Global Features are All You Need for Image Retrieval and Reranking
全局特征足以胜任图像检索与重排序任务
Abstract
摘要
Image retrieval systems conventionally use a two-stage paradigm, leveraging global features for initial retrieval and local features for reranking. However, the s cal ability of this method is often limited due to the significant storage and computation cost incurred by local feature matching in the reranking stage. In this paper, we present Super Global, a novel approach that exclusively employs global features for both stages, improving efficiency without sacrificing accuracy. Super Global introduces key enhancements to the retrieval system, specifically focusing on the global feature extraction and reranking processes. For extraction, we identify sub-optimal performance when the widely-used ArcFace loss and Generalized Mean (GeM) pooling methods are combined and propose several new modules to improve GeM pooling. In the reranking stage, we introduce a novel method to update the global features of the query and top-ranked images by only considering feature refinement with a small set of images, thus being very compute and memory efficient. Our experiments demonstrate substantial improvements compared to the state of the art in standard benchmarks. Notably, on the Revisited Oxford $^{\circ}+$ 1M Hard dataset, our single-stage results improve by $7.1%$ , while our two-stage gain reaches $3.7%$ with a strong 64, $865\times$ speedup. Our two-stage system surpasses the current single-stage state-of-the-art by $16.3%$ , offering a scalable, accurate alternative for high-performing image retrieval systems with minimal time overhead. Code: https://github.com/ShihaoShao-GH/Super Global.
图像检索系统传统上采用两阶段范式,即利用全局特征进行初始检索,再通过局部特征进行重排序。然而,由于重排序阶段局部特征匹配带来的巨大存储和计算开销,这种方法的可扩展性往往受限。本文提出Super Global,一种仅使用全局特征完成两阶段任务的新方法,在保持精度的同时提升效率。该方法对检索系统进行关键改进,重点优化全局特征提取与重排序流程:在提取阶段,我们发现广泛使用的ArcFace损失函数与广义均值(GeM)池化方法结合时性能欠佳,并提出多个新模块来改进GeM池化;在重排序阶段,我们引入仅需少量图像参与特征优化的全局特征更新机制,显著提升计算和内存效率。实验表明,本方法在标准基准测试中取得显著提升——在Revisited Oxford$^{\circ}+$1M Hard数据集上,单阶段结果提高7.1%,两阶段结果提升3.7%的同时实现64,865倍加速;我们的两阶段系统以16.3%的优势超越当前最优单阶段方案,为高性能图像检索系统提供了兼具可扩展性、精确性和低时延的解决方案。代码:https://github.com/ShihaoShao-GH/SuperGlobal。
1. Introduction
1. 引言
Image retrieval systems are tasked with searching large databases for visual contents similar to a query image. Generally, the search process consists of two stages. First, an efficient method sorts database images according to estimated high-level similarity to the query. Then, in the reranking stage, the most relevant database images found in the first stage undergo a more comprehensive matching process against the query, to return an improved ranked list of results.
图像检索系统的任务是从大型数据库中搜索与查询图像相似的视觉内容。通常,搜索过程分为两个阶段。首先,通过高效方法根据估计的高级相似度对数据库图像进行排序。然后,在重排序阶段,对第一阶段找到的最相关数据库图像与查询进行更全面的匹配,以返回改进的排序结果列表。
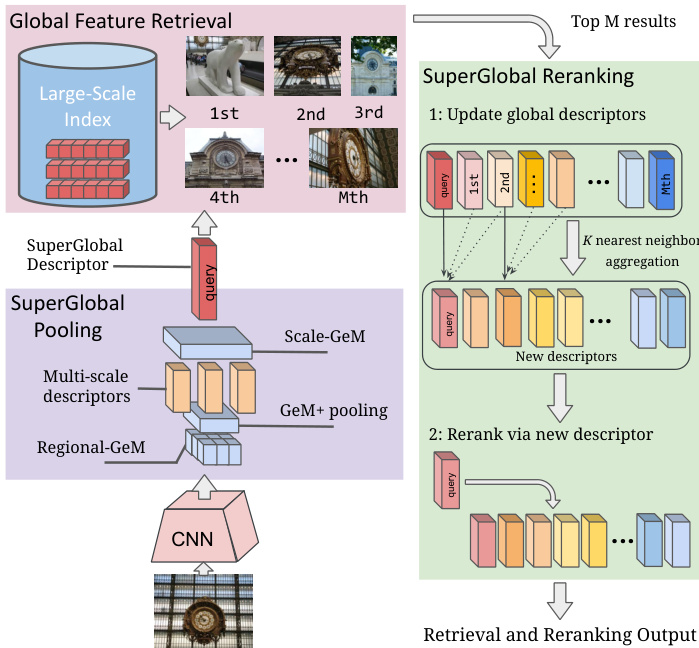
Figure 1: We introduce Super Global, a novel method for image retrieval and reranking which relies solely on global image features. Super Global leverages several improvements to the Generalized Mean (GeM) pooling function, across regions and scales, as indicated in the purple box on the left. Our reranking process, illustrated on the right green box, refines the global feature representation based on the query and top retrieved images to produce a more relevant set of results.
图 1: 我们提出了Super Global,一种仅依赖全局图像特征的图像检索与重排序新方法。如左侧紫色框所示,Super Global通过跨区域和多尺度改进广义均值(GeM)池化函数。右侧绿色框展示的重排序流程,基于查询图像和顶部检索结果优化全局特征表示,从而生成更相关的结果集。
In modern implementations, the first stage is instantiated with deep learning-based global features, which has received substantial attention in the past few years [35, 37, 26, 48]. The reranking stage is commonly executed via geometric matching of local image features [30, 32, 4, 8], which provides information on the spatial consistency between the query and a given database image.
在现代实现中,第一阶段采用基于深度学习(deep learning)的全局特征,这一方法在过去几年中受到了广泛关注[35, 37, 26, 48]。重排序阶段通常通过局部图像特征的几何匹配来执行[30, 32, 4, 8],这提供了查询图像与给定数据库图像之间的空间一致性信息。
A recent trend in this area is on leveraging sophisticated matching processes at the reranking stage, e.g. transformers [40] or 4D correlation networks [23], which have led to remarkable improvements in the quality of retrieved results. However, this has come at a significant cost, where reranking latency takes several seconds per query and requires more than 1MB of memory per database image – making these approaches challenging to scale to large repositories. Our work directly tackles this limitation by proposing the first method fully based on global image features for both stages. In addition, we rethink pooling techniques and propose modules to improve global feature extraction. An overview of our method, Super Global, is presented in Figure 1. More specifically, we introduce the following contributions.
该领域的最新趋势是在重排序阶段利用复杂的匹配流程,例如 Transformer [40] 或 4D 相关网络 [23],这些技术显著提升了检索结果的质量。然而,这带来了高昂的成本——每次查询的重排序延迟高达数秒,且每张数据库图像需占用超过 1MB 内存,使得这些方法难以扩展至大型数据库。我们的工作通过提出首个完全基于全局图像特征的双阶段方法,直接解决了这一局限性。此外,我们重新思考了池化技术,并提出改进全局特征提取的模块。图 1 展示了我们的方法 Super Global 的概览。具体而言,我们做出了以下贡献。
Contributions:
贡献:
(1) We propose improvements to the core global feature representation, based on enhanced pooling strategies. We point out undesired training behavior when learning global features combining GeM pooling [35] and ArcFace loss [11], and introduce a simple and effective solution to this problem with new pooling modules, including regional and multi-scale techniques.
(1) 我们基于增强的池化策略,对核心全局特征表示提出了改进方案。我们指出在结合GeM池化 [35] 和ArcFace损失 [11] 学习全局特征时存在的不良训练行为,并通过引入新的池化模块(包括区域化和多尺度技术)为该问题提供了简单有效的解决方案。
(2) We introduce a very efficient and effective reranking process, based solely on global features, that is able to adapt the representation of the query and top-ranked database images on the fly in order to better estimate their similarities. This method does away with any need for expensive local features and is inherently very scalable since the features used in both search stages are the same.
(2) 我们提出了一种仅基于全局特征的高效重排序方法,能够动态调整查询图像和排名靠前的数据库图像的表征,从而更准确地估计它们的相似度。该方法无需使用昂贵的局部特征,且由于两个搜索阶段使用相同的特征,因此具有天然的扩展性。
(3) Experiments on standard image retrieval benchmarks showcase the effectiveness of our methods, establishing new state-of-the-art results across the board. We boost singlestage results on Revisited Oxford $\mathbf{+1M}$ Hard [34] by $7.1%$ . But even more impressively, our simple reranking mechanism outperforms previous complex methods by $3.7%$ on the same dataset, while being more than four orders of magnitude faster and requiring $170\times$ less memory.
(3) 在标准图像检索基准测试上的实验证明了我们方法的有效性,全面刷新了当前最优性能。我们在Revisited Oxford $\mathbf{+1M}$ Hard [34]数据集上将单阶段检索结果提升了$7.1%$。更令人瞩目的是,在同一数据集上,我们简单的重排序机制以$3.7%$的优势超越了之前复杂的方法,同时速度快了四个数量级以上,内存消耗减少了$170\times$。
2. Related Work
2. 相关工作
Image retrieval methods. Early work in image retrieval leveraged hand-crafted local features [24, 7] as a core building block. While some papers proposed to retrieve directly based on local features [25, 24, 28], others used them to construct global representations, based on Bag-of-Words and similar techniques [39, 19, 20, 42]. Modern systems have revisited these image retrieval techniques with deep learning based components, e.g., deep local feature-based retrieval [27], deep local feature aggregation [41, 43, 46] or deep global feature modeling [6, 13, 37, 26, 48]. A recent survey in this area can be found in [9].
