Representation Learning and Identity Adversarial Training for Facial Behavior Understanding
Abstract
摘要
Facial Action Unit (AU) detection has gained significant attention as it enables the breakdown of complex facial expressions into individual muscle movements. In this paper, we revisit two fundamental factors in AU detection: diverse and large-scale data and subject identity regularization. Motivated by recent advances in foundation models, we highlight the importance of data and introduce Face9M, a diverse dataset comprising 9 million facial images from multiple public sources. Pre training a masked auto encoder on Face9M yields strong performance in AU detection and facial expression tasks. More importantly, we emphasize that the Identity Adversarial Training (IAT) has not been well explored in AU tasks. To fill this gap, we first show that subject identity in AU datasets creates shortcut learning for the model and leads to sub-optimal solutions to AU predictions. Secondly, we demonstrate that strong IAT regu lari z ation is necessary to learn identity-invariant features. Finally, we elucidate the design space of IAT and empirically show that IAT circumvents the identity-based shortcut learning and results in a better solution. Our proposed methods, Facial Masked Auto encoder (FMAE) and IAT, are simple, generic and effective. Remarkably, the proposed FMAE-IAT approach achieves new state-of-theart F1 scores on BP4D $(67.1%)$ , $B P4D+$ $(66.8%)$ , and DISFA $(70.1%)$ databases, significantly outperforming previous work. We release the code and model at https: //github.com/forever208/FMAE-IAT.
面部动作单元 (AU) 检测因其能将复杂面部表情分解为独立的肌肉运动而受到广泛关注。本文重新审视了AU检测中的两个关键因素:多样化的大规模数据和主体身份正则化。受基础模型 (foundation model) 近期进展的启发,我们强调了数据的重要性,并推出了Face9M数据集——该数据集整合了来自多个公开来源的900万张面部图像,具有高度多样性。在Face9M上预训练掩码自编码器 (masked auto encoder) 在AU检测和面部表情任务中展现出强劲性能。更重要的是,我们发现身份对抗训练 (Identity Adversarial Training, IAT) 在AU任务中尚未得到充分探索。为此我们首先论证了:AU数据集中的主体身份会导致模型陷入捷径学习 (shortcut learning),从而产生次优的AU预测方案;其次证明了强IAT正则化对学习身份无关特征的必要性;最后系统阐释了IAT的设计空间,并通过实验验证IAT能有效规避基于身份的捷径学习,获得更优解。我们提出的面部掩码自编码器 (Facial Masked Auto encoder, FMAE) 和IAT方法兼具简洁性、通用性和高效性。值得注意的是,FMAE-IAT在BP4D $(67.1%)$、BP4D+ $(66.8%)$ 和DISFA $(70.1%)$ 数据库上创造了新的最先进F1分数,显著超越前人工作。代码和模型已开源:https://github.com/forever208/FMAE-IAT。
1. Introduction
1. 引言
The Facial Action Coding System (FACS) was developed to objectively encode facial behavior through specific movements of facial muscles, named Action Units (AU) [19]. Compared with facial expression recognition (FER) [35, 37, 84] and valence and arousal estimation [51, 54, 85], detecting action units offers a more nuanced and detailed understanding of human facial behavior capturing multiple individual facial actions simultaneously.
面部动作编码系统 (Facial Action Coding System, FACS) 旨在通过面部肌肉的特定运动 (称为动作单元 (Action Unit, AU) [19]) 客观编码面部行为。与面部表情识别 (Facial Expression Recognition, FER) [35, 37, 84] 以及效价和唤醒度估计 [51, 54, 85] 相比,动作单元检测能同时捕捉多个独立面部动作,从而提供更细致、更详细的人类面部行为理解。
This problem attracted considerable interest within the deep learning community [13, 32, 56, 61, 72, 73]. Many works used a facial region prior [13, 39, 56], introduced extra modalities [69, 80, 81], or incorporated the inherent AU relationships [38, 46, 75] to solve the AU detection task and achieved significant advancements. Diverging from these approaches, which often necessitate complex model designs or depend heavily on prior AU knowledge, in this paper, we revisit two fundamental factors that significantly contribute to the AU detection task: diverse and large-scale data and subject identity regular iz ation.
该问题在深度学习领域引起了广泛关注 [13, 32, 56, 61, 72, 73]。许多研究通过引入面部区域先验 [13, 39, 56]、融合多模态信息 [69, 80, 81] 或利用动作单元 (AU) 固有关联性 [38, 46, 75] 来解决 AU 检测任务,并取得了显著进展。与这些通常需要复杂模型设计或高度依赖 AU 先验知识的方法不同,本文重新审视了影响 AU 检测任务的两个核心要素:多样化的大规模数据与主体身份正则化。
Recently, data has become pivotal in training foundation models [2, 42, 57, 64] and large language models [1, 8, 15, 65]. Following this trend, we introduce Face9M, a largescale and diverse facial dataset curated and refined from publicly available datasets for pre training. Different from contrastive learning methods [9, 13, 22], we propose to do facial representation learning using Masked Auto encoders (MAE) [27]. The underlying motivation is that most facial tasks require a fine-grained understanding of the face, and masked pre training results in lower-level semantics than contrastive learning according to [5]. Our large-scale facial representation learning approach demonstrates excellent generalization and s cal ability in downstream tasks. Notably, our proposed Facial Masked Auto encoder (FMAE), pretrained on Face9M, sets new state-of-the-art benchmarks in both AU detection and FER tasks.
近年来,数据已成为训练基础模型 [2, 42, 57, 64] 和大语言模型 [1, 8, 15, 65] 的关键要素。顺应这一趋势,我们推出了 Face9M——一个从公开数据集精心筛选并优化的大规模多样化人脸预训练数据集。不同于对比学习方法 [9, 13, 22],我们提出采用掩码自编码器 (MAE) [27] 进行人脸表征学习。其核心动机在于:根据 [5] 的研究,大多数人脸任务需要细粒度理解,而掩码预训练能产生比对比学习更底层的语义特征。我们的大规模人脸表征学习方法在下游任务中展现出卓越的泛化能力和可扩展性。值得注意的是,基于 Face9M 预训练的面部掩码自编码器 (FMAE) 在动作单元检测和面部表情识别任务中均创造了最新性能标杆。
Similar to the importance of data, domain knowledge and task-prior knowledge can be incorporated into the model in the form of regular iz ation [26, 31, 52, 55] to improve task performance. Our key observation is that popular AU detection benchmarks (i.e. BP4D [83], $\mathrm{BP4D+}$ [86], DISFA [50]) include at most 140 human subjects and 192,000 images, meaning that each subject has hundreds of annotated images. This abundance can lead models to prefer simple, easily recognizable patterns over more complex but general iz able ones, as suggested by the shortcut learning theory [23, 29]. Therefore, we hypothesize that AU detection models tend to learn the subject identity features to infer the AUs, resulting in learning a trivial solution that does not generalize well. To verify our hypothesis, we employed the linear probing technique — adding a learnable linear layer to a trained AU model while freezing the network backbone —to measure identity recognition accuracy. The high accuracy $(83%)$ we obtained in predicting the identities of the subjects clearly shows that the models effectively ‘memorize’ subject identities. To counteract the learning of identity-based features, we propose in this paper Identity Adversarial Training (IAT) for AU detection task by adding a linear identity prediction head and unlearning the identity feature using gradient reverse [20]. Further analysis shows that IAT significantly reduces the identity accuracy of linear probing and leads to better learning dynamics that avoid convergence to trivial solutions. This method further improves our AU models beyond the advantages brought by pre training with a large-scale dataset.
