RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL
RESDSQL: 解耦文本到SQL的模式链接与骨架解析
Abstract
摘要
One of the recent best attempts at Text-to-SQL is the pretrained language model. Due to the structural property of the SQL queries, the seq2seq model takes the responsibility of parsing both the schema items (i.e., tables and columns) and the skeleton (i.e., SQL keywords). Such coupled targets increase the difficulty of parsing the correct SQL queries especially when they involve many schema items and logic operators. This paper proposes a ranking-enhanced encoding and skeleton-aware decoding framework to decouple the schema linking and the skeleton parsing. Specifically, for a seq2seq encoder-decode model, its encoder is injected by the most relevant schema items instead of the whole unordered ones, which could alleviate the schema linking effort during SQL parsing, and its decoder first generates the skeleton and then the actual SQL query, which could implicitly constrain the SQL parsing. We evaluate our proposed framework on Spider and its three robustness variants: Spider-DK, Spider-Syn, and Spider-Realistic. The experimental results show that our framework delivers promising performance and robustness. Our code is available at https://github.com/RUC KB Reasoning/RESDSQL.
近期在文本到SQL (Text-to-SQL) 领域最成功的尝试之一是预训练语言模型。由于SQL查询的结构特性,序列到序列 (seq2seq) 模型需要同时解析模式项 (即表和列) 和骨架 (即SQL关键字)。这种耦合目标增加了解析正确SQL查询的难度,尤其是当涉及大量模式项和逻辑运算符时。本文提出了一种基于排序增强的编码和骨架感知解码框架,以解耦模式链接和骨架解析。具体而言,对于seq2seq编码器-解码器模型,其编码器注入的是最相关的模式项而非整个无序集合,从而减轻SQL解析时的模式链接负担;其解码器首先生成骨架,再生成实际SQL查询,从而隐式约束SQL解析过程。我们在Spider及其三个鲁棒性变体 (Spider-DK、Spider-Syn和Spider-Realistic) 上评估了所提框架。实验结果表明,该框架展现出优异的性能和鲁棒性。代码已开源:https://github.com/RUCKBReasoning/RESDSQL。
Introduction
引言
Relational databases that are used to store heterogeneous data types including text, integer, float, etc., are omnipresent in modern data management systems. However, ordinary users usually cannot make the best use of databases because they are not good at translating their requirements to the database language—i.e., the structured query language (SQL). To assist these non-professional users in querying the databases, researchers propose the Text-to-SQL task (Yu et al. 2018a; Cai et al. 2018), which aims to automatically translate users’ natural language questions into SQL queries. At the same time, related benchmarks are becoming increasingly complex, from the single-domain bench- marks such as ATIS (Iyer et al. 2017) and GeoQuery (Zelle and Mooney 1996) to the cross-domain benchmarks such as WikiSQL (Zhong, Xiong, and Socher 2017) and Spider (Yu et al. 2018c). Most of the recent works are done on Spider because it is the most challenging benchmark which involves many complex SQL operators (such as GROUP BY, ORDER BY, and HAVING, etc.) and nested SQL queries.
用于存储文本、整数、浮点数等异构数据类型的关系型数据库在现代数据管理系统中无处不在。然而,普通用户通常无法充分利用数据库,因为他们不擅长将自己的需求转化为数据库语言——即结构化查询语言(SQL)。为了帮助这些非专业用户查询数据库,研究人员提出了Text-to-SQL任务(Yu et al. 2018a; Cai et al. 2018),旨在将用户的自然语言问题自动翻译为SQL查询。与此同时,相关基准测试正变得越来越复杂,从ATIS(Iyer et al. 2017)和GeoQuery(Zelle and Mooney 1996)等单领域基准,发展到WikiSQL(Zhong, Xiong, and Socher 2017)和Spider(Yu et al. 2018c)等跨领域基准。近期大多数工作都基于Spider开展,因为这是最具挑战性的基准测试,涉及GROUP BY、ORDER BY、HAVING等复杂SQL运算符以及嵌套SQL查询。
| Question What are flight numbers of flights departing from City "Aberdeen"? | |||||
| Databaseschema(includingtablesandcolumns) | |||||
| airlines (airlines) | |||||
| uid (airline | id) | airline (airline name) | abbreviation abbreviation) | country country | |
| airports (airports) | |||||
| city (city) | airportcode (airport code) | airportname airport name | country (country) | ||
| countryabbrev (country abbrev) | |||||
| flights (flights) | |||||
| airline (airline) | flightno (flight number) | sourceairport (source airport) | |||
| destairport (destination airport) | |||||
| Serializeschemaitems. Schemasequence | |||||
| airlines: uid, airline, abbreviation, county|airports: city, airportcode, airportname, county, countyabbrev| flights: airline,flightno, sourceairport, destairport | |||||
| Question+Schemasequence | |||||
| Seq2seq PLM (such as BART and T5) | |||||
| SQL query Select flights.flightno from flights join airports on flights.sourceairport = airports.airportcode where airports.city="Aberdeen" | |||||
问题 从城市“Aberdeen”出发的航班有哪些航班号?
数据库模式(包括表和列)
airlines (航空公司表)
uid (航空公司id) | id) | airline (航空公司名称) | abbreviation (缩写) | country (国家)
airports (机场表)
city (城市) | airportcode (机场代码) | airportname (机场名称) | country (国家)
countryabbrev (国家缩写表)
flights (航班表)
airline (航空公司) | flightno (航班号) | sourceairport (出发机场) | destairport (目的地机场)
序列化模式项。模式序列
airlines: uid, airline, abbreviation, county|airports: city, airportcode, airportname, county, countyabbrev| flights: airline, flightno, sourceairport, destairport
问题+模式序列
Seq2seq PLM (如 BART 和 T5)
SQL 查询 Select flights.flightno from flights join airports on flights.sourceairport = airports.airportcode where airports.city="Aberdeen"
With the recent advances in pre-trained language models (PLMs), many existing works formulate the Text-to-SQL task as a semantic parsing problem and use a sequence-tosequence (seq2seq) model to solve it (Scholak, Schucher, and Bahdanau 2021; Shi et al. 2021; Shaw et al. 2021). Concretely, as shown in Figure 1, given a question and a database schema, the schema items are serialized into a schema sequence where the order of the schema items is either default or random. Then, a seq2seq PLM, such as BART (Lewis et al. 2020) and T5 (Raffel et al. 2020), is leveraged to generate the SQL query based on the concatenation of the question and the schema sequence. We observe that the target SQL query contains not only the skeleton that reveals the logic of the question but also the required schema items. For instance, for a SQL query: “SELECT petid FROM pets WHERE pet age $=1^{\cdot\cdot}$ , its skeleton is “SELECT FROM WHERE ” and its required schema items are “petid”, “pets”, and “pet age”.
随着预训练语言模型 (PLM) 的最新进展,许多现有工作将Text-to-SQL任务表述为语义解析问题,并使用序列到序列 (seq2seq) 模型来解决 (Scholak, Schucher, and Bahdanau 2021; Shi et al. 2021; Shaw et al. 2021)。具体来说,如图 1 所示,给定一个问题和一个数据库模式,模式项被序列化为一个模式序列,其中模式项的顺序是默认的或随机的。然后,利用seq2seq PLM,如 BART (Lewis et al. 2020) 和 T5 (Raffel et al. 2020),基于问题和模式序列的连接生成SQL查询。我们观察到目标SQL查询不仅包含揭示问题逻辑的骨架,还包含所需的模式项。例如,对于SQL查询:“SELECT petid FROM pets WHERE pet age $=1^{\cdot\cdot}$”,其骨架是“SELECT FROM WHERE”,所需的模式项是“petid”、“pets”和“pet age”。
Since Text-to-SQL needs to perform not only the schema linking which aligns the mentioned entities in the question to schema items in the database schema, but also the skeleton parsing which parses out the skeleton of the SQL query, the major challenges are caused by a large number of required schema items and the complex composition of operators such as GROUP BY, HAVING, and JOIN ON involved in a SQL query. The intertwining of the schema linking and the skeleton parsing complicates learning even more.
由于Text-to-SQL不仅需要执行将问题中提到的实体与数据库模式中的模式项对齐的模式链接(schema linking),还需要解析出SQL查询骨架的骨架解析(skeleton parsing),主要挑战源于SQL查询涉及大量必需的模式项以及GROUP BY、HAVING和JOIN ON等运算符的复杂组合。模式链接与骨架解析的相互交织使学习过程更加复杂。
To investigate whether the Text-to-SQL task could become easier if the schema linking and the skeleton parsing are decoupled, we conduct a preliminary experiment on Spider’s dev set. Concretely, we fine-tune a T5-Base model to generate the pure skeletons based on the questions (i.e., skeleton parsing task). We observe that the exact match accuracy on such a task achieves about $80%$ using the fine-tuned T5-Base. However, even the T5-3B model only achieves about $70%$ accuracy (Shaw et al. 2021; Scholak, Schucher, and Bahdanau 2021). This pre-experiment indicates that decoupling such two objectives could be a potential way of reducing the difficulty of Text-to-SQL.
