GAP: A Graph-aware Language Model Framework for Knowledge Graph-to-Text Generation
GAP: 面向知识图谱到文本生成的图感知大语言模型框架
Abstract
摘要
Recent improvements in KG-to-text generation are due to additional auxiliary pre-training tasks designed to give the fine-tune task a boost in performance. These tasks require extensive computational resources while only suggesting marginal improvements. Here, we demonstrate that by fusing graph-aware elements into existing pre-trained language models, we are able to outperform state-of-theart models and close the gap imposed by additional pre-training tasks. We do so by proposing a mask structure to capture neighborhood information and a novel type encoder that adds a bias to the graph-attention weights depending on the connection type. Experiments on two KG-to-text benchmark datasets show our models are competitive while involving fewer parameters and no additional pre- training tasks. By formulating the problem as a framework, we can interchange the various proposed components and begin interpreting KG-to-text generative models based on the topological and type information found in a graph. We publically release our code 1.
知识图谱到文本生成 (KG-to-text generation) 领域的最新进展源于旨在提升微调任务性能的辅助预训练任务。这些任务需要大量计算资源,却只能带来有限的改进。本文证明,通过将图感知元素融入现有预训练语言模型,我们能够超越最先进模型,并缩小由额外预训练任务带来的差距。具体而言,我们提出了一种捕获邻域信息的掩码结构,以及一种新型类型编码器——该编码器会根据连接类型对图注意力权重添加偏置。在两个知识图谱到文本基准数据集上的实验表明,我们的模型在参数量更少且无需额外预训练任务的情况下仍具竞争力。通过将该问题构建为框架形式,我们可以互换各种提出的组件,并基于图中发现的拓扑和类型信息开始解释知识图谱到文本生成模型。我们已公开代码[1]。
1 Introduction
1 引言
Due to the amount of data stored in Knowledge Graphs (KGs) (Auer et al., 2007; VrandeCic and Krötzsch, 2014; Bollacker et al., 2008; Yates et al., 2007; Bodenreider, 2004; Wishart et al., 2018), they are important to properly transcribe into natural language sentences, making them more easily comprehensible to a larger audience. This task, termed KG-to-text, has found recent success in generating knowledge-grounded dialog responses (Wen et al., 2016; Zhou et al., 2018), ques- tion answering (He et al., 2017; Bhowmik and de Melo, 2018; Pal et al., 2019; Agarwal et al., 2021), story generation (Guan et al., 2019; Ji et al.,
由于知识图谱 (Knowledge Graphs, KGs) [Auer et al., 2007; VrandeCic and Krötzsch, 2014; Bollacker et al., 2008; Yates et al., 2007; Bodenreider, 2004; Wishart et al., 2018] 中存储的数据量庞大,将其准确转录为自然语言句子对于扩大受众理解范围至关重要。这项被称为"知识图谱到文本 (KG-to-text)"的任务,近年来在生成基于知识的对话响应 [Wen et al., 2016; Zhou et al., 2018]、问答系统 [He et al., 2017; Bhowmik and de Melo, 2018; Pal et al., 2019; Agarwal et al., 2021] 和故事生成 [Guan et al., 2019; Ji et al.,
Figure 1: Given a graph, KG-to-text generation aims to describe the entities, relations, and its inherent structure via natural language text (grey callout). Corresponding graph-text components are color-coded.
图 1: 给定一个图谱,知识图谱到文本生成 (KG-to-text generation) 的目标是通过自然语言文本(灰色标注框)描述实体、关系及其内在结构。对应的图谱-文本组件采用颜色编码。
The Great Debate, also called the Shapley - Curtis Debate, was held on 26 April 1920 at the National Museum of Natural History, between the astronomers Harlow Shapley and Heber Doust Curtis. The format of the Great Debate has been used subsequently to argue the nature of fundamental questions in astronomy.
大辩论 (The Great Debate) ,又称沙普利-柯蒂斯之争 (Shapley - Curtis Debate) ,于1920年4月26日在美国国家自然历史博物馆举行,天文学家哈洛·沙普利 (Harlow Shapley) 和希伯·道斯特·柯蒂斯 (Heber Doust Curtis) 参与论战。此后,这种大辩论形式被广泛用于探讨天文学领域的核心问题。
2020), and event narration (Colas et al., 2021). KGto-text involves encoding a KG, often sparse, in order to generate a coherent and representative textual description of the KG as shown in Figure 1. In contrast, Abstract Meaning Representation (AMR)- to-text deals with a more restrictive space, where graphs follow a predefined dense, connected template (Ribeiro et al., 2021; Koncel-Kedziorski et al., 2019). Thus, when encoding a KG, one should carefully consider the graph’s structure to properly generate its corresponding text.
2020年)和事件叙述(Colas等人, 2021年)。知识图谱到文本(KG-to-text)涉及对通常稀疏的知识图谱进行编码, 以生成如图1所示的连贯且具有代表性的知识图谱文本描述。相比之下, 抽象意义表示到文本(AMR-to-text)处理的是一个更具限制性的空间, 其中的图遵循预定义的密集连接模板(Ribeiro等人, 2021年; Koncel-Kedziorski等人, 2019年)。因此, 在对知识图谱进行编码时, 应仔细考虑图的结构以正确生成其对应的文本。
Recently, pre-trained language models (LMs) have produced state-of-the-art results on the KGto-text generation task (Ribeiro et al., 2020a; Chen et al., 2020). These models tend to first linearize a graph into a sequence of tokens, and fine-tune on pre-trained LMs such as BART (Lewis et al., 2020), GPT (Radford et al., 2019), or T5 (Raffel et al., 2020), treating the task similarly to a text-totext task. Because of the performance gains caused by the self-supervised pre-training tasks, current work on KG-to-text has focused on developing pretrained tasks and large-scale unlabeled graph-text corpora, replicating the success in the text-to-text domain (Chen et al., 2020; Ke et al., 2021). How- ever, these works particularly focus on leveraging large amounts of pre-trained data for graph-to-text specific pre-trained tasks, e.g., recovering a masked text sequence based on a given complete KG.
最近,预训练语言模型 (LM) 在知识图谱到文本生成 (KG-to-text) 任务中取得了最先进的结果 [20][5]。这些模型通常先将图结构线性化为token序列,再对BART [12]、GPT [19] 或T5 [18] 等预训练模型进行微调,将该任务视为文本到文本任务处理。由于自监督预训练任务带来的性能提升,当前KG-to-text研究主要集中在开发预训练任务和大规模无标注图-文本语料库,复现文本到文本领域的成功经验 [5][11]。然而,这些工作特别侧重于利用海量预训练数据来完成图到文本的特定预训练任务,例如基于给定完整知识图谱恢复被遮蔽的文本序列。
Although recent work in KG-to-text has begun to combine LMs with a graph-aware approach (Ke et al., 2021), they do not adequately perform a graph-aware encoding, overlooking the KG’s topological information. Similarly, recent work in AMR-to-text has begun to observe the role of graph adaptors in dense, highly parallel data, using a Graph Convolutional Network (GCN) (Ribeiro et al., 2021). Instead, our framework leverages a topological attention mechanism, better adhering to the language model paradigm and giving room for interpretation.
尽管近期知识图谱到文本(KG-to-text)的研究开始将大语言模型与图感知方法结合 [20],但这些方法未能充分实现图感知编码,忽略了知识图谱的拓扑信息。类似地,近期抽象语义表示到文本(AMR-to-text)的研究开始关注图适配器在密集高并行数据中的作用,采用了图卷积网络(GCN) [21]。相比之下,我们的框架利用拓扑注意力机制,更符合语言模型范式,并为解释留出空间。
We argue and show empirically that without additional pre-trained tasks, a fully graph-aware encoding combined with the coverage of pre-trained LMs such as BART (Lewis et al., 2020), can compete with and in some cases outperform those approaches which rely on additional pre-training. By doing so, we unload the burden of requiring vast amounts of data and computational resources required for pre-training.
我们认为并通过实证表明,在没有额外预训练任务的情况下,结合BART (Lewis et al., 2020)等预训练语言模型(LM)的覆盖范围,完全图感知编码可以与依赖额外预训练的方法竞争,在某些情况下甚至优于这些方法。通过这种方式,我们减轻了对大量数据和预训练所需计算资源的需求。
We propose $G A P$ , a KG-to-text framework which fuses graph-aware elements into existing pre-trained LMs, capturing the advantages brought forth by both model types. Our framework has two main components: (i) Global Attention: A graph’s components are first encoded using an LM to capture their global semantic information, allowing the model to utilize the lexical coverage of pre-trained LMs (Davison et al., 2019; Gururangan et al., 2020; Vulic et al., 2020). (i) Graph-aware Attention: Next, we devise a topological-aware graph attention mechanism, with entity/relation type encoding.
我们提出 $G A P$,一个将图感知元素融入现有预训练大语言模型的知识图谱到文本框架,兼具两类模型的优势。该框架包含两个核心组件:(i) 全局注意力:首先使用大语言模型编码图谱组件的全局语义信息,使模型能利用预训练大语言模型的词汇覆盖能力 (Davison et al., 2019; Gururangan et al., 2020; Vulic et al., 2020);(ii) 图感知注意力:设计了融合实体/关系类型编码的拓扑感知图注意力机制。
Our framework attends to and updates entity, relation, or both representations. By proposing such a framework, where graph-aware components can be interchanged, we can begin exploring explain able generative models for the KG-to-text task.
我们的框架关注并更新实体、关系或两者的表示。通过提出这样一个可互换图感知组件的框架,我们可以开始探索面向知识图谱到文本任务的可解释生成式模型。
We evaluate GAP on two publicly available KGto-text datasets: WebNLG v2.0 (Shimorina and Gardent, 2018) and Event Narrative (Colas et al., 2021), achieving state-of-the-art results on various natural language generation (NLG) metrics and demonstrate the value of our fully graph-aware based approach. Our contributions are as follows:
我们在两个公开可用的知识图谱到文本 (KG-to-text) 数据集上评估 GAP:WebNLG v2.0 (Shimorina and Gardent, 2018) 和 Event Narrative (Colas et al., 2021),在多种自然语言生成 (NLG) 指标上取得了最先进的结果,并证明了我们完全基于图感知的方法的价值。我们的贡献如下:
We make our code publically available to motivate future research.
我们公开代码以推动未来研究。
2 Related Work
2 相关工作
2.1 KG-to-Text with Graph Transformers
2.1 基于图Transformer的知识图谱到文本生成
Graph Neural Networks (GNNs) (Velickovic et al., 2018) have shown to be effective at encoding graph data. For the KG-to-text task, recent works have leveraged GNNs to encode a graph’s neighborhood information (Koncel-Kedziorski et al., 2019; March egg ian i and Perez-Beltr a chin i, 2018; Ribeiro et al., 2020b; Schmitt et al., 2021; Guo et al., 2019; Jin et al., 2020) before decoding its corresponding textual representation. Other work instead choose a more global approach and base their encoder on a Transformer-based architecture (Vaswani et al., 2017), calculating self-attention from all the nodes in a graph (Zhu et al., 2019; Cai and Lam, 2020; Ke et al., 2021). Like previous work, we encode neighborhood information in the Graph-aware Attention module. Recently, graph convolution-based adaptors have been explored for Abstract Meaning Representation-to-text (Ribeiro et al., 2021). Unlike previous work, GAP is a framework for KG-to-text, where the KG’s topology and masking scheme are not set. While there has been work examining the effect of encoding a node’s relative position (Shaw et al., 2018; Schmitt et al., 2021), we instead encode type, arguing that a KG’s textual description is weighted based on its different types of connections, and empirically show its effect on KG-to-text generation.
