Modeling Label Semantics for Predicting Emotional Reactions
基于标签语义建模预测情绪反应
Abstract
摘要
Predicting how events induce emotions in the characters of a story is typically seen as a standard multi-label classification task, which usually treats labels as anonymous classes to predict. They ignore information that may be conveyed by the emotion labels themselves. We propose that the semantics of emotion labels can guide a model’s attention when representing the input story. Further, we observe that the emotions evoked by an event are often related: an event that evokes joy is unlikely to also evoke sadness. In this work, we explicitly model label classes via label embeddings, and add mechanisms that track label-label correlations both during training and inference. We also introduce a new semi-supervision strategy that regularizes for the correlations on unlabeled data. Our empirical evaluations show that modeling label semantics yields consistent benefits, and we advance the state-of-theart on an emotion inference task.
预测事件如何引发故事角色情绪通常被视为标准的多标签分类任务,这类方法通常将标签视为匿名类别进行预测,忽略了情绪标签本身可能传递的信息。我们提出情绪标签的语义能在表征输入故事时引导模型的注意力。此外,我们观察到事件触发的情感往往存在关联:能引发快乐的事件不太可能同时引发悲伤。本工作通过标签嵌入显式建模标签类别,并添加在训练和推理阶段追踪标签间相关性的机制。我们还提出一种新的半监督策略,对未标注数据中的相关性进行正则化处理。实证评估表明,建模标签语义能带来持续收益,我们在情绪推理任务上实现了最先进的性能。
1 Introduction
1 引言
Understanding how events in a story affect the characters involved is an integral part of narrative under standing. Rashkin et al. (2018) introduced an emotion inference task on a subset of the ROCStories dataset (Most af azad eh et al., 2016), labeling entities with the emotions they experience from the short story contexts. Previous work on this and related tasks typically frame them as multi-label classification problems. The standard approach uses an encoder that produces a representation of the target event along with the surrounding story events, and then pushes it through a classification layer to predict the possible emotion labels (Rashkin et al., 2018; Wang et al., 2018).
理解故事中事件如何影响相关角色是叙事理解的重要组成部分。Rashkin等人(2018)在ROCStories数据集(Mostafazadeh等人, 2016)的子集上提出了情感推理任务, 根据短篇故事上下文为实体标注其经历的情感。此前关于该任务及相关研究通常将其视为多标签分类问题。标准方法是使用编码器生成目标事件及周边故事事件的表征, 然后通过分类层预测可能的情感标签(Rashkin等人, 2018; Wang等人, 2018)。
This classification framework ignores the semantics of the emotions themselves. Each emotion label (e.g., joy) is just a binary prediction. However, consider the sentence, “Danielle was really short on money”. The emotional reaction is FEAR of being short on money. First, if a model had lexical foreknowledge of “fear”, we should expect an improved ability to decide if a target event evokes FEAR. Second, such a model might represent relationships between the emotions themselves. For example, an event that evokes FEAR is likely to evoke SADNESS and unlikely to evoke JOY. When previous models frame this as binary label prediction, they miss out on ways to leverage label semantics.
该分类框架忽略了情感本身的语义。每个情感标签(如joy)仅作为二元预测项。例如分析句子"Danielle was really short on money"时,其情感反应是对缺钱的恐惧(FEAR)。首先,若模型具备"fear"的词法先验知识,则应能更准确判断目标事件是否引发恐惧。其次,此类模型可能表征情感之间的关联性——例如引发恐惧的事件往往同时引发悲伤(SADNESS),而极少引发快乐(JOY)。当传统模型将其视为二元标签预测时,便错失了利用标签语义的潜在价值。
In this work, we show that explicitly modeling label semantics improves emotion inference. We describe three main contributions 1. First, we show how to use embeddings as the label semantics represent ation. We then propose a label attention network that produces label-informed representations of the event and the story context to improve prediction accuracy. Second, we add mechanisms that can make use of label-label correlations as part of both training and inference. During training, the correlations are used to add a regular iz ation loss. During inference, the prediction logits for each label are modified to incorporate the correlations, thus allowing the model’s confidence on one label to influence its prediction of other labels. Third, we show that the label correlations can be used as a semi-supervised signal on the unlabeled portion of the ROCStories dataset.
