Inter-Region Affinity Distillation for Road Marking Segmentation
跨区域亲和蒸馏在道路标线分割中的应用
Abstract
摘要
We study the problem of distilling knowledge from a large deep teacher network to a much smaller student network for the task of road marking segmentation. In this work, we explore a novel knowledge distillation $(K D)$ approach that can transfer ‘knowledge’ on scene structure more effectively from a teacher to a student model. Our method is known as Inter-Region Affinity KD (IntRA-KD). It decomposes a given road scene image into different regions and represents each region as a node in a graph. An inter-region affinity graph is then formed by establishing pairwise relationships between nodes based on their similarity in feature distribution. To learn structural knowledge from the teacher network, the student is required to match the graph generated by the teacher. The proposed method shows promising results on three large-scale road marking segmentation benchmarks, i.e., ApolloS cape, CULane and LLAMAS, by taking various lightweight models as students and ResNet-101 as the teacher. IntRAKD consistently brings higher performance gains on all lightweight models, compared to previous distillation methods. Our code is available at https://github.com/ cardwing/Codes-for-IntRA-KD.
我们研究从大型深度教师网络向更小型学生网络蒸馏知识以完成道路标线分割任务的问题。在本工作中,我们探索了一种新颖的知识蒸馏(KD)方法,能够更有效地将场景结构"知识"从教师模型传递给学生模型。该方法称为区域间亲和力知识蒸馏(IntRA-KD),其将给定道路场景图像分解为不同区域,并将每个区域表示为图中的节点,然后根据节点间特征分布的相似性建立成对关系,从而形成区域间亲和力图。为了从教师网络学习结构知识,要求学生网络匹配教师网络生成的图。通过采用多种轻量级模型作为学生网络、ResNet-101作为教师网络,所提方法在三个大规模道路标线分割基准数据集(ApolloScape、CULane和LLAMAS)上展现出优异效果。与现有蒸馏方法相比,IntRA-KD在所有轻量级模型上均能带来更高的性能提升。代码已开源:https://github.com/cardwing/Codes-for-IntRA-KD。
1. Introduction
1. 引言
Road marking segmentation serves various purposes in autonomous driving, e.g., providing cues for vehicle navigation or extracting basic road elements and lanes for constructing high-definition maps [7]. Training a deep network for road marking segmentation is known to be challenging due to various reasons [8], including tiny road elements, poor lighting conditions and occlusions caused by vehicles. The training difficulty is further compounded by the nature of segmentation labels available for training, which are usually sparse (e.g., very thin and long lane marking against a large background), hence affecting the capability of a network in learning the spatial structure of a road scene [8, 14].
道路标线分割在自动驾驶中有多种用途,例如为车辆导航提供线索,或提取基本道路元素和车道以构建高精地图 [7]。由于多种原因 [8],包括微小的道路元素、恶劣的光照条件以及车辆造成的遮挡,训练用于道路标线分割的深度网络被认为具有挑战性。可用于训练的分割标签通常较为稀疏(例如在广阔背景中非常细长的车道标线),这一特性进一步加剧了训练难度,从而影响网络学习道路场景空间结构的能力 [8, 14]。
The aforementioned challenges become especially crippling when one is required to train a small model for road marking segmentation. This requirement is not uncommon considering that small models are usually deployed on vehicles with limited computational resources. Knowledge distillation (KD) [6] offers an appealing way to facilitate the training of a small student model by transferring knowledge from a trained teacher model of larger capacity. Various KD methods have been proposed in the past, e.g., with knowledge transferred through softened class scores [6], feature maps matching [9, 13] or spatial attention maps matching [27].
当需要训练一个小型模型用于道路标记分割时,上述挑战尤为棘手。考虑到小型模型通常部署在计算资源有限的车辆上,这一需求并不罕见。知识蒸馏 (KD) [6] 提供了一种有吸引力的方法,通过从训练好的大容量教师模型转移知识来促进小型学生模型的训练。过去已提出多种知识蒸馏方法,例如通过软化类别分数 [6]、特征图匹配 [9, 13] 或空间注意力图匹配 [27] 来转移知识。
While existing KD methods are shown effective in many classification tasks, we found that they still fall short in transferring knowledge of scene structure for the task of road marking segmentation. Specifically, a road scene typically exhibits consistent configuration, i.e., road elements are orderly distributed in a scene. The structural relationship is crucial to providing the necessary constraint or regularization, especially for small networks, to combat against the sparsity of supervision. However, such structural relationship is rarely exploited in previous distillation methods. The lack of structural awareness makes small models struggle in differentiating visually similar but functionally different road markings.
虽然现有的知识蒸馏(KD)方法在许多分类任务中被证明有效,但我们发现它们在传递道路标线分割任务中的场景结构知识方面仍存在不足。具体而言,道路场景通常呈现一致的配置,即道路元素在场景中有序分布。这种结构关系对于提供必要的约束或正则化至关重要,特别是对于小型网络而言,可以对抗监督稀疏性问题。然而,这种结构关系在以往的蒸馏方法中很少被利用。缺乏结构感知能力使得小型模型难以区分视觉相似但功能不同的道路标线。
In this paper, we wish to enhance the structural awareness of a student model by exploring a more effective way to transfer the scene structure prior encoded in a teacher to a student. Our investigation is based on the premise that a teacher model should have a better capability in learning disc rim i native features and capturing contextual information due to its larger capacity in comparison to the student model. Feature distribution relationships encoded by the teacher on different parts of a deep feature map could reveal rich structural connections between different scene regions, e.g., the lane region should look different from the zebra crossing. Such priors can offer a strong constraint to regularize the learning of the student network.
本文旨在通过探索更有效的方式将教师模型中编码的场景结构先验传递给学生模型,从而增强学生模型的结构感知能力。我们的研究基于一个前提:由于教师模型相比学生模型具备更大的容量,它应当拥有更强的能力来学习判别性特征并捕获上下文信息。教师模型在深度特征图不同部分编码的特征分布关系,能够揭示不同场景区域间丰富的结构关联(例如车道区域应与斑马线区域呈现差异)。这种先验能为学生网络的学习提供强有力的正则化约束。
Our method is known as Inter-Region Affinity Knowledge Distillation (IntRA-KD). As the name implies, knowledge on scene structure is represented as inter-region affinity graphs, as shown as Fig. 1. Each region is a part of a deep feature map, while each node in the graph denotes the feature distribution statistics of each region. Each pair of nodes are connected by an edge representing their similarity in terms of feature distribution. Given the same input image, the student network and the teacher network will both produce their corresponding affinity graph. Through graph matching, a distillation loss on graph consistency is generated to update the student network.
我们的方法称为跨区域亲和知识蒸馏 (IntRA-KD)。顾名思义,场景结构知识被表示为跨区域亲和图,如图 1 所示。每个区域是深度特征图的一部分,而图中的每个节点表示每个区域的特征分布统计量。每对节点通过一条边连接,表示它们在特征分布上的相似性。给定相同的输入图像,学生网络和教师网络都会生成相应的亲和图。通过图匹配,生成图一致性的蒸馏损失来更新学生网络。
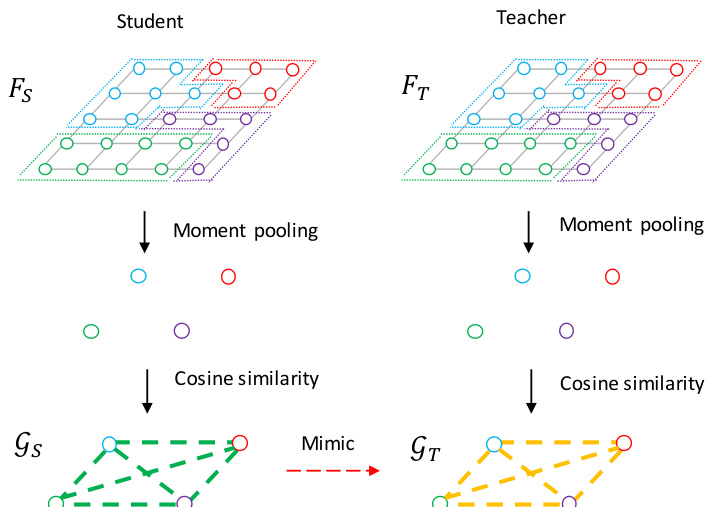
Figure 1. Illustration of the affinity distillation process. $F_{S}$ and $F_{T}$ are the intermediate activation s of the student and teacher models, respectively. $\mathcal{G}$ is the affinity graph that comprises nodes (feature vectors) and edges (cosine similarities). Note that each circle in the figure is a vector and different colors represent different classes.