图像检索方法。早期的图像检索工作利用手工设计的局部特征 [24, 7] 作为核心构建模块。部分论文提出直接基于局部特征进行检索 [25, 24, 28],而另一些研究则利用词袋 (Bag-of-Words) 及类似技术 [39, 19, 20, 42] 构建全局表示。现代系统通过基于深度学习的组件重新审视了这些图像检索技术,例如基于深度局部特征的检索 [27]、深度局部特征聚合 [41, 43, 46] 或深度全局特征建模 [6, 13, 37, 26, 48]。该领域的最新综述可参阅 [9]。
Global feature pooling. In particular, a critical aspect that has been studied for global feature learning is on how to properly pool contributions of image features from different regions into a single high-dimensional vector. SPoC [5] proposed sum pooling of convolutional features, while [36] introduced max pooling, which was later approximated by integral max pooling in R-MAC [44]. Along a similar line, CroW [21] introduced cross-dimensional weighted sum pooling. NetVLAD [2] introduced an aggregation inspired by the VLAD method [19]. Generalized Mean (GeM) pooling [35] is today considered the state-of-the-art method in this area, being used in several recent papers [23, 8, 48]. A key contribution of our paper is to revisit global pooling methods, by pointing out the sub-optimal behavior of GeM when using a popular training loss, and by improving regional and multi-scale pooling. Note that R-MAC [44] had explored regional pooling, with max pooling over regions and sum pooling of these regional descriptors. In contrast, we apply the more modern GeM pooling across regions and scales to achieve enhanced performance.
全局特征池化。具体而言,全局特征学习研究的一个关键方面在于如何将来自不同区域的图像特征贡献正确池化为单个高维向量。SPoC [5] 提出了卷积特征的和池化(sum pooling),而[36]引入了最大池化(max pooling),后来R-MAC [44]通过积分最大池化(integral max pooling)对其进行了近似。类似地,CroW [21]提出了跨维度加权和池化(cross-dimensional weighted sum pooling)。NetVLAD [2]引入了受VLAD方法[19]启发的聚合方式。广义均值(GeM)池化[35]目前被认为是该领域的最先进方法,被多篇近期论文采用[23,8,48]。本文的一个关键贡献是重新审视全局池化方法,指出GeM在使用流行训练损失时的次优表现,并改进区域和多尺度池化。值得注意的是,R-MAC [44]曾探索过区域池化,采用区域最大池化和这些区域描述符的和池化。相比之下,我们在区域和尺度上应用更现代的GeM池化以获得更强的性能。
Loss functions for image retrieval. Several types of loss functions have been developed to enhance instance-level disc rim inability, which is required in image retrieval systems. Earlier work [2, 13, 35] in this area relied on ranking-based losses such as contrastive [10] or triplet [38]. More advanced ranking losses based on differentiable versions of Average Precision (AP) [16] have also demonstrated strong results [37]. A recent trend is to leverage margin-based classification loss functions tuned to this problem, such as ArcFace [11], CosFace [45] or Curricular Face [18] – these have been adopted in image retrieval systems such as [23, 8, 48]. In this work, we point out a critical issue when these margin-based classification losses are coupled with GeM pooling – which we fix with new pooling modules.
图像检索的损失函数。为增强图像检索系统所需的实例级判别能力,已开发出多种类型的损失函数。该领域早期工作[2, 13, 35]采用基于排序的损失函数,如对比损失[10]或三元组损失[38]。基于平均精度(AP)可微版本的更先进排序损失[16]也展现出强劲性能[37]。最新趋势是采用针对该问题调整的基于间隔(margin)的分类损失函数,如ArcFace[11]、CosFace[45]或Curricular Face[18]——这些方法已被[23, 8, 48]等图像检索系统采用。本文指出当这些基于间隔的分类损失与GeM池化结合时存在关键问题——我们通过新型池化模块解决了该问题。
Reranking for image retrieval. The reranking of image retrieval results has been traditionally accomplished by local feature matching and Geometric Verification (GV) [30, 32, 4], most often coupled to RANSAC [12]. Modern deep local features [27, 8] have also been used in this manner. A more recent trend is to employ heavier techniques for reranking, based on transformers [40] or dense 4D correlation networks [23]. While achieving high performance, these incur substantial storage and compute costs due to the need to store local features and feed them through complex models. Contrary to this trend, we propose a much simpler reranking technique where only global features are needed – costing orders of magnitude less than the current state-ofthe-art solution [23] but still achieving higher accuracy.
图像检索的重新排序。图像检索结果的重新排序传统上通过局部特征匹配和几何验证 (GV) [30, 32, 4] 完成,通常与 RANSAC [12] 结合使用。现代深度局部特征 [27, 8] 也以这种方式被应用。最近的趋势是采用更复杂的技术进行重新排序,基于 Transformer [40] 或密集 4D 相关网络 [23]。虽然这些方法实现了高性能,但由于需要存储局部特征并通过复杂模型处理,它们带来了巨大的存储和计算成本。与这一趋势相反,我们提出了一种更简单的重新排序技术,仅需全局特征——其成本比当前最先进的解决方案 [23] 低几个数量级,同时仍能实现更高的准确率。
3. Improving Global Features
3. 改进全局特征
3.1. Background
3.1. 背景
GeM pooling. Generalized Mean (GeM) pooling [35] is a module that provides a generalized capability for feature aggregation. GeM pooling is widely adopted in ResNet [17] (RN for short) models for image retrieval [23, 8, 48], followed by a fully-connected layer [13], to whiten the aggregated representation. Formally, we denote the feature map from deep convolution layers by D ∈ RHd×Wd×Cd and a fully-connected whitening layer with weights and bias as $W\in\dot{\mathcal{R}}^{C_{g}\times C_{d}}$ and $b\in\mathcal{R}^{C_{g}}$ , where $C_{d}$ and $C_{g}$ are the channel dimensions of the output from the convolution layer and global features, respectively. These two components, GeM pooling and the whitening layer, produce the global feature $g\in\mathcal{R}^{C_{g}}$ by:
GeM池化。广义均值 (GeM) 池化 [35] 是一种提供特征聚合通用能力的模块。GeM池化被广泛应用于ResNet [17] (简称RN) 模型中用于图像检索 [23, 8, 48],随后接一个全连接层 [13] 来白化聚合后的表示。形式上,我们将深度卷积层的特征图表示为 D ∈ RHd×Wd×Cd,并将带有权重和偏置的全连接白化层表示为 $W\in\dot{\mathcal{R}}^{C_{g}\times C_{d}}$ 和 $b\in\mathcal{R}^{C_{g}}$,其中 $C_{d}$ 和 $C_{g}$ 分别是卷积层输出和全局特征的通道维度。这两个组件,GeM池化和白化层,通过以下方式生成全局特征 $g\in\mathcal{R}^{C_{g}}$:
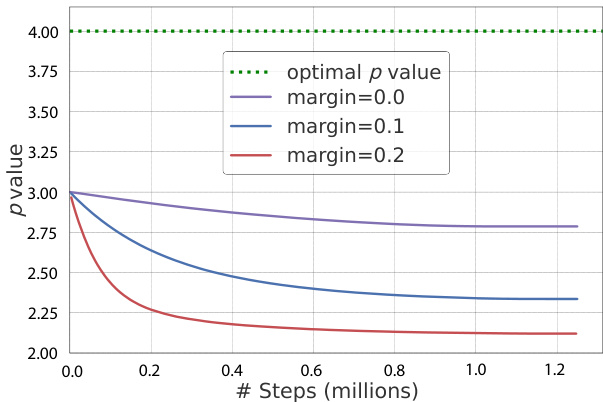
Figure 2: Trainable GeM pooling $p$ values during DELG training for different ArcFace margin values, as compared to the optimal $p$ value (4.0). Note that larger margins cause $p$ to deviate further from its optimal value.
图 2: 不同ArcFace边界值下DELG训练过程中可训练的GeM池化参数$p$值变化,与最优$p$值(4.0)的对比。注意较大的边界值会导致$p$值进一步偏离最优值。
$$
g=W\left(\frac{1}{H_{d}W_{d}}\sum_{h,w}D_{h,w}^{p}\right)^{1/p}+b,
$$
$$
g=W\left(\frac{1}{H_{d}W_{d}}\sum_{h,w}D_{h,w}^{p}\right)^{1/p}+b,
$$
where $p$ denotes the generalized mean power.
其中 $p$ 表示广义平均幂。
SoftMax-based loss functions with margin penalties. ArcFace [11] applies a geometric space penalty to expand the angular margin between different classes while gathering the same-class embedding to the center, therefore making it suitable for standard retrieval tasks [48, 8]. CurricularFace [18] proposes to further improve angular margin losses by embedding curriculum training into the loss function and has the ability to adaptively adjust the relative importance of easy and hard samples during the course of training, which has been used in recent image retrieval work [23].
基于SoftMax的带间隔惩罚损失函数。ArcFace [11] 采用几何空间惩罚来扩大不同类别之间的角度间隔,同时将同类嵌入聚集到中心,因此适用于标准检索任务 [48, 8]。CurricularFace [18] 提出通过将课程训练嵌入损失函数来进一步改进角度间隔损失,并能在训练过程中自适应调整简单样本与困难样本的相对重要性,该技术已被应用于近期图像检索工作 [23]。
Multi-scale inference. Multi-scale inference is one of the commonly used methods to aggregate features from different scales to further improve the performance of image retrieval, previous papers [8, 48, 23] commonly average the embeddings from different scales.
多尺度推理。多尺度推理是一种通过聚合不同尺度的特征来进一步提升图像检索性能的常用方法,先前的研究[8, 48, 23]通常会对不同尺度的嵌入向量进行平均处理。
3.2. Suboptimal GeM Pooling with Margin-based Losses
3.2. 基于边界损失的次优GeM池化
We observe that combining Curricular Face or ArcFace loss with GeM pooling systematically causes the trainable $p$ value in GeM pooling to converge to a lower value w.r.t. its optimal value for image retrieval. In Figure 2, we show such phenomena when training DELG [8] with learnable $p$ values initialized to 3.0, on GLDv2-clean [47]. The optimal $p$ value in the test split of GLDv2-retrieval, found by simple grid search to inform the best possible value, is marked with a dotted green line (in this case, the optimal $p$ value for the converged model was found to be the same for these three runs). During training, $p$ values keep decreasing from its original value, and are further away from the optimal value of 4.0. Moreover, higher angular margin causes $p$ to deviate further from its optimal value. In the cases of using fixed $p$ for GeM pooling during training, the optimal $p$ during inference could also be different from that in training. We examine the optimal $p$ values for inference by grid search in the test split of GLDv2-retrieval for different fixed $p$ values in training DELG models [8] on GLDv2-clean [47] and find that optimal $p$ at inference is always higher, as shown in Figure 3. SOLAR [26] pointed out a similar phenomenon for models trained with the contrastive loss, while the underlying reason was not explained.