图神经网络 (Graph Neural Networks, GNNs) (Velickovic et al., 2018) 已被证明能有效编码图数据。在知识图谱到文本 (KG-to-text) 任务中,近期研究利用 GNN 编码图的邻域信息 (Koncel-Kedziorski et al., 2019; March egg ian i and Perez-Beltr a chin i, 2018; Ribeiro et al., 2020b; Schmitt et al., 2021; Guo et al., 2019; Jin et al., 2020) 后再解码为对应文本表示。另有研究采用全局方法,基于 Transformer 架构 (Vaswani et al., 2017) 设计编码器,计算图中所有节点的自注意力 (Zhu et al., 2019; Cai and Lam, 2020; Ke et al., 2021)。与前者类似,我们在图感知注意力 (Graph-aware Attention) 模块中编码邻域信息。近期,基于图卷积的适配器被用于抽象语义表示到文本的转换 (Ribeiro et al., 2021)。不同于前人工作,GAP 是一个面向拓扑结构和掩码方案未预设的知识图谱到文本生成框架。虽有研究探索节点相对位置编码的影响 (Shaw et al., 2018; Schmitt et al., 2021),但我们选择编码类型信息,认为知识图谱的文本描述应基于不同类型连接进行加权,并通过实验验证了该方法对文本生成的影响。
2.2 KG-to-Text with Pre-trained LM
2.2 基于预训练语言模型的知识图谱到文本生成
With the advent of pre-trained LMs such as BART (Lewis et al., 2020), T5 (Raffel et al., 2020), and GPT (Radford et al., 2019), these models have been directly adapted and fine-tuned for the KGto-text task and in some cases outperformed GNNbased models (Ribeiro et al., 2020a; Kale and Rastogi, 2020; Chen et al., 2020; Mager et al., 2020). While work has begun to explore combining such pre-trained models with transformer-based architectures which encode node information (Ke et al., 2021), they assume connectivity between all nodes and do not leverage updating relation information. Instead, here we propose a framework which combines pre-trained models with graph-aware encoders which are specifically neighborhood-based and dependent on a given graph’s topology.
随着BART (Lewis等人, 2020)、T5 (Raffel等人, 2020)和GPT (Radford等人, 2019)等预训练语言模型(LM)的出现,这些模型被直接适配并微调用于知识图谱到文本(KG-to-text)任务,在某些情况下甚至超越了基于图神经网络(GNN)的模型 (Ribeiro等人, 2020a; Kale和Rastogi, 2020; Chen等人, 2020; Mager等人, 2020)。虽然已有研究开始探索将此类预训练模型与基于Transformer的节点信息编码架构相结合 (Ke等人, 2021),但这些方法假设所有节点之间都存在连接,且未利用关系信息的更新机制。为此,我们提出了一种将预训练模型与图感知编码器相结合的框架,该编码器专门基于邻域信息并依赖于给定图谱的拓扑结构。
self-attention is formulated as:
自注意力机制的计算公式为:
$$
X_{l}=\mathrm{Attn}(Q,K,V)=\mathrm{softmax}\left(\frac{Q K^{\top}}{\sqrt{d_{k}}}\right)V\quad
$$
$$
X_{l}=\mathrm{Attn}(Q,K,V)=\mathrm{softmax}\left(\frac{Q K^{\top}}{\sqrt{d_{k}}}\right)V\quad
$$
Query, key, and value are computed via ${\cal Q} =~$ ${X_{l-1}\mathrm{\bar{W}}{l}^{Q},\mathrm{\bar{K}}}=X_{l-1}W_{l}^{K}$ , and $V=X_{l-1}W_{l-1}^{V}$ $X_{l-1}\in\mathbb{R}^{n\times d}$ denotes the collection of vectors corresponding to the graph’s tokens. The model’s parameters are denoted by $W$ with size $d_{k}\times d_{k}$ , where $d_{k}$ is the dimension of word vectors.
查询 (query)、键 (key) 和值 (value) 通过 ${\cal Q} =~$ ${X_{l-1}\mathrm{\bar{W}}{l}^{Q},\mathrm{\bar{K}}}=X_{l-1}W_{l}^{K}$ 和 $V=X_{l-1}W_{l-1}^{V}$ 计算得出。其中 $X_{l-1}\in\mathbb{R}^{n\times d}$ 表示图中 token 对应的向量集合,模型参数由大小为 $d_{k}\times d_{k}$ 的 $W$ 表示,$d_{k}$ 为词向量维度。
4.2 Graph Aware Attention
4.2 图感知注意力 (Graph Aware Attention)
While the Global Attention assumes connectivity between all graph components, KG adj ace nci es are sparse in nature. To capture this, we propose a Graph-aware Attention module, by first retrieving entity/relation vectors from the word vectors. Some entities or relations contain several words or repeat several times in the linearized graph. To get a single vector for each entity/relation, we add a pooling layer, which takes the average of the corresponding word vectors for each entity/relation. Hence, we get the graph representation matrix Xlg ∈ Rm×d:
全局注意力 (Global Attention) 假设所有图组件之间存在连接,而知识图谱 (KG) 的邻接关系本质上是稀疏的。为捕捉这一特性,我们提出图感知注意力 (Graph-aware Attention) 模块,首先从词向量中检索实体/关系向量。某些实体或关系在序列化图中包含多个单词或重复出现。为每个实体/关系获取单一向量,我们添加了池化层 (pooling layer),对每个实体/关系对应的词向量取平均值。由此得到图表示矩阵 Xlg ∈ Rm×d:
3 Problem Statement
3 问题陈述
We aim to generate texts that describe a given KG. We define a KG to be a multi-relational graph $\mathcal{G}=$ $(\nu,\mathcal{E})$ , where $\nu$ is the set of entity vertices and $\mathcal{E}\subset\mathcal{V}\times\mathcal{R}\times\mathcal{V}$ is the set of edges that connect entities with a relation from $\mathcal{R}$ .
我们的目标是生成描述给定知识图谱 (KG) 的文本。我们将知识图谱定义为多关系图 $\mathcal{G}=$ $(\nu,\mathcal{E})$,其中 $\nu$ 是实体顶点集合,$\mathcal{E}\subset\mathcal{V}\times\mathcal{R}\times\mathcal{V}$ 是通过关系 $\mathcal{R}$ 连接实体的边集合。
4 Proposed Framework
4 提出的框架
As our model is built on top of LMs such as BART, we first linearize the knowledge graph into a text string (Distiawan et al., 2018; Moryossef et al., 2019; Su et al., 2021). The linear iz ation is a sequence of all triples in the KG, interleaved with tokens that separate each triple and the triple’s components (head, relation, and tail). Figure 2 shows an example linear iz ation for a small knowledge graph, along with its labeled components.
由于我们的模型建立在BART等大语言模型之上,我们首先将知识图谱线性化为文本字符串 [Distiawan et al., 2018; Moryossef et al., 2019; Su et al., 2021]。这种线性化过程是将知识图谱中的所有三元组序列化,并通过特定token分隔每个三元组及其组成部分(头实体、关系和尾实体)。图2展示了一个小型知识图谱的线性化示例及其标注组件。
4.1 Global Attention
4.1 全局注意力
We then use a transformer encoder to contextualize the vector representations. The first module in each transformer layer is a self-attention over the linearized graph, which acts as a Global Attention and captures the semantic relationships between all tokens. The Global Attention can be initialized with a pre-trained LM. At the l-th layer, the
然后我们使用一个Transformer编码器对向量表示进行上下文建模。每个Transformer层的第一个模块是对线性化图的自注意力机制,它充当全局注意力(Global Attention)并捕获所有token之间的语义关系。全局注意力可以用预训练的大语言模型(LM)进行初始化。在第l层时,
$$
X_{l}^{g}=\mathrm{pooling}(X_{l})
$$
$$
X_{l}^{g}=\mathrm{pooling}(X_{l})
$$
Note, $m<n$ , where m and n denote the number of graph components and number of tokens, respectively. In practice and for parallel iz ation $m$ will be a fixed number larger than this sum for all graphs in the dataset, and the graph representation can be accessed via masking. We propose a novel graph-aware attention on the graph representation $X_{l}^{g}$ by introducing a neighborhood-based masking scheme and novel type encoder:
注意,$m<n$,其中m和n分别表示图组件数量和token数量。在实际应用和并行化处理中,$m$会设置为大于数据集中所有图组件数量之和的固定值,并通过掩码机制访问图表示。我们在图表示$X_{l}^{g}$上提出了一种新颖的图感知注意力机制,通过引入基于邻域的掩码方案和新型类型编码器实现:
$$
\begin{array}{r}{\tilde{X}{l}^{g}=\mathrm{Attn}{M,T}(Q,K,V)=}\ {\mathrm{softmax}\left(\displaystyle\frac{Q K^{\top}}{\sqrt{d_{k}}}+M+\gamma(T)\right)V.}\end{array}
$$
$$
\begin{array}{r}{\tilde{X}{l}^{g}=\mathrm{Attn}{M,T}(Q,K,V)=}\ {\mathrm{softmax}\left(\displaystyle\frac{Q K^{\top}}{\sqrt{d_{k}}}+M+\gamma(T)\right)V.}\end{array}
$$
Here $Q,K,V$ are constructed from $X_{l}^{g}$ by multiplying it with their corresponding learnable parameter $W$ . While $M\in\mathbb{R}^{m\times m}$ is a mask that encodes the desired graph structure, and $\gamma(T)\in\mathbb R^{m\times m}$ is the type encoding matrix. Note, each row of $\mathsf Q$ , K, and $\mathrm{V}$ correspond to an element from the graph (an entity or a relation), and before applying a softmax in each row of $Q K^{\top}$ , we can mask/modify the scores based on the graph topology. For instance, $M_{i j}=-\infty$ forces the item $i$ to not attend to item $j$ or the value at $\gamma(T)_{i j}$ can add a bias to the attention score based on the type of connection between items $i$ and $j$ . We exploit this capacity to inject graph-awareness by adding a masking matrix $M$ and type encoding matrix $\gamma(T)$ .
这里 $Q,K,V$ 是通过将 $X_{l}^{g}$ 与对应的可学习参数 $W$ 相乘构建而成。而 $M\in\mathbb{R}^{m\times m}$ 是编码所需图结构的掩码矩阵,$\gamma(T)\in\mathbb R^{m\times m}$ 是类型编码矩阵。注意,$\mathsf Q$、K 和 $\mathrm{V}$ 的每一行都对应图中的元素(实体或关系),在对 $Q K^{\top}$ 的每一行应用 softmax 之前,我们可以基于图拓扑对分数进行掩码/修改。例如,$M_{i j}=-\infty$ 会强制第 $i$ 项不关注第 $j$ 项,或者 $\gamma(T)_{i j}$ 处的值可以根据第 $i$ 项和第 $j$ 项之间的连接类型为注意力分数添加偏置。我们通过添加掩码矩阵 $M$ 和类型编码矩阵 $\gamma(T)$ 来利用这种能力注入图感知。
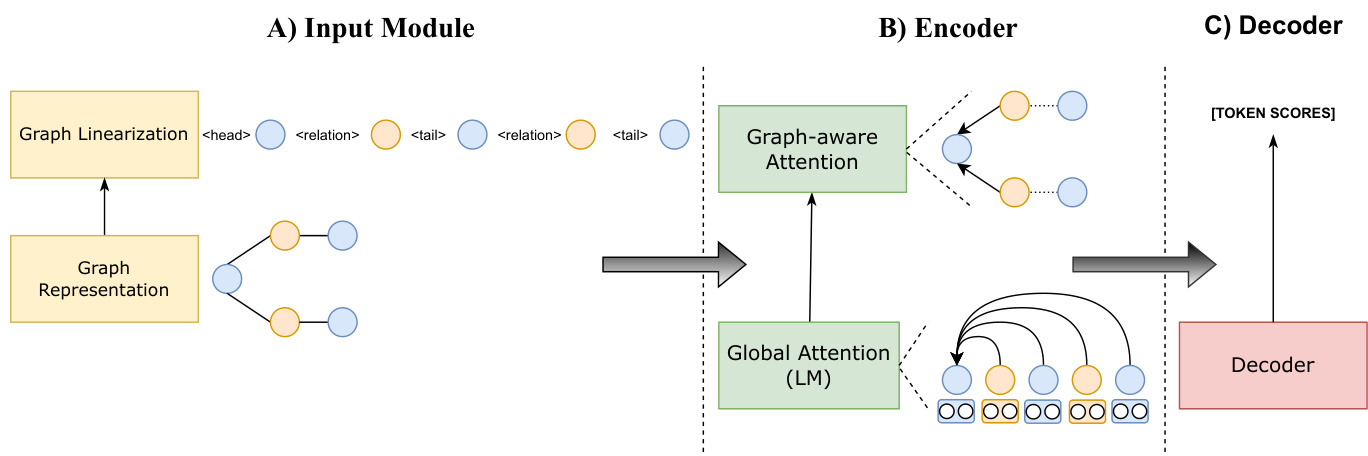
Figure 2: Overview of the Graph-aware framework for graph-to-text generation. Given a KG, we first transform the graph into its appropriate representation before linear i zing the graph. Next, each node of the KG is encoded via a global attention, followed by a graph-aware attention, ultimately being decoded into a sequence of tokens.
