MTCAE-DFER: Multi-Task Cascaded Auto encoder for Dynamic Facial Expression Recognition
MTCAE-DFER: 基于多任务级联自编码器的动态面部表情识别
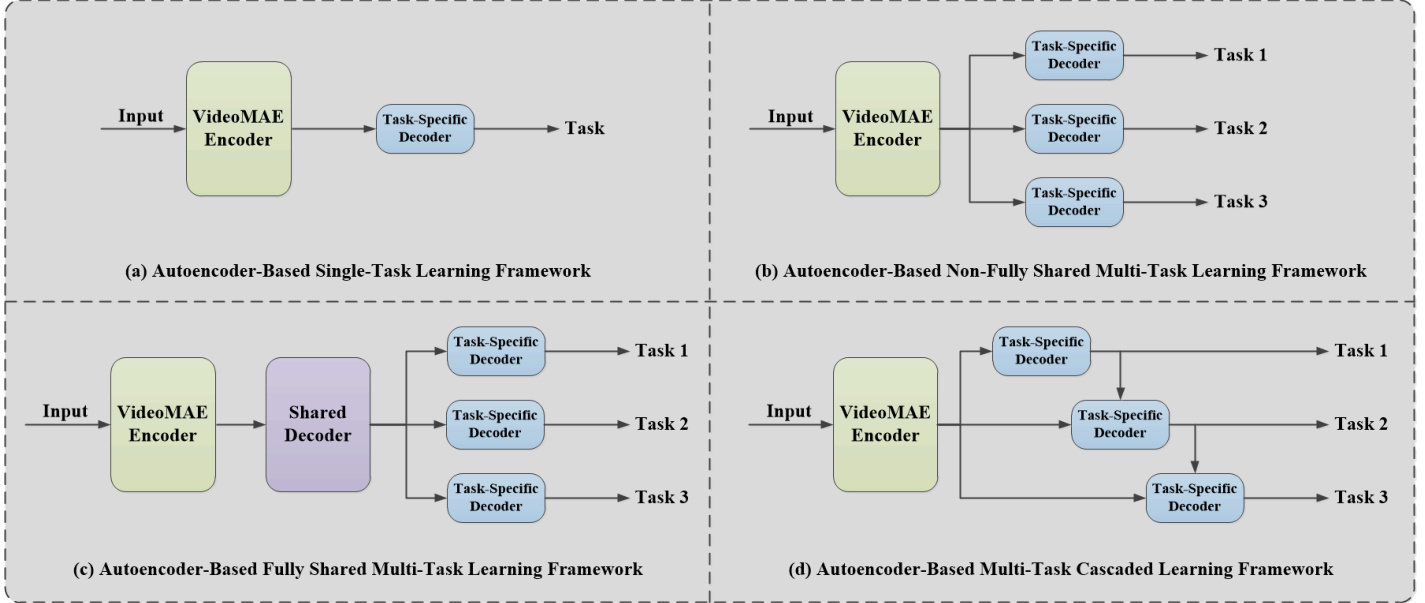
Fig. 1: Illustration of the differences between the following four frameworks: (a) Auto encoder-Based Single-Task Learning Framework, (b) Auto encoder-Based Non-Fully Shared Multi-Task Learning Framework, (c) Auto encoder-Based Fully Shared Multi-Task Learning Framework and (d) Our Auto encoder-Based Multi-Task Cascaded Learning Framework.
图 1: 四种框架的差异对比示意图:(a) 基于自动编码器(Auto encoder)的单任务学习框架,(b) 基于自动编码器的非全共享多任务学习框架,(c) 基于自动编码器的全共享多任务学习框架,(d) 我们提出的基于自动编码器的多任务级联学习框架。
Abstract— This paper expands the cascaded network branch of the auto encoder-based multi-task learning (MTL) framework for dynamic facial expression recognition, namely MultiTask Cascaded Auto encoder for Dynamic Facial Expression Recognition (MTCAE-DFER). MTCAE-DFER builds a plugand-play cascaded decoder module, which is based on the Vision Transformer (ViT) architecture and employs the decoder concept of Transformer to reconstruct the multi-head attention module. The decoder output from the previous task serves as the query (Q), representing local dynamic features, while the Video Masked Auto encoder (VideoMAE) shared encoder output acts as both the key $(\mathbf{K})$ and value (V), representing global dynamic features. This setup facilitates the interaction between global and local dynamic features across related tasks. Additionally, this proposal aims to alleviate over fitting of complex large model. We utilize auto encoder-based multi-task cascaded learning approach to explore the impact of dynamic face detection and dynamic face landmark on dynamic facial expression recognition, which enhances the model’s generalization ability. After we conduct extensive ablation experiments and comparison with state-of-the-art (SOTA) methods on various public datasets for dynamic facial expression recognition, the robustness of the MTCAE-DFER model and the effectiveness of global-local dynamic feature interaction among related tasks have been proven.
摘要—本文拓展了基于自动编码器(Auto Encoder)的多任务学习(MTL)框架的级联网络分支,即用于动态面部表情识别的多任务级联自动编码器(MTCAE-DFER)。MTCAE-DFER构建了一个即插即用的级联解码器模块,该模块基于视觉Transformer(ViT)架构,采用Transformer的解码器概念重构了多头注意力模块。前一任务的解码器输出作为查询向量(Q),代表局部动态特征;而视频掩码自动编码器(VideoMAE)共享编码器的输出同时作为键向量(K)和值向量(V),代表全局动态特征。这种设计促进了相关任务间全局与局部动态特征的交互。此外,本方案旨在缓解复杂大模型的过拟合问题。我们采用基于自动编码器的多任务级联学习方法,探究动态人脸检测和动态人脸关键点对动态表情识别的影响,从而提升模型泛化能力。通过在多个公开动态表情识别数据集上进行大量消融实验并与最先进(SOTA)方法对比,验证了MTCAE-DFER模型的鲁棒性及相关任务间全局-局部动态特征交互的有效性。
I. INTRODUCTION
I. 引言
Dynamic Facial Expression Recognition (DFER) is a crucial technology in human-computer interaction and affective computing, building on the foundations of Static Facial Expression Recognition (SFER) and further advancing its development. In SFER technology, most recognition models are static, serial, and context-free, such as Deep Emotion [1], FER-VT [2], and PAtt-Lite [3]. The preliminary stages of DFER development, many researchers used SFER techniques to perform frame-level processing of video stream data, but these methods often failed to meet the real-time and temporal correlations of human-computer interaction applications. Therefore, the feasibility of three-dimensional convolutional neural network (3DCNN) was considered, with examples like C3D [4], I3D [5], and SlowFast [6]. However, these networks require significant computational power and still unable to meet real-time. With the emergence of sequence models such as RNN [7], GRU [8], and LSTM [9], combining convolutional neural network with recurrent neural network has become a common trend. For example, models like ResNet1 $^{8\mathrm{+}}$ LSTM [10] and $\mathrm{C3D}+\mathrm{LSTM}$ [11] have been developed to construct DFER system.
动态面部表情识别 (DFER) 是人机交互与情感计算领域的关键技术,它在静态面部表情识别 (SFER) 的基础上进一步发展。在SFER技术中,大多数识别模型是静态、串行且无上下文关联的,例如Deep Emotion [1]、FER-VT [2] 和 PAtt-Lite [3]。DFER发展的初期阶段,许多研究者采用SFER技术对视频流数据进行帧级处理,但这些方法往往无法满足人机交互应用的实时性和时序相关性需求。因此,研究者开始考虑三维卷积神经网络 (3DCNN) 的可行性,例如C3D [4]、I3D [5] 和 SlowFast [6]。然而这些网络需要大量算力支撑,仍难以满足实时性要求。随着RNN [7]、GRU [8] 和 LSTM [9] 等序列模型的出现,将卷积神经网络与循环神经网络结合成为主流趋势,例如 ResNet1$^{8\mathrm{+}}$LSTM [10] 和 $\mathrm{C3D}+\mathrm{LSTM}$ [11] 等模型被用于构建DFER系统。
Moreover, since the introduction of the TimeS former [12] architecture, it is known for strengthening s patio temporal contextual relevance, while more suitable for dynamic data. Examples include Former-DFER [13], STT-DFER [14], LOGO-Former [15], and MAE-DFER [16]. However, since this architecture emphasizes the effectiveness of global feature extraction, it tends to overlook the key task-specific features. In other words, most current DFER models focus on global feature extraction and inference but lack attention to local feature and global-local interaction feature. This can lead to the model paying too much attention to broad features during the learning process, while ignoring the local features for the specific task.
