Face Forensics++: Learning to Detect Manipulated Facial Images
Face Forensics++: 学习检测被篡改的人脸图像
Andreas Rosslerl Davide Cozzolino2 Luisa Verdoliva² Christian Riess3 Justus Thies1 Matthias Nießner1 1Technical University of Munich 2 University Federico II of Naples 3 University of Erlangen-Nuremberg
Andreas Rosslerl Davide Cozzolino2 Luisa Verdoliva² Christian Riess3 Justus Thies1 Matthias Nießner1 1慕尼黑工业大学 2那不勒斯费德里科二世大学 3埃尔朗根-纽伦堡大学
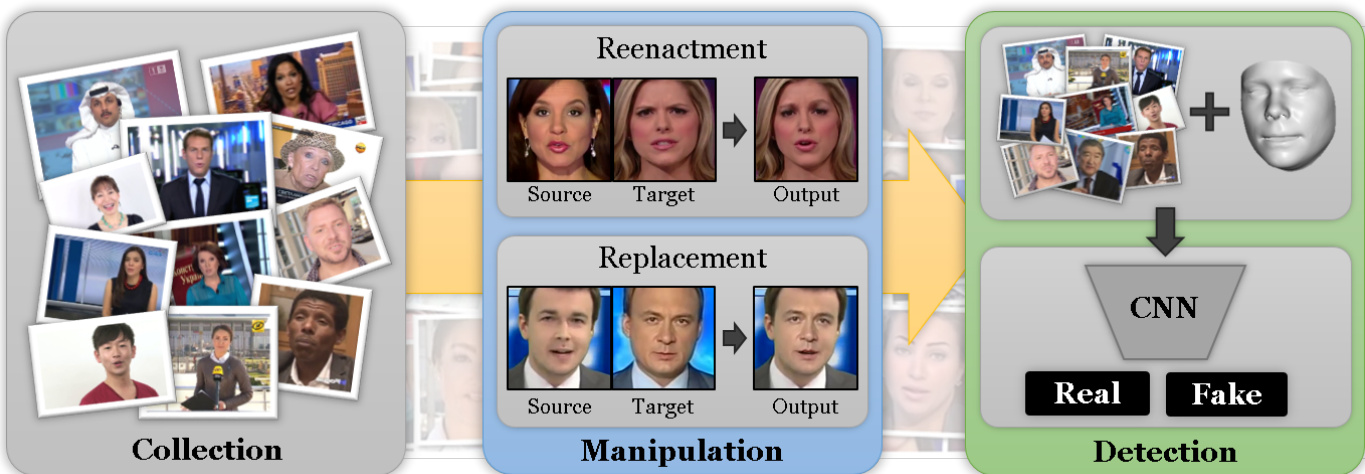
Figure 1: Face Forensics $^{++}$ is a dataset of facial forgeries that enables researchers to train deep-learning-based approaches in a supervised fashion. The dataset contains manipulations created with four state-of-the-art methods, namely, Face2Face, FaceSwap, DeepFakes, and Neural Textures.
图 1: Face Forensics++ 是一个面部伪造数据集,使研究人员能够以监督方式训练基于深度学习的方法。该数据集包含使用四种最先进方法 (Face2Face、FaceSwap、DeepFakes 和 Neural Textures) 创建的篡改内容。
Abstract
摘要
The rapid progress in synthetic image generation and manipulation has now come to a point where it raises significant concerns for the implications towards society. At best, this leads to a loss of trust in digital content, but could potentially cause further harm by spreading false information or fake news. This paper examines the realism of state-ofthe-art image manipulations, and how difficult it is to detect them, either automatically or by humans.
合成图像生成与处理技术的快速发展已到了引发社会重大关切的阶段。往轻了说,这会削弱人们对数字内容的信任;往重了想,它可能通过传播虚假信息或假新闻造成更深层次的危害。本文研究了当前最先进的图像处理技术的逼真程度,以及通过自动化手段或人工方式检测这些篡改图像的难度。
To standardize the evaluation of detection methods, we propose an automated benchmark for facial manipulation detection1. In particular, the benchmark is based on DeepFakes [1], Face2Face [59], FaceSwap [2] and NeuralTextures [57] as prominent representatives for facial manipulations at random compression level and size. The benchmark is publicly available2 and contains a hidden test set as well as a database of over 1.8 million manipulated images. This dataset is over an order of magnitude larger than comparable, publicly available, forgery datasets. Based on this data, we performed a thorough analysis of data-driven forgery detectors. We show that the use of additional domainspecific knowledge improves forgery detection to unprecedented accuracy, even in the presence of strong compression, and clearly outperforms human observers.
为规范检测方法的评估,我们提出了一种自动化的人脸篡改检测基准。该基准以DeepFakes [1]、Face2Face [59]、FaceSwap [2]和NeuralTextures [57]作为随机压缩级别和尺寸下人脸篡改的典型代表。该基准已公开可用,包含一个隐藏测试集以及超过180万张篡改图像的数据库,其规模比同类公开可用的伪造数据集大一个数量级。基于这些数据,我们对数据驱动的伪造检测器进行了全面分析。研究表明,即使存在强压缩情况,利用特定领域知识也能将伪造检测提升至前所未有的准确度,其性能明显优于人类观察者。
1. Introduction
1. 引言
Manipulation of visual content has now become ubiquitous, and one of the most critical topics in our digital society. For instance, DeepFakes [1] has shown how computer graphics and visualization techniques can be used to defame persons by replacing their face by the face of a different person. Faces are of special interest to current manipulation methods for various reasons: firstly, the reconstruction and tracking of human faces is a well-examined field in computer vision [68], which is the foundation of these editing approaches. Secondly, faces play a central role in human communication, as the face of a person can emphasize a message or it can even convey a message in its own right [28].
视觉内容操纵如今已无处不在,成为数字社会中最关键的议题之一。例如DeepFakes[1]展示了如何通过将人脸替换为他人面孔,利用计算机图形学和可视化技术进行诽谤。人脸成为当前操纵技术特别关注的对象有多重原因:首先,人脸的 reconstruction (重建) 和 tracking (追踪) 是计算机视觉领域深入研究的方向[68],这些编辑技术正是建立在此基础之上;其次,面部在人类交流中具有核心作用,既能强化信息传递,其本身也可作为独立的信息载体[28]。
Current facial manipulation methods can be separated into two categories: facial expression manipulation and facial identity manipulation (see Fig. 2). One of the most prominent facial expression manipulation techniques is the method of Thies et al. [59] called Face2Face. It enables the transfer of facial expressions of one person to another person in real time using only commodity hardware. Follow-up work such as “Synthesizing Obama” [55] is able to animate the face of a person based on an audio input sequence.
当前的面部操控方法可分为两类:面部表情操控和面部身份操控(见图 2)。最突出的面部表情操控技术之一是 Thies 等人 [59] 提出的 Face2Face 方法。该方法仅使用普通硬件即可实时将一个人的面部表情转移到另一个人脸上。后续研究如“Synthesizing Obama” [55] 能够基于音频输入序列驱动人物面部动画。

Figure 2: Advances in the digitization of human faces have become the basis for modern facial image editing tools. The editing tools can be split in two main categories: identity modification and expression modification. Aside from manually editing the face using tools such as Photoshop, many automatic approaches have been proposed in the last few years. The most prominent and widespread identity editing technique is face swapping, which has gained significant popularity as lightweight systems are now capable of running on mobile phones. Additionally, facial reenactment techniques are now available, which alter the expressions of a person by transferring the expressions of a source person to the target.
图 2: 人脸数字化的进步已成为现代面部图像编辑工具的基础。这些编辑工具可分为两大类:身份修改和表情修改。除了使用Photoshop等工具手动编辑面部外,过去几年还提出了许多自动化方法。最突出且广泛使用的身份编辑技术是换脸(face swapping),随着轻量级系统现在能在手机上运行,该技术已获得显著普及。此外,面部重演(facial reenactment)技术现已可用,该技术通过将源人物的表情转移到目标人物来改变其表情。
Identity manipulation is the second category of facial forgeries. Instead of changing expressions, these methods replace the face of a person with the face of another person. This category is known as face swapping. It became popular with wide-spread consumer-level applications like Snapchat. DeepFakes also performs face swapping, but via deep learning. While face swapping based on simple computer graphics techniques can run in real time, DeepFakes need to be trained for each pair of videos, which is a timeconsuming task.
身份操纵是面部伪造的第二类方法。与改变表情不同,这些方法会将一个人的脸替换成另一个人的脸。这类技术被称为换脸 (face swapping) ,随着Snapchat等消费级应用的普及而流行起来。DeepFakes同样通过深度学习实现换脸功能。基于简单计算机图形技术的换脸方案可以实时运行,但DeepFakes需要为每对视频进行训练,这是个耗时的工作。
In this work, we show that we can automatically and reliably detect such manipulations, and thereby outperform human observers by a significant margin. We leverage recent advances in deep learning, in particular, the ability to learn extremely powerful image features with convolutional neural networks (CNNs). We tackle the detection problem by training a neural network in a supervised fashion. To this end, we generate a large-scale dataset of manipulations based on the classical computer graphics-based methods Face2Face [59] and FaceSwap [2] as well as the learningbased approaches DeepFakes [1] and Neural Textures [57].
在本研究中,我们证明了能够自动且可靠地检测此类篡改操作,从而显著超越人类观察者的判断能力。我们利用深度学习领域的最新进展,特别是通过卷积神经网络(CNN)学习极其强大图像特征的能力。通过监督式训练神经网络来解决检测问题。为此,我们基于传统计算机图形学方法Face2Face [59]和FaceSwap [2],以及基于学习的DeepFakes [1]和Neural Textures [57]技术,构建了大规模篡改数据集。
As the digital media forensics field lacks a benchmark for forgery detection, we propose an automated benchmark that considers the four manipulation methods in a realistic scenario, i.e., with random compression and random dimensions. Using this benchmark, we evaluate the current state-of-the-art detection methods as well as our forgery detection pipeline that considers the restricted field of facial manipulation methods.
