EFFICIENT REMOTE SENSING WITH HARMONIZED TRANSFER LEARNING AND MODALITY ALIGNMENT
高效遥感:基于统一迁移学习与模态对齐的方法
ABSTRACT
摘要
With the rise of Visual and Language Pre training (VLP), an increasing number of downstream tasks are adopting the paradigm of pre training followed by finetuning. Although this paradigm has demonstrated potential in various multimodal downstream tasks, its implementation in the remote sensing domain encounters some obstacles. Specifically, the tendency for same-modality embeddings to cluster together impedes efficient transfer learning. To tackle this issue, we review the aim of multimodal transfer learning for downstream tasks from a unified perspective, and rethink the optimization process based on three distinct objectives. We propose “Harmonized Transfer Learning and Modality Alignment (HarMA)”, a method that simultaneously satisfies task constraints, modality alignment, and single-modality uniform alignment, while minimizing training overhead through parameter-efficient fine-tuning. Remarkably, without the need for external data for training, HarMA achieves state-of-the-art performance in two popular multimodal retrieval tasks in the field of remote sensing. Our experiments reveal that HarMA achieves competitive and even superior performance to fully fine-tuned models with only minimal adjustable parameters. Due to its simplicity, HarMA can be integrated into almost all existing multimodal pre training models. We hope this method can facilitate the efficient application of large models to a wide range of downstream tasks while significantly reducing the resource consumption 1.
随着视觉与语言预训练 (VLP) 的兴起,越来越多的下游任务开始采用预训练后微调的模式。尽管该模式在多模态下游任务中展现出潜力,但在遥感领域的应用仍面临一些障碍。具体而言,同模态嵌入倾向于聚集的特性会阻碍高效的迁移学习。为解决这一问题,我们从统一视角重新审视多模态迁移学习在下游任务中的目标,并基于三个不同目标重新思考优化过程。我们提出“协调迁移学习与模态对齐 (HarMA)”方法,该方法在满足任务约束、模态对齐和单模态均匀对齐的同时,通过高效参数微调最小化训练开销。值得注意的是,无需额外训练数据,HarMA 便在遥感领域两个主流多模态检索任务中实现了最先进的性能。实验表明,仅需极少量可调参数,HarMA 就能达到与全参数微调模型相当甚至更优的性能。由于其简洁性,HarMA 可集成到几乎所有现有多模态预训练模型中。我们希望该方法能促进大模型在广泛下游任务中的高效应用,同时显著降低资源消耗 [1]。
1 INTRODUCTION
1 引言
The advent of Visual and Language Pre training (VLP) has spurred a surge in studies employing large-scale pre training and subsequent fine-tuning for diverse multimodal tasks (Tan & Bansal, 2019; Li et al., 2020; 2021; 2022; Liu et al., 2023). When conducting transfer learning for downstream tasks in the multimodal domain, the common practice is to first perform large-scale pre-training and then fully fine-tune on a specific domain dataset (Hu & Singh, 2021; Akbari et al., 2021; Zhang et al., 2024b), which is also the case in the field of remote sensing image-text retrieval (Cheng et al., 2021; Pan et al., 2023b). However, this method has at least two notable limitations. Firstly, fully fine-tuning a large model is extremely expensive and not scalable (Zhang et al., 2024a). Secondly, the pre-trained model has already been trained on a large dataset for a long time, and fully fine-tuning on a small dataset may lead to reduced generalization ability or over fitting.
视觉与语言预训练 (Visual and Language Pre-training, VLP) 的出现推动了采用大规模预训练和后续微调来处理多样化多模态任务的研究热潮 (Tan & Bansal, 2019; Li et al., 2020; 2021; 2022; Liu et al., 2023)。在多模态领域进行下游任务迁移学习时,通常的做法是先进行大规模预训练,然后在特定领域数据集上完全微调 (Hu & Singh, 2021; Akbari et al., 2021; Zhang et al., 2024b),遥感图像-文本检索领域也是如此 (Cheng et al., 2021; Pan et al., 2023b)。然而,这种方法至少存在两个显著局限:首先,完全微调大模型成本极高且难以扩展 (Zhang et al., 2024a);其次,预训练模型已在大型数据集上经过长期训练,在小数据集上完全微调可能导致泛化能力下降或过拟合。
Recently, several works have attempted to use Parameter-Efficient Fine-Tuning (PEFT) to address this issue, aiming to freeze most of the model parameters and fine-tune only a few (Houlsby et al., 2019; Mao et al., 2021; Zhang et al., 2022). This strategy seeks to incorporate domain-specific knowledge into the model while preserving the bulk of its original learned information. For example, Houlsby et al. (2019) attempted to fine-tune the pre-trained model by simply introducing a singlemodality MLP layer. In contrast, Yuan et al. (2023) designed a cross-modal interaction adapter, aiming to enhance the model’s ability to integrate multimodal knowledge. Although the above works have achieved promising results, they either concentrate on single-modality features or overlook potential semantic mismatches when modeling the visual-language joint space.
最近,多项研究尝试使用参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT) 来解决这一问题,旨在冻结大部分模型参数,仅微调少量参数 (Houlsby et al., 2019; Mao et al., 2021; Zhang et al., 2022)。该策略试图在保留模型原有学习信息的同时,融入特定领域的知识。例如,Houlsby et al. (2019) 尝试通过简单引入单模态 MLP 层来微调预训练模型。相比之下,Yuan et al. (2023) 设计了一个跨模态交互适配器,旨在增强模型整合多模态知识的能力。尽管上述工作取得了不错的效果,但它们要么专注于单模态特征,要么在建模视觉-语言联合空间时忽略了潜在的语义不匹配问题。
We have observed that poorly performing models sometimes exhibit a clustering phenomenon within the same modality embedding. Figure 1 illustrates the visualization of the last layer embeddings for two models with differing performance in the filed of remote sensing image-text retrieval; the clustering phenomenon is noticeably more pronounced in the right image than in the left. We hypothesize that this may be attributed to the high intra-class and inter-class similarity of remote sensing images, leading to semantic confusion when modeling a low-rank visual-language joint space. This raises a critical question: “How can we model a highly aligned visual-language joint space while ensuring efficient transfer learning?”
我们观察到,性能较差的模型有时会在同一模态嵌入中表现出聚类现象。图 1: 展示了两个在遥感图像-文本检索领域表现不同的模型最后一层嵌入的可视化结果;右图中的聚类现象明显比左图更为突出。我们推测,这可能归因于遥感图像的高类内和类间相似性,导致在建模低秩视觉-语言联合空间时出现语义混淆。这引发了一个关键问题:"如何在确保高效迁移学习的同时,建模高度对齐的视觉-语言联合空间?"
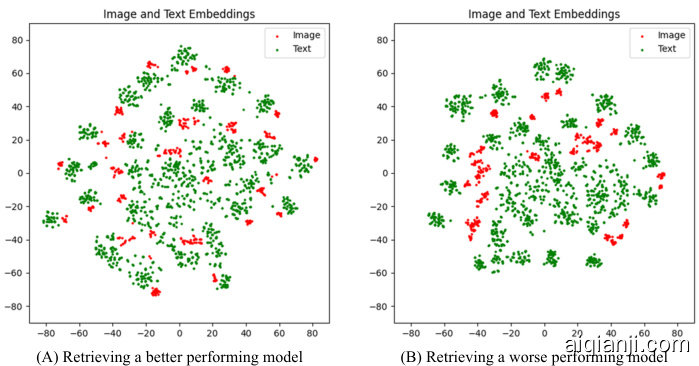
Figure 1: In remote sensing image-text retrieval, excessive clustering of the same modality sometimes leads to a decrease in performance. The experiment was conducted on the RSITMD dataset.