在本工作中,我们证明显式建模标签语义能提升情绪推理效果。我们阐述了三个主要贡献:
- 首先,我们展示了如何将嵌入(embedding)作为标签语义的表征方式,并提出一种标签注意力网络,该网络能生成融合标签信息的事件和故事上下文表征,从而提高预测准确率。
- 其次,我们增加了利用标签间相关性的机制,将其同时应用于训练和推理阶段。训练时通过相关性添加正则化损失(regularization loss);推理时则根据相关性调整每个标签的预测逻辑值(logit),使得模型对某个标签的置信度能影响其他标签的预测结果。
- 最后,我们证明标签相关性可作为半监督信号,应用于ROCStories数据集的未标注部分。
Our empirical evaluations show that adding label semantics consistently improves prediction accuracy, and produces labelings that are more consistent than models without label semantics. Our best model outperforms previously reported results and achieves more than 4.9 points absolute improvement over the BERT classification model yielding a new state-of-the-art result for this task.
我们的实证评估表明,加入标签语义能持续提升预测准确率,并生成比无标签语义模型更一致的标注结果。最佳模型性能超越此前报道的所有结果,相比BERT分类模型实现了4.9个百分点的绝对提升,为此任务创造了新的最优性能纪录。
2 Emotion Inference
2 情绪推断
The emotion inference task introduced by Rashkin et al. (2018) is defined over a subset of short stories from the ROCStories dataset (Most af azad eh et al., 2016). It infers the reactions that each event evokes in the characters of the story, given the story context thus far. For each sentence (i.e. event) in a story, the training data includes annotations of eight emotions. Given a sentence $x_{s}$ denoting a single event in a story, the task is to label the possible emotional reactions that an event evokes in each character in the story. Since an event can evoke multiple reactions, the task is formulated as a multi-label classification problem.
Rashkin等人(2018)提出的情绪推理任务基于ROCStories数据集(Mostafazadeh等人, 2016)的短篇故事子集。该任务在给定当前故事上下文的情况下,推断每个事件在故事角色中引发的反应。对于故事中的每个句子(即事件),训练数据包含八种情绪的标注。给定表示故事中单个事件的句子$x_{s}$,任务是为事件在故事每个角色中可能引发的情绪反应打标签。由于一个事件可能引发多种反应,该任务被构建为多标签分类问题。
The standard approach to this task has been as follows. For a given character $c$ and the target sentence $x_{s}$ , collect all previous sentences $x_{c}$ in the story in which the character $c$ is mentioned as the character context. Encode the target sentence, and the character context to obtain a single representation, and use it as input to a multi-label classification layer for prediction. Rashkin et al. (2018) benchmark the performance of multiple encoders (see Section 5).
该任务的标准方法如下:对于给定角色 $c$ 和目标句子 $x_{s}$,收集故事中所有提及该角色的先前句子 $x_{c}$ 作为角色上下文。对目标句子和角色上下文进行编码以获得单一表征,并将其作为多标签分类层的输入进行预测。Rashkin等人 (2018) 对多种编码器的性能进行了基准测试(参见第5节)。
We extend this previous work to integrate label semantics into the model by adding label embeddings (Section 3) and explicitly representing labellabel correlations (Section 4).
我们通过添加标签嵌入 (Section 3) 和显式表示标签间相关性 (Section 4) ,将标签语义整合到模型中,从而扩展了先前的工作。
3 Label Semantics using Embeddings
3 基于嵌入的标签语义
A simple strategy to model label semantics is to explicitly represent each with an embedding that captures the surface semantics of its label name. Since the emotion labels correspond to actual words (e.g., joy, fear, etc.), we can initialize them with their corresponding word embeddings (learned from a large corpus). We then use these label embeddings in two ways as detailed below.
