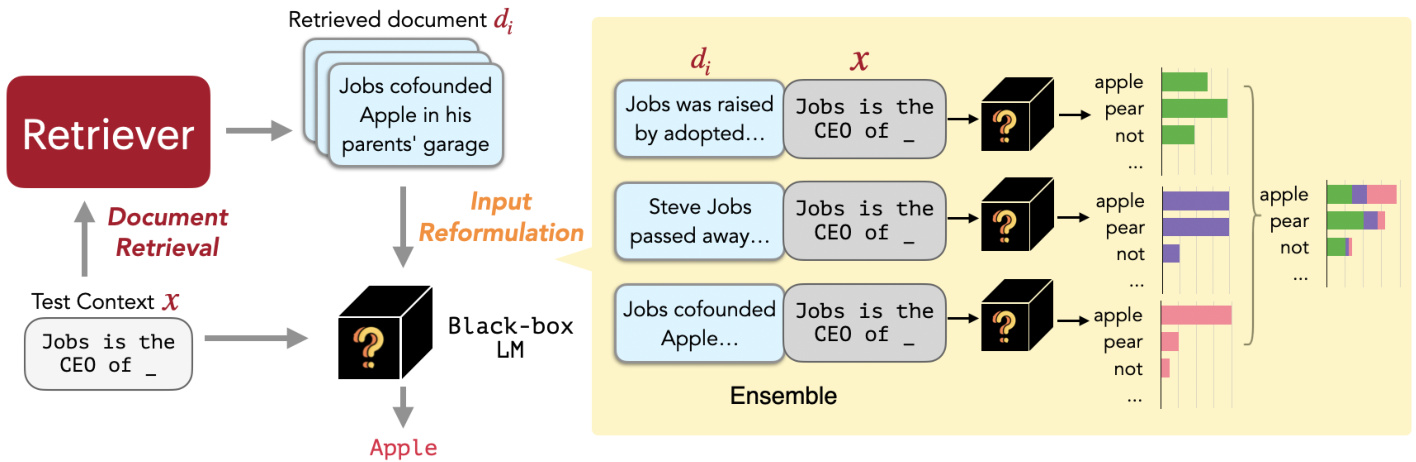
Figure 2. REPLUG at inference (§3). Given an input context, REPLUG first retrieves a small set of relevant documents from an external corpus using a retriever (§3.1 Document Retrieval). Then it prepends each document separately to the input context and ensembles output probabilities from different passes (§3.2 Input Reformulation).
图 2: REPLUG推理过程(§3)。给定输入上下文后,REPLUG首先使用检索器从外部语料库中检索出一小组相关文档(§3.1文档检索)。接着将每个文档分别拼接到输入上下文前,并对不同前向传播的输出概率进行集成(§3.2输入重构)。
3. REPLUG
3. REPLUG
We introduce REPLUG (Retrieve and Plug), a new retrievalaugmented LM paradigm where the language model is treated as black box and the retrieval component is added as a potentially tuneable module.
我们提出了REPLUG (Retrieve and Plug),这是一种新的检索增强大语言模型范式,其中语言模型被视为黑箱,检索组件作为可调模块添加。
As shown in Figure 2, given an input context, REPLUG first retrieves a small set of relevant documents from an external corpus using a retriever (§3.1). Then we pass the concatenation of each retrieved document with the input context through the LM in parallel, and ensemble the predicted probabilities (§3.2).
如图 2 所示,给定输入上下文后,REPLUG 首先使用检索器从外部语料库中检索出一小组相关文档(§3.1)。接着我们将每个检索到的文档与输入上下文拼接后并行输入大语言模型,并对预测概率进行集成(§3.2)。
3.1. Document Retrieval
3.1. 文档检索
Given an input context $x$ , the retriever aims to retrieve a small set of documents from a corpus $\mathcal{D}={d_{1}...d_{m}}$ that are relevant to $x$ . Following prior work (Qu et al., 2021; Izacard & Grave, 2021b; Ni et al., 2021), we use a dense retriever based on the dual encoder architecture, where an encoder is used to encode both the input context $x$ and the document $d$ . Specifically, the encoder maps each document $d\in D$ to an embedding ${\bf E}(d)$ by taking the mean pooling of the last hidden representation over the tokens in $d$ . At query time, the same encoder is applied to the input context $x$ to obtain a query embedding $\mathbf{E}(x)$ . The similarity between the query embedding and the document embedding is computed by their cosine similarity:
给定输入上下文 $x$,检索器的目标是从语料库 $\mathcal{D}={d_{1}...d_{m}}$ 中检索出一小部分与 $x$ 相关的文档。遵循先前工作 (Qu et al., 2021; Izacard & Grave, 2021b; Ni et al., 2021),我们采用基于双编码器架构的密集检索器,其中编码器同时用于编码输入上下文 $x$ 和文档 $d$。具体而言,编码器通过计算文档 $d\in D$ 中所有 token 的最后隐藏层表示的均值池化,将每个文档映射为嵌入向量 ${\bf E}(d)$。在查询时,同一编码器应用于输入上下文 $x$ 以获取查询嵌入 $\mathbf{E}(x)$。查询嵌入与文档嵌入之间的相似度通过它们的余弦相似度计算:
For efficient retrieval, we precompute the embedding of each document $d\in D$ and construct FAISS index (Johnson et al., 2019) over these embeddings.
为了高效检索,我们预先计算每个文档$d\in D$的嵌入向量,并基于这些向量构建FAISS索引 (Johnson et al., 2019)。
3.2. Input Reformulation
3.2. 输入重构
The retrieved top $k$ documents provide rich information about the original input context $x$ and can potentially help the LM to make a better prediction. One simple way to incorporate the retrieved documents as part of the input to the LM is to prepend $x$ with all $k$ documents. However, this simple scheme is fundamentally restricted by the number of documents (i.e., $k$ ) we can include, given the language model’s context window size. To address this limitation, we adopt an ensemble strategy described as follows. Assume $\mathcal{D}^{\prime}\subset\mathcal{D}$ consists of $k$ most relevant documents to $x$ , according to the scoring function in Eq. (1). We prepend each document $d\in\mathcal{D}^{\prime}$ to $x$ , pass this concatenation to the LM separately, and then ensemble output probabilities from all $k$ passes. Formally, given the input context $x$ and its top $k$ relevant documents ${\mathcal{D}^{\prime}}$ , the output probability of the next token $y$ is computed as a weighted average ensemble:
检索到的前 $k$ 个文档提供了关于原始输入上下文 $x$ 的丰富信息,可能有助于大语言模型做出更好的预测。将这些检索到的文档作为输入的一部分传递给大语言模型的一种简单方法是将所有 $k$ 个文档前置到 $x$ 之前。然而,这种简单方案从根本上受到语言模型上下文窗口大小的限制,即能包含的文档数量 (即 $k$)。为了解决这一限制,我们采用了如下所述的集成策略。假设 $\mathcal{D}^{\prime}\subset\mathcal{D}$ 包含根据式 (1) 中的评分函数与 $x$ 最相关的 $k$ 个文档。我们将每个文档 $d\in\mathcal{D}^{\prime}$ 前置到 $x$ 之前,分别将这种拼接传递给大语言模型,然后集成所有 $k$ 次传递的输出概率。形式上,给定输入上下文 $x$ 及其前 $k$ 个相关文档 ${\mathcal{D}^{\prime}}$,下一个 token $y$ 的输出概率计算为加权平均集成:
$$
p(y\mid x,\mathcal{D}^{\prime})=\sum_{d\in\mathcal{D}^{\prime}}p(y\mid d\circ x)\cdot\lambda(d,x),
$$
$$
p(y\mid x,\mathcal{D}^{\prime})=\sum_{d\in\mathcal{D}^{\prime}}p(y\mid d\circ x)\cdot\lambda(d,x),
$$
where $\circ$ denotes the concatenation of two sequences and the weight $\lambda(d,x)$ is based on the similarity score between the document $d$ and the input context $x$ :
其中 $\circ$ 表示两个序列的拼接,权重 $\lambda(d,x)$ 基于文档 $d$ 与输入上下文 $x$ 之间的相似度得分:
$$
\lambda(d,x)=\frac{e^{s(d,x)}}{\sum_{d\in\mathcal{D}^{\prime}}e^{s(d,x)}}
$$
$$
\lambda(d,x)=\frac{e^{s(d,x)}}{\sum_{d\in\mathcal{D}^{\prime}}e^{s(d,x)}}
$$
$$
s(d,x)=\cos({\bf E}(d),{\bf E}(x))
$$
$$
s(d,x)=\cos({\bf E}(d),{\bf E}(x))
$$
The top $k$ documents that have the highest similarity scores when compared with the input $x$ are retrieved in this step.