图 1: 在遥感图文检索任务中,同模态过度聚类有时会导致性能下降。该实验在RSITMD数据集上进行。
In the brains of congenitally blind individuals, parts of the visual cortex can take on the function of language processing (Bedny et al., 2011). Concurrently, in the typical human cortex, several small regions—such as the Angular Gyrus and the Visual Word Form Area (VWFA)—serve as hubs for integrated visual-language processing (Houk & Wise, 1995). These areas hierarchically manage both low-level and high-level stimuli information (Chen et al., 2019). Inspired by this natural phenomenon, we propose “Efficient Remote Sensing with Harmonized Transfer Learning and Modality Alignment (HarMA)”. Specifically, similar to the information processing methods of the human brain, we designed a hierarchical multimodal adapter with mini-adapters. This framework emulates the human brain’s strategy of utilizing shared mini-regions to process neural impulses originating from both visual and linguistic stimuli. It models the visual-language semantic space from low to high levels by hierarchically sharing multiple mini-adapters. Finally, we introduced a new objective function to alleviate the severe clustering of features within the same modality. Thanks to its simplicity, the method can be easily integrated into almost all existing multimodal frameworks.
在先天失明者的大脑中,视觉皮层的部分区域能够承担语言处理功能 (Bedny et al., 2011)。与此同时,典型人类大脑皮层中的多个小区域——如角回 (Angular Gyrus) 和视觉词形区 (Visual Word Form Area, VWFA)——充当着视觉-语言整合处理的枢纽 (Houk & Wise, 1995)。这些区域以层级化方式管理着从低阶到高阶的刺激信息 (Chen et al., 2019)。受此自然现象启发,我们提出了"高效遥感与协调迁移学习及模态对齐方法 (Harmonized Transfer Learning and Modality Alignment, HarMA)"。具体而言,我们仿照人脑信息处理方式,设计了一个包含微型适配器 (mini-adapter) 的层级化多模态适配框架。该框架模拟了人脑利用共享微型区域来处理源自视觉与语言刺激的神经脉冲策略,通过层级化共享多个微型适配器,实现了从低阶到高阶的视觉-语言语义空间建模。最后,我们引入新的目标函数来缓解同模态内部特征严重聚集的问题。得益于其简洁性,该方法可轻松集成到几乎所有现有多模态框架中。
2 METHOD
2 方法
2.1 OVERALL FRAMEWORK
2.1 整体框架

Figure 2: The overall framework of the proposed method.
图 2: 所提方法的整体框架。
Figure 2 illustrates our proposed HarMA framework. It initiates the process with the extraction of representations using image and text encoders, similar to CLIP (Radford et al., 2021b). These features are then processed by our unique multimodal gated adapter to obtain refined feature represent at ions. Unlike the simple linear layer interaction used in (Yuan et al., 2023), we employ a shared mini adapter as our interaction layer within the entire adapter. After that, we optimize using a contrastive learning objective and our adaptive triplet loss.
图 2: 展示了我们提出的 HarMA 框架。该框架首先使用图像和文本编码器提取表征,类似于 CLIP (Radford et al., 2021b)。这些特征随后通过我们独特的多模态门控适配器进行处理,以获得精细化的特征表示。与 (Yuan et al., 2023) 中使用的简单线性层交互不同,我们在整个适配器中采用共享的迷你适配器作为交互层。之后,我们使用对比学习目标和自适应三元组损失进行优化。
2.2 MULTIMODAL GATED ADAPTER
2.2 多模态门控适配器
Previous parameter-efficient fine-tuning methods in the multimodal domain (Jiang et al., 2022b; Yuan et al., 2023) use a simple shared-weight method for modal interaction, potentially causing semantic matching confusion in the inherent modal embedding space. To address this, we designed a cross-modal adapter with an adaptive gating mechanism (Figure 3).
多模态领域先前的参数高效微调方法 (Jiang et al., 2022b; Yuan et al., 2023) 采用简单的共享权重机制进行模态交互,可能导致固有模态嵌入空间中的语义匹配混乱。为此,我们设计了具有自适应门控机制的跨模态适配器 (图 3)。
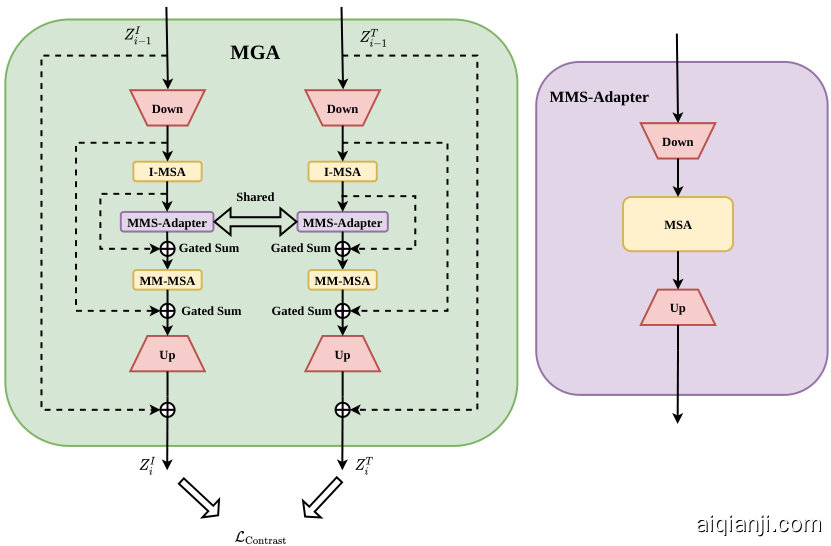
Figure 3: The specific structure of the multimodal gated adapter.The overall structure is shown on the left, while the structure of the shared multimodal sub-adapter is displayed on the right.
图 3: 多模态门控适配器的具体结构。左侧展示了整体结构,右侧显示了共享多模态子适配器的结构。
In this module, the extracted features $z_{I}$ and $z_{T}$ are first projected into low-dimensional embeddings. Different features $z_{I}$ $(z_{T})$ are further enhanced in feature expression after non-linear activation and subsequent processing by I-MSA. I-MSA and the subsequent MM-MSA share parameters. The features are then fed into our designed Multimodal Sub-Adapter (MMS-Adapter) for further interaction, the structure of this module is shown on the right side of Figure 3.
在此模块中,提取的特征$z_{I}$和$z_{T}$首先被投影到低维嵌入空间。通过非线性激活和随后的I-MSA处理,不同特征$z_{I}$ $(z_{T})$在特征表达上得到进一步增强。I-MSA与后续的MM-MSA共享参数。这些特征随后被输入到我们设计的Multimodal Sub-Adapter (MMS-Adapter)中进行进一步交互,该模块结构如[图3]右侧所示。
The MMS-Adapter, akin to standard adapters, aligns multimodal context representations via sharedweight self-attention. However, direct post-projection output of these aligned representations negatively impacts image-text retrieval performance, likely due to off-diagonal semantic key matches in the feature’s low-dimensional manifold space. This contradicts contrastive learning objectives.
MMS-Adapter与标准适配器类似,通过共享权重的自注意力机制对齐多模态上下文表征。然而,这些对齐表征的直接后投影输出会对图文检索性能产生负面影响,这可能是由于特征的低维流形空间中出现了非对角语义键匹配。这一现象与对比学习目标相矛盾。
To tackle this, the already aligned representations are further processed in the MSA with shared weights, thereby reducing model parameters and leveraging prior modality knowledge. And to ensure a finer-grained semantic match between image and text, we introduce early image-text matching supervision in the MGA output, significantly mitigating the occurrence of above issue.
为了解决这一问题,已对齐的表征会在共享权重的MSA(多头自注意力)中进一步处理,从而减少模型参数并利用先前的模态知识。此外,为确保图像与文本之间更细粒度的语义匹配,我们在MGA(多粒度对齐)输出中引入了早期图文匹配监督机制,显著缓解了上述问题的发生。
Ultimately, features are projected back to their original dimensions before adding the skip connection. The final layer is initialized to zero to safeguard the performance of the pre-trained model during the initial stages of training. Algorithm 1 summarizes the proposed method.
