Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation
视觉关系检测中的内部与外部语言知识蒸馏
Abstract
摘要
Understanding the visual relationship between two objects involves identifying the subject, the object, and a predicate relating them. We leverage the strong correlations between the predicate and the $\langle s u b j,o b j\rangle$ pair (both semantically and spatially) to predict predicates conditioned on the subjects and the objects. Modeling the three entities jointly more accurately reflects their relationships compared to modeling them independently, but it complicates learning since the semantic space of visual relationships is huge and training data is limited, especially for longtail relationships that have few instances. To overcome this, we use knowledge of linguistic statistics to regularize visual model learning. We obtain linguistic knowledge by mining from both training annotations (internal knowledge) and publicly available text, e.g., Wikipedia (external knowledge), computing the conditional probability distribution of a predicate given a $\langle s u b j,o b j\rangle$ pair. As we train the visual model, we distill this knowledge into the deep model to achieve better generalization. Our experimental results on the Visual Relationship Detection (VRD) and Visual Genome datasets suggest that with this linguistic knowledge distillation, our model outperforms the stateof-the-art methods significantly, especially when predicting unseen relationships (e.g., recall improved from $8.45%$ to $19.17%$ on VRD zero-shot testing set).
理解两个物体之间的视觉关系涉及识别主体、客体以及连接它们的谓词。我们利用谓词与$\langle subj, obj\rangle$对之间(语义和空间上)的强相关性,基于主体和客体来预测谓词。相比独立建模,联合建模这三个实体能更准确地反映它们的关系,但由于视觉关系的语义空间庞大且训练数据有限(尤其是实例稀少的长尾关系),这会增加学习难度。为此,我们利用语言统计知识来规范视觉模型学习:通过挖掘训练标注(内部知识)和公开文本(如维基百科等外部知识),计算给定$\langle subj, obj\rangle$对的谓词条件概率分布。在训练视觉模型时,我们将这类知识蒸馏到深度模型中以提高泛化能力。在视觉关系检测(VRD)和Visual Genome数据集上的实验表明,通过语言知识蒸馏,我们的模型显著优于现有方法,尤其在预测未见关系时(例如VRD零样本测试集的召回率从$8.45%$提升至$19.17%$)。
1. Introduction
1. 引言
Detecting visual relationships from images is a central problem in image understanding. Relationships are commonly defined as tuples consisting of a subject (subj), predicate (pred) and object (obj) [31, 8, 1]. Visual rela tion ships represent the visually observable interactions between subject and object $\langle s u b j,o b j\rangle$ pairs, such as $\langle p e r s o n,r i d e,h o r s e\rangle$ [19].
检测图像中的视觉关系是图像理解的核心问题。关系通常被定义为由主体(subj)、谓词(pred)和客体(obj)组成的元组[31, 8, 1]。视觉关系表示主体与客体$\langle subj,obj\rangle$对之间可观察到的视觉交互,例如$\langle person,ride,horse\rangle$[19]。
Recently, Lu et al. [19] introduce the visual relationship dataset (VRD) to study learning of a large number of visual relationships from images. Lu et al. predict the predicates independently from the subjects and objects, and use the product of their scores to predict relationships present in a given image using a linear model. The results in [19] suggest that predicates cannot be predicted reliably with a linear model that uses only visual cues, even when the ground truth categories and bounding boxes of the subject and object are given ([19] reports Recall $@100$ of only $7.11%$ for their visual prediction). Although the visual input analyzed by the CNN in [19] includes the subject and object, predicates are predicted without any knowledge about the object categories present in the image or their relative locations. In contrast, we propose a probabilistic model to predict the predicate name jointly with the subject and object names and their relative spatial arrangement:
最近,Lu等人[19]引入了视觉关系数据集(VRD)来研究从图像中学习大量视觉关系。Lu等人独立于主体和客体预测谓词,并使用它们的分数乘积通过线性模型预测给定图像中存在的关系。[19]中的结果表明,即使给出了主体和客体的真实类别和边界框( [19]报告其视觉预测的召回率$@100$仅为$7.11%$ ),仅使用视觉线索的线性模型无法可靠地预测谓词。尽管[19]中CNN分析的视觉输入包括主体和客体,但在预测谓词时没有任何关于图像中存在的对象类别或其相对位置的信息。相比之下,我们提出了一个概率模型,联合预测谓词名称与主体和客体名称及其相对空间排列:
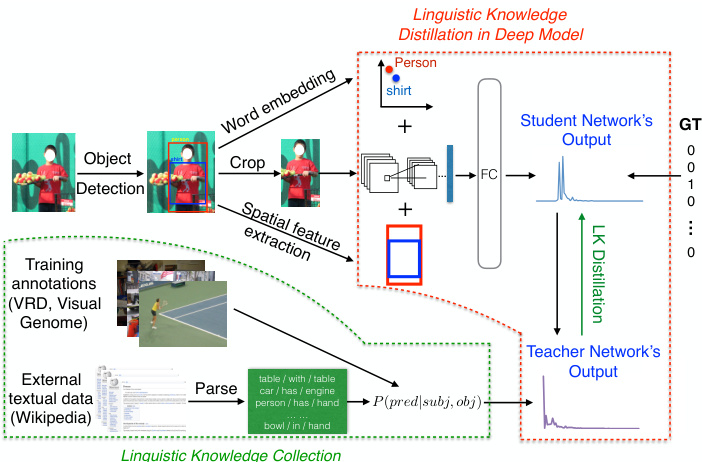
Figure 1. Linguistic Knowledge Distillation Framework. We extract linguistic knowledge from training annotations and a public text corpus (green box), then construct a teacher network to distill the knowledge into an end-to-end deep neural network (student) that predicts visual relationships from visual and semantic representations (red box). GT is the ground truth label and $\mho$ is the concatenation operator.
图 1: 语言知识蒸馏框架。我们从训练标注和公共文本语料库(绿色框)中提取语言知识,构建教师网络将知识蒸馏到端到端深度神经网络(学生)中,该网络通过视觉和语义表征(红色框)预测视觉关系。GT表示真实标签,$\mho$为拼接运算符。
$$
\begin{array}{r}{P(R|I)=P(p r e d|I_{\mathrm{union}},s u b j,o b j)P(s u b j)P(o b j).}\end{array}
$$
$$
\begin{array}{r}{P(R|I)=P(p r e d|I_{\mathrm{union}},s u b j,o b j)P(s u b j)P(o b j).}\end{array}
$$
While our method models visual relationships more accurately than [19], our model’s parameter space is also enlarged because of the large variety of relationship tuples. This leads to the challenge of insufficient labeled image data. The straightforward—but very costly—solution is to collect and annotate a larger image dataset that can be used to train this model. Due to the long tail distribution of rela tion ships, it is hard to collect enough training images for all relationships. To make the best use of available training images, we leverage linguistic knowledge (LK) to regularize the deep neural network. One way to obtain linguistic knowledge is to compute the conditional probabilities $P(p r e d|s u b j,o b j)$ from the training annotations.
虽然我们的方法比[19]更准确地建模视觉关系,但由于关系元组的多样性,模型的参数空间也随之扩大。这导致了标注图像数据不足的挑战。直接但成本高昂的解决方案是收集并标注更大的图像数据集用于训练。由于关系呈现长尾分布,很难为所有关系收集足够的训练图像。为了充分利用现有训练数据,我们引入语言知识 (linguistic knowledge, LK) 来正则化深度神经网络。获取语言知识的一种方式是从训练标注中计算条件概率 $P(pred|subj,obj)$。
However, the number of $\langle s u b j,p r e d,o b j\rangle$ combinations is too large for each triplet to be observed in a dataset of annotated images, so the internal statistics (e.g., statistics of the VRD dataset) only capture a small portion of the knowledge needed. To address this long tail problem, we collect external linguistic knowledge $(P(p r e d|s u b j,o b j))$ from public text on the Internet (Wikipedia). This external knowledge consists of statistics about the words that humans commonly use to describe the relationship between subject and object pairs, and importantly, it includes pairs unseen in our training data. Although the external knowledge is more general, it can be very noisy (e.g., due to errors in linguistic parsing).
然而,$\langle s u b j,p r e d,o b j\rangle$ 组合的数量过于庞大,导致标注图像数据集中无法观测到每个三元组,因此内部统计数据 (如VRD数据集的统计) 仅能捕获所需知识的一小部分。针对这一长尾问题,我们从互联网公开文本 (维基百科) 收集外部语言知识 $(P(p r e d|s u b j,o b j))$。该外部知识包含人类常用以描述主客体对关系的词汇统计,关键的是,它涵盖了训练数据中未出现的主客体对。尽管外部知识更具普适性,但其可能包含大量噪声 (例如由语言解析错误导致)。
We make use of the internal and external knowledge in a teacher-student knowledge distillation framework [10, 11], shown in Figure 1, where the output of the standard vision pipeline, called the student network, is augmented with the output of a model that uses the linguistic knowledge to score solutions; their combination is called the teacher network. The objective is formulated so that the student not only learns to predict the correct one-hot ground truth labels but also to mimic the teacher’s soft belief between predicates.
