VALOR: Vision-Audio-Language Omni-Perception Pre training Model and Dataset
VALOR:视觉-音频-语言全感知预训练模型及数据集
Abstract—In this paper, we propose a Vision-Audio-Language Omni-peRception pre training model (VALOR) for multi-modal understanding and generation. Different from widely-studied vision-language pre training models, VALOR jointly models relationships of vision, audio and language in an end-to-end manner. It contains three separate encoders for single modality representations, and a decoder for multimodal conditional text generation. We design two pretext tasks to pretrain VALOR model, including Multimodal Grouping Alignment (MGA) and Multimodal Grouping Captioning (MGC). MGA projects vision, language and audio to the same common space, building vision-language, audio-language and audiovisual-language alignment simultaneously. MGC learns how to generate text tokens in conditions of vision, audio or their both. To promote vision-audio-language pre training research, we construct a large-scale high-quality tri-modality dataset named VALOR-1M, which contains 1M audiable videos with human annotated audiovisual captions. Extensive experiments show that VALOR can learn strong multimodal correlations and be generalized to various downstream tasks (e.g., retrieval, captioning and question answering), with different input modalities (e.g., vision-language, audio-language and audiovisual-language). VALOR achieves new state-of-the-art performances on series of public cross-modality benchmarks. Code and data are available at project page https://casia-iva-group.github.io/projects/VALOR.
摘要—本文提出了一种面向多模态理解与生成的视觉-音频-语言全感知预训练模型(VALOR)。不同于广泛研究的视觉-语言预训练模型,VALOR以端到端方式联合建模视觉、音频和语言的关系。该模型包含三个独立的单模态编码器和一个多模态条件文本生成解码器。我们设计了两个预训练任务:多模态分组对齐(MGA)和多模态分组描述(MGC)。MGA将视觉、语言和音频映射到同一公共空间,同时建立视觉-语言、音频-语言及视听-语言的对齐关系;MGC则学习在视觉、音频或两者共同条件下生成文本token。为推进视听语言预训练研究,我们构建了大规模高质量三模态数据集VALOR-1M,包含100万条带人工标注视听描述的可听视频。大量实验表明,VALOR能学习强大多模态关联,并可泛化至不同输入模态(如视觉-语言、音频-语言及视听-语言)的各种下游任务(如检索、描述和问答)。VALOR在系列公开跨模态基准测试中实现了最先进性能。代码与数据详见项目页https://casia-iva-group.github.io/projects/VALOR。
Index Terms—Vision-Audio-Language Pre training, Multimodal Under sanding, Multimodal Pre training
索引术语—视觉-音频-语言预训练 (Vision-Audio-Language Pre-training), 多模态理解 (Multimodal Understanding), 多模态预训练 (Multimodal Pre-training)
1 INTRODUCTION
1 引言
As human beings, we perceive information from environment through multiple mediums (e.g. looking, reading, hearing, touching or smelling), and further understand or interact with the world based on those multimodal clues. An ideal intelligent system should also imitate this, to develop both cross-modal understanding and generation capabilities. Various cross-modality applications has been extensively studied, among which vision-language tasks take the main part, including text-to-vision retrieval [1], [2], vision captioning [3], [4], [5] and visual question answering [6], [7]. Fortunately, inspired by the great success of self-supervised pre training methods in natural language processing [8], [9], [10], vision-language pre training has developed rapidly, and achieved dominated performances over traditional methods on various of vision-language benchmarks.
作为人类,我们通过多种媒介(如观察、阅读、聆听、触摸或嗅闻)从环境中感知信息,并基于这些多模态线索进一步理解或与世界互动。理想的智能系统也应模仿这一点,同时发展跨模态理解与生成能力。多种跨模态应用已被广泛研究,其中视觉-语言任务占据主要部分,包括文本到视觉检索 [1]、[2]、视觉描述生成 [3]、[4]、[5] 以及视觉问答 [6]、[7]。值得庆幸的是,受自然语言处理中自监督预训练方法巨大成功的启发 [8]、[9]、[10],视觉-语言预训练迅速发展,并在各类视觉-语言基准测试中超越了传统方法的性能表现。
However, we argue that modeling relationship between vision and language is far from enough to establish a powerful multimodal system and additionally introducing audio modality to build tri-modality interactions is necessary. On one hand, audio signal usually contains semantic meanings complementary to vision, and thus utilizing three modalities can help machine understand aroundings more comprehensively and accurately. As the example in Figure 1 shown, we can only know what’s going on inside the room through observing video frames, but miss perceptions about the outside police car unless we hear the police siren. On the other hand, modeling three modalities in a unified end-to-end framework can enhance model’s generalization capabilities, and benefit various of vision-language, audiolanguage, audiovisual-language and vision-audio downstream tasks.
然而,我们认为仅建立视觉与语言的关系模型远不足以构建强大的多模态系统,还需引入音频模态以构建三模态交互。一方面,音频信号通常包含与视觉互补的语义信息,因此利用三种模态能帮助机器更全面、准确地理解环境。如图 1 所示,我们仅通过观察视频帧能获知室内情况,但除非听到警笛声,否则会遗漏对外部警车的感知。另一方面,在统一的端到端框架中对三种模态建模,可增强模型的泛化能力,并有益于各类视觉-语言、音频-语言、视听-语言及视觉-音频下游任务。
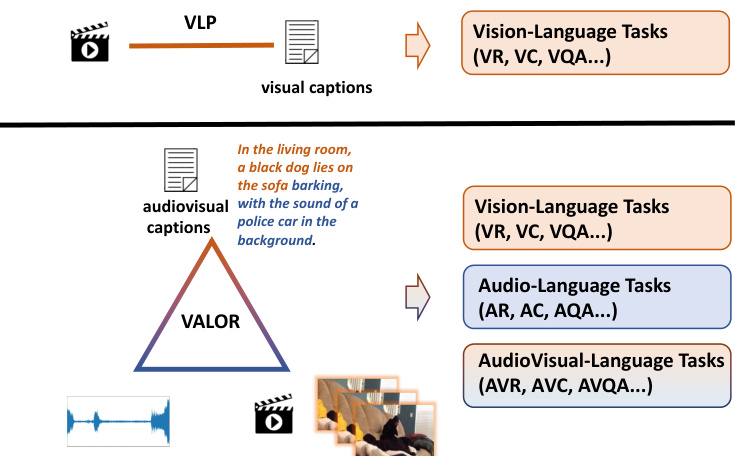
Fig. 1: VALOR takes correlated vision-audiolanguage data for pre training, and can generalize to multiple tasks. AVR/VR/AR represent text-toaudiovisual/visual/audio retrieval, AVC/VC/AC represent audiovisual/visual/audio captioning, and AVQA/VQA/AQA represent audiovisual/visual/audio question answering, respectively. Click the botton to play the audio.
图 1: VALOR 通过关联的视觉-音频-语言数据进行预训练,可泛化至多任务场景。AVR/VR/AR 分别表示文本到视听/视觉/音频检索,AVC/VC/AC 表示视听/视觉/音频描述生成,AVQA/VQA/AQA 表示视听/视觉/音频问答。点击按钮播放音频。
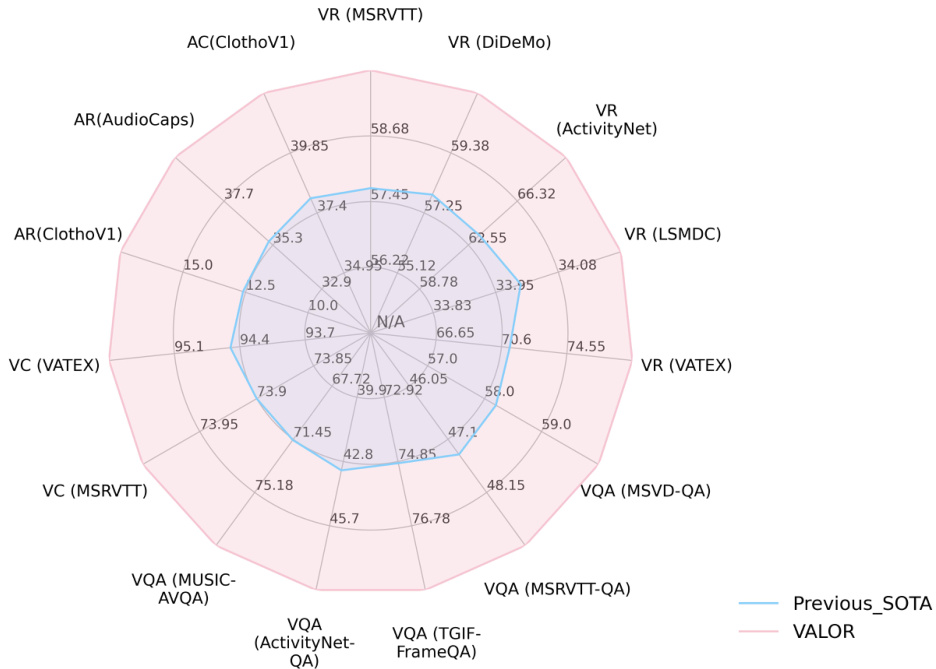
Fig. 2: VALOR achieves state-of-the-art performances on a broad range of tasks compared with other customized or foundation models. VR, VC, VQA represent text-to-video retrieval, video captioning and video QA, respectively.
图 2: 与其他定制模型或基础模型相比,VALOR 在广泛任务上实现了最先进的性能。VR、VC、VQA 分别代表文本到视频检索、视频描述生成和视频问答。
To this end, as shown in Figure 1, we propose a Vision-Audio-Language Omni-peRception pre training model (VALOR) to build universal connections among three modalities, and to fulfill tri-modality understanding and generation. As shown in Figure 5, VALOR encodes vision, audio and language separately with three single-modality encoders, and use a multimodal decoder for conditional text generation. Two pretext tasks, i.e., Multimodal Grouping Alignment (MGA) and Multimodal Grouping Captioning (MGC) are designed to endow VALOR with the capabilities to tackle both disc rim i native and generative tasks. Specifically, MGA projects three modalities into the same common space, and establishes fine-grained alignment between three modality groups including vision-language, audiolanguage and audiovisual-language via contrastive learning. MGC demands models to reconstruct randomly masked text tokens, conditioned by vision, audio, or their both via cross attention layers. Thanks to modality grouping strategy, VALOR can learn how to align or generate text according to different modality combinations, and such capabilities can be transferred to various kinds of cross-modality downstream tasks, including video/audio/audiovisual retrieval, captioning or question answering.
为此,如图 1 所示,我们提出了一种视觉-音频-语言全感知预训练模型 (Vision-Audio-Language Omni-peRception pre training model, VALOR) ,以建立三种模态之间的通用连接,并实现三模态的理解与生成。如图 5 所示,VALOR 分别通过三个单模态编码器对视觉、音频和语言进行编码,并使用一个多模态解码器进行条件文本生成。我们设计了两个预训练任务——多模态分组对齐 (Multimodal Grouping Alignment, MGA) 和多模态分组描述生成 (Multimodal Grouping Captioning, MGC) ,使 VALOR 具备处理判别式任务和生成式任务的能力。具体而言,MGA 将三种模态投影到同一公共空间,并通过对比学习建立视觉-语言、音频-语言以及视听-语言三组模态间的细粒度对齐关系。MGC 则要求模型在视觉、音频或两者共同条件下,通过交叉注意力层重建随机掩码的文本 token。得益于模态分组策略,VALOR 能够学习如何根据不同模态组合进行文本对齐或生成,这种能力可迁移至各类跨模态下游任务,包括视频/音频/视听检索、描述生成或问答任务。
In addition, we argue that strong correlated visionaudio-language triplets are indispensable for training strong tri-modality models. Current public vision-language datasets are incapable of tri-modality pre training for that i) all image-language datasets and some video-language datasets like WebVid-2.5M [13] do not contain audio signals. ii) Even if some video-language datasets like HowTo100M [11] and HD VILA 100M [12] contain audio modality, their audios are limited to human speech with less diversity, and their texts are ASR transcriptions instead of objective descriptions, which are overlapped with speech. To overcome above restrictions, we construct a large-scale high-quality vision-audio-language dataset (VALOR-1M) to promote trimodality pre training researches. It contains one million open-domain audiable videos, each of which is manually annotated with one audiovisual caption, describing both audio and visual contents simultaneously. VALOR-1M’s strong vision-language and audio-language correlations, and its large scaling make it the best choice for tri-modality pre training. Besides VALOR-1M, we also establish a new benchmark VALOR-32K for evaluations on audiovisuallanguage capabilities. It contains two new tasks, including audiovisual-retrieval (AVR) and audiovisual captioning (AVC).
此外,我们认为强关联的视觉-音频-语言三元组对于训练强大的三模态模型不可或缺。当前公开的视觉-语言数据集无法满足三模态预训练需求,原因在于:i) 所有图像-语言数据集及部分视频-语言数据集(如WebVid-2.5M [13])不包含音频信号;ii) 即使HowTo100M [11]和HD VILA 100M [12]等视频-语言数据集包含音频模态,其音频也仅限于人类语音且多样性不足,文本内容均为与语音重叠的ASR转录文本而非客观描述。为突破上述限制,我们构建了大规模高质量的视觉-音频-语言数据集(VALOR-1M)以推动三模态预训练研究。该数据集包含100万个开放域可听视频,每个视频均人工标注了同时描述音频与视觉内容的视听字幕。VALOR-1M具备强视觉-语言与音频-语言关联性及大规模特性,使其成为三模态预训练的最佳选择。除VALOR-1M外,我们还建立了新基准VALOR-32K用于评估视听语言能力,包含视听检索(AVR)和视听字幕生成(AVC)两项新任务。
Extensive ablation studies have been conducted to demonstrate effectiveness of proposed VALOR model and modality grouping strategy. Both quantitative and qualitative results prove that VALOR can utilize audiovisual clues for AVR and AVC tasks effectively. We extensively validate VALOR on series of public video-language, imagelanguage and audio-language benchmarks, and it achieved series of new state-of-the-art results. Specifically, as shown in Figure 2, VALOR outperforms previous state-of-the-art methods by $3.8%$ , $6.2%$ , $12.7%,$ , $0.6%$ , $10.4%$ $(\mathrm{R}@1)$ on textto-video retrieval benchmarks including MSRVTT, DiDeMo, Activity Net, LSMDC and VATEX; $3.8%$ , $3.4%$ , $5.1%$ , $12.5%$ (Acc) on Open-ended video question answering benchmarks including MSRVTT-QA, MSVD-QA, TGIF-FrameQA and Activity Net-QA; $38.9%$ , $13.0%$ $(\mathrm{R}@1)$ on text-to-audio retrieval benchmarks including ClothoV1 and AudioCaps. In addition, VALOR outperforms GIT2 big model [14] on VATEX captioning benchmark with only $0.26%$ training data and $11.6%$ parameters.
大量消融实验验证了所提出的VALOR模型和多模态分组策略的有效性。定量与定性结果均表明,VALOR能有效利用视听线索完成视听检索(AVR)和视听字幕生成(AVC)任务。我们在多个公开的视频-语言、图像-语言及音频-语言基准测试中进行了广泛验证,取得了一系列突破性的最优性能。如图2所示:在文本-视频检索任务中,VALOR在MSRVTT、DiDeMo、ActivityNet、LSMDC和VATEX数据集上的R@1指标分别超越此前最优方法3.8%、6.2%、12.7%、0.6%和10.4%;在开放式视频问答任务中,于MSRVTT-QA、MSVD-QA、TGIF-FrameQA和ActivityNet-QA基准测试的准确率(Acc)分别提升3.8%、3.4%、5.1%和12.5%;在文本-音频检索任务中,对ClothoV1和AudioCaps数据集的R@1指标分别提升38.9%和13.0%。此外,VALOR在VATEX字幕生成任务中,仅使用GIT2大模型[14]0.26%的训练数据和11.6%的参数量,性能仍优于后者。
Overall, the contribution of this work can be summaried as follows:
总体而言,本工作的贡献可总结如下:
I) We proposed an omni-perception pre training model (VALOR), which establishes correlations among vision, audio and language for tri-modality understanding and generation.
我们提出了一种全感知预训练模型 (VALOR),该模型建立了视觉、听觉和语言之间的关联,以实现三模态理解和生成。
II) We introduced MGA and MGC pre training tasks with modality grouping strategy to enhance model’s generalization capability with different modality inputs.
II) 我们引入了MGA和MGC预训练任务及模态分组策略,以增强模型对不同模态输入的泛化能力。
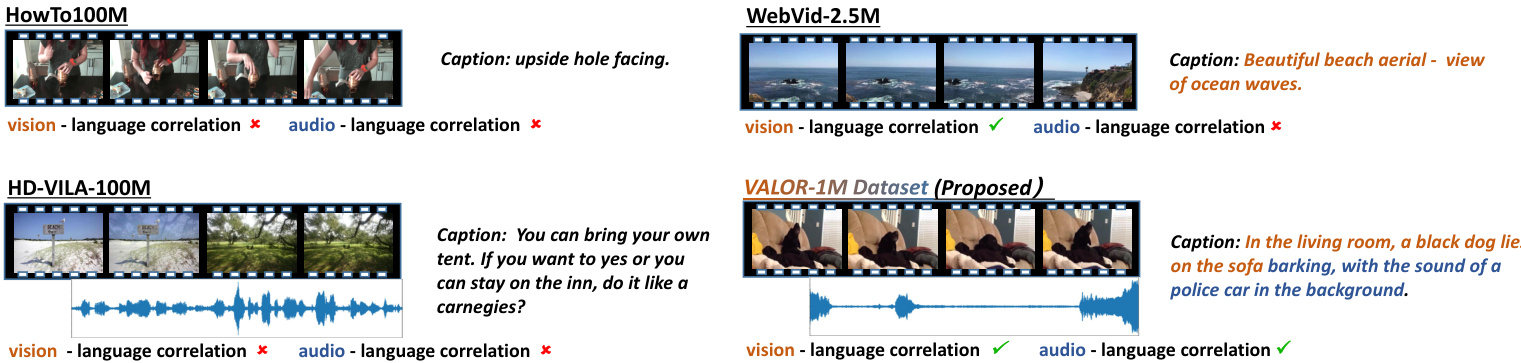
Fi g. 3: Visualization s of video-language pre training datasets including HowTo100M [11], HD VILA 100M [12], WebVid2,5M [13] and VALOR-1M. Click the bottons to play the audio.