最终,特征在添加跳跃连接前会被投影回原始维度。最后一层被初始化为零,以在训练初期保护预训练模型的性能。算法1总结了所提出的方法。
2.3 OBJECTIVE FUNCTION
2.3 目标函数
Here, $L_{\mathrm{task}}^{i}$ represents the task loss for the $i$ -th task, and $L_{\mathrm{align}}^{j k}$ denotes the alignment loss between different pairs of modalities $(j,k)$ . The expectation is taken over the data distribution $\mathcal{D}$ for each task. $\theta^{*}$ represents the target parameters for transfer learning.
这里,$L_{\mathrm{task}}^{i}$ 表示第 $i$ 个任务的任务损失,$L_{\mathrm{align}}^{j k}$ 表示不同模态对 $(j,k)$ 之间的对齐损失。期望是针对每个任务的数据分布 $\mathcal{D}$ 计算的。$\theta^{*}$ 表示迁移学习的目标参数。
In this equation, $L_{\mathrm{ini}}$ represents the initial optimization objective (Equation 1), which is composed of the task loss and alignment loss. $L_{\mathrm{uniform}}^{i}$ denotes the singe-modality uniformity loss for the $i$ -th modality, and $D(\theta,\theta^{*})$ is a cost measure between the original and updated model parameters, constrained to be less than $\delta$ . $\delta$ is the minimum parameter update cost in the ideal state.
在该等式中,$L_{\mathrm{ini}}$ 表示初始优化目标 (公式 1),由任务损失和对齐损失组成。$L_{\mathrm{uniform}}^{i}$ 表示第 $i$ 个模态的单模态均匀性损失,$D(\theta,\theta^{*})$ 是原始模型参数与更新后模型参数之间的成本度量,约束条件为小于 $\delta$。$\delta$ 是理想状态下的最小参数更新成本。
We observe that existing works often only explore one or two objectives, with most focusing either on how to efficiently fine-tune parameters for downstream tasks (Jiang et al., 2022b; Jie & Deng, 2022; Yuan et al., 2023) or on modality alignment (Chen et al., 2020; Ma et al., 2023; Pan et al., 2023a). Few can simultaneously satisfy the three requirements outlined in the above formula. We have satisfied the need for efficient transfer learning by introducing adapters that mimic the human brain. This prompts us to ask: how can we fulfill the latter two objectives—high alignment of embeddings across different modalities while preventing excessive clustering of embeddings within the same modality?
我们注意到,现有研究往往只探索一两个目标,其中大多数要么关注如何高效微调参数以适应下游任务 (Jiang et al., 2022b; Jie & Deng, 2022; Yuan et al., 2023) ,要么聚焦模态对齐 (Chen et al., 2020; Ma et al., 2023; Pan et al., 2023a) 。很少有工作能同时满足上述公式中的三个要求。通过引入模拟人脑的适配器 (adapter) ,我们已满足高效迁移学习的需求。这促使我们思考:如何实现后两个目标——在确保跨模态嵌入高度对齐的同时,避免同一模态内嵌入的过度聚类?
2.3.1 ADAPTIVE TRIPLET LOSS
2.3.1 自适应三元组损失
In image-text retrieval tasks, the bidirectional triplet loss established by Faghri et al. (2017) has become a mainstream loss function. However, if we choose to accumulate the losses of all samples in image-text matching, the model may struggle to optimize due to the high intra-class similarity and inter-class similarity prevalent in most regions of the images within the field of remote sensing (Yuan et al., 2022a). Therefore, We propose an Adaptive Triplet Loss that automatically mines and optimizes hard samples:
在图文检索任务中,Faghri等人(2017) 提出的双向三元组损失已成为主流损失函数。然而,若选择累积图像-文本匹配中所有样本的损失,由于遥感领域图像大部分区域普遍存在较高的类内相似性和类间相似性 (Yuan等人, 2022a),模型可能难以优化。因此,我们提出一种自动挖掘并优化困难样本的自适应三元组损失:
$$
\mathcal{L}{\mathrm{ada-triplet}}=\frac{1}{2}\left(\sum_{i=1}^{N}\sum_{j=1}^{N}w_{s,i j}\left[m+s_{i j}-s_{i i}\right]{+}+\sum_{j=1}^{N}\sum_{i=1}^{N}w_{s,j i}\left[m+s_{j i}-s_{i i}\right]_{+}\right),
$$
$$
\mathcal{L}{\mathrm{ada-triplet}}=\frac{1}{2}\left(\sum_{i=1}^{N}\sum_{j=1}^{N}w_{s,i j}\left[m+s_{i j}-s_{i i}\right]{+}+\sum_{j=1}^{N}\sum_{i=1}^{N}w_{s,j i}\left[m+s_{j i}-s_{i i}\right]_{+}\right),
$$
where $s_{i j}$ is the dot product between image feature $i$ and text feature $j,w_{i}$ and $w_{j}$ are the weights of sample $i$ and $j$ , determined by the loss size of different samples:
其中 $s_{i j}$ 是图像特征 $i$ 与文本特征 $j$ 的点积,$w_{i}$ 和 $w_{j}$ 分别是样本 $i$ 和 $j$ 的权重,由不同样本的损失大小决定:
$$
w_{s,i j}=(1-\exp(-[m+s_{i j}-s_{i i}]{+}))^{\gamma},w_{s,j i}=(1-\exp(-[m+s_{j i}-s_{i i}]_{+}))^{\gamma},
$$
$$
w_{s,i j}=(1-\exp(-[m+s_{i j}-s_{i i}]{+}))^{\gamma},w_{s,j i}=(1-\exp(-[m+s_{j i}-s_{i i}]_{+}))^{\gamma},
$$
where $\gamma$ is a hyper parameter adjusting the size of the weights. This loss function aims to bring the features of positive samples closer together, while distancing those between positive and negative samples. By dynamically adjusting the focus between hard and easy samples, our approach effectively satisfies the other two objectives proposed above. It not only aligns different modality samples at a fine-grained level but also prevents over-aggregation among samples of the same modality, thereby enhancing the model’s matching capability. Also, following the approach of (Radford et al., 2021b), we utilize a contrastive learning objective to align image and text semantic features. Consequently, the total objective is defined as:
其中 $\gamma$ 是一个调整权重大小的超参数。该损失函数旨在拉近正样本特征之间的距离,同时推远正负样本之间的特征。通过动态调整难样本与易样本的关注度,我们的方法有效满足了上述另外两个目标:不仅能在细粒度上对齐不同模态的样本,还能防止同模态样本的过度聚集,从而提升模型匹配能力。此外,我们沿用 (Radford et al., 2021b) 的方法,采用对比学习目标来对齐图像与文本语义特征。因此,总目标函数定义为:
$$
\begin{array}{r}{\mathcal{L}{\mathrm{total}}=(\lambda_{1}\mathcal{L}{\mathrm{ada-triplet}}+\lambda_{2}\mathcal{L}_{\mathrm{contrastive}}).}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{\mathrm{total}}=(\lambda_{1}\mathcal{L}{\mathrm{ada-triplet}}+\lambda_{2}\mathcal{L}_{\mathrm{contrastive}}).}\end{array}
$$
The $\lambda_{1}$ and $\lambda_{2}$ are parameters for balancing the loss. We offer detailed information on contrastive learning in Appendix A.4.
$\lambda_{1}$ 和 $\lambda_{2}$ 是用于平衡损失的参数。我们在附录 A.4 中提供了关于对比学习 (contrastive learning) 的详细信息。
3 EXPERIMENTS
3 实验
We evaluate our proposed HarMA framework on two widely used remote sensing (RS) image-text datasets: RSICD (Lu et al., 2017) and RSITMD (Yuan et al., 2022a). We use standard recall at TOP-K $(\mathrm{R}@\mathrm{K},\mathrm{K}=1,5,10)$ and mean recall (mR) to assess our model.
