DTrOCR: Decoder-only Transformer for Optical Character Recognition
DTrOCR: 仅解码器Transformer的光学字符识别
Abstract
摘要
Typical text recognition methods rely on an encoderdecoder structure, in which the encoder extracts features from an image, and the decoder produces recognized text from these features. In this study, we propose a simpler and more effective method for text recognition, known as the Decoder-only Transformer for Optical Character Recognition (DTrOCR). This method uses a decoder-only Trans- former to take advantage of a generative language model that is pre-trained on a large corpus. We examined whether a generative language model that has been successful in natural language processing can also be effective for text recognition in computer vision. Our experiments demonstrated that DTrOCR outperforms current state-of-the-art methods by a large margin in the recognition of printed, handwritten, and scene text in both English and Chinese.
典型文本识别方法依赖于编码器-解码器结构,其中编码器从图像中提取特征,解码器根据这些特征生成识别文本。在本研究中,我们提出了一种更简单高效的文本识别方法——仅解码器Transformer光学字符识别 (DTrOCR)。该方法利用仅解码器Transformer架构,充分发挥了在大规模语料库上预训练的生成式语言模型 (Generative Language Model) 优势。我们验证了在自然语言处理领域表现优异的生成式语言模型,是否同样适用于计算机视觉中的文本识别任务。实验表明,DTrOCR 在英文和中文的印刷体、手写体及场景文本识别任务中,均大幅领先当前最先进方法。
1. Introduction
1. 引言
The aim of text recognition, also known as optical character recognition (OCR), is to convert the text in images into digital text sequences. Many studies have been conducted on this technology owing to its wide range of real-world applications, including reading license plates and handwritten text, analyzing documents such as receipts and invoices [23, 58], and analyzing road signs in automated driving and natural scenes [14, 16]. However, the various fonts, lighting variations, complex backgrounds, low-quality images, occlusion, and text deformation make text recognition challenging. Numerous methods have been proposed to overcome these challenges.
文本识别(OCR)的目标是将图像中的文字转换为数字文本序列。由于该技术在现实世界中的广泛应用,包括车牌和手写文本识别、收据和发票等文档分析[23, 58],以及自动驾驶和自然场景中的路标分析[14, 16],已有大量相关研究。然而,多样的字体、光照变化、复杂背景、低质量图像、遮挡和文本变形等因素使得文本识别极具挑战性。为应对这些挑战,研究者们提出了众多方法。
Existing approaches have mainly employed an encoderdecoder architecture for robust text recognition [3, 13, 47]. In such methods, the encoder extracts the intermediate features from the image, and the decoder predicts the corresponding text sequence. Figures 1 (a)–(c) present the encoder-decoder model patterns of previous studies. The methods in Figures 1 (a) and (b) employ the convolutional neural network (CNN) [20] and Vision Transformer (ViT) [11] families as image encoding methods, with the recurrent neural network (RNN) [22] and Transformer [51] families as decoders, which can be used for batch inference (Figure 1 (a)) or recursively inferring characters one by one (Figure 1 (b)). Certain modules apply image curve correction [2] and high-resolution enhancement [38] to the input images to boost the accuracy. Owing to the limited information from images, several methods in recent years have focused on linguistic information and have employed language models (LMs) in the decoder either externally [13] or internally [3, 29], as illustrated in Figure 1 (c). Although these approaches can achieve high accuracy by leveraging linguistic information, the additional computational cost is an issue.
现有方法主要采用编码器-解码器架构来实现鲁棒文本识别[3, 13, 47]。这类方法中,编码器从图像中提取中间特征,解码器则预测对应的文本序列。图1(a)-(c)展示了先前研究的编码器-解码器模型模式。图1(a)和(b)中的方法分别采用卷积神经网络(CNN)[20]和视觉Transformer(ViT)[11]系列作为图像编码方法,配合循环神经网络(RNN)[22]和Transformer[51]系列作为解码器,可实现批量推理(图1(a))或逐字符递归推理(图1(b))。部分模块会对输入图像应用曲线校正[2]和高分辨率增强[38]以提升准确率。由于图像信息有限,近年一些方法开始关注语言信息,在解码器中外部[13]或内部[3, 29]集成语言模型(LM),如图1(c)所示。虽然这些方法通过利用语言信息能实现高准确率,但额外的计算成本仍是待解决的问题。
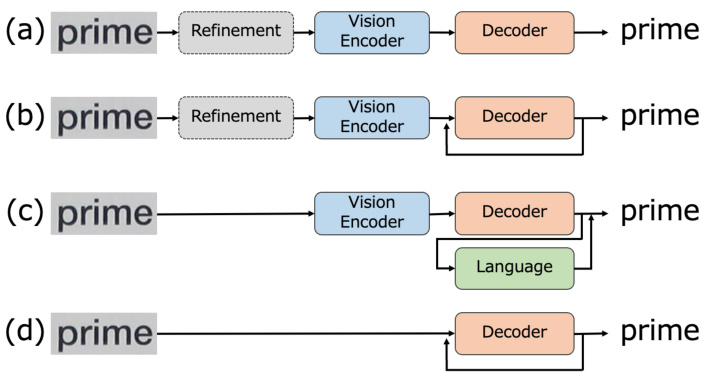
Figure 1. Model patterns for text recognition. The existing methods in (a) to (c) consist of a vision encoder to extract the image features and a decoder to predict text sequences from the features. Some methods use refinement modules to deal with low-quality images and an LM to correct the output text. Our approach differs significantly. As shown in (d), it consists of a simple model pattern in which the image is fed directly into the decoder to generate text.
图 1: 文本识别的模型模式。(a)至(c)中的现有方法包含一个视觉编码器用于提取图像特征,以及一个解码器用于从特征中预测文本序列。部分方法使用细化模块处理低质量图像,并借助语言模型(LM)校正输出文本。我们的方法截然不同,如(d)所示,采用直接将图像输入解码器生成文本的简洁模式。
LMs based on generative pre-training have been used successfully in various natural language processing (NLP) tasks [43, 44] in recent years. These models are built with a decoder-only Transformer. The model passes the input text directly to the decoder, which outputs the subsequent word token. The model is pre-trained with a large corpus to generate the following text sequence in the given text. The model needs to understand the meaning and context of the words and acquire language knowledge to generate the text sequence accurately. As the obtained linguistic information is powerful, it can be fine-tuned for various tasks in NLP. However, the applicability of such models to text recognition has yet to be demonstrated.
