General iz able Method for Face Anti-Spoofing with Semi-Supervised Learning
基于半监督学习的通用人脸防伪方法
Abstract
摘要
Face anti-spoofing has drawn a lot of attention due to the high security requirements in biometric authentication systems. Bringing face biometric to commercial hardware became mostly dependent on developing reliable methods for detecting fake login sessions without specialized sensors. Current CNN-based method perform well on the domains they were trained for, but often show poor generalization on previously unseen datasets. In this paper we describe a method for utilizing unsupervised pre training for improving performance across multiple datasets without any adaptation, introduce the Entry Anti spoofing Dataset for supervised fine-tuning, and propose a multi-class auxiliary classification layer for augmenting the binary classification task of detecting spoofing attempts with explicit interpret able signals. We demonstrate the efficiency of our model by achieving state-of-the-art results on cross-dataset testing on MSU-MFSD, Replay-Attack, and OULU-NPU datasets.
人脸防伪技术因生物特征识别系统的高安全性需求而备受关注。将面部生物识别技术引入商用硬件设备,主要依赖于开发可靠的检测方法,以在不依赖专用传感器的情况下识别虚假登录会话。当前基于CNN的方法在训练域内表现良好,但面对未见过的数据集时泛化能力往往较差。本文提出一种利用无监督预训练来提升跨数据集性能的方法(无需任何适配),引入了用于监督微调的Entry Anti spoofing数据集,并提出通过增加多类别辅助分类层来增强防伪检测二元分类任务,该层能提供明确可解释的信号。通过在MSU-MFSD、Replay-Attack和OULU-NPU数据集上的跨数据集测试达到最先进水平,验证了模型的高效性。
1. Introduction
1. 引言
Biometric authentication systems based on face recognition are taking prominence in both everyday life and highvalue transactions with strong security requirements. However, despite the recent advances in computer vision, these systems are still confined to specialized hardware that utilizes depth or NIR sensors for preventing Presentation Attacks. Among the Presentation Attacks, print and replay attacks are the most common, and detecting them became an important problem in the field of biometric authentication. From the practical application perspective, developing a robust algorithm for detecting such attacks on commercial webcams using only signals from the video stream would enable wide adoption of face-based authentication and verification.
基于人脸识别的生物认证系统在日常生活中以及高安全性要求的高价值交易中日益凸显其重要性。然而,尽管计算机视觉领域近期取得了进展,这些系统仍受限于依赖深度或近红外(NIR)传感器等专用硬件来防范呈现攻击(Presentation Attacks)。在各类呈现攻击中,打印攻击和重放攻击最为常见,其检测已成为生物认证领域的重要课题。从实际应用角度出发,若仅利用视频流信号就能开发出针对商用网络摄像头的鲁棒攻击检测算法,将极大推动基于人脸的身份认证与验证技术的普及。
Recently published results show that deep learningbased models can achieve good results on the datasets they were trained on [17] [14] [8], but the generalization to other datasets is not so easily achieved - i.e. when the model that achieved a state-of-the-art result on benchmark A is tested on benchmark B (the protocol we will be referring to as ”cross-test”), the discrepancy in scores is quite significant, even with the latest breakthroughs in domain adaptation that were aimed to address this problem. The consequences of such discrepancy in the real world are quite damaging for the application security.
近期发表的研究结果表明,基于深度学习 (deep learning) 的模型在训练数据集上能取得优异表现 [17][14][8],但泛化到其他数据集却并非易事——例如当在基准测试A上达到最先进 (state-of-the-art) 水平的模型被用于基准测试B(我们将此协议称为"交叉测试"(cross-test))时,即便采用针对该问题的最新领域自适应 (domain adaptation) 突破技术,其性能评分差异仍十分显著。这种差异在现实世界中对应用安全将造成严重影响。
The key motivation behind this work is that achieving strong generalization on cross-testing on multiple string benchmarks would reliably reflect the effectiveness of the algorithm in the wild. We propose to achieve this generalization by changing the approach to collecting training data. Moreover, motivated by the previous work in selfsupervised learning [3] [7], we experiment with the network pre training on larger datasets to improve the results further.
