BABEL: Bodies, Action and Behavior with English Labels
BABEL: 身体、动作与行为英语标注库
Abstract
摘要
Understanding the semantics of human movement – the what, how and why of the movement – is an important problem that requires datasets of human actions with semantic labels. Existing datasets take one of two approaches. Large-scale video datasets contain many action labels but do not contain ground-truth 3D human motion. Alternatively, motion-capture (mocap) datasets have precise body motions but are limited to a small number of actions. To address this, we present BABEL, a large dataset with language labels describing the actions being performed in mocap sequences. BABEL labels about 43 hours of mocap sequences from AMASS. Action labels are at two levels of abstraction – sequence labels which describe the overall action in the sequence, and frame labels which describe all actions in every frame of the sequence. Each frame label is precisely aligned with the duration of the corresponding action in the mocap sequence, and multiple actions can overlap. There are over $28k$ sequence labels, and $63k$ frame labels in BABEL, which belong to over 250 unique action categories. Labels from BABEL can be leveraged for tasks like action recognition, temporal action localization, motion synthesis, etc. To demonstrate the value of BABEL as a benchmark, we evaluate the performance of models on 3D action recognition. We demonstrate that BABEL poses interesting learning challenges that are applicable to real-world scenarios, and can serve as a useful benchmark of progress in 3D action recognition. The dataset, baseline method, and evaluation code is made available, and supported for academic research purposes at https://babel.is.tue.mpg.de/.
理解人类动作的语义——即动作的内容、方式和原因——是一个重要课题,需要带有语义标注的人类动作数据集。现有数据集采用两种方法之一:大规模视频数据集包含大量动作标签但缺乏真实3D人体运动数据;而动作捕捉(mocap)数据集虽具有精确身体运动数据,却仅限于少量动作类型。为此,我们推出BABEL数据集,该数据集通过语言标签描述动作捕捉序列中的行为。BABEL标注了来自AMASS的约43小时动作捕捉序列,提供两个抽象层级的动作标签:描述序列整体行为的序列级标签,以及描述序列每帧所有动作的帧级标签。每个帧标签都与动作捕捉序列中对应动作的持续时间精确对齐,且允许多个动作重叠出现。BABEL包含超过28k个序列标签和63k个帧标签,涵盖250余种独特动作类别。这些标签可应用于动作识别、时序动作定位、运动合成等任务。为验证BABEL作为基准数据集的价值,我们评估了3D动作识别模型的性能,证明该数据集提出了适用于真实场景的学习挑战,可作为3D动作识别研究进展的有效基准。该数据集、基线方法及评估代码已开源,支持学术研究用途:https://babel.is.tue.mpg.de/。
1. Introduction
1. 引言
A key goal in computer vision is to understand human movement in semantic terms. Relevant tasks include predicting semantic labels for a human movement, e.g., action recognition [14], video description [39], temporal localization [28, 41], and generating human movement that is conditioned on semantics, e.g., motion synthesis conditioned on actions [12], or sentences [3, 19].
计算机视觉的一个关键目标是以语义方式理解人体运动。相关任务包括预测人体运动的语义标签,例如动作识别[14]、视频描述[39]、时序定位[28,41],以及基于语义生成人体运动,例如基于动作[12]或语句[3,19]的运动合成。
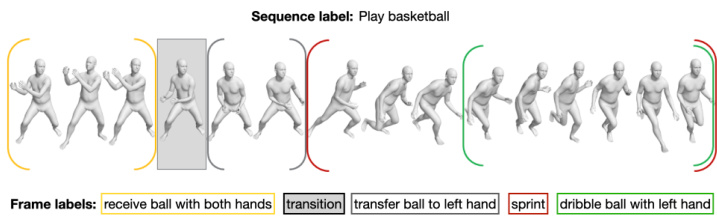
Figure 1. People moving naturally often perform multiple actions simultaneously, and sequentially, with transitions between them. BABEL contains sequence labels describing the overall action in the sequence, and frame labels where all frames and all actions are labeled. Each frame label is precisely aligned with the frames representing the action (colored brackets). This includes simultaneous actions (nested brackets) and transitions between actions (shaded gray box).
图 1: 人们自然移动时通常会同时或连续执行多个动作,并在其间过渡。BABEL包含描述序列整体动作的序列标签,以及标注所有帧和所有动作的帧标签。每个帧标签都与代表动作的帧精确对齐 (彩色括号) ,包括同时发生的动作 (嵌套括号) 和动作间的过渡 (灰色阴影框) 。
Large-scale datasets that capture variations in human movement and language descriptions that express the semantics of these movements, are critical to making progress on these challenging problems. Existing datasets contain detailed action descriptions for only 2D videos, e.g., ActivityNet [28], AVA [11] and HACS [41]. The large scale 3D datasets that contain action labels, e.g., NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 60 [29] and NTU $\mathrm{RGB}{+}\mathrm{D}$ 120 [42] do not contain ground truth 3D human motion but only noisy estimates. On the other hand, motion-capture (mocap) datasets [2, 10, 13, 16] are small in scale and are only sparsely labeled with very few actions. We address this shortcoming with BABEL, a large dataset of diverse, densely annotated, actions with labels for all the actions in a motion capture (mocap) sequence.
大规模数据集能够捕捉人类动作的变化及表达这些动作语义的语言描述,这对解决这些具有挑战性的问题至关重要。现有数据集仅包含针对2D视频的详细动作描述,例如ActivityNet [28]、AVA [11]和HACS [41]。包含动作标签的大规模3D数据集(如NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 60 [29]和NTU $\mathrm{RGB}{+}\mathrm{D}$ 120 [42])不包含真实3D人体运动数据,仅有噪声估计值。另一方面,动作捕捉(mocap)数据集[2, 10, 13, 16]规模较小,且标注稀疏,仅包含极少数动作。我们通过BABEL数据集解决了这一缺陷,该数据集规模庞大,包含多样化的密集标注动作,并为动作捕捉序列中的所有动作提供标签。
We acquire action labels for sequences in BABEL, at two different levels of resolution. Similar to existing mocap datasets, we collect a sequence label that describes the action being performed in the entire sequence, e.g., Play basketball in Fig. 1. At a finer-grained resolution, the frame labels describe the action being performed at each frame of the sequence, e.g., transfer ball to the left hand, sprint, etc. The frame labels are precisely aligned with the corresponding frames in the sequence that represent the action. BABEL also captures simultaneous actions, e.g., sprint and dribble ball with left hand. When collecting frame labels, we ensure that all frames in a sequence are labeled with at least one action, and all the actions in a frame are labeled. This results in dense action annotations for high-quality mocap data.
我们在BABEL中为动作序列获取了两种不同分辨率的动作标签。与现有动作捕捉数据集类似,我们收集了描述整个序列执行动作的序列标签,例如图1中的Play basketball。在更细粒度的分辨率下,帧标签描述了序列中每一帧执行的动作,例如transfer ball to the left hand、sprint等。帧标签与序列中表示动作的对应帧精确对齐。BABEL还能捕捉同时发生的动作,例如sprint和dribble ball with left hand。在收集帧标签时,我们确保序列中的所有帧都至少标记有一个动作,并且帧中的所有动作都被标记。这为高质量的动作捕捉数据提供了密集的动作标注。
BABEL leverages the recently introduced AMASS dataset [22] for mocap sequences. AMASS is a large corpus of mocap datasets that are unified with a common representation. It has $>43$ hours of mocap data performed by over 346 subjects. The scale and diversity of AMASS presents an opportunity for data-driven learning of semantic representations for 3D human movement.
BABEL利用最近引入的AMASS数据集[22]来获取动作捕捉序列。AMASS是一个采用统一表示方式的大型动作捕捉数据集集合,包含超过346名受试者表演的$>43$小时动作捕捉数据。AMASS的规模与多样性为数据驱动的3D人体运动语义表征学习提供了机遇。
Most existing large-scale datasets with action labels [2, 13, 21, 23, 28, 29, 41, 42] first determine a fixed set of actions that are of interest. Following this, actors performing these actions are captured (3D datasets), or videos containing the actions of interest are mined from the web (2D datasets). While this ensures the presence of the action of interest in the sequence, all other actions remain unlabeled. The sparse action label for a sequence, while useful, serves only as weak supervision for data-driven models that aim to correlate movements with semantic labels. This is suboptimal. 3D datasets such as NTU $\mathrm{RGB}{+}\mathrm{D}$ [21, 29] and HumanAct12 [42] handle this shortcoming by cropping out segments that do not correspond to the action of interest from natural human movement sequences. While the action labels for the short segments are accurate, the cropped segments are unlike the natural, continuous human movements in the real-world. Thus, the pre-segmented movements are less suitable as training data for real-world applications.