近年来,基于生成式预训练的大语言模型已成功应用于各种自然语言处理 (NLP) 任务 [43, 44]。这些模型采用仅包含解码器的 Transformer 架构,直接将输入文本传递给解码器以输出后续单词 Token。模型通过大规模语料库进行预训练,从而在给定文本中生成后续文本序列。该过程要求模型理解单词含义与上下文,并掌握语言知识以准确生成文本序列。由于所获取的语言信息具有强大表征能力,此类模型可针对不同 NLP 任务进行微调。然而,此类模型在文本识别任务中的适用性尚未得到验证。
Motivated by the above observations, this study presents a novel text recognition framework known as the Decoder-only Transformer for Optical Character Recognition (DTrOCR), which does not require a vision encoder for feature extraction. The proposed method transforms a pretrained generative LM with a high language representation capability into a text recognition model. Generative models that are used in NLP use a text sequence as input and generate the following text auto regressive ly. In this work, the model is trained to use an image as the input. The input image is converted into a patch sequence, and the recognition results are output auto regressive ly. The structure of the proposed method is depicted in Figure 1 (d). DTrOCR does not require vision encoders such as a CNN or ViT but has a simple model structure with only a decoder that leverages the internal generative LM. In addition, the proposed method employs fine-tuning from a pre-trained model, which reduces the computational resources. Despite its simple structure, DTrOCR is revealed to outperform existing methods in various text recognition benchmarks, such as handwritten, printed, and natural scene image text, in English and Chinese. The main contributions of this work are summarized as follows:
基于上述观察,本研究提出了一种新颖的文本识别框架——仅解码器Transformer光学字符识别(DTrOCR),该框架无需视觉编码器进行特征提取。该方法将具有高语言表征能力的预训练生成式大语言模型转化为文本识别模型。自然语言处理中使用的生成式模型以文本序列作为输入,并以自回归方式生成后续文本。本研究中,模型被训练为使用图像作为输入:输入图像被转换为图像块序列,并以自回归方式输出识别结果。图1(d)展示了所提方法的结构。DTrOCR无需CNN或ViT等视觉编码器,仅通过利用内部生成式大语言模型的解码器构成简洁模型结构。此外,该方法采用预训练模型微调策略,有效降低了计算资源需求。尽管结构简洁,实验表明DTrOCR在英语和中文的手写体、印刷体及自然场景图像文本等多种文本识别基准测试中均优于现有方法。本文主要贡献可归纳如下:
• We propose a novel decoder-only text recognition method known as DTrOCR, which differs from the mainstream encoder-decoder approach. • Despite its simple structure, DTrOCR achieves stateof-the-art results on various benchmarks by leveraging the internal LM, without relying on complex pre- or post-processing.
• 我们提出了一种新颖的仅解码器文本识别方法DTrOCR,该方法与主流的编码器-解码器架构不同。
• 尽管结构简单,DTrOCR通过利用内部语言模型 (LM) ,无需依赖复杂的预处理或后处理,便在多种基准测试中达到了最先进的性能。
2. Related Works
2. 相关工作
Scene Text Recognition. Scene text recognition refers to text recognition in natural scene images. Existing methods can be divided into three categories: word-based, characterbased, and sequence-based approaches. Word-based approaches perform text recognition as image classification, in which each word is a direct classification class [24]. Character-based approaches perform text recognition using detection, recognition, and grouping on a character-bycharacter basis [53]. Sequence-based approaches deal with the task as sequence labeling and are mainly realized using encoder-decoder structures [13, 29, 47]. The encoder, which can be constructed using the CNN and ViT families, aims to extract a visual representation of a text im- age. The goal of the decoder is to map the representation to text with connection is t temporal classification (CTC)-based methods [18, 47] or attention mechanisms [3, 29, 32, 61].
场景文本识别。场景文本识别指对自然场景图像中的文本进行识别。现有方法可分为三类:基于单词、基于字符和基于序列的方法。基于单词的方法将文本识别视为图像分类任务,每个单词直接作为一个分类类别[24]。基于字符的方法通过逐字符进行检测、识别和分组来完成文本识别[53]。基于序列的方法将该任务视为序列标注问题,主要采用编码器-解码器结构实现[13,29,47]。编码器可采用CNN和ViT系列架构构建,旨在提取文本图像的视觉表征。解码器的目标是通过基于连接时序分类(CTC)的方法[18,47]或注意力机制[3,29,32,61],将该表征映射为文本。
The encoder has been improved using a neural architecture search [65] and a graph convolutional network [59], whereas the decoder has been enhanced using multistep reasoning [5], two-dimensional features [28], semantic learn- ing [42], and feedback [4]. Furthermore, the accuracy can be improved by converting low-resolution inputs into high-resolution inputs [38], normalizing curved and irregular text images [2, 33, 48], or using diffusion models [15]. Some methods have predicted the text directly from encoders alone for computational efficiency [1, 12]. However, these approaches do not use linguistic information and face difficulties when the characters are hidden or unclear.
编码器通过神经架构搜索 [65] 和图卷积网络 [59] 进行了改进,而解码器则采用了多步推理 [5]、二维特征 [28]、语义学习 [42] 和反馈机制 [4] 来增强性能。此外,将低分辨率输入转换为高分辨率输入 [38]、对弯曲和不规则文本图像进行归一化处理 [2, 33, 48] 或使用扩散模型 [15] 均可提升准确率。部分方法为提升计算效率,仅通过编码器直接预测文本 [1, 12],但这些方法未利用语言信息,在字符被遮挡或模糊时表现欠佳。
Therefore, methods that leverage language knowledge have been proposed to make the models more robust in recent years. ABINet uses bi-directional context via external LMs [13]. In VisionLAN, an internal LM is constructed by selectively masking the image features of individual characters during training [56]. The learning of internal LMs using permutation language modeling was proposed in PARSeq [3]. In TrOCR, LMs that are pre-trained on an NLP corpus using masked language modeling (MLM) are used as the decoder [29]. MaskOCR includes sophisticated MLM pre-training methods to enhance the Transformerbased encoder-decoder structure [34]. The outputs of these encoders are either passed directly to the decoder or intricately linked by a cross-attention mechanism.
因此,近年来提出了利用语言知识的方法来增强模型的鲁棒性。ABINet通过外部语言模型(LM)利用双向上下文[13]。VisionLAN在训练期间通过选择性掩码单个字符的图像特征构建了内部语言模型[56]。PARSeq提出了使用排列语言建模(permutation language modeling)学习内部语言模型的方法[3]。TrOCR采用基于自然语言处理(NLP)语料库、通过掩码语言建模(MLM)预训练的语言模型作为解码器[29]。MaskOCR包含复杂的MLM预训练方法,用于增强基于Transformer的编码器-解码器结构[34]。这些编码器的输出要么直接传递给解码器,要么通过交叉注意力机制复杂地连接起来。
Our approach exhibits similarities to TrOCR [29] as both use linguistic information and pre-trained LMs for the decoding process. However, our method differs in two significant aspects. First, we use generative pre-training [43] as the pre-training method in the decoder, which predicts the next word token for generating text, instead of solving masked fill-in-the-blank problems using MLM. Second, we eliminate the encoder to obtain elaborate features from images. The images are patched and directly fed into the decoder. As a result, no complicated connections such as cross-attention are required to link the encoder and decoder because the image and text information are handled at the same sequence level. This enables our text recognition model to be simple yet effective.
我们的方法与TrOCR [29]有相似之处,两者都在解码过程中利用了语言信息和预训练的大语言模型。但我们的方法在两个方面存在显著差异:首先,我们在解码器中采用生成式预训练 [43] 作为预训练方法,通过预测下一个单词token来生成文本,而非使用MLM解决掩码填空问题;其次,我们移除了编码器来获取图像精细特征,直接将分块后的图像输入解码器。由于图像和文本信息在同一序列层级处理,因此无需通过跨注意力等复杂连接来关联编码器与解码器。这使得我们的文本识别模型简洁而高效。
Handwritten Text Recognition. Handwritten text recognition (HWR) has long been studied, and the recent methods have been reviewed [35]. In addition, the effects of different attention mechanisms of encoder-decoder structures in the HWR domain have been compared [36]. The combination of RNNs and CTC decoders has been established as the primary approach in this field [6, 36, 55], with improvements such as multi-dimensional long short-term memory [41] and attention mechanisms [10, 25] having been applied. In recent years, extensions using LMs have also been implemented [29]. Thus, we tested the effectiveness of our method in HWR to confirm its s cal ability.