这项工作的核心动机在于,若能实现在多个字符串基准测试上的强大泛化能力,将可靠反映算法在真实场景中的有效性。我们提出通过改变训练数据收集方法来实现这种泛化。此外,受自监督学习(selfsupervised learning)领域先前研究[3][7]的启发,我们尝试在更大规模数据集上进行网络预训练(pre training)以进一步提升结果。
To validate the effectiveness of the developed method, we report the evaluation results in two experimental settings: intra-dataset test is evaluated on a test portion of our internal dataset, and cross-test is evaluated on well-known and established benchmarks: MSU-MFSD [16], ReplayAttack [4], and OULU-NPU [2].
为验证所开发方法的有效性,我们在两种实验设置下报告评估结果:内部数据集测试在我们的内部数据集测试部分进行评估,交叉测试则在知名基准数据集上进行评估,包括 MSU-MFSD [16]、ReplayAttack [4] 和 OULU-NPU [2]。
1.1. Contribution
1.1. 贡献
In this paper we present the following results:
本文我们展示了以下成果:
2. Related work
2. 相关工作
Recent publications on task-agnostic self-supervised and semi-supervised pre training show that using large unlabeled datasets for unsupervised pre training followed by supervised fine-tuning is capable of outperforming standard supervised learning methods [3] [7]. This is especially promising for the field of face anti-spoofing, where the problem of lack of comprehensive labeled datasets suitable for building models viable for security applications is especially severe. There have been efforts to alleviate this problem with using rich semantic annotations [18]. Alternative paradigms of circumventing the data shortage by domain adaptation and generating synthetic data were demonstrated by [15] [8], citing the problem of domain shift as one of the most critical for anti-spoofing.
近期关于任务无关的自监督与半监督预训练的研究表明,先利用大规模无标注数据进行无监督预训练,再进行有监督微调的方法,能够超越传统有监督学习方法 [3][7]。这一发现为人脸防伪领域带来了重要启示,该领域长期面临缺乏适用于安全场景建模的完备标注数据集问题。已有研究尝试通过引入丰富语义标注来缓解该问题 [18]。另有学者通过领域自适应 [15] 和合成数据生成 [8] 来应对数据短缺,并指出领域偏移是防伪任务最关键挑战之一。
The main problem of existing methods is still in the domain shift and the lack of generalization between different datasets, as shown in cross-dataset tests, even in works that demonstrate state-of-the-art results on intra-dataset tests [15] [8] [14] [17].
现有方法的主要问题仍在于领域偏移和不同数据集间泛化能力的不足,这在跨数据集测试中尤为明显,即便是那些在数据集内测试中展现最先进成果的研究 [15] [8] [14] [17] 也是如此。
3. Method
3. 方法
3.1. Entry Anti spoofing Dataset
3.1. 入口反欺诈数据集
Existing datasets for face anti-spoofing cover too narrow a domain, compared to the diversity of camera/lighting/distance/attack conditions seen in the real world. While achieving low error scores on open-source benchmarks using a cross-dataset protocol is indicative of good performance of a network under some subset of conditions, it turned out to be an unreliable predictor of the stability and accuracy when used in a real application. Specifically, regardless of the Attack Presentation Classification Error Rate (APCER) and Bona Fide Presentation Classification Error Rate (BPCER) shown by a candidate model trained on open-source datasets, there always were multiple sets of conditions where the model’s predictions started being inconsistent. We have addressed this problem by building an internal dataset that would consist of the training portion and a test subset that would be comprehensive enough to address the missing subdomains in other benchmarks.