与输入$x$相比具有最高相似度得分的top $k$文档在此步骤中被检索出来。
Although our ensemble method requires running the LM $k$ times, the cross attention is performed between each retrieved document and the input context. Therefore, compared with the method of prepending all the retrieved documents, our ensemble methods do not incur additional computational cost overhead.
虽然我们的集成方法需要运行大语言模型 $k$ 次,但交叉注意力是在每个检索文档与输入上下文之间进行的。因此,与前置所有检索文档的方法相比,我们的集成方法不会产生额外的计算成本开销。
4. REPLUG LSR: Training the Dense Retriever
4. REPLUG LSR: 训练稠密检索器
Instead of relying only on existing neural dense retrieval models (Karpukhin et al., 2020a; Izacard et al., 2022a; Su et al., 2022), we further propose REPLUG LSR (REPLUG with LM-Supervised Retrieval), which adapts the retriever in REPLUG by using the LM itself to provide supervision about which documents should be retrieved.
我们不仅依赖于现有的神经密集检索模型 (Karpukhin et al., 2020a; Izacard et al., 2022a; Su et al., 2022),还进一步提出了REPLUG LSR (基于语言模型监督检索的REPLUG),该方法通过利用语言模型本身提供关于应检索哪些文档的监督信号,来调整REPLUG中的检索器。
Inspired by Sachan et al. (2022), our approach can be seen as adjusting the probabilities of the retrieved documents to match the probabilities of the output sequence perplexities of the language model. In other words, we would like the retriever to find documents that result in lower perplexity scores. As shown in Figure 3, our training algorithm consists of the four steps: (1) retrieving documents and computing the retrieval likelihood (§4.1), (2) scoring the retrieved documents by the language model (§4.2), (3) updating the retrieval model parameters by minimizing the KL divergence between the retrieval likelihood and the LM’s score distribution $(\S4.3)$ , and (4) asynchronous update of the datastore index $(\S4.4)$ .
受 Sachan 等人 (2022) 的启发,我们的方法可视为调整检索文档的概率以匹配语言模型输出序列困惑度的概率分布。换言之,我们希望检索器能找到降低困惑度得分的文档。如图 3 所示,我们的训练算法包含四个步骤:(1) 检索文档并计算检索似然 (§4.1)、(2) 通过语言模型对检索文档进行评分 (§4.2)、(3) 通过最小化检索似然与语言模型评分分布的 KL 散度来更新检索模型参数 $(\S4.3)$,以及 (4) 数据存储索引的异步更新 $(\S4.4)$。
4.1. Computing Retrieval Likelihood
4.1. 计算检索似然
We retrieve $k$ documents $\mathcal{D}^{\prime}\subset\mathcal{D}$ with the highest similarity scores from a corpus $\mathcal{D}$ given an input context $x$ , as described in $\S3.1$ . We then compute the retrieval likelihood of each retrieved document $d$ :
我们从一个语料库 $\mathcal{D}$ 中检索出与输入上下文 $x$ 相似度最高的 $k$ 个文档 $\mathcal{D}^{\prime}\subset\mathcal{D}$ ,如 $\S3.1$ 所述。然后计算每个检索文档 $d$ 的检索似然:
$$
P_{R}(d\mid x)={\frac{e^{s(d,x)/\gamma}}{\sum_{d\in{\mathcal{D}}^{\prime}}e^{s(d,x)/\gamma}}}
$$
$$
P_{R}(d\mid x)={\frac{e^{s(d,x)/\gamma}}{\sum_{d\in{\mathcal{D}}^{\prime}}e^{s(d,x)/\gamma}}}
$$
where $\gamma$ is a hyper parameter that controls the temerature of the softmax. Ideally, the retrieval likelihood is computed by marginal i zing over all the documents in the corpus $\mathcal{D}$ , which is intractable in practice. Therefore, we approximate the retrieval likelihood by only marginal i zing over the retrieved documents ${\mathcal{D}^{\prime}}$ .
其中$\gamma$是控制softmax温度的超参数。理想情况下,检索似然是通过对语料库$\mathcal{D}$中所有文档进行边缘化计算得到的,但这在实际中难以处理。因此,我们仅通过对检索到的文档${\mathcal{D}^{\prime}}$进行边缘化来近似计算检索似然。
4.2. Computing LM likelihood
4.2. 计算语言模型似然
We use the LM as a scoring function to measure how much each document could improve the LM perplexity. Specifically, we first compute $P_{L M}(y\mid d,x)$ , the LM probability of the ground truth output $y$ given the input context $x$ and a document $d$ . The higher the probability, the better the document $d_{i}$ is at improving the LM’s perplexity. We then compute the LM likelihood of each document $d$ as follows:
我们使用大语言模型 (LM) 作为评分函数来衡量每份文档能在多大程度上降低模型的困惑度。具体而言,我们首先计算 $P_{L M}(y\mid d,x)$ ,即在给定输入上下文 $x$ 和文档 $d$ 时,大语言模型对真实输出 $y$ 的预测概率。该概率越高,说明文档 $d_{i}$ 对降低模型困惑度的效果越好。随后按以下方式计算每份文档 $d$ 的似然得分:
$$
Q(d\mid x,y)=\frac{e^{P_{L M}(y\mid d,x)/\beta}}{\sum_{d\in\mathcal{D^{\prime}}}e^{P_{L M}(y\mid d,x)/\beta}}
$$
$$
Q(d\mid x,y)=\frac{e^{P_{L M}(y\mid d,x)/\beta}}{\sum_{d\in\mathcal{D^{\prime}}}e^{P_{L M}(y\mid d,x)/\beta}}
$$
where $\beta$ is another hyper parameter.