手写文本识别。手写文本识别 (HWR) 领域的研究由来已久,近期方法已有综述 [35]。此外,学界还比较了编码器-解码器结构中不同注意力机制在 HWR 领域的效果 [36]。目前 RNN 与 CTC 解码器的组合已成为该领域主流方法 [6, 36, 55],并衍生出多维长短期记忆网络 [41] 和注意力机制 [10, 25] 等改进方案。近年来还出现了结合语言模型 (LM) 的扩展研究 [29]。因此我们通过 HWR 任务验证了本方法的有效性以确认其扩展能力。
Chinese Text Recognition. Text recognition tasks on alphabets and symbols in English have been studied, and significant accuracy improvements have been achieved [3, 13]. The adaptation of recognition models to Chinese text recognition (CTR) has been investigated in recent years [34, 62]. However, studies on CTR remain lacking. CTR is a challenging task as Chinese has substantially more characters than English and contains many similar-appearing characters. Thus, we validated our method to determine whether it can be applied to Chinese in addition to English text.
中文文本识别。针对英文字母和符号的文本识别任务已有研究,并取得了显著的准确率提升 [3, 13]。近年来,识别模型在中文文本识别 (CTR) 上的适配性得到了探索 [34, 62]。然而针对 CTR 的研究仍然不足。由于中文字符数量远超英文且包含大量形近字,CTR 是一项极具挑战性的任务。为此我们验证了本方法在英文文本之外是否同样适用于中文。
Generative Pre-Trained Transformer. Generative pretrained Transformer (GPT) has emerged in NLP, which has attracted attention owing to its ability to produce results in various tasks [43,44]. The model can acquire linguistic ability by predicting the continuation of a given text. GPT comprises a decoder-only auto regressive transformer that does not require an encoder to acquire the input text features. Whereas previous studies [29] examined the adaptation of LMs that are learned using MLM to text recognition models, this study explores the extension of GPT to text recognition.
生成式预训练Transformer。生成式预训练Transformer (GPT) 在自然语言处理领域崭露头角,其能够生成多种任务结果的能力引起了广泛关注 [43,44]。该模型通过预测给定文本的后续内容来获得语言能力。GPT由一个仅包含解码器的自回归Transformer组成,无需编码器即可获取输入文本特征。尽管先前的研究 [29] 探讨了将使用掩码语言建模 (MLM) 学习的大语言模型适配到文本识别模型的方法,但本研究探索了将GPT扩展到文本识别的可能性。
3. Method
3. 方法
The pipeline of our method is illustrated in Figure 2. We use a generative LM [44] that incorporates Transformers [51] with a self-attention mechanism. Our model comprises two main components: the patch embedding and Transformer decoder. The input text image undergoes patch embedding to divide it into patch-sized image sequences. Subsequently, these sequences are passed through the decoder with the positional embedding. The decoder predicts the first-word token after receiving a special token [SEP] that separates the image and text sequence. Thereafter, it predicts the subsequent tokens in an auto regressive manner until the special token [EOS], which indicates the end of the text, and produces the final result. The modules and training methods are described in detail in the following sections.
我们方法的流程如图 2 所示。我们采用了一个结合 Transformer [51] 与自注意力机制的生成式大语言模型 [44]。该模型包含两大核心组件:图像块嵌入 (patch embedding) 和 Transformer 解码器。输入文本图像首先通过图像块嵌入被分割为图像块序列,随后这些序列与位置编码一起输入解码器。解码器在接收到分隔图像与文本序列的特殊标记 [SEP] 后,会预测首个单词标记 (token),之后以自回归方式持续预测后续标记,直至遇到表示文本结束的特殊标记 [EOS] 并输出最终结果。各模块及训练方法将在后续章节详细说明。
3.1. Patch Embedding Module
3.1. 图像块嵌入模块
Since the input to the transformer is a sequence of tokens, the patch embedding as the input to the Transformer is a sequence of tokens, the patch embedding module transforms the tokens so that the image can be input into the decoder. We employ the patch embedding procedure proposed in [11]. The input image is resized to a fixed-size image $\boldsymbol{I}\in\mathbb{R}^{W\times H\times C}$ , where $W,H$ , and $C$ are the width, height, and channel of the image, respectively. The input image is divided by fixed patch sizes $p_{w}\times p_{h}$ , where $p_{w}$ and $p_{h}$ are the width and height of the patch, respectively. The patch images are first transformed into vectors and adjusted to fit the input dimensions of the Transformer. Position encoding is added to preserve the information on the position of each patch. Subsequently, the resulting sequence, which contains both the transformed patches and position information, is sent to the decoder.
由于Transformer的输入是一个Token序列,作为Transformer输入的补丁嵌入模块会对这些Token进行转换,使得图像能够输入解码器。我们采用[11]中提出的补丁嵌入流程:输入图像被调整为固定尺寸的$\boldsymbol{I}\in\mathbb{R}^{W\times H\times C}$,其中$W,H$和$C$分别表示图像的宽度、高度和通道数。该图像被划分为固定尺寸为$p_{w}\times p_{h}$的补丁块,$p_{w}$和$p_{h}$分别代表补丁的宽度和高度。这些补丁图像首先被转换为向量,并调整以适应Transformer的输入维度。通过添加位置编码来保留每个补丁的位置信息。最终,包含转换后补丁和位置信息的序列将被送入解码器。
3.2. Decoder Module
3.2. 解码器模块
The decoder performs text recognition using a given image sequence. The decoder initially uses the input image sequence and generates the first predicted token by following a beginning token. This token is a special token named [SEP], which marks the division between the image and text sequence. Thereafter, the model uses the image and predicted token sequence to generate text auto regressive ly until it reaches the token [EOS]. The decoder output is projected by a linear layer from the dimension of the model to the vocabulary size $V$ . Thereafter, the probabilities are computed on the vocabulary using a softmax function. Finally, the beam search is employed to obtain the final output. The cross-entropy loss function is used in this process.
解码器通过给定的图像序列执行文本识别任务。解码器首先利用输入图像序列,并按照起始标记 [SEP] 生成第一个预测token。该标记是用于区分图像与文本序列的特殊分隔符。随后,模型以自回归方式结合图像和已预测token序列持续生成文本,直至遇到终止标记 [EOS]。解码器输出会通过线性层从模型维度映射到词汇表大小 $V$,再通过softmax函数计算词汇表概率分布,最终采用束搜索(beam search)获取最终输出。此过程使用交叉熵损失函数进行优化。
The decoder uses GPT [43, 44] to recognize the text accurately using linguistic knowledge. It predicts the next word in a sentence by maximizing the entropy. Pre-trained models are publicly available, which eliminates the need for computational resources to acquire language knowledge.
解码器采用GPT[43, 44]模型,通过语言学知识实现精准文本识别。其通过最大化熵值来预测句子中的下一个词。公开可用的预训练模型消除了获取语言知识所需的计算资源开销。
The decoder comprises multiple stacks, with the Transformer layer [51] constituting one block. This block includes a multi-head mask self-attention and feed-forward network. As opposed to previous encoder-decoder structures, this method only uses a decoder for prediction, thereby eliminating the need for cross-attention between the image features and text and significantly simplifying the design.