我们在师生知识蒸馏框架 [10, 11] 中利用内部和外部知识,如图 1 所示。其中标准视觉流程的输出(称为学生网络)通过一个利用语言知识对解决方案进行评分的模型输出进行增强,二者的组合称为教师网络。该目标的设计使得学生不仅学习预测正确的独热编码真实标签,还模仿教师对谓词之间的软置信度。
Our main contribution is that we exploit the role of both visual and linguistic representations in visual relationship detection and use internal and external linguistic knowledge to regularize the learning process of an end-to-end deep neural network to significantly enhance its predictive power and generalization. We evaluate our method on the VRD [19] and Visual Genome (VG) [13] datasets. Our experiments using Visual Genome show that while the improvements due to training set size are minimal, improvements due to the use of LK are large, implying that with current dataset sizes, it is more fruitful to incorporate other types knowledge (e.g., LK) than to increase the visual dataset size—this is particularly promising because visual data is expensive to annotate and there exist many readily available large scale sources of knowledge that have not yet been fully leveraged for visual tasks.
我们的主要贡献在于利用视觉和语言表征在视觉关系检测中的作用,并通过内部和外部语言知识来规范端到端深度神经网络的学习过程,从而显著提升其预测能力和泛化性。我们在VRD [19] 和Visual Genome (VG) [13] 数据集上评估了该方法。基于Visual Genome的实验表明,虽然训练集规模带来的改进有限,但语言知识 (LK) 的使用能带来显著提升,这意味着在当前数据集规模下,整合其他类型的知识(例如LK)比扩大视觉数据集规模更有效——这一发现尤其具有前景,因为视觉数据的标注成本高昂,而现有许多大规模知识源尚未被充分用于视觉任务。
2. Related Work
2. 相关工作
Knowledge Distillation in Deep Neural Networks: Recent work has exploited the use of additional information (or “knowledge”) to help train deep neural networks (DNN) [16, 3, 12, 9]. Hinton et al. [9] proposed a framework to distill knowledge, in this case the predicted distribution, from a large network into a smaller network. Recently, Hu et al. proposed a teacher-student framework to distill massive knowledge sources, including logic rules, into DNNs [10, 11].
深度神经网络中的知识蒸馏:最近的研究利用额外信息(或称“知识”)来辅助训练深度神经网络(DNN)[16, 3, 12, 9]。Hinton等人[9]提出了一种知识蒸馏框架,将大型网络中的预测分布迁移到小型网络中。近期,Hu等人提出师生框架,将包括逻辑规则在内的大量知识源蒸馏到DNN中[10, 11]。
Visual Relationship Detection: Visual relationships represent the interactions between object pairs in images. Lu et al. [19] formalized visual relationship prediction as a task and provided a dataset with a moderate number of relationships. Before [19], a large corpus of work had leveraged the interactions between objects (e.g. object cooccurrence, spatial relationships) to improve visual tasks [30, 27, 21, 14, 4, 5, 15]. To enable visual relationship detection on a large scale, Lu et al. [19] decomposed the prediction of a relationship into two individual parts: detecting objects and predicting predicates. Lu et al. used the sub-image containing the union of two bounding boxes of object pairs as visual input to predict the predicates and utilized language priors, such as the similarity between relationships and the likelihood of a relationship in the training data, to augment the visual module.
视觉关系检测:视觉关系表示图像中物体对之间的交互。Lu等人[19]将视觉关系预测形式化为一项任务,并提供了一个包含适量关系的数据集。在[19]之前,已有大量研究利用物体间的交互(如物体共现、空间关系)来改进视觉任务[30, 27, 21, 14, 4, 5, 15]。为了实现大规模的视觉关系检测,Lu等人[19]将关系预测分解为两个独立部分:检测物体和预测谓词。Lu等人使用包含物体对两个边界框并集的子图像作为视觉输入来预测谓词,并利用语言先验(如关系之间的相似性和训练数据中关系的可能性)来增强视觉模块。
Plummer et al. [25] grounded phrases in images by fusing several visual features like appearance, size, bounding boxes, and linguistic cues (like adjectives that describe attribute information). Despite focusing on phrase localization rather than visual phrase detection, when evaluated on the VRD dataset, [25] achieved comparable results with [19]. Recently, there are several new attempts for visual relationship detection task: Liang et al. [18] proposed to detect relationships and attributes within a reinforcement learning framework; Li et al. [17] trained an end-to-end system boost relationship detection through better object detection; Bo et al. [2] detected relationships via a relational modeling framework.
Plummer等[25]通过融合外观、尺寸、边界框等视觉特征和描述属性信息的形容词等语言线索,实现了短语在图像中的定位。虽然该方法侧重于短语定位而非视觉短语检测,但在VRD数据集上的评估结果显示[25]与[19]取得了相当的结果。近期视觉关系检测任务涌现了若干新尝试:Liang等[18]提出在强化学习框架中检测关系和属性;Li等[17]通过提升目标检测性能训练端到端系统来增强关系检测;Bo等[2]则通过关系建模框架进行关系检测。
We combine rich visual and linguistic representations in an end-to-end deep neural network that absorbs external linguistic knowledge using the teacher-student framework during the training process to enhance prediction and generalization. Unlike [19], which detected objects independently from relationship prediction, we model objects and relationships jointly. Unlike [17, 18, 2], which do not use linguistic knowledge explicitly, we focus on predicting predicates using the linguistic knowledge that models correlations between predicates and $\langle s u b j,o b j\rangle$ pairs, especially for the long-tail relationships. Unlike [9, 10, 11], which used either the teacher or the student as their final output, we combine both teacher and student networks, as they each have their own advantages: the teacher outperforms in cases with sufficient training data, while the student generalizes to cases with few or no training examples (the zero-shot case).
我们结合丰富的视觉和语言表征,构建了一个端到端的深度神经网络,在训练过程中通过师生框架吸收外部语言知识以增强预测和泛化能力。与[19]独立检测物体与关系预测不同,我们联合建模物体和关系。与[17, 18, 2]未显式利用语言知识不同,我们专注于通过建模谓词与$\langle 主体, 客体\rangle$对相关性的语言知识来预测谓词,尤其针对长尾关系。与[9, 10, 11]仅采用教师或学生网络作为最终输出不同,我们融合了师生网络的优势:教师网络在训练数据充足时表现更优,而学生网络能泛化至少样本或无训练样本的情况(零样本场景)。
3. Our Approach
3. 我们的方法
A straightforward way to predict relationship predicates is to train a CNN on the union of the two bounding boxes that contain the two objects of interest as the visual input, fuse semantic features (that encode the object categories) and spatial features (that encode the relative positions of the objects) with the CNN features (that encode the appearance of the objects), and feed them into a fully connected (FC) layer to yield an end-to-end prediction framework. However, the number of $\langle s u b j,p r e d,o b j\rangle$ tuples is very large and the parameter space of the end-to-end CNN would be huge. While the subject, predicate, and object are not statistically independent, a CNN would require a massive amount of data to discover the dependence structure while also learning the mapping from visual features to semantic relationships. To avoid over-fitting and achieve better predictive power without increasing the amount of visual training data, additional information is needed to help regularize the training of the CNN.
预测关系谓词的一种直接方法是:以包含两个目标物体的边界框并集作为视觉输入训练CNN (Convolutional Neural Network),将语义特征(编码物体类别)、空间特征(编码物体相对位置)与CNN特征(编码物体外观)融合,并输入全连接层(FC)构建端到端预测框架。然而,$\langle s u b j,p r e d,o b j\rangle$ 三元组数量庞大,端到端CNN的参数空间会非常巨大。虽然主语、谓词和宾语在统计上并非独立,但CNN需要海量数据来发现依赖结构,同时学习从视觉特征到语义关系的映射。为避免过拟合并在不增加视觉训练数据量的情况下提升预测能力,需要引入额外信息来规范CNN的训练过程。
Figure 1 summarizes our proposed model. Given an image, we extract three input components: the cropped images of the union of the two detected objects (BB-Union); the semantic object representations obtained from the object category confidence score distributions obtained from the detector; and the spatial features (SF) obtained from pairs of detected bounding boxes. We concatenate VGG features, semantic object vectors, and the spatial feature vectors, then train another FC layer using the ground truth label (GT) and the linguistic knowledge to predict the predicate. Unlike [19], which used the VGG features to train a linear model, our training is end-to-end without fixing the VGGnet. Following [10, 11], we call the data-driven model the “student”, and the linguistic knowledge regularized model the “teacher”.