一种简单的建模标签语义策略是显式地用嵌入表示每个标签,以捕捉其标签名称的表面语义。由于情感标签对应实际词语(如joy、fear等),我们可以用其对应的词嵌入(从大型语料库学习得到)进行初始化。随后通过以下两种方式使用这些标签嵌入:
3.1 Label Attention Network
3.1 标签注意力网络
The label embeddings can be used to guide an encoder network to extract emotion-related information from the sentences. We adopted the Label-Embedding Attentive Network (LEAM) architecture to produce label-focused representations (Wang et al., 2018). The main idea behind the LEAM model is to compute attention scores between the label and the representations of the tokens in the input that is to be classified 2. This can then be used to appropriately weight the contributions of each token to the final representations. In this work, we use LEAM to compute an attention matrix computed over the hidden states produced by the encoder and the label embeddings. The encoder used is the BERT features for each token $B_{t}$ in the text and each of the label sentences $J$ . The attention matrix is then used to produce a weighted combination of the contextual representations of the input, using the compatibility matrix $H$ , as computed in (Wang et al., 2018). This gives emotion focused representations $y$ to use for classification:
标签嵌入可用于指导编码器网络从句子中提取与情感相关的信息。我们采用标签嵌入注意力网络 (LEAM) 架构来生成以标签为中心的表示 (Wang et al., 2018)。LEAM 模型的核心思想是计算待分类输入中标签与各token表示之间的注意力分数,从而合理加权每个token对最终表示的贡献。本工作中,我们使用 LEAM 计算编码器生成的隐藏状态与标签嵌入之间的注意力矩阵。编码器采用文本中每个token $B_{t}$ 和各标签句子 $J$ 的 BERT 特征。随后通过兼容性矩阵 $H$ (计算方法见 Wang et al., 2018) 对输入的上下文表示进行加权组合,生成用于分类的情感聚焦表示 $y$:
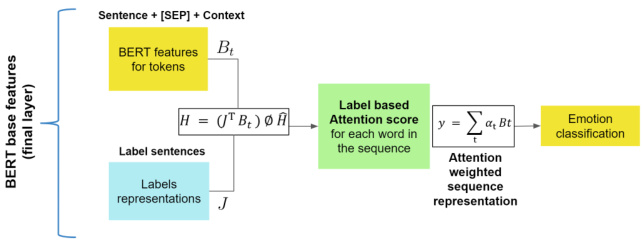
Figure 1: Label-Embedding Attentive Network using BERT Features. $y$ denotes the label attended story sentence and context representation, where $\alpha$ is the attention score. Figure 1 illustrates the key steps in the model.
图 1: 基于BERT特征的标签嵌入注意力网络。$y$表示经过标签注意力的故事句子和上下文表示,其中$\alpha$为注意力分数。图1展示了该模型的关键步骤。
$$
H=(J^{T}B_{t})\oslash\hat{H}
$$
$$
H=(J^{T}B_{t})\oslash\hat{H}
$$
3.2 Labels as Additional Input
3.2 标签作为额外输入
Rather than learning label embeddings from scratch, we also explore using contextual embeddings from transformer-based models like BERT. This allows us to use richer semantics derived from pre-training and also allows us to exploit the selfattention mechanism to introduce label semantics as part of the input itself. In addition to the target and context sentences, we also include emotionlabel sentences, $L_{s}$ , of the form “[character] is [emotional state]” as input to the classifier. For each instance, we add eight such sentences covering all emotional labels3. In this paper, we use the final layer of a pretrained Bert-base model to get representations for the input sentence and each of the emotion-label sentences. The selfattention mechanism will automatically learn to attend to these label sentences when constructing the representations for the input text.