与数据的重要性类似,领域知识和任务先验知识可以通过正则化 [26, 31, 52, 55] 的形式融入模型,以提升任务性能。我们注意到主流动作单元(AU)检测基准数据集(如BP4D [83]、$\mathrm{BP4D+}$ [86]、DISFA [50])最多包含140名受试者和192,000张图像,意味着每位受试者拥有数百张标注图像。这种数据冗余可能导致模型倾向于学习简单易识别的模式,而非复杂但泛化性强的特征,正如捷径学习理论 [23, 29] 所指出的。因此我们假设:AU检测模型容易通过学习受试者身份特征来推断动作单元,从而陷入泛化性差的平凡解。为验证该假设,我们采用线性探测技术——在训练好的AU模型上添加可学习线性层同时冻结主干网络——来测量身份识别准确率。实验获得高达$(83%)$的受试者身份预测准确率,清晰表明模型确实"记忆"了身份特征。为抑制基于身份的特征学习,本文提出身份对抗训练(IAT),通过添加线性身份预测头并使用梯度反转 [20] 来消除身份特征。进一步分析表明,IAT显著降低了线性探测的身份准确率,形成了避免陷入平凡解的优化动态。该方法使AU模型的性能提升超越了大规模预训练带来的优势。
Although Zhang et al. [87] first introduced identitybased adversarial training to AU detection tasks, the identity learning issue and its negative effect (identity shortcut learning) have not been explored. Also, the design space of IAT lacks illustration in [87]. We revisit the identity adversarial training method in depth to answer these unexplored questions. In contrast to the weak identity regular iz ation used in [87], we demonstrate that AU detection requires a strong identity regular iz ation. To this end, the linear identity head and a large gradient reverse scaler are necessities for the AU detection task. Our proposed FMAE with IAT sets a new record of F1 score on BP4D $(67.1%)$ , $\mathrm{BP4D+}$ $(66.8%)$ and DISFA $(70.1%)$ datasets, substantially surpassing previous work.
尽管张等人[87]首次将基于身份的对抗训练引入AU检测任务,但身份学习问题及其负面影响(身份捷径学习)尚未得到探索。此外,[87]中未阐明IAT的设计空间。我们深入重新审视身份对抗训练方法,以解答这些未探索的问题。与[87]中使用的弱身份正则化不同,我们证明AU检测需要强身份正则化。为此,线性身份头和大梯度反转缩放器是AU检测任务的必需品。我们提出的结合IAT的FMAE在BP4D $(67.1%)$、$\mathrm{BP4D+}$ $(66.8%)$和DISFA $(70.1%)$数据集上创造了新的F1分数记录,大幅超越先前工作。
Overall, the main contributions of this paper are:
本文的主要贡献包括:
2. Related Work
2. 相关工作
2.1. Action Unit Detection
2.1. 动作单元检测
Recent works have proposed several deep learning-based approaches for facial action unit (AU) detection. Some of them have divided the face into multiple regions or patches [39, 56, 88] to learn AU-specific representations and some have explicitly modeled the relationships among AUs [38, 46, 75]. The most recent approaches have focused on detecting AUs using vision transformers on RGB images [32] and on multimodal data including RGB, depth images, and thermal images [81]. Yin et al. [77] have used generative models to extract representations and a pyramid CNN interpreter to detect AUs. Yang et al. [74] jointly modeled AU-centered features, AU co-occurrences, and AU dynamics. Contrastive learning has recently been adopted for AU detection [41, 60]. Particularly, Chang et al. [13] have adopted contrastive learning among AU-related regions and performed predictive training considering the relationships among AUs. Zhang et al. [80] have proposed a weaklysupervised text-driven contrastive approach using coarsegrained activity information to enhance feature representations. In addition to fully supervised approaches, Tang et al. [63] have implemented a semi-supervised approach with discrete feedback. However, none of these approaches have made use of large-scale self-supervised pre training.
近期研究提出了多种基于深度学习的面部动作单元(AU)检测方法。部分方法将人脸划分为多个区域或局部区块[39,56,88]来学习特定AU的表征,另一些则显式建模了AU间关联[38,46,75]。最新研究主要聚焦于使用视觉Transformer(ViT)处理RGB图像[32]以及融合RGB、深度图像和热成像的多模态数据[81]进行AU检测。Yin等人[77]采用生成式模型提取表征,并配合金字塔CNN解释器进行AU检测。Yang等人[74]联合建模了以AU为中心的特征、AU共现关系及AU动态变化。对比学习技术近期也被引入AU检测领域[41,60],其中Chang等人[13]在AU相关区域间实施对比学习,并通过考虑AU间关系进行预测训练。Zhang等人[80]提出基于粗粒度活动信息的弱监督文本驱动对比方法以增强特征表征。除全监督方法外,Tang等人[63]还开发了带有离散反馈的半监督方案。然而这些方法均未利用大规模自监督预训练技术。
2.2. Facial Representation Learning
2.2. 面部表征学习
Facial representation learning [9, 10, 89] has seen substantial progress with the advent of self-supervised learning [7, 12, 14, 27, 28]. For example, Mask Contrastive Face [68] combines mask image modeling with contrastive learning to do self-distillation, thereby enhancing facial represent ation quality. Similarly, ViC-MAE [30] integrates MAE with temporal contrastive learning to enhance video and image representations. MAE-face [47] uses MAE for facial pertaining by 2 million facial images. Additionally, Contra Warping [71] employs global transformations and local warping to generate positive and negative samples for facial representation learning. To learn good local facial representations, Gao et al. [22] explicitly enforce the consistency of facial regions by matching the local facial representations across views. Different from the above-mentioned work that mainly focuses on models, we emphasize the importance of data (diversity and quantity). Our collected datasets contain 9 million images from various public resources.
面部表征学习 [9, 10, 89] 随着自监督学习 [7, 12, 14, 27, 28] 的出现取得了显著进展。例如,Mask Contrastive Face [68] 将掩码图像建模与对比学习相结合进行自蒸馏,从而提升面部表征质量。类似地,ViC-MAE [30] 将 MAE 与时序对比学习结合以增强视频和图像表征能力。MAE-face [47] 利用 200 万张面部图像通过 MAE 进行面部预训练。此外,Contra Warping [71] 采用全局变换和局部形变技术生成正负样本用于面部表征学习。为获取优质局部面部表征,Gao 等人 [22] 通过跨视角匹配局部面部表征来显式加强面部区域一致性。与上述主要聚焦模型的研究不同,我们强调数据(多样性与数量)的重要性。我们收集的数据集包含来自各类公开资源的 900 万张图像。
2.3. Adversarial Training and Gradient Reverse
2.3. 对抗训练与梯度反转
Adversarial training [25] is a regular iz ation technique in deep learning to enhance the model’s robustness specifically against input perturbations that could lead to incorrect outputs. Although gradient reverse technique [20] aims to minimize domain discrepancy for better generalization across different data distributions, these two techniques share the same spirit of the ’Min-Max’ training paradigm and are used to improve the model robustness [21, 36, 48, 66]. Gradient reverse has also been used for the regular iz ation of fairness [58] or for meta-learning [4].
对抗训练 [25] 是深度学习中一种用于增强模型鲁棒性的正则化技术,专门针对可能导致错误输出的输入扰动。虽然梯度反转技术 [20] 旨在最小化域差异以实现跨不同数据分布的更好泛化能力,但这两种技术都体现了"最小-最大"训练范式的核心思想,并被用于提升模型鲁棒性 [21, 36, 48, 66]。梯度反转技术还被应用于公平性正则化 [58] 和元学习 [4]。
The most relevant research to our paper is [87], where the authors introduce identity-based adversarial training for the AU detection task. However, they did not thoroughly investigate the identity learning phenomenon and its detrimental impacts. Moreover, their empirical settings, the small gradient reverse scaler and the 2-layer MLP identity head, have been [87] verified as an inferior solution to AU detection. By contrast, we conduct a comprehensive examination for IAT to address these unexplored questions.
与我们论文最相关的研究是[87],作者在该研究中为AU检测任务引入了基于身份的对抗训练。然而,他们并未深入探究身份学习现象及其负面影响。此外,其实验设置(小梯度反转缩放器和2层MLP身份头)已被[87]证实为AU检测的次优方案。相比之下,我们通过全面研究IAT来解答这些尚未探索的问题。
3. Methods
3. 方法
3.1. Large-scale Facial MAE Pre training
3.1. 大规模面部MAE预训练
While the machine learning community has long established the importance of having rich and diverse data for training, recent successes in foundation models and large language models illustrated the full potential of pretaining [1, 8, 42, 57, 65]. In line with this, our research pivots to- wards a nuanced exploration of data diversity and quantification in the context of facial representation learning. Unlike natural image datasets like ImageNet-1k, face datasets have low variance. Also, we observe that different facial datasets have domain shifts regarding the facial area, perspective and background. To increase the data diversity, we propose to collect a large facial dataset for pertaining from multiple data sources.