图 1: 总结了我们提出的模型。给定一张图像,我们提取三个输入组件:两个检测到对象的联合裁剪图像 (BB-Union);从检测器获得的对象类别置信度分数分布中获得的语义对象表示;以及从检测到的边界框对中获得的空间特征 (SF)。我们将 VGG 特征、语义对象向量和空间特征向量连接起来,然后使用真实标签 (GT) 和语言知识训练另一个全连接层来预测谓词。与 [19] 使用 VGG 特征训练线性模型不同,我们的训练是端到端的,无需固定 VGGnet。遵循 [10, 11],我们将数据驱动模型称为“学生”,将语言知识正则化模型称为“教师”。
3.1. Linguistic Knowledge Distillation
3.1. 语言知识蒸馏
3.1.1 Preliminary: Incorporating Knowledge in DNNs
3.1.1 预备知识:在深度神经网络中融入知识
The idea of incorporating additional information in DNNs has been exploited recently [9, 10, 11]. We adapted Hu et $a l.$ .’s teacher-student framework [10, 11] to distill linguistic knowledge in a data-driven model. The teacher network is constructed by optimizing the following criterion:
最近有研究探索了在深度神经网络(DNN)中融入额外信息的思路[9, 10, 11]。我们采用了Hu等学者提出的师生框架[10, 11],通过数据驱动模型来蒸馏语言学知识。教师网络的构建基于以下优化准则:
$$
\operatorname*{min}{t\in T}\mathrm{KL}(t(Y)||s_{\phi}(Y|X))-C\mathbb{E}_{t}[L(X,Y)],
$$
$$
\operatorname*{min}{t\in T}\mathrm{KL}(t(Y)||s_{\phi}(Y|X))-C\mathbb{E}_{t}[L(X,Y)],
$$
where $t(Y)$ and $s_{\phi}(Y|X)$ are the prediction results of the teacher and student networks; $\mathrm{^C}$ is a balancing term; $\phi$ is the parameter set of the student network; $L(X,Y)$ is a general constraint function that has high values to reward the predictions that meet the constraints and penalize the others. KL measures the KL-divergence of teacher’s and student’s prediction distributions. The closed-form solution of
其中 $t(Y)$ 和 $s_{\phi}(Y|X)$ 分别是教师网络和学生网络的预测结果;$\mathrm{^C}$ 是平衡项;$\phi$ 是学生网络的参数集;$L(X,Y)$ 是一个通用约束函数,其高值用于奖励符合约束的预测并惩罚其他情况。KL 衡量教师和学生预测分布的 KL 散度。闭式解为
the optimization problem is:
优化问题为:
$$
t(Y)\propto s(Y\vert X)\mathrm{exp}(C L(X,Y)).
$$
$$
t(Y)\propto s(Y\vert X)\mathrm{exp}(C L(X,Y)).
$$
The new objective which contains both ground truth labels and the teacher network is defined as:
新目标函数结合了真实标签和教师网络,其定义为:
$$
\operatorname*{min}{\phi\in\Phi}\frac{1}{n}\sum_{i=1}^{n}\alpha l(s_{i},y_{i})+(1-\alpha)l(s_{i},t_{i}),
$$
$$
\operatorname*{min}{\phi\in\Phi}\frac{1}{n}\sum_{i=1}^{n}\alpha l(s_{i},y_{i})+(1-\alpha)l(s_{i},t_{i}),
$$
where $s_{i}$ and $t_{i}$ are the student’s and teacher’s predictions for sample $i$ ; $y_{i}$ is the ground truth label for sample $i$ ; $\alpha$ is a balancing term between ground truth and the teacher network. $l$ is the loss function. More details can be found in [10, 11].
其中 $s_{i}$ 和 $t_{i}$ 分别是学生模型和教师模型对样本 $i$ 的预测结果;$y_{i}$ 是样本 $i$ 的真实标签;$\alpha$ 是真实标签与教师网络之间的平衡系数。$l$ 为损失函数。更多细节可参阅 [10, 11]。
3.1.2 Knowledge Distillation for Visual Relationship Detection
3.1.2 视觉关系检测中的知识蒸馏 (Knowledge Distillation)
Linguistic knowledge is modeled by a conditional probability that encodes the strong correlation between the pair of objects $\langle s u b j,o b j\rangle$ and the predicate that humans tend to use to describe the relationship between them:
语言知识通过条件概率建模,该概率编码了对象对 $\langle s u b j,o b j\rangle$ 与人类倾向于用来描述它们之间关系的谓词之间的强相关性:
$$
L(X,Y)=\log P(p r e d|s u b j,o b j),
$$
$$
L(X,Y)=\log P(p r e d|s u b j,o b j),
$$
where $\mathrm{X}$ is the input data and $Y$ is the output distribution of the student network. $P(p r e d|s u b j,o b j)$ is the conditional probability of a predicate given a fixed $\langle s u b j,o b j\rangle$ pair in the obtained linguistic knowledge set.
其中 $\mathrm{X}$ 是输入数据,$Y$ 是学生网络的输出分布。$P(p r e d|s u b j,o b j)$ 表示在获取的语言知识集合中,给定固定 $\langle s u b j,o b j\rangle$ 组合时谓词的条件概率。
By solving the optimization problem in Eq. 2, we construct a teacher network that is close to the student network, but penalizes a predicted predicate that is unlikely given the fixed $\langle s u b j,o b j\rangle$ pairs. The teacher’s output can be viewed as a projection of the student’s output in the solution space constrained by linguistic knowledge. For example, when predicting the predicate between a “plate” and a “table”, given the subject (“plate”) and the object (“table”), and the conditional probability $P(p r e d|p l a t e,t a b l e)$ , the teacher will penalize unlikely predicates, (e.g., “in”) and reward likely ones (e.g., “on”), helping the network avoid portions of the parameter space that lead to poor solutions.
通过求解公式2中的优化问题,我们构建了一个接近学生网络的教师网络,但会对给定固定$\langle s u b j,o b j\rangle$词对时不太可能的预测谓词进行惩罚。教师的输出可视为学生输出在语言知识约束解空间中的投影。例如,当预测"plate"和"table"之间的谓词时,给定主语("plate")、宾语("table")和条件概率$P(p r e d|p l a t e,t a b l e)$,教师会惩罚不太可能的谓词(如"in")并奖励可能谓词(如"on"),从而帮助网络避开会导致不良解的参数空间区域。
Given the ground truth label and the teacher network’s output distribution, we want the student network to not only predict the correct predicate labels but also mimic the linguistic knowledge regularized distributions. This is accomplished using a cross-entropy loss (see Eq. 4).
给定真实标签和教师网络的输出分布,我们希望学生网络不仅能预测正确的谓词标签,还能模仿经过语言知识正则化的分布。这一目标通过交叉熵损失函数实现(见公式4)。
One advantage of this LK distillation framework is that it takes advantage of both knowledge-based and data-driven systems. Distillation works as a regularize r to help train the data-driven system. On the other hand, since we construct the teacher network based on the student network, the knowledge regularized predictions (teacher’s output) will also be improved during training as the student’s output improves. Rather than using linguistic knowledge as a post-processing step, our framework enables the data-driven model to absorb the linguistic knowledge together with the ground truth labels, allowing the deep network to learn a better visual model during training rather than only having its output modified in a post-processing step. This leads to a data-driven model (the student) that generalizes better, especially in the zero-shot scenario where we lack linguistic knowledge about a $\langle s u b j,o b j\rangle$ pair. While [9, 10, 11] used either the student or the teacher as the final output, our experiments show that both the student and teacher in our framework have their own advantages, so we combine them to achieve the best predictive power (see section 4).
这种LK蒸馏框架的一个优势在于它同时利用了基于知识和数据驱动的系统。蒸馏作为一种正则化手段,有助于训练数据驱动系统。另一方面,由于我们基于学生网络构建教师网络,随着学生输出的改进,知识正则化的预测(教师输出)也会在训练过程中得到提升。与将语言学知识作为后处理步骤不同,我们的框架使数据驱动模型能够同时吸收语言学知识和真实标签,让深度网络在训练过程中学习更好的视觉模型,而不仅仅是在后处理阶段调整输出。这使得数据驱动模型(学生)具有更好的泛化能力,尤其是在缺乏关于$\langle s u b j,o b j\rangle$对的语言学知识的零样本场景中。虽然[9,10,11]仅使用学生或教师作为最终输出,但我们的实验表明框架中的学生和教师各有优势,因此我们将二者结合以获得最佳预测能力(见第4节)。
3.1.3 Linguistic Knowledge Collection
3.1.3 语言知识收集
To obtain the linguistic knowledge $P(p r e d|s u b j,o b j)$ , a straightforward method is to count the statistics of the training annotations, which reflect the knowledge used by an annotator in choosing an appropriate predicate to describe a visual relationship. Due to the long tail distribution of rela tion ships, a large number of combinations never occur in the training data; however, it is not reasonable to assume the probability of unseen relationships is 0. To tackle this problem, one can apply additive smoothing to assign a very small number to all 0’s [20]; however, the smoothed unseen conditional probabilities are uniform, which is still confusing at LK distillation time. To collect more useful linguistic knowledge of the long-tail unseen relationships, we exploit text data from the Internet.