我们不仅从零开始学习标签嵌入,还探索了使用基于Transformer的模型(如BERT)生成的上下文嵌入。这种方法使我们能够利用预训练获得的丰富语义,并通过自注意力机制将标签语义作为输入的一部分引入。除了目标句和上下文句外,我们还将形式为"[角色]处于[情绪状态]"的情绪标签句$L_{s}$作为分类器的输入。每个实例中,我们添加八条这样的句子以覆盖所有情绪标签[3]。本文采用预训练Bert-base模型的最后一层来获取输入句及各情绪标签句的表征。自注意力机制在构建输入文本表征时,会自动学习关注这些标签句。
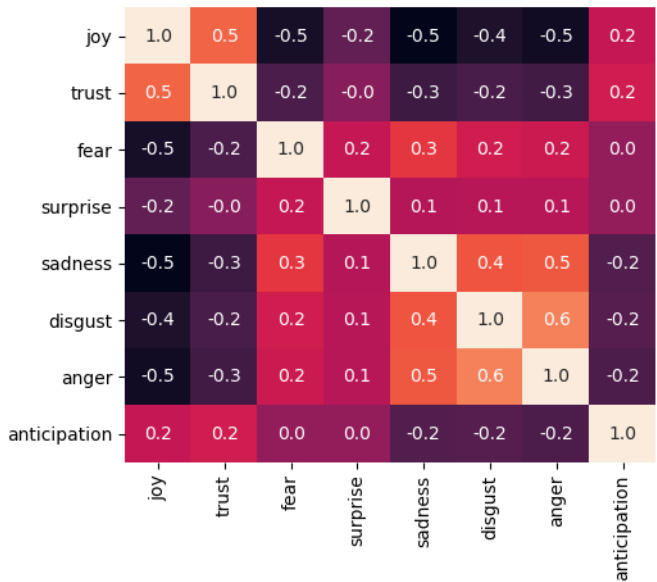
Figure 2: Emotion correlations as seen in the ground truth labels in the training data.
图 2: 训练数据中真实标签所呈现的情绪相关性。
4 Label Semantics using Correlations
4 基于相关性的标签语义
When more than one emotion is evoked by an event, they aren’t independent. Indeed, as shown in Figure 2, there are strong (positive and negative) correlations between the emotion labels in the ground truth. For instance, there is a negative correlation $(\rho~=~-0.5)$ between JOY and SAD labels and a positive correlation between JOY and TRUST $(\rho=0.5)$ . We propose two ways to incorporate these label correlations to improve prediction.
当某个事件引发多种情绪时,这些情绪并非相互独立。如图2所示,真实标注中的情绪标签之间存在显著(正向和负向)相关性。例如,JOY(喜悦)与SAD(悲伤)标签呈负相关 $(\rho~=~-0.5)$ ,而JOY与TRUST(信任)则呈正相关 $(\rho=0.5)$ 。我们提出两种利用这些标签相关性来优化预测的方法。
4.1 Correlations on Labeled Data
4.1 标注数据的相关性
In a multi-label setting, a good model should respect the label correlations. If it is confident about a particular label, then it should also be confident about other positively correlated labels, and conversely less confident about labels that are negatively correlated.