其中 $\beta$ 是另一个超参数。
4.3. Loss Function
4.3. 损失函数
Given the input context $x$ and the corresponding ground truth continuation $y$ , we compute the retrieval likelihood and the language model likelihood. The dense retriever is trained by minimizing the KL divergence between these two distributions:
给定输入上下文 $x$ 和对应的真实续写 $y$,我们计算检索似然和语言模型似然。通过最小化这两个分布之间的KL散度来训练密集检索器:
$$
\mathcal{L}=\frac{1}{\vert\mathcal{B}\vert}\sum_{\boldsymbol{x}\in\mathcal{B}}K L\Big(P_{R}(d\mid\boldsymbol{x})\parallel Q_{\mathrm{LM}}(d\mid\boldsymbol{x},\boldsymbol{y})\Big),
$$
$$
\mathcal{L}=\frac{1}{\vert\mathcal{B}\vert}\sum_{\boldsymbol{x}\in\mathcal{B}}K L\Big(P_{R}(d\mid\boldsymbol{x})\parallel Q_{\mathrm{LM}}(d\mid\boldsymbol{x},\boldsymbol{y})\Big),
$$
where $\boldsymbol{\mathcal{B}}$ is a set of input contexts. When minimizing the loss, we can only update the retrieval model parameters. The LM parameters are fixed due to our black-box assumption.
其中 $\boldsymbol{\mathcal{B}}$ 是一组输入上下文。最小化损失时,我们只能更新检索模型参数。由于黑盒假设,大语言模型参数保持固定。
4.4. Asynchronous Update of the Datastore Index
4.4. 数据存储索引的异步更新
Because the parameters in the retriever are updated during the training process, the previously computed document embeddings are no longer up to date. Therefore, following Guu et al. (2020), we recompute the document embeddings and rebuild the efficient search index using the new embeddings every $T$ training steps. Then we use the new document embeddings and index for retrieval, and repeat the training procedure.
由于检索器中的参数在训练过程中会更新,之前计算得到的文档嵌入 (embedding) 已不再是最新的。因此,我们遵循 Guu 等人 (2020) 的方法,每经过 $T$ 次训练步骤就重新计算文档嵌入,并使用新生成的嵌入重建高效搜索索引。随后,我们基于更新后的文档嵌入和索引进行检索,并重复上述训练流程。
5. Training Setup
5. 训练设置
In this section, we describe the details of our training procedure. We first describe the model setting in REPLUG (§5.1) and then describe the procedure for training the retriever in REPLUG LSR (§5.2).
在本节中,我们将详细介绍训练流程。首先说明REPLUG的模型设置(§5.1),然后阐述REPLUG LSR中检索器的训练过程(§5.2)。
5.1. REPLUG
5.1. REPLUG
In theory, any type of retriever, either dense (Karpukhin et al., 2020b; Ni et al., 2021) or sparse (Robertson et al., 2009), could be used for REPLUG. Following prior work (Izacard et al., 2022b), we use the Contriever (Izacard et al., 2022a) as the retrieval model for REPLUG, as it has demonstrated strong performance.
理论上,任何类型的检索器(无论是稠密型 (Karpukhin et al., 2020b; Ni et al., 2021) 还是稀疏型 (Robertson et al., 2009))都可用于REPLUG。遵循先前工作 (Izacard et al., 2022b),我们采用Contriever (Izacard et al., 2022a) 作为REPLUG的检索模型,因其已展现出卓越性能。
5.2. REPLUG LSR
5.2. REPLUG LSR
For REPLUG LSR, we initialize the retriever with the Contriever model (Izacard et al., 2022a). We use GPT-3 Curie (Brown et al., 2020b) as the supervision LM to compute the LM likelihood.
对于REPLUG LSR,我们使用Contriever模型 (Izacard et al., 2022a) 初始化检索器,并采用GPT-3 Curie (Brown et al., 2020b) 作为监督大语言模型来计算语言模型似然。
Training data We use 800K sequences of 256 tokens each, sampled from the Pile training data (Gao et al., 2020), as our training queries. Each query is split into two parts: the first 128 tokens are used as the input context $x$ , and the last 128 tokens are used as the ground truth continuation $y$ . For the external corpus $D$ , we sample 36M documents of 128 tokens from the Pile training data. To avoid trivial retrieval, we ensure that the external corpus documents do not overlap with the documents from which the training queries are sampled.
训练数据
我们使用从Pile训练数据(Gao et al., 2020)中采样的80万条序列(每条256个token)作为训练查询。每条查询被分为两部分:前128个token作为输入上下文$x$,后128个token作为真实延续$y$。对于外部语料库$D$,我们从Pile训练数据中采样了3600万份128个token的文档。为避免简单检索,我们确保外部语料库文档与训练查询采样文档之间没有重叠。
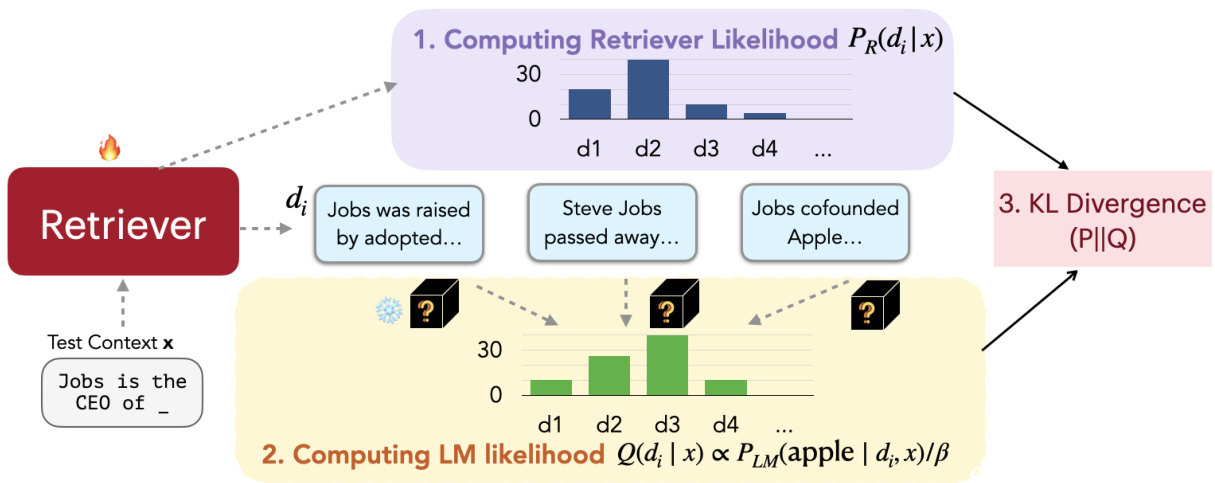
Figure 3. REPLUG LSR training process (§4). The retriever is trained using the output of a frozen language model as supervision signals.
图 3: REPLUG LSR训练流程(§4)。检索器使用冻结语言模型的输出作为监督信号进行训练。
Training details To make the training process more efficient, we pre-compute the document embeddings of the external corpus $D$ and create a FAISS index (Johnson et al., 2019) for fast similarity search. Given a query $x$ , we retrieve the top 20 documents from the FAISS index and compute the retrieval likelihood and the LM likelihood with a temperature of 0.1. We train the retriever using the Adam optimizer (Kingma & Ba, 2015) with a learning rate of 2e-5, a batch size of 64, and a warmup ratio of 0.1. We re-compute the document embeddings every $3\mathrm{k\Omega}$ steps and fine-tune the retriever for a total of $25\mathrm{k\Omega}$ steps.