图 3: 视频语言预训练数据集的可视化展示,包括 HowTo100M [11]、HD VILA 100M [12]、WebVid2.5M [13] 和 VALOR-1M。点击按钮播放音频。
III) We proposed VALOR-1M dataset which is the first large-scale human-annotated tri-modality dataset to promote vision-audio-language researches, and VALOR-32K benchmark for evaluations on audiovisual-language capabilities.
III) 我们提出了VALOR-1M数据集,这是首个大规模人工标注的三模态数据集,旨在推动视觉-音频-语言研究,并建立了VALOR-32K基准用于评估视听-语言能力。
IV) Pretrained on VALOR-1M and current public visionlanguage datasets, VALOR has achieved new state-of-the-art performances on series of cross-modality benchmarks with evident improvements.
IV) 在VALOR-1M和现有公开视觉语言数据集上预训练的VALOR,在一系列跨模态基准测试中取得了新的最优性能,并有显著提升。
2 RELATED WORK
2 相关工作
In this section, we first introduce common cross-modality datasets used for multimodal pre training. After that we review vision-language pre training methods. At last, we introduce typical methods utilizing more modalities beyond vision and text for video-language learning.
在本节中,我们首先介绍用于多模态预训练的常见跨模态数据集。随后回顾视觉-语言预训练方法。最后介绍超越视觉与文本模态的典型视频-语言学习方法。
2.1 Cross-Modality Datasets for Multimodal Pre training
2.1 用于多模态预训练的跨模态数据集
Generally, an ideal vision-language pre training dataset should meets two basic demands, large scaling enough and strong visual-textual correlations. Considering that sentence-level caption annotations are much more resourceconsuming than word-level label tagging, some methods attempts to collect videos which contains human speech, and extract ASR transcriptions as captions. For example, Miech et al. collected HowTo100M [11], which consists of 136M video clips sourced from 1.22M narrated instructional YouTube videos, and it has become the main-stream dataset used by early video-language pre training methods. Zellers et al. followed this approach and proposed YT-Temporal180M [15] which contains 180M clips from 6M YouTube videos. Xue et al. collected HD VILA 100M [12] that consists of 100M clips from 3.3M YouTube videos, with more diversity and larger image resolution.
理想的视觉语言预训练数据集通常需要满足两个基本要求:足够大的规模以及强烈的视觉-文本关联性。考虑到句子级标注比词级标签标注耗费更多资源,部分方法尝试收集含有人声的视频,并提取自动语音识别(ASR)文本作为描述。例如,Miech等人构建的HowTo100M [11] 数据集包含来自122万条YouTube教学视频的1.36亿个视频片段,成为早期视频语言预训练方法的主流数据集。Zellers等人沿用该方法提出了YT-Temporal180M [15],包含来自600万条YouTube视频的1.8亿个片段。Xue等人收集的HD VILA 100M [12] 包含来自330万条YouTube视频的1亿个片段,具有更丰富的多样性和更高的图像分辨率。
However, although this route can be friendly scaled up to get large amount of video-text pairs, the quality of captions are not satisfying. Besides probable speech recognition errors, ASR transcriptions usually convey subjective ideas and opinions of speechers, instead of objective descriptions of static objects and happening events. Even if some transcriptions indeed reflect visual contents, there exists temporal misalignment problem that they may correspond to video clips before or after [16]. To overcome this problem and pursue both quantity and quality, Bain et al. followed collection procedures of image-language Conceptual Captions datasets (CC3M [17], CC12M [18]), and collected WebVid [13], which consists of $2.5\mathrm{M}$ videos paired with alt-texts. Although sometimes unfluent and incomplete, alttexts have overall stronger correlations to video contents than ASR transcriptions, and have been widely used by latest video-language pre training methods. However, none of datasets mentioned above support vision-audio-language pre training, due to the missing of audio-language correlations, which motivates us to collect VALOR-1M dataset to push tri-modality pre training development.
然而,尽管这种方式可以轻松扩展以获取大量视频-文本对,但字幕质量并不理想。除了可能的语音识别错误外,ASR转录通常传达的是说话者的主观想法和观点,而非对静态物体和发生事件的客观描述。即使某些转录确实反映了视觉内容,仍存在时间错位问题——它们可能对应视频片段之前或之后的画面[16]。为解决这一问题并兼顾数量与质量,Bain等人遵循图像-语言概念描述数据集(CC3M[17]、CC12M[18])的收集流程,构建了包含250万视频与替代文本配对的WebVid[13]。虽然替代文本有时不够流畅完整,但其与视频内容的整体相关性仍显著优于ASR转录,因此被最新视频-语言预训练方法广泛采用。但上述数据集均因缺少音频-语言关联而无法支持视觉-音频-语言三模态预训练,这促使我们收集VALOR-1M数据集以推动三模态预训练发展。
2.2 Vision-Language Pre training
2.2 视觉语言预训练
Influenced by the success of BERT [8], vision-language pretraining has got rapid development, we summarize serveral main research directions as following.
受BERT [8]成功的影响,视觉语言预训练取得了快速发展,我们总结了以下几个主要研究方向。
I) Cross-Modality Pre training Framework Design. According to different network architectures, vision-language models can be mainly divided into dual-encoder paradigm [19], [20] and fusion-encoder paradigm [21], [22]. The former fuses vision and language lightly at the output of encoders by simple dot-product, which can be efficiently used for cross modality retrieval and zero-shot classification. The Latter use co-attention [22] or merge-attention [21] to fuse two modalities deeply, which are good at more fine-grained tasks like captioning or VQA. In addition, various of selfsupervised pretext tasks have been proposed for better cross-modality feature representation learning, including masked language modeling (MLM) [21], masked vision modeling (MVM) [21], [23], vision-text matching (VTM) [21], [24], vision-text contrastive learning (VTC) [13], [25], etc. With regards to visual representations, early methods separately use off-line object detectors (e.g., Faster-RCNN [26]) to extract object-level image features or 3D convolutional neural networks (e.g., S3D [19]) to extract clip-level video features. With the emerging of vision transformers [27], [28], image-language and video-language can be uni- fied by feeding models images or sparsely sampled frames.
I) 跨模态预训练框架设计。根据不同的网络架构,视觉语言模型主要可分为双编码器范式 [19]、[20] 和融合编码器范式 [21]、[22]。前者通过简单的点积在编码器输出端对视觉与语言进行轻量级融合,可高效用于跨模态检索和零样本分类;后者采用协同注意力 [22] 或合并注意力 [21] 实现深度模态融合,擅长图像描述或视觉问答等细粒度任务。此外,学界提出了多种自监督预训练任务以优化跨模态特征表示学习,包括掩码语言建模 (MLM) [21]、掩码视觉建模 (MVM) [21]、[23]、视觉文本匹配 (VTM) [21]、[24]、视觉文本对比学习 (VTC) [13]、[25] 等。在视觉表征方面,早期方法分别采用离线目标检测器 (如 Faster-RCNN [26]) 提取物体级图像特征,或使用 3D 卷积神经网络 (如 S3D [19]) 提取片段级视频特征。随着视觉 Transformer [27]、[28] 的出现,通过向模型输入图像或稀疏采样帧,可实现图像-语言与视频-语言的统一建模。
II) Unified Multi-Task Modeling. This series of works attempts to universally model different tasks with a unified framework and remove task-specific finetuning heads, to utilize pre training data more efficiently. VL-T5 [29] first uses a sequence-to-sequence framework to model visionlanguage tasks like VQA and viusal grounding. Later, finegrained localization tasks like object detection and text-toimage generation are also integrated [30], [31], [32], through box coordinates token iz ation [33] or image token iz ation [34], respectively. Besides sequence-to-sequence framework, some works also unify multiple vision-language tasks via contrastive learning [35] or masked language modeling [36]. However, even if above methods have unified multiple tasks, they are constrained in vision-language domain. In comparison, VALOR can generalize to visionaudio-language domain, and suitable for partial- and omniperception tasks.
II) 统一多任务建模。这一系列工作试图用统一框架建模不同任务,并移除任务特定的微调头,以更高效利用预训练数据。VL-T5 [29] 首次采用序列到序列框架建模视觉语言任务(如VQA和视觉定位)。随后,目标检测和文生图等细粒度定位任务也通过边界框坐标Token化 [33] 或图像Token化 [34] 被整合进来 [30][31][32]。除序列到序列框架外,部分工作还通过对比学习 [35] 或掩码语言建模 [36] 统一多模态任务。然而,上述方法虽统一了多任务,仍局限于视觉语言领域。相较之下,VALOR可泛化至视觉-音频-语言领域,并适用于部分感知与全感知任务。
III) Vision-Language Foundation Models. Visionlanguage models trained with extremely huge data and parameters are usually called big models or foundation models, and are often supervised with contrastive learning [37], [38], [39], [40], language modeling [14], [41], [42], [43] , or both [44]. Foundation models have achieved dominated performances on vision-language benchmarks. For example, Flamingo [42] increases model size to 80.2B parameters and got 84.0 Acc score on VQAv2 dataset, while GIT2 [14] increases data size to 12.9B image-text pairs and achieved 149.8 CIDEr score on COCO caption benchmark. However, due to high demands on computing resources, data storage and complicated distributed training, scaling vision-language pre training models from parameter and data dimensions shows limited efficiency. In comparison, we assume that VALOR can be viewed as scaling up from modality dimension, by introducing audio and building trimodality connections, which is effective and more efficient.
III) 视觉-语言基础模型 (Vision-Language Foundation Models)。通过海量数据和参数量训练的视觉-语言模型通常被称为大模型或基础模型,其训练常采用对比学习 [37][38][39][40]、语言建模 [14][41][42][43] 或二者结合 [44] 的监督方式。基础模型在视觉-语言基准测试中展现了统治级性能。例如 Flamingo [42] 将模型参数量提升至 802 亿并在 VQAv2 数据集取得 84.0 准确率,而 GIT2 [14] 将训练数据规模扩展至 129 亿图文对并在 COCO 图像描述基准实现 149.8 CIDEr 分数。但由于对计算资源、数据存储及复杂分布式训练的高要求,单纯从参数和数据维度扩展视觉-语言预训练模型的效率存在局限。相较而言,我们认为 VALOR 通过引入音频模态构建三模态关联,可视为从模态维度进行扩展,这种方式既高效又更具效益。
2.3 Auxiliary Modality Enhanced Video-Language Under standing
2.3 辅助模态增强的视频语言理解
Considering videos are naturally multimodal medium and each modality contains rich semantic meanings, some approaches exploited more modalities to enhance videolanguage learning. MMT [45] proposes a multimodal transformer to fuse seven modality experts for text-to-video retrieval. SMPFF [46] additionally introduce objective and audio features to improve video captioning. In large-scale pretraining scenario, audio and subtitle are the most commonly used auxiliary modalities to strengthen video representation. UniVL [47], VLM [48] and MV-GPT [19] fuse video and subtitle modalities, and pretrain on HowTo100M dataset for video captioning. VALUE [49] further exploit subtitle enhancement on more tasks including video retrieval and QA. With regards to audio enhancement, AVLNet [50] and MCN [51] utilize audio to enhance text-to-video retrieval. VATT [52] proposed a hierarchical contrastive loss for textvideo and video-audio alignment, but it targets at learning single-modality representations instead of improving crossmodality capabilities. MERLOT Reserve [15] and i-Code [53] also take vision, audio and language as input for pretraining, but has essential differences with VALOR in that i) those methods has severe pre training-finetuning inconsistency. Specifically, the audio-language relation are between human speech and ASR transcriptions during pre training, but general audios and objective descriptions during finetuning. By contrast, VALOR is trained on strong correlated tri-modality dataset and keeps pre training-finetuning consistency, which makes it can generalize to video-language, audio-language and audiovisual-language tasks. ii) those methods only targets at disc rim i native tasks like video QA, while VALOR can tackle disc rim i native, contrastive and generative tasks, thanks to the unified architecture and designed pre training tasks.
考虑到视频天然是多模态媒介且每种模态都蕴含丰富语义,部分研究通过整合更多模态来增强视频-语言学习。MMT [45] 提出多模态Transformer,融合七种模态专家进行文本-视频检索。SMPFF [46] 额外引入客观特征和音频特征以提升视频描述生成。在大规模预训练场景中,音频和字幕是最常用的辅助模态:UniVL [47]、VLM [48] 和 MV-GPT [19] 融合视频与字幕模态,基于HowTo100M数据集进行视频描述预训练;VALUE [49] 进一步将字幕增强拓展至视频检索和问答等任务。在音频增强方面,AVLNet [50] 和 MCN [51] 利用音频优化文本-视频检索。VATT [52] 提出分层对比损失函数对齐文本-视频和视频-音频,但其目标是学习单模态表征而非提升跨模态能力。MERLOT Reserve [15] 和 i-Code [53] 同样采用视觉、音频和语言进行预训练,但与VALOR存在本质差异:i) 这些方法存在严重的预训练-微调不一致性——预训练时音频-语言关系存在于人类语音与ASR转录文本之间,而微调时变为通用音频与客观描述。相比之下,VALOR基于强关联的三模态数据集训练并保持预训练-微调一致性,使其能泛化至视频-语言、音频-语言及视听-语言任务;ii) 这些方法仅针对判别式任务(如视频问答),而VALOR凭借统一架构和设计的预训练任务,可同时处理判别式、对比式和生成式任务。
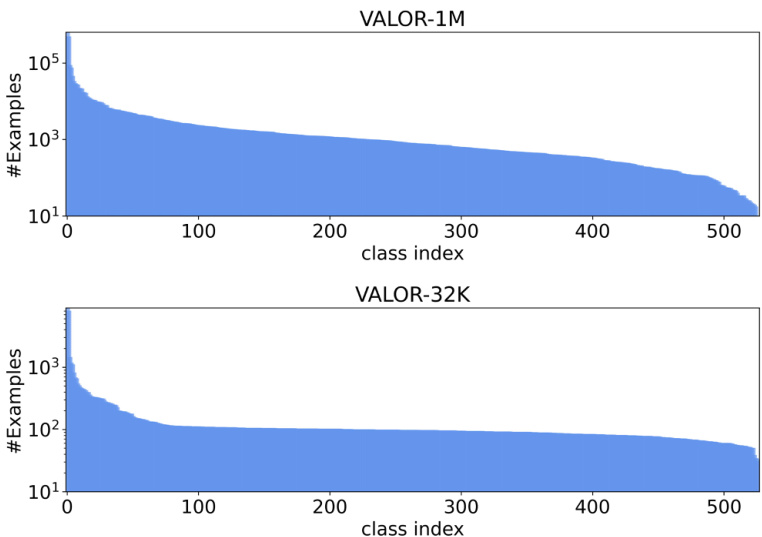
Fig. 4: The distributions of audio classes in VALOR-1M and VALOR-32K.
图 4: VALOR-1M 和 VALOR-32K 中音频类别的分布。
3 VALOR DATASET FOR AUDIOVISUAL- LANGUAGE PRE TRAINING
3 视听语言预训练的VALOR数据集
As explained in Section 2.1, video-language datasets whose captions are ASR transcriptions or alt-texts are not best choices for vision-audio-language pre training, due to the lack of explicit correspondence between textual sentences and audio concepts. To overcome this, we propose a visionaudio-language correlated dataset VALOR for tri-modality model pre training and benchmarking, by annotating public audiovisual data. In the following subsections, we elaborate data collection, annotation and benchmarking process, and then analysis the characteristics of VALOR dataset.
如第2.1节所述,以自动语音识别(ASR)转录文本或替代文本作为字幕的视频-语言数据集,由于缺乏文本语句与音频概念间的显式对应关系,并非视觉-音频-语言预训练的最佳选择。为此,我们通过标注公开音视频数据,提出了用于三模态模型预训练与基准测试的视觉-音频-语言关联数据集VALOR。后续小节将详细阐述数据收集、标注与基准测试流程,并分析VALOR数据集的特征。
3.1 AudioVisual Data Collection
3.1 视听数据收集
Ideally, videos of vision-audio-language dataset should contain both visual and audio tracks, with high quality and diversity. To this end, we choose videos from AudioSet [66], a large-scale dataset collected for audio event recognition. Specifically, AudioSet contains over 2 million 10-second video clips excised from YouTube videos and each video is labeled from 527 audio classes, according to a hierarchical ontology. It is splited into a 2M unbalanced train set, a $22\mathrm{k\Omega}$ balanced train set and a $20\mathrm{k\Omega}$ evaluation set. In balanced train and evaluation set, each audio class have comparable number of videos, while the class distribution in unbalanced train set is not restricted. We downloaded videos of AudioSet whose YouTube urls are still available, filtered low-quality broken videos, and finally achieved around 1M videos. Following [66], we split the dataset into VALOR1M as tri-modality pre training dataset and VALOR-32K as audiovisual-language downstream benchmark dataset, according to audio class distributions. Specifically, Videos of VALOR-1M originate from unbalanced train set of AudioSet, and videos of VALOR-32K originate from balanced train and evaluation set of AudioSet. As Fig 4 shown, VALOR-32K have more balanced audio class distribution compared to VALOR-1M.