现有大多数带动作标签的大规模数据集[2,13,21,23,28,29,41,42]会先确定一组固定的目标动作,随后通过捕捉演员执行这些动作(3D数据集)或从网络挖掘包含目标动作的视频(2D数据集)。虽然这能确保序列中存在目标动作,但其他所有动作仍处于未标注状态。这种稀疏的动作标签虽有一定作用,但对于试图将动作与语义标签相关联的数据驱动模型而言,仅能提供弱监督信号,效果欠佳。NTU $\mathrm{RGB}{+}\mathrm{D}$[21,29]和HumanAct12[42]等3D数据集通过从自然人体运动序列中裁剪非目标动作片段来解决此问题。虽然短片段的动作标签准确,但裁剪后的片段已不同于现实世界中自然连续的人体运动,因此这些预分割的运动数据较难作为实际应用的训练数据。
Our key idea with BABEL is that natural human movement often involves multiple actions and transitions between them. Thus, understanding the semantics of natural human movement not only involves modeling the relationship between an isolated action and its corresponding movement but also the relationship between different actions that occur simultaneously and sequentially. With BABEL, our goal is to provide accurate data for statistical learning, which reflects the variety, concurrence and temporal compositions of actions in natural human movement.
BABEL的核心思想在于,自然人体运动通常包含多个动作及其间的过渡。因此,理解自然人体运动的语义不仅需要建模孤立动作与其对应运动的关系,还需建模同时发生和连续发生的不同动作之间的关系。通过BABEL,我们的目标是提供反映自然人体运动中动作多样性、并发性和时序组合的精确统计学习数据。
BABEL contains action annotations for about 43.5 hours of mocap from AMASS, with 15472 unique language labels. Via a semi-automatic process of semantic clustering followed by manual categorization, we organize these into 260 action categories such as greet, hop, scratch, dance, play instrument, etc. The action categories in BABEL belong to 8 broad semantic categories involving simple actions (throw, jump), complex activities (martial arts, dance), body part interactions (scratch, touch face), etc. (see Sec. 3.4).
BABEL包含来自AMASS约43.5小时动作捕捉数据的动作标注,包含15472个独特语言标签。通过语义聚类半自动处理结合人工分类,我们将其组织为260个动作类别(如问候、单脚跳、抓挠、跳舞、演奏乐器等)。这些动作类别属于8个广义语义范畴,涵盖简单动作(投掷、跳跃)、复杂活动(武术、舞蹈)、身体部位交互(抓挠、摸脸)等(详见第3.4节)。
BABEL contains a total of 28055 sequence labels, and
BABEL 共包含 28055 个序列标签,
63353 frame labels. This corresponds to dense per-frame action annotations for 10892 sequences $(>37$ hours of mocap), and sequence-level annotations for all 13220 sequences $\mathrm{\Delta>43}$ hours of mocap). On average, a single mocap sequence has 6.06 segments, with 4.02 unique action categories. We collect the sequence labels via a web interface of our design, and the frame labels and alignments by adapting an existing web annotation tool, VIA [8] (see Sec. 3.1). Labeling was done by using Amazon Mechanical Turk [1].
63353个帧标签。这对应于10892段动作捕捉序列的逐帧密集标注(>37小时的动捕数据),以及全部13220段序列的序列级标注(>43小时的动捕数据)。平均每段动捕序列包含6.06个动作片段,涉及4.02个不同动作类别。我们通过自主设计的网页界面收集序列标签,并基于现有网络标注工具VIA[8](见第3.1节)完成帧标签与动作对齐标注。标注工作通过Amazon Mechanical Turk[1]平台完成。
We benchmark the performance of models on BABEL for the 3D action recognition task [29]. The goal is to predict the action category, given a segment of mocap that corresponds to a single action span. Unlike existing datasets that are carefully constructed for the actions of interest, action recognition with BABEL more closely resembles real-world applications due to the long-tailed distribution of classes in BABEL. We demonstrate that BABEL presents interesting learning challenges for an existing action recognition model that performs well on NTU $\mathrm{RGB+D}60$ . In addition to being a useful benchmark for action recognition, we believe that BABEL can be leveraged by the community for tasks like pose estimation, motion synthesis, temporal localization, few shot learning, etc.
我们在BABEL数据集上对3D动作识别任务[29]进行了模型性能基准测试。该任务的目标是根据对应单一动作片段的动作捕捉(mocap)数据段预测动作类别。与专为目标动作精心构建的现有数据集不同,由于BABEL中存在长尾分布的类别,其动作识别更贴近现实应用场景。我们证明了BABEL能为现有动作识别模型带来有趣的学习挑战,这些模型在NTU $\mathrm{RGB+D}60$ 数据集上表现优异。除作为动作识别的重要基准外,我们认为BABEL还可被学界用于姿态估计、运动合成、时序定位、少样本学习等任务。
In this work, we make the following contributions: (1) We provide the largest 3D dataset of dense action labels that are precisely aligned with their corresponding movement spans in the mocap sequence. (2) We categorize the raw language labels into over 250 action classes that can be leveraged for tasks requiring categorical label sets such as 3D action recognition. (3) We analyze the actions occurring in BABEL sequences in detail, furthering our semantic understanding of mocap data that is already widely used in vision tasks. (4) We benchmark the performance of baseline 3D action recognition models on BABEL, demonstrating that the distribution of actions that resembles realworld scenarios, poses interesting learning challenges. (5) The dataset, baseline models and evaluation code are publicly available for academic research purposes at https: //babel.is.tue.mpg.de/.
在本工作中,我们做出了以下贡献:(1) 提供了规模最大的3D密集动作标注数据集,所有标注都与动作捕捉序列中的对应运动区间精确对齐。(2) 将原始语言标签分类为250多个动作类别,可用于需要分类标签集的任务(如3D动作识别)。(3) 详细分析了BABEL序列中出现的动作,深化了对已广泛应用于视觉任务的动作捕捉数据的语义理解。(4) 在BABEL上对基准3D动作识别模型进行性能测试,表明接近真实场景的动作分布带来了有趣的学习挑战。(5) 数据集、基准模型和评估代码已公开供学术研究使用,访问地址:https://babel.is.tue.mpg.de/。
2. Related Work
2. 相关工作
Language labels and 3D mocap data. We first briefly review the action categories in large-scale 3D datasets, followed by a more detailed comparison in Table 1. The CMU Graphics Lab Motion Capture Database (CMU) [2] is widely used, and has 2605 sequences. The dataset has 6 semantic categories (e.g., ‘human interaction’, ‘interaction with environment’) that, overall, contain 23 subcat- egories, e.g., ‘two subjects’, ‘playground’, ‘pantomime’. Human3.6M [16] consists of 12 everyday actions in 6 semantic categories such as ‘walking variations’ (‘walking dog’, ‘walking pair’), ‘full body upright variations’ (‘greeting’, ‘posing’), etc. MoVi [10] consists of everyday actions and sports movements e.g., ‘clapping hands’, ‘pretending to take picture’, etc. KIT Whole-Body Human Motion Database (KIT) [23] focuses on both human move- ment and human-object interaction [34] containing grasping and manipulation actions in addition to activities such as climbing and playing sports. LaFan1 [13] is a recent dataset containing 15 different actions, including locomotion on uneven terrain, free dancing, fight movements, etc. These characterize the movement in the entire mocap sequence via simple tags or keywords. In contrast, the KIT Motion-Language Dataset [23] describes motion sequences with natural language sentences, e.g., ‘A person walks backward at a slow speed’. While our motivation to learn semantic representations of movement is similar, action labels in BABEL are precisely aligned with the sequence.
语言标签与3D动作捕捉数据。我们首先简要回顾大规模3D数据集中的动作类别,随后在表1中进行更详细的比较。CMU图形实验室动作捕捉数据库(CMU)[2]被广泛使用,包含2605个序列。该数据集具有6个语义类别(如"人际互动"、"环境交互"),共涵盖23个子类别,例如"双人互动"、"游乐场"、"哑剧表演"。Human3.6M[16]包含6个语义类别下的12种日常动作,如"行走变体"("遛狗"、"双人行走")、"直立全身动作"("问候"、"摆姿势")等。MoVi[10]收录日常动作与运动行为,例如"拍手"、"假装拍照"等。KIT全身人体运动数据库(KIT)[23]同时关注人体运动与人机交互[34],除攀爬、运动等活动外还包含抓取与操控动作。LaFan1[13]是近期数据集,包含15种不同动作,包括不平坦地形移动、自由舞蹈、打斗动作等。这些数据集通过简单标签或关键词描述整个动作捕捉序列中的运动特征。相比之下,KIT动作-语言数据集[23]使用自然语言句子描述运动序列,例如"一个人以慢速向后行走"。虽然我们学习运动语义表征的动机相似,但BABEL中的动作标签与序列实现了精确对齐。
Table 1. Comparison of existing datasets containing action labels for human movement. GT motion indicates whether the human movements are accurate (mocap) or noisy estimates (e.g., via tracking). # Actions indicates the total count of action categories in each dataset. # Hours indicates the total duration of all sequences in the dataset. Per-Frame? indicates whether the action labels are precisely aligned with the corresponding spans of movement in the sequence. Continuous? indicates whether the movement sequences are original, continuous, human movements or short cropped segments containing specific actions. BABEL uniquely provides large-scale dense (per-frame) action labels for 37.5 hours of natural, continuous, ground-truth human movement data from the AMASS [22] dataset. In addition, BABEL provides a label that describes the overall action in the entire sequence, for 43.5 hours of mocap from AMASS.
