TDSM: Triplet Diffusion for Skeleton-Text Matching in Zero-Shot Action Recognition
TDSM: 零样本动作识别中骨架-文本匹配的三重扩散方法
Abstract
摘要
We firstly present a diffusion-based action recognition with zero-shot learning for skeleton inputs. In zero-shot skeleton-based action recognition, aligning skeleton features with the text features of action labels is essential for accurately predicting unseen actions. Previous methods focus on direct alignment between skeleton and text latent spaces, but the modality gaps between these spaces hinder robust generalization learning. Motivated from the remarkable performance of text-to-image diffusion mod- els, we leverage their alignment capabilities between different modalities mostly by focusing on the training process during reverse diffusion rather than using their generative power. Based on this, our framework is designed as a Triplet Diffusion for Skeleton-Text Matching (TDSM) method which aligns skeleton features with text prompts through reverse diffusion, embedding the prompts into the unified skeleton-text latent space to achieve robust matching. To enhance disc rim i native power, we introduce a novel triplet diffusion (TD) loss that encourages our TDSM to correct skeleton-text matches while pushing apart incorrect ones. Our TDSM significantly outperforms the very recent state-of-the-art methods with large margins of $2.36%$ -point to $13.05%$ -point, demonstrating superior accuracy and s cal ability in zero-shot settings through effective skeleton-text matching.
我们首先提出了一种基于扩散 (diffusion) 的零样本 (zero-shot) 骨骼动作识别方法。在零样本骨骼动作识别中,将骨骼特征与动作标签的文本特征对齐对于准确预测未见动作至关重要。先前的方法侧重于骨骼与文本潜在空间之间的直接对齐,但这些空间之间的模态差异阻碍了鲁棒的泛化学习。受文本到图像 (text-to-image) 扩散模型卓越性能的启发,我们主要利用其在反向扩散 (reverse diffusion) 训练过程中对不同模态的对齐能力,而非依赖其生成能力。基于此,我们的框架设计为一种用于骨骼-文本匹配的三元组扩散方法 (Triplet Diffusion for Skeleton-Text Matching, TDSM),通过反向扩散将骨骼特征与文本提示 (text prompts) 对齐,并将提示嵌入统一的骨骼-文本潜在空间以实现鲁棒匹配。为了增强判别力,我们提出了一种新颖的三元组扩散 (TD) 损失函数,促使TDSM修正正确的骨骼-文本匹配,同时推开不正确的匹配。我们的TDSM以2.36%至13.05%的显著优势超越了当前最先进方法,通过有效的骨骼-文本匹配在零样本设置中展现出卓越的准确性和可扩展性。
1. Introduction
1. 引言
Human action recognition [25, 43, 51, 56] focuses on classifying actions from movements, with RGB videos commonly used due to their accessibility. However, recent advancements in depth sensors [22] and pose estimation algorithms [4, 50] have driven the adoption of skeleton-based action recognition. Skeleton data offers several advantages:
人体动作识别 [25, 43, 51, 56] 专注于通过运动对动作进行分类,由于易获取性,RGB视频常被使用。然而,深度传感器 [22] 和姿态估计算法 [4, 50] 的最新进展推动了基于骨架的动作识别的发展。骨架数据具有多项优势:

Figure 1. Motivation of the proposed TDSM pipeline. Previous methods rely on direct alignment between skeleton and text latent spaces, but suffer from modality gaps that limit generalization. Our TDSM overcomes this challenge by leveraging a reverse diffusion process to embed text prompts into the unified skeletontext latent space, ensuring more effective cross-modal alignment.
图 1: 所提出的 TDSM 流程的动机。先前方法依赖于骨架与文本潜在空间之间的直接对齐,但存在模态差距问题,限制了泛化能力。我们的 TDSM 通过利用反向扩散过程将文本提示嵌入统一的骨架-文本潜在空间来克服这一挑战,确保更有效的跨模态对齐。
it captures only human poses without background noise, ensuring a compact representation. Furthermore, 3D skeletons remain invariant to environmental factors such as lighting, background, and camera angles, providing consistent 3D coordinates across conditions [12].
它仅捕捉人体姿态而不含背景噪声,确保紧凑的表示形式。此外,3D骨骼对环境因素(如光照、背景和相机角度)保持不变性,能在不同条件下提供一致的3D坐标 [12]。
Despite these benefits, scaling skeleton-based recognition to large action sets remains challenging. Traditional methods [6, 8, 9, 11, 12, 63, 67, 70] require training on annotated data for each action, which is impractical for a large number of possible actions. Zero-shot skeleton-based action recognition [7, 16, 26, 30, 32, 47, 61, 69, 71] addresses this by enabling predictions for unseen actions without requiring explicit training data, making it valuable for applications such as surveillance, robotics, and human-computer interaction, where continuous learning is infeasible [15, 57].
尽管有这些优势,将基于骨架的动作识别扩展到大规模动作集仍然具有挑战性。传统方法 [6, 8, 9, 11, 12, 63, 67, 70] 需要对每个动作的标注数据进行训练,这对于大量可能的动作来说是不现实的。零样本基于骨架的动作识别 [7, 16, 26, 30, 32, 47, 61, 69, 71] 通过无需显式训练数据即可预测未见动作来解决这一问题,使其在监控、机器人和人机交互等需要持续学习但实际不可行的应用中具有重要价值 [15, 57]。
Zero-shot models offer the flexibility for unseen data by aligning pre-learned skeleton features with text-based descriptions corresponding to action labels, ensuring their s cal ability in real-world scenarios. However, achieving the effective alignment between skeleton data and text features entails significant challenges. While skeleton data captures temporal and spatial motion patterns, the text descriptions for action labels carry high-level semantic information. This modality gap makes it difficult to align their corresponding latent spaces effectively, hindering the genera liz ation learning for unseen actions—particularly when distinguishing between semantically similar actions (e.g., “Throw” vs. “Shoot”).
零样本模型通过将预学习的骨架特征与动作标签对应的文本描述对齐,为未见数据提供了灵活性,确保了其在现实场景中的可扩展性。然而,实现骨架数据与文本特征的有效对齐面临重大挑战。骨架数据捕捉了时空运动模式,而动作标签的文本描述则承载了高层语义信息。这种模态差异使得有效对齐它们的潜在空间变得困难,阻碍了对未见动作的泛化学习——尤其是在区分语义相似的动作时(例如"Throw"与"Shoot")。
Fig. 1 illustrates the key differences between previous methods and our proposed method. The previous methods [7, 16, 26, 30, 32, 47, 61, 69, 71] aim at directly aligning the different features of skeletons and text descriptions for action labels between the skeleton and text latent spaces, which struggles to generalize due to the inherent differences between these modalities in different latent spaces. On the other hand, our TDSM leverages a reverse diffusion training scheme to merge the skeleton features with their corresponding text prompts, which leads to disc rim i natively fused features in a unified latent space.
图 1: 展示了先前方法与我们提出方法的关键差异。先前方法 [7, 16, 26, 30, 32, 47, 61, 69, 71] 旨在直接对齐骨骼与文本潜在空间中动作标签的骨骼特征和文本描述特征,由于不同模态在不同潜在空间中的固有差异,这种方法难以泛化。相比之下,我们的 TDSM 采用逆向扩散训练方案,将骨骼特征与对应文本提示融合,从而在统一潜在空间中生成判别性融合特征。
Inspired by text-to-image diffusion models [14, 45], we propose a novel framework: Triplet Diffusion for SkeletonPrompt Matching (TDSM). Unlike to be a generative model, our TDSM leverages the reverse diffusion training scheme to merge skeleton features with text prompts which aims at achieving merged disc rim i native (not generative) features for improved action recognition tasks. More specifically, our TDSM learns to denoise noisy skeleton features conditioned on the corresponding text prompts, embedding the prompts into a merged skeleton-text latent space to ensure effective implicit alignment. This approach avoids the challenges of direct latent space alignment while enhancing robustness. Additionally, we introduce a novel triplet diffusion (TD) loss, which encourages tighter alignment for correct skeleton-text pairs and pushes apart incorrect ones, further improving the model’s disc rim i native power. As an additional benefit, the diffusion process, driven by the random noise added during training, acts as a natural regularization mechanism. This prevents over fitting and enhances the model’s ability to generalize effectively to unseen actions. Our contributions are threefold:
受文本到图像扩散模型 [14, 45] 的启发,我们提出了一种新颖框架:骨架提示匹配的三重扩散 (Triplet Diffusion for SkeletonPrompt Matching, TDSM)。与生成式模型不同,我们的TDSM利用反向扩散训练方案将骨架特征与文本提示融合,旨在获得融合的判别性(非生成性)特征以改进动作识别任务。具体而言,TDSM学习在对应文本提示条件下对含噪骨架特征进行去噪,将提示嵌入到融合的骨架-文本潜在空间中,确保有效的隐式对齐。该方法避免了直接潜在空间对齐的挑战,同时增强了鲁棒性。此外,我们提出了一种新颖的三重扩散 (Triplet Diffusion, TD) 损失函数,通过拉近正确骨架-文本对的距离并推开错误配对,进一步提升模型的判别能力。另一个优势是,训练过程中添加的随机噪声驱动的扩散过程可作为天然的正则化机制,防止过拟合并增强模型对未见动作的泛化能力。我们的贡献主要体现在三个方面:
state-of-the-art (SOTA) methods with large margins of $2.36%$ -point to $13.05%$ -point across multiple benchmarks, demonstrating s cal ability and robustness under various seen-unseen split settings.