为了研究将模式链接(schema linking)和骨架解析(skeleton parsing)解耦后是否能简化Text-to-SQL任务,我们在Spider开发集上进行了初步实验。具体而言,我们微调了一个T5-Base模型来基于问题生成纯骨架(即骨架解析任务)。实验观察到,使用微调后的T5-Base模型在该任务上的精确匹配准确率可达约$80%$,而即使是T5-3B模型也仅能达到约$70%$的准确率(Shaw et al. 2021; Scholak, Schucher, and Bahdanau 2021)。这一预实验表明,解耦这两个目标可能是降低Text-to-SQL任务难度的潜在途径。
To realize the above decoupling idea, we propose a Ranking-enhanced Encoding plus a Skeleton-aware Decoding framework for Text-to-SQL (RESDSQL). The former injects a few but most relevant schema items into the seq2seq model’s encoder instead of all schema items. In other words, the schema linking is conducted beforehand to filter out most of the irrelevant schema items in the database schema, which can alleviate the difficulty of the schema linking for the seq2seq model. For such purpose, we train an additional cross-encoder to classify the tables and columns simultaneously based on the input question, and then rank and filter them according to the classification probabilities to form a ranked schema sequence. The latter does not add any new modules but simply allows the seq2seq model’s decoder to first generate the SQL skeleton, and then the actual SQL query. Since skeleton parsing is much easier than SQL parsing, the first generated skeleton could implicitly guide the subsequent SQL parsing via the masked self-attention mechanism in the decoder.
为实现上述解耦思想,我们提出了一种面向Text-to-SQL的排序增强编码与骨架感知解码框架(RESDSQL)。前者仅向seq2seq模型的编码器注入少量但最相关的模式项,而非全部模式项。换言之,通过预先执行模式链接来过滤数据库模式中大部分无关模式项,从而减轻seq2seq模型处理模式链接的难度。为此,我们额外训练了一个交叉编码器,基于输入问题同时分类表和列,再根据分类概率进行排序筛选,形成有序模式序列。后者不添加新模块,而是让seq2seq模型的解码器先生成SQL骨架,再生成实际SQL查询。由于骨架解析比SQL解析简单得多,首先生成的骨架可通过解码器中的掩码自注意力机制隐式指导后续SQL解析。
Contributions (1) We investigate a potential way of decoupling the schema linking and the skeleton parsing to reduce the difficulty of Text-to-SQL. Specifically, we propose a ranking-enhanced encoder to alleviate the effort of the schema linking and a skeleton-aware decoder to implicitly guide the SQL parsing by the skeleton. (2) We conduct extensive evaluation and analysis and show that our framework not only achieves the new state-of-the-art (SOTA) performance on Spider but also exhibits strong robustness.
贡献 (1) 我们研究了一种解耦模式链接 (schema linking) 和骨架解析 (skeleton parsing) 的潜在方法,以降低 Text-to-SQL 的难度。具体而言,我们提出了一个排名增强编码器 (ranking-enhanced encoder) 来减轻模式链接的工作量,以及一个骨架感知解码器 (skeleton-aware decoder) 通过骨架隐式指导 SQL 解析。 (2) 我们进行了广泛的评估和分析,结果表明我们的框架不仅在 Spider 上实现了新的最先进 (SOTA) 性能,而且表现出强大的鲁棒性。
Problem Definition
问题定义
Database Schema A relational database is denoted as $\mathcal{D}$ . The database schema $s$ of $\mathcal{D}$ includes (1) a set of $N$ tables $\begin{array}{l l l}{\mathcal{T}}&{=}&{{t_{1},t_{2},\cdots,t_{N}}}\end{array}$ , (2) a set of columns $\mathcal{C}={c_{1}^{1},\cdot\cdot\cdot,c_{n_{1}}^{1},c_{1}^{2},\cdot\cdot\cdot,c_{n_{2}}^{2},\cdot\cdot\cdot,c_{1}^{N},\cdot\cdot\cdot,c_{n_{N}}^{N}}$ associated with the tables, where $n_{i}$ is the number of columns in the $i\cdot$ -th table, (3) and a set of foreign key relations $\mathcal{R}=$ ${(c_{k}^{i},c_{h}^{j})|c_{k}^{i},c_{h}^{j}~\in~\mathcal{C}}$ , where each $(c_{k}^{i},c_{h}^{j})$ denotes a for- eign key relation between column $c_{k}^{i}$ and column $\boldsymbol{c}_{h}^{j}$ . We use $\begin{array}{r}{M=\sum_{i=1}^{N}n_{i}}\end{array}$ to denote the total number of columns in $\mathcal{D}$
数据库模式
一个关系型数据库表示为 $\mathcal{D}$。数据库模式 $s$ 包含:(1) 一组 $N$ 个表 $\begin{array}{l l l}{\mathcal{T}}&{=}&{{t_{1},t_{2},\cdots,t_{N}}}\end{array}$,(2) 与表关联的列集合 $\mathcal{C}={c_{1}^{1},\cdot\cdot\cdot,c_{n_{1}}^{1},c_{1}^{2},\cdot\cdot\cdot,c_{n_{2}}^{2},\cdot\cdot\cdot,c_{1}^{N},\cdot\cdot\cdot,c_{n_{N}}^{N}}$,其中 $n_{i}$ 是第 $i$ 个表的列数,(3) 外键关系集合 $\mathcal{R}=$ ${(c_{k}^{i},c_{h}^{j})|c_{k}^{i},c_{h}^{j}~\in~\mathcal{C}}$,其中每个 $(c_{k}^{i},c_{h}^{j})$ 表示列 $c_{k}^{i}$ 和列 $\boldsymbol{c}_{h}^{j}$ 之间的外键关系。我们用 $\begin{array}{r}{M=\sum_{i=1}^{N}n_{i}}\end{array}$ 表示 $\mathcal{D}$ 中的总列数。
Original Name and Semantic Name We use “schema items” to uniformly refer to tables and columns in the database. Each schema item can be represented by an original name and a semantic name. The semantic name can indicate the semantics of the schema item more precisely. As shown in Figure 1, it is obvious that the semantic names “airline id” and “destination airport” are more clear than their original names “uid” and “de st airport”. Sometimes the semantic name is the same as the original name.
原始名称与语义名称
我们使用“模式项”统一指代数据库中的表和列。每个模式项可由原始名称和语义名称表示,语义名称能更精确地体现模式项的语义。如图 1 所示,语义名称 "airline id" 和 "destination airport" 显然比原始名称 "uid" 和 "de st airport" 更清晰。有时语义名称会与原始名称相同。
Text-to-SQL Task Formally, given a question $q$ in natural language and a database $\mathcal{D}$ with its schema $s$ , the Text-toSQL task aims to translate $q$ into a SQL query $l$ that can be executed on $\mathcal{D}$ to answer the question $q$ .
Text-to-SQL任务的形式化定义为:给定自然语言问题$q$和带有模式$s$的数据库$\mathcal{D}$,该任务旨在将$q$转换为可执行于$\mathcal{D}$的SQL查询$l$,从而回答问题$q$。
Methodology
方法
In this section, we first give an overview of the proposed framework and then delve into its design details.
在本节中,我们首先概述所提出的框架,然后深入探讨其设计细节。
Model Overview
模型概述
Following Shaw et al. (2021); Scholak, Schucher, and Bahdanau (2021), we treat Text-to-SQL as a translation task, which can be solved by an encoder-decoder transformer model. Facing the above problems, we extend the existing seq2seq Text-to-SQL methods by injecting the most relevant schema items in the input sequence and the SQL skeleton in the output sequence, which results in a ranking-enhanced encoder and a skeleton-aware decoder. We provide the highlevel overview of the proposed RESDSQL framework in Figure 2. The encoder of the seq2seq model receives the ranked schema sequence, such that the schema linking effort could be alleviated during SQL parsing. To obtain such a ranked schema sequence, an additional cross-encoder is proposed to classify the schema items according to the given question, and then we rank and filter them based on the classification probabilities. The decoder of the seq2seq model first parses out the SQL skeleton and then the actual SQL query, such that the SQL generation can be implicitly constrained by the previously parsed skeleton. By doing this, to a certain extent, the schema linking and the skeleton parsing are not intertwined but decoupled.