现有的人脸防伪数据集覆盖的领域过于狭窄,远不及现实世界中摄像头/光照/距离/攻击条件的多样性。虽然采用跨数据集协议在开源基准测试上取得低错误率能表明网络在部分条件下的良好性能,但事实证明这无法可靠预测实际应用中的稳定性和准确性。具体而言,无论基于开源数据集训练的候选模型展现出多低的攻击呈现分类错误率(APCER)和真实呈现分类错误率(BPCER),总存在多组条件会使模型预测出现不一致。我们通过构建内部数据集解决了这个问题,该数据集包含训练部分和测试子集,其覆盖面足以弥补其他基准测试缺失的子领域。
Entry Anti spoofing Dataset consists of 83000 live video recordings collected via a custom-built UI that simulates the process of logging into a web-based biometric authentication system like Entry. The recordings were collected and labeled via a crowd sourcing data labeling service, from 45000 participants from more than 20 countries on five continents. Each recording was made on a mobile or laptop webcam (with roughly $30%$ of recordings being from laptop cameras, and $70%$ - from mobile), with subject’s face visible from multiple angles. Subjects’ genders, ages and ethnicities are not correlated with their collected recordings being spoofing or bona fide sessions, but overall distribution was not restricted in order to be as close to real-life demographic of potential users as possible. The process of collecting the dataset was iterative, with each version of the dataset produced after identifying a ”blind spot subdomain” — specific set of camera/lighting/distance/other conditions, that were leading to unstable performance of the model. These blind spots were identified by crowd sourcing attacks on different iterations of earlier anti-spoofing models that were provided by our research team.
Entry反欺骗数据集包含83,000条通过定制UI采集的真人视频记录,该UI模拟了登录基于网络的生物识别认证系统(如Entry)的流程。这些记录通过众包数据标注服务采集并标注,参与者来自五大洲20多个国家的45,000人。每条记录均通过移动设备或笔记本电脑摄像头拍摄(约30%来自笔记本摄像头,70%来自移动设备),拍摄对象的面部从多角度可见。受试者性别、年龄和种族与其采集记录属于欺骗会话或真实会话无相关性,但总体分布未受限制,以尽可能接近潜在用户的真实人口统计特征。数据集采集过程采用迭代方式,每个版本的数据集均在识别出"盲点子域"(即导致模型性能不稳定的特定相机/光照/距离/其他条件组合)后生成。这些盲点通过众包攻击早期反欺骗模型迭代版本(由我们研究团队提供)的方式识别。
| 数据集 | 视频数量 | 受试者人数 |
|---|---|---|
| Entry | 83000 | 45000 |
| MSU-MFSD [16] | 280 | 35 |
| Replay-Attack [4] | 1300 | 50 |
| OULU-NPU [2] | 4950 | 55 |
3.2. Architecture and algorithm
3.2. 架构与算法
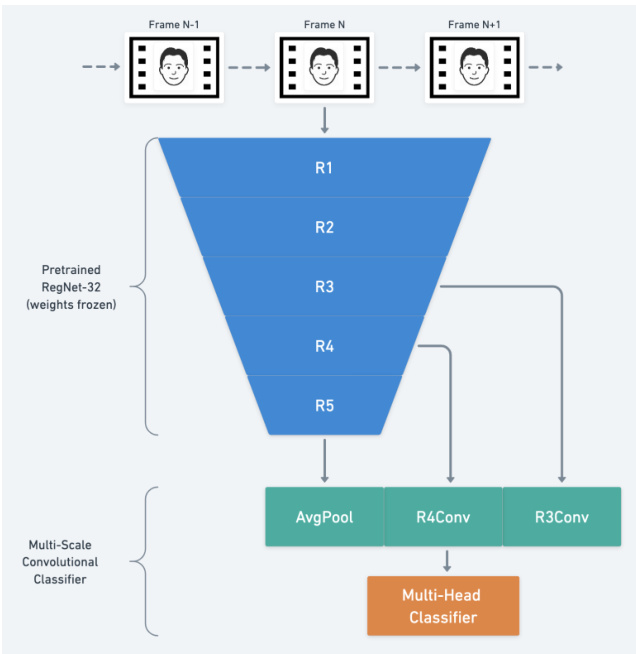
Figure 1. Network architecture. We apply the network for each frame in a video stream, sequentially before aggregating received predictions to get the final spoofing score for the entire session. Table 1. Comparison of existing datasets for face anti-spoofing.