尽管机器学习界早已认识到丰富多样数据对训练的重要性,但基础模型和大语言模型的最新成功展现了预训练 [1, 8, 42, 57, 65] 的完整潜力。与此一致,我们的研究转向在面部表征学习背景下对数据多样性和量化的细致探索。与ImageNet-1k等自然图像数据集不同,面部数据集的方差较低。此外,我们观察到不同面部数据集在面部区域、视角和背景方面存在域偏移。为了增加数据多样性,我们建议从多个数据源收集一个大型面部数据集用于预训练。
We first collect facial images from CelebA [44], FFHQ [33], VGGFace2 [11], CASIA-WebFace [76], MegaFace [34], EDFace-Celeb-1M [79], UMDFaces [6] and LAIONFace [89] datasets, because these datasets contain a massive number of identities collected in diverse scenarios. For instance, the facial images in UMDFaces also capture the upper body with various image sizes, while some datasets (FFHQ, CASIA-WebFace) mainly feature the center face. We then discard images whose width-height-ratio or heightwidth-ratio is larger than 1.5. Finally, the remaining images are resized to $224^{*}224$ . The whole process yields 9 million facial images (termed Face9M) which will be used for self-supervised facial pertaining.
我们首先从CelebA [44]、FFHQ [33]、VGGFace2 [11]、CASIA-WebFace [76]、MegaFace [34]、EDFace-Celeb-1M [79]、UMDFaces [6]和LAIONFace [89]数据集中收集面部图像,因为这些数据集包含大量在不同场景下采集的身份信息。例如,UMDFaces中的面部图像还捕捉了上半身,且图像尺寸各异,而某些数据集(如FFHQ、CASIA-WebFace)主要以中心面部为主。随后,我们丢弃宽高比或高宽比大于1.5的图像。最后,将剩余图像调整为$224^{*}224$尺寸。整个过程生成了900万张面部图像(称为Face9M),将用于自监督面部预训练。
Regarding representation learning methods, we apply Masked Image Modeling (MIM) [27] as it tends to learn more fine-grained features than contrastive learning according to the study in [5], which benefits facial behavior understanding. Specifically, we utilize Face9M to train a masked auto encoder (MAE) by the mean squared error between the reconstructed and original images in the pixel space. The resulting model is termed FMAE, and the decoder of FMAE is discarded for the downstream tasks.
关于表征学习方法,我们采用掩码图像建模 (Masked Image Modeling, MIM) [27],因为根据[5]的研究,它往往比对比学习能学到更细粒度的特征,这有利于面部行为理解。具体来说,我们利用Face9M训练一个掩码自编码器 (masked auto encoder, MAE),通过像素空间中重建图像与原始图像之间的均方误差。最终得到的模型称为FMAE,在下游任务中会丢弃FMAE的解码器。
3.2. Identity Adversarial Training
3.2. 身份对抗训练 (Identity Adversarial Training)
One of our key findings in this paper is that, the limited number of subjects in AU datasets makes identity recognition a trivial task and provides a shortcut learning path, resulting in a AU model that contains identity-related features and does not generalize well (see Section 5). Motivated by the gradient reverse in domain adaption [20], we propose to apply gradient reverse on AU detection to learn identityinvariant features, aiming at better model generalization.
我们在本文中的一个关键发现是,AU (Action Unit) 数据集中的受试者数量有限,使得身份识别成为一项简单任务,并提供了捷径学习路径,导致AU模型包含与身份相关的特征且泛化能力不佳(见第5节)。受领域自适应中梯度反转[20]的启发,我们提出在AU检测中应用梯度反转来学习身份不变特征,以提升模型的泛化能力。
Our model architecture is presented in Figure 1, where the backbone is a vision transformer and parameterized by $\theta_{f}$ , the AU head predicts the AUs and the ID head outputs the subject identities, respectively. The input image $\pmb{x}$ is first mapped by the backbone $G_{f}(\cdot;\theta_{f})$ to a D-dimensional feature vector $\pmb{f}\in\mathbb{R}^{D}$ , then the feature vector $f$ is fed into the AU head $G_{f}(\cdot;\theta_{a u})$ and the ID head $G_{f}(\cdot;\theta_{i d})$ . simultaneously. Assume that we have data samples $({\pmb x},{\pmb y},d)\sim D_{s}$ , parameters $\theta_{a u}$ of the AU head are optimized to minimize the AU loss $L_{a u}$ given AU label $y$ , and parameters $\theta_{i d}$ of the ID head are trained to minimize the identity loss $L_{i d}$ given the identity label $d$ .
我们的模型架构如图 1 所示,其主干网络是一个视觉 Transformer (Vision Transformer),由参数 $\theta_{f}$ 定义,AU 头部负责预测 AU,而 ID 头部则分别输出主体身份。输入图像 $\pmb{x}$ 首先通过主干网络 $G_{f}(\cdot;\theta_{f})$ 映射为一个 D 维特征向量 $\pmb{f}\in\mathbb{R}^{D}$,随后该特征向量 $f$ 被同时送入 AU 头部 $G_{f}(\cdot;\theta_{a u})$ 和 ID 头部 $G_{f}(\cdot;\theta_{i d})$。假设我们拥有数据样本 $({\pmb x},{\pmb y},d)\sim D_{s}$,AU 头部的参数 $\theta_{a u}$ 通过最小化给定 AU 标签 $y$ 的损失函数 $L_{a u}$ 进行优化,而 ID 头部的参数 $\theta_{i d}$ 则通过最小化给定身份标签 $d$ 的损失函数 $L_{i d}$ 进行训练。
To make the feature vector $f$ invariant to subject identity, we seek the parameters $\theta_{f}$ of the backbone that maximize the identity loss $L_{i d}$ (Equation 3), so that the backbone excludes the identity-based features. In the meantime, the backbone $G_{f}(\cdot;\theta_{f})$ is expected to minimize the AU loss $L_{a u}$ . Formally, we consider the following functional loss:
为了使特征向量 $f$ 不受主体身份影响,我们寻求使身份损失 $L_{id}$ (公式3) 最大化的主干网络参数 $\theta_{f}$,从而让主干网络排除基于身份的特征。与此同时,主干网络 $G_{f}(\cdot;\theta_{f})$ 需要最小化AU损失 $L_{au}$。形式上,我们考虑以下函数损失:
$$
\begin{array}{r}{L_{a u}=\mathbb{E}{(\pmb{x},y)\sim D_{s}}[C E(G_{y}(G_{f}(\pmb{x};\theta_{f});\theta_{a u}),y)]}\ {L_{i d}=\mathbb{E}{(\pmb{x},d)\sim D_{s}}[C E(G_{d}(G_{f}(\pmb{x};\theta_{f});\theta_{i d}),d)]}\end{array}
$$
$$
\begin{array}{r}{L_{a u}=\mathbb{E}{(\pmb{x},y)\sim D_{s}}[C E(G_{y}(G_{f}(\pmb{x};\theta_{f});\theta_{a u}),y)]}\ {L_{i d}=\mathbb{E}{(\pmb{x},d)\sim D_{s}}[C E(G_{d}(G_{f}(\pmb{x};\theta_{f});\theta_{i d}),d)]}\end{array}
$$
where $C E$ denotes the cross entropy loss function. We seek the parameters $\theta_{f}^{}$ $\gimel_{f}^{\ast},\theta_{a u}^{\ast},\theta_{i d}^{\ast}$ that deliver a solution: $(\theta_{f}^{},\theta_{a u}^{})=a r g_{\theta_{f},\theta_{a u}}^{\dot{m}i n}L_{a u}(D_{s};\theta_{f},\theta_{a u})-\lambda L_{i d}(D_{s};\theta_{f},\theta_{i d}^{*})$
其中 $CE$ 表示交叉熵损失函数。我们寻求参数 $\theta_{f}^{}$ $\gimel_{f}^{\ast},\theta_{a u}^{\ast},\theta_{i d}^{\ast}$ 以得到解:$(\theta_{f}^{},\theta_{a u}^{})=a r g_{\theta_{f},\theta_{a u}}^{\dot{m}i n}L_{a u}(D_{s};\theta_{f},\theta_{a u})-\lambda L_{i d}(D_{s};\theta_{f},\theta_{i d}^{*})$
$$
\theta_{i d}^{}=a r g\operatorname*{min}{\theta_{i d}}L_{i d}(D_{s};\theta_{f}^{*},\theta_{i d})
$$
$$
\theta_{i d}^{}=a r g\operatorname*{min}{\theta_{i d}}L_{i d}(D_{s};\theta_{f}^{*},\theta_{i d})
$$
where the parameter $\lambda$ controls the trade-off between the two objectives that shape the feature $f$ during learning. Comparing the identity loss $L_{i d}$ in Equation 3 and Equation 4, $\theta_{f}$ is optimized to maximize to increase $L_{i d}$ while $\theta_{i d}$ is learned to reduce $L_{i d}$ . To achieve these two opposite optimizations through regular gradient descent and backpropagation, the gradient reverse layer is designed to reverse the identity partial derivative ∂∂θLid before it is propagated to the backbone. The resultant derivative $-\lambda\frac{\partial L_{i d}}{\partial\theta_{f}}$ , together with ∂∂Lθau , are used to update the backbone parameter θf .