由于数字媒体取证领域缺乏伪造检测的基准,我们提出了一种自动化基准,该基准考虑了现实场景中的四种篡改方法(即随机压缩和随机尺寸)。利用这一基准,我们评估了当前最先进的检测方法,以及我们针对面部篡改方法受限领域设计的伪造检测流程。
Our paper makes the following contributions:
我们的论文做出了以下贡献:
• an automated benchmark for facial manipulation detection under random compression for a standardized comparison, including a human baseline, • a novel large-scale dataset of manipulated facial imagery composed of more than 1.8 million images from
• 一个用于面部操纵检测的自动化基准测试,支持随机压缩下的标准化比较,包括人类基线
• 一个新颖的大规模面部操纵图像数据集,包含来自...的超过180万张图像
1,000 videos with pristine (i.e., real) sources and target ground truth to enable supervised learning, • an extensive evaluation of state-of-the-art hand-crafted and learned forgery detectors in various scenarios, a state-of-the-art forgery detection method tailored to facial manipulations.
• 1000段带有原始(即真实)来源和目标基准真相的视频,用于支持监督学习
• 对各类场景下最先进的手工制作和学习的伪造检测器进行广泛评估
• 专为面部操作定制的最先进伪造检测方法
2. Related Work
2. 相关工作
The paper intersects several fields in computer vision and digital multimedia forensics. We cover the most important related papers in the following paragraphs.
该论文涉及计算机视觉和数字多媒体取证领域的多个交叉方向。下文将概述最重要的相关文献。
Face Manipulation Methods: In the last two decades, interest in virtual face manipulation has rapidly increased. A comprehensive state-of-the-art report has been published by Zollhofer et al. [68]. In particular, Bregler et al. [13] presented an image-based approach called Video Rewrite to auto mati call y create a new video of a person with generated mouth movements. With Video Face Replacement [20], Dale et al. presented one of the first automatic face swap methods. Using single-camera videos, they reconstruct a 3D model of both faces and exploit the corresponding 3D geometry to warp the source face to the target face. Garrido et al. [29] presented a similar system that replaces the face of an actor while preserving the original expressions. VDub [30] uses high-quality 3D face capturing techniques to photo-realistically alter the face of an actor to match the mouth movements of a dubber. Thies et al. [58] demonstrated the first real-time expression transfer for facial reenactment. Based on a consumer level RGB-D camera, they reconstruct and track a 3D model of the source and the target actor. The tracked deformations of the source face are applied to the target face model. As a final step, they blend the altered face on top of the original target video. Face2Face, proposed by Thies et al. [59], is an advanced real-time facial reenactment system, capable of altering facial movements in commodity video streams, e.g., videos from the internet. They combine 3D model reconstruction and image-based rendering techniques to generate their output. The same principle can be also applied in Virtual Reality in combination with eye-tracking and reenactment [60] or be extended to the full body [61]. Kim et al. [39] learn an image-to-image translation network to convert computer graphic renderings of faces to real images. Instead of a pure image-to-image translation network, Neural Textures [57] optimizes a neural texture in conjunction with a rendering network to compute the reenactment result. In comparison to Deep Video Portraits [39], it shows sharper results, especially, in the mouth region. Suwa jana korn et al. [55] learned the mapping between audio and lip motions, while their compositing approach builds on similar techniques to Face2Face [59]. Averbuch-Elor et al. [8] present a reenactment method, Bringing Portraits to Life, which employs 2D warps to deform the image to match the expressions of a source actor. They also compare to the Face2Face technique and achieve similar quality.
面部操纵方法:过去二十年间,人们对虚拟面部操纵的兴趣迅速增长。Zollhofer等人[68]发表了全面的技术前沿报告。Bregler等人[13]提出了一种基于图像的方法Video Rewrite,能自动生成带有嘴部动作的新人物视频。Dale等人[20]通过《视频人脸替换》提出了最早的自动换脸方法之一,他们利用单摄像头视频重建双方面部3D模型,并运用对应3D几何结构将源面部变形至目标面部。Garrido等人[29]开发了类似系统,可在保留演员原始表情的同时替换面部。VDub[30]采用高质量3D面部捕捉技术,使演员面部与配音者口型实现照片级匹配。Thies等人[58]首次实现了实时表情迁移的面部重演技术,基于消费级RGB-D相机重建并跟踪源演员与目标演员的3D模型,将源面部的形变跟踪数据应用于目标面部模型,最终将修改后的面部与原目标视频融合。Thies等人[59]提出的Face2Face是先进的实时面部重演系统,可修改普通视频流(如网络视频)中的面部动作,结合了3D模型重建与基于图像的渲染技术。该原理还可结合眼动追踪与重演技术应用于虚拟现实[60],或扩展至全身动作[61]。Kim等人[39]通过图像到图像转换网络将计算机生成的面部渲染图转化为真实图像。Neural Textures[57]不同于纯图像转换网络,它联合优化神经纹理与渲染网络来计算重演结果,相比《深度视频肖像》[39]能呈现更清晰的口型区域。Suwajanakorn等人[55]学习了语音与唇部运动的映射关系,其合成技术基于与Face2Face[59]相似的原理。Averbuch-Elor等人[8]提出重演方法《赋予肖像生命》,采用2D形变使图像匹配源演员表情,其效果与Face2Face技术相当。
Recently, several face image synthesis approaches using deep learning techniques have been proposed. Lu et al. [47] provide an overview. Generative adversarial networks (GANs) are used to apply Face Aging [7], to generate new viewpoints [34], or to alter face attributes like skin color [46]. Deep Feature Interpolation [62] shows impressive results on altering face attributes like age, mustache, smiling etc. Similar results of attribute interpolations are achieved by Fader Networks [43]. Most of these deep learning based image synthesis techniques suffer from low image resolutions. Recently, Karras et al. [37] have improved the image quality using progressive growing of GANs, producing high-quality synthesis of faces.
近年来,多项基于深度学习的人脸图像合成方法被提出。Lu等人[47]对此进行了综述。生成对抗网络(GAN)被用于实现人脸老化[7]、生成新视角[34]或改变肤色等面部属性[46]。深度特征插值[62]在改变年龄、胡须、微笑等面部属性方面展现出令人印象深刻的效果。Fader网络[43]也实现了类似的属性插值效果。大多数基于深度学习的图像合成技术都存在图像分辨率低的问题。最近,Karras等人[37]通过渐进式增长的GAN提升了图像质量,实现了高质量的人脸合成。
Multimedia Forensics: Multimedia forensics aims to ensure authenticity, origin, and provenance of an image or video without the help of an embedded security scheme. Focusing on integrity, early methods are driven by handcrafted features that capture expected statistical or physicsbased artifacts that occur during image formation. Surveys on these methods can be found in [26, 53]. More recent literature concentrates on CNN-based solutions, through both supervised and unsupervised learning [10, 17, 12, 9, 35, 67]. For videos, the main body of work focuses on detecting manip ul at ions that can be created with relatively low effort, such as dropped or duplicated frames [63, 31, 45], varying interpolation types [25], copy-move manipulations [11, 21], or chroma-key compositions [48].
多媒体取证:多媒体取证旨在无需依赖嵌入式安全方案的情况下,确保图像或视频的真实性、来源与出处。早期方法聚焦完整性检测,通过手工特征提取来捕捉图像形成过程中预期的统计或物理伪影 [26, 53]。近期研究则集中于基于CNN(卷积神经网络)的解决方案,涵盖监督式与无监督学习 [10, 17, 12, 9, 35, 67]。针对视频取证,主要工作集中于检测低技术门槛的篡改手段,例如丢帧或重复帧 [63, 31, 45]、插值类型变化 [25]、复制-移动篡改 [11, 21] 或色键合成 [48]。
Several other works explicitly refer to detecting manipulations related to faces, such as distinguishing computer generated faces from natural ones [22, 15, 51], morphed faces [50], face splicing [24, 23], face swapping [66, 38] and DeepFakes [5, 44, 33]. For face manipulation detection, some approaches exploit specific artifacts arising from the synthesis process, such as eye blinking [44], or color, texture and shape cues [24, 23]. Other works are more general and propose a deep network trained to capture the subtle inconsistencies arising from low-level and/or high level features [50, 66, 38, 5, 33]. These approaches show impressive results, however robustness issues often remain unaddressed, although they are of paramount importance for practical applications. For example, operations like compression and resizing are known for laundering manipulation traces from the data. In real-world scenarios, these basic operations are standard when images and videos are for example uploaded to social media, which is one of the most important application field for forensic analysis. To this end, our dataset is designed to cover such realistic scenarios, i.e., videos from the wild, manipulated and compressed with different quality levels (see Section 3). The availability of such a large and varied dataset can help researchers to benchmark their approaches and develop better forgery detectors for facial imagery.
其他研究则明确涉及面部相关篡改的检测,例如区分计算机生成面孔与自然面孔 [22, 15, 51]、融合面孔 (morphed faces) [50]、面部拼接 (face splicing) [24, 23]、面部替换 (face swapping) [66, 38] 以及 DeepFakes [5, 44, 33]。针对面部篡改检测,部分方法利用合成过程中产生的特定伪影,如眨眼 [44] 或颜色、纹理与形状线索 [24, 23];另一些研究则更通用地提出通过训练深度网络来捕捉底层和/或高层特征产生的微妙不一致性 [50, 66, 38, 5, 33]。这些方法虽展现出优异效果,但鲁棒性问题常未被解决——而这恰恰是实际应用中的关键所在。例如,压缩和尺寸调整等操作会消除数据中的篡改痕迹。现实场景中,当图像视频上传至社交媒体(取证分析最重要的应用领域之一)时,这类基础操作已成标准流程。为此,我们的数据集专门设计用于覆盖此类真实场景,即包含不同质量等级的野生视频、篡改视频及压缩视频(见第3节)。如此大规模多样化数据集的建立,可助力研究者对其方法进行基准测试,并开发更优秀的面部伪造检测器。
Forensic Analysis Datasets: Classical forensics datasets have been created with significant manual effort under very controlled conditions, to isolate specific properties of the data like camera artifacts. While several datasets were proposed that include image manipulations, only a few of them also address the important case of video footage. MICC F2000, for example, is an image copy-move manipulation dataset consisting of a collection of 700 forged images from various sources [6]. The First IEEE Image Forensics Challenge Dataset comprises a total of 1176 forged images; the Wild Web Dataset [64] with 90 real cases of manipulations coming from the web and the Realistic Tampering dataset [42] including 220 forged images. A database of 2010 FaceSwap- and SwapMe-generated images has been proposed by Zhou et al. [66]. Recently, Korshunov and Marcel [41] constructed a dataset of 620 Deepfakes videos created from multiple videos for each of 43 subjects. The National Institute of Standards and Technology (NIST) released the most extensive dataset for generic image manipulation comprising about 50, 000 forged images (both local and global manipulations) and around 500 forged videos [32].
