ClickDiff: Click to Induce Semantic Contact Map for Controllable Grasp Generation with Diffusion Models
ClickDiff: 通过点击诱导语义接触图实现基于扩散模型的可控抓取生成
ABSTRACT
摘要
Grasp generation aims to create complex hand-object interactions with a specified object. While traditional approaches for hand generation have primarily focused on visibility and diversity under scene constraints, they tend to overlook the fine-grained hand-object interactions such as contacts, resulting in inaccurate and undesired grasps. To address these challenges, we propose a controllable grasp generation task and introduce ClickDiff, a controllable conditional generation model that leverages a fine-grained Semantic Contact Map (SCM). Particularly when synthesizing interactive grasps, the method enables the precise control of grasp synthesis through either user-specified or algorithmic ally predicted Semantic Contact Map. Specifically, to optimally utilize contact supervision constraints and to accurately model the complex physical structure of hands, we propose a Dual Generation Framework. Within this framework, the Semantic Conditional Module generates reasonable contact maps based on fine-grained contact information, while the Contact Conditional Module utilizes contact maps alongside object point clouds to generate realistic grasps. We evaluate the evaluation criteria applicable to controllable grasp generation. Both unimanual and bimanual generation experiments on GRAB and ARCTIC datasets verify the validity of our proposed method, demonstrating the efficacy and robustness of ClickDiff, even with previously unseen objects. Our code is available at https://github.com/adventurer-w/ClickDiff.
抓握生成旨在创建与指定物体的复杂手部交互。传统的手部生成方法主要关注场景约束下的可见性和多样性,往往忽略了接触等细粒度的手物交互,导致生成不准确且不符合预期的抓握。为解决这些挑战,我们提出可控抓握生成任务,并推出ClickDiff——一个利用细粒度语义接触图(SCM)的可控条件生成模型。该方法在合成交互式抓握时,能通过用户指定或算法预测的语义接触图实现精准控制。具体而言,为充分利用接触监督约束并精确建模手部复杂物理结构,我们提出双生成框架:语义条件模块基于细粒度接触信息生成合理接触图,而接触条件模块则结合接触图与物体点云生成逼真抓握。我们制定了适用于可控抓握生成的评估标准。在GRAB和ARCTIC数据集上的单手/双手生成实验验证了方法的有效性,证明ClickDiff即使面对未见物体仍具备优异性能与鲁棒性。代码已开源:https://github.com/adventurer-w/ClickDiff。
CCS CONCEPTS
CCS概念
• Computing methodologies $\rightarrow$ Shape inference.
• 计算方法 $\rightarrow$ 形状推断
KEYWORDS
关键词
Controllable Grasp Generation, Human-Object Interaction, Semantic Contact Map
可控抓取生成、人-物交互、语义接触图
ACM Reference Format:
ACM 参考文献格式:
Peiming Li, Ziyi Wang, Mengyuan Liu, Hong Liu, and Chen Chen. 2024. ClickDiff: Click to Induce Semantic Contact Map for Controllable Grasp Generation with Diffusion Models. In Proceedings of the 32nd ACM International Conference on Multimedia (MM ’24), October 28-November 1, 2024, Melbourne, VIC, Australia Proceedings of the 32nd ACM International Conference on Multimedia (MM’24), October 28-November 1, 2024, Melbourne, Australia. ACM, New York, NY, USA, 9 pages. https://doi.org/10.1145/3664647.3680597
Peiming Li、Ziyi Wang、Mengyuan Liu、Hong Liu 和 Chen Chen。2024。ClickDiff:通过点击诱导语义接触图实现基于扩散模型的可控抓取生成。见:第32届ACM国际多媒体会议论文集(MM'24),2024年10月28日-11月1日,澳大利亚墨尔本。ACM,美国纽约州纽约市,9页。https://doi.org/10.1145/3664647.3680597
1 INTRODUCTION
1 引言
In recent years, the modeling of hand-object interactions [1, 2, 5, 7, 11, 15, 24, 25, 30, 34, 38] has gained substantial importance due to its significant role in applications across human-computer interaction [39], virtual reality [13, 39, 40], robotics [3, 37, 45], and animation [27]. Addressing the specific needs for hand-object interaction modeling emerges as a paramount concern. How do hands interact with a bowl? One can envision a variety of interaction types (e.g., "grabbing/holding") and numerous possible interaction locations (e.g., "rim/bottom"). The diversity of these interactions largely stems from the layouts of hands and objects, making the generation of accurate interactions challenging. An accurate generative model should account for factors such as which areas of the object will be touched and which parts of the hand will make contact. In contrast, a lack of thorough and precise modeling may result in unnatural and unrealistic interactions.
近年来,手与物体交互建模 [1, 2, 5, 7, 11, 15, 24, 25, 30, 34, 38] 因其在人机交互 [39]、虚拟现实 [13, 39, 40]、机器人学 [3, 37, 45] 和动画 [27] 等领域的重要应用价值而备受关注。如何满足手物交互建模的特定需求成为关键问题。例如,手如何与碗互动?人们可以设想多种交互类型(如"抓握/托持")和大量可能的交互位置(如"碗沿/底部")。这种多样性的根源在于手部与物体的空间布局关系,使得精准生成交互变得极具挑战性。一个精确的生成模型需要考虑诸如"物体的哪些区域会被触碰"以及"手部的哪些部位会参与接触"等因素。反之,若缺乏全面精确的建模,则可能导致不自然、失真的交互效果。
Traditional approaches [15, 24] for hand generation have primarily focused on visibility and diversity under scene constraints. Most existing control la bly generated hand-object interaction images rely on simple textual scene understandings, such as "a hand holding a cup" for input synthesis, failing to generate precise hand-object interactions due to the lack of fine-grained information. Methods [44] utilizing contact information often depend on contact mapping applied to object point clouds to indicate contact points. However, relying solely on information learned from contact maps as constraints still leaves the issue of which areas of the hand to use for touching unaddressed. Moreover, providing contact maps for both the object and the hand simultaneously is almost an impossible task in real-world applications.
传统方法 [15, 24] 在手部生成领域主要关注场景约束下的可见性与多样性。现有大多数可控生成的手-物交互图像依赖于简单的文本场景理解(例如输入"手握杯子"进行合成),由于缺乏细粒度信息而无法生成精确的手-物交互。基于接触信息的方法 [44] 通常需要将接触映射应用于物体点云来标注接触点,但仅依靠从接触图学习的信息作为约束,仍未解决"该用手部哪个区域接触"的问题。此外,在实际应用中同时提供物体和手部的接触图几乎是不可能完成的任务。
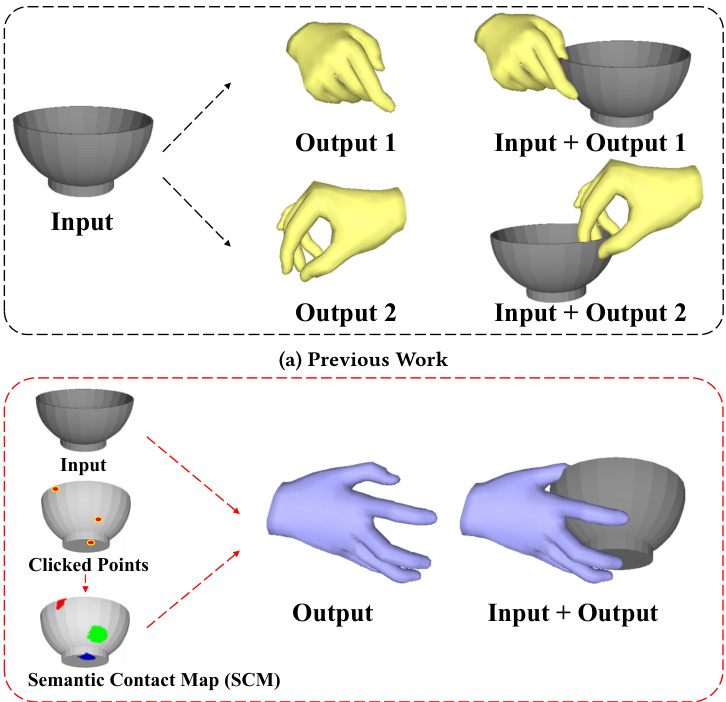
(b) Controllable Grasp with SCM (Ours) Figure 1: Previous works face issues of contact ambiguity, where an input object could lead to multiple undesired grasps, such as when a bowl is expected to be grabbed from the bottom, revealing the importance of controllable grasp generation. By manually determining contact points and specifying contact fingers, one can obtain SCM (each color represents the contact area of a different finger) by traversing the area around the clicked point. Finally, by utilizing SCM, it’s possible to achieve accurate user-expected grasp.