表 1: 现有人体运动动作标签数据集的对比。GT motion表示人体运动数据是精确的(动作捕捉)还是噪声估计的(例如通过跟踪)。# Actions表示每个数据集中动作类别的总数。# Hours表示数据集中所有序列的总时长。Per-Frame?表示动作标签是否与序列中相应的运动片段精确对齐。Continuous?表示运动序列是原始的、连续的人体运动还是包含特定动作的短裁剪片段。BABEL独特地为AMASS [22]数据集中37.5小时的自然、连续、真实人体运动数据提供了大规模密集(逐帧)动作标签。此外,BABEL还为AMASS中43.5小时的动作捕捉数据提供了描述整个序列整体动作的标签。
| Dataset | GTmotion? | #Actions | #Hours | Per-frame? | Continuous? |
|---|---|---|---|---|---|
| CMU MoCap [2] | 23 | 9 | |||
| MoVi [10] | 20 | 9 | × | √ | |
| Human3.6M [16] | √ | 17 | 18 | √ | |
| LaFan1 [13] | 12 | 4.6 | × | √ | |
| HumanAct12 [12] | × | 12 | 6 | × | |
| NTU RGB+D 60 [29] | × | 60 | 37 | × | × |
| NTU RGB+D 120 [21] | × | 120 | 74 | × | |
| BABEL (ours) | √ | 260 | 43.5 37.5 | × √ | √ |
Frame actions labels in 3D mocap. The CMU MMAC dataset [32] contains precise frame labels for a fixed set of 17 cooking actions (including ‘none’). Arikan et al. [4] and Muller et al. [25] partially automate labeling temporal segments for mocap using action class if i ers. While these works assume a known, fixed set of classes, in BABEL, we identify and precisely label all actions that occur in each frame.
在3D动作捕捉中标注帧动作标签。CMU MMAC数据集[32]包含17种固定烹饪动作(包括"无动作")的精确帧标签。Arikan等人[4]和Muller等人[25]利用动作分类器部分实现了动作捕捉时序片段的自动化标注。这些研究都假设已知固定的动作类别集合,而在BABEL项目中,我们识别并精确标注每一帧中出现的所有动作。
Action labels and tracked 3D data. NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 60 [29] and 120 [21] are large, widely used datasets for 3D action recognition. In NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ , RGBD sequences are captured via 3 Kinect sensors which track joint positions of the human skeleton. NTU $\mathrm{RGB}{+}\mathrm{D}$ has segmented sequences corresponding to specific actions. There are 3 semantic categories – ‘Daily actions’ (‘drink water’, ‘taking a selfie’), ‘Medical conditions’ (‘sneeze’, ‘falling down’)
动作标签与追踪的3D数据。NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 60 [29] 和 120 [21] 是广泛使用的3D动作识别大型数据集。在NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 中,RGBD序列通过3台Kinect传感器采集,用于追踪人体骨骼关节位置。NTU $\mathrm{RGB}{+}\mathrm{D}$ 包含对应特定动作的分段序列,涵盖3个语义类别——"日常动作"(如"喝水"、"自拍")、"医疗状况"(如"打喷嚏"、"摔倒")
and ‘Mutual actions’ (‘hugging’, ‘cheers and drink’). These datasets contain short cropped segments of actions, which differ from BABEL sequences, which are continuous, reflecting natural human movement data. The ability to model actions that can occur simultaneously, sequentially and the transitions between them is important for application to real world data [28]. See Table 1 for further comparison.
以及"互动行为"("拥抱"、"干杯饮酒")。这些数据集包含经过裁剪的短动作片段,与BABEL数据集中的连续序列不同,后者反映了自然的人类运动数据。建模能够同时发生、按顺序出现的行为及其间过渡的能力,对于现实世界数据的应用非常重要[28]。详细对比参见表1:
2D temporal localization . Many works over the years have contributed to progress in the action localization task [15, 31, 40]. Activity Net [28] contains 648 hours of videos and 200 human activities that are relevant to daily life, organized under a rich semantic taxonomy. It has 19,994 (untrimmed) videos, with an average of 1.54 activities per video. More recently, HACS [41] provides a larger temporal localization dataset with 140,000 segments of actions that are cropped from 50,000 videos that span over 200 actions. AVA [11] is another recent large-scale dataset that consists of dense annotations for long video sequences for 80 atomic classes. In [38], the authors introduce a test recorded by Kinect v2 in which they describe activities as compositions of action interactions with different objects. While BABEL also contains temporally annotated labels, it does not assume a fixed set of actions that are of interest. On the other hand, with BABEL, we elicit labels for all actions in the sequence including high-level (‘eating’), and low-level actions (‘raise right hand to mouth’).
2D时间定位。多年来,许多研究推动了动作定位任务的进展[15, 31, 40]。Activity Net[28]包含648小时视频和200种与日常生活相关的人类活动,按丰富的语义分类体系组织。该数据集包含19,994段(未修剪)视频,平均每段视频含1.54个活动。近期推出的HACS[41]提供了更大的时间定位数据集,包含从50,000段视频中裁剪出的140,000个动作片段,涵盖200余种动作。AVA[11]是另一个新推出的大规模数据集,包含对长视频序列中80个原子类别的密集标注。文献[38]作者通过Kinect v2录制测试数据,将活动描述为与不同对象的动作交互组合。虽然BABEL同样包含时间标注标签,但并未预设固定的关注动作集合。相反,通过BABEL我们获取序列中所有动作的标签,既包含高级动作(如"进食"),也包含低级动作(如"将右手举到嘴边")。
3. Dataset
3. 数据集
We first provide details regarding the crowd sourced data collection process. We then describe the types of labels in BABEL, and the label processing procedure.
我们首先详细介绍众包数据收集过程,随后说明BABEL中的标签类型及标签处理流程。
3.1. Data collection
3.1. 数据收集
We collect BABEL by showing rendered videos of mocap sequences from AMASS [22] to human annotators and eliciting action labels (Fig. 2). The mocap is processed to make sure the person in the video faces the annotator in the first frame. We observe that a sequence labeled as pick up object often also involves other actions such as walking to the object, bending down to pick up the object, grasping the object, straightening back up, turning around and walking away. We argue that labeling the entire sequence with the single label is imprecise, and problematic. First, many actions such as turn and grasp are ignored and remain unlabeled although they may be of interest to researchers [34]. Second, sequence labels provide weak supervision to statistical models, which are trained to map the concept of picking up object to the whole sequence when it, in fact, contains many different actions. To illustrate this point, we examine a typical sequence (see Qualitative Example 1 in the project website), and find that only $20%$ of the duration of the sequence labeled as pick up and place object corresponds to this action. Crucially, walking towards and away from the object – actions that remain unlabeled – account for $40%$ of the duration. While this makes semantic sense to a human – picking up and placing an object is the only action that changes the state of the world and hence worth mentioning, this might be suboptimal training data to a statistical model, especially when the dataset also contains the confusing classes walk, turn, etc. Finally, using noisy labels as ground truth during evaluation does not accurately reflect the capabilities of models.
我们通过向人工标注者展示来自AMASS [22]的动作捕捉序列渲染视频并收集动作标签来构建BABEL数据集(图 2)。这些动作捕捉数据经过处理,确保视频中的人物在第一帧时面向标注者。我们观察到,被标记为"捡起物体"的序列通常还包含其他动作,如走向物体、弯腰捡起物体、抓握物体、直起身、转身离开等。我们认为用单一标签标注整个序列是不精确且有问题的。首先,许多动作(如转身和抓握)被忽略且未被标注,尽管这些动作可能对研究者有价值[34]。其次,序列标签为统计模型提供的监督信号较弱,模型被训练将"捡起物体"的概念映射到整个序列,而实际上序列包含许多不同动作。为说明这一点,我们分析了一个典型序列(参见项目网站中的定性示例1),发现被标记为"捡起并放置物体"的序列中,只有20%时长确实对应这个动作。关键的是,走向和离开物体(这些未被标注的动作)占据了40%的时长。虽然对人类而言这具有语义合理性(捡起和放置物体是唯一改变世界状态的动作,因此值得提及),但对统计模型来说这可能是次优的训练数据,特别是当数据集中还包含容易混淆的类别(如行走、转身等)时。最后,在评估阶段使用带噪声的标签作为真实值不能准确反映模型的能力。
We address this with action labels at two levels of resolution – a label describing the overall action in the entire sequence, and fine-grained labels that are aligned with their corresponding spans of movement in the mocap sequence.
我们通过两个分辨率级别的动作标签来解决这个问题——一个描述整个序列中整体动作的标签,以及与动作捕捉序列中相应运动片段对齐的细粒度标签。
3.2. BABEL action labels
3.2. BABEL 动作标签
We collect BABEL labels in a two-stage process – first, we collect sequence labels, and determine whether the sequence contains multiple actions. We then collect frame labels for the sequences where 2 annotators agree that there are multiple actions.