解码器由多个堆叠层组成,其中Transformer层[51]构成一个模块。该模块包含多头掩码自注意力机制和前馈网络。与以往的编码器-解码器结构不同,该方法仅使用解码器进行预测,因此无需图像特征与文本之间的交叉注意力,大幅简化了设计。
3.3. Pre-training with Synthetic Datasets
3.3. 基于合成数据集的预训练
The decoder of our method gains language knowledge through GPT in NLP. However, it does not connect this knowledge with the image information. Thus, we trained the model on artificially generated datasets that included various text forms, such as scenes, handwritten, and printed text, to aid in acquiring image and language knowledge. Further details are provided in the experimental section.
我们方法的解码器通过自然语言处理(NLP)中的GPT获取语言知识。然而,它并未将这些知识与图像信息建立关联。为此,我们在人工生成的数据集上训练模型,这些数据集包含场景文本、手写体和印刷体等多种文本形式,以帮助获取图像与语言知识。更多细节详见实验部分。
3.4. Fine-Tuning with Real-World Datasets
3.4. 基于真实世界数据集的微调
Recent studies have demonstrated that synthetic datasets alone are insufficient for handling real-world problems [2, 3]. Text shapes, fonts, and features may vary depending on the type of recognition required, such as printed or handwritten text. Therefore, we fine-tuned the pre-trained models using actual data for specific tasks to solve real-world text recognition issues effectively. The training procedure for the real datasets was the same as that for the synthetic ones.
近期研究表明,仅靠合成数据集无法有效解决现实问题 [2, 3]。根据识别需求类型(如印刷体或手写体),文本形状、字体和特征会存在差异。为此,我们采用实际数据对预训练模型进行特定任务的微调,以高效解决真实场景的文本识别问题。真实数据集的训练流程与合成数据集保持一致。
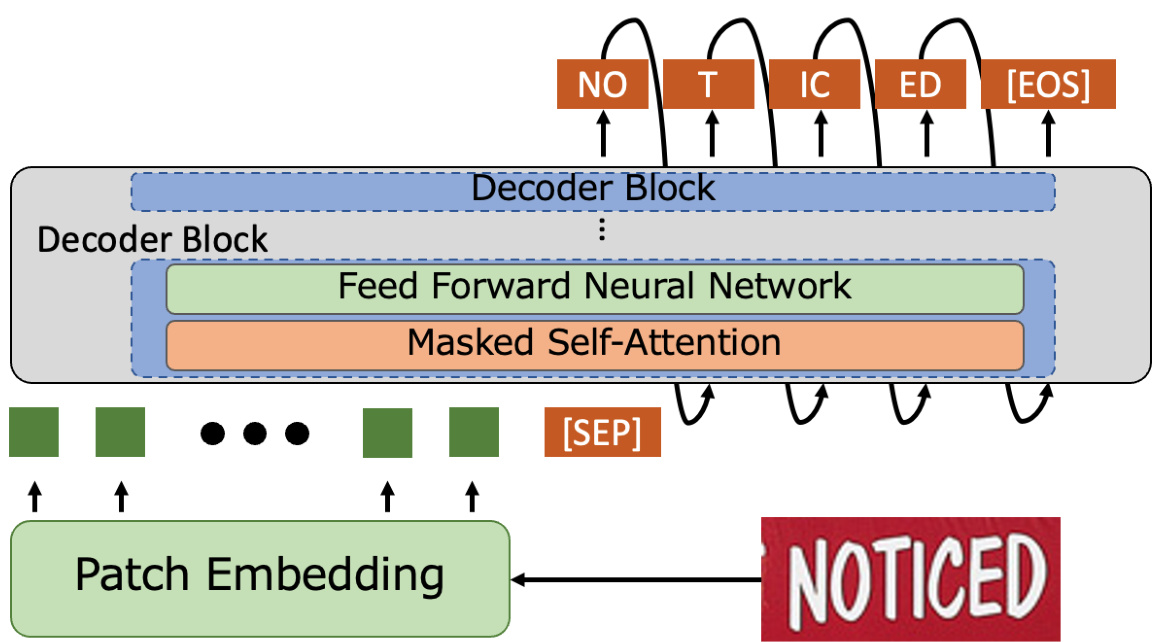
Figure 2. Architecture of proposed DTrOCR, which consists of patch embedding and decoder modules. The input images are transformed into one-dimensional sequences using the patch embedding and then sent to the decoder along with the positional encoding. The decoder uses the special token [SEP] to indicate sequence separation. Thereafter, it predicts the subsequent word token based on the sequence condition. It continues to generate text auto regressive ly until it reaches the end of the text token [EOS].
图 2: 提出的 DTrOCR 架构,由 patch embedding 和解码器模块组成。输入图像通过 patch embedding 转换为一维序列,随后与位置编码一起送入解码器。解码器使用特殊 token [SEP] 表示序列分隔,之后基于序列条件预测后续单词 token。该模型会自回归地持续生成文本,直至遇到文本结束 token [EOS]。
3.5. Inference
3.5. 推理
The proposed method uses the same training process for inference. Patch embedding is employed for the input images and decoder to generate predicted tokens iterative ly until the [EOS] token is reached for text recognition.
所提出的方法在推理阶段采用相同的训练流程。通过使用图像块嵌入 (patch embedding) 处理输入图像和解码器,迭代生成预测token,直至文本识别任务中出现[EOS] token为止。
4. Experiments
4. 实验

Figure 3. Comparison of recognition results of state-of-the-art methods and proposed method [3, 13]. The result corresponding to an image is shown on each line, with the ground truth at the top. The proposed method is robust to occlusion and irregularly arranged scenes and is accurate even for two lines.
图 3: 现有最优方法与提出方法的识别结果对比 [3, 13]。每行显示对应图像的识别结果,顶部为真实标注。所提出的方法对遮挡和非规则排列场景具有鲁棒性,即使对两行文本也能保持准确识别。
We evaluated the performance of the proposed method on scene image, printed, and handwritten text recognition in English and Chinese.
我们在英文和中文的场景图像、印刷体及手写体文本识别任务上评估了所提出方法的性能。
4.1. Datasets
4.1. 数据集
Pre-training with Synthetic Datasets. Our proposed method was pre-trained using synthetic datasets to connect the visual and language information in the LM of the decoder. Previous studies [29] obtained training data by extracting available PDFs from the Internet and using real-world receipt data with annotations that are generated by commercial OCR. However, substantial time and effort are required to prepare such data. We created annotated datasets from a text corpus using an artificial generation method to make the process more reproducible. We used large datasets that are commonly used to train LMs as our corpus for generating synthetic text images: PILE [17] for English, CC100 [57], and the Chinese NLP Corpus1 for Chinese with preprocessing [68].
基于合成数据集的预训练。我们提出的方法通过合成数据集进行预训练,以连接解码器大语言模型中的视觉与语言信息。先前研究[29]通过从互联网提取可用PDF文件,以及使用商业OCR生成标注的真实收据数据来获取训练数据,但此类数据准备过程需要耗费大量时间和精力。为提高实验可复现性,我们采用人工生成方法从文本语料库创建标注数据集。选用以下常用于训练大语言模型的大规模语料库生成合成文本图像:英语采用PILE[17],中文使用经过预处理的CC100[57]和Chinese NLP Corpus1[68]。
We used three open-source libraries to create synthetic datasets from our corpus. We randomly divided the corpus into three categories: scene, printed, and handwritten text recognition, with a distribution of $60%$ , $20%$ , and $20%$ , respectively, to ensure text recognition accuracy. We generated four billion horizontal and two billion vertical images of text for scene text recognition using SynthTIGER [60]. We employed the default font for English and 64 commonly used fonts for Chinese. We used the Multiline text image configuration in SynthTIGER, set the word count to five, and generated 100 million images using the MJSynth [24] and SynthText [19] corpora for the recognition of multiple lines of English text.