取证分析数据集:经典取证数据集是在高度受控条件下通过大量人工努力创建的,旨在分离数据的特定属性(如相机伪影)。虽然已有多个包含图像篡改的数据集被提出,但其中只有少数涉及视频素材这一重要案例。例如,MICC F2000是一个图像复制-移动篡改数据集,包含来自不同来源的700张伪造图像[6]。第一届IEEE图像取证挑战赛数据集共包含1176张伪造图像;Wild Web数据集[64]收录了来自网络的90个真实篡改案例,而Realistic Tampering数据集[42]则包含220张伪造图像。Zhou等人[66]提出了一个由2010张通过FaceSwap和SwapMe生成的图像数据库。最近,Korshunov和Marcel[41]构建了一个包含43名受试者的620段Deepfakes视频数据集,这些视频由多个原始视频生成。美国国家标准与技术研究院(NIST)发布了最全面的通用图像篡改数据集,包含约50,000张伪造图像(局部和全局篡改)以及约500段伪造视频[32]。
In contrast, we construct a database containing more than 1.8 million images from 4000 fake videos – an order of magnitude more than existing datasets. We evaluate the importance of such a large training corpus in Section 4.
相比之下,我们构建了一个包含4000部伪造视频中超过180万张图像的数据库,其规模比现有数据集大一个数量级。我们将在第4节评估如此庞大训练集的重要性。
3. Large-Scale Facial Forgery Database
3. 大规模人脸伪造数据库
A core contribution of this paper is our Face Forensics $^{++}$ dataset extending the preliminary Face Forensics dataset [52]. This new large-scale dataset enables us to train a stateof-the-art forgery detector for facial image manipulation in a supervised fashion (see Section 4). To this end, we leverage four automated state-of-the-art face manipulation methods, which are applied to 1,000 pristine videos downloaded from the Internet (see Fig. 3 for statistics). To imitate realistic scenarios, we chose to collect videos in the wild, specifically from YouTube. However, early experiments with all manipulation methods showed that the target face had to be nearly front-facing to prevent the manipulation methods from failing or producing strong artifacts. Thus, we perform a manual screening of the resulting clips to ensure a high-quality video selection and to avoid videos with face occlusions. We selected 1,000 video sequences containing 509, 914 images which we use as our pristine data.
本文的核心贡献是扩展了初步Face Forensics数据集[52]的Face Forensics++数据集。这一新的大规模数据集使我们能够以监督方式训练出最先进的面部图像篡改检测器(详见第4节)。为此,我们采用了四种自动化的一流面部篡改方法,应用于从互联网下载的1,000段原始视频(统计数据见图3)。为模拟真实场景,我们特意选择收集YouTube上的自然视频。但早期实验表明,所有篡改方法都要求目标人脸近乎正对镜头,否则会导致篡改失败或产生明显伪影。因此我们对视频片段进行了人工筛选,确保高质量的视频选择,并排除存在面部遮挡的视频。最终选取的1,000段视频序列包含509,914张图像,作为我们的原始数据。
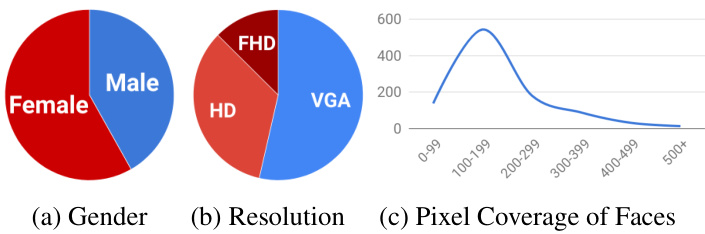
Figure 3: Statistics of our sequences. VGA denotes $480\mathrm{p}$ , $H D$ denotes $720\mathrm{p}$ , and $F H D$ denotes 1080p resolution of our videos. The graph (c) shows the number of sequences (y-axis) with given bounding box pixel height ( $\mathbf{\check{X}}$ -axis).
图 3: 我们的序列统计信息。VGA表示$480\mathrm{p}$,HD表示$720\mathrm{p}$,FHD表示1080p视频分辨率。图表(c)展示了边界框像素高度($\mathbf{\check{X}}$轴)对应的序列数量(y轴)。
To generate a large scale manipulation database, we adapted state-of-the-art video editing methods to work fully automatically. In the following paragraphs, we briefly describe these methods.
为构建大规模篡改数据库,我们采用前沿视频编辑技术实现全自动化处理。以下段落简要介绍这些方法。
For our dataset, we chose two computer graphics-based approaches (Face2Face and FaceSwap) and two learningbased approaches (DeepFakes and Neural Textures). All four methods require source and target actor video pairs as input. The final output of each method is a video composed of generated images. Besides the manipulation output, we also compute ground truth masks that indicate whether a pixel has been modified or not, which can be used to train forgery localization methods. For more information and hyper-parameters we refer to Appendix D.
在我们的数据集中,我们选择了两种基于计算机图形学的方法 (Face2Face 和 FaceSwap) 和两种基于学习的方法 (DeepFakes 和 Neural Textures)。这四种方法都需要源演员和目标演员的视频对作为输入。每种方法的最终输出是由生成图像组成的视频。除了篡改输出外,我们还计算了真实掩码 (ground truth masks),用于指示像素是否被修改,这些掩码可用于训练伪造定位方法。更多信息及超参数详见附录 D。
FaceSwap FaceSwap is a graphics-based approach to transfer the face region from a source video to a target video. Based on sparse detected facial landmarks the face region is extracted. Using these landmarks, the method fits a 3D template model using blend shapes. This model is backprojected to the target image by minimizing the difference between the projected shape and the localized landmarks using the textures of the input image. Finally, the rendered model is blended with the image and color correction is applied. We perform these steps for all pairs of source and target frames until one video ends. The implementation is computationally lightweight and can be efficiently run on the CPU.
FaceSwap
FaceSwap 是一种基于图形学的方法,用于将源视频中的人脸区域转移到目标视频中。该方法首先通过稀疏检测到的面部特征点提取人脸区域,并利用这些特征点通过混合变形 (blend shapes) 拟合一个3D模板模型。随后,通过最小化投影形状与定位特征点之间的差异(使用输入图像的纹理),将该模型反向投影到目标图像上。最后,将渲染的模型与图像进行混合并应用色彩校正。我们对所有源帧和目标帧对重复上述步骤,直到其中一个视频结束。该实现计算量轻,可高效运行在CPU上。
DeepFakes The term Deepfakes has widely become a synonym for face replacement based on deep learning, but it is also the name of a specific manipulation method that was spread via online forums. To distinguish these, we denote said method by DeepFakes in the following paper.
DeepFakes
Deepfakes一词已广泛成为基于深度学习的人脸替换代名词,但它同时也是通过在线论坛传播的特定篡改技术名称。为区分二者,本文后续将所述技术记为DeepFakes。
There are various public implementations of DeepFakes available, most notably FakeApp [3] and the faceswap github [1]. A face in a target sequence is replaced by a face that has been observed in a source video or image collection. The method is based on two auto encoders with a shared encoder that are trained to reconstruct training images of the source and the target face, respectively. A face detector is used to crop and to align the images. To create a fake image, the trained encoder and decoder of the source face are applied to the target face. The auto encoder output is then blended with the rest of the image using Poisson image editing [49].
目前存在多种公开的DeepFakes实现方案,最著名的包括FakeApp [3] 和faceswap github [1]。该方法通过将目标视频序列中的面部替换为源视频或图像集合中观察到的面部。其核心架构采用两个共享编码器的自编码器 (auto encoder) ,分别训练用于重建源人脸和目标人脸的训练图像。系统首先使用人脸检测器对图像进行裁剪和对齐处理。生成伪造图像时,将训练好的源人脸编码器和解码器应用于目标人脸,最后通过泊松图像编辑 (Poisson image editing) [49] 将自编码器输出与图像其余部分进行融合。
For our dataset, we use the faceswap github implementation. We slightly modify the implementation by replacing the manual training data selection with a fully automated data loader. We used the default parameters to train the video-pair models. Since the training of these models is very time-consuming, we also publish the models as part of the dataset. This facilitates generation of additional manipulations of these persons with different post-processing.
对于我们的数据集,我们使用了faceswap的GitHub实现。我们对该实现进行了轻微修改,将手动训练数据选择替换为全自动数据加载器。我们使用默认参数训练视频配对模型。由于这些模型的训练非常耗时,我们还将这些模型作为数据集的一部分发布。这便于通过不同后处理生成这些人物的额外操纵结果。
Face2Face Face2Face [59] is a facial reenactment system that transfers the expressions of a source video to a target video while maintaining the identity of the target person. The original implementation is based on two video input streams, with manual keyframe selection. These frames are used to generate a dense reconstruction of the face which can be used to re-synthesize the face under different illumination and expressions. To process our video database, we adapt the Face2Face approach to fully-automatically create reenactment manipulations. We process each video in a preprocessing pass; here, we use the first frames in order to obtain a temporary face identity (i.e., a 3D model), and track the expressions over the remaining frames. In order to select the keyframes required by the approach, we automatically select the frames with the left- and right-most angle of the face. Based on this identity reconstruction, we track the whole video to compute per frame the expression, rigid pose, and lighting parameters as done in the original imple ment ation of Face2Face. We generate the reenactment video outputs by transferring the source expression parameters of each frame (i.e., 76 Blendshape coefficients) to the target video. More details of the reenactment process can be found in the original paper [59].
Face2Face [59] 是一种面部重现系统,能够将源视频中的表情迁移至目标视频,同时保持目标人物的身份特征。原版实现基于双视频输入流,并采用手动关键帧选取方式。这些帧用于生成面部的密集重建,从而实现不同光照和表情下的面部重合成。为处理我们的视频数据库,我们改进了Face2Face方案以实现全自动化的重现操作。预处理阶段会对每段视频进行处理:使用起始帧获取临时面部身份(即3D模型),并在后续帧中追踪表情变化。为自动选取方法所需的关键帧,我们通过算法选择面部左右转角最大的帧。基于该身份重建结果,我们追踪整段视频以逐帧计算表情参数、刚性姿态和光照参数(与Face2Face原版实现一致)。最终通过将每帧源表情参数(即76个Blendshape系数)迁移至目标视频来生成重现视频输出。更多技术细节可参阅原始论文[59]。
Neural Textures Thies et al. [57] show facial reenactment as an example for their Neural Textures-based rendering approach. It uses the original video data to learn a neural texture of the target person, including a rendering network. This is trained with a photometric reconstruction loss in combination with an adversarial loss. In our imple ment ation, we apply a patch-based GAN-loss as used in Pix2Pix [36]. The Neural Textures approach relies on tracked geometry that is used during train and test times. We use the tracking module of Face2Face to generate these information. We only modify the facial expressions corresponding to the mouth region, i.e., the eye region stays unchanged (otherwise the rendering network would need conditional input for the eye movement similar to Deep Video Portraits [39]).