我们观察到,将Curricular Face或ArcFace损失与GeM池化结合使用时,GeM池化中可训练的$p$值会系统地收敛至低于图像检索最优值的水平。图2展示了在GLDv2-clean[47]数据集上训练DELG[8]时(可学习$p$值初始化为3.0)的这种现象。通过简单网格搜索确定的GLDv2-retrieval测试集最优$p$值(绿色虚线标记)显示,这三个训练轮次中收敛模型的最优$p$值相同。训练过程中$p$值持续从初始值下降,且与最优值4.0的偏离程度随角度间隔增大而加剧。即便训练时固定GeM池化的$p$值,推理阶段的最优$p$值也可能不同。我们在GLDv2-clean[47]训练DELG模型[8]时,针对不同固定$p$值进行网格搜索发现:如图3所示,推理阶段的最优$p$值始终更高。SOLAR[26]曾指出对比损失训练的模型存在类似现象,但未解释根本原因。
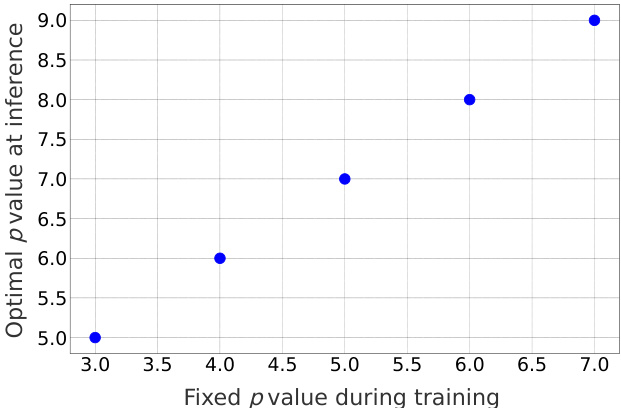
Figure 3: Optimal $p$ values at inference, shown on the $y$ -axis, for different fixed GeM pooling $p$ values during DELG training. We note that the optima $p$ for inference is larger than the fixed $p$ used for training.
图 3: 推理时的最优 $p$ 值 (y轴所示) 与DELG训练期间固定GeM池化 $p$ 值的对应关系。我们观察到,推理阶段的最优 $p$ 值始终大于训练时采用的固定 $p$ 值。
In this section, we provide an intuition on the change of $p$ over the course of training based on our empirical study as follows. A high $p$ value generally forces a small portion of features to dominate the aggregation process. On the contrary, a lower $p$ leads to the opposite behavior: e.g., for $p=1$ , equivalent to average pooling, all features contribute equally. At the beginning of training, when the features are not refined, a lower $p$ value is preferred in order to gather more information; this is supported by the observation that $p$ goes down rapidly at the start of the training in Figure 2. In the later stage of training, when the features are further refined, focusing on critical features rather than all features may further improve the model performance. However, due to the decaying learning rate, $p$ value is not allowed to go up although higher $p$ may be preferred in this case. This aligns with Figure 2, where $p$ slowly converges later at training.
在本节中,我们基于实证研究对训练过程中 $p$ 值的变化提供以下直观解释:较高的 $p$ 值通常迫使少量特征主导聚合过程,而较低的 $p$ 值则导致相反行为(例如 $p=1$ 时等同于平均池化,所有特征贡献均等)。训练初期特征未细化时,采用较低 $p$ 值有利于收集更多信息——这与图 2 中训练开始时 $p$ 值快速下降的现象一致。训练后期特征进一步细化后,聚焦关键特征而非全部特征可能提升模型性能。但由于学习率衰减,此时即使需要更高 $p$ 值也无法实现,这与图 2 中 $p$ 值后期缓慢收敛的趋势相符。
To conclude, we consistently observe that margin-based losses lead to a sub-optimal $p$ value, resulting in the degradation of retrieval performance. This finding provides evidence of improvements and inspires future work for several state-of-the-art models, e.g. CVNet [23] which uses CurricularFace loss function and DELG [8] with ArcFace loss. We introduce a set of modules specifically designed to optimize pooling for image retrieval in the following section.
总之,我们一致观察到基于间隔的损失会导致次优的 $p$ 值,从而降低检索性能。这一发现为多项前沿模型的改进提供了依据并启发了未来研究方向,例如使用CurricularFace损失函数的CVNet [23] 和采用ArcFace损失的DELG [8]。下一节我们将介绍一组专为优化图像检索池化而设计的模块。
3.3. Super Global Pooling
3.3. 超级全局池化 (Super Global Pooling)
In this section, we revisit global feature pooling and propose three new modules to enhance retrieval capabilities: $\mathbf{GeM}+$ , Scale-GeM and Regional-GeM – which are illustrated in the purple box in Figure 1.
在本节中,我们重新审视全局特征池化方法,并提出了三个增强检索能力的新模块:$\mathbf{GeM}+$、Scale-GeM和Regional-GeM——如图1紫色框所示。
$\mathbf{GeM+}$ . As discussed in the previous subsection, GeM’s $p$ value becomes sub-optimal with margin-based softmax losses. Thus, we propose a method that starts by training with margin-based loss, then introduces a parameter tuning stage that will adjust $p$ in an efficient manner. We find that in practice this tuning stage leads to the optimal value in a consistent manner for many datasets. This approach is named $\mathbf{GeM}+$ and seeks to find the optimal $p$ value of GeM pooling for image retrieval.
$\mathbf{GeM+}$。如前一节所述,在使用基于间隔的softmax损失时,GeM的$p$值会变得次优。因此,我们提出一种方法:先使用基于间隔的损失进行训练,再引入一个参数调优阶段来高效调整$p$值。实践表明,这种调优阶段能稳定地为多种数据集找到最优值。该方法命名为$\mathbf{GeM}+$,旨在为图像检索找到GeM池化的最优$p$值。
Regional-GeM. When adopting GeM for global pooling in image retrieval, we expect it to amplify disc rim i native information when aggregating the features to the final embedding. However, in addition to disc rim i native information at the global level, regional information such as object shape and arrangement can be important for distinguishing between different instances. Such fine-grained details may not be captured robustly when simply pooling at the global level. Therefore, besides using GeM pooling, we further adjust aggregation in order to incorporate regional information. We refer to this method as Regional-GeM.
区域GeM。在图像检索中采用GeM进行全局池化时,我们期望它在将特征聚合到最终嵌入向量时能放大判别性信息。然而,除了全局层面的判别信息外,物体形状和排列等区域信息对于区分不同实例可能至关重要。若仅在全局层面进行池化,这类细粒度细节可能无法被稳健捕捉。因此,除了使用GeM池化外,我们进一步调整聚合方式以融入区域信息。我们将该方法称为区域GeM。
We perform regional aggregation by adapting the $L_{p}$ pooling approach [15] to our network, with parameter $p_{r}$ . This can be viewed as a version of GeM pooling which acts on a regional level. In this setup, activation s from the feature map $D$ are aggregated in a convolutional manner, resulting in a new feature map, $M\in\mathcal{R}^{H_{d}\times W_{d}\times C_{d}}$ . We then combine $M$ and $D$ to produce a more robust feature map, obtaining an improved global feature as:
我们通过将 $L_{p}$ 池化方法 [15] 适配到网络中(参数为 $p_{r}$)进行区域聚合。这可以视为作用于区域层面的 GeM 池化变体。在该框架下,特征图 $D$ 的激活值以卷积方式进行聚合,生成新特征图 $M\in\mathcal{R}^{H_{d}\times W_{d}\times C_{d}}$ ,随后将 $M$ 与 $D$ 融合以生成更具鲁棒性的特征图,最终通过下式获得增强的全局特征:
$$
g_{r}=W\left(\frac{1}{H_{d}W_{d}}\sum_{h,w}(\frac{M_{h,w}+D_{h,w}}{2})^{p}\right)^{1/p}+b.
$$
$$
g_{r}=W\left(\frac{1}{H_{d}W_{d}}\sum_{h,w}(\frac{M_{h,w}+D_{h,w}}{2})^{p}\right)^{1/p}+b.
$$
With this formulation, we incorporate both regional information $\mathbf{\Phi}{M_{h,w}}$ produced by $L_{p}$ pooling with parameter $p_{r.}$ ) and global information $(D_{h,w}$ produced by the original convolutional layer) in GeM pooling. This module is integrated into our model without the need for additional training, leveraging the parameter $p$ obtained by the $\mathbf{GeM}+$ process.
通过这一公式,我们在GeM池化中同时整合了由参数 $p_{r.}$ 的 $L_{p}$ 池化生成的区域信息 $\mathbf{\Phi}{M_{h,w}}$ 和原始卷积层生成的全局信息 $(D_{h,w}$ 。该模块无需额外训练即可集成到模型中,直接利用 $\mathbf{GeM}+$ 过程获得的参数 $p$ 。
Scale-GeM. Though averaging multi-scale features can be effective [8, 48, 23], a more generalized multi-scale aggregation may unlock larger retrieval gains. With this motivation, we explore the application of GeM for enhanced multi-scale feature inference, and we refer to this as Scale-GeM.
Scale-GeM。尽管平均多尺度特征可能有效[8, 48, 23],但更通用的多尺度聚合可能会带来更大的检索增益。基于这一动机,我们探索了GeM在增强多尺度特征推理中的应用,并将其称为Scale-GeM。
GeM pooling can be applied before or after a fullyconnected whitening layer. Our preliminary experiments applying it prior to projection yield sub-optimal performance, so we proceed by first extracting each scale’s global feature according to Equation 2. Naively applying GeM pooling to such global features could fail due to the possible negative values in the features to be pooled. To address this issue, we consider a modified version of GeM designed for multi-scale inference as follows:
GeM池化可以在全连接白化层之前或之后应用。我们的初步实验表明,在投影之前应用会导致次优性能,因此我们首先根据公式2提取每个尺度的全局特征。直接对这类全局特征应用GeM池化可能因待池化特征中存在负值而失效。为解决该问题,我们设计了以下适用于多尺度推理的改进版GeM:
$$
g_{m s}=\left(\frac{1}{N}\sum_{s=1}^{N}(g_{s}+\zeta_{s})^{p_{m s}}\right)^{1/p_{m s}}-\zeta_{s},
$$
$$
g_{m s}=\left(\frac{1}{N}\sum_{s=1}^{N}(g_{s}+\zeta_{s})^{p_{m s}}\right)^{1/p_{m s}}-\zeta_{s},
$$
where $\zeta_{s}=-m i n(g_{s})$ denotes a shift of each scale’s global feature $g_{s}$ , $N$ denotes the number of scales and $p_{m s}$ is the multi-scale power parameter used in aggregation.