图 1: 亲和力蒸馏过程示意图。$F_{S}$ 和 $F_{T}$ 分别是学生模型和教师模型的中间激活。$\mathcal{G}$ 是由节点(特征向量)和边(余弦相似度)组成的亲和力图。注意图中的每个圆圈代表一个向量,不同颜色表示不同类别。
This novel notion of inter-region affinity knowledge distillation is appealing in its simplicity and generality. The method is applicable to various road marking scenarios with an arbitrary number of road element classes. It can also work together with other knowledge distillation methods. It can even be applied on more general segmentation tasks (e.g., Cityscapes [3]). We present an effective and efficient way of building inter-region affinity graphs, including a method to obtain regions from deep feature maps and a new moment pooling operator to derive feature distribution statistics from these regions. Extensive experiments on three popular datasets (ApolloS cape [11], CULane [14] and LLAMAS [1]) show that IntRA-KD consistently outperforms other KD methods, e.g., probability map distillation [6] and attention map distillation [27]. It generalizes well to various student architectures, e.g., ERFNet [20], ENet [16] and ResNet-18 [5]. Notably, with IntRA-KD, ERFNet achieves compelling performance in all benchmarks with $21\times$ fewer parameters $2.49\mathrm{ M~}$ v.s. $52.53\mathrm{ M})$ and runs $\mathbf{16}\times$ faster $10.2~\mathrm{ms}$ v.s. $171.2~\mathrm{ms}$ ) compared to ResNet-101 model. Encouraging results are also observed on Cityscapes [3]. Due to space limit, we include the results in the supplementary material.
这种新颖的区域间亲和性知识蒸馏(IntRA-KD)方法因其简洁性和通用性而颇具吸引力。该方法适用于包含任意数量道路元素类别的各种道路标线场景,并能与其他知识蒸馏方法协同工作,甚至可推广至更通用的分割任务(如Cityscapes [3])。我们提出了一种高效构建区域间亲和图的方法,包括从深度特征图获取区域的技术,以及通过新型矩池化算子从这些区域提取特征分布统计量。在三个主流数据集(Apolloscape [11]、CULane [14]和LLAMAS [1])上的大量实验表明,IntRA-KD始终优于其他知识蒸馏方法(如概率图蒸馏[6]和注意力图蒸馏[27]),并能良好适配多种学生架构(如ERFNet [20]、ENet [16]和ResNet-18 [5])。值得注意的是,采用IntRA-KD的ERFNet在所有基准测试中均取得优异性能:相比ResNet-101模型,参数量减少21倍(2.49M vs 52.53M),推理速度提升16倍(10.2ms vs 171.2ms)。在Cityscapes [3]数据集上也观察到令人鼓舞的结果,因篇幅限制,相关数据详见补充材料。
2. Related Work
2. 相关工作
Road marking segmentation. Road marking segmentation is conventionally handled using hand-crafted features to obtain road marking segments. Then, a classification network is employed to classify the category of each segment [10, 19]. These approaches have many drawbacks, e.g., require sophisticated feature engineering process and only work well in simple highway scenarios.
道路标线分割。传统方法通过人工设计特征来获取道路标线片段,随后使用分类网络对每个片段进行类别划分[10,19]。这类方法存在诸多缺陷,例如需要复杂的特征工程流程,且仅在简单高速公路场景中表现良好。
The emergence of deep learning has avoided manual feature design through learning features in an end-to-end manner. These approaches usually adopt the dense prediction formulation, i.e., assign each pixel a category label [8, 14, 24]. For example, Wang et al. [24] exploit deep neural networks to map an input image to a segmentation map. Since large models usually demand huge memory storage and have slow inference speed, many lightweight models, e.g., ERFNet [20], are leveraged to fulfil the requirement of fast inference and small storage [8]. However, due to the limited model size, these small networks perform poorly in road marking segmentation. A common observation is that such small models do not have enough capacity to capture sufficient contextual knowledge given the sparse supervision signals [8, 14, 29]. Several schemes have been proposed to relieve the sparsity problem. For instance, Hou et al. [8] reinforce the learning of contextual knowledge through self knowledge distillation, i.e., using deep-layer attention maps to guide the learning of shallower layers. SCNN [14] resolves this problem through message passing between deep feature layers. Zhang et al. [29] propose a framework to perform lane area segmentation and lane boundary detection simultaneously. The aforementioned methods do not take structural relationship between different areas into account and they do not consider knowledge distillation from teacher networks.
深度学习的出现通过端到端方式学习特征,避免了手动设计特征。这些方法通常采用密集预测形式,即为每个像素分配类别标签 [8, 14, 24]。例如,Wang等人 [24] 利用深度神经网络将输入图像映射为分割图。由于大型模型通常需要大量内存存储且推理速度较慢,许多轻量级模型(如ERFNet [20])被用来满足快速推理和小存储的需求 [8]。然而,由于模型尺寸有限,这些小网络在道路标线分割任务中表现不佳。常见现象是,在稀疏监督信号下,这些小模型缺乏足够的容量来捕获充分的上下文知识 [8, 14, 29]。已有多种方案被提出以缓解稀疏性问题。例如,Hou等人 [8] 通过自知识蒸馏(即使用深层注意力图指导浅层学习)来加强上下文知识的学习。SCNN [14] 通过深层特征层之间的消息传递来解决该问题。Zhang等人 [29] 提出了一个同时执行车道区域分割和车道边界检测的框架。上述方法未考虑不同区域间的结构关系,也未利用教师网络进行知识蒸馏。
Knowledge distillation. Knowledge distillation was originally introduced by [6] to transfer knowledge from a teacher model to a compact student model. The distilled knowledge can be in diverse forms, e.g., softened output logits [6], intermediate feature maps [4, 9, 13, 31] or pairwise similarity maps between neighbouring layers [26]. There is another line of work [8, 22] that uses self-derived knowledge to reinforce the representation learning of the network itself, without the supervision of a large teacher model. Recent studies have expanded knowledge distillation from one sample to several samples [12, 15, 17, 23]. For instance, Park et al. [15] transfer mutual relations between a batch of data samples in the distillation process. Tung et al. [23] take the similarity scores of features of different samples as distillation targets. The aforementioned approaches [12, 15, 17, 23] do not consider the structural relationship between different areas in one sample. On the contrary, the proposed IntRA-KD takes inter-region relationship into account, which is new in knowledge distillation.
知识蒸馏 (Knowledge Distillation)。知识蒸馏最初由[6]提出,旨在将教师模型的知识迁移到紧凑的学生模型中。蒸馏知识可以表现为多种形式,例如软化的输出逻辑值[6]、中间特征图[4,9,13,31]或相邻层间的成对相似性图[26]。另一类研究[8,22]利用自衍生知识增强网络自身的表征学习,而无需大型教师模型的监督。近期研究将知识蒸馏从单样本扩展到多样本场景[12,15,17,23]。例如,Park等人[15]在蒸馏过程中迁移批量数据样本间的互相关关系;Tung等人[23]将不同样本特征的相似度分数作为蒸馏目标。上述方法[12,15,17,23]均未考虑单个样本内不同区域间的结构关系。相比之下,本文提出的IntRA-KD首次在知识蒸馏中引入了区域间关系的考量。
3. Methodology
3. 方法论
Road marking segmentation is commonly formulated as a semantic segmentation task [24]. More specifically, given an input image $\mathbf{X}\in\mathbb{R}^{h\times w\times3}$ , the objective is to assign a label $l\in{0,\ldots,n-1}$ to each pixel $(i,j)$ of $\mathbf{X}$ , comprising the segmentation map O. Here, $h$ and $w$ are the height and width of the input image, $n$ is the number of classes and class 0 denotes the background. The objective is to learn a mapping $\mathcal{F}\colon\mathbf{X}\mapsto\mathbf{0}$ . Contemporary algorithms use CNN as $\mathcal{F}$ for end-to-end prediction.
道路标记分割通常被定义为一种语义分割任务 [24]。具体来说,给定输入图像 $\mathbf{X}\in\mathbb{R}^{h\times w\times3}$,目标是为 $\mathbf{X}$ 的每个像素 $(i,j)$ 分配一个标签 $l\in{0,\ldots,n-1}$,从而构成分割图 O。其中,$h$ 和 $w$ 分别表示输入图像的高度和宽度,$n$ 是类别数量,类别 0 表示背景。目标是学习一个映射 $\mathcal{F}\colon\mathbf{X}\mapsto\mathbf{0}$。现代算法使用 CNN 作为 $\mathcal{F}$ 进行端到端预测。
Since autonomous vehicles have limited computational resources and demand real-time performance, lightweight models are adopted to fulfil the aforementioned requirements. On account of limited parameter size as well as insufficient guidance due to sparse supervision signals, these small models usually fail in the challenging road marking segmentation task. Knowledge distillation [6, 8, 13] is a common approach to improving the performance of small models by means of distilling knowledge from large models. There are two networks in knowledge distillation, one is called the student and the other is called the teacher. The purpose of knowledge distillation is to transfer dark knowledge from the large, cumbersome teacher model to the small, compact student model. The dark knowledge can take on many forms, e.g., output logits and intermediate layer activation s. There exist previous distillation methods [15, 17, 23] that exploit the relationship between a batch of samples. These approaches, however, do not take into account the structural relationship between different areas within a sample.