图 2: 面向图到文本生成的图感知框架概览。给定一个知识图谱(KG),我们首先将图转换为适当的表示形式,然后对图进行线性化处理。接着,通过全局注意力机制对KG的每个节点进行编码,再经过图感知注意力机制,最终解码为一系列Token。
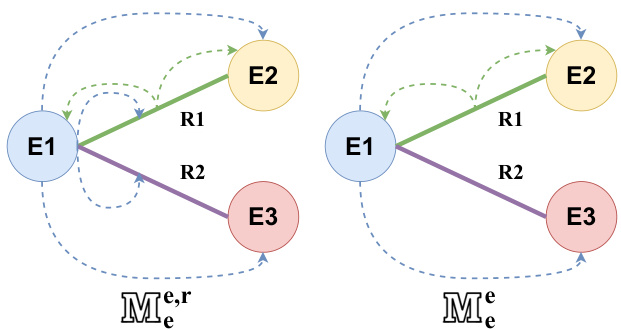
Figure 3: Two masking approaches. Left: $M_{e}^{e,r}$ mask, where E1 attends to its neighboring entities and relations, while R1 only attends to its neighboring entities. Right: $M_{e}^{e}$ mask, where E1 and R1 only attend to their neighboring entities.
图 3: 两种掩码方法。左图: $M_{e}^{e,r}$ 掩码,其中 E1 关注其相邻实体和关系,而 R1 仅关注其相邻实体。右图: $M_{e}^{e}$ 掩码,其中 E1 和 R1 仅关注其相邻实体。
4.2.1 Graph Topology Encoding
4.2.1 图拓扑编码
The proposed matrix $M\in\mathbb{R}^{m\times m}$ encodes the graph topology by assigning $-\infty$ where attention is blocked and 0 otherwise. $M$ can be thought of as a generalized adjacency matrix for graph $\mathcal{G}$ , which has both nodes and edges as its rows and columns. Hence, to encode neighborhood information for an entity, we can modify its corresponding row in $M$ to have the value 0 for its neighbors, and $-\infty$ otherwise. As the rows and columns of $M$ contain relations, we also have the capacity to let relations attend to their neighboring entity or relations.
所提出的矩阵 $M\in\mathbb{R}^{m\times m}$ 通过为被屏蔽的注意力位置分配 $-\infty$ 值(否则为0)来编码图拓扑结构。该矩阵可视为图 $\mathcal{G}$ 的广义邻接矩阵,其行和列同时包含节点和边。因此,为编码实体的邻域信息,我们可修改 $M$ 中对应行,使其邻居位置值为0,其余位置为 $-\infty$。由于 $M$ 的行列包含关系,我们还能让关系关注其相邻实体或其他关系。
From a graph topology perspective, we have several design choices for the matrix $M$ . We can let entities attend to neighboring entities, neighboring relations, or both. We also have these same options for when relations are playing the query role;
从图拓扑的角度来看,我们对矩阵$M$有几种设计选择。可以让实体关注相邻实体、相邻关系,或两者兼顾。当关系扮演查询角色时,我们同样面临这些选项。
that is, when choosing which components should relations attend to. For ease of reference and discussion, superscript denotes neighborhood types for entities, while subscript for relations, e.g. $M_{e,r}^{e,r}$ For instance, when entities attend to neighboring entities and relations, but relations only attend to entities, we denote the masking matrix by $M_{e}^{e,r}$ . Figure 3 illustrates two such matrices via a graph and its attending components.
即,在选择关系应关注哪些组件时。为便于参考和讨论,上标表示实体的邻域类型,下标表示关系的邻域类型,例如 $M_{e,r}^{e,r}$。举例来说,当实体关注相邻实体和关系,但关系仅关注实体时,我们用 $M_{e}^{e,r}$ 表示掩码矩阵。图 3 通过一个图及其关注组件展示了两个这样的矩阵。
4.2.2 Connection Type Encoding
4.2.2 连接类型编码
In contrast to $M$ which encodes the general graph topology, we also introduce a new type encoding $\boldsymbol{T}\in\mathbb{R}^{m\times m}$ , designed for biasing the attention values between the different graph components based on their connection type. For instance, when an entity $e$ is attending to its neighbor entities ${\boldsymbol{e}{i}}$ and relations ${r_{i}}$ , we encode the two connection types and bias their attention scores. Type information is stored in a matrix $T$ , and we then use an embedding lookup $\gamma:\mathbb{Z}\rightarrow\mathbb{R}$ to learn scalar embeddings for the types in $T$ .
与编码通用图拓扑结构的 $M$ 不同,我们还引入了一种新的类型编码 $\boldsymbol{T}\in\mathbb{R}^{m\times m}$,用于根据图组件的连接类型对它们之间的注意力值进行偏置。例如,当一个实体 $e$ 关注其邻居实体 ${\boldsymbol{e}{i}}$ 和关系 ${r_{i}}$ 时,我们会编码这两种连接类型并偏置它们的注意力分数。类型信息存储在一个矩阵 $T$ 中,然后我们使用嵌入查找 $\gamma:\mathbb{Z}\rightarrow\mathbb{R}$ 来学习 $T$ 中类型的标量嵌入。
We define type $T_{i j}$ between query $i$ and key $j$ based on two factors: (i) whether the two items are connected and (ii) the type of each item, i.e. whether the connection is entity–entity, entity– relation, relation–entity, or relation–relation:
我们基于两个因素定义查询 $i$ 和键 $j$ 之间的类型 $T_{ij}$:(i) 两个项是否相连;(ii) 每个项的类型,即连接是实体-实体、实体-关系、关系-实体还是关系-关系:
and 0 if there is no connection. The model then has the capacity to modify its attention scores based on the graph’s connection types. Intuitively, this capacity would allow us to interpolate between different choices of $M$ , or in the extreme case it can push model $M_{e,r}^{e,r}$ , to simulate any of the other more restrictive masks. For ease of reference, we explicitly state the type encoding whenever used.
若无连接则为0。该模型能够根据图的连接类型调整其注意力分数。直观上,这种能力使我们能够在不同$M$选择之间进行插值,或在极端情况下推动模型$M_{e,r}^{e,r}$模拟其他更具限制性的掩码。为便于参考,我们在使用时均明确标注类型编码。
Table 1: Statistics of the supervised KG-to-Text datasets used for experimenting.
表 1: 用于实验的有监督知识图谱到文本数据集的统计信息。
| 数据集 | 知识图谱-文本对数量 (训练集/验证集/测试集) |
|---|---|
| WebNLG | 34,352/4,316/4,224 |
| EventNarrative | 179,543/1,000/22,441 |
Finally, after producing the new graph representation ${\tilde{X}}{l}^{g}$ with equation (3), we gather the word representations from the graph representation, adding the new representations as a residual to $X_{l}$ , and generate the output from the $l$ -th layer:
最终,在通过方程(3)生成新的图表示${\tilde{X}}{l}^{g}$后,我们从图表示中收集词表征,并将新表征作为残差添加到$X_{l}$中,从而生成第$l$层的输出:
$$
\tilde{X}{l}=\mathrm{gather}(\tilde{X}{l}^{g})+X_{l}
$$
$$
\tilde{X}{l}=\mathrm{gather}(\tilde{X}{l}^{g})+X_{l}
$$
5 Experiments
5 实验
5.1 Datasets
5.1 数据集
We experiment on two KG-to-text supervised datasets: WebNLG v2.0 (Gardent et al., 2017; Shimorina and Gardent, 2018) and Event Narrative (Colas et al., 2021). We experiment with different con- fig u rations on the graph representation, attention mask, and type encoding on the WebNLG dataset, taking the best performing models to experiment further on Event Narrative. This is because of computational constraints caused by the size of EventNarrative. Table 1 outlines the statistical differences between the two datasets. We use the official data split for both.
我们在两个知识图谱到文本的监督数据集上进行实验:WebNLG v2.0 (Gardent et al., 2017; Shimorina and Gardent, 2018) 和 Event Narrative (Colas et al., 2021)。由于EventNarrative数据规模导致的算力限制,我们先在WebNLG数据集上测试图表示、注意力掩码和类型编码的不同配置方案,再将最优模型迁移至Event Narrative进行实验。表1列出了两个数据集的统计差异,实验均采用官方划分的数据集。
WebNLG is a crowd-sourced RDF triple-to-text dataset manually crafted by human annotators. The dataset contains graphs from DBpedia (Auer et al., 2007) with up to 7 triples paired with one or more reference texts. As in Chen et al. (2020) and Ke et al. (2021), we evaluate on the 2.0 release 2.
WebNLG是一个由人工标注者手动构建的众包RDF三元组到文本的数据集。该数据集包含来自DBpedia (Auer等人,2007)的图谱,每个图谱最多包含7个三元组,并配有一个或多个参考文本。按照Chen等人 (2020) 和Ke等人 (2021) 的做法,我们在2.0版本上进行评估。
Event Narrative is an automatically generated large-scale event-centric KG-to-text supervised dataset. Event KGs are extracted from Wikidata (Vrandecic and Krotzsch, 2014) and EventKG (Gottschalk and Demidova, 2018), which are then matched to Wikipedia sentences. EventNarrative contains a larger number of unique KG components compared to WebNLG.
事件叙事 (Event Narrative) 是一个自动生成的大规模以事件为中心的知识图谱到文本的监督数据集。事件知识图谱从 Wikidata (Vrandecic and Krotzsch, 2014) 和 EventKG (Gottschalk and Demidova, 2018) 中提取,然后与维基百科句子进行匹配。与 WebNLG 相比,EventNarrative 包含了更多独特的知识图谱组件。
5.2 Implementation and training details
5.2 实现与训练细节
We chose to use BART as our pre-trained LM (Lewis et al., 2020), and initialize its respective parameters with the Hugging Face’s pre-trained bart-base checkpoint 3. We left the default hyperparameters on the Global Attention module (BART) due to limited computational resources, instead experi men ting on the Graph-aware attention module.
我们选择使用 BART 作为预训练语言模型 (Lewis 等人, 2020), 并用 Hugging Face 的预训练 bart-base 检查点初始化其相应参数。由于计算资源有限, 我们保留了全局注意力模块 (BART) 的默认超参数, 转而专注于图感知注意力模块的实验。
When evaluating, we follow the existing work for KG-to-text and report the model’s performance with BLEU (Papineni et al., 2002), METEOR (Banerjee and Lavie, 2005), and ROUGEL (Lin, 2004) scores as the automatic NLG metrics.
评估时,我们遵循知识图谱到文本 (KG-to-text) 现有工作的做法,使用 BLEU (Papineni et al., 2002)、METEOR (Banerjee and Lavie, 2005) 和 ROUGEL (Lin, 2004) 分数作为自动自然语言生成 (NLG) 指标报告模型性能。
5.3 Baselines
5.3 基线方法
Fine-tuned LM. To evaluate the effect of the graph-aware attention module in our framework, we compare with a vanilla fine-tuned BART LM, which is not additionally pre-trained on any graphtext specific task. We do so for both WebNLG and Event Narrative, noting that for Event Narrative such a baseline is the state-of-the-art.
微调大语言模型 (Fine-tuned LM)。为评估图感知注意力模块在框架中的作用,我们与未在图文本特定任务上进行额外预训练的普通微调BART大语言模型进行对比。该对比实验在WebNLG和事件叙事 (Event Narrative) 数据集上均开展,需注意的是对于事件叙事任务而言,此类基线模型已是当前最优方法。
Pre-trained KG-to-Text Models. We further compare our framework with models which have pre-trained LMs on additional tasks, including KGPT (Chen et al., 2020) and JointGT (Ke et al., 2021). KGPT performs an additional KG-to-text generation pre-training task on KGText, a loosely-supervised large-scale KG-to-text dataset, before finetuning. JointGT performs three additional pre-training tasks for KG reconstruction, text reconstruction, and KG-text alignment on the KGText dataset before finetuning. For a fair comparison with JointGT, we also compare our results to JointGT’s BART pre-trained task, where they perform an additional text infilling and sentence permutation task on KGText.