训练细节
为使训练过程更高效,我们预先计算外部语料库$D$的文档嵌入,并建立FAISS索引 (Johnson et al., 2019) 以实现快速相似性搜索。给定查询$x$时,我们从FAISS索引中检索前20个文档,并以0.1的温度系数计算检索似然和语言模型似然。我们使用Adam优化器 (Kingma & Ba, 2015) 训练检索器,学习率为2e-5,批量大小为64,预热比例为0.1。每$3\mathrm{k\Omega}$步重新计算文档嵌入,共计微调检索器$25\mathrm{k\Omega}$步。
6. Experiments
6. 实验
We perform evaluations on both language modeling (§6.1) and downstream tasks such as MMLU (§6.2) and opendomain QA (§6.3). In all settings, REPLUG improve the performance of various black-box language models, showing the effectiveness and generality of our approach.
我们对语言建模(§6.1)和下游任务(如MMLU(§6.2)和开放域问答(§6.3))都进行了评估。在所有设置中,REPLUG都提升了各种黑盒大语言模型的性能,证明了我们方法的有效性和通用性。
6.1. Language Modeling
6.1. 语言建模
Datasets The Pile (Gao et al., 2020) is a language modeling benchmark that consists of text sources from diverse domains such as web pages, code and academic papers. Following prior work, we report bits per UTF-8 encoded byte (BPB) as the metric on each subset domain.
数据集
The Pile (Gao et al., 2020) 是一个语言建模基准,包含来自网页、代码和学术论文等多领域的文本源。遵循先前工作,我们以每UTF-8编码字节位数(BPB)作为各子领域的评估指标。
Baselines We consider GPT-3 and GPT-2 family language model as the baselines. The four models from GPT-3 (Davinci, Curie, Baddage and Ada) are black-box models that are only accessible through API
基线模型
我们选用GPT-3和GPT-2系列大语言模型作为基线。GPT-3中的四个模型(Davinci、Curie、Baddage和Ada)为黑盒模型,仅能通过API访问。
Our model We add REPLUG and REPLUG LSR to the baselines. We randomly subsampled Pile training data (367M documents of 128 tokens) and use them as the retrieval corpus for all models. As the Pile dataset has made efforts to de duplicate documents across train, validation and test splits (Gao et al., 2020), we did not do additional filtering. For both REPLUG and REPLUG LSR, we use a length of 128-token context to do retrieval and adopt the ensemble method (Section 3.2) to incorporate top 10 retrieved documents during inference.
我们的模型
我们将REPLUG和REPLUG LSR添加到基线中。随机从Pile训练数据(3.67亿份128 token的文档)中抽取子样本,并将其作为所有模型的检索语料库。由于Pile数据集已努力去重训练、验证和测试分割中的文档 [Gao et al., 2020],因此我们未进行额外过滤。对于REPLUG和REPLUG LSR,均使用128 token的上下文长度进行检索,并采用集成方法(第3.2节)在推理时整合前10个检索到的文档。
Results Table 1 reports the results of the original baselines, baselines augmented with the REPLUG, and baselines augmented with the REPLUG LSR. We observe that both REPLUG and REPLUG LSR significantly outperform the baselines. This demonstrates that simply adding a retrieval module to a frozen language model (i.e., the black-box setting) is effective at improving the performance of different sized language models on language modeling tasks. Furthermore, REPLUG LSR consistently performs better than REPLUG by a large margin. Specifically, REPLUG LSR results in $7.7%$ improvement over baselines compared to $4.7%$ improvement of REPLUG averaged over the 8 models. This indicates that further adapting the retriever to the target LM is beneficial.
结果
表 1: 报告了原始基线、REPLUG增强基线和REPLUG LSR增强基线的结果。我们观察到REPLUG和REPLUG LSR均显著优于基线。这表明仅通过向冻结语言模型(即黑盒设置)添加检索模块,就能有效提升不同规模语言模型在语言建模任务上的性能。此外,REPLUG LSR始终以较大优势优于REPLUG。具体而言,在8个模型上平均来看,REPLUG LSR相比基线实现了7.7%的性能提升,而REPLUG的提升幅度为4.7%。这表明使检索器进一步适配目标大语言模型是有益的。
6.2. MMLU
6.2. MMLU
Datasets Massive Multi-task Language Understanding (MMLU (Hendrycks et al., 2021)) is a multiple choice QA dataset that covers exam questions from 57 tasks including mathematics, computer science, law, US history and etc. The 57 tasks are grouped into 4 categories: humanities, STEM, social sciences and other. Following Chung et al. (2022a), we evaluate REPLUG in the 5-shot in-context learning setting.
数据集
大规模多任务语言理解 (MMLU (Hendrycks et al., 2021)) 是一个多选题问答数据集,涵盖来自57个任务的考试题目,包括数学、计算机科学、法律、美国历史等。这57个任务被分为4大类:人文、STEM (科学/技术/工程/数学)、社会科学和其他。参照 Chung et al. (2022a) 的方法,我们在5样本上下文学习设置下评估REPLUG。
Table 1. Both REPLUG and REPLUG LSR consistently enhanced the performance of different language models. Bits per byte (BPB) of the Pile using GPT-3 and GPT-2 family models (Original) and their retrieval-augmented versions (+REPLUG and $^+$ REPLUG LSR. The gain $%$ shows the relative improvement of our models compared to the original language model.
| Model | #Parameters | Original | +REPLUG | Gain % | +REPLUG GLSR | Gain % | |
| GPT-2 | Small | 117M | 1.33 | 1.26 | 5.3 | 1.21 | 9.0 |
| Medium | 345M | 1.20 | 1.14 | 5.0 | 1.11 | 7.5 | |
| Large | 774M | 1.19 | 1.15 | 3.4 | 1.09 | 8.4 | |
| XL | 1.5B | 1.16 | 1.09 | 6.0 | 1.07 | 7.8 | |
| GPT-3 | Ada | 350M | 1.05 | 0.98 | 6.7 | 0.96 | 8.6 |
| (black-box) | Babbage | 1.3B | 0.95 | 0.90 | 5.3 | 0.88 | 7.4 |
| Curie | 6.7B | 0.88 | 0.85 | 3.4 | 0.82 | 6.8 | |
| Davinci | 175B | 0.80 | 0.77 | 3.8 | 0.75 | 6.3 |
表 1: REPLUG 和 REPLUG LSR 持续提升了不同语言模型的性能。使用 GPT-3 和 GPT-2 系列模型 (原始版本) 及其检索增强版本 (+REPLUG 和 $^+$ REPLUG LSR) 在 Pile 数据集上的每字节比特数 (BPB)。增益 $%$ 表示我们的模型相比原始语言模型的相对改进。
| 模型 | 参数量 | 原始版本 | +REPLUG | 增益 % | +REPLUG LSR | 增益 % | |
|---|---|---|---|---|---|---|---|
| GPT-2 | Small | 117M | 1.33 | 1.26 | 5.3 | 1.21 | 9.0 |
| Medium | 345M | 1.20 | 1.14 | 5.0 | 1.11 | 7.5 | |
| Large | 774M | 1.19 | 1.15 | 3.4 | 1.09 | 8.4 | |
| XL | 1.5B | 1.16 | 1.09 | 6.0 | 1.07 | 7.8 | |
| GPT-3 (黑盒) | Ada | 350M | 1.05 | 0.98 | 6.7 | 0.96 | 8.6 |
| Babbage | 1.3B | 0.95 | 0.90 | 5.3 | 0.88 | 7.4 | |
| Curie | 6.7B | 0.88 | 0.85 | 3.4 | 0.82 | 6.8 | |
| Davinci | 175B | 0.80 | 0.77 | 3.8 | 0.75 | 6.3 |
Table 2. REPLUG and REPLUG LSR improves Codex by $4.5%$ and $5.1%$ respectively. Performance on MMLU broken down into 4 categories. The last column averages the performance over these categories. All models are evaluated based on 5-shot in-context learning with direct prompting.