图 1: 先前研究存在接触模糊性问题,输入物体可能导致多个非预期抓取方式(例如本应从底部抓取的碗)。通过手动确定接触点并指定接触手指,可遍历点击点周围区域获得SCM(每种颜色代表不同手指的接触区域)。最终利用SCM即可实现精准的用户预期抓取效果。
Previous efforts in grasp generation have emphasized achieving visibility and diversity, often overlooking the fine-grained handobject interactions such as contacts. This oversight has led to a notable deficit in both accuracy and practicality of generated grips, especially in scenarios requiring precise and controllable synthesis. To address these challenges, we propose a controllable grasp generation task, which can realize the generation through manually specified hand and object contact point pairs. Our key insight is that the movements of hand joints are largely driven by the geometry of fingers. Explicitly modeling the contact between fingers and object sampling points during training and inference can serve as a powerful proxy guide. Employing this guidance to link the movements of hands and objects can result in more realistic and precise interactions. What’s more, grip generation guided by artificially defined contact is more practical. Fig. 1 demonstrates the contact ambiguity issues present in past generation methods compared to controllable generation task with artificially designated contact points. To better model the artificially defined fine-grained contacts shown in Fig. 1, we introduce a novel, simple and easily specified contact representation method called Semantic Contact Map. By processing point clouds of objects and hands, it obtains representations of points on the object that are touched and the fingers touching those points, specifically providing: (1) The points on the object that are touched. (2) The number of the finger touching the point. A significant advantage is that one can click to customize the Semantic Contact Map to achieve user-controlled interactive generation. We show that utilizing Semantic Contact Map can achieve more natural and precise generation results than conventional methods that rely solely on contact map. Furthermore, to better utilize a human-specified SCM in contact supervision constraints, we propose a Dual Generation Framework based on conditional diffusion model [12, 19, 36, 43]. The denoising process of the diffusion model inherently involves constraints on the parameters of both hands, reducing unnatural and unrealistic interactions between them.
先前关于抓握生成的研究侧重于实现可见性和多样性,往往忽略了接触等细粒度的手部-物体交互。这种疏忽导致生成的抓握在准确性和实用性上存在明显不足,尤其是在需要精确可控合成的场景中。为解决这些问题,我们提出了一种可控抓握生成任务,可通过手动指定的手部与物体接触点对实现生成。我们的核心观点是:手部关节运动主要由手指几何形态驱动。在训练和推理过程中显式建模手指与物体采样点间的接触,能够成为强有力的代理引导。运用这种引导来关联手部与物体的运动,可以产生更真实精确的交互。此外,基于人工定义接触的抓握生成更具实用性。图1展示了传统生成方法存在的接触模糊问题,以及与人工指定接触点的可控生成任务的对比。
为更好地建模图1所示的人工定义细粒度接触,我们提出了一种新颖、简单且易于指定的接触表征方法——语义接触图(Semantic Contact Map)。该方法通过处理物体和手部的点云,获取被接触物体点及对应接触手指的表示,具体提供:(1) 物体表面被接触的点位;(2) 接触该点的手指编号。其显著优势在于支持点击自定义语义接触图,实现用户可控的交互式生成。实验证明,相比传统仅依赖接触图的方法,使用语义接触图能获得更自然精确的生成结果。
为进一步利用人工指定的语义接触图进行接触监督约束,我们提出了基于条件扩散模型[12,19,36,43]的双重生成框架。扩散模型的去噪过程天然包含对手部参数的双重约束,可减少手部间不自然、不真实的交互。
Building on the aforementioned observations, this paper introduces the ClickDiff based on Semantic Contact Map to realize controllable grasp generation, which is divided into two parts: (1) We explicitly model the contact between fingers and object sampling points by specifying the locations of contact points on the object and the finger numbers contacting those points, guiding the interactions between hands and objects. Benefit from previous work utilizing contact map [6, 10, 15, 24, 33], to embed Semantic Contact Map into the feature space for easy learning and utilization by the network, we propose the Semantic Conditional Module, which can generate plausible contact maps based on specified Semantic Contact Map and object point clouds. (2) Inspired by the grasps generation method in the RGB image domain [10], we propose the Contact Conditional Module, which synthesizes hand grasps based on generated contact maps and object point cloud information as conditions. To better utilize Semantic Contact Map, we propose Tactile-Guided Constraint. Tactile-Guided Constraint can extract pairs in the SCM that represents touching and integrate contact information into the Contact Conditional Module by calculating the distance between the centroid of each finger’s predefined set of points and the contact point on the object. Specifically, we provide a Dual Generation Framework that allows using Semantic Contact Map on a given object as a condition for generating contact maps, which then serve as a condition for generating grasps.
基于上述观察,本文提出基于语义接触图(Semantic Contact Map)的ClickDiff来实现可控抓取生成,该方法分为两部分:(1) 我们通过指定物体接触点位置和对应手指编号,显式建模手指与物体采样点间的接触关系,从而指导手部与物体的交互。受益于前人利用接触图[6,10,15,24,33]的工作,为将语义接触图嵌入特征空间便于网络学习利用,我们提出语义条件模块(Semantic Conditional Module),该模块能基于指定语义接触图和物体点云生成合理的接触图。(2) 受RGB图像域抓取生成方法[10]启发,我们提出接触条件模块(Contact Conditional Module),该模块以生成的接触图和物体点云信息为条件合成手部抓取姿态。为更好利用语义接触图,我们提出触觉引导约束(Tactile-Guided Constraint)。该约束能提取SCM中表示接触的点对,并通过计算手指预定义点集质心与物体接触点间的距离,将接触信息整合到接触条件模块中。具体而言,我们提供双生成框架(Dual Generation Framework),允许使用给定物体上的语义接触图作为生成接触图的条件,进而将接触图作为生成抓取姿态的条件。
In summary, our contributions are as follows:
总之,我们的贡献如下:
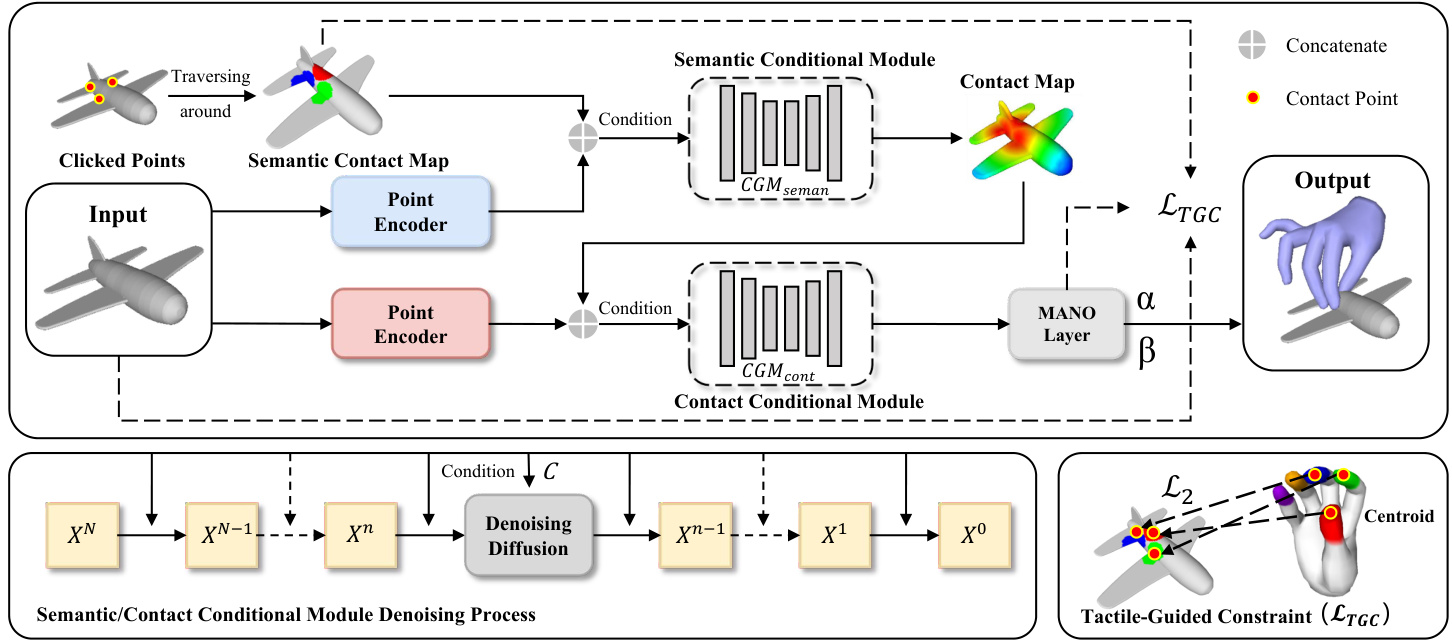
Figure 2: Overview of ClickDiff: The model initially takes an object’s point cloud as input and predicts the contact map conditioned on the Semantic Contact Map within the Semantic Conditional Module. Subsequently, the predicted contact map is fed into the Contact Conditional Module, where grasping is generated under the guidance of TGC and contact map.