预训练的知识图谱到文本模型。我们进一步将我们的框架与在额外任务上预训练过的大语言模型进行比较,包括KGPT (Chen et al., 2020) 和 JointGT (Ke et al., 2021) 。KGPT在微调前,先在KGText(一个弱监督的大规模知识图谱到文本数据集)上执行了额外的知识图谱到文本生成预训练任务。JointGT在微调前,针对知识图谱重构、文本重构和知识图谱-文本对齐三个任务,在KGText数据集上进行了额外的预训练。为了与JointGT公平对比,我们还将结果与JointGT的BART预训练任务进行比较,后者在KGText上额外执行了文本填充和句子排列任务。
5.4 Main results
5.4 主要结果
Table 2 and Table 3 show our results on the WebNLG and Event Narrative datasets, respectively. On both datasets, we observe improvements over existing LM-based models with GAP. For BLEU score on WebNLG, we observe a $+5.20%$ improvement over the state-of-the-art without any pre-training (Shimorina and Gardent, 2018) and a $+1.65%$ improvement over BART. This improvement suggests that the graph-aware component of
表 2 和表 3 分别展示了我们在 WebNLG 和 Event Narrative 数据集上的结果。在这两个数据集上,我们都观察到采用 GAP 的模型优于现有基于大语言模型的方案。在 WebNLG 的 BLEU 评分指标上,我们的方法相比无需预训练的最优方案 (Shimorina and Gardent, 2018) 提升了 5.20%,相较 BART 模型提升了 1.65%。这一改进表明图感知组件
Table 2: Performance comparison on WebNLG. KGPT and JointGT, marked with $\dagger$ and ${\ddag}$ , re-printed from Chen et al. (2020) and Ke et al. (2021), have been pre-trained on one and three additional tasks, where $P r e+$ denotes if additional pre-training was performed. We mark results from Shimorina and Gardent (2018) with $\sharp$ . We report our best models with and without type encoding, which have approximately the same number of parameters.
表 2: WebNLG上的性能对比。标记为$\dagger$的KGPT和${\ddag}$的JointGT分别摘自Chen等人(2020)和Ke等人(2021)的论文,这两个模型分别在1个和3个额外任务上进行了预训练,其中$Pre+$表示是否进行了额外预训练。我们用$\sharp$标记Shimorina和Gardent(2018)的结果。我们报告了带类型编码和不带类型编码的最佳模型,这两个模型的参数量大致相同。
| 模型 | Pre+ | #Param | BLEU | METEOR | ROUGE |
|---|---|---|---|---|---|
| GCN (Marcheggiani and Perez-Beltrachini, 2018) | No | 60.80 | 42.76 | 71.13 | |
| Shimorina and Gardent (2018) | No | 61.00# | 42.00# | 71.00# | |
| KGPTw/opretrain | No | 177M | 62.30 | 44.33 | 73.00 |
| KGPT | Yes | 177M | 64.11# | 46.3 | 74.57 |
| BART | Yes | 140M | 64.55 | 46.51 | 75.13 |
| JointGT(BART)-w/BARTPretrain | Yes | 160M | 64.60t | 46.78t | 75.74t |
| JointGT(BART)-w/JointGTPretrain | Yes | 160M | 65.92t | 47.15t | 76.1t |
| GAP (Ours) - Mer | No | 153M | 65.92 | 46.81 | 76.22 |
| GAP (Ours) - Me,r + | No | 153M | 66.20 | 46.77 | 76.36 |
Table 3: Performance comparison on EventNarrative. We compare to the pretrained baselines, T5 and BART, reprinted from (Colas et al., 2021), and adapt JointGT (Ke et al., 2021) to the dataset.
表 3: EventNarrative 上的性能对比。我们将预训练基线 T5 和 BART (Colas et al., 2021) 与适配到该数据集的 JointGT (Ke et al., 2021) 进行对比。
| 模型 | BLEU | METEOR | ROUGE | BERTScore |
|---|---|---|---|---|
| BART | 31.38 | 26.68 | 62.65 | 93.12 |
| T5 | 12.8 | 22.77 | 52.06 | 89.59 |
| JointGT | 31.19 | 26.58 | 64.91 | 93.68 |
| 34.02 | 26.93 | 62.90 | 93.13 | |
| Me,r + | 35.08 | 27.50 | 64.28 | 93.38 |
GAP makes use of the local neighborhood information when encoding graph components.
GAP 在编码图组件时利用了局部邻域信息。
We outperform both KGPT and JointGT (on WebNLG), which rely on additional pre-training tasks for graph-text reconstruction and alignment. On BLEU score, we observe an improvement of $+1.81%$ and $2.09%$ over KGPT, and $+1.32%$ and $1.6%$ over JointGT (with BART Pre train). Further, our $M^{e,r}$ with Type Encoding model outperforms JointGT (with Joint GT Pre train) by $0.28%$ without the need for any additional pre-training. JointGTPretrain refers to all three pre-trained tasks described in Ke et al. (2021). Instead of pre-training, we fill the gap with a modification to the encoder structure such that the model adapts to the graph structure. To summarize, we have shown that when adapting pre-trained language models such as BART, a careful modification of the encoder structure can better align the LM with the new task.
我们在WebNLG数据集上的表现优于依赖额外预训练任务进行图-文本重构和对齐的KGPT和JointGT。在BLEU分数上,我们相比KGPT分别提升了$+1.81%$和$2.09%$,相比JointGT(使用BART预训练)分别提升了$+1.32%$和$1.6%$。此外,我们的$M^{e,r}$(带类型编码模型)在无需任何额外预训练的情况下,比JointGT(使用JointGT预训练)高出$0.28%$。JointGTPretrain指代Ke等人(2021)中描述的所有三种预训练任务。我们通过修改编码器结构来填补这一差距,使模型适应图结构,而非依赖预训练。总之,我们证明了在适配BART等预训练语言模型时,对编码器结构进行细致修改能更好地使大语言模型与新任务对齐。
On Event Narrative, for model $M_{e}^{e,r}$ we achieve an improvement of $+3.70%$ , $+0.82%$ , $+1.63%$ on BLEU, METEOR, and ROUGE, relative to BART, further demonstrating that the graph-aware structure and type encoder can perform comparatively well on large and more complex graphs. We note a similar trend to WebNLG, where the type encoder can give an additional performance improvement to the graph-structure component of the model. For comparison, we adapt JointGT to Event Narrative, using the hyper parameters from Ke et al. (2021). We note all models have similar BERTScores.
在事件叙述任务中,模型 $M_{e}^{e,r}$ 相比 BART 在 BLEU、METEOR 和 ROUGE 指标上分别提升了 $+3.70%$、$+0.82%$ 和 $+1.63%$,进一步证明图感知结构和类型编码器在大型复杂图结构上也能表现良好。我们观察到与 WebNLG 类似的趋势,即类型编码器能为模型的图结构组件带来额外性能提升。作为对比,我们采用 Ke 等人 (2021) 的超参数将 JointGT 适配到事件叙述任务。所有模型的 BERTScore 表现相近。
Table 4: Experimental results of the different masks applied to the WebNLG $\mathrm{v}2.0$ test set.
表 4: 不同掩码在 WebNLG $\mathrm{v}2.0$ 测试集上的实验结果
| GAP | BLEU METEOR | ROUGE |
|---|---|---|
| 65.92 46.81 | 76.22 | |
| Me,r | 65.86 46.86 | 76.28 |
| Me | 65.11 46.33 | 75.62 |
| Me,r | 64.64 46.17 | 75.04 |
6 Analysis
6 分析
6.1 Ablation Studies
6.1 消融实验
We explore different maskings and type encodings for the graph-aware attention module on WebNLG. summarized on Table 4 and Table 5.
我们在WebNLG上探索了图感知注意力模块的不同掩码和类型编码方式。总结如表4和表5所示。
Masking Scheme. From bottom to top on Table 4, our first observation is that when relations directly attend to the neighboring relations, the performance drops by $1.28%$ , the largest difference. In fact, the results significantly improve when we completely block attention on relations $(M_{e}^{e})$ . However, for the entities, it is always best to attend to their edges (relations) as well as their neighboring entities. The top two results are comparable $(0.06%$ difference in BLEU score), and each one could be considered the best performing model depending on the evaluation metric. For relations, it might be somewhat helpful to not attend to neighboring relations, while for entities, attending to the relations will lead to better results $(+0.81%)$ .
掩码方案 (Masking Scheme)。从表 4 自下而上观察,我们的第一个发现是:当关系直接关注相邻关系时,性能下降了 1.28%,这是最大的差异。实际上,当我们完全阻断对关系的注意力 $(M_{e}^{e})$ 时,结果反而显著提升。但对于实体而言,始终最佳策略是同时关注其边(关系)和相邻实体。前两项结果具有可比性(BLEU 分数相差 0.06%),根据评估指标不同,二者均可视为最佳模型。对关系而言,不关注相邻关系可能略有助益,而对实体来说,关注关系会带来更好的结果 $(+0.81%)$。
Table 5: The results of different variations of our model with type encoding on the WebNLG $\mathrm{v}2.0$ test set.
表 5: 我们的模型在 WebNLG $\mathrm{v}2.0$ 测试集上采用类型编码的不同变体的结果。
| GAP w/ BLEU | METEOR ROUGE |
|---|---|
| Me,r 65.34 46.31 | 75.59 |
| Me,r 66.20 | 46.77 76.36 |
| 75.44 | |
| Me 65.24 Me,r 65.43 | 46.49 46.54 75.75 |
Type Encoder. Table 5 shows the effect of type encoding on the results on WebNLG. To better understand the effect of type encoding on each of the models, we compare Table 4 with Table 5. Recall that the type encoding $\gamma(T)$ for each model depends on the connections that exists in the model graph structure. For instance, the most general model $M_{e,r}^{e,r}$ has all four possible connection types encoded by equation (4), while the model with $M=M^{e,r}$ only has two types, which can be encoded by a restriction of equation (4). According to Table 4, the model $M_{e,r}^{e,r}$ performs worst without type encoding. However, because of its generality, i.e. having all the possible connection types, it is possible for this model to drift toward better configurations with the help of $\gamma(T)$ . The results in Table 5 help support these insights for model $M_{e,r}^{e,r}$ . Type encoding allows this model to simulate what we observed is best in the previous section, i.e. relations are better off not to attend to relations, whereas entities can attend to both while paying less attention to relations. This nuanced behavior seems to be achievable only via type encoding. Results for model with $M=M^{e,r}$ and type encoding also point towards this; type encoding seems to facilitate a non-uniform attention distribution based on the type and produces a better result.
类型编码器。表5展示了类型编码对WebNLG结果的影响。为了更好地理解类型编码对每个模型的影响,我们对比了表4和表5。需要注意的是,每个模型的类型编码$\gamma(T)$取决于模型图结构中存在的连接类型。例如,最通用的模型$M_{e,r}^{e,r}$通过公式(4)编码了全部四种可能的连接类型,而模型$M=M^{e,r}$仅包含两种类型,可通过公式(4)的约束进行编码。根据表4,未使用类型编码时$M_{e,r}^{e,r}$模型表现最差。但由于其通用性(即包含所有可能的连接类型),该模型有可能在$\gamma(T)$的帮助下趋向更优配置。表5的结果支持了对$M_{e,r}^{e,r}$模型的这一观察:类型编码使该模型能够模拟前文发现的最佳模式——关系最好不关注其他关系,而实体可以同时关注两者但对关系关注较少。这种精细化行为似乎只能通过类型编码实现。$M=M^{e,r}$模型在类型编码下的结果也印证了这一点:类型编码有助于根据类型实现非均匀的注意力分布,从而产生更好的结果。
6.2 Few-Shot Learning
6.2 少样本 (Few-shot) 学习
To further reinforce our claims that our model alleviates the need for pre-training in the KG-to-text task, we consider various few-shot learning settings where only a small percentage of training instances were used for finetuning. As highlighted in Table 6, GAP outperforms all state-of-the-art pretrainedbased approaches, without needing to pre-train, indicating that our fully graph-aware framework is more appropriate than established pre-trained tasks, especially when such data is not avialable.
为了进一步证实我们的模型减轻了知识图谱到文本任务中对预训练的需求,我们考虑了多种少样本学习设置,其中仅使用一小部分训练实例进行微调。如表 6 所示,GAP 在无需预训练的情况下优于所有基于预训练的最先进方法,这表明我们的全图感知框架比现有的预训练任务更合适,尤其是在此类数据不可用时。
Table 6: BLEU scores of various pre-trained models compared to GAP for few-shot learning on WebNLG.