以显著优势超越现有最优方法 (SOTA),在多个基准测试中提升幅度达 $2.36%$ 至 $13.05%$,展示了在不同已知-未知数据划分场景下的可扩展性和鲁棒性。
2. Related Work
2. 相关工作
2.1. Skeleton-based Action Recognition
2.1. 基于骨架的动作识别
Traditional skeleton-based action recognition assumes fully annotated training and test datasets, in contrast to other skeleton-based action recognition methods under zero-shot settings which aim to recognize unseen classes without explicit training samples. Early methods [31, 34, 66, 72] employed RNN-based models to capture the temporal dynamics of skeleton sequences. Subsequent studies [3, 12, 23, 62] explored CNN-based approaches, transforming skeleton data into pseudo-images. Recent advancements leverage graph convolutional networks (GCNs) [6, 9, 27, 28, 36, 60, 67, 70] to effectively represent the graph structures of skeletons, comprising joints and bones. ST-GCN [63] introduced graph convolutions along the skeletal axis combined with 1D temporal convolutions to capture motion over time. Shift-GCN [8] improved computational efficiency by implementing shift graph convolutions. Building on these methods, transformer-based models [11, 13, 39, 55, 68] have been proposed to address the limited receptive field of GCNs by capturing global skeletal-temporal dependencies. In this work, we adopt ST-GCN [63] and Shift-GCN [8] to extract skeletal-temporal representations from skeleton data, transforming input skeleton sequences into a latent space for further processing in the proposed framework.
传统的基于骨架的动作识别方法假设训练和测试数据集已完全标注,而零样本设置下的其他骨架动作识别方法则旨在识别未见过的类别,无需显式训练样本。早期方法[31, 34, 66, 72]采用基于RNN的模型捕捉骨架序列的时间动态特性。后续研究[3, 12, 23, 62]探索了基于CNN的方法,将骨架数据转换为伪图像。最新进展利用图卷积网络(GCN)[6, 9, 27, 28, 36, 60, 67, 70]有效表征由关节和骨骼组成的骨架图结构。ST-GCN[63]提出沿骨骼轴向的图卷积与一维时间卷积相结合,以捕捉时序运动特征。Shift-GCN[8]通过移位图卷积提升了计算效率。基于这些方法,研究者提出基于Transformer的模型[11, 13, 39, 55, 68],通过捕捉全局骨骼-时间依赖关系来解决GCN感受野受限的问题。本工作采用ST-GCN[63]和Shift-GCN[8]从骨架数据中提取骨骼-时间表征,将输入骨架序列转换至潜在空间以供所提框架进一步处理。
2.2. Zero-shot Skeleton-based Action Recognition
2.2. 零样本基于骨架的动作识别
Most of the existing works focus on aligning the skeleton latent space with the text latent space. These approaches can be categorized broadly into VAE-based methods [16, 30, 32, 47] and contrastive learning-based methods [7, 26, 61, 69, 71].
现有研究大多集中于将骨骼潜在空间与文本潜在空间对齐。这些方法大致可分为基于变分自编码器 (VAE) 的方法 [16, 30, 32, 47] 和基于对比学习的方法 [7, 26, 61, 69, 71]。
VAE-based. The previous work, CADA-VAE [47], leverages VAEs [24] to align skeleton and text latent spaces, ensuring that each modality’s decoder can generate useful outputs from the other’s latent representation. SynSE [16] refines this by introducing separate VAEs for verbs and nouns, improving the structure of the text latent space. MSF [30] extends this approach by incorporating action and motionlevel descriptions to enhance alignment. SA-DVAE [32] disentangles skeleton features into semantic-relevant and irrelevant components, aligning text features exclusively with relevant skeleton features for improved performance.
基于VAE的方法。先前的研究CADA-VAE [47] 利用VAE [24] 对齐骨架和文本的潜在空间,确保每种模态的解码器能从另一种模态的潜在表示生成有用输出。SynSE [16] 通过为动词和名词引入独立的VAE改进了这一方法,优化了文本潜在空间的结构。MSF [30] 进一步扩展该方法,结合动作和运动层级描述来增强对齐效果。SA-DVAE [32] 将骨架特征解耦为语义相关和无关组件,仅将文本特征与相关骨架特征对齐以提升性能。
Contrastive learning-based. Contrastive learning-based methods align skeleton and text features through positive and negative pairs [5]. SMIE [69] concatenates skeleton and text features, and applies contrastive learning by treating masked skeleton features as positive samples and other actions as negatives. PURLS [71] incorporates GPT-3 [1] to generate text descriptions based on body parts and motion evolution, using cross-attention to align text descrip- tions with skeleton features. STAR [7] extends this idea with GPT-3.5 [1], generating text descriptions for six distinct skeleton groups, and introduces learnable prompts to enhance alignment. DVTA [26] introduces a dual alignment strategy, performing direct alignment between skeleton and text features, while also generating augmented text features via cross-attention for improved alignment. InfoCPL [61] strengthens contrastive learning by generating 100 unique sentences per action label, enriching the alignment space.
基于对比学习的方法。基于对比学习的方法通过正负样本对来对齐骨架和文本特征[5]。SMIE[69]将骨架和文本特征拼接起来,并将掩码骨架特征作为正样本,其他动作作为负样本进行对比学习。PURLS[71]结合GPT-3[1]生成基于身体部位和运动演变的文本描述,使用交叉注意力机制将文本描述与骨架特征对齐。STAR[7]利用GPT-3.5[1]扩展了这一思路,为六个不同的骨架组生成文本描述,并引入可学习的提示词来增强对齐效果。DVTA[26]提出了一种双重对齐策略,直接在骨架和文本特征之间进行对齐,同时通过交叉注意力生成增强的文本特征以改善对齐效果。InfoCPL[61]通过为每个动作标签生成100个独特句子来强化对比学习,从而丰富了对齐空间。
While most existing methods rely on direct alignment between skeleton and text latent spaces, they often struggle with generalization due to inherent differences between the two modalities. To address these limitations, our TDSM leverages a novel triplet diffusion approach. It uses text prompts to guide the reverse diffusion process, embedding these prompts into the unified skeleton-text latent space for more effective implicit alignment via feature fusion. Also, our triplet diffusion loss, inspired by the triplet loss [19], further enhances the model’s disc rim i native power by promoting correct alignments and penalizing incorrect ones.
虽然现有方法大多依赖骨架与文本潜在空间之间的直接对齐,但由于两种模态的固有差异,它们往往难以实现泛化。为解决这些局限性,我们的TDSM采用了一种新颖的三重扩散方法,利用文本提示引导逆向扩散过程,将这些提示嵌入统一的骨架-文本潜在空间,通过特征融合实现更有效的隐式对齐。此外,受三重损失函数[19]启发,我们提出的三重扩散损失通过促进正确对齐并惩罚错误对齐,进一步增强了模型的判别能力。
2.3. Diffusion Models
2.3. 扩散模型
Diffusion models have become a fundamental to generative tasks by learning to reverse a noise-adding process for original data recovery. Denoising Diffusion Probabilistic Models (DDPMs) [18] introduced a step-by-step denoising framework, enabling the modeling of complex data distributions and establishing the foundation for diffusion-based generative models. Building on this, Latent Diffusion Models (LDMs) [14, 45] improve computational efficiency by operating in lower-dimensional latent spaces while maintaining high-quality outputs. LDMs have been particularly successful in text-to-image (T2I) generation, showing the potential of diffusion models for cross-modal alignment tasks. In the reverse diffusion process, LDMs employ a denoising U-Net [46] where text prompts are integrated with image features through cross-attention blocks, effectively guiding the model to align the two modalities. Further extending this line of research, Diffusion Transformers (DiTs) [41] integrate transformer architectures into diffusion processes, capturing long-range dependencies across spatial dimension. In this work, we leverage the aligned fusion capabilities of diffusion models, focusing on the learning process during reverse diffusion rather than their generative power. Specifically, we utilize a DiT-based network as a denoising model, where text prompts guide the denoising of noisy skeleton features. This approach embeds text prompts into the unified latent space in the reverse diffusion process, ensuring robust fusion of the two modalities and enabling effective generalization to unseen actions in zeroshot recognition settings.
扩散模型通过学习逆转数据加噪过程以恢复原始数据,已成为生成任务的基础方法。去噪扩散概率模型(DDPM) [18] 提出了逐步去噪框架,实现了对复杂数据分布的建模,为基于扩散的生成模型奠定基础。在此基础上,潜在扩散模型(LDM) [14,45] 通过在低维潜在空间中进行运算,在保持高质量输出的同时提升了计算效率。LDM在文生图(T2I)任务中表现尤为突出,展现了扩散模型在跨模态对齐任务中的潜力。在逆向扩散过程中,LDM采用去噪U-Net网络[46],通过交叉注意力模块将文本提示与图像特征融合,有效引导模型实现双模态对齐。扩散Transformer(DiT) [41] 进一步将Transformer架构引入扩散过程,捕捉空间维度的长程依赖关系。本研究重点利用扩散模型的对齐融合能力,关注逆向扩散过程中的学习机制而非生成能力。具体而言,我们采用基于DiT的网络作为去噪模型,通过文本提示引导噪声骨架特征的去噪过程。该方法在逆向扩散过程中将文本提示嵌入统一潜在空间,确保双模态的稳健融合,并实现零样本识别场景下对未知动作的有效泛化。
Zero-shot tasks with diffusion models. Recently, diffusion models have also been extended to zero-shot tasks in RGB-based vision applications, such as semantic corresponden ce [65], segmentation [2, 52], image captioning [64], and image classification [10, 29]. These approaches often rely on large-scale pretrained diffusion models, such as LDMs [14, 45], trained on datasets like LAION-5B [48] with billions of text-image pairs. In contrast, our approach demonstrates that diffusion models can be effectively applied to smaller, domain-specific tasks, such as skeletonbased action recognition, without the need for large-scale finetuning. This highlights the versatility of diffusion models beyond large-scale vision-language tasks, providing a practical solution to zero-shot generalization with limited data resources.