神经纹理 (Neural Textures)
Thies等人[57]以面部重演为例展示了其基于神经纹理的渲染方法。该方法利用原始视频数据学习目标人物的神经纹理,包含一个渲染网络。训练过程结合了光度重建损失和对抗损失。在我们的实现中,采用了Pix2Pix[36]使用的基于分块的GAN损失。神经纹理方法依赖于训练和测试阶段使用的跟踪几何信息,我们使用Face2Face的跟踪模块生成这些数据。仅修改与嘴部区域对应的面部表情(即眼部区域保持不变,否则渲染网络需要像Deep Video Portraits[39]那样接收眼部运动的条件输入)。
Post processing - Video Quality To create a realistic setting for manipulated videos, we generate output videos with different quality levels, similar to the video processing of many social networks. Since raw videos are rarely found on the internet, we compress the videos using the H.264 codec, which is widely used by social networks or videosharing websites. To generate high quality videos, we use a light compression denoted by $H Q$ (constant rate quantization parameter equal to 23) which is visually nearly lossless. Low quality videos $(L Q)$ are produced using a quantization of 40.
后处理 - 视频质量
为构建逼真的篡改视频场景,我们参照社交网络的视频处理流程,生成了不同质量等级的输出视频。鉴于互联网上极少出现原始视频,我们采用社交网络和视频分享网站广泛使用的H.264编解码器进行压缩。高质量视频(HQ)采用轻度压缩(量化参数恒定为23),视觉上几乎无损;低质量视频(LQ)则使用量化参数40生成。
4. Forgery Detection
4. 伪造检测
We cast the forgery detection as a per-frame binary classification problem of the manipulated videos. The following sections show the results of manual and automatic forgery detection. For all experiments, we split the dataset into a fixed training, validation, and test set, consisting of 720, 140, and 140 videos respectively. All evaluations are reported using videos from the test set. For all graphs, we list the exact numbers in Appendix B.
我们将伪造检测视为对篡改视频进行逐帧二元分类的问题。以下部分展示了人工和自动伪造检测的结果。在所有实验中,我们将数据集划分为固定的训练集、验证集和测试集,分别包含720、140和140个视频。所有评估均使用测试集中的视频进行报告。对于所有图表,我们在附录B中列出了具体数值。
4.1. Forgery Detection of Human Observers
4.1. 人类观察者的伪造检测
To evaluate the performance of humans in the task of forgery detection, we conducted a user study with 204 participants consisting mostly of computer science university students. This forms the baseline for the automated forgery detection methods.
为了评估人类在伪造检测任务中的表现,我们对204名参与者(主要为计算机科学专业的大学生)进行了用户研究。这构成了自动化伪造检测方法的基准线。
Layout of the User Study: After a short introduction to the binary task, users are instructed to classify randomly selected images from our test set. The selected images vary in image quality as well as manipulation method; we used a 50:50 split of pristine and fake images. Since the amount time for inspection of an image may be important, and to mimic scenario where a user only spends a limited amount of time per image as is common on social media, we randomly set a time limit of 2, 4 or 6 seconds after which we hide the image. Afterwards, the users were asked whether the displayed image is ‘real’ or ‘fake’. To ensure that the users spend the available time on inspection, the question is asked after the image has been displayed and not during the observation time. We designed the study to only take a few minutes per participant, showing 60 images per attendee, which results in a collection of 12240 human decisions.
用户研究布局:在简要介绍二元分类任务后,指导用户对我们测试集中随机选取的图像进行分类。所选图像在画质和篡改方法上存在差异,其中真实图像与伪造图像的比例为50:50。考虑到图像检查时间可能影响结果,并模拟社交媒体用户通常仅花费有限时间浏览单张图像的情景,我们随机设定2秒、4秒或6秒的显示时限,超时后隐藏图像。随后询问用户所显示的图像是"真实"还是"伪造"。为确保用户充分利用观察时间,问题仅在图像展示结束后提出而非观察期间。本研究设计为每位参与者仅需几分钟,每位受试者观看60张图像,最终收集到12240条人工判定结果。
Evaluation: In Fig. 4, we show the results of our study on all quality levels, showing a correlation between video quality and the ability to detect fakes. With a lower video quality, the human performance decreases in average from $68.7%$ to $58.7%$ . The graph shows the numbers averaged across all time intervals since the different time constraints did not result in significantly different observations.
评估:在图4中,我们展示了所有质量水平的研究结果,显示了视频质量与检测伪造能力之间的相关性。随着视频质量降低,人类平均表现从$68.7%$下降至$58.7%$。图表显示了所有时间间隔的平均数值,因为不同时间限制并未导致显著差异的观察结果。
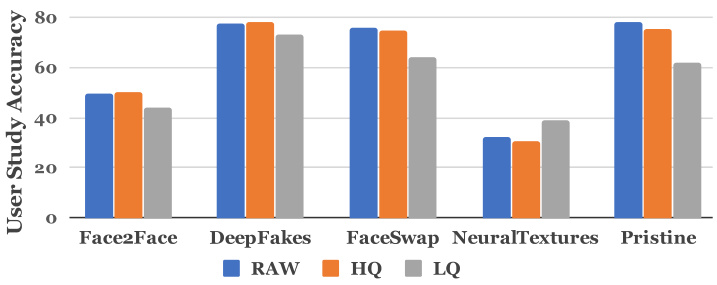
Figure 4: Forgery detection results of our user study with 204 participants. The accuracy is dependent on the video quality and results in a decreasing accuracy rate that is $68.69%$ in average on raw videos, $66.57%$ on high quality, and $58.73%$ on low quality videos.
图 4: 我们针对204名参与者的伪造检测用户研究结果。检测准确率取决于视频质量,呈现递减趋势:原始视频平均准确率为 $68.69%$,高质量视频为 $66.57%$,低质量视频为 $58.73%$。
Note that the user study contained fake images of all four manipulation methods and pristine images. In this setting, Face2Face and Neural Textures were particularly difficult to detect by human observers, as they do not introduce a strong semantic change, introducing only subtle visual artifacts in contrast to the face replacement methods. Neural Textures texture seems particularly difficult to detect as human detection accuracy is below random chance and only increases in the challenging low quality task.
请注意,用户研究中包含所有四种篡改方法的伪造图像和原始图像。在此设置下,Face2Face和Neural Textures尤其难以被人眼察觉,因为它们不会引发显著的语义变化,仅产生相比换脸方法更微弱的视觉伪影。Neural Textures的纹理似乎特别难以识别,人类检测准确率甚至低于随机概率,仅在具有挑战性的低质量任务中有所提升。
4.2. Automatic Forgery Detection Methods
4.2. 自动伪造检测方法
Our forgery detection pipeline is depicted in Fig. 5. Since our goal is to detect forgeries of facial imagery, we use additional domain-specific information that we can extract from input sequences. To this end, we use the stateof-the-art face tracking method by Thies et al. [59] to track the face in the video and to extract the face region of the image. We use a conservative crop (enlarged by a factor of 1.3) around the center of the tracked face, enclosing the reconstructed face. This incorporation of domain knowledge improves the overall performance of a forgery detector in comparison to a naive approach that uses the whole image as input (see Sec. 4.2.2). We evaluated various variants of our approach by using different state-of-the-art classification methods. We are considering learning-based methods used in the forensic community for generic manipulation detection [10, 17], computer-generated vs natural image detection [51] and face tampering detection [5]. In addition, we show that the classification based on Xc ep tion Net [14] outperforms all other variants in detecting fakes.
我们的伪造检测流程如图5所示。由于目标是检测面部图像的伪造痕迹,我们利用了从输入序列中提取的特定领域附加信息。为此,我们采用Thies等人[59]提出的最先进面部追踪方法,在视频中追踪人脸并提取图像中的面部区域。我们在追踪到的面部中心位置采用保守裁剪(扩大1.3倍),将重建面部完整包含在内。与直接使用整张图像作为输入的简单方法相比(参见第4.2.2节),这种领域知识的整合显著提升了伪造检测器的整体性能。我们通过不同前沿分类方法评估了本方案的多种变体,包括取证领域用于通用篡改检测[10,17]、计算机生成与自然图像鉴别[51]以及面部篡改检测[5]的学习方法。实验表明,基于Xception Net[14]的分类器在伪造检测任务中优于其他所有变体。

Figure 5: Our domain-specific forgery detection pipeline for facial manipulations: the input image is processed by a robust face tracking method; we use the information to extract the region of the image covered by the face; this region is fed into a learned classification network that outputs the prediction.
图 5: 针对面部篡改的领域专用伪造检测流程:输入图像通过鲁棒的人脸跟踪方法处理;利用该信息提取图像中人脸覆盖区域;将该区域输入训练好的分类网络以输出预测结果。
4.2.1 Detection based on St eg analysis Features:
4.2.1 基于隐写分析特征的检测方法:
We evaluate detection from st eg analysis features, following the method by Fridrich et al. [27] which employs handcrafted features. The features are co-occurrences on 4 pixels patterns along the horizontal and vertical direction on the high-pass images for a total feature length of 162. These features are then used to train a linear Support Vector Machine (SVM) classifier. This technique was the winning approach in the first IEEE Image Forensic Challenge [16]. We provide a $128\times128$ central crop-out of the face as input to the method. While the hand-crafted method outperforms human accuracy on raw images by a large margin, it struggles to cope with compression, which leads to an accuracy below human performance for low quality videos (see Fig. 6 and Table 1).