表 6: 不同预训练模型与 GAP 在 WebNLG 少样本学习中的 BLEU 分数对比
| 模型 | 数据比例 0.5% 1% | 数据比例 5% 10% |
|---|---|---|
| BART JointGT | 33.92 39.08 37.18 42.26 | 52.24 56.58 54.41 57.73 |
| Me,r + | 39.50 44.03 | 55.68 58.30 |
Table 7: BLEU scores for the different masks applied to the WebNLG $\mathrm{v}2.0$ test set for different graph sizes.
表 7: 不同掩码在 WebNLG $\mathrm{v}2.0$ 测试集上针对不同图大小的 BLEU 分数。
| GAP | #Triples |
|---|---|
| 1-3 | |
| Me,r | 71.48 |
| Me,r | 71.28 |
| Me | 70.18 |
| Me,r | 69.74 |
6.3 KG Size
6.3 知识图谱规模
As in Ke et al. (2021), we divide the WebNLG test set into two subsets (1-3 and 4-7 triples) to compare the performance of our different masking configurations. Table 7 shows that while all configurations perform similarly for larger graphs, the difference in performance is clearer on smaller graphs, where $M_{e}^{e,r}$ performs $+1.74%$ better than $M_{e,r}^{e,r}$ , suggesting that relations paying attention to relations can add too much complexity to the model, especially on simpler graph structures.
如 Ke 等人 (2021) 所述,我们将 WebNLG 测试集划分为两个子集 (1-3 和 4-7 三元组) 以比较不同掩码配置的性能。表 7 显示,虽然所有配置在较大图上表现相似,但在较小图上性能差异更明显,其中 $M_{e}^{e,r}$ 比 $M_{e,r}^{e,r}$ 高出 $+1.74%$ ,这表明关系关注关系可能会给模型增加过多复杂性,尤其是在较简单的图结构上。
6.4 Interpret ability
6.4 可解释性
We begin to interpret KG-to-text models by analyzing the graph-attention weights induced by each graph structure on a per-sample basis, analogous to analyzing node-to-node attention weights in the KG question-answering domain (Yasunaga et al., 2021). By introducing a framework to the KG-totext task, we can condition the changes in the output text on the different components of the framework, including the masking and type encoder. We can then observe the differences in the output text based on the graph’s topological structure or what relations and entities attend to.
我们通过分析每个样本上由不同图结构诱导出的图注意力权重,开始解释知识图谱到文本(KG-to-text)模型,这与分析知识图谱问答领域中节点到节点注意力权重的方法类似[20]。通过为该任务引入框架,我们可以将输出文本的变化归因于框架中的不同组件,包括掩码机制和类型编码器。随后能观察到输出文本如何随图谱拓扑结构变化,以及不同关系和实体的关注点差异。
In Figure 4 we show an example KG representing Aenir, an Australian fantasy novel, with its relations (orange) and entities (blue) along with the attention heatmaps and outputs from two of our framework decisions. The left (a) heatmap and output corresponds to our best performing model without type encoding, $M_{e}^{e,r}$ , while the right (b) corresponds to $M_{e}^{e}$ . We choose these two mask
图 4: 我们展示了代表澳大利亚奇幻小说《Aenir》的知识图谱示例,包含其关系(橙色)和实体(蓝色),以及两个框架决策的注意力热图和输出结果。左侧(a)热图和输出对应我们未使用类型编码的最佳性能模型 $M_{e}^{e,r}$ ,右侧(b)对应 $M_{e}^{e}$ 。我们选择这两个掩码
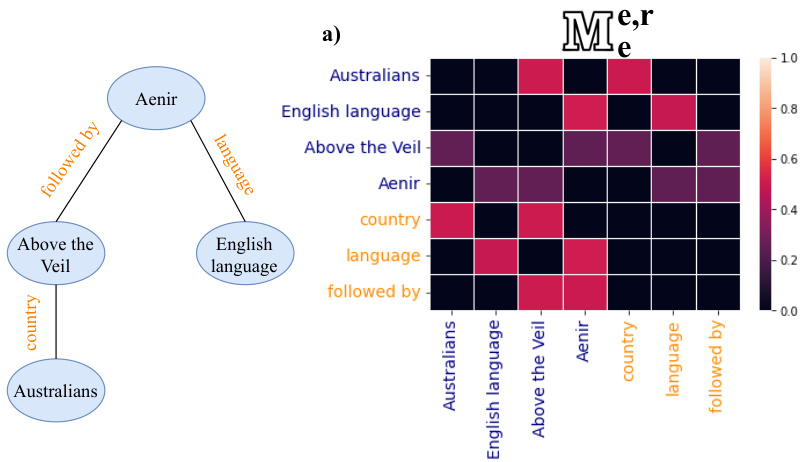
Output: Aenir is written in English and was followed by Above the Veil which is from the country of Australia.
《Aenir》以英文撰写,续作《Above the Veil》源自澳大利亚。
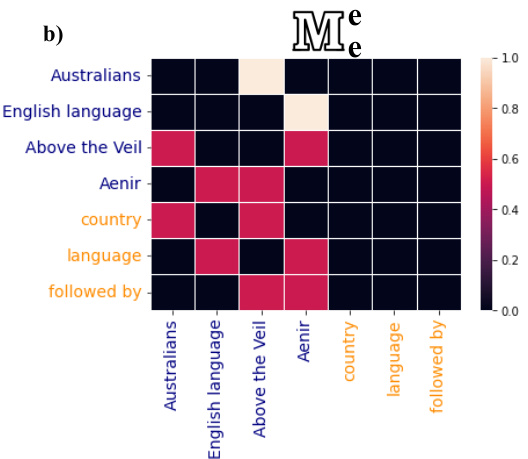
Output: Aenir, written in English, was followed by Above the Veil, which is written in the English language.
图 1: 英文撰写的《Aenir》之后是同样用英文写成的《Above the Veil》。
Figure 4: Interpreting KG-to-text models via analyzing graph attention weights, which the graph-aware encoder activates. We show each model’s output for further emphasis.
图 4: 通过分析图感知编码器激活的图注意力权重来解读知识图谱到文本(KG-to-text)模型。我们展示了每个模型的输出以作进一步强调。
ing configurations, because the attention-weight differences are apparent.
因为注意力权重差异明显。
From (a), entities attend to both entities and relations, whereas relations only attend to entities. Interestingly, the attention distribution appears uniform across all graph components (both for entities and relations). From (b) we see a similar uniform distribution across entities and relation attending to only entities. Thus, in (a), while relation ‘country’ attends to ‘Australians’ and vice-versa, in (b) ‘Australians’ does not attend to ‘country’, perhaps giving a difference in the output, as the final output in (a) contains ‘from the country of Australia’ while the text in (b) does not. Moreover, in both (a) and (b) ‘Above the Veil’ is the subject of the second clause. However, ‘Above the Veil’ attends to ‘country’ only in (a), therefore influencing (a)’s output of ‘Above the Veil which is from the country of Australia’. Instead, (b) introduces some redundancy in its second clause instead of transcribing new information from the KG.
从(a)可以看出,实体同时关注实体和关系,而关系仅关注实体。有趣的是,注意力分布对所有图组件(包括实体和关系)都呈现均匀分布。在(b)中,我们观察到类似的均匀分布模式:实体和关系都仅关注实体。因此,(a)中关系"country"会关注"Australians",反之亦然;而(b)中"Australians"不会关注"country",这可能导致输出差异——(a)的最终输出包含"from the country of Australia",而(b)的文本则没有。此外,(a)和(b)中"Above the Veil"都是第二个分句的主语。但仅在(a)中,"Above the Veil"会关注"country",从而影响(a)输出"Above the Veil which is from the country of Australia"。相比之下,(b)的第二个分句引入了冗余内容,而非从知识图谱(KG)转录新信息。
Figure 5 shows the output sentence, and the attention heatmap produced by our most general model with $M=M_{e,r}^{e,r}$ and type encoding, on the graph shown in Figure 4. We examine the differences between this model, referred to as model (1), and the model with $M=M_{e}^{e,r}$ and no type encoding, referred to as model (2). First, note that in terms of BLEU score (1) performs slightly worse than (2), however a human annotator may rank (1) over (2), as (1) is more concise while communicating the same information. For example, (1) uses the word ‘sequel to’ rather than ‘followed by’ and ‘published in’ instead of ‘from the country’, which can sound more natural to humans. Particularly, Australians pays less attention to country, compared to model (2), perhaps hinting at this result. Our framework provides a first step in interpreting this result by allowing one to compare different attention-weights across multiple models. With this in mind, we call upon future work to design more specific evaluation metrics for the KG-to-text task.
图 5 展示了输出句子,以及我们最通用的模型在如图 4 所示的图上生成的注意力热图,该模型采用 $M=M_{e,r}^{e,r}$ 和类型编码。我们将此模型称为模型 (1),并与采用 $M=M_{e}^{e,r}$ 且无类型编码的模型 (2) 进行比较。首先,就 BLEU 分数而言,(1) 的表现略逊于 (2),但人工标注者可能认为 (1) 优于 (2),因为 (1) 在传达相同信息时更为简洁。例如,(1) 使用 "续集" 而非 "随后",以及 "出版于" 而非 "来自国家",这些表达对人类来说可能更自然。特别是,与模型 (2) 相比,澳大利亚人对国家的关注度较低,或许暗示了这一结果。我们的框架通过允许比较多个模型间的不同注意力权重,为解释这一结果提供了第一步。基于此,我们呼吁未来工作为知识图谱到文本任务设计更具体的评估指标。
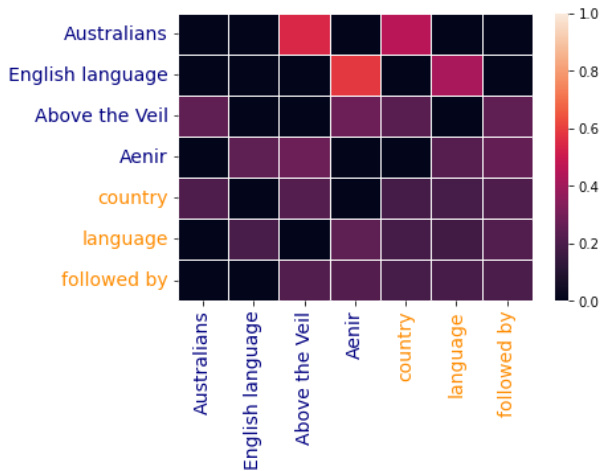
Output: Above the Veil was the sequel to Aenir which is written in English and was published in Australia. Figure 5: An additional case study of the graph attention weights for model $M_{e,r}^{e,r}$ with type encoding.
图 5: 模型 $M_{e,r}^{e,r}$ 带类型编码的图注意力权重附加案例研究。
7 Conclusion
7 结论
We presented GAP, a graph-aware language model framework for KG-to-text generation. Our framework instills the local information captured by graph attention into the global contextual i zed word vector representation within pre-trained LMs. We demonstrated multiple configurations of our framework by introducing a graph-aware attention masking scheme and novel type encoder module, and through qualitative analysis showed that GAP outperforms existing KG-to-text models, including those that rely on additional auxiliary pre-training tasks. By closely examining the different framework configurations, we introduce the capacity to interpret KG-to-text outputs through a graph’s attention structure and topology.
我们提出了GAP,一个面向知识图谱到文本生成 (KG-to-text) 的图感知大语言模型框架。该框架将图注意力捕获的局部信息注入预训练语言模型的全局上下文词向量表示中。我们通过引入图感知注意力掩码方案和新型类型编码器模块,展示了框架的多种配置,并通过定性分析证明GAP优于现有知识图谱到文本生成模型(包括依赖额外辅助预训练任务的模型)。通过深入分析不同框架配置,我们赋予了通过图的注意力结构和拓扑来解读知识图谱到文本生成输出的能力。
8 Broader Impacts
8 更广泛的影响
GAP provides researchers with a state-of-the-art framework for KG-to-text models. Though we experiment with supervised baselines which include a handcrafted dataset, WebNLG, and an automatically generated dataset, Event Narrative, repositories of structured data exist in the clinical (Johnson et al., 2016), medical (Boden rei der, 2004), and news crises (Leetaru and Schrodt, 2013; Ward et al., 2013) domains. By transforming clinical data into natural language narratives, patients with low health-literacy can benefit by more easily understanding their electronic medical records (EMRs), and doctors can more easily transcribe patient data for future use cases, i.e. connecting such data to the medical literature. Such models can also help analysts more easily understand crises data from various news sources, in turn helping them evaluate cause-effect relationships and detect misinformation. While malicious actors can exploit generative models for disinformation, we discourage the use of GAP in generating such data and openly release our model to help combat such efforts.
