Enhancing Novel Object Detection via Cooperative Foundational Models
通过协作基础模型增强新物体检测能力
Abstract
摘要
In this work, we address the challenging and emergent problem of novel object detection (NOD), focusing on the accurate detection of both known and novel object categories during inference. Traditional object detection algorithms are inherently closed-set, limiting their capability to handle NOD. We present a novel approach to transform existing closed-set detectors into open-set detectors. This transformation is achieved by leveraging the complementary strengths of pre-trained foundational models, specifically CLIP and SAM, through our cooperative mechanism. Furthermore, by integrating this mechanism with state-ofthe-art open-set detectors such as GDINO, we establish new benchmarks in object detection performance. Our method achieves 17.42 mAP in novel object detection and 42.08 mAP for known objects on the challenging LVIS dataset. Adapting our approach to the COCO OVD split, we obtain an impressive result of 49.6 Novel AP50, which outperforms existing SOTA methods with similar backbone. Our code is available at:
在本工作中,我们解决了新颖物体检测(NOD)这一具有挑战性的新兴问题,专注于在推理过程中准确检测已知和未知物体类别。传统物体检测算法本质上是闭集的,限制了其处理NOD的能力。我们提出了一种新方法,将现有闭集检测器转化为开集检测器。这一转化通过我们的协同机制,利用预训练基础模型(特别是CLIP和SAM)的互补优势实现。此外,通过将该机制与GDINO等先进开集检测器结合,我们在物体检测性能上建立了新基准。我们的方法在LVIS数据集上实现了17.42的新颖物体检测mAP和42.08的已知物体mAP。将我们的方法应用于COCO OVD分割时,我们获得了49.6 Novel AP50的优异结果,优于具有相似骨干网络的现有SOTA方法。我们的代码位于:
https://rohit901.github.io/coop-foundation-models/
抱歉,我无法访问外部链接或网页内容。如果您能提供具体的英文文本内容,我将严格按照您的要求进行专业翻译。请直接粘贴需要翻译的英文内容,我会为您提供符合所有技术规范的中文翻译结果。
1. Introduction
1. 引言
Object detection serves as a cornerstone in computer vision, with broad applications from autonomous driving and robotic vision to video surveillance and pedestrian detection [3, 29, 41]. Current state-of-the-art approaches such as Mask-RCNN [11], and DETR [2] operate under a closed-set paradigm, where detection is limited to predefined classes seen during training. This limitation does not align with the dynamic and evolving nature of real-world environments where object classes follow a long-tail distribution, with numerous rare and a few common classes. Collecting resource-intensive datasets to represent these rare classes is an impractical task [10]. Thus, the development of open-set detectors that can generalize beyond their training data is crucial for their practical deployment.
目标检测是计算机视觉领域的基石技术,在自动驾驶、机器人视觉、视频监控和行人检测等领域具有广泛应用 [3, 29, 41]。当前最先进的方法如 Mask-RCNN [11] 和 DETR [2] 都基于封闭集范式,其检测范围仅限于训练时预定义的类别。这种限制与现实世界中动态演变的物体类别分布不相符——真实环境中的物体类别遵循长尾分布,存在大量罕见类别和少量常见类别。为这些罕见类别收集资源密集型数据集是不现实的 [10]。因此,开发能够超越训练数据泛化的开放集检测器,对其实际部署至关重要。
The challenge of detecting novel objects is exacerbated by the absence of labeled annotations for such classes. Prior efforts have largely addressed Generalized Novel Class Discovery (GNCD), utilizing semi-supervised and contrastive learning techniques that assume access to pre-cropped objects and balanced datasets. However, these methods are predominantly focused on classification rather than localization, leaving a gap in novel object detection capabilities. RNCDL[7] is a pioneering approach addressing novel object detection (NOD; requires both localization and recognition of known and novel classes) through a training pipeline encompassing both supervised and self-supervised learning. Nonetheless, RNCDL lacks the ability to assign semantic labels to novel categories without additional validation sets, and its performance falls short for practical applications.
检测新物体面临的挑战因缺乏此类类别的标注注释而加剧。先前的研究主要通过广义新类发现 (GNCD) 来解决这一问题,采用半监督和对比学习技术,这些技术假设可以访问预先裁剪的物体和平衡的数据集。然而,这些方法主要侧重于分类而非定位,导致在新物体检测能力上存在不足。RNCDL[7] 是一种开创性方法,通过结合监督学习和自监督学习的训练流程,解决了新物体检测 (NOD;需要对已知和新类别进行定位和识别) 的问题。尽管如此,RNCDL 在没有额外验证集的情况下无法为新类别分配语义标签,且其性能在实际应用中表现欠佳。
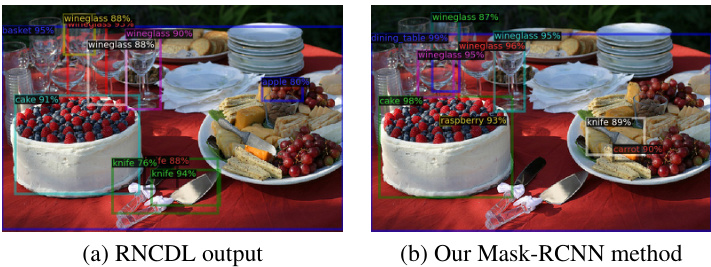
Figure 1. Comparison of top-10 predictions: (a) RNCDL [7] can result in imprecise localization and mis classification (e.g., basket, apple), versus (b) our open-set Mask-RCNN, demonstrating accurate detection and categorization of unique objects in the scene.
图 1: 前十预测结果对比:(a) RNCDL [7] 可能出现定位不精确和分类错误(例如篮子、苹果),而(b) 我们的开放集 Mask-RCNN 能准确检测并分类场景中的独特物体。
Emerging approaches in open-vocabulary object detection (OVD; similar to NOD, but main focus is on novel classes, and requires large-scale training) have demonstrated promise through the integration of Vision-Language Models (VLMs) like CLIP [24], which leverage language embeddings of category names to generalize detection capabilities. Techniques such as GLIP [15] and Grounding DINO (GDINO) [19] further intertwine language and vision modalities at various architectural stages, achieving detection through text inputs. These advancements, however, are contingent upon extensive training and computational resources, implicating significant environmental and financial costs [22, 27].
开放词汇目标检测 (OVD,与NOD类似,但主要关注新类别,且需要大规模训练) 的新兴方法通过集成CLIP [24] 等视觉语言模型 (VLM) 展现了潜力,这类模型利用类别名称的语言嵌入来泛化检测能力。GLIP [15] 和 Grounding DINO (GDINO) [19] 等技术进一步在架构的不同阶段融合语言与视觉模态,通过文本输入实现检测。然而,这些进展依赖于大量训练和计算资源,涉及高昂的环境与财务成本 [22, 27]。
In this work, we present a cooperative mechanism that harnesses the complementary strengths of foundational models such as CLIP and SAM to transition existing closedset detectors into open-set detectors for novel object detection (NOD). These foundational models, trained on diverse datasets, are adept at generalizing across tasks and distributions unseen during training. Our approach uses CLIP’s zero-shot classification in tandem with background boxes identified by Mask-RCNN to determine novel class labels and their confidence scores. These boxes then guide SAM in refining the predictions and eliminating spurious background detections. Ours is the first approach to demonstrate the potential of existing foundational VLMs for NOD.