我们使用三个开源库从语料库中创建合成数据集。为确保文本识别准确性,将语料库随机分为场景、印刷体和手写体文本识别三类,分布比例为$60%$、$20%$和$20%$。利用SynthTIGER [60]生成了40亿张水平文本图像和20亿张垂直文本图像用于场景文本识别,其中英文采用默认字体,中文采用64种常用字体。在SynthTIGER中使用多行文本图像配置,将单词数设置为5,并基于MJSynth [24]和SynthText [19]语料库生成了1亿张图像用于多行英文文本识别。
We created two billion datasets for printed text recognition using the default settings of Text Render2. Additionally, we employed TRDG3 to generate another two billion datasets for recognizing handwritten text. We followed the methods outlined in previous studies for our process [29]. We used 5,427 English and four Chinese hand
我们使用Text Render2的默认设置创建了20亿个印刷文本识别数据集。此外,还采用TRDG3生成了另外20亿个手写文本识别数据集。数据处理流程遵循了先前研究提出的方法 [29],共使用了5,427个英文和4个中文手写样本。
Table 1. Word accuracy on English scene text recognition benchmark datasets with 36 characters. “Synth” and “Real” refer to synthetic and real training datasets, respectively.
表 1: 36字符英文场景文本识别基准数据集上的单词准确率。"Synth"和"Real"分别指合成训练数据集和真实训练数据集。
| 方法 | 训练数据 | 测试数据集及样本数量 |
|---|---|---|
| IIIT5k | ||
| 3,000 | ||
| CRNN [47] | Synth | 81.8 |
| ViTSTRBASE [1] | Synth | 88.4 |
| TRBA [2] | Synth | 92.1 |
| ABINet [13] | Synth | 96.2 |
| PlugNet [38] | Synth | 94.4 |
| SRN [61] | Synth | 94.8 |
| TextScanner [53] | Synth | 95.7 |
| AutoSTR [65] | Synth | 94.7 |
| PREN2D [59] | Synth | 95.6 |
| VisionLAN [56] | Synth | 95.8 |
| JVSR [5] | Synth | 95.2 |
| CVAE-Feed [4] | Synth | 95.2 |
| DiffusionSTR [15] | Synth Synth | 97.3 |
| TrOCRBASE [29] | Synth | 90.1 91.0 |
| TrOCRLARGE [29] | Synth | 97.0 |
| PARSeq [3] | Synth | |
| MaskOCRBASE [34] MaskOCRLARGE [34] | Synth | 95.8 96.5 |
| SVTRBASE [12] | Synth | 96.0 |
| SVTRLARGE [12] | Synth | 96.3 |
| DTrOCR (Ours) | Synth | 98.4 |
| CRNN [3,47] | Real | 94.6 |
| TRBA [2,3] | Real | 98.6 |
| ABINet [3,13] | Real | 98.6 |
| PARSeq [3] DTrOCR (ours) | Real Real | 99.1 99.6 |
Table 2. Word-level recall, precision and F1 on SROIE Task 2.
表 2: SROIE任务2中的词级召回率、精确率和F1值
| 模型 | 召回率 | 精确率 | F1值 |
|---|---|---|---|
| CRNN [47] | 28.71 | 48.58 | 36.09 |
| H&H Lab [23] | 96.35 | 96.52 | 96.43 |
| MSOLab [23] | 94.77 | 94.88 | 94.82 |
| CLOVA OCR [23] | 94.30 | 94.88 | 94.59 |
| TrOCRLARGE [29] | 96.59 | 96.57 | 96.58 |
| DTrOCR (本方法) | 98.24 | 98.51 | 98.37 |
Table 3. CER on IAM Handwriting Database, where a lower score is better.
表 3: IAM手写数据库上的CER (字符错误率) ,数值越低越好。
| 模型 | 训练数据 | 外部语言模型 | CER |
|---|---|---|---|
| Bluche et al. [6] | Synthetic+IAM | 是 | 3.20 |
| Michael et al. [36] | IAM | 否 | 4.87 |
| Wang et al. [55] | IAM | 否 | 6.40 |
| Kang et al. [25] | Synthetic+IAM | 否 | 4.67 |
| Diazetal. [10] | Internal+IAM | 是 | 2.75 |
| TrOCRLARGE [29] | Synthetic+IAM | 否 | 2.89 |
| DTrOCR (本工作) | Synthetic+IAM | 否 | 2.38 |
writing fonts 4.
书写字体 4.
Fine-Tuning with Real-World and Evaluation Datasets. We fine-tuned the pre-trained models on each dataset and evaluated their performance on benchmarks. English scene text recognition models have traditionally been trained on large synthetic datasets owing to the limited availability of labeled real datasets. However, with the increasing amount of real-world datasets, models are now also being trained on real data. Therefore, following previous studies [2, 3], we trained our models on both synthetic and real datasets to validate the performance. Specifically, we used MJSynth [24] and SynthText [19] as synthetic datasets and COCO-Text [52], RCTW [49], Uber-Text [67], ArT [7], LSVT [50], MLT19 [39], and ReCTS [66] as real datasets. Each model was evaluated on six standard scene text datasets: ICDAR 2013 (IC13) [27], Street View Text (SVT) [54], IIIT5K-Words (IIIT5K) [37], ICDAR 2015 (IC15) [26], Street View Text-Perspective (SVTP) [40], and CUTE80 (CUTE) [45]. The initial three datasets mainly consist of standard text images, whereas the remaining datasets include images of text that are either curved or in perspective.
基于真实场景与评估数据集的微调。我们在每个数据集上对预训练模型进行微调,并在基准测试中评估其性能。由于标注真实数据集的稀缺性,英文场景文本识别模型传统上依赖大规模合成数据集进行训练。但随着现实世界数据集的增长,当前模型也开始采用真实数据训练。为此,我们遵循先前研究[2,3]的方法,同时使用合成与真实数据集进行模型训练以验证性能。具体而言,采用MJSynth[24]和SynthText[19]作为合成数据集,选用COCO-Text[52]、RCTW[49]、Uber-Text[67]、ArT[7]、LSVT[50]、MLT19[39]和ReCTS[66]作为真实数据集。所有模型均在六个标准场景文本数据集上评估:ICDAR 2013(IC13)[27]、Street View Text(SVT)[54]、IIIT5K-Words(IIIT5K)[37]、ICDAR 2015(IC15)[26]、Street View Text-Perspective(SVTP)[40]和CUTE80(CUTE)[45]。前三个数据集主要包含标准文本图像,其余数据集则涵盖弯曲或透视文本图像。
Table 4. Word accuracy on CTR benchmark.