图 2: ClickDiff概览:模型首先以物体的点云作为输入,在语义条件模块(Semantic Conditional Module)中基于语义接触图(Semantic Contact Map)预测接触图。随后,预测的接触图被输入到接触条件模块(Contact Conditional Module),在TGC和接触图的指导下生成抓取动作。
Additionally, we verify its robustness for unseen and out-ofdomain objects.
此外,我们验证了其对未见域外物体的鲁棒性。
2 RELATED WORK
2 相关工作
2.1 Controllable Human-Object Interaction
2.1 可控人物-物体交互
In recent years, there have been attempts to model fine-grained interactions between the human and objects. Recent methods have shifted focus towards the prediction of static human poses that are congruent with environmental constraints, particularly in scenarios involving afford ances and hand-object interactions. For instance, COUCH [44] presents a comprehensive model and dataset designed to facilitate the synthesis of controllable, contact-based interactions between humans and chairs. Furthermore, there has been notable exploration into the generation of motion conditional on external stimuli, such as music [23]. TOHO [22] exemplifies this by generating realistic and continuous task-oriented human-object interaction motions through prompt-based mechanisms. Additionally, advancements in custom diffusion guidance have significantly enhanced both the control l ability [14, 16, 28] and physical plausibility [41] of generated interactions. EgoEgo [21] fed head pose to a conditional diffusion model to generate the full-body pose. Nevertheless, a gap remains in concerning methods that specifically address finegrained interactions, particularly the nuanced contacts involved in hand-object interactions. Inspired by the aforementioned methods, our method enables a more precise prediction and control of grasping through user-specified or algorithmic ally predicted contacts.
近年来,学界开始尝试建模人与物体之间的细粒度交互。最新研究将重点转向预测符合环境约束的静态人体姿态,特别是在涉及功能可供性和手-物交互的场景中。例如,COUCH [44] 提出了一个综合性模型和数据集,旨在促进人类与椅子之间基于接触的可控交互合成。此外,在受外部刺激(如音乐 [23])条件约束的运动生成方面也取得了显著探索。TOHO [22] 通过基于提示的机制生成逼真且连续的任务导向型人物交互运动,成为该领域的典型代表。定制化扩散引导技术的进步则显著提升了生成交互的控制能力 [14, 16, 28] 和物理合理性 [41],例如EgoEgo [21] 将头部姿态输入条件扩散模型以生成全身姿态。然而,针对细粒度交互(尤其是手-物交互中微妙接触关系)的专门方法仍存在空白。受上述方法启发,我们的技术通过用户指定或算法预测的接触点,实现了更精确的抓握预测与控制。
2.2 Grasp Generation
2.2 抓取生成
The task of generating object grasps has undergone significant evolution, greatly benefitting from the introduction of novel 3D datasets. Taheri et al. [33] notably extended this research through the development of the GRAB dataset, which not only delineates the hand’s contact map but also incorporates the entire human body’s interaction with objects. ARCTIC [9] introduces a dataset of two hands that dexterously manipulate objects. It contains bimanual articulation of objects such as scissors or laptops, where hand poses and object states evolve jointly in time. To ensure the generated grasps with both physical plausibility and diversity, the majority of existing models employ a Conditional Variation al Autoencoder (CVAE) framework to sample hand MANO parameters [15, 29, 32, 33, 35] or hand joints [17], thus modeling the grasp variability primarily within the hand’s parameter space. Given an input object, liu et al. propose a novel approach utilizing a conditional generative model based on CVAE, named ContactGen [24], which, coupled with model-based optimization, predicts diverse and geometrically feasible grasps. Meanwhile, GraspTTA [15] introduces an innovative self-supervised task leveraging consistency constraints, allowing for the dynamic adjustment of the generation model even during testing time. Despite these advances, the CVAE models often overfit to prevalent grasp patterns due to the human hand’s high degree of freedom, leading to the production of unrealistic contacts and shapes. To address these challenges, our work employs a conditional diffusion model framework, which uniquely focuses on improving the fidelity of generation through user-specified contacts.
物体抓取生成任务经历了显著演变,这很大程度上得益于新型3D数据集的引入。Taheri等人[33]通过开发GRAB数据集显著推进了该领域研究,该数据集不仅标注了手部接触图,还整合了人体与物体的完整交互信息。ARCTIC[9]提出了一个双手机敏操作物体的数据集,包含剪刀、笔记本电脑等物体的双手协同操作,其中手部姿态与物体状态随时间同步演变。
为确保生成的抓取兼具物理合理性与多样性,现有模型大多采用条件变分自编码器(CVAE)框架来采样手部MANO参数[15,29,32,33,35]或手部关节[17],从而主要在手的参数空间内建模抓取变体。针对输入物体,liu等人提出了一种基于CVAE的条件生成模型新方法ContactGen[24],结合基于模型的优化,可预测多样且几何可行的抓取。与此同时,GraspTTA[15]引入了一项创新自监督任务,利用一致性约束实现测试期间对生成模型的动态调整。
尽管取得这些进展,由于人手的高自由度特性,CVAE模型常会过拟合到常见抓取模式,导致产生不真实的接触和形状。为解决这些问题,我们的工作采用条件扩散模型框架,其独特之处在于通过用户指定接触点来提升生成保真度。
3 OVERVIEW
3 概述
In this work, we primarily aim to answer two questions: (1) How can we characterize fine-grained contact information simply and efficiently to achieve controllable grasp generation? (2) How can we better utilize the related contact information to guide grasp generation? To address question (1), in Sec. 4.1, we propose a controllable contact representation Semantic Contact Map (SCM), which simultaneously represents the fine-grained contacts between fingers and objects. In Sec. 4.2 and Sec. 4.3, we propose a Dual Generation Framework and Tactile-Guided Constraints (TGC), using SCM to solve the contact ambiguity problem, thereby addressing question (2). Fig. 2 summarizes our process for generating grasps.