此外,自从TimeSformer [12]架构被提出以来,该架构以增强时空上下文相关性而闻名,同时更适用于动态数据。相关案例包括Former-DFER [13]、STT-DFER [14]、LOGO-Former [15]和MAE-DFER [16]。然而由于该架构强调全局特征提取的有效性,往往容易忽略针对具体任务的关键特征。换言之,当前大多数DFER模型聚焦于全局特征提取与推理,却缺乏对局部特征及全局-局部交互特征的关注。这可能导致模型在学习过程中过度关注宽泛特征,而忽略针对特定任务的局部特征。
To address the challenges mentioned above, although models like LOGO-Former [15] and MAE-DFER [16] have made some improvements, they still lack advanced technologies to further alleviate these shortcomings. Inspired by MTFormer [17] and MNC [18], we propose the multi-task cascaded learning approach to enhance the model robustness and the effectiveness of global-local feature interaction in DFER.
为解决上述挑战,尽管LOGO-Former [15]和MAE-DFER [16]等模型已做出部分改进,但仍缺乏先进技术来进一步缓解这些缺陷。受MTFormer [17]与MNC [18]启发,我们提出多任务级联学习方法,以增强动态面部表情识别(DFER)中模型的鲁棒性及全局-局部特征交互的有效性。
As shown in Fig. 1, (a) is Auto encoder-Based SingleTask Learning (STL) network, where the Video Masked Auto encoder (VideoMAE) [19] encoder is obtained by selfsupervised learning. It uses the Masked Auto encoder (MAE) [20] method, but this network structure has weak generalization ability. (b) is Auto encoder-Based Non-Fully Shared Multi-Task Learning (MTL) network. The VideoMAE [19] encoder is shared, while non-shared task-specific decoders are designed for different tasks, improving the model’s overall generalization ability through multiple tasks. (c) is Auto encoder-Based Fully Shared MTL network. It has a shared encoder-decoder pair and the task-specific decoder for each task, enhancing global feature interaction. (d) is Auto encoder-Based Multi-Task Cascaded Learning network. It employs the shared VideoMAE [19] encoder to obtain global representation information, and then uses the cascaded network to enable feature interaction across tasks, achieving global-local feature interaction of related tasks.
如图1所示,(a) 是基于自动编码器 (Auto encoder) 的单任务学习 (STL) 网络,其中视频掩码自动编码器 (VideoMAE) [19] 编码器通过自监督学习获得。它使用了掩码自动编码器 (MAE) [20] 方法,但该网络结构泛化能力较弱。(b) 是基于自动编码器的非全共享多任务学习 (MTL) 网络。VideoMAE [19] 编码器是共享的,同时为不同任务设计了非共享的任务特定解码器,通过多任务提升模型的整体泛化能力。(c) 是基于自动编码器的全共享多任务学习网络。它具有共享的编码器-解码器对以及每个任务的任务特定解码器,增强了全局特征交互。(d) 是基于自动编码器的多任务级联学习网络。它采用共享的 VideoMAE [19] 编码器获取全局表征信息,然后利用级联网络实现跨任务特征交互,达成相关任务的全局-局部特征交互。
Combined with the aforementioned solutions, our purpose is to explore the impact of dynamic face detection and dynamic face landmark on DFER within the MTL framework, as well as the effectiveness of global-local feature interaction between related face tasks in the cascaded network. Therefore, we will propose a new framework of MultiTask Cascaded Auto encoders for Dynamic Facial Expression Recognition, named MTCAE-DFER. The contributions of this work are as follows:
结合上述解决方案,我们的目的是探索动态人脸检测和动态人脸关键点对MTL框架内DFER的影响,以及级联网络中相关人脸任务间全局-局部特征交互的有效性。因此,我们将提出一种用于动态面部表情识别的新型多任务级联自编码器框架,命名为MTCAE-DFER。本工作的贡献如下:
II. RELATED WORK
II. 相关工作
A. Dynamic Facial Expression Recognition
A. 动态面部表情识别
DFER is the key part of dynamic emotion recognition, which focuses on the analysis and computation of facial emotions in visual data. At present, most DFER models use s patio temporal attention as their core and built on the ViT [22] architecture, to capture contextual global features related to dynamic facial expressions and improve recognition accuracy. Examples include models like LOGO-Former [15] and MAE-DFER [16]. The LOGO-Former [15] architecture introduces the global-local feature interaction mechanism, which interacts global and local features from the spatiotemporal level, enhancing the se par ability of different data attributes in feature space. Additionally, the MAE-DFER [16] architecture is one of SOTA models in DFER. It employs the VideoMAE [19] self-supervised learning method to address data scarcity in deep learning, thereby producing the pre-trained model with strong feature extraction capabilities. In this work, we will adopt global-local feature interaction concept and inherit this VideoMAE [19] encoder pre-trained model. This approach will extract global feature of dynamic facial expressions, while strengthening the se par ability of local key feature from different related tasks level.
动态面部表情识别 (DFER) 是动态情绪识别的关键组成部分,专注于视觉数据中面部情绪的分析与计算。目前大多数DFER模型以时空注意力机制为核心,并基于ViT [22]架构构建,旨在捕捉与动态面部表情相关的上下文全局特征,从而提高识别准确率。典型模型包括LOGO-Former [15]和MAE-DFER [16]。LOGO-Former [15]架构引入了全局-局部特征交互机制,从时空层面实现全局与局部特征的交互,增强了特征空间中不同数据属性的可分离性。此外,MAE-DFER [16]架构是当前DFER领域的SOTA模型之一,它采用VideoMAE [19]自监督学习方法解决深度学习中的数据稀缺问题,从而生成具有强大特征提取能力的预训练模型。本工作将采用全局-局部特征交互理念,并继承该VideoMAE [19]编码器预训练模型,在提取动态面部表情全局特征的同时,从不同相关任务层面强化局部关键特征的可分离性。
B. Multi-Task Learning
B. 多任务学习
MTL is mainly used for joint learning of multiple tasks to enhance the generalization ability of the model. MTL architectures usually consist of shared modules and taskspecific heads. Various MTL variants have been developed by designing the shared module to effectively distribute and share information across different tasks, as seen in structures like MTFormer [17]. In this study, we focus on exploring and extending the various MTL frameworks shown in Fig. 1. Since this paper primarily deals with DFER, the tasks chosen for MTL will all be facial-related. Our research reveals that in traditional approaches to DFER from video, multiple models are often used in sequence: first to detect the face in the video, then to detect facial landmarks, and finally to recognize facial expressions. However, we aim to streamline the process by constructing the end-to-end unified model that simultaneously performs these three tasks: dynamic face detection, dynamic face landmark, and DFER.
多任务学习 (MTL) 主要用于多任务联合学习以增强模型的泛化能力。MTL架构通常由共享模块和任务特定头组成。通过设计共享模块在不同任务间有效分配和共享信息,研究者已开发出多种MTL变体,例如MTFormer [17]等结构。本研究重点探索并扩展图1所示的各种MTL框架。由于本文主要研究动态面部表情识别 (DFER),所选MTL任务均为面部相关任务。我们发现,传统视频DFER方法通常需要串联使用多个模型:先检测视频中的人脸,再检测面部关键点,最后识别面部表情。而我们的目标是构建端到端统一模型,同步执行动态人脸检测、动态面部关键点定位和DFER这三个任务。
C. Cascaded Auto encoder
C. 级联自编码器
Cascaded auto encoder is the extension of the traditional auto encoder on cascaded network. Generally, the autoencoder consists of an encoder-decoder pair, where the encoder acts as the feature extractor in deep neural network architecture, and the decoder serves as the feature reasoner. Referring to the cascade concept of [18], the relationships between different related tasks can be captured through cascaded decoder. This architecture enhances the performance of MTL network by facilitating global-local feature interaction across related tasks, which helps focus on the critical features necessary for solving the tasks. In this paper, we adopt auto encoder-based cascaded multi-task network architecture. The cascaded decoder enable interaction between the global features extracted by the shared encoder and the local features derived from the task-specific decoder. This framework will be used to prove the effectiveness of global-local feature interaction across different related tasks, thereby improving the robustness of the overall model.