图 1: 网络架构。我们对视频流中的每一帧依次应用该网络,在聚合接收到的预测后得到整个会话的最终欺骗分数。
表 1: 现有面部反欺骗数据集的对比。
The training process is split into two steps in the following way:
训练过程按以下方式分为两个步骤:
3.2.1 Task-aware fine-tuning
3.2.1 任务感知微调
Our training process follows the general approach described by Chen et al. in [3]. To recap, their training pipeline starts with an unsupervised pre training of a large network on a large amount of unlabeled data, followed by supervised fine-tuning on a (typically smaller) task-specific labeled dataset. In our experiments, an open source pretrained network provided by Meta [7] substitutes the pre training step. We do not fine-tune the layers imported from RegNet, following the established practice [3] [7] based on the observation that a large self-supervised pretrained network improves the generalization.
我们的训练流程遵循Chen等人在[3]中描述的通用方法。概括而言,他们的训练流程首先在大规模无标注数据上对大型网络进行无监督预训练,随后在(通常较小的)任务特定标注数据集上进行监督微调。本实验中,我们采用Meta[7]提供的开源预训练网络替代预训练步骤。根据现有实践[3][7]的观察结论——大规模自监督预训练网络能提升泛化能力,我们不对从RegNet导入的层进行微调。
Our network structure is modified from RegNet-32g [7]: for the final layer we use a multi-headed classifier composed from 8 independent binary class if i ers with the following semantics:
我们的网络结构基于RegNet-32g [7]进行了修改:在最后一层使用了由8个独立二元分类器组成的多头分类器,其语义如下:
The training is done with the pretrained layers from [7] frozen. We are optimizing the Reduced Focal Loss function [12] with AdamW [10] for 3 epochs with learning rate set to $1e-6$ . Frames that are samples from source videos are heavily augmented to further prevent the domain shift with the following set of augmentations:
训练过程中保持[7]中的预训练层冻结。我们使用AdamW [10]优化器对Reduced Focal Loss函数[12]进行了3个周期的训练,学习率设置为$1e-6$。为防止域偏移,对源视频采样帧进行了以下增强处理:
During training, we optimize a multi-class classification loss function for heads 1-8, but during inference only the probability from Head 8 is used. We observe that introducing an explicit classification of visible signals in a spoofing attempt improves the convergence speed and stabilizes the training process, but the actual spoofing detection does not require fine-grained classification.
训练期间,我们针对头部1-8优化多分类损失函数,但推理时仅使用头部8的概率输出。实验表明,在欺骗攻击中引入可见信号的显式分类能提升收敛速度并稳定训练过程,但实际欺骗检测并不需要细粒度分类。
3.2.2 Network distillation
3.2.2 网络蒸馏
After the network is trained, we perform the distillation procedure with a smaller architecture, to make the real-time
网络训练完成后,我们采用更小的架构进行蒸馏处理,以实现实时
inference feasible. Since we have a large number of labeled videos in our training dataset $\mathcal{D}$ , we are leveraging the weighted distillation loss from [3]:
推理可行。由于我们的训练数据集 $\mathcal{D}$ 中包含大量带标签视频,我们采用了[3]中的加权蒸馏损失:
$$
\begin{array}{r l}&{\mathcal{L}=-\left({1-\alpha}\right)\displaystyle\sum_{\left(x_{i},y_{i}\right)\in{\mathcal{D}^{L}}}\bigg[\log P^{S}(y_{i}|x_{i})\bigg]}\ &{\quad\quad-\alpha\displaystyle\sum_{x_{i}\in{\mathcal{D}}}\bigg[\displaystyle\sum_{y}P^{T}(y|x_{i};\tau)\log P^{S}(y|x_{i};\tau)\bigg]}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}=-\left({1-\alpha}\right)\displaystyle\sum_{\left(x_{i},y_{i}\right)\in{\mathcal{D}^{L}}}\bigg[\log P^{S}(y_{i}|x_{i})\bigg]}\ &{\quad\quad-\alpha\displaystyle\sum_{x_{i}\in{\mathcal{D}}}\bigg[\displaystyle\sum_{y}P^{T}(y|x_{i};\tau)\log P^{S}(y|x_{i};\tau)\bigg]}\end{array}
$$
where $\tau$ is a scalar temperature parameter, $\alpha$ is a balancing parameter, $P^{T}(y|x_{i})$ is the output of the teacher network, which is frozen after training, and $P^{S}(y|x_{i})$ is the output of the student network.