GAP为研究人员提供了最先进的KG-to-text(知识图谱到文本)模型框架。尽管我们实验了包含手工制作数据集WebNLG和自动生成数据集Event Narrative的监督基线,但结构化数据仓库已存在于临床 (Johnson et al., 2016)、医学 (Bodenreider, 2004) 和新闻危机 (Leetaru and Schrodt, 2013; Ward et al., 2013) 领域。通过将临床数据转化为自然语言叙述,健康素养较低的患者能更轻松理解其电子病历 (EMR),医生也能更便捷地转录患者数据以供未来使用(例如将此类数据与医学文献关联)。此类模型还能帮助分析师更易理解来自各类新闻源的危机数据,进而评估因果关系并识别虚假信息。虽然恶意行为者可能利用生成式模型散布虚假信息,但我们不鼓励使用GAP生成此类数据,并公开模型以助力对抗此类行为。
Acknowledgements
致谢
This work was partially funded and supported by the GSPA at the University of Florida, the McKnight Doctoral Fellowship, the NSF under IIS Award #1526753, and DARPA under Award #FA8750-18-2-0014 (AIDA/GAIA).
本研究部分由佛罗里达大学GSPA、McKnight博士奖学金、美国国家科学基金会(NSF) IIS奖项#1526753以及美国国防高级研究计划局(DARPA)奖项#FA8750-18-2-0014 (AIDA/GAIA)资助支持。
References
参考文献
Oshin Agarwal, Heming Ge, Siamak Shakeri, and Rami Al-Rfou. 2021. Knowledge graph based synthetic corpus generation for knowledge-enhanced language model pre-training. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3554–3565, Online. Association for Computational Linguistics.
Oshin Agarwal、Heming Ge、Siamak Shakeri和Rami Al-Rfou。2021。基于知识图谱的合成语料生成技术用于知识增强型语言模型预训练。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第3554–3565页,线上会议。计算语言学协会。
Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives.
Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives.
Satanjeev Banerjee and Alon Lavie. 2005. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72.
Satanjeev Banerjee和Alon Lavie。2005。Meteor:一种改进与人工判断相关性的自动机器翻译评估指标。在《机器翻译和/或摘要内在与外在评估指标的acl研讨会论文集》中,第65-72页。
Rajarshi Bhowmik and Gerard de Melo. 2018. Generating fine-grained open vocabulary entity type descrip- tions. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 877–888.
Rajarshi Bhowmik和Gerard de Melo。2018。生成细粒度开放词汇实体类型描述。见《第56届计算语言学协会年会论文集(第一卷:长论文)》,第877-888页。
Olivier Boden rei der. 2004. The unified medical language system (umls): integrating biomedical terminology. Nucleic acids research, 32(suppl_1):D267– D270.
Olivier Bodenreider. 2004. 统一医学语言系统 (UMLS): 生物医学术语集成. Nucleic acids research, 32(suppl_1):D267–D270.
Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pages 1247–1250.
Kurt Bollacker、Colin Evans、Praveen Paritosh、Tim Sturge 和 Jamie Taylor。2008. Freebase: 一个协作构建的图数据库用于结构化人类知识。载于《2008年ACM SIGMOD国际数据管理会议论文集》,第1247–1250页。
Deng Cai and Wai Lam. 2020. Graph transformer for graph-to-sequence learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7464–7471.
Deng Cai和Wai Lam。2020。图到序列学习中的图Transformer (Graph Transformer)。见《AAAI人工智能会议论文集》第34卷,第7464-7471页。
Wenhu Chen, Yu Su, Xifeng Yan, and William Yang Wang. 2020. KGPT: Knowledge-grounded pretraining for data-to-text generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8635–8648, Online. Association for Computational Linguistics.
Wenhu Chen、Yu Su、Xifeng Yan 和 William Yang Wang。2020。KGPT: 面向数据到文本生成的知识驱动预训练。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第8635–8648页,线上。计算语言学协会。
Anthony Colas, Ali Sadeghian, Yue Wang, and Daisy Zhe Wang. 2021. Event narrative: A largescale event-centric dataset for knowledge graph-totext generation. In 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks.
Anthony Colas、Ali Sadeghian、Yue Wang和Daisy Zhe Wang。2021。事件叙事:一个面向知识图谱到文本生成的大规模事件中心数据集。见第35届神经信息处理系统会议(NeurIPS 2021)数据集与基准测试专题。
Joe Davison, Joshua Feldman, and Alexander M Rush. 2019. Commonsense knowledge mining from pretrained models. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLPIJCNLP), pages 1173–1178.
Joe Davison、Joshua Feldman和Alexander M Rush。2019。从预训练模型中挖掘常识知识。载于《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP),第1173–1178页。
Bayu Distiawan, Jianzhong Qi, Rui Zhang, and Wei Wang. 2018. Gtr-lstm: A triple encoder for sentence generation from rdf data. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1627–1637.
Bayu Distiawan、Jianzhong Qi、Rui Zhang和Wei Wang。2018. Gtr-lstm:基于RDF数据生成句子的三重编码器。载于《第56届计算语言学协会年会论文集(第一卷:长论文)》,第1627–1637页。
Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltr a chin i. 2017. The webnlg challenge: Generating text from rdf data. In Proceedings of the 10th International Conference on Natural Language Generation, pages 124–133.
Claire Gardent、Anastasia Shimorina、Shashi Narayan和Laura Perez-Beltrachini。2017。WebNLG挑战:从RDF数据生成文本。载于《第10届国际自然语言生成会议论文集》,第124-133页。
Simon Gottschalk and Elena Demidova. 2018. Eventkg: A multilingual event-centric temporal knowledge graph. In European Semantic Web Conference, pages 272–287. Springer.
Simon Gottschalk 和 Elena Demidova. 2018. EventKG: 一种多语言以事件为中心的时序知识图谱. 载于欧洲语义网会议, 第272–287页. Springer出版社.
Jian Guan, Yansen Wang, and Minlie Huang. 2019. Story ending generation with incremental encoding and commonsense knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6473–6480.
Jian Guan、Yansen Wang和Minlie Huang。2019。基于增量编码与常识知识的故事结尾生成。见《AAAI人工智能会议论文集》第33卷,第6473–6480页。
Zhijiang Guo, Yan Zhang, Zhiyang Teng, and Wei Lu. 2019. Densely connected graph convolutional networks for graph-to-sequence learning. Transactions of the Association for Computational Linguis- tics, 7:297–312.
Zhijiang Guo、Yan Zhang、Zhiyang Teng 和 Wei Lu。2019. 用于图到序列学习的密集连接图卷积网络。计算语言学协会汇刊,7:297–312。
Suchin Gururangan, Ana Marasovic, Swabha S way am dip ta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith. 2020. Don’t stop pre training: Adapt language models to domains and tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360.
Suchin Gururangan、Ana Marasovic、Swabha Swayamdipta、Kyle Lo、Iz Beltagy、Doug Downey和Noah A Smith。2020。不要停止预训练:将语言模型适配到领域和任务中。载于《第58届计算语言学协会年会论文集》,第8342–8360页。
Shizhu He, Cao Liu, Kang Liu, and Jun Zhao. 2017. Generating natural answers by incorporating copying and retrieving mechanisms in sequence-tosequence learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 199– 208.
Shizhu He, Cao Liu, Kang Liu, and Jun Zhao. 2017. 通过结合复制与检索机制的序列到序列学习生成自然答案。见《第55届计算语言学协会年会论文集(第一卷:长论文)》,第199-208页。
Haozhe Ji, Pei Ke, Shaohan Huang, Furu Wei, Xiaoyan Zhu, and Minlie Huang. 2020. Language generation with multi-hop reasoning on commonsense knowledge graph. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 725–736.
Haozhe Ji、Pei Ke、Shaohan Huang、Furu Wei、Xiaoyan Zhu和Minlie Huang。2020。基于常识知识图谱多跳推理的语言生成。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第725–736页。
Zhijing Jin, Qipeng Guo, Xipeng Qiu, and Zheng Zhang. 2020. Genwiki: A dataset of 1.3 million content-sharing text and graphs for unsupervised graph-to-text generation. In Proceedings of the 28th International Conference on Computational Linguistics, pages 2398–2409.
Zhijing Jin、Qipeng Guo、Xipeng Qiu和Zheng Zhang。2020。Genwiki:一个包含130万条内容共享文本与图的无监督图到文本生成数据集。载于《第28届国际计算语言学会议论文集》,第2398–2409页。
Alistair EW Johnson, Tom J Pollard, Lu Shen, H Lehman Li-Wei, Mengling Feng, Moham- mad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2016. Mimiciii, a freely accessible critical care database. Scientific data, 3(1):1–9.
Alistair EW Johnson、Tom J Pollard、Lu Shen、H Lehman Li-Wei、Mengling Feng、Moham- mad Ghassemi、Benjamin Moody、Peter Szolovits、Leo Anthony Celi 和 Roger G Mark。2016. MIMIC-III,一个可自由访问的重症监护数据库。科学数据,3(1):1-9。
Mihir Kale and Abhinav Rastogi. 2020. Text-to-text pre-training for data-to-text tasks. In Proceedings of the 13th International Conference on Natural Language Generation, pages 97–102.
Mihir Kale和Abhinav Rastogi。2020。面向数据到文本任务的文本到文本预训练。载于《第13届国际自然语言生成会议论文集》,第97-102页。
Pei Ke, Haozhe Ji, Yu Ran, Xin Cui, Liwei Wang, Linfeng Song, Xiaoyan Zhu, and Minlie Huang. 2021. JointGT: Graph-text joint representation learning for text generation from knowledge graphs. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2526–2538, Online. Association for Computational Linguistics.
Pei Ke、Haozhe Ji、Yu Ran、Xin Cui、Liwei Wang、Linfeng Song、Xiaoyan Zhu和Minlie Huang。2021. JointGT:面向知识图谱文本生成的图-文本联合表示学习方法。载于《计算语言学协会研究发现:ACL-IJCNLP 2021》,第2526–2538页,线上。计算语言学协会。
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. CoRR, abs/1412.6980.
Diederik P. Kingma 和 Jimmy Ba. 2015. Adam: 一种随机优化方法. CoRR, abs/1412.6980.
Rik Koncel-Kedziorski, Dhanush Bekal, Yi Luan, Mirella Lapata, and Hannaneh Hajishirzi. 2019. Text generation from knowledge graphs with graph transformers. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2284–2293.
Rik Koncel-Kedziorski、Dhanush Bekal、Yi Luan、Mirella Lapata 和 Hannaneh Hajishirzi。2019. 基于图Transformer (Graph Transformer) 的知识图谱文本生成。载于《2019年北美计算语言学协会人类语言技术会议论文集》第1卷(长论文与短论文),第2284–2293页。
Kalev Leetaru and Philip A Schrodt. 2013. Gdelt: Global data on events, location, and tone, 1979– 2012. In ISA annual convention, volume 2, pages 1–49. Citeseer.
Kalev Leetaru 和 Philip A Schrodt. 2013. GDELT: 全球事件、位置与基调数据 (1979–2012). 见: ISA年度会议, 第2卷, 第1–49页. Citeseer.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Z ett le moyer. 2020. Bart: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Veselin Stoyanov 和 Luke Zettlemoyer。2020。BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练。见《第58届计算语言学协会年会论文集》,第7871–7880页。
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text sum mari z ation branches out, pages 74–81.
Chin-Yew Lin. 2004. ROUGE: 自动摘要评估工具包. 见《文本摘要分支》, 第74-81页。
Manuel Mager, Ramón Fernandez Astudillo, Tahira Naseem, Md Arafat Sultan, Young-Suk Lee, Radu Florian, and Salim Roukos. 2020. Gpt-too: A language-model-first approach for amr-to-text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1846–1852.
Manuel Mager、Ramón Fernandez Astudillo、Tahira Naseem、Md Arafat Sultan、Young-Suk Lee、Radu Florian 和 Salim Roukos。2020. GPT-TOO:一种以语言模型为先的 AMR 到文本生成方法。载于《第58届计算语言学协会年会论文集》,第1846-1852页。
Diego March egg ian i and Laura Perez-Beltr a chin i. 2018. Deep graph convolutional encoders for structured data to text generation. In INLG.