扩散模型的零样本任务。近期,扩散模型也被扩展到基于RGB视觉应用的零样本任务中,例如语义对应[65]、分割[2,52]、图像描述[64]和图像分类[10,29]。这些方法通常依赖于大规模预训练的扩散模型(如LDMs[14,45]),这些模型在LAION-5B[48]等包含数十亿文本-图像对的数据集上进行训练。相比之下,我们的方法表明扩散模型可以有效地应用于更小规模的领域特定任务(如基于骨架的动作识别),而无需进行大规模微调。这凸显了扩散模型在大规模视觉-语言任务之外的多功能性,为数据资源有限的零样本泛化提供了实用解决方案。
3. Methods
3. 方法
3.1. Overview of TDSM
3.1. TDSM概述
In the training phase, we are given a dataset
在训练阶段,我们获得一个数据集
$$
\mathcal{D}{\mathrm{train}}={(\mathbf{X}{i},y_{i})}{i=1}^{N},\quad y_{i}\in\mathcal{V},
$$
$$
\mathcal{D}{\mathrm{train}}={(\mathbf{X}{i},y_{i})}{i=1}^{N},\quad y_{i}\in\mathcal{V},
$$
where $\mathbf{X}{i}\in\mathbb{R}^{T\times V\times M\times C_{\mathrm{in}}}$ represents a skeleton sequence, and $y_{i}$ is the corresponding ground truth label. Each skeleton sequence $\mathbf{X}{i}$ consists of sequence length $T$ , the number $V$ of joints, the number $M$ of actors, and the dimensionality $C_{\mathrm{in}}$ representing each joint. The label $y_{i}$ belongs to the set of seen class labels $\mathcal{V}$ . Here, $N$ denotes the total number of training samples in the seen dataset. In the inference phase, we are provided with a test dataset
其中 $\mathbf{X}{i}\in\mathbb{R}^{T\times V\times M\times C_{\mathrm{in}}}$ 表示骨骼序列,$y_{i}$ 是对应的真实标签。每个骨骼序列 $\mathbf{X}{i}$ 由序列长度 $T$、关节数量 $V$、参与者数量 $M$ 以及表示每个关节的维度 $C_{\mathrm{in}}$ 组成。标签 $y_{i}$ 属于可见类别标签集 $\mathcal{V}$。这里,$N$ 表示可见数据集中训练样本的总数。在推理阶段,我们会获得一个测试数据集
$$
\mathcal{D}{\mathrm{test}}={(\mathbf{X}{j}^{u},y_{j}^{u})}{j=1}^{N_{u}},\quad y_{j}^{u}\in\mathcal{V}_{u},
$$
$$
\mathcal{D}{\mathrm{test}}={(\mathbf{X}{j}^{u},y_{j}^{u})}{j=1}^{N_{u}},\quad y_{j}^{u}\in\mathcal{V}_{u},
$$
where $\mathbf{X}{j}^{u}\in\mathbb{R}^{T\times V\times M\times C_{\mathrm{in}}}$ denotes skeleton sequences from unseen classes, and $y_{j}^{u}$ are their corresponding labels. In this phase, $N_{u}$ represents the total number of test samples from unseen classes. In the zero-shot setting, the seen and unseen label sets are disjoint, i.e.,
其中 $\mathbf{X}{j}^{u}\in\mathbb{R}^{T\times V\times M\times C_{\mathrm{in}}}$ 表示来自未见类别的骨骼序列,$y_{j}^{u}$ 是其对应的标签。在此阶段,$N_{u}$ 代表来自未见类别的测试样本总数。在零样本设置中,可见与未见标签集互不相交,即
$$
{\mathcal{V}}\cap{\mathcal{V}}_{u}=\emptyset.
$$
$$
{\mathcal{V}}\cap{\mathcal{V}}_{u}=\emptyset.
$$
We train the TDSM using $\mathcal{D}{\mathrm{train}}$ and enable it to generalize to unseen classes from $\mathcal{D}{\mathrm{test}}$ . By learning a robust discriminative fusion of skeleton features and text descriptions, the model can predict the correct label $\hat{y}^{u}\in\mathcal{Y}{u}$ for an unseen skeleton sequence $\mathbf{X}_{j}^{u}$ during inference.
我们使用 $\mathcal{D}{\mathrm{train}}$ 训练 TDSM,使其能够泛化到 $\mathcal{D}{\mathrm{test}}$ 中的未见类别。通过学习骨架特征和文本描述的鲁棒判别性融合,该模型能在推理过程中为未见骨架序列 $\mathbf{X}{j}^{u}$ 预测出正确标签 $\hat{y}^{u}\in\mathcal{Y}_{u}$。
Fig. 2 provides an overview of our training framework of TDSM. The framework consists of three main components: (i) skeleton and text encoders, (ii) the forward process, and (iii) the reverse process. As detailed in Sec. 3.2, the pretrained skeleton encoder $\mathcal{E}{x}$ and text encoder $\mathcal{E}{d}$ embed the skeleton inputs $\mathbf{X}$ and prompt input $\mathbf{d}$ with an action label $y$ into their respective feature spaces, producing the skeleton feature $\mathbf{z}{x}$ and two types of text features: the global text feature ${\mathbf{z}}{g}$ and the local text feature $\mathbf{z}{l}$ . The skeleton feature $\mathbf{z}{x}$ undergoes the forward process, where noise $\epsilon$ is added to it. In the reverse process, as described in Sec. 3.3, the Diffusion Transformer $\mathcal{T}_{\mathrm{diff}}$ predicts the noise . The training objective function that ensures the TDSM to learn robust discri mi native power is discussed in Sec. 3.3. Finally, Sec. 3.4 explains the strategy used during the inference phase to predict the correct label $\hat{y}^{u}$ for unseen actions.
图 2: TDSM训练框架概述。该框架包含三个主要组件:(i) 骨架与文本编码器,(ii) 前向过程,以及(iii) 反向过程。如第3.2节所述,预训练的骨架编码器$\mathcal{E}{x}$和文本编码器$\mathcal{E}{d}$将带有动作标签$y$的骨架输入$\mathbf{X}$和提示输入$\mathbf{d}$嵌入到各自的特征空间,生成骨架特征$\mathbf{z}{x}$和两种文本特征:全局文本特征${\mathbf{z}}{g}$与局部文本特征$\mathbf{z}{l}$。骨架特征$\mathbf{z}{x}$经过前向过程,其中会添加噪声$\epsilon$。在第3.3节描述的反向过程中,Diffusion Transformer $\mathcal{T}_{\mathrm{diff}}$负责预测噪声。第3.3节还讨论了确保TDSM学习鲁棒判别能力的训练目标函数。最后,第3.4节说明了推理阶段用于预测未见动作正确标签$\hat{y}^{u}$的策略。

Figure 2. Training framework of our TDSM for zero-shot skeleton-based action recognition.
图 2: 我们提出的零样本基于骨架动作识别的TDSM训练框架。
3.2. Embedding Skeleton and Prompt Input
3.2. 嵌入骨架与提示输入
Following the LDMs [14, 45], we perform the diffusion process in a compact latent space by projecting both skeleton data and prompt into their respective feature spaces. For skeleton data, we adopt GCNs, specifically ST-GCN [63] and Shift-GCN [8], as the architecture for the skeleton encoder $\mathcal{E}{x}$ that is trained on $\mathcal{D}_{\mathrm{train}}$ using a cross-entropy loss:
遵循LDMs [14, 45]的方法,我们在紧凑的潜在空间中执行扩散过程,将骨架数据和提示分别投影到其特征空间。对于骨架数据,我们采用GCNs(具体为ST-GCN [63]和Shift-GCN [8])作为骨架编码器$\mathcal{E}{x}$的架构,该编码器在$\mathcal{D}_{\mathrm{train}}$上使用交叉熵损失进行训练:
$$
\mathcal{L}{\mathrm{CE}}=-\sum_{k=1}^{|\mathcal{V}|}\mathbf{y}(k)\log\hat{\mathbf{y}}(k),
$$
$$
\mathcal{L}{\mathrm{CE}}=-\sum_{k=1}^{|\mathcal{V}|}\mathbf{y}(k)\log\hat{\mathbf{y}}(k),
$$
where $\hat{\mathbf{y}}=\mathsf{M L P}(\mathcal{E}{x}(\mathbf{X}))$ is the predicted class label for a skeleton input $\mathbf{X}{i}$ , $\lvert\mathcal{V}\rvert$ is the number of seen classes and $\mathbf{y}$ is the one-hot vector of the ground truth label $y$ . Once trained, the parameters of skeleton encoder $\mathcal{E}{x}$ are frozen and used to generate the skeleton latent space representation $\mathbf{z}{x}=\mathcal{E}{x}(\mathbf{X})$ . After reshaping the feature for the attention layer, $\mathbf{z}{x}$ is represented in $\mathbb{R}^{M_{x}\times C}$ , where $M_{x}$ is the number of skeleton tokens, and $C$ is the feature dimension.