由于自动驾驶车辆计算资源有限且对实时性能有较高要求,通常采用轻量级模型来满足上述需求。但由于参数量有限以及稀疏监督信号导致的指导不足,这些小模型往往难以胜任具有挑战性的道路标记分割任务。知识蒸馏 [6, 8, 13] 是通过从大模型中提取知识来提升小模型性能的常用方法。知识蒸馏包含两个网络:学生网络和教师网络,其核心目的是将庞大笨重的教师模型中的暗知识(dark knowledge)迁移到小巧紧凑的学生模型中。暗知识可以表现为多种形式,例如输出逻辑值(logits)和中间层激活值。现有蒸馏方法 [15, 17, 23] 主要利用批量样本间的关系,但这些方法未能考虑单个样本内部不同区域间的结构关系。
3.1. Problem Formulation
3.1. 问题描述
Unlike existing KD approaches, IntRA-KD considers intrinsic structural knowledge within each sample as a form of knowledge for distillation. Specifically, we consider each input sample to have $n$ road marking classes including the background class. We treat each class map as a region. In practice, the number of classes/regions co-existing in a sample can be fewer than $n$ . Given the same input, an inter-region affinity graph $\mathcal{G}{S}$ for the student network and an inter-region affinity graph $\mathcal{G}_{T}$ for the teacher are constructed. Here, an affinity graph is defined as
与现有知识蒸馏 (KD) 方法不同,IntRA-KD 将每个样本内部的结构性知识视为一种待蒸馏的知识形式。具体而言,我们将每个输入样本视为包含 $n$ 个道路标记类别(含背景类),并将每个类别映射视为一个区域。实际场景中,样本中共存的类别/区域数量可能少于 $n$。给定相同输入时,会分别为学生网络构建区域间关联图 $\mathcal{G}{S}$,为教师网络构建区域间关联图 $\mathcal{G}_{T}$。其中,关联图定义为
$$
\begin{array}{r}{\mathcal{G}=\langle\pmb{\mu},\mathbf{C}\rangle,}\end{array}
$$
$$
\begin{array}{r}{\mathcal{G}=\langle\pmb{\mu},\mathbf{C}\rangle,}\end{array}
$$
where $\pmb{\mu}$ is a set of nodes, each of which represents feature distribution statistics of each region. Each pair of nodes are connected by an edge $\mathbf{C}$ that denotes the similarity between two nodes in terms of feature distribution.
其中 $\pmb{\mu}$ 是一组节点,每个节点代表每个区域的特征分布统计量。每对节点通过边 $\mathbf{C}$ 连接,表示两个节点在特征分布方面的相似性。
The overall pipeline of our IntRA-KD is shown in Fig. 2. The framework is composed of three main components: 1) Generation of areas of interest $(A O I)$ – to extract regions representing the spatial extent for each node in the graphs.
我们的IntRA-KD整体流程如图2所示。该框架由三个主要组件组成:1) 兴趣区域(AOI)生成——提取图中每个节点代表的空间范围区域。
3.2. Inter-Region Affinity Knowledge Distillation
3.2. 跨区域亲和力知识蒸馏
Generation of AOI. The first step of IntRA-KD is to extract regions from a given image to represent the spatial extent of each class. The output of this step is $n$ AOI maps constituting a set $\mathbf{M}\in\mathbb{R}^{h\times w\times n}$ , where $h$ is the height, $w$ is the width, and $n$ is the number of classes. Each mask map is binary – ‘1’ represents the spatial extent of a particular class, e.g., left lane, while $\mathbf{\nabla}^{\leftarrow}0^{\bullet}$ represents other classes and background.
AOI生成。IntRA-KD的第一步是从给定图像中提取区域以表示每个类别的空间范围。该步骤的输出是构成集合$\mathbf{M}\in\mathbb{R}^{h\times w\times n}$的$n$个AOI图,其中$h$为高度,$w$为宽度,$n$为类别数。每个掩码图均为二值图——'1'表示特定类别(如左车道)的空间范围,而$\mathbf{\nabla}^{\leftarrow}0^{\bullet}$表示其他类别及背景。
A straightforward solution is to use the ground-truth labels as AOI. However, ground-truth labels only consider the road markings but neglect the surrounding areas around the road markings. We empirically found that naive distillation in ground-truth areas is ineffective for the transfer of contextual information from a teacher to a student model.
一个直接的解决方案是使用真实标签作为关注区域 (AOI)。然而,真实标签仅考虑了道路标记,却忽略了道路标记周围的区域。我们通过实验发现,在真实标签区域进行简单蒸馏无法有效实现教师模型向学生模型的上下文信息迁移。
To include a larger area, we use a transformation operation to generate AOI from the ground-truth labels. Unlike labels that only contain road markings, areas obtained after the operation also take into account the surrounding areas of road markings. An illustration of AOI generation is shown in Fig. 3. Suppose we have $n$ binary ground-truth label maps comprising a set $\mathbf{L}\in\mathbb{R}^{h\times w\times n}$ . For each class label map $\b{L}\in\mathbb{R}^{h\times w}$ , we smooth the label map with an average kernel $\phi$ and obtain an AOI map for the corresponding class as $M=\mathbb{1}\left(\phi(L)>0\right)$ , where $\mathbb{1}(.)$ is an indicator function and $M\in\mathbb{R}^{h\times w}$ has the same size as $L$ . Repeating these steps for all $n$ ground-truth label maps provides us $n$ AOI maps. Note that AOI maps can also be obtained by image morphological operations.
为了覆盖更大区域,我们采用变换操作从真实标签生成关注区域(AOI)。与仅包含道路标记的标签不同,经过此操作获得的区域还会考虑道路标记的周边区域。图3展示了AOI生成过程示意图。假设我们有$n$个二值真实标签图构成的集合$\mathbf{L}\in\mathbb{R}^{h\times w\times n}$。对于每个类别标签图$\b{L}\in\mathbb{R}^{h\times w}$,我们使用平均核$\phi$对标签图进行平滑处理,得到对应类别的AOI图$M=\mathbb{1}\left(\phi(L)>0\right)$,其中$\mathbb{1}(.)$是指示函数,且$M\in\mathbb{R}^{h\times w}$与$L$尺寸相同。对所有$n$个真实标签图重复上述步骤,即可获得$n$个AOI图。需要注意的是,AOI图也可以通过图像形态学操作获得。
AOI-grounded moment pooling. Suppose the feature maps of a network are represented as F ∈ Rhf ×wf ×c, where $h_{f},w_{f}$ and $c$ denote the height, width and channel of the feature map, respectively. Once we obtain the AOI maps M, we can use them as masks to extract AOI features from $\mathbf{F}$ for each class region. The obtained AOI features can then be used to compute the inter-region affinity. For effective affinity computation, we regard AOI features of each region as a distribution. Affinity can then be defined as the similarity between two feature distributions.
AOI-grounded moment pooling。假设网络的特征图表示为F ∈ Rhf ×wf ×c,其中$h_{f},w_{f}$和$c$分别表示特征图的高度、宽度和通道数。一旦获得AOI映射M,便可将其作为掩码从$\mathbf{F}$中提取每个类别区域的AOI特征。提取的AOI特征随后可用于计算区域间亲和度。为实现有效的亲和度计算,我们将每个区域的AOI特征视为一个分布,此时亲和度可定义为两个特征分布之间的相似性。
Moments have been widely-used in many studies [18, 28]. Inspired by these prior studies, we calculate moment statistics of a distribution and use them for affinity computation. In particular, we extract the first moment $\pmb{\mu}{1}$ , second moment ${\pmb{\mu}}{2}$ and third moment ${\pmb\mu}_{3}$ as the high-level statistics of a distribution. The moments of features have explicit meanings, i.e., the first moment represents the mean of the distribution, the second moment (variance) and the third moment (skewness) describe the shape of that distribution. We empirically found that using higher-order moments brings marginal performance gains while requiring heavier computation cost.