Diego March egg ian i 和 Laura Perez-Beltr a chin i. 2018. 面向结构化数据到文本生成的深度图卷积编码器. 载于 INLG.
Amit Moryossef, Yoav Goldberg, and Ido Dagan. 2019. Step-by-step: Separating planning from realization in neural data-to-text generation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2267–2277.
Amit Moryossef、Yoav Goldberg和Ido Dagan。2019。分步实现:神经数据到文本生成中规划与实现的分离。载于《2019年北美计算语言学协会人类语言技术会议论文集》第1卷(长文与短文),第2267–2277页。
Vaishali Pal, Manish Shri vast ava, and Irshad Bhat. 2019. Answering naturally: Factoid to full length answer generation. In Proceedings of the 2nd Workshop on New Frontiers in Sum mari z ation, pages 1–9.
Vaishali Pal、Manish Shrivastava和Irshad Bhat。2019. 自然作答:从事实型到完整答案生成。见《第二届摘要新前沿研讨会论文集》,第1-9页。
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
Kishore Papineni、Salim Roukos、Todd Ward 和 WeiJing Zhu。2002. BLEU:一种机器翻译自动评估方法。载于《第40届计算语言学协会年会论文集》,第311–318页。
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training.
Alec Radford、Karthik Narasimhan、Tim Salimans 和 Ilya Sutskever。通过生成式预训练提升语言理解能力。
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei、Ilya Sutskever 等. 2019. 语言模型是无监督多任务学习者. OpenAI 博客, 1(8):9.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu。2020。探索文本到文本Transformer (Transformer) 迁移学习的极限。Journal of Machine Learning Research,21(140):1-67。
Leonardo F. R. Ribeiro, Yue Zhang, and Iryna Gurevych. 2021. Structural adapters in pretrained language models for AMR-to-Text generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4269–4282, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Leonardo F. R. Ribeiro、Yue Zhang 和 Iryna Gurevych。2021. 预训练语言模型中用于 AMR 到文本生成的结构化适配器。载于《2021年自然语言处理实证方法会议论文集》,第4269–4282页,线上及多米尼加共和国蓬塔卡纳。计算语言学协会。
Leonardo FR Ribeiro, Martin Schmitt, Hinrich Schütze, and Iryna Gurevych. 2020a. Investigating pretrained language models for graph-to-text generation. arXiv preprint arXiv:2007.08426.
Leonardo FR Ribeiro、Martin Schmitt、Hinrich Schütze 和 Iryna Gurevych。2020a。探究预训练语言模型在图到文本生成中的应用。arXiv预印本 arXiv:2007.08426。
Leonardo FR Ribeiro, Yue Zhang, Claire Gardent, and Iryna Gurevych. 2020b. Modeling global and local node contexts for text generation from knowledge graphs. Transactions of the Association for Computational Linguistics, 8:589–604.
Leonardo FR Ribeiro、Yue Zhang、Claire Gardent 和 Iryna Gurevych。2020b。面向知识图谱文本生成的全局与局部节点上下文建模。计算语言学协会汇刊,8:589–604。
Martin Schmitt, Leonardo FR Ribeiro, Philipp Dufter, Iryna Gurevych, and Hinrich Schütze. 2021. Modeling graph structure via relative position for text generation from knowledge graphs. In Proceedings of the Fifteenth Workshop on Graph-Based Methods for Natural Language Processing (TextGraphs-15), pages 10–21.
Martin Schmitt、Leonardo FR Ribeiro、Philipp Dufter、Iryna Gurevych 和 Hinrich Schütze。2021。通过相对位置建模图结构实现知识图谱文本生成。载于《第十五届基于图的自然语言处理方法研讨会论文集》(TextGraphs-15),第10-21页。
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. 2018. Self-attention with relative position representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 464–468.
Peter Shaw、Jakob Uszkoreit和Ashish Vaswani。2018。基于相对位置表示的自注意力机制。载于《2018年北美计算语言学协会人类语言技术会议论文集(短论文)》第2卷,第464-468页。
Anastasia Shimorina and Claire Gardent. 2018. Handling rare items in data-to-text generation. In Proceedings of the 11th International Conference on Natural Language Generation, pages 360–370.
Anastasia Shimorina和Claire Gardent。2018。数据到文本生成中的稀有项处理。载于《第11届国际自然语言生成会议论文集》,第360-370页。
Yixuan Su, David Vandyke, Sihui Wang, Yimai Fang, and Nigel Collier. 2021. Plan-then-generate: Controlled data-to-text generation via planning. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 895–909.
Yixuan Su、David Vandyke、Sihui Wang、Yimai Fang 和 Nigel Collier。2021. 先规划后生成:基于规划的可控数据到文本生成。载于《计算语言学协会发现:EMNLP 2021》,第895-909页。
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser 和 Illia Polosukhin。2017。Attention is all you need。载于《神经信息处理系统进展》,第5998–6008页。
Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph attention networks. In International Conference on Learning Representations.
Petar Velickovic、Guillem Cucurull、Arantxa Casanova、Adriana Romero、Pietro Liò和Yoshua Bengio。2018。图注意力网络 (Graph Attention Networks)。载于国际学习表征会议。
Denny Vrandecic and Markus Krotzsch. 2014. Wikidata: a free collaborative knowledge base. Communications of the ACM, 57(10):78–85.
Denny Vrandecic 和 Markus Krotzsch. 2014. Wikidata: 一个免费的协作知识库. Communications of the ACM, 57(10):78–85.
Ivan Vulic, Edoardo Maria Ponti, Robert Litschko, Goran Glavaš, and Anna Korhonen. 2020. Probing pretrained language models for lexical semantics. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7222–7240.
Ivan Vulic、Edoardo Maria Ponti、Robert Litschko、Goran Glavaš 和 Anna Korhonen。2020. 探究预训练语言模型的词汇语义。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第7222–7240页。
Michael D Ward, Andreas Beger, Josh Cutler, Matthew Dickenson, Cassy Dorff, and Ben Radford. 2013. Comparing gdelt and icews event data. Analysis, 21(1):267–297.
Michael D Ward、Andreas Beger、Josh Cutler、Matthew Dickenson、Cassy Dorff和Ben Radford。2013。GDELT与ICEWS事件数据比较。分析,21(1):267–297。
TH Wen, M Gasic, N Mrksic, LM Rojas-Barahona, PH Su, D Vandyke, and S Young. 2016. Multidomain neural network language generation for spoken dialogue systems. In 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2016-Proceedings of the Conference, pages 120–129.
TH Wen、M Gasic、N Mrksic、LM Rojas-Barahona、PH Su、D Vandyke 和 S Young。2016。面向口语对话系统的多领域神经网络语言生成。载于《2016年北美计算语言学协会会议:人类语言技术》(NAACL HLT 2016-会议论文集),第120-129页。
David S Wishart, Yannick D Feunang, An C Guo, Elvis J Lo, Ana Marcu, Jason R Grant, Tanvir Sajed, Daniel Johnson, Carin Li, Zinat Sayeeda, et al. 2018. Drugbank 5.0: a major update to the drugbank database for 2018. Nucleic acids research, 46(D1):D1074–D1082.
David S Wishart, Yannick D Feunang, An C Guo, Elvis J Lo, Ana Marcu, Jason R Grant, Tanvir Sajed, Daniel Johnson, Carin Li, Zinat Sayeeda 等. 2018. DrugBank 5.0: 2018年DrugBank数据库的重大更新. 《核酸研究》, 46(D1):D1074–D1082.
Michihiro Yasunaga, Hongyu Ren, Antoine Bosselut, Percy Liang, and Jure Leskovec. 2021. Qa-gnn: Reasoning with language models and knowledge graphs for question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 535–546.
Michihiro Yasunaga、Hongyu Ren、Antoine Bosselut、Percy Liang 和 Jure Leskovec。2021。QA-GNN:结合语言模型与知识图谱的问答推理。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第535–546页。
Alexander Yates, Michele Banko, Matthew Broadhead, Michael J Cafarella, Oren Etzioni, and Stephen Soderland. 2007. Textrunner: open information extraction on the web. In Proceedings of Human Language Technologies: The Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), pages 25–26.
Alexander Yates、Michele Banko、Matthew Broadhead、Michael J Cafarella、Oren Etzioni 和 Stephen Soderland。2007. Textrunner: 基于网络的开放信息抽取。见《人类语言技术会议论文集:北美计算语言学协会年会 (NAACL-HLT)》,第25-26页。
Hao Zhou, Tom Young, Minlie Huang, Haizhou Zhao, Jingfang Xu, and Xiaoyan Zhu. 2018. Commonsense knowledge aware conversation generation with graph attention. In IJCAI, pages 4623–4629.
Hao Zhou、Tom Young、Minlie Huang、Haizhou Zhao、Jingfang Xu和Xiaoyan Zhu。2018。基于图注意力机制的常识知识感知对话生成。见IJCAI,第4623–4629页。
Jie Zhu, Junhui Li, Muhua Zhu, Longhua Qian, Min Zhang, and Guodong Zhou. 2019. Modeling graph structure in transformer for better amr-to-text generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5459–5468.
Jie Zhu、Junhui Li、Muhua Zhu、Longhua Qian、Min Zhang和Guodong Zhou。2019。在Transformer中建模图结构以改进AMR到文本的生成。见《2019年自然语言处理实证方法会议暨第九届自然语言处理国际联合会议(EMNLP-IJCNLP)论文集》,第5459–5468页。
A Hyper parameter Details
超参数详情
As followed by Ke et al. (2021) and BART, we used a Byte-Pair Encoding (BPE) vocabulary (Radford et al., 2019) with a size of 50,265. The model’s parameters were optimized via Adam (Kingma and Ba, 2015), with a batch size of 16, a learning rate of 3e-5, and a maximum graph size of 50 and 60 for WebNLG and Event Narrative, respectively. Table 8 provides the model hyper parameter settings used for experimenting on both the WebNLG and Event Narrative datasets. We keep all listed hyper parameters constant with respect to the GAP configurations. We increase num nodes for the Event Narrative dataset due to the properties of the dataset, i.e. the possibility of having graphs composed of more than seven triples. We also set the eval period to 5,000 for Event Narrative due to its size, containing approximately 22,000 samples in its test set. As in (Colas et al., 2021), we set the max output size to 512 for all experiments on EventNarrative. BLEU score on the validation set was used for model selection. Each model was trained on two NVIDIA RTX 2080 Ti GPUs.
如Ke等人(2021)和BART所采用的方法,我们使用了包含50,265个token的字节对编码(BPE)词汇表(Radford等人,2019)。模型参数通过Adam优化器(Kingma和Ba,2015)进行优化,批处理大小为16,学习率为3e-5,WebNLG和事件叙事(Event Narrative)的最大图尺寸分别设置为50和60。表8展示了在WebNLG和事件叙事数据集上实验所使用的模型超参数设置。对于GAP配置,我们保持所有列出的超参数不变。由于事件叙事数据集可能存在包含超过七个三元组的图结构特性,我们增加了该数据集的节点数量。考虑到事件叙事测试集包含约22,000个样本的规模,我们将其评估周期设置为5,000。如Colas等人(2021)所述,我们在所有事件叙事实验中设置最大输出尺寸为512。验证集上的BLEU分数被用于模型选择。每个模型均在两块NVIDIA RTX 2080 Ti GPU上进行训练。
Table 8: Hyper parameters for GAP on both the WebNLG and Event Narrative datasets.
表 8: WebNLG 和 Event Narrative 数据集上 GAP 的超参数。
| 超参数 | WebNLG | EventNarrative |
|---|---|---|
| 学习率 (Learning Rate) | 2.00E-05 | 2.00E-05 |
| 预热步数 (WarmupSteps) | 1600 | 1600 |
| 评估周期 (EvalPeriod) | 500 | 5000 |
| 束搜索大小 (Beam Size) | 5 | 5 |
| 长度惩罚 (Length Penalty) | 1 | 5 |
| 优化器 (Optimizer) | Adam | Adam |
| 3 | 1.00E-08 | 1.00E-08 |
| 节点数量 (NumNodes) | 50 | 60 |
| 关系数量 (NumRelations) | 60 | 60 |
| 嵌入大小 (Embedding Size) | 128 | 128 |
| 全局层数 (NumGlobalLayers) | 6 | 6 |
| 图感知层数 (Num Graph-aware Layers) | 6 | 6 |
| 批大小 (Batch Size) | 16 | 16 |
B Additional Experimental Results
B 补充实验结果
We provide additional experimental results on both WebNLG v2.0 and Event Narrative for the proposed GAP framework for reference and further analysis.