我们在两个广泛使用的遥感 (RS) 图文数据集上评估了提出的 HarMA 框架:RSICD (Lu et al., 2017) 和 RSITMD (Yuan et al., 2022a)。采用标准 TOP-K 召回率 $(\mathrm{R}@\mathrm{K},\mathrm{K}=1,5,10)$ 和平均召回率 (mR) 作为评估指标。
3.1 COMPARATIVE EXPERIMENTS
3.1 对比实验
In this section, we compare the proposed method with state-of-the-art retrieval techniques on two remote sensing multimodal retrieval benchmarks. The backbone networks employed in our experiments are the CLIP (ViT-B-32) (Radford et al., 2021a) and the GeoRSCLIP (Zhang et al., 2023).
在本节中,我们在两个遥感多模态检索基准上,将所提方法与最先进的检索技术进行了比较。实验中采用的骨干网络为CLIP (ViT-B-32) (Radford等人, 2021a) 和 GeoRSCLIP (Zhang等人, 2023)。
Table 1: Retrieval Performance Test. $\ddagger$ : RSICD Test Set; ⋇ : RSITMD Test Set; $\dagger$ : The parameter count of a single adapter module, and $\dagger^{\prime}$ represents the results referenced from Yuan et al. (2023). Red: Our method; Blue: Full fine-tuned CLIP & GeoRSCLIP.
表 1: 检索性能测试。$\ddagger$: RSICD测试集;⋇: RSITMD测试集;$\dagger$: 单个适配器模块参数量,$\dagger^{\prime}$表示引用自Yuan等人(2023)的结果。红色: 我们的方法;蓝色: 全微调CLIP & GeoRSCLIP。
| 方法 | 主干网络(图像/文本) | 可训练参数量 | 图像到文本 | 文本到图像 | 平均召回率 | ||||
|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||||
| 传统方法 | |||||||||
| GaLR with MR (Yuan et al., 2022b) | ResNet18, biGRU | 46.89M | 6.59 | 19.85 | 31.04 | 4.69 | 19.48 | 32.13 | 18.96 |
| PIR (Pan et al., 2023a) | SwinTransformer, Bert | 9.88 | 27.26 | 39.16 | 6.97 | 24.56 | 38.92 | 24.46 | |
| 基于CLIP的方法 | |||||||||
| Full-FT CLIP (Radford et al., 2021a) | CLIP(ViT-B-32) | 151M | 15.89 | 36.14 | 47.93 | 12.21 | 32.97 | 48.84 | 32.33 |
| Full-FT GeoRSCLIP (Zhang et al., 2023) | GeoRSCLIP(ViT-B-32-RET-2) | 151M | 18.85 | 38.15 | 53.16 | 14.27 | 39.71 | 57.49 | 36.94 |
| Full-FT GeoRSCLIP(w/Extra Data) | GeoRSCLIP(ViT-B-32-RET-2) | 151M | 21.13 | 41.72 | 55.63 | 15.59 | 41.19 | 57.99 | 38.87 |
| Adapter (Houlsby et al., 2019) | CLIP(ViT-B-32) | 0.17M | 8.73 | 24.73 | 37.81 | 8.43 | 26.02 | 43.33 | 24.84 |
| CLIP-Adapter (Gao et al., 2021) | CLIP(ViT-B-32) | 0.52M | 7.11 | 19.48 | 31.01 | 7.67 | 24.87 | 39.73 | 21.65 |
| AdaptFormer(Chen et al., 2022) | CLIP(ViT-B-32) | 0.17M | 12.46 | 28.49 | 41.86 | 9.09 | 29.89 | 46.81 | 28.10 |
| Cross-Modal Adapter (Jiang et al., 2022a) | CLIP(ViT-B-32) | 0.16M | 11.18 | 27.31 | 40.62 | 9.57 | 30.74 | 48.36 | 27.96 |
| UniAdapter (Lu et al., 2023) | CLIP(ViT-B-32) | 0.55M | 12.65 | 30.81 | 42.74 | 9.61 | 30.06 | 47.16 | 28.84 |
| PE-RSITR (Yuan et al., 2023) | CLIP(ViT-B-32) | 0.16M | 14.13 | 31.51 | 44.78 | 11.63 | 33.92 | 50.73 | 31.12 |
| Ours (HarMA w/o Extra Data) | CLIP(ViT-B-32) | 0.50M | 16.36 | 34.48 | 47.74 | 12.92 | 37.17 | 53.07 | 33.62 |
| Ours (HarMA w/o Extra Data) | GeoRSCLIP(ViT-B-32-RET-2) | 0.50M | 20.52 | 41.37 | 54.66 | 15.84 | 41.92 | 59.39 | 38.95 |
| Full-FT CLIP (Radford et al., 2021a) | CLIP(ViT-B-32)* | 151M | 26.99 | 46.9 | 58.85 | 20.53 | 52.35 | 71.15 | 46.13 |
| Full-FT GeoRSCLIP (Zhang et al., 2023) | GeoRSCLIP(ViT-B-32-RET-2)* | 151M | 30.53 | 49.78 | 63.05 | 24.91 | 57.21 | 75.35 | 50.14 |
| Full-FT GeoRSCLIP (w/Extra Data) | GeoRSCLIP(ViT-B-32-RET-2)* | 151M | 32.30 | 53.32 | 67.92 | 25.04 | 57.88 | 74.38 | 51.81 |
| CLIP-Adapter (Gao et al., 2021) | CLIP(ViT-B-32)* | 0.52M | 12.83 | 28.84 | 39.05 | 13.30 | 40.20 | 60.06 | 32.38 |
| AdaptFormer (Chen et al., 2022) | CLIP(ViT-B-32)* | 0.17M | 16.71 | 30.16 | 42.91 | 14.27 | 41.53 | 61.46 | 34.81 |
| Cross-Modal Adapter (Jiang et al., 2022a) | CLIP(ViT-B-32)* | 0.16M | 18.16 | 36.08 | 48.72 | 16.31 | 44.33 | 64.75 | 38.06 |
| UniAdapter (Lu et al., 2023) | CLIP(ViT-B-32)* | 0.55M | 19.86 | 36.32 | 51.28 | 17.54 | 44.89 | 56.46 | 39.23 |
| PE-RSITR (Yuan et al., 2023) | CLIP(ViT-B-32)* | 0.16M | 23.67 | 44.07 | 60.36 | 20.10 | 50.63 | 67.97 | 44.47 |
| Ours(HarMA w/o Extra Data) | CLIP(ViT-B-32)* | 0.50M | 25.81 | 48.37 | 60.61 | 19.92 | 53.27 | 71.21 | 46.53 |
| Ours (HarMA w/o Extra Data) | GeoRSCLIP(ViT-B-32-RET-2)* | 0.50M | 32.74 | 53.76 | 69.25 | 25.62 | 57.65 | 74.60 | 52.27 |
Table 1 presents the retrieval performance on RSICD and RSITMD. Firstly, as indicated in the first column, our method surpasses traditional state-of-the-art approaches while requiring significantly fewer tuned parameters. Secondly, when using CLIP (ViT-B-32) (Radford et al., 2021a) as the backbone, our approach achieves competitive and even superior performance compared to fully fine-tuned methods. Specifically, when matched with methods that have a similar number of tunable parameters, our method’s Mean Recall (MR) sees an approximate increase of $50%$ over CLIP-Adapter (Gao et al., 2021) and $12.7%$ over UniAdapter (Lu et al., 2023) on RSICD, and an $18.6%$ improvement over UniAdapter on RSITMD. Remarkably, by utilizing the pretrained weights of GeoRSCLIP, HarMA establishes a new benchmark in the remote sensing field for two popular multimodal retrieval tasks. It only modifies less than $4%$ of the total model parameters, outperforming all current parameter-efficient fine-tuning methods and even surpassing the image-text retrieval performance of fully fine-tuned GeoRSCLIP on RSICD and RSITMD.