矩量已在众多研究中得到广泛应用[18, 28]。受前人研究启发,我们计算分布的各阶矩量统计值并将其用于亲和度计算。具体而言,我们提取一阶矩$\pmb{\mu}{1}$、二阶矩${\pmb{\mu}}{2}$和三阶矩${\pmb\mu}_{3}$作为分布的高阶统计量。这些特征矩量具有明确物理意义:一阶矩表征分布均值,二阶矩(方差)与三阶矩(偏度)则描述分布形态。实证表明,使用更高阶矩虽能带来边际性能提升,但会显著增加计算成本。
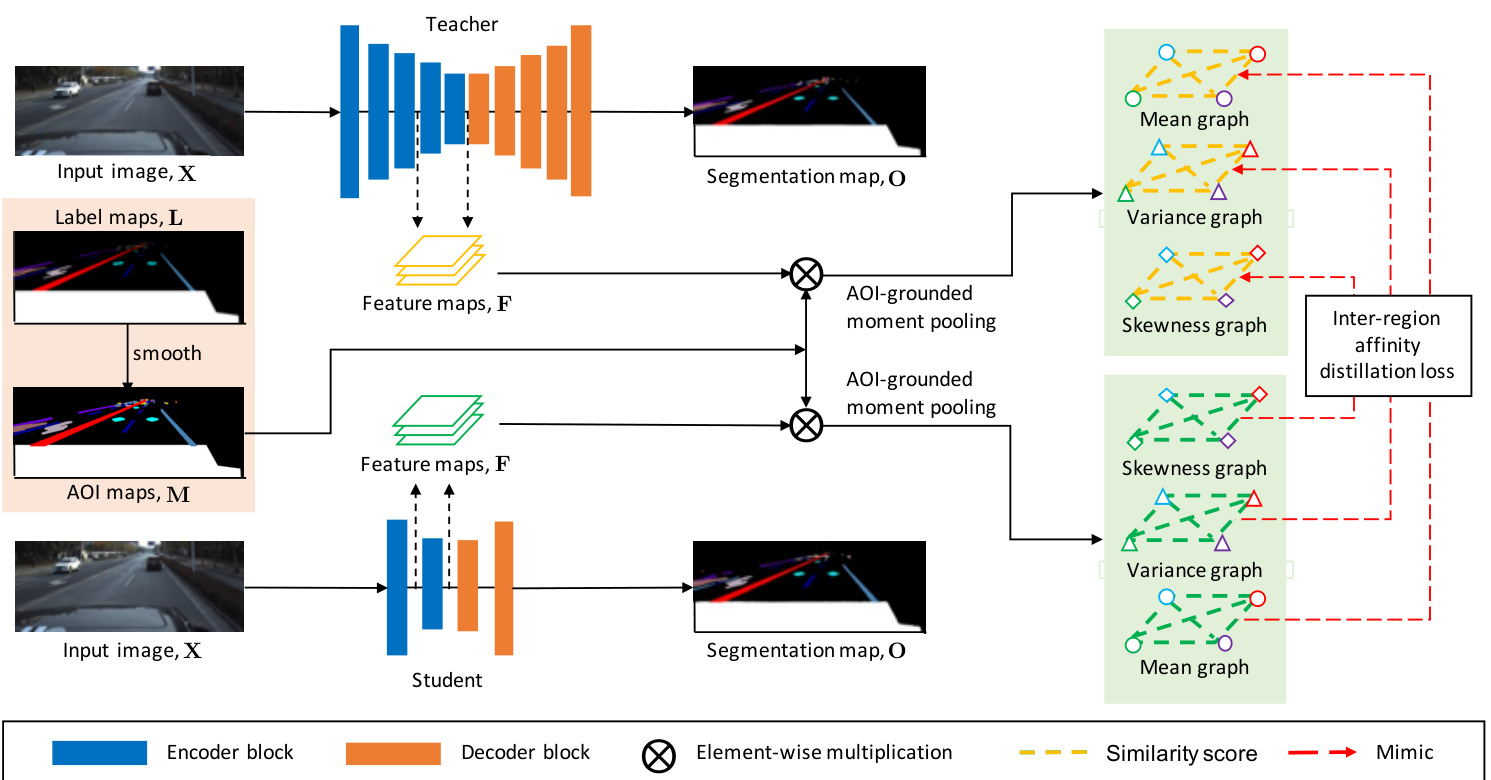
Figure 2. The pipeline of IntRA-KD. There are two networks in our approach, one serves as the student and the other serves as the teacher. Given an input image, the student is required to mimic the inter-region affinity graph of the trained teacher model at selected layers. Labels are pre-processed by a smoothing operation to obtain the areas of interest (AOI). AOI maps, shown as an integrated map here, provide the masks to extract features corresponding to each class region. Moment pooling is performed to compute the statistics of feature distribution for each region. This is followed by the construction of an inter-region affinity graph that captures the similarity of feature distribution between different regions. The inter-region affinity graph is composed of three sub-graphs, i.e., the mean graph, the variance graph and the skewness graph.
图 2: IntRA-KD的流程框架。我们的方法包含两个网络,一个作为学生模型,另一个作为教师模型。给定输入图像后,学生模型需要在选定层模仿训练好的教师模型的区域间亲和力图(inter-region affinity graph)。标签通过平滑操作预处理以获取关注区域(AOI)。AOI映射(此处显示为整合后的映射图)提供了提取每个类别区域对应特征的掩码。通过矩池化(moment pooling)计算每个区域的特征分布统计量,进而构建捕获不同区域间特征分布相似性的区域间亲和力图。该图由三个子图构成:均值图、方差图和偏度图。
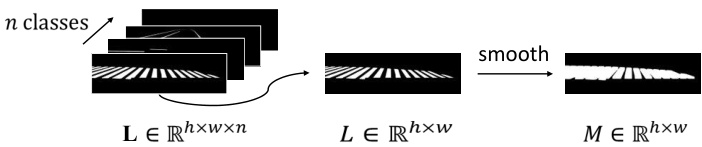
Figure 3. Generation of AOI. Take one class label map $L$ as example. We perform smoothing on $L$ and obtain one AOI map $M$ .
图 3: AOI生成过程。以类别标签图$L$为例,我们对$L$进行平滑处理并得到AOI图$M$。
To compute $\mu_{1}(k)$ , $\mu_{2}(k)$ and $\mu_{3}(k)$ of class $k$ , we introduce the moment pooling operation to process the AOI features.
为了计算类别 $k$ 的 $\mu_{1}(k)$、$\mu_{2}(k)$ 和 $\mu_{3}(k)$,我们引入了矩池化操作来处理AOI特征。
$$
\begin{array}{l}{\displaystyle\mu_{1}(k)=\frac{1}{|\mathbf{M}(:,:,k)|}\sum_{i=1}^{h_{f}}\sum_{j=1}^{w_{f}}\mathbf{M}(i,j,k)\mathbf{F}(i,j),}\ {\displaystyle\mu_{2}(k)=\frac{1}{|\mathbf{M}(:,:,k)|}\sum_{i=1}^{h_{f}}\sum_{j=1}^{w_{f}}(\mathbf{M}(i,j,k)\mathbf{F}(i,j)-\mu_{1}(k))^{2},}\ {\displaystyle\mu_{3}(k)=\frac{1}{|\mathbf{M}(:,:,k)|}\sum_{i=1}^{h_{f}}\sum_{j=1}^{w_{f}}\left(\frac{\mathbf{M}(i,j,k)\mathbf{F}(i,j)-\mu_{1}(k)}{\mu_{2}(k)}\right)^{3},}\end{array}
$$
$$
\begin{array}{l}{\displaystyle\mu_{1}(k)=\frac{1}{|\mathbf{M}(:,:,k)|}\sum_{i=1}^{h_{f}}\sum_{j=1}^{w_{f}}\mathbf{M}(i,j,k)\mathbf{F}(i,j),}\ {\displaystyle\mu_{2}(k)=\frac{1}{|\mathbf{M}(:,:,k)|}\sum_{i=1}^{h_{f}}\sum_{j=1}^{w_{f}}(\mathbf{M}(i,j,k)\mathbf{F}(i,j)-\mu_{1}(k))^{2},}\ {\displaystyle\mu_{3}(k)=\frac{1}{|\mathbf{M}(:,:,k)|}\sum_{i=1}^{h_{f}}\sum_{j=1}^{w_{f}}\left(\frac{\mathbf{M}(i,j,k)\mathbf{F}(i,j)-\mu_{1}(k)}{\mu_{2}(k)}\right)^{3},}\end{array}
$$
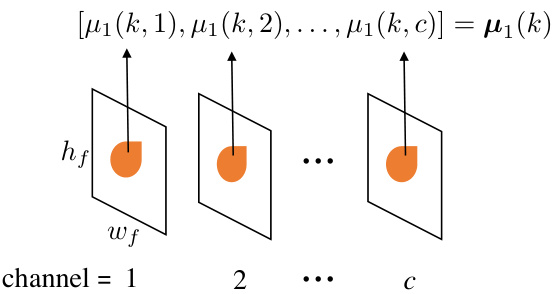
Figure 4. Performing moment pooling on deep feature $\textbf{F}\in$ $\mathbb{R}^{\tilde{h}{f}\times w_{f}\times c}$ . We use the pooling of first moment as an example.