其中 $\zeta_{s}=-m i n(g_{s})$ 表示每个尺度全局特征 $g_{s}$ 的偏移量,$N$ 表示尺度数量,$p_{m s}$ 是聚合中使用的多尺度幂参数。
4. Reranking with Global Features
4. 基于全局特征的重新排序
4.1. Refining Global Feature for Reranking
4.1. 优化全局特征以进行重排序
Robust image representations are critical for the accuracy of image retrieval. Combining the representations of similar images with that of the original image into an expanded represent ation that is then reissued as the query is a technique widely used to refine global features, generally leading to increased recall [14, 3]. Query expansion (QE) [14] is an example, as it replaces the original representation of the query image by its expanded version, which is then used to search better images in the database. On the other hand, database-side augmentation (DBA) [13] is a method to apply QE to each image in the database. The key idea is that visually similar images are highly likely to contain the same object from different viewpoints and illumination conditions. Feature refinement with these images improves the robustness of the image representation. It also emphasizes the key features of the object of interest, which further improves the representations. QE and DBA methods are very powerful but suffer from high cost: QE has to issue a new query against the entire database; DBA requires comparing all database images against each other, which can be infeasible in large scale. Furthermore, adding a new image to the database with DBA requires querying it against the entire database.
稳健的图像表征对图像检索的准确性至关重要。将相似图像的表征与原始图像的表征结合成一个扩展表征,然后重新作为查询发出,是一种广泛用于优化全局特征的技术,通常能提高召回率 [14, 3]。查询扩展 (query expansion, QE) [14] 就是一个例子,它用扩展版本替换查询图像的原始表征,然后用它在数据库中搜索更好的图像。另一方面,数据库端增强 (database-side augmentation, DBA) [13] 是一种将 QE 应用于数据库中每张图像的方法。其核心思想是视觉上相似的图像很可能包含来自不同视角和光照条件的同一物体。利用这些图像进行特征优化,可以提高图像表征的稳健性。同时,它还能突出感兴趣物体的关键特征,从而进一步提升表征效果。QE 和 DBA 方法非常强大,但成本高昂:QE 必须对整个数据库发起新查询;DBA 需要将所有数据库图像相互比较,这在大规模场景下可能不可行。此外,使用 DBA 向数据库添加新图像时,需要将其与整个数据库进行查询。
Reranking is usually conducted on the top $\mathcal{M}$ retrieved database images, where $M$ is much smaller than the database size – making it feasible to apply feature refinement for each of these images on the fly, to then issue the updated query against the $M$ retrieved images with the updated representations. Inspired by QE and DBA, our Super Global reranking proposes a simple but effective method to aggregate information between the top-ranked images and the query, to update their image representations. Unlike previous QE/DBA work [14, 3] that generally focuses on improving the features for a better recall, our work aims to refine the features for higher precision, since the reranking is performed on the top $\mathcal{M}$ results only.
重排序通常针对检索到的前$\mathcal{M}$个数据库图像进行,其中$M$远小于数据库大小——这使得能够实时对这些图像中的每一个应用特征细化,然后使用更新后的表征对检索到的$M$个图像发出更新后的查询。受QE和DBA的启发,我们的Super Global重排序提出了一种简单但有效的方法,用于聚合排名靠前的图像与查询之间的信息,以更新它们的图像表征。与以往主要关注通过改进特征来提高召回率的QE/DBA工作[14, 3]不同,我们的工作旨在细化特征以提高精确率,因为重排序仅针对前$\mathcal{M}$个结果执行。
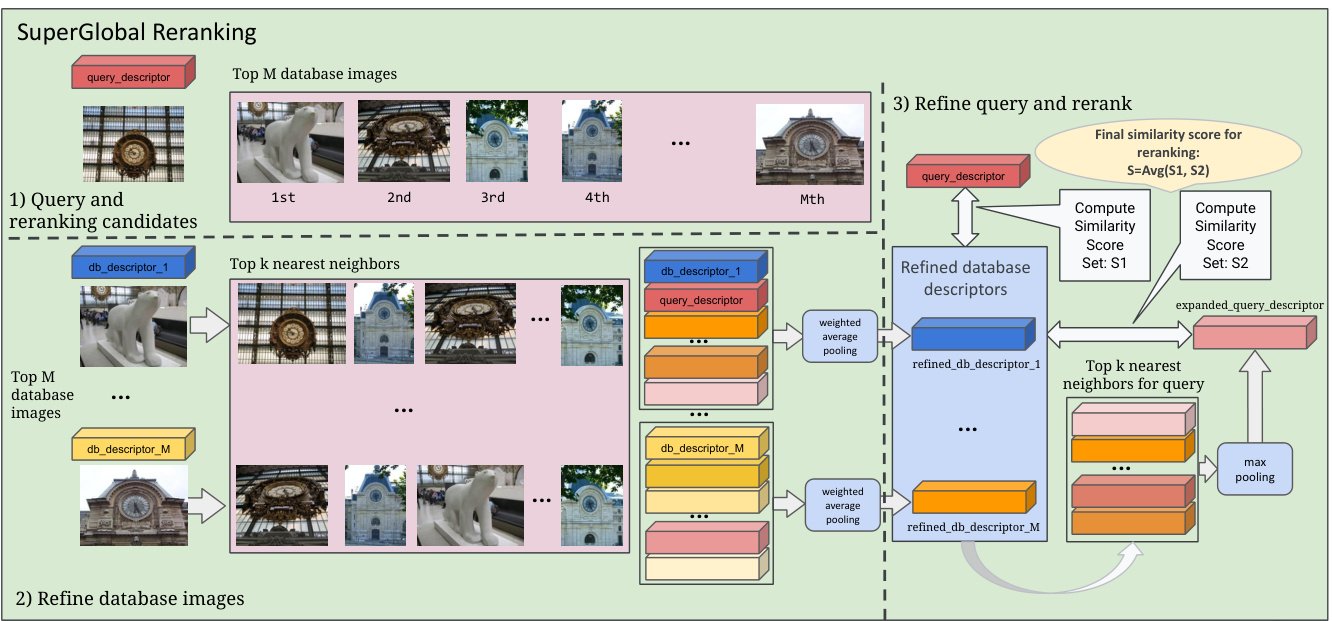
Figure 4: When reranking with global features, our system first performs feature aggregation for both query and top $M$ retrieved images and then runs reranking via updated global features. More details can be found in Section 4.2.
图 4: 在使用全局特征进行重排序时,我们的系统首先对查询和检索到的前 $M$ 张图像进行特征聚合,然后通过更新后的全局特征进行重排序。更多细节详见第4.2节。
Selecting the candidate images for feature refinement may be challenging, since we don’t have guarantees that they are actually relevant to the query. False positives may harm the expanded representation. Besides, the method to aggregate the features to reinforce the information shared between them and inject new information not available in the original representation is unclear. Our work addresses these challenges and proposes a reranking method only via refined global features, as described in the following.
为特征精炼选择候选图像可能具有挑战性,因为我们无法保证它们确实与查询相关。误报可能会损害扩展后的表征。此外,如何聚合特征以强化它们之间的共享信息并注入原始表征中不存在的新信息尚不明确。我们的工作解决了这些挑战,并提出了一种仅通过精炼全局特征进行重排序的方法,如下所述。
4.2. Super Global Reranking
4.2. 超级全局重排序
Super Global leverages GeM pooling to refine the global features for a given query and its top $\mathcal{M}$ retrieved images on the fly, and then reranks them via the updated descriptors, as illustrated in Figure 4. Different from previous studies and given that feature refinement runs at query time, the query image is also included as a candidate when refining the features for the database images. This helps to narrow the focus on query-specific feature refinement. The design details are discussed as follows.
Super Global利用GeM池化动态优化给定查询及其前$\mathcal{M}$张检索图像的全局特征,随后通过更新后的描述符进行重排序,如图4所示。与以往研究不同,鉴于特征优化在查询时执行,在优化数据库图像特征时也将查询图像作为候选纳入。这有助于聚焦于查询相关的特征优化。具体设计细节如下讨论。
Top $K$ nearest neighbors as refinement candidates. For a given query image, we retrieve the top $\mathcal{M}$ images based on the global descriptors, where $M$ is a constant and typically below 1000. Then for the query and the $M$ images, we fetch the top $K$ nearest neighbors via global feature similarity, which are the candidates for the feature refinement, where $K$ is a constant and usually $K\leq10$ .
前 $K$ 个最近邻作为优化候选。对于给定的查询图像,我们基于全局描述符检索前 $\mathcal{M}$ 张图像(其中 $M$ 为常数且通常小于1000)。随后针对查询图像和这 $M$ 张图像,通过全局特征相似度获取前 $K$ 个最近邻,这些邻居将作为特征优化的候选(其中 $K$ 为常数且通常满足 $K\leq10$)。
Feature refinement via $\mathbf{GeM}$ pooling. Super Global reranking leverages GeM pooling for feature refinement. As previously mentioned, if there are false positives in the nearest neighbors, they may not be helpful but instead harmful to the expanded representation. Without strong Geometric Verification of local features to select true positives, the top $K$ nearest neighbors could potentially contain false positives. Super Global proposes effective strategies for database and query side separately as illustrated in Figure 4.
通过 $\mathbf{GeM}$ 池化进行特征精炼。Super Global 重排序利用 GeM 池化进行特征优化。如前所述,如果最近邻中存在误匹配,它们可能无益反而会损害扩展表示的效果。在没有通过局部特征的强几何验证来筛选真实匹配的情况下,前 $K$ 个最近邻可能包含误匹配。如图 4 所示,Super Global 分别针对数据库端和查询端提出了有效策略。
For the database side, we propose a weighted pooling approach, with the global similarity score as the weight with additional multiplier factor $\beta$ . After weighting the features, we demonstrate that applying average pooling $(p=1)$ ) on top is the most effective for the database images. That is, $\begin{array}{r}{{g_{d r}}=({g_{d}}+\sum_{i=1}^{K}({g_{d}}\cdot{g_{i}})\beta{g_{i}})/(1+\sum_{i=1}^{K}({g_{d}}\cdot{g_{i}})\beta)}\end{array}$ , where $g_{d}$ is the original global feature of the database image, $g_{d r}$ is the refined global feature we get and $g_{i}$ is the $i$ -th most similar global feature to gd.