表1展示了在RSICD和RSITMD上的检索性能。首先,如第一列所示,我们的方法在需要显著更少调参量的情况下超越了传统最先进方法。其次,当使用CLIP (ViT-B-32) (Radford et al., 2021a)作为主干网络时,我们的方法相比完全微调方法实现了具有竞争力甚至更优的性能。具体而言,在与可调参量数量相近的方法对比时,我们的方法在RSICD上的平均召回率(MR)比CLIP-Adapter (Gao et al., 2021)提升约$50%$,比UniAdapter (Lu et al., 2023)提升$12.7%$;在RSITMD上比UniAdapter提升$18.6%$。值得注意的是,通过利用GeoRSCLIP的预训练权重,HarMA为遥感领域的两个热门多模态检索任务设立了新基准,仅修改不到$4%$的总模型参量,就超越了当前所有参数高效微调方法,甚至在RSICD和RSITMD上超越了完全微调GeoRSCLIP的图文检索性能。
4 CONCLUSION
4 结论
In this paper, we have revisited the learning objectives of multimodal downstream tasks from a unified perspective and proposed HarMA, an efficient framework that addresses the suboptimal multimodal alignment in remote sensing. HarMA uniquely enhances uniform alignment while preserving pretrained knowledge. Through the use of lightweight adapters and adaptive losses, HarMA achieves state-of-the-art retrieval performance with minimal parameter updates, surpassing even full fine-tuning. Despite all the benefits, one potential limitation is that designing pairwise objective functions may not provide more robust distribution constraints. Our future work will focus on extending this approach to more multimodal tasks.
本文从统一视角重新审视了多模态下游任务的学习目标,提出HarMA框架——一种解决遥感领域多模态次优对齐问题的高效方案。该框架在保持预训练知识的同时,通过独特设计实现了均匀对齐增强。借助轻量级适配器(adapter)和自适应损失函数,HarMA仅需极少的参数更新即达到最先进的检索性能,甚至超越全参数微调。尽管优势显著,该方法可能存在一个潜在局限:成对目标函数设计可能无法提供更强健的分布约束。我们未来工作将重点扩展该方法至更多多模态任务场景。
Zilun Zhang, Tiancheng Zhao, Yulong Guo, and Jianwei Yin. Rs5m: A large scale vision-language dataset for remote sensing vision-language foundation model. arXiv preprint arXiv:2306.11300, 2023.
张子伦, 赵天成, 郭玉龙, 尹建伟. RS5M: 面向遥感视觉-语言基础模型的大规模视觉-语言数据集. arXiv预印本 arXiv:2306.11300, 2023.
APPENDIX
附录
A PRELIMINARIES
初步准备
A.1 VISION TRANSFORMER (VIT)
A.1 视觉Transformer (ViT)
In the pipeline of ViT (Do sov it ski y et al., 2020), given an input image $I$ in $\mathbb{R}^{C\times H\times W}$ segmented into $N\times N$ patches, we define the input matrix $\bar{\mathbf{X}}\in\mathbb{R}^{({N^{2}}+\bar{1})\times{D}}$ consisting of patch embeddings and a class token. The self-attention mechanism in each Transformer layer transforms $\mathbf{X}$ into keys $K$ , values $V$ , and queries $Q$ , each in $\mathbb{R}^{(N^{2}+1)\times D}$ , and computes the self-attention (Vaswani et al., 2017) output as:
在ViT (Do sov it ski y等人,2020)的流程中,给定输入图像$I$ ($\mathbb{R}^{C\times H\times W}$),将其分割为$N\times N$个图像块后,定义输入矩阵$\bar{\mathbf{X}}\in\mathbb{R}^{({N^{2}}+\bar{1})\times{D}}$,该矩阵由图像块嵌入和一个类别Token组成。每个Transformer层中的自注意力机制将$\mathbf{X}$转换为键$K$、值$V$和查询$Q$ (均为$\mathbb{R}^{(N^{2}+1)\times D}$),并计算自注意力 (Vaswani等人,2017) 输出如下:
$$
{\mathrm{Attention}}(Q,K,V)={\mathrm{Softmax}}\left({\frac{Q K^{T}}{\sqrt{D}}}\right)V.
$$
$$
{\mathrm{Attention}}(Q,K,V)={\mathrm{Softmax}}\left({\frac{Q K^{T}}{\sqrt{D}}}\right)V.
$$
The subsequent processing involves a two-layer MLP, which refines the output across the embedded dimensions.
后续处理涉及一个双层MLP(多层感知机),用于在嵌入维度上优化输出。
A.2 ADAPTER
A.2 适配器
Adapters (Houlsby et al., 2019) are modular additions to pre-trained models, designed to allow adaptation to new tasks by modifying only a small portion of the model’s parameters. An adapter consists of a sequence of linear transformations and a non-linear activation:
适配器 (Houlsby et al., 2019) 是对预训练模型的模块化补充,旨在通过仅修改模型的一小部分参数来实现对新任务的适应。一个适配器由一系列线性变换和一个非线性激活组成:
$$
\begin{array}{r}{\mathrm{Adapter}(\mathbf{Z})=[\mathbf{W}^{\mathrm{up}}\sigma(\mathbf{W}^{\mathrm{down}}\mathbf{Z}^{T})]^{T},}\end{array}
$$
$$
\begin{array}{r}{\mathrm{Adapter}(\mathbf{Z})=[\mathbf{W}^{\mathrm{up}}\sigma(\mathbf{W}^{\mathrm{down}}\mathbf{Z}^{T})]^{T},}\end{array}
$$
where $\mathbf{W}^{\mathrm{down}}$ and $\mathbf{W}^{\mathrm{up}}$ are the weights for down-projection and up-projection, while $\sigma$ denotes a non-linear activation function that introduces non-linearity into the model.
其中 $\mathbf{W}^{\mathrm{down}}$ 和 $\mathbf{W}^{\mathrm{up}}$ 分别是下投影和上投影的权重,而 $\sigma$ 表示引入模型非线性的非线性激活函数。
Integrating adapters into the ViT architecture allows for efficient fine-tuning on specific tasks while keeping the majority of the Transformer’s weights unchanged. This approach not only retains the pre-trained visual understanding but also reduces the risk of catastrophic forgetting.
将适配器集成到ViT架构中,可以在保持Transformer大部分权重不变的同时,高效地对特定任务进行微调。这种方法不仅保留了预训练获得的视觉理解能力,还降低了灾难性遗忘的风险。
A.3 TRIPLET LOSS
A.3 三元组损失 (Triplet Loss)
In the domain of image-text retrieval tasks, the bidirectional triplet loss introduced by Faghri et al. (2017) has been widely adopted as a standard loss function. The formulation of the triplet loss is given by:
在图文检索任务领域,Faghri等人 (2017) 提出的双向三元组损失 (triplet loss) 已被广泛采用为标准损失函数。其数学表达式为:
$$
\mathcal{L}{\mathrm{triplet}}=\frac{1}{2}\left(\sum_{i=1}^{N}\sum_{j=1}^{N}[m+s_{i j}-s_{i i}]{+}+\sum_{j=1}^{N}\sum_{i=1}^{N}[m+s_{j i}-s_{i i}]_{+}\right).
$$
$$
\mathcal{L}{\mathrm{triplet}}=\frac{1}{2}\left(\sum_{i=1}^{N}\sum_{j=1}^{N}[m+s_{i j}-s_{i i}]{+}+\sum_{j=1}^{N}\sum_{i=1}^{N}[m+s_{j i}-s_{i i}]_{+}\right).
$$
The $m$ denotes the margin, a hyper parameter that defines the minimum distance between the nonmatching pairs. The function $s_{i j}$ represents the similarity score between the $i$ -th image and the $j$ -th text, and $s_{i i}$ is the similarity score between matching image-text pairs. The objective of the triplet loss is to ensure that the distance between non-matching pairs is greater than the distance between matching pairs by at least the margin $m$ .