图 4: 在深度特征 $\textbf{F}\in$ $\mathbb{R}^{\tilde{h}{f}\times w_{f}\times c}$ 上执行矩池化操作。我们以首阶矩池化为例进行说明。
where $|\mathbf{M}(:,:,k)|$ computes the number of non-zero elements in $\mathbf{M}(:,:,k)$ and $\mu_{r}(k)\in\mathbb{R}^{c},r\in{1,2,3}$ .
其中 $|\mathbf{M}(:,:,k)|$ 计算 $\mathbf{M}(:,:,k)$ 中非零元素的数量,且 $\mu_{r}(k)\in\mathbb{R}^{c},r\in{1,2,3}$。
An illustration of the process of moment pooling is depicted in Fig. 4. The moment pooling operation has the following properties. First, it can process areas with arbitrary shapes and sizes, which can be seen as an extension of the conventional average pooling. Second, the moment vectors obtained by the moment pooling operation can faithfully reflect the feature distribution of a particular region, and yet, the vectors are in a very low-dimension, thus facilitating efficient affinity computation in the subsequent step.
图 4: 展示了矩池化(moment pooling)过程的示意图。矩池化操作具有以下特性:首先,它能处理任意形状和大小的区域,可视为传统平均池化的扩展;其次,通过矩池化获得的矩向量能忠实反映特定区域的特征分布,同时这些向量处于极低维度,有利于后续步骤中高效计算亲和度(affinity)。
Inter-region affinity distillation. Since output feature maps of the teacher model and those of the student model may have different dimensions, performing matching of each pair of moment vectors would require extra parameters or operations to guarantee dimension consistency. Instead, we compute the cosine similarity of the moment vectors of class $k_{1}$ and class $k_{2}$ , i.e.,
跨区域亲和力蒸馏。由于教师模型和学生模型的输出特征图可能具有不同维度,直接匹配每对矩向量需要额外的参数或操作来保证维度一致性。因此,我们计算类别 $k_{1}$ 和类别 $k_{2}$ 的矩向量之间的余弦相似度,即
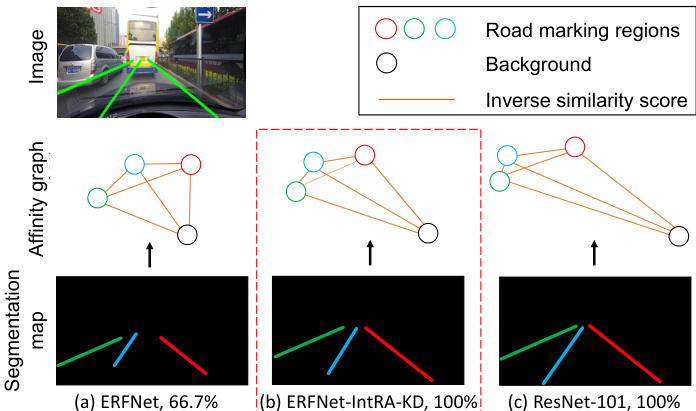
Figure 5. Visualization of the affinity graph generated by different methods. We represent edges in an affinity graph by inverse similarity score. The number next to the method’s name is $F_{1}$ - measure.
图 5: 不同方法生成的亲和力图可视化。我们通过逆相似度分数表示亲和力图中的边。方法名称旁边的数字是 $F_{1}$ 值。
$$
\mathbf{C}(k_{1},k_{2},r)=\frac{{\pmb{\mu}}{r}(k_{1})^{\mathsf{T}}{\pmb{\mu}}{r}(k_{2})}{|{\pmb{\mu}}{r}(k_{1})|{2}|{\pmb{\mu}}{r}(k_{2})|_{2}},r\in{1,2,3}.
$$
$$
\mathbf{C}(k_{1},k_{2},r)=\frac{{\pmb{\mu}}{r}(k_{1})^{\mathsf{T}}{\pmb{\mu}}{r}(k_{2})}{|{\pmb{\mu}}{r}(k_{1})|{2}|{\pmb{\mu}}{r}(k_{2})|_{2}},r\in{1,2,3}.
$$
The similarity score captures the similarity of each pair of classes and it is taken as the high-level knowledge to be learned by the student model. The moment vectors $\pmb{\mu}$ and the similarity scores $\mathbf{C}$ constitute the nodes and the edges of the affinity graph $\mathcal{G}=\langle\pmb{\mu},\mathbf{C}\rangle$ , respectively (see Fig. 2). The inter-region affinity distillation loss is given as follows:
相似度分数捕捉了每对类别之间的相似性,它被视为学生模型待学习的高层知识。矩向量 $\pmb{\mu}$ 和相似度分数 $\mathbf{C}$ 分别构成亲和图 $\mathcal{G}=\langle\pmb{\mu},\mathbf{C}\rangle$ 的节点和边 (见图 2)。区域间亲和蒸馏损失如下给出:
$$
\begin{array}{l}{{\displaystyle\mathcal{L}{m}({\bf C}{S},{\bf C}{T})=}}\ {{\displaystyle\frac{1}{3n^{2}}\sum_{r=1}^{3}\sum_{k_{1}=1}^{n}\sum_{k_{2}=1}^{n}|{\bf C}{S}(k_{1},k_{2},r)-{\bf C}{T}(k_{1},k_{2},r)|_{2}^{2}.}}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle\mathcal{L}{m}({\bf C}{S},{\bf C}{T})=}}\ {{\displaystyle\frac{1}{3n^{2}}\sum_{r=1}^{3}\sum_{k_{1}=1}^{n}\sum_{k_{2}=1}^{n}|{\bf C}{S}(k_{1},k_{2},r)-{\bf C}{T}(k_{1},k_{2},r)|_{2}^{2}.}}\end{array}
$$
The introduced affinity distillation is robust to the network differences between the teacher and student models since the distillation is only related to the number of classes and is irrelevant to the specific dimension of feature maps. In addition, the affinity knowledge is comprehensive since it gathers information from AOI features from both the foreground and background areas. Finally, in comparison to previous distillation methods [6] that use probability maps as distillation targets, the affinity graph is more memoryefficient since it reduces the size of the distillation targets from $h\times w\times n$ to $n^{2}$ where $n$ is usually thousands of times smaller than $h\times w$ .
引入的亲和力蒸馏对师生模型间的网络差异具有鲁棒性,因为蒸馏仅与类别数量相关,而与特征图的具体维度无关。此外,这种亲和力知识具有全面性,因为它整合了来自前景和背景区域AOI特征的信息。最后,与先前使用概率图作为蒸馏目标的方法[6]相比,亲和力图更具内存效率,它将蒸馏目标的大小从$h\times w\times n$缩减至$n^{2}$,其中$n$通常比$h\times w$小数千倍。
From Fig. 5, we can see that IntRA-KD not only improves the predictions of ERFNet, but also causes a closer feature structure between the student model and the ResNet101 teacher model. This is reflected by the very similar structure between the affinity graphs of ERFNet and
从图5可以看出,IntRA-KD不仅提升了ERFNet的预测效果,还使学生模型与ResNet101教师模型的特征结构更为接近。这一点通过ERFNet和...的亲和力图结构高度相似得到体现

Figure 6. Typical video frames of ApolloS cape, CULane and LLAMAS datasets.
图 6: ApolloS cape、CULane 和 LLAMAS 数据集的典型视频帧。
ResNet-101. It is interesting to see that those spatially close and visually similar road markings are pulled closer and those spatially distant and visually different markings are pulled apart in the feature space using IntRA-KD . An example is shown in Fig. 5, illustrating the effectiveness of IntRA-KD in transferring structural knowledge from the teacher model to the student model. We show in the experiment section that such transfers are essential to improve the performance of student models.