在数据库端,我们提出了一种加权池化方法,以全局相似度分数作为权重,并引入额外乘数因子 $\beta$。对特征加权后,我们证明在数据库图像上应用平均池化 $(p=1)$ 最为有效。具体公式为 $\begin{array}{r}{{g_{d r}}=({g_{d}}+\sum_{i=1}^{K}({g_{d}}\cdot{g_{i}})\beta{g_{i}})/(1+\sum_{i=1}^{K}({g_{d}}\cdot{g_{i}})\beta)}\end{array}$,其中 $g_{d}$ 表示数据库图像的原始全局特征,$g_{d r}$ 是我们得到的优化全局特征,$g_{i}$ 表示与 $g_{d}$ 相似度第 $i$ 高的全局特征。
For the query side, we apply GeM pooling to the refined features of the top $K$ retrieved database images to produce an expanded global descriptor $g_{q e}$ , and we find the optimal parameter $p$ is greater than 10, thus max pooling is applied (since, when $p\rightarrow\infty$ , GeM pooling becomes max pooling). Both the original and the expanded descriptors of the query image are then used to compute the similarity scores for the final reranking, as follows.
在查询端,我们对检索到的前 $K$ 张数据库图像的精炼特征应用GeM池化,生成扩展的全局描述符 $g_{qe}$。我们发现最优参数 $p$ 大于10,因此采用最大池化(因为当 $p\rightarrow\infty$ 时,GeM池化退化为最大池化)。随后,同时使用查询图像的原始描述符和扩展描述符计算相似度分数以进行最终重排序,具体如下。
Reranking with refined representations. Each query image possesses its original representation and the expanded representation. We compute the similarity scores $S1$ between each original descriptor $g_{q}$ and refined global descriptors $g_{d r}$ for each database image. We also compute another set of similarity scores $S2$ between the expanded query descriptor $g_{q e}$ and each $g_{d}$ . In the end, we average $S1$ and $S2$ similarity scores for the final reranking. Given the fact that today’s large-scale databases may contain billions of images, previous QE/DBA methods are much more costly compared to our approach, which has time complexity of $\mathcal{O}(M^{2})$ and is extremely efficient at reranking.
使用精炼表征进行重排序。每张查询图像拥有其原始表征和扩展表征。我们计算每个原始描述符 $g_{q}$ 与数据库图像的精炼全局描述符 $g_{d r}$ 之间的相似度分数 $S1$,同时计算扩展查询描述符 $g_{q e}$ 与每个 $g_{d}$ 之间的另一组相似度分数 $S2$。最终,我们对 $S1$ 和 $S2$ 的相似度分数取平均值以完成最终重排序。鉴于当今大规模数据库可能包含数十亿张图像,相比我们具有 $\mathcal{O}(M^{2})$ 时间复杂度且重排序效率极高的方法,先前的QE/DBA方法计算成本要高得多。
Medium Hard
Table 1: Results $%$ mAP) on the ROxford and RParis datasets (and their large-scale versions $\scriptstyle{\mathcal{R}}\mathrm{Oxf+lM}$ and $\mathcal{R}\mathrm{Par}{+}1\mathrm{M})$ , with both Medium and Hard evaluation protocols. The best scores for RN50 and RN101, with and without reranking, are highlighted in bold black and bold blue, respectively.
中等难度 高难度
| 方法 | ROxf | ROxf+1M | RPar | RPar+1M | ROxf | ROxf+1M | RPar | RPar+1M |
|---|---|---|---|---|---|---|---|---|
| 全局特征检索 | ||||||||
| RN50-DELG [8] | 73.6 | 60.6 | 85.7 | 68.6 | 51.0 | 32.7 | 71.5 | 44.4 |
| RN101-DELG [8] | 76.3 | 63.7 | 86.6 | 70.6 | 55.6 | 37.5 | 72.4 | 46.9 |
| RN50-DOLG [48] | 80.5 | 76.6 | 89.8 | 80.8 | 58.8 | 52.2 | 77.7 | 62.8 |
| RN101-DOLG [48] | 81.5 | 77.4 | 91.0 | 83.3 | 61.1 | 54.8 | 80.3 | 66.7 |
| RN50-CVNet[23] | 81.0 | 72.6 | 88.8 | 79.0 | 62.1 | 50.2 | 76.5 | 60.2 |
| RN101-CVNet[23] | 80.2 | 74.0 | 90.3 | 80.6 | 63.1 | 53.7 | 79.1 | 62.2 |
| RN50-SuperGlobal(无重排)[ours] | 83.9 | 74.7 | 90.5 | 81.3 | 67.7 | 53.6 | 80.3 | 65.2 |
| RN101-SuperGlobal(无重排)[ours] | 85.3 | 78.8 | 92.1 | 83.9 | 72.1 | 61.9 | 83.5 | 69.1 |
| 全局特征检索 + 局部特征重排 | ||||||||
| RN50-DELG(GV重排前100)[8] | 78.3 | 67.2 | 85.7 | 69.6 | 57.9 | 43.6 | 71.0 | 45.7 |
| RN101-DELG (GV重排前100) [8] | 81.2 | 69.1 | 87.2 | 71.5 | 64.0 | 47.5 | 72.8 | 48.7 |
| RN50-CVNet(重排前400) [23] | 87.9 | 80.7 | 90.5 | 82.4 | 75.6 | 65.1 | 80.2 | 67.3 |
| RN101-CVNet (重排前400) [23] | 87.2 | 81.9 | 91.2 | 83.8 | 75.9 | 67.4 | 81.1 | 69.3 |
| SuperGlobal检索与重排 | ||||||||
| RN50-SuperGlobal(重排前400)[ours] | 88.8 | 80.0 | 92.0 | 83.4 | 77.1 | 64.2 | 84.4 | 68.7 |
| RN101-SuperGlobal (重排前400) [ours] | 90.9 | 84.4 | 93.3 | 84.9 | 80.2 | 71.1 | 86.7 | 71.4 |
表 1: ROxford和RParis数据集(及其大规模版本$\scriptstyle{\mathcal{R}}\mathrm{Oxf+lM}$和$\mathcal{R}\mathrm{Par}{+}1\mathrm{M}$)上的结果($%$ mAP),采用中等和高难度评估协议。RN50和RN101在有重排和无重排情况下的最佳分数分别用黑色粗体和蓝色粗体标出。
5. Experiments
5. 实验
5.1. Experimental Setup
5.1. 实验设置
Common setting. Our proposed methods can be applied to any model in a plug-in style. Here, we adopt our methods to the well-known structure CVNet [23] with pre-trained weights downloaded from their GitHub repository. The modules we proposed in this paper are all implemented using TensorFlow [1] and Pytorch [29]. The training and inference are both conducted on four A100 GPUs with Inte Xeon Gold 6330 CPU $\ @2.00\mathrm{GHz}$ .
通用设置。我们提出的方法可以以插件形式应用于任何模型。本文采用知名架构CVNet [23]作为基础模型,其预训练权重从其GitHub仓库获取。所有提出的模块均使用TensorFlow [1]和Pytorch [29]实现。训练与推理均在四块A100 GPU(搭载Inte Xeon Gold 6330 CPU $\ @2.00\mathrm{GHz}$)平台上完成。
Estimating $p,p_{r}$ and $p_{m s}$ . We use ROxford 5k [34] as the tuning dataset to estimate the pooling parameters p, $p_{r}$ and $p_{m s}$ for $\mathbf{GeM}+$ , Regional-GeM and Scale-GeM, respectively, and show that the obtained values are sufficiently precise. Firstly, we run inference on the model and store the last feature map for every image. Then, we apply the different types of pooling, varying the pooling parameters, on the feature map for each image. To search for the optimal parameter, we begin by performing a grid search with a step size of 1 and monitor the mAP metric. We terminate the grid search if the mAP in the current iteration is smaller than the previous one. Then, we decrease the grid search step size to 0.1 and redo the previously mentioned steps. Once this procedure is completed, we obtain the values of $p=4.6$ and $p_{r}=2.5$ . For Scale-GeM, similar experimentation finds that $p_{m s}\rightarrow\infty$ , i.e., max pooling over the multi-scale global features, leads to the best performance. These final obtained parameters are used for experimentation on all evaluation datasets.
估计 $p$、$p_{r}$ 和 $p_{ms}$。我们使用 ROxford 5k [34] 作为调优数据集,分别估计 $\mathbf{GeM}+$、Regional-GeM 和 Scale-GeM 的池化参数 $p$、$p_{r}$ 和 $p_{ms}$,并证明所获值足够精确。首先,在模型上运行推理并存储每张图像的最后一个特征图。接着,对每张图像的特征图应用不同类型的池化,并调整池化参数。为搜索最优参数,我们首先以步长 1 进行网格搜索,并监测 mAP 指标。若当前迭代的 mAP 低于前一次,则终止网格搜索。随后,将网格搜索步长降至 0.1 并重复上述步骤。完成后,我们得到 $p=4.6$ 和 $p_{r}=2.5$。对于 Scale-GeM,类似实验发现 $p_{ms}\rightarrow\infty$(即对多尺度全局特征进行最大池化)能实现最佳性能。这些最终参数将用于所有评估数据集的实验。
Super Global reranking. For reranking evaluations, we follow the same setting as CVNet and rerank the top 400 candidates in most experiments, i.e. $M=400$ . Given that our method is drastically more efficient than CVNet, we also study the performance with larger $M$ in specific cases. We pick $K=9$ for the reranking method and set $\beta=0.15$ for feature refinement described in Section 4.2.
超级全局重排序。在重排序评估中,我们遵循与CVNet相同的设置,在大多数实验中重排前400个候选结果(即$M=400$)。鉴于我们的方法效率显著高于CVNet,我们还在特定情况下研究了更大$M$值的性能表现。重排序方法选取$K=9$,并为4.2节所述的特征优化设置$\beta=0.15$。
ReLU adjustment. During our reranking experimentation, following the same way as we explore the impact of $p$ in GeM pooling, we also revisit the ReLU activation [22] by considering a generalized version where the threshold is treated as a parameter denoted by $\alpha$ , which is reduced to vanilla ReLU when $\alpha=0$ . In the best setup, we set threshold $\alpha$ to 0.014 for the first block and the joints between blocks.