理想情况下,视觉-音频-语言数据集的视频应同时包含画面和音轨,并具备高质量与多样性。为此,我们从音频事件识别大规模数据集AudioSet [66]中选取视频。具体而言,AudioSet包含从YouTube视频中截取的超过200万段10秒视频片段,每段视频根据分层本体论标注了527个音频类别。该数据集被划分为200万条的非平衡训练集、22kΩ的平衡训练集和20kΩ的评估集。在平衡训练集和评估集中,每个音频类别的视频数量相当,而非平衡训练集的类别分布不受限制。我们下载了YouTube链接仍可访问的AudioSet视频,过滤低质量损坏视频,最终获得约100万条视频。依照[66]的方法,根据音频类别分布将数据集划分为三模态预训练数据集VALOR1M和视听语言下游基准数据集VALOR-32K。具体来说,VALOR-1M的视频源自AudioSet的非平衡训练集,VALOR-32K的视频源自AudioSet的平衡训练集和评估集。如图4所示,VALOR-32K的音频类别分布比VALOR-1M更为均衡。
TABLE 1: Statistics of common public video-language pre training datasets and downstream benchmark datasets. Audio: dataset contains audio or not. V-L: vision-language correlation. A-L: audio-language correlation. #Example: the number of videos/audios/images. #Clips: the number of video clips or audio clips. $\mathrm{Len}_{\mathrm{Cap}}$ : average caption length. ACD: audio concepts density.
| Dataset | Caption | Task | Domain | Audio | V-L | A-L | #Example | #Clips | LenCap | ACD (%) |
| PretrainingDatasets | ||||||||||
| HowTo100M [11] | ASR | Instructional | 1.22M | 136M | 4.0 | 3.4 | ||||
| HD_VILA_100M[12] | ASR | Open | 3.3M | 103M | 32.5 | 1.1 | ||||
| WebVid-2.5M [13] | Alt-text | Open | 2.5M | 2.5M | 14.2 | 3.3 | ||||
| CC3M [17] | Alt-text | Open | √ | × | 3.3M | 3.0 | ||||
| VALOR-1M | Manual | Open | √ | 1.18M | 1.18M | 16.4 | 9.7 | |||
| DownstreamBenchmarks | ||||||||||
| MSVD [54] | Manual | VR,VC,VQA | Open | 2K | 2K | 7.0 | 6.7 | |||
| MSRVTT [55] | Manual | VR,VC,VQA | Open | √ | 7K | 10K | 9.3 | 4.7 | ||
| VATEX[56] | Manual | VR,VC | Open | √ | 41.3K | 41.3K | 14.3 | 4.1 | ||
| YouCook2 [57] | Manual | VR,VC | Cooking | √ | 2K | 15.4K | 8.8 | 4.3 | ||
| DiDeMo [58] | Manual | VR | Open | √ | 10.5K | 26.9K | 8.0 | 6.3 | ||
| ActivityNet [59] | Manual | VR,VC | Action | √ | x | 20K | 100k | 13.5 | 3.4 | |
| LSMDC [60] | Manual | VR | Movie | √ | √ | 202 | 118K | 9.1 | 2.5 | |
| ClothoV1 [61] | Manual | AR,AC | Open | √ | √ | 5.0K | 5.0K | 11.3 | 10.4 | |
| AudioCaps [62] | Manual | AR,AC | Open | √ | √ | 51.3K | 51.3K | 8.8 | 17.3 | |
| Pano-AVQA[63] | Manual | AVQA | Panoramic | √ | √ | √ | 5.4K | 5.4K | ||
| MUSIC-AVQA [64] | Manual | AVQA | Music | √ | √ | √ | 9.3K | 9.3K | ||
| AVQA [65] | Manual | AVQA | Open | √ | 57K | 57K | ||||
| VALOR-32K | Manual | AVR, AVC | Open | √ | 32K | 32K | 19.8 | 9.1 | ||
表 1: 常见公开视频-语言预训练数据集及下游基准数据集统计。Audio: 是否包含音频。V-L: 视觉-语言相关性。A-L: 音频-语言相关性。#Example: 视频/音频/图像数量。#Clips: 视频片段或音频片段数量。$\mathrm{Len}_{\mathrm{Cap}}$: 平均字幕长度。ACD: 音频概念密度。
| Dataset | Caption | Task | Domain | Audio | V-L | A-L | #Example | #Clips | LenCap | ACD (%) |
|---|---|---|---|---|---|---|---|---|---|---|
| PretrainingDatasets | ||||||||||
| HowTo100M [11] | ASR | Instructional | 1.22M | 136M | 4.0 | 3.4 | ||||
| HD_VILA_100M[12] | ASR | Open | 3.3M | 103M | 32.5 | 1.1 | ||||
| WebVid-2.5M [13] | Alt-text | Open | 2.5M | 2.5M | 14.2 | 3.3 | ||||
| CC3M [17] | Alt-text | Open | √ | × | 3.3M | 3.0 | ||||
| VALOR-1M | Manual | Open | √ | 1.18M | 1.18M | 16.4 | 9.7 | |||
| DownstreamBenchmarks | ||||||||||
| MSVD [54] | Manual | VR,VC,VQA | Open | 2K | 2K | 7.0 | 6.7 | |||
| MSRVTT [55] | Manual | VR,VC,VQA | Open | √ | 7K | 10K | 9.3 | 4.7 | ||
| VATEX[56] | Manual | VR,VC | Open | √ | 41.3K | 41.3K | 14.3 | 4.1 | ||
| YouCook2 [57] | Manual | VR,VC | Cooking | √ | 2K | 15.4K | 8.8 | 4.3 | ||
| DiDeMo [58] | Manual | VR | Open | √ | 10.5K | 26.9K | 8.0 | 6.3 | ||
| ActivityNet [59] | Manual | VR,VC | Action | √ | x | 20K | 100k | 13.5 | 3.4 | |
| LSMDC [60] | Manual | VR | Movie | √ | √ | 202 | 118K | 9.1 | 2.5 | |
| ClothoV1 [61] | Manual | AR,AC | Open | √ | √ | 5.0K | 5.0K | 11.3 | 10.4 | |
| AudioCaps [62] | Manual | AR,AC | Open | √ | √ | 51.3K | 51.3K | 8.8 | 17.3 | |
| Pano-AVQA[63] | Manual | AVQA | Panoramic | √ | √ | √ | 5.4K | 5.4K | ||
| MUSIC-AVQA [64] | Manual | AVQA | Music | √ | √ | √ | 9.3K | 9.3K | ||
| AVQA [65] | Manual | AVQA | Open | √ | 57K | 57K | ||||
| VALOR-32K | Manual | AVR, AVC | Open | √ | 32K | 32K | 19.8 | 9.1 |
3.2 AudioVisual Caption Annotaion
3.2 视听字幕标注
We take the paid labeling manner to acquire audiovisual descriptions for VALOR datasets. Considering that this annotation task is novel and more complicated than traditional video description annotation, we design a three-step interactive annotating procedure.
我们采用付费标注的方式为VALOR数据集获取视听描述。考虑到这一标注任务新颖且比传统视频描述标注更复杂,我们设计了一个三步交互式标注流程。
Step1, annotator training. We conduct online training for 500 annotators, emphasizing that important components like main bodies, activities, scenes, objects, and sounds should be comprehensively reflected in descriptions. Some video-audiovisual caption pairs are provided by us to help annotators be familiar with annotation formats in advance. We also provide a dictionary that maps videoIDs to their AudioSet labels, and annotators are encouraged to query those labels first as prior references, before audiovisual description annotation.
步骤1:标注员培训。我们对500名标注员进行在线培训,强调主体、活动、场景、物体和声音等重要元素应在描述中全面体现。我们提供部分视频-视听字幕对,帮助标注员提前熟悉标注格式。同时提供视频ID与AudioSet标签的映射词典,鼓励标注员在开始视听描述标注前优先查询这些标签作为参考依据。
Step2, first-stage annotation. At this stage, we provide videos of VALOR-32K to annotators. The annotated descriptions are manually checked by us, and we feedback common problems and corresponding videoIDs. Then annotators are asked to re-annotate those unsatisfying exsamples, and build deeper understanding about annotation demands.
步骤2:第一阶段标注。在此阶段,我们向标注员提供VALOR-32K的视频。标注的描述由我们手动检查,并反馈常见问题及对应的videoID。然后要求标注员重新标注那些不满意的样本,并加深对标注需求的理解。
Step3, second-stage annotation. At this stage, annotators write audiovisual descriptions for videos of VALOR1M. Each description is further checked by three annotators to ensure annotation quality, and needed to be re-annotated if more than one annotator assumed it not satisfying. The whole annotation and checking processes have taken about 2 months.
步骤3,第二阶段标注。在此阶段,标注者为VALOR1M的视频撰写视听描述。每条描述需经三名标注者复核以确保标注质量,若超过一名标注者认为描述不达标,则需重新标注。整个标注与复核流程耗时约2个月。
3.3 VALOR-32K Benchmark
3.3 VALOR-32K 基准测试
Considering that current established audiovisual-language benchmarks only target at question answering (AVQA) [63], [64], [65], we established VALOR-32K benchmark to enlarge evaluation task fields, which consists of two tasks including audiovisual retrieval (AVR) and audiovisual captioning (AVC). As shown in Figure 8, AVC demands models to generate audiovisual captions for audiable videos and in AVR task, models are required to retrieve the most matching video candidate according to given audiovisual caption queries. Both AVR and AVC tasks are more challenging than existing text-to-video retrieval and video captioning tasks due to the introduction of audio modality. VALOR-32K are splited into 25K/3.5K/3.5K videos for training, validation and testing, respectively. The same evaluation metrics of video retrieval and video captioning are utilized for AVR and AVC tasks evaluation.
考虑到当前成熟的视听语言基准仅针对问答任务(AVQA) [63][64][65],我们建立了VALOR-32K基准以扩展评估任务领域,包含视听检索(AVR)和视听描述(AVC)两项任务。如图8所示,AVC要求模型为有声视频生成视听描述,而AVR任务则要求模型根据给定的视听描述查询检索最匹配的视频候选。由于音频模态的引入,AVR和AVC任务都比现有的文本-视频检索和视频描述任务更具挑战性。VALOR-32K被划分为25K/3.5K/3.5K视频分别用于训练、验证和测试。视频检索和视频描述的相同评估指标被用于AVR和AVC任务的评估。
3.4 Characteristics of VALOR Dataset
3.4 VALOR数据集特性
VALOR dataset is the first large-scale vision-audio-language strong-correlated dataset, and its biggest highlights lie in rich audio concepts and audiovisual captions. We make quantitative and qualitative comparisons between VALOR dataset and public video-language datasets in this subsection.
VALOR数据集是首个大规模视觉-音频-语言强关联数据集,其最大亮点在于丰富的音频概念和视听描述。本节我们将VALOR数据集与公开视频-语言数据集进行定量和定性对比。
Quantitative Comparison. To evaluate the richness of mentioned audio concepts in captions of different datasets, we define a metric named audio concept density (ACD). We established an audio concept set according to the 632 audio classes ontology proposed by [66]. Specifically, we split one class if it contains multiple similar concepts separated by comma, convert all words to lowercase and remove punctuations. To the end, we got 759 audio concepts. Given one caption, we preprocess it by removing punctuation s and converting to lowercase, and then detect the existence of every audio concept. After iterating the whole dataset, ACD metric can be computed as follows:
定量比较。为评估不同数据集标注中提及音频概念的丰富程度,我们定义了一个名为音频概念密度 (ACD) 的指标。我们根据[66]提出的632个音频类别本体建立了音频概念集:若某类别包含由逗号分隔的多个相似概念则进行拆分,将所有单词转为小写并去除标点,最终获得759个音频概念。给定一条标注文本时,我们先去除标点并将其转为小写,随后检测每个音频概念的存在情况。遍历整个数据集后,ACD指标计算公式如下:
$$
A C D={\frac{N_{A C}}{N_{W}}}
$$
where $N_{A C}$ equals to total number of detected audio concepts and $N_{W}$ is total number of words. As shown in Table 1, ACD metric of VALOR dataset is much bigger than other video-language datasets. In addition, the average caption length of VALOR-1M and VALOR-32K is 16.4 and 19.8, respectively, which is much longer than other datasets like WebVid-2.5M (14.2), CC3M (10.3), thanks to additional audio-related descriptions and high annotation quality.
其中 $N_{AC}$ 表示检测到的音频概念总数,$N_{W}$ 表示总词数。如表1所示,VALOR数据集的ACD指标远高于其他视频-语言数据集。此外,VALOR-1M和VALOR-32K的平均字幕长度分别为16.4和19.8,这得益于额外的音频相关描述和高质量标注,显著长于WebVid-2.5M (14.2)、CC3M (10.3)等数据集。
Qualitative Comparison. We compare VALOR-1M to ASR transcription captions based datasets like HowTo100M and HD VILA 100M, and alt-text captions based dataset like WebVid-2.5M. As figure 3 shown, captions of HowTo100M dataset are incomplete sentences which can not even understood by people, let alone vision-language correlations. Captions in HD VILA 100M are more completed, but vision-language correlations are still weak. Specifically, the caption is transcribed from a dialog that two people are talking about vacation recommendations, but important visual concepts like blue sky, wooden sign, and trees are not reflected in captions at all. Captions in WebVid-2.5M has stronger visual correlation and cover more visual concepts, but they contain less audio concepts or direct descriptions about audio signal. By contrast, the annotations of VALOR focus on visual and audio clues simultaneously, reflected by the mentioned visual concepts like black dog and sofa, and audio concepts like police alarm in the example.
定性比较。我们将VALOR-1M与基于ASR转录字幕的数据集(如HowTo100M和HD VILA 100M)以及基于替代文本字幕的数据集(如WebVid-2.5M)进行对比。如图3所示,HowTo100M数据集的字幕是不完整的句子,甚至人类都无法理解,更不用说视觉-语言关联性。HD VILA 100M中的字幕更为完整,但视觉-语言关联性仍然较弱。具体而言,该字幕转录自两人讨论假期推荐的对话,但诸如蓝天、木牌和树木等重要视觉概念在字幕中完全没有体现。WebVid-2.5M中的字幕具有更强的视觉关联性并涵盖更多视觉概念,但它们包含的音频概念或对音频信号的直接描述较少。相比之下,VALOR的标注同时关注视觉和音频线索,示例中提到的视觉概念(如黑狗和沙发)以及音频概念(如警报警报)体现了这一点。
4 VALOR MODEL
4 VALOR 模型
We expect VALOR model to meet following demands. I) It can be trained fully end-to-end, avoid of pre-extracting vision or audio features, so that single modality encoders can be tuned together to learn representations good at visionaudio-language interactions. II) Cross-modality alignment, disc rim i native and generative capabilities should be learned to improve VALOR’s adaptive capability for broader crossmodality tasks. III) Considering that different modalities are used in different downstream fields, VALOR should learn more generalized cross-modality capabilities, instead of restrained into specific modality group. To this end, we made dedicate designs about model architecture and pre training tasks, which will be elaborated in the following subsections.
我们期望VALOR模型能满足以下需求。I) 能够进行完全端到端的训练,避免预先提取视觉或音频特征,从而使单模态编码器能够共同调整,学习擅长视觉-音频-语言交互的表征。II) 应学习跨模态对齐、判别和生成能力,以提高VALOR在更广泛跨模态任务中的适应能力。III) 考虑到不同下游领域使用不同模态,VALOR应学习更通用的跨模态能力,而非局限于特定的模态组合。为此,我们在模型架构和预训练任务上进行了专门设计,这将在以下小节中详细阐述。
4.1 Model Architecture
4.1 模型架构
As shown in figure 5, VALOR consists of a text encoder, a vision encoder, an audio encoder and a multimodal decoder. This architecture attributes single-modality representation learning to separate encoders, whose parameters can be inherited from pretrained models to speed up convergence and improve performances.
如图 5 所示,VALOR 由文本编码器、视觉编码器、音频编码器和多模态解码器组成。该架构将单模态表征学习分配给独立的编码器,其参数可从预训练模型继承以加速收敛并提升性能。
Text Encoder. BERT [8] model is used as text encoder. The raw sentences are first tokenized by BERT’s tokenizer whose vocabulary size equals to 30522. The input are summation of word embeddings and positional embeddings. The output text features are $F_{t}\in\dot{\mathbb{R}}^{N_{t}\times C_{t}}$ , where $N_{t}$ and $C_{t}$ are pre-defined max token length and hidden size, respectively.
文本编码器。采用BERT [8]模型作为文本编码器。原始句子首先通过BERT的分词器进行分词(词汇量为30522)。输入数据由词嵌入和位置嵌入相加组成。输出的文本特征为$F_{t}\in\dot{\mathbb{R}}^{N_{t}\times C_{t}}$,其中$N_{t}$和$C_{t}$分别表示预定义的最大token长度和隐藏层维度。
Vision Encoder. We have tried two vision encoders including CLIP [37] and VideoSwin Transformer [67]. Both models can take image or video singals as input. For video inputs, we sparsely sample $\mathrm{N}{\mathrm{v}}$ frames from a video clip, and use patch embedding layers to encode patches. The output feature is $\boldsymbol{F_{v}}\in\mathbb{R}^{\breve{N}{v}\times\breve{S}{v}\times C_{v}}.$ , where $S_{v}$ is sequence length and $C_{v}$ is hidden size. Frames are independently passed through CLIP encoder, while make interactions via temporal window attention in VideoSwin Transformer. For image inputs $N_{v}$ equals to one.
视觉编码器 (Vision Encoder)。我们尝试了两种视觉编码器,包括 CLIP [37] 和 VideoSwin Transformer [67]。两种模型均可接收图像或视频信号作为输入。对于视频输入,我们从视频片段中稀疏采样 $\mathrm{N}{\mathrm{v}}$ 帧,并使用补丁嵌入层对补丁进行编码。输出特征为 $\boldsymbol{F_{v}}\in\mathbb{R}^{\breve{N}{v}\times\breve{S}{v}\times C_{v}}$,其中 $S_{v}$ 为序列长度,$C_{v}$ 为隐藏层大小。帧数据在 CLIP 编码器中独立处理,而在 VideoSwin Transformer 中通过时序窗口注意力机制进行交互。对于图像输入,$N_{v}$ 取值为 1。
Audio Encoder. Audio spec tr ogram transformer (AST) [68], [69] pretrained on AudioSet is used as audio encoder. Given an audio waveform, we split it into multiple 5 seconds long audio clips and random sample $N_{a}$ clips as input. Audio Clips are converted to 64-dimensional log Mel filterbank features computed with a 25ms Hamming window every $10\mathrm{ms}$ . This results in a $64\times512$ spec tr ogram for each clip. After that the spec tro grams are splited into patches, passed through patch embedding layer and fed into audio encoder. The output feature is $\dot{F_{a}}\in\dot{\mathbb{R}}^{N_{a}\times S_{a}\times C_{a}}.$ , where $S_{a}$ is sequence length and $C_{a}$ is hidden size.