遵循 Shaw 等人 (2021) 和 Scholak、Schucher 与 Bahdanau (2021) 的研究思路,我们将文本到 SQL (Text-to-SQL) 视为翻译任务,可通过编码器-解码器 Transformer 模型解决。针对上述问题,我们通过以下方式扩展现有 seq2seq 文本到 SQL 方法:在输入序列中注入最相关的模式项,在输出序列中注入 SQL 骨架,从而形成排名增强的编码器和骨架感知的解码器。图 2 展示了所提 RESDSQL 框架的高层概览。该 seq2seq 模型的编码器接收排序后的模式序列,从而减轻 SQL 解析过程中的模式链接负担。为获得此类排序模式序列,我们提出额外交叉编码器来根据给定问题对模式项进行分类,并基于分类概率进行排序筛选。该 seq2seq 模型的解码器首先解析出 SQL 骨架,再生成实际 SQL 查询,使得 SQL 生成过程能隐式受先前解析骨架的约束。通过这种方式,模式链接与骨架解析在一定程度上实现解耦而非交织。
Ranking-Enhanced Encoder
Ranking-Enhanced Encoder
Instead of injecting all schema items, we only consider the most relevant schema items in the input of the encoder. For this purpose, we devise a cross-encoder to classify the tables and columns simultaneously and then rank them based on their probabilities. Based on the ranking order, on one hand, we filter out the irrelevant schema items. On the other hand, we use the ranked schema sequence instead of the unordered schema sequence, so that the seq2seq model could capture potential position information for schema linking.
我们不再注入所有模式项,而是仅考虑编码器输入中最相关的模式项。为此,我们设计了一个交叉编码器来同时分类表和列,并根据其概率进行排序。基于排序结果,一方面我们过滤掉不相关的模式项;另一方面,我们用排序后的模式序列替代无序模式序列,使序列到序列模型能够捕获模式链接的潜在位置信息。
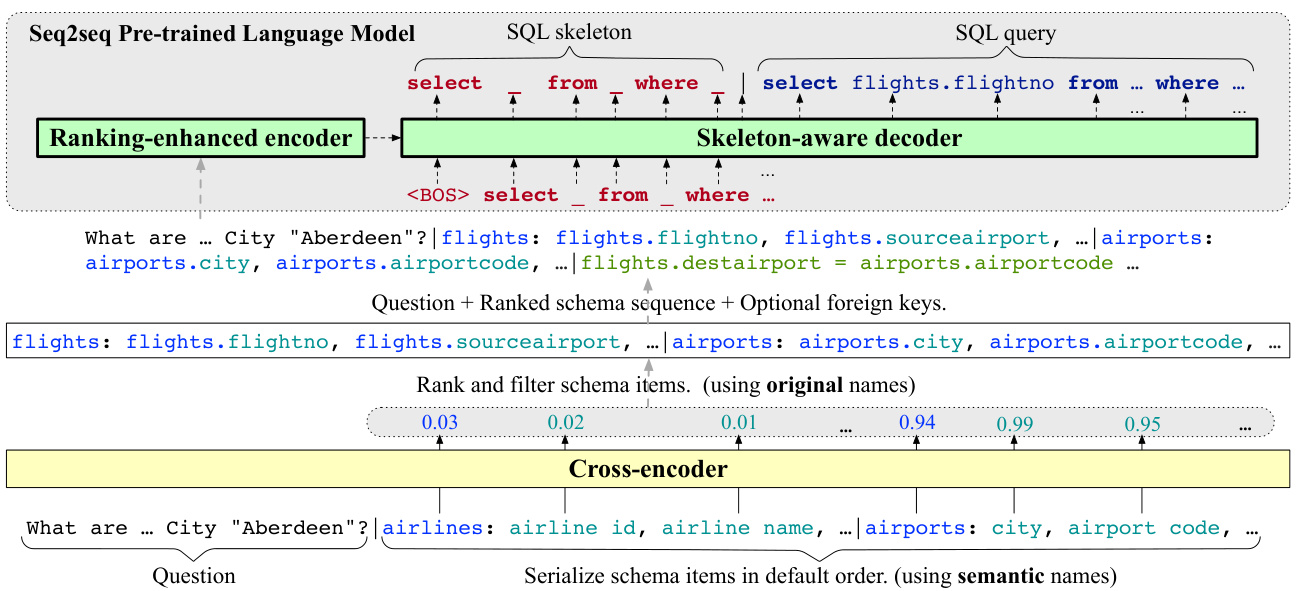
Figure 2: An overview of the ranking-enhanced encoding and skeleton-aware decoding framework. We train a cross-encoder for classifying the schema items. Then we take the question, the ranked schema sequence, and optional foreign keys as the input of the ranking-enhanced encoder. The skeleton-aware decoder first decodes the SQL skeleton and then the actual SQL query.
图 2: 排序增强编码与骨架感知解码框架概览。我们训练交叉编码器 (cross-encoder) 对模式项进行分类,随后将问题、排序后的模式序列及可选外键作为排序增强编码器的输入。骨架感知解码器先解码 SQL 骨架,再生成实际 SQL 查询。
As for the input of the cross-encoder, we flatten the schema items into a schema sequence in their default order and concatenate it with the question to form an input sequence: X = q | t1 : c11, · · · , c1n1 | · · · | tN : c1N , · · · , cnNN , where $|$ is the delimiter. To better represent the semantics of schema items, instead of their original names, we use their semantic names which are closer to the natural expression.
至于交叉编码器 (cross-encoder) 的输入,我们将模式项按默认顺序展平为模式序列,并将其与问题连接起来形成输入序列:X = q | t1 : c11, · · · , c1n1 | · · · | tN : c1N , · · · , cnNN ,其中 $|$ 是分隔符。为了更好地表示模式项的语义,我们使用更接近自然表达的语义名称,而非它们的原始名称。
Encoding Module We feed $X$ into RoBERTa (Liu et al. 2019), an improved version of BERT (Devlin et al. 2019). Since each schema item will be tokenized into one or more tokens by PLM’s tokenizer (e.g., the column “airline id” will be split into two tokens: “airline” and “id”), and our target is to represent each schema item as a whole for classification, we need to pool the output embeddings belonging to each schema item. To achieve this goal, we use a pooling module that consists of a two-layer BiLSTM (Hochreiter and Schmid huber 1997) and a non-linear fully-connected layer. After pooling, each table embedding can be denoted by ${\mathbf{}}T_{i}\in$ $\mathbb{R}^{1\times d}$ $(i\in{1,...,N})$ and each column embedding can be denoted by $\mathbf{\dot{}}{k}^{i}\in\mathbb{R}^{1\times d}(i\in{1,...,N},k\in{1,...,n_{i}})$ , where $d$ denotes the hidden size.
编码模块
我们将 $X$ 输入到 RoBERTa (Liu et al. 2019) ,这是 BERT (Devlin et al. 2019) 的改进版本。由于每个模式项会被 PLM 的 tokenizer 切分为一个或多个 token (例如列名 "airline id" 会被拆分为两个 token:"airline" 和 "id") ,而我们的目标是将每个模式项作为整体进行分类表示,因此需要池化属于每个模式项的输出嵌入。为实现这一目标,我们使用由双层 BiLSTM (Hochreiter and Schmidhuber 1997) 和非线性全连接层组成的池化模块。池化后,每个表嵌入可表示为 ${\mathbf{}}T_{i}\in$ $\mathbb{R}^{1\times d}$ $(i\in{1,...,N})$ ,每个列嵌入可表示为 $\mathbf{\dot{}}{k}^{i}\in\mathbb{R}^{1\times d}(i\in{1,...,N},k\in{1,...,n_{i}})$ ,其中 $d$ 表示隐藏层大小。
Column-Enhanced Layer We observe that some questions only mention the column name rather than the table name. For example in Figure 1, the question mentions a column name “city”, but its corresponding table name “airports” is ignored. This table name missing issue may compromise the table classification performance. Therefore, we propose a column-enhanced layer to inject the column information into the corresponding table embedding. In this way, a table could be identified even if the question only mentions its columns. Concretely, for the $i$ -th table, we inject the column information $C_{:}^{i}\in\mathbb{R}^{n_{i}\times d}$ into the table embedding $\mathbf{\delta}{\mathbf{\delta}\mathbf{\delta}\mathbf{-}\mathbf{\delta}\mathbf{-}\mathbf{\delta}\mathbf{\delta}\mathbf{-}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{T}_{i}}$ by stacking a multi-head scaled dot-product attention layer (Vaswani et al. 2017) and a feature fusion layer on the top of the encoding module:
列增强层
我们注意到,某些问题仅提及列名而未提及表名。例如在图1中,问题提到列名"city",但忽略了对应的表名"airports"。这种表名缺失问题可能会影响表格分类性能。因此,我们提出列增强层,将列信息注入到对应的表格嵌入中。通过这种方式,即使问题仅提及列名也能识别表格。具体而言,对于第$i$个表格,我们通过在多头缩放点积注意力层 (Vaswani et al. 2017) 和特征融合层叠加编码模块,将列信息$C_{:}^{i}\in\mathbb{R}^{n_{i}\times d}$注入表格嵌入$\mathbf{\delta}{\mathbf{\delta}\mathbf{\delta}\mathbf{-}\mathbf{\delta}\mathbf{-}\mathbf{\delta}\mathbf{\delta}\mathbf{-}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{T}_{i}}$中:
$$
\begin{array}{r l}&{{\bf{\varPsi}}{i}^{C}=M u l t i H e a d A t t n({{T}{i}},{C_{:}^{i}},{C_{:}^{i}},h),}\ &{{\hat{{\cal T}{i}}}=N o r m({{T}{i}}+{{T}_{i}^{C}}).}\end{array}
$$
$$
\begin{array}{r l}&{{\bf{\varPsi}}{i}^{C}=M u l t i H e a d A t t n({{T}{i}},{C_{:}^{i}},{C_{:}^{i}},h),}\ &{{\hat{{\cal T}{i}}}=N o r m({{T}{i}}+{{T}_{i}^{C}}).}\end{array}
$$
Here, $\pmb{T}{i}$ acts as the query and $C^{\bar{\iota}}$ acts as both the key and the value, $h$ is the number of heads, and $N o r m(\cdot)$ is a rowwise $L_{2}$ normalization function. $\pmb{T}{i}^{C}$ represents the columnattentive table embedding. We fuse the original table embedding $\pmb{T}{i}$ and the column-attentive table embedding $\pmb{T}{i}^{C}$ to obtain the column-enhanced table embedding $\hat{\pmb{T}}_{i}\in\mathbb{R}^{1\times d}$ .