在多标签场景下,好的模型应当遵循标签相关性。当模型对某个特定标签具有高置信度时,也应对其他正相关标签表现出高置信度,反之对负相关标签则应降低置信度。
Following Zhao et al. (2019), we add (i) a loss function that penalizes the model for making incongruous predictions, i.e. those that are not compatible with the label correlations, and (ii) a component that multiplies the classification logit vector $z$ with the learned label relations encoded as a learned correlation matrix $G$ . This component transforms the raw prediction score of each label to a weighted sum of the prediction scores of the other labels. For each label, these weights are given by its learned correlation with all the other labels. Therefore, the prediction score of each label is affected by the prediction score of the other labels, based on the correlation between label pairs. The final prediction scores are then calculated as shown in the
遵循 Zhao 等人 (2019) 的方法,我们添加了:(i) 一个惩罚模型做出不协调预测(即与标签相关性不兼容的预测)的损失函数;(ii) 一个将分类 logit 向量 $z$ 与学习到的标签关系(编码为学习到的相关矩阵 $G$)相乘的组件。该组件将每个标签的原始预测分数转换为其他标签预测分数的加权和。对于每个标签,这些权重由其与所有其他标签学习到的相关性决定。因此,每个标签的预测分数会受到其他标签预测分数的影响,影响程度取决于标签对之间的相关性。最终预测分数的计算方式如
equation:
方程:
$$
e=\sigma(z\cdot G)
$$
$$
e=\sigma(z\cdot G)
$$
The overall loss then comprises of two loss functions - the prediction loss $(\mathcal{L}{B C E})$ , and the correlation-loss $(\mathcal{L}_{c o r r})$ :
总体损失由两个损失函数组成:预测损失 $(\mathcal{L}{BCE})$ 和相关性损失 $(\mathcal{L}_{corr})$:
$$
\mathcal{L}(\theta)=\mathcal{L}{B C E}(e,y)+\mathcal{L}_{c o r r}(e,y^{\prime})
$$
$$
\mathcal{L}(\theta)=\mathcal{L}{B C E}(e,y)+\mathcal{L}_{c o r r}(e,y^{\prime})
$$
Where $\mathcal{L}_{c o r r}$ computes BCE Loss with continuous representation of the true labels $y$ , using the learned label correlation $G$ :
其中 $\mathcal{L}_{c o r r}$ 通过真实标签 $y$ 的连续表示计算 BCE Loss (Binary Cross-Entropy Loss) ,并使用学习到的标签相关性 $G$ :
$$
y^{\prime}=y\cdot G
$$
$$
y^{\prime}=y\cdot G
$$
4.2 Semi-supervision on Unlabeled Data
4.2 无标注数据的半监督学习
We also introduce a new semi-supervision idea to exploit label correlations as a regular iz ation signal on unlabeled data. The multi-label annotations used in this work (Rashkin et al., 2018) only comprises a small fraction of the original ROCStories data. There are ${\sim}40\mathrm{k}$ character-line pairs that have open text descriptions of emotional reactions, but these aren’t annotated with multi-label emotions, and therefore were not used in the above supervised emotion prediction tasks. We propose a new semisupervised method over BERT representations that augments the soft-training objective used in Section 4.1 with a label correlation incompatibility loss defined over the unlabeled portion of the ROCStories dataset.
我们还提出了一种新的半监督思路,通过利用标签相关性作为未标注数据的正则化信号。本工作采用的(Rashkin et al., 2018)多标签标注仅覆盖了原始ROCStories数据的一小部分。虽然存在约4万条角色-台词对带有开放式情感反应描述,但这些数据未进行多标签情感标注,因此未用于前述监督式情感预测任务。我们提出了一种基于BERT表征的新半监督方法,该方法通过引入在ROCStories未标注数据集上定义的标签相关性不兼容损失,对4.1节使用的软训练目标进行增强。
We use two loss functions: the loss computed in Equation 3, and the regular iz ation loss on the unlabeled training data (Equation 5). For the semisupervised training, we use an iterative batch-wise training. In the first step, all weights of the model are minimized by minimizing the loss in Equation 3. In the next step, the learned label correlations are updated using:
我们采用两种损失函数:公式3计算的损失,以及未标注训练数据的正则化损失(公式5)。对于半监督训练,我们采用迭代式批量训练方式。第一步通过最小化公式3的损失来优化模型所有权重。第二步使用以下方式更新学习到的标签关联:
$$
\mathcal{L}{r e g}=\sum_{i,j}G_{i j}\cdot d(e_{i},e_{j})
$$
$$
\mathcal{L}{r e g}=\sum_{i,j}G_{i j}\cdot d(e_{i},e_{j})
$$
$$
d(e_{i},e_{j})=\left{\begin{array}{l l}{\displaystyle||e_{i}-e_{j}||}&{\mathrm{for}G_{i j}\geq0,}\ {\displaystyle||e_{i}-e_{j}||-1}&{\mathrm{otherwise}.}\end{array}\right.
$$
$$
d(e_{i},e_{j})=\left{\begin{array}{l l}{\displaystyle||e_{i}-e_{j}||}&{\mathrm{for}G_{i j}\geq0,}\ {\displaystyle||e_{i}-e_{j}||-1}&{\mathrm{otherwise}.}\end{array}\right.
$$
This loss helps the model to produce consistent predictions based on the correlations by forcing positively correlated labels to have similar scores and negatively correlated ones to have dissimilar scores.