我们基于隐写分析特征进行评估,采用Fridrich等人[27]提出的手工特征方法。该方法通过在高通滤波图像上提取水平和垂直方向4像素模式的共生特征,总特征长度为162。随后用这些特征训练线性支持向量机(SVM)分类器,该技术曾荣获首届IEEE图像取证挑战赛冠军[16]。我们提供$128\times128$的人脸中心裁剪区域作为输入。虽然手工特征方法在原始图像上的检测准确率远超人类水平,但其抗压缩能力较弱,导致在低质量视频中的准确率低于人类表现(见图6和表1)。
4.2.2 Detection based on Learned Features:
4.2.2 基于学习特征 (Learned Features) 的检测
For detection from learned features, we evaluate five network architectures known from the literature to solve the classification task:
为了从学习到的特征中进行检测,我们评估了文献中已知的五种用于解决分类任务的网络架构:
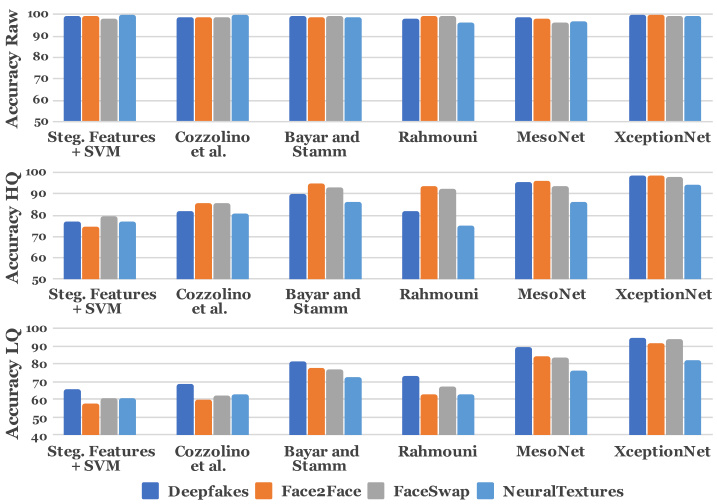
Figure 6: Binary detection accuracy of all evaluated architectures on the different manipulation methods using face tracking when trained on our different manipulation methods separately.
图 6: 使用面部跟踪时,所有评估架构在不同篡改方法上的二元检测准确率(各模型分别在我们提供的不同篡改方法数据上训练)。
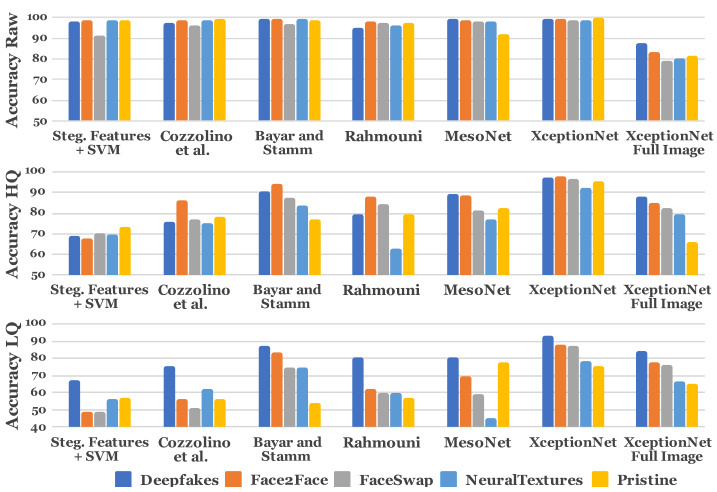
Figure 7: Binary precision values of our baselines when trained on all four manipulation methods simulate nous ly. See Table 1 for the average accuracy values. Aside from the Full Image Xc ep tion Net, we use the proposed preextraction of the face region as input to the approaches.
图 7: 我们的基线模型在四种篡改方法上模拟训练时的二分类精确度值。平均准确率数值请参见表 1。除Full Image Xception Net外,其他方法均采用我们提出的面部区域预提取作为输入。
to suppress the high-level content of the image. Similar to the previous methods, we use a centered $128\times128$ crop as input.
抑制图像的高级内容。与之前的方法类似,我们使用中心裁剪的 $128\times128$ 区域作为输入。
(3) Rahmouni et al. [51] adopt different CNN architectures with a global pooling layer that computes four statistics (mean, variance, maximum and minimum). We consider the Stats-2L network that had the best performance.
Rahmouni等人[51]采用了不同的CNN架构,并配备了一个计算四种统计量(均值、方差、最大值和最小值)的全局池化层。我们选择了其中表现最佳的Stats-2L网络。
(4) Meso Inception-4 [5] is a CNN-based network inspired by Inception Net [56] to detect face tampering in videos. The network has two inception modules and two classic convolution layers interlaced with max-pooling layers. Afterwards, there are two fully-connected layers. Instead of the classic cross-entropy loss, the authors propose the mean squared error between true and predicted labels. We resize the face images to $256\times256$ , the input of the network.
规则:
- 输出中文翻译部分时仅保留翻译标题,不包含任何冗余内容、重复或解释。
- 不输出与英文无关的内容。
- 保留原始段落格式及术语(如FLAC、JPEG)、公司缩写(如Microsoft、Amazon、OpenAI)。
- 人名不翻译。
- 保留论文引用标记(如[20])。
- 图表标题翻译为"图1: "、"表1: "并保留原有格式。
- 全角括号替换为半角括号,前后添加半角空格。
- 专业术语首次出现时标注英文原文(如"生成式AI (Generative AI)"),后续直接使用中文。
- 标准术语对照:
- Transformer -> Transformer
- Token -> Token
- LLM/Large Language Model -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
- 特殊字符/公式原样保留
- HTML表格转Markdown格式
- 准确翻译并符合中文表达习惯
(4) Meso Inception-4 [5] 是基于CNN的网络结构,受Inception Net [56]启发设计,用于检测视频中的人脸篡改。该网络包含两个Inception模块和两个经典卷积层,中间穿插最大池化层,最后接两个全连接层。作者采用真实标签与预测标签的均方误差替代传统交叉熵损失函数。我们将人脸图像调整为$256\times256$作为网络输入尺寸。
(5) Xc ep tion Net [14] is a traditional CNN trained on ImageNet based on separable convolutions with residual connections. We transfer it to our task by replacing the final fully connected layer with two outputs. The other layers are initialized with the ImageNet weights. To set up the newly inserted fully connected layer, we fix all weights up to the final layers and pre-train the network for 3 epochs. After this step, we train the network for 15 more epochs and choose the best performing model based on validation accuracy.
Xception Net [14] 是一种基于可分离卷积与残差连接的传统CNN(Convolutional Neural Network),在ImageNet上训练而成。我们通过将最后的全连接层替换为两个输出来适配当前任务,其余层均采用ImageNet预训练权重初始化。对于新插入的全连接层,我们固定所有前置层权重并进行3轮预训练,随后继续训练15轮并根据验证集准确率选择最佳模型。
A detailed description of our training and hyperparameters can be found in Appendix D.
我们的训练流程和超参数详细说明请参阅附录 D。
Comparison of our Forgery Detection Variants: Fig. 6 shows the results of a binary forgery detection task using all network architectures evaluated separately on all four manipulation methods and at different video quality levels. All approaches achieve very high performance on raw input data. Performance drops for compressed videos, particularly for hand-crafted features and for shallow CNN architectures [10, 17]. The neural networks are better at handling these situations, with Xc ep tion Net able to achieve compelling results on weak compression while still maintaining reasonable performance on low quality images, as it benefits from its pre-training on ImageNet as well as larger network capacity.
我们伪造检测变体的对比:图6展示了使用所有网络架构在四种篡改方法和不同视频质量水平上分别评估的二元伪造检测任务结果。所有方法在原始输入数据上都表现出极高的性能。对于压缩视频,性能有所下降,尤其是手工特征和浅层CNN架构[10, 17]。神经网络在这些情况下表现更好,XceptionNet在弱压缩条件下能取得令人信服的结果,同时在低质量图像上仍保持合理性能,这得益于其在ImageNet上的预训练以及更大的网络容量。
To compare the results of our user study to the performance of our automatic detectors, we also tested the detection variants on a dataset containing images from all ma- nipulation methods. Fig. 7 and Table 1 show the results on the full dataset. Here, our automated detectors outperform human performance by a large margin (cf. Fig. 4). We also evaluate a naive forgery detector operating on the full image (resized to the Xc ep tion Net input) instead of using face tracking information (see Fig. 7, rightmost column). Due to the lack of domain-specific information, the Xc ep tion Net classifier has a significantly lower accuracy in this scenario. To summarize, domain-specific information in combination with a Xc ep tion Net classifier shows the best performance in each test. We use this network to further understand the influence of the training corpus size and its ability to distinguish between the different manipulation methods.
为了将用户研究结果与自动检测器的性能进行比较,我们还在包含所有篡改方法图像的数据集上测试了检测变体。图7和表1展示了完整数据集上的结果。在此,我们的自动检测器大幅超越人类表现(参见图4)。我们还评估了一个基于整张图像(调整为Xception Net输入尺寸)的简单伪造检测器,而非使用面部追踪信息(见图7最右侧列)。由于缺乏领域特定信息,Xception Net分类器在此场景下的准确率显著降低。综上所述,结合领域特定信息的Xception Net分类器在各项测试中均表现最佳。我们利用该网络进一步探究训练集规模的影响及其区分不同篡改方法的能力。
Forgery Detection of GAN-based methods The experiments show that all detection approaches achieve a lower accuracy on the GAN-based Neural Textures approach. Neural Textures is training a unique model for every manipulation which results in a higher variation of possible artifacts. While DeepFakes is also training one model per manipulation, it uses a fixed post-processing pipeline similar to the computer-based manipulation methods and thus has consistent artifacts.
基于GAN方法的伪造检测
实验表明,所有检测方法在基于GAN的神经纹理(Neural Textures)方法上都取得了较低的准确率。神经纹理为每次操作训练独特模型,导致可能产生的伪影具有更高变异性。虽然DeepFakes同样为每次操作训练单独模型,但其采用类似计算机处理方法的固定后处理流程,因此伪影特征具有一致性。
Table 1: Binary detection accuracy of our baselines when trained on all four manipulation methods. Besides the naive full image Xc ep tion Net, all methods are trained on a conservative crop (enlarged by a factor of 1.3) around the center of the tracked face.
表 1: 基线方法在四种篡改方法上的二分类检测准确率。除原始全图Xception Net外,所有方法均在跟踪人脸中心区域1.3倍放大的保守裁剪图上训练。
| 压缩方式 | Raw | HQ | LQ |
|---|---|---|---|
| [14] XceptionNet全图 | 82.01 | 74.78 | 70.52 |
| [27] Steg.特征+SVM | 97.63 | 70.97 | 55.98 |
| [17] Cozzolino等 | 98.57 | 78.45 | 58.69 |
| [10] Bayar和Stamm | 98.74 | 82.97 | 66.84 |
| [51] Rahmouni等 | 97.03 | 79.08 | 61.18 |
| [5] MesoNet | 95.23 | 83.10 | 70.47 |
| [14] XceptionNet | 99.26 | 95.73 | 81.00 |

Figure 8: The detection performance of our approach using Xc ep tion Net depends on the training corpus size. Especially, for low quality video data, a large database is needed.