这里,$\pmb{T}{i}$ 作为查询(query),$C^{\bar{\iota}}$ 同时作为键(key)和值(value),$h$ 是头数(head number),$Norm(\cdot)$ 是行级(rowwise) $L_{2}$ 归一化函数。$\pmb{T}{i}^{C}$ 表示列注意力表嵌入(column-attentive table embedding)。我们将原始表嵌入 $\pmb{T}{i}$ 与列注意力表嵌入 $\pmb{T}{i}^{C}$ 融合,得到列增强表嵌入 $\hat{\pmb{T}}_{i}\in\mathbb{R}^{1\times d}$。
Loss Function of Cross-Encoder Cross-entropy loss is a well-adopted loss function in classification tasks. However, since a SQL query usually involves only a few tables and columns in the database, the label distribution of the training set is highly imbalanced. As a result, the number of negative examples is many times that of positive examples, which will induce serious training bias. To alleviate this issue, we employ the focal loss (Lin et al. 2017) as our classification loss. Then, we form the loss function of the cross-encoder in a multi-task learning way, which consists of both the table classification loss and the column classification loss, i.e.,
交叉编码器的损失函数
交叉熵损失是分类任务中广泛采用的损失函数。然而,由于SQL查询通常仅涉及数据库中的少量表和列,训练集的标签分布高度不平衡。因此,负样本数量往往是正样本的数十倍,这会导致严重的训练偏差。为缓解此问题,我们采用焦点损失 (focal loss) (Lin et al. 2017) 作为分类损失。随后,我们以多任务学习的方式构建交叉编码器的损失函数,该函数同时包含表分类损失和列分类损失,即
$$
\mathcal{L}{1}=\frac{1}{N}\sum_{i=1}^{N}F L(y_{i},\hat{y}{i})+\frac{1}{M}\sum_{i=1}^{N}\sum_{k=1}^{n_{i}}F L(y_{k}^{i},\hat{y}_{k}^{i}),
$$
$$
\mathcal{L}{1}=\frac{1}{N}\sum_{i=1}^{N}F L(y_{i},\hat{y}{i})+\frac{1}{M}\sum_{i=1}^{N}\sum_{k=1}^{n_{i}}F L(y_{k}^{i},\hat{y}_{k}^{i}),
$$
where $F L$ denotes the focal loss function and $y_{i}$ is the ground truth label of the $i$ -th table. $y_{i}~=~1$ indicates the table is referenced by the SQL query and 0 otherwise. $y_{k}^{i}$ is the ground truth label of the $k$ -th column in the $i$ -th table.
其中 $FL$ 表示焦点损失函数,$y_{i}$ 是第 $i$ 个表格的真实标签。$y_{i}~=~1$ 表示该表格被 SQL 查询引用,否则为 0。$y_{k}^{i}$ 是第 $i$ 个表格中第 $k$ 列的真实标签。
Similarly, $y_{k}^{i}=1$ indicates the column is referenced by the SQL query and 0 otherwise. $\hat{y}{i}$ and $\hat{y}{k}^{i}$ are predicted probabilities, which are estimated by two different MLP modules based on the table and column embeddings $\hat{\pmb{T}}{i}$ and $C_{k}^{i}$ :
同样,$y_{k}^{i}=1$ 表示该列被SQL查询引用,否则为0。$\hat{y}{i}$ 和 $\hat{y}{k}^{i}$ 是预测概率,由两个不同的MLP模块基于表嵌入 $\hat{\pmb{T}}{i}$ 和列嵌入 $C_{k}^{i}$ 估算得出:
$$
\begin{array}{r c l}{\hat{y}{i}}&{=}&{\sigma((\hat{T}{i}U_{1}^{t}+b_{1}^{t})U_{2}^{t}+b_{2}^{t}),}\ {\hat{y}{k}^{i}}&{=}&{\sigma((C_{k}^{i}U_{1}^{c}+b_{1}^{c})U_{2}^{c}+b_{2}^{c}),}\end{array}
$$
$$
\begin{array}{r c l}{\hat{y}{i}}&{=}&{\sigma((\hat{T}{i}U_{1}^{t}+b_{1}^{t})U_{2}^{t}+b_{2}^{t}),}\ {\hat{y}{k}^{i}}&{=}&{\sigma((C_{k}^{i}U_{1}^{c}+b_{1}^{c})U_{2}^{c}+b_{2}^{c}),}\end{array}
$$
where $U_{1}^{t}$ , $U_{1}^{c}\in\mathbb{R}^{d\times w}$ , $b_{1}^{t}$ , $b_{1}^{c}\in\mathbb{R}^{w}$ , $U_{2}^{t}$ , $U_{2}^{c}\in\mathbb{R}^{w\times2},$ , $b_{2}^{t}$ , $b_{2}^{c}\in\mathbb{R}^{2}$ are trainable parameters, and $\sigma(\cdot)$ denotes Softmax.
其中 $U_{1}^{t}$ , $U_{1}^{c}\in\mathbb{R}^{d\times w}$ , $b_{1}^{t}$ , $b_{1}^{c}\in\mathbb{R}^{w}$ , $U_{2}^{t}$ , $U_{2}^{c}\in\mathbb{R}^{w\times2},$ , $b_{2}^{t}$ , $b_{2}^{c}\in\mathbb{R}^{2}$ 是可训练参数,$\sigma(\cdot)$ 表示Softmax函数。
Prepare Input for Ranking-Enhanced Encoder During inference, for each Text-to-SQL instance, we leverage the above-trained cross-encoder to compute a probability for each schema item. Then, we only keep top $k_{1}$ tables in the database and top $\cdot k_{2}$ columns for each remained table to form a ranked schema sequence. $k_{1}$ and $k_{2}$ are two important hyper-parameters. When $k_{1}$ or $k_{2}$ is too small, a portion of the required tables or columns may be excluded, which is fatal for the subsequent seq2seq model. As $k_{1}$ or $k_{2}$ becomes larger, more and more irrelevant tables or columns may be introduced as noise. Therefore, we need to choose appropriate values for $k_{1}$ and $k_{2}$ to ensure a high recall while preventing the introduction of too much noise. The input sequence for the ranking-enhanced encoder (i.e., seq2seq model’s encoder) is formed as the concatenation of the question, the ranked schema sequence, and optional foreign key relations (see Figure 2). Foreign key relations contain rich information about the structure of the database, which could promote the generation of the JOIN ON clauses. In the ranked schema sequence, we use the original names instead of the semantic names because the schema items in the SQL queries are represented by their original names, and using the former will facilitate the decoder to directly copy required schema items from the input sequence.