$m$ 表示间隔 (margin),这是一个定义不匹配对之间最小距离的超参数。函数 $s_{i j}$ 表示第 $i$ 张图像与第 $j$ 段文本之间的相似度分数,而 $s_{i i}$ 是匹配的图像-文本对之间的相似度分数。三元组损失 (triplet loss) 的目标是确保不匹配对之间的距离比匹配对之间的距离至少大出间隔 $m$。
A.4 CONTRASTIVE LEARNING
A.4 对比学习 (Contrastive Learning)
where $\tau$ is the temperature parameter that scales the distribution of similarities. The overall contrastive loss is computed as the average of the vision-to-text and text-to-vision losses:
其中 $\tau$ 是温度参数,用于缩放相似度分布。整体对比损失计算为视觉到文本和文本到视觉损失的平均值:
$$
\mathcal{L}{\mathrm{contrastive}}=\frac{1}{2}\sum_{i=1}^{N}\left(\mathcal{L}{v2t}+\mathcal{L}_{t2v}\right).
$$
$$
\mathcal{L}{\mathrm{contrastive}}=\frac{1}{2}\sum_{i=1}^{N}\left(\mathcal{L}{v2t}+\mathcal{L}_{t2v}\right).
$$
This loss function encourages the model to distinguish between positive pairs (where images and texts correspond to each other) and negative pairs (where they do not), effectively learning a joint embedding space where similar concepts are closer together.
该损失函数鼓励模型区分正样本对(图像和文本相互对应)和负样本对(二者不相关),从而有效学习一个使相似概念更接近的联合嵌入空间。
A.5 RETRIEVAL EVALUATION METRICS
A.5 检索评估指标
The retrieval evaluation metrics are defined as the mean of the recall rates at different cutoff points for both text-to-image and image-to-text retrieval tasks:
检索评估指标定义为文本到图像和图像到文本检索任务在不同截断点处召回率的平均值:
$$
\mathrm{mR}=\left(\underbrace{R@1+R@5+R@10}{\mathrm{Text-to-image}}+\underbrace{R@1+R@5+R@10}_{\mathrm{Image-to-text}}\right)/6,
$$
$$
\mathrm{mR}=\left(\underbrace{R@1+R@5+R@10}{\mathrm{Text-to-image}}+\underbrace{R@1+R@5+R@10}_{\mathrm{Image-to-text}}\right)/6,
$$
where $R@k$ is the recall at rank $k$ , indicating the percentage of queries for which the correct item is found among the top $k$ retrieved results. The mean recall mR averages these recall values to provide a single performance metric that captures retrieval effectiveness at various depths of the result list.
其中 $R@k$ 表示排名 $k$ 处的召回率 (recall),衡量在前 $k$ 个检索结果中找到正确答案的查询比例。平均召回率 mR 通过计算这些召回值的均值,生成一个综合性能指标,用于评估结果列表不同深度下的检索效果。
B ALGORITHM
B 算法
Algorithm 1 MultiModal Gated Adapter (MGA) for cross-modal interaction.
算法 1: 跨模态交互的多模态门控适配器 (MultiModal Gated Adapter, MGA)
输入:分别来自图像和文本编码器的特征张量Z1和Zr。参数:权重矩阵W1、W2、W,偏置向量b1、b2、bi,以及可学习的门控参数λ1、λ2。
函数σ()是非线性激活函数(例如GELU)
函数MSA()是多头自注意力机制
函数MMSA()是多模态子适配器机制,定义如下:
MMSA(x) = W_up(MSA(α(W_downx + b_down))) + b_up
对于每个特征张量Z ∈ {Z1, Zr}执行:
f1 = σ(WZ + b1) # 处理图像和文本特征张量
f2 = MSA(f1)
f3 = λ1 MMSA(f2) + (1 - λ1)f2 # 应用带门控的多模态子适配器
f4 = λ2 MSA(f3) + (1 - λ2)f1
f_end = (W2f4 + b2) + Z
结束循环
C EXPERIMENT DETAILS
C 实验细节
C.1 DATASETS
C.1 数据集
RSICD. The Remote Sensing Image Captioning Dataset (RSICD) serves as a benchmark for the task of captioning remote sensing images (Lu et al., 2017). It encompasses over ten thousand remote sensing images sourced from Google Earth, Baidu Maps, MapABC, and Tianditu. The resolution of these images varies, with each being resized to a fixed dimension of $224\mathrm{x}224$ pixels. The dataset comprises a total of 10,921 images, with each image accompanied by five descriptive sentences.
RSICD。遥感图像描述数据集 (RSICD) 是遥感图像描述任务的基准 (Lu et al., 2017)。该数据集包含来自 Google Earth、百度地图、MapABC 和天地图的上万张遥感图像,图像分辨率各异,均被统一调整为 $224\mathrm{x}224$ 像素的固定尺寸。数据集共计 10,921 张图像,每张图像配有五条描述性语句。
RSITMD. The Remote Sensing Image-Text Matching Dataset (RSITMD) is a fine-grained and challenging dataset for remote sensing multimodal retrieval tasks, introduced by Yuan et al. (2022a).
RSITMD。遥感图像-文本匹配数据集 (RSITMD) 是由Yuan等人 (2022a) 提出的一个细粒度且具有挑战性的遥感多模态检索任务数据集。
Unlike other remote sensing image-text pairing datasets, it features detailed descriptions of the rela tion ships between objects. Additionally, the dataset includes keyword attributes (ranging from one to five keywords per image), facilitating keyword-based remote sensing text retrieval tasks. It comprises 4,743 images spanning 32 scenes, with a total of 23,715 annotations, of which 21,829 are unique.
与其他遥感图文配对数据集不同,该数据集的特点是详细描述了物体之间的关系。此外,数据集还包含关键词属性(每张图像包含1到5个关键词),便于基于关键词的遥感文本检索任务。该数据集包含32个场景的4743张图像,共有23715条标注,其中21829条是唯一的。
C.2 IMPLEMENTATION DETAILS
C.2 实现细节
Consistent with the experimental details established by Pan et al. (2023a), we partitioned the dataset into distinct sets for training, validation, and testing. For CLIP (ViT-B-32)2 or GeoRSCLIP, the final features are linearly projected to a 512-dimensional space. We set the temperature coefficient for the contrastive loss at 0.07 and the margin for the adaptive triplet loss at 0.2. Training was executed on either four A40 GPUs $(48\mathbf{G}\mathbf{B}\times2)$ or eight RTX 4090 GPUs $(24\mathbf G B\times4)$ with a batch size of 428. We utilized an AdamW optimizer (Loshchilov & Hutter, 2017) with a learning rate of 4e-4 (4e-6 for fine-tuning GeoRSCLIP), a weight decay of 0.04, and implemented a linear decay strategy for the learning rate. Following the approach of Yuan et al. (2022a), we employ a k-fold cross-validation strategy to obtain average results, with $k$ set to 5.
与Pan等人 (2023a) 建立的实验细节保持一致,我们将数据集划分为训练集、验证集和测试集。对于CLIP (ViT-B-32)或GeoRSCLIP,最终特征被线性投影到512维空间。我们将对比损失的温度系数设为0.07,自适应三元组损失的边界值设为0.2。训练在四块A40 GPU $(48\mathbf{G}\mathbf{B}\times2)$ 或八块RTX 4090 GPU $(24\mathbf G B\times4)$ 上执行,批次大小为428。我们采用AdamW优化器 (Loshchilov & Hutter, 2017),学习率为4e-4(微调GeoRSCLIP时为4e-6),权重衰减为0.04,并实施了学习率线性衰减策略。参照Yuan等人 (2022a) 的方法,我们采用k折交叉验证策略获取平均结果,设定 $k$ 值为5。
C.3 ABLATION STUDY
C.3 消融研究
To demonstrate the effectiveness of our proposed method, we compared it against three baselines: 1) a CLIP model fully fine-tuned with downstream domain data, 2) a CLIP model with MGA but without introducing a new objective function, and 3) a CLIP model with HarMA. We evaluate the experimental performance on the RSITMD dataset. Table 2 presents the results of the ablation study.