图 8: 我们采用 Xception Net 的检测方法性能取决于训练语料规模。特别是对于低质量视频数据,需要更大的数据库。
Evaluation of the Training Corpus Size: Fig. 8 shows the importance of the training corpus size. To this end, we trained the Xc ep tion Net classifier with different training corpus sizes on all three video quality level separately. The overall performance increases with the number of training images which is particularly important for low quality video footage, as can be seen in the bottom of the figure.
训练语料库规模的评估:图 8 展示了训练语料库规模的重要性。为此,我们分别针对三个视频质量级别,使用不同规模的训练语料库训练了 Xception Net 分类器。整体性能随着训练图像数量的增加而提升,这对于低质量视频片段尤为重要,如图底部所示。
5. Benchmark
5. 基准测试
In addition to our large-scale manipulation database, we publish a competitive benchmark for facial forgery detection. To this end, we collected 1000 additional videos and manipulated a subset of those in a similar fashion as in Section 3 for each of our four manipulation methods. As uploaded videos (e.g., to social networks) will be postprocessed in various ways, we obscure all selected videos multiple times (e.g., by unknown re-sizing, compression method and bit-rate) to ensure realistic conditions. This processing is directly applied on raw videos. Finally, we manually select a single challenging frame from each video based on visual inspection. Specifically, we collect a set of 1000 images, each image randomly taken from either the manipulation methods or the original footage. Note that we do not necessarily have an equal split of pristine and fake images nor an equal split of the used manipulation methods. The ground truth labels are hidden and are used on our host server to evaluate the classification accuracy of the submitted models. The automated benchmark allows submissions every two weeks from a single submitter to prevent over fitting (similar to existing benchmarks [19]).
除了我们的大规模篡改数据库,我们还发布了一个用于面部伪造检测的竞争性基准。为此,我们额外收集了1000个视频,并按照第3节中类似的方式,针对四种篡改方法分别对这些视频的子集进行了篡改。由于上传的视频(例如到社交网络)会经过各种后处理,我们对所有选定的视频进行了多次模糊处理(例如通过未知的尺寸调整、压缩方法和比特率),以确保条件真实。这一处理直接应用于原始视频。最后,我们基于视觉检查从每个视频中手动选择了一帧具有挑战性的画面。具体而言,我们收集了1000张图像,每张图像随机取自篡改方法或原始素材。需要注意的是,我们并未严格保证原始图像和伪造图像的数量均等,也未保证使用的篡改方法数量均等。真实标签被隐藏,并用于在我们的主机服务器上评估提交模型的分类准确率。该自动化基准允许每两周从单个提交者处接收一次提交,以防止过拟合(类似现有基准[19])。
As baselines, we evaluate the low quality versions of our previously trained models on the benchmark and report the numbers for each detection method separately (see Table 2). Aside from the Full Image Xc ep tion Net, we use the proposed pre-extraction of the face region as input to the approaches. The relative performance of the classification models is similar to our database test set (see Table 1). However, since the benchmark scenario deviates from the training database, the overall performance of the models is lower, especially for the pristine image detection precision; the major changes being the randomized quality level as well as possible tracking errors during test. Since our proposed method relies on face detections, we predict fake as default in case of a tracking failure.
作为基线,我们在基准测试中评估了先前训练模型的低质量版本,并分别报告每种检测方法的数值(见表 2)。除 Full Image Xception Net 外,我们采用所提出的面部区域预提取作为各方法的输入。分类模型的相对性能与我们的数据库测试集结果相似(见表 1)。但由于基准场景与训练数据库存在差异,模型整体性能有所下降,尤以原始图像检测精度为甚——主要变化在于随机化的质量等级以及测试过程中可能出现的跟踪误差。由于本方案依赖面部检测,当出现跟踪失败时,我们默认预测为伪造图像。
The benchmark is already publicly available to the community and we hope that it leads to a standardized comparison of follow-up work.
该基准测试已向社区公开,我们希望能以此促进后续工作的标准化比较。
6. Discussion & Conclusion
6. 讨论与结论
While current state-of-the-art facial image manipulation methods exhibit visually stunning results, we demonstrate that they can be detected by trained forgery detectors. It is particularly encouraging that also the challenging case of low-quality video can be tackled by learning-based approaches, where humans and hand-crafted features exhibit difficulties. To train detectors using domain-specific knowledge, we introduce a novel dataset of videos of manipulated faces that exceeds all existing publicly available forensic datasets by an order of magnitude.
虽然当前最先进的面部图像篡改方法能呈现视觉效果惊艳的结果,但我们证明这些篡改可被训练有素的伪造检测器识别。尤其令人鼓舞的是,基于学习的方法还能应对低质量视频这一棘手难题——而人类和手工设计特征在此类场景中表现欠佳。为利用领域知识训练检测器,我们提出了一个新颖的面部篡改视频数据集,其规模超出所有现有公开取证数据集一个数量级。
In this paper, we focus on the influence of compression to the detect ability of state-of-the-art manipulation methods, proposing a standardized benchmark for follow-up work. All image data, trained models, as well as our benchmark are publicly available and are already used by other researchers. In particular, transfer learning is of high interest in the forensic community. As new manipulation methods appear by the day, methods must be developed that are able to detect fakes with little to no training data. Our database is already used for this forensic transfer learning task, where knowledge of one source manipulation domain is transferred to another target domain, as shown by Cozzolino et al [18]. We hope that the dataset and benchmark become a stepping stone for future research in the field of digital media forensics, and in particular with a focus on facial forgeries.
本文重点研究压缩对当前最先进篡改方法检测能力的影响,提出了一个标准化的基准测试以供后续研究使用。所有图像数据、训练模型以及我们的基准测试均已公开,并被其他研究人员采用。特别是在取证领域,迁移学习备受关注。随着新型篡改技术日新月异,开发仅需少量甚至无需训练数据就能检测伪造内容的方法势在必行。如Cozzolino等人[18]所示,我们的数据库已应用于这种取证迁移学习任务——将源篡改领域的知识迁移至目标领域。我们希望该数据集和基准测试能成为数字媒体取证领域(尤其是面部伪造方向)未来研究的基石。
Table 2: Results of the low quality trained model of each detection method on our benchmark. We report precision results for DeepFakes (DF), Face2Face (F2F), FaceSwap (FS), Neural Textures (NT), and pristine images (Real) as well as the overall total accuracy.
表 2: 各检测方法在低质量训练模型上的基准测试结果。我们报告了DeepFakes (DF)、Face2Face (F2F)、FaceSwap (FS)、Neural Textures (NT) 和原始图像 (Real) 的精确率以及总体准确率。
| 准确率 | DF | F2F | FS | NT | Real | 总体 |
|---|---|---|---|---|---|---|
| Xcept. Full Image | 74.55 | 75.91 | 70.87 | 73.33 | 51.00 | 62.40 |
| Steg.Features | 73.64 | 73.72 | 68.93 | 63.33 | 34.00 | 51.80 |
| Cozzolinoetal. | 85.45 | 67.88 | 73.79 | 78.00 | 34.40 | 55.20 |
| Rahmouni et al. | 85.45 | 64.23 | 56.31 | 60.07 | 50.00 | 58.10 |
| Bayar and Stamm | 84.55 | 73.72 | 82.52 | 70.67 | 46.20 | 61.60 |
| MesoNet | 87.27 | 56.20 | 61.17 | 40.67 | 72.60 | 66.00 |
| XceptionNet | 96.36 | 86.86 | 90.29 | 80.67 | 52.40 | 70.10 |
7. Acknowledgement
7. 致谢
We gratefully acknowledge the support of this research by the AI Foundation, a TUM-IAS Rudolf MoBbauer Fellowship, the ERC Starting Grant Scan2CAD (804724), and a Google Faculty Award. We would also like to thank Google’s Chris Bregler for help with the cloud computing. In addition, this material is based on research sponsored by the Air Force Research Laboratory and the Defense Advanced Research Projects Agency under agreement number FA8750-16-2-0204. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of the Air Force Research Laboratory and the Defense Advanced Research Projects Agency or the U.S. Government.
我们衷心感谢AI基金会、TUM-IAS Rudolf MoBbauer Fellowship、ERC Starting Grant Scan2CAD (804724)以及谷歌教师奖对本研究的支持。同时感谢谷歌的Chris Bregler在云计算方面提供的帮助。此外,本研究材料基于空军研究实验室和国防高级研究计划局根据协议号FA8750-16-2-0204资助的研究项目。美国政府有权为政府目的复制和分发重印本,无论其上是否有版权标记。本文所载观点和结论仅为作者个人观点,不应被解释为代表空军研究实验室、国防高级研究计划局或美国政府的官方政策或认可,无论是明示还是暗示。
References
参考文献

Figure 9: Automatic face editing tools rely on the ability to track the face in the target video. State-of-the-art tracking methods like Thies et al. [59] fail in cases of profile imagery of a face (left). Rotations larger than $45^{\circ}$ (middle) and occlusions (right) lead to tracking errors.
图 9: 自动人脸编辑工具依赖于目标视频中的人脸追踪能力。Thies等人[59]提出的最先进追踪方法在处理侧面人脸图像时会失败(左)。超过$45^{\circ}$的旋转(中)和遮挡(右)会导致追踪错误。
| 方法 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| Pristine | 366,847 | 68,511 | 73,770 |
| DeepFakes | 366,835 | 68,506 | 73,768 |
| Face2Face | 366,843 | 68,511 | 73,770 |
| FaceSwap | 291,434 | 54,618 | 59,640 |
| NeuralTextures | 291,834 | 54,630 | 59,672 |
Table 3: Number of images per manipulation method. DeepFakes manipulates every frame of the target sequence, whereas FaceSwap and Neural Textures only manipulate the minimum number of frames across the source and target video. Face2Face, however, maps all source expressions to the target sequence and rewinds the target video if necessary. Number of manipulated frames can vary due to missdetection in the respective face tracking modules of our manipulation methods.