为了获取语言知识 $P(p r e d|s u b j,o b j)$ ,一种直接的方法是统计训练标注数据,这些数据反映了标注者在选择合适谓词描述视觉关系时所运用的知识。由于关系呈现长尾分布,训练数据中存在大量从未出现的组合;然而,将未见过关系的概率假设为0并不合理。为解决此问题,可采用加性平滑技术为所有零值分配极小数值 [20] ,但平滑后的未见条件概率是均匀分布的,这在语言知识蒸馏时仍会造成混淆。为收集长尾未见关系更有用的语言知识,我们利用了来自互联网的文本数据。
One challenge of collecting linguistic knowledge online is that the probability of finding text data that specifically describes objects and their relationships is low. This requires us to obtain the knowledge from a huge corpus that covers a very large domain of knowledge. Thus we choose the Wikipedia 2014-06-16 dump containing around 4 billion words and 450 million sentences that have been parsed to text by $[24]^{1}$ to extract knowledge.
在线收集语言知识的一个挑战是,找到专门描述对象及其关系的文本数据的概率很低。这要求我们从覆盖极大知识领域的海量语料库中获取知识。因此,我们选择由 $[24]^{1}$ 解析为文本的Wikipedia 2014-06-16转储文件(包含约40亿单词和4.5亿句子)进行知识提取。
We utilize the scene graph parser proposed in [28] to parse sentences into sets of $\langle s u b j,p r e d,o b j\rangle$ triplets, and we compute the conditional probabilities of predicates based on these triplets. However, due to the possible mistakes of the parser, especially on text from a much wider domain than the visual relationship detection task, the linguistic knowledge obtained can be very noisy. Naive methods such as using only the linguistic knowledge to predict the predicates or multiplying the conditional probability with the data-driven model’s output fail. Fortunately, since the teacher network of our LK-distillation framework is constructed from the student network that is also supervised by the labeled data, a well-trained student network can help correct the errors from the noisy external probability. To achieve good predictive power on the seen and unseen relationships, we obtain the linguistic knowledge from both training data and the Wikipedia text corpus by a weighted average of their conditional probabilities when we construct the teachers’ network, as shown in Eq. 4. We conduct a two-step knowledge distillation: during the first several training epoches, we only allow the student to absorb the knowledge from training annotations to first establish a good data-driven model. After that, we start distilling the external knowledge together with the knowledge extracted from training annotations weighted by the balancing term $C$ as shown in Eq. 4. The balancing terms are chosen by a validation set we select randomly from the training set (e.g., in VRD dataset, we select 1,000 out of 4,000 images to form the validation set) to achieve a balance between good genera liz ation on the zero-shot and good predictive power on the entire testing set.
我们利用[28]提出的场景图解析器将句子解析为$\langle s u b j,p r e d,o b j\rangle$三元组集合,并基于这些三元组计算谓词的条件概率。然而由于解析器可能出错(尤其在处理远超出视觉关系检测任务领域的文本时),获取的语言知识可能包含大量噪声。仅使用语言知识预测谓词,或将条件概率与数据驱动模型输出简单相乘等朴素方法均告失败。幸运的是,由于我们的语言知识蒸馏框架中教师网络由同样受标注数据监督的学生网络构建,训练良好的学生网络能帮助修正噪声外部概率的误差。
为实现对可见和不可见关系的良好预测能力,我们通过加权平均训练数据和维基百科语料库的条件概率来获取语言知识(如公式4所示),用于构建教师网络。采用两阶段蒸馏策略:在前几个训练周期中,仅允许学生从训练标注中吸收知识以建立优质数据驱动模型;之后开始同时蒸馏外部知识与训练标注提取的知识(通过公式4中的平衡项$C$加权)。平衡项参数通过从训练集随机选取的验证集确定(例如在VRD数据集中从4,000张图像选取1,000张构建验证集),以在零样本泛化能力与全测试集预测性能之间取得平衡。
3.2. Semantic and Spatial Representations
3.2. 语义与空间表征
In [19], Lu et al. used the cropped image containing the union of two objects’ bounding boxes to predict the predicate describing their relationship. While the cropped image encodes the visual appearance of both objects, it is difficult to directly model the strong semantic and spatial correlations between predicates and objects, as both semantic and spatial information is buried within the pixel values of the image. Meanwhile, the semantic and spatial representations capture similarities between visual relationships, which can generalize better to unseen relationships.
在[19]中,Lu等人使用包含两个物体边界框联合的裁剪图像来预测描述它们关系的谓词。虽然裁剪图像编码了两个物体的视觉外观,但由于语义和空间信息都隐藏在图像的像素值中,很难直接建模谓词与物体之间强烈的语义和空间相关性。同时,语义和空间表征能够捕捉视觉关系之间的相似性,从而更好地泛化到未见过的关系。
We utilize word-embedding [22] to represent the semantic meaning of each object by a vector. We then extract spatial features similarly to the ones in [23]:
我们利用词嵌入(word-embedding) [22] 通过向量表示每个对象的语义含义。随后按照[23]的方法提取空间特征:
$$
\left[\frac{x_{m i n}}{W},\frac{y_{m i n}}{H},\frac{x_{m a x}}{W},\frac{y_{m a x}}{H},\frac{A}{A_{i m g}}\right],
$$
$$
\left[\frac{x_{m i n}}{W},\frac{y_{m i n}}{H},\frac{x_{m a x}}{W},\frac{y_{m a x}}{H},\frac{A}{A_{i m g}}\right],
$$
where $W$ and $H$ are the width and height of the image, $A$ and $A_{i m g}$ are the areas of the object and the image, respectively. We concatenate the above features of two objects as the spatial feature (SF) for a $\langle s u b j,o b j\rangle$ pair.
其中 $W$ 和 $H$ 是图像的宽度和高度,$A$ 和 $A_{img}$ 分别是物体和图像的面积。我们将两个物体的上述特征拼接起来,作为 $\langle subj,obj \rangle$ 对的空间特征 (SF)。
We predict the predicate conditioned on the semantic and spatial representations of the subject and object:
我们基于主语和宾语的语义及空间表征来预测谓词:
$$
\begin{array}{r l}&{P(R|I)=P(p r e d|s u b j,o b j,B_{s},B_{o},I)}\ &{\qquad\cdot P(s u b j,B_{s}|I)P(o b j,B_{o}|I),}\end{array}
$$
$$
\begin{array}{r l}&{P(R|I)=P(p r e d|s u b j,o b j,B_{s},B_{o},I)}\ &{\qquad\cdot P(s u b j,B_{s}|I)P(o b j,B_{o}|I),}\end{array}
$$
where $s u b j$ and $o b j$ are represented using the semantic object representation, $B_{s}$ and $B_{o}$ are the spatial features, and $I$ is the image region of the union of the two bounding boxes. For the BB-Union input, we use the same VGGnet [29] in [19] to learn the visual feature representation. We adopt a pre-trained word2vec vectors weighted by confidence scores of each object category for the subject and the object, then concatenate the two vectors as the semantic representation of the subject and the object.
其中 $subj$ 和 $obj$ 使用语义对象表示,$B_{s}$ 和 $B_{o}$ 是空间特征,$I$ 是两个边界框并集的图像区域。对于 BB-Union 输入,我们采用与 [19] 相同的 VGGnet [29] 来学习视觉特征表示。我们使用预训练的 word2vec 向量,并根据主语和宾语对象类别的置信度得分进行加权,然后将这两个向量拼接作为主语和宾语的语义表示。
4. Experiments
4. 实验
We evaluate our method on Visual Relationship Detection [19] and Visual Genome [13] datasets for three tasks: Predicate detection: given an input image and a set of ground truth bounding boxes with corresponding object categories, predict a set of predicates describing each pair of objects. This task evaluates the prediction of predicates without relying on object detection. Phrase detection: given an input image, output a phrase $\langle s u b j,p r e d,o b j\rangle$ and localize the entire phrase as one bounding box. Relationship detection: given an input image, output a relationship $\langle s u b j,p r e d,o b j\rangle$ and both the subject and the object with their bounding boxes.