音频编码器。我们使用在AudioSet上预训练的音频频谱Transformer (AST) [68][69]作为音频编码器。给定一段音频波形,我们将其分割成多个5秒长的音频片段,并随机采样$N_{a}$个片段作为输入。音频片段被转换为64维对数梅尔滤波器组特征,该特征通过25ms汉明窗每$10\mathrm{ms}$计算一次。这为每个片段生成了一个$64\times512$的频谱图。之后,频谱图被分割成小块,经过块嵌入层并输入音频编码器。输出特征为$\dot{F_{a}}\in\dot{\mathbb{R}}^{N_{a}\times S_{a}\times C_{a}}$,其中$S_{a}$为序列长度,$C_{a}$为隐藏层大小。
Multimodal Decoder. We use pretrained BERT as multimodal decoder. A cross-attention layer is added between self-attention layer and feed-forward layer in every transformer block, whose parameters are randomly initialized. In cross-attention layer, text feature attends to conditional features which can be the output video features, audio features or their concatenation. Except for cross-attention layers, multimodal decoder share parameters with text encoder.
多模态解码器 (Multimodal Decoder)。我们使用预训练的 BERT 作为多模态解码器。在每个 Transformer 模块的自注意力层和前馈层之间添加了一个随机初始化参数的交叉注意力层。在交叉注意力层中,文本特征会关注条件特征(可以是输出视频特征、音频特征或它们的拼接)。除交叉注意力层外,多模态解码器与文本编码器共享参数。
4.2 Vision-Audio-Language Cross-Modality Learning
4.2 视觉-音频-语言跨模态学习
We propose Multimodal Grouping Alignment (MGA) and Multimodal Grouping Captioning (MGC) tasks to conduct unified vision-audio-language learning. They are separately implemented by contrastive learning and causal masked language modeling, based on modality grouping strategy. We mainly consider three modality groups including text-vision group (T-V), text-audio group (T-A), and textaudiovisual group (T-AV), corresponding to three kinds of mainstream downstream tasks (vision-language, audiolanguage and audiovisual-language tasks). This strategy is necessary, imaging that only one modality group (T-AV) is learned during pre training, the performances on visionlanguage and audio-language tasks will be restricted, because of the pretrain-finetune modality inconsistency.
我们提出多模态分组对齐(MGA)和多模态分组描述(MGC)任务,以实现视觉-音频-语言的统一学习。它们分别基于模态分组策略,通过对比学习和因果掩码语言建模实现。我们主要考虑三种模态分组:文本-视觉组(T-V)、文本-音频组(T-A)和文本-视听组(T-AV),对应三类主流下游任务(视觉语言、音频语言和视听语言任务)。这一策略十分必要,试想若预训练期间仅学习单一模态分组(T-AV),由于预训练-微调的模态不一致性,视觉语言和音频语言任务的性能将受到限制。
Multimodal Grouping Alignment (MGA). We build fine-grained alignment between text and modality $\boldsymbol{\mathrm X}$ via contrastive learning, and X represents different modalities including vision (V), audio (A) and audiovisual (AV). Text and modality $\boldsymbol{\mathrm X}$ are considered as positive sample if they match, and negative sample if they do not. Bi-directional contrastive loss is computed in batches to pull together positive samples and push away negative samples, which can be formulated as follows:
多模态分组对齐 (MGA)。我们通过对比学习在文本与模态 $\boldsymbol{\mathrm X}$ 之间建立细粒度对齐,其中X代表不同模态,包括视觉 (V)、音频 (A) 和视听 (AV)。匹配的文本与模态 $\boldsymbol{\mathrm X}$ 被视为正样本,不匹配的则为负样本。通过批量计算双向对比损失来拉近正样本并推开负样本,其公式如下:
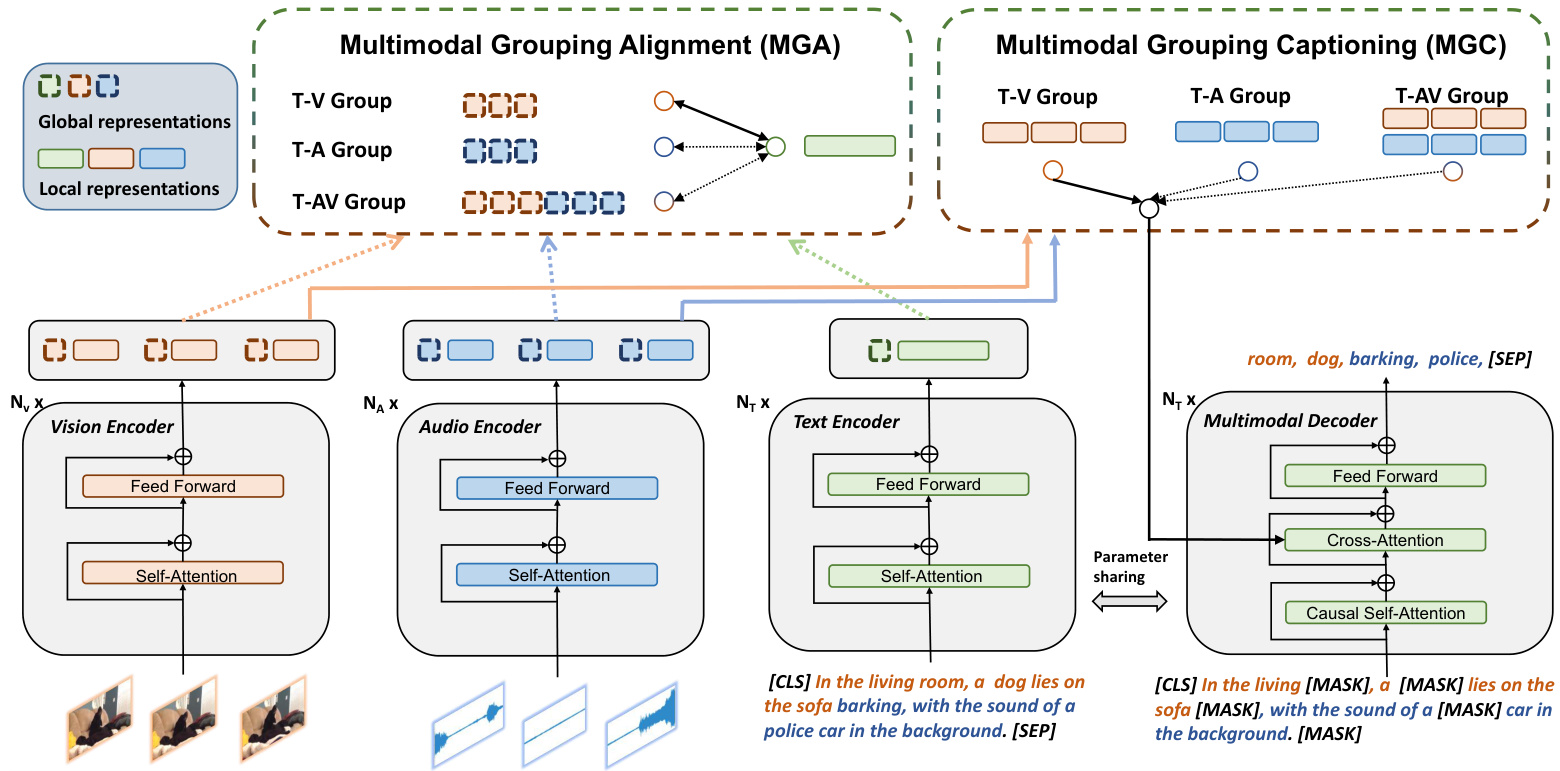
Fig. 5: Illustration of the overall pre training framework of VALOR. VALOR uses three separate encoders to achieve single modality representations, and a multimodal decoder which partly shares parameters with text encoder is used for text generation. MGA and MGC tasks based on modality grouping strategy are used to improve VALOR’s generalization capability to diffenent kinds of tasks and modalities.
图 5: VALOR整体预训练框架示意图。VALOR采用三个独立编码器实现单模态表征,并通过与文本编码器部分共享参数的多模态解码器进行文本生成。基于模态分组策略的MGA和MGC任务用于提升VALOR对不同任务及模态的泛化能力。
where $s(\cdot,\cdot)$ and $\tau$ denotes similarity function and temperature, respectively.
其中 $s(\cdot,\cdot)$ 和 $\tau$ 分别表示相似度函数和温度系数。
With regards to similarity computation $s(\cdot,\cdot),$ instead of directly aligning global representations of text and modality $\mathrm{\Delta}X,$ we build fine-grained correlations between every text token and every video frame or audio clip. Specifically, we first extract global representations for each video frame and audio clip by global average pooling or using [CLS] token feature, and then tri-modality features are projected into the same normalized semantic space via three linear projection layers. The normalized features are represented as $\dot{e}{t}\in\mathbb{R}^{N_{t}\times\dot{C}}$ , $\boldsymbol{e}{v}\in\mathbb{R}^{N_{v}\times C},$ and $\boldsymbol{e}{a}\in\mathbb{R}^{N_{a}\times C},$ , respectively, and $\textsf{C}$ is common hidden size. The audiovisual feature $e_{a v}\in\mathbb{R}^{(N_{v}+N_{a})\times C}$ is the concatenation of $e_{v}$ and $e_{a}$ . Then the fine-grained similarity matrix $S_{T X}\in\mathbb{R}^{N_{t}\times N_{x}}$ is computed by dot product of $e_{t}$ and $e_{x}.$ , where $e_{x}\in(e_{v},e_{a},e_{a v}),$ and overall similarity is the summation of bi-directional scores, each of which is computed by maximizing $S_{T X}$ along one matrix dimension, followed by taking average along the other dimension. Considering that different text tokens, visual frames or audio clips are not equally informative, we use learnable weighted average rather than equal average. The weights are achieved by feeding each modality features $e_{t},e_{v}$ and $e_{a}$ to independent linear layers and normalized with softmax function. The above process can be formulated as:
关于相似度计算 $s(\cdot,\cdot)$,我们并未直接对齐文本与模态 $\mathrm{\Delta}X$ 的全局表征,而是在每个文本token与每帧视频画面或音频片段之间建立细粒度关联。具体而言,我们首先通过全局平均池化或[CLS] token特征提取每帧视频和音频片段的全局表征,随后通过三个线性投影层将三模态特征映射到同一归一化语义空间。归一化后的特征表示为 $\dot{e}{t}\in\mathbb{R}^{N_{t}\times\dot{C}}$、$\boldsymbol{e}{v}\in\mathbb{R}^{N_{v}\times C}$ 和 $\boldsymbol{e}{a}\in\mathbb{R}^{N_{a}\times C}$,其中 $\textsf{C}$ 为统一隐藏层维度。视听特征 $e_{a v}\in\mathbb{R}^{(N_{v}+N_{a})\times C}$ 是 $e_{v}$ 与 $e_{a}$ 的拼接结果。细粒度相似度矩阵 $S_{T X}\in\mathbb{R}^{N_{t}\times N_{x}}$ 通过 $e_{t}$ 与 $e_{x}$ 的点积计算得出(其中 $e_{x}\in(e_{v},e_{a},e_{a v})$),整体相似度则为双向得分的总和——每个方向得分通过沿矩阵一个维度取最大值、再沿另一维度取平均获得。考虑到不同文本token、视觉帧或音频片段的信息密度不均等,我们采用可学习的加权平均而非简单平均,权重值通过将各模态特征 $e_{t},e_{v}$ 和 $e_{a}$ 输入独立线性层并经softmax函数归一化得到。该过程可表述为:
$$
\begin{array}{r}{\displaystyle{s(T,X)=\frac{1}{2}\sum_{i=1}^{N_{t}}f_{t,\theta}^{i}(e_{t})\operatorname*{max}{j=1}^{N_{x}}(e_{t}^{i})^{\mathrm{T}}e_{x}^{j}+}}\ {\displaystyle{\frac{1}{2}\sum_{j=1}^{N_{x}}f_{x,\theta}^{j}(e_{x})\operatorname*{max}{i=1}^{N_{t}}(e_{a v}^{j})^{\mathrm{T}}e_{t}^{i}}}\end{array}
$$
$$
\begin{array}{r}{\displaystyle{s(T,X)=\frac{1}{2}\sum_{i=1}^{N_{t}}f_{t,\theta}^{i}(e_{t})\operatorname*{max}{j=1}^{N_{x}}(e_{t}^{i})^{\mathrm{T}}e_{x}^{j}+}}\ {\displaystyle{\frac{1}{2}\sum_{j=1}^{N_{x}}f_{x,\theta}^{j}(e_{x})\operatorname*{max}{i=1}^{N_{t}}(e_{a v}^{j})^{\mathrm{T}}e_{t}^{i}}}\end{array}
$$
where $f_{\theta}$ represents the linear layers with weights $W\in$ $\mathbb{R}^{C\times1}$ . Total MGA loss is the average of three grouping alignment losses:
其中 $f_{\theta}$ 表示具有权重 $W\in$ $\mathbb{R}^{C\times1}$ 的线性层。总MGA损失是三个分组对齐损失的平均值:
$$
{\cal L}{M G A}={\frac{1}{3}}{\left({\cal L}{M G A\left(T-A V\right)}+{\cal L}{M G A\left(T-V\right)}+{\cal L}_{M G A\left(T-A\right)}\right)}.
$$
$$
{\cal L}{M G A}={\frac{1}{3}}{\left({\cal L}{M G A\left(T-A V\right)}+{\cal L}{M G A\left(T-V\right)}+{\cal L}_{M G A\left(T-A\right)}\right)}.
$$
Multimodal Grouping Captioning (MGC). Causal masked language modeling are used for this task. Specifically, input text tokens of multimodal decoder are randomly replaced with [MASK] tokens with $60%$ probability, and their output features are fed into a MLP layer to reconstruct original tokens. In self-attention layers of multimodal decoder, causal attention mask is used to prevent information leakage and keep consist en ce with auto regressive inference process. Text, vision and audio features are fused through cross attention layers. Before fusion, we first reshape $F_{a}$ and $F_{v}$ into two dimensions by flattening along temporal dimension, and transform them to same hidden size through linear layers, which results in $F_{a^{'}}\in\mathbb{R}^{n_{v}\times C^{'}}$ and Fv′ ∈ Rna×C , where $n_{v} =N_{v}\times S_{v},$ $n_{a}=N_{a}\times S_{a}$ and $C^{'}$ equals to multimodal decoder’s hidden size. The fusion audiovisual feature $F_{a v}\in~\mathbb{R}^{(n_{v}+n_{a})\times C^{'}}$ is the concatenation of them along sequence dimension. MGC loss with modality $\boldsymbol{\mathrm X}$ as condition can be formulated as:
多模态分组字幕生成 (MGC)。该任务采用因果掩码语言建模方法。具体而言,多模态解码器的输入文本token会以60%的概率被随机替换为[MASK]token,其输出特征通过MLP层重建原始token。在多模态解码器的自注意力层中,使用因果注意力掩码防止信息泄露,保持与自回归推理过程的一致性。文本、视觉和音频特征通过交叉注意力层进行融合。在融合前,我们首先将$F_{a}$和$F_{v}$沿时间维度展平为二维形式,并通过线性层转换为相同隐藏大小,得到$F_{a^{'}}\in\mathbb{R}^{n_{v}\times C^{'}}$和$F_{v^{'}}\in\mathbb{R}^{n_{a}\times C^{'}}$,其中$n_{v}=N_{v}\times S_{v}$,$n_{a}=N_{a}\times S_{a}$,$C^{'}$等于多模态解码器的隐藏大小。融合后的视听特征$F_{av}\in~\mathbb{R}^{(n_{v}+n_{a})\times C^{'}}$是两者沿序列维度的拼接。以模态$\boldsymbol{\mathrm X}$为条件的MGC损失可表示为:
TABLE 2: Model configurations of $\mathrm{VALOR_{B}}$ and $\mathrm{VALOR_{L}}$ . #Example: total number of used vision-text pairs or visionaudio-text triplets. Res: resolution of images or video frames.
表 2: $\mathrm{VALOR_{B}}$ 和 $\mathrm{VALOR_{L}}$ 的模型配置。#Example: 使用的视觉-文本对或视觉-音频-文本三元组的总数。Res: 图像或视频帧的分辨率。
| Model | Tri-modality dataset | Dual-modality dataset | #Example | Vision encoder | Batch size | Iteration | Params | Res |
|---|---|---|---|---|---|---|---|---|
| VALORB | VALOR-1M | WebVid-2.5M+CC3M | 6.5M | VideoSwinB | 512 | 200K | 342M | 224 |
| VALORL | VALOR-1M | WebVid-2.5M+CC14M+HD_VILA_10M | 33.5M | CLIPL | 1024 | 500K | 593M | 224 |
$$
L_{M G C(T-X)}=-\mathbb{E}{(T,X)\in D}\mathrm{log}P(T_{m}|T_{<m},F_{x})
$$
$$
L_{M G C(T-X)}=-\mathbb{E}{(T,X)\in D}\mathrm{log}P(T_{m}|T_{<m},F_{x})
$$
where $\mathrm{D}$ , $T_{m}$ and $T_{<m}$ denote the training batch, masked token, and tokens ahead of current masked token, respectively, and $F_{x}\in~\left(F_{v^{'}},F_{a^{'}},F_{a v}\right)$ . Total MGC loss is the average of three grouping captioning losses:
其中 $\mathrm{D}$、$T_{m}$ 和 $T_{<m}$ 分别表示训练批次、掩码 token 和当前掩码 token 之前的 token,且 $F_{x}\in~\left(F_{v^{'}},F_{a^{'}},F_{a v}\right)$。总 MGC 损失是三个分组描述损失的平均值:
$$
{\cal L}{M G C}=\frac{1}{3}\big({\cal L}{M G C(T-A V)}+{\cal L}{M G C(T-V)}+{\cal L}_{M G C(T-A)}\big)
$$
$$
{\cal L}{M G C}=\frac{1}{3}\big({\cal L}{M G C(T-A V)}+{\cal L}{M G C(T-V)}+{\cal L}_{M G C(T-A)}\big)
$$
In each training step, MGA and MGC is optimized simultaneously, with a tunable hype parameter $\alpha$ to control the ratio of two tasks, so the whole training loss is formulated as :
在每一步训练中,MGA和MGC同时被优化,通过可调超参数$\alpha$控制两项任务的权重比例,因此整体训练损失函数表示为:
$$
{\cal L}=\alpha{\cal L}{M G A}+{\cal L}_{M G C}
$$
$$
{\cal L}=\alpha{\cal L}{M G A}+{\cal L}_{M G C}
$$
4.3 Adaptation to Downstream Tasks
4.3 下游任务适配
Thanks to MGA and MGC pre training tasks introduced above, VALOR can be easily adapted to different types of downstream tasks and modalities. For retrieval tasks (AVR, VR, AR), we use $L_{M G A(T-A V)},L_{M G A(T-V)},L_{M G A(T-A)}$ as training objective, respectively, and multimodal decoder is not used. At inference time, we compute the similarity scores between each query and all candidates through Eqn. 3, and rank all candidates.