表 3: 各篡改方法处理的图像数量。DeepFakes会处理目标序列的每一帧,而FaceSwap和Neural Textures仅处理源视频与目标视频之间的最小帧数。Face2Face则将所有源表情映射到目标序列,并在必要时回放目标视频。由于各篡改方法的人脸追踪模块可能存在漏检,实际处理的帧数可能有所波动。
Appendix
附录
In Face Forensic $s{++}$ , we evaluate the performance of state-of-the-art facial manipulation detection approaches using a large-scale dataset that we generated with four different facial manipulation methods. In addition, we proposed an automated benchmark to compare future detection approaches as well as their robustness against unknown post-processing operations such as compression.
在Face Forensic$s{++}$中,我们使用通过四种不同面部篡改方法生成的大规模数据集,评估了最先进的面部篡改检测方法的性能。此外,我们提出了一个自动化基准,用于比较未来的检测方法及其对未知后处理操作(如压缩)的鲁棒性。
This supplemental document reports details on our pristine data acquisition (Appendix A), ensuring suited input sequences. Appendix B lists the exact numbers of our binary classification experiments presented in the main paper. Besides binary classification, the database is also interesting for evaluating manipulation classification (Appendix C). In Appendix D, we list all chosen hyper parameters of both the manipulation methods as well as the detection techniques.
本补充文档详细报告了原始数据采集过程(附录A),以确保输入序列的适用性。附录B列出了主论文中二元分类实验的具体数据。除二元分类外,该数据库对评估篡改分类(附录C)也具有重要意义。附录D列出了所有选定的篡改方法及检测技术的超参数。
A. Pristine Data Acquisition
A. 原始数据采集
For a realistic scenario, we chose to collect videos in the wild, more specifically from YouTube. Early experiments with all manipulation methods showed that the pristine videos have to fulfill certain criteria. The target face has to be nearly front-facing and without occlusions, to prevent the methods from failing or producing strong artifacts (see Fig. 9). We use the YouTube $\cdot8\mathrm{m}$ dataset [4] to collect videos with the tags “face”, “newscaster” or “newsprogram” and also included videos which we obtained from the YouTube search interface with the same tags and additional tags like “interview”, “blog”, or “video blog”. To ensure adequate video quality, we only downloaded videos that offer a resolution of 480p or higher. For every video, we save its metadata to sort them by properties later on. In order to match the above requirements, we first process all downloaded videos with the Dlib face detector [40], which is based on Histograms of Oriented Gradients (HOG). During this step, we track the largest detected face by ensuring that the centers of two detections of consecutive frames are pixel-wise close. The histogram-based face tracker was chosen to ensure that the resulting video sequences contain little occlusions and, thus, contain easy-to-manipulate faces.
为了模拟真实场景,我们选择从YouTube采集野外视频数据。初期全量篡改方法实验表明,原始视频必须满足特定条件:目标人脸需近乎正面且无遮挡,以避免算法失效或产生严重伪影(见图9)。我们采用YouTube·8m数据集[4],通过"face"、"newscaster"或"newsprogram"标签采集视频,同时从YouTube搜索接口获取含"interview"、"blog"或"video blog"等补充标签的同主题视频。为确保画质,仅下载480p及以上分辨率视频,并为每个视频保存元数据供后续属性分类。
为满足上述要求,首先使用基于方向梯度直方图(HOG)的Dlib人脸检测器[40]处理所有视频。该步骤通过确保连续帧检测的人脸中心像素距离相近,实现最大人脸的持续追踪。选择基于直方图的人脸追踪方案,可保证最终视频序列包含低遮挡、易篡改的人脸数据。
Except FaceSwap, all methods need a sufficiently large set of image in a target sequence to train on. We select sequences with at least 280 frames. To ensure a high quality video selection and to avoid videos with face occlusions, we perform a manual screening of the clips which resulted in 1,000 video sequences containing 509, 914 images.
除FaceSwap外,所有方法都需要在目标序列中拥有足够大的图像集进行训练。我们筛选了至少包含280帧的序列。为确保视频素材质量并避免面部遮挡,我们对片段进行了人工筛查,最终得到1,000个视频序列,共包含509,914张图像。
All examined manipulation methods need a source and a target video. In case of facial reenactment, the expres- sions of the source video are transferred to the target video while retaining the identity of the target person. In contrast, face swapping methods replace the face in the target video with the face in the source video. To ensure high quality face swapping, we select video pairs with similar large faces (considering the bounding box sizes detected by DLib), the same gender of the persons and similar video frame rates.
所有被检测的操纵方法都需要一个源视频和一个目标视频。在面部重现的情况下,源视频的表情会被转移到目标视频中,同时保留目标人物的身份。相比之下,人脸交换方法会将目标视频中的脸部替换为源视频中的脸部。为确保高质量的人脸交换,我们选择了具有相似大脸(考虑DLib检测到的边界框大小)、相同性别和相似视频帧率的视频对。
Table 3 lists the final numbers of our dataset for all manipulation methods and the pristine data.
表 3: 列出了所有操作方法及原始数据的最终数据集数量。
B. Forgery Detection
B. 伪造检测
In this section, we list all numbers from the graphs of the main paper. Table 4 shows the accuracies of the manipulation-specific forgery detectors (i.e., the detectors are trained on the respective manipulation method). In contrast, Table 5 shows the accuracies of the forgery detectors trained on the whole Face Forensics $^{++}$ dataset. In Table 6, we show the importance of a large-scale database. The numbers of our user study are listed in Table 7 including the modality which is used to inspect the images.
在本节中,我们列出了主论文图表中的所有数据。表4展示了针对特定篡改方法的伪造检测器(即检测器分别在对应篡改方法上训练)的准确率。相比之下,表5显示了在整个Face Forensics++数据集上训练的伪造检测器的准确率。表6中我们展示了大规模数据库的重要性。表7列出了用户研究的数据,包括用于检测图像的模态。
Table 4: Accuracy of manipulation-specific forgery detectors. We show the results for raw and the compressed datasets of all four manipulation methods (DF: DeepFakes, F2F: Face2Face, FS: FaceSwap and NT: Neural Textures).
表 4: 特定篡改伪造检测器的准确率。我们展示了所有四种篡改方法 (DF: DeepFakes, F2F: Face2Face, FS: FaceSwap 和 NT: Neural Textures) 的原始数据集和压缩数据集的检测结果。
| Raw | Compressed23 | Compressed40 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DF | F2F | FS | NT | DF | F2F | FS | NT | DF | F2F | FS | NT | |
| Steg. Features + SVM [27] | 99.03 | 99.13 | 98.27 | 99.88 | 77.12 | 74.68 | 79.51 | 76.94 | 65.58 | 57.55 | 60.58 | 60.69 |
| Cozzolino et al. [17] | 98.83 | 98.56 | 98.89 | 99.88 | 81.78 | 85.32 | 85.69 | 80.60 | 68.26 | 59.38 | 62.08 | 62.42 |
| Bayar and Stamm [10] | 99.28 | 98.79 | 98.98 | 98.78 | 90.18 | 94.93 | 93.14 | 86.04 | 80.95 | 77.30 | 76.83 | 72.38 |
| Rahmouni et al. [51] | 98.03 | 98.96 | 98.94 | 96.06 | 82.16 | 93.48 | 92.51 | 75.18 | 73.25 | 62.33 | 67.08 | 62.59 |
| MesoNet [5] | 98.41 | 97.96 | 96.07 | 97.05 | 95.26 | 95.84 | 93.43 | 85.96 | 89.52 | 84.44 | 83.56 | 75.74 |
| XceptionNet [14] | 99.59 | 99.61 | 99.14 | 99.36 | 98.85 | 98.36 | 98.23 | 94.5 | 94.28 | 91.56 | 93.7 | 82.11 |
Table 5: Detection accuracies when trained on all manipulation methods at once and evaluated on specific manipulation methods or pristine data (DF: DeepFakes, F2F: Face2Face, FS: FaceSwap, NT: Neural Textures, and P: Pristine). The average accuricies are listed in the main paper.
表 5: 在所有篡改方法上联合训练并在特定篡改方法或原始数据上评估的检测准确率 (DF: DeepFakes, F2F: Face2Face, FS: FaceSwap, NT: Neural Textures, P: 原始数据)。平均准确率已在主论文中列出。
| Raw | Compressed 23 | Compressed 40 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DF | F2F | FS | NT | P | DF | F2F | FS | NT | P | DF | F2F | FS | NT | P | |
| Steg.Features+SVM[27] | 97.96 | 98.40 | 91.35 | 98.56 | 98.70 | 68.80 | 67.69 | 70.12 | 69.21 | 72.98 | 67.07 | 48.55 | 48.68 | 55.84 | 56.94 |
| Cozzolino et al. [17] | 97.24 | 98.51 | 95.93 | 98.74 | 99.53 | 75.51 | 86.34 | 76.81 | 75.34 | 78.41 | 75.63 | 56.01 | 50.67 | 62.15 | 56.27 |
| Bayar and Stamm [10] | 99.25 | 99.04 | 96.80 | 99.11 | 98.92 | 90.25 | 93.96 | 87.74 | 83.69 | 77.02 | 86.93 | 83.66 | 74.28 | 74.36 | 53.87 |
| Rahmouniet al.[51] | 94.83 | 98.25 | 97.59 | 96.21 | 97.34 | 79.66 | 87.87 | 84.34 | 62.65 | 79.52 | 80.36 | 62.04 | 59.90 | 59.99 | 56.79 |
| MesoNet [5] | 99.24 | 98.35 | 98.15 | 97.96 | 92.04 | 89.55 | 88.60 | 81.24 | 76.62 | 82.19 | 80.43 | 69.06 | 59.16 | 44.81 | 77.58 |
| XceptionNet [14] | 99.29 | 99.23 | 98.39 | 98.64 | 99.64 | 97.49 | 97.69 | 96.79 | 92.19 | 95.41 | 93.36 | 88.09 | 87.42 | 78.06 | 75.27 |
| Full ImageXception[14] | 87.73 | 83.22 | 79.29 | 79.97 | 81.46 | 88.00 | 84.98 | 82.23 | 79.60 | 65.85 | 84.06 | 77.56 | 76.12 | 66.03 | 65.09 |
Table 6: Analysis of the training corpus size. Numbers reflect the accuracies of the Xc ep tion Net detector trained on single and all manipulation methods (DF: DeepFakes, F2F: Face2Face, FS: FaceSwap, NT: Neural Textures and All: all manipulation methods).