其中参数$\lambda$控制着在学习过程中塑造特征$f$的两个目标之间的权衡。对比式3与式4中的身份损失$L_{id}$,$\theta_f$被优化以最大化$L_{id}$,而$\theta_{id}$则被学习用于降低$L_{id}$。为实现这两个相反的优化目标,梯度反转层被设计用于在身份偏导数$\frac{\partial L_{id}}{\partial\theta}$传播至主干网络前将其反转。最终得到的导数$-\lambda\frac{\partial L_{id}}{\partial\theta_f}$将与$\frac{\partial L_{au}}{\partial\theta}$共同用于更新主干网络参数$\theta_f$。
Intuitively, the backbone is still optimized to learn the AU-related features, but under the force of reducing the identity-related features. The ‘Min-Max’ training paradigm in gradient reverse (see Equation 3) resembles the adversarial training [49] and Generative Adversarial Networks (GANs) [24], so we name our method ‘Identity Adversarial Training’ for the AU detection task.
直观上,主干网络仍被优化以学习AU相关特征,但受到抑制身份相关特征的作用力驱动。梯度反转中的"Min-Max"训练范式(见公式3)类似于对抗训练[49]和生成对抗网络(GANs)[24],因此我们将该方法命名为面向AU检测任务的"身份对抗训练"。
Importantly, we reveal the key design of identity adversarial training for AU detection: a strong adversarial regular iz ation (large magnitude of $-\lambda\frac{\partial{{L}{i d}}}{\partial{{\theta}_{f}}})$ is required to learn identity-invariant features for the backbone.
重要的是,我们揭示了身份对抗训练在AU检测中的关键设计:需要强对抗正则化(大幅度的$-\lambda\frac{\partial{{L}{i d}}}{\partial{{\theta}_{f}}}$)来学习主干网络的身份不变特征。
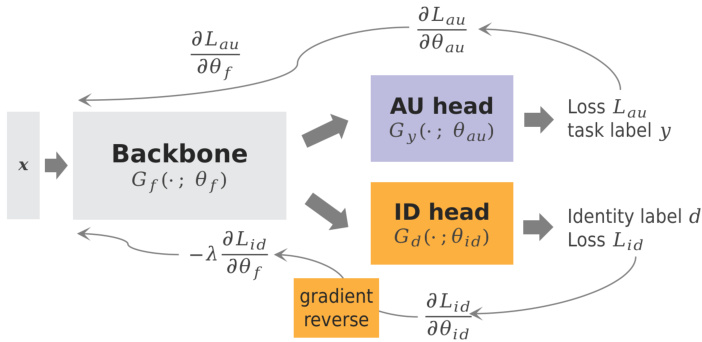
Figure 1. Architecture of Identity Adversarial Training. The AU head and ID head both are a linear classifier predicting the AUs and identity, respectively. The backbone $G_{f}(\cdot;\theta_{f})$ is the encoder of the pretrained FMAE. During training, the AU head is optimized by ∂∂Lθau and the ID head is optimized by ∂Lid . The gra∂θf dient reverse layer multiplies the gradient by a negative value $-\lambda$ to unlearn the features capable of recognizing identities. Finally, the parameters of the backbone are optimized by the two forces: $-\lambda\frac{\mathbf{\hat{\delta}}}{\partial\theta_{f}}$ ∂Lid and $\frac{\partial L_{a u}}{\partial\theta_{f}}$
图 1: 身份对抗训练架构。AU头部和ID头部均为线性分类器,分别用于预测AU和身份。主干网络 $G_{f}(\cdot;\theta_{f})$ 是预训练FMAE的编码器。训练过程中,AU头部通过 $\frac{\partial L_{au}}{\partial \theta_{au}}$ 优化,ID头部通过 $\frac{\partial L_{id}}{\partial \theta_{id}}$ 优化。梯度反转层将梯度乘以负值 $-\lambda$ 以消除可识别身份的特征。最终,主干网络参数由两种优化力共同调整:$-\lambda\frac{\partial L_{id}}{\partial \theta_{f}}$ 和 $\frac{\partial L_{au}}{\partial \theta_{f}}$
Specifically, we propose to use a large $\lambda$ and a linear projection layer for the ID head. The former scales up the ∂∂Lθid and the latter ensures a large Lid, leading to a large $\begin{array}{r}{||-\lambda\frac{\partial L_{i d}}{\partial\theta_{f}}||}\end{array}$ during training. In Section 5.3, we will show that the small and 2-layer MLP ID head used by [87] would lead to a weak identity regular iz ation (small magnitude of $-\lambda\frac{\partial L_{i d}}{\partial\theta_{f}})$ and inferior AU performance. We defer more details and analysis to Section 5.3
具体而言,我们建议使用较大的$\lambda$值并为ID头设计线性投影层。前者用于放大∂∂Lθid,后者确保较大的Lid,从而在训练过程中获得较大的$\begin{array}{r}{||-\lambda\frac{\partial L_{i d}}{\partial\theta_{f}}||}\end{array}$。在第5.3节中,我们将展示[87]所采用的小型2层MLP ID头会导致较弱的身份正则化(即$-\lambda\frac{\partial L_{i d}}{\partial\theta_{f}}$的幅值较小),进而影响AU性能表现。更多细节与分析详见第5.3节。
4. Experiments
4. 实验
We test the performance of FMAE and FMAE-IAT on AU benchmarks, using the F1 score. To illustrate the represent ation learning efficacy of FMAE, we also report its facial expression recognition (FER) accuracy on RAF-DB [59] and AffectNet [53] databases, and compare FMAE with previous face models pretrained based on contrastive learning.
我们在AU基准测试中使用F1分数评估FMAE和FMAE-IAT的性能。为展示FMAE的表征学习效果,我们还报告了其在RAF-DB [59]和AffectNet [53]数据库上的面部表情识别(FER)准确率,并将FMAE与基于对比学习预训练的先前人脸模型进行对比。
4.1. Datasets
4.1. 数据集
BP4D [83] is a manually annotated database of spontaneous behavior containing videos of 41 subjects. There are 8 activities designed to elicit various spontaneous emotional responses, resulting in 328 video clips. A total of 140,000 frames are annotated by expert FACS annotators. Following [39, 69, 80], we split all annotated frames into three subject-exclusive folds for 12 AUs.
BP4D [83] 是一个人工标注的自发行为数据库,包含41名受试者的视频。设计了8项活动以引发各种自发情绪反应,共产生328个视频片段。专家FACS标注员共标注了14万帧图像。参照[39, 69, 80]的方法,我们将所有标注帧按12个动作单元(AU)划分为三个受试者互斥的数据折。
$\mathbf{BP4D+}$ [86] is an extended dataset of BP4D and features 140 participants. For each subject, 20 seconds from 4 activities are manually annotated by FACS annotators, resulting in 192,000 labelled frames. We divide the subjects into four folds as per guidelines in [80, 82] and 12 AUs are used for
$\mathbf{BP4D+}$ [86] 是 BP4D 的扩展数据集,包含 140 名参与者。每位受试者的 4 项活动中各选取 20 秒片段,由 FACS 标注员手动标注,共生成 192,000 帧标记数据。我们按照 [80, 82] 的指导原则将受试者分为四折,并选用 12 个 AU 进行...
AU detection.
AU检测。
DISFA [50] contains left-view and right-view videos of 27 subjects. Similar to [73, 80], we use 8 of 12 AUs. We treat samples with AU intensities higher or equal to 2 as positive samples. The database contains 130,000 manually annotated images. Following [80] we perform subjectexclusive 3-fold cross-validation.
DISFA [50] 包含27名受试者的左视图和右视图视频。与 [73, 80] 类似,我们使用12个AU (Action Unit) 中的8个。将AU强度大于或等于2的样本视为正样本。该数据库包含130,000张人工标注的图像。按照 [80] 的方法,我们进行了受试者排他性3折交叉验证。
RAF-DB [59] contains 15,000 facial images with annotations for 7 basic expressions namely neutral, happiness, surprise, sadness, anger, disgust, and fear. Following the previous work [61, 80], we use 12,271 images for training and the remaining 3,068 for testing.