我们在Visual Relationship Detection [19]和Visual Genome [13]数据集上评估了我们的方法,针对三个任务:
谓词检测:给定输入图像和一组带有对应物体类别的真实边界框,预测描述每对物体的谓词集合。该任务评估不依赖物体检测的谓词预测能力。
短语检测:给定输入图像,输出一个短语$\langle s u b j,p r e d,o b j\rangle$并将整个短语定位为一个边界框。
关系检测:给定输入图像,输出一个关系$\langle s u b j,p r e d,o b j\rangle$并同时定位主语和宾语及其边界框。
Both datasets have a zero-shot testing set that contains relationships that never occur in the training data. We evaluate on the zero-shot sets to demonstrate the generalization improvements brought by linguistic knowledge distillation.
两个数据集都包含一个零样本 (zero-shot) 测试集,其中含有训练数据中从未出现过的关系。我们在零样本集上评估,以证明语言知识蒸馏带来的泛化性能提升。
Implementation Details. We use VGG-16 [29] to learn the visual representations of the BB-Union of two objects. We use a pre-trained word2vec [22] model to project the subjects and objects into vector space, and the final semantic representation is the weighted average based on the confidence scores of a detection. For the balancing terms, we choose $C=1$ and $\alpha=0.5$ to encourage the student network to mimic the teacher and the ground truth equally.
实现细节。我们使用VGG-16 [29] 来学习两个物体BB-Union的视觉表示。通过预训练的word2vec [22] 模型将主体和客体映射到向量空间,最终语义表示是基于检测置信度得分的加权平均。对于平衡项,我们选择 $C=1$ 和 $\alpha=0.5$ 以促使学生网络均等地模仿教师网络和真实标注。
Evaluation Metric. We follow [19, 25] using Recall $@n$ $({\mathsf{R@}}n)$ as our evaluation metric (mAP metric would mistakenly penalize true positives because annotations are not exhaustive). For two detected objects, multiple predicates are predicted with different confidences. The standard $\mathbf{R}\ @{n}$ metric ranks all predictions for all object pairs in an image and compute the recall of top $n$ . However, instead of computing recall based on all predictions, [19] considers only the predicate with highest confidence for each object pair. Such evaluation is more efficient and forced the diversity of object pairs. However, multiple predicates can correctly describe the same object pair and the annotator only chooses one as ground truth, e.g., when describing a person “next to” another person, predicate “near” is also plausible. So we believe that a good predicted distribution should have high probabilities for all plausible predicate(s) and probabilities close to 0 for remaining ones. Evaluating only the top prediction per object pair may mistakenly penalize correct predictions since annotators have bias over several plausible predicates. So we treat the number of chosen predictions per object pair $(k)$ as a hyper-parameter, and report $\mathbf{R}\ @{n}$ for different $k$ ’s to compare with other methods [19, 25, 26]. Since the number of predicates is 70, $k=70$ is equivalent to evaluating all predictions w.r.t. two detected objects.
评估指标。我们遵循[19, 25]采用召回率$@n$ $({\mathsf{R@}}n)$作为评估指标(mAP指标会因标注不全面而错误惩罚真阳性)。对于两个检测到的物体,系统会以不同置信度预测多个谓词。标准$\mathbf{R}\ @{n}$指标会对图像中所有物体对的所有预测进行排序,并计算前$n$个预测的召回率。但与基于全部预测计算召回率不同,[19]仅考虑每个物体对置信度最高的谓词。这种评估方式更高效且能强制保证物体对的多样性。然而,多个谓词可能都正确描述同一物体对,而标注者仅选择其中一个作为真实标签,例如描述一个人"next to"另一个人时,"near"也是合理的谓词。因此我们认为,良好的预测分布应对所有合理谓词给出高概率,其余谓词概率接近0。仅评估每个物体对的最高预测可能错误惩罚正确结果,因为标注者对多个合理谓词存在偏好。因此我们将每个物体对的候选预测数量$(k)$设为超参数,通过报告不同$k$值下的$\mathbf{R}\ @{n}$来与其他方法[19, 25, 26]比较。由于谓词总数为70,$k=70$等价于评估两个检测物体相关的所有预测。
Table 1. Predicate Detection on VRD Testing Set: “U” is the union of two objects’ bounding boxes; “SF” is the spatial feature; “W” is the word-embedding based semantic representations; “L” means using LK distillation; “S” is the student network; “T” is the teacher network and $\mathrm{^{66}S+T^{3}}$ is the combination of them. Part 1 uses the VRD training images; Part 2 uses the training images in VRD [19] and images of Visual Genome (VG) [13] dataset.
表 1: VRD测试集上的谓词检测结果: "U"表示两个物体边界框的并集; "SF"表示空间特征; "W"表示基于词嵌入的语义表示; "L"表示使用LK蒸馏; "S"表示学生网络; "T"表示教师网络; $\mathrm{^{66}S+T^{3}}$ 表示它们的组合。第1部分使用VRD训练图像; 第2部分使用VRD[19]和Visual Genome(VG)[13]数据集的训练图像。
| 完整集 | 零样本 | |||||
|---|---|---|---|---|---|---|
| R@100/502 k=1 | R@100 k=70 | R@50 k=70 | R@100/50 k=1 | R@100 k=70 | R@50 k=70 | |
| 第1部分: 仅使用VRD训练图像 | ||||||
| Visual Phrases[26] | 1.91 | |||||
| Joint CNN [6] | 2.03 | |||||
| VRD-V only [19] | 7.11 | 37.20 | 28.36 | 3.52 | 32.34 | 23.95 |
| VRD-Full [19] | 47.87 | 84.34 | 70.97 | 8.45 | 50.04 | 29.77 |
| Baseline: U only | 34.82 | 83.15 | 70.02 | 12.75 | 69.42 | 47.84 |
| Baseline:L only | 51.34 | 85.34 | 80.64 | 3.68 | 18.22 | 8.13 |
| U+W | 37.15 | 83.78 | 70.75 | 13.44 | 69.77 | 49.01 |
| U+W+L:S | 42.98 | 84.94 | 71.83 | 13.89 | 72.53 | 51.37 |
| U+W+L:T | 52.96 | 88.98 | 83.26 | 7.81 | 40.15 | 32.62 |
| U+SF | 36.33 | 83.68 | 69.87 | 14.33 | 69.01 | 48.32 |
| U+SF+L:S | 41.06 | 84.81 | 71.27 | 15.14 | 72.72 | 51.62 |
| U+SF+L:T | 51.67 | 87.71 | 83.84 | 8.05 | 41.51 | 32.77 |
| U+W+SF | 41.33 | 84.89 | 72.29 | 14.13 | 69.41 | 48.13 |
| U+W+SF+L:S | 47.50 | 86.97 | 74.98 | 16.98 | 74.65 | 54.20 |
| U+W+SF+L:T | 54.13 | 89.41 | 82.54 | 8.80 | 41.53 | 32.81 |
| U+W+SF+L:T+S | 55.16 | 94.65 | 85.64 | |||
| 第2部分: 使用VRD+VG训练图像 | ||||||
| Baseline: U | 36.97 | 84.49 | 70.19 | 13.31 | 70.56 | 50.34 |
| U+W+SF | 42.08 | 85.89 | 72.83 | 14.51 | 70.79 | 50.64 |
| U+W+SF+L:S | 48.61 | 87.15 | 75.45 | 17.16 | 75.26 | 55.41 |
| U+W+SF+L:T | 54.61 | 90.09 | 82.97 | 9.23 | 43.21 | 33.40 |
| U+W+SF+L:T+S | 55.67 | 95.19 | 86.14 |
4.1. Evaluation on VRD Dataset
4.1. VRD数据集评估
4.1.1 Predicate Prediction
4.1.1 谓词预测
We first evaluate it on predicate prediction (as in [19]). Since [25, 17, 18] do not report results of predicate prediction, we compare our results with ones in [19, 26].
我们首先在谓词预测任务上评估其性能 (如[19]所述)。由于[25, 17, 18]未报告谓词预测结果,我们将自身结果与[19, 26]中的数据进行对比。
Part 1 of Table 1 shows the results of linguistic knowledge distillation with different sets of features in our deep neural networks. In addition to the data-driven baseline “Baseline: U only”, we also compare with the baseline that only uses linguistic priors to predict a predicate, which is denoted as “Baseline: L only”. The “Visual Phrases” method [26] trains deformable parts models for each relationship; “Joint CNN” [6] trains a 270-way CNN to predict the subject, object and predicate together. The visual only model and the full model of [19] that uses both visual input and language priors are denoted as “VRD-V only” and “VRD-Full”. S denotes using the student network’s output as the final prediction; T denotes using the teacher network’s output. $\mathrm{T}{+}\mathrm{S}$ denotes that for $\langle s u b j,o b j\rangle$ pairs that occur in the training data, we use the teacher network’s output as the final prediction; for $\langle s u b j,o b j\rangle$ pairs that never occur in training, we use the student network’s output.