我们针对提出的GAP框架在WebNLG v2.0和Event Narrative数据集上提供了补充实验结果,以供参考和进一步分析。
B.1 Graph Length
B.1 图长度
Here we examine a comparative study to that of Table 7 for the Event Narrative dataset. Table 9 reveals an exponential decay in BLEU score, with lengths 1-3, 4-7, and $^{7+}$ having $44.48%$ , $23.86%$ , $11.47%$ , respectively. Compared to WebNLG, the BLEU scores are significantly lower, suggesting that Event Narrative is a more challenging dataset. Table 10 gives a brief synopsis of the dataset sizes with respect to the number of triples. Compared to WebNLG which has no KGs greater than length 7, EventKG contains over $1{,}000\mathrm{KGs}$ larger than length 7, making the dataset more diverse.
我们在此对事件叙述数据集进行了与表7类似的对比研究。表9显示BLEU分数呈指数级下降,长度1-3、4-7和$^{7+}$的得分分别为$44.48%$、$23.86%$和$11.47%$。与WebNLG相比,这些BLEU分数明显更低,表明事件叙述是一个更具挑战性的数据集。表10简要概述了不同三元组数量对应的数据集规模。与WebNLG(其知识图谱长度不超过7)不同,EventKG包含超过$1{,}000\mathrm{KGs}$的长度大于7的知识图谱,使得该数据集更加多样化。
Table 9: BLEU scores for the Event Narrative test set for different graph sizes.
表 9: 不同图规模下事件叙事测试集的BLEU分数。
| GAP | #Triples |
|---|---|
| 1-3 | |
| Me,r | 44.48 |
| 数据集 | 1-3 | 4-7 | 7+ |
|---|---|---|---|
| WebNLG | 1,017 | 583 | 0 |
| EventNarrative | 16,103 | 5,152 | 1,184 |
Table 10: Distribution for number of triples in both the WebNLG and Event Narrative datasets.
表 10: WebNLG和Event Narrative数据集中三元组数量的分布情况。
B.2 Entity Accuracy
B.2 实体准确性
To give more insight into KG-to-text generation with GAP, we provide the results for entity accuracy. We define entity accuracy to be the number of entities from the KG that appear in the generated text over those that appear in the reference text. Table 11 shows that all models perform exceedingly well in generating the correct entities from their respective KGs, suggesting that future KG-to-text research should focus on sentence structure and descriptors, i.e. quantifiers and determiners.
为了更深入地理解使用GAP进行知识图谱到文本生成(KG-to-text)的过程,我们提供了实体准确率的结果。我们将实体准确率定义为生成文本中出现的知识图谱实体数量与参考文本中出现的实体数量之比。表11显示,所有模型在从各自知识图谱生成正确实体方面表现非常出色,这表明未来的知识图谱到文本研究应重点关注句子结构及描述性成分(如量词和限定词)。
Table 11: Entity accuracy on the WebNLG test set.
表 11: WebNLG测试集上的实体准确率。
| 数据集 | 准确率 | 准确率 |
|---|---|---|
| 无(T) | 有(T) | |
| Me,r | 94.06 | 94.04 |
| Me,r | 93.99 | 94.48 |
| Me | 93.64 | 94.50 |
| Me.r | 93.82 | 94.28 |
Additional Examples and Error Analysis
附加示例与错误分析
We now present example outputs generated by GAP both on the WebNLG and Event Narrative dataset in Tables 12 and 13 below.
我们现在展示GAP在WebNLG和事件叙事数据集上生成的示例输出,如下表12和表13所示。
C.1 WebNLG
C.1 WebNLG
We showcase five different examples from the WebNLG test set output by our $M^{e,r}+\gamma(T)$ (Prediction 1) and $M_{e,r}^{e,r}+\gamma(T)$ (Prediction 2) models. As can be seen in all the examples, GAP is able to generate fluent and complete sentences. In the first two examples, the output from both models are identical. The outputs from the third example can be viewed as paraphrases of one another, where Prediction 1 mentions ‘US national’ while Prediction 2 instead uses the adjective ‘American’ to convey the same information. Furthermore, in both predictions we learn that ‘Alan Bean’ was a ‘test pilot’ and ‘selected by NASA’ but in slightly different formats. In the fourth example, Prediction 2 is missing the name of the rock band, ‘NRBQ’, while maintaining the rest of the information. Like the third example, the predictions in the fifth example are paraphrases.
我们展示了来自WebNLG测试集的五个不同示例,这些示例由我们的$M^{e,r}+\gamma(T)$(预测1)和$M_{e,r}^{e,r}+\gamma(T)$(预测2)模型输出。从所有示例中可以看出,GAP能够生成流畅且完整的句子。在前两个示例中,两个模型的输出完全相同。第三个示例的输出可以视为彼此的改写,其中预测1提到"US national",而预测2则使用形容词"American"来传达相同的信息。此外,在两个预测中,我们都了解到"Alan Bean"曾是一名"test pilot"并且"selected by NASA",但表述方式略有不同。在第四个示例中,预测2缺少摇滚乐队名称"NRBQ",但保留了其余信息。与第三个示例类似,第五个示例中的预测也是改写版本。
C.2 Event Narrative
C.2 事件叙述
Because of the length of output in EventNarrative, we present four different types of examples to elaborate on the limitations of KG-to-text models. Here, we show example outputs from our $M_{e}^{e,r}$ (Prediction 1) and $M^{e,r}+\gamma(T)$ (Prediction 2) models. In the first example, we observe a contradiction in both Prediction 1 and 2: the gubernato- rial candidate was a democratic nominee, while our predictions conveyed otherwise. The second example shows two predictions which are identical, both missing information, specifically ‘ozone park’ and ‘for three - year - olds and up’. Upon further inspection, these two pieces of information are not within the KG. Similarly, in the third example the only piece of information missing from the predictions, namely ‘cork county board’, is not part of the KG. This example also contains invalid information, $^{\prime}I I2t h^{\prime}$ instead of $\acute{I O}3r d^{\prime}$ . The last example also contains invalid information regarding the dates in both predictions. Additionally, Prediction 2 is missing information about the ‘village of ignacewo’.
由于EventNarrative的输出长度限制,我们通过四种不同类型的示例来阐述KG-to-text(知识图谱到文本)模型的局限性。此处展示了$M_{e}^{e,r}$(预测1)和$M^{e,r}+\gamma(T)$(预测2)模型的输出示例。第一个示例中,预测1和2均出现矛盾:州长候选人是民主党提名者,而模型预测结果与之相反。第二个示例显示两个完全相同的预测结果,均遗漏了"ozone park"和"for three-year-olds and up"信息,经核查发现这两项信息未包含在知识图谱中。第三个示例中,预测结果唯一缺失的"cork county board"信息同样不存在于知识图谱,且包含无效信息$^{\prime}I I2t h^{\prime}$(应为$\acute{I O}3r d^{\prime}$)。最后一个示例中,两个预测的日期信息均存在错误,且预测2还遗漏了"village of ignacewo"相关信息。
Table 12: Examples of output texts generated from $M^{e,r}+\gamma(T)$ (Prediction 1) and $M_{e,r}^{e,r}+\gamma(T)$ (Prediction 2) on the WebNLG test set.
表 12: 在WebNLG测试集上由 $M^{e,r}+\gamma(T)$ (预测1) 和 $M_{e,r}^{e,r}+\gamma(T)$ (预测2) 生成的输出文本示例。
| 预测1 | 预测2 | 参考文本 |
|---|---|---|
| Amsterdam Airport Schiphol serves the city of Amsterdam and is -3.3528 above sea level . The runway name is 18L/36R Aalsmeerbaan and it has a length of 2014.0 . | Amsterdam Airport Schiphol serves the city of Amsterdam and is -3.3528 above sea level . The runway name is 18L/36R Aalsmeerbaan and it has a length of 2014.0 . | Amsterdam Airport Schiphol is -3.3528 above sea level , has a runway name 18L/36R'Aalsmeerbaan which is 2014.0 in length and serves the city of Amster- dam. |
| Baked Alaska is from Hong Kong and the United States . The main ingredients are meringue , ice cream , sponge cake or Christmas pudding · | Baked Alaska is from Hong Kong and the United States . The main ingredients are meringue , ice cream , sponge cake or Christmas pudding . | Baked Alaska comes from both Hong Kong and the United States . The main ingredi- ents are Meringue , ice cream , sponge cake or Christmas pudding . |
| Alan Bean is a US national who was born in Wheeler , Texas . He served as a test pilot before being selected by NASA in 1963 . He is now retired . | Alan Bean is an American test pilot who was born in Wheeler , Texas . He was selected by NASA in 1963 . He is now retired . | The American test pilot Alan Bean ( born in Wheeler , Texas ) was selected by NASA in 1963 .He is now retired . |
| Al Anderson is a member of rock band NRBQ . Rock music originated from country music which originated from blues music . A musical fusion of rock music is bhangra music. | Al Anderson plays rock music which originated from blues and country music . Bhangra music is part of the fusion genre , partly coming from Rock music which uses the banjo . | Al Anderson plays with the rock band NRBQ . Rock has its origins in the blues and country music , where the banjo is played , and Bhangra is a rock fusion . |
| Paulo Sousa is the manager of ACF Fiorentina . He has played for Inter Milan , Juventus FC and Maccabi Tel Aviv F.C . | Paulo Sousa is the manager of ACF Fiorentina . He has played for Inter Milan , Maccabi Tel Aviv FC and Juventus FC . | Paulo Sousa once played for Inter Milan and Juventus FC . He now manages ACF Fiorentina and plays for Maccabi Tel Aviv F.C . |
Table 13: Examples of output texts generated from $M_{e}^{e,r}$ (Prediction 1) and $M^{e,r}+\gamma(T)$ (Prediction 2) on the Event Narrative test set.
| 预测1 | 1971年密西西比州州长选举于1971年11月2日举行。现任州长比尔·沃勒以较大优势击败民主党提名者、前众议院议长托马斯·H·威廉姆斯,成功连任第二任期。 |
| 预测2 | 1971年密西西比州州长选举于1971年11月2日举行,旨在选举密西西比州州长。1972年首次当选的现任州长比尔·沃勒未遭遇民主党对手,因此无需进行决选。 |
| 参考 | 1971年密西西比州州长选举于1971年11月2日举行,选举密西西比州州长一职。民主党人比尔·沃勒当选,并于1972至1976年间担任密西西比州州长。 |
| 预测1 | 《体育专页》让赛是美国纽约州皇后区Aqueduct赛马场每年举办的纯种马赛事。 |
| 预测2 | 《体育专页》让赛是美国纽约州皇后区Aqueduct赛马场每年举办的纯种马赛事。 |
| 参考 | 《体育专页》让赛曾是每年在美国纽约州皇后区臭氧公园Aqueduct赛马场举办的纯种马赛事,参赛马匹需年满三岁及以上。 |
| 预测1 | 1991年科克高级曲棍球锦标赛是科克顶级曲棍球赛事的第112届,也是科克球队参与的第86届。 |
| 预测2 | 1991年科克高级曲棍球锦标赛是该赛事自1887年创立以来的第112届科克顶级俱乐部曲棍球赛事。 |
| 参考 | 1991年科克高级曲棍球锦标赛是科克县委员会自1887年创立该赛事以来的第103届科克高级曲棍球锦标赛。 |
| 预测1 | 伊格纳采沃第一战是一月起义的早期战役之一,发生于1863年1月28日,地点在俄罗斯控制的波兰会议王国西南角科宁县伊格纳凯沃村附近。 |
| 预测2 | 伊格纳采沃第一战是一月起义的早期战役之一,发生于1863年1月6日,地点在波兰会议王国的科宁村附近。 |
| 参考 | 伊格纳采沃第一战是一月起义中的多次冲突之一。该战役发生于1863年5月8日,地点在科宁县伊格纳采沃村附近,当时该地区属于俄罗斯帝国的波兰会议王国。 |
表 13: 事件叙述测试集上由 $M_{e}^{e,r}$ (预测1) 和 $M^{e,r}+\gamma(T)$ (预测2) 生成的输出文本示例。