| Model | #Parameters | Humanities | Social. | STEM | Other | All |
| Codex | 175B | 74.2 | 76.9 | 57.8 | 70.1 | 68.3 |
| PaLM | 540B | 77.0 | 81.0 | 55.6 | 69.6 | 69.3 |
| Flan-PaLM | 540B | - | 72.2 | |||
| Atlas | 11B | 46.1 | 54.6 | 38.8 | 52.8 | 47.9 |
| Codex+REPLUG | 175B | 76.0 | 79.7 | 58.8 | 72.1 | 71.4 |
| Codex + REPLUG LSR | 175B | 76.5 | 79.9 | 58.9 | 73.2 | 71.8 |
表 2: REPLUG 和 REPLUG LSR 分别将 Codex 的性能提升了 $4.5%$ 和 $5.1%$。MMLU 性能按 4 个类别划分。最后一列是这些类别的平均性能。所有模型均基于 5-shot 上下文学习 (in-context learning) 和直接提示进行评估。
| 模型 | #参数 | 人文 | 社科 | STEM | 其他 | 平均 |
|---|---|---|---|---|---|---|
| Codex | 175B | 74.2 | 76.9 | 57.8 | 70.1 | 68.3 |
| PaLM | 540B | 77.0 | 81.0 | 55.6 | 69.6 | 69.3 |
| Flan-PaLM | 540B | - | - | - | - | 72.2 |
| Atlas | 11B | 46.1 | 54.6 | 38.8 | 52.8 | 47.9 |
| Codex+REPLUG | 175B | 76.0 | 79.7 | 58.8 | 72.1 | 71.4 |
| Codex + REPLUG LSR | 175B | 76.5 | 79.9 | 58.9 | 73.2 | 71.8 |
Baselines We consider two groups of strong previous models as baselines for comparisons. The first group of base- lines is the state-of-the-art LLMs including Codex1 (Chen et al., 2021b), PaLM (Chowdhery et al., 2022), and FlanPaLM (Chung et al., 2022b). According to Chung et al. (2022b), these three models rank top-3 in the leader board of MMLU. The second group of baselines consists of retrieval-augmented language models. We only include Atlas (Izacard et al., 2022b) in this group, as no other retrievalaugmented LMs have been evaluated on the MMLU dataset. Atlas trains both the retriever and the language model, which we consider a white-box retrieval LM setting.
基线模型
我们选取两组先进的现有模型作为对比基线。第一组基线是最先进的大语言模型 (LLM),包括 Codex1 (Chen et al., 2021b)、PaLM (Chowdhery et al., 2022) 和 FlanPaLM (Chung et al., 2022b)。根据 Chung 等人 (2022b) 的研究,这三个模型在 MMLU 排行榜上位列前三。第二组基线由检索增强语言模型构成,由于其他检索增强语言模型尚未在 MMLU 数据集上进行评估,我们仅纳入 Atlas (Izacard et al., 2022b)。Atlas 同时训练检索器和语言模型,属于白盒式检索语言模型设置。
Our model We add REPLUG and REPLUG LSR only to Codex because other models such as PaLM and Flan-PaLM are not accessible to the public. We use the test question as the query to retrieve 10 relevant documents from Wikipedia (2018, December) and prepend each retrieved document to the test question, resulting in 10 separate inputs. These inputs are then separately fed into the language models, and the output probabilities are ensemble together.
我们的模型
我们仅将 REPLUG 和 REPLUG LSR 添加到 Codex 中,因为其他模型如 PaLM 和 Flan-PaLM 尚未公开。我们使用测试问题作为查询,从 Wikipedia (2018 年 12 月) 中检索 10 篇相关文档,并将每篇检索到的文档附加到测试问题前,生成 10 个独立输入。这些输入随后分别输入大语言模型,并将输出概率集成在一起。
Results Table 2 presents the results from the baselines, REPLUG, and REPLUG LSR on the MMLU dataset. We observe that both the REPLUG and REPLUG LSR improve the original Codex model by $4.5%$ and $5.1%$ , respectively. In addition, REPLUG LSR largely outperforms the previous retrieval-augmented language model, Atlas, demonstrating the effectiveness of our black-box retrieval language model setting. Although our models slightly under perform FlanPaLM, this is still a strong result because Flan-PaLM has three times more parameters. We would expect that the REPLUG LSR could further improve Flan-PaLM, if we had access to the model.
结果 表2展示了MMLU数据集上基线方法、REPLUG和REPLUG LSR的结果。我们观察到,REPLUG和REPLUG LSR分别将原始Codex模型提升了$4.5%$和$5.1%$。此外,REPLUG LSR大幅超越了之前的检索增强语言模型Atlas,证明了我们黑盒检索语言模型设置的有效性。虽然我们的模型表现略逊于FlanPaLM,但这仍然是强有力的结果,因为Flan-PaLM的参数数量是我们的三倍。如果我们能访问该模型,预计REPLUG LSR可以进一步提升Flan-PaLM的性能。
Another interesting observation is that the REPLUG LSR outperforms the original model by $1.9%$ even in the STEM category. This suggests that retrieval may improve a language model’s problem-solving abilities.
另一个有趣的观察是,REPLUG LSR 在 STEM 类别中甚至比原始模型高出 $1.9%$。这表明检索可能会提升语言模型的问题解决能力。
6.3. Open Domain QA
6.3. 开放域问答 (Open Domain QA)
Lastly, we conduct evaluation on two open-domain QA datasets: Natural Questions (NQ) (Kwiatkowski et al., 2019) and TriviaQA (Joshi et al., 2017).
最后,我们在两个开放域问答数据集上进行了评估:Natural Questions (NQ) (Kwiatkowski et al., 2019) 和 TriviaQA (Joshi et al., 2017)。
Datasets NQ and TriviaQA are two open-domain QA datasets consisting of questions, answers collected from
数据集 NQ 和 TriviaQA 是两个开放领域的问答数据集,包含从
Table 3. Performance on NQ and TQA. We report results for both few-shot (64 shots for Chinchilla, PaLM, and Atlas; 16 shots for Codex-based models) and full training data settings. REPLUG LSR improves Codex by $12.0%$ on NQ and $5.0%$ on TQA, making it the best-performing model in the few-shot setting. Note that models with $\dagger$ are finetuned using training examples, while other models use in-context learning.
| Model | NQ | TQA | ||
| Few-shot | Full | Few-shot | Full | |
| Chinchilla | 35.5 | 64.6 | ||
| PaLM | 39.6 | |||
| Codex | 40.6 | 73.6 | ||
| RETROt | 45.5 | |||
| R2-D2t | - | 55.9 | 69.9 | |
| Atlast | 42.4 | 60.4 | 74.5 | 79.8 |
| Codex + Contrievercc | 44.2 | 76.0 | ||
| Codex+REPLUG | 44.7 | 76.8 | ||
| Codex+REPLUG LSR | 45.5 | 77.3 | ||
表 3: NQ和TQA上的性能表现。我们报告了少样本(Chinchilla、PaLM和Atlas为64样本,基于Codex的模型为16样本)和全训练数据设置下的结果。REPLUG LSR在NQ上将Codex提高了$12.0%$,在TQA上提高了$5.0%$,使其成为少样本设置下性能最佳的模型。请注意,带有$\dagger$的模型使用训练示例进行了微调,而其他模型使用上下文学习。
| 模型 | NQ | TQA |
|---|---|---|
| 少样本 | 全数据 | |
| Chinchilla | 35.5 | |
| PaLM | 39.6 | |
| Codex | 40.6 | |
| RETRO$\dagger$ | 45.5 | |
| R2-D2$\dagger$ | - | 55.9 |
| Atlas$\dagger$ | 42.4 | 60.4 |
| Codex + Contriever$\dagger$ | 44.2 | |
| Codex+REPLUG | 44.7 | |
| Codex+REPLUG LSR | 45.5 |
Wikipedia and the Web. Following prior work (Izacard & Grave, 2021a; Si et al., 2022), we report results for the filtered set of TriviaQA. For evaluation, we consider the fewshot setting where the model is only given a few training examples and full data where the model is given all the training examples.