为排序增强编码器准备输入
在推理阶段,对于每个Text-to-SQL实例,我们利用上述训练好的交叉编码器计算每个模式项的概率。然后仅保留数据库中top $k_{1}$ 表和每个保留表中top $\cdot k_{2}$ 列,形成排序后的模式序列。$k_{1}$ 和 $k_{2}$ 是两个重要超参数:当$k_{1}$ 或 $k_{2}$ 过小时,可能排除部分必需的表或列,这对后续seq2seq模型是致命的;而当$k_{1}$ 或 $k_{2}$ 过大时,会引入越来越多无关表或列作为噪声。因此需要为$k_{1}$ 和 $k_{2}$ 选择合适的值,在保证高召回率的同时避免引入过多噪声。
排序增强编码器(即seq2seq模型的编码器)的输入序列由问题文本、排序后的模式序列及可选的外键关系组成(见图2)。外键关系包含数据库结构的丰富信息,可促进JOIN ON子句的生成。在排序模式序列中,我们使用原始名称而非语义名称,因为SQL查询中的模式项均以其原始名称表示,这样能使解码器更直接从输入序列复制所需模式项。
Skeleton-Aware Decoder
Skeleton-Aware Decoder
Most seq2seq Text-to-SQL methods tell the decoder to generate the target SQL query directly. However, the apparent gap between the natural language and the SQL query makes it difficult to perform the correct generation. To alleviate this problem, we would like to decompose the SQL generation into two steps: (1) generate the SQL skeleton based on the semantics of the question, and then (2) select the required “data” (i.e., tables, columns, and values) from the input sequence to fill the slots in the skeleton.
大多数seq2seq文本到SQL方法直接让解码器生成目标SQL查询。然而,自然语言与SQL查询之间的显著差距使得正确生成变得困难。为了缓解这个问题,我们建议将SQL生成分解为两个步骤:(1) 根据问题语义生成SQL骨架,然后(2) 从输入序列中选择所需的"数据"(即表、列和值)来填充骨架中的槽位。
To realize the above decomposition idea without adding additional modules, we propose a new generation objective based on the intrinsic characteristic of the transformer decoder, which generates the $t$ -th token depending on not only the output of the encoder but also the output of the decoder before the $t$ -th time step (Vaswani et al. 2017). Concretely, instead of decoding the target SQL directly, we encourage the decoder to first decode the skeleton of the SQL query, and based on this, we continue to decode the SQL query.
为实现上述分解思路而不增加额外模块,我们基于Transformer解码器的固有特性提出了一种新的生成目标:生成第$t$个token时不仅依赖编码器输出,还依赖于第$t$个时间步之前的解码器输出 (Vaswani et al. 2017)。具体而言,我们不直接解码目标SQL,而是引导解码器先解码SQL查询的骨架结构,在此基础上继续解码完整SQL查询。
By parsing the skeleton first and then parsing the SQL query, at each decoding step, SQL generation will be easier because the decoder could either copy a “data” from the input sequence or a SQL keyword from the previously parsed skeleton. Now, the objective of the seq2seq model is:
通过先解析骨架再解析SQL查询,在每一个解码步骤中,SQL生成会变得更加容易,因为解码器既可以从输入序列中复制一个"数据",也可以从先前解析的骨架中复制一个SQL关键字。此时,seq2seq模型的目标是:
Table 1: An example from Spider. Here, Q, $\mathrm{SQL}{o}$ , $\operatorname{SQL}{n}$ , and $\mathrm{SQL}_{s}$ denote the question, the original SQL query, the normalized SQL query, and the SQL skeleton, respectively.
表 1: Spider 中的示例。其中 Q、$\mathrm{SQL}{o}$、$\operatorname{SQL}{n}$ 和 $\mathrm{SQL}_{s}$ 分别表示问题、原始 SQL 查询、规范化 SQL 查询和 SQL 骨架。
| List the duration, file size and format of songs whose genre is pop, ordered by title? SELECT T1.duration, T1.file_size,T1.formats | |
|---|---|
| SQLo | FROM files AS T1 JOIN song AS T2 ON T1.fid = T2.fid WHERE T2.genre-is = "pop" ORDER BY |
| SQLn | tfiles.duration,f files.file_size,files.formats from files join song on files.fid = song.fid where song.genre_is = 'pop' order by song.song-name asc |
| SQLs | select_from_where_orderby-asc |
$$
\mathcal{L}{2}=\frac{1}{G}\sum_{i=1}^{G}p(l_{i}^{s},l_{i}|S_{i}),
$$
$$
\mathcal{L}{2}=\frac{1}{G}\sum_{i=1}^{G}p(l_{i}^{s},l_{i}|S_{i}),
$$
where $G$ is the number of Text-to-SQL instances, $S_{i}$ is the input sequence of the $i$ -th instance which consists of the question, the ranked schema sequence, and optional foreign key relations. $l_{i}$ denotes the $i$ -th target SQL query and $\mathit{l}{i}^{s}$ is the skeleton extracted from $l_{i}$ . We will present some necessary details on how to normalize SQL queries and how to extract their skeletons.
其中 $G$ 是 Text-to-SQL 实例的数量,$S_{i}$ 是第 $i$ 个实例的输入序列,由问题、排序后的模式序列和可选的外键关系组成。$l_{i}$ 表示第 $i$ 个目标 SQL 查询,$\mathit{l}{i}^{s}$ 是从 $l_{i}$ 中提取的骨架。我们将介绍如何规范化 SQL 查询以及如何提取其骨架的一些必要细节。
SQL Normalization The Spider dataset is manually created by 11 annotators with different annotation habits, which results in slightly different styles among the final annotated SQL queries, such as uppercase versus lowercase keywords. Although different styles have no impact on the execution results, the model requires some extra effort to learn and adapt to them. To reduce the learning difficulty, we normalize the original SQL queries before training by (1) unifying the keywords and schema items into lowercase, (2) adding spaces around parentheses and replacing double quotes with single quotes, (3) adding an ASC keyword after the ORDER BY clause if it does not specify the order, and (4) removing the AS clause and replacing all table aliases with their original names. We present an example in Table 1.
SQL规范化
Spider数据集由11名具有不同标注习惯的标注者手动创建,这导致最终标注的SQL查询在风格上略有差异,例如关键字的大小写不一致。虽然不同风格对执行结果没有影响,但模型需要额外学习并适应这些差异。为了降低学习难度,我们在训练前对原始SQL查询进行了规范化处理:(1) 将关键字和模式项统一为小写,(2) 在括号周围添加空格并将双引号替换为单引号,(3) 在未指定排序方向的ORDER BY子句后添加ASC关键字,(4) 移除AS子句并将所有表别名替换为原始名称。表1展示了一个示例。
SQL Skeleton Extraction Based on the normalized SQL queries, we can extract their skeletons which only contain SQL keywords and slots. Specifically, given a normalized SQL query, we keep its keywords and replace the rest parts with slots. Note that we do not keep the JOIN ON keyword because it is difficult to find a counterpart from the question (Gan et al. 2021b). As shown in Table 1, although the original SQL query looks complex, its skeleton is simple and each keyword can find a counterpart from the question. For example, “order by asc” in the skeleton can be inferred from “ordered by title?” in the question.
基于归一化SQL查询的骨架提取
根据归一化后的SQL查询,我们可以提取仅包含SQL关键词和占位槽的骨架。具体而言,给定一个归一化SQL查询时,我们保留其关键词并将剩余部分替换为占位槽。需注意我们不保留JOIN ON关键词,因为难以从问题中找到对应表述 (Gan et al. 2021b)。如表1所示,虽然原始SQL查询看似复杂,但其骨架十分简洁,每个关键词都能从问题中找到对应表述。例如骨架中的"order by asc"可从问题中的"ordered by title?"推断而来。
Execution-Guided SQL Selector Since we do not constrain the decoder with SQL grammar, the model may generate some illegal SQL queries. To alleviate this problem, we follow Suhr et al. (2020) to use an execution-guided SQL selector which performs the beam search during the decoding procedure and then selects the first executable SQL query in the beam as the final result.
执行引导的SQL选择器
由于我们没有用SQL语法约束解码器,模型可能会生成一些非法的SQL查询。为了缓解这个问题,我们遵循Suhr等人 (2020) 的方法,使用执行引导的SQL选择器,在解码过程中执行束搜索,然后选择束中第一个可执行的SQL查询作为最终结果。
Experiments
实验
Experimental Setup
实验设置
Datasets We conduct extensive experiments on Spider and its three variants which are proposed to evaluate the robustness of the Text-to-SQL parser. Spider (Yu et al. 2018c) is the most challenging benchmark for the cross-domain and multi-table Text-to-SQL task. Spider contains a training set with 7,000 samples1, a dev set with 1,034 samples, and a hidden test set with 2,147 samples. There is no overlap between the databases in different splits. For robustness, we train the model on Spider’s training set but evaluate it on Spider-DK (Gan, Chen, and Purver 2021) with 535 samples, Spider-Syn (Gan et al. 2021a) with 1034 samples, and Spider-Realistic (Deng et al. 2021) with 508 samples. These evaluation sets are derived from Spider by modifying questions to simulate real-world application scenarios. Concretely, Spider-DK incorporates some domain knowledge to paraphrase questions. Spider-Syn replaces schemarelated words with synonyms in questions. Spider-Realistic removes explicitly mentioned column names in questions.