在本工作中,我们主要致力于回答两个问题:(1) 如何简单高效地表征细粒度接触信息以实现可控抓取生成?(2) 如何更好地利用相关接触信息指导抓取生成?针对问题(1),我们在第4.1节提出了一种可控接触表征方法——语义接触图(SCM),它能同时表征手指与物体间的细粒度接触。在第4.2节和第4.3节,我们提出了双生成框架和触觉引导约束(TGC),利用SCM解决接触歧义问题,从而解决问题(2)。图2总结了我们的抓取生成流程。
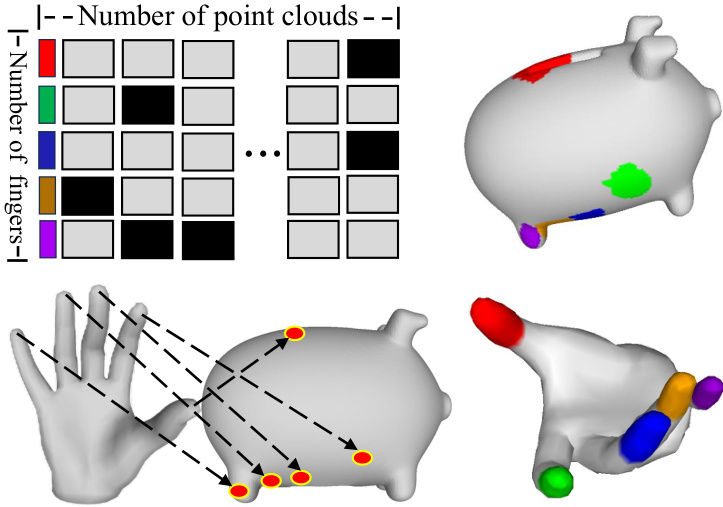
Figure 3: Illustration of the Semantic Contact Map. The fingers are divided into five parts, represented by different colors. The SCM indicates the points on the object that are being touched and the finger parts touching these points. Each point may be touched by more than one finger.
图 3: 语义接触图 (Semantic Contact Map) 示意图。手指被划分为五个部分,用不同颜色表示。SCM 显示了物体上被接触的点以及接触这些点的手指部位。每个点可能被多个手指同时接触。
4 METHOD
4 方法
4.1 Semantic Contact Map (SCM)
4.1 语义接触图谱 (SCM)
Following [9], the contact map $C\in\mathbb{R}^{N\times1}$ represented by heatmap, each $c_{i}\in C$ ranges between [0, 1], represents the distance to the nearest finger point at each object point. Intuitively, a contact map shows which part of an object might be touched by a hand. However, relying solely on contact maps is insufficient for modeling complex grasps due to ambiguity about how and where the hands touch the object. To overcome this issue caused by the lack of finegrained contact representations, inspired by [18, 24], we propose the following Semantic Contact Map:
根据[9],接触图 $C\in\mathbb{R}^{N\times1}$ 以热图形式表示,其中每个 $c_{i}\in C$ 的取值范围为[0, 1],表示每个物体点到最近手指点的距离。直观来看,接触图显示了物体可能被手触碰的部分。然而,由于缺乏关于手如何及何处接触物体的细粒度表征,仅依赖接触图难以建模复杂抓取动作。受[18, 24]启发,我们提出以下语义接触图(Semantic Contact Map)来解决该问题:
$$
S C M_{o\times f}=F i n g e r t o u c h A n a l y s i s(O,H)\in\mathbb{R}^{N\times5},
$$
$$
S C M_{o\times f}=F i n g e r t o u c h A n a l y s i s(O,H)\in\mathbb{R}^{N\times5},
$$
where $o$ represents object sampling points $\in R^{2048}$ , $f$ represents finger indices ∈ 𝑅5, 𝑂 represents the object point clouds ∈ 𝑅2048×3, $H$ represents the hand point clouds $\in\dot{R^{778\times3}}$ .
其中 $o$ 表示物体采样点 $\in R^{2048}$,$f$ 表示手指索引 ∈ 𝑅5,𝑂 表示物体点云 ∈ 𝑅2048×3,$H$ 表示手部点云 $\in\dot{R^{778\times3}}$。
Different from the part map (one-hot vector whose value is the nearest hand labels) proposed by ContactGen [24] for the entire hand reliant only on the SDF, in our understanding, the contact relationship between fingers and object points can be many-tomany. Moreover, utilizing finger control and emphasizing the finger number rather than the hand part is more convenient and flexible for user-defined controllable generation. Therefore, we heuristically represent finger-object point pairs with a distance below the threshold in SCM as 0. At the same time, Tactile-Guided Constraint designed for SCM is used to better learn embedding conditions. Fig. 3 shows an example of SCM. By processing point clouds of objects and hands, SCM contains information on whether points on the object are touched and the numbering of the fingers touching those points, which is more important for interactive grasp control. Apart from being generated through Finger touch-Analysis, the most important aspect of SCM is that it can be customized by the user by clicking and traversing the pre calculated weights of the area around the clicked points, hence we can achieve controllable grasp generation.
与ContactGen[24]提出的仅依赖SDF(有符号距离场)的全局手部单热点阵图(其值为最近的手部标签)不同,我们认为手指与物体点之间的接触关系是多对多的。此外,利用手指控制并强调手指编号而非手部区域,能为用户自定义的可控生成提供更便捷灵活的方式。因此,我们启发式地将SCM中距离低于阈值的指-物点对表示为0。同时,专为SCM设计的触觉引导约束(Tactile-Guided Constraint)被用于更好地学习嵌入条件。图3展示了SCM的示例。通过处理物体和手部的点云,SCM包含物体点是否被触碰以及触碰该点的手指编号信息,这对交互式抓握控制更为重要。除通过手指触觉分析生成外,SCM最关键的特性是允许用户通过点击并遍历预计算点击点周边区域权重来自定义,从而实现可控的抓握生成。
4.2 Dual Generation Framework
4.2 双重生成框架
Inspired by controllable contact-based method [10, 44], we use conventional contact maps during generation to ensure that the model learns the correct distribution. However, it’s challenging to provide realistic contact maps in practical applications and relying solely contact maps introduces ambiguity regarding which part of the hand touches and how it makes contact. Furthermore, past research [15, 18, 24] has shown that single-stage models struggle to generate high-quality grasps. Therefore, we propose a Dual Generation Framework, comprising a Semantic Conditional Module and a Contact Conditional Module. We first use Semantic Contact Map to infer the most probable contact maps based on SCM, then generate controllable grasps under the guidance of Tactile-Guided Constraint. As a result, we achieve controllable generation by starting from a user-defined SCM. Fig. 2 summarizes our process for training and testing.
受基于可控接触的方法 [10, 44] 启发,我们在生成过程中使用传统接触图来确保模型学习正确的分布。然而,在实际应用中提供真实的接触图具有挑战性,且仅依赖接触图会引入关于手部哪部分接触以及如何接触的模糊性。此外,过去的研究 [15, 18, 24] 表明,单阶段模型难以生成高质量的抓取动作。因此,我们提出了一种双生成框架,包含语义条件模块和接触条件模块。我们首先使用语义接触图 (Semantic Contact Map, SCM) 基于 SCM 推断最可能的接触图,然后在触觉引导约束 (Tactile-Guided Constraint) 的指导下生成可控抓取动作。最终,我们通过从用户定义的 SCM 出发实现了可控生成。图 2 总结了我们的训练和测试流程。
4.2.1 Training: In Semantic Conditional Module, the parameters $C\in\mathbb{R}^{2048}$ are composed of the object’s contact map parameters. We use a conditional generation model to infer probable contact maps $C$ based on user-specified or algorithmic ally predicted Semantic Contact Maps. The process is as follows:
4.2.1 训练:在语义条件模块中,参数 $C\in\mathbb{R}^{2048}$ 由物体的接触图参数组成。我们使用条件生成模型,基于用户指定或算法预测的语义接触图来推断可能的接触图 $C$。具体流程如下:
$$
\tilde{C}^{0}=C\mathcal{G}\mathcal{M}(\tilde{C}^{n}|S C M,O),
$$
$$
\tilde{C}^{0}=C\mathcal{G}\mathcal{M}(\tilde{C}^{n}|S C M,O),
$$
where $\tilde{C^{n}}$ denotes the contact map at noise level n, $O$ denotes the object point clouds and $\mathit{C g M}$ denotes conditional generation model. In Contact Conditional Module, MANO parameters [29] $\pmb{M}\in\mathbb{R}^{61}$ are composed of the hand’s MANO parameters. We also use a conditional generation model based on contact maps predicted by the Semantic Conditional Module and constrained by Semantic Contact Maps to infer MANO parameters. The training of two modules can be carried out independently. To enable the model to learn additional finger information from simple contact maps, we design Tactile-Guided Constraint, which will be detailed in the next section. The entire process can be represented as:
其中 $\tilde{C^{n}}$ 表示噪声级别为 n 时的接触图,$O$ 表示物体点云,$\mathit{C g M}$ 表示条件生成模型。在接触条件模块中,MANO参数 [29] $\pmb{M}\in\mathbb{R}^{61}$ 由手的MANO参数组成。我们还使用基于语义条件模块预测并由语义接触图约束的条件生成模型来推断MANO参数。两个模块的训练可以独立进行。为了使模型能够从简单接触图中学习更多手指信息,我们设计了触觉引导约束,具体细节将在下一节详述。整个过程可表示为:
$$
\tilde{M}^{0}=C\mathcal{G}M(\tilde{M}^{n}|\tilde{C}^{0},O),
$$
$$
\tilde{M}^{0}=C\mathcal{G}M(\tilde{M}^{n}|\tilde{C}^{0},O),
$$
where $\tilde{M}^{n}$ represents MANO parameters at nosie level n, $O$ represents object point clouds.