维基百科与网络。遵循先前工作 (Izacard & Grave, 2021a; Si et al., 2022) 的做法,我们报告了过滤版TriviaQA数据集的结果。评估时,我们考虑两种设置:少样本场景(模型仅获得少量训练示例)和全数据场景(模型获得全部训练示例)。
Baselines We compare our model with several state-ofthe-art baselines, both in a few-shot setting and with full training data. The first group of models consists of powerful large language models, including Chinchilla (Hoffmann et al., 2022), PaLM (Chowdhery et al., 2022), and Codex. These models are all evaluated using in-context learning under the few-shot setting, with Chinchilla and PaLM evaluated using 64 shots, and Codex using 16 shots. The second group of models for comparison includes retrievalaugmented language models such as RETRO (Borgeaud et al., 2021), R2-D2 (Fajcik et al., 2021), and Atlas (Izacard et al., 2022b). All of these retrieval-augmented models are finetuned on the training data, either in a few-shot setting or with full training data. Specifically, Atlas is finetuned on 64 examples in the few-shot setting.
基线模型
我们将模型与多个先进基线在少样本和全量训练数据场景下进行对比。第一组对比模型包含强大大语言模型:Chinchilla (Hoffmann et al., 2022)、PaLM (Chowdhery et al., 2022) 和 Codex。这些模型均在少样本设置下采用上下文学习进行评估,其中 Chinchilla 和 PaLM 使用 64 样本,Codex 使用 16 样本。第二组对比模型包含检索增强语言模型:RETRO (Borgeaud et al., 2021)、R2-D2 (Fajcik et al., 2021) 和 Atlas (Izacard et al., 2022b)。所有检索增强模型均在训练数据上微调,采用少样本或全量训练数据。具体而言,Atlas 在少样本设置下使用 64 个样本进行微调。
Our model We add REPLUG and REPLUG LSR to Codex with Wikipedia (2018, December) as the retrieval corpus to evaluate the model in a 16-shot in context learning. Similar to the setting in language modeling and MMLU, we incorporate top-10 retrieved documents using our proposed ensemble method.
我们的模型
我们将REPLUG和REPLUG LSR添加到Codex中,以维基百科(2018年12月)作为检索语料库,在16样本上下文学习环境中评估模型。与语言建模和MMLU中的设置类似,我们采用提出的集成方法整合前10个检索到的文档。
Results As shown in Table 3, REPLUG LSR significantly improves the performance of the original Codex by $12.0%$ on NQ and $5.0%$ on TQA. It outperforms the previous best model, Atlas, which was fine-tuned with 64 training examples, achieving a new state-of-the-art in the few-shot setting. However, this result still lags behind the performance of retrieval-augmented language models fine-tuned on the full training data. This is likely due to the presence of nearduplicate test questions in the training set (e.g., Lewis et al. (2021) found that $32.5%$ of test questions overlap with the training sets in NQ).
结果 如表 3 所示,REPLUG LSR 在 NQ 上比原始 Codex 性能显著提升了 12.0%,在 TQA 上提升了 5.0%。它超越了之前使用 64 个训练样本微调的最佳模型 Atlas,在少样本设定下达到了新的最优水平。但这一结果仍落后于基于完整训练数据微调的检索增强语言模型,可能是由于训练集中存在近似重复的测试问题 (例如 Lewis 等人 (2021) 发现 NQ 数据集中 32.5% 的测试问题与训练集存在重叠) [20]。

Figure 4. Ensembling random documents does not result in improved performance. BPB of Curie augmented with different methods (random, REPLUG and REPLUG LSR) when varying the number of documents (i.e.; number of ensemble times.)
图 4: 随机文档集成不会带来性能提升。当改变文档数量(即集成次数)时,采用不同增强方法(随机、REPLUG和REPLUG LSR)的Curie模型的BPB指标。
7. Analysis
7. 分析
7.1. REPLUG performance gain does not simply come from the ensembling effect
7.1. REPLUG的性能提升并非仅来自集成效应
The core of our method design is the use of an ensemble method that combines output probabilities of different passes, in which each retrieved document is prepended separately to the input and fed into a language model. To study whether the gains come solely from the ensemble method, we compare our method to ensembling random documents. For this, we randomly sample several documents, concatenated each random document with the input, and ensemble the outputs of different runs (referred to as "random"). As shown in Figure 6, we evaluated the performance of GPT-3 Curie on Pile when augmented with random documents, documents retrieved by REPLUG, and documents retrieved by REPLUG LSR. We observed that ensembling random documents leads to worse performance, indicating that the performance gains of REPLUG do not solely come from the ensembling effect. Instead, ensembling the relevant documents is crucial for the success of REPLUG. Additionally, as more documents were ensembled, the performance of REPLUG and REPLUG LSR improved monotonically. However, a small number of documents (e.g., 10) was sufficient to achieve large performance gains.
我们方法设计的核心在于使用了一种集成方法,该方法结合了不同处理路径的输出概率,其中每个检索到的文档被单独前置到输入中并输入到大语言模型。为了研究性能提升是否仅来自集成方法,我们将本方法与随机文档集成进行对比。具体操作是随机采样若干文档,将每个随机文档与输入拼接,并对不同运行结果进行集成(称为"随机")。如图6所示,我们评估了GPT-3 Curie在Pile数据集上的表现,分别测试了使用随机文档、REPLUG检索文档和REPLUG LSR检索文档增强时的性能。实验表明,集成随机文档会导致性能下降,这说明REPLUG的性能提升并非仅来自集成效应。相反,集成相关文档对REPLUG的成功至关重要。此外,随着集成文档数量的增加,REPLUG和REPLUG LSR的性能呈现单调上升趋势。不过,仅需少量文档(例如10个)即可实现显著的性能提升。

Figure 5. GPT-2, BLOOM and OPT models of varying sizes consistently benefit from REPLUG. The $\mathbf{X}$ -axis indicates the size of the language model and the $\mathrm{y}$ -axis is its perplexity on Wikitext-103.