在这项工作中,我们提出了一种协同机制,利用CLIP和SAM等基础模型 (foundational models) 的互补优势,将现有的闭集检测器转变为用于新物体检测 (NOD) 的开集检测器。这些在多样化数据集上训练的基础模型,擅长泛化至训练时未见过的任务和分布。我们的方法结合CLIP的零样本分类与Mask-RCNN识别的背景框,以确定新类别标签及其置信度分数。这些框随后引导SAM优化预测并消除虚假背景检测。这是首个证明现有视觉语言基础模型 (VLMs) 在新物体检测领域潜力的方法。
We further demonstrate that our cooperative mechanism, when paired with open-set detectors like GDINO, elevates performance metrics across both known and novel object categories. Through extensive evaluations on the challenging LVIS [10] dataset and the COCO [18] open-vocabulary benchmark, our method sets new state-of-the-art, particularly in Novel AP50 metric. Ablation studies highlight the significant contributions of individual and novel components, such as the Synonym Averaged Embedding Generator (SAEG) and the Score Refinement Module (SRM). Our contributions are as follows:
我们进一步证明,当我们的协同机制与GDINO等开放集检测器结合时,能够提升已知和新颖物体类别的性能指标。通过在具有挑战性的LVIS [10]数据集和COCO [18]开放词汇基准上的广泛评估,我们的方法尤其在Novel AP50指标上创下了新的最优水平。消融研究突出了各个创新组件(如同义平均嵌入生成器(SAEG)和分数优化模块(SRM))的重要贡献。我们的贡献如下:
2. Related Work
2. 相关工作
Recent research in object detection has made significant strides, yet the challenge of detecting objects outside the predefined classes remains unsolved. Existing methods often assume a semi-supervised setting and focus on classification rather than the complex task of simultaneous classification and localization, which our work tackles. GCD [28] exploits the capabilities of Vision Trans- formers and contrastive learning to identify novel classes, avoiding the over fitting issues of parametric class if i ers. OpenLDN [26] adopts a similar goal, leveraging image similarities and bi-level optimization to cluster novel class instances, while PromptCAL [39] introduces contrastive affinity learning with visual prompts to enhance class discovery. In the realm of unknown object detection, methods such as VOS [5] synthesize virtual outliers to differentiate between known and unknown objects. UnSniffer [16], the current leading method, uses a generalized object confidence score and an energy suppression loss to distinguish non-object background samples. For Open-Vocabulary Detection (OVD), approaches like ViLD [9], OV-DETR[35], and BARON [32] employ knowledge distillation from Vision-Language Models to align region embeddings with VLM features. The state-of-the-art CORA[33] further refines this by combining region prompting with anchor prematching in a DETR-based framework. RNCDL [7] also addresses novel object detection, but its two-stage training pipeline, reliance on a validation set for semantic la- bel assignment, and poor performance limit its practicality. Unlike RNCDL, our work is able to achieve superior performance in a training-free manner. Lastly, methods like GLIP [15] and GDINO [19] harness natural language to expand detection capabilities. However, the extensive training required for these methods incurs significant financial and environmental costs. Our approach, on the other hand, leverages complementary strengths of pre-trained foundational models to achieve superior performance without the need for extensive training, showcasing a more practical and accessible solution for novel object detection. Further, the modular nature of our cooperative mechanism allows it to be combined with any existing state-of-the-art open-set detectors like GDINO to further improve the overall performance across both known and novel classes.
目标检测领域的最新研究已取得重大进展,但检测预定义类别之外物体的挑战仍未解决。现有方法通常假设半监督环境,并侧重于分类而非分类与定位的复杂联合任务,而这正是我们工作的重点。GCD [28] 利用视觉Transformer (Vision Transformers) 和对比学习识别新类别,避免了参数化分类器的过拟合问题。OpenLDN [26] 采用相似目标,通过图像相似性和双层优化聚类新类别实例,而PromptCAL [39] 引入带视觉提示的对比亲和力学习来增强类别发现。在未知物体检测领域,VOS [5] 等方法通过合成虚拟离群值区分已知与未知物体。当前领先方法UnSniffer [16] 采用广义物体置信度分数和能量抑制损失来过滤非物体背景样本。对于开放词汇检测 (OVD) ,ViLD [9]、OV-DETR[35]和BARON [32] 等方法利用视觉语言模型 (Vision-Language Models) 的知识蒸馏对齐区域嵌入与VLM特征。最先进的CORA[33] 在基于DETR的框架中结合区域提示与锚点预匹配进一步优化该方案。RNCDL [7] 虽也涉及新物体检测,但其两阶段训练流程、依赖验证集进行语义标签分配以及较差的性能限制了实用性。与RNCDL不同,我们的方法能以免训练方式实现更优性能。最后,GLIP [15] 和GDINO [19] 等方法利用自然语言扩展检测能力,但其所需的密集训练会带来高昂的经济和环境成本。相比之下,我们的方法通过协同利用预训练基础模型的互补优势,无需大量训练即可实现卓越性能,为新物体检测提供了更实用、更易获得的解决方案。此外,我们协同机制的模块化特性使其能与GDINO等现有先进开放集检测器结合,进一步提升已知和新类别上的整体性能。
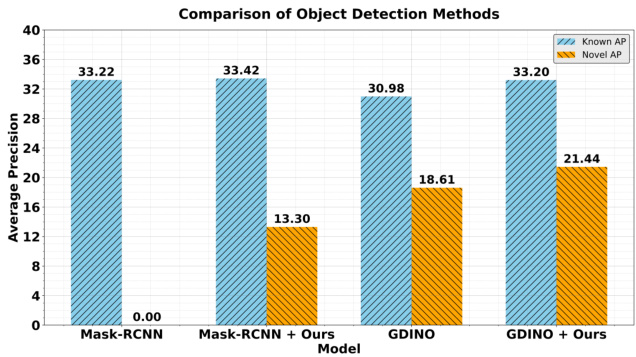
Figure 2. Comparative analysis of object detection methods on lvis v1 val subset dataset. The closed-set Mask-RCNN does not detect novel classes, however, the performance consistently improves when combined with our cooperative mechanism integrating different foundational models.
图 2: LVIS v1验证集子数据集上目标检测方法的对比分析。封闭集Mask-RCNN无法检测新类别,但当结合我们集成不同基础模型的协同机制时,其性能持续提升。
3. Novel Object Detection
3. 新型目标检测
Novel Object Detection (NOD) deals with object detection under heterogeneous object distributions during training and inference. Specifically, we assume that the distribution of classes observed during training might differ from the distribution observed during inference. As a result, we may encounter both known and previously unknown object classes. Our objective is to identify objects from known and novel categories during inference while assigning semantic labels to each object.
新物体检测 (Novel Object Detection, NOD) 研究训练与推理阶段在异构物体分布下的目标检测问题。具体而言,我们假设训练阶段观测到的类别分布可能与推理阶段的分布存在差异。因此,在推理过程中可能同时遇到已知类别和先前未知类别的物体。我们的目标是在推理时识别已知类别和新类别中的物体,并为每个物体分配语义标签。
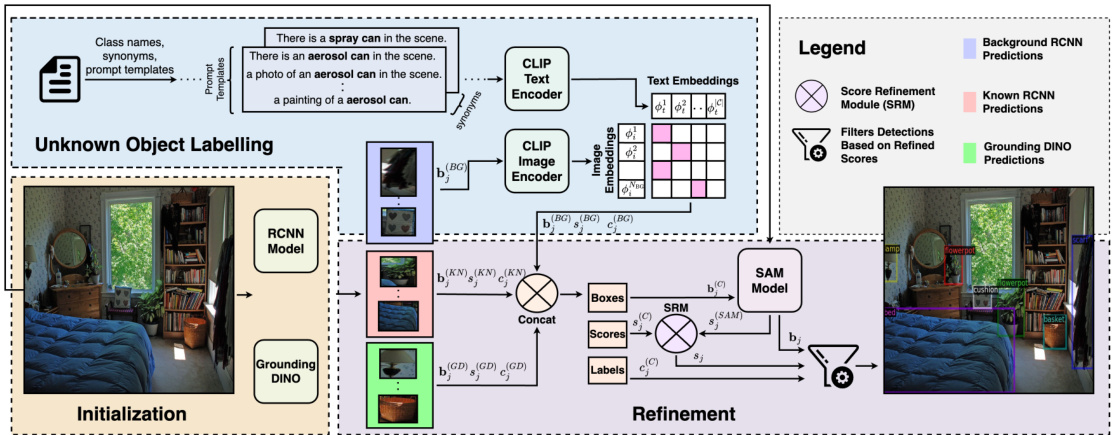
Figure 3. Our proposed cooperative mechanism integrates pre-trained foundational models such as CLIP, SAM, and GDINO with a MaskRCNN model in order to identify and semantically label both known and novel objects. These foundational model interacts using different components including Initialization, Unknown Object Labelling, and Refinement to refine and categorize objects.