数据集
我们在Spider及其三个变体上进行了大量实验,这些变体旨在评估Text-to-SQL解析器的鲁棒性。Spider (Yu et al. 2018c) 是跨领域多表Text-to-SQL任务最具挑战性的基准,包含7,000个样本的训练集、1,034个样本的开发集和2,147个样本的隐藏测试集,且不同划分间的数据库无重叠。为测试鲁棒性,我们在Spider训练集上训练模型,但分别在以下数据集评估:
- Spider-DK (Gan, Chen, and Purver 2021) :535个样本,通过融入领域知识改写问题
- Spider-Syn (Gan et al. 2021a) :1,034个样本,用同义词替换问题中的模式相关词汇
- Spider-Realistic (Deng et al. 2021) :508个样本,删除问题中明确提及的列名
这些评估集均通过对Spider问题的修改来模拟真实应用场景。
Evaluation Metrics To evaluate the performance of the Text-to-SQL parser, following Yu et al. 2018c; Zhong, Yu, and Klein 2020, we adopt two metrics: Exact-set-Match accuracy (EM) and EXecution accuracy (EX). The former measures whether the predicted SQL query can be exactly matched with the gold SQL query by converting them into a special data structure (Yu et al. 2018c). The latter compares the execution results of the predicted SQL query and the gold SQL query. The EX metric is sensitive to the generated values, but the EM metric is not. In practice, we use the sum of EM and EX to select the best checkpoint of the seq2seq model. For the cross-encoder, we use Area Under ROC Curve (AUC) to evaluate its performance. Since the cross-encoder classifies tables and columns simultaneously, we adopt the sum of table AUC and column AUC to select the best checkpoint of the cross-encoder.
评估指标
为评估Text-to-SQL解析器的性能,参照Yu等人2018c及Zhong、Yu和Klein 2020的研究,我们采用两项指标:精确集合匹配准确率(EM)和执行准确率(EX)。前者通过将预测SQL查询与标准SQL查询转换为特定数据结构(Yu等人2018c)来判定二者是否完全匹配。后者则对比预测SQL与标准SQL查询的执行结果。EX指标对生成值敏感,而EM指标不具备此特性。实践中,我们使用EM与EX的总和来选择seq2seq模型的最佳检查点。对于交叉编码器(cross-encoder),我们采用受试者工作特征曲线下面积(AUC)评估其性能。由于交叉编码器需同时分类表格和列,我们以表格AUC与列AUC的总和作为选择其最佳检查点的依据。
Implementation Details We train RESDSQL in two stages. In the first stage, we train the cross-encoder for ranking schema items. The number of heads $h$ in the columnenhanced layer is 8. We use AdamW (Loshchilov and Hutter 2019) with batch size 32 and learning rate 1e-5 for optimization. In the focal loss, the focusing parameter $\gamma$ and the weighted factor $\alpha$ are set to 2 and 0.75 respectively. Then, $k_{1}$ and $k_{2}$ are set to 4 and 5 according to the statistics of the datasets. For training the seq2seq model in the second stage, we consider three scales of T5: Base, Large, and 3B. We fine-tune them with Adafactor (Shazeer and Stern 2018) using different batch size (bs) and learning rate (lr), resulting in RESDSQL-Base $\mathrm{bs}=32$ , $\ln=1\mathrm{e}{-4}$ ), RESDSQL-Large (bs $=32$ , $\mathrm{lr}=5\mathrm{e}{-5}$ ), and RESDSQL-3B $\mathrm{\mathbf{b}s}=96$ , $\mathrm{lr}=5\mathrm{e}{-5}$ ). For both stages of training, we adopt linear warm-up (the first $10%$ training steps) and cosine decay to adjust the learning rate. We set the beam size to 8 during decoding. Moreover, following Lin, Socher, and Xiong (2020), we extract potentially useful contents from the database to enrich the column information.
实现细节
我们分两个阶段训练RESDSQL。第一阶段训练用于模式项排序的交叉编码器。列增强层中的头数$h$设为8,使用AdamW (Loshchilov and Hutter 2019)优化器,批量大小为32,学习率为1e-5。焦点损失中的聚焦参数$\gamma$和加权因子$\alpha$分别设为2和0.75。根据数据集统计,$k_{1}$和$k_{2}$分别设为4和5。
第二阶段训练seq2seq模型时,我们采用三种规模的T5:Base、Large和3B。使用Adafactor (Shazeer and Stern 2018)进行微调,不同模型配置分别为:RESDSQL-Base ($\mathrm{bs}=32$, $\ln=1\mathrm{e}{-4}$)、RESDSQL-Large (bs$=32$, $\mathrm{lr}=5\mathrm{e}{-5}$) 和 RESDSQL-3B ($\mathrm{\mathbf{b}s}=96$, $\mathrm{lr}=5\mathrm{e}{-5}$)。两个训练阶段均采用线性预热(前$10%$训练步数)和余弦衰减调整学习率,解码时束搜索大小为8。此外,参照Lin, Socher和Xiong (2020)的方法,我们从数据库提取潜在有用内容以丰富列信息。
Environments We conduct all experiments on a server with one NVIDIA A100 (80G) GPU, one Intel(R) Xeon(R) Silver 4316 CPU, 256 GB memory and Ubuntu 20.04.2 LTS operating system.
实验环境
我们在配备单块NVIDIA A100 (80G) GPU、Intel(R) Xeon(R) Silver 4316 CPU、256GB内存及Ubuntu 20.04.2 LTS操作系统的服务器上完成所有实验。
Results on Spider
Spider 实验结果
Table 2 reports EM and EX results on Spider. Noticeably, we observe that RESDSQL-Base achieves better performance than the bare T5-3B, which indicates that our decoupling idea can substantially reduce the learning difficulty of Text-to-SQL. Then, RESDSQL-3B outperforms the best baseline by $1.6%$ EM and $1.3%$ EX on the dev set. Furthermore, when combined with NatSQL (Gan et al. 2021b), an intermediate representation of SQL, RESDSQLLarge achieves competitive results compared to powerful baselines on the dev set, and RESDSQL-3B achieves new SOTA performance on both the dev set and the test set. Specifically, on the dev set, RESDSQL $\mathrm{3B+NatSQL}$ brings $4.2%$ EM and $3.6%$ EX absolute improvements. On the hidden test set, $\mathrm{RESDSQL}\mathbf{-}3\mathbf{B}+\mathrm{NatSQL}$ achieves competitive performance on EM and dramatically increases EX from $75.5%$ to $79.9%$ $(+4.4%)$ , showing the effectiveness of our approach. The reason for the large gap between EM $(72.0%)$ and EX $(79.9%)$ is that EM is overly strict (Zhong, Yu, and Klein 2020). For example in Spider, given a question “Find id of the candidate who most recently accessed the course?”, its gold SQL query is “select candidate id from candidate assessments order by assessment date desc limit 1”. In fact, there is another SQL query “select candidate id from candidate assessments where assessment date $=$ (select max(assessment date) from candidate assessments)” which can also be executed to answer the question (i.e., EX is positive). However, EM will judge the latter to be wrong, which leads to false negatives.
表 2: 报告了Spider上的EM和EX结果。值得注意的是,我们发现RESDSQL-Base的性能优于裸T5-3B,这表明我们的解耦思想能显著降低Text-to-SQL的学习难度。接着,RESDSQL-3B在开发集上以1.6% EM和1.3% EX的优势超越了最佳基线。此外,当结合NatSQL (Gan et al. 2021b)这种SQL中间表示时,RESDSQL-Large在开发集上与强基线模型表现相当,而RESDSQL-3B在开发集和测试集上均实现了新的SOTA性能。具体而言,在开发集上,RESDSQL 3B+NatSQL带来了4.2% EM和3.6% EX的绝对提升。在隐藏测试集上,RESDSQL-3B+NatSQL在EM上表现优异,并将EX从75.5%显著提升至79.9% (+4.4%),证明了我们方法的有效性。EM (72.0%)与EX (79.9%)之间存在较大差距的原因是EM标准过于严格 (Zhong, Yu, and Klein 2020)。例如在Spider中,给定问题"查找最近访问课程的候选人ID",其标准SQL查询为"select candidate id from candidate assessments order by assessment date desc limit 1"。实际上,另一个SQL查询"select candidate id from candidate assessments where assessment date = (select max(assessment date) from candidate assessments)"同样能正确回答问题 (即EX为阳性),但EM会判定后者错误,从而导致假阴性。
Results on Robustness Settings
鲁棒性设置下的结果
Recent studies (Gan et al. 2021a; Deng et al. 2021) show that neural Text-to-SQL parsers are fragile to question perturbations because explicitly mentioned schema items are removed or replaced with semantically consistent words (e.g., synonyms), which increases the difficulty of schema linking. Therefore, more and more efforts have been recently devoted to improving the robustness of neural Text-to-SQL parsers, such as TKK (Qin et al. 2022) and SUN (Gao et al. 2022). To validate the robustness of RESDSQL, we train our model on Spider’s training set and evaluate it on three challenging Spider variants: Spider-DK, Spider-Syn, and SpiderRealistic. Results are reported in Table 3. We can observe that in all three datasets, RESDSQL-3B $^+$ NatSQL surprisingly outperforms all strong competitors by a large margin, which suggests that our decoupling idea can also improve the robustness of seq2seq Text-to-SQL parsers. We attribute this to the fact that our proposed cross-encoder can alleviate the difficulty of schema linking and thus exhibits robustness in terms of question perturbations.