级联自动编码器是传统自动编码器在级联网络上的扩展。通常,自动编码器由编码器-解码器对组成,其中编码器在深度神经网络架构中充当特征提取器,解码器则作为特征推理器。参考[18]的级联概念,不同相关任务之间的关系可以通过级联解码器捕获。该架构通过促进相关任务间的全局-局部特征交互来提升多任务学习(MTL)网络的性能,有助于聚焦解决任务所需的关键特征。本文采用基于自动编码器的级联多任务网络架构。级联解码器使得共享编码器提取的全局特征与任务特定解码器衍生的局部特征能够交互。该框架将用于验证不同相关任务间全局-局部特征交互的有效性,从而提升整体模型的鲁棒性。
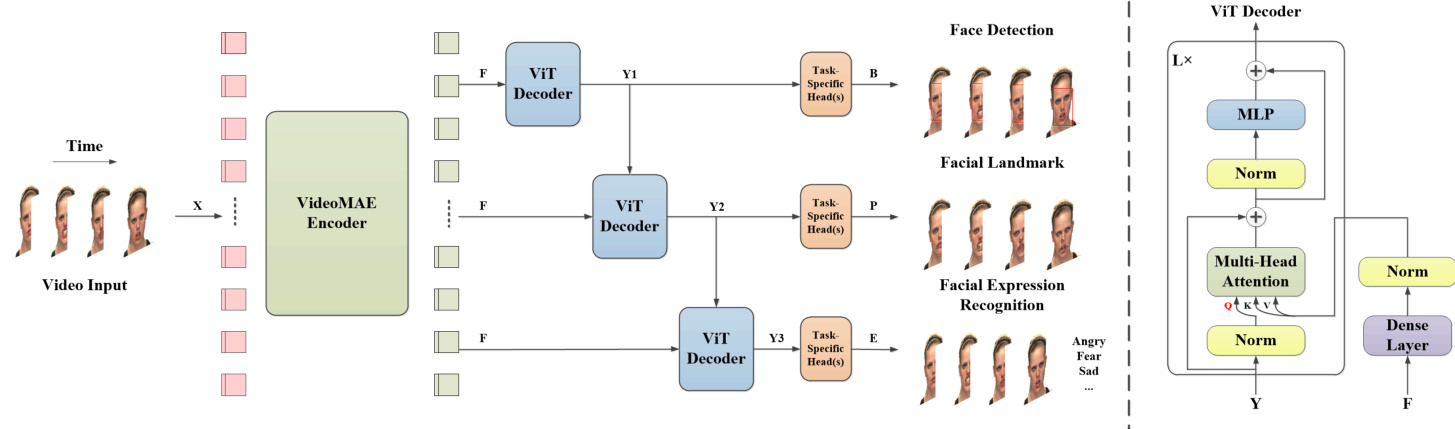
Fig. 2: MTCAE-DFER Model Structure
图 2: MTCAE-DFER 模型结构
III. METHOD
III. 方法
A. Revisiting VideoMAE
A. 重温VideoMAE
VideoMAE [19] is a significant advancement in selfsupervised learning within the field of dynamic vision. It learns dynamic visual representation information by applying some pixel patches with tube masking over consecutive video frames and then using the auto encoder to reconstruct these masked patches. The VideoMAE [19] structure consists of a pair of asymmetric encoder-decoder, and the core theory is derived from ImageMAE [20]. Their basic backbone network is ViT [22], which leverages the s patio temporal attention module to capture the long short-term dependencies between dynamic features. According to our analysis, the VideoMAE [19] encoder extracts dynamic features from video information, while the decoder performs inference on these dynamic features to reconstruct those masked pixel patches.
VideoMAE [19] 是动态视觉领域自监督学习的重要进展。它通过在连续视频帧上应用管状掩膜 (tube masking) 遮挡部分像素块,再利用自动编码器 (auto encoder) 重建这些被遮挡区域来学习动态视觉表征信息。VideoMAE [19] 结构采用非对称编码器-解码器架构,其核心理论源自ImageMAE [20],基础骨干网络为ViT [22],该网络通过时空注意力 (spatio temporal attention) 模块捕捉动态特征间的长短时依赖关系。经分析,VideoMAE [19] 的编码器负责从视频信息中提取动态特征,解码器则对这些动态特征进行推理以重建被遮挡的像素块。
In this work, we directly inherit the VideoMAE [19] encoder as the shared feature extractor. As shown in Figure 2, the VideoMAE [19] encoder is used as the pre-trained model to obtain dynamic representation information. The input size is $\mathbf{X}\in R^{1\dot{6}\times224\times224\times3}$ , representing the frame count, image height, image width, and image channels, respectively. In addition, the kernel size of the 3D patch is $2\times16\times16\times3$ . After patching, the sequence matrix $\mathbf{S}\in R^{1568\times1536}$ can be obtained. Since the embedding layer dimension is 1024, which matrix is reduced to $\hat{\mathbf{X}}\in\bar{R^{1568}}\times1024$ token sequences. Through the operation of the pre-trained encoder model, we can obtain the global dynamic representation information about the video, and its output size is $\mathbf{F} \in~R^{1568\times1024}$ . The mathematical expressions for the above process are as follows:
在本工作中,我们直接继承了VideoMAE [19]编码器作为共享特征提取器。如图2所示,VideoMAE [19]编码器被用作预训练模型以获取动态表征信息。输入尺寸为$\mathbf{X}\in R^{1\dot{6}\times224\times224\times3}$,分别表示帧数、图像高度、图像宽度和图像通道数。此外,3D补丁的核尺寸为$2\times16\times16\times3$。经过分块处理后,可获得序列矩阵$\mathbf{S}\in R^{1568\times1536}$。由于嵌入层维度为1024,该矩阵被降维为$\hat{\mathbf{X}}\in\bar{R^{1568}}\times1024$的token序列。通过预训练编码器模型的操作,我们可以获得关于视频的全局动态表征信息,其输出尺寸为$\mathbf{F} \in~R^{1568\times1024}$。上述过程的数学表达式如下:
$$
\begin{array}{c}{{\bf S}=\mathrm{Patching}({\bf X})}\ {{\hat{\bf X}}=\mathrm{Embedding}({\bf S})}\ {{\bf F}=\mathrm{Encoder}({\hat{\bf X}})}\end{array}
$$
$$
\begin{array}{c}{{\bf S}=\mathrm{Patching}({\bf X})}\ {{\hat{\bf X}}=\mathrm{Embedding}({\bf S})}\ {{\bf F}=\mathrm{Encoder}({\hat{\bf X}})}\end{array}
$$
B. Cascaded ViT Decoder Module Design
B. 级联 ViT 解码器模块设计
The Cascaded ViT Decoder is a plug-and-play module based on ViT [22] as the basic architecture and uses the Transformer [21] decoder concept to reconstruct the multihead attention (MHA), as illustrated in Fig. 2 ViT Decoder. The focus is on the attention mechanism, where the query $(Q)$ , key $(K)$ , and value $(V)$ inputs aren’t sourced from the same input. Specifically, $Q$ is the normalized output from the previous stage, while $K$ and $V$ are the normalized dense outputs from the VideoMAE [19] encoder. Furthermore, as shown in Algorithm 1, the ViT Decoder has recursive algorithm of the built-in module, which the values of $K$ and $V$ remain constant, while $Q$ continuously updates throughout the recursion. $Q,K$ , and $V$ are then processed through the MHA mechanism to generate the interaction features $Z$ . Once the interaction features $Z$ are computed, the next operations follow the standard ViT architecture. Specifically, $Z$ undergoes residual connection $Y$ to produce $Z^{\prime}$ , followed by normalization and multi-layer perceptron (MLP) operations to obtain $Y^{\prime}$ . Finally, another residual connection between $Z^{\prime}$ and $Y^{\prime}$ completes the recursive output $Y$ .
级联ViT解码器是一种基于ViT[22]基础架构的即插即用模块,采用Transformer[21]解码器概念重构多头注意力机制(MHA),如图2 ViT解码器所示。其核心在于注意力机制中查询$(Q)$、键$(K)$和值$(V)$输入并非同源:$Q$来自前一阶段归一化输出,而$K$和$V$则源自VideoMAE[19]编码器的归一化稠密输出。如算法1所示,该解码器内置模块采用递归算法,其中$K$和$V$保持恒定,而$Q$在递归过程中持续更新。$Q,K$和$V$经MHA机制处理后生成交互特征$Z$,后续操作遵循标准ViT架构:$Z$通过残差连接$Y$生成$Z^{\prime}$,经归一化和多层感知机(MLP)运算得到$Y^{\prime}$,最终通过$Z^{\prime}$与$Y^{\prime}$的残差连接完成递归输出$Y$。
This module leverages MHA to directly associate feature maps from different feature layers, generating crucial feature attention map. More importantly, for facilitating the interaction between global and local dynamic features, the design of this module ensures that the feature matrix output from the VideoMAE [19] encoder serves as the global dynamic representation information. To prevent the forgetting of original global feature relationships, the form of $K$ and $V$ matrix is input into the attention layer, while the local representation information is input as the form of $Q$ matrix. In the cascaded mode, the $Q$ matrix is sourced from the output of the previous stage. In the recursive mode, the $Q$ matrix comes from the recursive computation output. In this setup, the shared feature matrix $K$ and $V$ represent global dynamic features and remain constant throughout the process. By associating them with the local dynamic features matrix $Q$ , the process promotes interaction between global and local dynamic features.