其中 $\tilde{M}^{n}$ 表示噪声级别 n 下的 MANO 参数,$O$ 表示物体点云。
4.2.2 Testing: As shown in Fig. 2, in the denoising step n, we combine the contact map predicted by the Semantic Conditional Module, along with features extracted by PointNet, as input to the Contact Conditional Module, and estimate $M^{0}$ , which can be represented as:
4.2.2 测试: 如图 2 所示, 在去噪步骤 n 中, 我们将语义条件模块 (Semantic Conditional Module) 预测的接触图与 PointNet 提取的特征相结合, 作为接触条件模块 (Contact Conditional Module) 的输入, 并估算 $M^{0}$ , 其表达式为:
$$
\tilde{C}^{n-1}=C\mathcal G M_{s e m a n}(\tilde{C}^{n}|S C M,O),\tilde{M}^{n-1}=C\mathcal G M_{c o n t}(\tilde{M}^{n}|\tilde{C}^{0},O),
$$
$$
\tilde{C}^{n-1}=C\mathcal G M_{s e m a n}(\tilde{C}^{n}|S C M,O),\tilde{M}^{n-1}=C\mathcal G M_{c o n t}(\tilde{M}^{n}|\tilde{C}^{0},O),
$$
$$
\tilde{C}^{0}=C\mathcal{G}\mathcal{M}{s e m a n}(\tilde{C}^{1}|S C M,O),\qquad\tilde{M}^{0}=C\mathcal{G}\mathcal{M}{c o n t}(\tilde{M}^{1}|\tilde{C}^{0},O).
$$
$$
\tilde{C}^{0}=C\mathcal{G}\mathcal{M}{s e m a n}(\tilde{C}^{1}|S C M,O),\qquad\tilde{M}^{0}=C\mathcal{G}\mathcal{M}{c o n t}(\tilde{M}^{1}|\tilde{C}^{0},O).
$$
4.3 Tactile-Guided Constraint (TGC)
4.3 触觉引导约束 (TGC)
In the Contact Conditional Module, simply utilizing contact map as a condition introduces ambiguity regarding which part of the hand is in contact with the object. Based on the Semantic Contact Map, we tailored Tactile-Guided Constraint as follows:
在接触条件模块中,仅使用接触图作为条件会引入关于手部哪部分与物体接触的模糊性。基于语义接触图,我们定制了触觉引导约束如下:
$$
\mathcal{L}{T G C}=\sum_{k=1}^{N}\lVert O(i_{k})-H(j_{k})\rVert_{2},
$$
$$
\mathcal{L}{T G C}=\sum_{k=1}^{N}\lVert O(i_{k})-H(j_{k})\rVert_{2},
$$
where $(i_{k},j_{k})$ represents $k_{t h}$ pair of indices in the SCM that represents touching. $i_{k}$ denotes the index of points. $j_{k}$ denotes the index of fingers. $O(i_{k})$ denotes coordinates of the object point. $H(j_{k})$ denotes coordinates of the centroid for each touched finger. For each finger, we predefine a set of contact points that are weighted differently depending on the distance to the inner surface of the finger. Then a centroid selection algorithm computes the weighted average value from the set to determine the touch centroid for that finger. $N$ denotes the number of contact pairs designated within the SCM.
其中 $(i_{k},j_{k})$ 表示SCM中代表接触的第 $k$ 对索引。$i_{k}$ 表示点的索引,$j_{k}$ 表示手指的索引。$O(i_{k})$ 表示物体点的坐标,$H(j_{k})$ 表示每个接触手指的质心坐标。对于每根手指,我们预定义了一组接触点,这些点根据到手指内表面的距离进行不同权重分配。随后通过质心选择算法计算该集合的加权平均值,以确定该手指的接触质心。$N$ 表示SCM中指定的接触对数。
The Tactile-Guided Constraint loss $(\mathcal{L}{T G C})$ specifically targets the vertices within the finger sets proximal to the object’s surface, ensuring that fingers accurately align with the designated groundtruth contact areas by accurately indexing the point pairs in the SCM and calculating the distance between the centroid of each finger’s predefined set of points and the contact point on the object. We adopt the $L_{2}$ distance to compute the distance error between object and hand point clouds.
触觉引导约束损失 $(\mathcal{L}{T G C})$ 专门针对靠近物体表面的手指顶点集,通过精确索引SCM中的点对并计算每个手指预定义点集的质心与物体接触点之间的距离,确保手指与指定的真实接触区域准确对齐。我们采用 $L_{2}$ 距离来计算物体与手部点云之间的距离误差。
We denote the reconstruction loss in the training of Semantic Conditional Module between the predicted contact map and the ground-truth as:
我们将预测接触图与真实值之间的语义条件模块训练中的重建损失表示为:
$$
\mathcal{L}{R}=\left|\left|\tilde{C}-C\right|\right|_{2}^{2}.
$$
$$
\mathcal{L}{R}=\left|\left|\tilde{C}-C\right|\right|_{2}^{2}.
$$
The reconstruction loss on MANO parameters in the training of Contact Conditional Module is defined in a similar way as:
接触条件模块训练中对MANO参数的重建损失定义方式类似:
$$
\begin{array}{r}{\mathcal{L}{R}=\vert\vert\tilde{M}-M\vert\vert_{2}^{2}.}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{R}=\vert\vert\tilde{M}-M\vert\vert_{2}^{2}.}\end{array}
$$
At the same time, we design a contact-map-based loss for Semantic Conditional Module training, followed as:
同时,我们设计了一种基于接触图(contact-map)的损失函数用于语义条件模块训练,具体如下:
$$
\mathcal{L}_{C}=\sum|(1-B)\odot\tilde{C}|,
$$
$$
\mathcal{L}_{C}=\sum|(1-B)\odot\tilde{C}|,
$$
where $B_{o}$ represents the binary map’s value when the distance $C_{o}$ between a sampled point on the hand and a corresponding object point $o$ is less than the predefined threshold 𝜏threshold and $\odot$ denotes matrix dot product. The efficacy of the $\mathcal{L}_{C}$ loss function is attributed to its focus on hand-object point pairs, which are systematically selected based on the contact map during the training phase.