我们通过两个阶段收集BABEL标签——首先收集序列标签,并确定该序列是否包含多个动作。随后针对2位标注者均判定存在多个动作的序列,进行逐帧标签采集。
Sequence labels. In this labeling task, annotators answer two questions regarding a sequence. We first ask annotators if the video contains more than one action (yes/no).1 If the annotator chooses ‘no’, we ask them to name the action in the video. If they instead choose ‘yes’, we elicit a sequence label with the question, “If you had to describe the whole sequence as one action, what would it be?” We provide the web-based task interface in the project website.
序列标签。在此标注任务中,标注者需回答关于视频序列的两个问题。首先询问标注者视频是否包含多个动作(是/否)。若标注者选择"否",则要求其命名视频中的动作;若选择"是",则通过提问"若必须将整个序列描述为一个动作,你会如何描述?"来获取序列标签。基于网页的任务界面详见项目网站。
(注:根据用户提供的术语表,文中未出现需要特殊处理的AI术语;"yes/no"保留英文形式符合技术文档惯例;项目网站未给出具体URL故采用中性表述;严格遵循了用户要求的标点符号规范)
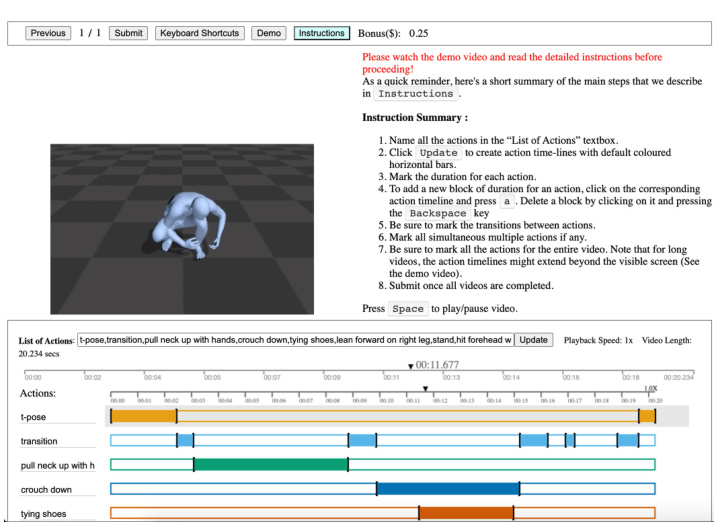
Figure 2. BABEL annotation interface to collect frame-level action labels. Annotators first name all the actions in the video. They then, precisely align the length of the action segment (colored horizontal bar) with the corresponding duration of the action in the video. This provides dense action labels for the entire sequence.
图 2: BABEL标注界面用于收集帧级动作标签。标注者首先为视频中的所有动作命名,然后精确调整动作片段(彩色水平条)的长度以匹配视频中对应动作的持续时间,从而为整个序列提供密集的动作标注。
We ask annotators to enter the sequence labels in a textbox, with the option of choosing from an auto-complete drop-down menu that is populated with a list of basic actions. We specifically elicit free-form labels (as opposed to a fixed list of categories) from annotators to discover the diversity in actions in the mocap sequences. We find that in most cases, annotators tend to enter their own action labels. This also presents a challenge, acting as a source of label variance. Apart from varying vocabulary, free-form descriptions are subject to ambiguity regarding the ‘correct’ level in the hierarchy of actions [11], e.g., raise left leg, step, walk, walk backwards, walk backwards stylishly, etc.
我们要求标注者在文本框中输入动作序列标签,并提供一个自动补全下拉菜单选项,其中包含一系列基本动作列表。我们特意让标注者自由输入标签(而非从固定类别列表中选择),以发现动作捕捉序列中动作的多样性。研究发现,大多数情况下标注者倾向于输入自定义动作标签。这也带来了挑战,成为标签差异的来源之一。除了词汇差异外,自由形式的描述还存在动作层级结构中"正确"级别的模糊性问题 [11],例如:抬左腿、迈步、行走、后退行走、时尚后退行走等。
We collect 2 labels per sequence, and in case of disagreement regarding multiple actions, a third label. We determine that a sequence contains a single action or multiple actions based on the majority vote of annotators’ labels. Overall, BABEL contains 28055 sequence labels2.
我们为每个序列收集2个标注,若对多个动作存在分歧,则引入第三个标注。根据标注者标签的多数表决,我们判定序列包含单个动作或多个动作。总体而言,BABEL数据集包含28055个序列标注2。
Frame labels. Frame labels contain language descriptions of all actions that occur in the sequence, and precisely identify the span in the sequence that corresponds to the action. We leverage an existing video annotation tool, VIA [8], and modify the front-end interface and back-end functionality to suit our annotation purposes. For instance, we ensure that every frame in the sequence is annotated with at least one action label. This includes ‘transition’ which indicates a transition between two actions, or ‘unknown’ which indicates that the annotator is unclear as to what action is being performed. This provides us with dense annotations of action labels for the sequence. A screenshot of the AMT task interface for frame label annotation in BABEL is shown in Fig. 2.
帧标签。帧标签包含序列中所有动作的语言描述,并精确标识与动作对应的序列范围。我们利用现有的视频标注工具VIA[8],修改其前端界面和后端功能以满足标注需求。例如,我们确保序列中的每一帧都至少标注一个动作标签,包括表示两个动作间过渡的"transition",或标注者无法确定当前动作的"unknown"。这为序列提供了密集的动作标签标注。图2展示了BABEL中用于帧标签标注的AMT任务界面截图。
To provide frame labels, an annotator first watches the whole video and enters all the actions in the ‘List of Actions’ text-box below the video. This populates a set of empty colored box outlines corresponding to each action. The annotator then labels the span of an action by creating a segment (colored rectangular box) with a button press. The duration of the segment and the start/end times can be changed via simple click-and-drag operations. The video frame is continuously updated to the appropriate time-stamp corresponding to the end time of the current active segment. This provides the annotator real-time feedback regarding the exact starting point of the action. Once the segment is placed, its precision can be verified by a ‘play segment’ option that plays the video span corresponding to the current segment. In case of errors, the segment can be further adjusted. We provide detailed instructions via text, and a video tutorial that explains the task with examples, and demonstrates operation of the annotation interface. The web interface of the task is provided in the project website.
为提供帧标签,标注者首先观看完整段视频,并在视频下方的"动作列表"文本框中输入所有动作。这将生成一组对应每个动作的彩色空框轮廓。随后,标注者通过按键操作创建彩色矩形框段来标记动作区间。通过简单的点击拖拽操作可调整片段时长及起止时间。视频帧会持续更新至当前活动片段的结束时间戳,为标注者提供动作起始点的实时反馈。放置片段后,可通过"播放片段"功能验证其精确度,该功能会播放当前片段对应的视频区间。若存在误差,可进一步调整片段。我们通过文字说明和视频教程提供详细指导,其中视频教程通过示例解释任务并演示标注界面操作。该任务的网页界面可在项目网站中查看。
We collect frame labels for 6663 sequences where both annotators who provided sequence labels agree that the sequence contains multiple actions3.
我们收集了6663个序列的帧级标签,这些序列的标注者在提供序列标签时一致认为该序列包含多个动作3。
Overall, BABEL contains dense annotations for a total of 66018 action segments for 10892 sequences. This includes both frame labels from sequences containing multiple actions, and sequence labels from sequences containing a single action. If an entire sequence has only a single action, it counts as 1 segment.
总体而言,BABEL数据集为10892个动作序列提供了共计66018个动作片段的密集标注。这些标注既包含多动作序列的逐帧标签,也包含单动作序列的序列级标签。若整个序列仅包含单一动作,则计为1个片段。
3.3. Annotators
3.3. 标注员
We recruit all annotators for our tasks via the Amazon Mechanical Turk (AMT)4 crowd-sourcing platform. These annotators are located either in the US or Canada. In the sequence label annotation task, we recruit $>850$ unique annotators with $>~5000$ HITs approved and an approval rate $>95%$ . In the frame labeling task, which is more involved, we first run small-scale tasks to recruit annotators. For further tasks, we only qualify about 130 annotators who demonstrate an understanding of the task and provide satisfactory action labels and precise segments in the sequence. In both tasks, we plan for a median hourly pay of $\sim\$12$ . We also provide bonus pay as an incentive for thorough work in the frame labeling task (details in Sup. Mat.).
我们通过亚马逊土耳其机器人(Amazon Mechanical Turk, AMT)众包平台招募所有任务标注员。这些标注员均位于美国或加拿大。在序列标注任务中,我们招募了超过850名独立标注员,其通过审核的HIT数量超过5000次,批准率高于95%。对于更复杂的框架标注任务,我们先通过小规模任务筛选标注员,最终仅保留约130名能准确理解任务要求、提供满意动作标签和精确片段划分的合格标注员。两项任务的小时工资中位数均设定为约12美元,并在框架标注任务中设置奖金机制以激励细致工作(详见补充材料)。
3.4. Label processing
3.4. 标签处理
BABEL contains a total of 15472 unique raw action labels. Note that while each action label is a unique string, labels are often semantically similar (walk, stroll, etc.), are minor variations of an action word (walking, walked, etc.) or are misspelled. Further, tasks like classification require a smaller categorical label set. We organize the raw labels into two smaller sets of semantically higherlevel labels – action categories, and semantic categories.