其中 $\hat{\mathbf{y}}=\mathsf{M L P}(\mathcal{E}{x}(\mathbf{X}))$ 是骨架输入 $\mathbf{X}{i}$ 的预测类别标签,$\lvert\mathcal{V}\rvert$ 是可见类别数量,$\mathbf{y}$ 是真实标签 $y$ 的独热向量。训练完成后,骨架编码器 $\mathcal{E}{x}$ 的参数被冻结,用于生成骨架潜在空间表示 $\mathbf{z}{x}=\mathcal{E}{x}(\mathbf{X})$。经过注意力层特征重塑后,$\mathbf{z}{x}$ 表示为 $\mathbb{R}^{M_{x}\times C}$,其中 $M_{x}$ 是骨架 token 数量,$C$ 是特征维度。
For text encoder $\mathcal{E}{d}$ , we leverage the text prompts provided by SA-DVAE [32] to capture rich semantic information about the action labels. Each ground truth (GT) label is associated with a prompt $\mathbf{d}{p}$ , while a wrong label (negative sample) is assigned a prompt ${\bf d}{n}$ . To encode these prompts, we utilize a pretrained text encoder, such as CLIP [21, 44], which provides two types of output features: a global text feature $\mathbf{z}{g}$ and a local text feature $\mathbf{z}_{l}$ . The text encoder’s output for a given prompt $\mathbf{d}$ can be represented as:
对于文本编码器 $\mathcal{E}{d}$,我们利用SA-DVAE [32]提供的文本提示来捕捉动作标签的丰富语义信息。每个真实标签(GT)关联一个提示 $\mathbf{d}{p}$,而错误标签(负样本)则分配提示 ${\bf d}{n}$。为了编码这些提示,我们使用预训练的文本编码器(如CLIP [21, 44]),该编码器提供两种输出特征:全局文本特征 $\mathbf{z}{g}$ 和局部文本特征 $\mathbf{z}_{l}$。给定提示 $\mathbf{d}$ 的文本编码器输出可表示为:
$$
\begin{array}{r}{[{\bf z}{g}\mid{\bf z}{l}]=\mathcal{E}_{d}({\bf d}),}\end{array}
$$
$$
\begin{array}{r}{[{\bf z}{g}\mid{\bf z}{l}]=\mathcal{E}_{d}({\bf d}),}\end{array}
$$
where $[\cdot|\cdot]$ indicates token-wise concatenation, $\mathbf{z}{g}\in$ $\mathbb{R}^{1\times C}$ is a global text feature, and $\mathbf{z}{l}\in\mathbb{R}^{M_{l}\times C}$ is a local text feature, with $M_{l}$ text tokens.
其中 $[\cdot|\cdot]$ 表示按token拼接,$\mathbf{z}{g}\in$ $\mathbb{R}^{1\times C}$ 是全局文本特征,$\mathbf{z}{l}\in\mathbb{R}^{M_{l}\times C}$ 是包含 $M_{l}$ 个文本token的局部文本特征。
For each GT label (positive sample), the text encoder $\mathcal{E}{d}$ extracts both the global and local text features, denoted as ${\bf z}{g,p}$ and $\mathbf{z}{l,p}$ , respectively. Similarly, for each wrong label (negative sample), the encoder extracts the features $\mathbf{z}{g,n}$ and $\mathbf{z}_{l,n}$ . These four features later guide the diffusion process by conditioning the denoising of noisy skeleton features.
对于每个GT标签(正样本),文本编码器$\mathcal{E}{d}$会提取全局和局部文本特征,分别表示为${\bf z}{g,p}$和$\mathbf{z}{l,p}$。同样地,对于每个错误标签(负样本),编码器会提取特征$\mathbf{z}{g,n}$和$\mathbf{z}_{l,n}$。这四个特征随后通过条件化去噪骨架特征来指导扩散过程。
3.3. Diffusion Process
3.3. 扩散过程
Our framework leverages a conditional denoising diffusion process, not to generate data but to learn a discriminative skeleton latent space by fusing skeleton features with text prompts through the reverse diffusion process. Our TDSM is trained to denoise skeleton features such that the resulting latent space becomes disc rim i native with respect to action labels. Guided by our triplet diffusion (TD) loss, the denoising process conditions on text prompts to strengthen the disc rim i native fusion of skeleton features and their corresponding prompts. The TD loss encourages correct skeleton-text pairs to be pulled closer in the fused skeleton-text latent space while pushing apart incorrect pairs, enhancing the model’s disc rim i native power.
我们的框架利用条件去噪扩散过程,并非生成数据,而是通过反向扩散过程将骨架特征与文本提示融合,从而学习一个判别性骨架潜在空间。我们的TDSM被训练用于去噪骨架特征,使得最终潜在空间对动作标签具有判别性。在三重扩散(TD)损失的引导下,去噪过程以文本提示为条件,强化骨架特征与其对应提示的判别性融合。TD损失促使正确的骨架-文本对在融合的骨架-文本潜在空间中更接近,同时推开不正确的配对,从而增强模型的判别能力。
Forward process. Random Gaussian noise is added to the skeleton feature $\mathbf{z}{x}$ at a random timestep $t\sim\mathcal{U}(T)$ within total $T$ steps. At each randomly selected step $t$ , the noisy feature $\mathbf{z}_{x,t}$ is generated as:
前向过程。在总步数 $T$ 步中随机选取时间步 $t\sim\mathcal{U}(T)$ ,向骨架特征 $\mathbf{z}{x}$ 添加随机高斯噪声。在每个随机选取的步 $t$ 处,含噪特征 $\mathbf{z}_{x,t}$ 的生成公式为:
$$
\mathbf{z}{x,t}=\sqrt{\bar{\alpha}{t}}\mathbf{z}{x}+\sqrt{1-\bar{\alpha}_{t}}\pmb{\epsilon},
$$
$$
\mathbf{z}{x,t}=\sqrt{\bar{\alpha}{t}}\mathbf{z}{x}+\sqrt{1-\bar{\alpha}_{t}}\pmb{\epsilon},
$$
where $\mathbf{\boldsymbol{\epsilon}}\sim\mathcal{N}(\mathbf{0},\mathbf{I})$ is Gaussian noise, and $\bar{\alpha}{t}=\Pi_{s=1}^{t}(1-$ $\beta_{s.}$ ) controls the noise level at step $t$ [18].
其中 $\mathbf{\boldsymbol{\epsilon}}\sim\mathcal{N}(\mathbf{0},\mathbf{I})$ 是高斯噪声,$\bar{\alpha}{t}=\Pi_{s=1}^{t}(1-$ $\beta_{s.}$ ) 控制第 $t$ 步的噪声水平 [18]。
Reverse process. The Diffusion Transformer $\tau_{\mathrm{diff}}$ predicts noise $\hat{\epsilon}$ from noisy feature $\mathbf{z}{x,t}$ , conditioned on the global and local text features $\mathbf{z}{g}$ and $\mathbf{z}_{l}$ at given timestep $t$ :
逆向过程。Diffusion Transformer $\tau_{\mathrm{diff}}$ 根据全局和局部文本特征 $\mathbf{z}{g}$ 与 $\mathbf{z}{l}$,在给定时间步 $t$ 下从含噪特征 $\mathbf{z}_{x,t}$ 预测噪声 $\hat{\epsilon}$:
$$
\hat{\pmb{\epsilon}}={\mathcal T}{\mathrm{diff}}\left({\bf z}{x,t},{\bf z}{g},{\bf z}_{l},t\right).
$$
$$
\hat{\pmb{\epsilon}}={\mathcal T}{\mathrm{diff}}\left({\bf z}{x,t},{\bf z}{g},{\bf z}_{l},t\right).
$$
where $\mathsf{P E}{x}$ and $\mathsf{P E}{l}$ are positional embeddings applied to the feature maps, capturing spatial positional information, while ${\mathsf{T}}\mathsf{E}{t}$ is a timestep embedding [53] that maps the scalar $t$ to a higher-dimensional space. The embedded features $\mathbf{f}{x,t},\mathbf{f}{c}$ , and $\mathbf{f}{l}$ are then passed through $B$ CrossDiT Blocks, followed by a Layer Normalization (LN) and a final Linear layer to predict the noise $\hat{\mathbf{\epsilon}}\in\mathbb{R}^{M_{x}\times C}$ .