该模块利用MHA直接关联来自不同特征层的特征图,生成关键特征注意力图。更重要的是,为了促进全局与局部动态特征之间的交互,该模块的设计确保VideoMAE [19]编码器输出的特征矩阵作为全局动态表征信息。为防止遗忘原始全局特征关系,$K$矩阵和$V$矩阵以注意力层输入的形式存在,而局部表征信息则以$Q$矩阵的形式输入。在级联模式下,$Q$矩阵来源于前一阶段的输出;在递归模式下,$Q$矩阵来自递归计算输出。此设置中,共享特征矩阵$K$和$V$代表全局动态特征,并在整个过程中保持不变。通过将其与局部动态特征矩阵$Q$关联,该过程促进了全局与局部动态特征的交互。
In this work, the MTL framework employs the cascaded learning approach to accomplish three tasks: dynamic face
在这项工作中,MTL框架采用级联学习方法完成三项任务:动态人脸
Algorithm 1 ViT Decoder Algorithm
算法 1 ViT解码器算法
| Input: Y, F |
| Parameter:L |
| Output: Y |
| 1: Let l = 1. |
| 2: K, V = Norm(Dense(F)) |
| 3:whilel≤Ldo |
| 4: Q = Norm(Y) |
| 5: Z = MHA(Q, K, V) |
| Z'=Z+Y |
| 6: |
| 7: Y' = MLP(Norm(Z')) Y = Y' + Z' |
| 8: |
| 9:end while |
| 10:return Y |
| 输入: Y, F |
| 参数: L |
| 输出: Y |
| 1: 设 l = 1 |
| 2: K, V = Norm(Dense(F)) |
| 3: 当 l ≤ L 时执行 |
| 4: Q = Norm(Y) |
| 5: Z = MHA(Q, K, V) |
| Z' = Z + Y |
| 6: |
| 7: Y' = MLP(Norm(Z')) Y = Y' + Z' |
| 8: |
| 9: 结束循环 |
| 10: 返回 Y |
detection, dynamic face landmark, and DFER tasks. As illustrated in Fig. 2, each task is equipped with the Cascaded ViT Decoder module to explore the effectiveness of globallocal feature interaction across different related tasks. Based on this framework, we propose the following hypotheses for each task stage:
检测、动态面部关键点和动态面部表情识别 (DFER) 任务。如图 2 所示,每个任务都配备了级联 ViT 解码器模块,以探索全局-局部特征交互在不同相关任务中的有效性。基于此框架,我们针对每个任务阶段提出以下假设:
• First Task Stage (Dynamic Face Detection): The hypothesis is to identify the primary facial target features and eliminate non-target spatial noise from the feature dimensions. This stage focuses on filtering out irrelevant features to ensure the robustness of the following tasks. • Second Task Stage (Dynamic Face Landmark): The hypothesis is to locate critical facial landmarks, reducing interference from other facial features that are less relevant to the subsequent expression recognition task. • Third Task Stage (DFER): The hypothesis involves segmenting the expression feature information space based on both global dynamic features and key local facial features. The goal is to enhance expression recognition by combining fine-grained local information (such as the movements of specific facial landmarks) with over arching global context.
• 第一阶段任务(动态人脸检测):假设是识别主要面部目标特征,并从特征维度消除非目标空间噪声。该阶段专注于过滤无关特征,以确保后续任务的鲁棒性。
• 第二阶段任务(动态面部关键点定位):假设是定位关键面部标志点,减少与后续表情识别任务相关性较低的其他面部特征的干扰。
• 第三阶段任务(动态面部表情识别(DFER)):假设涉及基于全局动态特征和关键局部面部特征对表情特征信息空间进行分割。目标是通过结合细粒度局部信息(如特定面部标志点的运动)与整体全局上下文来增强表情识别。
In short, by incorporating the global-local feature interaction at each task level to strengthen the attention of finegrained local features, so that the information representation space is generalized.
简而言之,通过在每项任务层级融入全局-局部特征交互机制,强化对细粒度局部特征的注意力,从而使信息表征空间更具泛化性。
C. MTCAE-DFER: Model Structure
C. MTCAE-DFER: 模型结构
As shown in Fig. 2, the MTCAE-DFER model mainly consists of VideoMAE [19] encoder, Cascaded ViT Decoder(s) and Task-Specific Head(s). This model directly takes video as input, and its input size is $\mathbf{X}\in R^{16\times224\times22\bar{4}\times3}$ . As mentioned in Section III.A, the VideoMAE [19] encoder serves as the shared feature extractor for all tasks, which generates global dynamic features $\mathbf{F}\in R^{1568\times1024}$ . In addition, three face-related tasks are addressed using the multi-task cascaded learning approach, where three ViT Decoder modules with feature dimension of 512 are constructed to produce three different local dynamic feature outputs $\textbf{Y}\in{R}^{1568\times512}$ . Each ViT Decoder for these tasks uses $\mathbf{F}$ as the shared global feature input, which is fed into $K$ and $V$ to stand for global representation information. On the other hand, the local feature input $Q$ of each task is different. Except for the first dynamic face detection task, which uses $\mathbf{F}$ as local representation information. The other tasks use the ViT Decoder output $\mathbf{Y}$ of the previous task as local representation information. For example, Y1 serves as the local feature input for the second task, and Y2 serves as the local feature input for the third task as shown in Fig. 2. The mathematical expressions for the above process are as follows:
如图 2 所示,MTCAE-DFER 模型主要由 VideoMAE [19] 编码器、级联 ViT 解码器和任务特定头组成。该模型直接以视频作为输入,其输入尺寸为 $\mathbf{X}\in R^{16\times224\times22\bar{4}\times3}$。如第 III.A 节所述,VideoMAE [19] 编码器作为所有任务的共享特征提取器,生成全局动态特征 $\mathbf{F}\in R^{1568\times1024}$。此外,采用多任务级联学习方法处理三个面部相关任务,其中构建了三个特征维度为 512 的 ViT 解码器模块,以生成三个不同的局部动态特征输出 $\textbf{Y}\in{R}^{1568\times512}$。每个任务的 ViT 解码器将 $\mathbf{F}$ 作为共享全局特征输入,分别馈入 $K$ 和 $V$ 以表示全局表征信息。另一方面,各任务的局部特征输入 $Q$ 则不同。除首个动态人脸检测任务使用 $\mathbf{F}$ 作为局部表征信息外,其余任务均使用前一任务的 ViT 解码器输出 $\mathbf{Y}$ 作为局部表征信息。例如,Y1 作为第二个任务的局部特征输入,Y2 作为第三个任务的局部特征输入(如图 2 所示)。上述过程的数学表达式如下:
$$
\mathbf{Y1}={\mathrm{ViT~Decoder}}(\mathbf{F},\mathbf{F})
$$
$$
\mathbf{Y1}={\mathrm{ViT~解码器}}(\mathbf{F},\mathbf{F})
$$
$$
\begin{array}{r}{\mathbf{Y2}=\mathrm{ViT~Decoder}(\mathbf{Y1},\mathbf{F})}\ {{}}\ {\mathbf{Y3}=\mathrm{ViT~Decoder}(\mathbf{Y2},\mathbf{F})}\end{array}
$$
$$
\begin{array}{r}{\mathbf{Y2}=\mathrm{ViT~Decoder}(\mathbf{Y1},\mathbf{F})}\ {{}}\ {\mathbf{Y3}=\mathrm{ViT~Decoder}(\mathbf{Y2},\mathbf{F})}\end{array}
$$
Finally, the ViT Decoder output $\mathbf{Y}$ of each task is input to the corresponding Task-Specific Head. The Task-Specific Head includes Normalization layer, Pooling layer and Fully Connected layer. Y1 is input to the dynamic face detection Task-Specific Head to determine the position of the face in each video frame, represented by the bounding box $\textbf{B}\in$ $R^{16\times4}$ . Y2 is input to the dynamic face landmark TaskSpecific Head to obtain the five points $\mathbf{P}\in R^{16\times10}$ (left eye, right eye, nose, left mouth corner, and right mouth corner) in each video frame. Y3 is input to the DFER Task-Specific Head to calculate the probability of each facial expression ${\bf E}\in{\cal R}^{1\times7}$ (assuming there are 7 facial expression classes) in each video. The mathematical expressions for the above process are as follows:
最后,ViT解码器输出的每个任务的$\mathbf{Y}$被输入到相应的任务特定头部(Task-Specific Head)。任务特定头部包括归一化层(Normalization layer)、池化层(Pooling layer)和全连接层(Fully Connected layer)。Y1被输入到动态人脸检测任务特定头部,用于确定每帧视频中人脸的位置,由边界框$\textbf{B}\in$ $R^{16\times4}$表示。Y2被输入到动态人脸关键点任务特定头部,以获取每帧视频中的五个点$\mathbf{P}\in R^{16\times10}$(左眼、右眼、鼻子、左嘴角和右嘴角)。Y3被输入到动态面部表情识别(DFER)任务特定头部,用于计算每段视频中每个面部表情${\bf E}\in{\cal R}^{1\times7}$(假设有7种面部表情类别)的概率。上述过程的数学表达式如下:
$$
\mathbf{B}=\mathrm{FC}(\mathrm{Pool}(\mathrm{Norm}(\mathbf{Y1})))
$$
$$
\mathbf{B}=\mathrm{FC}(\mathrm{Pool}(\mathrm{Norm}(\mathbf{Y1}))
$$
$$
\mathbf{P}=\mathrm{FC}(\mathrm{Pool}(\mathrm{Norm}(\mathbf{Y2})))
$$
$$
\mathbf{P}=\mathrm{FC}(\mathrm{Pool}(\mathrm{Norm}(\mathbf{Y2})))
$$
$$
\mathbf{E}=\mathrm{FC}(\mathrm{Pool}(\mathrm{Norm}(\mathbf{Y3})))
$$
$$
\mathbf{E}=\mathrm{FC}(\mathrm{Pool}(\mathrm{Norm}(\mathbf{Y3})))
$$
IV. EXPERIMENTS
IV. 实验
A. Datasets
A. 数据集
- RAVDESS [23]: The Ryerson Audio-Visual Database of Emotional Speech and Song is a dataset composed of emotional performances by 24 North American professional actors, recorded in a laboratory environment with North American accent. The facial emotions described in this dataset include anger, disgust, fear, happiness, neutral, sadness, and surprise. Each emotion includes two intensity variations: normal and strong. In this work, we only use the visual dataset, which contains 1,440 video files. Among them, there are 288 videos for neutral emotions, and 192 videos for each of the other emotions. Our model evaluation is conducted using 5-fold cross-validation on subjects-independent of the emotion.