BABEL共包含15472个独特的原始动作标签。需要注意的是,虽然每个动作标签都是唯一的字符串,但这些标签在语义上往往相似(如walk、stroll等),或是动作词的微小变体(如walking、walked等),甚至存在拼写错误。此外,分类等任务需要更小的类别标签集。我们将原始标签组织成两个语义更高层次的较小标签集——动作类别和语义类别。
Action categories. We map the variants of an action into a single category via a semi-automatic process that involves clustering the raw labels, followed by manual adjustment.
动作类别。我们通过半自动化流程将动作变体映射到单一类别,该流程包括对原始标签进行聚类,然后进行手动调整。
We first pre-process the raw string labels by lowercasing, removing the beginning and ending white-spaces, and lemma ti z ation. We then obtain semantic representations for the raw labels by projecting them into a 300D space via Word2Vec embeddings [24]. Word2Vec is a widely used word embedding model that is based on the distri but ional hypothesis – words with similar meanings have similar contexts. Given a word, the model is trained to predict surrounding words (context). An intermediate representation from the model serves as a word embedding for the given word. For labels with multiple words, the overall representation is the mean of the Word2Vec embeddings of all words in the label. Labels containing words that are semantically similar, are close in the representation space.
我们首先对原始字符串标签进行预处理,包括转为小写、去除首尾空格及词形还原。随后通过Word2Vec嵌入[24]将这些原始标签映射到300维空间,获得其语义表示。Word2Vec是一种基于分布假说的经典词嵌入模型——具有相似含义的词语拥有相近的上下文语境。该模型通过预测目标词的周边词汇(上下文)进行训练,其中间层输出即为该词的向量表示。对于多词标签,整体表征取标签内所有词语Word2Vec嵌入的均值。语义相似的标签在表征空间中距离相近。
We cluster labels that are similar in the representation space via $\mathrm{K}$ -means ( ${K}=200$ clusters). This results in several semantically meaningful clusters, e.g., walk, stroll, stride, etc. which are all mapped to the same cluster. We then manually verify the cluster assignments and fix them to create a semantically meaningful organization of the action labels. Raw labels that are not represented by Word2Vec (e.g., $\operatorname{T-pose})$ are manually organized into relevant categories in this stage. For each cluster, we determine a category name that is either a synonym or hypernym that describes all action labels in the cluster.
我们通过 $\mathrm{K}$ -means (${K}=200$ 个簇) 在表示空间中对相似标签进行聚类。这产生了多个具有语义意义的簇,例如 walk、stroll、stride 等都被映射到同一个簇中。随后,我们手动验证簇分配并调整它们,以创建一个具有语义意义的动作标签组织。未被 Word2Vec 表示的原始标签 (例如 $\operatorname{T-pose}$) 在此阶段被手动归类到相关类别中。对于每个簇,我们确定一个类别名称,该名称要么是同义词,要么是上位词 ,用于描述该簇中的所有动作标签。
Some raw labels, e.g., rotate wrists can be composed into multiple actions like circular movement and wrist movement. Thus, raw labels are occasionally assigned membership to multiple action categories.
某些原始标签(例如"旋转手腕")可能由多个动作(如圆周运动和手腕运动)组合而成。因此,原始标签有时会被归入多个动作类别。
Overall, the current version of BABEL has 260 action categories. Interestingly, the most frequent action in BABEL is ‘transition’ – a movement that usually remains unlabeled in most datasets. There are 18447 transitions between different actions in BABEL. Un surprisingly, the frequency of actions decreases exponentially following Zipf’s law – the 50th most frequent action category catch occurs 417 times, the 100th most frequent action category misc. activities, occurs 86 times, and the 200th most frequent action category disagree, occurs 8 times. We visualize the action categories containing the largest number of raw labels (cluster elements) in Fig. 3 (outer circle). Raw labels corresponding to these categories are shown on the right. We provide histograms of duration and number of segments per-action, in the Sup. Mat and project webpage.
总体而言,当前版本的BABEL包含260个动作类别。有趣的是,BABEL中出现频率最高的动作是"过渡(transition)"——这种运动在大多数数据集中通常未被标注。BABEL中共有18447次不同动作之间的过渡。不出所料,动作频率按照Zipf定律呈指数级下降:第50频繁的动作类别"catch"出现417次,第100频繁的杂项活动(misc. activities)出现86次,第200频繁的"disagree"动作仅出现8次。我们在图3(外圈)中可视化了包含最多原始标签(聚类元素)的动作类别,右侧展示了这些类别对应的原始标签。补充材料和项目网页中提供了每个动作的持续时间和片段数量的直方图分布。
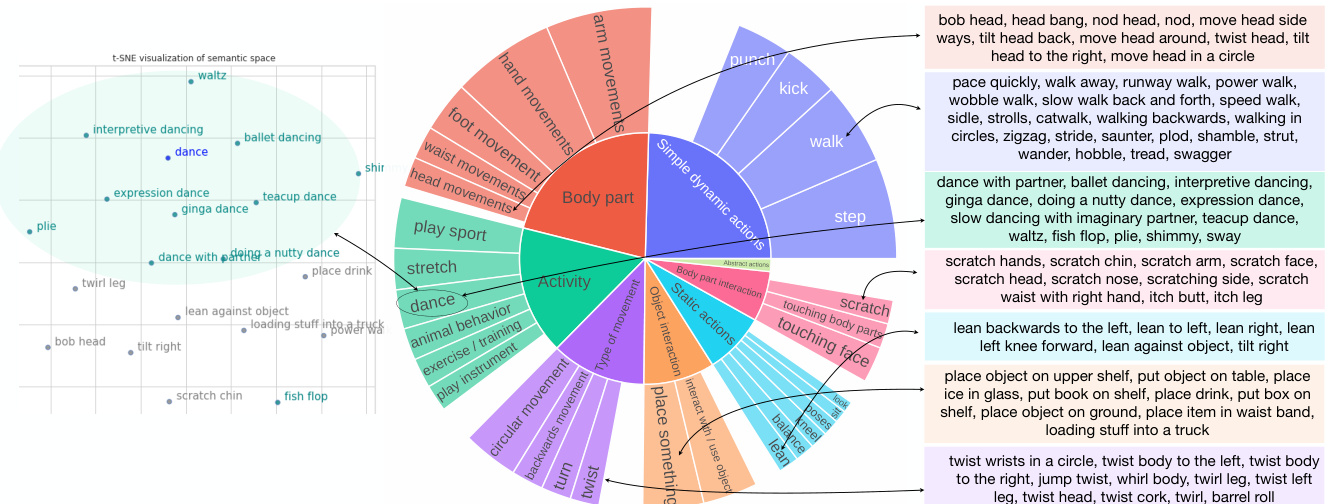
Figure 3. Left. 2D t-SNE [36] visualization of the semantic space that we project raw labels into. Similar labels are grouped via K-means clustering. The green shading and points represent the ‘dance’ cluster and its members respectively. Center. Distribution of (a subset of) action categories (outer circle) under each semantic category (inner circle) in BABEL. The angle occupied by the action category is proportional to the number of unique raw label strings associated with it. Action categories with a large number of fine-grained descriptions are shown. Right. Subset of the fine-grained descriptions associated with selected action categories.
图 3: 左图. 我们将原始标签映射到的语义空间的2D t-SNE [36]可视化。通过K-means聚类将相似标签分组。绿色阴影和点分别代表'dance'聚类及其成员。中图. BABEL中每个语义类别(内圈)下的动作类别(外圈)分布(子集)。动作类别所占角度与其关联的独特原始标签字符串数量成正比。展示了具有大量细粒度描述的动作类别。右图. 与选定动作类别关联的细粒度描述子集。
Semantic categories of labels. Action categories often reflect qualitatively different types of actions like interacting with objects, actions that describe the trajectory of movement, complex activities involving multiple actions, etc. We formalize the different types of actions in BABEL into 8 semantic categories (inner circle in Fig. 3):
标签的语义类别。动作类别通常反映定性上不同类型的动作,如与物体交互、描述运动轨迹的动作、涉及多个动作的复杂活动等。我们将BABEL中的不同类型动作形式化为8个语义类别(图3内圈):
abstract actions in BABEL.
BABEL中的抽象动作
The diversity in the types of action labels in BABEL can be leveraged by tasks modeling movement at various levels of semantic abstraction, e.g., movement of body parts like circular movement of wrist at a low level, or high-level semantic activities such as dancing the waltz. Further, depending on the task and model, one can exploit either the discrete set of action categories (e.g., action recognition), or embed the raw action labels into a semantic space to provide a semantic representation of the segment of movement (e.g., action synthesis).