得益于上述MGA和MGC预训练任务,VALOR能够轻松适配不同类型的下游任务与模态。对于检索任务(AVR、VR、AR),我们分别使用$L_{M G A(T-A V)},L_{M G A(T-V)},L_{M G A(T-A)}$作为训练目标,且不使用多模态解码器。在推理阶段,通过公式3计算每个查询与所有候选样本的相似度分数,并对候选样本进行排序。
For captioning tasks (AVC, VC, AC), we use $L_{M G C(T-A V)},L_{M G C(T-V)},L_{M G C(T-A)}$ as training objective, respectively. Text tokens are generated auto regressive ly during inference. Specifically, “[CLS] [MASK]” is fed to predict the first token [TK1], and “[CLS] [TK1] [MASK]” is fed to predict next token. The process is repeated until [SEP] token is generated.
对于字幕任务 (AVC、VC、AC),我们分别使用 $L_{M G C(T-A V)},L_{M G C(T-V)},L_{M G C(T-A)}$ 作为训练目标。在推理过程中,文本 token 以自回归方式生成。具体而言,输入 "[CLS] [MASK]" 来预测第一个 token [TK1],然后输入 "[CLS] [TK1] [MASK]" 来预测下一个 token。该过程重复进行,直到生成 [SEP] token。
For question answering tasks (AVQA, VQA, AQA), we formulate them as generative problem, so answers can be predicted from the whole vocabulary instead of predefined top-k high frequency answer candidate sets. During training, MGC loss is used as training objective like captioning tasks. Specifically, question tokens and answer tokens are concatenated to be fed into decoder, and only answer tokens are masked while question tokens are all kept visible. The self-attention masks in multimodal decoder are bi-directional for question tokens and causal for answer tokens. The answer inference process is also auto regressive.
对于问答任务(AVQA、VQA、AQA),我们将其构建为生成式问题,因此可以从整个词汇表中预测答案,而非预定义的高频候选答案集。训练时,与字幕任务类似,采用MGC损失作为训练目标。具体而言,问题token和答案token会被拼接后输入解码器,其中仅掩码答案token而保持所有问题token可见。多模态解码器中的自注意力掩码对问题token采用双向机制,对答案token则采用因果机制。答案推断过程同样采用自回归方式。
5 EXPERIMENTS
5 实验
In this section, we first introduce basic experiment settings including pre training datasets, downstream benchmarks and implementation details. After that we compare VALOR to state-of-the-art methods on various of benchmarks. Finally, we present detailed ablation studies to demonstrate effectiveness of proposed method and visualize VALOR’s prediction results.
在本节中,我们首先介绍包括预训练数据集、下游基准测试和实现细节在内的基本实验设置。随后,我们将VALOR与多种基准测试上的最先进方法进行比较。最后,通过详细的消融研究验证所提方法的有效性,并可视化VALOR的预测结果。
5.1 Experiment Settings
5.1 实验设置
5.1.1 Pre training Datasets
5.1.1 预训练数据集
The following 4 datasets are used for VALOR’s pre training. VALOR-1M is the proposed tri-modality dataset, which contains one million open-domain audiable videos with manually annotated audiovisual captions.
VALOR的预训练使用了以下4个数据集。VALOR-1M是提出的三模态数据集,包含100万个开放域可听视频,并带有手动标注的视听字幕。
WebVid-2.5M [13] is a web-crawled dataset which contains about 2.5M videos paired with alt-texts. Recently its larger version, WebVid-10M is also released, but is not utilized in this work.
WebVid-2.5M [13] 是一个网络爬取的数据集,包含约250万个视频及其替代文本。近期其更大版本 WebVid-10M 也已发布,但未在本研究中采用。
CC14M is a combination of series of image-language datasets including MSCOCO [90], Visual Genome [91], SBU [92], CC3M [17] and CC12M [18], leading to total 14M images or 20M image-text pairs. We exclude SBU dataset due to that too much images are invalid when downloading.
CC14M是多个图像-语言数据集的组合,包括MSCOCO [90]、Visual Genome [91]、SBU [92]、CC3M [17]和CC12M [18],总计包含1400万张图像或2000万图文对。由于下载时过多图像无效,我们排除了SBU数据集。
HD VILA 100M [12] is a high resolution open-domain video-text datasets. It consists of 100M videos with ASR transcriptions. Due to storage limitation, we only use a randomly sampled 10M videos subset (HD VILA 10M).
HD VILA 100M [12] 是一个高分辨率开放域视频文本数据集。它包含1亿条带自动语音识别(ASR)转录的视频。由于存储限制,我们仅随机采样了1000万条视频子集(HD VILA 10M)。
5.1.2 Downstream Tasks
5.1.2 下游任务
For retrieval tasks, we evaluate VALOR on 9 public datasets including VR (MSRVTT [55], DiDeMo [58], LSMDC [60], Activity Net [59], VATEX [56] and MSCOCO [90]), AR (ClothoV1 [61] and AudioCaps [62]) and AVR (proposed VALOR-32K). For DiDeMo and Activity Net datasets, we follow other works to concatenate multiple short temporal descriptions into long sentences, and evaluate paragragh-tovideo retrieval. Recall at rank K (R@K, $\mathrm{K}{=}1,5,10$ ) are used as metrics.
对于检索任务,我们在9个公共数据集上评估VALOR,包括视频检索(VR)(MSRVTT [55]、DiDeMo [58]、LSMDC [60]、ActivityNet [59]、VATEX [56]和MSCOCO [90])、音频检索(AR)(ClothoV1 [61]和AudioCaps [62])以及音视频联合检索(AVR)(我们提出的VALOR-32K)。针对DiDeMo和ActivityNet数据集,我们遵循其他工作的做法,将多个短时态描述拼接成长句子,并评估段落到视频的检索性能。采用K阶召回率(R@K,$\mathrm{K}{=}1,5,10$)作为评估指标。
For captioning tasks, we evaluate VALOR on 7 public datasets including VC (MSVD [54], MSRVTT, VATEX and MSCOCO), AC (ClothoV1 and AudioCaps) and AVC (proposed VALOR-32K). BLEU4 (B4) [93], METEOR (M) [94], ROUGE-L (R) [95], CIDEr (C) [96] and SPICE (S) [97] are used as metrics. During inference, beam search is used and beam size is 3.
在字幕生成任务中,我们在7个公开数据集上评估VALOR,包括视频字幕(VC)(MSVD [54]、MSRVTT、VATEX和MSCOCO)、音频字幕(AC)(ClothoV1和AudioCaps)以及视听字幕(AVC)(提出的VALOR-32K)。采用BLEU4(B4)[93]、METEOR(M)[94]、ROUGE-L(R)[95]、CIDEr(C)[96]和SPICE(S)[97]作为评估指标。推理阶段使用束搜索(beam search),束宽(beam size)设为3。
For open-ended question answering tasks, we evaluate on 6 public datasets including VQA (MSVD-QA [98], MSRVTT-QA [98], Activity Net-QA [99], TGIF-Frame QA [100], VQAv2 [101]) and AVQA (MUSIC-AVQA [64]). Accuracy is used as metric. During inference, we use greedy search to generate answers from whole vocabulary with no restrictions.
对于开放式问答任务,我们在6个公开数据集上进行了评估,包括VQA (MSVD-QA [98], MSRVTT-QA [98], Activity Net-QA [99], TGIF-Frame QA [100], VQAv2 [101]) 和 AVQA (MUSIC-AVQA [64])。采用准确率作为评估指标。在推理阶段,我们使用贪心搜索从完整词表中无限制地生成答案。
5.1.3 Implementation Details
5.1.3 实现细节
All models are trained based on PyTorch framework and 8 Tesla A100 cards. The pre training learning rate is 1e-4. Warm up and linear learning rate decay scheduler is used. For ablation studies, unless specially explained, we use Video Swin Transformer-small pretrained on Kinetics-400 as vision encoder. We pretrain on VALOR-1M for 4 epoch with 512 batch size.
所有模型均基于PyTorch框架和8张Tesla A100显卡进行训练。预训练学习率为1e-4,采用学习率预热(warm up)和线性衰减调度策略。消融实验中如无特别说明,视觉编码器默认采用Kinetics-400预训练的Video Swin Transformer-small版本。我们在VALOR-1M数据集上以512的批量大小进行了4个epoch的预训练。
TABLE 3: Comparison with state-of-the-art methods on VALOR-32K text-to-audiovisual retrieval benchmark and 5 textto-video retrieval benchmarks. $\mathrm{R}@1/\mathrm{R}@5/\mathrm{R}@10$ is reported. #Example represents the number of used vision-text pairs or vision-audio-text triplets. Mod represents utilized modalities and V, A, S is short for vision, audio and subtitle, respectively. $+\mathrm{DSL}$ means that using dual softmax [70] post processing during evaluation. Results on VALOR-32K are achieved by us using their public released codes.
| Method | #Example | Mod | VALOR-32K | MSRVTT | DiDeMo | ActivityNet | LSMDC | VATEX |
| Group-A:pretrainwith<10Mexamples V | ||||||||
| ClipBert [71] | 5.6M | V | 22.0/46.8/59.9 | 20.4/48.0/60.8 | ||||
| Frozen [13] | 6.1M | 32.9/60.4/71.2 | 32.5/61.5/71.2 | 31.0/59.8/72.4 | 15.0/30.8/39.8 | |||
| BridgeFormer[72] | 5.5M | V | 37.6/64.8/75.1 | 37.0/62.2/73.9 | 17.9/35.4/44.5 | |||
| MILES [73] | 5.5M | V | 37.7/63.6/73.8 | 36.6/63.9/74.0 | 17.8/35.6/44.1 | |||
| OA-Trans [74] | 5.5M | V | 35.8/63.4/76.5 | 34.8/64.4/75.1 | - | 18.2/34.3/43.7 | ||
| Nagrani et al. [75] | 1.03M | V+A | 35.8/65.1/76.9 | - | ||||
| LF-VILA [76] | 8.5M | V | 35.0/64.5/75.8 | 35.3/65.4/- | ||||
| VALOR (Ours) | 5.5M | V | 43.3/70.3/80.0 | 36.2/64.7/75.4 | 43.2/73.9/82.4 | 37.5/67.9/80.4 | 20.0/39.1/49.0 | 59.4/90.5/95.4 |
| VALORg(Ours) | 6.5M | V+A | 67.9/89.7/94.4 | 43.0/72.2/82.1 | 52.2/80.8/86.8 | 50.5/79.6/89.1 | 25.1/45.8/55.2 | 67.5/94.1/97.4 |
| Group-B:pretrainwith>10M examples orinherit CLIPmodelweights | ||||||||
| SINGULARITY [77] | 17M | V | 41.5/68.7/77.0 | 53.9/79.4/86.9 | 47.1/75.5/85.5 | |||
| LAVENDER [36] | 30M | V | 40.7/66.9/77.6 | 53.4/78.6/85.3 | 26.1/46.4/57.3 | |||
| MV-GPT [19] | 53M | V+S | 37.3/65.5/75.1 | |||||
| TACo [78] | 136M | V | 28.4/57.8/71.2 | 30.4/61.2/- | ||||
| Support-set [79] | 136M | V | 30.1/58.5/69.3 | 29.2/61.6/- | 44.9/82.1/89.7 | |||
| MMT [45] | 136M | V+A | 26.6/57.1/69.6 | 28.7/61.4/- | 12.9/29.9/40.1 | |||
| AVLNet [50] | 136M | V+A | 21.6/47.2/59.8 | 22.5/50.5/64.1 | 11.4/26.0/34.6 | |||
| Gabeur et al. [80] | 136M | V+A+S | 28.7/59.5/70.3 | 29.0/61.7/- | ||||
| All-in-one [81] | 138M | V | 37.9/68.1/77.1 | 32.7/61.4/73.5 | 22.4/53.7/67.7 | |||
| VIOLET [82] | 186M | V | 34.5/63.0/73.4 | 32.6/62.8/74.7 | 16.1/36.6/41.2 | |||
| CLIP4Clip [83] | V | 43.4/69.9/79.7 | 44.5/71.4/81.6 | 43.4/70.2/80.6 | 40.5/72.4/- | 22.6/41.0/49.1 | 55.9/89.2/95.0 | |
| TS2-Net [84] | V | 49.4/75.6/85.3 | 41.8/71.6/82.0 | 41.0/73.6/84.5 | 23.4/42.3/50.9 | 59.1/90.0/95.2 | ||
| X-CLIP [85] | V | 49.3/75.8/84.8 | 47.8/79.3/- | 46.2/75.5/- | 26.1/48.4/46.7 | |||
| ECLIPSE [86] | V+A | 44.2/-/- | 45.3/75.7/86.2 | |||||
| DCR [87] | V | 50.2/76.5/84.7 | 49.0/76.5/84.5 | 46.2/77.3/88.2 | 26.5/47.6/56.8 | 65.7/92.6/96.7 | ||
| HunYuan_tvr+DSL [88] | V | 55.0/80.4/86.8 | 52.1/78.2/85.7 | 57.3/84.8/93.1 | 29.7/46.4/55.4 | |||
| CLIP-VIP+DSL [20] | 100M | V | 57.7/80.5/88.2 | 55.3/82.0/89.3 | 61.4/85.7/92.6 | 30.7/51.4/60.6 | ||
| InternVideo+DSL[89] | 147.6M | V | 55.2/-/- | 57.9/-/- | 62.2/-/- | 34.0/-/- | 71.1/-/- | |
| VALORL(Ours) | 33.5M | V+A | 73.2/91.6/95.4 | 54.4/79.8/87.6 | 57.6/83.3/88.8 | 63.4/87.8/94.1 | 31.8/52.8/62.4 | 76.9/96.7/98.6 |
| VALORL+DSL(Ours) | 33.5M | V+A | 80.9/93.9/97.1 | 59.9/83.5/89.6 | 61.5/85.3/90.4 | 70.1/90.8/95.3 | 34.2/56.0/64.1 | 78.5/97.1/98.7 |
表 3: 在VALOR-32K文本-视听检索基准和5个文本-视频检索基准上与最先进方法的比较。报告了$\mathrm{R}@1/\mathrm{R}@5/\mathrm{R}@10$。#Example表示使用的视觉-文本对或视觉-音频-文本三元组的数量。Mod表示使用的模态,V、A、S分别代表视觉、音频和字幕。$+\mathrm{DSL}$表示在评估时使用了双softmax [70]后处理。VALOR-32K上的结果是我们使用其公开代码获得的。
| 方法 | #Example | Mod | VALOR-32K | MSRVTT | DiDeMo | ActivityNet | LSMDC | VATEX |
|---|---|---|---|---|---|---|---|---|
| Group-A: 预训练样本<10M | ||||||||
| ClipBert [71] | 5.6M | V | 22.0/46.8/59.9 | 20.4/48.0/60.8 | ||||
| Frozen [13] | 6.1M | 32.9/60.4/71.2 | 32.5/61.5/71.2 | 31.0/59.8/72.4 | 15.0/30.8/39.8 | |||
| BridgeFormer [72] | 5.5M | V | 37.6/64.8/75.1 | 37.0/62.2/73.9 | 17.9/35.4/44.5 | |||
| MILES [73] | 5.5M | V | 37.7/63.6/73.8 | 36.6/63.9/74.0 | 17.8/35.6/44.1 | |||
| OA-Trans [74] | 5.5M | V | 35.8/63.4/76.5 | 34.8/64.4/75.1 | - | 18.2/34.3/43.7 | ||
| Nagrani et al. [75] | 1.03M | V+A | 35.8/65.1/76.9 | - | ||||
| LF-VILA [76] | 8.5M | V | 35.0/64.5/75.8 | 35.3/65.4/- | ||||
| VALOR (Ours) | 5.5M | V | 43.3/70.3/80.0 | 36.2/64.7/75.4 | 43.2/73.9/82.4 | 37.5/67.9/80.4 | 20.0/39.1/49.0 | 59.4/90.5/95.4 |
| VALORg (Ours) | 6.5M | V+A | 67.9/89.7/94.4 | 43.0/72.2/82.1 | 52.2/80.8/86.8 | 50.5/79.6/89.1 | 25.1/45.8/55.2 | 67.5/94.1/97.4 |
| Group-B: 预训练样本>10M或继承CLIP模型权重 | ||||||||
| SINGULARITY [77] | 17M | V | 41.5/68.7/77.0 | 53.9/79.4/86.9 | 47.1/75.5/85.5 | |||
| LAVENDER [36] | 30M | V | 40.7/66.9/77.6 | 53.4/78.6/85.3 | 26.1/46.4/57.3 | |||
| MV-GPT [19] | 53M | V+S | 37.3/65.5/75.1 | |||||
| TACo [78] | 136M | V | 28.4/57.8/71.2 | 30.4/61.2/- | ||||
| Support-set [79] | 136M | V | 30.1/58.5/69.3 | 29.2/61.6/- | 44.9/82.1/89.7 | |||
| MMT [45] | 136M | V+A | 26.6/57.1/69.6 | 28.7/61.4/- | 12.9/29.9/40.1 | |||
| AVLNet [50] | 136M | V+A | 21.6/47.2/59.8 | 22.5/50.5/64.1 | 11.4/26.0/34.6 | |||
| Gabeur et al. [80] | 136M | V+A+S | 28.7/59.5/70.3 | 29.0/61.7/- | ||||
| All-in-one [81] | 138M | V | 37.9/68.1/77.1 | 32.7/61.4/73.5 | 22.4/53.7/67.7 | |||
| VIOLET [82] | 186M | V | 34.5/63.0/73.4 | 32.6/62.8/74.7 | 16.1/36.6/41.2 | |||
| CLIP4Clip [83] | V | 43.4/69.9/79.7 | 44.5/71.4/81.6 | 43.4/70.2/80.6 | 40.5/72.4/- | 22.6/41.0/49.1 | 55.9/89.2/95.0 | |
| TS2-Net [84] | V | 49.4/75.6/85.3 | 41.8/71.6/82.0 | 41.0/73.6/84.5 | 23.4/42.3/50.9 | 59.1/90.0/95.2 | ||
| X-CLIP [85] | V | 49.3/75.8/84.8 | 47.8/79.3/- | 46.2/75.5/- | 26.1/48.4/46.7 | |||
| ECLIPSE [86] | V+A | 44.2/-/- | 45.3/75.7/86.2 | |||||
| DCR [87] | V | 50.2/76.5/84.7 | 49.0/76.5/84.5 | 46.2/77.3/88.2 | 26.5/47.6/56.8 | 65.7/92.6/96.7 | ||
| HunYuan_tvr+DSL [88] | V | 55.0/80.4/86.8 | 52.1/78.2/85.7 | 57.3/84.8/93.1 | 29.7/46.4/55.4 | |||
| CLIP-VIP+DSL [20] | 100M | V | 57.7/80.5/88.2 | 55.3/82.0/89.3 | 61.4/85.7/92.6 | 30.7/51.4/60.6 | ||
| InternVideo+DSL [89] | 147.6M | V | 55.2/-/- | 57.9/-/- | 62.2/-/- | 34.0/-/- | 71.1/-/- | |
| VALORL (Ours) | 33.5M | V+A | 73.2/91.6/95.4 | 54.4/79.8/87.6 | 57.6/83.3/88.8 | 63.4/87.8/94.1 | 31.8/52.8/62.4 | 76.9/96.7/98.6 |
| VALORL+DSL (Ours) | 33.5M | V+A | 80.9/93.9/97.1 | 59.9/83.5/89.6 | 61.5/85.3/90.4 | 70.1/90.8/95.3 | 34.2/56.0/64.1 | 78.5/97.1/98.7 |
For state-of-the-arts comparison, we train two models with different scales, namely $\mathrm{VALOR_{B}}$ and $\mathrm{VALOR_{L}}$ whose specific configurations are presented in Table 2. Compared to $\mathrm{VALOR_{B}}$ , $\mathrm{VALOR_{L}}$ is trained with more training data, larger batch size, more iterations, and use more powerful vision encoder. Except for different vision encoders, both model use the same text/multimodal encoder $\mathrm{(BERT_{B},}$ ) and audio encoder (AST). At each iteration, we sample a dataset according to pre-defined weights, and if a dual-modality dataset is sampled, no audio is used. For each video, we sample 1 video frame and 1 audio clip during pre training. During finetuning, we use task-specfic learning rate and sample numbers.