- RAVDESS [23]: 该数据集由24位北美专业演员在实验室环境下录制的情感表演组成,采用北美口音。数据集描述的面部情绪包括愤怒、厌恶、恐惧、快乐、中性、悲伤和惊讶。每种情绪包含两种强度变化:普通和强烈。本工作中仅使用视觉数据集,包含1,440个视频文件。其中中性情绪视频288个,其他每种情绪视频192个。我们采用与受试者无关的5折交叉验证进行模型评估。
- CREMA-D [24]: The Crowd-sourced Emotional Multimodal Actor Dataset contains emotional performances by 91 professional actors from around the world, representing various countries and ethnicities. These actors performed emotional expressions in the laboratory environment with different accents. Each actor displays six different emotions: anger, disgust, fear, happiness, neutral and sadness. In addition, each emotion was expressed at low, medium, high, and unspecified intensity levels during dialogues. The dataset has a total of 7,442 video clips, which 1,087 video clips depicting neutral emotions, and 1,271 video clips for each of the other emotions. The model evaluation adopts 5-fold cross-validation with subjects-independent of the emotion.
- CREMA-D [24]: 该众包情感多模态演员数据集收录了来自全球各地91位专业演员的情感表演,涵盖不同国家和种族。演员们在实验室环境中以不同口音演绎情感表达,每人呈现愤怒、厌恶、恐惧、快乐、中立和悲伤六种基本情绪。每种情绪还包含对话场景下的低、中、高及未指定强度等级。数据集共含7,442个视频片段,其中中立情绪视频1,087段,其余每种情绪各1,271段。模型评估采用5折交叉验证,且确保被试者与情感类别相互独立。
- MEAD [25]: The Multi-view Emotional Audio-visual Dataset is a video corpus of talking faces from 60 actors, who speak with eight different emotions (anger, disgust, contempt, fear, happiness, sadness, surprise, and neutral) at three different intensity levels (except neutral). The videos were recorded simultaneously from seven different angles under strictly controlled environment to capture high-quality facial expression details. According to the publicly available part of this dataset, we used data from 48 actors, comprising a total of 6,568 video clips. Among these, 380 clips depict neutral emotions, while each of the other emotions has 884 clips. The model evaluation still uses 5-fold cross-validation with subjects-independent of the emotion.
- MEAD [25]: 多视角情感视听数据集 (Multi-view Emotional Audio-visual Dataset) 是一个包含60名演员谈话面孔的视频语料库,这些演员以八种不同情绪(愤怒、厌恶、轻蔑、恐惧、快乐、悲伤、惊讶和中性)和三种不同强度水平(中性除外)进行表达。视频在严格受控环境下从七个不同角度同步录制,以捕捉高质量的面部表情细节。根据该数据集公开可用的部分,我们使用了48名演员的数据,共计6,568个视频片段。其中380个片段为中性情绪,其他每种情绪各有884个片段。模型评估仍采用与受试者情绪无关的5折交叉验证。
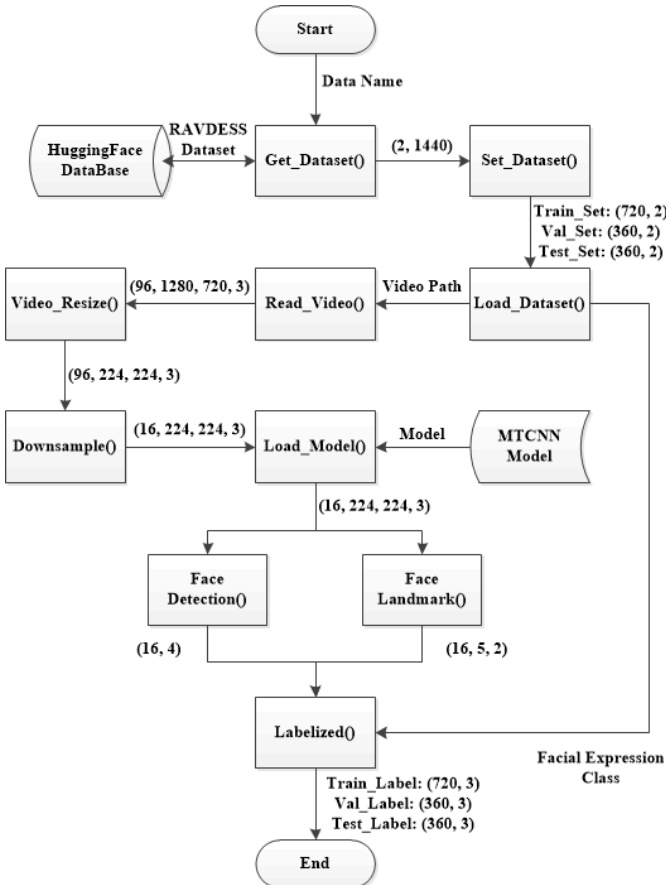
Fig. 3: Multi-Task Label Data Preprocessing Flow-Chart
图 3: 多任务标签数据预处理流程图
B. Implementation Details
B. 实现细节
- Preprocessing: In this study, our main preprocessing work is to perform multi-task labeling on various dataset. Since the various dataset used don’t include face position and face landmark labels, we employ the MTCNN [26] model to perform frame-level annotations on the video data, leveraging its face detection and landmark functions to collect multi-task data labels. Using the RAVDESS [23] dataset as an example, it consists of two sub-datasets: video path data and emotion label data. The video path data is input into the Read Video() function, allowing us to retrieve video information, especially the total number of frames, resolution, and the number of channels. To meet the input requirements of the VideoMAE [19] encoder model, we preprocess these video datasets by adjusting the resolution of each frame to $224\times224$ using the image scaling function.
- 预处理:在本研究中,我们的主要预处理工作是对各类数据集进行多任务标注。由于所用数据集未包含人脸位置和面部关键点标签,我们采用MTCNN [26]模型对视频数据进行帧级标注,利用其人脸检测和关键点功能收集多任务数据标签。以RAVDESS [23]数据集为例,它包含两个子数据集:视频路径数据和情感标签数据。视频路径数据被输入Read Video()函数,使我们能够获取视频信息,特别是总帧数、分辨率和通道数。为满足VideoMAE [19]编码器模型的输入要求,我们通过图像缩放函数将每帧分辨率调整为$224\times224$对这些视频数据集进行预处理。
Additionally, since the maximum input is 16 frames of video, we process the total frame count of the source videos using average down sampling to ensure that all videos have exactly 16 frames. Next, we load the MTCNN [26] model to perform face detection and face landmark on the pre processed videos $\begin{array}{r}{\textbf{X}\in_R^{16\times224\times224\times3}}\end{array}$ , obtaining frame-level face bounding box annotations $16\times4$ and 5- point annotations $16\times5\times2$ . Finally, we summarize and categorize the emotion label data to complete the multi-task labeling data preprocessing. The data preprocessing process is illustrated in Fig. 3.
此外,由于最大输入为16帧视频,我们对源视频的总帧数进行平均下采样处理,确保所有视频都恰好包含16帧。接着,我们加载MTCNN [26]模型对预处理后的视频 $\begin{array}{r}{\textbf{X}\in_R^{16\times224\times224\times3}}\end{array}$ 进行人脸检测和面部关键点定位,获得帧级人脸边界框标注 $16\times4$ 以及5点关键点标注 $16\times5\times2$。最后,我们对情感标签数据进行汇总分类,完成多任务标注数据的预处理。数据预处理流程如图3所示。
- Fine-tuning: After preprocessing the video dataset to obtain data that meets the input requirements of the VideoMAE [19] encoder, we use the pre-trained model based on the ViT-L [22] model from MAE-DFER [16]. As described in Section III.B, to enhance global-local feature interactions across tasks, the 5-layer, 3-head ViT Decoder cascaded module is configured for each task to associate global and local representation information. Additionally, MTL is employed to handle each task, particularly using task-specific heads equipped with Pooling layer and Fully Connected layer for fine-tuning on downstream tasks, as shown in Fig. 4.