RAF-DB [59] 包含15,000张面部图像,标注了7种基本表情:中性、快乐、惊讶、悲伤、愤怒、厌恶和恐惧。遵循先前工作 [61, 80] 的设置,我们使用12,271张图像进行训练,其余3,068张用于测试。
AffectNet [53] is currently the largest FER dataset with annotations for 8 expressions (neutral, happy, angry, sad, fear, surprise, disgust, contempt). AffectNet-8 includes all expression images with 287,568 training samples and 4,000 testing samples. In practice, we only use 37,553 images (from Kaggle) for training as training on the whole training set is expensive.
AffectNet [53] 是目前最大的面部表情识别(FER)数据集,标注了8种表情(中性、快乐、愤怒、悲伤、恐惧、惊讶、厌恶、轻蔑)。AffectNet-8包含全部表情图像,其中训练样本287,568个,测试样本4,000个。实际应用中,我们仅使用37,553张图像(来自Kaggle)进行训练,因为在整个训练集上训练成本过高。
4.2. Implementation details
4.2. 实现细节
Regarding facial representation learning, we pretrain FMAE with Face9M for 50 epochs (including two warmup epochs) using four NVIDIA A100 GPUs. The remaining parameter settings follow [27] without any changes. After the pertaining, we finetune FMAE for FER tasks with crossentropy loss, and fine-tune FMAE and FMAE-IAT for AU detection with binary cross-entropy loss. In most cases, we finetune the model for 30 epochs with a batch size of 64 and a base learning rate of 0.0005. Following MAE [28], we use a weight decay of 0.05, Auto Augmentation [16] and Random Erasing 0.25 [90] for regular iz ation. By default, we apply ViT-large for FMAE and FMAE-IAT throughout this paper, if not specified otherwise. The complete code, hyper parameters and training/testing protocols are posted on our GitHub repository for reproducibility.
关于面部表征学习,我们使用4块NVIDIA A100 GPU在Face9M数据集上对FMAE进行了50轮预训练(包含2轮预热阶段),其余参数设置完全遵循[27]。预训练完成后,我们采用交叉熵损失对FMAE进行面部表情识别(FER)任务的微调,并使用二元交叉熵损失对FMAE及FMAE-IAT进行动作单元(AU)检测的微调。在大多数情况下,我们以64的批次大小和0.0005的基础学习率对模型进行30轮微调。参照MAE[28]的方法,我们采用0.05权重衰减、自动数据增强(Auto Augmentation)[16]和0.25随机擦除(Random Erasing)[90]作为正则化手段。如无特别说明,本文默认采用ViT-large架构实现FMAE和FMAE-IAT。完整代码、超参数及训练/测试方案已发布在GitHub仓库以确保可复现性。
4.3. Result of FMAE
4.3. FMAE 结果
We first show the F1 score of FMAE on the BP4D dataset in Table 1. FMAE achieves the same average F1 $(66.6%)$ with the state-of-the-art method MDHR [69] which utilizes a two-stage model to learn the hierarchical AU relationships. Here, we see the effectiveness of data-centric facial representation learning, and demonstrate that a simple vision transformer [18], which is the architecture of FMAE, is capable of learning complex AU relationships. FMAE surpasses all previous work on $\mathrm{BP4D+}$ and DISFA by achieving $66.2%$ and $68.7%$ F1 scores, respectively (see Table 2 and Table 3).
我们首先在表1中展示了FMAE在BP4D数据集上的F1分数。FMAE以$(66.6%)$的平均F1分数与当前最先进方法MDHR [69]持平,后者采用两阶段模型学习层次化AU关系。这表明以数据为中心的面部表征学习的有效性,并验证了FMAE采用的简单视觉Transformer [18]架构能够学习复杂AU关系。FMAE在$\mathrm{BP4D+}$和DISFA数据集上分别以$66.2%$和$68.7%$的F1分数超越所有先前工作(见表2和表3)。
To further verify the importance of the Face9M dataset, we compare FMAE pretrained on Face9M with FMAE pretrained on ImageNet-1k [17], using BP4D as the test set. Figure 2 shows that FMAE pretrained on Face9M always outperforms the one pretrained on ImageNet-1k given the same model size (ViT-base or ViT-large). Also, we empirically demonstrate that FMAE benefits from the scaling effect of model size on AU detection tasks (see the green line in Figure 2).
为了进一步验证Face9M数据集的重要性,我们将在Face9M上预训练的FMAE与在ImageNet-1k [17]上预训练的FMAE进行比较,使用BP4D作为测试集。图2显示,在相同模型规模(ViT-base或ViT-large)下,基于Face9M预训练的FMAE始终优于基于ImageNet-1k预训练的版本。此外,我们通过实验证明FMAE在AU检测任务中受益于模型规模的扩展效应(见图2中的绿色曲线)。
Table 1. F1 scores (in $%$ ) achieved for 12 AUs on BP4D dataset. The best and the second-best results of each column are indicated with bold font and underline, respectively.
表 1: BP4D数据集上12个AU的F1分数(单位: $%$)。每列最优和次优结果分别用粗体和下划线标出。
| 方法 | 会议 | AU | 1 | 2 | 4 | 6 | 7 | 10 | 12 | 14 | 15 | 17 | 23 | 24 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HMP-PS [62] | CVPR'21 | 53.1 | 46.1 | 56.0 | 76.5 | 76.9 | 82.1 | 86.4 | 64.8 | 51.5 | 63.0 | 49.9 | 54.5 | ||
| SEV-Net [73] | CVPR'21 | 58.2 | 50.4 | 58.3 | 81.9 | 73.9 | 87.8 | 87.5 | 61.6 | 52.6 | 62.2 | 44.6 | 47.6 | ||
| FAUT [32] | CVPR'21 | 51.7 | 49.3 | 61.0 | 77.8 | 79.5 | 82.9 | 86.3 | 67.6 | 51.9 | 63.0 | 43.7 | 56.3 | ||
| PIAP [63] | ICCV'21 | 55.0 | 50.3 | 51.2 | 80.0 | 79.7 | 84.7 | 90.1 | 65.6 | 51.4 | 63.8 | 50.5 | 50.9 | ||
| KSRL [13] | CVPR'22 | 53.3 | 47.4 | 56.2 | 79.4 | 80.7 | 85.1 | 89.0 | 67.4 | 55.9 | 61.9 | 48.5 | 49.0 | ||
| ANFL [46] | JCAI'22 | 52.7 | 44.3 | 60.9 | 79.9 | 80.1 | 85.3 | 89.2 | 69.4 | 55.4 | 64.4 | 49.8 | 55.1 | ||
| CLEF [80] | ICCV'23 | 55.8 | 46.8 | 63.3 | 79.5 | 77.6 | 83.6 | 87.8 | 67.3 | 55.2 | 63.5 | 53.0 | 57.8 | ||
| MCM [81] | WACV'24 | 54.4 | 48.5 | 60.6 | 79.1 | 77.0 | 84.0 | 89.1 | 61.7 | 59.3 | 64.7 | 53.0 | 60.5 | ||
| AUFormer[78] | ECCV'24 | - | - | - | |||||||||||
| MDHR [69] | CVPR'24 | 58.3 | 50.9 | 58.9 | 78.4 | 80.3 | 84.9 | 88.2 | 69.5 | 56.0 | 65.5 | 49.5 | 59.3 | ||
| FMAE | (ours) | 59.2 | 50.0 | 62.7 | 80.0 | 79.2 | 84.7 | 89.8 | 63.5 | 52.8 | 65.1 | 55.3 | 56.9 | ||
| FMAE-IAT | (ours) | 62.7 | 51.9 | 62.7 | 79.8 | 80.1 | 84.8 | 89.9 | 64.6 | 54.9 | 65.4 | 53.1 | 54.7 |
Table 2. F1 scores (in $%$ ) achieved for 12 AUs on $\mathrm{BP4D+}$ dataset. The best and the second-best results of each column are indicated with bold font and underline, respectively. $\mathrm{MFT^{*}}$ uses extra depth modality.