其中 $\mathsf{P E}{x}$ 和 $\mathsf{P E}{l}$ 是应用于特征图的位置嵌入 (positional embedding),用于捕捉空间位置信息,而 ${\mathsf{T}}\mathsf{E}{t}$ 是将标量 $t$ 映射到高维空间的时间步嵌入 (timestep embedding) [53]。嵌入后的特征 $\mathbf{f}{x,t},\mathbf{f}{c}$ 和 $\mathbf{f}{l}$ 随后通过 $B$ 个 CrossDiT 块 (CrossDiT Block),再经过层归一化 (Layer Normalization, LN) 和最终的线性层,以预测噪声 $\hat{\mathbf{\epsilon}}\in\mathbb{R}^{M_{x}\times C}$。
where $i\in{x,l}$ denotes the skeleton or local text feature, respectively. The parameters $\alpha,\beta$ , and $\gamma$ are conditioned on the global text feature $\mathbf{z}_{g}$ and timestep $t$ , allowing the block to modulate feature representations effectively. Also, we compute query, key, and value matrices for both skeleton and local text features separately:
其中 $i\in{x,l}$ 分别表示骨架或局部文本特征。参数 $\alpha,\beta$ 和 $\gamma$ 以全局文本特征 $\mathbf{z}_{g}$ 和时间步 $t$ 为条件,使该模块能有效调节特征表示。此外,我们分别计算骨架和局部文本特征的查询(query)、键(key)和值(value)矩阵:
$$
\left[\mathbf{q}{i}\mid\mathbf{k}{i}\mid\mathbf{v}{i}\right]=\mathsf{L i n e a r}(\mathbf{f}_{i}).
$$
$$
\left[\mathbf{q}{i}\mid\mathbf{k}{i}\mid\mathbf{v}{i}\right]=\mathsf{L i n e a r}(\mathbf{f}_{i}).
$$
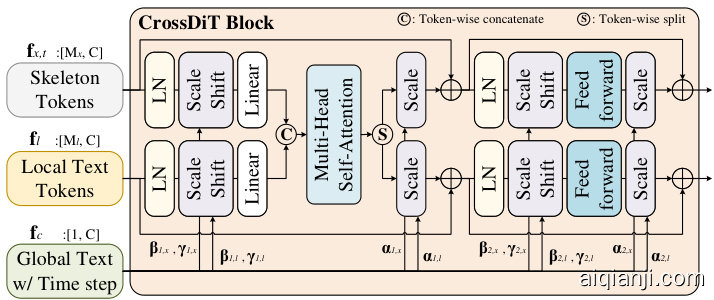
Figure 3. A detail structure of our CrossDiT Block.
图 3: 我们的CrossDiT模块的详细结构。
These matrices are token-wise concatenated and fed into a multi-head self-attention module, followed by a split to retain token-specific information as:
这些矩阵按token级拼接后输入多头自注意力模块,随后通过分割操作保留各token的特定信息:
$$
[\mathbf{f}{x}\mid\mathbf{f}{l}]\leftarrow\mathsf{S o f t M a x}\left(\left[\mathbf{q}{x}\mid\mathbf{q}{l}\right]\left[\mathbf{k}{x}\mid\mathbf{k}{l}\right]^{\mathsf{T}}\right)\left[\mathbf{v}{x}\mid\mathbf{v}_{l}\right].
$$
$$
[\mathbf{f}{x}\mid\mathbf{f}{l}]\leftarrow\mathsf{S o f t M a x}\left(\left[\mathbf{q}{x}\mid\mathbf{q}{l}\right]\left[\mathbf{k}{x}\mid\mathbf{k}{l}\right]^{\mathsf{T}}\right)\left[\mathbf{v}{x}\mid\mathbf{v}_{l}\right].
$$
By leveraging the attention from skeleton, timestep, and text features, the CrossDiT Block ensures efficient interaction between modalities, promoting the skeleton-text fusion for disc rim i native feature learning and improved generalization to unseen actions.
通过利用骨架、时间步和文本特征的注意力机制,CrossDiT模块确保了模态间的高效交互,促进骨架-文本融合以实现判别性特征学习,并提升对未见动作的泛化能力。
Loss function design. The overall training objective combines a diffusion loss and our triplet diffusion (TD) loss to promote both effective noise prediction and disc rim i native alignment (fusion). The total loss is defined as:
损失函数设计。整体训练目标结合了扩散损失和我们的三重扩散 (TD) 损失,以促进有效的噪声预测和判别性对齐 (融合)。总损失定义为:
$$
{\mathcal{L}}{\mathrm{total}}={\mathcal{L}}{\mathrm{diff}}+\lambda{\mathcal{L}}_{\mathrm{TD}},
$$
$$
{\mathcal{L}}{\mathrm{total}}={\mathcal{L}}{\mathrm{diff}}+\lambda{\mathcal{L}}_{\mathrm{TD}},
$$
where ${\mathcal{L}}{\mathrm{diff}}$ ensures accurate denoising, and $\mathcal{L}{\mathrm{TD}}$ enhances the ability to differentiate between correct and incorrect label predictions. The diffusion loss ${\mathcal{L}}_{\mathrm{diff}}$ [18] is given by:
其中 ${\mathcal{L}}{\mathrm{diff}}$ 确保准确去噪,而 $\mathcal{L}{\mathrm{TD}}$ 增强区分正确与错误标签预测的能力。扩散损失 ${\mathcal{L}}_{\mathrm{diff}}$ [18] 由下式给出:
$$
\begin{array}{r}{\mathcal{L}{\mathrm{diff}}=|\epsilon-\hat{\epsilon}{p}|_{2},}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{\mathrm{diff}}=|\epsilon-\hat{\epsilon}{p}|_{2},}\end{array}
$$
where $\epsilon$ is a true noise, and $\hat{\epsilon}{p}$ is a predicted noise for the GT text feature. Our triplet diffusion loss $\mathcal{L}_{\mathrm{TD}}$ is defined as:
其中 $\epsilon$ 为真实噪声,$\hat{\epsilon}{p}$ 为 GT 文本特征的预测噪声。我们的三元组扩散损失 $\mathcal{L}_{\mathrm{TD}}$ 定义为:
$$
\mathcal{L}{\mathrm{TD}}=\operatorname*{max}\left(|\epsilon-\hat{\epsilon}{p}|{2}-|\epsilon-\hat{\epsilon}{n}|_{2}+\tau,0\right),
$$
$$
\mathcal{L}{\mathrm{TD}}=\operatorname*{max}\left(|\epsilon-\hat{\epsilon}{p}|{2}-|\epsilon-\hat{\epsilon}{n}|_{2}+\tau,0\right),
$$
3.4. Inference Phase
3.4. 推理阶段
Our approach enhances disc rim i native fusion through the TD loss, which is designed to denoise GT skeleton-text pairs effectively while preventing the fusion of incorrect pairs within the seen dataset. This selective denoising process promotes a robust fusion of skeleton and text features, allowing the model to develop a disc rim i native feature space that can generalize to unseen action labels.
我们的方法通过TD损失增强了判别性融合,该损失旨在有效去噪GT骨架-文本对,同时防止在可见数据集中融合错误对。这种选择性去噪过程促进了骨架和文本特征的稳健融合,使模型能够开发出可泛化到未见动作标签的判别性特征空间。

Figure 4. Inference framework of our TDSM for zero-shot skeleton-based action recognition.
图 4: 我们提出的 TDSM (零样本基于骨架动作识别) 推理框架。
Importantly, human actions often share common skeletal movements across related actions, and our model leverages them within seen skeleton data to extrapolate and associate unseen skeleton sequences with their corresponding text prompts. This capability to infer from familiar patterns reinforces the model’s disc rim i native power, enabling reliable zero-shot recognition of previously unseen actions.
重要的是,人类动作在相关行为间常共享相似的骨骼运动模式。我们的模型利用已见骨骼数据中的这些共性,通过外推将未见骨骼序列与对应文本提示关联起来。这种基于熟悉模式进行推断的能力,强化了模型的判别力,使其能可靠地实现零样本识别未知动作。
4.2. Experiment Setup
4.2. 实验设置
Our TDSM were implemented in PyTorch [40] and conducted on a single NVIDIA GeForce RTX 3090 GPU. Our model variants were trained for 50,000 iterations, with a warm-up period of 100 steps. We employed the AdamW optimizer [38] with a learning rate of $1\times10^{-4}$ and a weight decay of 0.01. A cosine-annealing scheduler [37] was used to dynamically update the learning rate at each iteration. The batch size was set to 256, but for the TD loss computation, the batch was duplicated for positive and negative samples, resulting in an effective batch size of 512. Through empirical validation, the loss weight $\lambda$ and margin $\tau$ were both set to 1.0. The diffusion process was trained with a total timestep of $T=50$ . For inference, the optimal timestep $t_{\mathrm{test}}~=~25$ was selected based on accuracy trends across datasets (Fig. 5). We utilized $B=12$ CrossDiT Blocks, each containing a multi-head self-attention module with 12 heads. All feature dimensions were set to $C=768$ . The local text features contained $M_{l}=35$ tokens, while the skeleton features were represented by a single token $M_{x}=1$ . To ensure reproducibility, the random seed was fixed at 2,025 throughout all experiments. For the SynSE [16] and PURLS [71] seen and unseen split settings, we used the Shift-GCN [8] architecture as our skeleton encoder. In the SMIE [69] split setting, we employed the ST-GCN [63] structure. Additionally, for the SynSE and SMIE settings, we utilized both the text prompts and skeleton features provided by SADVAE [32]. However, as the PURLS setting did not offer pre-trained skeleton features, we directly trained them using cross-entropy loss $\mathcal{L}_{\mathrm{CE}}$ . Across all tasks, we adopted the text encoder from CLIP-ViT-H/14 [21, 44] to transform text prompts into latent representations.