其中 $B_{o}$ 表示当手部采样点与对应物体点 $o$ 的距离 $C_{o}$ 小于预设阈值 𝜏threshold 时二值映射的值,$\odot$ 表示矩阵点积。$\mathcal{L}_{C}$ 损失函数的有效性源于其对接触图训练阶段系统筛选的手-物点对的聚焦。
Furthermore, to enhance the accuracy of hand posture modeling within Contact Conditional Module, we employ a loss function that measures the discrepancy between predicted vertices 𝑉 and the ground-truth vertices $V$ , which is mathematically represented as:
此外,为提高接触条件模块中手部姿态建模的精度,我们采用了测量预测顶点𝑉与真实顶点$V$间差异的损失函数,其数学表达式为:
$$
\begin{array}{r}{\mathcal{L}{V}=||\tilde{V}-V||_{2}^{2}.}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{V}=||\tilde{V}-V||_{2}^{2}.}\end{array}
$$
In a short summary, the whole loss for training the Semantic Conditional Module is:
简而言之,训练语义条件模块 (Semantic Conditional Module) 的整体损失为:
$$
\mathcal{L}{s e m a n t i c}=\lambda_{\alpha}\cdot\mathcal{L}{R}+\lambda_{\beta}\cdot\mathcal{L}_{C}.
$$
$$
\mathcal{L}{s e m a n t i c}=\lambda_{\alpha}\cdot\mathcal{L}{R}+\lambda_{\beta}\cdot\mathcal{L}_{C}.
$$
And the training loss of Contact Conditional Module is defined as:
接触条件模块的训练损失定义为:
$$
\mathcal{L}{c o n t a c t}=\lambda_{\alpha}\cdot\mathcal{L}{R}+\lambda_{\beta}\cdot\mathcal{L}{V}+\lambda_{\theta}\cdot\mathcal{L}_{T G C}.
$$
$$
\mathcal{L}{c o n t a c t}=\lambda_{\alpha}\cdot\mathcal{L}{R}+\lambda_{\beta}\cdot\mathcal{L}{V}+\lambda_{\theta}\cdot\mathcal{L}_{T G C}.
$$
5 EXPERIMENT
5 实验
5.1 Experimental Details
5.1 实验细节
5.1.1 Datasets: We employ the GRAB dataset [33] to train the ClickDiff and assess the efficacy of our proposed approach in a unimanual grip scenario. The GRAB [33], which comprises real human grasp data for 51 objects across 10 different subjects, is instrumental in our analysis. Notably, the dataset’s test set consists of six objects that are not encountered during training, presenting an opportunity to assess the model’s generalization capabilities. Furthermore, ARCTIC [9] is a dataset of dexterously bimanual manipulating articulated objects. It facilitates our exploration into the realm of dexterous bimanual manipulation.
5.1.1 数据集:我们采用GRAB数据集[33]训练ClickDiff,并在单手握持场景中评估所提方法的有效性。GRAB[33]包含10名受试者对51个物体的真实人类抓取数据,对我们的分析至关重要。值得注意的是,该数据集的测试集包含训练阶段未出现的6个物体,为评估模型泛化能力提供了机会。此外,ARCTIC[9]是一个灵巧双手操作铰接物体的数据集,为我们探索灵巧双手操作领域提供了支持。
5.1.2 Implementation Details: The ClickDiff is trained on the GRAB [33] and ARCTIC [9] datasets, which takes $=2048$ points sampled from GRAB object surface and $\mathrm{N}=600$ points sampled from ARCTIC object surface as input. We extract object features using PointNet [4] and adopt the standard Adam optimizer [20] with a learning rate of $1\times10^{-5}$ and betas of 0.9 and 0.999. We train our model with batch size of 256 for $600\mathrm{k}$ steps. The loss weights are $\lambda_{\alpha}:=:2$ , $\lambda_{\beta}=0.5$ and $\lambda_{\theta}=1$ . The network is implemented in PyTorch and trained on a single NVIDIA RTX 3090 GPU.
5.1.2 实现细节:ClickDiff在GRAB [33]和ARCTIC [9]数据集上进行训练,输入为从GRAB物体表面采样的$=2048$个点以及从ARCTIC物体表面采样的$\mathrm{N}=600$个点。我们使用PointNet [4]提取物体特征,并采用标准Adam优化器 [20],学习率为$1\times10^{-5}$,beta参数为0.9和0.999。模型训练批次大小为256,共进行$600\mathrm{k}$步迭代。损失权重设置为$\lambda_{\alpha}:=:2$、$\lambda_{\beta}=0.5$和$\lambda_{\theta}=1$。网络基于PyTorch实现,在单块NVIDIA RTX 3090 GPU上完成训练。
5.1.3 Evaluation Metrics: Our objective is to synthesize highly accurate, contact-based, fine-grained hand grips on objects to achieve controllable grasp generation. Thus, we evaluate the evaluation criteria applicable to controllable grasp generation. To evaluate the performance of our model, following [8, 9, 26, 31, 42], we use three metrics previously utilized (MPJPE, MRRPE, CDev) along with a custom metric (Success Rate). To ensure that contacts made by hands touching or holding objects are controllable and accurate, we measure precision using metrics known as Contact Deviation (CDev) and Success Rate. Moreover, capturing the correct posture of the hand and the position of its bones accurately when the hand moves or interacts with an object is crucial. We check these details utilizing Mean Per-Joint Position Error (MPJPE) and Mean RelativeRoot Position Error (MRRPE). The definitions are as follows:
5.1.3 评估指标: 我们的目标是合成高精度、基于接触的细粒度物体抓握手势,以实现可控抓握生成。因此,我们评估适用于可控抓握生成的评价标准。为评估模型性能,参照 [8, 9, 26, 31, 42],我们采用三个既有指标 (MPJPE、MRRPE、CDev) 和一个自定义指标 (成功率)。为确保手部接触或抓握物体时的可控性与准确性,我们使用接触偏差 (Contact Deviation, CDev) 和成功率来衡量精度。此外,准确捕捉手部运动或与物体交互时的手部姿态及骨骼位置至关重要,我们通过平均每关节位置误差 (Mean Per-Joint Position Error, MPJPE) 和平均相对根位置误差 (Mean RelativeRoot Position Error, MRRPE) 来校验这些细节。具体定义如下:
• Mean Per-Joint Position Error (MPJPE): The $L_{2}$ distance between the 21 predicted and ground-truth joints for each hand after subtracting its root. • Mean Relative-Root Position Error (MRRPE): Measures the root translation between the hand and object:
• 平均每关节位置误差 (MPJPE): 减去根部后,每只手21个预测关节与真实关节之间的$L_{2}$距离。
• 平均相对根部位置误差 (MRRPE): 测量手与物体之间的根部平移:
$$
\mathrm{MRRPE}{a\rightarrow b}=\left|\left(\mathbf{J}^{a}-\mathbf{J}^{b}\right)-\left(\hat{\mathbf{J}}^{a}-\hat{\mathbf{J}}^{b}\right)\right|_{2},
$$
$$
\mathrm{MRRPE}{a\rightarrow b}=\left|\left(\mathbf{J}^{a}-\mathbf{J}^{b}\right)-\left(\hat{\mathbf{J}}^{a}-\hat{\mathbf{J}}^{b}\right)\right|_{2},
$$
where $a,b\in{l,r,o}$ , with $l,r,o$ representing the left hand, right hand, and the object, respectively, $\boldsymbol{\mathrm{J}}\in\mathbb{R}^{3}$ is the groundtruth root joint position and $\hat{\bf J}$ is the predicted one. We only adopt this metric on the ARCTIC dataset to measure the bimanual grasps.
其中 $a,b\in{l,r,o}$ ,$l,r,o$ 分别代表左手、右手和物体,$\boldsymbol{\mathrm{J}}\in\mathbb{R}^{3}$ 是真实根关节位置,$\hat{\bf J}$ 是预测值。我们仅在 ARCTIC 数据集中采用该指标来衡量双手抓取效果。

Figure 4: Qualitative comparison results on GRAB dataset [33]. While GA and CG produce unnatural distortions and huge contact deviations, our method produces more plausible and accurate grasps for unseen objects.