近期研究 (Gan et al. 2021a; Deng et al. 2021) 表明,神经文本到SQL解析器对问题扰动十分敏感,因为显式提及的模式项会被移除或替换为语义一致的词(如同义词),这增加了模式链接的难度。因此,越来越多的研究开始致力于提升神经文本到SQL解析器的鲁棒性,例如 TKK (Qin et al. 2022) 和 SUN (Gao et al. 2022)。为验证 RESDSQL 的鲁棒性,我们在 Spider 训练集上训练模型,并在三个具有挑战性的 Spider 变体上进行评估:Spider-DK、Spider-Syn 和 SpiderRealistic。结果如表 3 所示。可以观察到,在所有三个数据集中,RESDSQL-3B $^+$ NatSQL 以显著优势超越所有强劲竞争对手,这表明我们的解耦思路也能提升序列到序列文本到SQL解析器的鲁棒性。我们将此归因于所提出的交叉编码器能够缓解模式链接的难度,从而在问题扰动方面展现出鲁棒性。
Table 2: EM and EX results on Spider’s development set and hidden test set $(%)$ . We compare our approach with some powerfu baseline methods from the top of the official leader board of Spider.
表 2: Spider开发集和隐藏测试集上的EM和EX结果 (%) 。我们将我们的方法与Spider官方排行榜上的一些强大基线方法进行了比较。
| 方法 | 开发集 | 测试集 |
|---|---|---|
| EM | EX | |
| 非序列到序列方法 | ||
| RAT-SQL+GRAPPA (Yu et al. 2021) | 73.4 | - |
| RAT-SQL+GAP+NatSQL (Gan et al. 2021b) | 73.7 | 75.0 |
| SMBoP+GRAPPA (Rubin and Berant 2021) | 74.7 | 75.0 |
| DT-Fixup SQL-SP+RoBERTa (Xu et al. 2021) | 75.0 | - |
| LGESQL+ELECTRA (Cao et al. 2021) | 75.1 | - |
| S2SQL+ELECTRA (Hui et al. 2022) | 76.4 | - |
| 序列到序列方法 | ||
| T5-3B (Scholak, Schucher, and Bahdanau 2021) | 71.5 | 74.4 |
| T5-3B+PICARD (Scholak, Schucher, and Bahdanau 2021) | 75.5 | 79.3 |
| RASAT+PICARD (Qi et al. 2022) | 75.3 | 80.5 |
| 我们提出的方法 | ||
| RESDSQL-Base | 71.7 | 77.9 |
| RESDSQL-Base+NatSQL | 74.1 | 80.2 |
| RESDSQL-Large | 75.8 | 80.1 |
| RESDSQL-Large+NatSQL | 76.7 | 81.9 |
| RESDSQL-3B | 78.0 | 81.8 |
| RESDSQL-3B+NatSQL | 80.5 | 84.1 |
Ablation Studies
消融实验
We take a thorough ablation study on Spider’s dev set to analyze the effect of each design.
我们在Spider的开发集上进行了全面的消融研究,以分析每个设计的效果。
Effect of Column-Enhanced Layer We investigate the effectiveness of the column-enhanced layer, which is designed to alleviate the table missing problem. Table 4 shows that removing such a layer will lead to a decrease in the total AUC, as it can inject the human prior into the cross-encoder.
列增强层效果研究
我们研究了列增强层的有效性,该层旨在缓解表格缺失问题。表 4 显示,移除该层会导致总 AUC 下降,因为它能将人类先验知识注入交叉编码器 (cross-encoder) 中。
Effect of Focal Loss We also study the effect of focal loss by replacing it with the cross-entropy loss for schema item classification. Table 4 shows that cross-entropy leads to a performance drop because it cannot alleviate the labelimbalance problem in the training data.
焦点损失的效果
我们还研究了用交叉熵损失替换模式项分类中的焦点损失的效果。表 4 显示,交叉熵会导致性能下降,因为它无法缓解训练数据中的标签不平衡问题。
Effect of Ranking Schema Items As shown in Table 5, when we replace the ranked schema sequence with the original unordered schema sequence, EM and EX significantly decrease by $4.5%$ and $7.8%$ respectively. This result proves that the ranking-enhanced encoder takes a crucial role.
排序模式项的效果
如表 5 所示,当我们将排序后的模式序列替换为原始无序模式序列时,EM 和 EX 分别显著下降了 $4.5%$ 和 $7.8%$。这一结果证明了排序增强编码器起到了关键作用。
Effect of Skeleton Parsing Meanwhile, from Table 5, we can observe that EM and EX drop $0.7%$ and $0.8%$ respectively when removing the SQL skeleton from the decoder’s output (i.e., without skeleton parsing). This is because the seq2seq model needs to make extra efforts to bridge the gap between natural language questions and SQL queries when parsing SQL queries directly.
骨架解析的影响
同时,从表 5 可以看出,当从解码器输出中移除 SQL 骨架 (即不进行骨架解析) 时,EM 和 EX 分别下降了 $0.7%$ 和 $0.8%$。这是因为在直接解析 SQL 查询时,seq2seq 模型需要额外努力来弥合自然语言问题与 SQL 查询之间的差距。
Related Work
相关工作
Our method is related to the encoder-decoder architecture designed for Text-to-SQL, the schema item classification task, and the intermediate representation.
我们的方法与为Text-to-SQL设计的编码器-解码器架构、模式项分类任务以及中间表示相关。
Encoder-Decoder Architecture
编码器-解码器架构
The encoder aims to jointly encode the question and database schema, which is generally divided into sequence encoder and graph encoder. The decoder aims to generate the SQL queries based on the output of the encoder. Due to the special format of SQL, grammar- and execution-guided decoders are studied to constrain the decoding results.
编码器旨在联合编码问题和数据库模式,通常分为序列编码器和图编码器。解码器则根据编码器的输出生成SQL查询。由于SQL的特殊格式,研究人员设计了语法导向和执行导向的解码器来约束解码结果。
Sequence Encoder The input is a sequence that concatenates the question with serialized database schema (Yu et al. 2021; Lin, Socher, and Xiong 2020). Then, each token in the sequence is encoded by a PLM encoder, such as BERT (Devlin et al. 2019) and encoder part of T5 (Raffel et al. 2020).
序列编码器
输入是一个将问题与序列化数据库模式 (Yu et al. 2021; Lin, Socher, and Xiong 2020) 拼接而成的序列。随后,序列中的每个 Token 会通过一个预训练语言模型 (PLM) 编码器进行编码,例如 BERT (Devlin et al. 2019) 或 T5 (Raffel et al. 2020) 的编码器部分。
Graph Encoder The input is one or more heterogeneous graphs (Wang et al. 2020a; Hui et al. 2022; Cao et al. 2021; Cai et al. 2021), where a node represents a question token, a table or a column, and an edge represents the relation between two nodes. Then, relation-aware transformer networks (Shaw, Uszkoreit, and Vaswani 2018) or relational graph neural networks, such as RGCN (Sch licht kru ll et al. 2018) and RGAT (Wang et al. 2020b), are applied to encode each node. Some works also employ PLM encoders to initialize the representation of nodes on the graph (Cao et al. 2021; Wang et al. 2020a; Rubin and Berant 2021). It is undeniable that the graph encoder can flexibly and explicitly represent the relations between any two nodes via edges (e.g., foreign key relations). However, compared to
图编码器
输入为一个或多个异构图 (Wang et al. 2020a; Hui et al. 2022; Cao et al. 2021; Cai et al. 2021),其中节点表示问题token、表或列,边表示两个节点之间的关系。随后采用关系感知Transformer网络 (Shaw, Uszkoreit, and Vaswani 2018) 或关系图神经网络(如RGCN (Schlichtkrull et al. 2018) 和RGAT (Wang et al. 2020b))对每个节点进行编码。部分研究还使用PLM编码器初始化图中节点的表示 (Cao et al. 2021; Wang et al. 2020a; Rubin and Berant 2021)。不可否认,图编码器能通过边(例如外键关系)灵活且显式地表示任意两节点间的关系。然而相较于...