表 1 的第 1 部分展示了我们深度神经网络中采用不同特征集进行语言知识蒸馏 (linguistic knowledge distillation) 的结果。除了数据驱动的基线模型 "Baseline: U only" 外,我们还与仅使用语言先验知识来预测谓词的基线模型进行了比较,该模型标记为 "Baseline: L only"。"Visual Phrases" 方法 [26] 为每种关系训练可变形部件模型;"Joint CNN" [6] 训练一个 270 路 CNN 来同时预测主语、宾语和谓词。[19] 的纯视觉模型及同时使用视觉输入和语言先验知识的完整模型分别标记为 "VRD-V only" 和 "VRD-Full"。S 表示使用学生网络的输出作为最终预测;T 表示使用教师网络的输出。$\mathrm{T}{+}\mathrm{S}$ 表示对于训练数据中出现的 $\langle s u b j,o b j\rangle$ 对,我们使用教师网络的输出作为最终预测;对于训练中从未出现的 $\langle s u b j,o b j\rangle$ 对,则使用学生网络的输出。
End-to-end CNN training with semantic and spatial representations. Comparing our baseline, which uses the same visual representation (BB-Union) as [19], and the “VRD-V only” model, our huge recall improvement $(\mathrm{R}@100/50,\mathrm{k}{=}1$ increases from $7.11%$ [19] to $34.82%$ ) reveals that the end-to-end training with soft-max prediction outperforms extracting features from a fixed $\mathrm{CNN+}$ linear model method in [19], highlighting the importance of finetuning. In addition, adding the semantic representation and the spatial features improves the predictive power and genera liz ation of the data-driven model4.
端到端CNN训练结合语义与空间表征。相比采用与[19]相同视觉表征(BB-Union)的基线模型和"仅VRD-V"模型,我们的召回率显著提升$(R@100/50,k{=}1$从[19]的$7.11%$提升至$34.82%)$,这表明采用soft-max预测的端到端训练优于[19]中固定$\mathrm{CNN+}$线性模型的特征提取方法,凸显了微调的重要性。此外,引入语义表征和空间特征进一步增强了数据驱动模型的预测能力与泛化性4。

(b) Zero-shot Relationships Figure 2. Visualization of predicate detection results: “Data-driven” denotes the baseline using BB-Union; “LK only” denotes the baseline using only the linguistic knowledge without looking at the image; “Full model student” denotes the student network with $\mathrm{U}+\mathrm{W}{+}\mathrm{SF}$ features; “Full model teacher” denotes the teacher network with $\mathrm{U+W{+}S F}$ features.
图 2: 谓词检测结果可视化:(b) 零样本关系。"Data-driven"表示使用BB-Union的基线;"LK only"表示仅使用语言知识而不看图像的基线;"Full model student"表示具有$\mathrm{U}+\mathrm{W}{+}\mathrm{SF}$特征的学生网络;"Full model teacher"表示具有$\mathrm{U+W{+}S F}$特征的教师网络。
To demonstrate the effectiveness of LK-distillation, we compare the results of using different combinations of features with/without using LK-distillation. In Part 1 of Table 1, we train and test our model on only the VRD dataset, and use the training annotation as our linguistic knowledge. “Linguistic knowledge only” baseline (“Baseline: L only”) itself has a strong predictive power and it outperforms the state-of-the-art method [19] by a large margin (e.g., $51.34%$ vs. $47.87%$ for $\mathrm{R}@100/50$ , $\mathrm{k}{=}1$ on the entire VRD test set), which implies the knowledge we distill in the datadriven model is reliable and disc rim i native. However, since, some $\langle s u b j,o b j\rangle$ pairs in the zero-shot test set never occur in the linguistic knowledge extracted from the VRD train set, trusting only the linguistic knowledge without looking at the images leads to very poor performance on the zeroshot set of VRD, which explains the poor generalization of “Baseline: L only” method and addresses the need for combining both data-driven and knowledge-based methods as the LK-distillation framework we propose does.
为验证LK-distillation的有效性,我们对比了使用不同特征组合(含/不含LK-distillation)的实验结果。表1第一部分显示,我们仅在VRD数据集上训练测试模型,并将训练标注作为语言知识使用。"仅语言知识"基线("Baseline: L only")本身具有较强预测能力,其性能大幅超越现有最优方法[19](例如在整个VRD测试集上$\mathrm{R}@100/50$、$\mathrm{k}{=}1$指标达到$51.34%$ vs. $47.87%$),这表明我们通过数据驱动模型提炼的知识具备可靠性和区分性。然而,由于零样本测试集中部分$\langle s u b j,o b j\rangle$组合未出现在VRD训练集提取的语言知识中,仅依赖语言知识而不参考图像会导致VRD零样本集上表现极差,这解释了"Baseline: L only"方法泛化能力不足的原因,也印证了我们提出的LK-distillation框架需要结合数据驱动与知识驱动方法的必要性。
The benefit of LK distillation is visible across all feature settings: the data-driven neural networks that absorb linguistic knowledge (“student” with LK) outperform the data-driven models significantly (e.g., $\mathrm{R}@100/50$ , $\mathrm{k}{=}1$ is improved from $37.15%$ to $42.98%$ for $\mathrm{^{66}U+W^{5}}$ features on the entire VRD test set). We also observe consistent improvement of the recall on the zero-shot test set of datadriven models that absorb the linguistic knowledge. The student networks with LK-distillation yield the best genera liz ation, and outperform the data-driven baselines and knowledge only baselines by a large margin.
语言知识 (LK) 蒸馏的优势在所有特征设置中均可见:吸收了语言知识的数据驱动神经网络 (带LK的"学生") 显著优于纯数据驱动模型 (例如,在整个VRD测试集上,使用 $\mathrm{^{66}U+W^{5}}$ 特征时,$\mathrm{R}@100/50$ 和 $\mathrm{k}{=}1$ 从 $37.15%$ 提升至 $42.98%$)。我们还观察到,吸收了语言知识的数据驱动模型在零样本测试集上的召回率持续提升。经过LK蒸馏的学生网络展现出最佳泛化能力,大幅超越纯数据驱动基线和纯知识基线。
Unlike [9, 10, 11], where either the student or the teacher is the final output, we achieve better predictive power by combining both: we use the teacher network to predict the predicates whose $\langle s u b j,o b j\rangle$ pairs occur in the training data, and use the student network for the remaining. The setting ${}^{\leftarrow}\mathrm{U}{+}\mathrm{W}{+}\mathrm{SF}{+}\mathrm{LK}$ : $\mathrm{T}{+}\mathrm{S}^{\mathrm{}\mathrm{}\mathrm{}}$ performs the best. Fig. 2(a) and 2(b) show a visualization of different methods.
与[9, 10, 11]仅使用学生网络或教师网络作为最终输出不同,我们通过结合两者获得了更好的预测能力:使用教师网络预测训练数据中出现$\langle subj,obj\rangle$对的谓词,其余情况则使用学生网络。设置${}^{\leftarrow}\mathrm{U}{+}\mathrm{W}{+}\mathrm{SF}{+}\mathrm{LK}$: $\mathrm{T}{+}\mathrm{S}^{\mathrm{}\mathrm{}\mathrm{}}$时性能最佳。图2(a)和2(b)展示了不同方法的可视化对比。
4.1.2 Phrase and Relationship Detection
4.1.2 短语与关系检测
To enable fully automatic phrase and relationship detection, we train a Fast R-CNN detector [7] using VGG-16 for object detection. Given the confidence scores of detected each detected object, we use the weighed word2vec vectors as the semantic object representation, and extract spatial features from each detected bounding box pairs. We then use the pipeline in Fig. 1 to obtain the predicted predicate distribution for each pair of objects. According to Eq. 7, we use the product of the predicate distribution and the confidence scores of the subject and object as our final prediction results. We also adopt the triplet NMS in [17] to remove redundant detections. To compare with [19], we report $\mathbf R\ @\mathbf{n}$ , $\mathrm{k}{=}1$ for both phrase detection and relationship detection. For fair comparison with [25] (denoted as “Linguistic Cues”), we choose $_{\mathrm{k=10}}$ as they did to report recall. In addition, we report the full recall measurement $\mathrm{k}{=}70$ . Evaluation results on the entire dataset and the zero-shot setting are shown in Part 1 of Tables 2 and 3. Our method outperforms the state-of-the-art methods in [19] and [25] significantly on both entire testing set and zero-shot setting. The observations about student and teacher networks are consistent with predicate prediction evaluation. We also compare our method with the very recently introduced “VIP-CNN” in [17] and “VRL” [18] and achieve better or comparable results. For phrase detection, we achieve better results than [18] and get similar result for $\mathrm{R}\ @50$ to [17]. One possible reason that [17] gets better result for $\mathrm{R}@100$ is that they jointly model the object and predicate detection while we use an off-the-shelf detector. For relationship detection, we outperform both methods, especially on the zero-shot set.