表 6: 训练语料规模分析。数值反映 Xception Net 检测器在单一及全部篡改方法上的准确率 (DF: DeepFakes, F2F: Face2Face, FS: FaceSwap, NT: Neural Textures 和 All: 全部篡改方法)。
| Raw | Compressed 23 | Compressed 40 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DF | F2F | FS | NT | All | DF | F2F | FS | NT | All | DF | F2F | FS | NT | All | |
| 10 videos | 89.18 | 76.6 | 90.89 | 93.53 | 92.81 | 76.06 | 59.84 | 81.15 | 76.73 | 67.71 | 64.55 | 53.99 | 60.04 | 65.14 | 60.55 |
| 50 videos | 99.52 | 98.84 | 97.56 | 96.67 | 95.89 | 92.48 | 91.33 | 92.63 | 85.98 | 82.89 | 75.53 | 66.44 | 74.25 | 71.48 | 65.76 |
| 100 videos | 99.51 | 99.09 | 98.64 | 98.23 | 97.54 | 95.39 | 95.8 | 95.56 | 90.09 | 87.19 | 83.68 | 72.69 | 79.56 | 73.72 | 66.81 |
| 300 videos | 99.59 | 99.53 | 98.78 | 98.73 | 98.88 | 97.3 | 97.41 | 97.51 | 92.4 | 92.65 | 91.57 | 86.38 | 88.35 | 79.65 | 76.01 |
| Raw | Compressed 23 | Compressed 40 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DF | F2F | FS | NT | P | DF | F2F | FS | NT | P | DF | F2F | FS | NT | P | |
| Average | 77.60 | 49.60 | 76.12 | 32.28 | 78.19 | 78.17 | 50.19 | 74.80 | 30.75 | 75.41 | 73.18 | 43.86 | 64.26 | 39.07 | 62.06 |
| Desktop PC | 80.41 | 53.73 | 75.10 | 34.36 | 80.12 | 81.17 | 51.57 | 79.51 | 29.50 | 78.10 | 71.71 | 44.09 | 62.99 | 35.71 | 64.32 |
| MobilePhone | 74.80 | 44.96 | 77.11 | 30.58 | 76.40 | 75.47 | 48.95 | 70.08 | 31.97 | 72.84 | 74.62 | 43.62 | 65.50 | 41.85 | 60.00 |
Table 7: User study result w.r.t. the used device to watch the images (DF: DeepFakes, F2F: Face2Face, FS: FaceSwap, NT: Neural Textures and P: Pristine). 99 participants used a PC and 105 a mobile phone.
表 7: 用户研究结果(按观看图像使用的设备分类)(DF: DeepFakes, F2F: Face2Face, FS: FaceSwap, NT: Neural Textures 和 P: Pristine)。99名参与者使用PC,105名使用手机。
C. Classification of Manipulation Method
C. 操纵方法分类
To train the Xc ep tion Net classification network to distinguish between all four manipulation methods and the pristine images, we adapted the final output layer to return five class probabilities. The network is trained on the full dataset containing all pristine and manipulated images. On raw data the network is able to achieve a $99.03%$ accuracy, which slightly decreases for the high quality compression to $95.42%$ and to $80.49%$ on low quality images.
为了训练Xception Net分类网络区分所有四种篡改方法和原始图像,我们调整了最终输出层以返回五个类别的概率。该网络在包含所有原始和篡改图像的完整数据集上进行训练。在原始数据上,网络能达到99.03%的准确率,高质量压缩图像上略微降至95.42%,低质量图像上则降至80.49%。
D. Hyper parameters
D. 超参数
For reproducibility, we detail the hyper parameters used for the methods in the main paper. We structured this section into two parts, one for the manipulation methods and the second part for the classification approaches used for forgery detection.
为确保可复现性,我们详细列出了主论文中使用方法的超参数。本节分为两部分:第一部分针对篡改方法,第二部分针对用于伪造检测的分类方法。
D.1. Manipulation Methods
D.1. 操作方法
DeepFakes and Neural Textures are learning-based, for the other manipulation methods we used the default parameters of the approaches.
DeepFakes和神经纹理(Neural Textures)是基于学习的,对于其他操作方法我们使用了这些方法的默认参数。
DeepFakes: Our DeepFakes implementation is based on the deepfakes faceswap github project [1]. MTCNN ([65]) is used to extract and align the images for each video. Specifically, the largest face in the first frame of a sequence is detected and tracked throughout the whole video. This tracking information is used to extract the training data for DeepFakes. The auto-encoder takes input images of 64 (default). It uses a shared encoder consisting of four convolutional layers which downsizes the image to a bottleneck of $4\times4$ , where we flatten the input, apply a fully connected layer, reshape the dense layer and apply a single upscaling using a convolutional layer as well as a pixel shuffle layer (see [54]). The two decoders use three identical up-scaling layers to attain full input image resolution. All layers use Leaky ReLus as non-linear i ties. The network is trained using Adam with a learning rate of $10^{-5}$ , $\beta_{1}~=0.5$ and $\beta_{2}=~0.999$ as well as a batch size of 64. In our experiments, we run the training for 200000 iterations on a cloud platform. By exchanging the decoder of one person to another, we can generate an identity-swapped face region. To insert the face into the target image, we chose Poisson Image Editing [49] to achieve a seamless blending result.
DeepFakes:我们的DeepFakes实现基于deepfakes faceswap GitHub项目[1]。使用MTCNN [65]提取并对齐每个视频的图像,具体流程为:在视频序列首帧检测最大人脸,并在整个视频中进行跟踪。这些跟踪信息将作为DeepFakes的训练数据。自动编码器默认接收64×64的输入图像,其共享编码器包含四个卷积层,可将图像下采样至$4\times4$的瓶颈层。在此处我们将输入展平,应用全连接层,重塑稠密层,并通过卷积层和像素混洗层[54]进行单次上采样。两个解码器使用三个相同的上采样层来恢复原始图像分辨率。所有层均采用Leaky ReLU作为非线性激活函数。网络训练采用Adam优化器,参数设置为:学习率$10^{-5}$、$\beta_{1}~=0.5$、$\beta_{2}=~0.999$,批量大小为64。实验中,我们在云平台进行了20万次迭代训练。通过将一个人的解码器替换为另一个人的解码器,即可生成身份替换的人脸区域。为将生成人脸无缝融合至目标图像,我们采用泊松图像编辑[49]技术。
Neural Textures: Neural Textures is based on a U-Net architecture. For data generation, we employ the original pipeline and network architecture (for details see [57]). In addition to the photo-metric consistency, we added an adversarial loss. This adversarial loss is based on the patchbased disc rim in at or used in Pix2Pix [36]. During training we weight the photo-metric loss with 1 and the adversarial loss with 0.001. We train three models per manipulation for a fixed 45 epochs using the Adam optimizer (with default settings) and manually choose the best performing model based on visual quality. All manipulations are created at a resolution of $512\times512$ as in the original paper, with a texture resolution of $512\times512$ and 16 feature per texel. Instead of using the entire image, we only train and modify the cropped image containing the face bounding box ensuring high resolution outputs even on higher resolution images. To do so, we enlarge the bounding box obtained by the Face2Face tracker by a factor of 1.8.
神经纹理 (Neural Textures): 神经纹理基于U-Net架构。在数据生成方面,我们沿用原始流程和网络架构(详见[57])。除光度一致性外,我们还引入了对抗损失 (adversarial loss),该损失基于Pix2Pix [36] 采用的基于图像块的判别器。训练时我们将光度损失权重设为1,对抗损失权重设为0.001。每个编辑任务训练三个模型,固定45个epoch,使用Adam优化器(默认参数),最终根据视觉质量人工选择最佳模型。所有编辑操作均按照原论文设定在$512\times512$分辨率下完成,纹理分辨率为$512\times512$,每个纹素包含16个特征。为确保高分辨率输出,我们仅对包含人脸边界框的裁剪图像进行训练和修改,而非整张图像。具体实现时,我们将Face2Face追踪器获取的边界框扩大1.8倍。
D.2. Classification Methods
D.2. 分类方法
For our forgery detection pipeline proposed in the main paper, we conducted studies with five classification approaches based on convolutional neural networks. The networks are trained using the Adam optimizer with different parameters for learning-rate and batch-size. In particular, for the network proposed in Cozzolino at al. [17] the used learning-rate is $10^{-5}$ with batch-size 16. For the proposal of Bayar and Stamm [10], we use a learning-rate equal to $10^{-5}$ with a batch-size of 64. The network proposed by Rahmouni [51] is trained with a learning-rate of $10^{-4}$ and a batch-size equal to 64. MesoNet [5] uses a batch-size of 76 and the learning-rate is set to $10^{-3}$ . Our Xc ep tion Net [14]- based approach is trained with a learning-rate of 0.0002 and a batch-size of 32. All detection methods are trained with the Adam optimizer using the default values for the moments ( $\beta_{1}=0.9$ , $\beta_{2}=0.999$ , $\epsilon=10^{-8}$ ).
针对主论文中提出的伪造检测流程,我们采用五种基于卷积神经网络的分类方法进行实验。所有网络均使用Adam优化器训练,并设置了不同的学习率和批量大小参数。具体而言:
- Cozzolino等人[17]提出的网络采用学习率$10^{-5}$和批量大小16;
- Bayar和Stamm[10]的方案使用学习率$10^{-5}$和批量大小64;
- Rahmouni[51]的网络以学习率$10^{-4}$和批量大小64进行训练;
- MesoNet[5]设置批量大小为76,学习率为$10^{-3}$;
- 我们基于Xception Net[14]的方法采用学习率0.0002和批量大小32。
所有检测方法均使用Adam优化器,其动量参数保持默认值($\beta_{1}=0.9$, $\beta_{2}=0.999$, $\epsilon=10^{-8}$)。
We compute validation accuracies ten times per epoch and stop the training process if the validation accuracy does not change for 10 consecutive checks. Validation and test accuracies are computed on 100 images per video, training is evaluated on 270 images per video to account for frame count imbalance in our videos. Finally, we solve the imbalance between real and fake images in the binary task (i.e., the number of fake images being roughly four times as large as the number of pristine images) by weighing the training images correspondingly.
我们每轮训练计算十次验证准确率,若连续10次检查中验证准确率无变化,则停止训练过程。验证集和测试集的准确率基于每个视频的100张图像计算,训练集则使用每个视频的270张图像进行评估,以平衡视频间的帧数差异。最后,针对二分类任务中真实图像与伪造图像的数量不平衡问题(伪造图像数量约为原始图像的4倍),我们通过对训练图像进行相应加权来解决。