Table 3: Evaluation results on Spider-DK, Spider-Syn, and Spider-Realistic $(%)$ .
表 3: Spider-DK、Spider-Syn 和 Spider-Realistic 上的评估结果 $(%)$ 。
| 方法 | Spider-DK | Spider-Syn | Spider-Realistic | |||
|---|---|---|---|---|---|---|
| EM | EX | EM | EX | EM | EX | |
| RAT-SQL+BERT (Wang et al.2020a) | 40.9 | 48.2 | 58.1 | 62.1 | ||
| RAT-SQL+GRAPPA(Yuetal.2021) | 38.5 | 49.1 | 59.3 | |||
| T5-3B (Ga0 et al.2022) | 59.4 | 65.3 | 63.2 | 65.0 | ||
| LGESQL+ELECTRA (Ca0 et al.2021) | 48.4 | 64.6 | 69.2 | |||
| TKK-3B (Ga0et al.2022) | 63.0 | 68.2 | 68.5 | 71.1 | ||
| T5-3B+PICARD(Qietal.2022) | 68.7 | 71.4 | ||||
| RASAT+PICARD (Qiet al.2022) | 69.7 | 71.9 | ||||
| LGESQL+ELECTRA+ SUN (Qin et al.2022) | 52.7 | 66.9 | 70.9 | |||
| RESDSQL-3B+NatSQL | 53.3 | 66.0 | 69.1 | 76.9 | 77.4 | 81.9 |
Table 4: Ablation studies of the cross-encoder.
表 4: 交叉编码器的消融研究
| 模型变体 | 表AUC | 列AUC | 总计 |
|---|---|---|---|
| Cross-encoder | 0.9973 | 0.9957 | 1.9930 |
| - w/o enh. layer | 0.9965 | 0.9939 | 1.9904 |
| - w/o focal loss | 0.9958 | 0.9943 | 1.9901 |
Table 5: The effect of key designs.
表 5: 关键设计的影响。
| Modelvariant | EM (%) | EX (%) |
|---|---|---|
| RESDSQL-Base | 71.7 | 77.9 |
| - w/o ranking schema items | 67.2 | 70.1 |
| - w/o skeleton parsing | 71.0 | 77.1 |
PLMs, graph neural networks (GNNs) usually cannot be designed too deep due to the limitation of the over-smoothing issue (Chen et al. 2020), which restricts the representation ability of GNNs. Then, PLMs have already encoded language patterns in their parameters after pre-training (Zhang et al. 2021), however, the parameters of GNNs are usually randomized. Moreover, the graph encoder relies heavily on the design of relations, which may limit its robustness and generality on other datasets (Gao et al. 2022).
预训练语言模型 (PLM) 和图神经网络 (GNN) 由于过平滑问题 (over-smoothing) 的限制 (Chen et al. 2020),通常无法设计得太深,这限制了 GNN 的表征能力。其次,PLM 经过预训练后参数中已编码了语言模式 (Zhang et al. 2021),而 GNN 的参数通常是随机初始化的。此外,图编码器高度依赖关系设计,这可能限制其在不同数据集上的鲁棒性和泛化性 (Gao et al. 2022)。
Grammar-Based Decoder To inject the SQL grammar into the decoder, Yin and Neubig (2017); Krishna mur thy, Dasigi, and Gardner (2017) propose a top-down decoder to generate a sequence of pre-defined actions that can describe the grammar tree of the SQL query. Rubin and Berant (2021) devise a bottom-up decoder instead of the topdown paradigm. PICARD (Scholak, Schucher, and Bahdanau 2021) incorporates an incremental parser into the auto-regressive decoder of PLMs to prune the invalid partially generated SQL queries during beam search.
基于语法的解码器
为将SQL语法注入解码器,Yin和Neubig (2017)、Krishnamurthy、Dasigi和Gardner (2017)提出了一种自顶向下解码器,用于生成能描述SQL查询语法树的预定义动作序列。Rubin和Berant (2021)则设计了一种自底向上解码器替代自顶向下范式。PICARD (Scholak、Schucher和Bahdanau 2021)在PLM的自回归解码器中集成了增量解析器,以在束搜索过程中剪枝无效的部分生成SQL查询。
Execution-Guided Decoder Some works use an off-theshelf SQL executor such as SQLite to ensure grammatical correctness. Wang et al. (2018) leverage a SQL executor to check and discard the partially generated SQL queries which raise errors during decoding. To avoid modifying the decoder, Suhr et al. (2020) check the exe cut ability of each candidate SQL query, which is also adopted by our method.
执行引导解码器
部分研究使用现成的SQL执行器(如SQLite)来确保语法正确性。Wang等人(2018)利用SQL执行器检查并丢弃解码过程中引发错误的部分生成SQL查询。为避免修改解码器,Suhr等人(2020)会检查每个候选SQL查询的可执行性,该方法也被我们的方案所采用。
Schema Item Classification
模式项分类
Schema item classification is often introduced as an auxiliary task to improve the schema linking performance for Text-to-SQL. For example, GRAPPA (Yu et al. 2021) and GAP (Shi et al. 2021) further pre-train the PLMs by using the schema item classification task as one of the pre-training objectives. Then, Text-to-SQL can be viewed as a downstream task to be fine-tuned. Cao et al. (2021) combine the schema item classification task with the Text-to-SQL task in a multi-task learning way. The above-mentioned methods enhance the encoder by pre-training or the multi-task learning paradigm. Instead, we propose an independent cross- encoder as the schema item classifier which is easier to be trained. We use the classifier to re-organize the input of the seq2seq model, which can produce a more direct impact on schema linking. Bogin, Gardner, and Berant (2019) calculate a relevance score for each schema item, which is then used as the soft coefficient of the schema items in the subsequent graph encoder. Compared with them, our method can be viewed as a hard filtering of schema items which can reduce noise more effectively.
模式项分类常被引入作为辅助任务,以提升Text-to-SQL的模式链接性能。例如,GRAPPA (Yu et al. 2021) 和 GAP (Shi et al. 2021) 通过将模式项分类任务作为预训练目标之一,进一步预训练PLMs。随后,Text-to-SQL可视为待微调的下游任务。Cao等人 (2021) 以多任务学习方式将模式项分类任务与Text-to-SQL任务结合。上述方法通过预训练或多任务学习范式增强了编码器。与之不同,我们提出一个独立的交叉编码器作为模式项分类器,更易于训练。我们利用该分类器重新组织seq2seq模型的输入,从而对模式链接产生更直接的影响。Bogin、Gardner和Berant (2019) 为每个模式项计算相关性分数,随后将其用作图编码器中模式项的软系数。相比之下,我们的方法可视为模式项的硬过滤,能更有效地降低噪声。
Intermediate Representation
中间表示
Because there is a huge gap between natural language questions and their corresponding SQL queries, some works have focused on how to design an efficient intermediate representation (IR) to bridge the aforementioned gap (Yu et al. 2018b; Guo et al. 2019; Gan et al. 2021b). Instead of directly generating full-fledged SQL queries, these IR-based methods encourage models to generate IRs, which can be translated to SQL queries via a non-trainable transpiler.
由于自然语言问题与其对应的SQL查询之间存在巨大鸿沟,部分研究聚焦于如何设计高效中间表示(intermediate representation,IR)来弥合这一差距(Yu et al. 2018b; Guo et al. 2019; Gan et al. 2021b)。这些基于IR的方法不直接生成完整SQL查询,而是引导模型生成可通过不可训练转译器转换为SQL查询的中间表示。
Conclusion
结论
In this paper, we propose RESDSQL, a simple yet powerful Text-to-SQL parser. We first train a cross-encoder to rank and filter schema items which are then injected into the encoder of the seq2seq model. We also let the decoder generate the SQL skeleton first, which can implicitly guide the subsequent SQL generation. To a certain extent, such a framework decouples schema linking and skeleton parsing, which can alleviate the difficulty of Text-to-SQL. Extensive experiments on Spider and its three variants demonstrate the performance and robustness of RESDSQL.
本文提出RESDSQL,一种简洁高效的Text-to-SQL解析器。我们首先训练交叉编码器(cross-encoder)对模式(schema)项进行排序筛选,随后将其注入seq2seq模型的编码器。同时让解码器首先生成SQL骨架(skeleton),从而隐式引导后续SQL生成。该框架在某种程度上解耦了模式链接(schema linking)与骨架解析(skeleton parsing),缓解了Text-to-SQL的难度。在Spider及其三个变体上的大量实验验证了RESDSQL的性能与鲁棒性。