为了进行最先进技术的比较,我们训练了两种不同规模的模型,即 $\mathrm{VALOR_{B}}$ 和 $\mathrm{VALOR_{L}}$,其具体配置如表 2 所示。与 $\mathrm{VALOR_{B}}$ 相比,$\mathrm{VALOR_{L}}$ 使用了更多训练数据、更大的批次规模、更多迭代次数以及更强大的视觉编码器。除了不同的视觉编码器外,两个模型均采用相同的文本/多模态编码器 $\mathrm{(BERT_{B},}$ ) 和音频编码器 (AST)。在每次迭代时,我们根据预设权重采样数据集,若采样到双模态数据集则不使用音频。对于每个视频,在预训练阶段我们采样 1 帧视频画面和 1 段音频片段。在微调阶段,我们采用任务特定的学习率和采样数量。
5.2 Comparison to State-of-the-arts
5.2 与最先进技术的比较
5.2.1 Video-Language Benchmarks
5.2.1 视频-语言基准测试
Text-to-Video Retrieval. As shown in Table 3, VALORB outperforms all models in Group-A with evident gaps on VALOR-32K, MSRVTT, DiDeMo and LSMDC datasets. On Activity Net and VATEX datasets, VALORB even surpasses all models in Group-B, with only $6.5\mathrm{M}$ pretraining data, which demonstrates high effectiveness and efficiency of VALOR. We also train a base-level model using only WebVid-2.5M and CC3M and without involving audio in both pre training and finetuning, which is denoted as $\mathrm{VALOR}{\mathrm{B}}^{-}$ . From the comparison between VALORB and $\mathrm{VALOR_{B}^{-}}$ we can find VALOR-1M dataset and audio modality vitals for VALOR’s high performance. In addition, compared with models in Group-B, $\mathrm{VALOR_{L}}$ achieves new SOTA results on MSRVTT, DiDeMo, Activity Net, LSMDC, VATEX datasets, and outperforms previous SOTA performances $(\mathrm{R}@1)$ by $3.8%$ , $6.2%$ , $12.7%$ , $0.6%$ , $10.4%,$ respec- tively. We attribute VALOR’s huge improvements to i) vision-audio-language alignment construction instead of dual modality alignment. ii) fine-grained alignment construction between text and audiovisual signals instead of coarse-grained alignment.
文本到视频检索。如表 3 所示,VALORB 在 VALOR-32K、MSRVTT、DiDeMo 和 LSMDC 数据集上以明显优势超越 Group-A 的所有模型。在 Activity Net 和 VATEX 数据集上,VALORB 甚至超越了 Group-B 的所有模型,仅使用 $6.5\mathrm{M}$ 预训练数据,这证明了 VALOR 的高效性和有效性。我们还仅使用 WebVid-2.5M 和 CC3M 训练了一个基础级模型,且在预训练和微调阶段均未涉及音频,记为 $\mathrm{VALOR}{\mathrm{B}}^{-}$。通过对比 VALORB 和 $\mathrm{VALOR_{B}^{-}}$,可以发现 VALOR-1M 数据集和音频模态对 VALOR 的高性能至关重要。此外,与 Group-B 的模型相比,$\mathrm{VALOR_{L}}$ 在 MSRVTT、DiDeMo、Activity Net、LSMDC 和 VATEX 数据集上取得了新的 SOTA 结果,并在 $(\mathrm{R}@1)$ 指标上分别以 $3.8%$、$6.2%$、$12.7%$、$0.6%$ 和 $10.4%$ 的优势超越了之前的 SOTA 性能。我们将 VALOR 的巨大改进归因于:i) 构建视觉-音频-语言对齐而非双模态对齐;ii) 在文本与视听信号之间构建细粒度对齐而非粗粒度对齐。
It is noted that VALOR also outperforms methods which additionally utilize audio, subtitle or both modalities [19], [45], [50], [75], [86], demonstrating the effectiveness of fine-grained tri-modality alignment modeling in VALOR, and also the importance of utilizing strong-correlated trimodality pre training data. Different from short-form video retrieval datasets $(<30s)$ like MSRVTT and LSMDC, longform datasets $({>}1\mathrm{min})$ including DiDeMo and Activity Net are more challenging due to more complicated temporal relationship between long videos and paragraghs. VALOR significantly outperforms methods that specializes in longform video retrieval [76], [86] without bells and whistles, which has shown VALOR’s powerful generalization capabilities given that VALOR only saw short videos (around 10s) during pre training. In addition, compared with methods [36], [77] who train models with video-text matching (VTM) loss, VALOR possesses higher inference efficiency and performance at the same time.
值得注意的是,VALOR 的表现甚至优于那些额外利用音频、字幕或双模态的方法 [19][45][50][75][86] ,这证明了 VALOR 中细粒度三模态对齐建模的有效性,也凸显了使用强关联三模态预训练数据的重要性。与 MSRVTT 和 LSMDC 等短视频 $(<30s)$ 检索数据集不同,包含 DiDeMo 和 Activity Net 的长视频 $(>1\mathrm{min})$ 数据集由于长视频与段落间更复杂的时间关系而更具挑战性。VALOR 在没有任何额外修饰的情况下,显著优于专攻长视频检索的方法 [76][86] ,这表明尽管 VALOR 在预训练期间仅接触过短视频(约 10 秒),但其泛化能力依然强大。此外,与使用视频文本匹配 (VTM) 损失训练模型的方法 [36][77] 相比,VALOR 同时具备更高的推理效率和性能。
Video Captioning. As presented in Table 4, VALORB outperforms all models in Group-A on 4 benchmarks. In
视频字幕生成。如表 4 所示,VALORB 在 4 个基准测试中均优于 Group-A 的所有模型。
TABLE 4: Comparison with state-of-the-art methods on VALOR-32K audiovisual captioning benchmark and 3 video captioning benchmarks. Given that most methods use reinforcement learning method [102] to improve model’s performance on VATEX dataset, we also follow them for fair comparison, and corresponding results are marked with *. Results on VALOR-32K are achieved by us using their public released codes.
表 4: 在 VALOR-32K 视听字幕基准和 3 个视频字幕基准上与最先进方法的比较。鉴于大多数方法使用强化学习方法 [102] 来提高模型在 VATEX 数据集上的性能,为了公平比较,我们也采用了相同方法,并用 * 标记相应结果。VALOR-32K 上的结果是我们使用其公开代码获得的。
| 方法 | #示例 | 模态 | VALOR-32K | MSVD | MSRVTT | VATEX | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B@4 | M | R | C | B@4 | M | R | C | B@4 | M | R | C | B@4 | M | R | C | |||
| Group-A: 预训练样本 <10M | ||||||||||||||||||
| ORG-TRL [103] | 54.3 | 36.4 | 73.9 | 95.2 | 43.6 | 28.8 | 62.1 | 50.9 | 32.1 | 22.2 | 48.9 | 49.7 | ||||||
| OpenBook [104] | 42.8 | 29.3 | 61.7 | 52.9 | 33.9 | 23.7 | 50.2 | 57.5 | ||||||||||
| SwinBERT [105] | 5.4 | 10.7 | 27.2 | 27.3 | 58.2 | 41.3 | 77.5 | 120.6 | 41.9 | 29.9 | 62.1 | 53.8 | 38.7 | 26.2 | 53.2 | 73.0 | ||
| SMPFF [46] | V+A | 7.5 | 12.6 | 28.6 | 37.1 | 48.4 | 30.6 | 64.9 | 58.5 | 39.7 | 26.0 | 53.6 | 70.5 | |||||
| VIOLETv2 [23] | 5.5M | 139.2 | 58.0 | |||||||||||||||
| VALOR (Ours) | 5.5M | 8.0 | 13.5 | 29.4 | 44.3 | 74.3 | 47.1 | 83.8 | 156.1 | 48.1 | 30.4 | 64.3 | 61.5 | 40.7 | 26.1 | 53.8 | 71.6 | |
| VALORg (Ours) | 6.5M | V+A | 8.9 | 14.8 | 30.8 | 55.7 | 76.1 | 48.0 | 85.2 | 162.1 | 53.8 | 32.3 | 67.0 | 66.6 | 41.9 | 26.6 | 54.6 | 73.9 |
| Group-B: 预训练样本 >10M | ||||||||||||||||||
| LAVENDER [36] | 30M | V | 150.7 | 60.1 | = | |||||||||||||
| Support-set [79] | 136M | V | 38.9 | 28.2 | 59.8 | 48.6 | 32.8 | 24.4 | 49.1 | 51.2 | ||||||||
| VALUE [49] | 136M | V+S | 32.9 | 24.0 | 50.0 | 58.1 | ||||||||||||
| MV-GPT [19] | 136M | V+S | - | 48.9 | 38.7 | 64.0 | 60.0 | |||||||||||
| GITL [14] | 20M | V | - | 75.8 | 48.7 | 85.5 | 162.9 | 48.7 | 30.9 | 64.9 | 64.1 | 41.6* | 26.2* | 54.3* | 72.5* | |||
| GIT [14] | 800M | V | 79.5 | 51.1 | 87.3 | 180.2 | 53.8 | 32.9 | 67.7 | 73.9 | 41.6* | 28.1* | 55.4* | 91.5* | ||||
| GIT2 (5.1B) [14] | 12.9B | V | 82.2 | 52.3 | 88.7 | 185.4 | 54.8 | 33.1 | 68.2 | 75.9 | 42.7* | 28.8* | 56.5* | 94.5* | ||||
| VALORL (Ours) | 33.5M | V+A | 9.6 | 15.4 | 31.8 | 61.5 | 80.7 | 51.0 | 87.9 | 178.5 | 54.4 | 32.9 | 68.0 | 74.0 | 45.6* | 29.4* | 57.4* | 95.8* |
TABLE 5: Comparison with state-of-the-art methods on 5 open-ended video QA and audio vi us al QA benchmarks.
表 5: 在5个开放式视频问答和视听问答基准上与最先进方法的比较
| 方法 | #示例 | 模态 | MSRVTT-QA | MSVD-QA | TGIF-FrameQA | ActivityNet-QA | MUSIC-AVQA |
|---|---|---|---|---|---|---|---|
| Group-A: 预训练样本<1000万 | |||||||
| QueST [106] | - | V | 34.6 | 34.6 | 59.7 | - | - |
| MUSIC-AVQA [64] | - | V+A | - | - | - | - | 71.5 |
| ClipBERT [71] | 5.6M | V | 37.4 | - | 60.3 | - | - |
| VIOLET [23] | 5.5M | V | 44.5 | 54.7 | 72.8 | - | - |
| Clover [107] | 5.5M | V | 43.9 | 51.9 | 71.4 | - | - |
| VALOR (Ours) | 5.5M | V | 44.5 | 54.9 | 73.0 | 43.7 | 74.8 |
| VALORg (Ours) | 6.5M | V+A | 46.7 | 56.4 | 74.5 | 44.8 | 76.6 |
| Group-B: 预训练样本>1000万 | |||||||
| SINGULARITY [77] | 17M | V | 43.5 | - | - | 43.1 | - |
| LAVENDER [36] | 30M | V | 45.0 | 56.6 | 73.5 | - | - |
| JustAsk [108] | 69M | V | 41.5 | 46.3 | - | 38.9 | - |
| MV-GPT [19] | 53M | V+S | 41.7 | - | - | 39.1 | - |
| MERLOT [109] | 180M | V | 43.1 | - | 69.5 | 41.4 | - |
| All-in-one [81] | 228.5M | V | 46.8 | 48.3 | 66.3 | - | - |
| Flamingo (80B) [42] | 2.3B | V | 47.4 | - | - | - | - |
| FrozenBiLM [110] | 10M | V | 47.0 | 54.8 | 68.6 | 43.2 | - |
| InternVideo [89] | 147.6M | V | 47.1 | 55.5 | 72.2 | - | - |
| VideoCoCa (2.1B) [111] | 4.8B | V | 46.0 | 56.9 | - | - | - |
| GITL [14] | 20M | V | 42.7 | 55.1 | 71.9 | - | - |
| GIT [14] | 800M | V | 43.2 | 56.8 | 72.8 | - | - |
| GIT2 (5.1B) [14] | 12.9B | V | 45.6 | 58.2 | 74.9 | - | - |
| VALORL (Ours) | 33.5M | V+A | 49.2 | 60.0 | 78.7 | 48.6 | 78.9 |
(注:V=视觉模态,A=听觉模态,S=语音模态)
Group-B, we mainly compare VALOR to GIT model [14], a recently proposed large-scale generative pre training model which has achieved SOTA results on many vision captioning benchmarks. Specifically, GIT has four scales, named $\mathrm{GIT_{B}}$ , $\mathrm{GIT_{L}},$ GIT and GIT2 according to different parameter and data size. It is noted that $\mathrm{GIT_{L}}$ uses comparable amount of training data and the same vision encoder as $\mathrm{VALOR_{L}}$ (i.e., ${\mathrm{CLIP}}{\mathrm{L}}$ ), while GIT uses a bigger vision encoder (CoSwin model pretrained by Florence [39] and larger data size. GIT2 even uses a 4.8B DaViT [119] as vision encoder and 12.9B vision-text pairs as training data. From comparison results we can find that $\mathrm{VALOR_{L}}$ outperforms $\mathrm{GIT_{L}}$ and GIT on most metrics of all three benchmarks with huge margins. In addition, $\mathrm{VALOR_{L}}$ even outperforms GIT2 on VATEX benchmarks, with much smaller parameters $(11.6%)$ , data size $(0.26%)$ and image resolution (224 vs 384). These results demonstrate that learning audiovisual conditioned text generation (scaling up pre training model from modality dimension) is more efficient and effective compared with scaling up from model parameter and data size dimensions.
在Group-B中,我们主要将VALOR与GIT模型[14]进行比较。GIT是近期提出的大规模生成式预训练模型,已在多项视觉描述基准测试中取得SOTA成果。具体而言,GIT根据参数量和数据规模分为四个版本:$\mathrm{GIT_{B}}$、$\mathrm{GIT_{L}}$、GIT和GIT2。值得注意的是,$\mathrm{GIT_{L}}$使用的训练数据量与$\mathrm{VALOR_{L}}$相当(即${\mathrm{CLIP}}{\mathrm{L}}$视觉编码器),而GIT采用了更大的视觉编码器(基于Florence[39]预训练的CoSwin模型)和更大规模的数据。GIT2甚至使用4.8B参数的DaViT[119]作为视觉编码器,并采用12.9B视觉-文本对作为训练数据。对比结果表明,$\mathrm{VALOR_{L}}$在所有三个基准测试的大部分指标上都大幅领先$\mathrm{GIT_{L}}$和GIT。此外,$\mathrm{VALOR_{L}}$在VATEX基准上甚至超越了GIT2,而参数量仅为其11.6%、数据规模仅0.26%、图像分辨率更低(224 vs 384)。这些结果证明,通过学习视听条件文本生成(从模态维度扩展预训练模型)比单纯扩大模型参数量和数据规模更高效有效。
Open-Ended Video QA. As tabel 5 shows, $\mathrm{VALOR_{B}}$ outperforms all models in Group-A on five benchmarks. In Group-B, FrozenBiLM uses the same vision encoder as $\mathrm{VALOR_{L}}$ (i.e., ${\mathrm{CLIP}}{\mathrm{L}}$ ), and a more powerful decoder (a 890M DeBERTa-V2-XLarge model [120]). Flamingo has $135\times$ parameters and $68.7\times$ training data than $\mathrm{VALOR_{L}}$ . VideoCoCa inherited weights form CoCa which has $3.5\times$ parameters and $143.3\times$ training data than $\mathrm{VALOR_{L}}$ . GIT2 has $8.6\times$ parameters and $382.1\times$ training data than $\mathrm{VALOR_{L}}$ . Even with much smaller parameters and training data, $\mathrm{VALOR_{L}}$ achieves new SOTA performances on MSRVTT-QA, MSVDQA, TGIF-FrameQA, Activity Net-QA benchmarks, and surpasses previous SOTA methods by $3.8%$ , $3.4%$ , $5.1%$ , $12.5%,$ respectively. On audiovisual question answering benchmark MUSIC-AVQA, $\mathrm{VALOR_{B}}$ and $\mathrm{VALOR_{L}}$ improves the baseline by $7.1%$ and $10.3%$ , respectively.