ReLU调整。在我们的重排序实验中,与探索GeM池化中$p$的影响方式相同,我们也重新审视了ReLU激活[22],考虑其广义版本,其中阈值被视为参数$\alpha$,当$\alpha=0$时退化为普通ReLU。在最佳设置中,我们将第一个块及块间连接处的阈值$\alpha$设为0.014。
5.2. Evaluation Benchmarks
5.2. 评估基准
We conduct our experiments on several well-established benchmarks. First, we use Oxford [31] and Paris [33] with revisited annotations [34], referred to as ${\cal R O x t}$ and RPar, respectively. There are 4993 (6322) database images in the ROxf (RPar) dataset, and a different query set for each, both with 70 images. Large-scale results are further reported with the $\mathcal{R}1\mathbf{M}$ distractor set [34], which contains 1M images. In addition, we also report results on the Google Landmarks dataset v2 (GLDv2) [47], using the latest ground-truth version (2.1). GLDv2-retrieval has 1129 queries (379 validation and 750 testing) and 762k database images.
我们在多个成熟基准测试上进行实验。首先使用带修订标注[34]的Oxford[31]和Paris[33]数据集(分别记为${\cal R O x t}$和RPar),其中ROxf(RPar)数据集包含4993(6322)张库图像,各配备70张独立查询图像。大规模实验结果还采用了包含100万图像的$\mathcal{R}1\mathbf{M}$干扰集[34]。此外,我们还基于最新真实标注版本(2.1)在Google Landmarks数据集v2(GLDv2)[47]上报告结果,该检索任务包含1129个查询(379个验证集/750个测试集)和76.2万张库图像。
Table 2: Latency and Memory on the ROxford and RParis datasets . Extraction time measures the time needed for the model to produce global features. Reranking time measures the latency of the reranking stage after the global/local features are already computed. Memory usage measures the hardware memory required to store the features.
表 2: ROxford和RParis数据集上的延迟与内存占用 。提取时间衡量模型生成全局特征所需时间。重排序时间衡量全局/局部特征计算完成后重排序阶段的延迟。内存使用量衡量存储特征所需的硬件内存。
| 方法 | 多尺度 | 提取时间 (ms/图像) | 重排序时间 (ms/重排序top-400) | 内存 (GB) | ||
|---|---|---|---|---|---|---|
| 全局 | 局部 | ROxf | RPar | |||
| 全局特征 | ||||||
| RN101-DELG[8] | 3 | 7 | 65 | 3.6 × 106 on 100 | 4.25 | 5.35 |
| RN101-CVNet[23] | 3 | 1 | 65 | 2.4 × 104 on 400 | 27.02 | 33.55 |
| RN101-CVNetQ [23] | 3 | 1 | 65 | 2.4 × 104 on 400 | 6.88 | 8.52 |
| RN101-SuperGlobal(本文) | 3 | 65 | 0.37on400 | 0.04 | 0.05 |
Table 3: GLDv2-retrieval evaluation. Experimental results on GLDv2-retrieval [47]. The best scores are presented in bold black and bold blue colors for each ResNet backbone.
表 3: GLDv2-retrieval评估。在GLDv2-retrieval [47]上的实验结果。每种ResNet主干网络的最佳分数以黑色加粗和蓝色加粗显示。
| 方法 | mAP@100 |
|---|---|
| RN50-DELGretrieval | 24.1 |
| + GV (Rerank top-100) RN101-DELGretrieval | 24.3 |
| + GV (Rerank top-100) | 26.0 |
| RN50-CVNetretrieval | 26.8 |
| + CVNet reranking (Rerank top-100) | 30.2 |
| RN101-CVNetRetrieval | 32.4 |
| + CVNet-reranking (Rerank top-100) | 32.5 |
| RN50-SuperGlobalretrieval[ours] | 34.9 |
| + SuperGlobal reranking (Rerank top-100) | 31.1 |
| 32.5 | |
| +SuperGlobalreranking (Reranktop-800) | 32.7 |
| + SuperGlobal reranking (Rerank top-1600) | 32.6 |
| RN101-SuperGlobal retrieval[ours] | 33.4 |
| +SuperGlobalreranking(Rerank top-100) | 34.6 |
| + SuperGlobal reranking (Rerank top-800) | 34.9 |
| +SuperGlobalreranking(Reranktop-1600) | 35.0 |
5.3. Results
5.3. 结果
We compare different components of Super Global against state-of-the-art models in Table 1. We split the settings into three categories: (1) Global feature retrieval. (2) Global feature retrieval $^+$ Local feature reranking. (3) Super Global retrieval and reranking. In addition to the comparisons of performance, to illustrate the efficiency of our method, we compare Super Global against CVNet and DELG in the number of scales, reranking time and the peak memory consumption, and summarize the results in Table 2.
我们在表1中将Super Global的不同组件与最先进的模型进行了比较。我们将设置分为三类:(1) 全局特征检索。(2) 全局特征检索 $^+$ 局部特征重排序。(3) Super Global检索与重排序。除了性能比较外,为了说明我们方法的效率,我们还在尺度数量、重排序时间和峰值内存消耗方面将Super Global与CVNet和DELG进行了对比,并将结果总结在表2中。
Firstly, as seen from Table. 1, Super Global retrieval significantly outperforms existing models in single-stage retrieval. For instance, in setting (1), our methods (RN101- Super Global without reranking) outperform the second best RN101-DOLG by a significant margin of $+7.1%$ in Revisited Oxford $\mathbf{+lM}$ Hard. Under the retrieval then reranking paradigm in setting (2), Super Global retrieval and reranking in setting (3) achieves $+3.7%$ against the second best RN101- CVNet when reranking top 400 in Revisited Oxford $\mathbf{+1M}$ Hard. Moreover, Super Global reranking is 64, $865\times$ faster and requires $170\times$ less memory, as indicated by Table. 2. Remarkably, our method, even including the reranking time, is almost as efficient as RN101-CVNet-Global with only almost zero overhead.
首先,从表1可以看出,Super Global检索在单阶段检索中显著优于现有模型。例如,在设置(1)中,我们的方法(RN101-Super Global无重排序)在Revisited Oxford +lM Hard上比第二好的RN101-DOLG高出+7.1%。在设置(2)的检索后重排序范式下,Super Global检索和设置(3)的重排序在Revisited Oxford +1M Hard中对前400名进行重排序时,比第二好的RN101-CVNet高出+3.7%。此外,如表2所示,Super Global重排序速度快64,865倍,内存需求减少170倍。值得注意的是,我们的方法即使包括重排序时间,效率也几乎与RN101-CVNet-Global相当,几乎零开销。
To evaluate our proposed method when reranking more candidates, we further conduct experiments on GLDv2- retrieval and show the results in Table. 3. First, by increasing the number of images in reranking, Super Global achieves further performance improvements. Considering the significantly reduced latency and memory requirements of our method, Super Global is capable of reranking many more images with the same compute budget. When increasing the reranking budget to top 800 or 1600 candidates, SuperGlobal shows superior performance compared with CVNet reranking (rerank top 100), while still being 16, $216\times$ faster and $85\times$ more memory efficient.
为了评估我们提出的方法在更多候选者重新排序时的表现,我们进一步在GLDv2检索数据集上进行了实验,结果如表3所示。首先,通过增加重新排序的图像数量,Super Global实现了进一步的性能提升。考虑到我们方法显著降低的延迟和内存需求,Super Global能够在相同的计算预算下重新排序更多图像。当将重新排序预算增加到前800或1600名候选者时,SuperGlobal展现出优于CVNet重新排序(前100名)的性能,同时仍保持16倍的速度提升和85倍的内存效率提升。
5.4. Ablation Study
5.4. 消融研究
To evaluate the contribution from each module, we conduct a detailed ablation on $\mathcal{R}\mathrm{Oxf}$ and Par, based on the RN101-CVNet pre-trained backbone. We sequentially add the modules one by one to examine whether they lead to a higher performance. Results are presented in Table 4. In summary, $\mathbf{GeM}+$ contributes the most to the performance, while Regional-GeM and Scale-GeM make further improvements. Our finding of modifying ReLU also brings an additional $+1%$ improvement.
为了评估各模块的贡献,我们在基于RN101-CVNet预训练骨干网络的$\mathcal{R}\mathrm{Oxf}$和Par数据集上进行了详细消融实验。通过逐一添加模块来验证其是否带来性能提升,结果如表4所示。总体而言,$\mathbf{GeM}+$对性能提升贡献最大,而Regional-GeM和Scale-GeM进一步带来改进。我们还发现修改ReLU能额外带来$+1%$的性能提升。
5.5. Qualitative Results
5.5. 定性结果
Retrieval only. In Figure 5, we show images with different ranks retrieved from Super Global and CVNet, in the absence of reranking. The ranking positions are selected such that Super Global retrieves matching images (highlighted in green boxes) while CVNet doesn’t (highlighted in red boxes). We observe that Super Global pays more attention to the finegrained details of the query image because of the updated pooling techniques proposed in this work.
仅检索。在图5中,我们展示了未经重排序时从Super Global和CVNet检索到的不同排名图像。所选排名位置使得Super Global能检索到匹配图像(绿色框高亮)而CVNet未能检索到(红色框高亮)。我们观察到,由于本文提出的改进池化技术,Super Global更关注查询图像的细粒度细节。
Reranking. Figure 6 shows top results after Super Global retrieval and reranking. The ranking positions are selected such that the reranked images (highlighted in green boxes) match the query whereas the retrieved images (highlighted in red boxes) do not. These examples show the additional improvement over single-stage Super Global retrieval by applying Super Global reranking, demonstrating the techniques in Section 4.2 further refine the order of the top candidates.
重排序。图 6 展示了经过 Super Global 检索和重排序后的前几位结果。所选排名位置使得重排序后的图像 (用绿色框高亮) 与查询匹配,而检索到的图像 (用红色框高亮) 则不匹配。这些示例表明,通过应用 Super Global 重排序,相比单阶段 Super Global 检索有了额外提升,印证了 4.2 节所述技术能进一步优化候选结果的排序。
| 方法 | GeM+ | Regional-GeM | Scale-GeM | ReLU | ROxf (Medium) | RPar (Medium) | ROxf (Hard) | RPar (Hard) |
|---|---|---|---|---|---|---|---|---|
| 全局特征 | ||||||||
| RN101-CVNet-Global[23] | x | x | x | 80.2 | 90.3 | 63.1 | 79.1 | |
| RN101-CVNet-Global | √ | x | x | x | 84.7 | 90.8 | 69.6 | 81.1 |
| RN101-CVNet-Global | x | x | 84.8 | 91.3 | 70.6 | 81.9 | ||
| RN101-CVNet-Global | 84.7 | 91.5 | 71.1 | 82.5 | ||||
| RN101-CVNet-Global (SuperGlobal检索) | √ | √ | 85.3 | 92.1 | 72.1 | 83.5 |

Table 4: Results $%$ mAP) on the ROxford 5k and RParis 6k datasets, with both Medium and Hard evaluation protocols. Note reranking is not applied in the evaluation. Figure 5: Examples of Super Global retrieval and CVNet retrieval results on ${\cal R O x f}$ and RPar dataset.