其中 $\tau$ 是标量温度参数,$\alpha$ 是平衡参数,$P^{T}(y|x_{i})$ 是教师网络(teacher network)的输出(训练后冻结),$P^{S}(y|x_{i})$ 是学生网络(student network)的输出。
The architecture for the student network is Efficient NetB3 [13].
学生网络的架构为Efficient NetB3 [13]。
4. Experiments
4. 实验
4.1. Benchmarks
4.1. 基准测试
We evaluate the effectiveness of our network from two aspects: an evaluation portion of Entry Anti spoofing Dataset for intra-test, and MSU-MFSD, Replay-Attack, and OULU-NPU for cross-database tests. When it comes to the baselines, we compare the results of our models that were never fine-tuned on target datasets to both intra-test and cross-test results of existing state-of-the-art methods, indicating which is which in the tables. When the prior crosstest result is reported for a particular baseline, we choose the best score of all cross-tests for that model.
我们从两个方面评估网络的有效性:使用Entry Anti spoofing Dataset的评估部分进行内部测试,以及采用MSU-MFSD、Replay-Attack和OULU-NPU进行跨数据库测试。在基线对比方面,我们将未经目标数据集微调的模型结果与现有最先进方法的内部测试和跨测试结果进行比较,并在表格中明确标注。若某基线模型已报告过跨测试结果,则选用该模型所有跨测试中的最佳分数。
MSU-MFSD. This dataset contains 280 videos of 35 subjects. Despite smaller scale, this benchmark is more challenging due to higher average quality of recordings used for spoofing, which is reflected in the baseline scored cited in this work.
MSU-MFSD。该数据集包含35名受试者的280段视频。尽管规模较小,但由于用于欺骗的录制素材平均质量更高,该基准更具挑战性,这一点在本工作引用的基线得分中有所体现。
Replay-Attack. This dataset contains 1300 videos of 50 subjects. All videos are generated by either having a (real) client trying to access a laptop through a built-in webcam or by displaying a photo or a video recording of the same client for at least 9 seconds.
重放攻击 (Replay-Attack)。该数据集包含50名受试者的1300段视频。所有视频均通过以下两种方式生成:(1) 真实用户尝试通过内置网络摄像头访问笔记本电脑;(2) 展示同一用户的照片或视频录像,时长均不少于9秒。
OULU-NPU. This dataset contains 4950 videos of 55 subjects, collected in different lighting conditions, on six different mobile devices.
OULU-NPU。该数据集包含55名受试者的4950段视频,采集于不同光照条件下,使用六种不同的移动设备。
4.2. Protocol
4.2. 协议
The main goal of this work is to demonstrate strong genera liz ation of our model across several challenging benchmarks.
这项工作的主要目标是展示我们的模型在多个具有挑战性的基准测试上的强大泛化能力。
4.3. Metric
4.3. 指标
Our reported metric for cross-test evaluation is HTER (Half Total Error Rate) [1], which is widely used for comparing models in the field of biometric anti-spoofing. It is defined in terms of two error rates, False Acceptance Rate (FAR) and False Rejection Rate (FRR):
我们报告的跨测试评估指标是HTER (Half Total Error Rate) [1],该指标在生物特征反欺骗领域被广泛用于模型比较。它由两个错误率定义:错误接受率(FAR)和错误拒绝率(FRR):
$$
H T E R=\frac{F A R+F R R}{2}
$$
$$
H T E R=\frac{F A R+F R R}{2}
$$
5. Results
5. 结果
In this paper we are reporting the results on two models, sharing the same general architecture and trained on the same data, with one architectural difference:
本文报告了两种模型的结果,它们共享相同的总体架构并在相同数据上训练,仅存在一处架构差异:
5.1. Intra-test on Entry Dataset
5.1. 入口数据集内部测试
First, we examine the results of the intra-test on a test subset of the internal Entry Anti spoofing Dataset.
首先,我们在内部Entry Anti spoofing数据集的测试子集上检查了内部测试的结果。
Table 2. $\mathrm{HTER}(%)$ scores on internal test subset of Entry Antispoofing Dataset.