图 4: GRAB数据集 [33] 上的定性对比结果。GA和CG方法会产生不自然的形变和显著接触偏差,而我们的方法能为未见物体生成更合理且准确的抓取姿态。
• Contact Deviation (CDev): Measures the deviation between the vertices of the hand and the assumed contact vertices on the object.
• 接触偏差 (CDev): 测量手部顶点与物体上假定接触顶点之间的偏差。
$$
\begin{array}{r}{\frac{1}{C}\sum_{i=1}^{C}||\hat{\bf h}{i}-\hat{\bf o}_{i}||,}\end{array}
$$
$$
\begin{array}{r}{\frac{1}{C}\sum_{i=1}^{C}||\hat{\bf h}{i}-\hat{\bf o}_{i}||,}\end{array}
$$
Table 1: Quantitative comparison results of state-of-the-art methods and ours on the GRAB dataset [33] on different out-ofdomain objects. GN denotes GrabNet [33], GL denotes GOAL [32], GA denotes GraspTTA [15] and CG denotes ContactGen [24].
表 1: 在GRAB数据集[33]上对不同域外物体的先进方法与我们方法的定量比较结果。GN表示GrabNet[33],GL表示GOAL[32],GA表示GraspTTA[15],CG表示ContactGen[24]。
| MPJPE(mm)↓ | CDev(mm)↓ | Success Rate (%)↑ | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GN[33] | GA[15] | GL[32] | CG[24] | GN[33] | GA[15] | GL[32] | CG[24] | GN[33] | GA[15] | GL[32] | CG[24] | |
| ECCV | ICCV | CVPR | ICCV | Ours | ECCV | ICCV | CVPR | ICCV | Ours | ECCV | ICCV | CVPR |
| 2020 | 2021 | 2022 | 2023 | 2020 | 2021 | 2022 | 2023 | 2020 | 2021 | 2022 | 2023 | |
| Binoculars | 87.26 | 64.31 | 80.56 | 82.92 | 40.09 | 103.14 | 78.67 | 87.21 | 98.15 | 43.42 | 46.85 | 63.57 |
| Camera | 79.65 | 62.55 | 75.82 | 80.44 | 29.98 | 85.87 | 77.22 | 95.96 | 78.02 | 48.91 | 55.23 | 67.55 |
| Frying pan | 72.17 | 55.12 | 73.76 | 67.31 | 45.40 | 90.44 | 64.28 | 72.41 | 122.83 | 76.35 | 71.60 | 84.17 |
| Mug | 75.11 | 58.67 | 67.12 | 77.78 | 51.53 | 96.47 | 80.21 | 86.83 | 84.24 | 53.26 | 50.03 | 67.79 |
| Toothpaste | 81.83 | 59.82 | 72.95 | 68.62 | 29.34 | 93.72 | 81.34 | 92.73 | 68.72 | 46.33 | 49.56 | 81.34 |
| Wineglass | 88.09 | 64.46 | 83.62 | 83.68 | 44.26 | 95.70 | 98.30 | 85.28 | 75.27 | 46.11 | 58.26 | 58.73 |
| 61.36 | 75.96 | 78.32 | 40.57 | 93.95 | 81.90 | 86.28 | 84.59 | 52.05 | 55.90 | 66.78 | ||
| Average | 80.35 |
Table 2: Quantitative comparison results of state-of-the-art methods and ours on the ARCTIC dataset [9].
表 2: 在 ARCTIC 数据集 [9] 上当前最优方法与我们的定量对比结果。
| 方法 | 领域内/外 | 手 | MPJPE (mm)↓ | MRRPE (mm)↓ | CDev (mm)↓ | 成功率 (%) ↑ |
|---|---|---|---|---|---|---|
| GraspTTA [15] | 领域内 | 61.57 | 1183.05 | 1174.30 | 53.41 | |
| GraspTTA [15] | 领域内 | 54.13 | 678.45 | 657.08 | 50.64 | |
| GraspTTA [15] | 领域内 | 57.85 | 930.75 | 915.69 | 52.03 | |
| Ours (w/o SCM) | 领域内 | 48.65 | 75.72 | 77.67 | 78.46 | |
| Ours (w/o SCM) | 领域内 | 43.35 | 69.54 | 78.97 | 79.23 | |
| Ours (w/o SCM) | 领域内 | 46.00 | 72.63 | 78.32 | 78.85 | |
| Ours (SCM) | 领域内 | 39.48 | 66.79 | 70.27 | 81.44 | |
| Ours (SCM) | 领域内 | 37.58 | 65.02 | 65.16 | 82.78 | |
| Ours (SCM) | 领域内 | 38.53 | 65.91 | 67.75 | 82.11 | |
| GraspTTA [15] | 领域外 | 51.53 | 876.59 | 1007.14 | 58.89 | |
| GraspTTA [15] | 领域外 | 57.61 | 612.74 | 571.70 | 50.72 | |
| GraspTTA [15] | 领域外 | 54.57 | 749.15 | 789.42 | 54.81 | |
| Ours (w/o SCM) | 领域外 | 51.78 | 119.20 | 112.35 | 79.16 | |
| Ours (w/o SCM) | 领域外 | 53.39 | 90.36 | 102.12 | 70.68 | |
| Ours (w/o SCM) | 领域外 | 52.59 | 104.78 | 107.24 | 74.92 | |
| Ours (SCM) | 领域外 | 47.16 | 102.54 | 92.06 | 84.01 | |
| Ours (SCM) | 领域外 | 48.21 | 84.60 | 92.10 | 72.87 | |
| Ours (SCM) | 领域外 | 47.69 | 93.57 | 92.08 | 78.44 |
5.2 Experimental Results
5.2 实验结果
5.2.1 Results on GRAB dataset. We evaluate the generalization capability of our models on the GRAB dataset [33]. The dataset’s testset, consisting of six objects not previously encountered during training, serves as a benchmark to evaluate our model’s adaptability to new scenarios. Tab. 1 shows comparison of our method with GrabNet [33], GOAL [32], ContactGen [24] and GraspTTA [15] on the GRAB dataset [33], our method achieves performance in each metric on almost all objects. Fig. 4 illustrates a significant reduction in contact deviation when implementing the Semantic Contact Map, revealing the importance of controllable grasp generation. As GraspTTA struggles to produce valid grasps for unseen objects, the contact deviation is substantial while ContactGen often produces unnatural distortions. The results reveal that the hands produced by both GraspTTA and ContactGen lack coordination and deviate significantly from the expected contact areas. In comparison to them, our method achieves notably lower penetration and better stability, which is the closest to ground-truth.
5.2.1 GRAB数据集实验结果。我们在GRAB数据集[33]上评估模型的泛化能力。该数据集的测试集包含训练阶段未接触过的六种物体,用于衡量模型对新场景的适应能力。表1展示了我们的方法与GrabNet[33]、GOAL[32]、ContactGen[24]以及GraspTTA[15]在GRAB数据集上的对比结果,我们的方法在几乎所有物体的各项指标上均取得最优表现。图4显示采用语义接触图(Semantic Contact Map)后接触偏差显著降低,印证了可控抓取生成的重要性。由于GraspTTA难以对未见物体生成有效抓取,其接触偏差较大;而ContactGen常产生不自然的形变。结果表明这两种方法生成的手部动作缺乏协调性,且与预期接触区域存在显著偏差。相较之下,我们的方法穿透量更低、稳定性更优,最接近真实值。
5.2.2 Results on ARCTIC dataset. Tab. 2 shows comparison of our method with GraspTTA [15] on the ARCTIC dataset, examining performance on both in-domain and out-of-domain objects. When the unimanual generation method is applied to the bimanual generation, the metric between two hands has a huge gap and incongruous effect, and tends to fail. On the contrary, our approach demonstrates superior performance in coordinating both hands, underscoring the efficacy of our dual-frame strategy and the diffusion model’s inherent constraints, which facilitate the synchronized generation of bimanual parameters. Our method consistently achieves the lowest joint position deviation and the highest success rate. Notably, the implementation of the Semantic Contact Map further enhances qualitative metrics.