ResNet-101。有趣的是,通过IntRA-KD,那些空间上接近且视觉相似的道路标记在特征空间中被拉得更近,而那些空间上远离且视觉不同的标记则被拉开。如图 5 所示,该示例展示了IntRA-KD在将教师模型的结构知识迁移到学生模型方面的有效性。我们在实验部分表明,这种迁移对于提升学生模型的性能至关重要。
Adding IntRA-KD to training. The final loss is composed of three terms, i.e., the cross entropy loss, the inter-region affinity distillation loss and the attention map distillation loss. The attention map distillation loss is optional in our framework but it is useful to complement the region-level knowledge. The final loss is written as
在训练中加入IntRA-KD。最终损失由三部分组成,即交叉熵损失、区域间亲和力蒸馏损失和注意力图蒸馏损失。注意力图蒸馏损失在我们的框架中是可选的,但它有助于补充区域级知识。最终损失可表示为
$$
\begin{array}{r}{\mathcal{L}=\mathcal{L}{\mathrm{seg}}(\mathbf{O},\mathbf{L})+\alpha_{1}\mathcal{L}{\mathrm{m}}(\mathbf{C}{S},\mathbf{C}{T})+\alpha_{2}\mathcal{L}{\mathrm{a}}(\mathbf{A}{S},\mathbf{A}_{T}).}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}=\mathcal{L}{\mathrm{seg}}(\mathbf{O},\mathbf{L})+\alpha_{1}\mathcal{L}{\mathrm{m}}(\mathbf{C}{S},\mathbf{C}{T})+\alpha_{2}\mathcal{L}{\mathrm{a}}(\mathbf{A}{S},\mathbf{A}_{T}).}\end{array}
$$
Here, $\alpha_{1}$ and $\alpha_{2}$ are used to balance the effect of different distillation losses on the main task loss $\mathcal{L}{\mathrm{seg}}$ . Different from the mimicking of feature maps $\mathbf{F}\in\mathbb{R}^{h_{f}\times\overline{{w}}{f}\times c}$ , which demand huge memory resources and are hard to learn, attention maps $\mathbf{A}\in\mathbb{R}^{h_{f}\times w_{f}}$ are more memory-friendly and eas- ier to mimic since only several important areas are needed to learn. The attention map distillation loss is given as follows:
这里,$\alpha_{1}$ 和 $\alpha_{2}$ 用于平衡不同蒸馏损失对主任务损失 $\mathcal{L}{\mathrm{seg}}$ 的影响。与特征图 $\mathbf{F}\in\mathbb{R}^{h_{f}\times\overline{{w}}{f}\times c}$ 的模仿不同(特征图模仿需要大量内存资源且难以学习),注意力图 $\mathbf{A}\in\mathbb{R}^{h_{f}\times w_{f}}$ 对内存更友好且更易于模仿,因为只需学习少数重要区域。注意力图蒸馏损失如下:
$$
\mathcal{L}{a}(\mathbf{A}{S},\mathbf{A}{T})=\sum_{i=1}^{h_{f}}\sum_{j=1}^{w_{f}}|\mathbf{A}{S}(i,j)-\mathbf{A}{T}(i,j)|_{2}^{2}.
$$
$$
\mathcal{L}{a}(\mathbf{A}{S},\mathbf{A}{T})=\sum_{i=1}^{h_{f}}\sum_{j=1}^{w_{f}}|\mathbf{A}{S}(i,j)-\mathbf{A}{T}(i,j)|_{2}^{2}.
$$
We follow [27] to derive attention maps from feature maps.
我们遵循[27]的方法从特征图中提取注意力图。
4. Experiments
4. 实验
Datasets. We conduct experiments on three datasets, namely ApolloS cape [11], CULane [14] and LLAMAS [1]. Figure 6 shows a selected video frame from each of the three datasets. These three datasets are challenging due to poor light conditions, occlusions and the presence of many tiny road markings. Note that CULane and LLAMAS only label lanes according to their relative positions to the ego vehicle while ApolloS cape labels every road marking on the road according to their functions. Hence, ApolloS cape has much more classes and it is more challenging compared with the other two datasets. Apart from the public result [11], we also reproduce the most related and stateof-the-art methods (e.g., ResNet-50 and UNet-ResNet-34) on ApolloS cape for comparison. As to LLAMAS dataset, since the official submission server is not established, the evaluation on the original testing set is impossible. Hence, we split the original validation set into two parts, i.e., one is used for validation and the other is used for testing. Table 1 summarizes the details and train/val/test partitions of the datasets.
数据集。我们在三个数据集上进行实验,分别是ApolloScape [11]、CULane [14]和LLAMAS [1]。图6展示了从这三个数据集中各选取的一帧视频画面。由于光照条件差、遮挡以及存在大量微小道路标记,这三个数据集具有较高挑战性。需要注意的是,CULane和LLAMAS仅根据车道线与自车的相对位置进行标注,而ApolloScape则根据功能标注路面所有道路标记。因此,ApolloScape的类别数量远多于另外两个数据集,难度也更大。除公开结果[11]外,我们还在ApolloScape上复现了最相关且最先进的方法(如ResNet-50和UNet-ResNet-34)进行比较。对于LLAMAS数据集,由于官方未建立提交服务器,无法在原测试集上评估。因此我们将原验证集划分为两部分,一部分用于验证,另一部分用于测试。表1总结了数据集详情及训练/验证/测试划分情况。
Table 1. Basic information of three road marking segmentation datasets.
表 1: 三种道路标线分割数据集的基本信息。
| 名称 | #帧数 | 训练集 | 验证集 | 测试集 | 分辨率 | #类别 | 时序连续? |
|---|---|---|---|---|---|---|---|
| ApolloScape [11] | 114,538 | 103,653 | 10,000 | 885 | 3384×2710 | 36 | |
| CULane [14] | 133,235 | 88,880 | 9,675 | 34,680 | 1640×590 | 5 | |
| LLAMAS [1] | 79,113 | 58,269 | 10,029 | 10,815 | 1276×717 | 5 |
Evaluation metrics. We use different metrics on each dataset following the guidelines of the benchmark and practices of existing studies.
评估指标。我们根据基准指南和现有研究的实践,在每个数据集上使用不同的指标。
- ApolloS cape. We use the official metric, i.e., mean intersection-over-union (mIoU) as evaluation criterion [11]. 2) CULane. Following [14], we use $F_{1}$ -measure as the evaluation metric, which is defined as: $\begin{array}{r l}{F_{1}}&{{}=}\end{array}$ $\frac{2\times P r e c i s i o n\times R e c a l l}{P r e c i s i o n+R e c a l l}$ , where Precision $\begin{array}{r l}{=}&{{}{\frac{T P}{T P+F P}}}\end{array}$ and Recall = T P T +PF N .
- ApolloS cape。我们采用官方评估指标,即平均交并比 (mIoU) 作为评价标准 [11]。
- CULane。遵循 [14] 的做法,我们使用 $F_{1}$ 值作为评估指标,其定义为:$\begin{array}{r l}{F_{1}}&{{}=}\end{array}$ $\frac{2\times 精确率\times 召回率}{精确率+召回率}$,其中 精确率 $\begin{array}{r l}{=}&{{}{\frac{TP}{TP+FP}}}\end{array}$,召回率 = $\frac{TP}{TP+FN}$。
$3)L L A M A S$ . We use mean average precision (mAP) to evaluate the performance of different algorithms [1].
$3)L L A M A S$。我们采用平均精度均值 (mAP) 来评估不同算法的性能 [1]。
Implementation details. Since there is no road marking in the upper areas of the input image, we remove the upper part of the original image during both training and testing phases. The size of the processed image is $3384\times1010$ for ApolloS cape, $1640~\times 350$ for CULane, and $1276~\times 384$ for LLAMAS. To save memory usage, we further resize the processed image to $1692\times505$ , $976\times208$ and $960~\times$ 288, respectively. We use SGD [2] to train our models and the learning rate is set as 0.01. Batch size is set as 12 for CULane and LLAMAS, and 8 for ApolloS cape. The total number of training episodes is set as 80K for CULane and LLAMAS, and 180K for ApolloS cape since ApolloS cape is more challenging. The cross entropy loss of background pixels is multiplied by 0.4 for CULane and LLAMAS, and 0.05 for ApolloS cape since class imbalance is more severe in ApolloS cape. For the teacher model, i.e., ResNet-101, we add the pyramid pooling module [30] to obtain both local and global context information. $\alpha_{1}$ and $\alpha_{2}$ are both set as 0.1 and the size of the averaging kernel for obtaining AOI maps is set as $5\times5$ . Our results are not sensitive to the kernel size.
实现细节。由于输入图像的上部区域没有道路标记,我们在训练和测试阶段都移除了原始图像的上部。处理后的图像尺寸为:ApolloS cape数据集$3384\times1010$,CULane数据集$1640~\times 350$,LLAMAS数据集$1276~\times 384$。为节省内存占用,我们进一步将处理后的图像调整为$1692\times505$(ApolloS cape)、$976\times208$(CULane)和$960~\times288$(LLAMAS)。使用SGD [2]优化器训练模型,学习率设为0.01。CULane和LLAMAS的批量大小设为12,ApolloS cape设为8。训练总轮数设置为:CULane和LLAMAS 80K轮,更具挑战性的ApolloS cape 180K轮。针对类别不平衡问题,CULane和LLAMAS的背景像素交叉熵损失乘以0.4,ApolloS cape乘以0.05。教师模型ResNet-101增加了金字塔池化模块[30]以获取局部和全局上下文信息。$\alpha_{1}$和$\alpha_{2}$均设为0.1,生成AOI映射的平均池化核尺寸为$5\times5$,实验结果对核尺寸不敏感。
In our experiments, we use either ERFNet [20], ENet [16] or ResNet-18 [5] as the student and ResNet-101 as the teacher. While we choose ERFNet to report most of our ablation studies in this paper, we also report overall results of ENet [16] and ResNet-18 [5]. Detailed results are provided in the supplementary material. We extract both high-level features and middle-level features from ResNet101 as distillation targets. Specifically, we let the features of block 2 and block 3 of ERFNet to mimic those of block 3 and block 5 of ResNet-101, respectively.