表 4: CTR 基准测试中的单词准确率
| 方法 | 数据集 | 参数量 (M) | FPS | |||
|---|---|---|---|---|---|---|
| 场景 | 网页 | 文档 | 手写体 | |||
| CRNN [47] | 54.9 | 56.2 | 97.4 | 48.0 | 12.4 | 751.0 |
| ASTER [48] | 59.4 | 57.8 | 97.6 | 45.9 | 27.2 | 107.3 |
| MORAN [33] | 54.7 | 49.6 | 91.7 | 30.2 | 28.5 | 301.5 |
| SAR [28] | 53.8 | 50.5 | 96.2 | 31.0 | 27.8 | 93.1 |
| SEED [42] | 45.4 | 31.4 | 96.1 | 21.1 | 36.1 | 106.6 |
| MASTER [32] | 62.1 | 53.4 | 82.7 | 18.5 | 62.8 | 16.3 |
| ABINet [13] | 60.9 | 51.1 | 91.7 | 13.8 | 53.1 | 92.1 |
| TrOCR [29] | 67.8 | 62.7 | 97.9 | 51.7 | 83.9 | 164.6 |
| MaskOCRBASE [34] | 73.9 | 74.8 | 99.3 | 63.7 | 100 | — |
| MaskOCRLARGE [34] | 76.2 | 76.8 | 99.4 | 67.9 | 318 | — |
| DTrOCR (ours) | 87.4 | 89.7 | 99.9 | 81.4 | 105 | 97.9 |
Thereafter, we tested the accuracy of the printed text recognition in receipt images using Scanned Receipts OCR and Information Extraction (SROIE) Task 2 [23]. A total of 626 training and 361 evaluation receipt images were used in the testing.
此后,我们使用扫描收据OCR和信息提取(SROIE)任务2 [23]测试了收据图像中打印文本识别的准确性。测试共使用了626张训练收据图像和361张评估收据图像。
We employed the widely used IAM Handwriting Database to evaluate the English HWR. Aachen’s partition was used, which resulted in a training set of 6,161 lines from 747 forms, a validation set of 966 lines from 115 forms, and a test set of 2,915 lines from 336 forms.
我们采用广泛使用的IAM手写数据库来评估英文手写识别(HWR)。使用了Aachen划分方案,最终得到来自747份表单的6,161行训练集、115份表单的966行验证集,以及336份表单的2,915行测试集。
We evaluated the models for CTR on a large CTR benchmark dataset [62]. This dataset includes four subsets (scene, web, document, and handwriting), with a total of $1.4~\mathrm{mil}$ - lion fully labeled images. The scene subset is derived from scene text datasets such as RCTW [49], ReCTS [66], LSVT [50], ArT [7], and CTW [63]. It consists of 509,164, 63,645, and 63,646 samples for training, validation, and testing, respectively. The web subset is built on the MTWI dataset [21], with 112,471, 14,059, and 14,059 samples for training, validation, and testing, respectively. The document subset was generated in document style by Text Render and consists of 400,000 training, 50,000 validation, and 50,000 testing samples. The handwriting subset was obtained from the handwriting dataset SCUT-HCCDoc [64]. It consists of 74,603, 18,651, and 23,389 training, validation, and testing samples, respectively.
我们在一个大型CTR基准数据集[62]上评估了模型的CTR性能。该数据集包含四个子集(场景、网页、文档和手写),共计140万张全标注图像。场景子集源自RCTW[49]、ReCTS[66]、LSVT[50]、ArT[7]和CTW[63]等场景文本数据集,训练集、验证集和测试集分别包含509,164、63,645和63,646个样本。网页子集基于MTWI数据集[21]构建,训练集、验证集和测试集分别包含112,471、14,059和14,059个样本。文档子集通过Text Render生成文档风格样本,包含40万训练样本、5万验证样本和5万测试样本。手写子集来自SCUT-HCCDoc手写数据集[64],训练集、验证集和测试集分别包含74,603、18,651和23,389个样本。
4.2. Evaluation Metrics
4.2. 评估指标
We used different metrics for the various benchmarks. The word accuracy was used for the standard scene text recognition and CTR benchmarks; a prediction was considered as correct if the characters at all positions matched. SROIE Task 2 was evaluated using the word-level precision, recall, and F1 scores. Finally, the character error rate (CER) with case sensitivity was used for the HWR benchmark IAM.
我们对不同基准测试采用了不同的评估指标。标准场景文本识别和CTR基准测试使用单词准确率(accuracy)作为指标,只有当所有位置的字符完全匹配时,预测结果才被视为正确。SROIE Task 2采用词级精确率(precision)、召回率(recall)和F1分数进行评估。最后,手写识别基准测试IAM使用区分大小写的字符错误率(CER)作为评估标准。
We followed the standard protocols for the English scene text recognition [2, 3] and CTR [62] to process the predictions and ground truth. We filtered the string to fit the 36- character character set (lowercase alphanumeric) to ensure a fair comparison in the English scene text recognition task. We implemented specific processes for the CTR: (i) fullwidth characters were converted into half-width ones; (ii) traditional Chinese characters were converted into simplified ones; (iii) uppercase letters were converted into lowercase ones; and (iv) all spaces were removed.
我们遵循英文场景文本识别[2, 3]和中文文本识别(CTR)[62]的标准协议处理预测结果和真实标签。在英文场景文本识别任务中,我们对字符串进行过滤以匹配36字符的字符集(小写字母数字组合),确保公平比较。针对中文文本识别任务,我们实施了以下特定处理流程:(i) 全角字符转换为半角字符;(ii) 繁体中文转换为简体中文;(iii) 大写字母转换为小写字母;(iv) 移除所有空格。
4.3. Implementation Details
4.3. 实现细节
We used the English6 and Chinese7 GPT-2 [44] models with 12 layers, 768 hidden dimensions, and a Transformer with 12 heads for our decoder model. These models use a bytepair encoding vocabulary [46], and we followed previous research [3] for image patch embedding with a size of $8\times4$ . We used relative position encoding and set the maximum token length to 512.
我们使用了英文6和中文7的GPT-2 [44]模型作为解码器,该模型具有12层、768个隐藏维度以及12个头的Transformer。这些模型采用字节对编码词汇表[46],并遵循先前研究[3]中大小为$8\times4$的图像块嵌入方法。我们使用了相对位置编码,并将最大token长度设置为512。
We used an English pre-training dataset for English and a combination of English and Chinese datasets for Chinese to train the proposed model. Model training was performed for one epoch with a batch size of 32. We used the AdamW optimizer with a learning rate of 1e-4 [31].
我们使用英文预训练数据集训练英文模型,并混合中英文数据集训练中文模型。模型训练采用批量大小32进行一个周期训练,使用AdamW优化器 (学习率1e-4) [31]。
During the fine-tuning phase, the models were initialized using pre-trained weights and subsequently trained for the target datasets using a learning rate of 5e-6 for one epoch, except for SROIE, for which the models were trained for four epochs. The same optimizer and batch size were used in the pre-training phase.
在微调阶段,模型使用预训练权重进行初始化,随后以5e-6的学习率对目标数据集训练一个周期(SROIE数据集除外,该数据集训练了四个周期)。优化器和批量大小与预训练阶段保持一致。
We approximately followed previous work for the data augmentation and label pre-processing [3]. We applied Rand Augment [8], except for Sharpness. Invert, Gaussian blur, and Poisson noise were added owing to their effectiveness. The Rand Augment policy of three layers and a magnitude of five was used. All images were resized to $128\times32$ pixels. Furthermore, the original orientation was retained, rotated clockwise, or rotated with a probability of $95%$ , $2.5%$ , and $2.5%$ , to account for images that were rotated 90 degrees clockwise. Eventually, the image was standardized to fit into the range of -1 to 1.