表 2: 在 $\mathrm{BP4D+}$ 数据集上 12 个 AU 的 F1 分数 (单位: $%$ )。每列最优和次优结果分别用粗体和下划线标出。 $\mathrm{MFT^{*}}$ 使用了额外的深度模态。
| 方法 | 会议 | AU1 | AU2 | AU4 | AU6 | AU7 | AU10 | AU12 | AU14 | AU15 | AU17 | AU23 | AU24 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ViT [18] | ICLR'21 | 45.6 | 38.2 | 35.5 | 85.9 | 88.3 | 90.3 | 89.0 | 81.9 | 45.8 | 48.8 | 57.2 | 34.6 | |
| CLIP [57] | ICML'21 | 49.4 | 39.7 | 38.9 | 85.7 | 87.6 | 90.6 | 89.0 | 80.6 | 44.9 | 50.3 | 56.1 | 32.8 | |
| SEV-Net [73] | CVPR'21 | 47.9 | 40.8 | 31.2 | 86.9 | 87.5 | 89.7 | 88.9 | 82.6 | 39.9 | 55.6 | 59.4 | 27.1 | |
| MFT [82] | FG'21 | 48.4 | 37.1 | 34.4 | 85.6 | 88.6 | 90.7 | 88.8 | 81.0 | 47.6 | 51.5 | 55.6 | 36.9 | |
| MFT* [82] | FG'21 | 49.6 | 42.0 | 43.5 | 85.8 | 88.6 | 90.6 | 89.7 | 80.8 | 49.8 | 52.2 | 59.1 | 38.4 | |
| CLEF [80] | ICCV'23 | 47.5 | 39.6 | 40.2 | 86.5 | 87.3 | 90.5 | 89.9 | 81.6 | 47.0 | 46.6 | 54.3 | 41.5 | |
| GLTE-Net [3] | Intelli'24 | 51.5 | 46.6 | 43.5 | 86.8 | 89.6 | 91.0 | 89.8 | 82.3 | 46.8 | 49.3 | 60.9 | 50.9 | |
| FMAE | (ours) | 53.9 | 45.5 | 45.9 | 86.2 | 88.3 | 91.2 | 89.9 | 82.3 | 51.3 | 56.3 | 60.7 | 42.7 | |
| FMAE-IAT | (ours) | 54.2 | 47.0 | 53.9 | 85.7 | 88.4 | 91.2 | 89.7 | 82.4 | 50.3 | 54.4 | 61.0 | 43.4 |
In addition to AU detection, we benchmark FMAE on the downstream facial task of FER to verify the effectiveness of masked image representation learning. We present the results of FMAE on AffectNet-8 and RAF-DB in Table 4 and compare FMAE with other contrastive learning-based models. FMAE sets a new state-of-art accuracy on both datasets $(64.79%$ on AffectNet-8 and $93.45%$ on RAF-DB). Note that, we did not test FMAE-IAT on FER tasks because these datasets do not include the identity labels and do not suffer from identity shortcut learning due to the large number of subjects.
除了AU检测外,我们还在FER(面部表情识别)下游任务上对FMAE进行基准测试,以验证掩码图像表征学习的有效性。我们在表4中展示了FMAE在AffectNet-8和RAF-DB上的结果,并将FMAE与其他基于对比学习的模型进行了比较。FMAE在这两个数据集上都创下了新的最先进准确率(AffectNet-8为64.79%,RAF-DB为93.45%)。需要注意的是,我们没有在FER任务上测试FMAE-IAT,因为这些数据集不包含身份标签,且由于受试者数量众多,不存在身份捷径学习问题。
4.4. Results of FMAE-IAT
4.4. FMAE-IAT 实验结果
Although FMAE has already achieved superior results on AU benchmarks, we highlight that the Identity Adversarial Training could further boost the performance of FMAE across all AU datasets. Specifically, we compare FMAEIAT with the most recent state of the art methods on BP4D, $\mathrm{BP4D+}$ and DISFA datasets. Table 1 suggests that FMAEIAT shows superior performance by achieving an average F1 Score of $67.1%$ and FMAE-IAT ranks as the best or second-best performer in several individual AUs, notably AU 1, 2, 4, 12, 17 and 23. Similarly, FMAE-IAT also stands out on $\mathrm{BP4D+}$ dataset with the highest average F1 score of $66.8%$ shown in Table 2. Our results on the DISFA benchmark given in Table 3 are even more distinguishing, FMAEIAT gains the best or the second-best performance on 6 out of 8 AUs, pushing the average F1 score beyond the $70%$ mark.
尽管FMAE在AU基准测试中已取得优异成果,但我们强调身份对抗训练(Identity Adversarial Training)能进一步提升FMAE在所有AU数据集上的表现。具体而言,我们将FMAEIAT与BP4D、$\mathrm{BP4D+}$和DISFA数据集上的最新先进方法进行对比。表1显示FMAEIAT以$67.1%$的平均F1分数展现出卓越性能,并在AU 1、2、4、12、17和23等多个单项AU中位列第一或第二。类似地,表2表明FMAE-IAT在$\mathrm{BP4D+}$数据集上以$66.8%$的最高平均F1分数脱颖而出。表3所示的DISFA基准测试结果更为显著,FMAEIAT在8个AU中的6个上获得最佳或次佳表现,将平均F1分数推升至$70%$以上。
For the gradient reverse layer, we use $\lambda=2.0$ for BP4D, $\lambda=1.0$ for $\mathrm{BP4D+}$ and $\lambda=0.5$ for DISFA. Differing from the setting $\lambda\in[0.008,0.08]$ used in [87], we emphasize that a strong IAT regular iz ation is necessary for AU tasks and we defer the in-depth discussion throughout Section 5.
对于梯度反转层,我们在BP4D中使用$\lambda=2.0$,在$\mathrm{BP4D+}$中使用$\lambda=1.0$,在DISFA中使用$\lambda=0.5$。与[87]中使用的$\lambda\in[0.008,0.08]$设置不同,我们强调AU任务需要强力的IAT正则化,具体讨论将在第5节展开。
Table 3. F1 scores (in $%$ ) achieved for 8 AUs on DISFA dataset. The best and the second-best results of each column are indicated with bold font and underline, respectively.
表 3: DISFA数据集上8个AU的F1分数(单位:$%$)。每列最优和第二优结果分别用粗体和下划线标出。
| 方法 | 会议 | AU 2 | AU 4 | AU 6 | AU 9 | AU 12 | AU 25 | AU 26 | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| FAUT [32] | CVPR'21 | 46.1 | 48.6 | 72.8 | 56.7 | 50.0 | 72.1 | 90.8 | 55.4 |
| PIAP [63] | ICCV'21 | 50.2 | 51.8 | 71.9 | 50.6 | 54.5 | 79.7 | 94.1 | 57.2 |
| ANFL [46] | IJCAI'22 | 54.6 | 47.1 | 72.9 | 54.0 | 55.7 | 76.7 | 91.1 | 53.0 |
| KSRL [13] | CVPR'22 | 60.4 | 59.2 | 67.5 | 52.7 | 51.5 | 76.1 | 91.3 | 57.7 |
| KS [40] | ICCV'23 | 53.8 | 59.9 | 69.2 | 54.2 | 50.8 | 75.8 | 92.2 | 46.8 |
| CLEF [80] | ICCV'23 | 64.3 | 61.8 | 68.4 | 49.0 | 55.2 | 72.9 | 89.9 | 57.0 |
| SACL [43] | TAC'23 | 62.0 | 65.7 | 74.5 | 53.2 | 43.1 | 76.9 | 95.6 | 53.1 |
| MDHR [69] | CVPR'24 | 65.4 | 60.2 | 75.2 | 50.2 | 52.4 | 74.3 | 93.7 | 58.2 |
| AUFormer[78] | ECCV'24 | - | - | ||||||
| GPT-4V [45] | CVPRW'24 | 52.6 | 56.4 | 82.9 | 64.3 | 55.3 | 75.4 | 91.2 | 66.4 |
| FMAE | (本工作) | 62.7 | 59.5 | 67.3 | 55.6 | 61.8 | 77.9 | 95.0 | 69.8 |
| FMAE-IAT | (本工作) | 64.7 | 61.3 | 70.8 | 58.1 | 59.4 | 79.9 | 95.2 | 71.3 |

Figure 2. F1 results of FMAE using different model sizes on 12 AUs of the BP4D. Models pretrained on Face9M are better than the ones pretrained on ImageNet-1k. MAE paper does not train ViT-small on ImageNet-1k, thus this entry is missing.
图 2: FMAE 在不同模型尺寸下对 BP4D 12 个 AU 的 F1 结果。基于 Face9M 预训练的模型优于 ImageNet-1k 预训练模型。MAE 论文未在 ImageNet-1k 上训练 ViT-small 模型,因此该项数据缺失。
Table 4. Results of accuracy on FER benchmarks. FMAE surpasses all previous contrastive-related work.