BABEL中动作标签类型的多样性可被用于建模不同语义抽象层次的动作任务,例如低层次的肢体动作(如手腕画圈)或高层次的语义活动(如跳华尔兹)。此外,根据任务和模型需求,开发者既可利用离散的动作类别集合(如动作识别任务),也可将原始动作标签嵌入语义空间以提供动作片段的语义表征(如动作合成任务)。
We provide the full set of semantic categories, action categories, and raw action labels in BABEL in the project webpage.
我们在项目网页中提供了BABEL完整的语义类别、动作类别和原始动作标签集。
4. Analysis
4. 分析
Natural human movement often contains multiple actions and transitions between them. Modeling the likelihood of simultaneous actions and action transitions has applications in reasoning about action afford ances in robotics and virtual avatars, motion synthesis [35], activity forecasting [18], animation [33], and action recognition.
自然人体运动通常包含多个动作及其之间的过渡。同时建模动作共存和动作过渡的可能性,在机器人学和虚拟化身中的动作可供性推理、运动合成[35]、活动预测[18]、动画制作[33]以及动作识别等领域具有应用价值。
4.1. Simultaneous actions
4.1. 同步动作
Although people often perform multiple actions simultaneously in real life, this is rarely captured in labeled datasets. Recall from Sec. 3.2 that in BABEL, we ask annotators to label all actions that are occurring in each frame of the sequence. Overall, BABEL has 49952 instances of simultaneous actions that occur with 2907 unique pairs of action categories. Simultaneous actions are defined as actions that overlap for a duration of $>0.1$ seconds. We exclude the overlap of an action with transition since this implies adjacent actions.
虽然在现实生活中人们经常同时执行多个动作,但标注数据集中很少捕捉到这种情况。回顾第3.2节,在BABEL中,我们要求标注者为序列每一帧中发生的所有动作打标签。总体而言,BABEL包含49952个同时动作实例,涉及2907组独特的动作类别组合。同时动作定义为持续时间重叠超过$>0.1$秒的动作。我们排除了动作与过渡状态的重叠,因为这种情况意味着相邻动作。
4.2. Temporally adjacent actions
4.2. 时间相邻动作
The dense labels in BABEL capture the progression of actions in mocap sequences. We analyze adjacent actions where where action $a_{i}$ follows $a_{j}$ (denoted by $a_{j}\rightarrow a_{i},$ ). $a_{i}$ and $a_{j}$ denote action segments, i.e., a contiguous set of frames corresponding to an action (and not the action for a single frame). Thus, $a_{i}\neq a_{j}$ if the actions are adjacent. We say $a_{j}\rightarrow a_{i}$ if the frame succeeding the last frame of $a_{j}$ is the first frame of $a_{i}$ . In practice, we account for imprecise human temporal annotations by ignoring a small overlap in duration ( $<0.1$ sec.) between $a_{i}$ and $a_{j}$ . We also disregard the separation of actions by transition; i.e., $a_{j}\rightarrow a_{i}$ if $a_{j}\rightarrow a_{t}$ and $a_{t}\to a_{i}$ , where $a_{t}=$ transition.
BABEL中的密集标签捕捉了动作捕捉序列中动作的进展。我们分析相邻动作,其中动作$a_{i}$跟随$a_{j}$(表示为$a_{j}\rightarrow a_{i}$)。$a_{i}$和$a_{j}$表示动作片段,即对应于一个动作的连续帧集合(而非单帧动作)。因此,若动作相邻,则$a_{i}\neq a_{j}$。当$a_{j}$最后一帧的下一帧是$a_{i}$的首帧时,我们称$a_{j}\rightarrow a_{i}$。实际处理中,为应对人工时间标注的不精确性,我们忽略$a_{i}$与$a_{j}$之间的小幅重叠($<0.1$秒)。同时忽略过渡动作分隔的情况,即若$a_{j}\rightarrow a_{t}$且$a_{t}\to a_{i}$(其中$a_{t}=$过渡动作),仍视为$a_{j}\rightarrow a_{i}$。
We visualize the frequent transitions between actions, i.e., $a_{j}\rightarrow a_{i}$ sorted by Count $(a_{j}\to a_{i})$ in BABEL, in Fig. 4. We observe that $\mathtt{w a l k}$ , un surprisingly, has the most diverse set of adjacent actions, i.e., Count $(\mathtt{w a l k}\to a_{i}$ ) and Count( $a_{j}\rightarrow\mathrm{w}\mathrm{a}\mathrm{1k}$ ) are large. While transitions between action pairs such as (jog, turn), (walk, t-pose) are bidirectional (with $\sim$ equal frequency), others have fewer adjacent actions. Some action categories with few transitions illustrate semantically meaningful action chains, e.g., sit $\rightarrow$ stand u $)\rightarrow\mathrm{walk}$ and $\mathtt{w a l k}\to\mathtt{b e n d}\to$ pick something up $\rightarrow$ place something. Unidirectional transitions such as sit $\rightarrow$ stand up and $\mathrm{walk}\rightarrow\mathrm{sit}$ implicitly indicate the arrow of time [26]. Interestingly, the transition from sit $\rightarrow$ stand up, and the lack of transition from sit $\rightarrow$ stand delineates the subtle difference between the labels stand (static action of ‘maintaining an upright position’) and stand up (dynamic action of ‘rising into an upright position’).
我们在图4中可视化BABEL数据集中按出现次数 $(a_{j}\to a_{i})$ 排序的高频动作转换。不出所料,$\mathtt{walk}$(行走)拥有最多样的相邻动作组合,即Count $(\mathtt{walk}\to a_{i}$) 和Count( $a_{j}\rightarrow\mathrm{walk}$) 数值较大。虽然(慢跑,转身)、(行走,T姿势)等动作对呈现双向转换(频率 $\sim$ 相等),但其他动作的相邻动作较少。某些低频转换的动作类别揭示了有语义意义的动作链,例如坐 $\rightarrow$ 起立 $\rightarrow$ 行走,以及行走 $\rightarrow$ 弯腰 $\rightarrow$ 拾物 $\rightarrow$ 放置物品。单向转换如坐 $\rightarrow$ 起立和行走 $\rightarrow$ 坐下隐式体现了时间箭头[26]。值得注意的是,从坐 $\rightarrow$ 起立的转换与坐 $\rightarrow$ 站立转换的缺失,揭示了"站立"(保持直立姿态的静态动作)与"起立"(变为直立姿态的动态动作)标签间的微妙差异。
Given the temporally adjacent actions in BABEL, we attempt to model the transition probabilities between actions, i.e., $\textstyle P(a_{i}|a_{j})$ . Concretely, we compute
鉴于BABEL中时间上相邻的动作,我们尝试建模动作之间的转移概率,即 $P(a_{i}|a_{j})$ 。具体而言,我们计算

Figure 4. Node represent actions, and an edge represents a transition between these actions in the mocap sequence. Edge thickness $\propto\mathrm{Count}\left(a_{i}\rightarrow a_{j}\right)$ (frequency of transition) in BABEL.
图 4: 节点表示动作,边表示动作捕捉序列中这些动作之间的过渡。边的粗细与 BABEL 数据集中 $\propto\mathrm{Count}\left(a_{i}\rightarrow a_{j}\right)$ (转移频率) 成正比。
Table 2. Random walk samples based on action transition probabilities learned from BABEL. The generated samples are plausible action sequences simulating natural human movement.
表 2: 基于从BABEL学习的动作转移概率的随机游走样本。生成的样本是模拟自然人类运动的合理动作序列。
| # | 动作转移 |
|---|---|
| 2 | 行走、转移、拾取、放下、转移、顺时针行走、转移、站立A姿势、转移、双手内外挥动、左前挥臂、转移、左腿交叉 |
| 3 | 圆形手势系列、转移、左视T姿势、站立、转移、右视、站立 |
| 向前踏步、站立、转身、后退行走、前进行走、站立、失去平衡、转移、转身、行走、站立 |
$P(a_{i}|a_{i-1},a_{i-2},a_{i-3})$ , an order 3 Markov Chain [9], and observe in Table 2 that random walks along this chain generate plausible action sequences for human movement.
$P(a_{i}|a_{i-1},a_{i-2},a_{i-3})$ ,一个三阶马尔可夫链 [9] ,并在表 2 中观察到沿该链的随机游走生成了合理的人类动作序列。
4.3. Bias
4.3. 偏差
There are a few potential sources of bias in BABEL, which we report in the Sup. Mat. Specifically, we discuss potential biases introduced by the interface design, pay structure, and label processing method. We also analyze the inter-annotator variation in BABEL labels by collecting 5 unique annotations for each of 29 sequences. We find that for the same sequence, annotators vary in the labeled action categories, the number of actions, and segments. In general, the variance appears to be larger for sequences of longer duration. We provide further details in the Sup. Mat.