我们的TDSM模型基于PyTorch [40]框架实现,并在单块NVIDIA GeForce RTX 3090 GPU上运行。模型变体训练50,000次迭代,包含100步预热阶段。采用AdamW优化器[38],学习率为$1\times10^{-4}$,权重衰减0.01。通过余弦退火调度器[37]动态调整每步学习率,批量大小设为256,但计算TD损失时对正负样本进行复制,实际有效批量达512。经实验验证,损失权重$\lambda$与边界$\tau$均设为1.0。扩散过程总时间步$T=50$,推理时根据数据集精度趋势(图5)选择最优时间步$t_{\mathrm{test}}~=~25$。模型使用$B=12$个CrossDiT模块,每个含12头多头自注意力机制,所有特征维度$C=768$。局部文本特征包含$M_{l}=35$个token,骨架特征由单token$M_{x}=1$表示。为保障可复现性,所有实验固定随机种子为2,025。在SynSE[16]和PURLS[71]的已知/未知类别划分设置中,采用Shift-GCN[8]作为骨架编码器;SMIE[69]划分设置则使用ST-GCN[63]结构。对于SynSE和SMIE设置,同时采用SADVAE[32]提供的文本提示与骨架特征。由于PURLS设置未提供预训练骨架特征,直接使用交叉熵损失$\mathcal{L}_{\mathrm{CE}}$进行训练。所有任务均采用CLIP-ViT-H/14[21,44]的文本编码器将提示文本转换为潜在表示。
Table 1. Top-1 accuracy results of various zero-shot skeleton-based action recognition methods evaluated on the SynSE and PURLS benchmarks for the NTU-60 and NTU-120 datasets. Each split is denoted as X/Y, where X represents the number of seen classes and Y the number of unseen classes. The results in red highlight the best-performing model, while those in blue indicate the second-best. For our TDSM framework, the reported accuracy is the average value obtained from 10 trials, each with different Gaussian noise.
表 1: 不同零样本基于骨架的动作识别方法在 NTU-60 和 NTU-120 数据集上 SynSE 和 PURLS 基准测试的 Top-1 准确率结果。每个分割表示为 X/Y,其中 X 代表已见类别数,Y 代表未见类别数。红色标注结果为最优模型,蓝色为次优模型。我们的 TDSM 框架报告准确率为 10 次试验的平均值,每次试验使用不同高斯噪声。
| 方法 | 发表会议 | NTU-60 (Acc,%) | NTU-120 (Acc,%) |
|---|---|---|---|
| 55/5 split | 48/12 split | ||
| ReViSE [20] | ICCV2017 | 53.91 | 17.49 |
| JPoSE [59] | ICCV2019 | 64.82 | 28.75 |
| CADA-VAE [47] | CVPR2019 | 76.84 | 28.96 |
| SynSE [16] | ICIP2021 | 75.81 | 33.30 |
| SMIE [69] | ACMMM2023 | 77.98 | 40.18 |
| PURLS [71] | CVPR2024 | 79.23 | 40.99 |
| SA-DVAE [32] | ECCV2024 | 82.37 | 41.38 |
| STAR [7] | ACMMM2024 | 81.40 | 45.10 |
| TDSM (Ours) | 86.49 | 56.03 |
4.3. Performance Evaluation
4.3. 性能评估
Evaluation on SynSE [16] and PURLS [71] benchmarks.
在SynSE [16]和PURLS [71]基准上的评估。
Table 1 presents the performance comparison on the SynSE and PURLS benchmark splits across the NTU-60 and NTU120 datasets. The SynSE benchmark focuses on standard settings, offering 55/5 and 48/12 splits on NTU-60, and 110/10 and 96/24 splits on NTU-120. These settings assess the model’s ability to generalize across typical seenunseen splits. In contrast, the PURLS benchmark presents more extreme cases with 40/20 and 30/30 splits on NTU60, and 80/40 and 60/60 splits on NTU-120, introducing higher levels of complexity by increasing the proportion of unseen labels in the test set. To account for the stochastic nature of noise during inference, we averaged the 10 runs with different Gaussian noise realization s. As shown in Table 1, our TDSM significantly outperforms the very recent state-of-the-art results across all benchmark splits, demonstrating superior generalization and robustness for various splits. Specifically, TDSM outperforms the existing methods on both standard (SynSE) and extreme (PURLS) settings, with $4.12%$ -point, $9.93%$ -point, $5.04%$ -point, and $2.36%$ -point improvements in top-1 accuracy on the NTU60 55/5, 48/12, 40/20, and 30/30 splits, respectively, compared to the second best models. Also compared to the second best models, our TDSM attains $2.20%$ -point, $13.05%$ - point, $8.57%$ -point, and $7.58%$ -point accuracy improvements on the NTU-120 splits, further validating its scalability to larger datasets and more complex unseen classes.
表 1: 展示了在 NTU-60 和 NTU-120 数据集上 SynSE 和 PURLS 基准分割的性能对比。SynSE 基准侧重于标准设置,在 NTU-60 上提供 55/5 和 48/12 分割,在 NTU-120 上提供 110/10 和 96/24 分割。这些设置评估了模型在典型可见/未见分割上的泛化能力。相比之下,PURLS 基准呈现了更极端的情况,在 NTU-60 上采用 40/20 和 30/30 分割,在 NTU-120 上采用 80/40 和 60/60 分割,通过增加测试集中未见标签的比例引入了更高的复杂性。为了考虑推理过程中噪声的随机性,我们对 10 次不同高斯噪声实现的运行结果进行了平均。如表 1 所示,我们的 TDSM 在所有基准分割上均显著优于最新的最先进结果,展示了在各种分割上的卓越泛化能力和鲁棒性。具体而言,TDSM 在标准 (SynSE) 和极端 (PURLS) 设置下均优于现有方法,在 NTU-60 的 55/5、48/12、40/20 和 30/30 分割上,Top-1 准确率分别比第二好的模型提高了 $4.12%$、$9.93%$、$5.04%$ 和 $2.36%$。同样,与第二好的模型相比,我们的 TDSM 在 NTU-120 的分割上实现了 $2.20%$、$13.05%$、$8.57%$ 和 $7.58%$ 的准确率提升,进一步验证了其对更大数据集和更复杂未见类别的可扩展性。
Table 2. Top-1 accuracy results of various zero-shot skeletonbased action recognition methods evaluated on the NTU-60, NTU120, and PKU-MMD datasets under the SMIE benchmark. The reported values are the average performance across three splits.
表 2: 在SMIE基准下,各种零样本基于骨架的动作识别方法在NTU-60、NTU-120和PKU-MMD数据集上的Top-1准确率结果。报告值为三次分割的平均性能。
| 方法 | NTU-60 (Acc,%) | NTU-120 (Acc,%) | PKU-MMD (Acc,%) |
|---|---|---|---|
| 55/5分割 | 110/10分割 | 46/5分割 | |
| ReViSE [20] | 60.94 | 44.90 | 59.34 |
| JPoSE [59] | 59.44 | 46.69 | 57.17 |
| CADA-VAE[47] | 61.84 | 45.15 | 60.74 |
| SynSE [16] | 64.19 | 47.28 | 53.85 |
| SMIE [69] | 65.08 | 46.40 | 60.83 |
| SA-DVAE [32] | 84.20 | 50.67 | 66.54 |
| STAR [7] | 77.50 | - | 70.60 |
| TDSM (Ours) | 88.88 | 69.47 | 70.76 |
Evaluation on SMIE [69] benchmark. The SMIE benchmark provides three distinct splits to evaluate the generalization capability of models across different sets of unseen labels. Each split ensures that unseen labels do not overlap with seen ones, thereby rigorously testing the model’s ability to recognize new classes without prior exposure. For fair comparison, the reported performance is the average of the three splits. In this benchmark, as shown in Table 2, our TDSM outperforms the other methods, demonstrating strong generalization across all evaluated datasets.
在SMIE [69]基准测试上的评估。SMIE基准提供了三个独立的数据划分,用于评估模型在不同未见标签集合上的泛化能力。每个划分确保未见标签与已见标签无重叠,从而严格测试模型在未接触新类别时的识别能力。为公平比较,报告结果为三个划分的平均性能。如表2所示,在该基准测试中,我们的TDSM方法优于其他方法,展现了在所有评估数据集上的强大泛化性能。
4.4. Ablation Studies
4.4. 消融实验
Effect of loss function design. The ablation study shown in Table 3 evaluates the impact of combining the diffusion loss ${\mathcal{L}}{\mathrm{diff}}$ and the triplet diffusion (TD) loss $\mathcal{L}{\mathrm{TD}}$ on the model’s performance. The results demonstrate that leveraging both losses yields superior performance compared to using either one alone. Specifically, when only ${\mathcal{L}}{\mathrm{diff}}$ is employed, the model focuses on accurately denoising the skeleton features conditioned on the text prompts but may lack sufficient disc rim i native power between similar actions. Conversely, applying only $\mathcal{L}_{\mathrm{TD}}$ enhances discriminative fusion but without ensuring optimal noise prediction. The combination of both losses strikes a balance, ensuring disc rim i native fusion, which resulting in the highest performance across all evaluated splits.
损失函数设计的影响。表3所示的消融研究评估了扩散损失${\mathcal{L}}{\mathrm{diff}}$与三元组扩散(TD)损失$\mathcal{L}{\mathrm{TD}}$结合对模型性能的影响。结果表明,同时使用两种损失比单独使用任一种都能获得更优性能。具体而言,当仅使用${\mathcal{L}}{\mathrm{diff}}$时,模型侧重于基于文本提示准确去噪骨架特征,但可能对相似动作的区分能力不足;而仅使用$\mathcal{L}_{\mathrm{TD}}$能增强判别性融合,却无法保证最优噪声预测。两种损失的组合实现了平衡,确保了判别性融合,从而在所有评估分项中取得最高性能。

Figure 5. Effect of varying inference timesteps $t_{\mathrm{test}}$ across multiple datasets. Each plot shows the top-1 accuracy trend on the NTU-60 and NTU-120 datasets under different splits. The solid red line represents the average accuracy of our method, with the shaded orange area indicating the variation in accuracy across 10 different random Gaussian noise instances. Dashed blue line corresponds to the second-best method in each benchmark.