- 微调 (Fine-tuning): 将视频数据集预处理为符合VideoMAE [19]编码器输入要求的数据后,我们采用基于MAE-DFER [16]中ViT-L [22]模型的预训练模型。如第III.B节所述,为增强跨任务的全局-局部特征交互,为每个任务配置了5层3头ViT解码器级联模块,用于关联全局与局部表征信息。同时采用多任务学习 (MTL) 处理各任务,特别是使用配备池化层 (Pooling layer) 和全连接层 (Fully Connected layer) 的任务专用头 (task-specific heads) 在下游任务上进行微调,如图4所示。
For fine-tuning, the AdamW [27] optimizer is used with the base learning rate of 1e-3 and the weight decay of 0.001. Mean squared error (MSE) is used as the loss function for dynamic face detection and landmark, with the loss weight of 0.5 for each task. Sparse Categorical Cross-Entropy is used as the loss function for DFER, with the loss weight of 1.5, and Accuracy is used as the training evaluation metric. The DFER evaluation metrics for the model include Unweighted Average Recall (UAR) and Weighted Average Recall (WAR). 3) Structure strategy: To demonstrate the effectiveness of the multi-task cascaded network in global-local feature interaction, we propose six structure strategies of the network framework to analyze various architectures from STL to MTL. The following structure strategies are extensions based on Fig. 1.
在微调过程中,我们采用AdamW [27]优化器,基础学习率为1e-3,权重衰减为0.001。动态人脸检测和关键点任务使用均方误差(MSE)作为损失函数,各任务损失权重为0.5。动态面部表情识别(DFER)采用稀疏分类交叉熵作为损失函数,损失权重为1.5,并以准确率(Accuracy)作为训练评估指标。模型DFER评估指标包括未加权平均召回率(UAR)和加权平均召回率(WAR)。3) 结构策略:为验证多任务级联网络在全局-局部特征交互中的有效性,我们提出六种网络框架结构策略,用于分析从单任务学习(STL)到多任务学习(MTL)的各种架构。以下结构策略均基于图1进行扩展。
• First Architecture: The STL network, consisting of the VideoMAE [19] encoder and the task-specific head with only Fully Connected layer. • Second and Third Architectures: Non-Fully Shared MTL networks, consisting of the VideoMAE [19] encoder and multiple task-specific decoders. In the second architecture, all task-specific decoders are MLP, while in the third architecture, all task-specific decoders are our proposed ViT Decoder.
• 第一种架构:STL网络,由VideoMAE [19]编码器和仅含全连接层的任务特定头部组成。
• 第二和第三种架构:非完全共享的MTL网络,由VideoMAE [19]编码器和多个任务特定解码器组成。第二种架构中,所有任务特定解码器均为MLP;第三种架构中,所有任务特定解码器均采用我们提出的ViT解码器。
• Fourth and Fifth Architectures: Fully Shared MTL networks, consisting of the VideoMAE [19] encoder, a single shared decoder, and multiple task-specific decoders. In the fourth architecture, both the shared decoder and task-specific decoders are MLP. In the fifth architecture, both the shared decoder and task-specific decoders are our proposed ViT Decoder. • Sixth Architecture: Our proposed multi-task cascaded network, which consists of the VideoMAE [19] encoder and multiple cascaded task-specific decoders, where the task-specific decoders are ViT Decoder.
- 第四和第五种架构:全共享多任务学习 (MTL) 网络,由 VideoMAE [19] 编码器、单个共享解码器和多个任务特定解码器组成。在第四种架构中,共享解码器和任务特定解码器均为 MLP。在第五种架构中,共享解码器和任务特定解码器均采用我们提出的 ViT 解码器。
- 第六种架构:我们提出的多任务级联网络,由 VideoMAE [19] 编码器和多个级联的任务特定解码器组成,其中任务特定解码器为 ViT 解码器。

Fig. 4: MTCAE-DFER Program Flow-Chart
图 4: MTCAE-DFER 程序流程图
TABLE I: Ablation study on the structure strategies. MTL: Multitask learning method or not. Decoder: MLP or ViT Decoder. UAR: unweighted average recall. WAR: weighted average recall. BOLD: The best results.
表 1: 结构策略消融研究。MTL: 是否采用多任务学习方法。Decoder: MLP或ViT解码器。UAR: 未加权平均召回率。WAR: 加权平均召回率。BOLD: 最佳结果。
| 数据集 | MTL | 类型 | 解码器 | UAR | WAR |
|---|---|---|---|---|---|
| RAVDESS [23] | × | 72.36 | 74.44 | ||
| Non-Fully Shared | MLP | 75.56 | 77.28 | ||
| Non-Fully Shared | ViTDecoder | 81.11 | 82.17 | ||
| Fully Shared | MLP | 75.95 | 76.84 | ||
| Fully Shared | ViTDecoder | 80.02 | 81.43 | ||
| Cascaded | ViTDecoder | 82.73 | 83.69 | ||
| CREMA-D [24] | × | 75.87 | 76.21 | ||
| Non-Fully Shared | MLP | 77.23 | 79.89 | ||
| Non-Fully Shared | ViTDecoder | 83.40 | 83.67 | ||
| √ | Fully Shared | MLP | 76.25 | 77.55 | |
| √ | Fully Shared | ViTDecoder | 81.64 | 82.38 | |
| √ | Cascaded | ViTDecoder | 84.71 | 85.03 | |
| MEAD [25] | × | 77.83 | 79.61 | ||
| Non-Fully Shared | MLP | 81.40 | 82.14 | ||
| √ | Non-Fully Shared | ViTDecoder | 84.75 | 86.57 | |
| √ | Fully Shared | MLP | 79.12 | 80.93 | |
| Fully Shared | ViTDecoder | 84.03 | 84.74 | ||
| √ | Cascaded | ViTDecoder | 87.51 | 88.44 |
C. Results
C. 结果
- Ablation Study: According to the structure strategy in Section IV.B, ablation experiments are conducted on STL and various MTL with different decoder types. We first start with the analysis of the RAVDESS [23] dataset. As shown in TABLE I, the ablation results of the six architectures show that compared to STL, the various MTL strategies improve WAR by at least $2.4%$ ( $76.84%$ vs. $74.44%$ ). Notably, the cascaded structure further improves WAR by $9.25%$ $83.69%$ vs. $74.44%$ . Furthermore, among the MTL strategies, archi tec ture s with the ViT Decoder module outperform those with MLP decoder. Specifically, the performance difference in WAR for the Non-Fully Shared type is $4.89%$ $(82.17%$ vs. $77.28%$ ), while the performance difference for the Fully Shared type is $4.59%$ $81.43%$ vs. $76.84%$ ) WAR. Finally, when employing the ViT Decoder module and further using the cascaded structure to handle tasks, WAR improves by $1.52%$ $(83.69%$ vs. $82.17%$ ) compared with the Non-Fully Shared with the ViT Decoder, and $2.26%$ ( $83.69%$ vs. $81.43%)$ WAR higher than the Fully Shared with the ViT Decoder.
- 消融研究:根据第IV.B节的结构策略,我们对STL和采用不同解码器类型的多种MTL进行了消融实验。首先从RAVDESS[23]数据集的分析开始。如表1所示,六种架构的消融结果表明,与STL相比,各类MTL策略将WAR至少提升了2.4%(76.84% vs. 74.44%)。值得注意的是,级联结构进一步将WAR提升了9.25%(83.69% vs. 74.44%)。此外,在MTL策略中,采用ViT解码器模块的架构表现优于MLP解码器。具体而言,非全共享类型的WAR性能差异为4.89%(82.17% vs. 77.28%),而全共享类型的性能差异为4.59%(81.43% vs. 76.84%)。最后,当采用ViT解码器模块并进一步使用级联结构处理任务时,与采用ViT解码器的非全共享结构相比,WAR提升了1.52%(83.69% vs. 82.17%),比采用ViT解码器的全共享结构高出2.26%(83.69% vs. 81.43%)。
Similarly, from the ablation experiment results for the CREMA-D [24] shown in TABLE I, it can be observed that the performance of MTL structure better than STL structure, with the increased by at least $1.34%$ ( $77.55%$ vs. $76.21%)$ in terms of WAR. The multi-task cascaded network further increases by $8.82%$ $85.03%$ vs. $76.21%$ WAR. Additionally, compared to the MTL with MLP decoder, the Non-Fully Shared MTL with ViT Decoder improves WAR performance by $3.78%$ $83.67%$ vs. $79.89%$ ), while the Fully Shared MTL with ViT Decoder improves performance by $4.83%$ $(82.38%$ vs. $77.55%$ ) WAR. More importantly, the cascaded MTL with ViT Decoder not only outperforms the NonFully Shared MTL with ViT Decoder by $1.36%$ ( $85.03%$ vs. $83.67%)$ WAR, but also exceeds the Fully Shared MTL with ViT Decoder by $2.65%$ ( $85.03%$ vs. $82.38%$ ) WAR.