5.2.2 ARCTIC数据集结果。表2展示了我们的方法与GraspTTA [15]在ARCTIC数据集上的对比,分别考察了域内和域外物体的表现。当单手生成方法应用于双手生成时,双手间的指标存在巨大差距且效果不协调,容易失败。相比之下,我们的方法在双手协调方面表现出优越性能,凸显了双帧策略的有效性以及扩散模型固有约束的优势,这些特性促进了双手参数的同步生成。我们的方法始终保持着最低的关节位置偏差和最高的成功率。值得注意的是,语义接触图(Semantic Contact Map)的引入进一步提升了定性指标。
Table 4: Impact of dual framework on the GRAB dataset [33], BM denotes binary map and GM denotes guassian map.
表 4: 双框架对 GRAB 数据集 [33] 的影响,BM 表示二值图,GM 表示高斯图。
| Frame | Contact Condtion | MPJPE (mm)↓ | CDev (mm)↓ | SR (%) ↑ | ||
|---|---|---|---|---|---|---|
| BM | GM | SCM | ||||
| Single | x | x | 45.92 | 71.07 | 66.34 | |
| x | x | 44.74 | 66.28 | 66.96 | ||
| × | 44.81 | 62.02 | 67.88 | |||
| x | 42.54 | 59.91 | 68.23 | |||
| Dual | x | x | 40.57 | 52.05 | 72.85 |
Table 5: Impact of loss selection on the GRAB dataset [33].
表 5: 损失函数选择对GRAB数据集的影响 [33]。
| LTGC | Lv | Lc | MPJPE (mm) ↓ | CDev (mm) ↓ | SR (%) ↑ |
|---|---|---|---|---|---|
| x | x | x | 44.11 | 59.35 | 68.76 |
| x | 42.02 | 53.24 | 71.87 | ||
| 40.83 | 60.88 | 68.87 | |||
| x | 41.58 | 66.62 | 68.92 | ||
| 40.57 | 52.05 | 72.85 |
Table 3: Impact of different contact condition in Semantic Conditional Module on the GRAB dataset [33], BM denotes binary map and GM denotes guassian map.
表 3: 语义条件模块中不同接触条件对GRAB数据集[33]的影响,BM表示二值图,GM表示高斯图。
| 接触条件 | BM | GM | SCM | MPJPE (mm) ↓ | CDev (mm) ↓ | SR (%) ↑ |
|---|---|---|---|---|---|---|
| x | x | 44.87 | 70.92 | 66.35 | ||
| × | 46.13 | 68.71 | 67.97 | |||
| x | x | 43.17 | 62.77 | 68.47 | ||
| x | x | 40.57 | 52.05 | 72.85 |
5.3 Ablation Study
5.3 消融研究
We first perform ablation studies on GRAB dataset [33] for evaluating the proposed Semantic Contact Map in sec 5.3.1. We then analyse designs of Dual Generation Framework in sec 5.3.2. Finally, we compare different loss selection in sec 5.3.3.
我们首先在GRAB数据集[33]上进行消融实验,以评估第5.3.1节提出的语义接触图 (Semantic Contact Map) 。接着在第5.3.2节分析双生成框架 (Dual Generation Framework) 的设计。最后在第5.3.3节比较不同损失函数的选择。
5.3.1 Impact of contact condition. We compare three different kinds of representations for contact conditions within the Semantic Conditional Module, as summarized in Tab. 3. Initially, the first model employs a binary map that represents whether points on the object are touched. Subsequently, the second model enhances this binary map with a gaussian kernel. Our third model introduces our novel Semantic Contact Map (SCM). Additionally, we examine a model variant devoid of any contact conditions like previous work. The results in the Tab. 3 show that the model utilizing SCM can perform better in both hand posture and contact position, especially with a $18.87\mathrm{mm}$ reduction in Contact Deviation (CDev). The absence of specific contact information results in a challenging oneto-many mapping problem in grasp prediction. The quantitative results verify the effectiveness of employing the Semantic Contact Map for controllable grasp generation.
5.3.1 接触条件的影响。我们在语义条件模块中比较了三种不同的接触条件表示方法,如表 3 所示。最初,第一个模型使用二进制图表示物体上的点是否被接触。随后,第二个模型通过高斯核增强了该二进制图。我们的第三个模型引入了新颖的语义接触图 (Semantic Contact Map, SCM)。此外,我们还测试了一个如先前工作般完全不包含接触条件的模型变体。表 3 的结果表明,使用 SCM 的模型在手部姿势和接触位置方面表现更优,尤其是接触偏差 (CDev) 降低了 $18.87\mathrm{mm}$。缺乏特定接触信息会导致抓取预测中出现具有挑战性的一对多映射问题。定量结果验证了采用语义接触图对于可控抓取生成的有效性。
5.3.2 Impact of dual framework. In our assessment of the Dual Generation Framework, we explore five distinct strategies: (1) employing a binary map as the condition in a single-stage generation model to directly synthesize grasps; (2) using a gaussian-kernelprocessed binary map as the condition in a single-stage generation model; (3) integrating our SCM within a single-stage generation model; (4) implementing a single-stage generation model without any conditions; and (5) applying SCM in conjunction with a Dual Generation Framework. The experiments presented in Tab. 4 show that the strategy with Dual Generation Framework is very superior quantitatively, as evidenced by an increase of $4.62%$ in Success Rate and a decrease of $7.86\mathrm{mm}$ in CDev. Previous work [15, 24] has shown that single-stage generation exhibits limitations in accurately generating both hand posture and contact position. This analysis confirms the effectiveness of our Dual Generation Framework, particularly when augmented by SCM.
5.3.2 双框架的影响
在我们的双生成框架(Dual Generation Framework)评估中,我们探索了五种不同策略:(1) 在单阶段生成模型中使用二值图作为条件直接合成抓取;(2) 在单阶段生成模型中使用高斯核处理后的二值图作为条件;(3) 将我们的SCM集成到单阶段生成模型中;(4) 实现无任何条件的单阶段生成模型;(5) 将SCM与双生成框架结合使用。表4所示的实验表明,采用双生成框架的策略在定量上具有显著优势,成功率提升4.62%,CDev降低7.86mm。先前研究[15,24]表明,单阶段生成在准确生成手部姿态和接触位置方面存在局限性。该分析证实了我们双生成框架的有效性,尤其是在SCM增强的情况下。
5.3.4 Impact of controllable generation on time. We analyze the influence of the addition of controllable contact conditions on time. In terms of total time, our controllable grasp generation time has increased by only $30%$ (from 13.5 hours to 17.5 hours) compared to the model devoid of any contact conditions with batch size of 128 for $600\mathrm{k}$ steps on a single NVIDIA RTX 3090 GPU.
5.3.4 可控生成对时间的影响。我们分析了添加可控接触条件对时间的影响。在总时间方面,与没有任何接触条件、在单个NVIDIA RTX 3090 GPU上以128的批次大小进行600k步训练的模型相比,我们的可控抓取生成时间仅增加了30%(从13.5小时增加到17.5小时)。
6 CONCLUSION
6 结论
In this work, we introduce ClickDiff: Click to Induce Semantic Contact Map for Controllable Grasp Generation with Diffusion Models. To solve the contact ambiguity problem and achieve controllable grasp generation, we propose a simple and efficient Semantic Contact Map that can be defined by users by clicking. At the same time, Dual Generation Framework and Tactile-Guided Constraint are proposed to utilize SCM. Our method demonstrates superior performance to existing grasp generation methods, both qualitatively and quantitatively.
在本工作中,我们提出了ClickDiff:通过点击诱导语义接触图(Semantic Contact Map)实现基于扩散模型(Diffusion Models)的可控抓取生成。为解决接触歧义问题并实现可控抓取生成,我们提出了一种可由用户通过点击定义的简洁高效语义接触图。同时,我们设计了双生成框架(Dual Generation Framework)和触觉引导约束(Tactile-Guided Constraint)来利用该语义接触图。实验表明,我们的方法在定性和定量评估中均优于现有抓取生成方法。