表 2: Entry反欺骗数据集内部测试子集的$\mathrm{HTER}(%)$分数。
| 方法 | Entry内部测试 |
|---|---|
| Entry-V1 | 3.54 |
| Entry-V2 | 0.74 |
Our primary hypothesis related to the dataset is that if the model achieving low HTER scores on it is capable of achieving similarly low error rates on other datasets, it will attest to the high level of generalization across domains it provides, and suggest that this dataset could be used on its own for comprehensive quality assessment moving forward.
我们关于该数据集的主要假设是,如果模型在其上能实现较低的HTER分数,且在其他数据集上也能达到类似的低错误率,这将证明其具备高水平的跨领域泛化能力,并表明该数据集可独立用于未来全面的质量评估。
5.2. Cross-test
5.2. 交叉测试
We consider the general iz ability of the model to be the main goal of building an accurate anti-spoofing algorithm, which is why we make the emphasis on cross-database testing. Following the established practice for conducting cross-database evaluation, we evaluate HTER scores on three challenging datasets: MSU-MFSD [16], ReplayAttack [4], OULU-NPU [2]. For the OULU-NPU evaluation, we chose Protocol I to be able to compare with the existing state-of-the-art results.
我们将模型的泛化能力视为构建精准反欺骗算法的主要目标,因此重点进行跨数据库测试。遵循跨数据库评估的既定实践,我们在三个具有挑战性的数据集上评估HTER分数:MSU-MFSD [16]、ReplayAttack [4]、OULU-NPU [2]。对于OULU-NPU评估,我们选择Protocol I以便与现有最优结果进行比较。
Model Entry V2 achieves $H T E R=0$ on MSU-MFSD and Replay-Attack, therefore, it’s possible to make a direct comparison with the results obtained on intra-tests that use Equal Error Rate metric, which is equivalen to $H T E R$ at $E E R=0$ .
模型Entry V2在MSU-MFSD和Replay-Attack上实现了$H T E R=0$,因此可以直接与使用等错误率(Equal Error Rate)指标的内部测试结果进行比较,该指标在$E E R=0$时等同于$H T E R$。
Table 3. Cross-dataset HTER $(%)$ scores on MSU-MFSD [16].
表 3: 跨数据集 HTER $(%)$ 在 MSU-MFSD [16] 上的得分
| 方法 | MSU-MFSD |
|---|---|
| CNN-LSTMAM (Replay → MFSD) [14] | 25.72 |
| GFA-CNN (Replay → MFSD) [15] | 23.5 |
| Entry-V1 | 2.4 |
| Entry-V2 | 0 |
Table 4. Cross-dataset HTER $(%)$ scores on Replay-Attack [4].
表 4: Replay-Attack [4] 上的跨数据集 HTER $(%)$ 分数。
| 方法 | Replay-Attack |
|---|---|
| CNN-LSTMAM (MFSD → Replay) [14] | 12.37 |
| GFA-CNN (CASIA → Replay) [15] | 21.4 |
| GFA-CNN (MFSD → Replay) [15] | 25.8 |
| CNCN (CASIA → Replay) [17] | 15.5 |
| CNCN++ (CASIA → Replay) [17] | 6.5 |
| Entry-V1 | 2.7 |
| Entry-V2 | 0 |
Table 5. Cross-dataset $\mathrm{HTER}(%)$ scores comparison on Protocol I of the OULU-NPU dataset.
表 5. OULU-NPU数据集协议I上的跨数据集 $\mathrm{HTER}(%)$ 分数对比。
| 方法 | OULU-NPU |
|---|---|
| A-DeepPixBis (Replay →→ OULU) [9] | 25.57 |
| DeepPixBiS (Replay →→ OULU) [6] | 22.7 |
| Bi-FAS-S (Replay →→ OULU) [11] | 21.24 |
| Bi-FAS (Replay → OULU) [11] | 18.33 |
| LBP-SVM (Replay → OULU) [6] | 12.1 |
| IQM-SVM (Replay → OULU) [5] | 3.9 |
| Entry-V1 (ours) | 5.6 |
| Entry-V2 (ours) | 2.6 |
Additionally, for OULU-NPU we report the comparison on ACER metric.