表4: ROxford 5k和RParis 6k数据集在Medium和Hard评估协议下的结果(单位:% mAP)。注意评估中未应用重排序。
图5: ${\cal R O x f}$和RPar数据集上Super Global检索与CVNet检索结果的示例。
5.6. Local vs Global Feature Reranking
5.6. 局部特征与全局特征重排序
Super Global is proved to be significantly more efficient than CVNet reranking. For completeness, we perform experiments to examine whether conducting CVNet reranking on top of the Super Global reranking results can further improve the performance. Table 5 shows that the results are not improved via CVNet reranking, except for a marginal improvement in Oxford Hard. This indicates that local and global feature reranking somehow overlap in the cases which they are able to improve, and our hypothesis for this is as follows. Global feature reranking combines features from visually similar images with diverse viewpoints and lighting conditions, leading to enhanced representation capability and robustness of the updated features. Therefore, global feature reranking could play a similar role as local feature reranking in retrieval systems and this might result in negligible gains when applying CVNet reranking on top of Super Global.
Super Global 被证明比 CVNet 重排序更高效。为了全面验证,我们进行了实验来检验在 Super Global 重排序结果基础上再进行 CVNet 重排序是否能进一步提升性能。表 5 显示,除 Oxford Hard 数据集有微弱提升外,CVNet 重排序并未改善结果。这表明局部特征与全局特征重排序在可优化的案例中存在某种程度的重叠,我们的假设如下:全局特征重排序通过融合不同视角和光照条件下视觉相似图像的特征,增强了更新后特征的表征能力和鲁棒性。因此,全局特征重排序在检索系统中可能起到与局部特征重排序类似的作用,这导致在 Super Global 基础上应用 CVNet 重排序时收益微乎其微。

Figure 6: Examples of Super Global retrieval and reranking results on ROxf and RPar dataset.
图 6: ROxf和RPar数据集上的Super Global检索与重排序结果示例。
Table 5: Results $(%\mathrm{mAP})$ of conducting CVNet reranking on top of our Super Global reranking results on the ROxford and RParis datasets, with both Medium and Hard evaluation protocols.
表 5: 在ROxford和RParis数据集上,基于我们的Super Global重排序结果进行CVNet重排序的性能结果 $(%\mathrm{mAP})$ ,包括Medium和Hard两种评估协议。
| 方法 | CVNet重排序 | Medium | Hard | ||
|---|---|---|---|---|---|
| ROxf | RPar | ROxf | RPar | ||
| SuperGlobal | x | 90.9 | 93.3 | 80.2 | 86.7 |
| SuperGlobal | √ | 90.9 | 91.9 | 81.0 | 79.6 |
6. Conclusions
6. 结论
In this paper, we propose a novel image retrieval system, Super Global, which consists of various modules to refine global features for image retrieval and reranking. All of our proposed methods can be plugged into other existing models, and are easy to implement. For global feature refinement, we proposed improved pooling techniques by better training, besides leveraging regional and multi-scale components. In contrast to conventional expensive reranking systems, we devise a strategy that requires only global features, delivering much improved performance while being four orders of magnitude more efficient. This paper marks a first solution to the retrieval and reranking problems relying on a single global image feature. We hope this will spur further research around this direction, to enable continued improvements to the scalabity of these systems.
本文提出了一种新颖的图像检索系统Super Global,该系统包含多个模块,用于优化图像检索和重排序的全局特征。我们提出的所有方法均可嵌入其他现有模型,且易于实现。在全局特征优化方面,我们通过改进训练方法提出了增强的池化技术,同时整合了区域和多尺度组件。与传统高成本的重排序系统不同,我们设计了一种仅需全局特征的策略,在性能显著提升的同时实现了四个数量级的效率提升。该论文首次提出了仅依赖单一全局图像特征的检索与重排序解决方案。我们期待这一成果能推动该方向的后续研究,持续提升此类系统的可扩展性。
Appendix
附录
A. Reranking more candidates in Super Global
A. 超级全局中的更多候选重排序
This section serves as an extension to Section 5.3 and further evaluates using Super Global with additional candidates on Revisited Oxford 5k $(+1\mathbf{M})$ and Revisited Paris 6k $\left(+1\mathbf{M}\right)$ [34]. As presented in Table 6, Super Global achieves further performance improvements when reranking additional images. It significantly outperforms CVNet reranking by $6.9%$ on Revisited Oxford $+1\mathbf{M}$ Hard, and surpasses Super Global (rerank top 400) by $3.2%$ in the same dataset. Even with additional candidates, Super Global (rerank top 1600) enjoys significant latency gains over CVNet reranking (rerank top 400).
本节作为第5.3节的延伸,进一步评估了在Revisited Oxford 5k $(+1\mathbf{M})$和Revisited Paris 6k $\left(+1\mathbf{M}\right)$[34]数据集上使用Super Global结合额外候选图像的效果。如表6所示,当对更多图像进行重排序时,Super Global实现了进一步的性能提升。在Revisited Oxford $+1\mathbf{M}$ Hard数据集上,其性能显著优于CVNet重排序方法6.9%,同时在同一数据集上比Super Global(重排序前400)高出3.2%。即使处理更多候选图像,Super Global(重排序前1600)相比CVNet重排序(重排序前400)仍具有显著的延迟优势。
Hard
| 方法 | ROxf | ROxf+1M | RPar | RPar+1M | ROxf | ROxf+1M | RPar | RPar+1M |
|---|---|---|---|---|---|---|---|---|
| 全局特征检索 | ||||||||
| RN50-DELG [8] | 73.6 | 60.6 | 85.7 | 68.6 | 51.0 | 32.7 | 71.5 | 44.4 |
| RN101-DELG [8] | 76.3 | 63.7 | 86.6 | 70.6 | 55.6 | 37.5 | 72.4 | 46.9 |
| RN50-DOLG [48] | 80.5 | 76.6 | 89.8 | 80.8 | 58.8 | 52.2 | 77.7 | 62.8 |
| RN101-D0LG [48] | 81.5 | 77.4 | 91.0 | 83.3 | 61.1 | 54.8 | 80.3 | 66.7 |
| RN50-CVNet [23] | 81.0 | 72.6 | 88.8 | 79.0 | 62.1 | 50.2 | 76.5 | 60.2 |
| RN101-CVNet [23] | 80.2 | 74.0 | 90.3 | 80.6 | 63.1 | 53.7 | 79.1 | 62.2 |
| RN50-SuperGlobal [ours] | 83.9 | 74.7 | 90.5 | 81.3 | 67.7 | 53.6 | 80.3 | 65.2 |
| RN101-SuperGlobal [ours] | 85.3 | 78.8 | 92.1 | 83.9 | 72.1 | 61.9 | 83.5 | 69.1 |
| 全局特征检索 + 局部特征重排序 | ||||||||
| RN50-DELG (GV重排前100) [8] | 78.3 | 67.2 | 85.7 | 69.6 | 57.9 | 43.6 | 71.0 | 45.7 |
| RN101-DELG (GV重排前100) [8] | 81.2 | 69.1 | 87.2 | 71.5 | 64.0 | 47.5 | 72.8 | 48.7 |
| RN50-CVNet (重排前400) [23] | 87.9 | 80.7 | 90.5 | 82.4 | 75.6 | 65.1 | 80.2 | 67.3 |
| RN101-CVNet (重排前400) [23] | 87.2 | 81.9 | 91.2 | 83.8 | 75.9 | 67.4 | 81.1 | 69.3 |
| SuperGlobal特征检索与重排序 | ||||||||
| RN50-SuperGlobal (重排前400) [ours] | 88.8 | 80.0 | 92.0 | 83.4 | 77.1 | 64.2 | 84.4 | 68.7 |
| RN101-SuperGlobal (重排前400) [ours] | 90.9 | 84.4 | 93.3 | 84.9 | 80.2 | 71.1 | 86.7 | 71.4 |
| RN50-SuperGlobal (重排前800) [ours] | 88.9 | 81.3 | 93.0 | 85.4 | 77.4 | 67.0 | 86.2 | 75.4 |
| RN101-SuperGlobal (重排前800) [ours] | 91.2 | 85.5 | 94.1 | 86.5 | 80.7 | 73.5 | 88.2 | 74.6 |
| RN50-SuperGlobal (重排前1600) [ours] | 88.9 | 82.0 | 93.3 | 86.8 | 76.9 | 68.2 | 86.4 | 75.0 |
| RN101-SuperGlobal (重排前1600) [ours] | 91.2 | 85.9 | 94.2 | 87.7 | 80.6 | 74.3 | 88.4 | 77.0 |
B. Parameter study for each module
B. 各模块参数研究
Our method consists of several modules that are sensitive to the choice of parameter. Therefore, one important aspect of our work is to seek the optimal values for the core parameters of each component. In this section, we verify the validity of these values by conducting grid searches on different parameter values. When appropriate, we present two digits after the decimal due to the minor differences in values.
我们的方法由多个对参数选择敏感的模块组成。因此,我们工作的一个重要方面是为每个组件的核心参数寻找最优值。本节中,我们通过对不同参数值进行网格搜索来验证这些值的有效性。在适当情况下,由于数值差异较小,我们保留了小数点后两位数字。
$p$ for $\mathbf{GeM+}$ . As mentioned in Section 5.1, we used Oxford 5k [34] to estimate $p$ and obtain the value of 4.6 for $\mathbf{GeM}+$ We show the results of different $p$ values in Table 7 to verify that our $p$ is optimal.
$p$ 对于 $\mathbf{GeM+}$。如第5.1节所述,我们使用Oxford 5k [34]来估计 $p$,并得到 $\mathbf{GeM}+$ 的最佳值为4.6。表7展示了不同 $p$ 值的结果,以验证我们的 $p$ 是最优的。
$p_{m s}$ for Scale-GeM. Here we perform grid search to explore the influence of $p_{m s}$ in Scale-GeM. The results are detailed in Table 8.