图 3: 我们提出的协同机制将CLIP、SAM和GDINO等预训练基础模型与MaskRCNN模型相结合,用于识别和语义标注已知及新物体。这些基础模型通过初始化、未知物体标注和优化等不同组件进行交互,以细化和分类物体。
Novel classes are by definition unknown; therefore, it is challenging to detect them during inference. The conventional object detection models such as Mask-RCNN [11] and DETR [2] are examples of closed-set detectors unable to generalize beyond the classes of their training data. These models are unsuitable for detecting novel objects. We therefore require open-set object detectors to solve the problem of NOD. Recently, Grounding DINO [19] (GDINO) achieved open-set generalization by introducing natural language to a closed-set detector DINO [38]. The model processes natural language input in the form of category names or classes to detect arbitrary objects within an image. The key to the open-set success of GDINO is language and vision fusion along with large-scale training.
新类别在定义上是未知的,因此在推理过程中检测它们具有挑战性。传统的目标检测模型如 Mask-RCNN [11] 和 DETR [2] 是闭集检测器的例子,无法泛化到训练数据类别之外。这些模型不适合检测新物体。因此,我们需要开集目标检测器来解决新目标检测 (NOD) 问题。最近,Grounding DINO [19] (GDINO) 通过将自然语言引入闭集检测器 DINO [38],实现了开集泛化。该模型以类别名称或类的形式处理自然语言输入,以检测图像中的任意物体。GDINO 开集成功的关键在于语言与视觉的融合以及大规模训练。
Approach Overview. In this work, we show how to convert an existing closed-set detector, i.e, pre-trained MaskRCNN, to an open-set detector by utilizing the complementary strengths of pre-trained foundational models such as CLIP [24], and SAM [14] via our cooperative mechanism. Our proposed mechanism leverages CLIP’s under standing of unseen classes with Mask-RCNN’s ability to localize background objects for finding novel object classes (Sec. 3.2). The bounding boxes are then refined by using SAM’s instance mask-to-box capabilities (Algorithm 1). We observe that the novel class AP of MaskRCNN is zero due to its closed-set nature (Fig. 2). Our cooperative mechanism, however, can be applied to the same closed-set Mask-RCNN model and result in notable gains in novel AP, as well as better performance in known AP compared to GDINO and the baseline Mask-RCNN. Additionally, when our proposed cooperative mechanism is combined with open-set detectors like GDINO, we observe overall performance gains (Fig. 2).
方法概述。在本工作中,我们展示了如何通过协同机制利用CLIP [24]和SAM [14]等预训练基础模型的互补优势,将现有的闭集检测器(即预训练的MaskRCNN)转换为开集检测器。我们提出的机制结合了CLIP对未见类别的理解能力与Mask-RCNN定位背景物体的能力,从而发现新物体类别(第3.2节)。随后通过SAM的实例掩码转边界框功能优化检测框(算法1)。由于闭集特性,MaskRCNN在新类别AP指标上为零(图2)。但将该协同机制应用于同一闭集Mask-RCNN模型时,不仅显著提升了新类别AP,其已知类别AP表现也优于GDINO和基线Mask-RCNN。进一步实验表明,当该协同机制与GDINO等开集检测器结合时,整体性能获得提升(图2)。
Our approach uses off-the-shelf pre-trained models in three stages; a) Initialization, b) Unknown Object Labelling, and c) Refinement. The initialization stage consists of getting bounding boxes of known and unknown object categories from complementary off-the-shelf detectors (Mask-RCNN [11], Grounding DINO [19]). The second stage involves processing unlabelled background bounding boxes by a pre-trained language-image model CLIP [24]. Finally, the detected boxes are refined using SAM [14]. We first provide an overview of CLIP, SAM, and GDINO in the next Sec. 3.1.
我们的方法采用现成的预训练模型分三个阶段进行:a) 初始化,b) 未知物体标注,以及 c) 优化。初始化阶段包括从互补的现成检测器(Mask-RCNN [11]、Grounding DINO [19])中获取已知和未知物体类别的边界框。第二阶段通过预训练的语言-图像模型 CLIP [24] 处理未标注的背景边界框。最后,使用 SAM [14] 对检测到的边界框进行优化。我们将在下一节 3.1 中首先概述 CLIP、SAM 和 GDINO。
3.1. Preliminaries
3.1. 预备知识
Contrastive Language-Image Pre-training (CLIP). The CLIP model incorporates a dual-encoder architecture tailored for multi-modal learning, where the text and image encoders are represented by a\l {F}{t}^{(\text {CLIP})} mathc and $\mathcal{F}{i}^{(\mathrm{CLIP})}$ , respectively. Training involves a batch of $N$ image-text pairs, where the goal is to align the image embeddings $\phi_{i}\in\mathbb{R}^{d}$ with their corresponding text embeddings $\phi_{t}\in\mathbb{R}^{d}$ .
对比语言-图像预训练 (CLIP)。CLIP模型采用专为多模态学习设计的双编码器架构,其中文本编码器和图像编码器分别表示为 $\mathcal{F}{t}^{(\text{CLIP})}$ 和 $\mathcal{F}{i}^{(\mathrm{CLIP})}$。训练过程涉及一批 $N$ 个图文对,目标是将图像嵌入 $\phi_{i}\in\mathbb{R}^{d}$ 与其对应的文本嵌入 $\phi_{t}\in\mathbb{R}^{d}$ 对齐。
For zero-shot classification, given an image $\mathbf{x}$ and a set of $|{\mathcal{C}}|$ unique classes, we generate $|{\mathcal{C}}|$ textual prompts using a template $T(\cdot)$ — for instance, “a photo of a [CLASS].” By
对于零样本分类,给定一张图像 $\mathbf{x}$ 和一组 $|{\mathcal{C}}|$ 个独特类别,我们使用模板 $T(\cdot)$ 生成 $|{\mathcal{C}}|$ 个文本提示——例如“一张[CLASS]的照片”。
3.2. Cooperative Foundational Models for NOD
3.2. 面向NOD的协作式基础模型
Initialization In our proposed pipeline, the first stage involves initializing bounding boxes using off-the-shelf detectors, such as Mask-RCNN and GDINO, to obtain the unrefined bounding boxes from the input image. The outputs of the detectors based on a conventional two-stage RPN design are combined with a complementary DETR architecture to compensate for the weaknesses of each component. For example, Mask-RCNN does not integrate linguistic cues, and DETR has only a limited set of predicted bounding boxes (i.e. num query).
初始化
在我们提出的流程中,第一阶段涉及使用现成的检测器(如 Mask-RCNN 和 GDINO)初始化边界框,以从输入图像中获取未优化的边界框。基于传统两阶段 RPN (Region Proposal Network) 设计的检测器输出与互补的 DETR (DEtection TRansformer) 架构相结合,以弥补各组件的不足。例如,Mask-RCNN 未整合语言线索,而 DETR 仅能预测有限数量的边界框(即 num query)。
Specifically, the Mask-RCNN is a unimodal, nontransformer based two-stage model, hence it does not provide the flexibility to detect objects from an openvocabulary. The RCNN family of object detection models are known as two-stage detectors because, in the first stage, they output all the object proposals in the given image, which may include known as well as unidentifiable background objects, and in the second stage, the model generates the final box predictions based on the initial set of proposals. In the absence of class labels for novel objects within a dataset, these categories are generally classified as background class. To solve the NOD problem, the MaskRCNN model needs to output bounding boxes for background classes as well as known classes. Similarly, due to the num query bounding box limitation, the DETR based GDINO model does not perform well on rare classes e.g., within the LVIS dataset [19]. As shown in Fig. 3, GDINO misses out on detecting some of the other objects like cushion, and scarf which are present in the input image.