图 5: 不同推理时间步 $t_{\mathrm{test}}$ 在多个数据集上的效果。每个子图展示了NTU-60和NTU-120数据集在不同划分下的top-1准确率趋势。红色实线表示我们方法的平均准确率,橙色阴影区域表示10组不同随机高斯噪声实例的准确率波动范围。蓝色虚线对应各基准测试中次优方法的表现。
Table 3. Top-1 accuracy of different loss function configurations on the NTU-60 and NTU-120 datasets. The results compare models trained with only the diffusion loss ${\mathcal{L}}{\mathrm{diff}}$ , only the triplet diffu- sion loss $\mathcal{L}_{\mathrm{TD}}$ , and the combination of both losses.
表 3: 不同损失函数配置在NTU-60和NTU-120数据集上的Top-1准确率。结果比较了仅使用扩散损失 ${\mathcal{L}}{\mathrm{diff}}$、仅使用三重扩散损失 $\mathcal{L}_{\mathrm{TD}}$ 以及两者组合训练的模型。
| CTD | NTU-60 (Acc,%) | NTU-60 (Acc,%) | NTU-120 (Acc,%) | NTU-120 (Acc,%) | |
|---|---|---|---|---|---|
| 55/5split | 48/12split | 110/10 split | 96/24split | ||
| √ | 79.87 | 53.03 | 72.44 | 57.65 | |
| 80.90 | 54.36 | 70.73 | 60.95 | ||
| √ | 86.49 | 56.03 | 74.15 | 65.06 |
Impact of total timesteps $T$ . The results of the ablation study on diffusion timesteps are shown in Table 4. We observe that the choice of $T$ has a significant impact on performance across all datasets and splits. When $T$ is too small, the model tends to overfit, as the problem becomes too simple, limiting the diversity in noise added to the skeleton features during training. On the other hand, too large $T$ values introduces diverse noise strengths, making it challenging for the model to denoise effectively, which deteriorates performance. The best $T$ is found empirically with $T=50$ , striking a balance between maintaining a challenging task and avoiding over fitting.
总时间步数 $T$ 的影响。扩散时间步数的消融研究结果如表 4 所示。我们观察到,$T$ 的选择对所有数据集和分割的性能都有显著影响。当 $T$ 过小时,模型容易过拟合,因为问题变得过于简单,限制了训练期间添加到骨架特征的噪声多样性。另一方面,过大的 $T$ 值会引入多样化的噪声强度,使模型难以有效去噪,从而导致性能下降。通过实验发现最佳 $T$ 值为 $T=50$ ,在保持任务挑战性和避免过拟合之间取得了平衡。
Impact of timestep $t_{\mathbf{test}}$ and noise $\mathbf{\epsilon}{\mathbf{{test}}}$ in inference. We conducted experiments across different test timesteps $t_{\mathrm{test}}\in[0,50]$ and observed the accuracy trends on multiple datasets, as illustrated in Fig. 5. Based on these observations, we set $t_{\mathrm{test}}=25$ for all experiments. To examine the impact of noise during inference, we repeated experiments with 10 different random Gaussian noise samples. In Fig. 5, the shaded orange regions in the graphs depict the variances in top-1 accuracy due to noise, while the red lines represent the average accuracy. The blue dashed lines indicate the second-best method’s accuracy for comparison. Our analysis shows that while noise variations can cause up to a $\pm2.5%$ -point changes in top-1 accuracy at $t_{\mathrm{test}}=25$ , our TDSM shows consistently outperforming the state-ofthe-art methods regardless of noise levels.
时间步长 $t_{\mathbf{test}}$ 和噪声 $\mathbf{\epsilon}{\mathbf{{test}}}$ 在推理中的影响。我们在不同测试时间步长 $t_{\mathrm{test}}\in[0,50]$ 上进行了实验,并观察了多个数据集的准确率趋势,如图 5 所示。基于这些观察结果,我们在所有实验中设定 $t_{\mathrm{test}}=25$。为了研究推理过程中噪声的影响,我们使用 10 个不同的随机高斯噪声样本重复了实验。在图 5 中,图表中的橙色阴影区域描绘了由于噪声导致的 top-1 准确率变化,而红线表示平均准确率。蓝色虚线表示次优方法的准确率以供比较。我们的分析表明,虽然在 $t_{\mathrm{test}}=25$ 时噪声变化可能导致 top-1 准确率出现高达 $\pm2.5%$ 的变化,但无论噪声水平如何,我们的 TDSM 始终优于最先进的方法。
Table 4. Top-1 accuracy with varying total timesteps $T$ on the NTU-60 and NTU-120 datasets.
表 4: 不同总时间步长 $T$ 在 NTU-60 和 NTU-120 数据集上的 Top-1 准确率。
| TotalT | NTU-60 (Acc,%) | NTU-60 (Acc,%) | NTU-120 (Acc,%) | NTU-120 (Acc,%) |
|---|---|---|---|---|
| 55/5 split | 48/12 split | 110/10 split | 96/24 split | |
| 1 | 85.03 | 44.10 | 69.91 | 60.35 |
| 10 | 84.51 | 50.89 | 69.97 | 62.04 |
| 50 | 86.49 | 56.03 | 74.15 | 65.06 |
| 100 | 83.48 | 56.27 | 71.05 | 64.57 |
| 500 | 81.34 | 53.43 | 71.93 | 60.81 |
4.5. Limitations
4.5. 局限性
Sensitivity to noise variation. As illustrated in Fig. 5, although our method achieves superior performance, its results exhibit some sensitivity to noise $\epsilon_{\mathrm{{test}}}$ during inference. Recent studies [17] have suggested that predicting the initial state $\mathbf{z}_{x}$ during the reverse diffusion process yields more stable results compared to direct noise (ϵ) prediction, especially under varying noise conditions. As part of future work, we plan to explore this refinement to enhance the robustness against noise fluctuations.
对噪声变化的敏感性。如图 5 所示,尽管我们的方法取得了优异性能,但其结果在推理过程中对噪声 $\epsilon_{\mathrm{{test}}}$ 表现出一定敏感性。近期研究 [17] 表明,在反向扩散过程中预测初始状态 $\mathbf{z}_{x}$ 比直接预测噪声 (ϵ) 能获得更稳定的结果,尤其在噪声条件变化时。作为未来工作的一部分,我们计划探索这一改进方案以增强对噪声波动的鲁棒性。
5. Conclusion
5. 结论
Our TDSM is the first framework to apply diffusion models to zero-shot skeleton-based action recognition. The selective denoising process promotes a robust fusion of skeleton and text features, allowing the model to develop a discri mi native feature space that can generalize to unseen action labels. Also, our approach enhances disc rim i native fu- sion through the TD loss which is designed to denoise GT skeleton-text pairs effectively while preventing the fusion of incorrect pairs within the seen dataset. Extensive experiments show that our TDSM significantly outperforms the very recent SOTA models with large margins for various benchmark datasets.
我们的TDSM是首个将扩散模型应用于零样本基于骨架动作识别的框架。选择性去噪过程促进了骨架与文本特征的鲁棒融合,使模型能够构建可泛化到未见动作类别的判别性特征空间。此外,我们通过TD损失(旨在有效去噪真实骨架-文本对,同时防止在已见数据集中错误对的融合)增强了判别性融合能力。大量实验表明,我们的TDSM在多个基准数据集上以显著优势超越了当前最先进的SOTA模型。
A. Additional Discussions on Results
A. 结果补充讨论
A.1. Analysis of Split Settings
A.1. 分割设置分析
Table 2 presents the average performance of our model across split 1, split 2, and split 3 on the SMIE [69] benchmark. For a more detailed analysis, Table 5 reports the performance for each individual split. Notably, in the NTU-60 55/5 split, our TDSM achieves the highest performance for split 2. The unseen classes in this split—“wear a shoe”, “put on a hat/cap”, “kicking something”, “nausea or vomiting condition”, and “kicking other person”—exhibit clear and distinct motion patterns. For example, “wear a shoe” involves downward torso motion, “put on a hat/cap” features upward hand movements, “kicking something” emphasizes significant leg activity, “nausea or vomiting condition” depicts upper body contraction, and “kicking other person” is unique as it involves two skeletons interacting. These distinct characteristics make our TDSM easier to distinguish the classes, leading to higher performance. Fig. 6 illustrates this trend through the confusion matrix and perclass accuracy visualization, highlighting the clear separability of these actions.
表 2 展示了我们的模型在 SMIE [69] 基准测试中 split 1、split 2 和 split 3 的平均性能。更详细的分析请见表 5,其中报告了每个单独 split 的性能。值得注意的是,在 NTU-60 55/5 split 中,我们的 TDSM 在 split 2 上取得了最高性能。该 split 中的未见类别——"wear a shoe"、"put on a hat/cap"、"kicking something"、"nausea or vomiting condition" 和 "kicking other person"——表现出清晰且独特的运动模式。例如,"wear a shoe" 涉及躯干向下运动,"put on a hat/cap" 以手部向上动作为特征,"kicking something" 强调显著的腿部活动,"nausea or vomiting condition" 描绘了上半身收缩,而 "kicking other person" 的独特之处在于涉及两个骨架的交互。这些鲜明的特征使我们的 TDSM 更容易区分这些类别,从而获得更高的性能。图 6 通过混淆矩阵和每类准确率可视化展示了这一趋势,突出了这些动作的清晰可分离性。
In contrast, our TDSM shows relatively lower performance for the split 1 in the PKU-MMD 46/5 split, although the split 1 contains fewer unseen classes (“falling”, “make a phone call/answer phone”, “put on a hat/cap”, “taking a selfie”, and “wear on glasses”). Except for “falling”, the remaining classes involve similar upward hand movements and interactions with objects (e.g., phones, hats, glasses) that are not explicitly visible in skeleton data. This lack of contextual information makes it significantly harder to distinguish these actions, resulting in degraded performance. As visualized in Fig. 7, the confusion matrix and per-class accuracy further reveal the challenge of separating actions with overlapping motion patterns, emphasizing the limitations of skeleton-only data when distinguishing semanti- cally similar actions. These observations underscore the importance of distinct motion patterns in unseen classes for robust zero-shot recognition.