为实现全自动短语和关系检测,我们采用VGG-16训练了一个Fast R-CNN检测器[7]进行目标检测。基于每个检测目标的置信度分数,使用加权word2vec向量作为语义对象表示,并从每对检测边界框中提取空间特征。随后通过图1所示的流程获取每对对象的谓词预测分布。根据公式7,我们将谓词分布与主客体置信度分数的乘积作为最终预测结果,并采用[17]中的三元组非极大值抑制(NMS)去除冗余检测。
为与[19]对标,我们在短语检测和关系检测中均报告$\mathbf{R}\ @\mathbf{n}$($\mathrm{k}{=}1$)指标。为公平对比[25](标记为"Linguistic Cues"),我们与其保持一致采用$_{\mathrm{k=10}}$进行召回率统计,同时补充报告完整召回指标$\mathrm{k}{=}70$。完整数据集和零样本场景下的评估结果见表2和表3的Part 1部分。我们的方法在整个测试集和零样本设定下均显著优于[19]和[25]的现有最优方法,关于学生网络与教师网络的观察结论与谓词预测评估一致。
与最新提出的"VIP-CNN"[17]和"VRL"[18]相比,我们取得了更优或相当的结果:在短语检测方面优于[18],$\mathrm{R}\ @50$指标与[17]持平;[17]在$\mathrm{R}@100$指标上表现更优,可能源于其采用联合建模目标与谓词检测的策略,而我们使用现成检测器。在关系检测任务中,我们的方法全面超越两者,零样本集优势尤为显著。
Table 2. Phrase and Relationship Detection: Distillation of Linguistic Knowledge. We use the same notations as in Table 1.
表 2. 短语与关系检测:语言知识蒸馏。我们使用与表 1 相同的符号。
| 短语检测 | 关系检测 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@100, k=1 | R@50, k=1 | R@100, k=10 | R@50, k=10 | R@100, k=70 | R@50, k=70 | R@100, k=1 | R@50, k=1 | R@100, k=10 | R@50, k=10 | R@100, k=70 | R@50, k=70 | |
| 第一部分:仅使用 VRD 训练图像 | ||||||||||||
| Visual Phrases [26] | 0.07 | 0.04 | ||||||||||
| Joint CNN [6] | 0.09 | 0.07 | 0.09 | 0.07 | ||||||||
| VRD-Vonly [19] | 2.61 | 2.24 | 1.85 | 1.58 | ||||||||
| VRD-Full [19] | 17.03 | 16.17 | 25.52 | 20.42 | 24.90 | 20.04 | 14.70 | 13.86 | 22.03 | 17.43 | 21.51 | 17.35 |
| Linguistic Cues [25] | 20.70 | 16.89 | - | 18.37 | 15.08 | |||||||
| VIP-CNN [17] | 27.91 | 22.78 | 20.01 | 17.32 | ||||||||
| VRL [18] | 22.60 | 21.37 | 20.79 | 18.19 | ||||||||
| U+W+SF+L:S | 19.98 | 19.15 | 25.16 | 22.95 | 25.54 | 22.59 | 17.69 | 16.57 | 27.98 | 19.92 | 28.94 | 20.12 |
| U+W+SF+L:T | 23.57 | 22.46 | 29.14 | 25.96 | 29.09 | 25.86 | 20.61 | 18.56 | 29.41 | 21.92 | 31.13 | 21.98 |
| U+W+SF+L:T+S | 24.03 | 23.14 | 29.76 | 26.47 | 29.43 | 26.32 | 21.34 | 19.17 | 29.89 | 22.56 | 31.89 | 22.68 |
| 第二部分:使用 VRD + VG 训练图像 | ||||||||||||
| U+W+SF+L:S | 20.32 | 19.96 | 25.71 | 23.34 | 25.97 | 22.83 | 18.32 | 16.98 | 28.24 | 20.15 | 29.85 | 21.88 |
| U+W+SF+L:T | 23.89 | 22.92 | 29.82 | 26.34 | 29.97 | 26.15 | 20.94 | 18.93 | 29.95 | 22.62 | 31.78 | 22.65 |
| U+W+SF+L:T+S | 24.42 | 23.51 | 30.13 | 26.73 | 30.01 | 26.58 | 21.72 | 19.68 | 30.45 | 22.84 | 32.56 | 23.18 |
Table 3. Phrase and Relationship Detection: Distillation of Linguistic Knowledge - Zero Shot. We use the same notations as in Table
表 3: 短语与关系检测:语言知识蒸馏 - 零样本。我们使用与表
| 短语检测 | 关系检测 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@100, k=1 | R@50, k=1 | R@100, k=10 | R@50, k=10 | R@100, k=70 | R@50, k=70 | R@100, k=1 | R@50, k=1 | R@100, k=10 | R@50, k=10 | R@100, k=70 | R@50, k=70 | |
| 第一部分:训练图像仅VRD | ||||||||||||
| VRD-Vonly [19] | 1.12 | 0.95 | 0.78 | 0.67 | ||||||||
| VRD-Full [19] | 3.75 | 3.36 | 12.57 | 7.56 | 12.92 | 7.96 | 3.52 | 3.13 | 11.46 | 7.01 | 11.70 | 7.13 |
| Linguistic Cues [25] | 15.23 | 10.86 | 13.43 | 9.67 | ||||||||
| VRL [18] | ||||||||||||
| U+W+SF+L:S | 10.89 | 9.17 | 17.24 | 13.01 | 17.24 | 12.96 | 8.52 | 7.94 | 16.15 | 12.31 | 15.89 | 12.02 |
| U+W+SF+L:T | 6.71 | 6.54 | 11.27 | 9.45 | 9.84 | 7.86 | 6.44 | 6.07 | 9.71 | 7.82 | 10.21 | 8.75 |
| 第二部分:训练图像 VRD+VG | ||||||||||||
| U+W+SF+L:S | 11.23 | 10.87 | 17.89 | 13.53 | 17.88 | 13.41 | 9.75 | 9.41 | 16.81 | 12.72 | 16.37 | 12.29 |
| U+W+SF+L:T | 7.03 | 6.94 | 11.85 | 9.88 | 10.12 | 8.97 | 6.89 | 6.56 | 10.34 | 8.23 | 10.53 | 9.03 |
4.2. Evaluation on Visual Genome Dataset
4.2. Visual Genome数据集评估
We also evaluate predicate detection on Visual Genome (VG) [13], the largest dataset that has visual relationship annotations. We randomly split the VG dataset into training (88,077 images) and testing set (20,000 images) and select the relationships whose predicates and objects occur in the VRD dataset. We conduct a similar evaluation on the dataset (99,864 relationship instances in training and 19,754 in testing; 2,056 relationship test instances are never seen in training). We use the linguistic knowledge extracted from VG and report predicate prediction results in Table 4.
我们还在视觉基因组 (Visual Genome, VG) [13] 上评估了谓词检测性能,这是目前拥有视觉关系标注的最大数据集。我们将VG数据集随机划分为训练集 (88,077张图像) 和测试集 (20,000张图像),并筛选出谓词和客体均在VRD数据集中出现的关系。对该数据集 (训练集包含99,864个关系实例,测试集包含19,754个实例;其中2,056个测试关系实例在训练集中未出现) 进行了类似评估。利用从VG提取的语言学知识,我们在表4中报告了谓词预测结果。
Not surprisingly, we observe similar behavior as on the VRD dataset—LK distillation regularizes the deep model and improves its generalization. We conduct another experiment in which images from Visual Genome dataset augment the training set of VRD and evaluate on the VRD test set. From the Part 2 of Tables 1, 2 and 3, we observe that training with more data leads to only marginal improvement over almost all baselines and proposed methods. However, for all experimental settings, our LK distillation framework still brings significant improvements, and the combination of the teacher and student networks still yields the best performance. This reveals that incorporating additional knowledge is more beneficial than collecting more data5.