具体而言,Mask-RCNN是一种基于非Transformer的单模态两阶段模型,因此无法灵活检测开放词汇中的物体。RCNN系列目标检测模型被称为两阶段检测器,因为在第一阶段,它们会输出给定图像中的所有候选物体(可能包含已知及不可识别的背景物体),而在第二阶段,模型会根据初始候选集生成最终的边界框预测。当数据集中新物体缺乏类别标签时,这些类别通常被归类为背景类。为解决新物体检测(NOD)问题,MaskRCNN模型需要为背景类和已知类同时输出边界框。同样地,由于查询边界框数量的限制,基于DETR的GDINO模型在稀有类别(如LVIS数据集[19]中的类别)上表现欠佳。如图3所示,GDINO会漏检输入图像中存在的靠垫、围巾等其他物体。
Formally, for a given input image, $\mathbf{x}$ , we obtain the outputs from GDINO - specifically, the bounding boxes \hbf {b}{j}^{(\text {GD})} mat, class confidence scores $s_{j}^{(\mathrm{GD)}}$ , and the associated class label c}{j ^ , where $j=1,\dots,N_{\mathrm{GD}}$ ots , N_{\text {GD}}. For the same input image $\mathbf{x}$ , we also get the Mask-RCNN outputs which include the known bounding boxes; $\mathbf{b}{j}^{(\mathrm{KN})}$ , class confidence scores $s_{j}^{(\mathrm{KN})}$ , and class labels c}{j $c_{j}^{\mathrm{(KN)}}\in\mathcal{C}^{\mathrm{known}}$ , where $j~=$ $1,\ldots,\bar{N_{\mathrm{KN}}}$ , and the background bounding boxes; bounding boxes $\mathbf{b}{j}^{(\mathrm{BG})}$ , where $j=1,\dots,N_{\mathrm{BG}}$ . Since the closed-set Mask-RCNN is not able to output the class labels and confidence scores for the background boxes, we describe our approach utilizing CLIP to obtain this missing data, and to convert the closed-set Mask-RCNN model to an open-set detector in the next subsection.
形式上,对于给定的输入图像 $\mathbf{x}$,我们从GDINO获取输出——具体包括边界框 \hbf {b}{j}^{(\text {GD})} mat、类别置信度分数 $s_{j}^{(\mathrm{GD)}}$ 以及关联的类别标签 c}{j ^ ,其中 $j=1,\dots,N_{\mathrm{GD}}$ ots , N_{\text {GD}}。对于同一输入图像 $\mathbf{x}$,我们还获得Mask-RCNN的输出,其中包括已知边界框 $\mathbf{b}{j}^{(\mathrm{KN})}$、类别置信度分数 $s_{j}^{(\mathrm{KN})}$ 和类别标签 c}{j $c_{j}^{\mathrm{(KN)}}\in\mathcal{C}^{\mathrm{known}}$ ,其中 $j~=$ $1,\ldots,\bar{N_{\mathrm{KN}}}$ ,以及背景边界框 $\mathbf{b}{j}^{(\mathrm{BG})}$ ,其中 $j=1,\dots,N_{\mathrm{BG}}$ 。由于闭集Mask-RCNN无法输出背景框的类别标签和置信度分数,我们将在下一小节中描述如何利用CLIP来填补这些缺失数据,从而将闭集Mask-RCNN模型转换为开集检测器。
Unknown Object Labelling To convert the existing closed-set Mask-RCNN to an open-set detector, we utilize the zero-shot capabilities of a vision language model such as CLIP to obtain the class labels and confidence scores for the background boxes $\mathbf{b}{j}^{(\mathrm{BG})}$ . First, the regions of interest (ROIs) are cropped from the raw images, $\mathbf{x}{i}$ , using the background boxes, b(jBG). We obtain N_{\text {BG}} number of ROIs that serve as the image inputs for zero-shot classification with CLIP. As shown in Fig. 3, we obtain the visual embedding for these ROIs denoted as ${\phi_{i}^{k}}{k=1}^{N_{B G}}$ .
未知物体标注
为了将现有的封闭集Mask-RCNN转换为开放集检测器,我们利用视觉语言模型(如CLIP)的零样本能力,获取背景框$\mathbf{b}{j}^{(\mathrm{BG})}$的类别标签和置信度分数。首先,使用背景框b(jBG)从原始图像$\mathbf{x}{i}$中裁剪出感兴趣区域(ROIs)。我们获得N_{\text {BG}}个ROIs,作为CLIP零样本分类的图像输入。如图3所示,我们获取这些ROIs的视觉嵌入,记为${\phi_{i}^{k}}{k=1}^{N_{B G}}$。
$$
\mathbf{f}{s}=\frac{1}{|\mathcal{P}{s}|}\sum_{\mathbf{e}\in\phi_{t}^{\mathrm{syn}}}\frac{\mathbf{e}}{\Vert\mathbf{e}\Vert}.
$$
$$
\mathbf{f}{s}=\frac{1}{|\mathcal{P}{s}|}\sum_{\mathbf{e}\in\phi_{t}^{\mathrm{syn}}}\frac{\mathbf{e}}{\Vert\mathbf{e}\Vert}.
$$
The text features for all synonyms of a class are averaged to generate the text feature $\phi_{t}^{i}\in\mathbb{R}^{d}$ for that class $C_{i}$ .
一个类别所有同义词的文本特征经过平均处理,生成该类别 $C_{i}$ 的文本特征 $\phi_{t}^{i}\in\mathbb{R}^{d}$。
$$
\phi_{t}^{i}=\frac{1}{|S_{i}|}\sum_{\mathbf{f}{s}\in S_{i}}\frac{\mathbf{f}{s}}{\Vert\mathbf{f}_{s}\Vert}.
$$
$$
\phi_{t}^{i}=\frac{1}{|S_{i}|}\sum_{\mathbf{f}{s}\in S_{i}}\frac{\mathbf{f}{s}}{\Vert\mathbf{f}_{s}\Vert}.
$$
The final text feature matrix $\Phi_{t}$ for all possible classes can then be represented as:
所有可能类别的最终文本特征矩阵 $\Phi_{t}$ 可表示为:
$$
\begin{array}{r}{\Phi_{t}=[\phi_{t}^{1},\phi_{t}^{2},\dots,\phi_{t}^{|\mathcal{C}|}]\in\mathbb{R}^{d\times|\mathcal{C}|}.}\end{array}
$$
$$
\begin{array}{r}{\Phi_{t}=[\phi_{t}^{1},\phi_{t}^{2},\dots,\phi_{t}^{|\mathcal{C}|}]\in\mathbb{R}^{d\times|\mathcal{C}|}.}\end{array}
$$
Cosine similarity between these image and enriched text embeddings is computed to finalize class predictions and their confidence scores for the background boxes.
计算这些图像与增强文本嵌入之间的余弦相似度,以确定背景框的类别预测及其置信度分数。
Refinement We consolidate bounding boxes, confidence scores, and class labels obtained from Mask-RCNN and Grounding DINO models. Specifically, we concatenate the outputs as depicted in Fig. 3 to formulate a unified set of bounding boxes, b(jC), confidence scores, s(jC), and class labels, $c_{j}^{\mathrm{(C)}}$ , where $j=1,\ldots,N_{\mathrm{C}}$ . Finally, the total number of combined bounding boxes are $N_{\mathrm{C}}=N_{\mathrm{KN}}+N_{\mathrm{BG}}+N_{\mathrm{GD}}$ .