该损失函数通过强制正相关标签具有相似分数、负相关标签具有不同分数,帮助模型基于相关性生成一致的预测结果。
Table 1: Comparison Results on ROCStories with Plutchik emotion labels
表 1: ROCStories数据集上基于Plutchik情绪标签的对比结果
| Baselines | Model | Precision | Recall | F1 |
|---|---|---|---|---|
| Rashkin et al. (2018) BiLSTM CNN REN | 25.31 24.47 25.30 | 33.44 38.87 37.30 | 28.81 30.04 30.15 | |
| NPN Paul and Frank (2019) | 24.33 59.66 | 40.10 51.33 | 30.29 55.18 | |
| BERT | 65.63 | 56.91 | 60.96 | |
| Adding Label Semantics | Label Embeddings | |||
| LEAM w/ GloVe LEAMw/BERTFeatures | 59.81 | 54.46 54.48 | 57.03 | |
| BERT + Labels as Input | 67.29 63.05 | 61.70 | 60.22 62.36 | |
| Label Correlation | ||||
| Learned Correlations | 71.47 | 63.11 | ||
| Semi-supervision | 56.50 57.94 | 76.35 | 65.88 |
5 Experimental Setup
5 实验设置
We compare our proposed models with the models presented in Rashkin et al. (2018), the LEAM architecture of Wang et al. (2018), and fine-tuned BERT models (Devlin et al., 2019) for multi-label classification without label semantics. For all the models we report the micro-averaged Precision, Recall and F1 score of the emotion prediction task.
我们将提出的模型与Rashkin等人 (2018) 的模型、Wang等人 (2018) 的LEAM架构以及Devlin等人 (2019) 未经标签语义微调的BERT多标签分类模型进行对比。所有模型均报告情绪预测任务的微观平均精确率 (Precision)、召回率 (Recall) 和F1分数 (F1 score)。
Rashkin et al. (2018) modeled character context and pre-trained on free response data to predict the mental states of characters using different encoderdecoder setups, including BiLSTMs, CNNs, the recurrent entity network (REN) (Henaff et al., 2016), and neural process networks (NPN) (Bosselut et al., 2017). Additionally, we compare with the selfattention architecture proposed in (Paul and Frank, 2019), without the knowledge from ConceptNet (Speer and Havasi, 2012) and ELMo embeddings (Peters et al., 2018).
Rashkin等人(2018)通过建模角色上下文并在自由应答数据上进行预训练,使用包括BiLSTM、CNN、循环实体网络(REN)(Henaff等人,2016)和神经过程网络(NPN)(Bosselut等人,2017)在内的不同编码器-解码器架构来预测角色的心理状态。此外,我们还与(Paul和Frank,2019)提出的自注意力架构进行了比较,该架构未使用ConceptNet(Speer和Havasi,2012)的知识和ELMo嵌入(Peters等人,2018)。
To compare against LEAM, we compare it against our proposal of the LEAM $+$ BERT model, where our label attention is computed from BERT representations of each of the label sentences, and words in the input sentence. We also encode the sentence and context separately in a BiLSTM layer as done in Rashkin et al. (2018).