为验证所提方法的有效性,我们将其与三个基线模型进行对比:1) 在下游领域数据上完全微调的CLIP模型,2) 采用MGA但未引入新目标函数的CLIP模型,3) 采用HarMA的CLIP模型。我们在RSITMD数据集上评估实验性能。表2展示了消融研究结果。
Table 2: Comparison of different methods on RSITMD dataset. The first row represents the results of the fully fine-tuned CLIP (Full-ft CLIP). The subsequent rows, from top to bottom, represent the CLIP with the Multimodal Gating Adapter (MGA) where only the MGA is fine-tuned (CLIP w/ MGA), and CLIP with both the MGA and the adaptive triplet loss, where only the MGA is finetuned (CLIP w/ MGA $^+$ Adaptive Triplet Loss).
表 2: RSITMD数据集上不同方法的比较。第一行表示完全微调的CLIP (Full-ft CLIP)的结果。随后的行从上到下分别表示仅微调多模态门控适配器(MGA)的CLIP (CLIP w/ MGA),以及同时使用MGA和自适应三元组损失且仅微调MGA的CLIP (CLIP w/ MGA $^+$ Adaptive Triplet Loss)。
| Method | Backbone | MGA | AdaptiveTripletLoss | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | MR |
|---|---|---|---|---|---|---|---|---|---|---|
| Full-FTCLIP | ViT-B-32 | x | 26.99 | 46.9 | 58.85 | 20.53 | 52.35 | 71.15 | 46.13 | |
| CLIPw/MGA | ViT-B-32 | √ | 25.33 | 47.96 | 60.26 | 18.71 | 53.13 | 70.52 | 45.98 | |
| CLIP(HarMA) | ViT-B-32 | √ | 25.81 | 48.37 | 60.61 | 19.92 | 53.27 | 71.21 | 46.53 |
Table 3: Model trainable parameters comparison.
表 3: 模型可训练参数量对比。
| 方法 | 可训练参数量 (%) |
|---|---|
| Full-FTCLIP | 100.00 |
| Adapter r (Houlsby et al., 2019) | 2.60 |
| CLIP-Adapter (Ga0 et al., 2021) | 4.13 |
| CLIP w/MGA (Ours) | 3.82 |
| HarMA (Ours) | 3.82 |
In our experiments, for a fair comparison, we selected CLIP (ViT-B-32) (Radford et al., 2021b) as the backbone model to conduct ablation studies. As shown in Table 2, the first row presents the performance of CLIP following comprehensive fine-tuning on downstream datasets, achieving a robust performance $(\mathrm{m}\mathrm{R}{=}46.13)$ ). However, this method requires fine-tuning the entire model, which is computationally intensive and difficult to scale. By simply integrating the Multimodal Gated Adapter (MGA) as depicted in the third row, we achieve results comparable to full finetuning (45.98 vs 46.13). The third row illustrates that the inclusion of our proposed adaptive triplet loss further enhances performance, slightly surpassing that of full fine-tuning (46.53 vs 46.13). This improvement can be attributed to the introduction of the objective function that addresses the issue of semantic confusion within the same modality, as discussed in Section 1, when modeling the joint visual-language space. Our experiments validate the effectiveness of the proposed modules, offering a promising solution to address this challenge. Table 3 presents the percentage of parameters that require fine-tuning for each method, relative to the total number of parameters in the model.
在我们的实验中,为公平比较,我们选择 CLIP (ViT-B-32) (Radford et al., 2021b) 作为主干模型进行消融研究。如表 2 所示,第一行展示了 CLIP 在下游数据集上全面微调后的性能,达到了稳健的表现 $(\mathrm{m}\mathrm{R}{=}46.13)$ 。然而,这种方法需要微调整个模型,计算量大且难以扩展。如第三行所示,仅通过集成多模态门控适配器 (MGA) 即可获得与全微调相当的结果 (45.98 vs 46.13)。第三行表明,加入我们提出的自适应三元组损失可进一步提升性能,略微超越全微调 (46.53 vs 46.13)。这一改进可归因于目标函数的引入,它解决了第 1 节讨论的联合视觉-语言空间建模中同一模态内语义混淆的问题。我们的实验验证了所提模块的有效性,为解决这一挑战提供了有前景的方案。表 3 展示了每种方法需微调的参数量占模型总参数量的百分比。
D QUALITATIVE ANALYSIS
D 定性分析
D.1 IMAGE-TO-TEXT RESULTS ANALYSIS
D.1 图像到文本结果分析

Figure 4: Image-to-Text Retrieval Visual Results. We compare the top-5 retrieved captions from HarMA (Ours) and the fully fine-tuned CLIP (Full-FT CLIP). Green text indicates correct retrieval, while red text indicates incorrect retrieval. The image on the far right corresponds to the text where retrieval errors occurred. Overall, HarMA demonstrates superior retrieval performance compared to Full-FT CLIP. Our method accurately captures the semantic elements, such as the tennis court in the first image, and associates them with the overall context. In contrast, Full-FT CLIP tends to overemphasize irrelevant details, mistakenly treating partial shadows and surrounding trees as the main subject matter.
图 4: 图像到文本检索可视化结果。我们将 HarMA (Ours) 和全微调 CLIP (Full-FT CLIP) 检索到的前 5 条描述进行对比。绿色文字表示正确检索结果,红色文字表示错误检索结果。最右侧图像对应发生检索错误的文本。总体而言,HarMA 展现出优于 Full-FT CLIP 的检索性能。我们的方法能准确捕捉语义要素(如第一张图中的网球场)并将其与整体语境关联,而 Full-FT CLIP 则倾向于过度强调无关细节,错误地将局部阴影和周边树木视作主体内容。
Figure 4 presents the qualitative results for image-to-text retrieval, comparing the top-5 retrieved captions from HarMA (Ours) and the fully fine-tuned CLIP (Full-ft CLIP). Overall, HarMA demonstrates superior retrieval performance compared to Full-ft CLIP.
图 4: 展示了图像到文本检索的定性结果,对比了HarMA (Ours)和完全微调的CLIP (Full-ft CLIP)检索出的前5条描述。总体而言,HarMA展现出比Full-ft CLIP更优的检索性能。
Notably, in the first case, even though our method’s fifth-ranked retrieval result is incorrect, it effectively captures the overall semantics rather than irrelevant details. For instance, we identify the “two tennis courts” as the core semantic element of the image and retrieve a highly similar text (see the incorrect example in the rightmost column). In contrast, Full-ft CLIP mistakenly treats the “slight shadows” of the tennis courts and the surrounding “trees and lawn” as the primary semantics, as evidenced by the second (shadow of green farmland) and third (some trees and pentagonal squares of lawns) retrieved texts. This observation may provide two insights from an interpret able perspective: 1) HarMA is better at recognizing overall semantics, and 2) Full-ft CLIP may be prone to over fitting, focusing excessively on unimportant details in the image.
值得注意的是,在第一种情况下,尽管我们方法的第五个检索结果不正确,但它有效捕捉了整体语义而非无关细节。例如,我们将"两个网球场"识别为图像的核心语义元素,并检索到高度相似的文本(见最右侧列的错误示例)。相比之下,Full-ft CLIP错误地将网球场的"轻微阴影"和周围的"树木与草坪"作为主要语义,这从第二个(绿色农田的阴影)和第三个(一些树木和五边形草坪广场)检索文本中可以得到印证。这一观察可能从可解释性角度提供两个启示:1) HarMA更擅长识别整体语义;2) Full-ft CLIP可能容易过拟合,过度关注图像中不重要的细节。
In the second scenario, we focus on a forest image, which poses a greater challenge. Unlike the first scenario, here trees typically seen in the background are brought to the foreground, testing the model’s ability to generalize. Here, although HarMA retrieves two incorrect texts, each corresponding to a specific image. Interestingly, as shown on the far right, the retrieved image is also a forest. From a human evaluation perspective, the incorrectly retrieved results may provide more detailed descriptions than the correct text, while the original dataset annotation appears rather simplistic. The results retrieved by Full-ft CLIP, on the other hand, deviate significantly from the actual image semantics, with the primary semantics being squares (TOP-1), farmland (TOP-2), and industrial areas (TOP-4). We hypothesize that HarMA, by introducing downstream domain knowledge through adapters while retaining some of the original large-scale pre-training priors, is better equipped to handle the “noise problem” in small datasets compared to full fine-tuning.