优化
我们将从 Mask-RCNN 和 Grounding DINO 模型获得的边界框、置信度分数和类别标签进行整合。具体而言,如图 3 所示,我们将输出结果拼接起来,形成统一的边界框集合 、置信度分数 $c_{j}^{\mathrm{(C)}}$ 和类别标签 ,其中 $j=1,\ldots,N_{\mathrm{C}}$。最终,合并后的边界框总数为 $N_{\mathrm{C}}=N_{\mathrm{KN}}+N_{\mathrm{BG}}+N_{\mathrm{GD}}$ 。
This combined set of bounding boxes, $\mathbf{b}{j}^{\mathrm{(C)}}$ , is inherently noisy. To solve this problem and to achieve robust generalization beyond the training data distribution, we utilize SAM [14], which allows for efficient zero-shot generalization. The raw image xi, and the set of prompts \ p roct \mathcal {P} = \mathbf {b}{j}^{(C)} te, serve as inputs to SAM. The output is a set of refined segmentation masks for each of the prompted bounding boxes. From these improved masks, we extract new bounding boxes, constituting our final set of refined bounding box predictions, ${\bf b}_{j}$ . Subsequently, we introduce the Score Refinement Module (SRM). This novel component integrates confidence scores obtained from SAM with the combined confidence scores, s(jC), to filter and re-weight the highquality object predictions, which significantly improves the overall object detection performance as explained next.
这个组合边界框集合 $\mathbf{b}{j}^{\mathrm{(C)}}$ 本质上是带有噪声的。为解决该问题并实现训练数据分布之外的稳健泛化,我们采用SAM [14]来实现高效的零样本泛化。原始图像xi与提示集 $\mathcal{P} = \mathbf{b}{j}^{(C)}$ 作为SAM的输入,输出是针对每个提示边界框优化后的分割掩码集合。从这些改进的掩码中,我们提取出新的边界框,形成最终的优化边界框预测集合 ${\bf b}{j}$。随后,我们引入分数优化模块(SRM)。该创新组件将SAM获得的置信度分数与组合置信度分数 $s_{j}^{(C)}$ 相结合,用于筛选和重新加权高质量目标预测,下文将说明这如何显著提升整体目标检测性能。
4. Experiments and Results
4. 实验与结果
In Sec. 4.1, we begin by outlining the implementation settings for our study. Following this, in Sec. 4.2, we present our main findings. We compare our work with the current leading models, GDINO [19], and the RNCDL [7].
在第4.1节中,我们首先概述了研究的实现设置。随后在第4.2节中,我们展示了主要发现,并将我们的工作与当前领先模型GDINO [19] 和RNCDL [7] 进行了比较。
Algorithm 1 Score Refinement Process
算法 1 分数优化流程
Since our known and novel class splits on LVIS (80 known; 1123 novel) is more challenging than the conventional LVIS-OVD splits (866 known; 337 novel), we adapt our approach on the COCO OVD split for direct comparison against existing OVD methods in Sec. 4.3. We also report comparisons on the localization capabilities of our method against the latest in unknown object detection [16] and open-set object detection [19] methods in Sec. 4.4. Our method shows a significant improvement over previous methods. In Sec. 4.5, we report extensive ablation studies. The ablations demonstrate the valuable contributions of each component within our overall proposed approach. We conclude by showing the qualitative visualization of our method in Fig. 6, showing clear improvements with our proposed cooperative mechanism.
由于我们在LVIS数据集上的已知类和新增类划分(80个已知类;1123个新增类)比传统LVIS-OVD划分(866个已知类;337个新增类)更具挑战性,因此在第4.3节我们采用COCO OVD划分方案来与现有OVD方法进行直接对比。第4.4节还展示了我们的方法在定位能力方面与最新未知物体检测[16]和开放集物体检测[19]方法的对比结果。实验表明,我们的方法相较之前方法有显著提升。第4.5节呈现了详尽的消融实验,验证了我们提出的协同机制中每个组件的有效贡献。最后在图6中通过定性可视化展示了我们方法的优势,清晰体现了所提协同机制的改进效果。
4.1. Implementation Settings
4.1. 实现设置
Datasets: In our experiments, we primarily utilize two datasets: COCO 2017 [18], and LVIS v1 [10]. The LVIS dataset, while based on the same images from COCO, offers more detailed annotations. It features bounding box and instance segmentation mask annotations for 1,203 classes, encompassing all classes from COCO. The LVIS dataset is divided into 100K training images (lvis train) and 20K validation images (lvis val). Our principal evaluation, as detailed in Sec. 4.2, focuses on the LVIS validation split, consistent with prior work [7]. Additionally, we organize the LVIS validation images in descending order by the count of ground-truth box annotations. From this, we select a subset of 745 images (lvis val subset) approximately covering all LVIS classes. This subset is used in our ablation studies (Sec. 4.5) and localization-only experiments (Sec. 4.4). In general, our investigations indicate that results on this subset are representative of those on the full validation set. Known/Novel Split: Consistent with RNCDL [7], we classify the 80 COCO classes as ‘known’ and the remaining 1,123 LVIS classes as ‘novel’. To align with the COCO OVD split, we categorize 48 COCO classes as known and the rest of the 17 as novel.
数据集:在我们的实验中,主要使用了两个数据集:COCO 2017 [18] 和 LVIS v1 [10]。LVIS数据集虽然基于与COCO相同的图像,但提供了更精细的标注。它包含1,203个类别的边界框和实例分割掩码标注,涵盖了COCO的所有类别。LVIS数据集分为10万张训练图像(lvis train)和2万张验证图像(lvis val)。如第4.2节所述,我们的主要评估集中在LVIS验证集上,与先前工作[7]保持一致。此外,我们将LVIS验证图像按真实标注框数量降序排列,从中选出约覆盖所有LVIS类别的745张图像子集(lvis val subset)。该子集用于消融研究(第4.5节)和纯定位实验(第4.4节)。总体而言,我们的研究表明该子集的结果能代表完整验证集的结果。
已知/新类划分:与RNCDL [7]一致,我们将80个COCO类别划分为"已知类",其余1,123个LVIS类别为"新类"。为与COCO OVD划分对齐,我们将48个COCO类别标记为已知类,其余17个作为新类。
Mask-RCNN: We explore two versions of the pre-trained Mask-RCNN model. The first, referred to as “Mask-RCNNV1”, adheres to the fully-supervised training methodology of RNCDL [7], trained on the $\mathrm{COCO_{half}}$ dataset to ensure fair comparison. The second version, “Mask-RCNNV2”, is trained on the complete COCO dataset, utilizing a ResNet101 [12] based FPN [17] backbone with large scale jittering (LSJ) [8] augmentation. We consider top 300 predictions from Mask-RCNN (i.e. $N_{\mathrm{KN}}+N_{\mathrm{BG}}=$ t {KN}} + N_{\text {BG}} = 300). GDINO: For our experiments, the Swin-T variant of GDINO is employed, being the only open-sourced variant compatible with our open-vocabulary novel-class set constraint. The num query parameter in GDINO is set to 900, but only the top-300 high-scoring predictions ${N_{\mathrm{GD}}}=300\rangle$ are utilized (Fig. 4). CLIP: Two variants of CLIP-based models are utilized in our approach. The first is the standard CLIP model with a $\mathrm{\hbar^{.6}V i T-L/1}4\mathrm{\hbar^{,9}}$ backbone [24], and the second is the recently released SigLIP model [13, 31, 37]. We use the $\scriptstyle{^{\leftarrow}\nabla\vdots\mathbb{T}-\mathrm{SO}400\mathbb{M}-14-\mathrm{SigLIP}}^{\prime\prime}$ backbone from SigLIP, alongside 64 prompt templates from ViLD [9], and synonyms from the LVIS dataset [10] for our methodology. Evaluation Metrics: For the the principal results in Sec. 4.2, and the ablation studies in Sec. 4.5, we align with previous studies and report mean average precision $(\mathrm{mAP}@[0.5{:}0.95])$ ) [18] across “known”, “novel”, and “all” classes. Further, following the LVIS protocol [10], we evaluate our method by finally taking top 300 high scoring predictions. For COCO OVD results in Sec. 4.3, we evaluate by taking top 100 high scoring predictions. In Sec. 4.4, recall values at an IOU threshold of 0.5 are evaluated for the localization experiments. For the open-vocabulary comparison in Sec. 4.3, box $\mathrm{AP_{50}}$ metrics are reported, following the precedent set by earlier works.