此外,对于OULU-NPU数据集,我们报告了基于ACER指标的对比结果。
5.3. Application
5.3. 应用
This work was done as a part of R&D effort inside XIX.ai supporting the key technology behind our biometric authentication system Entry. That was the reason why the generalization and performance requirements were dictated by the real-world applicability.
这项工作作为XIX.ai内部研发的一部分,旨在支持我们生物特征认证系统Entry背后的关键技术。这也是为什么通用性和性能要求都由实际应用需求所决定。
- High accuracy after distillation. While the initial large network produces remarkable results, its size makes the s cal ability inefficient and, depending on the GPU accelerator used, prohibitively expensive. We have found that knowledge distillation does not have a noticeable effect on the model’s accuracy when finetuned on Entry Anti spoofing.
- 蒸馏后的高精度。虽然初始的大型网络能产生显著效果,但其规模导致可扩展性效率低下,且根据所使用的GPU加速器不同,成本可能高得令人望而却步。我们发现,在入门级反欺骗任务上进行微调时,知识蒸馏对模型准确率的影响微乎其微。
Table 6. Cross-dataset $\operatorname{ACER}(%)$ scores on Protocol I of the OULU-NPU dataset for more direct comparison with existing intra-tests. All models except ours were trained on OULU specifically. This comparison illustrates the closing gap between the results obtained by a strongly general iz able model (Entry) and the ones trained exclusively on OULU.
表 6. 跨数据集 $\operatorname{ACER}(%)$ 在 OULU-NPU 数据集协议 I 上的得分,用于与现有内部测试进行更直接比较。除我们的模型外,所有模型均专门在 OULU 上训练。该比较展示了强泛化模型 (Entry) 与仅在 OULU 上训练的模型之间结果的差距正在缩小。
| 方法 | OULU-NPU(ACER) |
|---|---|
| LBP-SVM (内部测试) [6] | 25.0 |
| IQM-SVM (内部测试) [5] | 32.29 |
| A-DeepPixBis (内部测试) [9] | 0.75 |
| DeepPixBiS (内部测试) [6] | 0.42 |
| Bi-FAS-S (内部测试) [11] | 1.97 |
| Bi-FAS (内部测试) [11] | 3.12 |
| Entry-V1 (我们的) | 3.33 |
| Entry-V2 (我们的) | 3.2 |
- Real-time inference. The anti-spoofing network, as all security-critical components, is being run on the backend, using cloud-hosted GPU accelerators. Since it turned out to be possible to distill the large model into a lightweight Efficient Net-B3, the throughput capacity was more than enough for processing multiple parallel video streams.
- 实时推理。与所有安全关键组件一样,防伪网络在后端运行,使用云托管的GPU加速器。由于可以将大模型蒸馏为轻量级的Efficient Net-B3,其吞吐量足以处理多个并行视频流。
6. Conclusions
6. 结论
In this paper we have presented an approach to training highly general iz able neural networks for face anti-spoofing, outlined the requirements for collecting labeled data sufficient for achieving the level of accuracy required for secure biometric authentication, and described the approach for post-processing of a model needed for deploying it as a part of a real-time video processing pipeline. We have shown the significant increase in accuracy on multiple established benchmarks by achieving the new state-of-the-art results from a combination of unsupervised pre training and fine-tuning for the specific problem.
本文提出了一种训练高度通用的人脸防伪神经网络的方法,概述了为达到安全生物识别认证所需精度而收集足够标记数据的要求,并描述了将模型部署为实时视频处理流程组成部分所需的后处理方法。通过结合无监督预训练和针对特定问题的微调,我们在多个权威基准测试中实现了最新技术水平,显著提升了准确率。
Augmenting the training objective with classification outputs predicting specific attributes of a spoofing attack alongside with the probability of an attack itself consistently improves the accuracy of the model further, without compromising on the generalization.
在训练目标中增加分类输出,预测欺骗攻击的特定属性及攻击本身的概率,能持续提升模型准确率,同时不影响泛化能力。
Finally, we have tested the performance differences and the increase in the inference throughput after the model distillation to prove the viability of this model in a live application.
最后,我们测试了模型蒸馏后的性能差异和推理吞吐量的提升,以证明该模型在实际应用中的可行性。