在我们的实验中,我们使用ERFNet [20]、ENet [16]或ResNet-18 [5]作为学生模型,ResNet-101作为教师模型。虽然本文主要选择ERFNet进行消融研究,但我们也报告了ENet [16]和ResNet-18 [5]的整体结果。详细结果见补充材料。我们从ResNet101中提取高层特征和中间层特征作为蒸馏目标。具体而言,我们让ERFNet的block 2和block 3分别模仿ResNet-101的block 3和block 5的特征。
Table 2. Performance of different methods on ApolloS cape-test.
表 2: 不同方法在ApolloScape测试集上的性能
| 类型 | 算法 | mIoU |
|---|---|---|
| Baseline | Wide ResNet-38 [25] ENet [16] ResNet-50 [5] UNet-ResNet-34 [21] | 42.2 39.8 41.3 42.4 |
| Teacher | ResNet-101 [5] | 46.6 |
| Student | ERFNet [20] | 40.4 |
| Selfdistillation | ERFNet-DKS [22] ERFNet-SAD [8] | 40.8 40.9 |
| Teacher-student distillation | ERFNet-KD [6] ERFNet-SKD [13] ERFNet-PS-N [26] ERFNet-IRG [12] ERFNet-BiFPN [31] ERFNet-IntRA-KD(ours) | 40.7 40.9 40.6 41.0 41.6 43.2 |
Baseline distillation algorithms. In addition to the stateof-the-art algorithms in each benchmark, we also compare the proposed IntRA-KD with contemporary knowledge distillation algorithms, i.e., KD [6], SKD [13], PS-N [26], IRG [12] and BiFPN [31]. Here, KD denotes probability map distillation; SKD employs both probability map distillation and pairwise similarity map distillation; PS-N takes the pairwise similarity map of neighbouring layers as knowledge; IRG uses the instance features, instance relationship and inter-layer transformation of three consecutive frames for distillation, and BiFPN uses attention maps of neighbouring layers as distillation targets.
基线蒸馏算法。除了各基准中的最先进算法外,我们还将提出的IntRA-KD与当前主流的知识蒸馏算法进行比较,包括KD [6]、SKD [13]、PS-N [26]、IRG [12]和BiFPN [31]。其中,KD表示概率图蒸馏;SKD同时采用概率图蒸馏和成对相似度图蒸馏;PS-N以相邻层的成对相似度图作为知识;IRG利用连续三帧的实例特征、实例关系和层间变换进行蒸馏;BiFPN则将相邻层的注意力图作为蒸馏目标。
4.1. Results
4.1. 结果
Tables 2- 4 summarize the performance of our method, i.e., ERFNet-IntRA-KD , against state-of-the-art algorithms on the testing set of ApolloS cape [11], CULane [14] and LLAMAS [1]. We also report the runtime and parameter size of different models in Table 3. The runtime is recorded using a single GPU (GeForce GTX TITAN X Maxwell) and averages across 100 samples. ERFNet-IntRA-KD outperforms all baselines and previous distillation methods in all three benchmarks. Note that ERFNet-IntRA-KD has 21 $\times$ fewer parameters and runs $16~\times$ faster compared with ResNet-101 on CULane testing set; the appealing performance strongly suggests the effectiveness of IntRA-KD.
表 2-4 总结了我们的方法 ERFNet-IntRA-KD 在 ApolloS cape [11]、CULane [14] 和 LLAMAS [1] 测试集上与当前最优算法的性能对比。表 3 还报告了不同模型的运行时间和参数量。运行时间使用单块 GPU (GeForce GTX TITAN X Maxwell) 测量并取 100 次样本的平均值。ERFNet-IntRA-KD 在三个基准测试中均优于所有基线方法和先前的蒸馏方法。值得注意的是,在 CULane 测试集上,ERFNet-IntRA-KD 的参数量比 ResNet-101 少 21 $\times$,运行速度快 $16~\times$;这一优异表现充分证明了 IntRA-KD 的有效性。
We also apply IntRA-KD to ENet and ResNet-18, and find that IntRA-KD can equivalently bring more performance gains to the backbone models than the state-of-theart BiFPN [31] on ApolloS cape dataset (Fig. 7). Note that BiFPN is a competitive algorithm in all benchmarks. Encouraging results are also observed on CULane and LLAMAS when applying IntRA-KD to ENet and ResNet-18. Due to space limit, we report detailed performance of applying different distillation algorithms to ENet and ResNet18 in the supplementary material. The effectiveness of our IntRA-KD on different backbone models validates the good generalization ability of our method.
我们还将IntRA-KD应用于ENet和ResNet-18,发现与当前最先进的BiFPN [31]相比,IntRA-KD在ApolloScape数据集上能为骨干模型带来更显著的性能提升(图7)。值得注意的是,BiFPN在所有基准测试中都是极具竞争力的算法。当将IntRA-KD应用于ENet和ResNet-18时,在CULane和LLAMAS数据集上也观察到了令人鼓舞的结果。由于篇幅限制,我们在补充材料中报告了不同蒸馏算法应用于ENet和ResNet-18的详细性能表现。IntRA-KD在不同骨干模型上的有效性验证了我们方法良好的泛化能力。
Table 3. Performance of different methods on CULane-test. To save space, baseline, teacher, student, self distillation and teacherstudent distillation in the first column are abbreviated as B, T, S, SD and TSD, respectively.
表 3: 不同方法在CULane-test上的性能。为节省空间,第一列中的基线、教师、学生、自蒸馏和师生蒸馏分别缩写为B、T、S、SD和TSD。
| 类型 | 算法 | F1 | 运行时间 (ms) | 参数量 (M) |
|---|---|---|---|---|
| B | SCNN [14] ResNet-18-SAD [8] | 71.6 70.5 | 133.5 25.3 | 20.72 12.41 |
| T | ResNet-34-SAD [8] ResNet-101 [5] | 70.7 72.8 | 50.5 171.2 | 22.72 52.53 |
| S | ERFNet [20] | 70.2 | - | - |
| SD | ERFNet-DKS [22] ERFNet-SAD [8] | 70.6 71.0 | 10.2 | 2.49 |
| TSD | ERFNet-KD [6] ERFNet-SKD [13] ERFNet-PS-N [26] ERFNet-IRG [12] ERFNet-BiFPN [31] ERFNet-IntRA-KD (ours) | 70.5 70.7 70.6 70.7 71.4 72.4 | - | - |
Table 4. Performance of different methods on LLAMAS-test.
表 4: 不同方法在LLAMAS-test上的性能表现
| 类型 | 算法 | mAP |
|---|---|---|
| 基线方法 | SCNN [14] ResNet-50 [5] UNet-ResNet-34[21] | 0.597 0.578 0.592 |
| 教师模型 | ResNet-101 [5] | 0.607 |
| 学生模型 | ERFNet [20] | 0.570 |
| 自蒸馏 | ERFNet-DKS [22] ERFNet-SAD [8] | 0.573 0.575 |
| 师生蒸馏 | ERFNet-KD [6] ERFNet-SKD [13] ERFNet-PS-N [26] ERFNet-IRG[12] ERFNet-BiFPN [31] | 0.572 0.576 0.575 0.576 0.583 |
We also show some qualitative results of our IntRAKD and BiFPN [31] (the most competitive baseline) on three benchmarks. As shown in (a) and (c) of Fig. 8, IntRAKD helps ERFNet predict more accurately on both long and thin road markings. As to other challenging scenarios of crowded roads and poor light conditions, ERFNet and ERFNet-BiFPN either predict lanes inaccurately or miss the predictions. By contrast, predictions yielded by ERFNetIntRA-KD are more complete and accurate.
我们还展示了IntRAKD和最具竞争力的基线方法BiFPN [31]在三个基准测试上的定性结果。如图8(a)和(c)所示,IntRAKD帮助ERFNet在细长道路标线的预测上更加准确。针对拥挤道路和弱光条件等挑战性场景,ERFNet和ERFNet-BiFPN要么预测不准确,要么漏检车道线。相比之下,ERFNetIntRA-KD生成的预测结果更完整且准确。
Apart from model predictions, we also show the deep feature embeddings of different methods. As can be seen from Fig. 9, the embedding of ERFNet-IntRA-KD is more structured compared with that of ERFNet and ERFNetBiFPN. In particular, the features of ERFNet-IntRA-KD are more distinctly clustered according to their classes in the embedding, with similar distribution to the embedding of the ResNet-101 teacher. The results suggest the importance of structural information in knowledge distillation.