图 5: 不同规模的 GPT-2、BLOOM 和 OPT 模型均受益于 REPLUG。X 轴表示语言模型的规模,y 轴为模型在 Wikitext-103 上的困惑度。
7.2. REPLUG is applicable to diverse language models
7.2. REPLUG适用于多种语言模型
Here we further study whether REPLUG could enhance diverse language model families that have been pre-trained using different data and methods. Specifically, we focus on three groups of language models with varying sizes: GPT2 (117M, 345M, 774M, 1.5B parameters) (Brown et al., 2020a), OPT (125M, 350M, 1.3B, 2.7B, 6.7B, 13B, 30B, 66B) (Zhang et al., 2022b) and BLOOM (560M, 1.1B, 1.7B, 3B and 7B) (Scao et al., 2022). We evaluate each model on Wikitext-103 (Stephen et al., 2017) test data and report its perplexity. For comparison, we augment each model with REPLUG that adopts the ensemble method to incorporate top 10 retrieved documents. Following prior work (Khandelwal et al., 2020), we use Wikitext-103 training data as the retrieval corpus.
我们进一步研究REPLUG是否能增强采用不同数据和预训练方法的多样化大语言模型家族。具体聚焦三组不同规模的模型:GPT2(117M/345M/774M/1.5B参数)(Brown et al., 2020a)、OPT(125M/350M/1.3B/2.7B/6.7B/13B/30B/66B)(Zhang et al., 2022b)和BLOOM(560M/1.1B/1.7B/3B/7B)(Scao et al., 2022)。在Wikitext-103(Stephen et al., 2017)测试集评估各模型困惑度时,采用集成方法融合前10检索文档的REPLUG进行增强对比。参照前人工作(Khandelwal et al., 2020),使用Wikitext-103训练集作为检索语料库。
Figure 5 shows the performance of different-sized language models with and without REPLUG. We observe that the performance gain brought by REPLUG stays consistent with model size. For example, OPT with 125M parameters achieves $6.9%$ perplexity improvement, while OPT with 66B parameters achieves $5.6%$ perplexity improvement. Additionally, REPLUG improves the perplexity of all the model families. This indicates that REPLUG is applicable to diverse language models with different sizes.
图 5: 展示了不同规模语言模型在使用和未使用 REPLUG 时的性能表现。我们观察到 REPLUG 带来的性能提升在不同模型规模下保持稳定。例如,1.25亿参数的 OPT 实现了 $6.9%$ 的困惑度提升,而 660亿参数的 OPT 则实现了 $5.6%$ 的困惑度提升。此外,REPLUG 对所有模型家族的困惑度都有改善。这表明 REPLUG 适用于不同规模的多样化语言模型。
7.3. Qualitative Analysis: rare entities benefit from retrieval
7.3. 定性分析:稀有实体从检索中受益
To understand why the REPLUG improves language modeling performance, we conducted manual analysis of examples in which the REPLUG results in a decrease in perplexity. We find that REPLUG is more helpful when texts contain rare entities. Figure 6 shows a test context and its continuation from the Wikitext-103 test set. For REPLUG, we use the test context as a query to retrieve a relevant document from Wikitext-103 training data. We then compute the perplexity of the continuation using the original GPT-2 1.5B and its REPLUG enhanced version. After incorporating the retrieved document, the perplexity of the continuation improves by $11%$ . Among all tokens in the continuation, we found that REPLUG is most helpful for the rare entity name "Li Bai". This is likely because the original LM does not have sufficient information about this rare entity name. However, by incorporating the retrieved document, REPLUG was able to match the name with the relevant information in the retrieved document, resulting in better performance.
为了理解REPLUG为何能提升语言建模性能,我们对其降低困惑度的案例进行了人工分析。发现当文本包含罕见实体时,REPLUG的辅助效果更为显著。图6展示了Wikitext-103测试集中的测试上下文及其后续内容。在REPLUG实验中,我们将测试上下文作为查询语句,从Wikitext-103训练数据中检索相关文档,随后分别使用原始GPT-2 1.5B及其REPLUG增强版计算后续内容的困惑度。引入检索文档后,后续内容的困惑度降低了$11%$。在后续内容的所有token中,REPLUG对罕见实体名"Li Bai"的预测改善最为明显。这可能是因为原始语言模型缺乏关于该罕见实体的足够信息,而REPLUG通过检索文档将实体名与相关信息匹配,从而提升了预测性能。

Figure 6. Rare entities benefit from retrieval. After incorporating the retrieved document during inference, the entity $"L i$ Bai" and the token "greatest" in the continuation show the most improvement in perplexity ( $15%$ for $"L i B a i"$ and $5%$ for "greatest"). Other tokens’ perplexity changes are within $5%$ .
图 6: 罕见实体通过检索获益。在推理过程中加入检索文档后,实体"Li Bai"和续写中的token"greatest"在困惑度(perplexity)上提升最显著(分别提升15%和5%),其余token的困惑度变化幅度均在5%以内。
8. Conclusion
8. 结论
We introduce REPLUG, a retrieval-augmented language modeling paradigm that treats the language model as a black box and augments it with a tuneable retrieval model. Our evaluation shows that REPLUG can be integrated with any existing language model to improve their performance on language modeling or downstream tasks. This work opens up new possibilities for integrating retrieval into largescale black-box language models and demonstrates even the state-of-the-art large-scale LMs could benefit from retrieval. However, REPLUG lacks interpret ability as it is unclear when the model relies on retrieved knowledge or parametric knowledge. Future research could focus on developing more interpret able retrieval-augmented language models.
我们提出了REPLUG,这是一种检索增强的语言建模范式,将语言模型视为黑盒,并通过可调优的检索模型对其进行增强。评估表明,REPLUG可以与任何现有语言模型集成,以提升其在语言建模或下游任务中的表现。这项工作为将检索集成到大规模黑盒语言模型中开辟了新可能性,并证明即使是当前最先进的大规模语言模型也能从检索中受益。然而,REPLUG缺乏可解释性,因为无法明确模型何时依赖检索知识或参数化知识。未来研究可聚焦于开发更具可解释性的检索增强语言模型。
Goyal, A., Friesen, A., Banino, A., Weber, T., Ke, N. R., Badia, A. P., Guez, A., Mirza, M., Humphreys, P. C., Konyushova, K., et al. Retrieval-augmented reinforcement learning. In International Conference on Machine Learning, pp. 7740–7765. PMLR, 2022.
Goyal, A., Friesen, A., Banino, A., Weber, T., Ke, N. R., Badia, A. P., Guez, A., Mirza, M., Humphreys, P. C., Konyushova, K., 等. 检索增强的强化学习. 见: 国际机器学习大会, 第7740–7765页. PMLR, 2022.
preprint arXiv:2210.09150, 2022.
预印本 arXiv:2210.09150, 2022.
Si, C., Gan, Z., Yang, Z., Wang, S., Wang, J., Boyd-Graber, J., and Wang, L. Prompting gpt-3 to be reliable. In Proc. of ICLR, 2023. URL https://openreview.net/ forum?id=98 p 5 x 51 L 5 af.
Si, C., Gan, Z., Yang, Z., Wang, S., Wang, J., Boyd-Graber, J., and Wang, L. 提升GPT-3的可靠性. 载于ICLR会议论文集, 2023. 网址 https://openreview.net/ forum?id=98 p 5 x 51 L 5 af.