相比之下,我们的TDSM在PKU-MMD 46/5划分的split 1中表现相对较低,尽管split 1包含较少未见类别("falling"、"make a phone call/answer phone"、"put on a hat/cap"、"taking a selfie"和"wear on glasses")。除"falling"外,其余类别都涉及相似的上抬手部动作以及与物体(如手机、帽子、眼镜)的交互,而这些在骨骼数据中并不明显可见。这种上下文信息的缺乏使得区分这些动作变得尤为困难,从而导致性能下降。如图7所示,混淆矩阵和每类准确率进一步揭示了区分具有重叠运动模式动作的挑战,凸显了仅依赖骨骼数据在区分语义相似动作时的局限性。这些观察结果强调了未见类别中独特运动模式对于稳健零样本识别的重要性。
B. Further Ablation Studies
B. 进一步消融研究
B.1. Effect of Random Gaussian Noise
B.1. 随机高斯噪声的影响
In our work, we utilize the inherent alignment capability of diffusion models during the training of the reverse diffusion process to bridge cross-modal gaps. To examine the role of Gaussian noise in training, we performed ablation studies using fixed Gaussian noise in both training and inference stages instead of feeding new random noise at each training step. As shown in Table 6, the use of fixed Gaussian noise simplifies the problem excessively, causing the network to overfit specific noise patterns and reducing its generalization ability. In contrast, random Gaussian noise introduces variability in the learning process, acting as a regular iz ation mechanism that prevents over fitting. This ensures robustness and enhances the alignment between skeleton features and text prompts.
在我们的工作中,我们利用扩散模型在反向扩散过程训练中固有的对齐能力来弥合跨模态差距。为了研究高斯噪声在训练中的作用,我们在训练和推理阶段使用固定高斯噪声进行了消融实验,而非在每一步训练时输入新的随机噪声。如表 6 所示,使用固定高斯噪声会过度简化问题,导致网络过拟合特定噪声模式并降低其泛化能力。相比之下,随机高斯噪声为学习过程引入了可变性,起到正则化机制的作用,从而防止过拟合。这确保了鲁棒性,并增强了骨架特征与文本提示之间的对齐。
Table 5. Top-1 accuracy results of TDSM evaluated on the NTU60, NTU-120, and PKU-MMD datasets under the SMIE [69] benchmark.
表 5: TDSM 在 SMIE [69] 基准下于 NTU60、NTU-120 和 PKU-MMD 数据集上的 Top-1 准确率结果。
| Ours | NTU-60(Acc,%) | NTU-120 (Acc,%) | PKU-MMD (Acc,%) |
|---|---|---|---|
| 55/5split | 110/10 split | 46/5 split | |
| Split 1 | 87.97 | 74.45 | 57.40 |
| Split 2 | 96.06 | 63.91 | 76.92 |
| Split 3 | 82.60 | 70.04 | 77.97 |
| Average | 88.88 | 69.47 | 70.76 |
Table 6. Top-1 accuracy with varying Gaussian noise on the NTU60 and NTU-120 datasets.
表 6. NTU60 和 NTU-120 数据集上不同高斯噪声下的 Top-1 准确率。
| Gaussian noiseE | NTU-60 (Acc,%) | NTU-120 (Acc,%) |
|---|---|---|
| 55/5split | 48/12 split | |
| Fixed | 76.40 | 44.25 |
| Random | 86.49 | 56.03 |
Table 7. Top-1 accuracy of different type of text feature on the NTU-60 and NTU-120 datasets. The results compare models trained with only the global text feature $\mathbf{z}{g}$ , only the local text feature $\mathbf{z}{l}$ , and the combination of both losses.
表 7: 不同文本特征在NTU-60和NTU-120数据集上的Top-1准确率。结果比较了仅使用全局文本特征$\mathbf{z}{g}$、仅使用局部文本特征$\mathbf{z}{l}$以及同时使用两种损失的模型。
| Global Zg | Local Zl | NTU-60 (Acc,%) | NTU-60 (Acc,%) | NTU-120 (Acc,%) | NTU-120 (Acc,%) |
|---|---|---|---|---|---|
| 55/5 split | 48/12 split | 110/10 split | 96/24 split | ||
| √ | 83.41 | 51.50 | 70.14 | 61.90 | |
| 人 | 83.33 | 52.63 | 69.95 | 62.10 | |
| √ | 人 | 86.49 | 56.03 | 74.15 | 65.06 |
B.2. Contribution of Global and Local Text Features
B.2. 全局与局部文本特征的贡献
Our TDSM framework employs two types of text features for skeleton-text matching: a global text feature $\mathbf{z}{g}$ that encodes the entire sentence as a single token, and local text features $\mathbf{z}_{l}$ that preserve token-level details for each word in the sentence. As shown in Table 7, combining the global and local text features achieves the best performance, outperforming the models that use either feature independently.
我们的TDSM框架采用两种文本特征进行骨架-文本匹配:全局文本特征 $\mathbf{z}{g}$ (将整个句子编码为单个token)和局部文本特征 $\mathbf{z}_{l}$ (保留句子中每个词的token级细节)。如表7所示,结合全局和局部文本特征能达到最佳性能,优于单独使用任一特征的模型。
The global text feature provides overall disc rim i native power by capturing high-level semantics of the action description, enabling robust matching across diverse action categories. Meanwhile, local text features retain finer details that are effective for distinguishing subtle differences between semantically similar actions. By integrating both features, our TDSM framework ensures a balance between capturing holistic semantic information and preserving action-specific nuances, leading to improved alignment and enhanced zero-shot recognition performance.
全局文本特征通过捕捉动作描述的高层语义,提供了整体判别力,实现了跨多样化动作类别的稳健匹配。与此同时,局部文本特征保留了更精细的细节,能有效区分语义相似动作间的细微差异。通过融合这两种特征,我们的TDSM框架在捕捉整体语义信息和保留动作特定细节之间取得了平衡,从而提升了对齐效果并增强了零样本识别性能。

Figure 6. Confusion matrix and per-class top-1 accuracy visualization for NTU-60 55/5 Split 2.
图 6: NTU-60 55/5 Split 2 的混淆矩阵及各类别 top-1 准确率可视化

Figure 7. Confusion matrix and per-class top-1 accuracy visualization for PKU-MMD 46/5 Split 1.
图 7: PKU-MMD 46/5 Split 1 的混淆矩阵及各类别 top-1 准确率可视化
C. Implementation Details
C. 实现细节
Table 8 provides a detailed summary of the variables used in TDSM. Skeleton features $\left(\mathbf{z}_{x}\right)$ are extracted using pretrained encoders (Shift-GCN [8] or ST-GCN [63]) provided by SA-DVAE [32], resulting in a channel dimension of 256. For text features, two descriptions per action are encoded using the CLIP-ViT-H/14 [21, 44] text encoder, producing features with a channel dimension of 1,024. These features are concatenated along the channel dimension to form a unified text representation.
表 8: 详细总结了TDSM中使用的变量。骨骼特征 $\left(\mathbf{z}_{x}\right)$ 通过SA-DVAE [32]提供的预训练编码器(Shift-GCN [8]或ST-GCN [63])提取,通道维度为256。对于文本特征,每个动作的两个描述使用CLIP-ViT-H/14 [21, 44]文本编码器进行编码,生成通道维度为1,024的特征。这些特征沿通道维度拼接形成统一的文本表示。
For datasets without pretrained skeleton features (e.g., NTU-60 [49] and NTU-120 [35] under the PURLS [71] benchmark), we trained the skeleton encoder using official implementations. For datasets without text descriptions (e.g., PKU-MMD [33]), we used GPT-4 [1] to generate two descriptions per action, ensuring consistency with the existing text styles. These adjustments enable robust skeleton- text alignment, which is crucial for zero-shot skeletonbased action recognition.
对于没有预训练骨架特征的数据集(例如PURLS [71]基准下的NTU-60 [49]和NTU-120 [35]),我们使用官方实现训练了骨架编码器。对于没有文本描述的数据集(例如PKU-MMD [33]),我们使用GPT-4 [1]为每个动作生成两条描述,确保与现有文本风格一致。这些调整实现了稳健的骨架-文本对齐,这对零样本基于骨架的动作识别至关重要。
Table 8. The details of feature shape.
表 8: 特征形状的详细信息
| 模块 | 输出形状 | |
|---|---|---|
| X | TxV×M×3 | |
| Zc | Ex | Mx × 256 |
| fx,t | Zr Embed | Mx× 768 |
| Zg Z1 | Ed | 1 × (1024 +1024) M × (1024 + 1024) |
| fc | tEmbed Zg Embed | 1 × 768 |
| f | ZEmbed | Mx 768 |
| E,E | Mx × 256 |