同样,从表1所示的CREMA-D[24]消融实验结果可以看出,MTL结构的性能优于STL结构,在WAR指标上至少提升了1.34%(77.55% vs. 76.21%)。多任务级联网络进一步将WAR提升了8.82%(85.03% vs. 76.21%)。此外,与采用MLP解码器的MTL相比,采用ViT解码器的非全共享MTL将WAR性能提高了3.78%(83.67% vs. 79.89%),而采用ViT解码器的全共享MTL则提升了4.83%(82.38% vs. 77.55%)。更重要的是,采用ViT解码器的级联MTL不仅以1.36%(85.03% vs. 83.67%)的WAR优势超越了采用ViT解码器的非全共享MTL,还以2.65%(85.03% vs. 82.38%)的WAR优势超过了采用ViT解码器的全共享MTL。
Finally, as shown in TABLE I MEAD [25] ablation results, the MTL structure outperforms the STL structure, with the improved by at least $1.32%$ ( $80.93%$ vs. $79.61%$ ) in terms of WAR, while the multi-task cascaded network exceeds its by $8.83%$ $88.44%$ vs. $79.61%$ ) WAR. In the NonFully Shared MTL structure, the network with ViT Decoder achieves $4.43%$ $86.57%$ vs. $82.14%\$ ) WAR better than the one with MLP. In the Fully Shared MTL structure, the network with ViT Decoder outperforms the one with MLP by $3.81%$ $84.74%$ vs. $80.93%$ ) WAR. Moreover, the multi-task cascaded network significantly outperforms both the NonFully Shared MTL with ViT Decoder and the Fully Shared MTL with ViT Decoder, increasing WAR by $1.87%$ $88.44%$ vs. $86.57%$ ) and $3.70%$ $88.44%$ vs. ) respectively.
最后,如表 1 所示 MEAD [25] 消融实验结果,MTL (Multi-Task Learning) 结构优于 STL (Single-Task Learning) 结构,WAR (Weighted Average Recall) 指标至少提升 1.32% (80.93% vs. 79.61%),而多任务级联网络的 WAR 超出 STL 结构 8.83% (88.44% vs. 79.61%)。在非全共享 MTL 结构中,采用 ViT (Vision Transformer) Decoder 的网络比 MLP (Multilayer Perceptron) 网络 WAR 高 4.43% (86.57% vs. 82.14%)。在全共享 MTL 结构中,ViT Decoder 网络比 MLP 网络 WAR 高 3.81% (84.74% vs. 80.93%)。此外,多任务级联网络显著优于非全共享 MTL (ViT Decoder) 和全共享 MTL (ViT Decoder),WAR 分别提升 1.87% (88.44% vs. 86.57%) 和 3.70% (88.44% vs. )。
- Comparison with State-of-the-art Methods: We first compared MTCAE-DFER with other previous SOTA models on the RAVDESS [23]. As shown in TABLE II, the SOTA STL supervised model is 3D ResNeXt-50 [29], which has WAR performance difference of $20.70%$ $(83.69%$ vs. $62.99%$ with our MTCAE-DFER model. Compared to the SOTA STL self-supervised model, MTCAE-DFER outperforms the MAE-DFER [16] model by $8.13%$ $(83.69%$ vs. $75.56%$ ) in terms of WAR. Furthermore, our proposed MTCAE-DFER model achieves performance by $9.50%$ $(83.69%$ vs. $74.19%$ ) WAR over the SOTA MTL supervised model MTL-ER [31]. When compared to the SOTA MTL self-supervised model MTFormer [17], the MTCAE-DFER model increases WAR by $4.01%$ ( $83.69%$ vs. $79.68%$ ).
- 与最先进方法的对比: 我们首先在RAVDESS [23]数据集上将MTCAE-DFER与其他SOTA模型进行对比。如表II所示, SOTA单任务学习监督模型3D ResNeXt-50 [29]的加权准确率(WAR)比我们的MTCAE-DFER模型低20.70% (83.69% vs. 62.99%)。与SOTA单任务学习自监督模型相比, MTCAE-DFER在WAR指标上以8.13%的优势(83.69% vs. 75.56%)超越MAE-DFER [16]模型。此外, 我们提出的MTCAE-DFER模型在WAR指标上以9.50%的优势(83.69% vs. 74.19%)超越SOTA多任务学习监督模型MTL-ER [31]。与SOTA多任务学习自监督模型MTFormer [17]相比, MTCAE-DFER模型的WAR提升了4.01% (83.69% vs. 79.68%)。
The previous SOTA model results on CREMA-D [24] are presented in TABLE III. We observed that the MTCAEDFER model surpasses the 3D ResNeXt-50 [29] STL supervised model by $15.89%$ $85.03%$ vs. $69.14%$ ) in WAR. Compared to the STL self-supervised model MAE-DFER [16], it improves performance by $7.65%$ $85.03%$ vs. $77.38%)$ in terms of WAR. Additionally, in the field of MTL, the MTCAE-DFER model outperforms the MTL-ER [31] supervised learning model by $9.41%$ $85.03%$ vs. $75.62%$ ) WAR, while compared to the self-supervised learning model MTFormer [17], it achieves WAR performance increase of $4.29%$ ( $85.03%$ vs. $80.74%$ .
表 III 展示了CREMA-D [24]数据集上先前的最先进(SOTA)模型结果。我们观察到,MTCAEDFER模型在加权准确率(WAR)上以15.89%的优势超越3D ResNeXt-50 [29]单任务学习(STL)监督模型(85.03% vs. 69.14%)。与STL自监督模型MAE-DFER [16]相比,其WAR性能提升7.65%(85.03% vs. 77.38%)。此外在多任务学习(MTL)领域,MTCAE-DFER模型以9.41%的优势超越MTL-ER [31]监督学习模型(85.03% vs. 75.62%),同时相比自监督学习模型MTFormer [17],其WAR性能提升4.29%(85.03% vs. 80.74%)。
TABLE II: Comparison with state-of-the-art methods on RAVDESS (7-class). SSL: self-supervised learning method or not. MTL: Multi-task learning method or not. UAR: unweighted average recall. WAR: weighted average recall.
表 II: RAVDESS (7分类) 与前沿方法的对比。SSL: 是否采用自监督学习方法。MTL: 是否采用多任务学习方法。UAR: 未加权平均召回率。WAR: 加权平均召回率。
| 方法 | SSL | MTL | UAR | WAR |
|---|---|---|---|---|
| VO-LSTM[28] | × | 60.50 | ||
| 3D ResNeXt-50[29] | × | 62.99 | ||
| SVFAP [30] | √ | × | 75.15 | 75.01 |
| MAE-DFER [16] | 人 | 75.91 | 75.56 | |
| MNC [18] | 61.81 | 61.43 | ||
| MTL-ER [31] | × | 73.54 | 74.19 | |
| MTFormer [17] | 人 | 79.40 | 79.68 | |
| MTCAE-DFER (ours) | 82.73 | 83.69 |
TABLE III: Comparison with state-of-the-art methods on CREMAD (6-class). SSL: self-supervised learning method or not. MTL: Multi-task learning method or not. UAR: unweighted average recall. WAR: weighted average recall.
表 III: CREMAD (6类) 上现有最优方法的对比。SSL: 是否为自监督学习方法。MTL: 是否为多任务学习方法。UAR: 未加权平均召回率。WAR: 加权平均召回率。
| 方法 | SSL | MTL | UAR | WAR |
|---|---|---|---|---|
| VO-LSTM [28] | × | 66.80 | ||
| 3DResNeXt-50 [29] | × | × | ■ | 69.14 |
| SVFAP [30] | √ | × | 77.31 | 77.37 |
| MAE-DFER [16] | × | 77.33 | 77.38 | |
| MNC [18] | × | √ | 67.93 | 68.57 |
| MTL-ER [31] | 74.45 | 75.62 | ||
| MTFormer [17] | √ | 79.34 | 80.74 | |
| MTCAE-DFER (ours) | 84.71 | 85.03 |
TABLE IV: Comparison with state-of-the-art methods on MEAD (8-class). SSL: self-supervised learning method or not. MTL: Multitask learning method or not. UAR: unweighted average recall. WAR: weighted average recall.
表 IV: MEAD (8类) 上与其他先进方法的比较。SSL: 是否采用自监督学习方法。MTL: 是否采用多任务学习方法。UAR: 未加权平均召回率。WAR: 加权平均召回率。
| 方法 | SSL | MTL | UAR | WAR |
|---|---|---|---|---|
| VO-LSTM[28] | × | × | 68.87 | |
| 3D ResNeXt-50 [29] | × | × | 72.56 | |
| SVFAP [30] | × | 80.04 | 80.23 | |
| MAE-DFER [16] | 人 | 80.71 | 80.95 | |
| MNC [18] | 70.82 | 70.16 | ||
| MTL-ER [31] | × | 77.26 | 78.36 | |
| MTFormer [17] | √ | 人 | 84.03 | 84.74 |
| MTCAE-DFER (ours) | 87.51 | 88.44 |
In TABLE IV, we compare the results of the current SOTA models on the MEAD [25]. The results show that the MTCAE-DFER outperforms both the STL supervised model 3D ResNeXt-50 [29] and the STL self-supervised model MAE-DFER [16], increasing the WAR results by $15.88%$ $88.44%$ vs. $72.56%$ ) and $7.49%$ $88.44%$ vs. $80.95%$ , respectively. Moreover, compared with the MTL model results, the MTCAE-DFER model improves WAR by $10.08%$ $88.44%$ vs. $78.36%$ ) over the MTL-ER [31] supervised model, and outperforms the MTFormer [17] self-supervised model by $3.7%$ ( $88.44%$ vs. $84.74%)$ WAR.