我们大致遵循了先前研究的数据增强和标签预处理方法 [3]。除锐度(Sharpness)外,我们应用了Rand Augment [8],并因其有效性增加了反相(Invert)、高斯模糊(Gaussian blur)和泊松噪声(Poisson noise)。采用三层Rand Augment策略,幅度设为五。所有图像尺寸调整为$128\times32$像素。此外,为处理顺时针旋转90度的图像,原始方向保留、顺时针旋转或旋转的概率分别为$95%$、$2.5%$和$2.5%$。最终,图像被标准化到-1至1的范围。
The models were trained using PyTorch on Nvidia A100 GPUs with mixed precision. The inference was performed on the RTX $2080\mathrm{Ti}$ to measure the processing speed under the same conditions as those of a previous study [62]. The reported scores are averaged from four replicates per model, following a previous study [3], except for SROIE Task 2.
模型使用PyTorch框架在Nvidia A100 GPU上采用混合精度进行训练。推理环节在RTX $2080\mathrm{Ti}$ 显卡上执行,以匹配先前研究[62]的测试条件。除SROIE Task 2外,报告分数均按文献[3]方法对每个模型进行四次重复实验取平均值。
4.4. Comparison with State-of-the-Art Methods
4.4. 与最先进方法的对比
Scene Text Recognition. We compared the proposed method with several state-of-the-art scene text recognition methods. Table 1 presents the results for several widely used English benchmark datasets: IIIT5K, SVT, IC13, IC15, SVTP, and CUTE. As the training dataset conditions differed for each method, we present the results of the synthetic and real-world datasets separately. As can be observed from Table 1, our method outperformed the existing state-of-the-art methods on all benchmarks by a large margin for both the synthetic and real datasets. The competitive methods for the synthetic datasets, namely TrOCR, ABINet, PARSeq, and MaskOCR, employ an encoder and incorporate LMs to achieve high accuracy. However, our method, which does not use an encoder, achieved superior accuracy. This suggests that vision encoders are not necessary to achieve high accuracy in scene text recognition tasks. As previous studies have demonstrated that training on real datasets is more effective than that on synthetic datasets [2], we also trained our proposed method on real datasets. We confirmed that the proposed method also achieved better accuracy when it was trained on real datasets.
场景文本识别。我们将所提方法与多种最先进的场景文本识别方法进行了对比。表1展示了在多个广泛使用的英文基准数据集(IIIT5K、SVT、IC13、IC15、SVTP和CUTE)上的结果。由于各方法的训练数据集条件不同,我们分别呈现了合成数据集和真实数据集的结果。从表1可以看出,无论是在合成数据还是真实数据上,我们的方法在所有基准测试中都大幅领先现有最优方法。针对合成数据集的竞争方法(如TrOCR、ABINet、PARSeq和MaskOCR)都采用编码器并整合语言模型(LM)来获得高精度。然而,我们未使用编码器的方法却实现了更高的准确率,这表明在场景文本识别任务中视觉编码器并非实现高精度的必要条件。由于先前研究[2]已证明在真实数据集上训练比合成数据集更有效,我们也在真实数据集上训练了所提方法,并证实该方法在真实数据训练下同样能获得更优的准确率。
Figure 3 depicts the recognition results of training several state-of-the-art methods [3, 13] on real datasets. The proposed method performed text recognition reasonably well compared to the other methods, even under occlusion and an irregular layout. Moreover, the proposed method correctly read the two-line text, which methods in previous studies failed to achieve.
图 3: 展示了在真实数据集上训练几种先进方法 [3, 13] 的识别结果。即使在遮挡和不规则布局的情况下,所提方法的文本识别效果仍优于其他方法。此外,该方案成功读取了双行文本,而此前研究中的方法均未能实现该效果。
SROIE Task 2. Table 2 presents the results of the existing and proposed methods on SROIE Task 2. The CRNN, H&H Lab, MSOLab, and CLOVA OCR methods use CNN-based feature extractors to take advantage of image information, whereas TrOCR uses the ViT families. The results demonstrate that our method outperformed the existing methods without either approach. Thus, the proposed method can be applied not only to reading text in natural scene images but also to text in printed documents in the real world.
SROIE任务2。表2展示了现有方法和所提方法在SROIE任务2上的结果。CRNN、H&H Lab、MSOLab和CLOVA OCR方法使用基于CNN (Convolutional Neural Network) 的特征提取器来利用图像信息,而TrOCR则采用了ViT (Vision Transformer) 系列模型。结果表明,我们的方法在不依赖这两种方案的情况下仍优于现有方法。因此,所提方法不仅适用于自然场景图像中的文本识别,也能有效处理现实世界印刷文档中的文本。
IAM Handwriting Database. Table 3 summarizes the results of the proposed and existing methods on the IAM Handwriting Database. Our method was superior to the most significant existing approach, which was trained with Diaz’s internal annotated dataset and used an external LM [10]. Our method does not make use of either of these and can achieve better accuracy solely through synthetic and benchmark datasets. Our method also performed better than TrOCR, which uses Transformers, under similar conditions. The experimental results affirm that the proposed text recognition method with the generative LM is also effective for recognizing handwritten text.
IAM手写数据库。表3总结了所提方法与现有方法在IAM手写数据库上的结果。我们的方法优于最重要的现有方法[10](该方法使用Diaz内部标注数据集并借助外部语言模型训练)。本方法无需依赖上述资源,仅通过合成数据和基准数据集即可实现更高准确率。在相似条件下,本方法表现也优于采用Transformer架构的TrOCR。实验结果证实,所提出的基于生成式语言模型的文本识别方法对手写文本同样有效。
CTR. Table 4 summarizes the results of the proposed and previous approaches on the CTR benchmark, which has more characters to categorize and is more challenging than the English benchmark. The results confirm the generality of our method. In terms of accuracy, the proposed method outperformed the existing methods by a large margin for all subsets. The Transformer-based encoder-decoder methods, namely TrOCR and MaskOCR, achieved high accuracy in previous studies. Both of those decoders are pre-trained models based on MLM. However, the proposed method is based on generative pre-training by predicting the next word token. We confirm that the decoder with the generative model can model sequential patterns more flexibly, even for complex text sequences such as Chinese.
CTR。表4总结了所提方法和先前方法在CTR基准测试上的结果,该基准比英文基准具有更多字符分类类别且更具挑战性。结果验证了我们方法的通用性。在准确率方面,所提方法在所有子集上都显著优于现有方法。基于Transformer的编码器-解码器方法(即TrOCR和MaskOCR)在先前研究中取得了较高准确率,这两种解码器都是基于MLM的预训练模型。而我们的方法基于通过预测下一个单词token的生成式预训练。我们证实,即使对于中文这类复杂文本序列,采用生成模型的解码器也能更灵活地建模序列模式。
Our method has fewer parameters and is more accurate than the existing large-scale model Mask OCR LARGE [34]. Therefore, our method significantly improves the tradeoff between the number of parameters and accuracy. Furthermore, the reported processing speed, which is also known as the frames per second (FPS), has been low in previous studies. Our work is based on generative LMs, and because acceleration research has recently been conducted to make LMs easier to handle [9], we believe that further improvements in terms of speed can be expected by applying these techniques.