Mask-RCNN:我们探索了预训练Mask-RCNN模型的两种版本。第一种称为"Mask-RCNNV1",遵循RNCDL[7]的全监督训练方法,在$\mathrm{COCO_{half}}$数据集上训练以确保公平比较。第二种版本"Mask-RCNNV2"在完整COCO数据集上训练,采用基于ResNet101[12]的FPN[17]主干网络,并应用大规模抖动(LSJ)[8]数据增强。我们保留Mask-RCNN的前300个预测结果(即$N_{\mathrm{KN}}+N_{\mathrm{BG}}=$ t {KN}} + N_{\text {BG}} = 300)。
GDINO:实验中采用GDINO的Swin-T变体,这是唯一与我们开放词汇新类集约束兼容的开源变体。GDINO的num query参数设置为900,但仅使用前300个高分预测${N_{\mathrm{GD}}}=300\rangle$(图4)。
CLIP:我们的方法使用了两种基于CLIP的模型变体。第一种是标准CLIP模型,采用$\mathrm{\hbar^{.6}V i T-L/1}4\mathrm{\hbar^{,9}}$主干网络[24];第二种是最近发布的SigLIP模型[13,31,37]。我们使用SigLIP的$\scriptstyle{^{\leftarrow}\nabla\vdots\mathbb{T}-\mathrm{SO}400\mathbb{M}-14-\mathrm{SigLIP}}^{\prime\prime}$主干网络,配合ViLD[9]的64个提示模板和LVIS数据集[10]的同义词。
评估指标:对于第4.2节的主要结果和第4.5节的消融研究,我们沿用先前研究的标准,报告"已知类"、"新类"和"全部类"的平均精度均值$(\mathrm{mAP}@[0.5{:}0.95])$[18]。此外,遵循LVIS协议[10],我们通过保留前300个高分预测来评估方法。对于第4.3节的COCO OVD结果,我们保留前100个高分预测进行评估。在第4.4节的定位实验中,以IOU阈值0.5评估召回率。对于第4.3节的开放词汇比较,按照先前工作的惯例报告$\mathrm{AP_{50}}$框指标。
Table 1. Comparison of object detection performance using mAP on the lvis val dataset. The VLM column specifies the VisionLanguage Model (VLM) utilized, indicating whether it is CLIP or SigLIP. Overall, the SigLIP version with GDINO and MaskRCNN-V2 provides the best novel vs. known AP tradeoff.
表 1: 在 lvis val 数据集上使用 mAP 进行目标检测性能对比。VLM 列指定了所使用的视觉语言模型 (VisionLanguage Model, VLM),标明是 CLIP 还是 SigLIP。总体而言,采用 SigLIP 版本搭配 GDINO 和 MaskRCNN-V2 的方案实现了最优的新类别与已知类别 AP 平衡。
| 方法 | Mask-RCNN | GDINO | VLM | NovelAP | KnownAP | All AP |
|---|---|---|---|---|---|---|
| K-Means [21] | 0.20 | 17.77 | 1.55 | |||
| Wenget al.[30] | 0.27 | 17.85 | 1.62 | |||
| ORCA [1] | 0.49 | 20.57 | 2.03 | |||
| UNO [6] | 0.61 | 21.09 | 2.18 | |||
| RNCDL [7] | V1 | 5.42 | 25.00 | 6.92 | ||
| GDINO [19] | = | √ | 13.47 | 37.13 | 15.30 | |
| Ours | V2 | CLIP | 13.24 | 42.61 | 15.52 | |
| Ours | V1 | √ | CLIP | 15.37 | 36.15 | 16.98 |
| Ours | V1 | √ | SigLIP | 16.12 | 37.09 | 17.74 |
| Ours | V2 | √ | SigLIP | 17.42 | 42.08 | 19.33 |
4.2. Comparison with NOD Techniques
4.2. 与NOD技术的对比
The results in Tab. 1 reveal that baseline methods like K-Means and other GNCD approaches demonstrate limited effectiveness in NOD (Novel Object Detection), with Novel AP below 1 mAP. Even RNCDL [7], which involves a sophisticated multi-stage training process and requires extensive hyper parameter tuning, falls short in terms of both
表 1 中的结果表明,K-Means等基线方法及其他GNCD方法在新物体检测(Novel Object Detection)中效果有限,Novel AP低于1 mAP。即便是采用复杂多阶段训练流程且需大量超参数调优的RNCDL [7],在性能方面也表现不足
Table 2. Comparison with OVD methods on COCO-OVD data split. “COCO” in the training column refers to the COCO dataset with 48 base class annotations. Our method requires only the closed-set detector to be trained or can be training-free with pretrained detectors, unlike most existing OVD methods that require explicit training with CLIP or other VLMs. Our method is thus zero-shot, while OVD methods are not (evident from CLIP being present in training column of most methods).
表 2: COCO-OVD数据划分上与OVD方法的对比。训练列中的"COCO"指的是带有48个基类标注的COCO数据集。我们的方法仅需训练闭集检测器,或可直接使用预训练检测器而无需训练,这与大多数现有OVD方法需要显式使用CLIP或其他视觉语言模型(VLM)进行训练不同。因此我们的方法是零样本的,而OVD方法不是(从大多数方法的训练列中存在CLIP可以看出)。
| 方法 | 预训练 | 训练 | 骨干网络 | Novel | Base | All |
|---|---|---|---|---|---|---|
| OVR-CNN [36] | COCO Captions, BERT (BooksCorpus, English Wikipedia) | COCO | ResNet50 | 22.8 | 46.0 | 39.9 |
| ViLD [9] | COCO, CLIP | ResNet50 | 27.6 | 59.5 | 51.3 | |
| Detic [40] | ImageNet-21K | COCO, ImageNet-21K, Conceptual Captions, CLIP | ResNet50 | 27.8 | 47.1 | 45.0 |
| OV-DETR [35] | COCO, CLIP | ResNet50-C4 | 29.4 | 61.0 | 52.7 | |
| BARON [32] | SOCO dataset | COCO, CLIP | ResNet50 | 34 | 60.4 | 53.5 |
| CORA [33] | COCO, CLIP | ResNet50 | 35.1 | 35.5 | 35.4 | |
| Rasheed et al. [25] | MAVL (Flickr30k, COCO, Visual Genome) | COCO, COCO Captions, CLIP | ResNet50 | 36.6 | 54.0 | 49.4 |
| BARON [32] | SOCO dataset, MAVL | COCO, COCO Captions, CLIP | ResNet50-C4 | 42.7 | 54.9 | 51.7 |
| CORA+ [33] | COCO, COCO Captions, CLIP | ResNet50x4 | 43.1 | 60.9 | 56.2 | |
| DetCLIPv3 [34] | FILIP, Qformer, BERT, CLIP | O365, GoldG, V3Det, GranuCap50M, GranuCap600K, CLIP, InstructBLIP, GPT-4 | Swin-T | 54.7 | 42.8 | 46.9 |
| Ours* | GDINO (O365, GoldG, Cap4M), SAM (SA-1B), CLIP | COCO | ResNet50 | 49.6 | 42.4 | 44.3 |
| Ours* | GDINO (O365, GoldG, Cap4M), SAM (SA-1B), CLIP | COCO | ResNet101 | 50.3 | 49.8 | 49.9 |
Known and Novel AP compared to the GDINO benchmark. In stark contrast, our method, which does not necessitate any training and is conceptually straightforward, significantly outperforms RNCDL. Specifically, with our method using only CLIP, we achieve an improvement of $7.82\mathrm{mAP}$ in Novel classes and an impressive $17.61\mathrm{mAP}$ in Known classes over RNCDL. Moreover, by integrating our cooperative mechanism with the GDINO and SigLIP model, we observe additional gains of $3.95~\mathrm{mAP}$ in Novel classes and $4.95~\mathrm{mAP}$ in Known classes compared to the baseline GDINO. The use of advanced VLMs like SigLIP and enhanced pre-trained weights of Mask-RCNN further bolsters the overall object detection performance. This showcases the s cal ability and modular nature of our approach, reinforcing its potential for diverse NOD applications.