在第二种场景中,我们聚焦于更具挑战性的森林图像。与第一种场景不同,此处通常作为背景的树木被置于前景,以测试模型的泛化能力。尽管HarMA检索到了两条错误文本(每条对应特定图像),但有趣的是,如最右侧所示,检索到的图像同样是森林。从人类评估视角看,错误检索结果可能比原始数据集标注的正确文本提供更详细描述,而原始标注显得过于简化。相比之下,Full-ft CLIP的检索结果严重偏离实际图像语义,主要语义为方形区域(TOP-1)、农田(TOP-2)和工业区(TOP-4)。我们假设HarMA通过适配器引入下游领域知识的同时,保留部分原始大规模预训练先验,相比全参数微调更能应对小数据集中的"噪声问题"。
D.2 TEXT-TO-IMAGE RESULTS ANALYSIS
D.2 文生图结果分析
Figure 5 illustrates the top-5 text-to-image retrieval results on the RSITMD test set for our HarMA and the fully fine-tuned CLIP models. Similar to the image-to-text case, our HarMA outperforms the fully fine-tuned CLIP overall.
图 5: 展示了我们的HarMA模型与全微调CLIP模型在RSITMD测试集上的前5名文本到图像检索结果。与图像到文本的情况类似,我们的HarMA在整体上优于全微调CLIP。
Let us examine the first case. In the first row, the query image depicts “a city with a lot of green plants.” Our HarmA successfully retrieves a matching image in the top-1 result. Encouragingly, the top-2 to top-4 results are primarily semantically associated with “city” and “green plants.” Although the final top-5 result is semantically unrelated, the distorted river channel bears striking resemblance to the winding road in the query image. The second row shows the retrieval results from the fully fine-tuned CLIP, which, similar to the image-to-text case, focuses on irrelevant details (e.g., the green lake in top-4 and the green playground in top-5).
让我们来看第一个案例。第一行的查询图像描绘了"一座拥有大量绿色植物的城市"。我们的HarmA成功在top-1结果中检索到匹配图像。令人鼓舞的是,top-2到top-4结果主要与"城市"和"绿色植物"存在语义关联。虽然最终的top-5结果在语义上不相关,但扭曲的河道与查询图像中蜿蜒的道路具有惊人的相似性。第二行展示了全参数微调CLIP的检索结果,与图文检索案例类似,其关注点集中在无关细节上(例如top-4的绿色湖泊和top-5的绿色操场)。
In the second case, both HarMA and the fully fine-tuned CLIP exhibit varying degrees of “hallucination” by associating the winding river with distorted roads. However, HarMA still outperforms the fully fine-tuned CLIP in terms of retrieval confidence and overall semantic relevance. For instance, HarMA still captures the overall semantics of “A river with dark green water.”
在第二种情况下,HarMA和完全微调的CLIP都表现出不同程度的"幻觉",将蜿蜒的河流与扭曲的道路联系起来。但HarMA在检索置信度和整体语义相关性方面仍优于完全微调的CLIP。例如,HarMA仍能捕捉到"一条深绿色河水"的整体语义。
In conclusion, the image-to-text and text-to-image retrieval results demonstrate HarMA’s effectiveness in mitigating hallucinations and resisting noise. In the future, we aim to extend it to LLMs.
总之,图像到文本和文本到图像的检索结果证明了 HarMA 在减少幻觉 (hallucination) 和抵抗噪声方面的有效性。未来,我们计划将其扩展到大语言模型 (LLM)。

Figure 5: Text-to-Image Retrieval Visual Results. On the left side, we show the query text, and the ground-truth image is displayed below. The top-5 retrieved images based on the query text are presented on the right side, where green boxes indicate matches and red boxes indicate mismatches. For the mismatched retrieved images, we identify the main semantics of their associated text above the images. It is worth noting that in the rsitmd dataset, the relationship between images and texts is one-to-many, meaning that Image-to-Text can retrieve multiple results, while Text-to-Image has only one correct result.
图 5: 文本到图像检索可视化结果。左侧展示查询文本,下方显示真实图像。右侧呈现基于查询文本检索到的前5张图像,其中绿色框表示匹配项,红色框表示不匹配项。对于不匹配的检索图像,我们在图像上方标出其关联文本的主要语义。值得注意的是,在rsitmd数据集中,图像与文本的关系是一对多的,这意味着图像到文本可以检索到多个结果,而文本到图像只有一个正确结果。
D.3 VISUAL RESULTS OF EMBEDDING SPACE
D.3 嵌入空间的视觉结果
In this subsection, we present the t-SNE (Van der Maaten & Hinton, 2008) visualization s of the image and text embeddings. To capture the highest-level semantics, we select the embeddings from the final transformer layer for t-SNE processing. We employ a CLIP model with a ViT-B-32 backbone and conduct experiments on the RSITMD test set.
在本小节中,我们展示了图像和文本嵌入的t-SNE (Van der Maaten & Hinton, 2008) 可视化结果。为捕捉最高层级的语义信息,我们选取最终Transformer层的嵌入进行t-SNE处理。实验采用基于ViT-B-32骨干网络的CLIP模型,并在RSITMD测试集上完成。

Figure 6: The leftmost figure illustrates the visualization results of the CLIP model outputs without fine-tuning on downstream data. The central figure depicts the visualization of the CLIP outputs with MGA. The rightmost figure showcases the results of our HarMA framework.
图 6: 最左侧的图展示了未经下游数据微调的CLIP模型输出可视化结果。中间的图描绘了采用MGA方法的CLIP输出可视化。最右侧的图展示了我们的HarMA框架的输出结果。
As shown in Figure 6, the visualization of the CLIP model outputs without fine-tuning on downstream data reveals a significant distance between the embeddings of different modalities, indicating suboptimal modal alignment. The CLIP output results with MGA demonstrate excellent modal alignment; however, the distances within the same modality are excessively small (exhibiting partial clustering), potentially hindering the capture of fine-grained semantic differences.
如图 6 所示,未经下游数据微调的 CLIP 模型输出可视化结果显示,不同模态的嵌入之间存在显著距离,表明模态对齐效果欠佳。采用 MGA 的 CLIP 输出结果展现出优异的模态对齐能力,但同一模态内的距离过小(呈现局部聚类现象),可能阻碍细粒度语义差异的捕捉。

Figure 7: Visualization of the embedding space. The first image illustrates the output of an overfitted CLIP model, the second image depicts the results from a fully fine-tuned CLIP model, and the third image presents the outputs after fine-tuning with the HarMA framework.
图 7: 嵌入空间可视化。第一张图展示了过拟合 CLIP 模型的输出,第二张图描绘了完全微调 CLIP 模型的结果,第三张图呈现了使用 HarMA 框架微调后的输出。
Figure 7 presents the visualization results of the embedding space under various conditions. The retrieval performance is ranked as follows: HarMA $>$ Fully fine-tuned $\mathrm{CLIP>}$ Overfitted CLIP. The overfitted CLIP model shows almost no alignment between visual and textual embeddings, resulting in the poorest retrieval performance. The fully fine-tuned CLIP model achieves basic modality alignment but still exhibits some clustering phenomena mentioned in Section 1. Conversely, regardless of whether in Figure 6 or Figure 7, the output results of the complete HarMA framework not only exhibit robust modal alignment but also mitigate the aforementioned intra-modal clustering phenomenon, thereby validating the effectiveness of our proposed method.
图 7: 展示了不同条件下嵌入空间的可视化结果。检索性能排序为: HarMA $>$ 全微调 CLIP $>$ 过拟合 CLIP。过拟合 CLIP 模型在视觉和文本嵌入之间几乎不存在对齐关系,导致检索性能最差。全微调 CLIP 模型实现了基本的模态对齐,但仍存在第 1 节提到的聚类现象。相反,无论是在图 6 还是图 7 中,完整 HarMA 框架的输出结果不仅展现出稳健的模态对齐特性,还缓解了前述的模态内聚类现象,从而验证了我们所提方法的有效性。