我们的方法参数更少,且比现有的大规模模型Mask OCR LARGE [34]更准确。因此,我们的方法显著改善了参数量与准确率之间的权衡关系。此外,以往研究中报告的每秒帧数(FPS)处理速度一直较低。我们的工作基于生成式大语言模型,由于近期已有研究致力于提升大语言模型的处理效率[9],我们相信通过应用这些技术有望进一步提升速度表现。
Table 5. Architecture analysis.
表 5: 架构分析。
| 模型 | 编码器 | 解码器 | STR | CTR |
|---|---|---|---|---|
| Completemodel | — | 12层 (GPT-2 [44]) | 97.7 | 89.6 |
| Model (a) | 12层 (ViT [11]) | 12层 (GPT-2 [44]) | 97.5 | 90.0 |
| TrOCR | 12层 (ViT [11]) | 12层 (RoBERTa [30]) | 92.6 | 79.3 |
Table 6. Effects of training process.
表 6: 训练过程效果对比
| STR | CTR | |
|---|---|---|
| 从头训练 | 61.0 | 43.4 |
| + 预训练解码器 | 88.1 | 81.3 |
| + 数据增强 | 95.3 | 88.9 |
| + 真实数据集微调 | 97.7 | 89.6 |
Table 7. Effects of pre-training dataset.
表 7. 预训练数据集的影响
| 模型 | 数据集量 | 训练轮数 | STR | CTR |
|---|---|---|---|---|
| 完整模型 | 100% | 1 | 97.7 | 89.6 |
| 模型 (b) | 50% | 2 | 97.5 | 89.1 |
| 模型 (c) | 25% | 4 | 96.2 | 85.7 |
| 模型 (d) | 25% | 1 | 91.4 | 77.9 |
Table 8. Effects of pre-trained decoder architecture.
表 8: 预训练解码器架构的影响
| 模型 | 解码器 | 参数量 (百万) | STR |
|---|---|---|---|
| 完整模型 | GPT-2 | 128 | 97.7 |
| 模型 (e) | GPT-2Medium | 359 | 97.9 |
| 模型 (f) | GPT-2 Large | 778 | 98.3 |
4.5. Detailed Analysis
4.5. 详细分析
The English scene text recognition (STR) and Chinese Text Recognition (CTR) were used to confirm the effectiveness of the proposed method in detail. We used the real dataset for training and reported the average subset scores.
采用英文场景文本识别(STR)和中文文本识别(CTR)详细验证了所提方法的有效性。训练使用真实数据集,并报告了平均子集分数。
Architecture Analysis. We analyzed the effects of the model structure on the performance, as indicated in Table 5. The configurations show the number of Transformer layers and models used. Model (a) used a sequence of features that were extracted by the encoder instead of a patch-embedded image sequence. Therefore, model (a) was expected to produce more sophisticated features because it incorporates an image-specific encoder. The results show that model (a) achieved slightly higher accuracy in the CTR, whereas the proposed method was superior in the STR. As many Chinese characters appear similar in CTR, more sophisticated features may be required, resulting in a difference in the accuracy. However, sufficient accuracy was also achieved with the decoder-only structure, which indicates that an encoder is not always necessary. We also trained TrOCR, which uses RoBERTa [30] as the decoder and is pre-trained with MLM. The comparison of the decoders confirmed that the model that was pre-trained with GPT was superior in the text recognition task. Thus, the architecture analysis confirms that the text recognition model may not require the encoder-decoder architecture, and GPT is a better decoder approach.
架构分析。我们分析了模型结构对性能的影响,如表 5 所示。配置显示了使用的 Transformer 层数和模型数量。模型 (a) 使用了编码器提取的特征序列而非图像块嵌入序列,因此预期能生成更精细的特征,因为它包含了图像专用编码器。结果显示模型 (a) 在 CTR 任务中准确率略高,而本文方法在 STR 任务中表现更优。由于 CTR 中许多汉字外观相似,可能需要更复杂的特征,导致准确率差异。但仅使用解码器的结构也达到了足够精度,表明编码器并非必需。我们还训练了使用 RoBERTa [30] 作为解码器并经 MLM 预训练的 TrOCR,解码器对比实验证实经 GPT 预训练的模型在文本识别任务中更优。因此架构分析表明:文本识别模型可能不需要编码器-解码器架构,且 GPT 是更优的解码器方案。
Effects of Model Training. We verified the effects of the training process on the accuracy of our method. Table 6 presents the results for each training process. The decoder initialization using pre-trained models, data augmentation, and fine-tuning with real datasets yielded significant improvements over the training from scratch.
模型训练效果。我们验证了训练过程对方法准确性的影响。表6展示了各训练阶段的结果。使用预训练模型初始化解码器、数据增强以及真实数据集微调相比从头训练均带来了显著提升。
Effects of Pre-training Dataset. We examined the effects of the amount of pre-training datasets and training epochs, as summarized in Table 7. The proposed method was trained on the entire synthetic dataset for one epoch to avoid over fitting models. Models (b) and (c) were trained by reducing the training data using random sampling while the overall number of training iterations was maintained. The results indicate that increasing the number of data variations is more critical for our method than increasing the training iterations with fewer data. Furthermore, model (d), which was simply trained with a reduced amount of data, exhibited significantly reduced accuracy, thereby confirming the importance of the pre-training dataset size.
预训练数据集的影响。我们研究了预训练数据集规模和训练轮次的影响,结果总结如表 7 所示。为避免过拟合,本方法在完整合成数据集上仅训练一个轮次。模型 (b) 和 (c) 通过随机抽样减少训练数据,同时保持总训练迭代次数不变。实验表明,相较于使用较少数据增加训练迭代次数,提升数据多样性对本方法更为关键。此外,仅简单减少数据量训练的模型 (d) 准确率显著下降,由此证实了预训练数据集规模的重要性。
Model Size Effects of Pre-trained Decoder. We verified the variation in the accuracy according to the decoder. Table 8 presents the number of parameters and accuracy of each decoder. This experiment was conducted on English benchmarks owing to the limited availability of pre-trained models. The more extensive models tended to achieve higher accuracy. Thus, the experimental results confirm that a higher ability of the LM is also more critical for text recognition.
预训练解码器的模型规模效应。我们验证了不同解码器对准确率的影响。表8展示了各解码器的参数量与准确率。由于预训练模型的可用性有限,本实验仅在英文基准测试上进行。模型规模越大,往往能获得更高的准确率。因此,实验结果证实了语言模型(LM)能力越强,对文本识别任务也越关键。
表8:
5. Conclusion
5. 结论
We have presented a new text recognition method known as DTrOCR, which uses a decoder-only Transformer model. In this method, a powerful generative LM that is pre-trained on a large corpus is used as a decoder, and the correspondence between the input images and recognition texts is learned. We demonstrated that in this manner, a simple text recognition structure considering linguistic information is possible. The experimental results revealed that our method outperformed existing works on various benchmarks. This study contributes to a fundamental shift in text recognition by showing that text recognition can be performed without the encoder-decoder structure approach and highlighting the possibility of decoder-only Transformer models.
我们提出了一种名为DTrOCR的新文本识别方法,该方法采用仅含解码器的Transformer模型。该方案使用在大规模语料库上预训练的强效生成式大语言模型作为解码器,通过学习输入图像与识别文本间的对应关系实现识别。实验证明,这种考虑语言信息的简易文本识别结构具有可行性。测试结果表明,本方法在多项基准测试中优于现有方案。本研究通过证实文本识别无需编码器-解码器结构即可实现,并突显了纯解码器Transformer模型的潜力,为文本识别领域带来了根本性变革。