开放域视频问答。如表5所示,$\mathrm{VALOR_{B}}$在五个基准测试中均优于Group-A的所有模型。在Group-B中,FrozenBiLM采用了与$\mathrm{VALOR_{L}}$相同的视觉编码器(即${\mathrm{CLIP}}{\mathrm{L}}$)和更强大的解码器(8.9亿参数的DeBERTa-V2-XLarge模型[120])。Flamingo的参数量是$\mathrm{VALOR_{L}}$的135倍,训练数据量是其68.7倍;VideoCoCa继承了CoCa的权重,其参数量为$\mathrm{VALOR_{L}}$的3.5倍,训练数据量是其143.3倍;GIT2的参数量为$\mathrm{VALOR_{L}}$的8.6倍,训练数据量是其382.1倍。尽管参数量和训练数据量远低于对比模型,$\mathrm{VALOR_{L}}$仍在MSRVTT-QA、MSVDQA、TGIF-FrameQA和ActivityNet-QA基准测试中刷新了SOTA性能,分别以3.8%、3.4%、5.1%和12.5%的优势超越前人方法。在视听问答基准MUSIC-AVQA上,$\mathrm{VALOR_{B}}$和$\mathrm{VALOR_{L}}$分别将基线性能提升了7.1%和10.3%。
5.2.2 Audio-Language Benchmarks
5.2.2 音频-语言基准测试
As shown in Table 6, with regards to text-to-audio retrieval task, VALOR achieves new sota performances on ClothoV1,
如表 6 所示,在文本到音频检索任务中,VALOR 在 ClothoV1 上取得了新的 sota (state-of-the-art) 性能。
TABLE 6: Comparison with state-of-the-art methods on 4 audio-language benchmarks.
表 6: 在4个音频-语言基准上与最先进方法的比较
| 方法 | ClothoV1 R@1 | ClothoV1 R@5 | ClothoV1 R@10 | AudioCaps R@1 | AudioCaps R@5 | AudioCaps R@10 |
|---|---|---|---|---|---|---|
| Oncescu et al. [112] | 9.6 | - | 40.1 | 25.1 | - | 73.2 |
| Nagrani et al. [75] | 12.6 | - | 45.4 | 35.5 | - | 84.5 |
| VALORB | 17.5 | 42.7 | 55.3 | 40.1 | 73.9 | 83.1 |
| 方法 | ClothoV1 B@4 | ClothoV1 M | AudioCaps B@4 | AudioCaps M | AudioCaps R | AudioCaps C |
|---|---|---|---|---|---|---|
| Kim et al. [62] | - | - | - | 21.9 | 20.3 | 45.0 59.3 |
| Xu et al. [113] | 15.6 | 16.2 | 36.8 | 33.8 | - | - |
| Chen et al. [114] | 15.1 | 16.0 | 35.6 | 34.6 | - | - |
| Xu et al. [115] | 15.9 | 16.9 | 36.8 | 37.7 | 23.1 | 22.9 46.7 66.0 |
| Koh et al. [116] | 16.8 | 16.5 | 37.3 38.0 | - | - | - |
| ACT [117] | - | - | 25.2 | 22.2 | 46.8 | 67.9 |
| Liu et al. [118] | - | - | - | 25.1 23.2 | 48.0 | 66.7 |
| VALORB | 16.2 | 17.4 | 38.2 | 42.3 | 27.0 | 23.1 49.4 74.1 |
TABLE 7: Comparison with state-of-the-art methods on 3 image-language benchmarks. Results marked with * indicate that they are achieved by using reinforcement learning. VALOR takes 392 as image resolution on all three benchmarks.
表 7: 在3个图像-语言基准上与最先进方法的比较。标有*的结果表示是通过强化学习实现的。VALOR在所有三个基准上采用392作为图像分辨率。
| 方法 | COCO-Retrieval | COCO-Caption | VQAv2 | |||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | C | S | dev | std | ||
| UNITER [21] | 10M | 52.9 | 79.9 | 88.0 | 73.82 | 74.02 | ||
| Oscar [121] | 10M | 57.5 | 82.8 | 89.8 | 140.9* | 25.2* | 73.61 | 73.82 |
| UFO [122] | 10M | 59.2 | 83.6 | 90.5 | 131.2 | 23.3 | 76.64 | 76.76 |
| VinVL[123] | 10M | 58.8 | 83.5 | 90.3 | 140.0* | 24.5* | 76.52 | 76.60 |
| ALBEF [25] | 20M | 60.7 | 84.3 | 90.5 | 75.84 | 76.04 | ||
| METER[124] | 10M | 57.9 | 82.7 | 90.1 | 77.68 | 77.64 | ||
| ALIGN [38] | 1.8B | 59.9 | 83.3 | 89.8 | " | |||
| FILIP [125] | 340M | 61.2 | 84.3 | 90.6 | ||||
| Florence [39] | 900M | 63.2 | 85.7 | 一 | 80.16 | 80.36 | ||
| BLIP[126] | 135M | 65.1 | 86.3 | 91.8 | 136.7 | 78.25 | 78.32 | |
| Flamingo (80B) [42] | 2.3B | 138.1 | 82.0 | 82.1 | ||||
| LEMON [127] | 200M | 145.5* | 25.5* | |||||
| SimVLM [41] | 1.8B | 143.3 | 25.4 | 80.03 | 80.34 | |||
| CoCa [44] | 4.8B | 143.6 | 24.7 | 82.3 | 82.3 | |||
| GITL [14] | 20M | 144.6* | 25.4* | 75.5 | ||||
| GIT [14] | 800M | 151.1* | 26.3* | 78.6 | 78.8 | |||
| GIT2 (5.1B) [14] | 12.9B | 152.7* | 26.4* | 81.7 | 81.9 | |||
| PALI (16.9B)[14] | 1.6B | 149.1 | = | 84.3 | 84.3 | |||
| VALORL | 33.5M | 61.4 | 84.4 | 90.9 | 152.5* | 25.7* | 78.46 | 78.62 |
AudioCaps benchmarks, and outperforms previous SOTA methods $(\mathrm{R}@1)$ by $38.9%$ , $13.0%$ , respectively. Nagarani’s method pretrains tri-modality model on their proposed VideoCC3M dataset [75], which is achieved by collecting videos from InterNet which have high similarities to CC3M’s images, and directly take CC3M’s captions as video captions. By contrast, VALOR achieves evidently better performances on two text-to-audio benchmarks, thanks to that audio-language correlations in VALOR-1M are much more explicit and stronger than those in VideoCC3M. In addition, their method needs to separately pretrain two models for video and audio retrieval, while we can finetune a single pretaining model on video, audio and audiovisual retrieval tasks, thanks to proposed modality grouping strategy. With regards to audio captioning benchmarks, compared with models directly training on target datasets, VALOR shows better results and achieves new SOTA results on two benchmarks.
AudioCaps基准测试,并分别以38.9%和13.0%的优势超越之前的SOTA方法$(\mathrm{R}@1)$。Nagarani的方法在其提出的VideoCC3M数据集[75]上预训练三模态模型,该数据集通过收集与CC3M图像高度相似的互联网视频,并直接采用CC3M的标题作为视频标题。相比之下,由于VALOR-1M中的音频-语言关联比VideoCC3M中的更明确且更强,VALOR在两个文本到音频基准测试上表现明显更优。此外,他们的方法需要分别为视频和音频检索预训练两个模型,而我们得益于提出的模态分组策略,可以在视频、音频及视听检索任务上微调单一预训练模型。在音频字幕基准测试方面,与直接在目标数据集上训练的模型相比,VALOR显示出更好的结果,并在两个基准测试上取得了新的SOTA成绩。
5.2.3 Image-Language Benchmarks
5.2.3 图像-语言基准测试
We evaluate $\mathrm{VALOR_{L}}$ on three image-language benchmarks including text-to-image retrieval, image captioning and
我们评估了 $\mathrm{VALOR_{L}}$ 在三个图像语言基准上的表现,包括文本到图像检索、图像描述生成和
VQA. As presented results in Table 7, $\mathrm{VALOR_{L}}$ achieves decent performances on three benchmarks. Specifically, $\mathrm{VALOR_{L}}$ achieves comparable performance with FILIP [125] on COCO retrieval benchmark. On COCO caption benchmark, $\mathrm{VALOR_{L}}$ outperforms GIT and achieves comparable results with GIT2 model, with much less paramters and data. On VQAv2 benchmark, $\mathrm{VALOR_{L}}$ outperforms similar scaling $\mathrm{GIT_{L}}$ with big margins and achieves comparable performances with larger GIT model.
VQA。如表 7 所示,$\mathrm{VALOR_{L}}$ 在三个基准测试中取得了不错的性能。具体而言,$\mathrm{VALOR_{L}}$ 在 COCO 检索基准测试中与 FILIP [125] 表现相当。在 COCO 字幕基准测试中,$\mathrm{VALOR_{L}}$ 优于 GIT,并与 GIT2 模型表现相当,同时参数和数据量大幅减少。在 VQAv2 基准测试中,$\mathrm{VALOR_{L}}$ 以显著优势超越同等规模的 $\mathrm{GIT_{L}}$,并与更大规模的 GIT 模型表现相当。
5.3 Ablation Study
5.3 消融实验
5.3.1 Vision-Audio-Language Cross-Modality Learning
5.3.1 视觉-音频-语言跨模态学习
We first conduct experiments to show the necessity of vision-audio-language cross-modality learning. Specifically, we train models on 9 benchmarks of 6 tasks with different input modalities, in both w and w/o VALOR pre training settings. As Figure 6 shows, compared to using single vision or audio modality, utilizing both modalities can get consistent improvements for 9 benchmarks, under both w or w/o pre training settings. These results prove that combining two modalities indeed help model understand videos universally. In addition, vision-audio-language pre training can further enhance model’s tri-modality inference capabilities. Audio modality is more functional for audiovisuallanguage tasks than vision-language tasks. For example, introduction of audio modality can improve AVR(VALOR) and VR(MSRVTT) performance by $26.0%$ and $14.9%$ , respectively. This is because audiovisual-language tasks are directly related to audio, unlike vision-language tasks using audio as an auxiliary modality.
我们首先通过实验验证视觉-音频-语言跨模态学习的必要性。具体而言,我们在6类任务的9个基准数据集上训练了不同输入模态的模型,分别采用有/无VALOR预训练两种设置。如图6所示,在有无预训练的条件下,相比仅使用视觉或音频单模态,同时利用两种模态能为所有9个基准带来一致性能提升。这些结果证明结合双模态确实能帮助模型更全面地理解视频内容。此外,视觉-音频-语言预训练能进一步增强模型的三模态推理能力。对于视听语言任务,音频模态比视觉语言任务更具功能性。例如引入音频模态可使AVR(VALOR)和VR(MSRVTT)性能分别提升$26.0%$和$14.9%$,这是因为视听语言任务与音频直接相关,而视觉语言任务仅将音频作为辅助模态。
5.3.2 Modality Grouping Strategy
5.3.2 模态分组策略
As introduced in section 4.2, we use modality grouping strategy in both MGA and MGC tasks during pre training, which aims at enhancing model’s generalization capabilities towards tasks with different modalities input. To demonstrate its effectiveness, we pretrain models with different modality groups, and evaluate on multiple benchmarks. Taking MGA as an example, from results presented in Table 8 we can get following conclusions. I) Using T-V (M1) or T-A groups (M2) separately for MGA pre training can get relatively good results on corresponding T-V or T-A benchmarks, but low performance on T-AV benchmark. By contrast, pretrained with T-AV group (M3) can achieve better performance on T-AV benchmark, but its performances on T-V and T-A benchmarks are separately weaker than M1 and M2, due to the inconsistency between tri-modality pre training and dual-modality adapting. II) Based on M3, additionally introducing T-V or T-A group can help enhance corresponding benchmark performance, but decreases the other. For example, M4 achieves better performances on TV benchmarks than M3, and are comparable to M1, but its performance on T-A benchmark drops harder compared to M3. III) The model trained with $\mathrm{T-AV+T-V+T-A}$ groups (M6) can achieves decent performances on T-AV, T-V and T-A benchmarks, under both zero-shot and finetuning settings. IV) Based on M6, further introducing V-A, A-TV and VTA groups can improve performances on corresponding benchmarks, but will also result in evident performance drops for main-stream T-AV, T-V and T-A benchmarks. To this end we choose M6 as default settings. Besides MGA, modality grouping strategy also functions at MGC task, and similar conclusions can be observed from Table 9.
如第4.2节所述,我们在预训练阶段的MGA和MGC任务中均采用模态分组策略,旨在增强模型对不同模态输入任务的泛化能力。为验证其有效性,我们使用不同模态组进行模型预训练,并在多个基准测试中评估性能。以MGA任务为例,从表8所示结果可得出以下结论:I) 单独使用T-V组(M1)或T-A组(M2)进行MGA预训练时,在对应T-V或T-A基准上表现较好,但在T-AV基准上性能较低;相比之下,采用T-AV组(M3)预训练的模型在T-AV基准表现更优,但由于三模态预训练与双模态适配的不一致性,其在T-V和T-A基准的性能分别弱于M1和M2。II) 在M3基础上额外引入T-V或T-A组能提升对应基准性能,但会降低其他基准表现。例如M4在TV基准上表现优于M3且与M1相当,但其T-A基准性能较M3下降更显著。III) 采用$\mathrm{T-AV+T-V+T-A}$组(M6)训练的模型在零样本和微调设置下,均能在T-AV、T-V和T-A基准取得均衡表现。IV) 在M6基础上进一步引入V-A、A-TV和VTA组虽能提升对应基准性能,但会导致主流T-AV、T-V和T-A基准性能明显下降。因此我们选择M6作为默认配置。该策略在MGC任务中同样有效,表9可观察到类似结论。

Fig. 6: Experiment results of using audio (A), vision (V) or both modalities(AV) for 9 benchmarks of 6 tasks. W or w/o pre training denotes whether the model is pretrained on VALOR-1M or not. $\mathbb{R}@1$ , CIDEr and Acc metrics are reported for retrieval, captioning and QA tasks, respectively.
图 6: 在6个任务的9个基准测试中使用音频(A)、视觉(V)或双模态(AV)的实验结果。W/w/o预训练表示模型是否经过VALOR-1M数据集预训练。检索、字幕生成和问答任务分别报告$\mathbb{R}@1$、CIDEr和Acc指标。
TABLE 8: Downstream performances of models pretrained on VALOR-1M with different modality groups in MGA task. Only $L_{M G A}$ is used. Zero-shot $\mathrm{R@1~/}$ finetune $\mathrm{R@1}$ are reported.
表 8: 在VALOR-1M上使用不同模态组预训练的模型在MGA任务中的下游性能。仅使用 $L_{M G A}$ 。报告了零样本 $\mathrm{R@1~/}$ 和微调 $\mathrm{R@1}$ 。
| Name | PretrainingModality Groups | T-V | T-A | T-AV | V-A | A-TV | V-TA | VALOR-32K | MSVD | VALOR-32K | ClothoV1 | VALOR-32K | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T-V | T-A | T-AV | V-A | A-TV | V-TA | VALOR-32K | MSVD | VALOR-32K | ClothoV1 | VALOR-32K | ||||
| M1 | 38.3/42.7 | 30.7/36.0 | 0.0/7.2 | 0.2/9.0 | 38.3/46.9 | |||||||||
| M2 | 0.0/18.1 | 0.2/14.7 | 17.1/16.7 | 8.4/16.5 | 14.5/30.8 | |||||||||
| M3 | √ | 34.9/40.1 | 28.7/34.8 | 10.2/12.3 | 8.1/14.7 | 50.5/55.4 | ||||||||
| M4 | √ | 36.9/42.5 | 30.4/36.2 | 8.8/11.1 | 7.2/14.4 | 50.5/55.5 | ||||||||
| M5 | √ | 33.9/39.1 | 27.6/33.6 | 17.1/17.9 | 9.6/16.8 | 52.0/54.8 | " | |||||||
| M6 | √ | √ | 37.1/41.8 | 29.8/35.4 | 16.9/17.0 | 9.2/16.6 | 50.7/55.6 | 5.6/10.2 | 18.5/20.5 | 39.8/45.6 | ||||
| M7 | √ | √ | 34.5/40.7 | 28.5/34.3 | 16.9/17.6 | 8.2/15.9 | 48.2/54.0 | 11.7/18.5 | 24.6/27.9 | 41.2/52.9 |

Fig. 7: Illustrations of variants with different attention mechanisms in multimodal decoder used for MGC task
图 7: 用于MGC任务的多模态解码器中采用不同注意力机制变体的示意图
TABLE 9: Downstream performances of models pretrained on VALOR-1M with different modality groups in MGC task. Only $L_{M G C}$ is used. Zero-shot CIDEr / finetune CIDEr are reported.
表 9: 在VALOR-1M上使用不同模态组预训练的模型在MGC任务中的下游性能。仅使用 $L_{M G C}$ 。报告了零样本CIDEr/微调CIDEr。
| 模态组 | AVC (VALOR-32K) | VC (MSVD) | AC (Clotho) |
|---|---|---|---|
| T-V | T-A | T-AV | |
| √ | 31.5/47.5 | ||
| 20.7/39.2 | |||
| 43.1/50.0 | |||
| √ | 41.6/49.9 | ||
| √ | √ | 42.7/49.6 | |
| 41.4/49.8 |
text token/vision patch/audio patch representations
文本Token/视觉块/音频块表示
| 方法 | AVR(VALOR-32K) | VR (MSR) |
|---|---|---|
| R@1 | R@5 | |
| 粗粒度+分数融合 | 53.4 | 81.3 |
| 粗粒度+特征融合 | 54.9 | 81.5 |
| 细粒度+分数融合 | 54.5 | 82.3 |
| 细粒度+特征融合 | 54.9 | 81.7 |
| 细粒度+特征融合+加权平均 | 55.4 | 82.7 |
TABLE 10: Downstream performances of models pretrained on VALOR-1M with different audiovisual fusion methods for MGA task. Models are pretrained on VALOR-1M with $L_{M G A(T-A V)}$ only. MSR is short for MSRVTT dataset. Bold lines are default setting.