表 4: FER基准测试准确率结果。FMAE超越了所有先前的对比学习相关工作。
| 模型 | 对比式MIM | AffectNet-8 | RAF-DB |
|---|---|---|---|
| MCF [68] | √ | 60.98 | 86.86 |
| FaRL [89] | √ | 88.31 | |
| CLEF [80] | 62.77 | 90.09 | |
| FRA [22] | 90.76 | ||
| LA-Net [70] | 64.54 | 91.78 | |
| FMAE (本工作) | √ | 64.79 | 93.45 |
5. Analysis of Identity Adversarial Training
5. 身份对抗训练分析
In this section, we elucidate IAT by first showing the identity learning issue in AU tasks (Section 5.1), then demonstrating the learning dynamics refined by IAT (Section 5.2), and finally illustrating the importance of ensuring a strong regular iz ation of IAT (Section 5.3).
在本节中,我们首先阐明AU任务中的身份学习问题(第5.1节),接着展示通过IAT改进的学习动态(第5.2节),最后说明确保IAT强正则化的重要性(第5.3节)。
5.1. Linear probing for identity recognition
5.1. 线性探测用于身份识别
Motivated by the shortcut learning theory [23, 29], we hypothesize that each subject of AU datasets is exposed to the neural network hundreds of times in a single training epoch, which provides an identity shortcut for the model to learn the subject identity. This identity learning issue is undesired, as the model is supposed to generalize to unseen subjects.
受捷径学习理论 [23, 29] 启发,我们假设AU数据集的每个主体在单个训练周期内会向神经网络暴露数百次,这为模型学习主体身份提供了捷径。这种身份学习问题是不希望出现的,因为模型本应推广到未见过的个体。
To demonstrate identity learning in AU detection, we quantitatively and qualitatively evaluate the identity features via linear probing [14] and t-SNE [67] technique, respectively. In detail, we apply linear probing on a trained AU detection model (FMAE) and evaluate the identity recognition accuracy on the BP4D dataset, which contains 41 subjects with the identity labels. Specifically, we freeze the backbone $G_{f}(\cdot;\theta_{f})$ of a well-trained FMAE and add a learnable linear classifier on top of the backbone to predict the identity label. For each subject in BP4D, we randomly draw 70 samples for training and 30 samples for testing. The resultant accuracy under linear probing is shown in Figure 3, the red line indicates that FMAE can recognize more than half of people among the 41 subjects even though the model is only trained for one epoch. Given enough training, the identity recognition accuracy can be as high as $83%$ . By contrast, IAT significantly alleviates this identity learning issue with $4.6%$ accuracy after one epoch of training and $27.9%$ accuracy at epoch 19. An interesting phenomenon is that even under the strong identity unlearning regularization, FMAE-IAT seems still to partially learn the identitybased features, by showing $27.9%$ accuracy (higher than the random guess accuracy $2.4%$ ). We believe that the inherent high correlation between training and testing images for each subject provides the possibility for the model to infer the identity by looking at the non-face area.
为验证动作单元(AU)检测中的身份学习现象,我们分别通过线性探测[14]和t-SNE[67]技术对身份特征进行了定量与定性评估。具体而言,我们在训练好的AU检测模型(FMAE)上实施线性探测,并在包含41名标注身份受试者的BP4D数据集上评估身份识别准确率。具体操作是冻结训练好的FMAE主干网络$G_{f}(\cdot;\theta_{f})$,并在其顶部添加可学习的线性分类器来预测身份标签。对于BP4D中的每个受试者,我们随机选取70个样本训练和30个样本测试。线性探测结果如图3所示,红线显示FMAE仅训练一个周期(epoch)就能识别41名受试者中过半人员身份。经过充分训练后,身份识别准确率可达$83%$。相比之下,IAT方法显著缓解了身份学习问题——训练第一周期准确率仅$4.6%$,第19周期为$27.9%$。有趣的是,即使在强身份遗忘正则化约束下,FMAE-IAT仍表现出$27.9%$的准确率(高于随机猜测的$2.4%$),这表明模型仍部分学习了基于身份的特征。我们认为这是由于每个受试者的训练图像与测试图像存在固有高度相关性,使得模型有可能通过观察非面部区域推断身份。

Figure 3. Identity recognition accuracy $(%)$ evaluated by linear probing on the BP4D dataset. IAT greatly reduces the identityrelated features learned by the network backbone $G_{f}(\cdot;\theta_{f})$ .
图 3: 在 BP4D 数据集上通过线性探测评估的身份识别准确率 $(%)$ 。IAT 显著降低了网络主干 $G_{f}(\cdot;\theta_{f})$ 学习到的身份相关特征。
We also visualize the feature output from the backbone of FMAE and FMAE-IAT using t-SNE and see how these features are clustered according to the identity label. Figure 4 presents the t-SNE results for 20 subjects in BP4D (41 subjects in total), given trained FMAE and FMAE-IAT models. It is clear that the identity-based feature clusters in FMAE become less linearly distinguishable (the ID head is a linear layer) under the effect of IAT.
我们还使用t-SNE对FMAE和FMAE-IAT主干网络输出的特征进行了可视化,观察这些特征如何根据身份标签进行聚类。图4展示了在BP4D数据集中20名受试者(共41名)经过训练的FMAE和FMAE-IAT模型的t-SNE结果。可以明显看出,在IAT的作用下,FMAE中基于身份的特征聚类在线性可分性(身份识别头是一个线性层)方面有所降低。
5.2. IAT mitigates identity shortcut learning
5.2. IAT 缓解身份捷径学习问题
After showing that a regular AU model (FMAE) learns the subject identity, we now illustrate that the identity shortcut learning leads to a trivial AU prediction solution that is inferior to the solution delivered by IAT. Concretely, we observe that FMAE and FMAE-IAT have totally different learning dynamics in terms of AU predictions (indicated by F1 score). Figure 5 shows the F1 score of both models along the training epochs, where the two models share the same learning rate, batch size and initial training states. It is clear from Figure 5 that FMAE is optimized quickly and converges at the third epoch with an F1 score of $65.45%$ under the identity shortcut. In contrast, FMAE-IAT learns the AU decision boundary progressively and converges only at epoch 15 with an F1 score of $66.66%$ . One can infer that IAT explicitly pushes the backbone $G_{f}(\cdot;\theta_{f})$ away from the identity-related solution region and delivers a better so
在证明常规AU模型(FMAE)会学习主体身份后,我们现在说明这种身份捷径学习会导致一个劣于IAT解决方案的平凡AU预测方案。具体而言,我们观察到FMAE和FMAE-IAT在AU预测(F1分数衡量)方面具有完全不同的学习动态。图5展示了两模型在训练周期中的F1分数变化,两个模型采用相同学习率、批大小和初始训练状态。从图5可以明显看出,FMAE在身份捷径下快速优化,并在第3个周期以65.45%的F1分数收敛。相比之下,FMAE-IAT逐步学习AU决策边界,直到第15个周期才以66.66%的F1分数收敛。可以推断,IAT显式地将主干网络$G_{f}(\cdot;\theta_{f})$推离与身份相关的解区域,从而提供了更好的...

Figure 4. t-SNE visualization of the backbone features on BP4D dataset regarding the identity labels, each color stands for a subject. Only 20 subjects are visualized for readability even though BP4D contains 41 subjects. FMAE features are more identityclustered than FMAE-IAT features
图 4: BP4D数据集主干特征针对身份标签的t-SNE可视化,每种颜色代表一个受试者。为提升可读性仅展示20名受试者(实际BP4D包含41名)。FMAE特征比FMAE-IAT特征具有更强的身份聚集性
lution for AU detection tasks.
AU检测任务的解决方案。
5.3. Large is necessary
5.3. 较大的 是必要的
In Section 3.2, we have mentioned the key design space of IAT: a linear projection layer for the ID head and a large $\lambda$ for the gradient reverse layer. These two factors together ensure the large magnitude of $-\lambda\frac{\partial L_{i d}}{\partial\theta_{f}}$ λ ∂∂Lθid during the adversarial training of the backbone $G_{f}(\cdot;\theta_{f})$ . We elaborate here on the specifics of the IAT design space. We postulate that learning the subject identity is relatively easy, since there are many facial components and non-facial cues that can be used for identity recognition. Therefore, a strong regularization of IAT (i.e., a large $||-\lambda\frac{\partial L_{i d}}{\partial\theta_{f}}||)$ is required to counteract the identity-related learning tendency.