Knowledge: Arctic Ocean. Although over half of Europe’s original forests disappeared through the centuries of deforestation, Europe still has over one quarter of its land area as forest, such as the broadleaf and mixed forests, taiga of Scandinavia and Russia, mixed rainforests of the Caucasus and the Cork oak forests in the western Mediterranean. During recent times, deforestation has been slowed and many trees have been planted. However, in many cases monoculture plantations of conifers have replaced the original mixed natural forest, because these grow quicker. The plantations now cover vast areas of land, but offer poorer habitats for many European
知识:北冰洋。尽管欧洲原始森林因几个世纪的砍伐已消失过半,但欧洲仍有超过四分之一的陆地面积为森林覆盖,例如阔叶混交林、斯堪的纳维亚和俄罗斯的针叶林、高加索地区的混合雨林以及西地中海地区的栓皮栎林。近年来,毁林速度已放缓并开展了大量植树活动。然而,由于生长速度更快,许多地区用针叶树单一栽培林取代了原有的混合天然林。这些人工林如今占据了广阔的土地,却为许多欧洲(物种)提供了更差的栖息地。
question: As of 2015, since 1990 forests have in Europe and have in Africa and the Ame
问题:截至2015年,自1990年以来欧洲的森林面积有所增加,而非洲和美洲的森林面积有所减少。
A. "increased, increased" B. "increased, decreased" C. "decreased, increased" D. "decreased, decreased"
A. "增加,增加"
B. "增加,减少"
C. "减少,增加"
D. "减少,减少"
Answer: B
答案:B
Knowledge: Over the past decades, the political outlook of Americans has become more progressive, with those below the age of thirty being considerably more liberal than the overall population. According to recent polls, $56\text{%}$ of those age 18 to 29 favor gay marriage, $68\text{%}$ state environmental protection to be as important as job creation, $52\text{%}$ "think immigrants strengthen the country with their hard work and talents," $62\text{%}$ favor a "tax financed, government-administrated universal health care" program and $74\text{%}$ "say peoples willshould have more influence on U.S. laws than the Bible, compared to $37\text{%}$ , $49\text{%}$ , $38\text{%}$ , $47\text{%}$ and $58\text{%}$ among the
知识:过去几十年间,美国人的政治倾向日趋进步,30岁以下群体的自由主义倾向显著高于整体人口。最新民调显示,18至29岁人群中:56%支持同性婚姻,68%认为环保与创造就业同等重要,52%认为"移民通过勤劳和才能为国家注入活力",‰支持"税收筹资、政府管理的全民医保"制度,74%主张"民意应比圣经对美国法律产生更大影响";而全体受访者中上述比例分别为37%、49%、38%、47%和58%。
Question: As of 2019, about what percentage of Americans agree that the state is run for the benefit of all the people? A. $31\text{%}$ B. $46\text{%}$ C. $61\text{%}$ D. $76\text{%}$
问题:截至2019年,约有多少百分比的美国人认为政府是为全民利益而运作的?
A. $31\text{%}$
B. $46\text{%}$
C. $61\text{%}$
D. $76\text{%}$
Answer: B
答案:B
Knowledge: last week at a United Nations climate meeting in Germany, China and India should easily exceed the targets they set for themselves in the 2015 Paris Agreement... India is now expected to obtain 40 percent of its electricity from non-fossil fuel sources by 2022, eight years ahead of schedule." Solar power in Japan has been expanding since the late 1990s. By the end of 2017, cumulative installed PV capacity reached over $50\mathrm{GW}$ with nearly 8 GW installed in the year 2017. The country is a leading manufacturer of solar panels and is in the top 4 ranking for countries
知识:上周在德国举行的联合国气候会议上,中国和印度应能轻松超越其在2015年《巴黎协定》中设定的目标...印度预计将在2022年前实现40%电力来自非化石燃料能源,比原计划提前八年。"日本太阳能发电自20世纪90年代末开始扩张。截至2017年底,光伏累计装机容量超过$50\mathrm{GW}$,其中2017年新增装机近8GW。该国是太阳能电池板的主要生产国,在全球排名前四位
Question: Which of the following countries generated the most total energy from solar sources in 2019? A. China B. United States C. Germany D. Japan
问题:以下哪个国家在2019年太阳能发电总量最高?
A. 中国
B. 美国
C. 德国
D. 日本
Table 4. Prompt for MMLU
表 4: MMLU提示模板
Knowledge: received 122,000 buys (excluding WWE Network views), down from the previous years 199,000 buys. The event is named after the Money In The Bank ladder match, in which multiple wrestlers use ladders to retrieve a briefcase hanging above the ring. The winner is guaranteed a match for the WWE World Heavyweight Championship at a time of their choosing within the next year. On the June 2 episode of "Raw", Alberto Del Rio qualified for the match by defeating Dolph Ziggler. The following week, following Daniel Bryan being stripped of his WWE World Championship due to injury, Stephanie McMahon changed the
知识:共获得122,000次购买(不含WWE Network观看量),低于上一年的199,000次。该赛事得名于"银行阶梯赛"(Money In The Bank ladder match),多名摔角手需借助梯子争夺悬挂在擂台上方的公文包,获胜者将获得在未来一年内任意时间挑战WWE世界重量级冠军的资格。在6月2日的《Raw》节目中,Alberto Del Rio通过击败Dolph Ziggler获得参赛资格。次周,由于Daniel Bryan因伤被剥夺WWE世界冠军头衔,Stephanie McMahon宣布...
Question: Who won the mens money in the bank match? Answer: Braun Strowman
问题:谁赢得了男子公文包大赛?
答案:Braun Strowman
Knowledge: in 3D on March 17, 2017. The first official presentation of the film took place at Disneys three-day D23 Expo in August 2015. The world premiere of "Beauty and the Beast" took place at Spencer House in London, England on February 23, 2017; and the film later premiered at the El Capitan Theatre in Hollywood, California, on March 2, 2017. The stream was broadcast onto YouTube. A sing along version of the film released in over 1,200 US theaters nationwide on April 7, 2017. The United Kingdom received the same version on April 21, 2017. The film was re-released in
知识:2017年3月17日以3D形式上映。该片的首次官方亮相是在2015年8月迪士尼为期三天的D23博览会上。《美女与野兽》全球首映礼于2017年2月23日在英国伦敦斯宾塞庄园举行;随后影片于2017年3月2日在加利福尼亚州好莱坞埃尔卡皮坦剧院首映。首映式通过YouTube平台直播。2017年4月7日,影片的卡拉OK版本在全美超过1200家影院上映。英国于2017年4月21日推出同版本。该片还以...(注:原文截断未完成)
Question: When does beaty and the beast take place Answer: Rococo-era
问题:美女与野兽的故事发生在什么时期?
答案:洛可可时代
Knowledge: Love Yourself "Love Yourself" is a song recorded by Canadian singer Justin Bieber for his fourth studio album "Purpose" (2015). The song was released first as a promotional single on November 8, 2015, and later was released as the albums third single. It was written by Ed Sheeran, Benny Blanco and Bieber, and produced by Blanco. An acoustic pop song, "Love Yourself" features an electric guitar and a brief flurry of trumpets as its main instrumentation. During the song, Bieber uses a husky tone in the lower registers. Lyrically, the song is a kiss-off to a narcissistic ex-lover who did
知识:《Love Yourself》
《Love Yourself》是加拿大歌手Justin Bieber为其第四张录音室专辑《Purpose》(2015)录制的歌曲。该曲于2015年11月8日作为宣传单曲首发,后成为专辑第三支正式单曲。歌曲由Ed Sheeran、Benny Blanco和Bieber共同创作,Blanco担任制作人。这首原声流行乐以电吉他和短暂的小号旋律为主要配器,Bieber在演唱中运用了低沉沙哑的声线。歌词内容直指一位自恋的前任,表达决绝态度。
Question: love yourself by justin bieber is about who
问题:Justin Bieber的《Love Yourself》是关于谁的