在表 IV 中,我们比较了当前 SOTA 模型在 MEAD [25] 上的结果。结果表明,MTCAE-DFER 在 WAR 指标上均优于 STL 监督模型 3D ResNeXt-50 [29] 和 STL 自监督模型 MAE-DFER [16],分别提升了 $15.88%$ ( $88.44%$ vs. $72.56%$ ) 和 $7.49%$ ( $88.44%$ vs. $80.95%$ )。此外,与 MTL 模型相比,MTCAE-DFER 将 WAR 指标较监督模型 MTL-ER [31] 提升了 $10.08%$ ( $88.44%$ vs. $78.36%$ ),并较自监督模型 MTFormer [17] 提高了 $3.7%$ ( $88.44%$ vs. $84.74%$ )。
- Analysis and Reasoning: Based on the above results, whether in STL or MTL, the results of multi-task cascaded learning MTCAE-DFER consistently surpass the current SOTA models across all datasets. This demonstrates that the Cascaded ViT Decoder module plays a crucial role in handling the cascading relationship between related tasks, which highlights the necessity of global and local feature interaction.
- 分析与推理:基于上述结果,无论是STL还是MTL,多任务级联学习MTCAE-DFER在所有数据集上的表现均超越当前SOTA模型。这表明级联ViT解码器模块在处理相关任务间的级联关系时起到关键作用,凸显了全局与局部特征交互的必要性。
Considering different structure strategies, we observed in the ablation study that even when all using the ViT Decoder module, the performance of the MTL framework is inferior to the multi-task cascaded learning framework. This suggests that the cascaded network is effective in transmitting representational information between related tasks, while the cascaded approach strengthens the effectiveness of globallocal dynamic feature interaction to a certain extent. Moreover, all with the same shared VideoMAE encoder, there is a noticeable performance difference between STL and MTL, further indicating that the MTL framework enhances the model’s generalization ability.
在消融研究中,我们对比了不同结构策略,发现即使全部采用ViT解码器模块,多任务学习(MTL)框架性能仍逊于多任务级联学习框架。这表明级联网络能有效传递相关任务间的表征信息,同时级联方式在一定程度上强化了全局-局部动态特征交互的有效性。此外,在共享相同VideoMAE编码器的情况下,单任务学习(STL)与MTL存在显著性能差异,进一步证明MTL框架增强了模型的泛化能力。
Finally, in this work, utilizing the ViT Decoder module to cascade the three face-related tasks effectively explains that the local key features generated between related tasks guide the global dynamic features. This approach helps the main task focus on key features, while eliminating some redundant features.
最后,本工作利用ViT解码器模块级联三个面部相关任务,有效证明了相关任务间生成的局部关键特征能引导全局动态特征。该方法帮助主任务聚焦关键特征,同时消除部分冗余特征。
V. CONCLUSIONS AND FUTURE WORKS
V. 结论与未来工作
A. Conclusions
A. 结论
This work is the further exploration of auto encoder-based MTL structure on cascaded network. We constructed the ViT Decoder module to address the inter-task relationships, enhancing global-local feature interactions across related tasks. Based on this module, we propose a new multi-task cascaded learning framework to improve the accuracy of DFER task. This paper studies the performance of MTL network structure under the same module configuration (shared VideoMAE [19] encoder, and multiple task-specific decoders, either ViT Decoder or MLP). By exploring six different structure strategies, we examined the robustness of the multi-task cascaded network and the effectiveness of global-local dynamic feature interaction.
本研究进一步探索了基于自动编码器的多任务学习(MTL)结构在级联网络中的应用。我们构建了ViT解码器模块来解决任务间关系问题,增强相关任务间的全局-局部特征交互。基于该模块,我们提出了一种新的多任务级联学习框架,以提高动态面部表情识别(DFER)任务的准确性。本文研究了相同模块配置下(共享VideoMAE[19]编码器,多个任务专用解码器,包括ViT解码器或MLP)MTL网络结构的性能。通过探索六种不同结构策略,我们验证了多任务级联网络的鲁棒性以及全局-局部动态特征交互的有效性。
The results show that, whether ablation study or comparisons with SOTA model, the Cascaded ViT Decoder module enhances the generalization ability of the model in MTL networks. Moreover, this network architecture provides insight into the local dynamic feature generated from dynamic face detection and dynamic face landmark tasks, which helps identify key dynamic features necessary for DFER within the global representation information space.
结果表明,无论是消融研究还是与SOTA模型的比较,级联ViT解码器 (Cascaded ViT Decoder) 模块都提升了MTL网络中模型的泛化能力。此外,该网络架构揭示了动态人脸检测与动态人脸关键点任务生成的局部动态特征,有助于在全局表征信息空间中识别DFER所需的关键动态特征。
B. Future Works
B. 未来工作
In future work, this framework has a certain versatility and can be applied to various related tasks to strengthen globallocal feature interaction across tasks. Specifically, it could be combined with current emotion-based text generation tasks (video content description, video subject emotion inference, and video subject emotion description) to understand the emotional changes of the subject in the video, while better evaluate the model’s ability to extract dynamic features within video understanding.
在未来的工作中,该框架具有一定通用性,可应用于多种相关任务以加强跨任务的全局-局部特征交互。具体而言,可与当前基于情感的文本生成任务(视频内容描述、视频主体情感推断、视频主体情感描述)结合,理解视频中主体的情绪变化,同时更好地评估模型在视频理解中提取动态特征的能力。
On the other hand, this work can be extended to multimodal model by integrating a unified multi-modal feature encoder to process multi-modal information, thereby obtaining global multi-modal features. The multi-task cascaded network uses these features to further improve the accuracy of each task.
另一方面,这项工作可通过集成统一的多模态特征编码器处理多模态信息来扩展至多模态模型,从而获取全局多模态特征。多任务级联网络利用这些特征进一步提升各任务的准确性。
ETHICAL IMPACT STATEMENT
伦理影响声明
Since the results of this technology are derived from publicly available datasets and do not involve human subjects research, ethical review board (such as IRB) oversight was not sought for this technology. On the other hand, all public datasets used in this research were utilized only after obtaining authorization from the researchers of the original datasets.
由于该技术的结果来源于公开可用数据集且不涉及人类受试者研究,因此未寻求伦理审查委员会(如IRB)对该技术的监督。另一方面,本研究中使用的所有公共数据集均是在获得原始数据集研究人员的授权后才使用的。
In practical applications, this technology may pose a risk of privacy infringement related to facial features, as it collects and extracts human facial characteristics (potentially carrying the risk of leaking/identifying personal information) to analyze changes in human facial expressions in real-world scenarios. Consequently, the abuse, misuse, or misunderstanding of this technology could lead to the exposure of emotional information from facial expressions, potentially triggering social conflicts. Furthermore, using this technology to identify facial expressions for controlling others’ emotions could cause emotional distress or even lead to psychological disorders in the individuals being identified.
在实际应用中,该技术可能带来与面部特征相关的隐私侵权风险,因为它会收集并提取人类面部特征(可能携带泄露/识别个人信息的风险)以分析现实场景中人类面部表情的变化。因此,滥用、误用或误解该技术可能导致面部表情中情绪信息的暴露,进而可能引发社会冲突。此外,使用该技术识别面部表情以控制他人情绪,可能会对被识别者造成情绪困扰,甚至导致心理障碍。
To mitigate the aforementioned risks to some extent, we will strengthen the control of data, code, and models. For data and models, adhering to the principle of non-disclosure and non-sharing, they will only be stored on local area network computers, with encryption protection. Access to these files will be granted only to individuals who apply for access and have received authorization from the original dataset researchers. Regarding the code, certain modules will be made open-source, while access to the complete code will require a formal application, including a review of the reasons for its use, before authorization is granted.
为在一定程度上缓解上述风险,我们将加强对数据、代码和模型的控制。对于数据和模型,遵循不公开、不共享的原则,仅存储在局域网计算机上,并采取加密保护措施。只有申请访问权限并获得原始数据集研究者授权的人员才能接触这些文件。关于代码,部分模块将开源,而获取完整代码需提交正式申请,包括使用理由审查,通过后方可授权。
Through control strategies, we aim to mitigate the social impact caused by the recognition of facial features, preventing the abuse, misuse, or misunderstanding of this technology. This approach helps to some extent protect against the risk of exposing human emotional information and also restricts unrelated researchers from profiting by the use of this technology.
通过控制策略,我们旨在减轻面部特征识别带来的社会影响,防止该技术被滥用、误用或误解。这一方法在一定程度上有助于防范人类情感信息暴露的风险,同时也限制了无关研究人员利用该技术牟利。