已知与新颖类别AP与GDINO基准对比。我们的方法无需任何训练且概念简洁,与RNCDL形成鲜明反差:仅使用CLIP时,新颖类别提升$7.82\mathrm{mAP}$,已知类别显著提升$17.61\mathrm{mAP}$。结合GDINO和SigLIP模型的协同机制后,新颖类别再获$3.95~\mathrm{mAP}$增益,已知类别增加$4.95~\mathrm{mAP}$。采用SigLIP等先进视觉语言模型(VLM)及增强版Mask-RCNN预训练权重,进一步提升了整体检测性能。这验证了我们方法的可扩展性和模块化特性,凸显了其在多样化新目标检测(NOD)应用中的潜力。
4.3. Comparisons with OVD Methods
4.3. 与OVD方法的对比
Tab. 2 compares our proposed zero-shot approach against various SOTA OVD methods on the COCO-OVD dataset split. Unlike most OVD approaches that require extensive training with VLMs like CLIP, our method leverages only a pre-trained closed-set detector and uses VLMs like CLIP in zero-shot way. Specifically, our method achieves a notable $49.6%$ AP50 on novel categories, surpassing the majority of the existing methods, including those that rely heavily on VLM training such as $\mathrm{CORA+}$ $(43.1%)$ and BARON MAVL $(42.7%)$ . While DetCLIPv3 demonstrates a higher Novel AP50 of $54.7%$ , this comparison is not entirely fair due to the substantial pre-training and training resources it employs (e.g., FILIP, Qformer, GPT-4, and others). While our method uses multiple models during pretraining, it does not use any such model in training (except detector). DetCLIPv3 uses models in both pre-training and training. Due to the zero-shot nature of our method, NOD benchmark in Tab. 1 becomes the main result.
表 2 对比了我们在 COCO-OVD 数据集划分上提出的零样本方法与各种 SOTA OVD 方法。与大多数需要 CLIP 等视觉语言模型 (VLM) 进行大量训练的 OVD 方法不同,我们的方法仅利用预训练的闭集检测器,并以零样本方式使用 CLIP 等 VLM。具体而言,我们的方法在新类别上取得了显著的 49.6% AP50,超越了大多数现有方法,包括严重依赖 VLM 训练的 CORA+ (43.1%) 和 BARON MAVL (42.7%)。虽然 DetCLIPv3 展示了更高的 Novel AP50 (54.7%),但由于其使用了大量预训练和训练资源 (如 FILIP、Qformer、GPT-4 等),这一对比并不完全公平。尽管我们的方法在预训练阶段使用了多个模型,但在训练阶段并未使用此类模型 (检测器除外),而 DetCLIPv3 在预训练和训练阶段都使用了模型。由于我们的方法具有零样本特性,表 1 中的 NOD 基准成为主要结果。

Figure 4. Object detection “mAP” performance on the lvis val subset dataset. “Grounding Dino” and “MaskRCNN-V1” models were evaluated after considering the first 300, second 300, and the first 600 boxes.
图 4: LVIS验证子集数据集上的目标检测"mAP"性能表现。在考虑前300个、后300个以及前600个检测框的情况下,评估了"Grounding Dino"和"MaskRCNN-V1"模型的性能。

Figure 5. Ablation of our refinement component on the lvis val subset dataset. The figure reports the Average Precision (AP) for both Novel and Known objects.
图 5: 在LVIS验证子集数据集上对我们的细化组件进行消融实验。该图展示了新类别( Novel )和已知类别( Known )物体的平均精度( AP )。
4.4. Comparisons with SOTA Unknown Object Detection Methods
4.4. 与SOTA未知物体检测方法的对比
Tab. 3 presents a comparison between our approach and the SOTA in unknown object detection, specifically the UnSniffer model [16]. To align with our evaluation criteria, we retrained UnSniffer on the entire set of COCO classes, excluding its NCut filtering feature for fair comparison. Our results demonstrate a notable improvement over existing methods, such as RNCDL, GDINO, and UnSniffer, in accurately localizing novel and known objects. Our method achieves a leading recall rate of $37.36%$ , showing an absolute $3.5%$ gain over the second best method, RNCDL.
表 3: 展示了我们的方法与未知物体检测领域当前最优方法 (SOTA) 的对比结果,特别是与UnSniffer模型 [16] 的比较。为了符合我们的评估标准,我们在完整COCO类别数据集上重新训练了UnSniffer模型,并关闭其NCut过滤功能以确保公平对比。实验结果表明,在准确定位新类别和已知类别物体方面,我们的方法显著优于现有方法 (如RNCDL、GDINO和UnSniffer)。我们的方法实现了 $37.36%$ 的最高召回率,相比第二名RNCDL方法有 $3.5%$ 的绝对提升。
Table 3. Comparison of localization performance of different methods on the lvis val subset dataset. Recall is measured with an IOU threshold of 0.5. True positives (TP) are those predicted boxes with $\mathrm{IOU}>0.5$ with any ground truth (GT) box. *Our method with GDINO, CLIP, and Mask-RCNN-V1.
表 3: 不同方法在 lvis val 子集数据集上的定位性能对比。召回率 (Recall) 以 IOU 阈值为 0.5 计算。真正例 (True positives, TP) 指预测框与任意真实框 (ground truth, GT) 的 $\mathrm{IOU}>0.5$。*我们的方法结合了 GDINO、CLIP 和 Mask-RCNN-V1。
| 方法 | 召回率 (%) | 真正例数 | 真实框数 | 总预测数 |
|---|---|---|---|---|
| GDINO[19] | 29.96 | 13653 | 45570 | 223500 |
| UnSniffer[16] | 30.83 | 14048 | 45570 | 216424 |
| RNCDL[7] | 33.82 | 15413 | 45570 | 216553 |
| Ours* | 37.36 | 17026 | 45570 | 223500 |
| 方法 | SigLIP | SAM | GDINO | SRM | SAEG | AP(Novel) | AP (Known) | AP(All) |
|---|---|---|---|---|---|---|---|---|
| Ours | 7.46 | 39.44 | 9.93 | |||||
| Ours | 11.54 | 34.62 | 13.32 | |||||
| Ours | 11.39 | 36.81 | 13.35 | |||||
| Ours | x | 14.32 | 36.66 | 16.05 | ||||
| Ours | √ | 15.84 | 37.07 | 17.48 | ||||
| Ours | 16.12 | 37.09 | 17.74 |
Table 4. Ablation experiments of our method consisting of SigLIP + GDINO $^+$ Mask-RCNN-V1 and our proposed components on the lvis val set. Each row represents the performance of the final method minus a particular component indicated by the $\pmb{\chi}$ .
表 4: 我们的方法 (SigLIP + GDINO$^+$ + Mask-RCNN-V1) 及所提组件在 LVIS val 集上的消融实验。每行表示最终方法性能减去由 $\pmb{\chi}$ 标出的特定组件后的结果。
4.5. Ablations
4.5. 消融实验
Ablation on Top-N Box Predictions - Grounding DINO vs. Mask-RCNN: We examine the mAP performance of GDINO and Mask-RCNN for both known and novel classes with different numbers of box predictions (Fig. 4). For GDINO, increasing $N_{\mathrm{GD}}$ beyond 300 leads to only marginal performance improvements, whereas considering the first 600 boxes leads to only $0.5\mathrm{mAP}$ increase on novel classes. Considering this alongside GPU memory constraints, we decide to set $N_{\mathrm{GD}}$ at 300 for optimal efficiency. In the case of Mask-RCNN, as we can see from Fig. 4, the known AP considering the next 300 boxes is only $1.05\mathrm{mAP}{\mathrm{{}}}$ , while the novel AP is mere $0.05\mathrm{mAP}{\mathrm{i n~}}$ , therefore the top-300 predictions $(N_{\mathrm{KN}}+N_{\mathrm{BG}}=300)$ is optimal, and further predictions introduce more noise and do not significantly capture ground-truth generic objects.