为了与LEAM进行对比,我们将其与我们提出的LEAM $+$ BERT模型进行比较。在该模型中,标签注意力是从每个标签句子及输入句子中单词的BERT表示计算得出的。同时,我们按照Rashkin等人 (2018) 的方法,在BiLSTM层中分别对句子和上下文进行编码。
We also fine-tuned a BERT-base-uncased model for emotion classification, using $x_{s}$ , $x_{c}$ and $L_{s}$ as inputs. This beats the other baselines by a significant margin, and is thus a strong new baseline. All our models are evaluated on the emotion reaction prediction task over the eight emotion labels (Plutchik categories) annotated in the Rashkin et al. (2018)
我们还微调了一个BERT-base-uncased模型用于情绪分类,使用$x_{s}$、$x_{c}$和$L_{s}$作为输入。这显著超越了其他基线模型,因此成为一个强有力的新基线。我们所有模型都在情绪反应预测任务上进行了评估,针对Rashkin等人(2018)标注的八种情绪标签(Plutchik分类)。
dataset. We follow their evaluation setup, and report the final results on the test set. We use pretrained GloVe embeddings (100d) and BERT-baseuncased representations with the LEAM model. The final classifier used in all models is a feedforward layer, followed by a sigmoid.
数据集。我们沿用他们的评估设置,并报告测试集上的最终结果。所有模型均使用预训练的GloVe词向量(100维)和BERT-base-uncased表征作为LEAM模型的输入。最终分类器采用前馈层加Sigmoid激活的结构。
6 Results
6 结果
Table 1 compares the performance of the baselines with our models that use label semantics. Among the baselines, the fine-tuned BERT base model obtains the best results. Adding label embeddings (section 3.1) to the basic BiLSTM via LEAM model provides substantial increase, more than 27 absolute points in F1. We swapped in BERT features instead of GloVe and found a further 3 point improvement. The BERT baseline beat both of these, but appending label sentences as additional input to fine-tuned BERT increased its performance by 1.4 F1 points.
表 1 比较了基线模型与采用标签语义的我们模型的性能。在基线模型中,经过微调的 BERT base 模型取得了最佳结果。通过 LEAM 模型向基础 BiLSTM 添加标签嵌入 (section 3.1) 带来了显著提升,F1 值绝对增幅超过 27 分。我们用 BERT 特征替换 GloVe 后,发现性能进一步提高了 3 分。虽然 BERT 基线模型优于这两个方案,但向微调后的 BERT 追加标签语句作为额外输入后,其 F1 值又提升了 1.4 分。
A further increase of 2 points in F1 is achieved by tracking label-label correlations through training loss and inference logits. In addition, adding semi-supervision yields the best gain of more than 4.9 points in F1 over basic BERT, providing a significant advance in state-of-the-art results for emotion inference in this dataset. We also checked the statistical significance of the Semi-supervision model (Table 1) against the Learned Correlations, BERT+Labels as Input, LEAM w/ BERT Features and the BERT model using the Random iz ation Test (Smucker et al., 2007). This involved comparing the outputs of the Semi-supervision model with the above mentioned models after creating 100,000 random permutations. The Semi-supervision model achieved statistically significant improvement over all the baselines.
通过训练损失和推理对数跟踪标签间相关性,F1分数进一步提升2点。此外,加入半监督学习相比基础BERT模型带来超过4.9点的F1值增益,显著推进了该数据集情感推理任务的当前最优水平。我们还使用随机化检验 (Smucker et al., 2007) 验证了半监督模型 (表1) 与Learned Correlations、BERT+Labels as Input、LEAM w/ BERT Features以及BERT模型的统计显著性差异。具体方法是通过创建10万次随机排列,将半监督模型输出与上述模型进行对比。统计结果表明,半监督模型在所有基线模型上均取得显著改进。
Table 2: Prediction of labels with label semantics (LS) versus without label semantics (NoLS). Including label semantics helps the model predict semantically labels (high correlations), with high probability.
表 2: 带标签语义 (LS) 与不带标签语义 (NoLS) 的标签预测对比。包含标签语义有助于模型以高概率预测语义化标签 (高相关性) 。
| 句子 | 真实标签 | LS | NoLS |
|---|---|---|---|
| And nobody could give him any direction | Sad, Disgust Surprise | Sad, Disgust Anger | Sad |
| She said Mark can come for free | Joy, Trust Anticipation | Joy ,Trust Anticipation | Joy, Anticipation |
| He is relieved that it was not harmed | Joy, Surprise Anticipation | Joy, Surprise Anticipation | Fear, Surprise |
| The marshmallows were totally smooshed | Anger, Sad | Anger, Sad | Joy, Anticipation |
We did further qualitative analysis of the results on the dev set to better understand the performance of the Semi-supervised Label Semantics model. Compared to base BERT, this model predicts more emotion classes per instance (8839 vs 5024). The wrong predictions of this model have lower probabilities than the correct labels suggesting that classification could be further improved with proper threshold identification. This model is also better at capturing the semantic relations between labels during prediction. This is highlighted through some examples in Table 2.