不出所料,我们在VRD数据集上观察到了类似现象——LK蒸馏对深度模型起到了正则化作用并提升了泛化能力。我们进行了另一项实验:用Visual Genome数据集的图像扩充VRD训练集,并在VRD测试集上评估。从表1、表2和表3的第二部分可见,增加训练数据对所有基线方法和我们提出的方法都只能带来微弱提升。但在所有实验设置中,我们的LK蒸馏框架仍能带来显著改进,且教师网络与学生网络的组合始终保持着最佳性能。这表明:引入额外知识比收集更多数据更具效益[5]。
Table 4. Predicate Detection on Visual Genome Dataset. Notations are the same as in Table 1.
表 4: Visual Genome数据集上的谓词检测。标注与表 1 相同。
| EntireSet | Zero-shot | |||||
|---|---|---|---|---|---|---|
| R@100/50 k=1 | R@100 k=70 | R@50 k=70 | R@100/50 k=1 | R@100 k=70 | R@50 k=70 | |
| U | 37.81 | 82.05 | 81.41 | 7.54 | 81.00 | 65.22 |
| U+W+SF | 40.92 | 86.81 | 84.92 | 8.66 | 82.50 | 67.72 |
| U+W+SF+L:S | 49.88 | 91.25 | 88.14 | 11.28 | 88.23 | 72.96 |
| U+W+SF+L:T | 55.02 | 94.92 | 91.47 | 3.94 | 62.99 | 47.62 |
| U+W+SF+L:T+S | 55.89 | 95.68 | 92.31 |
Table 5. Predicate Detection on VRD Testing Set: External Linguistic Knowledge. Part 1 uses the LK from VRD dataset; Part 2 uses the LK from VG dataset; Part 3 uses the LK from both VRD and VG dataset. Part 4 uses the LK from parsing Wikipedia text; Part 5 uses the LK from from both VRD dataset and Wikipedia. Notations are the same as as in Table 1.
表 5. VRD测试集上的谓词检测:外部语言知识。第1部分使用VRD数据集中的LK;第2部分使用VG数据集中的LK;第3部分同时使用VRD和VG数据集中的LK;第4部分使用维基百科文本解析的LK;第5部分同时使用VRD数据集和维基百科的LK。标注方式与表1相同。
| 整个集合 | 零样本 | |||||
|---|---|---|---|---|---|---|
| R@100/50 k=1 | R@100 k=70 | R@50 k=70 | R@100/50 k=1 | R@100 k=70 | R@50 k=70 | |
| 第1部分 LK:VRD | ||||||
| VRD-Vonly[19] | 7.11 | 37.20 | 28.36 | 3.52 | 32.34 | 23.95 |
| VRD-Full[19] | 47.87 | 84.34 | 70.97 | 8.45 | 50.04 | 29.77 |
| U+W+SF+L:S | 47.50 | 86.97 | 74.98 | 16.98 | 74.65 | 54.20 |
| U+W+SF+L:T | 54.13 | 89.41 | 82.54 | 8.80 | 41.53 | 32.81 |
| 第2部分 LK:VG | ||||||
| U+W+SF+L:S | 45.00 | 81.64 | 74.76 | 16.88 | 72.29 | 52.51 |
| U+W+SF+L:T | 51.54 | 87.00 | 79.70 | 11.01 | 54.66 | 45.25 |
| 第3部分 LK:VRD+VG | ||||||
| U+W+SF+L:S | 48.21 | 87.76 | 76.51 | 17.21 | 74.89 | 54.65 |
| U+W+SF+L:T | 54.82 | 90.63 | 83.97 | 12.32 | 47.22 | 38.24 |
| 第4部分 LK:Wiki | ||||||
| U+W+SF+L:S | 36.05 | 77.88 | 68.16 | 11.80 | 64.24 | 49.19 |
| U+W+SF+L:T | 30.41 | 69.86 | 60.25 | 11.12 | 63.58 | 44.65 |
| 第5部分 LK:VRD+Wiki | ||||||
| U+W+SF+L:S | 48.94 | 87.11 | 77.79 | 19.17 | 76.42 | 56.81 |
| U+W+SF+L:T | 54.06 | 88.93 | 81.78 | 9.65 | 42.24 | 34.61 |
4.3. Distillation with External Knowledge
4.3. 基于外部知识的蒸馏
The above experiments show the benefits of extracting linguistic knowledge from internal training annotations and distilling them in a data-driven model. However, training annotations only represent a small portion of all possible rela tion ships and do not necessarily represent the real world distribution, which has a long tail. For unseen long-tail relationships in the VRD dataset, we extract the linguistic knowledge from external sources: the Visual Genome annotations and Wikipedia, whose domain is much larger than any annotated dataset. In Table 5, we show predicate detection results on the VRD test set using our linguistic knowledge distillation framework with different sources of knowledge. From Part 2 and Part 4 of Table 5, we observe that using only the external knowledge, especially the very noisy one obtained from Wikipedia, leads to bad performance. However, interestingly, although the external knowledge can be very noisy (Wikipedia) and has a different distribution when compared with the VRD dataset (Visual Genome), the performance of the teacher network using external knowledge is much better than using only the internal knowledge (Part 1). This suggests that by properly distilling external knowledge, our framework obtains both good predictive power on the seen relationships and better generalization on unseen ones. Evaluation results of combining both internal and external linguistic knowledge are shown in Part 3 and Part 5 of Table 5. We observe that by distilling external knowledge and the internal one, we improve generalization significantly (e.g., LK from Wikipedia boosts the recall to $19.17%$ on the zero-shot set) while maintaining good predictive power on the entire test set.
上述实验表明,从内部训练标注中提取语言学知识并将其蒸馏到数据驱动模型中具有优势。然而,训练标注仅占所有可能关系的一小部分,且不一定反映真实世界中的长尾分布。针对VRD数据集中未见的尾部关系,我们从外部资源(Visual Genome标注和维基百科)提取语言学知识,其覆盖领域远超任何标注数据集。表5展示了使用不同知识源的语言学知识蒸馏框架在VRD测试集上的谓词检测结果。通过表5第2和第4部分可见,仅使用外部知识(尤其是从维基百科获取的高噪声知识)会导致性能下降。但有趣的是,尽管外部知识可能存在高噪声(维基百科)且与VRD数据集(Visual Genome)分布不同,使用外部知识的教师网络性能仍显著优于仅用内部知识(第1部分)。这表明通过适当蒸馏外部知识,我们的框架既能对已知关系保持良好预测力,又能提升对未知关系的泛化能力。表5第3和第5部分展示了结合内外语言学知识的评估结果:蒸馏外部与内部知识可显著提升泛化性(如维基百科的LK将零样本集召回率提升至$19.17%$),同时在整个测试集上保持优异预测性能。

Figure 3. Performance with varying sizes of training examples. “Our Method” denotes the student network that absorbs linguistic knowledge from both VRD training annotations and the Wikipedia text. “VRD-Full” is the full model in [19].
图 3: 不同训练样本规模下的性能表现。"Our Method"表示从VRD训练标注和维基百科文本中吸收语言知识的学生网络。"VRD-Full"是文献[19]中的完整模型。
Fig. 3 shows the comparison between our student network that absorbs linguistic knowledge from both VRD training annotations and the Wikipedia text (denoted as “Our Method”) and the full model in [19] (denoted as “VRD-Full”). We observe that our method significantly outperforms the existing method, especially for the zeroshot (relationships with 0 training instance) and the fewshot setting (relationships with few training instances, e.g., $\leq10,$ . By distilling linguistic knowledge into a deep model, our data-driven model improves dramatically, which is hard to achieve by only training on limited labeled images.
图 3: 展示了我们的学生网络(标注为"Our Method")与文献[19]中的完整模型(标注为"VRD-Full")之间的对比。我们的网络同时吸收了VRD训练标注和维基百科文本中的语言学知识。实验表明,我们的方法显著优于现有方法,特别是在零样本(0训练实例的关系)和少样本(少量训练实例的关系,例如$\leq10$)场景下。通过将语言学知识蒸馏到深度模型中,我们的数据驱动模型取得了显著提升,这是仅靠有限标注图像训练难以实现的。
5. Conclusion
5. 结论
We proposed a framework that distills linguistic knowledge into a deep neural network for visual relationship detection. We incorporated rich representations of a visual relationship in our deep model, and utilized a teacher-student distillation framework to help the data-driven model absorb internal (training annotations) and external (public text on the Internet) linguistic knowledge. Experiments on the VRD and the Visual Genome datasets show significant improvements in accuracy and generalization capability.
我们提出了一种将语言知识蒸馏到深度神经网络中以进行视觉关系检测的框架。我们在深度模型中融入了视觉关系的丰富表征,并利用师生蒸馏框架帮助数据驱动模型吸收内部(训练标注)和外部(互联网公开文本)的语言知识。在VRD和Visual Genome数据集上的实验表明,该框架在准确性和泛化能力方面均有显著提升。