表 10: 采用不同视听融合方法在VALOR-1M上预训练的模型在MGA任务中的下游性能表现。模型仅使用 $L_{M G A(T-A V)}$ 在VALOR-1M上进行预训练。MSR是MSRVTT数据集的缩写。加粗行为默认设置。
5.3.3 Audiovisual Fusion
5.3.3 视听融合
Audiovisual Fusion in MGA (T-AV). MGA task with TAV group aims at building fine-grained alignment between language and the fusion of audio and vision. We compare it to coarse-grained alignment counterpart, in which global representation of a whole sentence is aligned with the fusion of global representations of whole video and audio. In addition, we compare two audiovisual fusion methods, including feature fusion and score fusion. Feature fusion fuse audio and visual features first (concatenate them along hidden dimension for coarse-grained alignment or along sequence dimension for fine-grained alignment) before computing similarity with texts, while score fusion independently compute text-video and text-audio similarity scores, and then add them as total scores. From results shown in Table 10, we find that fine-grained alignment combined with feature fusion achieves best results on both VALOR-32K and MSRVTT datasets, among all four combinations. Using weighted average introduced in Section 4.2 can further improve performance consistently on two benchmarks.
多模态接地任务中的视听融合 (T-AV)。TAV 组的 MGA 任务旨在建立语言与视听融合之间的细粒度对齐。我们将其与粗粒度对齐方案进行对比,后者将整句的全局表征与完整视频和音频的全局表征融合结果进行对齐。此外,我们比较了两种视听融合方法:特征融合和分数融合。特征融合先融合音频和视觉特征(粗粒度对齐沿隐藏维度拼接,细粒度对齐沿序列维度拼接)再计算与文本的相似度;而分数融合则独立计算文本-视频和文本-音频相似度分数,再相加得到总分。表 10 结果显示,在 VALOR-32K 和 MSRVTT 数据集上,四种组合中细粒度对齐结合特征融合的方案表现最佳。使用第 4.2 节介绍的加权平均方法可进一步提升两个基准测试的指标。
TABLE 11: Downstream performances of models pretrained on VALOR-1M with different E different audiovisual fusion methods for MGC task. Models are pretrained on VALOR1M with $L_{M G C(T-A V)}$ only. CIDEr metric is reported for captioning task.Bold lines are default setting.
表 11: 采用不同视听融合方法在VALOR-1M上预训练的模型在MGC任务中的下游性能。模型仅使用 $L_{M G C(T-A V)}$ 在VALOR-1M上进行预训练。字幕任务报告CIDEr指标。加粗行为默认设置。
| 方法 | AVC(VALOR-32K) | VC (MSR) | VQA (MSR) |
|---|---|---|---|
| Mergeattention | 48.2 | 56.0 | 43.4 |
| Audio-visualcrossattention | 49.6 | 57.0 | 43.7 |
| Visual-audiocrossattention | 49.6 | 57.4 | 43.6 |
| Parallelcrossattention | 49.5 | 57.4 | 43.8 |
| Concatecrossattention | 50.0 | 59.0 | 44.1 |
TABLE 12: Downstream performances of models pretrained on VALOR-1M with different MGA and MGC tasks combination settings. $\mathrm{R@1}$ and CIDEr is reported for retrieval and captioning, respectively.
表 12: 采用不同 MGA 和 MGC 任务组合设置在 VALOR-1M 上预训练模型的下游性能。检索和字幕生成分别报告 $\mathrm{R@1}$ 和 CIDEr 指标。
| Shareweights | AVR (VALOR-32K) | AVC (VALOR-32K) | VQA (MSR) | |
|---|---|---|---|---|
| 1 | 53.8 | 50.3 | 44.1 | |
| √ | 1 | 54.7 | 50.0 | 44.1 |
| √ | 0.5 | 53.0 | 50.8 | 44.1 |
| √ | 1.5 | 54.9 | 50.4 | 44.0 |
| √ | 3.0 | 55.4 | 49.9 | 43.8 |
Audiovisual Fusion in MGC (T-AV). MGC task with TAV group demands model to predict masked tokens with both visual and audio feature as conditions. We make comparison among five variants with different attention mechanisms in multimodal decoder, which is illustrated in Figure 7. Specifically, audio-visual cross-attention (a) and visual-audio cross attention (b) variants introduce two crossattention layers and attends to two modalities in order. Merge attention (c) directly concatenates tri-modality features and use part-causal mask for self-attention layers, enabling vision and audio can fully attend to each other, while preventing information leakage for text. Concatenate cross attention (e) introduces one cross-attention layer and attends to the concatenation of two modalities. Parallel cross attention (d) use independent parameters for two modalities instead of sharing weights as (e). From the results shown in Table 11, we can find concatenate cross attention mechanism achieves best results consistently on AVC, VC and VQA tasks.
MGC中的视听融合(T-AV)。TAV组的MGC任务要求模型以视觉和音频特征为条件预测被遮蔽的token。我们在多模态解码器中比较了五种不同注意力机制的变体,如图7所示。具体而言:(a) 音频-视觉交叉注意力和(b) 视觉-音频交叉注意力变体引入了两个交叉注意力层并按顺序处理两种模态;(c) 合并注意力直接拼接三模态特征,并对自注意力层使用部分因果掩码,使视觉和音频能充分交互,同时防止文本信息泄露;(e) 拼接交叉注意力引入单个交叉注意力层来处理两种模态的拼接特征;(d) 并行交叉注意力则对两种模态使用独立参数而非如(e)共享权重。表11结果显示,拼接交叉注意力机制在AVC、VC和VQA任务上始终取得最佳效果。
Combination of MGA and MGC. When models are trained together with MGA and MGC tasks, we share the common parameters of text encoder and decoder, and a hyper pa meter $\alpha$ is used to balance two losses. As shown in Table 12, training two tasks together get performance drop on AVR $(53.8~\mathrm{VS}~55.6)$ and improvement on AVC (50.3 vs 49.6) tasks, compared to the results of separate training in Table 8 and Table 9. Parameter sharing can improve 0.9 points on AVR task, with only slight decrease on AVC task. Using a larger $\alpha$ will make model focus more on MGA task and get higher AVR performance, but AVC performance gets lower. Video QA is relatively not sensitive to different settings. To the end, we choose parameter sharing and set $\alpha=1.5$ , for its decent performances on multiple tasks.
MGA与MGC的结合。当模型同时训练MGA和MGC任务时,我们共享文本编码器和解码器的公共参数,并使用超参数$\alpha$来平衡两个损失。如表12所示,与表8和表9中单独训练的结果相比,同时训练两个任务在AVR任务上性能下降$(53.8~\mathrm{VS}~55.6)$,而在AVC任务上有所提升(50.3 vs 49.6)。参数共享可使AVR任务提升0.9分,而AVC任务仅有轻微下降。使用更大的$\alpha$会使模型更关注MGA任务并获得更高的AVR性能,但AVC性能会降低。视频问答(Video QA)对不同设置相对不敏感。最终,我们选择参数共享并设置$\alpha=1.5$,因其在多项任务中表现均衡。
5.3.4 Effect of VALOR-1M Dataset
5.3.4 VALOR-1M数据集的影响
In Table 14, we make comparison between VALOR-1M and other public video-language pre training datasets including WebVid-2.5M, CC3M and HD VILA 10M. The model pretrained on VALOR-1M use both vision and audio modalities, while models pretrained on other datasets only use vision modality. All models are finetuned on MSRVTT dataset with both visual and audio modalities. From the results we can find that the model pretrained on VALOR-1M surpasses other models on all three benchmarks with evident margins, thanks to the high-quality audiovisual captions in VALOR1M.
在表 14 中,我们将 VALOR-1M 与其他公开的视频语言预训练数据集 (包括 WebVid-2.5M、CC3M 和 HD VILA 10M) 进行了对比。基于 VALOR-1M 预训练的模型同时使用了视觉和听觉模态,而其他数据集预训练的模型仅使用视觉模态。所有模型均在 MSRVTT 数据集上针对视觉和听觉模态进行了微调。结果显示,得益于 VALOR-1M 高质量的视听字幕,基于该数据集预训练的模型在全部三个基准测试中均以显著优势超越其他模型。
5.3.5 Model Architecture Choices
5.3.5 模型架构选择
We make comparisons about different model architectures in Table 13. As the results shown, when $\mathrm{BERT_{B}}$ is chosen as text encoder, using more powerful vision encoder gives more improvement on all four retrieval benchmarks. In addition, we make comparison of text encoders when $\mathrm{CLIP_{L}}$ is chosen as vision encoder. If using $\mathrm{BERT_{B}}$ as text encoder, three single-modality encoders are not aligned at the start of MGA learning. By contrast, if using $\mathrm{CLIP_{L}}$ as text encoder, vision and text have already been aligned in advance before MGA learning. As the results shown, when pre training data is limited to VALOR-1M, $\mathrm{CLIP_{L}}$ evidently outperforms $\mathrm{BERT_{B}}$ on 3 VR benchmarks, due to the benifit of large scale CLIP contrastive pre training. However, performance of $\mathrm{CLIP_{L}}$ on AVR benchmark fall behinds $\mathrm{BERT}{\mathrm{B}}$ , we assume that pre-aligning vision and language makes model tend to ignore the learning of audiovisual-language correlation, cause simply utilizing vision information can result in a small loss at the start of pre training. When utilizing more training data (33.5M), the disadvantage of $\mathrm{BERT_{B}}$ on VR benchmarks gets largely relieved while its advantage on AVR benchmark remains. In addition, we also tried to scale up text encoder from $\mathrm{BERT_{B}}$ to $\mathrm{BERT_{L}},$ and observed performance gains on three benchmarks except for MSRVTT. In the end, we choose $\mathrm{CLIP_{L}}$ and $\mathrm{BERT_{B}}$ as $\mathrm{VALOR_{L}}^{.}$ ’s deafult design for its high effectiveness and efficiency.
我们在表13中对不同模型架构进行了比较。结果显示,当选择$\mathrm{BERT_{B}}$作为文本编码器时,使用更强大的视觉编码器在所有四个检索基准上都能带来更大提升。此外,我们比较了选择$\mathrm{CLIP_{L}}$作为视觉编码器时的文本编码器表现。若使用$\mathrm{BERT_{B}}$作为文本编码器,三个单模态编码器在MGA学习开始时并未对齐;而使用$\mathrm{CLIP_{L}}$作为文本编码器时,视觉与文本在MGA学习前已预先对齐。结果表明,当预训练数据限于VALOR-1M时,得益于大规模CLIP对比预训练的优势,$\mathrm{CLIP_{L}}$在3个VR基准上明显优于$\mathrm{BERT_{B}}$。然而$\mathrm{CLIP_{L}}$在AVR基准上的表现落后于$\mathrm{BERT}{\mathrm{B}}$,我们认为视觉与语言的预对齐会使模型倾向于忽略视听-语言关联的学习,因为仅利用视觉信息就可能在预训练初期获得较小损失。当使用更多训练数据(33.5M)时,$\mathrm{BERT_{B}}$在VR基准上的劣势大幅缓解,而在AVR基准上的优势仍然保持。我们还尝试将文本编码器从$\mathrm{BERT_{B}}$扩展到$\mathrm{BERT_{L}}$,除MSRVTT外其他三个基准均观察到性能提升。最终我们选择$\mathrm{CLIP_{L}}$和$\mathrm{BERT_{B}}$作为$\mathrm{VALOR_{L}}^{.}$的默认设计,因其高效性与高效能。
5.4 Visualization s
5.4 可视化
In Figure 8, we make qualitative comparisons on VALOR32K benchmarks between $\mathrm{VALOR_{B}}$ and task-specific methods including AVLNet [50] and SMPFF [46], both of which take vision and audio as inputs. From the visualization
在图 8 中,我们在 VALOR32K 基准上对 $\mathrm{VALOR_{B}}$ 和特定任务方法(包括 AVLNet [50] 和 SMPFF [46])进行了定性比较,这两种方法都以视觉和音频作为输入。从可视化结果来看
TABLE 13: Downstream performances of models with different architectures. Both vision and audio are used for pre training and finetuning. All models use $\mathrm{AST_{B}}$ as audio encoder.
表 13: 不同架构模型的下游性能表现。视觉和音频均用于预训练和微调。所有模型均使用 $\mathrm{AST_{B}}$ 作为音频编码器。
| 视觉编码器 | 文本编码器 | 样本数 | AVR(VALOR-32K) | VR(MSRTT) | VR(DiDeMo) | VR(LSMDC) |
|---|---|---|---|---|---|---|
| VideoSwinB | BERTB | 1M | 56.8/83.1/89.9 | 39.3/69.0/80.4 | 41.1/73.1/81.8 | 19.8/41.3/52.5 |
| CLIPB | BERTB | 1M | 61.8/86.0/92.3 | 45.0/74.1/84.4 | 46.3/75.6/84.2 | 22.7/45.4/56.1 |
| CLIPL | BERTB | 1M | 64.3/87.3/92.8 | 47.7/76.1/84.6 | 47.3/77.9/85.1 | 27.8/51.4/60.9 |
| CLIPL | CLIPL | 1M | 59.3/84.4/91.0 | 50.6/79.0/87.8 | 53.4/80.2/88.3 | 29.2/51.6/58.8 |
| CLIPL | BERTL | 1M | 66.5/88.1/93.4 | 46.1/76.7/85.4 | 49.0/77.4/84.9 | 29.2/50.7/60.5 |
| CLIPL | BERTB | 33.5M | 73.2/91.6/95.4 | 54.4/79.8/87.6 | 57.6/83.3/88.8 | 31.8/52.8/62.4 |
| CLIPL | CLIPL | 33.5M | 67.8/89.5/94.0 | 55.3/80.5/88.1 | 57.1/82.9/88.6 | 32.6/52.6/62.7 |
AudioVisual Retrieval (AVR)
视听检索 (AVR)
Query: With the sound of the wind and the sound of birds, a man in white tried to row in the water. Rank top-3 candidates by AVLNet:
查询:在风声与鸟鸣中,一位白衣男子试图在水中划船。根据AVLNet排名前3的候选结果:

GT: As the noise rang, a yellow train slowly turned, the picture turned, and a white train started slowly from the stillness with the noise. Generated by SMPFF: A train was slowly moving along the track. Generated by VALOR(Ours): A train was slowly moving along the track with the roar of the engine and the voice of people. Fig. 8: Visualization of prediction results of different models on VALOR-32K benchmarks. Click the bottons to play the audio.
图 8: 不同模型在VALOR-32K基准上的预测结果可视化。点击按钮播放音频。
TABLE 14: Downstream performances of models pretrained on different datasets. Models are trained with same iterations on each dataset for fair comparison.
表 14: 不同预训练数据集下游任务性能对比。为确保公平比较,各模型在相同迭代次数下训练。
| Dataset | VR (MSRVTT) | VC (MSRVTT) | VQA (MSRVTT) |
|---|---|---|---|
| HD_VILA_10M | 30.4 | 55.4 | 43.2 |
| WebVid-2.5M | 35.7 | 58.8 | 43.8 |
| CC3M | 36.3 | 58.8 | 44.0 |
| VALOR-1M | 39.5 | 60.7 | 44.5 |
results we can find that compared to AVLNet, VALOR can accurately rank video candidates given audiovisual text query and successfully retrieve the ground truth one. Compared to the rank#1 video, the rank#2 video also shows a man in white on water, and is accompanied with wind sound, but the bird sound is missing. The rank#3 video is more conflicted to the query, from both vision and audio perspective. With regards to AVC task, SMPFF either recognizes sound wrongly (in example 1), or describes vision wrongly (in example 2), or totally ignores audio information (in example 3). By contrast, VALOR can comprehensively recognize both visual and audio concepts, and generate accurate descriptions for all three examples.
从结果中我们可以发现,与AVLNet相比,VALOR能够根据视听文本查询准确排序候选视频并成功检索出真实匹配项。排名第二的视频虽然同样呈现白衣男子在水面上的画面,并伴有风声,但缺少了鸟鸣声。排名第三的视频在视觉和听觉维度都与查询内容存在更大冲突。在AVC任务中,SMPFF要么错误识别声音(示例1)、要么错误描述视觉内容(示例2)、要么完全忽略音频信息(示例3)。相比之下,VALOR能全面识别视觉和听觉概念,并为所有三个示例生成精准描述。
6 CONCLUSION
6 结论
This paper proposed a unified vision-audio-language crossmodality pre training model VALOR, which models trimodality understanding and generation through two designed pretraing tasks including Multimodal Grouping Alignment and Multimodal Grouping Captioning. Extensive experiments have been conducted to demonstrate that VALOR possesses good versatility and s cal ability. The first strong correlated vision-audio-language dataset VALOR-1M is proposed to promote tri-modality pre training research and VALOR-32K is proposed for audiovisual-language retrieval and captioning benchmarking. Trained on VALOR1M and other public vision-language datasets, VALOR achieves series of new state-of-the-art performances on downstream vision/audio/audiovisual retrieval, captioning and question answering tasks. In future, we plan to increase the scaling of VALOR-1M dataset via uns per vised methods like generating and filtering pesudo audiovisual captions. In addition, we also plan to additionally introduce vision and audio generation modeling into current VALOR framework.
本文提出了一种统一的视觉-音频-语言跨模态预训练模型VALOR,通过设计的多模态分组对齐(Multimodal Grouping Alignment)和多模态分组描述(Multimodal Grouping Captioning)两项预训练任务,实现了三模态理解与生成的统一建模。大量实验表明VALOR具有良好的泛化能力和扩展性。为促进三模态预训练研究,我们构建了首个强关联视觉-音频-语言数据集VALOR-1M,并推出VALOR-32K作为音视频-语言检索与描述任务的基准测试集。在VALOR-1M及其他公开视觉-语言数据集上训练的VALOR模型,在下游视觉/音频/音视频检索、描述和问答任务中取得了一系列最先进性能。未来我们计划通过生成和过滤伪音视频描述等无监督方法扩大VALOR-1M数据规模,同时将在现有VALOR框架中引入视觉与音频生成建模能力。