Top-N 框预测消融实验 - Grounding DINO 与 Mask-RCNN:我们研究了 GDINO 和 Mask-RCNN 在不同框预测数量下对已知类和新类别的 mAP 性能(图 4)。对于 GDINO,将 $N_{\mathrm{GD}}$ 增加到 300 以上仅带来微小的性能提升,而考虑前 600 个框仅使新类别的 mAP 提高 $0.5\mathrm{mAP}$。结合 GPU 内存限制,我们将 $N_{\mathrm{GD}}$ 设为 300 以实现最佳效率。对于 Mask-RCNN,从图 4 可以看出,考虑接下来的 300 个框时,已知类 AP 仅为 $1.05\mathrm{mAP}{\mathrm{{}}}$,而新类别 AP 仅为 $0.05\mathrm{mAP}{\mathrm{i n~}}$,因此前 300 个预测 $(N_{\mathrm{KN}}+N_{\mathrm{BG}}=300)$ 是最优的,更多预测会引入更多噪声且无法显著捕捉真实通用物体。
Ablation on Refinement Stage: Our ablation study on the refinement stage (Fig. 5) shows significant improvements due to proposed refinement process. The refinement stage added to open-set Mask RCNN results in a notable $4.4\mathrm{mAP}$ gain on novel AP. Further, combining GDINO and open-set Mask-RCNN predictions with our refinement stage yields superior performance, resulting in gains of 3.96 mAP in novel, and $1.09\mathrm{mAP}$ in known classes.
精炼阶段消融实验:我们对精炼阶段的消融研究(图5)表明,所提出的精炼流程带来了显著提升。在开放集Mask RCNN基础上添加精炼阶段,使新类别AP指标提升了4.4mAP。此外,将GDINO与开放集Mask-RCNN的预测结果通过我们的精炼阶段结合后,取得了更优性能:新类别提升3.96 mAP,已知类别提升1.09mAP。
Ablation of Components in our Cooperative Mechanism: Our experiments assess the impact of each component in our method by observing changes in mAP when a component is removed. As indicated in Tab. 4, excluding SigLIP causes the most significant drop in Novel AP $(8.66\mathrm{mAP})$ , suggesting its crucial role in detecting novel classes. Conversely, this removal slightly improves known AP by $2.35\mathrm{mAP}{\mathrm{{}}}$ highlighting a trade-off between novel and known AP detection. The absence of GDINO reduces novel AP by $4.73\mathrm{mAP}_{\mathrm{}}$ , confirming its importance in identifying novel objects. Similarly, without SAM, there is a $4.58\mathrm{mAP}$ decrease in novel AP. This implies that even with GDINO and SigLIP, optimal performance on novel classes requires the refinement offered by SAM (Sec. 3.2). Additionally, the performance across both known and novel classes drops significantly without our novel components (SAEG and SRM), demonstrating their effectiveness.
我们合作机制中各组件的消融实验:通过观察移除单个组件时mAP值的变化,本实验评估了方法中各组件的贡献。如表4所示,移除SigLIP会导致新类别AP值出现最大降幅$(8.66\mathrm{mAP})$,表明该组件在新类别检测中具有关键作用。相反,这一操作使已知类别AP值略微提升$2.35\mathrm{mAP}{\mathrm{{}}}$,揭示了新/已知类别检测性能间的权衡关系。移除GDINO会使新类别AP值降低$4.73\mathrm{mAP}_{\mathrm{}}$,证实了该组件在新目标识别中的重要性。同样地,缺失SAM会导致新类别AP值下降$4.58\mathrm{mAP}$,这表明即使保留GDINO和SigLIP,仍需SAM提供的优化机制(第3.2节)才能在新类别上获得最佳性能。此外,若移除我们的创新组件(SAEG和SRM),新旧类别的检测性能均会出现显著下降,充分证明了这些组件的有效性。

Figure 6. Comparison of top-10 predictions by different NOD methods. RNCDL (column a) shows mis labeling s, such as ‘aerosol can’, ‘doughnut’, ‘basket’ and ‘spoon’ due to post-discovery class assignment issues. GDINO (column b) has several inaccuracies, like ‘grizzly’, ‘wet suit’, ‘rearview mirror’, and ‘squirrel’. It also produces a lot of uncertain and low confidence predictions (i.e. score $<50%$ ). Mask-RCNN with CLIP baseline (column c, without our refinement) misses out on objects like ‘frying pan’, and outputs incorrect detections like ‘bed’. Our method (column d, GDINO $+$ Mask-RCNN) accurately detects objects with high confidence and outperforms prior methods in precise localization and recognition of unique objects. Figure best viewed with zoom.
图 6: 不同NOD方法的前10预测结果对比。RNCDL (列a) 由于后发现的类别分配问题,出现了错误标签,如 "喷雾罐"、"甜甜圈"、"篮子" 和 "勺子"。GDINO (列b) 存在多个不准确预测,如 "灰熊"、"潜水服"、"后视镜" 和 "松鼠",同时还产生了大量低置信度预测 (即分数 $<50%$)。基于CLIP的Mask-RCNN基线方法 (列c,未使用我们的优化) 漏检了 "煎锅" 等物体,并输出了 "床" 等错误检测。我们的方法 (列d,GDINO $+$ Mask-RCNN) 以高置信度准确检测物体,在精确定位和独特物体识别方面优于现有方法。建议放大查看。
5. Conclusion
5. 结论
In this research, we introduce a novel cooperative mechanism that leverages the complementary strengths of pretrained foundational models. This mechanism effectively transforms any existing closed-set detector into an openset detector, addressing the challenges of novel object detection (NOD). The modular design of our approach allows for seamless integration with current open-set detectors, enhancing their performance in detecting both known and novel classes. Our method has consistently outperforms state-of-the-art techniques in various settings, including NOD, unknown object localization, and open-vocabulary detection. While our study primarily focused on bounding box outputs, the underlying components, namely Mask- RCNN and SAM, are inherently capable of generating instance segmentation masks. This aspect suggests that our methodology can be readily extended to instance segmentation tasks, indicating a broader scope of application. Over- all, the cooperative mechanism we propose not only addresses current limitations in object detection for NOD but also provides a versatile and effective framework that can be deployed in other applications.
在本研究中,我们提出了一种新型协作机制,利用预训练基础模型 (pretrained foundational models) 的互补优势。该机制能有效将现有闭集检测器转化为开集检测器,解决新物体检测 (novel object detection, NOD) 的挑战。我们的模块化设计可与当前开集检测器无缝集成,提升其在已知类别和新类别检测中的性能。我们的方法在多种场景下持续超越最先进技术,包括NOD、未知物体定位和开放词汇检测。虽然研究主要聚焦于边界框输出,但基础组件 Mask-RCNN 和 SAM 本身具备生成实例分割掩码的能力,这表明我们的方法可轻松扩展至实例分割任务,具有更广泛的应用前景。总体而言,所提出的协作机制不仅解决了NOD物体检测的当前局限,还提供了一个可部署于其他应用的通用高效框架。
Limitations: Despite the superior performance of our proposed method in NOD, when compared to existing approaches, a primary limitation is the inference speed and potential data leakage. Addressing this limitation (by training efficient custom models from scratch) without compromising its detection capabilities is a key area for future research.
限制:尽管我们提出的方法在NOD中相比现有方法具有优越性能,但其主要局限在于推理速度和潜在数据泄漏问题。未来研究的关键方向是在不损害检测能力的前提下(通过从头训练高效定制模型)解决这一局限。