除了模型预测结果,我们还展示了不同方法的深度特征嵌入。从图 9 可以看出,ERFNet-IntRA-KD 的嵌入比 ERFNet 和 ERFNetBiFPN 更具结构性。特别是,ERFNet-IntRA-KD 的特征在嵌入中根据类别形成了更明显的聚类,其分布与 ResNet-101 教师的嵌入相似。这些结果表明了结构信息在知识蒸馏中的重要性。

Figure 7. Comparison between IntRA-KD and BiFPN on ENet, ERFNet and ResNet-18 on ApolloS cape-test.
图 7: IntRA-KD与BiFPN在ApolloS cape-test数据集上对ENet、ERFNet和ResNet-18的对比结果

Figure 8. Performance of different methods on (a) ApolloS cape, (b) CULane and (c) LLAMAS testing sets. The number below each image denotes the accuracy for (a) and (c), $F_{1}$ -measure for (b). Ground-truth labels are drawn on the input image. Second rows of (a) and (c) are enlarged areas covered by the red dashed rectangle.
图 8: 不同方法在 (a) ApolloS cape, (b) CULane 和 (c) LLAMAS 测试集上的性能表现。每张图片下方的数字分别表示 (a) 和 (c) 的准确率,以及 (b) 的 $F_{1}$ 分数。输入图像上绘制了真实标注。(a) 和 (c) 的第二行是红色虚线矩形框区域的放大视图。
4.2. Ablation Study
4.2. 消融研究
In this section, we investigate the effect of each component, i.e., different loss terms and the associated coefficients, on the final performance.
在本节中,我们研究了每个组件(即不同的损失项及其相关系数)对最终性能的影响。
Effect of different loss terms. From Fig. 10, we have the following observations: (1) Considering all moments from both middle- and high-level features, i.e., the blue bar with $\mathcal{L}{\mu_{1}}+\mathcal{L}{\mu_{2}}+\mathcal{L}{\mu_{3}}$ , brings the most performance gains. (2) Attention map distillation, $\mathcal{L}_{a}$ also brings considerable gains compared with the baseline without distillation. (3) Distillation of high-level features brings more performance gains than that of middle-level features. This may be caused by the fact that high-level features contain more semanticrelated information, which is beneficial to the segmentation task. (4) Inter-region affinity distillation and attention map distillation are complementary, leading to best performance (i.e., 43.2 mIoU as shown by the red vertical dash line).
不同损失项的效果。从图10中,我们得出以下观察结果:(1) 同时考虑中高层特征的所有矩(即蓝色柱状图对应的 $\mathcal{L}{\mu_{1}}+\mathcal{L}{\mu_{2}}+\mathcal{L}{\mu_{3}}$)能带来最大的性能提升。(2) 注意力图蒸馏($\mathcal{L}_{a}$)相比无蒸馏基线也带来了显著增益。(3) 高层特征蒸馏比中层特征蒸馏产生更多性能提升,这可能是因为高层特征包含更多语义相关信息,有利于分割任务。(4) 区域间亲和力蒸馏与注意力图蒸馏具有互补性,共同作用时达到最佳性能(如红色垂直虚线所示的43.2 mIoU)。

Figure 9. Deep feature embeddings (first row) and predictions (second row) of (a) ERFNet (b) ERFNet-BiFPN (c) ResNet-101 (teacher) (d) ERFNet-IntRA-KD. The number next to the model’s name denotes accuracy $(%)$ . Regions of the model prediction, which are covered by the red dashed rectangle, are highlighted in the third row. The color bar of the deep embeddings is the same as that of the model prediction except the background, whose color is changed from black to pink for better visualization. Note that we crop the upper part of the label and model prediction for better visualization and we use $\mathbf{t}{\cdot}\mathbf{SNE}$ to visualize the feature maps (first row).
图 9: (a) ERFNet (b) ERFNet-BiFPN (c) ResNet-101 (教师模型) (d) ERFNet-IntRA-KD 的深度特征嵌入 (第一行) 和预测结果 (第二行)。模型名称旁的数字表示准确率 $(%)$。红色虚线矩形框覆盖的模型预测区域在第三行高亮显示。深度嵌入的色条与模型预测的色条相同(背景除外),为便于观察背景色由黑色改为粉色。注意:为优化显示效果,我们裁剪了标签和模型预测的上半部分,并使用 $\mathbf{t}{\cdot}\mathbf{SNE}$ 可视化特征图 (第一行)。
Effect of loss coefficients. The coefficients of the attention map loss and affinity distillation loss are all set as 0.1 to normalize the loss values. Here, we test different selections of the loss coefficients, i.e., selecting coefficient value from ${0.05,0.10,0.15}$ . ERFNet-IntRA-KD achieves similar performance in all benchmarks, i.e., ${43.18,43.20,43.17}$ mIoU in ApolloS cape, ${72.36,72.39,72.38}$ $F_{1}$ -measure in CULane and ${0.597,0.598,0.598}$ mAP in LLAMAS. Hence, IntRA-KD is robust to the loss coefficients.
损失系数的影响。注意力图损失和亲和力蒸馏损失的系数均设为0.1以归一化损失值。此处我们测试不同损失系数的选择,即从${0.05,0.10,0.15}$中选取系数值。ERFNet-IntRA-KD在所有基准测试中表现相近:ApolloS cape达到${43.18,43.20,43.17}$ mIoU,CULane获得${72.36,72.39,72.38}$ $F_{1}$-measure,LLAMAS取得${0.597,0.598,0.598}$ mAP。因此IntRA-KD对损失系数具有鲁棒性。
5. Conclusion
5. 结论
We have proposed a simple yet effective distillation approach, i.e., IntRA-KD , to effectively transfer scene structural knowledge from a teacher model to a student model. The structural knowledge is represented as an inter-region affinity graph to capture similarity of feature distribution of different scene regions. We applied IntRA-KD to various lightweight models and observed consistent performance gains to these models over other contemporary distillation methods. Promising results on three large-scale road marking segmentation benchmarks strongly suggest the effectiveness of IntRA-KD. Results on Cityscapes are provided in the supplementary material.
我们提出了一种简单而有效的蒸馏方法IntRA-KD,能够高效地将场景结构知识从教师模型迁移到学生模型。该结构知识通过区域间亲和图表示,用于捕捉不同场景区域特征分布的相似性。我们将IntRA-KD应用于多种轻量化模型,发现相较于其他现有蒸馏方法,该方法能为这些模型带来持续的性能提升。在三个大规模道路标线分割基准测试中取得的优异成果,充分证明了IntRA-KD的有效性。Cityscapes数据集上的实验结果详见补充材料。

Figure 10. Performance (mIoU) of ERFNet using different loss terms of IntRA-KD on ApolloS cape-test. Here, “High” denotes the mimicking of high-level features (block 5) and “Middle” denotes the mimicking of middle-level features (block 3) of the teacher model. $\mathcal{L}{\mu_{\mathrm{i}}}$ denotes the variant where only the $i$ -th order moment is deployed for inter-region affinity distillation. Here, $^{\mathrm{66}}40.4^{\mathrm{5}}$ is the performance of ERFNet without distillation and $^{\cdot}43.2^{\cdot}{}^{\cdot}$ is the performance of ERFNet-IntRA-KD that considers ${\mathcal{L}}{\mu_{1}}+{\mathcal{L}}{\mu_{2}}+{\mathcal{L}}{\mu_{3}}$ and $\mathcal{L}_{a}$ . The number besides each bar is performance gain brought by each loss term compared with ERFNet.
图 10: ERFNet在ApolloScape-test集上使用不同IntRA-KD损失项的性能(mIoU)。其中"High"表示模仿教师模型的高层特征(block 5),"Middle"表示模仿教师模型的中层特征(block 3)。$\mathcal{L}{\mu_{\mathrm{i}}}$表示仅采用第$i$阶矩进行区域间亲和力蒸馏的变体。$^{\mathrm{66}}40.4^{\mathrm{5}}$表示未使用蒸馏的ERFNet性能,$^{\cdot}43.2^{\cdot}{}^{\cdot}$表示同时考虑${\mathcal{L}}{\mu_{1}}+{\mathcal{L}}{\mu_{2}}+{\mathcal{L}}{\mu_{3}}$和$\mathcal{L}_{a}$的ERFNet-IntRA-KD性能。柱状图旁数字表示各损失项相较ERFNet带来的性能提升。