我们对开发集的结果进行了进一步的定性分析,以更好地理解半监督标签语义模型的性能。与基础BERT相比,该模型为每个实例预测了更多的情感类别(8839 vs 5024)。该模型的错误预测概率低于正确标签,表明通过适当的阈值识别可以进一步改进分类。该模型在预测过程中还能更好地捕捉标签之间的语义关系。表2中的一些例子突出展示了这一点。
7 Related Work
7 相关工作
One of the most widely-used work in narrative understanding introduced ROCStories, a dataset for evaluating story understanding (Most af azad eh et al., 2016). On a subset of these stories (Rashkin et al., 2018) added annotations for causal links between events in stories and mental states of characters. They model entity state to predict emotional reactions and motivations for causing events occurring in ROCStories. Additionally, they also introduce a new dataset annotation that tracks emotional reactions and motivations of characters in stories. Other work looked at encoding external knowledge sources to augment motivation inference (Paul and Frank, 2019) on the same dataset. Both treat labels as anonymous classes, whereas this work explores modeling the semantics of the emotion labels explicitly. Recent work in multi-label emotion classification has shown that using the relation information between labels can improve performance. (Kurata et al., 2016) use the label co-occurrence information in the final layer of the neural network to improve multi-label classification. Correlationbased label representations have also been used for music classification styles (Zhao et al., 2019). Our work builds on these and adds a similar result showing that label correlations can have significant impact for emotion label inference.
叙事理解领域最广泛使用的研究之一是ROCStories数据集,该数据集用于评估故事理解能力(Mostafazadeh et al., 2016)。Rashkin等人(2018)在这些故事子集上添加了事件间因果关联和角色心理状态的标注。他们通过建模实体状态来预测ROCStories中事件触发的情感反应和动机。此外,他们还引入了一个新的数据集标注方案,用于追踪故事角色的情感反应和动机。Paul和Frank(2019)则在相同数据集上探索了利用外部知识源增强动机推理的方法。这些研究都将标签视为匿名类别,而本文则显式建模情感标签的语义。近期多标签情感分类研究表明,利用标签间关系信息能提升性能——Kurata等人(2016)在神经网络最后一层使用标签共现信息改进多标签分类,Zhao等人(2019)也将基于相关性的标签表征应用于音乐风格分类。我们的研究在此基础上进一步证明,标签相关性对情感标签推理具有显著影响。
8 Conclusions
8 结论
We present new results for the multi-label emotion classification task of Rashkin et al. (2018), extending previous reported results by $10.7~\mathrm{F}1$ points (55.1 to 65.8). The multi-label nature of emotion prediction lends itself naturally to use the correlations between the labels themselves. Further, we showed that modeling the class labels as semantic embeddings helped to learn better representations with more meaningful predictions. As with many tasks, BERT provided additional context, but our integration of these label semantics showed significant improvements. We believe these models can improve many other NLP tasks where the class labels carry inherent semantic meaning in their names.
我们针对Rashkin等人(2018)提出的多标签情感分类任务展示了新的研究成果,将先前报告的F1值提升了10.7分(从55.1提升至65.8)。情感预测的多标签特性天然适合利用标签之间的相关性。此外,我们发现将类别标签建模为语义嵌入(embedding)有助于学习更具代表性的特征,从而产生更有意义的预测结果。与许多任务类似,BERT模型提供了额外的上下文信息,但我们整合的这些标签语义特征显示出显著的改进效果。我们相信这些模型可以改进许多其他自然语言处理任务,特别是当类别标签名称本身就包含内在语义信息时。