$p_{ms}$ 用于 Scale-GeM。我们通过网格搜索来探究 $p_{ms}$ 在 Scale-GeM 中的影响,具体结果详见表 8。
$p_{r}$ for Regional-GeM. Regional GeM consists of $L_{p}$ pool and $\mathbf{GeM}+$ . Table 9 shows how the $p_{r}$ value of $L_{p}$ pool affects retrieval performance.
$p_{r}$ 对应 Regional-GeM。Regional-GeM 由 $L_{p}$ 池化和 $\mathbf{GeM}+$ 组成。表 9 展示了 $L_{p}$ 池化的 $p_{r}$ 值如何影响检索性能。
Medium Table 7: Results $(%\mathrm{mAP})$ of conducting grid search on different ${\bf G e M+}p$ values on the Oxford and Paris datasets [34], with both Medium and Hard evaluation protocols.
表 7: 在 Oxford 和 Paris 数据集 [34] 上对不同 ${\bf G e M+}p$ 值进行网格搜索的结果 $(%\mathrm{mAP})$ ,包括 Medium 和 Hard 评估协议。
| 方法 | p | Medium ROxf | Medium RPar | peH ROxf | peH RPar |
|---|---|---|---|---|---|
| SuperGlobal | 4.2 | 90.9 | 93.4 | 80.1 | 86.7 |
| SuperGlobal | 4.4 | 90.9 | 93.4 | 80.1 | 86.8 |
| SuperGlobal | 4.6 | 90.9 | 93.3 | 80.2 | 86.7 |
| SuperGlobal | 4.8 | 91.0 | 92.3 | 80.3 | 86.7 |
| 5.0 | 90.8 | 93.3 | 80.0 | 86.7 |
Table 6: Comparison to the state-of-the-art methods in image retrieval tasks. Results $%$ mAP) on the ROxford and $\mathcal{R}$ Paris datasets[34] (and their large-scale versions $\scriptstyle{\mathcal{R}}\mathrm{Oxf+lM}$ and $\mathcal{R}\mathrm{Par+lM},$ , with both Medium and Hard evaluation protocols. Our Super Global retrieval framework outperforms state-of-the-art image retrieval methods by a large margin for every measure. The best scores for RN50 and RN101, with and without reranking, are highlighted in bold black and bold blue, respectively. Table 8: Results $\mathrm{'}%\operatorname{mAP})$ of conduct grid search on different Scale-GeM $p_{m s}$ values on the $\mathcal{R}$ Oxford and $\mathcal{R}$ Paris datasets [34], with both Medium and Hard evaluation protocols.
表 6: 图像检索任务中与最先进方法的对比。结果以 mAP (%) 形式展示在 ROxford 和 $\mathcal{R}$ Paris 数据集[34]上 (及其大规模版本 $\scriptstyle{\mathcal{R}}\mathrm{Oxf+lM}$ 和 $\mathcal{R}\mathrm{Par+lM}$),包含 Medium 和 Hard 两种评估协议。我们的 Super Global 检索框架在所有指标上都大幅领先现有图像检索方法。RN50 和 RN101 的最佳得分(无论是否使用重排序)分别用黑色加粗和蓝色加粗标出。
表 8: 在不同 Scale-GeM $p_{m s}$ 值上对 $\mathcal{R}$ Oxford 和 $\mathcal{R}$ Paris 数据集[34]进行网格搜索的结果 (mAP %),包含 Medium 和 Hard 两种评估协议。
| 方法 | pms | Medium (ROxf) | Medium (RPar) | Hard (ROxf) | Hard (RPar) |
|---|---|---|---|---|---|
| SuperGlobal | 1.0 | 89.5 | 93.1 | 77.8 | 86.2 |
| SuperGlobal | 1.5 | 89.5 | 93.1 | 77.9 | 86.2 |
| SuperGlobal | 2.0 | 89.7 | 93.1 | 78.1 | 86.2 |
| SuperGlobal | 2.5 | 90.4 | 93.1 | 79.1 | 86.2 |
| SuperGlobal | 3.0 | 90.6 | 93.1 | 79.3 | 86.3 |
| SuperGlobal | +8 | 90.9 | 93.3 | 80.2 | 86.7 |
ReLU threshold. Here we present the study of the relationship between the threshold $\alpha$ of ReLU and retrieval performance. We conduct grid search to investigate the optimal $\alpha$ and summarize the results in Table 10.
ReLU阈值。本文研究了ReLU的阈值$\alpha$与检索性能之间的关系。我们通过网格搜索探究最优$\alpha$值,并将结果总结在表10中。
Table 9: Results $(%\mathrm{mAP})$ of conducting grid search on different RegionalGeM $p_{r}$ values on the ROxford and RParis datasets [34], with both Medium and Hard evaluation protocols.
表 9: 在 ROxford 和 RParis 数据集 [34] 上对不同 RegionalGeM $p_{r}$ 值进行网格搜索的结果 $(%\mathrm{mAP})$,包括 Medium 和 Hard 评估协议。
| 方法 | $p_{r}$ | ROxf | RPar | ROxf | RPar |
|---|---|---|---|---|---|
| SuperGlobal | 2.0 | 90.9 | 93.3 | 80.2 | 86.7 |
| SuperGlobal | 2.2 | 90.9 | 93.3 | 80.2 | 86.7 86.7 |
| SuperGlobal | 2.4 | 90.9 90.8 | 93.3 93.3 | 80.2 80.0 | 86.7 |
| SuperGlobal | 2.6 2.8 | 90.8 | 93.4 | 80.0 | 86.7 |
Table 10: Results $\mathrm{\mathit{\Omega}}^{\prime}%\mathrm{mAP}\mathrm{,}$ ) of conducting grid search on different ReLU threshold on the Oxford and Paris datasets [34], with both Medium and Hard evaluation protocols.
表 10: 在不同 ReLU 阈值下对 Oxford 和 Paris 数据集 [34] 进行网格搜索的结果 ( $\mathrm{\mathit{\Omega}}^{\prime}%\mathrm{mAP}\mathrm{,}$ ) ,包括 Medium 和 Hard 评估协议。
| 方法 | Medium | peH | |||
|---|---|---|---|---|---|
| ROxf | RPar | ROxf | RPar | ||
| SuperGlobal | 0.012 | 90.7 | 93.3 | 79.8 | 86.7 |
| SuperGlobal | 0.014 | 90.9 | 93.3 | 80.2 | 86.7 |
| SuperGlobal | 0.016 | 90.9 | 93.4 | 80.0 | 86.7 |
| SuperGlobal | 0.018 | 90.9 | 93.4 | 80.2 | 86.7 |
| SuperGlobal | 0.020 | 90.8 | 93.3 | 80.1 | 86.6 |
C. Combining Super Global with other state-ofthe-art models.
C. 将 Super Global 与其他先进模型相结合
Super Global can easily be adopted to existing retrieval methods for further improvements. Table 11 demonstrates that adopting Super Global modules $(\mathrm{GeM}+\$ , Scale-GeM, and Regional-GeM) and further performing Super Global reranking on the DELG [8] pretrained weights outperforms CVNet reranking [23].
Super Global可以轻松应用于现有检索方法以进一步提升性能。表11表明,采用Super Global模块$(\mathrm{GeM}+\$、Scale-GeM和Regional-GeM)并对DELG[8]预训练权重进行Super Global重排序,其效果优于CVNet重排序[23]。
D. Generalizing Super Global reranking
D. 泛化超级全局重排序
Super Global proposes the idea to rerank by further improving global feature of images via feature aggregation. This idea can be generalized when combined with other global features, e.g., DELG-Global [8], DOLG [48] or CVNet-Global [23]. Here, we evaluate retrieval performance when applying Super Global reranking on top of CVNetGlobal. Please note that the other modules introduced in SuperGlobal (e.g. $\mathbf{GeM}+$ , Scale-GeM, Regional-GeM) are not included in this section of experiments. As shown in Table 12, we report that applying Super Global reranking module to CVNet-Global significantly improve the performance in both Oxford and Paris datasets. When comparing with CVNet reranking (Table 6), using Super Global reranking still shows superior performance in the RParis dataset.
Super Global提出了一种通过特征聚合进一步提升图像全局特征来进行重排序的思路。该思路可与其他全局特征(如DELG-Global [8]、DOLG [48]或CVNet-Global [23])结合实现泛化。本文评估了在CVNet-Global基础上应用Super Global重排序的检索性能。需说明的是,SuperGlobal中提出的其他模块(如$\mathbf{GeM}+$、Scale-GeM、Regional-GeM)未包含在本节实验中。如表12所示,将Super Global重排序模块应用于CVNet-Global后,Oxford和Paris数据集的性能均获得显著提升。与CVNet重排序(表6)相比,Super Global重排序在RParis数据集上仍展现出更优性能。
Medium Hard Table 12: Results $(%\mathrm{mAP})$ of adopting Super Global (only reranking) on CVNet-Global [23] on the ROxford and RParis datasets [34], with both Medium and Hard evaluation protocols.
中等难度与高难度 表 12: 在ROxford和RParis数据集[34]上采用Super Global(仅重排序)在CVNet-Global[23]上的结果$(%\mathrm{mAP})$,包含中等和高难度评估协议。
| DOnOI | ROxf | RPar | ROxf | RPar |
|---|---|---|---|---|
| RN101-DELG[8] | 76.3 | 86.6 | 55.6 | 72.4 |
| RN101-DELG+SuperGlobalpooling[one-stage] | 80.0 | 90.6 | 60.0 | 79.8 |
| RN101-DELG+SuperGlobal pooling and reranking (top 400) | 88.4 | 93.1 | 77.3 | 86.8 |
Table 11: Results $(%\mathrm{mAP})$ of adopting Super Global to make further improvement on DELG [8] on the ROxford and RParis datasets [34], with both Medium and Hard evaluation protocols.
表 11: 在ROxford和RParis数据集[34]上采用SuperGlobal对DELG[8]进行进一步改进的结果$(%\mathrm{mAP})$,包含Medium和Hard两种评估协议。
| 方法 | SuperGlobal (重排前400) | Medium | Hard |
|---|---|---|---|
| ROxf | RPar | ||
| RN101-CVNet-Global[23] | x | 80.2 | 90.3 |
| RN101-CVNet-Global[23] | √ | 83.7 | 91.6 |