BABEL存在几个潜在的偏差来源,具体内容已在补充材料中报告。我们重点讨论了界面设计、支付结构和标签处理方法可能引入的偏差。通过为29个动作序列各收集5组独立标注,我们还分析了BABEL标签的标注者间差异。研究发现:对同一动作序列,不同标注者在动作类别标记、动作数量划分和片段切分上均存在差异,且时长越长的序列差异越显著。补充材料提供了更详细的分析数据。
5. Experiments
5. 实验
The dense action labels in BABEL can be leveraged for multiple vision tasks like pose estimation, motion synthesis, temporal localization, etc. In this section, we demonstrate the value of BABEL for the 3D action recognition task [21, 29], where the goal is to predict a single action category $y\in\mathcal{V}$ , for a given motion segment $\left(\mathbf{x}{t},\cdots,\mathbf{x}_{t^{\prime}}\right)$
BABEL中的密集动作标签可用于多种视觉任务,如姿态估计、运动合成、时间定位等。在本节中,我们展示了BABEL在3D动作识别任务[21, 29]中的价值,其目标是为给定的运动片段$\left(\mathbf{x}{t},\cdots,\mathbf{x}_{t^{\prime}}\right)$预测单一动作类别$y\in\mathcal{V}$。
Motion representation. A mocap sequence in AMASS, is an array of poses over time, $\mathbf{M}=(\mathbf{p}{1},\cdots,\mathbf{p}{L})$ , where $\mathbf{p}{i}$ are pose parameters of the SMPL-H body model [27].
动作表示。AMASS中的动作捕捉序列是一个随时间变化的姿态数组,$\mathbf{M}=(\mathbf{p}{1},\cdots,\mathbf{p}{L})$,其中$\mathbf{p}_{i}$是SMPL-H人体模型[27]的姿态参数。
For consistency with prior work, we predict the 25-joint skeleton used in NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ [29] from the vertices of the SMPL-H mesh; see Sup. Mat.
为了与先前工作保持一致,我们从SMPL-H网格顶点预测了NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ [29]中使用的25关节骨架,详见补充材料。
Thus, we represent a movement sequence as $\mathrm{\bf X~}=$ $\left(\mathbf{x}{1},\cdots,\mathbf{x}{L}\right)$ , where $\mathbf{x}_{i} \in~\mathbb{R}^{J\times3}$ represents the position of the $J(=\mathrm{~25})$ joints in the skeleton, in Cartesian coordinates, $(x,y,z)$ .
因此,我们将运动序列表示为 $\mathrm{ \bf X~}=$ $\left(\mathbf{x}{1},\cdots,\mathbf{x}{L}\right)$ ,其中 $\mathbf{x}_{i} \in~\mathbb{R}^{J\times3}$ 表示骨架中 $J(=\mathrm{~25})$ 个关节在笛卡尔坐标系 $(x,y,z)$ 下的位置。
Labels. In BABEL, a raw action label is mapped to the segment of human movement $\mathbf{X}{s}=\left(\mathbf{x}{t s},\cdot\cdot\cdot\mathbf{\nabla},\mathbf{x}{t e}\right)$ corresponding to the action. Recall that a raw action label for a segment can belong to multiple action categories $\mathcal{D}{s}$ (e.g., rotate wrists $\rightarrow$ circular movement, wrist movement). Overall, BABEL contains $N$ movement segments, and their action categories $(\mathbf{X}{s},\mathcal{Y}_{s})^{N}$ .
标签。在BABEL中,原始动作标签被映射到与动作对应的人体运动片段$\mathbf{X}{s}=\left(\mathbf{x}{t s},\cdot\cdot\cdot\mathbf{\nabla},\mathbf{x}{t e}\right)$。需注意,一个片段的原始动作标签可能属于多个动作类别$\mathcal{D}{s}$(例如转动手腕$\rightarrow$圆周运动、手腕运动)。总体而言,BABEL包含$N$个运动片段及其动作类别$(\mathbf{X}{s},\mathcal{Y}_{s})^{N}$。
Architecture. We benchmark performance on BABEL with the 2-Stream-Adaptive Graph Convolutional Network (2s-AGCN) [30], a popular architecture that performs graph convolutions spatially (along bones in the skeleton), and temporally (joints across time). Crucially, the graph structure follows the kinematic chain of the skeleton in the first layer but is adaptive – the topology is a function of the layer and the sample. The model achieves good performance on both 2D and 3D action recognition. GCNs remain the architecture of choice even in more recent state-of-theart approaches [6].
架构。我们在BABEL上使用2-Stream-Adaptive Graph Convolutional Network (2s-AGCN) [30]进行性能基准测试,这是一种流行的架构,可在空间(沿骨骼)和时间(跨时间关节)上执行图卷积。关键的是,图结构在第一层遵循骨骼的运动学链,但具有自适应性——其拓扑结构是层和样本的函数。该模型在2D和3D动作识别上均表现良好。即使在最新的最先进方法中[6],GCN仍是首选架构。
2s-AGCN consists of two streams with the same architecture – one which accepts joint positions, and the other, bone lengths and orientations, as input respectively. The final prediction is the average score from the two streams. On NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ , 2s-AGCN achieves achieves an accuracy of $88.5%$ on the cross-subject task. In our experiments, we use only the joint stream, which achieves $2%$ lower accuracy compared to 2s-AGCN [30].
2s-AGCN由两个结构相同的流组成——一个接收关节位置作为输入,另一个分别接收骨骼长度和方向作为输入。最终预测结果是两个流得分的平均值。在NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 数据集上,2s-AGCN在跨主体任务中达到了 $88.5%$ 的准确率。我们的实验中仅使用关节流,其准确率比2s-AGCN低 $2%$ [30]。
Data pre-processing. We normalize the input skeleton by transforming the coordinates such that the joint position of the middle spine is the origin, the shoulder blades are parallel to the X-axis and the spine to the Y-axis, similar to Shahroudy et al. [29]. We follow the 2s-AGCN preprocessing approach and divide a segment $\mathbf{X}{s}$ into contiguous, non-overlapping 5 sec. chunks, $\mathbf{X}{s}^{i}$ , at 30fps, i.e., $\mathbf{X}{s}=(\mathbf{X}{s}^{1},\cdot\cdot\cdot,\mathbf{X}{s}^{K})$ . Note that the number of chunks per segment, $\begin{array}{r l}{K=\left\lceil\frac{t e}{5*30}\right\rceil}&{{}}\end{array}$ . If the $K$ th chunk $\mathbf{X}{s}^{K}$ has duration $<5$ sec., we repeat $\mathbf{\check{X}}_{s}^{K}$ , and truncate at 5 sec.
数据预处理。我们通过坐标变换对输入骨架进行归一化处理,使中脊柱关节位置作为原点,肩胛骨平行于X轴,脊柱平行于Y轴,方法与Shahroudy等人[29]类似。采用2s-AGCN预处理方案,将片段$\mathbf{X}{s}$在30帧/秒条件下划分为连续不重叠的5秒块$\mathbf{X}{s}^{i}$,即$\mathbf{X}{s}=(\mathbf{X}{s}^{1},\cdot\cdot\cdot,\mathbf{X}{s}^{K})$。注意每个片段的块数计算公式为$\begin{array}{r l}{K=\left\lceil\frac{t e}{5*30}\right\rceil}&{{}}\end{array}$。若第$K$个块$\mathbf{X}{s}^{K}$时长不足5秒,则重复$\mathbf{\check{X}}_{s}^{K}$并截断至5秒。
Thus, a single sample in action recognition is a 5 sec. motion chunk $\mathbf{X}{s}^{i}\in\mathbf{X}{s}$ , and the action category labeled for its corresponding segment $y\in\mathcal{Y}_{s}$ in BABEL.
因此,动作识别中的一个样本是5秒的运动片段$\mathbf{X}{s}^{i}\in\mathbf{X}{s}$,其在BABEL数据集中对应标注的动作类别为$y\in\mathcal{Y}_{s}$。
BABEL action recognition splits. BABEL contains 260 action categories with a long-tailed distribution of samples per class, unlike other popular 3D action recognition datasets NTU $\mathrm{RGB}{+}\mathrm{D}$ [21, 29]. To understand the challenge posed by the long-tailed distribution of action categories in BABEL, we perform experiments with 2 different datasets containing 60 and 120 action categories (see Table 3). These are motion annotation pairs of the 60 and 120 action categories that are obtained from the dense subset of BABEL, containing 10892 sequences described in section 3.2. While BABEL-60 is already long-tailed, BABEL- 120 contains both extremely frequent and extremely rare classes. We randomly split the 13220 sequences in BABEL into train $(60%)$ ), val. $(20%)$ and test $(20%)$ sets. We choose the model with best performance on the val. set, and report performance on the test set. We provide the precise distribution of action categories for the train and val. splits in the project webpage.