在3.2节中,我们提到了IAT (Identity-Adversarial Training) 的关键设计空间:用于ID头部的线性投影层和梯度反转层的大$\lambda$值。这两个因素共同确保了主干网络$G_{f}(\cdot;\theta_{f})$对抗训练期间$-\lambda\frac{\partial L_{i d}}{\partial\theta_{f}}$的大幅梯度。此处我们将详细阐述IAT设计空间的具体细节。我们认为学习主体身份相对容易,因为存在许多面部组件和非面部线索可用于身份识别。因此需要强正则化的IAT (即较大的$||-\lambda\frac{\partial L_{i d}}{\partial\theta_{f}}||)$来抵消与身份相关的学习倾向。
We first show the effect of using different $\lambda$ on the fold2 of the BP4D dataset. All models share the same training settings except for $\lambda$ . In Table 5, ‘Epoch’ indicates the training convergence point in terms of the F1 score and $\lambda=0$ represents the group without IAT. We see that a small $\lambda$ $(\lambda=0.02)$ , such as the one used in [87], has little gain of F1 score, whereas the large $\lambda$ $(\lambda=1,2,3)$ yields significant improvement of AU prediction. Moreover, the larger $\lambda$ we use, the more training epochs are required to reach a better optimization point, which is consistent with the phenomenon in Figure 5. Additionally, we perform the ablation study on $\lambda$ using the AU datasets to demonstrate that $\lambda$ is an easy hyper-parameter to tune in practice. Table 6 shows that $\lambda$ values within the set of [0.5, 1, 2], which are used across all AU datasets in this paper, consistently result in an improvement in the F1 score.
我们首先展示了不同$\lambda$值对BP4D数据集fold2的影响。所有模型除$\lambda$外共享相同的训练设置。在表5中,"Epoch"表示以F1分数衡量的训练收敛点,$\lambda=0$代表未使用IAT的对照组。我们发现较小的$\lambda$值$(\lambda=0.02)$(如[87]所用)对F1分数提升有限,而较大的$\lambda$值$(\lambda=1,2,3)$能显著改善AU预测性能。此外,$\lambda$值越大,达到更优训练点所需的epoch数越多,这与图5所示现象一致。我们还通过AU数据集对$\lambda$进行了消融实验,证明$\lambda$在实际应用中是一个易于调节的超参数。表6显示,本文所有AU数据集中使用的$\lambda$值集合[0.5, 1, 2]均能持续提升F1分数。

Figure 5. F1 dynamics of FMAE and FMAE-IAT on $\mathrm{BP4D+}$ during training. Fold-2 of $\mathrm{BP4D+}$ is used for visualization.
图 5: FMAE 和 FMAE-IAT 在 $\mathrm{BP4D+}$ 训练期间的 F1 动态变化。采用 $\mathrm{BP4D+}$ 的 Fold-2 进行可视化。
Table 5. The effect of different $\lambda$ on BP4D. F1 is reported on fold-2 of BP4D and Epoch means the convergence epoch during training.
表 5: 不同 $\lambda$ 对 BP4D 的影响。F1 值在 BP4D 的 fold-2 上报告,Epoch 表示训练过程中的收敛周期。
| λ | 0 | 0.02 (used in [87]) | 1 | 2 | 3 |
|---|---|---|---|---|---|
| F1 | 68.33 | 68.60 | 69.26 | 69.57 | 69.47 |
| Epoch | 2 | 10 | 20 | 21 | 27 |
Table 6. Ablation study of $\lambda$ on BP4D, $\mathrm{BP4D+}$ and DISFA. F1 scores are reported for one fold of each dataset, with the numbers in parentheses indicating the absolute improvement in F1 compared to the baseline $\lambda=0$ .
表 6: 在 BP4D、BP4D+ 和 DISFA 数据集上对 $\lambda$ 的消融研究。报告了每个数据集一个折叠的 F1 分数,括号中的数字表示与基线 $\lambda=0$ 相比 F1 的绝对提升。
| 数据集 | 0 | 0.5 | 1 | 2 |
|---|---|---|---|---|
| BP4D | 68.81 | 69.22 (+0.41) | 69.26 (+0.45) | 69.57 (+0.76) |
| BP4D+ | 65.45 | 66.58 (+1.13) | 66.66 (+1.21) | 66.62 (+1.17) |
| DISFA | 71.06 | 73.48 (+2.42) | 73.23 (+2.17) | 73.01 (+1.95) |
Furthermore, we show that recognizing identity is a trivial task since we find that a non-linear ID head $G_{f}(\cdot;\theta_{i d})$ can still recognize the subjects given the identity-invariant features (regularized by IAT). To investigate this in more detail, we increase the model capacity of the $\mathrm{ID}$ head $G_{f}(\cdot;\theta_{i d})$ given the backbone trained with a large $\lambda$ , and measure the identity loss. Table 7 shows the results of using different MLP layers for FMAE-IAT under the same regular iz ation strength $(\lambda=2)$ ). The ID loss in Table 7 suggests that the model gradually learns the identity given some model capacity. By contrast, using the 1-layer MLP (linear projection layer) for the ID head leads to a large ID loss $L_{i d}$ , thus ensuring the large magnitude of $-\lambda\frac{\partial{\cal L}{i d}}{\partial\theta_{f}}$ . Therefore the linear projection layer is another necessity for IAT in AU detection. The convergence epoch and F1 score in Table 7 also imply that the 2-layer MLP and 3-layer MLP both converge fast and learn a sub-optimal solution to the AU tasks, which is consistent with our previous observations.
此外,我们发现识别身份是一项简单任务,因为非线性ID头 $G_{f}(\cdot;\theta_{i d})$ 在给定身份不变特征(经IAT正则化)时仍能识别主体。为深入探究,我们在骨干网络使用较大 $\lambda$ 训练后,增加 $\mathrm{ID}$ 头 $G_{f}(\cdot;\theta_{i d})$ 的模型容量,并测量身份损失。表7展示了相同正则化强度 $(\lambda=2)$ 下FMAE-IAT采用不同MLP层数的结果。表7中的ID损失表明,模型在具备一定容量后会逐步学习身份特征。相比之下,使用单层MLP(线性投影层)作为ID头会导致较大的ID损失 $L_{i d}$ ,从而确保 $-\lambda\frac{\partial{\cal L}{i d}}{\partial\theta_{f}}$ 具有较大幅度。因此线性投影层是IAT应用于AU检测的另一必要组件。表7中的收敛轮次和F1分数还表明,2层MLP和3层MLP都能快速收敛并为AU任务学习到次优解,这与我们之前的观察结果一致。
Table 7. The effect of different MLPs for the ID head. Epoch in the table shows the convergence epoch during training and ID loss indicates the average identity loss at the convergence epoch using the training set. A higher ID loss implies a lower ID accuracy.
表 7: 不同MLP对ID头的影响。表中的Epoch表示训练过程中的收敛轮次,ID loss表示使用训练集在收敛轮次时的平均身份损失。ID loss越高意味着ID准确率越低。
| ID head | 1-layer MLP | 2-layers MLP (used in [87]) | 3-layers MLP |
|---|---|---|---|
| F1 | 69.57 | 69.00 | 68.90 |
| ID loss | 0.152 | 0.096 | 0.085 |
| Epoch | 21 | 7 | 6 |
6. Conclusion
6. 结论
In conclusion, we have proposed to use a masked autoencoder (FMAE) with diverse pre-training for the AU detection task in this paper. We have leveraged a vast and diverse dataset (Face9M) for pre training, combined with masked image modeling to significantly improve AU detection performance. Moreover, we have demonstrated the identity learning issue and its harmful effect on AU prediction models. The use of Identity Adversarial Training helped in mitigating the model’s learning of identityrelated features. Also, we elucidated the two design factors of IAT, and our experiments consistently demonstrated superior performance over previous methods, achieving new SOTA results on AU benchmarks like BP4D, $\mathrm{BP4D+}$ and DISFA.
综上所述,本文提出采用带多样化预训练的掩码自编码器(FMAE)进行动作单元(AU)检测任务。我们利用海量多样化数据集(Face9M)进行预训练,结合掩码图像建模技术显著提升了AU检测性能。此外,我们揭示了身份特征学习问题及其对AU预测模型的有害影响,采用身份对抗训练(IAT)有效抑制了模型对身份相关特征的学习。同时,我们阐明了IAT的两大设计要素,实验结果表明该方法在BP4D、$\mathrm{BP4D+}$和DISFA等AU基准测试中持续超越现有方法,创造了新的最先进(SOTA)性能。
We also noticed that the scaling effect of FMAE pretrained on Face9M has not converged even using the ViTlarge model. The potential of using ViT-huge and distilling it into a smaller model for practical use is promising, and we leave this for future work.
我们还注意到,即使在ViTlarge模型上,基于Face9M预训练的FMAE的扩展效应仍未收敛。使用ViT-huge并将其蒸馏为更小模型以投入实际应用的潜力巨大,我们将此留作未来工作。