BABEL动作识别划分。BABEL包含260个动作类别,每个类别的样本呈长尾分布,这与NTU $\mathrm{RGB}{+}\mathrm{D}$ [21, 29]等其他流行的3D动作识别数据集不同。为理解BABEL中动作类别的长尾分布带来的挑战,我们使用包含60和120个动作类别的2个不同数据集进行实验(见表3)。这些是从BABEL密集子集中获取的60和120个动作类别的运动标注对,包含3.2节描述的10892个序列。虽然BABEL-60已是长尾分布,但BABEL-120同时包含极高频率和极低频率的类别。我们将BABEL中的13220个序列随机划分为训练集 $(60%)$、验证集 $(20%)$ 和测试集 $(20%)$。选择验证集上性能最佳的模型,并报告测试集性能。具体动作类别在训练集和验证集的分布详见项目网页。
Metrics. Top-1 measures the accuracy of the highestscoring prediction. evaluates whether the groundtruth category is present among the top 5 highest-scoring predictions. It accounts for labeling noise and inherent label ambiguity. Note that it also accounts for the possible presence of multiple action categories $\mathcal{D}_{s}$ , per input movement sequence. Ideal models will score all the categories relevant to a sample highly. Top-1-norm is the mean Top-1 across categories. The magnitude of $(\mathrm{Top-1-norm})$ - $(\mathrm{Top}-1)$ illustrates the class-specific bias in the model performance. In BABEL, it reflects the impact of class imbalance on learning.
指标。Top-1衡量最高分预测的准确率。评估真实类别是否出现在前5个最高分预测中。该指标考虑了标注噪声和固有标签模糊性,同时兼顾了每个输入动作序列可能存在的多动作类别$\mathcal{D}_{s}$。理想模型会为样本所有相关类别赋予高分。Top-1-norm是跨类别的平均Top-1值。$(Top-1-norm)$ - $(Top-1)$的差值大小反映了模型性能的类别特异性偏差,在BABEL中体现类别不平衡对学习的影响。
Training. We experiment with two losses – standard cross-entropy loss, and the recently introduced focal loss [20]. Focal loss compensates for class imbalance by weighting the cross-entropy loss higher for inaccurate predictions. We observe that a class-balanced loss [7] further improves performance. We refer to this setting of the class-balanced focal loss as Focal in Table 3.
训练。我们尝试了两种损失函数——标准交叉熵损失和近期提出的焦点损失 (focal loss) [20]。焦点损失通过增加错误预测的交叉熵权重来缓解类别不平衡问题。我们发现结合类别平衡损失 (class-balanced loss) [7] 能进一步提升性能。在表 3 中将这种类别平衡焦点损失的配置记为 Focal。
We use the Adam optimizer [17] with a learning rate of 0.001, and an annealing scheme that decreases the learning rate by a factor of 10 at epochs 20, 40, and 60, following Shi et al. [30]. We used ‘Weights & Biases’5 for tracking experiments [5].
我们采用Adam优化器[17],初始学习率为0.001,并按照Shi等人[30]的方案在20、40和60个epoch时将学习率降至原值的十分之一。实验跟踪使用"Weights & Biases"[5]。
Results. We observe that the decrease in $\mathrm{Top-1}$ and performance with the increase in number of classes is relatively small, in Table 3. Importantly, we note that Top-1-norm is much lower than $\mathrm{Top-1}$ . This clearly points to inefficient learning from the long-tailed class distribution in BABEL. The Focal losses significantly improves $\mathrm{Top-1-norm}$ performance on all BABEL subsets. This is encouraging for efforts to learn models with lower class-specific biases despite severe class imbalance.
结果。我们观察到,随着类别数量的增加,$\mathrm{Top-1}$ 和 性能的下降相对较小(表3)。值得注意的是,Top-1-norm 远低于 $\mathrm{Top-1}$。这明显表明从BABEL的长尾类别分布中学习效率低下。Focal损失显著提高了所有BABEL子集上的 $\mathrm{Top-1-norm}$ 性能。这对于在严重类别不平衡情况下学习具有较低类别特定偏见的模型来说是一个令人鼓舞的进展。
Table 3. 3D action recognition performance on different subsets of BABEL with 2s-AGCN [30]. CE indicates Cross-Entropy loss and Focal indicates the combination of class-balanced [7] focal loss [20].
表 3: 采用2s-AGCN [30]在BABEL不同子集上的3D动作识别性能。CE表示交叉熵损失(Cross-Entropy loss),Focal表示类别平衡[7]焦点损失(focal loss) [20]的组合。
| #动作数 | 损失类型 | Top-5 | Top-1 | Top-1-norm |
|---|---|---|---|---|
| 60 | CE Focal | 73.18 67.83 | 41.14 33.41 | 24.46 30.42 |
| 120 | CE Focal | 70.49 57.96 | 38.41 27.91 | 17.56 26.17 |
BABEL as a recognition benchmark. On the widely used NTU $\mathrm{RGB}{+}\mathrm{D}$ benchmark, $\mathrm{Top-1}$ recognition performance approaches $87%$ with 2s-AGCN [30]. Note that unlike NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ whose distribution of motions and actions is carefully controlled, the diversity and long-tailed distribution of samples in BABEL makes the recognition task more challenging. The few-shot recognition split of NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 120 partly addresses this issue. However, considering few-shot learning as a separate task typically involves measuring performance on only the few-shot classes, ignoring the larger distribution. Models in the real world ideally need to learn and perform well on both the frequent and infrequent classes of an imbalanced distribution [37]. We present BABEL as an additional benchmark for 3D action recognition, which evaluates the ability of models to learn from more realistic distributions of actions.
BABEL作为识别基准。在广泛使用的NTU $\mathrm{RGB}{+}\mathrm{D}$ 基准测试中,2s-AGCN [30]的 $\mathrm{Top-1}$ 识别准确率接近 $87%$。需要注意的是,与严格控制动作分布和类别的NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 不同,BABEL样本的多样性和长尾分布使识别任务更具挑战性。NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 120的少样本识别划分部分解决了这个问题。然而,将少样本学习作为独立任务通常只评估少样本类别上的性能,而忽略了整体分布。现实世界中的模型需要在数据不平衡分布中的高频和低频类别上都能良好学习和表现[37]。我们提出BABEL作为3D动作识别的补充基准,用于评估模型从更真实动作分布中学习的能力。
6. Conclusion
6. 结论
We presented BABEL, a large-scale dataset with dense action labels for mocap sequences. Unlike existing 3D datasets with action labels, BABEL has labels for all actions that occur in the sequence including simultaneously occurring actions, and transitions between actions. We analyzed the relationships between temporally adjacent actions and simultaneous actions occurring in a sequence. We demonstrated that the action recognition task on BABEL is challenging due to the label diversity and long-tailed distribution of samples. We believe that BABEL will serve as a useful additional benchmark for action recognition since it evaluates the ability to model realistic distributions of data. We hope that this large-scale, high quality dataset will accelerate progress in the challenging problem of understanding human movement in semantic terms.
我们推出了BABEL,这是一个为动作捕捉序列提供密集动作标签的大规模数据集。与现有的带动作标签的3D数据集不同,BABEL为序列中发生的所有动作(包括同时发生的动作和动作间的过渡)都提供了标注。我们分析了序列中时间相邻动作与同步动作之间的关系,并证明由于标签多样性和样本的长尾分布特性,BABEL上的动作识别任务具有挑战性。我们相信BABEL将成为动作识别领域有价值的补充基准,因为它能评估对真实数据分布建模的能力。希望这个大规模高质量数据集能加速"从语义层面理解人体运动"这一难题的研究进展。
Acknowledgements. We thank Joachim Tesch for support with rendering mocap sequences, the Software Workshop at MPI-IS for their support with the BABEL Action Recognition Challenge, Taylor McConnell, Leyre Sanchez Vinuela, Tsvetelina Alexiadis, Mila Gorecki for their support with categorization of labels, Muhammed Kocabas for the interesting discussions, Cornelia Kohler and Omid Taheri for feedback on the manuscript. Nikos Athanasiou acknowledges funding by Max Planck Graduate Center for Computer and Information Science Doctoral Program.
致谢。我们感谢Joachim Tesch在动作捕捉序列渲染方面的支持,感谢MPI-IS软件工作坊对BABEL动作识别挑战赛的支持,感谢Taylor McConnell、Leyre Sanchez Vinuela、Tsvetelina Alexiadis和Mila Gorecki在标签分类方面的协助,感谢Muhammed Kocabaş富有启发性的讨论,感谢Cornelia Kohler和Omid Taheri对论文的反馈。Nikos Athanasiou感谢马克斯·普朗克计算机与信息科学研究生院博士项目的资助。
Disclosure: MJB has received research gift funds from Adobe, Intel, Nvidia, Facebook, and Amazon. While MJB is a part-time employee of Amazon, his research was performed solely at, and funded solely by, Max Planck. MJB has financial interests in Amazon, Datagen Technologies, and Meshcapade GmbH.
披露声明:MJB曾获Adobe、Intel、Nvidia、Facebook及Amazon的研究捐赠资金。尽管MJB为Amazon兼职员工,其研究完全在马克斯·普朗克研究所独立完成并仅由该机构资助。MJB持有Amazon、Datagen Technologies及Meshcapade GmbH的财务权益。